磁共振能夠獲得不同對比度的多模態圖像,為臨床診斷提供了豐富的信息。但是常常由于患者難以配合或掃描條件限制造成某些對比度圖像沒有被掃描或者獲得的圖像質量不能達到診斷要求。圖像合成技術是彌補這種圖像缺失的一種方法。近年來,深度學習在磁共振圖像合成領域得到了廣泛應用。本文提出了一種基于多模態融合的合成網絡,首先利用特征編碼器將多個單模態圖像分別進行特征編碼后,再通過特征融合模塊將不同模態圖像特征進行融合,最終生成目標模態圖像。通過引入基于圖像域和K空間域的動態加權組合損失函數,改進了網絡中目標圖像與預測圖像的相似性度量方法。經實驗驗證并定量比較,本文提出的多模態融合深度學習網絡可以有效合成高質量的磁共振液體衰減反轉恢復(FLAIR)序列圖像。綜上,本文提出的方法可以減少患者的磁共振掃描時間,以及解決FLAIR圖像缺失或圖像質量難以滿足診斷要求的臨床問題。
引用本文: 周家檸, 郭紅宇, 陳紅. 基于深度學習的磁共振液體衰減反轉恢復序列圖像合成方法. 生物醫學工程學雜志, 2023, 40(5): 903-911. doi: 10.7507/1001-5515.202302012 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
0 引言
磁共振成像(magnetic resonance imaging,MRI)是一種應用廣泛的前沿醫學成像技術,能夠提供同一解剖結構的多種不同對比度的圖像。在MRI的成像過程中,只需要改變掃描序列的各種參數,就可以生成多個不同對比度的參數圖像,也稱為不同模態的圖像,這些圖像具有相似的解剖結構,但突出了不同的組織,豐富了臨床應用和研究的診斷信息[1-2]。但是在實際掃描中,過長的掃描時間使得患者難以全程配合或者會增加掃描成本,因此很難保證每個患者都能采集到所有模態的圖像,從而導致缺少一些非常重要的模態圖像。圖像合成技術是彌補這種缺憾的一種有效方式,即通過已采集獲得的模態圖像,合成新的模態圖像。傳統的基于信號模型的多模態圖像合成方法,通常需要提前獲取定量參數和復雜的參數調優過程,適用范圍有限。
近年來,深度學習憑借強大的非線性映射能力,逐漸應用于醫學圖像合成領域[3]。為了挖掘多模態圖像特征的互補作用,目前許多研究的策略是提取多種模態圖像特征作為網絡輸入,通過融合模塊進行特征融合,并生成目標模態圖像。早期基于深度學習的MRI圖像合成方法大多使用單模態數據[4-5]。為了應用更多模態數據以提供更多圖像特征信息,許多研究人員開始致力于制定研發更有效的多模態數據特征融合策略[6]。例如,Yang等[7]提出了一種基于順序的生成對抗網絡(generative adversarial networks,GAN)和半監督學習的雙模醫學圖像合成方法。Kim等[8]提出了一種基于深度神經網絡并使用三種不同對比度MRI圖像生成短時反轉恢復(short time inversion recovery,STIR)圖像的方法。將多模態數據作為輸入以合成醫學圖像的方法中,需解決的關鍵問題是,不僅需要有效提取各種輸入數據特征,還要使用合適的融合策略,才能實現多模態數據特征的有效融合[9]。比如,Havaei等[10]使用統計特征(均值和方差)作為圖像的嵌入表達進行特征融合。Zhou等[3]提出了一種多模態新型混合融合網絡(hybrid fusion network,Hi-net),該網絡學習從多種源模態圖像(已有模態)到目標圖像(缺失模態)的映射,通過混合融合模塊(mixed fusion block,MFB)將各模態圖像特征緊密結合,最終生成目標圖像。Fei等[11]為了利用不同模態提供的互補信息,將多模態MRI圖像作為輸入,提出了一個多模態網絡模型,將特征分離策略應用于合成MRI圖像中。此外,生成對抗網絡也被廣泛用于跨模態圖像合成領域,并取得了巨大成功[12]。
液體衰減反轉恢復(fluid-attenuated inversion recovery,FLAIR)序列,通過施加反轉恢復脈沖后間隔一個較長的恢復時間再進行信號激發和采集,能夠有效抑制腦脊液信號,提高組織對比度,在腦卒中、腦腫瘤等疾病診斷中具有非常高的檢出敏感性。基于此,本文提出了一個基于多模態結構圖像融合策略的MRI圖像合成網絡,用于合成FLAIR對比度圖像。本文主要貢獻有:
(1)提出多模態特征融合策略:利用單模態特征提取器提取每個源模態的圖像特征,并通過異模態特征融合策略將各類特征有效融合,生成目標模態圖像。
(2)提出K空間損失:為了更多地挖掘圖像間的相似性,使合成圖像在K空間域也能更加逼近真實圖像,在本網絡中提出使用聯合圖像域和K空間域的動態加權損失函數。
1 數據與預處理
本文使用了2018年多模態腦腫瘤分割(brain tumor segmentation,BraTS)挑戰賽的官方數據集[13-15]。該數據集為公開數據集,包含了285個病例,每個病例有四種模態的MRI圖像,包括T1、T1對比增強(T1 contrast enhanced,T1 CE)、T2和FLAIR,每種模態圖像大小相同,都為155 × 240 × 240。數據預處理對于網絡訓練非常重要,本文的數據預處理分為以下幾個步驟:
(1)沿著圖像的軸向方向進行切片,將每個腦體積切割成240 × 240的軸向平面切片。為了能將全腦所有層面圖像都輸入網絡,節省算力和內存空間,加快訓練速度,本文將每個切片圖像的大小統一重采樣調整為192 × 192。
(2)去除對網絡訓練沒有意義的一些層面的圖像,例如空圖像。
(3)每個模態的圖像分別歸一化到[0,1]范圍內。
2 方法
2.1 理論分析
MRI是利用磁共振原理,通過給處于一定靜磁場下的成像組織施加特定頻率的射頻信號后,激勵組織中的氫原子核發生共振,進而獲取組織相關特性的一種成像方式。在MRI掃描中,針對同一組織使用不同掃描序列,并調節掃描參數可以得到反映該組織不同參數的圖像,這些不同參數的圖像通常也稱為不同模態的圖像[16],它們表現為具有不同圖像對比度。MRI圖像合成技術可行性在于:同一解剖結構的不同模態圖像,組織結構上是相同的,只是以不同對比形式表現這個結構[17];各模態圖像在信號表達式上存在著一定的依賴關系和信息相關性,比如FLAIR圖像的信號表達式中就含有T1與T2的相關信息,如式(1)所示:
 |
其中,S為FLAIR圖像的信號強度,S0為質子密度信號強度,序列反轉時間(inversion time,TI)的參數符號以TI表示,序列重復時間(repetition time,TR)的參數符號以TR表示,序列回波時間(echo time,TE)的參數符號以TE表示,T1、T2分別為組織的縱向弛豫時間常數和橫向弛豫時間常數。
2.2 網絡設計
2.2.1 單模態特征編碼器
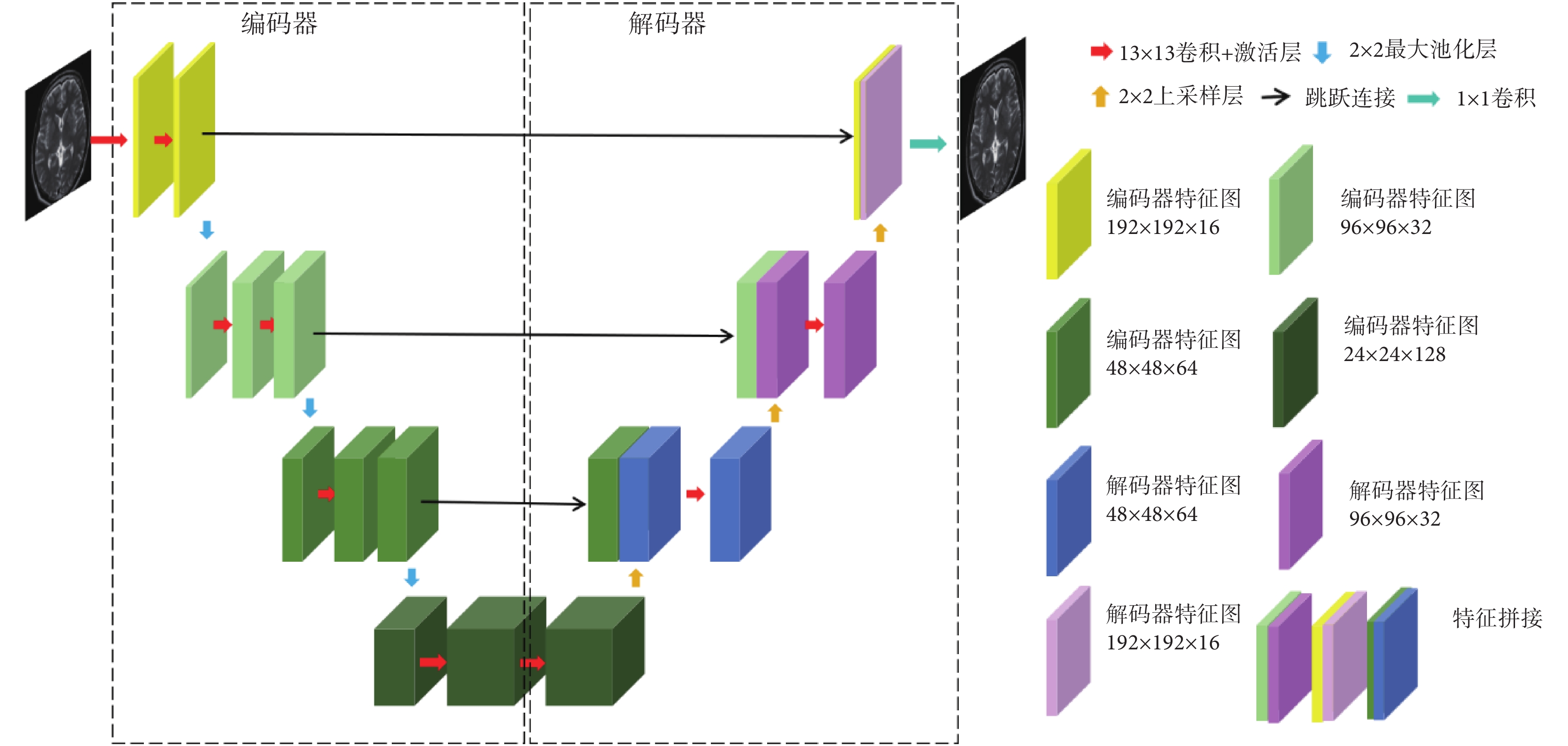
本文首先設計了一個單模態特征編碼器(mono-modal feature encoder,MFE),用于提取每種源模態圖像的特征。MFE由一個大卷積核U型網絡(U-net)構成。左邊網絡使用卷積層與最大池化層作為編碼器,提取多尺度特征;右邊網絡使用卷積層與上采樣層作為解碼器,進行特征融合,網絡框架如圖1所示。考慮算力情況,且要保持批大小在合理范圍,所以選擇可計算的最大卷積核大小作為卷積層的實際卷積核大小,本文將其設置為13 × 13。網絡參數通過預訓練得到。
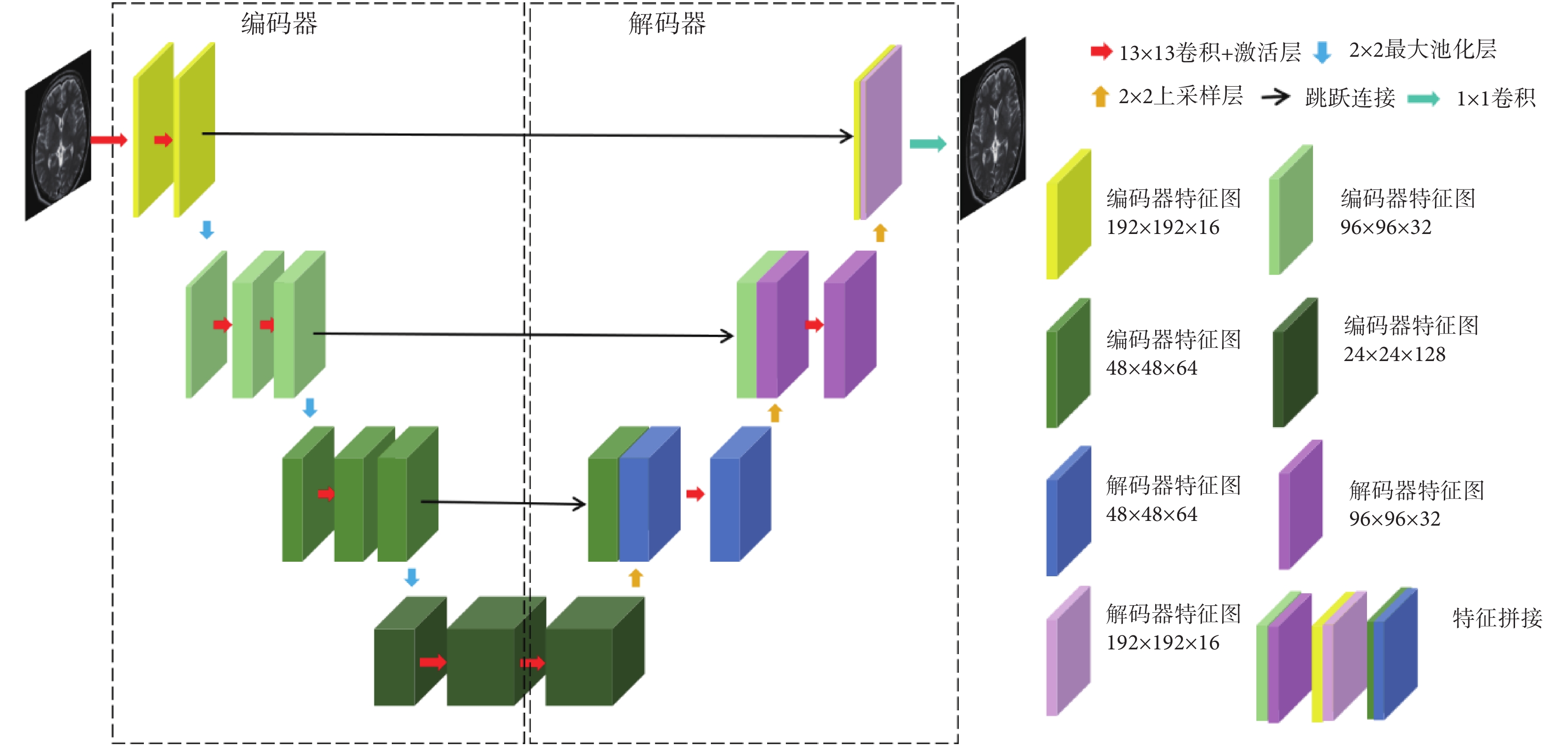 圖1
單模態特征編碼器應用到的U-net網絡架構
Figure1.
U-net architecture applied to momo-modal feature encoder
圖1
單模態特征編碼器應用到的U-net網絡架構
Figure1.
U-net architecture applied to momo-modal feature encoder
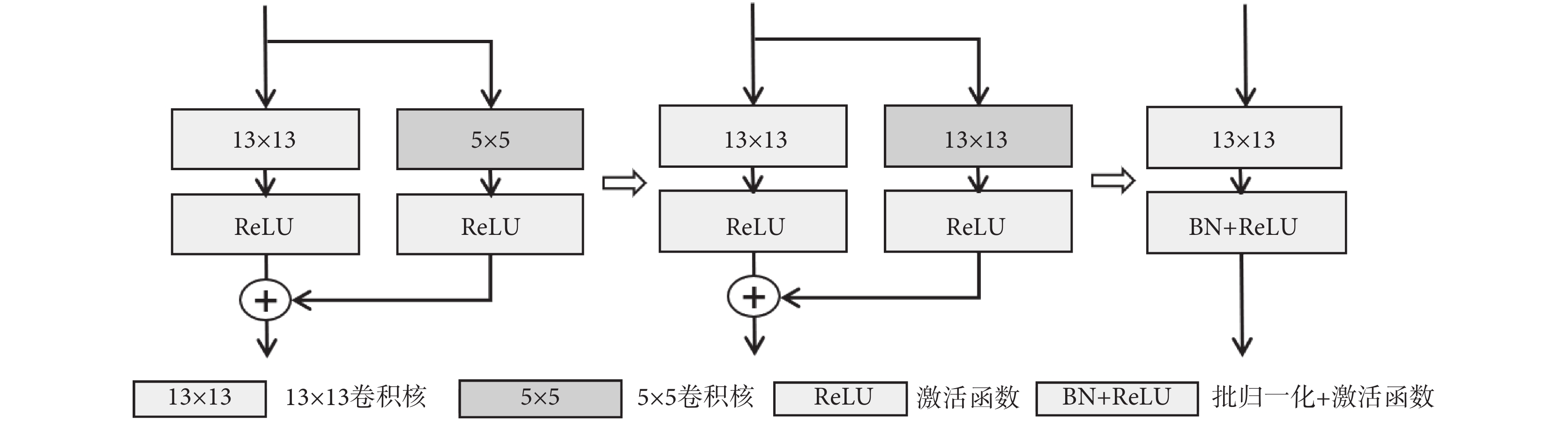
近年來,關于超大卷積核神經網絡的研究工作表明,轉換器(transformer)的優越性能并不單純來源于注意力機制,而是來自有效感受野的增大[18-22]。因此為了改進網絡效果,本文也采用了大卷積核增大有效感受野的方法。為了解決直接使用大卷積核會帶來圖像特征過平滑的問題,MFE中使用了卷積核的重參數化策略,其計算過程如圖2所示。卷積過程中有兩條執行支路,一條支路的5 × 5 卷積核邊緣填充0到13 × 13尺寸,并將填充后的卷積核與另一條支路的13 × 13卷積核權重相加,符號“⊕”表示權重相加,然后按新卷積核進行卷積計算,最后進行批歸一化(batch normalization,BN)和線性整流函數(rectified linear unit,ReLU)激活輸出。
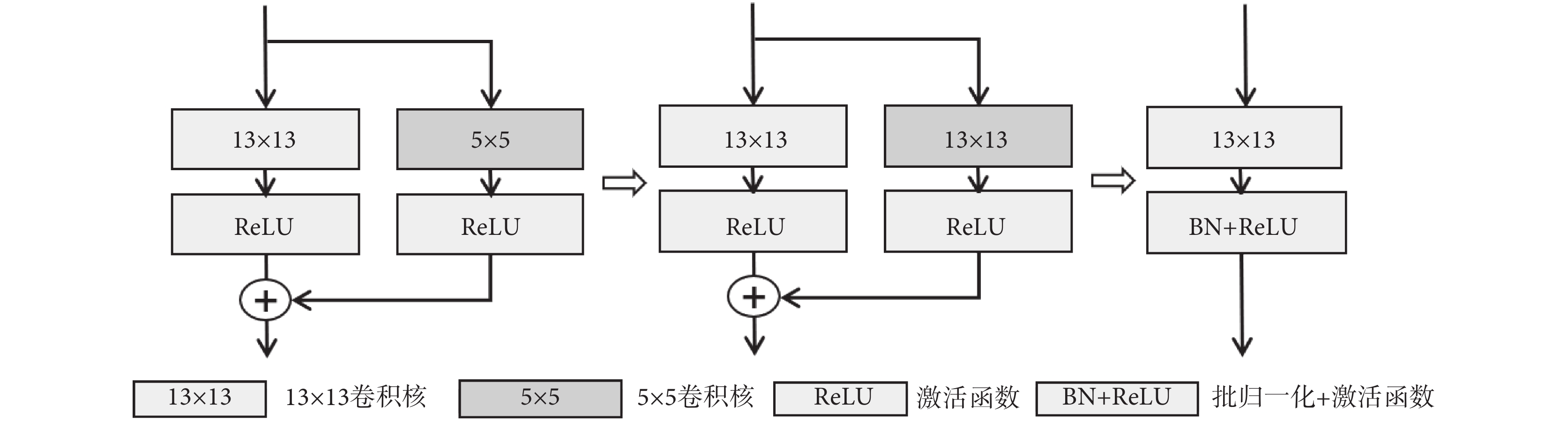 圖2
卷積核的重參數化過程示意圖
Figure2.
Diagram of the convolution kernel reparameterization process
圖2
卷積核的重參數化過程示意圖
Figure2.
Diagram of the convolution kernel reparameterization process
MFE網絡的輸入為特定單模態圖像,輸出為目標模態圖像。訓練完成后,將網絡參數凍結,提取網絡的倒數第二層及與其尺寸相同的網絡第二層的特征圖作為單模態特征提取器的輸出,用于后續的特征融合與合成。
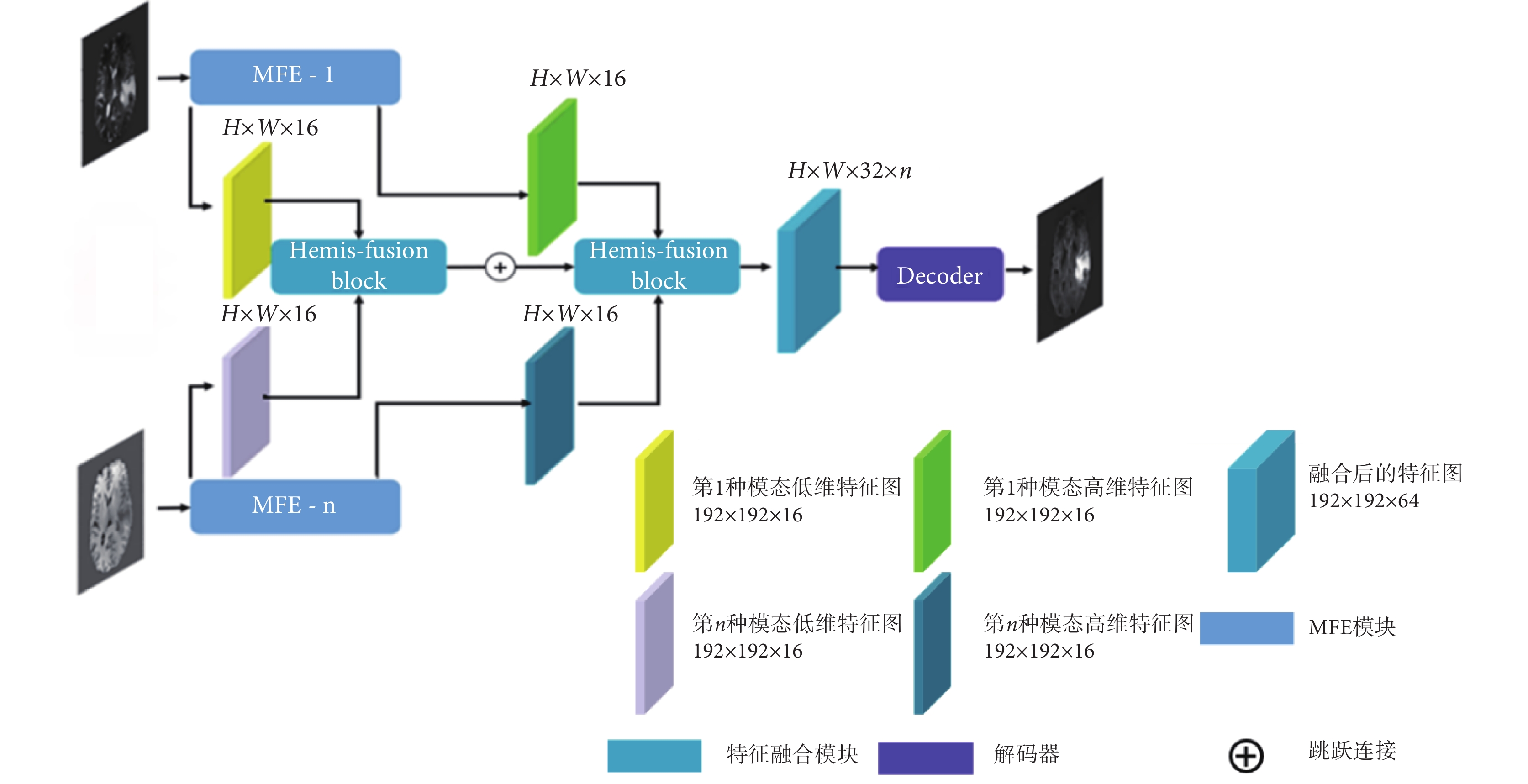
2.2.2 多模態融合網絡
多模態融合網絡,用于融合多個MFE網絡提取的特征。目標模態圖像與輸入的多個單模態圖像的關系如式(2)所示:
 |
其中,n為使用的源模態種類數,Itarget表示目標模態圖像,Isource 表示第i種源模態圖像,Mi(·)是第i種模態特征提取函數,R(·)是多模態特征融合函數。本文中Itarget是FLAIR圖像,Isource是T1和T2加權圖像。單模態特征提取器參數訓練完成后,特征編碼器將
表示第i種源模態圖像,Mi(·)是第i種模態特征提取函數,R(·)是多模態特征融合函數。本文中Itarget是FLAIR圖像,Isource是T1和T2加權圖像。單模態特征提取器參數訓練完成后,特征編碼器將  進行特征編碼,非線性函數R(·)負責融合源模態特征,并映射到相應的目標模態,即
進行特征編碼,非線性函數R(·)負責融合源模態特征,并映射到相應的目標模態,即  。融合算法采用異模態圖像分割(hetero-modal image segmentation,Hemis)融合方法[21]。
。融合算法采用異模態圖像分割(hetero-modal image segmentation,Hemis)融合方法[21]。
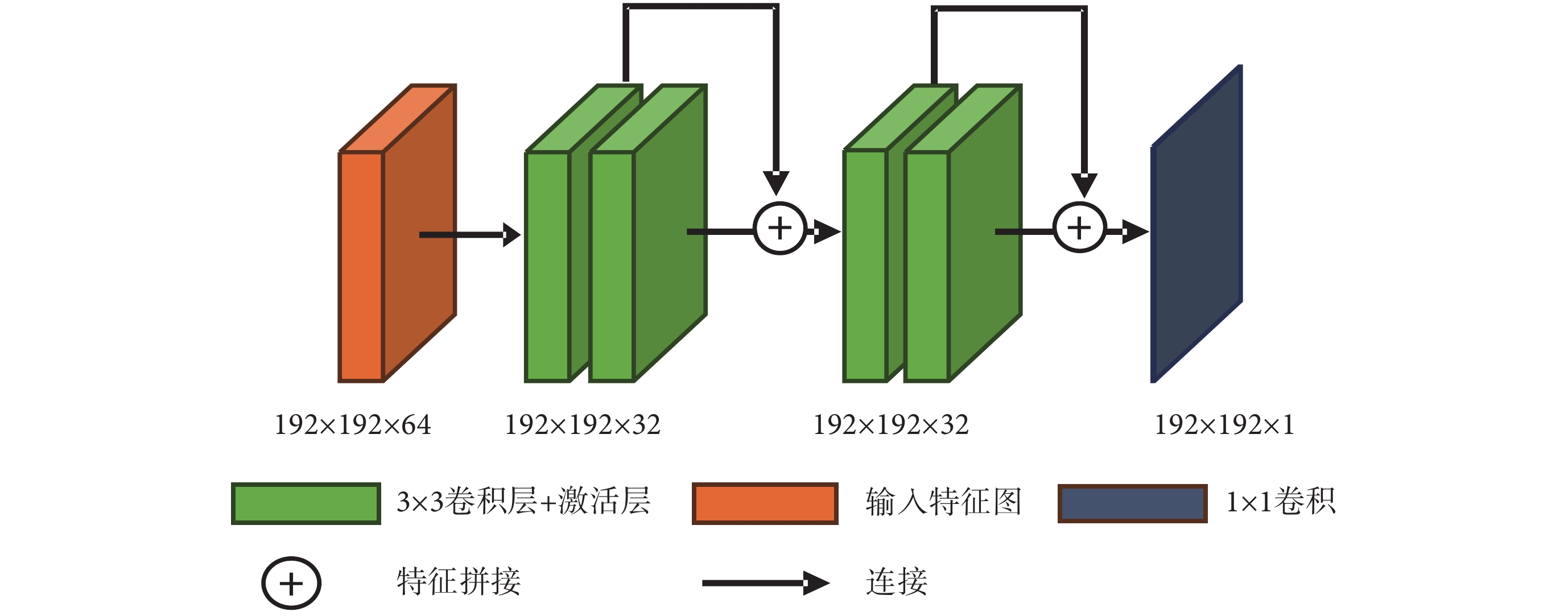
多模態融合網絡如圖3所示,該網絡由n個單模態特征編碼器(MFE-1,MFE-n),2個特征Hemis融合模塊(Hemis-fusion block)以及1個解碼器(Decoder)組成。每個MFE的結構相同,用于提取源模態圖像的高低維度兩部分特征。特征圖的大小為H × W,本文設置為192 × 192,通道數為16。將多種源模態的兩部分特征圖分別輸入特征融合模塊,進行高低維特征融合,然后經數據連接拼接為通道32 × n的特征圖,最后經過Decoder生成目標圖像。解碼器由兩個殘差模塊連接組成,其結構如圖4所示,每個殘差模塊由兩個卷積加激活層構成,特征拼接后通過1 × 1卷積輸出結果圖像,符號“⊕”代表特征拼接。
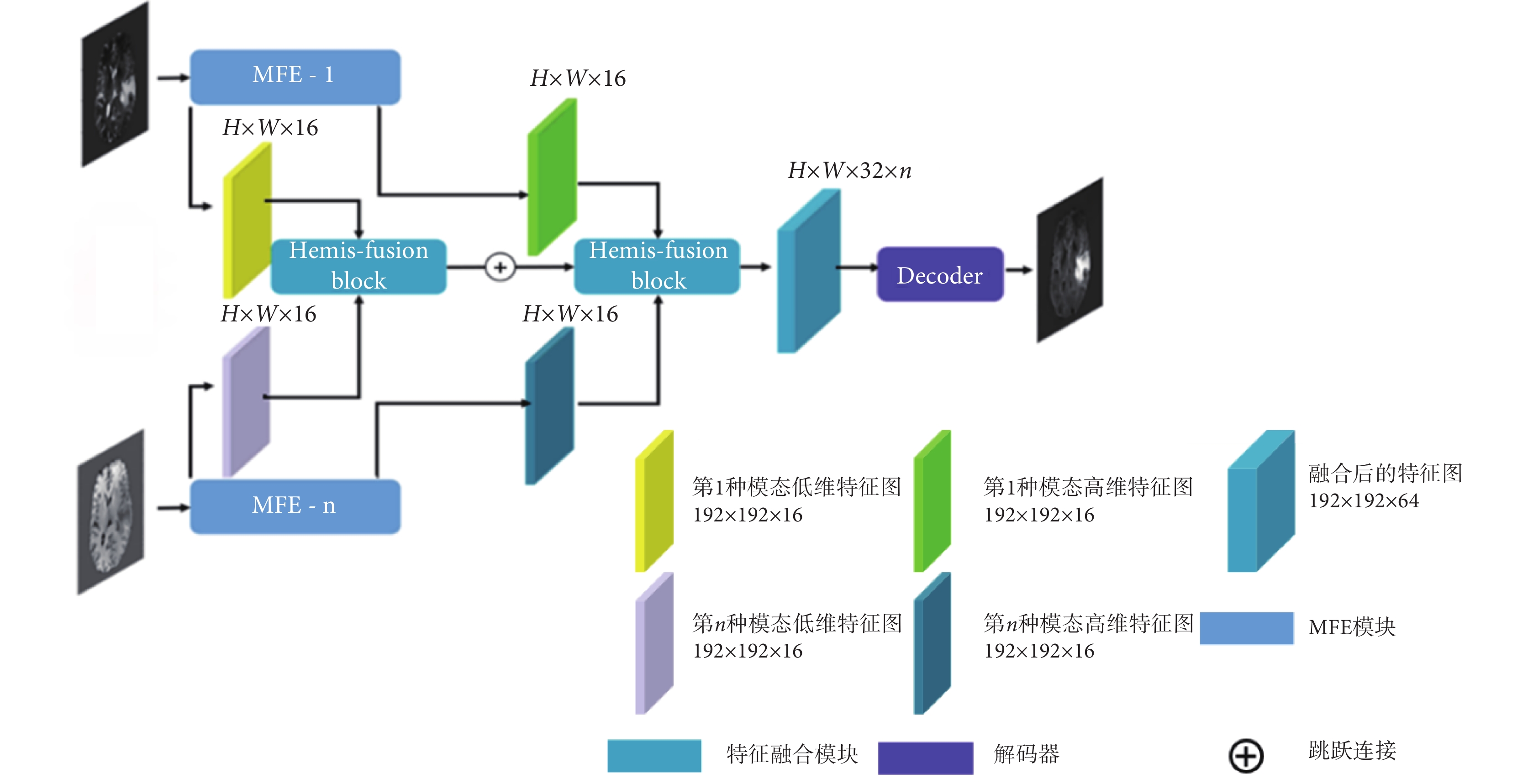 圖3
多模態融合合成網絡框架
Figure3.
Framework for multimodal convergence networks
圖3
多模態融合合成網絡框架
Figure3.
Framework for multimodal convergence networks
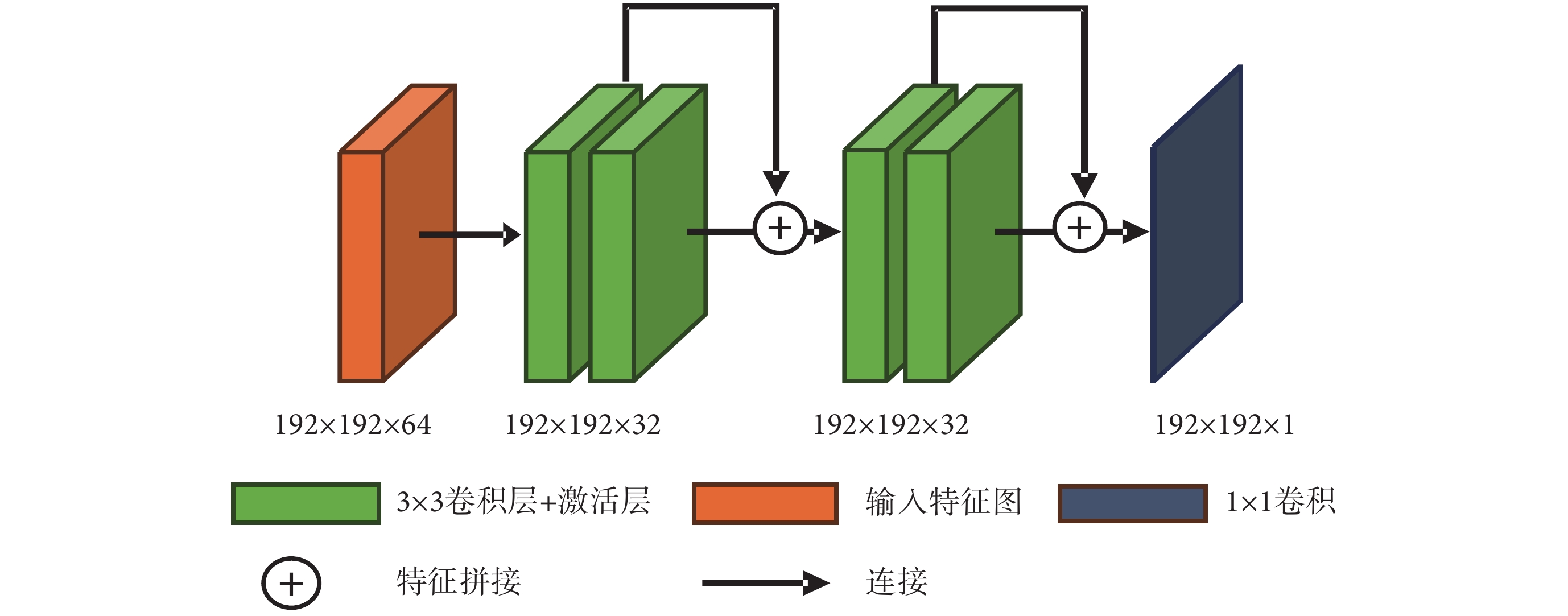 圖4
解碼器結構
Figure4.
Decoder architecture
圖4
解碼器結構
Figure4.
Decoder architecture
2.3 雙域組合損失函數
在網絡訓練中使用了兩個損失函數,分別基于圖像域和K空間域,即內容損失和K空間損失。內容損失如式(3)所示:
 |
其中,Lcontent(·)代表內容損失函數,是網絡的第l層的真實目標圖像特征圖(P)和生成的圖像特征(F)的歐氏距離。 代表第l層生成圖像的第i個特征圖的第j個輸出值,
代表第l層生成圖像的第i個特征圖的第j個輸出值, 代表第l層目標圖像的第i個特征圖的第j個輸出值,符號∑i, j是對所有i和j的項求和。式(3)用最小二乘法求解得出最小值,使迭代后的生成圖像特征接近迭代后的真實圖像特征,如式(4)所示:
代表第l層目標圖像的第i個特征圖的第j個輸出值,符號∑i, j是對所有i和j的項求和。式(3)用最小二乘法求解得出最小值,使迭代后的生成圖像特征接近迭代后的真實圖像特征,如式(4)所示:
 |
K空間損失LK的計算過程如式(5)~式(7)所示:
 |
 |
 |
其中,Ktruth代表目標真實值的K空間數據。Ksys代表合成圖像的K空間數據。kx、ky代表K空間域的x和y頻率分量,它隨采樣時間的變化而變化。N是K空間數據點的個數,d(·)表示差值函數,|·|表示計算絕對值操作, 是根據真實圖像和合成圖像K空間的差值大小計算出來的權重。α是一個可調參數,控制K空間的權重大小,其作用是在訓練過程中根據合成的難易程度對不同的分量進行動態加權,本文中將α設為2。這里認為兩幅圖像差異較大的部分是學習困難的部分,因為網絡收斂方向往往傾向于任務的簡單部分。加權損失函數使模型能夠自適應地關注合成困難的頻率成分,并降低容易合成的成分的權重。因此,總損失函數可以表示如式(8)所示:
是根據真實圖像和合成圖像K空間的差值大小計算出來的權重。α是一個可調參數,控制K空間的權重大小,其作用是在訓練過程中根據合成的難易程度對不同的分量進行動態加權,本文中將α設為2。這里認為兩幅圖像差異較大的部分是學習困難的部分,因為網絡收斂方向往往傾向于任務的簡單部分。加權損失函數使模型能夠自適應地關注合成困難的頻率成分,并降低容易合成的成分的權重。因此,總損失函數可以表示如式(8)所示:
 |
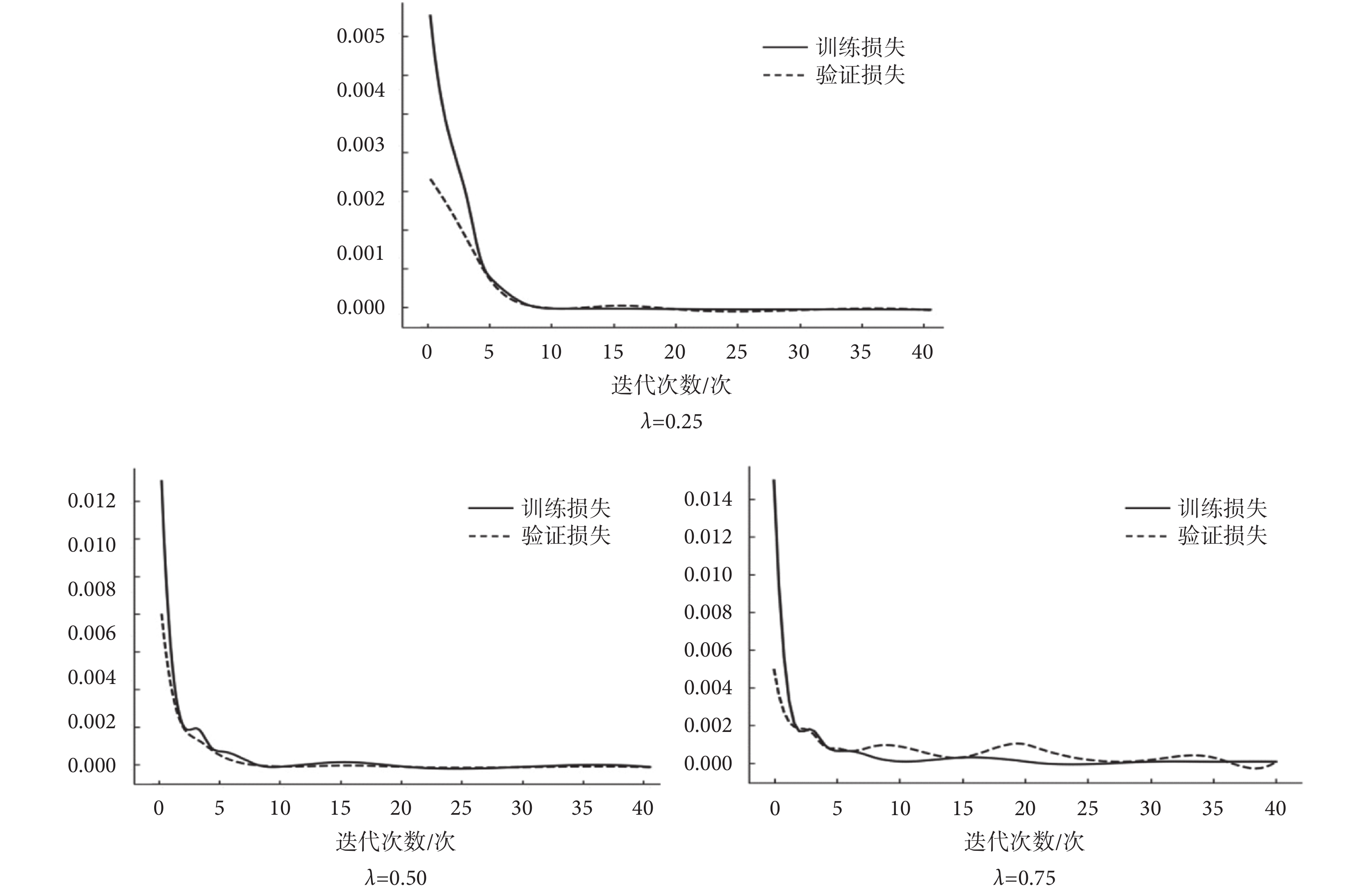
其中,Ltotal、Lcontent、LK分別代表總的損失函數、內容損失函數和K空間損失函數,λ是一個權重超參數,控制兩個不同損失函數的貢獻。固定網絡其他參數后,實驗分析λ對訓練結果的影響,比較訓練損失和驗證損失值的收斂情況,如圖5所示,當設定為λ = 0.25時,網絡模型魯棒性更高,收斂速度更快。
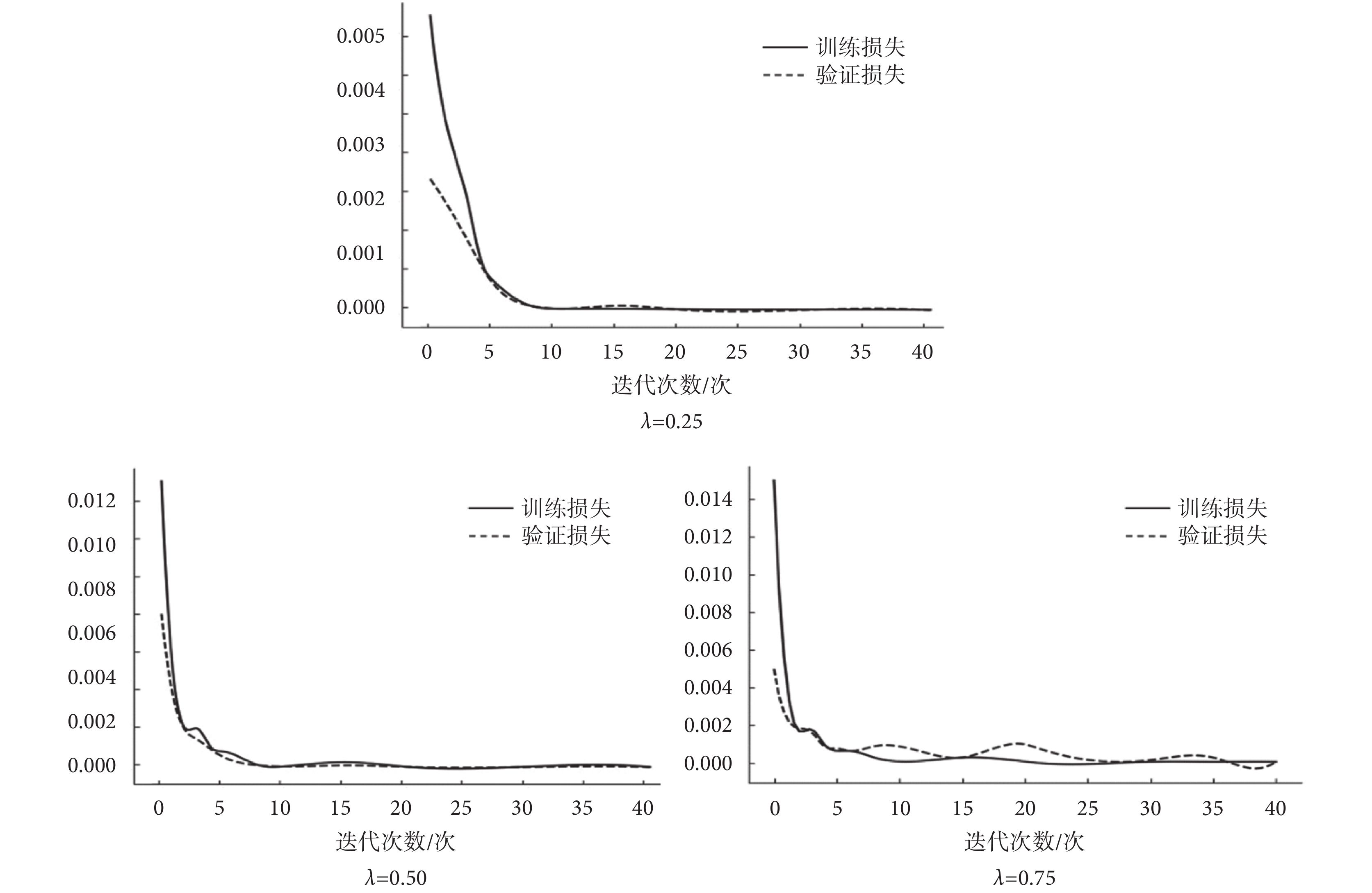 圖5
不同超參數對訓練效果的影響
Figure5.
Influence of different hyperparameter on training result
圖5
不同超參數對訓練效果的影響
Figure5.
Influence of different hyperparameter on training result
2.4 訓練過程
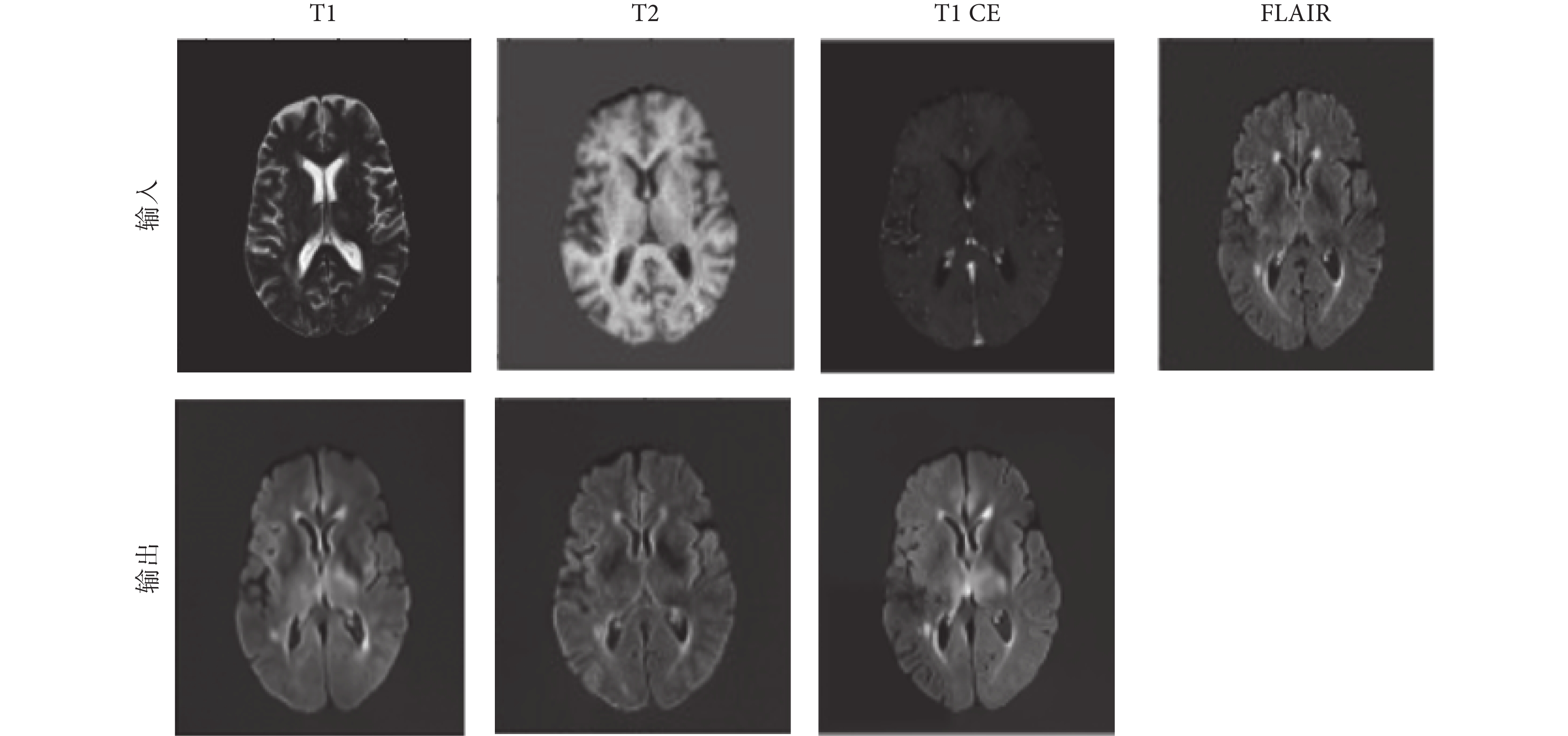
在訓練中,FLAIR序列圖像作為目標模態圖像,作為網絡輸出;T1和T2加權圖像作為源模態,作為網絡輸入。每個受試者的圖像數據中選擇80個切片作為訓練集和驗證集。在實驗中,從125名受試者中隨機選擇了10 000個切片用于訓練模型,再隨機選擇35名受試者的2 800個切片進行測試。首先,通過學習該模態圖像到目標模態圖像的映射關系,獲得每個模態對應的MFE模塊參數。在MFE訓練過程中,每個卷積層使用ReLU激活函數,標準化凱明初始化器初始化網絡參數。幾種常見的模態的特征提取效果如圖6所示,圖像特征與目標圖像相似性高,可以證明MFE模塊的有效性。
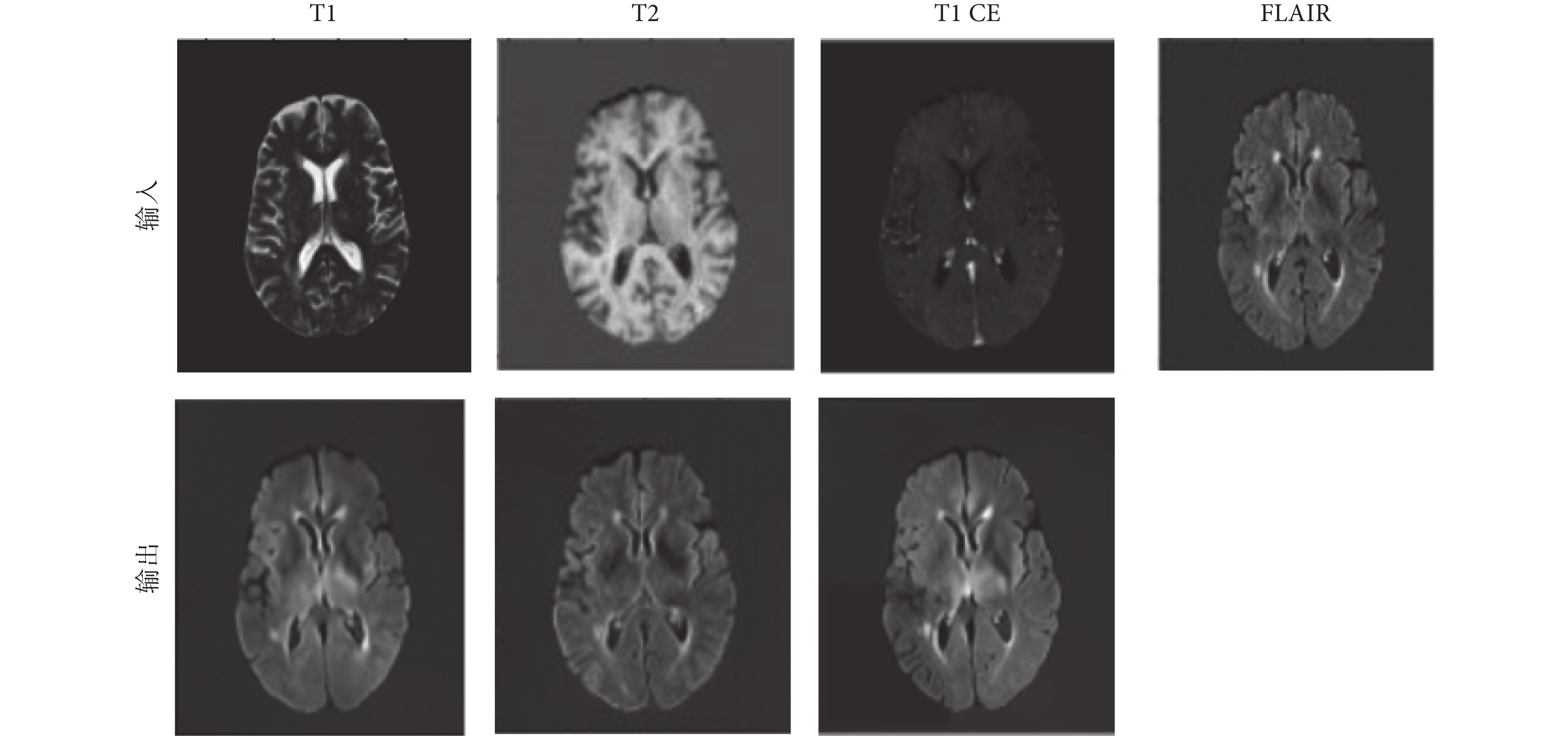 圖6
MFE模塊的特征提取的結果
Figure6.
Results of MFE feature extraction
圖6
MFE模塊的特征提取的結果
Figure6.
Results of MFE feature extraction
將MFE網絡提取的特征進行融合后,輸入解碼器進行圖像合成。整體訓練過程在圖像處理器NVIDIA GTX2080Ti(NVIDIA Inc.,美國)上進行,運用深度學習平臺Tensorflow2.3(Google Inc.,美國),使用自適應矩估計(adaptive moment estimation,Adam)優化算法訓練120個周期,設置學習率為0.000 3,批處理大小為32。
2.5 結果與分析
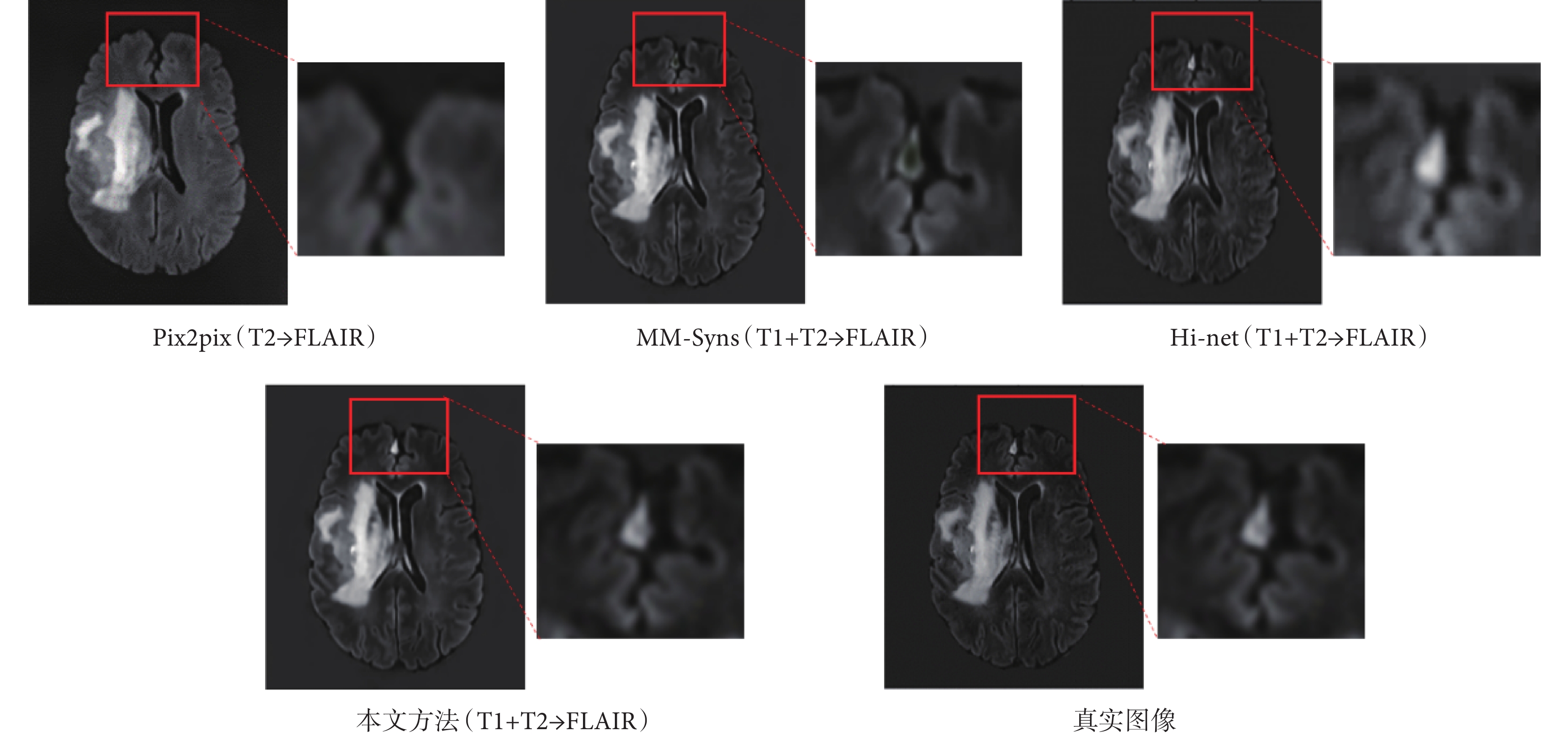
為了定量評價合成方法的性能,本文采用了三個常用的評價指標:峰值信噪比(peak signal-to-noise ratio,PSNR)、歸一化均方根誤差(normalized root mean square error,NRMSE)和結構相似度指數(structural similarity,SSIM)。PSNR常用來評價合成圖像的保真度,該值越大,圖像質量越好;NRMSE用來衡量生成圖像的合成誤差,該值越小越好;SSIM用來衡量生成圖像在明度、對比度和結構相似性方面的保真度度量,該值越大,圖像質量越好。為了證明本文提出的多模態融合合成網絡的有效性,使用前文提到的腦腫瘤分割挑戰賽數據集,將本文提出的合成結果與前人提出的三種經典的跨模態合成方法[23-25],包括像素到像素(pixel to pixel,Pix2pix)模型、多模態輸入多模態輸出合成(multi-input multi-output synthesis,MM-Syns)網絡模型和Hi-net模型的結果進行了比較,并以真實采集的FLAIR圖像作為標準圖像。其中Pix2pix輸入為T2圖像,其他三種方法的輸入都是T1和T2圖像。結果圖像如圖7所示,本文方法的結構細節與標準圖像更加接近,紅框部分進行了細節放大。對應的定量評價指標結果如表1所示,本文方法在三個指標上都表現最好。
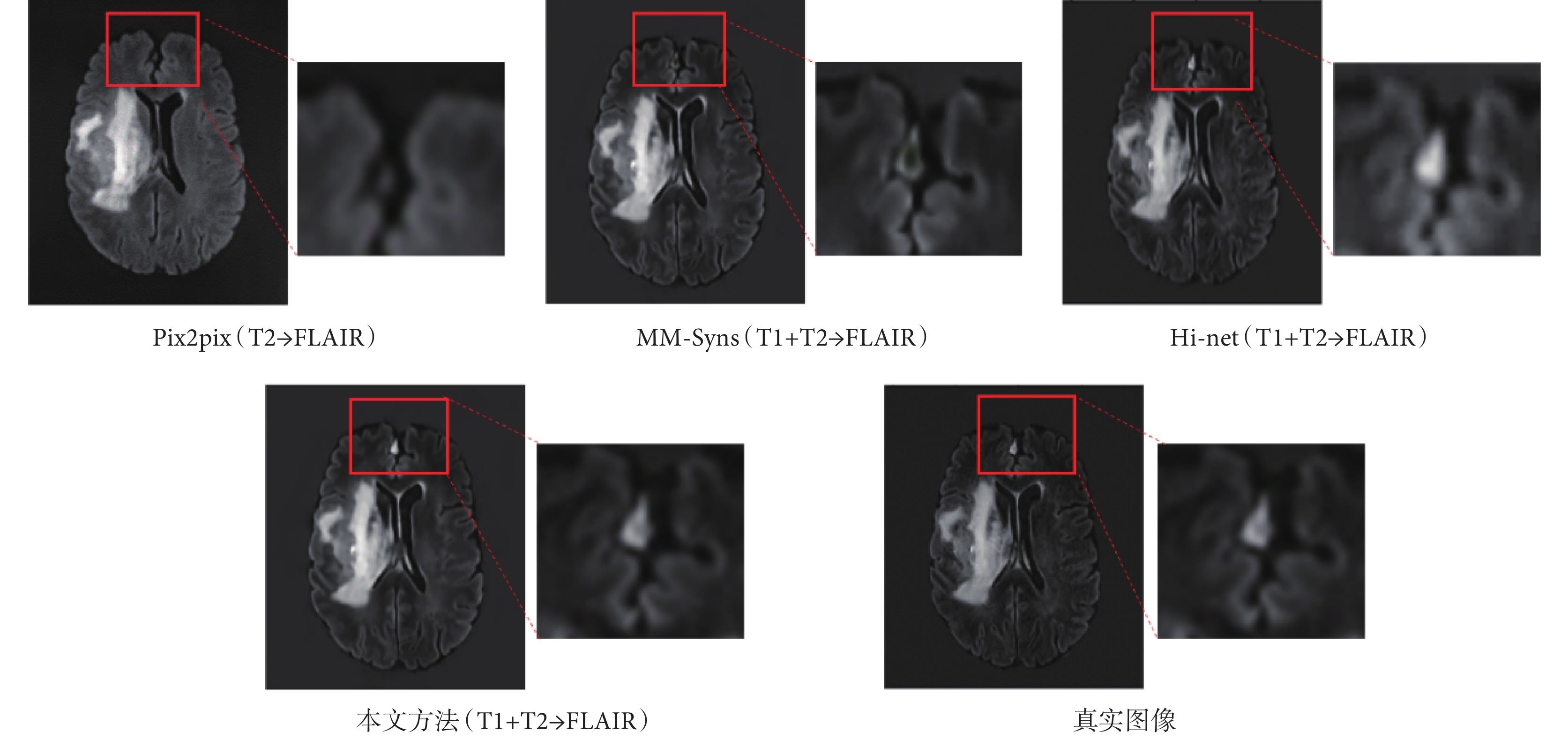 圖7
不同方法的合成結果與對應紅色選擇區域放大圖
Figure7.
Results of different networks with enlarged view of the corresponding red selected area
圖7
不同方法的合成結果與對應紅色選擇區域放大圖
Figure7.
Results of different networks with enlarged view of the corresponding red selected area
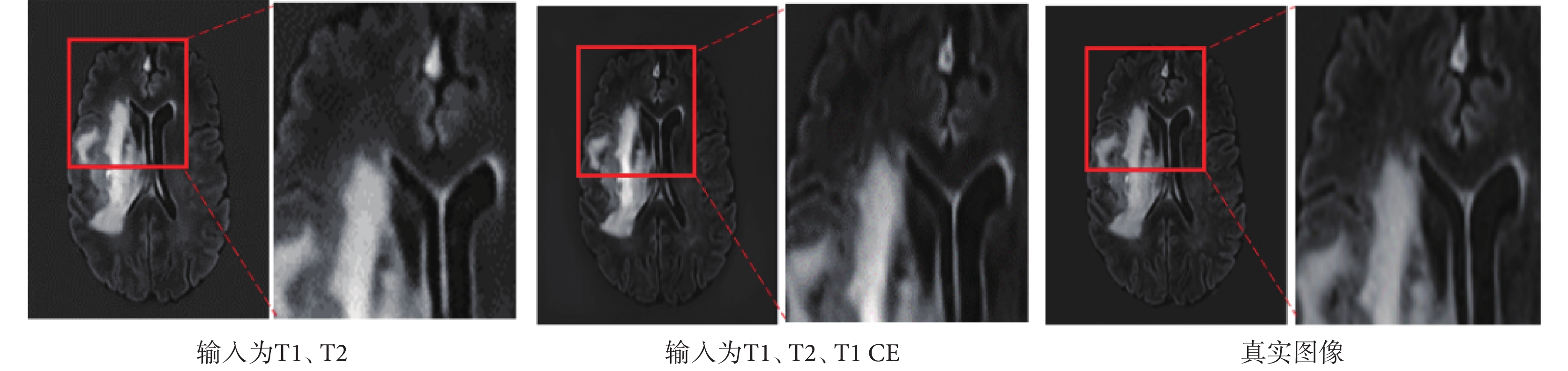
增加T1 CE模態作為源模態圖像輸入多模態融合合成網絡用于合成FLAIR圖像,將合成結果與二輸入的合成結果對比發現,隨著輸入模態種類增加,合成圖像在PSNR指標上更加優異,SSIM稍低,視覺上更接近真實圖像。合成效果如圖8所示,紅框部分進行了細節放大;定量評價如表2所示。
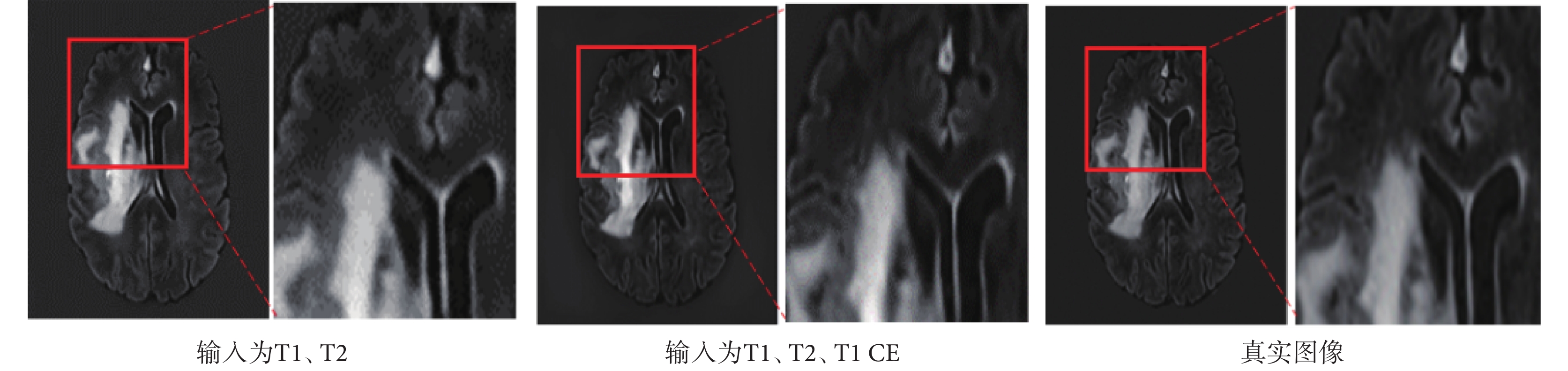 圖8
增加輸入模態對合成結果的影響
Figure8.
Effect of increasing input modal variety on synthesis results
圖8
增加輸入模態對合成結果的影響
Figure8.
Effect of increasing input modal variety on synthesis results
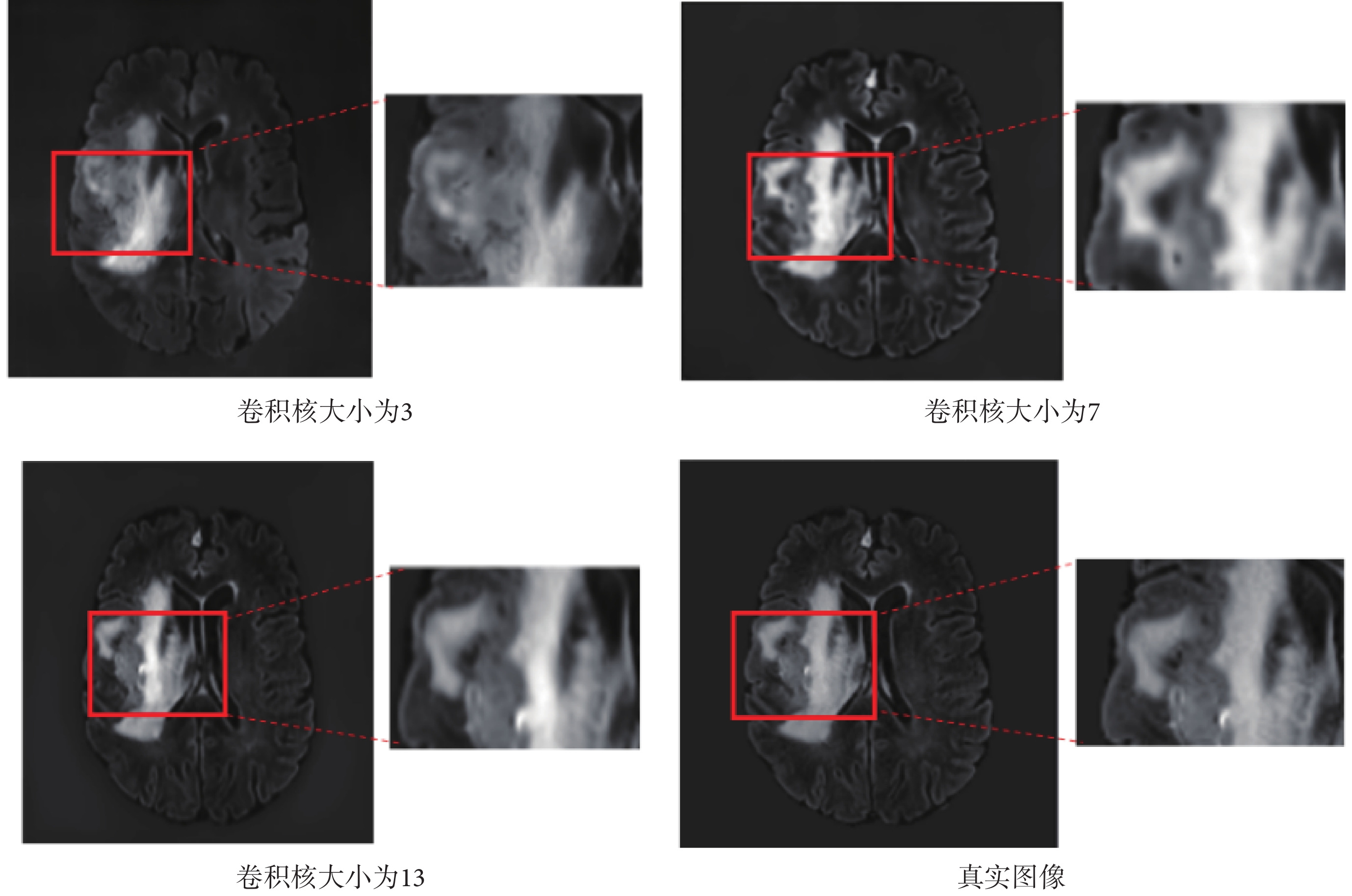
隨著卷積核的增大,模型在包含病灶的切片合成圖像中紋理更加清晰,圖像細節更豐富,驗證了大卷積核在圖像合成任務中有一定優勢。合成結果圖像如圖9所示,分別為卷積核大小為3、7、13時的合成結果圖像,紅框部分進行了細節放大;對應的定量評價如表3所示。
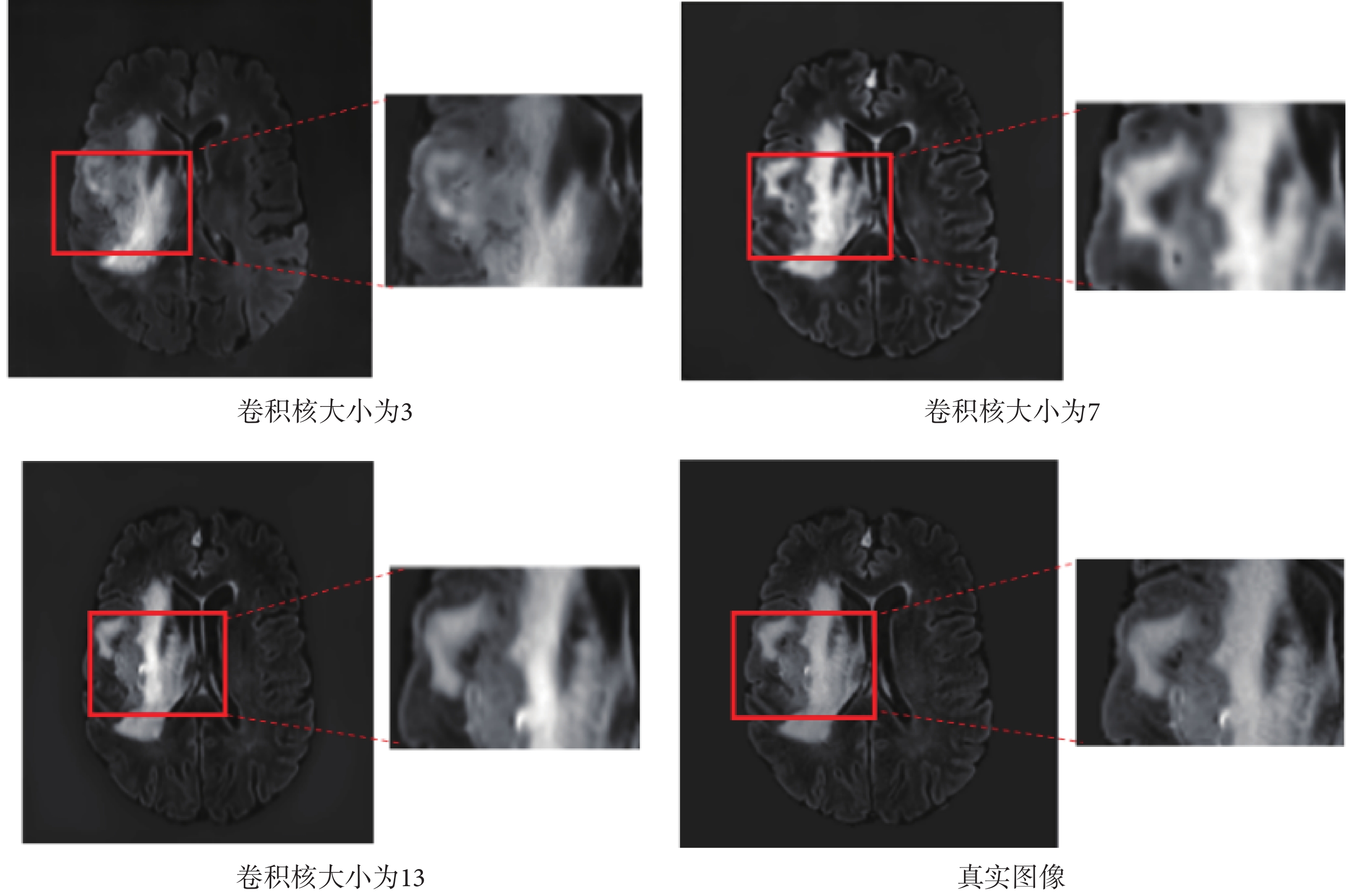 圖9
卷積核大小對合成結果的影響
Figure9.
Effect of convolution kernel size on synthesis results
圖9
卷積核大小對合成結果的影響
Figure9.
Effect of convolution kernel size on synthesis results
3 結論和展望
MRI相比電子計算機斷層掃描(computer tomography,CT)等其他成像設備的一個巨大的優點是能夠同時獲得表征組織不同特性的多個不同對比度模態圖像,為醫生的臨床診斷提供更多參考信息。但是通過掃描方式獲取多種模態圖像,耗費時間較長。此外,由于被掃描者或設備原因,經常出現個別模態圖像的缺失或圖像質量不能達到診斷要求[25-27]。因此,圖像合成技術可以一定程度解決臨床應用中部分模態圖像缺失和圖像質量不達標的問題。FLAIR序列增加了病灶與周圍組織的對比度,提高了病灶檢出能力,在臨床應用中非常重要,而且日常掃描中FLAIR圖像特別容易產生腦脊液搏動等偽影,因此合成FLAIR圖像具有重要意義。相比單模態網絡,本文提出的多模態結構圖融合MRI圖像合成深度學習網絡,輸入的模態更多,提供了更加豐富的互為補充的特征,更加準確地合成了FLAIR圖像。實驗結果證明,在網絡中通過引入K空間和圖像域組合的損失函數,能使圖像合成細節更加完善,避免了合成圖像的過度平滑。
本文提出的網絡主要用于合成FLAIR序列圖像,但是網絡結構中并未專門針對FLAIR圖像做強約束,因此只要通過使用新模態數據對網絡重新訓練,也可以用于其他模態圖像的合成中。本文通過在輸入模態圖像中增加T1 CE圖像,以實驗驗證了其合成結果要優于沒有T1 CE圖像的合成效果。本文實驗采用的數據集是大部分研究人員普遍使用的公開數據集,未來將使用更多的臨床數據對網絡進行優化和驗證。本文研究結果表明,基于深度學習的MRI圖像合成技術,能夠更有效地挖掘不同模態圖像中的深層次信息,剔除冗余信息,相比傳統方法可以更加準確和快速地合成圖像;本文方法還可用于加速MRI掃描、偽影消除、圖像分割及圖像預測等多個場景,具有非常大的發展潛力。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:周家檸負責整體算法設計、代碼編寫與實驗分析,以及論文初稿撰寫;郭紅宇負責算法設計指導和網絡優化,以及論文的修改完善;陳紅負責參與圖像質量評價和結果分析。
0 引言
磁共振成像(magnetic resonance imaging,MRI)是一種應用廣泛的前沿醫學成像技術,能夠提供同一解剖結構的多種不同對比度的圖像。在MRI的成像過程中,只需要改變掃描序列的各種參數,就可以生成多個不同對比度的參數圖像,也稱為不同模態的圖像,這些圖像具有相似的解剖結構,但突出了不同的組織,豐富了臨床應用和研究的診斷信息[1-2]。但是在實際掃描中,過長的掃描時間使得患者難以全程配合或者會增加掃描成本,因此很難保證每個患者都能采集到所有模態的圖像,從而導致缺少一些非常重要的模態圖像。圖像合成技術是彌補這種缺憾的一種有效方式,即通過已采集獲得的模態圖像,合成新的模態圖像。傳統的基于信號模型的多模態圖像合成方法,通常需要提前獲取定量參數和復雜的參數調優過程,適用范圍有限。
近年來,深度學習憑借強大的非線性映射能力,逐漸應用于醫學圖像合成領域[3]。為了挖掘多模態圖像特征的互補作用,目前許多研究的策略是提取多種模態圖像特征作為網絡輸入,通過融合模塊進行特征融合,并生成目標模態圖像。早期基于深度學習的MRI圖像合成方法大多使用單模態數據[4-5]。為了應用更多模態數據以提供更多圖像特征信息,許多研究人員開始致力于制定研發更有效的多模態數據特征融合策略[6]。例如,Yang等[7]提出了一種基于順序的生成對抗網絡(generative adversarial networks,GAN)和半監督學習的雙模醫學圖像合成方法。Kim等[8]提出了一種基于深度神經網絡并使用三種不同對比度MRI圖像生成短時反轉恢復(short time inversion recovery,STIR)圖像的方法。將多模態數據作為輸入以合成醫學圖像的方法中,需解決的關鍵問題是,不僅需要有效提取各種輸入數據特征,還要使用合適的融合策略,才能實現多模態數據特征的有效融合[9]。比如,Havaei等[10]使用統計特征(均值和方差)作為圖像的嵌入表達進行特征融合。Zhou等[3]提出了一種多模態新型混合融合網絡(hybrid fusion network,Hi-net),該網絡學習從多種源模態圖像(已有模態)到目標圖像(缺失模態)的映射,通過混合融合模塊(mixed fusion block,MFB)將各模態圖像特征緊密結合,最終生成目標圖像。Fei等[11]為了利用不同模態提供的互補信息,將多模態MRI圖像作為輸入,提出了一個多模態網絡模型,將特征分離策略應用于合成MRI圖像中。此外,生成對抗網絡也被廣泛用于跨模態圖像合成領域,并取得了巨大成功[12]。
液體衰減反轉恢復(fluid-attenuated inversion recovery,FLAIR)序列,通過施加反轉恢復脈沖后間隔一個較長的恢復時間再進行信號激發和采集,能夠有效抑制腦脊液信號,提高組織對比度,在腦卒中、腦腫瘤等疾病診斷中具有非常高的檢出敏感性。基于此,本文提出了一個基于多模態結構圖像融合策略的MRI圖像合成網絡,用于合成FLAIR對比度圖像。本文主要貢獻有:
(1)提出多模態特征融合策略:利用單模態特征提取器提取每個源模態的圖像特征,并通過異模態特征融合策略將各類特征有效融合,生成目標模態圖像。
(2)提出K空間損失:為了更多地挖掘圖像間的相似性,使合成圖像在K空間域也能更加逼近真實圖像,在本網絡中提出使用聯合圖像域和K空間域的動態加權損失函數。
1 數據與預處理
本文使用了2018年多模態腦腫瘤分割(brain tumor segmentation,BraTS)挑戰賽的官方數據集[13-15]。該數據集為公開數據集,包含了285個病例,每個病例有四種模態的MRI圖像,包括T1、T1對比增強(T1 contrast enhanced,T1 CE)、T2和FLAIR,每種模態圖像大小相同,都為155 × 240 × 240。數據預處理對于網絡訓練非常重要,本文的數據預處理分為以下幾個步驟:
(1)沿著圖像的軸向方向進行切片,將每個腦體積切割成240 × 240的軸向平面切片。為了能將全腦所有層面圖像都輸入網絡,節省算力和內存空間,加快訓練速度,本文將每個切片圖像的大小統一重采樣調整為192 × 192。
(2)去除對網絡訓練沒有意義的一些層面的圖像,例如空圖像。
(3)每個模態的圖像分別歸一化到[0,1]范圍內。
2 方法
2.1 理論分析
MRI是利用磁共振原理,通過給處于一定靜磁場下的成像組織施加特定頻率的射頻信號后,激勵組織中的氫原子核發生共振,進而獲取組織相關特性的一種成像方式。在MRI掃描中,針對同一組織使用不同掃描序列,并調節掃描參數可以得到反映該組織不同參數的圖像,這些不同參數的圖像通常也稱為不同模態的圖像[16],它們表現為具有不同圖像對比度。MRI圖像合成技術可行性在于:同一解剖結構的不同模態圖像,組織結構上是相同的,只是以不同對比形式表現這個結構[17];各模態圖像在信號表達式上存在著一定的依賴關系和信息相關性,比如FLAIR圖像的信號表達式中就含有T1與T2的相關信息,如式(1)所示:
|
其中,S為FLAIR圖像的信號強度,S0為質子密度信號強度,序列反轉時間(inversion time,TI)的參數符號以TI表示,序列重復時間(repetition time,TR)的參數符號以TR表示,序列回波時間(echo time,TE)的參數符號以TE表示,T1、T2分別為組織的縱向弛豫時間常數和橫向弛豫時間常數。
2.2 網絡設計
2.2.1 單模態特征編碼器
本文首先設計了一個單模態特征編碼器(mono-modal feature encoder,MFE),用于提取每種源模態圖像的特征。MFE由一個大卷積核U型網絡(U-net)構成。左邊網絡使用卷積層與最大池化層作為編碼器,提取多尺度特征;右邊網絡使用卷積層與上采樣層作為解碼器,進行特征融合,網絡框架如圖1所示。考慮算力情況,且要保持批大小在合理范圍,所以選擇可計算的最大卷積核大小作為卷積層的實際卷積核大小,本文將其設置為13 × 13。網絡參數通過預訓練得到。
圖1
單模態特征編碼器應用到的U-net網絡架構
Figure1.
U-net architecture applied to momo-modal feature encoder
近年來,關于超大卷積核神經網絡的研究工作表明,轉換器(transformer)的優越性能并不單純來源于注意力機制,而是來自有效感受野的增大[18-22]。因此為了改進網絡效果,本文也采用了大卷積核增大有效感受野的方法。為了解決直接使用大卷積核會帶來圖像特征過平滑的問題,MFE中使用了卷積核的重參數化策略,其計算過程如圖2所示。卷積過程中有兩條執行支路,一條支路的5 × 5 卷積核邊緣填充0到13 × 13尺寸,并將填充后的卷積核與另一條支路的13 × 13卷積核權重相加,符號“⊕”表示權重相加,然后按新卷積核進行卷積計算,最后進行批歸一化(batch normalization,BN)和線性整流函數(rectified linear unit,ReLU)激活輸出。
圖2
卷積核的重參數化過程示意圖
Figure2.
Diagram of the convolution kernel reparameterization process
MFE網絡的輸入為特定單模態圖像,輸出為目標模態圖像。訓練完成后,將網絡參數凍結,提取網絡的倒數第二層及與其尺寸相同的網絡第二層的特征圖作為單模態特征提取器的輸出,用于后續的特征融合與合成。
2.2.2 多模態融合網絡
多模態融合網絡,用于融合多個MFE網絡提取的特征。目標模態圖像與輸入的多個單模態圖像的關系如式(2)所示:
|
其中,n為使用的源模態種類數,Itarget表示目標模態圖像,Isource 表示第i種源模態圖像,Mi(·)是第i種模態特征提取函數,R(·)是多模態特征融合函數。本文中Itarget是FLAIR圖像,Isource是T1和T2加權圖像。單模態特征提取器參數訓練完成后,特征編碼器將 進行特征編碼,非線性函數R(·)負責融合源模態特征,并映射到相應的目標模態,即 。融合算法采用異模態圖像分割(hetero-modal image segmentation,Hemis)融合方法[21]。
多模態融合網絡如圖3所示,該網絡由n個單模態特征編碼器(MFE-1,MFE-n),2個特征Hemis融合模塊(Hemis-fusion block)以及1個解碼器(Decoder)組成。每個MFE的結構相同,用于提取源模態圖像的高低維度兩部分特征。特征圖的大小為H × W,本文設置為192 × 192,通道數為16。將多種源模態的兩部分特征圖分別輸入特征融合模塊,進行高低維特征融合,然后經數據連接拼接為通道32 × n的特征圖,最后經過Decoder生成目標圖像。解碼器由兩個殘差模塊連接組成,其結構如圖4所示,每個殘差模塊由兩個卷積加激活層構成,特征拼接后通過1 × 1卷積輸出結果圖像,符號“⊕”代表特征拼接。
圖3
多模態融合合成網絡框架
Figure3.
Framework for multimodal convergence networks
圖4
解碼器結構
Figure4.
Decoder architecture
2.3 雙域組合損失函數
在網絡訓練中使用了兩個損失函數,分別基于圖像域和K空間域,即內容損失和K空間損失。內容損失如式(3)所示:
|
其中,Lcontent(·)代表內容損失函數,是網絡的第l層的真實目標圖像特征圖(P)和生成的圖像特征(F)的歐氏距離。 代表第l層生成圖像的第i個特征圖的第j個輸出值, 代表第l層目標圖像的第i個特征圖的第j個輸出值,符號∑i, j是對所有i和j的項求和。式(3)用最小二乘法求解得出最小值,使迭代后的生成圖像特征接近迭代后的真實圖像特征,如式(4)所示:
|
K空間損失LK的計算過程如式(5)~式(7)所示:
|
|
|
其中,Ktruth代表目標真實值的K空間數據。Ksys代表合成圖像的K空間數據。kx、ky代表K空間域的x和y頻率分量,它隨采樣時間的變化而變化。N是K空間數據點的個數,d(·)表示差值函數,|·|表示計算絕對值操作, 是根據真實圖像和合成圖像K空間的差值大小計算出來的權重。α是一個可調參數,控制K空間的權重大小,其作用是在訓練過程中根據合成的難易程度對不同的分量進行動態加權,本文中將α設為2。這里認為兩幅圖像差異較大的部分是學習困難的部分,因為網絡收斂方向往往傾向于任務的簡單部分。加權損失函數使模型能夠自適應地關注合成困難的頻率成分,并降低容易合成的成分的權重。因此,總損失函數可以表示如式(8)所示:
|
其中,Ltotal、Lcontent、LK分別代表總的損失函數、內容損失函數和K空間損失函數,λ是一個權重超參數,控制兩個不同損失函數的貢獻。固定網絡其他參數后,實驗分析λ對訓練結果的影響,比較訓練損失和驗證損失值的收斂情況,如圖5所示,當設定為λ = 0.25時,網絡模型魯棒性更高,收斂速度更快。
圖5
不同超參數對訓練效果的影響
Figure5.
Influence of different hyperparameter on training result
2.4 訓練過程
在訓練中,FLAIR序列圖像作為目標模態圖像,作為網絡輸出;T1和T2加權圖像作為源模態,作為網絡輸入。每個受試者的圖像數據中選擇80個切片作為訓練集和驗證集。在實驗中,從125名受試者中隨機選擇了10 000個切片用于訓練模型,再隨機選擇35名受試者的2 800個切片進行測試。首先,通過學習該模態圖像到目標模態圖像的映射關系,獲得每個模態對應的MFE模塊參數。在MFE訓練過程中,每個卷積層使用ReLU激活函數,標準化凱明初始化器初始化網絡參數。幾種常見的模態的特征提取效果如圖6所示,圖像特征與目標圖像相似性高,可以證明MFE模塊的有效性。
圖6
MFE模塊的特征提取的結果
Figure6.
Results of MFE feature extraction
將MFE網絡提取的特征進行融合后,輸入解碼器進行圖像合成。整體訓練過程在圖像處理器NVIDIA GTX2080Ti(NVIDIA Inc.,美國)上進行,運用深度學習平臺Tensorflow2.3(Google Inc.,美國),使用自適應矩估計(adaptive moment estimation,Adam)優化算法訓練120個周期,設置學習率為0.000 3,批處理大小為32。
2.5 結果與分析
為了定量評價合成方法的性能,本文采用了三個常用的評價指標:峰值信噪比(peak signal-to-noise ratio,PSNR)、歸一化均方根誤差(normalized root mean square error,NRMSE)和結構相似度指數(structural similarity,SSIM)。PSNR常用來評價合成圖像的保真度,該值越大,圖像質量越好;NRMSE用來衡量生成圖像的合成誤差,該值越小越好;SSIM用來衡量生成圖像在明度、對比度和結構相似性方面的保真度度量,該值越大,圖像質量越好。為了證明本文提出的多模態融合合成網絡的有效性,使用前文提到的腦腫瘤分割挑戰賽數據集,將本文提出的合成結果與前人提出的三種經典的跨模態合成方法[23-25],包括像素到像素(pixel to pixel,Pix2pix)模型、多模態輸入多模態輸出合成(multi-input multi-output synthesis,MM-Syns)網絡模型和Hi-net模型的結果進行了比較,并以真實采集的FLAIR圖像作為標準圖像。其中Pix2pix輸入為T2圖像,其他三種方法的輸入都是T1和T2圖像。結果圖像如圖7所示,本文方法的結構細節與標準圖像更加接近,紅框部分進行了細節放大。對應的定量評價指標結果如表1所示,本文方法在三個指標上都表現最好。
圖7
不同方法的合成結果與對應紅色選擇區域放大圖
Figure7.
Results of different networks with enlarged view of the corresponding red selected area
增加T1 CE模態作為源模態圖像輸入多模態融合合成網絡用于合成FLAIR圖像,將合成結果與二輸入的合成結果對比發現,隨著輸入模態種類增加,合成圖像在PSNR指標上更加優異,SSIM稍低,視覺上更接近真實圖像。合成效果如圖8所示,紅框部分進行了細節放大;定量評價如表2所示。
圖8
增加輸入模態對合成結果的影響
Figure8.
Effect of increasing input modal variety on synthesis results
隨著卷積核的增大,模型在包含病灶的切片合成圖像中紋理更加清晰,圖像細節更豐富,驗證了大卷積核在圖像合成任務中有一定優勢。合成結果圖像如圖9所示,分別為卷積核大小為3、7、13時的合成結果圖像,紅框部分進行了細節放大;對應的定量評價如表3所示。
圖9
卷積核大小對合成結果的影響
Figure9.
Effect of convolution kernel size on synthesis results
3 結論和展望
MRI相比電子計算機斷層掃描(computer tomography,CT)等其他成像設備的一個巨大的優點是能夠同時獲得表征組織不同特性的多個不同對比度模態圖像,為醫生的臨床診斷提供更多參考信息。但是通過掃描方式獲取多種模態圖像,耗費時間較長。此外,由于被掃描者或設備原因,經常出現個別模態圖像的缺失或圖像質量不能達到診斷要求[25-27]。因此,圖像合成技術可以一定程度解決臨床應用中部分模態圖像缺失和圖像質量不達標的問題。FLAIR序列增加了病灶與周圍組織的對比度,提高了病灶檢出能力,在臨床應用中非常重要,而且日常掃描中FLAIR圖像特別容易產生腦脊液搏動等偽影,因此合成FLAIR圖像具有重要意義。相比單模態網絡,本文提出的多模態結構圖融合MRI圖像合成深度學習網絡,輸入的模態更多,提供了更加豐富的互為補充的特征,更加準確地合成了FLAIR圖像。實驗結果證明,在網絡中通過引入K空間和圖像域組合的損失函數,能使圖像合成細節更加完善,避免了合成圖像的過度平滑。
本文提出的網絡主要用于合成FLAIR序列圖像,但是網絡結構中并未專門針對FLAIR圖像做強約束,因此只要通過使用新模態數據對網絡重新訓練,也可以用于其他模態圖像的合成中。本文通過在輸入模態圖像中增加T1 CE圖像,以實驗驗證了其合成結果要優于沒有T1 CE圖像的合成效果。本文實驗采用的數據集是大部分研究人員普遍使用的公開數據集,未來將使用更多的臨床數據對網絡進行優化和驗證。本文研究結果表明,基于深度學習的MRI圖像合成技術,能夠更有效地挖掘不同模態圖像中的深層次信息,剔除冗余信息,相比傳統方法可以更加準確和快速地合成圖像;本文方法還可用于加速MRI掃描、偽影消除、圖像分割及圖像預測等多個場景,具有非常大的發展潛力。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:周家檸負責整體算法設計、代碼編寫與實驗分析,以及論文初稿撰寫;郭紅宇負責算法設計指導和網絡優化,以及論文的修改完善;陳紅負責參與圖像質量評價和結果分析。