醫學圖像配準在醫療診斷和治療規劃等領域具有重要意義。然而,當前基于深度學習的配準方法仍然面臨著一些挑戰,如對全局信息提取能力不足、網絡模型參數量大、推理速度慢等問題。為此,本文提出了一種新的模型LCU-Net,采用并行輕量化卷積以提升全局信息的提取能力;通過多尺度融合來解決網絡參數量大和推理速度慢的問題。實驗結果顯示,LCU-Net的Dice系數達到0.823,Hausdorff距離為1.258,網絡參數量相對于多尺度融合之前減少了約四分之一。本文提出的算法在醫學圖像配準任務中表現出顯著優勢,不僅在性能上超越了現有的對比算法,而且具有出色的泛化性能以及廣泛的應用前景。
引用本文: 沈瑜, 嚴源, 宋婧, 劉廣輝, 許佳文, 魏子易. 基于并行輕量化卷積和多尺度融合的腦部磁共振圖像配準. 生物醫學工程學雜志, 2024, 41(2): 213-219. doi: 10.7507/1001-5515.202309014 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
0 引言
圖像配準作為醫學圖像分析處理中最基本的任務,旨在有效地融合不同模態或時間點的醫學圖像,提升信息利用率,增強診斷準確性[1]。目前,基于無監督學習的醫學圖像配準框架被廣泛應用,其中包括使用卷積神經網絡(convolutional neural networks,CNN)[2-3],或者依賴于自注意力機制的Transformer架構[4-5]。CNN擅長提取局部細節信息,例如,Balakrishnan等[6]提出了一種名為VoxelMorph的基于CNN的網絡模型,采用了U型架構,通過端到端的配準方式實現了良好的配準效果;而Mok等[7]則提出了一種快速對稱差分圖像配準方法,使得配準后的圖像保持了拓撲性和變換的可逆性。然而,由于計算資源的限制以及卷積核的局限性,CNN存在提取全局信息不足的問題。隨著Transformer的發展,研究人員開始探索在醫學圖像配準中的應用。例如,Mingrui等[8]使用Transformer進行非局部配準,設計了基于卷積的高效多頭自注意力模塊,以捕捉局部空間上下文信息,從而有效減少了注意力機制中的語義歧義;此外,Chen等[9]提出TransMorph架構,結合了CNN和Transformer的優點,在保持良好拓撲效果的同時提高了配準效果。然而,基于Transformer的架構存在著模型參數量較多、訓練耗時長等問題。
為了應對上述挑戰,本文提出了基于并行輕量化卷積和多尺度融合的圖像配準模型LCU-Net。該模型專注于單模態腦部核磁共振成像(magnetic resonance imaging,MRI)的配準任務,通過并行輕量化卷積提升全局信息的提取能力,同時利用多尺度融合技術解決網絡參數量大和推理速度慢的問題。
1 本文算法
1.1 算法框架
本文采用的無監督醫學圖像配準框架如圖1所示,將固定圖像f和待配準圖像m拼接輸入到LCU-Net網絡,以獲取形變場 ,隨后,利用空間變換網絡[10](spatial transformer net,STN),對形變場
,隨后,利用空間變換網絡[10](spatial transformer net,STN),對形變場 和待配準圖像m進行插值重采樣,得到配準后的圖像,并通過迭代學習來最小化損失函數以優化圖像之間的相似性,其形式如公式(1)所示:
和待配準圖像m進行插值重采樣,得到配準后的圖像,并通過迭代學習來最小化損失函數以優化圖像之間的相似性,其形式如公式(1)所示:
 圖1
無監督醫學圖像配準框架
Figure1.
Unsupervised medical image registration framework
圖1
無監督醫學圖像配準框架
Figure1.
Unsupervised medical image registration framework
 |
其中, 為最佳形變場,
為最佳形變場, 為最小化損失函數,m°?表示m由形變場?得到的扭曲圖像,
為最小化損失函數,m°?表示m由形變場?得到的扭曲圖像, 相似性度量和
相似性度量和 正則化作為損失函數約束網絡訓練,
正則化作為損失函數約束網絡訓練, 為超參數。
為超參數。
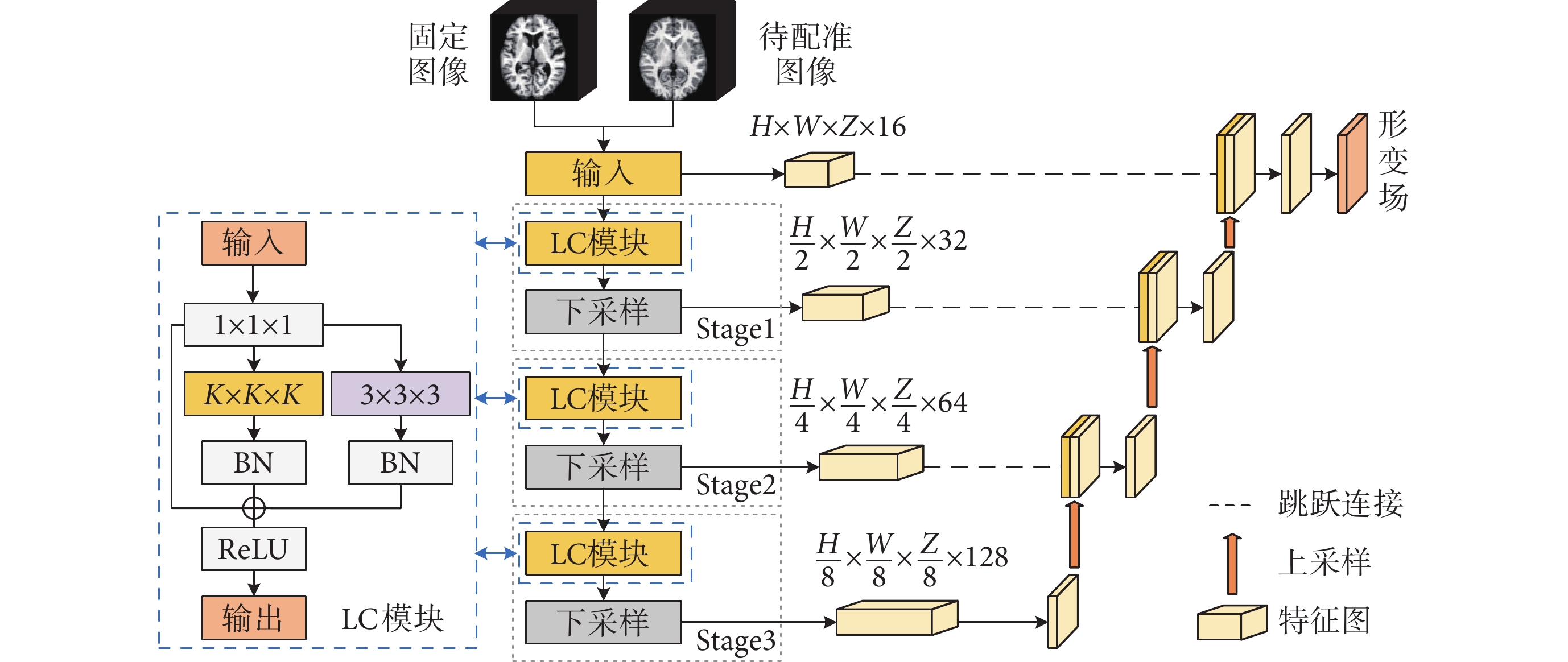
LCU-Net網絡模型結構如圖2所示。首先,以固定圖像為模板,與待配準圖像拼接作為輸入,經過三個特征提取模塊提取出圖像的淺層特征,每個模塊包括一個輕量化卷積(lightweight convolutional,LC)模塊和一個下采樣層。在解碼階段,采用三次上采樣,將深層特征與相同尺度下的淺層特征通過跳躍連接融合,通過一個步長為1的3 × 3 × 3卷積層降低通道數輸出形變場;隨后,計算待配準圖像對的相似性損失,加入正則化損失以更新網絡參數,再以待配準圖像為模板,與固定圖像拼接輸入,經過LCU-Net網絡再次訓練,得到形變場后計算損失并反向傳播更新網絡參數。最終,得到的形變場保持一定的拓撲性。
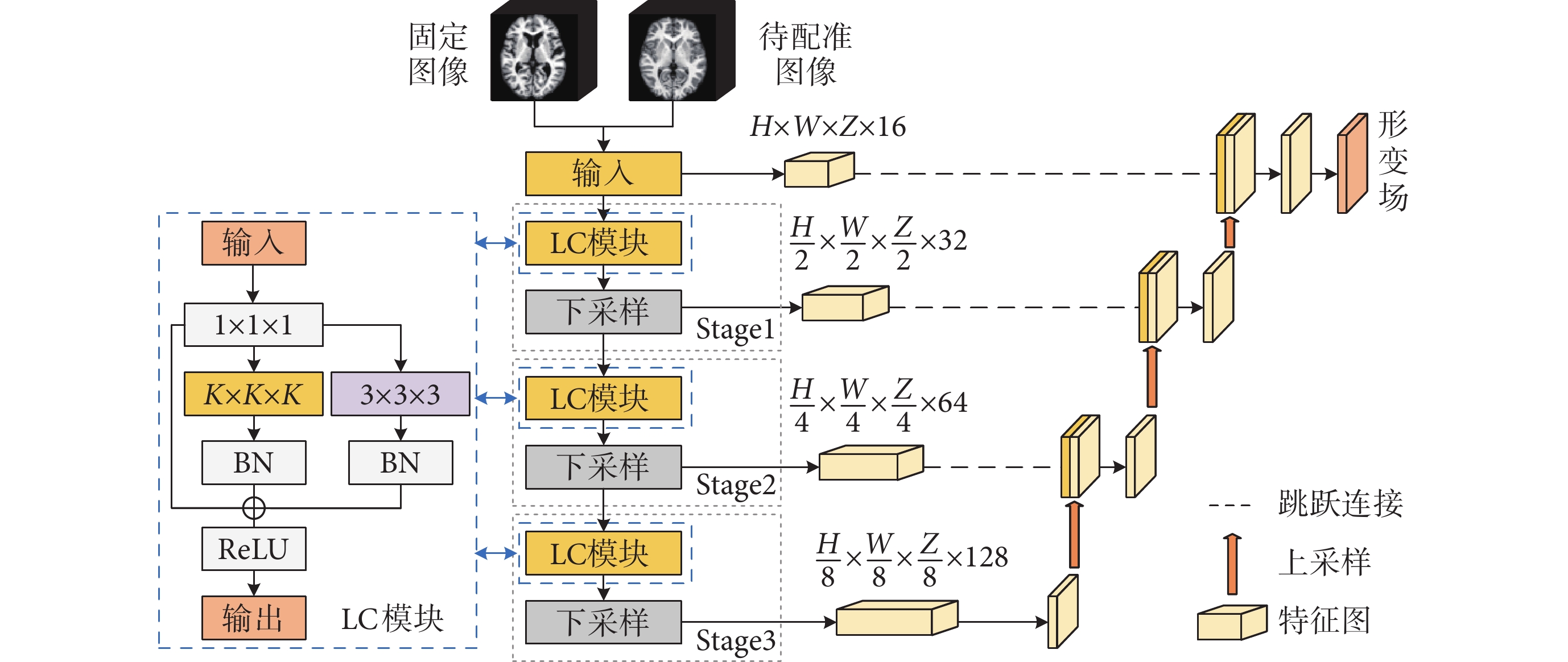 圖2
LCU-Net網絡配準模型
Figure2.
LCU-Net network registration model
圖2
LCU-Net網絡配準模型
Figure2.
LCU-Net network registration model
1.2 LC模塊
隨著計算機硬件性能的提升,一些學者開始研究用大卷積核代替多個小卷積核的設計,以提高網絡的性能,并充分利用計算機資源。例如,Ding等[11]研究了卷積網絡的大內核設計,通過增大卷積核的大小,有效地增加了網絡感受野,從而提高了網絡性能;Jia等[12]改進U-Net網絡,與具有超強遠程建模能力的Transformer進行比較,結果顯示,具有大內核的改進網絡具有顯著優勢。
為了解決卷積層提取信息不足的問題,本文參考上述研究設計了一個具有大內核的并行輕量化卷積LC模塊,如圖3所示。該模塊包括捷徑、BN層、ReLU激活層、1 × 1 × 1卷積層、3 × 3 × 3卷積層以及具有大內核(k × k × k)的深度卷積層。首先,輸入圖像通過一個1 × 1 × 1卷積層,改變通道數并降低計算量;然后,采用3 × 3 × 3卷積層提取局部細節信息,采用k × k × k卷積層提取豐富的全局信息;捷徑用于增強網絡的表達能力;BN層用來加速網絡的收斂速度,并使用ReLU激活層進行函數激活。
 圖3
多尺度融合
Figure3.
Multi-scale fusion
圖3
多尺度融合
Figure3.
Multi-scale fusion
引入多尺度融合對大卷積核進行重新參數化,可以有效解決直接擴大內核導致的配準精度下降的問題,并解決了參數量增加可能會導致的崩潰和過擬合問題,同時對網絡模型進行優化,加快推理速度。該過程主要分為兩個步驟:BN融合和內核融合。
卷積層的運算中,假設卷積核權重為W,卷積過程即為將W在輸入特征圖中進行滑窗計算。假設W中的一個元素為w,輸入特征圖中的一個元素為x,則卷積過程可以表示為式(2),其中b為正則化參數:
 |
(1)BN融合:式(3)顯示了在訓練過程中BN層的計算過程。在一個Batch中,假設第i個樣本經過卷積層后的輸出為  ,則經過BN層后的輸出
,則經過BN層后的輸出  可以表示為:
可以表示為:
 |
其中,μ為一個Batch內的均值,δ2為方差,ε是防止分母為0時產生除零錯誤而設置的一個非常小的常數。在這個公式中,γ和β是BN層中的可學習參數,在網絡訓練過程中通過梯度下降進行學習更新。
在驗證測試階段,γ和β這兩個參數的值固定不變,均值μ和方差δ2來自于訓練樣本的數據分布。因此,式(3)可以變形為式(4):
 |
其中令 ,
, ,上述式子也可以改寫為式(5):
,上述式子也可以改寫為式(5):
 |
在驗證測試階段, 、
、 均為固定值。通過式(4)和式(5)可以看出,在卷積層計算中,加入BN層等價于計算偏置項
均為固定值。通過式(4)和式(5)可以看出,在卷積層計算中,加入BN層等價于計算偏置項  和
和  。
。
(2)內核融合:小內核(3 × 3 × 3)和大內核(k × k × k)可以提取不同的淺層特征和深層特征信息。其中,小內核更加關注局部細節信息,而大內核可以獲得更大的感受野,從而提取更加全面的信息。假設  和
和  分別為3 × 3 × 3卷積層和k × k × k卷積層對應卷積核的權重,
分別為3 × 3 × 3卷積層和k × k × k卷積層對應卷積核的權重, 和
和  為3 × 3 × 3卷積和原始k × k × k卷積分支的輸出,則可以得到式(6):
為3 × 3 × 3卷積和原始k × k × k卷積分支的輸出,則可以得到式(6):
 |
其中, 為公式(2)的卷積運算,
為公式(2)的卷積運算, 表示對應位置的核參數逐元素相加。
表示對應位置的核參數逐元素相加。
1.3 損失函數
本文采用無監督的圖像配準方法,使用圖像相似性度量作為損失函數來約束網絡的訓練,損失函數定義如式(7)所示:
 |
其中, 代表待配準圖像對之間的相似性度量損失,用于懲罰外觀差異;
代表待配準圖像對之間的相似性度量損失,用于懲罰外觀差異; 對網絡預測的形變場進行空間正則化,懲罰形變場
對網絡預測的形變場進行空間正則化,懲罰形變場 的局部空間變化,以約束形變場的空間平滑性。
的局部空間變化,以約束形變場的空間平滑性。 是超參數,經過多次實驗后綜合考慮收斂速度和配準效果,設為固定值4.0。本文采用互相關系數來測量圖像對之間的相似性,采用L2正則化來防止發生過擬合現象。
是超參數,經過多次實驗后綜合考慮收斂速度和配準效果,設為固定值4.0。本文采用互相關系數來測量圖像對之間的相似性,采用L2正則化來防止發生過擬合現象。
2 實驗與結果分析
2.1 數據集
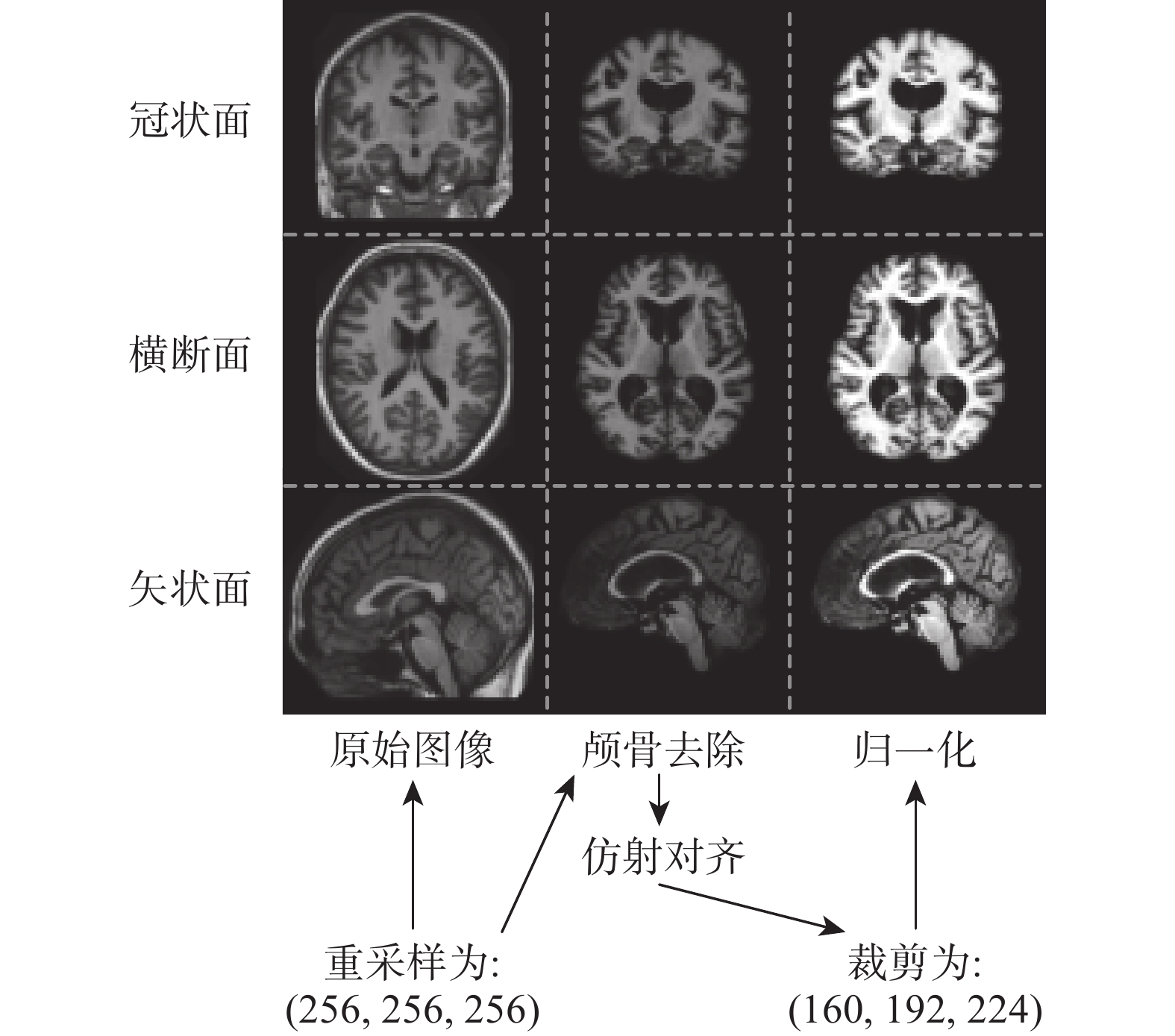
本文針對腦部MRI可變形區域進行配準研究,使用了公開醫學影像數據集OASIS[13]和LPBA40[14]作為實驗的測試數據集和泛化性驗證數據集。OASIS數據集包含414幅腦部MRI圖像,需要做數據預處理操作;LPBA40數據集包含40幅腦部MRI圖像,這些圖像已經對齊到mni305空間,僅需要進行歸一化和裁剪操作。本文參考Alessa等[15]提出的圖像預處理策略對OASIS數據集進行預處理操作。預處理過程包括圖像重采樣、顱骨去除、仿射對齊、裁剪和歸一化等步驟,如圖4所示。經過預處理的OASIS數據集中,數據圖像的尺寸為160 × 192 × 224,體素間隔為1 × 1 × 1。在實驗中,隨機選擇了一幅圖像作為固定圖像,333幅圖像作為訓練數據,40幅圖像作為驗證數據,另外40幅圖像作為測試數據。標簽數據則采用了由Freesurfer軟件制作的包含35個解剖結構的圖像數據。
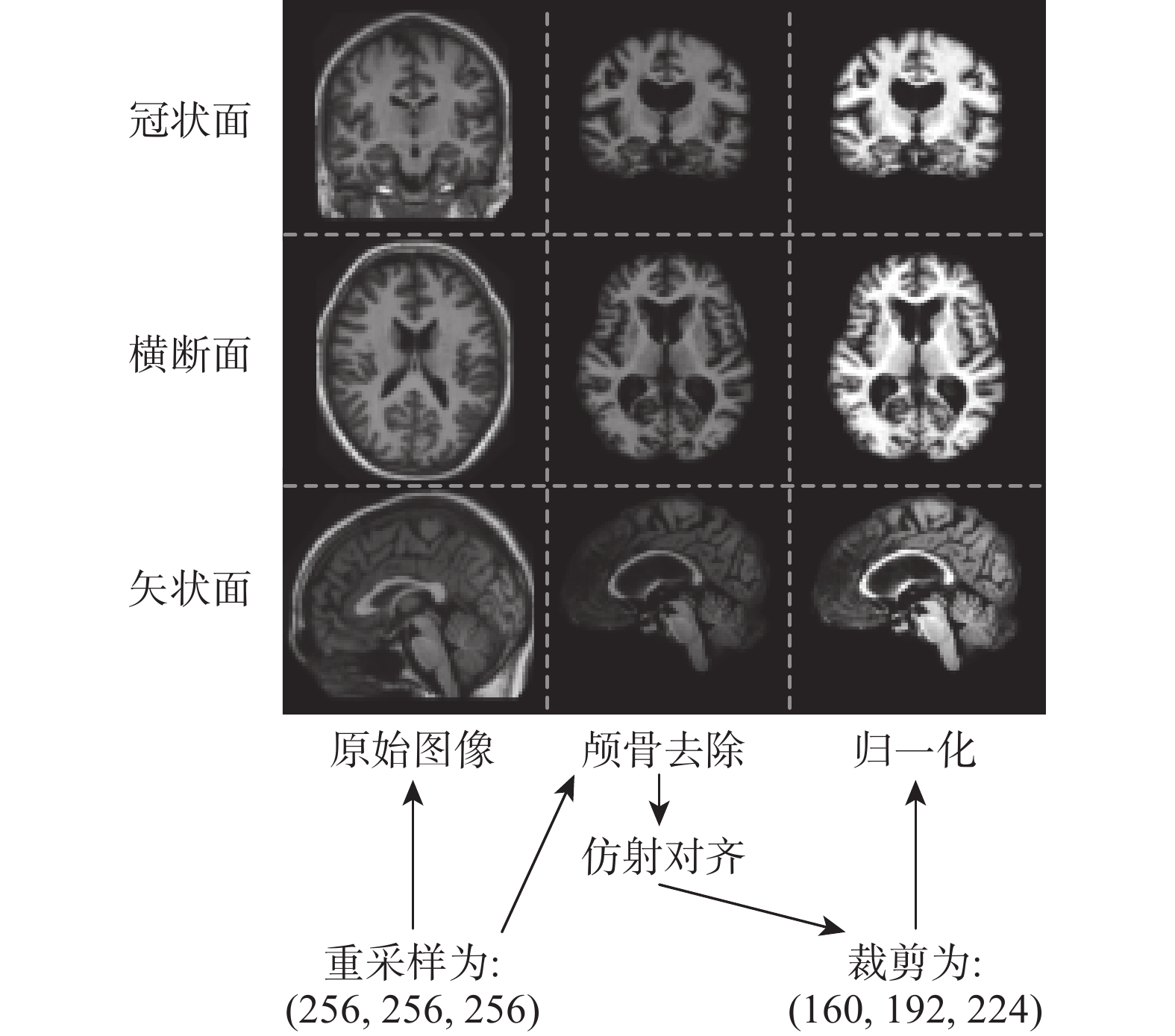 圖4
腦部MRI圖像預處理
Figure4.
Brain MRI image preprocessing
圖4
腦部MRI圖像預處理
Figure4.
Brain MRI image preprocessing
本實驗在Windows 10 64位系統下,在PyTorch環境中進行了實驗和驗證,使用了一張24 GB顯存的RTX 3090顯卡。批處理大小(batch size)被設置為1。優化器選用Adam,學習率設置為0.000 1。訓練設置了300個epoch,總迭代次數為99 900次。在損失函數中,超參數 設為4.0。
設為4.0。
2.2 評價指標
本文的評價指標主要包括三個方面:參數量、配準時間和配準精度。為了比較不同大小卷積核的網絡模型,我們將它們標記為LCU-Netk,k為卷積核的大小。此外,我們還設置了多核模型LCU-Net多核,其第一個特征提取模塊的卷積核大小為23 × 23 × 23,第二個特征提取模塊的卷積核大小為13 × 13 × 13,第三個特征提取模塊的大小為3 × 3 × 3。
采用戴斯相似性系數(Dice similarity coefficient,Dice)和豪斯多夫距離(Hausdorff distance,Hausdorff)評估網絡的配準性能,其中Dice用于計算配準圖像和固定圖像之間的重疊程度,反映兩幅圖像之間的相似程度,取值范圍為0~1,越接近1則表示配準效果越好;Hausdorff距離用于衡量兩個點集之間的距離,數值越小代表兩幅圖像之間的相似度越高。
2.3 對比分析
本文以基于ANTs軟件包的SYN算法[16]、基于CNN的VoxelMorph和SYM-Net和基于Transformer的SymTrans和TransMorph作為對比算法。SYN算法關注形變場的拓撲結構保持,是一個經典有效的醫學圖像配準軟件。在參數設置方面,基于ANTs軟件包的SYN算法采用軟件默認參數;VoxelMorph、SYM-Net、SymTrans和TransMorph使用基于pytorch的框架,設置與LCU-Net網絡同樣的參數配置。
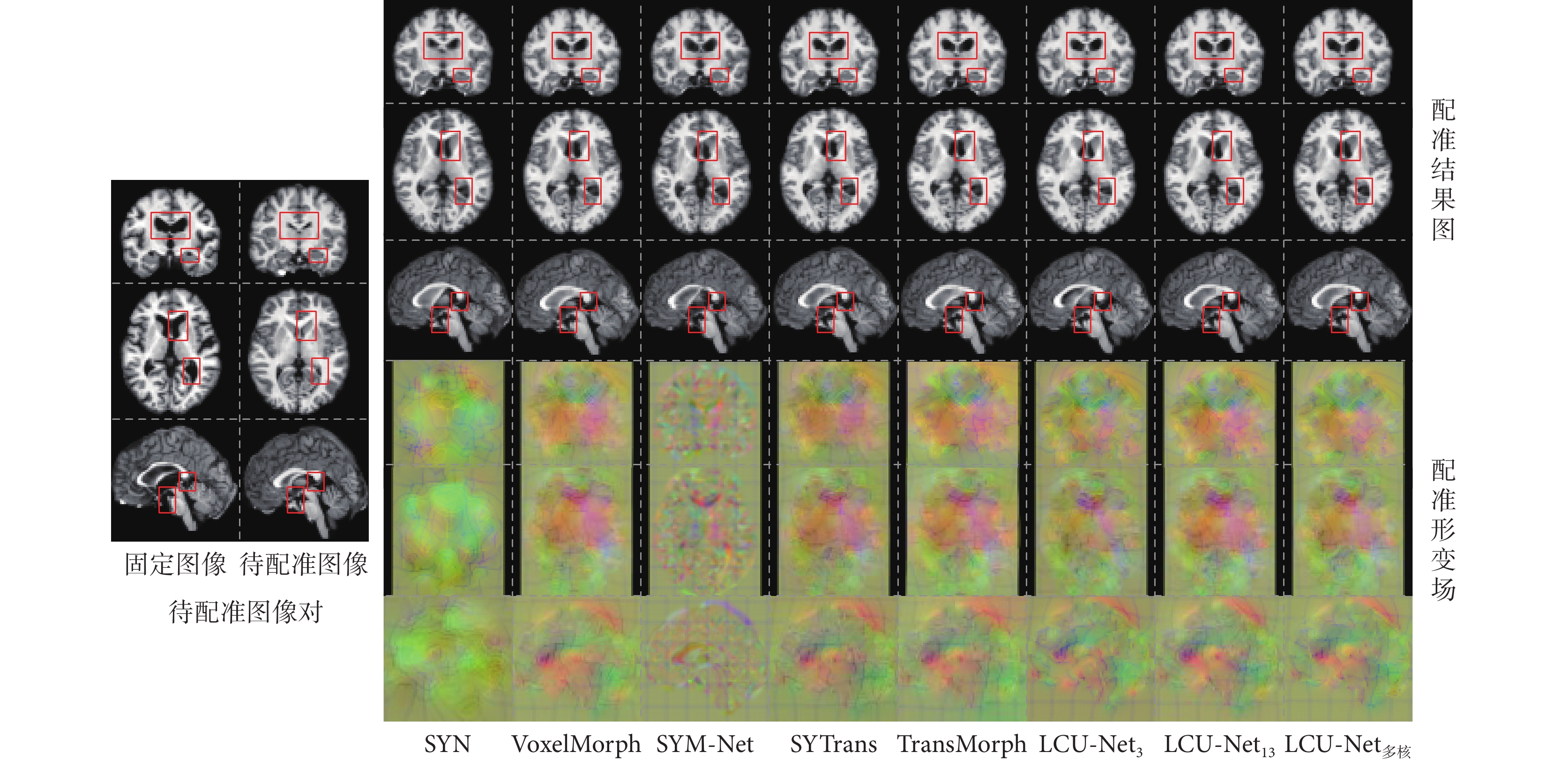
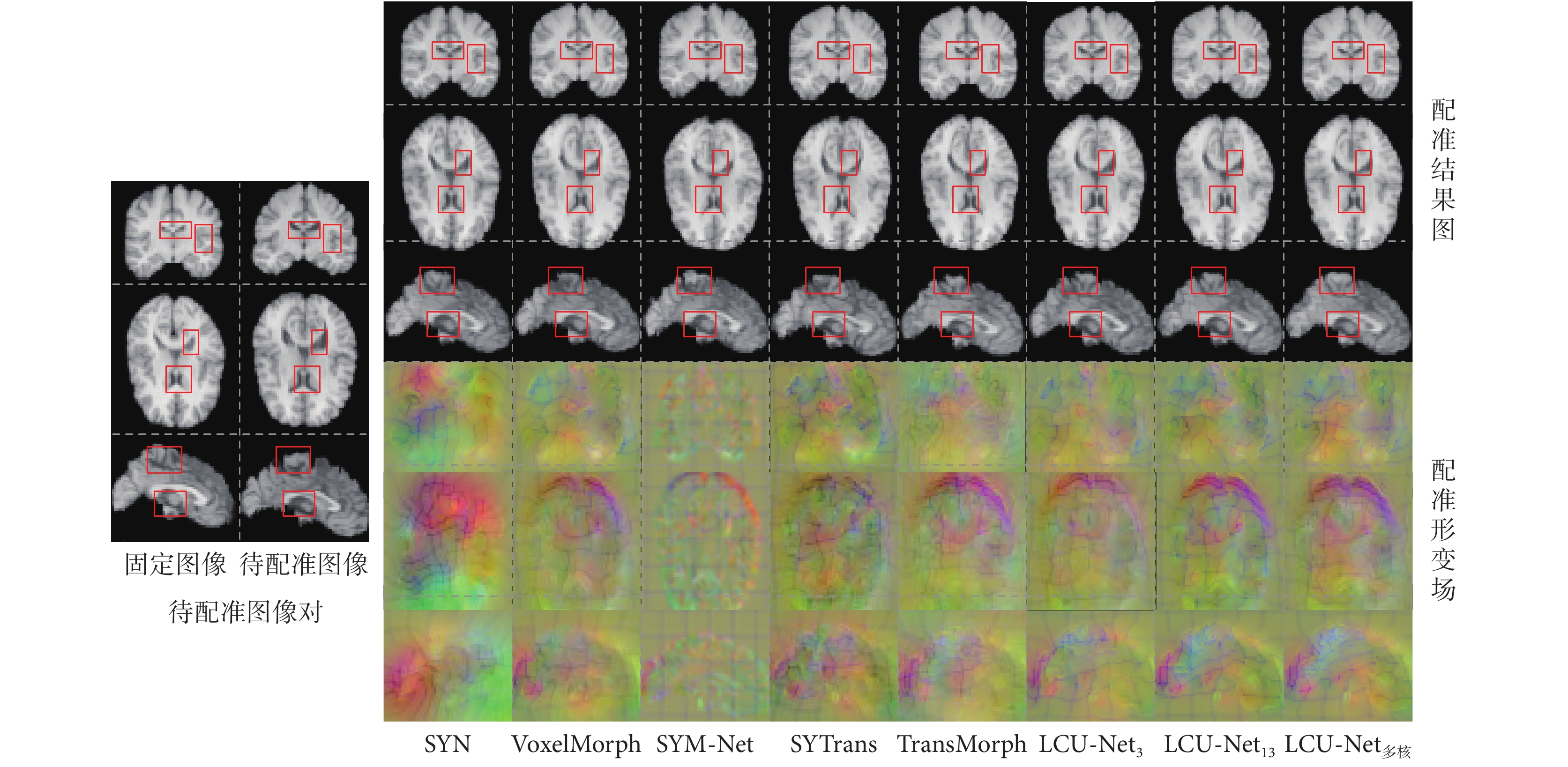
從測試集中選擇一對圖像,通過不同網絡模型配準,得到如圖5所示的不同網絡模型配準結果的二維切片可視化圖,圖中分別展示了腦部MRI圖像的冠狀面、橫斷面和矢狀面。從待配準圖像對中可以觀察到,固定圖像和待配準圖像之間存在較大的結構差異,對比五種算法和本文算法生成的結果圖和形變場圖,可以觀察到本文算法的三個模型生成的配準形變場較為平滑。在圖中用紅色方框標記側腦室、脈絡叢、透明隔、腦干等解剖結構區域,通過比較不同配準方法所生成的形變后的分割標簽與固定圖像之間的重疊程度,可以發現本文算法在在保持局部細節信息完整的同時,在全局上可獲得更加精確和完整的配準效果,隨著卷積核的增大,配準效果也變得更好,保持了大腦結構的完整性。
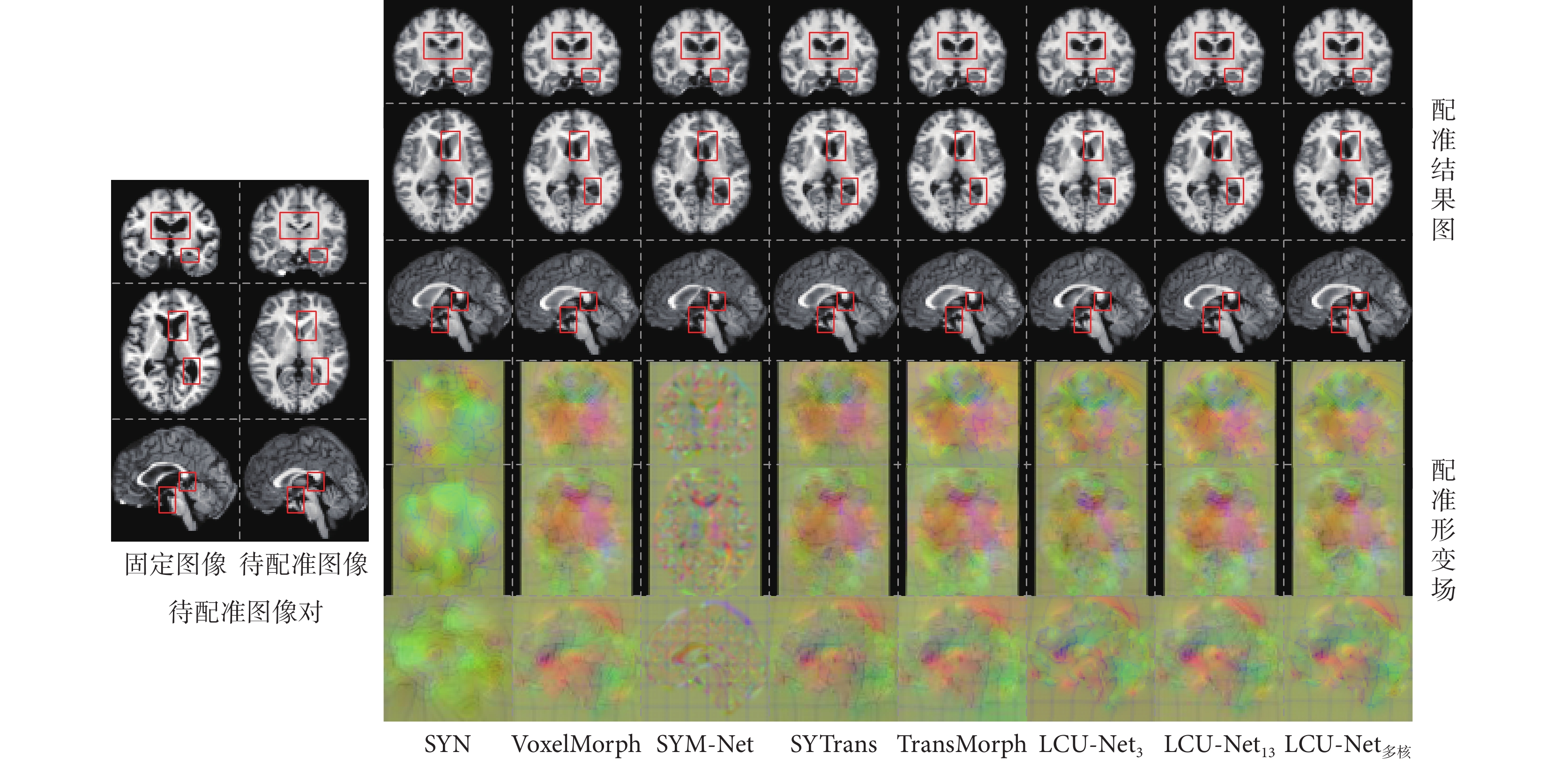 圖5
不同方法配準結果和形變場
Figure5.
Registration results and deformation fields by different methods
圖5
不同方法配準結果和形變場
Figure5.
Registration results and deformation fields by different methods
各個網絡模型量化分析結果如表1所示,從參數量、配準精度、配準時間三個方面進行比較,其中SYN算法基于ANTs軟件包,沒有詳細參數量對比,僅用來比較配準效果和配準時間。根據Dice和Hausdorff這兩個評價指標可以觀察到,當LCU-Net的卷積核大小為3 × 3 × 3時,其配準精度與VoxelMorph和SYM-Net相當,但綜合網絡參數量和配準時間,LCU-Net3優于VoxelMorph和SYM-Net;當LCU-Net的卷積核大小為13 × 13 × 13時,其配準精度超過了對比算法SYN和SymTrans,且網絡參數量遠小于SymTrans,配準耗時短。綜合上述實驗結果分析,LCU-Net優于五種對比算法,且多核LCU-Net的性能優于單核LCU-Net,LCU-Net多核得到的配準精度最好,Dice達到0.823,并且配準時間相對較短。
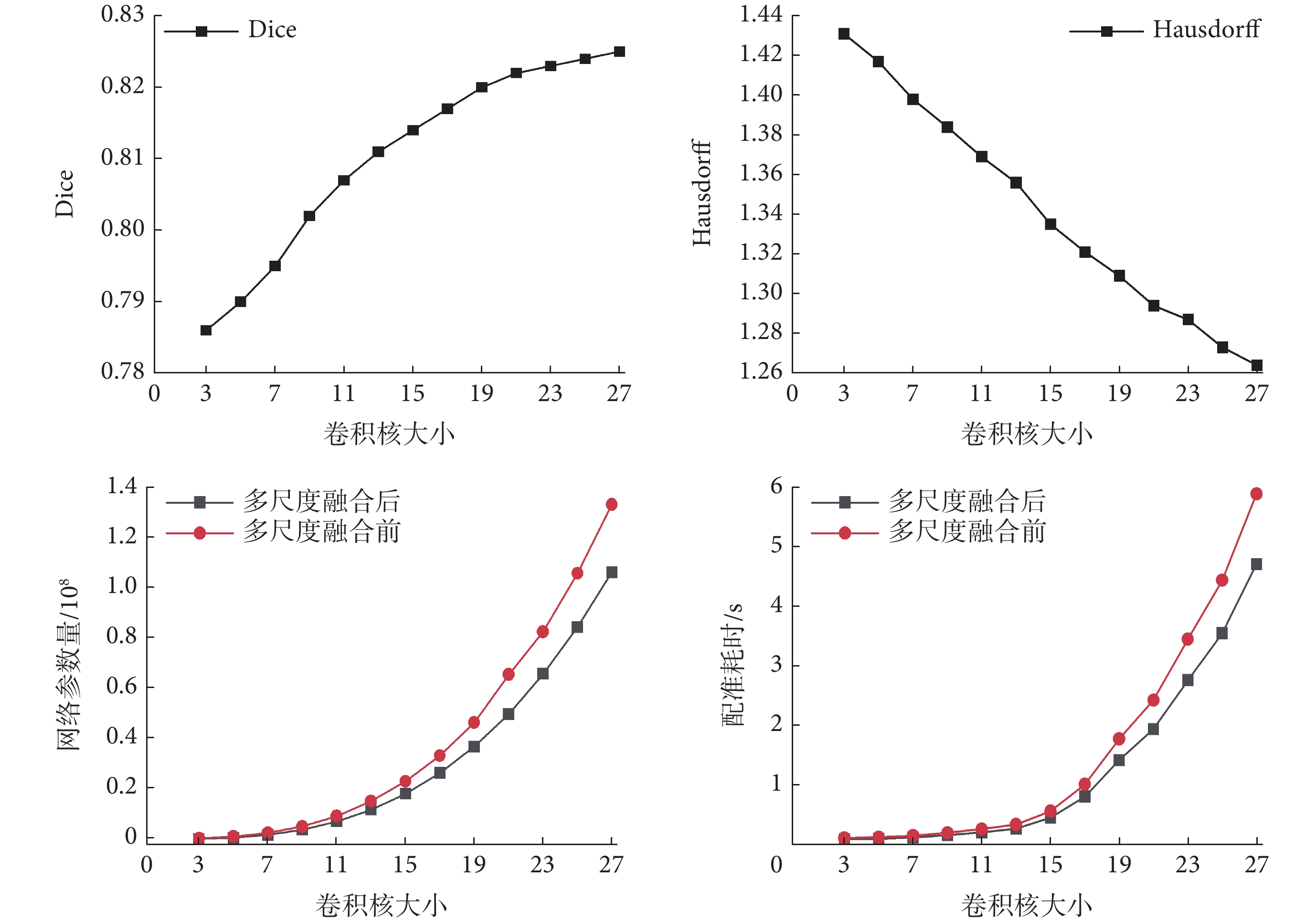
圖6展示了單核LCU-Net網絡模型在不同卷積核大小(從3~27)下的Dice和Hausdorff結果。通過對比可以觀察到以下情況:隨著卷積核的增大,圖像的配準效果逐漸提升,但在較大卷積核時,配準效果的提升并不十分顯著。此外,在卷積核較大時,網絡的參數量也會顯著增加,導致網絡配準需要耗費更多時間。因此,僅僅采用單核大卷積模型并不能取得良好的效果。經過多尺度融合后,網絡的參數量降低了約25%,配準速度提高了約18%。特別是在使用大卷積核模型時,多尺度融合的效果尤為明顯。
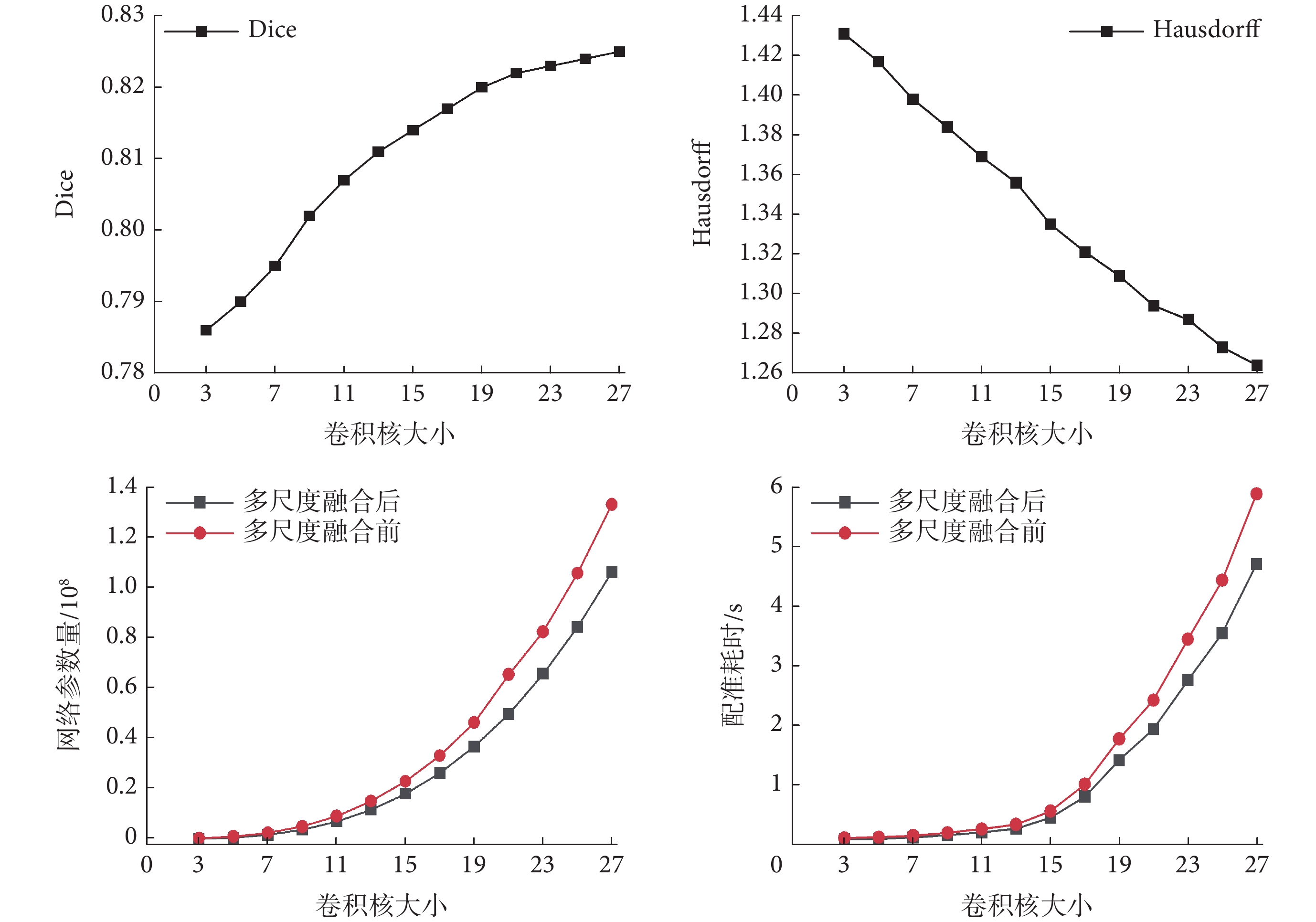 圖6
多尺度融合分析
Figure6.
Multi-scale fusion analysis
圖6
多尺度融合分析
Figure6.
Multi-scale fusion analysis
2.4 泛化性對比
為了評估網絡模型的泛化性,本文在LPBA40數據集上對五個對比算法以及本文算法LCU-Net的三個模型的訓練最優結果進行了實驗。在不改變任何參數的情況下,將40幅LPBA40數據集圖像作為驗證測試集,使用已訓練好的模型進行配準,實驗結果如圖7所示。
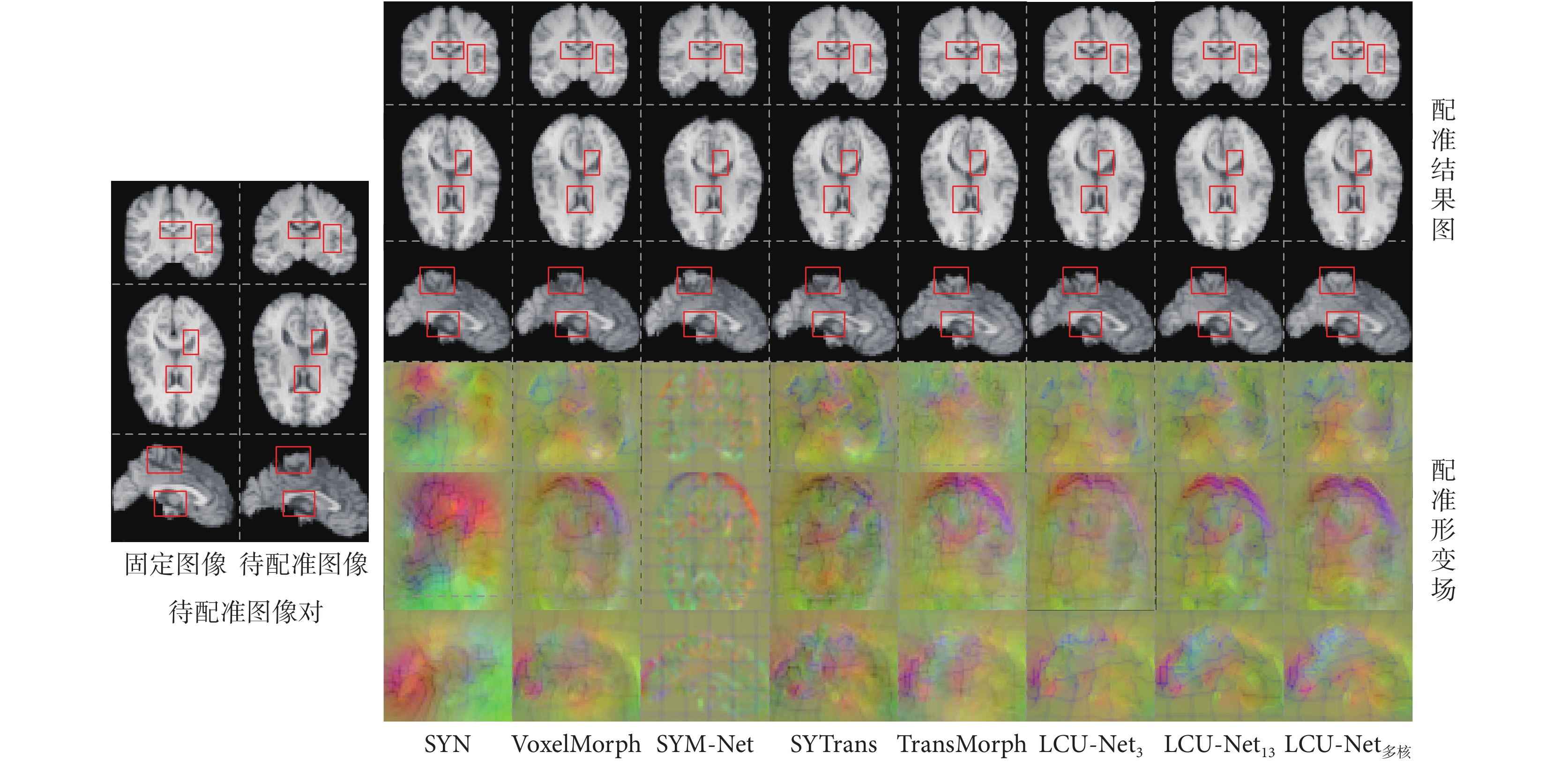 圖7
泛化性對比結果
Figure7.
Generalization comparison results
圖7
泛化性對比結果
Figure7.
Generalization comparison results
表2為量化分析結果,比較了各網絡的配準精度,以Dice和Hausdorff作為評價指標。可以觀察到本文所提出的方法具有更高的準確度和精度,特別在紅色方框中所標記的解剖區域,LCU-Net網絡的配準效果優于對比算法。其中,LCU-Net多核網絡泛化性最好。
3 結論
本文提出了一種基于并行輕量化卷積和多尺度融合的網絡模型LCU-Net,設計具有三層并行路徑的LC模塊,在獲取更多感受野的同時不會喪失對局部細節信息的捕獲能力。在驗證推理階段,通過多尺度融合將網絡的BN層和內核融合,從而降低了網絡模型的復雜度,提高了推理速度,減少了配準時間。在OASIS數據集上,本文所提出的網絡模型與SYN、VoxelMorph、SYN-Net、SymTrans和TransMorph五種算法進行了比較。實驗結果表明,LCU-Net在性能上超過了對比算法模型,其中多核LCU-Net模型的配準效果最佳。同時,本文在LPBA40數據集上進行了泛化性對比實驗,LCU-Net表現出良好的泛化性能。本組實驗結果表明,在腦部單模態MRI可變形配準方面,LCU-Net網絡優于對比網絡,具有較大的應用價值。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:沈瑜、嚴源負責算法設計與實現、數據處理與分析、論文寫作與修改;宋婧、劉廣輝提供實驗指導及論文審閱修訂;許佳文、魏子易參與數據集收集及預處理并負責整理實驗結果。
0 引言
圖像配準作為醫學圖像分析處理中最基本的任務,旨在有效地融合不同模態或時間點的醫學圖像,提升信息利用率,增強診斷準確性[1]。目前,基于無監督學習的醫學圖像配準框架被廣泛應用,其中包括使用卷積神經網絡(convolutional neural networks,CNN)[2-3],或者依賴于自注意力機制的Transformer架構[4-5]。CNN擅長提取局部細節信息,例如,Balakrishnan等[6]提出了一種名為VoxelMorph的基于CNN的網絡模型,采用了U型架構,通過端到端的配準方式實現了良好的配準效果;而Mok等[7]則提出了一種快速對稱差分圖像配準方法,使得配準后的圖像保持了拓撲性和變換的可逆性。然而,由于計算資源的限制以及卷積核的局限性,CNN存在提取全局信息不足的問題。隨著Transformer的發展,研究人員開始探索在醫學圖像配準中的應用。例如,Mingrui等[8]使用Transformer進行非局部配準,設計了基于卷積的高效多頭自注意力模塊,以捕捉局部空間上下文信息,從而有效減少了注意力機制中的語義歧義;此外,Chen等[9]提出TransMorph架構,結合了CNN和Transformer的優點,在保持良好拓撲效果的同時提高了配準效果。然而,基于Transformer的架構存在著模型參數量較多、訓練耗時長等問題。
為了應對上述挑戰,本文提出了基于并行輕量化卷積和多尺度融合的圖像配準模型LCU-Net。該模型專注于單模態腦部核磁共振成像(magnetic resonance imaging,MRI)的配準任務,通過并行輕量化卷積提升全局信息的提取能力,同時利用多尺度融合技術解決網絡參數量大和推理速度慢的問題。
1 本文算法
1.1 算法框架
本文采用的無監督醫學圖像配準框架如圖1所示,將固定圖像f和待配準圖像m拼接輸入到LCU-Net網絡,以獲取形變場,隨后,利用空間變換網絡[10](spatial transformer net,STN),對形變場和待配準圖像m進行插值重采樣,得到配準后的圖像,并通過迭代學習來最小化損失函數以優化圖像之間的相似性,其形式如公式(1)所示:
圖1
無監督醫學圖像配準框架
Figure1.
Unsupervised medical image registration framework
|
其中,為最佳形變場,為最小化損失函數,m°?表示m由形變場?得到的扭曲圖像,相似性度量和正則化作為損失函數約束網絡訓練,為超參數。
LCU-Net網絡模型結構如圖2所示。首先,以固定圖像為模板,與待配準圖像拼接作為輸入,經過三個特征提取模塊提取出圖像的淺層特征,每個模塊包括一個輕量化卷積(lightweight convolutional,LC)模塊和一個下采樣層。在解碼階段,采用三次上采樣,將深層特征與相同尺度下的淺層特征通過跳躍連接融合,通過一個步長為1的3 × 3 × 3卷積層降低通道數輸出形變場;隨后,計算待配準圖像對的相似性損失,加入正則化損失以更新網絡參數,再以待配準圖像為模板,與固定圖像拼接輸入,經過LCU-Net網絡再次訓練,得到形變場后計算損失并反向傳播更新網絡參數。最終,得到的形變場保持一定的拓撲性。
圖2
LCU-Net網絡配準模型
Figure2.
LCU-Net network registration model
1.2 LC模塊
隨著計算機硬件性能的提升,一些學者開始研究用大卷積核代替多個小卷積核的設計,以提高網絡的性能,并充分利用計算機資源。例如,Ding等[11]研究了卷積網絡的大內核設計,通過增大卷積核的大小,有效地增加了網絡感受野,從而提高了網絡性能;Jia等[12]改進U-Net網絡,與具有超強遠程建模能力的Transformer進行比較,結果顯示,具有大內核的改進網絡具有顯著優勢。
為了解決卷積層提取信息不足的問題,本文參考上述研究設計了一個具有大內核的并行輕量化卷積LC模塊,如圖3所示。該模塊包括捷徑、BN層、ReLU激活層、1 × 1 × 1卷積層、3 × 3 × 3卷積層以及具有大內核(k × k × k)的深度卷積層。首先,輸入圖像通過一個1 × 1 × 1卷積層,改變通道數并降低計算量;然后,采用3 × 3 × 3卷積層提取局部細節信息,采用k × k × k卷積層提取豐富的全局信息;捷徑用于增強網絡的表達能力;BN層用來加速網絡的收斂速度,并使用ReLU激活層進行函數激活。
圖3
多尺度融合
Figure3.
Multi-scale fusion
引入多尺度融合對大卷積核進行重新參數化,可以有效解決直接擴大內核導致的配準精度下降的問題,并解決了參數量增加可能會導致的崩潰和過擬合問題,同時對網絡模型進行優化,加快推理速度。該過程主要分為兩個步驟:BN融合和內核融合。
卷積層的運算中,假設卷積核權重為W,卷積過程即為將W在輸入特征圖中進行滑窗計算。假設W中的一個元素為w,輸入特征圖中的一個元素為x,則卷積過程可以表示為式(2),其中b為正則化參數:
|
(1)BN融合:式(3)顯示了在訓練過程中BN層的計算過程。在一個Batch中,假設第i個樣本經過卷積層后的輸出為 ,則經過BN層后的輸出 可以表示為:
|
其中,μ為一個Batch內的均值,δ2為方差,ε是防止分母為0時產生除零錯誤而設置的一個非常小的常數。在這個公式中,γ和β是BN層中的可學習參數,在網絡訓練過程中通過梯度下降進行學習更新。
在驗證測試階段,γ和β這兩個參數的值固定不變,均值μ和方差δ2來自于訓練樣本的數據分布。因此,式(3)可以變形為式(4):
|
其中令,,上述式子也可以改寫為式(5):
|
在驗證測試階段,、 均為固定值。通過式(4)和式(5)可以看出,在卷積層計算中,加入BN層等價于計算偏置項 和 。
(2)內核融合:小內核(3 × 3 × 3)和大內核(k × k × k)可以提取不同的淺層特征和深層特征信息。其中,小內核更加關注局部細節信息,而大內核可以獲得更大的感受野,從而提取更加全面的信息。假設 和 分別為3 × 3 × 3卷積層和k × k × k卷積層對應卷積核的權重, 和 為3 × 3 × 3卷積和原始k × k × k卷積分支的輸出,則可以得到式(6):
|
其中,為公式(2)的卷積運算,表示對應位置的核參數逐元素相加。
1.3 損失函數
本文采用無監督的圖像配準方法,使用圖像相似性度量作為損失函數來約束網絡的訓練,損失函數定義如式(7)所示:
|
其中,代表待配準圖像對之間的相似性度量損失,用于懲罰外觀差異;對網絡預測的形變場進行空間正則化,懲罰形變場的局部空間變化,以約束形變場的空間平滑性。是超參數,經過多次實驗后綜合考慮收斂速度和配準效果,設為固定值4.0。本文采用互相關系數來測量圖像對之間的相似性,采用L2正則化來防止發生過擬合現象。
2 實驗與結果分析
2.1 數據集
本文針對腦部MRI可變形區域進行配準研究,使用了公開醫學影像數據集OASIS[13]和LPBA40[14]作為實驗的測試數據集和泛化性驗證數據集。OASIS數據集包含414幅腦部MRI圖像,需要做數據預處理操作;LPBA40數據集包含40幅腦部MRI圖像,這些圖像已經對齊到mni305空間,僅需要進行歸一化和裁剪操作。本文參考Alessa等[15]提出的圖像預處理策略對OASIS數據集進行預處理操作。預處理過程包括圖像重采樣、顱骨去除、仿射對齊、裁剪和歸一化等步驟,如圖4所示。經過預處理的OASIS數據集中,數據圖像的尺寸為160 × 192 × 224,體素間隔為1 × 1 × 1。在實驗中,隨機選擇了一幅圖像作為固定圖像,333幅圖像作為訓練數據,40幅圖像作為驗證數據,另外40幅圖像作為測試數據。標簽數據則采用了由Freesurfer軟件制作的包含35個解剖結構的圖像數據。
圖4
腦部MRI圖像預處理
Figure4.
Brain MRI image preprocessing
本實驗在Windows 10 64位系統下,在PyTorch環境中進行了實驗和驗證,使用了一張24 GB顯存的RTX 3090顯卡。批處理大小(batch size)被設置為1。優化器選用Adam,學習率設置為0.000 1。訓練設置了300個epoch,總迭代次數為99 900次。在損失函數中,超參數設為4.0。
2.2 評價指標
本文的評價指標主要包括三個方面:參數量、配準時間和配準精度。為了比較不同大小卷積核的網絡模型,我們將它們標記為LCU-Netk,k為卷積核的大小。此外,我們還設置了多核模型LCU-Net多核,其第一個特征提取模塊的卷積核大小為23 × 23 × 23,第二個特征提取模塊的卷積核大小為13 × 13 × 13,第三個特征提取模塊的大小為3 × 3 × 3。
采用戴斯相似性系數(Dice similarity coefficient,Dice)和豪斯多夫距離(Hausdorff distance,Hausdorff)評估網絡的配準性能,其中Dice用于計算配準圖像和固定圖像之間的重疊程度,反映兩幅圖像之間的相似程度,取值范圍為0~1,越接近1則表示配準效果越好;Hausdorff距離用于衡量兩個點集之間的距離,數值越小代表兩幅圖像之間的相似度越高。
2.3 對比分析
本文以基于ANTs軟件包的SYN算法[16]、基于CNN的VoxelMorph和SYM-Net和基于Transformer的SymTrans和TransMorph作為對比算法。SYN算法關注形變場的拓撲結構保持,是一個經典有效的醫學圖像配準軟件。在參數設置方面,基于ANTs軟件包的SYN算法采用軟件默認參數;VoxelMorph、SYM-Net、SymTrans和TransMorph使用基于pytorch的框架,設置與LCU-Net網絡同樣的參數配置。
從測試集中選擇一對圖像,通過不同網絡模型配準,得到如圖5所示的不同網絡模型配準結果的二維切片可視化圖,圖中分別展示了腦部MRI圖像的冠狀面、橫斷面和矢狀面。從待配準圖像對中可以觀察到,固定圖像和待配準圖像之間存在較大的結構差異,對比五種算法和本文算法生成的結果圖和形變場圖,可以觀察到本文算法的三個模型生成的配準形變場較為平滑。在圖中用紅色方框標記側腦室、脈絡叢、透明隔、腦干等解剖結構區域,通過比較不同配準方法所生成的形變后的分割標簽與固定圖像之間的重疊程度,可以發現本文算法在在保持局部細節信息完整的同時,在全局上可獲得更加精確和完整的配準效果,隨著卷積核的增大,配準效果也變得更好,保持了大腦結構的完整性。
圖5
不同方法配準結果和形變場
Figure5.
Registration results and deformation fields by different methods
各個網絡模型量化分析結果如表1所示,從參數量、配準精度、配準時間三個方面進行比較,其中SYN算法基于ANTs軟件包,沒有詳細參數量對比,僅用來比較配準效果和配準時間。根據Dice和Hausdorff這兩個評價指標可以觀察到,當LCU-Net的卷積核大小為3 × 3 × 3時,其配準精度與VoxelMorph和SYM-Net相當,但綜合網絡參數量和配準時間,LCU-Net3優于VoxelMorph和SYM-Net;當LCU-Net的卷積核大小為13 × 13 × 13時,其配準精度超過了對比算法SYN和SymTrans,且網絡參數量遠小于SymTrans,配準耗時短。綜合上述實驗結果分析,LCU-Net優于五種對比算法,且多核LCU-Net的性能優于單核LCU-Net,LCU-Net多核得到的配準精度最好,Dice達到0.823,并且配準時間相對較短。
圖6展示了單核LCU-Net網絡模型在不同卷積核大小(從3~27)下的Dice和Hausdorff結果。通過對比可以觀察到以下情況:隨著卷積核的增大,圖像的配準效果逐漸提升,但在較大卷積核時,配準效果的提升并不十分顯著。此外,在卷積核較大時,網絡的參數量也會顯著增加,導致網絡配準需要耗費更多時間。因此,僅僅采用單核大卷積模型并不能取得良好的效果。經過多尺度融合后,網絡的參數量降低了約25%,配準速度提高了約18%。特別是在使用大卷積核模型時,多尺度融合的效果尤為明顯。
圖6
多尺度融合分析
Figure6.
Multi-scale fusion analysis
2.4 泛化性對比
為了評估網絡模型的泛化性,本文在LPBA40數據集上對五個對比算法以及本文算法LCU-Net的三個模型的訓練最優結果進行了實驗。在不改變任何參數的情況下,將40幅LPBA40數據集圖像作為驗證測試集,使用已訓練好的模型進行配準,實驗結果如圖7所示。
圖7
泛化性對比結果
Figure7.
Generalization comparison results
表2為量化分析結果,比較了各網絡的配準精度,以Dice和Hausdorff作為評價指標。可以觀察到本文所提出的方法具有更高的準確度和精度,特別在紅色方框中所標記的解剖區域,LCU-Net網絡的配準效果優于對比算法。其中,LCU-Net多核網絡泛化性最好。
3 結論
本文提出了一種基于并行輕量化卷積和多尺度融合的網絡模型LCU-Net,設計具有三層并行路徑的LC模塊,在獲取更多感受野的同時不會喪失對局部細節信息的捕獲能力。在驗證推理階段,通過多尺度融合將網絡的BN層和內核融合,從而降低了網絡模型的復雜度,提高了推理速度,減少了配準時間。在OASIS數據集上,本文所提出的網絡模型與SYN、VoxelMorph、SYN-Net、SymTrans和TransMorph五種算法進行了比較。實驗結果表明,LCU-Net在性能上超過了對比算法模型,其中多核LCU-Net模型的配準效果最佳。同時,本文在LPBA40數據集上進行了泛化性對比實驗,LCU-Net表現出良好的泛化性能。本組實驗結果表明,在腦部單模態MRI可變形配準方面,LCU-Net網絡優于對比網絡,具有較大的應用價值。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:沈瑜、嚴源負責算法設計與實現、數據處理與分析、論文寫作與修改;宋婧、劉廣輝提供實驗指導及論文審閱修訂;許佳文、魏子易參與數據集收集及預處理并負責整理實驗結果。