為解決當前醫療設備維修難等問題,本研究提出一種基于長短時記憶網絡(LSTM)的醫療設備故障智能診斷方法。首先,在無電路圖紙、未知電路板信號走向情況下,采集 7 種不同故障類別的醫療設備電路板征兆現象及端口電信號兩種類別特征,并進行特征編碼、歸一化以及融合篩選等預處理;其次,基于 LSTM 搭建故障智能診斷模型,使用融合并篩選的多模態特征,進行故障診斷分類識別實驗,然后實驗結果與使用端口電信號、征兆現象及兩種類別特征融合等方式進行故障診斷識別對比;此外,與 BP 神經網絡(BPNN)、循環神經網絡(RNN)、卷積神經網絡(CNN)等算法進行故障診斷性能對比和評估。結果表明:基于融合并篩選的多模態特征,LSTM 算法模型的分類診斷準確率平均達到 0.970 9,較單獨利用端口電信號、征兆現象及兩種類別特征融合的故障診斷準確率更高;較 BPNN、RNN、CNN 等算法也具有更高的故障診斷準確率,為同類設備的故障智能診斷提供了一種相對可行的新思路。
引用本文: 劉香君, 郎朗, 張詩慧, 肖晶晶, 范莉萍, 馬建川, 種銀保. 基于長短時記憶網絡的醫療設備故障智能診斷研究. 生物醫學工程學雜志, 2021, 38(2): 361-368. doi: 10.7507/1001-5515.201912019 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
引言
醫療設備作為現代醫學的重要組成部分,是開展醫療活動的必要條件和重要支撐,一旦發生故障停機,輕則影響診療效率,重則威脅醫、患安全[1]。因此,如何快速修復故障,保障其可靠運行尤為重要。但現代醫療設備普遍電路設計復雜、技術資料缺乏、維修壟斷嚴重[2],臨床工程師面臨不敢修、不會修、不能修的困境[3]。因此,引入新的理論技術、方法策略來指導現代醫療設備故障診斷與維修具有重要現實意義。
近年來,智能故障診斷理論進入人們視角:基于圖論、基于專家系統等定性方法[4],基于模型、基于數據驅動等定量方法逐漸興起[5]。隨著人工智能快速發展和深度學習廣泛應用[6],基于數據驅動的機器學習方法在很多傳統診斷分類識別中取得顯著效果[7]。其中,深層神經網絡模型具有強大學習能力,能通過挖掘學習過往數據、經驗中的潛在特征[8],不斷提高訓練性能,已在電力[9]、列車[10]、航空[11]等領域的故障診斷分類取得一定進展。但多數神經網絡如卷積神經網絡(convolutional neural networks,CNN)等是基于目標的空間信息進行處理,在處理時序性特征時將數據視為獨立單元,無法充分利用其包含的序列及時間變化[12]。相比之下,長短時記憶網絡(long short term memory,LSTM)能夠捕獲數據序列變化及時間信息[13],并很好解決梯度消失和梯度爆炸問題[14],有效提高了故障診斷分類效果。在這方面,王維鋒等[15]提出一種基于 LSTM 的故障診斷方法,對齒輪故障進行診斷,準確率達到 0.997 6;de Bruin 等[16]在常用的測量信號基礎上,利用 LSTM 來完成鐵路線路故障的及時檢測和識別,識別率高達 0.997 0,驗證了其在故障診斷方面的有效性。受上述研究啟發,考慮到醫療設備故障診斷分類與上述領域存在一定相通性,本文基于 LSTM 算法來進行醫療設備故障智能診斷研究。
1 數據獲取
1.1 研究對象
研究對象為急慢性軟組織損傷治療儀(YDB-Ⅲ,河南天盛光電,中國)(以下簡稱“治療儀”),其豐富的功能實現,主要依托于設備內部的控制中樞——主控板來實現,如圖 1 所示。
 圖1
治療儀主控板
Figure1.
The main control board of therapeutic instrument
圖1
治療儀主控板
Figure1.
The main control board of therapeutic instrument
通過收集或人為設置方法,遴選 30 臺具有 6 種常見故障類別(外加 1 種正常狀態)的該型設備,并對其故障元器件類別進行標簽化處理,如表 1 所示。
本研究在不介入主控板內部的前提下,結合各故障類別對應的征兆現象,連續采集其 7 個外接端口共 45 個可及引腳電信號,并基于征兆現象及端口電信號進行故障智能診斷。具體地,在治療儀同一工作條件,即處方設置為 3、強度設置為 100 時,搜集記錄 7 種故障類別分別對應的征兆現象,并設定采集頻率 3 000 Hz[17],采集時間 1 s,采集 7 種故障類別下端口電信號。為保證數據量充足,克服單板數據的偶然性,在相同外設工作條件下,共采集 30 塊主控板數據。
1.2 征兆現象數據
治療儀在正常工作時的直觀征兆現象包括面板是否有顯示、按鍵是否正常、輸出波形形狀(需借助示波器)等現象特征。其中“顯示”狀態分有顯示、無顯示,包括:① 刺激導入、② TDP 磁振、③ 電源、④ 處方顯示、⑤ 強度顯示、⑥ 定時顯示等 6 個顯示位置;“按鍵”狀態分按鍵有效、按鍵無效,包括:① 復位、② 急性、③ 電源、④ TDP 磁振、⑤ 處方選擇、⑥ 定時、⑦ 強度、⑧ 觸發等 8 個按鍵位置;“輸出波形”借助示波器顯示,包括:① 密疏波、② 斷續波、③ 疏-斷續波、④ 無刺激輸出等 4 種輸出。在主控板上某元器件發生故障時,會有所變化,分別記錄各故障類別下的征兆現象,建立相應數據庫。
針對征兆現象描述性特征,借鑒自然語言處理中對詞進行獨熱編碼[18]的操作,將每個征兆現象所對應描述性特征進行編碼,形成征兆現象特征集。具體地,6 個“顯示”位置的 2 種狀態,8 個“按鍵”位置的 2 種狀態,1 個“輸出波形”的 4 個類別征兆現象共編碼形成 32 維的特征向量(標記為“X1”~“X32”),各故障類別某時刻的征兆現象編碼結果如表 2 所示。
1.3 端口電信號數據
端口電信號數據采集基于程序開發環境 LabVIEW 2018(NI Inc.,美國),使用數據采集卡 NI USB-6216(NI Inc.,美國)進行,45 個引腳信號依次標記為 V0~V44,詳細數據表示如表 3 所示。
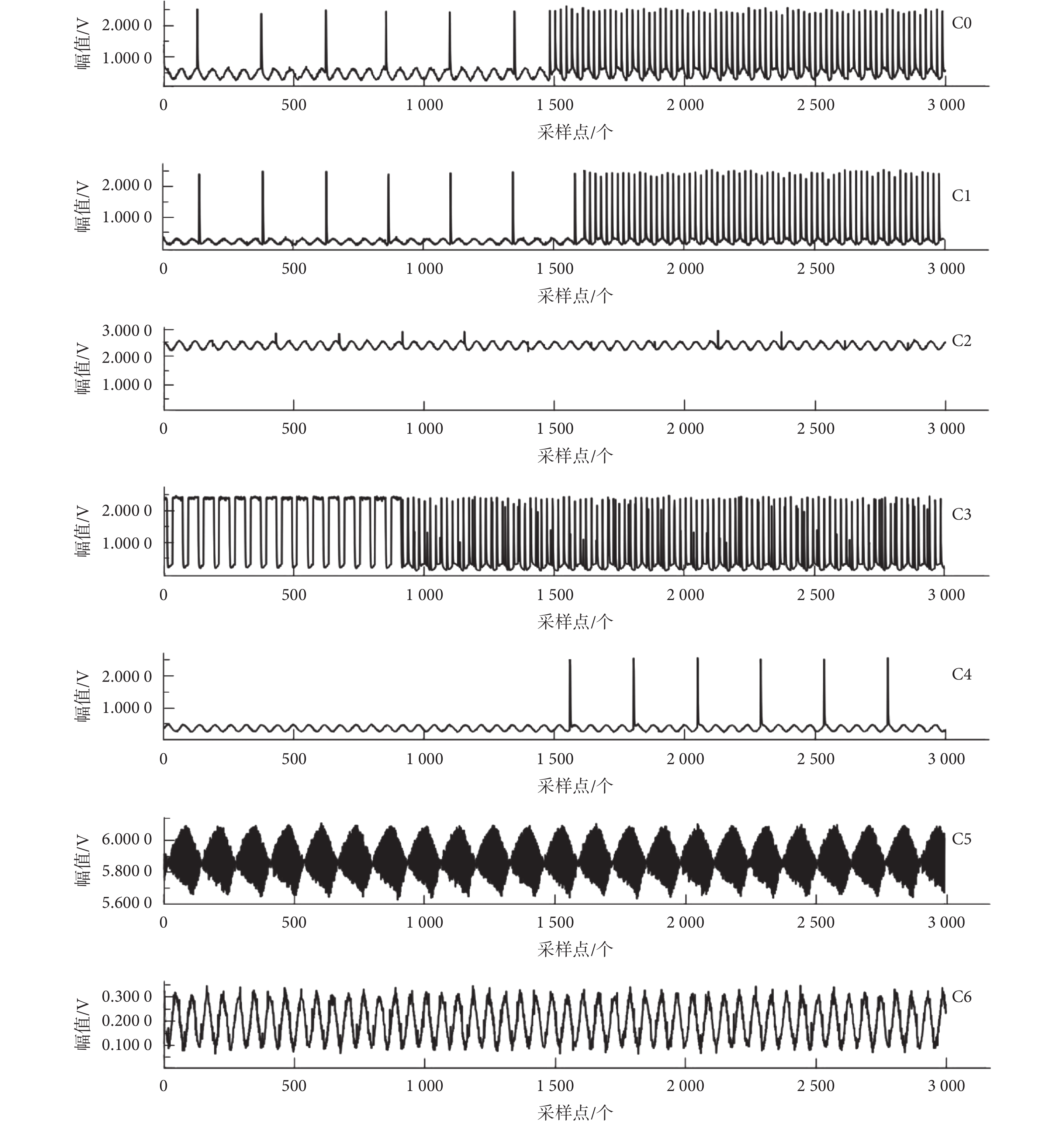
以“V32”為例,“C0~C6”7 種故障類別下端口電信號波形如圖 2 所示。
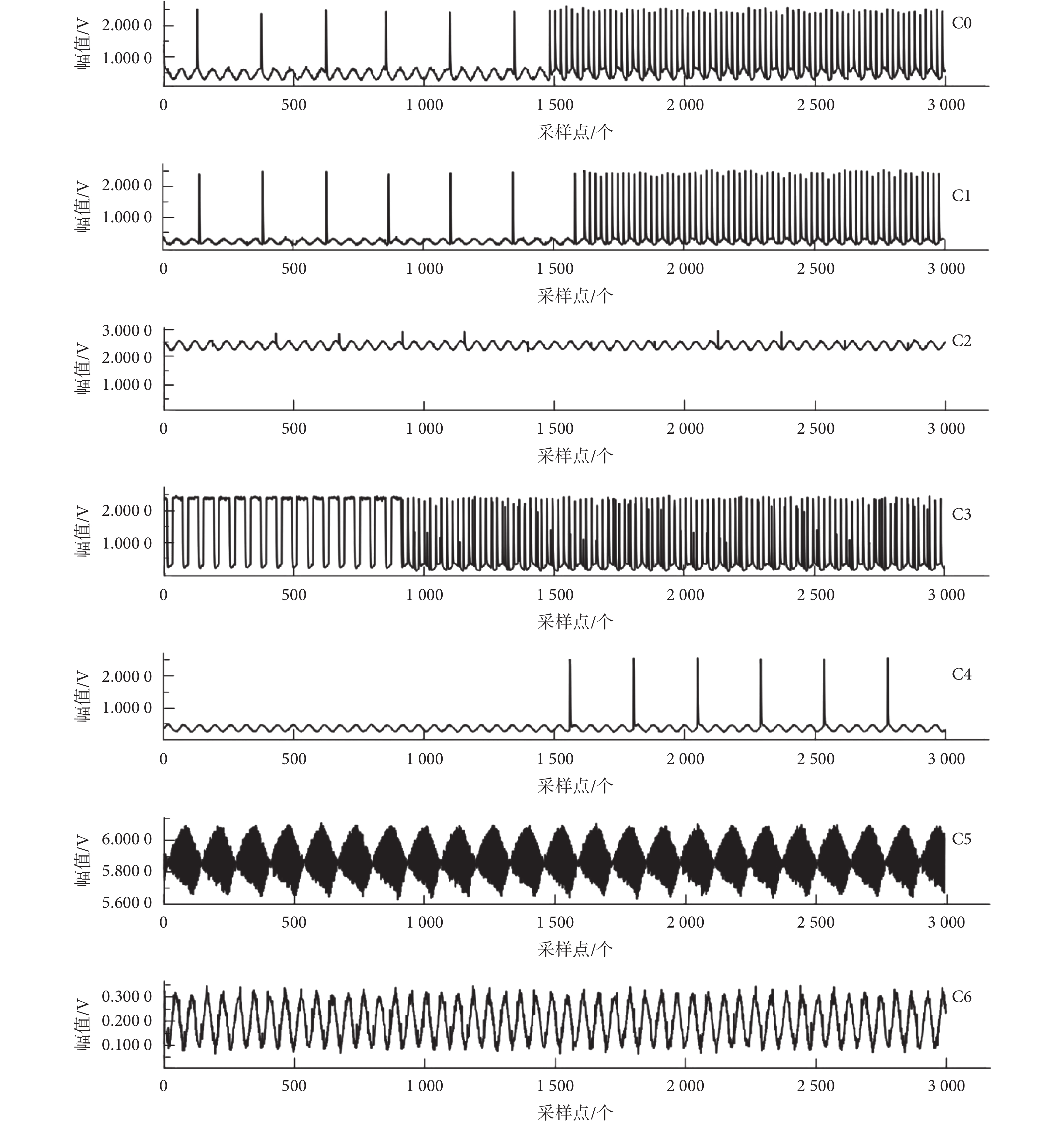 圖2
主控板七種故障類別下端口電信號“V32”示例
Figure2.
Port electrical signal of “V32” at seven different categories of fault
圖2
主控板七種故障類別下端口電信號“V32”示例
Figure2.
Port electrical signal of “V32” at seven different categories of fault
同樣的,因 45 個引腳電信號幅值各不相同,差異較大,直接使用原始數據進行網絡訓練,會突出幅值較高信號的作用,相反的削弱幅值較低信號的作用,使用線性歸一化方法[19]分別對各通道信號數據進行標準化預處理,將其統一處理至[0,1]范圍內,形成電信號特征集。
1.4 特征融合及篩選
經編碼的征兆現象特征與經歸一化預處理的端口電信號特征通過拼接融合,形成融合特征集。
融合后的樣本數據集特征維數高達 77,高度冗余。因此,使用基于支持向量機的遞歸特征消除法(support vector machine-recursive feature elimination,SVM-RFE)來進行特征篩選,使特征數量達到一個理想值[20],從而達到降低特征維度目的,進而提高訓練效果。使用 SVM-RFE 方法篩選出不同數量的特征數(20、30、40、50、60、70、77),通過固定學習率、隱層神經元數目、模型訓練次數等參數,依次將其輸入初始設定網絡,觀察記錄模型經過一個訓練周期的訓練時間、準確率等,5 次實驗結果如表 4 所示。
 )
Table4.
Comparison of training time and classification accuracy under different number of features (
)
Table4.
Comparison of training time and classification accuracy under different number of features ( )
)
同時結合特征數量越少越好的原則,得出:當選取權重最大的 40 個維度特征(包括 22 個端口電信號特征、18 個征兆現象編碼特征)作為系統輸入時,模型診斷效果最好。所篩選出的 40 維特征信號組成的特征集為:
 |
2 基于 LSTM 的故障診斷模型
2.1 模型建立
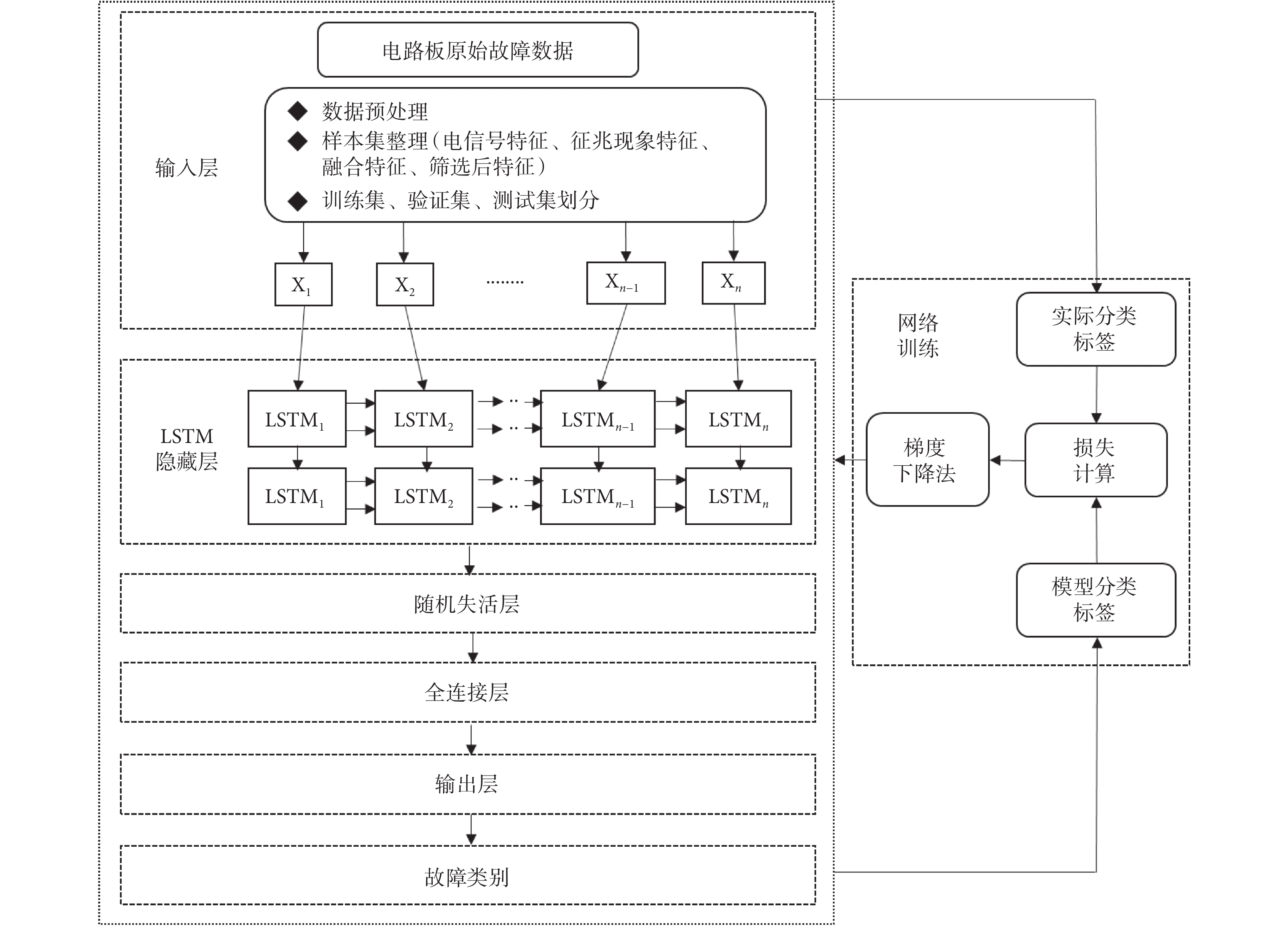
LSTM 獨特的門結構使其能夠捕獲數據序列變化及時間信息,不僅考慮當前時刻的輸入,而且賦予網絡對之前內容的記憶功能[21]。針對本文的多通道序列電信號數據,LSTM 可以處理同一時刻、多通道數據特征,并結合該時刻前后一段時間各個通道的數據特征,比提取特征空間信息的網絡優勢更加突出[22]。因此,本文利用研究對象端口電信號以及征兆現象多模態特征,基于 LSTM 網絡來搭建故障智能診斷模型。網絡模型整體框架如圖 3 所示,其中 X1,X2, ,Xn ? 1,Xn 表示 n 維的數據特征。
,Xn ? 1,Xn 表示 n 維的數據特征。
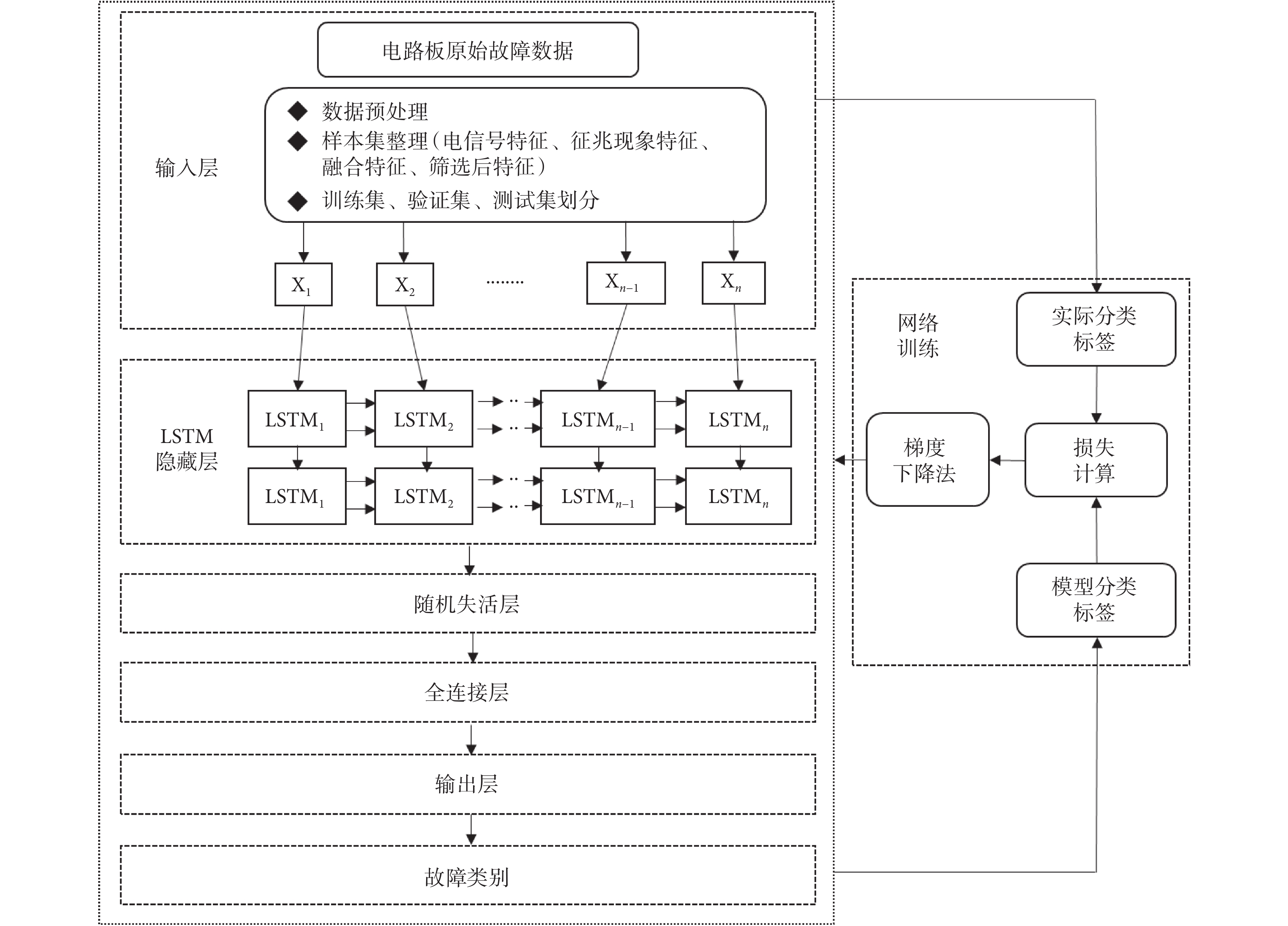 圖3
基于 LSTM 的治療儀主控板故障診斷模型框架
Figure3.
Fault diagnosis model of therapeutic instrument’s main board based on LSTM
圖3
基于 LSTM 的治療儀主控板故障診斷模型框架
Figure3.
Fault diagnosis model of therapeutic instrument’s main board based on LSTM
神經網絡模型基本結構框架包括輸入層、隱藏層、輸出層。本文在此基礎上做了相應擴充和改進:輸入層方面,為經預處理后的樣本特征集;隱藏層方面,采取兩層 LSTM 隱藏層的設計,兼顧模型訓練效果和效率;引入隨機失活層(Dropout)進行處理,在訓練過程中將隱藏層的某些神經元按一定概率隨機刪除,使得全連接網絡具有一定稀疏化,從而增強泛化能力,提高網絡收斂速度[23];輸出向量進入全連接層(Dense)進行全連接,將每一個結點與上一層所有結點相連接,實現特征的非線性組合;鑒于本文的多分類屬性(7 個類別),輸出層選用多分類器(Softmax),輸出一個與預定義類別維數相等的向量[24],得到分類識別結果,即預測值。再將此結果傳入網絡優化模塊,調節性能參數,不斷優化網絡模型,使模型分類效果達到最優[25]。
本文選擇的目標函數為交叉熵損失函數,其刻畫的是模型實際輸出概率與理論輸出概率分布的距離和差異,值越小,表示兩概率分布差異越小,分類結果越好[26]。交叉熵損失函數可表示為式(1)所示:
 '/> '/> |
其中,yi 表示期望輸出的概率分布, 表示模型當前實際輸出的概率分布,L 表示交叉熵損失函數,也即目標函數。模型的參數反向輸入,通過梯度下降優化算法對其進行更新和調整、反饋調節,從而實現模型優化。
表示模型當前實際輸出的概率分布,L 表示交叉熵損失函數,也即目標函數。模型的參數反向輸入,通過梯度下降優化算法對其進行更新和調整、反饋調節,從而實現模型優化。
2.2 模型評價
本文除使用準確率(accuracy,Acc)(以符號 Acc 表示)來評價模型分類性能以外,還采用查準率(precision,P)(以符號 P 表示)、查全率(recall,R)(以符號 R 表示)、F1 分數(F1-score,F1)(以符號 F1 表示)、接收者操作特征曲線下面積(area under curve,AUC)(以符號 AUC 表示)、混淆矩陣等來對診斷效果進行輔助評價。其中準確率表示模型預測正確的樣本數占樣本總數的比例,各指標具體定義公式如式(2)~式(5)所示:
 |
 |
 |
 |
其中,真陽性(true positive,TP)(以符號 TP 表示)表示預測為正,實際也是正的樣本數;假陽性(false positive,FP)(以符號 FP 表示)表示預測為正,實際是負的樣本數;真陰性(true negative,TN)(以符號 TN 表示)表示預測為負,實際也是負的樣本數;假陰性(false negative,FN)(以符號 FN 表示)表示預測為負,實際是正的樣本數[27]。
3 實驗與分析
本文基于機器學習平臺 Tensorflow(Google Inc.,美國),采用計算機編程語言 Python3.6.8 構建網絡模型。計算機環境為:中央處理器(central processing unit,CPU)(Xeon(R)E5-2640 v4 @ 2.4GHz @ 3.4 GHz,Intel,美國)。
3.1 模型訓練參數設置
將融合并篩選的特征集以每 300 個連續采集點劃分為一個樣本,實驗所采集的 30 組共 630 000 個數據點共劃分為 2 100 個樣本。樣本亂序后進行訓練集、驗證集和測試集劃分,比例為 4∶1∶1,樣本量分別為 1 400 個、350 個和 350 個。為獲得良好的網絡模型訓練效果,在文獻調研基礎上,結合反復多次性能分析與參數調試的實驗結果,本文算法模型主要訓練參數設置情況如表 5 所示[16, 21, 28]。
同時,模型引入早停機制(early stopping)[29]來適時終止模型的訓練,以提高其泛化能力。
3.2 實驗結果與分析
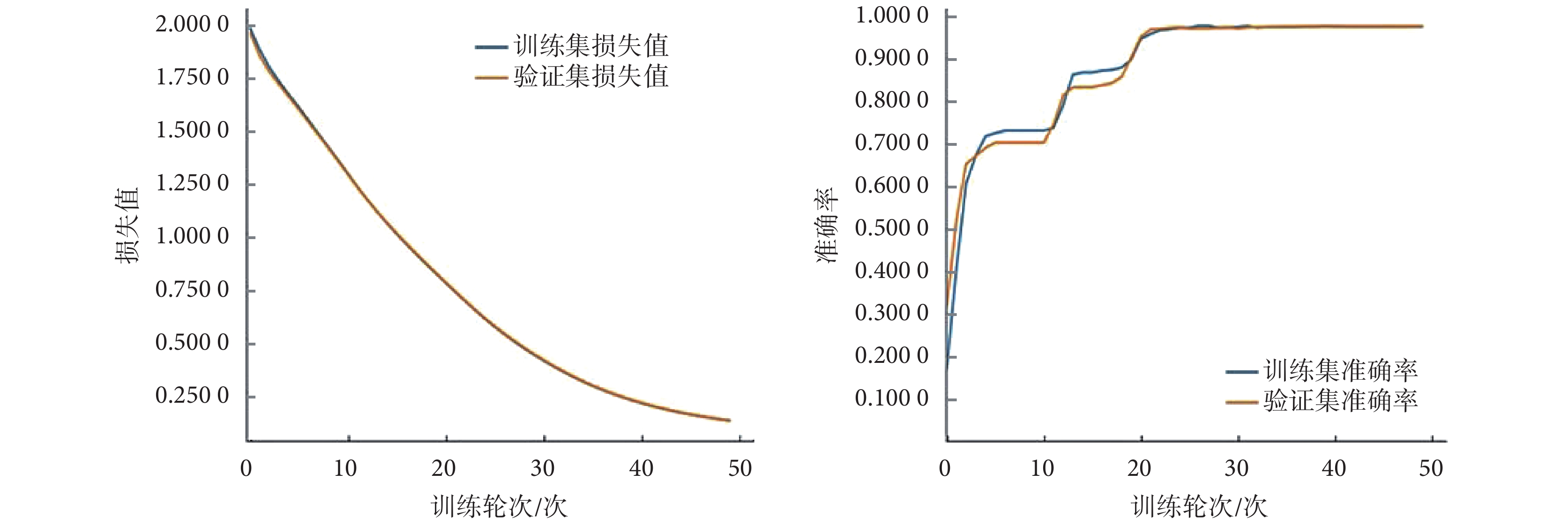
模型訓練過程的損失值及準確率隨訓練次數的變化情況如圖 4 所示。
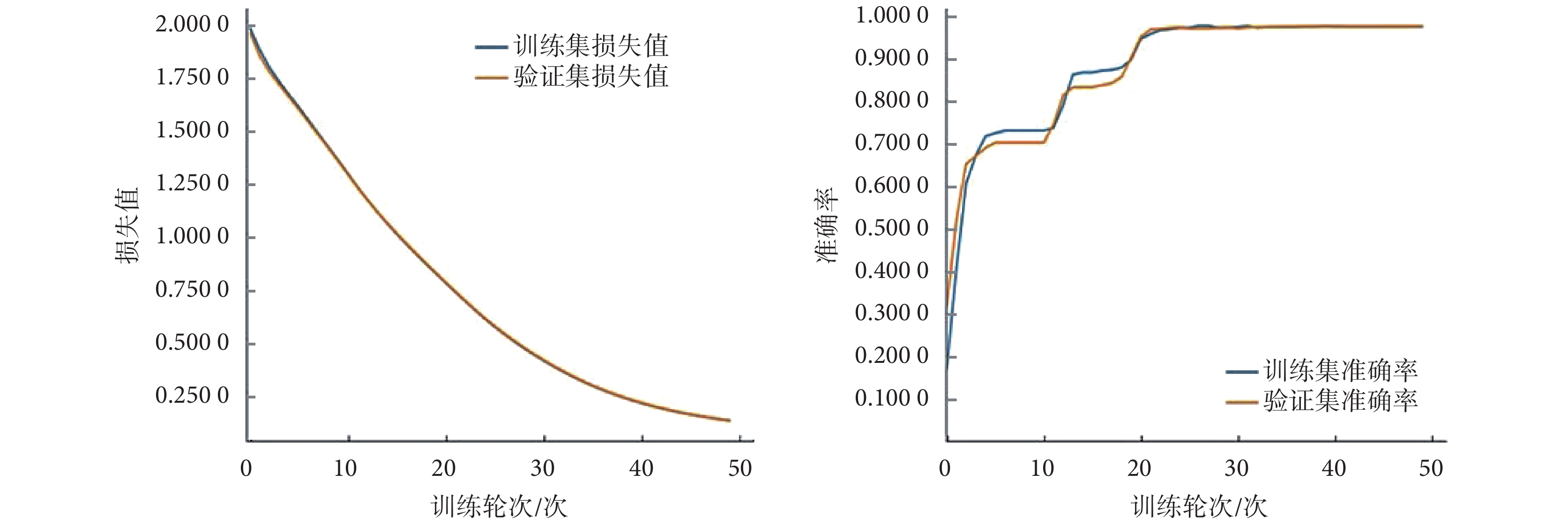 圖4
分類損失值及準確率變化曲線
Figure4.
Loss and accuracy on training and validation data
圖4
分類損失值及準確率變化曲線
Figure4.
Loss and accuracy on training and validation data
由圖 4 可以看出,經過不到 50 次訓練,模型達到相對穩定。該模型對測試集分類診斷結果混淆矩陣如表 6 所示,7 類故障診斷具體結果如表 7 所示。
由表 6、表 7 可知,使用融合并篩選的多模態特征,基于 LSTM 模型對測試集的故障診斷分類查準率為 0.971 7、查全率為 0.970 9、F1 分數為 0.970 4、接收者操作特征曲線下面積為 0.994 3。為驗證多特征融合并篩選方法在故障診斷中的有效性,本文分別基于端口電信號、征兆現象、兩種類別特征融合、融合并篩選等四種基礎特征,在同一測試條件、不改變參數情況下,進行 5 次重復實驗,結果如表 8 所示。
 )
Table8.
Comparison of accuracy on different features (
)
Table8.
Comparison of accuracy on different features ( )
)
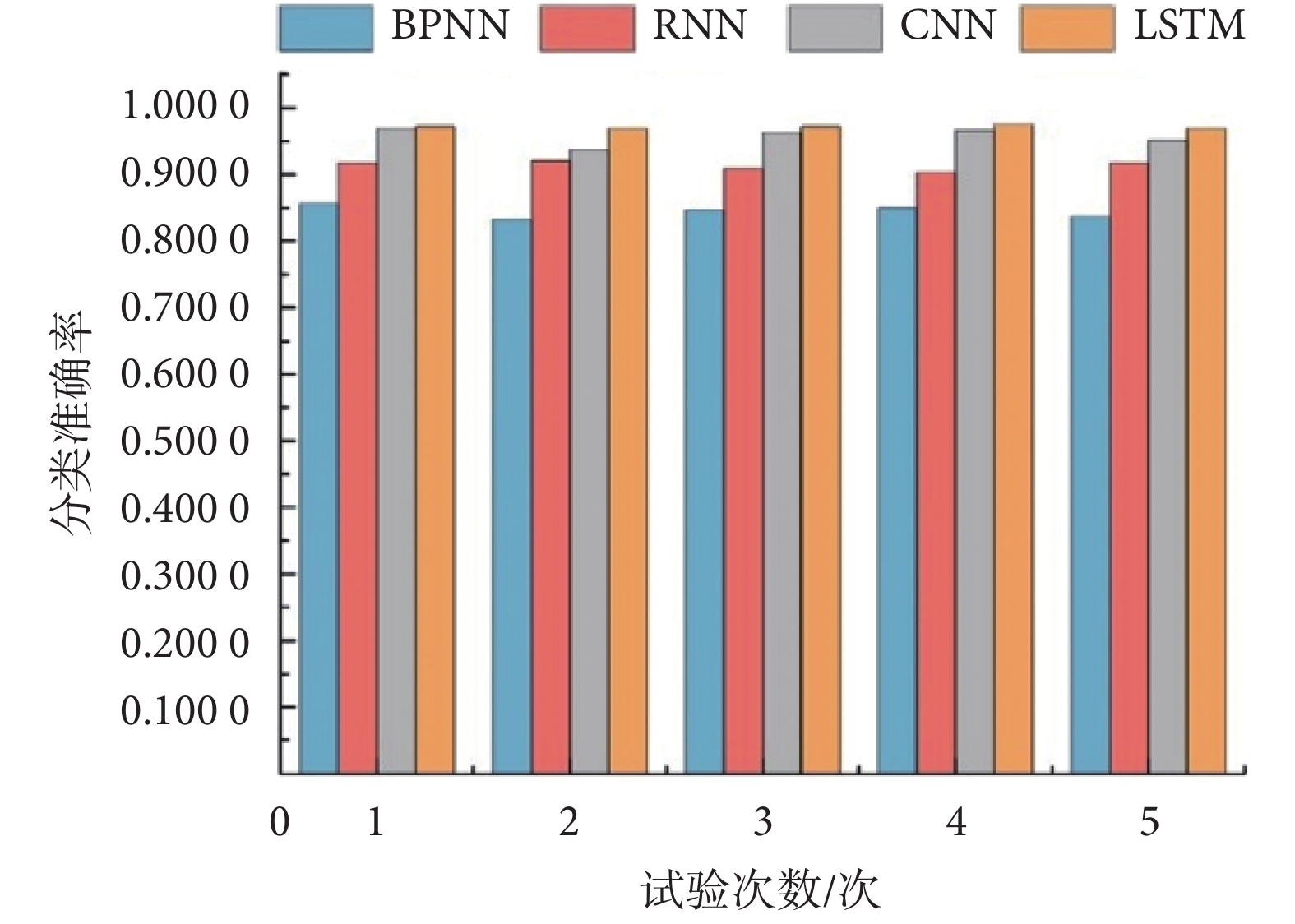
為對比本文算法與當前主流的故障智能診斷方法的優劣,本文基于融合并篩選特征,將其與 BP 神經網絡(back propagation neural network,BPNN)、循環神經網絡(recurrent neural network,RNN)、CNN 等算法進行了對比實驗。三種方法參數設置分別為:① BPNN:采用 2 層隱藏層結構,各隱層神經元個數分別為 40、20,學習率設定為 0.001;② RNN:采取與本文方法類似的網絡模型結構,包含 2 個隱藏層,各隱層神經元個數分別為 40、20,1 個池化層及 1 個全連接層,激活函數采用修正線性單元(rectified linear unit,ReLU),學習率設定為 0.001;③ CNN:同樣的,包含 2 個隱藏層,各隱層神經元個數分別為 40、20,1 個池化層及 1 個全連接層,激活函數采用 ReLU 函數,學習率設定為 0.001;5 次實驗結果如圖 5 所示。
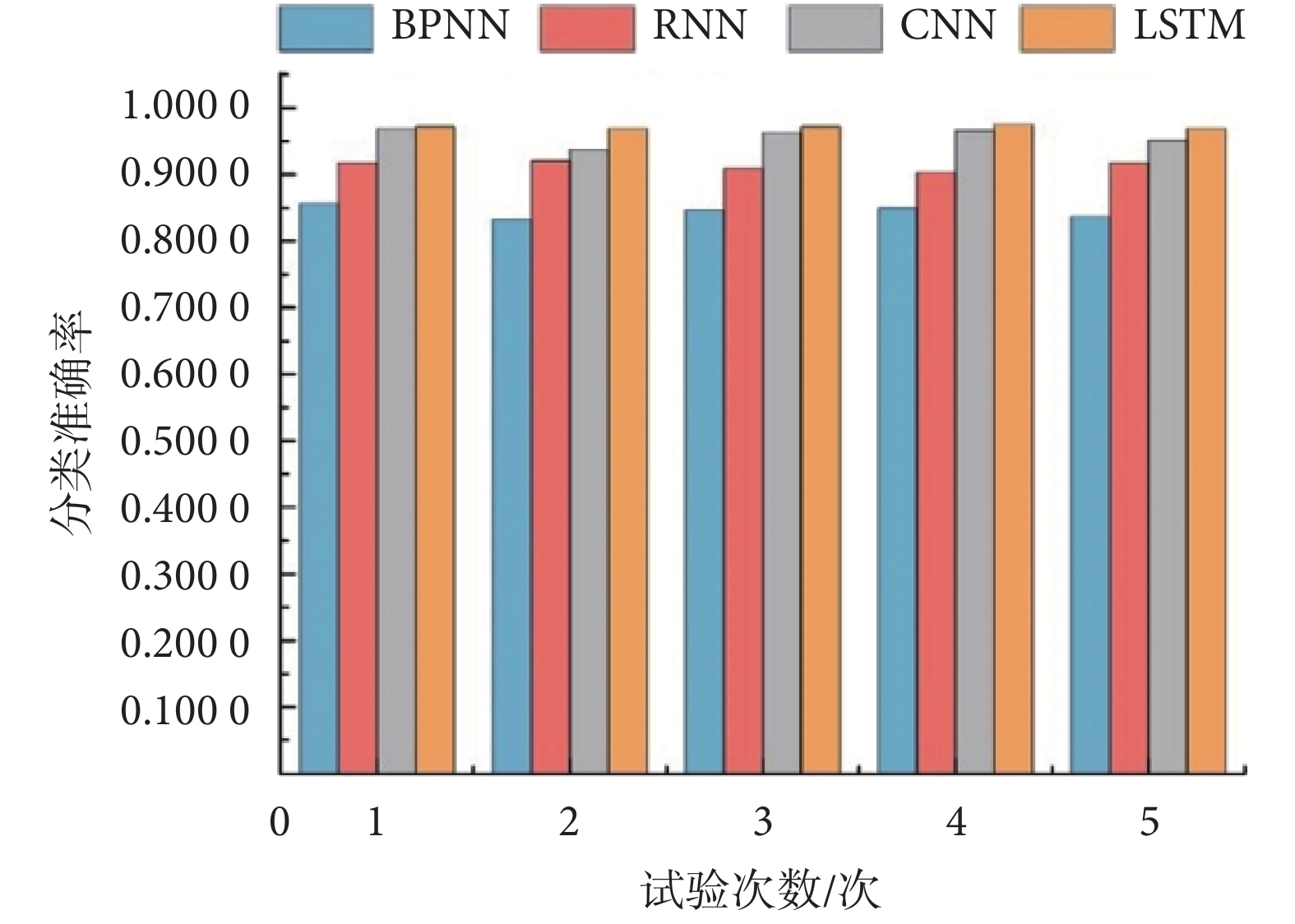 圖5
不同算法診斷準確率對比
Figure5.
Comparison of accuracy of different methods
圖5
不同算法診斷準確率對比
Figure5.
Comparison of accuracy of different methods
由表 8 可知:基于融合并篩選的特征,使用 LSTM 算法模型對治療儀主控板進行故障診斷分類,模型診斷準確率平均達到 0.970 9,比單獨使用端口電信號特征、征兆現象特征及融合特征平均分別高出 0.084 1、0.249 8、0.059 4;由圖 5 可知:基于融合并篩選特征,使用 LSTM 算法模型對治療儀主控板進行故障診斷分類,準確率平均達到 0.970 9,比 BPNN、RNN、CNN 平均分別高出 0.125 7、0.047 1、0.005 7,驗證了本文設計的 LSTM 算法模型在治療儀主控板常規故障的智能診斷方面的有效性。
4 結論
本文立足于傳統維修技術與方法難以適應現代維修的現狀,在未知電路圖紙、未知電路板信號走向情況下獲取醫療設備電路板不同故障類別下端口時序性電信號及對應征兆現象,經過特征預處理、多模態融合、特征篩選并整理劃分數據特征集,通過構建 LSTM 算法模型并訓練、預測,探索對故障進行智能診斷分類的新方法。
本文通過對模型的評估以及試驗分析對比,結果證明了 LSTM 在具有時序性問題上優越的處理能力,可達到更好的診斷分類效果,有效提高故障診斷準確率,平均達到 0.970 9。以上分析表明,本文研究結果可為醫療設備電路板故障診斷與維修提供新的思路。下一步,將引入更多故障類別,或根據情況設定復合故障,增大數據來源,進一步訓練和改善網絡模型,提高其分類識別準確率及泛化能力,同時結合實際需要,開發在線智能故障診斷系統,實現故障的實時在線診斷,并將該方法遷移應用到其他醫療設備,提高其魯棒性及適用范圍。
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
引言
醫療設備作為現代醫學的重要組成部分,是開展醫療活動的必要條件和重要支撐,一旦發生故障停機,輕則影響診療效率,重則威脅醫、患安全[1]。因此,如何快速修復故障,保障其可靠運行尤為重要。但現代醫療設備普遍電路設計復雜、技術資料缺乏、維修壟斷嚴重[2],臨床工程師面臨不敢修、不會修、不能修的困境[3]。因此,引入新的理論技術、方法策略來指導現代醫療設備故障診斷與維修具有重要現實意義。
近年來,智能故障診斷理論進入人們視角:基于圖論、基于專家系統等定性方法[4],基于模型、基于數據驅動等定量方法逐漸興起[5]。隨著人工智能快速發展和深度學習廣泛應用[6],基于數據驅動的機器學習方法在很多傳統診斷分類識別中取得顯著效果[7]。其中,深層神經網絡模型具有強大學習能力,能通過挖掘學習過往數據、經驗中的潛在特征[8],不斷提高訓練性能,已在電力[9]、列車[10]、航空[11]等領域的故障診斷分類取得一定進展。但多數神經網絡如卷積神經網絡(convolutional neural networks,CNN)等是基于目標的空間信息進行處理,在處理時序性特征時將數據視為獨立單元,無法充分利用其包含的序列及時間變化[12]。相比之下,長短時記憶網絡(long short term memory,LSTM)能夠捕獲數據序列變化及時間信息[13],并很好解決梯度消失和梯度爆炸問題[14],有效提高了故障診斷分類效果。在這方面,王維鋒等[15]提出一種基于 LSTM 的故障診斷方法,對齒輪故障進行診斷,準確率達到 0.997 6;de Bruin 等[16]在常用的測量信號基礎上,利用 LSTM 來完成鐵路線路故障的及時檢測和識別,識別率高達 0.997 0,驗證了其在故障診斷方面的有效性。受上述研究啟發,考慮到醫療設備故障診斷分類與上述領域存在一定相通性,本文基于 LSTM 算法來進行醫療設備故障智能診斷研究。
1 數據獲取
1.1 研究對象
研究對象為急慢性軟組織損傷治療儀(YDB-Ⅲ,河南天盛光電,中國)(以下簡稱“治療儀”),其豐富的功能實現,主要依托于設備內部的控制中樞——主控板來實現,如圖 1 所示。
圖1
治療儀主控板
Figure1.
The main control board of therapeutic instrument
通過收集或人為設置方法,遴選 30 臺具有 6 種常見故障類別(外加 1 種正常狀態)的該型設備,并對其故障元器件類別進行標簽化處理,如表 1 所示。
本研究在不介入主控板內部的前提下,結合各故障類別對應的征兆現象,連續采集其 7 個外接端口共 45 個可及引腳電信號,并基于征兆現象及端口電信號進行故障智能診斷。具體地,在治療儀同一工作條件,即處方設置為 3、強度設置為 100 時,搜集記錄 7 種故障類別分別對應的征兆現象,并設定采集頻率 3 000 Hz[17],采集時間 1 s,采集 7 種故障類別下端口電信號。為保證數據量充足,克服單板數據的偶然性,在相同外設工作條件下,共采集 30 塊主控板數據。
1.2 征兆現象數據
治療儀在正常工作時的直觀征兆現象包括面板是否有顯示、按鍵是否正常、輸出波形形狀(需借助示波器)等現象特征。其中“顯示”狀態分有顯示、無顯示,包括:① 刺激導入、② TDP 磁振、③ 電源、④ 處方顯示、⑤ 強度顯示、⑥ 定時顯示等 6 個顯示位置;“按鍵”狀態分按鍵有效、按鍵無效,包括:① 復位、② 急性、③ 電源、④ TDP 磁振、⑤ 處方選擇、⑥ 定時、⑦ 強度、⑧ 觸發等 8 個按鍵位置;“輸出波形”借助示波器顯示,包括:① 密疏波、② 斷續波、③ 疏-斷續波、④ 無刺激輸出等 4 種輸出。在主控板上某元器件發生故障時,會有所變化,分別記錄各故障類別下的征兆現象,建立相應數據庫。
針對征兆現象描述性特征,借鑒自然語言處理中對詞進行獨熱編碼[18]的操作,將每個征兆現象所對應描述性特征進行編碼,形成征兆現象特征集。具體地,6 個“顯示”位置的 2 種狀態,8 個“按鍵”位置的 2 種狀態,1 個“輸出波形”的 4 個類別征兆現象共編碼形成 32 維的特征向量(標記為“X1”~“X32”),各故障類別某時刻的征兆現象編碼結果如表 2 所示。
1.3 端口電信號數據
端口電信號數據采集基于程序開發環境 LabVIEW 2018(NI Inc.,美國),使用數據采集卡 NI USB-6216(NI Inc.,美國)進行,45 個引腳信號依次標記為 V0~V44,詳細數據表示如表 3 所示。
以“V32”為例,“C0~C6”7 種故障類別下端口電信號波形如圖 2 所示。
圖2
主控板七種故障類別下端口電信號“V32”示例
Figure2.
Port electrical signal of “V32” at seven different categories of fault
同樣的,因 45 個引腳電信號幅值各不相同,差異較大,直接使用原始數據進行網絡訓練,會突出幅值較高信號的作用,相反的削弱幅值較低信號的作用,使用線性歸一化方法[19]分別對各通道信號數據進行標準化預處理,將其統一處理至[0,1]范圍內,形成電信號特征集。
1.4 特征融合及篩選
經編碼的征兆現象特征與經歸一化預處理的端口電信號特征通過拼接融合,形成融合特征集。
融合后的樣本數據集特征維數高達 77,高度冗余。因此,使用基于支持向量機的遞歸特征消除法(support vector machine-recursive feature elimination,SVM-RFE)來進行特征篩選,使特征數量達到一個理想值[20],從而達到降低特征維度目的,進而提高訓練效果。使用 SVM-RFE 方法篩選出不同數量的特征數(20、30、40、50、60、70、77),通過固定學習率、隱層神經元數目、模型訓練次數等參數,依次將其輸入初始設定網絡,觀察記錄模型經過一個訓練周期的訓練時間、準確率等,5 次實驗結果如表 4 所示。
)
Table4.
Comparison of training time and classification accuracy under different number of features ()
同時結合特征數量越少越好的原則,得出:當選取權重最大的 40 個維度特征(包括 22 個端口電信號特征、18 個征兆現象編碼特征)作為系統輸入時,模型診斷效果最好。所篩選出的 40 維特征信號組成的特征集為:
|
2 基于 LSTM 的故障診斷模型
2.1 模型建立
LSTM 獨特的門結構使其能夠捕獲數據序列變化及時間信息,不僅考慮當前時刻的輸入,而且賦予網絡對之前內容的記憶功能[21]。針對本文的多通道序列電信號數據,LSTM 可以處理同一時刻、多通道數據特征,并結合該時刻前后一段時間各個通道的數據特征,比提取特征空間信息的網絡優勢更加突出[22]。因此,本文利用研究對象端口電信號以及征兆現象多模態特征,基于 LSTM 網絡來搭建故障智能診斷模型。網絡模型整體框架如圖 3 所示,其中 X1,X2,,Xn ? 1,Xn 表示 n 維的數據特征。
圖3
基于 LSTM 的治療儀主控板故障診斷模型框架
Figure3.
Fault diagnosis model of therapeutic instrument’s main board based on LSTM
神經網絡模型基本結構框架包括輸入層、隱藏層、輸出層。本文在此基礎上做了相應擴充和改進:輸入層方面,為經預處理后的樣本特征集;隱藏層方面,采取兩層 LSTM 隱藏層的設計,兼顧模型訓練效果和效率;引入隨機失活層(Dropout)進行處理,在訓練過程中將隱藏層的某些神經元按一定概率隨機刪除,使得全連接網絡具有一定稀疏化,從而增強泛化能力,提高網絡收斂速度[23];輸出向量進入全連接層(Dense)進行全連接,將每一個結點與上一層所有結點相連接,實現特征的非線性組合;鑒于本文的多分類屬性(7 個類別),輸出層選用多分類器(Softmax),輸出一個與預定義類別維數相等的向量[24],得到分類識別結果,即預測值。再將此結果傳入網絡優化模塊,調節性能參數,不斷優化網絡模型,使模型分類效果達到最優[25]。
本文選擇的目標函數為交叉熵損失函數,其刻畫的是模型實際輸出概率與理論輸出概率分布的距離和差異,值越小,表示兩概率分布差異越小,分類結果越好[26]。交叉熵損失函數可表示為式(1)所示:
| '/> |
其中,yi 表示期望輸出的概率分布,表示模型當前實際輸出的概率分布,L 表示交叉熵損失函數,也即目標函數。模型的參數反向輸入,通過梯度下降優化算法對其進行更新和調整、反饋調節,從而實現模型優化。
2.2 模型評價
本文除使用準確率(accuracy,Acc)(以符號 Acc 表示)來評價模型分類性能以外,還采用查準率(precision,P)(以符號 P 表示)、查全率(recall,R)(以符號 R 表示)、F1 分數(F1-score,F1)(以符號 F1 表示)、接收者操作特征曲線下面積(area under curve,AUC)(以符號 AUC 表示)、混淆矩陣等來對診斷效果進行輔助評價。其中準確率表示模型預測正確的樣本數占樣本總數的比例,各指標具體定義公式如式(2)~式(5)所示:
|
|
|
|
其中,真陽性(true positive,TP)(以符號 TP 表示)表示預測為正,實際也是正的樣本數;假陽性(false positive,FP)(以符號 FP 表示)表示預測為正,實際是負的樣本數;真陰性(true negative,TN)(以符號 TN 表示)表示預測為負,實際也是負的樣本數;假陰性(false negative,FN)(以符號 FN 表示)表示預測為負,實際是正的樣本數[27]。
3 實驗與分析
本文基于機器學習平臺 Tensorflow(Google Inc.,美國),采用計算機編程語言 Python3.6.8 構建網絡模型。計算機環境為:中央處理器(central processing unit,CPU)(Xeon(R)E5-2640 v4 @ 2.4GHz @ 3.4 GHz,Intel,美國)。
3.1 模型訓練參數設置
將融合并篩選的特征集以每 300 個連續采集點劃分為一個樣本,實驗所采集的 30 組共 630 000 個數據點共劃分為 2 100 個樣本。樣本亂序后進行訓練集、驗證集和測試集劃分,比例為 4∶1∶1,樣本量分別為 1 400 個、350 個和 350 個。為獲得良好的網絡模型訓練效果,在文獻調研基礎上,結合反復多次性能分析與參數調試的實驗結果,本文算法模型主要訓練參數設置情況如表 5 所示[16, 21, 28]。
同時,模型引入早停機制(early stopping)[29]來適時終止模型的訓練,以提高其泛化能力。
3.2 實驗結果與分析
模型訓練過程的損失值及準確率隨訓練次數的變化情況如圖 4 所示。
圖4
分類損失值及準確率變化曲線
Figure4.
Loss and accuracy on training and validation data
由圖 4 可以看出,經過不到 50 次訓練,模型達到相對穩定。該模型對測試集分類診斷結果混淆矩陣如表 6 所示,7 類故障診斷具體結果如表 7 所示。
由表 6、表 7 可知,使用融合并篩選的多模態特征,基于 LSTM 模型對測試集的故障診斷分類查準率為 0.971 7、查全率為 0.970 9、F1 分數為 0.970 4、接收者操作特征曲線下面積為 0.994 3。為驗證多特征融合并篩選方法在故障診斷中的有效性,本文分別基于端口電信號、征兆現象、兩種類別特征融合、融合并篩選等四種基礎特征,在同一測試條件、不改變參數情況下,進行 5 次重復實驗,結果如表 8 所示。
)
Table8.
Comparison of accuracy on different features ()
為對比本文算法與當前主流的故障智能診斷方法的優劣,本文基于融合并篩選特征,將其與 BP 神經網絡(back propagation neural network,BPNN)、循環神經網絡(recurrent neural network,RNN)、CNN 等算法進行了對比實驗。三種方法參數設置分別為:① BPNN:采用 2 層隱藏層結構,各隱層神經元個數分別為 40、20,學習率設定為 0.001;② RNN:采取與本文方法類似的網絡模型結構,包含 2 個隱藏層,各隱層神經元個數分別為 40、20,1 個池化層及 1 個全連接層,激活函數采用修正線性單元(rectified linear unit,ReLU),學習率設定為 0.001;③ CNN:同樣的,包含 2 個隱藏層,各隱層神經元個數分別為 40、20,1 個池化層及 1 個全連接層,激活函數采用 ReLU 函數,學習率設定為 0.001;5 次實驗結果如圖 5 所示。
圖5
不同算法診斷準確率對比
Figure5.
Comparison of accuracy of different methods
由表 8 可知:基于融合并篩選的特征,使用 LSTM 算法模型對治療儀主控板進行故障診斷分類,模型診斷準確率平均達到 0.970 9,比單獨使用端口電信號特征、征兆現象特征及融合特征平均分別高出 0.084 1、0.249 8、0.059 4;由圖 5 可知:基于融合并篩選特征,使用 LSTM 算法模型對治療儀主控板進行故障診斷分類,準確率平均達到 0.970 9,比 BPNN、RNN、CNN 平均分別高出 0.125 7、0.047 1、0.005 7,驗證了本文設計的 LSTM 算法模型在治療儀主控板常規故障的智能診斷方面的有效性。
4 結論
本文立足于傳統維修技術與方法難以適應現代維修的現狀,在未知電路圖紙、未知電路板信號走向情況下獲取醫療設備電路板不同故障類別下端口時序性電信號及對應征兆現象,經過特征預處理、多模態融合、特征篩選并整理劃分數據特征集,通過構建 LSTM 算法模型并訓練、預測,探索對故障進行智能診斷分類的新方法。
本文通過對模型的評估以及試驗分析對比,結果證明了 LSTM 在具有時序性問題上優越的處理能力,可達到更好的診斷分類效果,有效提高故障診斷準確率,平均達到 0.970 9。以上分析表明,本文研究結果可為醫療設備電路板故障診斷與維修提供新的思路。下一步,將引入更多故障類別,或根據情況設定復合故障,增大數據來源,進一步訓練和改善網絡模型,提高其分類識別準確率及泛化能力,同時結合實際需要,開發在線智能故障診斷系統,實現故障的實時在線診斷,并將該方法遷移應用到其他醫療設備,提高其魯棒性及適用范圍。
利益沖突聲明:本文全體作者均聲明不存在利益沖突。