傳統基于機器學習的睡眠呼吸暫停(SA)檢測方法,需花大量工作在特征工程與分類器設計上。本文提出了一種基于卷積神經網絡(CNN)的 SA 自動檢測方法,構建了一個包含 4 個卷積層、4 個池化層、2 個全連接層和 1 個分類層的一維 CNN 網絡模型,通過網絡自身結構實現特征自動提取與分類。利用呼吸暫停-心電圖(Apnea-ECG)數據庫中 70 例整晚單通道睡眠心電圖(ECG)數據對該方法進行了驗證,通過對比實驗發現當輸入為單通道 ECG 信號、RR 間期(RRI)序列、R 峰值序列、RRI 序列+R 峰值序列四種情況時,網絡在 SA 片段檢測上的準確率為 80.1%~88.0%,表明該 CNN 網絡是有效的,能從原始單通道 ECG 信號或其派生信號 RRI、R 峰值序列中自動提取特征并分類。當網絡輸入為 RRI 序列+R 峰值序列時效果最好,在片段 SA 檢測上的準確率、靈敏度和特異度分別為 88.0%、85.1% 和 89.9%,個體 SA 診斷準確率達 100%。研究結果表明,本文提出的方法能有效提高 SA 檢測的準確性和魯棒性,且性能優于近年主要文獻報道,有望應用于配備遠程服務器的便攜式 SA 篩查診斷設備中。
引用本文: 高群霞, 商麗娟, 吳凱. 基于卷積神經網絡的睡眠呼吸暫停自動檢測方法. 生物醫學工程學雜志, 2021, 38(4): 678-685. doi: 10.7507/1001-5515.202012025 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
引言
睡眠呼吸暫停(sleep apnea,SA)是一種常見的睡眠呼吸障礙疾病,長期患病會導致一些嚴重的心血管和神經系統疾病[1]。多導睡眠監測(polysomnography,PSG)是臨床上 SA 篩查診斷的金標準,該方法需要患者在醫院佩戴多導電極線入睡,并且整個操作和診斷過程需由有經驗的專家完成[2],診斷費用較高,對患者身心干擾大,不利于普及到家庭。此外,由于 SA 高發于中年人群,隨著人口老齡化加劇,越來越多人受到 SA 疾病的困擾,但現實中各種因素制約使患者無法去醫院進行及時就診,因此研究可以舒適便捷檢測 SA 的替代技術具有重要意義。
心電圖(electrocardiogram,ECG)信號是與 SA 最相關的生理信號之一,根據 ECG 信號可有效檢測 SA [3]。由于 ECG 數據能通過可穿戴設備輕松采集,基于 ECG 信號診斷 SA 的研究有助于 SA 篩查在公共衛生中的普及。近年,已有許多采用單通道 ECG 信號檢測 SA 的研究[4-11],大多采用機器學習的方法,通過提取 ECG 信號及其衍生信號中的時域、頻域及時頻域中的多個特征來構建模型,取得了一定效果。近年文獻報道效果較好的方法中,常用的 ECG 信號派生信號有心率變異性(heart rate variability,HRV)、ECG 衍生的呼吸(ECG-derived respiration,EDR)、RR 間期(RR interval,RRI)、R 峰值序列等,常用的分類器有支持向量機(support vector machine,SVM)、最小二乘支持向量機(least squares support vector machine,LS-SVM)、K最近鄰(K-nearest neighbor,KNN)、多層感知機(multi-layer perceptron,MLP)等。Atri 等[4]利用 LS-SVM 對 HRV 和 EDR 信號中的特征進行分類,個體 SA 診斷的準確率(accuracy,Acc)達 94.12%。Jafari[5]利用 SVM 對從 ECG 信號中提取到的非線性特征和頻域特征進行分類,個體 SA 診斷 Acc 達 94.8%。T?MU?等[6]利用 KNN 對 HRV 等特征進行分類,個體 SA 診斷 Acc 達 97%。Chen 等[7]利用 SVM 對 RRI 序列中的特征進行分類,個體 SA 診斷 Acc 達 97.41%。Sharma 等[8]利用徑向基函數為核函數的 LS-SVM 來對 RRI 序列和 EDR 信號分類,片段 SA 檢測 Acc 為 83.8%。Varon 等[9]利用 LS-SVM 對 HRV 和 RRI 序列進行分類,片段 SA 檢測 Acc 為 84.7%。Song 等[10]提出了一種基于隱馬爾可夫模型(hidden Markov model,HMM)檢測 SA 的方法,利用 SVM 結合 HMM 對從 ECG 信號中提取的頻域和時域特征進行分類,SA 片段檢測 Acc 達 86.2%。Wang 等[11]提取 RRI 序列和 R 峰值序列中的多個特征,利用 MLP 實現分類,取得了較先進的水平,在 SA 片段檢測和個體 SA 診斷中 Acc 分別達到 87.3% 和 97.1%。
以上基于傳統機器學習的方法主要在于特征提取與分類器設計上,雖然能達到一定效果,但特征提取工作量較大,且較主觀,無法從原始數據自身中學到特征。卷積神經網絡(convolutional neural networks,CNN)是一種模擬人類視覺深層層次結構的深層神經網絡,是最常用的深度學習結構,相較傳統機器學習方法,CNN 可以通過網絡自身層次結構自動提取特征并分類,具有較好的魯棒性。隨著深度學習技術的發展,CNN 技術在醫學領域中也得到廣泛應用,如心力衰竭檢測[12]、癲癇腦電信號檢測[13]、心音信號分類[14]、肺結節檢測[15]、心肌梗死檢測[16]等。
目前,只有少量利用深度學習技術實現 SA 自動檢測的研究,覃恒基等[17]提出一種基于自編碼器和 HMM 的 SA 檢測方法,利用棧式稀疏自編碼器自動提取 ECG 信號特征,利用 SVM 和人工神經網絡分別結合 HMM 后組成決策融合分類器,SA 片段檢測 Acc 為 84.7%,個體 SA 診斷正確率達 100%。該方法雖然取得較好效果,但過程較復雜,不能實現自動特征提取與分類,不利于移植使用。
在上述研究基礎上,本文提出一種基于 CNN 的 SA 自動檢測方法,構建了一個主要包含 4 個卷積層(convolution,Conv)、4 個池化層(Pooling)、2 個全連接層(Dense)和 1 個分類層的 CNN 網絡模型,利用 ECG 信號及其派生信號 RRI 序列、R 峰值序列作為網絡輸入,先通過網絡自身結構中的卷積和池化操作實現特征提取,接著通過 Dense 和分類層實現分類,進而實現對每個片段是否出現 SA 進行檢測,最后通過計算每個記錄中 SA 片段的總數及呼吸暫停低通氣指數(apnea-hypopnea index,AHI)兩項指標實現個體 SA 診斷。該端到端 SA 檢測方法能很好實現特征的自動提取與分類,具有較好的魯棒性,能應用于配備遠程服務器的便攜式可穿戴家用睡眠呼吸健康監護產品中為 SA 疾病做預篩、預診,同時輔助睡眠技術人員標注 SA 事件。
1 總體框架
1.1 SA 檢測總體流程
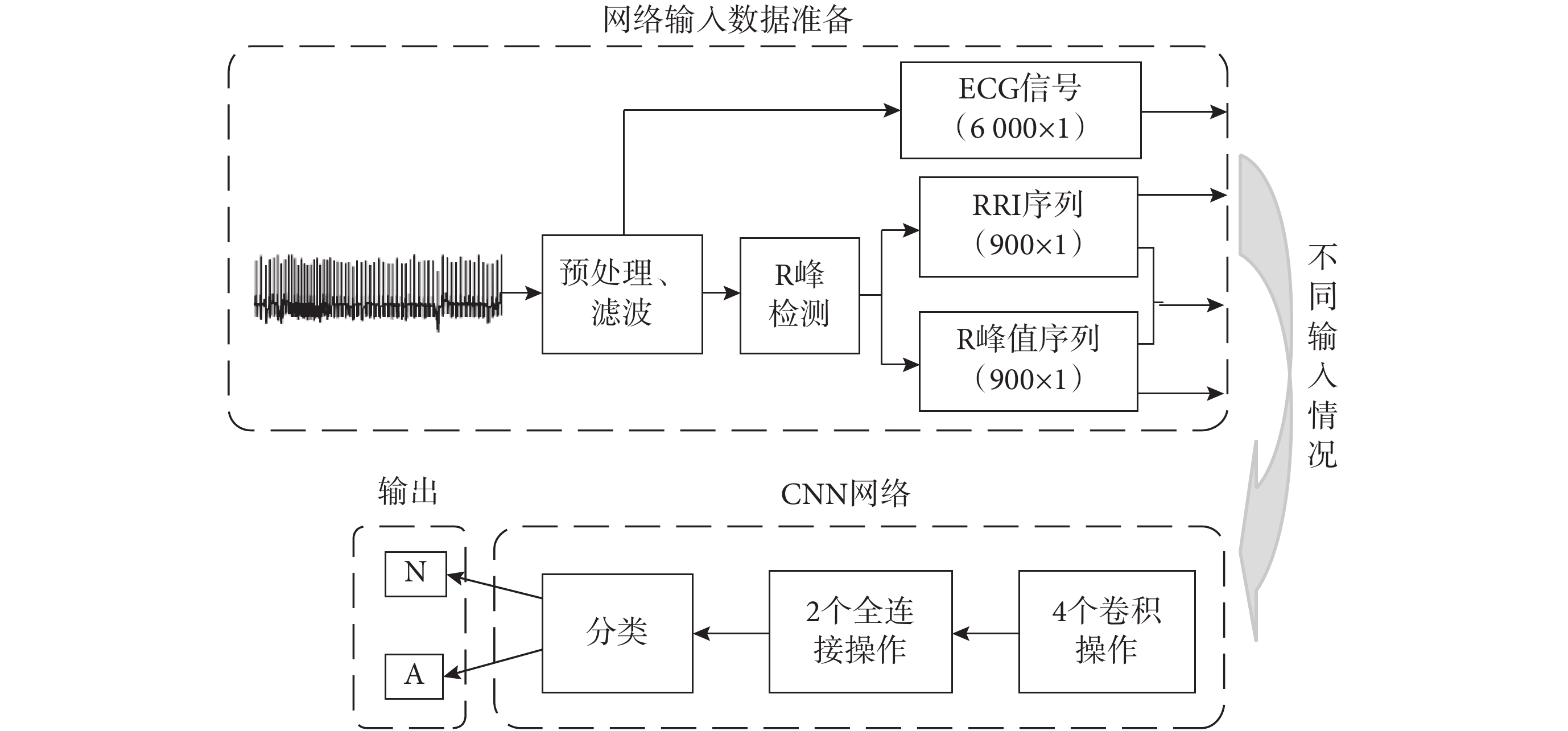
基于 CNN 的 SA 自動檢測流程如圖 1 所示,由于每個 ECG 數據記錄由多個 ECG 數據片段組成,每個片段預測的 Acc 直接影響每個記錄的分類效果。先通過構建的 CNN 網絡模型實現 SA 片段檢測,然后根據 SA 片段總數和 AHI 兩項指標判斷該個體是否屬于 SA 患者,最后將結果輸出。
 圖1
基于 CNN 的 SA 自動檢測總體流程圖
Figure1.
Overall flow chart of SA automatic detection based on CNN
圖1
基于 CNN 的 SA 自動檢測總體流程圖
Figure1.
Overall flow chart of SA automatic detection based on CNN
1.2 SA 片段檢測實驗流程
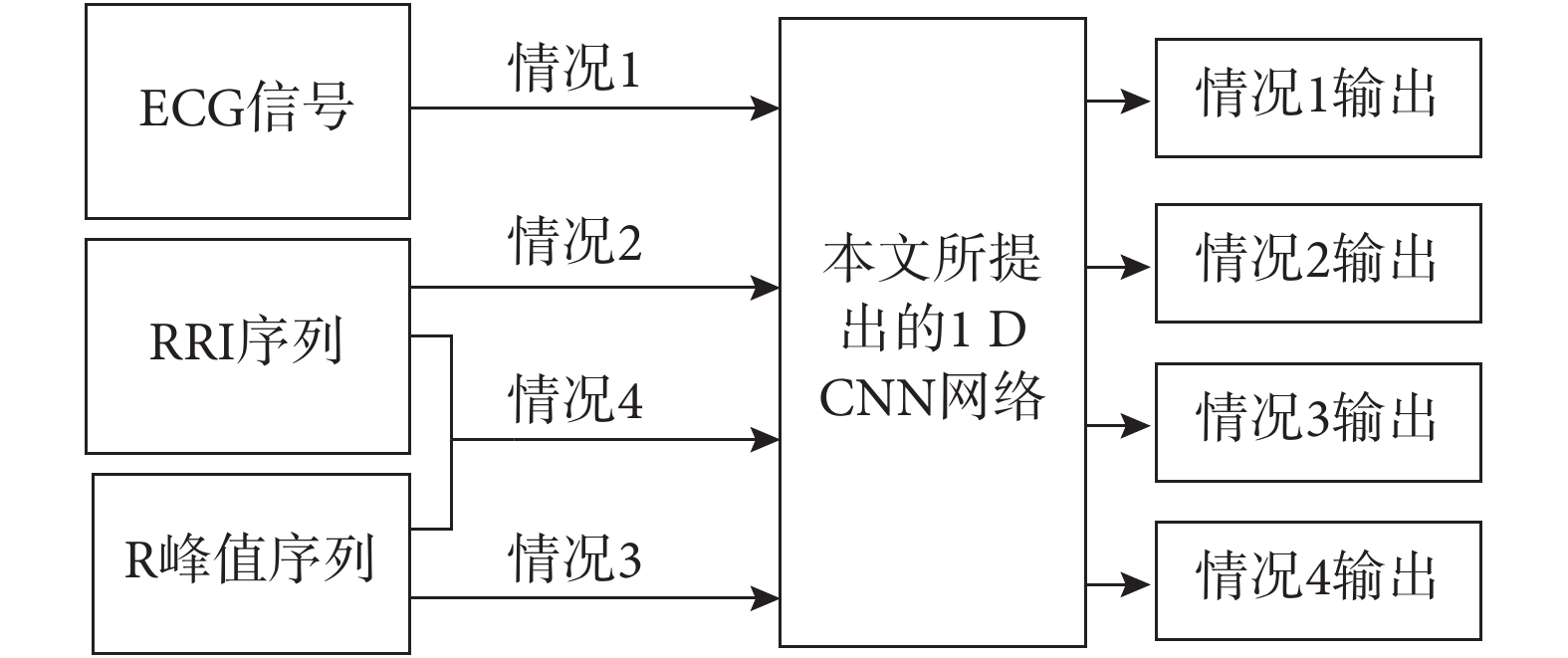
為驗證所提出的 CNN 網絡在 SA 片段檢測上的效果,通過輸入四組不同信號進行測試,對比實驗總體流程如圖 2 所示。先準備網絡的輸入數據,然后測試當輸入為單通道 ECG 信號、RRI 序列、R 峰值序列和 RRI 序列+R 峰值序列四種不同情況時網絡的分類效果,從而驗證所提 CNN 網絡在 SA 片段檢測中的有效性。CNN 分類結果以出現呼吸暫停(apnea,A)或呼吸正常(normal,N)兩類標識輸出。
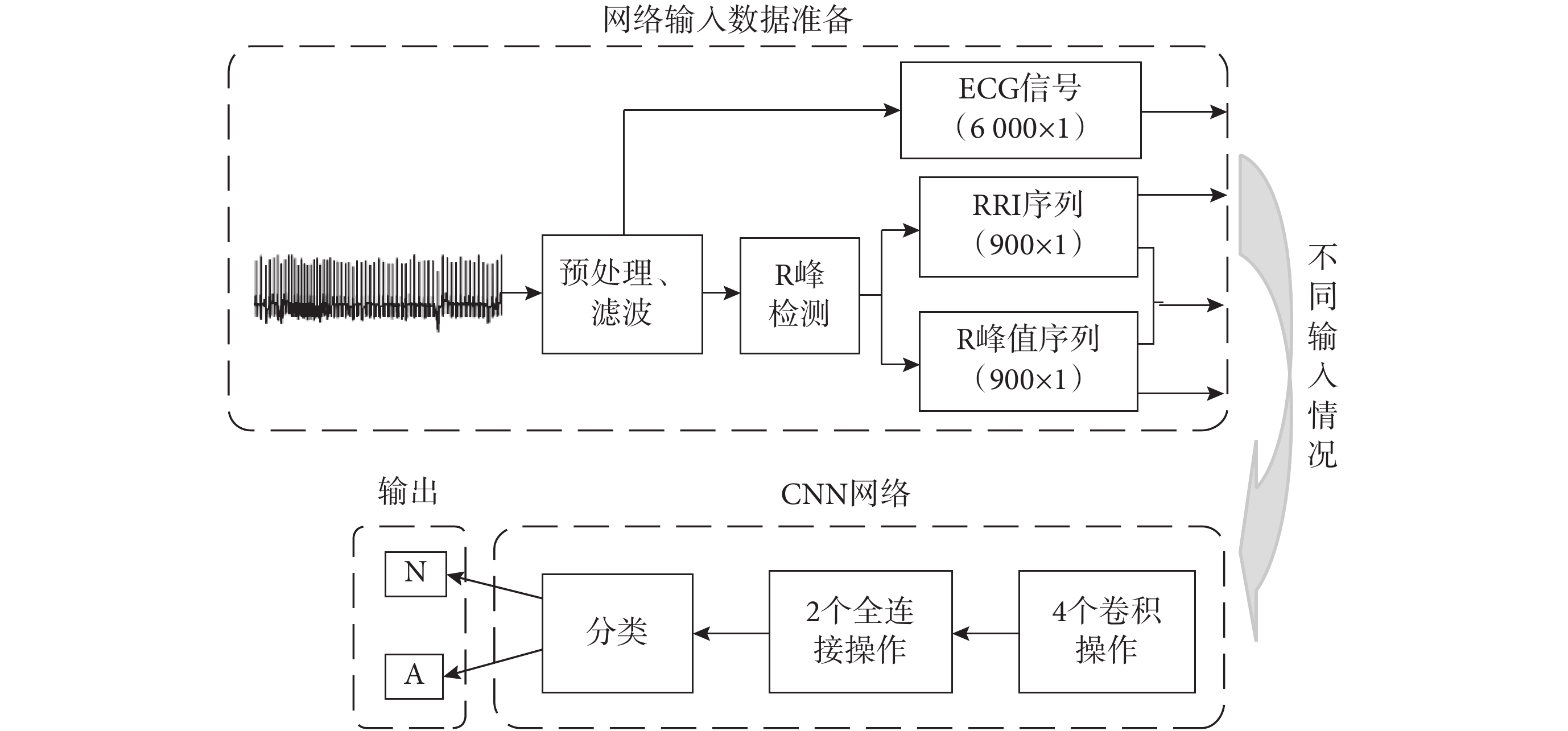 圖2
SA 片段檢測實驗流程圖
Figure2.
Per-segment SA detection experiment flowchart
圖2
SA 片段檢測實驗流程圖
Figure2.
Per-segment SA detection experiment flowchart
2 SA 片段檢測 CNN 網絡結構
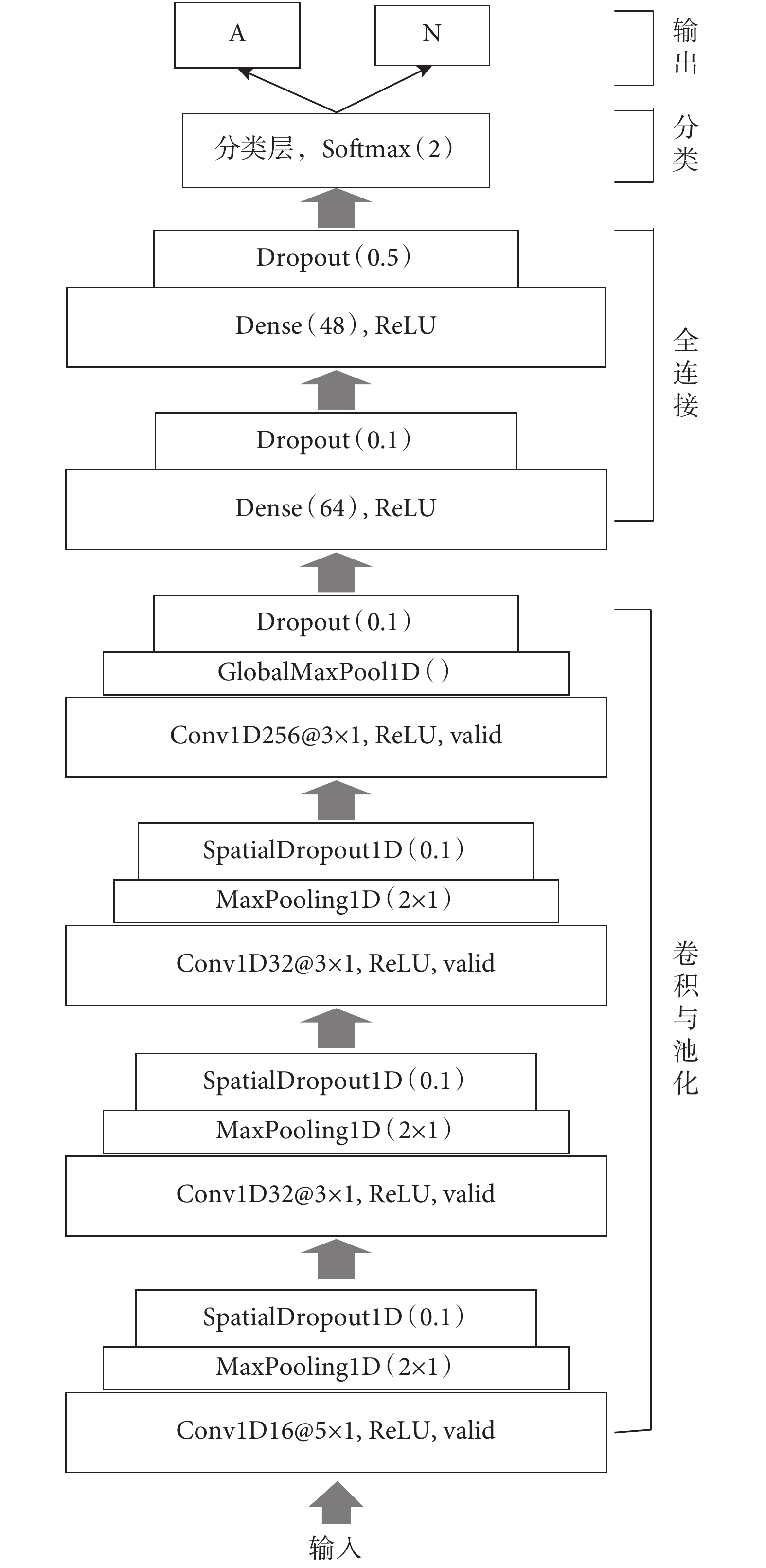
一個典型的 CNN 常由多個 Conv、Pooling 及 Dense 組成,Conv 通過卷積操作,可從輸入信號中自動提取出特征;Pooling 對特征進行降采樣,減小特征維度;Dense 可實現特征整合及分類[18]。由于所涉及的數據是時間序列,因此構建一個一維(one dimensional,1D)CNN 模型,主要包含 4 個 Conv、4 個 Pooling、2 個 Dense 和 1 個分類層,網絡具體結構如圖 3 所示。
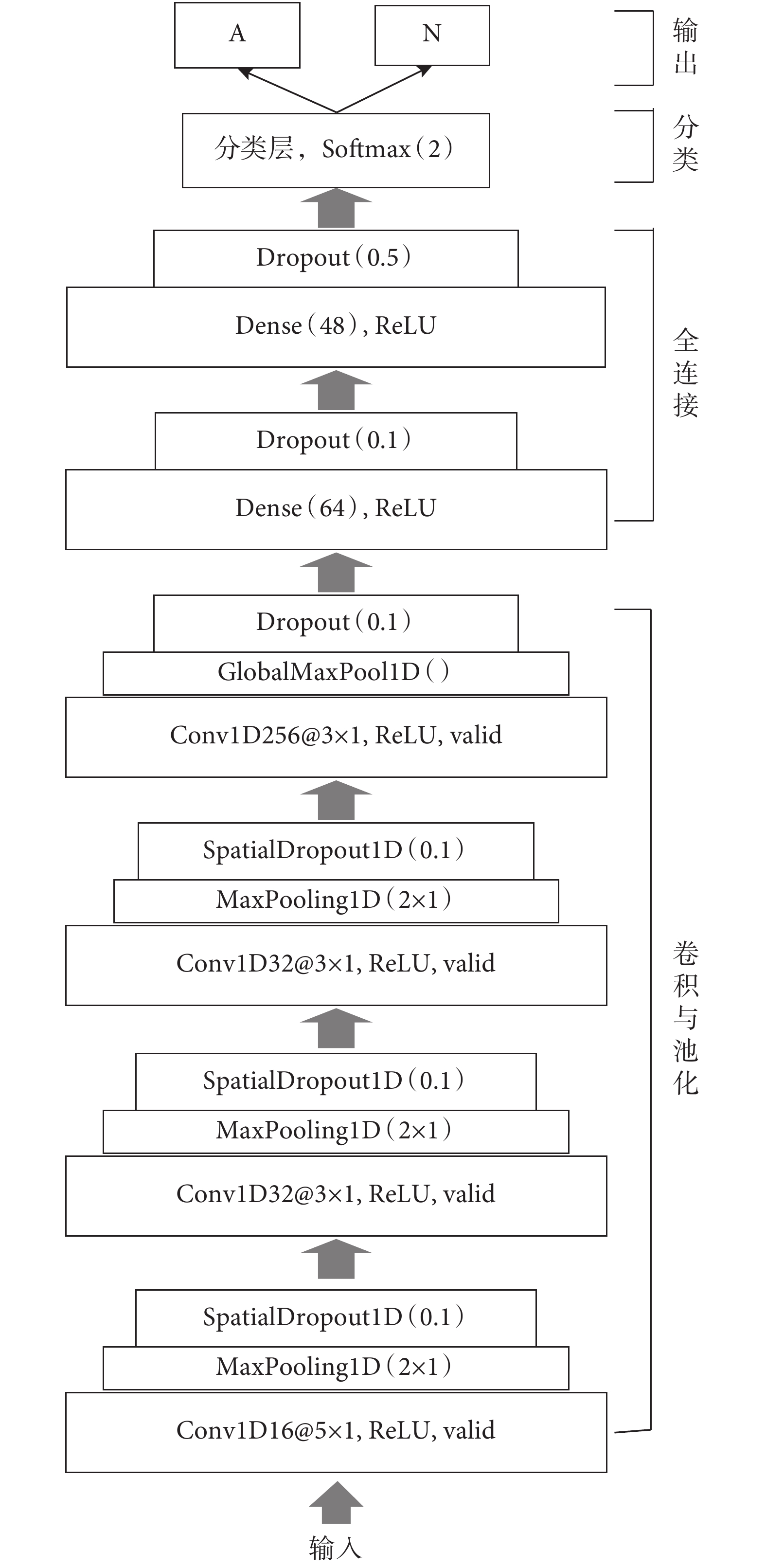 圖3
用于 SA 片段檢測的 CNN 網絡結構
Figure3.
CNN structure for per-segment SA detection
圖3
用于 SA 片段檢測的 CNN 網絡結構
Figure3.
CNN structure for per-segment SA detection
該模型結構及參數具體描述如下:
(1)Conv:用于從輸入信號中自動提取特征,卷積的計算過程如式(1)所示:
 |
其中,Hi?1、Hi分別代表第i層卷積操作的輸入和輸出集合,Wi、bi分別代表第i層卷積核的權值向量和第i層的偏移向量,符號“ ”代表卷積操作,
”代表卷積操作, 代表激活函數[18]。
代表激活函數[18]。
由于輸入的是 1 D 信號,所以構建 1 D Conv(Conv1D)從輸入數據中提取特征。網絡中第一個 Conv1D 由 16 個大小為 5 × 1 的濾波器組成,第二和第三個 Conv1D 由 32 個大小為 3 × 1 的濾波器組成,第四個 Conv1D 由 256 個大小為 3 × 1 的濾波器組成。每個 Conv1D 中都采用修正線性單元(rctified linear unit,ReLU)激活函數,采用不填充(valid)策略作為卷積運算中的邊緣填充規則。
(2)Pooling:為提高運算速度,使特征更突出,在卷積操作后加入 Pooling 實現下采樣。前 3 個 Conv1D 后都緊跟一個池化大小為 2 × 1 的 1D 最大 Pooling(MaxPooling1D)[15],第四個 Conv1D 后緊跟一個全局 MaxPooling1D(GlobalMaxPool1D)實現全局下采樣。
(3)隨機失活層(Dropout):為防止過擬合,在網絡中引入 Dropout,使訓練過程中每次更新參數時按一定概率隨機失活部分神經元。GlobalMaxPool1D 和兩個 Dense 后都緊跟一個 Dropout,隨機失活率分別為 0.1、0.1、0.5。前 3 個 MaxPooling1D 后都引入一個隨機失活率分別為 0.1 的 1D 空間 Dropout(SpatialDropout1D),其作用與 Dropout 類似,但它斷開的是整個 1D 特征圖,有助于提高特征圖之間的獨立性。
(4)Dense:為整合特征,網絡中加入兩個 Dense,神經元個數分別為 64 和 48,且都采用 ReLU 為激活函數。
(5)分類層:該層也屬于 Dense,只是采用歸一化指數函數(Softmax)作為激活函數,類別個數設置為 2,從而實現 2 分類。
3 實驗
3.1 實驗方法
3.1.1 數據庫介紹
本文的實驗數據來源于復雜生理信號研究資源(Research Resource for Complex Physiologic Signals,PhysioNet)網站(網址為:
該 70 條記錄被分為訓練集和測試集兩個互不相交的集合,各含 35 個記錄,其中 15 個為正常(每個記錄的 AHI < 5 且 SA 片段總數小于 100 個),20 個為 SA 患病(每個記錄的 AHI > 5 且至少含有 100 個 SA 片段)[20]。
3.1.2 數據預處理
對原始 ECG 信號進行濾波并獲取其派生信號 RRI 序列和 R 峰值序列。首先利用截止頻率為 5~15 Hz 的有限長單位沖激響應(finite impulse response,FIR)帶通濾波器對原始 ECG 信號進行降噪,最大限度保留 QRS 波群的能量。接著采用 Hamilton[21]提出的算法查找 R 峰的位置,由于 ECG 信號存在生理上不可解釋的異常點,使用 Chen 等[7]提出的中值濾波器進行消除,然后通過 R 峰的位置來獲得 RRI 序列,并提取出 R 峰值序列。為實現片段 SA 檢測,即判斷每 1 min 片段內是否發生 SA,需先根據 Apnea-ECG 數據庫中的注釋標簽對 ECG 信號進行分段處理,經分段并剔除異常片段操作后,數據庫中訓練集和測試集分別被切分成 16 709 個片段和 16 945 個片段,實驗數據集詳細信息如表 1 所示。
此外,為匹配 CNN 網絡的輸入,將輸入數據組織為網絡能接收的形式,對于每 1 min 片段數據,當輸入為 ECG 信號時,數據被組織為 6 000 × 1 的矩陣形式,其中 1 代表通道個數,6 000 代表 1 個通道的數據量。當輸入為 RRI 序列或 R 峰值序列時,利用三次樣條插值法將 1 min 的 RRI 序列片段和 R 峰值序列片段都插值為 900 個點,從而將輸入數據組織為 900 × 1 的矩陣形式。而當輸入為 RRI 序列+R 峰值序列時,數據將被組織為 900 × 2 的矩陣形式,其中 2 代表通道數。為實現 2 分類,對類別標簽進行獨熱編碼轉換。
3.1.3 評價指標
包含分類效果評價指標及 SA 診斷指標兩類。
(1)分類評價指標
為評價 CNN 網絡的分類效果,本文采用 Acc、靈敏度(sensitivity,Se)、特異度(specificity,Sp)和 F1 值四個指標來衡量[15-16],四個指標具體計算方法如式(2)~式(5)所示:
 |
 |
 |
 |
其中,真陽性(true positive,TP)代表正樣本被正確分類的個數,真陰性(true negative,TN)代表負樣本被正確分類的個數,假陽性(false positive,FP)代表負樣本被錯誤地分類為正樣本的個數,假陰性(false negative,FN)代表正樣本被錯誤地分類為負樣本的個數[15]。
(2)AHI
臨床上判斷個體是否為 SA 患者的金標準是 AHI 指標[22],根據 SA 片段檢測分類結果便可計算出 AHI,具體計算方法如式(6)所示:
 |
其中,Total(SA)代表記錄中出現 SA 片段的總數,T為 ECG 信號的長度(單位為 min)[22]。
3.1.4 實驗環境
本文所有實驗都在一臺惠普筆記本電腦(DDR3 8GB,三星,中國)上完成,其中央處理器為 Core(TM)i5-6200U@2.30 GHz(Intel,美國)。使用深度學習開源軟件 Keras 2.2.0(Google,美國)搭建所提出的 CNN 網絡結構,使用 python 語言編寫所有代碼。
3.1.5 訓練設置
模型訓練時,采用自適應矩估計(adaptive moment estimation,Adam)優化器對網絡權值進行更新。為匹配分類層的 Softmax 激活函數,采用多類交叉熵作為損失函數實現二分類。利用預處理步驟中得到的訓練集和測試集數據來訓練和評估模型,訓練時將訓練集中 80% 的數據用于網絡訓練,剩下的 20% 數據作為驗證集,用于加速網絡收斂。
3.2 實驗結果與討論
3.2.1 網絡訓練結果
為找到最優參數組合,利用網格搜索法尋找學習率(lr)、批大小和迭代次數(epochs)的最優參數設置。實驗結果表明當網絡輸入為 ECG 信號時,lr 設置為 0.001,批大小設置為 50,epochs 設置為 40 時網絡效果最好;其他三種輸入情況時,lr 設置為 0.000 1,批大小設置為 50,epochs 設置為 150 時網絡效果最好。為獲取最優模型,避免訓練陷入過擬合,使用早停(EarlyStopping)策略,當網絡連續 15 批次驗證集上的損失值(loss)不再下降時終止訓練,并保存最優權重及模型結構。
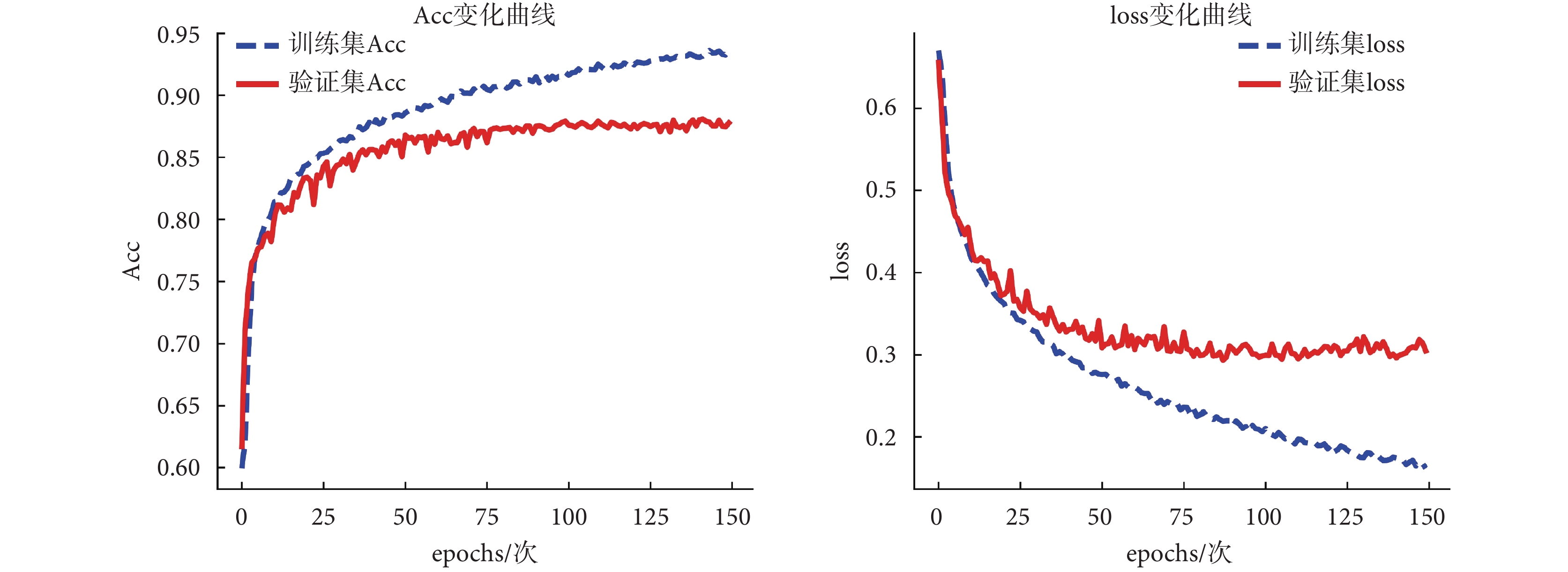
loss 能反映預測值與期望值之間的誤差程度,Acc 能反映正確預測的概率,網絡訓練的目的是減小預測值與期望值之間的誤差,因此 loss 越小越好,Acc 越高越好。所提出的 CNN 網絡在以上獲得的最優訓練參數設置下,利用 RRI 序列+R 峰值序列作為網絡輸入時,模型訓練過程中的 Acc 與 loss 變化情況如圖 4 所示。從圖中曲線變化情況可看出,經過多輪迭代訓練,Acc 和 loss 基本趨于穩定。
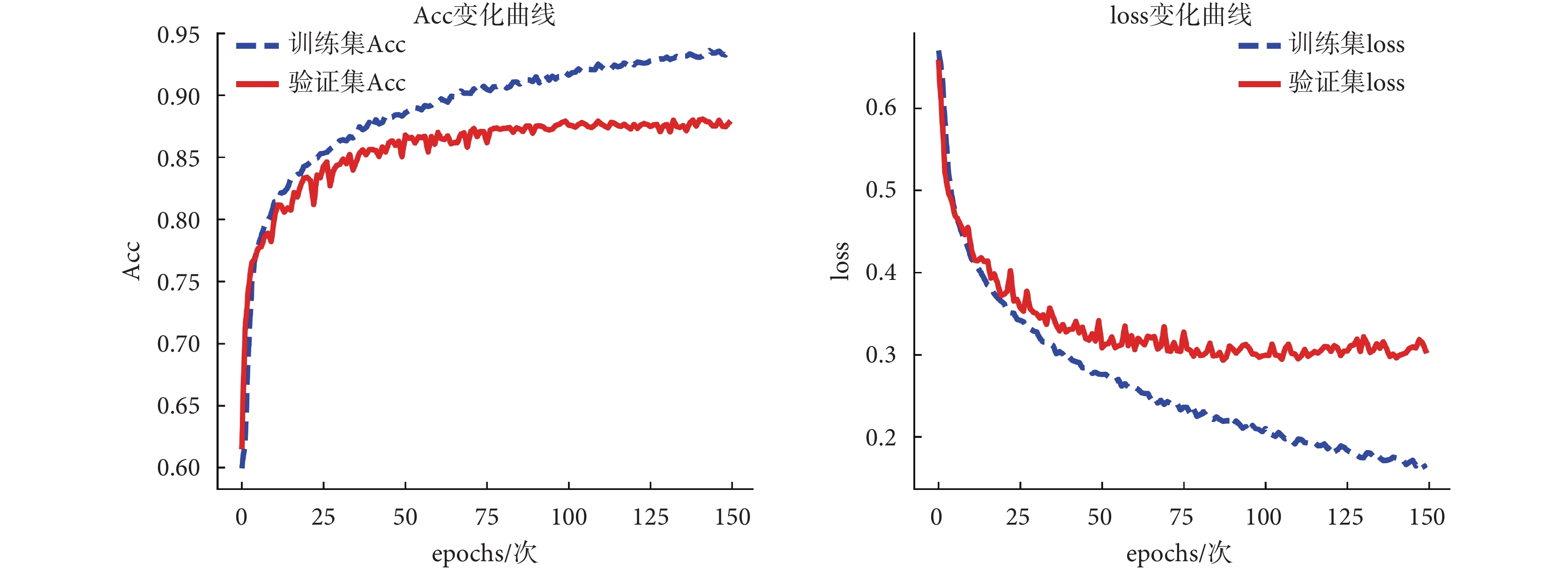 圖4
CNN 模型訓練過程中 Acc 與 loss 變化曲線
Figure4.
Change curve of Acc and loss during the CNN model training
圖4
CNN 模型訓練過程中 Acc 與 loss 變化曲線
Figure4.
Change curve of Acc and loss during the CNN model training
3.2.2 四組輸入對比實驗
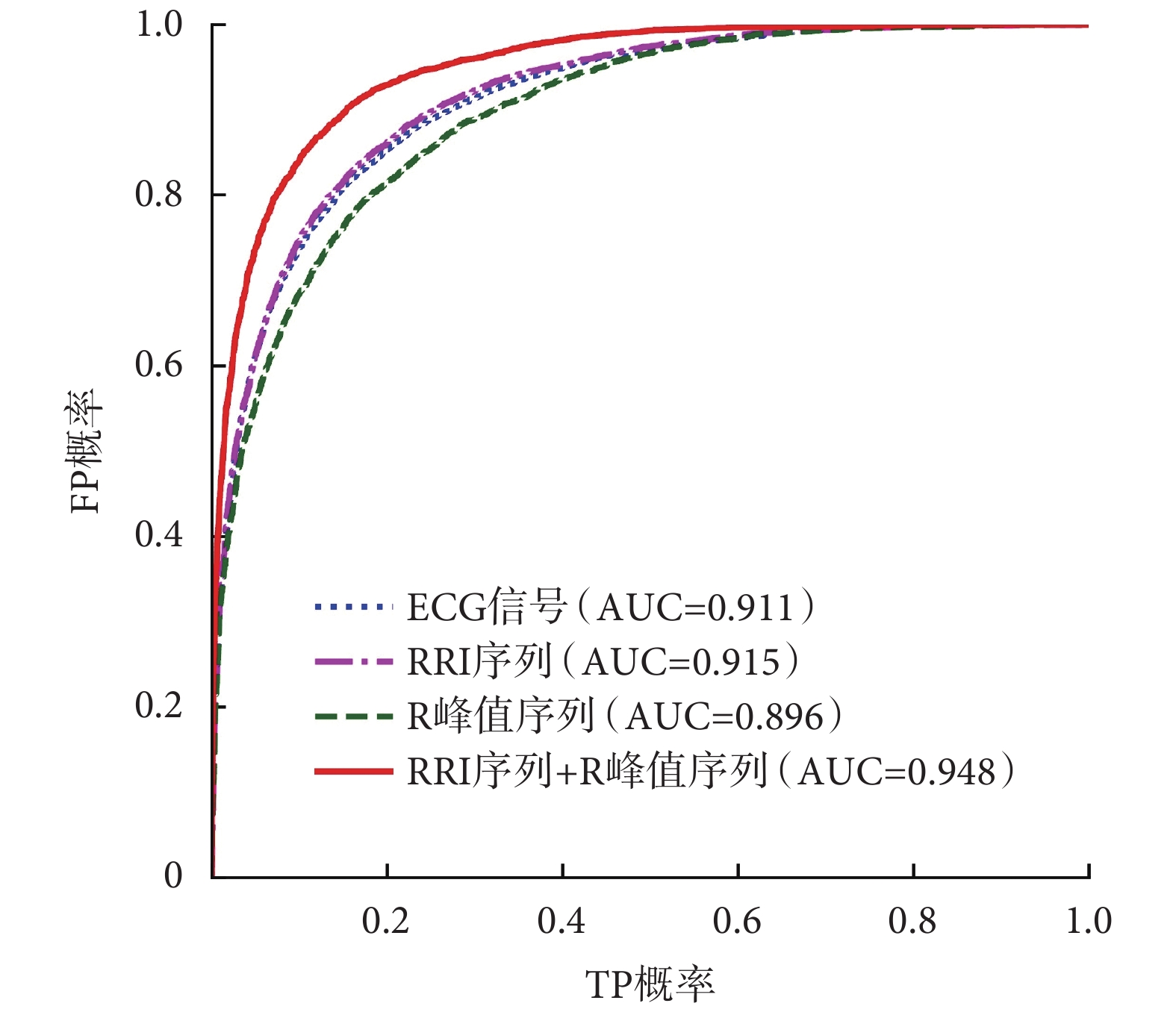
為測試網絡分類效果,尋找最佳輸入,分別測試了當輸入為 ECG 信號、RRI 序列、R 峰值序列和 RRI 序列+R 峰值序列四種情況時,網絡在 SA 片段檢測上的效果,實驗流程如圖 5 所示。四組輸入對比實驗得到的最優模型在測試集上的識別結果如表 2 所示,此外為更好區分效果,繪制了分類結果接受者操作特征曲線(receiver operator characteristic curve,ROC)如圖 6 所示。
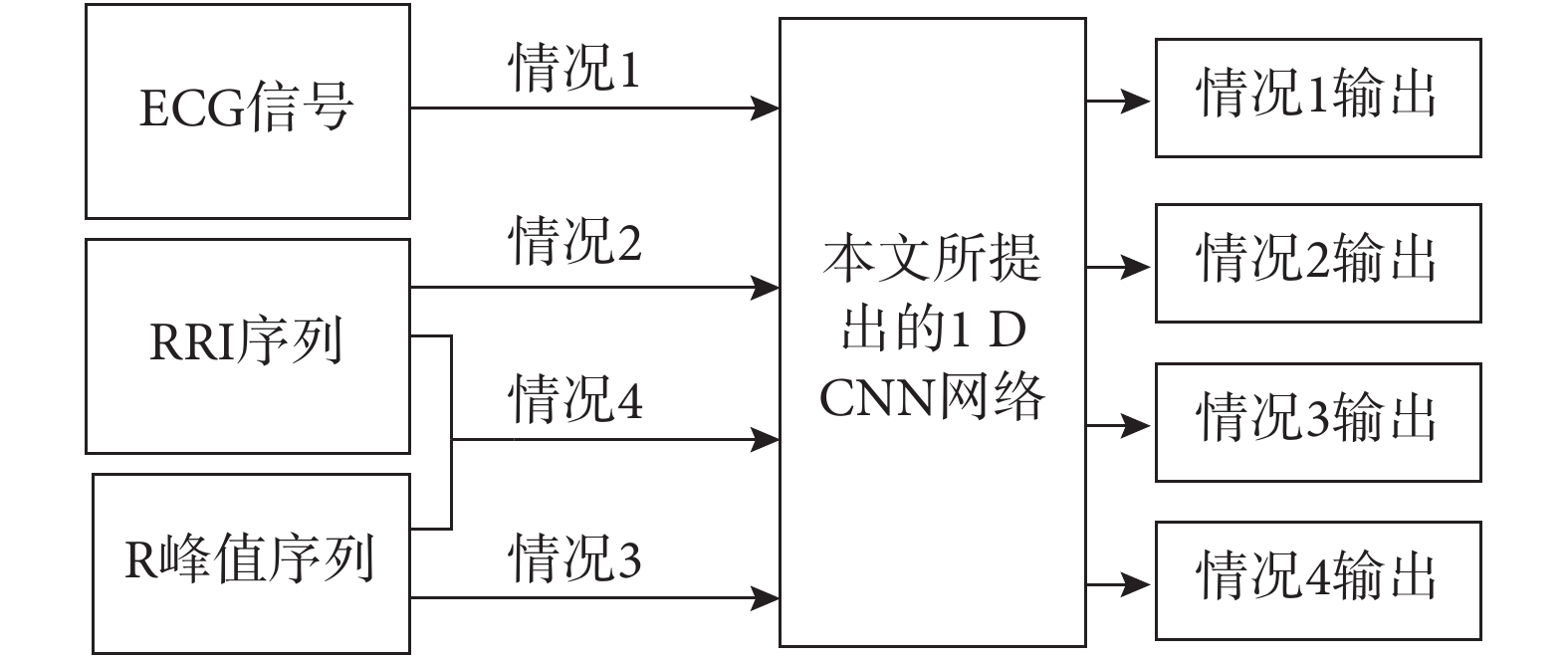 圖5
四種輸入情況 SA 片段檢測對比實驗
Figure5.
Comparison experiment of per-segment SA detection under four different inputs
圖5
四種輸入情況 SA 片段檢測對比實驗
Figure5.
Comparison experiment of per-segment SA detection under four different inputs
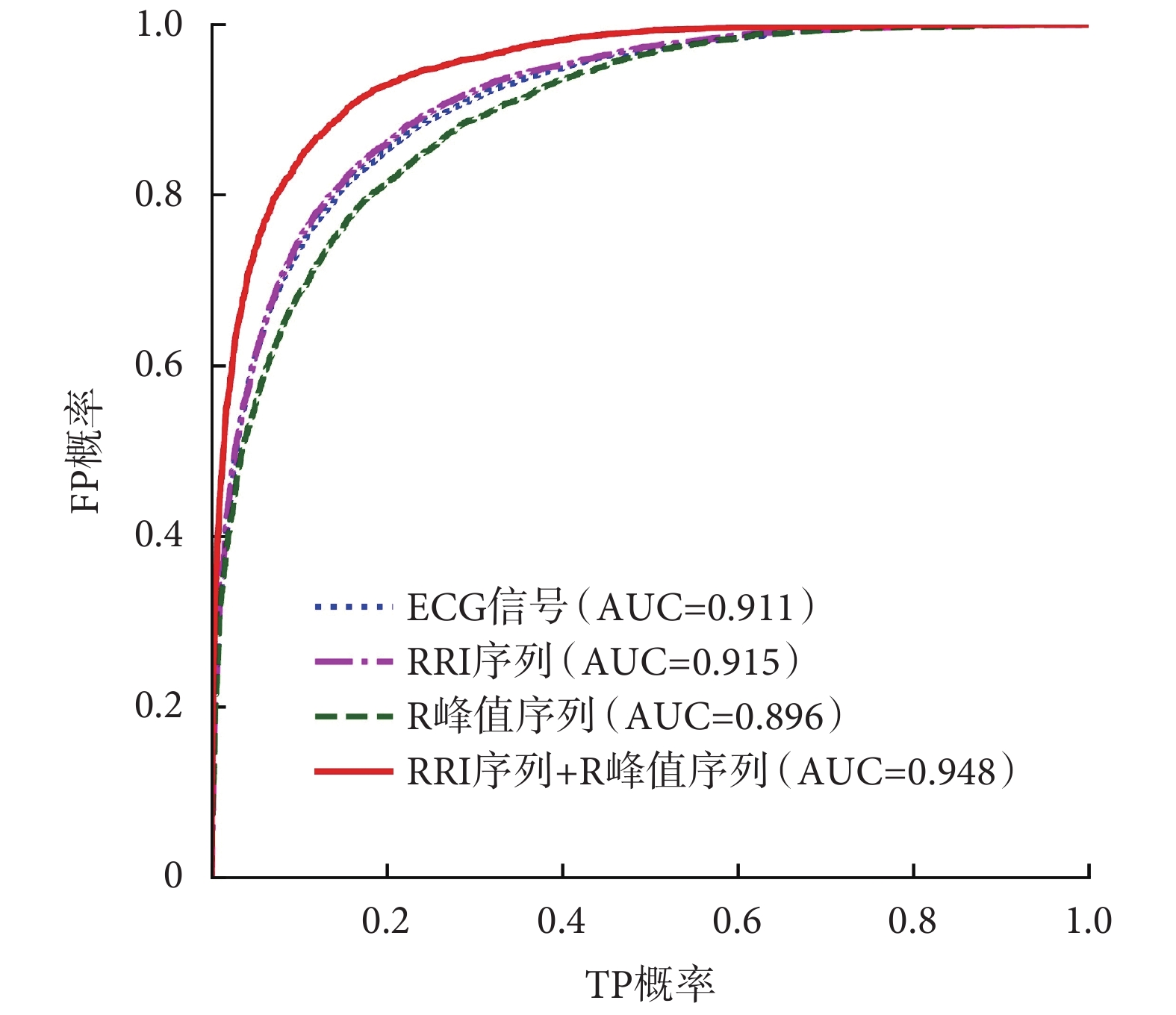 圖6
四種輸入情況時 CNN 網絡分類效果 ROC 曲線對比
Figure6.
Comparison of ROC curve of the CNN model classifi cation effect under four different inputs
圖6
四種輸入情況時 CNN 網絡分類效果 ROC 曲線對比
Figure6.
Comparison of ROC curve of the CNN model classifi cation effect under four different inputs
從表 2 中可知,四種不同輸入信號情況下,CNN 網絡 SA 片段識別 Acc 在 80.1%~88.0% 之間,說明該網絡結構能較好從輸入信號中自動提取特征并分類。當輸入為 ECG 信號和 RRI 序列兩種情況時,Acc 相差不大,分別為 83.5% 和 83.7%,同時 Se 都比 Sp 低。當輸入為 R 峰值信號時,網絡的識別 Acc 最低,但也能達到 80.1%,同時 Se 高于 Sp。當輸入 RRI 序列+R 峰值序列兩種組合信號時效果最好,Acc、Se 和 Sp 都最高,分別為 88.0%、85.1% 和 89.9%,且 Se 和 Sp 之間無太大差距。
從圖 6 中也可觀察到,當輸入為 RRI 序列+R 峰值序列時,ROC 曲線下與坐標軸圍成的面積(area under curve,AUC)最大,說明該種輸入情況下網絡分類效果最好,證明選用從原始 ECG 信號中派生出的 RRI 和 R 峰值兩種組合信號作為網絡輸入是最優選擇。
3.2.3 SA 檢測結果
RRI 序列+R 峰值序列兩種組合信號作為網絡輸入時,本文提出的 CNN 模型在片段 SA 檢測中的表現如表 3 所示,在個體 SA 診斷中的表現如表 4 所示。從表 3 中測試集的結果可以看出本文所提 CNN 模型在片段 SA 檢測上 Acc、Se、Sp 和 F1 值分別達到 88.0%、85.1%、89.9% 和 84.5%,模型能很好實現 SA 片段檢測。從表 4 中測試集的結果可知,所提出的以 CNN 為主體的 SA 檢測方法在個體 SA 患病診斷上 Acc 達 100%,能很好實現個體 SA 患病篩查。
3.2.4 與近年相關研究對比
為進一步證實所提方法的有效性,與近年基于單通道 ECG 信號檢測 SA 的相關研究成果進行對比。由于一些文獻只做了片段 SA 檢測或個體 SA 診斷中的一種,所以進行分開對比。在使用相同數據源 Apnea-ECG 數據庫作為實驗數據的情況下,本文方法與近年較好方法在 SA 片段檢測中的效果對比如表 5 所示,在個體 SA 診斷中的效果對比如表 6 所示,表中結果均為訓練好的模型在測試集上的表現。
從表 5 和表 6 中的對比數據可見,相較于傳統機器學習方法,如文獻[4-11]的方法,本文的方法在片段 SA 檢測及 SA 個體診斷上效果都更好,各方面性能都更優,并且避免了特征工程和分類器設計的工作。相較于一些基于深度學習的現有研究,如文獻[17]的方法,本文所提出的 CNN 模型在片段 SA 檢測上的 Acc 更高,雖然在相同測試集下個體 SA 診斷 Acc 都為 100%,但隨著數據樣本量的增加,片段 SA 檢測效果定會影響個體 SA 診斷結果,片段 SA 檢測 Acc 越高,個體 SA 診斷 Acc 也會越高。同時,文獻[17]的方法只用深度學習技術實現特征自動提取,分類工作仍采用機器學習的方法,特征提取與分類任務分離,不利于模型的移植和使用。本文所提方法真正突出了深度學習網絡結構自身能實現特征自動提取與分類的優勢,具有更好的效果及魯棒性。
4 結論
本文提出了一種基于 CNN 的 SA 自動檢測方法,構建了一個由 4 個 Conv、4 個 Pooling、2 個 Dense 和 1 個分類層組成的 1D CNN 網絡模型,首先通過網絡自身結構自動提取輸入信號的特征并分類,從而實現對每個片段是否出現 SA 進行檢測,然后通過 Total(SA)及 AHI 值兩項指標實現個體 SA 診斷。使用 Apnea-ECG 數據庫中的 70 例整晚單通道睡眠 ECG 數據對該方法進行了驗證,實驗結果表明,構建的 1D CNN 網絡模型是有效的,能很好實現從原始輸入信號中自動提取特征并分類,當輸入為單通道 ECG 信號、RRI 序列、R 峰值序列、RRI 序列+R 峰值序列四種情況時,網絡在 SA 片段檢測上的 Acc 為 80.1%~88.0%,當利用從 ECG 信號派生出的 RRI 序列+R 峰值序列作為網絡輸入時效果最好,在測試集上的片段 SA 檢測 Acc、Se 和 Sp 分別為 88.0%、85.1% 和 89.9%,個體 SA 診斷 Acc 達 100%。與近年研究結果對比,本文方法效果更好,相比傳統機器學習方法,具有更好魯棒性,可為配備遠程服務器的便攜式 SA 篩查診斷工具提供方法支撐,同時可輔助睡眠技術人員標注 SA 事件。
由于數據庫中自帶的標簽未對呼吸暫停和呼吸不足做區分,因此不能對 SA 做出更具體分類,此外實驗中只用到了一種公開數據庫,且存在類不均衡情況,后繼將在 SA 類型細分及類不平衡解決策略上做進一步研究,并使用更多數據集驗證模型,以進一步提高分類效果,增強模型的泛化能力和適用性。
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
引言
睡眠呼吸暫停(sleep apnea,SA)是一種常見的睡眠呼吸障礙疾病,長期患病會導致一些嚴重的心血管和神經系統疾病[1]。多導睡眠監測(polysomnography,PSG)是臨床上 SA 篩查診斷的金標準,該方法需要患者在醫院佩戴多導電極線入睡,并且整個操作和診斷過程需由有經驗的專家完成[2],診斷費用較高,對患者身心干擾大,不利于普及到家庭。此外,由于 SA 高發于中年人群,隨著人口老齡化加劇,越來越多人受到 SA 疾病的困擾,但現實中各種因素制約使患者無法去醫院進行及時就診,因此研究可以舒適便捷檢測 SA 的替代技術具有重要意義。
心電圖(electrocardiogram,ECG)信號是與 SA 最相關的生理信號之一,根據 ECG 信號可有效檢測 SA [3]。由于 ECG 數據能通過可穿戴設備輕松采集,基于 ECG 信號診斷 SA 的研究有助于 SA 篩查在公共衛生中的普及。近年,已有許多采用單通道 ECG 信號檢測 SA 的研究[4-11],大多采用機器學習的方法,通過提取 ECG 信號及其衍生信號中的時域、頻域及時頻域中的多個特征來構建模型,取得了一定效果。近年文獻報道效果較好的方法中,常用的 ECG 信號派生信號有心率變異性(heart rate variability,HRV)、ECG 衍生的呼吸(ECG-derived respiration,EDR)、RR 間期(RR interval,RRI)、R 峰值序列等,常用的分類器有支持向量機(support vector machine,SVM)、最小二乘支持向量機(least squares support vector machine,LS-SVM)、K最近鄰(K-nearest neighbor,KNN)、多層感知機(multi-layer perceptron,MLP)等。Atri 等[4]利用 LS-SVM 對 HRV 和 EDR 信號中的特征進行分類,個體 SA 診斷的準確率(accuracy,Acc)達 94.12%。Jafari[5]利用 SVM 對從 ECG 信號中提取到的非線性特征和頻域特征進行分類,個體 SA 診斷 Acc 達 94.8%。T?MU?等[6]利用 KNN 對 HRV 等特征進行分類,個體 SA 診斷 Acc 達 97%。Chen 等[7]利用 SVM 對 RRI 序列中的特征進行分類,個體 SA 診斷 Acc 達 97.41%。Sharma 等[8]利用徑向基函數為核函數的 LS-SVM 來對 RRI 序列和 EDR 信號分類,片段 SA 檢測 Acc 為 83.8%。Varon 等[9]利用 LS-SVM 對 HRV 和 RRI 序列進行分類,片段 SA 檢測 Acc 為 84.7%。Song 等[10]提出了一種基于隱馬爾可夫模型(hidden Markov model,HMM)檢測 SA 的方法,利用 SVM 結合 HMM 對從 ECG 信號中提取的頻域和時域特征進行分類,SA 片段檢測 Acc 達 86.2%。Wang 等[11]提取 RRI 序列和 R 峰值序列中的多個特征,利用 MLP 實現分類,取得了較先進的水平,在 SA 片段檢測和個體 SA 診斷中 Acc 分別達到 87.3% 和 97.1%。
以上基于傳統機器學習的方法主要在于特征提取與分類器設計上,雖然能達到一定效果,但特征提取工作量較大,且較主觀,無法從原始數據自身中學到特征。卷積神經網絡(convolutional neural networks,CNN)是一種模擬人類視覺深層層次結構的深層神經網絡,是最常用的深度學習結構,相較傳統機器學習方法,CNN 可以通過網絡自身層次結構自動提取特征并分類,具有較好的魯棒性。隨著深度學習技術的發展,CNN 技術在醫學領域中也得到廣泛應用,如心力衰竭檢測[12]、癲癇腦電信號檢測[13]、心音信號分類[14]、肺結節檢測[15]、心肌梗死檢測[16]等。
目前,只有少量利用深度學習技術實現 SA 自動檢測的研究,覃恒基等[17]提出一種基于自編碼器和 HMM 的 SA 檢測方法,利用棧式稀疏自編碼器自動提取 ECG 信號特征,利用 SVM 和人工神經網絡分別結合 HMM 后組成決策融合分類器,SA 片段檢測 Acc 為 84.7%,個體 SA 診斷正確率達 100%。該方法雖然取得較好效果,但過程較復雜,不能實現自動特征提取與分類,不利于移植使用。
在上述研究基礎上,本文提出一種基于 CNN 的 SA 自動檢測方法,構建了一個主要包含 4 個卷積層(convolution,Conv)、4 個池化層(Pooling)、2 個全連接層(Dense)和 1 個分類層的 CNN 網絡模型,利用 ECG 信號及其派生信號 RRI 序列、R 峰值序列作為網絡輸入,先通過網絡自身結構中的卷積和池化操作實現特征提取,接著通過 Dense 和分類層實現分類,進而實現對每個片段是否出現 SA 進行檢測,最后通過計算每個記錄中 SA 片段的總數及呼吸暫停低通氣指數(apnea-hypopnea index,AHI)兩項指標實現個體 SA 診斷。該端到端 SA 檢測方法能很好實現特征的自動提取與分類,具有較好的魯棒性,能應用于配備遠程服務器的便攜式可穿戴家用睡眠呼吸健康監護產品中為 SA 疾病做預篩、預診,同時輔助睡眠技術人員標注 SA 事件。
1 總體框架
1.1 SA 檢測總體流程
基于 CNN 的 SA 自動檢測流程如圖 1 所示,由于每個 ECG 數據記錄由多個 ECG 數據片段組成,每個片段預測的 Acc 直接影響每個記錄的分類效果。先通過構建的 CNN 網絡模型實現 SA 片段檢測,然后根據 SA 片段總數和 AHI 兩項指標判斷該個體是否屬于 SA 患者,最后將結果輸出。
圖1
基于 CNN 的 SA 自動檢測總體流程圖
Figure1.
Overall flow chart of SA automatic detection based on CNN
1.2 SA 片段檢測實驗流程
為驗證所提出的 CNN 網絡在 SA 片段檢測上的效果,通過輸入四組不同信號進行測試,對比實驗總體流程如圖 2 所示。先準備網絡的輸入數據,然后測試當輸入為單通道 ECG 信號、RRI 序列、R 峰值序列和 RRI 序列+R 峰值序列四種不同情況時網絡的分類效果,從而驗證所提 CNN 網絡在 SA 片段檢測中的有效性。CNN 分類結果以出現呼吸暫停(apnea,A)或呼吸正常(normal,N)兩類標識輸出。
圖2
SA 片段檢測實驗流程圖
Figure2.
Per-segment SA detection experiment flowchart
2 SA 片段檢測 CNN 網絡結構
一個典型的 CNN 常由多個 Conv、Pooling 及 Dense 組成,Conv 通過卷積操作,可從輸入信號中自動提取出特征;Pooling 對特征進行降采樣,減小特征維度;Dense 可實現特征整合及分類[18]。由于所涉及的數據是時間序列,因此構建一個一維(one dimensional,1D)CNN 模型,主要包含 4 個 Conv、4 個 Pooling、2 個 Dense 和 1 個分類層,網絡具體結構如圖 3 所示。
圖3
用于 SA 片段檢測的 CNN 網絡結構
Figure3.
CNN structure for per-segment SA detection
該模型結構及參數具體描述如下:
(1)Conv:用于從輸入信號中自動提取特征,卷積的計算過程如式(1)所示:
|
其中,Hi?1、Hi分別代表第i層卷積操作的輸入和輸出集合,Wi、bi分別代表第i層卷積核的權值向量和第i層的偏移向量,符號“”代表卷積操作,代表激活函數[18]。
由于輸入的是 1 D 信號,所以構建 1 D Conv(Conv1D)從輸入數據中提取特征。網絡中第一個 Conv1D 由 16 個大小為 5 × 1 的濾波器組成,第二和第三個 Conv1D 由 32 個大小為 3 × 1 的濾波器組成,第四個 Conv1D 由 256 個大小為 3 × 1 的濾波器組成。每個 Conv1D 中都采用修正線性單元(rctified linear unit,ReLU)激活函數,采用不填充(valid)策略作為卷積運算中的邊緣填充規則。
(2)Pooling:為提高運算速度,使特征更突出,在卷積操作后加入 Pooling 實現下采樣。前 3 個 Conv1D 后都緊跟一個池化大小為 2 × 1 的 1D 最大 Pooling(MaxPooling1D)[15],第四個 Conv1D 后緊跟一個全局 MaxPooling1D(GlobalMaxPool1D)實現全局下采樣。
(3)隨機失活層(Dropout):為防止過擬合,在網絡中引入 Dropout,使訓練過程中每次更新參數時按一定概率隨機失活部分神經元。GlobalMaxPool1D 和兩個 Dense 后都緊跟一個 Dropout,隨機失活率分別為 0.1、0.1、0.5。前 3 個 MaxPooling1D 后都引入一個隨機失活率分別為 0.1 的 1D 空間 Dropout(SpatialDropout1D),其作用與 Dropout 類似,但它斷開的是整個 1D 特征圖,有助于提高特征圖之間的獨立性。
(4)Dense:為整合特征,網絡中加入兩個 Dense,神經元個數分別為 64 和 48,且都采用 ReLU 為激活函數。
(5)分類層:該層也屬于 Dense,只是采用歸一化指數函數(Softmax)作為激活函數,類別個數設置為 2,從而實現 2 分類。
3 實驗
3.1 實驗方法
3.1.1 數據庫介紹
本文的實驗數據來源于復雜生理信號研究資源(Research Resource for Complex Physiologic Signals,PhysioNet)網站(網址為:
該 70 條記錄被分為訓練集和測試集兩個互不相交的集合,各含 35 個記錄,其中 15 個為正常(每個記錄的 AHI < 5 且 SA 片段總數小于 100 個),20 個為 SA 患病(每個記錄的 AHI > 5 且至少含有 100 個 SA 片段)[20]。
3.1.2 數據預處理
對原始 ECG 信號進行濾波并獲取其派生信號 RRI 序列和 R 峰值序列。首先利用截止頻率為 5~15 Hz 的有限長單位沖激響應(finite impulse response,FIR)帶通濾波器對原始 ECG 信號進行降噪,最大限度保留 QRS 波群的能量。接著采用 Hamilton[21]提出的算法查找 R 峰的位置,由于 ECG 信號存在生理上不可解釋的異常點,使用 Chen 等[7]提出的中值濾波器進行消除,然后通過 R 峰的位置來獲得 RRI 序列,并提取出 R 峰值序列。為實現片段 SA 檢測,即判斷每 1 min 片段內是否發生 SA,需先根據 Apnea-ECG 數據庫中的注釋標簽對 ECG 信號進行分段處理,經分段并剔除異常片段操作后,數據庫中訓練集和測試集分別被切分成 16 709 個片段和 16 945 個片段,實驗數據集詳細信息如表 1 所示。
此外,為匹配 CNN 網絡的輸入,將輸入數據組織為網絡能接收的形式,對于每 1 min 片段數據,當輸入為 ECG 信號時,數據被組織為 6 000 × 1 的矩陣形式,其中 1 代表通道個數,6 000 代表 1 個通道的數據量。當輸入為 RRI 序列或 R 峰值序列時,利用三次樣條插值法將 1 min 的 RRI 序列片段和 R 峰值序列片段都插值為 900 個點,從而將輸入數據組織為 900 × 1 的矩陣形式。而當輸入為 RRI 序列+R 峰值序列時,數據將被組織為 900 × 2 的矩陣形式,其中 2 代表通道數。為實現 2 分類,對類別標簽進行獨熱編碼轉換。
3.1.3 評價指標
包含分類效果評價指標及 SA 診斷指標兩類。
(1)分類評價指標
為評價 CNN 網絡的分類效果,本文采用 Acc、靈敏度(sensitivity,Se)、特異度(specificity,Sp)和 F1 值四個指標來衡量[15-16],四個指標具體計算方法如式(2)~式(5)所示:
|
|
|
|
其中,真陽性(true positive,TP)代表正樣本被正確分類的個數,真陰性(true negative,TN)代表負樣本被正確分類的個數,假陽性(false positive,FP)代表負樣本被錯誤地分類為正樣本的個數,假陰性(false negative,FN)代表正樣本被錯誤地分類為負樣本的個數[15]。
(2)AHI
臨床上判斷個體是否為 SA 患者的金標準是 AHI 指標[22],根據 SA 片段檢測分類結果便可計算出 AHI,具體計算方法如式(6)所示:
|
其中,Total(SA)代表記錄中出現 SA 片段的總數,T為 ECG 信號的長度(單位為 min)[22]。
3.1.4 實驗環境
本文所有實驗都在一臺惠普筆記本電腦(DDR3 8GB,三星,中國)上完成,其中央處理器為 Core(TM)i5-6200U@2.30 GHz(Intel,美國)。使用深度學習開源軟件 Keras 2.2.0(Google,美國)搭建所提出的 CNN 網絡結構,使用 python 語言編寫所有代碼。
3.1.5 訓練設置
模型訓練時,采用自適應矩估計(adaptive moment estimation,Adam)優化器對網絡權值進行更新。為匹配分類層的 Softmax 激活函數,采用多類交叉熵作為損失函數實現二分類。利用預處理步驟中得到的訓練集和測試集數據來訓練和評估模型,訓練時將訓練集中 80% 的數據用于網絡訓練,剩下的 20% 數據作為驗證集,用于加速網絡收斂。
3.2 實驗結果與討論
3.2.1 網絡訓練結果
為找到最優參數組合,利用網格搜索法尋找學習率(lr)、批大小和迭代次數(epochs)的最優參數設置。實驗結果表明當網絡輸入為 ECG 信號時,lr 設置為 0.001,批大小設置為 50,epochs 設置為 40 時網絡效果最好;其他三種輸入情況時,lr 設置為 0.000 1,批大小設置為 50,epochs 設置為 150 時網絡效果最好。為獲取最優模型,避免訓練陷入過擬合,使用早停(EarlyStopping)策略,當網絡連續 15 批次驗證集上的損失值(loss)不再下降時終止訓練,并保存最優權重及模型結構。
loss 能反映預測值與期望值之間的誤差程度,Acc 能反映正確預測的概率,網絡訓練的目的是減小預測值與期望值之間的誤差,因此 loss 越小越好,Acc 越高越好。所提出的 CNN 網絡在以上獲得的最優訓練參數設置下,利用 RRI 序列+R 峰值序列作為網絡輸入時,模型訓練過程中的 Acc 與 loss 變化情況如圖 4 所示。從圖中曲線變化情況可看出,經過多輪迭代訓練,Acc 和 loss 基本趨于穩定。
圖4
CNN 模型訓練過程中 Acc 與 loss 變化曲線
Figure4.
Change curve of Acc and loss during the CNN model training
3.2.2 四組輸入對比實驗
為測試網絡分類效果,尋找最佳輸入,分別測試了當輸入為 ECG 信號、RRI 序列、R 峰值序列和 RRI 序列+R 峰值序列四種情況時,網絡在 SA 片段檢測上的效果,實驗流程如圖 5 所示。四組輸入對比實驗得到的最優模型在測試集上的識別結果如表 2 所示,此外為更好區分效果,繪制了分類結果接受者操作特征曲線(receiver operator characteristic curve,ROC)如圖 6 所示。
圖5
四種輸入情況 SA 片段檢測對比實驗
Figure5.
Comparison experiment of per-segment SA detection under four different inputs
圖6
四種輸入情況時 CNN 網絡分類效果 ROC 曲線對比
Figure6.
Comparison of ROC curve of the CNN model classifi cation effect under four different inputs
從表 2 中可知,四種不同輸入信號情況下,CNN 網絡 SA 片段識別 Acc 在 80.1%~88.0% 之間,說明該網絡結構能較好從輸入信號中自動提取特征并分類。當輸入為 ECG 信號和 RRI 序列兩種情況時,Acc 相差不大,分別為 83.5% 和 83.7%,同時 Se 都比 Sp 低。當輸入為 R 峰值信號時,網絡的識別 Acc 最低,但也能達到 80.1%,同時 Se 高于 Sp。當輸入 RRI 序列+R 峰值序列兩種組合信號時效果最好,Acc、Se 和 Sp 都最高,分別為 88.0%、85.1% 和 89.9%,且 Se 和 Sp 之間無太大差距。
從圖 6 中也可觀察到,當輸入為 RRI 序列+R 峰值序列時,ROC 曲線下與坐標軸圍成的面積(area under curve,AUC)最大,說明該種輸入情況下網絡分類效果最好,證明選用從原始 ECG 信號中派生出的 RRI 和 R 峰值兩種組合信號作為網絡輸入是最優選擇。
3.2.3 SA 檢測結果
RRI 序列+R 峰值序列兩種組合信號作為網絡輸入時,本文提出的 CNN 模型在片段 SA 檢測中的表現如表 3 所示,在個體 SA 診斷中的表現如表 4 所示。從表 3 中測試集的結果可以看出本文所提 CNN 模型在片段 SA 檢測上 Acc、Se、Sp 和 F1 值分別達到 88.0%、85.1%、89.9% 和 84.5%,模型能很好實現 SA 片段檢測。從表 4 中測試集的結果可知,所提出的以 CNN 為主體的 SA 檢測方法在個體 SA 患病診斷上 Acc 達 100%,能很好實現個體 SA 患病篩查。
3.2.4 與近年相關研究對比
為進一步證實所提方法的有效性,與近年基于單通道 ECG 信號檢測 SA 的相關研究成果進行對比。由于一些文獻只做了片段 SA 檢測或個體 SA 診斷中的一種,所以進行分開對比。在使用相同數據源 Apnea-ECG 數據庫作為實驗數據的情況下,本文方法與近年較好方法在 SA 片段檢測中的效果對比如表 5 所示,在個體 SA 診斷中的效果對比如表 6 所示,表中結果均為訓練好的模型在測試集上的表現。
從表 5 和表 6 中的對比數據可見,相較于傳統機器學習方法,如文獻[4-11]的方法,本文的方法在片段 SA 檢測及 SA 個體診斷上效果都更好,各方面性能都更優,并且避免了特征工程和分類器設計的工作。相較于一些基于深度學習的現有研究,如文獻[17]的方法,本文所提出的 CNN 模型在片段 SA 檢測上的 Acc 更高,雖然在相同測試集下個體 SA 診斷 Acc 都為 100%,但隨著數據樣本量的增加,片段 SA 檢測效果定會影響個體 SA 診斷結果,片段 SA 檢測 Acc 越高,個體 SA 診斷 Acc 也會越高。同時,文獻[17]的方法只用深度學習技術實現特征自動提取,分類工作仍采用機器學習的方法,特征提取與分類任務分離,不利于模型的移植和使用。本文所提方法真正突出了深度學習網絡結構自身能實現特征自動提取與分類的優勢,具有更好的效果及魯棒性。
4 結論
本文提出了一種基于 CNN 的 SA 自動檢測方法,構建了一個由 4 個 Conv、4 個 Pooling、2 個 Dense 和 1 個分類層組成的 1D CNN 網絡模型,首先通過網絡自身結構自動提取輸入信號的特征并分類,從而實現對每個片段是否出現 SA 進行檢測,然后通過 Total(SA)及 AHI 值兩項指標實現個體 SA 診斷。使用 Apnea-ECG 數據庫中的 70 例整晚單通道睡眠 ECG 數據對該方法進行了驗證,實驗結果表明,構建的 1D CNN 網絡模型是有效的,能很好實現從原始輸入信號中自動提取特征并分類,當輸入為單通道 ECG 信號、RRI 序列、R 峰值序列、RRI 序列+R 峰值序列四種情況時,網絡在 SA 片段檢測上的 Acc 為 80.1%~88.0%,當利用從 ECG 信號派生出的 RRI 序列+R 峰值序列作為網絡輸入時效果最好,在測試集上的片段 SA 檢測 Acc、Se 和 Sp 分別為 88.0%、85.1% 和 89.9%,個體 SA 診斷 Acc 達 100%。與近年研究結果對比,本文方法效果更好,相比傳統機器學習方法,具有更好魯棒性,可為配備遠程服務器的便攜式 SA 篩查診斷工具提供方法支撐,同時可輔助睡眠技術人員標注 SA 事件。
由于數據庫中自帶的標簽未對呼吸暫停和呼吸不足做區分,因此不能對 SA 做出更具體分類,此外實驗中只用到了一種公開數據庫,且存在類不均衡情況,后繼將在 SA 類型細分及類不平衡解決策略上做進一步研究,并使用更多數據集驗證模型,以進一步提高分類效果,增強模型的泛化能力和適用性。
利益沖突聲明:本文全體作者均聲明不存在利益沖突。