阿爾茨海默病(AD)作為一種常見的神經系統退行性疾病,其致病機制不明,尤其是對處于 AD 不同階段的輕度認知障礙(MCI)患者的萎縮區域難以確定,導致誤診率偏高。為此,提出了基于 3 維卷積神經網絡(3DCNN)和遺傳算法(GA)相結合的 AD 早期輔助診斷模型。首先用 3DCNN 針對感興趣區域(ROI)訓練出候選基分類器,然后利用 GA 算法從中挑選出最優基分類器組合,最后集成起來進行分類,實現輔助診斷。同時,由于基分類器與腦區之間是一一對應的,進而可以找出具有顯著分類能力的腦區。實驗結果表明,AD 與正常組(NC)的分類準確率為 88.6%,轉化為 AD 的 MCI(MCIc)與 NC 的分類準確率為 88.1%,未轉化為 AD 的 MCI(MCInc)與 MCIc 的分類準確率為 71.3%。此外,通過對關鍵 ROI(即腦區)所對應的行為域數據進行統計分析,GA 篩選的關鍵腦區除了左延髓海馬、左尾部海馬和內外側杏仁核、左海馬旁回,還新發現了右顳中回前顳上溝、右扣帶回背側 23 等區域。實驗得出所選腦區的功能主要影響情緒、記憶和認知等方面,這與 AD 患者出現的感情冷淡、記憶力下降、行動能力下降和認知水平下降等外在表現基本吻合。這些均表明所提方法是有效的。
引用本文: 潘丹, 鄒超, 容華斌, 曾安. 基于遺傳算法和三維卷積神經網絡集成模型的阿爾茨海默癥早期輔助診斷. 生物醫學工程學雜志, 2021, 38(1): 47-55, 64. doi: 10.7507/1001-5515.201911046 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
引言
阿爾茨海默癥(Alzheimer’s disease,AD)是一種常見的神經系統退行性疾病。輕度認知障礙(mild cognitive impairment,MCI)通常被認為是 AD 的一種早期階段,是從正常對照(normal control,NC)到 AD 的過渡狀態[1],尤其是晚期 MCI 很可能發展為 AD[2],因此一般將 MCI 分為轉化為 AD 的 MCI(MCI patients who will convert to AD,MCIc)和未轉化為 AD 的 MCI(MCI patients who will not convert to AD,MCInc)。據國際阿爾茨海默病組織(Alzheimer's Disease International)公布[3],2018 年全球有 5 000 萬 AD 患者,到 2050 年,這一數字將增至 1.52 億人。盡管目前還缺乏有效治愈 AD 的方法,但對 AD 進行早期干預可以延緩其發展進程。而且,隨著我國老齡化人口比重逐年遞增,AD 患者人數龐大,國內眾多學者也對 AD 展開了多方面的研究[4]。如何在臨床上快速準確地早期診斷 AD/MCI 仍然是一個具有挑戰的問題。目前,隨著磁共振影像(magnetic resonance imaging,MRI)技術的發展,越來越多的研究者開始基于 MRI 醫學影像對 AD 展開研究。
MRI 包括結構性核磁共振(structural MRI,sMRI)和功能性核磁共振(functional MRI,fMRI)。sMRI 是一種非侵入性、功能強大的神經成像工具,有助于捕獲區域性腦萎縮和理解與 AD 相關的解剖結構的變化,特別是其捕捉到的海馬和內嗅皮層的萎縮可以在一定程度上反映疾病所處的階段,并預測 MCI 向 AD 的進展[5-6]。因此,研究者嘗試從 sMRI 影像捕獲 AD 疾病信息,以期獲得較好的分類準確率。
有研究表明 sMRI 影像的體積、皮層厚度、皮層表面積等大腦形態學指標特征可用來診斷 AD[7]。例如,Salvatore 等[8]針對 509 張 sMRI 影像,對被試全腦影像體素采用主成分分析(principal components analysis,PCA)方法進行特征提取,然后將提取到的特征用支持向量機(support vector machine,SVM)進行訓練。該方法在 AD vs. NC、MCIc vs. NC 和 MCIc vs. MCInc 等人群的分類準確率分別達到 76%、72%、66%,取得了一定的效果。但伴隨圖像而來的是上百萬的體素,而樣本的數量是有限的,容易發生過擬合。另外,傳統的機器學習方法靠手工提取特征,這在很大程度上依賴于專業知識,不但耗時而且存在主觀因素[9]。
近年來,深度學習尤其是深度卷積神經網絡(convolutional neural network,CNN),因其強大的提取有效特征的能力而在各種醫學圖像分割、分類和配準等任務中得到了廣泛運用[10]。如:Hosseini-Asl 等[11]提出了深度監督自適應 3D-CNN(3D-ACNN)模型。該模型特色之處在于通過自編碼器提取 AD 生物標志物,實現了病癥的分類。Li 等[12]將大腦 sMRI 影像劃分為 27 個區域,結合 K-Means 方法對每個區域的 patches 進行分組,再采用 DenseNet[13]網絡模型對分組后的 patches 進行訓練,并將各個區域學習到的特性進行融合,最后進行分類。但是上述實驗的參數量巨大,并且模型內存消耗大,訓練時間較長。本團隊[14]提出了基于 sMRI 影像三個維度的不同二維切片的基分類器集成模型,該模型通過簡單 8 層網絡[15]訓練出基于 sMRI 的不同軸(X,Y,Z)的切片基分類器,選取單軸準確率前五名的基分類器進行簡單的投票集成。該方法在 AD vs. NC、MCIc vs. NC 和 MCIc vs. MCInc 等人群的分類準確率分別達到 81%、79%、62%。盡管 2DCNN 的訓練參數明顯少于 3DCNN,但二維切片并沒有充分利用 sMRI 的空間信息,且切片之間的相關性考慮不充分,同時,簡單地按驗證集上的準確率高低挑選基分類器進行集成,獲得的模型不一定是最優的。在最新的研究中,Spasov 等[16]提出了一種基于三維可分離卷積的雙任務學習的深度學習體系結構。該實驗以 sMRI 影像、人口統計學、神經心理學和 APOe4 基因數據作為輸入,實現了 MCI 向 AD 轉化的預測,盡管該方法取得了較好的效果,但除圖像外,其他醫療數據較難獲取,因此存在一定局限。
綜上所述,文獻[4-6]表明,與 AD 有關的僅是部分腦區,而不是整個大腦。其他不相關腦區圖像會對分類結果造成影響。因此,可根據疾病特點選擇感興趣區域(regions of interest,ROI)腦區圖像作為樣本。盡管目前已有一些 AD 輔助診斷模型,但這些模型不是訓練難度大、耗時較長,就是僅停留在提高分類準確率的目的上,缺乏關于對 AD 早期診斷有幫助的腦區的有效判定。為解決上述問題,本文提出了基于 ROI 的 3DCNN 和遺傳算法(genetic algorithm,GA)相結合的 AD 早期診斷集成模型。
1 方法
1.1 分類性能指標
本文采用了 5 種分類性能指標進行評價,分別是分類準確率(accuracy)、召回率(recall)、精度(precision)、f1 值(f1-score)和 ROC 曲線下面積(area under curve,AUC),相關計算公式如下。
 |
 |
 |
 |
上式中的 TP、TN、FP 和 FN 見表 1。
1.2 集成模型框架
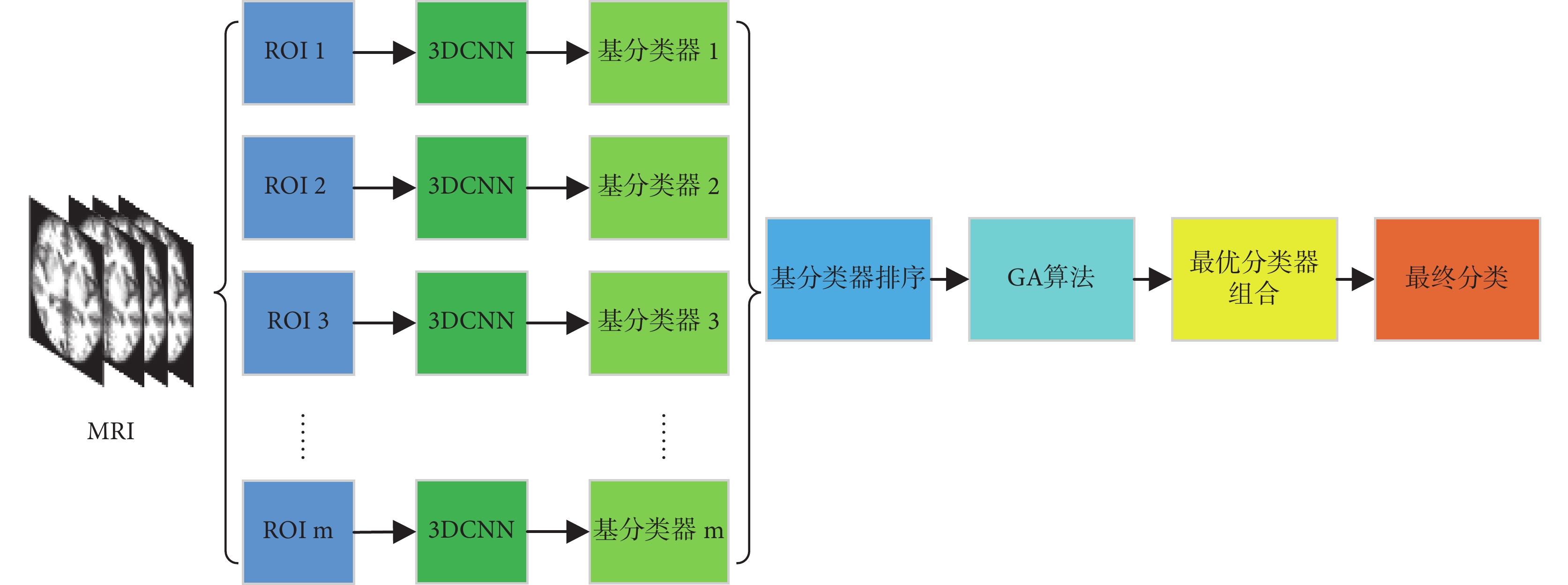
由于 T1 加權(T1-Weight)圖像被廣泛應用,常作為 AD 診斷的首選影像[17],因此,本文采用它們來測試所提出的方法。本文提出的基于 ROI 的 3DCNN+GA 的 AD 早期診斷集成模型框架如圖 1 所示,根據大腦分區模板提取 sMRI 不同的 ROI 影像,針對每個 ROI 影像基于 3DCNN 訓練出對應的基分類器,最后經 GA 篩選出最優基分類器組合并進行集成分類。
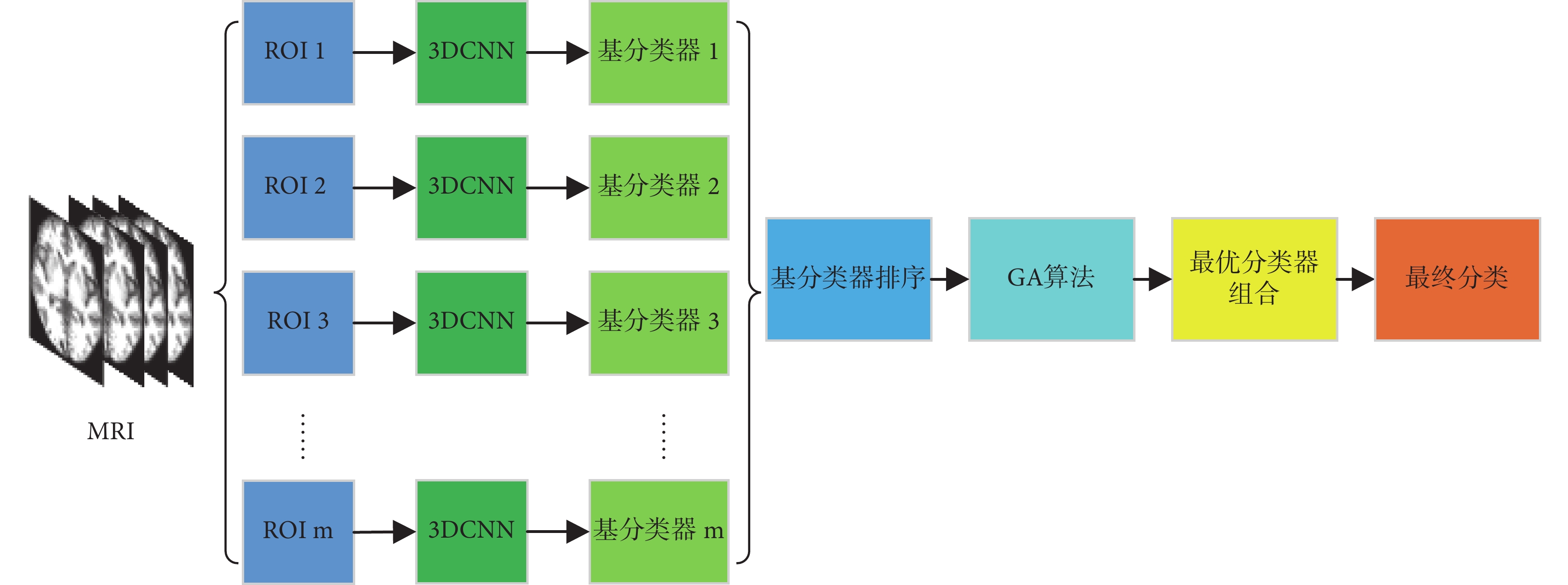 圖1
集成分類模型框架
Figure1.
The framework of classification ensemble model
圖1
集成分類模型框架
Figure1.
The framework of classification ensemble model
1.3 3DCNN
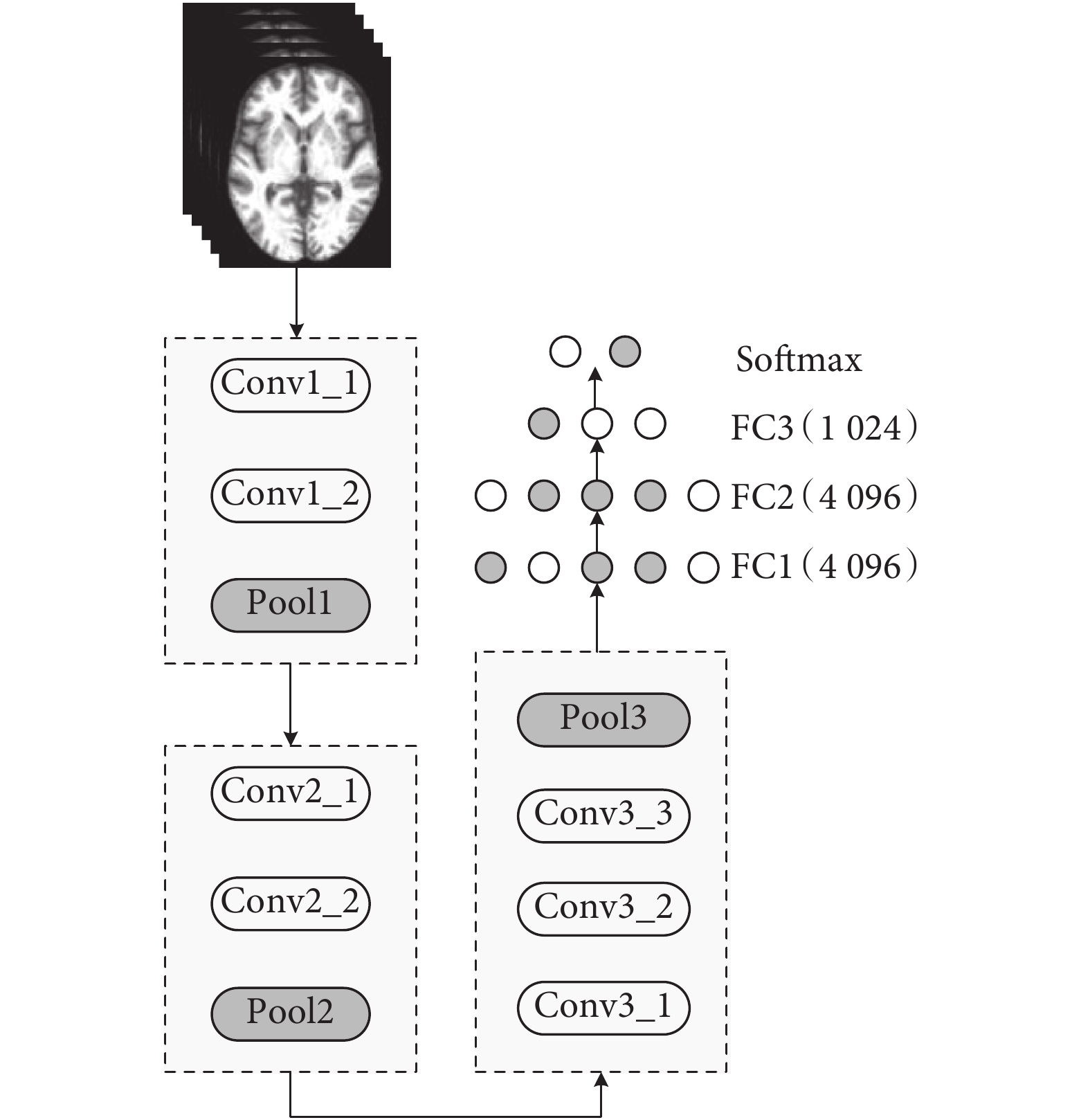
CNN 的強大之處在于它的多層網絡結構可以自動學習圖像特征。淺層的卷積層學習圖像局部特征,深層的卷積層對這些局部特征進行進一步學習,從而獲得更加抽象的特征。研究表明,CNN 通過加深網絡結構可提高網絡的特征表示能力,使得圖像特征信息可以通過多層網絡傳到分類器端,從而提高最終的分類效果[18]。但是,由于獲得大量帶有標記的樣本較為困難,因此,為了減小過擬合風險,淺層的網絡結構是首選。這樣,有效構建出基于小數據樣本進行分類的網絡體系結構仍然非常重要[19]。于是,本文構建了如圖 2 所示的精簡 3DCNN 結構,主要包括三個卷積模塊 Conv1(Conv1_1,Conv1_2,Pool1)、Conv2(Conv2_1,Conv2_2,Pool2)、Conv3(Conv3_1,Conv3_2,Conv3_3,Pool3)和三個全連接層(FC4,FC5,FC6)和一個 Softmax 層。
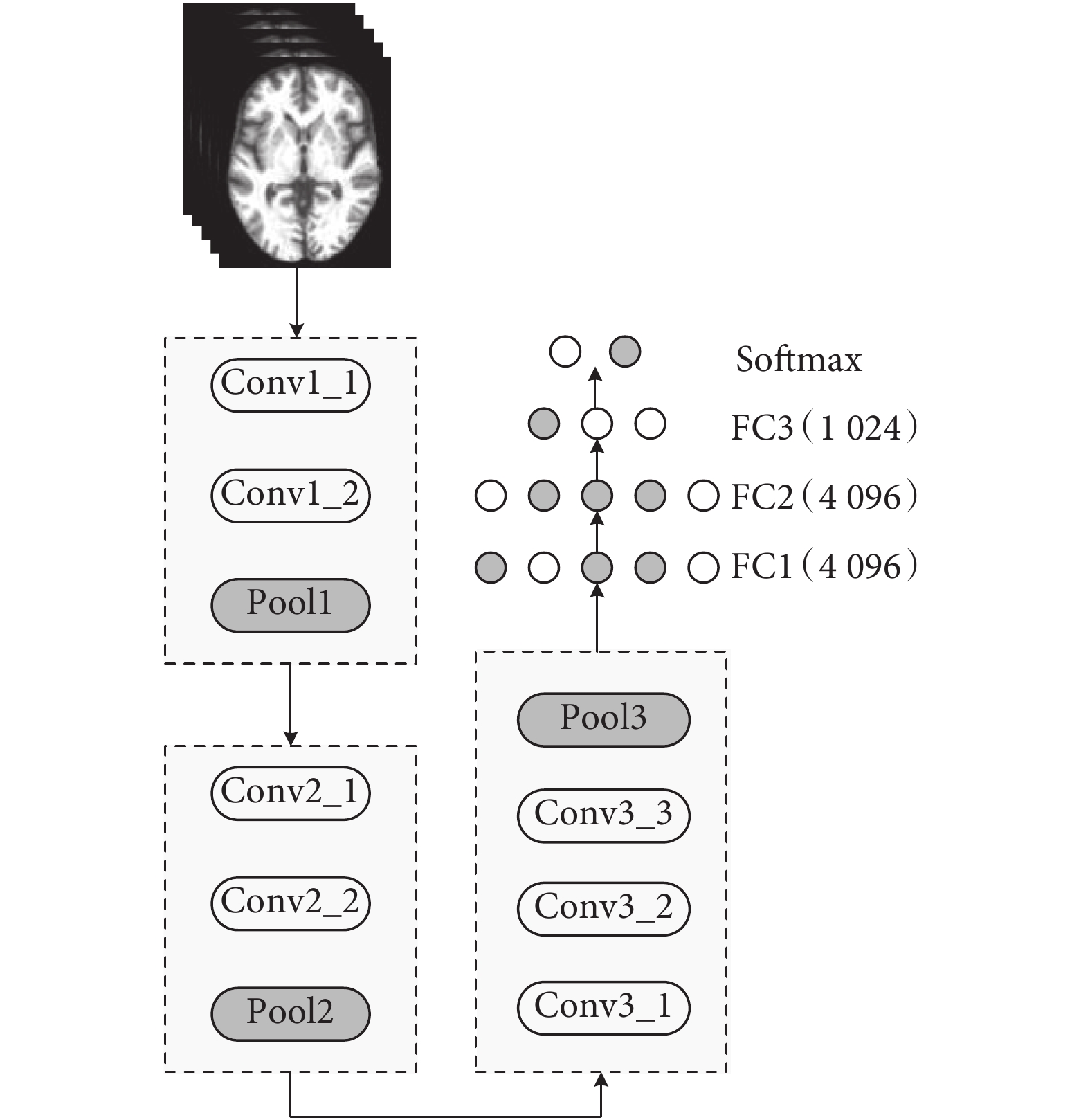 圖2
本文提出的 3DCNN 網絡結構
Figure2.
The proposed 3D CNN architecture
圖2
本文提出的 3DCNN 網絡結構
Figure2.
The proposed 3D CNN architecture
1.4 基分類器的優選
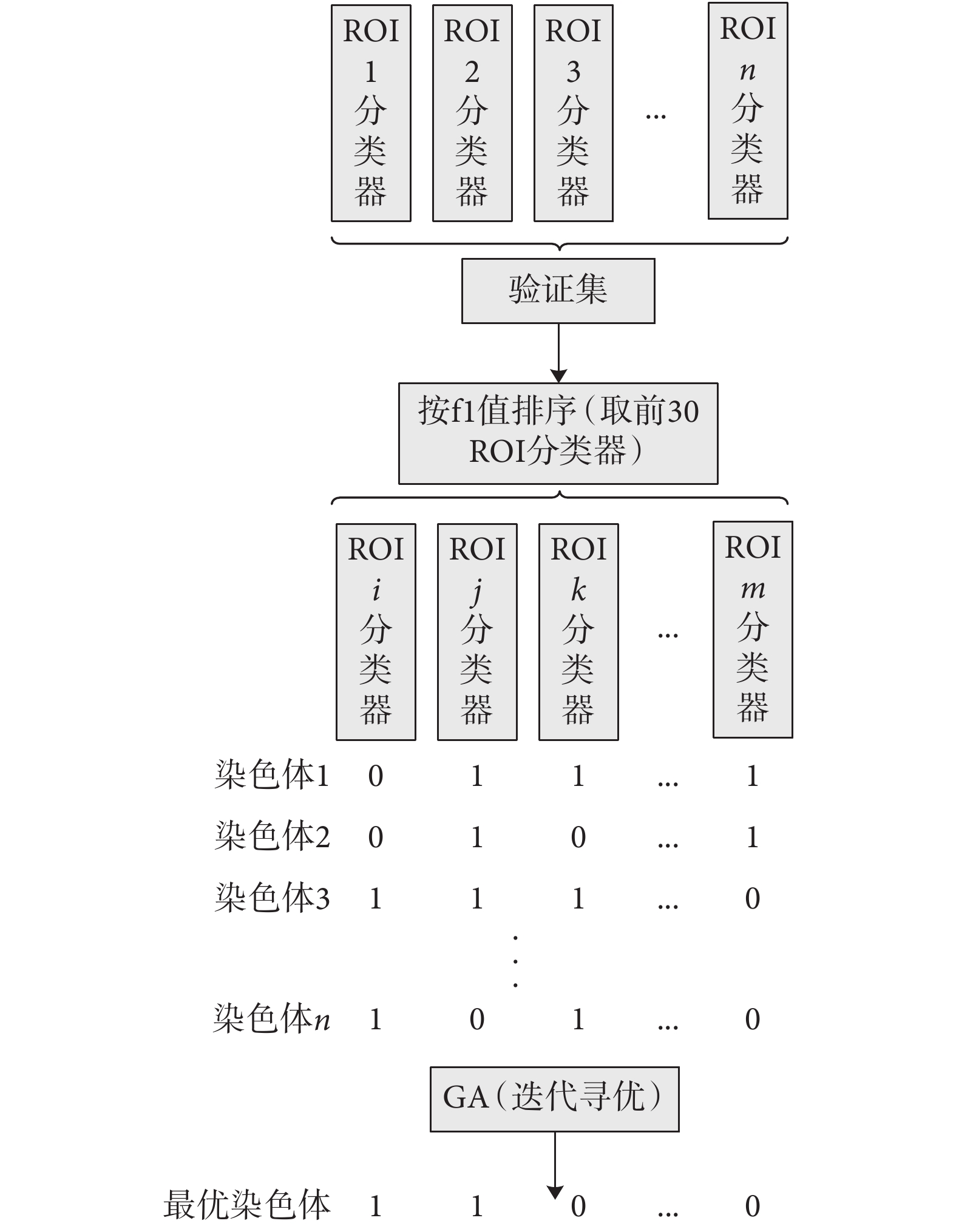
相比于文獻[14]具有主觀性的簡單集成方法,本文通過 GA 來完成對基分類器的優選,可使選取的基分類器更具客觀性。事實上,每個基分類器學習到的特征只是對應單個腦區圖像的特征信息,通過集成,就可以把多個基分類器對同一未知標簽樣本的預測結果融合在一起,共同決定該樣本的分類標簽。本文采用的 GA 優選方法如圖 3 所示。首先,針對每個腦區,成功訓練出相應的 3DCNN 基分類器;然后,按照這些基分類器在驗證集上的 f1 值指標高低對其進行排序,選出排名前 30 的基分類器;然后對這 30 個基分類器進行染色體編碼(即初始化種群,1 代表選擇此基分類器,0 代表不選擇)。經過 GA 算法的不斷迭代尋優,最終篩選出 ROI 關鍵基分類器組合進行集成,以此決定最終的預測結果。本模型最大特點在于利用 GA 來挑選具有顯著分類效果的 3DCNN 基分類器。這樣,不但可以實現 AD 分類,還可分析挑選出的腦區所對應的行為域,發現與 AD 有關的生物標志物,進而為臨床的治療提供一定的幫助。
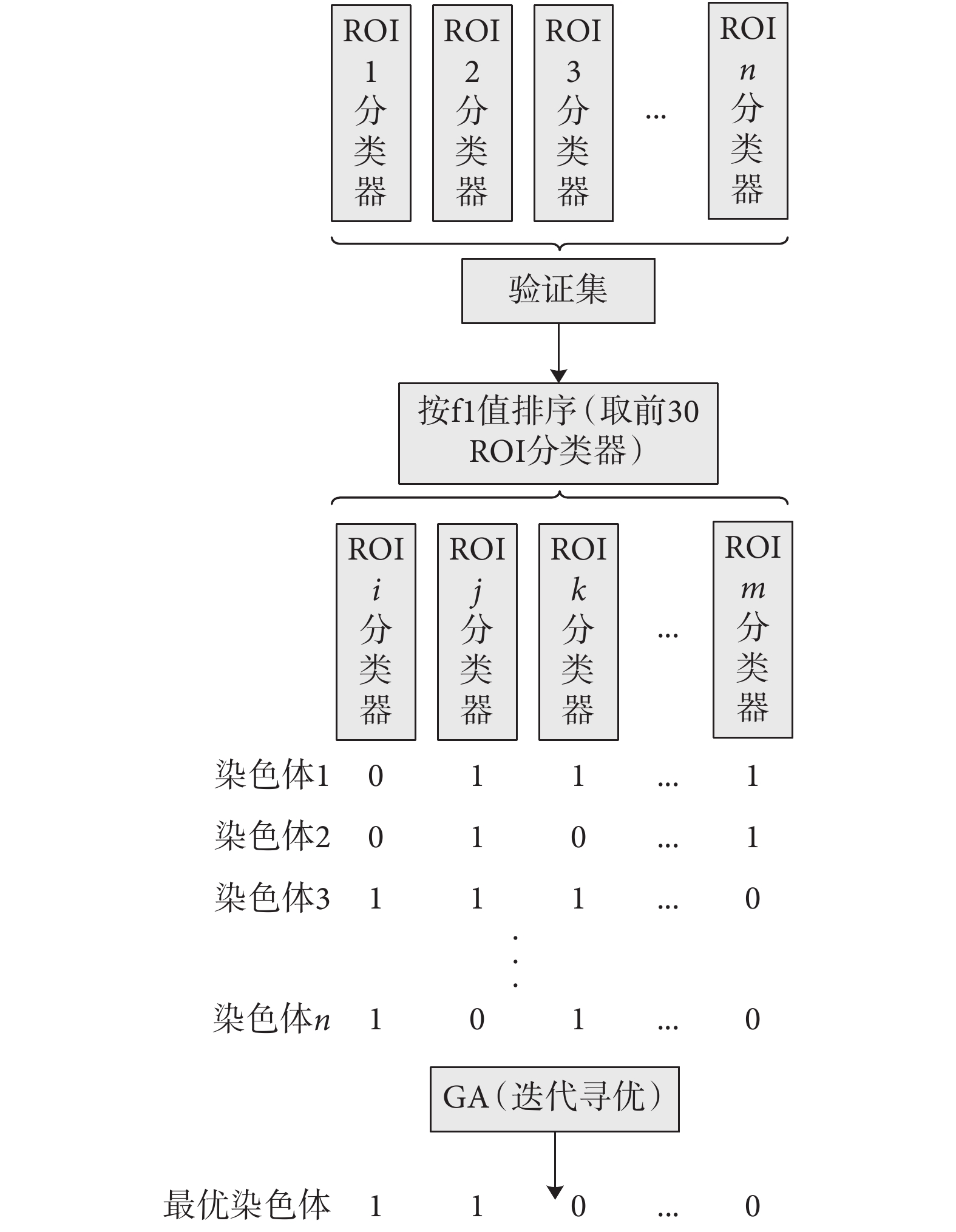 圖3
GA 算法優選
Figure3.
GA optimization
圖3
GA 算法優選
Figure3.
GA optimization
2 實驗
2.1 數據集及預處理
本文使用的 sMRI 影像來自阿爾茨海默病神經影像學倡議(Alzheimer’s Disease Neuroimaging Initiativ,ADNI)數據庫(www.loni.ucla.edu/adni)。ADNI 于 2003 年由美國國家老齡研究所(National Institute of Aging,NIA)、美國國家生物醫學成像和生物工程研究所(National Institute of Biomedical Imaging and Bioengineering,NIBIB)、美國食品和藥物管理局(Food and Drug Administration,FDA)、私營制藥公司和非營利組織共同發起的。ADNI 的主要目標是發現對 AD 早期階段診斷最有效的方法,為相關研究人員節省成本并為治療提供輔助,并為全球研究者展開共同合作和數據共享提供便利。
本文從 ADNI 數據庫下載的 sMRI 影像數據劃分為四類人群:① 正常對照組(NC);② 重度認知障礙類(轉化為 AD 型,MCIc);③ 輕度認知障礙類(未轉化為 AD 型,MCInc);④ 阿爾茨海默病類(AD)。總共下載了 787 張 T1-Weight 的 sMRI 影像,包括 262 張 NC 影像、237 張 AD 影像、173 張 MCInc 影像和 115 張 MCIc 影像。在數據的使用上,本文將數據分為兩部分,其中一部分用于本模型訓練和測試,記作訓練&&測試集(n = 509);另外一部分作為驗證集(n = 278),相關被試的詳細信息如表 2 和表 3 所示。
由于從 ADNI 數據庫下載的圖像都為.nii 格式,實驗利用基于 MATLAB 軟件的 CAT12 工具包(http://dbm.neuro.uni-jena.de/cat/)進行圖像預處理,預處理包括去頭骨,配準到蒙特利爾神經病學研究所(Montreal Neurological Institute,MNI)標準空間中,圖像平滑(平滑核為 2 × 2 × 2),參數使用 CAT12 工具包默認參數。隨后對每個 sMRI 進行灰度歸一化,使灰度值在 0~1 之間,有利于模型加速收斂,預處理流程如圖 4 所示。
 圖4
橫截面預處理流程
Figure4.
Preprocessing of axial plane
圖4
橫截面預處理流程
Figure4.
Preprocessing of axial plane
2.2 ROI 圖像提取
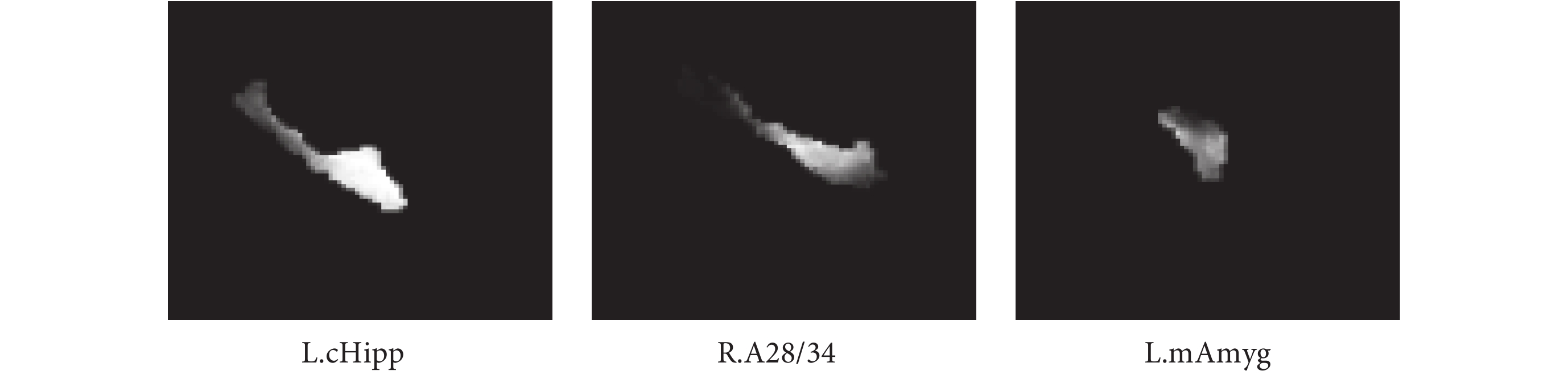
由于 AD 的產生同時伴隨著顳葉和海馬體的萎縮,這些變化可以通過 sMRI 進行測量。文獻[20]已經證實,AD 與腦萎縮有密切關系,而腦萎縮主要反映在皮層表面積的縮小及皮質厚度降低和灰質體積減少上,因此,這一步的目的是根據大腦分區模板從 sMRI 影像提取出 ROI 圖像。
如圖 5 所示,分別為被試的左海馬區域(L.cHipp)、右海馬旁回區域(R.A28/34)、左杏仁核區域(L.mAmyg)等 ROI 圖像切片。具體做法:當經過預處理后的 sMRI 影像在大小和坐標空間與 Brainnetome Atlas[21]模板一致時,根據模板劃分腦區的掩碼(Mask)提取特定腦區的圖像作為本模型的輸入樣本。
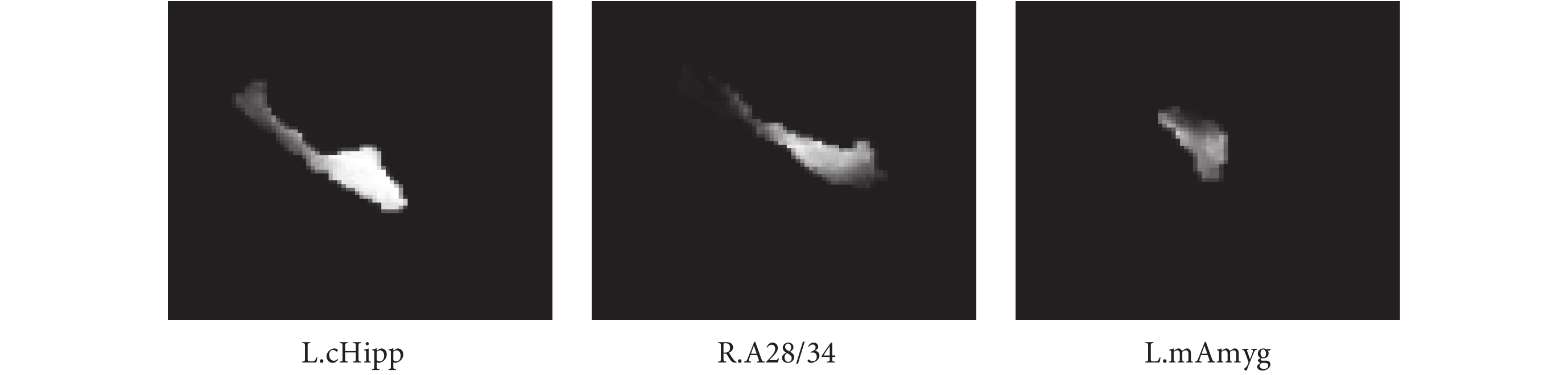 圖5
ROI 圖像的切片示意圖
Figure5.
Slices of ROI images
圖5
ROI 圖像的切片示意圖
Figure5.
Slices of ROI images
2.3 實驗設置
本文利用 ADNI 數據庫中 787 名被試的 T1-Weight 的 sMRI 影像進行 AD 分類實驗。圖像處理過程如第 2.1 節所示,處理后 sMRI 影像大小為 91 × 109 × 91,圖像分辨率為 2 mm3。3DCNN 模型參數如表 4 所示。
訓練時,整個網絡的權重默認 Glorot 等[22]初始化的方法。Batch_size 為 4,Epochs 為 40,采用 Adam[23]梯度下降方法進行參數的更新,學習率為 0.001,Dropout 為 0.25,并且對參數進行了 L2 正則化來降低過擬合風險。另外,GA 種群數為 30,總共迭代 6 000 次,交叉概率設為 0.75,變異概率設為 0.05,f1 值作為適應度值。由于 GA 一般收斂速度慢,會因所有群體出現同一極值而導致停止進化,即早熟現象。又因為適應度值間差別小,故對種群適應度值選擇進行了放大操作。
 |
 |
公式(5)(6)中 fitvalue 表示當前迭代次數的所有種群各自適應度值,pi 則為各個種群被選擇的概率。測試時,把經預處理后的 sMRI 影像輸入到經 GA 篩選獲得的集成模型中,獲得最終的測試結果。實驗采用了 5 種分類性能指標進行評價(如 1.1 節所示)。
2.4 實驗方案
所有實驗均在同一個服務器上運行。服務器總共有 5 個節點,每個節點分別配置了 2 塊顯存為 16 GB、最大功耗為 250 W 的 NVIDIA 的 Tesla P100 GPU 顯卡。本文實現了以下模型:
(1)3DCNN,利用被試的全腦 sMRI 影像來訓練本文的 3DCNN 模型。
(2)3DCNN+Ensemble,先根據 2.2 節方法,利用 Brainnetome Atlas 模板從 sMRI 中提取出每個腦區的 ROI 圖像,總共 246 個腦區,然后,將每個腦區的 ROI 圖像用于訓練一個 3DCNN 模型,即得到 246 個 3DCNN 基分類器。接著,利用驗證集獲得每個基分類器的 f1 值,進行排序后,取出排名前 30 的 3DCNN 基分類器進行簡單投票集成。
(3)3DCNN+GA,先根據 2.2 節方法,利用 Brainnetome Atlas 模板從 sMRI 中提取出每個腦區的 ROI 圖像,總共 246 個腦區,然后,將每個腦區的 ROI 圖像用于訓練一個 3DCNN 模型,即得到 246 個 3DCNN 基分類器。最后根據 1.4 節,對排名前 30 的 ROI 基分類器進行編碼,適應值為 f1 值,再用 GA 在驗證集上篩選出最優 3DCNN 基分類器組合,最后對測試集中樣本進行簡單投票集成測試。
3 實驗結果
3.1 方法結果比較
在本文中,實驗使用 5 折分層交叉驗證策略來訓練和測試所提出方法,以減少隨機因素影響。然后采用驗證集數據(見表 3),并利用改進的 GA 算法,完成 3DCNN 基分類器的挑選,取在驗證集上的預測結果中最好的結果所對應的腦區組合作為最終集成模型。每種指標可得 5 次結果,取其平均值作為性能指標。所提方法在 AD vs. NC、MCIc vs. NC 和 MCIc vs. MCInc 的 5 種指標結果,即準確率、AUC、召回率、精度和 f1 值及其對應的標準差如表 5 所示。
為了和其他方法進行公平比較,選擇了實驗所用的訓練集和測試集數據與本文相同的文獻[8,14],并做了多組對比試驗。其他文獻雖使用了 ADNI 數據庫的數據,但具體挑選的數據集并不一樣,同時 MCI 的劃分也存在不同,因此,較難直接進行精確比較。于是,本文選擇了在不同樣本中分類效果比較好的文獻方法進行了大致比較。例如,有些實驗把 MCI 劃分為進展型 MCI(progressive MCI,pMCI)和穩定型 MCI(stable MCI,sMCI),這在某種程度上與本文的 MCIc 以及 MCInc 相對應。表 6 給出了各方法的實驗分類準確率和樣本數量。Yang 等[24]通過獨立主成分分析(independent components analysis,ICA)提取圖像特征,然后將提取到的特征用 SVM 進行訓練,最終實現 AD 的預測。文獻[25]把 Bagging 和 SVM 相結合實現 AD/NC 的分類。李書通等[26]提出了一種基于非監督學習的 3D-PCANet 方法,實現了 AD 輔助診斷。文獻[2]基于堆棧自編碼器對 AD 進行分類。文獻[10]通過提取圖像局部密度特征,并結合圖的示例學習技術完成了對 AD 的分類。
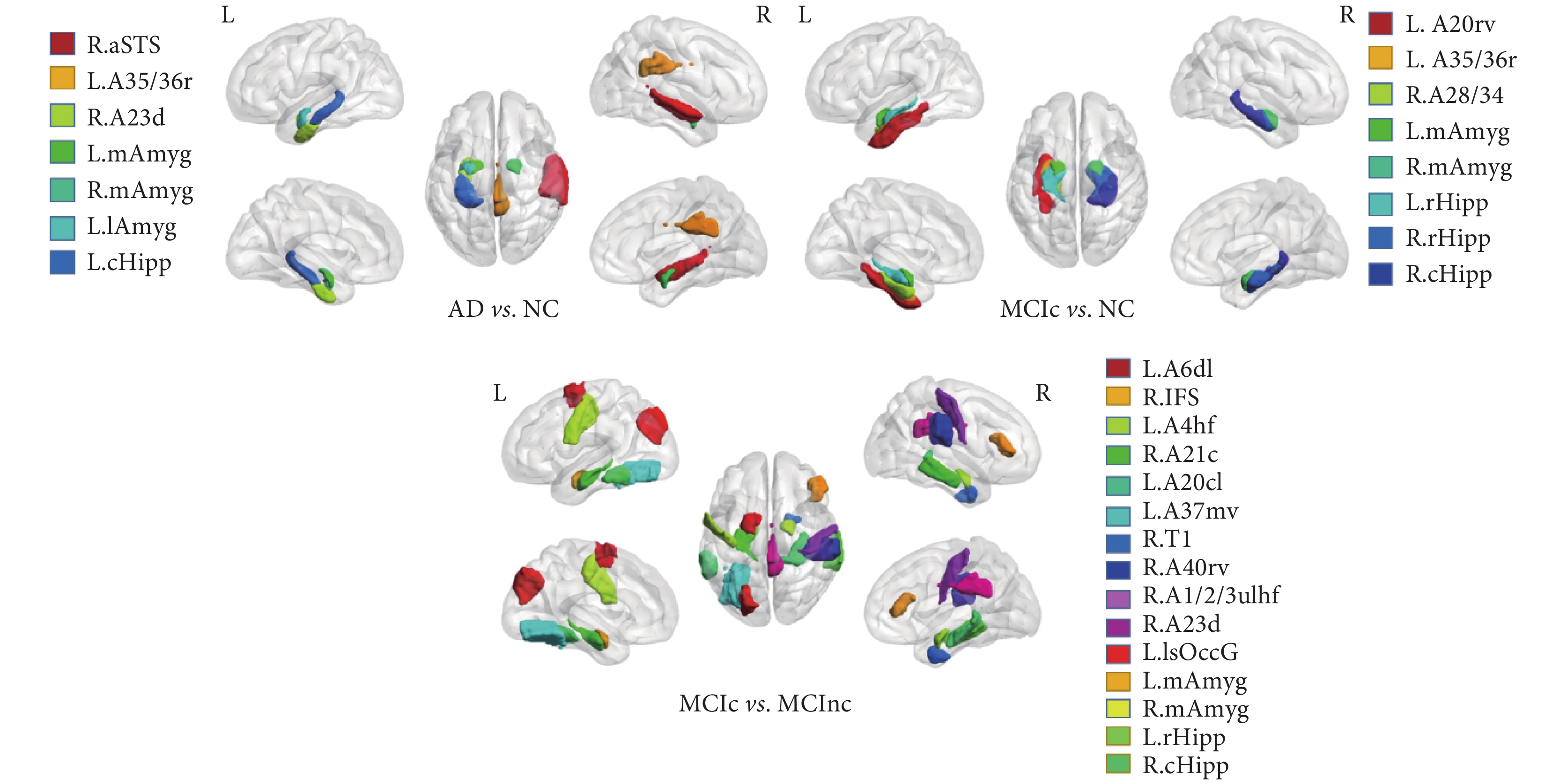
本方法的 3DCNN 網絡的參數量總共為 31 610 258,單個 ROI 模型訓練需要 0.78 h,大小為 361.83 MB,一個 ROI 基分類器的五折交叉驗證模型則耗費 3.9 h 左右,總共 246 個腦區,因此,完成一組分類實驗將花費 959.4 h,合計約 40 天,最終完成整個實驗訓練約需耗費 120 天左右。盡管從訓練周期來看,時間成本巨大,但從實驗結果來看,分類準確率顯著提高。此外,經 GA 算法挑選后,在驗證集上取得最高 f1 值的 ROI 腦區通過 BrainNet Viewer[27]進行三維可視化,如圖 6 所示。
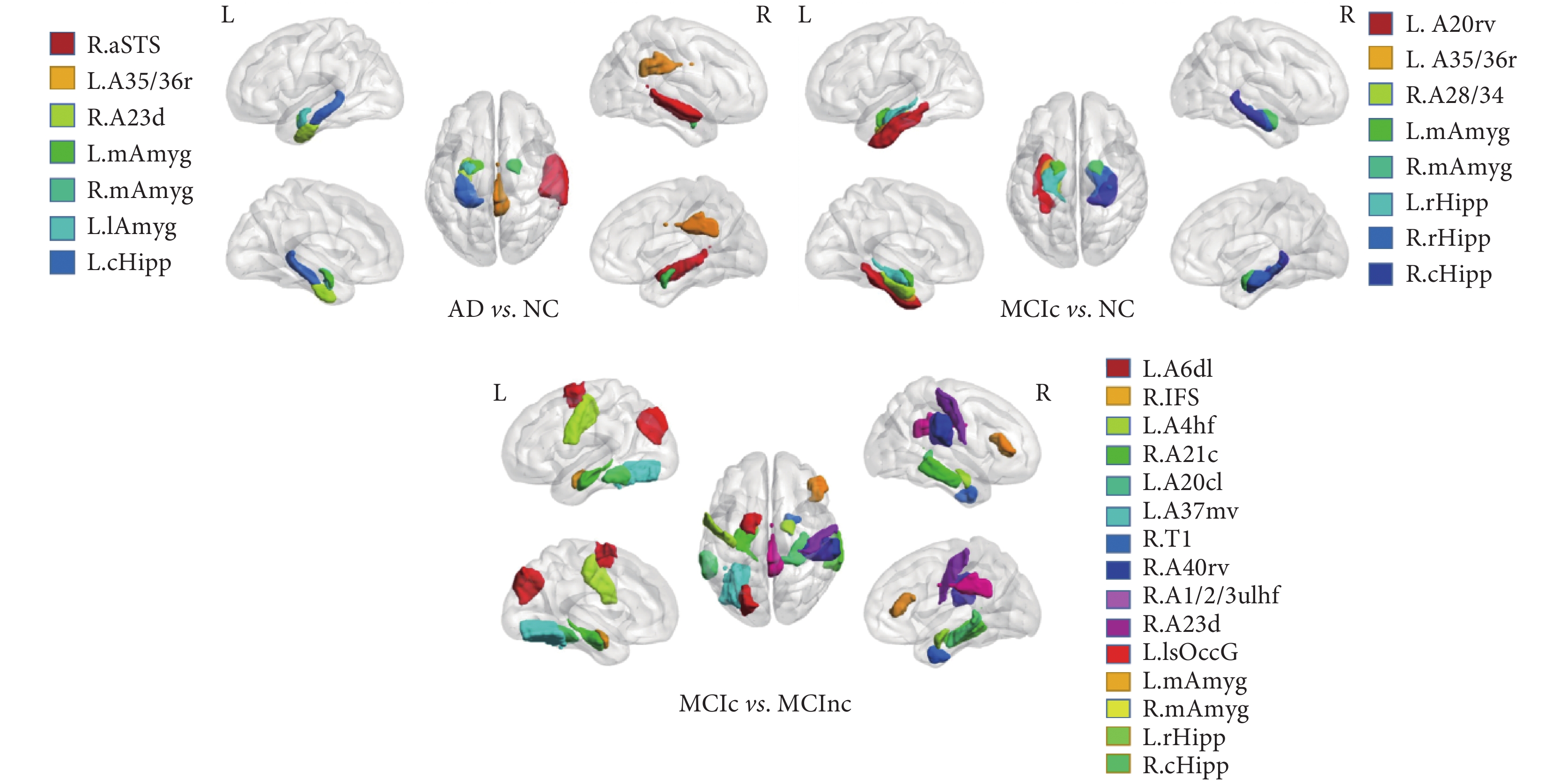 圖6
GA 所篩選的腦區
Figure6.
Brain regions chosen with GA
圖6
GA 所篩選的腦區
Figure6.
Brain regions chosen with GA
3.2 行為域值統計結果
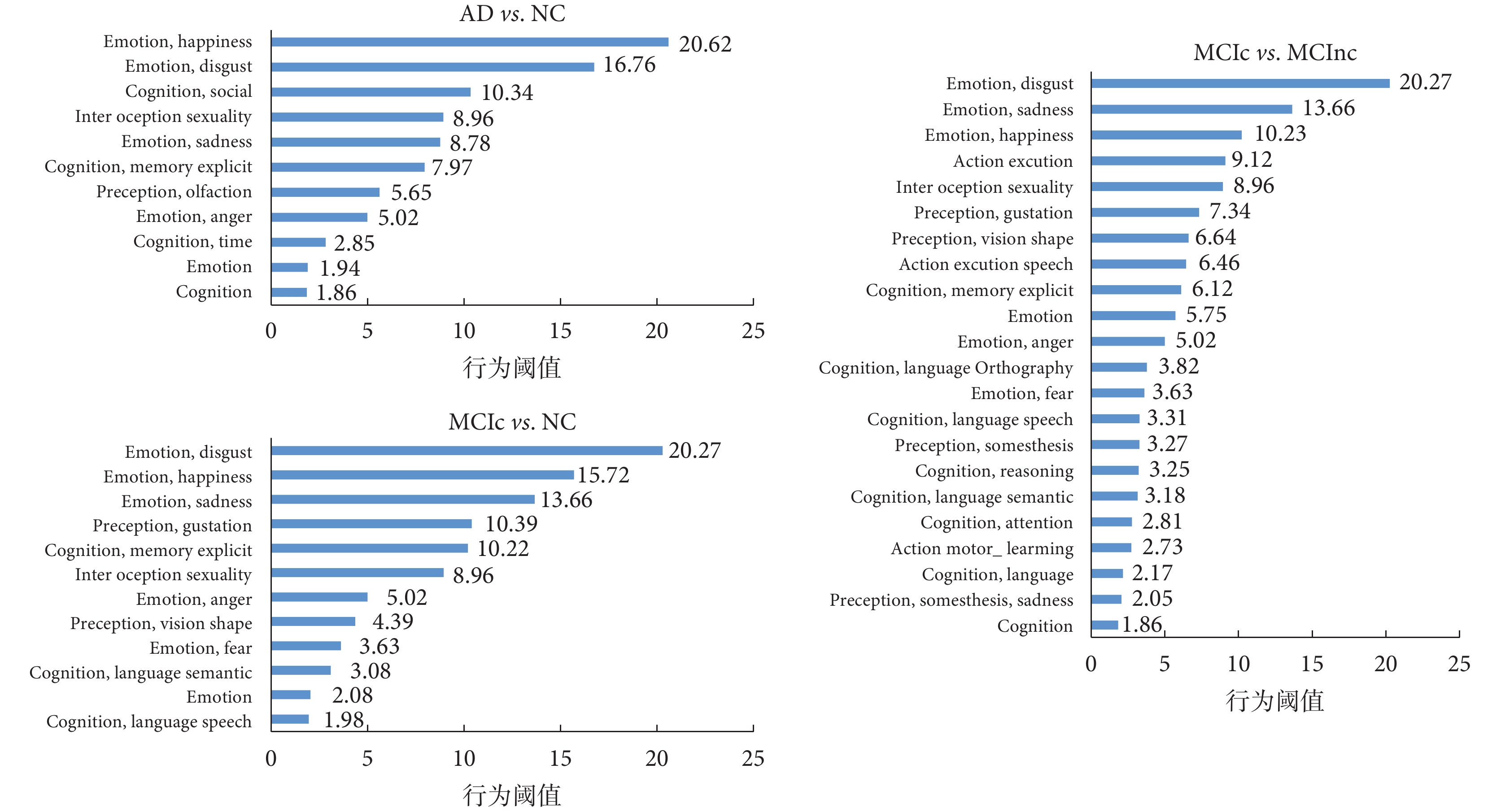
本實驗根據 Brainnetome Atlas 官網的各腦區行為域數據,對上述腦區統計出 AD vs. NC、MCIc vs. NC 和 MCIc vs. MCInc 各顯著腦區的相關行為域數據,然后分別分析出各組實驗中根據 GA 算法挑選的較顯著的腦區 ROI 區域主要影響哪些行為,每組實驗統計結果是取每個腦區行為域值最高的前三項(例如,R.mAmyg 腦區行為域域值最高的前三項分別為:Emotion.anger 域值為 5.02,Emotion.sadness 域值為 8.78,Emotion.disgust 域值為 7.87),然后對相同行為域對應的域值進行累加,最終得到如圖 7 所示的統計圖。
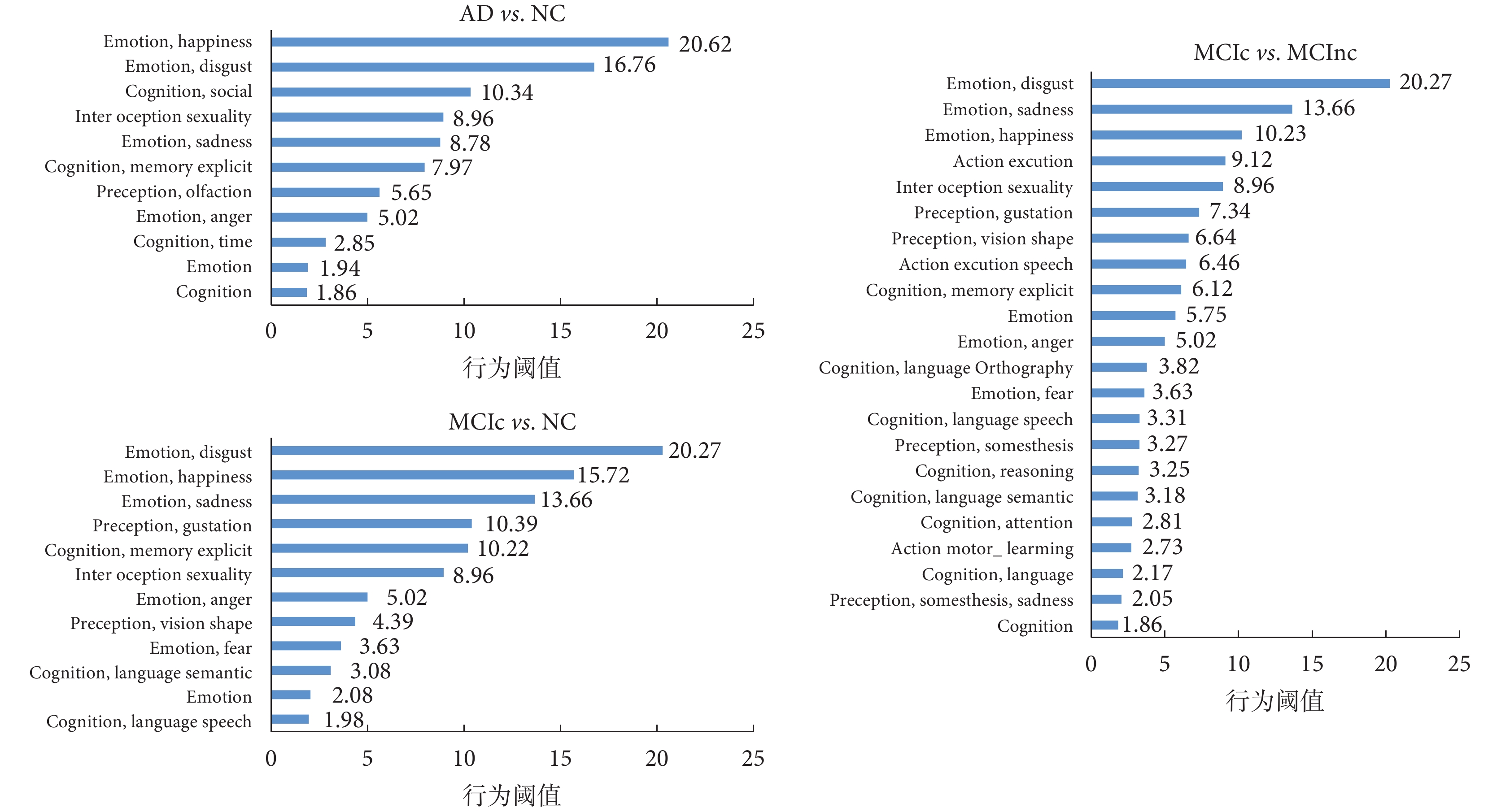 圖7
三組實驗中顯著腦區的行為域分布
Figure7.
The distribution of behavioral domains corresponding to discriminable brain regions in the three binary experiments
圖7
三組實驗中顯著腦區的行為域分布
Figure7.
The distribution of behavioral domains corresponding to discriminable brain regions in the three binary experiments
4 討論與總結
本文提出了基于腦區 ROI 的 3DCNN 和 GA 結合 AD 早期輔助診斷集成模型。模型中的每個基分類器是每個 ROI 圖像用 3DCNN 模型訓練出來的,然后對這些基分類器按 f1 值進行排序篩選,這比 Aderghal 等[28]使用先驗知識只選取海馬體的圖像訓練 CNN 模型更為合理。實驗所有 sMRI 影像均來自 ADNI 數據庫,在與文獻[8,14]使用的數據完全相同的情況下做了多組對比實驗,來檢驗模型的有效性。由表 5、表 6 實驗結果可知,本模型具有以下特點:
(1)僅對被試全腦影像進行訓練的前提下,單純 3DCNN 的 AD vs. NC 和 MCIc vs. NC 實驗準確率比文獻[8]的 PCA+SVM 以及文獻[14]的 2DCNN 均有提高,表明本文 3DCNN 模型在特征提取方面具有一定優勢。
(2)在提取 ROI 的前提下,3DCNN+Ensemble 和 3DCNN+GA 的實驗結果明顯高于單純使用全腦影像的方法和 2DCNN 方法,一方面說明對圖像提取 ROI 特征處理后,減少了其他無關特征的干擾,另一方面通過集成學習將挑選出的各個優秀基分類器集成起來共同對整個 MRI 的類別進行分類,使得最終的集成模型比單個全腦 CNN 基分類器具有更高的分類準確率和穩定性。
(3)集成模型 3DCNN+GA 比 3DCNN+Ensemble 和 2DCNN+Ensemble 效果更好,表明優化算法選出不同被試組中差異最大的 ROI 組合可以擺脫已有經驗的束縛,充分利用 sMRI 的空間信息,從而相比于文獻[14]簡單排序投票集成,GA 算法在特征組合上更具優勢,實驗結果也證明了這一點。在 3DCNN+GA 方法中,AD vs. NC 的準確率為 88.6%,f1 值為 88.3%,GA 篩選的關鍵腦區除了左延髓海馬、左尾部海馬和內外側杏仁核、左海馬旁回,還新發現了了右顳中回前顳上溝、右扣帶回背側 23 等區域;MCIc vs. NC 的準確率為 88.1%,f1 值為 86.5%,GA 篩選的腦區除了右延髓海馬、右尾部海馬和內外側杏仁核、左海馬旁回,還新發現了了左梭狀回延髓 20 等區域;MCIc vs. MCInc 的準確率為 71.3%,f1 值為 69.4%,GA 篩選的腦區為延髓海馬、內外側杏仁核、左梭狀回、右扣帶回背側 23 和楔前葉背內側枕壁溝等區域。
(4)此外,本文還對所有選出腦區的行為域值進行了分析,如圖 7 所示,發現這些分類特征顯著的腦區主要與情感、記憶、語言等功能相關,這與 AD 患者感情淡漠、失憶、喪失語言能力、喪失行動能力等臨床表現基本一致。這進一步印證了 GA 算法所選 ROI 腦區的正確性和有效性,也表明了本研究所得到的腦區與 AD 具有較強的關聯性。
當然,該方法也存在一定的局限性。例如,文獻[12]認為,所有患病人群腦功能發生異常不總是發生在相同的所選 ROI 腦區,因此,固定相同的腦區可能會導致丟失用以區分患者的關鍵信息。這不利于更好地區分患病人群。而且,選擇不同的腦區模板可能也會對分類結果有影響。另外,該模型在提高分類性能的同時,增加了訓練時長。但是,一方面本研究結果在提高了 AD 診斷率的同時,還為 AD 早期診斷有幫助的腦區的有效判定提供了新思路;另一方面,sMRI 影像對腦萎縮、腦血管疾病和腫瘤等疾病的結構變化尤為靈敏[29],因此,這種方式不只局限于 AD 的輔助診斷,還可用于腦血管疾病和腫瘤等其他大腦疾病。這些將是下一步研究的方向。
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
引言
阿爾茨海默癥(Alzheimer’s disease,AD)是一種常見的神經系統退行性疾病。輕度認知障礙(mild cognitive impairment,MCI)通常被認為是 AD 的一種早期階段,是從正常對照(normal control,NC)到 AD 的過渡狀態[1],尤其是晚期 MCI 很可能發展為 AD[2],因此一般將 MCI 分為轉化為 AD 的 MCI(MCI patients who will convert to AD,MCIc)和未轉化為 AD 的 MCI(MCI patients who will not convert to AD,MCInc)。據國際阿爾茨海默病組織(Alzheimer's Disease International)公布[3],2018 年全球有 5 000 萬 AD 患者,到 2050 年,這一數字將增至 1.52 億人。盡管目前還缺乏有效治愈 AD 的方法,但對 AD 進行早期干預可以延緩其發展進程。而且,隨著我國老齡化人口比重逐年遞增,AD 患者人數龐大,國內眾多學者也對 AD 展開了多方面的研究[4]。如何在臨床上快速準確地早期診斷 AD/MCI 仍然是一個具有挑戰的問題。目前,隨著磁共振影像(magnetic resonance imaging,MRI)技術的發展,越來越多的研究者開始基于 MRI 醫學影像對 AD 展開研究。
MRI 包括結構性核磁共振(structural MRI,sMRI)和功能性核磁共振(functional MRI,fMRI)。sMRI 是一種非侵入性、功能強大的神經成像工具,有助于捕獲區域性腦萎縮和理解與 AD 相關的解剖結構的變化,特別是其捕捉到的海馬和內嗅皮層的萎縮可以在一定程度上反映疾病所處的階段,并預測 MCI 向 AD 的進展[5-6]。因此,研究者嘗試從 sMRI 影像捕獲 AD 疾病信息,以期獲得較好的分類準確率。
有研究表明 sMRI 影像的體積、皮層厚度、皮層表面積等大腦形態學指標特征可用來診斷 AD[7]。例如,Salvatore 等[8]針對 509 張 sMRI 影像,對被試全腦影像體素采用主成分分析(principal components analysis,PCA)方法進行特征提取,然后將提取到的特征用支持向量機(support vector machine,SVM)進行訓練。該方法在 AD vs. NC、MCIc vs. NC 和 MCIc vs. MCInc 等人群的分類準確率分別達到 76%、72%、66%,取得了一定的效果。但伴隨圖像而來的是上百萬的體素,而樣本的數量是有限的,容易發生過擬合。另外,傳統的機器學習方法靠手工提取特征,這在很大程度上依賴于專業知識,不但耗時而且存在主觀因素[9]。
近年來,深度學習尤其是深度卷積神經網絡(convolutional neural network,CNN),因其強大的提取有效特征的能力而在各種醫學圖像分割、分類和配準等任務中得到了廣泛運用[10]。如:Hosseini-Asl 等[11]提出了深度監督自適應 3D-CNN(3D-ACNN)模型。該模型特色之處在于通過自編碼器提取 AD 生物標志物,實現了病癥的分類。Li 等[12]將大腦 sMRI 影像劃分為 27 個區域,結合 K-Means 方法對每個區域的 patches 進行分組,再采用 DenseNet[13]網絡模型對分組后的 patches 進行訓練,并將各個區域學習到的特性進行融合,最后進行分類。但是上述實驗的參數量巨大,并且模型內存消耗大,訓練時間較長。本團隊[14]提出了基于 sMRI 影像三個維度的不同二維切片的基分類器集成模型,該模型通過簡單 8 層網絡[15]訓練出基于 sMRI 的不同軸(X,Y,Z)的切片基分類器,選取單軸準確率前五名的基分類器進行簡單的投票集成。該方法在 AD vs. NC、MCIc vs. NC 和 MCIc vs. MCInc 等人群的分類準確率分別達到 81%、79%、62%。盡管 2DCNN 的訓練參數明顯少于 3DCNN,但二維切片并沒有充分利用 sMRI 的空間信息,且切片之間的相關性考慮不充分,同時,簡單地按驗證集上的準確率高低挑選基分類器進行集成,獲得的模型不一定是最優的。在最新的研究中,Spasov 等[16]提出了一種基于三維可分離卷積的雙任務學習的深度學習體系結構。該實驗以 sMRI 影像、人口統計學、神經心理學和 APOe4 基因數據作為輸入,實現了 MCI 向 AD 轉化的預測,盡管該方法取得了較好的效果,但除圖像外,其他醫療數據較難獲取,因此存在一定局限。
綜上所述,文獻[4-6]表明,與 AD 有關的僅是部分腦區,而不是整個大腦。其他不相關腦區圖像會對分類結果造成影響。因此,可根據疾病特點選擇感興趣區域(regions of interest,ROI)腦區圖像作為樣本。盡管目前已有一些 AD 輔助診斷模型,但這些模型不是訓練難度大、耗時較長,就是僅停留在提高分類準確率的目的上,缺乏關于對 AD 早期診斷有幫助的腦區的有效判定。為解決上述問題,本文提出了基于 ROI 的 3DCNN 和遺傳算法(genetic algorithm,GA)相結合的 AD 早期診斷集成模型。
1 方法
1.1 分類性能指標
本文采用了 5 種分類性能指標進行評價,分別是分類準確率(accuracy)、召回率(recall)、精度(precision)、f1 值(f1-score)和 ROC 曲線下面積(area under curve,AUC),相關計算公式如下。
|
|
|
|
上式中的 TP、TN、FP 和 FN 見表 1。
1.2 集成模型框架
由于 T1 加權(T1-Weight)圖像被廣泛應用,常作為 AD 診斷的首選影像[17],因此,本文采用它們來測試所提出的方法。本文提出的基于 ROI 的 3DCNN+GA 的 AD 早期診斷集成模型框架如圖 1 所示,根據大腦分區模板提取 sMRI 不同的 ROI 影像,針對每個 ROI 影像基于 3DCNN 訓練出對應的基分類器,最后經 GA 篩選出最優基分類器組合并進行集成分類。
圖1
集成分類模型框架
Figure1.
The framework of classification ensemble model
1.3 3DCNN
CNN 的強大之處在于它的多層網絡結構可以自動學習圖像特征。淺層的卷積層學習圖像局部特征,深層的卷積層對這些局部特征進行進一步學習,從而獲得更加抽象的特征。研究表明,CNN 通過加深網絡結構可提高網絡的特征表示能力,使得圖像特征信息可以通過多層網絡傳到分類器端,從而提高最終的分類效果[18]。但是,由于獲得大量帶有標記的樣本較為困難,因此,為了減小過擬合風險,淺層的網絡結構是首選。這樣,有效構建出基于小數據樣本進行分類的網絡體系結構仍然非常重要[19]。于是,本文構建了如圖 2 所示的精簡 3DCNN 結構,主要包括三個卷積模塊 Conv1(Conv1_1,Conv1_2,Pool1)、Conv2(Conv2_1,Conv2_2,Pool2)、Conv3(Conv3_1,Conv3_2,Conv3_3,Pool3)和三個全連接層(FC4,FC5,FC6)和一個 Softmax 層。
圖2
本文提出的 3DCNN 網絡結構
Figure2.
The proposed 3D CNN architecture
1.4 基分類器的優選
相比于文獻[14]具有主觀性的簡單集成方法,本文通過 GA 來完成對基分類器的優選,可使選取的基分類器更具客觀性。事實上,每個基分類器學習到的特征只是對應單個腦區圖像的特征信息,通過集成,就可以把多個基分類器對同一未知標簽樣本的預測結果融合在一起,共同決定該樣本的分類標簽。本文采用的 GA 優選方法如圖 3 所示。首先,針對每個腦區,成功訓練出相應的 3DCNN 基分類器;然后,按照這些基分類器在驗證集上的 f1 值指標高低對其進行排序,選出排名前 30 的基分類器;然后對這 30 個基分類器進行染色體編碼(即初始化種群,1 代表選擇此基分類器,0 代表不選擇)。經過 GA 算法的不斷迭代尋優,最終篩選出 ROI 關鍵基分類器組合進行集成,以此決定最終的預測結果。本模型最大特點在于利用 GA 來挑選具有顯著分類效果的 3DCNN 基分類器。這樣,不但可以實現 AD 分類,還可分析挑選出的腦區所對應的行為域,發現與 AD 有關的生物標志物,進而為臨床的治療提供一定的幫助。
圖3
GA 算法優選
Figure3.
GA optimization
2 實驗
2.1 數據集及預處理
本文使用的 sMRI 影像來自阿爾茨海默病神經影像學倡議(Alzheimer’s Disease Neuroimaging Initiativ,ADNI)數據庫(www.loni.ucla.edu/adni)。ADNI 于 2003 年由美國國家老齡研究所(National Institute of Aging,NIA)、美國國家生物醫學成像和生物工程研究所(National Institute of Biomedical Imaging and Bioengineering,NIBIB)、美國食品和藥物管理局(Food and Drug Administration,FDA)、私營制藥公司和非營利組織共同發起的。ADNI 的主要目標是發現對 AD 早期階段診斷最有效的方法,為相關研究人員節省成本并為治療提供輔助,并為全球研究者展開共同合作和數據共享提供便利。
本文從 ADNI 數據庫下載的 sMRI 影像數據劃分為四類人群:① 正常對照組(NC);② 重度認知障礙類(轉化為 AD 型,MCIc);③ 輕度認知障礙類(未轉化為 AD 型,MCInc);④ 阿爾茨海默病類(AD)。總共下載了 787 張 T1-Weight 的 sMRI 影像,包括 262 張 NC 影像、237 張 AD 影像、173 張 MCInc 影像和 115 張 MCIc 影像。在數據的使用上,本文將數據分為兩部分,其中一部分用于本模型訓練和測試,記作訓練&&測試集(n = 509);另外一部分作為驗證集(n = 278),相關被試的詳細信息如表 2 和表 3 所示。
由于從 ADNI 數據庫下載的圖像都為.nii 格式,實驗利用基于 MATLAB 軟件的 CAT12 工具包(http://dbm.neuro.uni-jena.de/cat/)進行圖像預處理,預處理包括去頭骨,配準到蒙特利爾神經病學研究所(Montreal Neurological Institute,MNI)標準空間中,圖像平滑(平滑核為 2 × 2 × 2),參數使用 CAT12 工具包默認參數。隨后對每個 sMRI 進行灰度歸一化,使灰度值在 0~1 之間,有利于模型加速收斂,預處理流程如圖 4 所示。
圖4
橫截面預處理流程
Figure4.
Preprocessing of axial plane
2.2 ROI 圖像提取
由于 AD 的產生同時伴隨著顳葉和海馬體的萎縮,這些變化可以通過 sMRI 進行測量。文獻[20]已經證實,AD 與腦萎縮有密切關系,而腦萎縮主要反映在皮層表面積的縮小及皮質厚度降低和灰質體積減少上,因此,這一步的目的是根據大腦分區模板從 sMRI 影像提取出 ROI 圖像。
如圖 5 所示,分別為被試的左海馬區域(L.cHipp)、右海馬旁回區域(R.A28/34)、左杏仁核區域(L.mAmyg)等 ROI 圖像切片。具體做法:當經過預處理后的 sMRI 影像在大小和坐標空間與 Brainnetome Atlas[21]模板一致時,根據模板劃分腦區的掩碼(Mask)提取特定腦區的圖像作為本模型的輸入樣本。
圖5
ROI 圖像的切片示意圖
Figure5.
Slices of ROI images
2.3 實驗設置
本文利用 ADNI 數據庫中 787 名被試的 T1-Weight 的 sMRI 影像進行 AD 分類實驗。圖像處理過程如第 2.1 節所示,處理后 sMRI 影像大小為 91 × 109 × 91,圖像分辨率為 2 mm3。3DCNN 模型參數如表 4 所示。
訓練時,整個網絡的權重默認 Glorot 等[22]初始化的方法。Batch_size 為 4,Epochs 為 40,采用 Adam[23]梯度下降方法進行參數的更新,學習率為 0.001,Dropout 為 0.25,并且對參數進行了 L2 正則化來降低過擬合風險。另外,GA 種群數為 30,總共迭代 6 000 次,交叉概率設為 0.75,變異概率設為 0.05,f1 值作為適應度值。由于 GA 一般收斂速度慢,會因所有群體出現同一極值而導致停止進化,即早熟現象。又因為適應度值間差別小,故對種群適應度值選擇進行了放大操作。
|
|
公式(5)(6)中 fitvalue 表示當前迭代次數的所有種群各自適應度值,pi 則為各個種群被選擇的概率。測試時,把經預處理后的 sMRI 影像輸入到經 GA 篩選獲得的集成模型中,獲得最終的測試結果。實驗采用了 5 種分類性能指標進行評價(如 1.1 節所示)。
2.4 實驗方案
所有實驗均在同一個服務器上運行。服務器總共有 5 個節點,每個節點分別配置了 2 塊顯存為 16 GB、最大功耗為 250 W 的 NVIDIA 的 Tesla P100 GPU 顯卡。本文實現了以下模型:
(1)3DCNN,利用被試的全腦 sMRI 影像來訓練本文的 3DCNN 模型。
(2)3DCNN+Ensemble,先根據 2.2 節方法,利用 Brainnetome Atlas 模板從 sMRI 中提取出每個腦區的 ROI 圖像,總共 246 個腦區,然后,將每個腦區的 ROI 圖像用于訓練一個 3DCNN 模型,即得到 246 個 3DCNN 基分類器。接著,利用驗證集獲得每個基分類器的 f1 值,進行排序后,取出排名前 30 的 3DCNN 基分類器進行簡單投票集成。
(3)3DCNN+GA,先根據 2.2 節方法,利用 Brainnetome Atlas 模板從 sMRI 中提取出每個腦區的 ROI 圖像,總共 246 個腦區,然后,將每個腦區的 ROI 圖像用于訓練一個 3DCNN 模型,即得到 246 個 3DCNN 基分類器。最后根據 1.4 節,對排名前 30 的 ROI 基分類器進行編碼,適應值為 f1 值,再用 GA 在驗證集上篩選出最優 3DCNN 基分類器組合,最后對測試集中樣本進行簡單投票集成測試。
3 實驗結果
3.1 方法結果比較
在本文中,實驗使用 5 折分層交叉驗證策略來訓練和測試所提出方法,以減少隨機因素影響。然后采用驗證集數據(見表 3),并利用改進的 GA 算法,完成 3DCNN 基分類器的挑選,取在驗證集上的預測結果中最好的結果所對應的腦區組合作為最終集成模型。每種指標可得 5 次結果,取其平均值作為性能指標。所提方法在 AD vs. NC、MCIc vs. NC 和 MCIc vs. MCInc 的 5 種指標結果,即準確率、AUC、召回率、精度和 f1 值及其對應的標準差如表 5 所示。
為了和其他方法進行公平比較,選擇了實驗所用的訓練集和測試集數據與本文相同的文獻[8,14],并做了多組對比試驗。其他文獻雖使用了 ADNI 數據庫的數據,但具體挑選的數據集并不一樣,同時 MCI 的劃分也存在不同,因此,較難直接進行精確比較。于是,本文選擇了在不同樣本中分類效果比較好的文獻方法進行了大致比較。例如,有些實驗把 MCI 劃分為進展型 MCI(progressive MCI,pMCI)和穩定型 MCI(stable MCI,sMCI),這在某種程度上與本文的 MCIc 以及 MCInc 相對應。表 6 給出了各方法的實驗分類準確率和樣本數量。Yang 等[24]通過獨立主成分分析(independent components analysis,ICA)提取圖像特征,然后將提取到的特征用 SVM 進行訓練,最終實現 AD 的預測。文獻[25]把 Bagging 和 SVM 相結合實現 AD/NC 的分類。李書通等[26]提出了一種基于非監督學習的 3D-PCANet 方法,實現了 AD 輔助診斷。文獻[2]基于堆棧自編碼器對 AD 進行分類。文獻[10]通過提取圖像局部密度特征,并結合圖的示例學習技術完成了對 AD 的分類。
本方法的 3DCNN 網絡的參數量總共為 31 610 258,單個 ROI 模型訓練需要 0.78 h,大小為 361.83 MB,一個 ROI 基分類器的五折交叉驗證模型則耗費 3.9 h 左右,總共 246 個腦區,因此,完成一組分類實驗將花費 959.4 h,合計約 40 天,最終完成整個實驗訓練約需耗費 120 天左右。盡管從訓練周期來看,時間成本巨大,但從實驗結果來看,分類準確率顯著提高。此外,經 GA 算法挑選后,在驗證集上取得最高 f1 值的 ROI 腦區通過 BrainNet Viewer[27]進行三維可視化,如圖 6 所示。
圖6
GA 所篩選的腦區
Figure6.
Brain regions chosen with GA
3.2 行為域值統計結果
本實驗根據 Brainnetome Atlas 官網的各腦區行為域數據,對上述腦區統計出 AD vs. NC、MCIc vs. NC 和 MCIc vs. MCInc 各顯著腦區的相關行為域數據,然后分別分析出各組實驗中根據 GA 算法挑選的較顯著的腦區 ROI 區域主要影響哪些行為,每組實驗統計結果是取每個腦區行為域值最高的前三項(例如,R.mAmyg 腦區行為域域值最高的前三項分別為:Emotion.anger 域值為 5.02,Emotion.sadness 域值為 8.78,Emotion.disgust 域值為 7.87),然后對相同行為域對應的域值進行累加,最終得到如圖 7 所示的統計圖。
圖7
三組實驗中顯著腦區的行為域分布
Figure7.
The distribution of behavioral domains corresponding to discriminable brain regions in the three binary experiments
4 討論與總結
本文提出了基于腦區 ROI 的 3DCNN 和 GA 結合 AD 早期輔助診斷集成模型。模型中的每個基分類器是每個 ROI 圖像用 3DCNN 模型訓練出來的,然后對這些基分類器按 f1 值進行排序篩選,這比 Aderghal 等[28]使用先驗知識只選取海馬體的圖像訓練 CNN 模型更為合理。實驗所有 sMRI 影像均來自 ADNI 數據庫,在與文獻[8,14]使用的數據完全相同的情況下做了多組對比實驗,來檢驗模型的有效性。由表 5、表 6 實驗結果可知,本模型具有以下特點:
(1)僅對被試全腦影像進行訓練的前提下,單純 3DCNN 的 AD vs. NC 和 MCIc vs. NC 實驗準確率比文獻[8]的 PCA+SVM 以及文獻[14]的 2DCNN 均有提高,表明本文 3DCNN 模型在特征提取方面具有一定優勢。
(2)在提取 ROI 的前提下,3DCNN+Ensemble 和 3DCNN+GA 的實驗結果明顯高于單純使用全腦影像的方法和 2DCNN 方法,一方面說明對圖像提取 ROI 特征處理后,減少了其他無關特征的干擾,另一方面通過集成學習將挑選出的各個優秀基分類器集成起來共同對整個 MRI 的類別進行分類,使得最終的集成模型比單個全腦 CNN 基分類器具有更高的分類準確率和穩定性。
(3)集成模型 3DCNN+GA 比 3DCNN+Ensemble 和 2DCNN+Ensemble 效果更好,表明優化算法選出不同被試組中差異最大的 ROI 組合可以擺脫已有經驗的束縛,充分利用 sMRI 的空間信息,從而相比于文獻[14]簡單排序投票集成,GA 算法在特征組合上更具優勢,實驗結果也證明了這一點。在 3DCNN+GA 方法中,AD vs. NC 的準確率為 88.6%,f1 值為 88.3%,GA 篩選的關鍵腦區除了左延髓海馬、左尾部海馬和內外側杏仁核、左海馬旁回,還新發現了了右顳中回前顳上溝、右扣帶回背側 23 等區域;MCIc vs. NC 的準確率為 88.1%,f1 值為 86.5%,GA 篩選的腦區除了右延髓海馬、右尾部海馬和內外側杏仁核、左海馬旁回,還新發現了了左梭狀回延髓 20 等區域;MCIc vs. MCInc 的準確率為 71.3%,f1 值為 69.4%,GA 篩選的腦區為延髓海馬、內外側杏仁核、左梭狀回、右扣帶回背側 23 和楔前葉背內側枕壁溝等區域。
(4)此外,本文還對所有選出腦區的行為域值進行了分析,如圖 7 所示,發現這些分類特征顯著的腦區主要與情感、記憶、語言等功能相關,這與 AD 患者感情淡漠、失憶、喪失語言能力、喪失行動能力等臨床表現基本一致。這進一步印證了 GA 算法所選 ROI 腦區的正確性和有效性,也表明了本研究所得到的腦區與 AD 具有較強的關聯性。
當然,該方法也存在一定的局限性。例如,文獻[12]認為,所有患病人群腦功能發生異常不總是發生在相同的所選 ROI 腦區,因此,固定相同的腦區可能會導致丟失用以區分患者的關鍵信息。這不利于更好地區分患病人群。而且,選擇不同的腦區模板可能也會對分類結果有影響。另外,該模型在提高分類性能的同時,增加了訓練時長。但是,一方面本研究結果在提高了 AD 診斷率的同時,還為 AD 早期診斷有幫助的腦區的有效判定提供了新思路;另一方面,sMRI 影像對腦萎縮、腦血管疾病和腫瘤等疾病的結構變化尤為靈敏[29],因此,這種方式不只局限于 AD 的輔助診斷,還可用于腦血管疾病和腫瘤等其他大腦疾病。這些將是下一步研究的方向。
利益沖突聲明:本文全體作者均聲明不存在利益沖突。