白血病是一種常見多發且較為兇險的血液疾病,其早期發現與治療至關重要。目前白血病類型的診斷主要依靠病理醫師對血細胞圖像進行形態學檢查,該過程枯燥、費時,且診斷結果有較強的主觀性,易發生誤診與漏診。針對上述問題,本文提出了一種基于改進Vision Transformer的血細胞圖像識別方法。首先,使用快速區域卷積神經網絡從圖像中定位并裁剪出單個血細胞圖像切片。然后,將單細胞圖像劃分為多個圖像塊并輸入到編碼層中進行特征提取。本文基于Transformer的自注意機制提出了稀疏注意力模塊,該模塊能夠篩選出圖像中的辨識性區域,進一步提升模型的細粒度特征表達能力。最后,本文采用對比損失函數,進一步增加分類特征的類內一致性與類間差異性。實驗結果表明,本文模型在慕尼黑血細胞形態學數據集上的識別準確率為91.96%,有望為醫師臨床診斷提供參考依據。
引用本文: 孫天宇, 朱慶濤, 楊健, 曾亮. 基于改進Vision Transformer的血細胞圖像識別方法研究. 生物醫學工程學雜志, 2022, 39(6): 1097-1107. doi: 10.7507/1001-5515.202203008 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
引言
白血病[1]是一種人體造血系統的惡性腫瘤,在所有惡性腫瘤中占比約5%,是我國重點防治的十大惡性腫瘤之一。白血病可導致外周血中血細胞的形態與數量出現異常,患者臨床表現為貧血、出血、發熱、乏力等。白血病的致死率較高,其早期發現與治療對延長患者生存時間、改善患者生活質量至關重要[2]。血細胞形態學檢查是白血病診斷常規檢查的一部分[3],通常由訓練有素的醫師對顯微設備采集的血細胞圖像進行觀察,統計不同類型的血細胞數量,然后,根據FAB分類標準[4]對白血病類型進行初步診斷。但是該方法也存在不足,人工分類計數繁瑣費時,診斷結果具有較強的主觀性。此外,細胞形態學人才資源緊缺,培養精通細胞病理診斷的醫師要耗費大量的時間。因此,研究血細胞自動化識別技術來輔助臨床診斷,可以實現診斷流程的標準化、快速化與智能化,將醫生從繁重的病理工作中解放出來,具有重要的臨床意義和廣闊的應用前景。
近年來,基于深度學習的方法在醫學影像處理領域取得了巨大的成功[5-6]。國內外學者紛紛開始探索基于深度學習的血細胞識別方法,研究領域包括了血細胞圖像檢測[7-12]、分類[13-19]、語義分割[20-22]等。血細胞檢測任務是從圖像中定位血細胞并分類。檢測方法根據是否生成候選區域分為兩個流派,一類是基于候選區域的雙階段檢測算法,即先從圖像中定位包含血細胞的區域,再對區域進行坐標回歸與分類;另一類是單階段檢測算法,其將圖像劃分為多個網格并對每個網格預測邊界框和類別。在雙階段檢測方面,Dhieb等[7]使用掩膜區域卷積神經網絡(mask region-based convolutional neural network,Mask R-CNN)對紅細胞與白細胞進行檢測,模型以Resnet-101網絡作為主干,并使用FPN網絡提取多尺度特征來檢測不同大小的細胞,該方法對紅細胞與白細胞識別準確率分別為92%與96%。Tobias等[8]基于快速區域卷積神經網絡對紅細胞與白細胞進行識別,對紅細胞、白細胞的識別準確率分別為98%、99%。在單階段檢測方面,Shakarami等[9]基于YOLOv3(you look only once v3)單階段目標檢測網絡提出了快速高效的YOLOv3檢測模型(Fast and Efficient YOLOv3 Detector,FED),該模型以Efficientnet作為主干網絡并在三個尺度上對血細胞進行檢測,該方法在BCCD數據集上對血小板、紅細胞、白細胞的平均識別準確率分別為90.25%、80.41%、98.92%。在血細胞圖像分類領域,學者們也進行了廣泛的研究。Matek等[13]開源了一個包含15類總計18 375張圖像的血細胞數據集,接著采用ResNext模型進行分類,網絡對于常見的血細胞如中性粒細胞、淋巴細胞、單核細胞的識別準確率達到了94%。Fu等[14]基于陸軍軍醫大學第二附屬醫院收集的65 986幅骨髓血細胞圖像開發了一個完整的自動化檢測識別系統morphogo,該研究使用了27層的卷積神經網絡,對12類骨髓血細胞的平均分類準確率為85.7%。Huang等[15]首先基于RetinaNet檢測網絡得到單個血細胞的切片圖像,接著將自適應注意力模塊引入到卷積神經網絡中,該模塊增強了與分類任務相關區域特征的權重,提升了模型的特征表達能力,模型對六類白細胞的平均分類準確率為95.3%。Mori等[16]按細胞質顆粒減少的程度將血細胞劃分為四類,然后使用Resnet-152網絡進行分類,平均靈敏度與特異性分別為85.2%、98.9%。
雖然上述研究在血細胞識別方面取得了長足的進步,但大多基于通用的目標檢測、分類網絡,并未針對血細胞的特性進行改進。此外,很多研究只關注了血細胞大類,未關注其中的子類別如粒細胞的原始、早幼、中幼與晚幼等階段,血細胞子類之間差異較小使得其自動化識別更具挑戰性。最近,Vision Transformer[23]在視覺分類任務中效果良好,這表明Transformer[24]的自注意機制可以捕獲圖像塊序列中的重要部分,使得模型具有更強的局部與全局特征表達能力。因此,本文結合血細胞特性對血細胞細粒度分類進行研究,提出了一種基于改進Vision Transformer的血細胞識別方法。首先,使用快速區域卷積神經網絡[25]從圖像中檢測出細胞邊界并進行裁剪,去除背景等干擾。接著,本文提出一種重疊圖像塊劃分方法將裁剪后的圖像分割為多個圖像塊并嵌入,然后嵌入向量經過多個編碼層進行特征提取。本文基于多頭自注意機制[24]提出了稀疏注意力模塊,該模塊可以捕捉血細胞圖像中的辨識性區域,并將篩選后的特征輸入到編碼層。最后,網絡輸出的分類特征用于細胞識別。在訓練過程中,本文采用對比損失[25]進一步增加分類特征的類內一致性與類間差異性。本文相關代碼與數據已在GitHub開源:
1 數據集與預處理
1.1 ?數據集
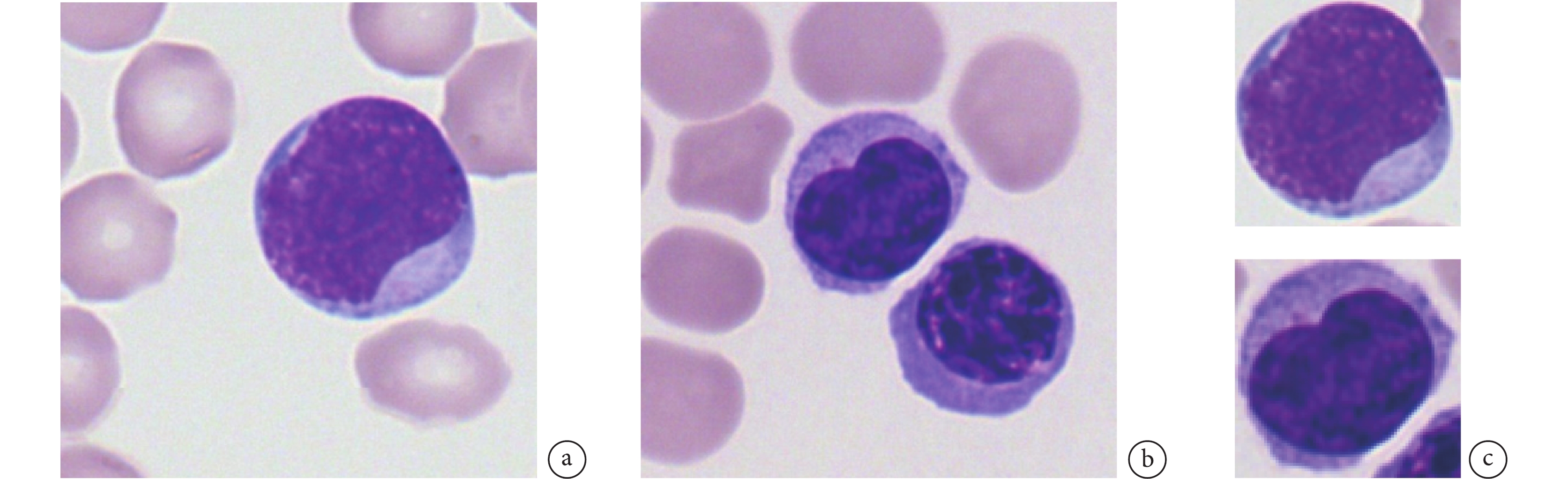
本文采用了The Cancer Imaging Archive平臺上開源的慕尼黑血細胞形態學數據集(The Munich AML Morphology Dataset,TMAMD)[26]。該數據來自慕尼黑醫院2014年至2017年間100位被診斷為急性白血病的患者與100位無血液惡性腫瘤的患者。該數據集包含了15類由專家標記的18 635張單細胞圖像。如圖1a所示,圖像背景中有較多的成熟紅細胞,這類細胞沒有細胞核,不屬于本次分類所關注的類別。有的圖像中包含多個細胞,如圖1b所示。上述因素會導致網絡分類性能下降,因此我們對原圖像進行血細胞邊界框檢測并裁剪,處理后的單張血細胞圖像如圖1c所示。
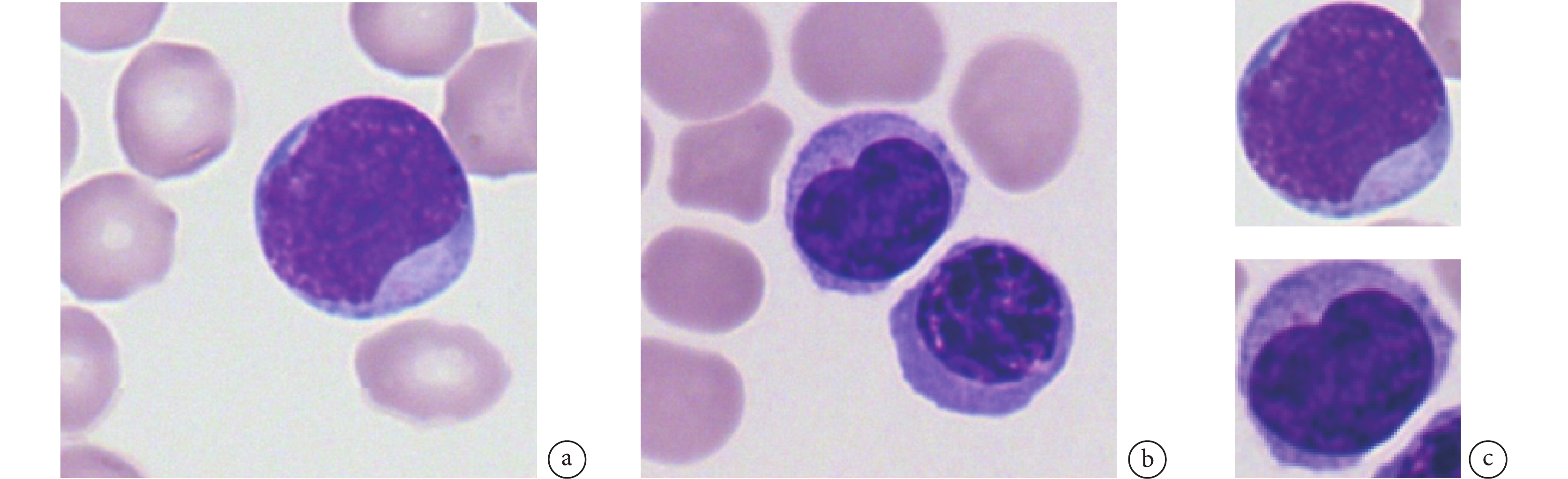 圖1
血細胞形態學數據集圖像
圖1
血細胞形態學數據集圖像
a. 單個血細胞圖像;b. 包含兩個血細胞的圖像;c. 裁剪后圖像
Figure1. The images of The Munich AML Morphology Dataseta. single cell images; b. image containing two blood cells; c. cropped cell images
1.2 數據預處理
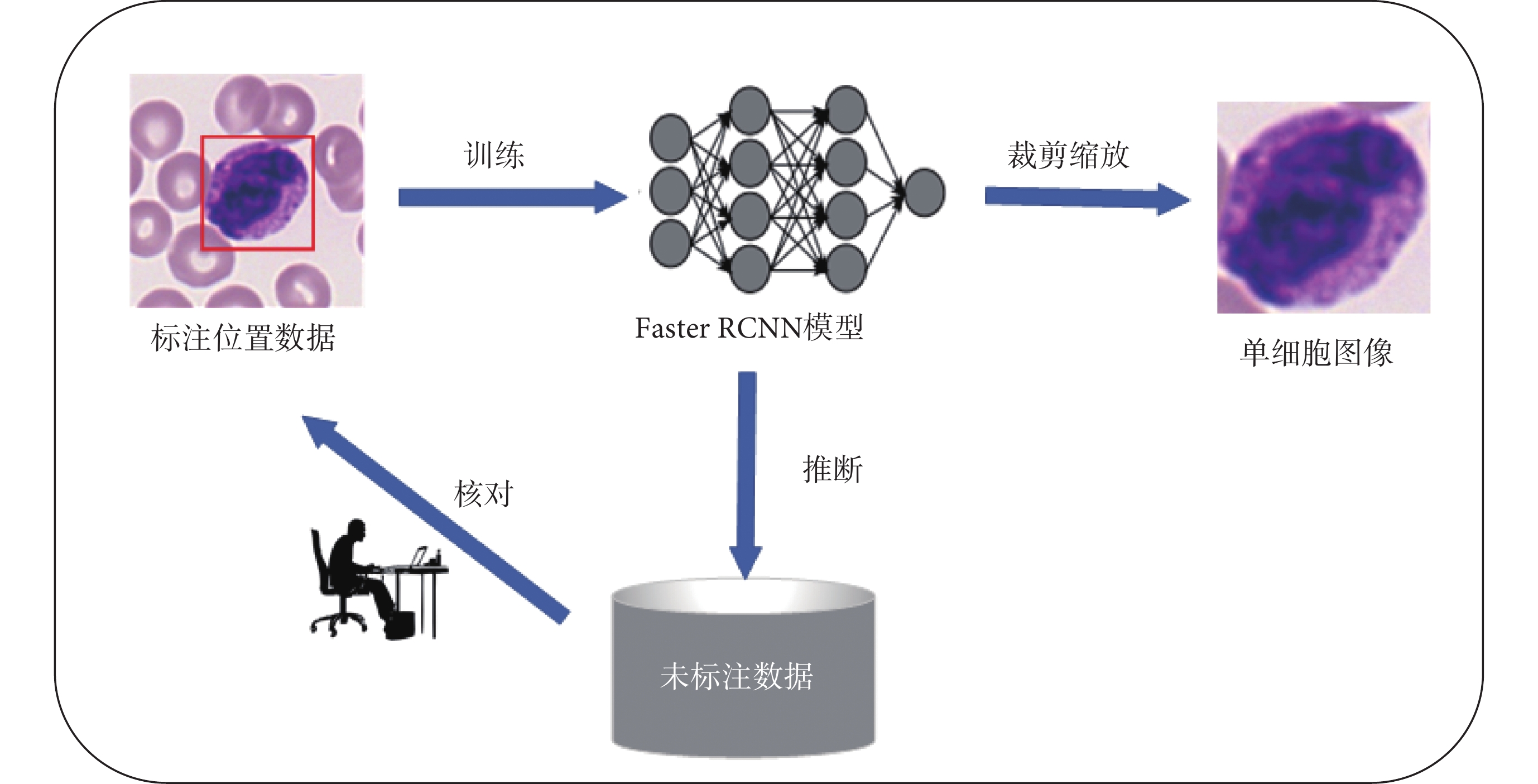
TMAMD數據集不包含血細胞的坐標標注信息,因此需要人工標注血細胞的邊界并進行裁剪。因為數據集較大,本文采用快速區域卷積神經網絡[27]結合主動學習[10,28]方法完成血細胞邊界框信息的標注。首先,使用標注軟件Labelme人工標注小部分血細胞邊界框。隨后,將Labelme軟件的json標注格式轉換為MS COCO格式。然后,使用部分標注的數據對預訓練的快速區域卷積模型進行微調,得到初步的血細胞檢測網絡。接著,使用該模型對未標注的數據進行推理,將檢測結果反饋到標注軟件中進行人工核對,從而降低標注工作量。最后使用更新后數據重新訓練檢測模型,在數據集較大或有新增數據的情況下,經過幾次模型的迭代與人工核查,即可完成所有數據的標注。最終,單個血細胞圖像從原圖像中剪切出來。整個流程如圖2所示。
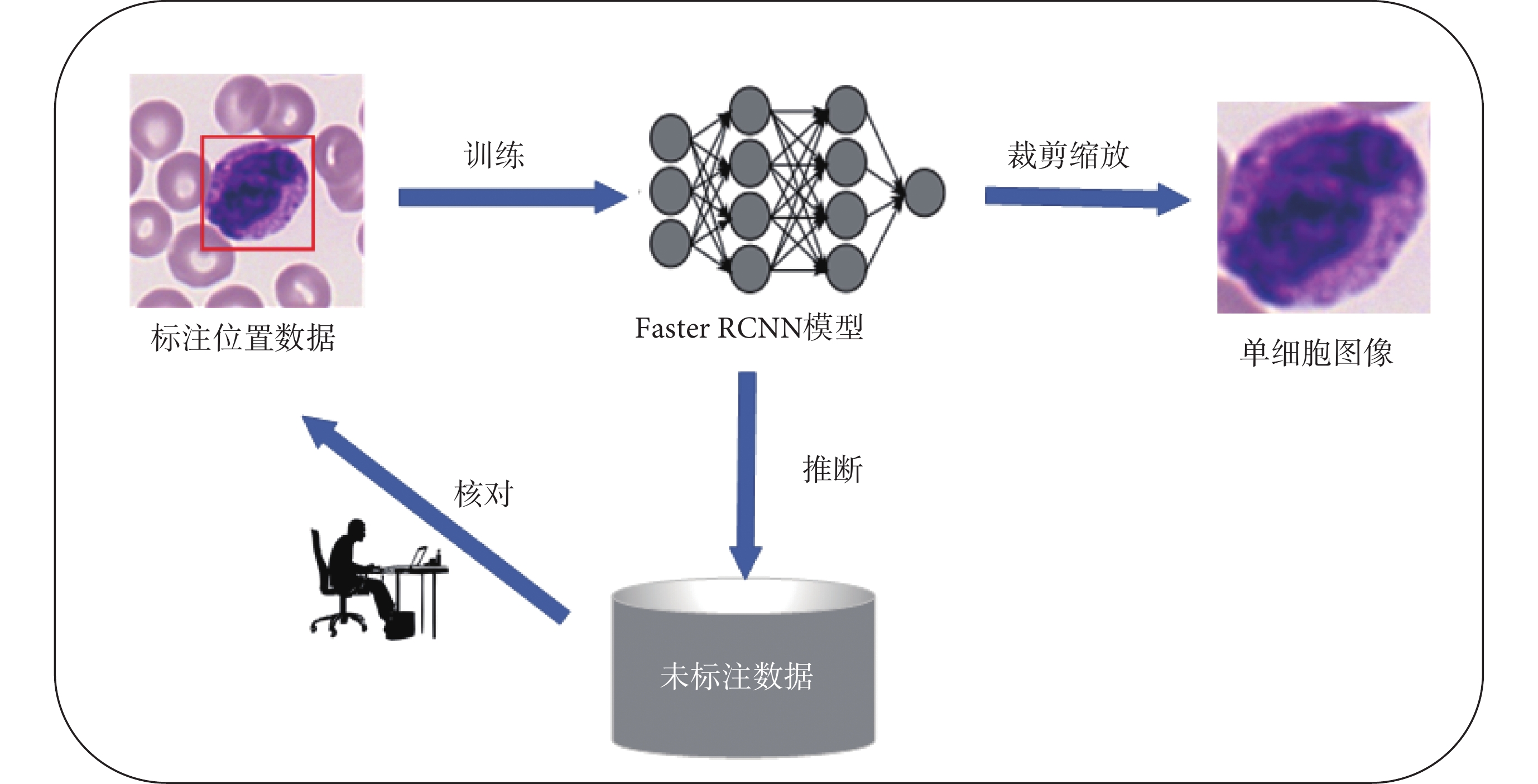 圖2
血細胞數據集標注與預處理流程
Figure2.
The annotation and processing flow of blood cell dataset
圖2
血細胞數據集標注與預處理流程
Figure2.
The annotation and processing flow of blood cell dataset
盡管原數據集包含15類血細胞,但是存在較嚴重的類別不平衡問題,部分類別的數量小于30,使得網絡難以有效地進行特征學習。本文只關注了樣本數量大于30的十個類別。在這十個類別中,對于數量較多的類別采用隨機欠采樣減少樣本數量,對于數量較少的類別,采用水平、垂直翻轉與旋轉90 、180
、180 的方式進行數據擴充,表1為原數據集的分布情況與數據增強[29]后的樣本分布情況。
的方式進行數據擴充,表1為原數據集的分布情況與數據增強[29]后的樣本分布情況。
2 方法
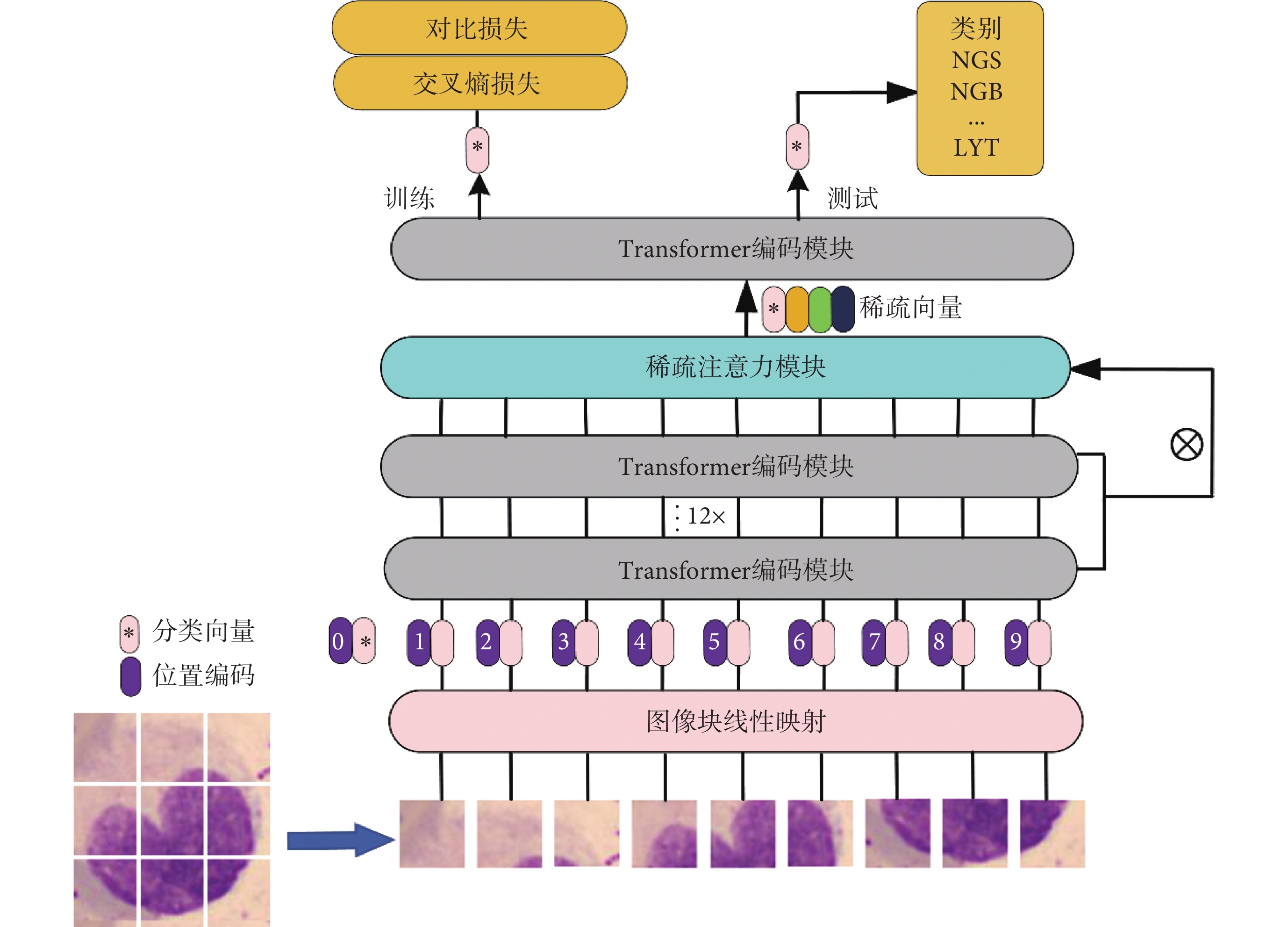
圖3為本文提出的基于Vision Transformer的血細胞識別網絡框架。首先將輸入的血細胞圖像分割為N個P × P 大小的圖像塊,接著將圖像塊線性映射為序列化嵌入向量,其次加入可學習的分類向量與位置編碼信息。然后嵌入向量被輸入到多個堆疊的編碼模塊中進行特征提取。在最后一層編碼模塊前,使用稀疏注意力模塊來尋找圖像中的區分性像素塊并將它對應的隱含特征作為輸入。最后編碼器輸出的分類特征經過全連接層得到血細胞的類別信息。
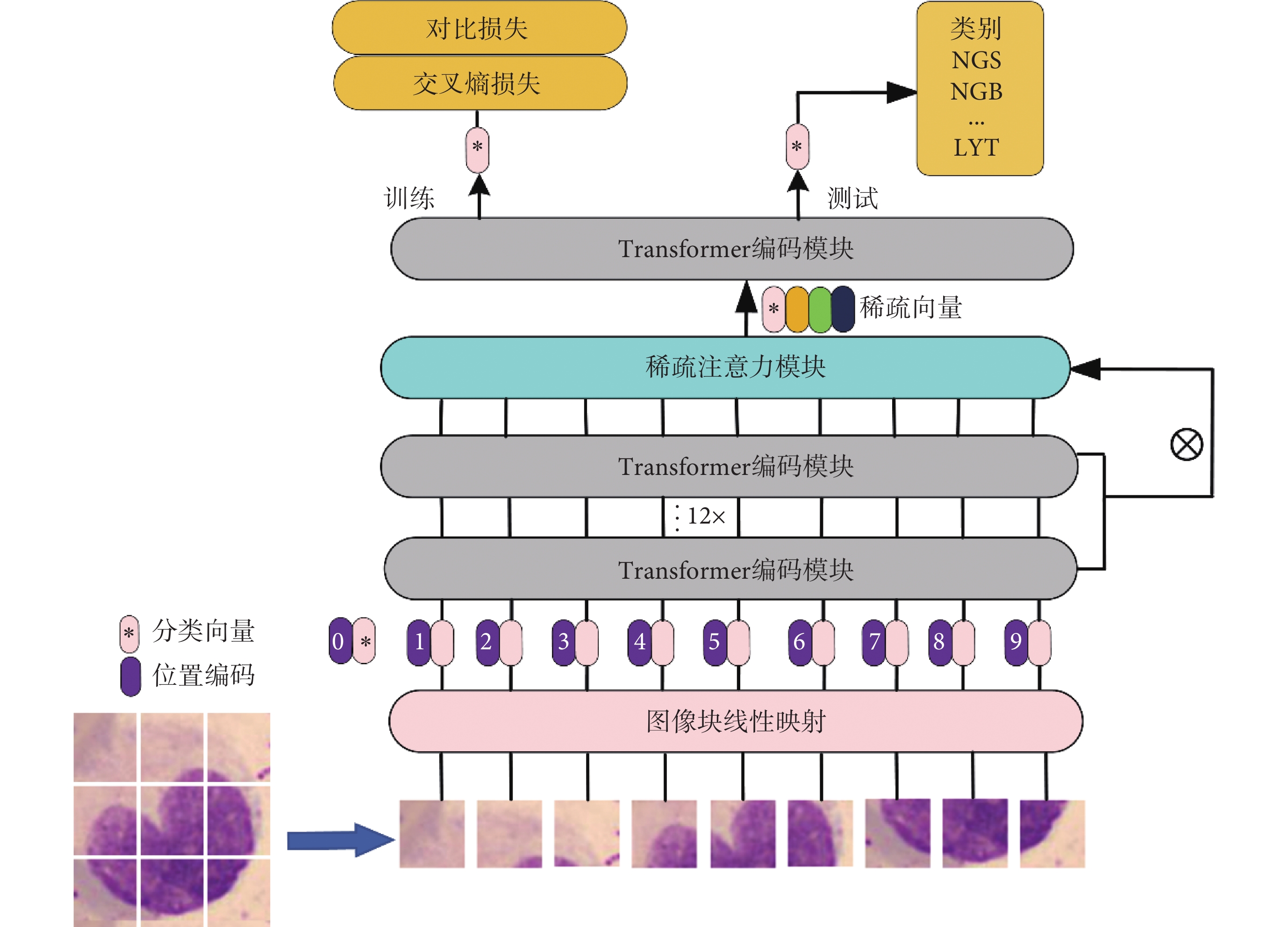 圖3
基于改進Vision Transformer的血細胞識別模型
Figure3.
An improved Vision Transformer for blood cell recognition
圖3
基于改進Vision Transformer的血細胞識別模型
Figure3.
An improved Vision Transformer for blood cell recognition
2.1 圖像劃分與嵌入
Vision Transformer模型接收的輸入為序列化數據,因此需要將圖像劃分為圖像塊并線性映射為序列化向量。Vision Transformer模型將圖像劃分成大小為P×P且互不重疊的像素塊,但這樣劃分會破壞圖像的局部結構,例如辨識性區域被劃分到兩個相鄰的圖像塊中。為避免該問題,本文采用滑動窗的方法來生成有重疊的圖像塊。當輸入圖像的尺寸為H×W×C、圖像塊大小為P、滑動窗的步長為S時,圖像將會被劃分為N個像素塊,其中N如式(1)所示。
 |
通過滑動窗的方式,兩個相鄰像素塊的重疊面積為(P ? S)×P,更好地保留了圖像的局部信息。S越小,局部結構保存得越完整,但會增加序列化向量的數量導致計算開銷變大。綜合利弊,在實驗中將S的大小設置為 。圖像劃分完成后,需要將2-D的圖像塊轉化為1-D的序列向量,首先將圖像塊展平為一組向量
。圖像劃分完成后,需要將2-D的圖像塊轉化為1-D的序列向量,首先將圖像塊展平為一組向量 ,然后通過線性變換將其映射到D的維度大小。上述轉化在具體實現上等價于對原圖像進行D個
,然后通過線性變換將其映射到D的維度大小。上述轉化在具體實現上等價于對原圖像進行D個 尺寸的卷積核、步長為
尺寸的卷積核、步長為 的卷積操作。由于嵌入后的向量不包含位置信息,需要加入一個特殊的可學習位置編碼。此外還加入可學習分類向量作為最終的輸出特征用于圖像分類。嵌入后的序列數據
的卷積操作。由于嵌入后的向量不包含位置信息,需要加入一個特殊的可學習位置編碼。此外還加入可學習分類向量作為最終的輸出特征用于圖像分類。嵌入后的序列數據 如式(2)所示,其中Ε為投影矩陣,Εpos為位置編碼,xclass為分類向量。
如式(2)所示,其中Ε為投影矩陣,Εpos為位置編碼,xclass為分類向量。
 |
2.2 編碼器
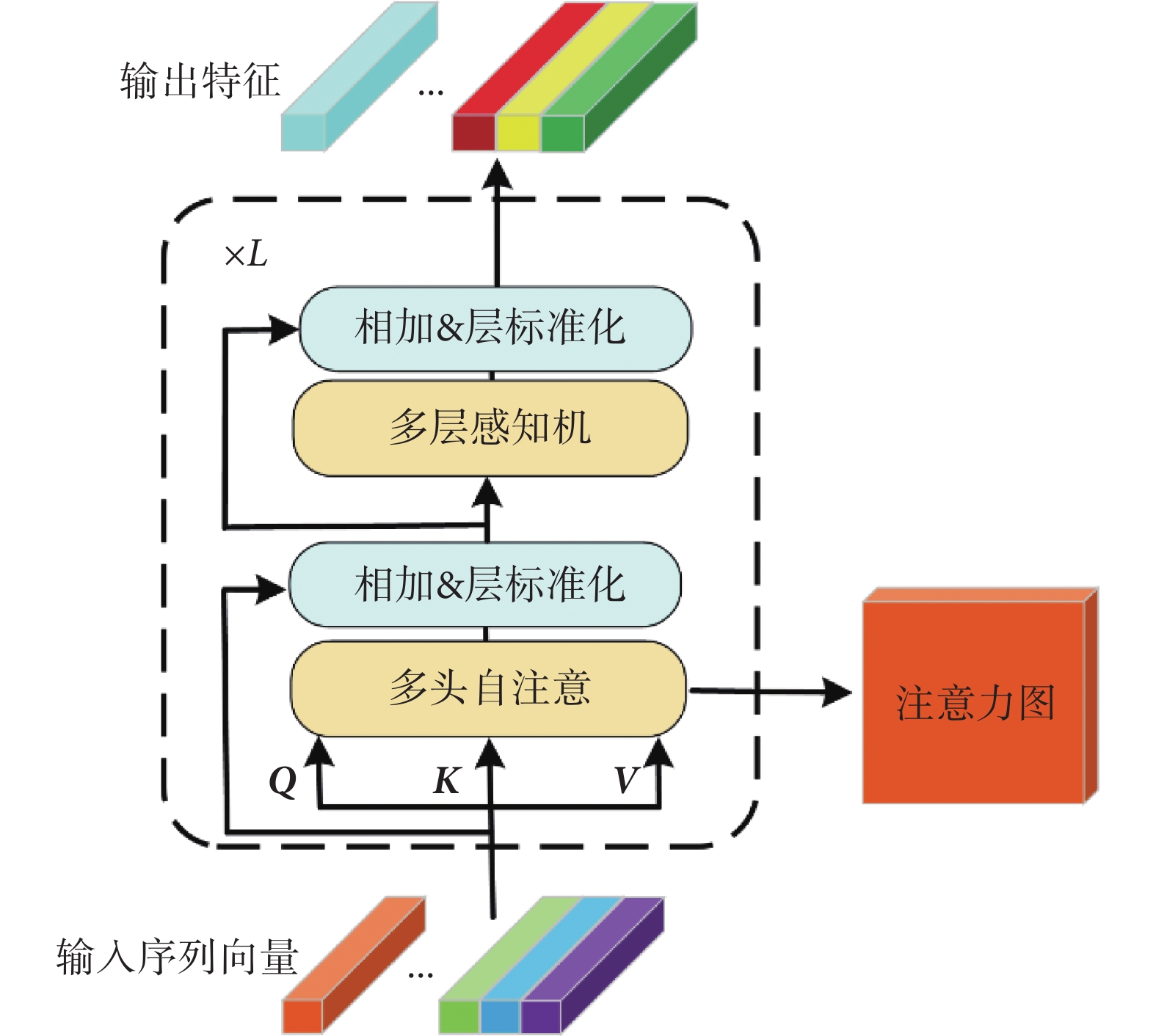
Vision Transformer的編碼器由L個結構相同的編碼模塊堆疊而成,編碼模塊結構如圖4所示。
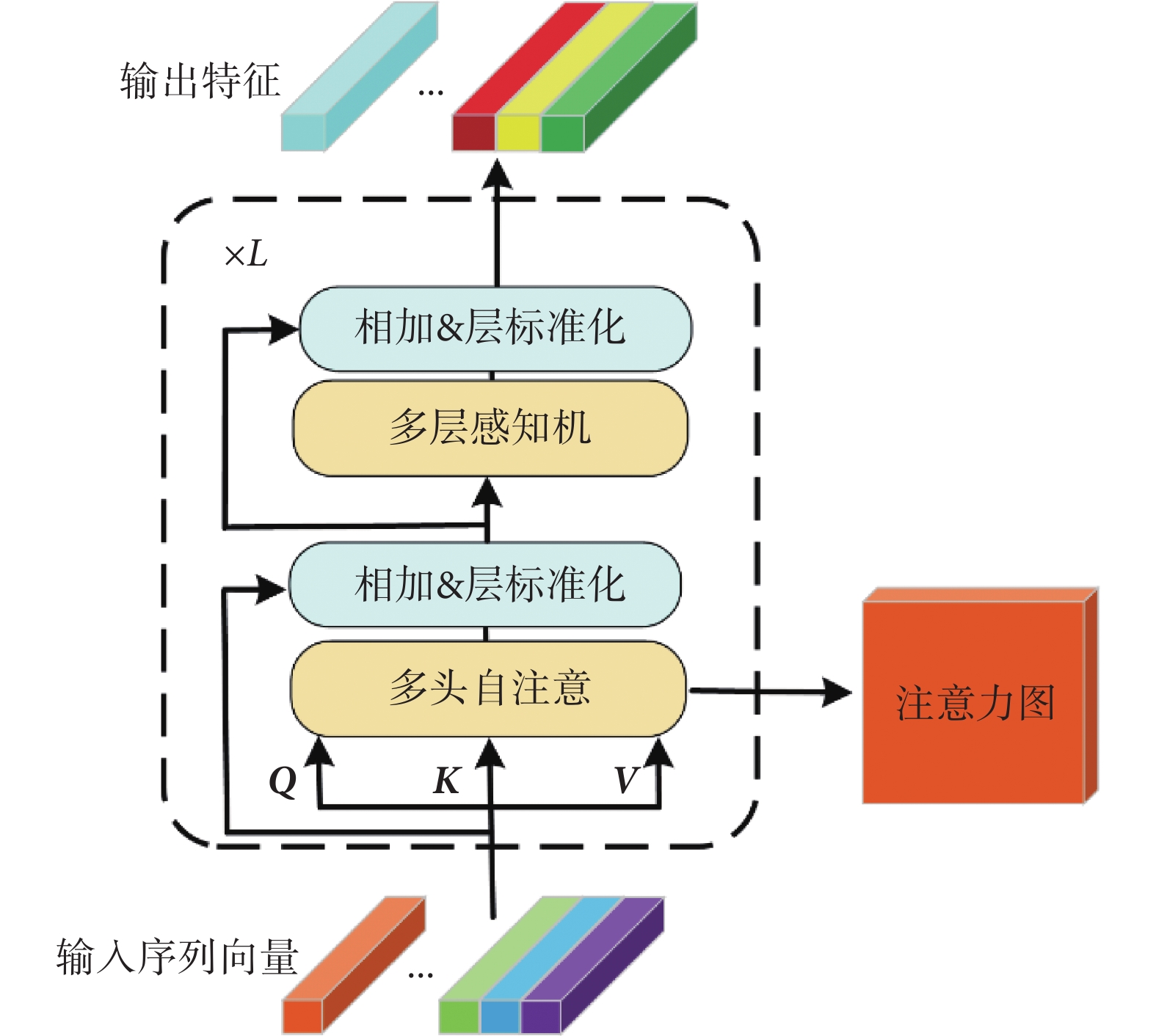 圖4
Vision Transformer編碼模塊結構
Figure4.
Vision Transformer encoder block architecture
圖4
Vision Transformer編碼模塊結構
Figure4.
Vision Transformer encoder block architecture
編碼模塊包含了多頭自注意(multi-head self-attention,MSA)與多層感知機(multi-layer perceptron,MLP)。多頭自注意模塊由 個單頭自注意單元(self-attention,SA)組成。對于單頭自注意單元,首先將輸入
個單頭自注意單元(self-attention,SA)組成。對于單頭自注意單元,首先將輸入 ,輸入經過線性變換得到查詢矩陣Q、鍵矩陣K、值矩陣V。線性變換如式(3)所示:
,輸入經過線性變換得到查詢矩陣Q、鍵矩陣K、值矩陣V。線性變換如式(3)所示:
 |
其中 ,得到Q、K、V后,注意力權重矩陣A的計算公式如下:
,得到Q、K、V后,注意力權重矩陣A的計算公式如下:
 |
矩陣A中的元素 表示第
表示第 個特征與第
個特征與第 個特征之間的相關性,值越大則相關性越強,
個特征之間的相關性,值越大則相關性越強, 是縮放因子。注意力權重矩陣A點乘值矩陣V得到單頭自注意單元的輸出
是縮放因子。注意力權重矩陣A點乘值矩陣V得到單頭自注意單元的輸出  :
:
 '/> '/> |
不同的單頭自注意單元在互不干擾、獨立的特征子空間中學習相關特征,最終多頭自注意模塊對單頭自注意單元輸出的結果進行拼接,再經過線性變換得到該模塊的輸出。該輸出與  進行殘差連接,經過層標準化(layer normalization,LN)作為下一個多層感知機模塊的輸入。
進行殘差連接,經過層標準化(layer normalization,LN)作為下一個多層感知機模塊的輸入。
 |
其中 為權重,
為權重, 為偏置。
為偏置。
多層感知機模塊由兩個全連接層組成,第一個全連接層的激活函數為ReLU,第二個全連接層不使用激活函數,計算公式如下:
 |
若 為第p個編碼模塊的輸入,該編碼模塊的輸出如下式所示:
為第p個編碼模塊的輸入,該編碼模塊的輸出如下式所示:
 '/> '/> |
2.3 稀疏注意力模塊
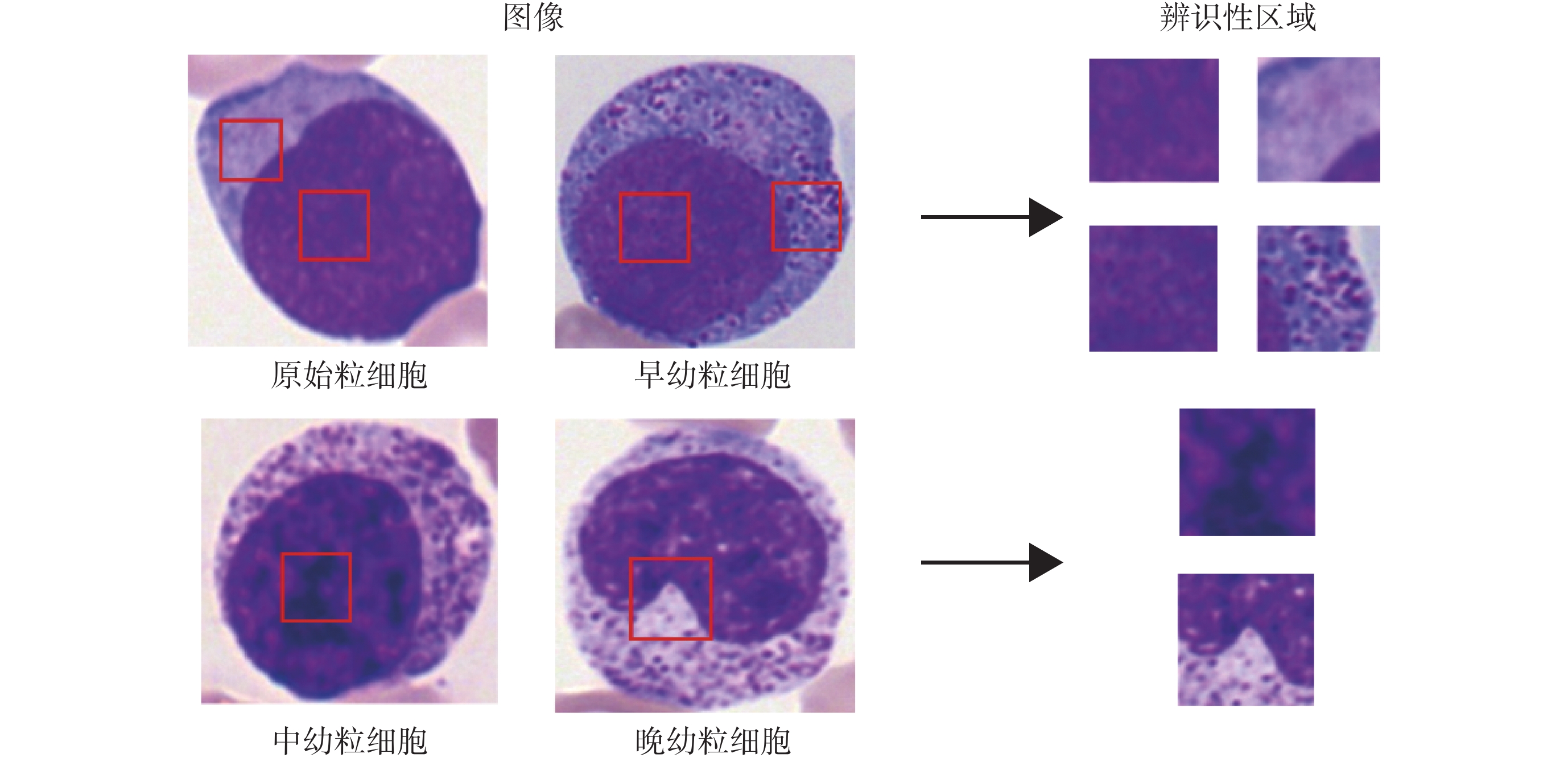
血細胞分類中的關鍵問題是能否準確定位到圖像中的辨識性區域,以圖5中的粒細胞為例,不同發育階段的粒細胞差異較為細微,原始粒細胞與早幼粒細胞染色質都較為細致,區別主要是細胞質中是否存在非特異性顆粒。中幼粒細胞與晚幼粒細胞染色質都呈現出聚集的索塊狀,區別主要是細胞核形態是否存在凹陷。在卷積神經網絡中主要通過區域推薦網絡或者弱監督的分割掩碼來定位圖像中的辨識性區域,而在Vision Transformer模型中,其多頭自注意機制可以自主學習不同圖像塊的權重。為了充分利用此權重信息實現辨識性區域的定位,本文提出了稀疏注意力模塊。
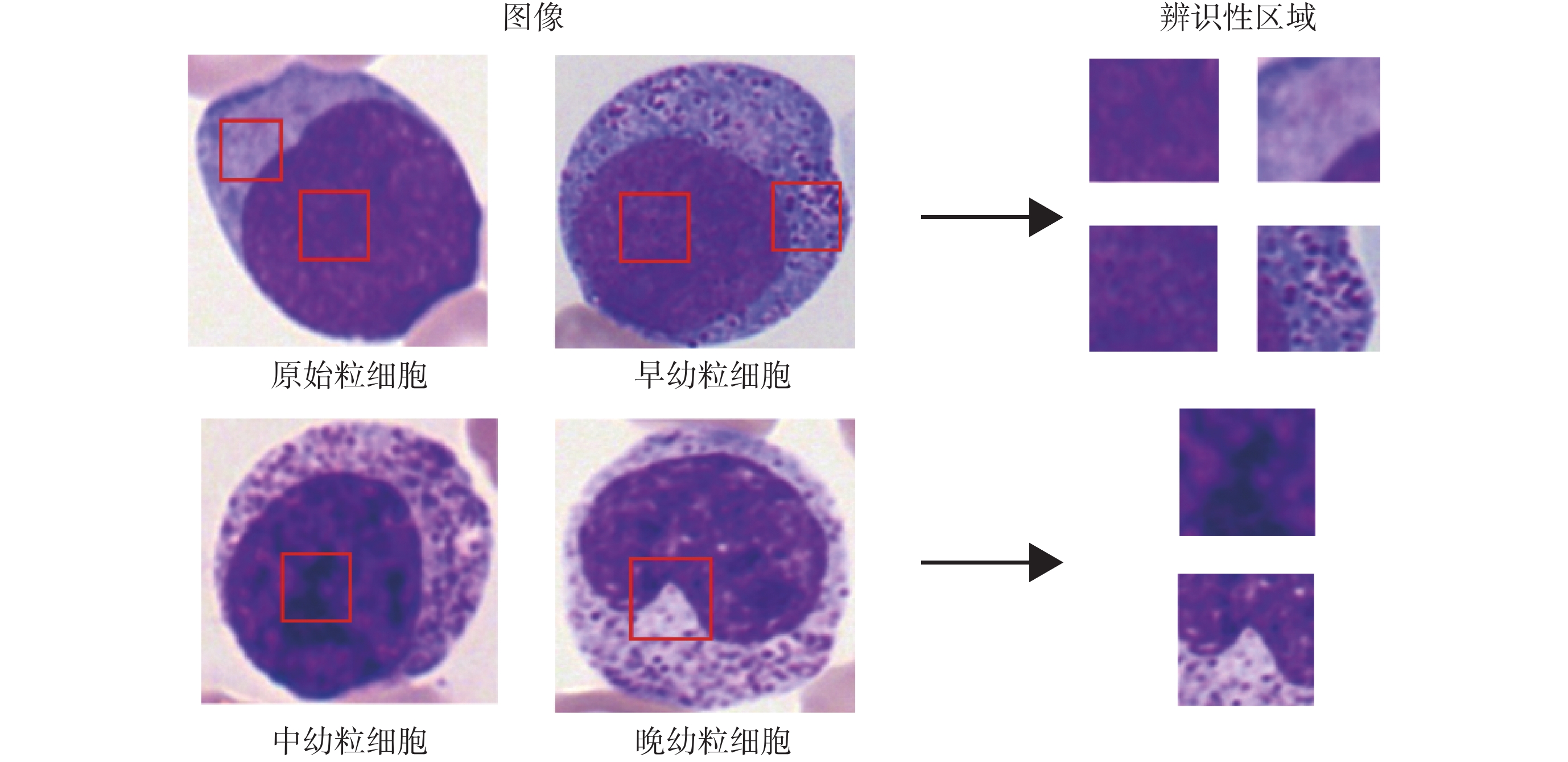 圖5
不同類別血細胞的辨識性區域
Figure5.
Discriminative parts of different type of blood cells
圖5
不同類別血細胞的辨識性區域
Figure5.
Discriminative parts of different type of blood cells
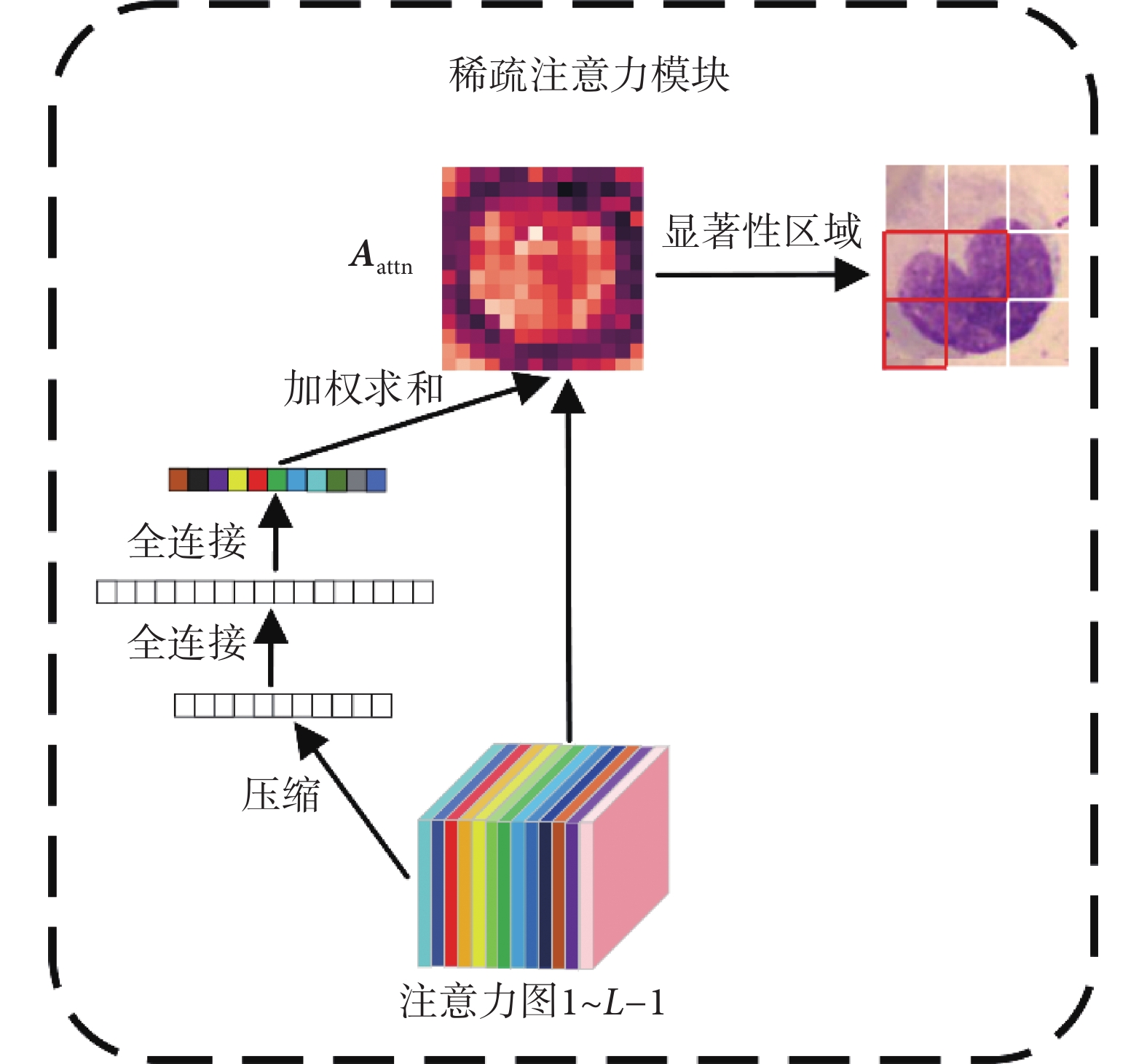
若Vision Transformer網絡包含L個編碼模塊,稀疏注意力模塊利用前L ? 1個編碼層學習到的權重對最后編碼層輸入的隱含特征  進行篩選。前L ? 1個編碼層學習到的權重圖如式(9)所示。
進行篩選。前L ? 1個編碼層學習到的權重圖如式(9)所示。
 |
由于高層次特征的抽象性,其注意力圖不一定能代表對應輸入圖像塊的重要性,因此我們利用先前所有編碼模塊的注意力圖信息并結合壓縮激發模塊來自主學習每個注意力圖的權重。該模塊首先將注意力圖全局平均池化為一個描述符,接著使用兩個全連接層建模注意力圖間的相關性,最終得到每個注意力圖的權重值 。將權重值歸一化后與注意力圖加權求和得到最終的注意力權重
。將權重值歸一化后與注意力圖加權求和得到最終的注意力權重 ,如式(10)所示。整個流程如圖6所示。
,如式(10)所示。整個流程如圖6所示。
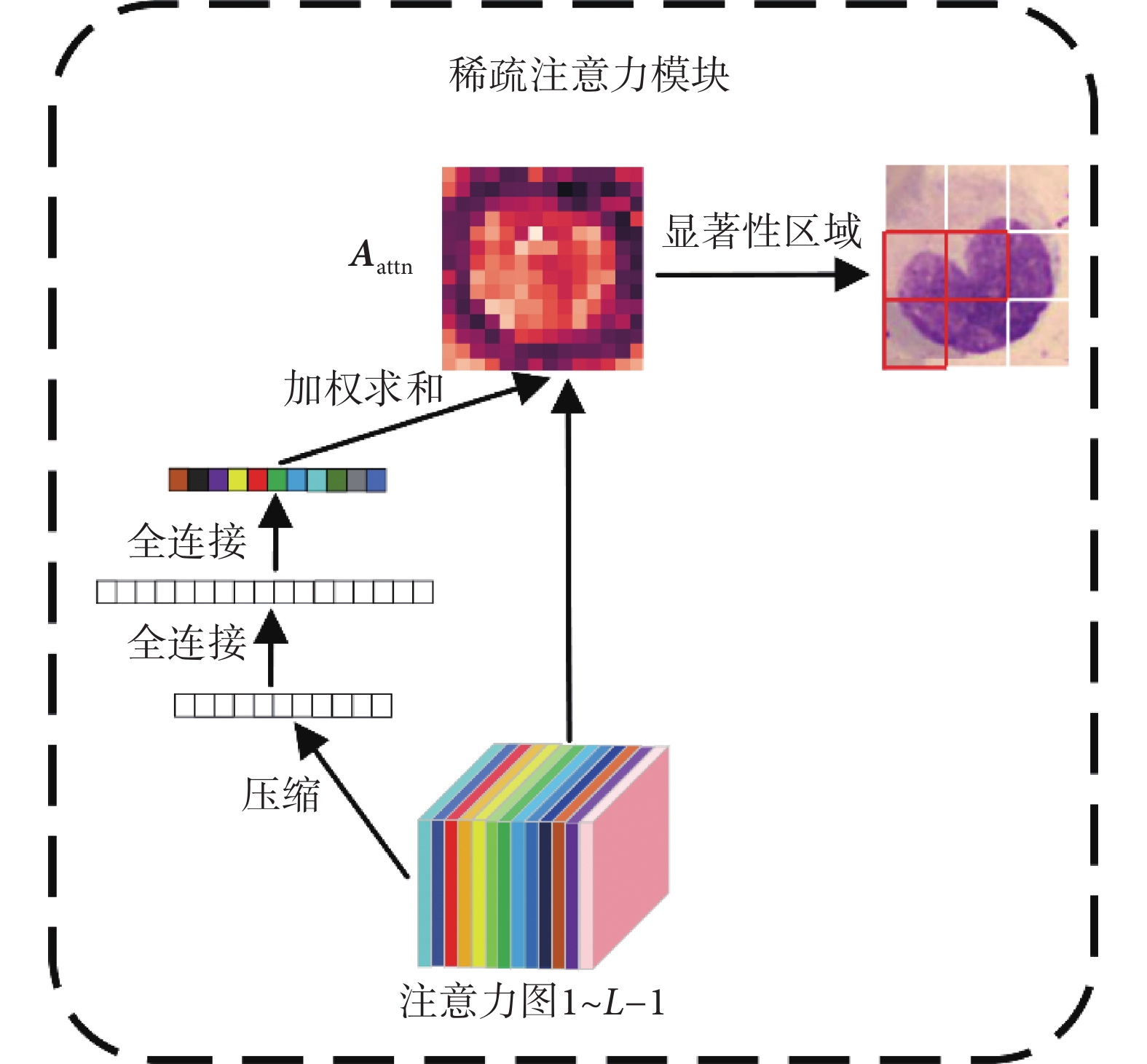 圖6
稀疏注意力模塊
Figure6.
Sparse attention model
圖6
稀疏注意力模塊
Figure6.
Sparse attention model
 |
 包含了低層特征與高層特征全部的注意力權重信息,相比于單層的注意力權重
包含了低層特征與高層特征全部的注意力權重信息,相比于單層的注意力權重 更適合篩選辨識性區域。我們使用
更適合篩選辨識性區域。我們使用 中分類向量對應的權重
中分類向量對應的權重 ,在
,在 個自注意頭中篩選出最大權重所對應的隱含特征。最后,將這些隱含特征與分類向量進行拼接作為最后一層編碼模塊的輸入。
個自注意頭中篩選出最大權重所對應的隱含特征。最后,將這些隱含特征與分類向量進行拼接作為最后一層編碼模塊的輸入。
 |
稀疏注意力模塊將全部序列向量替換為辨識性區域對應的特征向量并與分類向量進行拼接,然后輸入到最后一個編碼模塊中,這樣不僅保留了全局分類特征信息,還強制讓最后一個編碼層關注到不同類別之間的細微差異部分,同時舍棄了大量區分度較低的區域信息如背景、超類共同特征等,從而提升了網絡的細粒度特征表達能力。
2.4 損失函數
像Vision Transformer一樣,我們將網絡輸出的第一個向量即分量向量用于圖像分類。網絡的損失函數包括了交叉熵損失 與對比損失
與對比損失 ,如式(12)所示:
,如式(12)所示:
 '/> '/> |
交叉熵損失用于衡量真實標簽 與網絡預測標簽的
與網絡預測標簽的 的相似性,定義如式(13)所示:
的相似性,定義如式(13)所示:
 '/> '/> |
為了進一步增加網絡提取特征的類內相似性與類間差異性,我們加入了對比損失 。對比損失使得不同標簽對應的分類特征相似度最小,相同標簽的分類特征相似度最大。為了使正負樣本均衡,防止損失被簡單的負樣本(相似度很小的不同類別特征)所支配,我們引入閾值
。對比損失使得不同標簽對應的分類特征相似度最小,相同標簽的分類特征相似度最大。為了使正負樣本均衡,防止損失被簡單的負樣本(相似度很小的不同類別特征)所支配,我們引入閾值 ,只有不同類別樣本特征的相似度大于
,只有不同類別樣本特征的相似度大于 時才計入到損失中,當輸入數據的批大小為N時,對比損失定義如式(14)所示:
時才計入到損失中,當輸入數據的批大小為N時,對比損失定義如式(14)所示:
 |
3 實驗結果與分析
3.1 實驗環境與參數配置
如1.1節所述,單細胞圖像通過快速區域卷積神經網絡從原圖像中裁剪出來,隨后將單細胞圖像大小調整為 224 × 224。實驗中圖像塊的大小設置為16 × 16,滑動窗步長大小為12,式(14)中的閾值 大小為0.4,批尺寸大小設置為32。我們在Linux操作系統下的NVIDIA GeForce RTX 3090顯卡上訓練模型。訓練使用的深度學習框架為Pytorch 1.10.1,優化器使用隨機梯度下降算法(stochastic gradient descent,SGD),動量設置為0.9,權重衰減設置為5e-4,學習率初始化為0.001,在第40、70、90個epoch時變為原來的1/10。整個訓練過程在第100個epoch停止。
大小為0.4,批尺寸大小設置為32。我們在Linux操作系統下的NVIDIA GeForce RTX 3090顯卡上訓練模型。訓練使用的深度學習框架為Pytorch 1.10.1,優化器使用隨機梯度下降算法(stochastic gradient descent,SGD),動量設置為0.9,權重衰減設置為5e-4,學習率初始化為0.001,在第40、70、90個epoch時變為原來的1/10。整個訓練過程在第100個epoch停止。
為了定量評估分類算法的性能,我們使用五折交叉驗證與精確率(Precision)、召回率(Recall)、準確率(Accuracy)等評價指標,定義如式(15)~(17)所示:
 |
 |
 |
其中,TP為正確預測為正類的正樣本數量;FP為錯誤預測為正類的負樣本數量;TN為正確預測為負類的負樣本數量;FN為錯誤預測為負類的正樣本數量。
3.2 識別網絡性能對比實驗
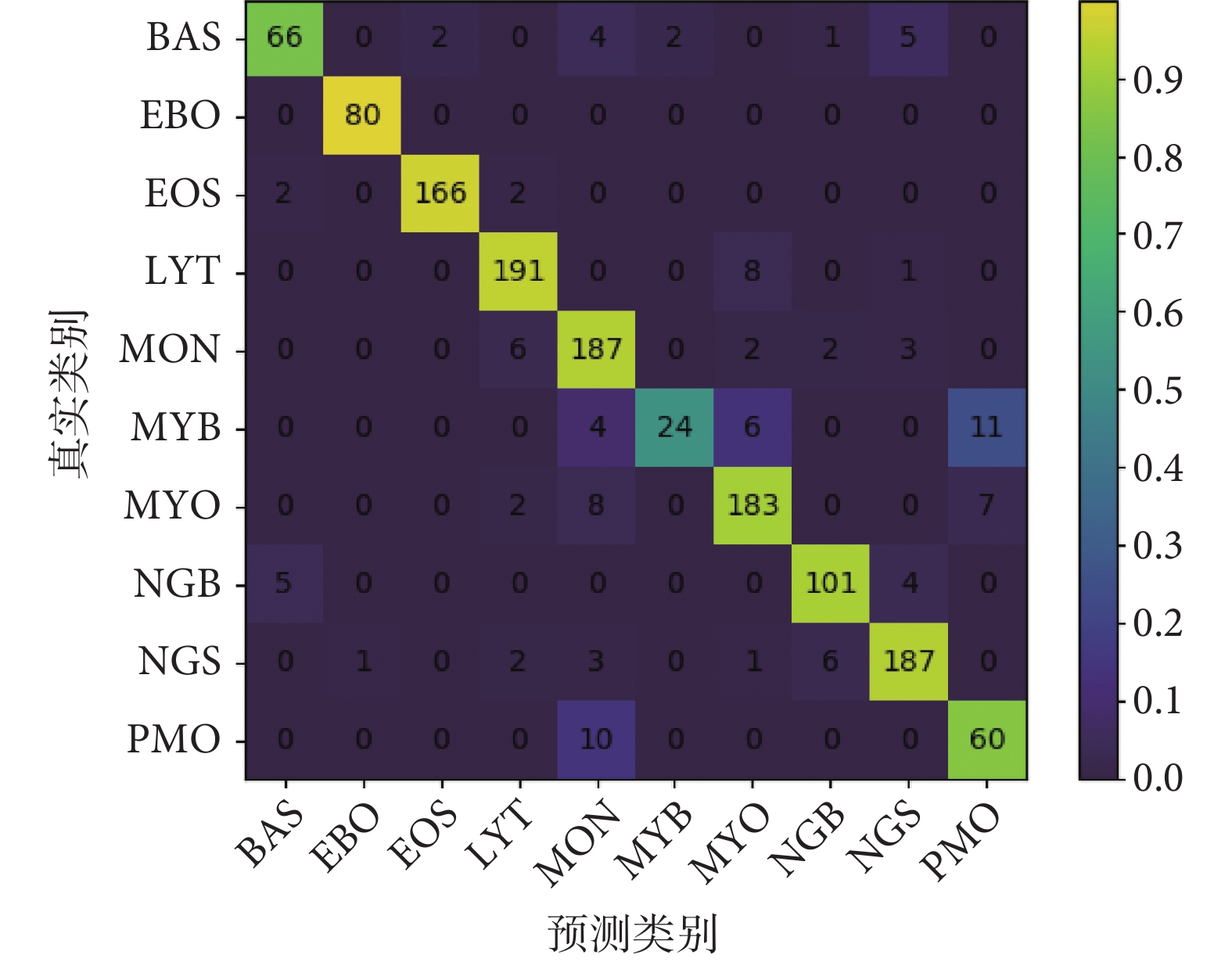
本文方法在TMAMD數據集上各類精確率與召回率如表2所示,混淆矩陣如圖7所示。網絡的top-1平均分類準確率為91.96%,top-5平均分類正確率為99.48%。我們注意到對于最常見的血細胞類型,例如分葉核、桿狀核嗜中性粒細胞,典型的淋巴細胞,嗜酸性粒細胞,以及有核紅細胞,網絡預測結果與醫生標注達到了極好的一致性,精確率與召回率均高于90%。而其他類別例如不同發育階段的粒細胞以及嗜堿性粒細胞,由于相鄰發育階段的粒細胞差異較為細微并且原始樣本數量較少,識別更具挑戰性,存在誤分類是可以容忍的。
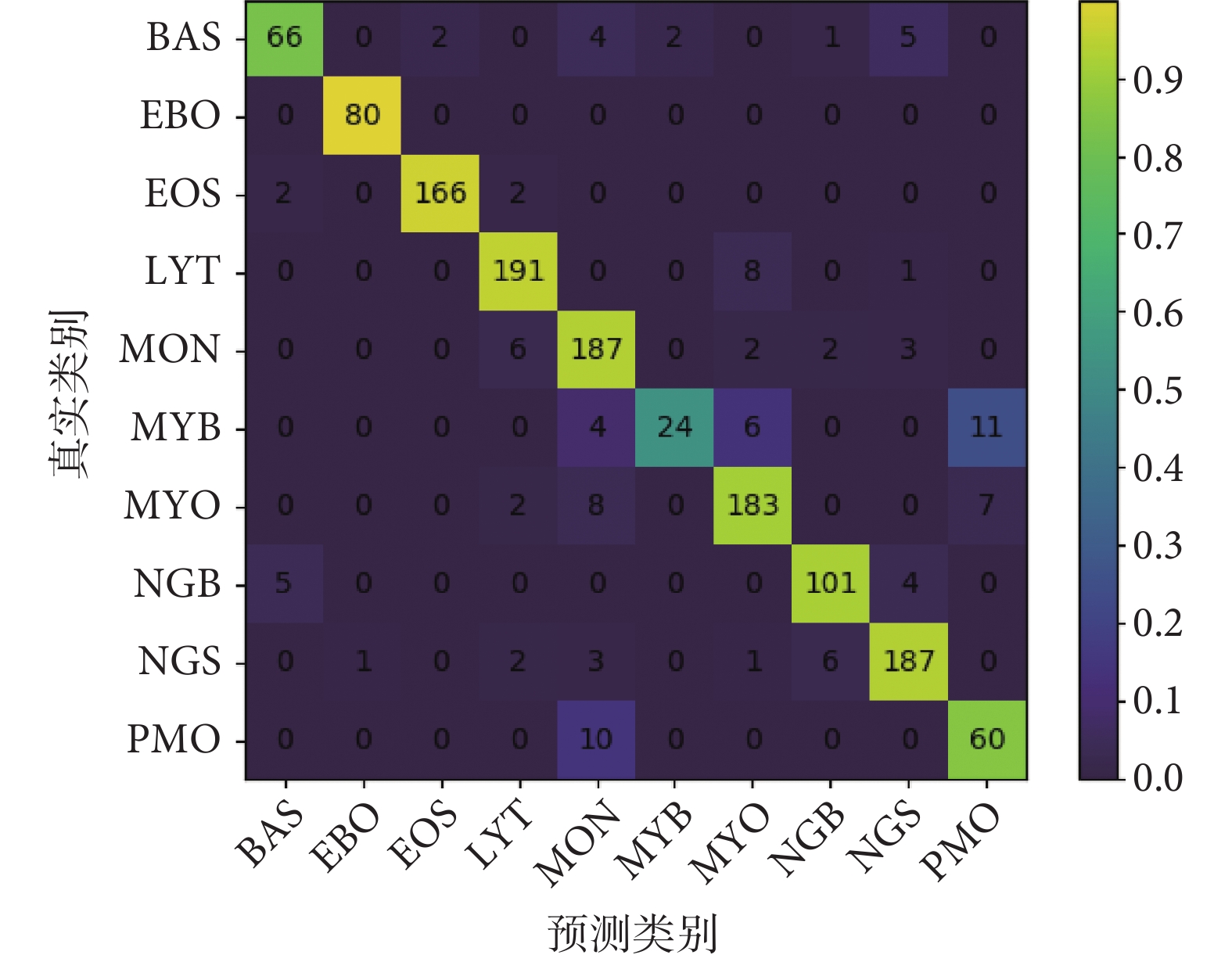 圖7
本文模型的識別混淆矩陣
Figure7.
The confusion matrix of proposed method
圖7
本文模型的識別混淆矩陣
Figure7.
The confusion matrix of proposed method
此外,我們將本文提出的方法與其他深度學習方法例如VGG[30]、ResNet[31]、SE-ResNet[32]、ResNext[33]、EfficientNet[34]、Vision Transformer[23]進行了對比。表3為不同方法在TMAMD數據集上的識別結果,表3第三列結果表明我們的方法在TMAMD數據上的識別準確率優于其他的方法,取得了有競爭力的性能。具體而言,我們改進的Vision Transformer與卷積神經網絡相比識別準確率提升了1.5%~3.0%,本文圖像塊非重疊的模型與其基礎框架相比識別準確率提升了0.74%,而模型的浮點運算次數僅增加0.09 GFLOPS,參數量增加7.08 MB。
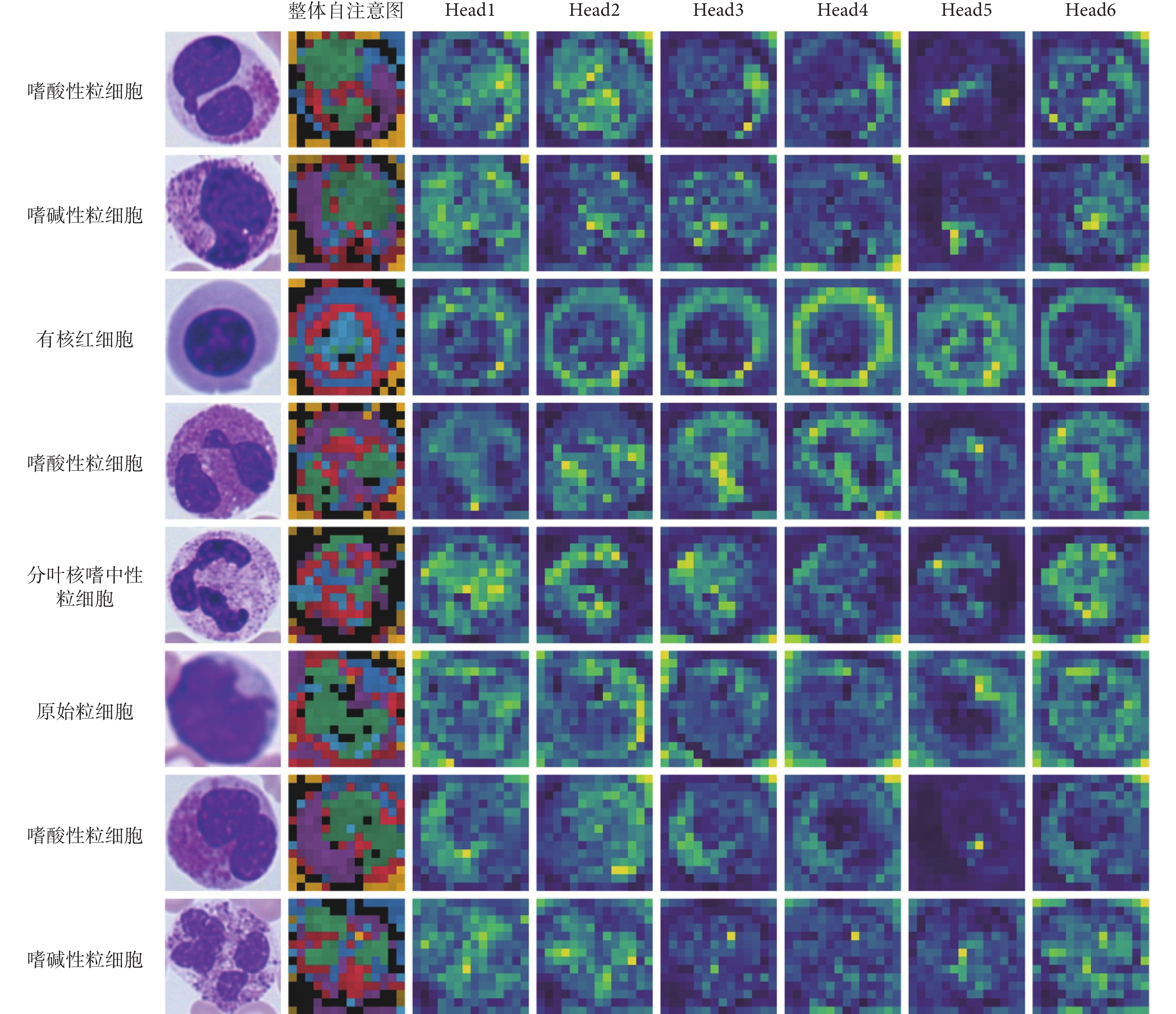
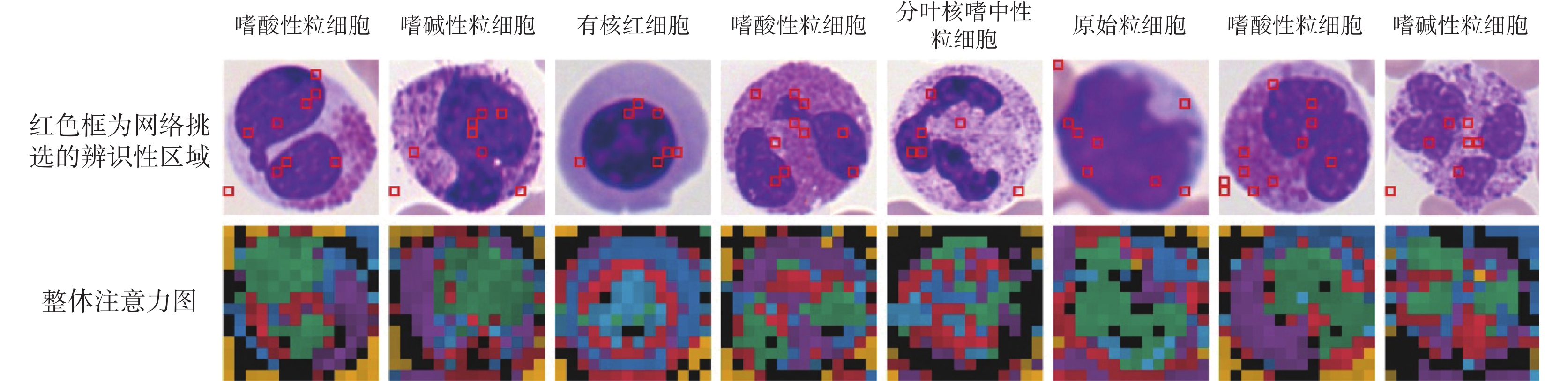
圖8中展示了本文模型的自注意力圖。我們在數據集中隨機選取了八個血細胞,圖中第一列為原始圖像,第二列為整合后的注意力圖,每種顏色表示不同頭部的注意力。第三到八列為稀疏注意力模塊多頭注意力單元前六個頭部所對應的注意力圖。從整合注意力圖中我們可以看到,細胞核、細胞質與背景分別被不同頭部標記為不同的顏色。因此,本文模型的自注意機制有能力區分目標的不同區域。此外,我們將稀疏注意力模塊每個頭部最大權重對應的圖像塊進行標記,如圖9所示。第一行圖像中的紅色邊框為稀疏注意力模塊所挑選的圖像塊區域,第二行為整體注意力圖。我們看到模型主要關注了細胞核與細胞質等辨識性區域。以上可視化結果表明,本文模型成功捕捉到了細胞中的辨識性區域。
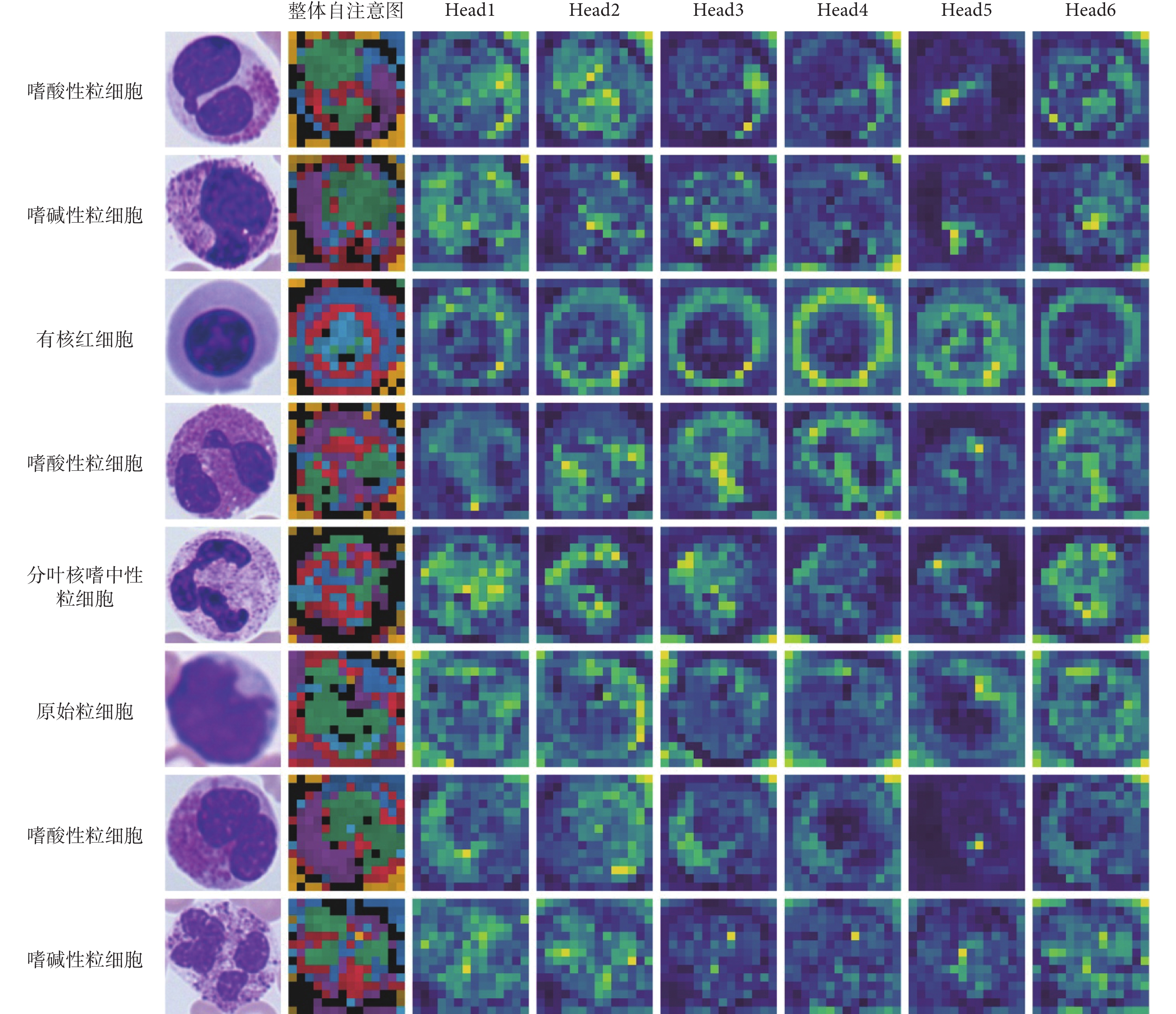 圖8
可視化自注意力圖
Figure8.
Visualization results of self-attention maps
圖8
可視化自注意力圖
Figure8.
Visualization results of self-attention maps
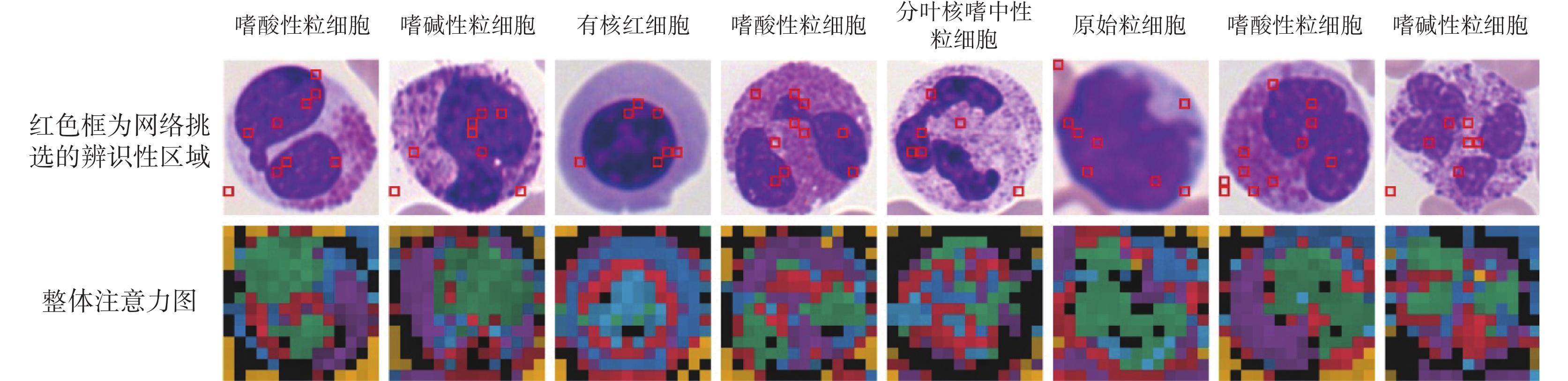 圖9
稀疏注意力模塊選擇的圖像塊
Figure9.
Image patches selected by the sparse attention model
圖9
稀疏注意力模塊選擇的圖像塊
Figure9.
Image patches selected by the sparse attention model
從表3中可以看到,本文最優模型的浮點運算次數與參數量大小均大于卷積神經網絡方法,而卷積網絡中的EfficientNet模型通過神經架構搜索,具有更優運算次數與識別準確率。因此,本文進一步探究了Transformer結構中嵌入向量的維度、編碼層數量、多頭注意力的頭數與模型準確率的關系,從而找到更好的模型速率與準確率的平衡。我們設計不同的超參數如表4所示。編碼層數量為4、頭數量為4,嵌入向量維度為256時,模型最小只有7 MB,運算次數為1.18 GFLOPS,但準確率較低僅有78.08%。當將編碼層的層數從12減少到2層,多頭自注意的數量與嵌入向量維度不變時,模型的準確度由91.88%下降到了83.17%。當編碼層數相同時,嵌入向量維度越低,模型的識別準確率也相應降低。整體來說,當本文模型識別準確率高于卷積網絡時,參數量與運算次數也高于卷積網絡。未來我們會關注Transformer網絡的結構搜索,以期找到更加精準的模型速率與準確率的平衡。
3.3 消融實驗
我們將本文模型進行消融實驗研究來分析不同模塊對細胞圖像識別的影響,分別評估了圖像塊的劃分方法、稀疏注意力模塊以及對比損失的影響。
3.3.1 圖像塊劃分方法
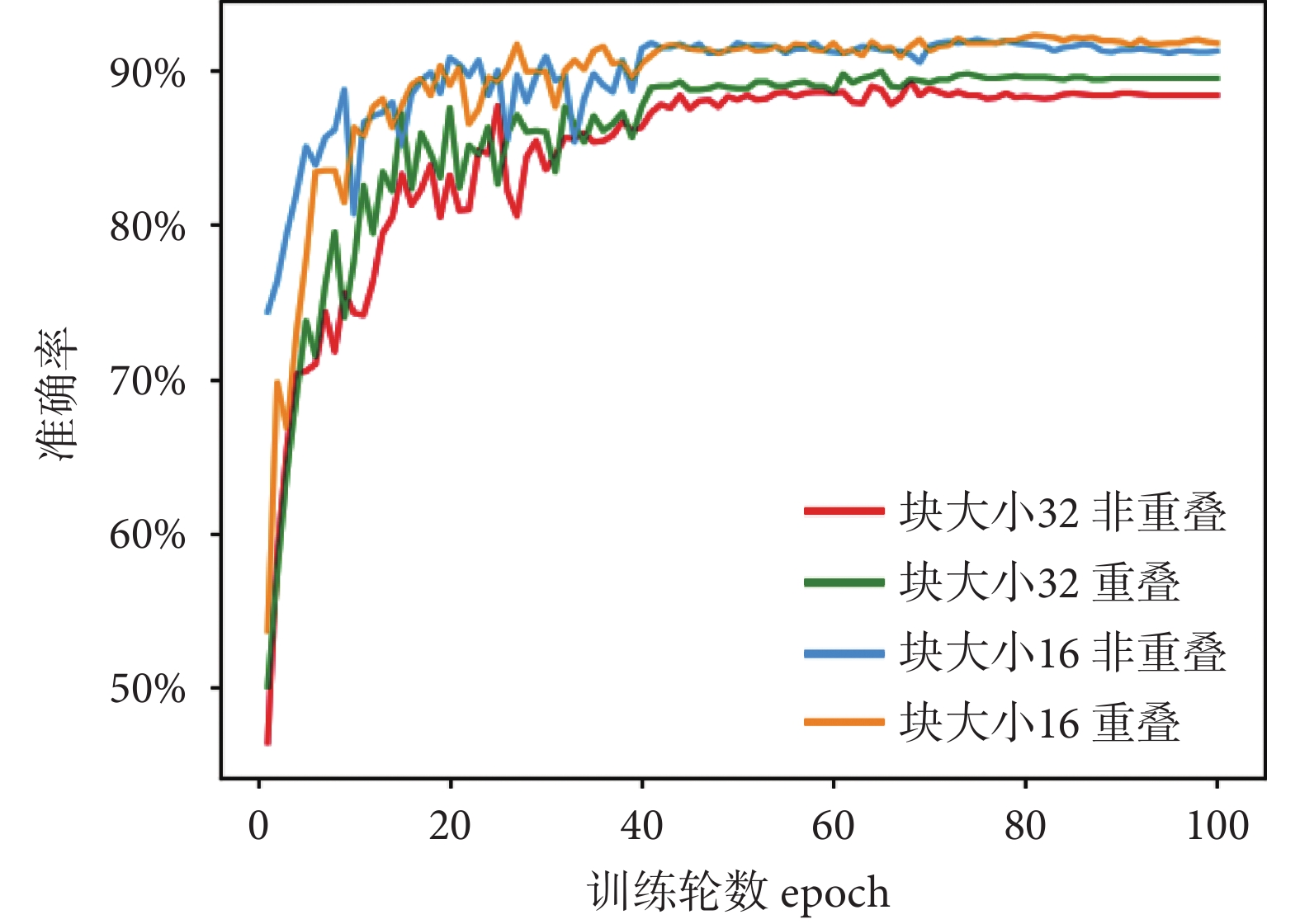
我們探究了圖像塊劃分大小與圖像塊是否重疊對模型識別準確率的影響,實驗結果如表5所示。圖像塊大小為32相比于大小為16的劃分方式,嵌入后向量數量與模型的計算量都大幅降低,訓練與推理的時間也減少約3/4,但是模型的識別準確率較差。無論塊大小是16還是32,重疊劃分方式相比非重疊劃分方式模型識別準確率均有提高,而由此引入的額外計算成本也是可以接受的。圖10實驗結果表明,圖像塊劃分越小,圖像塊之間存在重疊可以使得圖像的局部細節保留得更加完整,模型的識別準確率越高。
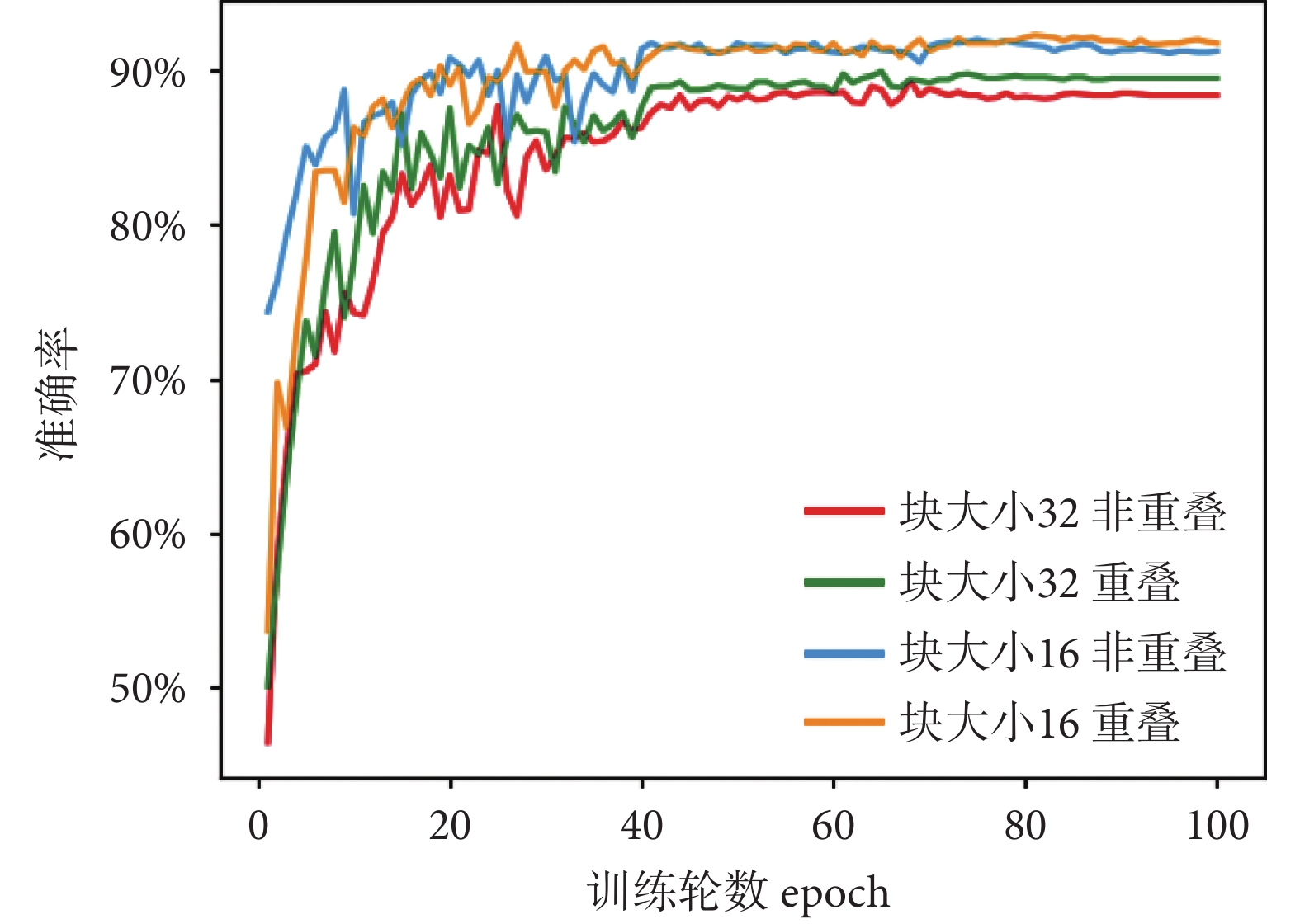 圖10
圖像塊劃分方式對模型性能的影響
Figure10.
The effect of image patch split method on model accuracy
圖10
圖像塊劃分方式對模型性能的影響
Figure10.
The effect of image patch split method on model accuracy
3.3.2 稀疏注意力模塊
通過稀疏注意力模塊來選擇顯著性圖像塊作為最后編碼層的輸入,模型的識別準確率可從91.14%提高到91.88%。我們認為通過稀疏注意力的方式,模型將采樣最具辨別力的圖像塊作為輸入,從而明確丟棄一些無用的圖像塊并迫使網絡對重要的部分進行學習。
3.3.3 對比損失
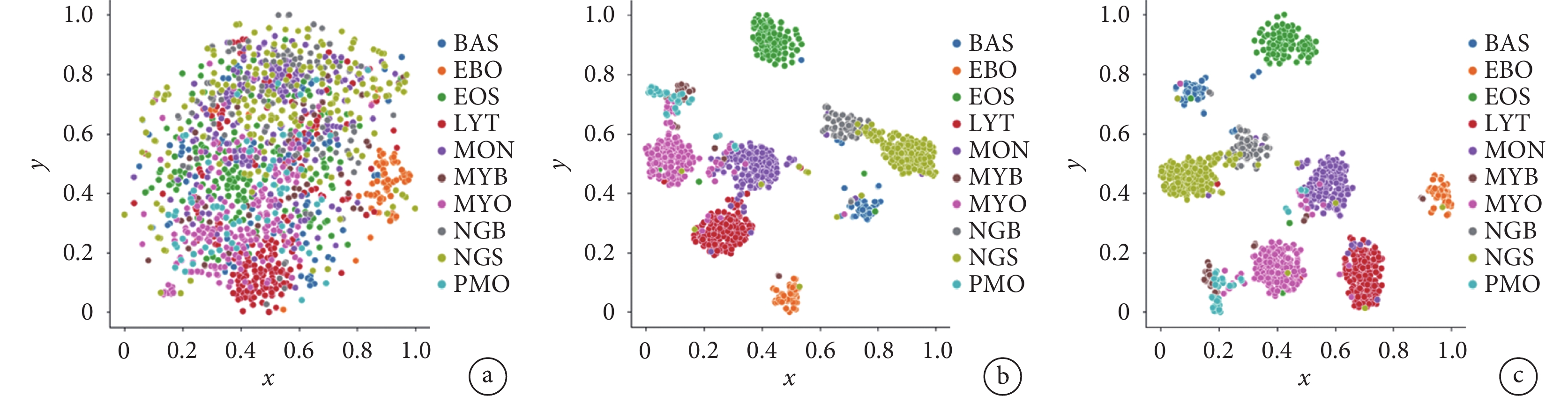
Vision Transformer與本文模型在有無對比損失情況下的識別性能如表6所示。實驗結果表明,通過加入對比損失,Vision Transformer的識別準確率提升了0.52%,本文模型的識別準確率提升了0.59%。圖11為測試集圖像與本文模型輸出分類特征的t-SNE[35]降維可視化結果,我們發現加入對比損失后,不同類別的分類特征在嵌入到二維空間后距離增大,相同類別的分類特征距離減小。綜合上述結果,我們認為加入對比損失可有效擴大相似子類之間的特征距離,并減少相同類別之間的特征距離,從而提升模型的識別性能。
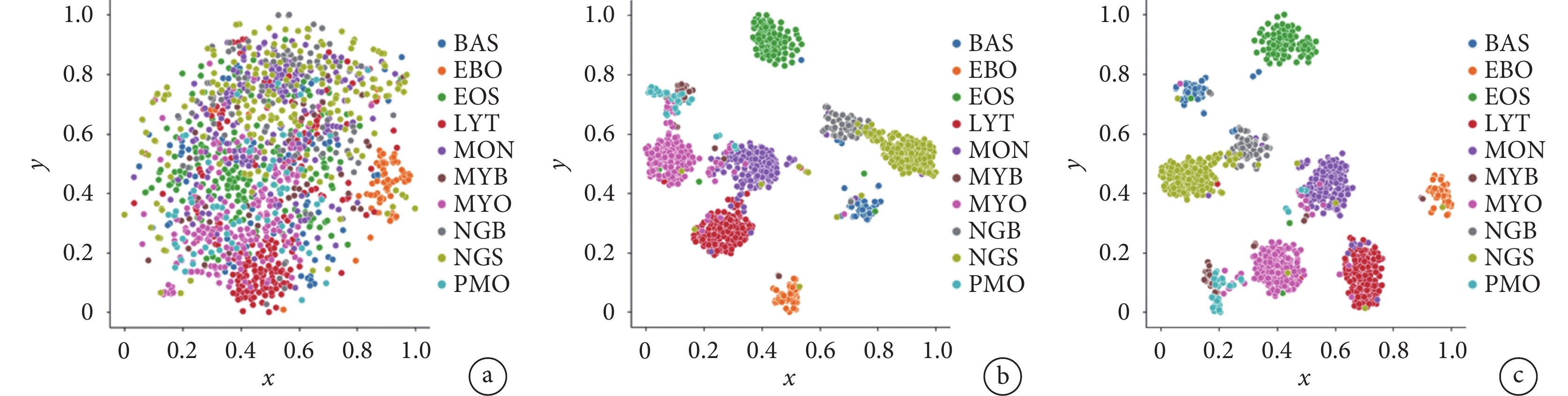 圖11
t-SNE降維可視化結果
圖11
t-SNE降維可視化結果
a. 測試集圖像t-SNE降維;b. 無對比損失類別特征t-SNE降維;c. 使用對比損失類別特征t-SNE降維
Figure11. The visualization results of t-SNEa. the t-SNE dimensional reduction of the test image set; b. t-SNE dimensional reduction for categorical features without contrast loss; c. t-SNE dimensional reduction for categorical features with contrast loss
4 結論
目前血細胞識別研究主要側重于五類血細胞的粗分類,很少有研究關注血細胞大類中子類的識別,針對上述問題,本文提出了一種基于改進Vision Transformer的血細胞識別模型。我們基于Vision Transformer中的自注意機制提出了稀疏注意力模塊,該模塊綜合利用了所有編碼層的注意力權重信息,捕捉到圖像中的辨識性區域,提升了模型的細粒度特征表達能力。本文采用對比損失進一步增加了網絡學習特征的類內一致性與類間差異性。本文方法在TMAMD數據集上展示了先進的性能,定性與定量的可視化結果均體現了本方法的有效性與可解釋性。相較于其他識別方法,本文方法具有更高的識別準確率,有望為醫生臨床診斷提供參考依據,具有潛在的臨床應用前景。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:孫天宇主要負責實驗方案設計、代碼編寫與調試、實驗結果分析與論文撰寫;朱慶濤主要負責數據集預處理與算法驗證;楊健主要負責算法咨詢與建議、論文撰寫指導;曾亮主要負責項目主持、實驗指導、數據分析指導以及論文審閱修訂。
引言
白血病[1]是一種人體造血系統的惡性腫瘤,在所有惡性腫瘤中占比約5%,是我國重點防治的十大惡性腫瘤之一。白血病可導致外周血中血細胞的形態與數量出現異常,患者臨床表現為貧血、出血、發熱、乏力等。白血病的致死率較高,其早期發現與治療對延長患者生存時間、改善患者生活質量至關重要[2]。血細胞形態學檢查是白血病診斷常規檢查的一部分[3],通常由訓練有素的醫師對顯微設備采集的血細胞圖像進行觀察,統計不同類型的血細胞數量,然后,根據FAB分類標準[4]對白血病類型進行初步診斷。但是該方法也存在不足,人工分類計數繁瑣費時,診斷結果具有較強的主觀性。此外,細胞形態學人才資源緊缺,培養精通細胞病理診斷的醫師要耗費大量的時間。因此,研究血細胞自動化識別技術來輔助臨床診斷,可以實現診斷流程的標準化、快速化與智能化,將醫生從繁重的病理工作中解放出來,具有重要的臨床意義和廣闊的應用前景。
近年來,基于深度學習的方法在醫學影像處理領域取得了巨大的成功[5-6]。國內外學者紛紛開始探索基于深度學習的血細胞識別方法,研究領域包括了血細胞圖像檢測[7-12]、分類[13-19]、語義分割[20-22]等。血細胞檢測任務是從圖像中定位血細胞并分類。檢測方法根據是否生成候選區域分為兩個流派,一類是基于候選區域的雙階段檢測算法,即先從圖像中定位包含血細胞的區域,再對區域進行坐標回歸與分類;另一類是單階段檢測算法,其將圖像劃分為多個網格并對每個網格預測邊界框和類別。在雙階段檢測方面,Dhieb等[7]使用掩膜區域卷積神經網絡(mask region-based convolutional neural network,Mask R-CNN)對紅細胞與白細胞進行檢測,模型以Resnet-101網絡作為主干,并使用FPN網絡提取多尺度特征來檢測不同大小的細胞,該方法對紅細胞與白細胞識別準確率分別為92%與96%。Tobias等[8]基于快速區域卷積神經網絡對紅細胞與白細胞進行識別,對紅細胞、白細胞的識別準確率分別為98%、99%。在單階段檢測方面,Shakarami等[9]基于YOLOv3(you look only once v3)單階段目標檢測網絡提出了快速高效的YOLOv3檢測模型(Fast and Efficient YOLOv3 Detector,FED),該模型以Efficientnet作為主干網絡并在三個尺度上對血細胞進行檢測,該方法在BCCD數據集上對血小板、紅細胞、白細胞的平均識別準確率分別為90.25%、80.41%、98.92%。在血細胞圖像分類領域,學者們也進行了廣泛的研究。Matek等[13]開源了一個包含15類總計18 375張圖像的血細胞數據集,接著采用ResNext模型進行分類,網絡對于常見的血細胞如中性粒細胞、淋巴細胞、單核細胞的識別準確率達到了94%。Fu等[14]基于陸軍軍醫大學第二附屬醫院收集的65 986幅骨髓血細胞圖像開發了一個完整的自動化檢測識別系統morphogo,該研究使用了27層的卷積神經網絡,對12類骨髓血細胞的平均分類準確率為85.7%。Huang等[15]首先基于RetinaNet檢測網絡得到單個血細胞的切片圖像,接著將自適應注意力模塊引入到卷積神經網絡中,該模塊增強了與分類任務相關區域特征的權重,提升了模型的特征表達能力,模型對六類白細胞的平均分類準確率為95.3%。Mori等[16]按細胞質顆粒減少的程度將血細胞劃分為四類,然后使用Resnet-152網絡進行分類,平均靈敏度與特異性分別為85.2%、98.9%。
雖然上述研究在血細胞識別方面取得了長足的進步,但大多基于通用的目標檢測、分類網絡,并未針對血細胞的特性進行改進。此外,很多研究只關注了血細胞大類,未關注其中的子類別如粒細胞的原始、早幼、中幼與晚幼等階段,血細胞子類之間差異較小使得其自動化識別更具挑戰性。最近,Vision Transformer[23]在視覺分類任務中效果良好,這表明Transformer[24]的自注意機制可以捕獲圖像塊序列中的重要部分,使得模型具有更強的局部與全局特征表達能力。因此,本文結合血細胞特性對血細胞細粒度分類進行研究,提出了一種基于改進Vision Transformer的血細胞識別方法。首先,使用快速區域卷積神經網絡[25]從圖像中檢測出細胞邊界并進行裁剪,去除背景等干擾。接著,本文提出一種重疊圖像塊劃分方法將裁剪后的圖像分割為多個圖像塊并嵌入,然后嵌入向量經過多個編碼層進行特征提取。本文基于多頭自注意機制[24]提出了稀疏注意力模塊,該模塊可以捕捉血細胞圖像中的辨識性區域,并將篩選后的特征輸入到編碼層。最后,網絡輸出的分類特征用于細胞識別。在訓練過程中,本文采用對比損失[25]進一步增加分類特征的類內一致性與類間差異性。本文相關代碼與數據已在GitHub開源:
1 數據集與預處理
1.1 ?數據集
本文采用了The Cancer Imaging Archive平臺上開源的慕尼黑血細胞形態學數據集(The Munich AML Morphology Dataset,TMAMD)[26]。該數據來自慕尼黑醫院2014年至2017年間100位被診斷為急性白血病的患者與100位無血液惡性腫瘤的患者。該數據集包含了15類由專家標記的18 635張單細胞圖像。如圖1a所示,圖像背景中有較多的成熟紅細胞,這類細胞沒有細胞核,不屬于本次分類所關注的類別。有的圖像中包含多個細胞,如圖1b所示。上述因素會導致網絡分類性能下降,因此我們對原圖像進行血細胞邊界框檢測并裁剪,處理后的單張血細胞圖像如圖1c所示。
圖1
血細胞形態學數據集圖像
a. 單個血細胞圖像;b. 包含兩個血細胞的圖像;c. 裁剪后圖像
Figure1. The images of The Munich AML Morphology Dataseta. single cell images; b. image containing two blood cells; c. cropped cell images
1.2 數據預處理
TMAMD數據集不包含血細胞的坐標標注信息,因此需要人工標注血細胞的邊界并進行裁剪。因為數據集較大,本文采用快速區域卷積神經網絡[27]結合主動學習[10,28]方法完成血細胞邊界框信息的標注。首先,使用標注軟件Labelme人工標注小部分血細胞邊界框。隨后,將Labelme軟件的json標注格式轉換為MS COCO格式。然后,使用部分標注的數據對預訓練的快速區域卷積模型進行微調,得到初步的血細胞檢測網絡。接著,使用該模型對未標注的數據進行推理,將檢測結果反饋到標注軟件中進行人工核對,從而降低標注工作量。最后使用更新后數據重新訓練檢測模型,在數據集較大或有新增數據的情況下,經過幾次模型的迭代與人工核查,即可完成所有數據的標注。最終,單個血細胞圖像從原圖像中剪切出來。整個流程如圖2所示。
圖2
血細胞數據集標注與預處理流程
Figure2.
The annotation and processing flow of blood cell dataset
盡管原數據集包含15類血細胞,但是存在較嚴重的類別不平衡問題,部分類別的數量小于30,使得網絡難以有效地進行特征學習。本文只關注了樣本數量大于30的十個類別。在這十個類別中,對于數量較多的類別采用隨機欠采樣減少樣本數量,對于數量較少的類別,采用水平、垂直翻轉與旋轉90、180的方式進行數據擴充,表1為原數據集的分布情況與數據增強[29]后的樣本分布情況。
2 方法
圖3為本文提出的基于Vision Transformer的血細胞識別網絡框架。首先將輸入的血細胞圖像分割為N個P × P 大小的圖像塊,接著將圖像塊線性映射為序列化嵌入向量,其次加入可學習的分類向量與位置編碼信息。然后嵌入向量被輸入到多個堆疊的編碼模塊中進行特征提取。在最后一層編碼模塊前,使用稀疏注意力模塊來尋找圖像中的區分性像素塊并將它對應的隱含特征作為輸入。最后編碼器輸出的分類特征經過全連接層得到血細胞的類別信息。
圖3
基于改進Vision Transformer的血細胞識別模型
Figure3.
An improved Vision Transformer for blood cell recognition
2.1 圖像劃分與嵌入
Vision Transformer模型接收的輸入為序列化數據,因此需要將圖像劃分為圖像塊并線性映射為序列化向量。Vision Transformer模型將圖像劃分成大小為P×P且互不重疊的像素塊,但這樣劃分會破壞圖像的局部結構,例如辨識性區域被劃分到兩個相鄰的圖像塊中。為避免該問題,本文采用滑動窗的方法來生成有重疊的圖像塊。當輸入圖像的尺寸為H×W×C、圖像塊大小為P、滑動窗的步長為S時,圖像將會被劃分為N個像素塊,其中N如式(1)所示。
|
通過滑動窗的方式,兩個相鄰像素塊的重疊面積為(P ? S)×P,更好地保留了圖像的局部信息。S越小,局部結構保存得越完整,但會增加序列化向量的數量導致計算開銷變大。綜合利弊,在實驗中將S的大小設置為。圖像劃分完成后,需要將2-D的圖像塊轉化為1-D的序列向量,首先將圖像塊展平為一組向量,然后通過線性變換將其映射到D的維度大小。上述轉化在具體實現上等價于對原圖像進行D個尺寸的卷積核、步長為的卷積操作。由于嵌入后的向量不包含位置信息,需要加入一個特殊的可學習位置編碼。此外還加入可學習分類向量作為最終的輸出特征用于圖像分類。嵌入后的序列數據如式(2)所示,其中Ε為投影矩陣,Εpos為位置編碼,xclass為分類向量。
|
2.2 編碼器
Vision Transformer的編碼器由L個結構相同的編碼模塊堆疊而成,編碼模塊結構如圖4所示。
圖4
Vision Transformer編碼模塊結構
Figure4.
Vision Transformer encoder block architecture
編碼模塊包含了多頭自注意(multi-head self-attention,MSA)與多層感知機(multi-layer perceptron,MLP)。多頭自注意模塊由個單頭自注意單元(self-attention,SA)組成。對于單頭自注意單元,首先將輸入,輸入經過線性變換得到查詢矩陣Q、鍵矩陣K、值矩陣V。線性變換如式(3)所示:
|
其中,得到Q、K、V后,注意力權重矩陣A的計算公式如下:
|
矩陣A中的元素表示第個特征與第個特征之間的相關性,值越大則相關性越強,是縮放因子。注意力權重矩陣A點乘值矩陣V得到單頭自注意單元的輸出 :
| '/> |
不同的單頭自注意單元在互不干擾、獨立的特征子空間中學習相關特征,最終多頭自注意模塊對單頭自注意單元輸出的結果進行拼接,再經過線性變換得到該模塊的輸出。該輸出與 進行殘差連接,經過層標準化(layer normalization,LN)作為下一個多層感知機模塊的輸入。
|
其中為權重,為偏置。
多層感知機模塊由兩個全連接層組成,第一個全連接層的激活函數為ReLU,第二個全連接層不使用激活函數,計算公式如下:
|
若為第p個編碼模塊的輸入,該編碼模塊的輸出如下式所示:
| '/> |
2.3 稀疏注意力模塊
血細胞分類中的關鍵問題是能否準確定位到圖像中的辨識性區域,以圖5中的粒細胞為例,不同發育階段的粒細胞差異較為細微,原始粒細胞與早幼粒細胞染色質都較為細致,區別主要是細胞質中是否存在非特異性顆粒。中幼粒細胞與晚幼粒細胞染色質都呈現出聚集的索塊狀,區別主要是細胞核形態是否存在凹陷。在卷積神經網絡中主要通過區域推薦網絡或者弱監督的分割掩碼來定位圖像中的辨識性區域,而在Vision Transformer模型中,其多頭自注意機制可以自主學習不同圖像塊的權重。為了充分利用此權重信息實現辨識性區域的定位,本文提出了稀疏注意力模塊。
圖5
不同類別血細胞的辨識性區域
Figure5.
Discriminative parts of different type of blood cells
若Vision Transformer網絡包含L個編碼模塊,稀疏注意力模塊利用前L ? 1個編碼層學習到的權重對最后編碼層輸入的隱含特征 進行篩選。前L ? 1個編碼層學習到的權重圖如式(9)所示。
|
由于高層次特征的抽象性,其注意力圖不一定能代表對應輸入圖像塊的重要性,因此我們利用先前所有編碼模塊的注意力圖信息并結合壓縮激發模塊來自主學習每個注意力圖的權重。該模塊首先將注意力圖全局平均池化為一個描述符,接著使用兩個全連接層建模注意力圖間的相關性,最終得到每個注意力圖的權重值。將權重值歸一化后與注意力圖加權求和得到最終的注意力權重,如式(10)所示。整個流程如圖6所示。
圖6
稀疏注意力模塊
Figure6.
Sparse attention model
|
包含了低層特征與高層特征全部的注意力權重信息,相比于單層的注意力權重更適合篩選辨識性區域。我們使用中分類向量對應的權重,在個自注意頭中篩選出最大權重所對應的隱含特征。最后,將這些隱含特征與分類向量進行拼接作為最后一層編碼模塊的輸入。
|
稀疏注意力模塊將全部序列向量替換為辨識性區域對應的特征向量并與分類向量進行拼接,然后輸入到最后一個編碼模塊中,這樣不僅保留了全局分類特征信息,還強制讓最后一個編碼層關注到不同類別之間的細微差異部分,同時舍棄了大量區分度較低的區域信息如背景、超類共同特征等,從而提升了網絡的細粒度特征表達能力。
2.4 損失函數
像Vision Transformer一樣,我們將網絡輸出的第一個向量即分量向量用于圖像分類。網絡的損失函數包括了交叉熵損失與對比損失,如式(12)所示:
| '/> |
交叉熵損失用于衡量真實標簽與網絡預測標簽的的相似性,定義如式(13)所示:
| '/> |
為了進一步增加網絡提取特征的類內相似性與類間差異性,我們加入了對比損失。對比損失使得不同標簽對應的分類特征相似度最小,相同標簽的分類特征相似度最大。為了使正負樣本均衡,防止損失被簡單的負樣本(相似度很小的不同類別特征)所支配,我們引入閾值,只有不同類別樣本特征的相似度大于時才計入到損失中,當輸入數據的批大小為N時,對比損失定義如式(14)所示:
|
3 實驗結果與分析
3.1 實驗環境與參數配置
如1.1節所述,單細胞圖像通過快速區域卷積神經網絡從原圖像中裁剪出來,隨后將單細胞圖像大小調整為 224 × 224。實驗中圖像塊的大小設置為16 × 16,滑動窗步長大小為12,式(14)中的閾值大小為0.4,批尺寸大小設置為32。我們在Linux操作系統下的NVIDIA GeForce RTX 3090顯卡上訓練模型。訓練使用的深度學習框架為Pytorch 1.10.1,優化器使用隨機梯度下降算法(stochastic gradient descent,SGD),動量設置為0.9,權重衰減設置為5e-4,學習率初始化為0.001,在第40、70、90個epoch時變為原來的1/10。整個訓練過程在第100個epoch停止。
為了定量評估分類算法的性能,我們使用五折交叉驗證與精確率(Precision)、召回率(Recall)、準確率(Accuracy)等評價指標,定義如式(15)~(17)所示:
|
|
|
其中,TP為正確預測為正類的正樣本數量;FP為錯誤預測為正類的負樣本數量;TN為正確預測為負類的負樣本數量;FN為錯誤預測為負類的正樣本數量。
3.2 識別網絡性能對比實驗
本文方法在TMAMD數據集上各類精確率與召回率如表2所示,混淆矩陣如圖7所示。網絡的top-1平均分類準確率為91.96%,top-5平均分類正確率為99.48%。我們注意到對于最常見的血細胞類型,例如分葉核、桿狀核嗜中性粒細胞,典型的淋巴細胞,嗜酸性粒細胞,以及有核紅細胞,網絡預測結果與醫生標注達到了極好的一致性,精確率與召回率均高于90%。而其他類別例如不同發育階段的粒細胞以及嗜堿性粒細胞,由于相鄰發育階段的粒細胞差異較為細微并且原始樣本數量較少,識別更具挑戰性,存在誤分類是可以容忍的。
圖7
本文模型的識別混淆矩陣
Figure7.
The confusion matrix of proposed method
此外,我們將本文提出的方法與其他深度學習方法例如VGG[30]、ResNet[31]、SE-ResNet[32]、ResNext[33]、EfficientNet[34]、Vision Transformer[23]進行了對比。表3為不同方法在TMAMD數據集上的識別結果,表3第三列結果表明我們的方法在TMAMD數據上的識別準確率優于其他的方法,取得了有競爭力的性能。具體而言,我們改進的Vision Transformer與卷積神經網絡相比識別準確率提升了1.5%~3.0%,本文圖像塊非重疊的模型與其基礎框架相比識別準確率提升了0.74%,而模型的浮點運算次數僅增加0.09 GFLOPS,參數量增加7.08 MB。
圖8中展示了本文模型的自注意力圖。我們在數據集中隨機選取了八個血細胞,圖中第一列為原始圖像,第二列為整合后的注意力圖,每種顏色表示不同頭部的注意力。第三到八列為稀疏注意力模塊多頭注意力單元前六個頭部所對應的注意力圖。從整合注意力圖中我們可以看到,細胞核、細胞質與背景分別被不同頭部標記為不同的顏色。因此,本文模型的自注意機制有能力區分目標的不同區域。此外,我們將稀疏注意力模塊每個頭部最大權重對應的圖像塊進行標記,如圖9所示。第一行圖像中的紅色邊框為稀疏注意力模塊所挑選的圖像塊區域,第二行為整體注意力圖。我們看到模型主要關注了細胞核與細胞質等辨識性區域。以上可視化結果表明,本文模型成功捕捉到了細胞中的辨識性區域。
圖8
可視化自注意力圖
Figure8.
Visualization results of self-attention maps
圖9
稀疏注意力模塊選擇的圖像塊
Figure9.
Image patches selected by the sparse attention model
從表3中可以看到,本文最優模型的浮點運算次數與參數量大小均大于卷積神經網絡方法,而卷積網絡中的EfficientNet模型通過神經架構搜索,具有更優運算次數與識別準確率。因此,本文進一步探究了Transformer結構中嵌入向量的維度、編碼層數量、多頭注意力的頭數與模型準確率的關系,從而找到更好的模型速率與準確率的平衡。我們設計不同的超參數如表4所示。編碼層數量為4、頭數量為4,嵌入向量維度為256時,模型最小只有7 MB,運算次數為1.18 GFLOPS,但準確率較低僅有78.08%。當將編碼層的層數從12減少到2層,多頭自注意的數量與嵌入向量維度不變時,模型的準確度由91.88%下降到了83.17%。當編碼層數相同時,嵌入向量維度越低,模型的識別準確率也相應降低。整體來說,當本文模型識別準確率高于卷積網絡時,參數量與運算次數也高于卷積網絡。未來我們會關注Transformer網絡的結構搜索,以期找到更加精準的模型速率與準確率的平衡。
3.3 消融實驗
我們將本文模型進行消融實驗研究來分析不同模塊對細胞圖像識別的影響,分別評估了圖像塊的劃分方法、稀疏注意力模塊以及對比損失的影響。
3.3.1 圖像塊劃分方法
我們探究了圖像塊劃分大小與圖像塊是否重疊對模型識別準確率的影響,實驗結果如表5所示。圖像塊大小為32相比于大小為16的劃分方式,嵌入后向量數量與模型的計算量都大幅降低,訓練與推理的時間也減少約3/4,但是模型的識別準確率較差。無論塊大小是16還是32,重疊劃分方式相比非重疊劃分方式模型識別準確率均有提高,而由此引入的額外計算成本也是可以接受的。圖10實驗結果表明,圖像塊劃分越小,圖像塊之間存在重疊可以使得圖像的局部細節保留得更加完整,模型的識別準確率越高。
圖10
圖像塊劃分方式對模型性能的影響
Figure10.
The effect of image patch split method on model accuracy
3.3.2 稀疏注意力模塊
通過稀疏注意力模塊來選擇顯著性圖像塊作為最后編碼層的輸入,模型的識別準確率可從91.14%提高到91.88%。我們認為通過稀疏注意力的方式,模型將采樣最具辨別力的圖像塊作為輸入,從而明確丟棄一些無用的圖像塊并迫使網絡對重要的部分進行學習。
3.3.3 對比損失
Vision Transformer與本文模型在有無對比損失情況下的識別性能如表6所示。實驗結果表明,通過加入對比損失,Vision Transformer的識別準確率提升了0.52%,本文模型的識別準確率提升了0.59%。圖11為測試集圖像與本文模型輸出分類特征的t-SNE[35]降維可視化結果,我們發現加入對比損失后,不同類別的分類特征在嵌入到二維空間后距離增大,相同類別的分類特征距離減小。綜合上述結果,我們認為加入對比損失可有效擴大相似子類之間的特征距離,并減少相同類別之間的特征距離,從而提升模型的識別性能。
圖11
t-SNE降維可視化結果
a. 測試集圖像t-SNE降維;b. 無對比損失類別特征t-SNE降維;c. 使用對比損失類別特征t-SNE降維
Figure11. The visualization results of t-SNEa. the t-SNE dimensional reduction of the test image set; b. t-SNE dimensional reduction for categorical features without contrast loss; c. t-SNE dimensional reduction for categorical features with contrast loss
4 結論
目前血細胞識別研究主要側重于五類血細胞的粗分類,很少有研究關注血細胞大類中子類的識別,針對上述問題,本文提出了一種基于改進Vision Transformer的血細胞識別模型。我們基于Vision Transformer中的自注意機制提出了稀疏注意力模塊,該模塊綜合利用了所有編碼層的注意力權重信息,捕捉到圖像中的辨識性區域,提升了模型的細粒度特征表達能力。本文采用對比損失進一步增加了網絡學習特征的類內一致性與類間差異性。本文方法在TMAMD數據集上展示了先進的性能,定性與定量的可視化結果均體現了本方法的有效性與可解釋性。相較于其他識別方法,本文方法具有更高的識別準確率,有望為醫生臨床診斷提供參考依據,具有潛在的臨床應用前景。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:孫天宇主要負責實驗方案設計、代碼編寫與調試、實驗結果分析與論文撰寫;朱慶濤主要負責數據集預處理與算法驗證;楊健主要負責算法咨詢與建議、論文撰寫指導;曾亮主要負責項目主持、實驗指導、數據分析指導以及論文審閱修訂。