受試者招募是影響臨床試驗進展和結果的關鍵環節,一般通過篩選標準(包括納入標準和排除標準)進行招募。篩選標準的語義類別研究可以優化臨床試驗設計和促進受試者自動篩選系統開發。本文通過學術測評的方式探究了利用人工智能技術對中文臨床試驗篩選標準語義類別的自動分類問題。本文收集了 38 341 條帶語義標注的中文篩選標準文本,并預先定義了 44 種語義類別。總共有 75 支隊伍報名參加測評,其中 27 支隊伍提交了結果。結果分析發現大部分參賽隊伍使用了混合模型,主流的方法是引入能提供豐富語義表示的預訓練語言模型,結合神經網絡模型,針對分類任務進行微調,最后進行模型集成提高最終性能。研究結果顯示,最佳系統的性能達到 0.81 的宏平均 F1 值,其主要是使用了基于預訓練語言模型——變換器雙向編碼表征模型(BERT)與模型融合的方法。結果錯誤分析顯示,從數據處理步驟來看,數據的預處理和后處理非常重要;從語料數量來看,數量較少類別的分類效果一般。通過本文研究,最終期望本文研究成果能為中文臨床試驗篩選標準短文本分類研究領域提供可供研究的數據集和最新結果。
引用本文: 宗輝, 張澤宇, 楊金璇, 雷健波, 李作峰, 郝天永, 張曉艷. 基于人工智能的中文臨床試驗篩選標準文本分類研究. 生物醫學工程學雜志, 2021, 38(1): 105-110, 121. doi: 10.7507/1001-5515.202006035 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
引言
臨床試驗是指通過人體(志愿者,也稱受試者)進行的科學研究,目的是確定一種藥物或一項治療方法的療效、安全性以及存在的副作用,對于促進醫學發展和提高人類健康有著積極的作用。根據臨床試驗目的不同,受試者可能是患者或健康志愿者。受試者篩選標準,是臨床試驗設計者擬定的鑒定受試者是否滿足該臨床試驗的主要指標,分為入組標準和排除標準,一般為無規則的自由文本形式。
臨床試驗的受試者招募一般是通過人工比較病歷記錄和臨床試驗篩選標準完成,這種方式費時、費力且效率低下。因此,臨床試驗面臨諸多困境,比如受試者招募困難導致臨床試驗難以按期完成、入組患者流失影響試驗的有效性等。近年來,隨著臨床試驗數目越來越多、設計越來越復雜,基于自然語言處理和信息抽取的臨床試驗受試者自動化招募系統開始嶄露頭角呈現出不錯的效果,且具有很大的實用前景和醫學臨床價值,然而目前這類研究大多針對英文臨床試驗篩選標準及英文電子健康記錄數據[1]。近些年來,隨著中國醫療信息化的發展,中文電子健康數據的相關研究已經取得了很多進展,然而針對中文臨床試驗篩選標準的自然語言處理研究很少,因此通過自然語言處理以及人工智能(artificial intelligence,AI)技術推進中文臨床試驗篩選標準的結構化和標準化等工作,對于推進中國臨床試驗研究的自動化和信息化發展具有重要意義。
第五屆中國健康信息處理會議(China conference on health information processing,CHIP2019)(網址:http://www.cips-chip.org.cn/)的主題為“人工智能+醫療健康”。會議共享測評的任務三,是聚焦于“中文臨床試驗篩選標準短文本分類”,希望能通過最新的基于自然語言處理技術和深度學習算法的人工智能技術,促進中文臨床試驗篩選標準的相關研究。測評任務三,總計開放了 38 341 條帶標注的中文臨床試驗篩選標準文本,以及預先定義好的 44 種語義類別標簽。在此次測評任務中,給定一條真實的臨床試驗篩選標準,系統需要返回其對應的語義類別。測評任務最終排名指標為宏平均 F1 值。下述為兩條示例數據:
例 1 輸入:近期顱內或椎管內手術史
輸出:Therapy or Surgery
例 2 輸入:年齡大于 65 歲
輸出:Age
1 中文醫療文本分類研究的相關工作
1.1 中文電子醫療記錄的文本分類研究進展
文本分類是自然語言處理中的基礎任務之一,有著成熟的技術和廣泛的應用。隨著醫學信息化的發展,醫療文本分類在輔助診斷、信息結構化方面發揮著重要的作用。中文醫療文本分類任務是一項基礎性任務,研究數據一般包括現代電子醫療記錄和傳統中醫藥文本兩類。Zhang 等[2]將中文的產科電子醫療記錄分為主訴、體格檢查、產科檢查和輔助檢查四個類別,通過潛在狄利克雷分配(latent dirichlet allocation,LDA)主題模型抽取文本特征,使用跳字模型(skip-gram)方法訓練詞向量,訓練了四種不同的多類別分類器,用于輔助診斷。Yao 等[3]針對中醫藥的臨床記錄研究不同類型的特征和分類算法的效果,并提取了一種將深度學習文本表示與中醫藥領域知識相結合的新方法,獲得了最佳分類性能。Zhang 等[4]則側重于中醫證候類別鑒定,基于血管性輕度認知障礙數據,使用潛在類別分析模型來識別證候類型,并開發了相關軟件。
1.2 臨床試驗篩選標準的語義類別研究
英文臨床試驗篩選標準的語義類別相關研究一直備受學者關注。經由領域內專家們達成的共識,美國國家癌癥研究所的生物醫學研究整合領域研究組(the biomedical research integrated domain group,BRIDG)針對英文篩選標準定義了 17 種類別屬性[5]。Luo 等[6-7]下載了 27 278 條來自美國臨床試驗注冊中心網站(網址:clinicaltrials.gov)中真實世界英文臨床試驗篩選標準語句,使用一體化醫學語言系統(unified medical language system,UMLS)語義類型構建句子特征,通過由底向上的層次聚類算法和人工歸納總結,最終獲得了 27 類語義類型,并設計了不同的機器學習分類器且取得了不錯的效果。而針對中文臨床試驗篩選標準的語義類別鮮有研究,在此次 CHIP2019 測評任務三的前期實驗中,本文通過下載來自中國臨床試驗注冊中心的中文篩選標準數據,并經層次聚類和人工歸納,總結出了 44 種中文臨床試驗篩選標準語義類別。
臨床試驗篩選標準的語義類別研究可以優化篩選標準設計,有效促進受試者招募。Zhang 等[8]通過臨床試驗篩選標準的自動分類促進了特定人群(如艾滋病病毒感染者和孕婦)的臨床試驗匹配。2018 年國際自然語言處理臨床挑戰賽(national natural language processing clinical challenges,N2C2 2018)測評任務一開放了 288 份糖尿病患者完整的縱向敘述型醫療記錄,以及事先定義好的 13 條篩選標準,聚焦于探索是否可以通過構建自動化的自然語言處理系統來鑒定符合條件的受試者[9],排名第一的系統使用基于規則的方法,其宏平均 F1 值達到了 0.91[10]。2017 年美國臨床腫瘤學會(American society of clinical oncology,ASCO)通過研究臨床試驗入組患者和真實世界的患者分布,提出對多種篩選標準類別應該優化并適當放寬限制條件,這些篩選標準包括兒童患者入組成人癌癥臨床試驗的最低年齡限制[11]、納入艾滋病病毒(或乙肝、丙肝)感染者[12]、納入器官功能障礙者、納入第二原發癌或有既往史者[13]和納入腦轉移癌癥患者[14]等。不同語義類型的篩選標準可以在不同醫療資料中找到對應的信息,并在醫療臨床研究中發揮著重要的作用,正確鑒定臨床試驗中的篩選標準語義類別是這些研究的基礎和支撐。此次 CHIP2019 測評任務三聚焦于中文臨床試驗篩選標準類別的分類任務,希望能通過最新的基于自然語言處理技術和深度學習算法的人工智能技術,促進中文臨床試驗篩選標準的相關研究。
2 實驗數據
CHIP2019 測評任務三的數據集來源于中國臨床試驗注冊中心網站(網址:www.chictr.org.cn)的真實臨床試驗篩選標準,該網站臨床試驗注冊信息數據公開透明,可用于科學研究。篩選標準一般為一段非結構化的自由文本數據,長度不一,用來描述符合某臨床試驗的受試者的各種信息,如年齡、性別和疾病等。本文在前期實驗中通過層次聚類和人工歸納,總結出了 7 種主題和 44 種語義類別,并對每種類別定義了描述信息和標注規則。2 名具有生物醫學信息學研究經驗的標注者根據定義好的標注規則對篩選標準語句進行了標注,然后本文根據科恩卡帕評分(Cohen’s kappa)對每個類別進行標注一致性計算,總體的一致性分數為 0.992。
CHIP2019 測評任務三最終公布的數據集包括 44 種語義類別定義和 38 341 條篩選標準,其中包括訓練集 22 962 條,驗證集 7 682 條,測試集 7 697 條。該數據集存在類別數據量分布不均衡的特點,數量較多的類別如疾病(disease)包含有 8 518 條數據,數量較少的類別如種族(ethnicity)僅包含 23 條數據,詳細信息如表 1 所示。
3 實驗結果
根據 CHIP2019 會議測評時間安排,在測評期間,參賽團隊均通過郵箱進行報名。測評任務的訓練集、驗證集以及評估腳本于 2019 年 9 月 15 日發布后,參賽團隊搭建并測試各自開發的模型。測試集數據于 10 月 31 日發布,每支參賽團隊在測試集公布期間最多提交 5 次測試集結果。測評任務三于 2019 年 11 月 5 日截止,總共 75 支隊伍報名參加測評,共計 104 人,其中 66 支隊伍來自科研院校等機構,7 支隊伍來自企業,2 支隊伍為個人報名。最終 27 支隊伍提交了模型測評結果,根據參賽規則,參賽隊伍的測評方法和結果,由測評組織者進行學術測評分析研究。
3.1 評估指標
測評使用的評價指標包括宏平均準確率、宏平均召回率和宏平均 F1 值。最終排名以宏平均 F1 值為基準。假設有 n 個類別: C1, ,Ci,
,Ci, ,Cn,則各類別的準確率 Pi、各類別的召回率 Ri、宏平均準確率、宏平均召回率和宏平均 F1 值的計算公式如式(1)~式(5)所示:
,Cn,則各類別的準確率 Pi、各類別的召回率 Ri、宏平均準確率、宏平均召回率和宏平均 F1 值的計算公式如式(1)~式(5)所示:
 |
 |
 |
 |
 |
3.2 結果分析
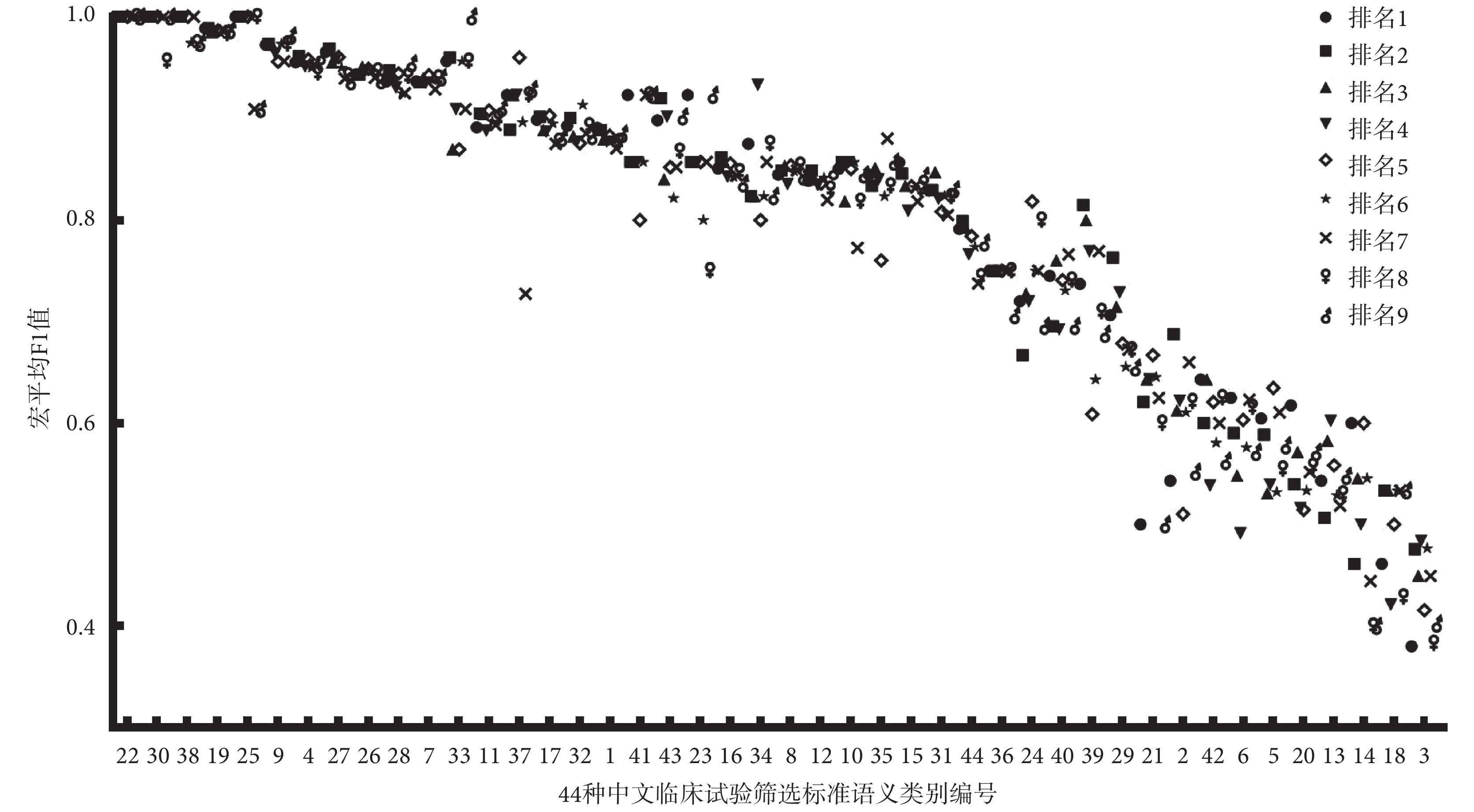
對 27 支隊伍提交的測評結果進行分析,宏平均 F1 值的平均數為 0.770 502,最大值為 0.810 263,最小值為 0.553 736,中位數為 0.788 728。排名前九的隊伍提交的各自最優的結果信息如表 2 所示,包括參賽單位、方法描述、是否使用外部數據集和宏平均 F1 值。排名前九的隊伍系統的結果在中文篩選標準各個語義類別上的具體表現如圖 1 所示。
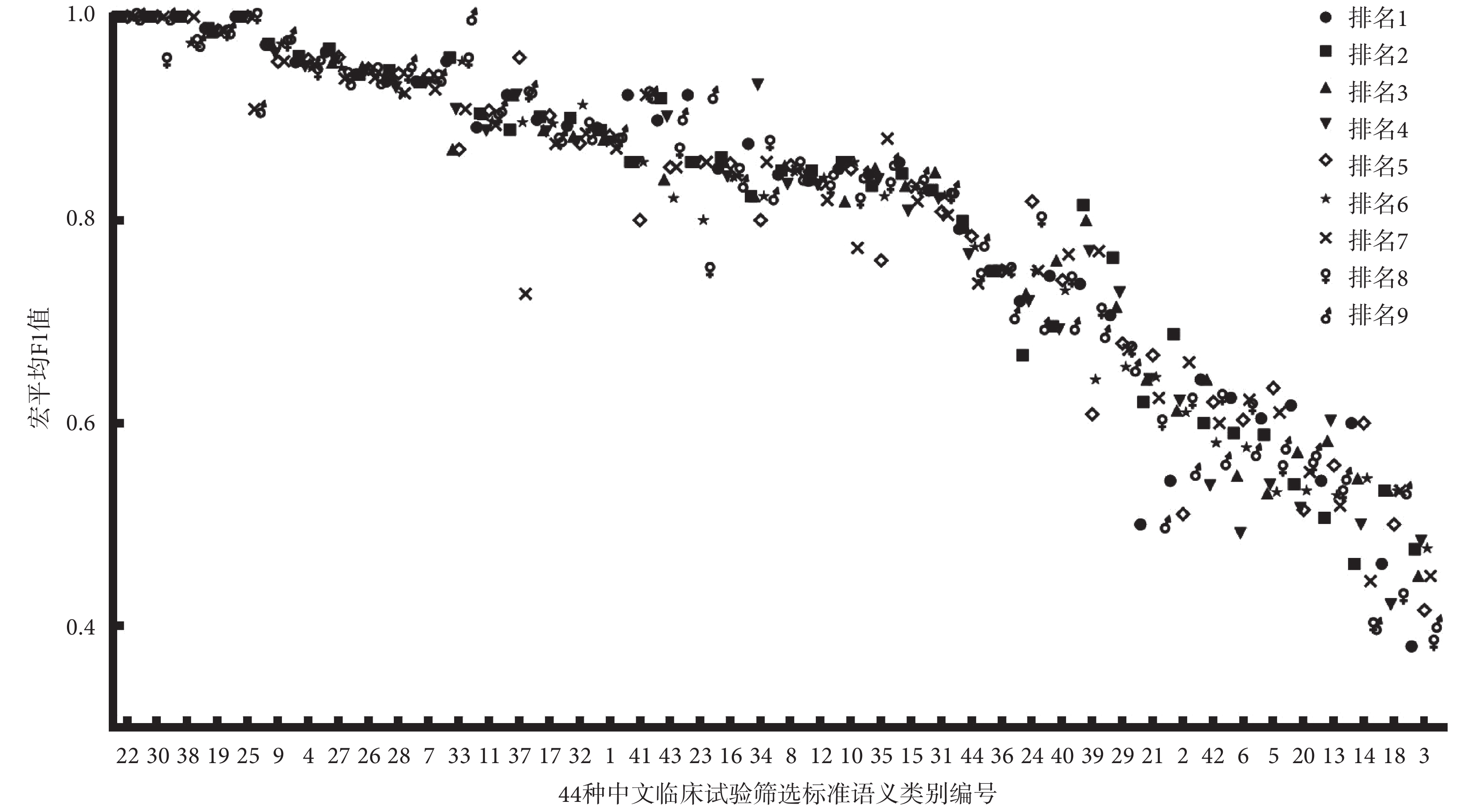 圖1
排名前九的隊伍的最終結果分別在 44 種語義類別上的性能表現
Figure1.
The performance in 44 semantic categories of final results of the top nine teams
圖1
排名前九的隊伍的最終結果分別在 44 種語義類別上的性能表現
Figure1.
The performance in 44 semantic categories of final results of the top nine teams
3.3 方法分析
引入預訓練語言模型,結合神經網絡模型,然后針對分類任務進行微調,最后進行多種模型集成是解決中文臨床試驗篩選標準短文本分類任務的主流解決思路。預訓練語言模型一般使用大規模文本語料庫進行預訓練,能夠提供豐富的語義表示信息,并且可以針對特定任務進行微調。任務三的參賽隊伍使用了多種預訓練語言模型,主要包括語言模型嵌入(embeddings from language models,ELMO)、變換器雙向編碼表征模型(bidirectional encoder representations from transformers,BERT)、強力優化變換器雙向編碼表征模型(robustly optimized BERT,RoBERT)、知識整合增強表征模型(enhanced representation from knowledge integration,ERNIE)、語言理解的廣義自回歸預訓練模型(generalized autoregressive pretraining for language understanding,XLNERT)。其中 BERT 模型使用次數最多,在單獨使用時效果也最好。此外多種機器學習算法通過與預訓練語言模型拼接進行分類,包括神經網絡模型,如卷積神經網絡模型(convolutional neural network,CNN)、深層金字塔卷積神經網絡模型(deep pyramid convolutional neural networks,DPCNN)、長短期記憶網絡模型(long short-term memory,LSTM)和注意力機制模型(attention mechanism)等,統計學模型如支持向量機(support vector machine,SVM)和隨機森林(random forest,RF)等。提交的最終結果顯示,相比于統計學模型,神經網絡模型在多分類任務中具有更好的性能表現,但不同的神經網絡模型之間差別不大。在模型微調中,排名第二的團隊采用了傾斜的三角學習率方法,使得模型可以在訓練開始時快速收斂到參數空間的合適區域,然后再細化其參數。
數據預處理可以使模型更好地提取到文本中的特征,提高模型的預測和泛化能力。在此次測評中大多數隊伍都對數據進行預處理操作,主要包括以下幾點:① 去除重復數據;② 刪除特殊表述(如長串數字、停用詞和標點符號);③ 變形詞識別和替換(如繁體字轉換為簡體字、英文大寫轉換為小寫、全角字符轉換為半角字符、特殊符號替換、同音形近字替換);④ 將過長的文本截斷。結果顯示,這些預處理操作能有效提升模型最終的表現。此外加入其它特征也能對模型產生一定的影響,這些特征主要包括句法特征(如句子的主謂賓)、關鍵詞特征、詞性特征、詞頻-逆文檔頻率特征、句子長度、句子中的特殊符號數量(如數字個數、比較符個數和英文字母個數)等,這些特征的提取工作一般借助于中文自然語言處理工具包和結巴分詞實現。
3.4 錯誤分析
如圖 1 所示為排名前九的隊伍提交結果在中文篩選標準各個語義類別上的表現,縱坐標表示 F1 值,橫坐標表示 44 種語義類別,并按照 F1 值的從大到小進行排序。大多數類別的 F1 值都在 0.80 以上。性別(gender)分類效果最優,所有隊伍結果中 F1 值都為 1.0,主要原因是性別(gender)這類數據數量多,句子長度較短,句子信息有很強的辨識性。體征(sign)分類效果最差,成績在 0.38~0.48 之間,這主要是因為體征(sign)表示臨床醫生通過查體發現的患者異常現象,在中文臨床試驗篩選標準中,描述信息包括體征名稱、發生時間、狀態、嚴重程度等,不同的臨床試驗,其篩選標準文本對體征描述側重不同,這些都會影響分類器的學習和泛化能力。
結合各類別的數據量和文本描述信息分析,可以發現數據量大、數據具有獨特性描述特征的語義類別分類效果較好,而數據稀疏性強的語義類別分類效果較差。系統表現好的篩選標準類別,如性別(gender)、倫理審查(ethical audit)、吸煙狀況(smoking status)和年齡(age)一般其文本描述信息獨特性高、辨識性強,這都會幫助分類器表現出好的分類效果。分類效果差的篩選標準類別,如特殊患者特征(special patient characteristic)、設備(device)、護理(nursing)、受體狀態(receptor status)和體征(sign),由于數據量少、而且數據集中文本描述差異性明顯,因此分類效果表現一般。
此外,含多個類別(multiple)的平均 F1 值達到了 0.773 915。與其他單語義類別篩選標準相比,這個類別包含二種以上語義類別信息,文本一般長度較長且更復雜,是這次測評任務三中獨特的一個類別。
結合不同隊伍的系統方案分析,發現在分類效果好的篩選標準語義類別中,各系統方案的表現差別不大,在分類效果差的這些類別中,各系統方案表現差異明顯。因此提升這些數據量少、辨識性低的類別的分類效果,對系統總體的提升有明顯的幫助。預訓練語言模型結合神經網絡分類模型是大多數隊伍采用的方案,總體分類效果會很高。而僅采用預訓練語言模型的方案在某些類別中的表現卻明顯高于其他方案,如排名第 4 的系統使用了 BERT 模型、ERNIE 模型、XLNET 模型在類別鍛煉(exercise)中效果最好,排名第 5 的系統僅使用了 BERT 模型在性取向(sexual related)和居住情況(address)類別中效果最好,排名第 9 的系統僅使用了 ERNIE 在睡眠(bedtime)類別中效果最好。
4 結語
CHIP2019 中國健康信息處理會議共享測評任務三為中文臨床試驗篩選標準短文本分類,總共開放了 38 341 條篩選標準和預先定義好的 44 種語義類別。一共 27 支隊伍提交了最終結果,排名第 1 的系統宏平均 F1 值達到 0.810 263,其使用了預訓練語言模型 BERT 和模型融合的分類方法。大部分參賽團隊都使用各種預訓練語言模型,結合神經網絡模型,然后針對分類任務進行微調,最后進行模型集成提高最終系統表現。結果分析顯示排名前九的系統總體表現很接近,在宏平均 F1 值在 0.79~0.81 之間。但不同類別的篩選標準分類結果差異明顯,F1 值最低為 0.38,最高可達到 1.0。數據量大、描述文本獨特性高、辨識性強的類別效果明顯較好。這次 CHIP2019 共享測評任務三同時也為中文醫學文本分類任務提供了可供參考的數據集和最新結果(下載網址:https://github.com/zonghui0228/chip2019task3)。在未來的工作中,學習不同語義類別的差異性知識,提高小類別的表現,可以進一步提高醫學短文本分類系統的性能。
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
引言
臨床試驗是指通過人體(志愿者,也稱受試者)進行的科學研究,目的是確定一種藥物或一項治療方法的療效、安全性以及存在的副作用,對于促進醫學發展和提高人類健康有著積極的作用。根據臨床試驗目的不同,受試者可能是患者或健康志愿者。受試者篩選標準,是臨床試驗設計者擬定的鑒定受試者是否滿足該臨床試驗的主要指標,分為入組標準和排除標準,一般為無規則的自由文本形式。
臨床試驗的受試者招募一般是通過人工比較病歷記錄和臨床試驗篩選標準完成,這種方式費時、費力且效率低下。因此,臨床試驗面臨諸多困境,比如受試者招募困難導致臨床試驗難以按期完成、入組患者流失影響試驗的有效性等。近年來,隨著臨床試驗數目越來越多、設計越來越復雜,基于自然語言處理和信息抽取的臨床試驗受試者自動化招募系統開始嶄露頭角呈現出不錯的效果,且具有很大的實用前景和醫學臨床價值,然而目前這類研究大多針對英文臨床試驗篩選標準及英文電子健康記錄數據[1]。近些年來,隨著中國醫療信息化的發展,中文電子健康數據的相關研究已經取得了很多進展,然而針對中文臨床試驗篩選標準的自然語言處理研究很少,因此通過自然語言處理以及人工智能(artificial intelligence,AI)技術推進中文臨床試驗篩選標準的結構化和標準化等工作,對于推進中國臨床試驗研究的自動化和信息化發展具有重要意義。
第五屆中國健康信息處理會議(China conference on health information processing,CHIP2019)(網址:http://www.cips-chip.org.cn/)的主題為“人工智能+醫療健康”。會議共享測評的任務三,是聚焦于“中文臨床試驗篩選標準短文本分類”,希望能通過最新的基于自然語言處理技術和深度學習算法的人工智能技術,促進中文臨床試驗篩選標準的相關研究。測評任務三,總計開放了 38 341 條帶標注的中文臨床試驗篩選標準文本,以及預先定義好的 44 種語義類別標簽。在此次測評任務中,給定一條真實的臨床試驗篩選標準,系統需要返回其對應的語義類別。測評任務最終排名指標為宏平均 F1 值。下述為兩條示例數據:
例 1 輸入:近期顱內或椎管內手術史
輸出:Therapy or Surgery
例 2 輸入:年齡大于 65 歲
輸出:Age
1 中文醫療文本分類研究的相關工作
1.1 中文電子醫療記錄的文本分類研究進展
文本分類是自然語言處理中的基礎任務之一,有著成熟的技術和廣泛的應用。隨著醫學信息化的發展,醫療文本分類在輔助診斷、信息結構化方面發揮著重要的作用。中文醫療文本分類任務是一項基礎性任務,研究數據一般包括現代電子醫療記錄和傳統中醫藥文本兩類。Zhang 等[2]將中文的產科電子醫療記錄分為主訴、體格檢查、產科檢查和輔助檢查四個類別,通過潛在狄利克雷分配(latent dirichlet allocation,LDA)主題模型抽取文本特征,使用跳字模型(skip-gram)方法訓練詞向量,訓練了四種不同的多類別分類器,用于輔助診斷。Yao 等[3]針對中醫藥的臨床記錄研究不同類型的特征和分類算法的效果,并提取了一種將深度學習文本表示與中醫藥領域知識相結合的新方法,獲得了最佳分類性能。Zhang 等[4]則側重于中醫證候類別鑒定,基于血管性輕度認知障礙數據,使用潛在類別分析模型來識別證候類型,并開發了相關軟件。
1.2 臨床試驗篩選標準的語義類別研究
英文臨床試驗篩選標準的語義類別相關研究一直備受學者關注。經由領域內專家們達成的共識,美國國家癌癥研究所的生物醫學研究整合領域研究組(the biomedical research integrated domain group,BRIDG)針對英文篩選標準定義了 17 種類別屬性[5]。Luo 等[6-7]下載了 27 278 條來自美國臨床試驗注冊中心網站(網址:clinicaltrials.gov)中真實世界英文臨床試驗篩選標準語句,使用一體化醫學語言系統(unified medical language system,UMLS)語義類型構建句子特征,通過由底向上的層次聚類算法和人工歸納總結,最終獲得了 27 類語義類型,并設計了不同的機器學習分類器且取得了不錯的效果。而針對中文臨床試驗篩選標準的語義類別鮮有研究,在此次 CHIP2019 測評任務三的前期實驗中,本文通過下載來自中國臨床試驗注冊中心的中文篩選標準數據,并經層次聚類和人工歸納,總結出了 44 種中文臨床試驗篩選標準語義類別。
臨床試驗篩選標準的語義類別研究可以優化篩選標準設計,有效促進受試者招募。Zhang 等[8]通過臨床試驗篩選標準的自動分類促進了特定人群(如艾滋病病毒感染者和孕婦)的臨床試驗匹配。2018 年國際自然語言處理臨床挑戰賽(national natural language processing clinical challenges,N2C2 2018)測評任務一開放了 288 份糖尿病患者完整的縱向敘述型醫療記錄,以及事先定義好的 13 條篩選標準,聚焦于探索是否可以通過構建自動化的自然語言處理系統來鑒定符合條件的受試者[9],排名第一的系統使用基于規則的方法,其宏平均 F1 值達到了 0.91[10]。2017 年美國臨床腫瘤學會(American society of clinical oncology,ASCO)通過研究臨床試驗入組患者和真實世界的患者分布,提出對多種篩選標準類別應該優化并適當放寬限制條件,這些篩選標準包括兒童患者入組成人癌癥臨床試驗的最低年齡限制[11]、納入艾滋病病毒(或乙肝、丙肝)感染者[12]、納入器官功能障礙者、納入第二原發癌或有既往史者[13]和納入腦轉移癌癥患者[14]等。不同語義類型的篩選標準可以在不同醫療資料中找到對應的信息,并在醫療臨床研究中發揮著重要的作用,正確鑒定臨床試驗中的篩選標準語義類別是這些研究的基礎和支撐。此次 CHIP2019 測評任務三聚焦于中文臨床試驗篩選標準類別的分類任務,希望能通過最新的基于自然語言處理技術和深度學習算法的人工智能技術,促進中文臨床試驗篩選標準的相關研究。
2 實驗數據
CHIP2019 測評任務三的數據集來源于中國臨床試驗注冊中心網站(網址:www.chictr.org.cn)的真實臨床試驗篩選標準,該網站臨床試驗注冊信息數據公開透明,可用于科學研究。篩選標準一般為一段非結構化的自由文本數據,長度不一,用來描述符合某臨床試驗的受試者的各種信息,如年齡、性別和疾病等。本文在前期實驗中通過層次聚類和人工歸納,總結出了 7 種主題和 44 種語義類別,并對每種類別定義了描述信息和標注規則。2 名具有生物醫學信息學研究經驗的標注者根據定義好的標注規則對篩選標準語句進行了標注,然后本文根據科恩卡帕評分(Cohen’s kappa)對每個類別進行標注一致性計算,總體的一致性分數為 0.992。
CHIP2019 測評任務三最終公布的數據集包括 44 種語義類別定義和 38 341 條篩選標準,其中包括訓練集 22 962 條,驗證集 7 682 條,測試集 7 697 條。該數據集存在類別數據量分布不均衡的特點,數量較多的類別如疾病(disease)包含有 8 518 條數據,數量較少的類別如種族(ethnicity)僅包含 23 條數據,詳細信息如表 1 所示。
3 實驗結果
根據 CHIP2019 會議測評時間安排,在測評期間,參賽團隊均通過郵箱進行報名。測評任務的訓練集、驗證集以及評估腳本于 2019 年 9 月 15 日發布后,參賽團隊搭建并測試各自開發的模型。測試集數據于 10 月 31 日發布,每支參賽團隊在測試集公布期間最多提交 5 次測試集結果。測評任務三于 2019 年 11 月 5 日截止,總共 75 支隊伍報名參加測評,共計 104 人,其中 66 支隊伍來自科研院校等機構,7 支隊伍來自企業,2 支隊伍為個人報名。最終 27 支隊伍提交了模型測評結果,根據參賽規則,參賽隊伍的測評方法和結果,由測評組織者進行學術測評分析研究。
3.1 評估指標
測評使用的評價指標包括宏平均準確率、宏平均召回率和宏平均 F1 值。最終排名以宏平均 F1 值為基準。假設有 n 個類別: C1,,Ci,,Cn,則各類別的準確率 Pi、各類別的召回率 Ri、宏平均準確率、宏平均召回率和宏平均 F1 值的計算公式如式(1)~式(5)所示:
|
|
|
|
|
3.2 結果分析
對 27 支隊伍提交的測評結果進行分析,宏平均 F1 值的平均數為 0.770 502,最大值為 0.810 263,最小值為 0.553 736,中位數為 0.788 728。排名前九的隊伍提交的各自最優的結果信息如表 2 所示,包括參賽單位、方法描述、是否使用外部數據集和宏平均 F1 值。排名前九的隊伍系統的結果在中文篩選標準各個語義類別上的具體表現如圖 1 所示。
圖1
排名前九的隊伍的最終結果分別在 44 種語義類別上的性能表現
Figure1.
The performance in 44 semantic categories of final results of the top nine teams
3.3 方法分析
引入預訓練語言模型,結合神經網絡模型,然后針對分類任務進行微調,最后進行多種模型集成是解決中文臨床試驗篩選標準短文本分類任務的主流解決思路。預訓練語言模型一般使用大規模文本語料庫進行預訓練,能夠提供豐富的語義表示信息,并且可以針對特定任務進行微調。任務三的參賽隊伍使用了多種預訓練語言模型,主要包括語言模型嵌入(embeddings from language models,ELMO)、變換器雙向編碼表征模型(bidirectional encoder representations from transformers,BERT)、強力優化變換器雙向編碼表征模型(robustly optimized BERT,RoBERT)、知識整合增強表征模型(enhanced representation from knowledge integration,ERNIE)、語言理解的廣義自回歸預訓練模型(generalized autoregressive pretraining for language understanding,XLNERT)。其中 BERT 模型使用次數最多,在單獨使用時效果也最好。此外多種機器學習算法通過與預訓練語言模型拼接進行分類,包括神經網絡模型,如卷積神經網絡模型(convolutional neural network,CNN)、深層金字塔卷積神經網絡模型(deep pyramid convolutional neural networks,DPCNN)、長短期記憶網絡模型(long short-term memory,LSTM)和注意力機制模型(attention mechanism)等,統計學模型如支持向量機(support vector machine,SVM)和隨機森林(random forest,RF)等。提交的最終結果顯示,相比于統計學模型,神經網絡模型在多分類任務中具有更好的性能表現,但不同的神經網絡模型之間差別不大。在模型微調中,排名第二的團隊采用了傾斜的三角學習率方法,使得模型可以在訓練開始時快速收斂到參數空間的合適區域,然后再細化其參數。
數據預處理可以使模型更好地提取到文本中的特征,提高模型的預測和泛化能力。在此次測評中大多數隊伍都對數據進行預處理操作,主要包括以下幾點:① 去除重復數據;② 刪除特殊表述(如長串數字、停用詞和標點符號);③ 變形詞識別和替換(如繁體字轉換為簡體字、英文大寫轉換為小寫、全角字符轉換為半角字符、特殊符號替換、同音形近字替換);④ 將過長的文本截斷。結果顯示,這些預處理操作能有效提升模型最終的表現。此外加入其它特征也能對模型產生一定的影響,這些特征主要包括句法特征(如句子的主謂賓)、關鍵詞特征、詞性特征、詞頻-逆文檔頻率特征、句子長度、句子中的特殊符號數量(如數字個數、比較符個數和英文字母個數)等,這些特征的提取工作一般借助于中文自然語言處理工具包和結巴分詞實現。
3.4 錯誤分析
如圖 1 所示為排名前九的隊伍提交結果在中文篩選標準各個語義類別上的表現,縱坐標表示 F1 值,橫坐標表示 44 種語義類別,并按照 F1 值的從大到小進行排序。大多數類別的 F1 值都在 0.80 以上。性別(gender)分類效果最優,所有隊伍結果中 F1 值都為 1.0,主要原因是性別(gender)這類數據數量多,句子長度較短,句子信息有很強的辨識性。體征(sign)分類效果最差,成績在 0.38~0.48 之間,這主要是因為體征(sign)表示臨床醫生通過查體發現的患者異常現象,在中文臨床試驗篩選標準中,描述信息包括體征名稱、發生時間、狀態、嚴重程度等,不同的臨床試驗,其篩選標準文本對體征描述側重不同,這些都會影響分類器的學習和泛化能力。
結合各類別的數據量和文本描述信息分析,可以發現數據量大、數據具有獨特性描述特征的語義類別分類效果較好,而數據稀疏性強的語義類別分類效果較差。系統表現好的篩選標準類別,如性別(gender)、倫理審查(ethical audit)、吸煙狀況(smoking status)和年齡(age)一般其文本描述信息獨特性高、辨識性強,這都會幫助分類器表現出好的分類效果。分類效果差的篩選標準類別,如特殊患者特征(special patient characteristic)、設備(device)、護理(nursing)、受體狀態(receptor status)和體征(sign),由于數據量少、而且數據集中文本描述差異性明顯,因此分類效果表現一般。
此外,含多個類別(multiple)的平均 F1 值達到了 0.773 915。與其他單語義類別篩選標準相比,這個類別包含二種以上語義類別信息,文本一般長度較長且更復雜,是這次測評任務三中獨特的一個類別。
結合不同隊伍的系統方案分析,發現在分類效果好的篩選標準語義類別中,各系統方案的表現差別不大,在分類效果差的這些類別中,各系統方案表現差異明顯。因此提升這些數據量少、辨識性低的類別的分類效果,對系統總體的提升有明顯的幫助。預訓練語言模型結合神經網絡分類模型是大多數隊伍采用的方案,總體分類效果會很高。而僅采用預訓練語言模型的方案在某些類別中的表現卻明顯高于其他方案,如排名第 4 的系統使用了 BERT 模型、ERNIE 模型、XLNET 模型在類別鍛煉(exercise)中效果最好,排名第 5 的系統僅使用了 BERT 模型在性取向(sexual related)和居住情況(address)類別中效果最好,排名第 9 的系統僅使用了 ERNIE 在睡眠(bedtime)類別中效果最好。
4 結語
CHIP2019 中國健康信息處理會議共享測評任務三為中文臨床試驗篩選標準短文本分類,總共開放了 38 341 條篩選標準和預先定義好的 44 種語義類別。一共 27 支隊伍提交了最終結果,排名第 1 的系統宏平均 F1 值達到 0.810 263,其使用了預訓練語言模型 BERT 和模型融合的分類方法。大部分參賽團隊都使用各種預訓練語言模型,結合神經網絡模型,然后針對分類任務進行微調,最后進行模型集成提高最終系統表現。結果分析顯示排名前九的系統總體表現很接近,在宏平均 F1 值在 0.79~0.81 之間。但不同類別的篩選標準分類結果差異明顯,F1 值最低為 0.38,最高可達到 1.0。數據量大、描述文本獨特性高、辨識性強的類別效果明顯較好。這次 CHIP2019 共享測評任務三同時也為中文醫學文本分類任務提供了可供參考的數據集和最新結果(下載網址:https://github.com/zonghui0228/chip2019task3)。在未來的工作中,學習不同語義類別的差異性知識,提高小類別的表現,可以進一步提高醫學短文本分類系統的性能。
利益沖突聲明:本文全體作者均聲明不存在利益沖突。