擴散張量成像技術能提供腦白質信息,可用于探究腦區組織結構變化,但缺乏對腦組織微結構信息的特異性描述。神經突起方向離散度與密度成像模型彌補了其不足,但獲取腦組織微結構的準確估計參數需要大量的擴散梯度,同時通過最大似然擬合,整個過程計算復雜、消耗時間長。為此本文提出了一種基于近端梯度網絡估計微結構參數的方法,進一步避免了經典的擬合范式。該方法能夠在減少擴散梯度數量的情況下,仍能夠準確估計參數,實現成像質量優于神經突起方向離散度與密度成像模型和通過凸優化加速微觀結構成像模型的目的。
引用本文: 徐永紅, 王朋飛, 丁玲. 基于近端梯度網絡的腦組織微結構參數估計方法. 生物醫學工程學雜志, 2021, 38(2): 333-341. doi: 10.7507/1001-5515.202004043 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
引言
在過去的 20 年中,擴散磁共振成像(diffusion magnetic resonance imaging,dMRI)已經成為研究組織微結構最有前景的方法之一,特別是在腦白質研究中[1]。擴散加權磁共振信號作為微結構的探針,通過捕獲神經組織中水分子位移的各向異性模式,以非侵入的方式揭示細胞層面的組織信息。微結構成像是目前非常活躍的研究領域,對了解腦發育及老化、腦疾病的病理變化及神經損傷的研究具有重要價值[2-5]。
擴散張量成像(diffusion tensor imaging,DTI)是 dMRI 技術應用最廣泛的模型之一,對水分子擴散的各向異性建模,從中推斷大腦內白質纖維的方向[6]。但 DTI 缺乏對組織的特異性描述,也無法描述多個纖維交叉、彎曲等復雜結構特征。由于 DTI 過于簡單,目前已經提出了許多微結構成像技術,將組織結構與擴散信號相聯系建立生物物理模型,從中推斷微觀結構信息,例如:受阻與受限制復合擴散模型(composite hindered and restricted model of diffusion,CHARMED)[7]、神經突方向分散度和密度成像(neurite orientation dispersion and density imaging,NODDI)[8]等多隔室模型。微結構成像技術將體素中的信號視為多個隔室的共同作用的結果,每個隔室針對不同細胞成分的水分子擴散建模,經數值擬合得到軸突密度、軸突直徑和方向分布等微觀特征。Zhang 等[8]提出 NODDI 模型對細胞內、細胞外和腦脊液(cerebrospinal fluid,CSF)三種組織環境建模,評估神經突微結構的復雜性以反映神經纖維的形態學信息,但模型采用非線性擬合導致計算復雜度高、計算時間過長而難以應用于臨床。隨后,Daducci 等[9]提出凸優化加速微觀結構成像(accelerated microstructure imaging via convex optimization,AMICO)框架,利用凸優化的通用性將 NODDI 模型重新描述為等價但簡單的線性系統,將擬合速度提高一個數量級。
近年來,深度學習算法已成功應用于計算機視覺領域并顯現出特有優勢[10],且在醫學圖像處理和圖像分析領域快速發展[11-12]。目前已有研究將深度學習算法應用于腦組織微結構成像同時取得較好結果:Golkov 等[13]應用多層感知機在減少擴散梯度數量的情況下估計 NODDI 模型參數,相較于傳統方法在掃描時間與圖像質量之間進行平衡。Gibbons 等[14]開發一種多維深度學習方法,從高度欠采樣的 q 空間數據中同時生成 NODDI 指標和廣義各向異性分數圖像。除此之外,還有一類網絡基于優化學習的策略在解決逆問題方面具有一定的優勢。例如,在解決正則化最小二乘問題時,可根據展開與截斷常規迭代優化過程構建網絡,通過網絡學習權重無需預設權重。在速度和準確性方面,這些方法已被證明可以與傳統的優化方法進行比較。已有研究人員應用優化算法來計算組織微結構。Ye[15-16]展開迭代硬閾值過程來計算具有學習權重的稀疏表示;之后 Ye 等[17]又將改進的長短時記憶單元用于網絡設計,在迭代優化過程中自適應納入歷史信息以降低稀疏重建的誤差。
目前微結構成像技術正在實現從技術研究到臨床應用研究的轉變,面臨著擬合時間較長、減少擴散梯度估計質量變差、參數較多導致調整困難等挑戰。本文針對上述問題,提出擴散梯度數量減少時實現快速而穩定的微結構參數估計算法。算法受磁共振成像(magnetic resonance imaging,MRI)快速重建方法[18]啟發,基于優化學習的策略[19]設計深度網絡,采用數據驅動的方法來學習最佳正則化參數,應用近端梯度算法[20]展開估計稀疏向量迭代過程,并與其他組件連接起來以計算組織的微結構。進一步,利用已開發的多種優化算法[21-24]來解決正則化最小二乘問題,將近端梯度算法重寫為深度網絡進行迭代更新[18],更為簡單直接地隱式學習正則化函數,實現 NODDI 模型的微觀結構快速估計。然后,在公開數據集上與 NODDI 模型傳統擬合方法、AMICO 框架對比。最終,期望本文實驗結果能夠實現設計的擬合方法速度明顯優于傳統擬合方法,達到提高擬合精度的目的。
1 數據與方法
1.1 數據
本實驗使用的 MRI 數據來自華盛頓大學、明尼蘇達大學和牛津大學聯合構建的人類連接組項目(human connectome project,HCP)(網址為:https://www.humanconnectome.org/study/hcp-young-adult)的開源數據集[25]。該數據集在 3T MRI 掃描儀上獲取 1 200 名健康成年受試者的 dMRI 成像,數據分辨率為各向同性 1.25 mm,包括 270 個擴散梯度方向,b 值分別為 1 000、2 000、3 000 s/mm2 的擴散加權圖像及 18 個 b 值為 0 s/mm2 的非擴散加權圖像組成,此數據集已經過包括針對運動和平面回波成像(echo planar imaging,EPI)失真的預處理。目前已發表的論文多采用 HCP 數據庫來驗證提出方法的性能。
1.2 NODDI 模型
NODDI 建立的組織模型可區分三種微結構環境下的水擴散:細胞內、細胞外和 CSF 隔室。細胞內和細胞外環境分別代表神經突內部和外部的組織成分,CSF 隔室指 CSF 所占據的空間。不同環境導致水分子不同的擴散模式,并產生各自的歸一化 MRI 信號。完整的標準化信號A可表示為如式(1)所示:
 |
其中,Aic、Aec 和 Aiso 分別表示細胞內、細胞外和 CSF 隔室的標準化信號,各隔室體積分數包括:細胞內體積分數(volume fraction of the intra-cellular compartment,Vic)(以符號 vic 表示)、腦脊液體積分數(volume fraction of the CSF compartment,Viso)(以符號 viso 表示)。
(1)細胞內隔室指神經突膜環繞的空間,當水分子的擴散垂直于神經突方向時受限制,沿神經突方向則不受阻礙。NODDI 模型用一組呈沃森(Watson)分布的零半徑圓柱體將細胞內信號 歸一化為如式(2)所示:
歸一化為如式(2)所示:
 |
其中,q 和 b 分別表示與擴散梯度相關的梯度方向和 b 值, 表示單位球面,
表示單位球面, 表示沿方向 n 發現圓柱體的概率,方向分布函數
表示沿方向 n 發現圓柱體的概率,方向分布函數  符合 Watson 分布,方向分布函數
符合 Watson 分布,方向分布函數  計算如式(3)所示:
計算如式(3)所示:
 |
其中,M 是合流超幾何函數,μ 表示神經突的方向,κ 表示方向分散程度參數。
(2)細胞外隔室指神經突周圍空間,水分子的擴散雖不受限制但受到阻礙,因此可以建模簡單的各向異性擴散,細胞外信號模型表示為如式(4)所示:
 |
其中,D(n)表示主要擴散方向為 n 的圓柱對稱張量,d‖ 和 d⊥ 分別為與 n 垂直和平行的擴散系數,平行擴散系數 d‖ 與細胞內隔室內部擴散系數相同,垂直擴散系數 d⊥ 可由簡單曲折度模型計算  。
。
(3)在 CSF 隔室中,水分子自由擴散,因此可以建模擴散系數 diso 為各向同性高斯分布,標準化信號 viso 表示為如式(5)所示:
 |
模型將 d‖ 和 diso 固定為先驗值,將觀測的擴散信號應用最大似然法估計模型中未知參數 μ、vic、viso 和 κ。方向分散度(orientation dispersion,OD)(以符號 OD 表示)可由 κ 計算如式(6)所示:
 |
NODDI 模型中參數 vic、viso 和 OD 共同描述了腦組織的微觀結構特征,為大腦的發育及老化和神經系統疾病的研究提供微觀結構指標,其中 vic 可以反映神經密度,OD 量化軸突的彎曲和分叉度。
1.3 近端梯度網絡
受 AMICO 框架的啟發,將原有字典學習方法擴展為數據驅動學習方法。本文使用基于優化的學習策略設計深度神經網絡,無需再人為設計字典,具體通過設計和展開估計稀疏向量的迭代過程來構建網絡,再將其他模塊連接到網絡中來計算組織微觀結構。近端梯度網絡包括兩個級聯階段,第一部分計算擴散信號的空間角度稀疏表示,第二部分將稀疏表示映射到組織微結構,兩階段功能不同,兩個階段中的參數是共同學習的。
假設每個體素中的 dMRI 信號具有稀疏表示,對于擴散信號  存在字典 Φ 和字典系數 f 表示如式(7)所示:
存在字典 Φ 和字典系數 f 表示如式(7)所示:
 |
角域稀疏編碼問題可以表示為如式(8)所示:
 |
其中,β 是調整字典系數 f 稀疏度的可調參數。已有算法可以解決式(8)的凸優化問題[26-27],本文應用近端梯度法迭代求解,對于第 k 次迭代,執行梯度更新 f 如式(9)所示:
 |
 表示字典的轉置,t 是設置梯度步長大小,字典原子的系數 f 預測為 f(k+)。之后解決正則化函數近端問題,如式(10)所示:
表示字典的轉置,t 是設置梯度步長大小,字典原子的系數 f 預測為 f(k+)。之后解決正則化函數近端問題,如式(10)所示:
 |
u 是作為輔助變量將正則化轉換為容易解決的凸優化問題。在第 k 次迭代結束,字典系數 f(k) 通過式(9)計算得到 f(k+1)。對于特定的正則化步驟如  ,近端問題可看作一個簡單的軟閾值步驟。針對 dMRI 圖像中不同的 b 值與梯度方向,本文采用數據驅動的方式來學習最優正則化函數和正則化參數替代傳統方法。
,近端問題可看作一個簡單的軟閾值步驟。針對 dMRI 圖像中不同的 b 值與梯度方向,本文采用數據驅動的方式來學習最優正則化函數和正則化參數替代傳統方法。
盡管可以直接學習正則化函數,但是學習式(10)的近端步驟可以更為簡單直接地隱式學習正則化函數。將近端步驟替換為要學習的深度神經網絡,式(10)重寫為如式(6)所示:
 |
其中, 中 θk 是學習的參數,式(9)和式(11)的步驟通過固定迭代次數展開,信號稀疏表示的字典 ΦN 和擴散信號矢量 y 作為模型
中 θk 是學習的參數,式(9)和式(11)的步驟通過固定迭代次數展開,信號稀疏表示的字典 ΦN 和擴散信號矢量 y 作為模型  的輸入,由字典 ΦNi 和第
的輸入,由字典 ΦNi 和第  次迭代得到的字典系數計算擴散信號
次迭代得到的字典系數計算擴散信號  、字典系數
、字典系數  ,如式(12)所示:
,如式(12)所示:
 |
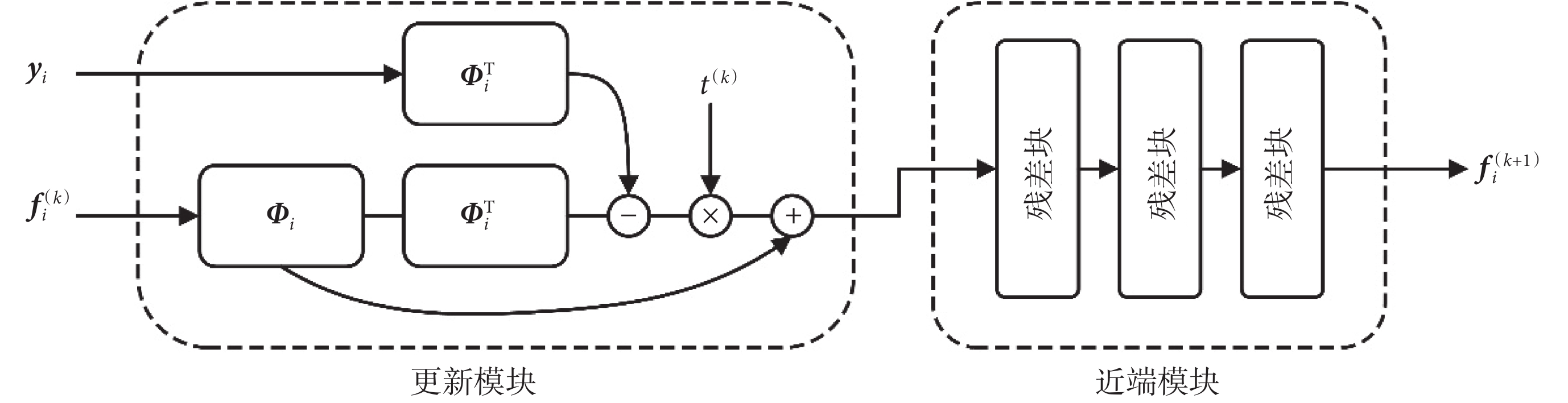
使用 fi 進一步計算所求微結構參數,近端梯度模塊結構如圖 1 所示。
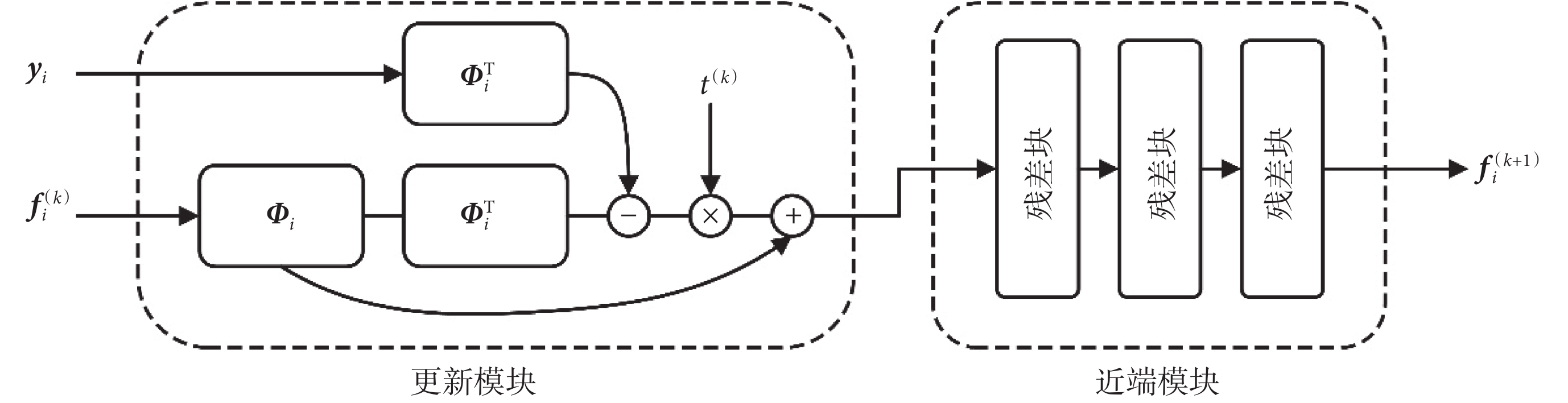 圖1
近端梯度模塊
Figure1.
Proximal gradient block
圖1
近端梯度模塊
Figure1.
Proximal gradient block
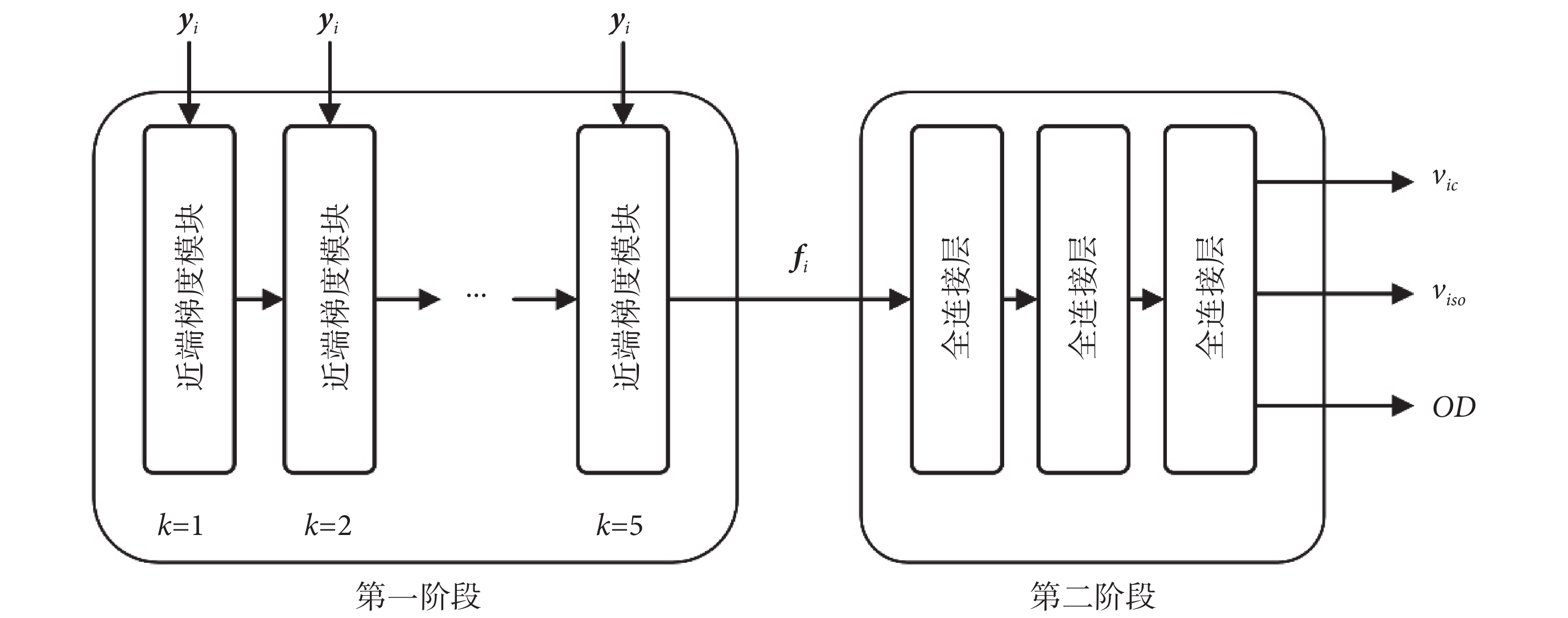
第二階段確定從字典系數f到組織微結構參數的映射。由于未在第一階段中明確設計字典,因此映射的形式未知,第二階段的全連接層將提取的特征映射到最終預測,使用三個全連接層估計微觀結構,每層由 300 個隱藏節點組成,再經過線性激活函數(rectified linear unit,ReLU)。如圖 2 所示為設計的基于深度學習的近端梯度網絡模型的結構。
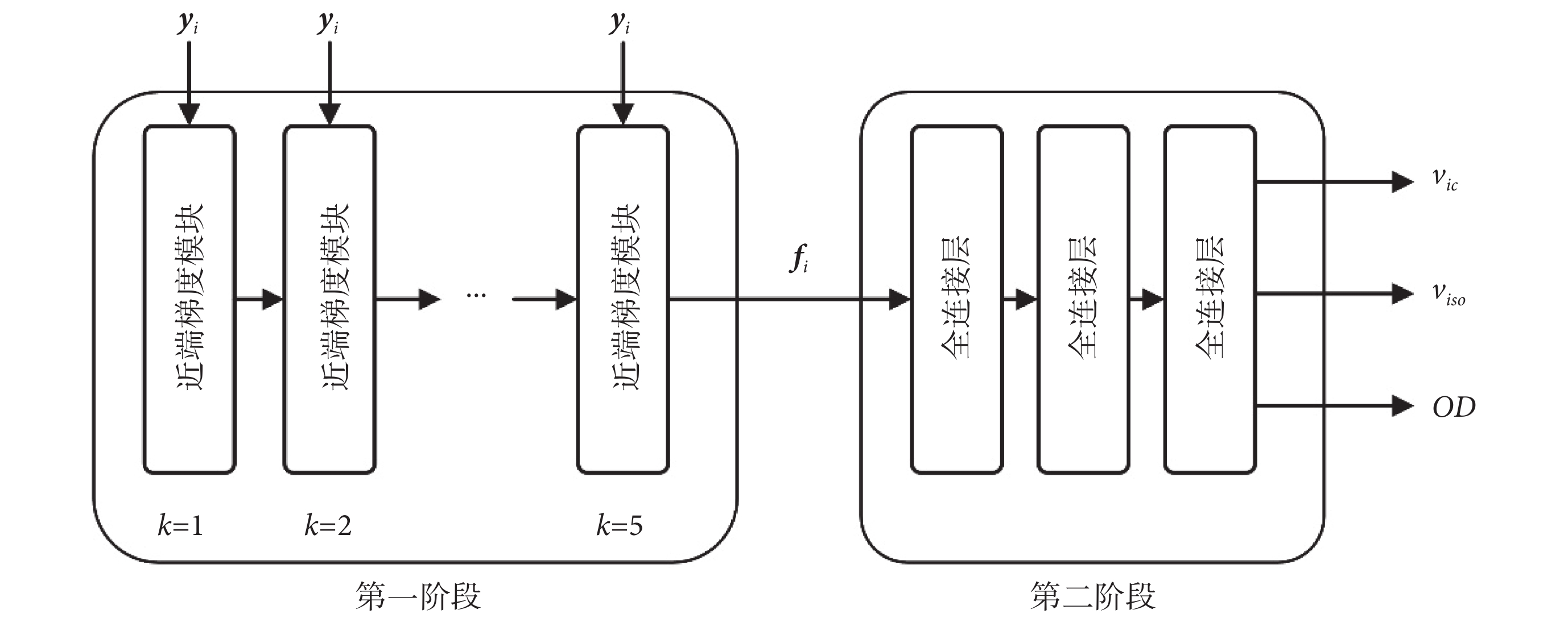 圖2
近端梯度網絡總體結構
Figure2.
Overall Structure of proximal gradient
圖2
近端梯度網絡總體結構
Figure2.
Overall Structure of proximal gradient
近端梯度網絡共分為兩個階段,網絡中使用殘差塊提高了網絡模型的泛化能力,使模型能夠很好地應對梯度彌散的狀況,yi 代表數據信號,Φi 代表第 i 次迭代的字典,ΦiT 代表 Φi 的轉置, 代表梯度步長,k 表示近端梯度模塊執行迭代的次數。
代表梯度步長,k 表示近端梯度模塊執行迭代的次數。
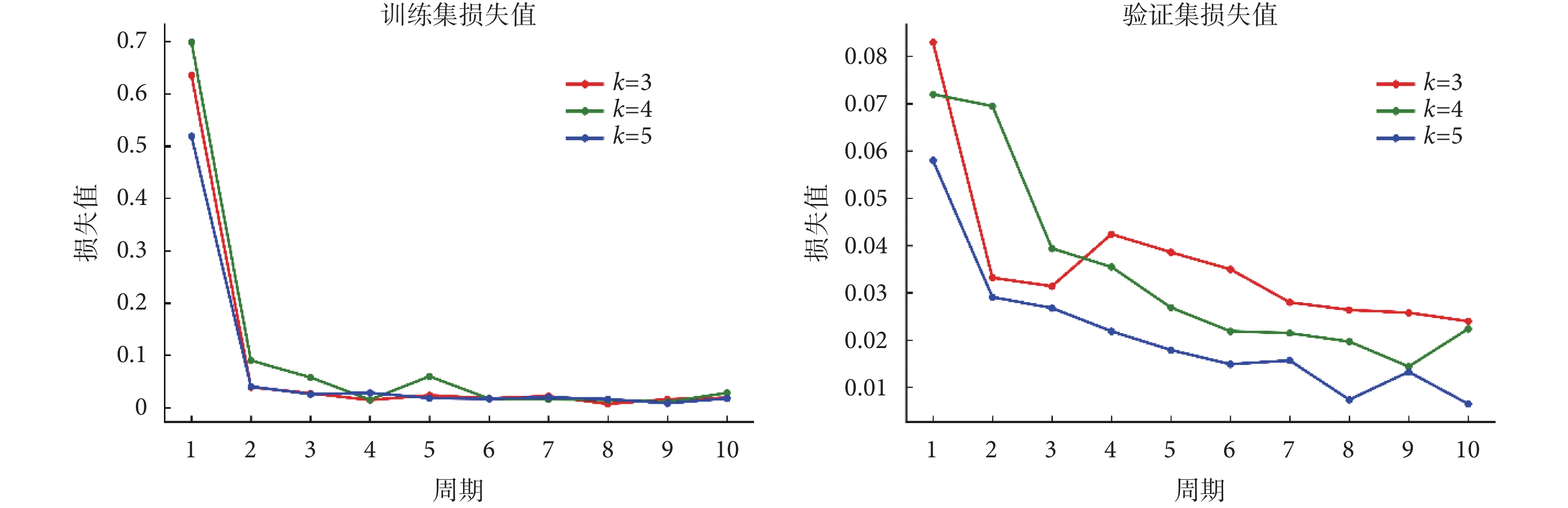
隨后,對近端梯度網絡的訓練階段進行研究,如圖 3 所示顯示了使用不同迭代次數并在每個周期之后繪制相應的訓練集和驗證集損失值,損失值指的是微觀結構參數預測的均方誤差。可以看出在 10 個周期后訓練集損失值和驗證集損失值都變得穩定。當近端梯度模塊迭代次數k增加時存在較小的訓練損失,驗證損失減少。出于訓練時間和訓練數據擬合質量的考慮,最終將迭代次數設置為 5。
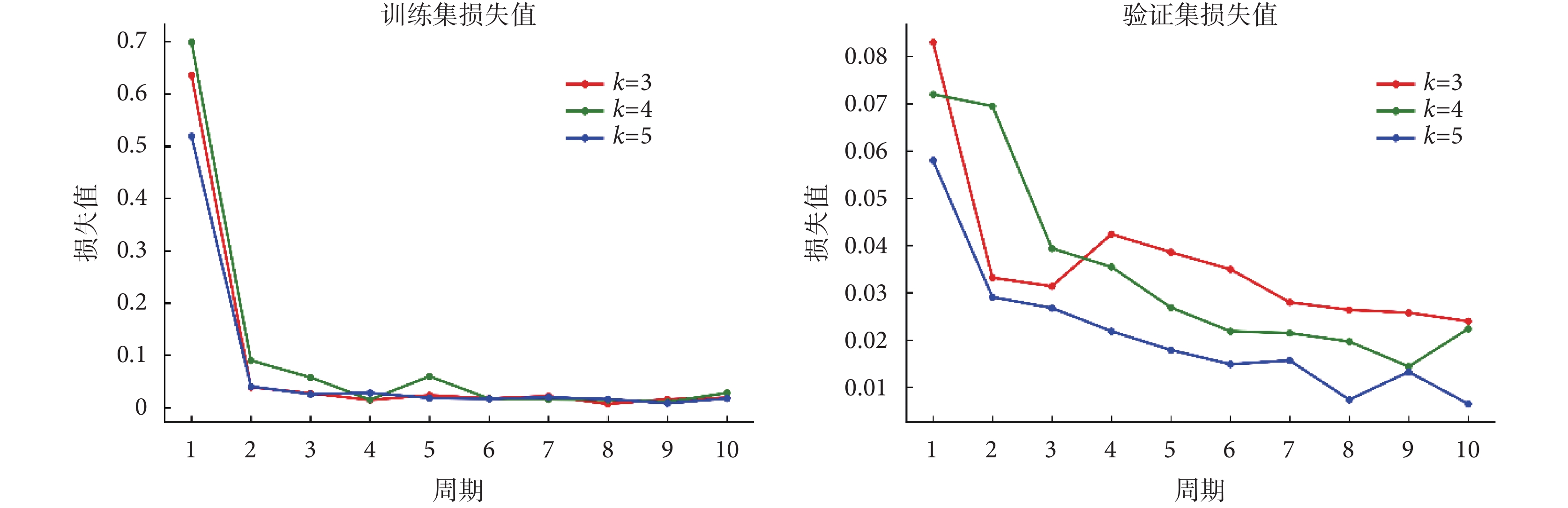 圖3
近端梯度網絡每個周期的訓練集和驗證集損失值
Figure3.
The training and validation loss after each epoch in the training phase in proximal gradient network
圖3
近端梯度網絡每個周期的訓練集和驗證集損失值
Figure3.
The training and validation loss after each epoch in the training phase in proximal gradient network
從 Nath 等[28]設計的網絡中得到啟發,網絡第一階段近端模塊中殘差塊神經元選為 300、200、300。近端梯度網絡通過最小化微結構參數vic、viso、OD的均方誤差之和共同學習所有網絡權重,選擇 Adam 算法作為優化器,學習率為 0.000 1,批量大小為 128,迭代周期為 10 次。網絡模型中將 10% 的訓練樣本作為驗證集,避免訓練階段出現過擬合現象[13]。
1.4 實驗軟硬件環境
本文實驗運行于微軟操作系統 Windows 10(Microsoft Inc.,美國)和操作系統 Ubuntu 16.04(Canonical Inc.,美國)下,中央處理器為 AMD(Ryzen 5-2600,AMD Inc.,美國),內存大小為 24 GB,圖形處理器為 GTX1650(NVIDIA Inc.,美國)。在 Windows 10 系統上使用 NODDI Matlab 工具箱(http://mig.cs.ucl.ac.uk/index.php?n=Tutorial.NODDImatlab)實現傳統擬合方法;并在此系統上利用開源人工神經網絡庫 Keras(Google Inc.,美國)和深度學習框架 Theano(蒙特利爾大學,加拿大)作為后端搭建近端梯度網絡。此外,在 Ubuntu 16.04 系統上搭建 AMICO 算法框架作為對比算法擬合數據。
1.5 評價指標
本文采用均方根誤差(root mean square error,RMSE)(以符號RMSE表示)、峰值信噪比(peak signal to noise ratio,PSNR)(以符號PSNR表示)、結構相似性(structural similarity index,SSIM)(以符號SSIM表示)作為圖像質量的評價指標。RMSE 用于表征兩圖之間的偏差,數值越小表示預測圖像越好;PSNR 其值越大則表示預測圖像失真越少;SSIM 由亮度、對比度、結構相似性三個因素組成,是衡量圖片相似度的指標,數值越大代表兩幅圖越相似,三個指標的計算公式分別如式(13)~(15)所示:
 |
式中, 表示擬合結果,
表示擬合結果, 表示金標準,
表示金標準, 指全部體素的數量。
指全部體素的數量。
 |
 表示圖像像素值值域的最大值,而 MSE 是原圖像與處理圖像之間均方誤差,其中 PSNR 的單位為 dB。
表示圖像像素值值域的最大值,而 MSE 是原圖像與處理圖像之間均方誤差,其中 PSNR 的單位為 dB。
 |
其中, 是圖像
是圖像  的均值,
的均值, 是圖像
是圖像  的均值;
的均值; 為
為  的方差,
的方差, 為
為  的方差;
的方差; 是
是  和
和  的方差,
的方差, 、
、 均為常數來避免分母為零,
均為常數來避免分母為零, 和
和  分別默認為 0.01、0.03,L 指像素范圍。
分別默認為 0.01、0.03,L 指像素范圍。
2 結果
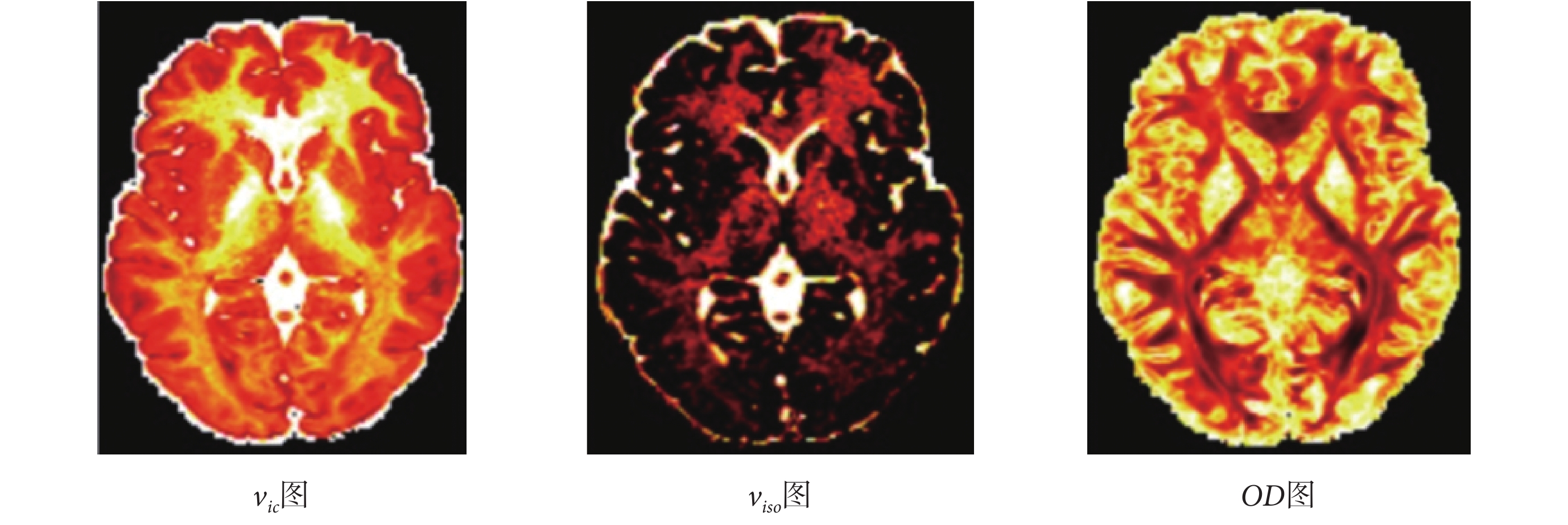
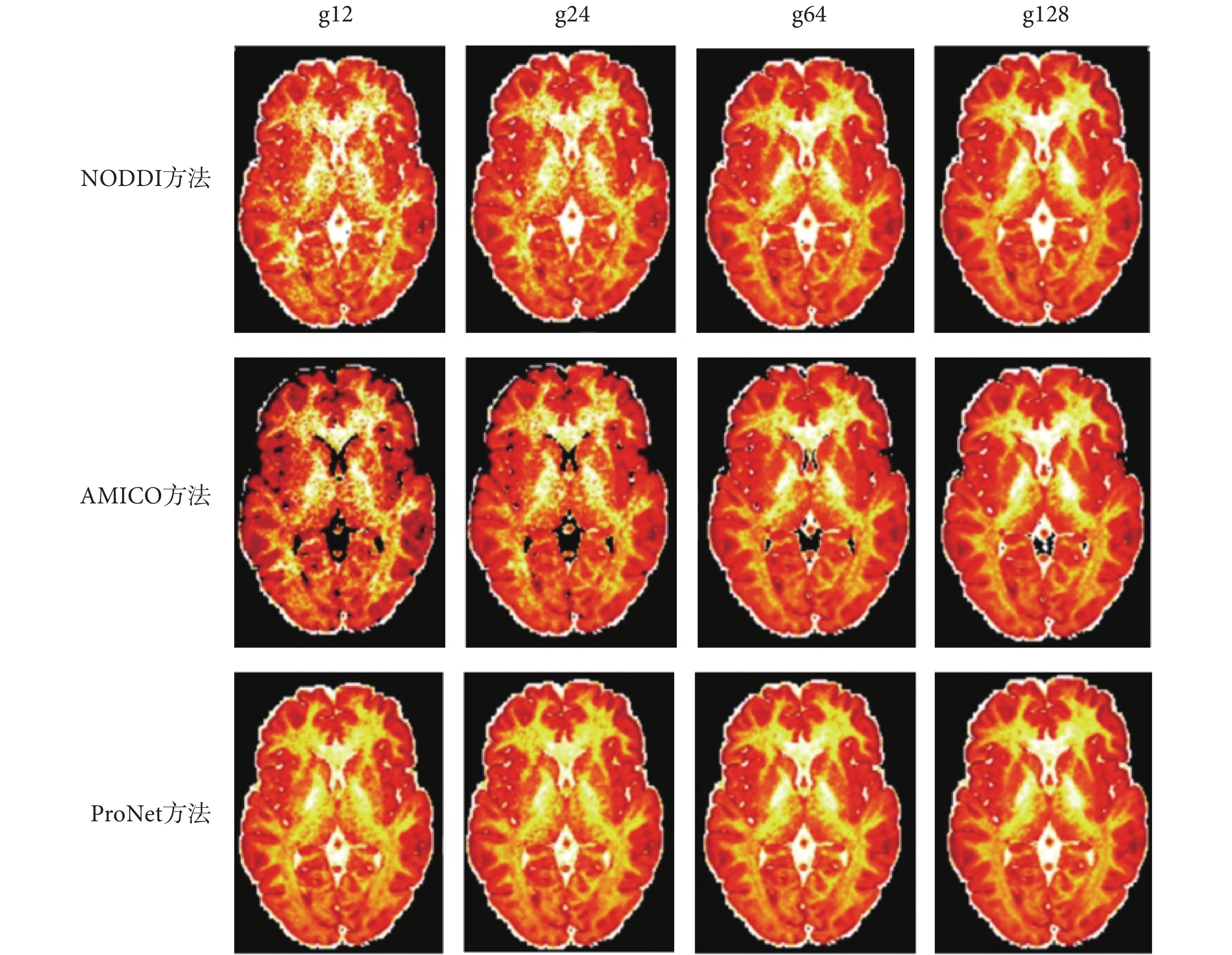
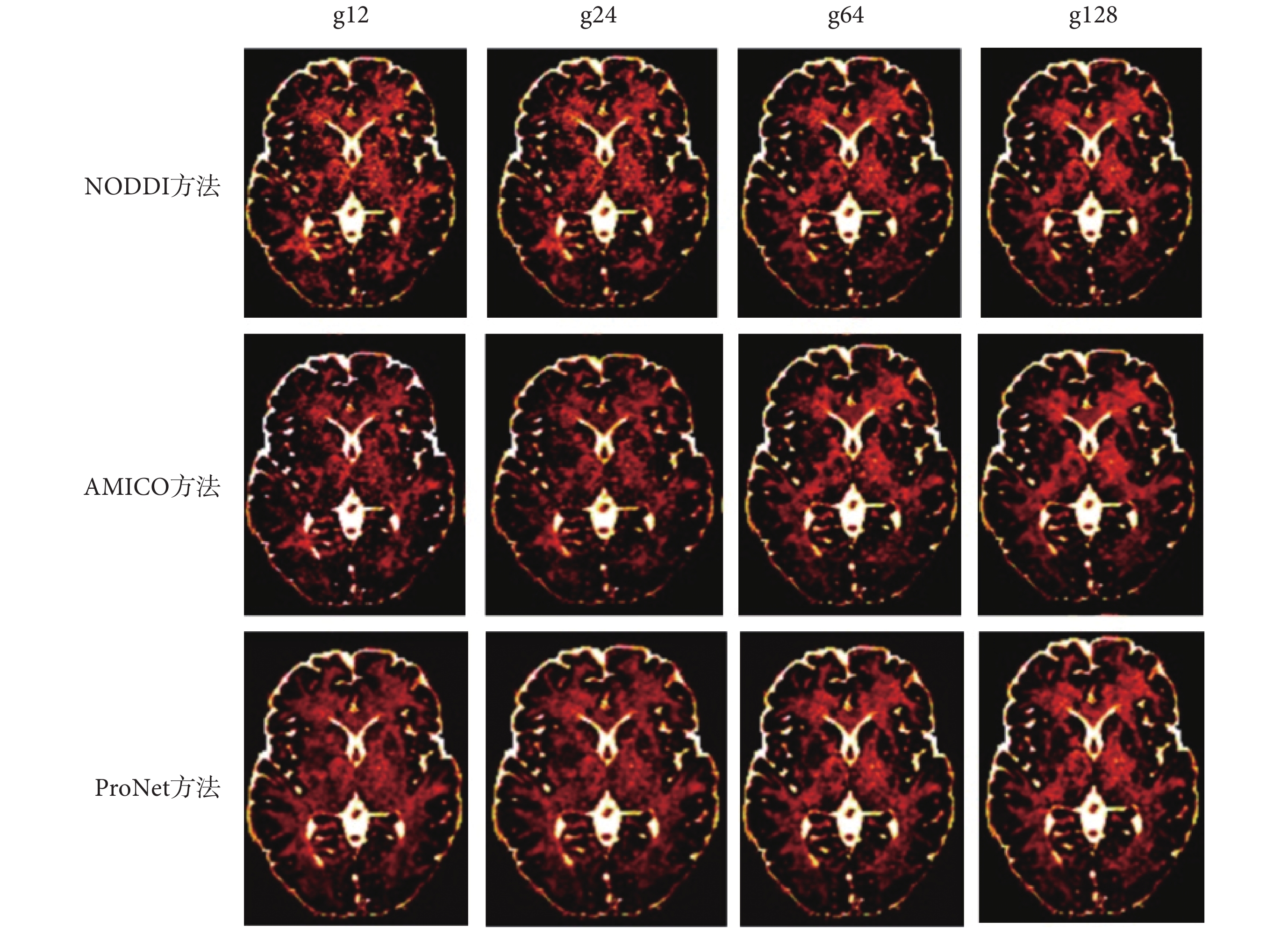
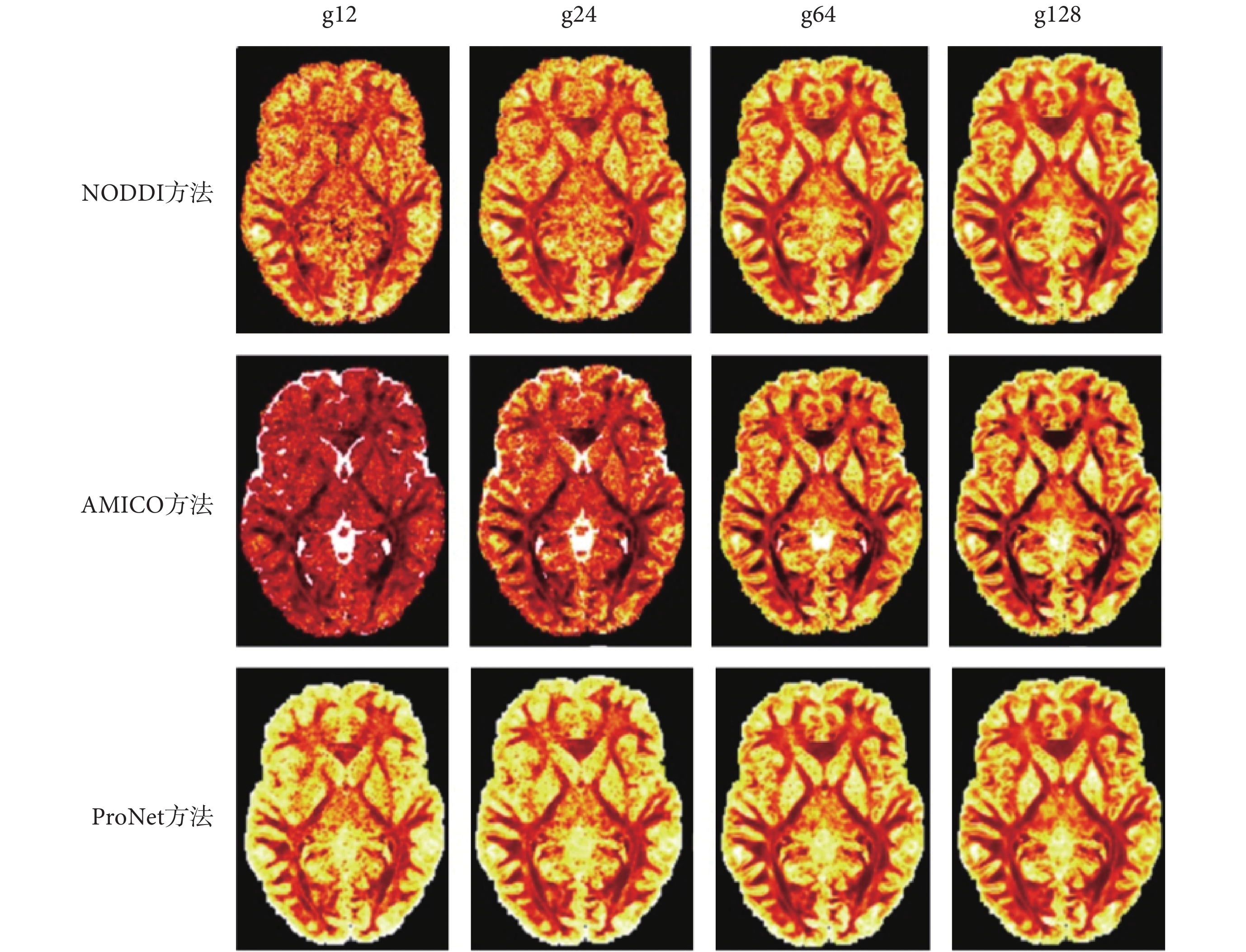
針對原數據過大且對硬件內存要求較高,本實驗把原數據格式 145 × 174 × 145 × 288 下采樣為 145 × 174 × 43 × 288 格式,然后以全梯度下 NODDI 方法擬合結果作為標準,以 10 個數據作為訓練集訓練網絡,并在不同下采樣梯度下與 NODDI、AMICO 方法進行比較,金標準圖如圖 4 所示,三種方法生成的 vic、viso、OD 參數圖分別如圖 5、圖 6、圖 7 所示,圖 5、圖 6、圖 7 從上到下第一行方法為 NODDI,第二行方法為 AMICO,第三行方法為本文方法(在下文中用 ProNet 表示);每一行從左到右梯度分別為 12、24、64、128。NODDI、AMICO 和 ProNet 方法在 RMSE、PSNR 和 SSIM 評價指標下的平均值如表 1 所示。
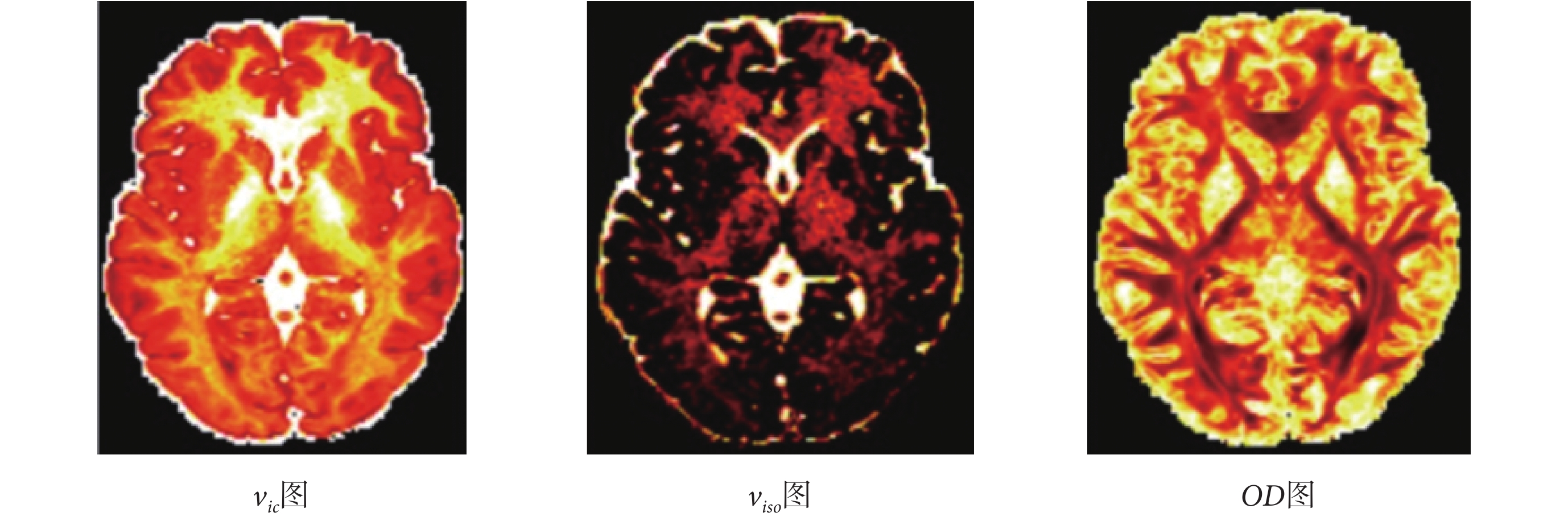 圖4
金標準vic、viso、OD圖
Figure4.
The gold standard of figure vic、figure viso and figure OD
圖4
金標準vic、viso、OD圖
Figure4.
The gold standard of figure vic、figure viso and figure OD
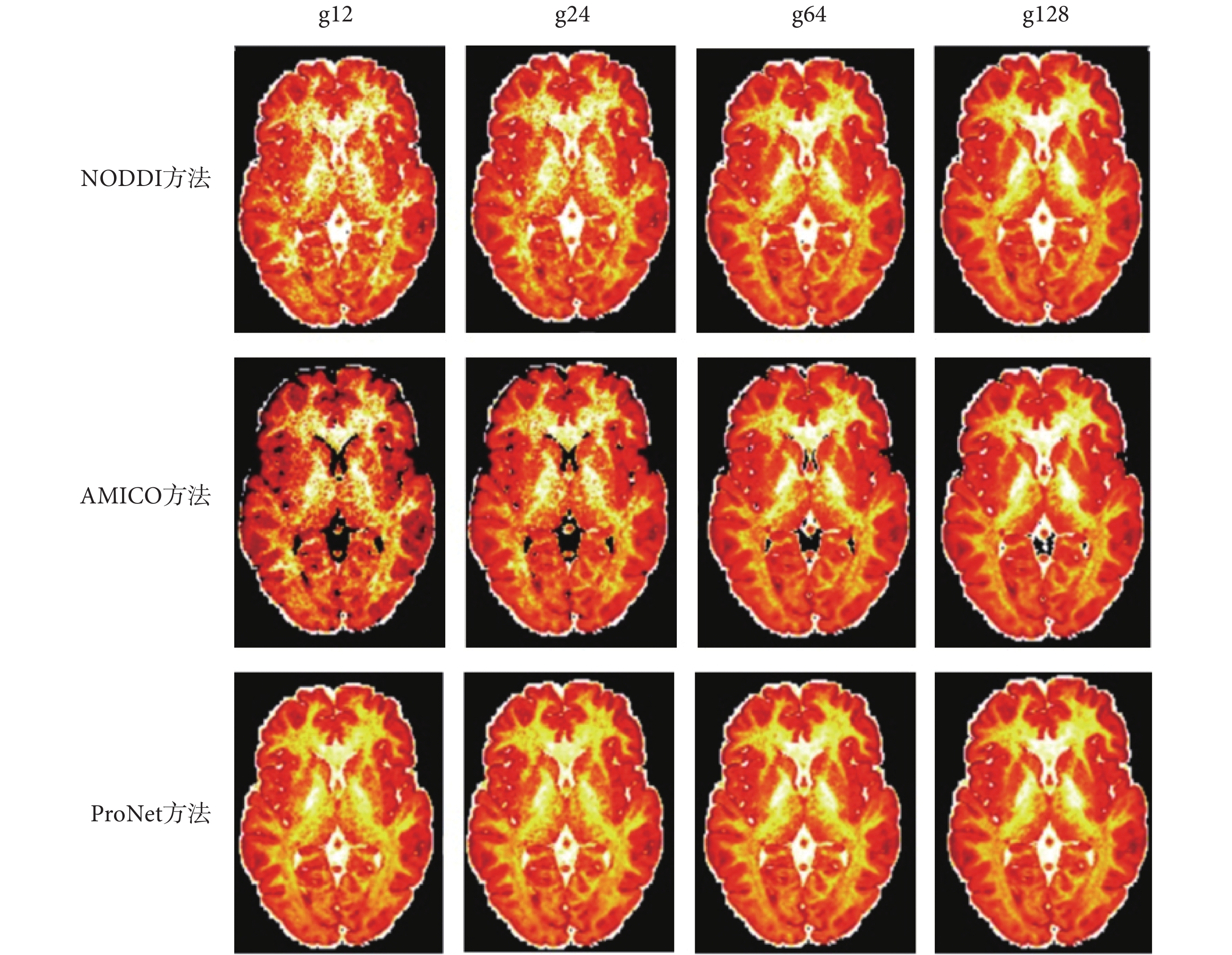 圖5
三種方法不同梯度下vic成像
Figure5.
Three methods of vic imaging with different gradients
圖5
三種方法不同梯度下vic成像
Figure5.
Three methods of vic imaging with different gradients
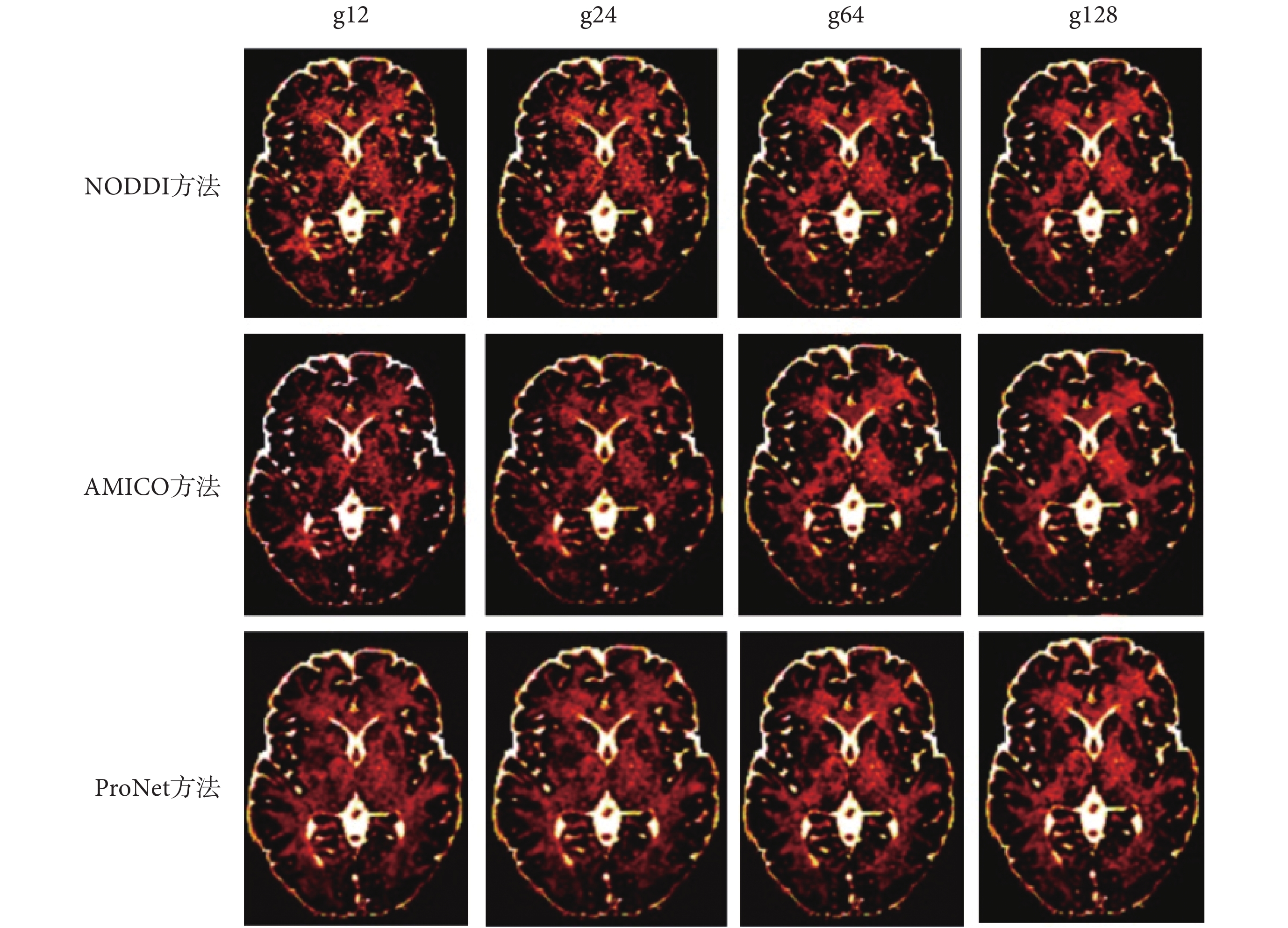 圖6
三種方法不同梯度下viso成像
Figure6.
Three methods of viso imaging with different gradients
圖6
三種方法不同梯度下viso成像
Figure6.
Three methods of viso imaging with different gradients
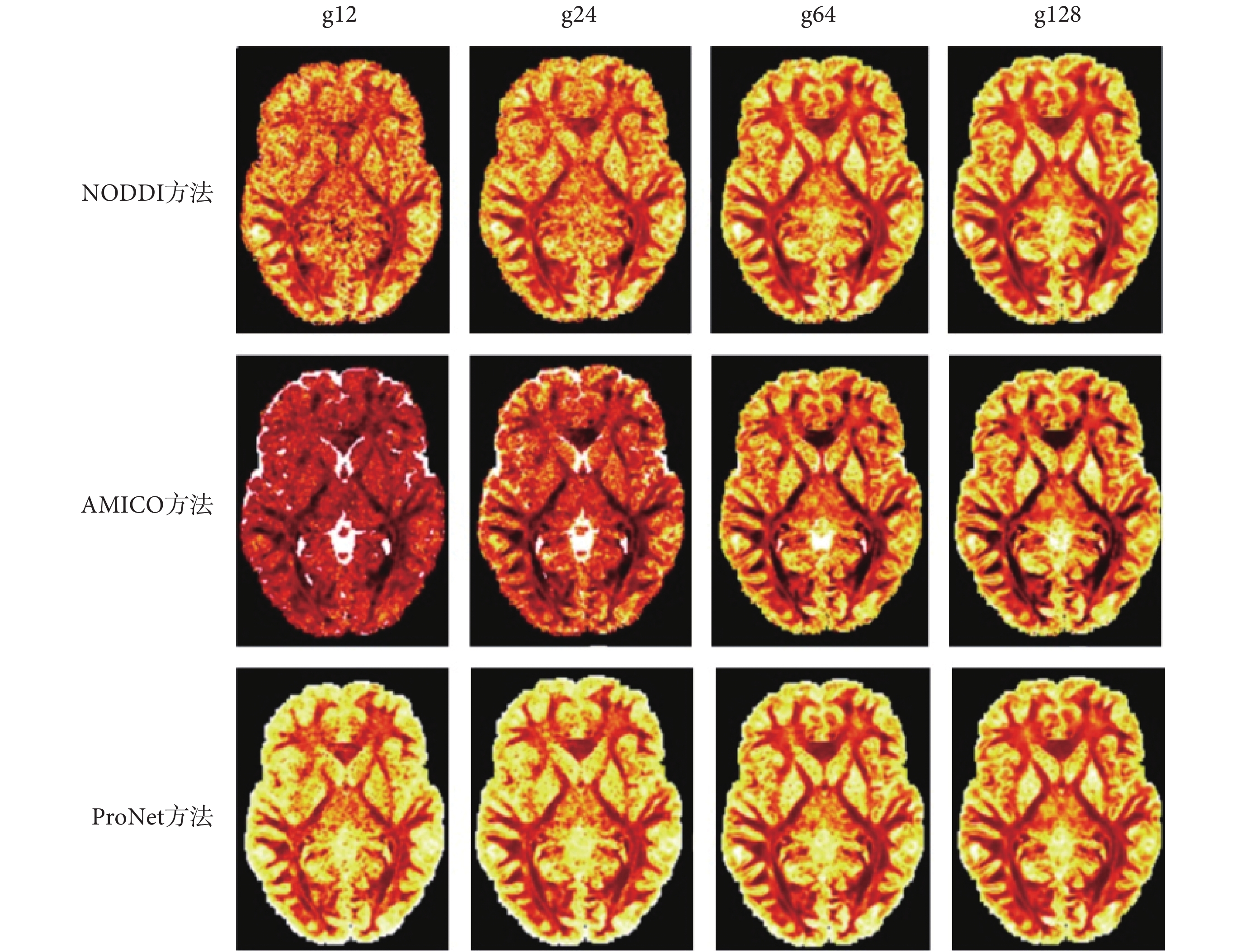 圖7
三種方法不同梯度下OD成像
Figure7.
Three methods of OD imaging with different gradients
圖7
三種方法不同梯度下OD成像
Figure7.
Three methods of OD imaging with different gradients
如圖 5、圖 7 所示,可以看出 NODDI 和 AMICO 方法成像受梯度影響較大,ProNet 方法隨梯度變化較小,在擴散梯度為 12 時,vic 和 OD 參數圖的成像對比,可見 AMICO 方法受梯度影響最大。
在評價指標 RMSE、PSNR 和 SSIM 下三種擬合方法對比如表 1 所示,表 1 中用 g 代表梯度,g12、g24、g64 和 g128 分別表示擴散梯度方向的數量為 12、24、64 和 128。從表 1 中數值可以看出三種方法的 RMSE 值隨著梯度的增加均降低,PSNR 值和 SSIM 值隨著梯度的增加均增加。NODDI 方法始終優于 AMICO 方法,ProNet 方法在梯度為 64、128 時評價指標 SSIM 低于 NODDI 方法,其余情況下 ProNet 方法在 RMSE、PSNR 和 SSIM 均優于 NODDI 和 AMICO 方法。特別在擴散梯度為 64 時,ProNet 方法的 RMSE 值低于梯度為 128 時 AMICO 方法,對應的 PSNR 和 SSIM 指標高于 AMICO 方法,說明基于深度神經網絡的 ProNet 方法在擴散梯度減少時仍能提供準確穩定的腦組織微結構參數估計。改進方法 AMICO 雖然擬合結果略差于傳統方法 NODDI 和基于深度學習的 ProNet 方法,但擬合速度明顯優于傳統 NODDI 方法,以梯度為 12 為例三種擬合方法所用時間對比如下:NODDI 方法用時 35 460 s;AMICO 方法用時 1 491 s;本文提出的 ProNet 方法訓練用時 4 260 s,擬合測試數據用時 169 s。實驗顯示 NODDI 方法運行時間過長,測試數據在 ProNet 方法上擬合速度最快。
3 討論與分析
基于深度神經網絡的 ProNet 方法與原有 NODDI 模型擬合方法、AMICO 框架方法相比大大縮短擬合時間。在大量擴散梯度時,ProNet 方法擬合參數結果略差于 NODDI 方法,是因為在加速成像過程中去除傳統方法的蒙特卡洛下采樣所導致;ProNet 方法在擴散梯度為 64、128 時,SSIM 指標數值低于 NODDI 方法,考慮可能由于網絡黑匣子的特性導致存在一定的不確定性。ProNet 方法在較少擴散梯度情況下,仍能維持穩定的微結構參數估計,并且在擬合速度上相對于傳統方法 NODDI 和改進方法 AMICO 顯現出突出優勢。但基于深度神經網絡的 ProNet 對數據有依賴性,若沒有足夠訓練集將難以達到理想效果,這將是實際應用中需要解決的難題。
本文通過殘差網絡學習近端梯度算法更新參數來解決凸優化問題,設計了一種近端梯度神經網絡,相對于 NODDI 和 AMICO 模型擬合方法,ProNet 方法能夠更好地挖掘到 dMRI 數據中腦組織微結構的信息,同時打破了傳統方法受擴散梯度的限制,并且擬合速度較快,對于數據的采集和后期數據的處理都有重大意義。基于深度學習的微結構參數估計方法為微結構成像技術的臨床應用開創了新的前景,一方面深度學習算法與模型擬合方法相比,能夠從有限的擴散加權成像數據挖掘到更多信息;另一方面使用擴散加權圖像的數量可以自由選擇,比傳統方法更加靈活地權衡了掃描時間與圖像質量。
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
引言
在過去的 20 年中,擴散磁共振成像(diffusion magnetic resonance imaging,dMRI)已經成為研究組織微結構最有前景的方法之一,特別是在腦白質研究中[1]。擴散加權磁共振信號作為微結構的探針,通過捕獲神經組織中水分子位移的各向異性模式,以非侵入的方式揭示細胞層面的組織信息。微結構成像是目前非常活躍的研究領域,對了解腦發育及老化、腦疾病的病理變化及神經損傷的研究具有重要價值[2-5]。
擴散張量成像(diffusion tensor imaging,DTI)是 dMRI 技術應用最廣泛的模型之一,對水分子擴散的各向異性建模,從中推斷大腦內白質纖維的方向[6]。但 DTI 缺乏對組織的特異性描述,也無法描述多個纖維交叉、彎曲等復雜結構特征。由于 DTI 過于簡單,目前已經提出了許多微結構成像技術,將組織結構與擴散信號相聯系建立生物物理模型,從中推斷微觀結構信息,例如:受阻與受限制復合擴散模型(composite hindered and restricted model of diffusion,CHARMED)[7]、神經突方向分散度和密度成像(neurite orientation dispersion and density imaging,NODDI)[8]等多隔室模型。微結構成像技術將體素中的信號視為多個隔室的共同作用的結果,每個隔室針對不同細胞成分的水分子擴散建模,經數值擬合得到軸突密度、軸突直徑和方向分布等微觀特征。Zhang 等[8]提出 NODDI 模型對細胞內、細胞外和腦脊液(cerebrospinal fluid,CSF)三種組織環境建模,評估神經突微結構的復雜性以反映神經纖維的形態學信息,但模型采用非線性擬合導致計算復雜度高、計算時間過長而難以應用于臨床。隨后,Daducci 等[9]提出凸優化加速微觀結構成像(accelerated microstructure imaging via convex optimization,AMICO)框架,利用凸優化的通用性將 NODDI 模型重新描述為等價但簡單的線性系統,將擬合速度提高一個數量級。
近年來,深度學習算法已成功應用于計算機視覺領域并顯現出特有優勢[10],且在醫學圖像處理和圖像分析領域快速發展[11-12]。目前已有研究將深度學習算法應用于腦組織微結構成像同時取得較好結果:Golkov 等[13]應用多層感知機在減少擴散梯度數量的情況下估計 NODDI 模型參數,相較于傳統方法在掃描時間與圖像質量之間進行平衡。Gibbons 等[14]開發一種多維深度學習方法,從高度欠采樣的 q 空間數據中同時生成 NODDI 指標和廣義各向異性分數圖像。除此之外,還有一類網絡基于優化學習的策略在解決逆問題方面具有一定的優勢。例如,在解決正則化最小二乘問題時,可根據展開與截斷常規迭代優化過程構建網絡,通過網絡學習權重無需預設權重。在速度和準確性方面,這些方法已被證明可以與傳統的優化方法進行比較。已有研究人員應用優化算法來計算組織微結構。Ye[15-16]展開迭代硬閾值過程來計算具有學習權重的稀疏表示;之后 Ye 等[17]又將改進的長短時記憶單元用于網絡設計,在迭代優化過程中自適應納入歷史信息以降低稀疏重建的誤差。
目前微結構成像技術正在實現從技術研究到臨床應用研究的轉變,面臨著擬合時間較長、減少擴散梯度估計質量變差、參數較多導致調整困難等挑戰。本文針對上述問題,提出擴散梯度數量減少時實現快速而穩定的微結構參數估計算法。算法受磁共振成像(magnetic resonance imaging,MRI)快速重建方法[18]啟發,基于優化學習的策略[19]設計深度網絡,采用數據驅動的方法來學習最佳正則化參數,應用近端梯度算法[20]展開估計稀疏向量迭代過程,并與其他組件連接起來以計算組織的微結構。進一步,利用已開發的多種優化算法[21-24]來解決正則化最小二乘問題,將近端梯度算法重寫為深度網絡進行迭代更新[18],更為簡單直接地隱式學習正則化函數,實現 NODDI 模型的微觀結構快速估計。然后,在公開數據集上與 NODDI 模型傳統擬合方法、AMICO 框架對比。最終,期望本文實驗結果能夠實現設計的擬合方法速度明顯優于傳統擬合方法,達到提高擬合精度的目的。
1 數據與方法
1.1 數據
本實驗使用的 MRI 數據來自華盛頓大學、明尼蘇達大學和牛津大學聯合構建的人類連接組項目(human connectome project,HCP)(網址為:https://www.humanconnectome.org/study/hcp-young-adult)的開源數據集[25]。該數據集在 3T MRI 掃描儀上獲取 1 200 名健康成年受試者的 dMRI 成像,數據分辨率為各向同性 1.25 mm,包括 270 個擴散梯度方向,b 值分別為 1 000、2 000、3 000 s/mm2 的擴散加權圖像及 18 個 b 值為 0 s/mm2 的非擴散加權圖像組成,此數據集已經過包括針對運動和平面回波成像(echo planar imaging,EPI)失真的預處理。目前已發表的論文多采用 HCP 數據庫來驗證提出方法的性能。
1.2 NODDI 模型
NODDI 建立的組織模型可區分三種微結構環境下的水擴散:細胞內、細胞外和 CSF 隔室。細胞內和細胞外環境分別代表神經突內部和外部的組織成分,CSF 隔室指 CSF 所占據的空間。不同環境導致水分子不同的擴散模式,并產生各自的歸一化 MRI 信號。完整的標準化信號A可表示為如式(1)所示:
|
其中,Aic、Aec 和 Aiso 分別表示細胞內、細胞外和 CSF 隔室的標準化信號,各隔室體積分數包括:細胞內體積分數(volume fraction of the intra-cellular compartment,Vic)(以符號 vic 表示)、腦脊液體積分數(volume fraction of the CSF compartment,Viso)(以符號 viso 表示)。
(1)細胞內隔室指神經突膜環繞的空間,當水分子的擴散垂直于神經突方向時受限制,沿神經突方向則不受阻礙。NODDI 模型用一組呈沃森(Watson)分布的零半徑圓柱體將細胞內信號歸一化為如式(2)所示:
|
其中,q 和 b 分別表示與擴散梯度相關的梯度方向和 b 值, 表示單位球面, 表示沿方向 n 發現圓柱體的概率,方向分布函數 符合 Watson 分布,方向分布函數 計算如式(3)所示:
|
其中,M 是合流超幾何函數,μ 表示神經突的方向,κ 表示方向分散程度參數。
(2)細胞外隔室指神經突周圍空間,水分子的擴散雖不受限制但受到阻礙,因此可以建模簡單的各向異性擴散,細胞外信號模型表示為如式(4)所示:
|
其中,D(n)表示主要擴散方向為 n 的圓柱對稱張量,d‖ 和 d⊥ 分別為與 n 垂直和平行的擴散系數,平行擴散系數 d‖ 與細胞內隔室內部擴散系數相同,垂直擴散系數 d⊥ 可由簡單曲折度模型計算 。
(3)在 CSF 隔室中,水分子自由擴散,因此可以建模擴散系數 diso 為各向同性高斯分布,標準化信號 viso 表示為如式(5)所示:
|
模型將 d‖ 和 diso 固定為先驗值,將觀測的擴散信號應用最大似然法估計模型中未知參數 μ、vic、viso 和 κ。方向分散度(orientation dispersion,OD)(以符號 OD 表示)可由 κ 計算如式(6)所示:
|
NODDI 模型中參數 vic、viso 和 OD 共同描述了腦組織的微觀結構特征,為大腦的發育及老化和神經系統疾病的研究提供微觀結構指標,其中 vic 可以反映神經密度,OD 量化軸突的彎曲和分叉度。
1.3 近端梯度網絡
受 AMICO 框架的啟發,將原有字典學習方法擴展為數據驅動學習方法。本文使用基于優化的學習策略設計深度神經網絡,無需再人為設計字典,具體通過設計和展開估計稀疏向量的迭代過程來構建網絡,再將其他模塊連接到網絡中來計算組織微觀結構。近端梯度網絡包括兩個級聯階段,第一部分計算擴散信號的空間角度稀疏表示,第二部分將稀疏表示映射到組織微結構,兩階段功能不同,兩個階段中的參數是共同學習的。
假設每個體素中的 dMRI 信號具有稀疏表示,對于擴散信號 存在字典 Φ 和字典系數 f 表示如式(7)所示:
|
角域稀疏編碼問題可以表示為如式(8)所示:
|
其中,β 是調整字典系數 f 稀疏度的可調參數。已有算法可以解決式(8)的凸優化問題[26-27],本文應用近端梯度法迭代求解,對于第 k 次迭代,執行梯度更新 f 如式(9)所示:
|
表示字典的轉置,t 是設置梯度步長大小,字典原子的系數 f 預測為 f(k+)。之后解決正則化函數近端問題,如式(10)所示:
|
u 是作為輔助變量將正則化轉換為容易解決的凸優化問題。在第 k 次迭代結束,字典系數 f(k) 通過式(9)計算得到 f(k+1)。對于特定的正則化步驟如 ,近端問題可看作一個簡單的軟閾值步驟。針對 dMRI 圖像中不同的 b 值與梯度方向,本文采用數據驅動的方式來學習最優正則化函數和正則化參數替代傳統方法。
盡管可以直接學習正則化函數,但是學習式(10)的近端步驟可以更為簡單直接地隱式學習正則化函數。將近端步驟替換為要學習的深度神經網絡,式(10)重寫為如式(6)所示:
|
其中, 中 θk 是學習的參數,式(9)和式(11)的步驟通過固定迭代次數展開,信號稀疏表示的字典 ΦN 和擴散信號矢量 y 作為模型 的輸入,由字典 ΦNi 和第 次迭代得到的字典系數計算擴散信號 、字典系數 ,如式(12)所示:
|
使用 fi 進一步計算所求微結構參數,近端梯度模塊結構如圖 1 所示。
圖1
近端梯度模塊
Figure1.
Proximal gradient block
第二階段確定從字典系數f到組織微結構參數的映射。由于未在第一階段中明確設計字典,因此映射的形式未知,第二階段的全連接層將提取的特征映射到最終預測,使用三個全連接層估計微觀結構,每層由 300 個隱藏節點組成,再經過線性激活函數(rectified linear unit,ReLU)。如圖 2 所示為設計的基于深度學習的近端梯度網絡模型的結構。
圖2
近端梯度網絡總體結構
Figure2.
Overall Structure of proximal gradient
近端梯度網絡共分為兩個階段,網絡中使用殘差塊提高了網絡模型的泛化能力,使模型能夠很好地應對梯度彌散的狀況,yi 代表數據信號,Φi 代表第 i 次迭代的字典,ΦiT 代表 Φi 的轉置, 代表梯度步長,k 表示近端梯度模塊執行迭代的次數。
隨后,對近端梯度網絡的訓練階段進行研究,如圖 3 所示顯示了使用不同迭代次數并在每個周期之后繪制相應的訓練集和驗證集損失值,損失值指的是微觀結構參數預測的均方誤差。可以看出在 10 個周期后訓練集損失值和驗證集損失值都變得穩定。當近端梯度模塊迭代次數k增加時存在較小的訓練損失,驗證損失減少。出于訓練時間和訓練數據擬合質量的考慮,最終將迭代次數設置為 5。
圖3
近端梯度網絡每個周期的訓練集和驗證集損失值
Figure3.
The training and validation loss after each epoch in the training phase in proximal gradient network
從 Nath 等[28]設計的網絡中得到啟發,網絡第一階段近端模塊中殘差塊神經元選為 300、200、300。近端梯度網絡通過最小化微結構參數vic、viso、OD的均方誤差之和共同學習所有網絡權重,選擇 Adam 算法作為優化器,學習率為 0.000 1,批量大小為 128,迭代周期為 10 次。網絡模型中將 10% 的訓練樣本作為驗證集,避免訓練階段出現過擬合現象[13]。
1.4 實驗軟硬件環境
本文實驗運行于微軟操作系統 Windows 10(Microsoft Inc.,美國)和操作系統 Ubuntu 16.04(Canonical Inc.,美國)下,中央處理器為 AMD(Ryzen 5-2600,AMD Inc.,美國),內存大小為 24 GB,圖形處理器為 GTX1650(NVIDIA Inc.,美國)。在 Windows 10 系統上使用 NODDI Matlab 工具箱(http://mig.cs.ucl.ac.uk/index.php?n=Tutorial.NODDImatlab)實現傳統擬合方法;并在此系統上利用開源人工神經網絡庫 Keras(Google Inc.,美國)和深度學習框架 Theano(蒙特利爾大學,加拿大)作為后端搭建近端梯度網絡。此外,在 Ubuntu 16.04 系統上搭建 AMICO 算法框架作為對比算法擬合數據。
1.5 評價指標
本文采用均方根誤差(root mean square error,RMSE)(以符號RMSE表示)、峰值信噪比(peak signal to noise ratio,PSNR)(以符號PSNR表示)、結構相似性(structural similarity index,SSIM)(以符號SSIM表示)作為圖像質量的評價指標。RMSE 用于表征兩圖之間的偏差,數值越小表示預測圖像越好;PSNR 其值越大則表示預測圖像失真越少;SSIM 由亮度、對比度、結構相似性三個因素組成,是衡量圖片相似度的指標,數值越大代表兩幅圖越相似,三個指標的計算公式分別如式(13)~(15)所示:
|
式中,表示擬合結果,表示金標準,指全部體素的數量。
|
表示圖像像素值值域的最大值,而 MSE 是原圖像與處理圖像之間均方誤差,其中 PSNR 的單位為 dB。
|
其中, 是圖像 的均值, 是圖像 的均值; 為 的方差, 為 的方差; 是 和 的方差,、 均為常數來避免分母為零, 和 分別默認為 0.01、0.03,L 指像素范圍。
2 結果
針對原數據過大且對硬件內存要求較高,本實驗把原數據格式 145 × 174 × 145 × 288 下采樣為 145 × 174 × 43 × 288 格式,然后以全梯度下 NODDI 方法擬合結果作為標準,以 10 個數據作為訓練集訓練網絡,并在不同下采樣梯度下與 NODDI、AMICO 方法進行比較,金標準圖如圖 4 所示,三種方法生成的 vic、viso、OD 參數圖分別如圖 5、圖 6、圖 7 所示,圖 5、圖 6、圖 7 從上到下第一行方法為 NODDI,第二行方法為 AMICO,第三行方法為本文方法(在下文中用 ProNet 表示);每一行從左到右梯度分別為 12、24、64、128。NODDI、AMICO 和 ProNet 方法在 RMSE、PSNR 和 SSIM 評價指標下的平均值如表 1 所示。
圖4
金標準vic、viso、OD圖
Figure4.
The gold standard of figure vic、figure viso and figure OD
圖5
三種方法不同梯度下vic成像
Figure5.
Three methods of vic imaging with different gradients
圖6
三種方法不同梯度下viso成像
Figure6.
Three methods of viso imaging with different gradients
圖7
三種方法不同梯度下OD成像
Figure7.
Three methods of OD imaging with different gradients
如圖 5、圖 7 所示,可以看出 NODDI 和 AMICO 方法成像受梯度影響較大,ProNet 方法隨梯度變化較小,在擴散梯度為 12 時,vic 和 OD 參數圖的成像對比,可見 AMICO 方法受梯度影響最大。
在評價指標 RMSE、PSNR 和 SSIM 下三種擬合方法對比如表 1 所示,表 1 中用 g 代表梯度,g12、g24、g64 和 g128 分別表示擴散梯度方向的數量為 12、24、64 和 128。從表 1 中數值可以看出三種方法的 RMSE 值隨著梯度的增加均降低,PSNR 值和 SSIM 值隨著梯度的增加均增加。NODDI 方法始終優于 AMICO 方法,ProNet 方法在梯度為 64、128 時評價指標 SSIM 低于 NODDI 方法,其余情況下 ProNet 方法在 RMSE、PSNR 和 SSIM 均優于 NODDI 和 AMICO 方法。特別在擴散梯度為 64 時,ProNet 方法的 RMSE 值低于梯度為 128 時 AMICO 方法,對應的 PSNR 和 SSIM 指標高于 AMICO 方法,說明基于深度神經網絡的 ProNet 方法在擴散梯度減少時仍能提供準確穩定的腦組織微結構參數估計。改進方法 AMICO 雖然擬合結果略差于傳統方法 NODDI 和基于深度學習的 ProNet 方法,但擬合速度明顯優于傳統 NODDI 方法,以梯度為 12 為例三種擬合方法所用時間對比如下:NODDI 方法用時 35 460 s;AMICO 方法用時 1 491 s;本文提出的 ProNet 方法訓練用時 4 260 s,擬合測試數據用時 169 s。實驗顯示 NODDI 方法運行時間過長,測試數據在 ProNet 方法上擬合速度最快。
3 討論與分析
基于深度神經網絡的 ProNet 方法與原有 NODDI 模型擬合方法、AMICO 框架方法相比大大縮短擬合時間。在大量擴散梯度時,ProNet 方法擬合參數結果略差于 NODDI 方法,是因為在加速成像過程中去除傳統方法的蒙特卡洛下采樣所導致;ProNet 方法在擴散梯度為 64、128 時,SSIM 指標數值低于 NODDI 方法,考慮可能由于網絡黑匣子的特性導致存在一定的不確定性。ProNet 方法在較少擴散梯度情況下,仍能維持穩定的微結構參數估計,并且在擬合速度上相對于傳統方法 NODDI 和改進方法 AMICO 顯現出突出優勢。但基于深度神經網絡的 ProNet 對數據有依賴性,若沒有足夠訓練集將難以達到理想效果,這將是實際應用中需要解決的難題。
本文通過殘差網絡學習近端梯度算法更新參數來解決凸優化問題,設計了一種近端梯度神經網絡,相對于 NODDI 和 AMICO 模型擬合方法,ProNet 方法能夠更好地挖掘到 dMRI 數據中腦組織微結構的信息,同時打破了傳統方法受擴散梯度的限制,并且擬合速度較快,對于數據的采集和后期數據的處理都有重大意義。基于深度學習的微結構參數估計方法為微結構成像技術的臨床應用開創了新的前景,一方面深度學習算法與模型擬合方法相比,能夠從有限的擴散加權成像數據挖掘到更多信息;另一方面使用擴散加權圖像的數量可以自由選擇,比傳統方法更加靈活地權衡了掃描時間與圖像質量。
利益沖突聲明:本文全體作者均聲明不存在利益沖突。