目前癲癇患者的發病預測手段十分耗時且易受主觀因素干擾,因此文中提出了一種基于共空間模式算法(CSP)和支持向量機(SVM)二重分類的癲癇發病自動預測方法。此方法將提取空域特征的共空間模式算法應用到癲癇腦電信號檢測中,但是該算法未考慮信號的非線性動力學特征且忽略了其時頻信息,所以在特征提取階段選取了標準差、熵和小波包能量這幾種互補特征來進行組合。分類過程采取一種基于支持向量機的全新二重分類模式,即將癲癇患者正常期、發作間期和發作期三個階段分成正常期和準發病期(包括發作間期和發作期)兩類進行支持向量機識別,然后對屬于準發病期的樣本進行發作間期和發作期的分類,最終實現三個時期的分類識別。實驗數據來自德國波恩大學的癲癇研究數據庫。實驗結果顯示,第一重分類平均識別率為 98.73%,第二重分類平均識別率可達 99.90%。結果表明,引入空域特征和二重分類模式能夠有效解決眾多文獻中發作間期和發作期識別率不高的問題,提升各個時期的識別效率,為癲癇患者的發病預測提供有效的檢測手段。
引用本文: 王玉瀟, 姜威, 劉治, 包丞嘯. 基于共空間模式算法和支持向量機二重分類的癲癇發病預測. 生物醫學工程學雜志, 2021, 38(1): 39-46. doi: 10.7507/1001-5515.201911042 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
引言
癲癇是一種常見的神經系統疾病,全世界約有 6 500 萬的癲癇患者,發病人群涉及各個年齡階段。癲癇發病的危險因素有:癲癇病家族史、顱腦損傷、熱性驚厥、新生兒疾病和孕期危險因素[1]。目前我國在抗癲癇藥物[2]以及添加治療、微創手術和共病防治等[3]治療手段方面都進行了深入研究。這種疾病具有反復發作和發作前無固定征兆的特點。據統計,約 80% 癲癇患者的腦電圖(electroencephalogram,EEG)在發作間期會表現異常,因此目前監控腦電圖是判斷癲癇患者發病情況的主要手段。癲癇種類繁多且腦電圖具有非直觀性,所以僅依靠專業醫師主觀經驗進行判斷,效率低下,易發生誤判。因此癲癇患者腦電信號的實時檢測和高精度分類識別是當前研究的主要方向。
幾十年來,為了提高腦電圖的診斷性能,學者們從時域、頻域和非線性動力學等方面提取了腦電信號中的有效信息[4]。Gotman[5]在 1982 年最早提出了癲癇腦電時域特征的提取方法,用信號的波峰幅度、斜率和變異系數等參數作為表征腦電信號的時域特征。功率譜(power spectral density,PSD)為最常用的頻域特征,在 2010 年 Naghsh-Nilchi 等[6]采用了基于譜值的特征提取方法,從每個子帶的功率譜中提取相應的均值、標準差、熵等參數,成功地將時域特征融于頻域特征。之后考慮到腦電信號的非平穩特性和單方面特征的局限性,人們開始進行時頻分析,主要方法有短時傅里葉變換(short-time Fourier transform,STFT)[7]、小波變換(wavelet transform,WT)[8-9]、Hilbert-Huang 變換[10]、經驗模態分解(empirical mode decomposition,EMD)[11]等。隨著研究深入,人們發現大腦可看作一個非線性動力系統,于是引入基于熵的特征提取方法。Pincus 從衡量時間序列復雜性角度提出近似熵(approximation entropy,ApEn)的概念,其缺點是易受數據長度的影響[12]。隨后 Richman 等[13]提出樣本熵的概念,彌補了近似熵的缺陷。文獻[14]應用排列熵特征進行癲癇腦電信號的識別,從而取得了顯著效果。
分類效果較好的方法有支持向量機(support vector machine,SVM)(不同情況可選擇不同的核函數)[15]、人工神經網絡(artificial neural network,ANN)[16]、K-最近鄰分類器[17]以及 Boosting 算法[18]。目前分類識別效果較好的方法中多是時頻域和非線性動力學的組合,沒有考慮到信號的空域特征,未能達到高精度的分類識別率。分類過程多是二分類或者直接進行三分類,忽略了癲癇發作(由正常期到發作間期再到發作期)的連續性。
本文結合以上文獻中的方法,針對癲癇腦電信號的三分類問題提出一種全新的檢測模式。首先利用共空間模式(common spatial model,CSP)算法提取多通道癲癇腦電信號的空域特征,然后結合時頻域和非線性動力學方面的特征,共同送入不同核函數的 SVM 中進行二重分類。第一重是對正常期和準發病期(包括發作間期和發作期)進行分類,第二重是對屬于準發病期的樣本進行發作間期和發作期的分類,最終實現正常期、發作間期和發作期三個時期的檢測。整個實驗流程如圖 1 所示。
 圖1
癲癇腦電信號自動檢測流程
Figure1.
Automatic detection process of epileptic electroencephalogram signal
圖1
癲癇腦電信號自動檢測流程
Figure1.
Automatic detection process of epileptic electroencephalogram signal
1 方法
1.1 實驗數據
本文利用德國波恩大學的癲癇研究數據進行了有效性驗證[19]。數據分 A、B、C、D、E 五組,分別為患者正常時期清醒睜眼、正常時期清醒閉眼、發作間期致癇灶外、發作間期致癇灶內和發作期。每組數據集有 100 段腦電信號,每段總計 4 097 個數據,采樣頻率 173.6 Hz。本文進行分類的三個時期分別為:A、B 組正常期,C、D 組發作間期,E 組發作期。本文假定腦電信號為五通道采集,則每組數據集包含 20 組五通道數據,因每段腦電數據點過多,使用前將每段第一個點舍棄,然后等分為 4 段,最終五組數據集共得到 400 個五通道樣本。
1.2 共空間模式算法
CSP 算法最早由 Fukunage 等提出[20],目前在運動想象腦電信號識別和情感腦電信號分類中應用較多,考慮到癲癇發作過程中也會伴隨一些身體上的行為,和運動想象過程有一定的相關度,所以本文嘗試將 CSP 算法應用于癲癇患者三個時期的檢測。CSP 算法的核心思想是利用矩陣的對角化找出最佳空間濾波器,使得腦電信號矩陣濾波后,方差值差異最大化,從而得到具有較高區分度的特征向量。其算法具體流程如下:假設 X1 和 X2 為兩類腦電信號矩陣,它們的維數為 N·T,N 為腦電通道數,T 為每個通道所采集的樣本數,則 X1 和 X2 可以分別寫為:
 |
歸一化后的協方差矩陣 R1 和 R2 分別為:
 |
分別使用  和
和  代表兩類腦電信號的空間協方差矩陣,則混合空間協方差矩陣為:
代表兩類腦電信號的空間協方差矩陣,則混合空間協方差矩陣為:
 |
而 R 可以表示為  ,其中 U 是矩陣的特征向量,
,其中 U 是矩陣的特征向量, 是對應的特征值。然后對特征值進行降序排列,利用主成分分析法求出白化矩陣:
是對應的特征值。然后對特征值進行降序排列,利用主成分分析法求出白化矩陣:
 |
則協方差矩陣 R1 和 R2 可變換為:
 |
然后對 S1 和 S2 做主分量分解,得到:
 |
通過上面的式子可以證明兩個矩陣的特征向量是相等的,即 B1 = B2 = V,同時,兩個特征值的對角矩陣  和
和  之和為單位矩陣,即
之和為單位矩陣,即  ,所以 S1 的最大特征值所對應的特征向量使 S2 有最小的特征值,反之亦然。將白化后的腦電信號投影到特征向量 B的前 m 和后 m 列特征向量,便可得到最佳的分類特征,投影矩陣可表示為 W = BTP,單次腦電信號的采集數據 Xi 可變換為 Zi = W·Xi。
,所以 S1 的最大特征值所對應的特征向量使 S2 有最小的特征值,反之亦然。將白化后的腦電信號投影到特征向量 B的前 m 和后 m 列特征向量,便可得到最佳的分類特征,投影矩陣可表示為 W = BTP,單次腦電信號的采集數據 Xi 可變換為 Zi = W·Xi。
構造好空間濾波器后,對原始數據進行空間濾波便可選取出特征向量 fi:
 |
1.3 互補特征的選取
空間濾波很適合處理多維的腦電信號,它能夠同步利用腦電信號的空間相關性,有效提取出不同通道上腦電信號的空域特征。鑒于單一特征難以全面地反映信號攜帶的信息,為獲得更好的分類識別效果,本文采用多特征結合的方式,共選取 4 個互補特征如表 1 所示。其中標準差屬于時域特征,樣本熵和排列熵屬于非線性動力學的典型特征,小波包能量是時頻分析中基于小波變換的進一步處理[18]。特征之間的互補信息如表 2 所示。
傳統的小波變換對信號分解后的低頻成分能夠再次分解,但是對于高頻成分卻無法分析,因此并不能充分地提取信號特征。所以本文選取能夠對高頻成分做進一步分析的小波包分解來提取時頻特征。頻帶 j 的小波包能量可定義為:
 |
其中 N 為對應頻帶系數個數,ni 為小波包系數。
經典的三種熵方法是近似熵、樣本熵和排列熵,因樣本熵是文獻[21]提出來的一種近似熵的改進算法,故本文僅選擇了樣本熵和排列熵。樣本熵可表示為:
 |
其中 m 為嵌入維度,r 稱為相似容限,是一個給定值,取值范圍為r = 0.1~0.25 std(std 代表序列的標準差)。
排列熵是文獻[21]提出來的一種動力學突變檢測方法,能夠方便準確地定位系統突變的時刻,并對信號的微小變化具有放大作用。其定義式為:
 |
其中 m 為嵌入維度, 為一種排列方式,
為一種排列方式, 為對應每個 i 值
為對應每個 i 值  出現的概率。
出現的概率。
1.4 基于 SVM 的二重分類
本文首次提出一種基于 SVM 的二重分類模式。其分類流程如下:
(1)第一重分類:將發作間期和發作期定義為準發病期,然后對正常期和準發病期進行 SVM 分類識別;
(2)第二重分類:對準發病期的樣本進行發作間期和發作期的 SVM 識別。
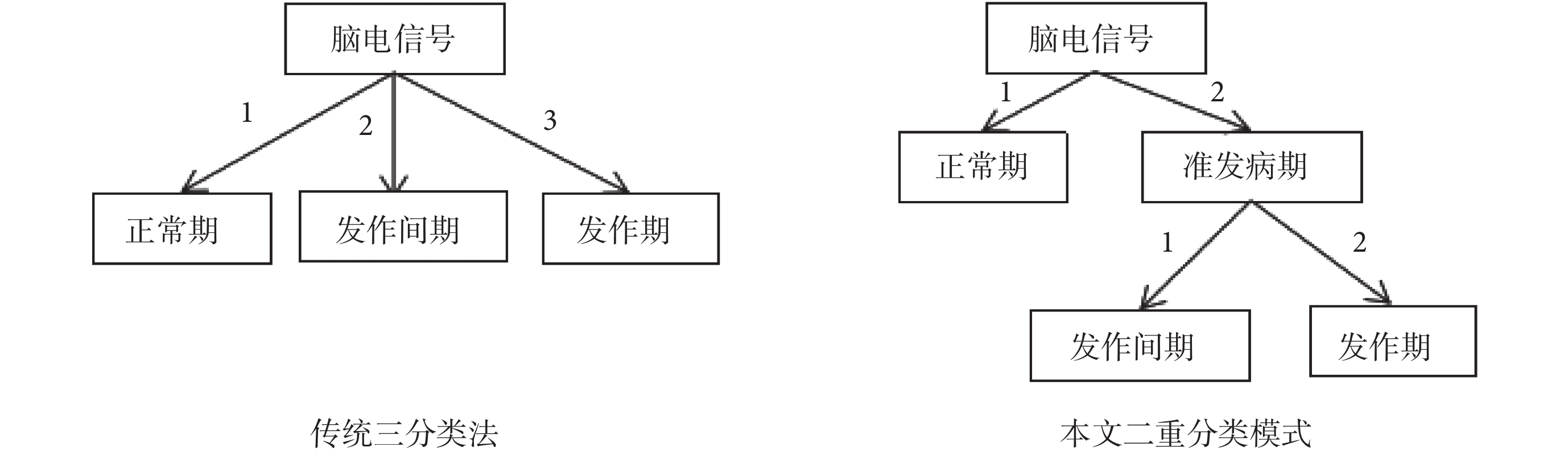
傳統三分類法需將腦電信號進行三次比對,本文分類模式著眼于正常期到發作間期、發作間期到發作期的轉化過程,只需對患者腦電信號進行兩次比對即可完成分類識別。與傳統三分類法相比,有效節省了識別時間,使得醫療介入更加及時。對比分類流程如圖 2 所示。
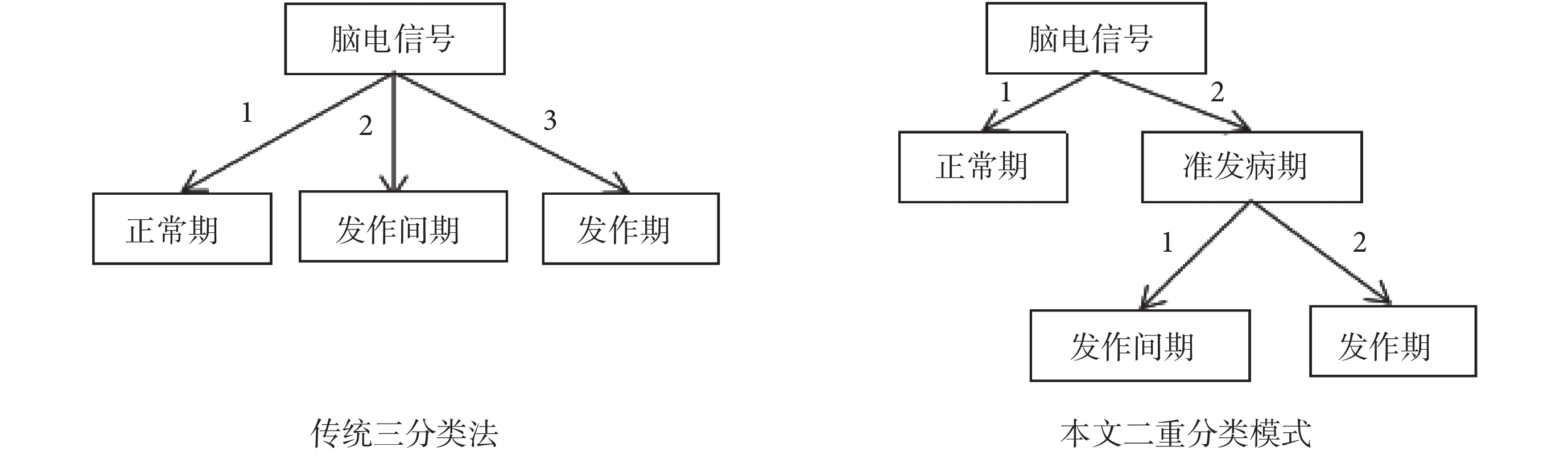 圖2
傳統三分類法與二重分類模式流程對比圖
Figure2.
Flow diagram of traditional triple classification and double classification model
圖2
傳統三分類法與二重分類模式流程對比圖
Figure2.
Flow diagram of traditional triple classification and double classification model
SVM 有著簡單的拓撲結構和良好的泛化能力,被廣泛應用于分類、函數擬合和時間序列預測等領域。其主要思想是通過合適的非線性映射將輸入向量映射到高維的特征空間,從而使得數據總能被一個超平面分割。為了將兩類數據正確分開,且分類間隔達到最大,需要找到一個最優分類面WTX + b = 0,進而可轉換為求解以下二次規劃問題:
 |
利用拉格朗日對偶和 KKT 條件繼續推導,并引入核函數和正則化項,模型最終變為求解:
 |
對于非線性問題,相應的最優決策函數變為:
 |
2 實驗結果與討論
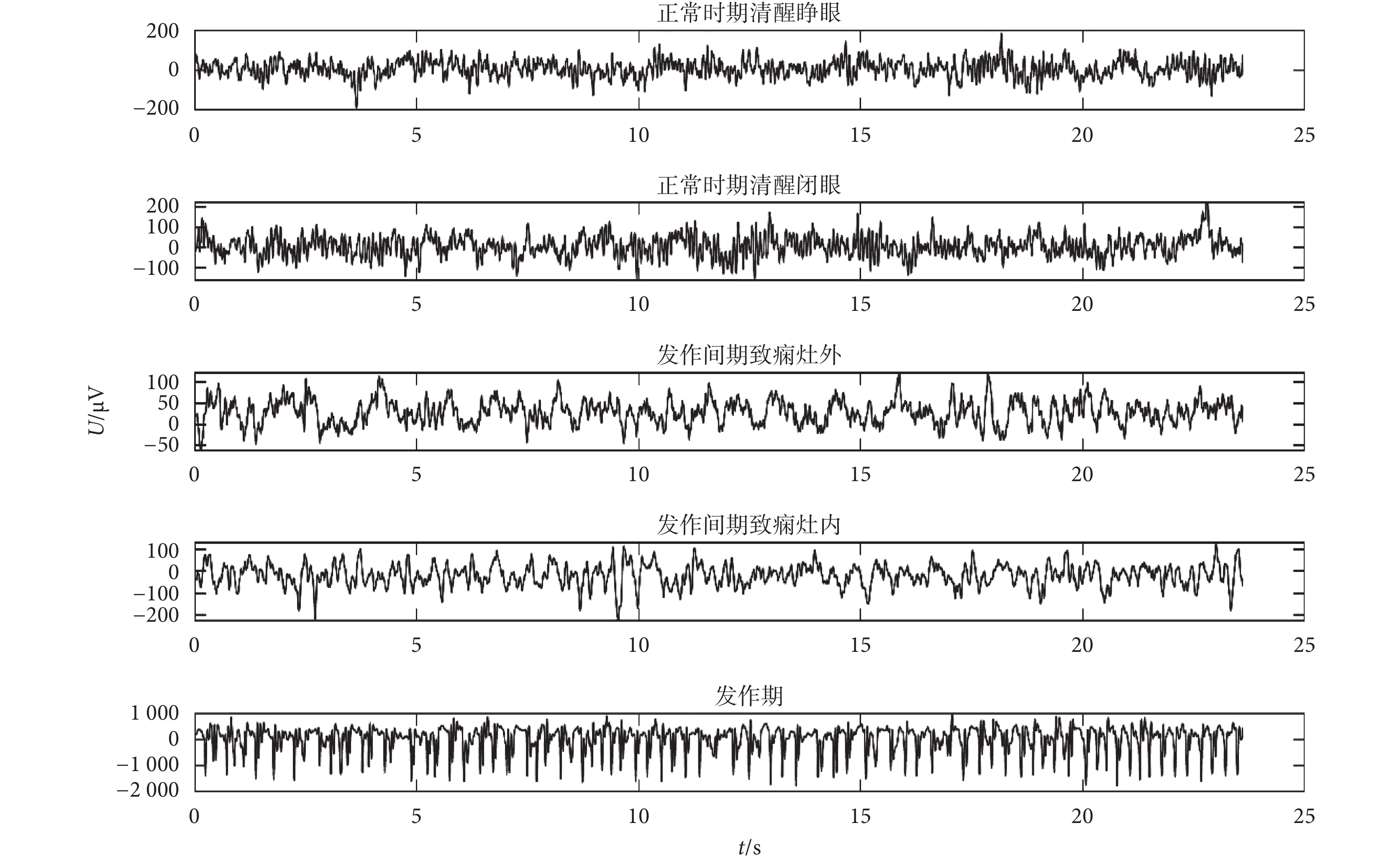
腦電原始數據波形如圖 3 所示,從上到下依次為患者正常時期清醒睜眼、正常時期清醒閉眼、發作間期致癇灶外、發作間期致癇灶內和發作期。由圖 3 可看出三個時期的腦電波形存在一定差異,但是依靠人工判讀,難以滿足實時性要求,因此需要對三個時期的腦電信號進行有效特征提取,進而完成癲癇腦電信號的自動檢測。
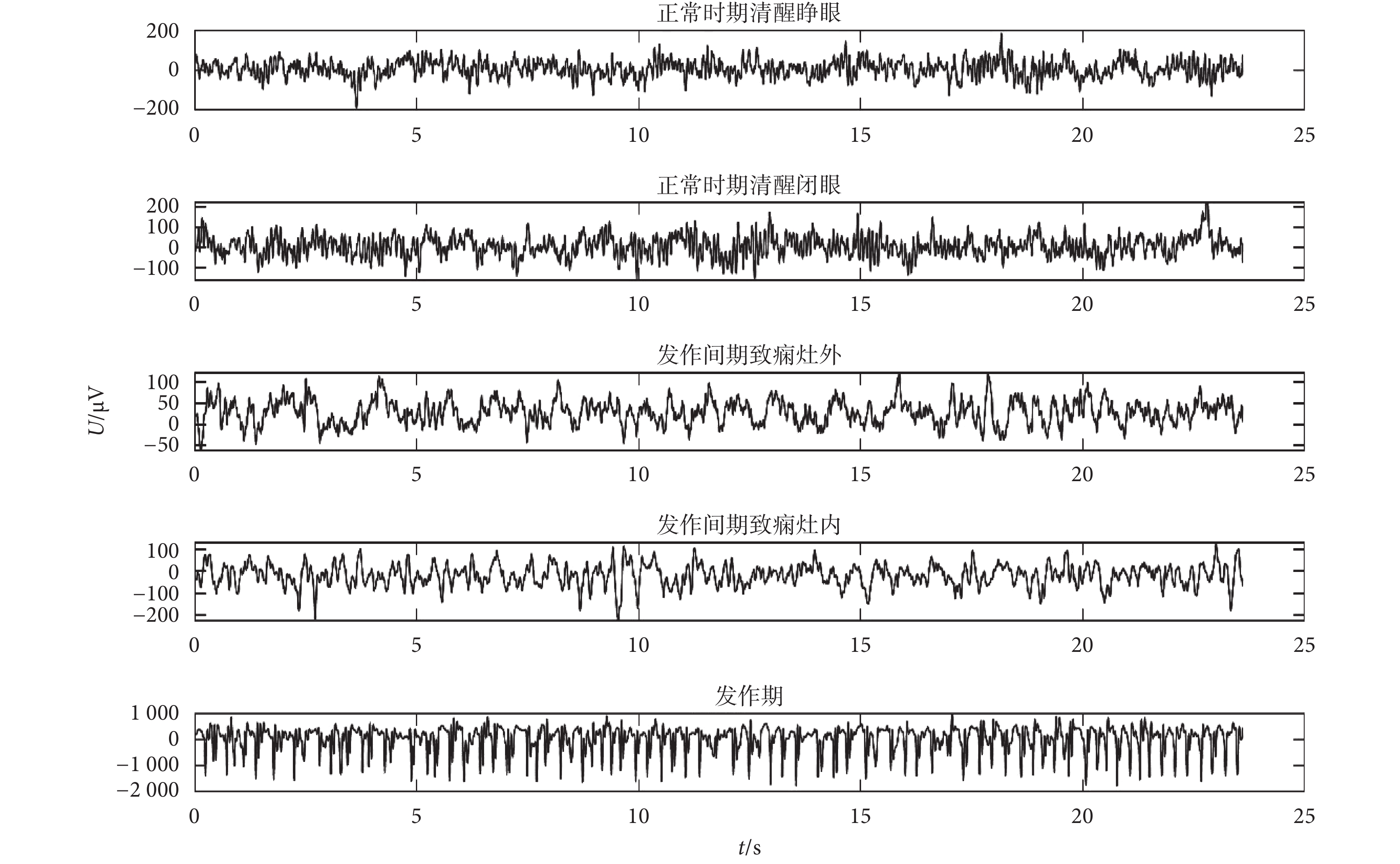 圖3
各數據集腦電信號波形
Figure3.
EEG waveform of each dataset
圖3
各數據集腦電信號波形
Figure3.
EEG waveform of each dataset
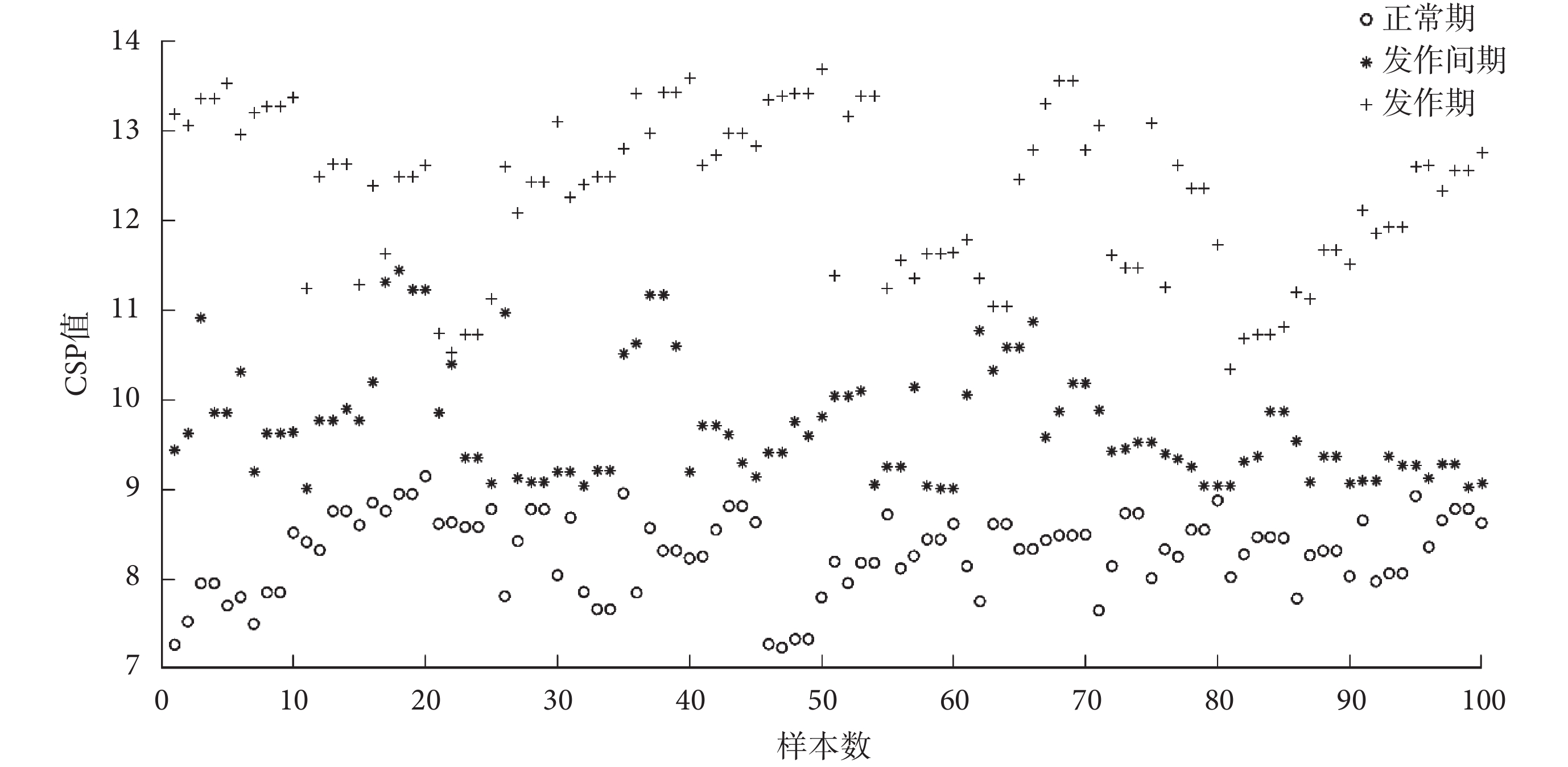
特征提取階段,首先利用 CSP 算法對 400 個五通道腦電數據進行空域濾波和特征提取,空域特征在三個時期的分布規律如圖 4 所示。
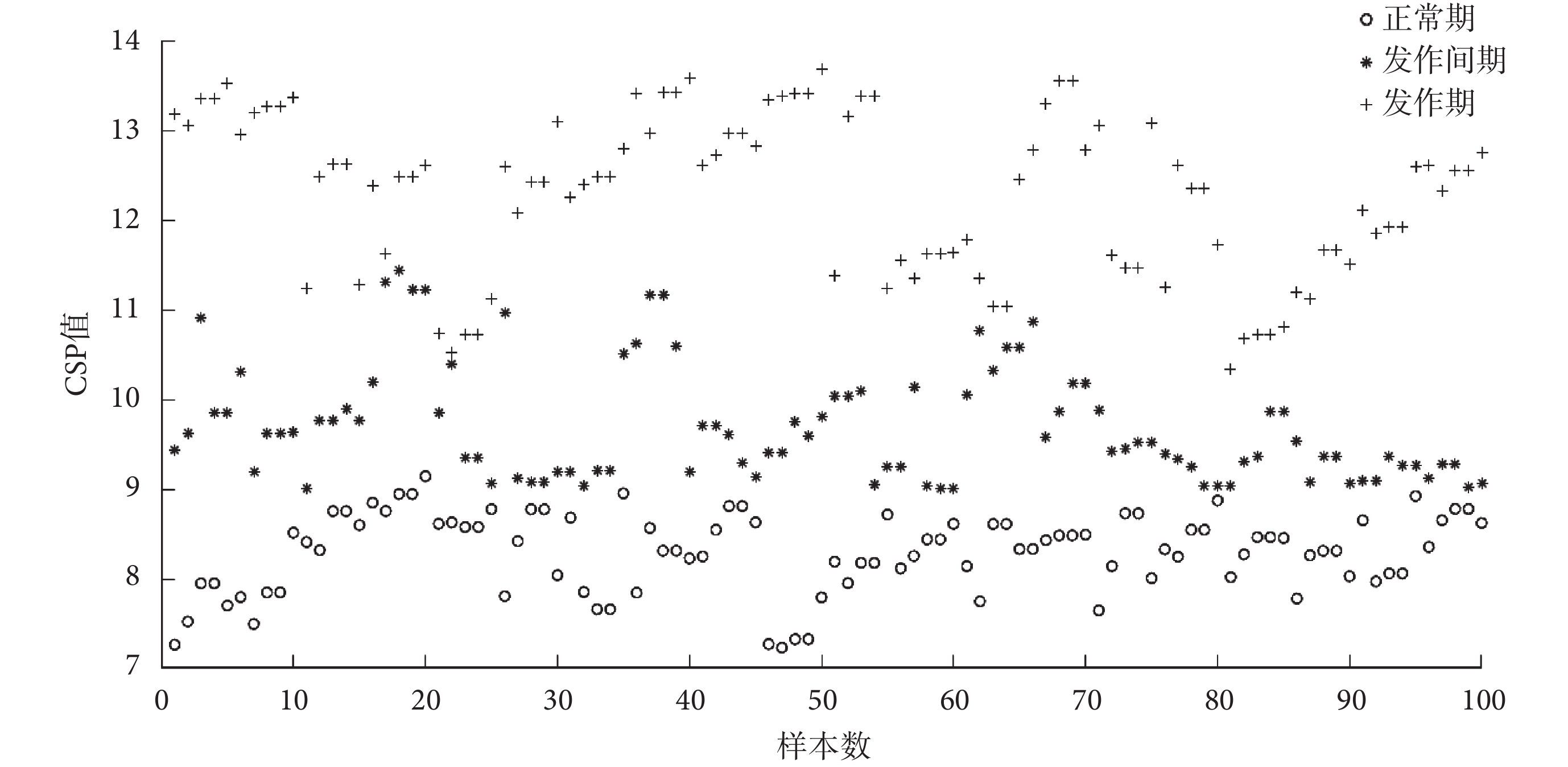 圖4
CSP 值在三個時期的分布情況
Figure4.
Distribution of CSP values in three periods
圖4
CSP 值在三個時期的分布情況
Figure4.
Distribution of CSP values in three periods
然后提取腦電數據的互補特征:標準差、樣本熵、排列熵和小波包能量。宏觀上,樣本熵和排列熵對非線性序列有較強的表征能力,當樣本熵參數m = 2、r = 0.2 × std 時能夠達到最佳的分類效果[22];當參數m = 5 時,排列熵取得最佳嵌入維度[14]。小波包能量特征提取時最優的小波基函數為 Daubechies4 小波,最佳的級數為前 7 級小波包能量。
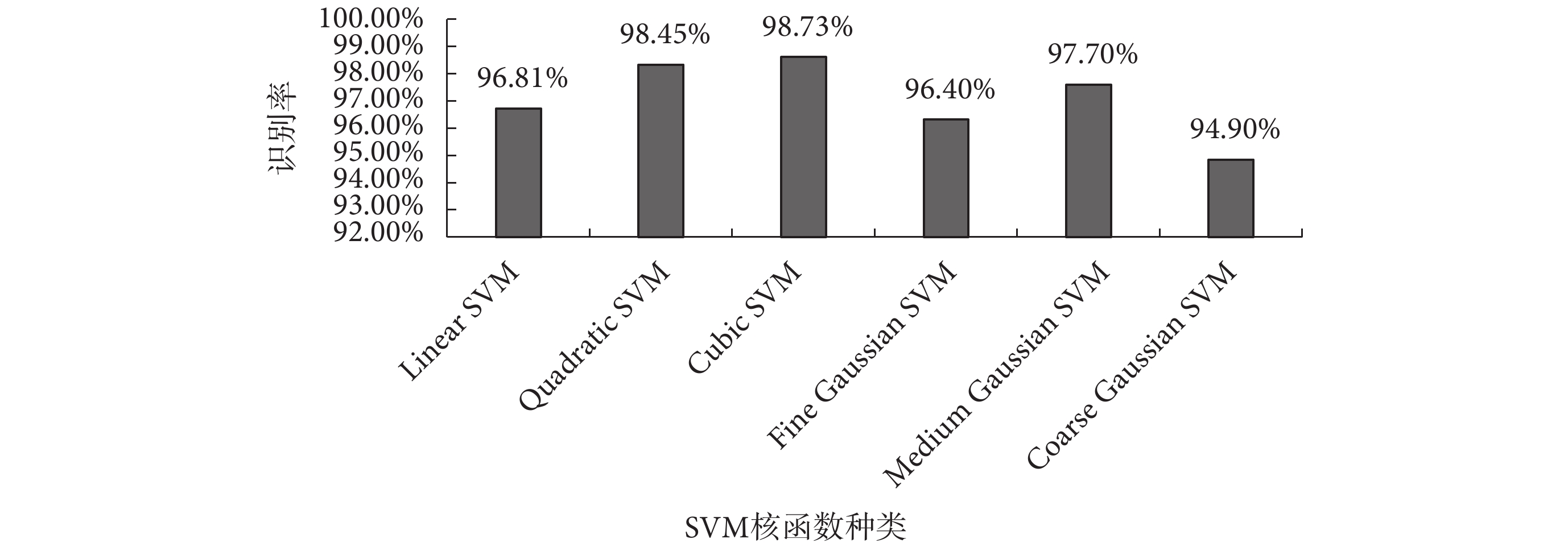
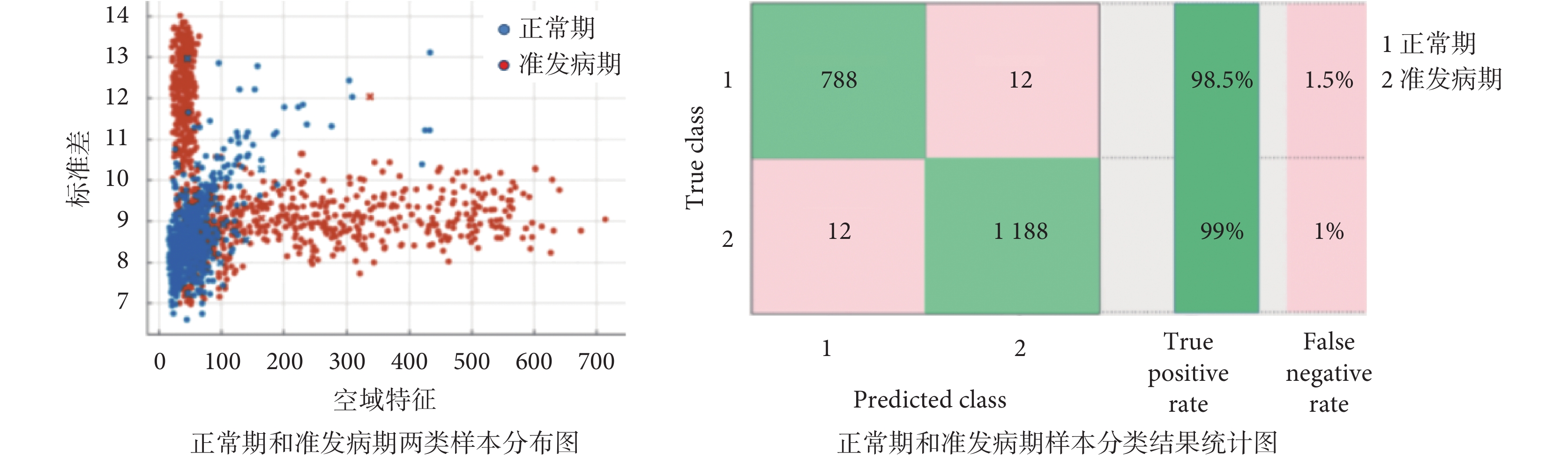
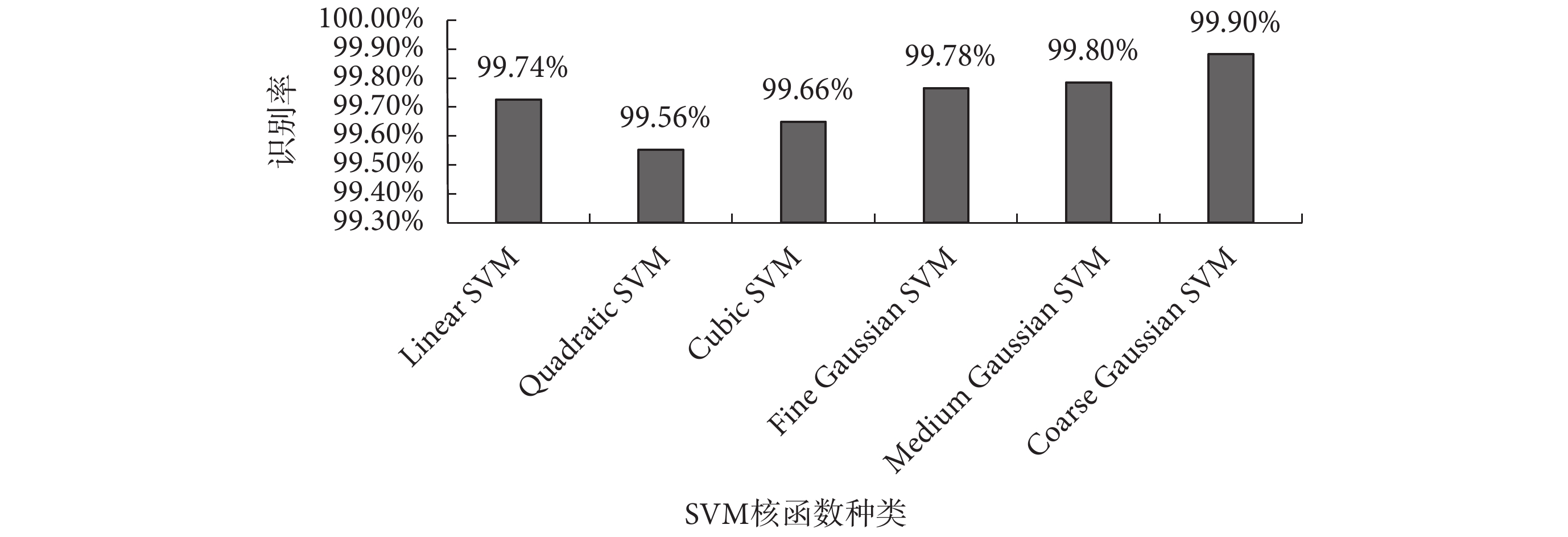
五個特征全部提取完畢,其中標準差、樣本熵、排列熵和 CSP 提取的空域特征均為單一特征值,前 7 級小波包能量為 7 維特征向量,將五個特征采用并行組合的方式,構成 11 維特征向量,送入 SVM 進行分類。本文共采用六種核函數的 SVM[23],第一重的分類結果如圖 5 所示。Cubic SVM 對正常期和準發病期的分類效果最好,與文獻[18]相比正常期的識別率提高了 0.77%。Cubic SVM 詳細分類情況如圖 6 所示,其中左圖為正常期和準發病期兩類樣本分布圖,橫縱坐標分別為空域特征和標準差(特征組合中任意兩個特征值均可作為橫縱坐標),藍色點和紅色點分別代表正常期與準發病期;正常期和準發病期樣本分類結果統計圖中,“1”和“2”分別代表正常期與準發病期。
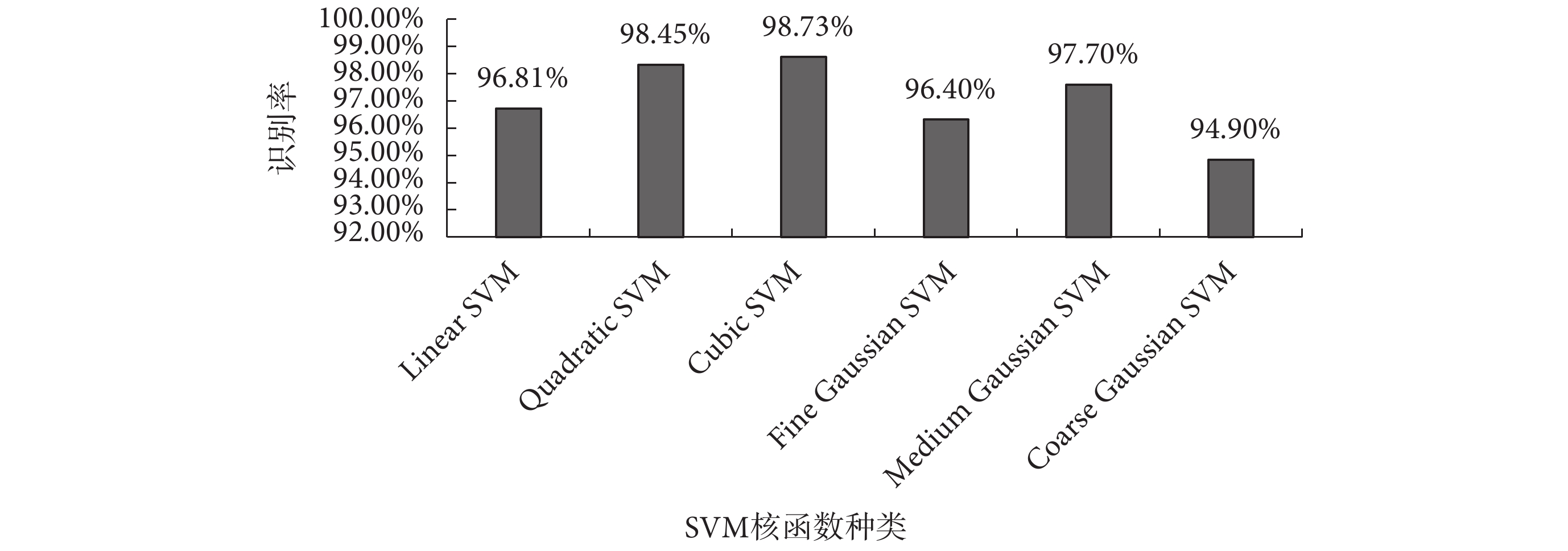 圖5
第一重不同核函數 SVM 下的平均識別率
Figure5.
The first average recognition rate of SVM with different kernel functions
圖5
第一重不同核函數 SVM 下的平均識別率
Figure5.
The first average recognition rate of SVM with different kernel functions
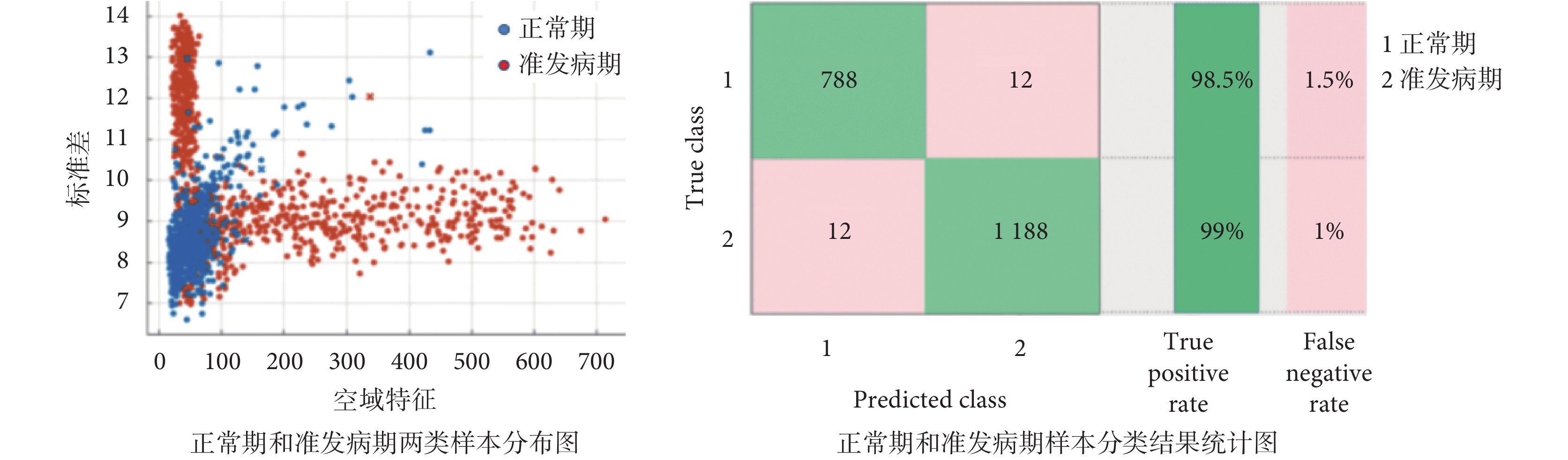 圖6
正常期與準發病期的 Cubic SVM 分類結果
Figure6.
Cubic SVM classification results of normal and paroxysmal periods
圖6
正常期與準發病期的 Cubic SVM 分類結果
Figure6.
Cubic SVM classification results of normal and paroxysmal periods
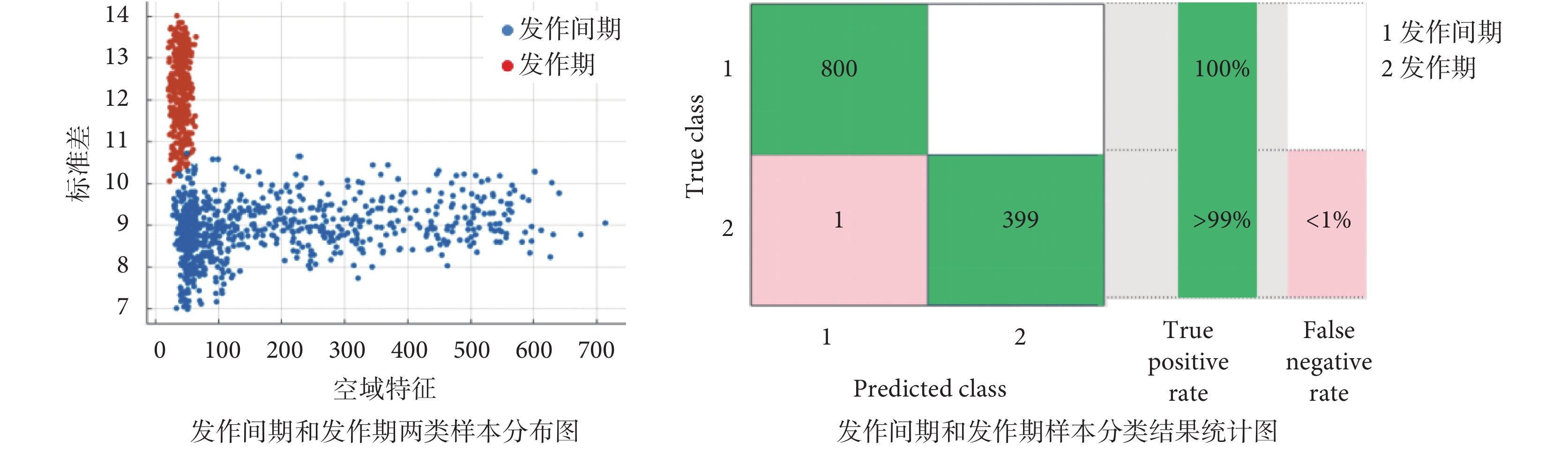
第二重的分類結果如圖 7 所示。其中 Coarse Gaussian SVM 能夠穩定達到 99.90% 及以上的高識別率,因此本文選取 Coarse Gaussian SVM。其詳細分類情況如圖 8 所示。發作間期和發作期兩類樣本分布圖中,藍色點和紅色點分別代表發作間期與發作期;發作間期和發作期樣本分類結果統計圖中,“1”和“2”分別代表發作間期與發作期。分類結果與文獻[18]相比,發作間期和發作期的識別率分別提高了 3.90% 和 1.50%,大幅度提高了癲癇患者發病的預測準確率。
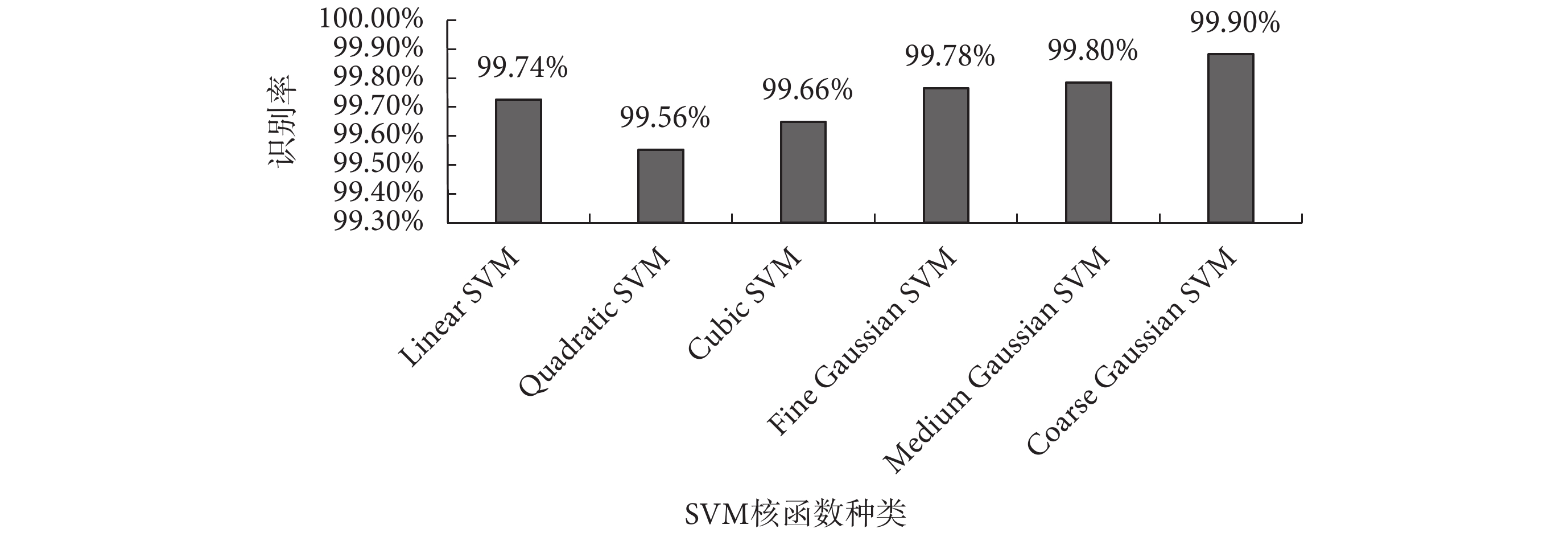 圖7
第二重不同核函數 SVM 下的平均識別率
Figure7.
The second average recognition rate of SVM with different kernel functions
圖7
第二重不同核函數 SVM 下的平均識別率
Figure7.
The second average recognition rate of SVM with different kernel functions
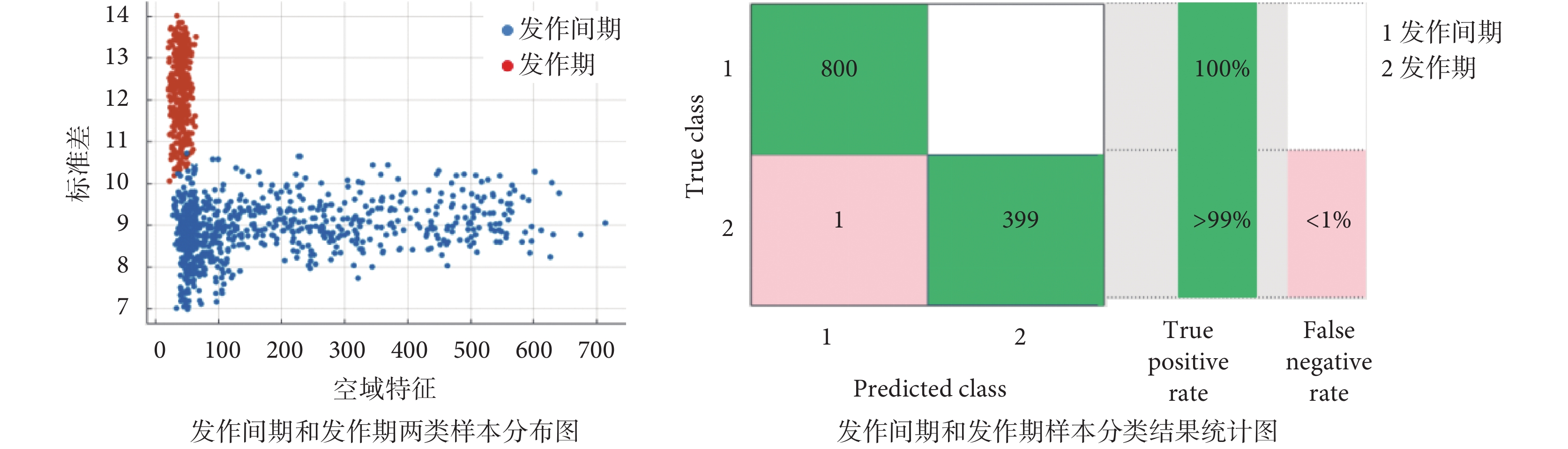 圖8
發作間期與發作期的 Coarse Gaussian SVM 分類結果
Figure8.
Coarse Gaussian SVM classification results of interictal and ictal periods
圖8
發作間期與發作期的 Coarse Gaussian SVM 分類結果
Figure8.
Coarse Gaussian SVM classification results of interictal and ictal periods
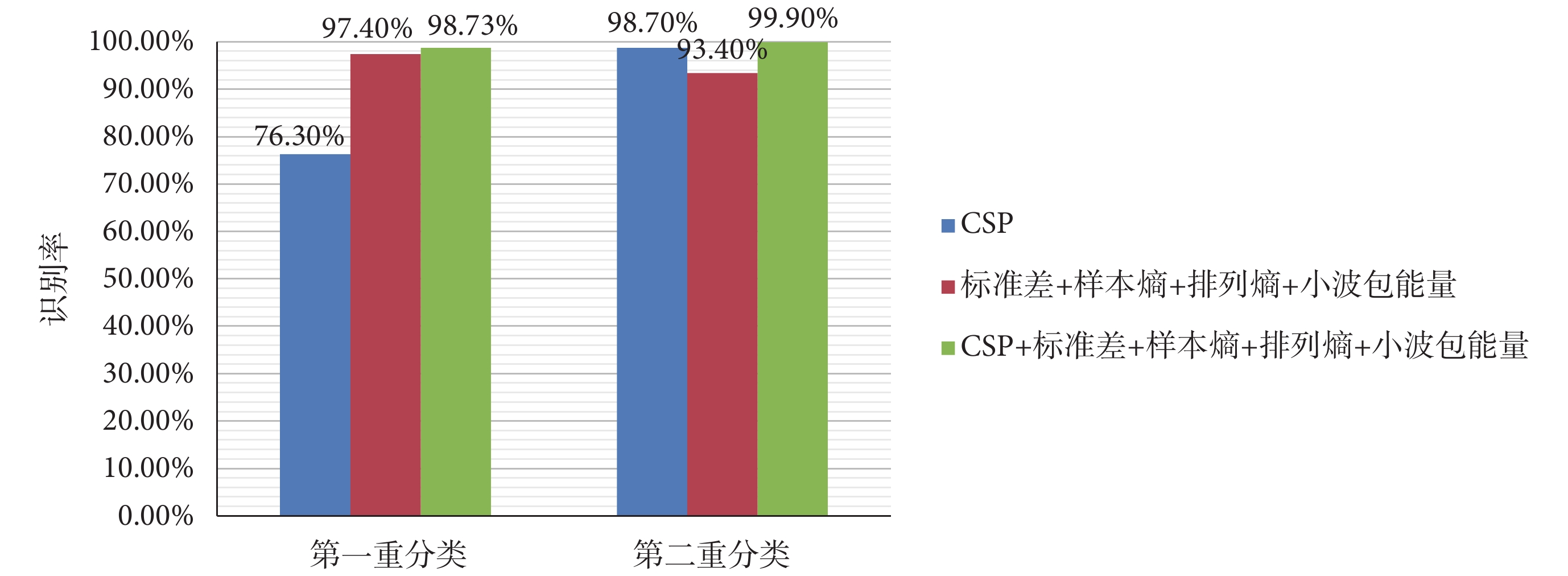
為了證明將空域特征和上述互補特征組合的有效性,本文對僅采用 CSP 算法、僅采用互補特征、采用 CSP+互補特征三種分類情況進行了對比,如圖 9 所示。結果表明,當空域特征與其他方面特征組合時能夠達到更好的分類效果。
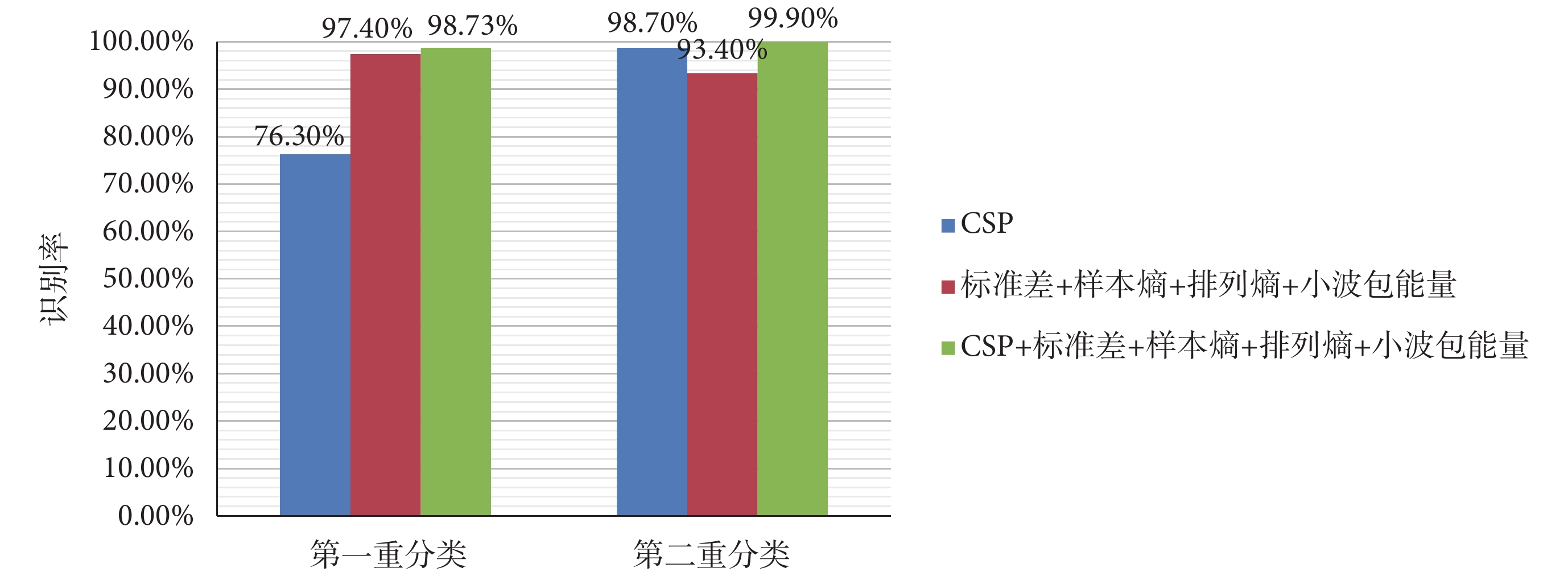 圖9
不同特征下的識別率
Figure9.
Recognition rate of different features
圖9
不同特征下的識別率
Figure9.
Recognition rate of different features
同時為了證明本文二重分類算法的有效性,將提取到的組合特征送入 SVM 直接進行三分類。分類結果最好的為 Cubic SVM,識別率為 98.00%,而二重分類兩個階段的識別率均高于該值(詳見圖 9 中的綠色柱形圖),因此我們可以證明二重分類模式在癲癇三個時期的識別分類中發揮了重要作用。
采用同一數據集的其他相關文獻的分類效果如表 3 所示。與文獻[16]相比,本文在特征方面進一步添加了空域特征,使得腦電信號的信息提取更加充分,從而產生了更高的識別率;同時,本文的二重分類模式僅需運用 2 次 SVM 分類,而文獻[9]中的傳統 SVM 分類方法則需運用 3 次 SVM 分類。實驗證明本文方法在癲癇腦電數據的多分類問題上,不僅減少了時間開銷,在分類識別率上也有了較大提升。
3 結論
為提高癲癇患者正常期、發作間期和發作期的識別率和識別效率,本文引入 CSP 算法提取的空域特征,并在特征提取階段選取了標準差、熵和小波包能量這幾種互補特征來進行組合,最后采用 SVM 二重分類模式實現三個時期的高精度分類。實驗證明,當空域特征與其他特征進行結合時,識別率能夠得到有效提升。此外,SVM 的二重分類模式充分考慮了癲癇患者由正常到發作的連續性,優化了分類識別流程,提升了識別效率,同時對分類識別率也起到了積極作用。與既往的癲癇腦電數據的多分類方法相比,本文方法在癲癇患者的實時檢測中具有更高的可靠性,能夠更好地應用于臨床實踐,同時也為心電分類和情緒分類等研究提供了可借鑒的方法。但是該算法在第一重分類上仍存在較大的提升空間,今后我們可考慮選取不同的特征組合以及優化特征組合方式等途徑,來提高正常期與準發病期的識別率,另外可嘗試在更多的數據集中驗證此方法的有效性,使得本文方法能夠得到更加廣泛的應用。
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
引言
癲癇是一種常見的神經系統疾病,全世界約有 6 500 萬的癲癇患者,發病人群涉及各個年齡階段。癲癇發病的危險因素有:癲癇病家族史、顱腦損傷、熱性驚厥、新生兒疾病和孕期危險因素[1]。目前我國在抗癲癇藥物[2]以及添加治療、微創手術和共病防治等[3]治療手段方面都進行了深入研究。這種疾病具有反復發作和發作前無固定征兆的特點。據統計,約 80% 癲癇患者的腦電圖(electroencephalogram,EEG)在發作間期會表現異常,因此目前監控腦電圖是判斷癲癇患者發病情況的主要手段。癲癇種類繁多且腦電圖具有非直觀性,所以僅依靠專業醫師主觀經驗進行判斷,效率低下,易發生誤判。因此癲癇患者腦電信號的實時檢測和高精度分類識別是當前研究的主要方向。
幾十年來,為了提高腦電圖的診斷性能,學者們從時域、頻域和非線性動力學等方面提取了腦電信號中的有效信息[4]。Gotman[5]在 1982 年最早提出了癲癇腦電時域特征的提取方法,用信號的波峰幅度、斜率和變異系數等參數作為表征腦電信號的時域特征。功率譜(power spectral density,PSD)為最常用的頻域特征,在 2010 年 Naghsh-Nilchi 等[6]采用了基于譜值的特征提取方法,從每個子帶的功率譜中提取相應的均值、標準差、熵等參數,成功地將時域特征融于頻域特征。之后考慮到腦電信號的非平穩特性和單方面特征的局限性,人們開始進行時頻分析,主要方法有短時傅里葉變換(short-time Fourier transform,STFT)[7]、小波變換(wavelet transform,WT)[8-9]、Hilbert-Huang 變換[10]、經驗模態分解(empirical mode decomposition,EMD)[11]等。隨著研究深入,人們發現大腦可看作一個非線性動力系統,于是引入基于熵的特征提取方法。Pincus 從衡量時間序列復雜性角度提出近似熵(approximation entropy,ApEn)的概念,其缺點是易受數據長度的影響[12]。隨后 Richman 等[13]提出樣本熵的概念,彌補了近似熵的缺陷。文獻[14]應用排列熵特征進行癲癇腦電信號的識別,從而取得了顯著效果。
分類效果較好的方法有支持向量機(support vector machine,SVM)(不同情況可選擇不同的核函數)[15]、人工神經網絡(artificial neural network,ANN)[16]、K-最近鄰分類器[17]以及 Boosting 算法[18]。目前分類識別效果較好的方法中多是時頻域和非線性動力學的組合,沒有考慮到信號的空域特征,未能達到高精度的分類識別率。分類過程多是二分類或者直接進行三分類,忽略了癲癇發作(由正常期到發作間期再到發作期)的連續性。
本文結合以上文獻中的方法,針對癲癇腦電信號的三分類問題提出一種全新的檢測模式。首先利用共空間模式(common spatial model,CSP)算法提取多通道癲癇腦電信號的空域特征,然后結合時頻域和非線性動力學方面的特征,共同送入不同核函數的 SVM 中進行二重分類。第一重是對正常期和準發病期(包括發作間期和發作期)進行分類,第二重是對屬于準發病期的樣本進行發作間期和發作期的分類,最終實現正常期、發作間期和發作期三個時期的檢測。整個實驗流程如圖 1 所示。
圖1
癲癇腦電信號自動檢測流程
Figure1.
Automatic detection process of epileptic electroencephalogram signal
1 方法
1.1 實驗數據
本文利用德國波恩大學的癲癇研究數據進行了有效性驗證[19]。數據分 A、B、C、D、E 五組,分別為患者正常時期清醒睜眼、正常時期清醒閉眼、發作間期致癇灶外、發作間期致癇灶內和發作期。每組數據集有 100 段腦電信號,每段總計 4 097 個數據,采樣頻率 173.6 Hz。本文進行分類的三個時期分別為:A、B 組正常期,C、D 組發作間期,E 組發作期。本文假定腦電信號為五通道采集,則每組數據集包含 20 組五通道數據,因每段腦電數據點過多,使用前將每段第一個點舍棄,然后等分為 4 段,最終五組數據集共得到 400 個五通道樣本。
1.2 共空間模式算法
CSP 算法最早由 Fukunage 等提出[20],目前在運動想象腦電信號識別和情感腦電信號分類中應用較多,考慮到癲癇發作過程中也會伴隨一些身體上的行為,和運動想象過程有一定的相關度,所以本文嘗試將 CSP 算法應用于癲癇患者三個時期的檢測。CSP 算法的核心思想是利用矩陣的對角化找出最佳空間濾波器,使得腦電信號矩陣濾波后,方差值差異最大化,從而得到具有較高區分度的特征向量。其算法具體流程如下:假設 X1 和 X2 為兩類腦電信號矩陣,它們的維數為 N·T,N 為腦電通道數,T 為每個通道所采集的樣本數,則 X1 和 X2 可以分別寫為:
|
歸一化后的協方差矩陣 R1 和 R2 分別為:
|
分別使用 和 代表兩類腦電信號的空間協方差矩陣,則混合空間協方差矩陣為:
|
而 R 可以表示為 ,其中 U 是矩陣的特征向量, 是對應的特征值。然后對特征值進行降序排列,利用主成分分析法求出白化矩陣:
|
則協方差矩陣 R1 和 R2 可變換為:
|
然后對 S1 和 S2 做主分量分解,得到:
|
通過上面的式子可以證明兩個矩陣的特征向量是相等的,即 B1 = B2 = V,同時,兩個特征值的對角矩陣 和 之和為單位矩陣,即 ,所以 S1 的最大特征值所對應的特征向量使 S2 有最小的特征值,反之亦然。將白化后的腦電信號投影到特征向量 B的前 m 和后 m 列特征向量,便可得到最佳的分類特征,投影矩陣可表示為 W = BTP,單次腦電信號的采集數據 Xi 可變換為 Zi = W·Xi。
構造好空間濾波器后,對原始數據進行空間濾波便可選取出特征向量 fi:
|
1.3 互補特征的選取
空間濾波很適合處理多維的腦電信號,它能夠同步利用腦電信號的空間相關性,有效提取出不同通道上腦電信號的空域特征。鑒于單一特征難以全面地反映信號攜帶的信息,為獲得更好的分類識別效果,本文采用多特征結合的方式,共選取 4 個互補特征如表 1 所示。其中標準差屬于時域特征,樣本熵和排列熵屬于非線性動力學的典型特征,小波包能量是時頻分析中基于小波變換的進一步處理[18]。特征之間的互補信息如表 2 所示。
傳統的小波變換對信號分解后的低頻成分能夠再次分解,但是對于高頻成分卻無法分析,因此并不能充分地提取信號特征。所以本文選取能夠對高頻成分做進一步分析的小波包分解來提取時頻特征。頻帶 j 的小波包能量可定義為:
|
其中 N 為對應頻帶系數個數,ni 為小波包系數。
經典的三種熵方法是近似熵、樣本熵和排列熵,因樣本熵是文獻[21]提出來的一種近似熵的改進算法,故本文僅選擇了樣本熵和排列熵。樣本熵可表示為:
|
其中 m 為嵌入維度,r 稱為相似容限,是一個給定值,取值范圍為r = 0.1~0.25 std(std 代表序列的標準差)。
排列熵是文獻[21]提出來的一種動力學突變檢測方法,能夠方便準確地定位系統突變的時刻,并對信號的微小變化具有放大作用。其定義式為:
|
其中 m 為嵌入維度, 為一種排列方式, 為對應每個 i 值 出現的概率。
1.4 基于 SVM 的二重分類
本文首次提出一種基于 SVM 的二重分類模式。其分類流程如下:
(1)第一重分類:將發作間期和發作期定義為準發病期,然后對正常期和準發病期進行 SVM 分類識別;
(2)第二重分類:對準發病期的樣本進行發作間期和發作期的 SVM 識別。
傳統三分類法需將腦電信號進行三次比對,本文分類模式著眼于正常期到發作間期、發作間期到發作期的轉化過程,只需對患者腦電信號進行兩次比對即可完成分類識別。與傳統三分類法相比,有效節省了識別時間,使得醫療介入更加及時。對比分類流程如圖 2 所示。
圖2
傳統三分類法與二重分類模式流程對比圖
Figure2.
Flow diagram of traditional triple classification and double classification model
SVM 有著簡單的拓撲結構和良好的泛化能力,被廣泛應用于分類、函數擬合和時間序列預測等領域。其主要思想是通過合適的非線性映射將輸入向量映射到高維的特征空間,從而使得數據總能被一個超平面分割。為了將兩類數據正確分開,且分類間隔達到最大,需要找到一個最優分類面WTX + b = 0,進而可轉換為求解以下二次規劃問題:
|
利用拉格朗日對偶和 KKT 條件繼續推導,并引入核函數和正則化項,模型最終變為求解:
|
對于非線性問題,相應的最優決策函數變為:
|
2 實驗結果與討論
腦電原始數據波形如圖 3 所示,從上到下依次為患者正常時期清醒睜眼、正常時期清醒閉眼、發作間期致癇灶外、發作間期致癇灶內和發作期。由圖 3 可看出三個時期的腦電波形存在一定差異,但是依靠人工判讀,難以滿足實時性要求,因此需要對三個時期的腦電信號進行有效特征提取,進而完成癲癇腦電信號的自動檢測。
圖3
各數據集腦電信號波形
Figure3.
EEG waveform of each dataset
特征提取階段,首先利用 CSP 算法對 400 個五通道腦電數據進行空域濾波和特征提取,空域特征在三個時期的分布規律如圖 4 所示。
圖4
CSP 值在三個時期的分布情況
Figure4.
Distribution of CSP values in three periods
然后提取腦電數據的互補特征:標準差、樣本熵、排列熵和小波包能量。宏觀上,樣本熵和排列熵對非線性序列有較強的表征能力,當樣本熵參數m = 2、r = 0.2 × std 時能夠達到最佳的分類效果[22];當參數m = 5 時,排列熵取得最佳嵌入維度[14]。小波包能量特征提取時最優的小波基函數為 Daubechies4 小波,最佳的級數為前 7 級小波包能量。
五個特征全部提取完畢,其中標準差、樣本熵、排列熵和 CSP 提取的空域特征均為單一特征值,前 7 級小波包能量為 7 維特征向量,將五個特征采用并行組合的方式,構成 11 維特征向量,送入 SVM 進行分類。本文共采用六種核函數的 SVM[23],第一重的分類結果如圖 5 所示。Cubic SVM 對正常期和準發病期的分類效果最好,與文獻[18]相比正常期的識別率提高了 0.77%。Cubic SVM 詳細分類情況如圖 6 所示,其中左圖為正常期和準發病期兩類樣本分布圖,橫縱坐標分別為空域特征和標準差(特征組合中任意兩個特征值均可作為橫縱坐標),藍色點和紅色點分別代表正常期與準發病期;正常期和準發病期樣本分類結果統計圖中,“1”和“2”分別代表正常期與準發病期。
圖5
第一重不同核函數 SVM 下的平均識別率
Figure5.
The first average recognition rate of SVM with different kernel functions
圖6
正常期與準發病期的 Cubic SVM 分類結果
Figure6.
Cubic SVM classification results of normal and paroxysmal periods
第二重的分類結果如圖 7 所示。其中 Coarse Gaussian SVM 能夠穩定達到 99.90% 及以上的高識別率,因此本文選取 Coarse Gaussian SVM。其詳細分類情況如圖 8 所示。發作間期和發作期兩類樣本分布圖中,藍色點和紅色點分別代表發作間期與發作期;發作間期和發作期樣本分類結果統計圖中,“1”和“2”分別代表發作間期與發作期。分類結果與文獻[18]相比,發作間期和發作期的識別率分別提高了 3.90% 和 1.50%,大幅度提高了癲癇患者發病的預測準確率。
圖7
第二重不同核函數 SVM 下的平均識別率
Figure7.
The second average recognition rate of SVM with different kernel functions
圖8
發作間期與發作期的 Coarse Gaussian SVM 分類結果
Figure8.
Coarse Gaussian SVM classification results of interictal and ictal periods
為了證明將空域特征和上述互補特征組合的有效性,本文對僅采用 CSP 算法、僅采用互補特征、采用 CSP+互補特征三種分類情況進行了對比,如圖 9 所示。結果表明,當空域特征與其他方面特征組合時能夠達到更好的分類效果。
圖9
不同特征下的識別率
Figure9.
Recognition rate of different features
同時為了證明本文二重分類算法的有效性,將提取到的組合特征送入 SVM 直接進行三分類。分類結果最好的為 Cubic SVM,識別率為 98.00%,而二重分類兩個階段的識別率均高于該值(詳見圖 9 中的綠色柱形圖),因此我們可以證明二重分類模式在癲癇三個時期的識別分類中發揮了重要作用。
采用同一數據集的其他相關文獻的分類效果如表 3 所示。與文獻[16]相比,本文在特征方面進一步添加了空域特征,使得腦電信號的信息提取更加充分,從而產生了更高的識別率;同時,本文的二重分類模式僅需運用 2 次 SVM 分類,而文獻[9]中的傳統 SVM 分類方法則需運用 3 次 SVM 分類。實驗證明本文方法在癲癇腦電數據的多分類問題上,不僅減少了時間開銷,在分類識別率上也有了較大提升。
3 結論
為提高癲癇患者正常期、發作間期和發作期的識別率和識別效率,本文引入 CSP 算法提取的空域特征,并在特征提取階段選取了標準差、熵和小波包能量這幾種互補特征來進行組合,最后采用 SVM 二重分類模式實現三個時期的高精度分類。實驗證明,當空域特征與其他特征進行結合時,識別率能夠得到有效提升。此外,SVM 的二重分類模式充分考慮了癲癇患者由正常到發作的連續性,優化了分類識別流程,提升了識別效率,同時對分類識別率也起到了積極作用。與既往的癲癇腦電數據的多分類方法相比,本文方法在癲癇患者的實時檢測中具有更高的可靠性,能夠更好地應用于臨床實踐,同時也為心電分類和情緒分類等研究提供了可借鑒的方法。但是該算法在第一重分類上仍存在較大的提升空間,今后我們可考慮選取不同的特征組合以及優化特征組合方式等途徑,來提高正常期與準發病期的識別率,另外可嘗試在更多的數據集中驗證此方法的有效性,使得本文方法能夠得到更加廣泛的應用。
利益沖突聲明:本文全體作者均聲明不存在利益沖突。