精神障礙疾病成因復雜,早識別早干預是公認避免隨時間推移造成大腦不可逆轉損傷的有效途徑。已有的計算機輔助識別方法多關注于多模態數據融合,忽略了多模態數據異步采集問題。為此,本文提出一種基于可視圖的精神障礙識別框架,以期解決數據異步采集問題。首先,通過映射時序腦電(EEG)數據到空間可視圖(VG);然后,采用改進自回歸模型,精準計算時序EEG數據特征,分析時空映射關系,合理選擇空間度量特征;最后,以時空信息互補為基礎,為各時空特征賦予不同貢獻系數,發掘特征最大潛能并做出決策。對照實驗結果表明,本文方法能夠有效提高精神障礙疾病的識別準確率,以阿爾茨海默癥與抑郁癥為例,分別獲得了最高93.73%和90.35%的識別率。綜上所述,本文結果為精神障礙疾病的快速臨床診斷提供了一種有效的計算機輔助工具。
引用本文: 張冰濤, 魏丹, 常文文, 楊志飛, 李延林. 基于可視圖的精神障礙識別方法. 生物醫學工程學雜志, 2023, 40(3): 442-449. doi: 10.7507/1001-5515.202208077 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
0 引言
2020年,我國男性的抑郁癥和焦慮癥患病率分別為3.50%和4.80%,女性分別為4.60%和5.20%[1]。2022年2月《柳葉刀》發表了來自11個國家25位專家撰寫的《柳葉刀—世界精神病學協會抑郁癥重大報告》,其內容涵蓋范圍從神經科學到其它學科領域,該報告指出抑郁癥等精神障礙疾病患病率呈快速增長趨勢;并且還呼吁政府、科研人員、醫療服務提供者協調一致填補抑郁癥研究領域的知識空白[2]。針對精神障礙疾病成因復雜、發病率高、復發率高等特點,為防止隨時間推移導致大腦功能產生不可逆轉損傷,目前醫學界公認最有效的方法是早識別早干預[3]。
傳統基于精神障礙診斷與統計手冊(diagnostic and statistical manual of mental disorders, DSM)、簡明國際神經精神障礙訪談檢查(mini international neuropsychiatric interview,MINI)等結構化量表的面對面訪談精神障礙疾病診斷方式耗時費力,且嚴重依賴醫生的主觀經驗和患者提供信息的真實性[4]。隨著多學科交叉技術發展,研究人員發現大腦異常活動與精神障礙患者認知能力改變有關,這些異常活動實質是神經元異常放電,并以腦電(electroencephalograms,EEG)形式呈現在大腦皮層。EEG數據作為中樞神經系統記錄信息的載體,具有非侵入、易采集、不可掩飾等優勢,廣泛用于精神障礙疾病識別領域[5-6]。EEG數據作為基礎數據,Peng等[7]基于字典學習和稀疏表示提出了一種新穎的癲癇自動檢測算法。以靜息態EEG數據構建腦功能網絡為切入點,Zhang等[8]通過遞進式分析策略,發掘若干抑郁癥識別潛在標識物,實現了較準確的抑郁癥識別。
精神障礙疾病成因復雜,僅從單模態視角出發,不可避免會丟失部分有價值信息。從多模態融合視角出發,能夠有效提高識別的準確率(accuracy,Acc)。相對于單模態,多模態融合能夠更全面還原事物本質[9]。因此,本文通過多模態融合挖掘EEG數據中隱藏的更多有價值信息,開展精神障礙識別研究。
多模態融合的精神障礙識別研究,需解決兩個關鍵問題:① 如何處理多模態融合中數據異步采集問題;② 何種融合方法更適合于精神障礙識別?當前多數研究者關注于不同類型數據融合,如融合EEG數據特征與磁共振成像(magnetic resonance imaging,MRI)特征,旨在結合EEG數據高時間分辨率和MRI數據高空間分辨率來提高精神障礙疾病的識別Acc [10]。馬江河等[11]融合EEG信號與語音信號實現了多模態情感識別,與單獨EEG信號或者語音信號相比,多模態融合識別率分別提高了8.19%和6.52%。Zhang等[12]基于多智能體策略實現EEG信號特征和聲音信號特征融合,并獲得76.41%的抑郁癥識別Acc。由于設備限制,當前不同類型基礎數據同步采集在技術上是不可行的,而數據異步采集后融合會影響識別性能。為彌補設備限制,針對第一個關鍵問題,本文將時序EEG數據映射到空間可視圖(visibility graph,VG),進而實現時空模態特征融合,解決數據異步采集問題。
典型數據融合方法包括像素級融合、特征級融合和決策級融合[13-14]。像素級融合對原始數據進行預處理前進行綜合分析,常用于圖像領域。決策級融合是指不同識別模型先各自單獨決策,再相互協調或者組合做出全局決策。特征級融合在特征提取后,以線性或非線性方式將不同類型特征組合獲得一個新特征集,再通過識別模型做出決策。特征級融合綜合其他兩種融合方法的優點,融合后原始信息不易丟失,且后續識別模型耗時較少。綜合考慮,針對第二個關鍵問題,本文將在特征級融合基礎上展開研究和探索。
在上述討論和分析基礎上,本文提出了一種時空特征融合的精神障礙識別方法,時空特征融合實現信息互補,為不同特征賦予不同貢獻系數,以發掘特征最大潛能,進而為輔助臨床診斷做出決策提供助力。
1 精神障礙識別模型
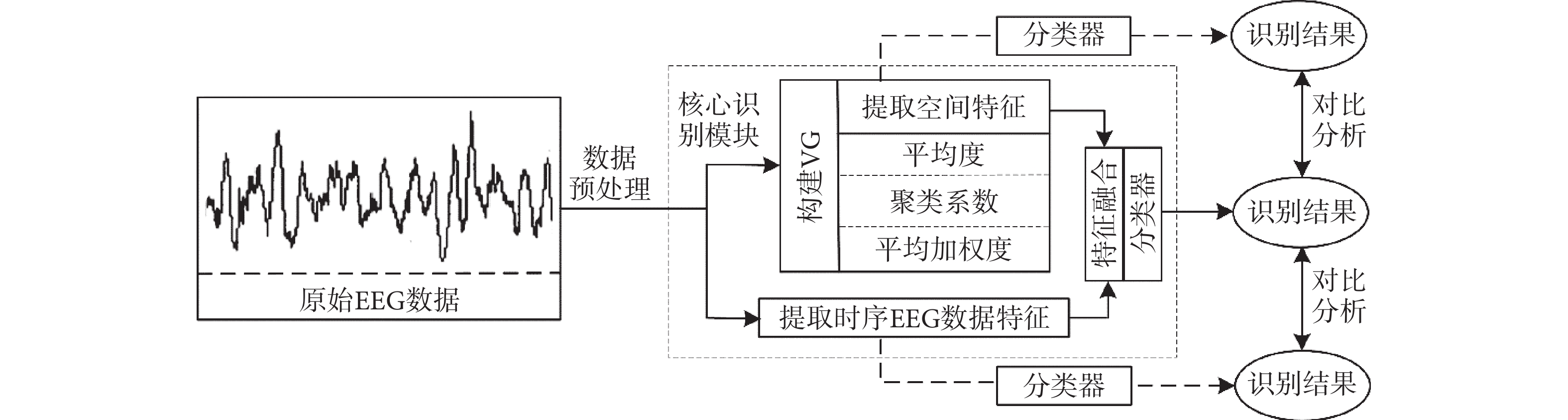
為說明本研究核心思想,給出基于可視圖的精神障礙識別模型,如圖1所示。該模型主要包含三部分:① 原始EEG數據及預處理。② 核心識別模塊,即時序EEG數據映射到VG;提取時序EEG數據特征和空間度量特征,并以基于貢獻度的時空融合特征作為分類器輸入。③ 精神障礙識別結果。此外,將本文提出的融合方法與時序EEG數據特征和空間度量特征方法進行對比。本研究重點是核心識別模塊,對其他部分只作簡要介紹。
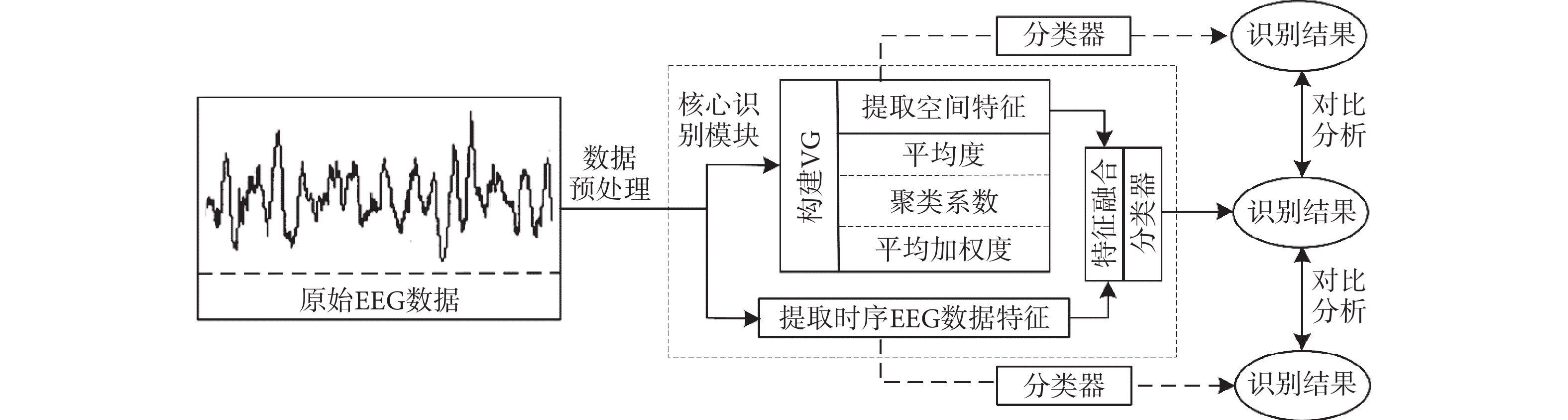 圖1
精神障礙識別模型
Figure1.
Mental disorders recognition model
圖1
精神障礙識別模型
Figure1.
Mental disorders recognition model
1.1 時序EEG信號特征
EEG數據是神經元離子電流引起的電壓波動,外在形式是頭皮上任意電極之間的電壓差。持續記錄電壓差即可捕獲EEG數據,也就是說,EEG數據是一種典型時序信號。時序EEG數據中可提取多種特征,本文選取與精神障礙疾病密切相關的3種特征[15]:功率譜密度(power spectrum density,PSD)均值(average_PSD)、最大值(max_PSD)、總和(sum_PSD)。自回歸(auto regression,AR)模型是計算PSD常用方法。固定階AR模型把信號xt表示為其先前值xt-i和白噪聲?t的加權和[16],如式(1)所示:
 |
式中,i是EEG數據序列編號,ai是模型系數,p是模型階數。為獲得準確EEG特征,本文提出一種自適應AR模型方法以計算PSD,該方法使用赤池信息量準則(akaike information criterion,AIC)反復迭代以自適應逼近AR模型的最佳階數p。基于自適應AR模型計算average_PSD、max_PSD、sum_PSD的過程如式(2)~式(4)所示:
 |
 |
 |
式中,N是樣本數量,e為指數函數,j是虛數, 是信號x的PSD,計算過程如式(5)所示:
是信號x的PSD,計算過程如式(5)所示:
 |
式中,optimal_p是AR模型的最佳階數, 是白噪聲方差。
是白噪聲方差。
1.2 構建VG及空間度量特征
設VG(V,E)由節點集V和邊集E組成,時序EEG數據{xt| t=1, 2, …, n}映射到空間VG包括兩步:①節點生成:映射時序EEG數據點xt至節點集V中的節點vt,設v1的橫坐標為0,則vt的橫坐標為t,縱坐標為EEG信號值。②連接生成:任意節點對vi(i, xi)和vj(j, xj)具有連接性,即它們之間存在節點vk(k, xk)滿足如式(6)所示條件:
 |
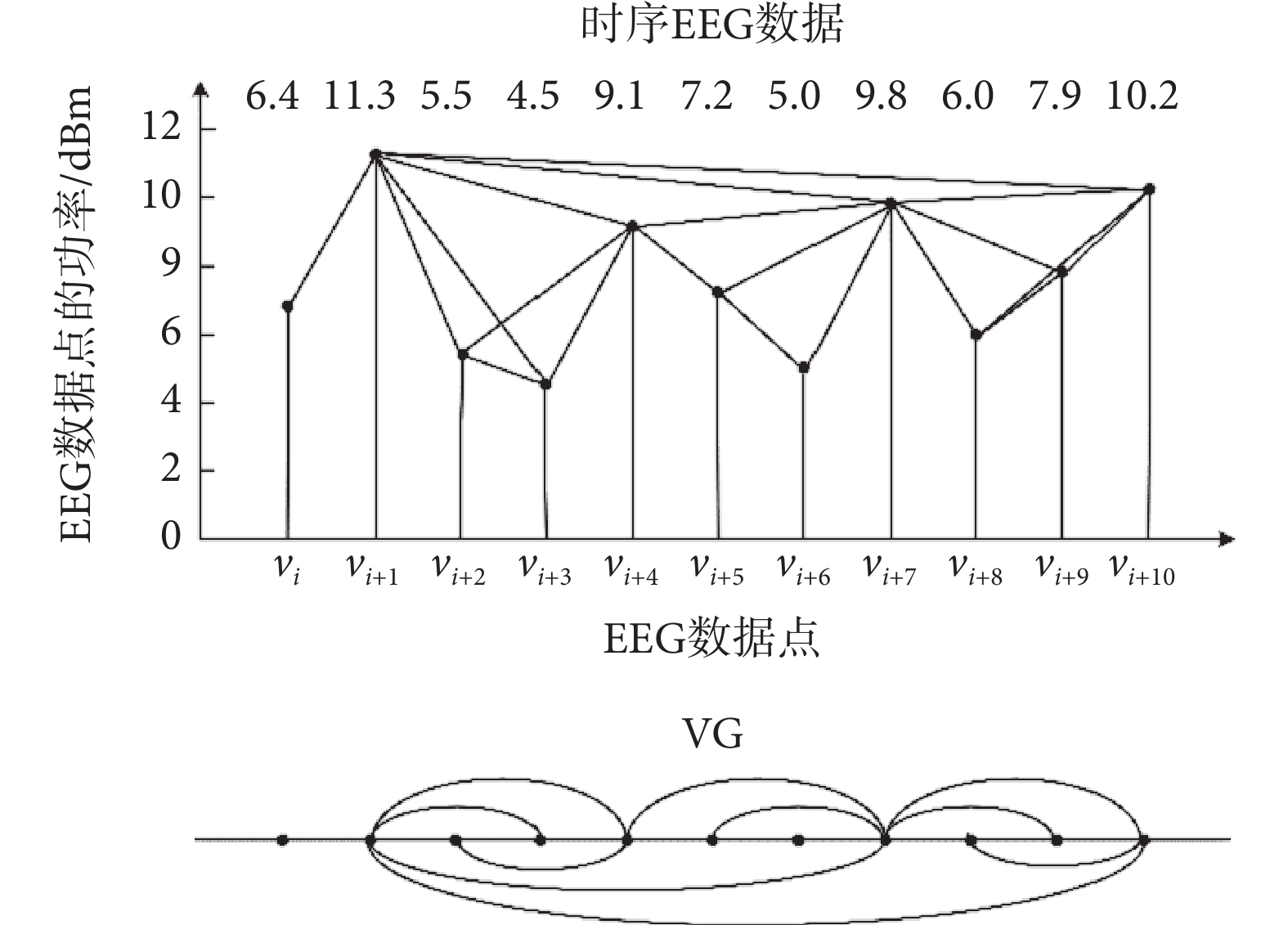
式中,i,j,k均為EEG數據序列編號。為闡明VG構建過程,隨機選取一段時序EEG數據xt = {6.4, 11.3, 5.5, 4.5, 9.1, 7.2, 5.0, 9.8, 6.0, 7.9, 10.2},該數據序列與其所生成的VG如圖2所示。VG的節點序列如表1所示,節點間生成的連接依次為:e(vi,vi+1)、e(vi+1,vi+2)、e(vi+1,vi+3)、e(vi+1,vi+4)、e(vi+1,vi+7)、e(vi+1,vi+10)、e(vi+2,vi+3)、e(vi+2,vi+4)、e(vi+3,vi+4)、e(vi+4,vi+5)、e(vi+4,vi+7)、e(vi+5,vi+6)、e(vi+5,vi+7)、e(vi+6,vi+7)、e(vi+7,vi+8)、e(vi+7,vi+9)、e(vi+7,vi+10)、e(vi+8,vi+9)、e(vi+8,vi+10)、e(vi+9,vi+10),其中,v是時序EEG數據對應VG中的節點,e是節點間生成的連接。
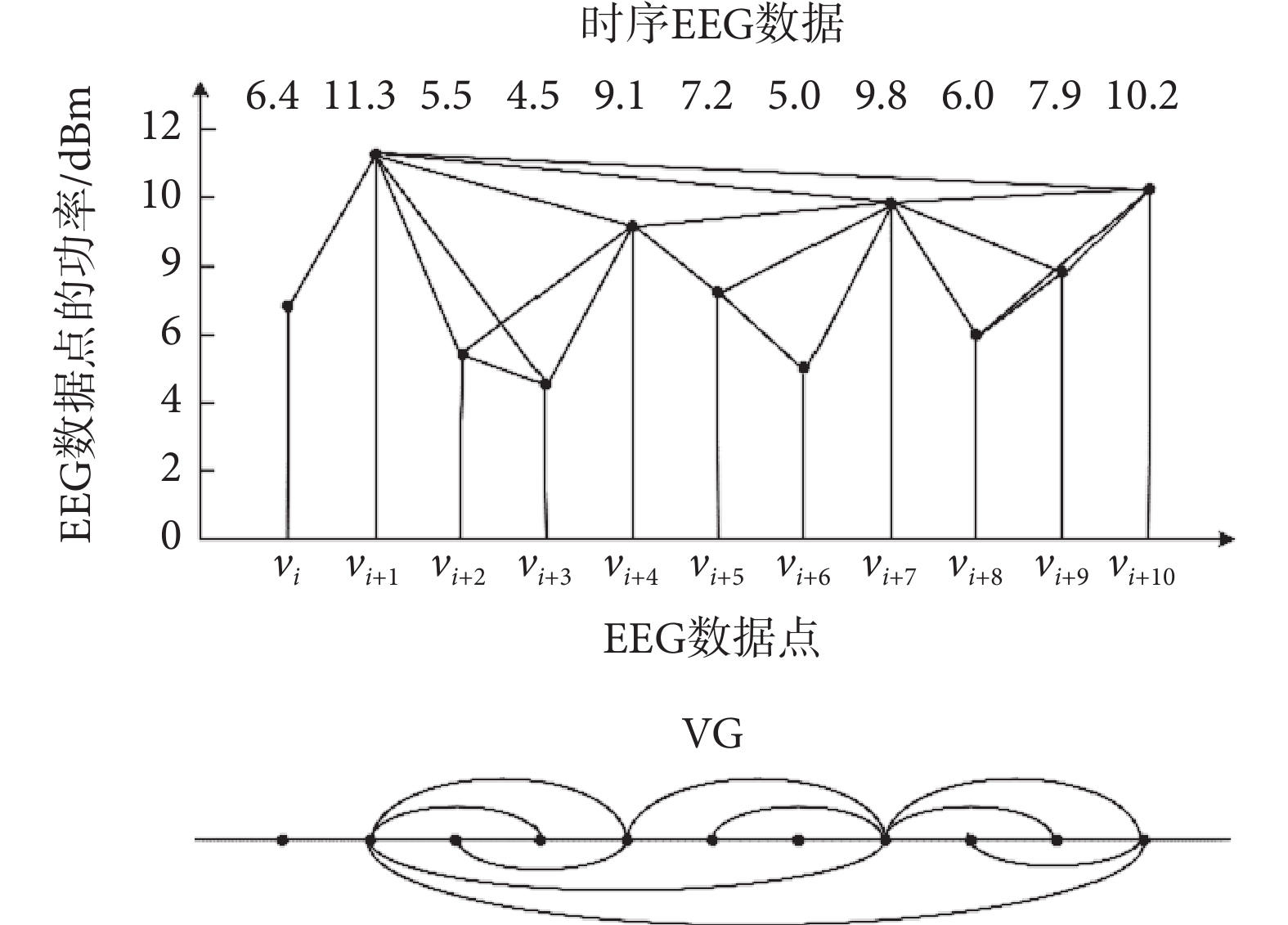 圖2
時序EEG數據及VG構建
Figure2.
Time series EEG data and VG construction
圖2
時序EEG數據及VG構建
Figure2.
Time series EEG data and VG construction
研究表明,連接權重蘊含辨別網絡重要或薄弱環節的重要信息[17],因此本文引入連接權重信息生成權重VG,節點間連接權重wij計算過程如式(7)所示:
 |
式中,vi,vj是VG中任意兩個節點。VG繼承了時序EEG數據動態屬性,蘊含著前后時序EEG數據之間的關聯性。盡管VG不能直接反映精神障礙疾病的具體生理特性改變,但是通過對VG空間度量特征分析,從空間層面對前后時序EEG數據變化與精神障礙疾病之間關聯性可以進行探索與挖掘。由于節點度反映了節點在網絡中的重要程度,因此,本文提取VG中與度相關的空間度量特征:平均度( )、聚類系數(C)和平均加權度(average _WD)。
)、聚類系數(C)和平均加權度(average _WD)。 是網絡連接數與節點數的比值,計算過程如式(8)所示:
是網絡連接數與節點數的比值,計算過程如式(8)所示:
 |
式中,E和N分別是網絡連接數量和節點數量。C反映了網絡節點的聚集程度,計算過程如式(9)所示:
 |
式中,Ci是第i個節點的聚類系數,計算過程如式(10)所示:
 |
式中,ti是第i個節點與其鄰接節點構成三角形的數量,di是第i個節點的度。average _WD是網絡中全部節點總權重的平均值,反映了網絡的連接強度,計算過程如式(11)所示:
 |
式中,wi是第i個節點的權重,計算過程如式(12)所示:
 |
式中,wij是節點i和節點j之間的連接權重。
1.3 基于貢獻度的時空特征融合
僅從時間或者空間維度進行決策識別,將使得決策信息不夠充足。使用一維特征融合,如單獨時間特征或者空間特征融合,則難以充分發揮特征融合優勢。為此,本文通過融合時序EEG數據特征和VG空間度量特征,以保證時空特征融合優勢最大化。同時,時空兩類特征均來自EEG數據,從而有效解決基于多模態融合的精神障礙識別中數據異步采集問題。
傳統精神障礙識別模型通常假設所有特征具有同等重要性,忽略不同特征對識別任務貢獻差異,導致模型泛化能力降低[18]。貢獻度反映了不同特征對識別任務貢獻的大小,能夠影響識別Acc。基于上述分析,本文提出基于貢獻度的時空特征融合方法,用于解決精神障礙識別中融合方法的問題。該方法核心思想是對時空特征進行線性組合,為不同特征分配不同貢獻系數,具體實現如式(13)所示:
 |
式中,ftim_i和fspa_j分別為時序EEG數據特征和VG空間度量特征, 是貢獻度系數,
是貢獻度系數, 。
。 的實現過程如下:隨機選擇一個樣本R,從R同類樣本集中找到最近鄰樣本H,不同類樣本集中找到最近鄰樣本M;然后根據以下規則更新每個特征的權重:如果一個特征上R和H的距離小于R和M的距離,則表明該特征有利于區分同類和不同類,則增加特征權值;反之,則減少特征權值。重復上述過程k次,得到每個特征的平均權重值,進而計算每個特征相對于其他特征的貢獻系數。
的實現過程如下:隨機選擇一個樣本R,從R同類樣本集中找到最近鄰樣本H,不同類樣本集中找到最近鄰樣本M;然后根據以下規則更新每個特征的權重:如果一個特征上R和H的距離小于R和M的距離,則表明該特征有利于區分同類和不同類,則增加特征權值;反之,則減少特征權值。重復上述過程k次,得到每個特征的平均權重值,進而計算每個特征相對于其他特征的貢獻系數。
1.4 識別及性能評估
權衡信息量與運行時間,4 s為一個時間窗口提取時序EEG數據特征,2 s為一個重疊窗口。為保持時空信息一致性,構建4 s時間窗口VG,計算空間度量特征。接著生成時空特征融合二維表,二維表中每條記錄由兩部分組成:特征值和類標簽。驗證提出方法有效性,二維表中每條記錄作為K最近鄰(K-nearest neighbor,KNN)分類器輸入,已有研究表明在精神障礙識別方面KNN優于其他分類器[19]。本文中KNN參數設置為:鄰居數量k值是3,計算KNN采用k維樹算法,距離度量采用歐氏距離方法,KNN分類器執行10折交叉驗證。Acc、敏感性(sensitivity,Sen)和特異性(specificity,Spe)用于評估識別性能,其計算如式(14)~式(16)所示:
 |
 |
 |
式中,真陽性(true positive,TP)是指正類別中正確分類樣本的數量;真陰性(true negative, TN)是指負類別中正確分類樣本的數量;假陽性(false positive,FP)是指正類別中錯誤分類樣本的數量;假陰性(false negative,FN)是指負類別中錯誤分類樣本的數量。
2 實驗與結果
2.1 實驗數據及預處理
本文實驗數據包含阿爾茨海默癥和抑郁癥兩部分精神障礙受試者的靜息態EEG數據,均來自公開數據集,其中阿爾茨海默癥數據來自歐洲第七科技框架計劃(seventh science and technology framework plan,FP7)項目決議檔案[20],抑郁癥數據來自精神障礙分析多模態開放數據集(a multi-modal open dataset for mental-disorder analysis,MODMA)[21]。考慮到耳垂參考電極記錄EEG數據更為準確,以及年齡和教育程度匹配,前者使用耳垂參考電極數據。后者MODMA包含128電極和3電極兩種類型數據,為減少計算量,本文使用3電極EEG數據。阿爾茨海默癥受試者的簡易智力狀態檢查(mini-mental state examination,MMSE)量表得分<27;抑郁癥受試者的患者健康問卷9項(patient health questionnaire 9-items,PHQ-9)量表得分≥5。阿爾茨海默癥及對照組數據記錄于19個電極,采樣率為256 Hz;抑郁癥及對照組數據采樣率為250 Hz。
數據采集過程不可避免會引入噪聲,不能直接用于精神障礙分析和研究,需進行必要預處理。研究表明,與精神障礙相關EEG數據主要分布在0.5~45.0 Hz之間[22],因此本文采用低截止頻率為0.5 Hz、高截止頻率為45.0 Hz的有限沖激響應帶通濾波器,以消除低頻漂移和高頻噪聲。眼電(electrooculogram,EOG)是EEG數據噪聲的主要來源,且在0~16 Hz之間與EEG數據嚴重重疊,即使靜息態下眨眼產生的EOG信號振幅也是EEG信號振幅十倍以上。為此,本研究基于Peng等[23]提出的自適應濾波器結合小波變換模型剔除EOG信號噪聲,以獲得更純凈EEG數據。
2.2 單模態特征與時空特征融合對比
為驗證時空特征融合性能,本研究設計了對比實驗,分別將單模態時序EEG數據特征組合、單模態空間度量特征組合以及時空特征融合作為KNN輸入,對比單模態特征與時空特征融合的精神障礙識別性能,如式(17)~式(19)所示:
 |
 |
 |
式中,ctim表示單模態時序EEG數據特征組合,cspa表示單模態空間度量特征組合,ftim_spa表示時空特征融合,ftim_i表示時序EEG數據特征,fspa_j表示空間度量特征。
阿爾茨海默癥和抑郁癥兩類精神障礙的單模態時序EEG數據特征獲得Acc為76.42%和78.02%,單模態空間度量特征獲得的Acc僅為65.11%和69.43%,時空特征融合獲得的Acc為88.73%和84.17%。上述結果表明,相比空間度量特征,時序EEG數據特征能夠獲得更高的Acc,本研究認為由于時序EEG數據中包含更多對于精神障礙疾病識別有價值的信息,時空特征融合獲得最高Acc是由于信息互補提高了識別性能。基于此分析,本文后續實驗重點關注時空特征融合對精神障礙識別性能的影響。
2.3 基于特征貢獻系數的識別結果
本節討論貢獻系數對精神障礙識別性能的影響,忽略不同電極記錄EEG數據差異。組間特征值平均后計算相應貢獻系數,即阿爾茨海默癥及其對照組的19個電極特征值分別平均,抑郁癥及其對照組的3個電極特征值分別平均。最大化不同特征對識別性能貢獻,基于1.3節方法依次計算每個特征對應權值和貢獻系數,結果如表2~表4所示。對表4中貢獻系數統計分析,可以發現時序EEG數據特征貢獻系數總占比均大于空間度量特征,間接證明了時序EEG信號中包含更多精神障礙識別有價值信息。
驗證特征貢獻系數對精神障礙識別性能的影響,基于式(13)將表2~表4中貢獻系數添加至對應特征作為KNN輸入,結果如表5和表6所示。與未添加貢獻系數識別Acc相比,阿爾茨海默癥和抑郁癥分別平均提高了5.25%和5.72%。無論是單模態特征,還是時空特征融合,添加貢獻系數均能提高識別Acc,此結果表明,不同特征對識別任務貢獻不同,傳統機器學習模型忽略了不同特征對識別任務的貢獻差異。因此,探索不同特征對特定識別任務貢獻差異,通過添加貢獻系數可以有效提高機器學習模型識別能力,充分挖掘不同特征各自優勢,改進精神障礙識別性能。
從表5和表6可以看出,阿爾茨海默癥和抑郁癥添加貢獻系數后時空特征融合方法均獲得最高Acc,平均Acc分別為93.73%和90.35%。
2.4 不同類型算法性能比較
為驗證KNN在精神障礙識別領域優于其他分類器的先前結論[19]在本研究中是否成立,本文特設計對比實驗,基于式(13)將表4中貢獻系數添加至對應特征后作為典型識別算法輸入,對比KNN與典型識別算法之間性能差異。這些典型算法包括基于統計學習理論的支持向量機(support vector machine,SVM)和基于集成學習的隨機森林(random forest,RF)。
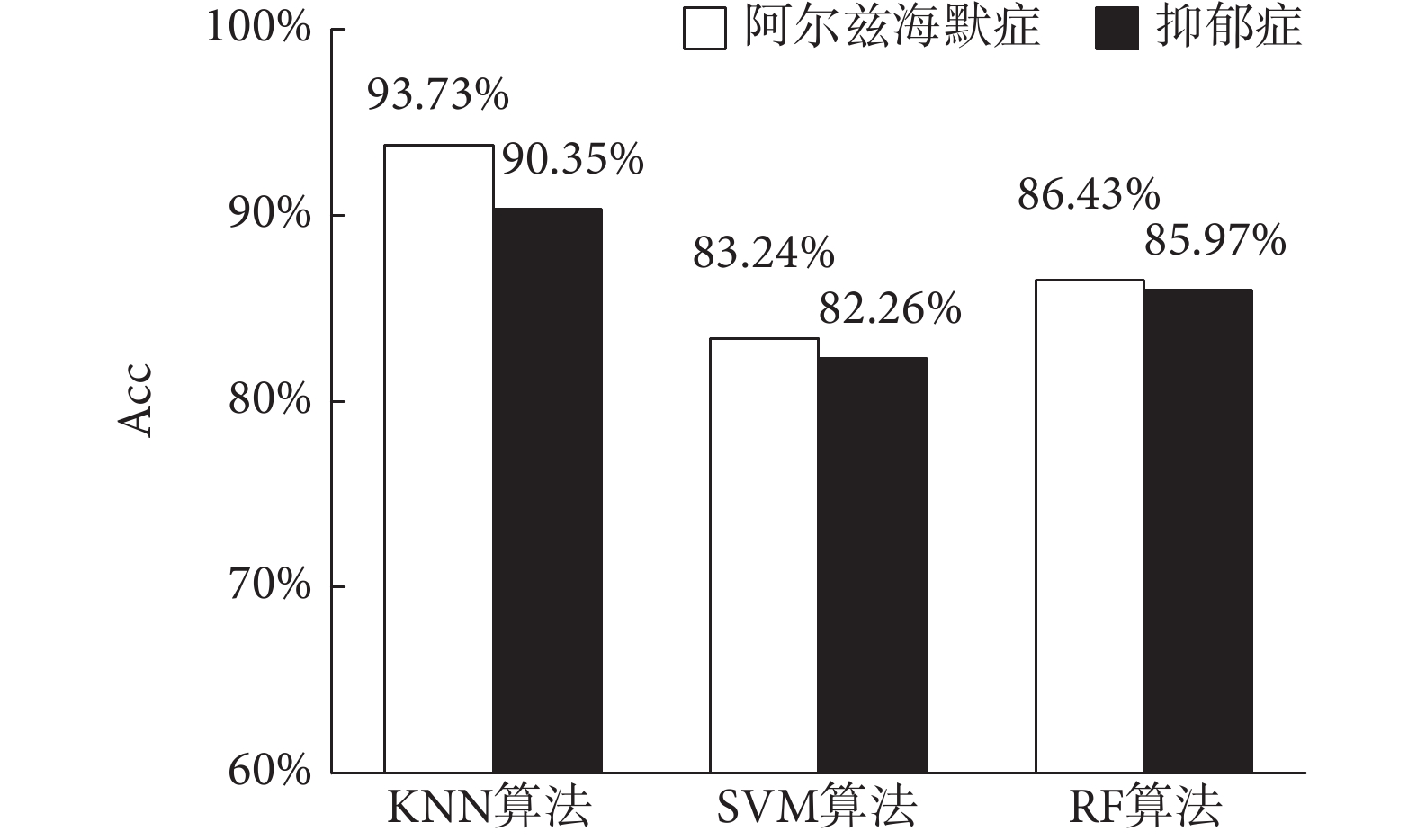
實驗對比結果如圖3所示,可以看出KNN在本文中仍獲得最高識別Acc。與SVM相比,阿爾茨海默癥和抑郁癥分別提高了10.49%和8.09%的識別Acc。SVM獲得最低識別Acc的主要原因可以歸納為以下兩方面:一方面由于SVM訓練過程中自帶權值系數,添加貢獻系數對其識別Acc改善未起作用;另一方面典型SVM的固定懲罰系數C = 1.0,正負兩類樣本產生的誤差損失不同,典型SVM固定懲罰系數使其獲得相對較低的Acc。
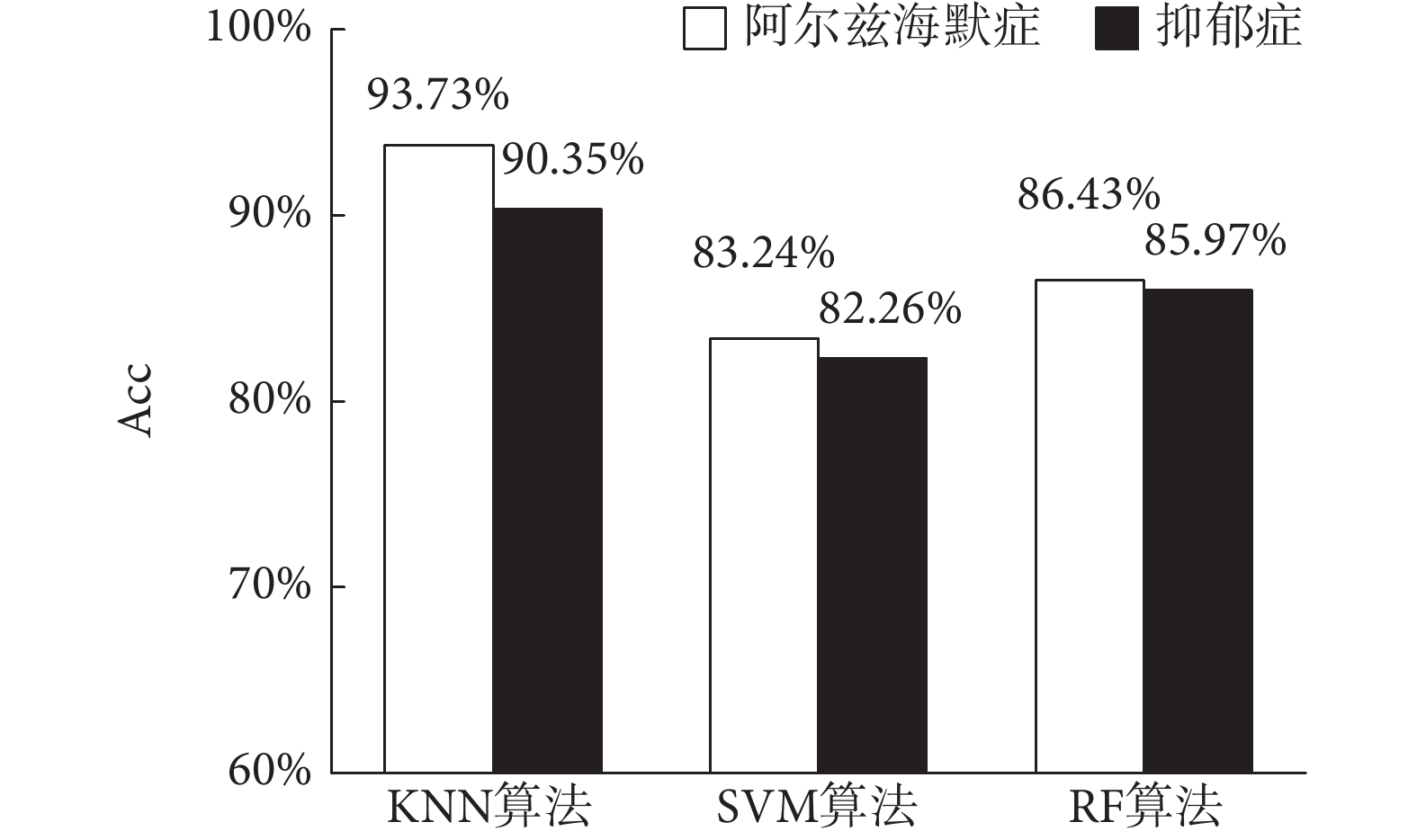 圖3
不同識別算法Acc對比
Figure3.
Acc comparison of different recognition algorithms
圖3
不同識別算法Acc對比
Figure3.
Acc comparison of different recognition algorithms
2.5 本文方法與現有方法比較
為闡明本方法優勢,基于本研究使用的阿爾茨海默癥和抑郁癥兩個數據集,將其他已發表文獻[19-20, 24]的研究方法與本文基于VG的時空特征融合方法進行綜合對比,包括研究方法、Acc、Sen、Spe等內容。如表7所示,基于VG的時空特征融合方法識別Acc均高于其他研究方法。盡管通過識別Acc并不能充分反映各種方法的全部優缺點,但其可以部分或間接地說明本方法在一定程度上優于其他方法。
3 結論
為解決精神障礙類疾病早識別早干預問題,本文提出了一種基于VG的計算機輔助精神障礙識別方法,旨在通過時空信息互補和特征差異化處理來提高識別性能。通過映射時序EEG數據到空間VG,以解決空間信息獲取問題,進而避免多模態生理數據異步采集過程中的技術限制問題。發掘更多時空特征中精神疾病識別有價值的信息,本文設計并實現了基于特征貢獻系數的時空特征融合方法,使得時空特征優勢最大化,從而提高識別模型的Acc。
為驗證本文提出方法的有效性,使用來自公開數據集的阿爾茨海默癥和抑郁癥兩類精神障礙靜息態EEG數據,先后從單模態特征與時空特征融合對比、基于特征貢獻系數的識別性能對比、不同類型算法性能對比、本文方法與現有方法比較等四個方面設計對比實驗。結果表明,時空特征融合與單模態特征相比,能夠有效提高精神障礙疾病識別的Acc;通過對不同特征添加不同貢獻系數,充分發掘特征最大潛能,進一步提高精神障礙疾病識別性能,并且阿爾茨海默癥與抑郁癥分別獲得最高93.73%和90.35%的識別Acc;通過對比不同類型算法的識別性能,進一步驗證了精神障礙識別方面KNN算法優于其他算法的已有研究結論。
在基于VG的精神障礙識別研究基礎上,課題組今后將重點關注本方法對不同精神障礙疾病識別的差異化處理,從而進一步提高具體精神障礙疾病識別的Acc。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:張冰濤負責研究方案設計,論文撰寫;魏丹負責實驗數據處理;常文文負責數據分析;楊志飛負責論文審閱;李延林負責圖表繪制。
0 引言
2020年,我國男性的抑郁癥和焦慮癥患病率分別為3.50%和4.80%,女性分別為4.60%和5.20%[1]。2022年2月《柳葉刀》發表了來自11個國家25位專家撰寫的《柳葉刀—世界精神病學協會抑郁癥重大報告》,其內容涵蓋范圍從神經科學到其它學科領域,該報告指出抑郁癥等精神障礙疾病患病率呈快速增長趨勢;并且還呼吁政府、科研人員、醫療服務提供者協調一致填補抑郁癥研究領域的知識空白[2]。針對精神障礙疾病成因復雜、發病率高、復發率高等特點,為防止隨時間推移導致大腦功能產生不可逆轉損傷,目前醫學界公認最有效的方法是早識別早干預[3]。
傳統基于精神障礙診斷與統計手冊(diagnostic and statistical manual of mental disorders, DSM)、簡明國際神經精神障礙訪談檢查(mini international neuropsychiatric interview,MINI)等結構化量表的面對面訪談精神障礙疾病診斷方式耗時費力,且嚴重依賴醫生的主觀經驗和患者提供信息的真實性[4]。隨著多學科交叉技術發展,研究人員發現大腦異常活動與精神障礙患者認知能力改變有關,這些異常活動實質是神經元異常放電,并以腦電(electroencephalograms,EEG)形式呈現在大腦皮層。EEG數據作為中樞神經系統記錄信息的載體,具有非侵入、易采集、不可掩飾等優勢,廣泛用于精神障礙疾病識別領域[5-6]。EEG數據作為基礎數據,Peng等[7]基于字典學習和稀疏表示提出了一種新穎的癲癇自動檢測算法。以靜息態EEG數據構建腦功能網絡為切入點,Zhang等[8]通過遞進式分析策略,發掘若干抑郁癥識別潛在標識物,實現了較準確的抑郁癥識別。
精神障礙疾病成因復雜,僅從單模態視角出發,不可避免會丟失部分有價值信息。從多模態融合視角出發,能夠有效提高識別的準確率(accuracy,Acc)。相對于單模態,多模態融合能夠更全面還原事物本質[9]。因此,本文通過多模態融合挖掘EEG數據中隱藏的更多有價值信息,開展精神障礙識別研究。
多模態融合的精神障礙識別研究,需解決兩個關鍵問題:① 如何處理多模態融合中數據異步采集問題;② 何種融合方法更適合于精神障礙識別?當前多數研究者關注于不同類型數據融合,如融合EEG數據特征與磁共振成像(magnetic resonance imaging,MRI)特征,旨在結合EEG數據高時間分辨率和MRI數據高空間分辨率來提高精神障礙疾病的識別Acc [10]。馬江河等[11]融合EEG信號與語音信號實現了多模態情感識別,與單獨EEG信號或者語音信號相比,多模態融合識別率分別提高了8.19%和6.52%。Zhang等[12]基于多智能體策略實現EEG信號特征和聲音信號特征融合,并獲得76.41%的抑郁癥識別Acc。由于設備限制,當前不同類型基礎數據同步采集在技術上是不可行的,而數據異步采集后融合會影響識別性能。為彌補設備限制,針對第一個關鍵問題,本文將時序EEG數據映射到空間可視圖(visibility graph,VG),進而實現時空模態特征融合,解決數據異步采集問題。
典型數據融合方法包括像素級融合、特征級融合和決策級融合[13-14]。像素級融合對原始數據進行預處理前進行綜合分析,常用于圖像領域。決策級融合是指不同識別模型先各自單獨決策,再相互協調或者組合做出全局決策。特征級融合在特征提取后,以線性或非線性方式將不同類型特征組合獲得一個新特征集,再通過識別模型做出決策。特征級融合綜合其他兩種融合方法的優點,融合后原始信息不易丟失,且后續識別模型耗時較少。綜合考慮,針對第二個關鍵問題,本文將在特征級融合基礎上展開研究和探索。
在上述討論和分析基礎上,本文提出了一種時空特征融合的精神障礙識別方法,時空特征融合實現信息互補,為不同特征賦予不同貢獻系數,以發掘特征最大潛能,進而為輔助臨床診斷做出決策提供助力。
1 精神障礙識別模型
為說明本研究核心思想,給出基于可視圖的精神障礙識別模型,如圖1所示。該模型主要包含三部分:① 原始EEG數據及預處理。② 核心識別模塊,即時序EEG數據映射到VG;提取時序EEG數據特征和空間度量特征,并以基于貢獻度的時空融合特征作為分類器輸入。③ 精神障礙識別結果。此外,將本文提出的融合方法與時序EEG數據特征和空間度量特征方法進行對比。本研究重點是核心識別模塊,對其他部分只作簡要介紹。
圖1
精神障礙識別模型
Figure1.
Mental disorders recognition model
1.1 時序EEG信號特征
EEG數據是神經元離子電流引起的電壓波動,外在形式是頭皮上任意電極之間的電壓差。持續記錄電壓差即可捕獲EEG數據,也就是說,EEG數據是一種典型時序信號。時序EEG數據中可提取多種特征,本文選取與精神障礙疾病密切相關的3種特征[15]:功率譜密度(power spectrum density,PSD)均值(average_PSD)、最大值(max_PSD)、總和(sum_PSD)。自回歸(auto regression,AR)模型是計算PSD常用方法。固定階AR模型把信號xt表示為其先前值xt-i和白噪聲?t的加權和[16],如式(1)所示:
|
式中,i是EEG數據序列編號,ai是模型系數,p是模型階數。為獲得準確EEG特征,本文提出一種自適應AR模型方法以計算PSD,該方法使用赤池信息量準則(akaike information criterion,AIC)反復迭代以自適應逼近AR模型的最佳階數p。基于自適應AR模型計算average_PSD、max_PSD、sum_PSD的過程如式(2)~式(4)所示:
|
|
|
式中,N是樣本數量,e為指數函數,j是虛數,是信號x的PSD,計算過程如式(5)所示:
|
式中,optimal_p是AR模型的最佳階數,是白噪聲方差。
1.2 構建VG及空間度量特征
設VG(V,E)由節點集V和邊集E組成,時序EEG數據{xt| t=1, 2, …, n}映射到空間VG包括兩步:①節點生成:映射時序EEG數據點xt至節點集V中的節點vt,設v1的橫坐標為0,則vt的橫坐標為t,縱坐標為EEG信號值。②連接生成:任意節點對vi(i, xi)和vj(j, xj)具有連接性,即它們之間存在節點vk(k, xk)滿足如式(6)所示條件:
|
式中,i,j,k均為EEG數據序列編號。為闡明VG構建過程,隨機選取一段時序EEG數據xt = {6.4, 11.3, 5.5, 4.5, 9.1, 7.2, 5.0, 9.8, 6.0, 7.9, 10.2},該數據序列與其所生成的VG如圖2所示。VG的節點序列如表1所示,節點間生成的連接依次為:e(vi,vi+1)、e(vi+1,vi+2)、e(vi+1,vi+3)、e(vi+1,vi+4)、e(vi+1,vi+7)、e(vi+1,vi+10)、e(vi+2,vi+3)、e(vi+2,vi+4)、e(vi+3,vi+4)、e(vi+4,vi+5)、e(vi+4,vi+7)、e(vi+5,vi+6)、e(vi+5,vi+7)、e(vi+6,vi+7)、e(vi+7,vi+8)、e(vi+7,vi+9)、e(vi+7,vi+10)、e(vi+8,vi+9)、e(vi+8,vi+10)、e(vi+9,vi+10),其中,v是時序EEG數據對應VG中的節點,e是節點間生成的連接。
圖2
時序EEG數據及VG構建
Figure2.
Time series EEG data and VG construction
研究表明,連接權重蘊含辨別網絡重要或薄弱環節的重要信息[17],因此本文引入連接權重信息生成權重VG,節點間連接權重wij計算過程如式(7)所示:
|
式中,vi,vj是VG中任意兩個節點。VG繼承了時序EEG數據動態屬性,蘊含著前后時序EEG數據之間的關聯性。盡管VG不能直接反映精神障礙疾病的具體生理特性改變,但是通過對VG空間度量特征分析,從空間層面對前后時序EEG數據變化與精神障礙疾病之間關聯性可以進行探索與挖掘。由于節點度反映了節點在網絡中的重要程度,因此,本文提取VG中與度相關的空間度量特征:平均度()、聚類系數(C)和平均加權度(average _WD)。是網絡連接數與節點數的比值,計算過程如式(8)所示:
|
式中,E和N分別是網絡連接數量和節點數量。C反映了網絡節點的聚集程度,計算過程如式(9)所示:
|
式中,Ci是第i個節點的聚類系數,計算過程如式(10)所示:
|
式中,ti是第i個節點與其鄰接節點構成三角形的數量,di是第i個節點的度。average _WD是網絡中全部節點總權重的平均值,反映了網絡的連接強度,計算過程如式(11)所示:
|
式中,wi是第i個節點的權重,計算過程如式(12)所示:
|
式中,wij是節點i和節點j之間的連接權重。
1.3 基于貢獻度的時空特征融合
僅從時間或者空間維度進行決策識別,將使得決策信息不夠充足。使用一維特征融合,如單獨時間特征或者空間特征融合,則難以充分發揮特征融合優勢。為此,本文通過融合時序EEG數據特征和VG空間度量特征,以保證時空特征融合優勢最大化。同時,時空兩類特征均來自EEG數據,從而有效解決基于多模態融合的精神障礙識別中數據異步采集問題。
傳統精神障礙識別模型通常假設所有特征具有同等重要性,忽略不同特征對識別任務貢獻差異,導致模型泛化能力降低[18]。貢獻度反映了不同特征對識別任務貢獻的大小,能夠影響識別Acc。基于上述分析,本文提出基于貢獻度的時空特征融合方法,用于解決精神障礙識別中融合方法的問題。該方法核心思想是對時空特征進行線性組合,為不同特征分配不同貢獻系數,具體實現如式(13)所示:
|
式中,ftim_i和fspa_j分別為時序EEG數據特征和VG空間度量特征, 是貢獻度系數,。 的實現過程如下:隨機選擇一個樣本R,從R同類樣本集中找到最近鄰樣本H,不同類樣本集中找到最近鄰樣本M;然后根據以下規則更新每個特征的權重:如果一個特征上R和H的距離小于R和M的距離,則表明該特征有利于區分同類和不同類,則增加特征權值;反之,則減少特征權值。重復上述過程k次,得到每個特征的平均權重值,進而計算每個特征相對于其他特征的貢獻系數。
1.4 識別及性能評估
權衡信息量與運行時間,4 s為一個時間窗口提取時序EEG數據特征,2 s為一個重疊窗口。為保持時空信息一致性,構建4 s時間窗口VG,計算空間度量特征。接著生成時空特征融合二維表,二維表中每條記錄由兩部分組成:特征值和類標簽。驗證提出方法有效性,二維表中每條記錄作為K最近鄰(K-nearest neighbor,KNN)分類器輸入,已有研究表明在精神障礙識別方面KNN優于其他分類器[19]。本文中KNN參數設置為:鄰居數量k值是3,計算KNN采用k維樹算法,距離度量采用歐氏距離方法,KNN分類器執行10折交叉驗證。Acc、敏感性(sensitivity,Sen)和特異性(specificity,Spe)用于評估識別性能,其計算如式(14)~式(16)所示:
|
|
|
式中,真陽性(true positive,TP)是指正類別中正確分類樣本的數量;真陰性(true negative, TN)是指負類別中正確分類樣本的數量;假陽性(false positive,FP)是指正類別中錯誤分類樣本的數量;假陰性(false negative,FN)是指負類別中錯誤分類樣本的數量。
2 實驗與結果
2.1 實驗數據及預處理
本文實驗數據包含阿爾茨海默癥和抑郁癥兩部分精神障礙受試者的靜息態EEG數據,均來自公開數據集,其中阿爾茨海默癥數據來自歐洲第七科技框架計劃(seventh science and technology framework plan,FP7)項目決議檔案[20],抑郁癥數據來自精神障礙分析多模態開放數據集(a multi-modal open dataset for mental-disorder analysis,MODMA)[21]。考慮到耳垂參考電極記錄EEG數據更為準確,以及年齡和教育程度匹配,前者使用耳垂參考電極數據。后者MODMA包含128電極和3電極兩種類型數據,為減少計算量,本文使用3電極EEG數據。阿爾茨海默癥受試者的簡易智力狀態檢查(mini-mental state examination,MMSE)量表得分<27;抑郁癥受試者的患者健康問卷9項(patient health questionnaire 9-items,PHQ-9)量表得分≥5。阿爾茨海默癥及對照組數據記錄于19個電極,采樣率為256 Hz;抑郁癥及對照組數據采樣率為250 Hz。
數據采集過程不可避免會引入噪聲,不能直接用于精神障礙分析和研究,需進行必要預處理。研究表明,與精神障礙相關EEG數據主要分布在0.5~45.0 Hz之間[22],因此本文采用低截止頻率為0.5 Hz、高截止頻率為45.0 Hz的有限沖激響應帶通濾波器,以消除低頻漂移和高頻噪聲。眼電(electrooculogram,EOG)是EEG數據噪聲的主要來源,且在0~16 Hz之間與EEG數據嚴重重疊,即使靜息態下眨眼產生的EOG信號振幅也是EEG信號振幅十倍以上。為此,本研究基于Peng等[23]提出的自適應濾波器結合小波變換模型剔除EOG信號噪聲,以獲得更純凈EEG數據。
2.2 單模態特征與時空特征融合對比
為驗證時空特征融合性能,本研究設計了對比實驗,分別將單模態時序EEG數據特征組合、單模態空間度量特征組合以及時空特征融合作為KNN輸入,對比單模態特征與時空特征融合的精神障礙識別性能,如式(17)~式(19)所示:
|
|
|
式中,ctim表示單模態時序EEG數據特征組合,cspa表示單模態空間度量特征組合,ftim_spa表示時空特征融合,ftim_i表示時序EEG數據特征,fspa_j表示空間度量特征。
阿爾茨海默癥和抑郁癥兩類精神障礙的單模態時序EEG數據特征獲得Acc為76.42%和78.02%,單模態空間度量特征獲得的Acc僅為65.11%和69.43%,時空特征融合獲得的Acc為88.73%和84.17%。上述結果表明,相比空間度量特征,時序EEG數據特征能夠獲得更高的Acc,本研究認為由于時序EEG數據中包含更多對于精神障礙疾病識別有價值的信息,時空特征融合獲得最高Acc是由于信息互補提高了識別性能。基于此分析,本文后續實驗重點關注時空特征融合對精神障礙識別性能的影響。
2.3 基于特征貢獻系數的識別結果
本節討論貢獻系數對精神障礙識別性能的影響,忽略不同電極記錄EEG數據差異。組間特征值平均后計算相應貢獻系數,即阿爾茨海默癥及其對照組的19個電極特征值分別平均,抑郁癥及其對照組的3個電極特征值分別平均。最大化不同特征對識別性能貢獻,基于1.3節方法依次計算每個特征對應權值和貢獻系數,結果如表2~表4所示。對表4中貢獻系數統計分析,可以發現時序EEG數據特征貢獻系數總占比均大于空間度量特征,間接證明了時序EEG信號中包含更多精神障礙識別有價值信息。
驗證特征貢獻系數對精神障礙識別性能的影響,基于式(13)將表2~表4中貢獻系數添加至對應特征作為KNN輸入,結果如表5和表6所示。與未添加貢獻系數識別Acc相比,阿爾茨海默癥和抑郁癥分別平均提高了5.25%和5.72%。無論是單模態特征,還是時空特征融合,添加貢獻系數均能提高識別Acc,此結果表明,不同特征對識別任務貢獻不同,傳統機器學習模型忽略了不同特征對識別任務的貢獻差異。因此,探索不同特征對特定識別任務貢獻差異,通過添加貢獻系數可以有效提高機器學習模型識別能力,充分挖掘不同特征各自優勢,改進精神障礙識別性能。
從表5和表6可以看出,阿爾茨海默癥和抑郁癥添加貢獻系數后時空特征融合方法均獲得最高Acc,平均Acc分別為93.73%和90.35%。
2.4 不同類型算法性能比較
為驗證KNN在精神障礙識別領域優于其他分類器的先前結論[19]在本研究中是否成立,本文特設計對比實驗,基于式(13)將表4中貢獻系數添加至對應特征后作為典型識別算法輸入,對比KNN與典型識別算法之間性能差異。這些典型算法包括基于統計學習理論的支持向量機(support vector machine,SVM)和基于集成學習的隨機森林(random forest,RF)。
實驗對比結果如圖3所示,可以看出KNN在本文中仍獲得最高識別Acc。與SVM相比,阿爾茨海默癥和抑郁癥分別提高了10.49%和8.09%的識別Acc。SVM獲得最低識別Acc的主要原因可以歸納為以下兩方面:一方面由于SVM訓練過程中自帶權值系數,添加貢獻系數對其識別Acc改善未起作用;另一方面典型SVM的固定懲罰系數C = 1.0,正負兩類樣本產生的誤差損失不同,典型SVM固定懲罰系數使其獲得相對較低的Acc。
圖3
不同識別算法Acc對比
Figure3.
Acc comparison of different recognition algorithms
2.5 本文方法與現有方法比較
為闡明本方法優勢,基于本研究使用的阿爾茨海默癥和抑郁癥兩個數據集,將其他已發表文獻[19-20, 24]的研究方法與本文基于VG的時空特征融合方法進行綜合對比,包括研究方法、Acc、Sen、Spe等內容。如表7所示,基于VG的時空特征融合方法識別Acc均高于其他研究方法。盡管通過識別Acc并不能充分反映各種方法的全部優缺點,但其可以部分或間接地說明本方法在一定程度上優于其他方法。
3 結論
為解決精神障礙類疾病早識別早干預問題,本文提出了一種基于VG的計算機輔助精神障礙識別方法,旨在通過時空信息互補和特征差異化處理來提高識別性能。通過映射時序EEG數據到空間VG,以解決空間信息獲取問題,進而避免多模態生理數據異步采集過程中的技術限制問題。發掘更多時空特征中精神疾病識別有價值的信息,本文設計并實現了基于特征貢獻系數的時空特征融合方法,使得時空特征優勢最大化,從而提高識別模型的Acc。
為驗證本文提出方法的有效性,使用來自公開數據集的阿爾茨海默癥和抑郁癥兩類精神障礙靜息態EEG數據,先后從單模態特征與時空特征融合對比、基于特征貢獻系數的識別性能對比、不同類型算法性能對比、本文方法與現有方法比較等四個方面設計對比實驗。結果表明,時空特征融合與單模態特征相比,能夠有效提高精神障礙疾病識別的Acc;通過對不同特征添加不同貢獻系數,充分發掘特征最大潛能,進一步提高精神障礙疾病識別性能,并且阿爾茨海默癥與抑郁癥分別獲得最高93.73%和90.35%的識別Acc;通過對比不同類型算法的識別性能,進一步驗證了精神障礙識別方面KNN算法優于其他算法的已有研究結論。
在基于VG的精神障礙識別研究基礎上,課題組今后將重點關注本方法對不同精神障礙疾病識別的差異化處理,從而進一步提高具體精神障礙疾病識別的Acc。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:張冰濤負責研究方案設計,論文撰寫;魏丹負責實驗數據處理;常文文負責數據分析;楊志飛負責論文審閱;李延林負責圖表繪制。