肝臟計算機斷層掃描成像(CT)的三維(3D)肝臟和腫瘤分割對于輔助醫生的診斷及預后具有非常重要的臨床價值。為了準確快速地分割肝臟及腫瘤區域,本文提出了一種基于條件生成對抗網絡(cGAN)的腫瘤 3D 條件生成對抗分割網絡(T3scGAN),同時采用了一個由粗到細的 3D 自動分割框架對肝臟及腫瘤區域實施精準分割。本文采用 2017 年肝臟和腫瘤分割挑戰賽(LiTS)公開數據集中的 130 個病例進行訓練、驗證和測試 T3scGAN 模型。最終 3D 肝臟區域分割的驗證集和測試集的平均戴斯(Dice)系數分別為 0.963 和 0.961,而 3D 腫瘤區域分割的驗證集和測試集的平均 Dice 系數分別為 0.819 和 0.796。實驗結果表明,提出的 T3scGAN 模型能夠有效地分割 3D 肝臟及其腫瘤區域,因此能夠更好地輔助醫生進行肝臟腫瘤的精準診斷和治療。
引用本文: 張澤林, 李寶明, 徐軍. 基于條件生成對抗網絡的三維肝臟及腫瘤區域自動分割. 生物醫學工程學雜志, 2021, 38(1): 80-88. doi: 10.7507/1001-5515.201912077 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
引言
肝臟是承擔人體代謝功能的重要器官,肝臟一旦出現惡性腫瘤病變將會嚴重威脅人體生命健康。計算機斷層掃描成像(computed tomography,CT)是目前在肝臟病變診斷中普遍采用的常規診斷方式。CT 圖像可以反映出肝臟腫瘤的形態、數目、部位、邊界等信息,因此基于 CT 影像技術對肝臟腫瘤區域實施有效的分割具有重要的臨床價值。但是由于 CT 圖像中肝臟與周邊臟器的灰度值非常接近,且不同患者個體差異大等原因,導致肝臟與肝臟腫瘤的三維(three dimensional,3D)分割非常困難。傳統的肝臟分割方法,有利用形狀先驗、灰度分布以及邊界和區域信息來描述肝臟特征并劃定其邊界的統計變形模型,也有基于紋理和灰度等級的方法。這些分割方法的效率很低,魯棒性比較差,而且需要根據經驗調節大量的參數。例如,Stawiaski 等[1]使用最小曲面和馬爾科夫隨機場對肝臟腫瘤進行分割。Smeets 等[2]提出了一種基于水平集的半自動分割方法,并使用該方法對 CT 影像中的肝臟腫瘤及肝臟轉移區域進行分割。Li 等[3]提出了一種新的統一水平集模型,該模型通過整合圖像的梯度、圖像的區域競爭及先驗信息對 CT 圖像中的肝臟腫瘤進行分割。Li 等[4]提出了一種水平集模型,該模型將似然能量和邊緣能量結合在一起對 CT 圖像中的肝臟腫瘤區域進行分割。Zhang 等[5]提出了一種交互式的半自動分割方法來分割 CT 圖像中的肝臟及腫瘤區域,該方法首先對輸入的 CT 圖像進行預處理,粗略地分割出肝臟區域,然后在肝臟腫瘤區域設置一些種子點,最后用這些種子點位置的灰度值訓練一個支持向量機(support vector machine,SVM)[6],并用一些形態學的后處理方式對 SVM 的分類結果粗略地勾畫出肝臟腫瘤區域的邊界。近年來,隨著深度學習技術的發展,研究人員開發了一系列基于深度學習的分割算法來分割肝臟及腫瘤區域。例如,Li[7]提出了一種卷積分類網絡模型,該模型對二維(two dimensional,2D)CT 圖像中 17 × 17 大小的圖像塊進行逐塊預測,判斷該圖像塊究竟為病變區域還是其他區域,最終可以分割出肝臟腫瘤。Li 等[8]提出了一種混合密集連接 U 型網絡(hybrid densely connected Unet,H-DenseUNet)分割模型,該模型先對肝臟 2D CT 圖像中的肝臟及腫瘤區域進行分割,然后將學習到的 2D 圖像高維特征用一個 3D 的卷積網絡進行融合,最終得到肝臟和腫瘤的 3D 分割結果。Bi 等[9]提出了一種基于卷積殘差網絡(residual network,Resnet)[10]的多尺度模型,該模型可以在多個尺度上對 CT 圖像中的肝臟腫瘤進行識別,從而提高了識別的精度。Gruber 等[11]比較研究了兩種肝臟腫瘤分割方案,第一種是直接采用了 1 個 2D U 型網絡(Unet)[12]對肝臟腫瘤進行端到端分割;第二種方案則使用了 2 個 2D Unet,其中第一個 Unet 用于分割肝臟區域,然后把分割的肝臟感興趣區域(region of interest,ROI)乘以輸入 CT 圖像提取肝臟區域,之后用提取的肝臟區域圖像又訓練了一個 2D Unet 對肝臟腫瘤進行 2D 分割。通過對比發現,級聯的分割網絡可以達到更好的肝臟腫瘤分割性能。Dey 等[13]設計了一種級聯的肝臟腫瘤分割模型,該模型先用一個 2D 深度卷積分割網絡分割出肝臟及較大的腫瘤區域,然后再用一個 3D 深度卷積分割網絡檢測分割出小腫瘤區域,從而提高了 CT 圖像中肝臟腫瘤的分割準確率。Deng 等[14]先用 1 個 3D 密集連接卷積分類網絡檢測肝臟腫瘤的邊緣,然后用 3D 密集連接卷積分類網絡輸出的腫瘤邊緣概率動態調節水平集分割參數,同時根據分類網絡檢測的腫瘤區域位置初始化水平集腫瘤分割局部窗口的大小,最后分割出肝臟腫瘤;Lu 等[15]先構建了 1 個 3D 卷積網絡對肝臟區域進行分割并輸出概率圖,然后基于概率圖用圖切法得到最終的肝臟分割結果。
與傳統的肝臟腫瘤分割方法相比,基于深度學習的分割方法在分割效率和準確率上都有很大提升,但是也普遍存在以下幾個問題:① 直接進行 3D 分割的模型計算量太大,因此大部分 3D 分割模型都是基于將 2D 分割結果拼接成 3D 的分割結果。基于 2D 分割結果再拼接成 3D 分割結果的分割方法雖然可以減少模型的運算量,但是分割的結果卻不如直接以 3D 分割模型進行分割的結果。因為 2D 分割模型的優化目標是 ROI 邊界曲線,而 3D 分割模型可以優化 ROI 的整個曲面;② 需要大量的預處理和后處理操作。在肝臟腫瘤的 2D 切面中,由于肝臟腫瘤的大小、位置、紋理等信息在不同的病例中差異較大,如果使用端到端的網絡很難直接定位到腫瘤區域;③ 需要很多標記數據進行模型的訓練。因為腫瘤的分割檢測比較困難,提升模型的性能就需要增加模型的復雜度和可訓練參數量,如果訓練集的數量過少就會導致模型分割性能不足或者過擬合。
本文基于條件對抗生成網絡(conditional generative adversarial networks,cGAN)[16]構建了一個新型的腫瘤 3D 分割條件對抗生成網絡(tumor 3D segmentation conditional generative adversarial networks,T3scGAN)作為主要的分割模型對 3D 肝臟區域和 3D 肝臟腫瘤區域進行分割,同時使用了一個由粗到細的 3D 分割框架來精確地分割肝臟腫瘤,從而輔助醫生實現對肝臟病變及肝臟腫瘤的快速定位與識別,達到精準診療的目的。
1 由粗到細的肝臟腫瘤分割框架
在 CT 影像中,肝臟腫瘤的全自動精準分割對分割算法具有較大的挑戰性,主要原因是不同病例的肝臟腫瘤之間位置、形態和紋理特征差異性很大。因此,本文采用了一個由粗到細的 3D 分割框架來精確分割肝臟腫瘤。分割框架流程圖如圖 1 所示,當輸入一個 3D 的 CT 測試病例時,整個分割框架首先進行自動數據預處理,然后用訓練好的肝臟分割 T3scGAN 模型對肝臟區域進行自動 3D 分割,得到肝臟區域 3D 分割結果。之后基于肝臟分割的結果結合預處理后的 CT 圖像進行自動肝臟 3D ROI 提取,最后用訓練好的肝臟腫瘤分割 T3scGAN 模型對肝臟腫瘤區域進行自動 3D 分割。
 圖1
由粗到細的肝臟腫瘤 3D 分割框架
Figure1.
3D coarse-to-fine liver tumors segmentation framework
圖1
由粗到細的肝臟腫瘤 3D 分割框架
Figure1.
3D coarse-to-fine liver tumors segmentation framework
1.1 數據預處理
在訓練和測試過程中,本文首先將原始 CT 影像的窗寬設置為 300,窗位設置為 100。之后重新采樣到 256 × 256 × 128 大小,再將重采樣的數據歸一化至 0~1 區間作為網絡的輸入。
1.2 T3scGAN
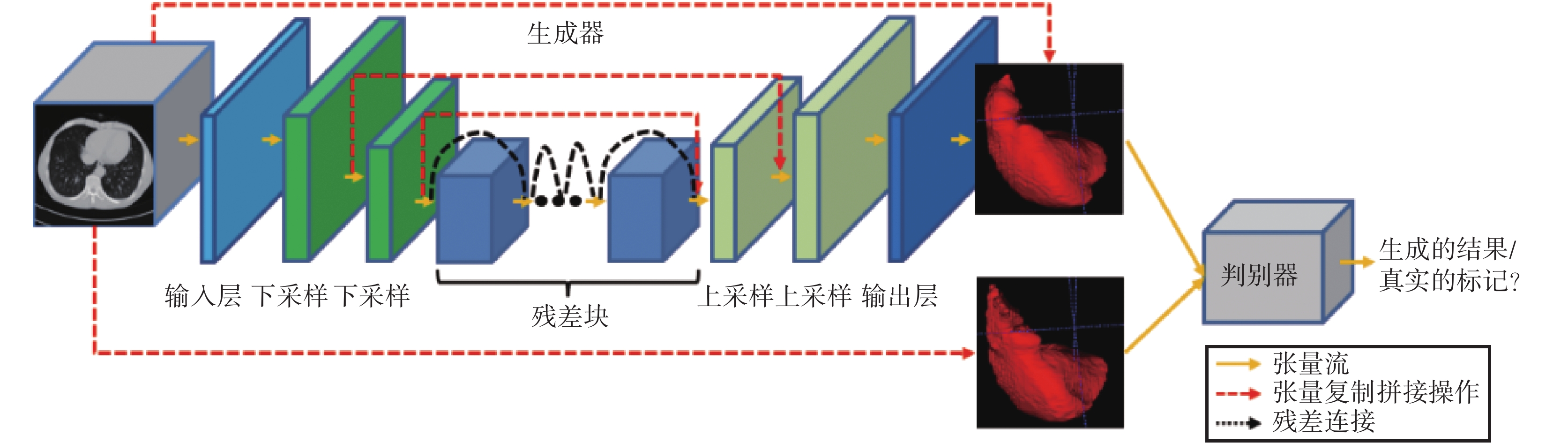
傳統的 3D 分割模型都有一個預定義的損失函數作為優化目標來訓練網絡,因此損失函數的選擇對網絡的性能影響較大。cGAN 提供了可訓練的損失函數機制[17]。像素點到像素點(pixel to pixel,pix2pix)的圖像翻譯模型[18]首次應用這種機制完美地解決了圖像翻譯問題。受 cGAN 和 pix2pix 模型的啟發,本文構建了一種新型的 3D 條件對抗網絡模型(T3scGAN)來分割肝臟及腫瘤區域,模型結構如圖 2 所示。
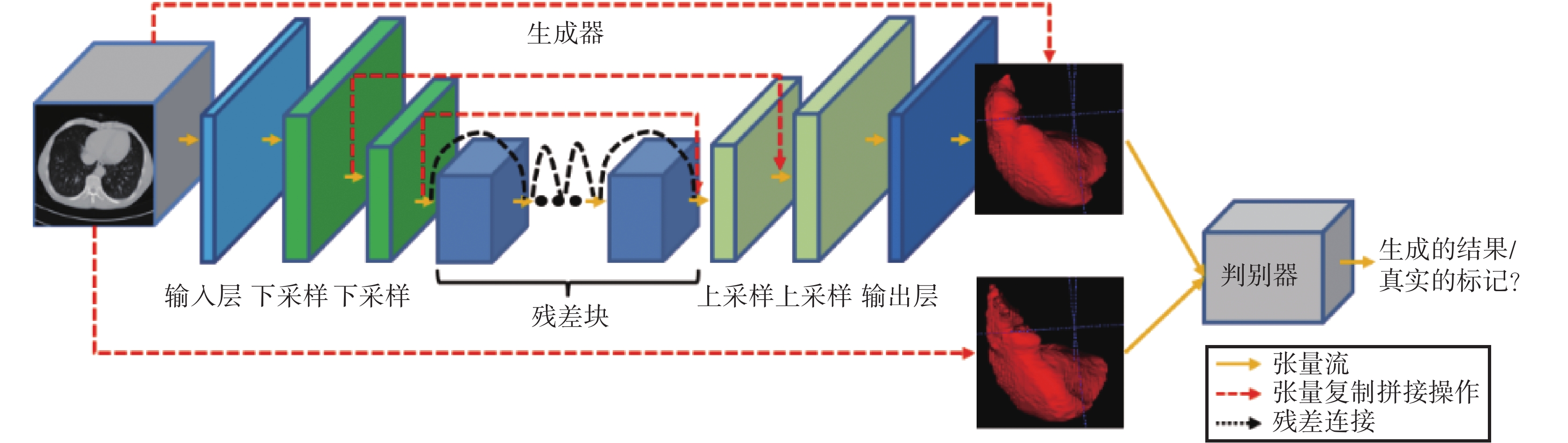 圖2
T3scGAN 模型結構
Figure2.
T3scGAN model structure
圖2
T3scGAN 模型結構
Figure2.
T3scGAN model structure
T3scGAN 包含 1 個生成器網絡和 1 個判別器網絡。生成器網絡是一個端到端的 3D 分割結構,判別器網絡是一個多層的分類模型。
1.2.1 生成器結構
在醫學圖像分割任務中,Unet 是目前非常流行的深度框架。Unet 受到全卷積神經網絡(fully convolutional networks,FCN)模型[19]的啟發,將多個尺度下提取的深度特征進行了融合,但不同于 FCN 直接拼接融合的方式,Unet 采用了相同尺度的編碼器和解碼器結構,將編碼器不同尺度下的深度特征和相同尺度的解碼器特征相融合,這樣就可以將原始圖像的細節信息盡可能地保留下來,同時 Unet 在編碼器部分采用了最大池化的方法,使得快速下采樣的同時又能夠保證分割的精度。3D Unet 模型[20]是基于 Unet 的 3D 分割版本模型。
受 3D Unet 結構的啟發,T3scGAN 生成器中也使用了一系列的跳躍式連接,從而可以使得一些細節部分得以保留。生成器中對特征的下采樣和上采樣均使用卷積和轉置卷積操作,這樣可以更加平滑地融合各個部分的細節信息。但是在 Unet 中直接將編碼器部分的低維特征拼接到解碼器部分的高維特征進行操作會導致語義代溝[21]。為了緩解這個問題,本文采用了特征深度融合的方式來使得低維形態特征和高維語義特征之間盡可能相似。
Resnet 模型提供了一種非常有效的特征深度融合方式,其最大的特點是將輸入的特征圖和輸出的特征圖相加作為最終的輸出。對于一個殘差塊的輸入 x 和輸出 y 之間的映射關系如式(1)所示:
 |
其中 F 表示整個殘差塊的映射,x 和 Wx 代表輸入和對應輸入的卷積操作, 表示殘差塊中的激活函數。為了方便反向傳播求梯度,一般
表示殘差塊中的激活函數。為了方便反向傳播求梯度,一般  為線性整流單元(rectified linear unit,ReLU)函數。ReLU 函數的表達式如式(2)所示:
為線性整流單元(rectified linear unit,ReLU)函數。ReLU 函數的表達式如式(2)所示:
 |
ReLU 激活函數僅保留輸入特征中大于 0 的部分,并且直接將大于 0 的部分輸出,所以在反向傳播求梯度的過程中,該激活函數對大于 0 的輸入 x 的偏導數恒等于 1,因此使用 ReLU 激活函數可以加快網絡的訓練。
在 Wx 操作中一般會用一個標準化層來對卷積的輸出進行標準化。標準化層的作用非常大,它會將網絡的輸出一直保持在相同的分布區間,避免梯度消失,同時正則化網絡,提高網絡的泛化能力。在卷積操作之后常用的標準化方式為批量標準化(batch normalization,BN)[22],該標準化方式的表達式如式(3)所示:
 |
其中,z 代表 3D 卷積層(3D convolutional layer,Conv3d)輸出的特征張量 B × C × H × W × D,B 表示批量樣本的數量,C 表示特征張量的通道數,H × W × D 指的是特征張量中的 3D 特征矩陣。但是受限于計算機圖形處理器(graphics processing unit,GPU)的顯存大小,批量樣本的數量只能設置很小,這對于 BN 的方式非常不利,所以本文采用了組標準化(group normalization,GN)[23]的方式來替代 BN。GN 和 BN 的主要區別是 GN 首先將特征張量的通道分為許多組,然后對每一組做歸一化。即,將特征張量矩陣的維度由[B,C,H,W,D]改變為[B,C,G,C/G,H,W,D],然后歸一化的維度(求均值和方差的維度)為[C/G,H,W,D]。
因此在加入 Resnet 連接的反向傳播中,如果對公式(1)求  的偏導數可以得到如式(4)所示:
的偏導數可以得到如式(4)所示:
 |
所以當網絡很深的時候,dF/dx 有可能變為 0,此時 df/dx 恒等于 1,對于整個網絡的前向傳播仍然有效。所以 T3scGAN 在編碼器和解碼器之間采用了 3D 殘差結構來過渡,即將原始的殘差塊結構中的操作由 2D 全部替換成了 3D,這樣既保證了編碼器輸出的深度特征充分融合,并且通過增加網絡可訓練參數來增加網絡的魯棒性,而且也可以避免梯度消失的問題。
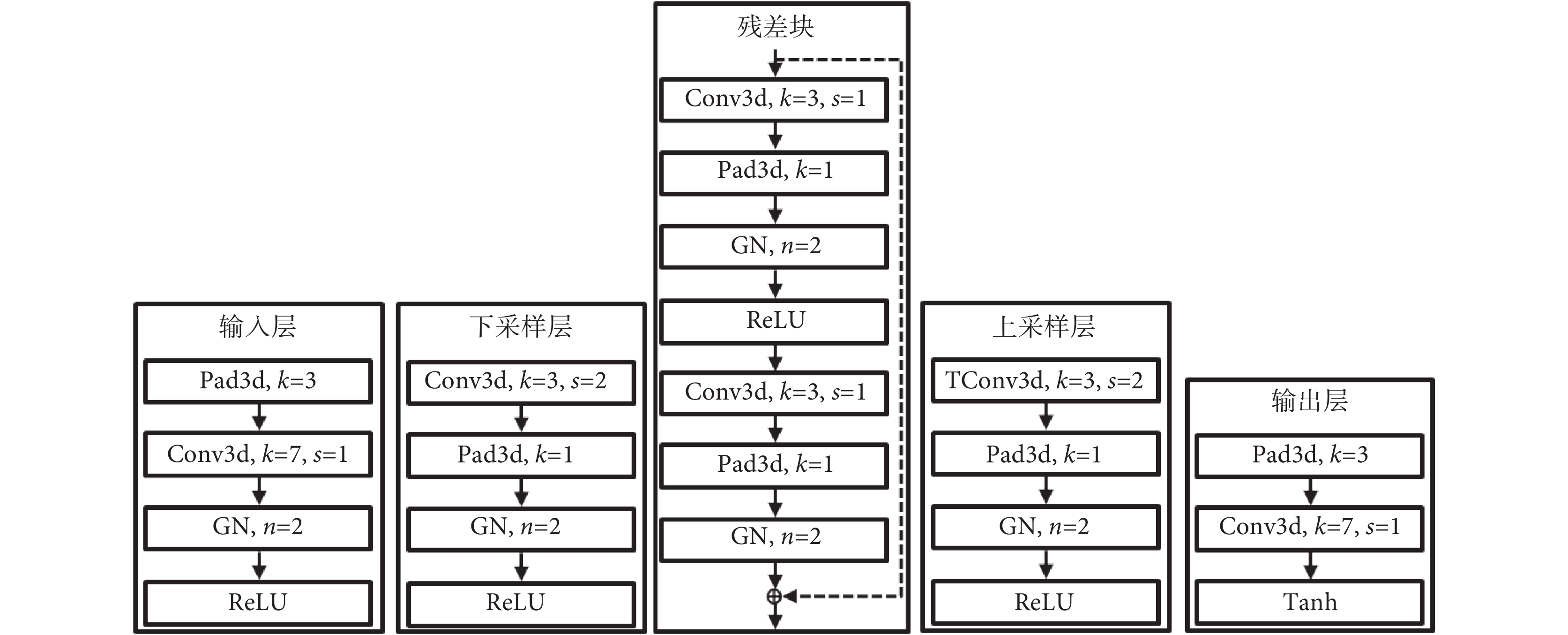
T3scGAN 只采用了 2 個尺度下的特征融合,這樣做的目的是在保證 3D 分割準確率的條件下,盡可能地減少網絡參數和網絡計算量,同時避免了下采樣尺度過多而導致對尺寸小的腫瘤區域造成不可恢復的細節損失,從而保留更多的細節信息在相等大小輸入輸出的殘差連接中深度融合。在生成器的編碼部分,從左到右相鄰兩個尺度的特征圖譜之間的尺寸為正 2 倍的關系,濾波器數量為負 2 倍的關系。對應的在生成器的解碼部分,從左到右相鄰兩個尺度的特征圖譜之間的尺寸為負 2 倍的關系,濾波器數量為正 2 倍的關系。在輸入層中 T3scGAN 采用了一組卷積操作將輸入 CT 映射至特征,同時將原始數據的單通道快速增加為多通道。并且采用了卷積核大小為 7 × 7 × 7,卷積步長為 1 × 1 × 1 的大卷積核來快速地對原始數據進行降維。輸出層同樣用大卷積核來快速過渡,其主要的作用是與輸入層對稱,將深度特征的多通道平滑地減少為單通道。并且在輸出層的末尾采用雙曲正切(hyperbolic tangent,Tanh)激活函數對卷積輸出進行激活,因為在輸出層的卷積輸出特征圖中目標和背景的特征相差已經很明顯了,而且 Tanh 激活函數是 0 均值輸出。在輸入和輸出層中,為了保證特征的大小不變,因此都在卷積前單獨做了 3 × 3 × 3 的特征圖 3D 填充(3D padding,Pad3d)。T3scGAN 中采用了邊緣復制的方式對輸入的特征圖進行 Pad3d。在 2 個下采樣層中使用了 3 × 3 × 3 的小卷積核有助于平滑有效地提取特征,同時為了將輸入特征圖下采樣 2 倍,卷積的步長為 2 × 2 × 2,并且在卷積后進行了大小為 1 × 1 × 1 的 Pad3d。同樣地,在上采樣層中 T3scGAN 采用了相同的卷積核大小,卷積步長以及 Pad3d 保證輸入和輸出的特征圖之間的 2 倍關系。不同的是,在上采樣層中所有的卷積操作都被替換成了 3D 轉置卷積(3D transposed convolution,TConv3d)操作。在殘差塊中同樣采用了 3 × 3 × 3 的小卷積核,同時為了保證輸入輸出特征圖的大小不變,卷積步長為 1 × 1 × 1,而且在卷積后進行了大小為 1 × 1 × 1 的 Pad3d。
如圖 3 所示的 T3scGAN 生成器結構中,從左到右依次為圖 2 中生成器的 5 個主要部分。卷積濾波器的通道數量由輸入層的基本通道數量決定,即相鄰的下采樣層后一層是前一層的 2 倍。
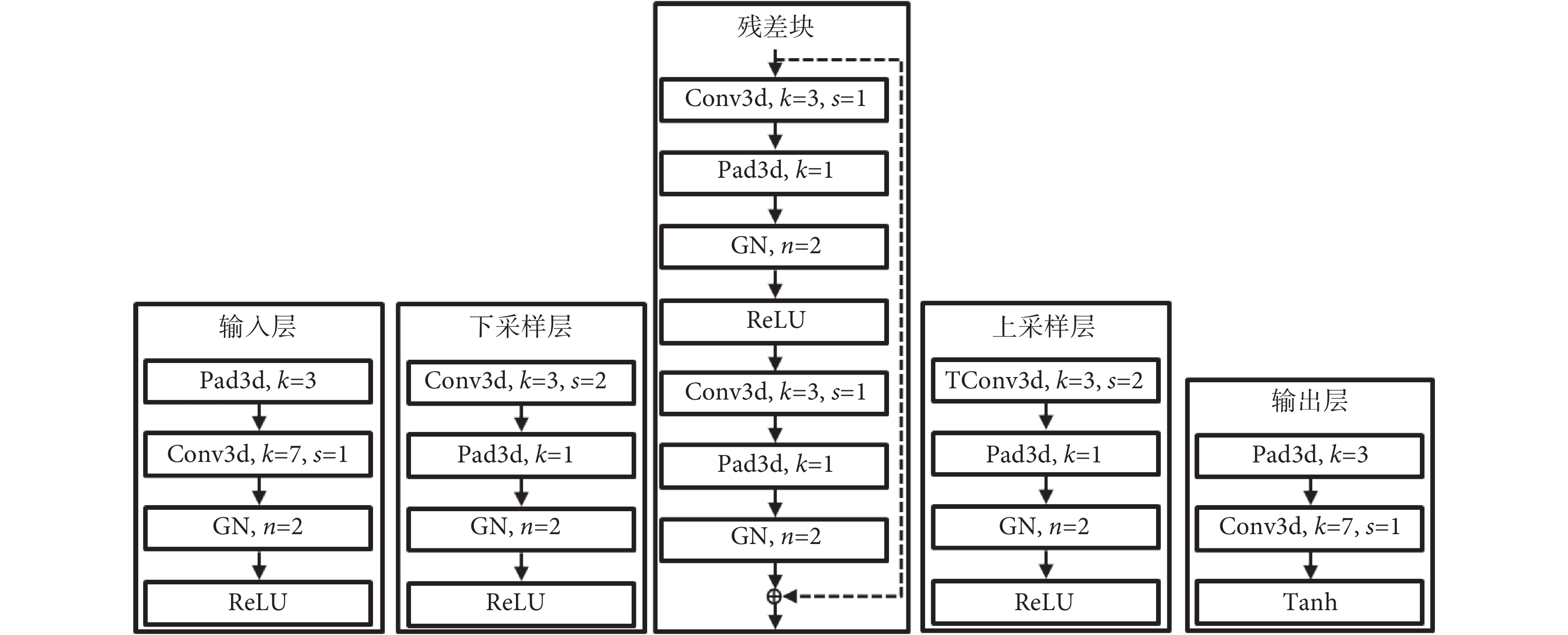 圖3
T3scGAN 生成器模塊的詳細結構
Figure3.
Detailed structure of the modules in the generator of T3scGAN
圖3
T3scGAN 生成器模塊的詳細結構
Figure3.
Detailed structure of the modules in the generator of T3scGAN
1.2.2 判別器結構
在 cGAN 中判別器的主要作用是判斷一張圖是真實的圖像還是生成器生成的結果,即判斷生成器生成的結果和真實數據的差異性。因此判別器可以很好地監督生成器的訓練,主要是因為它可以從深層的數據分布上比較生成器生成的結果和真實數據之間的差異。所以判別器就等價于是給生成器訓練提供了一個可訓練的損失函數。同時判別器的輸出只是真實/生成(1/0),所以判別器可以用一個二分類的卷積神經網絡替代。
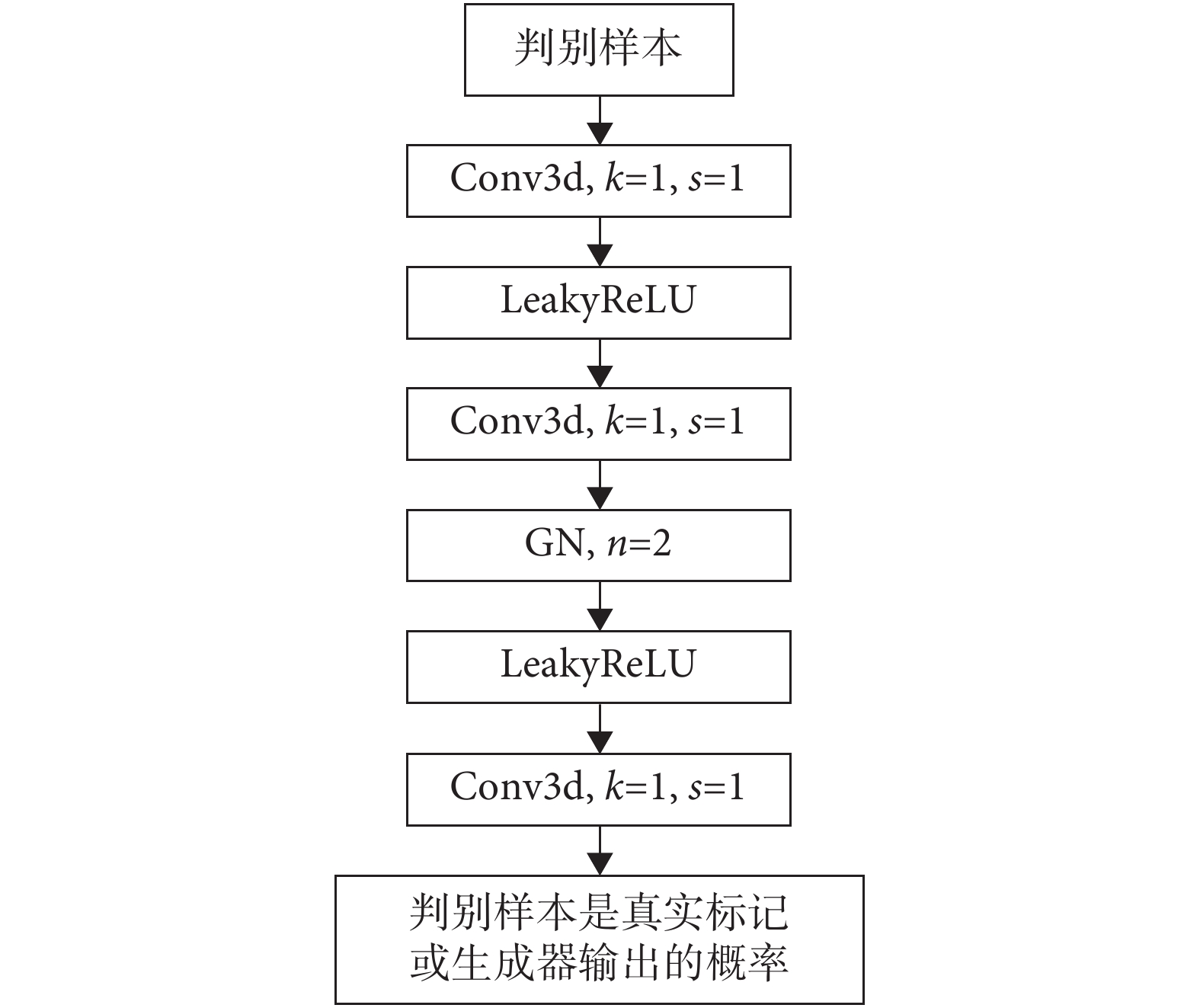
為了讓網絡適應多尺度的輸入,本文采用了 pix2pix 中提出的圖像塊 GAN 技術。該技術的核心是在判別器中,去掉了傳統分類網絡的特征扁平化操作和全連接層,直接讓判別器輸出一個單通道的特征圖,然后用真實數據得到的特征圖和生成數據得到的特征圖進行誤差計算。同時為了盡可能有效匹配小腫瘤區域的特征,T3scGAN 的判別器都采用了 1 × 1 × 1 的小卷積核和 1 × 1 × 1 的卷積步長保證了特征張量只在通道數量上進行變化,所以判別器最終輸出的特征張量維度為[B,1,H,W,D]。為了使得判別器的判別有效,本文采用了 cGAN 的框架,把生成器的輸入原始 CT 數據作為判別條件,和生成結果或真實標記在通道維度上進行拼接之后輸入判別器網絡,所以判別器的輸入維度為[B,2,H,W,D]。同時為了保證判別器結構中不會出現“死神經元”現象,所以在判別器網絡中卷積層之間使用了泄露的 ReLU(LeakyReLU)激活函數。LeakyReLU 激活函數不同于 ReLU 函數,當輸入特征張量中的值小于零時,會有一個泄露值輸出,這樣就不會導致只要輸入的特征張量值小于零時輸出始終為 0,其一階導數也始終為 0,以致于神經元不能更新參數,也就是神經元不學習的情況出現。LeakyReLU 的表達式如式(5)所示:
 |
本文在判別器中的 LeakyReLU 激活函數的泄露值 ε 均設置為 0.2。
判別器結構如圖 4 所示,為了避免判別器判別能力過強而導致生成器的訓練崩潰,并且考慮到判別器參數量過多可能會導致判別器過擬合,所以本文采用了一個只有 3 層卷積的判別器。
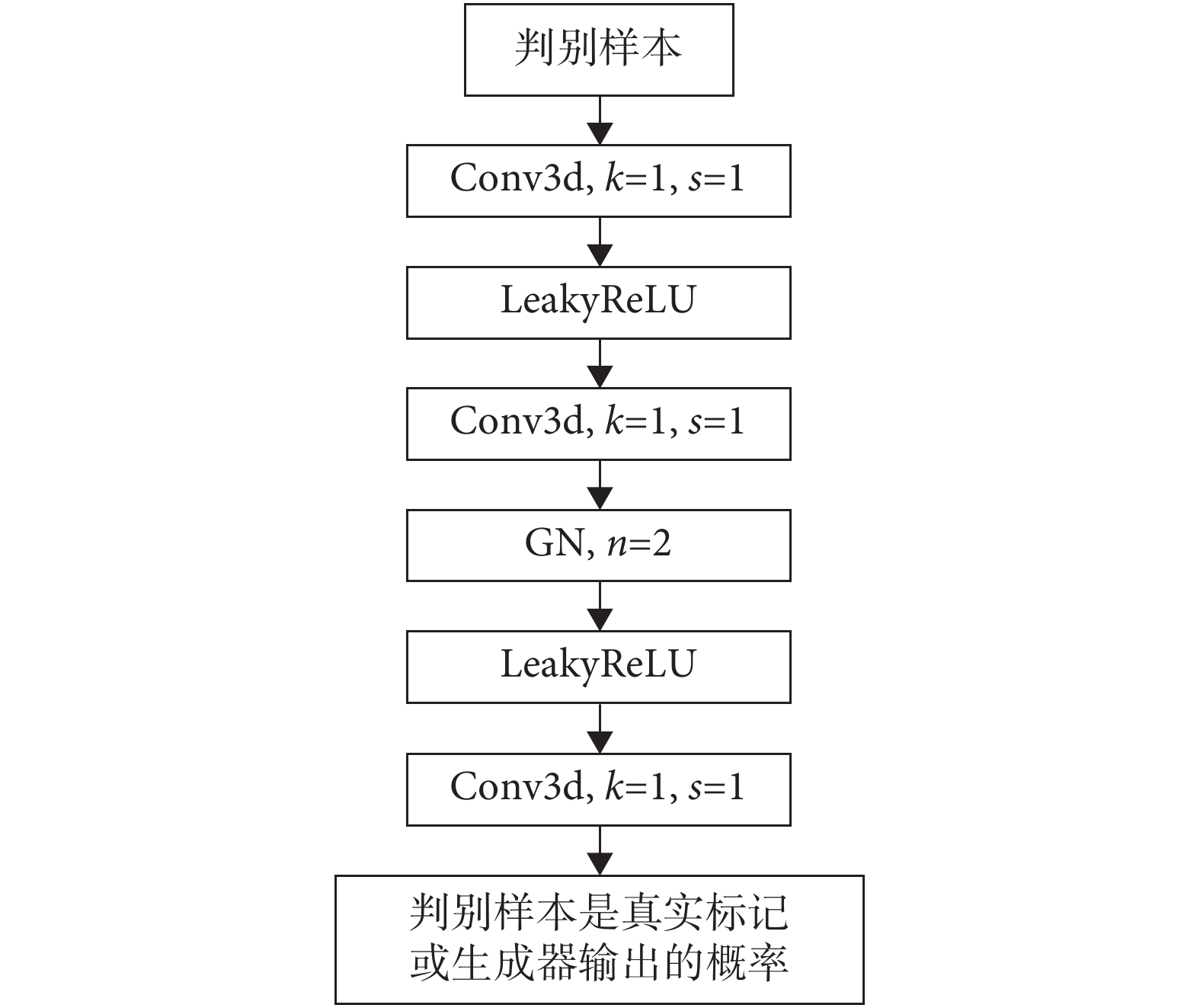 圖4
T3scGAN 判別器結構
Figure4.
T3scGAN discriminator structure
圖4
T3scGAN 判別器結構
Figure4.
T3scGAN discriminator structure
1.2.3 損失函數
對于整個 cGAN 模型而言,優化目標函數如式(6)所示:
 |
其中,I 是生成器的輸入原始數據,M 是真實的標記數據, 和
和  分別代表生成器網絡和判別器網絡。同時為了增加生成器網絡的泛化性,提高其生成能力,T3scGAN 同時使用了 L1 損失函數[24]來優化生成器。L1 損失函數如式(7)所示:
分別代表生成器網絡和判別器網絡。同時為了增加生成器網絡的泛化性,提高其生成能力,T3scGAN 同時使用了 L1 損失函數[24]來優化生成器。L1 損失函數如式(7)所示:
 |
所以最終的損失函數表達式如式(8)所示:
 |
其中 λ 為 L1 損失函數的懲罰系數,在本工作中 λ = 10。
2 實驗及評估
2.1 實驗數據
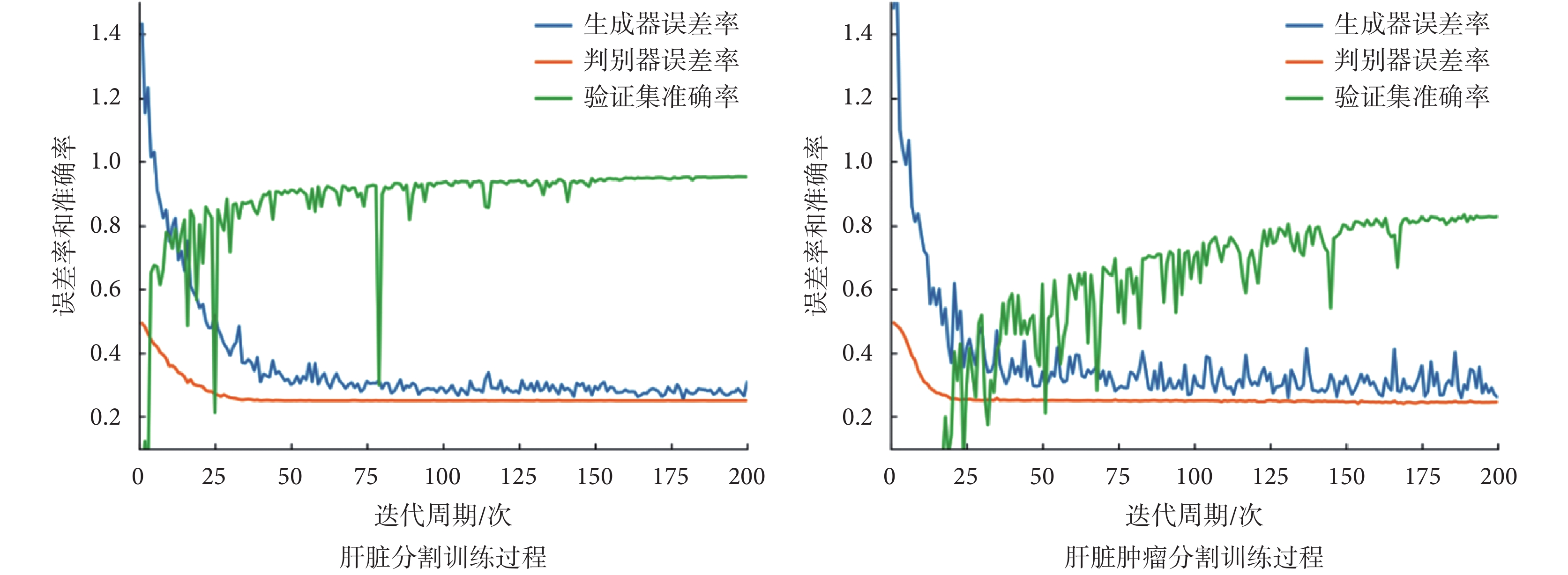
本文采用 2017 肝臟和腫瘤分割挑戰賽(liver and tumor segmentation challenge,LiTS)公開數據集中的訓練集進行實驗。該數據集總共有 131 例標記了 3D 肝臟及 3D 肝臟腫瘤的 CT 病例,所有的 CT 維度均為 512 × 512 × D(D 的范圍在 75~750 之間)。本文從中挑選了 130 例 3D 肝臟區域標記清晰的病例作為肝臟分割數據集,然后又從挑選的 130 例肝臟分割數據集中挑選出了 75 例腫瘤標記清晰并且準確的病例作為肝臟腫瘤分割數據集。為了盡量保持肝臟腫瘤的完整性,尤其是體積比較小的肝臟腫瘤,本文采用 256 × 256 × 128 的尺寸作為肝臟 3D 分割的標準尺寸。然后用標記的肝臟區域和原始的 CT 數據點乘提取出肝臟的 3D ROI,并根據最小外接長方體裁剪出 ROI。本文發現裁剪之后的 ROI 維度[H,W,D]大致為 H:185~235、W:135~190、D:20~41,所以將裁剪出來的 ROI 重采樣為 256 × 256 × 32 尺寸,作為肝臟腫瘤分割的標準尺寸。本文隨機地在肝臟分割數據集中取出 10 個病例作為驗證集,然后隨機取出 20 個病例作為測試集,剩下的 100 個病例作為訓練集。對于肝臟腫瘤分割數據集劃分,本文仍然是按照隨機的 10∶1∶2 分為訓練集、驗證集和測試集。在訓練過程中,每個迭代周期結束后都在驗證集上做一次驗證。T3scGAN 在兩個數據集上訓練和驗證的過程記錄曲線如圖 5 所示,其中藍色曲線代表生成器的損失曲線,橙色代表判別器的損失曲線,綠色代表驗證集的準確率曲線。
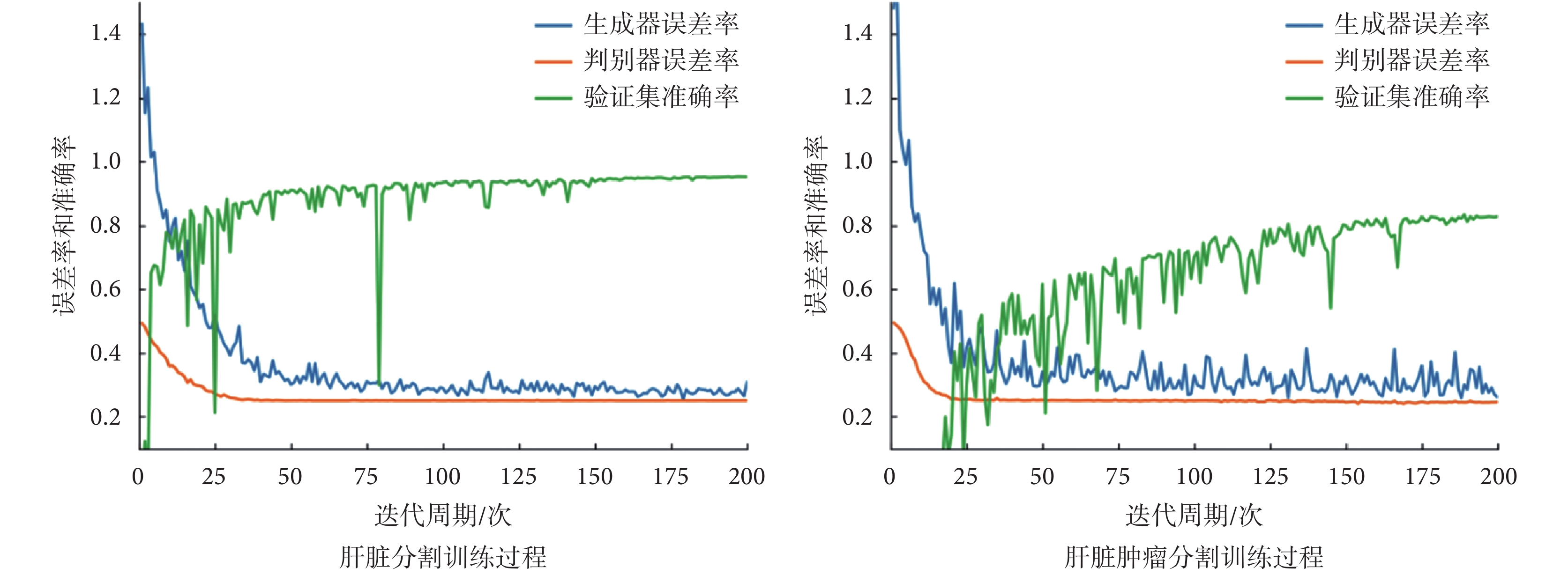 圖5
T3scGAN 訓練過程曲線
Figure5.
Training process curve of T3scGAN
圖5
T3scGAN 訓練過程曲線
Figure5.
Training process curve of T3scGAN
從圖 5 中可以看出,在兩個數據集上訓練時,T3scGAN 的訓練過程比較穩定,并且收斂的速度也比較快。本文采用戴斯(Dice)系數[25]作為驗證集準確率的評估指標。Dice 系數是醫學圖像分割中常用來評估分割結果和人工標記之間相似度的評估矩陣,Dice 系數(以符號 Dice 表示)的計算公式如式(9)所示:
 |
其中 yi 和 zi 分別表示真實標記和模型預測輸出。當 T3scGAN 訓練穩定時,在肝臟數據集和肝臟腫瘤數據集的驗證集中 Dice 系數分別為 0.983 和 0.814。為了驗證 T3scGAN 的穩定性,在兩個數據集上分別對 T3scGAN 進行了 3 折 20 次的交叉驗證,最后在肝臟分割數據集和肝臟腫瘤分割數據集上 T3scGAN 的交叉驗證 Dice 系數分別為 98.3 ± 0.02 和 82.4 ± 0.03。
本文采用的實驗平臺為:操作系統 Ubuntu 16.04(開源,美國)、GPU 硬件 GTX 1080Ti(英偉達,美國),可視化軟件為 Itk-snap[26-27](賓夕法尼亞大學,美國)。網絡固定的超參數為:優化器選用自適應的 Adam[28-29],初始化學習率為 0.000 2,訓練的總迭代次數為 200,深度學習框架 Pytorch1.0(Facebook,美國)。
2.2 肝臟及腫瘤 3D 分割實驗評估
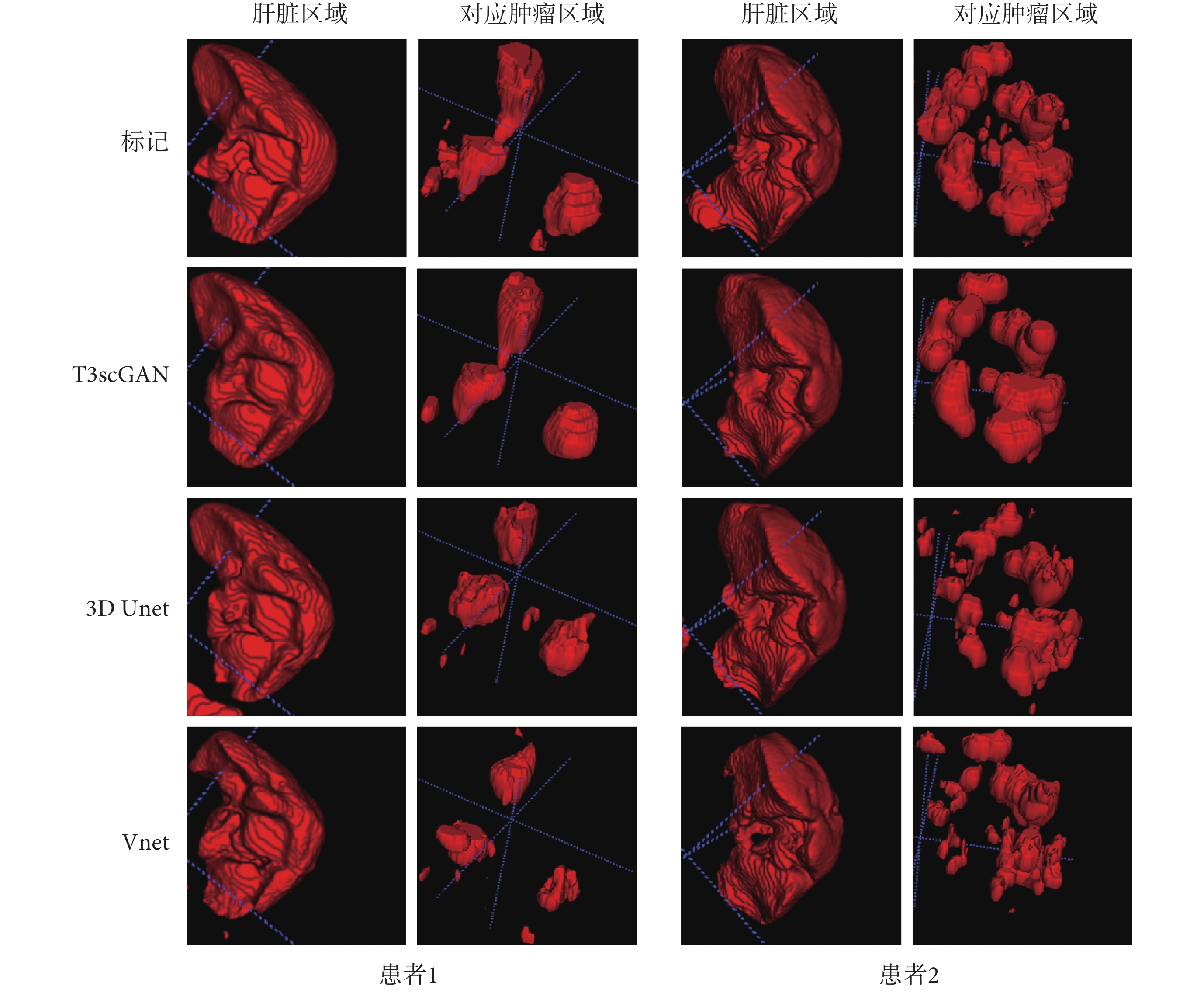
CT 圖像中肝臟器官的邊界清晰,尺寸較大,并且在不同病例之間的紋理相似度較高,所以相對于腫瘤分割,肝臟區域分割比較簡單。相對于肝臟區域分割,肝臟腫瘤區域分割更加困難,因為肝臟腫瘤的邊界模糊,并且腫瘤的尺寸、位置、紋理等特征差異性大,因此對模型的精準分割是很大的挑戰。本文在 2 個數據集上同時對比了 3D Unet 分割模型和 V 型網絡(Vnet)分割模型[30],不同模型在肝臟區域及對應的腫瘤區域分割結果對比如圖 6 所示。
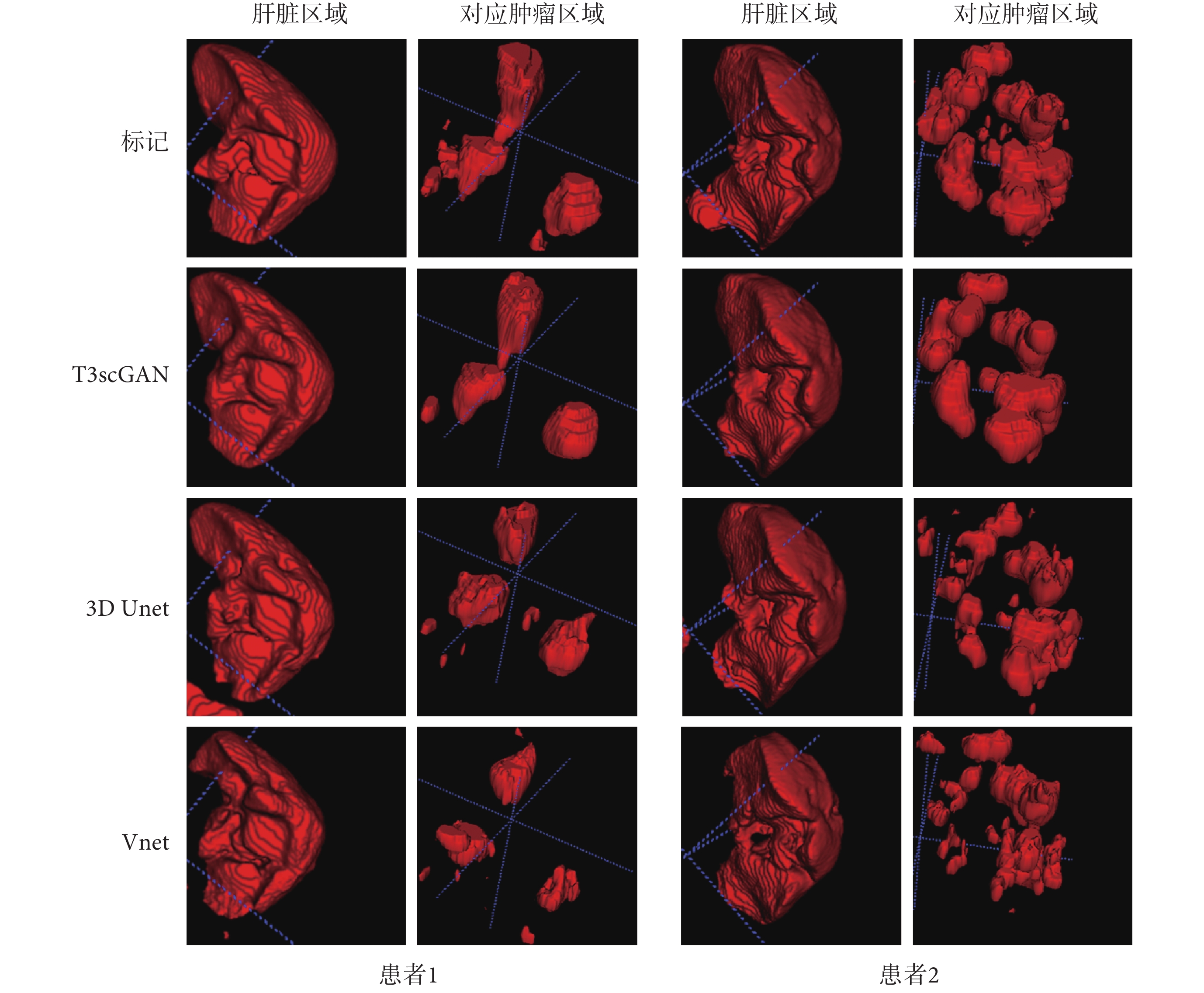 圖6
肝臟及對應腫瘤分割測試對比結果
Figure6.
Comparison of liver and corresponding tumor segmentation test results
圖6
肝臟及對應腫瘤分割測試對比結果
Figure6.
Comparison of liver and corresponding tumor segmentation test results
和腫瘤區域分割相比較,肝臟區域分割的數據輸入尺寸較大,受限于 GPU 顯存,所以本文將基本通道數量設置為 4,批量的樣本數量為 5。肝臟腫瘤分割時,基本通道數量設置為 8,批量的樣本數量為 4。
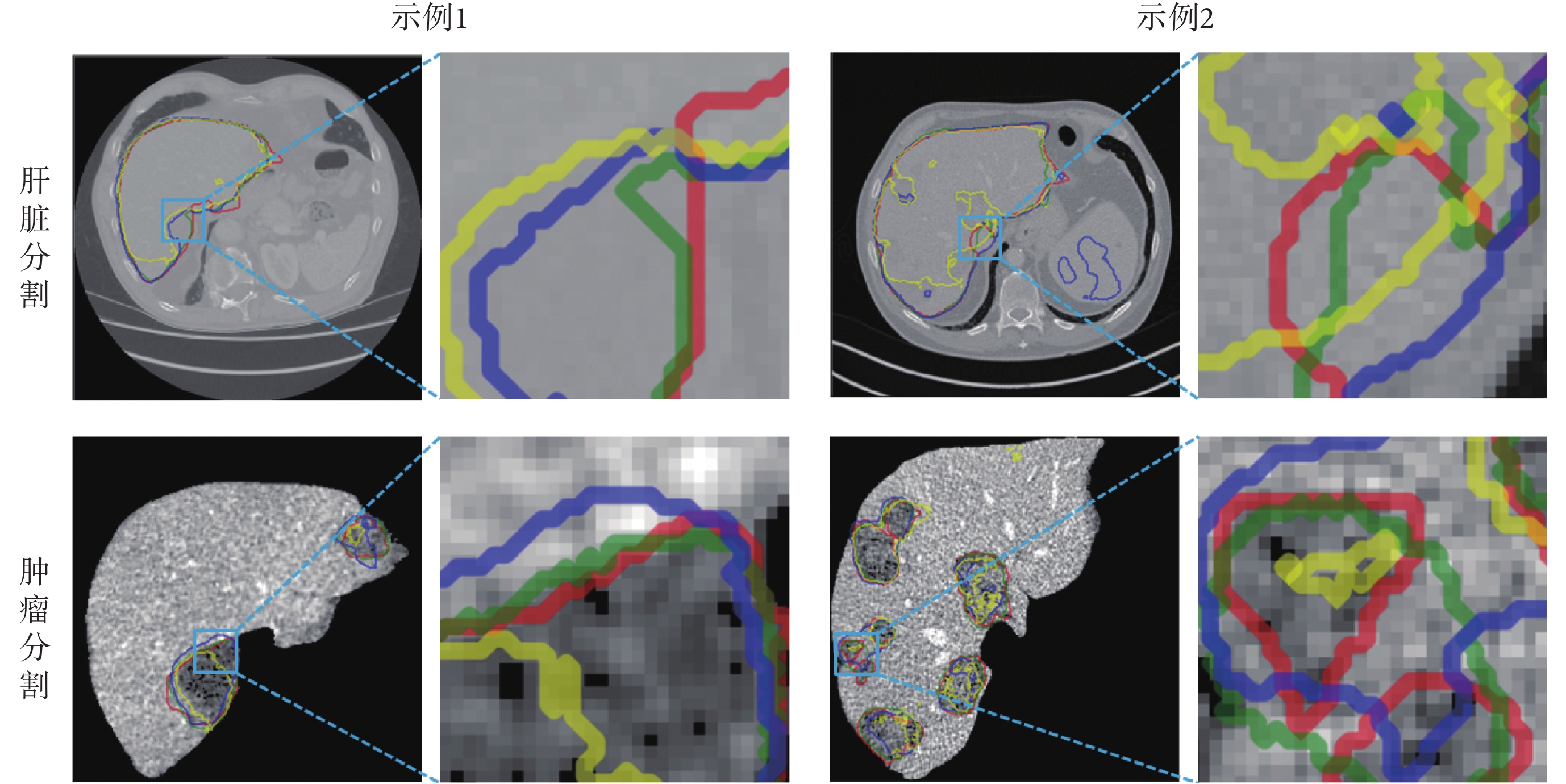
從圖 6 的 3D 可視化結果中看到,3 種模型在肝臟分割數據集上的分割性能類似,但是在肝臟腫瘤分割數據集上,3 種模型的分割性能差異較大,T3scGAN 可以達到最好的性能。一些分割結果的 2D 圖像細節如圖 7 所示,其中紅、綠、藍、黃線分別代表:標記、T3scGAN 的分割結果、3D Unet 分割結果和 Vnet 分割結果。
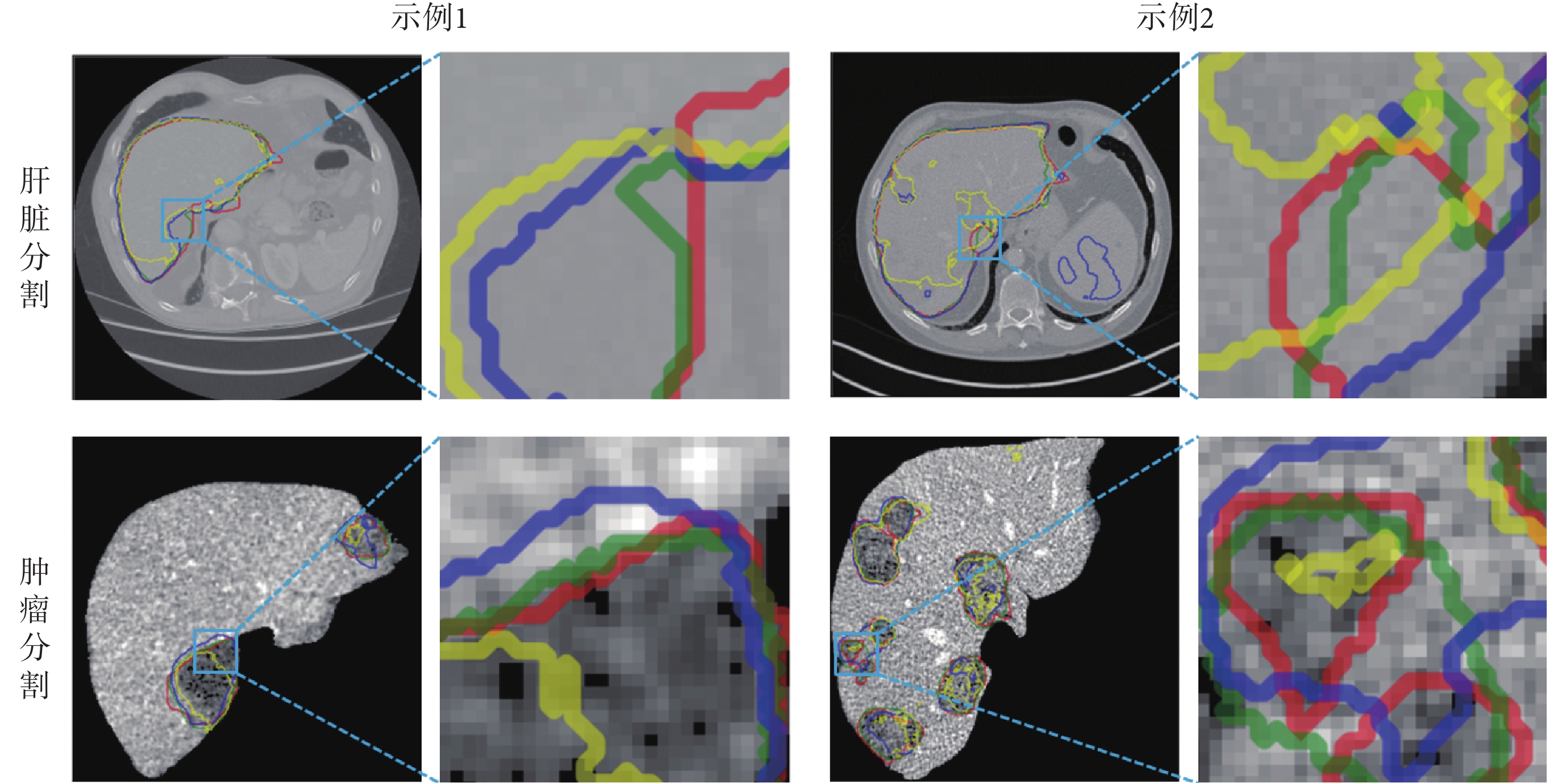 圖7
2D 切面細節展示
Figure7.
2D slices details
圖7
2D 切面細節展示
Figure7.
2D slices details
從圖 7 中可以發現,3D Unet 對肝臟腫瘤區域的識別假陽率較高,Vnet 不能夠很好地分割出腫瘤的邊界。從這兩種模型的模型結構上分析,3D Unet 是因為使用了過多的跳躍連接,所以可以在分割中很好地保留細節信息,但是也造成了模型的敏感度很高,所以會將很多相似的非腫瘤小區域預測為腫瘤區域。Vnet 的分割性能要比 3D Unet 好,Vnet 結構中不僅使用了許多跳躍連接,而且網絡的參數容量更大,所以數量較少的腫瘤分割訓練集會導致 Vnet 訓練不充分,無法精確地分割出腫瘤區域的邊界。同時 3D Unet 和 Vnet 模型的參數容量較多,3 種模型的網絡參數量對比如表 1 所示。
從表 1 中可以看出,3D Unet 和 Vnet 模型的參數容量要遠大于 T3scGAN 的模型參數容量,所以 3D Unet 和 Vnet 對訓練集的數量要求更大。因此在語義信息和空間信息較差,并且數據量較少的腫瘤分割數據集上,3D Unet 和 Vnet 的分割效果都比較差。
本文分別計算了肝臟和肝臟腫瘤測試集中所有樣本的 Dice 系數,然后計算了它們的平均值作為評估不同模型性能的指標,評估結果如表 2 所示。
從表 2 可以看出,與 3D Unet 和 Vnet 相比,本文提出的 T3scGAN 模型以及由粗到細的腫瘤分割框架對肝臟區域和肝臟腫瘤區域均具有更高的分割精度。
3 總結與討論
肝臟及腫瘤區域的全自動精準分割是輔助醫生診斷和治療的重要前提,但是對于一般的深度學習模型[30]而言是一個非常具有挑戰性的任務。本文所構建的 T3scGAN 模型具有如下優點:① 模型的復雜度低、參數量少,可以避免網絡太深而導致的訓練困難和過擬合問題,減少了對訓練數據量的要求;② 模型具有很好的監督損失函數機制使得模型得到了充分的訓練;③ 模型不僅能優化低維的空間信息(邊界、曲面等),而且能保留高維的語義特征(細節、位置等)。本文的下一步工作是將構建的框架和模型應用于更多器官及其腫瘤區域的分割問題,同時基于自動分割結果構建疾病的預測和預后模型。
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
引言
肝臟是承擔人體代謝功能的重要器官,肝臟一旦出現惡性腫瘤病變將會嚴重威脅人體生命健康。計算機斷層掃描成像(computed tomography,CT)是目前在肝臟病變診斷中普遍采用的常規診斷方式。CT 圖像可以反映出肝臟腫瘤的形態、數目、部位、邊界等信息,因此基于 CT 影像技術對肝臟腫瘤區域實施有效的分割具有重要的臨床價值。但是由于 CT 圖像中肝臟與周邊臟器的灰度值非常接近,且不同患者個體差異大等原因,導致肝臟與肝臟腫瘤的三維(three dimensional,3D)分割非常困難。傳統的肝臟分割方法,有利用形狀先驗、灰度分布以及邊界和區域信息來描述肝臟特征并劃定其邊界的統計變形模型,也有基于紋理和灰度等級的方法。這些分割方法的效率很低,魯棒性比較差,而且需要根據經驗調節大量的參數。例如,Stawiaski 等[1]使用最小曲面和馬爾科夫隨機場對肝臟腫瘤進行分割。Smeets 等[2]提出了一種基于水平集的半自動分割方法,并使用該方法對 CT 影像中的肝臟腫瘤及肝臟轉移區域進行分割。Li 等[3]提出了一種新的統一水平集模型,該模型通過整合圖像的梯度、圖像的區域競爭及先驗信息對 CT 圖像中的肝臟腫瘤進行分割。Li 等[4]提出了一種水平集模型,該模型將似然能量和邊緣能量結合在一起對 CT 圖像中的肝臟腫瘤區域進行分割。Zhang 等[5]提出了一種交互式的半自動分割方法來分割 CT 圖像中的肝臟及腫瘤區域,該方法首先對輸入的 CT 圖像進行預處理,粗略地分割出肝臟區域,然后在肝臟腫瘤區域設置一些種子點,最后用這些種子點位置的灰度值訓練一個支持向量機(support vector machine,SVM)[6],并用一些形態學的后處理方式對 SVM 的分類結果粗略地勾畫出肝臟腫瘤區域的邊界。近年來,隨著深度學習技術的發展,研究人員開發了一系列基于深度學習的分割算法來分割肝臟及腫瘤區域。例如,Li[7]提出了一種卷積分類網絡模型,該模型對二維(two dimensional,2D)CT 圖像中 17 × 17 大小的圖像塊進行逐塊預測,判斷該圖像塊究竟為病變區域還是其他區域,最終可以分割出肝臟腫瘤。Li 等[8]提出了一種混合密集連接 U 型網絡(hybrid densely connected Unet,H-DenseUNet)分割模型,該模型先對肝臟 2D CT 圖像中的肝臟及腫瘤區域進行分割,然后將學習到的 2D 圖像高維特征用一個 3D 的卷積網絡進行融合,最終得到肝臟和腫瘤的 3D 分割結果。Bi 等[9]提出了一種基于卷積殘差網絡(residual network,Resnet)[10]的多尺度模型,該模型可以在多個尺度上對 CT 圖像中的肝臟腫瘤進行識別,從而提高了識別的精度。Gruber 等[11]比較研究了兩種肝臟腫瘤分割方案,第一種是直接采用了 1 個 2D U 型網絡(Unet)[12]對肝臟腫瘤進行端到端分割;第二種方案則使用了 2 個 2D Unet,其中第一個 Unet 用于分割肝臟區域,然后把分割的肝臟感興趣區域(region of interest,ROI)乘以輸入 CT 圖像提取肝臟區域,之后用提取的肝臟區域圖像又訓練了一個 2D Unet 對肝臟腫瘤進行 2D 分割。通過對比發現,級聯的分割網絡可以達到更好的肝臟腫瘤分割性能。Dey 等[13]設計了一種級聯的肝臟腫瘤分割模型,該模型先用一個 2D 深度卷積分割網絡分割出肝臟及較大的腫瘤區域,然后再用一個 3D 深度卷積分割網絡檢測分割出小腫瘤區域,從而提高了 CT 圖像中肝臟腫瘤的分割準確率。Deng 等[14]先用 1 個 3D 密集連接卷積分類網絡檢測肝臟腫瘤的邊緣,然后用 3D 密集連接卷積分類網絡輸出的腫瘤邊緣概率動態調節水平集分割參數,同時根據分類網絡檢測的腫瘤區域位置初始化水平集腫瘤分割局部窗口的大小,最后分割出肝臟腫瘤;Lu 等[15]先構建了 1 個 3D 卷積網絡對肝臟區域進行分割并輸出概率圖,然后基于概率圖用圖切法得到最終的肝臟分割結果。
與傳統的肝臟腫瘤分割方法相比,基于深度學習的分割方法在分割效率和準確率上都有很大提升,但是也普遍存在以下幾個問題:① 直接進行 3D 分割的模型計算量太大,因此大部分 3D 分割模型都是基于將 2D 分割結果拼接成 3D 的分割結果。基于 2D 分割結果再拼接成 3D 分割結果的分割方法雖然可以減少模型的運算量,但是分割的結果卻不如直接以 3D 分割模型進行分割的結果。因為 2D 分割模型的優化目標是 ROI 邊界曲線,而 3D 分割模型可以優化 ROI 的整個曲面;② 需要大量的預處理和后處理操作。在肝臟腫瘤的 2D 切面中,由于肝臟腫瘤的大小、位置、紋理等信息在不同的病例中差異較大,如果使用端到端的網絡很難直接定位到腫瘤區域;③ 需要很多標記數據進行模型的訓練。因為腫瘤的分割檢測比較困難,提升模型的性能就需要增加模型的復雜度和可訓練參數量,如果訓練集的數量過少就會導致模型分割性能不足或者過擬合。
本文基于條件對抗生成網絡(conditional generative adversarial networks,cGAN)[16]構建了一個新型的腫瘤 3D 分割條件對抗生成網絡(tumor 3D segmentation conditional generative adversarial networks,T3scGAN)作為主要的分割模型對 3D 肝臟區域和 3D 肝臟腫瘤區域進行分割,同時使用了一個由粗到細的 3D 分割框架來精確地分割肝臟腫瘤,從而輔助醫生實現對肝臟病變及肝臟腫瘤的快速定位與識別,達到精準診療的目的。
1 由粗到細的肝臟腫瘤分割框架
在 CT 影像中,肝臟腫瘤的全自動精準分割對分割算法具有較大的挑戰性,主要原因是不同病例的肝臟腫瘤之間位置、形態和紋理特征差異性很大。因此,本文采用了一個由粗到細的 3D 分割框架來精確分割肝臟腫瘤。分割框架流程圖如圖 1 所示,當輸入一個 3D 的 CT 測試病例時,整個分割框架首先進行自動數據預處理,然后用訓練好的肝臟分割 T3scGAN 模型對肝臟區域進行自動 3D 分割,得到肝臟區域 3D 分割結果。之后基于肝臟分割的結果結合預處理后的 CT 圖像進行自動肝臟 3D ROI 提取,最后用訓練好的肝臟腫瘤分割 T3scGAN 模型對肝臟腫瘤區域進行自動 3D 分割。
圖1
由粗到細的肝臟腫瘤 3D 分割框架
Figure1.
3D coarse-to-fine liver tumors segmentation framework
1.1 數據預處理
在訓練和測試過程中,本文首先將原始 CT 影像的窗寬設置為 300,窗位設置為 100。之后重新采樣到 256 × 256 × 128 大小,再將重采樣的數據歸一化至 0~1 區間作為網絡的輸入。
1.2 T3scGAN
傳統的 3D 分割模型都有一個預定義的損失函數作為優化目標來訓練網絡,因此損失函數的選擇對網絡的性能影響較大。cGAN 提供了可訓練的損失函數機制[17]。像素點到像素點(pixel to pixel,pix2pix)的圖像翻譯模型[18]首次應用這種機制完美地解決了圖像翻譯問題。受 cGAN 和 pix2pix 模型的啟發,本文構建了一種新型的 3D 條件對抗網絡模型(T3scGAN)來分割肝臟及腫瘤區域,模型結構如圖 2 所示。
圖2
T3scGAN 模型結構
Figure2.
T3scGAN model structure
T3scGAN 包含 1 個生成器網絡和 1 個判別器網絡。生成器網絡是一個端到端的 3D 分割結構,判別器網絡是一個多層的分類模型。
1.2.1 生成器結構
在醫學圖像分割任務中,Unet 是目前非常流行的深度框架。Unet 受到全卷積神經網絡(fully convolutional networks,FCN)模型[19]的啟發,將多個尺度下提取的深度特征進行了融合,但不同于 FCN 直接拼接融合的方式,Unet 采用了相同尺度的編碼器和解碼器結構,將編碼器不同尺度下的深度特征和相同尺度的解碼器特征相融合,這樣就可以將原始圖像的細節信息盡可能地保留下來,同時 Unet 在編碼器部分采用了最大池化的方法,使得快速下采樣的同時又能夠保證分割的精度。3D Unet 模型[20]是基于 Unet 的 3D 分割版本模型。
受 3D Unet 結構的啟發,T3scGAN 生成器中也使用了一系列的跳躍式連接,從而可以使得一些細節部分得以保留。生成器中對特征的下采樣和上采樣均使用卷積和轉置卷積操作,這樣可以更加平滑地融合各個部分的細節信息。但是在 Unet 中直接將編碼器部分的低維特征拼接到解碼器部分的高維特征進行操作會導致語義代溝[21]。為了緩解這個問題,本文采用了特征深度融合的方式來使得低維形態特征和高維語義特征之間盡可能相似。
Resnet 模型提供了一種非常有效的特征深度融合方式,其最大的特點是將輸入的特征圖和輸出的特征圖相加作為最終的輸出。對于一個殘差塊的輸入 x 和輸出 y 之間的映射關系如式(1)所示:
|
其中 F 表示整個殘差塊的映射,x 和 Wx 代表輸入和對應輸入的卷積操作, 表示殘差塊中的激活函數。為了方便反向傳播求梯度,一般 為線性整流單元(rectified linear unit,ReLU)函數。ReLU 函數的表達式如式(2)所示:
|
ReLU 激活函數僅保留輸入特征中大于 0 的部分,并且直接將大于 0 的部分輸出,所以在反向傳播求梯度的過程中,該激活函數對大于 0 的輸入 x 的偏導數恒等于 1,因此使用 ReLU 激活函數可以加快網絡的訓練。
在 Wx 操作中一般會用一個標準化層來對卷積的輸出進行標準化。標準化層的作用非常大,它會將網絡的輸出一直保持在相同的分布區間,避免梯度消失,同時正則化網絡,提高網絡的泛化能力。在卷積操作之后常用的標準化方式為批量標準化(batch normalization,BN)[22],該標準化方式的表達式如式(3)所示:
|
其中,z 代表 3D 卷積層(3D convolutional layer,Conv3d)輸出的特征張量 B × C × H × W × D,B 表示批量樣本的數量,C 表示特征張量的通道數,H × W × D 指的是特征張量中的 3D 特征矩陣。但是受限于計算機圖形處理器(graphics processing unit,GPU)的顯存大小,批量樣本的數量只能設置很小,這對于 BN 的方式非常不利,所以本文采用了組標準化(group normalization,GN)[23]的方式來替代 BN。GN 和 BN 的主要區別是 GN 首先將特征張量的通道分為許多組,然后對每一組做歸一化。即,將特征張量矩陣的維度由[B,C,H,W,D]改變為[B,C,G,C/G,H,W,D],然后歸一化的維度(求均值和方差的維度)為[C/G,H,W,D]。
因此在加入 Resnet 連接的反向傳播中,如果對公式(1)求 的偏導數可以得到如式(4)所示:
|
所以當網絡很深的時候,dF/dx 有可能變為 0,此時 df/dx 恒等于 1,對于整個網絡的前向傳播仍然有效。所以 T3scGAN 在編碼器和解碼器之間采用了 3D 殘差結構來過渡,即將原始的殘差塊結構中的操作由 2D 全部替換成了 3D,這樣既保證了編碼器輸出的深度特征充分融合,并且通過增加網絡可訓練參數來增加網絡的魯棒性,而且也可以避免梯度消失的問題。
T3scGAN 只采用了 2 個尺度下的特征融合,這樣做的目的是在保證 3D 分割準確率的條件下,盡可能地減少網絡參數和網絡計算量,同時避免了下采樣尺度過多而導致對尺寸小的腫瘤區域造成不可恢復的細節損失,從而保留更多的細節信息在相等大小輸入輸出的殘差連接中深度融合。在生成器的編碼部分,從左到右相鄰兩個尺度的特征圖譜之間的尺寸為正 2 倍的關系,濾波器數量為負 2 倍的關系。對應的在生成器的解碼部分,從左到右相鄰兩個尺度的特征圖譜之間的尺寸為負 2 倍的關系,濾波器數量為正 2 倍的關系。在輸入層中 T3scGAN 采用了一組卷積操作將輸入 CT 映射至特征,同時將原始數據的單通道快速增加為多通道。并且采用了卷積核大小為 7 × 7 × 7,卷積步長為 1 × 1 × 1 的大卷積核來快速地對原始數據進行降維。輸出層同樣用大卷積核來快速過渡,其主要的作用是與輸入層對稱,將深度特征的多通道平滑地減少為單通道。并且在輸出層的末尾采用雙曲正切(hyperbolic tangent,Tanh)激活函數對卷積輸出進行激活,因為在輸出層的卷積輸出特征圖中目標和背景的特征相差已經很明顯了,而且 Tanh 激活函數是 0 均值輸出。在輸入和輸出層中,為了保證特征的大小不變,因此都在卷積前單獨做了 3 × 3 × 3 的特征圖 3D 填充(3D padding,Pad3d)。T3scGAN 中采用了邊緣復制的方式對輸入的特征圖進行 Pad3d。在 2 個下采樣層中使用了 3 × 3 × 3 的小卷積核有助于平滑有效地提取特征,同時為了將輸入特征圖下采樣 2 倍,卷積的步長為 2 × 2 × 2,并且在卷積后進行了大小為 1 × 1 × 1 的 Pad3d。同樣地,在上采樣層中 T3scGAN 采用了相同的卷積核大小,卷積步長以及 Pad3d 保證輸入和輸出的特征圖之間的 2 倍關系。不同的是,在上采樣層中所有的卷積操作都被替換成了 3D 轉置卷積(3D transposed convolution,TConv3d)操作。在殘差塊中同樣采用了 3 × 3 × 3 的小卷積核,同時為了保證輸入輸出特征圖的大小不變,卷積步長為 1 × 1 × 1,而且在卷積后進行了大小為 1 × 1 × 1 的 Pad3d。
如圖 3 所示的 T3scGAN 生成器結構中,從左到右依次為圖 2 中生成器的 5 個主要部分。卷積濾波器的通道數量由輸入層的基本通道數量決定,即相鄰的下采樣層后一層是前一層的 2 倍。
圖3
T3scGAN 生成器模塊的詳細結構
Figure3.
Detailed structure of the modules in the generator of T3scGAN
1.2.2 判別器結構
在 cGAN 中判別器的主要作用是判斷一張圖是真實的圖像還是生成器生成的結果,即判斷生成器生成的結果和真實數據的差異性。因此判別器可以很好地監督生成器的訓練,主要是因為它可以從深層的數據分布上比較生成器生成的結果和真實數據之間的差異。所以判別器就等價于是給生成器訓練提供了一個可訓練的損失函數。同時判別器的輸出只是真實/生成(1/0),所以判別器可以用一個二分類的卷積神經網絡替代。
為了讓網絡適應多尺度的輸入,本文采用了 pix2pix 中提出的圖像塊 GAN 技術。該技術的核心是在判別器中,去掉了傳統分類網絡的特征扁平化操作和全連接層,直接讓判別器輸出一個單通道的特征圖,然后用真實數據得到的特征圖和生成數據得到的特征圖進行誤差計算。同時為了盡可能有效匹配小腫瘤區域的特征,T3scGAN 的判別器都采用了 1 × 1 × 1 的小卷積核和 1 × 1 × 1 的卷積步長保證了特征張量只在通道數量上進行變化,所以判別器最終輸出的特征張量維度為[B,1,H,W,D]。為了使得判別器的判別有效,本文采用了 cGAN 的框架,把生成器的輸入原始 CT 數據作為判別條件,和生成結果或真實標記在通道維度上進行拼接之后輸入判別器網絡,所以判別器的輸入維度為[B,2,H,W,D]。同時為了保證判別器結構中不會出現“死神經元”現象,所以在判別器網絡中卷積層之間使用了泄露的 ReLU(LeakyReLU)激活函數。LeakyReLU 激活函數不同于 ReLU 函數,當輸入特征張量中的值小于零時,會有一個泄露值輸出,這樣就不會導致只要輸入的特征張量值小于零時輸出始終為 0,其一階導數也始終為 0,以致于神經元不能更新參數,也就是神經元不學習的情況出現。LeakyReLU 的表達式如式(5)所示:
|
本文在判別器中的 LeakyReLU 激活函數的泄露值 ε 均設置為 0.2。
判別器結構如圖 4 所示,為了避免判別器判別能力過強而導致生成器的訓練崩潰,并且考慮到判別器參數量過多可能會導致判別器過擬合,所以本文采用了一個只有 3 層卷積的判別器。
圖4
T3scGAN 判別器結構
Figure4.
T3scGAN discriminator structure
1.2.3 損失函數
對于整個 cGAN 模型而言,優化目標函數如式(6)所示:
|
其中,I 是生成器的輸入原始數據,M 是真實的標記數據, 和 分別代表生成器網絡和判別器網絡。同時為了增加生成器網絡的泛化性,提高其生成能力,T3scGAN 同時使用了 L1 損失函數[24]來優化生成器。L1 損失函數如式(7)所示:
|
所以最終的損失函數表達式如式(8)所示:
|
其中 λ 為 L1 損失函數的懲罰系數,在本工作中 λ = 10。
2 實驗及評估
2.1 實驗數據
本文采用 2017 肝臟和腫瘤分割挑戰賽(liver and tumor segmentation challenge,LiTS)公開數據集中的訓練集進行實驗。該數據集總共有 131 例標記了 3D 肝臟及 3D 肝臟腫瘤的 CT 病例,所有的 CT 維度均為 512 × 512 × D(D 的范圍在 75~750 之間)。本文從中挑選了 130 例 3D 肝臟區域標記清晰的病例作為肝臟分割數據集,然后又從挑選的 130 例肝臟分割數據集中挑選出了 75 例腫瘤標記清晰并且準確的病例作為肝臟腫瘤分割數據集。為了盡量保持肝臟腫瘤的完整性,尤其是體積比較小的肝臟腫瘤,本文采用 256 × 256 × 128 的尺寸作為肝臟 3D 分割的標準尺寸。然后用標記的肝臟區域和原始的 CT 數據點乘提取出肝臟的 3D ROI,并根據最小外接長方體裁剪出 ROI。本文發現裁剪之后的 ROI 維度[H,W,D]大致為 H:185~235、W:135~190、D:20~41,所以將裁剪出來的 ROI 重采樣為 256 × 256 × 32 尺寸,作為肝臟腫瘤分割的標準尺寸。本文隨機地在肝臟分割數據集中取出 10 個病例作為驗證集,然后隨機取出 20 個病例作為測試集,剩下的 100 個病例作為訓練集。對于肝臟腫瘤分割數據集劃分,本文仍然是按照隨機的 10∶1∶2 分為訓練集、驗證集和測試集。在訓練過程中,每個迭代周期結束后都在驗證集上做一次驗證。T3scGAN 在兩個數據集上訓練和驗證的過程記錄曲線如圖 5 所示,其中藍色曲線代表生成器的損失曲線,橙色代表判別器的損失曲線,綠色代表驗證集的準確率曲線。
圖5
T3scGAN 訓練過程曲線
Figure5.
Training process curve of T3scGAN
從圖 5 中可以看出,在兩個數據集上訓練時,T3scGAN 的訓練過程比較穩定,并且收斂的速度也比較快。本文采用戴斯(Dice)系數[25]作為驗證集準確率的評估指標。Dice 系數是醫學圖像分割中常用來評估分割結果和人工標記之間相似度的評估矩陣,Dice 系數(以符號 Dice 表示)的計算公式如式(9)所示:
|
其中 yi 和 zi 分別表示真實標記和模型預測輸出。當 T3scGAN 訓練穩定時,在肝臟數據集和肝臟腫瘤數據集的驗證集中 Dice 系數分別為 0.983 和 0.814。為了驗證 T3scGAN 的穩定性,在兩個數據集上分別對 T3scGAN 進行了 3 折 20 次的交叉驗證,最后在肝臟分割數據集和肝臟腫瘤分割數據集上 T3scGAN 的交叉驗證 Dice 系數分別為 98.3 ± 0.02 和 82.4 ± 0.03。
本文采用的實驗平臺為:操作系統 Ubuntu 16.04(開源,美國)、GPU 硬件 GTX 1080Ti(英偉達,美國),可視化軟件為 Itk-snap[26-27](賓夕法尼亞大學,美國)。網絡固定的超參數為:優化器選用自適應的 Adam[28-29],初始化學習率為 0.000 2,訓練的總迭代次數為 200,深度學習框架 Pytorch1.0(Facebook,美國)。
2.2 肝臟及腫瘤 3D 分割實驗評估
CT 圖像中肝臟器官的邊界清晰,尺寸較大,并且在不同病例之間的紋理相似度較高,所以相對于腫瘤分割,肝臟區域分割比較簡單。相對于肝臟區域分割,肝臟腫瘤區域分割更加困難,因為肝臟腫瘤的邊界模糊,并且腫瘤的尺寸、位置、紋理等特征差異性大,因此對模型的精準分割是很大的挑戰。本文在 2 個數據集上同時對比了 3D Unet 分割模型和 V 型網絡(Vnet)分割模型[30],不同模型在肝臟區域及對應的腫瘤區域分割結果對比如圖 6 所示。
圖6
肝臟及對應腫瘤分割測試對比結果
Figure6.
Comparison of liver and corresponding tumor segmentation test results
和腫瘤區域分割相比較,肝臟區域分割的數據輸入尺寸較大,受限于 GPU 顯存,所以本文將基本通道數量設置為 4,批量的樣本數量為 5。肝臟腫瘤分割時,基本通道數量設置為 8,批量的樣本數量為 4。
從圖 6 的 3D 可視化結果中看到,3 種模型在肝臟分割數據集上的分割性能類似,但是在肝臟腫瘤分割數據集上,3 種模型的分割性能差異較大,T3scGAN 可以達到最好的性能。一些分割結果的 2D 圖像細節如圖 7 所示,其中紅、綠、藍、黃線分別代表:標記、T3scGAN 的分割結果、3D Unet 分割結果和 Vnet 分割結果。
圖7
2D 切面細節展示
Figure7.
2D slices details
從圖 7 中可以發現,3D Unet 對肝臟腫瘤區域的識別假陽率較高,Vnet 不能夠很好地分割出腫瘤的邊界。從這兩種模型的模型結構上分析,3D Unet 是因為使用了過多的跳躍連接,所以可以在分割中很好地保留細節信息,但是也造成了模型的敏感度很高,所以會將很多相似的非腫瘤小區域預測為腫瘤區域。Vnet 的分割性能要比 3D Unet 好,Vnet 結構中不僅使用了許多跳躍連接,而且網絡的參數容量更大,所以數量較少的腫瘤分割訓練集會導致 Vnet 訓練不充分,無法精確地分割出腫瘤區域的邊界。同時 3D Unet 和 Vnet 模型的參數容量較多,3 種模型的網絡參數量對比如表 1 所示。
從表 1 中可以看出,3D Unet 和 Vnet 模型的參數容量要遠大于 T3scGAN 的模型參數容量,所以 3D Unet 和 Vnet 對訓練集的數量要求更大。因此在語義信息和空間信息較差,并且數據量較少的腫瘤分割數據集上,3D Unet 和 Vnet 的分割效果都比較差。
本文分別計算了肝臟和肝臟腫瘤測試集中所有樣本的 Dice 系數,然后計算了它們的平均值作為評估不同模型性能的指標,評估結果如表 2 所示。
從表 2 可以看出,與 3D Unet 和 Vnet 相比,本文提出的 T3scGAN 模型以及由粗到細的腫瘤分割框架對肝臟區域和肝臟腫瘤區域均具有更高的分割精度。
3 總結與討論
肝臟及腫瘤區域的全自動精準分割是輔助醫生診斷和治療的重要前提,但是對于一般的深度學習模型[30]而言是一個非常具有挑戰性的任務。本文所構建的 T3scGAN 模型具有如下優點:① 模型的復雜度低、參數量少,可以避免網絡太深而導致的訓練困難和過擬合問題,減少了對訓練數據量的要求;② 模型具有很好的監督損失函數機制使得模型得到了充分的訓練;③ 模型不僅能優化低維的空間信息(邊界、曲面等),而且能保留高維的語義特征(細節、位置等)。本文的下一步工作是將構建的框架和模型應用于更多器官及其腫瘤區域的分割問題,同時基于自動分割結果構建疾病的預測和預后模型。
利益沖突聲明:本文全體作者均聲明不存在利益沖突。