如何從復雜的靜息態功能核磁共振成像(rs-fMRI)數據中提取高鑒別性特征,是提升精神分裂癥識別精度的關鍵。本文使用一種加權稀疏腦網絡構建方法,采用肯德爾相關系數(KCC)從腦網絡中提取連接特征,并基于線性支持向量機對 57 例精神分裂癥患者與 64 例健康受試者進行分類研究,最終得到了較高的分類精度(81.82%)。本文研究結果表明,相較于傳統的皮爾遜相關和基于稀疏表示的腦網絡構建方法,以及常用的雙樣本t檢驗(t-test)和最小絕對收縮與選擇算子(Lasso)特征選擇方法,本文提出的算法可以更有效地提取出能夠區分精神分裂癥患者與健康人群的腦功能網絡連接特征,進而提升分類精度;同時本研究中所提取的鑒別性連接特征或可作為潛在的臨床生物學標志物,用以輔助精神分裂癥的診斷。
引用本文: 余仁萍, 余海飛, 萬紅. 基于靜息態功能磁共振成像的精神分裂癥腦網絡特征分類研究. 生物醫學工程學雜志, 2020, 37(4): 661-669. doi: 10.7507/1001-5515.201908007 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
引言
精神分裂癥是一種嚴重的全球性精神類疾病,其病因未知,癥狀各異。一旦患病,患者會出現感知、思維、情感和行為等多方面的障礙及精神活動的不協調[1]。目前臨床上對精神分裂癥的診斷主要依靠醫生對患者病史以及臨床癥狀的全面評估,然而精神疾病之間重疊的癥狀與醫生評估的主觀性使得傳統的診斷方法并不高效。
靜息態功能核磁共振成像(resting-state functional magnetic resonance image,rs-fMRI)具有無創性、無放射性、時空分辨率高、易于操作且可重復等優點,同時數據采集時不需要受試者配合完成復雜的任務,近年來已廣泛應用于腦功能相關的各項研究[2-3]。在靜息狀態下,功能核磁共振信號的低頻血氧水平依賴(blood oxygen level dependent,BOLD)信號被認為可以反映大腦的自發性神經波動,而該波動與大腦的內在神經活動密切相關,這使得 rs-fMRI 可以捕捉到更復雜更精確的神經活動[4]。已有研究表明,人腦的各個功能區域并不是獨立工作的,而是通過相互之間的協調配合達到完成某項任務的目的,而腦網絡可以有效地表示大腦各個功能區域之間的這種協調交互作用[5],根據腦功能磁共振數據構建出有意義的腦功能連接網絡是針對所有后續關于疾病等預測分類的前提和基礎,因此如何構建腦功能連接網絡并提取有助于分類的高鑒別性特征是分析研究的關鍵所在。
皮爾遜相關(Pearson’s correlation,PC)是目前構建腦網絡最常用的方法,這種方法通過計算兩兩預定義節點間的相關系數(作為連接邊)來構建相關矩陣(作為腦網絡),但是這僅僅描述了在不考慮其他變量影響下兩個變量間的內在功能相關性。對于包含多變量的情況,如多個腦區信號,兩個變量間的關系往往會受到其他變量的影響。為了將這種影響考慮在網絡構建中,有研究者提出稀疏表示(sparse representation,SR)腦網絡建模方法[6]。通過這一方法,腦網絡稀疏性先驗被加入到網絡的構建中,從而可以得到更容易解釋的稀疏連接網絡。但 SR 模型在求取兩兩節點之間的連接時,雖然考慮了其他節點的影響,卻將所有其他節點等同對待,這會導致在稀疏性的約束下求取的連接系數不能真實地反映腦區間關聯。
因此,為克服目前常用腦網絡建模方法的不足,本文采用前期工作提出的基于 SR 的加權稀疏腦網絡模型(weighted sparse representation,WSR)來對腦功能網絡進行建模[7]。該模型假設目標腦區的 BOLD 信號更趨向于被一些波動高度一致的腦區 BOLD 信號來線性表達,使用懲罰系數對原 正則化項進行改進,從而可以構建一種更具生物學意義的腦網絡。然后,本研究將網絡連接作為特征,使用肯德爾相關系數(Kendall correlation coefficient,KCC)進行特征選擇,并用支持向量機(support vector machine,SVM)對精神分裂癥患者和正常健康人群進行分類,以期尋找可用于臨床診斷的生物學標志物,提升當前精神分裂癥自動診斷精度。本研究可以為腦網絡構建及精神分裂癥患者腦功能分析提供一個新的建模方法,同時本文中所選取的特征/連接或可作為潛在的生物學標志物以期輔助臨床上精神分裂癥的診斷。
正則化項進行改進,從而可以構建一種更具生物學意義的腦網絡。然后,本研究將網絡連接作為特征,使用肯德爾相關系數(Kendall correlation coefficient,KCC)進行特征選擇,并用支持向量機(support vector machine,SVM)對精神分裂癥患者和正常健康人群進行分類,以期尋找可用于臨床診斷的生物學標志物,提升當前精神分裂癥自動診斷精度。本研究可以為腦網絡構建及精神分裂癥患者腦功能分析提供一個新的建模方法,同時本文中所選取的特征/連接或可作為潛在的生物學標志物以期輔助臨床上精神分裂癥的診斷。
1 材料和方法
1.1 數據采集及預處理
本文實驗所采用的數據來自于美國腦網絡研究機構(the Mind Research Network)和新墨西哥大學在網上公開分享的數據集,該數據集項目由美國國立衛生研究院生物醫學研究中心(the Center for Biomedical Research Excellence,COBRE)資助,下載網址為:http://fcon_1000.projects.nitrc.org/indi/retro/cobre.html。實驗數據集中包含 57 例慢性精神分裂癥患者以及 64 例健康受試者的數據,并以健康受試者的數據作為正常對照,數據集樣本的人口統計學信息如表 1 所示。
所有患者均按美國精神疾病診斷與統計手冊第四版(diagnostic and statistical manual of mental disorders,DSM-IV)診斷標準,由合格的精神科醫師鑒定確診,癥狀嚴重程度采用陽性和陰性綜合征量表(positive and negative syndrome scale,PANSS)評定。排除標準包括:① 患有其他 DSM-IV 診斷標準確認的精神障礙;② 曾有藥物濫用史;③ 曾具有臨床意義的頭部創傷。同時,所有正常對照也均已證實沒有精神分裂癥或其他精神障礙、沒有藥物濫用史或重大的頭部外傷史。
rs-fMRI 圖像通過梯度平面回波成像序列獲取,其中重復時間/回波時間 = 2 000 ms/29 ms;采集矩陣 = 64 × 64;層數 = 32;體素大小 = 3 mm × 3 mm × 4 mm;視野 = 256 mm × 256 mm。
使用統計參數圖軟件 SPM8(The Wellcome Centre for Human Neuroimaging,UCL Queen Square Institute of Neurology,英國)以及 rs-fMRI 數據預處理助手軟件 DPARSF(State Key Laboratory of Cognitive Neuroscience and Learning,Beijing Normal University,中國)對采集數據進行預處理。處理步驟包括:① 去除所有對象的前 10 個時間點,以排除掃描前期的不穩定影響。由此,最終得到的數據含 150 個時間點;② 進行時間層校正;③ 去除頭動偽影的影響;④ 將圖像配準至蒙特利爾神經研究所(Montreal Neurological Institute,MNI)的標準空間,重采樣體素大小為 3 mm × 3 mm × 3 mm;⑤ 進行帶通濾波以減少低頻漂移和高頻生理噪聲;⑥ 回歸干擾信號;⑦ 使用自動解剖標記(the automated anatomical labeling atlas,AAL2)圖譜將腦部劃分為 120 個腦區[8]。更多詳細的數據集信息及預處理過程請參考文獻[9]及 COBRE 網站。
1.2 加權稀疏腦網絡建模
如引言部分所述,傳統的腦網絡建模往往使用的是 PC 或者 SR 方法。PC 方法通過直接計算兩兩腦區平均區域時間序列之間的 PC 系數作為腦區之間的連接關系,如式(1)所示:
 |
式中, ,
,
 為腦區 i 和腦區 j 的平均區域時間序列,M=150 為 rs-fMRI 圖像總的時間點數;corr()表示計算 xi 與 xj 的 PC 系數 Wij;Wij 表示兩腦區間的連接邊。SR 方法通過引入稀疏約束對腦網絡稀疏化先驗進行建模,其模型如式(2)所示:
為腦區 i 和腦區 j 的平均區域時間序列,M=150 為 rs-fMRI 圖像總的時間點數;corr()表示計算 xi 與 xj 的 PC 系數 Wij;Wij 表示兩腦區間的連接邊。SR 方法通過引入稀疏約束對腦網絡稀疏化先驗進行建模,其模型如式(2)所示:
 |
式中, 為腦區 i 與其他所有腦區之間連接邊組成的列向量,這里 N=120 為預定義腦區數;
為腦區 i 與其他所有腦區之間連接邊組成的列向量,這里 N=120 為預定義腦區數;
 ,表示對應于表達第 i 個腦區信號 xi 時對應的字典,將字典第 i 列置為 0 是為了避免平凡解;λ是正則化參數。WSR 方法則是在 SR 模型中引入了不同的懲罰權重 ci,使得實際求解中對不同的表達系數施加不同的懲罰強度,其模型如式(3)所示:
,表示對應于表達第 i 個腦區信號 xi 時對應的字典,將字典第 i 列置為 0 是為了避免平凡解;λ是正則化參數。WSR 方法則是在 SR 模型中引入了不同的懲罰權重 ci,使得實際求解中對不同的表達系數施加不同的懲罰強度,其模型如式(3)所示:
 |
式中, ,
, ,Pji 為第 j 個腦區 xj 與第 i 個腦區 xi 之間的 PC 系數。σ 為調整對應連接強度權重衰減速度的非負參數,設置為所有樣本所有{|Pji|}的標準差。⊙表示對應元素相乘。由(3)式可以看出,WSR 模型整合了 PC 以及 SR 建模方法的優點,既考慮了建模過程中多變量的影響,又將 PC 度量的腦區的內在連接強度體現到了模型中。
,Pji 為第 j 個腦區 xj 與第 i 個腦區 xi 之間的 PC 系數。σ 為調整對應連接強度權重衰減速度的非負參數,設置為所有樣本所有{|Pji|}的標準差。⊙表示對應元素相乘。由(3)式可以看出,WSR 模型整合了 PC 以及 SR 建模方法的優點,既考慮了建模過程中多變量的影響,又將 PC 度量的腦區的內在連接強度體現到了模型中。
1.3 腦功能網絡連接特征選擇
由上述 WSR 模型,可以通過交替方向乘子法求解構建每個個體的腦功能網絡。需要注意的是,在不加約束情況下,稀疏類方法得到的腦網絡往往是非對稱的。而已有研究表明這種非對稱關系并不利于分類任務,因此這里采用對稱化處理得到最終腦網絡,如式(4)所示:
 |
由此可以得到 7 140 維特征。由于特征維度高且存在信息冗余,為提高算法效率以及找出對疾病敏感的功能連接生物學標記,本文選取 KCC 方法對特征進行選擇[10]。
假設兩個集合分別為A和Y,本文中A和Y分別代表特征集合與標簽向量。其中A的每一行表示一個樣本,每一列表示樣本的一個特征;Y是與A排序相對應的樣本的標簽向量。考察兩個不同類樣本第i個特征以及樣本標簽間的關系,則這兩個樣本的第i個特征為一致特征對的定義如式(5)所示,為不一致特征對的定義如式(6)所示:
 |
 |
則功能連接特征i的 KCC(以符號 KCC 表示)的計算如式(7)~式(10)所示:
 |
 |
 |
 |
其中,S 為總樣本數目,D 為特征 i 一致的樣本對數,E 為特征i 不一致的樣本對數。N3 為所有樣本所有可能的兩兩組合,N1、N2 分別是向量 A?i 和 Y 中相同元素可能的兩兩組合,s 表示將 A?i 中的相同元素分別組合成小集合的數目,Uθ 表示第 θ 個小集合所包含的元素個數。同理,t 和 Vθ 在集合 Y 的基礎上計算可得。
由此得到所有特征的 KCC,之后使用 KCC 的絕對值大小代表相應特征的分類鑒別力,絕對值越大,則說明這一特征在正常組和患者組中差異越大,其分類鑒別力越強。
1.4 模型參數選擇
特征選擇后使用線性 SVM 來對樣本進行分類。SVM 在分類任務中應用廣泛,它通過尋找最大間隔超平面來劃分兩類樣本,具有較強的魯棒性。尤其當樣本量較少時,SVM 經證明是十分有效的。
在本文的方法框架中,λ參數的選取影響著最終的分類結果,需要對其尋優來最大化分類器性能。為此,采用內嵌的留一交叉驗證法(leave-one-out cross-validation,LOOCV)對相應的參數在[2?5,2?4, ,24,25]幾個備選值上進行網格尋優的同時,對分類器的泛化性能進行評估[11]。具體的,假設數據集中共有S個樣本,首先留下一個作為外層留一數據用于測試,剩下的 S ? 1 個樣本用于訓練。對上述步驟重復 S 次,每次留出不同的樣本作為測試數據,這樣就可以得到 S 個測試結果,最終分類器的泛化性能即可由這 S 個測試結果的正確率得出。而為了確定最優的參數 λ,在上述每次留出的過程中執行另外的留一交叉驗證算法,即先選定一個 λ 值,然后在 S ? 1 個訓練數據上留出一個樣本作為內層測試數據,在余下 S ?2 個數據上訓練分類器,之后將內層的測試數據在此分類器上進行測試,得到一個分類結果。對上述內嵌的留出過程執行 S? 1 次,可得到當前 λ 取值下 S ? 1 個 SVM 分類器的分類結果,該結果正確率即為當前 λ 取值下分類器的性能。變換參數 λ,即可得到不同 λ 取值下的分類器性能。最后,選擇性能最好也即正確率最高的 λ 值作為最優參數,并將外層留一的測試數據在該參數組合下 S ? 1 個 SVM 分類器上進行預測,最終使用眾數投票方法得到該外層測試數據的分類結果。
,24,25]幾個備選值上進行網格尋優的同時,對分類器的泛化性能進行評估[11]。具體的,假設數據集中共有S個樣本,首先留下一個作為外層留一數據用于測試,剩下的 S ? 1 個樣本用于訓練。對上述步驟重復 S 次,每次留出不同的樣本作為測試數據,這樣就可以得到 S 個測試結果,最終分類器的泛化性能即可由這 S 個測試結果的正確率得出。而為了確定最優的參數 λ,在上述每次留出的過程中執行另外的留一交叉驗證算法,即先選定一個 λ 值,然后在 S ? 1 個訓練數據上留出一個樣本作為內層測試數據,在余下 S ?2 個數據上訓練分類器,之后將內層的測試數據在此分類器上進行測試,得到一個分類結果。對上述內嵌的留出過程執行 S? 1 次,可得到當前 λ 取值下 S ? 1 個 SVM 分類器的分類結果,該結果正確率即為當前 λ 取值下分類器的性能。變換參數 λ,即可得到不同 λ 取值下的分類器性能。最后,選擇性能最好也即正確率最高的 λ 值作為最優參數,并將外層留一的測試數據在該參數組合下 S ? 1 個 SVM 分類器上進行預測,最終使用眾數投票方法得到該外層測試數據的分類結果。
2 實驗結果
本文采用 PC、SR 以及 WSR 方法分別構建腦網絡,并使用了雙樣本t檢驗(two-sample t-test,t-test)、最小絕對收縮與選擇算子(least absolute shrinkage and selection operator,Lasso)以及 KCC 三種特征選擇方法,一共 9 組方法進行對比實驗。實驗中,除了網絡構建和特征選擇方法有所不同,樣本量、參數選擇與泛化性能評估方法等完全相同。
2.1 網絡可視化
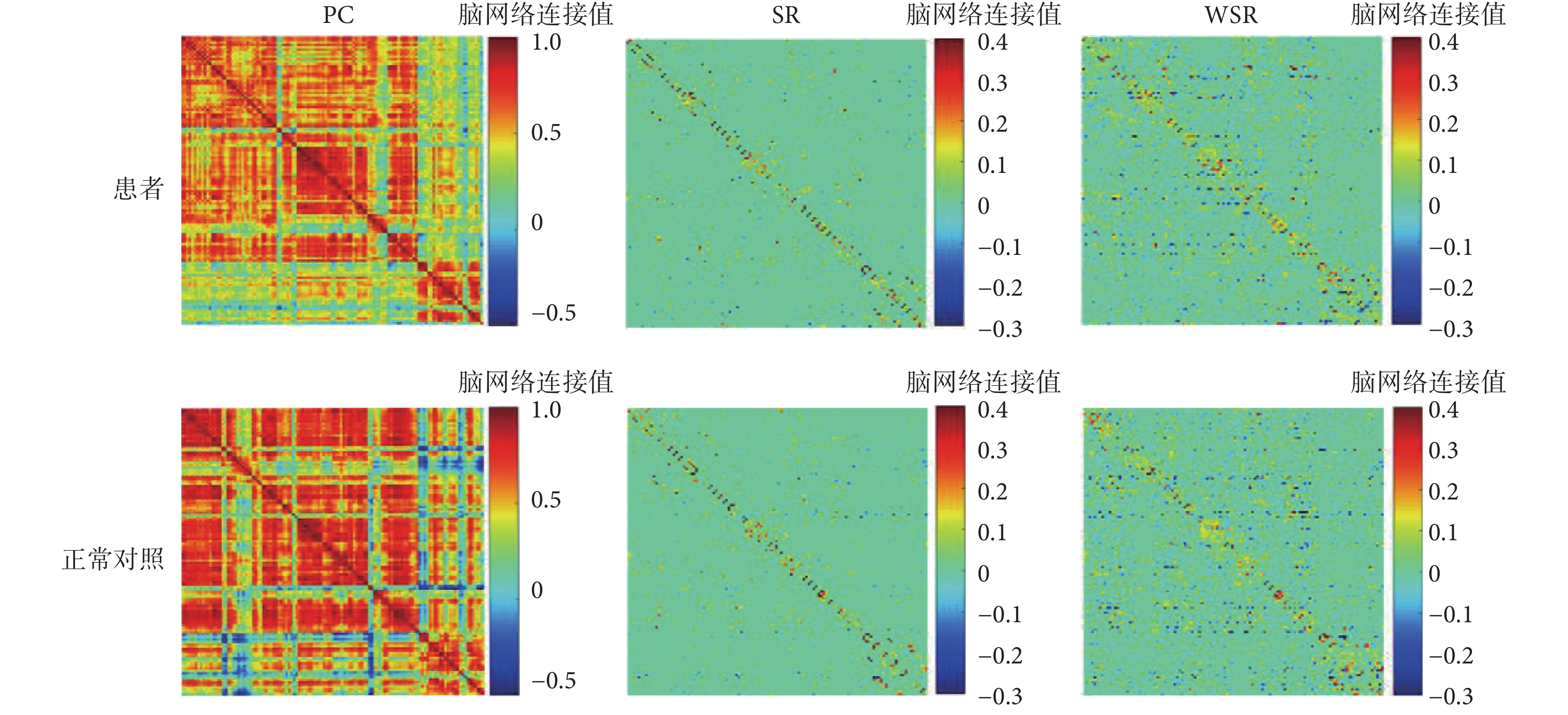
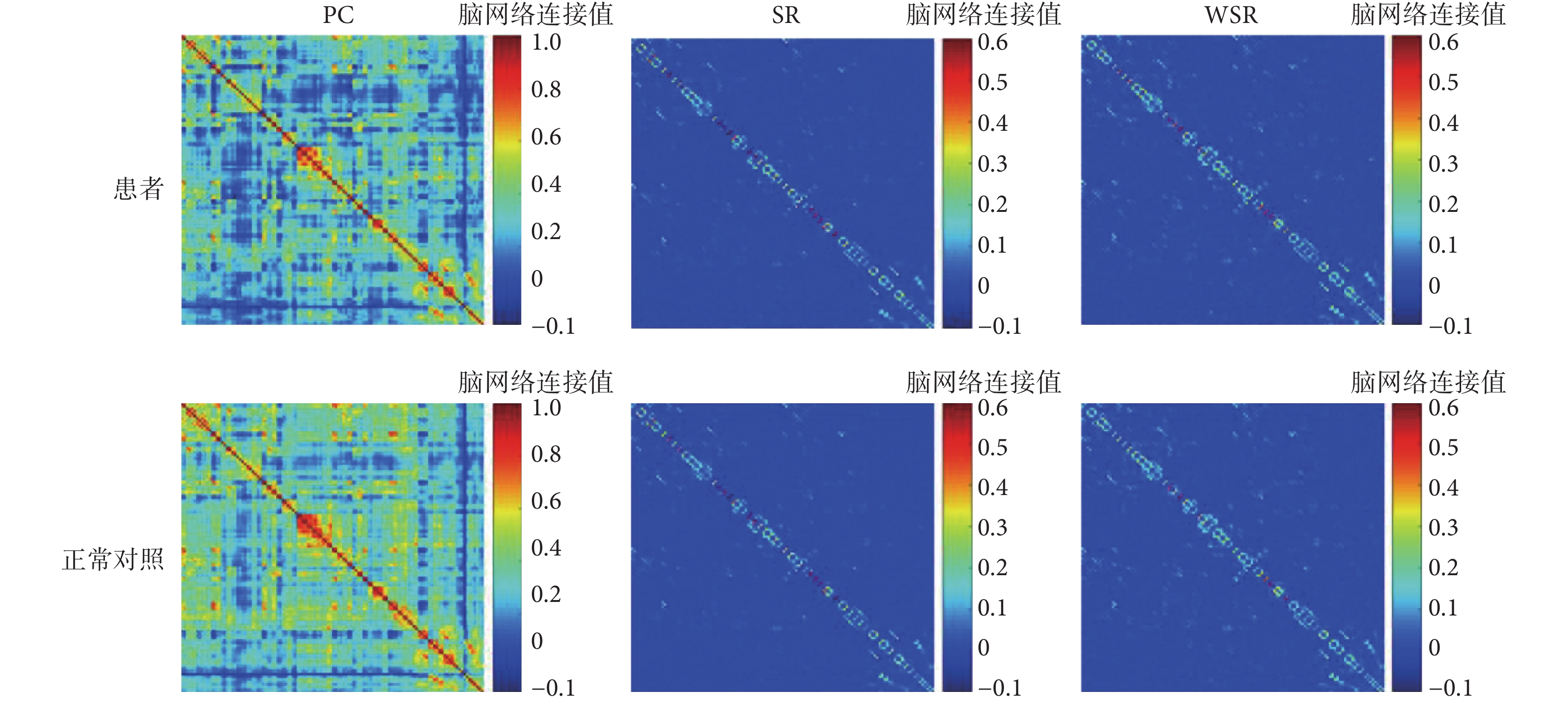
三種方法構建出的腦網絡可視化圖如圖 1 和圖 2 所示,兩圖中從上到下兩行分別為精神分裂癥樣本腦網絡與正常對照樣本腦網絡,從左到右三列分別為使用 PC、SR 和 WSR 三種方法構建的腦網絡,其中 SR 網絡中λ = 23,WSR 網絡中λ = 22。圖 1 是從數據集中隨機選取的精神分裂癥樣本與正常對照樣本的腦網絡可視化圖,圖 2 是兩個群組樣本的平均腦網絡可視化圖。分別對比圖 1 與圖 2 中三列可以看出,使用 PC 方法得出的網絡為全連接網絡,明顯要比 SR 和 WSR 構建出的網絡更稠密;而 WSR 網絡又比 SR 網絡稠密,呈現出更多的非零連接和模塊化結構,這表明了 WSR 網絡結合了 PC 度量能夠比 SR 網絡構建出更具有生物學意義的腦功能網絡。分別對比圖 1 與圖 2 中兩行網絡可以看出,正常對照的腦網絡相對精神分裂癥患者的網絡更為稠密,這在 PC 網絡中最為明顯,反映了精神分裂癥患者在功能腦網絡連接上的特異性變化。
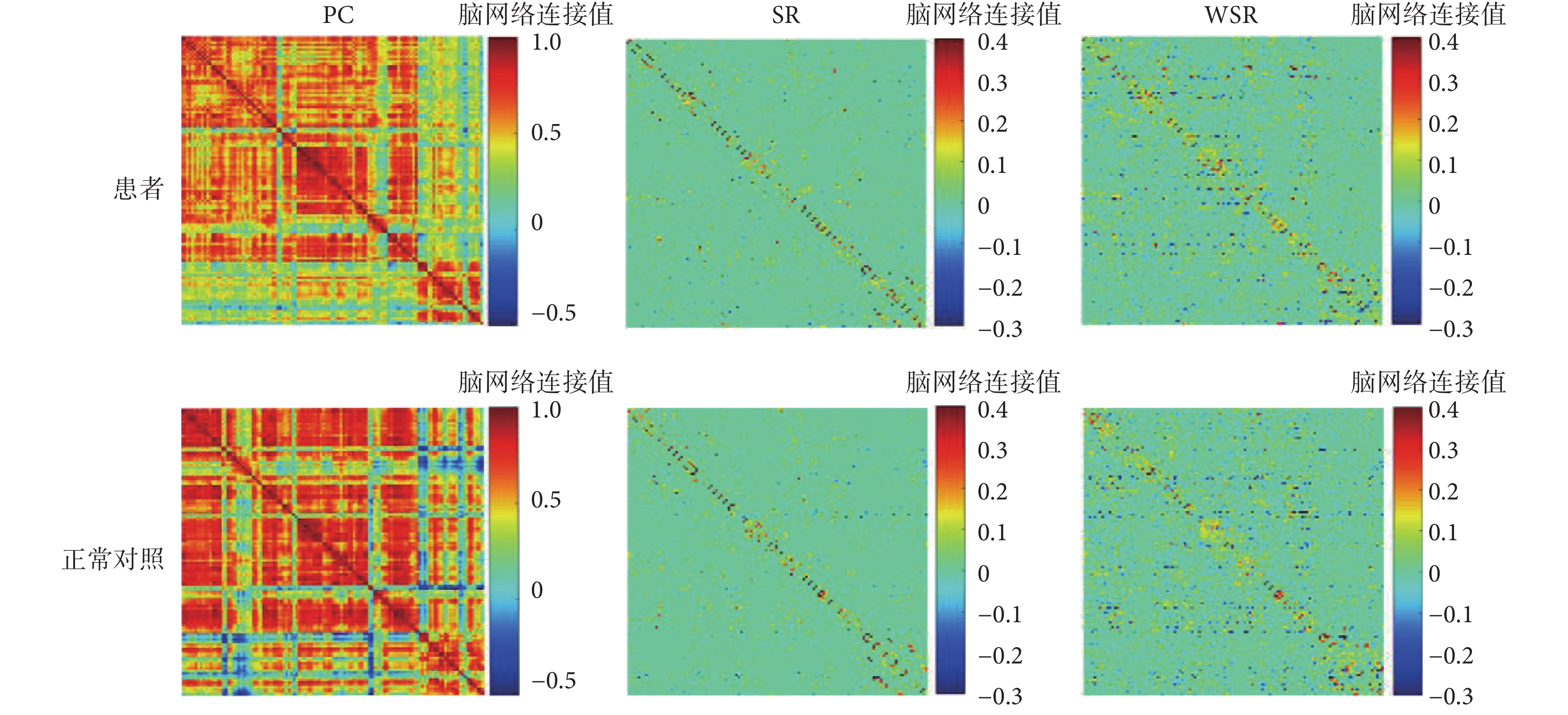 圖1
隨機選取的兩個樣本的腦網絡可視化圖
Figure1.
The brain network visualization of two randomly selected samples
圖1
隨機選取的兩個樣本的腦網絡可視化圖
Figure1.
The brain network visualization of two randomly selected samples
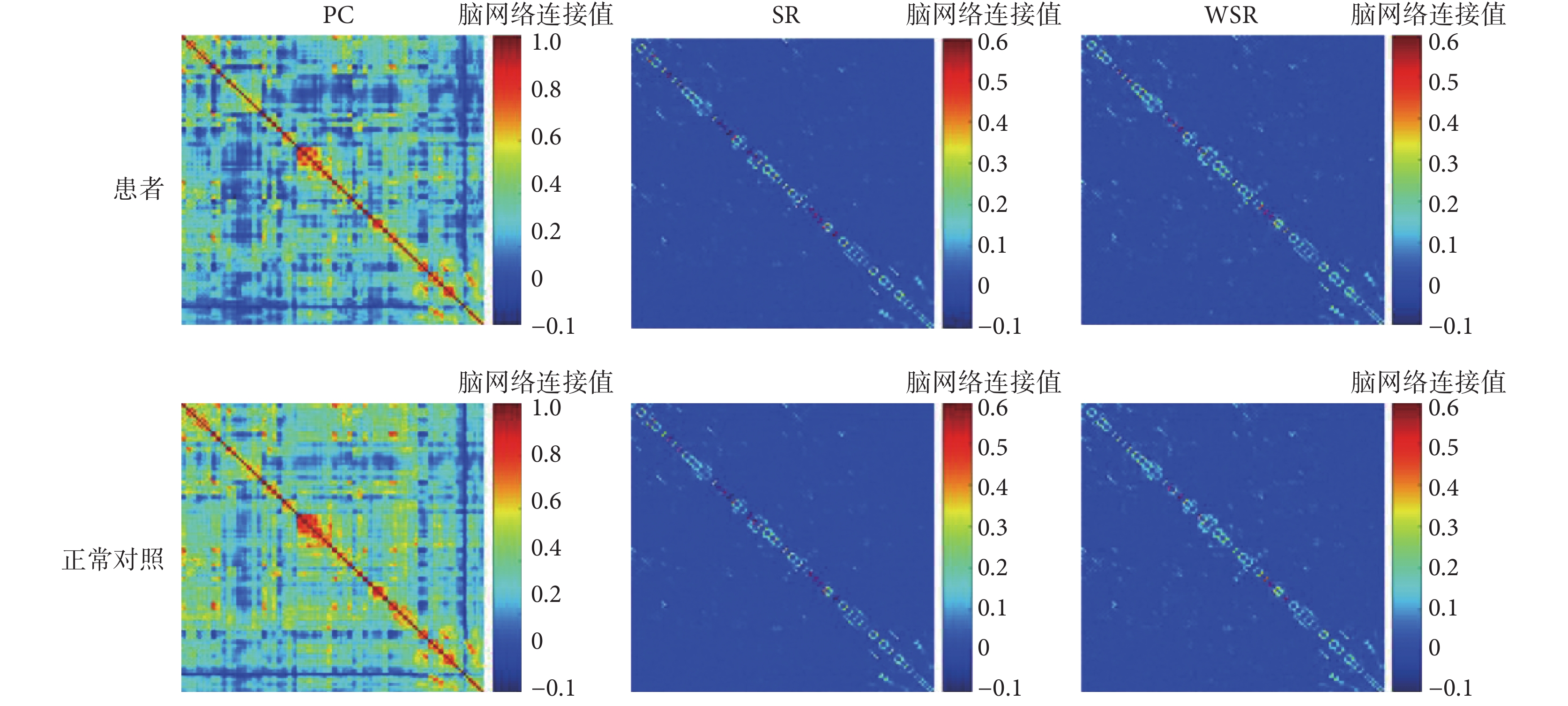 圖2
群組平均腦網絡可視化圖
Figure2.
The averaged brain network of different groups constructed by three construction methods
圖2
群組平均腦網絡可視化圖
Figure2.
The averaged brain network of different groups constructed by three construction methods
2.2 連接特征分布
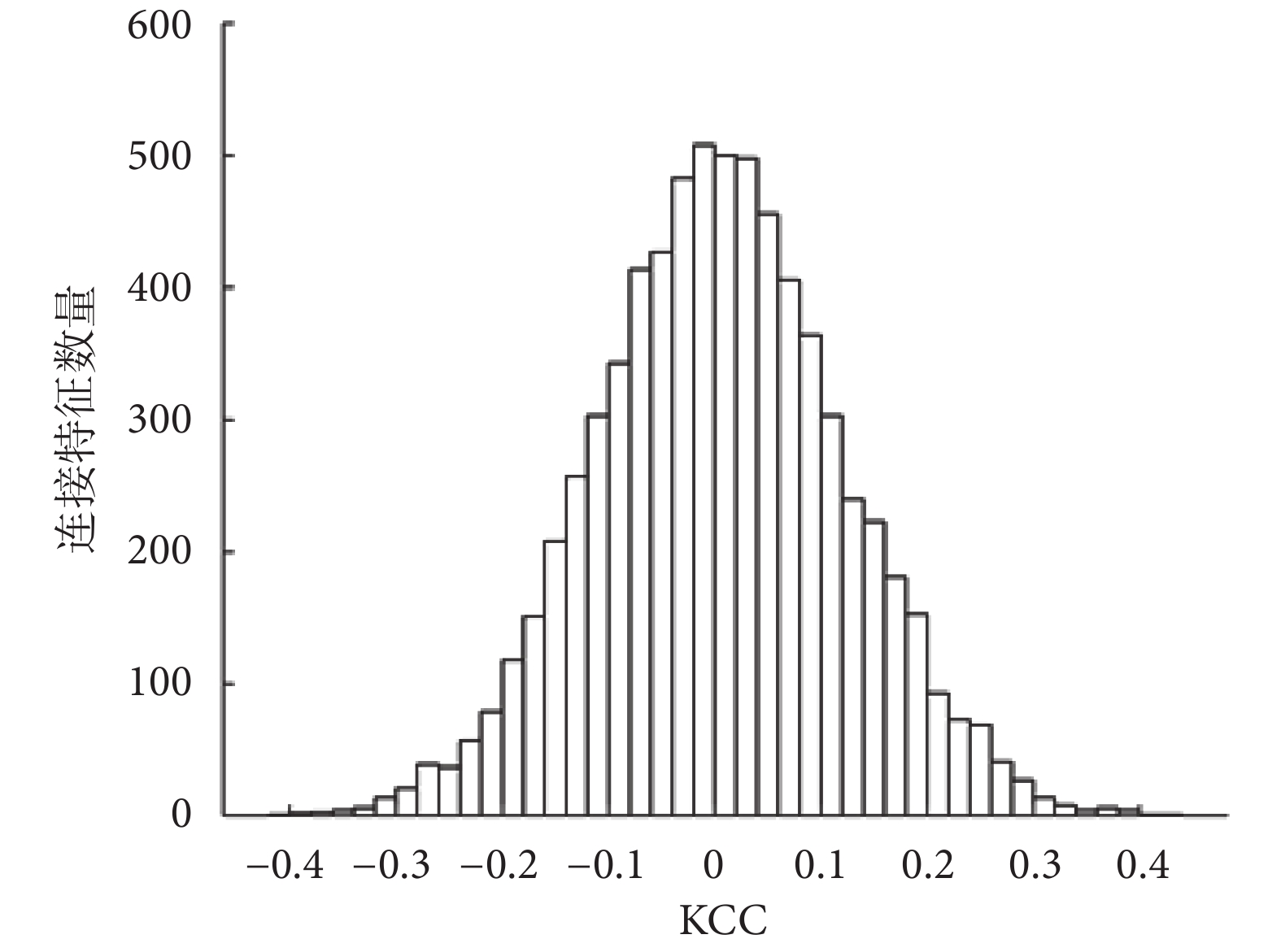
為了更直觀地觀察連接特征的鑒別力,本文統計了所有連接特征的 KCC 值,其統計分布直方圖如圖 3 所示。可以看出,特征的 KCC 近似服從正態分布,絕大多數特征的 KCC 分布在 ? 0.2~0.2 之間。因為本文將特征的 KCC 絕對值作為特征的分類鑒別力,所以實驗中只有直方圖兩側的小部分特征(約 450 個特征)被選擇用來參與后續分類,而位于圖中 0 值附近的特征并沒有顯著的鑒別能力,因此未被選擇。
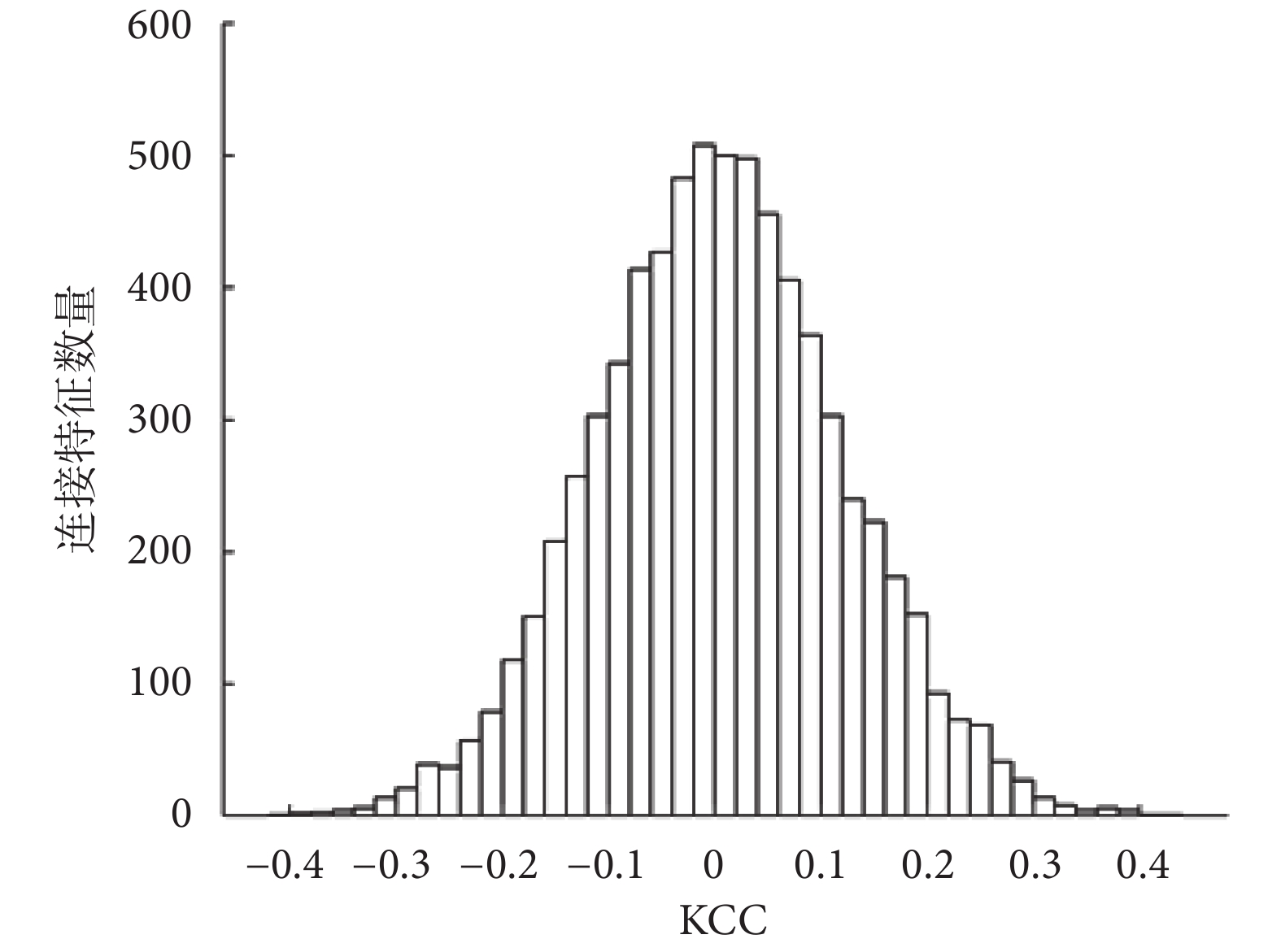 圖3
所有連接特征的 KCC 分布直方圖
Figure3.
Histogram of KCC for all connection features
圖3
所有連接特征的 KCC 分布直方圖
Figure3.
Histogram of KCC for all connection features
2.3 分類性能指標及結果
本文使用分類精度(accuracy,Acc)(以符號Acc表示)、靈敏度(sensitivity,Se)(以符號Se表示)、特異性(specificity,Sp)(以符號Sp表示)以及曲線下面積(area under curve,Auc)(以符號Auc表示)4 個定量指標來分析不同方法得到結果,同時給出了不同建模方法的受試者工作特征(receiver operating characteristic,ROC)曲線。其中,Acc、Se、Sp的計算如式(11)~式(13)所示:
 |
 |
 |
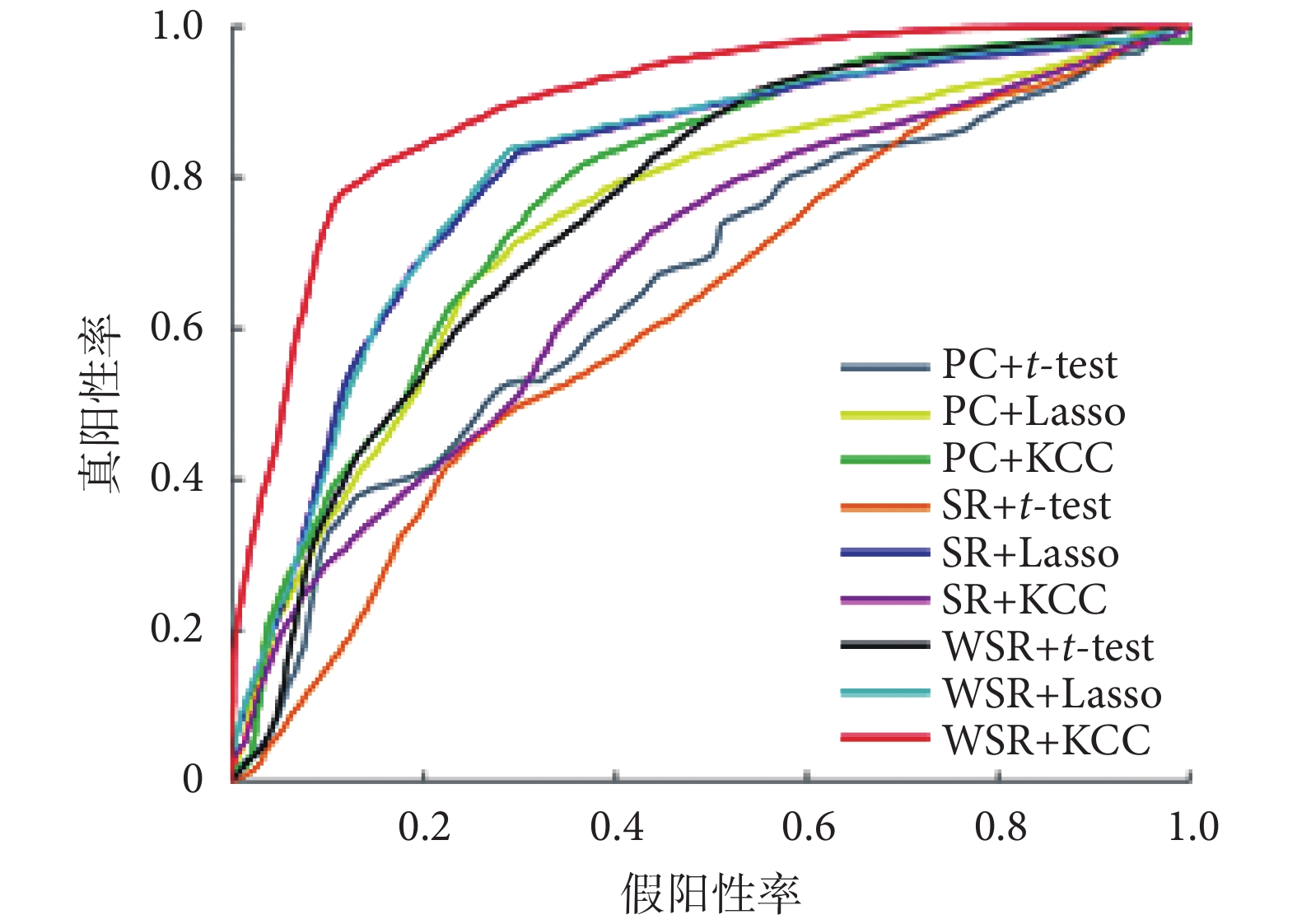
式中,TP、TN、FP、FN分別表示患者被正確分類、正常對照被正確分類、正常對照被錯分為患者、患者被錯分為正常對照的具體數值。9 組不同方法組合的分類定量結果如表 2 所示,受試者工作特征曲線如圖 4 所示。
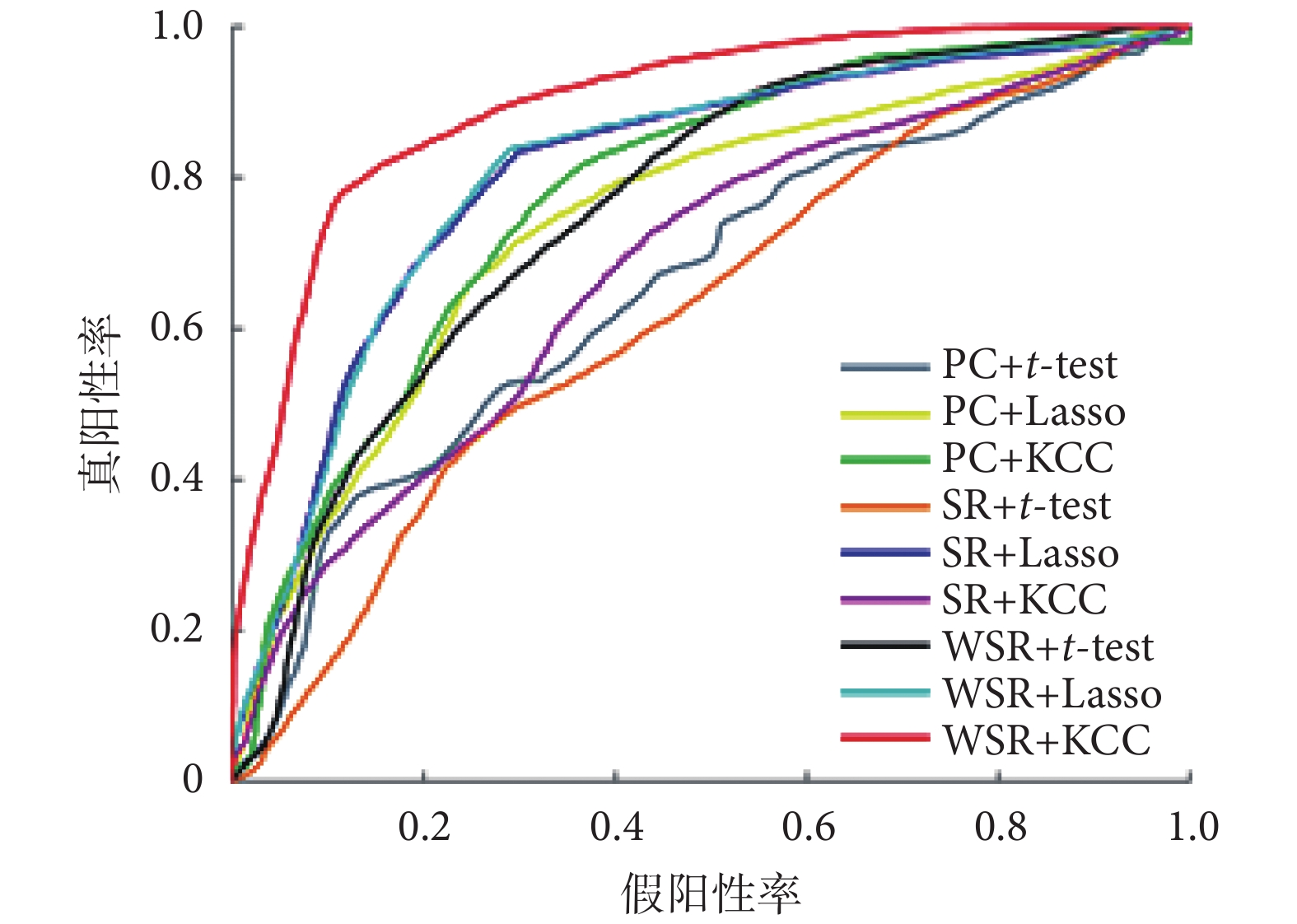 圖4
受試者工作特征曲線
Figure4.
Receiver operating characteristic curve
圖4
受試者工作特征曲線
Figure4.
Receiver operating characteristic curve
3 分析與討論
3.1 分類性能對比
PC 腦網絡建模方法可以較好地刻畫兩兩腦區間的內在功能連接強度[12],但構建的網絡包含一些冗余、不重要的連接,這些連接對腦區間的關系挖掘不夠充分,不能較好地分類患者和健康對照。SR 腦網絡建模方法在計算兩兩腦區之間的連接時對其他腦區的影響進行了考慮,但卻將所有其他腦區等同對待,求解過程中會導致一些符合目標函數最小但不符合內在連接強度的計算結果產生,因此并不能給分類性能帶來直接的提升。而 WSR 腦網絡建模方法則能夠整合 PC 和 SR 兩種方法的優點,更深入地挖掘到更復雜的腦區間連接關系,有效提升分類精度。由表 2 可以看出,無論采用哪種特征選擇方法,WSR 方法都能夠獲得比 PC 和 SR 更高的分類精度,尤其當使用 KCC 進行特征選擇時,能夠得到 81.82% 的分類精度。
對比不同的特征選擇方法,可以發現 KCC 方法在 PC 腦網絡與 WSR 腦網絡上都表現出色,明顯優于t-test 與 Lasso 兩種特征選取方法,而基于 Lasso 的特征選取方法又優于t-test。這與不同特征選擇方法的原理有關:其中t-test 只是將兩組中某一特征的均值是否一致作為特征選擇的依據,并且將各個特征單獨處理,較為粗糙;Lasso 特征選擇方法則考慮了特征之間的相互影響,聯合所有特征來選擇特征子集,因此可以得到與 KCC 相近的分類結果;而 KCC 是用于測量兩個隨機變量之間的序數關聯的統計量,相對于另外兩種方法,它可以更敏感更直接地反映出患者組中的某一特征相對于正常組是否普遍發生了變化,與分類任務十分契合。此外,基于 Lasso 的特征選擇方法在三種腦網絡中都得到了最高的靈敏度,這意味著采用這種特征選擇方法的分類框架對患者更加敏感,這在實際疾病診斷中是更重要的,因為錯誤將患者診斷為正常人則可能導致其錯失疾病治療的最佳時機。
3.2 最具鑒別力的連接及相關腦區
復雜網絡理論的出現,為在數學框架下對功能連接進行定量描述提供了手段,目前已大量應用在與腦科學相關的研究中[13]。靜息態下尤其是默認模式網絡(default mode network,DMN)中的功能連接被認為反映了自我參照和自省的精神過程[14],已有研究表明精神分裂癥患者在自我歸因、自我參照、自我意識等方面都表現出了明顯的不同[15-16],許多研究人員認為這種不同與精神分裂癥患者腦區間的異常功能整合密切相關。一種被普遍接受的說法是精神分裂癥的功能失連接假說,即腦區之間正常功能相互作用的復雜模式在精神分裂癥患者中發生了改變[17]。更進一步,一些研究指出,這種功能失連接并不僅僅局限于某些特定的腦區,而是廣泛分布于精神分裂癥患者的全腦中[18]。
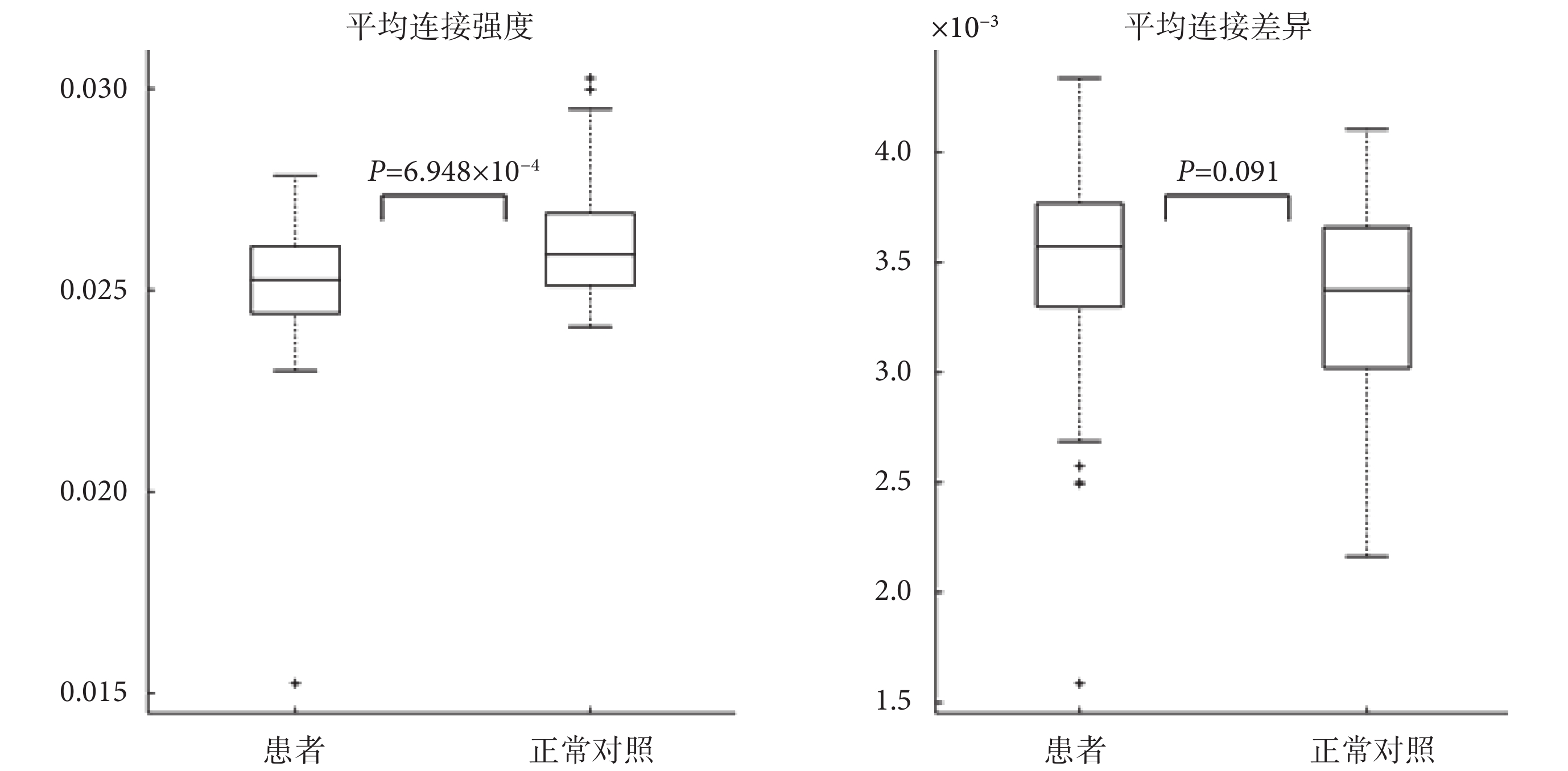
本文的研究同樣驗證了之前關于精神分裂癥功能連接改變的結論。兩組樣本 WSR 功能網絡平均連接強度與平均連接差異的箱線圖如圖 5 所示(網絡的λ參數選在 22,進行統計之前對網絡中元素做了絕對值處理)。其中,某樣本功能連接的平均連接強度的計算方式如下:先計算該樣本腦網絡矩陣中每列元素的均值作為單個腦區的功能連接強度,再對所有腦區的功能連接強度求均值得到;類似的,某樣本功能連接的平均連接差異的計算方式如下:先計算該樣本腦網絡矩陣中每列元素的方差作為單個腦區的功能連接差異,再對所有腦區的功能連接差異求均值得到。
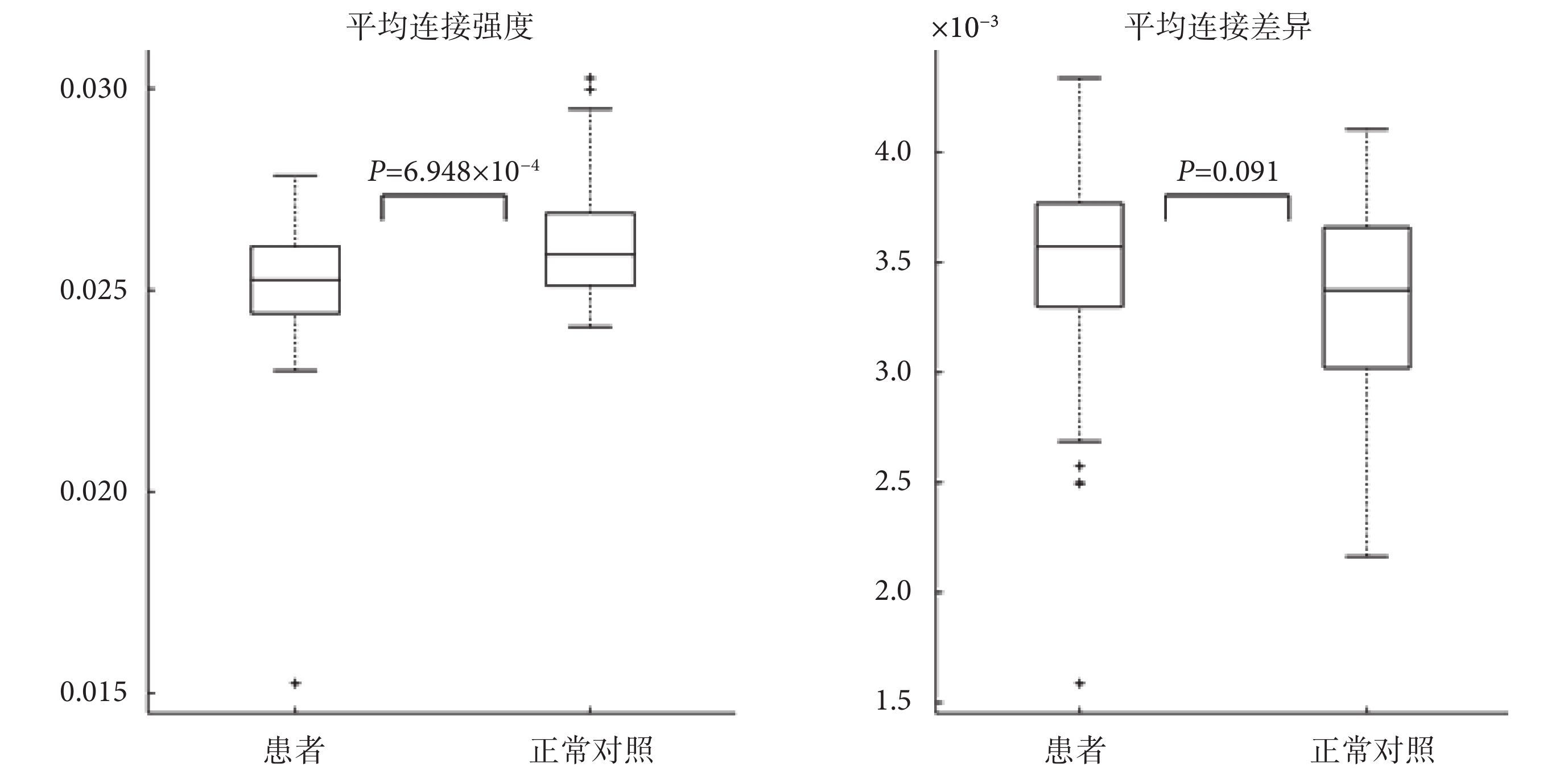 圖5
兩組樣本的 WSR 網絡的平均連接強度與平均連接差異
Figure5.
Average connection strength and average connection diversity of two groups
圖5
兩組樣本的 WSR 網絡的平均連接強度與平均連接差異
Figure5.
Average connection strength and average connection diversity of two groups
由圖 5 中可以看出,對比正常對照組,精神分裂癥患者組的平均功能連接強度有著顯著的下降,說明患者的腦連接呈現出減弱的趨勢,這也與之前的研究相符合[19]。
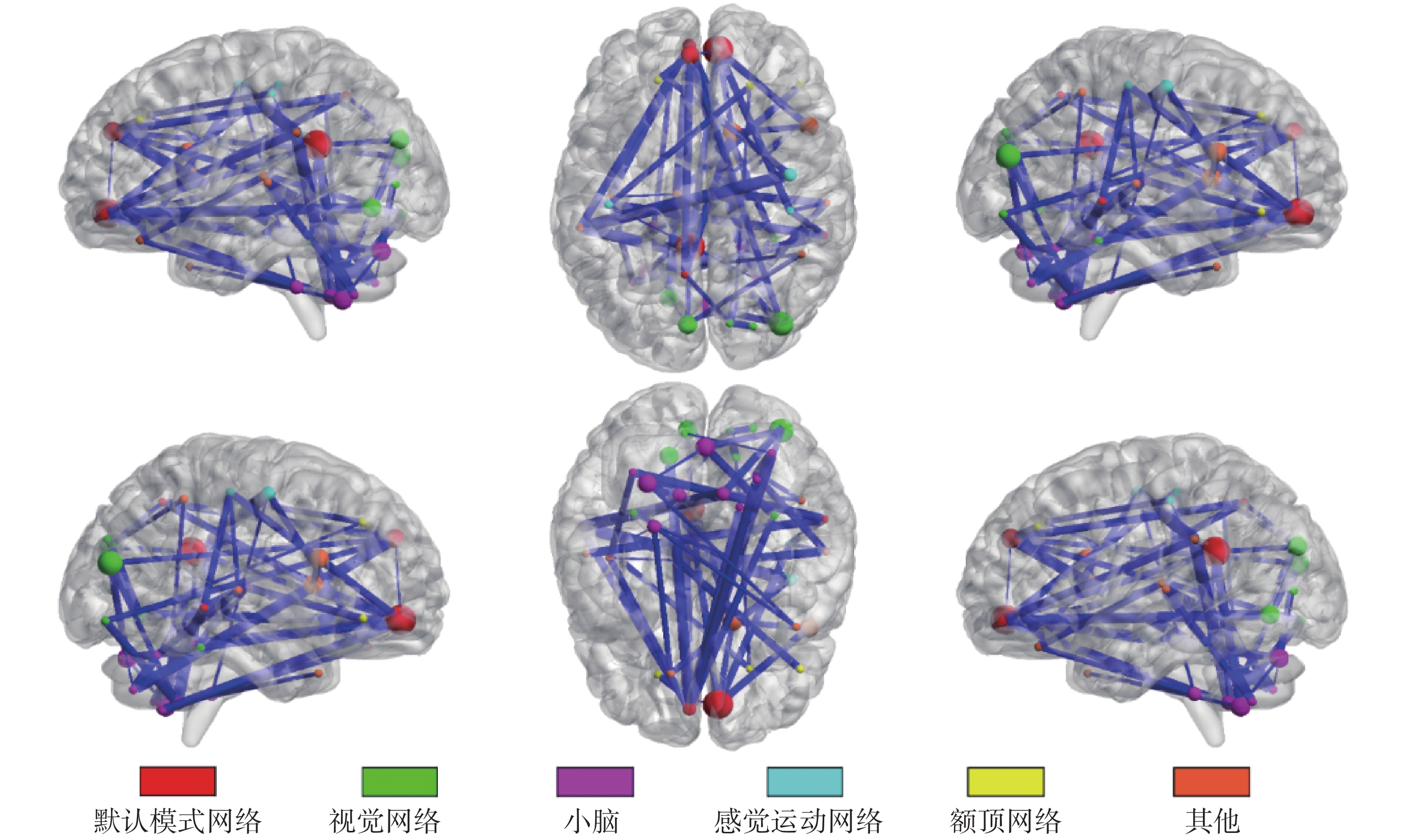
之前許多研究都報道了精神分裂癥患者在默認模式網絡[20],視覺網絡(visual network,VIN)與小腦網絡(cerebellum network,CEN)等網絡上的特異性變化[10, 21]。在使用本文提出的分類框架(WSR + KCC)對精神分裂癥患者進行分類時,涉及到這些網絡的連接同樣起到了重要的作用。為了更深入地了解到哪些連接特征對分類任務的貢獻最大,本文統計了訓練測試過程中所有樣本、所有留一循環中都一致被選擇的連接特征,并進一步篩選得到共 55 條連接(涉及 43 個腦區)。在全腦視圖下對這些連接以及涉及的腦區進行展示,如圖 6 所示。其中,圓點代表大腦腦區,其對應的顏色表示腦區所屬的大腦固有網絡。圓點的大小與邊的粗細反映了相應腦區和連接在分類任務中的重要程度,圓點越大,則對應腦區在所有分類過程中被選擇的次數越多,邊越粗,則表示對應連接在分類過程中越具有鑒別力。
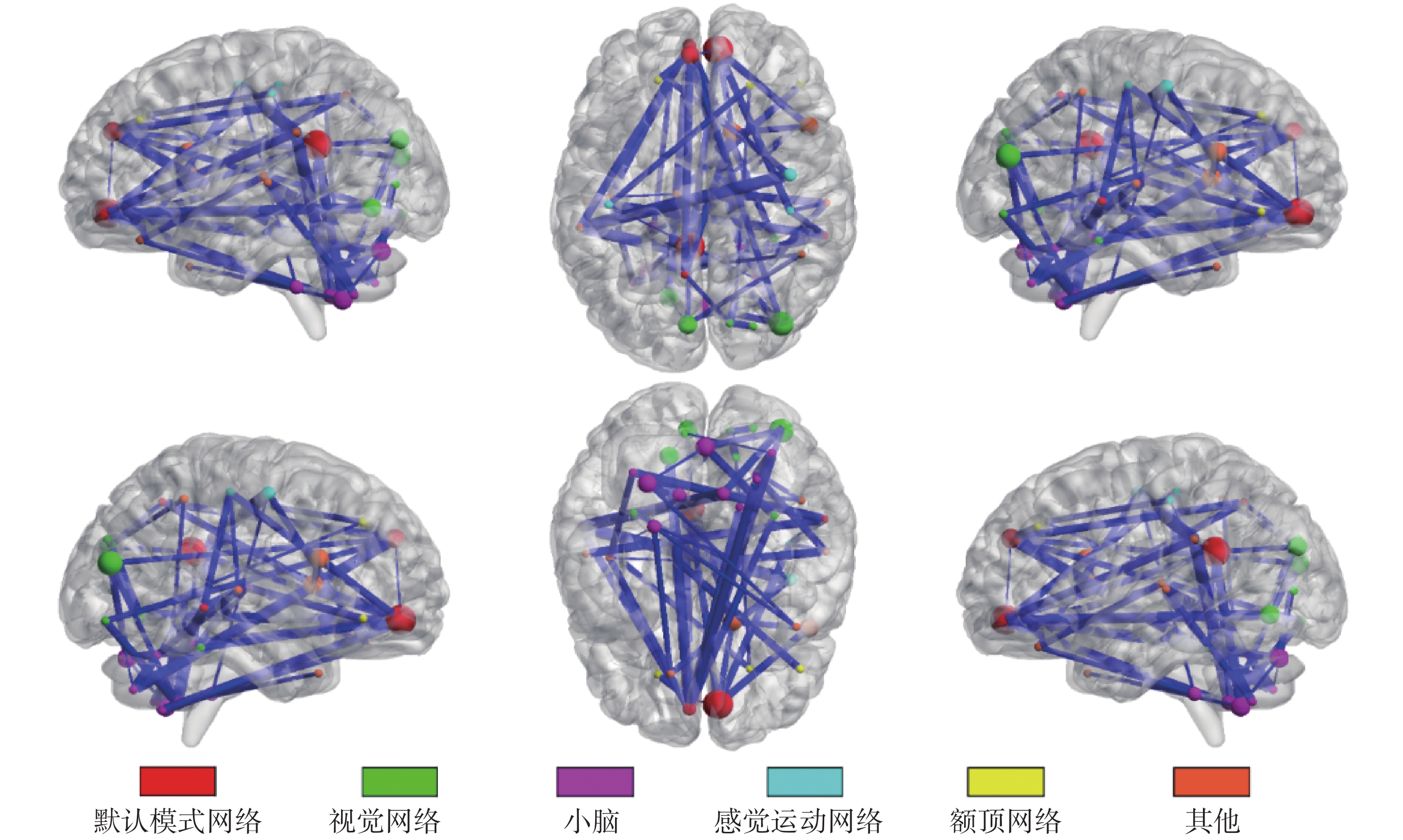 圖6
全腦視圖下最具鑒別力的腦區和連接
Figure6.
The most discriminating connections and brain regions in the whole brain view
圖6
全腦視圖下最具鑒別力的腦區和連接
Figure6.
The most discriminating connections and brain regions in the whole brain view
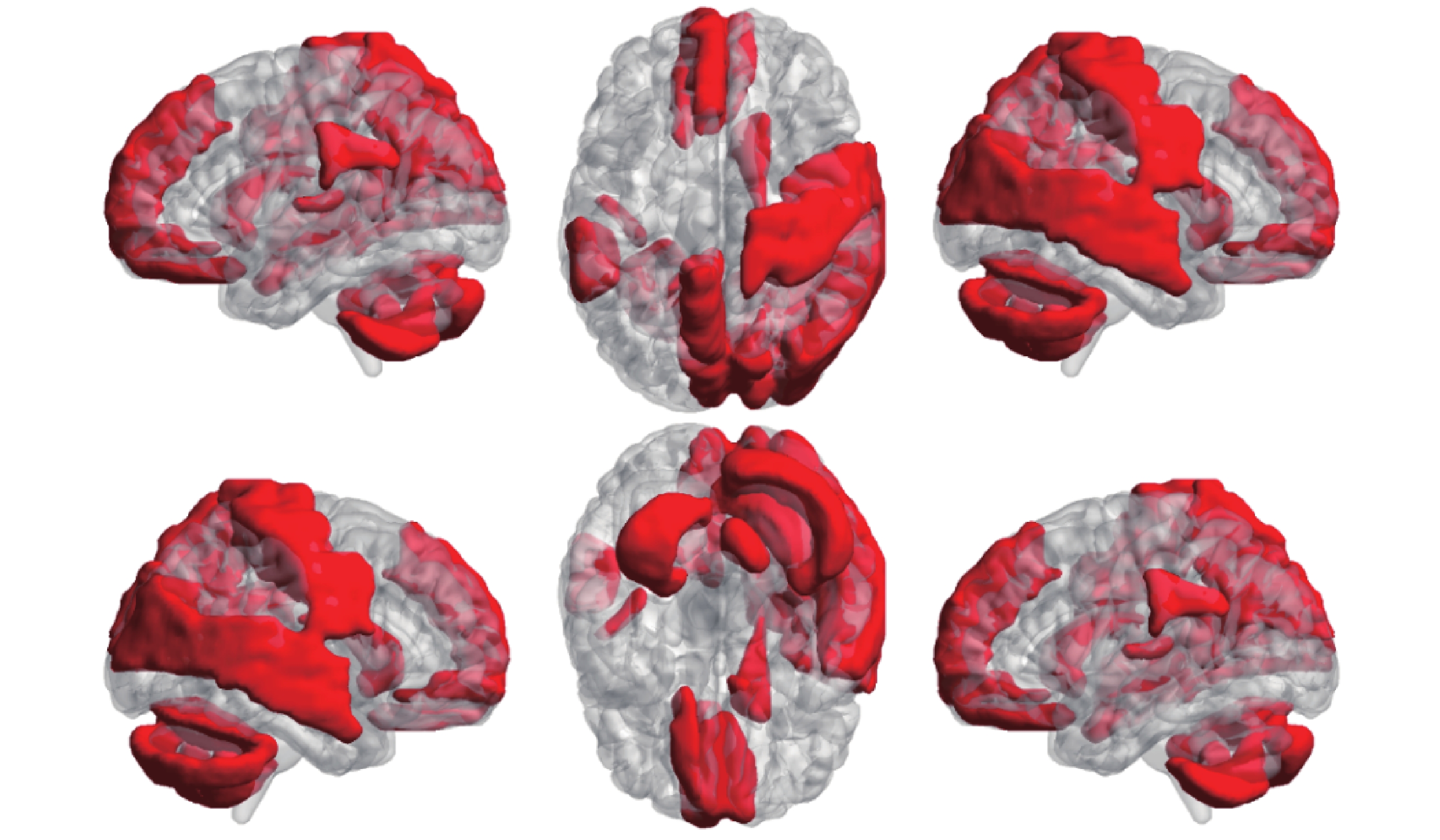
統計發現,所有 55 條連接中與默認模式網絡相關的連接數量最多,涉及的默認模式網絡腦區包括框內額上回、內側額上回、后扣帶回、楔前葉、顳中回等。其次為視覺網絡和小腦網絡,涉及的視覺網絡腦區包括楔葉、枕中葉、舌回、枕下回等;涉及的小腦網絡腦區包括 Cerebelum_8L、CerebelumCrus2R、Cerebelum6R、Cerebelum9R 等。在所有 43 個腦區中,進一步篩選出參與到 55 條連接中至少 3 條的腦區,將其映射在大腦皮層表面,如圖 7 所示。
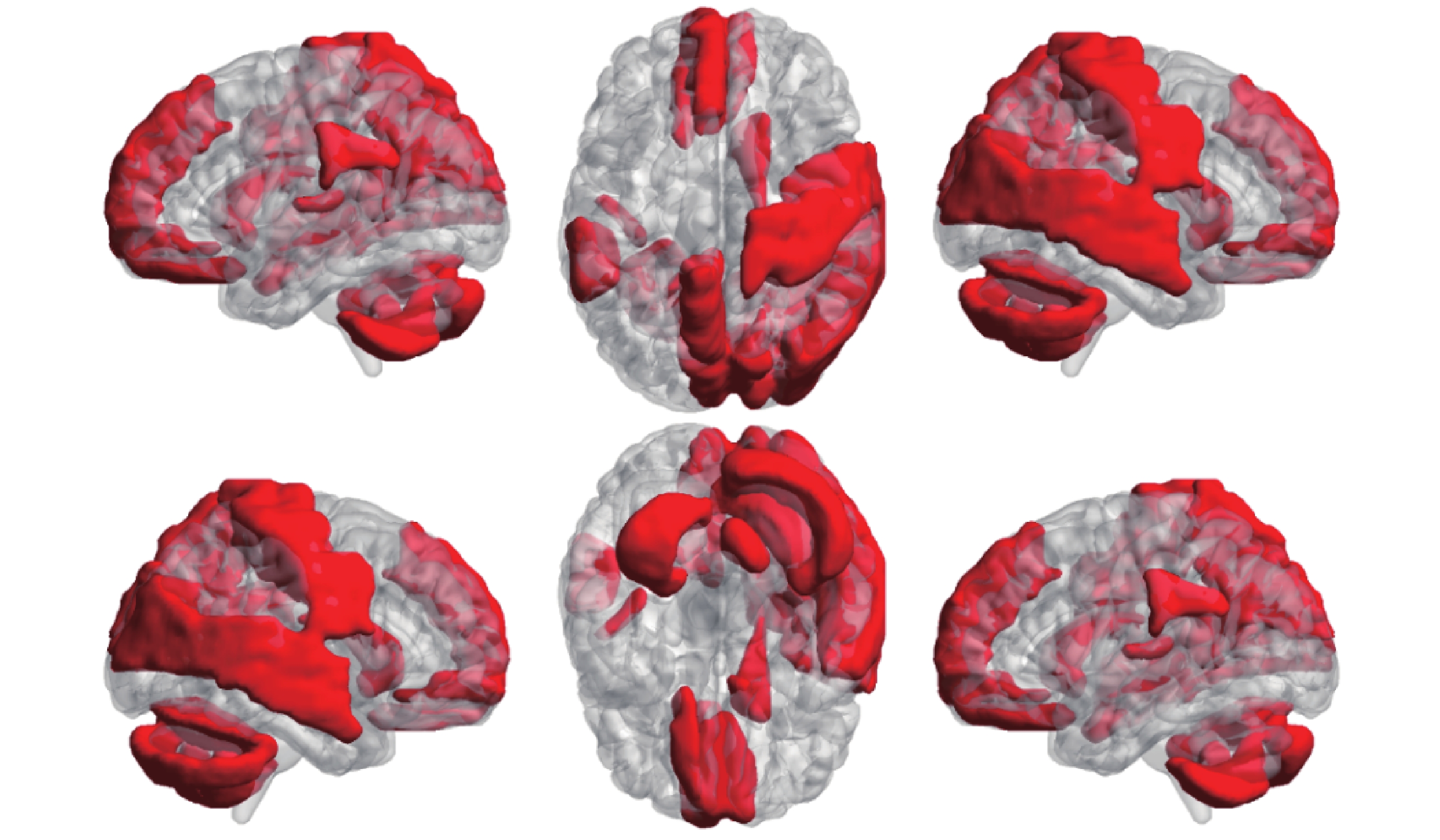 圖7
最具鑒別力腦區在皮層表面的投影
Figure7.
Projection of the most discriminating brain regions on the surface of the cortex
圖7
最具鑒別力腦區在皮層表面的投影
Figure7.
Projection of the most discriminating brain regions on the surface of the cortex
3.3 算法運算量
由于樣本數量的限制,本文在參數尋優及性能評估中采用內嵌的留一交叉驗證策略,這不可避免地帶來了計算量的增加。在 i7-4790 處理器,12 G 運行內存的 64 位計算機上,本文分類框架(WSR+KCC)的總體訓練分類時間約為 14 h,其中模型訓練占用了絕大多數時間。這在實際應用中是可以接受的,因為模型訓練通常在線下進行。
十折交叉驗證也是常用的分類器性能評估策略,本文實驗在十次十折交叉驗證下的結果如表 3 所示,可以看出,在十次十折交叉驗證下的分類精度總體都有下降。原因可能是由于十折交叉驗證使得數據集劃分方式不唯一,并且訓練樣本數相較于留一法策略下的訓練樣本數更少,從而導致訓練的分類器泛化能力較弱。但從表 3 中的結果可以看出,本文提出的方法仍然具有優勢。
3.4 局限與展望
本文提出的方法在識別精神分裂癥患者的問題上取得了較好的實驗結果,但研究仍具有一些局限性。首先,有文獻表明抗精神病藥物的使用會對患者的腦功能網絡造成影響[22],但 COBRE 數據集中并未給出患者詳細的用藥信息,因此藥物對研究的影響難以評估。其次,識別精神分裂癥高風險人群顯然比識別精神分裂癥患者更具臨床應用價值以及挑戰性,使用本文方法對精神分裂癥高風險人群進行分類預測將是本課題組未來的研究方向。最后,多模態、多中心數據集的使用是此類研究未來的發展方向,結合多模態、多中心數據集對疾病進行分類,豐富數據數量及類型,并進一步提高分類效果將非常有意義。
4 總結
本文提出采用 WSR 構建方法對腦功能網絡進行建模,并在此基礎上使用 KCC 特征選擇方法選擇最具鑒別力的特征,進行精神分裂癥患者與正常對照的分類研究,在與幾種對照方法的對比中獲得了最高的分類精度。相比于傳統的 PC 與 SR 腦網絡建模方法,WSR 方法能夠構建出更符合實際生物學意義的腦功能網絡,而相比于t-test 與 Lasso 特征選擇方法,KCC 方法能夠從網絡中提取出更具鑒別力的連接特征用于分類。此外,本文討論了精神分裂癥患者在功能連接及腦區上的特異性變化,這進一步證明了精神分裂癥的腦功能失連接假說,同時也可以為此疾病的發病機制及生物學標志物的確定提供線索,從而指導疾病的預防與治療。
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
引言
精神分裂癥是一種嚴重的全球性精神類疾病,其病因未知,癥狀各異。一旦患病,患者會出現感知、思維、情感和行為等多方面的障礙及精神活動的不協調[1]。目前臨床上對精神分裂癥的診斷主要依靠醫生對患者病史以及臨床癥狀的全面評估,然而精神疾病之間重疊的癥狀與醫生評估的主觀性使得傳統的診斷方法并不高效。
靜息態功能核磁共振成像(resting-state functional magnetic resonance image,rs-fMRI)具有無創性、無放射性、時空分辨率高、易于操作且可重復等優點,同時數據采集時不需要受試者配合完成復雜的任務,近年來已廣泛應用于腦功能相關的各項研究[2-3]。在靜息狀態下,功能核磁共振信號的低頻血氧水平依賴(blood oxygen level dependent,BOLD)信號被認為可以反映大腦的自發性神經波動,而該波動與大腦的內在神經活動密切相關,這使得 rs-fMRI 可以捕捉到更復雜更精確的神經活動[4]。已有研究表明,人腦的各個功能區域并不是獨立工作的,而是通過相互之間的協調配合達到完成某項任務的目的,而腦網絡可以有效地表示大腦各個功能區域之間的這種協調交互作用[5],根據腦功能磁共振數據構建出有意義的腦功能連接網絡是針對所有后續關于疾病等預測分類的前提和基礎,因此如何構建腦功能連接網絡并提取有助于分類的高鑒別性特征是分析研究的關鍵所在。
皮爾遜相關(Pearson’s correlation,PC)是目前構建腦網絡最常用的方法,這種方法通過計算兩兩預定義節點間的相關系數(作為連接邊)來構建相關矩陣(作為腦網絡),但是這僅僅描述了在不考慮其他變量影響下兩個變量間的內在功能相關性。對于包含多變量的情況,如多個腦區信號,兩個變量間的關系往往會受到其他變量的影響。為了將這種影響考慮在網絡構建中,有研究者提出稀疏表示(sparse representation,SR)腦網絡建模方法[6]。通過這一方法,腦網絡稀疏性先驗被加入到網絡的構建中,從而可以得到更容易解釋的稀疏連接網絡。但 SR 模型在求取兩兩節點之間的連接時,雖然考慮了其他節點的影響,卻將所有其他節點等同對待,這會導致在稀疏性的約束下求取的連接系數不能真實地反映腦區間關聯。
因此,為克服目前常用腦網絡建模方法的不足,本文采用前期工作提出的基于 SR 的加權稀疏腦網絡模型(weighted sparse representation,WSR)來對腦功能網絡進行建模[7]。該模型假設目標腦區的 BOLD 信號更趨向于被一些波動高度一致的腦區 BOLD 信號來線性表達,使用懲罰系數對原正則化項進行改進,從而可以構建一種更具生物學意義的腦網絡。然后,本研究將網絡連接作為特征,使用肯德爾相關系數(Kendall correlation coefficient,KCC)進行特征選擇,并用支持向量機(support vector machine,SVM)對精神分裂癥患者和正常健康人群進行分類,以期尋找可用于臨床診斷的生物學標志物,提升當前精神分裂癥自動診斷精度。本研究可以為腦網絡構建及精神分裂癥患者腦功能分析提供一個新的建模方法,同時本文中所選取的特征/連接或可作為潛在的生物學標志物以期輔助臨床上精神分裂癥的診斷。
1 材料和方法
1.1 數據采集及預處理
本文實驗所采用的數據來自于美國腦網絡研究機構(the Mind Research Network)和新墨西哥大學在網上公開分享的數據集,該數據集項目由美國國立衛生研究院生物醫學研究中心(the Center for Biomedical Research Excellence,COBRE)資助,下載網址為:http://fcon_1000.projects.nitrc.org/indi/retro/cobre.html。實驗數據集中包含 57 例慢性精神分裂癥患者以及 64 例健康受試者的數據,并以健康受試者的數據作為正常對照,數據集樣本的人口統計學信息如表 1 所示。
所有患者均按美國精神疾病診斷與統計手冊第四版(diagnostic and statistical manual of mental disorders,DSM-IV)診斷標準,由合格的精神科醫師鑒定確診,癥狀嚴重程度采用陽性和陰性綜合征量表(positive and negative syndrome scale,PANSS)評定。排除標準包括:① 患有其他 DSM-IV 診斷標準確認的精神障礙;② 曾有藥物濫用史;③ 曾具有臨床意義的頭部創傷。同時,所有正常對照也均已證實沒有精神分裂癥或其他精神障礙、沒有藥物濫用史或重大的頭部外傷史。
rs-fMRI 圖像通過梯度平面回波成像序列獲取,其中重復時間/回波時間 = 2 000 ms/29 ms;采集矩陣 = 64 × 64;層數 = 32;體素大小 = 3 mm × 3 mm × 4 mm;視野 = 256 mm × 256 mm。
使用統計參數圖軟件 SPM8(The Wellcome Centre for Human Neuroimaging,UCL Queen Square Institute of Neurology,英國)以及 rs-fMRI 數據預處理助手軟件 DPARSF(State Key Laboratory of Cognitive Neuroscience and Learning,Beijing Normal University,中國)對采集數據進行預處理。處理步驟包括:① 去除所有對象的前 10 個時間點,以排除掃描前期的不穩定影響。由此,最終得到的數據含 150 個時間點;② 進行時間層校正;③ 去除頭動偽影的影響;④ 將圖像配準至蒙特利爾神經研究所(Montreal Neurological Institute,MNI)的標準空間,重采樣體素大小為 3 mm × 3 mm × 3 mm;⑤ 進行帶通濾波以減少低頻漂移和高頻生理噪聲;⑥ 回歸干擾信號;⑦ 使用自動解剖標記(the automated anatomical labeling atlas,AAL2)圖譜將腦部劃分為 120 個腦區[8]。更多詳細的數據集信息及預處理過程請參考文獻[9]及 COBRE 網站。
1.2 加權稀疏腦網絡建模
如引言部分所述,傳統的腦網絡建模往往使用的是 PC 或者 SR 方法。PC 方法通過直接計算兩兩腦區平均區域時間序列之間的 PC 系數作為腦區之間的連接關系,如式(1)所示:
|
式中,, 為腦區 i 和腦區 j 的平均區域時間序列,M=150 為 rs-fMRI 圖像總的時間點數;corr()表示計算 xi 與 xj 的 PC 系數 Wij;Wij 表示兩腦區間的連接邊。SR 方法通過引入稀疏約束對腦網絡稀疏化先驗進行建模,其模型如式(2)所示:
|
式中, 為腦區 i 與其他所有腦區之間連接邊組成的列向量,這里 N=120 為預定義腦區數;,表示對應于表達第 i 個腦區信號 xi 時對應的字典,將字典第 i 列置為 0 是為了避免平凡解;λ是正則化參數。WSR 方法則是在 SR 模型中引入了不同的懲罰權重 ci,使得實際求解中對不同的表達系數施加不同的懲罰強度,其模型如式(3)所示:
|
式中,,,Pji 為第 j 個腦區 xj 與第 i 個腦區 xi 之間的 PC 系數。σ 為調整對應連接強度權重衰減速度的非負參數,設置為所有樣本所有{|Pji|}的標準差。⊙表示對應元素相乘。由(3)式可以看出,WSR 模型整合了 PC 以及 SR 建模方法的優點,既考慮了建模過程中多變量的影響,又將 PC 度量的腦區的內在連接強度體現到了模型中。
1.3 腦功能網絡連接特征選擇
由上述 WSR 模型,可以通過交替方向乘子法求解構建每個個體的腦功能網絡。需要注意的是,在不加約束情況下,稀疏類方法得到的腦網絡往往是非對稱的。而已有研究表明這種非對稱關系并不利于分類任務,因此這里采用對稱化處理得到最終腦網絡,如式(4)所示:
|
由此可以得到 7 140 維特征。由于特征維度高且存在信息冗余,為提高算法效率以及找出對疾病敏感的功能連接生物學標記,本文選取 KCC 方法對特征進行選擇[10]。
假設兩個集合分別為A和Y,本文中A和Y分別代表特征集合與標簽向量。其中A的每一行表示一個樣本,每一列表示樣本的一個特征;Y是與A排序相對應的樣本的標簽向量。考察兩個不同類樣本第i個特征以及樣本標簽間的關系,則這兩個樣本的第i個特征為一致特征對的定義如式(5)所示,為不一致特征對的定義如式(6)所示:
|
|
則功能連接特征i的 KCC(以符號 KCC 表示)的計算如式(7)~式(10)所示:
|
|
|
|
其中,S 為總樣本數目,D 為特征 i 一致的樣本對數,E 為特征i 不一致的樣本對數。N3 為所有樣本所有可能的兩兩組合,N1、N2 分別是向量 A?i 和 Y 中相同元素可能的兩兩組合,s 表示將 A?i 中的相同元素分別組合成小集合的數目,Uθ 表示第 θ 個小集合所包含的元素個數。同理,t 和 Vθ 在集合 Y 的基礎上計算可得。
由此得到所有特征的 KCC,之后使用 KCC 的絕對值大小代表相應特征的分類鑒別力,絕對值越大,則說明這一特征在正常組和患者組中差異越大,其分類鑒別力越強。
1.4 模型參數選擇
特征選擇后使用線性 SVM 來對樣本進行分類。SVM 在分類任務中應用廣泛,它通過尋找最大間隔超平面來劃分兩類樣本,具有較強的魯棒性。尤其當樣本量較少時,SVM 經證明是十分有效的。
在本文的方法框架中,λ參數的選取影響著最終的分類結果,需要對其尋優來最大化分類器性能。為此,采用內嵌的留一交叉驗證法(leave-one-out cross-validation,LOOCV)對相應的參數在[2?5,2?4,,24,25]幾個備選值上進行網格尋優的同時,對分類器的泛化性能進行評估[11]。具體的,假設數據集中共有S個樣本,首先留下一個作為外層留一數據用于測試,剩下的 S ? 1 個樣本用于訓練。對上述步驟重復 S 次,每次留出不同的樣本作為測試數據,這樣就可以得到 S 個測試結果,最終分類器的泛化性能即可由這 S 個測試結果的正確率得出。而為了確定最優的參數 λ,在上述每次留出的過程中執行另外的留一交叉驗證算法,即先選定一個 λ 值,然后在 S ? 1 個訓練數據上留出一個樣本作為內層測試數據,在余下 S ?2 個數據上訓練分類器,之后將內層的測試數據在此分類器上進行測試,得到一個分類結果。對上述內嵌的留出過程執行 S? 1 次,可得到當前 λ 取值下 S ? 1 個 SVM 分類器的分類結果,該結果正確率即為當前 λ 取值下分類器的性能。變換參數 λ,即可得到不同 λ 取值下的分類器性能。最后,選擇性能最好也即正確率最高的 λ 值作為最優參數,并將外層留一的測試數據在該參數組合下 S ? 1 個 SVM 分類器上進行預測,最終使用眾數投票方法得到該外層測試數據的分類結果。
2 實驗結果
本文采用 PC、SR 以及 WSR 方法分別構建腦網絡,并使用了雙樣本t檢驗(two-sample t-test,t-test)、最小絕對收縮與選擇算子(least absolute shrinkage and selection operator,Lasso)以及 KCC 三種特征選擇方法,一共 9 組方法進行對比實驗。實驗中,除了網絡構建和特征選擇方法有所不同,樣本量、參數選擇與泛化性能評估方法等完全相同。
2.1 網絡可視化
三種方法構建出的腦網絡可視化圖如圖 1 和圖 2 所示,兩圖中從上到下兩行分別為精神分裂癥樣本腦網絡與正常對照樣本腦網絡,從左到右三列分別為使用 PC、SR 和 WSR 三種方法構建的腦網絡,其中 SR 網絡中λ = 23,WSR 網絡中λ = 22。圖 1 是從數據集中隨機選取的精神分裂癥樣本與正常對照樣本的腦網絡可視化圖,圖 2 是兩個群組樣本的平均腦網絡可視化圖。分別對比圖 1 與圖 2 中三列可以看出,使用 PC 方法得出的網絡為全連接網絡,明顯要比 SR 和 WSR 構建出的網絡更稠密;而 WSR 網絡又比 SR 網絡稠密,呈現出更多的非零連接和模塊化結構,這表明了 WSR 網絡結合了 PC 度量能夠比 SR 網絡構建出更具有生物學意義的腦功能網絡。分別對比圖 1 與圖 2 中兩行網絡可以看出,正常對照的腦網絡相對精神分裂癥患者的網絡更為稠密,這在 PC 網絡中最為明顯,反映了精神分裂癥患者在功能腦網絡連接上的特異性變化。
圖1
隨機選取的兩個樣本的腦網絡可視化圖
Figure1.
The brain network visualization of two randomly selected samples
圖2
群組平均腦網絡可視化圖
Figure2.
The averaged brain network of different groups constructed by three construction methods
2.2 連接特征分布
為了更直觀地觀察連接特征的鑒別力,本文統計了所有連接特征的 KCC 值,其統計分布直方圖如圖 3 所示。可以看出,特征的 KCC 近似服從正態分布,絕大多數特征的 KCC 分布在 ? 0.2~0.2 之間。因為本文將特征的 KCC 絕對值作為特征的分類鑒別力,所以實驗中只有直方圖兩側的小部分特征(約 450 個特征)被選擇用來參與后續分類,而位于圖中 0 值附近的特征并沒有顯著的鑒別能力,因此未被選擇。
圖3
所有連接特征的 KCC 分布直方圖
Figure3.
Histogram of KCC for all connection features
2.3 分類性能指標及結果
本文使用分類精度(accuracy,Acc)(以符號Acc表示)、靈敏度(sensitivity,Se)(以符號Se表示)、特異性(specificity,Sp)(以符號Sp表示)以及曲線下面積(area under curve,Auc)(以符號Auc表示)4 個定量指標來分析不同方法得到結果,同時給出了不同建模方法的受試者工作特征(receiver operating characteristic,ROC)曲線。其中,Acc、Se、Sp的計算如式(11)~式(13)所示:
|
|
|
式中,TP、TN、FP、FN分別表示患者被正確分類、正常對照被正確分類、正常對照被錯分為患者、患者被錯分為正常對照的具體數值。9 組不同方法組合的分類定量結果如表 2 所示,受試者工作特征曲線如圖 4 所示。
圖4
受試者工作特征曲線
Figure4.
Receiver operating characteristic curve
3 分析與討論
3.1 分類性能對比
PC 腦網絡建模方法可以較好地刻畫兩兩腦區間的內在功能連接強度[12],但構建的網絡包含一些冗余、不重要的連接,這些連接對腦區間的關系挖掘不夠充分,不能較好地分類患者和健康對照。SR 腦網絡建模方法在計算兩兩腦區之間的連接時對其他腦區的影響進行了考慮,但卻將所有其他腦區等同對待,求解過程中會導致一些符合目標函數最小但不符合內在連接強度的計算結果產生,因此并不能給分類性能帶來直接的提升。而 WSR 腦網絡建模方法則能夠整合 PC 和 SR 兩種方法的優點,更深入地挖掘到更復雜的腦區間連接關系,有效提升分類精度。由表 2 可以看出,無論采用哪種特征選擇方法,WSR 方法都能夠獲得比 PC 和 SR 更高的分類精度,尤其當使用 KCC 進行特征選擇時,能夠得到 81.82% 的分類精度。
對比不同的特征選擇方法,可以發現 KCC 方法在 PC 腦網絡與 WSR 腦網絡上都表現出色,明顯優于t-test 與 Lasso 兩種特征選取方法,而基于 Lasso 的特征選取方法又優于t-test。這與不同特征選擇方法的原理有關:其中t-test 只是將兩組中某一特征的均值是否一致作為特征選擇的依據,并且將各個特征單獨處理,較為粗糙;Lasso 特征選擇方法則考慮了特征之間的相互影響,聯合所有特征來選擇特征子集,因此可以得到與 KCC 相近的分類結果;而 KCC 是用于測量兩個隨機變量之間的序數關聯的統計量,相對于另外兩種方法,它可以更敏感更直接地反映出患者組中的某一特征相對于正常組是否普遍發生了變化,與分類任務十分契合。此外,基于 Lasso 的特征選擇方法在三種腦網絡中都得到了最高的靈敏度,這意味著采用這種特征選擇方法的分類框架對患者更加敏感,這在實際疾病診斷中是更重要的,因為錯誤將患者診斷為正常人則可能導致其錯失疾病治療的最佳時機。
3.2 最具鑒別力的連接及相關腦區
復雜網絡理論的出現,為在數學框架下對功能連接進行定量描述提供了手段,目前已大量應用在與腦科學相關的研究中[13]。靜息態下尤其是默認模式網絡(default mode network,DMN)中的功能連接被認為反映了自我參照和自省的精神過程[14],已有研究表明精神分裂癥患者在自我歸因、自我參照、自我意識等方面都表現出了明顯的不同[15-16],許多研究人員認為這種不同與精神分裂癥患者腦區間的異常功能整合密切相關。一種被普遍接受的說法是精神分裂癥的功能失連接假說,即腦區之間正常功能相互作用的復雜模式在精神分裂癥患者中發生了改變[17]。更進一步,一些研究指出,這種功能失連接并不僅僅局限于某些特定的腦區,而是廣泛分布于精神分裂癥患者的全腦中[18]。
本文的研究同樣驗證了之前關于精神分裂癥功能連接改變的結論。兩組樣本 WSR 功能網絡平均連接強度與平均連接差異的箱線圖如圖 5 所示(網絡的λ參數選在 22,進行統計之前對網絡中元素做了絕對值處理)。其中,某樣本功能連接的平均連接強度的計算方式如下:先計算該樣本腦網絡矩陣中每列元素的均值作為單個腦區的功能連接強度,再對所有腦區的功能連接強度求均值得到;類似的,某樣本功能連接的平均連接差異的計算方式如下:先計算該樣本腦網絡矩陣中每列元素的方差作為單個腦區的功能連接差異,再對所有腦區的功能連接差異求均值得到。
圖5
兩組樣本的 WSR 網絡的平均連接強度與平均連接差異
Figure5.
Average connection strength and average connection diversity of two groups
由圖 5 中可以看出,對比正常對照組,精神分裂癥患者組的平均功能連接強度有著顯著的下降,說明患者的腦連接呈現出減弱的趨勢,這也與之前的研究相符合[19]。
之前許多研究都報道了精神分裂癥患者在默認模式網絡[20],視覺網絡(visual network,VIN)與小腦網絡(cerebellum network,CEN)等網絡上的特異性變化[10, 21]。在使用本文提出的分類框架(WSR + KCC)對精神分裂癥患者進行分類時,涉及到這些網絡的連接同樣起到了重要的作用。為了更深入地了解到哪些連接特征對分類任務的貢獻最大,本文統計了訓練測試過程中所有樣本、所有留一循環中都一致被選擇的連接特征,并進一步篩選得到共 55 條連接(涉及 43 個腦區)。在全腦視圖下對這些連接以及涉及的腦區進行展示,如圖 6 所示。其中,圓點代表大腦腦區,其對應的顏色表示腦區所屬的大腦固有網絡。圓點的大小與邊的粗細反映了相應腦區和連接在分類任務中的重要程度,圓點越大,則對應腦區在所有分類過程中被選擇的次數越多,邊越粗,則表示對應連接在分類過程中越具有鑒別力。
圖6
全腦視圖下最具鑒別力的腦區和連接
Figure6.
The most discriminating connections and brain regions in the whole brain view
統計發現,所有 55 條連接中與默認模式網絡相關的連接數量最多,涉及的默認模式網絡腦區包括框內額上回、內側額上回、后扣帶回、楔前葉、顳中回等。其次為視覺網絡和小腦網絡,涉及的視覺網絡腦區包括楔葉、枕中葉、舌回、枕下回等;涉及的小腦網絡腦區包括 Cerebelum_8L、CerebelumCrus2R、Cerebelum6R、Cerebelum9R 等。在所有 43 個腦區中,進一步篩選出參與到 55 條連接中至少 3 條的腦區,將其映射在大腦皮層表面,如圖 7 所示。
圖7
最具鑒別力腦區在皮層表面的投影
Figure7.
Projection of the most discriminating brain regions on the surface of the cortex
3.3 算法運算量
由于樣本數量的限制,本文在參數尋優及性能評估中采用內嵌的留一交叉驗證策略,這不可避免地帶來了計算量的增加。在 i7-4790 處理器,12 G 運行內存的 64 位計算機上,本文分類框架(WSR+KCC)的總體訓練分類時間約為 14 h,其中模型訓練占用了絕大多數時間。這在實際應用中是可以接受的,因為模型訓練通常在線下進行。
十折交叉驗證也是常用的分類器性能評估策略,本文實驗在十次十折交叉驗證下的結果如表 3 所示,可以看出,在十次十折交叉驗證下的分類精度總體都有下降。原因可能是由于十折交叉驗證使得數據集劃分方式不唯一,并且訓練樣本數相較于留一法策略下的訓練樣本數更少,從而導致訓練的分類器泛化能力較弱。但從表 3 中的結果可以看出,本文提出的方法仍然具有優勢。
3.4 局限與展望
本文提出的方法在識別精神分裂癥患者的問題上取得了較好的實驗結果,但研究仍具有一些局限性。首先,有文獻表明抗精神病藥物的使用會對患者的腦功能網絡造成影響[22],但 COBRE 數據集中并未給出患者詳細的用藥信息,因此藥物對研究的影響難以評估。其次,識別精神分裂癥高風險人群顯然比識別精神分裂癥患者更具臨床應用價值以及挑戰性,使用本文方法對精神分裂癥高風險人群進行分類預測將是本課題組未來的研究方向。最后,多模態、多中心數據集的使用是此類研究未來的發展方向,結合多模態、多中心數據集對疾病進行分類,豐富數據數量及類型,并進一步提高分類效果將非常有意義。
4 總結
本文提出采用 WSR 構建方法對腦功能網絡進行建模,并在此基礎上使用 KCC 特征選擇方法選擇最具鑒別力的特征,進行精神分裂癥患者與正常對照的分類研究,在與幾種對照方法的對比中獲得了最高的分類精度。相比于傳統的 PC 與 SR 腦網絡建模方法,WSR 方法能夠構建出更符合實際生物學意義的腦功能網絡,而相比于t-test 與 Lasso 特征選擇方法,KCC 方法能夠從網絡中提取出更具鑒別力的連接特征用于分類。此外,本文討論了精神分裂癥患者在功能連接及腦區上的特異性變化,這進一步證明了精神分裂癥的腦功能失連接假說,同時也可以為此疾病的發病機制及生物學標志物的確定提供線索,從而指導疾病的預防與治療。
利益沖突聲明:本文全體作者均聲明不存在利益沖突。