胎兒心電信號提取對圍產期胎兒監護具備重要意義。為提高胎兒心電信號的預測精度,本文提出一種基于遺傳算法(GA)優化的長短時記憶(LSTM)網絡胎兒心電信號提取方法(GA-LSTM)。首先根據母體腹壁混合心電信號的特征,利用 GA 的全局搜索能力對 LSTM 網絡中隱層神經元個數、學習率和訓練次數進行尋優,計算參數的最優組合,使網絡拓撲結構與母體腹壁混合信號的特征相匹配;然后,使用 GA 求出的最優網絡參數構建 LSTM 網絡模型,并利用 GA-LSTM 網絡模型估計母體胸部心電信號傳輸到母體腹壁時的非線性變換;最后,利用母體胸部心電信號和 GA-LSTM 網絡模型求得的非線性變換,估計腹壁信號中所含的母體心電信號,從腹壁混合信號中減去估計出的母體心電信號,得到純凈的胎兒心電信號。本文實驗應用兩個數據庫的臨床心電信號進行實驗分析,最終結果表明:與傳統歸一化最小均方誤差(NLMS)方法、支持向量機(SVM)方法、遺傳算法支持向量機(GA-SVM)方法和 LSTM 網絡方法相比,本文所提出的方法可以提取出更為清晰的胎兒心電信號,其準確率、靈敏度、精確性和總體概率均有較好的提高,表明本文方法可以提取出較為純凈的胎兒心電信號,對圍產期胎兒健康監護具有一定的應用價值。
引用本文: 錢龍, 王文波, 陳貴詞, 喻敏. 一種基于遺傳算法優化的長短時記憶網絡胎兒心電信號提取方法. 生物醫學工程學雜志, 2021, 38(2): 257-267. doi: 10.7507/1001-5515.202004063 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
引言
孕婦圍產期胎兒監護對了解胎兒在子宮內的生長發育狀況十分重要,通常采用胎音聽診、胎心率檢測以及觀測胎兒心電圖的變化來診斷胎兒在母體子宮內的健康狀況,后者通過分析心電圖波形形態可以更早地發現妊娠期胎兒心臟的各種電生理活動是否異常。檢測胎兒心電圖中 QRS 波的變化可及時判斷胎兒是否存在缺氧、臍帶繞頸等妊娠期問題[1]。然而胎兒心電信號通常采用間接法從母親腹壁獲取,因而會包含多種噪聲:電極干擾、母體心電信號成分以及基線漂移等[2]。所以,如何消除采集的胎兒心電信號所包含的噪聲,從而分離出清晰的胎兒心電信號成為胎兒健康監護的一個重要研究內容[3]。
目前關于胎兒心電信號提取的方式提出了多種檢測方法:① 獨立成分分析法[4-5](independent component analysis,ICA)假定胎兒心電信號、母體心電信號以及噪聲相互統計獨立,從而建立 ICA 模型,在模型基礎上提取胎兒心電信號,但是此方法不適合處理超高斯和亞高斯信號,而且容易陷入局部最優解。② 盲源提取技術[6-7]在各個源信號未知的條件下,從腹壁混合信號中分離得到胎兒的心電信號,但是在該模型中,胎兒心電信號的相關特征并未得到充分利用,導致提取的胎兒心電信號準確率較低且不能清楚地反映信號的生理學意義,而且該模型的算法對胎兒心電信號的時間延遲周期的依賴性較大,其心電信號提取性能具有局限性。③ 自適應濾波法[8-9]計算簡單,但對于非平穩性胎兒心電信號的測量具有局限性。④ 匹配濾波法算法[10-11]對胎兒心電信號識別率低,容易出現誤漏診。⑤ 小波分解法[12-13]對小波基等參數的選擇較為困難,不宜實時提取,而且對于母體心電信號和胎兒心電信號重疊的部分很難進行胎兒心電信號提取。⑥ 奇異值分解法[14-15]分解出的分矩陣解釋性往往不強且分解矩陣隨時間越來越大。⑦ 神經網絡[16-18]和支持向量機方法[19]取得了較好的胎兒心電信號提取效果,但存在泛化能力弱、易落入部分最優值、網絡結構設計難等問題。
近年來,循環神經網絡(recurrent neural network,RNN)因處理時間序列信息功能強大而得到了發展。Hochreater 等[20]對 RNN 的單元結構進行改進提出了長短時記憶(long short term memory networks,LSTM)網絡模型,通過設計“門”結構解決了梯度消失和梯度爆炸以及 RNN 信息記憶能力不足的問題,提示可采用遠距離的時序信息[21]。LSTM 網絡在語音識別[22]、文本處理[23]等領域已得到成功應用,卻存在關鍵超參數,如隱層神經元數、學習率和訓練次數等難以確定的缺陷[24]。因為隱含層神經元數對模型的擬合能力起著決定性作用,學習率和訓練次數直接影響模型收斂速度和計算時長,所以 LSTM 網絡的結構參數直接控制模型拓撲結構,因此采用不同的超參數建立的網絡模型其預測性能具有較大差異,如何選擇合適參數對于建立模型來說顯得至關重要。目前,往往依賴研究者的經驗和多次實驗結果去選擇網絡模型的超參數,隨機性較大,降低了模型的預測性能。
為了提取出純凈的胎兒心電信號,本文以 LSTM 網絡模型為技術基礎,研究建立了胎兒心電信號的提取模型。考慮到目前 LSTM 網絡的胎兒心電信號提取模型的關鍵參數難以確定,利用遺傳算法(genetic algorithm,GA)對 LSTM 網絡的關鍵超參數進行優化。該模型以單通道母體的胸部心電信號作為神經網絡的輸入信號,以單通道母體的腹壁混合信號作為提取目標的輸出信號,采用 GA 優化的 LSTM 網絡來建立 GA-LSTM 網絡模型來檢測和評算母體胸部的心電信號傳輸到母體腹壁的最佳心電信號估計;在此基礎上實現從母體腹壁混合信號分離出胎兒心電信號,并與目前經典的歸一化最小均方誤差(normalized least mean square algorithm,NLMS)方法、支持向量機(support vector machines,SVM)方法、GA-SVM、LSTM 雙導聯網絡方法進行對比實驗。最終,期望通過實驗結果可以驗證本文提出的方法能有效克服胎兒心電信號不易提取的難題,為今后圍產期和妊娠期胎兒健康的長期監護提供一種可行的方法。
1 胎兒心電信號提取原理
目前普遍使用置電極法采集胎兒心電信號:在時刻 i,由置于孕婦胸部的電極采集孕婦胸部心電信號 mi,且同時刻由置于孕婦腹壁的電極采集孕婦腹壁混合信號 ui。而在孕婦腹壁心電信號 ui 中包含母體心電信號成分 si、胎兒心電信號 di 和噪聲 zi 三類信號,三類信號函數關系如式(1)所示:
 |
其中,母體心電信號成分 si 是在時刻 i 由母體胸部心電信號 mi 經非線性變換傳輸到孕婦腹壁所形成的信號,所以腹壁混合信號中的母體心電信號成分 si 的相位和幅度等相關參數都會發生改變[19, 25],非線性變換函數關系如式(2)所示:
 |
式(2)中,f(·)表示心電信號的非線性變換函數。假設能求得 f(·)的最佳估計值  ,那么就能夠利用 mi 求得 si 的最佳估計值
,那么就能夠利用 mi 求得 si 的最佳估計值  ,因此從腹壁混合信號 ui 中消除母體心電信號成分的最佳估計值
,因此從腹壁混合信號 ui 中消除母體心電信號成分的最佳估計值  就能得到僅含少量噪聲的胎兒心電信號最佳估計值
就能得到僅含少量噪聲的胎兒心電信號最佳估計值  ,函數關系如式(3)所示:
,函數關系如式(3)所示:
 |
因此,對于胎兒心電信號提取,首先使用采集的胎兒心電信號數據集的部分樣本作為訓練數據集{(Mi,ui),i = 1,2, ,l},求得輸入信號 Mi 和目標輸出信號 ui 之間的非線性變換函數 f(·)的最佳估計值
,l},求得輸入信號 Mi 和目標輸出信號 ui 之間的非線性變換函數 f(·)的最佳估計值  ,其中信號 Mi 由母體胸部心電信號 mi 和它的 J 維時間導數構成[25]。本文選取 GA-LSTM 網絡對非線性變換函數 f(·)進行擬合,首先利用訓練集數據構建 GA-LSTM 網絡模型,然后將測試集數據輸入 GA-LSTM 網絡模型,最后進行胎兒心電信號的提取。
,其中信號 Mi 由母體胸部心電信號 mi 和它的 J 維時間導數構成[25]。本文選取 GA-LSTM 網絡對非線性變換函數 f(·)進行擬合,首先利用訓練集數據構建 GA-LSTM 網絡模型,然后將測試集數據輸入 GA-LSTM 網絡模型,最后進行胎兒心電信號的提取。
如圖 1 所示為該模型提取胎兒心電信號流程圖,采用單導聯母體胸部信號作為網絡輸入,單導聯母體腹壁混合信號為目標輸出,然后利用 GA-LSTM 網絡模型估計母體胸部心電信號傳至腹壁的最佳映射,將母體胸部信號的最佳估計從母體腹壁的混合信號中進行分離,即可分離提取得到最佳的胎兒心電信號的估計。
 圖1
胎兒心電信號提取方法流程圖
Figure1.
Principle diagram of fetal electrocardiogram signal extraction algorithm
圖1
胎兒心電信號提取方法流程圖
Figure1.
Principle diagram of fetal electrocardiogram signal extraction algorithm
2 基于 GA 優化的 LSTM 網絡
2.1 LSTM 網絡
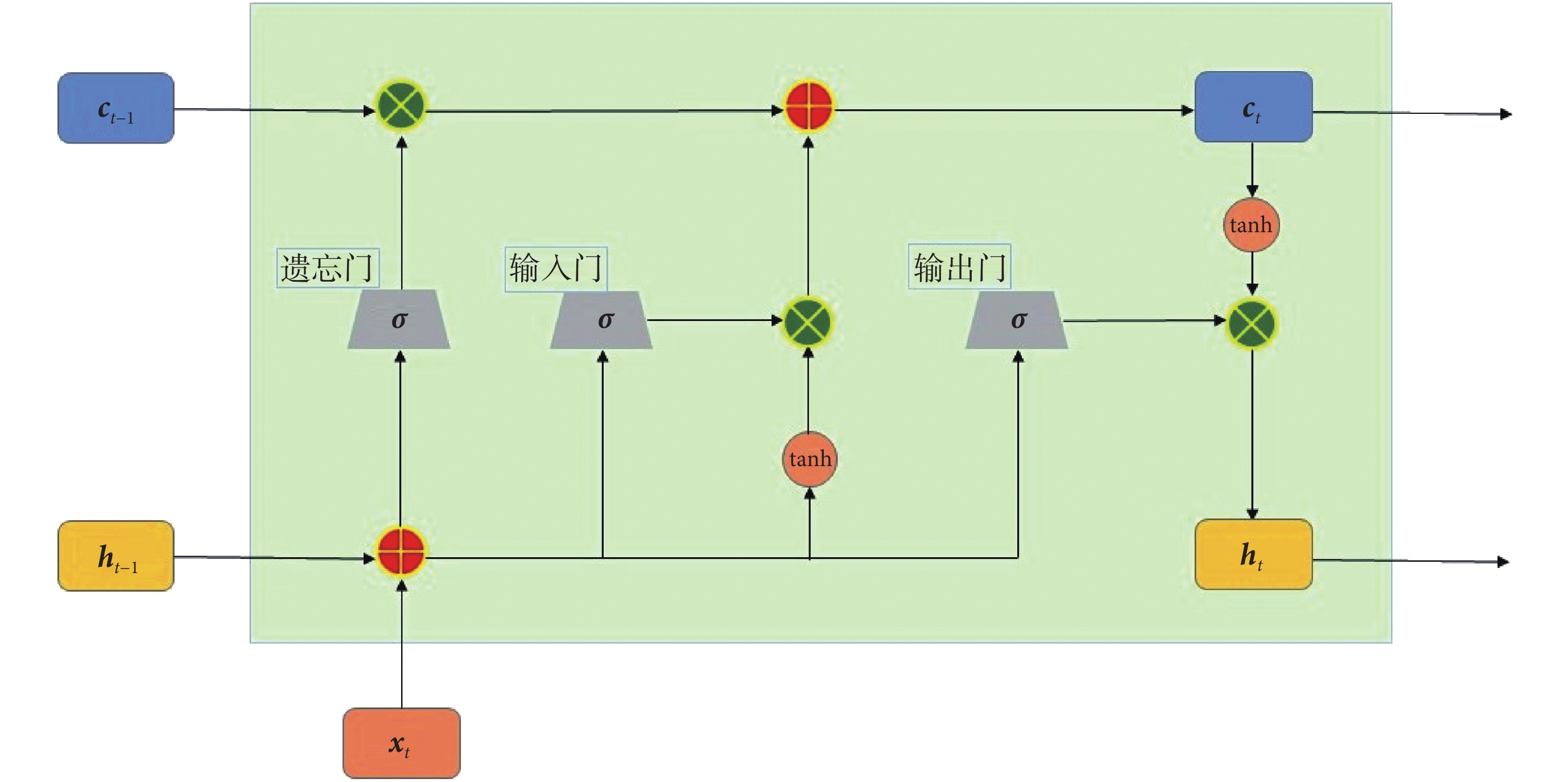
LSTM 網絡解決了網絡單元以鏈式方式鏈接的傳統遞歸神經網絡梯度消失和爆炸的問題,可有效提高學習時間[21]。在處理有關時間序列的預測和非線性映射問題中,具備記憶能力的 LSTM 網絡模型表現出較強的優勢[20, 22]。LSTM 網絡結構中添加了一種叫做記憶單元(memory cell,mc)的結構來記憶過去的信息,并且增加了輸入門(input gate,ig)、輸出門(output gate,og)和遺忘門(forget gate,fg)三種門結構來控制歷史信息的傳遞[21]。
LSTM 網絡結構如圖 2 所示。設網絡輸入為 ,隱層狀態為
,隱層狀態為 ,網絡在時刻 t,各個單元和門控的計算如式(4)~(9)所示:
,網絡在時刻 t,各個單元和門控的計算如式(4)~(9)所示:
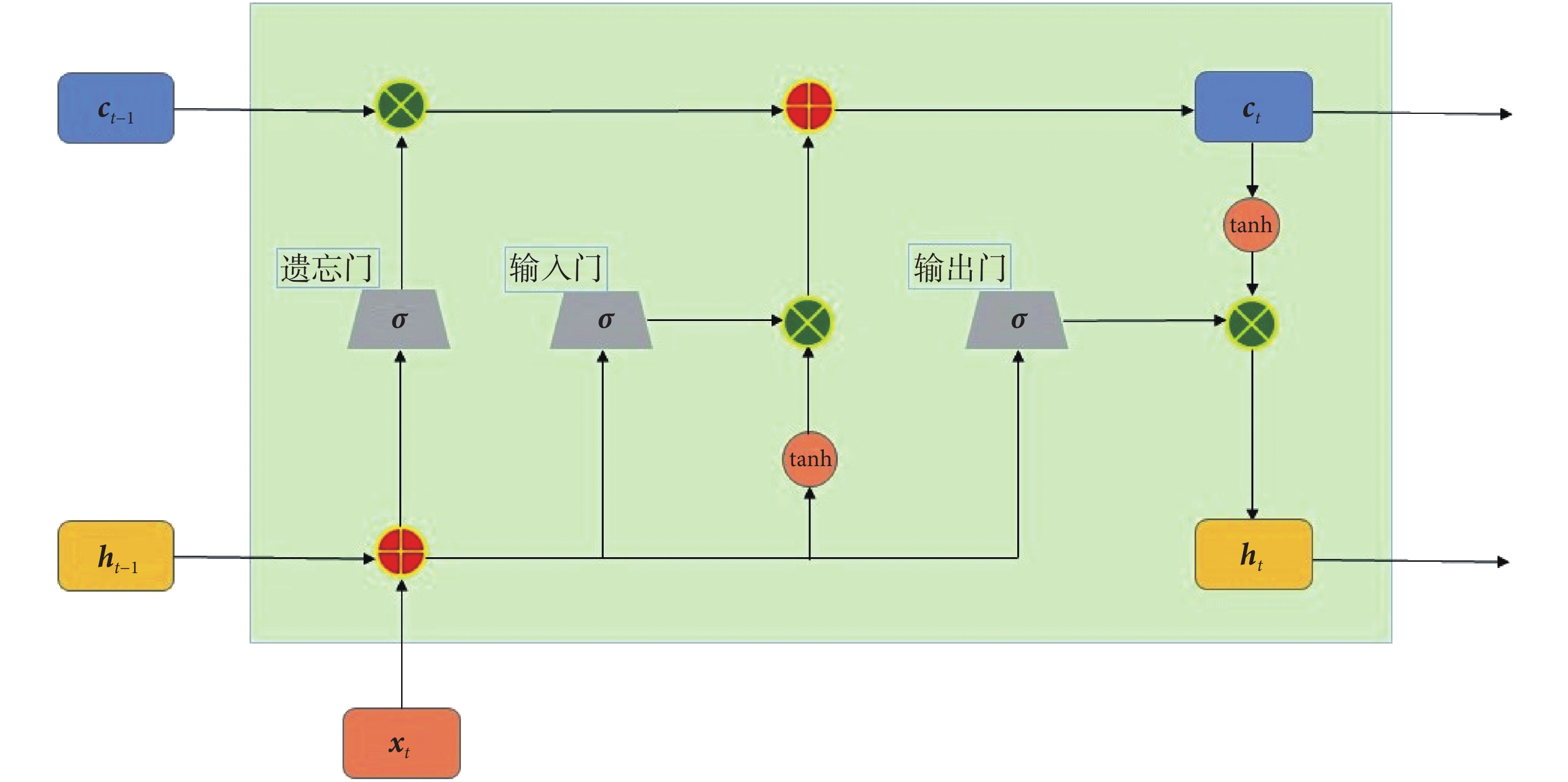 圖2
LSTM 網絡結構圖
Figure2.
LSTM network structure diagram
圖2
LSTM 網絡結構圖
Figure2.
LSTM network structure diagram
 |
 |
 |
 |
 |
 |
式(4)~(9)中,it、ft、ot 分別為輸入門、遺忘門和輸出門的計算;其中,輸入門主要用來決定保留多少當前時刻的輸入信息到當前時刻的單元狀態;遺忘門主要用來決定保留多少上一時刻的單元狀態 ct ? 1 的信息到當前時刻單元狀態 ct 中;輸出門主要用來決定當前時刻的單元狀態有多少輸出。ht 為當前時刻網絡最終輸出,ht ? 1 為上一時刻網絡的輸出, 為當前輸入的單元狀態;ct 為當前時刻的單元狀態;wig、wfg、wcg、wog 分別為三個門控和單元狀態的權重矩陣;big、bfg、bcg、bog 分別為各個門控和單元狀態的偏置;σ(·)和 tanh(·)為傳輸函數,· 代表向量內積,符號
為當前輸入的單元狀態;ct 為當前時刻的單元狀態;wig、wfg、wcg、wog 分別為三個門控和單元狀態的權重矩陣;big、bfg、bcg、bog 分別為各個門控和單元狀態的偏置;σ(·)和 tanh(·)為傳輸函數,· 代表向量內積,符號  表示按元素相乘。
表示按元素相乘。
2.2 GA 優化的 LSTM 網絡心電信號提取模型
GA 通常是計算機模擬達爾文生物進化論的生物科學研究算法,1977 年由 Holland 等[26]提出。在 GA 中關于種群的遺傳演化中發現,以染色體作為種群遺傳的主要載體,并且借助多種隨機操作:基因選擇、基因交叉和基因變異等,不斷演化出一種新的解集種群,據個體適應度和選擇函數的取值可以選擇最優的種群個體,即為 GA 中優化問題的最優解。
本文利用 GA 對 LSTM 網絡的關鍵超參數進行尋優處理,采用 GA 強大的全局隨機搜索能力,得到 LSTM 網絡中神經元個數、學習率和訓練次數的最優組合。基本思路如下:
(1)染色體編碼
將 LSTM 網絡中的隱藏層神經元數目、學習率和訓練次數作為 GA 的初始化對象,通過實數編碼形式進行染色體編碼。隱藏層神經元的區間范圍為[5,40],學習率的區間范圍為[0.001,0.1],訓練次數的區間范圍為[50,500]。
(2)適應度函數
適應度函數的選擇直接影響到 GA 優化后網絡的性能,進而影響到胎兒心電信號的提取效果。本文主要從母親心電信號估計值和真實值之間的整體擬合程度出發來構建適應度函數。假設孕婦胸部心電信號為 m,腹壁混合心電信號為 u,而腹壁心電信號 u 中包含母體心電信號成分 s、胎兒心電信號 d 和噪聲 z,其數學關系如式(10)所示:
 |
式(10)中,母體心電信號成分 s 是由母體胸部心電信號 m 經非線性變換傳輸到孕婦腹壁所形成的心電信號,如式(11)所示:
 |
式(11)中, 表示心電信號的非線性變換函數。假設能求得
表示心電信號的非線性變換函數。假設能求得  的最佳估計值
的最佳估計值  ,那么就能夠利用
,那么就能夠利用  求得
求得  的最佳估計值
的最佳估計值  (
( ),因此從腹壁混合信號
),因此從腹壁混合信號  中消除母體心電信號成分的最佳估計值
中消除母體心電信號成分的最佳估計值  就能得到僅含少量噪聲的胎兒心電信號最佳估計值
就能得到僅含少量噪聲的胎兒心電信號最佳估計值  ,如式(12)所示:
,如式(12)所示:
 |
LSTM 估計出母親心電信號  后,剩余心電信號
后,剩余心電信號  的均方誤差如式(13)所示:
的均方誤差如式(13)所示:
 |
考慮到胎兒心電信號、噪聲信號與母體心電信號之間相互獨立,且胎兒心電信號幅值較小[1-2],因此可得如式(14)所示:
 |
所以可得剩余心電信號  ,如式(15)所示:
,如式(15)所示:
 |
由式(15)可以看出,當  時,
時, 達到最小值,此時
達到最小值,此時  ,也即通過非線性變換函數
,也即通過非線性變換函數  求出了母體心電信號的最佳估計值
求出了母體心電信號的最佳估計值  。因此,在利用 GA 優化非線性變換 LSTM 時,當均方誤差函數達到最小值時,可以認為 LSTM 得到了母體心電信號的最優估計,也即此時對胎兒心電信號進行了最優提取。所以,本文中選擇混合心電信號
。因此,在利用 GA 優化非線性變換 LSTM 時,當均方誤差函數達到最小值時,可以認為 LSTM 得到了母體心電信號的最優估計,也即此時對胎兒心電信號進行了最優提取。所以,本文中選擇混合心電信號  與非線性估計信號
與非線性估計信號  的均方誤差作為 GA 優化時的適應度函數,如式(16)所示:
的均方誤差作為 GA 優化時的適應度函數,如式(16)所示:
 |
式(16)中,fitness 為適應度函數值,N 為心電數據總量, 為母親腹壁混合信號中母體心電信號的網絡預測值,
為母親腹壁混合信號中母體心電信號的網絡預測值, 為母親腹壁混合信號的真實值。
為母親腹壁混合信號的真實值。
(3)選擇算子、交叉算子和變異算子
選擇算子是在當前種群中選擇適應性較好的個體作為親本,并將遺傳信息傳遞給子代。在這里采用錦標賽選擇算法作為 GA 的選擇策略。該選擇算法具有高效的算法執行率和易于實現的特點,算法復雜度遠低于其他選擇策略且易于并行化,在選擇過程中不易陷入局部個體最優點,并且不需要對所有個體的適應度值排序。
交叉算子使用洗牌交叉算法,在交叉之前在父代中利用隨機排序函數進行洗牌運算,然后當在(0,1)之間產生的隨機數小于所給的交叉率大小,則進行交叉變換。在變異算子中,當在(0,1)之間產生的隨機數小于所給的變異率大小,則進行變異操作。
2.3 GA-LSTM 胎兒心電信號提取模型
本文將 GA 與 LSTM 網絡相融合,構建基于 GA-LSTM 的胎兒心電信號提取模型。首先采用 GA 對 LSTM 網絡的超參數作尋優處理,得出學習率、隱層神經元數和訓練次數的最佳組合,進一步提高模型的非線性映射能力;然后利用尋優的參數組合構建的 GA-LSTM 模型作為母體胸部心電信號與腹壁混合信號之間的非線性變換函數 f(·);在此基礎上應用非線性變換函數 f(·)求得母體胸部信號的最佳估計,最后從母體腹壁的混合信號中進行分離,即可分離提取得到最佳的胎兒心電信號的估計。模型具體操作流程如下:
(1)選擇訓練數據集。為了得到函數 f(·)的最佳擬合效果,GA-LSTM 模型的輸入數據由母體心電信號 mi 及其 J 維時間導數構成,本文取 J = 2。GA-LSTM 模型的輸入信號用向量 M 表示,目標輸出信號用向量 u 表示,如式(17)所示:
 |
(2)利用 GA 優化 LSTM 網絡參數。
a. 將 LSTM 網絡模型中時間窗口大小、批處理大小、隱藏層單元數目作為優化對象,執行種群的初始化以及染色體編碼與解碼操作。
b. 計算初始種群中各個個體適應度大小;
c. 對染色體進行選擇、交叉和變異操作;
d. 對染色體解碼、計算種群內個體的適應度,在該算法中適應度越小,則越應保留該個體,否則淘汰該個體;
e. 若不符合遺傳終止條件則回到 c 步;若符合遺傳終止條件,則將 GA 求出的最優參數作為 LSTM 網絡模型的最終參數;
(3)訓練 GA-LSTM。將 u 和 M 輸入最優參數組合的 GA-LSTM 網絡,GA-LSTM 網絡模型的輸出為腹壁混合信號中的母體心電信號成分 s = f(M)。將目標信號 u 與輸出信號 s 之差用誤差信號 e 表示,即 e = u-s。GA-LSTM 網絡模型根據均方誤差最小化擬合誤差 E(eTe),最終得到母體胸部心電信號經歷非線性變換 f(·)傳輸到腹壁的最優擬合函數  。
。
(4)提取胎兒心電信號。將心電信號數據{(mi,ui),i = 1,2,···,N} 送入 GA-LSTM 模型,利用最優擬合函數  計算得到腹壁混合信號 ui 中的母體心電信號成分
計算得到腹壁混合信號 ui 中的母體心電信號成分  。則胎兒心電信號
。則胎兒心電信號  就可以利用下式計算:
就可以利用下式計算: 。
。
3 實驗與結果
3.1 模型評價標準
胎兒心電信號提取模型的性能通過靈敏度(sensitivity,Se)(以符號 Se 表示)、精確率(positive predictive value,Ppv)(以符號 Ppv 表示)、整體準確率(accuracy,Acc)(以符號 Acc 表示)和總體概率(F1-measure,F1)(以符號 F1 來表示)四個指標來衡量。每個指標的具體計算方法如式(18)~(21)所示[14]:
 |
 |
 |
 |
其中,真陽性(true positive,TP)(符號記為:TP)表示樣本本來是陽性,被正確分類的樣本個數,即正確檢測到的胎兒心電信號個數;假陽性(false positive,FP)(符號記為:FP)表示樣本本來是陰性,被錯誤分類為陽性的樣本個數,即錯誤檢測到的胎兒心電信號個數;假陰性(false negative,FN)(符號記為:FN)表示樣本本來是陽性,被錯誤地分類為陰性的樣本個數,即漏檢的胎兒心電信號個數。
3.2 實驗數據和實驗方法
3.2.1 數據來源
在本文的研究中使用了兩個不同的數據庫來進行評估所提出方法的可行性以及提取性能。第一個數據庫心電信號選取系統識別數據集(database for the identification of systems,DaISy)(網址:http://homes.esat.kuleuven.be/~smc/daisy/)進行研究,該數據庫由魯汶大學電工工程系的一個研究部門—斯塔迪烏斯(STADIUS)開發、維護和托管,可在 STADIUS 主頁進行公開下載。DaISy 數據庫由 de Lathauwer 等[16]提供,心電數據采樣頻率為 250 Hz,記錄時長為 10 s,各通道心電數據長度為 2 500,采用電極放置法從孕婦體表獲取八導聯(chanel,ch)(ch1~ch8)心電信號,其中 ch1~ch5 導聯記錄孕婦腹部混合信號,ch6~ch8 導聯記錄孕婦胸部信號。第二個數據庫由麻省理工學院計算生理學實驗室提供并發布在生理網(PhysioNet)(網址:https://www.physionet.org)上的一個免費公開使用的醫學研究數據庫,實驗選取 PhysioNet 中的無創胎兒心電數據庫(non-invasive fetalelectrocardiogramdatabase)(網址:https://www.physionet.org/content/nifecgdb/1.0.0/),該數據庫包含一系列 55 個多通道腹部無創胎兒心電信號記錄,取自妊娠 21~40 周的單個受試者,每條記錄包含 2 個胸部心電信號,3 或 4 個腹部心電信號,采樣頻率為 1 kHz。相比 DaISy 數據庫,無創胎兒心電數據庫中的腹部信號信噪比低,胎兒心電信號被嚴重污染,從中提取胎兒心電信號的難度更大。
3.2.2 實驗方法
本文實驗綜合考慮模型運算復雜度、計算時長和提取性能,選擇前 1 500 點數據{(mi,ui),i = 1,2,···,1 500}作為訓練數據集,全部 2 500 點數據{(mi,ui),i = 1,2,···,2 500}作為測試數據集。NLMS 方法中,迭代步長設為 0.005,迭代次數設為 1 000。SVM 方法中選擇徑向基函數  作為核函數,核函數參數 σ 和懲罰系數 C 的取值分別為 C = 50,σ2 = 3。LSTM 網絡中隱藏層神經元選為 30 個,迭代次數設為 400,學習率取為 0.01。
作為核函數,核函數參數 σ 和懲罰系數 C 的取值分別為 C = 50,σ2 = 3。LSTM 網絡中隱藏層神經元選為 30 個,迭代次數設為 400,學習率取為 0.01。
3.3 實驗結果對比分析
3.3.1 數據預處理
DaIsy 數據集中的心電信號基本上沒有基線漂移和其他噪聲的影響,且可以明顯看出母體和胎兒心電信號 QRS 波的位置,因此該數據在實驗中可直接使用。而無創胎兒心電信號數據庫包含的數據較多,本文選取組號為 ecgca244 心電信號進行實驗,該組心電信號記錄 6 個通道心電信號,包含 2 個胸部心電信號和 4 個腹部心電信號,因為該數據庫心電信號噪聲污染嚴重,所以對 6 個通道心電信號分別采用 3 階高通和 3 階低通巴特沃斯雙向濾波器去除高頻信號和低頻信號。
3.3.2 胎兒心電信號提取在 DaISy 數據庫可視化結果對比分析
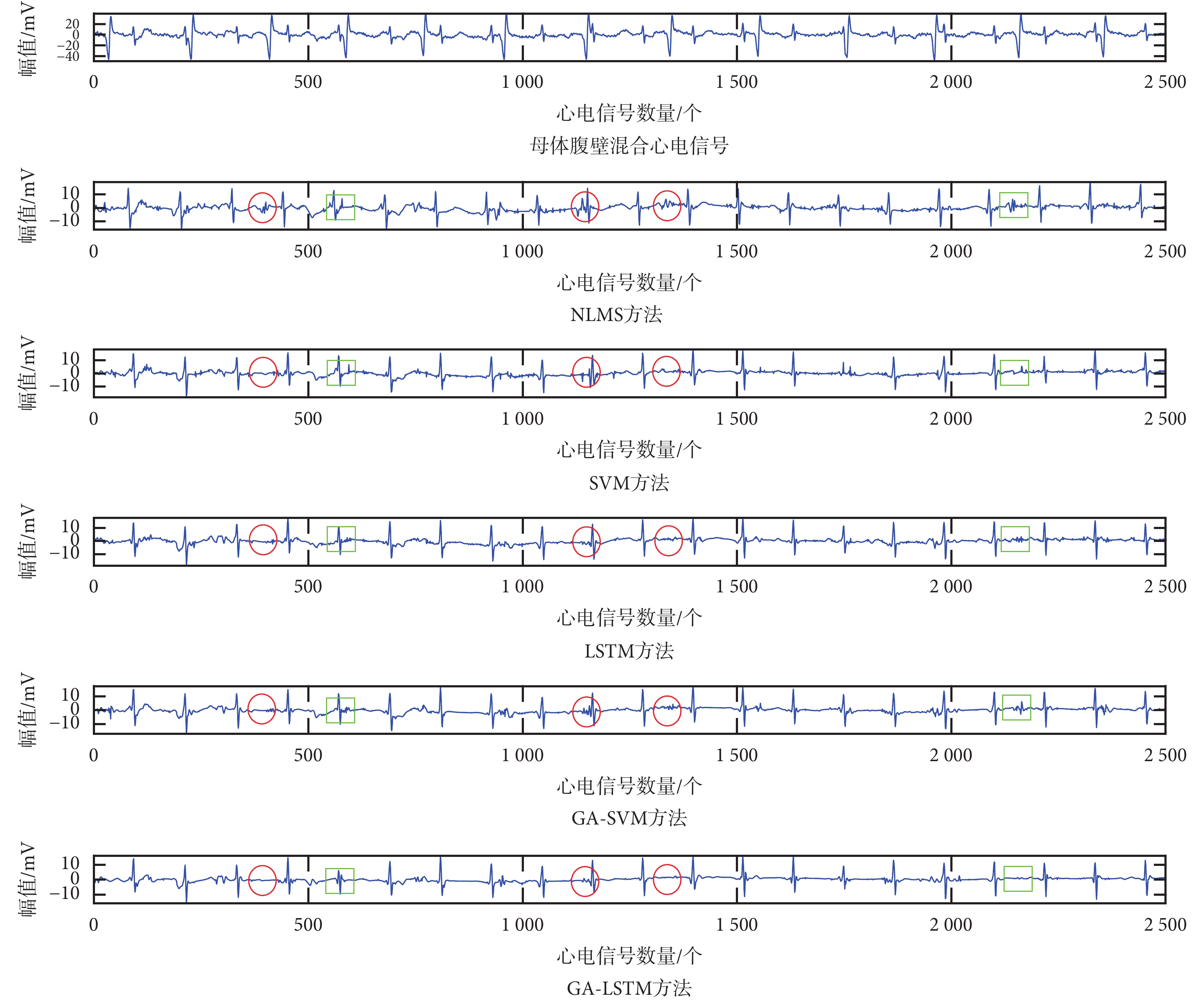
首先將 ch1 和 ch8 導聯心電信號作為兩導聯系統采集得的 ui 和 mi,然后將 GA-LSTM 方法與 NLMS 方法、SVM 方法、GA-SVM 方法和 LSTM 方法進行胎兒心電信號提取對比實驗,實驗結果如圖 3 所示。
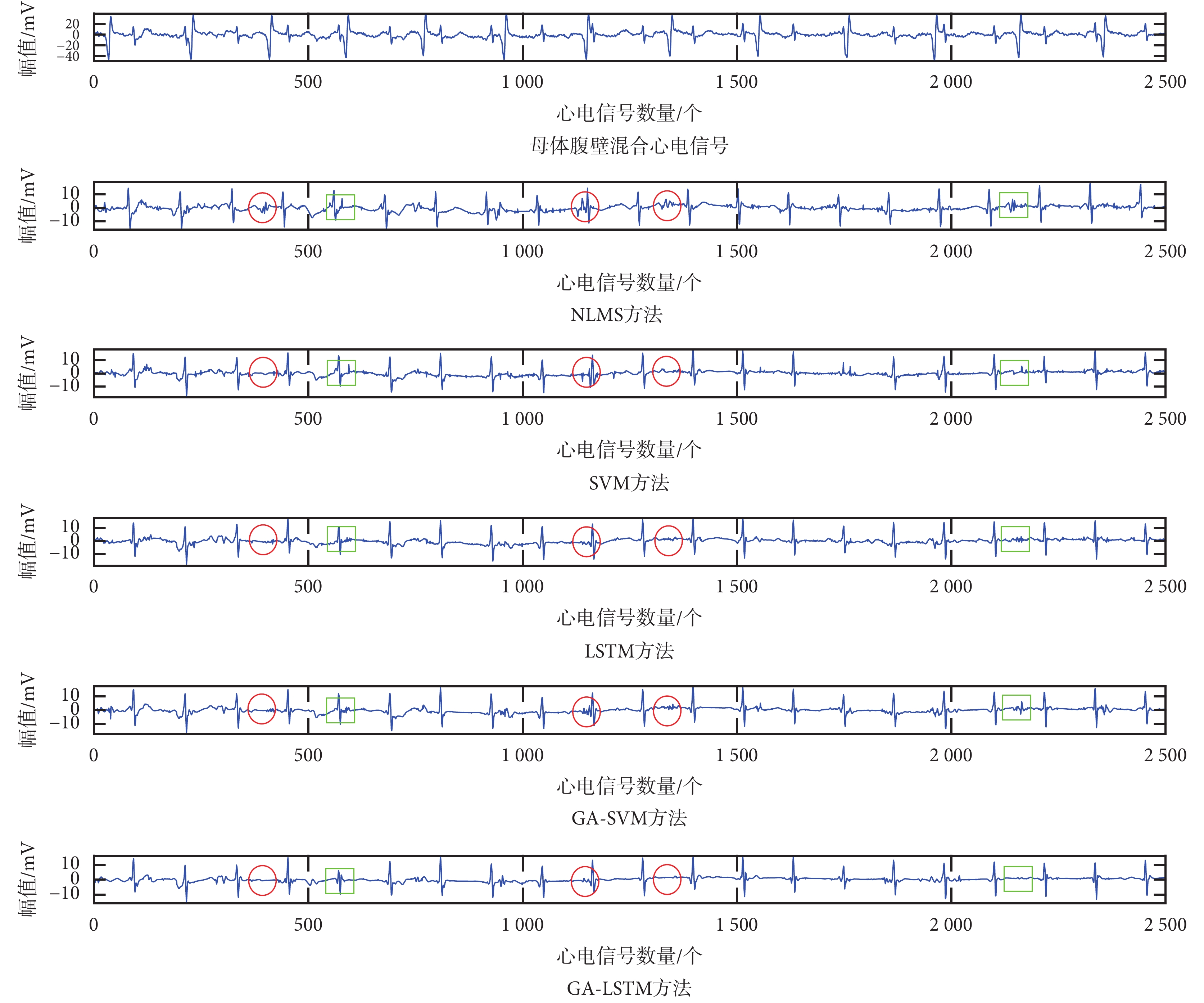 圖3
5 種方法的胎兒心電信號提取結果比較
Figure3.
Comparison of extracted fetal electrocardiogram signals in 5 algorithms
圖3
5 種方法的胎兒心電信號提取結果比較
Figure3.
Comparison of extracted fetal electrocardiogram signals in 5 algorithms
由圖 3 可見:① NLMS 方法的胎兒心電信號的 QRS 波提取結果并不理想,在最終提取的胎兒心電信號效果圖中仍混合部分母體的心電信號成分,如圖 3 中 NLMS 方法子圖紅圈所示;② 在提取所得的母體心電信號和胎兒心電信號之間存在 QRS 波相互分離或者相互重疊的部分,其中采用 SVM、LSTM、GA-SVM 和 GA-LSTM 方法對胎兒心電信號進行提取可有效抑制母體心電信號成分的干擾。
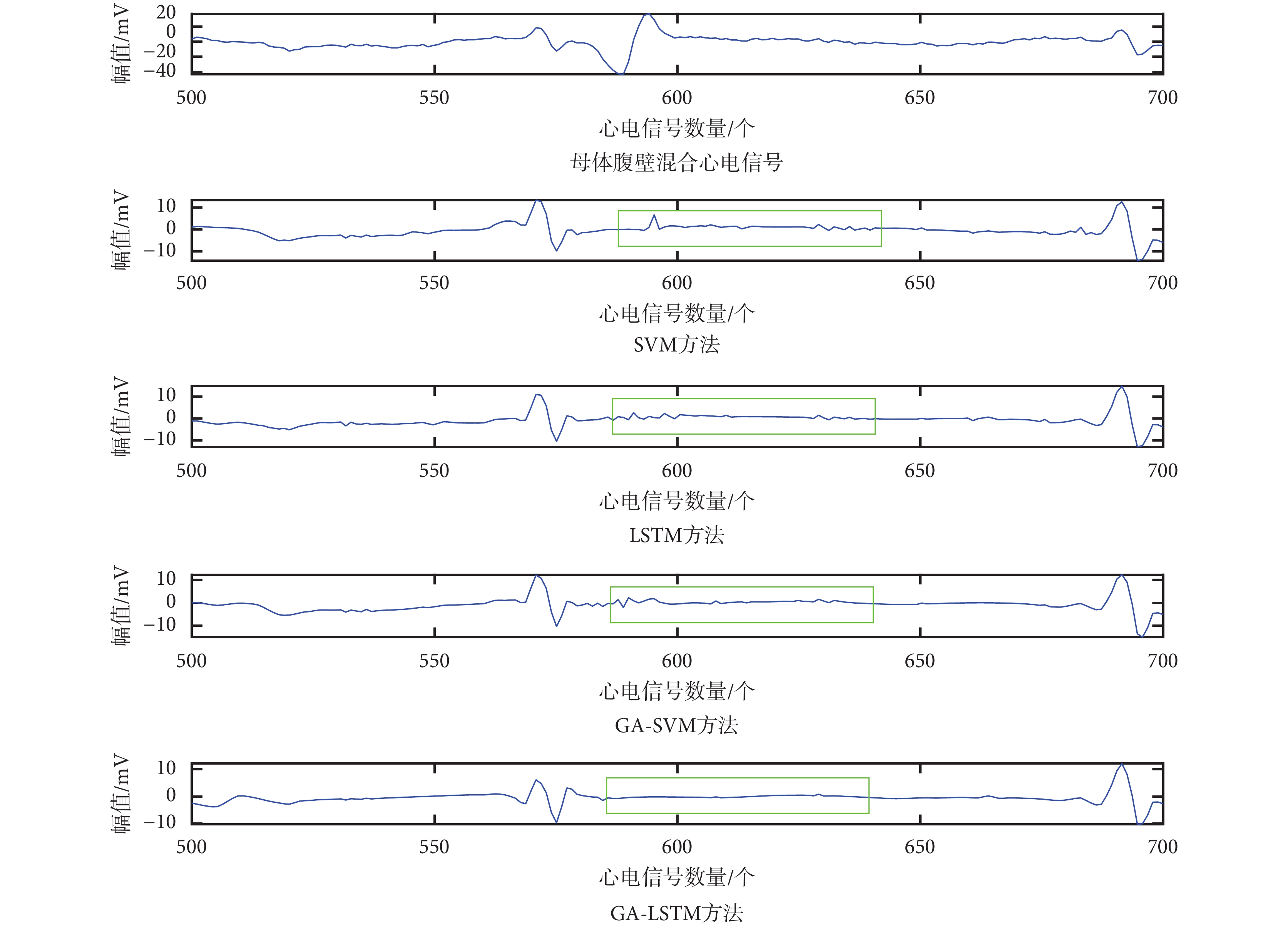
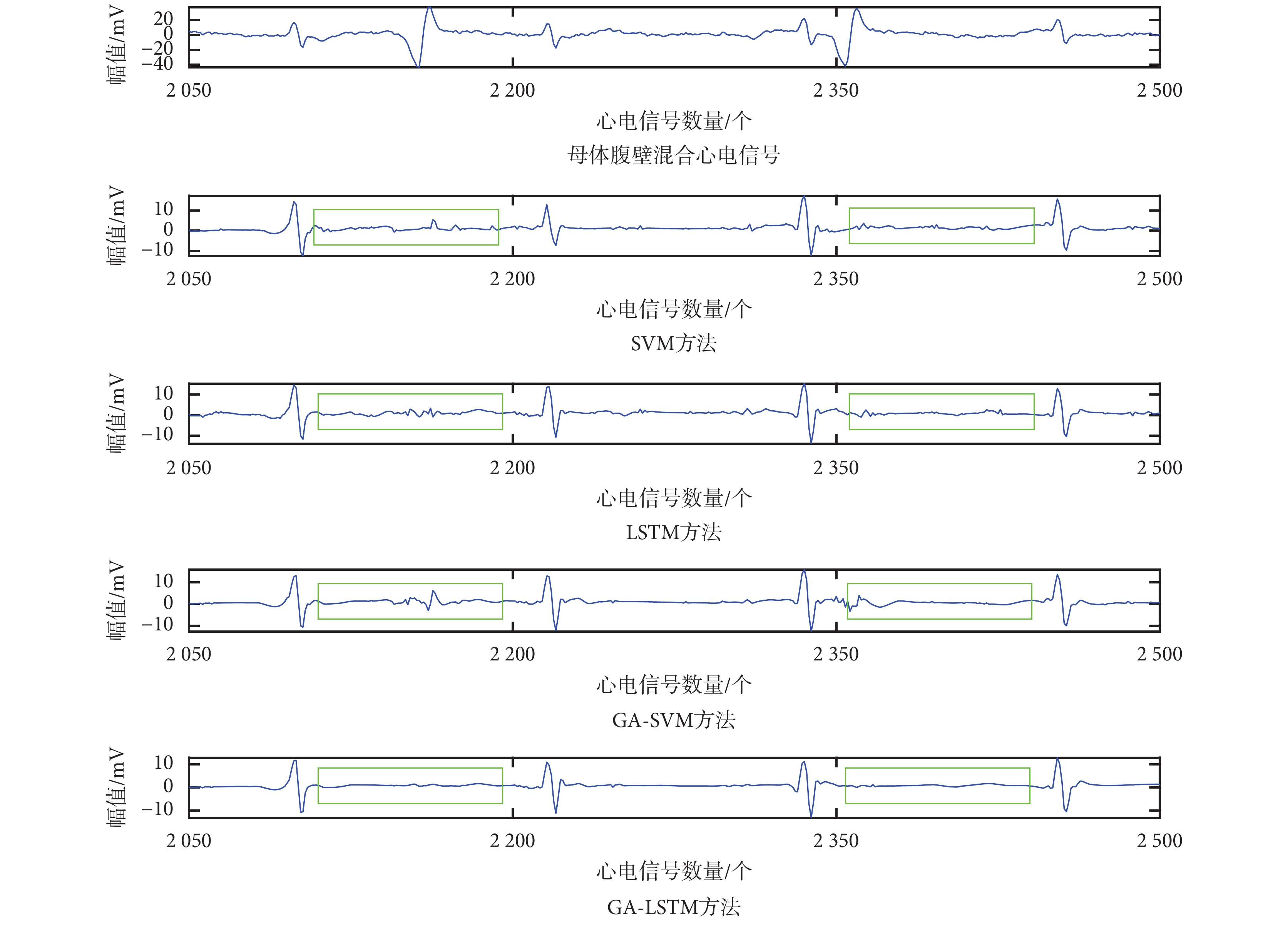
為了更好地比較 SVM、GA-SVM、LSTM 和 GA-LSTM 四種胎兒心電信號提取方法的優劣,將圖 3 的綠色方框處分別放大為如圖 4、5 所示。
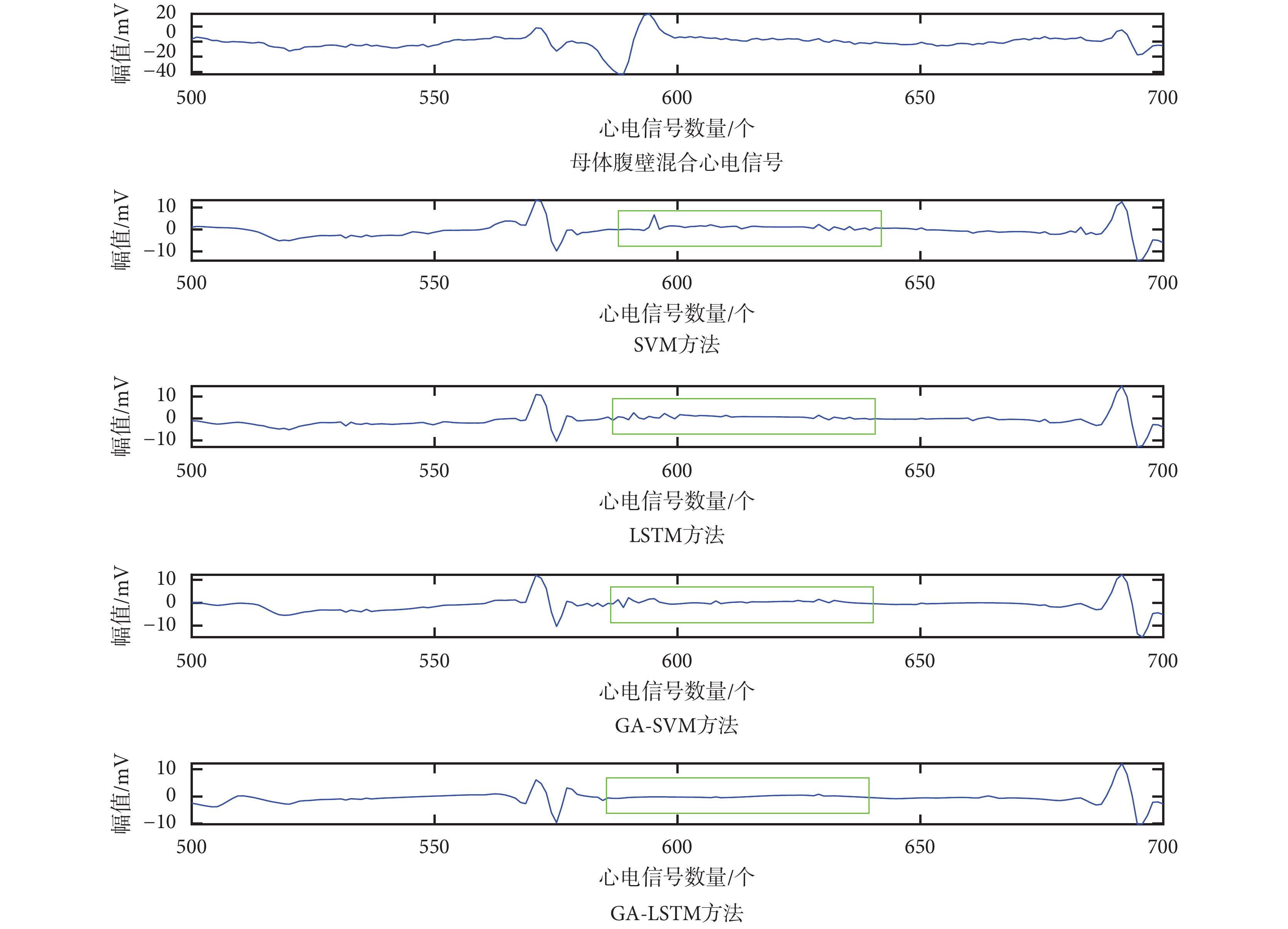 圖4
胎兒心電信號提取實驗結果對比(500~700 點)
Figure4.
Comparison of experimental results of fetal electrocardiogram signal extraction (500~700 points)
圖4
胎兒心電信號提取實驗結果對比(500~700 點)
Figure4.
Comparison of experimental results of fetal electrocardiogram signal extraction (500~700 points)
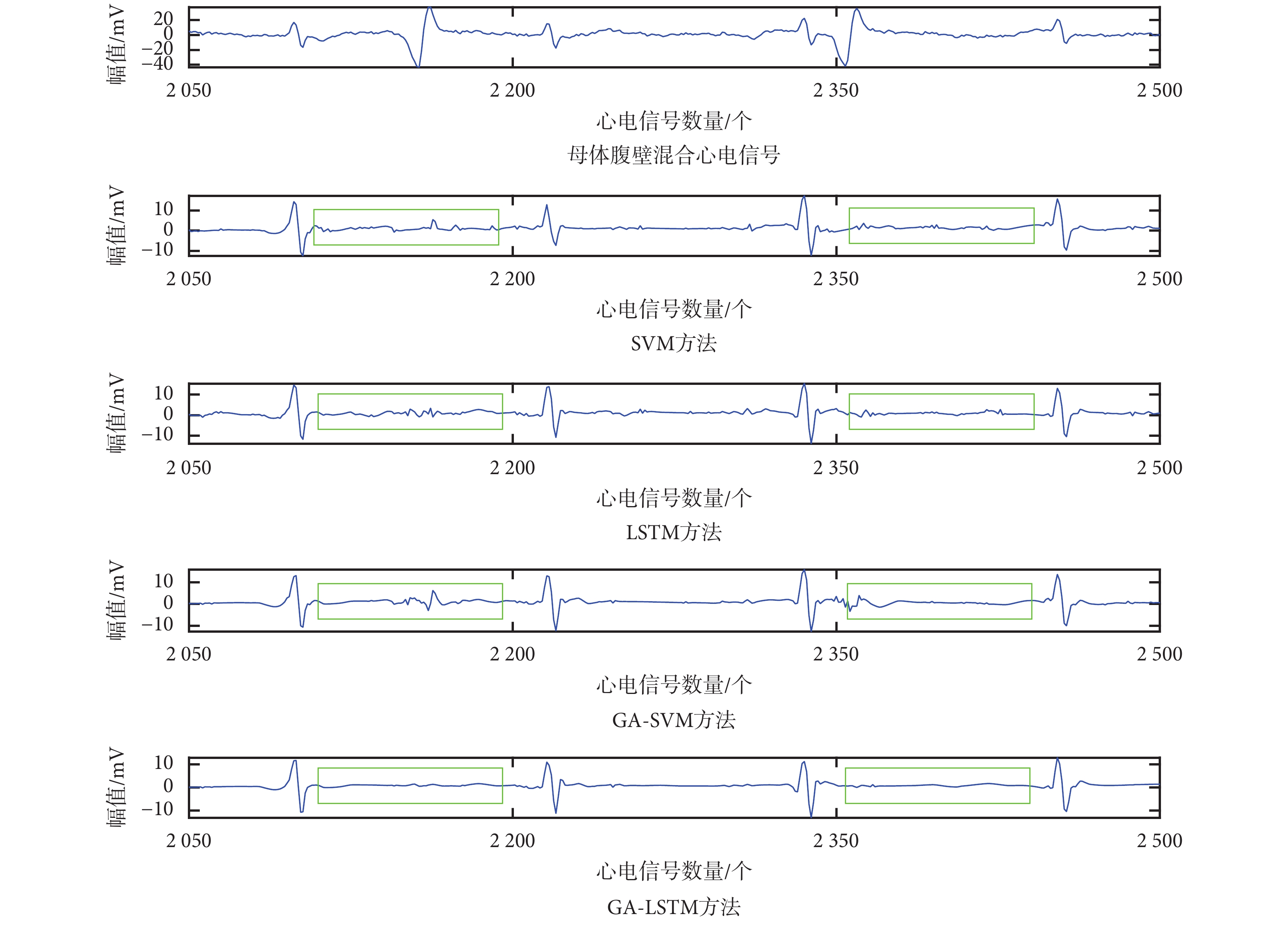 圖5
胎兒心電信號提取實驗結果對比(2 050~2 500 點)
Figure5.
Comparison of experimental results of fetal electrocardiogram signal extraction (2 050~2 500 points)
圖5
胎兒心電信號提取實驗結果對比(2 050~2 500 點)
Figure5.
Comparison of experimental results of fetal electrocardiogram signal extraction (2 050~2 500 points)
由圖 4、圖 5 可見:① 采用 SVM、GA-SVM 和 LSTM 方法對胎兒心電信號的 QRS 波進行提取,所得結果中仍混合部分母體心電信號成分(如圖 4、圖 5 中綠色方框所示);② 采用 GA-LSTM 方法可有效消除母體腹壁混合信號中關于母體的心電信號成分,原因在于 GA 算法求出了更優的網絡參數組合,使得本文方法性能優于基于 SVM、GA-SVM 和 LSTM 的胎兒心電信號提取方法。
3.3.3 DaISy 數據集性能指標對比分析
為了定量研究 GA-LSTM 模型在 DaISy 數據集上的提取效果,采用 Se、Ppv、Acc 和 F1 四個指標來進行定量分析[14]。用 DaISy 數據集中 ch1~ch5 共 5 個通道孕婦腹壁心電信號數據進行統計分析,該數據集中每個通道記錄有 22 個胎兒心電信號 QRS 波,本文統計五個通道共 110 個胎兒心電信號 QRS 波。五種方法的統計分析結果如表 1 所示。
由表 1 可知,GA-LSTM 心電信號提取模型在五組腹壁心電數據上的提取性能最好,該模型可以提取到 105 個胎兒心電信號 QRS 波,誤檢 3 個 QRS 波,漏檢 5 個 QRS 波,并且 Acc 為 92.92%,Se 為 95.45%,Ppv 為 97.22%,F1 為 96.33%。NLMS 模型能夠提取到 96 個胎兒心電信號 QRS 波,誤檢 9 個 QRS 波,漏檢 14 個 QRS 波,且 Acc 為 80.67%,Se、Ppv 和 F1 分別為 87.27%、91.43% 和 89.30%,四項統計指標都相對較低,原因在于 NLMS 模型對胎兒心電信號適應性不強,尤其在母體心電信號與胎兒心電信號重疊部分,導致對胎兒心電信號的識別率較低。SVM 模型可以提取到 98 個胎兒心電信號 QRS 波,誤檢 8 個 QRS 波,漏檢 12 個 QRS 波,且 Acc 為 83.05%,Se 為 89.09%,Ppv 為 92.45%,F1 為 90.07%,可見 SVM 模型對胎兒心電信號提取的性能并不突出,這是由于 SVM 存在泛化能力弱,易陷入局部極值的原因。GA-SVM 方法可以提取到 102 個胎兒心電信號 QRS 波,誤檢 6 個 QRS 波,漏檢 8 個 QRS 波,且 Acc 為 87.93%,Se 為 92.73%,Ppv 為 94.44%,F1 為 93.58%,可見即使采用 GA 對 SVM 的超參數進行優化,該模型的心電信號提取性能也并不突出。LSTM 模型可以提取到 103 個胎兒心電信號 QRS 波,誤檢 5 個 QRS 波,漏檢 7 個 QRS 波,并且 Acc 為 88.79%,Se 為 93.64%,Ppv 為 94.50%,F1 為 94.06%,該模型在胎兒心電信號提取實驗中也表現出較強的優勢,但其性能不及本文所提出的方法,這是因為 LSTM 模型的超參數很難人工取到最優值,從而使得模型提取性能低于 GA-LSTM 模型。可見利用 GA 先對 LSTM 網絡模型的超參數進行尋優處理,然后利用最優參數組合構建 GA-LSTM 胎兒心電信號提取模型,可以有效提高胎兒心電信號提取的性能。
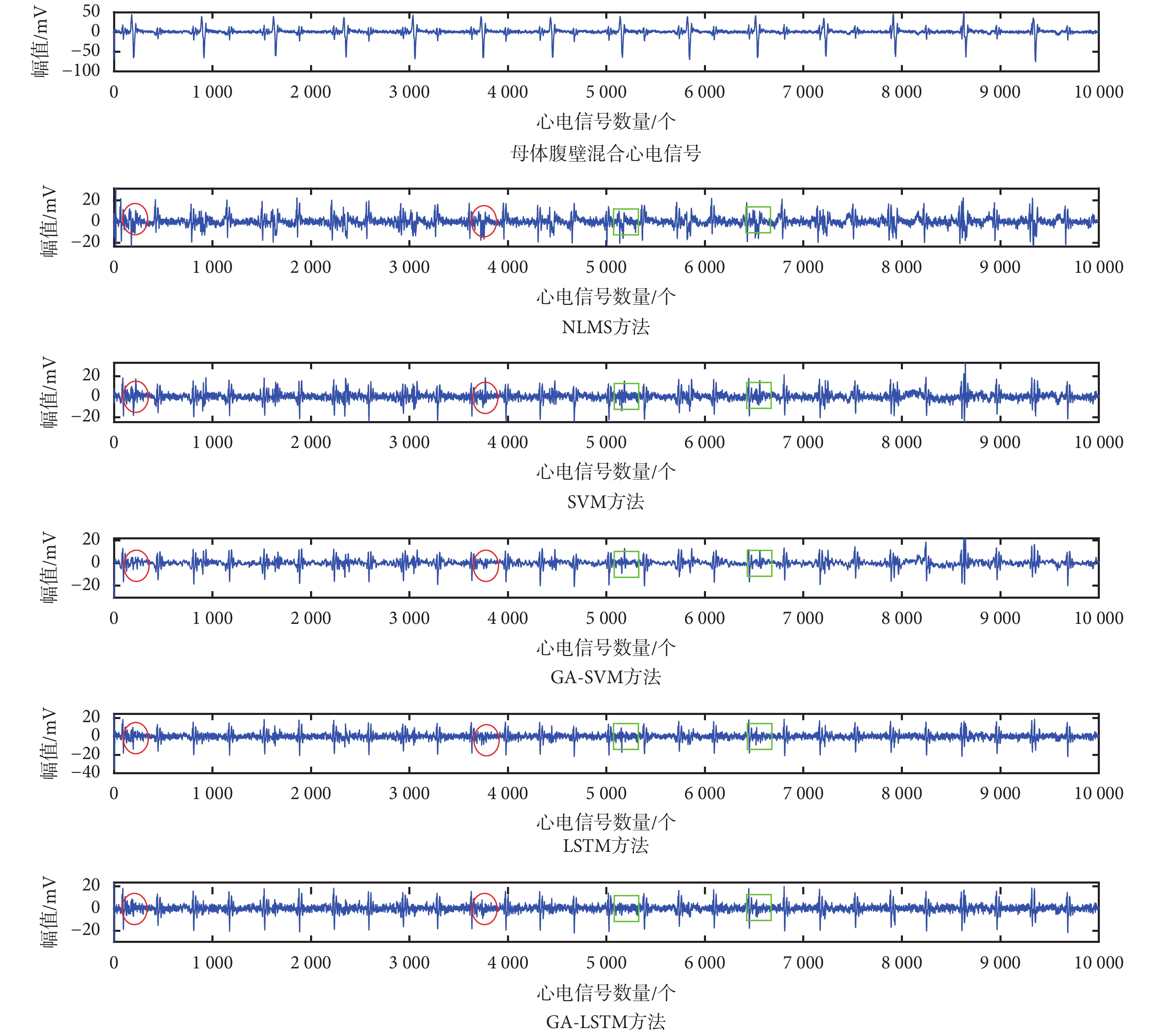
3.3.4 胎兒心電信號提取在無創胎兒心電信號數據庫可視化結果對比分析
在無創胎兒心電信號數據庫組號 ecgca244 中選取前 10 000 個數據進行可視化對比分析,實驗結果如圖 6 所示。
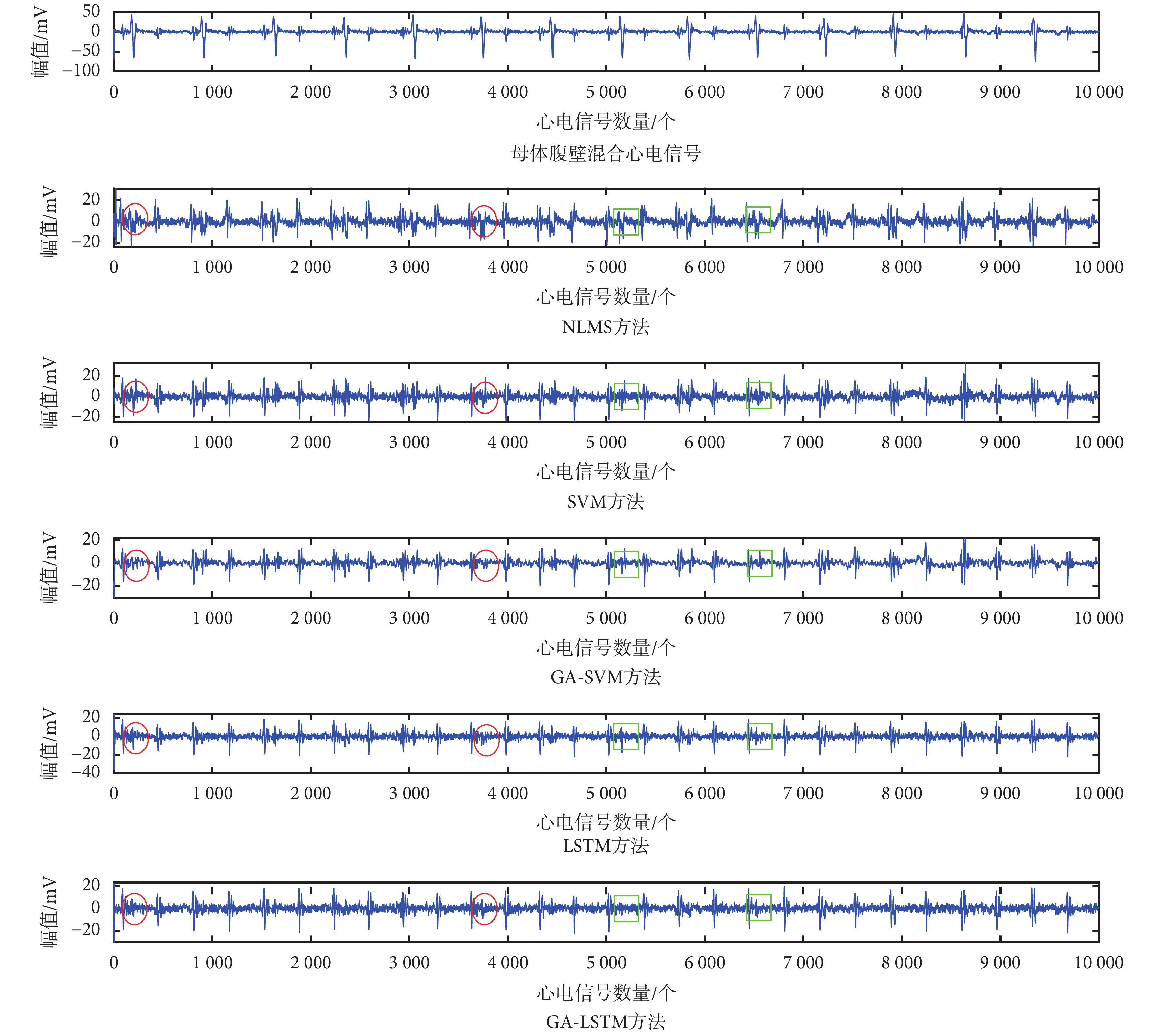 圖6
5 種方法的胎兒心電信號提取結果比較
Figure6.
Comparison of extracted fetal electrocardiogram signals in 5 algorithms
圖6
5 種方法的胎兒心電信號提取結果比較
Figure6.
Comparison of extracted fetal electrocardiogram signals in 5 algorithms
由圖 6 可見:① NLMS 方法和 SVM 方法的胎兒心電信號的 QRS 波提取結果較差,在最終提取的胎兒心電信號效果圖中仍混合較多的母體心電信號成分(如圖 6 中紅圈所示);② GA-SVM 模型在該數據集的提取效果也并不突出,其提取結果仍有部分母體心電信號成分;(如圖 6 中綠色方框所示);③ 在母體心電信號和胎兒心電信號之間存在 QRS 波相互分離或者相互重疊的部分,其中采用 LSTM 和 GA-LSTM 的對胎兒心電信號進行提取可有效抑制母體心電信號成分的干擾,而 GA-LSTM 方法的提取性能更為突出,可以提取出更為清晰準確的胎兒心電信號。
3.3.5 無創胎兒心電信號數據庫性能指標對比分析
在無創胎兒心電信號數據庫中,已經明顯地標注了胎兒心電信號 QRS 波的位置和個數,實驗選取的前 10 000 個數據點中每組腹部通道包含 28 個 QRS 波,四組共 112 個胎兒心電信號 QRS 波。由表 2 可知,雖然該數據集受噪聲污染和基線漂移影響嚴重,但 GA-LSTM 心電信號提取模型依然可以提取出較多的胎兒心電信號 QRS 波,漏檢和誤檢的胎兒心電信號 QRS 波也較少,四項統計指標均優于其他四種方法,進一步證明了本文所提出方法的可行性。
3.3.6 網絡實時性和推廣性分析
實驗采用 Windows 10(Microsoft,美國)系統進行,中央處理器(central processing unit,CPU)使用 2.90 GHz 的 i5 處理器,內存為 16.0 GB,實驗軟件使用 MATLAB 2019a(MathWorks,美國)的版本進行。在本文的實驗中,初始種群數量設置為 40,最大迭代次數為 100 次,采用網絡的訓練時間和訓練后的執行時間兩部分來進行網絡實時性與推廣性方面的對比和討論,實驗結果如表 3 所示。
通過表 3 的對比分析可知,實驗所采取的方法在網絡構建時均需要消耗一定的時間,而網絡結構的差異性使得網絡訓練時所用的時間也不同。從表 3 可以看出:① 網絡訓練階段,NLMS 所需時間最短,SVM 方法和 LSTM 方法訓練時間相當。加入了 GA 算法后,網絡訓練階段的耗時提高了大約 2 倍,GA-SVM 方法和 GA-LSTM 方法的訓練時長仍基本相同,約為 3 min。② 在網絡執行階段,SVM 方法耗時最長,本文方法(GA-LSTM)與其他方法相比,耗時并沒有顯著增加,而是略有降低。在 MATLAB2019a 環境下,本文方法執行階段的耗時約為 0.4 s。
可以看出,在實際應用中,除了在程序啟動訓練階段需要等待 3 min 左右,其他時間段都可以較快地獲得胎兒心電信號提取結果。如果 C 等編譯語言將算法寫入硬件中運行,會進一步提高運行的速度。因此,本文方法在實時性方面可以滿足一定場景下的需求,具有較好的推廣性。
4 結論
本文以 LSTM 網絡為基礎構建 GA-LSTM 胎兒心電信號提取模型,采用 GA 對 LSTM 網絡的超參數進行優化處理,有效提高了模型的預測性能,減少了人為確定超參數因素的影響。并選取兩個臨床實時數據集進行實驗,實驗表明,相比于傳統的 NLMS、SVM、GA-SVM 和 LSTM 網絡模型,本文所提出的 GA-LSTM 心電信號提取模型在 DaISy 數據集和無創胎兒心電信號數據集上均表現出更優的提取性能,能夠提取出更加清晰的胎兒心電信號 QRS 波,誤檢和漏檢的胎兒心電信號較少,具有很強的抗噪能力和泛化能力,很好地解決了胎兒心電信號不易提取的難題,為圍產期和妊娠期胎兒健康監測提供了新方法,具有重要的臨床應用價值,在胎兒心電信號提取的研究中具有較好的應用前景。
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
引言
孕婦圍產期胎兒監護對了解胎兒在子宮內的生長發育狀況十分重要,通常采用胎音聽診、胎心率檢測以及觀測胎兒心電圖的變化來診斷胎兒在母體子宮內的健康狀況,后者通過分析心電圖波形形態可以更早地發現妊娠期胎兒心臟的各種電生理活動是否異常。檢測胎兒心電圖中 QRS 波的變化可及時判斷胎兒是否存在缺氧、臍帶繞頸等妊娠期問題[1]。然而胎兒心電信號通常采用間接法從母親腹壁獲取,因而會包含多種噪聲:電極干擾、母體心電信號成分以及基線漂移等[2]。所以,如何消除采集的胎兒心電信號所包含的噪聲,從而分離出清晰的胎兒心電信號成為胎兒健康監護的一個重要研究內容[3]。
目前關于胎兒心電信號提取的方式提出了多種檢測方法:① 獨立成分分析法[4-5](independent component analysis,ICA)假定胎兒心電信號、母體心電信號以及噪聲相互統計獨立,從而建立 ICA 模型,在模型基礎上提取胎兒心電信號,但是此方法不適合處理超高斯和亞高斯信號,而且容易陷入局部最優解。② 盲源提取技術[6-7]在各個源信號未知的條件下,從腹壁混合信號中分離得到胎兒的心電信號,但是在該模型中,胎兒心電信號的相關特征并未得到充分利用,導致提取的胎兒心電信號準確率較低且不能清楚地反映信號的生理學意義,而且該模型的算法對胎兒心電信號的時間延遲周期的依賴性較大,其心電信號提取性能具有局限性。③ 自適應濾波法[8-9]計算簡單,但對于非平穩性胎兒心電信號的測量具有局限性。④ 匹配濾波法算法[10-11]對胎兒心電信號識別率低,容易出現誤漏診。⑤ 小波分解法[12-13]對小波基等參數的選擇較為困難,不宜實時提取,而且對于母體心電信號和胎兒心電信號重疊的部分很難進行胎兒心電信號提取。⑥ 奇異值分解法[14-15]分解出的分矩陣解釋性往往不強且分解矩陣隨時間越來越大。⑦ 神經網絡[16-18]和支持向量機方法[19]取得了較好的胎兒心電信號提取效果,但存在泛化能力弱、易落入部分最優值、網絡結構設計難等問題。
近年來,循環神經網絡(recurrent neural network,RNN)因處理時間序列信息功能強大而得到了發展。Hochreater 等[20]對 RNN 的單元結構進行改進提出了長短時記憶(long short term memory networks,LSTM)網絡模型,通過設計“門”結構解決了梯度消失和梯度爆炸以及 RNN 信息記憶能力不足的問題,提示可采用遠距離的時序信息[21]。LSTM 網絡在語音識別[22]、文本處理[23]等領域已得到成功應用,卻存在關鍵超參數,如隱層神經元數、學習率和訓練次數等難以確定的缺陷[24]。因為隱含層神經元數對模型的擬合能力起著決定性作用,學習率和訓練次數直接影響模型收斂速度和計算時長,所以 LSTM 網絡的結構參數直接控制模型拓撲結構,因此采用不同的超參數建立的網絡模型其預測性能具有較大差異,如何選擇合適參數對于建立模型來說顯得至關重要。目前,往往依賴研究者的經驗和多次實驗結果去選擇網絡模型的超參數,隨機性較大,降低了模型的預測性能。
為了提取出純凈的胎兒心電信號,本文以 LSTM 網絡模型為技術基礎,研究建立了胎兒心電信號的提取模型。考慮到目前 LSTM 網絡的胎兒心電信號提取模型的關鍵參數難以確定,利用遺傳算法(genetic algorithm,GA)對 LSTM 網絡的關鍵超參數進行優化。該模型以單通道母體的胸部心電信號作為神經網絡的輸入信號,以單通道母體的腹壁混合信號作為提取目標的輸出信號,采用 GA 優化的 LSTM 網絡來建立 GA-LSTM 網絡模型來檢測和評算母體胸部的心電信號傳輸到母體腹壁的最佳心電信號估計;在此基礎上實現從母體腹壁混合信號分離出胎兒心電信號,并與目前經典的歸一化最小均方誤差(normalized least mean square algorithm,NLMS)方法、支持向量機(support vector machines,SVM)方法、GA-SVM、LSTM 雙導聯網絡方法進行對比實驗。最終,期望通過實驗結果可以驗證本文提出的方法能有效克服胎兒心電信號不易提取的難題,為今后圍產期和妊娠期胎兒健康的長期監護提供一種可行的方法。
1 胎兒心電信號提取原理
目前普遍使用置電極法采集胎兒心電信號:在時刻 i,由置于孕婦胸部的電極采集孕婦胸部心電信號 mi,且同時刻由置于孕婦腹壁的電極采集孕婦腹壁混合信號 ui。而在孕婦腹壁心電信號 ui 中包含母體心電信號成分 si、胎兒心電信號 di 和噪聲 zi 三類信號,三類信號函數關系如式(1)所示:
|
其中,母體心電信號成分 si 是在時刻 i 由母體胸部心電信號 mi 經非線性變換傳輸到孕婦腹壁所形成的信號,所以腹壁混合信號中的母體心電信號成分 si 的相位和幅度等相關參數都會發生改變[19, 25],非線性變換函數關系如式(2)所示:
|
式(2)中,f(·)表示心電信號的非線性變換函數。假設能求得 f(·)的最佳估計值 ,那么就能夠利用 mi 求得 si 的最佳估計值 ,因此從腹壁混合信號 ui 中消除母體心電信號成分的最佳估計值 就能得到僅含少量噪聲的胎兒心電信號最佳估計值 ,函數關系如式(3)所示:
|
因此,對于胎兒心電信號提取,首先使用采集的胎兒心電信號數據集的部分樣本作為訓練數據集{(Mi,ui),i = 1,2,,l},求得輸入信號 Mi 和目標輸出信號 ui 之間的非線性變換函數 f(·)的最佳估計值 ,其中信號 Mi 由母體胸部心電信號 mi 和它的 J 維時間導數構成[25]。本文選取 GA-LSTM 網絡對非線性變換函數 f(·)進行擬合,首先利用訓練集數據構建 GA-LSTM 網絡模型,然后將測試集數據輸入 GA-LSTM 網絡模型,最后進行胎兒心電信號的提取。
如圖 1 所示為該模型提取胎兒心電信號流程圖,采用單導聯母體胸部信號作為網絡輸入,單導聯母體腹壁混合信號為目標輸出,然后利用 GA-LSTM 網絡模型估計母體胸部心電信號傳至腹壁的最佳映射,將母體胸部信號的最佳估計從母體腹壁的混合信號中進行分離,即可分離提取得到最佳的胎兒心電信號的估計。
圖1
胎兒心電信號提取方法流程圖
Figure1.
Principle diagram of fetal electrocardiogram signal extraction algorithm
2 基于 GA 優化的 LSTM 網絡
2.1 LSTM 網絡
LSTM 網絡解決了網絡單元以鏈式方式鏈接的傳統遞歸神經網絡梯度消失和爆炸的問題,可有效提高學習時間[21]。在處理有關時間序列的預測和非線性映射問題中,具備記憶能力的 LSTM 網絡模型表現出較強的優勢[20, 22]。LSTM 網絡結構中添加了一種叫做記憶單元(memory cell,mc)的結構來記憶過去的信息,并且增加了輸入門(input gate,ig)、輸出門(output gate,og)和遺忘門(forget gate,fg)三種門結構來控制歷史信息的傳遞[21]。
LSTM 網絡結構如圖 2 所示。設網絡輸入為,隱層狀態為,網絡在時刻 t,各個單元和門控的計算如式(4)~(9)所示:
圖2
LSTM 網絡結構圖
Figure2.
LSTM network structure diagram
|
|
|
|
|
|
式(4)~(9)中,it、ft、ot 分別為輸入門、遺忘門和輸出門的計算;其中,輸入門主要用來決定保留多少當前時刻的輸入信息到當前時刻的單元狀態;遺忘門主要用來決定保留多少上一時刻的單元狀態 ct ? 1 的信息到當前時刻單元狀態 ct 中;輸出門主要用來決定當前時刻的單元狀態有多少輸出。ht 為當前時刻網絡最終輸出,ht ? 1 為上一時刻網絡的輸出, 為當前輸入的單元狀態;ct 為當前時刻的單元狀態;wig、wfg、wcg、wog 分別為三個門控和單元狀態的權重矩陣;big、bfg、bcg、bog 分別為各個門控和單元狀態的偏置;σ(·)和 tanh(·)為傳輸函數,· 代表向量內積,符號 表示按元素相乘。
2.2 GA 優化的 LSTM 網絡心電信號提取模型
GA 通常是計算機模擬達爾文生物進化論的生物科學研究算法,1977 年由 Holland 等[26]提出。在 GA 中關于種群的遺傳演化中發現,以染色體作為種群遺傳的主要載體,并且借助多種隨機操作:基因選擇、基因交叉和基因變異等,不斷演化出一種新的解集種群,據個體適應度和選擇函數的取值可以選擇最優的種群個體,即為 GA 中優化問題的最優解。
本文利用 GA 對 LSTM 網絡的關鍵超參數進行尋優處理,采用 GA 強大的全局隨機搜索能力,得到 LSTM 網絡中神經元個數、學習率和訓練次數的最優組合。基本思路如下:
(1)染色體編碼
將 LSTM 網絡中的隱藏層神經元數目、學習率和訓練次數作為 GA 的初始化對象,通過實數編碼形式進行染色體編碼。隱藏層神經元的區間范圍為[5,40],學習率的區間范圍為[0.001,0.1],訓練次數的區間范圍為[50,500]。
(2)適應度函數
適應度函數的選擇直接影響到 GA 優化后網絡的性能,進而影響到胎兒心電信號的提取效果。本文主要從母親心電信號估計值和真實值之間的整體擬合程度出發來構建適應度函數。假設孕婦胸部心電信號為 m,腹壁混合心電信號為 u,而腹壁心電信號 u 中包含母體心電信號成分 s、胎兒心電信號 d 和噪聲 z,其數學關系如式(10)所示:
|
式(10)中,母體心電信號成分 s 是由母體胸部心電信號 m 經非線性變換傳輸到孕婦腹壁所形成的心電信號,如式(11)所示:
|
式(11)中,表示心電信號的非線性變換函數。假設能求得 的最佳估計值 ,那么就能夠利用 求得 的最佳估計值 (),因此從腹壁混合信號 中消除母體心電信號成分的最佳估計值 就能得到僅含少量噪聲的胎兒心電信號最佳估計值 ,如式(12)所示:
|
LSTM 估計出母親心電信號 后,剩余心電信號 的均方誤差如式(13)所示:
|
考慮到胎兒心電信號、噪聲信號與母體心電信號之間相互獨立,且胎兒心電信號幅值較小[1-2],因此可得如式(14)所示:
|
所以可得剩余心電信號 ,如式(15)所示:
|
由式(15)可以看出,當 時, 達到最小值,此時 ,也即通過非線性變換函數 求出了母體心電信號的最佳估計值 。因此,在利用 GA 優化非線性變換 LSTM 時,當均方誤差函數達到最小值時,可以認為 LSTM 得到了母體心電信號的最優估計,也即此時對胎兒心電信號進行了最優提取。所以,本文中選擇混合心電信號 與非線性估計信號 的均方誤差作為 GA 優化時的適應度函數,如式(16)所示:
|
式(16)中,fitness 為適應度函數值,N 為心電數據總量, 為母親腹壁混合信號中母體心電信號的網絡預測值, 為母親腹壁混合信號的真實值。
(3)選擇算子、交叉算子和變異算子
選擇算子是在當前種群中選擇適應性較好的個體作為親本,并將遺傳信息傳遞給子代。在這里采用錦標賽選擇算法作為 GA 的選擇策略。該選擇算法具有高效的算法執行率和易于實現的特點,算法復雜度遠低于其他選擇策略且易于并行化,在選擇過程中不易陷入局部個體最優點,并且不需要對所有個體的適應度值排序。
交叉算子使用洗牌交叉算法,在交叉之前在父代中利用隨機排序函數進行洗牌運算,然后當在(0,1)之間產生的隨機數小于所給的交叉率大小,則進行交叉變換。在變異算子中,當在(0,1)之間產生的隨機數小于所給的變異率大小,則進行變異操作。
2.3 GA-LSTM 胎兒心電信號提取模型
本文將 GA 與 LSTM 網絡相融合,構建基于 GA-LSTM 的胎兒心電信號提取模型。首先采用 GA 對 LSTM 網絡的超參數作尋優處理,得出學習率、隱層神經元數和訓練次數的最佳組合,進一步提高模型的非線性映射能力;然后利用尋優的參數組合構建的 GA-LSTM 模型作為母體胸部心電信號與腹壁混合信號之間的非線性變換函數 f(·);在此基礎上應用非線性變換函數 f(·)求得母體胸部信號的最佳估計,最后從母體腹壁的混合信號中進行分離,即可分離提取得到最佳的胎兒心電信號的估計。模型具體操作流程如下:
(1)選擇訓練數據集。為了得到函數 f(·)的最佳擬合效果,GA-LSTM 模型的輸入數據由母體心電信號 mi 及其 J 維時間導數構成,本文取 J = 2。GA-LSTM 模型的輸入信號用向量 M 表示,目標輸出信號用向量 u 表示,如式(17)所示:
|
(2)利用 GA 優化 LSTM 網絡參數。
a. 將 LSTM 網絡模型中時間窗口大小、批處理大小、隱藏層單元數目作為優化對象,執行種群的初始化以及染色體編碼與解碼操作。
b. 計算初始種群中各個個體適應度大小;
c. 對染色體進行選擇、交叉和變異操作;
d. 對染色體解碼、計算種群內個體的適應度,在該算法中適應度越小,則越應保留該個體,否則淘汰該個體;
e. 若不符合遺傳終止條件則回到 c 步;若符合遺傳終止條件,則將 GA 求出的最優參數作為 LSTM 網絡模型的最終參數;
(3)訓練 GA-LSTM。將 u 和 M 輸入最優參數組合的 GA-LSTM 網絡,GA-LSTM 網絡模型的輸出為腹壁混合信號中的母體心電信號成分 s = f(M)。將目標信號 u 與輸出信號 s 之差用誤差信號 e 表示,即 e = u-s。GA-LSTM 網絡模型根據均方誤差最小化擬合誤差 E(eTe),最終得到母體胸部心電信號經歷非線性變換 f(·)傳輸到腹壁的最優擬合函數 。
(4)提取胎兒心電信號。將心電信號數據{(mi,ui),i = 1,2,···,N} 送入 GA-LSTM 模型,利用最優擬合函數 計算得到腹壁混合信號 ui 中的母體心電信號成分 。則胎兒心電信號 就可以利用下式計算:。
3 實驗與結果
3.1 模型評價標準
胎兒心電信號提取模型的性能通過靈敏度(sensitivity,Se)(以符號 Se 表示)、精確率(positive predictive value,Ppv)(以符號 Ppv 表示)、整體準確率(accuracy,Acc)(以符號 Acc 表示)和總體概率(F1-measure,F1)(以符號 F1 來表示)四個指標來衡量。每個指標的具體計算方法如式(18)~(21)所示[14]:
|
|
|
|
其中,真陽性(true positive,TP)(符號記為:TP)表示樣本本來是陽性,被正確分類的樣本個數,即正確檢測到的胎兒心電信號個數;假陽性(false positive,FP)(符號記為:FP)表示樣本本來是陰性,被錯誤分類為陽性的樣本個數,即錯誤檢測到的胎兒心電信號個數;假陰性(false negative,FN)(符號記為:FN)表示樣本本來是陽性,被錯誤地分類為陰性的樣本個數,即漏檢的胎兒心電信號個數。
3.2 實驗數據和實驗方法
3.2.1 數據來源
在本文的研究中使用了兩個不同的數據庫來進行評估所提出方法的可行性以及提取性能。第一個數據庫心電信號選取系統識別數據集(database for the identification of systems,DaISy)(網址:http://homes.esat.kuleuven.be/~smc/daisy/)進行研究,該數據庫由魯汶大學電工工程系的一個研究部門—斯塔迪烏斯(STADIUS)開發、維護和托管,可在 STADIUS 主頁進行公開下載。DaISy 數據庫由 de Lathauwer 等[16]提供,心電數據采樣頻率為 250 Hz,記錄時長為 10 s,各通道心電數據長度為 2 500,采用電極放置法從孕婦體表獲取八導聯(chanel,ch)(ch1~ch8)心電信號,其中 ch1~ch5 導聯記錄孕婦腹部混合信號,ch6~ch8 導聯記錄孕婦胸部信號。第二個數據庫由麻省理工學院計算生理學實驗室提供并發布在生理網(PhysioNet)(網址:https://www.physionet.org)上的一個免費公開使用的醫學研究數據庫,實驗選取 PhysioNet 中的無創胎兒心電數據庫(non-invasive fetalelectrocardiogramdatabase)(網址:https://www.physionet.org/content/nifecgdb/1.0.0/),該數據庫包含一系列 55 個多通道腹部無創胎兒心電信號記錄,取自妊娠 21~40 周的單個受試者,每條記錄包含 2 個胸部心電信號,3 或 4 個腹部心電信號,采樣頻率為 1 kHz。相比 DaISy 數據庫,無創胎兒心電數據庫中的腹部信號信噪比低,胎兒心電信號被嚴重污染,從中提取胎兒心電信號的難度更大。
3.2.2 實驗方法
本文實驗綜合考慮模型運算復雜度、計算時長和提取性能,選擇前 1 500 點數據{(mi,ui),i = 1,2,···,1 500}作為訓練數據集,全部 2 500 點數據{(mi,ui),i = 1,2,···,2 500}作為測試數據集。NLMS 方法中,迭代步長設為 0.005,迭代次數設為 1 000。SVM 方法中選擇徑向基函數 作為核函數,核函數參數 σ 和懲罰系數 C 的取值分別為 C = 50,σ2 = 3。LSTM 網絡中隱藏層神經元選為 30 個,迭代次數設為 400,學習率取為 0.01。
3.3 實驗結果對比分析
3.3.1 數據預處理
DaIsy 數據集中的心電信號基本上沒有基線漂移和其他噪聲的影響,且可以明顯看出母體和胎兒心電信號 QRS 波的位置,因此該數據在實驗中可直接使用。而無創胎兒心電信號數據庫包含的數據較多,本文選取組號為 ecgca244 心電信號進行實驗,該組心電信號記錄 6 個通道心電信號,包含 2 個胸部心電信號和 4 個腹部心電信號,因為該數據庫心電信號噪聲污染嚴重,所以對 6 個通道心電信號分別采用 3 階高通和 3 階低通巴特沃斯雙向濾波器去除高頻信號和低頻信號。
3.3.2 胎兒心電信號提取在 DaISy 數據庫可視化結果對比分析
首先將 ch1 和 ch8 導聯心電信號作為兩導聯系統采集得的 ui 和 mi,然后將 GA-LSTM 方法與 NLMS 方法、SVM 方法、GA-SVM 方法和 LSTM 方法進行胎兒心電信號提取對比實驗,實驗結果如圖 3 所示。
圖3
5 種方法的胎兒心電信號提取結果比較
Figure3.
Comparison of extracted fetal electrocardiogram signals in 5 algorithms
由圖 3 可見:① NLMS 方法的胎兒心電信號的 QRS 波提取結果并不理想,在最終提取的胎兒心電信號效果圖中仍混合部分母體的心電信號成分,如圖 3 中 NLMS 方法子圖紅圈所示;② 在提取所得的母體心電信號和胎兒心電信號之間存在 QRS 波相互分離或者相互重疊的部分,其中采用 SVM、LSTM、GA-SVM 和 GA-LSTM 方法對胎兒心電信號進行提取可有效抑制母體心電信號成分的干擾。
為了更好地比較 SVM、GA-SVM、LSTM 和 GA-LSTM 四種胎兒心電信號提取方法的優劣,將圖 3 的綠色方框處分別放大為如圖 4、5 所示。
圖4
胎兒心電信號提取實驗結果對比(500~700 點)
Figure4.
Comparison of experimental results of fetal electrocardiogram signal extraction (500~700 points)
圖5
胎兒心電信號提取實驗結果對比(2 050~2 500 點)
Figure5.
Comparison of experimental results of fetal electrocardiogram signal extraction (2 050~2 500 points)
由圖 4、圖 5 可見:① 采用 SVM、GA-SVM 和 LSTM 方法對胎兒心電信號的 QRS 波進行提取,所得結果中仍混合部分母體心電信號成分(如圖 4、圖 5 中綠色方框所示);② 采用 GA-LSTM 方法可有效消除母體腹壁混合信號中關于母體的心電信號成分,原因在于 GA 算法求出了更優的網絡參數組合,使得本文方法性能優于基于 SVM、GA-SVM 和 LSTM 的胎兒心電信號提取方法。
3.3.3 DaISy 數據集性能指標對比分析
為了定量研究 GA-LSTM 模型在 DaISy 數據集上的提取效果,采用 Se、Ppv、Acc 和 F1 四個指標來進行定量分析[14]。用 DaISy 數據集中 ch1~ch5 共 5 個通道孕婦腹壁心電信號數據進行統計分析,該數據集中每個通道記錄有 22 個胎兒心電信號 QRS 波,本文統計五個通道共 110 個胎兒心電信號 QRS 波。五種方法的統計分析結果如表 1 所示。
由表 1 可知,GA-LSTM 心電信號提取模型在五組腹壁心電數據上的提取性能最好,該模型可以提取到 105 個胎兒心電信號 QRS 波,誤檢 3 個 QRS 波,漏檢 5 個 QRS 波,并且 Acc 為 92.92%,Se 為 95.45%,Ppv 為 97.22%,F1 為 96.33%。NLMS 模型能夠提取到 96 個胎兒心電信號 QRS 波,誤檢 9 個 QRS 波,漏檢 14 個 QRS 波,且 Acc 為 80.67%,Se、Ppv 和 F1 分別為 87.27%、91.43% 和 89.30%,四項統計指標都相對較低,原因在于 NLMS 模型對胎兒心電信號適應性不強,尤其在母體心電信號與胎兒心電信號重疊部分,導致對胎兒心電信號的識別率較低。SVM 模型可以提取到 98 個胎兒心電信號 QRS 波,誤檢 8 個 QRS 波,漏檢 12 個 QRS 波,且 Acc 為 83.05%,Se 為 89.09%,Ppv 為 92.45%,F1 為 90.07%,可見 SVM 模型對胎兒心電信號提取的性能并不突出,這是由于 SVM 存在泛化能力弱,易陷入局部極值的原因。GA-SVM 方法可以提取到 102 個胎兒心電信號 QRS 波,誤檢 6 個 QRS 波,漏檢 8 個 QRS 波,且 Acc 為 87.93%,Se 為 92.73%,Ppv 為 94.44%,F1 為 93.58%,可見即使采用 GA 對 SVM 的超參數進行優化,該模型的心電信號提取性能也并不突出。LSTM 模型可以提取到 103 個胎兒心電信號 QRS 波,誤檢 5 個 QRS 波,漏檢 7 個 QRS 波,并且 Acc 為 88.79%,Se 為 93.64%,Ppv 為 94.50%,F1 為 94.06%,該模型在胎兒心電信號提取實驗中也表現出較強的優勢,但其性能不及本文所提出的方法,這是因為 LSTM 模型的超參數很難人工取到最優值,從而使得模型提取性能低于 GA-LSTM 模型。可見利用 GA 先對 LSTM 網絡模型的超參數進行尋優處理,然后利用最優參數組合構建 GA-LSTM 胎兒心電信號提取模型,可以有效提高胎兒心電信號提取的性能。
3.3.4 胎兒心電信號提取在無創胎兒心電信號數據庫可視化結果對比分析
在無創胎兒心電信號數據庫組號 ecgca244 中選取前 10 000 個數據進行可視化對比分析,實驗結果如圖 6 所示。
圖6
5 種方法的胎兒心電信號提取結果比較
Figure6.
Comparison of extracted fetal electrocardiogram signals in 5 algorithms
由圖 6 可見:① NLMS 方法和 SVM 方法的胎兒心電信號的 QRS 波提取結果較差,在最終提取的胎兒心電信號效果圖中仍混合較多的母體心電信號成分(如圖 6 中紅圈所示);② GA-SVM 模型在該數據集的提取效果也并不突出,其提取結果仍有部分母體心電信號成分;(如圖 6 中綠色方框所示);③ 在母體心電信號和胎兒心電信號之間存在 QRS 波相互分離或者相互重疊的部分,其中采用 LSTM 和 GA-LSTM 的對胎兒心電信號進行提取可有效抑制母體心電信號成分的干擾,而 GA-LSTM 方法的提取性能更為突出,可以提取出更為清晰準確的胎兒心電信號。
3.3.5 無創胎兒心電信號數據庫性能指標對比分析
在無創胎兒心電信號數據庫中,已經明顯地標注了胎兒心電信號 QRS 波的位置和個數,實驗選取的前 10 000 個數據點中每組腹部通道包含 28 個 QRS 波,四組共 112 個胎兒心電信號 QRS 波。由表 2 可知,雖然該數據集受噪聲污染和基線漂移影響嚴重,但 GA-LSTM 心電信號提取模型依然可以提取出較多的胎兒心電信號 QRS 波,漏檢和誤檢的胎兒心電信號 QRS 波也較少,四項統計指標均優于其他四種方法,進一步證明了本文所提出方法的可行性。
3.3.6 網絡實時性和推廣性分析
實驗采用 Windows 10(Microsoft,美國)系統進行,中央處理器(central processing unit,CPU)使用 2.90 GHz 的 i5 處理器,內存為 16.0 GB,實驗軟件使用 MATLAB 2019a(MathWorks,美國)的版本進行。在本文的實驗中,初始種群數量設置為 40,最大迭代次數為 100 次,采用網絡的訓練時間和訓練后的執行時間兩部分來進行網絡實時性與推廣性方面的對比和討論,實驗結果如表 3 所示。
通過表 3 的對比分析可知,實驗所采取的方法在網絡構建時均需要消耗一定的時間,而網絡結構的差異性使得網絡訓練時所用的時間也不同。從表 3 可以看出:① 網絡訓練階段,NLMS 所需時間最短,SVM 方法和 LSTM 方法訓練時間相當。加入了 GA 算法后,網絡訓練階段的耗時提高了大約 2 倍,GA-SVM 方法和 GA-LSTM 方法的訓練時長仍基本相同,約為 3 min。② 在網絡執行階段,SVM 方法耗時最長,本文方法(GA-LSTM)與其他方法相比,耗時并沒有顯著增加,而是略有降低。在 MATLAB2019a 環境下,本文方法執行階段的耗時約為 0.4 s。
可以看出,在實際應用中,除了在程序啟動訓練階段需要等待 3 min 左右,其他時間段都可以較快地獲得胎兒心電信號提取結果。如果 C 等編譯語言將算法寫入硬件中運行,會進一步提高運行的速度。因此,本文方法在實時性方面可以滿足一定場景下的需求,具有較好的推廣性。
4 結論
本文以 LSTM 網絡為基礎構建 GA-LSTM 胎兒心電信號提取模型,采用 GA 對 LSTM 網絡的超參數進行優化處理,有效提高了模型的預測性能,減少了人為確定超參數因素的影響。并選取兩個臨床實時數據集進行實驗,實驗表明,相比于傳統的 NLMS、SVM、GA-SVM 和 LSTM 網絡模型,本文所提出的 GA-LSTM 心電信號提取模型在 DaISy 數據集和無創胎兒心電信號數據集上均表現出更優的提取性能,能夠提取出更加清晰的胎兒心電信號 QRS 波,誤檢和漏檢的胎兒心電信號較少,具有很強的抗噪能力和泛化能力,很好地解決了胎兒心電信號不易提取的難題,為圍產期和妊娠期胎兒健康監測提供了新方法,具有重要的臨床應用價值,在胎兒心電信號提取的研究中具有較好的應用前景。
利益沖突聲明:本文全體作者均聲明不存在利益沖突。