在計算機輔助醫療診斷領域,獲取含標簽的醫學數據代價昂貴,同時對模型的可解釋性要求較高,而目前大多數深度學習模型存在數據缺乏和可解釋性差的局限。為此,本文提出一種新穎的用于醫學圖像分割的數據增強方法,其優勢和新穎之處在于,通過梯度類激活熱力圖提取數據效用特征并與原圖像進行融合,然后構建新的通道權重特征提取器來學習不同通道間的權重,最終實現了不具有破壞性的數據增強效果,提升了模型的性能、數據效用和可解釋性。將本文方法應用于超光譜-克瓦希爾(Hyper-Kvasir)數據集,U型網絡(U-net)模型的交并比(IoU)和戴斯(Dice)系數分別有所提升;在國際皮膚成像合作組織(ISIC)檔案文件(Archive)數據集(ISIC-Archive)上,深度研究實驗室V3+網絡(DeepLabV3+)模型的指標IoU和Dice系數也分別有所提升。此外,在僅使用70%的訓練數據的情況下,依然取得了原模型在整個數據集上訓練所得性能的95%,表現出良好的數據效用。而且,該方法所使用的數據效用特征具有內置的可解釋信息,有助于提高模型的可解釋性。本文所提方法普適性較好,可以即插即用,適用于不同的分割方法,且無需修改網絡結構,因此易于集成到現有的醫學圖像分割工作中,可提高今后研究和應用的便利性。
引用本文: 武星, 陶晨杰, 李智, 張健, 孫群, 韓先花, 陳延偉. 基于通道權重和數據效用特征的醫學圖像分割數據增強方法. 生物醫學工程學雜志, 2024, 41(2): 220-227, 236. doi: 10.7507/1001-5515.202302024 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
0 引言
醫學圖像分割是計算機輔助醫學診斷的一個重要領域,人工智能模型可以幫助醫生準確分析患者病變組織的病理位置和邊界,從而提高醫學診斷的準確性。自從Minaee等[1]提出全卷積網絡(fully convolutional networks,FCN)以來,越來越多的基于深度卷積網絡的模型相繼應用于醫學圖像分割領域,并都取得了一定的成功[2-3]。盡管這些網絡模型多次突破醫學圖像分割算法性能瓶頸,但是仍然存在一定的缺陷。一方面,這些模型大多數是以純黑盒的形式存在,人們難以理解模型的決策依據;另一方面,目前許多研究都是通過提出新的模型結構來獲取更好的模型性能,卻很少從數據效用的角度提出一些適用性廣的方法來改善現有模型的性能[4-6]。實際上,由于醫學數據的特殊性,難以獲得大量含標簽的醫學圖像數據,因此如果能充分發揮有限數據的數據效用就變得格外重要[7-9]。
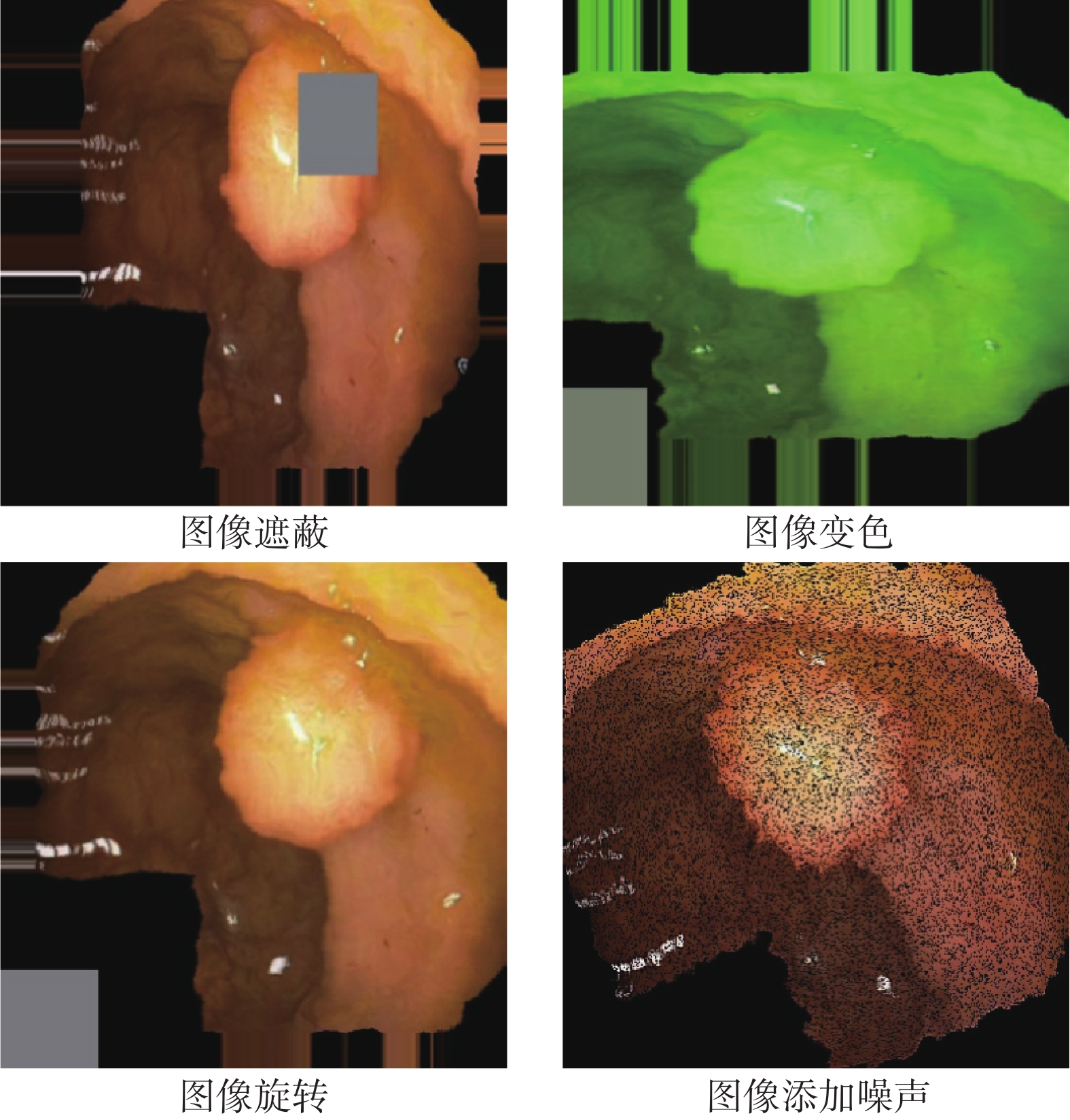
數據增強,是提升模型數據效用的一種常見方法,但是醫學圖像分割任務中的數據增強方法大多來自于圖像分類任務,比如旋轉、變色和遮蔽等[10-11]。這些方法對于分割目標的固有特征具有一定的破壞性,并且會產生離群的數據樣本。對于醫學圖像來說,有些人體生物特征是相對固定的,例如組織的位置和色澤等。然而,傳統的分類任務數據增強方法在一定程度上會破壞這些固有的生物信息,如圖1所示。
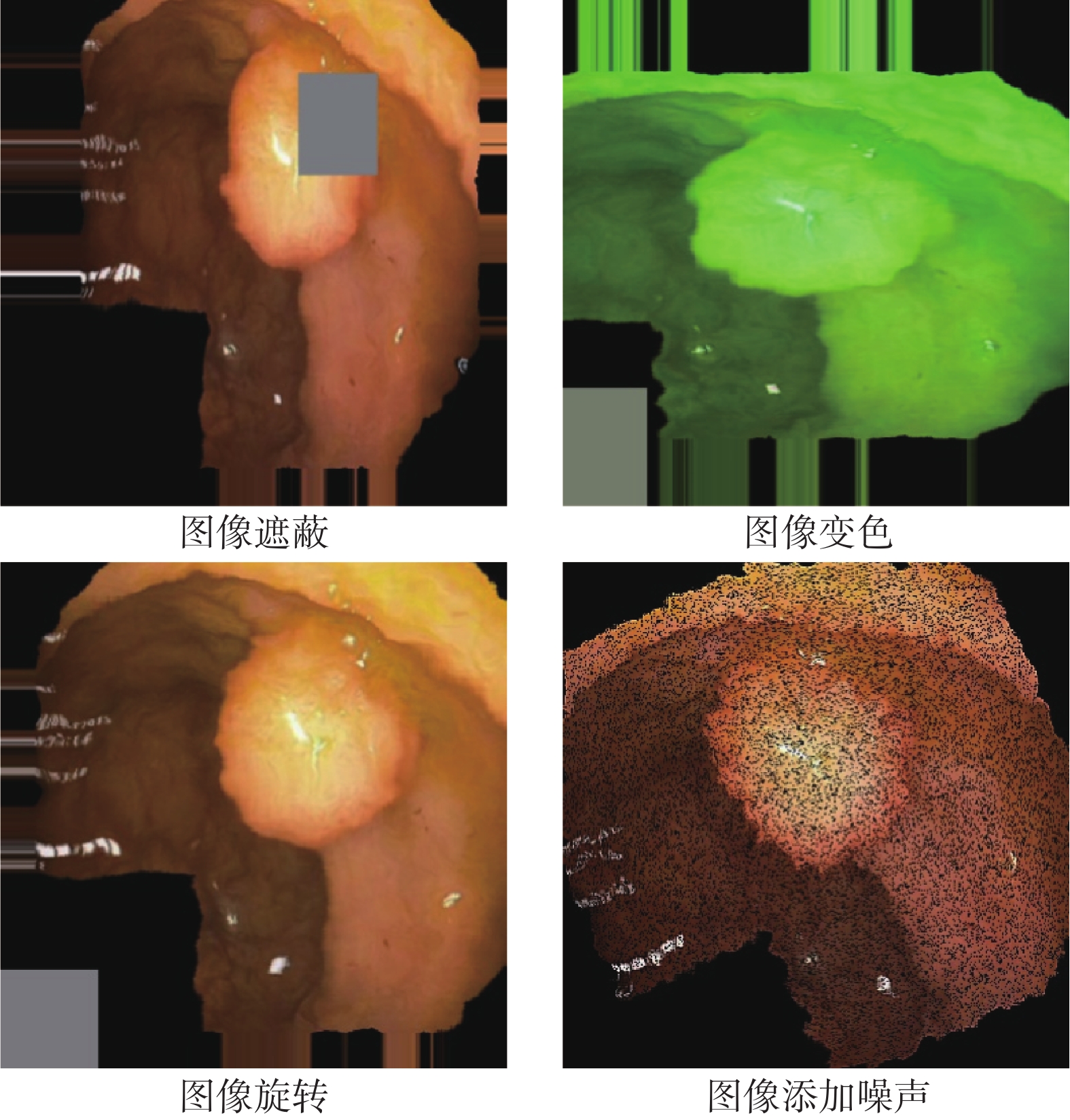 圖1
破壞性數據增強結果
Figure1.
The results of destructive data augmentation
圖1
破壞性數據增強結果
Figure1.
The results of destructive data augmentation
對于分類任務來說,這種破壞對于模型的性能影響相對可接受,因為分類通常只需要捕捉目標的某些特征即可進行判斷(圖像級別)。但對于分割任務來說,需要對圖像中的每個像素點進行分類(像素級別),因此這種破壞性的數據增強方法會導致模型性能不穩定。此外,許多分割模型本身就是黑盒,而在數據增強階段使用這些方法產生的離群樣本進行訓練,進一步降低了臨床醫生對模型預測結果的信任度。
整體來說,目前研究遭遇的瓶頸體現在三個方面:① 含標簽醫學數據獲取代價昂貴,需要模型具有較好的數據效用,需在有限的數據條件下獲取更好的性能;② 醫療診斷有其特殊性,醫學圖像分割領域對于模型可解釋性的要求比其他領域更高;③ 目前用于醫學圖像分割的數據增強方法具有破壞性,甚至會導致模型性能和可解釋性下降。因此,提出一種能夠同時提升模型性能、數據效用和可解釋性的數據增強方法是具有重要意義的。
本文提出一種新穎的數據增強方法,該方法通過使用梯度加權類激活映射(gradient-weighted class activation maps,Grad-CAM)技術來提取基于卷積神經網絡的分類模型的注意力,并將這些注意力作為數據效用特征。本文首先使用 Grad-CAM 技術進行數據效用特征提取,之后采用維度拓展的方式將提取的數據效用特征作為原紅綠藍(red,green,blue,RGB)色彩模式圖像的第四維信息輸入通道權重特征提取器。數據效用特征的引入不僅可提升模型的性能,而且由于這些特征具有內置的可解釋信息,有助于提高模型的可解釋性,這對于醫療診斷領域尤為重要,因為它可以幫助醫生理解模型的決策過程。本文旨在提出一種創新的醫學圖像分割數據增強方法,以解決在計算機輔助醫療診斷領域中面臨的數據獲取成本高、模型可解釋性要求高以及現有數據增強方法可能具有破壞性的問題。該方法的普適性和即插即用的特性使其能夠輕松集成到現有的醫學圖像分割工作中,無需修改網絡結構,這不僅能提高研究的便利性,也可為實際的醫療診斷應用提供一種有效的工具。
1 相關工作
卷積操作和池化操作是圖像分割模型中最為基礎的兩種操作,它們能夠有效地擴大感受野,提高模型的特征編碼能力。但是它們在獲得局部高階特征的同時往往會導致特征圖變小,而分割任務需要獲得原圖像大小的全像素分類結果,所以分割模型中往往還需要一個上采樣的解碼模塊來恢復特征圖的大小。Ronneberger等[12]提出的U型網絡(U-net)模型中的U型結構很好地解決了上述問題,并成為了后續眾多分割模型的基礎結構,比如:巢穴U-net(U-net++)[13]、金字塔場景解析網絡(pyramid scene parsing network,PSPnet)[14]和深度研究實驗室V3+網絡(DeepLabV3+)[15]等分割模型都具有這種編碼—解碼的U型結構。在信息關注層面,目前有大量研究表明,不同維度的信息對模型決策的重要性不同。通過設計和使用自動權重學習模塊,可以讓模型更好地關注那些重要的信息,從而獲得更優異的模型性能[16-18]。
此外,醫學數據稀少,提升模型的數據效用越來越受到研究者的重視。數據效用,指通過一定的方法使相同模型在相同數據上取得更好的性能,或者使相同的模型在更少的數據上獲得與使用全部數據相近的性能。目前,提升數據效用的方法整體可以分為三類:一種是遷移學習,通過引入外域數據來提升當前數據域的模型性能 [19-21];還有一種是高價值樣本挑選,從數據集中挑選出那些對模型預測具有強影響的樣本,來減少訓練數據[22-24];最后一種是數據增強,通過在原有數據的基礎上產生新的樣本或者新的數據表現形式來豐富數據信息。其中,數據增強方法是最為常用的手段,它使用方式最簡單,訓練成本低而且速度快。
在可解釋性方面,決策樹模型是一種自帶可解釋性的人工智能模型,但是在大數據時代它的性能表現往往不如深度神經網絡[25-26]。然而,深度神經網絡本身是一個黑盒子,其決策過程缺乏可解釋性。為了解釋深度神經網絡的決策過程,Zhou等[27]提出了類激活熱力圖(class activation map,CAM)來對卷積神經網絡進行外部解釋。該方法通過模型的全局平均池化層和全連接層獲取最后一層卷積結果中每個通道的權重。然后,將通道權重與卷積結果進行逐通道相乘和相加,得到圖像中不同區域對于模型決策的影響值。該方法完成了對不同卷積模型的通用解釋,并產生了深遠的影響。但是其不足之處在于,并不是每個卷積神經網絡都會使用全局平均池化層和全連接層進行計算。所以,Selvaraju等[28]提出了Grad-CAM,將權重的計算放在卷積結果的每個元素的梯度值上,而梯度值是所有卷積神經網絡都會存在的,從而拓展了CAM的使用范圍。
2 本文方法
2.1 數據來源
(1)本文實驗使用的用于胃腸道疾病檢測的超光譜-克瓦希爾數據集(hyper-spectral and Kvasir dataset for gastrointestinal disease detection,Hyper-Kvasir)是由挪威大學、挪威科學技術大學和挪威衛生部合作創建的公開腸胃內窺鏡數據集,一共包含了10 662張含分類標簽的圖像,以及1 000張息肉分割數據。本文將息肉類和染色息肉類數據合并為息肉類數據,其他類別數據合并為非息肉類數據來訓練分類模型,從而獲取數據效用特征。最后用1 000張息肉分割數據來訓練和測試所提方法對于分割模型的有效性。詳細下載以及數據集信息可參考文獻[29]。
(2) 本文實驗使用的國際皮膚圖像聯盟存檔數據集(International Skin Imaging Collaboration Archive, ISIC-Archive)是由國際皮膚圖像聯盟(International Skin Imaging Collaboration)公開的皮膚黑色素瘤醫學圖像數據集,包括分類和分割標注。本文從官方網站下載了4 000 張良性和惡性黑色素瘤分類圖像來訓練分類模型。然后使用了1 084張惡性黑色素瘤分割圖像來訓練和測試分割模型。詳細下載操作可參考文獻[30]。
2.2 整體網絡結構
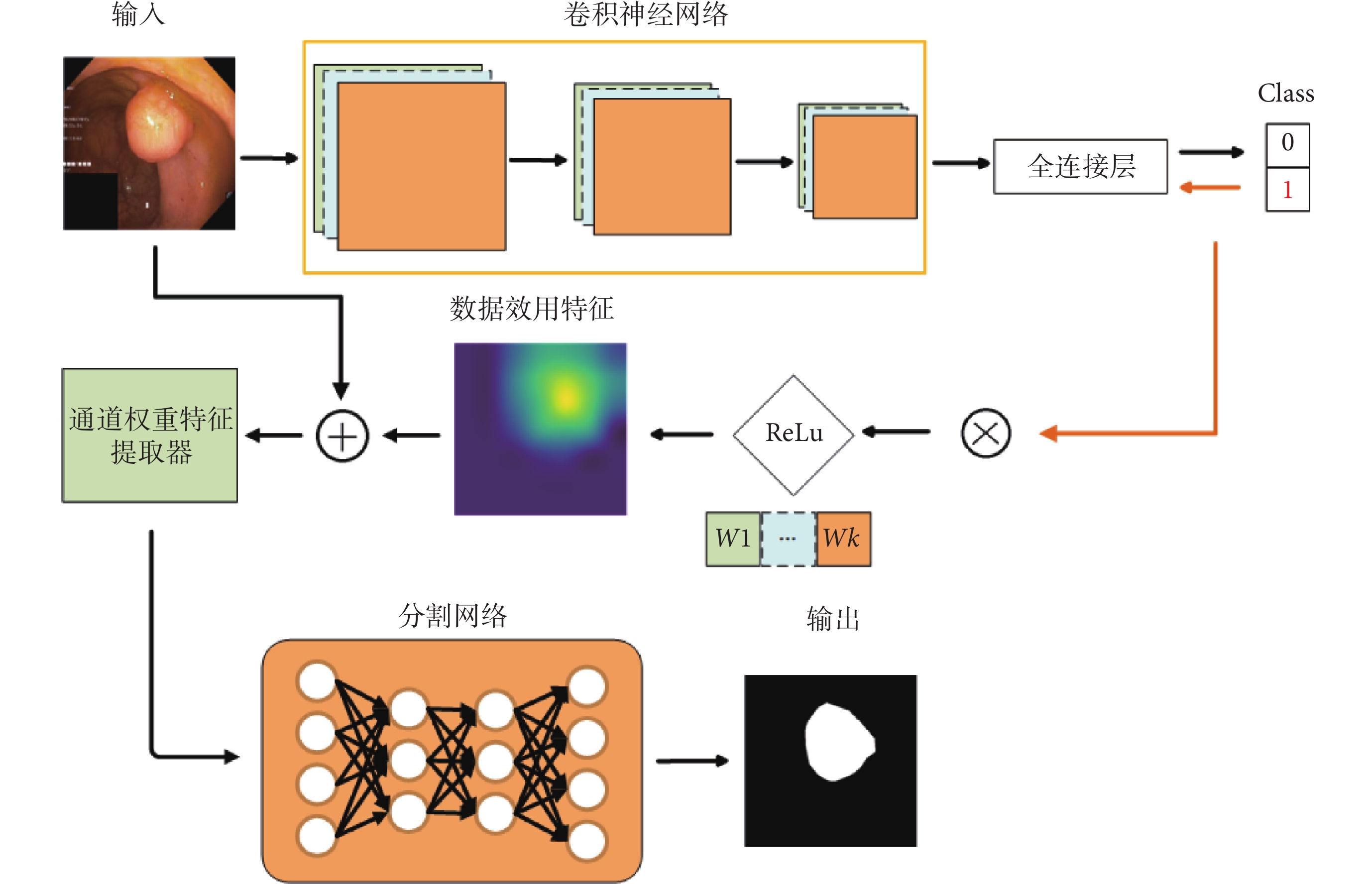
本文創新地將可解釋性領域的Grad-CAM用作數據效用特征提取手段,首次將其從可解釋性領域應用到模型性能提升。本文通過 Grad-CAM 提取圖像中不同區域對于分類模型的影響,將其視為數據效用特征,并采用通道維度特征拼接的方式,將該數據效用特征與原圖像進行融合。再將融合后的數據,輸入通道權重特征提取器進行自動通道權重學習和特征提取,最后將處理好的數據輸入任意不同的分割模型進行訓練。該方法的整體網絡結構如圖2所示,其中,Class表示圖像類別, 表示權重。圖2中上半部分,表示使用Grad-CAM進行數據效用特征提取;中間部分,表示將數據效用特征和原圖像進行融合并輸入通道權重特征提取器;下半部分,表示將上述方法應用于任意現有的分割模型。該方法拓展性高,可以使用在任意分割模型的輸入端而不需要修改模型的網絡結構,就能提升模型的性能、數據效用和可解釋性。
表示權重。圖2中上半部分,表示使用Grad-CAM進行數據效用特征提取;中間部分,表示將數據效用特征和原圖像進行融合并輸入通道權重特征提取器;下半部分,表示將上述方法應用于任意現有的分割模型。該方法拓展性高,可以使用在任意分割模型的輸入端而不需要修改模型的網絡結構,就能提升模型的性能、數據效用和可解釋性。
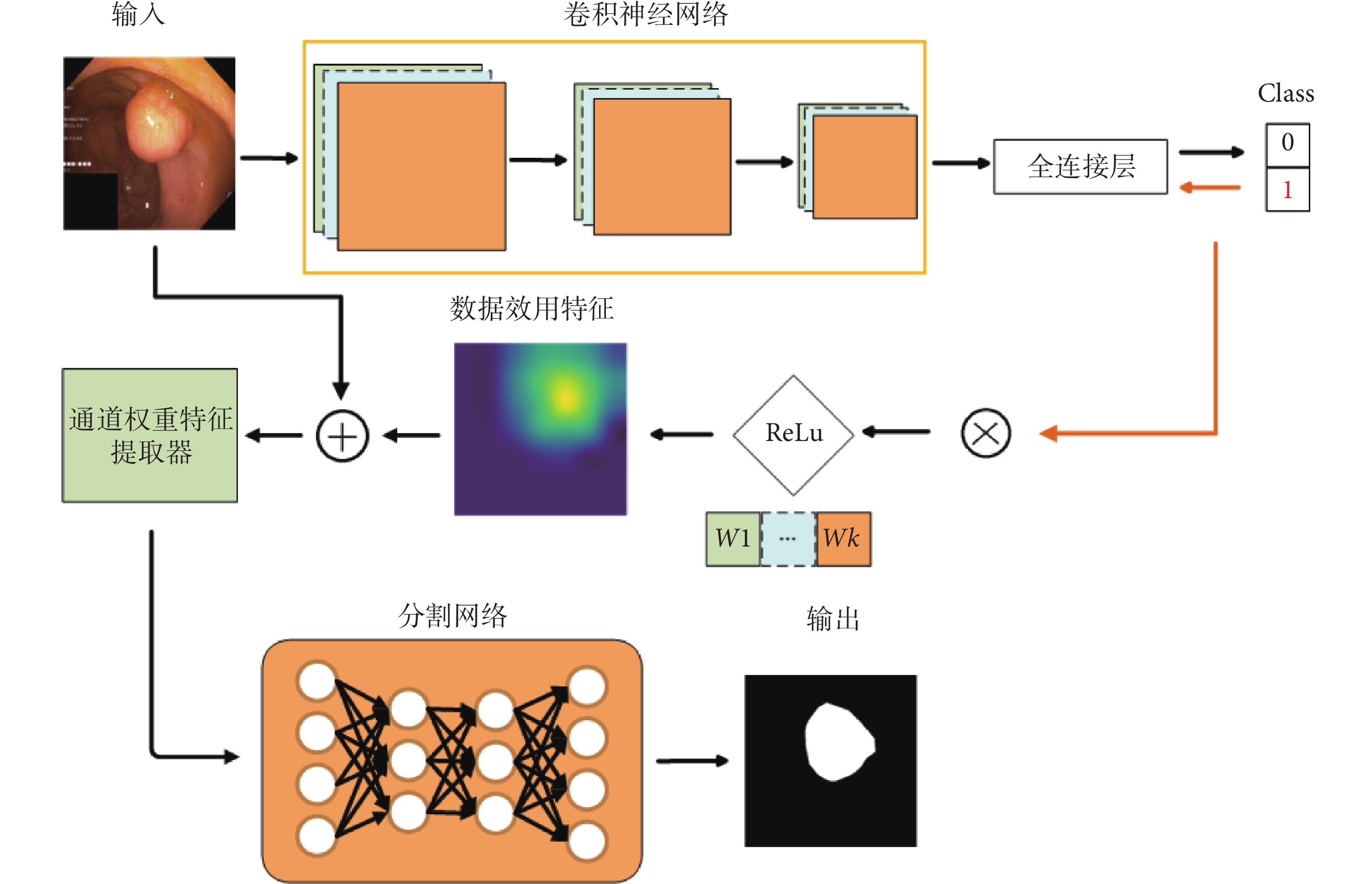 圖2
所提方法網絡結構圖
Figure2.
The network architecture of the proposed method
圖2
所提方法網絡結構圖
Figure2.
The network architecture of the proposed method
2.3 數據效用特征提取和融合
本文采用Grad-CAM對卷積分類神經網絡的模型注意力區域進行提取,并通過修正線性單元(rectified linear unit,ReLU)函數進行激活,得到數據效用特征Fh 。具體來說,先訓練好一個卷積分類神經網絡,然后輸入一張圖像并對目標類別得分進行反向梯度傳播,求取最后一層卷積特征圖中每個元素的梯度,然后再對每個梯度圖求平均,這個平均值就對應于每個特征圖的權重,然后再將權重與特征圖進行加權求和,并使用ReLU進行激活得到數據效用特征。使用ReLU進行激活的原因在于,本文希望提取的數據效用特征中的信息是圖中有益于分類模型決策的區域信息,而ReLU函數能夠將負值歸零,實現負面信息消除。
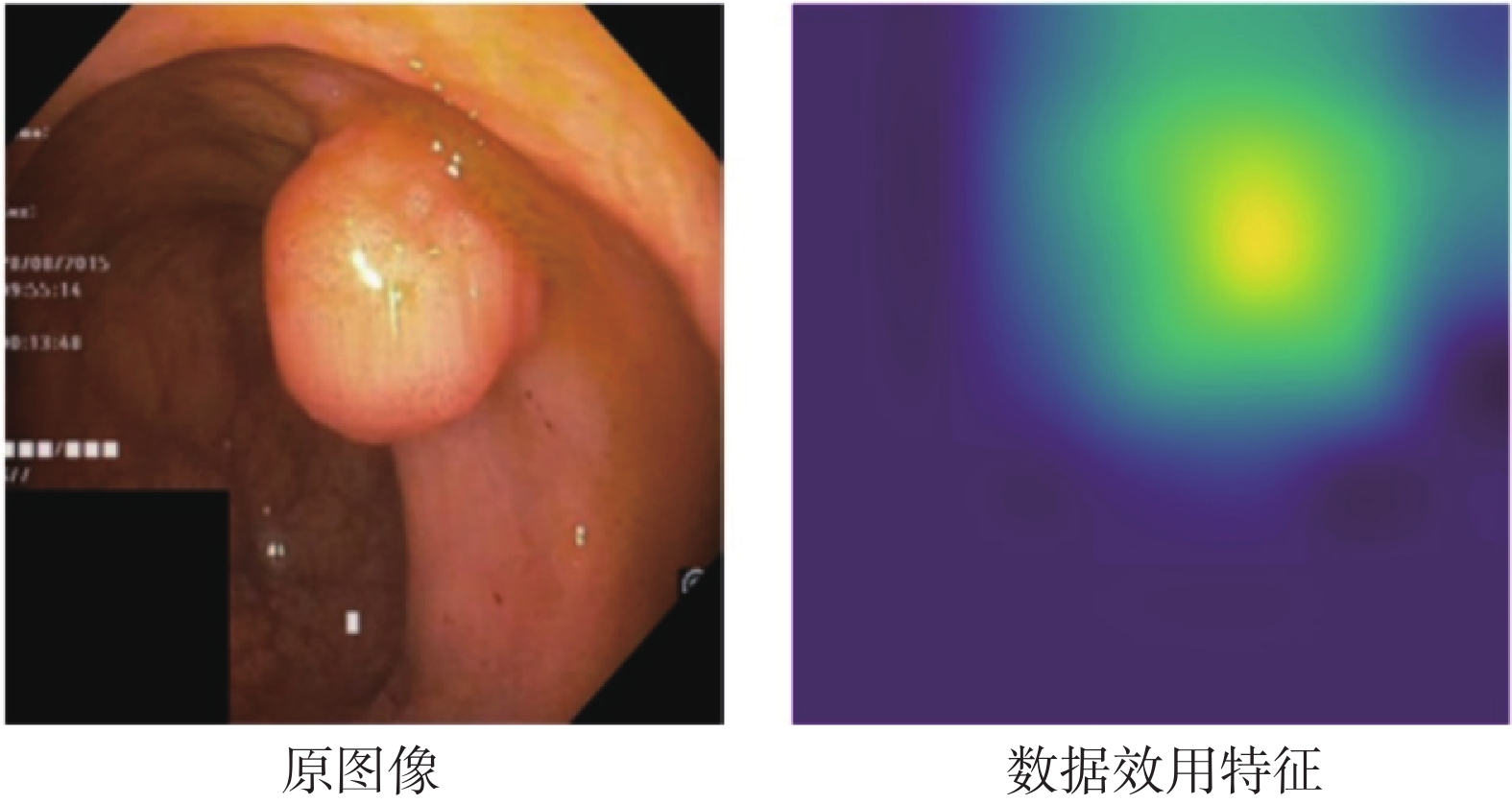
如圖3所示,展示了提取的數據效用特征的可視化結果,顏色越亮表示正向影響越高。可以發現,這些高亮區域攜帶著息肉的位置、形狀等信息,具有較強的可解釋性。然后本文將數據效用特征與原圖像進行拼接,如式(1)所示:
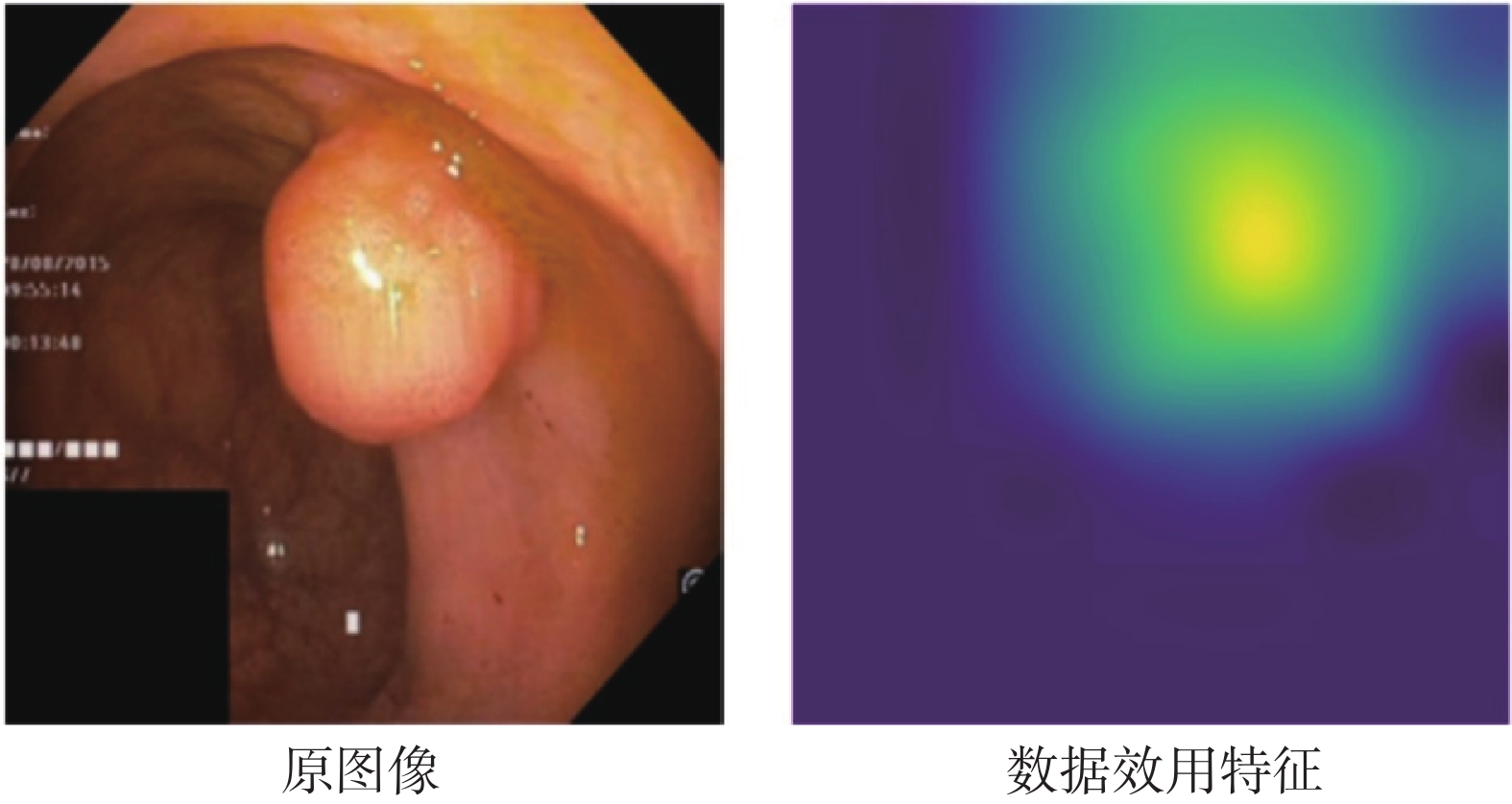 圖3
數據效用特征示意圖
Figure3.
Schematic diagram of data-efficient features
圖3
數據效用特征示意圖
Figure3.
Schematic diagram of data-efficient features
 |
其中, 表示通道維度拼接操作,將RGB三通道的原圖像與數據效用特征進行通道維度拼接后變成四通道的融合數據;IRGB代表RGB圖像,IRGBF代表RGB三通道與數據效用特征拼接后的圖像。通過這種方式融合產生的新數據會保留原圖像中的信息,實現了引入信息增益的同時,不破壞原圖像中分割目標的生物特征。
表示通道維度拼接操作,將RGB三通道的原圖像與數據效用特征進行通道維度拼接后變成四通道的融合數據;IRGB代表RGB圖像,IRGBF代表RGB三通道與數據效用特征拼接后的圖像。通過這種方式融合產生的新數據會保留原圖像中的信息,實現了引入信息增益的同時,不破壞原圖像中分割目標的生物特征。
2.4 通道特征提取器
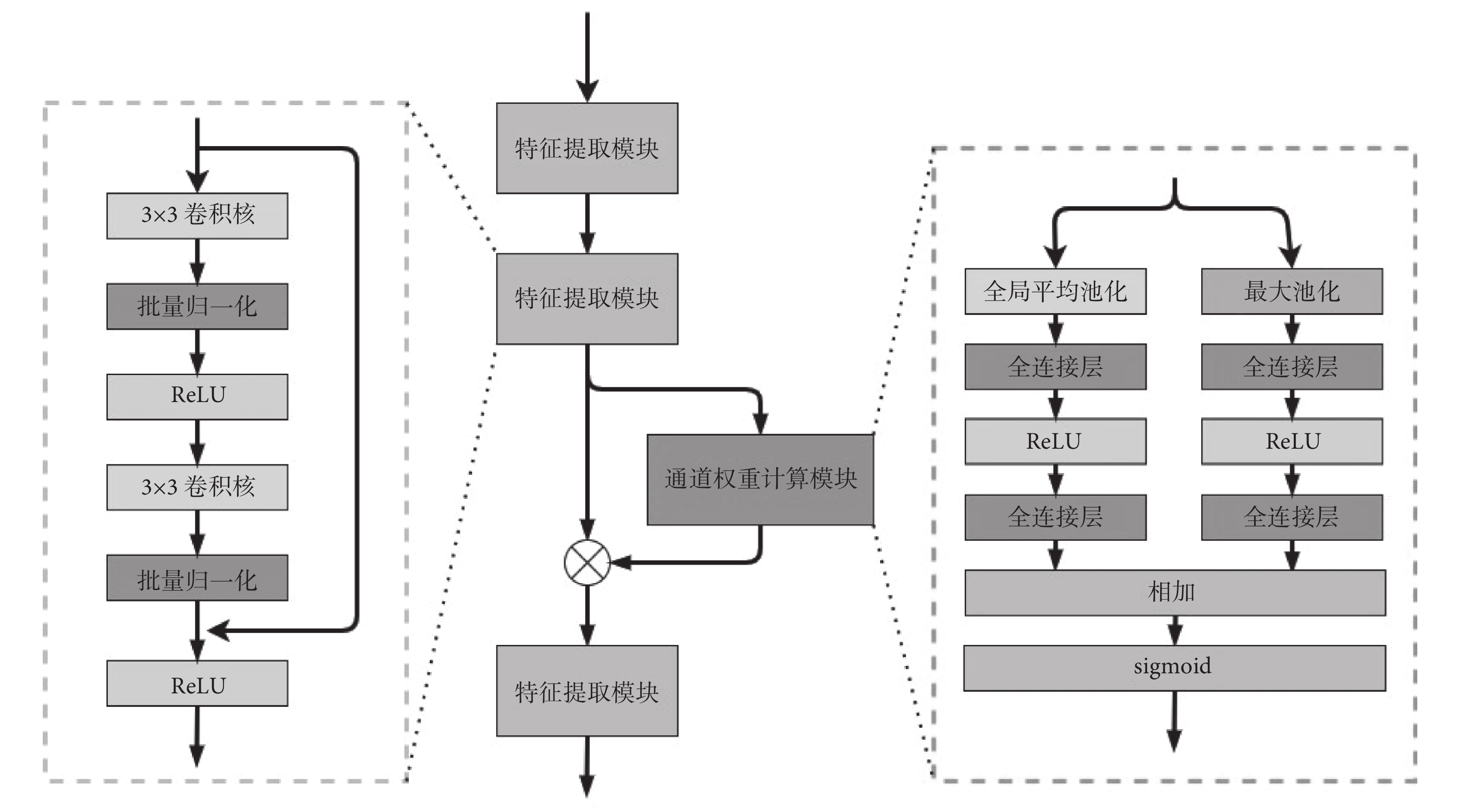
融合后的新數據會比原圖像多一個數據效用通道。本文認為,數據效用通道與原圖像的RGB三色通道在特征提取后產生的不同通道維度對于分割的作用是不一樣的。本文創建了新的通道權重特征提取器,對不同的通道進行自動權重學習和特征提取,其具體網絡結構如圖4所示。
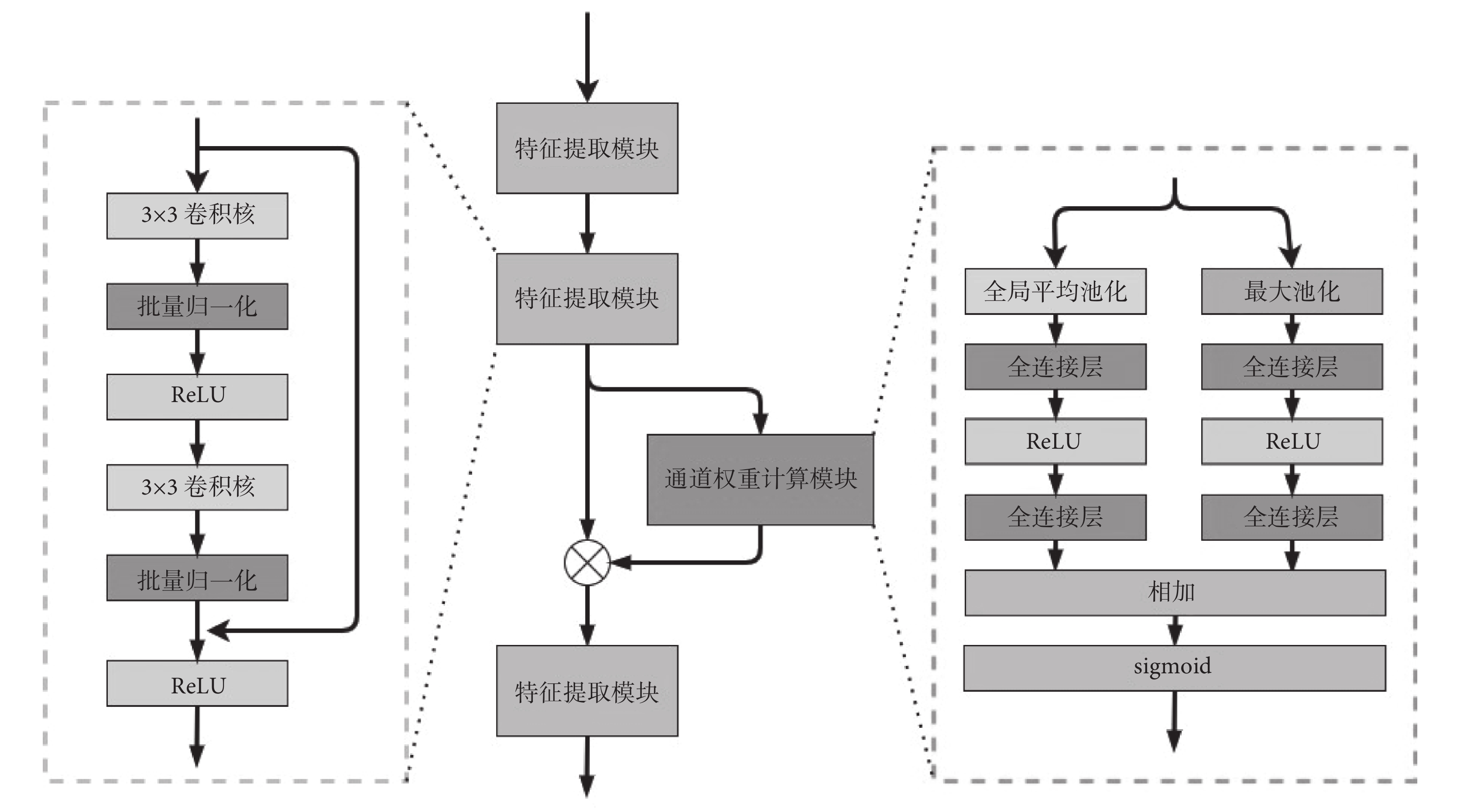 圖4
通道權重特征提取器
Figure4.
Channel weight feature extractor
圖4
通道權重特征提取器
Figure4.
Channel weight feature extractor
整個提取器包含三個特征提取模塊和一個通道權重計算模塊。每個特征提取模塊由兩個3 × 3的卷積和殘差連接構成,每個卷積后緊跟著批量歸一化層和ReLU激活函數。通道權重計算模塊,通過全局平均池化和最大池化獲取  的每個通道的平均值和最大值。其中,
的每個通道的平均值和最大值。其中, 為第二個特征提取模塊的輸出,H和W是經過特征提取后特征圖的長和寬,C為通道維數。然后,將所得的平均值和最大值分別輸入兩個全連接層和一個ReLu激活函數,再通過S型生長曲線(sigmoid)函數進行權重計算,如式(2)所示。其中,最后一層全連接層的輸出神經元的個數與第二個特征提取模塊的通道維數C相等。最后,將計算好的通道權重
為第二個特征提取模塊的輸出,H和W是經過特征提取后特征圖的長和寬,C為通道維數。然后,將所得的平均值和最大值分別輸入兩個全連接層和一個ReLu激活函數,再通過S型生長曲線(sigmoid)函數進行權重計算,如式(2)所示。其中,最后一層全連接層的輸出神經元的個數與第二個特征提取模塊的通道維數C相等。最后,將計算好的通道權重  與特征提取模塊輸出的數據,按通道相乘獲得不同通道權重下的數據
與特征提取模塊輸出的數據,按通道相乘獲得不同通道權重下的數據  ,如式(3)所示:
,如式(3)所示:
 |
 |
3 實驗與分析
3.1 實驗設置
本文實驗程序均使用編程語言Python(Python Software Foundation, 美國)進行編寫,采用了神經網絡開源框架Pytorch(Facebook AI Research, 美國)進行底層模型的搭建和相關接口調用。程序運行操作系統為Linux(Canonical Ltd., 英國),訓練平臺為圖形處理單元NVIDIA Geforce RTX 3090(NVIDIA Inc., 美國)。實驗圖像輸入長、寬為224 × 224,每個批次使用8張圖片,并使用深度學習優化器Adam(OpenAI,美國)進行參數優化,采用的學習率為0.000 1。
3.2 評價指標
本文采用了分割任務中最為常用的兩種性能指標來對實驗結果進行驗證和比較。這兩種指標分別是交并比(intersetion over union,IoU)和戴斯(Dice)系數,其計算公式分別如式(4)和式(5)所示:
 |
 |
其中,Ai表示來自標簽類別為i的像素集合,Bi是來自模型預測為i類的像素集合。IoU和 Dice系數的值越高,說明預測掩碼和真實數據(ground truth)之間的相似度越高,模型的性能越好。
3.3 結果與分析
本文在四種具有高使用率的分割模型和兩種不同的公開數據集上進行對比實驗,其實驗結果如表1和表2所示。實驗結果表明,本文的方法在不同的數據集上對不同的模型都具有性能提升作用。在Hyper-Kvasir數據集上,使用U-net模型的IoU系數和Dice系數明顯提高;在ISIC-Archive數據集上,使用DeepLabV3+模型的IoU系數和Dice系數也有明顯的提升。
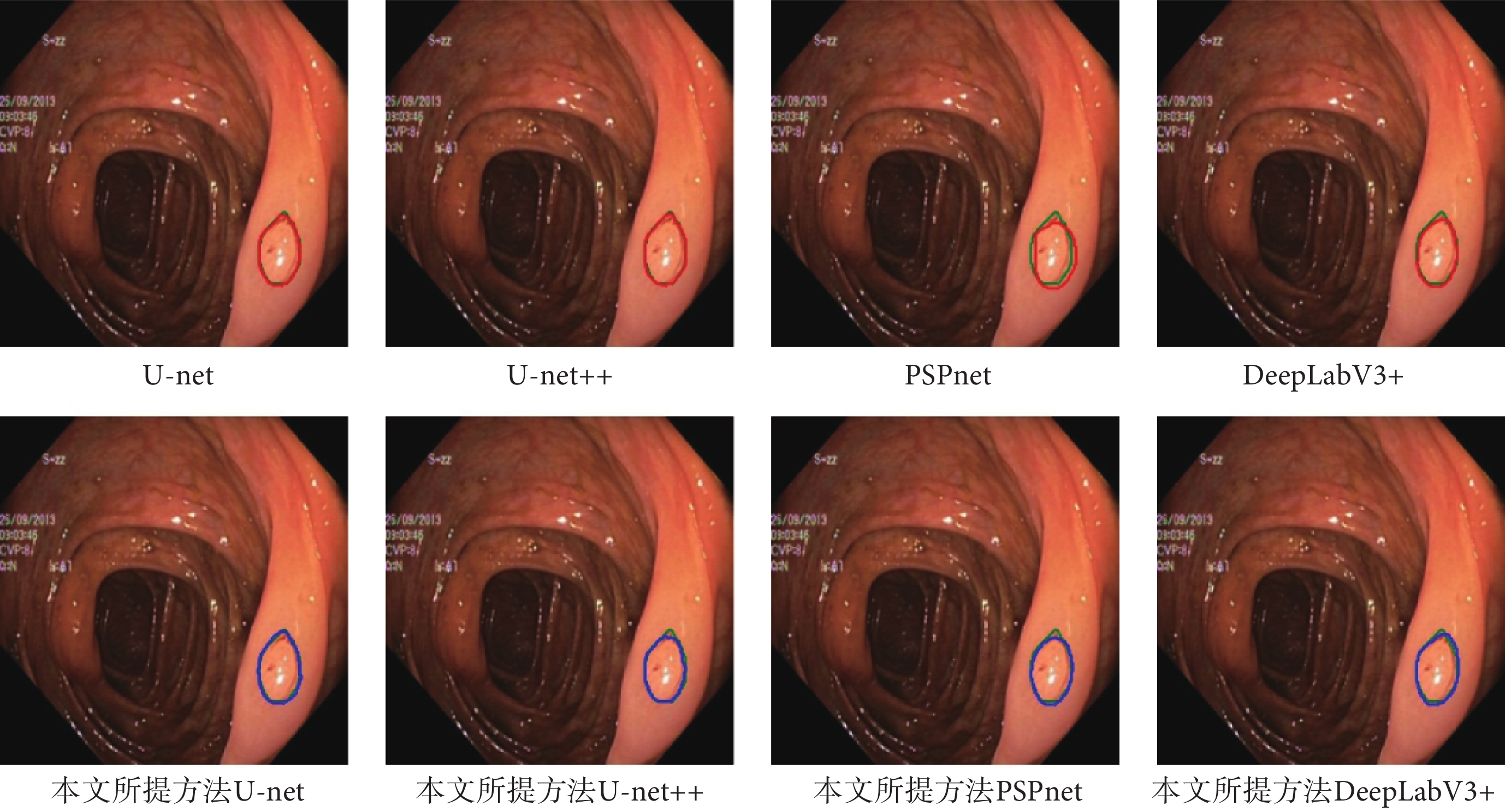
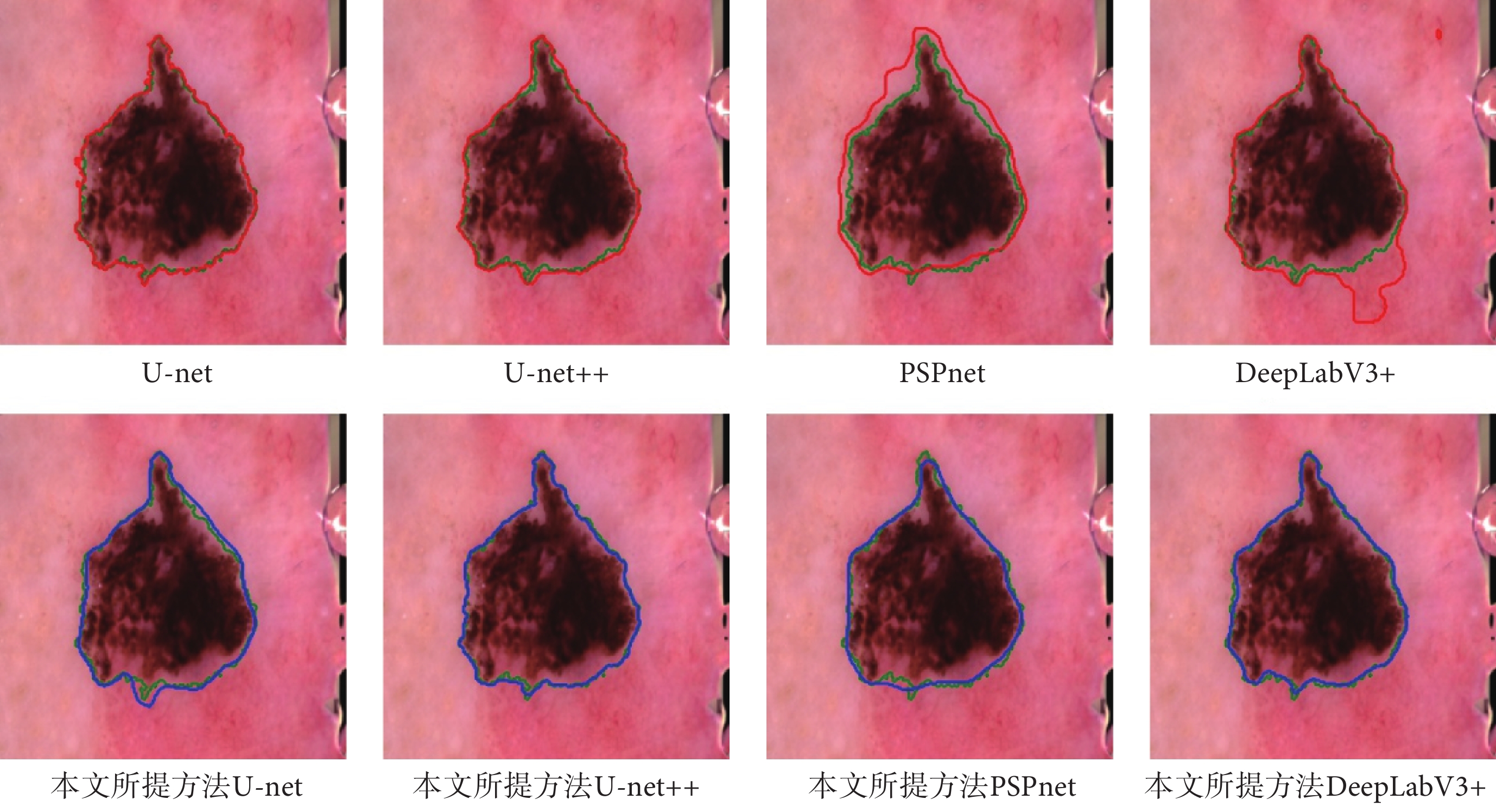
如圖5和圖6所示,分別展示了在Hyper-Kvasir數據集和ISIC-Archive數據集上,原模型的分割結果和使用了本文方法后的分割結果的可視化圖。從圖5和圖6中可以發現,使用了本文方法后產生的分割曲線(藍色)比原模型的分割曲線(紅色)要更加貼近ground truth曲線(綠色),并且整體分割曲線更為平滑和光整。
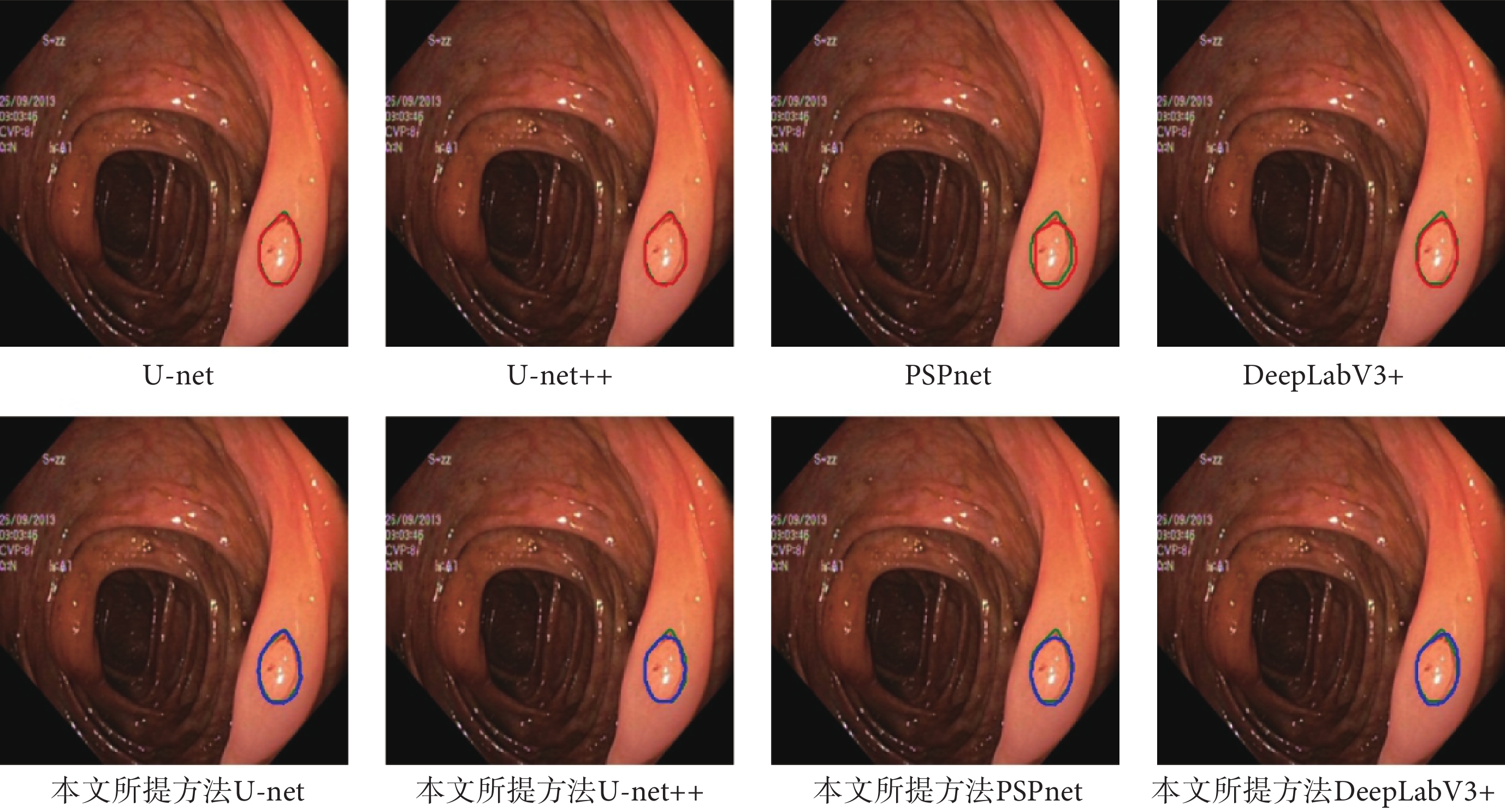 圖5
Hyper-Kvasir可視化結果
Figure5.
Visualization results on Hyper-Kvasir
圖5
Hyper-Kvasir可視化結果
Figure5.
Visualization results on Hyper-Kvasir
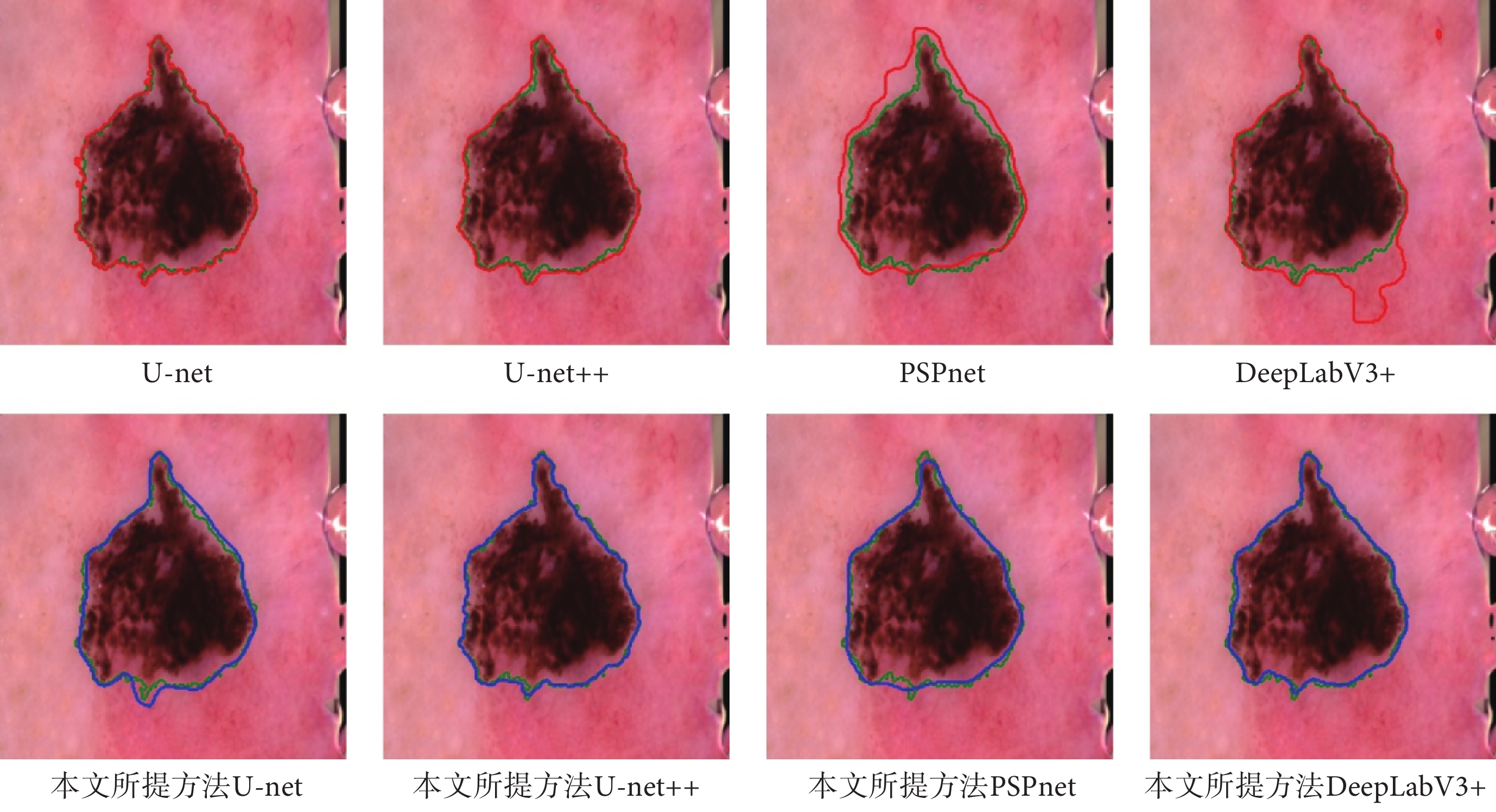 圖6
ISIC-Archive可視化結果
Figure6.
Visualization results on ISIC-Archive
圖6
ISIC-Archive可視化結果
Figure6.
Visualization results on ISIC-Archive
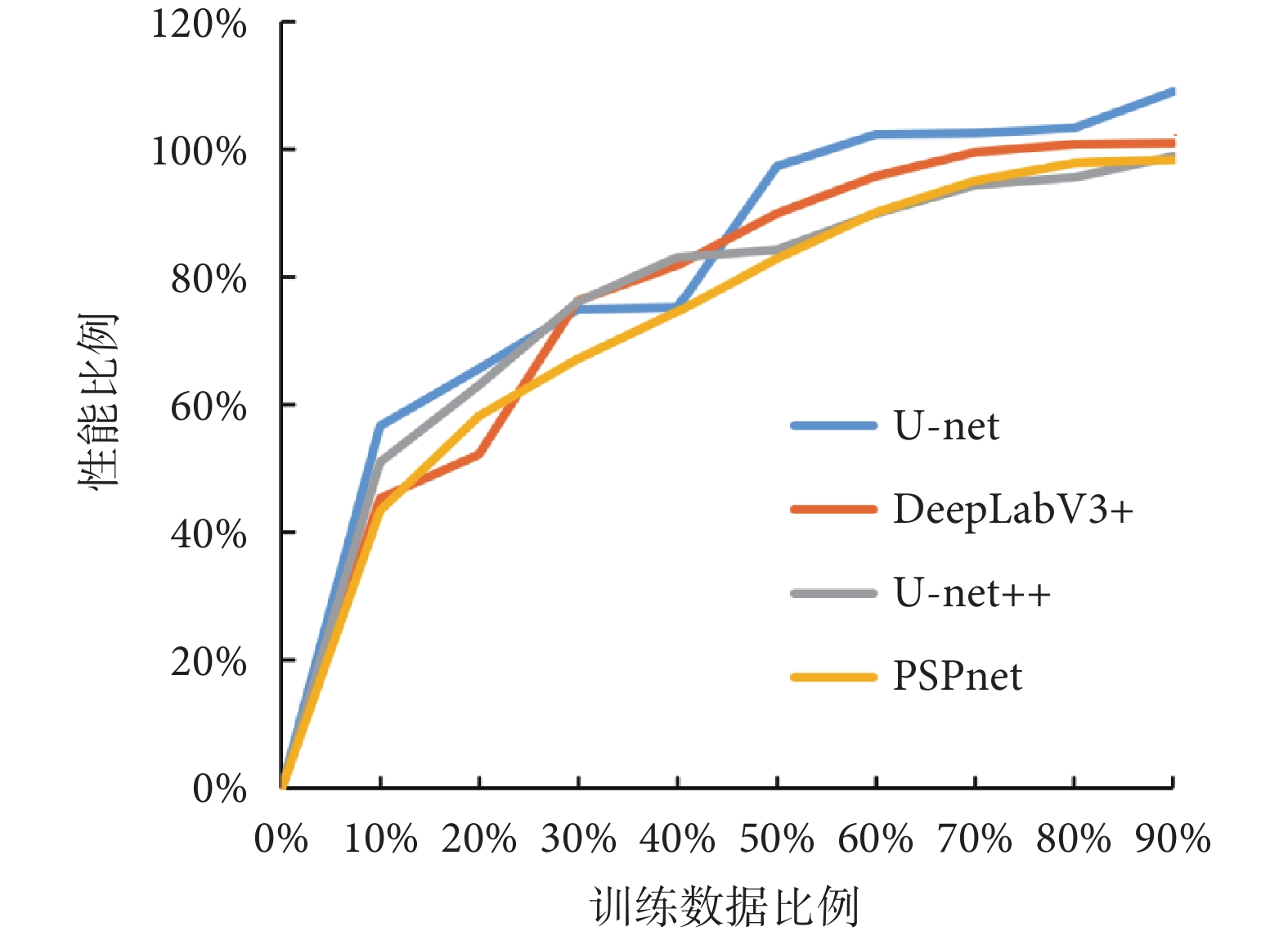
為了進一步驗證所提方法的數據效用,本文在Hyper-Kvasir數據集上每次減少10%的訓練數據,訓練了多個不同數據量下的模型,并觀察了它們在整個數據集上的性能與原始模型的對比。如圖7所示,展示了模型性能隨著訓練數據量的變化趨勢。
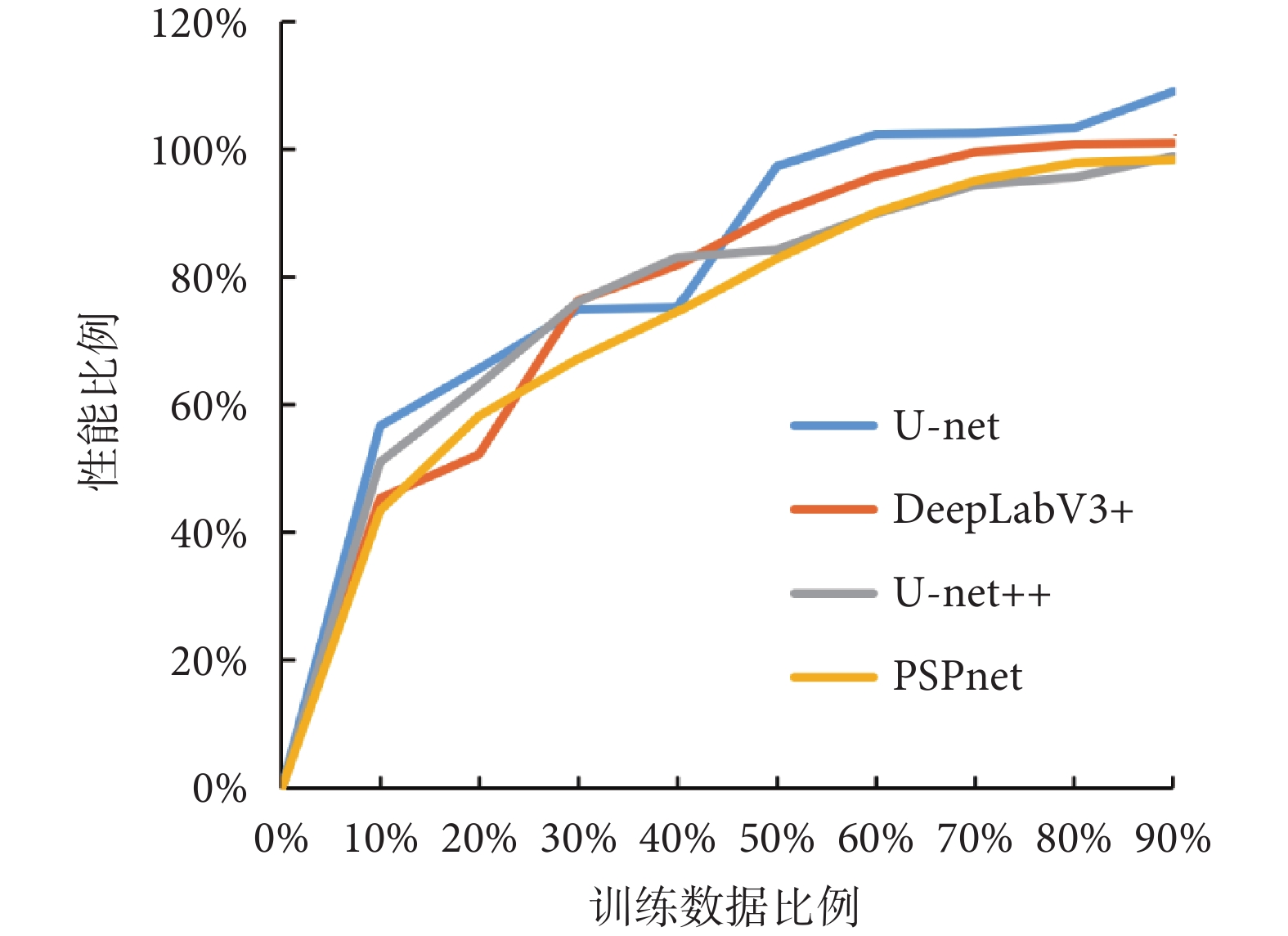 圖7
性能變化趨勢圖
Figure7.
Performance trend chart
圖7
性能變化趨勢圖
Figure7.
Performance trend chart
從圖7中可以發現,在數據量減少至70%時,所提方法依然能夠使得模型達到原模型在整個數據集上訓練所得性能的95%左右。這表明了所提方法不僅能夠提升模型的性能,還能夠提升模型在更少數據量下的數據效用。
從實驗結果對比中可以發現,模型會根據分割目標的位置和形狀等信息進行判斷,并能夠利用數據效用特征攜帶的位置和形狀等信息來更好地完成任務,這表明本文方法能夠在數據層面提升模型的可解釋性。
4 結論
本文提出了一種適用于醫學圖像分割的新型數據增強方法。與傳統的數據增強方法不同,該方法通過維度拓展的方式將數據效用特征與原圖像進行融合,從而在獲得信息增益的同時保留了原圖像信息,實現了非破壞性的效果。同時,本文還構建了通道權重特征提取器,以使模型更好地關注有用信息并提高模型性能。為了深入展示本文方法的數據效用,本文通過逐步減少訓練數據,比較了不同訓練數據量下的模型性能和使用整個數據集訓練所得的模型性能之間的比值。總的來說,本文的方法不僅能提高模型性能,而且還能提高模型的數據效用和可解釋性。因此,它能夠有效地解決醫療診斷領域中的熱點問題,為人工智能輔助醫療診斷做出貢獻。具體而言,本文所提的醫學圖像數據增強方法具有以下三點創新和優勢:
(1)本文所提方法能夠實現不具有破壞性的維度層面數據增強,使不同的分割模型的性能、數據效用和可解釋性得到了提升。
(2)構建了新的通道權重特征提取器,能夠自動學習數據效用特征和原圖像通道之間的權重值,使模型關注到更重要的信息。
(3)提出的方法使用方式簡便,可以應用在任意分割模型上而不需要改變原有的模型結構。
但是,本文方法也存在著一定的局限性,該方法需要先訓練出一個能夠很好提取出數據效用特征的分類模型,然而這并不容易。如何設計出一套高效的方法,讓一個分類模型能夠充分關注到數據效用區域,并通過Grad-CAM提取出來也是未來研究的一個難點和重要方向。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:武星主要負責實驗指導和設計、論文撰寫以及審閱修訂;陶晨杰主要負責數據收集與分析、算法程序設計以及論文撰寫;張健、孫群主要負責實驗素材收集;韓先花主要負責實驗數據分析;陳延偉主要負責論文審閱修訂。
0 引言
醫學圖像分割是計算機輔助醫學診斷的一個重要領域,人工智能模型可以幫助醫生準確分析患者病變組織的病理位置和邊界,從而提高醫學診斷的準確性。自從Minaee等[1]提出全卷積網絡(fully convolutional networks,FCN)以來,越來越多的基于深度卷積網絡的模型相繼應用于醫學圖像分割領域,并都取得了一定的成功[2-3]。盡管這些網絡模型多次突破醫學圖像分割算法性能瓶頸,但是仍然存在一定的缺陷。一方面,這些模型大多數是以純黑盒的形式存在,人們難以理解模型的決策依據;另一方面,目前許多研究都是通過提出新的模型結構來獲取更好的模型性能,卻很少從數據效用的角度提出一些適用性廣的方法來改善現有模型的性能[4-6]。實際上,由于醫學數據的特殊性,難以獲得大量含標簽的醫學圖像數據,因此如果能充分發揮有限數據的數據效用就變得格外重要[7-9]。
數據增強,是提升模型數據效用的一種常見方法,但是醫學圖像分割任務中的數據增強方法大多來自于圖像分類任務,比如旋轉、變色和遮蔽等[10-11]。這些方法對于分割目標的固有特征具有一定的破壞性,并且會產生離群的數據樣本。對于醫學圖像來說,有些人體生物特征是相對固定的,例如組織的位置和色澤等。然而,傳統的分類任務數據增強方法在一定程度上會破壞這些固有的生物信息,如圖1所示。
圖1
破壞性數據增強結果
Figure1.
The results of destructive data augmentation
對于分類任務來說,這種破壞對于模型的性能影響相對可接受,因為分類通常只需要捕捉目標的某些特征即可進行判斷(圖像級別)。但對于分割任務來說,需要對圖像中的每個像素點進行分類(像素級別),因此這種破壞性的數據增強方法會導致模型性能不穩定。此外,許多分割模型本身就是黑盒,而在數據增強階段使用這些方法產生的離群樣本進行訓練,進一步降低了臨床醫生對模型預測結果的信任度。
整體來說,目前研究遭遇的瓶頸體現在三個方面:① 含標簽醫學數據獲取代價昂貴,需要模型具有較好的數據效用,需在有限的數據條件下獲取更好的性能;② 醫療診斷有其特殊性,醫學圖像分割領域對于模型可解釋性的要求比其他領域更高;③ 目前用于醫學圖像分割的數據增強方法具有破壞性,甚至會導致模型性能和可解釋性下降。因此,提出一種能夠同時提升模型性能、數據效用和可解釋性的數據增強方法是具有重要意義的。
本文提出一種新穎的數據增強方法,該方法通過使用梯度加權類激活映射(gradient-weighted class activation maps,Grad-CAM)技術來提取基于卷積神經網絡的分類模型的注意力,并將這些注意力作為數據效用特征。本文首先使用 Grad-CAM 技術進行數據效用特征提取,之后采用維度拓展的方式將提取的數據效用特征作為原紅綠藍(red,green,blue,RGB)色彩模式圖像的第四維信息輸入通道權重特征提取器。數據效用特征的引入不僅可提升模型的性能,而且由于這些特征具有內置的可解釋信息,有助于提高模型的可解釋性,這對于醫療診斷領域尤為重要,因為它可以幫助醫生理解模型的決策過程。本文旨在提出一種創新的醫學圖像分割數據增強方法,以解決在計算機輔助醫療診斷領域中面臨的數據獲取成本高、模型可解釋性要求高以及現有數據增強方法可能具有破壞性的問題。該方法的普適性和即插即用的特性使其能夠輕松集成到現有的醫學圖像分割工作中,無需修改網絡結構,這不僅能提高研究的便利性,也可為實際的醫療診斷應用提供一種有效的工具。
1 相關工作
卷積操作和池化操作是圖像分割模型中最為基礎的兩種操作,它們能夠有效地擴大感受野,提高模型的特征編碼能力。但是它們在獲得局部高階特征的同時往往會導致特征圖變小,而分割任務需要獲得原圖像大小的全像素分類結果,所以分割模型中往往還需要一個上采樣的解碼模塊來恢復特征圖的大小。Ronneberger等[12]提出的U型網絡(U-net)模型中的U型結構很好地解決了上述問題,并成為了后續眾多分割模型的基礎結構,比如:巢穴U-net(U-net++)[13]、金字塔場景解析網絡(pyramid scene parsing network,PSPnet)[14]和深度研究實驗室V3+網絡(DeepLabV3+)[15]等分割模型都具有這種編碼—解碼的U型結構。在信息關注層面,目前有大量研究表明,不同維度的信息對模型決策的重要性不同。通過設計和使用自動權重學習模塊,可以讓模型更好地關注那些重要的信息,從而獲得更優異的模型性能[16-18]。
此外,醫學數據稀少,提升模型的數據效用越來越受到研究者的重視。數據效用,指通過一定的方法使相同模型在相同數據上取得更好的性能,或者使相同的模型在更少的數據上獲得與使用全部數據相近的性能。目前,提升數據效用的方法整體可以分為三類:一種是遷移學習,通過引入外域數據來提升當前數據域的模型性能 [19-21];還有一種是高價值樣本挑選,從數據集中挑選出那些對模型預測具有強影響的樣本,來減少訓練數據[22-24];最后一種是數據增強,通過在原有數據的基礎上產生新的樣本或者新的數據表現形式來豐富數據信息。其中,數據增強方法是最為常用的手段,它使用方式最簡單,訓練成本低而且速度快。
在可解釋性方面,決策樹模型是一種自帶可解釋性的人工智能模型,但是在大數據時代它的性能表現往往不如深度神經網絡[25-26]。然而,深度神經網絡本身是一個黑盒子,其決策過程缺乏可解釋性。為了解釋深度神經網絡的決策過程,Zhou等[27]提出了類激活熱力圖(class activation map,CAM)來對卷積神經網絡進行外部解釋。該方法通過模型的全局平均池化層和全連接層獲取最后一層卷積結果中每個通道的權重。然后,將通道權重與卷積結果進行逐通道相乘和相加,得到圖像中不同區域對于模型決策的影響值。該方法完成了對不同卷積模型的通用解釋,并產生了深遠的影響。但是其不足之處在于,并不是每個卷積神經網絡都會使用全局平均池化層和全連接層進行計算。所以,Selvaraju等[28]提出了Grad-CAM,將權重的計算放在卷積結果的每個元素的梯度值上,而梯度值是所有卷積神經網絡都會存在的,從而拓展了CAM的使用范圍。
2 本文方法
2.1 數據來源
(1)本文實驗使用的用于胃腸道疾病檢測的超光譜-克瓦希爾數據集(hyper-spectral and Kvasir dataset for gastrointestinal disease detection,Hyper-Kvasir)是由挪威大學、挪威科學技術大學和挪威衛生部合作創建的公開腸胃內窺鏡數據集,一共包含了10 662張含分類標簽的圖像,以及1 000張息肉分割數據。本文將息肉類和染色息肉類數據合并為息肉類數據,其他類別數據合并為非息肉類數據來訓練分類模型,從而獲取數據效用特征。最后用1 000張息肉分割數據來訓練和測試所提方法對于分割模型的有效性。詳細下載以及數據集信息可參考文獻[29]。
(2) 本文實驗使用的國際皮膚圖像聯盟存檔數據集(International Skin Imaging Collaboration Archive, ISIC-Archive)是由國際皮膚圖像聯盟(International Skin Imaging Collaboration)公開的皮膚黑色素瘤醫學圖像數據集,包括分類和分割標注。本文從官方網站下載了4 000 張良性和惡性黑色素瘤分類圖像來訓練分類模型。然后使用了1 084張惡性黑色素瘤分割圖像來訓練和測試分割模型。詳細下載操作可參考文獻[30]。
2.2 整體網絡結構
本文創新地將可解釋性領域的Grad-CAM用作數據效用特征提取手段,首次將其從可解釋性領域應用到模型性能提升。本文通過 Grad-CAM 提取圖像中不同區域對于分類模型的影響,將其視為數據效用特征,并采用通道維度特征拼接的方式,將該數據效用特征與原圖像進行融合。再將融合后的數據,輸入通道權重特征提取器進行自動通道權重學習和特征提取,最后將處理好的數據輸入任意不同的分割模型進行訓練。該方法的整體網絡結構如圖2所示,其中,Class表示圖像類別,表示權重。圖2中上半部分,表示使用Grad-CAM進行數據效用特征提取;中間部分,表示將數據效用特征和原圖像進行融合并輸入通道權重特征提取器;下半部分,表示將上述方法應用于任意現有的分割模型。該方法拓展性高,可以使用在任意分割模型的輸入端而不需要修改模型的網絡結構,就能提升模型的性能、數據效用和可解釋性。
圖2
所提方法網絡結構圖
Figure2.
The network architecture of the proposed method
2.3 數據效用特征提取和融合
本文采用Grad-CAM對卷積分類神經網絡的模型注意力區域進行提取,并通過修正線性單元(rectified linear unit,ReLU)函數進行激活,得到數據效用特征Fh 。具體來說,先訓練好一個卷積分類神經網絡,然后輸入一張圖像并對目標類別得分進行反向梯度傳播,求取最后一層卷積特征圖中每個元素的梯度,然后再對每個梯度圖求平均,這個平均值就對應于每個特征圖的權重,然后再將權重與特征圖進行加權求和,并使用ReLU進行激活得到數據效用特征。使用ReLU進行激活的原因在于,本文希望提取的數據效用特征中的信息是圖中有益于分類模型決策的區域信息,而ReLU函數能夠將負值歸零,實現負面信息消除。
如圖3所示,展示了提取的數據效用特征的可視化結果,顏色越亮表示正向影響越高。可以發現,這些高亮區域攜帶著息肉的位置、形狀等信息,具有較強的可解釋性。然后本文將數據效用特征與原圖像進行拼接,如式(1)所示:
圖3
數據效用特征示意圖
Figure3.
Schematic diagram of data-efficient features
|
其中, 表示通道維度拼接操作,將RGB三通道的原圖像與數據效用特征進行通道維度拼接后變成四通道的融合數據;IRGB代表RGB圖像,IRGBF代表RGB三通道與數據效用特征拼接后的圖像。通過這種方式融合產生的新數據會保留原圖像中的信息,實現了引入信息增益的同時,不破壞原圖像中分割目標的生物特征。
2.4 通道特征提取器
融合后的新數據會比原圖像多一個數據效用通道。本文認為,數據效用通道與原圖像的RGB三色通道在特征提取后產生的不同通道維度對于分割的作用是不一樣的。本文創建了新的通道權重特征提取器,對不同的通道進行自動權重學習和特征提取,其具體網絡結構如圖4所示。
圖4
通道權重特征提取器
Figure4.
Channel weight feature extractor
整個提取器包含三個特征提取模塊和一個通道權重計算模塊。每個特征提取模塊由兩個3 × 3的卷積和殘差連接構成,每個卷積后緊跟著批量歸一化層和ReLU激活函數。通道權重計算模塊,通過全局平均池化和最大池化獲取 的每個通道的平均值和最大值。其中, 為第二個特征提取模塊的輸出,H和W是經過特征提取后特征圖的長和寬,C為通道維數。然后,將所得的平均值和最大值分別輸入兩個全連接層和一個ReLu激活函數,再通過S型生長曲線(sigmoid)函數進行權重計算,如式(2)所示。其中,最后一層全連接層的輸出神經元的個數與第二個特征提取模塊的通道維數C相等。最后,將計算好的通道權重 與特征提取模塊輸出的數據,按通道相乘獲得不同通道權重下的數據 ,如式(3)所示:
|
|
3 實驗與分析
3.1 實驗設置
本文實驗程序均使用編程語言Python(Python Software Foundation, 美國)進行編寫,采用了神經網絡開源框架Pytorch(Facebook AI Research, 美國)進行底層模型的搭建和相關接口調用。程序運行操作系統為Linux(Canonical Ltd., 英國),訓練平臺為圖形處理單元NVIDIA Geforce RTX 3090(NVIDIA Inc., 美國)。實驗圖像輸入長、寬為224 × 224,每個批次使用8張圖片,并使用深度學習優化器Adam(OpenAI,美國)進行參數優化,采用的學習率為0.000 1。
3.2 評價指標
本文采用了分割任務中最為常用的兩種性能指標來對實驗結果進行驗證和比較。這兩種指標分別是交并比(intersetion over union,IoU)和戴斯(Dice)系數,其計算公式分別如式(4)和式(5)所示:
|
|
其中,Ai表示來自標簽類別為i的像素集合,Bi是來自模型預測為i類的像素集合。IoU和 Dice系數的值越高,說明預測掩碼和真實數據(ground truth)之間的相似度越高,模型的性能越好。
3.3 結果與分析
本文在四種具有高使用率的分割模型和兩種不同的公開數據集上進行對比實驗,其實驗結果如表1和表2所示。實驗結果表明,本文的方法在不同的數據集上對不同的模型都具有性能提升作用。在Hyper-Kvasir數據集上,使用U-net模型的IoU系數和Dice系數明顯提高;在ISIC-Archive數據集上,使用DeepLabV3+模型的IoU系數和Dice系數也有明顯的提升。
如圖5和圖6所示,分別展示了在Hyper-Kvasir數據集和ISIC-Archive數據集上,原模型的分割結果和使用了本文方法后的分割結果的可視化圖。從圖5和圖6中可以發現,使用了本文方法后產生的分割曲線(藍色)比原模型的分割曲線(紅色)要更加貼近ground truth曲線(綠色),并且整體分割曲線更為平滑和光整。
圖5
Hyper-Kvasir可視化結果
Figure5.
Visualization results on Hyper-Kvasir
圖6
ISIC-Archive可視化結果
Figure6.
Visualization results on ISIC-Archive
為了進一步驗證所提方法的數據效用,本文在Hyper-Kvasir數據集上每次減少10%的訓練數據,訓練了多個不同數據量下的模型,并觀察了它們在整個數據集上的性能與原始模型的對比。如圖7所示,展示了模型性能隨著訓練數據量的變化趨勢。
圖7
性能變化趨勢圖
Figure7.
Performance trend chart
從圖7中可以發現,在數據量減少至70%時,所提方法依然能夠使得模型達到原模型在整個數據集上訓練所得性能的95%左右。這表明了所提方法不僅能夠提升模型的性能,還能夠提升模型在更少數據量下的數據效用。
從實驗結果對比中可以發現,模型會根據分割目標的位置和形狀等信息進行判斷,并能夠利用數據效用特征攜帶的位置和形狀等信息來更好地完成任務,這表明本文方法能夠在數據層面提升模型的可解釋性。
4 結論
本文提出了一種適用于醫學圖像分割的新型數據增強方法。與傳統的數據增強方法不同,該方法通過維度拓展的方式將數據效用特征與原圖像進行融合,從而在獲得信息增益的同時保留了原圖像信息,實現了非破壞性的效果。同時,本文還構建了通道權重特征提取器,以使模型更好地關注有用信息并提高模型性能。為了深入展示本文方法的數據效用,本文通過逐步減少訓練數據,比較了不同訓練數據量下的模型性能和使用整個數據集訓練所得的模型性能之間的比值。總的來說,本文的方法不僅能提高模型性能,而且還能提高模型的數據效用和可解釋性。因此,它能夠有效地解決醫療診斷領域中的熱點問題,為人工智能輔助醫療診斷做出貢獻。具體而言,本文所提的醫學圖像數據增強方法具有以下三點創新和優勢:
(1)本文所提方法能夠實現不具有破壞性的維度層面數據增強,使不同的分割模型的性能、數據效用和可解釋性得到了提升。
(2)構建了新的通道權重特征提取器,能夠自動學習數據效用特征和原圖像通道之間的權重值,使模型關注到更重要的信息。
(3)提出的方法使用方式簡便,可以應用在任意分割模型上而不需要改變原有的模型結構。
但是,本文方法也存在著一定的局限性,該方法需要先訓練出一個能夠很好提取出數據效用特征的分類模型,然而這并不容易。如何設計出一套高效的方法,讓一個分類模型能夠充分關注到數據效用區域,并通過Grad-CAM提取出來也是未來研究的一個難點和重要方向。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:武星主要負責實驗指導和設計、論文撰寫以及審閱修訂;陶晨杰主要負責數據收集與分析、算法程序設計以及論文撰寫;張健、孫群主要負責實驗素材收集;韓先花主要負責實驗數據分析;陳延偉主要負責論文審閱修訂。