結合正電子發射斷層掃描(PET)和計算機斷層掃描(CT)的PET/CT成像技術是目前較先進的影像學檢查手段,主要用于腫瘤篩查、良惡性鑒別診斷和分期分級。本文提出了一種基于PET/CT雙模態圖像的乳腺癌病灶分割方法,設計了一種雙路U型網絡框架,主要包括編碼器模塊、特征融合模塊和解碼器模塊三個組成部分。其中,編碼器模塊使用傳統的卷積進行單模態圖像特征提取;特征融合模塊采用協同學習特征融合技術,并使用轉換器(Transformer)提取融合圖的全局特征;解碼器模塊主要采用多層感知機以實現病灶分割。本文實驗使用實際臨床PET/CT數據評估算法的有效性,實驗結果表明乳腺癌病灶分割的精確率、召回率和準確率分別達到95.67%、97.58%和96.16%,均優于基線算法。研究結果證明了本文實驗設計的卷積與Transformer相結合的單、雙模態特征提取方式的合理性,為多模態醫學圖像分割或分類等任務的特征提取方法提供參考。
引用本文: 翟悅淞, 陳智麗, 邵丹. 基于協同學習特征融合和轉換器的乳腺癌病灶分割方法. 生物醫學工程學雜志, 2024, 41(2): 237-245. doi: 10.7507/1001-5515.202306063 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
0 引言
乳腺癌發病率高,已嚴重威脅女性健康,根據2020年全球乳腺癌分析登記數據顯示,新發乳腺癌患者超過226萬人,死亡約68.5萬人,在所有癌癥患者中占比已高達11.7%[1]。在我國,女性乳腺癌發病死亡人數每年持續上升,預計到2030年發病數和死亡數將分別增加36.27%和54.01%[2-3]。盡管隨著醫療診斷與治療手段的不斷進步,我國乳腺癌患者生存率已有所提升,但每年依然有眾多患者深受乳腺癌折磨[4]。
結合正電子發射斷層掃描(positron emission tomography,PET)和計算機斷層掃描(computed tomography,CT)的PET/CT技術,是一種解剖結構顯像和功能顯像結合的成像手段,其不僅可以顯示病變的形態學特征,還可以報告病變的代謝信息。醫生可根據PET/CT的結果調整乳腺癌患者的治療方案進而提高患者生存率[5]。PET成像需要給患者注射用正電子核素標記的葡萄糖類似物作為示蹤劑,根據腫瘤的代謝特點,PET圖像會顯示出高代謝病變區域;但除腫瘤外,人體的高代謝器官也會大量吸收示蹤劑,從而造成病灶區分困難。此外,PET圖像分辨率較低,導致病灶邊界模糊,也會影響醫生的判斷[6]。CT是一種具有高分辨率的結構成像,但由于CT圖像中各區域強度分布相似,難以區分病變組織與周圍正常軟組織。因此,結合PET功能代謝成像特點以及CT清晰的結構成像特點可以幫助醫生對病患作出準確的診斷[7-8]。
為了更好地利用PET/CT技術幫助醫生診治病患以減少人工識別影像可能產生的誤差,目前已有大量研究將圖像分割技術用于醫學影像病灶分割任務。由于存在目標邊界模糊和易受噪聲干擾等局限,到目前為止,尚不存在一種普適完美的圖像分割方法。近年來,隨著圖形處理器(graphics processing unit,GPU)算力的增長以及數據集的完善,基于深度學習的語義分割算法飛速發展,圖像分割技術水平大幅提高,目標分割完整度和分割精度得到顯著提升。Cruz-Roa等[9]使用卷積神經網絡(convolutional neural network,CNN)替代人工提取特征方法,使乳腺X線影像的病灶分類準確度明顯提高。趙旭[10]采用全卷積網絡(fully convolutional network,FCN)對全視野的乳腺數據進行特征提取,減少了數據采樣對小腫塊檢測結果的影響,提高了檢測精確度。徐勝舟等[11]設計的基于FCN遷移學習的乳腺腫塊分割方法進一步驗證了該算法的分割效果明顯優于傳統分割算法的結論。Al-antari等[12]提出了一種深度網絡模型——全分辨率CNN,它對大數據量乳腺X線影像進行分割,結果表明該模型在腫塊分割方面優于傳統的深度學習方法,可用來協助放射科醫師診斷乳腺腫塊。Ronneberger等[13]提出的U型網絡(U-Net),是使用FCN進行語義分割的主流算法之一,其設計的初衷是為了解決醫學圖像分割的問題,并在國際生物醫學圖像研討會(International Symposium on Biomedical Imaging,ISBI)細胞跟蹤挑戰賽中獲得多個第一名。之后,U-Net憑借其突出的分割效果而廣泛應用于語義分割領域。Chen等[14]提出的深度試驗模型三加版本,作為該系列最后一版將原深度試驗第三版模型當作編碼器,再通過添加解碼器得到全新的模型,并將空間特征金字塔結構與編碼器、解碼器結構相結合實現多尺度分割。Zhuang[15]提出了一種多路徑U-Net,以實現多模態數據的輸入,為多模態分割任務提供參考。Kumar等[16]提出了一種多模態特征融合算法用于實時分割PET/CT影像中的肺部結構、胸腔縱膈以及腫瘤,結果顯示該算法最終戴斯(Dice)系數為0.82,真陽性率為0.84。Xiao等[17]在U-Net中加入殘差結構,設計出殘差U-Net,用于視網膜血管分割任務。Guan等[18]將密集連接加入到U-Net中,提出全連接密集U-Net,用于去除圖像中的偽影。Isensee等[19]提出的精簡U-Net,不在U-Net基礎上添加新的結構,而是在激活函數、批量正則化、數據處理等技術層面中進行改進,在很多任務中取得了不錯的成績。Chen等[20]將轉換器(Transformer)引入U-Net,提出了結合Transformer和U-Net的復合網絡(Transformer+U-Net,TransUNet),在多器官分割和心臟分割等醫學任務中表現出更好的分割效果。Jain等[21]提出Transformer通用模型,這是第一個基于Transformer的多任務通用圖像分割框架,在全景、語義以及實例分割上的聯合訓練效果優于其他單獨訓練的模型。
在自然語言任務上取得了前所未有的成功后,Transformer已成功地應用于各種計算機視覺問題并取得了可觀的成果。隨著Transformer的廣泛應用,醫學影像領域也開始關注并逐步嘗試使用Transformer。與作用于局部感受野的CNN相比,Transformer的全局上下文建模能力對于醫學圖像的精準分割至關重要,因為通過構建空間像素之間的關系,可以對分布在大感受野上的器官進行有效的特征提取。近年來,在醫學影像界基于Transformer的技術快速發展,尤其是視覺Transformer,其在醫學圖像分割、檢測、分類、重建、合成、配準、臨床報告生成和其他很多任務中都取得了不錯的效果[22]。
綜上,為解決乳腺癌病灶精準分割的問題,本文綜合考慮PET/CT雙模態影像的成像特點,利用雙模態數據的優勢,使用實際臨床PET/CT雙模態影像數據,參考Kumar等[16]提出的協同學習(collaborative learning,Co-learning)特征融合方法,同時參考Xie等[23]提出的Transformer分割模型,提出一種融合PET/CT雙模態影像特征的乳腺癌病灶分割方法。此方法在以CNN為特征提取核心的“編碼器?特征融合?解碼器”結構的基礎上引入了Transformer。其目的在于結合了CNN的局部特征提取能力和Transformer的全局特征提取能力,在保留單模態圖像病灶細節的同時獲取融合特征的全局信息,能夠更好地區分病灶與非病灶區域,解決單一使用CNN作為特征提取器所出現的感受野不足、全局特征關聯性差而導致的誤分割問題,進而提升乳腺癌病灶分割精度。
1 本文算法
1.1 網絡結構
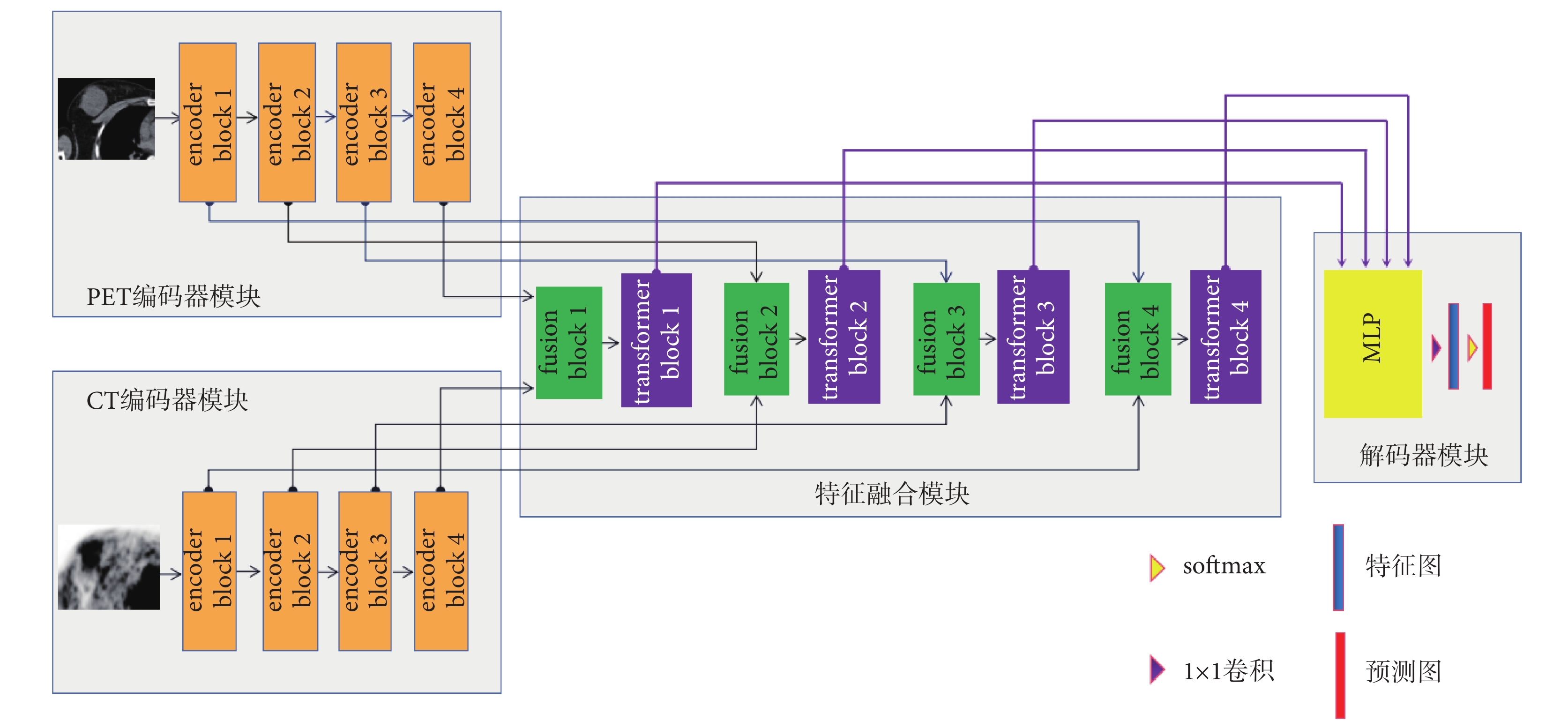
本文采用編碼器、特征融合和解碼器的網絡結構,借鑒多路徑U-Net的網絡設計實現雙模態數據的輸入以及各自的特征提取功能[15],整體網絡結構如圖1所示。首先編碼器模塊分為兩個分支,其一是PET編碼器模塊分支,另一個為CT編碼器模塊分支,每個分支以四個編碼器塊(encoder blcok)作為單模態圖像特征提取器,圖1中分別為encoder block1~4。隨后每個encoder blcok提取的特征信息輸入到特征融合模塊進行雙模態特征信息融合;特征融合模塊由四個融合塊(fusion block)和四個Transformer塊(transformer block)組成,圖1中分別為fusion block1~4和transformer block1~4;特征融合模塊提取到的特征輸入到由多層感知機(multi-layer perceptron,MLP)、1 × 1卷積、歸一化指數函數(softmax)構成的解碼器模塊當中,實現從特征圖到預測圖的轉換并得到最終的分割預測結果。其中MLP實現上采樣(upsample)和特征圖組合功能,1 × 1卷積實現降通道數功能,softmax預測屬于病灶的概率。
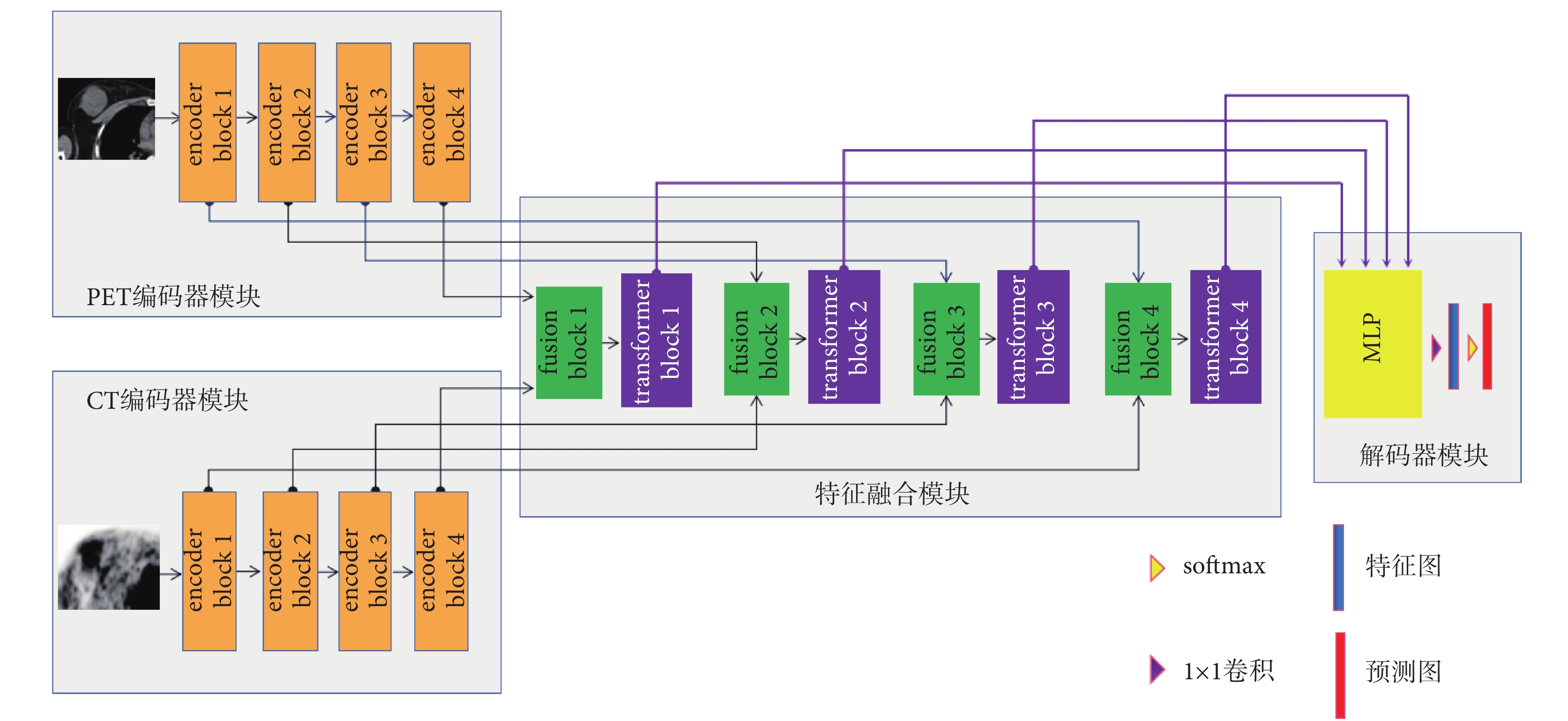 圖1
本文基于Co-learning特征融合和Transformer的雙路U-Net網絡結構
Figure1.
The dual-path U-Net network structure based on Co-learning feature fusion and transformer in this article
圖1
本文基于Co-learning特征融合和Transformer的雙路U-Net網絡結構
Figure1.
The dual-path U-Net network structure based on Co-learning feature fusion and transformer in this article
1.2 模塊結構
1.2.1 編碼器模塊
近幾年,Transformer模型在圖像分類、目標檢測、語義分割等下游任務中均取得了卓越的性能,因此在初期研究階段本課題組曾嘗試使用Transformer完全代替CNN作為編碼器的特征提取核心,然而通過實驗發現該方式并不能得到更好的分割效果反而增加了網絡的參數量,故最終沒有采用。
通過總結大量Transformer相關工作的文獻發現,視覺Transformer、滑動窗Transformer等以Transformer為核心的技術均應用于圖像特征較為復雜的場景當中[24],而單模態醫學影像特征復雜度相對較低,對其單一使用Transformer并不能得到更好的分割效果。對比Transformer與CNN,Transformer感受野更大,通過注意力機制來捕獲全局的上下文信息從而對目標建立起長距離依賴,可以提取更高級的特征。然而高級的特征表示依賴于底層特征,因此本文考慮保留提取底層特征能力更好的CNN作為單模態圖像特征提取器,在特征融合模塊獲得信息較為復雜的融合圖之后引入Transformer進行全局特征提取。
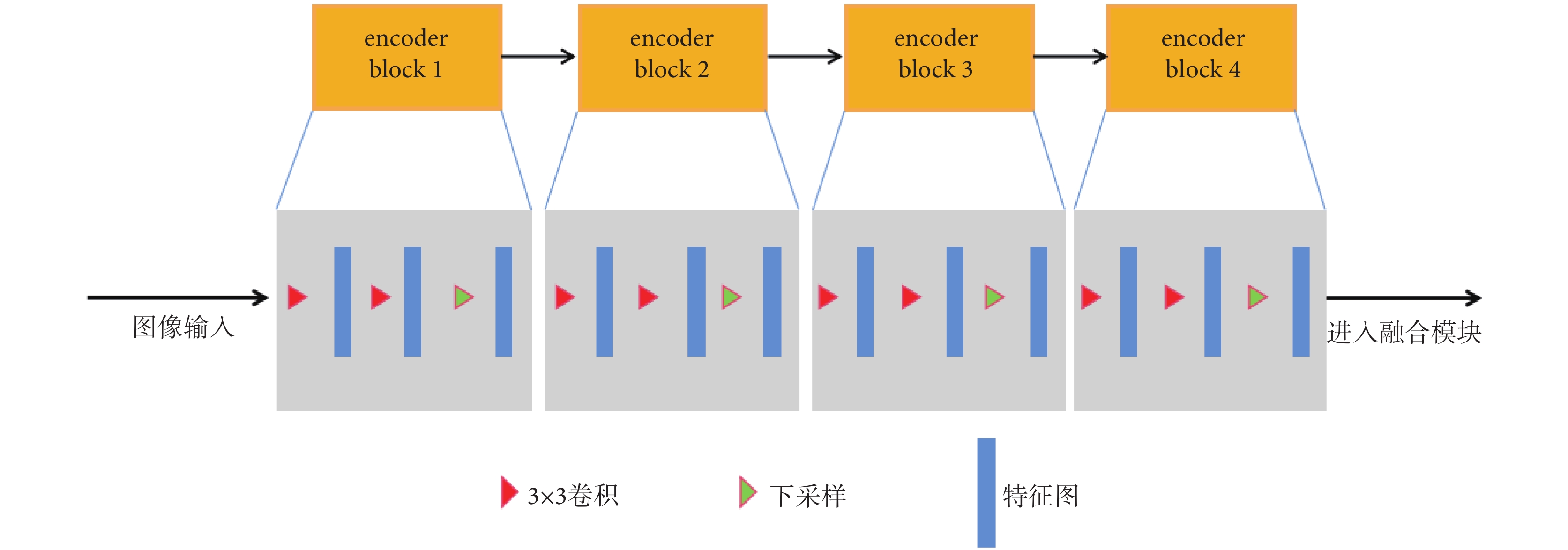
如圖2所示,本文的單個編碼器模塊分支由四個encoder block組成,分別為encoder block1~4。每個encoder block由兩組3×3卷積和一個下采樣層所組成,以實現特征提取、生成特征圖的功能。
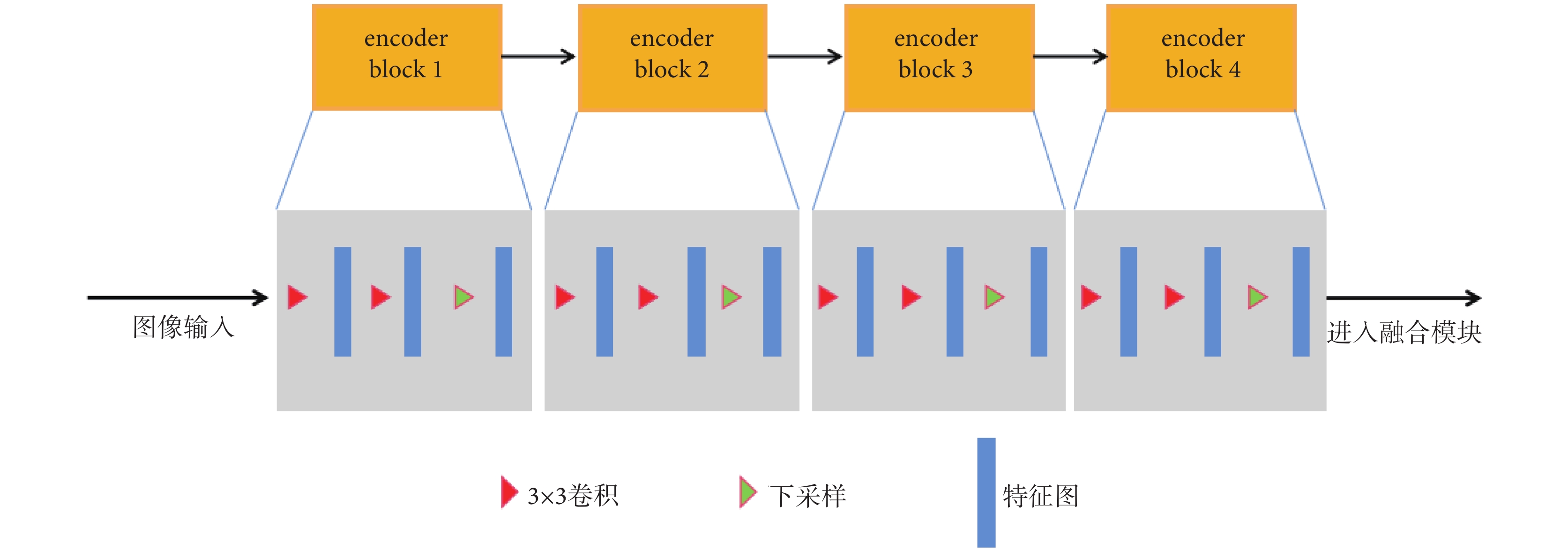 圖2
編碼器模塊
Figure2.
Encoder module
圖2
編碼器模塊
Figure2.
Encoder module
1.2.2 特征融合模塊
(1)fusion block
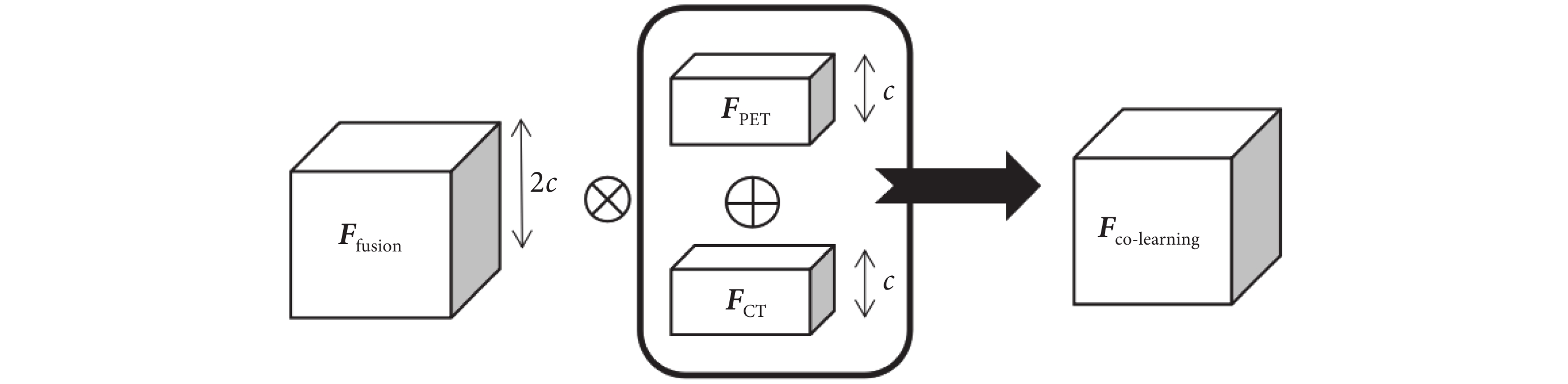
兩個編碼器模塊分支輸出的成對單模態特征圖在fusion block中進行特征融合。首先使用三維(three dimensional,3D)卷積提取空間融合信息[25],再對單模態特征圖進行通道方向的疊加(concatenate)生成堆疊特征圖,隨后將兩部分的結果進行像素乘積生成最終的特征融合圖[16],如式(1)所示:
 |
其中,Ffusion是3D卷積提取的空間融合信息,FPET是PET圖像特征圖,FCT是CT圖像特征圖,Fco-learning是最終生成的特征融合圖, 是逐元素乘法,
是逐元素乘法, 是concatenate操作。PET/CT雙模態特征融合過程如圖3所示,其中c為通道數。
是concatenate操作。PET/CT雙模態特征融合過程如圖3所示,其中c為通道數。
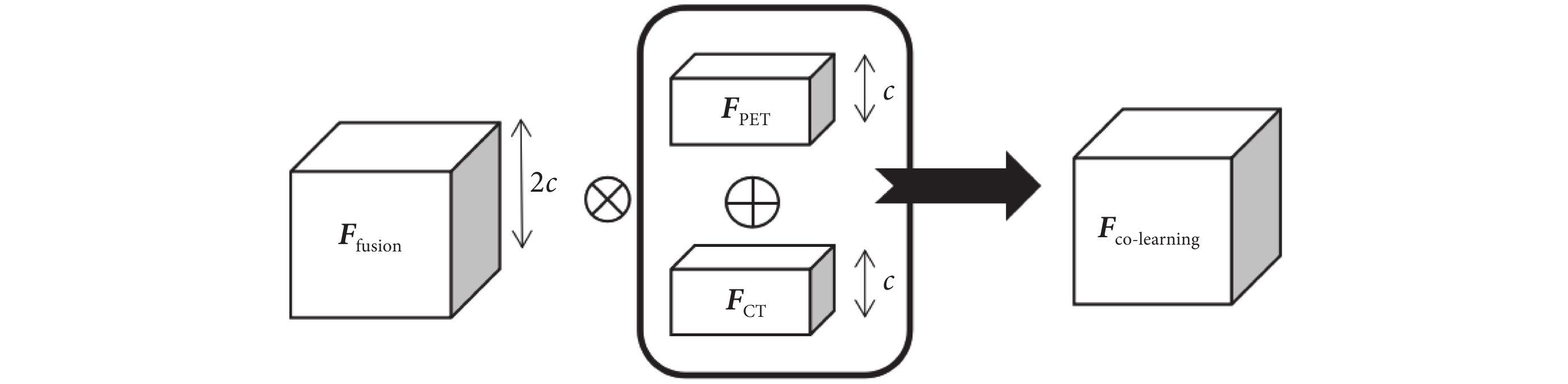 圖3
特征融合圖的生成
Figure3.
Generation of feature fusion maps
圖3
特征融合圖的生成
Figure3.
Generation of feature fusion maps
(2)transformer block
在此特別說明,在特征融合之后而非在單模態網絡支路引入Transformer的原因如下:考慮特征融合之前為單模態的特征提取,特征信息相對單一,因此著重使用CNN提取細節信息;而經過特征融合后病灶特征更為顯著,病灶區與非病灶區的特征差異會更加明顯,需建立遠距離像素之間的聯系,以更好地區分各組織區域;Transformer具有更大的感受野、強大的全局特征提取能力,能夠更好地建立像素與像素之間的關聯性,有利于提取病灶區域特征;并且在fusion block之后引入transformer block對比在encoder block中引入transformer block可以降低參數量,以達到輕量化網絡的作用;因此本文在特征融合之后引入Transformer作為空間信息提取器。
谷歌團隊在文獻[26]中提出的算法的核心即為Transformer,而其中的“多頭自注意力機制”即為Transformer的核心。自注意力機制(self-attention)將輸入向量分為查詢(query,Q)、鍵值(key,K)、賦值(value,V)(分別以符號Q、K、V表示),而Q、K、V的概念源自于信息檢索系統,Q為需要檢索的名稱,K為根據Q來匹配此物品所需要的特征,然后根據Q和K的相似度得到匹配的內容V,self-attention中的Q、K、V也是類似的作用。而“多頭”的好處在于,不同的“頭”關注的子空間特征不同,某些“頭”更看重當前特征點附近的信息,有些“頭”會比較關注長距離信息,這樣提取到的特征會更加豐富。self-attention計算方式,如式(2)所示:
 |
首先,Q和K進行點積計算出一個評分,然后除以根號下向量維度 起到標準化、減少計算量的作用,隨后進行softmax計算特征之間關聯度的概率值,最后乘以V得到最終的self-attention的結果。
起到標準化、減少計算量的作用,隨后進行softmax計算特征之間關聯度的概率值,最后乘以V得到最終的self-attention的結果。
本文的transformer block如圖4所示,由兩組以高效自注意力機制(efficient self-attention)、前饋網絡(feed forward networks,FFN)以及重疊塊融合(overlapped patch merging)所構成的層所組成。FFN由1 × 1卷積、深度可分離卷積和高斯誤差線性單元函數(Gaussian error linear units,GELU)構成。
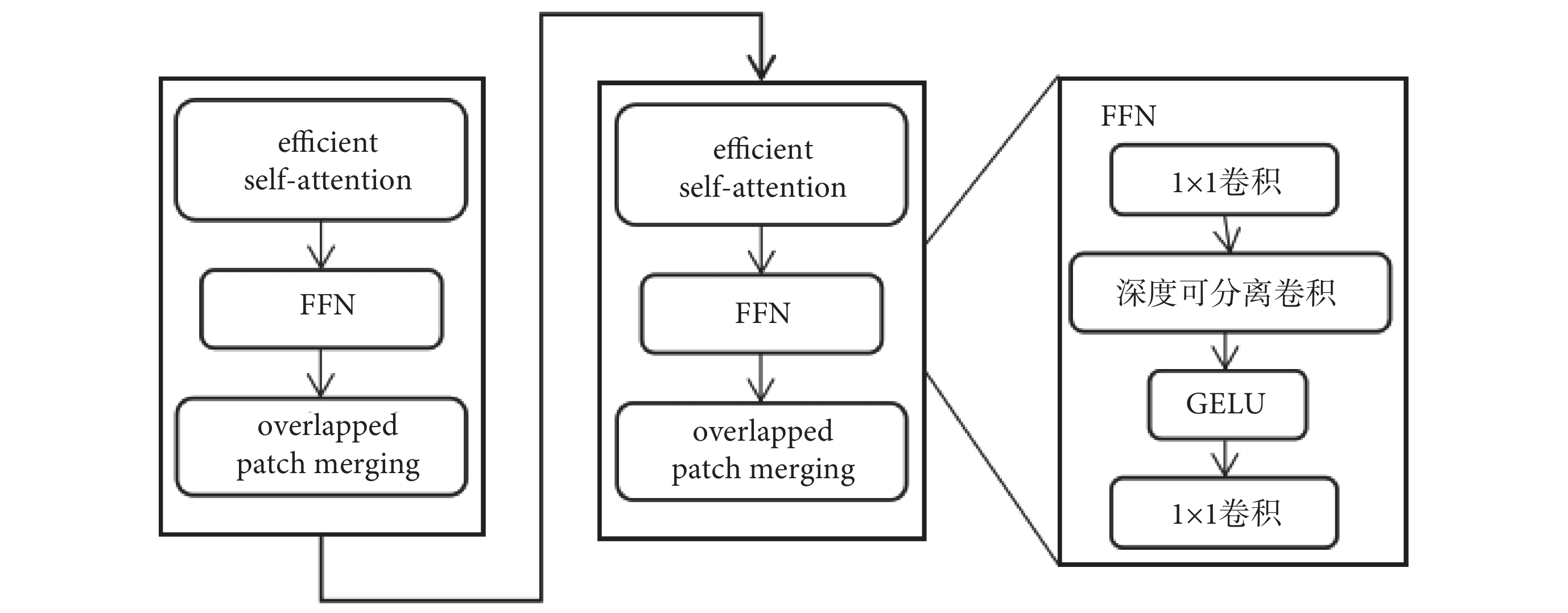 圖4
Transformer塊
Figure4.
Transformer block
圖4
Transformer塊
Figure4.
Transformer block
其中,efficient self-attention由Xie等[23]提出,該作者認為網絡的計算量主要體現在self-attention上,為了降低網絡整體的計算復雜度,他們在self-attention基礎上,添加縮放因子R以降低每一個self-attention模塊的計算復雜度(O(N2)→O ),如式(3)與式(4)所示:
),如式(3)與式(4)所示:
 |
 |
其中,N為圖像的寬與高的乘積,C為通道數。具體的縮放方式首先通過重塑函數(Reshape)將K重新改變其形狀為 (C·R),然后通過線性函數(Linear)改變其通道數,使得最終K的維度變為
(C·R),然后通過線性函數(Linear)改變其通道數,使得最終K的維度變為  ,以降低計算的復雜度。
,以降低計算的復雜度。
FFN由多個神經元組成,每個神經元接收來自上一層神經元的輸出,并通過一定的權重和偏置進行加權和處理,最終得到本層神經元的輸出,進而作為下一層神經元的輸入。FFN由1 × 1卷積、深度可分離卷積、GELU組成。其中,1 × 1卷積的作用是改變通道數;深度可分離卷積將卷積操作分解為深度卷積和逐點卷積,從而顯著減少參數量,進而降低計算復雜度;使用GELU作為激活函數除加速收斂、引入非線性計算的功能以外,其在負輸入時會將輸入值映射為一個非零值,從而避免了神經元死亡的問題。overlapped patch merging的主要作用是將圖像分割成多個小的補丁,并對這些補丁進行合并和特征提取,以獲得更豐富的特征表示[24]。
1.2.3 解碼器模塊
本文解碼器的設計得益于Transformer中的非局部注意力,在結構不復雜的情況下獲得更大的接受域,同時產生高度局部和非局部關注。結構如圖5所示,將來自特征融合模塊的四組特征圖通過1 × 1卷積與不同參數的upsample,使長、寬、通道數完全一致,在同維度的條件下進行通道方向上的concatenate操作,然后再次使用1 × 1卷積將通道數降至2(二分類:病灶與非病灶),最終通過softmax函數預測屬于病灶的概率。
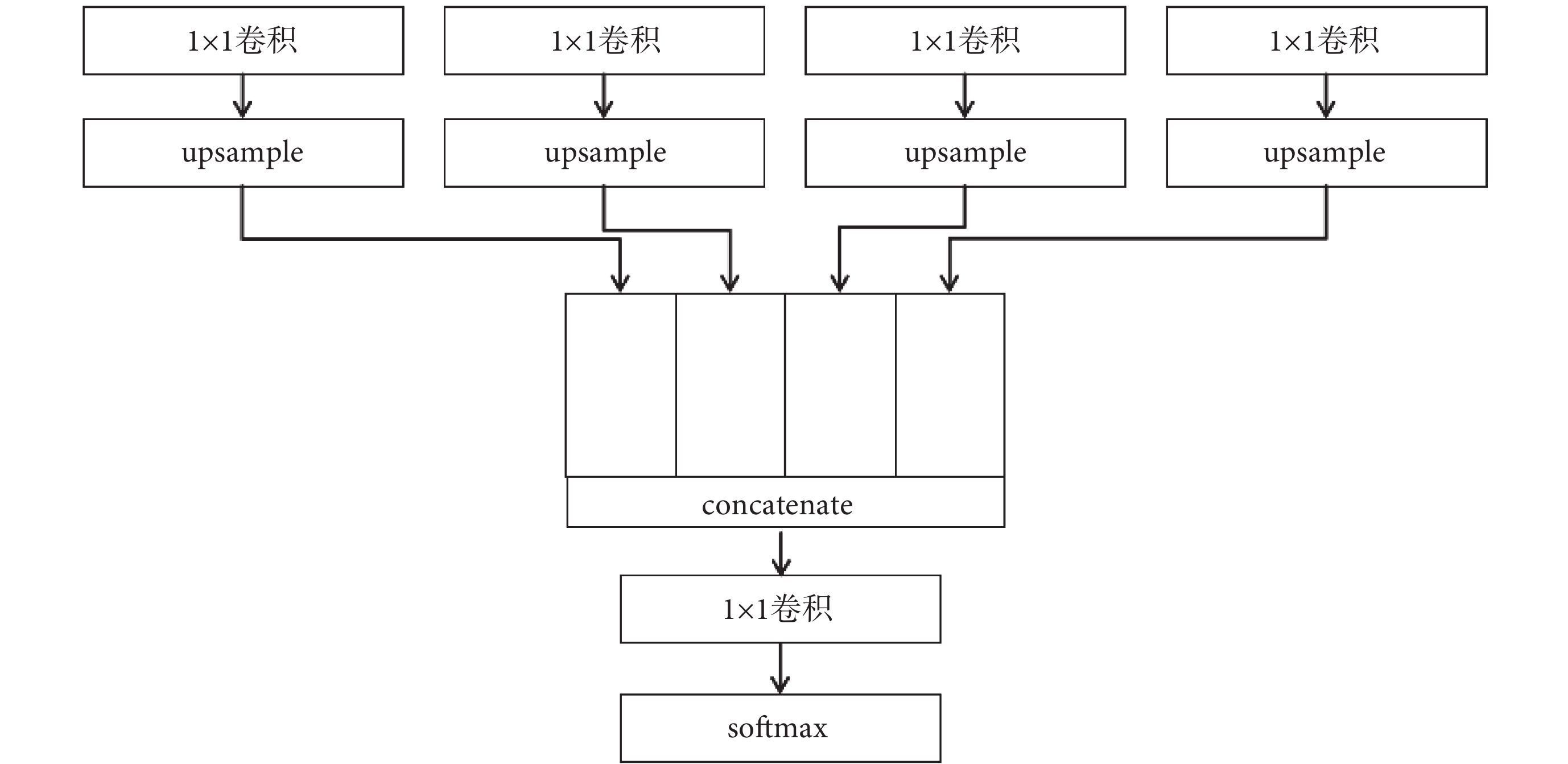 圖5
解碼器模塊
Figure5.
Decoder module
圖5
解碼器模塊
Figure5.
Decoder module
2 實驗結果和分析
2.1 實驗準備
2.1.1 數據集
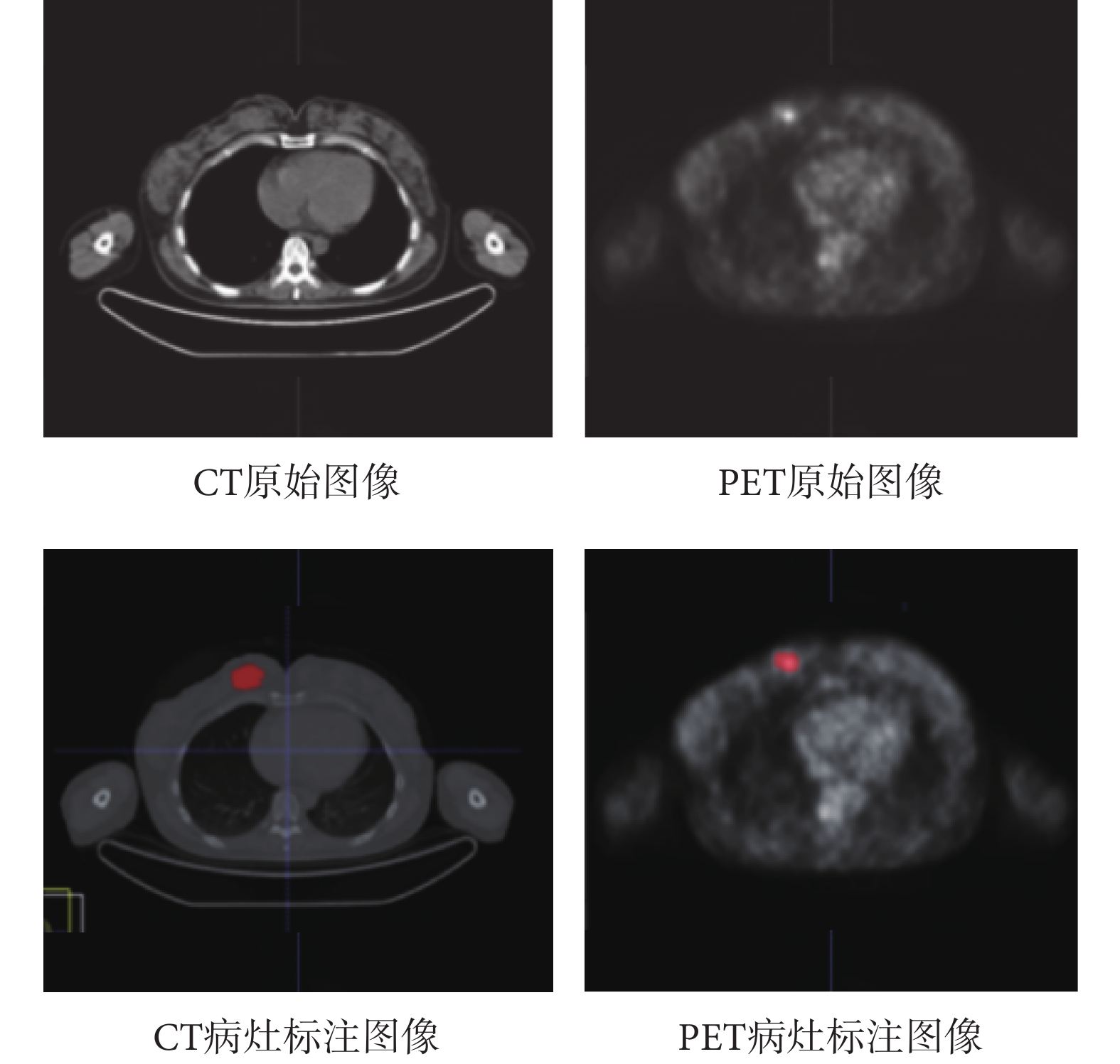
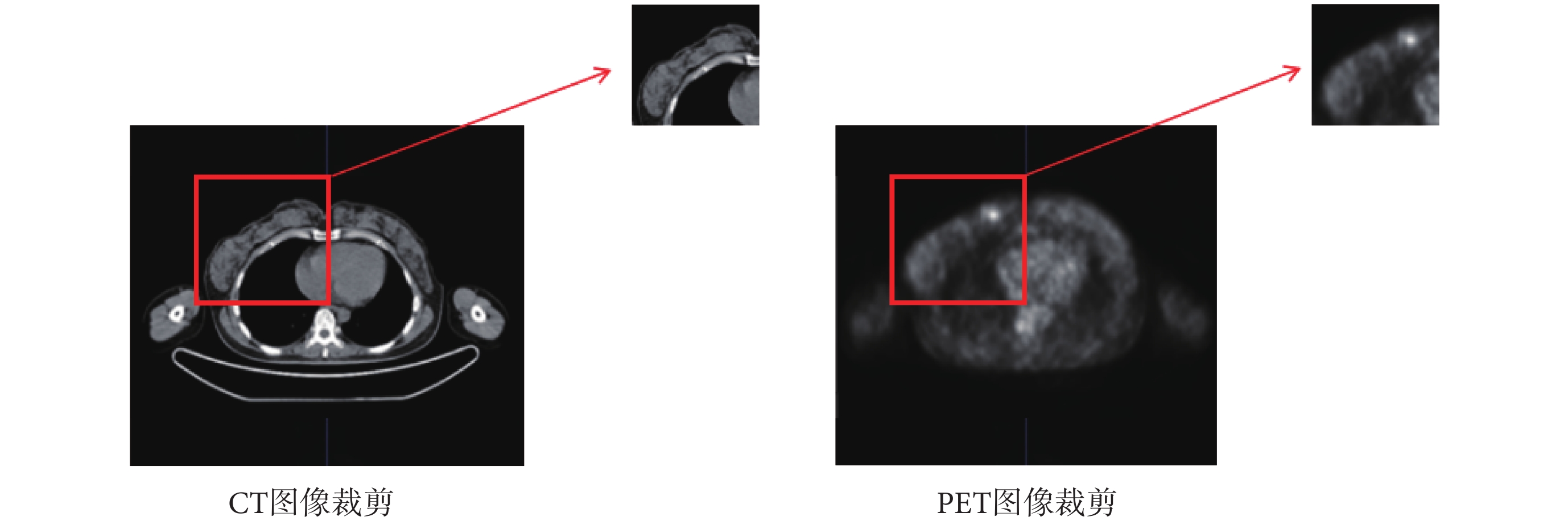
本文數據采集于廣東省人民醫院,受試者為205位年齡范圍在26~78歲之間患有不同亞型、不同等級乳腺癌的女性群體,已獲得所有受試者的知情同意書。本文實驗研究已通過廣東省人民醫院(廣東省醫學科學院)醫學研究倫理委員會倫理審查[批號:GDREC2019696H(R1)],并獲得數據使用授權。數據集包含2 159對來自受試者的PET/CT原始掃描橫斷影像組(PET圖像大小為128 × 128 × 3,CT圖像大小為512 × 512 × 3),及其對應的由專業醫生標注了病灶位置的標注圖像。如圖6所示,左上為CT原始圖像;左下為CT原始圖像對應的病灶標注圖像;右上為PET原始圖像;右下為PET原始圖像對應的病灶標注圖像,病灶標注圖像中紅色區域即為專業醫生標注的病灶位置。
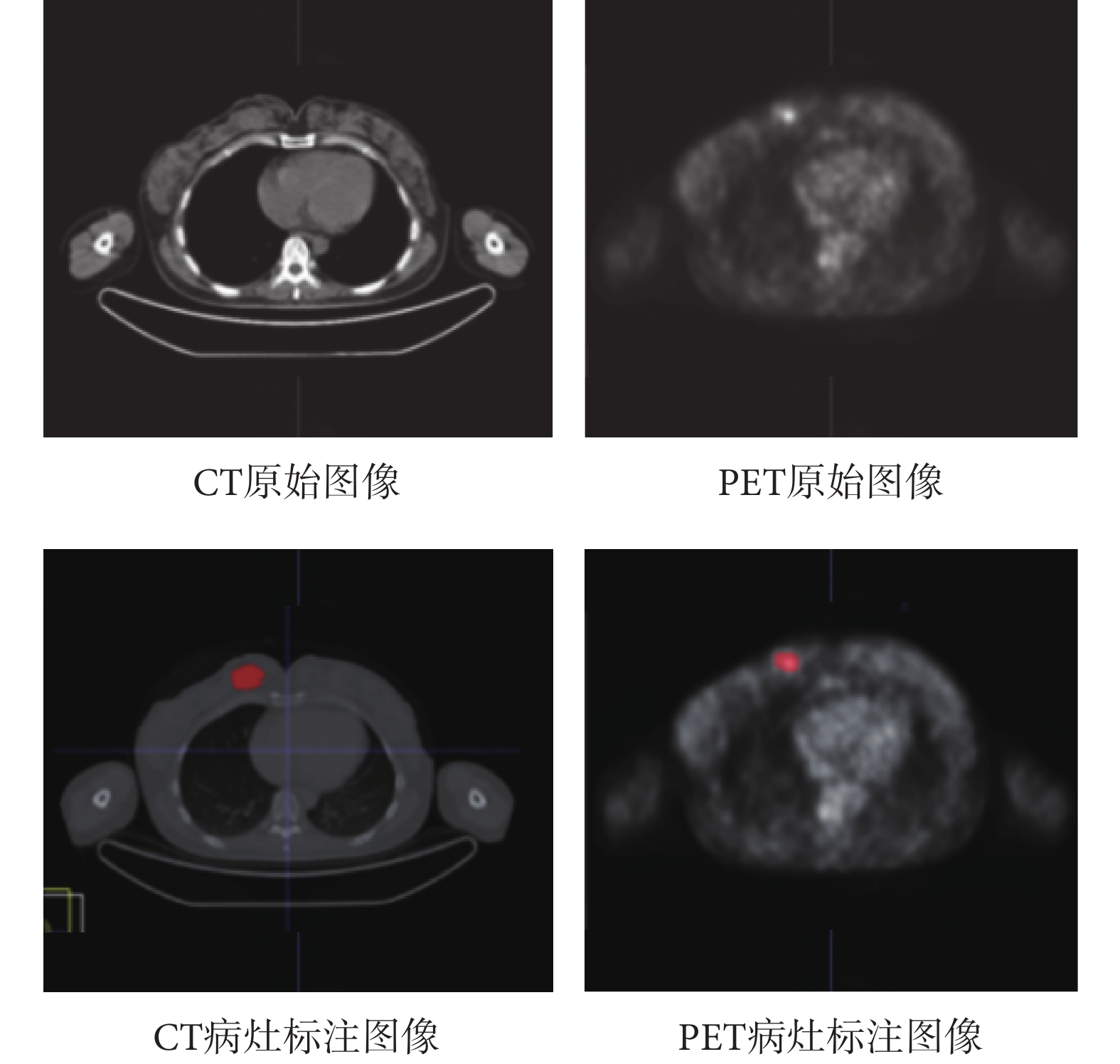 圖6
乳腺癌PET/CT影像
Figure6.
PET/CT imaging of breast cancer
圖6
乳腺癌PET/CT影像
Figure6.
PET/CT imaging of breast cancer
2.1.2 數據預處理
因原始PET圖像與CT圖像尺寸不同、分辨率不同以及各自圖像病灶占比較小、圖像噪聲較多、數據量有限等因素,需要對原始圖像進行預處理。首先,將每一對圖像使用圖像配準工具Elastix 5.1.0(Image Sciences Institute,美國)進行配準,保證空間位置上的重合[27]。其次,對于分割任務,圖像的預裁剪可以去除大量的背景干擾,聚焦感興趣區域以得到更好的訓練效果[28]。裁剪方法首先以圖像中軸線為基準區分左胸病灶圖像和右胸病灶圖像,再選取合適的左右胸裁剪框坐標,最后通過編寫腳本實現批量裁剪,如圖7所示,其中紅色矩形為裁剪框,紅色箭頭所指向的即為裁剪后的圖像。需要說明的是,為驗證本文方法對非病灶區域的軟組織結構或其他高代謝器官(心臟、肺等)的抗干擾能力,在裁剪圖像時,沒有完全去除這類組織和器官,而是保留了部分干擾因素。本文采用的數據增強方式為水平和垂直方向的隨機翻轉,數據量增加為原始數據量的三倍,通過數據增強可以解決數據匱乏和數據不均衡而導致的模型性能欠佳、魯棒性較差的問題[29]。
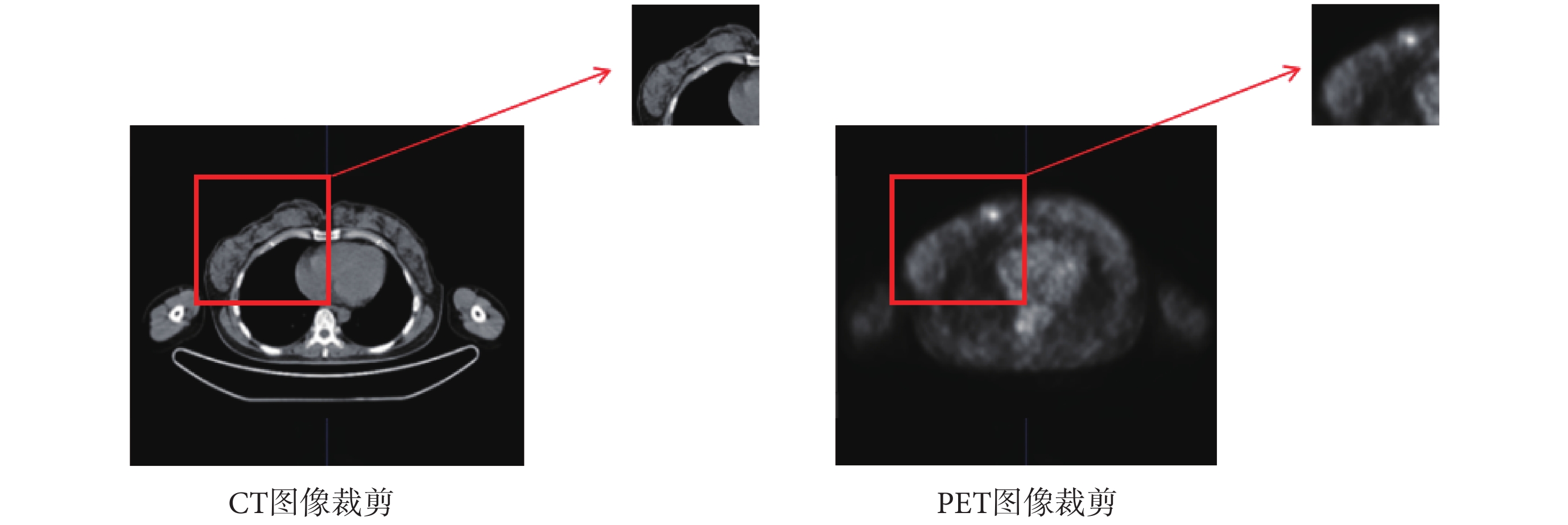 圖7
圖像裁剪
Figure7.
Image cropping
圖7
圖像裁剪
Figure7.
Image cropping
2.2 實驗設置
本文實驗采用深度學習框架TensorFlow2.1-GPU版本(Google Brain,美國),使用英偉達顯卡RTX 2080super(NVIDIA,美國),統一計算設備架構CUDA 10.1版本(NVIDIA,美國),神經網絡加速庫cuDNN 7.6.5版本(NVIDIA,美國)對訓練過程進行GPU加速。為使模型更快收斂,本文采用了動量梯度下降法優化器,并在訓練過程中使用動態衰減方法設置學習率,初始學習率設置為0.001,學習率衰減步數為10 000,衰減率為0.5,批量大小設置為2,訓練總輪數為50輪。實驗使用80%的數據用于訓練,20%的數據用于測試,即訓練集包含1 727對PET/CT影像組,測試集包含432對PET/CT影像組,數據劃分時避免同一受試者的影像數據同時出現在訓練集和測試集。
2.3 評價指標
本文的評價指標為精確率(precision,Pre)、召回率(recall,Rec)和準確率(accuracy,Acc)。Pre描述模型區分真實病灶和假病灶的性能;Rec描述模型檢測病灶區域的性能;Acc描述模型正確分割病灶和背景的性能,計算式如式(5)~式(7)所示:
 |
 |
 |
其中,真陽性(true positive,TP)為圖像中被預測為病灶且實際也是病灶的像素數量;假陰性(false negative,FN)為圖像中被預測為非病灶但實際是病灶的像素數量;真陰性(true negative,TN)為圖像中被預測為非病灶且實際也是非病灶的像素數量;假陽性(false positive,FP)為圖像中被預測為病灶但實際是非病灶的像素數量[30]。
2.4 實驗結果分析
2.4.1 結果分析
考慮到醫學圖像分割和PET/CT雙模態數據融合的特殊性,同時為了確保對比實驗的有效性、公平性,本文以與本文密切相關的文獻[16]作為基線算法,并與其進行實驗對比。實驗上采用五折交叉驗證來評估本文算法以及基線算法的分割性能,如表1所示。實驗結果表明,本文算法在所有評價指標上均優于基線算法。
此外,為驗證本文算法中Transformer與MLP引入的有效性進行了消融實驗,結果如表2所示。單模態與雙模態數據的對比結果以及本文算法與代表性醫學圖像分割算法的對比結果如表3所示,其中TransUNet作為第一個將Transformer與U-Net結合的模型打開了Transformer進入醫學影像分割領域的大門,其思想對本文的網絡設計有一定的啟發,因此將其引入本文的對比實驗。
此外,本文對比了分割結果圖像,如圖8所示。圖8中,展示了一組左胸病灶分割結果對比示例和一組右胸病灶分割結果對比示例,其中每一組對比示例均展示出各自的PET/CT圖像、標簽圖像、本文算法的分割結果以及基線算法的分割結果。通過本文算法分割結果圖和基線算法分割結果圖的對比可以清晰地發現本文算法在解決“過分割”情況的突出表現,量化指標上體現在Pre的提升,在本文中Pre表示分割結果中被正確分割為乳腺癌病灶的像素點占分割結果中被預測為乳腺癌病灶的像素點的比例。精確度越高,說明分割結果中“過分割”的情況越少。因此,無論從定量實驗指標還是分割的可視化結果均可以看出本文算法解決“過分割”能力的突出表現,證明了本文算法的有效性。
 圖8
本文算法與基線算法的分割結果比較
Figure8.
Comparison of segmentation results between our proposed algorithm and the baseline algorithm
圖8
本文算法與基線算法的分割結果比較
Figure8.
Comparison of segmentation results between our proposed algorithm and the baseline algorithm
3 結語
本文提出了一種將雙路U-Net、Co-learning特征融合以及Transformer技術相結合的PET/CT乳腺癌病灶分割方法。利用PET圖像與CT圖像的影像特點,通過特征融合技術將PET圖像特征與CT圖像特征結合,使病灶特征更加突出;利用CNN的局部細節提取能力和Transformer的全局特征提取能力,合理地將二者作為本文算法的單、雙模態的特征提取器以獲得更加精準的分割結果。實驗結果表明,本文算法較現有方法取得了更好的分割結果,證明了本文網絡設計的合理性,可為多模態醫學圖像的特征提取方式提供參考。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:本文的算法研究工作、實驗設計以及論文初稿撰寫主要由第一作者翟悅淞完成。陳智麗和邵丹為共同通信作者,陳智麗教授對論文研究工作與文稿撰寫給予了大量指導和修改意見,并直接參與了論文修改稿的撰寫。邵丹主任醫師對論文工作從核醫學角度提供了專業指導與建議,并對實驗數據標注給予了指導與把關。
倫理聲明:本研究通過了廣東省人民醫院(廣東省醫學科學院)醫學研究倫理委員會的審批[批號:GDREC2019696H(R1)]
0 引言
乳腺癌發病率高,已嚴重威脅女性健康,根據2020年全球乳腺癌分析登記數據顯示,新發乳腺癌患者超過226萬人,死亡約68.5萬人,在所有癌癥患者中占比已高達11.7%[1]。在我國,女性乳腺癌發病死亡人數每年持續上升,預計到2030年發病數和死亡數將分別增加36.27%和54.01%[2-3]。盡管隨著醫療診斷與治療手段的不斷進步,我國乳腺癌患者生存率已有所提升,但每年依然有眾多患者深受乳腺癌折磨[4]。
結合正電子發射斷層掃描(positron emission tomography,PET)和計算機斷層掃描(computed tomography,CT)的PET/CT技術,是一種解剖結構顯像和功能顯像結合的成像手段,其不僅可以顯示病變的形態學特征,還可以報告病變的代謝信息。醫生可根據PET/CT的結果調整乳腺癌患者的治療方案進而提高患者生存率[5]。PET成像需要給患者注射用正電子核素標記的葡萄糖類似物作為示蹤劑,根據腫瘤的代謝特點,PET圖像會顯示出高代謝病變區域;但除腫瘤外,人體的高代謝器官也會大量吸收示蹤劑,從而造成病灶區分困難。此外,PET圖像分辨率較低,導致病灶邊界模糊,也會影響醫生的判斷[6]。CT是一種具有高分辨率的結構成像,但由于CT圖像中各區域強度分布相似,難以區分病變組織與周圍正常軟組織。因此,結合PET功能代謝成像特點以及CT清晰的結構成像特點可以幫助醫生對病患作出準確的診斷[7-8]。
為了更好地利用PET/CT技術幫助醫生診治病患以減少人工識別影像可能產生的誤差,目前已有大量研究將圖像分割技術用于醫學影像病灶分割任務。由于存在目標邊界模糊和易受噪聲干擾等局限,到目前為止,尚不存在一種普適完美的圖像分割方法。近年來,隨著圖形處理器(graphics processing unit,GPU)算力的增長以及數據集的完善,基于深度學習的語義分割算法飛速發展,圖像分割技術水平大幅提高,目標分割完整度和分割精度得到顯著提升。Cruz-Roa等[9]使用卷積神經網絡(convolutional neural network,CNN)替代人工提取特征方法,使乳腺X線影像的病灶分類準確度明顯提高。趙旭[10]采用全卷積網絡(fully convolutional network,FCN)對全視野的乳腺數據進行特征提取,減少了數據采樣對小腫塊檢測結果的影響,提高了檢測精確度。徐勝舟等[11]設計的基于FCN遷移學習的乳腺腫塊分割方法進一步驗證了該算法的分割效果明顯優于傳統分割算法的結論。Al-antari等[12]提出了一種深度網絡模型——全分辨率CNN,它對大數據量乳腺X線影像進行分割,結果表明該模型在腫塊分割方面優于傳統的深度學習方法,可用來協助放射科醫師診斷乳腺腫塊。Ronneberger等[13]提出的U型網絡(U-Net),是使用FCN進行語義分割的主流算法之一,其設計的初衷是為了解決醫學圖像分割的問題,并在國際生物醫學圖像研討會(International Symposium on Biomedical Imaging,ISBI)細胞跟蹤挑戰賽中獲得多個第一名。之后,U-Net憑借其突出的分割效果而廣泛應用于語義分割領域。Chen等[14]提出的深度試驗模型三加版本,作為該系列最后一版將原深度試驗第三版模型當作編碼器,再通過添加解碼器得到全新的模型,并將空間特征金字塔結構與編碼器、解碼器結構相結合實現多尺度分割。Zhuang[15]提出了一種多路徑U-Net,以實現多模態數據的輸入,為多模態分割任務提供參考。Kumar等[16]提出了一種多模態特征融合算法用于實時分割PET/CT影像中的肺部結構、胸腔縱膈以及腫瘤,結果顯示該算法最終戴斯(Dice)系數為0.82,真陽性率為0.84。Xiao等[17]在U-Net中加入殘差結構,設計出殘差U-Net,用于視網膜血管分割任務。Guan等[18]將密集連接加入到U-Net中,提出全連接密集U-Net,用于去除圖像中的偽影。Isensee等[19]提出的精簡U-Net,不在U-Net基礎上添加新的結構,而是在激活函數、批量正則化、數據處理等技術層面中進行改進,在很多任務中取得了不錯的成績。Chen等[20]將轉換器(Transformer)引入U-Net,提出了結合Transformer和U-Net的復合網絡(Transformer+U-Net,TransUNet),在多器官分割和心臟分割等醫學任務中表現出更好的分割效果。Jain等[21]提出Transformer通用模型,這是第一個基于Transformer的多任務通用圖像分割框架,在全景、語義以及實例分割上的聯合訓練效果優于其他單獨訓練的模型。
在自然語言任務上取得了前所未有的成功后,Transformer已成功地應用于各種計算機視覺問題并取得了可觀的成果。隨著Transformer的廣泛應用,醫學影像領域也開始關注并逐步嘗試使用Transformer。與作用于局部感受野的CNN相比,Transformer的全局上下文建模能力對于醫學圖像的精準分割至關重要,因為通過構建空間像素之間的關系,可以對分布在大感受野上的器官進行有效的特征提取。近年來,在醫學影像界基于Transformer的技術快速發展,尤其是視覺Transformer,其在醫學圖像分割、檢測、分類、重建、合成、配準、臨床報告生成和其他很多任務中都取得了不錯的效果[22]。
綜上,為解決乳腺癌病灶精準分割的問題,本文綜合考慮PET/CT雙模態影像的成像特點,利用雙模態數據的優勢,使用實際臨床PET/CT雙模態影像數據,參考Kumar等[16]提出的協同學習(collaborative learning,Co-learning)特征融合方法,同時參考Xie等[23]提出的Transformer分割模型,提出一種融合PET/CT雙模態影像特征的乳腺癌病灶分割方法。此方法在以CNN為特征提取核心的“編碼器?特征融合?解碼器”結構的基礎上引入了Transformer。其目的在于結合了CNN的局部特征提取能力和Transformer的全局特征提取能力,在保留單模態圖像病灶細節的同時獲取融合特征的全局信息,能夠更好地區分病灶與非病灶區域,解決單一使用CNN作為特征提取器所出現的感受野不足、全局特征關聯性差而導致的誤分割問題,進而提升乳腺癌病灶分割精度。
1 本文算法
1.1 網絡結構
本文采用編碼器、特征融合和解碼器的網絡結構,借鑒多路徑U-Net的網絡設計實現雙模態數據的輸入以及各自的特征提取功能[15],整體網絡結構如圖1所示。首先編碼器模塊分為兩個分支,其一是PET編碼器模塊分支,另一個為CT編碼器模塊分支,每個分支以四個編碼器塊(encoder blcok)作為單模態圖像特征提取器,圖1中分別為encoder block1~4。隨后每個encoder blcok提取的特征信息輸入到特征融合模塊進行雙模態特征信息融合;特征融合模塊由四個融合塊(fusion block)和四個Transformer塊(transformer block)組成,圖1中分別為fusion block1~4和transformer block1~4;特征融合模塊提取到的特征輸入到由多層感知機(multi-layer perceptron,MLP)、1 × 1卷積、歸一化指數函數(softmax)構成的解碼器模塊當中,實現從特征圖到預測圖的轉換并得到最終的分割預測結果。其中MLP實現上采樣(upsample)和特征圖組合功能,1 × 1卷積實現降通道數功能,softmax預測屬于病灶的概率。
圖1
本文基于Co-learning特征融合和Transformer的雙路U-Net網絡結構
Figure1.
The dual-path U-Net network structure based on Co-learning feature fusion and transformer in this article
1.2 模塊結構
1.2.1 編碼器模塊
近幾年,Transformer模型在圖像分類、目標檢測、語義分割等下游任務中均取得了卓越的性能,因此在初期研究階段本課題組曾嘗試使用Transformer完全代替CNN作為編碼器的特征提取核心,然而通過實驗發現該方式并不能得到更好的分割效果反而增加了網絡的參數量,故最終沒有采用。
通過總結大量Transformer相關工作的文獻發現,視覺Transformer、滑動窗Transformer等以Transformer為核心的技術均應用于圖像特征較為復雜的場景當中[24],而單模態醫學影像特征復雜度相對較低,對其單一使用Transformer并不能得到更好的分割效果。對比Transformer與CNN,Transformer感受野更大,通過注意力機制來捕獲全局的上下文信息從而對目標建立起長距離依賴,可以提取更高級的特征。然而高級的特征表示依賴于底層特征,因此本文考慮保留提取底層特征能力更好的CNN作為單模態圖像特征提取器,在特征融合模塊獲得信息較為復雜的融合圖之后引入Transformer進行全局特征提取。
如圖2所示,本文的單個編碼器模塊分支由四個encoder block組成,分別為encoder block1~4。每個encoder block由兩組3×3卷積和一個下采樣層所組成,以實現特征提取、生成特征圖的功能。
圖2
編碼器模塊
Figure2.
Encoder module
1.2.2 特征融合模塊
(1)fusion block
兩個編碼器模塊分支輸出的成對單模態特征圖在fusion block中進行特征融合。首先使用三維(three dimensional,3D)卷積提取空間融合信息[25],再對單模態特征圖進行通道方向的疊加(concatenate)生成堆疊特征圖,隨后將兩部分的結果進行像素乘積生成最終的特征融合圖[16],如式(1)所示:
|
其中,Ffusion是3D卷積提取的空間融合信息,FPET是PET圖像特征圖,FCT是CT圖像特征圖,Fco-learning是最終生成的特征融合圖, 是逐元素乘法, 是concatenate操作。PET/CT雙模態特征融合過程如圖3所示,其中c為通道數。
圖3
特征融合圖的生成
Figure3.
Generation of feature fusion maps
(2)transformer block
在此特別說明,在特征融合之后而非在單模態網絡支路引入Transformer的原因如下:考慮特征融合之前為單模態的特征提取,特征信息相對單一,因此著重使用CNN提取細節信息;而經過特征融合后病灶特征更為顯著,病灶區與非病灶區的特征差異會更加明顯,需建立遠距離像素之間的聯系,以更好地區分各組織區域;Transformer具有更大的感受野、強大的全局特征提取能力,能夠更好地建立像素與像素之間的關聯性,有利于提取病灶區域特征;并且在fusion block之后引入transformer block對比在encoder block中引入transformer block可以降低參數量,以達到輕量化網絡的作用;因此本文在特征融合之后引入Transformer作為空間信息提取器。
谷歌團隊在文獻[26]中提出的算法的核心即為Transformer,而其中的“多頭自注意力機制”即為Transformer的核心。自注意力機制(self-attention)將輸入向量分為查詢(query,Q)、鍵值(key,K)、賦值(value,V)(分別以符號Q、K、V表示),而Q、K、V的概念源自于信息檢索系統,Q為需要檢索的名稱,K為根據Q來匹配此物品所需要的特征,然后根據Q和K的相似度得到匹配的內容V,self-attention中的Q、K、V也是類似的作用。而“多頭”的好處在于,不同的“頭”關注的子空間特征不同,某些“頭”更看重當前特征點附近的信息,有些“頭”會比較關注長距離信息,這樣提取到的特征會更加豐富。self-attention計算方式,如式(2)所示:
|
首先,Q和K進行點積計算出一個評分,然后除以根號下向量維度起到標準化、減少計算量的作用,隨后進行softmax計算特征之間關聯度的概率值,最后乘以V得到最終的self-attention的結果。
本文的transformer block如圖4所示,由兩組以高效自注意力機制(efficient self-attention)、前饋網絡(feed forward networks,FFN)以及重疊塊融合(overlapped patch merging)所構成的層所組成。FFN由1 × 1卷積、深度可分離卷積和高斯誤差線性單元函數(Gaussian error linear units,GELU)構成。
圖4
Transformer塊
Figure4.
Transformer block
其中,efficient self-attention由Xie等[23]提出,該作者認為網絡的計算量主要體現在self-attention上,為了降低網絡整體的計算復雜度,他們在self-attention基礎上,添加縮放因子R以降低每一個self-attention模塊的計算復雜度(O(N2)→O),如式(3)與式(4)所示:
|
|
其中,N為圖像的寬與高的乘積,C為通道數。具體的縮放方式首先通過重塑函數(Reshape)將K重新改變其形狀為(C·R),然后通過線性函數(Linear)改變其通道數,使得最終K的維度變為 ,以降低計算的復雜度。
FFN由多個神經元組成,每個神經元接收來自上一層神經元的輸出,并通過一定的權重和偏置進行加權和處理,最終得到本層神經元的輸出,進而作為下一層神經元的輸入。FFN由1 × 1卷積、深度可分離卷積、GELU組成。其中,1 × 1卷積的作用是改變通道數;深度可分離卷積將卷積操作分解為深度卷積和逐點卷積,從而顯著減少參數量,進而降低計算復雜度;使用GELU作為激活函數除加速收斂、引入非線性計算的功能以外,其在負輸入時會將輸入值映射為一個非零值,從而避免了神經元死亡的問題。overlapped patch merging的主要作用是將圖像分割成多個小的補丁,并對這些補丁進行合并和特征提取,以獲得更豐富的特征表示[24]。
1.2.3 解碼器模塊
本文解碼器的設計得益于Transformer中的非局部注意力,在結構不復雜的情況下獲得更大的接受域,同時產生高度局部和非局部關注。結構如圖5所示,將來自特征融合模塊的四組特征圖通過1 × 1卷積與不同參數的upsample,使長、寬、通道數完全一致,在同維度的條件下進行通道方向上的concatenate操作,然后再次使用1 × 1卷積將通道數降至2(二分類:病灶與非病灶),最終通過softmax函數預測屬于病灶的概率。
圖5
解碼器模塊
Figure5.
Decoder module
2 實驗結果和分析
2.1 實驗準備
2.1.1 數據集
本文數據采集于廣東省人民醫院,受試者為205位年齡范圍在26~78歲之間患有不同亞型、不同等級乳腺癌的女性群體,已獲得所有受試者的知情同意書。本文實驗研究已通過廣東省人民醫院(廣東省醫學科學院)醫學研究倫理委員會倫理審查[批號:GDREC2019696H(R1)],并獲得數據使用授權。數據集包含2 159對來自受試者的PET/CT原始掃描橫斷影像組(PET圖像大小為128 × 128 × 3,CT圖像大小為512 × 512 × 3),及其對應的由專業醫生標注了病灶位置的標注圖像。如圖6所示,左上為CT原始圖像;左下為CT原始圖像對應的病灶標注圖像;右上為PET原始圖像;右下為PET原始圖像對應的病灶標注圖像,病灶標注圖像中紅色區域即為專業醫生標注的病灶位置。
圖6
乳腺癌PET/CT影像
Figure6.
PET/CT imaging of breast cancer
2.1.2 數據預處理
因原始PET圖像與CT圖像尺寸不同、分辨率不同以及各自圖像病灶占比較小、圖像噪聲較多、數據量有限等因素,需要對原始圖像進行預處理。首先,將每一對圖像使用圖像配準工具Elastix 5.1.0(Image Sciences Institute,美國)進行配準,保證空間位置上的重合[27]。其次,對于分割任務,圖像的預裁剪可以去除大量的背景干擾,聚焦感興趣區域以得到更好的訓練效果[28]。裁剪方法首先以圖像中軸線為基準區分左胸病灶圖像和右胸病灶圖像,再選取合適的左右胸裁剪框坐標,最后通過編寫腳本實現批量裁剪,如圖7所示,其中紅色矩形為裁剪框,紅色箭頭所指向的即為裁剪后的圖像。需要說明的是,為驗證本文方法對非病灶區域的軟組織結構或其他高代謝器官(心臟、肺等)的抗干擾能力,在裁剪圖像時,沒有完全去除這類組織和器官,而是保留了部分干擾因素。本文采用的數據增強方式為水平和垂直方向的隨機翻轉,數據量增加為原始數據量的三倍,通過數據增強可以解決數據匱乏和數據不均衡而導致的模型性能欠佳、魯棒性較差的問題[29]。
圖7
圖像裁剪
Figure7.
Image cropping
2.2 實驗設置
本文實驗采用深度學習框架TensorFlow2.1-GPU版本(Google Brain,美國),使用英偉達顯卡RTX 2080super(NVIDIA,美國),統一計算設備架構CUDA 10.1版本(NVIDIA,美國),神經網絡加速庫cuDNN 7.6.5版本(NVIDIA,美國)對訓練過程進行GPU加速。為使模型更快收斂,本文采用了動量梯度下降法優化器,并在訓練過程中使用動態衰減方法設置學習率,初始學習率設置為0.001,學習率衰減步數為10 000,衰減率為0.5,批量大小設置為2,訓練總輪數為50輪。實驗使用80%的數據用于訓練,20%的數據用于測試,即訓練集包含1 727對PET/CT影像組,測試集包含432對PET/CT影像組,數據劃分時避免同一受試者的影像數據同時出現在訓練集和測試集。
2.3 評價指標
本文的評價指標為精確率(precision,Pre)、召回率(recall,Rec)和準確率(accuracy,Acc)。Pre描述模型區分真實病灶和假病灶的性能;Rec描述模型檢測病灶區域的性能;Acc描述模型正確分割病灶和背景的性能,計算式如式(5)~式(7)所示:
|
|
|
其中,真陽性(true positive,TP)為圖像中被預測為病灶且實際也是病灶的像素數量;假陰性(false negative,FN)為圖像中被預測為非病灶但實際是病灶的像素數量;真陰性(true negative,TN)為圖像中被預測為非病灶且實際也是非病灶的像素數量;假陽性(false positive,FP)為圖像中被預測為病灶但實際是非病灶的像素數量[30]。
2.4 實驗結果分析
2.4.1 結果分析
考慮到醫學圖像分割和PET/CT雙模態數據融合的特殊性,同時為了確保對比實驗的有效性、公平性,本文以與本文密切相關的文獻[16]作為基線算法,并與其進行實驗對比。實驗上采用五折交叉驗證來評估本文算法以及基線算法的分割性能,如表1所示。實驗結果表明,本文算法在所有評價指標上均優于基線算法。
此外,為驗證本文算法中Transformer與MLP引入的有效性進行了消融實驗,結果如表2所示。單模態與雙模態數據的對比結果以及本文算法與代表性醫學圖像分割算法的對比結果如表3所示,其中TransUNet作為第一個將Transformer與U-Net結合的模型打開了Transformer進入醫學影像分割領域的大門,其思想對本文的網絡設計有一定的啟發,因此將其引入本文的對比實驗。
此外,本文對比了分割結果圖像,如圖8所示。圖8中,展示了一組左胸病灶分割結果對比示例和一組右胸病灶分割結果對比示例,其中每一組對比示例均展示出各自的PET/CT圖像、標簽圖像、本文算法的分割結果以及基線算法的分割結果。通過本文算法分割結果圖和基線算法分割結果圖的對比可以清晰地發現本文算法在解決“過分割”情況的突出表現,量化指標上體現在Pre的提升,在本文中Pre表示分割結果中被正確分割為乳腺癌病灶的像素點占分割結果中被預測為乳腺癌病灶的像素點的比例。精確度越高,說明分割結果中“過分割”的情況越少。因此,無論從定量實驗指標還是分割的可視化結果均可以看出本文算法解決“過分割”能力的突出表現,證明了本文算法的有效性。
圖8
本文算法與基線算法的分割結果比較
Figure8.
Comparison of segmentation results between our proposed algorithm and the baseline algorithm
3 結語
本文提出了一種將雙路U-Net、Co-learning特征融合以及Transformer技術相結合的PET/CT乳腺癌病灶分割方法。利用PET圖像與CT圖像的影像特點,通過特征融合技術將PET圖像特征與CT圖像特征結合,使病灶特征更加突出;利用CNN的局部細節提取能力和Transformer的全局特征提取能力,合理地將二者作為本文算法的單、雙模態的特征提取器以獲得更加精準的分割結果。實驗結果表明,本文算法較現有方法取得了更好的分割結果,證明了本文網絡設計的合理性,可為多模態醫學圖像的特征提取方式提供參考。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:本文的算法研究工作、實驗設計以及論文初稿撰寫主要由第一作者翟悅淞完成。陳智麗和邵丹為共同通信作者,陳智麗教授對論文研究工作與文稿撰寫給予了大量指導和修改意見,并直接參與了論文修改稿的撰寫。邵丹主任醫師對論文工作從核醫學角度提供了專業指導與建議,并對實驗數據標注給予了指導與把關。
倫理聲明:本研究通過了廣東省人民醫院(廣東省醫學科學院)醫學研究倫理委員會的審批[批號:GDREC2019696H(R1)]