肺實質的準確分割是計算機輔助影像學診斷肺部疾病的關鍵。隨著深度學習技術的發展,基于全卷積網絡的圖像分割模型取得了很好的效果,但對于邊緣模糊和肺實質密度不均勻的情形仍會誤分割。針對該問題,本文提出一種基于非局域注意力機制和多任務學習的胸部X線片圖像肺實質分割方法。首先,基于殘差連接的編-解碼卷積網絡提取肺實質多層級語義特征信息并預測肺實質邊界輪廓;其次,通過非局域注意力機制建立肺實質輪廓與全局語義特征信息之間的相關性并增強輪廓區域特征信息權重;再次,基于增強的特征信息進行多任務監督學習,實現肺實質的準確分割;最后,在JSRT和Montgomery公開數據集上驗證了本文方法的有效性和模型泛化能力,對比其他幾種代表性的分割模型,其Dice系數和準確性最大分別提高1.99%和2.27%。實驗結果表明,通過增強特征信息中邊界輪廓的注意力,能有效減少肺實質密度不均勻時的誤分割并提高模糊邊緣的分割精度。
引用本文: 熊亮, 秦小林, 劉欣. 基于非局域注意力和多任務學習的胸部X線片肺實質分割方法. 生物醫學工程學雜志, 2023, 40(5): 912-919. doi: 10.7507/1001-5515.202211079 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
0 引言
胸部X線片(chest X-ray,CXR)作為最常用的心臟和肺部疾病影像學檢查技術,具有非侵入性、輻射劑量低、成本低以及容易獲取等優點,已廣泛應用于臨床疾病診斷、治療和預后評估[1]。從胸部X線片圖像中準確分割和精確測量肺實質形態結構可以幫助醫生更快、更準確地診斷和評估如肺結核、肺癌、塵肺病、新冠肺炎等各種肺部疾病[2]。
由于不同個體肺實質形狀、紋理差異較大,而且胸部X線片圖像對比度低、邊緣模糊,以及各種肺部疾病導致肺實質密度均勻性差等原因,自動準確分割肺實質仍面臨很大挑戰[3]。傳統圖像處理方法如閾值分割法[4]、區域生長法[5]、邊緣檢測法[6]以及基于肺實質形狀模型[7]的方法等,都是基于經驗知識的淺層特征學習,不能有效挖掘數據之間復雜的非線性關系,對圖像質量及肺實質密度變化非常敏感。隨著深度卷積神經網絡廣泛應用于圖像語義分割,已有很多研究將它用于肺實質分割,其中全卷積網絡(fully convolutional networks,FCN)[8]和U-Net[9]是兩種常用的模型。Hooda等[10]提出改進的全卷積網絡模型FCN4,通過跳躍連接融合更多淺層特征,減少上采樣率以保留更多細節特征,在肺實質分割任務中獲得了95.88%的分割交并比。Rashid等[11]基于U-Net分割模型和圖像后處理算法,在JSRT數據集上的平均分割精度為97.1%。同時,邊界輪廓作為分割目標的組成部分,在特征提取過程中可以提供重要的空間先驗約束信息。Chen等[12]提出深度輪廓感知網絡在多任務學習模型中實現腺體及其輪廓的精確分割。Kholiavchenko等[13]利用肺實質及其邊界輪廓信息進行多任務分割學習,進一步提高了分割精度。
全卷積網絡模型在肺實質分割任務中取得了很好的效果,但對于邊緣模糊和肺實質密度不均勻的情形仍會誤分割[3],如圖1所示。由于卷積神經網絡存在感受野局限性,只能捕捉局部信息,通過堆疊卷積層和下采樣操作獲取全局語義信息則會導致細節特征丟失。如何在擴大感受野獲取目標全局語義信息的同時保留細節特征是計算機視覺研究的熱點。為此,研究人員提出空洞卷積[14]、通道/空間注意力[15-16]、非局域注意力[17]以及自注意力[18]等方法來獲取全局語義信息,在圖像分類[19]、目標檢測[20]、語義分割[21]等任務中都獲得了極大的成功。這些方法在圖像分割任務中能夠有效獲取目標全局語義信息,但忽略了邊界輪廓信息在目標分割時的重要作用,或者只是將邊界輪廓分割作為網絡模型的子任務[12-13, 22],沒有將邊界空間先驗信息與全局特征信息進行深度融合。例如,Ding等[23]通過構建邊界感知特征傳播模塊提高同區域局部特征的相似性,實現街景的語義分割;Hong等[24]通過迭代計算選擇出邊界關鍵點作為監督學習的標簽值,實現皮膚病變斑塊和醫學超聲圖像中模糊邊界的分割;Wang等[25]結合邊界關鍵點信息和Transformer模型實現皮膚病變斑塊模糊邊界分割任務。
 圖1
肺實質分割示例
Figure1.
Example of lung segmentation
圖1
肺實質分割示例
Figure1.
Example of lung segmentation
受以上研究工作啟發,結合卷積神經網絡在細節特征提取和非局域注意力機制在全局語義信息獲取方面的優勢,本文提出一種基于非局域注意力機制和多任務學習的胸部X線片圖像肺實質分割方法。首先,基于殘差連接的編-解碼卷積網絡提取肺實質多層級語義特征信息并預測肺實質輪廓;其次,通過非局域注意力機制建立肺實質輪廓與全局語義特征信息之間的相關性,同時增加邊界輪廓區域特征信息權重;再次,基于增強的特征信息進行多任務監督學習,實現肺實質和邊界輪廓的準確分割;最后,在胸部X線片數據集上驗證了本文方法的有效性。
1 研究方法
1.1 本文方法
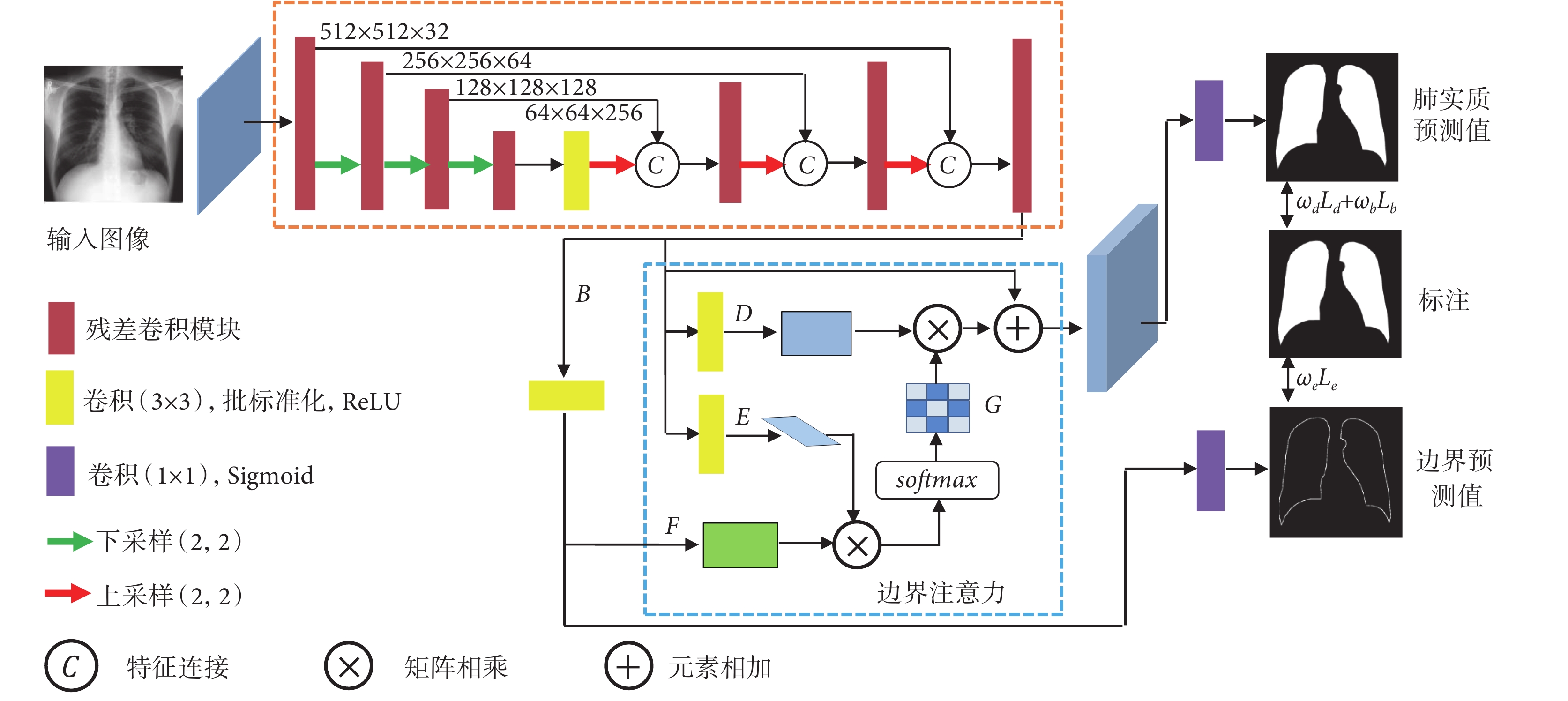
本文模型如圖2所示。胸部X線片圖像經過預處理后,輸入由殘差卷積模塊組成的編-解碼網絡,提取多層級特征信息并預測肺實質邊界輪廓;將只包含邊界輪廓的特征信息輸入邊界注意力模塊,建立邊界輪廓與全局特征信息之間的相關性并增強肺實質輪廓區域特征信息權重;最后,基于增強的特征信息進行多任務監督學習,實現肺實質的準確分割。
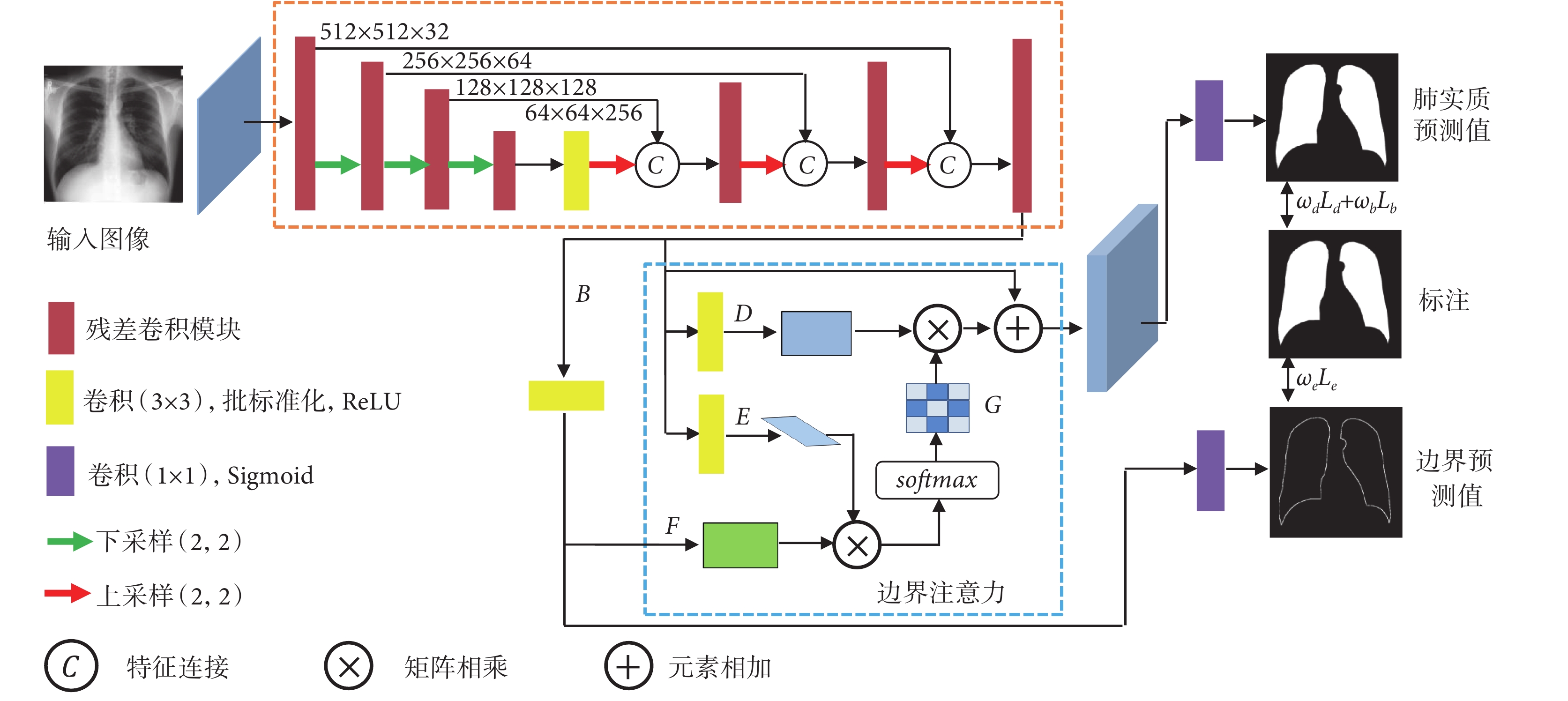 圖2
肺實質分割整體流程
Figure2.
Overall flow chart of lung segmentation
圖2
肺實質分割整體流程
Figure2.
Overall flow chart of lung segmentation
1.2 數據預處理
本文采用的數據集中原始圖像和標注圖像的分辨率不一致,同時為了加快模型訓練,需要對數據進行預處理。預處理包括兩個步驟:① 圖像縮放:將原始圖像和標注圖像通過雙線性插值法縮放至相同分辨率,即512像素 × 512像素;② Z-score標準化:通過減去圖像灰度值的均值并除以方差計算。
1.3 殘差卷積網絡
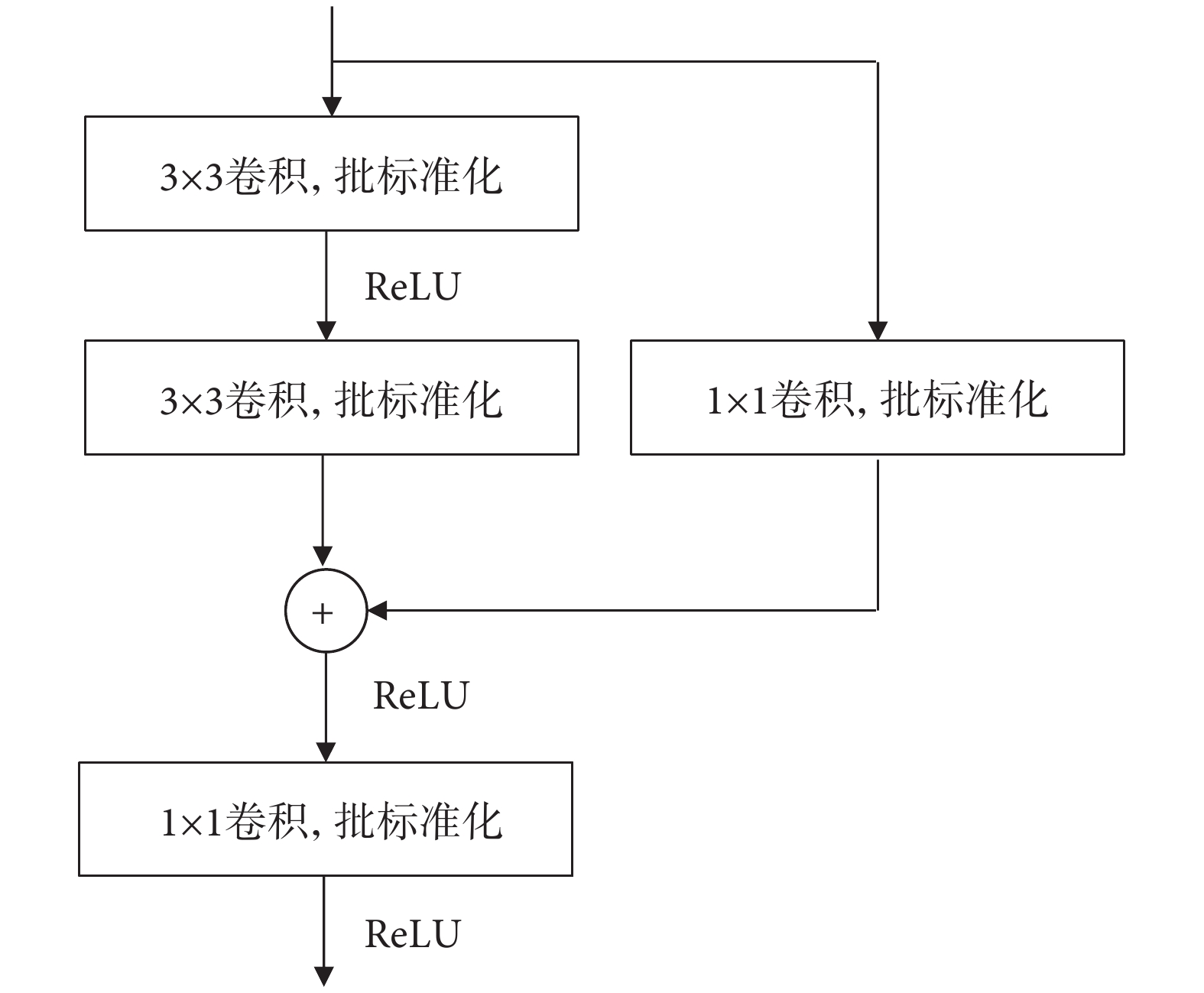
卷積神經網絡越深,其訓練難度越大,同時還容易產生梯度消失和梯度爆炸。He等[26]提出了殘差網絡,通過在網絡中引入直接連接加強特征的傳遞,減輕網絡訓練過程中的梯度消失問題,使網絡能夠提取到更深層次的特征。本文模型中的殘差卷積結構如圖3所示,輸入經過2層3 × 3卷積層提取語義信息后與側邊1 × 1卷積層的特征信息對應元素相加組成殘差結構,最后通過1 × 1卷積層調節輸出通道數,本文編-解碼網絡中殘差卷積模塊的輸出通道數分別為:32,64,128,256,128,64,32。
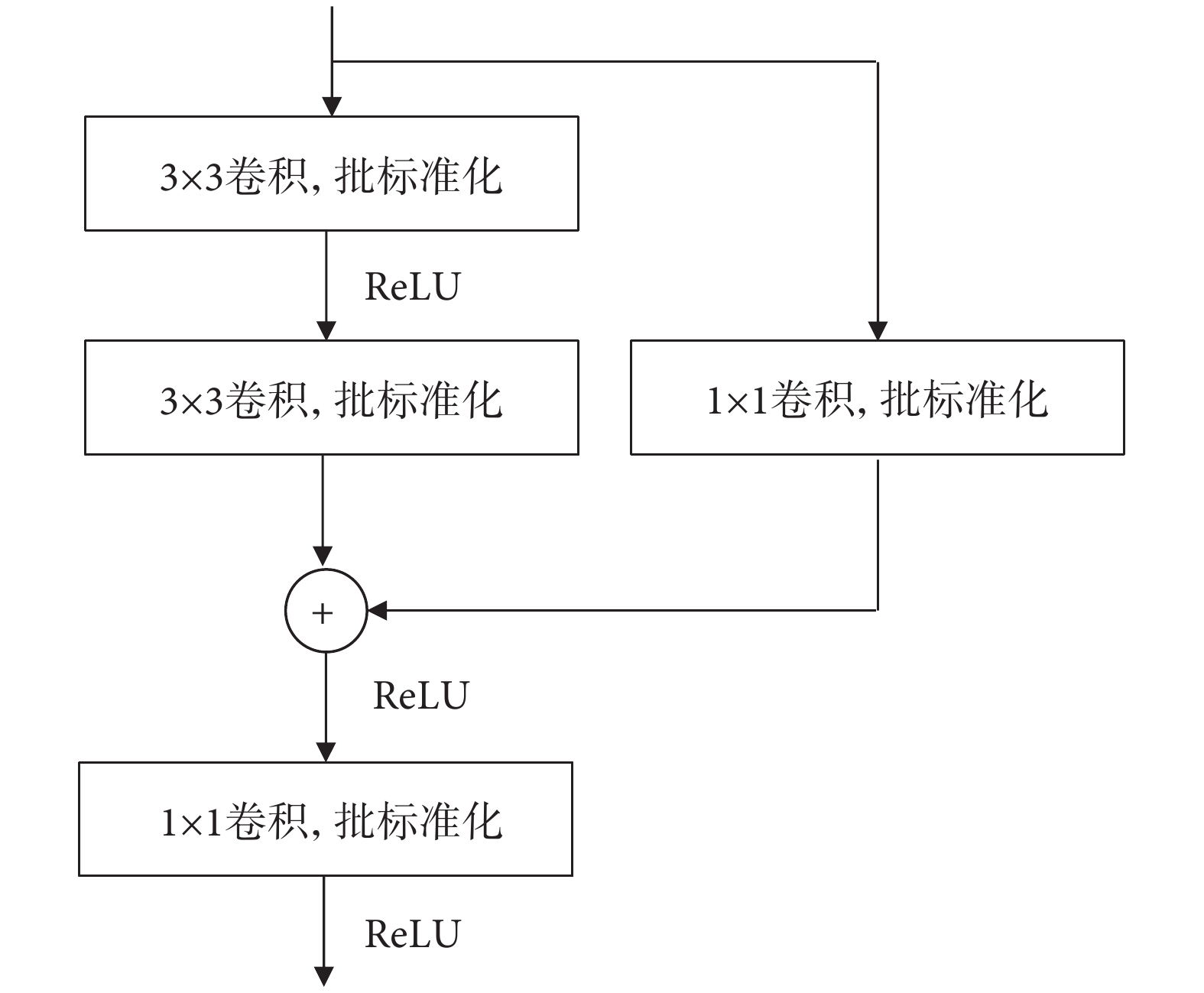 圖3
殘差卷積模塊
Figure3.
Structure of the residual convolution module
圖3
殘差卷積模塊
Figure3.
Structure of the residual convolution module
1.4 邊界注意力
與空間注意力機制[15]和非局域注意力機制[17]通過計算特征信息內部之間的相似性來增強重要信息不同,邊界注意力(boundary attention,BA)只計算邊界輪廓上每個像素的特征信息與全局特征信息之間的相似性,從而實現通過空間位置約束來增強邊界輪廓的特征信息。設特征圖  (C表示通道數)分別經過 3 × 3 卷積層后生成新的特征圖
(C表示通道數)分別經過 3 × 3 卷積層后生成新的特征圖  、
、 、
、 ,將特征圖F經過 1 × 1 卷積層和 sigmoid 激活函數后與標注圖經過Canny邊緣檢測算法[27]生成的邊界輪廓進行監督學習得到邊界預測值,此時特征圖F中主要包含邊界輪廓的特征信息。將特征圖D、E、F分別轉換成二維矩陣形式
,將特征圖F經過 1 × 1 卷積層和 sigmoid 激活函數后與標注圖經過Canny邊緣檢測算法[27]生成的邊界輪廓進行監督學習得到邊界預測值,此時特征圖F中主要包含邊界輪廓的特征信息。將特征圖D、E、F分別轉換成二維矩陣形式  、
、 、
、 (其中
(其中  表示特征圖中每個通道的像素數量),然后將矩陣E與矩陣F的轉置相乘并經過 softmax 函數歸一化后得到邊界注意力矩陣
表示特征圖中每個通道的像素數量),然后將矩陣E與矩陣F的轉置相乘并經過 softmax 函數歸一化后得到邊界注意力矩陣  :
:
 |
 表示邊界輪廓特征圖F中位置i與特征圖E中位置j之間的相關性。
表示邊界輪廓特征圖F中位置i與特征圖E中位置j之間的相關性。
將邊界注意力矩陣G與矩陣D相乘并進行維度轉換,然后與特征圖B對應元素相加,得到邊界注意力增強的特征圖  :
:
 '/> '/> |
最后,將邊界輪廓特征增強的特征圖  經過1 × 1卷積層和sigmoid激活函數后與標注圖進行監督學習得到肺實質的預測值。
經過1 × 1卷積層和sigmoid激活函數后與標注圖進行監督學習得到肺實質的預測值。
1.5 損失函數
損失函數用于評估預測結果與真實結果之間的差異。圖像分割是一個像素級的二分類問題,因此采用二分類交叉熵損失函數(binary cross entropy,BCE),通過逐像素計算像素點預測值與標注值之間的差異得到損失函數的值。其計算公式為:
 |
式中,y表示圖像標注值, 表示模型預測值。
表示模型預測值。
Dice相似性系數通常用于度量兩個圖像樣本之間的重疊區域,因此定義Dice損失函數為:
 |
式中,N表示像素個數, 表示每個像素標注值,
表示每個像素標注值, 表示每個像素的預測值經過二值化處理后的值。
表示每個像素的預測值經過二值化處理后的值。
對于邊界輪廓預測任務,通過計算標注圖邊界輪廓與邊界預測值的二分類交叉熵作為損失函數,其計算公式為:
 |
其中,z表示標注圖邊界輪廓值, 表示邊界預測值。
表示邊界預測值。
因此,總的損失函數為:
 |
 、
、 、
、 分別為二分類交叉熵損失函數、Dice損失函數和邊界輪廓損失函數的權重。
分別為二分類交叉熵損失函數、Dice損失函數和邊界輪廓損失函數的權重。
2 實驗與分析
2.1 數據集
本文用于模型訓練和測試的胸部X線片圖像來自公開數據集JSRT[28]和Montgomery[29]。JSRT數據集包括來自日本和美國共14個研究中心采集的247例后前位胸部X線片,其中93張為正常圖像,154張圖像有肺部結節,圖像分辨率為2 048 × 2 048,灰度值深度為12 bits。相應的肺實質人工分割標注圖采用SCR[7]數據集,圖像分辨率為1 024 × 1 024,灰度值深度為8 bits。Montgomery數據集來自美國馬里蘭州蒙哥馬利縣衛生與人類服務部的結核病控制計劃,包含138例后前位胸部X線片,其中80張為正常圖像,58張有肺結核病灶,圖像分辨率為4 020 × 4 892,灰度值深度為8 bits。相應的肺實質人工標注圖分辨率為4 020 × 4 892,灰度值深度為1 bit。所有數據都已去除與患者隱私有關的信息并允許用于科學研究。
2.2 評價指標
在圖像分割任務中,Dice系數和Jaccard系數是重要的評價指標,靈敏度(SE)和準確度(ACC)可以幫助評估模型的魯棒性,所有評價指標越高表明模型分割結果與標注圖像越接近。設TP(true positive)是被正確分類為肺實質的肺部像素數量,TN(true negative)是被正確分類為背景的背景像素數量,FP(false positive)是被錯誤分類為肺實質的背景像素數量,FN(false negative)是被錯誤分類為背景的肺實質像素數量,評價指標定義如式(7)~(10)所示:
 |
 |
 |
 |
2.3 實驗設置
將數據集JSRT中的247例圖像預處理后隨機抽取80%樣本用于訓練和驗證,20%樣本用于測試。并且,將訓練好的模型在Montgomery數據集上進行測試,以評估模型的泛化能力。本文實現的模型算法均使用相同的數據預處理和參數設置,實驗使用兩塊NVIDIA Geforce RTX 3090 GPU顯卡進行模型訓練,深度學習框架為Keras 2.3.1,后端引擎為Tensorflow 2.1.0,操作系統為ubuntu18.04,采用Adam優化算法,學習率設為  ,訓練集批大小設為4,訓練集中驗證集比例設為0.1,訓練批次設為300,損失函數權重為:
,訓練集批大小設為4,訓練集中驗證集比例設為0.1,訓練批次設為300,損失函數權重為: 、
、 、
、 ,實驗發現標注圖邊界寬度設為7時效果最優,最后使用軟件MATLAB R2018b(MathWorks Inc.,美國)對實驗數據進行處理和顯示。
,實驗發現標注圖邊界寬度設為7時效果最優,最后使用軟件MATLAB R2018b(MathWorks Inc.,美國)對實驗數據進行處理和顯示。
2.4 消融實驗
為了驗證邊界注意力和多任務學習在分割模型中的作用,在JSRT數據集上對這兩部分功能進行消融實驗。實驗結果如表1所示。由結果可見,只進行肺實質分割任務時Dice系數最低,為96.02%;同時進行肺實質和邊界輪廓分割任務時,Dice系數提高了0.77%,而靈敏度SE提高了2.28%,這表明通過邊界輪廓分割任務的約束,能夠引導模型有效學習邊緣特征信息,減少肺實質中被誤分割的像素;而引入非局域注意力機制增強邊界輪廓特征信息后,Dice系數、靈敏度SE、準確度ACC分別提高了1.71%、3.53%、1.15%,表明邊界注意力機制能夠通過建立全局相關性進一步挖掘肺實質全局特征信息,減少肺實質誤分割和提高分割精度。
2.5 與其他分割算法的對比實驗
為了驗證本文方法的有效性,與幾種代表性的分割網絡模型進行對比實驗。表2為在JSRT數據集的實驗結果。表明本文方法在各項評估指標上都優于其他幾種分割網絡。其中,U-Net模型[9]采用編-解碼網絡結構提取圖像語義信息和恢復細節特征,由于沒有采用殘差連接的方式以學習更深層的特征信息,其分割精度低于本文中基于殘差卷積結構的編-解碼網絡模型;DeepLab V3+[14]采用特征金字塔策略,利用不同擴張率的空洞卷積來提取多尺度圖像特征以擴大感受野,這在某種程度上可以幫助提取肺實質不連續區域的全局特征信息,其Dice系數比U-Net模型提高了0.7%,靈敏度SE和準確度ACC與U-Net模型接近,說明其提取全局特征信息的能力有限;Attention U-Net[16]通過在解碼過程中加入注意力機制突出重要特征信息,同時抑制無關特征信息,從而提高模型學習全局語義信息的能力,其Dice系數、靈敏度SE和準確度ACC比U-Net模型分別提高了1.42%、1.88%和0.89%。表3為將訓練好的模型在Montgomery數據集上測試的結果。從實驗結果來看,本文方法的分割效果最優。同時,由于肺結核病灶對肺實質紋理及胸片圖像對比度的影響,幾種模型性能都有所下降。綜合來看,本文方法的泛化能力優于其他幾種網絡模型。
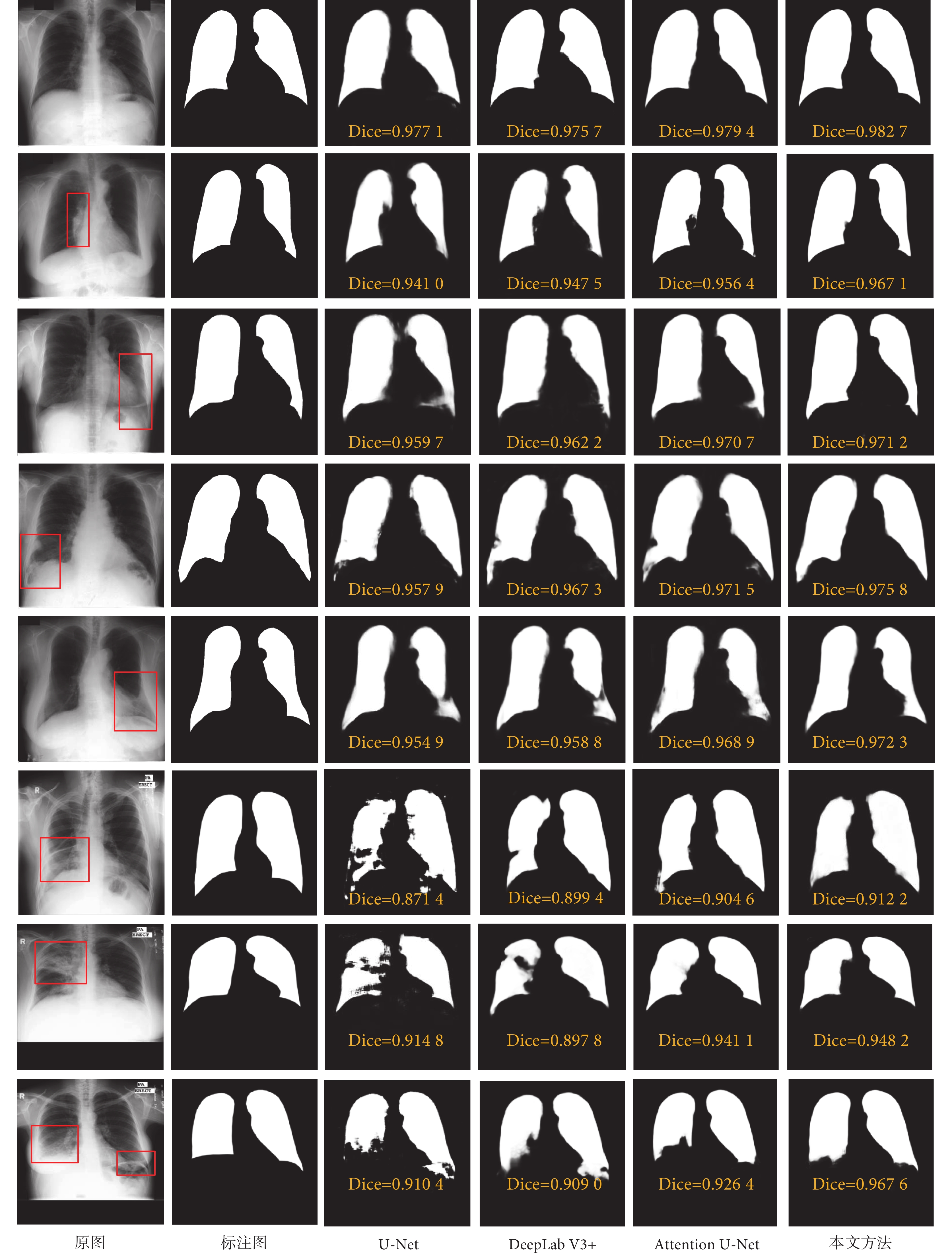
為了直觀比較幾種分割算法的準確性,圖4展示了部分胸部X線片圖像分割結果及其Dice系數。可以看出,對于肺實質密度均勻且邊界輪廓明顯的胸部X線片圖像(如圖4第一行),所有模型均取得了很高的分割精度。而對于肺實質密度不均勻和邊緣模糊的胸部X線片圖像(如圖4第二至第五行),以及有肺結核病灶陰影的胸部X線片圖像(如圖4第六至第八行),U-Net模型在肺實質邊界輪廓的分割效果最差,且對于肺實質中對比度低和不連續的區域(紅色方框所示)會出現欠分割和分割目標不連通的情況,其原因可能是卷積網絡感受野有限,模型訓練時難以有效學習到全局語義信息;DeepLab V3+模型通過多尺度空洞卷積金字塔結構擴大感受野范圍,在肺實質不連續的區域分割效果要好于U-Net模型;Attention U-Net模型能夠通過注意力機制聚合重要的全局特征信息,在肺實質不連續的區域也能實現較完整的分割;而本文方法對肺結核病灶造成的邊界模糊、對比度低以及肺實質不連續區域的分割能夠較好地保持肺實質形狀的完整性。
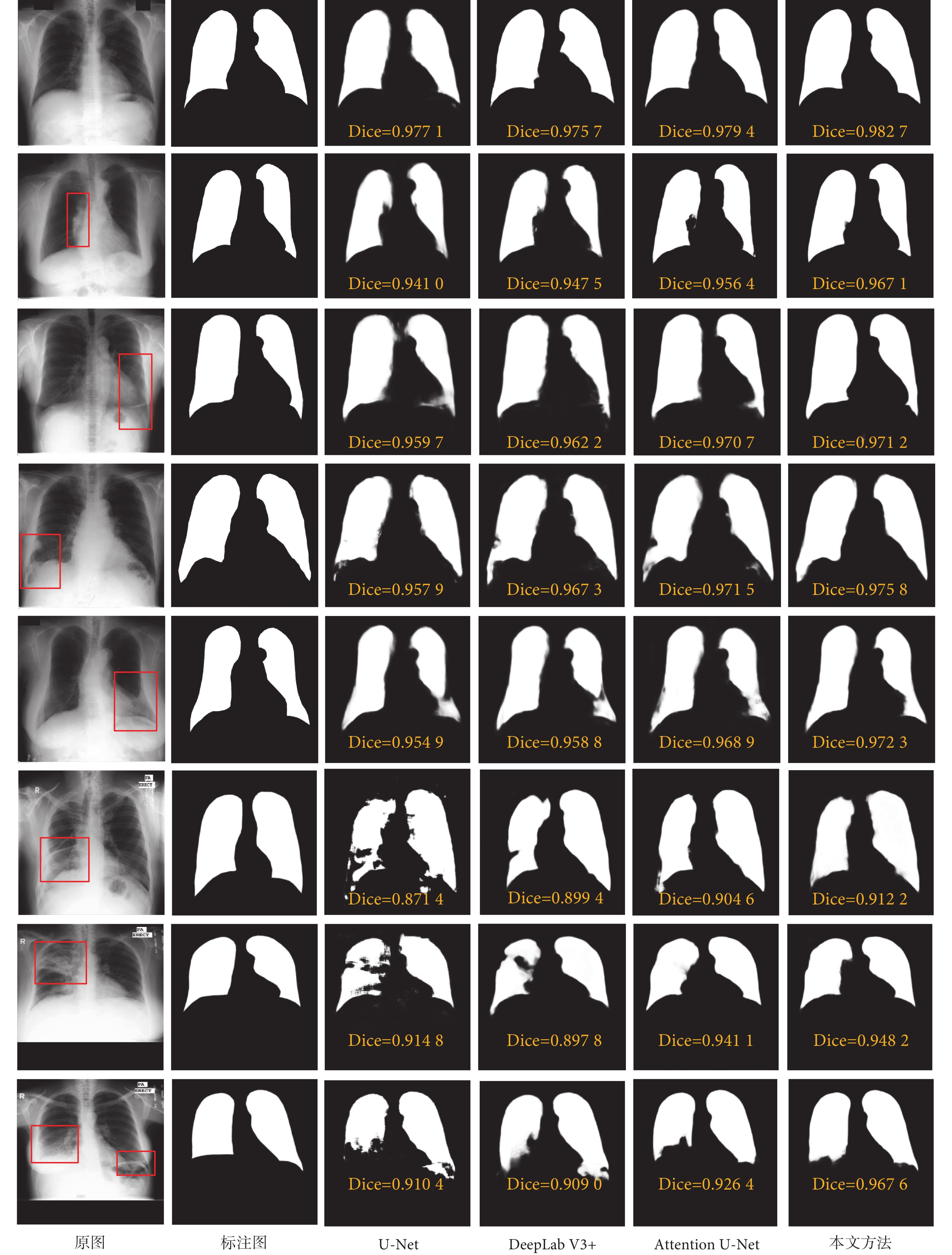 圖4
肺實質分割結果示例
Figure4.
Examples of lung segmentation
圖4
肺實質分割結果示例
Figure4.
Examples of lung segmentation
3 結語
由于各種肺部疾病可導致胸部X線片圖像中肺實質密度不均勻和肺實質內部區域不連續,準確地分割肺實質是一個難點。本文提出一種基于非局域注意力機制和多任務學習的肺實質分割模型。首先,在多任務監督訓練中,通過邊界輪廓引導特征提取網絡能更有效地學習肺實質和邊界輪廓的特征;然后,通過非局域注意力機制增強肺實質邊界輪廓特征信息,并保持肺實質密度不均勻區域的連續性和完整性,消融實驗以及對比實驗結果表明本文方法能有效減少肺實質密度不均勻和肺實質內部區域不連續時的誤分割,并提高模糊邊緣的分割精度。最后,將在JSRT數據集中訓練好的模型在Montgomery數據集上進行測試,驗證了本文方法的泛化能力優于其他幾種分割方法,并且對肺結核病灶引起的肺實質對比度低和不連續等情形也能實現較完整的分割。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:本文由熊亮完成研究思路設計、算法編程實現、數據分析和文章撰寫,秦小林對研究思路、論文結構給予重要指導并對文章進行審校,劉欣對算法的臨床研究意義進行指導并負責實驗數據收集、實驗結果檢驗,所有作者均參與論文審閱討論和修訂。
0 引言
胸部X線片(chest X-ray,CXR)作為最常用的心臟和肺部疾病影像學檢查技術,具有非侵入性、輻射劑量低、成本低以及容易獲取等優點,已廣泛應用于臨床疾病診斷、治療和預后評估[1]。從胸部X線片圖像中準確分割和精確測量肺實質形態結構可以幫助醫生更快、更準確地診斷和評估如肺結核、肺癌、塵肺病、新冠肺炎等各種肺部疾病[2]。
由于不同個體肺實質形狀、紋理差異較大,而且胸部X線片圖像對比度低、邊緣模糊,以及各種肺部疾病導致肺實質密度均勻性差等原因,自動準確分割肺實質仍面臨很大挑戰[3]。傳統圖像處理方法如閾值分割法[4]、區域生長法[5]、邊緣檢測法[6]以及基于肺實質形狀模型[7]的方法等,都是基于經驗知識的淺層特征學習,不能有效挖掘數據之間復雜的非線性關系,對圖像質量及肺實質密度變化非常敏感。隨著深度卷積神經網絡廣泛應用于圖像語義分割,已有很多研究將它用于肺實質分割,其中全卷積網絡(fully convolutional networks,FCN)[8]和U-Net[9]是兩種常用的模型。Hooda等[10]提出改進的全卷積網絡模型FCN4,通過跳躍連接融合更多淺層特征,減少上采樣率以保留更多細節特征,在肺實質分割任務中獲得了95.88%的分割交并比。Rashid等[11]基于U-Net分割模型和圖像后處理算法,在JSRT數據集上的平均分割精度為97.1%。同時,邊界輪廓作為分割目標的組成部分,在特征提取過程中可以提供重要的空間先驗約束信息。Chen等[12]提出深度輪廓感知網絡在多任務學習模型中實現腺體及其輪廓的精確分割。Kholiavchenko等[13]利用肺實質及其邊界輪廓信息進行多任務分割學習,進一步提高了分割精度。
全卷積網絡模型在肺實質分割任務中取得了很好的效果,但對于邊緣模糊和肺實質密度不均勻的情形仍會誤分割[3],如圖1所示。由于卷積神經網絡存在感受野局限性,只能捕捉局部信息,通過堆疊卷積層和下采樣操作獲取全局語義信息則會導致細節特征丟失。如何在擴大感受野獲取目標全局語義信息的同時保留細節特征是計算機視覺研究的熱點。為此,研究人員提出空洞卷積[14]、通道/空間注意力[15-16]、非局域注意力[17]以及自注意力[18]等方法來獲取全局語義信息,在圖像分類[19]、目標檢測[20]、語義分割[21]等任務中都獲得了極大的成功。這些方法在圖像分割任務中能夠有效獲取目標全局語義信息,但忽略了邊界輪廓信息在目標分割時的重要作用,或者只是將邊界輪廓分割作為網絡模型的子任務[12-13, 22],沒有將邊界空間先驗信息與全局特征信息進行深度融合。例如,Ding等[23]通過構建邊界感知特征傳播模塊提高同區域局部特征的相似性,實現街景的語義分割;Hong等[24]通過迭代計算選擇出邊界關鍵點作為監督學習的標簽值,實現皮膚病變斑塊和醫學超聲圖像中模糊邊界的分割;Wang等[25]結合邊界關鍵點信息和Transformer模型實現皮膚病變斑塊模糊邊界分割任務。
圖1
肺實質分割示例
Figure1.
Example of lung segmentation
受以上研究工作啟發,結合卷積神經網絡在細節特征提取和非局域注意力機制在全局語義信息獲取方面的優勢,本文提出一種基于非局域注意力機制和多任務學習的胸部X線片圖像肺實質分割方法。首先,基于殘差連接的編-解碼卷積網絡提取肺實質多層級語義特征信息并預測肺實質輪廓;其次,通過非局域注意力機制建立肺實質輪廓與全局語義特征信息之間的相關性,同時增加邊界輪廓區域特征信息權重;再次,基于增強的特征信息進行多任務監督學習,實現肺實質和邊界輪廓的準確分割;最后,在胸部X線片數據集上驗證了本文方法的有效性。
1 研究方法
1.1 本文方法
本文模型如圖2所示。胸部X線片圖像經過預處理后,輸入由殘差卷積模塊組成的編-解碼網絡,提取多層級特征信息并預測肺實質邊界輪廓;將只包含邊界輪廓的特征信息輸入邊界注意力模塊,建立邊界輪廓與全局特征信息之間的相關性并增強肺實質輪廓區域特征信息權重;最后,基于增強的特征信息進行多任務監督學習,實現肺實質的準確分割。
圖2
肺實質分割整體流程
Figure2.
Overall flow chart of lung segmentation
1.2 數據預處理
本文采用的數據集中原始圖像和標注圖像的分辨率不一致,同時為了加快模型訓練,需要對數據進行預處理。預處理包括兩個步驟:① 圖像縮放:將原始圖像和標注圖像通過雙線性插值法縮放至相同分辨率,即512像素 × 512像素;② Z-score標準化:通過減去圖像灰度值的均值并除以方差計算。
1.3 殘差卷積網絡
卷積神經網絡越深,其訓練難度越大,同時還容易產生梯度消失和梯度爆炸。He等[26]提出了殘差網絡,通過在網絡中引入直接連接加強特征的傳遞,減輕網絡訓練過程中的梯度消失問題,使網絡能夠提取到更深層次的特征。本文模型中的殘差卷積結構如圖3所示,輸入經過2層3 × 3卷積層提取語義信息后與側邊1 × 1卷積層的特征信息對應元素相加組成殘差結構,最后通過1 × 1卷積層調節輸出通道數,本文編-解碼網絡中殘差卷積模塊的輸出通道數分別為:32,64,128,256,128,64,32。
圖3
殘差卷積模塊
Figure3.
Structure of the residual convolution module
1.4 邊界注意力
與空間注意力機制[15]和非局域注意力機制[17]通過計算特征信息內部之間的相似性來增強重要信息不同,邊界注意力(boundary attention,BA)只計算邊界輪廓上每個像素的特征信息與全局特征信息之間的相似性,從而實現通過空間位置約束來增強邊界輪廓的特征信息。設特征圖 (C表示通道數)分別經過 3 × 3 卷積層后生成新的特征圖 、、,將特征圖F經過 1 × 1 卷積層和 sigmoid 激活函數后與標注圖經過Canny邊緣檢測算法[27]生成的邊界輪廓進行監督學習得到邊界預測值,此時特征圖F中主要包含邊界輪廓的特征信息。將特征圖D、E、F分別轉換成二維矩陣形式 、、(其中 表示特征圖中每個通道的像素數量),然后將矩陣E與矩陣F的轉置相乘并經過 softmax 函數歸一化后得到邊界注意力矩陣 :
|
表示邊界輪廓特征圖F中位置i與特征圖E中位置j之間的相關性。
將邊界注意力矩陣G與矩陣D相乘并進行維度轉換,然后與特征圖B對應元素相加,得到邊界注意力增強的特征圖 :
| '/> |
最后,將邊界輪廓特征增強的特征圖 經過1 × 1卷積層和sigmoid激活函數后與標注圖進行監督學習得到肺實質的預測值。
1.5 損失函數
損失函數用于評估預測結果與真實結果之間的差異。圖像分割是一個像素級的二分類問題,因此采用二分類交叉熵損失函數(binary cross entropy,BCE),通過逐像素計算像素點預測值與標注值之間的差異得到損失函數的值。其計算公式為:
|
式中,y表示圖像標注值, 表示模型預測值。
Dice相似性系數通常用于度量兩個圖像樣本之間的重疊區域,因此定義Dice損失函數為:
|
式中,N表示像素個數, 表示每個像素標注值, 表示每個像素的預測值經過二值化處理后的值。
對于邊界輪廓預測任務,通過計算標注圖邊界輪廓與邊界預測值的二分類交叉熵作為損失函數,其計算公式為:
|
其中,z表示標注圖邊界輪廓值, 表示邊界預測值。
因此,總的損失函數為:
|
、、分別為二分類交叉熵損失函數、Dice損失函數和邊界輪廓損失函數的權重。
2 實驗與分析
2.1 數據集
本文用于模型訓練和測試的胸部X線片圖像來自公開數據集JSRT[28]和Montgomery[29]。JSRT數據集包括來自日本和美國共14個研究中心采集的247例后前位胸部X線片,其中93張為正常圖像,154張圖像有肺部結節,圖像分辨率為2 048 × 2 048,灰度值深度為12 bits。相應的肺實質人工分割標注圖采用SCR[7]數據集,圖像分辨率為1 024 × 1 024,灰度值深度為8 bits。Montgomery數據集來自美國馬里蘭州蒙哥馬利縣衛生與人類服務部的結核病控制計劃,包含138例后前位胸部X線片,其中80張為正常圖像,58張有肺結核病灶,圖像分辨率為4 020 × 4 892,灰度值深度為8 bits。相應的肺實質人工標注圖分辨率為4 020 × 4 892,灰度值深度為1 bit。所有數據都已去除與患者隱私有關的信息并允許用于科學研究。
2.2 評價指標
在圖像分割任務中,Dice系數和Jaccard系數是重要的評價指標,靈敏度(SE)和準確度(ACC)可以幫助評估模型的魯棒性,所有評價指標越高表明模型分割結果與標注圖像越接近。設TP(true positive)是被正確分類為肺實質的肺部像素數量,TN(true negative)是被正確分類為背景的背景像素數量,FP(false positive)是被錯誤分類為肺實質的背景像素數量,FN(false negative)是被錯誤分類為背景的肺實質像素數量,評價指標定義如式(7)~(10)所示:
|
|
|
|
2.3 實驗設置
將數據集JSRT中的247例圖像預處理后隨機抽取80%樣本用于訓練和驗證,20%樣本用于測試。并且,將訓練好的模型在Montgomery數據集上進行測試,以評估模型的泛化能力。本文實現的模型算法均使用相同的數據預處理和參數設置,實驗使用兩塊NVIDIA Geforce RTX 3090 GPU顯卡進行模型訓練,深度學習框架為Keras 2.3.1,后端引擎為Tensorflow 2.1.0,操作系統為ubuntu18.04,采用Adam優化算法,學習率設為 ,訓練集批大小設為4,訓練集中驗證集比例設為0.1,訓練批次設為300,損失函數權重為:、、,實驗發現標注圖邊界寬度設為7時效果最優,最后使用軟件MATLAB R2018b(MathWorks Inc.,美國)對實驗數據進行處理和顯示。
2.4 消融實驗
為了驗證邊界注意力和多任務學習在分割模型中的作用,在JSRT數據集上對這兩部分功能進行消融實驗。實驗結果如表1所示。由結果可見,只進行肺實質分割任務時Dice系數最低,為96.02%;同時進行肺實質和邊界輪廓分割任務時,Dice系數提高了0.77%,而靈敏度SE提高了2.28%,這表明通過邊界輪廓分割任務的約束,能夠引導模型有效學習邊緣特征信息,減少肺實質中被誤分割的像素;而引入非局域注意力機制增強邊界輪廓特征信息后,Dice系數、靈敏度SE、準確度ACC分別提高了1.71%、3.53%、1.15%,表明邊界注意力機制能夠通過建立全局相關性進一步挖掘肺實質全局特征信息,減少肺實質誤分割和提高分割精度。
2.5 與其他分割算法的對比實驗
為了驗證本文方法的有效性,與幾種代表性的分割網絡模型進行對比實驗。表2為在JSRT數據集的實驗結果。表明本文方法在各項評估指標上都優于其他幾種分割網絡。其中,U-Net模型[9]采用編-解碼網絡結構提取圖像語義信息和恢復細節特征,由于沒有采用殘差連接的方式以學習更深層的特征信息,其分割精度低于本文中基于殘差卷積結構的編-解碼網絡模型;DeepLab V3+[14]采用特征金字塔策略,利用不同擴張率的空洞卷積來提取多尺度圖像特征以擴大感受野,這在某種程度上可以幫助提取肺實質不連續區域的全局特征信息,其Dice系數比U-Net模型提高了0.7%,靈敏度SE和準確度ACC與U-Net模型接近,說明其提取全局特征信息的能力有限;Attention U-Net[16]通過在解碼過程中加入注意力機制突出重要特征信息,同時抑制無關特征信息,從而提高模型學習全局語義信息的能力,其Dice系數、靈敏度SE和準確度ACC比U-Net模型分別提高了1.42%、1.88%和0.89%。表3為將訓練好的模型在Montgomery數據集上測試的結果。從實驗結果來看,本文方法的分割效果最優。同時,由于肺結核病灶對肺實質紋理及胸片圖像對比度的影響,幾種模型性能都有所下降。綜合來看,本文方法的泛化能力優于其他幾種網絡模型。
為了直觀比較幾種分割算法的準確性,圖4展示了部分胸部X線片圖像分割結果及其Dice系數。可以看出,對于肺實質密度均勻且邊界輪廓明顯的胸部X線片圖像(如圖4第一行),所有模型均取得了很高的分割精度。而對于肺實質密度不均勻和邊緣模糊的胸部X線片圖像(如圖4第二至第五行),以及有肺結核病灶陰影的胸部X線片圖像(如圖4第六至第八行),U-Net模型在肺實質邊界輪廓的分割效果最差,且對于肺實質中對比度低和不連續的區域(紅色方框所示)會出現欠分割和分割目標不連通的情況,其原因可能是卷積網絡感受野有限,模型訓練時難以有效學習到全局語義信息;DeepLab V3+模型通過多尺度空洞卷積金字塔結構擴大感受野范圍,在肺實質不連續的區域分割效果要好于U-Net模型;Attention U-Net模型能夠通過注意力機制聚合重要的全局特征信息,在肺實質不連續的區域也能實現較完整的分割;而本文方法對肺結核病灶造成的邊界模糊、對比度低以及肺實質不連續區域的分割能夠較好地保持肺實質形狀的完整性。
圖4
肺實質分割結果示例
Figure4.
Examples of lung segmentation
3 結語
由于各種肺部疾病可導致胸部X線片圖像中肺實質密度不均勻和肺實質內部區域不連續,準確地分割肺實質是一個難點。本文提出一種基于非局域注意力機制和多任務學習的肺實質分割模型。首先,在多任務監督訓練中,通過邊界輪廓引導特征提取網絡能更有效地學習肺實質和邊界輪廓的特征;然后,通過非局域注意力機制增強肺實質邊界輪廓特征信息,并保持肺實質密度不均勻區域的連續性和完整性,消融實驗以及對比實驗結果表明本文方法能有效減少肺實質密度不均勻和肺實質內部區域不連續時的誤分割,并提高模糊邊緣的分割精度。最后,將在JSRT數據集中訓練好的模型在Montgomery數據集上進行測試,驗證了本文方法的泛化能力優于其他幾種分割方法,并且對肺結核病灶引起的肺實質對比度低和不連續等情形也能實現較完整的分割。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:本文由熊亮完成研究思路設計、算法編程實現、數據分析和文章撰寫,秦小林對研究思路、論文結構給予重要指導并對文章進行審校,劉欣對算法的臨床研究意義進行指導并負責實驗數據收集、實驗結果檢驗,所有作者均參與論文審閱討論和修訂。