心房顫動(房顫)是一種常見的心律失常,可導致血栓形成并增加腦卒中甚至死亡的風險。針對臨床應用中疾病篩檢低假陰性率的需求,本文提出一種改進的低假陰性率卷積神經網絡。通過在交叉熵損失函數中引入正則化系數,差別對待陽性和陰性樣本的代價成本,使得網絡訓練時可加大對假陰性的懲罰。采用三甲醫院采集的包含 21 077 位受試者的患者間臨床數據集進行驗證,相對于傳統交叉熵損失函數,使用改進的損失函數可將假陰性率由 2.22% 降低至 0.97%,所選正則化系數可將靈敏度由 97.78% 提升至 98.35%,準確率 96.62% 亦較原來的 96.49% 有所提升。所提算法可在不犧牲準確率的前提下降低假陰性率,降低漏診可能性以免錯過最佳治療時期,可為其他疾病的臨床輔助診斷提供一種可變參數的損失函數。
引用本文: 濮玉, 朱俊江, 張德濤, 嚴天宏. 基于改進卷積神經網絡的房顫篩查算法. 生物醫學工程學雜志, 2021, 38(4): 686-694. doi: 10.7507/1001-5515.202007039 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
引言
心房顫動(以下簡稱房顫)是 21 世紀的心血管流行病,目前我國大于 35 歲居民中房顫患病率為 0.71%,且仍處于上升狀態[1-2]。房顫發生時心房失去有效收縮,影響心臟排血功能,一方面易形成附壁血栓脫落后發生動脈栓塞,另一方面心輸出量減少使血壓降低易加重或誘發心絞痛、心力衰竭等[3]。研究表明,房顫引起腦卒中的概率為一般人群的 5 倍,是迫切需要醫學觀察的心血管疾病[4]。通常情況下,房顫的早期階段表現為陣發性和無癥狀性,若不及時終止,可能發展為持續性甚至永久性房顫,增加復律難度[5-6]。因此,準確診斷房顫是阻止房顫進一步發展為其他心臟疾病和腦卒中并發癥的關鍵[7]。
近幾年得益于人工智能技術的發展,針對心電信號的房顫智能篩查,國內外已經出現大量具有指導意義的成果。Andreotti 等[8]使用殘差網絡(residual networks,ResNets)進行房顫檢測,網絡中的剩余連接有助于解決梯度消失的問題,從而可以訓練更深的網絡。Xiong 等[9]提出了一個 16 層一維卷積神經網絡(1D convolutional neural network,1-D CNN),通過跳過連接來提高整個網絡的信息傳輸速率。Fan 等[10]提出了一種多尺度融合的深卷積神經網絡(multi-scaled fusion of deep convolutional neural networks,MS-CNN),采用兩條具有不同尺寸過濾器的卷積網絡結構來捕獲不同規模的特征。Andersen 等[11]提出結合 CNN 和遞歸神經網絡(convolutional- and recurrent-neural networks,CNN-RNN)的方法,采用端到端模型,以從 RR 間隔(RR intervals,RRIs)的片段中提取高級特征。Shi 等[12]提出了由 CNN 和長短期記憶(long short-term memory,LSTM)網絡組成多輸入深度神經網絡(multiple-input deep neural network,MIDNN),并通過主動學習(active learning,AL)和遷移學習(transfer learning,TL)相結合來選擇樣本和更新模型。Jin 等[13]提出了一種多域雙注意力卷積長短期記憶神經網絡(twin-attentional convolutional long short-term memory neural network,TAC-LSTM)方法,結合了時域和頻域特征并采用注意機制提高了模型的可解釋性。Mousavi 等[14]提出了一種分層注意網絡,使用波形、心跳和窗口三個注意機制級別來對導致 AF 的心電圖(electrocardiogram,ECG)模式進行多分辨率分析。目前大部分基于深度學習的房顫智能篩查的研究著重于提出可以更好地處理分類任務的強大架構,但是卻采用通用的模型框架和損失函數,無差別對待陽性和陰性樣本的代價成本,無法滿足單純追求低假陰性率的需求。然而,臨床上往往希望算法能夠盡量降低假陰性率,減少漏診量以避免耽誤最佳治療時期。
為此,本文研究了基于 CNN 的心電信號房顫判別算法。為了降低假陰性率,對交叉熵函數進行了改進:通過在原有交叉熵損失函數中引入正則化系數,使其懲罰方向可控,通過合理設置參數,可使 CNN 在訓練時加大對假陰性的懲罰。
1 方法
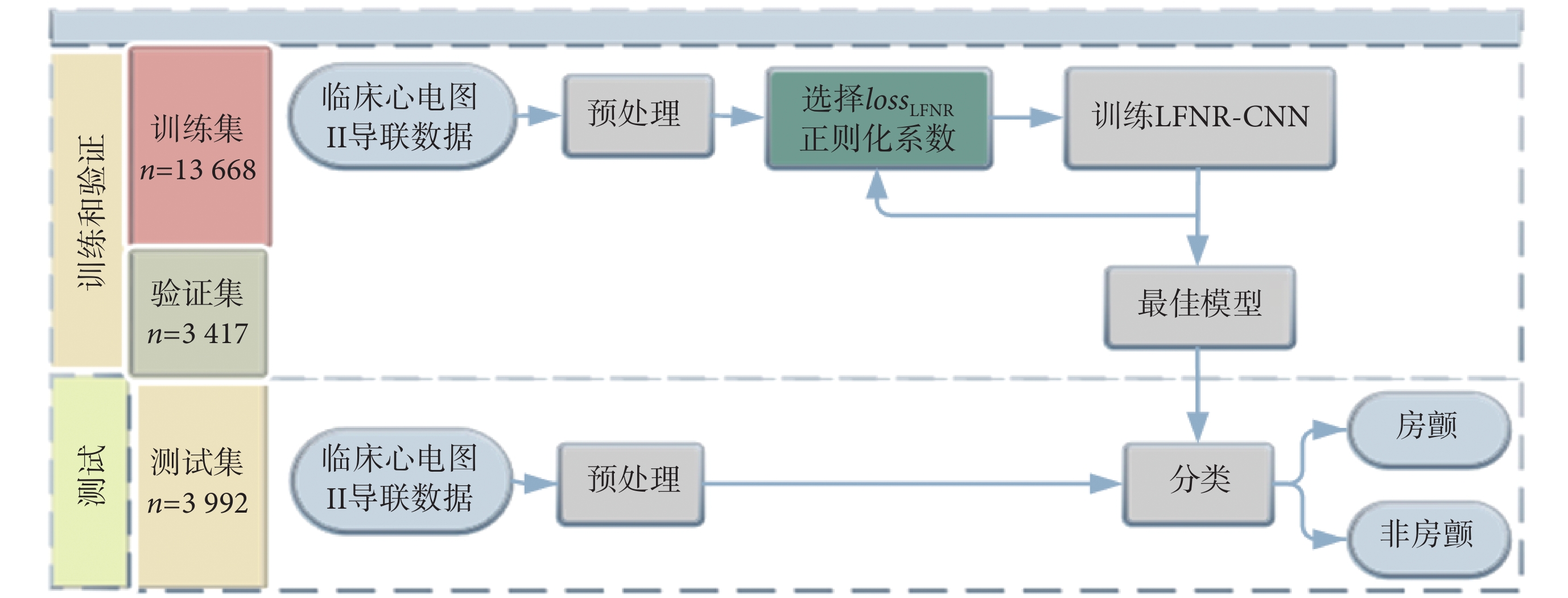
采用深度學習的方法進行房顫檢測,檢測流程如圖 1 所示,將預處理后的心電信號作為對比試驗的數據,選出所改進損失函數理想的正則化系數,最后基于改進的低假陰性率卷積神經網絡(convolutional neural network with low false-negative rate,LFNR-CNN)對房顫進行篩查。
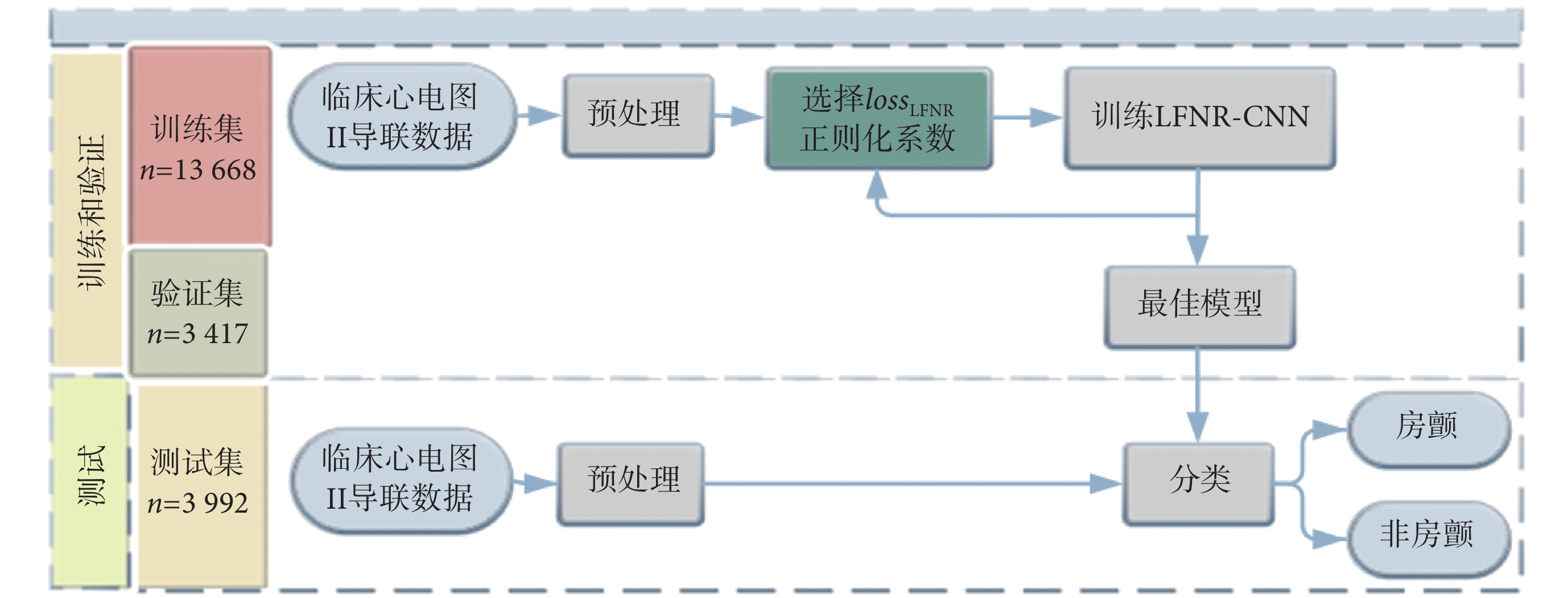 圖1
基于 LFNR-CNN 的房顫診斷算法流程圖
Figure1.
Flow chart of atrial fibrillation diagnosis algorithm based on LFNR-CNN
圖1
基于 LFNR-CNN 的房顫診斷算法流程圖
Figure1.
Flow chart of atrial fibrillation diagnosis algorithm based on LFNR-CNN
1.1 數據集和預處理
本方法所用房顫篩查數據集由上海數創醫療科技有限公司采集的三甲醫院臨床數據組成,其中 17 085 條數據作為訓練集,3 992 條數據作為測試集,如表 1 所示。數據集為醫院實地采集的門診和住院患者短心電記錄,已進行數據脫敏且得到合作單位的數據使用授權。本方法均選取Ⅱ型導聯的心電記錄作為數值實驗數據,采樣頻率為 500 Hz,持續時間為 10 s。數據集中有效心臟疾病標簽種類為 64 個,其中只含單個標簽的記錄占 17.8%,大部分心電記錄包含多個疾病標簽,單條記錄中最高標簽數量達 7 個。目前很多大型醫院都設有房顫中心,在房顫中心應用的算法更關注哪些是房顫患者,因此本文是對房顫的單獨篩檢,只分為房顫和非房顫兩類。同一樣本出現多標簽的情況下若其中包含房顫則判定為房顫,否則判為非房顫。心電信號是一種微弱的體表生物電信號,且極易受環境干擾[15-16]。ST 段頻帶(0.7~2 Hz)與基線漂移(0.05~1.5 Hz)有部分重疊,因此選擇小波變換去除基線漂移[17]。
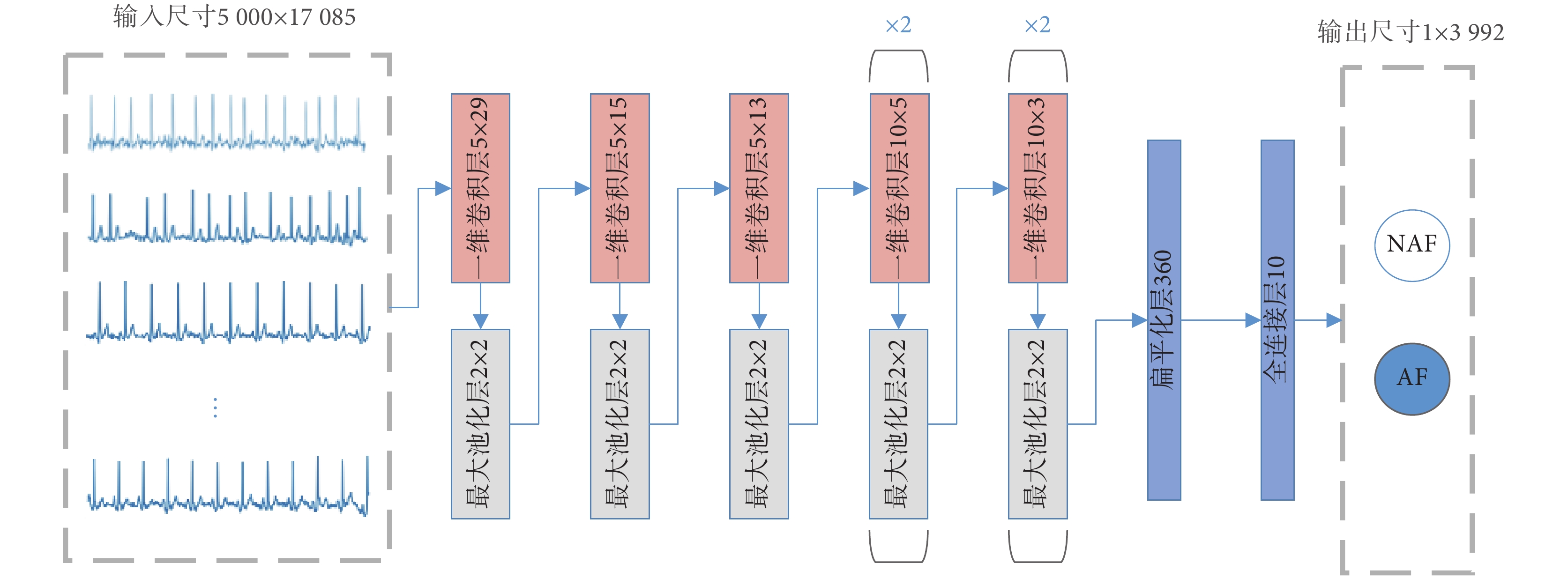
1.2 卷積神經網絡
CNN 有著從輸入數據中提取良好特征的巨大潛力,可以避免人工提取特征的過程中由于缺乏基礎心電知識而導致的特征質量低和冗余的問題[18]。CNN 通常由特征提取器和完全連接的多層感知器(multilayer perceptron,MLP)兩部分組成,特征提取器部分包括卷積層和池化層[19]。對于房顫檢測這個二分類問題,全連接層選用簡單的 sigmoid 分類器。本方法所用網絡結構如圖 2 所示。首先進行前向傳播,計算層與層之間的特征圖。一旦前向傳播獲得了預測輸出  ,則使用損失函數來計算預測誤差。然后執行反向傳播,預測誤差逐層在每個參數上反向傳播,并且通過所計算的權重梯度來調整權重[20]。重復執行向前和向后傳播,直到達到特定數量的迭代或滿足其他任何停止標準為止。
,則使用損失函數來計算預測誤差。然后執行反向傳播,預測誤差逐層在每個參數上反向傳播,并且通過所計算的權重梯度來調整權重[20]。重復執行向前和向后傳播,直到達到特定數量的迭代或滿足其他任何停止標準為止。
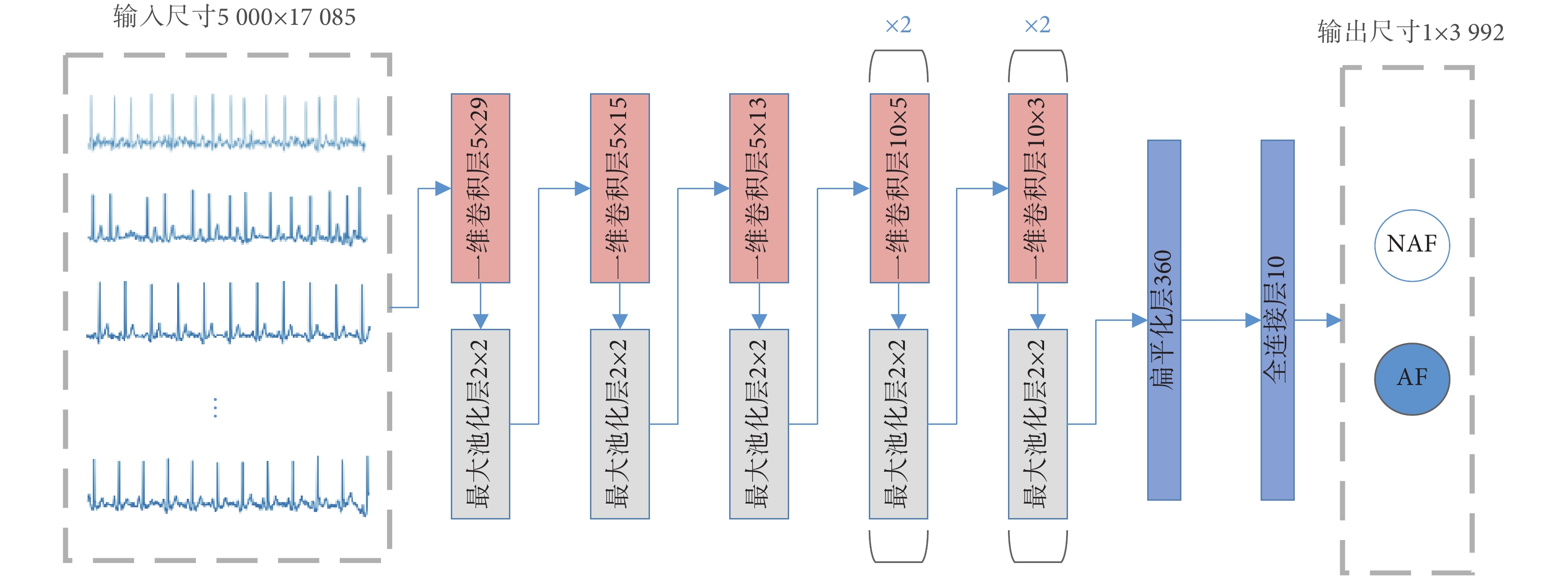 圖2
卷積神經網絡結構
Figure2.
The structure of the CNN
圖2
卷積神經網絡結構
Figure2.
The structure of the CNN
房顫篩查本質上是互相排斥的二分類問題,因此選用交叉熵損失函數來對正負樣本分類計算各自的損失。傳統的交叉熵損失函數[21]定義為:
 |
式中, 表示損失值大小,
表示損失值大小, 為樣本個數,
為樣本個數, 為樣本
為樣本 對應的真實值,
對應的真實值, 為當前的網絡模型以樣本
為當前的網絡模型以樣本  為輸入計算所得的輸出值。選用 sigmoid 激活函數配合交叉熵損失函數[22],則
為輸入計算所得的輸出值。選用 sigmoid 激活函數配合交叉熵損失函數[22],則
 |
式中, 為激活前的輸出值,化簡后有
為激活前的輸出值,化簡后有
 |
式中, 為樣本
為樣本  對應的真實值,
對應的真實值, 為最后一個全連接層的輸出矩陣,
為最后一個全連接層的輸出矩陣, 為最后一個全連接層的權重矩陣,
為最后一個全連接層的權重矩陣, 為最后一個全連接層的偏置,根據鏈式求導法則求得
為最后一個全連接層的偏置,根據鏈式求導法則求得  關于權重
關于權重  和偏置
和偏置  的偏導數:
的偏導數:
 |
 |
式中, 為當前卷積層的索引,
為當前卷積層的索引, 為學習率。求得的偏導數則為網絡中參數的變化率,根據式(8)和式(9)一步步地反向更新參數
為學習率。求得的偏導數則為網絡中參數的變化率,根據式(8)和式(9)一步步地反向更新參數  和
和  ,更新過程為:
,更新過程為:
 |
 |
從式(5)可發現, 本質上是一個關于權重
本質上是一個關于權重  和偏置
和偏置  的函數,所用梯度下降的目的則是尋找一組
的函數,所用梯度下降的目的則是尋找一組  、
、 使得
使得  最小,因此,調整
最小,因此,調整  本質上是一個調整參數
本質上是一個調整參數  、
、 的過程。在整個調整權重的過程中對于陽性樣本
的過程。在整個調整權重的過程中對于陽性樣本  和陰性樣本
和陰性樣本  的力度是相同的。網絡模型預測結果
的力度是相同的。網絡模型預測結果  越接近真實值
越接近真實值  ,表明模型的預測能力越強,則其對應的損失函數值
,表明模型的預測能力越強,則其對應的損失函數值  越小,否則,損失函數值
越小,否則,損失函數值  越大。
越大。
1.3 改進的交叉熵損失函數
損失函數在神經網絡中可以起到讓預測值逼近真實值的作用,而傳統的損失函數沒有單獨考慮陽性樣本和陰性樣本的代價成本,不能控制其懲罰的方向。因此,提出一種改進的交叉熵損失函數。改進的交叉熵損失函數定義為,
 |
式中  、
、 為正則化系數,原交叉熵損失函數本質上有
為正則化系數,原交叉熵損失函數本質上有  ,為了更好地研究
,為了更好地研究  、
、 對神經網絡預測結果的影響,設置
對神經網絡預測結果的影響,設置  。所涉及的房顫分類問題本質上是一個二分類問題,其真實值只有
。所涉及的房顫分類問題本質上是一個二分類問題,其真實值只有  (即陰性)和
(即陰性)和  (即陽性),則有
(即陽性),則有
 |
結合 sigmoid 激活函數  ,其中
,其中  ,根據鏈式求導法求出
,根據鏈式求導法求出  關于權重
關于權重  和偏置
和偏置  的偏導數:
的偏導數:
 |
 |
考慮到真實值只有  (即陰性)和
(即陰性)和  (即陽性),對兩種情況分開研究,則有,
(即陽性),對兩種情況分開研究,則有,
 |
 |
當樣本為陽性( )時,假設
)時,假設  ,改進損失函數后根據式 (11) 必有
,改進損失函數后根據式 (11) 必有  ,根據式 (14) 隨之有
,根據式 (14) 隨之有  ,
, 沿著梯度的反方向更新
沿著梯度的反方向更新  ,則
,則  的更新幅度隨之增大,參數更新的方向始終朝著使得損失值減小的方向。當樣本為陽性時,損失值小的方向則指向
的更新幅度隨之增大,參數更新的方向始終朝著使得損失值減小的方向。當樣本為陽性時,損失值小的方向則指向  的方向,因此,本方法所改進的損失函數
的方向,因此,本方法所改進的損失函數  ,其參數
,其參數  、
、 的更新可以更大幅度地朝著
的更新可以更大幅度地朝著  的方向進行。
的方向進行。
1.4 評價指標
采用準確率(accuracy,ACC)、靈敏度(sensitivity,SE)、特異度(specificity,SP)、假陽性率(false positive rate,FPR)、假陰性率(false negative rate,FNR)五個指標來評價算法,其計算方式如式 (16)~式 (20) 所示。SE 表示實驗方法正確檢測出房顫的能力,其數值越高表明實驗方法對房顫的正確檢出能力越強。SP 表示實驗方法對非房顫的檢出能力。FPR 又稱誤診率,FPR 越低表明實驗方法的房顫誤診率越低。FNR 又稱漏診率,表示實驗方法漏診房顫的情況。
 |
 |
 |
 |
 |
式中,TP 為真陽性(ture positive),表示將給定房顫正確判別為房顫的數目;FP 為假陽性(false positive),表示將給定其他類型誤判為房顫的數目,即誤診量;TN 為真陰性(ture negative),表示實際為其他類型且被正確檢測為非房顫的數目;FN 為假陰性(false negative),表示實際為房顫卻被漏判為非房顫的數目,即漏診量。
2 實驗及結果分析
2.1 實驗方法
針對房顫篩查,選用簡單的一維卷積神經網絡,由七個卷積層、七個池化層和一個全連接層組成,每個卷積層后面都跟有一個池化層。卷積層的激活函數選用計算更加高效的 Relu 函數[23],全連接層則選用可區分細微特征的 sigmoid 函數,各層的參數如表 2 所示。損失值由公式 (5) 中所提到的  計算。學習率初始值設置為一個較大的值 0.01,并根據每次迭代中的損失值
計算。學習率初始值設置為一個較大的值 0.01,并根據每次迭代中的損失值  進行更改。為了驗證上述基于改進損失函數的房顫自動篩查方法的效果,用隨機抽取的方式選擇 17 085 條不同患者心電記錄作為評估算法效果的訓練集,改變損失函數
進行更改。為了驗證上述基于改進損失函數的房顫自動篩查方法的效果,用隨機抽取的方式選擇 17 085 條不同患者心電記錄作為評估算法效果的訓練集,改變損失函數  的正則化系數
的正則化系數  、
、 ,在固定其他參數的前提下進行對比試驗。為了避免固定迭代次數 epoch 對對比試驗結果的影響,選用較大迭代次數
,在固定其他參數的前提下進行對比試驗。為了避免固定迭代次數 epoch 對對比試驗結果的影響,選用較大迭代次數  ,并設置早停機制,監測訓練準確率的變化,當其 10 次迭代中沒有變化,則提前結束訓練。
,并設置早停機制,監測訓練準確率的變化,當其 10 次迭代中沒有變化,則提前結束訓練。
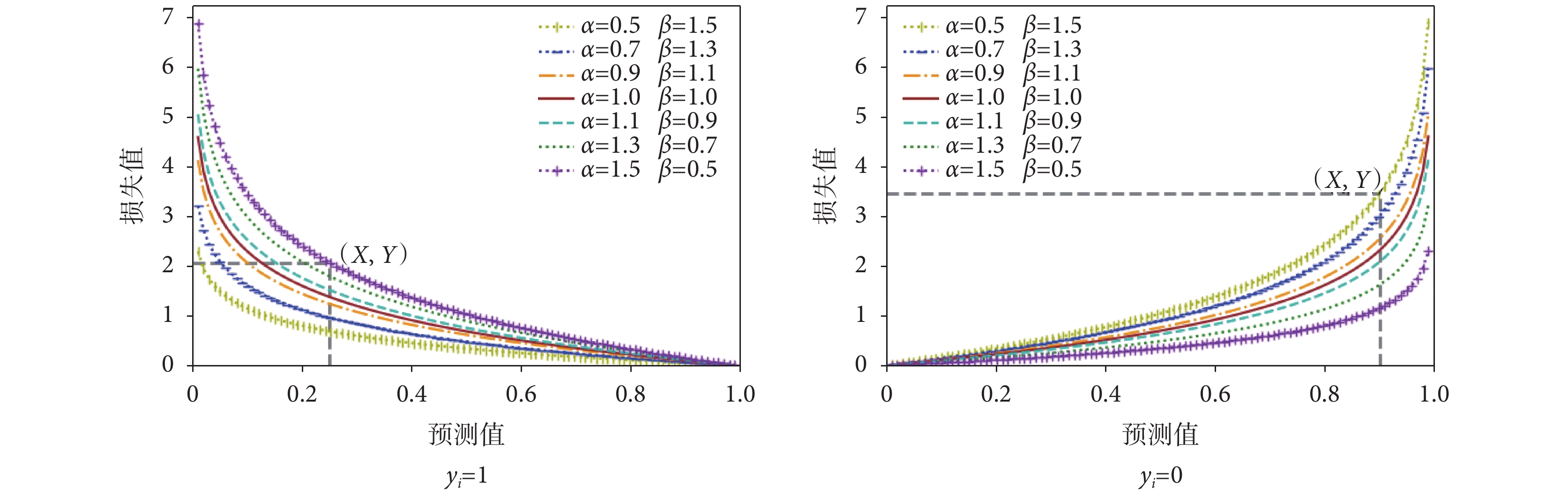
2.2 交叉熵損失函數改進結果
對于改進的交叉熵損失函數,通過設置不同的正則化系數,得到圖 3 關于  、
、 與損失值的關系曲線。假設樣本
與損失值的關系曲線。假設樣本  真實值
真實值  (即樣本為房顫),則有
(即樣本為房顫),則有  。從圖中可以看出,當
。從圖中可以看出,當  時,除兩端點外均有
時,除兩端點外均有  ,反之,則有
,反之,則有  。當
。當  時,隨著
時,隨著  值的增大,損失值
值的增大,損失值  增大,表明其對網絡的懲罰隨之增大,迫使參數的更新傾向于使
增大,表明其對網絡的懲罰隨之增大,迫使參數的更新傾向于使  更接近真實值 1 的方向。假設樣本
更接近真實值 1 的方向。假設樣本  真實值
真實值  (即樣本為非房顫),則有
(即樣本為非房顫),則有 
 。可以發現,當
。可以發現,當  時,除兩端點外均有
時,除兩端點外均有  。當
。當  時,隨著
時,隨著  值的增大,損失值
值的增大,損失值  減小,表明其對網絡的懲罰隨之減小。
減小,表明其對網絡的懲罰隨之減小。
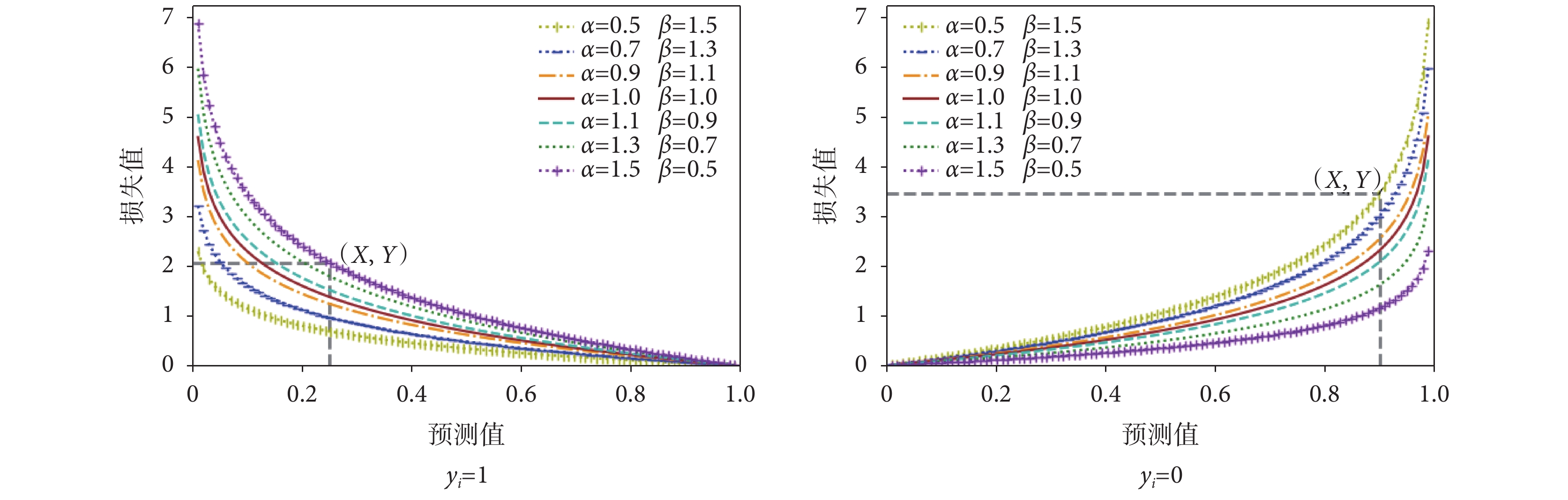 圖3
不同樣本 yi 時不同 α、β 取值的損失曲線
Figure3.
The loss curve of loss function with different α and β values when the sample yi is different
圖3
不同樣本 yi 時不同 α、β 取值的損失曲線
Figure3.
The loss curve of loss function with different α and β values when the sample yi is different
2.3 實驗結果及分析
如何在不犧牲準確率的前提下降低假陰性率以滿足臨床應用是本研究的出發點。提出了一種基于 LFNR-CNN 的房顫智能篩查方法,通過改進損失函數來實現假陰性率的降低,并在包含 21 077 條短心電圖的患者間臨床數據集中驗證所改進損失函數的有效性。表 3 列出了在不同正則化系數  、
、 下,基于 LFNR-CNN 的房顫篩查結果。可以發現,除去
下,基于 LFNR-CNN 的房顫篩查結果。可以發現,除去  和
和  兩端點外,模型的最高 ACC 為 96.62%。當
兩端點外,模型的最高 ACC 為 96.62%。當  時,FNR 最高為 11.99%,當
時,FNR 最高為 11.99%,當  時,FNR 最低達 0.97%,表明本方法降低 FNR 的效果顯著,可以明顯降低房顫漏診的數量。綜合考慮 ACC 和 SE,選擇正則化系數
時,FNR 最低達 0.97%,表明本方法降低 FNR 的效果顯著,可以明顯降低房顫漏診的數量。綜合考慮 ACC 和 SE,選擇正則化系數  ,
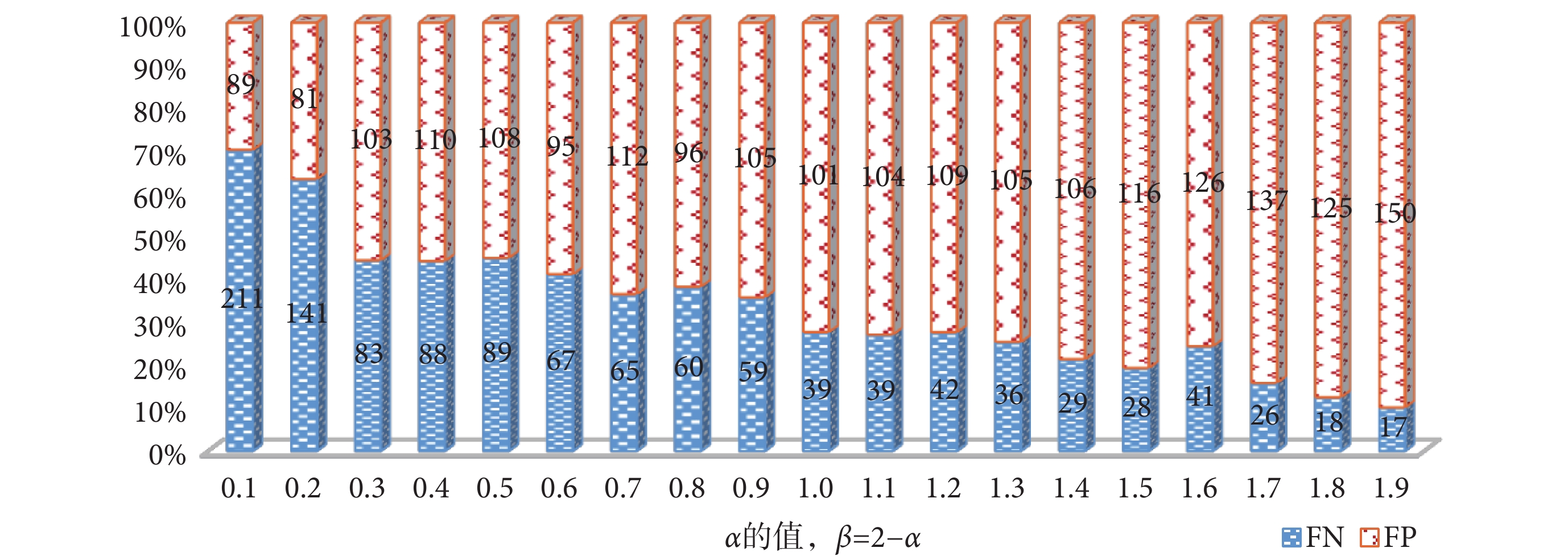
, 。用所選正則化系數優化損失函數后,FNR 由原來的 2.22% 降低至 1.65%,SE 由 97.78% 提升至 98.35%,ACC 為 96.62% 亦較原來的 96.49% 有所提升,SP 為 95.25% 較原來的 95.47% 略有下降,但仍在可接受范圍內。結果表明使用所改進的損失函數可以在兼顧準確率的前提下降低假陰性率。從圖 4 中可發現改進損失函數后 FN 由 39 降低為 29,下降率達 25.64%,為患者的早確診早治療提供了可能性。
。用所選正則化系數優化損失函數后,FNR 由原來的 2.22% 降低至 1.65%,SE 由 97.78% 提升至 98.35%,ACC 為 96.62% 亦較原來的 96.49% 有所提升,SP 為 95.25% 較原來的 95.47% 略有下降,但仍在可接受范圍內。結果表明使用所改進的損失函數可以在兼顧準確率的前提下降低假陰性率。從圖 4 中可發現改進損失函數后 FN 由 39 降低為 29,下降率達 25.64%,為患者的早確診早治療提供了可能性。
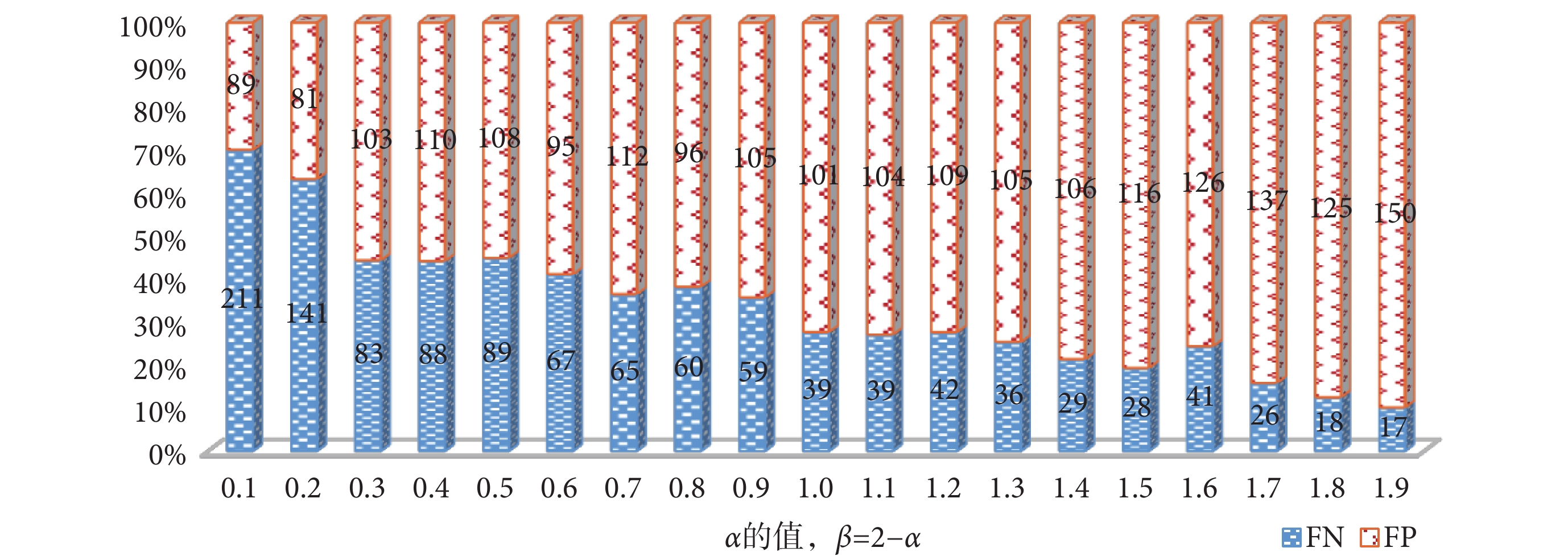 圖4
隨著 α、β 的變化,LFNR-CNN 預測結果中 FN 和 FP 的變化趨勢
Figure4.
The trend of FP and FN in the prediction results of LFNR-CNN with the change of α and β
圖4
隨著 α、β 的變化,LFNR-CNN 預測結果中 FN 和 FP 的變化趨勢
Figure4.
The trend of FP and FN in the prediction results of LFNR-CNN with the change of α and β
在公開數據庫 MIT-BIH Atrial Fibrillation Database(AFDB)中進一步驗證所提方法,分別采用患者內和患者間兩種數據處理形式。從表 4 中可發現,使用改進損失函數后患者內數據集中 FN 由原來的 136 下降為 65,這一現象在患者間數據集中同樣存在。優化損失函數正則化系數后患者間數據集中 SE 由原來的 87.53% 提高至 95.83%,FN 由 1 825 下降至 610,下降率達 66.58%。且兩種數據處理形式下實驗準確率均有所提升,進一步證明了本方法可在兼顧準確率的前提下降低房顫篩查的漏診量。
為了研究 LFNR-CNN 中正則化系數  、
、 變化與其陽性預測能力的關系,在其他參數固定的情況下進行對比試驗,同時也研究了使用原始交叉熵損失函數(
變化與其陽性預測能力的關系,在其他參數固定的情況下進行對比試驗,同時也研究了使用原始交叉熵損失函數( 、
、 時
時  )的實驗結果。從圖 5 中可以發現,就 FNR 而言,隨著
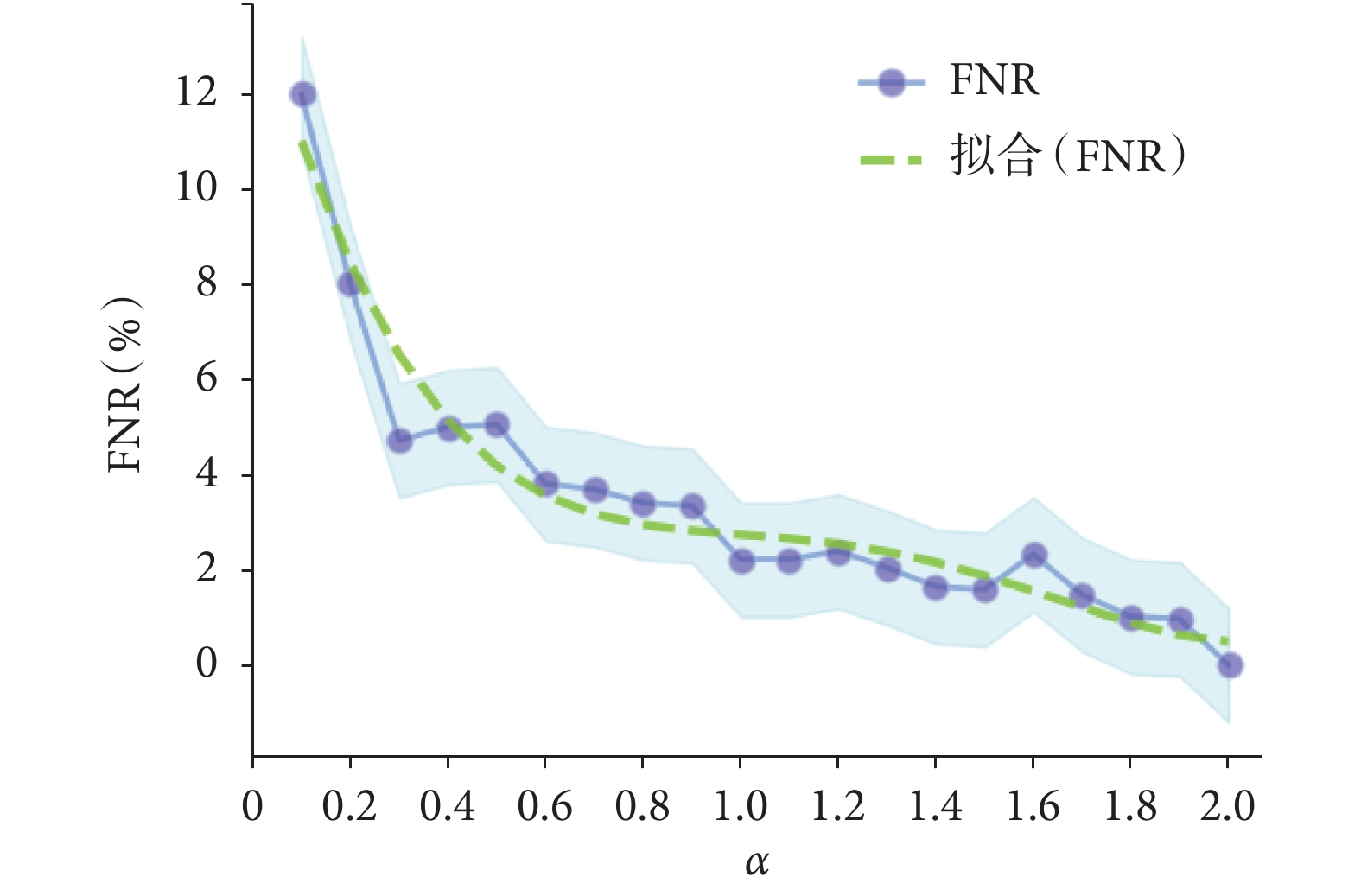
)的實驗結果。從圖 5 中可以發現,就 FNR 而言,隨著  的逐步增大,其大致呈下降趨勢。當
的逐步增大,其大致呈下降趨勢。當  時,均有 LFNR-CNN 的 FNR 大于原始 CNN 的現象;當
時,均有 LFNR-CNN 的 FNR 大于原始 CNN 的現象;當  時,大多數 LFNR-CNN 的 FNR 小于原始 CNN,但是少數點存在異常波動,其可能是由于隨機初始化導致損失函數值落入局部極小值的現象產生。而訓練神經網絡時,通常并不關心精確的全局最小值,只要在求解空間內損失值小到可以接受的范圍即可[24]。FNR 的多項式擬合曲線為
時,大多數 LFNR-CNN 的 FNR 小于原始 CNN,但是少數點存在異常波動,其可能是由于隨機初始化導致損失函數值落入局部極小值的現象產生。而訓練神經網絡時,通常并不關心精確的全局最小值,只要在求解空間內損失值小到可以接受的范圍即可[24]。FNR 的多項式擬合曲線為 
 ,當
,當  時,始終存在 FNR 擬合曲線的一階導數
時,始終存在 FNR 擬合曲線的一階導數 
 ,則表明其呈遞減趨勢,進一步說明隨著
,則表明其呈遞減趨勢,進一步說明隨著  的增大,其 FNR 大致隨之減小。
的增大,其 FNR 大致隨之減小。
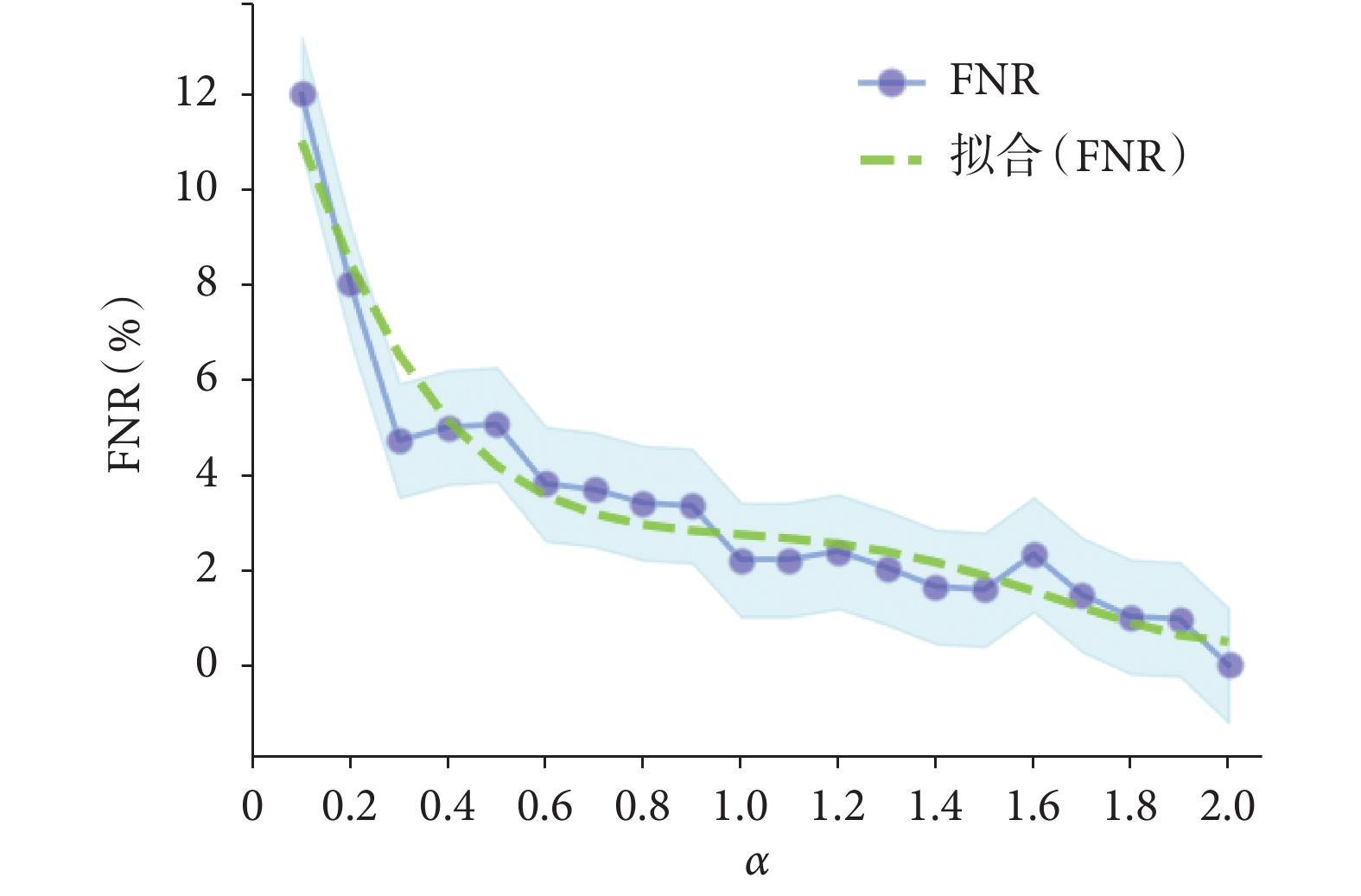 圖5
α、β 變化與 LFNR-CNN 假陰性率的關系
Figure5.
The relationship between the change of α and β and the FNR of LFNR-CNN
圖5
α、β 變化與 LFNR-CNN 假陰性率的關系
Figure5.
The relationship between the change of α and β and the FNR of LFNR-CNN
圖 5 給出了隨著  、
、 的變化,LFNR-CNN 預測結果中 FN 和 FP 的變化趨勢。可以看出,隨著
的變化,LFNR-CNN 預測結果中 FN 和 FP 的變化趨勢。可以看出,隨著  的增大,FN 大致呈下降趨勢,同時隨著
的增大,FN 大致呈下降趨勢,同時隨著  的減小,FP 也同樣大致呈下降趨勢。從對比實驗的結果來看,LFNR-CNN 中增大
的減小,FP 也同樣大致呈下降趨勢。從對比實驗的結果來看,LFNR-CNN 中增大  ,可以迫使參數的更新傾向于使
,可以迫使參數的更新傾向于使  更接近真實值 1 的方向,可獲得較低的假陰性率。反之,減小
更接近真實值 1 的方向,可獲得較低的假陰性率。反之,減小  ,可以迫使參數的更新傾向于使
,可以迫使參數的更新傾向于使  更接近真實值 0 的方向,則可獲得較低的誤診數量。值得注意的是,當
更接近真實值 0 的方向,則可獲得較低的誤診數量。值得注意的是,當  時,會導致部分陰性樣本被誤分為陽性類別,但這種假陽性樣本可以通過后期醫生的進一步檢查得以排查,5% 的假陽性比例在臨床上是可以接受的,醫生可以通過有限的工作量進行核減,而假陰性樣本則會錯過最佳的治療時間,延誤病情。本研究的目的是讓陽性樣本盡可能地被預測為陽性類別,降低漏診的可能性,讓患者及時得到治療。另外,本文所用臨床靜息心電數據其長度固定為 10 s,因此,上述規律均基于 10 s 長度數據進行實驗和總結,后期將進一步研究數據長度對所改進損失函數效果的影響。
時,會導致部分陰性樣本被誤分為陽性類別,但這種假陽性樣本可以通過后期醫生的進一步檢查得以排查,5% 的假陽性比例在臨床上是可以接受的,醫生可以通過有限的工作量進行核減,而假陰性樣本則會錯過最佳的治療時間,延誤病情。本研究的目的是讓陽性樣本盡可能地被預測為陽性類別,降低漏診的可能性,讓患者及時得到治療。另外,本文所用臨床靜息心電數據其長度固定為 10 s,因此,上述規律均基于 10 s 長度數據進行實驗和總結,后期將進一步研究數據長度對所改進損失函數效果的影響。
3 討論
將所提算法性能與其他方法進行對比,如表 5[13-14,25-29]所示。文獻[25]采用融合特征工程和線性支持向量機的方法,花費大量精力提取空窗格比率和由 RR 間隔差值變化網格圖所構造的概率密度分布,而本方法則采用深度學習。可看出本方法所得 ACC、SE 和 SP 均優于文獻[25]在 AFDB 中的表現。本方法所選用的 CNN 網絡其分層數據處理性質可產生高度描述性和信息性的特征,這種端到端模式可以避免人工提取特征的繁瑣,同時降低了研究過程中對于心電圖基礎醫學知識的準入門檻。與同樣采用深度學習的文獻相比,在 AFDB 數據集中采用患者內數據方法的實驗結果亦優于文獻[13-14]、[26-28],但這種患者內數據的實驗對臨床的實際意義有待考究[30]。與患者間實驗相比,在 MIT-BIH 心律不齊數據庫(MIT-BIH arrhythmia database,MITDB)中文獻[29]獲得了高于本方法的 SE,然而相比于 SE(73.24% vs. 68.00%),該文獻所獲得的 ACC(73.21% vs. 90.29%)和 SP(73.02% vs. 92.50%)卻明顯低于本文方法。在 AFDB 數據集中相比于文獻[14],本文方法的 ACC(86.61% vs. 79.55%)、SE(95.82% vs. 89.20%)和 SP(77.03% vs. 74.38%)均有所提升,這進一步證明本方法可實現在不犧牲準確率的前提下提高靈敏度(降低假陰性率)的目標,可為其他疾病的智能篩查提供新的損失函數。值得注意的是,從表 6 中可看出本方法與其他作者所用數據集不同,但本方法所用臨床數據的受試者數量(21 077 例)要遠大于其他作者所用數據集(AFDB 中 23 例,MITDB 中 48 例),且臨床環境中的心電圖來自不同的患者,患者之間存在年齡、性別和并發癥等個體差異。所用數據集中疾病種類(64 種)也明顯大于其他作者所用數據集(AFDB 中含 4 種,MITDB 中含 27 種)。同時可保證用于訓練和測試的心電圖來自不同的受試者,即患者間的分類,因此本研究的實驗更接近臨床環境,對于臨床應用具有更大的參考意義。
4 結論
提出了一種改進的低假陰性率卷積神經網絡,通過改進交叉熵損失函數,添加合理的正則化系數最低可得到 0.97% 的假陰性率。本方法在包含大量受試者的臨床患者間數據集中得到驗證,實驗結果表明,本方法可在保證準確率的同時降低假陰性率,為疾病的早確診早治療提供可能性,同時可為其他疾病的臨床輔助篩查提供具有通用性的損失函數。
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
引言
心房顫動(以下簡稱房顫)是 21 世紀的心血管流行病,目前我國大于 35 歲居民中房顫患病率為 0.71%,且仍處于上升狀態[1-2]。房顫發生時心房失去有效收縮,影響心臟排血功能,一方面易形成附壁血栓脫落后發生動脈栓塞,另一方面心輸出量減少使血壓降低易加重或誘發心絞痛、心力衰竭等[3]。研究表明,房顫引起腦卒中的概率為一般人群的 5 倍,是迫切需要醫學觀察的心血管疾病[4]。通常情況下,房顫的早期階段表現為陣發性和無癥狀性,若不及時終止,可能發展為持續性甚至永久性房顫,增加復律難度[5-6]。因此,準確診斷房顫是阻止房顫進一步發展為其他心臟疾病和腦卒中并發癥的關鍵[7]。
近幾年得益于人工智能技術的發展,針對心電信號的房顫智能篩查,國內外已經出現大量具有指導意義的成果。Andreotti 等[8]使用殘差網絡(residual networks,ResNets)進行房顫檢測,網絡中的剩余連接有助于解決梯度消失的問題,從而可以訓練更深的網絡。Xiong 等[9]提出了一個 16 層一維卷積神經網絡(1D convolutional neural network,1-D CNN),通過跳過連接來提高整個網絡的信息傳輸速率。Fan 等[10]提出了一種多尺度融合的深卷積神經網絡(multi-scaled fusion of deep convolutional neural networks,MS-CNN),采用兩條具有不同尺寸過濾器的卷積網絡結構來捕獲不同規模的特征。Andersen 等[11]提出結合 CNN 和遞歸神經網絡(convolutional- and recurrent-neural networks,CNN-RNN)的方法,采用端到端模型,以從 RR 間隔(RR intervals,RRIs)的片段中提取高級特征。Shi 等[12]提出了由 CNN 和長短期記憶(long short-term memory,LSTM)網絡組成多輸入深度神經網絡(multiple-input deep neural network,MIDNN),并通過主動學習(active learning,AL)和遷移學習(transfer learning,TL)相結合來選擇樣本和更新模型。Jin 等[13]提出了一種多域雙注意力卷積長短期記憶神經網絡(twin-attentional convolutional long short-term memory neural network,TAC-LSTM)方法,結合了時域和頻域特征并采用注意機制提高了模型的可解釋性。Mousavi 等[14]提出了一種分層注意網絡,使用波形、心跳和窗口三個注意機制級別來對導致 AF 的心電圖(electrocardiogram,ECG)模式進行多分辨率分析。目前大部分基于深度學習的房顫智能篩查的研究著重于提出可以更好地處理分類任務的強大架構,但是卻采用通用的模型框架和損失函數,無差別對待陽性和陰性樣本的代價成本,無法滿足單純追求低假陰性率的需求。然而,臨床上往往希望算法能夠盡量降低假陰性率,減少漏診量以避免耽誤最佳治療時期。
為此,本文研究了基于 CNN 的心電信號房顫判別算法。為了降低假陰性率,對交叉熵函數進行了改進:通過在原有交叉熵損失函數中引入正則化系數,使其懲罰方向可控,通過合理設置參數,可使 CNN 在訓練時加大對假陰性的懲罰。
1 方法
采用深度學習的方法進行房顫檢測,檢測流程如圖 1 所示,將預處理后的心電信號作為對比試驗的數據,選出所改進損失函數理想的正則化系數,最后基于改進的低假陰性率卷積神經網絡(convolutional neural network with low false-negative rate,LFNR-CNN)對房顫進行篩查。
圖1
基于 LFNR-CNN 的房顫診斷算法流程圖
Figure1.
Flow chart of atrial fibrillation diagnosis algorithm based on LFNR-CNN
1.1 數據集和預處理
本方法所用房顫篩查數據集由上海數創醫療科技有限公司采集的三甲醫院臨床數據組成,其中 17 085 條數據作為訓練集,3 992 條數據作為測試集,如表 1 所示。數據集為醫院實地采集的門診和住院患者短心電記錄,已進行數據脫敏且得到合作單位的數據使用授權。本方法均選取Ⅱ型導聯的心電記錄作為數值實驗數據,采樣頻率為 500 Hz,持續時間為 10 s。數據集中有效心臟疾病標簽種類為 64 個,其中只含單個標簽的記錄占 17.8%,大部分心電記錄包含多個疾病標簽,單條記錄中最高標簽數量達 7 個。目前很多大型醫院都設有房顫中心,在房顫中心應用的算法更關注哪些是房顫患者,因此本文是對房顫的單獨篩檢,只分為房顫和非房顫兩類。同一樣本出現多標簽的情況下若其中包含房顫則判定為房顫,否則判為非房顫。心電信號是一種微弱的體表生物電信號,且極易受環境干擾[15-16]。ST 段頻帶(0.7~2 Hz)與基線漂移(0.05~1.5 Hz)有部分重疊,因此選擇小波變換去除基線漂移[17]。
1.2 卷積神經網絡
CNN 有著從輸入數據中提取良好特征的巨大潛力,可以避免人工提取特征的過程中由于缺乏基礎心電知識而導致的特征質量低和冗余的問題[18]。CNN 通常由特征提取器和完全連接的多層感知器(multilayer perceptron,MLP)兩部分組成,特征提取器部分包括卷積層和池化層[19]。對于房顫檢測這個二分類問題,全連接層選用簡單的 sigmoid 分類器。本方法所用網絡結構如圖 2 所示。首先進行前向傳播,計算層與層之間的特征圖。一旦前向傳播獲得了預測輸出 ,則使用損失函數來計算預測誤差。然后執行反向傳播,預測誤差逐層在每個參數上反向傳播,并且通過所計算的權重梯度來調整權重[20]。重復執行向前和向后傳播,直到達到特定數量的迭代或滿足其他任何停止標準為止。
圖2
卷積神經網絡結構
Figure2.
The structure of the CNN
房顫篩查本質上是互相排斥的二分類問題,因此選用交叉熵損失函數來對正負樣本分類計算各自的損失。傳統的交叉熵損失函數[21]定義為:
|
式中, 表示損失值大小, 為樣本個數, 為樣本 對應的真實值, 為當前的網絡模型以樣本 為輸入計算所得的輸出值。選用 sigmoid 激活函數配合交叉熵損失函數[22],則
|
式中, 為激活前的輸出值,化簡后有
|
式中, 為樣本 對應的真實值, 為最后一個全連接層的輸出矩陣, 為最后一個全連接層的權重矩陣, 為最后一個全連接層的偏置,根據鏈式求導法則求得 關于權重 和偏置 的偏導數:
|
|
式中, 為當前卷積層的索引, 為學習率。求得的偏導數則為網絡中參數的變化率,根據式(8)和式(9)一步步地反向更新參數 和 ,更新過程為:
|
|
從式(5)可發現, 本質上是一個關于權重 和偏置 的函數,所用梯度下降的目的則是尋找一組 、 使得 最小,因此,調整 本質上是一個調整參數 、 的過程。在整個調整權重的過程中對于陽性樣本 和陰性樣本 的力度是相同的。網絡模型預測結果 越接近真實值 ,表明模型的預測能力越強,則其對應的損失函數值 越小,否則,損失函數值 越大。
1.3 改進的交叉熵損失函數
損失函數在神經網絡中可以起到讓預測值逼近真實值的作用,而傳統的損失函數沒有單獨考慮陽性樣本和陰性樣本的代價成本,不能控制其懲罰的方向。因此,提出一種改進的交叉熵損失函數。改進的交叉熵損失函數定義為,
|
式中 、 為正則化系數,原交叉熵損失函數本質上有 ,為了更好地研究 、 對神經網絡預測結果的影響,設置 。所涉及的房顫分類問題本質上是一個二分類問題,其真實值只有 (即陰性)和 (即陽性),則有
|
結合 sigmoid 激活函數 ,其中 ,根據鏈式求導法求出 關于權重 和偏置 的偏導數:
|
|
考慮到真實值只有 (即陰性)和 (即陽性),對兩種情況分開研究,則有,
|
|
當樣本為陽性()時,假設 ,改進損失函數后根據式 (11) 必有 ,根據式 (14) 隨之有 , 沿著梯度的反方向更新 ,則 的更新幅度隨之增大,參數更新的方向始終朝著使得損失值減小的方向。當樣本為陽性時,損失值小的方向則指向 的方向,因此,本方法所改進的損失函數 ,其參數 、 的更新可以更大幅度地朝著 的方向進行。
1.4 評價指標
采用準確率(accuracy,ACC)、靈敏度(sensitivity,SE)、特異度(specificity,SP)、假陽性率(false positive rate,FPR)、假陰性率(false negative rate,FNR)五個指標來評價算法,其計算方式如式 (16)~式 (20) 所示。SE 表示實驗方法正確檢測出房顫的能力,其數值越高表明實驗方法對房顫的正確檢出能力越強。SP 表示實驗方法對非房顫的檢出能力。FPR 又稱誤診率,FPR 越低表明實驗方法的房顫誤診率越低。FNR 又稱漏診率,表示實驗方法漏診房顫的情況。
|
|
|
|
|
式中,TP 為真陽性(ture positive),表示將給定房顫正確判別為房顫的數目;FP 為假陽性(false positive),表示將給定其他類型誤判為房顫的數目,即誤診量;TN 為真陰性(ture negative),表示實際為其他類型且被正確檢測為非房顫的數目;FN 為假陰性(false negative),表示實際為房顫卻被漏判為非房顫的數目,即漏診量。
2 實驗及結果分析
2.1 實驗方法
針對房顫篩查,選用簡單的一維卷積神經網絡,由七個卷積層、七個池化層和一個全連接層組成,每個卷積層后面都跟有一個池化層。卷積層的激活函數選用計算更加高效的 Relu 函數[23],全連接層則選用可區分細微特征的 sigmoid 函數,各層的參數如表 2 所示。損失值由公式 (5) 中所提到的 計算。學習率初始值設置為一個較大的值 0.01,并根據每次迭代中的損失值 進行更改。為了驗證上述基于改進損失函數的房顫自動篩查方法的效果,用隨機抽取的方式選擇 17 085 條不同患者心電記錄作為評估算法效果的訓練集,改變損失函數 的正則化系數 、,在固定其他參數的前提下進行對比試驗。為了避免固定迭代次數 epoch 對對比試驗結果的影響,選用較大迭代次數 ,并設置早停機制,監測訓練準確率的變化,當其 10 次迭代中沒有變化,則提前結束訓練。
2.2 交叉熵損失函數改進結果
對于改進的交叉熵損失函數,通過設置不同的正則化系數,得到圖 3 關于 、 與損失值的關系曲線。假設樣本 真實值 (即樣本為房顫),則有 。從圖中可以看出,當 時,除兩端點外均有 ,反之,則有 。當 時,隨著 值的增大,損失值 增大,表明其對網絡的懲罰隨之增大,迫使參數的更新傾向于使 更接近真實值 1 的方向。假設樣本 真實值 (即樣本為非房顫),則有 。可以發現,當 時,除兩端點外均有 。當 時,隨著 值的增大,損失值 減小,表明其對網絡的懲罰隨之減小。
圖3
不同樣本 yi 時不同 α、β 取值的損失曲線
Figure3.
The loss curve of loss function with different α and β values when the sample yi is different
2.3 實驗結果及分析
如何在不犧牲準確率的前提下降低假陰性率以滿足臨床應用是本研究的出發點。提出了一種基于 LFNR-CNN 的房顫智能篩查方法,通過改進損失函數來實現假陰性率的降低,并在包含 21 077 條短心電圖的患者間臨床數據集中驗證所改進損失函數的有效性。表 3 列出了在不同正則化系數 、 下,基于 LFNR-CNN 的房顫篩查結果。可以發現,除去 和 兩端點外,模型的最高 ACC 為 96.62%。當 時,FNR 最高為 11.99%,當 時,FNR 最低達 0.97%,表明本方法降低 FNR 的效果顯著,可以明顯降低房顫漏診的數量。綜合考慮 ACC 和 SE,選擇正則化系數 ,。用所選正則化系數優化損失函數后,FNR 由原來的 2.22% 降低至 1.65%,SE 由 97.78% 提升至 98.35%,ACC 為 96.62% 亦較原來的 96.49% 有所提升,SP 為 95.25% 較原來的 95.47% 略有下降,但仍在可接受范圍內。結果表明使用所改進的損失函數可以在兼顧準確率的前提下降低假陰性率。從圖 4 中可發現改進損失函數后 FN 由 39 降低為 29,下降率達 25.64%,為患者的早確診早治療提供了可能性。
圖4
隨著 α、β 的變化,LFNR-CNN 預測結果中 FN 和 FP 的變化趨勢
Figure4.
The trend of FP and FN in the prediction results of LFNR-CNN with the change of α and β
在公開數據庫 MIT-BIH Atrial Fibrillation Database(AFDB)中進一步驗證所提方法,分別采用患者內和患者間兩種數據處理形式。從表 4 中可發現,使用改進損失函數后患者內數據集中 FN 由原來的 136 下降為 65,這一現象在患者間數據集中同樣存在。優化損失函數正則化系數后患者間數據集中 SE 由原來的 87.53% 提高至 95.83%,FN 由 1 825 下降至 610,下降率達 66.58%。且兩種數據處理形式下實驗準確率均有所提升,進一步證明了本方法可在兼顧準確率的前提下降低房顫篩查的漏診量。
為了研究 LFNR-CNN 中正則化系數 、 變化與其陽性預測能力的關系,在其他參數固定的情況下進行對比試驗,同時也研究了使用原始交叉熵損失函數(、 時 )的實驗結果。從圖 5 中可以發現,就 FNR 而言,隨著 的逐步增大,其大致呈下降趨勢。當 時,均有 LFNR-CNN 的 FNR 大于原始 CNN 的現象;當 時,大多數 LFNR-CNN 的 FNR 小于原始 CNN,但是少數點存在異常波動,其可能是由于隨機初始化導致損失函數值落入局部極小值的現象產生。而訓練神經網絡時,通常并不關心精確的全局最小值,只要在求解空間內損失值小到可以接受的范圍即可[24]。FNR 的多項式擬合曲線為 ,當 時,始終存在 FNR 擬合曲線的一階導數 ,則表明其呈遞減趨勢,進一步說明隨著 的增大,其 FNR 大致隨之減小。
圖5
α、β 變化與 LFNR-CNN 假陰性率的關系
Figure5.
The relationship between the change of α and β and the FNR of LFNR-CNN
圖 5 給出了隨著 、 的變化,LFNR-CNN 預測結果中 FN 和 FP 的變化趨勢。可以看出,隨著 的增大,FN 大致呈下降趨勢,同時隨著 的減小,FP 也同樣大致呈下降趨勢。從對比實驗的結果來看,LFNR-CNN 中增大 ,可以迫使參數的更新傾向于使 更接近真實值 1 的方向,可獲得較低的假陰性率。反之,減小 ,可以迫使參數的更新傾向于使 更接近真實值 0 的方向,則可獲得較低的誤診數量。值得注意的是,當 時,會導致部分陰性樣本被誤分為陽性類別,但這種假陽性樣本可以通過后期醫生的進一步檢查得以排查,5% 的假陽性比例在臨床上是可以接受的,醫生可以通過有限的工作量進行核減,而假陰性樣本則會錯過最佳的治療時間,延誤病情。本研究的目的是讓陽性樣本盡可能地被預測為陽性類別,降低漏診的可能性,讓患者及時得到治療。另外,本文所用臨床靜息心電數據其長度固定為 10 s,因此,上述規律均基于 10 s 長度數據進行實驗和總結,后期將進一步研究數據長度對所改進損失函數效果的影響。
3 討論
將所提算法性能與其他方法進行對比,如表 5[13-14,25-29]所示。文獻[25]采用融合特征工程和線性支持向量機的方法,花費大量精力提取空窗格比率和由 RR 間隔差值變化網格圖所構造的概率密度分布,而本方法則采用深度學習。可看出本方法所得 ACC、SE 和 SP 均優于文獻[25]在 AFDB 中的表現。本方法所選用的 CNN 網絡其分層數據處理性質可產生高度描述性和信息性的特征,這種端到端模式可以避免人工提取特征的繁瑣,同時降低了研究過程中對于心電圖基礎醫學知識的準入門檻。與同樣采用深度學習的文獻相比,在 AFDB 數據集中采用患者內數據方法的實驗結果亦優于文獻[13-14]、[26-28],但這種患者內數據的實驗對臨床的實際意義有待考究[30]。與患者間實驗相比,在 MIT-BIH 心律不齊數據庫(MIT-BIH arrhythmia database,MITDB)中文獻[29]獲得了高于本方法的 SE,然而相比于 SE(73.24% vs. 68.00%),該文獻所獲得的 ACC(73.21% vs. 90.29%)和 SP(73.02% vs. 92.50%)卻明顯低于本文方法。在 AFDB 數據集中相比于文獻[14],本文方法的 ACC(86.61% vs. 79.55%)、SE(95.82% vs. 89.20%)和 SP(77.03% vs. 74.38%)均有所提升,這進一步證明本方法可實現在不犧牲準確率的前提下提高靈敏度(降低假陰性率)的目標,可為其他疾病的智能篩查提供新的損失函數。值得注意的是,從表 6 中可看出本方法與其他作者所用數據集不同,但本方法所用臨床數據的受試者數量(21 077 例)要遠大于其他作者所用數據集(AFDB 中 23 例,MITDB 中 48 例),且臨床環境中的心電圖來自不同的患者,患者之間存在年齡、性別和并發癥等個體差異。所用數據集中疾病種類(64 種)也明顯大于其他作者所用數據集(AFDB 中含 4 種,MITDB 中含 27 種)。同時可保證用于訓練和測試的心電圖來自不同的受試者,即患者間的分類,因此本研究的實驗更接近臨床環境,對于臨床應用具有更大的參考意義。
4 結論
提出了一種改進的低假陰性率卷積神經網絡,通過改進交叉熵損失函數,添加合理的正則化系數最低可得到 0.97% 的假陰性率。本方法在包含大量受試者的臨床患者間數據集中得到驗證,實驗結果表明,本方法可在保證準確率的同時降低假陰性率,為疾病的早確診早治療提供可能性,同時可為其他疾病的臨床輔助篩查提供具有通用性的損失函數。
利益沖突聲明:本文全體作者均聲明不存在利益沖突。