隨著智能手機等移動設備感知、計算能力的飛速提升,以移動設備作為載體的人體活動識別成為新的研究熱點。利用智能移動設備中的加速度傳感器等采集到的慣導信息進行人體活動識別,相比于常用的計算機視覺識別,具有應用方便、成本低且更能反映人體運動本質等優勢。本文采用智能手機采集到的 WISDM 數據集,構建了基于加速度計慣導信息和卷積神經網絡(CNN) 的人體活動識別模型,并同時引入 K 最近鄰算法(KNN)和隨機森林算法來對 CNN 網絡進行評估。CNN 模型的分類正確率達到了 92.73%,相較于 KNN 和隨機森林都有很大提高。實驗結果表明,與 KNN、隨機森林算法相比,CNN 算法模型可以實現更精確的人體活動識別,在預測和促進人體健康水平方面具有廣闊的應用前景。
引用本文: 李新科, 劉欣雨, 李勇明, 曹海林, 陳藝航, 林宜成, 黃新鑫. 基于慣導信息和卷積神經網絡的人體活動識別. 生物醫學工程學雜志, 2020, 37(4): 596-601. doi: 10.7507/1001-5515.201905042 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
引言
人體活動識別作為人工智能醫療健康領域的一個研究方向,隨著社會發展以及人們生活水平的提高而受到越來越多的關注[1-2]。基于可穿戴傳感器的人體生理特征監測系統在醫療領域應得到了廣泛的應用,其中監測的數據包括患者的體溫、心率、大腦活動、肌肉動作和其他重要的生理數據。這些傳感器能夠提供很多關于人體活動精確的、可靠的數據,通過傳感器提供的監測數據,護理人員能實時地了解患者是否處于一個相對健康的狀況,隨時關注患者的病情變化,并及時為患者提供需要的幫助。Tapia 等[3]使用五個三軸無線加速度計和一個無線心率監測器識別來自 21 個用戶的 30 個人體物理活動。Gyorbiro 等[4]將每個用戶的主要部位如手腕、臀部和腳踝作為 MotionBand,每個 MotionBand 包含一個三軸加速計、磁力計和陀螺儀。然后利用這些相連的“MotionBands”來區分六種不同的運動模式。Ling 等[5]開發了一種人體活動識別系統,用放置在使用者身體上五個不同位置的雙軸加速度計來識別二十項活動。還有一些工作集中在基于加速度計的活動識別構建的應用程序上[6],包括識別用戶的活動水平并預測他們的能量消耗,以及檢測跌倒和跌倒后用戶的移動。當下,智能手機已融入多樣化、功能強大的傳感器[7],如圖像傳感器、光傳感器、溫度傳感器、GPS 傳感器、音頻傳感器(即麥克風)和加速度計等。智能手機的優點是攜帶方便,不需額外的設備來進行數據收集,也不會對用戶的生活造成其他影響,還具有相當強大的數據傳輸和數據處理功能。因此采用便攜式的智能手機,可以方便有效地監測用戶活動來預測和促進人體健康水平。例如,Anderson 等[8]采用智能手機記錄了一個人早、中、晚的休息與運動時間,從而評估該研究對象的作息規律與健康水平。
本文采用的是基于 Android 手機的 WISDM 數據集[6]。該數據集收集了來自 29 位用戶的加速度計數據,參與數據采集的用戶執行了包括步行、慢跑、上樓、下樓、坐和站立等活動。不同于以往基于圖像數據進行人體活動識別的卷積神經網絡(convolutional neural network,CNN)算法[9],本文將基于加速度計慣導信息的原始時間序列數據匯總到示例中,其中每個示例都標有收集數據時發生的活動,在進行數據轉換和特征生成后構架 CNN 算法來完成活動識別。在傳統分類算法中,K 最近鄰算法(K nearest neighbor algorithm,KNN)和隨機森林算法比樸素貝葉斯和決策樹算法具有更高的分類識別率,而支持向量機適用于小樣本數據的分類。因此,KNN 和隨機森林是現今常用的簡單有效的分類算法。本文引入了 KNN 和隨機森林來處理數據,并用來評估 CNN 算法的分類準確率。
1 人體活動數據
1.1 人體活動 WISDM 數據集
WISDM 數據集(http://www.cis.fordham.edu/wisdm/dataset.php)收集了人體活動識別所需要的原始數據,該數據集是通過 29 位測試者執行一組特定的活動并基于他們攜帶的 Android 系統智能手機獲取的。這些受試者將 Android 手機放在褲子前側口袋中,并被要求執行走路、慢跑、上樓梯、下樓梯、坐下和站立等活動。數據收集由該研究團隊創建的在手機上執行的應用程序控制。該應用程序允許該研究團隊控制 GPS、加速度計傳感器等數據的收集以及收集的頻率。
在所有情況下,研究者每隔 50 ms 收集一次加速度計數據,所以每秒鐘需要處理 20 個樣本。數據收集由 WISDM 團隊成員之一負責監督,以確保數據的質量。該數據集包括超過一百萬條用戶活動狀態及對應的加速度數值,還包括記錄用戶活動數據的時間段。原始數據集包含的樣本數量為 1 098 207 個,其中有慢跑、步行、上樓、下樓、坐、站立六種活動狀態。表 1 為六種活動所占比例。
1.2 人體活動狀態
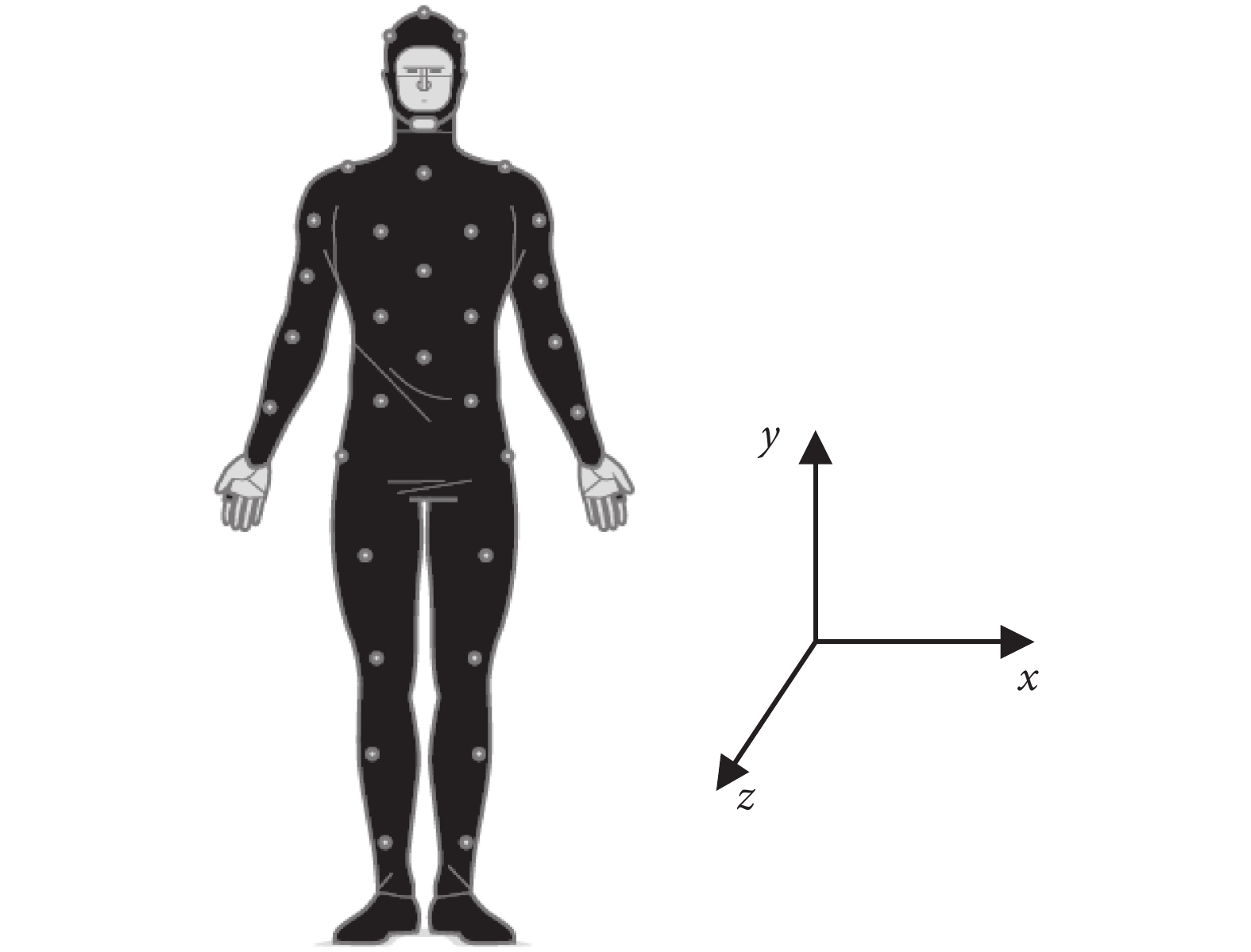
WISDM 數據集中的六種活動狀態是在日常生活中大量時間段內經常發生的動作,因而數據集比較豐富。同時這些活動都涉及了重復動作,也使其可以被方便地分類識別。當實驗需要記錄每個活動的數據時,如圖 1 所示,記錄三軸加速度計對應的三個軸的加速度值,z 軸記錄腿部向前的運動,y 軸記錄向上和向下的運動,x 軸記錄用戶腿部的水平移動,即水平橫移。
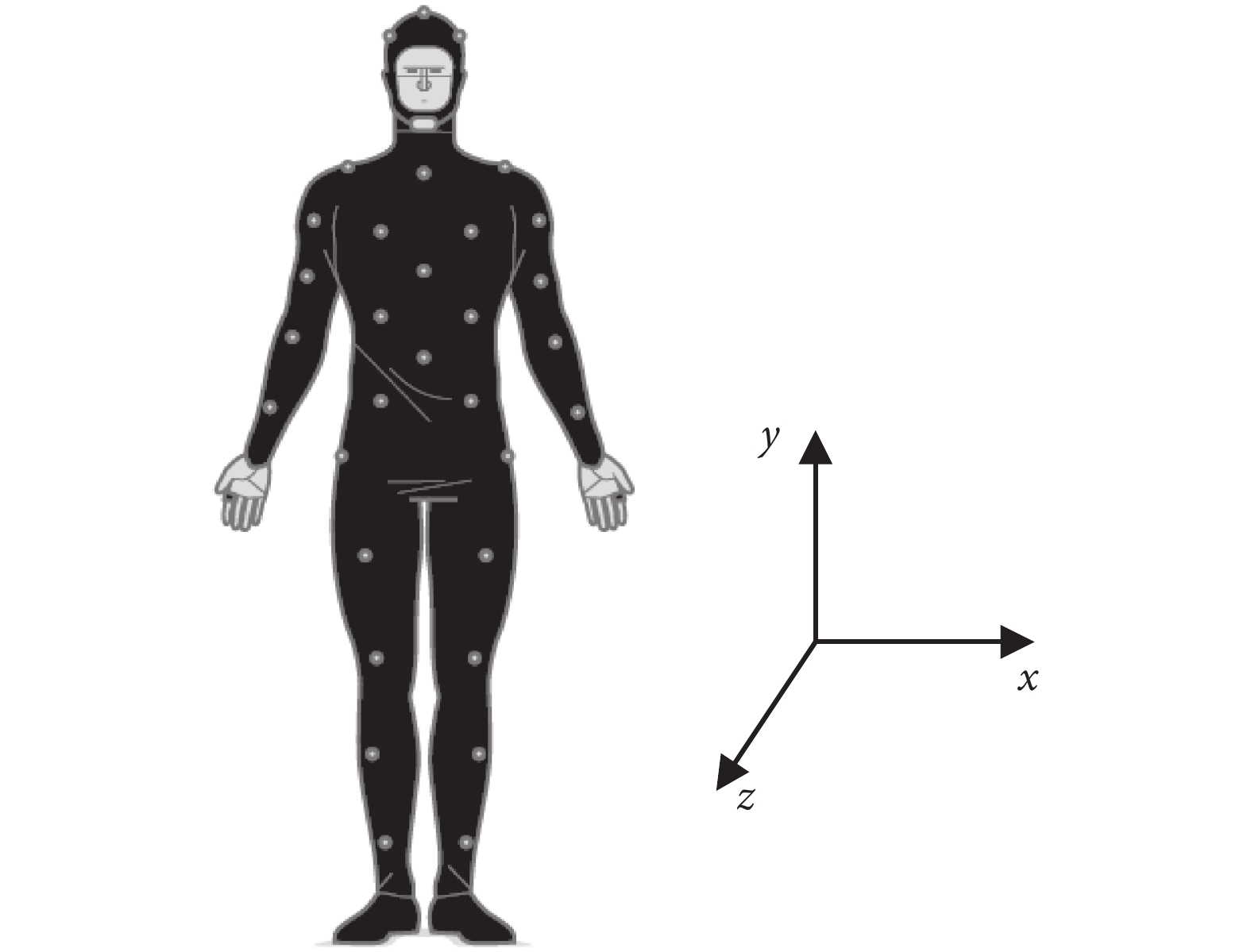 圖1
相對于用戶的運動軸
Figure1.
The axis of motion relative to users
圖1
相對于用戶的運動軸
Figure1.
The axis of motion relative to users
這樣基于三軸加速度計數據可以生成六個活動的加速度計數據波形。其中,坐和站立不顯示周期性行為,但基于 x、y 和 z 軸的值的相對大小具有其獨特的模式,而其他四項活動都涉及了重復性運動,表現出周期性行為。由于上樓的加速度相比于慢跑、步行等活動變化較慢,在有限的時間內,具有一定的周期性,但不是十分明顯。
2 基于慣導信息的人體行為識別
2.1 特征生成和數據轉換
為了將三軸加速度計采集的慣導信息通過分類模型進行識別,首先將原始時間序列數據轉換為相應的特征向量。本文將數據劃分為 10 s 一個區段,然后生成基于每個 10 秒段內包含的 200 個讀數的特征[10-11]。其中每個讀數包含三個軸/維度對應的 x、y 和 z 值,總共產生了 43 個信息特征,主要包括以下要素類型[12-13]:① 平均加速度:平均加速度(對于每個軸);② 標準偏差:標準偏差(對于每個軸);③ 平均絕對差:每個分段示例的持續時間(example duration,ED)內 200 個讀數每個值與這 200 個值的平均值之間的平均絕對差值(對于每個軸);④ 平均絕對加速度:每個軸的平方和平方根的平均值  ;⑤ 峰間時間:與大多數活動相關的正弦波峰值之間的所包含時間(以 ms 為單位);⑥ 分級分配:我們確定每個軸的值范圍(最大值~最小值),將此范圍分成 10 個相同大小的數據段,然后記錄 200 個值在每個數據段內的數量分布。
;⑤ 峰間時間:與大多數活動相關的正弦波峰值之間的所包含時間(以 ms 為單位);⑥ 分級分配:我們確定每個軸的值范圍(最大值~最小值),將此范圍分成 10 個相同大小的數據段,然后記錄 200 個值在每個數據段內的數量分布。
為了估計“峰間時間”這個值,對于每個 ED,首先使用相關方法識別波形中的所有峰值,確定每個軸的最高峰值,然后根據此值的百分比設置閾值,并找到其他達到或超過此閾值的峰值;如果沒有峰值符合這個標準,那么閾值會降低,直到找到至少三個峰值,測量連續峰值之間的時間并計算平均值。對于找不到至少三個峰值的樣品,峰與峰之間的時間標記為未知。這種方法能夠準確地找出具有明確重復模式的活動峰值之間的時間,如步行和慢跑。
每個用戶為每項活動生成的示例數量都不相同。轉換后的數據集包含例子數量為 5 424,六種活動分布如表 2 所示。對于轉換過程,需要 10 s 的時間段加速計樣本(原始文件中的 200 條記錄/行),并將它們轉換為一個包含 45 個值的單個示例/元組[10]。處理后的字段說明如下:
{ID,X0..X9,XAVG,XPEAK,XABSO,XSTAND,Y0..Y9,YAVG,YPEAK,YABSO,YSTAND,Z0..Z9,ZAVG,ZPEAK,ZABSO,ZSTAND,RESULTANT,class}
數據第一列是數據來源的用戶的 ID 號碼,與最后的分類結果是不相關的,將其作為無效數字處理;X0..X9,Y0..Y9,Z0..Z9 是分段數據的數值;XAVG、YAVG、ZAVG 分別對應于 x、y 和 z 的平均值;XPEAK、YPEAK、ZPEAK 對應于峰間時間。如果峰的數量小于 3,則門限降低到至少可以找到 3 個峰值。XABSO、YABSO、ZABSO 是絕對的平均值偏離每個軸的平均值。XSTAND、YSTAND、ZSTAND 是標準偏差,也是對應于每個軸。RESULTANT 的值對應于平均絕對加速度,最后一列的 class 是在此示例中用戶正在執行的活動,即識別和預測的人體活動狀態。數據轉換和特征生成的流程圖如圖 2 所示。
 圖2
特征生成和數據轉換流程圖
Figure2.
The flowchart of the generation of features and the data conversion
圖2
特征生成和數據轉換流程圖
Figure2.
The flowchart of the generation of features and the data conversion
2.2 CNN 分類識別算法
CNN 的結構主要分為兩層,第一層是特征提取層,這一層中神經元的輸入端直接與前一層的接受域相連,能夠提取到接受域的特征,而成功提取到相關特征后,與每個特征之間的位置關系就確定了下來。第二層為特征映射層,多個特征映射組成了 CNN 的計算層[14-15]。本文所采用的 CNN 模型,包括五層結構:輸入層、卷積層、池化層、全連接層、輸出層。其中卷積層提供多個相同的局部過濾器,形成多個輸出矩陣,每個輸出矩陣的大小是 N ? m + 1,計算過程如下:
 |
其中  中的 l 表示第 l 個卷積層,i 表示第 i 個卷積輸出矩陣的某個值,j 表示對應的輸出矩陣的編號,從左往右依次表示為 0 到 N,N 為卷積輸出矩陣的個數。f 表示非線性函數,本文采用了影響函數核小的 sigmoid 函數。sigmoid 函數計算公式如下:
中的 l 表示第 l 個卷積層,i 表示第 i 個卷積輸出矩陣的某個值,j 表示對應的輸出矩陣的編號,從左往右依次表示為 0 到 N,N 為卷積輸出矩陣的個數。f 表示非線性函數,本文采用了影響函數核小的 sigmoid 函數。sigmoid 函數計算公式如下:
 |
本文的池化層采用局部求均值的方式進行降維。計算公式如下:
 |
式中, 表示進行池化過程后局部的一個輸出項,它是由上一層大小為 n*n 的局部小矩陣進行求均值所得到的。
表示進行池化過程后局部的一個輸出項,它是由上一層大小為 n*n 的局部小矩陣進行求均值所得到的。
全連接層:將網絡學習到的特征映射到樣本的標記空間中,全連接層會把卷積輸出的二維特征向量轉化成一維的特征向量。
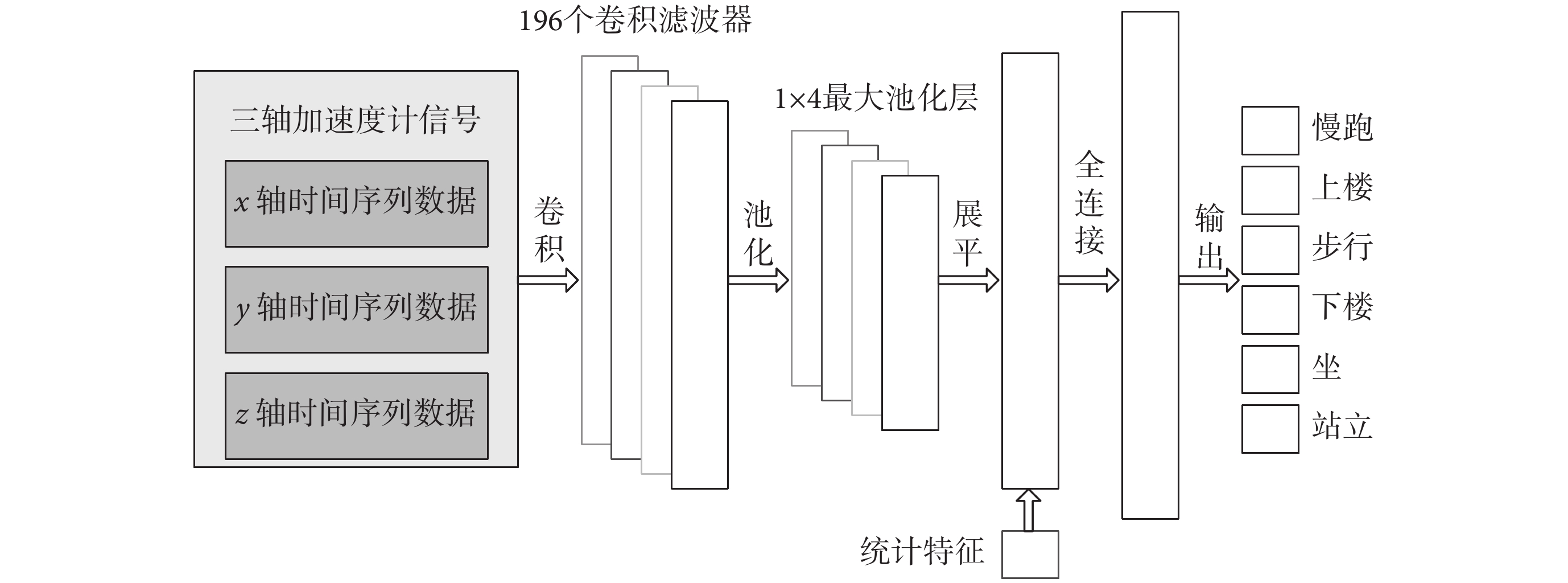
本文基于以上步驟構建了 CNN 模型結構,對三軸數據進行并行處理。首先通過輸入層輸入三軸加速度計采集到的原始時間序列數據,然后通過卷積層進行數據處理:使用 196 個卷積濾波器進行并行學習,創建豐富的數據特征表示,其中每個濾波器的大小為 1 × 12,卷積的步長為 1。隨機失活率為 0.15。將 sigmoid 函數應用于生成的 200 個特征表示,使用 1 × 4 大小的最大池化層進行 4 倍降維。再將池化層的輸出展平,并與其他統計特征(平均加速度、標準偏差、平均絕對差、平均絕對加速度等)疊加在一起。聯合組成的特征向量隨后被傳遞到全連接層,進行特征標記分類,最后通過輸出層輸出六種活動的一維特征向量[16],CNN 訓練流程圖如圖 3 所示。
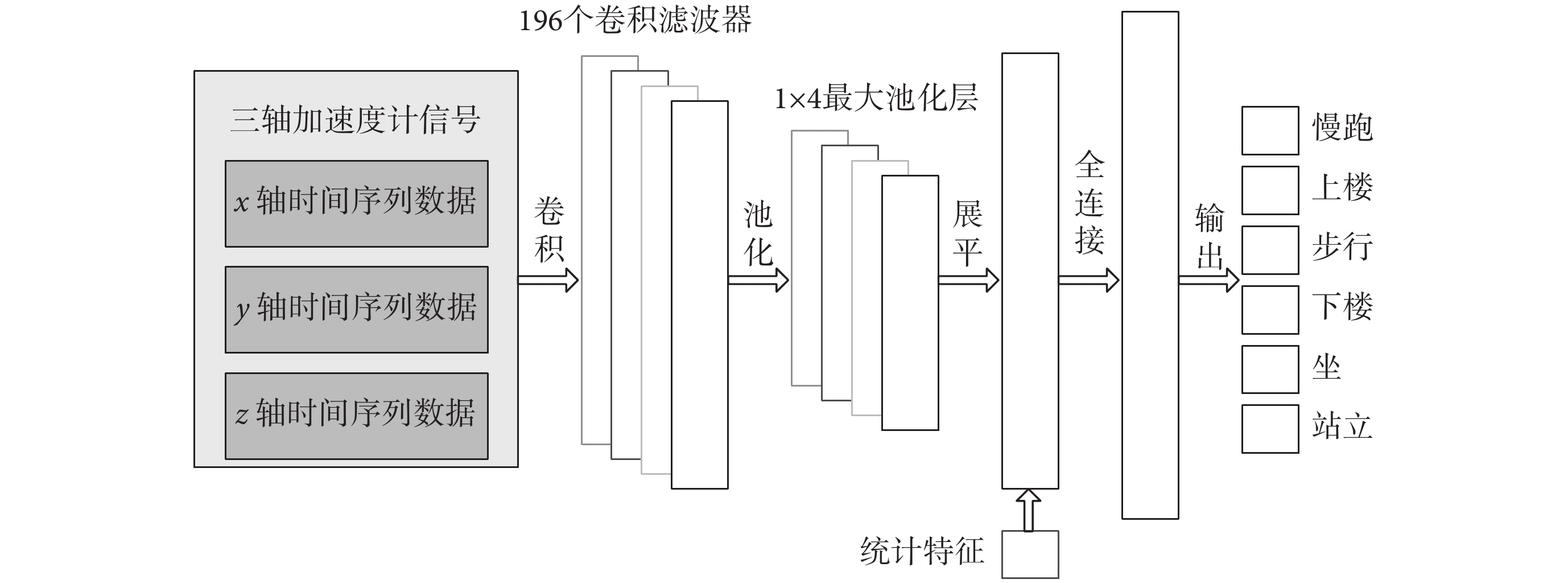 圖3
CNN 模型流程圖
Figure3.
The flowchart of CNN training
圖3
CNN 模型流程圖
Figure3.
The flowchart of CNN training
CNN 中同一個特征映射面上所有神經元的權值都是一樣的,所以網絡學習過程可以是并行學習,這也是相較于其他由神經元直接相連構成的網絡的優勢。由于 CNN 的這一特性,其在語音識別、圖像處理等方面具有相當大的優勢,權值共享這一特性大大降低了神經網絡的復雜程度,在處理具有多維輸入的數據方面具有極大的優勢,從而極大地提高了 CNN 的可用性[17]。
3 實驗結果及其分析
本文基于 Tensorflow 平臺,采用 Python 編程語言,構建 CNN 識別模型并進行分析,同時引入 KNN 與隨機森林識別模型作為對比,進一步評估基于 CNN 識別模型的準確率[18]。
表 3 比較了基于 CNN、KNN 及隨機森林的分類結果,采用如下三個指標進行識別結果的評價:準確率(Accuracy)表示模型對正樣本的準確度,召回率(Recall)表示模型對正樣本的識別正確率;F1 分數(F1-score)表示一個模型的綜合評價指標,是基于召回率和精確率(Precision)計算的。Accuracy 計算公式如下:
 |
式中,TP(true positive)表示實際為正樣本預測為正樣本,TN(true negative)表示實際為負樣本預測為負樣本,FP(false positive)表示實際為負樣本預測為正樣本,FN(false negative)表示實際為正樣本預測為負樣本。其中,分類正確的是正樣本,分類錯誤的是負樣本。
Recall 計算公式如下:
 |
F1-score 計算公式如下:
 |
式中,Precision 計算公式為:
 |
WISDM 數據庫是常用的人體活動識別評價數據集[19],本文將 CNN 與傳統的 KNN 和隨機森林分類算法進行比較。這里,KNN 算法中采用歐氏距離找到鄰近的樣本,K 值選為 5,隨機森林算法中樹的數目為 n_estimators = 100。通過實驗結果可以看到:對于相同的 WISDM 數據集,KNN 的平均分類識別正確率為 73.00%,對上樓、下樓、坐和站立的識別準確率都只能達到 30% 左右,召回率值為 68.44%,所以在本實驗中 KNN 相較于 CNN 具有明顯的劣勢,而且對部分活動 30% 左右的識別率完全達不到實驗要求。而隨機森林的平均分類識別正確率為 82.90%,對上樓、下樓、坐和站立的識別準確率都比 KNN 算法的識別準確率高,召回率能達到 83.05%。由此可見,隨機森林分類模型的分類結果要明顯好于 KNN,但相較于 CNN,仍然具有一定的差距。這是由于 CNN 比傳統算法對局部和相關特征具有更高的識別能力,而且本文中的人體活動識別數據具有時間連續性,采用 CNN 識別也就更有優勢,所以活動識別率相差較大。
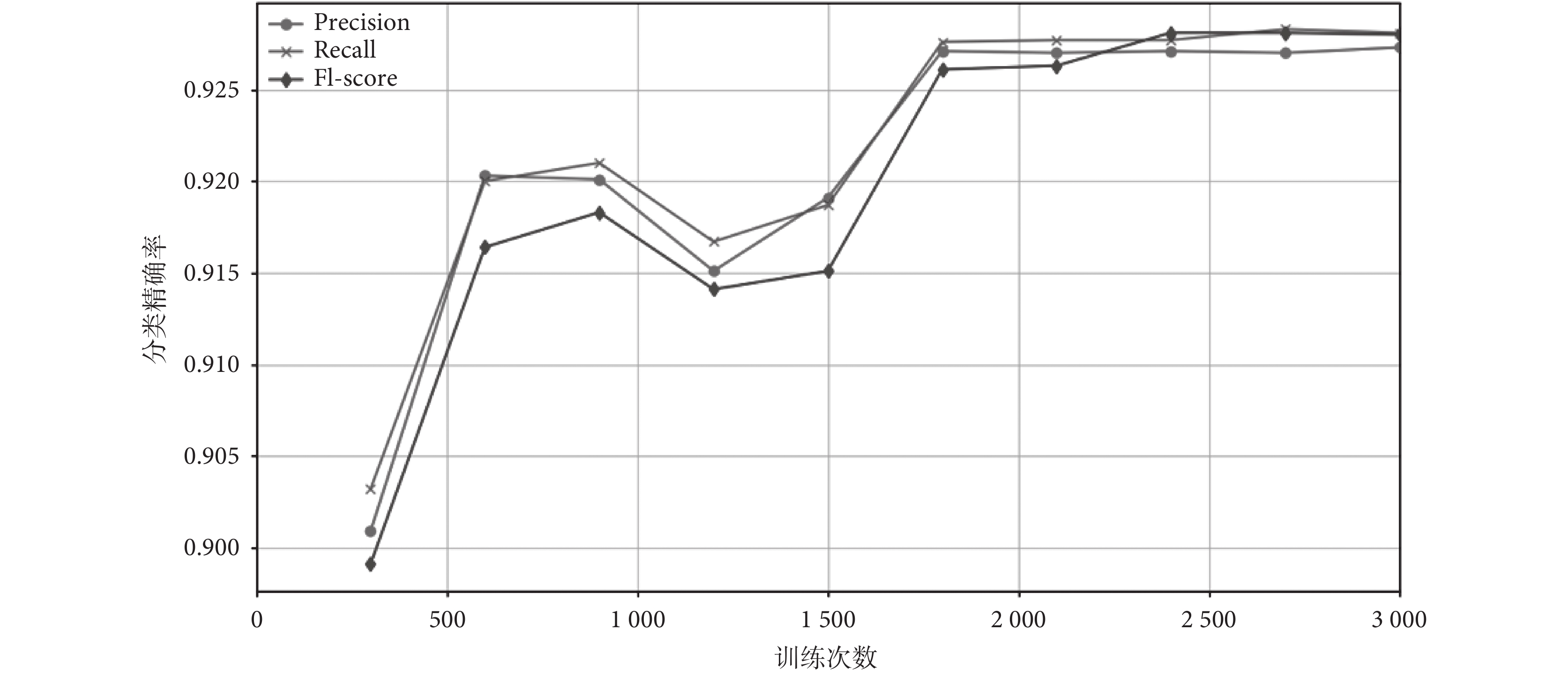
使用 CNN 對轉換后的 WISDM 數據集進行分類時,當訓練次數達到 3 000 次(表中所列數據),分類的正確率能達到 92.73%;當訓練次數逐漸增加,在 50 000 次時,模型正確率能達到 93.16%,這完全符合實驗預期和要求。但考慮到實際情況,若每一個模型的訓練次數都為 50 000 次,不僅耗費的時間長,而且 3 000 次和 50 000 次的識別正確率相差不大。在實際測試中,達到 3 000 次的訓練次數就能滿足要求了,若訓練次數持續增加,考慮到運行時間、設備要求,則實驗性價比會相應降低。CNN 對每個活動的識別率都很高,對站立和上樓梯的識別相對較低,但也能達到 82% 以上;而且準確率和 F1 分數也能達到較好的效果。CNN 訓練次數與分類精確率之間的關系如圖 4 所示。有一些研究將傳統的分類模型對人體活動進行集成分類,也取得了不錯的分類效果。如 Cagatay 等[20]采用的一種優化集成分類器,其人體活動的平均識別率為 91.62%,而本文的 CNN 模型達到了 92.73%。上述實驗結果表明,基于 CNN 的識別模型能有效地識別人體活動。
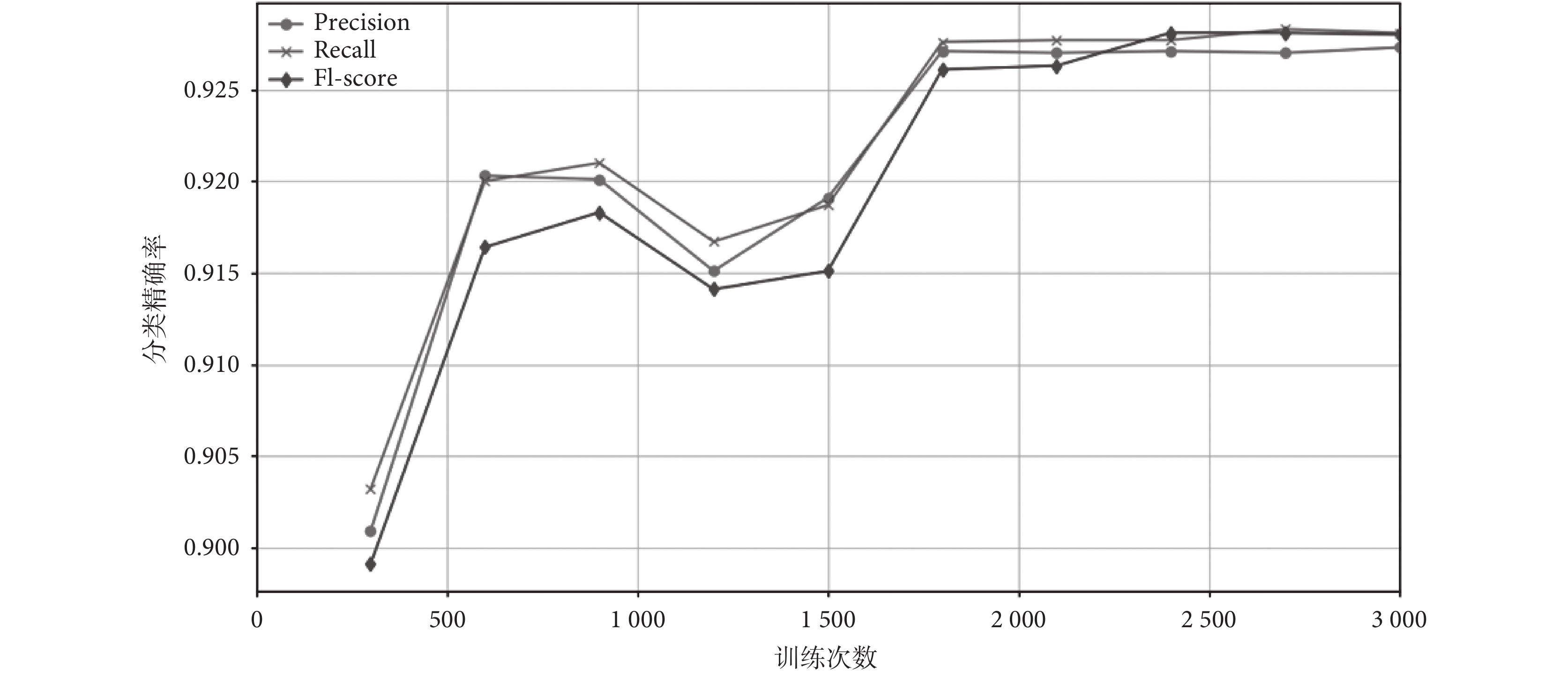 圖4
CNN 訓練次數與分類精確率之間的關系
Figure4.
Relation between training times of CNN and classification precision
圖4
CNN 訓練次數與分類精確率之間的關系
Figure4.
Relation between training times of CNN and classification precision
4 結論
人體活動識別研究可以為用戶的身體活動、能量消耗及鍛煉需求等提供客觀評價和合理建議,在慢性疾病的預防和輔助治療等生物醫學領域具有重要意義[21]。本文使用 CNN 模型對基于 WISDM 的數據集進行了人體活動分類識別,并對模型進行了評估。分類結果表明,基于 CNN 模型的人體活動識別具有較高的分類精度和魯棒性。在今后的研究中,可以進一步融入智能移動設備中的陀螺儀和磁力計等其他慣導數據,實現更準確的識別精度以及更多的活動分類,從而促進基于智能移動設備的人體活動識別在生物醫學和人體健康領域發揮更重要作用。
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
引言
人體活動識別作為人工智能醫療健康領域的一個研究方向,隨著社會發展以及人們生活水平的提高而受到越來越多的關注[1-2]。基于可穿戴傳感器的人體生理特征監測系統在醫療領域應得到了廣泛的應用,其中監測的數據包括患者的體溫、心率、大腦活動、肌肉動作和其他重要的生理數據。這些傳感器能夠提供很多關于人體活動精確的、可靠的數據,通過傳感器提供的監測數據,護理人員能實時地了解患者是否處于一個相對健康的狀況,隨時關注患者的病情變化,并及時為患者提供需要的幫助。Tapia 等[3]使用五個三軸無線加速度計和一個無線心率監測器識別來自 21 個用戶的 30 個人體物理活動。Gyorbiro 等[4]將每個用戶的主要部位如手腕、臀部和腳踝作為 MotionBand,每個 MotionBand 包含一個三軸加速計、磁力計和陀螺儀。然后利用這些相連的“MotionBands”來區分六種不同的運動模式。Ling 等[5]開發了一種人體活動識別系統,用放置在使用者身體上五個不同位置的雙軸加速度計來識別二十項活動。還有一些工作集中在基于加速度計的活動識別構建的應用程序上[6],包括識別用戶的活動水平并預測他們的能量消耗,以及檢測跌倒和跌倒后用戶的移動。當下,智能手機已融入多樣化、功能強大的傳感器[7],如圖像傳感器、光傳感器、溫度傳感器、GPS 傳感器、音頻傳感器(即麥克風)和加速度計等。智能手機的優點是攜帶方便,不需額外的設備來進行數據收集,也不會對用戶的生活造成其他影響,還具有相當強大的數據傳輸和數據處理功能。因此采用便攜式的智能手機,可以方便有效地監測用戶活動來預測和促進人體健康水平。例如,Anderson 等[8]采用智能手機記錄了一個人早、中、晚的休息與運動時間,從而評估該研究對象的作息規律與健康水平。
本文采用的是基于 Android 手機的 WISDM 數據集[6]。該數據集收集了來自 29 位用戶的加速度計數據,參與數據采集的用戶執行了包括步行、慢跑、上樓、下樓、坐和站立等活動。不同于以往基于圖像數據進行人體活動識別的卷積神經網絡(convolutional neural network,CNN)算法[9],本文將基于加速度計慣導信息的原始時間序列數據匯總到示例中,其中每個示例都標有收集數據時發生的活動,在進行數據轉換和特征生成后構架 CNN 算法來完成活動識別。在傳統分類算法中,K 最近鄰算法(K nearest neighbor algorithm,KNN)和隨機森林算法比樸素貝葉斯和決策樹算法具有更高的分類識別率,而支持向量機適用于小樣本數據的分類。因此,KNN 和隨機森林是現今常用的簡單有效的分類算法。本文引入了 KNN 和隨機森林來處理數據,并用來評估 CNN 算法的分類準確率。
1 人體活動數據
1.1 人體活動 WISDM 數據集
WISDM 數據集(http://www.cis.fordham.edu/wisdm/dataset.php)收集了人體活動識別所需要的原始數據,該數據集是通過 29 位測試者執行一組特定的活動并基于他們攜帶的 Android 系統智能手機獲取的。這些受試者將 Android 手機放在褲子前側口袋中,并被要求執行走路、慢跑、上樓梯、下樓梯、坐下和站立等活動。數據收集由該研究團隊創建的在手機上執行的應用程序控制。該應用程序允許該研究團隊控制 GPS、加速度計傳感器等數據的收集以及收集的頻率。
在所有情況下,研究者每隔 50 ms 收集一次加速度計數據,所以每秒鐘需要處理 20 個樣本。數據收集由 WISDM 團隊成員之一負責監督,以確保數據的質量。該數據集包括超過一百萬條用戶活動狀態及對應的加速度數值,還包括記錄用戶活動數據的時間段。原始數據集包含的樣本數量為 1 098 207 個,其中有慢跑、步行、上樓、下樓、坐、站立六種活動狀態。表 1 為六種活動所占比例。
1.2 人體活動狀態
WISDM 數據集中的六種活動狀態是在日常生活中大量時間段內經常發生的動作,因而數據集比較豐富。同時這些活動都涉及了重復動作,也使其可以被方便地分類識別。當實驗需要記錄每個活動的數據時,如圖 1 所示,記錄三軸加速度計對應的三個軸的加速度值,z 軸記錄腿部向前的運動,y 軸記錄向上和向下的運動,x 軸記錄用戶腿部的水平移動,即水平橫移。
圖1
相對于用戶的運動軸
Figure1.
The axis of motion relative to users
這樣基于三軸加速度計數據可以生成六個活動的加速度計數據波形。其中,坐和站立不顯示周期性行為,但基于 x、y 和 z 軸的值的相對大小具有其獨特的模式,而其他四項活動都涉及了重復性運動,表現出周期性行為。由于上樓的加速度相比于慢跑、步行等活動變化較慢,在有限的時間內,具有一定的周期性,但不是十分明顯。
2 基于慣導信息的人體行為識別
2.1 特征生成和數據轉換
為了將三軸加速度計采集的慣導信息通過分類模型進行識別,首先將原始時間序列數據轉換為相應的特征向量。本文將數據劃分為 10 s 一個區段,然后生成基于每個 10 秒段內包含的 200 個讀數的特征[10-11]。其中每個讀數包含三個軸/維度對應的 x、y 和 z 值,總共產生了 43 個信息特征,主要包括以下要素類型[12-13]:① 平均加速度:平均加速度(對于每個軸);② 標準偏差:標準偏差(對于每個軸);③ 平均絕對差:每個分段示例的持續時間(example duration,ED)內 200 個讀數每個值與這 200 個值的平均值之間的平均絕對差值(對于每個軸);④ 平均絕對加速度:每個軸的平方和平方根的平均值 ;⑤ 峰間時間:與大多數活動相關的正弦波峰值之間的所包含時間(以 ms 為單位);⑥ 分級分配:我們確定每個軸的值范圍(最大值~最小值),將此范圍分成 10 個相同大小的數據段,然后記錄 200 個值在每個數據段內的數量分布。
為了估計“峰間時間”這個值,對于每個 ED,首先使用相關方法識別波形中的所有峰值,確定每個軸的最高峰值,然后根據此值的百分比設置閾值,并找到其他達到或超過此閾值的峰值;如果沒有峰值符合這個標準,那么閾值會降低,直到找到至少三個峰值,測量連續峰值之間的時間并計算平均值。對于找不到至少三個峰值的樣品,峰與峰之間的時間標記為未知。這種方法能夠準確地找出具有明確重復模式的活動峰值之間的時間,如步行和慢跑。
每個用戶為每項活動生成的示例數量都不相同。轉換后的數據集包含例子數量為 5 424,六種活動分布如表 2 所示。對于轉換過程,需要 10 s 的時間段加速計樣本(原始文件中的 200 條記錄/行),并將它們轉換為一個包含 45 個值的單個示例/元組[10]。處理后的字段說明如下:
{ID,X0..X9,XAVG,XPEAK,XABSO,XSTAND,Y0..Y9,YAVG,YPEAK,YABSO,YSTAND,Z0..Z9,ZAVG,ZPEAK,ZABSO,ZSTAND,RESULTANT,class}
數據第一列是數據來源的用戶的 ID 號碼,與最后的分類結果是不相關的,將其作為無效數字處理;X0..X9,Y0..Y9,Z0..Z9 是分段數據的數值;XAVG、YAVG、ZAVG 分別對應于 x、y 和 z 的平均值;XPEAK、YPEAK、ZPEAK 對應于峰間時間。如果峰的數量小于 3,則門限降低到至少可以找到 3 個峰值。XABSO、YABSO、ZABSO 是絕對的平均值偏離每個軸的平均值。XSTAND、YSTAND、ZSTAND 是標準偏差,也是對應于每個軸。RESULTANT 的值對應于平均絕對加速度,最后一列的 class 是在此示例中用戶正在執行的活動,即識別和預測的人體活動狀態。數據轉換和特征生成的流程圖如圖 2 所示。
圖2
特征生成和數據轉換流程圖
Figure2.
The flowchart of the generation of features and the data conversion
2.2 CNN 分類識別算法
CNN 的結構主要分為兩層,第一層是特征提取層,這一層中神經元的輸入端直接與前一層的接受域相連,能夠提取到接受域的特征,而成功提取到相關特征后,與每個特征之間的位置關系就確定了下來。第二層為特征映射層,多個特征映射組成了 CNN 的計算層[14-15]。本文所采用的 CNN 模型,包括五層結構:輸入層、卷積層、池化層、全連接層、輸出層。其中卷積層提供多個相同的局部過濾器,形成多個輸出矩陣,每個輸出矩陣的大小是 N ? m + 1,計算過程如下:
|
其中 中的 l 表示第 l 個卷積層,i 表示第 i 個卷積輸出矩陣的某個值,j 表示對應的輸出矩陣的編號,從左往右依次表示為 0 到 N,N 為卷積輸出矩陣的個數。f 表示非線性函數,本文采用了影響函數核小的 sigmoid 函數。sigmoid 函數計算公式如下:
|
本文的池化層采用局部求均值的方式進行降維。計算公式如下:
|
式中, 表示進行池化過程后局部的一個輸出項,它是由上一層大小為 n*n 的局部小矩陣進行求均值所得到的。
全連接層:將網絡學習到的特征映射到樣本的標記空間中,全連接層會把卷積輸出的二維特征向量轉化成一維的特征向量。
本文基于以上步驟構建了 CNN 模型結構,對三軸數據進行并行處理。首先通過輸入層輸入三軸加速度計采集到的原始時間序列數據,然后通過卷積層進行數據處理:使用 196 個卷積濾波器進行并行學習,創建豐富的數據特征表示,其中每個濾波器的大小為 1 × 12,卷積的步長為 1。隨機失活率為 0.15。將 sigmoid 函數應用于生成的 200 個特征表示,使用 1 × 4 大小的最大池化層進行 4 倍降維。再將池化層的輸出展平,并與其他統計特征(平均加速度、標準偏差、平均絕對差、平均絕對加速度等)疊加在一起。聯合組成的特征向量隨后被傳遞到全連接層,進行特征標記分類,最后通過輸出層輸出六種活動的一維特征向量[16],CNN 訓練流程圖如圖 3 所示。
圖3
CNN 模型流程圖
Figure3.
The flowchart of CNN training
CNN 中同一個特征映射面上所有神經元的權值都是一樣的,所以網絡學習過程可以是并行學習,這也是相較于其他由神經元直接相連構成的網絡的優勢。由于 CNN 的這一特性,其在語音識別、圖像處理等方面具有相當大的優勢,權值共享這一特性大大降低了神經網絡的復雜程度,在處理具有多維輸入的數據方面具有極大的優勢,從而極大地提高了 CNN 的可用性[17]。
3 實驗結果及其分析
本文基于 Tensorflow 平臺,采用 Python 編程語言,構建 CNN 識別模型并進行分析,同時引入 KNN 與隨機森林識別模型作為對比,進一步評估基于 CNN 識別模型的準確率[18]。
表 3 比較了基于 CNN、KNN 及隨機森林的分類結果,采用如下三個指標進行識別結果的評價:準確率(Accuracy)表示模型對正樣本的準確度,召回率(Recall)表示模型對正樣本的識別正確率;F1 分數(F1-score)表示一個模型的綜合評價指標,是基于召回率和精確率(Precision)計算的。Accuracy 計算公式如下:
|
式中,TP(true positive)表示實際為正樣本預測為正樣本,TN(true negative)表示實際為負樣本預測為負樣本,FP(false positive)表示實際為負樣本預測為正樣本,FN(false negative)表示實際為正樣本預測為負樣本。其中,分類正確的是正樣本,分類錯誤的是負樣本。
Recall 計算公式如下:
|
F1-score 計算公式如下:
|
式中,Precision 計算公式為:
|
WISDM 數據庫是常用的人體活動識別評價數據集[19],本文將 CNN 與傳統的 KNN 和隨機森林分類算法進行比較。這里,KNN 算法中采用歐氏距離找到鄰近的樣本,K 值選為 5,隨機森林算法中樹的數目為 n_estimators = 100。通過實驗結果可以看到:對于相同的 WISDM 數據集,KNN 的平均分類識別正確率為 73.00%,對上樓、下樓、坐和站立的識別準確率都只能達到 30% 左右,召回率值為 68.44%,所以在本實驗中 KNN 相較于 CNN 具有明顯的劣勢,而且對部分活動 30% 左右的識別率完全達不到實驗要求。而隨機森林的平均分類識別正確率為 82.90%,對上樓、下樓、坐和站立的識別準確率都比 KNN 算法的識別準確率高,召回率能達到 83.05%。由此可見,隨機森林分類模型的分類結果要明顯好于 KNN,但相較于 CNN,仍然具有一定的差距。這是由于 CNN 比傳統算法對局部和相關特征具有更高的識別能力,而且本文中的人體活動識別數據具有時間連續性,采用 CNN 識別也就更有優勢,所以活動識別率相差較大。
使用 CNN 對轉換后的 WISDM 數據集進行分類時,當訓練次數達到 3 000 次(表中所列數據),分類的正確率能達到 92.73%;當訓練次數逐漸增加,在 50 000 次時,模型正確率能達到 93.16%,這完全符合實驗預期和要求。但考慮到實際情況,若每一個模型的訓練次數都為 50 000 次,不僅耗費的時間長,而且 3 000 次和 50 000 次的識別正確率相差不大。在實際測試中,達到 3 000 次的訓練次數就能滿足要求了,若訓練次數持續增加,考慮到運行時間、設備要求,則實驗性價比會相應降低。CNN 對每個活動的識別率都很高,對站立和上樓梯的識別相對較低,但也能達到 82% 以上;而且準確率和 F1 分數也能達到較好的效果。CNN 訓練次數與分類精確率之間的關系如圖 4 所示。有一些研究將傳統的分類模型對人體活動進行集成分類,也取得了不錯的分類效果。如 Cagatay 等[20]采用的一種優化集成分類器,其人體活動的平均識別率為 91.62%,而本文的 CNN 模型達到了 92.73%。上述實驗結果表明,基于 CNN 的識別模型能有效地識別人體活動。
圖4
CNN 訓練次數與分類精確率之間的關系
Figure4.
Relation between training times of CNN and classification precision
4 結論
人體活動識別研究可以為用戶的身體活動、能量消耗及鍛煉需求等提供客觀評價和合理建議,在慢性疾病的預防和輔助治療等生物醫學領域具有重要意義[21]。本文使用 CNN 模型對基于 WISDM 的數據集進行了人體活動分類識別,并對模型進行了評估。分類結果表明,基于 CNN 模型的人體活動識別具有較高的分類精度和魯棒性。在今后的研究中,可以進一步融入智能移動設備中的陀螺儀和磁力計等其他慣導數據,實現更準確的識別精度以及更多的活動分類,從而促進基于智能移動設備的人體活動識別在生物醫學和人體健康領域發揮更重要作用。
利益沖突聲明:本文全體作者均聲明不存在利益沖突。