現有的近紅外無創血糖檢測模型研究大多數關注的是近紅外吸光度與血糖濃度之間的關系,但沒有考慮人體生理狀態對血糖濃度的影響。為了提升血糖預測模型性能,本文采用了粒子群優化算法(PSO)對反向傳播(BP)神經網絡的結構參數進行訓練,并引入了收縮壓、脈率、體溫以及1 550 nm吸光度作為血糖濃度預測模型的輸入變量,采用BP神經網絡作為預測模型。為解決傳統BP神經網絡容易陷入局部最優的問題,本文提出了一種基于PSO-BP的混合模型。結果表明,訓練得到的PSO-BP模型預測效果優于傳統的BP神經網絡。十折交叉驗證預測均方根誤差和相關系數分別為0.95 mmol/L和0.74;克拉克誤差網格分析結果表明,模型預測結果落入A區域的比例為84.39%,落入B區域的比例為15.61%,均滿足臨床要求。該模型可以快速地測量血糖濃度,且具相對較高的精度。
引用本文: 葉東海, 程錦繡, 季忠. 基于粒子群和反向傳播神經網絡的近紅外光無創血糖檢測方法研究. 生物醫學工程學雜志, 2022, 39(1): 158-165. doi: 10.7507/1001-5515.202009053 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
引言
糖尿病是一種較為常見的代謝性疾病,其主要特征為血液中葡萄糖濃度升高或長期處于較高水平。長期處于高血糖濃度的狀態會造成許多并發癥,影響患者的身體健康。臨床上需要經常對患者血糖濃度值進行測量,要求患者嚴格控制其飲食并結合口服降血糖類的藥物或注射胰島素等措施將血糖濃度水平控制在正常范圍內[1]。目前,血糖的自我監測大多通過有創技術來完成,頻繁的有創檢測給患者帶來痛苦甚至心理創傷,還有感染的風險[2]。因此,迫切需要一種無創血糖測量方法,實現血糖的無痛、快速、安全檢測。國內外現有的無創血糖檢測技術主要有反向離子滲透法、超聲法、熱發射光譜法、光聲光譜法、生物阻抗頻譜法、拉曼光譜法、近紅外光譜法和中紅外光譜法等[3]。其中近紅外光譜法因其具有靈敏度高、成本低、精度高、效率高的優點,被普遍認為是最具前景的無創血糖檢測技術。
目前,有大量研究采用了不同波長范圍的近紅外光進行無創檢測,但大多數位于600~2 500 nm波長范圍內[4]。Goodarzi等[5]指出,位于第一泛音區的1 500~1 850 nm和組合泛音區的2 050~2 392 nm波長范圍內的近紅外光對于無創連續血糖檢測中的多元線性回歸建模最為有用。Yadav等[6]也報道了相同的區域。Maruo等[7]指出,校準模型的回歸系數向量在1 600 nm附近獲得了一個正峰,該波長與葡萄糖的特征吸收峰相對應。Marbach等[8]指出,在水溶液(100 mg/dL)中,葡萄糖在1 575 nm處有最大吸收值。考慮到人體血液中其他成分如水、脂肪、蛋白質等成分的吸收峰,并結合市場上現有的激光光源型號,本文最終選擇選擇了1 550 nm的近紅外光作為測量光。它具有以下優點:葡萄糖對該波長具有較強的吸收性,對其他血液成分的吸收較弱,且該波長能量較高,能夠保證足夠的組織穿透深度。
研究者基于不同的檢測部位進行了很多研究,包括手指、下唇、前臂、耳垂、舌頭、臉頰等[9]。Robinson等[10]采集了三位Ⅰ型糖尿病患者波長范圍為800~1 300 nm的手指透射近紅外光譜,采用偏最小二乘回歸模型獲得最優校正結果,交叉驗證平均絕對誤差為1.1 mmol/L(19.8 mg/dL)。Tenhunen等[11]采用1 500~1 850 nm波長范圍內的近紅外光對手指的近紅外光譜進行測量,使用偏最小二乘回歸模型得到預測結果的標準誤差和相關系數分別為1.14 mmol/L和0.51。Ming等[12]比較了偏最小二乘回歸模型和反向傳播(back propagation,BP)神經網絡模型在近紅外無創血糖濃度預測中的效果。該研究采集了100組1 500~1 800 nm波長范圍內的手指近紅外反射光譜。結果表明與偏最小二乘回歸模型相比,神經網絡模型的預測均方根誤差為0.295 2 mmol/L,相關系數為0.986 3,預測效果較好。考慮到手指經常暴露在外面,比較容易被檢測,此外指尖含有豐富的毛細血管,更容易獲得有效的血液信息,因此,本次研究選擇手指指尖作為檢測部位,并通過漫反射檢測方式采集近紅外光信號。
考慮到血液成分的復雜性和成分之間的相互作用,在無創測量血糖的應用場景下,依賴于Lambert-Beer法則的線性方法可能不再適用,因此有必要引入非線性模型。人工神經網絡(artificial neural networks,ANN)是一種有效的回歸工具,已廣泛應用于各個工程領域。在各種形式的人工神經網絡中,BP神經網絡使用最廣泛。故本次研究引入了BP神經網絡模型作為預測模型。但是BP模型本身存在著固有缺陷,如局部收斂、收斂速度和隱層神經元的選擇等問題[13]。粒子群算法(particle swarm optimization,PSO)是一種非常有效的參數尋優方法,具有良好的全局搜索能力,可以在沒有誤差函數梯度信息的情況下尋找近似的最優解[14]。為了克服傳統BP模型容易陷入局部最優的缺點,本文引入了PSO對網絡進行訓練,找到網絡的最佳權重和偏差,即PSO-BP模型。
在近紅外無創血糖檢測過程中,檢測到的與血糖相關的近紅外光信號很微弱,且容易受到生理參數影響[15],例如人體溫度和血壓等。在整個心動周期中,近紅外光信號也受到血容量脈動的影響,因此,除1 550 nm近紅外吸光度之外,本文還引入了收縮壓、脈率和體溫,將這四個參數作為PSO-BP網絡模型的輸入變量,最終得到無創血糖預測模型,以期用于體內血糖濃度的無創檢測。
1 原理與方法
1.1 BP神經網絡
人工神經網絡是一種有效的回歸工具,其不僅可以擬合線性關系,還具有良好的非線性關系刻畫能力。BP神經網絡是前饋神經網絡的一種,廣泛應用于工程建模問題中。其典型的拓撲結構如圖1所示[16],由輸入層、隱含層和輸出層組成。
 圖1
人工神經網絡拓撲結構
Figure1.
The topology structure of the artificial neural network
圖1
人工神經網絡拓撲結構
Figure1.
The topology structure of the artificial neural network
其學習過程是一個迭代的過程,輸出層的誤差變化值由輸出層傳遞到隱含層再到輸入層,每次迭代過程中根據一定的學習規則修改各個神經元之間的權重系數。針對三層神經網絡,Kolmogorov給出了輸入層神經元個數和隱含層神經元個數之間的關系:
 |
1.2 粒子群算法
PSO是由Eberhart和Kennedy于1995年首次提出的一種參數尋優算法,具有良好的全局尋優能力[17]。它通過模擬鳥群隨機搜尋食物的過程,將一定數量的粒子置于優化問題的解空間中,由一個隨機解出發實現對復雜問題的迭代尋優求解。相較于模擬退火、遺傳算法等進化算法,PSO具有規則簡單、概念簡明、實現方便、收斂速度快、參數設置少、魯棒性好等諸多優點。PSO中每個解的優劣由欲求解問題給出的適應度函數量化比較。每個粒子通過追蹤整個種群當前所找到的最優解,即全局最優,以及本身所找到的最優解,即個體最優,來調整自身在解空間中的位置,使得粒子向狀態更好的方向靠近,進而在迭代中逼近真實的最優解。
假設在當前D維空間中,粒子總數為n,第i個粒子在D維搜索空間中的位置表示為xi = [xi1, xi2, , xiD],速度表示為vi = [vi1, vi2,
, xiD],速度表示為vi = [vi1, vi2, , viD],在D維空間中,從時刻t到時刻t+1粒子的速度和位置更新方法如下:
, viD],在D維空間中,從時刻t到時刻t+1粒子的速度和位置更新方法如下:
 |
 |
式中,i = 1, 2,  , n;
, n; 為慣性權重;c1、c2為學習因子;r1、r2為[0,1]的隨機數;
為慣性權重;c1、c2為學習因子;r1、r2為[0,1]的隨機數; 為粒子pi本身在時刻t所找到的個體最優解;
為粒子pi本身在時刻t所找到的個體最優解; 為整個種群粒子在時刻t所找到的全局最優解;
為整個種群粒子在時刻t所找到的全局最優解; 表示的是約束因子,控制搜索步長。據式(2)和式(3)可以看出,PSO中粒子位置更新方法綜合了粒子自身最優和群體最優,因此算法具有較快的全局收斂速度。
表示的是約束因子,控制搜索步長。據式(2)和式(3)可以看出,PSO中粒子位置更新方法綜合了粒子自身最優和群體最優,因此算法具有較快的全局收斂速度。
1.3 PSO-BP算法
考慮到BP神經網絡容易陷入局部最優的缺陷,本文引入了PSO對人工神經網絡的參數(包括權重和閾值)進行優化,使網絡具有最小的誤差,即PSO-BP算法。
1.3.1 適應度函數
首先,必須確定適當的適應度函數,用于評估粒子在優化過程中的適應度值。這里將誤差平方和(the sum of squares of error,SSE)函數作為適應度函數,即網絡輸出值和目標值之間偏差的平方和,計算公式如下:
 |
其中 N 為樣本容量, 和
和 分別為目標值和網絡的輸出值。SSE越小,說明網絡擬合效果越好;反之,網絡擬合效果越差。
分別為目標值和網絡的輸出值。SSE越小,說明網絡擬合效果越好;反之,網絡擬合效果越差。
1.3.2 編碼策略
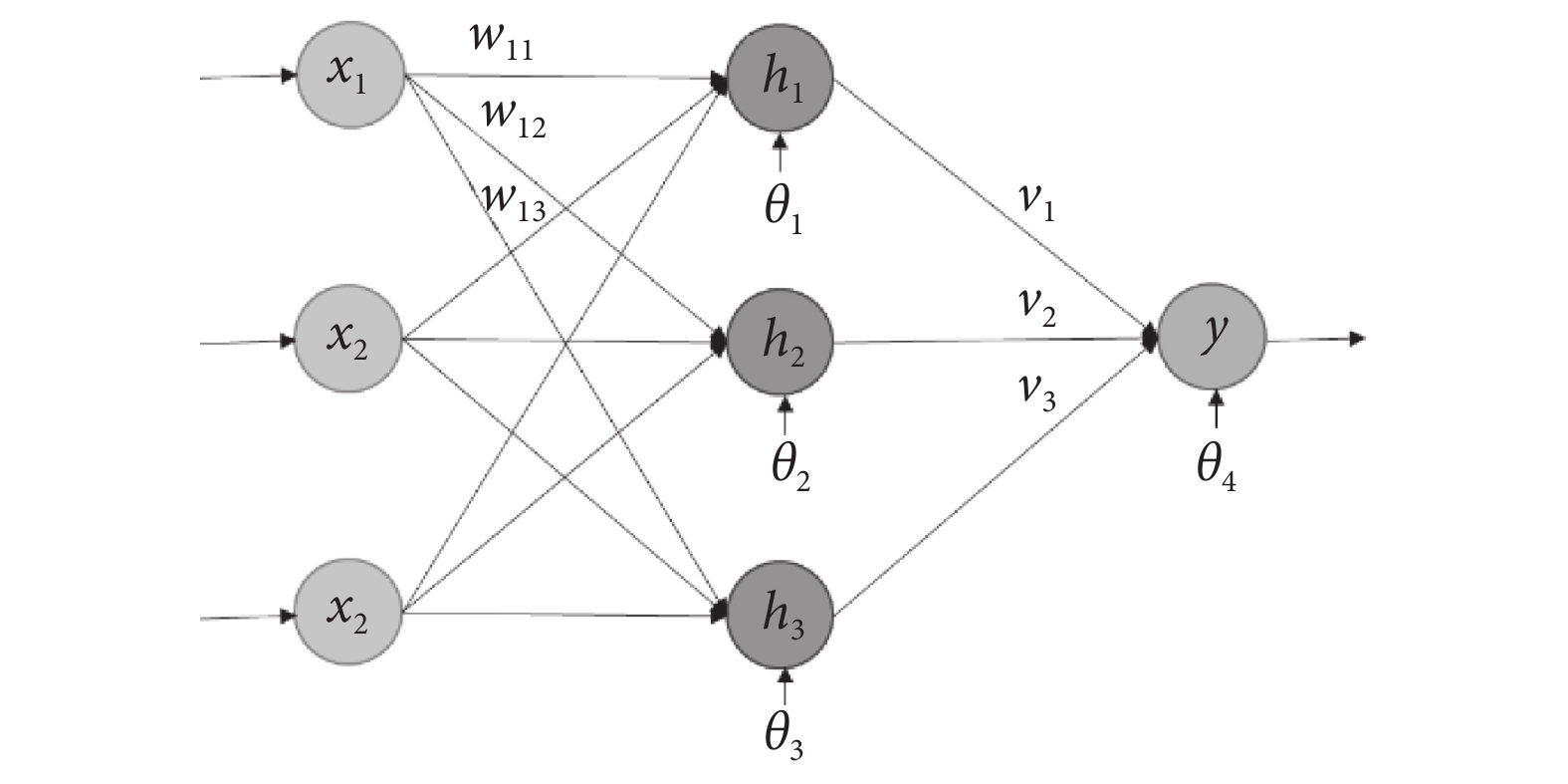
其次,選擇適當的編碼策略。這里采用矩陣的編碼方式,以圖2所示的網絡結構為例,對于一個粒子i,其編碼為:
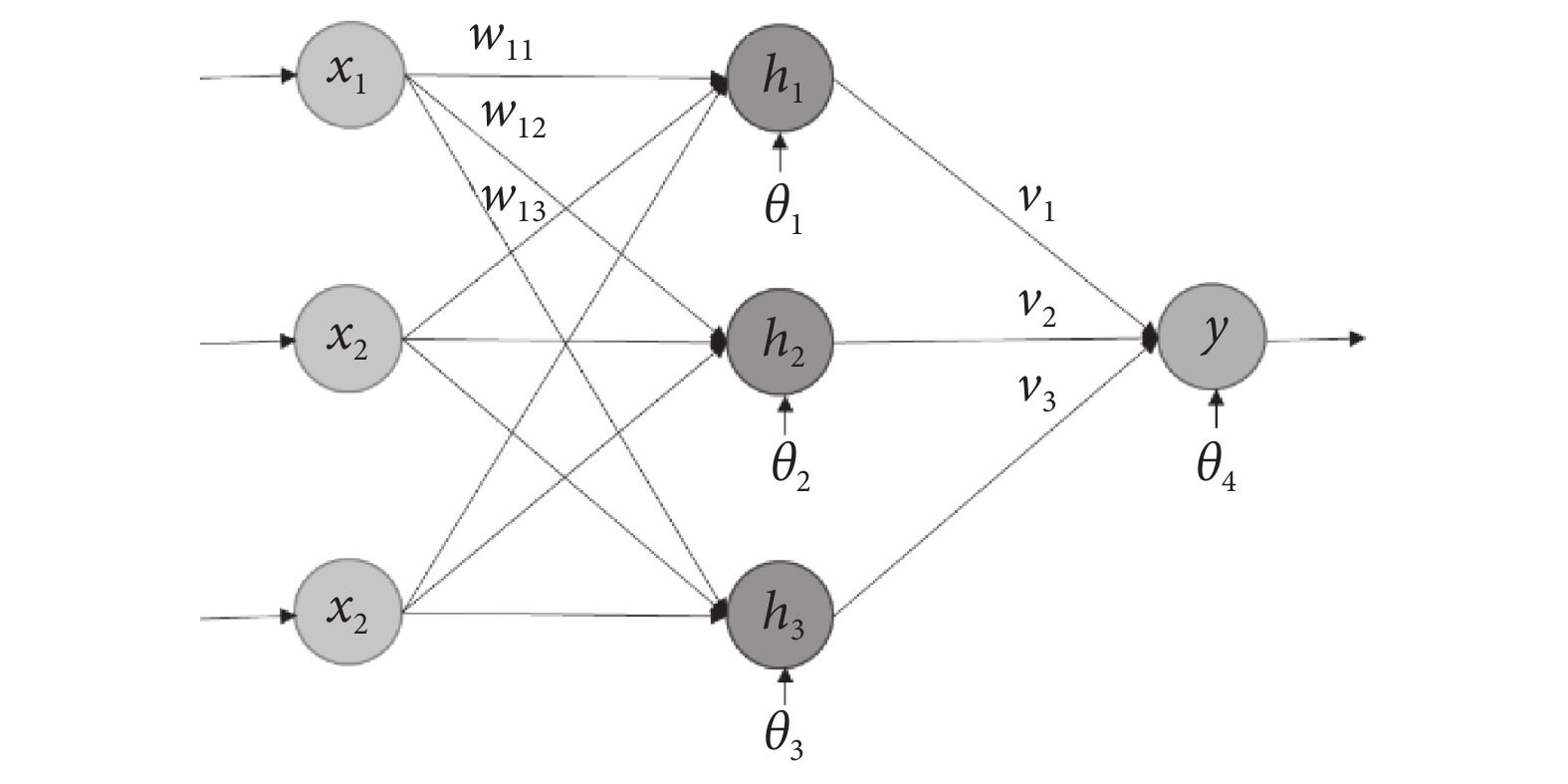 圖2
具有3-3-1結構的BP神經網絡
Figure2.
Typically representation of BP neural network with 3-3-1 structure
圖2
具有3-3-1結構的BP神經網絡
Figure2.
Typically representation of BP neural network with 3-3-1 structure
 |
其中,
 '/> '/> |
式中,W為輸入層到隱含層的權重矩陣,B1為隱含層的閾值向量,V′為隱含層到輸出層的權重矩陣的轉置,B2為輸出層的閾值向量。
1.3.3 粒子群算法優化BP神經網絡
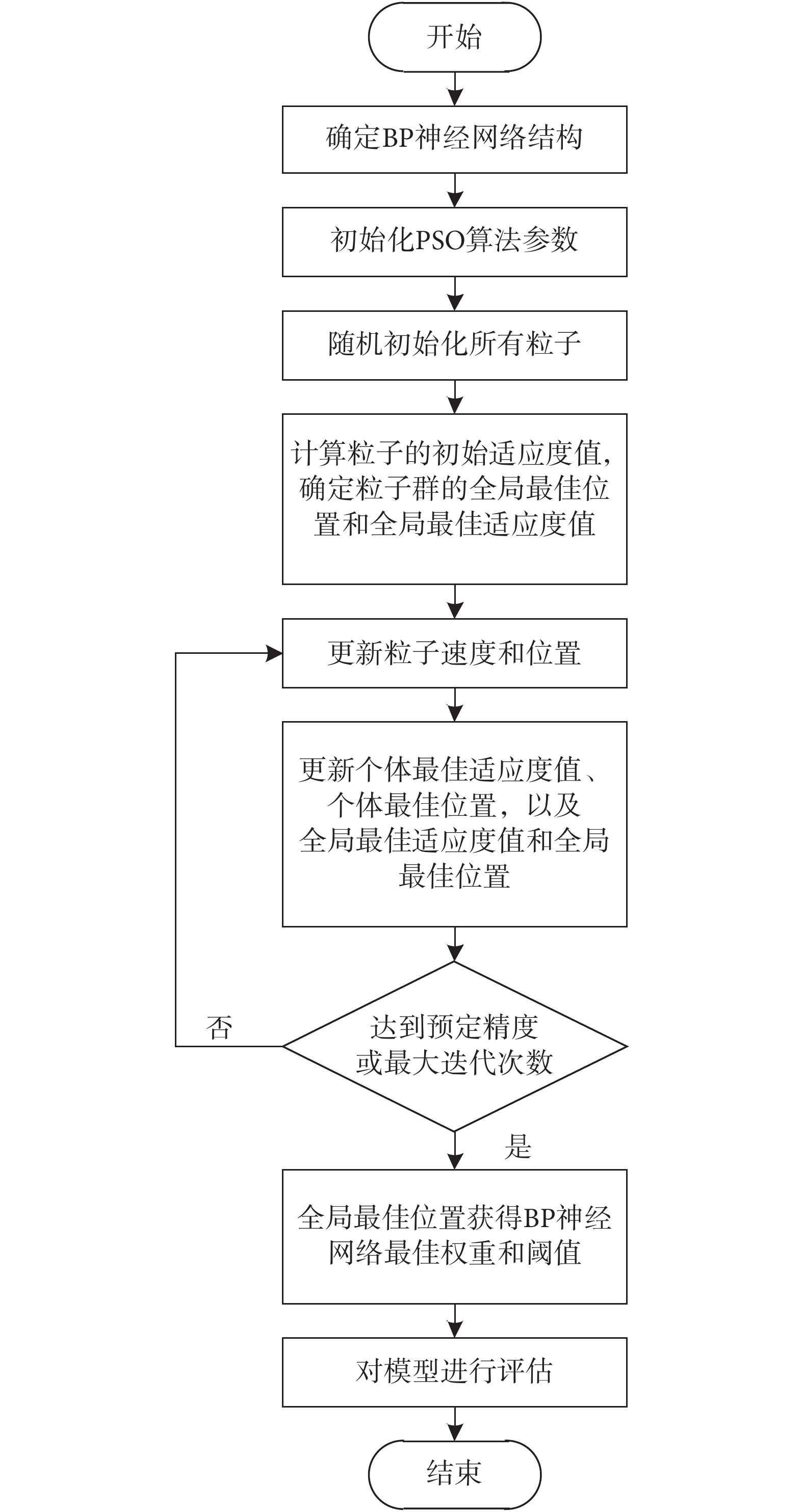
PSO-BP模型將BP神經網絡的各個權重和閾值作為PSO的粒子位置,根據所設置的適應度函數評估粒子的適應度值,然后通過PSO搜索全局最優解。如果搜索完成,則全局最佳粒子的位置即為網絡最佳權重和最佳閾值的組合。本文引入收縮壓、脈率、體溫和1 550 nm近紅外吸光度共4個變量作為模型的輸入,建立PSO-BP模型,步驟如下:
1)確定BP神經網絡的結構。采用單隱含層神經網絡結構,即網絡結構僅包含3層。網絡輸入神經元個數對應輸入變量的個數為4個,輸出神經元個數對應輸出的血糖濃度預測值為1個,隱含層神經元個數根據式(1)確定為9。
2)初始化PSO的算法參數。設置粒子數為200,加速度常數c1 = c2 = 1.5,慣性因子  = 2,約束因子
= 2,約束因子  = 2,最大迭代次數Tmax = 1 000,預定精度
= 2,最大迭代次數Tmax = 1 000,預定精度  = 0.001。
= 0.001。
3)隨機初始化所有粒子的位置即BP神經網絡的權重和閾值。
4)根據相應的適應度函數計算每個粒子的初始適應度值,確定粒子群的全局最佳位置和全局最佳適應度值。
5)根據式(2)~(3)更新粒子的速度和位置。
6)更新每個粒子的個體最佳適應度值和個體最佳位置,更新群體的全局最佳適應度值和全局最佳位置。
7)如果未達到預定精度 或最大迭代次數Tmax,則轉到步驟5;否則,停止迭代并從全局最佳位置獲得最優解,即BP神經網絡的最佳權重和閾值。
或最大迭代次數Tmax,則轉到步驟5;否則,停止迭代并從全局最佳位置獲得最優解,即BP神經網絡的最佳權重和閾值。
8)對模型預測性能進行評估。
PSO-BP算法流程如圖3所示。
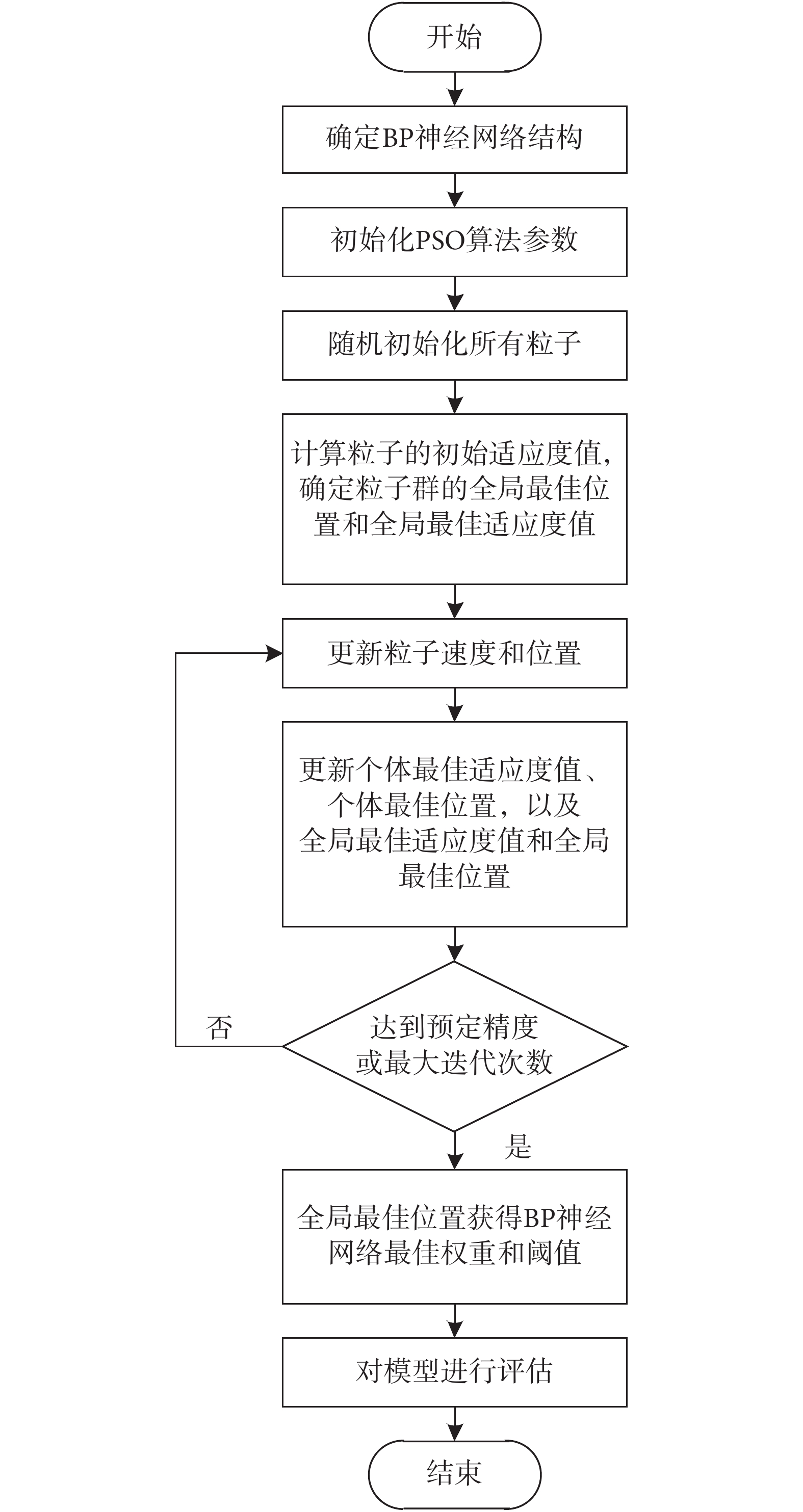 圖3
PSO-BP算法流程圖
Figure3.
Flowchart of PSO-BP algorithm
圖3
PSO-BP算法流程圖
Figure3.
Flowchart of PSO-BP algorithm
1.3.4 模型評估
針對數據樣本量有限的情況,K折交叉驗證法是對模型性能進行評估的有效方法[18]。該方法首先將全部的數據集分為相互獨立且大小相同的K組。每次從K組數據集中選取K-1組作為訓練集,剩余1組作為驗證集對模型預測性能進行驗證。該操作重復K次,每組數據均被留下來一次作為驗證集。最后計算K次驗證結果評價參數的平均值來對模型的預測性能進行估計,計算方式如下:
 |
其中L為評價參數函數, 為除去每次K折交叉驗證的驗證子集dj后剩下的樣本集,也就是訓練集,s為由訓練集訓練得到的模型。
為除去每次K折交叉驗證的驗證子集dj后剩下的樣本集,也就是訓練集,s為由訓練集訓練得到的模型。
采用以下幾個參數對模型的性能進行評估:
1)均方根誤差
均方根誤差(root mean squared error,RMSE)是預測值和參考值之間偏差的平方和與樣本容量比值的平方根。其計算公式如下:
 |
其中N為樣本容量, 和
和  分別為實測值和模型的預測值。均方根誤差能夠靈敏地反映一組預測數據中的較大誤差,是評價模型預測性能的一個重要指標,RMSE越小說明模型預測精度越高。
分別為實測值和模型的預測值。均方根誤差能夠靈敏地反映一組預測數據中的較大誤差,是評價模型預測性能的一個重要指標,RMSE越小說明模型預測精度越高。
2)相關系數
相關系數(correlation coefficient,CORR)是參考值和預測值的協方差與其標準差的比值。相關系數是計算數據擬合優度的一個重要指標,可以表征兩組數據線性關系的緊密程度,其計算公式為:
 |
其中  和
和  分別為實測值和模型預測值,
分別為實測值和模型預測值, 和
和  分別為實測值和模型預測值的平均值。
分別為實測值和模型預測值的平均值。
3)克拉克誤差網格分析
為了更加科學專業地評估患者的血糖預測值相較于參考值的臨床精確度,1987年,Clarke等[19]提出克拉克誤差網格分析(Clarke error grid analysis,EGA)方法,對血糖濃度檢測產品的檢測精度進行評估。該網格的X軸和Y軸分別代表血糖濃度的參考值和預測值,對角線表示兩者之間的完美一致性,而線下和線上方的點分別表示實際值的高估和低估。根據不同的準確性以及導致的臨床后果的嚴重程度,克拉克誤差網格分為A、B、C、D和E共5個區域。其中區域A表示偏離參考值約20%或在低血糖范圍內(< 4 mmol/L)的血糖濃度預測值,該范圍內的預測值是準確的,因此可以據此做出正確的臨床治療決策。區域B的預測值偏離參考值超過20%;而區域C、D和E中的預測值表示具有潛在的危險,且有可能導致重大的臨床錯誤。
2 實驗
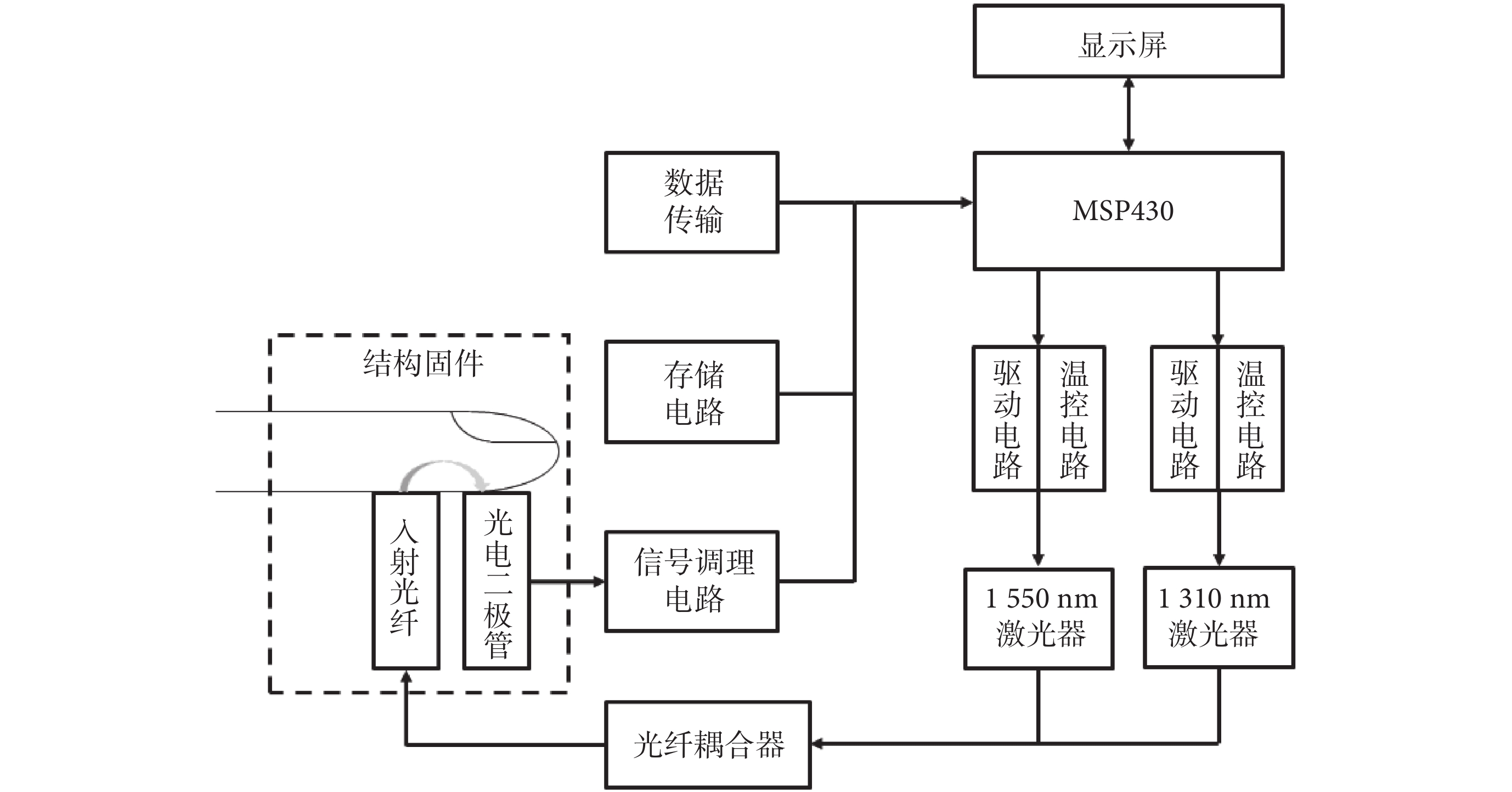
本次研究需要采集的數據有環境溫濕度、收縮壓、脈率、體溫、1 550 nm近紅外吸光度以及血糖濃度參考值(Y)。數據采集過程中各參數測量所用到的儀器如表1所示。其中用于1 550 nm近紅外吸光度測量的無創血糖檢測光學子系統由本課題組自主研發設計,其功能結構如圖4所示。
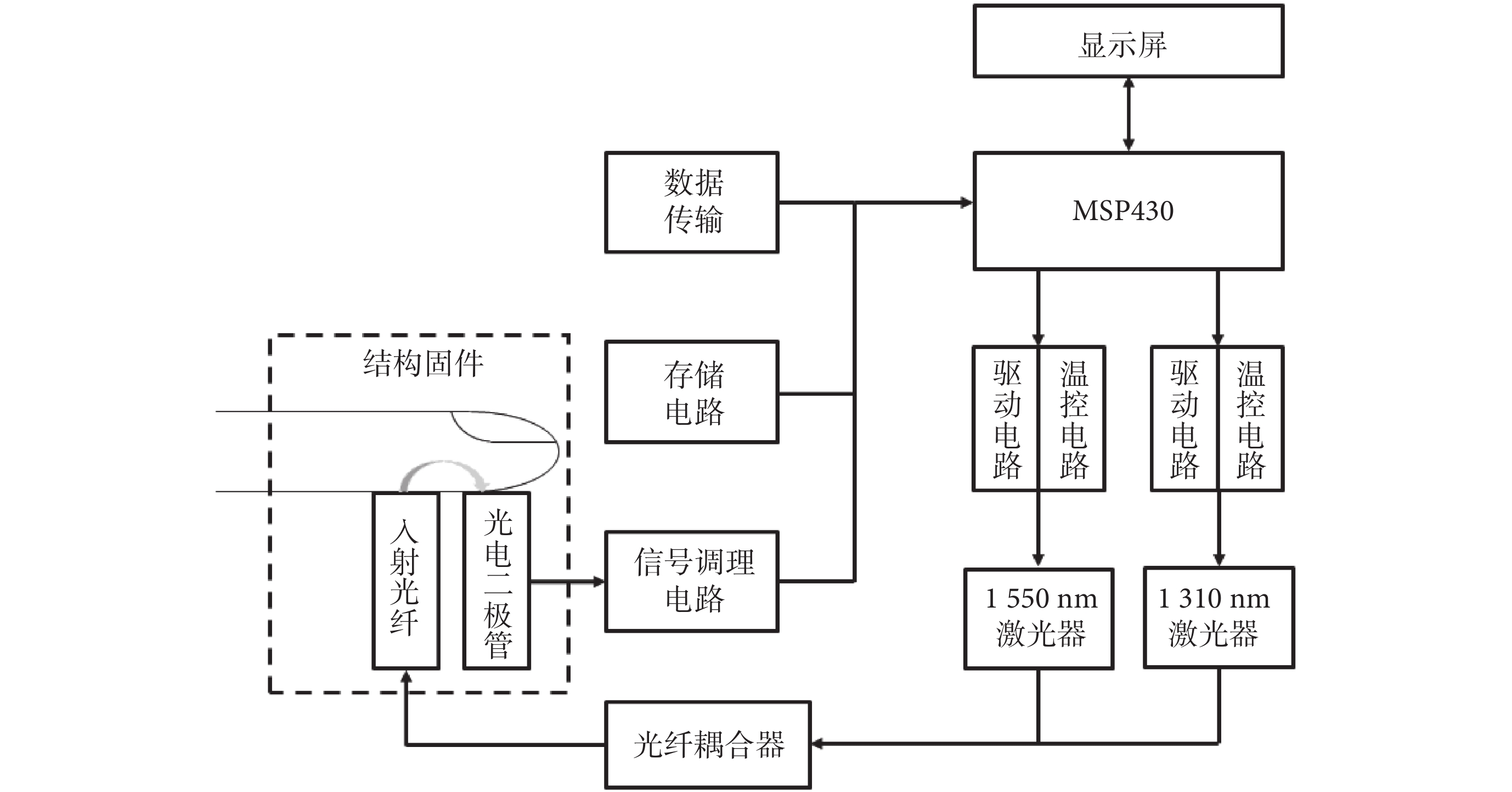 圖4
無創血糖檢測系統結構框圖
Figure4.
The system structure diagram of optical subsystem for noninvasive blood glucose detection
圖4
無創血糖檢測系統結構框圖
Figure4.
The system structure diagram of optical subsystem for noninvasive blood glucose detection
該樣機具有如下基本技術參數:
工作條件要求:① 可電池供電,亦可市網供電;② 電池電壓范圍:3.7~ 4.2 V;③ 熔斷器:I ≤ 4 A;④ 電源適配器輸入范圍:220(1 ± 10%)V~50 Hz,0.2 A;⑤ 電源適配器輸出范圍:5.0 V~1 A。
光路系統要求:① 測量光波長為(1 550 ± 0.1)nm,參考光波長為(1 310 ± 0.1)nm;② 光源輸出功率要求 ≥ 20 mW;③ 光電探測器性能要求:光響應要求0.85 mA/mW。
AD性能指標要求:① 分辨率:≥ 10 bit(1 024);② 轉換速率:≤ 200 ksps;③ 輸入電壓范圍:0~3.3V。
為了方便測試,進行了實驗裝置的產品造型設計與界面交互設計,設計中綜合考慮了整個測試過程的手與眼的使用流程及適應檢測人員的人機交互體驗關系,設計后的樣機能為測試者提供更好的檢測體驗,利用3D打印制作后成品測試樣機如圖5所示。
 圖5
無創血糖檢測儀測試樣機及人機交互界面
Figure5.
The test prototype and user interface of the noninvasive blood glucose detector
圖5
無創血糖檢測儀測試樣機及人機交互界面
Figure5.
The test prototype and user interface of the noninvasive blood glucose detector
實驗步驟如下:實驗數據采集前,打開光學子系統的電源,使之處于實驗準備狀態。志愿者使用20~30 ℃的水和肥皂以及酒精清洗雙手以保持清潔,并晾干。為了避免手指結構差異的影響,將吸光度檢測位置固定為左手食指,并盡可能保證每次數據采集過程中的手指擺放位置和壓力恒定。志愿者以自然舒適的狀態坐在椅子上,將左手食指放置于光學子系統的檢測室中,保持食指指腹與準直器輕微接觸,避免手指擠壓變形,然后測得1 550 nm近紅外吸光度值。然后采用歐姆龍電子血壓計測量志愿者的收縮壓和脈率,采用紅外溫度計測量志愿者的體溫。以上參數采集均重復三次取平均值作為最終的參數值。
本研究共征集了14名志愿者(9名女性和5名男性,年齡范圍為22~25歲)。實驗開始前已告知志愿者實驗過程以及風險,并獲得志愿者許可后進行實驗數據的采集,符合實驗倫理要求。實驗從上午8:30開始,每隔30 min進行一次數據采集。每位志愿者數據采集結束時間因個人情況而異。6名志愿者采集了2天的數據,另外8名志愿者采集了1天的數據,共采集到205組樣本數據,每組樣本數據均由四個變量(收縮壓、脈率、體溫和1 550 nm近紅外吸光度)以及血糖濃度參考值組成。測得的血糖濃度參考值范圍為4.2~10 mmol/L,其標準差為1.35 mmol/L。
3 結果與討論
3.1 結果
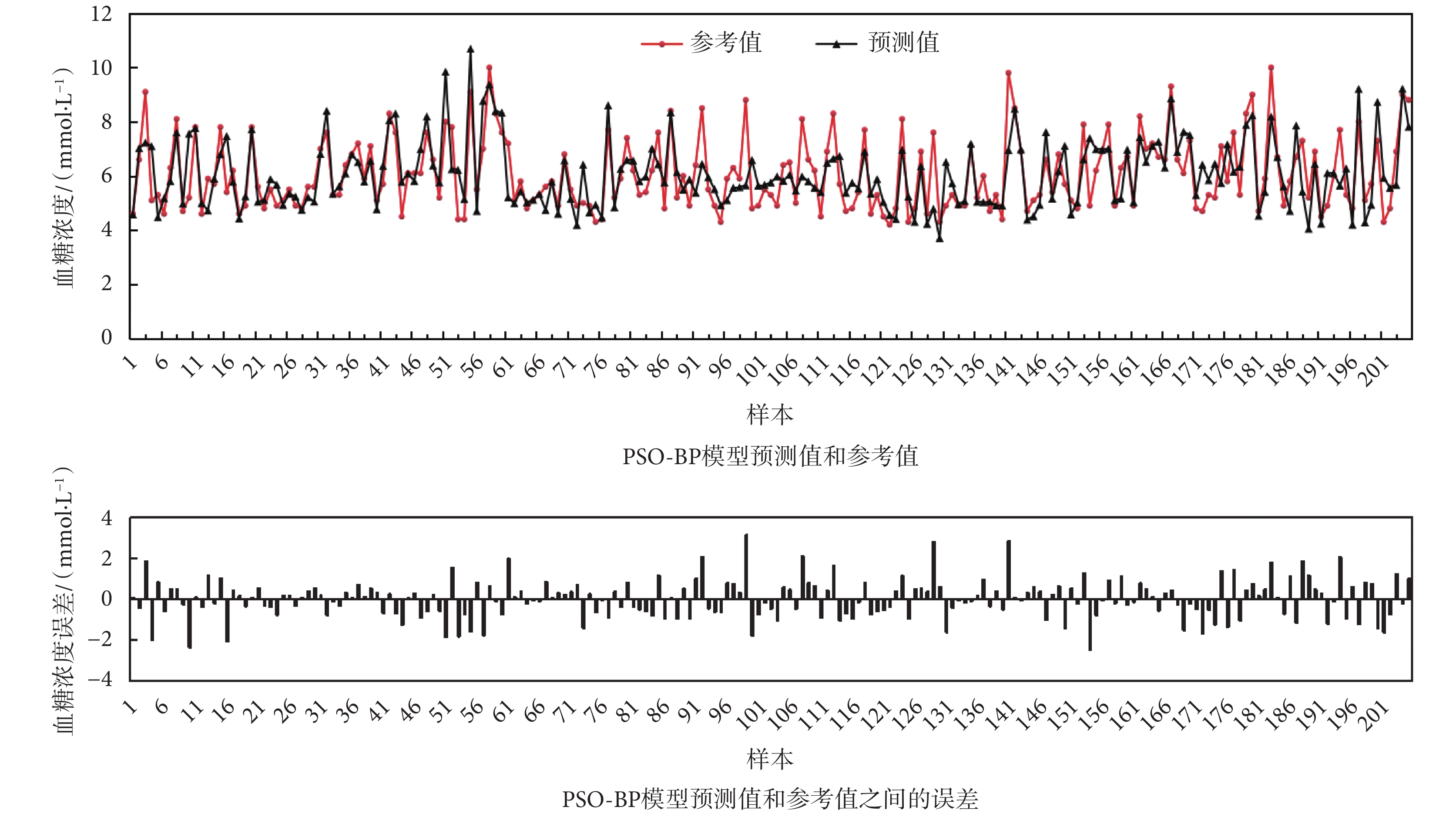
按照上述模型建立方法建立PSO-BP模型。這里采用十折交叉驗證法,將全部的205組樣本數據根據血糖濃度參考值隨機分為大小近似相同的十組子樣本數據集,作為十折交叉驗證的數據集,對模型的預測性能進行驗證。模型預測結果如圖6所示,X軸標簽為樣本編號。由圖6可以看出,4Vs-PSO-BP模型的血糖濃度預測值大部分比較接近血糖濃度參考值,存在個別模型預測值和參考值偏差較大的樣本點,如樣本點101、131和143等。
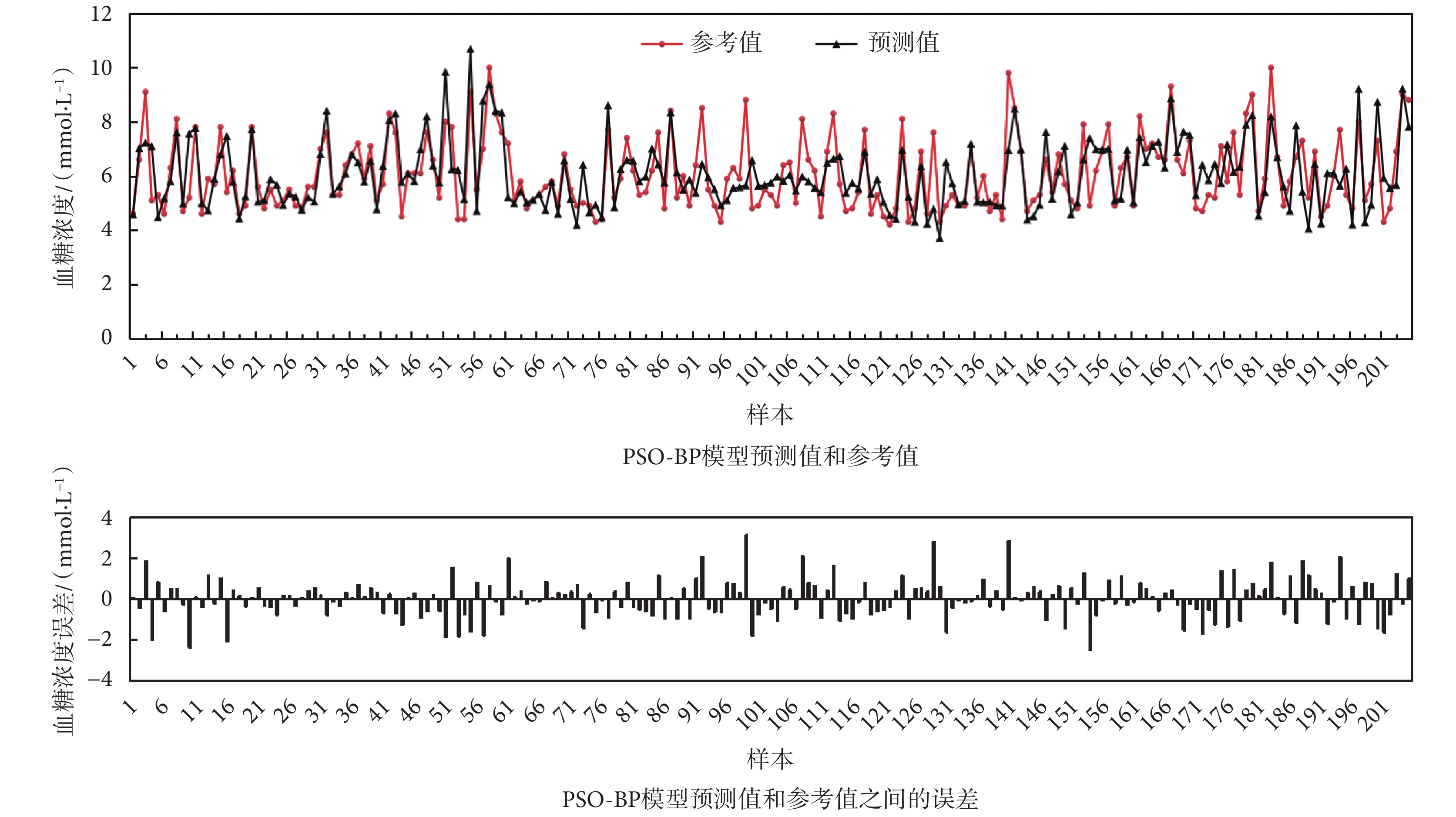 圖6
PSO-BP模型預測結果
Figure6.
The prediction results and errors of the PSO-BP model
圖6
PSO-BP模型預測結果
Figure6.
The prediction results and errors of the PSO-BP model
3.2 結果比較
為了對本文所建立的PSO-BP模型的有效性進行分析,還建立了BP模型,采用Levenberg-Marquardt算法對其進行訓練,同樣采用十折交叉驗證方法對其進行驗證,最后將驗證結果與PSO-BP模型進行對比。
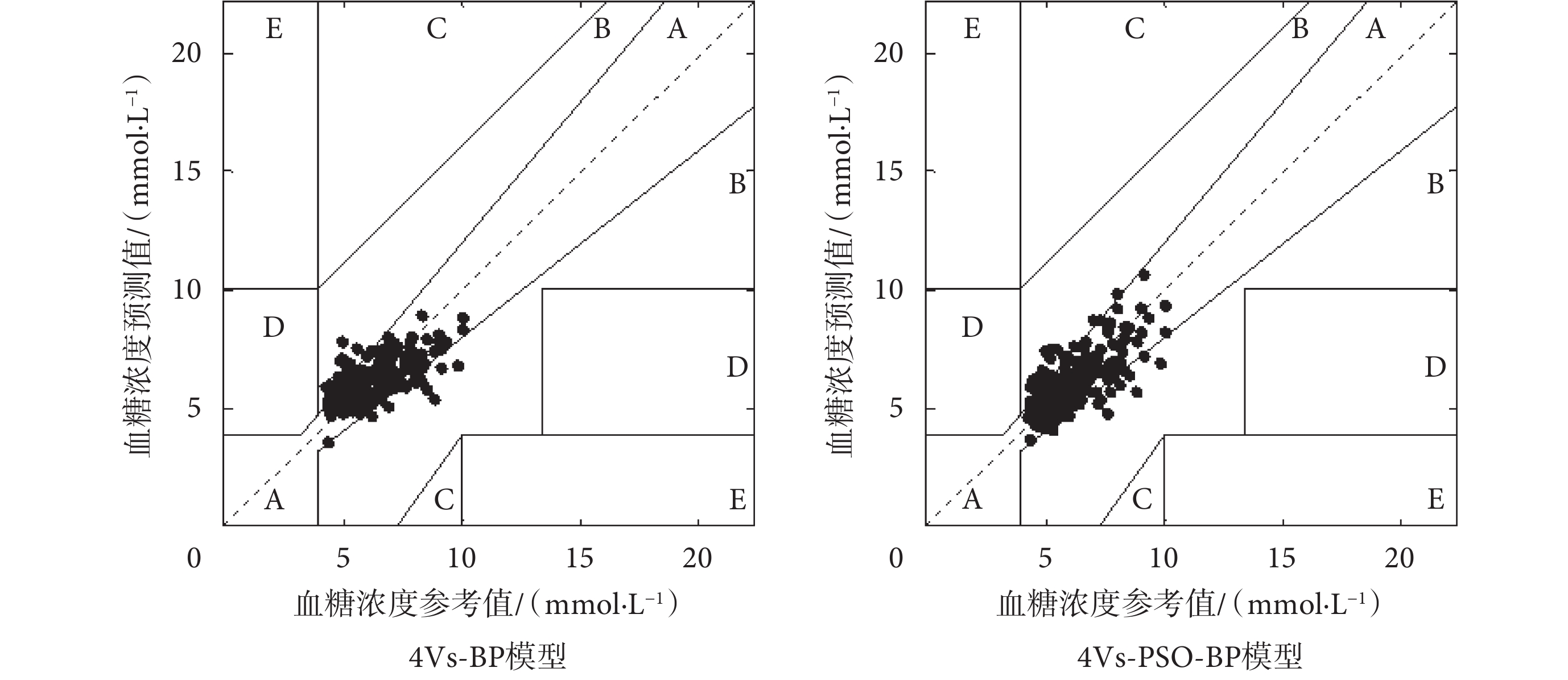
圖7分別給出了兩個模型的Clarke誤差網格分析結果。結果表明,本文建立的BP模型和PSO-BP模型的預測值全部分布在Clarke誤差網格的區域A和B中,其準確性在臨床上均是可以接受的。其中,相比于BP模型,PSO-BP模型的預測結果和參考值之間的相關性明顯更強,且在高血糖濃度范圍的預測性能要優于BP模型。
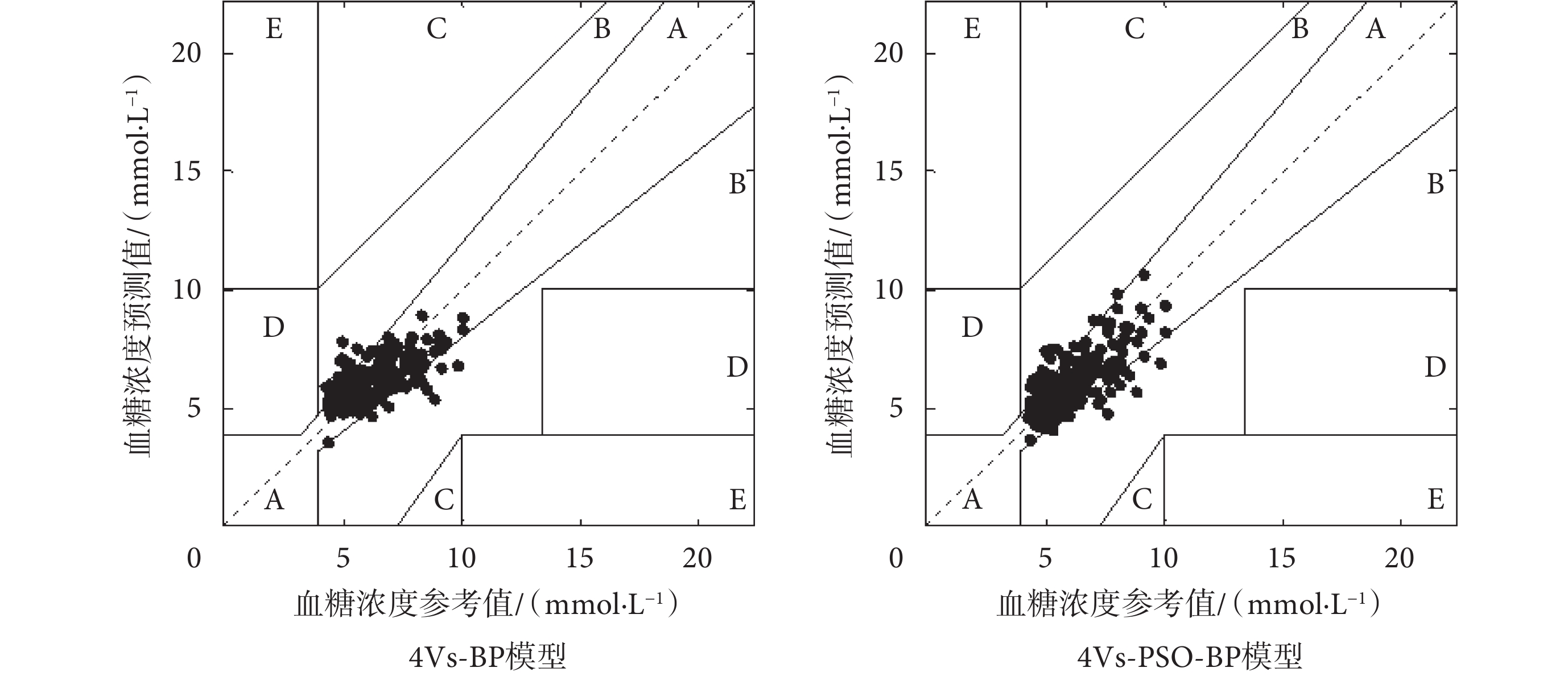 圖7
Clarke誤差網格分析結果
Figure7.
The results of the Clarke error grid analysis
圖7
Clarke誤差網格分析結果
Figure7.
The results of the Clarke error grid analysis
通過計算RMSE、CORR和Clarke誤差網格分析中落入每個區域的預測結果的百分比,進一步定量比較了這兩個模型的預測性能,具體結果如表2所示。
由表2可知,結合PSO的BP神經網絡模型相較于傳統的BP神經網絡模型預測精度得到了一定的提高。PSO-BP模型驗證集的RMSE和CORR分別為0.95 mmol/L和0.74,Clarke誤差網格分析中落入A區域的預測結果的百分比為84.39%。相較于BP模型,PSO-BP的RMSE下降了2.06%,CORR和屬于A區的測試集的百分比分別增加了5.71%和1.17%。可以初步得出結論,采用PSO對BP神經網絡進行訓練,從一定程度上克服了BP神經網絡傳統梯度下降訓練算法容易陷入局部最優的缺陷,提高了模型的預測精度以及血糖濃度預測值和參考值之間的相關性,尤其是高血糖濃度范圍的預測效果明顯提升。
盡管本文所建立的PSO-BP模型達到了一定的精度,但在Clarke誤差網格分析的B區域中仍然存在不理想的預測結果。因此,模型的預測精度還有必要進一步提高,從而繼續降低RMSE,提高CORR以及Clarke誤差網格分析中B區域預測結果的百分比。此外,本次研究所采集到的數量較少,且征集到的參與數據采集的志愿者比較單一,模型的有效性還有待于進一步驗證。
4 結論
本次研究基于BP神經網絡模型和PSO建立了一種混合模型,即PSO-BP模型。考慮到生理參數對近紅外無創血糖檢測的影響,引入了收縮壓、脈率、體溫和1 550 nm近紅外吸光度作為輸入變量參與模型的建立。采用PSO對BP神經網絡的權重和閾值進行優化,得到最后的PSO-BP模型。RMSE、CORR和Clarke誤差網格分析結果表明,相比于單一的BP模型,PSO-BP模型具有更高的預測精度。且模型一旦訓練完成,可快速用于血糖濃度的無創檢測。
基于現有的實驗數據和本文提出的方法,獲得了一定精度的無創血糖檢測結果。但所建立的無創血糖濃度預測模型的準確性和魯棒性仍需進一步驗證。將進行大規模實驗,以擴大數據樣本量,增加數據和志愿者的多樣性,進一步提高預測模型的性能。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:葉東海負責樣機設計、數據采集和分析、論文寫作;程錦繡負責實驗設計、數據收集和方法研究、論文寫作;季忠負責樣機研究、數據分析和方法研究。
倫理聲明:本研究通過了重慶大學附屬腫瘤醫院倫理委員會的審批(批文編號:2020年倫審(055)號)。
引言
糖尿病是一種較為常見的代謝性疾病,其主要特征為血液中葡萄糖濃度升高或長期處于較高水平。長期處于高血糖濃度的狀態會造成許多并發癥,影響患者的身體健康。臨床上需要經常對患者血糖濃度值進行測量,要求患者嚴格控制其飲食并結合口服降血糖類的藥物或注射胰島素等措施將血糖濃度水平控制在正常范圍內[1]。目前,血糖的自我監測大多通過有創技術來完成,頻繁的有創檢測給患者帶來痛苦甚至心理創傷,還有感染的風險[2]。因此,迫切需要一種無創血糖測量方法,實現血糖的無痛、快速、安全檢測。國內外現有的無創血糖檢測技術主要有反向離子滲透法、超聲法、熱發射光譜法、光聲光譜法、生物阻抗頻譜法、拉曼光譜法、近紅外光譜法和中紅外光譜法等[3]。其中近紅外光譜法因其具有靈敏度高、成本低、精度高、效率高的優點,被普遍認為是最具前景的無創血糖檢測技術。
目前,有大量研究采用了不同波長范圍的近紅外光進行無創檢測,但大多數位于600~2 500 nm波長范圍內[4]。Goodarzi等[5]指出,位于第一泛音區的1 500~1 850 nm和組合泛音區的2 050~2 392 nm波長范圍內的近紅外光對于無創連續血糖檢測中的多元線性回歸建模最為有用。Yadav等[6]也報道了相同的區域。Maruo等[7]指出,校準模型的回歸系數向量在1 600 nm附近獲得了一個正峰,該波長與葡萄糖的特征吸收峰相對應。Marbach等[8]指出,在水溶液(100 mg/dL)中,葡萄糖在1 575 nm處有最大吸收值。考慮到人體血液中其他成分如水、脂肪、蛋白質等成分的吸收峰,并結合市場上現有的激光光源型號,本文最終選擇選擇了1 550 nm的近紅外光作為測量光。它具有以下優點:葡萄糖對該波長具有較強的吸收性,對其他血液成分的吸收較弱,且該波長能量較高,能夠保證足夠的組織穿透深度。
研究者基于不同的檢測部位進行了很多研究,包括手指、下唇、前臂、耳垂、舌頭、臉頰等[9]。Robinson等[10]采集了三位Ⅰ型糖尿病患者波長范圍為800~1 300 nm的手指透射近紅外光譜,采用偏最小二乘回歸模型獲得最優校正結果,交叉驗證平均絕對誤差為1.1 mmol/L(19.8 mg/dL)。Tenhunen等[11]采用1 500~1 850 nm波長范圍內的近紅外光對手指的近紅外光譜進行測量,使用偏最小二乘回歸模型得到預測結果的標準誤差和相關系數分別為1.14 mmol/L和0.51。Ming等[12]比較了偏最小二乘回歸模型和反向傳播(back propagation,BP)神經網絡模型在近紅外無創血糖濃度預測中的效果。該研究采集了100組1 500~1 800 nm波長范圍內的手指近紅外反射光譜。結果表明與偏最小二乘回歸模型相比,神經網絡模型的預測均方根誤差為0.295 2 mmol/L,相關系數為0.986 3,預測效果較好。考慮到手指經常暴露在外面,比較容易被檢測,此外指尖含有豐富的毛細血管,更容易獲得有效的血液信息,因此,本次研究選擇手指指尖作為檢測部位,并通過漫反射檢測方式采集近紅外光信號。
考慮到血液成分的復雜性和成分之間的相互作用,在無創測量血糖的應用場景下,依賴于Lambert-Beer法則的線性方法可能不再適用,因此有必要引入非線性模型。人工神經網絡(artificial neural networks,ANN)是一種有效的回歸工具,已廣泛應用于各個工程領域。在各種形式的人工神經網絡中,BP神經網絡使用最廣泛。故本次研究引入了BP神經網絡模型作為預測模型。但是BP模型本身存在著固有缺陷,如局部收斂、收斂速度和隱層神經元的選擇等問題[13]。粒子群算法(particle swarm optimization,PSO)是一種非常有效的參數尋優方法,具有良好的全局搜索能力,可以在沒有誤差函數梯度信息的情況下尋找近似的最優解[14]。為了克服傳統BP模型容易陷入局部最優的缺點,本文引入了PSO對網絡進行訓練,找到網絡的最佳權重和偏差,即PSO-BP模型。
在近紅外無創血糖檢測過程中,檢測到的與血糖相關的近紅外光信號很微弱,且容易受到生理參數影響[15],例如人體溫度和血壓等。在整個心動周期中,近紅外光信號也受到血容量脈動的影響,因此,除1 550 nm近紅外吸光度之外,本文還引入了收縮壓、脈率和體溫,將這四個參數作為PSO-BP網絡模型的輸入變量,最終得到無創血糖預測模型,以期用于體內血糖濃度的無創檢測。
1 原理與方法
1.1 BP神經網絡
人工神經網絡是一種有效的回歸工具,其不僅可以擬合線性關系,還具有良好的非線性關系刻畫能力。BP神經網絡是前饋神經網絡的一種,廣泛應用于工程建模問題中。其典型的拓撲結構如圖1所示[16],由輸入層、隱含層和輸出層組成。
圖1
人工神經網絡拓撲結構
Figure1.
The topology structure of the artificial neural network
其學習過程是一個迭代的過程,輸出層的誤差變化值由輸出層傳遞到隱含層再到輸入層,每次迭代過程中根據一定的學習規則修改各個神經元之間的權重系數。針對三層神經網絡,Kolmogorov給出了輸入層神經元個數和隱含層神經元個數之間的關系:
|
1.2 粒子群算法
PSO是由Eberhart和Kennedy于1995年首次提出的一種參數尋優算法,具有良好的全局尋優能力[17]。它通過模擬鳥群隨機搜尋食物的過程,將一定數量的粒子置于優化問題的解空間中,由一個隨機解出發實現對復雜問題的迭代尋優求解。相較于模擬退火、遺傳算法等進化算法,PSO具有規則簡單、概念簡明、實現方便、收斂速度快、參數設置少、魯棒性好等諸多優點。PSO中每個解的優劣由欲求解問題給出的適應度函數量化比較。每個粒子通過追蹤整個種群當前所找到的最優解,即全局最優,以及本身所找到的最優解,即個體最優,來調整自身在解空間中的位置,使得粒子向狀態更好的方向靠近,進而在迭代中逼近真實的最優解。
假設在當前D維空間中,粒子總數為n,第i個粒子在D維搜索空間中的位置表示為xi = [xi1, xi2,, xiD],速度表示為vi = [vi1, vi2,, viD],在D維空間中,從時刻t到時刻t+1粒子的速度和位置更新方法如下:
|
|
式中,i = 1, 2, , n; 為慣性權重;c1、c2為學習因子;r1、r2為[0,1]的隨機數; 為粒子pi本身在時刻t所找到的個體最優解; 為整個種群粒子在時刻t所找到的全局最優解; 表示的是約束因子,控制搜索步長。據式(2)和式(3)可以看出,PSO中粒子位置更新方法綜合了粒子自身最優和群體最優,因此算法具有較快的全局收斂速度。
1.3 PSO-BP算法
考慮到BP神經網絡容易陷入局部最優的缺陷,本文引入了PSO對人工神經網絡的參數(包括權重和閾值)進行優化,使網絡具有最小的誤差,即PSO-BP算法。
1.3.1 適應度函數
首先,必須確定適當的適應度函數,用于評估粒子在優化過程中的適應度值。這里將誤差平方和(the sum of squares of error,SSE)函數作為適應度函數,即網絡輸出值和目標值之間偏差的平方和,計算公式如下:
|
其中 N 為樣本容量,和分別為目標值和網絡的輸出值。SSE越小,說明網絡擬合效果越好;反之,網絡擬合效果越差。
1.3.2 編碼策略
其次,選擇適當的編碼策略。這里采用矩陣的編碼方式,以圖2所示的網絡結構為例,對于一個粒子i,其編碼為:
圖2
具有3-3-1結構的BP神經網絡
Figure2.
Typically representation of BP neural network with 3-3-1 structure
|
其中,
| '/> |
式中,W為輸入層到隱含層的權重矩陣,B1為隱含層的閾值向量,V′為隱含層到輸出層的權重矩陣的轉置,B2為輸出層的閾值向量。
1.3.3 粒子群算法優化BP神經網絡
PSO-BP模型將BP神經網絡的各個權重和閾值作為PSO的粒子位置,根據所設置的適應度函數評估粒子的適應度值,然后通過PSO搜索全局最優解。如果搜索完成,則全局最佳粒子的位置即為網絡最佳權重和最佳閾值的組合。本文引入收縮壓、脈率、體溫和1 550 nm近紅外吸光度共4個變量作為模型的輸入,建立PSO-BP模型,步驟如下:
1)確定BP神經網絡的結構。采用單隱含層神經網絡結構,即網絡結構僅包含3層。網絡輸入神經元個數對應輸入變量的個數為4個,輸出神經元個數對應輸出的血糖濃度預測值為1個,隱含層神經元個數根據式(1)確定為9。
2)初始化PSO的算法參數。設置粒子數為200,加速度常數c1 = c2 = 1.5,慣性因子 = 2,約束因子 = 2,最大迭代次數Tmax = 1 000,預定精度 = 0.001。
3)隨機初始化所有粒子的位置即BP神經網絡的權重和閾值。
4)根據相應的適應度函數計算每個粒子的初始適應度值,確定粒子群的全局最佳位置和全局最佳適應度值。
5)根據式(2)~(3)更新粒子的速度和位置。
6)更新每個粒子的個體最佳適應度值和個體最佳位置,更新群體的全局最佳適應度值和全局最佳位置。
7)如果未達到預定精度或最大迭代次數Tmax,則轉到步驟5;否則,停止迭代并從全局最佳位置獲得最優解,即BP神經網絡的最佳權重和閾值。
8)對模型預測性能進行評估。
PSO-BP算法流程如圖3所示。
圖3
PSO-BP算法流程圖
Figure3.
Flowchart of PSO-BP algorithm
1.3.4 模型評估
針對數據樣本量有限的情況,K折交叉驗證法是對模型性能進行評估的有效方法[18]。該方法首先將全部的數據集分為相互獨立且大小相同的K組。每次從K組數據集中選取K-1組作為訓練集,剩余1組作為驗證集對模型預測性能進行驗證。該操作重復K次,每組數據均被留下來一次作為驗證集。最后計算K次驗證結果評價參數的平均值來對模型的預測性能進行估計,計算方式如下:
|
其中L為評價參數函數,為除去每次K折交叉驗證的驗證子集dj后剩下的樣本集,也就是訓練集,s為由訓練集訓練得到的模型。
采用以下幾個參數對模型的性能進行評估:
1)均方根誤差
均方根誤差(root mean squared error,RMSE)是預測值和參考值之間偏差的平方和與樣本容量比值的平方根。其計算公式如下:
|
其中N為樣本容量, 和 分別為實測值和模型的預測值。均方根誤差能夠靈敏地反映一組預測數據中的較大誤差,是評價模型預測性能的一個重要指標,RMSE越小說明模型預測精度越高。
2)相關系數
相關系數(correlation coefficient,CORR)是參考值和預測值的協方差與其標準差的比值。相關系數是計算數據擬合優度的一個重要指標,可以表征兩組數據線性關系的緊密程度,其計算公式為:
|
其中 和 分別為實測值和模型預測值, 和 分別為實測值和模型預測值的平均值。
3)克拉克誤差網格分析
為了更加科學專業地評估患者的血糖預測值相較于參考值的臨床精確度,1987年,Clarke等[19]提出克拉克誤差網格分析(Clarke error grid analysis,EGA)方法,對血糖濃度檢測產品的檢測精度進行評估。該網格的X軸和Y軸分別代表血糖濃度的參考值和預測值,對角線表示兩者之間的完美一致性,而線下和線上方的點分別表示實際值的高估和低估。根據不同的準確性以及導致的臨床后果的嚴重程度,克拉克誤差網格分為A、B、C、D和E共5個區域。其中區域A表示偏離參考值約20%或在低血糖范圍內(< 4 mmol/L)的血糖濃度預測值,該范圍內的預測值是準確的,因此可以據此做出正確的臨床治療決策。區域B的預測值偏離參考值超過20%;而區域C、D和E中的預測值表示具有潛在的危險,且有可能導致重大的臨床錯誤。
2 實驗
本次研究需要采集的數據有環境溫濕度、收縮壓、脈率、體溫、1 550 nm近紅外吸光度以及血糖濃度參考值(Y)。數據采集過程中各參數測量所用到的儀器如表1所示。其中用于1 550 nm近紅外吸光度測量的無創血糖檢測光學子系統由本課題組自主研發設計,其功能結構如圖4所示。
圖4
無創血糖檢測系統結構框圖
Figure4.
The system structure diagram of optical subsystem for noninvasive blood glucose detection
該樣機具有如下基本技術參數:
工作條件要求:① 可電池供電,亦可市網供電;② 電池電壓范圍:3.7~ 4.2 V;③ 熔斷器:I ≤ 4 A;④ 電源適配器輸入范圍:220(1 ± 10%)V~50 Hz,0.2 A;⑤ 電源適配器輸出范圍:5.0 V~1 A。
光路系統要求:① 測量光波長為(1 550 ± 0.1)nm,參考光波長為(1 310 ± 0.1)nm;② 光源輸出功率要求 ≥ 20 mW;③ 光電探測器性能要求:光響應要求0.85 mA/mW。
AD性能指標要求:① 分辨率:≥ 10 bit(1 024);② 轉換速率:≤ 200 ksps;③ 輸入電壓范圍:0~3.3V。
為了方便測試,進行了實驗裝置的產品造型設計與界面交互設計,設計中綜合考慮了整個測試過程的手與眼的使用流程及適應檢測人員的人機交互體驗關系,設計后的樣機能為測試者提供更好的檢測體驗,利用3D打印制作后成品測試樣機如圖5所示。
圖5
無創血糖檢測儀測試樣機及人機交互界面
Figure5.
The test prototype and user interface of the noninvasive blood glucose detector
實驗步驟如下:實驗數據采集前,打開光學子系統的電源,使之處于實驗準備狀態。志愿者使用20~30 ℃的水和肥皂以及酒精清洗雙手以保持清潔,并晾干。為了避免手指結構差異的影響,將吸光度檢測位置固定為左手食指,并盡可能保證每次數據采集過程中的手指擺放位置和壓力恒定。志愿者以自然舒適的狀態坐在椅子上,將左手食指放置于光學子系統的檢測室中,保持食指指腹與準直器輕微接觸,避免手指擠壓變形,然后測得1 550 nm近紅外吸光度值。然后采用歐姆龍電子血壓計測量志愿者的收縮壓和脈率,采用紅外溫度計測量志愿者的體溫。以上參數采集均重復三次取平均值作為最終的參數值。
本研究共征集了14名志愿者(9名女性和5名男性,年齡范圍為22~25歲)。實驗開始前已告知志愿者實驗過程以及風險,并獲得志愿者許可后進行實驗數據的采集,符合實驗倫理要求。實驗從上午8:30開始,每隔30 min進行一次數據采集。每位志愿者數據采集結束時間因個人情況而異。6名志愿者采集了2天的數據,另外8名志愿者采集了1天的數據,共采集到205組樣本數據,每組樣本數據均由四個變量(收縮壓、脈率、體溫和1 550 nm近紅外吸光度)以及血糖濃度參考值組成。測得的血糖濃度參考值范圍為4.2~10 mmol/L,其標準差為1.35 mmol/L。
3 結果與討論
3.1 結果
按照上述模型建立方法建立PSO-BP模型。這里采用十折交叉驗證法,將全部的205組樣本數據根據血糖濃度參考值隨機分為大小近似相同的十組子樣本數據集,作為十折交叉驗證的數據集,對模型的預測性能進行驗證。模型預測結果如圖6所示,X軸標簽為樣本編號。由圖6可以看出,4Vs-PSO-BP模型的血糖濃度預測值大部分比較接近血糖濃度參考值,存在個別模型預測值和參考值偏差較大的樣本點,如樣本點101、131和143等。
圖6
PSO-BP模型預測結果
Figure6.
The prediction results and errors of the PSO-BP model
3.2 結果比較
為了對本文所建立的PSO-BP模型的有效性進行分析,還建立了BP模型,采用Levenberg-Marquardt算法對其進行訓練,同樣采用十折交叉驗證方法對其進行驗證,最后將驗證結果與PSO-BP模型進行對比。
圖7分別給出了兩個模型的Clarke誤差網格分析結果。結果表明,本文建立的BP模型和PSO-BP模型的預測值全部分布在Clarke誤差網格的區域A和B中,其準確性在臨床上均是可以接受的。其中,相比于BP模型,PSO-BP模型的預測結果和參考值之間的相關性明顯更強,且在高血糖濃度范圍的預測性能要優于BP模型。
圖7
Clarke誤差網格分析結果
Figure7.
The results of the Clarke error grid analysis
通過計算RMSE、CORR和Clarke誤差網格分析中落入每個區域的預測結果的百分比,進一步定量比較了這兩個模型的預測性能,具體結果如表2所示。
由表2可知,結合PSO的BP神經網絡模型相較于傳統的BP神經網絡模型預測精度得到了一定的提高。PSO-BP模型驗證集的RMSE和CORR分別為0.95 mmol/L和0.74,Clarke誤差網格分析中落入A區域的預測結果的百分比為84.39%。相較于BP模型,PSO-BP的RMSE下降了2.06%,CORR和屬于A區的測試集的百分比分別增加了5.71%和1.17%。可以初步得出結論,采用PSO對BP神經網絡進行訓練,從一定程度上克服了BP神經網絡傳統梯度下降訓練算法容易陷入局部最優的缺陷,提高了模型的預測精度以及血糖濃度預測值和參考值之間的相關性,尤其是高血糖濃度范圍的預測效果明顯提升。
盡管本文所建立的PSO-BP模型達到了一定的精度,但在Clarke誤差網格分析的B區域中仍然存在不理想的預測結果。因此,模型的預測精度還有必要進一步提高,從而繼續降低RMSE,提高CORR以及Clarke誤差網格分析中B區域預測結果的百分比。此外,本次研究所采集到的數量較少,且征集到的參與數據采集的志愿者比較單一,模型的有效性還有待于進一步驗證。
4 結論
本次研究基于BP神經網絡模型和PSO建立了一種混合模型,即PSO-BP模型。考慮到生理參數對近紅外無創血糖檢測的影響,引入了收縮壓、脈率、體溫和1 550 nm近紅外吸光度作為輸入變量參與模型的建立。采用PSO對BP神經網絡的權重和閾值進行優化,得到最后的PSO-BP模型。RMSE、CORR和Clarke誤差網格分析結果表明,相比于單一的BP模型,PSO-BP模型具有更高的預測精度。且模型一旦訓練完成,可快速用于血糖濃度的無創檢測。
基于現有的實驗數據和本文提出的方法,獲得了一定精度的無創血糖檢測結果。但所建立的無創血糖濃度預測模型的準確性和魯棒性仍需進一步驗證。將進行大規模實驗,以擴大數據樣本量,增加數據和志愿者的多樣性,進一步提高預測模型的性能。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:葉東海負責樣機設計、數據采集和分析、論文寫作;程錦繡負責實驗設計、數據收集和方法研究、論文寫作;季忠負責樣機研究、數據分析和方法研究。
倫理聲明:本研究通過了重慶大學附屬腫瘤醫院倫理委員會的審批(批文編號:2020年倫審(055)號)。