青光眼是致盲性眼病之一,視杯盤比是篩查青光眼的主要依據,因此準確分割視杯盤具有重要意義。本文提出一種基于線性化注意力和雙重注意力的視杯盤分割模型。首先,根據視盤特性定位裁剪感興趣區域。其次,引入線性化注意力的殘差網絡-34(ResNet-34)作為特征提取網絡。最后,通過線性化注意力的輸出特征生成通道和空間雙重注意力權重,用于校準解碼器輸出特征獲取視杯盤分割圖像。實驗結果表明,所提模型在視神經頭分割的視網膜圖像(DRISHTI-GS)數據集中,視盤、視杯交并比分別為0.962 3、0.856 4;用于視神經評估的開放式視網膜圖像-V3(RIM-ONE-V3)數據集中,視盤、視杯交并比分別為0.956 3、0.784 4。所提模型優于對比算法,在青光眼的早期篩查中具有一定的醫學價值。此外,本文利用知識蒸餾技術生成兩種規模更小的模型,有利于將模型應用于嵌入式設備。
引用本文: 藍子俊, 謝珺, 郭燕, 張喆, 孫彬. 基于線性化注意力和雙重注意力的視杯盤分割模型. 生物醫學工程學雜志, 2023, 40(5): 920-927. doi: 10.7507/1001-5515.202208061 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
0 引言
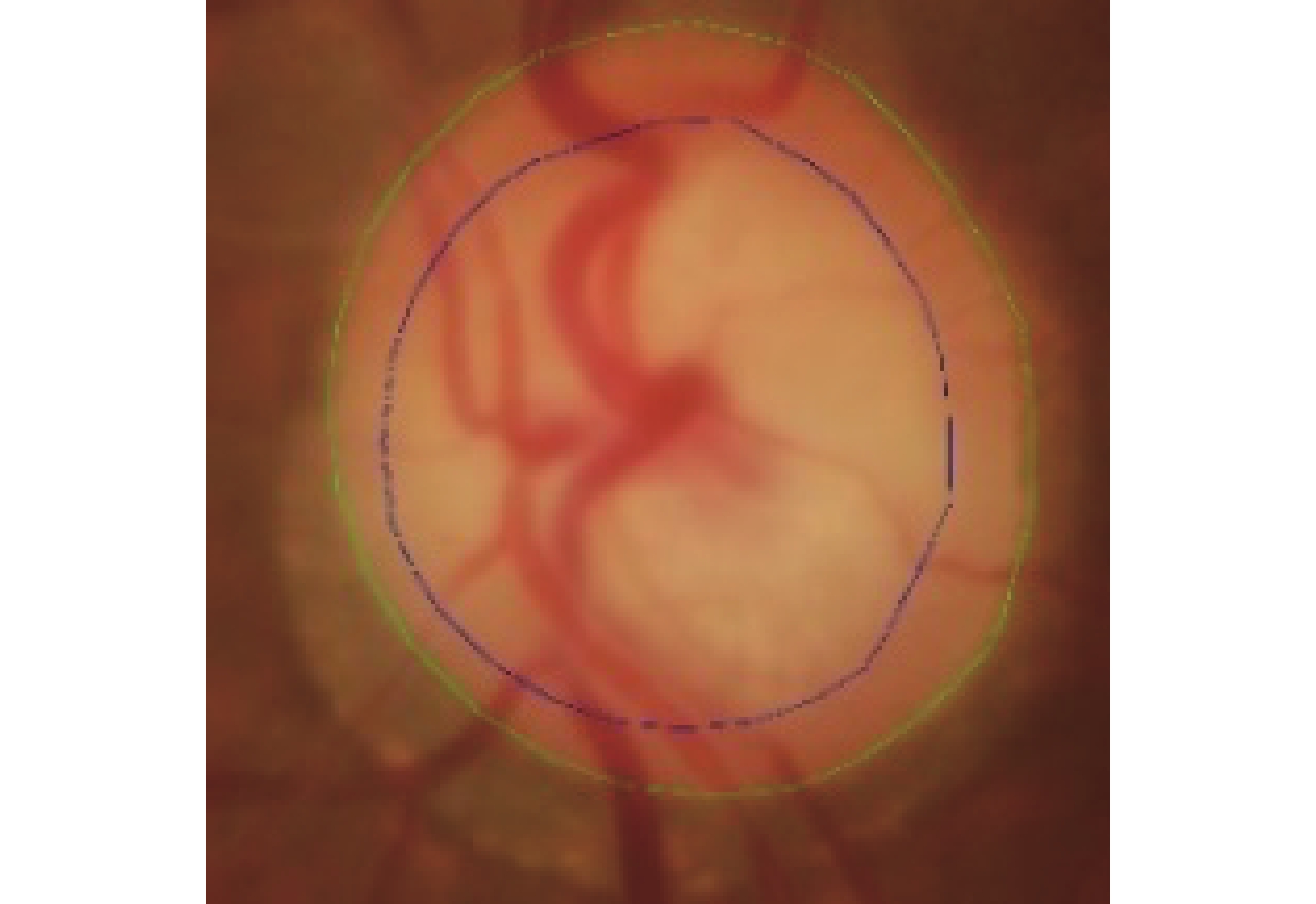
青光眼是導致視力下降甚至失明的嚴重眼病之一。截止2020年,全球青光眼患者高達7 600萬,其中我國青光眼患者數約2 100萬,是全球青光眼患者最多的國家[1]。青光眼篩查的重要依據是視杯盤比(cut to disc radio,CDR),眼底視杯盤區域如圖1所示,視杯盤比越大,患青光眼概率越高。近年來,隨著人工智能技術的發展,其在醫學影像領域的應用愈加廣泛,有效輔助專業醫師對眼病的診斷。因此,利用計算機技術快速準確地進行視盤(optic disc,OD)與視杯(optic cup,OC)分割,已成為青光眼輔助篩查的重要手段。
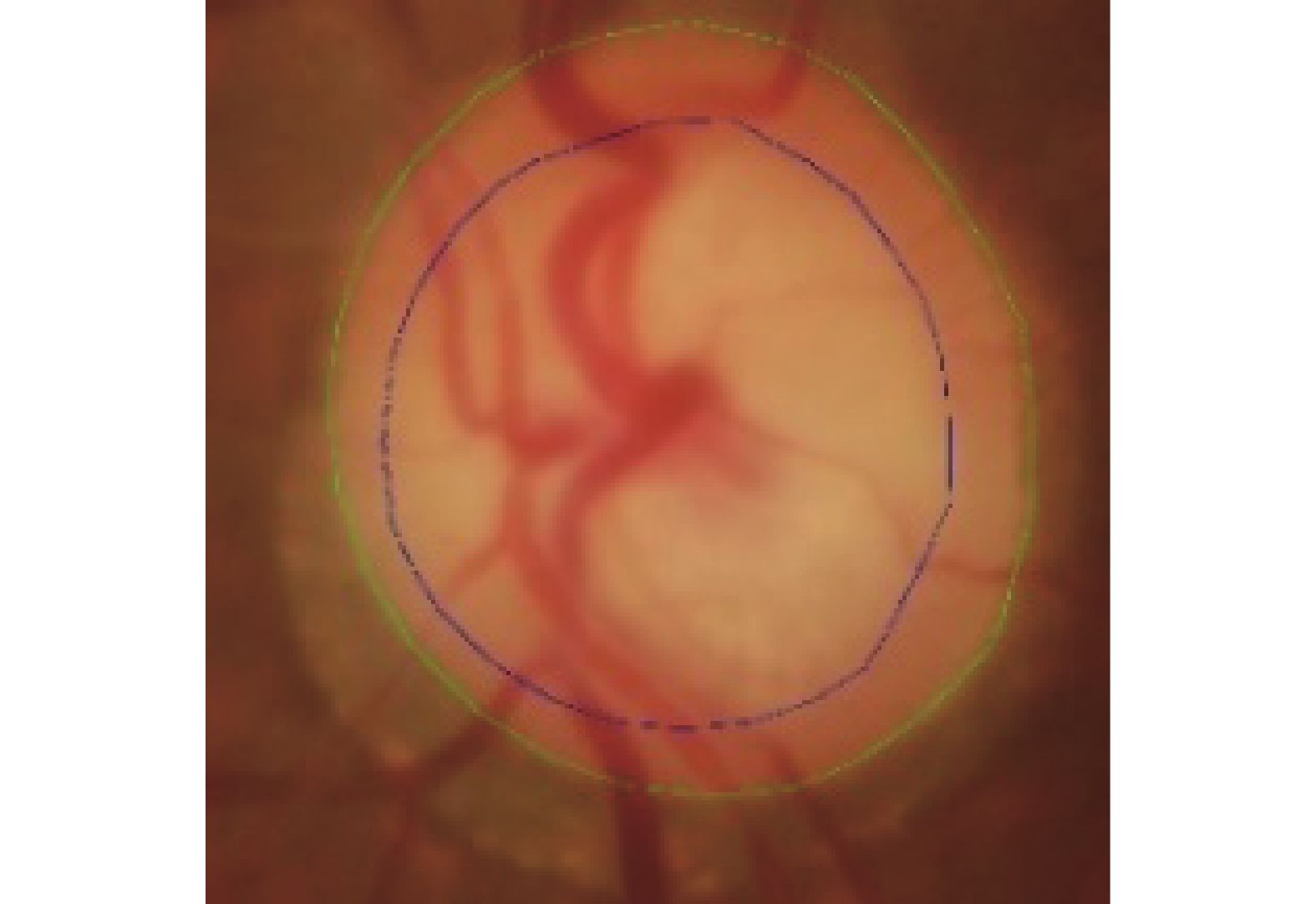 圖1
眼底圖像視杯與視盤區域
Figure1.
Fundus image showing optic cup and optic disc areas
圖1
眼底圖像視杯與視盤區域
Figure1.
Fundus image showing optic cup and optic disc areas
目前,視杯盤分割方法主要分為基于圖像處理的方法和基于深度學習的方法。基于圖像處理的方法已開展的研究部分列舉如下:Aquino等[2]利用以圓形霍夫變換(Hough transform)為基礎的形態學方法和邊緣檢測技術來分割圓形視盤邊界。Cheng等[3]用超像素分類方法對青光眼進行視盤和視杯的分割,使用直方圖和中心環繞統計量對每個超像素進行視盤分類。Yu等[4]利用視盤內部豐富的血管特征,結合血管收斂性和強度的形態學方法定位視盤,采用距離正則化窄帶的水平集演化算法(distance regularized narrowband level set evolution,DRNLSE)提取視盤邊界。Issac等[5]提出了一種自適應閾值檢測視盤的方法,利用眼底圖像平均值、標準差等特征,獲取紅色和綠色通道的視盤區域,使用直方圖確定閾值,從而進行視盤檢測。曹新容等[6]利用視盤的形態特征快速定位視盤區域,融入眼底圖像的視覺顯著性特征和旋轉掃描方法獲取視盤輪廓進行分割。Ramani等[7]采用基于區域的像素密度計算方法進行視盤定位,采用改進的圓形霍夫變換和霍夫峰值選擇進行視盤分割。以上基于圖像處理的研究集中于視盤分割,它們能快速獲取視盤區域,然而面對位于視盤內部的視杯區域,因其本身與視盤高度相似,很難通過圖像處理取得較好的視杯分割結果。
另一方面,卷積神經網絡等基于深度學習的方法在圖像分割任務上取得了比傳統基于圖像處理方法更好的性能。Sevastopolsky[8]提出了一種基于深度學習的通用視杯盤自動分割方法,在確保精度的前提下,改進U型網絡(U-Net)[9],實現網絡的輕量化。Al-Bander等[10]在視盤分割任務中采用密集連接卷積網絡(densely connected convolutional network,DenseNet),其對稱的U形結構允許按像素分類,預測的視盤和視杯邊界用于估計青光眼兩軸上的視杯盤比。Fu等[11]使用多尺度輸入構建圖像金字塔,以U-Net作為主體網絡結構,多標簽損失函數共同組成一個名為M型網絡(M-Net)的模型結構,并引入極坐標變換提高分割精度。Yu等[12]采取一種改進的U-Net結構進行視盤分割,將預訓練殘差網絡-34(residual network-34,ResNet-34)模型替換U-Net編碼器的原始卷積層,并與解碼器相結合。侯向丹等[13]在原始U-Net基礎上引入預訓練的ResNet-34模塊以增強特征提取能力,并融合注意力機制增強有用特征和抑制無用特征,對網絡輸出圖像進行連通域判決,來消除預測圖像中誤檢的細微像素點影響。呂鵬飛等[14]提取顏色特征、深度特征和背景先驗信息融合到單層元胞自動機中進行視盤區域的精確分割。劉洪普等[15]對圖像進行極坐標轉換,采用聚合模塊聚合圖像上下文信息,利用注意力指導模塊提取有用信息,并在視杯分割中引入先驗知識,約束視杯分割。劉熠翕等[16]在U-Net上進行改進,引入金字塔切分注意力模塊獲取更多維度的特征。基于上述研究總體看來,深度學習的方法雖然能實現自動分割視盤、視杯,達到輔助青光眼篩查的基本目的,但是必然會面臨計算資源的問題,例如采用ResNet-34作為特征提取網絡的模型參數不低于2×108,DenseNet能有效降低參數量,然而密集的卷積層連接導致計算速度大幅下降。綜上所述,現有的視杯盤分割算法無法很好地做到模型性能、模型規模、計算速度三者之間平衡。
相比以往的視杯盤分割方法,本文的研究有以下三點貢獻:① 基于眼底圖像中視盤的顏色、形狀等信息,利用形態學、自適應閾值等圖像處理方法,提出一種視盤定位算法。② 以ResNet-34作為特征提取網絡,在編碼器特征圖后引入多頭線性化注意力(multi-headed linear-attention,MLA)關聯全局權重,并將MLA的輸出特征改進為通道、空間雙重注意力(dual attention,DA),用于校準解碼器特征圖,從而設計了一種端到端的視杯盤分割方法。③ 利用知識蒸餾方法壓縮本文算法,生成殘差網絡-18(residual network-18,ResNet-18)和移動網絡-V2(mobile network-V2,MobileNetV2)系列規模更小的分割模型。總體而言,本文算法在視杯盤分割中取得良好的效果,對于青光眼篩查相關研究具有一定的參考意義。此外,在確保高精度的條件下本文研究生成小規模的分割模型,這對后續植入嵌入式設備中相關應用奠定了理論基礎。
1 方法實現
1.1 視盤定位
眼底圖像中,視盤區域占比較小,全圖視盤檢測中干擾項、無用信息會影響最終視杯盤分割精度,因此需在分割前先對視盤進行定位,解決亮病灶等因素導致分割精度下降的問題。視盤在眼底圖像中呈現亮黃色近似橢圓區域,并包含豐富的血管信息,基于這些特性,利用定位算法對視盤及周邊背景進行定位。
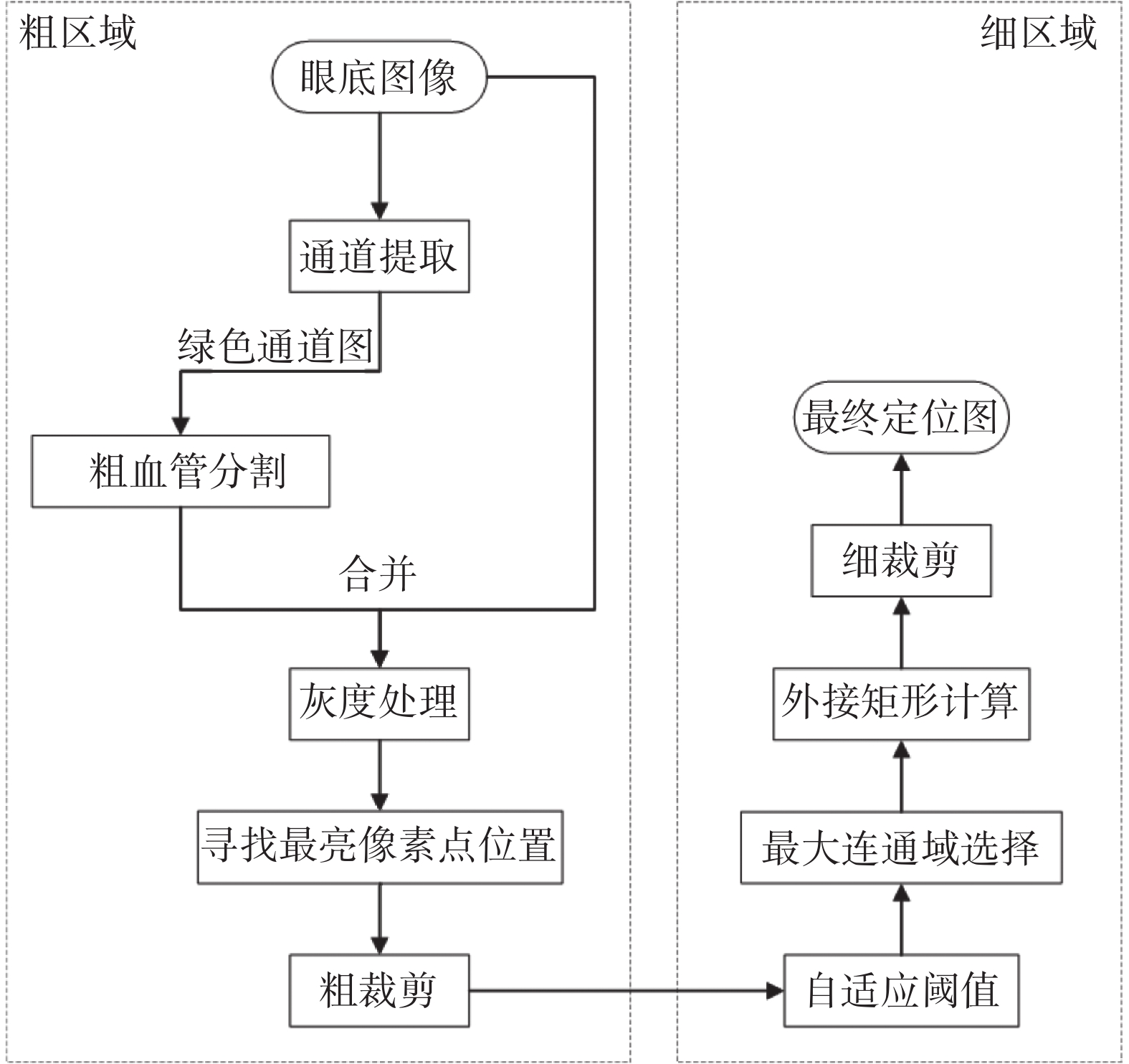
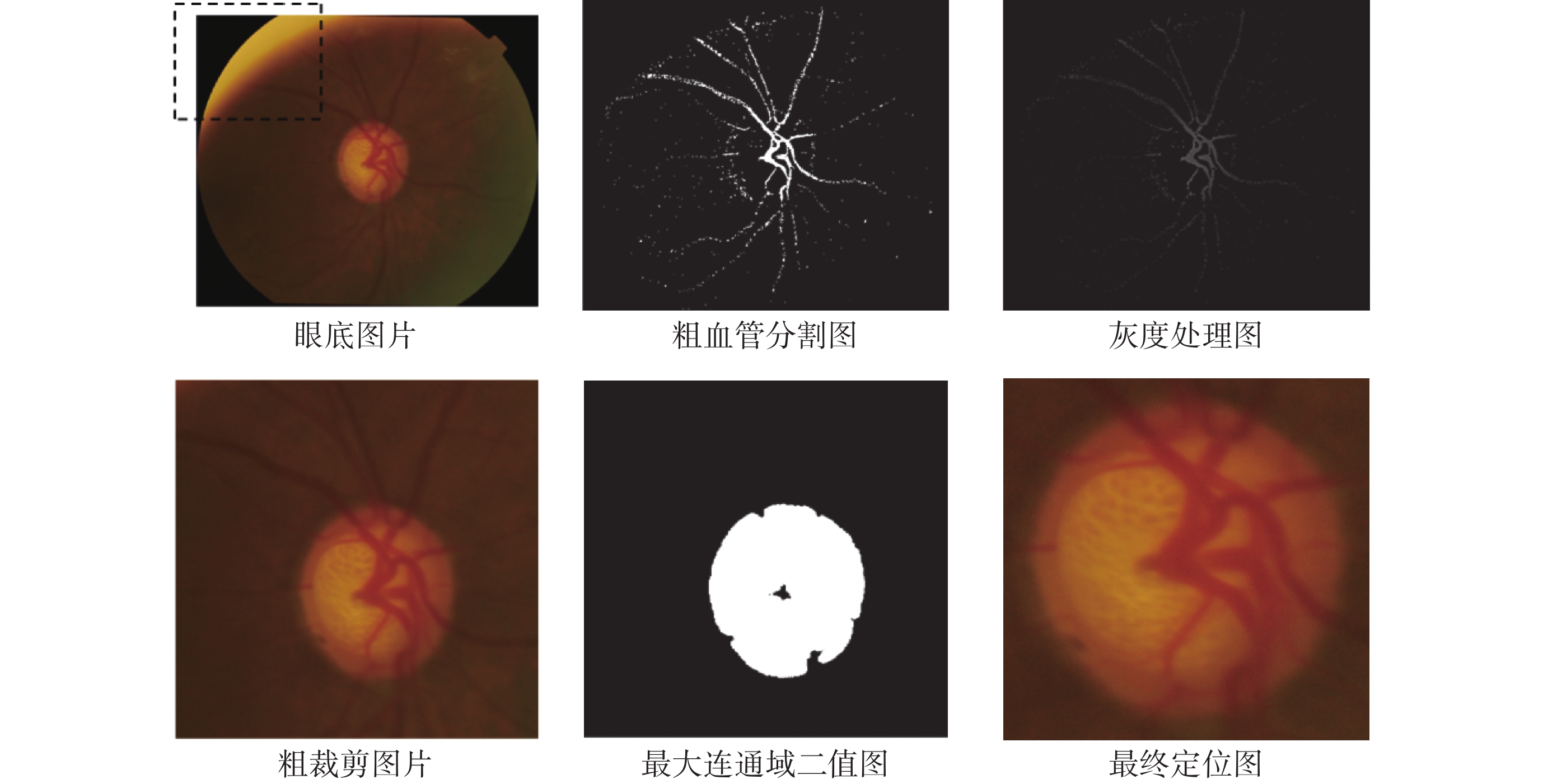
視盤定位流程如圖2所示。首先對彩色眼底圖像提取紅綠藍(red green blue,RGB)色彩通道,其中綠色通道用于粗血管分割,紅色通道用于二值分割。利用相位拉伸變換結合多尺度高斯濾波得到粗血管分割圖,去除圖片中光照不均導致的高亮部分,即去除眼底圖片左上角虛線框部分,如圖3所示。將原始圖片與粗血管分割圖合并進行灰度處理生成灰度處理圖,其中高亮像素點集中在視盤部位,粗裁剪獲得大致的視盤區域。自適應閾值選取最大連通域,獲得二值圖。最終利用外接矩形獲取白色像素中心點以及長和寬,細裁剪得到最終視盤定位圖片。
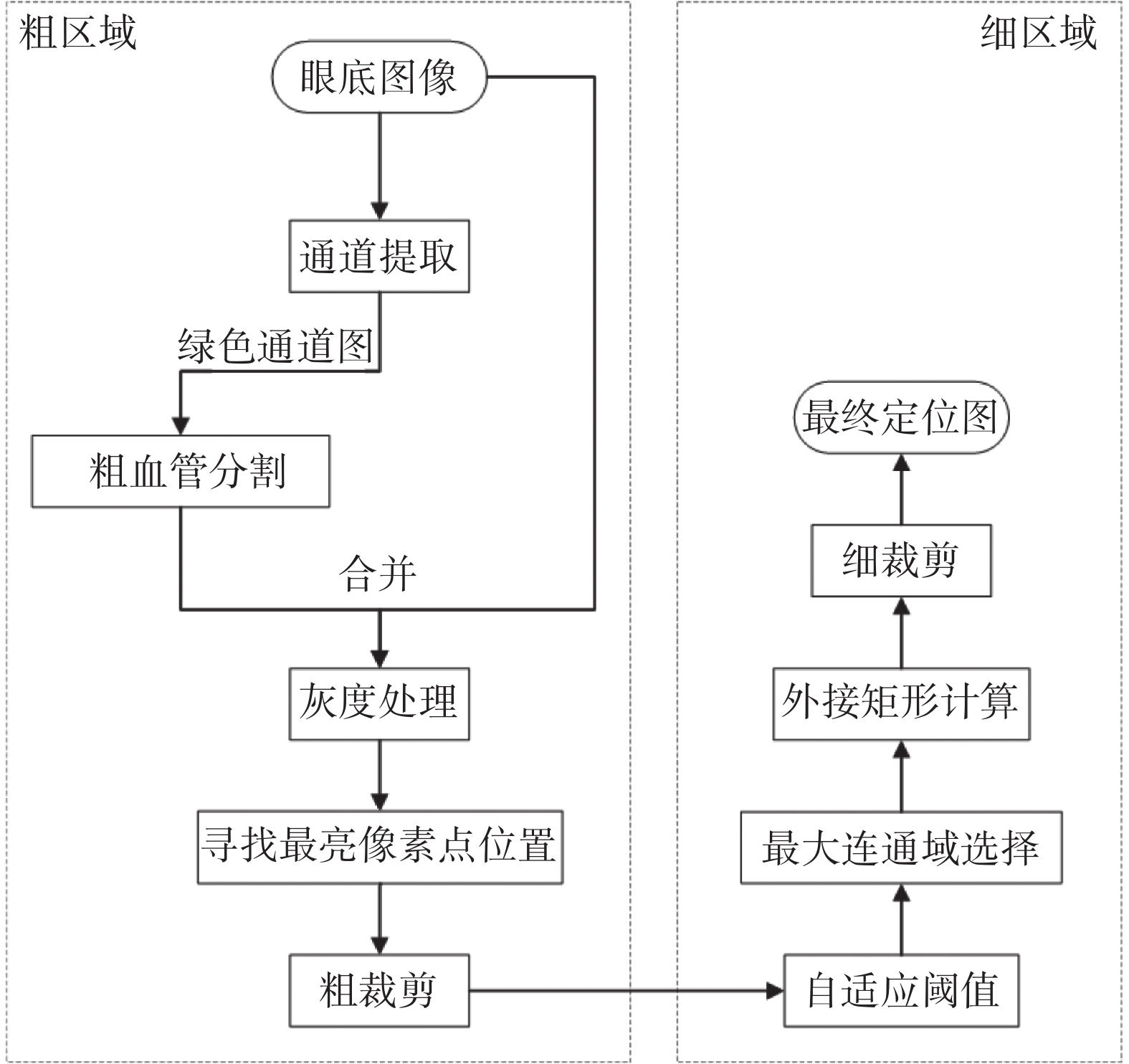 圖2
視盤定位流程圖
Figure2.
Flow chart of optic disc localization
圖2
視盤定位流程圖
Figure2.
Flow chart of optic disc localization
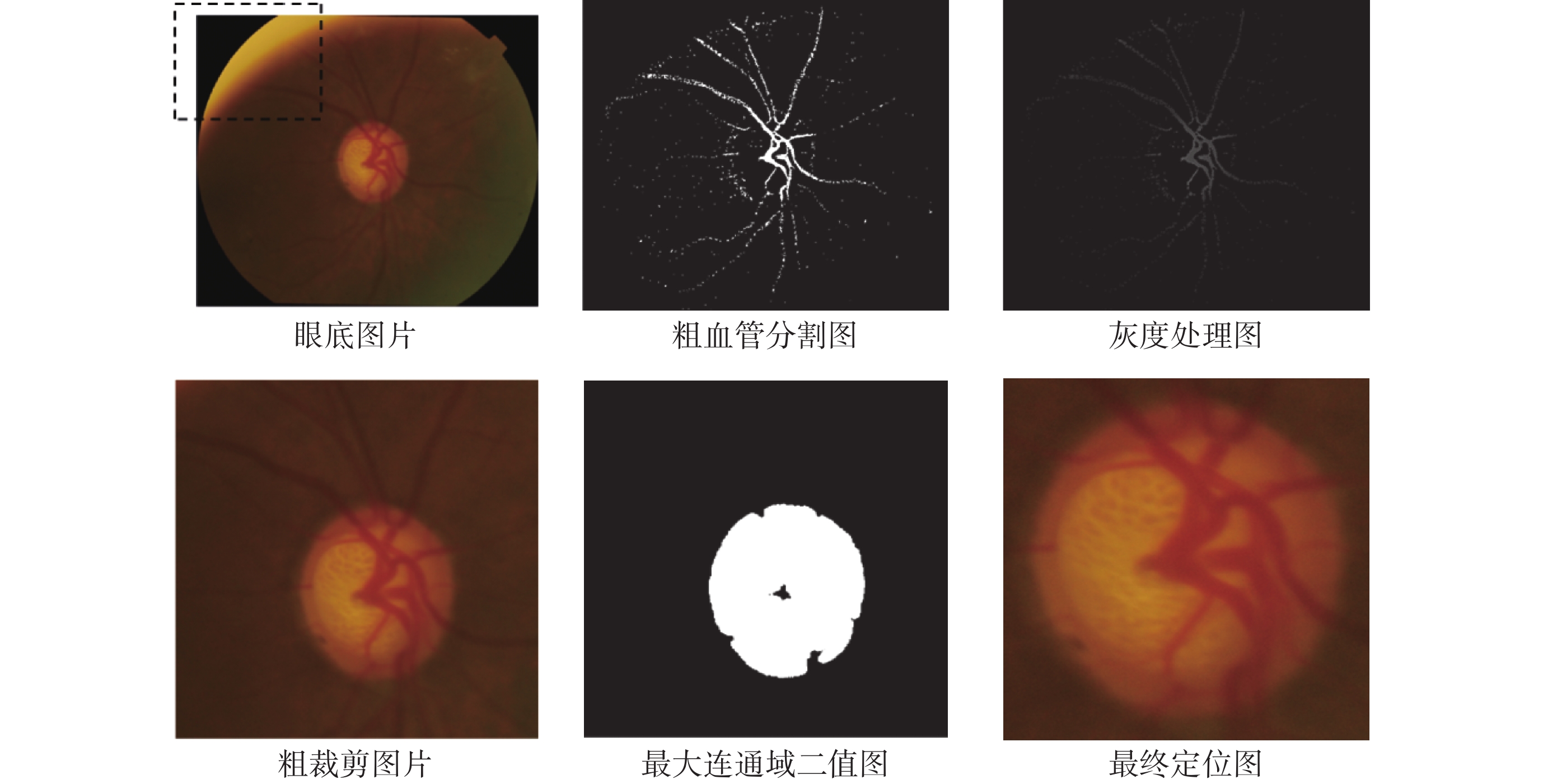 圖3
部分流程可視化結果
Figure3.
Visualization results of partial process
圖3
部分流程可視化結果
Figure3.
Visualization results of partial process
1.2 線性化注意力
自注意力(self-attention,SA)機制通過三元組(Q, K, V )提供了一種有效捕捉全局上下文信息的建模方式,其中N為特征圖高和寬的乘積,表示圖像切片個數;D為圖像通道維度。SA的復雜度可近似為矩陣乘法[Q·K]T,計算復雜度為O(N2D);其中,T為轉置符號。
)提供了一種有效捕捉全局上下文信息的建模方式,其中N為特征圖高和寬的乘積,表示圖像切片個數;D為圖像通道維度。SA的復雜度可近似為矩陣乘法[Q·K]T,計算復雜度為O(N2D);其中,T為轉置符號。
為降低SA的計算復雜度,線性化注意力(linear-attention,LA)旨在將SA的計算復雜度盡可能地減低。本文將Q、K添加縮放指數線性單元函數(scaled exponential linear units,SELU)以限制Q、K中的元素取值范圍,模擬SA中使用歸一化指數函數(softmax)保證[Q·K]T相似性系數矩陣的非負性,如式(1)所示:
 |
其中,x為輸入變量,φ(x)代表激活函數,替換SA中的softmax,確保輸出的非負性。
由于LA中先對K、V進行矩陣乘法,因此LA的計算復雜度可降低為O(D2N),LA的數學表達如式(2)所示:
 |
其中,LA(Q, K, V)為經過加權的輸出值。
1.3 融合多頭線性化注意力和雙重注意力的視杯盤分割模型
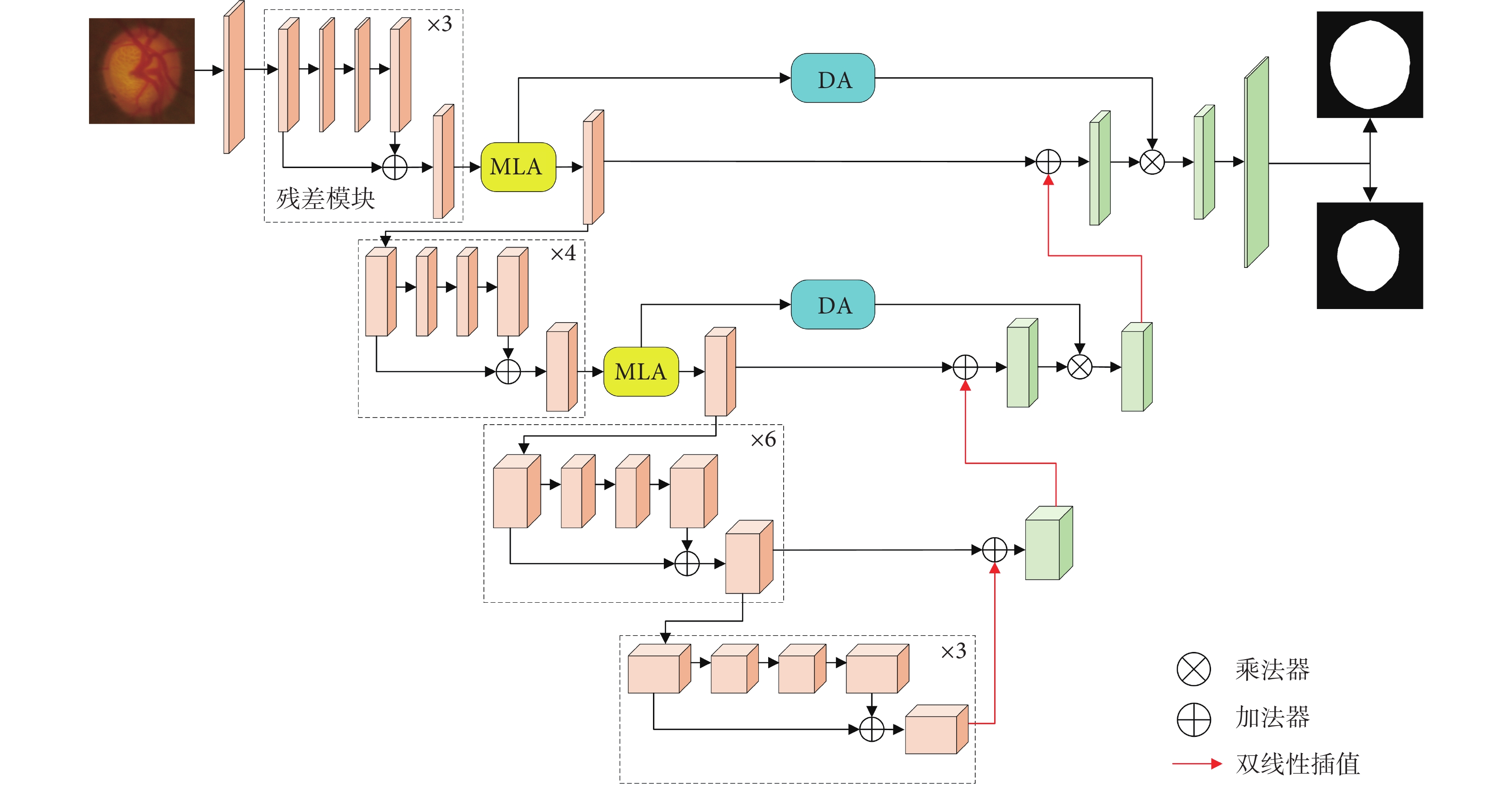
編碼器部分使用預訓練的ResNet-34作為特征提取網絡,實現下采樣過程。考慮SA機制的計算成本與特征圖尺寸之間的關系,編碼器前兩層引入MLA模塊從全局尺度上獲取關聯權重。解碼器將上采樣特征圖與編碼器同級特征圖相加,以保留更多淺層特征中蘊含的高分辨率細節信息,并利用MLA的輸出特征生成適應卷積神經網絡的DA重新校準解碼器特征圖,網絡模型如圖4所示。
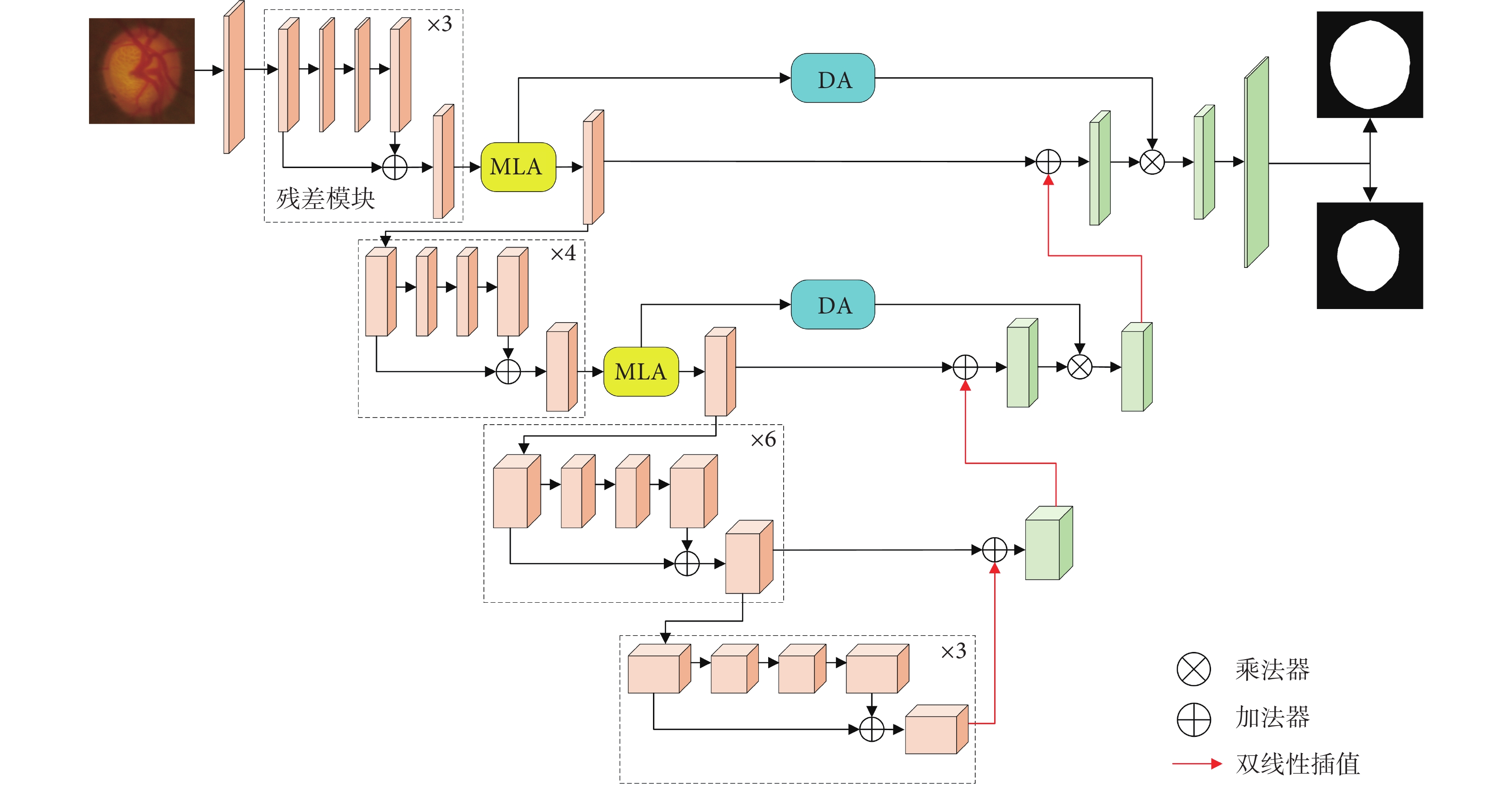 圖4
所提網絡模型圖
Figure4.
Diagram of proposed network model
圖4
所提網絡模型圖
Figure4.
Diagram of proposed network model
1.4 基于多頭線性化注意力的雙重注意力
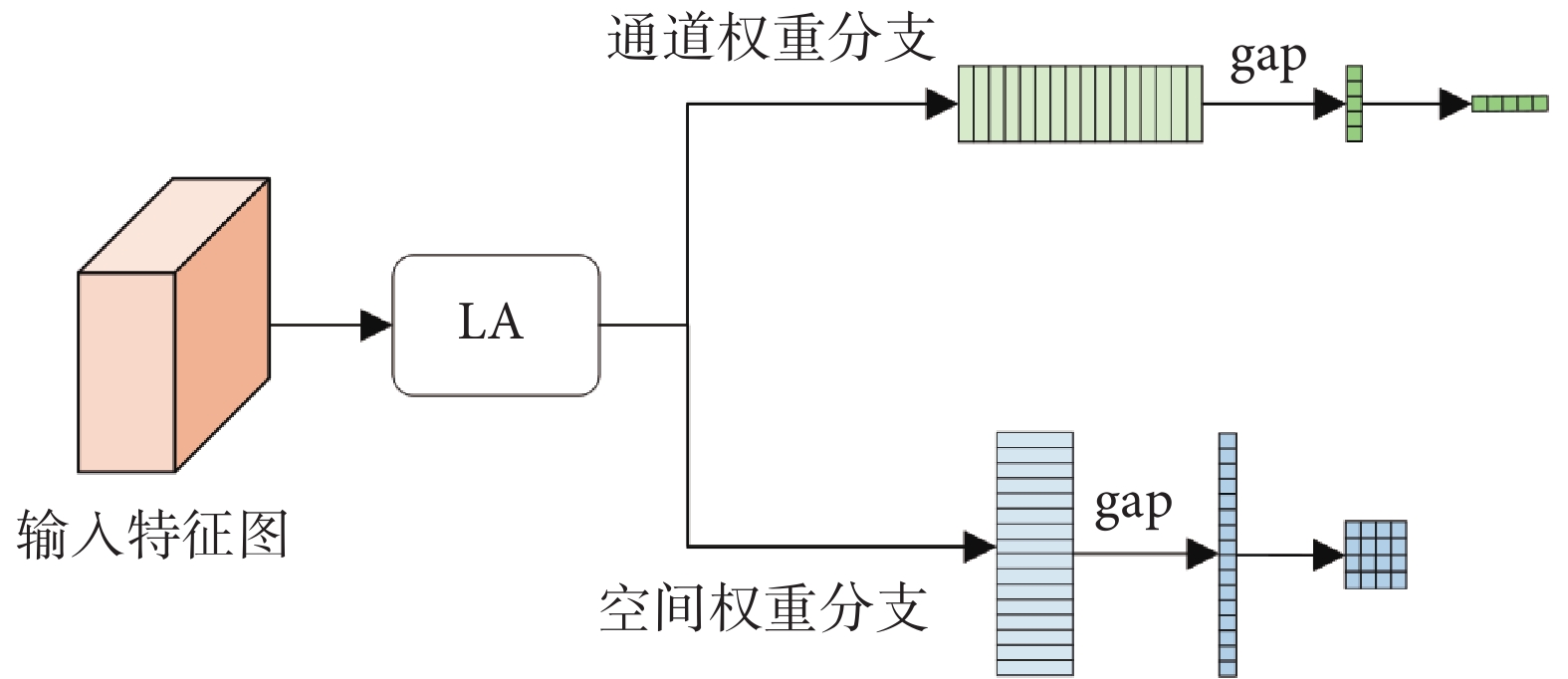
本文利用MLA模塊的輸出特征生成注意力權重,該注意力是以通過MLA的圖像塊為基礎生成的通道、空間DA。
1.4.1 通道注意力
通道注意力以不同通道權重系數來強調相關特征與抑制無關特征。將MLA的特征輸出作為注意力權重輸入端,為保證維度統一,利用全連接調整通道維度。其次對特征圖進行全局平均池化(global average pooling,gap),如式(3)所示,確保通道特征是對所有圖像塊的總體權重計算,生成適配卷積神經網絡計算的通道注意力權重,如式(4)所示:
 |
 |
其中,x 為輸入特征圖,Nc為特征通道數,Ns為序列長度,xs
為輸入特征圖,Nc為特征通道數,Ns為序列長度,xs 為每一個通道的序列,V為維度擴展,fc為全連接層,Sigmoid為S型生長曲線函數,gaps是對序列維度進行gap,wch為生成的通道權重。
為每一個通道的序列,V為維度擴展,fc為全連接層,Sigmoid為S型生長曲線函數,gaps是對序列維度進行gap,wch為生成的通道權重。
1.4.2 空間注意力
空間注意力為每個位置生成權重并加權輸出,增強感興趣區域并弱化無關的背景區域。空間注意力由淺層特征構成,將MLA的輸出特征進行gap,如式(5)所示,并對每一個圖像塊合并通道,轉換維度形成卷積特征圖。淺層空間注意力代表與它同級的解碼特征圖的像素點級別的權重系數,如式(6)所示:
 |
 |
其中,xc 為每一個序列的通道特征,Conv為1×1卷積,gapc是對通道維度進行gap,wsp為生成的空間權重,最終DA如圖5所示。
為每一個序列的通道特征,Conv為1×1卷積,gapc是對通道維度進行gap,wsp為生成的空間權重,最終DA如圖5所示。
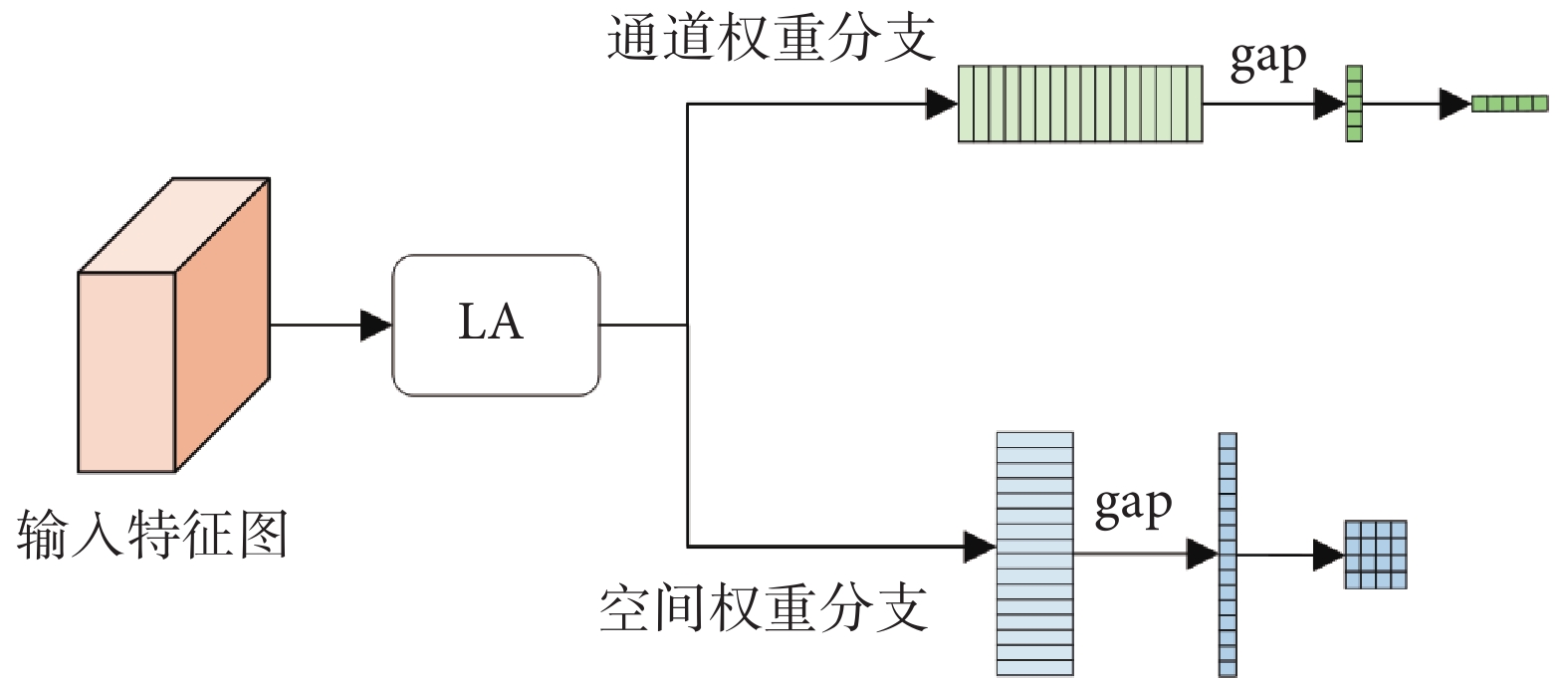 圖5
DA示意圖
Figure5.
DA flow chart
圖5
DA示意圖
Figure5.
DA flow chart
1.5 模型壓縮優化
模型壓縮優化旨在基本不影響模型分割效果前提下,減少視杯盤分割模型的參數量,提升模型的計算效率。本文使用知識蒸餾方法對模型進行壓縮,知識蒸餾中最直接的方法是將學生模型和教師模型之間每個像素的類概率分布對齊,如式(7)所示:
 |
其中, 和
和 為學生和教師在(h, w)處的軟標簽概率,s為學生網絡,t為教師網絡,均方誤差(mean squared error,MSE)損失以MSE(·)表示,H,W為軟標簽的高和寬,Lkd為輸出的損失函數值。
為學生和教師在(h, w)處的軟標簽概率,s為學生網絡,t為教師網絡,均方誤差(mean squared error,MSE)損失以MSE(·)表示,H,W為軟標簽的高和寬,Lkd為輸出的損失函數值。
2 實驗結果
2.1 實驗數據
本文使用兩個公開的青光眼診斷數據集中的視網膜眼底圖像,用于視盤和視杯的像素級語義分割:① 視神經頭分割的視網膜圖像數據集(Retinal Image Dataset for Optic Nerve Head Segmentation,DRISHTI-GS)來源于亞拉文眼科醫院(Aravind eye hospital)[17-18]。該數據集包含50張訓練圖像和51張測試圖像,以視盤為中心,視場為30o,圖像尺寸為2 896 × 1 944像素,并由四位青光眼專家提供視盤和視杯標簽。② 用于視神經評估的開放式視網膜圖像數據庫—V3[19](retinal image database for optic nerve evaluation,RIM-ONE-V3)從3家西班牙醫院收集。數據集包含159幅視網膜圖像,其中85幅健康眼底圖像和74幅青光眼眼底圖像,并由兩位眼科醫生進行注釋。由于RIM-ONE-V3中未區分訓練集與測試集,因此采取隨機抽取方式以比例8 : 2劃分訓練集與測試集。
2.2 實驗環境
本次實驗在代碼集成開發環境PyCharm 2 022.3.2(JetBrains Inc,捷克)上運行,使用計算機編程語言Python 3.8(Guido van Rossum,荷蘭),采用深度學習框架Pytorch 1.12.1 + cu113(Facebook Inc,美國),實驗使用處理器Intel(R) Xeon(R) Silver 4210R CPU @ 2.40GHz(Intel Inc,美國)和顯卡NVIDIA GeForce RTX 3090 Ti GPU(Nvidia Inc,美國)。
2.3 實驗細節
由于數據集中提供的眼底圖像視盤占比較小,采用基于顯著性的視盤定位方法對眼底圖像和金標準進行預處理。為確保視盤輪廓與原圖的一致性,對眼底圖像裁剪感興趣區域,考慮原始數據集中數據量較少,本文對原始數據進行數據增強,包括水平翻轉、90°旋轉、調整亮度和模糊變化來模擬眼底照相機在拍照過程中可能出現的光照變化和運動模糊。在訓練之前,將圖像大小調整為512 × 512,輸入圖像像素范圍調整至(?1.6,1.6)。網絡使用自適應矩估計(adaptive moment estimation,Adam)優化器,初始學習率為1×10?4,之后輪次學習率逐漸遞減,批訓練大小(batch size)設置為8,訓練輪次(epoch)為100輪。
2.4 評價指標
為了評價網絡分割結果,使用戴斯(Dice)相似性系數和交并比(intersection over union,IOU)作為評價指標。兩者都是用于衡量兩個集合之間的相似度,在圖像分割中用來衡量網絡分割結果與金標準之間的相似度,Dice與IOU計算公式分別如式(8)~式(9)所示:
 |
 |
其中,M為金標準中的視杯盤區域,A為本文算法預測的視杯盤區域,Dice與IOU取值范圍為(0, 1),值越大,說明分割圖片越接近于金標準。
2.5 實驗結果與分析
2.5.1 消融實驗
消融實驗用于驗證網絡中多頭SA(multi-headed SA,MSA)模塊、MLA模塊和DA機制對模型性能的影響。MLA放置于ResNet-34的第二層和第三層之后,MSA放置于ResNet-34的第四層和第五層之后。如表1所示,各模塊對模型性能有一定影響,MLA在視杯盤分割中起到提升效果,對比基線模型,引入MLA模塊的模型在兩個數據集的視杯盤分割中Dice和IOU分別有所提升。添加DA機制的MLA網絡在性能上進一步提升,并在視杯盤分割中取得了最優值(粗體顯示),這可能是因為經過MLA的高分辨率特征生成的注意力權重對解碼器特征圖進行修正,緩解下采樣引起的細節丟失問題。然而,深層特征圖中引入的MSA模塊對模型沒有正向提升效果,尤其是當三個模塊同時添加時,模型性能在兩個數據集上都出現了不同程度的下降。在網絡中引入過多的SA機制使得模型獲取的特征愈發抽象,從而丟失了圖像的細節,模型對圖像邊緣分割效果不佳,導致生成的預測圖邊緣不夠平滑。
此外,本文對模塊的參數量和計算速度進行探討,如表2所示,模型的參數和速度主要由基線模型決定。引入MLA和DA模塊所上升的參數十分有限,可以忽略不計,模塊對速度的影響在5 幀/s以內,說明模塊對網絡速度影響較小。需要說明的是,在ResNet-34第二層和第三層后添加MSA會極大的增加模型的計算時間(下降至19.09 幀/s),因此并未考慮該部分的消融實驗。
2.5.2 對比實驗
為了驗證算法的有效性,本文算法與U-Net、上下文編碼網絡(context encoder network,CENet)[20]、空洞卷積網絡-V3(atrous convolution network,DeeplabV3)[21]、輕量級上下文引導網絡(light-weight context guided network,CGNet)[22]、剩余注意力U-Net(residual attention U-Net,RAU-Net)[23]在兩個公開數據集上進行比較。如表3所示,本文算法在兩個數據集中視盤分割的Dice達到0.980 8、0.977 6,IOU達到0.962 3、0.956 3;視杯分割的Dice達到0.921 5、0.872 9,IOU達到0.856 4、0.784 4;兩項指標對比其他算法均達到最優。相比U-Net網絡,本文算法在DRISHTI-GS中視盤和視杯IOU均有提升,RIM-ONE-V3中視盤和視杯IOU也有提升。通過對比實驗,說明除U-Net和CGNet以外,網絡對視盤分割的精度都保持在一個較高的水平,這與視盤在眼底圖片中呈現的幾何、顏色等多方面差異特征有關。然而,視盤內部的視杯沒有明顯的邊界信息,呈現與視盤高度相似的狀態,網絡的分割精度有所下降。模型的最終分割效果與醫生所標注的標簽類似,不同醫生對視盤的標注結果僅有細微的差別,視杯的標注結果卻差異性很大,側面印證了視盤與視杯在分割難度上的不同。
2.5.3 模型大小和推理速度
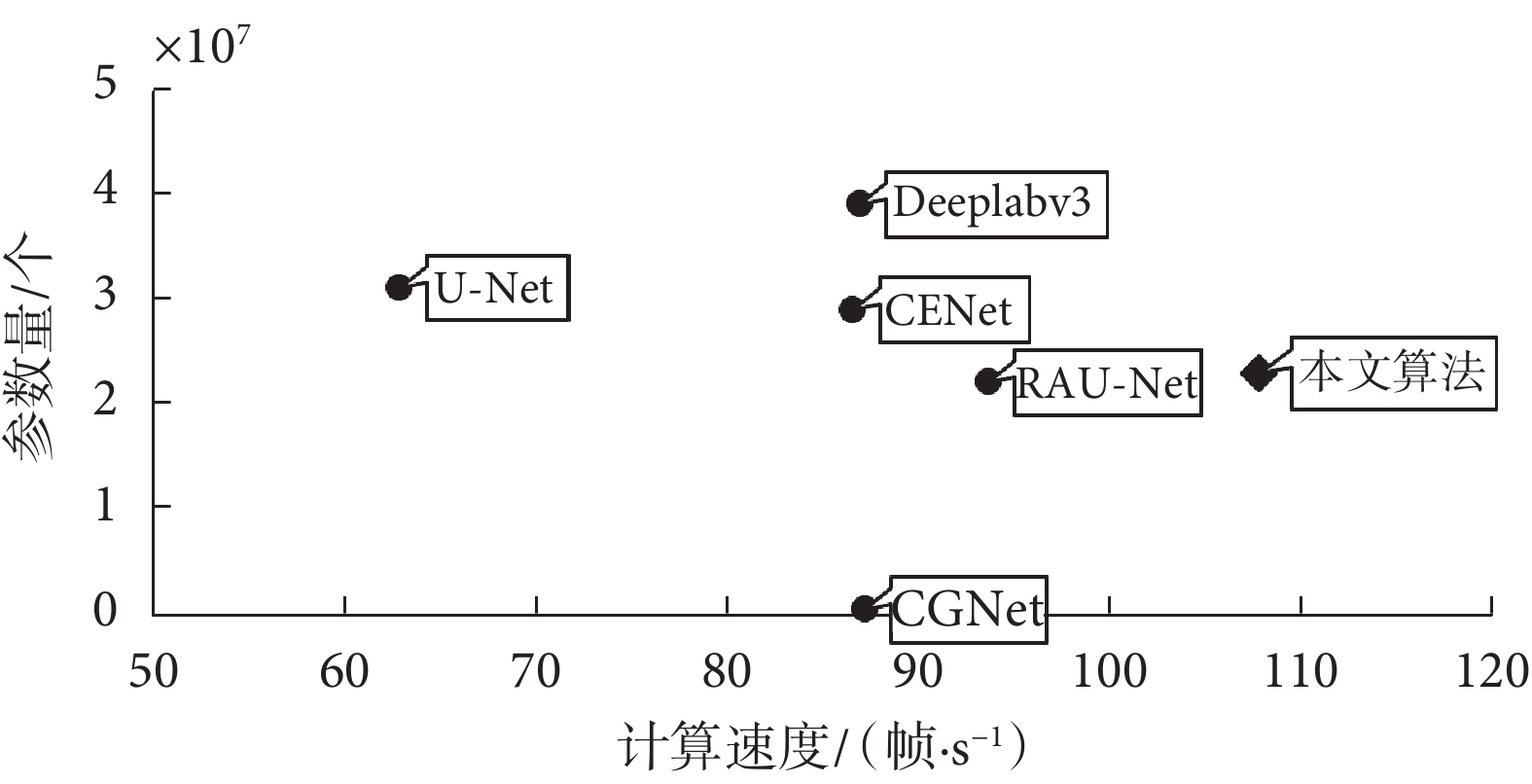
網絡的參數量和運行速度如圖6所示,本文算法參數量為2.3×107 個,運行速度為107.79 幀/s。與速度最快的RAU-Net相比,本文算法的速度提升在15 幀/s左右。在參數方面,盡管輕量級語義分割網絡CGNet能有效減少模型參數量,但如表3所示,對比實驗說明CGNet的分割精度與其他模型相差較大。
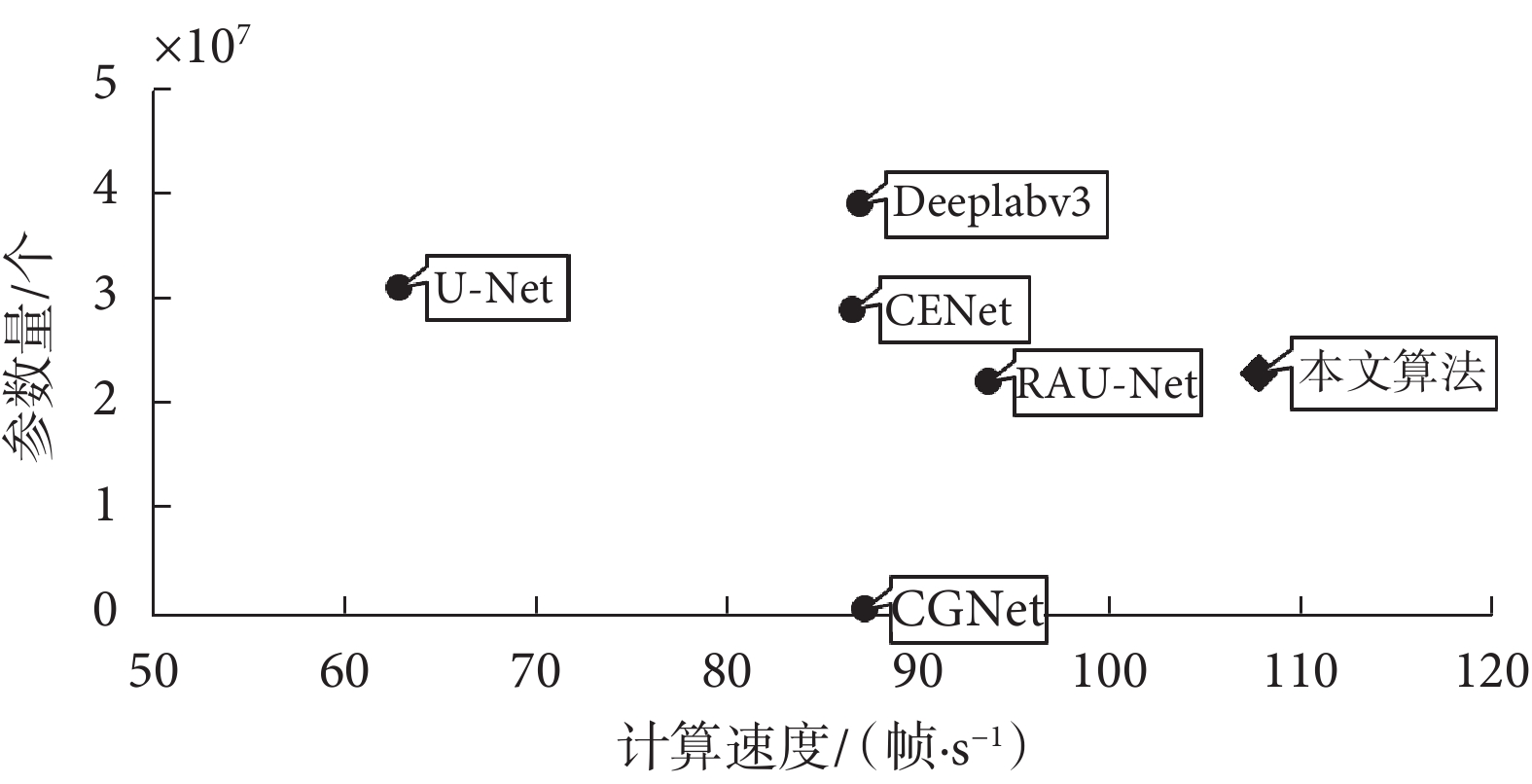 圖6
不同模型的參數量和計算速度
Figure6.
Parameter quantity and calculation speed of different models
圖6
不同模型的參數量和計算速度
Figure6.
Parameter quantity and calculation speed of different models
2.5.4 輕量化設計
如表2所示,模型的計算成本主要是由特征提取網絡RseNet-34本身決定。本文將特征提取網絡替換為ResNet-18和MobilevNetV2用于降低網絡的計算成本。如表4所示,以ResNet-18為特征提取網絡的模型的參數量為1.289 × 107 個,運行時間為135.58 幀/s,較原網絡有很大提升。MobileNetV2的模型參數量僅為2.16 × 106 個,運行時間為91.11 幀/s,參數量大幅減小。與直接訓練的模型相比,引入知識蒸餾策略的模型在性能更接近教師模型,說明從教師網絡生成的軟標簽能輔助提升學生模型的分割性能。
2.5.5 模型分割可視化結果
為了直觀體現本文算法的效果,如圖7所示,本文展示了部分數據的可視化結果,并與U-Net、DeeplabV3、CENet、CGNet、RAU-Net進行視杯盤的可視化對比。第一列是裁剪后的目標原始圖像區域,第二列是專家標定真值(標簽),第三至第八列分別代表不同算法的可視化分割效果。通過對比不同模型的可視化結果可以直觀感受其差異,其中U-Net和CGNet在視盤分割中評價指標與其他網絡相差較小,但僅代表它們能實現視盤的整體分割,而對于邊界像素點不能準確預測,可視化結果表現為預測圖邊界不夠平滑,視杯分割中存在很多誤檢或漏檢的點,導致分割精度有明顯下降。DeeplabV3、CENet、RAU-Net和本文算法在視盤分割上性能相近,但在高難度的視杯分割中存在差異。例如樣本3通過人為觀察能得到視杯右側與視盤交接部分有較為明顯的顏色差異,而視杯左側很難分辨,CENet、RAU-Net和本文算法對右側分割是較為精準的,DeeplabV3分割效果不理想;對于視杯左側,CENet出現明顯誤檢情況,RAU-Net缺失部分視杯區域。相較于其他網絡,本文網絡對視杯和視盤都能實現較好的分割。
 圖7
部分圖像預測可視化結果
Figure7.
Visualization results of partial image prediction
圖7
部分圖像預測可視化結果
Figure7.
Visualization results of partial image prediction
3 結論
本文提出一種采用MLA和DA的視杯盤分割模型。MLA應用于編碼器的淺層位置,起到關聯全局信息的作用,彌補原始編碼器僅通過卷積層獲取局部感受野的問題。DA是經由MLA輸出的注意力權重,主要用于解決模型在多次下采樣后細節丟失的問題,使得最終分割邊界有更好的效果。本文算法在兩個眼底數據集上均體現出其優越性,并且模塊引入所增加的計算成本較小。此外,本文利用知識蒸餾方法壓縮模型,生成以RseNet-18和MobileNetV2為特征提取網絡的輕量級視杯盤分割模型。在接下來的工作中,本文將逐步獲取用于青光眼診斷的數據集,將模型應用于青光眼的篩查。此外,本文也將關注模型的跨設備遷移的方法,用于解決嵌入式設備植入模型的問題。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:藍子俊負責程序編寫與論文寫作;謝珺負責論文指導與審閱;郭燕負責論文相關醫學知識指導;張喆負責實驗設計與指導;孫彬負責數據收集與分析。
0 引言
青光眼是導致視力下降甚至失明的嚴重眼病之一。截止2020年,全球青光眼患者高達7 600萬,其中我國青光眼患者數約2 100萬,是全球青光眼患者最多的國家[1]。青光眼篩查的重要依據是視杯盤比(cut to disc radio,CDR),眼底視杯盤區域如圖1所示,視杯盤比越大,患青光眼概率越高。近年來,隨著人工智能技術的發展,其在醫學影像領域的應用愈加廣泛,有效輔助專業醫師對眼病的診斷。因此,利用計算機技術快速準確地進行視盤(optic disc,OD)與視杯(optic cup,OC)分割,已成為青光眼輔助篩查的重要手段。
圖1
眼底圖像視杯與視盤區域
Figure1.
Fundus image showing optic cup and optic disc areas
目前,視杯盤分割方法主要分為基于圖像處理的方法和基于深度學習的方法。基于圖像處理的方法已開展的研究部分列舉如下:Aquino等[2]利用以圓形霍夫變換(Hough transform)為基礎的形態學方法和邊緣檢測技術來分割圓形視盤邊界。Cheng等[3]用超像素分類方法對青光眼進行視盤和視杯的分割,使用直方圖和中心環繞統計量對每個超像素進行視盤分類。Yu等[4]利用視盤內部豐富的血管特征,結合血管收斂性和強度的形態學方法定位視盤,采用距離正則化窄帶的水平集演化算法(distance regularized narrowband level set evolution,DRNLSE)提取視盤邊界。Issac等[5]提出了一種自適應閾值檢測視盤的方法,利用眼底圖像平均值、標準差等特征,獲取紅色和綠色通道的視盤區域,使用直方圖確定閾值,從而進行視盤檢測。曹新容等[6]利用視盤的形態特征快速定位視盤區域,融入眼底圖像的視覺顯著性特征和旋轉掃描方法獲取視盤輪廓進行分割。Ramani等[7]采用基于區域的像素密度計算方法進行視盤定位,采用改進的圓形霍夫變換和霍夫峰值選擇進行視盤分割。以上基于圖像處理的研究集中于視盤分割,它們能快速獲取視盤區域,然而面對位于視盤內部的視杯區域,因其本身與視盤高度相似,很難通過圖像處理取得較好的視杯分割結果。
另一方面,卷積神經網絡等基于深度學習的方法在圖像分割任務上取得了比傳統基于圖像處理方法更好的性能。Sevastopolsky[8]提出了一種基于深度學習的通用視杯盤自動分割方法,在確保精度的前提下,改進U型網絡(U-Net)[9],實現網絡的輕量化。Al-Bander等[10]在視盤分割任務中采用密集連接卷積網絡(densely connected convolutional network,DenseNet),其對稱的U形結構允許按像素分類,預測的視盤和視杯邊界用于估計青光眼兩軸上的視杯盤比。Fu等[11]使用多尺度輸入構建圖像金字塔,以U-Net作為主體網絡結構,多標簽損失函數共同組成一個名為M型網絡(M-Net)的模型結構,并引入極坐標變換提高分割精度。Yu等[12]采取一種改進的U-Net結構進行視盤分割,將預訓練殘差網絡-34(residual network-34,ResNet-34)模型替換U-Net編碼器的原始卷積層,并與解碼器相結合。侯向丹等[13]在原始U-Net基礎上引入預訓練的ResNet-34模塊以增強特征提取能力,并融合注意力機制增強有用特征和抑制無用特征,對網絡輸出圖像進行連通域判決,來消除預測圖像中誤檢的細微像素點影響。呂鵬飛等[14]提取顏色特征、深度特征和背景先驗信息融合到單層元胞自動機中進行視盤區域的精確分割。劉洪普等[15]對圖像進行極坐標轉換,采用聚合模塊聚合圖像上下文信息,利用注意力指導模塊提取有用信息,并在視杯分割中引入先驗知識,約束視杯分割。劉熠翕等[16]在U-Net上進行改進,引入金字塔切分注意力模塊獲取更多維度的特征。基于上述研究總體看來,深度學習的方法雖然能實現自動分割視盤、視杯,達到輔助青光眼篩查的基本目的,但是必然會面臨計算資源的問題,例如采用ResNet-34作為特征提取網絡的模型參數不低于2×108,DenseNet能有效降低參數量,然而密集的卷積層連接導致計算速度大幅下降。綜上所述,現有的視杯盤分割算法無法很好地做到模型性能、模型規模、計算速度三者之間平衡。
相比以往的視杯盤分割方法,本文的研究有以下三點貢獻:① 基于眼底圖像中視盤的顏色、形狀等信息,利用形態學、自適應閾值等圖像處理方法,提出一種視盤定位算法。② 以ResNet-34作為特征提取網絡,在編碼器特征圖后引入多頭線性化注意力(multi-headed linear-attention,MLA)關聯全局權重,并將MLA的輸出特征改進為通道、空間雙重注意力(dual attention,DA),用于校準解碼器特征圖,從而設計了一種端到端的視杯盤分割方法。③ 利用知識蒸餾方法壓縮本文算法,生成殘差網絡-18(residual network-18,ResNet-18)和移動網絡-V2(mobile network-V2,MobileNetV2)系列規模更小的分割模型。總體而言,本文算法在視杯盤分割中取得良好的效果,對于青光眼篩查相關研究具有一定的參考意義。此外,在確保高精度的條件下本文研究生成小規模的分割模型,這對后續植入嵌入式設備中相關應用奠定了理論基礎。
1 方法實現
1.1 視盤定位
眼底圖像中,視盤區域占比較小,全圖視盤檢測中干擾項、無用信息會影響最終視杯盤分割精度,因此需在分割前先對視盤進行定位,解決亮病灶等因素導致分割精度下降的問題。視盤在眼底圖像中呈現亮黃色近似橢圓區域,并包含豐富的血管信息,基于這些特性,利用定位算法對視盤及周邊背景進行定位。
視盤定位流程如圖2所示。首先對彩色眼底圖像提取紅綠藍(red green blue,RGB)色彩通道,其中綠色通道用于粗血管分割,紅色通道用于二值分割。利用相位拉伸變換結合多尺度高斯濾波得到粗血管分割圖,去除圖片中光照不均導致的高亮部分,即去除眼底圖片左上角虛線框部分,如圖3所示。將原始圖片與粗血管分割圖合并進行灰度處理生成灰度處理圖,其中高亮像素點集中在視盤部位,粗裁剪獲得大致的視盤區域。自適應閾值選取最大連通域,獲得二值圖。最終利用外接矩形獲取白色像素中心點以及長和寬,細裁剪得到最終視盤定位圖片。
圖2
視盤定位流程圖
Figure2.
Flow chart of optic disc localization
圖3
部分流程可視化結果
Figure3.
Visualization results of partial process
1.2 線性化注意力
自注意力(self-attention,SA)機制通過三元組(Q, K, V)提供了一種有效捕捉全局上下文信息的建模方式,其中N為特征圖高和寬的乘積,表示圖像切片個數;D為圖像通道維度。SA的復雜度可近似為矩陣乘法[Q·K]T,計算復雜度為O(N2D);其中,T為轉置符號。
為降低SA的計算復雜度,線性化注意力(linear-attention,LA)旨在將SA的計算復雜度盡可能地減低。本文將Q、K添加縮放指數線性單元函數(scaled exponential linear units,SELU)以限制Q、K中的元素取值范圍,模擬SA中使用歸一化指數函數(softmax)保證[Q·K]T相似性系數矩陣的非負性,如式(1)所示:
|
其中,x為輸入變量,φ(x)代表激活函數,替換SA中的softmax,確保輸出的非負性。
由于LA中先對K、V進行矩陣乘法,因此LA的計算復雜度可降低為O(D2N),LA的數學表達如式(2)所示:
|
其中,LA(Q, K, V)為經過加權的輸出值。
1.3 融合多頭線性化注意力和雙重注意力的視杯盤分割模型
編碼器部分使用預訓練的ResNet-34作為特征提取網絡,實現下采樣過程。考慮SA機制的計算成本與特征圖尺寸之間的關系,編碼器前兩層引入MLA模塊從全局尺度上獲取關聯權重。解碼器將上采樣特征圖與編碼器同級特征圖相加,以保留更多淺層特征中蘊含的高分辨率細節信息,并利用MLA的輸出特征生成適應卷積神經網絡的DA重新校準解碼器特征圖,網絡模型如圖4所示。
圖4
所提網絡模型圖
Figure4.
Diagram of proposed network model
1.4 基于多頭線性化注意力的雙重注意力
本文利用MLA模塊的輸出特征生成注意力權重,該注意力是以通過MLA的圖像塊為基礎生成的通道、空間DA。
1.4.1 通道注意力
通道注意力以不同通道權重系數來強調相關特征與抑制無關特征。將MLA的特征輸出作為注意力權重輸入端,為保證維度統一,利用全連接調整通道維度。其次對特征圖進行全局平均池化(global average pooling,gap),如式(3)所示,確保通道特征是對所有圖像塊的總體權重計算,生成適配卷積神經網絡計算的通道注意力權重,如式(4)所示:
|
|
其中,x為輸入特征圖,Nc為特征通道數,Ns為序列長度,xs為每一個通道的序列,V為維度擴展,fc為全連接層,Sigmoid為S型生長曲線函數,gaps是對序列維度進行gap,wch為生成的通道權重。
1.4.2 空間注意力
空間注意力為每個位置生成權重并加權輸出,增強感興趣區域并弱化無關的背景區域。空間注意力由淺層特征構成,將MLA的輸出特征進行gap,如式(5)所示,并對每一個圖像塊合并通道,轉換維度形成卷積特征圖。淺層空間注意力代表與它同級的解碼特征圖的像素點級別的權重系數,如式(6)所示:
|
|
其中,xc為每一個序列的通道特征,Conv為1×1卷積,gapc是對通道維度進行gap,wsp為生成的空間權重,最終DA如圖5所示。
圖5
DA示意圖
Figure5.
DA flow chart
1.5 模型壓縮優化
模型壓縮優化旨在基本不影響模型分割效果前提下,減少視杯盤分割模型的參數量,提升模型的計算效率。本文使用知識蒸餾方法對模型進行壓縮,知識蒸餾中最直接的方法是將學生模型和教師模型之間每個像素的類概率分布對齊,如式(7)所示:
|
其中,和為學生和教師在(h, w)處的軟標簽概率,s為學生網絡,t為教師網絡,均方誤差(mean squared error,MSE)損失以MSE(·)表示,H,W為軟標簽的高和寬,Lkd為輸出的損失函數值。
2 實驗結果
2.1 實驗數據
本文使用兩個公開的青光眼診斷數據集中的視網膜眼底圖像,用于視盤和視杯的像素級語義分割:① 視神經頭分割的視網膜圖像數據集(Retinal Image Dataset for Optic Nerve Head Segmentation,DRISHTI-GS)來源于亞拉文眼科醫院(Aravind eye hospital)[17-18]。該數據集包含50張訓練圖像和51張測試圖像,以視盤為中心,視場為30o,圖像尺寸為2 896 × 1 944像素,并由四位青光眼專家提供視盤和視杯標簽。② 用于視神經評估的開放式視網膜圖像數據庫—V3[19](retinal image database for optic nerve evaluation,RIM-ONE-V3)從3家西班牙醫院收集。數據集包含159幅視網膜圖像,其中85幅健康眼底圖像和74幅青光眼眼底圖像,并由兩位眼科醫生進行注釋。由于RIM-ONE-V3中未區分訓練集與測試集,因此采取隨機抽取方式以比例8 : 2劃分訓練集與測試集。
2.2 實驗環境
本次實驗在代碼集成開發環境PyCharm 2 022.3.2(JetBrains Inc,捷克)上運行,使用計算機編程語言Python 3.8(Guido van Rossum,荷蘭),采用深度學習框架Pytorch 1.12.1 + cu113(Facebook Inc,美國),實驗使用處理器Intel(R) Xeon(R) Silver 4210R CPU @ 2.40GHz(Intel Inc,美國)和顯卡NVIDIA GeForce RTX 3090 Ti GPU(Nvidia Inc,美國)。
2.3 實驗細節
由于數據集中提供的眼底圖像視盤占比較小,采用基于顯著性的視盤定位方法對眼底圖像和金標準進行預處理。為確保視盤輪廓與原圖的一致性,對眼底圖像裁剪感興趣區域,考慮原始數據集中數據量較少,本文對原始數據進行數據增強,包括水平翻轉、90°旋轉、調整亮度和模糊變化來模擬眼底照相機在拍照過程中可能出現的光照變化和運動模糊。在訓練之前,將圖像大小調整為512 × 512,輸入圖像像素范圍調整至(?1.6,1.6)。網絡使用自適應矩估計(adaptive moment estimation,Adam)優化器,初始學習率為1×10?4,之后輪次學習率逐漸遞減,批訓練大小(batch size)設置為8,訓練輪次(epoch)為100輪。
2.4 評價指標
為了評價網絡分割結果,使用戴斯(Dice)相似性系數和交并比(intersection over union,IOU)作為評價指標。兩者都是用于衡量兩個集合之間的相似度,在圖像分割中用來衡量網絡分割結果與金標準之間的相似度,Dice與IOU計算公式分別如式(8)~式(9)所示:
|
|
其中,M為金標準中的視杯盤區域,A為本文算法預測的視杯盤區域,Dice與IOU取值范圍為(0, 1),值越大,說明分割圖片越接近于金標準。
2.5 實驗結果與分析
2.5.1 消融實驗
消融實驗用于驗證網絡中多頭SA(multi-headed SA,MSA)模塊、MLA模塊和DA機制對模型性能的影響。MLA放置于ResNet-34的第二層和第三層之后,MSA放置于ResNet-34的第四層和第五層之后。如表1所示,各模塊對模型性能有一定影響,MLA在視杯盤分割中起到提升效果,對比基線模型,引入MLA模塊的模型在兩個數據集的視杯盤分割中Dice和IOU分別有所提升。添加DA機制的MLA網絡在性能上進一步提升,并在視杯盤分割中取得了最優值(粗體顯示),這可能是因為經過MLA的高分辨率特征生成的注意力權重對解碼器特征圖進行修正,緩解下采樣引起的細節丟失問題。然而,深層特征圖中引入的MSA模塊對模型沒有正向提升效果,尤其是當三個模塊同時添加時,模型性能在兩個數據集上都出現了不同程度的下降。在網絡中引入過多的SA機制使得模型獲取的特征愈發抽象,從而丟失了圖像的細節,模型對圖像邊緣分割效果不佳,導致生成的預測圖邊緣不夠平滑。
此外,本文對模塊的參數量和計算速度進行探討,如表2所示,模型的參數和速度主要由基線模型決定。引入MLA和DA模塊所上升的參數十分有限,可以忽略不計,模塊對速度的影響在5 幀/s以內,說明模塊對網絡速度影響較小。需要說明的是,在ResNet-34第二層和第三層后添加MSA會極大的增加模型的計算時間(下降至19.09 幀/s),因此并未考慮該部分的消融實驗。
2.5.2 對比實驗
為了驗證算法的有效性,本文算法與U-Net、上下文編碼網絡(context encoder network,CENet)[20]、空洞卷積網絡-V3(atrous convolution network,DeeplabV3)[21]、輕量級上下文引導網絡(light-weight context guided network,CGNet)[22]、剩余注意力U-Net(residual attention U-Net,RAU-Net)[23]在兩個公開數據集上進行比較。如表3所示,本文算法在兩個數據集中視盤分割的Dice達到0.980 8、0.977 6,IOU達到0.962 3、0.956 3;視杯分割的Dice達到0.921 5、0.872 9,IOU達到0.856 4、0.784 4;兩項指標對比其他算法均達到最優。相比U-Net網絡,本文算法在DRISHTI-GS中視盤和視杯IOU均有提升,RIM-ONE-V3中視盤和視杯IOU也有提升。通過對比實驗,說明除U-Net和CGNet以外,網絡對視盤分割的精度都保持在一個較高的水平,這與視盤在眼底圖片中呈現的幾何、顏色等多方面差異特征有關。然而,視盤內部的視杯沒有明顯的邊界信息,呈現與視盤高度相似的狀態,網絡的分割精度有所下降。模型的最終分割效果與醫生所標注的標簽類似,不同醫生對視盤的標注結果僅有細微的差別,視杯的標注結果卻差異性很大,側面印證了視盤與視杯在分割難度上的不同。
2.5.3 模型大小和推理速度
網絡的參數量和運行速度如圖6所示,本文算法參數量為2.3×107 個,運行速度為107.79 幀/s。與速度最快的RAU-Net相比,本文算法的速度提升在15 幀/s左右。在參數方面,盡管輕量級語義分割網絡CGNet能有效減少模型參數量,但如表3所示,對比實驗說明CGNet的分割精度與其他模型相差較大。
圖6
不同模型的參數量和計算速度
Figure6.
Parameter quantity and calculation speed of different models
2.5.4 輕量化設計
如表2所示,模型的計算成本主要是由特征提取網絡RseNet-34本身決定。本文將特征提取網絡替換為ResNet-18和MobilevNetV2用于降低網絡的計算成本。如表4所示,以ResNet-18為特征提取網絡的模型的參數量為1.289 × 107 個,運行時間為135.58 幀/s,較原網絡有很大提升。MobileNetV2的模型參數量僅為2.16 × 106 個,運行時間為91.11 幀/s,參數量大幅減小。與直接訓練的模型相比,引入知識蒸餾策略的模型在性能更接近教師模型,說明從教師網絡生成的軟標簽能輔助提升學生模型的分割性能。
2.5.5 模型分割可視化結果
為了直觀體現本文算法的效果,如圖7所示,本文展示了部分數據的可視化結果,并與U-Net、DeeplabV3、CENet、CGNet、RAU-Net進行視杯盤的可視化對比。第一列是裁剪后的目標原始圖像區域,第二列是專家標定真值(標簽),第三至第八列分別代表不同算法的可視化分割效果。通過對比不同模型的可視化結果可以直觀感受其差異,其中U-Net和CGNet在視盤分割中評價指標與其他網絡相差較小,但僅代表它們能實現視盤的整體分割,而對于邊界像素點不能準確預測,可視化結果表現為預測圖邊界不夠平滑,視杯分割中存在很多誤檢或漏檢的點,導致分割精度有明顯下降。DeeplabV3、CENet、RAU-Net和本文算法在視盤分割上性能相近,但在高難度的視杯分割中存在差異。例如樣本3通過人為觀察能得到視杯右側與視盤交接部分有較為明顯的顏色差異,而視杯左側很難分辨,CENet、RAU-Net和本文算法對右側分割是較為精準的,DeeplabV3分割效果不理想;對于視杯左側,CENet出現明顯誤檢情況,RAU-Net缺失部分視杯區域。相較于其他網絡,本文網絡對視杯和視盤都能實現較好的分割。
圖7
部分圖像預測可視化結果
Figure7.
Visualization results of partial image prediction
3 結論
本文提出一種采用MLA和DA的視杯盤分割模型。MLA應用于編碼器的淺層位置,起到關聯全局信息的作用,彌補原始編碼器僅通過卷積層獲取局部感受野的問題。DA是經由MLA輸出的注意力權重,主要用于解決模型在多次下采樣后細節丟失的問題,使得最終分割邊界有更好的效果。本文算法在兩個眼底數據集上均體現出其優越性,并且模塊引入所增加的計算成本較小。此外,本文利用知識蒸餾方法壓縮模型,生成以RseNet-18和MobileNetV2為特征提取網絡的輕量級視杯盤分割模型。在接下來的工作中,本文將逐步獲取用于青光眼診斷的數據集,將模型應用于青光眼的篩查。此外,本文也將關注模型的跨設備遷移的方法,用于解決嵌入式設備植入模型的問題。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:藍子俊負責程序編寫與論文寫作;謝珺負責論文指導與審閱;郭燕負責論文相關醫學知識指導;張喆負責實驗設計與指導;孫彬負責數據收集與分析。