青光眼是不可逆性失明的首要原因,早期癥狀不明顯,容易被忽視,因此青光眼早期篩查尤為重要。杯盤比是臨床上用于青光眼篩查的重要指標,所以精準分割視杯視盤是計算杯盤比的關鍵。本文提出了一種基于全卷積多尺度殘差神經網絡的視杯視盤分割方法。首先,對眼底圖像進行對比度增強,并引入極坐標變換。隨后,構造 W-Net 作為主體網絡,用帶殘差多尺度全卷積模塊來替代標準卷積單元,輸入端口加入圖像金字塔來構造多尺度輸入,側輸出層作為早期的分類器生成局部預測輸出。最后,提出了一種新的多標簽損失函數來指導網絡分割。實驗采用 REFUGE 數據集驗證,最終視杯、視盤分割的平均交并比分別為 0.904 0、0.955 3,重疊誤差分別為 0.178 0、0.066 5。結果表明,該方法不僅實現了視杯視盤聯合分割,而且有效提高了其分割精度。該方法將有助于大規模青光眼早期篩查的推廣。
引用本文: 袁鑫, 鄭秀娟, 吉彬, 李淼, 李彬. 基于多尺度殘差卷積神經網絡的視杯視盤聯合分割. 生物醫學工程學雜志, 2020, 37(5): 875-884. doi: 10.7507/1001-5515.201909006 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
引言
青光眼是全世界第二大致盲眼病(僅次于白內障),也是造成不可逆性失明的首要原因[1]。青光眼造成的視力損傷是不可逆的,且早期癥狀不易發現,因此對青光眼的早期篩查與診斷至關重要。目前,眼底圖像和三維光學相干層析成像(optical coherence tomography,OCT)常被用于輔助診斷青光眼。其中 OCT 圖像成本相對昂貴且普及率低,不適用于大規模的青光眼篩查,故大多數醫生常選擇使用成本較低和容易獲得的眼底圖像進行青光眼篩查與診斷。當下,評估眼底圖像中視神經乳頭的技術是主流的青光眼篩查技術[2],它采用一個二分類來判斷是否屬于青光眼疾病。然而眼底圖像常由經驗豐富的眼科醫生手動標注,費時費力且帶有很大的主觀性,因此手工標注眼底圖像不適用于青光眼的大規模篩查。
在眼底彩色圖像中,視盤呈現亮黃色且形狀近似橢圓,可分為兩個明顯的區域:中間明亮區(視杯)和外圍區(視神經網膜邊緣)。青光眼大規模篩查技術中,多種自動評估視神經乳頭的方法被相繼被提出,例如垂直杯盤比(vertical cup to disc ratio,CDR)[3]、視杯(optic cup,OC)視盤(optic disc,OD)面積比以及視盤直徑[4]等。而在臨床上,醫生主要采用杯盤比評估視神經頭。杯盤比是指垂直杯徑與垂直盤徑的比。通常情況下,杯盤比值越大,則患青光眼的概率越大。因此,準確地分割視杯視盤是篩查和診斷青光眼的關鍵。
在醫學圖像分割算法中,主要分為基于手工提取特征的傳統方法[5-8]和利用卷積神經網絡來自動提取特征的深度學習框架[9-11]。早期研究中的視杯視盤分割方法通常是利用手工提取視覺特征進行分割,其主要包括顏色、紋理、對比度閾值、邊緣檢測、分割模型和區域分割方法[12-19],但這些方法容易受到眼底圖像拍攝環境和圖像本身質量的影響,從而影響目標的分割效果。此外,從眾多像素中提取出特征訓練分類器不易實現,故有學者[20]提出采用超像素策略來減少像素數,并采用超像素分類進行視杯視盤分割。但該方法需要手工構造特征來獲得分割結果,其實現過程繁瑣且可重復性差。深度學習在計算機視覺任務中克服了人工設計特征的局限性,并可自動學習高度的可區分性特征進行表示。在醫學圖像分割領域,早期的深度學習方法大多是基于圖像塊[21-22],其局限性是滑動窗會導致冗余計算和無法學習到圖像的全局特征。接著,端到端的全卷積神經網絡(fully convolutional neural network,FCN)被提出并在圖像分類和分割中得到廣泛應用[23-24]。在全卷積神經網絡基礎上,Ronneberger 等[25]提出在醫學圖像分割領域具有卓越性能的 U-Net 結構,并且該結構已經成為該領域的重要結構。通常,U-Net[25]結構可以被認為是編、解碼器的結構。編碼器的目的是逐步減少特征映射的空間維數,來獲取更高層次的語義特征。而解碼器則是為了恢復目標中的空間維數和結構細節。因此,在編碼器中應盡可能捕獲更多的高級特征,而在解碼器中應盡可能地保留空間信息。之后,在 U-Net 基礎上又發展出許多改進網絡結構,包括 M-Net[26-27]、U-Net++[28-29]等,均在醫學圖像分割任務中取得了不錯的效果。
現有眼底圖像分析方法大多是對視杯視盤分別進行分割[12-15.30]。文獻[12-13]將視杯視盤分割分為兩個獨立階段,即分別利用各自的特征進行分割。在分割視杯時,先定位到視盤,把視盤分割出來后再提取感興趣區域來分割視杯,造成了視盤分割信息的浪費。文獻[14]則提出將視杯視盤分割集成在同一分割框架內。但這些方法忽略了視杯和視盤之間存在的先驗信息,例如形狀約束和結構約束,即視杯視盤均接近橢圓形,視杯包含于視盤之中。同時,上述幾種方法都將視杯視盤看作非獨立標簽,每個像素只對應一個標簽(即視杯、視盤或背景),割裂了兩者的聯系。
針對上述問題,本文以 U-Net[25]與 M-Net[26]為基礎,提出了一個新的 W-Net 網絡結構用于視杯視盤聯合分割。相比于 U-Net[25]或 M-Net[26],W-Net 主網絡結構是以 W 型卷積神經網絡為主體框架,加深了網絡深度,有利于網絡進行深層信息學習。此外,W-Net 引入了多尺度輸入和不同網絡深度的監督,其中多尺度輸入可構造圖像金字塔,使輸入圖像信息更加豐富;另外在網絡中加入不同的深度監督,可使側輸出層計算梯度能更容易地反向傳播到前面的卷積層中,可有效抑制梯度消失問題和有利于網絡的早期訓練。同時,本文還提出了一種殘差多尺度全卷積學習模塊來代替 U-Net 和 M-Net 中的標準卷積學習單元,加深了網絡寬度,從而能在有限的尺度范圍內捕獲更多尺度特征。最后,提出了一種新的多標簽損失函數來指導網絡進行視杯視盤分割。
1 方法
1.1 數據集
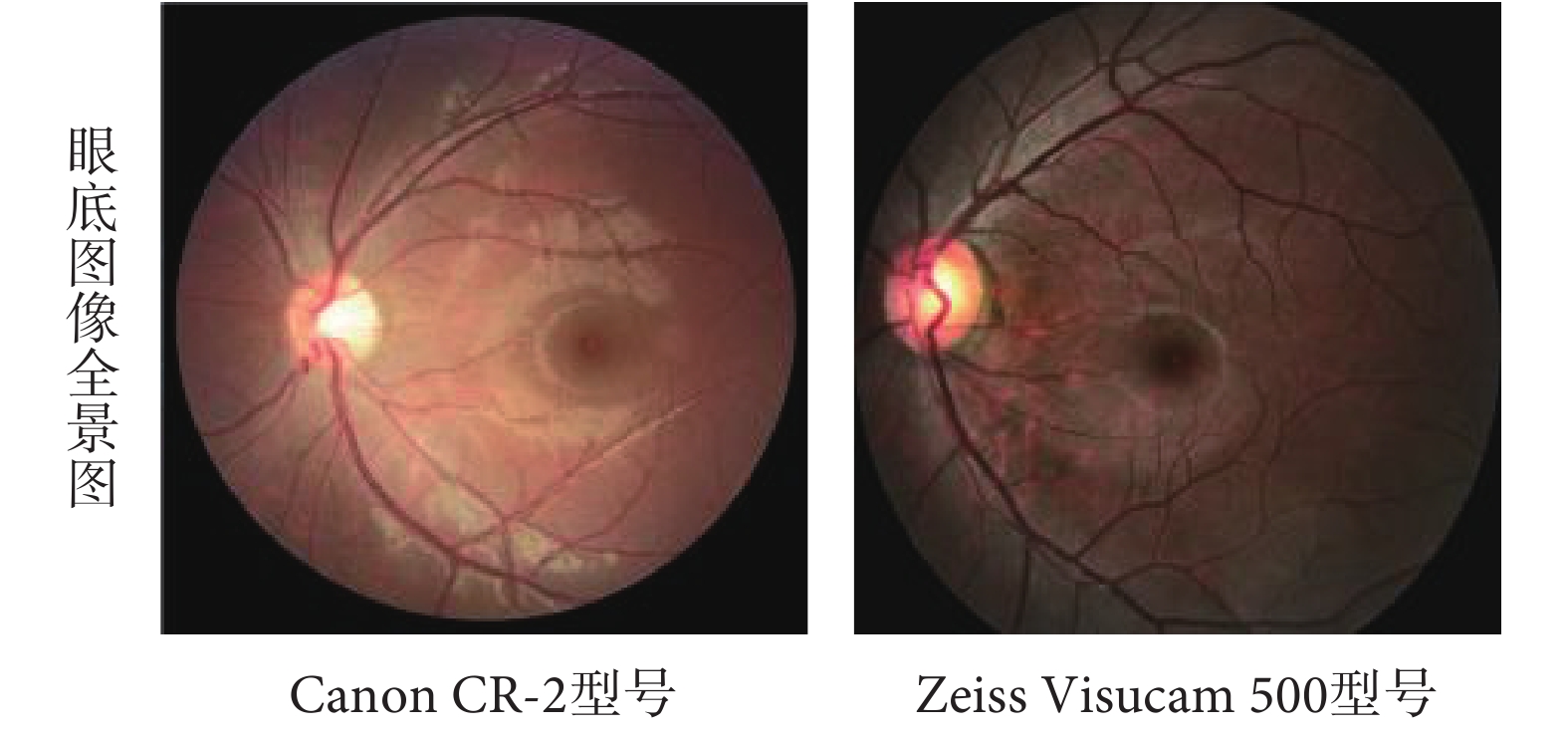
本文選用 REFUGE 數據集(https://refuge.grand-challenge.org/Home/)進行方法驗證。該數據庫是目前青光眼眼底照片精標數據庫中最全面的標注數據庫,主要包括青光眼與非青光眼兩種類型數據,其中青光眼和非青光眼圖像的比例分別為 10% 和 90%。每張眼底圖像分別包含診斷、圖像分割及定位三方面信息,由七位專家人工標記并融合,克服了之前許多青光眼公開數據集存在的只有診斷標簽信息,無視杯、視盤等關鍵結構的標注信息,且參與標注的專家較少等缺點。所有圖像均以后極(posterior pole)為中心,同時含有黃斑和視盤。在這個數據集中,由訓練集、驗證集和測試集三個組成。訓練集中有 400 張像素為 2 142 × 2 056 的眼底圖像,是使用 Zeiss Visucam 500 眼底相機拍攝的,而驗證集和測試集各由 400 張像素均為 1 634 × 1 634 的眼底圖像組成,是使用 Canon CR-2 眼底相機拍攝的。由于各個集合被不同的眼底照相機拍攝,故而圖像在顏色、紋理等光學性質上會呈現不同,如圖 1 所示。
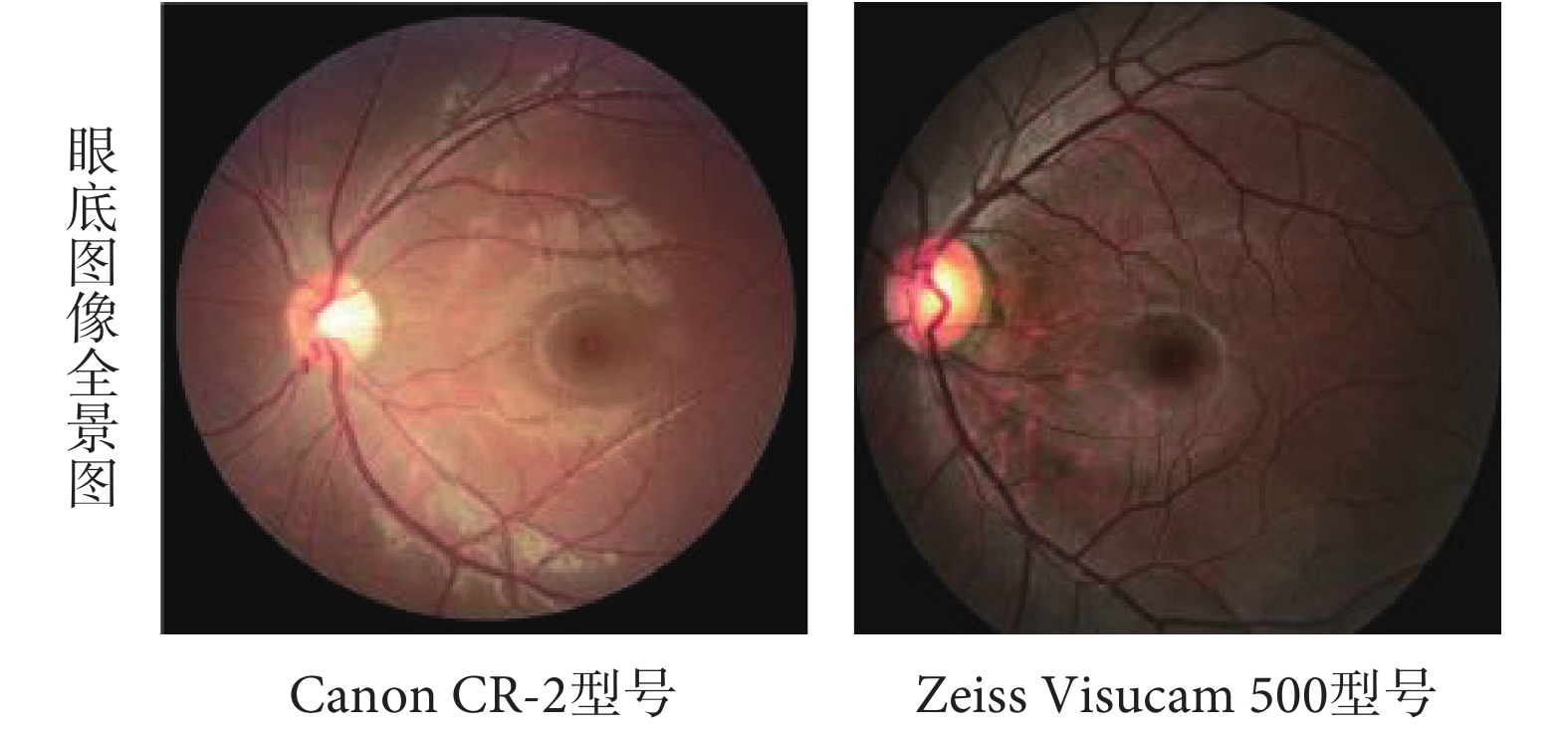 圖1
不同眼底照相機拍攝的眼底圖像
Figure1.
Fundus images taken by different fundus cameras
圖1
不同眼底照相機拍攝的眼底圖像
Figure1.
Fundus images taken by different fundus cameras
1.2 圖像預處理
1.2.1 極坐標變換
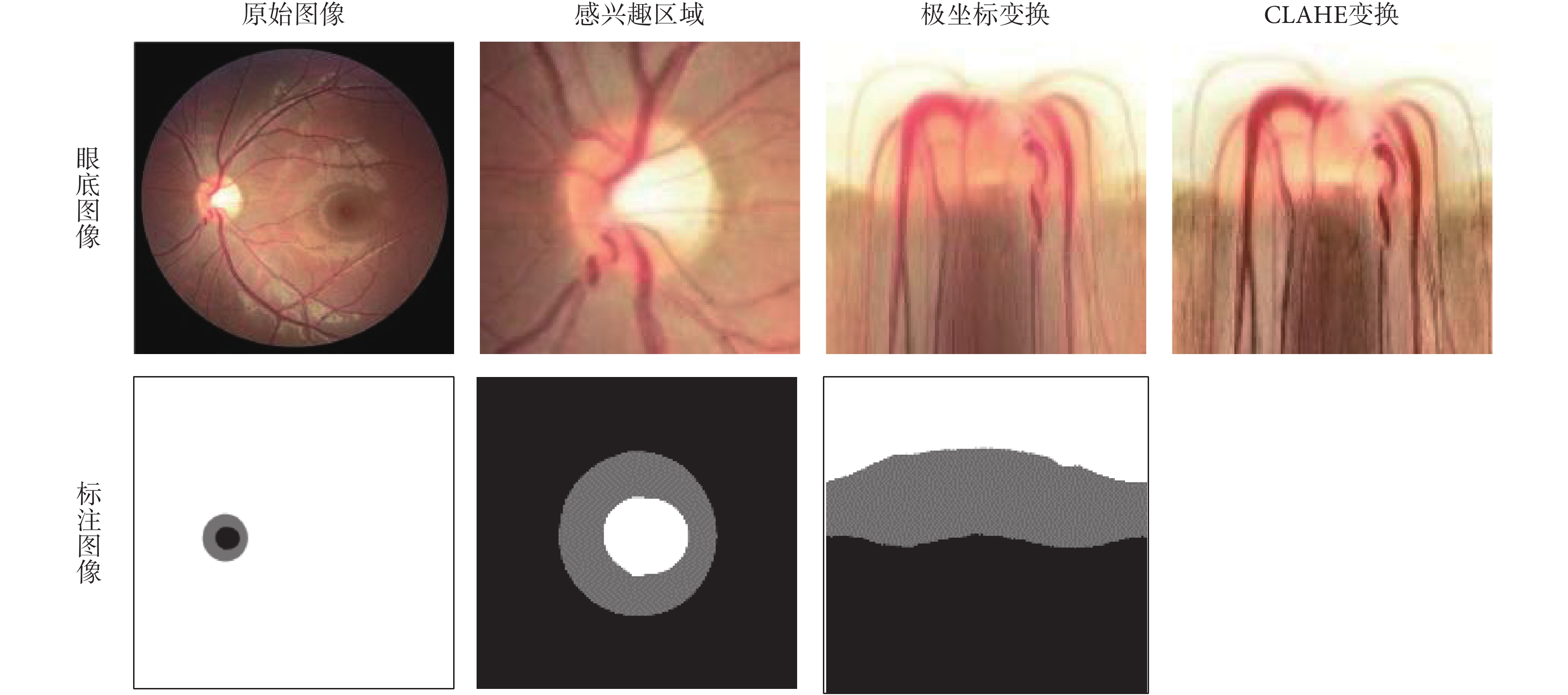
對于圖像的預處理操作,如圖 2 所示。在該方法中,最初得到的是一張包含了感興趣區域的眼底圖像全景圖,首先使用現有的視盤自動檢測方法對視盤的中心進行定位[31],按照指定的像素大小對視盤區域進行分割,以得到感興趣區域。然后,將得到的感興趣區域進行極坐標變換,像素級坐標變換將原始的眼底圖像映射到極坐標系統,其轉換關系如式(1)所示:
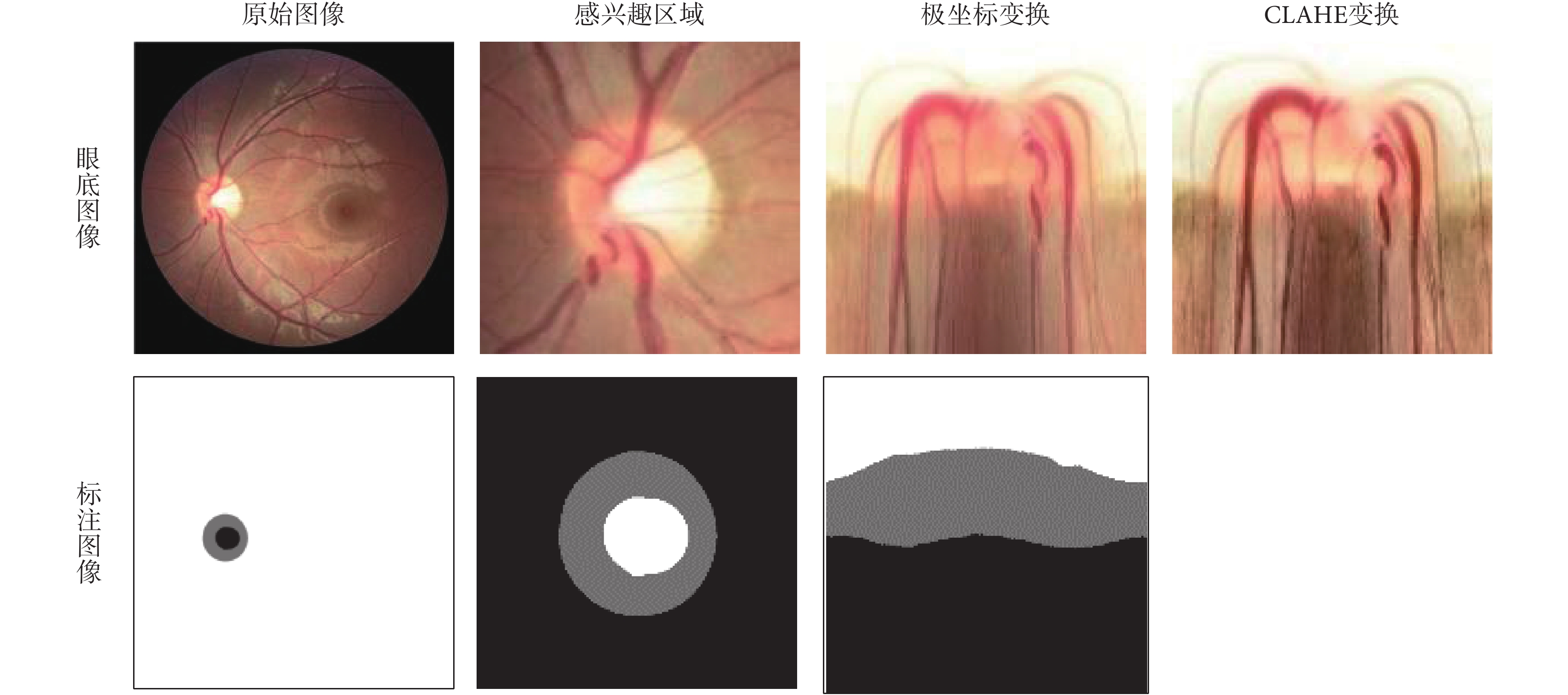 圖2
眼底圖像和標注圖像的預處理過程
Figure2.
The preprocessing process of fundus image and annotated image
圖2
眼底圖像和標注圖像的預處理過程
Figure2.
The preprocessing process of fundus image and annotated image
 |
其中 u、v 表示某個像素在笛卡爾坐標系下的橫縱坐標;θ、r 表示某個像素在極坐標下的方向角和半徑。
極坐標變換的作用主要有:① 空間約束。原始的眼底圖像中,存在一個有效的幾何約束是視杯包含于視盤之中,且兩者形狀是近似橢圓形,這些信息的表達和約束在網絡中的實現比較困難,且各個圖像的差異性(大小和位置等)較大。但在極坐標系統下,可以容易地將這種幾何約束轉換成空間關系,即視杯、視盤和背景呈現出有序的層結構。正因為有這種層結構,本文便將其作為先驗空間約束。具體來說,在視杯分割結果中,預測視杯像素不可能存在于預測標注圖像的下方 1/2 處,可直接將其設置為背景部分;同理,在視盤分割的預測標注圖像的下方 1/3 處可以直接將其設置為背景部分。② 平衡杯盤比。在原始的眼底圖像中,視杯視盤與背景的像素分布有很大的偏差。即使截取到的感興趣區域中,視杯區域僅占 4% 左右,這種極不平衡的結構區域很容易造成神經網絡在訓練過程中的偏差與過擬合,大大影響視盤、視杯分割的精度。極坐標變換是基于視盤中心的圖像平坦化,可以通過插值來擴大視杯在圖像中的比例。經過極坐標變換的視杯區域比率比感興趣區域部分高 23.4%[26],能有效提高杯盤比,平衡數據集,防止過擬合和提高分割精度。
1.2.2 數據增強
由于數據集中眼底圖像數量有限,在得到感興趣區域并進行極坐標變換之后,使用數據集增強來防止模型過擬合。隨機圖像處理方法可以提高數據增強的能力,對圖像進行隨機變換,包括隨機水平翻轉、圖形隨機移動和 HSV(Hue,Saturation,Value)顏色空間中的顏色抖動。
1.2.3 歸一化處理
通常眼底圖像存在光照不均勻、對比度低和血管干擾等問題,這些因素都會降低青光眼診斷的有效性。在視杯視盤分割任務中,先將視杯視盤和背景的對比度增大,再對增強后的圖像進行限制對比度自適應直方圖均衡化處理(contrast limited adaptive histogram equalization,CLAHE)[32]和顏色歸一化以糾正不均勻的光照和改善低對比度,最后將處理后的圖像與處理前的圖像組合起來,構成一個新的六通道圖像數據,以此來豐富圖像信息,讓模型學習到具有更強可分性的特征。
1.3 全卷積多尺度神經網絡模型的建立
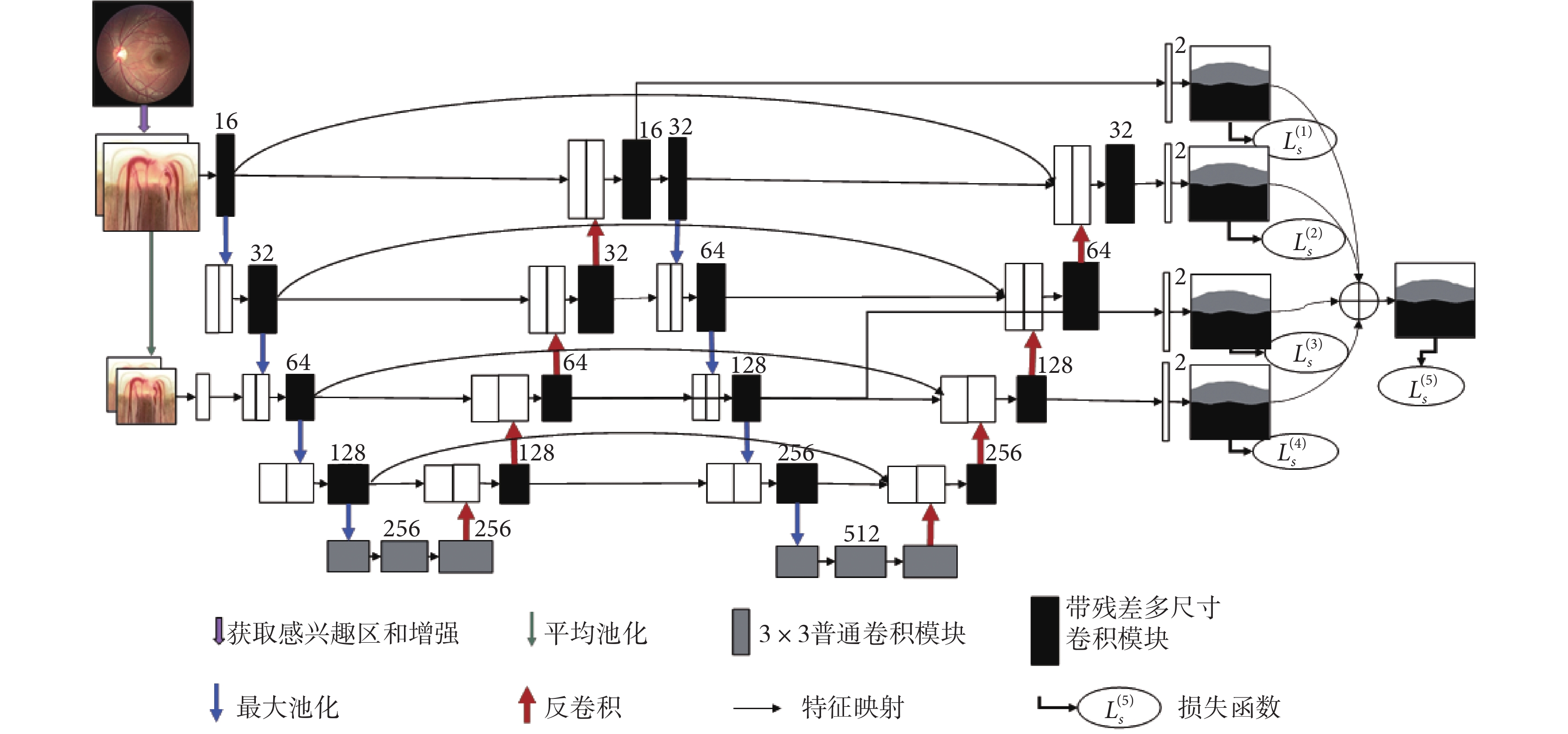
本文所提出的 W-Net 是一個端到端的多標簽深度神經網絡,由四個主要部分組成,如圖 3 所示。第一部分是多尺度層,用于構造圖像金字塔的輸入,實現不同尺度和光學性質的原始語義信息輸入,極大地豐富語義信息。第二部分是采用 W 型的卷積神經網絡作為主體結構,用于學習圖像中所包含的不同層次的深淺特征。第三部分是在不同網絡深度層次的多個側輸出層來實現深層監控,讓梯度信息更好反向回傳到前層,有效抑制神經網絡的梯度消失和有利于網絡的訓練學習。此外,還提出了帶殘差多尺度全卷積模塊來代替普通卷積模塊,實現在不同尺度感受野下提取更多可分性強的特征,增加網絡的特征提取能力。最后,提出了一個多標簽損失函數來指導視盤、視杯的聯合分割實現。
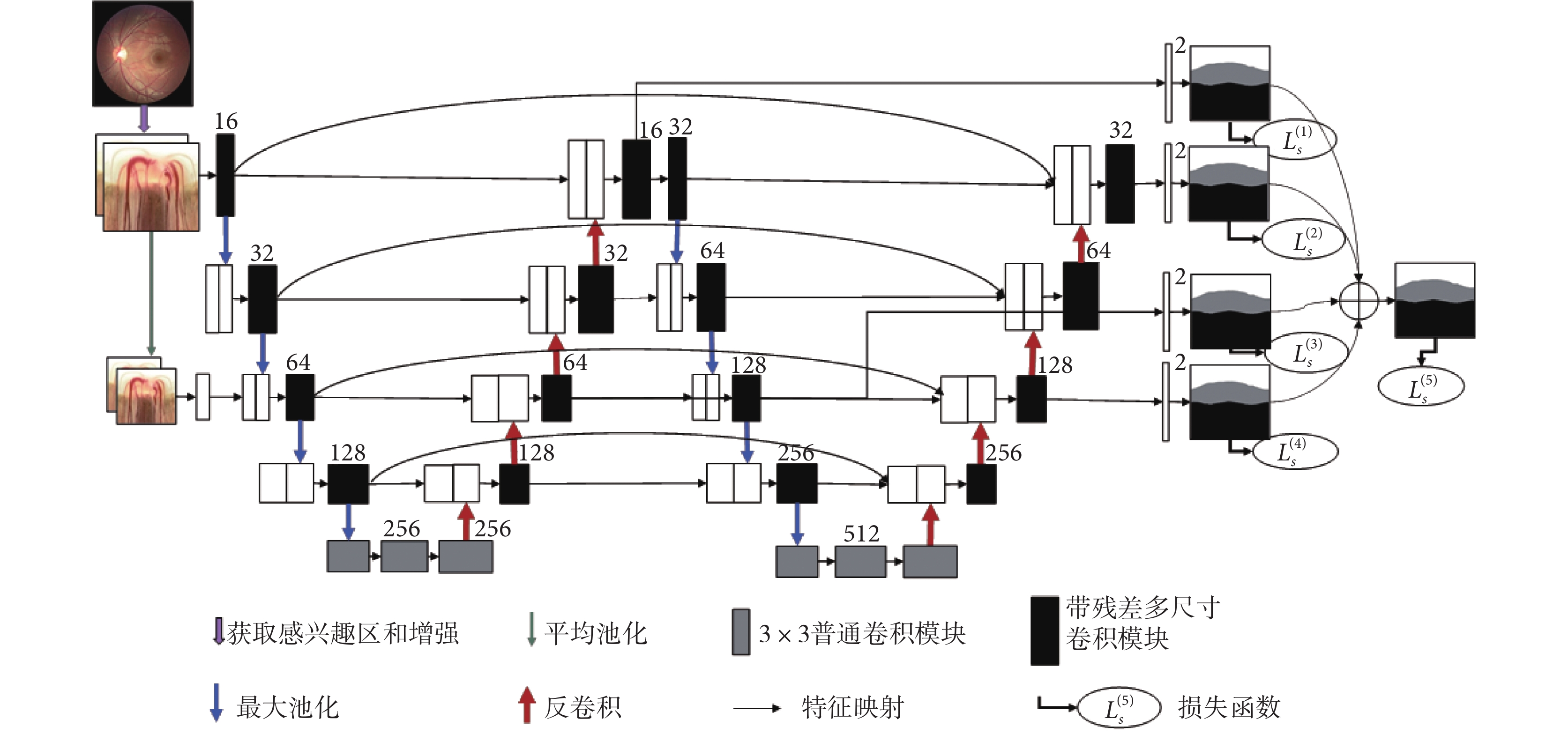 圖3
W-Net 主網絡結構圖
圖3
W-Net 主網絡結構圖
包括一個多尺度輸入層、一個 W 形卷積網絡、四個側輸出和多標簽損失函數
Figure3. Main network structureincluding a multi-scale output layer, a W-shaped convolutional network, four side outputs, and a multi-label loss function
1.3.1 主網絡結構
借鑒 U-Net[25]、M-Net[26],本文將兩個 U-Net 進行級聯作為網絡的主體,如圖 3 所示。U-Net 是一種高效的生物醫學圖像分割的全卷積神經網絡,由編碼路徑和解碼路徑兩部分組成,但是對于較復雜的多標簽任務,往往 U-Net 的分割精度不高,本文主網絡是將兩個 U-Net 進行級聯,前 U 型網絡為后 U 型網絡提供了較為淺層的語義表達,后 U 型網絡對前 U 型網絡提供的淺層信息進行進一步語義抽象與增強。這種結構加深了神經的深度,從而使得網絡能在訓練過程中學習到更多深層結構信息和更加抽象的語義信息;再加之網絡中的跳躍連接,可以實現網絡中同一尺度深、淺不同層次之間的語義信息融合和減少不同語義之間的語義鴻溝,來指導網絡提取深層的可分性語義表示。此外,淺層特征可最大程度保留圖像原始的結構信息,而深層特征則包含更多抽象結構信息,兩者進行融合有利于在最后的卷積通道中恢復目標中的空間維數和結構細節,進而提高分割精度。
每個編碼路徑與卷積核一起執行卷積層以產生一組編碼器特征映射,并且利用修正線性單元(rectified linear unit,ReLU)激活函數,編碼器路徑還利用卷積層來輸出解碼器特征圖。最后,將最終的解碼器層輸出的高維特征表示輸入到可訓練的多標簽分類卷積層中,最終分類器采用 Sigmoid 激活函數來生成預測概率圖,實現像素級分類。本文將視杯視盤多標簽分割任務輸出為三個通道(分別為視杯、視盤和背景)的概率預測圖,概率映射的預測結果即為在每個像素處具有最大概率的類別。
1.3.2 多尺度輸入層
文獻[26]對多尺度輸入或圖像金字塔已經進行驗證,可有效提高網絡分割性能。經過圖像的預處理之后,將 RGB 圖像拓展到了六個通道。本文使用平均池化對圖像進行降采樣,并在編碼路徑中構造多尺度輸入。這樣可以將多尺度輸入集成到編碼層之中,有效避免參數大量增長,以及等效增加編碼路徑的網絡寬度。與其他工作[26]不同,我們發現當圖像金字塔的深度與網絡深度一致時,網絡學習性能并非能達到最佳。因為在持續的降采樣過程中,雖然會丟失一些圖像信息,同時得到一些新的結構信息,但這之中存在大量冗余信息,會導致網絡存在過擬合和泛化性能差等問題。因此在本文中進行了一次降采樣跨網絡深度的處理,既增加了網絡深度,又能較好地抑制網絡中的輸入信息冗余,有效實現兩者的平衡。
1.3.3 側輸出層
側輸出層充當一個早期分類器,為早期層生成一個局部伴隨輸出映射。M-Net[26]中有四個側輸出層,并將四個側輸出層保持權重一致、簡單平均疊加,得到最后的輸出。本文發現,網絡的幾個側輸出層對最后的輸出的貢獻并非相等。側輸出層選擇不同深度網絡的一、三通道,與前面的多尺度輸出層結構保持一致,這樣既保證網絡輸出之間冗余信息的有效減少,又可對網絡進行有效深度監督。最后,將不同的側輸出層進行加權融合,給出下式的目標函數:
 |
其中, 表示每個側輸出層的損失函數的融合權重,Ls(n)表示第 n 個側輸出層的多標簽損失,N 表示側輸出層的個數。在本文中,設置最后一層的損失函數權重為 0.6,其余權重均為 0.1。
表示每個側輸出層的損失函數的融合權重,Ls(n)表示第 n 個側輸出層的多標簽損失,N 表示側輸出層的個數。在本文中,設置最后一層的損失函數權重為 0.6,其余權重均為 0.1。
側輸出層的主要優點是可以將邊輸出的損失函數反向傳播到對應的淺層卷積層中,可有效抑制梯度消失問題,有利于實現早期層的訓練。此外,側輸出層的多尺度融合實現了特征高性能的融合,側輸出層對各尺度的輸出預測結果實現深度監督,從而獲得更好的輸出結果。
1.3.4 多標簽損失函數
視杯、視盤聯合分割任務是一個多標簽問題。現有的分割方法通常屬于多類設置,它將每個實例按照某種規則對其進行唯一標記。而在多標簽方法中,每一類都是一個獨立的二進制分類,某一實例按照某種規則對每一類進行判斷,這意味著某一實例可分別屬于多個類別。這點在視杯、視盤分割任務中十分重要,因為視杯、視盤有嚴格的幾何約束,視盤區域包含視杯區域,表明屬于視杯的像素也一定屬于視盤。在病變的青光眼之中,視盤區域中排除掉視杯區域的部分僅僅只是一個很薄的圓環,這就會造成視盤與背景區域像素面積極不平衡,而采用多標簽的方法可有效提高視盤與背景的比例,可以解決類別極不平衡的問題。在該方法中,我們提出一個基于 DICE[33]和 Focal-Loss[34]的多標號損失函數,見公式(3)~(5)。DICE 系數是一個重疊的度量,廣泛用于評估分割性能。DICE 損失函數指示前景掩碼重疊比,并且可以處理前景像素與背景的不平衡問題。Focal-Loss 則主要為了解決數據集不平衡問題,因為它更關注于小樣本中難以分割的區域。
 |
 |
 |
其中, 和
和  分別表示第
分別表示第  個像素的實際類別和真實類別;ε、α、γ 為常值系數,設置
個像素的實際類別和真實類別;ε、α、γ 為常值系數,設置 
 。
。
1.3.5 殘差多尺度卷積模塊
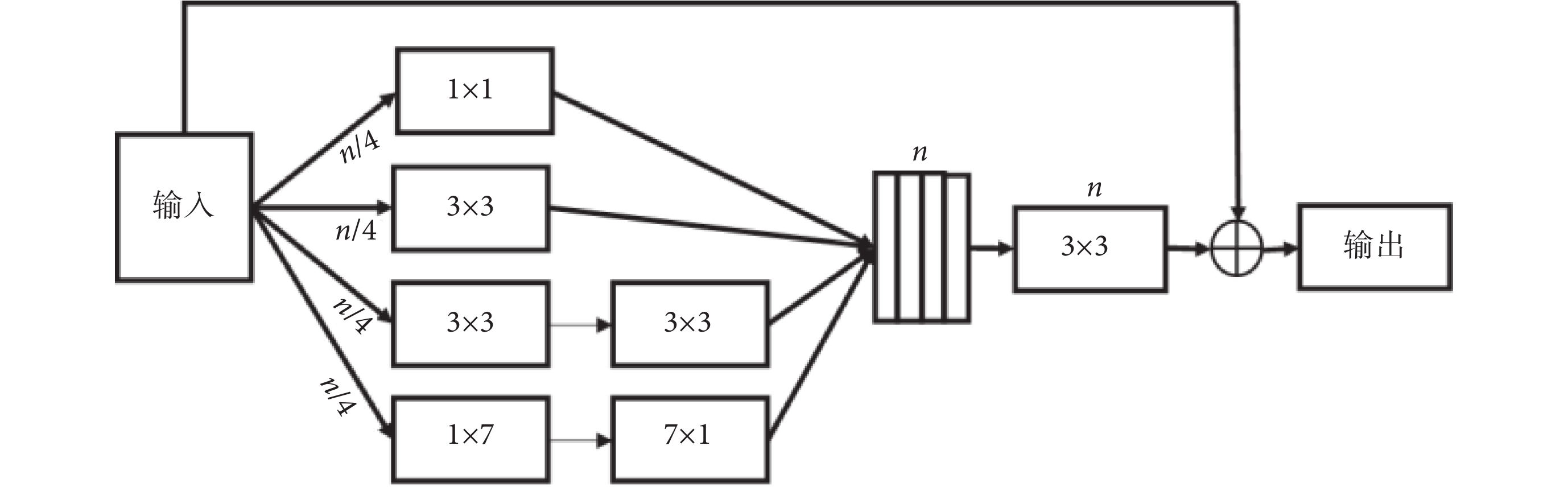
在深度學習網絡中,Inception[35]和 ResNet[36]是兩個經典的框架。Inception 結構通過拓寬網絡寬度來接收不同尺度的感受野。而 ResNet 則引入了跳躍連接機制來克服網絡退化和梯度消失的問題,這使得神經網絡深度首次突破 1 000 層以上的有效學習。Inception-ResNet[37]模塊結合了 Inception 和 ResNet,繼承了這兩種方法的優點,使之成為深度卷積神經網絡中一種基本的方法。在 Inception-ResNet-V4 模塊的啟發之下,我們提出了一種殘差多尺度卷積模塊來提取高層次的語義特征映射,如圖 4 所示。在通常的情況下,具有大感受野的卷積核可以提取大目標和產生豐富的抽象特征,而小的感受野卷積核則更適合提取小目標和細節的特征。在殘差多尺度卷積模塊中,使用兩個 3 × 3 的卷積單元代替一個 5 × 5 的卷積模塊,使用 1 × 7 和 7 × 1 兩個模塊來代替 7 × 7 的模塊,且每個通道采用原來 1/4 的卷積核。這些改進不僅減少了網絡參數,同時能夠保持較大的感受野。除了通過四條卷積通道進行特征映射,還引入了類似 ResNet 中的跳躍連接。然后再經過一個標準 3 × 3 卷積單元和 1 × 1 的卷積單元來進行降維和非線性激勵,以提升網絡的表達能力。最后對所得到的卷積單元再與輸入特征進行跳躍連接,實現不同深、淺層次特征融合。
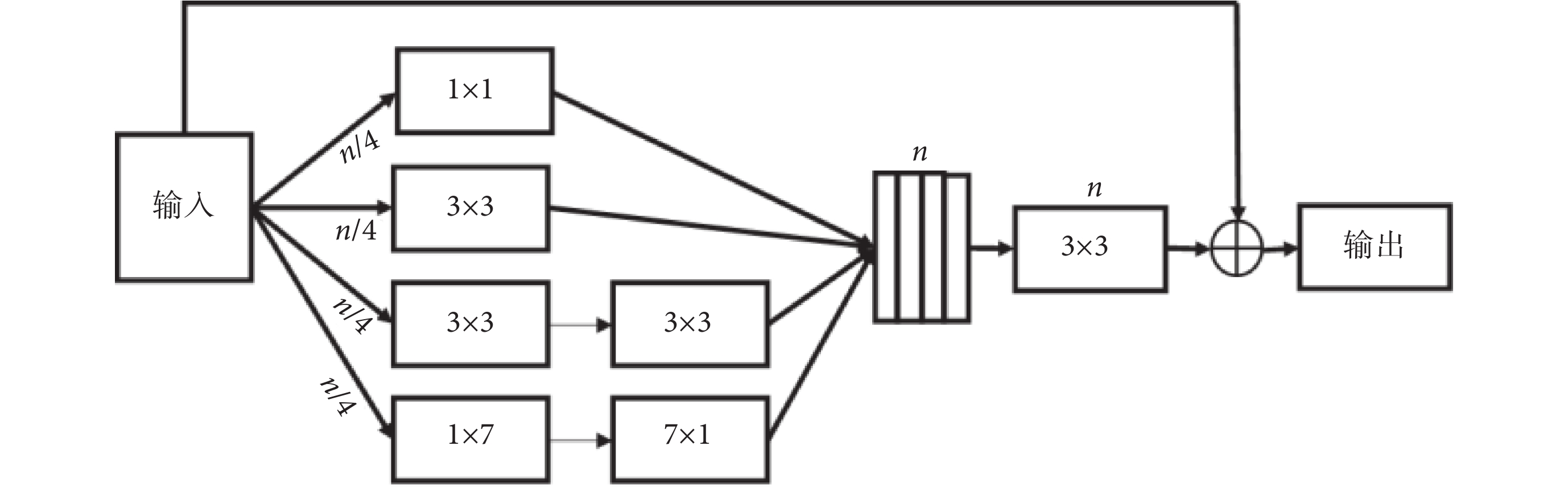 圖4
殘差多尺度卷積模塊結構圖
Figure4.
Structure of residual multi-scale convolution module
圖4
殘差多尺度卷積模塊結構圖
Figure4.
Structure of residual multi-scale convolution module
1.4 評價指標
為了評價所提出 W-Net 網絡的分割性能,引入了一系列評價指標來分析所得視杯、視盤和背景區域的預測分割結果,這些指標一般都用來評價視杯視盤分割的準確性[38],包括了精確度(pixels accuracy,PA)、平均精確度(mean accuracy,MA)、平均交并比(mean intersection over union,MIoU)、加權交并比(frequency weighted intersection over union,FWIoU)、以及重疊誤差(overlapping error,OE)。具體表達式見公式(6)~(10)。
 |
 |
 |
 |
 |
其中, 表示類別數;
表示類別數; 表示所有像素的數目;
表示所有像素的數目; 表示屬于第
表示屬于第  類的像素總數。
類的像素總數。 表示實際類別為第
表示實際類別為第  類卻錯分為第
類卻錯分為第  類的像素數目。
類的像素數目。
2 結果
2.1 實驗環境
在實驗中,主要步驟:① 圖像預處理;② 利用網絡訓練來學習系統最優參數,并在每個訓練周期結束后的驗證階段保存最佳網絡模型;③ 測試最佳網絡模型并預測結果;④ 預測結果評估。本文實驗是基于 Keras 的 Python 和 Tensorflow 后端實現的,采用的顯存為 8 GB 的 Nvidia GeForce GTX 1 080 GPU 和主頻 3.50 GHz 的 Inter(R)i7-5 930k CPU。在訓練過程采用 Adam 優化器對深度模型進行優化。網絡基于圖像數據集,采用數據集作為參考進行有監督訓練,其中 75% 即 600 張眼底圖像用于訓練,12.5% 即 100 張圖像用于驗證,12.5% 即 100 張圖像用于測試。訓練中每一次選取的樣本數設置為 6,訓練集每訓練一個周期結束,對驗證集進行一次整體評測,訓練過程持續 200 個周期。實驗測試結果與專家標注結果作比較,采用測試圖片定量評價的平均值作為定量分析的結果。
2.2 實驗結果
本研究在 REFUGE 眼底圖像數據庫上進行實驗并與當前最先進的方法進行了對比,包括 U-Net[25]、M-Net[26]以及基于它們的一些改進模型。為了驗證所提出的殘差多尺度卷積單元相較于標準卷積模塊的優越性能,使用 U-Net[25]、M-Net[26]作為主體框架,將其中的普通卷積單元替換為殘差多尺度卷積單元,分別稱之為 U-Net-Mcon 和 M-Net-Mcon,再與本文所提出的 W-Net 為主體框架的模型分別以普通卷積單元(W-Net)和殘差多尺度卷積單元(W-Net-Mcon)進行比較。通過定量分析 ACC、MA、MIoU、FWIoU 以及 OE 五個評價指標,分別評估提出的 W-Net-Mcon 在視杯、視盤的分割性能。
表1 顯示了在 REFUGE 數據集[31]中使用包括 U-Net[25]、M-Net[26]在內的六種網絡方法進行視杯、視盤聯合分割所得到的性能指標。不難看出,本文提出的 W-Net-Mcon 網絡的視杯、視盤分割結果在上述五個評價指標均優于其他網絡。在實驗結果中,視盤分割結果的 ACC、MA、MIoU、FWIoU、OE 分別為 0.983 3,0.978 6,0.955 3,0.967 4 和 0.066 5,視杯分割結果分別為 0.987 0、0.949 6、0.904 0、0.975 3 和 0.178 0。
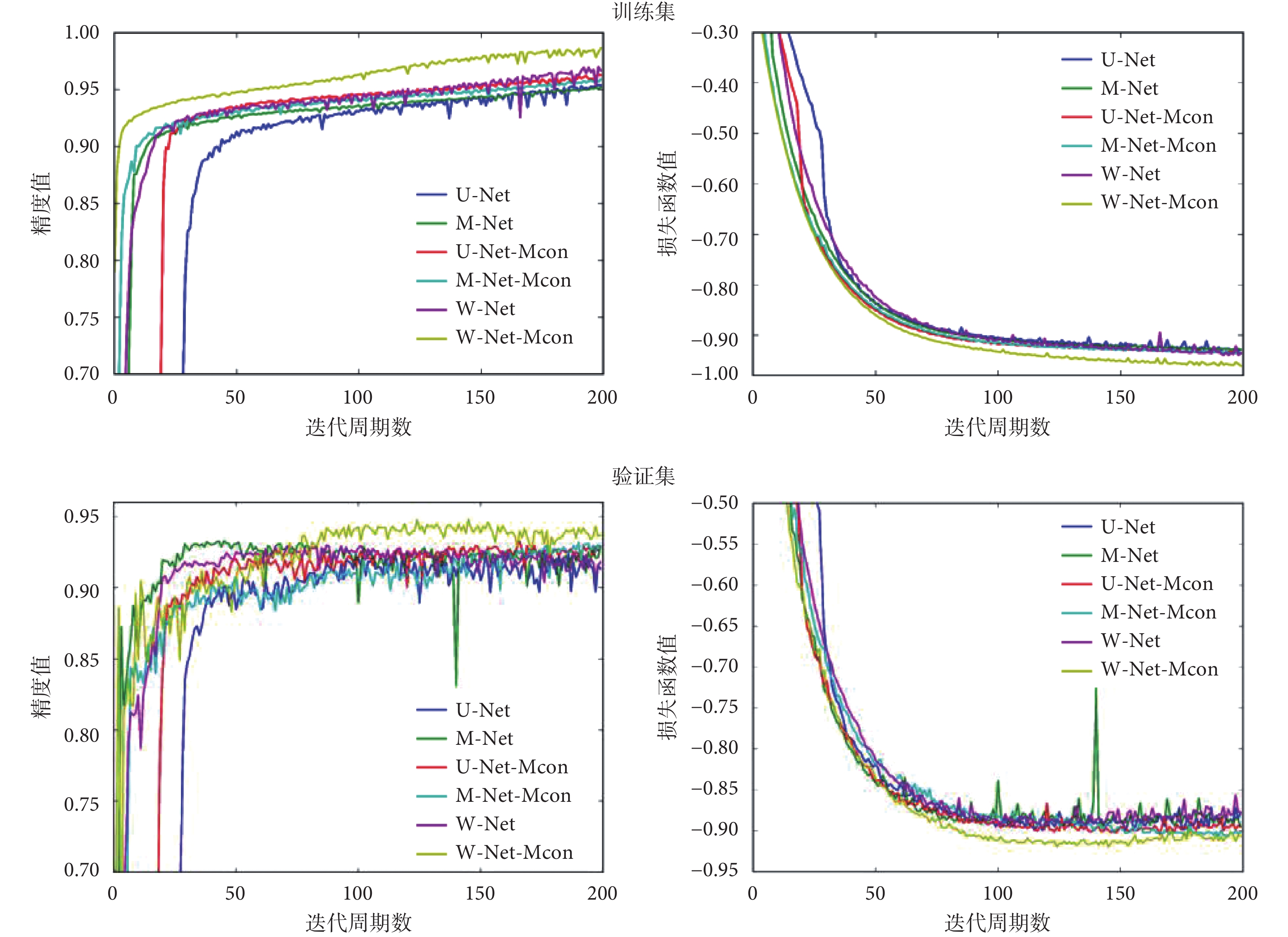
圖5 顯示了網絡優化過程訓練集和驗證集的精度和損失函數變化情況。可以看出,W-Net-Mcon 在精度上明顯高于其他網絡,同時損失函數能夠快速收斂且取得最優。
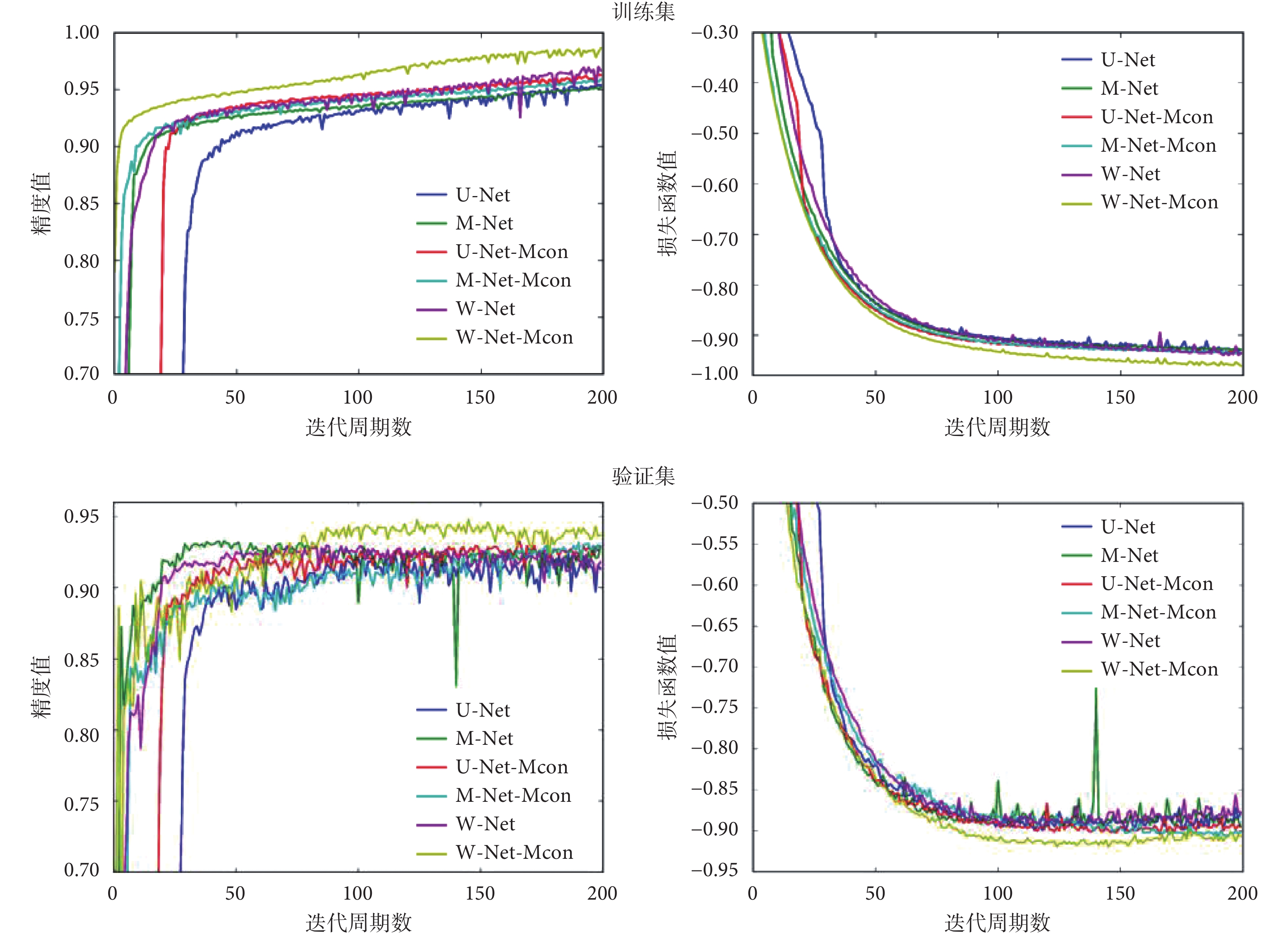 圖5
訓練集和驗證集的精度與損失函數值在網絡訓練過程中隨周期迭代的變化情況
Figure5.
The accuracy and loss function values of the training set and the validation set varing with the cycle iteration during the network training process
圖5
訓練集和驗證集的精度與損失函數值在網絡訓練過程中隨周期迭代的變化情況
Figure5.
The accuracy and loss function values of the training set and the validation set varing with the cycle iteration during the network training process
圖 6 顯示了在 REFUGE 數據集得到的視杯、視盤分割實驗結果實例。為了證明所提方法的泛化性能,選取了數據集中兩種不同光學性質的眼底圖像,分別為圖 6 中的 1、2、3 組和 4、5、6 組。不難看出,該方法在處理對比度較高或較低的兩類不同眼底圖像時,均可以實現視杯視盤的高精度聯合分割。
 圖6
各網絡視杯視盤聯合分割的效果比較
Figure6.
Comparison of the joint segmentation of the disc and cup of each network
圖6
各網絡視杯視盤聯合分割的效果比較
Figure6.
Comparison of the joint segmentation of the disc and cup of each network
3 討論
本研究利用深度學習中的全卷積神經網絡對眼底圖像中的視杯視盤進行聯合分割。為了解決傳統圖像處理算法無法實現低對比度圖像和不同光學圖像之間低泛化性的視杯視盤聯合分割問題,本研究利用全卷積神經網絡強大的特征提取和特征表達能力,提出一種新型網絡結構和帶殘差多尺度卷積學習模塊的網絡(W-Net-Mcon),實現了高維與低維特征的融合,提高了特征的使用率。
從圖 5 可以看出,與其他網絡相比,本文構建的網絡在不同方面均表現出了一定的優勢。在精度上,本文構建的網絡高于其他網絡,能夠使損失函數快速收斂且取得最優。這表明本文方法相較于其他網絡,在訓練集上有較強的擬合能力和特征提取能力。而在驗證集上的高精度則表明網絡沒有出現因對訓練集的過度學習而引發的過擬合,該方法具有較強的泛化性和魯棒性,能夠學習圖像語義信息中的強可分性特征表示,從而使得網絡具有更好的分割性能。這些優勢也體現在表 1 的結果中。
表 1 羅列的是評價指標的定量分析。首先,在各個網絡框架的分割效果中的優勢:實驗中選用了 U-Net、M-Net 和 W-Net 進行比較,W-Net 各項指標均高于另外兩組數據,尤其是在視盤、視杯的 OE 指標表現優異,這表明本文提出的 W-Net 網絡結構在某些方面優于其他網絡。其優勢主要由于:① W-Net 的多尺度輸入層相較于 U-Net 加深了網絡寬度以提供豐富的原始語義信息,同時相較于 M-Net 又減少了原始語義信息中的重復、冗余信息,有效實現兩者平衡;② W-Net 中不同網絡深度的側輸出層實現了網絡各層的深度監督,從而指導網絡學習特征信息;③ 引入跳躍連接,將同一尺度不同深、淺層次的特征信息融合,有利于減少網絡參數和網絡梯度反向傳播,可避免梯度消失問題。
其次,在所提出的殘差多尺度卷積模塊的優勢:實驗將 U-Net、U-Net-Mcon,M-Net、M-Net-Mcon 和 W-Net、W-Net-Mcon 兩兩分別對比,在 U-Net 框架中,除了視盤中 MA 指標略低,U-Net-Mcon 的各項指標均高于原始 U-Net;在 M-Net 中,除視盤中 ACC 指標略低,M-Net-Mcon 的其他指標均比 M-Net 好;對于 W-Net 結構,使用殘差多尺度卷積模塊的 W-Net-Mcon 所有指標均比 W-Net 的結果好。通過實驗對比,在相同的網絡框架下,使用帶殘差多尺度卷積模塊的網絡性能明顯優于普通卷積單元,這是因為殘差多尺度卷積具有不同尺度的感受野來提取網絡中不同層次的特征和豐富語義信息。同時,將不同尺度的特征映射連接起來進行特征融合,另有外面的跳躍連接構成殘差學習進而使得網絡更加容易訓練,可有效抑制梯度消失問題和網絡退化問題。因此,W-Net 雖加深了網絡,但其性能并未退化,并使得分割效果有所提高。
最后,本文將帶殘差多尺度卷積模塊和 W-Net 深度神經網絡框架進行結合,即 W-Net-Mcon。W-Net-Mcon 與其他網絡比較,在所有評價指標中均最好。這是因為 W-Net 通過易于實現的級聯方式,拓展了網絡的深度使得網絡提取到更深層次的語義信息。同時為了解決網絡加深可能導致的網絡退化和梯度消失問題,引入了跳躍連接和深度監督。一方面,可以使網絡在梯度反向傳播時更容易到達淺層的神經層;另一方面,可鼓勵特征復用,加強特征傳播,實現不同深淺層次的特征融合,進而能抑制梯度消失并減少訓練參數的數量。通過上述分析,我們可以認為所提的網絡 W-Net-Mcon 明顯優于原始的 U-Net[25]和 M-Net[26],視杯、視盤分割結果在主要評價指標 OE 中分別降至 0.178 0 和 0.066 5,達到最精準的分割效果。
圖 6 中直觀地展示了不同網絡的分割效果。從總體上來看,W-Net-Mcon 網絡輸出的分割結果形狀更接近于專家標注的圖像形狀,且噪聲點更少;從細節來看,W-Net-Mcon 網絡輸出的分割結果顯示邊緣不規則形狀更少,且更加平滑,這與表 1 的結果是一致的。因此,W-Net-Mcon 會產生更加精確的視杯、視盤分割結果,能夠有效幫助醫生快速分割出視杯視盤,進而評估杯盤比和完成青光眼的輔助篩查與診斷,從而提高醫生的效率和降低因醫生疲勞或主觀性可能造成的誤診風險,也可將其推廣到青光眼大規模篩查任務中。
此外,本研究對未來工作提出了兩個重要方向。一是泛化數據集,需要在更多的數據集上進行驗證,以確保方法具有更強的泛化性能和魯棒性。因此我們計劃完成并發布一個包含眼底圖像視杯視盤分割的多目標數據集,利用數據驅動深度學習技術發展。二是關于超參數的選擇,本文中一些超參數的選擇主要還是根據經驗和實驗效果來人工選擇的,缺乏系統的調參方式,這也是目前深度學習面臨的一個重要問題,因此我們將不斷對其進行探究與完善。
4 結論
本文提出了一種稱為 W-Net-Mcon 的殘差多尺度全卷積深度神經網絡結構,并將視盤、視杯聯合分割任務看作單階段多標簽標記問題。在圖像預處理階段,我們引入了極坐標變換來實現空間約束和平衡杯盤比。我們提出的 W-Net-Mcon 是以 W 型的全卷積網絡作為主體框架,在網絡輸入口加入圖像金字塔來構造多尺度輸入層,同時在與之對應相同尺度的網絡中構造多個側輸出層作為早期的分類器來生成局部預測輸出。此外,本文還提出了帶殘差多尺度全卷積模塊,利用不同大小的感受野來提取不同層次的語義信息,再加上同一尺度的不同深度層次的跳躍連接,起到了鼓勵特征復用、加強特征傳播、不同深淺層次的特征融合作用。最后,提出了一種多標簽損失函數來指導網絡分割。我們已經證明該系統在 REFUGE 數據集[31]獲得了較好的分割結果。實驗結果表明,該網絡實現了視盤、視杯聯合分割并有效提高了分割精度,這將有助于推進大規模的青光眼早期篩查,因此 W-Net-Mcon 的殘差多尺度全卷積深度神經網絡結構具有良好的應用前景。
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
引言
青光眼是全世界第二大致盲眼病(僅次于白內障),也是造成不可逆性失明的首要原因[1]。青光眼造成的視力損傷是不可逆的,且早期癥狀不易發現,因此對青光眼的早期篩查與診斷至關重要。目前,眼底圖像和三維光學相干層析成像(optical coherence tomography,OCT)常被用于輔助診斷青光眼。其中 OCT 圖像成本相對昂貴且普及率低,不適用于大規模的青光眼篩查,故大多數醫生常選擇使用成本較低和容易獲得的眼底圖像進行青光眼篩查與診斷。當下,評估眼底圖像中視神經乳頭的技術是主流的青光眼篩查技術[2],它采用一個二分類來判斷是否屬于青光眼疾病。然而眼底圖像常由經驗豐富的眼科醫生手動標注,費時費力且帶有很大的主觀性,因此手工標注眼底圖像不適用于青光眼的大規模篩查。
在眼底彩色圖像中,視盤呈現亮黃色且形狀近似橢圓,可分為兩個明顯的區域:中間明亮區(視杯)和外圍區(視神經網膜邊緣)。青光眼大規模篩查技術中,多種自動評估視神經乳頭的方法被相繼被提出,例如垂直杯盤比(vertical cup to disc ratio,CDR)[3]、視杯(optic cup,OC)視盤(optic disc,OD)面積比以及視盤直徑[4]等。而在臨床上,醫生主要采用杯盤比評估視神經頭。杯盤比是指垂直杯徑與垂直盤徑的比。通常情況下,杯盤比值越大,則患青光眼的概率越大。因此,準確地分割視杯視盤是篩查和診斷青光眼的關鍵。
在醫學圖像分割算法中,主要分為基于手工提取特征的傳統方法[5-8]和利用卷積神經網絡來自動提取特征的深度學習框架[9-11]。早期研究中的視杯視盤分割方法通常是利用手工提取視覺特征進行分割,其主要包括顏色、紋理、對比度閾值、邊緣檢測、分割模型和區域分割方法[12-19],但這些方法容易受到眼底圖像拍攝環境和圖像本身質量的影響,從而影響目標的分割效果。此外,從眾多像素中提取出特征訓練分類器不易實現,故有學者[20]提出采用超像素策略來減少像素數,并采用超像素分類進行視杯視盤分割。但該方法需要手工構造特征來獲得分割結果,其實現過程繁瑣且可重復性差。深度學習在計算機視覺任務中克服了人工設計特征的局限性,并可自動學習高度的可區分性特征進行表示。在醫學圖像分割領域,早期的深度學習方法大多是基于圖像塊[21-22],其局限性是滑動窗會導致冗余計算和無法學習到圖像的全局特征。接著,端到端的全卷積神經網絡(fully convolutional neural network,FCN)被提出并在圖像分類和分割中得到廣泛應用[23-24]。在全卷積神經網絡基礎上,Ronneberger 等[25]提出在醫學圖像分割領域具有卓越性能的 U-Net 結構,并且該結構已經成為該領域的重要結構。通常,U-Net[25]結構可以被認為是編、解碼器的結構。編碼器的目的是逐步減少特征映射的空間維數,來獲取更高層次的語義特征。而解碼器則是為了恢復目標中的空間維數和結構細節。因此,在編碼器中應盡可能捕獲更多的高級特征,而在解碼器中應盡可能地保留空間信息。之后,在 U-Net 基礎上又發展出許多改進網絡結構,包括 M-Net[26-27]、U-Net++[28-29]等,均在醫學圖像分割任務中取得了不錯的效果。
現有眼底圖像分析方法大多是對視杯視盤分別進行分割[12-15.30]。文獻[12-13]將視杯視盤分割分為兩個獨立階段,即分別利用各自的特征進行分割。在分割視杯時,先定位到視盤,把視盤分割出來后再提取感興趣區域來分割視杯,造成了視盤分割信息的浪費。文獻[14]則提出將視杯視盤分割集成在同一分割框架內。但這些方法忽略了視杯和視盤之間存在的先驗信息,例如形狀約束和結構約束,即視杯視盤均接近橢圓形,視杯包含于視盤之中。同時,上述幾種方法都將視杯視盤看作非獨立標簽,每個像素只對應一個標簽(即視杯、視盤或背景),割裂了兩者的聯系。
針對上述問題,本文以 U-Net[25]與 M-Net[26]為基礎,提出了一個新的 W-Net 網絡結構用于視杯視盤聯合分割。相比于 U-Net[25]或 M-Net[26],W-Net 主網絡結構是以 W 型卷積神經網絡為主體框架,加深了網絡深度,有利于網絡進行深層信息學習。此外,W-Net 引入了多尺度輸入和不同網絡深度的監督,其中多尺度輸入可構造圖像金字塔,使輸入圖像信息更加豐富;另外在網絡中加入不同的深度監督,可使側輸出層計算梯度能更容易地反向傳播到前面的卷積層中,可有效抑制梯度消失問題和有利于網絡的早期訓練。同時,本文還提出了一種殘差多尺度全卷積學習模塊來代替 U-Net 和 M-Net 中的標準卷積學習單元,加深了網絡寬度,從而能在有限的尺度范圍內捕獲更多尺度特征。最后,提出了一種新的多標簽損失函數來指導網絡進行視杯視盤分割。
1 方法
1.1 數據集
本文選用 REFUGE 數據集(https://refuge.grand-challenge.org/Home/)進行方法驗證。該數據庫是目前青光眼眼底照片精標數據庫中最全面的標注數據庫,主要包括青光眼與非青光眼兩種類型數據,其中青光眼和非青光眼圖像的比例分別為 10% 和 90%。每張眼底圖像分別包含診斷、圖像分割及定位三方面信息,由七位專家人工標記并融合,克服了之前許多青光眼公開數據集存在的只有診斷標簽信息,無視杯、視盤等關鍵結構的標注信息,且參與標注的專家較少等缺點。所有圖像均以后極(posterior pole)為中心,同時含有黃斑和視盤。在這個數據集中,由訓練集、驗證集和測試集三個組成。訓練集中有 400 張像素為 2 142 × 2 056 的眼底圖像,是使用 Zeiss Visucam 500 眼底相機拍攝的,而驗證集和測試集各由 400 張像素均為 1 634 × 1 634 的眼底圖像組成,是使用 Canon CR-2 眼底相機拍攝的。由于各個集合被不同的眼底照相機拍攝,故而圖像在顏色、紋理等光學性質上會呈現不同,如圖 1 所示。
圖1
不同眼底照相機拍攝的眼底圖像
Figure1.
Fundus images taken by different fundus cameras
1.2 圖像預處理
1.2.1 極坐標變換
對于圖像的預處理操作,如圖 2 所示。在該方法中,最初得到的是一張包含了感興趣區域的眼底圖像全景圖,首先使用現有的視盤自動檢測方法對視盤的中心進行定位[31],按照指定的像素大小對視盤區域進行分割,以得到感興趣區域。然后,將得到的感興趣區域進行極坐標變換,像素級坐標變換將原始的眼底圖像映射到極坐標系統,其轉換關系如式(1)所示:
圖2
眼底圖像和標注圖像的預處理過程
Figure2.
The preprocessing process of fundus image and annotated image
|
其中 u、v 表示某個像素在笛卡爾坐標系下的橫縱坐標;θ、r 表示某個像素在極坐標下的方向角和半徑。
極坐標變換的作用主要有:① 空間約束。原始的眼底圖像中,存在一個有效的幾何約束是視杯包含于視盤之中,且兩者形狀是近似橢圓形,這些信息的表達和約束在網絡中的實現比較困難,且各個圖像的差異性(大小和位置等)較大。但在極坐標系統下,可以容易地將這種幾何約束轉換成空間關系,即視杯、視盤和背景呈現出有序的層結構。正因為有這種層結構,本文便將其作為先驗空間約束。具體來說,在視杯分割結果中,預測視杯像素不可能存在于預測標注圖像的下方 1/2 處,可直接將其設置為背景部分;同理,在視盤分割的預測標注圖像的下方 1/3 處可以直接將其設置為背景部分。② 平衡杯盤比。在原始的眼底圖像中,視杯視盤與背景的像素分布有很大的偏差。即使截取到的感興趣區域中,視杯區域僅占 4% 左右,這種極不平衡的結構區域很容易造成神經網絡在訓練過程中的偏差與過擬合,大大影響視盤、視杯分割的精度。極坐標變換是基于視盤中心的圖像平坦化,可以通過插值來擴大視杯在圖像中的比例。經過極坐標變換的視杯區域比率比感興趣區域部分高 23.4%[26],能有效提高杯盤比,平衡數據集,防止過擬合和提高分割精度。
1.2.2 數據增強
由于數據集中眼底圖像數量有限,在得到感興趣區域并進行極坐標變換之后,使用數據集增強來防止模型過擬合。隨機圖像處理方法可以提高數據增強的能力,對圖像進行隨機變換,包括隨機水平翻轉、圖形隨機移動和 HSV(Hue,Saturation,Value)顏色空間中的顏色抖動。
1.2.3 歸一化處理
通常眼底圖像存在光照不均勻、對比度低和血管干擾等問題,這些因素都會降低青光眼診斷的有效性。在視杯視盤分割任務中,先將視杯視盤和背景的對比度增大,再對增強后的圖像進行限制對比度自適應直方圖均衡化處理(contrast limited adaptive histogram equalization,CLAHE)[32]和顏色歸一化以糾正不均勻的光照和改善低對比度,最后將處理后的圖像與處理前的圖像組合起來,構成一個新的六通道圖像數據,以此來豐富圖像信息,讓模型學習到具有更強可分性的特征。
1.3 全卷積多尺度神經網絡模型的建立
本文所提出的 W-Net 是一個端到端的多標簽深度神經網絡,由四個主要部分組成,如圖 3 所示。第一部分是多尺度層,用于構造圖像金字塔的輸入,實現不同尺度和光學性質的原始語義信息輸入,極大地豐富語義信息。第二部分是采用 W 型的卷積神經網絡作為主體結構,用于學習圖像中所包含的不同層次的深淺特征。第三部分是在不同網絡深度層次的多個側輸出層來實現深層監控,讓梯度信息更好反向回傳到前層,有效抑制神經網絡的梯度消失和有利于網絡的訓練學習。此外,還提出了帶殘差多尺度全卷積模塊來代替普通卷積模塊,實現在不同尺度感受野下提取更多可分性強的特征,增加網絡的特征提取能力。最后,提出了一個多標簽損失函數來指導視盤、視杯的聯合分割實現。
圖3
W-Net 主網絡結構圖
包括一個多尺度輸入層、一個 W 形卷積網絡、四個側輸出和多標簽損失函數
Figure3. Main network structureincluding a multi-scale output layer, a W-shaped convolutional network, four side outputs, and a multi-label loss function
1.3.1 主網絡結構
借鑒 U-Net[25]、M-Net[26],本文將兩個 U-Net 進行級聯作為網絡的主體,如圖 3 所示。U-Net 是一種高效的生物醫學圖像分割的全卷積神經網絡,由編碼路徑和解碼路徑兩部分組成,但是對于較復雜的多標簽任務,往往 U-Net 的分割精度不高,本文主網絡是將兩個 U-Net 進行級聯,前 U 型網絡為后 U 型網絡提供了較為淺層的語義表達,后 U 型網絡對前 U 型網絡提供的淺層信息進行進一步語義抽象與增強。這種結構加深了神經的深度,從而使得網絡能在訓練過程中學習到更多深層結構信息和更加抽象的語義信息;再加之網絡中的跳躍連接,可以實現網絡中同一尺度深、淺不同層次之間的語義信息融合和減少不同語義之間的語義鴻溝,來指導網絡提取深層的可分性語義表示。此外,淺層特征可最大程度保留圖像原始的結構信息,而深層特征則包含更多抽象結構信息,兩者進行融合有利于在最后的卷積通道中恢復目標中的空間維數和結構細節,進而提高分割精度。
每個編碼路徑與卷積核一起執行卷積層以產生一組編碼器特征映射,并且利用修正線性單元(rectified linear unit,ReLU)激活函數,編碼器路徑還利用卷積層來輸出解碼器特征圖。最后,將最終的解碼器層輸出的高維特征表示輸入到可訓練的多標簽分類卷積層中,最終分類器采用 Sigmoid 激活函數來生成預測概率圖,實現像素級分類。本文將視杯視盤多標簽分割任務輸出為三個通道(分別為視杯、視盤和背景)的概率預測圖,概率映射的預測結果即為在每個像素處具有最大概率的類別。
1.3.2 多尺度輸入層
文獻[26]對多尺度輸入或圖像金字塔已經進行驗證,可有效提高網絡分割性能。經過圖像的預處理之后,將 RGB 圖像拓展到了六個通道。本文使用平均池化對圖像進行降采樣,并在編碼路徑中構造多尺度輸入。這樣可以將多尺度輸入集成到編碼層之中,有效避免參數大量增長,以及等效增加編碼路徑的網絡寬度。與其他工作[26]不同,我們發現當圖像金字塔的深度與網絡深度一致時,網絡學習性能并非能達到最佳。因為在持續的降采樣過程中,雖然會丟失一些圖像信息,同時得到一些新的結構信息,但這之中存在大量冗余信息,會導致網絡存在過擬合和泛化性能差等問題。因此在本文中進行了一次降采樣跨網絡深度的處理,既增加了網絡深度,又能較好地抑制網絡中的輸入信息冗余,有效實現兩者的平衡。
1.3.3 側輸出層
側輸出層充當一個早期分類器,為早期層生成一個局部伴隨輸出映射。M-Net[26]中有四個側輸出層,并將四個側輸出層保持權重一致、簡單平均疊加,得到最后的輸出。本文發現,網絡的幾個側輸出層對最后的輸出的貢獻并非相等。側輸出層選擇不同深度網絡的一、三通道,與前面的多尺度輸出層結構保持一致,這樣既保證網絡輸出之間冗余信息的有效減少,又可對網絡進行有效深度監督。最后,將不同的側輸出層進行加權融合,給出下式的目標函數:
|
其中, 表示每個側輸出層的損失函數的融合權重,Ls(n)表示第 n 個側輸出層的多標簽損失,N 表示側輸出層的個數。在本文中,設置最后一層的損失函數權重為 0.6,其余權重均為 0.1。
側輸出層的主要優點是可以將邊輸出的損失函數反向傳播到對應的淺層卷積層中,可有效抑制梯度消失問題,有利于實現早期層的訓練。此外,側輸出層的多尺度融合實現了特征高性能的融合,側輸出層對各尺度的輸出預測結果實現深度監督,從而獲得更好的輸出結果。
1.3.4 多標簽損失函數
視杯、視盤聯合分割任務是一個多標簽問題。現有的分割方法通常屬于多類設置,它將每個實例按照某種規則對其進行唯一標記。而在多標簽方法中,每一類都是一個獨立的二進制分類,某一實例按照某種規則對每一類進行判斷,這意味著某一實例可分別屬于多個類別。這點在視杯、視盤分割任務中十分重要,因為視杯、視盤有嚴格的幾何約束,視盤區域包含視杯區域,表明屬于視杯的像素也一定屬于視盤。在病變的青光眼之中,視盤區域中排除掉視杯區域的部分僅僅只是一個很薄的圓環,這就會造成視盤與背景區域像素面積極不平衡,而采用多標簽的方法可有效提高視盤與背景的比例,可以解決類別極不平衡的問題。在該方法中,我們提出一個基于 DICE[33]和 Focal-Loss[34]的多標號損失函數,見公式(3)~(5)。DICE 系數是一個重疊的度量,廣泛用于評估分割性能。DICE 損失函數指示前景掩碼重疊比,并且可以處理前景像素與背景的不平衡問題。Focal-Loss 則主要為了解決數據集不平衡問題,因為它更關注于小樣本中難以分割的區域。
|
|
|
其中, 和 分別表示第 個像素的實際類別和真實類別;ε、α、γ 為常值系數,設置 。
1.3.5 殘差多尺度卷積模塊
在深度學習網絡中,Inception[35]和 ResNet[36]是兩個經典的框架。Inception 結構通過拓寬網絡寬度來接收不同尺度的感受野。而 ResNet 則引入了跳躍連接機制來克服網絡退化和梯度消失的問題,這使得神經網絡深度首次突破 1 000 層以上的有效學習。Inception-ResNet[37]模塊結合了 Inception 和 ResNet,繼承了這兩種方法的優點,使之成為深度卷積神經網絡中一種基本的方法。在 Inception-ResNet-V4 模塊的啟發之下,我們提出了一種殘差多尺度卷積模塊來提取高層次的語義特征映射,如圖 4 所示。在通常的情況下,具有大感受野的卷積核可以提取大目標和產生豐富的抽象特征,而小的感受野卷積核則更適合提取小目標和細節的特征。在殘差多尺度卷積模塊中,使用兩個 3 × 3 的卷積單元代替一個 5 × 5 的卷積模塊,使用 1 × 7 和 7 × 1 兩個模塊來代替 7 × 7 的模塊,且每個通道采用原來 1/4 的卷積核。這些改進不僅減少了網絡參數,同時能夠保持較大的感受野。除了通過四條卷積通道進行特征映射,還引入了類似 ResNet 中的跳躍連接。然后再經過一個標準 3 × 3 卷積單元和 1 × 1 的卷積單元來進行降維和非線性激勵,以提升網絡的表達能力。最后對所得到的卷積單元再與輸入特征進行跳躍連接,實現不同深、淺層次特征融合。
圖4
殘差多尺度卷積模塊結構圖
Figure4.
Structure of residual multi-scale convolution module
1.4 評價指標
為了評價所提出 W-Net 網絡的分割性能,引入了一系列評價指標來分析所得視杯、視盤和背景區域的預測分割結果,這些指標一般都用來評價視杯視盤分割的準確性[38],包括了精確度(pixels accuracy,PA)、平均精確度(mean accuracy,MA)、平均交并比(mean intersection over union,MIoU)、加權交并比(frequency weighted intersection over union,FWIoU)、以及重疊誤差(overlapping error,OE)。具體表達式見公式(6)~(10)。
|
|
|
|
|
其中, 表示類別數; 表示所有像素的數目; 表示屬于第 類的像素總數。 表示實際類別為第 類卻錯分為第 類的像素數目。
2 結果
2.1 實驗環境
在實驗中,主要步驟:① 圖像預處理;② 利用網絡訓練來學習系統最優參數,并在每個訓練周期結束后的驗證階段保存最佳網絡模型;③ 測試最佳網絡模型并預測結果;④ 預測結果評估。本文實驗是基于 Keras 的 Python 和 Tensorflow 后端實現的,采用的顯存為 8 GB 的 Nvidia GeForce GTX 1 080 GPU 和主頻 3.50 GHz 的 Inter(R)i7-5 930k CPU。在訓練過程采用 Adam 優化器對深度模型進行優化。網絡基于圖像數據集,采用數據集作為參考進行有監督訓練,其中 75% 即 600 張眼底圖像用于訓練,12.5% 即 100 張圖像用于驗證,12.5% 即 100 張圖像用于測試。訓練中每一次選取的樣本數設置為 6,訓練集每訓練一個周期結束,對驗證集進行一次整體評測,訓練過程持續 200 個周期。實驗測試結果與專家標注結果作比較,采用測試圖片定量評價的平均值作為定量分析的結果。
2.2 實驗結果
本研究在 REFUGE 眼底圖像數據庫上進行實驗并與當前最先進的方法進行了對比,包括 U-Net[25]、M-Net[26]以及基于它們的一些改進模型。為了驗證所提出的殘差多尺度卷積單元相較于標準卷積模塊的優越性能,使用 U-Net[25]、M-Net[26]作為主體框架,將其中的普通卷積單元替換為殘差多尺度卷積單元,分別稱之為 U-Net-Mcon 和 M-Net-Mcon,再與本文所提出的 W-Net 為主體框架的模型分別以普通卷積單元(W-Net)和殘差多尺度卷積單元(W-Net-Mcon)進行比較。通過定量分析 ACC、MA、MIoU、FWIoU 以及 OE 五個評價指標,分別評估提出的 W-Net-Mcon 在視杯、視盤的分割性能。
表1 顯示了在 REFUGE 數據集[31]中使用包括 U-Net[25]、M-Net[26]在內的六種網絡方法進行視杯、視盤聯合分割所得到的性能指標。不難看出,本文提出的 W-Net-Mcon 網絡的視杯、視盤分割結果在上述五個評價指標均優于其他網絡。在實驗結果中,視盤分割結果的 ACC、MA、MIoU、FWIoU、OE 分別為 0.983 3,0.978 6,0.955 3,0.967 4 和 0.066 5,視杯分割結果分別為 0.987 0、0.949 6、0.904 0、0.975 3 和 0.178 0。
圖5 顯示了網絡優化過程訓練集和驗證集的精度和損失函數變化情況。可以看出,W-Net-Mcon 在精度上明顯高于其他網絡,同時損失函數能夠快速收斂且取得最優。
圖5
訓練集和驗證集的精度與損失函數值在網絡訓練過程中隨周期迭代的變化情況
Figure5.
The accuracy and loss function values of the training set and the validation set varing with the cycle iteration during the network training process
圖 6 顯示了在 REFUGE 數據集得到的視杯、視盤分割實驗結果實例。為了證明所提方法的泛化性能,選取了數據集中兩種不同光學性質的眼底圖像,分別為圖 6 中的 1、2、3 組和 4、5、6 組。不難看出,該方法在處理對比度較高或較低的兩類不同眼底圖像時,均可以實現視杯視盤的高精度聯合分割。
圖6
各網絡視杯視盤聯合分割的效果比較
Figure6.
Comparison of the joint segmentation of the disc and cup of each network
3 討論
本研究利用深度學習中的全卷積神經網絡對眼底圖像中的視杯視盤進行聯合分割。為了解決傳統圖像處理算法無法實現低對比度圖像和不同光學圖像之間低泛化性的視杯視盤聯合分割問題,本研究利用全卷積神經網絡強大的特征提取和特征表達能力,提出一種新型網絡結構和帶殘差多尺度卷積學習模塊的網絡(W-Net-Mcon),實現了高維與低維特征的融合,提高了特征的使用率。
從圖 5 可以看出,與其他網絡相比,本文構建的網絡在不同方面均表現出了一定的優勢。在精度上,本文構建的網絡高于其他網絡,能夠使損失函數快速收斂且取得最優。這表明本文方法相較于其他網絡,在訓練集上有較強的擬合能力和特征提取能力。而在驗證集上的高精度則表明網絡沒有出現因對訓練集的過度學習而引發的過擬合,該方法具有較強的泛化性和魯棒性,能夠學習圖像語義信息中的強可分性特征表示,從而使得網絡具有更好的分割性能。這些優勢也體現在表 1 的結果中。
表 1 羅列的是評價指標的定量分析。首先,在各個網絡框架的分割效果中的優勢:實驗中選用了 U-Net、M-Net 和 W-Net 進行比較,W-Net 各項指標均高于另外兩組數據,尤其是在視盤、視杯的 OE 指標表現優異,這表明本文提出的 W-Net 網絡結構在某些方面優于其他網絡。其優勢主要由于:① W-Net 的多尺度輸入層相較于 U-Net 加深了網絡寬度以提供豐富的原始語義信息,同時相較于 M-Net 又減少了原始語義信息中的重復、冗余信息,有效實現兩者平衡;② W-Net 中不同網絡深度的側輸出層實現了網絡各層的深度監督,從而指導網絡學習特征信息;③ 引入跳躍連接,將同一尺度不同深、淺層次的特征信息融合,有利于減少網絡參數和網絡梯度反向傳播,可避免梯度消失問題。
其次,在所提出的殘差多尺度卷積模塊的優勢:實驗將 U-Net、U-Net-Mcon,M-Net、M-Net-Mcon 和 W-Net、W-Net-Mcon 兩兩分別對比,在 U-Net 框架中,除了視盤中 MA 指標略低,U-Net-Mcon 的各項指標均高于原始 U-Net;在 M-Net 中,除視盤中 ACC 指標略低,M-Net-Mcon 的其他指標均比 M-Net 好;對于 W-Net 結構,使用殘差多尺度卷積模塊的 W-Net-Mcon 所有指標均比 W-Net 的結果好。通過實驗對比,在相同的網絡框架下,使用帶殘差多尺度卷積模塊的網絡性能明顯優于普通卷積單元,這是因為殘差多尺度卷積具有不同尺度的感受野來提取網絡中不同層次的特征和豐富語義信息。同時,將不同尺度的特征映射連接起來進行特征融合,另有外面的跳躍連接構成殘差學習進而使得網絡更加容易訓練,可有效抑制梯度消失問題和網絡退化問題。因此,W-Net 雖加深了網絡,但其性能并未退化,并使得分割效果有所提高。
最后,本文將帶殘差多尺度卷積模塊和 W-Net 深度神經網絡框架進行結合,即 W-Net-Mcon。W-Net-Mcon 與其他網絡比較,在所有評價指標中均最好。這是因為 W-Net 通過易于實現的級聯方式,拓展了網絡的深度使得網絡提取到更深層次的語義信息。同時為了解決網絡加深可能導致的網絡退化和梯度消失問題,引入了跳躍連接和深度監督。一方面,可以使網絡在梯度反向傳播時更容易到達淺層的神經層;另一方面,可鼓勵特征復用,加強特征傳播,實現不同深淺層次的特征融合,進而能抑制梯度消失并減少訓練參數的數量。通過上述分析,我們可以認為所提的網絡 W-Net-Mcon 明顯優于原始的 U-Net[25]和 M-Net[26],視杯、視盤分割結果在主要評價指標 OE 中分別降至 0.178 0 和 0.066 5,達到最精準的分割效果。
圖 6 中直觀地展示了不同網絡的分割效果。從總體上來看,W-Net-Mcon 網絡輸出的分割結果形狀更接近于專家標注的圖像形狀,且噪聲點更少;從細節來看,W-Net-Mcon 網絡輸出的分割結果顯示邊緣不規則形狀更少,且更加平滑,這與表 1 的結果是一致的。因此,W-Net-Mcon 會產生更加精確的視杯、視盤分割結果,能夠有效幫助醫生快速分割出視杯視盤,進而評估杯盤比和完成青光眼的輔助篩查與診斷,從而提高醫生的效率和降低因醫生疲勞或主觀性可能造成的誤診風險,也可將其推廣到青光眼大規模篩查任務中。
此外,本研究對未來工作提出了兩個重要方向。一是泛化數據集,需要在更多的數據集上進行驗證,以確保方法具有更強的泛化性能和魯棒性。因此我們計劃完成并發布一個包含眼底圖像視杯視盤分割的多目標數據集,利用數據驅動深度學習技術發展。二是關于超參數的選擇,本文中一些超參數的選擇主要還是根據經驗和實驗效果來人工選擇的,缺乏系統的調參方式,這也是目前深度學習面臨的一個重要問題,因此我們將不斷對其進行探究與完善。
4 結論
本文提出了一種稱為 W-Net-Mcon 的殘差多尺度全卷積深度神經網絡結構,并將視盤、視杯聯合分割任務看作單階段多標簽標記問題。在圖像預處理階段,我們引入了極坐標變換來實現空間約束和平衡杯盤比。我們提出的 W-Net-Mcon 是以 W 型的全卷積網絡作為主體框架,在網絡輸入口加入圖像金字塔來構造多尺度輸入層,同時在與之對應相同尺度的網絡中構造多個側輸出層作為早期的分類器來生成局部預測輸出。此外,本文還提出了帶殘差多尺度全卷積模塊,利用不同大小的感受野來提取不同層次的語義信息,再加上同一尺度的不同深度層次的跳躍連接,起到了鼓勵特征復用、加強特征傳播、不同深淺層次的特征融合作用。最后,提出了一種多標簽損失函數來指導網絡分割。我們已經證明該系統在 REFUGE 數據集[31]獲得了較好的分割結果。實驗結果表明,該網絡實現了視盤、視杯聯合分割并有效提高了分割精度,這將有助于推進大規模的青光眼早期篩查,因此 W-Net-Mcon 的殘差多尺度全卷積深度神經網絡結構具有良好的應用前景。
利益沖突聲明:本文全體作者均聲明不存在利益沖突。