皮膚是人體最大的器官,很多內臟疾病會直接體現在皮膚上,準確分割皮膚病灶圖像具有重要的臨床意義。針對皮膚病灶區域顏色復雜、邊界模糊、尺度信息參差不齊等特點,本文提出一種基于密集空洞空間金字塔池化(DenseASPP)和注意力機制的皮膚病灶圖像分割方法。該方法以U型網絡(U-Net)為基礎,首先重新設計新的編碼器,以大量殘差連接代替普通的卷積堆疊,在拓展網絡深度后還能有效保留關鍵特征;其次,將通道注意力與空間注意力融合并加入殘差連接,從而使網絡自適應地學習圖像的通道與空間特征;最后,引入并重新設計的DenseASPP以擴大感受野尺寸并獲取多尺度特征信息。本文所提算法在國際皮膚影像協會官方公開數據集(ISIC2016)中得到令人滿意的結果,平均交并比(mIOU)、敏感度(SE)、精確率(PC)、準確率(ACC)和戴斯相似性系數(Dice)分別為0.901 8、0.945 9、0.948 7、0.968 1、0.947 3。實驗結果證明,本文方法能夠提高皮膚病灶圖像分割效果,有望能為專業皮膚病醫生提供輔助診斷。
引用本文: 尹穩, 周冬明, 范騰, 余卓璞, 李禎. 基于密集空洞空間金字塔池化和注意力機制的皮膚病灶圖像分割方法. 生物醫學工程學雜志, 2022, 39(6): 1108-1116. doi: 10.7507/1001-5515.202208015 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
引言
皮膚病是一種常見的身體疾病。皮膚病的種類繁多,很多內臟疾病會直接體現在皮膚上。近年來,以黑色素瘤為代表的色素障礙性皮膚病發病率逐年上升。據美國癌癥協會(American cancer society,ACS)統計,2022 年美國新增黑色素瘤患者將達到99 780例,預計死亡病例達7 650例[1]。但如果能在早期發現黑色素瘤,其 5 年生存率可達到90% 以上[2]。因此,快速診斷并治療黑色素瘤對挽救患者生命具有重要意義。目前,皮膚病的診斷方法大多依賴皮膚鏡技術[3],皮膚病灶圖像分割可快速分離出正常區域與病變區域,能夠為皮膚鏡檢查提供關鍵依據。但早期皮膚病患者病灶區域顏色淺、邊緣模糊,且病變區域常常藏匿于毛發之間,與正常皮膚和常見的良性痣難以區分,即便是專業的醫護人員也會有漏診和誤診情況,所以急需一種分割方法實現皮膚病灶區域的自動分割。
傳統的分割方法在過去很長一段時間內占有主導地位,這類算法大多是對圖像表層信息的提取,最具代表性的算法有基于閾值[4-6]、區域[7-8]、聚類[9-11]、邊緣檢測[12-13]等。例如Glaister等[14]提出一種基于紋理清晰度(texture distinctiveness,TD)的皮膚病灶分割算法,該算法以TD度量為核心,在學習輸入圖片的稀疏紋理分布后,根據TD度量捕捉到的紋理分布之間的差異,合理設置閾值,將圖片分割為正常區域與病變區域。Masood等[15]提出一種基于聚類、閾值并結合模糊C均值算法的皮膚鏡圖像分割方法,首先用平滑濾波的方法對圖像進行預處理,再用模糊C均值使圖像中的每個像素和C聚類中心之間的加權相似性度量的目標函數最優,使得每個像素被準確分到某一類。
近年來,隨著深度學習方法的迅猛發展,圖像處理技術得到很大提升,圖像分割越來越多地用于醫學領域,利用計算機輔助診斷的方式也已廣泛應用于臨床診斷中,研究人員提出了各種算法以解決皮膚病灶圖像邊緣容易忽略、分割不準確的難點。Long等[16]開創性地提出一種全卷積神經網絡(fully convolutional network,FCN),以端到端的方式實現了圖像像素級別的分割,開創了語義分割的先河。而醫學領域圖像分割的真正流行,是在于Ronneberger等[17]提出具有編碼器-解碼器結構的U型網絡(U-Net),該網絡編碼部分與解碼部分完全對稱,為避免上下采樣造成的特征丟失,網絡在編碼與解碼之間采用跳躍連接的方式相連,實現高低級語義特征的融合。如今U-Net已經有多種變體,如巢穴U-Net (U-Net++)[18]、殘差U-Net(residual U-Net,Res-UNet)[19]、循環殘差U-Net(recurrent residual U-Net,R2U-Net)[20]、注意力U-Net(attention U-Net,Atten-UNet)[21]、改進巢穴U-Net(UNet3+)[22]等,這些變形網絡也被大量用在皮膚病灶圖像分割中。例如,Oktay等[21]將注意力機制加入到分割網絡中,擴展了卷積神經網絡的表達能力,自適應地學習特征權重,賦予重要特征更大的權重,更快速地學習皮膚病灶特征。Yuan等[23-24]提出一種新的基于杰卡德距離(Jaccard distance)的損失函數以實現皮膚病灶圖像的自動分割。Chen等[25]將變換器(Transformer)運用到醫學圖像分割,提出Transformer U-Net(Trans-UNet),能夠對像素信息進行精準定位,解決U-Net在顯式建模中的局限性。Valanarasu等[26]將多層感知機(multilayer perceptron,MLP)運用到U-Net網絡中形成新的分割網絡——感知器U-Net(UNeXt),大大減少了網絡參數量,實現皮膚病灶圖像的快速分割。但以上算法依然存在著大量不足:U-Net系列在上下采樣過程中容易造成空間信息丟失,導致分割精度下降;Transformer系列參數較多,計算量大,需要依靠強大的硬件設備,且捕捉局部特征的能力不足,尤其在醫學圖像這樣的小數據集身上。
針對上述問題,本文提出一種基于密集空洞空間金字塔池化(dense atrous spatial pyramid pooling,DenseASPP)和注意力機制的新型皮膚病灶圖像分割方法[27],文章的主要貢獻有:
(1)基于U-Net網絡,提出全新的編碼器-解碼器分割網絡,以端到端的方式訓練該網絡。對原始網絡的編碼器模塊進行了新的設計,以兩次殘差連接代替原來簡單的卷積(convolution,Conv)堆疊,有效解決上下采樣過程造成的特征丟失。
(2)引入空間注意力與通道注意力雙重高效注意力機制,賦予網絡學習病灶特征的能力,同時用殘差方式連接以提高網絡的編解碼能力。
(3)修改了瓶頸層的結構,重新設計的DenseASPP運用于瓶頸層,在擴大感受野的同時,通過密集跳躍連接來獲取不同高低級尺度的特征信息。
1 算法描述
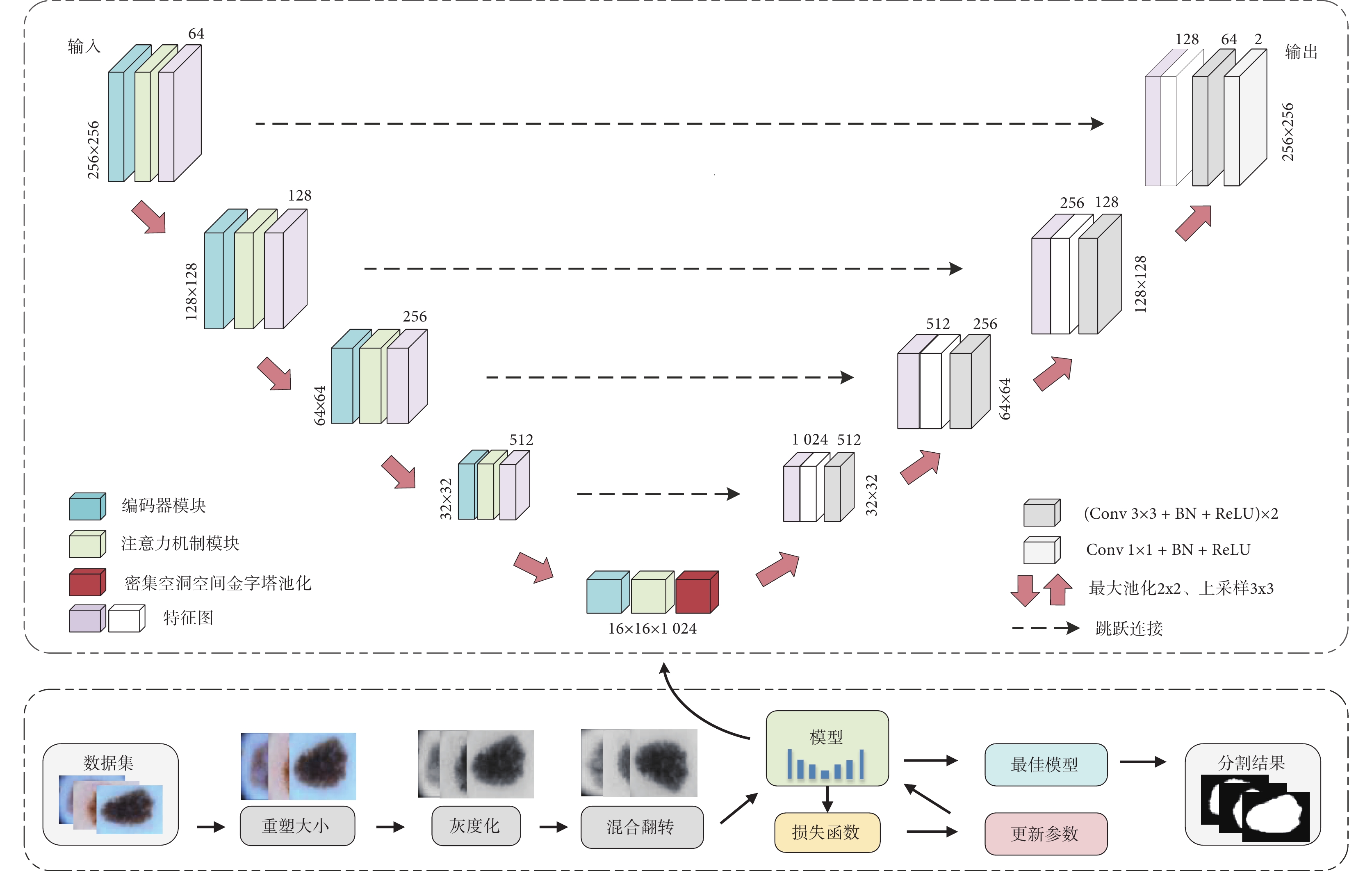
本文以U-Net模型為基礎,結合殘差網絡、空洞Conv、密集網絡以及注意力機制等思想,提出全新的皮膚病灶圖像分割模型,整體分割流程和網絡結構如圖1所示,其中模塊兩側數字表示圖片尺寸大小,模塊頂部數字表示通道數。不同尺寸大小的圖片在預處理階段進行統一裁剪、灰度化處理和翻轉操作,使得圖片大小統一為256 × 256,通道數目統一為1。圖片送入網絡后,依次經過5次下采樣和5次上采樣,下采樣過程中,圖片尺寸逐漸變小,通道逐漸增多,能夠有效提取病灶特征;上采樣過程中,圖片尺寸逐漸增大,通道數逐漸減少,病灶特征逐漸恢復。在上下采樣的中間,用了一層瓶頸層連接,瓶頸層加入新設計的DenseASPP模塊,用不同大小擴張系數的空洞Conv獲取多尺度信息。
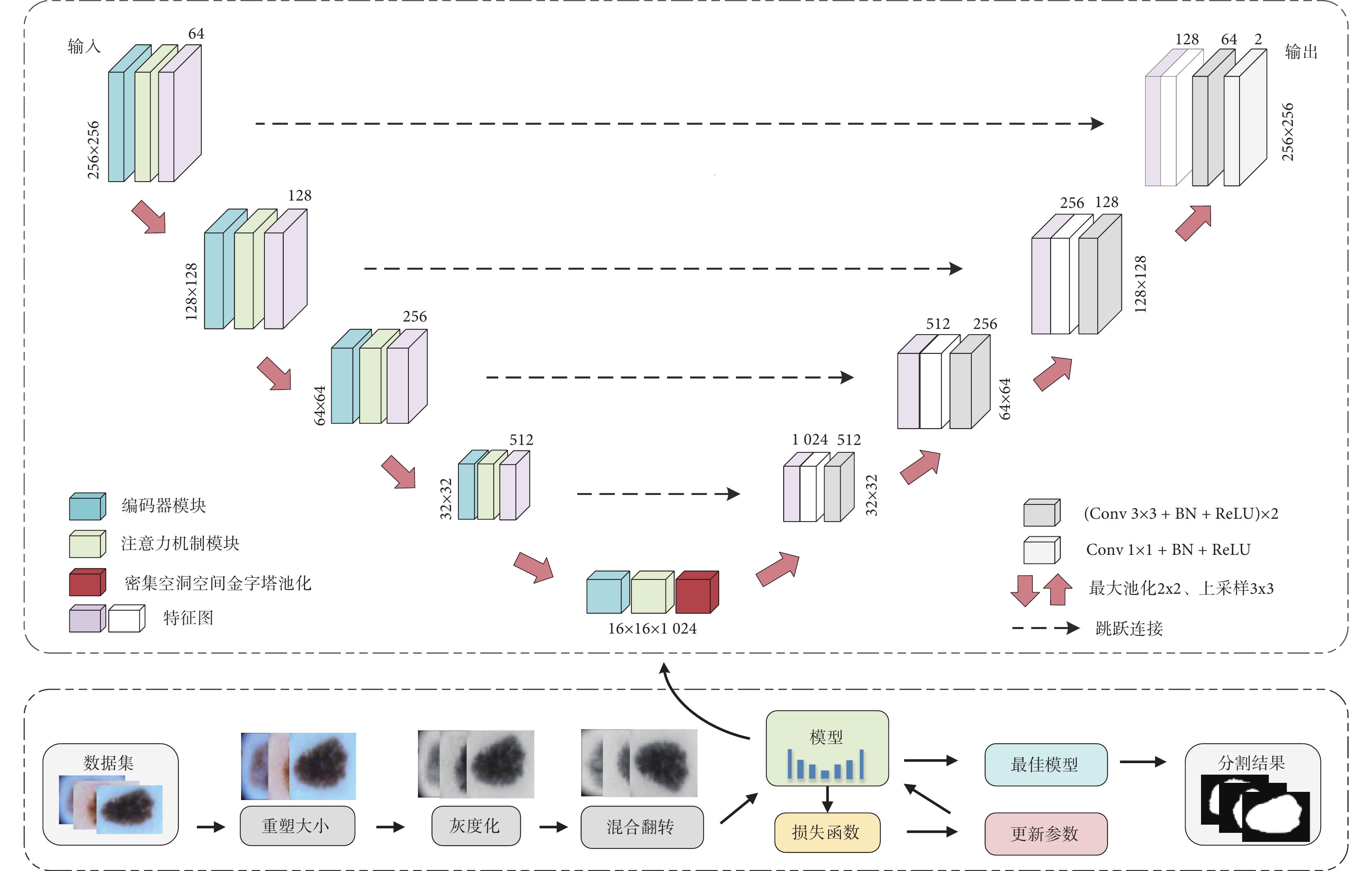 圖1
分割流程及網絡結構圖
Figure1.
Segmentation process and network structure
圖1
分割流程及網絡結構圖
Figure1.
Segmentation process and network structure
1.1 編碼器模塊
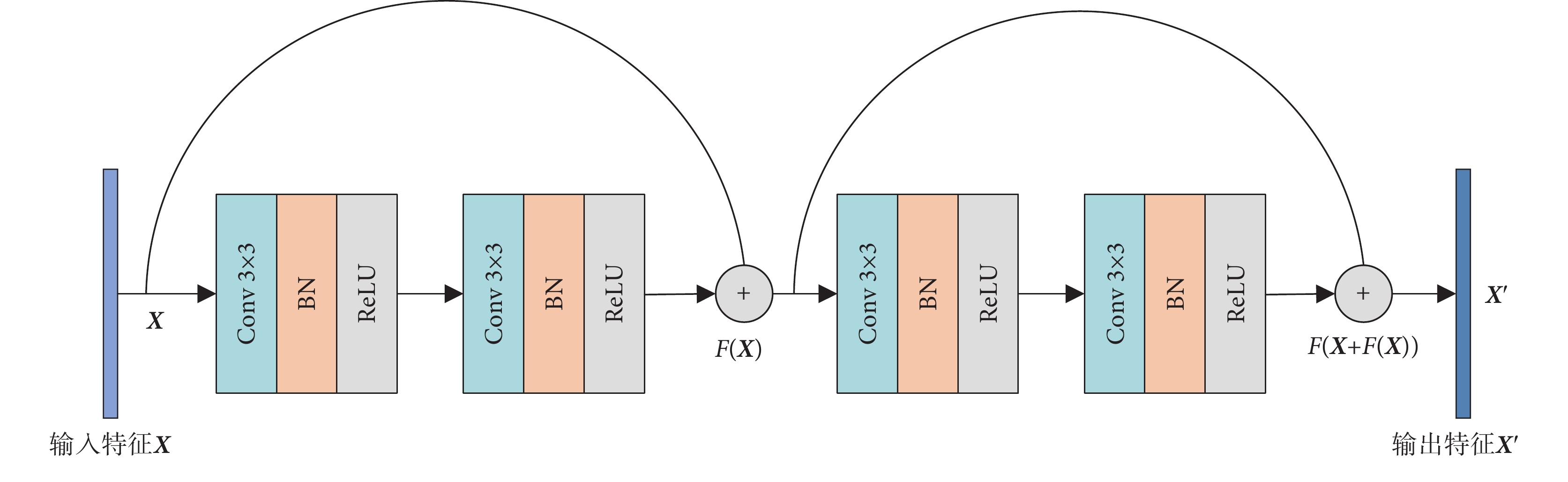
由于皮膚病灶圖像復雜,特征分布不均,需要經過多次重復運算才能提高模型的擬合能力,理論上來說,網絡越深,模型的擬合能力就越好。但在訓練的時候,隨著網絡層數的增多,網絡可能發生退化現象,反向傳播的特征不能及時返回,淺層特征得不到訓練,容易產生梯度消失和梯度爆炸的問題。原始U-Net在特征提取時,只運用了簡單的Conv和池化操作,重復的Conv操作雖然使得網絡深度得以加深,但在上下采樣過程中,不可避免會帶來上下文信息丟失,使得模型分割精度不足。為此,本文在編碼器模塊中引入殘差連接以替換原始網絡中簡單的Conv堆疊,如圖2所示。輸入特征X經過兩次Conv 3 × 3、批歸一化(batch normalization,BN)和線性修正單元( rectified linear units,ReLU) 得到F(X),F(X)與特征X相加之后再次送入第二個Conv 3 × 3、BN和ReLU得到最終特征向量  ,計算過程如式(1)所示:
,計算過程如式(1)所示:
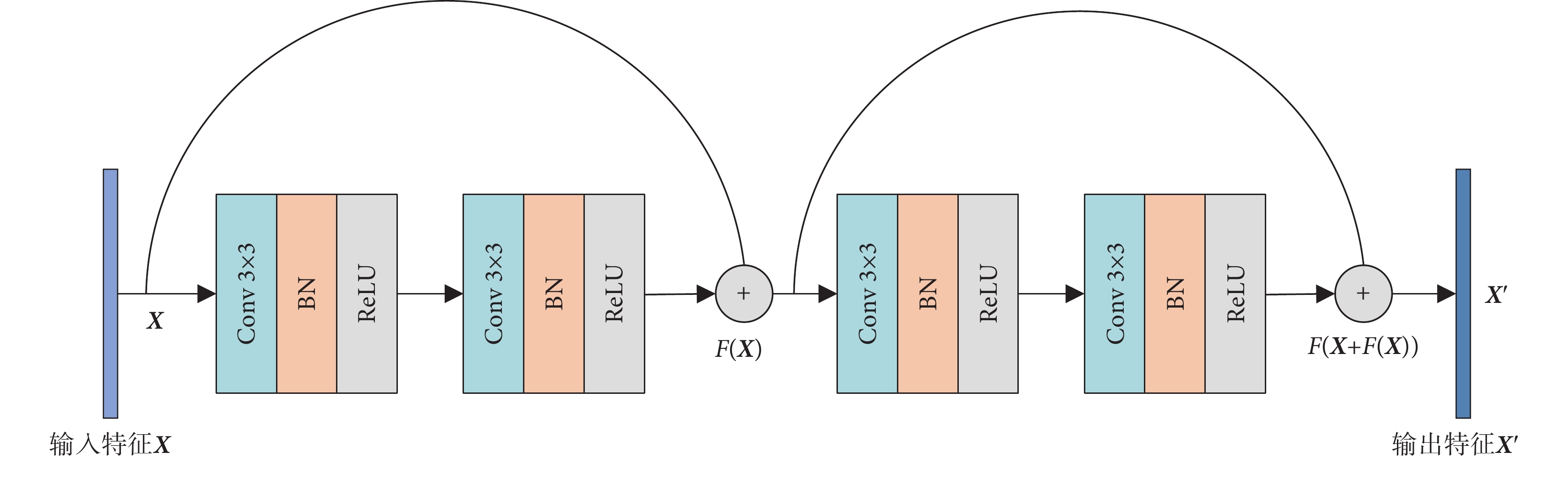 圖2
編碼器模塊
Figure2.
Encoder Module
圖2
編碼器模塊
Figure2.
Encoder Module
 '/> '/> |
這樣,新的網絡深度在編碼器部分就增加到了20層,擬合能力大大提升。同時,每一次下采樣的信息都會得到保留,下采樣的結果會通過跳躍連接的方式直接復制給上采樣,使得圖像細節特征不會丟失,更有利于皮膚病灶圖像分割。
1.2 密集空洞空間金字塔池化
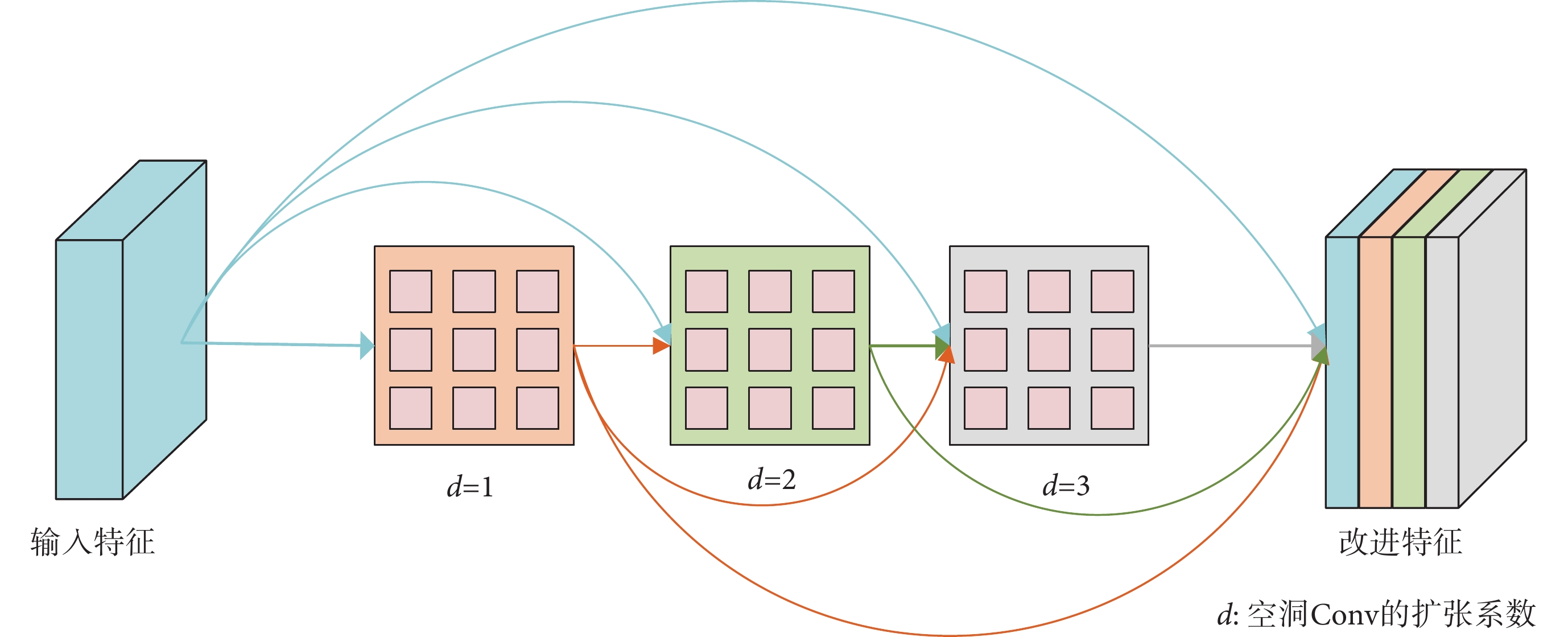
在深度學習中,通常用Conv來進行特征提取,但是當大量使用Conv操作時,容易導致參數過多、權重優化較難等問題[28]。為了更好地提取局部信息和全局信息,本文重新設計了DenseASPP用于瓶頸層,通過設置不同大小的擴張率得到具有不同感受野大小的特征圖,以捕獲分割目標的多尺度信息[29],新設計的DenseASPP結構如圖3所示。
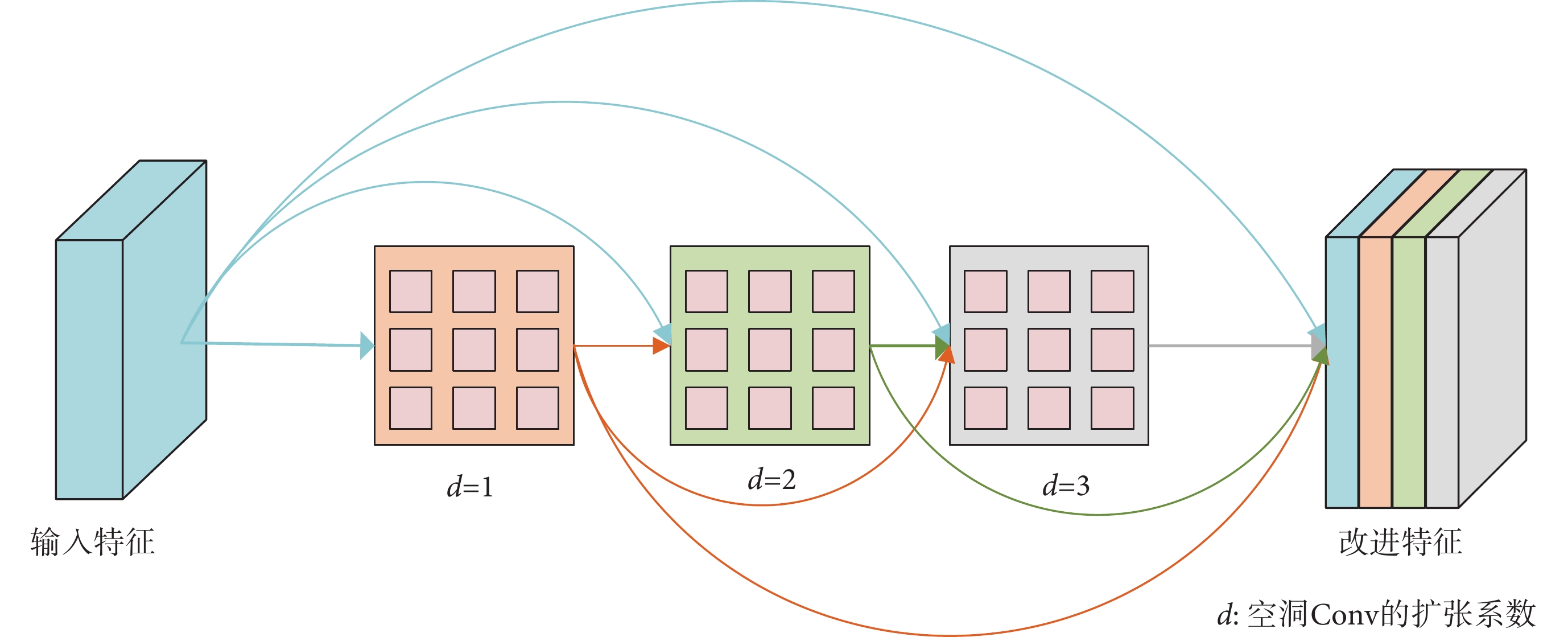 圖3
DenseASPP模式圖
Figure3.
Illustration of DenseASPP
圖3
DenseASPP模式圖
Figure3.
Illustration of DenseASPP
感受野的大小在深度神經網絡中有著舉足輕重的作用。一般來說感受野越大,神經元能夠接受輸入特征的信息就越多,就能夠更好捕捉全局信息;反之,感受野越小,神經元能夠接受輸入特征的信息就越少,就能夠更好捕捉局部信息。對于皮膚病灶圖像分割,全局信息與局部信息同樣重要,這就需要有不同大小的Conv核來同時獲取全局信息和局部信息,充分利用多尺度信息進行皮膚病灶圖像分割。原始DenseASPP作為獨立的一個網絡用于場景分割中,其結構包含5個擴張Conv,但過大的感受野會因為網格效應使得圖片的一些像素被忽略,丟失局部信息。為此,本文設計了空洞Conv擴張系數大小分別為1、2、3的DenseASPP,每個擴張系數分別對應一個尺度的擴張Conv,輸入特征采用密集連接的方式分別送入多個擴張Conv形成多條獨立分支,經過擴張Conv處理后,這些密集的獨立分支又會融合成一條支路,使得連接方式更密集,感受野大小也較為合理。
與空洞空間金字塔池化(atrous spatial pyramid pooling,ASPP)相比,DenseASPP采用了密集連接的方式,有著更密集的特征金字塔,能夠接受更多的圖片像素。圖3中,d 表示空洞Conv的擴張系數(dilation rate)。對于Conv核大小為K,擴張系數為d的空洞Conv,當前層感受野的理論大小如式(2)所示:
 |
若是兩個空洞Conv疊加,則感受野的理論大小如式(3)所示:
 |
在數據預處理階段,已經將圖片統一重塑為256 × 256的大小,在經過編碼網絡5次下采樣操作后,圖片大小變為16 × 16,故在DenseASPP模塊中,擴張系數d分別選擇為1、2、3。由式(2)和式(3)可以計算出,當前感受野的大小為13,已經超過特征圖像的一半且不大于特征圖像,可以很好地捕捉整張圖片的特征信息。利用稠密連接的方式將多個具有不同擴張系數的空洞Conv連接起來,在不降低空間維度的同時擴大感受野范圍,從而獲得多尺度信息[30],可以大大提高分割效果。
1.3 卷積模塊注意力機制
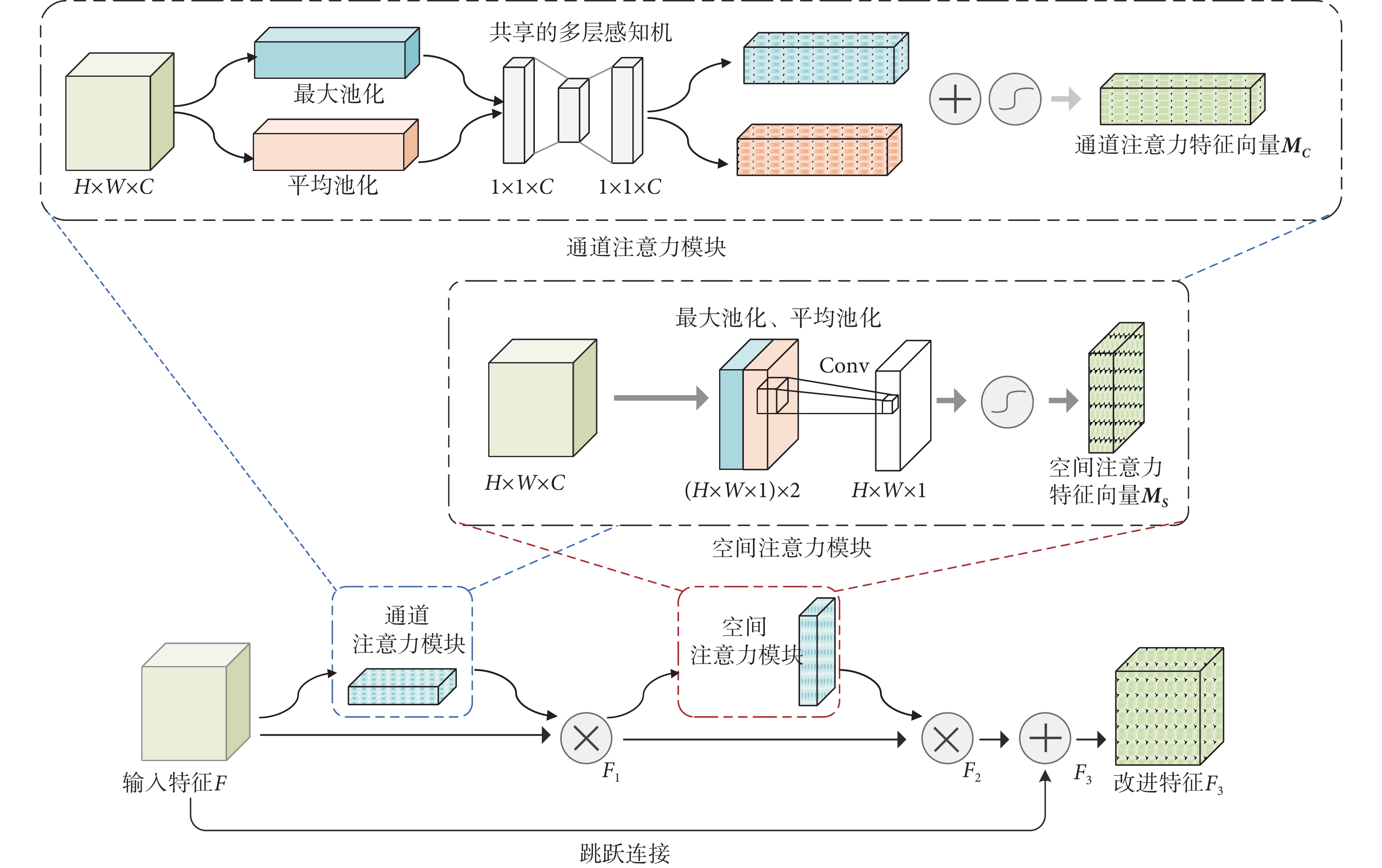
由于皮膚病灶區域邊界模糊,且常常伴有毛發遮擋,在進行圖像處理時往往難以準確分割,為此本文引入Conv模塊注意力機制(convolutional block attention module,CBAM)[31],讓模型增加注意力能力,重點關注病灶區域而忽略雜亂無章的背景信息。CBAM是一種軟注意力機制,與其他注意力機制不同的是,CBAM由通道注意力和空間注意力兩個模塊組成,是一種混合注意力機制,整體結構如圖4所示。
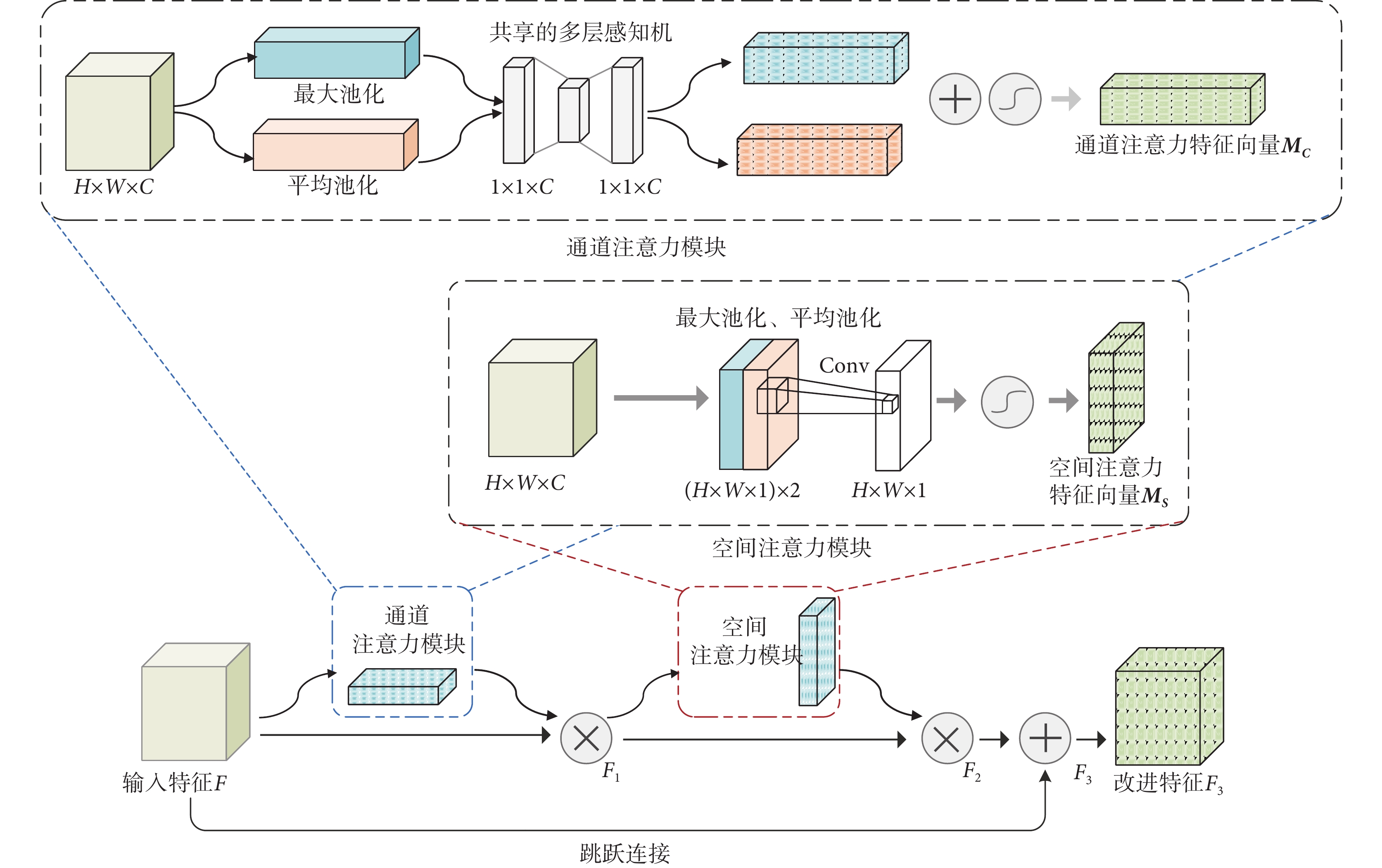 圖4
CBAM示意圖
Figure4.
Illustration of CBAM
圖4
CBAM示意圖
Figure4.
Illustration of CBAM
本文在CBAM中加入跳躍連接以防止特征丟失,同時將CBAM放于每一個解碼模塊后,每一次跳躍連接之前。輸入特征先后經過通道注意力與空間注意力模塊,并與原特征相加得到具有注意力權值的特征。其中,通道注意力關注“是什么”,即什么樣的特征需要被關注,具體過程如圖4中通道注意力模塊所示:給定輸入特征F的大小為H × W × C,F經過并行的最大池化和平均池化后得到兩個大小為1 × 1 × C的特征向量F’和F’’,再把F’和F’’分別送入同一個多層感知機進行參數共享,之后還原為1 × 1 × C的大小。最后把兩個特征向量相加送入S型生長曲線(sigmoid)函數激活,得到具有通道位置權重的特征向量MC(F),MC(F)大小為H × W × C,計算過程如式(4)所示:
 |
式中,σ代表sigmoid激活函數;多層感知機以符號MLP表示;平均池化以符號poolavg表示,最大池化以poolmax表示。
空間注意力關注“在哪里”,即哪里的特征需要被關注,具體過程如圖4中空間注意力模塊所示。經過通道注意力處理后的特征F1大小為H × W × C,F1通過最大池化和平均池化后得到兩個大小為H × W×1的特征向量F1’和F1’’,之后把F1’和F1’’拼接成H × W × 2的新向量,這個新向量送入Conv核大小為7 × 7,步長為1的Conv進行降維,并用sigmoid函數激活,最終得到具有空間位置權重的特征向量MS(F),MS(F)大小為H × W × 1。計算過程如式(5)所示:
 |
式中,σ代表sigmoid激活函數, 代表Conv核大小為7 × 7的Conv操作,平均池化以符號poolavg表示,最大池化以poolmax表示。
代表Conv核大小為7 × 7的Conv操作,平均池化以符號poolavg表示,最大池化以poolmax表示。
整體CBAM操作如下:輸入特征F與經過通道注意力機制處理后的MC(F)相乘得到F1,F1送入空間注意力機制處理得到MS(F),MS(F)與F1再次相乘得到改進特征F2,最后,輸入的F與F2相加得到改進特征F3,如式(6)~式(8)所示:
 |
 |
 |
式中, 表示特征相乘。
表示特征相乘。
2 實驗結果與分析
2.1 實施細節
本次實驗基于操作系統Windows(Microsoft Inc.,美國),深度學習框架PyTorch(Meta Inc.,美國)進行研究操作,中央處理器為Core(TM) i5-12 600 KF(Intel,美國),內存16 G,圖形處理器為RTX 3 060(NVIDIA,美國),顯存12 G,編程語言為Python 3.7(Centrum Wiskunde & Informatica,荷蘭)。
實驗采用均方根傳遞算法(root mean square prop,RMSProp)作為優化器,沖量設置為0.9,權重衰退為1 × 10?8,學習率設置為1 × 10?5。實驗采用分批策略進行訓練,批大小(batch size)為8,共迭代500個訓練周期,保存驗證集損失最低的模型作為最終模型。
訓練過程采用二元交叉熵損失函數(binary cross entropy loss function,BCE-Loss)(以符號L表示),其數學定義式如式(9)~式(10)所示:
 |
 |
其中,N為批處理的個數, 為第n個批處理所對應的損失值,
為第n個批處理所對應的損失值, 代表樣本n的真實標簽,
代表樣本n的真實標簽, 代表樣本n預測的輸出值,σ為sigmoid函數。
代表樣本n預測的輸出值,σ為sigmoid函數。
2.2 數據集與評價指標
數據集采用國際皮膚影像協會(International Skin Imaging Collaboration,ISIC)官方公開數據集ISIC 2016(網址:https://challenge.isic-archive.com/)[32]。該數據集共有訓練集圖像900張,測試集圖像379張,收錄多種皮膚病原圖并含有真實標簽圖。由于數據集圖像大小不一,且所有圖像分辨率均大于500 × 500,為節約計算資源,加快收斂速度,本次實驗將所有訓練圖片重塑為256 × 256的大小。同時,訓練數據在送入網絡時先進行了灰度化處理,并利用隨機水平、垂直及混合翻轉等數據增強方式進行數據集擴充。
評價指標是衡量一個算法優劣的直接體現,本文主要采用平均交并比(mean intersection over union,mIOU)、敏感度(sensitivity,SE)、精確率(precision,PC)、準確率(accuracy,ACC)和戴斯相似性系數(Dice)五種指標進行算法評價。各指標數學定義式如式(11)~式(15)所示:
 |
 |
 |
 |
 |
式中,真陽性(true positive,TP)表示模型正確分割出手工標簽圖病灶區域的樣本數;真陰性(true negative,TN)表示模型正確分割出背景區域的樣本數;假陽性(false positive,FP)表示模型將背景誤分為手工標簽圖病灶區域的樣本數;假陰性(false negative,FN)表示模型將手工標簽圖病灶區域誤分為背景的樣本數。其中,對于mIOU來說,C = 2,表示分割任務中的類別數,即病灶區域和背景區域兩類。理論上來說,上述指標越接近于1,分割效果越好。
2.3 實驗結果及分析
為驗證本文模型的優劣,本文與U-Net、UNet++、UNeXt等模型對比,結果如表1所示,其中最優指標加粗顯示。表1內數據均采用作者官方公布的代碼重新訓練,除了網絡模型不同,其他訓練環境均相同。
由表1可以看出,在數據集ISIC 2016中,本文算法在mIOU、PC、ACC和Dice四個指標中得分均為最優,SE位列第三位。但相比原始U-Net網絡,五個指標均有大幅提升。圖像分割中mIOU是一個極為重要的指標,本文模型相比其他各組均有較大提升,說明本文模型的編碼器能夠有效提取皮膚病灶特征,解碼器能夠有效恢復圖像特征。BCE-Loss函數的使用,更有效地降低了外界噪聲的干擾,并保留了更多病灶邊緣信息。同時,Dice系數、ACC、SE和PC也有不同程度的提高,說明本文模型能夠更加有效地平衡病灶區域與背景區域,能夠有效提高復雜背景下的皮膚病灶圖像分割效果。
為了更直觀有效地顯示不同算法的皮膚病灶圖像分割效果,圖5選取了各模型的部分分割結果圖,本文隨機選取了8例患者,每一行代表一例患者,以其在數據集ISIC 2016中的名稱為名。其中第1列和第9列分別為皮膚病灶圖像原圖和對應的手工標簽圖,第2~7列分別為R2U-Net[17]、U-Net[14]、U-Net++[15]、UNeXt[23]、UNet3+[19]、Atten-UNet[18] 的分割結果圖,第8列為本文模型的分割結果圖。從圖5中可以看到,UNeXt對細節顏色相似的地方不能有效區分,Atten-UNet對于大面積的病灶區域分割效果較好,但邊緣不平滑,UNet++在進行分割時會出現空洞現象,U-Net 、R2U-Net和UNet3+存在大量漏檢誤檢現象,容易把背景和病灶區域誤分。由于早期的皮膚疾病患者病變不明顯,病灶區域與正常皮膚相似度較高,如圖5第2、3行所示,U-Net、U-Net++和UNet3+都把正常皮膚顏色較深的區域當做病灶區域,而病灶區域較淺的地方被誤認為正常區域,誤檢現象十分明顯。同時,由于皮膚疾病的特殊性,病灶區域經常藏匿于毛發之下,毛發遮擋常常成為分割的難點,如圖5第5行所示,R2U-Net、U-Net++以及UNeXt都不能準確識別病灶區域與毛發區域,在毛發與病灶區域的邊緣分割粗糙,呈現毛發的輪廓。相比之下,本文算法對于毛發遮擋的地方,模型不僅能夠準確識別毛發與病灶區域,還能平滑地將其分割開來,病灶邊緣分割更準確平滑,細節部位能更好地保留,在病變區域和背景極為相似的地方也能夠做到精準分割,不會把正常皮膚與病灶區域相混淆,漏檢和誤檢現象基本沒有,分割效果更勝一籌。
 圖5
不同網絡模型在數據集ISIC 2016的可視化分割結果
Figure5.
Visualization of segmentation results of different network models on ISIC 2016 dataset
圖5
不同網絡模型在數據集ISIC 2016的可視化分割結果
Figure5.
Visualization of segmentation results of different network models on ISIC 2016 dataset
2.4 消融實驗
為驗證所提模型對分割效果的有效性,本文進行了模塊消融實驗,對本文所提出的三個模塊:編碼器模塊、CBAM、DenseASPP,以及CBAM中的跳躍連接進行消融實驗,結果如表2所示。
表2第1行,為未對網絡做任何改變的基準模型,即標準U-Net模型;第2行為僅修改編碼器模塊的網絡模型,第3~5行是分別在第2行的基礎上依次加入CBAM、跳躍連接以及DenseASPP的網絡模型。由表2內數據可以看到,5個評價指標均呈上升趨勢,尤其是CBAM的加入,mIOU指標數值上升明顯,其余4個指標SE、PC、ACC、Dice也都有所增長。各模塊的加入對5個評價指標均有不同程度的提升,這表明不同模塊的合理組合有利于提高皮膚病灶分割的性能,本文所提出的模塊是有效的。
3 結論
本文提出一種基于DenseASPP和注意力機制的皮膚病灶圖像分割方法,設計了3個新的網絡模塊:編碼器模塊、DenseASPP和CBAM。編碼器對皮膚病灶圖像進行特征提取,注意力機制關注病灶特征信息使得分割更加精準,同時利用DenseASPP來擴大感受野的范圍以獲取多尺度特征信息。本研究通過5個評價指標合理評價算法,并通過消融實驗證明所提模塊的有效性,在數據集ISIC 2016中取得最高的mIOU、PC、ACC和Dice。本文方法的提出為圖像分割提供了新的思路,有望為專業醫生提供相關醫學參考。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:尹穩負責算法設計與實現、數據處理與分析、論文寫作與修改;周冬明提供實驗指導及論文審閱修訂;范騰和余卓璞參與數據集收集及預處理;李禎負責整理實驗結果。
引言
皮膚病是一種常見的身體疾病。皮膚病的種類繁多,很多內臟疾病會直接體現在皮膚上。近年來,以黑色素瘤為代表的色素障礙性皮膚病發病率逐年上升。據美國癌癥協會(American cancer society,ACS)統計,2022 年美國新增黑色素瘤患者將達到99 780例,預計死亡病例達7 650例[1]。但如果能在早期發現黑色素瘤,其 5 年生存率可達到90% 以上[2]。因此,快速診斷并治療黑色素瘤對挽救患者生命具有重要意義。目前,皮膚病的診斷方法大多依賴皮膚鏡技術[3],皮膚病灶圖像分割可快速分離出正常區域與病變區域,能夠為皮膚鏡檢查提供關鍵依據。但早期皮膚病患者病灶區域顏色淺、邊緣模糊,且病變區域常常藏匿于毛發之間,與正常皮膚和常見的良性痣難以區分,即便是專業的醫護人員也會有漏診和誤診情況,所以急需一種分割方法實現皮膚病灶區域的自動分割。
傳統的分割方法在過去很長一段時間內占有主導地位,這類算法大多是對圖像表層信息的提取,最具代表性的算法有基于閾值[4-6]、區域[7-8]、聚類[9-11]、邊緣檢測[12-13]等。例如Glaister等[14]提出一種基于紋理清晰度(texture distinctiveness,TD)的皮膚病灶分割算法,該算法以TD度量為核心,在學習輸入圖片的稀疏紋理分布后,根據TD度量捕捉到的紋理分布之間的差異,合理設置閾值,將圖片分割為正常區域與病變區域。Masood等[15]提出一種基于聚類、閾值并結合模糊C均值算法的皮膚鏡圖像分割方法,首先用平滑濾波的方法對圖像進行預處理,再用模糊C均值使圖像中的每個像素和C聚類中心之間的加權相似性度量的目標函數最優,使得每個像素被準確分到某一類。
近年來,隨著深度學習方法的迅猛發展,圖像處理技術得到很大提升,圖像分割越來越多地用于醫學領域,利用計算機輔助診斷的方式也已廣泛應用于臨床診斷中,研究人員提出了各種算法以解決皮膚病灶圖像邊緣容易忽略、分割不準確的難點。Long等[16]開創性地提出一種全卷積神經網絡(fully convolutional network,FCN),以端到端的方式實現了圖像像素級別的分割,開創了語義分割的先河。而醫學領域圖像分割的真正流行,是在于Ronneberger等[17]提出具有編碼器-解碼器結構的U型網絡(U-Net),該網絡編碼部分與解碼部分完全對稱,為避免上下采樣造成的特征丟失,網絡在編碼與解碼之間采用跳躍連接的方式相連,實現高低級語義特征的融合。如今U-Net已經有多種變體,如巢穴U-Net (U-Net++)[18]、殘差U-Net(residual U-Net,Res-UNet)[19]、循環殘差U-Net(recurrent residual U-Net,R2U-Net)[20]、注意力U-Net(attention U-Net,Atten-UNet)[21]、改進巢穴U-Net(UNet3+)[22]等,這些變形網絡也被大量用在皮膚病灶圖像分割中。例如,Oktay等[21]將注意力機制加入到分割網絡中,擴展了卷積神經網絡的表達能力,自適應地學習特征權重,賦予重要特征更大的權重,更快速地學習皮膚病灶特征。Yuan等[23-24]提出一種新的基于杰卡德距離(Jaccard distance)的損失函數以實現皮膚病灶圖像的自動分割。Chen等[25]將變換器(Transformer)運用到醫學圖像分割,提出Transformer U-Net(Trans-UNet),能夠對像素信息進行精準定位,解決U-Net在顯式建模中的局限性。Valanarasu等[26]將多層感知機(multilayer perceptron,MLP)運用到U-Net網絡中形成新的分割網絡——感知器U-Net(UNeXt),大大減少了網絡參數量,實現皮膚病灶圖像的快速分割。但以上算法依然存在著大量不足:U-Net系列在上下采樣過程中容易造成空間信息丟失,導致分割精度下降;Transformer系列參數較多,計算量大,需要依靠強大的硬件設備,且捕捉局部特征的能力不足,尤其在醫學圖像這樣的小數據集身上。
針對上述問題,本文提出一種基于密集空洞空間金字塔池化(dense atrous spatial pyramid pooling,DenseASPP)和注意力機制的新型皮膚病灶圖像分割方法[27],文章的主要貢獻有:
(1)基于U-Net網絡,提出全新的編碼器-解碼器分割網絡,以端到端的方式訓練該網絡。對原始網絡的編碼器模塊進行了新的設計,以兩次殘差連接代替原來簡單的卷積(convolution,Conv)堆疊,有效解決上下采樣過程造成的特征丟失。
(2)引入空間注意力與通道注意力雙重高效注意力機制,賦予網絡學習病灶特征的能力,同時用殘差方式連接以提高網絡的編解碼能力。
(3)修改了瓶頸層的結構,重新設計的DenseASPP運用于瓶頸層,在擴大感受野的同時,通過密集跳躍連接來獲取不同高低級尺度的特征信息。
1 算法描述
本文以U-Net模型為基礎,結合殘差網絡、空洞Conv、密集網絡以及注意力機制等思想,提出全新的皮膚病灶圖像分割模型,整體分割流程和網絡結構如圖1所示,其中模塊兩側數字表示圖片尺寸大小,模塊頂部數字表示通道數。不同尺寸大小的圖片在預處理階段進行統一裁剪、灰度化處理和翻轉操作,使得圖片大小統一為256 × 256,通道數目統一為1。圖片送入網絡后,依次經過5次下采樣和5次上采樣,下采樣過程中,圖片尺寸逐漸變小,通道逐漸增多,能夠有效提取病灶特征;上采樣過程中,圖片尺寸逐漸增大,通道數逐漸減少,病灶特征逐漸恢復。在上下采樣的中間,用了一層瓶頸層連接,瓶頸層加入新設計的DenseASPP模塊,用不同大小擴張系數的空洞Conv獲取多尺度信息。
圖1
分割流程及網絡結構圖
Figure1.
Segmentation process and network structure
1.1 編碼器模塊
由于皮膚病灶圖像復雜,特征分布不均,需要經過多次重復運算才能提高模型的擬合能力,理論上來說,網絡越深,模型的擬合能力就越好。但在訓練的時候,隨著網絡層數的增多,網絡可能發生退化現象,反向傳播的特征不能及時返回,淺層特征得不到訓練,容易產生梯度消失和梯度爆炸的問題。原始U-Net在特征提取時,只運用了簡單的Conv和池化操作,重復的Conv操作雖然使得網絡深度得以加深,但在上下采樣過程中,不可避免會帶來上下文信息丟失,使得模型分割精度不足。為此,本文在編碼器模塊中引入殘差連接以替換原始網絡中簡單的Conv堆疊,如圖2所示。輸入特征X經過兩次Conv 3 × 3、批歸一化(batch normalization,BN)和線性修正單元( rectified linear units,ReLU) 得到F(X),F(X)與特征X相加之后再次送入第二個Conv 3 × 3、BN和ReLU得到最終特征向量 ,計算過程如式(1)所示:
圖2
編碼器模塊
Figure2.
Encoder Module
| '/> |
這樣,新的網絡深度在編碼器部分就增加到了20層,擬合能力大大提升。同時,每一次下采樣的信息都會得到保留,下采樣的結果會通過跳躍連接的方式直接復制給上采樣,使得圖像細節特征不會丟失,更有利于皮膚病灶圖像分割。
1.2 密集空洞空間金字塔池化
在深度學習中,通常用Conv來進行特征提取,但是當大量使用Conv操作時,容易導致參數過多、權重優化較難等問題[28]。為了更好地提取局部信息和全局信息,本文重新設計了DenseASPP用于瓶頸層,通過設置不同大小的擴張率得到具有不同感受野大小的特征圖,以捕獲分割目標的多尺度信息[29],新設計的DenseASPP結構如圖3所示。
圖3
DenseASPP模式圖
Figure3.
Illustration of DenseASPP
感受野的大小在深度神經網絡中有著舉足輕重的作用。一般來說感受野越大,神經元能夠接受輸入特征的信息就越多,就能夠更好捕捉全局信息;反之,感受野越小,神經元能夠接受輸入特征的信息就越少,就能夠更好捕捉局部信息。對于皮膚病灶圖像分割,全局信息與局部信息同樣重要,這就需要有不同大小的Conv核來同時獲取全局信息和局部信息,充分利用多尺度信息進行皮膚病灶圖像分割。原始DenseASPP作為獨立的一個網絡用于場景分割中,其結構包含5個擴張Conv,但過大的感受野會因為網格效應使得圖片的一些像素被忽略,丟失局部信息。為此,本文設計了空洞Conv擴張系數大小分別為1、2、3的DenseASPP,每個擴張系數分別對應一個尺度的擴張Conv,輸入特征采用密集連接的方式分別送入多個擴張Conv形成多條獨立分支,經過擴張Conv處理后,這些密集的獨立分支又會融合成一條支路,使得連接方式更密集,感受野大小也較為合理。
與空洞空間金字塔池化(atrous spatial pyramid pooling,ASPP)相比,DenseASPP采用了密集連接的方式,有著更密集的特征金字塔,能夠接受更多的圖片像素。圖3中,d 表示空洞Conv的擴張系數(dilation rate)。對于Conv核大小為K,擴張系數為d的空洞Conv,當前層感受野的理論大小如式(2)所示:
|
若是兩個空洞Conv疊加,則感受野的理論大小如式(3)所示:
|
在數據預處理階段,已經將圖片統一重塑為256 × 256的大小,在經過編碼網絡5次下采樣操作后,圖片大小變為16 × 16,故在DenseASPP模塊中,擴張系數d分別選擇為1、2、3。由式(2)和式(3)可以計算出,當前感受野的大小為13,已經超過特征圖像的一半且不大于特征圖像,可以很好地捕捉整張圖片的特征信息。利用稠密連接的方式將多個具有不同擴張系數的空洞Conv連接起來,在不降低空間維度的同時擴大感受野范圍,從而獲得多尺度信息[30],可以大大提高分割效果。
1.3 卷積模塊注意力機制
由于皮膚病灶區域邊界模糊,且常常伴有毛發遮擋,在進行圖像處理時往往難以準確分割,為此本文引入Conv模塊注意力機制(convolutional block attention module,CBAM)[31],讓模型增加注意力能力,重點關注病灶區域而忽略雜亂無章的背景信息。CBAM是一種軟注意力機制,與其他注意力機制不同的是,CBAM由通道注意力和空間注意力兩個模塊組成,是一種混合注意力機制,整體結構如圖4所示。
圖4
CBAM示意圖
Figure4.
Illustration of CBAM
本文在CBAM中加入跳躍連接以防止特征丟失,同時將CBAM放于每一個解碼模塊后,每一次跳躍連接之前。輸入特征先后經過通道注意力與空間注意力模塊,并與原特征相加得到具有注意力權值的特征。其中,通道注意力關注“是什么”,即什么樣的特征需要被關注,具體過程如圖4中通道注意力模塊所示:給定輸入特征F的大小為H × W × C,F經過并行的最大池化和平均池化后得到兩個大小為1 × 1 × C的特征向量F’和F’’,再把F’和F’’分別送入同一個多層感知機進行參數共享,之后還原為1 × 1 × C的大小。最后把兩個特征向量相加送入S型生長曲線(sigmoid)函數激活,得到具有通道位置權重的特征向量MC(F),MC(F)大小為H × W × C,計算過程如式(4)所示:
|
式中,σ代表sigmoid激活函數;多層感知機以符號MLP表示;平均池化以符號poolavg表示,最大池化以poolmax表示。
空間注意力關注“在哪里”,即哪里的特征需要被關注,具體過程如圖4中空間注意力模塊所示。經過通道注意力處理后的特征F1大小為H × W × C,F1通過最大池化和平均池化后得到兩個大小為H × W×1的特征向量F1’和F1’’,之后把F1’和F1’’拼接成H × W × 2的新向量,這個新向量送入Conv核大小為7 × 7,步長為1的Conv進行降維,并用sigmoid函數激活,最終得到具有空間位置權重的特征向量MS(F),MS(F)大小為H × W × 1。計算過程如式(5)所示:
|
式中,σ代表sigmoid激活函數, 代表Conv核大小為7 × 7的Conv操作,平均池化以符號poolavg表示,最大池化以poolmax表示。
整體CBAM操作如下:輸入特征F與經過通道注意力機制處理后的MC(F)相乘得到F1,F1送入空間注意力機制處理得到MS(F),MS(F)與F1再次相乘得到改進特征F2,最后,輸入的F與F2相加得到改進特征F3,如式(6)~式(8)所示:
|
|
|
式中, 表示特征相乘。
2 實驗結果與分析
2.1 實施細節
本次實驗基于操作系統Windows(Microsoft Inc.,美國),深度學習框架PyTorch(Meta Inc.,美國)進行研究操作,中央處理器為Core(TM) i5-12 600 KF(Intel,美國),內存16 G,圖形處理器為RTX 3 060(NVIDIA,美國),顯存12 G,編程語言為Python 3.7(Centrum Wiskunde & Informatica,荷蘭)。
實驗采用均方根傳遞算法(root mean square prop,RMSProp)作為優化器,沖量設置為0.9,權重衰退為1 × 10?8,學習率設置為1 × 10?5。實驗采用分批策略進行訓練,批大小(batch size)為8,共迭代500個訓練周期,保存驗證集損失最低的模型作為最終模型。
訓練過程采用二元交叉熵損失函數(binary cross entropy loss function,BCE-Loss)(以符號L表示),其數學定義式如式(9)~式(10)所示:
|
|
其中,N為批處理的個數,為第n個批處理所對應的損失值,代表樣本n的真實標簽,代表樣本n預測的輸出值,σ為sigmoid函數。
2.2 數據集與評價指標
數據集采用國際皮膚影像協會(International Skin Imaging Collaboration,ISIC)官方公開數據集ISIC 2016(網址:https://challenge.isic-archive.com/)[32]。該數據集共有訓練集圖像900張,測試集圖像379張,收錄多種皮膚病原圖并含有真實標簽圖。由于數據集圖像大小不一,且所有圖像分辨率均大于500 × 500,為節約計算資源,加快收斂速度,本次實驗將所有訓練圖片重塑為256 × 256的大小。同時,訓練數據在送入網絡時先進行了灰度化處理,并利用隨機水平、垂直及混合翻轉等數據增強方式進行數據集擴充。
評價指標是衡量一個算法優劣的直接體現,本文主要采用平均交并比(mean intersection over union,mIOU)、敏感度(sensitivity,SE)、精確率(precision,PC)、準確率(accuracy,ACC)和戴斯相似性系數(Dice)五種指標進行算法評價。各指標數學定義式如式(11)~式(15)所示:
|
|
|
|
|
式中,真陽性(true positive,TP)表示模型正確分割出手工標簽圖病灶區域的樣本數;真陰性(true negative,TN)表示模型正確分割出背景區域的樣本數;假陽性(false positive,FP)表示模型將背景誤分為手工標簽圖病灶區域的樣本數;假陰性(false negative,FN)表示模型將手工標簽圖病灶區域誤分為背景的樣本數。其中,對于mIOU來說,C = 2,表示分割任務中的類別數,即病灶區域和背景區域兩類。理論上來說,上述指標越接近于1,分割效果越好。
2.3 實驗結果及分析
為驗證本文模型的優劣,本文與U-Net、UNet++、UNeXt等模型對比,結果如表1所示,其中最優指標加粗顯示。表1內數據均采用作者官方公布的代碼重新訓練,除了網絡模型不同,其他訓練環境均相同。
由表1可以看出,在數據集ISIC 2016中,本文算法在mIOU、PC、ACC和Dice四個指標中得分均為最優,SE位列第三位。但相比原始U-Net網絡,五個指標均有大幅提升。圖像分割中mIOU是一個極為重要的指標,本文模型相比其他各組均有較大提升,說明本文模型的編碼器能夠有效提取皮膚病灶特征,解碼器能夠有效恢復圖像特征。BCE-Loss函數的使用,更有效地降低了外界噪聲的干擾,并保留了更多病灶邊緣信息。同時,Dice系數、ACC、SE和PC也有不同程度的提高,說明本文模型能夠更加有效地平衡病灶區域與背景區域,能夠有效提高復雜背景下的皮膚病灶圖像分割效果。
為了更直觀有效地顯示不同算法的皮膚病灶圖像分割效果,圖5選取了各模型的部分分割結果圖,本文隨機選取了8例患者,每一行代表一例患者,以其在數據集ISIC 2016中的名稱為名。其中第1列和第9列分別為皮膚病灶圖像原圖和對應的手工標簽圖,第2~7列分別為R2U-Net[17]、U-Net[14]、U-Net++[15]、UNeXt[23]、UNet3+[19]、Atten-UNet[18] 的分割結果圖,第8列為本文模型的分割結果圖。從圖5中可以看到,UNeXt對細節顏色相似的地方不能有效區分,Atten-UNet對于大面積的病灶區域分割效果較好,但邊緣不平滑,UNet++在進行分割時會出現空洞現象,U-Net 、R2U-Net和UNet3+存在大量漏檢誤檢現象,容易把背景和病灶區域誤分。由于早期的皮膚疾病患者病變不明顯,病灶區域與正常皮膚相似度較高,如圖5第2、3行所示,U-Net、U-Net++和UNet3+都把正常皮膚顏色較深的區域當做病灶區域,而病灶區域較淺的地方被誤認為正常區域,誤檢現象十分明顯。同時,由于皮膚疾病的特殊性,病灶區域經常藏匿于毛發之下,毛發遮擋常常成為分割的難點,如圖5第5行所示,R2U-Net、U-Net++以及UNeXt都不能準確識別病灶區域與毛發區域,在毛發與病灶區域的邊緣分割粗糙,呈現毛發的輪廓。相比之下,本文算法對于毛發遮擋的地方,模型不僅能夠準確識別毛發與病灶區域,還能平滑地將其分割開來,病灶邊緣分割更準確平滑,細節部位能更好地保留,在病變區域和背景極為相似的地方也能夠做到精準分割,不會把正常皮膚與病灶區域相混淆,漏檢和誤檢現象基本沒有,分割效果更勝一籌。
圖5
不同網絡模型在數據集ISIC 2016的可視化分割結果
Figure5.
Visualization of segmentation results of different network models on ISIC 2016 dataset
2.4 消融實驗
為驗證所提模型對分割效果的有效性,本文進行了模塊消融實驗,對本文所提出的三個模塊:編碼器模塊、CBAM、DenseASPP,以及CBAM中的跳躍連接進行消融實驗,結果如表2所示。
表2第1行,為未對網絡做任何改變的基準模型,即標準U-Net模型;第2行為僅修改編碼器模塊的網絡模型,第3~5行是分別在第2行的基礎上依次加入CBAM、跳躍連接以及DenseASPP的網絡模型。由表2內數據可以看到,5個評價指標均呈上升趨勢,尤其是CBAM的加入,mIOU指標數值上升明顯,其余4個指標SE、PC、ACC、Dice也都有所增長。各模塊的加入對5個評價指標均有不同程度的提升,這表明不同模塊的合理組合有利于提高皮膚病灶分割的性能,本文所提出的模塊是有效的。
3 結論
本文提出一種基于DenseASPP和注意力機制的皮膚病灶圖像分割方法,設計了3個新的網絡模塊:編碼器模塊、DenseASPP和CBAM。編碼器對皮膚病灶圖像進行特征提取,注意力機制關注病灶特征信息使得分割更加精準,同時利用DenseASPP來擴大感受野的范圍以獲取多尺度特征信息。本研究通過5個評價指標合理評價算法,并通過消融實驗證明所提模塊的有效性,在數據集ISIC 2016中取得最高的mIOU、PC、ACC和Dice。本文方法的提出為圖像分割提供了新的思路,有望為專業醫生提供相關醫學參考。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:尹穩負責算法設計與實現、數據處理與分析、論文寫作與修改;周冬明提供實驗指導及論文審閱修訂;范騰和余卓璞參與數據集收集及預處理;李禎負責整理實驗結果。