在全球的死亡案例中,心血管疾病(CVD)是主要的致死原因之一。心音分類識別在心血管疾病的早期發現中起著關鍵作用。正常心音和異常心音之間的區別并不明顯,本文為提升心音分類模型的準確度,提出一種基于雙譜分析的心音特征提取方法,并將其與卷積神經網絡(CNN)結合,對心音進行分類。該算法能夠有效地利用雙譜分析來抑制高斯噪聲,而且不需要準確分割心音信號就能提取其特征,同時結合了卷積神經網絡的強大分類性能,從而實現對心音的準確分類。根據實驗結果顯示,在相同的數據和實驗條件下,本文提出的算法在準確率、靈敏度和特異性方面分別達到了0.910、0.884和0.940。與其他心音分類算法相比,本文算法提升明顯,并具有較強的魯棒性和泛化能力,因此有望應用于先心病的輔助檢測。
引用本文: 彭利勇, 全海燕. 基于雙譜特征提取和卷積神經網絡的心音分類算法. 生物醫學工程學雜志, 2024, 41(5): 977-985, 994. doi: 10.7507/1001-5515.202310016 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
0 引言
根據世界衛生組織(World Health Organization,WHO)的數據顯示,心血管疾病(cardiovascular disease,CVD)是全球死亡率上升的主要原因之一,它嚴重影響人們的預期壽命[1]。心音信號包含了大量心血管系統的信息,心音信號的分析對于診斷和預防心血管疾病有重要意義[2]。自動心音分析檢測系統,是預防和診斷心血管疾病的重要手段。在早期,心音分析完全依賴于經驗豐富的醫生以聽診的方式進行,然而這種方法存在主觀性較大的問題,不夠客觀、準確。如今,隨著計算機輔助心音分析技術的快速發展,越來越多的自動化心音分析方法受到關注。這些技術的出現為心音分析帶來了新的可能性,有望提高診斷準確性并降低主觀誤差。
目前,心音分類識別是自動心音分析技術的一大挑戰。在心音分類任務中的心音信號特征提取和分類識別算法是國內外許多研究者長期關注的領域。Bozkurt等[3]對心音信號的特征進行了分類,分為時域、頻域以及時域和頻域相結合的特征;時域特征包括第一心音、第二心音以及收縮期和舒張期,而頻域特征包括梅爾頻率倒譜系數(Mel-frequency cepstrum coefficient,MFCC)濾波器的特定系數能量和梅爾譜圖特征,其方法達到了81.5%的分類精度。Chen等[4]對心音信號進行短時傅里葉變換(short-time Fourier transform,STFT),將得到的特征譜圖作為卷積神經網絡(convolutional neural networks,CNN)的輸入,然后對心音進行分類識別,該方法最終在測試集上得到了95.49%的準確率(accuracy,Acc)。Asmare等[5]從心音樣本中提取了對數梅爾頻率譜系數(log Melfrequency spectral coefficients,MFSC)分量作為心音特征圖,結合CNN進行分類,采用170個心音樣本,得到了96.10%的準確率。文獻[4]和文獻[5]都取得了較高的分類準確率,可是它們所使用的心音數據樣本量較少,其準確率的可信度較低,很難在實際應用中推廣。此外,文獻[5]使用MFSC方法可能會引入冗余特征,從而降低分類準確率。Li等[6]使用MFSC作為特征與深度CNN(deep CNN,DCNN)相結合的分類模型,實現了89.6%的無權平均召回,其靈敏度(sensitivity,Se)和特異性(specific,Sp)分別達到了89.5%和89.7%。Ryu等[7]使用漢明窗濾波器去除原始心音信號中的不相關噪聲,然后將固定長度的心音貼片送入四層一維CNN進行分類。Rubin等[8]將原心音信號轉換為MFCC的二維時頻特征,然后通過與CNN相結合的方法實現心音的分類,最終得到了84.80%的準確率。Nilanon等[9]使用心音信號的功率譜密度(power spectral density,PSD)特征譜,然后結合CNN實現心音分類,最終得到88.2%的準確率。文獻[8]通過隱藏半馬爾可夫模型采用第一心音開始的3 s心音片段作為輸入,而文獻[9]采用固定長度的滑動片段作為輸入。
上述方法在心音的特征提取和分類識別方面都取得了很好的效果,但還存在許多的問題,如模型復雜、使用數據樣本較少、準確度低和提取后的特征包含信息較少等。如何設計一種更輕量型、分類效果好且能包含更多心音信息的特征提取方式,對心音分類任務來說具有十分重要的意義[10]。當前,大多數心音信號分析方法主要采用時域和頻域分析,通常結合了時頻域特征。這些方法主要依賴于二階統計量作為數學工具,但忽略了有用的高階信息,導致其結果難以令人滿意。為了解決這些問題,需要采用更高階的方法來更準確地表征信號特征。高階譜分析(higher order spectral analysis,HOSA),是信號處理學科的前沿性研究方向,是處理非線性、非高斯信號的有力工具。高階譜分析通過考慮更高階概率結構來描述隨機信號,彌補了僅依賴于二階統計量的方法的不足。這種分析方法不僅能夠反映信號的能量分布,還能保留信號的相位信息。此外,從理論上來看,高階譜具備完全抑制高斯噪聲的能力,因此在降噪方面具有卓越表現。本文采用高階譜中階數最低的三階譜來提取心音信號的特征。一般稱三階譜為雙譜(bispectrum),雙譜相對于更高階的譜分析來說計算量最小,但它仍然具備高階譜的特性,能在保留心音高階特征信息的同時也具有很好的降噪性能。
綜上所述,為簡化分類過程,在盡可能保留心音信號更多信息的同時提升分類的準確率,本文提出一種基于雙譜分析特征提取與CNN相結合的心音信號分類識別方法,通過對心音信號進行雙譜分析得到心音雙譜特征圖,然后利用CNN對雙譜特征圖進行分類,并在公開心音數據集上進行測試,以期取得較好的分類效果。本文所提算法提供了一種將傳統心音信號處理算法與深度學習算法有機結合的新思路,這將有助于推動心臟信號處理算法和心臟疾病輔助檢測技術的進一步探索和發展。
1 方法分析
1.1 算法框架
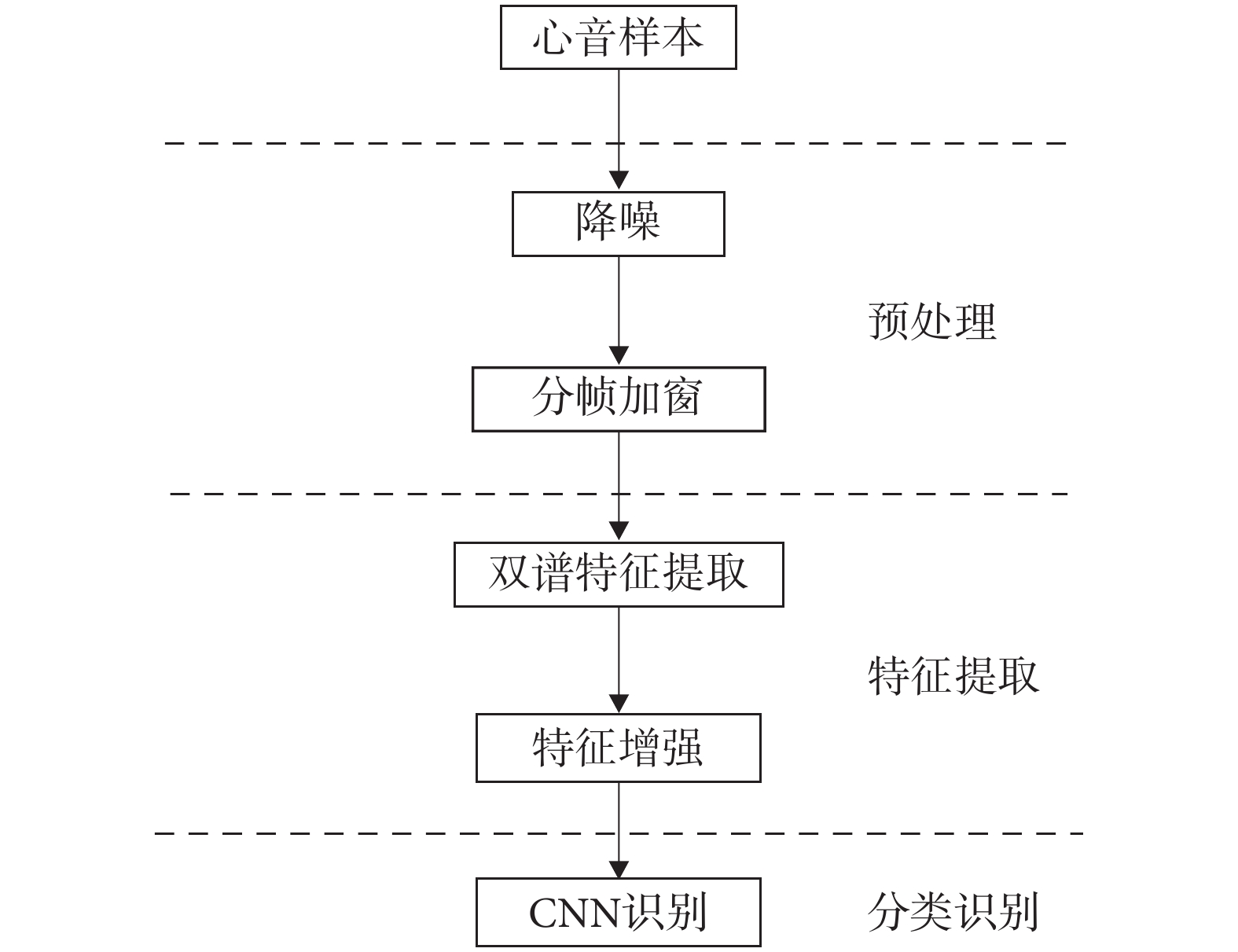
通常心音分類算法大致分為心音預處理(降噪、分割等)、心音特征提取和心音分類識別等步驟。本文算法首先對心音進行分幀加窗處理,將每一幀作為一個樣本心音。然后,對這些樣本心音進行雙譜分析,生成心音雙譜特征圖,從而實現將一維信息轉換成二維譜圖形式[11]。接下來,對雙譜特征圖進行非線性歸一化處理,以增強心音雙譜特征的細節,并避免部分特征圖損失關鍵信息。最終,利用CNN實現對心音信號的分類識別。本文算法框圖如圖1所示。
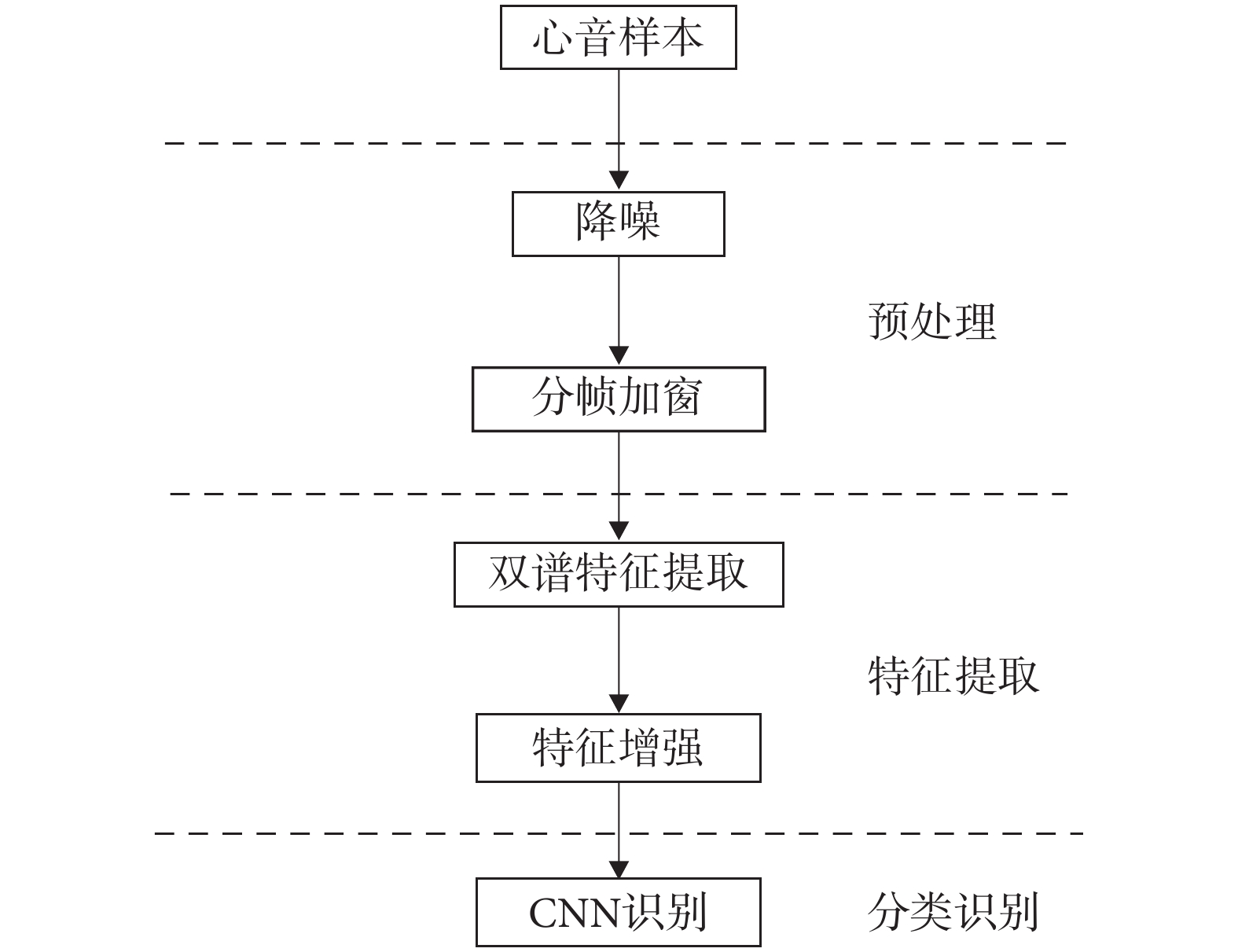 圖1
心音分類模型框圖
Figure1.
Block diagram of the heart sound classification model
圖1
心音分類模型框圖
Figure1.
Block diagram of the heart sound classification model
1.2 數據來源
本文所用數據集為公開數據集,來自于正常/異常心音記錄分類:2016年物理網/心臟病學計算挑戰賽(classification of normal/abnormal heart sound recordings: the physionet/computing in cardiology challenge 2016)[12]。該數據集由6個子數據集(trainning_a~ trainning_f)組成,數據集中包含來自健康受試者和各種心臟病(主要為:心臟瓣膜缺陷和冠狀動脈疾病)患者的3 240份原始心音信號。這些信號是由各種電子聽診器采集,信號長度從5~120 s不等,如表1所示,每個心音樣本均被標記為異常或正常,錄音都被重新取樣到2 000 Hz,并以.wav格式保存。這個心音數據庫采集了來自人體4個不同部位的心音信號,包括主動脈區、肺心病區、三尖瓣區和二尖瓣區。正常心音源自于健康人群,而異常心音則來自于確診患心臟疾病的患者。需要指出的是,異常心音記錄沒有進一步的具體分類。這一數據集存在類別不平衡問題,正常心音有2 575條,而異常心音僅有665條[13]。
1.3 數據預處理
對心音信號分類的主要目的是檢測信號中是否存在異常而不是進一步去識別它,所以無需對心音進行精確分割[14]。連續第一心音(或第二心音)之間的時間間隔構成一個心動周期。正常心音收縮的持續時間范圍為300~400 ms,而舒張期的持續時間范圍在500~600 ms,典型的心動周期通常持續時間范圍在800~1 000 ms[15]。心音信號的周期性特點對于心音分類識別研究具有十分重要的意義。
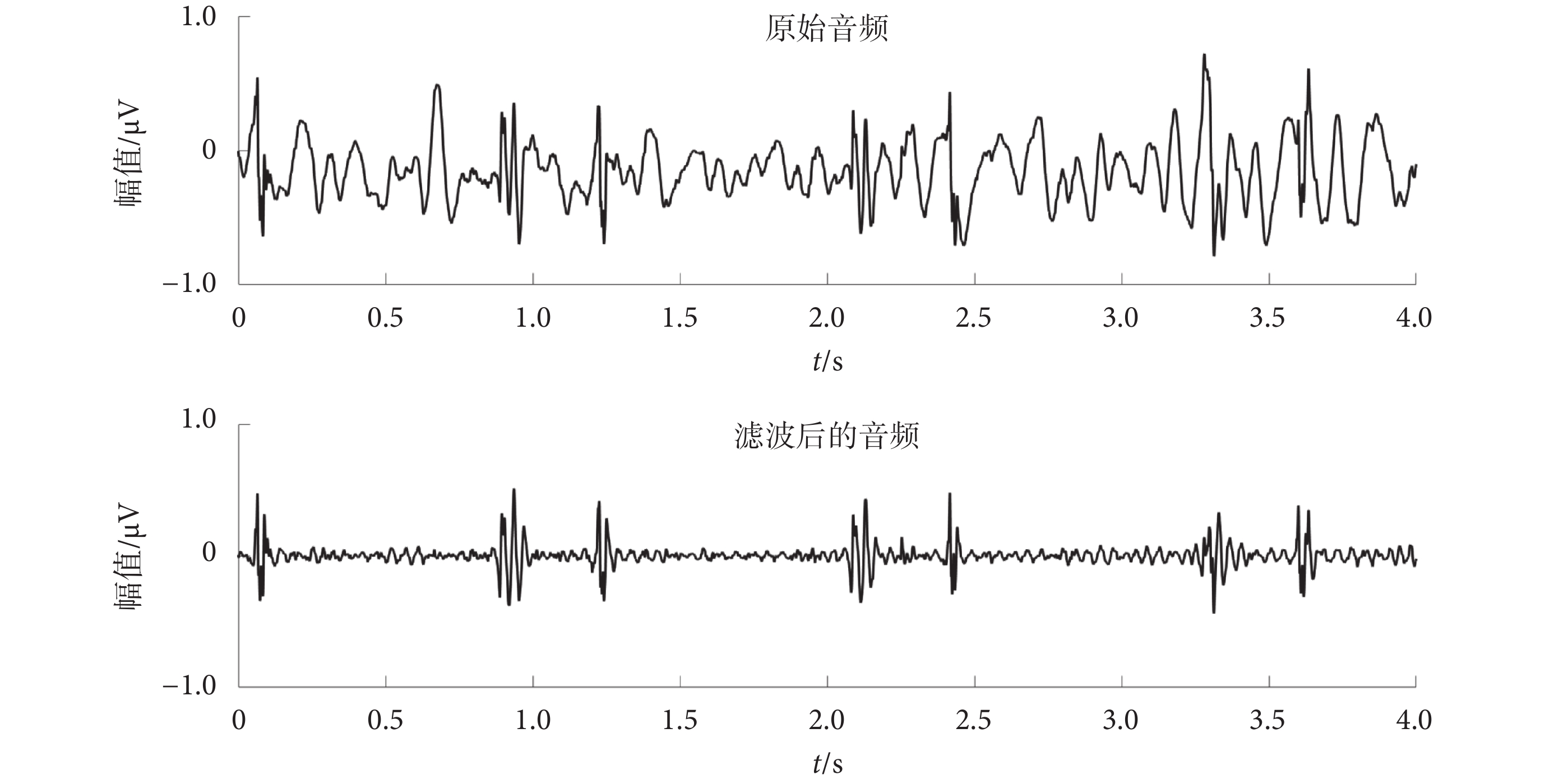
本文首先去除每個心音樣本最開始1 s和最后1 s,消除儀器接入和撤離的干擾,然后用五階巴特沃斯濾波器對每個心音樣本進行濾波,濾波器的通頻帶為20~800 Hz,消除低頻偽影和高頻噪聲的影響,結果如圖2所示。
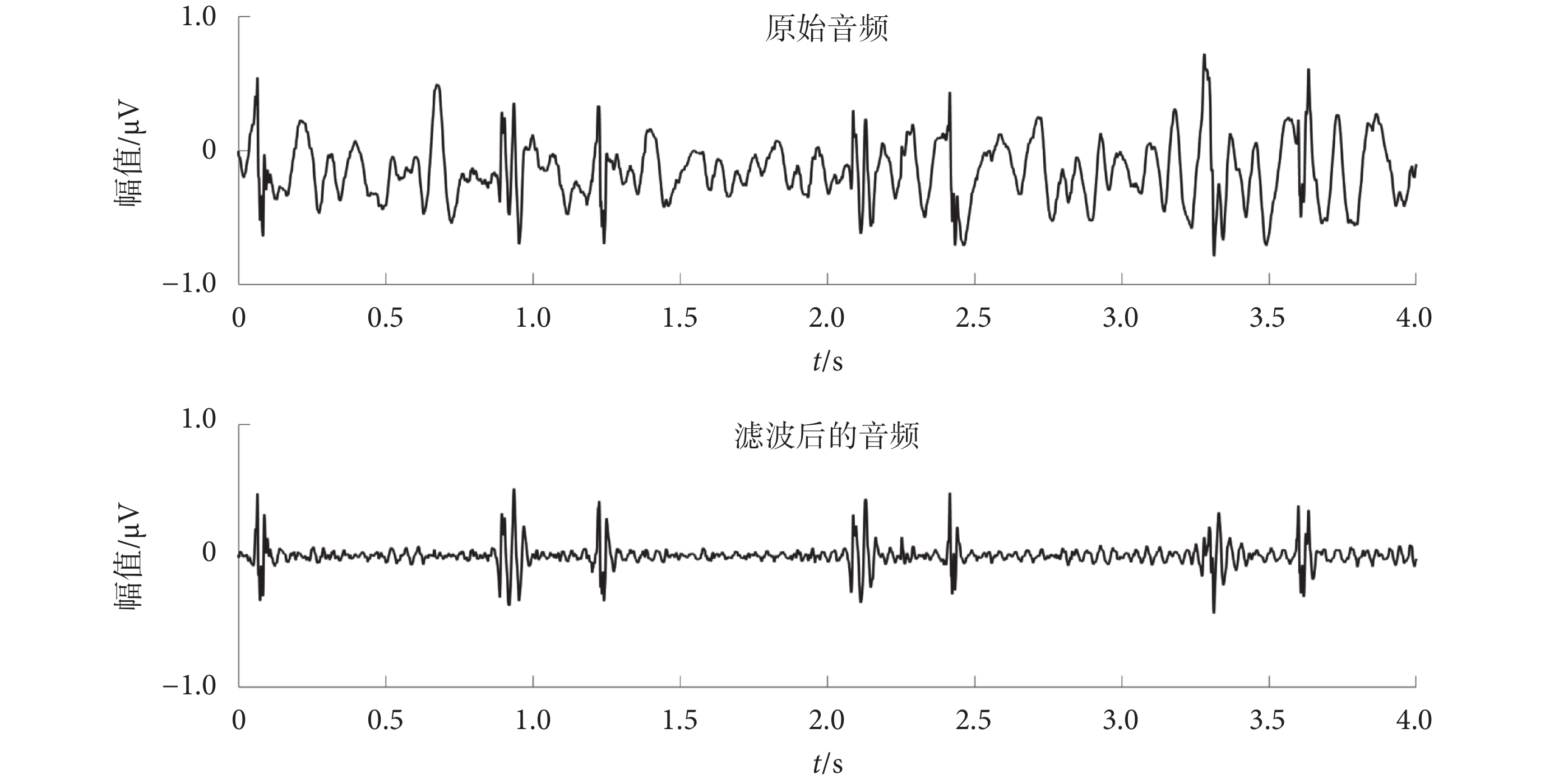 圖2
降噪前后對比
Figure2.
Before and after noise reduction
圖2
降噪前后對比
Figure2.
Before and after noise reduction
由于CNN對輸入的要求,盡量保證每個輸入樣本的形狀相同。本文對每個數據分幀加窗處理,幀長為4 s,幀移為2 s,對每一幀的樣本加漢明窗并保存,這樣得到處理后的心音樣本幀序列,正常樣本19 964個,異常樣本6 109個。
1.4 預特征提取
對于音頻信號分類來說,特征提取是分類任務中的關鍵。由于心音數據為時域的高維信息,直接用來識別非常困難,特征提取通過變換的方法將高維信息進行維數壓縮。一般經典譜估計法在特征提取中最為常用。而本文所使用的雙譜分析考慮了音頻信號的非線性相互關系,這意味著它可以捕獲到音頻信號中更復雜的頻域結構和相互作用。而心音信號包含許多不同頻率成分,使用雙譜分析可以更好地捕獲心音信號中的頻率交互和非線性特征,包括心音的共振結構和特定頻率組合,這有助于提取更豐富的心音特征,以區分不同心臟病癥或不同的心音狀態。此外,作為高階譜的一種,雙譜完整地保留了信號的幅度、頻率和相位等信息,具有時移不變性、尺度變化性和相位保持性等特性,并能夠抑制高斯有色噪聲,所以被廣泛應用于信號分析和處理中[16]。
1.4.1 雙譜定義
信號的雙譜(即三階譜)是一種階數最低的高階譜,相對于其他高階譜應用較為廣泛,理論和方法比較成熟[17]。一般滿足短時平穩的信號,其三階累積量的二階傅里葉變換被稱做雙譜[18],其定義式如式(1)所示:
 |
其中,ω1、ω2分別代表兩個不同的頻率分量,且|ω1| ≤ π,|ω2| ≤ π,|ω1+ω2| ≤ π;τ1、τ2是任意時間延遲;C3x(τ1, τ2)為三階累積量且滿足絕對可和;Bx(?)是雙譜特征矩陣;j為虛數單位。
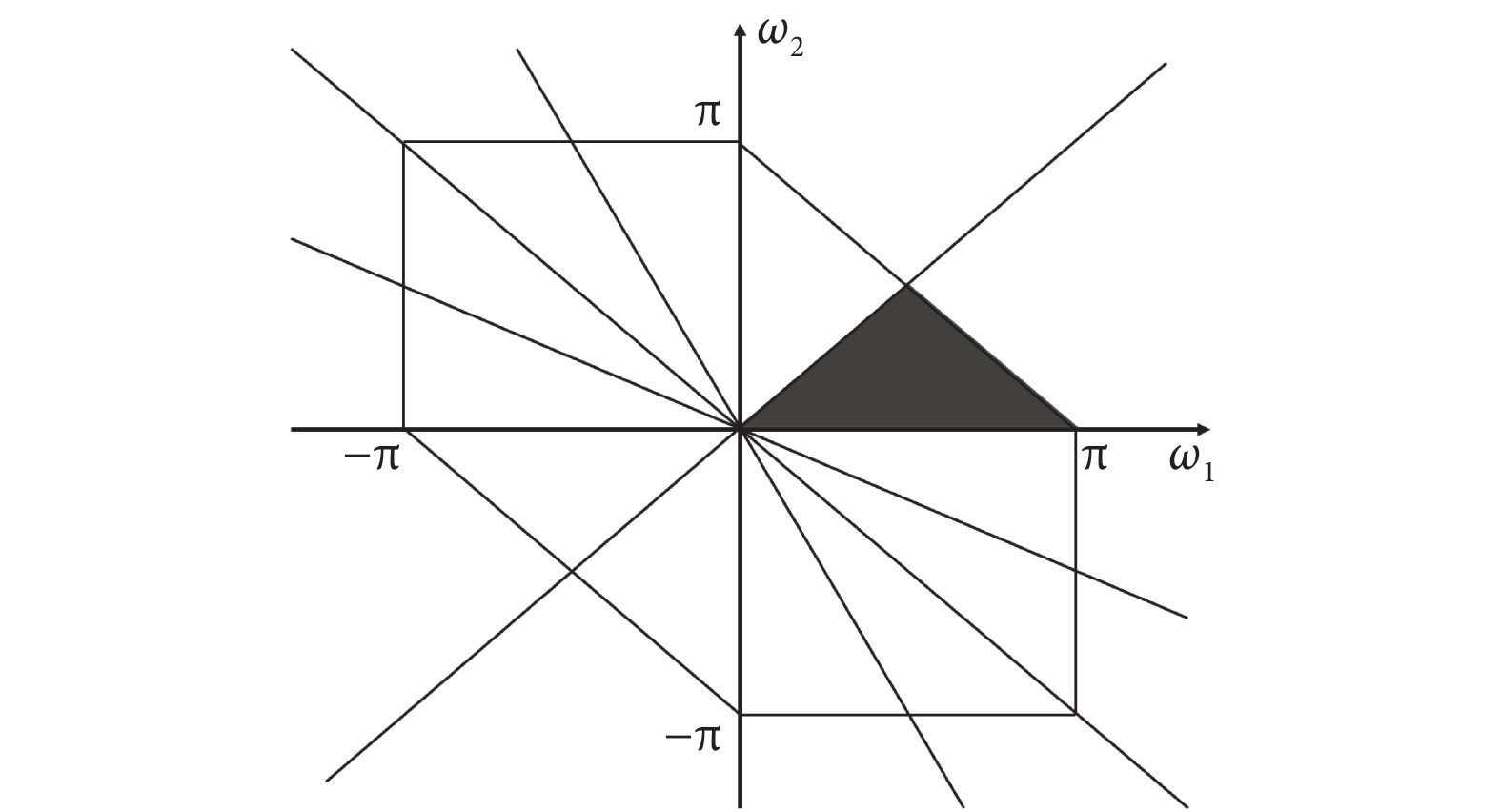
雙譜具有對稱性,只要知道雙譜的主域信息,如圖3陰影部分所示,就可以根據對稱性得出雙譜的全部信息[19]。如圖3所示,本文根據后續處理分類需求,取ω1 ≥ 0、ω2 ≥ 0的部分區域來進行研究。
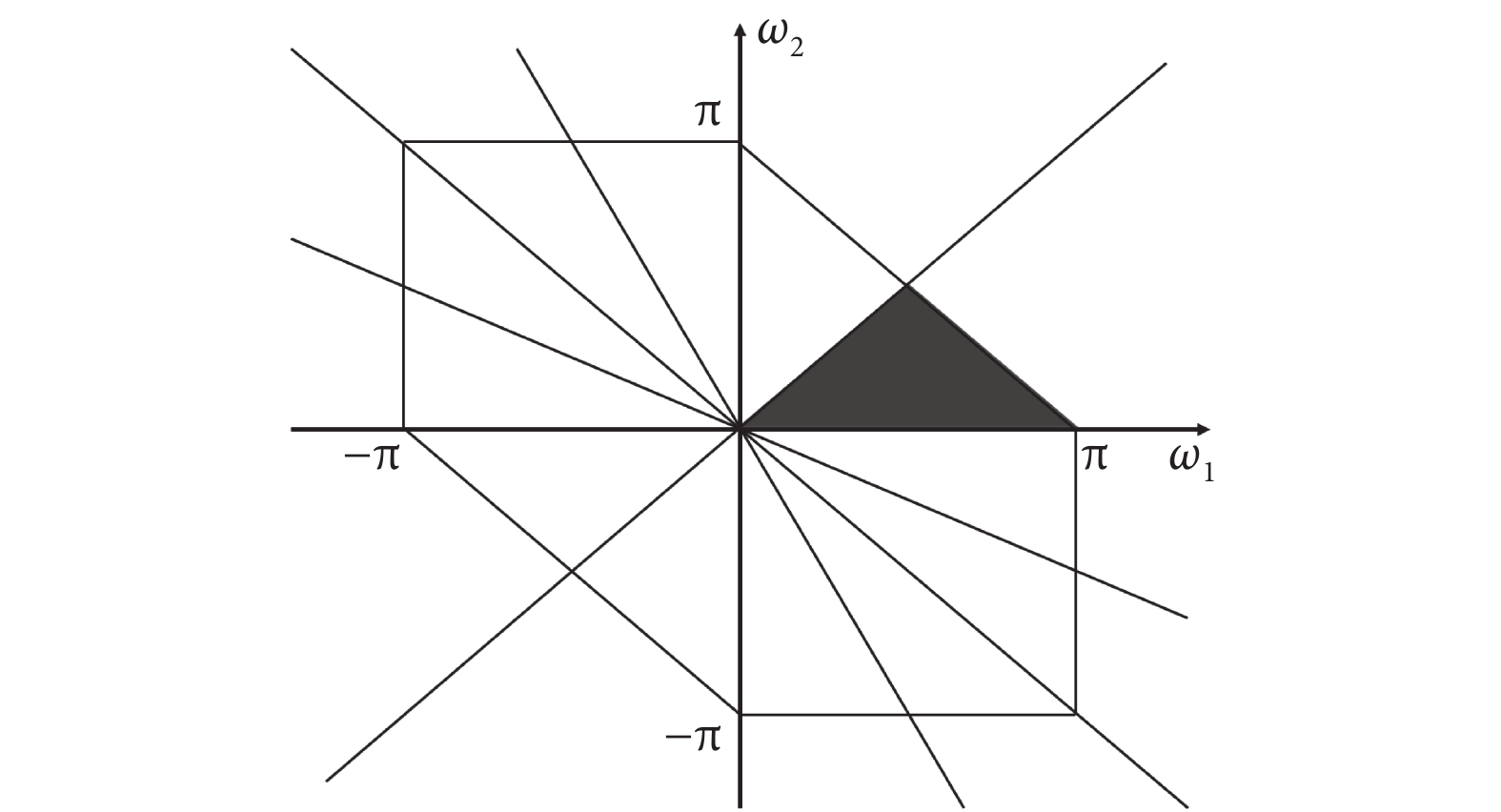 圖3
雙譜對稱區域圖
Figure3.
Bispectral symmetry map
圖3
雙譜對稱區域圖
Figure3.
Bispectral symmetry map
1.4.2 雙譜計算方法
雙譜的計算方法通常有參數法和非參數模型法兩種,本文采用非參數模型法計算心音信號的雙譜。具體步驟如下:
步驟1:將信號{x(0),x(1),…,x(N ? 1)}數據分為K段,每段包含M個樣本,允許兩段相鄰數據之間有重疊,本文取50%的重復率,對每段數據都減去該段數據的均值,第k段記為xk(n),其中,k = 1,2,···,K;n = 0,1,···,M ? 1。
步驟2:進一步計算每段的傅里葉系數,如式(2)所示:
 |
其中,Xk(λ)為第k段的傅里葉系數;λ = 0,1,2,···,M/2。
步驟3:通常,設M = M1 × N0,此處M1為正整數,且與任意變量L1的關系為:M1 = 2L1 + 1;N0為總頻率樣本數。計算傅里葉系數的三重相關,如式(3)所示:
 |
其中, (·)表示第k段信號的傅里葉系數的三重相關, i1與 i2表示兩不同的任意頻移。Δ0 = fs/N0表示在雙譜區域沿水平和垂直方向的兩個頻率采樣點之間的間隔,fs為信號采樣率;λ1和λ2表示任意兩不同的頻率分量,且 0 ≤ λ2 ≤ λ1,λ1 + λ2 ≤ fs/2。
(·)表示第k段信號的傅里葉系數的三重相關, i1與 i2表示兩不同的任意頻移。Δ0 = fs/N0表示在雙譜區域沿水平和垂直方向的兩個頻率采樣點之間的間隔,fs為信號采樣率;λ1和λ2表示任意兩不同的頻率分量,且 0 ≤ λ2 ≤ λ1,λ1 + λ2 ≤ fs/2。
步驟4:由K段雙譜估計的均值可以求出給定樣本信號的雙譜,如式(4)所示:
 |
其中,  (·)表示信號的雙譜特征矩陣,ω1 = ((2πfs)/N0)λ1,ω2 = ((2πfs)/N0)λ2。
(·)表示信號的雙譜特征矩陣,ω1 = ((2πfs)/N0)λ1,ω2 = ((2πfs)/N0)λ2。
1.4.3 雙譜的選擇
由1.4.2小節里雙譜的計算可以看出,傳統非參數直接計算法計算雙譜是將每個輸入看作多個段,最后計算其均值,以滿足信號做雙譜計算必須為短時平穩的要求。而對于心音信號而言,其病理性特點并非均勻分布于每一個心音周期內,且部分心音的重要信息分布具有不規律性,這種直接計算均值的方式會使得最后提取的特征信息量有所減少。根據異常心音的這一特點,本文需對1.4.2小節中步驟4進行實驗改進,以改進均值計算的缺點,從而確定最優的雙譜特征計算結果。
1.4.4 獲取雙譜特征圖
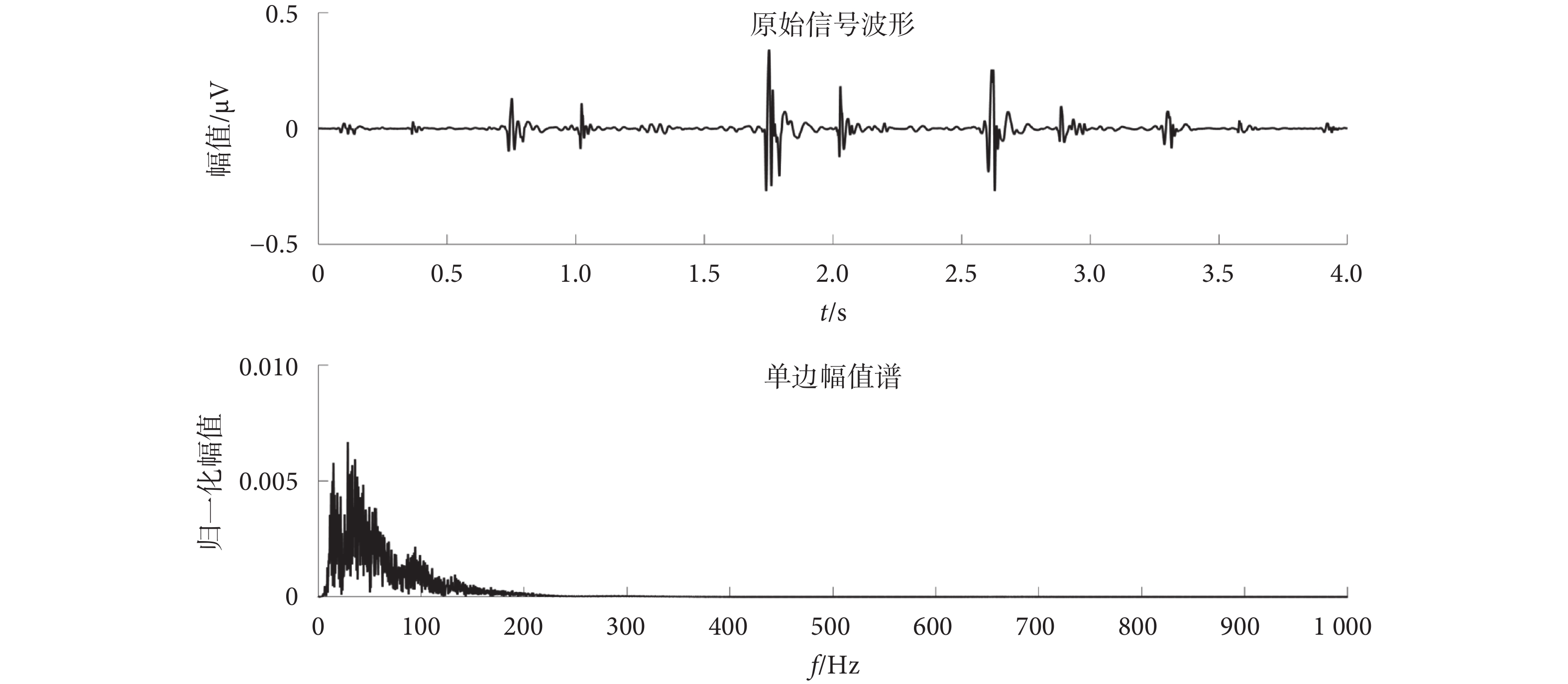
本文將預處理后的每4 s的樣本幀進行1 024個點的離散傅里葉變換,可視化結果如圖4所示。
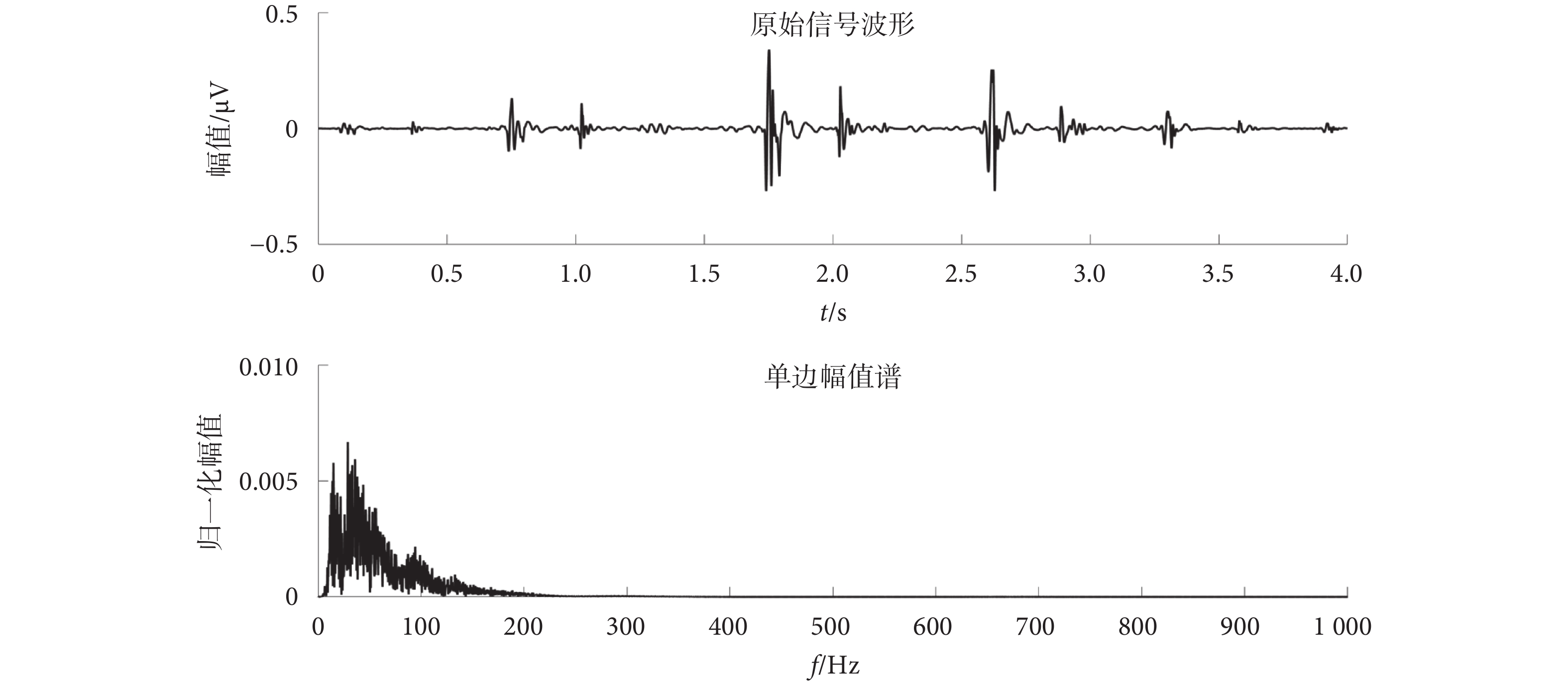 圖4
心音樣本離散傅里葉變換結果圖
Figure4.
DFT results of heart sound samples
圖4
心音樣本離散傅里葉變換結果圖
Figure4.
DFT results of heart sound samples
圖4中,樣本心音信號的有效信息主要頻帶在0~200 Hz之間。如式(2)~式(4)所示,對樣本做雙譜分析后得到一個1 024 × 1 024的二維復數矩陣。
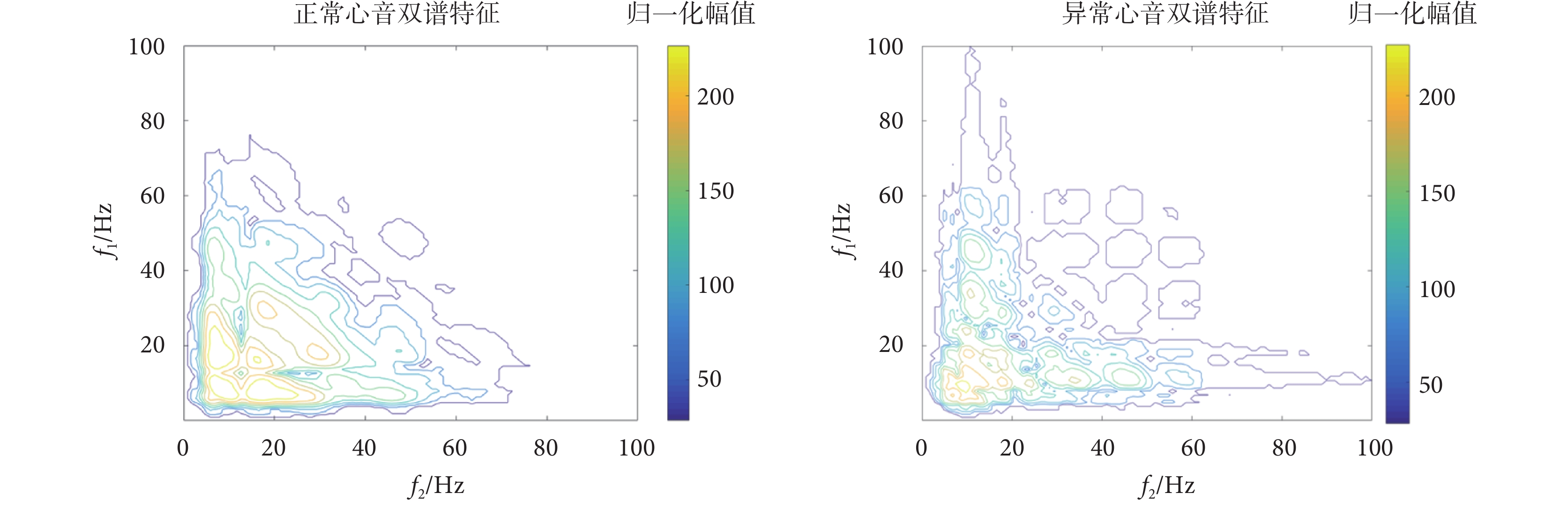
取復數矩陣的實部構成特征矩陣,其數值代表了信號中兩個頻率分量之間的相關性大小。數值越大,表示兩個頻率分量之間的相關性越強。結合圖4心音的頻譜特征和1.4.1小節中雙譜的對稱性特點截取特征圖,最終得到大小為102×102的心音雙譜特征圖,如圖5所示,為正常心音(左)和異常心音(右)樣本經特征提取后得到的心音雙譜特征圖。
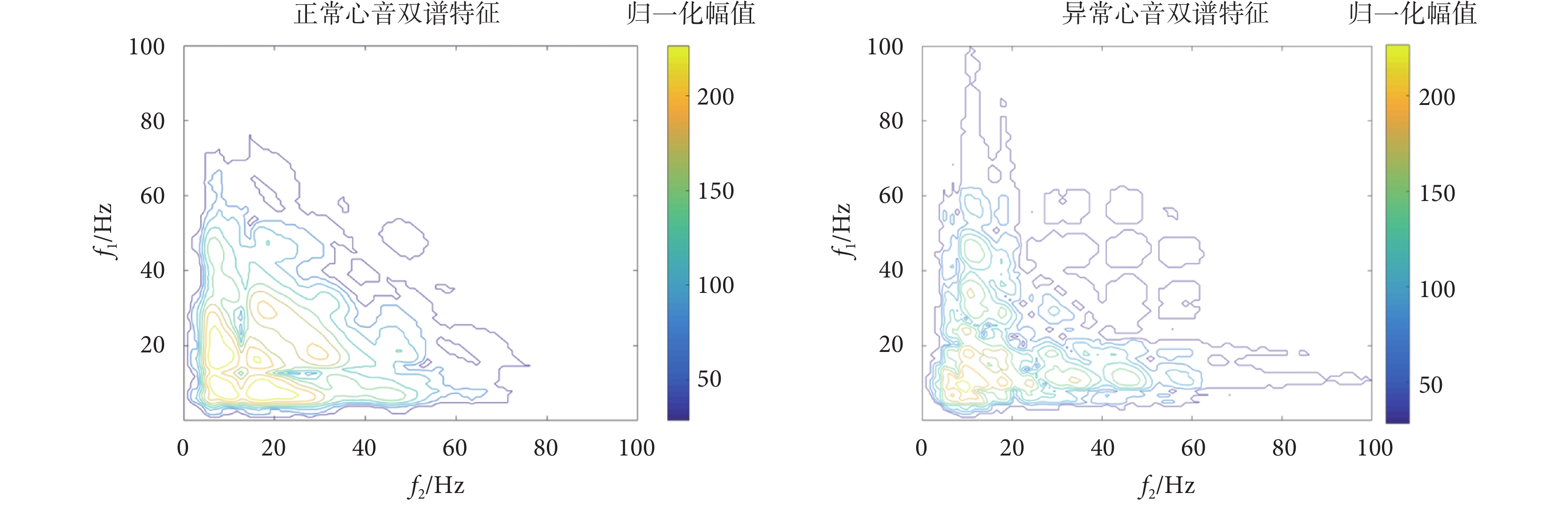 圖5
正常(左)和異常(右)心音雙譜特征圖
Figure5.
Bispectral characteristics of normal (left) and abnormal (right) heart sounds
圖5
正常(左)和異常(右)心音雙譜特征圖
Figure5.
Bispectral characteristics of normal (left) and abnormal (right) heart sounds
1.4.5 雙譜特征圖增強處理
圖像增強處理涉及將原始圖像進行轉換,以獲得一個通用標準圖像的過程。對特征圖像增強的好處在于它能夠提升后續算法中特征圖的適用性[20]。本文中,由于得到的雙譜特征圖中不同的灰度都可能包含心音的有用信息,因此為避免使用CNN對后續圖像特征再提取和分類計算時,由于灰度分布不均導致忽略部分低灰度區域有用信息,本文在分類前,將得到的二維雙譜圖進行特征圖像非線性歸一化處理。本文采用對數變換法對雙譜特征圖進行處理,對數變換法公式如式(5)所示:
 |
其中,r為輸入,S為輸出,v為底數,c為倍數因子,本文中取:c = 255/log(1 + max(r))。根據輸入圖像中的最大像素值,本文使用式(5)中c的取值來動態調整,以便將輸出限定在標準的0~255范圍內,以利于保持圖像的視覺質量和對比度。
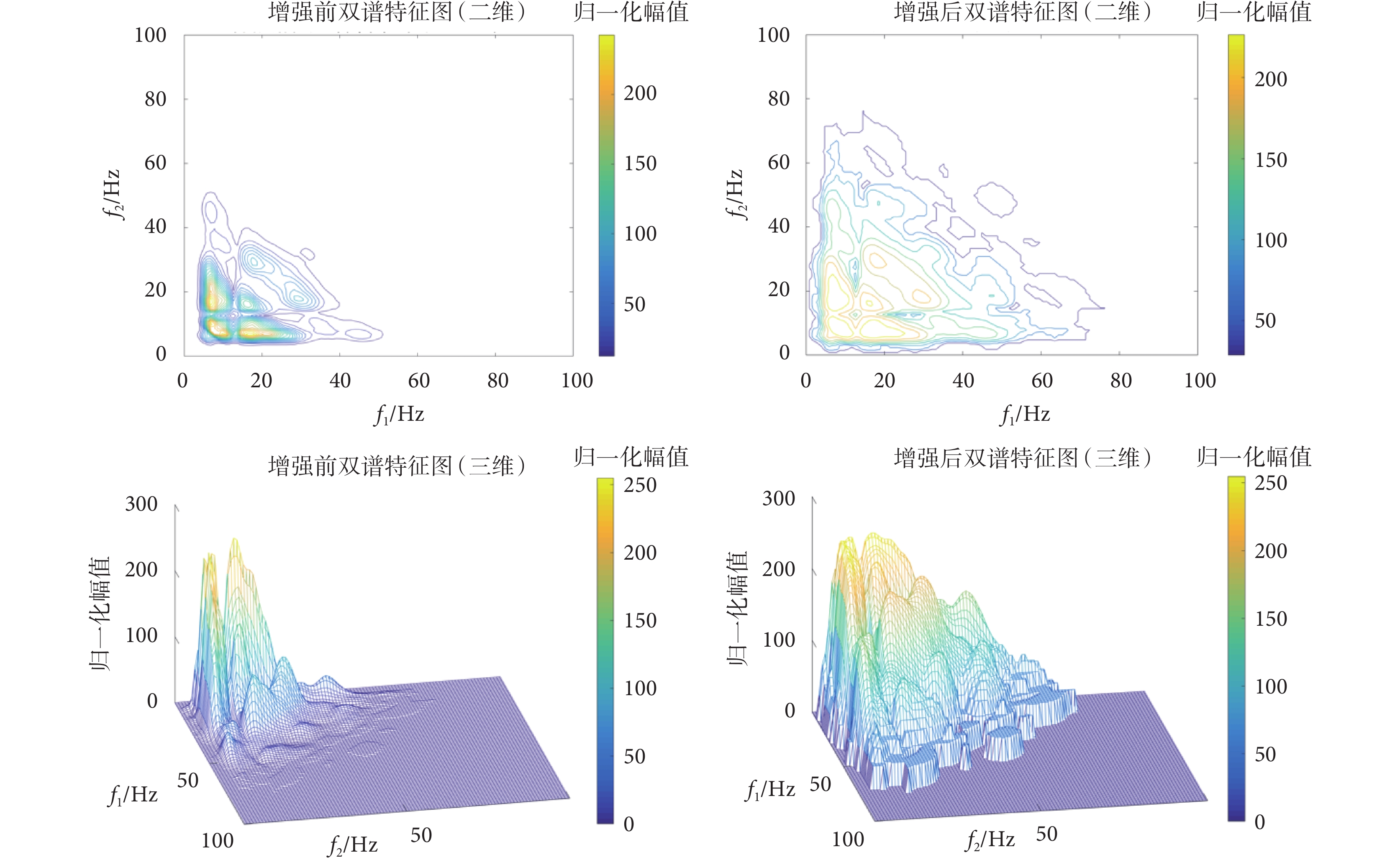
由上述對數變換法變換處理后,二維和三維特征圖像變換前后的對比如圖6所示。
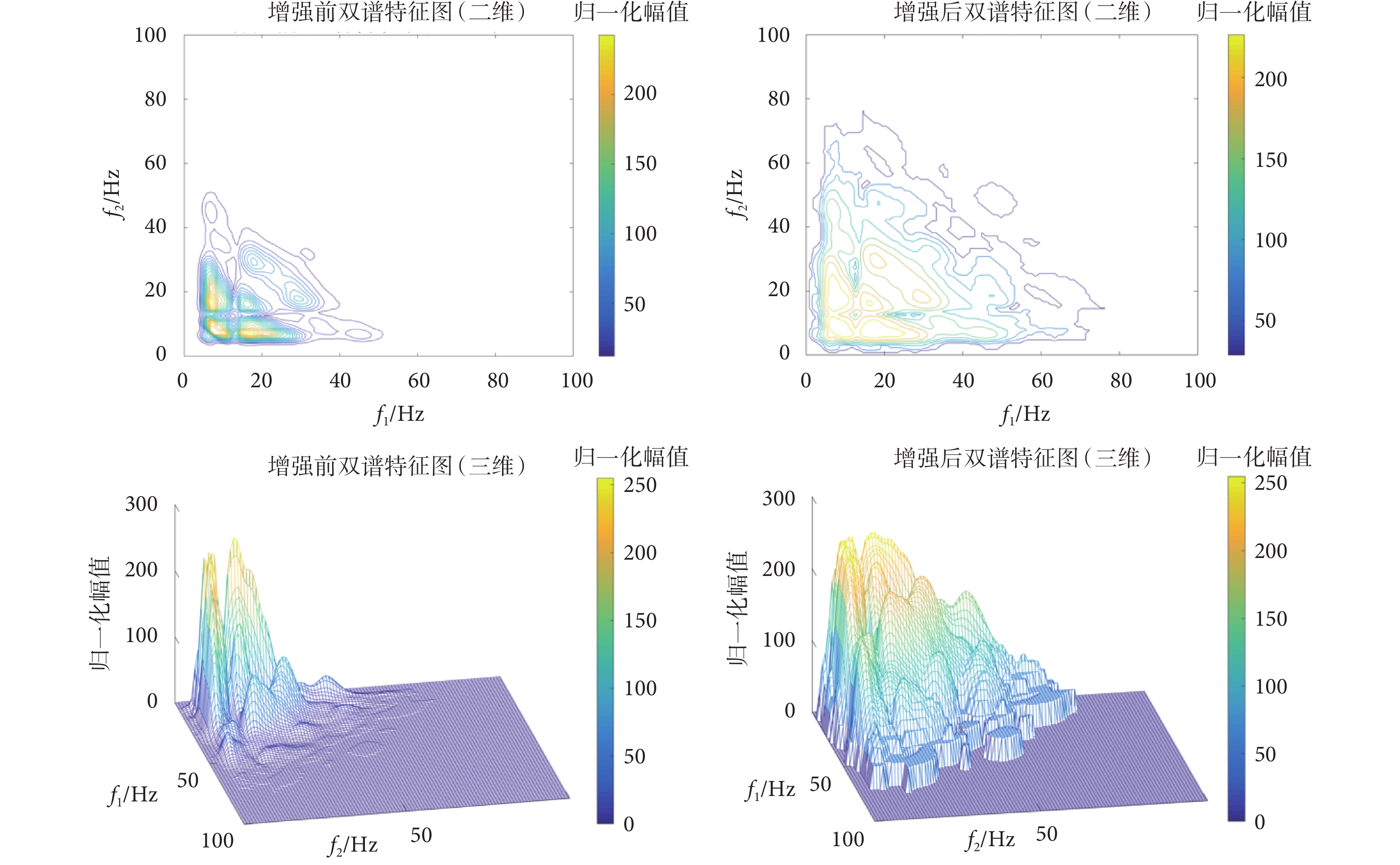 圖6
對數變換前后對比
Figure6.
Before and after logarithmic transformation
圖6
對數變換前后對比
Figure6.
Before and after logarithmic transformation
當引入了對數變換法增強特征圖后,部分低灰度區域的特征被增強,使得雙譜特征圖的特征更加豐富,避免了在后續CNN中進行卷積運算的時候將有用信息忽略,從而使得心音的特征更明顯,以便于提升分類的準確度,增強分類模型的性能。
1.5 分類模型
近年來,深度學習發展迅速,許多研究者用深度學習構建分類模型取得很不錯的效果。CNN是深度學習的主要研究方向之一,其在語音識別、自然語言處理、圖像識別等方面的應用較為成熟[21]。CNN獨特的結構和圖像處理方式使得它非常適合于圖像分類問題[6]。本文將使用CNN對心音雙譜特征進行特征提取和分類。
如表2所示,本文所搭建的CNN結構,由三個卷積層、三個池化層、兩個全連接層和一個輸出層組成,激活函數選用線性整流函數(rectified linear unit,ReLU),池化選擇最大池化方式。首先,展開特征圖為一個向量,通過一個含128個神經元的全連接層傳輸到輸出層,使用輸出層抑制過擬合,其值設置為0.5。輸出層只有一個神經元,而本文研究的是二分類任務,所以只需要一個輸出來表示樣本屬于正類別的概率。輸出層,采用S型生長曲線(sigmoid)作為激活函數,計算公式如式(6)所示:
 |
其中,σ(?)是sigmoid激活函數,x為輸入的特征圖的值,函數將輸入x映射到一個0~1之間的概率值。通常,將0.5作為閾值,當sigmoid函數的輸出大于0.5時,模型將樣本分類為正類別;當輸出小于0.5時,模型將樣本分類為負類別。
在訓練過程中,使用二元交叉熵損失函數來衡量模型的預測與真實標簽之間的差異。由于本文所有數據集存在數據類不平衡的問題,因此引入類別權重。通過對損失函數(以符號Loss表示)中的類賦予不同的權重,以使模型更加關注數據量較少的類,從而達到平衡數據的作用,如式(7)所示:
 |
其中,y是二元標簽,取0或者1;p(yi)是輸出屬y標簽的概率,通常在0~1之間;N為輸出個數。本文設正負數據類權重分別為α和β,可根據數據類不平衡程度對其值進行相應調整。本文正樣本19 964個,負樣本6 109個,于是將α的值設置為1/4,β設為3/4。
2 實驗分析
2.1 實驗環境與數據說明
本研究軟件環境:算法主體編程軟件為Pycharm2023專業版(JetBrains Inc.,捷克),編程語言為Python3.9(Python Software Foundation Inc.,美國),所使用CNN分類網絡模型在TensorFlow2.0(Google Inc.,美國)框架中實現。
本研究硬件環境:中央處理器i7-13700H CPU @2.4G Hz(Intel Inc.,美國),獨立顯卡(NVIDIA Inc.,美國)。
本研究所有實驗均使用同一數據集且在同一臺設備進行。
2.2 評估指標
為了與目前最先進的基于CNN的心音分類算法模型進行比較,本文引入下述評價指標對模型性能進行評價:準確率、靈敏度、特異性。準確率,是指模型在整個測試數據集上正確分類的樣本數量與總樣本數量之比;它衡量了模型正確分類樣本的能力,但在不平衡數據集中可能不夠敏感。靈敏度,衡量了模型對于正例樣本的識別能力;它表示在所有實際正例中,模型正確識別為正例的比例。特異性,衡量了模型對于負例樣本的識別能力;它表示在所有實際負例中,模型正確識別為負例的比例。高特異性,意味著模型能夠有效地排除負例,降低了誤報的可能性[22]。
2.3 實驗結果分析
為證明本文所提分類模型的有效性,分別進行了4組實驗。實驗一:對前文1.4.2小節心音雙譜特征計算中步驟4改進,對比三種計算方法對分類指標的影響,得出更適合的雙譜特征圖。實驗二:對比式(5)中不同對數底數值v對實驗結果的影響,從而得到較為理想的v的取值。實驗三:通過實驗對比不同特征提取方法下心音分類模型的評價指標,證明本文所提基于高階統計量的心音信號雙譜特征提取方法的有效性。實驗四:將本文所提心音分類模型與當前已有的心音分類模型做對比,通過各種模型評價指標證實本文所提基于雙譜特征提取與CNN相結合的心音分類算法的有效性和優越性。
實驗一:如式(4)所示,對心音樣本進行雙譜分析特征提取計算,將每一個小片段的三重相關結果求和,然后求取平均值。為解決1.4.3小節中所提問題,本文采取對比實驗計算三種雙譜特征結果,確定更適合的心音雙譜特征,分別為均值(mean,M)、方差(variance,Var)和標準差(standard deviation,SD)。該實驗所使用的分類網絡模型結構如表2所示,實驗所使用數據集均為表1所示數據,均使用了底數為10的對數變換法對特征圖像增強,實驗結果如表3所示。
表3中,加粗的數據代表同一評價指標下實驗結果最好的數據。由實驗結果可以看出,基于標準差計算的心音雙譜特征更適合作為心音分類模型的特征,這可能是因為病理性的特征分布不均導致的。許多算法在心音預處理過程中僅進行了簡單的心音分割,導致某些片段所含的病理性特征較少,而噪聲較多。如果對這些異常特征較少的樣本片段直接采用傳統的雙譜計算方法進行均值處理,所得的雙譜特征圖與正常心音的雙譜特征相差無幾,從而增加了分類的難度,導致異常樣本的識別率較低。這在實驗結果中表現為特異性較低,且與實驗事實相符。
實驗二:不同的特征圖增強效果直接影響分類的結果,本文采用非線性圖像增強方法中對數變換法對雙譜特征圖進行增強,其中對數的底數變化對于特征圖的增強效果有差異,如圖7所示。
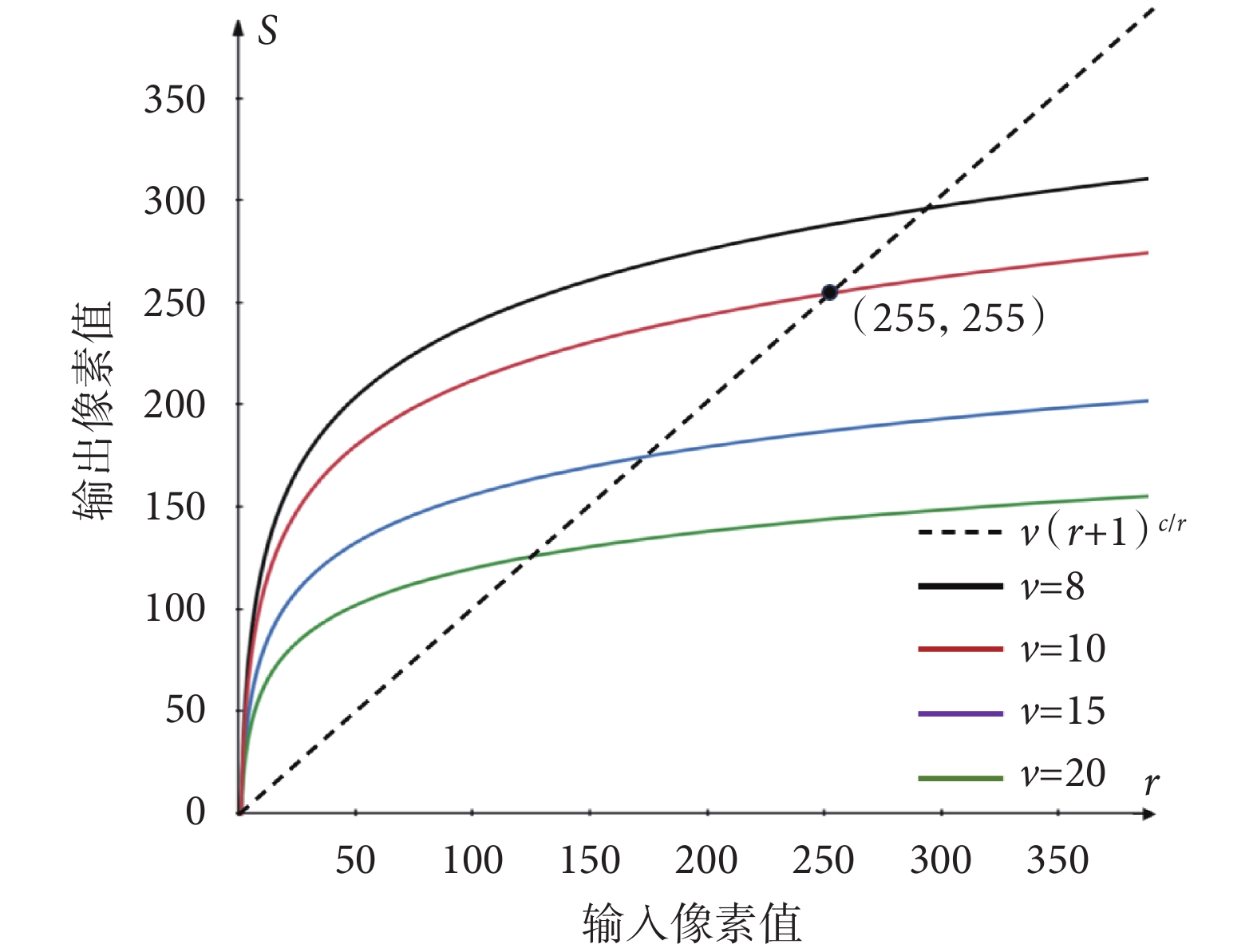 圖7
不同底數對數變換函數
Figure7.
Logarithmic transformation function with different bases
圖7
不同底數對數變換函數
Figure7.
Logarithmic transformation function with different bases
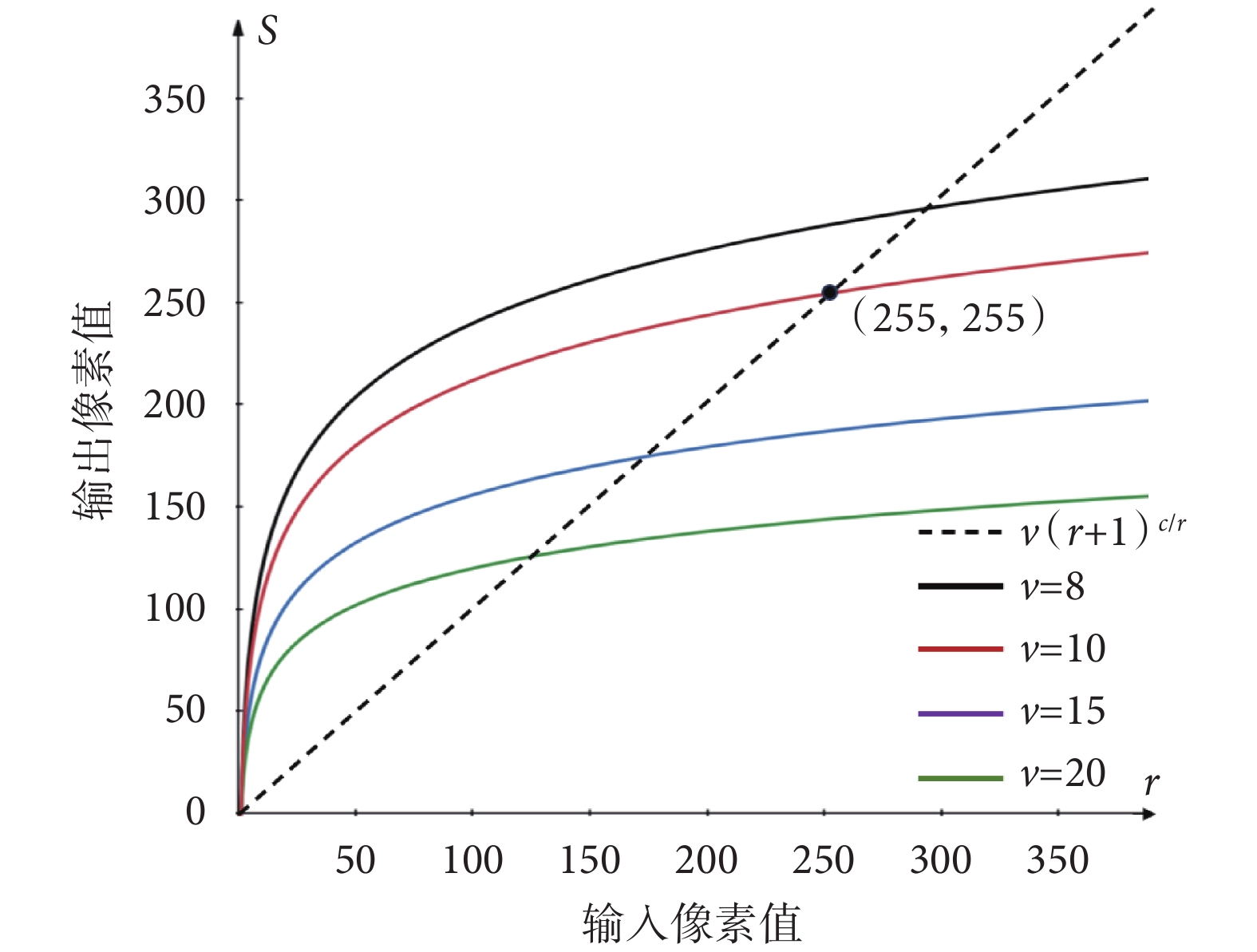
對數變換法對特征圖低灰度值有拉伸效果,避免了后續計算中部分特征的丟失。不同的底數v的值對特征圖的增強效果不同,其中v = (r + 1)c/r表示沒有進行對數變換增強的特征圖,以對比當沒有進行圖像增強時的模型分類性能。本文實驗了5種不同底數,分別是:(r + 1)c/r、8、10、15、20,對心音分類模型的分類準確率的影響。實驗所使用的分類網絡模型結構如表2所示,5個實驗所使用數據均為表1所示數據集,且均使用了基于標準差計算的雙譜特征圖作為心音特征譜圖。實驗結果如表4所示。
從實驗結果來看,沒有進行圖像增強的心音特征圖分類效果最差;而當v值約為10時,模型分類效果最好。如圖7所示,當v = 10時,其拉伸曲線與不進行對數變換的虛線相交于點(255,255),這表示v = 10時的對數變換計算對像素值為255附近的像素拉伸或壓縮不明顯。對特征圖進行非線性變換的目的在于增強灰度較低的部分,使得其不至于被后續識別網絡所忽略,從而保證特征圖的信息量不減少;與此同時,也應盡量不對高灰度區域的值進行過度的改變,從而保證特征圖的高對比度;這也是選擇非線性方法的一個重要原因。
實驗三:本研究對比了另外5種特征提取方式與CNN結合的心音分類實驗,所有分類網絡模型均采用表1中數據,且均使用了表2所示的CNN結構,其中基于雙譜特征的分類實驗所使用的雙譜特征是基于標準差的分類實驗結果,且對雙譜特征進行了對數變換增強,其底數為10。所有分類模型評價指標的對比實驗結果,如表5所示。其中,一維+CNN,表示直接使用一維心音序列結合CNN對心音信號進行分類識別。
從表5的實驗結果來看,基于高階統計量的心音雙譜特征相比于其他基于一二階心音特征的分類模型來說,分類的準確率更高,這與雙譜特征包含有更為豐富的心音特征有關。心音信號通常包含多個頻率成分,每個頻率成分都對應于心臟的某種生理過程。這些頻率成分之間可能存在復雜的相互作用和耦合關系,例如:心室顫動、心室撲動等心律失常疾病。而雙譜可以用來分析這些不同頻率成分之間的相互作用,以識別各種疾病更具體的特征。
實驗四:為證明本文所提基于雙譜特征提取和CNN的心音分類算法的有效性,將其與其他4種當前較為先進的心音分類算法做性能比較[8-9, 23-24],評價指標除前文2.2小節中所述準確率、靈敏度、特異性以外,還增加了模型參量、是否精確分割等兩個指標,對各種心音分類模型進行綜合評估。5組實驗均使用表1所示數據集,且在同一設備進行。實驗結果如表6所示,其中“—”代表無數據可查。
從表6的實驗結果可以看出,本文所提出的基于雙譜特征和CNN相結合的心音分類算法模型性能達到了較為先進的水平,文獻[8]雖然也具有很好的準確率和特異性,但是其模型參量較大,而本文的算法模型參量僅為0.04 × 106個,且不需要對心音數據進行精確分割。
綜上所述,本文所提心音分類算法模型綜合性能優于其他算法,這說明基于高階統計量的心音特征提取方法與CNN結合的心音分類算法模型在提高心音分類模型的綜合性能方面更具優勢。
3 結論
在心音分類任務中,心音的病理及生理特征不僅僅包含在幅度和頻率中。為更有效地提取心音特征,本文針對低階統計量(功率譜等)提取心音特征不足的局限,提出采用基于高階統計量中的雙譜對心音信號進行特征提取。高階譜具有很強的消噪能力,理論上能完全抑制高斯噪聲。就雙譜的物理意義而言,體現了信號在頻譜中的斜度,而以高斯噪聲為例,其在頻譜中斜度為零,因此雙譜可直接對比心音信號中非線性、非對稱性的特征成分。本文還采用對數變換法對心音特征圖像進行增強,將特征圖標準化的同時也能突出更多的信號特征,這有利于CNN對特征圖像的分類處理,從而增強模型分類效果。本文實驗結果表明,基于雙譜特征提取和CNN相結合的方式對心音進行分類,效果顯著提升,準確率達到0.91,且模型參量低,無需對原始信號進行精確分割,綜合性能優于其他同類算法,有望應用于心臟疾病的輔助檢查等方面。但,本文研究也存在一定局限,比如本文只實現了正常心音和異常心音的分類,對于代表具體心臟疾病的異常心音信號并沒有做詳細的分類,這將成為本課題組今后的研究重點。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:彭利勇負責實驗構思與設計、數據收集、數據分析和論文寫作;全海燕負責實驗指導、論文寫作指導、數據審查和論文整體審查。
0 引言
根據世界衛生組織(World Health Organization,WHO)的數據顯示,心血管疾病(cardiovascular disease,CVD)是全球死亡率上升的主要原因之一,它嚴重影響人們的預期壽命[1]。心音信號包含了大量心血管系統的信息,心音信號的分析對于診斷和預防心血管疾病有重要意義[2]。自動心音分析檢測系統,是預防和診斷心血管疾病的重要手段。在早期,心音分析完全依賴于經驗豐富的醫生以聽診的方式進行,然而這種方法存在主觀性較大的問題,不夠客觀、準確。如今,隨著計算機輔助心音分析技術的快速發展,越來越多的自動化心音分析方法受到關注。這些技術的出現為心音分析帶來了新的可能性,有望提高診斷準確性并降低主觀誤差。
目前,心音分類識別是自動心音分析技術的一大挑戰。在心音分類任務中的心音信號特征提取和分類識別算法是國內外許多研究者長期關注的領域。Bozkurt等[3]對心音信號的特征進行了分類,分為時域、頻域以及時域和頻域相結合的特征;時域特征包括第一心音、第二心音以及收縮期和舒張期,而頻域特征包括梅爾頻率倒譜系數(Mel-frequency cepstrum coefficient,MFCC)濾波器的特定系數能量和梅爾譜圖特征,其方法達到了81.5%的分類精度。Chen等[4]對心音信號進行短時傅里葉變換(short-time Fourier transform,STFT),將得到的特征譜圖作為卷積神經網絡(convolutional neural networks,CNN)的輸入,然后對心音進行分類識別,該方法最終在測試集上得到了95.49%的準確率(accuracy,Acc)。Asmare等[5]從心音樣本中提取了對數梅爾頻率譜系數(log Melfrequency spectral coefficients,MFSC)分量作為心音特征圖,結合CNN進行分類,采用170個心音樣本,得到了96.10%的準確率。文獻[4]和文獻[5]都取得了較高的分類準確率,可是它們所使用的心音數據樣本量較少,其準確率的可信度較低,很難在實際應用中推廣。此外,文獻[5]使用MFSC方法可能會引入冗余特征,從而降低分類準確率。Li等[6]使用MFSC作為特征與深度CNN(deep CNN,DCNN)相結合的分類模型,實現了89.6%的無權平均召回,其靈敏度(sensitivity,Se)和特異性(specific,Sp)分別達到了89.5%和89.7%。Ryu等[7]使用漢明窗濾波器去除原始心音信號中的不相關噪聲,然后將固定長度的心音貼片送入四層一維CNN進行分類。Rubin等[8]將原心音信號轉換為MFCC的二維時頻特征,然后通過與CNN相結合的方法實現心音的分類,最終得到了84.80%的準確率。Nilanon等[9]使用心音信號的功率譜密度(power spectral density,PSD)特征譜,然后結合CNN實現心音分類,最終得到88.2%的準確率。文獻[8]通過隱藏半馬爾可夫模型采用第一心音開始的3 s心音片段作為輸入,而文獻[9]采用固定長度的滑動片段作為輸入。
上述方法在心音的特征提取和分類識別方面都取得了很好的效果,但還存在許多的問題,如模型復雜、使用數據樣本較少、準確度低和提取后的特征包含信息較少等。如何設計一種更輕量型、分類效果好且能包含更多心音信息的特征提取方式,對心音分類任務來說具有十分重要的意義[10]。當前,大多數心音信號分析方法主要采用時域和頻域分析,通常結合了時頻域特征。這些方法主要依賴于二階統計量作為數學工具,但忽略了有用的高階信息,導致其結果難以令人滿意。為了解決這些問題,需要采用更高階的方法來更準確地表征信號特征。高階譜分析(higher order spectral analysis,HOSA),是信號處理學科的前沿性研究方向,是處理非線性、非高斯信號的有力工具。高階譜分析通過考慮更高階概率結構來描述隨機信號,彌補了僅依賴于二階統計量的方法的不足。這種分析方法不僅能夠反映信號的能量分布,還能保留信號的相位信息。此外,從理論上來看,高階譜具備完全抑制高斯噪聲的能力,因此在降噪方面具有卓越表現。本文采用高階譜中階數最低的三階譜來提取心音信號的特征。一般稱三階譜為雙譜(bispectrum),雙譜相對于更高階的譜分析來說計算量最小,但它仍然具備高階譜的特性,能在保留心音高階特征信息的同時也具有很好的降噪性能。
綜上所述,為簡化分類過程,在盡可能保留心音信號更多信息的同時提升分類的準確率,本文提出一種基于雙譜分析特征提取與CNN相結合的心音信號分類識別方法,通過對心音信號進行雙譜分析得到心音雙譜特征圖,然后利用CNN對雙譜特征圖進行分類,并在公開心音數據集上進行測試,以期取得較好的分類效果。本文所提算法提供了一種將傳統心音信號處理算法與深度學習算法有機結合的新思路,這將有助于推動心臟信號處理算法和心臟疾病輔助檢測技術的進一步探索和發展。
1 方法分析
1.1 算法框架
通常心音分類算法大致分為心音預處理(降噪、分割等)、心音特征提取和心音分類識別等步驟。本文算法首先對心音進行分幀加窗處理,將每一幀作為一個樣本心音。然后,對這些樣本心音進行雙譜分析,生成心音雙譜特征圖,從而實現將一維信息轉換成二維譜圖形式[11]。接下來,對雙譜特征圖進行非線性歸一化處理,以增強心音雙譜特征的細節,并避免部分特征圖損失關鍵信息。最終,利用CNN實現對心音信號的分類識別。本文算法框圖如圖1所示。
圖1
心音分類模型框圖
Figure1.
Block diagram of the heart sound classification model
1.2 數據來源
本文所用數據集為公開數據集,來自于正常/異常心音記錄分類:2016年物理網/心臟病學計算挑戰賽(classification of normal/abnormal heart sound recordings: the physionet/computing in cardiology challenge 2016)[12]。該數據集由6個子數據集(trainning_a~ trainning_f)組成,數據集中包含來自健康受試者和各種心臟病(主要為:心臟瓣膜缺陷和冠狀動脈疾病)患者的3 240份原始心音信號。這些信號是由各種電子聽診器采集,信號長度從5~120 s不等,如表1所示,每個心音樣本均被標記為異常或正常,錄音都被重新取樣到2 000 Hz,并以.wav格式保存。這個心音數據庫采集了來自人體4個不同部位的心音信號,包括主動脈區、肺心病區、三尖瓣區和二尖瓣區。正常心音源自于健康人群,而異常心音則來自于確診患心臟疾病的患者。需要指出的是,異常心音記錄沒有進一步的具體分類。這一數據集存在類別不平衡問題,正常心音有2 575條,而異常心音僅有665條[13]。
1.3 數據預處理
對心音信號分類的主要目的是檢測信號中是否存在異常而不是進一步去識別它,所以無需對心音進行精確分割[14]。連續第一心音(或第二心音)之間的時間間隔構成一個心動周期。正常心音收縮的持續時間范圍為300~400 ms,而舒張期的持續時間范圍在500~600 ms,典型的心動周期通常持續時間范圍在800~1 000 ms[15]。心音信號的周期性特點對于心音分類識別研究具有十分重要的意義。
本文首先去除每個心音樣本最開始1 s和最后1 s,消除儀器接入和撤離的干擾,然后用五階巴特沃斯濾波器對每個心音樣本進行濾波,濾波器的通頻帶為20~800 Hz,消除低頻偽影和高頻噪聲的影響,結果如圖2所示。
圖2
降噪前后對比
Figure2.
Before and after noise reduction
由于CNN對輸入的要求,盡量保證每個輸入樣本的形狀相同。本文對每個數據分幀加窗處理,幀長為4 s,幀移為2 s,對每一幀的樣本加漢明窗并保存,這樣得到處理后的心音樣本幀序列,正常樣本19 964個,異常樣本6 109個。
1.4 預特征提取
對于音頻信號分類來說,特征提取是分類任務中的關鍵。由于心音數據為時域的高維信息,直接用來識別非常困難,特征提取通過變換的方法將高維信息進行維數壓縮。一般經典譜估計法在特征提取中最為常用。而本文所使用的雙譜分析考慮了音頻信號的非線性相互關系,這意味著它可以捕獲到音頻信號中更復雜的頻域結構和相互作用。而心音信號包含許多不同頻率成分,使用雙譜分析可以更好地捕獲心音信號中的頻率交互和非線性特征,包括心音的共振結構和特定頻率組合,這有助于提取更豐富的心音特征,以區分不同心臟病癥或不同的心音狀態。此外,作為高階譜的一種,雙譜完整地保留了信號的幅度、頻率和相位等信息,具有時移不變性、尺度變化性和相位保持性等特性,并能夠抑制高斯有色噪聲,所以被廣泛應用于信號分析和處理中[16]。
1.4.1 雙譜定義
信號的雙譜(即三階譜)是一種階數最低的高階譜,相對于其他高階譜應用較為廣泛,理論和方法比較成熟[17]。一般滿足短時平穩的信號,其三階累積量的二階傅里葉變換被稱做雙譜[18],其定義式如式(1)所示:
|
其中,ω1、ω2分別代表兩個不同的頻率分量,且|ω1| ≤ π,|ω2| ≤ π,|ω1+ω2| ≤ π;τ1、τ2是任意時間延遲;C3x(τ1, τ2)為三階累積量且滿足絕對可和;Bx(?)是雙譜特征矩陣;j為虛數單位。
雙譜具有對稱性,只要知道雙譜的主域信息,如圖3陰影部分所示,就可以根據對稱性得出雙譜的全部信息[19]。如圖3所示,本文根據后續處理分類需求,取ω1 ≥ 0、ω2 ≥ 0的部分區域來進行研究。
圖3
雙譜對稱區域圖
Figure3.
Bispectral symmetry map
1.4.2 雙譜計算方法
雙譜的計算方法通常有參數法和非參數模型法兩種,本文采用非參數模型法計算心音信號的雙譜。具體步驟如下:
步驟1:將信號{x(0),x(1),…,x(N ? 1)}數據分為K段,每段包含M個樣本,允許兩段相鄰數據之間有重疊,本文取50%的重復率,對每段數據都減去該段數據的均值,第k段記為xk(n),其中,k = 1,2,···,K;n = 0,1,···,M ? 1。
步驟2:進一步計算每段的傅里葉系數,如式(2)所示:
|
其中,Xk(λ)為第k段的傅里葉系數;λ = 0,1,2,···,M/2。
步驟3:通常,設M = M1 × N0,此處M1為正整數,且與任意變量L1的關系為:M1 = 2L1 + 1;N0為總頻率樣本數。計算傅里葉系數的三重相關,如式(3)所示:
|
其中,(·)表示第k段信號的傅里葉系數的三重相關, i1與 i2表示兩不同的任意頻移。Δ0 = fs/N0表示在雙譜區域沿水平和垂直方向的兩個頻率采樣點之間的間隔,fs為信號采樣率;λ1和λ2表示任意兩不同的頻率分量,且 0 ≤ λ2 ≤ λ1,λ1 + λ2 ≤ fs/2。
步驟4:由K段雙譜估計的均值可以求出給定樣本信號的雙譜,如式(4)所示:
|
其中, (·)表示信號的雙譜特征矩陣,ω1 = ((2πfs)/N0)λ1,ω2 = ((2πfs)/N0)λ2。
1.4.3 雙譜的選擇
由1.4.2小節里雙譜的計算可以看出,傳統非參數直接計算法計算雙譜是將每個輸入看作多個段,最后計算其均值,以滿足信號做雙譜計算必須為短時平穩的要求。而對于心音信號而言,其病理性特點并非均勻分布于每一個心音周期內,且部分心音的重要信息分布具有不規律性,這種直接計算均值的方式會使得最后提取的特征信息量有所減少。根據異常心音的這一特點,本文需對1.4.2小節中步驟4進行實驗改進,以改進均值計算的缺點,從而確定最優的雙譜特征計算結果。
1.4.4 獲取雙譜特征圖
本文將預處理后的每4 s的樣本幀進行1 024個點的離散傅里葉變換,可視化結果如圖4所示。
圖4
心音樣本離散傅里葉變換結果圖
Figure4.
DFT results of heart sound samples
圖4中,樣本心音信號的有效信息主要頻帶在0~200 Hz之間。如式(2)~式(4)所示,對樣本做雙譜分析后得到一個1 024 × 1 024的二維復數矩陣。
取復數矩陣的實部構成特征矩陣,其數值代表了信號中兩個頻率分量之間的相關性大小。數值越大,表示兩個頻率分量之間的相關性越強。結合圖4心音的頻譜特征和1.4.1小節中雙譜的對稱性特點截取特征圖,最終得到大小為102×102的心音雙譜特征圖,如圖5所示,為正常心音(左)和異常心音(右)樣本經特征提取后得到的心音雙譜特征圖。
圖5
正常(左)和異常(右)心音雙譜特征圖
Figure5.
Bispectral characteristics of normal (left) and abnormal (right) heart sounds
1.4.5 雙譜特征圖增強處理
圖像增強處理涉及將原始圖像進行轉換,以獲得一個通用標準圖像的過程。對特征圖像增強的好處在于它能夠提升后續算法中特征圖的適用性[20]。本文中,由于得到的雙譜特征圖中不同的灰度都可能包含心音的有用信息,因此為避免使用CNN對后續圖像特征再提取和分類計算時,由于灰度分布不均導致忽略部分低灰度區域有用信息,本文在分類前,將得到的二維雙譜圖進行特征圖像非線性歸一化處理。本文采用對數變換法對雙譜特征圖進行處理,對數變換法公式如式(5)所示:
|
其中,r為輸入,S為輸出,v為底數,c為倍數因子,本文中取:c = 255/log(1 + max(r))。根據輸入圖像中的最大像素值,本文使用式(5)中c的取值來動態調整,以便將輸出限定在標準的0~255范圍內,以利于保持圖像的視覺質量和對比度。
由上述對數變換法變換處理后,二維和三維特征圖像變換前后的對比如圖6所示。
圖6
對數變換前后對比
Figure6.
Before and after logarithmic transformation
當引入了對數變換法增強特征圖后,部分低灰度區域的特征被增強,使得雙譜特征圖的特征更加豐富,避免了在后續CNN中進行卷積運算的時候將有用信息忽略,從而使得心音的特征更明顯,以便于提升分類的準確度,增強分類模型的性能。
1.5 分類模型
近年來,深度學習發展迅速,許多研究者用深度學習構建分類模型取得很不錯的效果。CNN是深度學習的主要研究方向之一,其在語音識別、自然語言處理、圖像識別等方面的應用較為成熟[21]。CNN獨特的結構和圖像處理方式使得它非常適合于圖像分類問題[6]。本文將使用CNN對心音雙譜特征進行特征提取和分類。
如表2所示,本文所搭建的CNN結構,由三個卷積層、三個池化層、兩個全連接層和一個輸出層組成,激活函數選用線性整流函數(rectified linear unit,ReLU),池化選擇最大池化方式。首先,展開特征圖為一個向量,通過一個含128個神經元的全連接層傳輸到輸出層,使用輸出層抑制過擬合,其值設置為0.5。輸出層只有一個神經元,而本文研究的是二分類任務,所以只需要一個輸出來表示樣本屬于正類別的概率。輸出層,采用S型生長曲線(sigmoid)作為激活函數,計算公式如式(6)所示:
|
其中,σ(?)是sigmoid激活函數,x為輸入的特征圖的值,函數將輸入x映射到一個0~1之間的概率值。通常,將0.5作為閾值,當sigmoid函數的輸出大于0.5時,模型將樣本分類為正類別;當輸出小于0.5時,模型將樣本分類為負類別。
在訓練過程中,使用二元交叉熵損失函數來衡量模型的預測與真實標簽之間的差異。由于本文所有數據集存在數據類不平衡的問題,因此引入類別權重。通過對損失函數(以符號Loss表示)中的類賦予不同的權重,以使模型更加關注數據量較少的類,從而達到平衡數據的作用,如式(7)所示:
|
其中,y是二元標簽,取0或者1;p(yi)是輸出屬y標簽的概率,通常在0~1之間;N為輸出個數。本文設正負數據類權重分別為α和β,可根據數據類不平衡程度對其值進行相應調整。本文正樣本19 964個,負樣本6 109個,于是將α的值設置為1/4,β設為3/4。
2 實驗分析
2.1 實驗環境與數據說明
本研究軟件環境:算法主體編程軟件為Pycharm2023專業版(JetBrains Inc.,捷克),編程語言為Python3.9(Python Software Foundation Inc.,美國),所使用CNN分類網絡模型在TensorFlow2.0(Google Inc.,美國)框架中實現。
本研究硬件環境:中央處理器i7-13700H CPU @2.4G Hz(Intel Inc.,美國),獨立顯卡(NVIDIA Inc.,美國)。
本研究所有實驗均使用同一數據集且在同一臺設備進行。
2.2 評估指標
為了與目前最先進的基于CNN的心音分類算法模型進行比較,本文引入下述評價指標對模型性能進行評價:準確率、靈敏度、特異性。準確率,是指模型在整個測試數據集上正確分類的樣本數量與總樣本數量之比;它衡量了模型正確分類樣本的能力,但在不平衡數據集中可能不夠敏感。靈敏度,衡量了模型對于正例樣本的識別能力;它表示在所有實際正例中,模型正確識別為正例的比例。特異性,衡量了模型對于負例樣本的識別能力;它表示在所有實際負例中,模型正確識別為負例的比例。高特異性,意味著模型能夠有效地排除負例,降低了誤報的可能性[22]。
2.3 實驗結果分析
為證明本文所提分類模型的有效性,分別進行了4組實驗。實驗一:對前文1.4.2小節心音雙譜特征計算中步驟4改進,對比三種計算方法對分類指標的影響,得出更適合的雙譜特征圖。實驗二:對比式(5)中不同對數底數值v對實驗結果的影響,從而得到較為理想的v的取值。實驗三:通過實驗對比不同特征提取方法下心音分類模型的評價指標,證明本文所提基于高階統計量的心音信號雙譜特征提取方法的有效性。實驗四:將本文所提心音分類模型與當前已有的心音分類模型做對比,通過各種模型評價指標證實本文所提基于雙譜特征提取與CNN相結合的心音分類算法的有效性和優越性。
實驗一:如式(4)所示,對心音樣本進行雙譜分析特征提取計算,將每一個小片段的三重相關結果求和,然后求取平均值。為解決1.4.3小節中所提問題,本文采取對比實驗計算三種雙譜特征結果,確定更適合的心音雙譜特征,分別為均值(mean,M)、方差(variance,Var)和標準差(standard deviation,SD)。該實驗所使用的分類網絡模型結構如表2所示,實驗所使用數據集均為表1所示數據,均使用了底數為10的對數變換法對特征圖像增強,實驗結果如表3所示。
表3中,加粗的數據代表同一評價指標下實驗結果最好的數據。由實驗結果可以看出,基于標準差計算的心音雙譜特征更適合作為心音分類模型的特征,這可能是因為病理性的特征分布不均導致的。許多算法在心音預處理過程中僅進行了簡單的心音分割,導致某些片段所含的病理性特征較少,而噪聲較多。如果對這些異常特征較少的樣本片段直接采用傳統的雙譜計算方法進行均值處理,所得的雙譜特征圖與正常心音的雙譜特征相差無幾,從而增加了分類的難度,導致異常樣本的識別率較低。這在實驗結果中表現為特異性較低,且與實驗事實相符。
實驗二:不同的特征圖增強效果直接影響分類的結果,本文采用非線性圖像增強方法中對數變換法對雙譜特征圖進行增強,其中對數的底數變化對于特征圖的增強效果有差異,如圖7所示。
圖7
不同底數對數變換函數
Figure7.
Logarithmic transformation function with different bases
對數變換法對特征圖低灰度值有拉伸效果,避免了后續計算中部分特征的丟失。不同的底數v的值對特征圖的增強效果不同,其中v = (r + 1)c/r表示沒有進行對數變換增強的特征圖,以對比當沒有進行圖像增強時的模型分類性能。本文實驗了5種不同底數,分別是:(r + 1)c/r、8、10、15、20,對心音分類模型的分類準確率的影響。實驗所使用的分類網絡模型結構如表2所示,5個實驗所使用數據均為表1所示數據集,且均使用了基于標準差計算的雙譜特征圖作為心音特征譜圖。實驗結果如表4所示。
從實驗結果來看,沒有進行圖像增強的心音特征圖分類效果最差;而當v值約為10時,模型分類效果最好。如圖7所示,當v = 10時,其拉伸曲線與不進行對數變換的虛線相交于點(255,255),這表示v = 10時的對數變換計算對像素值為255附近的像素拉伸或壓縮不明顯。對特征圖進行非線性變換的目的在于增強灰度較低的部分,使得其不至于被后續識別網絡所忽略,從而保證特征圖的信息量不減少;與此同時,也應盡量不對高灰度區域的值進行過度的改變,從而保證特征圖的高對比度;這也是選擇非線性方法的一個重要原因。
實驗三:本研究對比了另外5種特征提取方式與CNN結合的心音分類實驗,所有分類網絡模型均采用表1中數據,且均使用了表2所示的CNN結構,其中基于雙譜特征的分類實驗所使用的雙譜特征是基于標準差的分類實驗結果,且對雙譜特征進行了對數變換增強,其底數為10。所有分類模型評價指標的對比實驗結果,如表5所示。其中,一維+CNN,表示直接使用一維心音序列結合CNN對心音信號進行分類識別。
從表5的實驗結果來看,基于高階統計量的心音雙譜特征相比于其他基于一二階心音特征的分類模型來說,分類的準確率更高,這與雙譜特征包含有更為豐富的心音特征有關。心音信號通常包含多個頻率成分,每個頻率成分都對應于心臟的某種生理過程。這些頻率成分之間可能存在復雜的相互作用和耦合關系,例如:心室顫動、心室撲動等心律失常疾病。而雙譜可以用來分析這些不同頻率成分之間的相互作用,以識別各種疾病更具體的特征。
實驗四:為證明本文所提基于雙譜特征提取和CNN的心音分類算法的有效性,將其與其他4種當前較為先進的心音分類算法做性能比較[8-9, 23-24],評價指標除前文2.2小節中所述準確率、靈敏度、特異性以外,還增加了模型參量、是否精確分割等兩個指標,對各種心音分類模型進行綜合評估。5組實驗均使用表1所示數據集,且在同一設備進行。實驗結果如表6所示,其中“—”代表無數據可查。
從表6的實驗結果可以看出,本文所提出的基于雙譜特征和CNN相結合的心音分類算法模型性能達到了較為先進的水平,文獻[8]雖然也具有很好的準確率和特異性,但是其模型參量較大,而本文的算法模型參量僅為0.04 × 106個,且不需要對心音數據進行精確分割。
綜上所述,本文所提心音分類算法模型綜合性能優于其他算法,這說明基于高階統計量的心音特征提取方法與CNN結合的心音分類算法模型在提高心音分類模型的綜合性能方面更具優勢。
3 結論
在心音分類任務中,心音的病理及生理特征不僅僅包含在幅度和頻率中。為更有效地提取心音特征,本文針對低階統計量(功率譜等)提取心音特征不足的局限,提出采用基于高階統計量中的雙譜對心音信號進行特征提取。高階譜具有很強的消噪能力,理論上能完全抑制高斯噪聲。就雙譜的物理意義而言,體現了信號在頻譜中的斜度,而以高斯噪聲為例,其在頻譜中斜度為零,因此雙譜可直接對比心音信號中非線性、非對稱性的特征成分。本文還采用對數變換法對心音特征圖像進行增強,將特征圖標準化的同時也能突出更多的信號特征,這有利于CNN對特征圖像的分類處理,從而增強模型分類效果。本文實驗結果表明,基于雙譜特征提取和CNN相結合的方式對心音進行分類,效果顯著提升,準確率達到0.91,且模型參量低,無需對原始信號進行精確分割,綜合性能優于其他同類算法,有望應用于心臟疾病的輔助檢查等方面。但,本文研究也存在一定局限,比如本文只實現了正常心音和異常心音的分類,對于代表具體心臟疾病的異常心音信號并沒有做詳細的分類,這將成為本課題組今后的研究重點。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:彭利勇負責實驗構思與設計、數據收集、數據分析和論文寫作;全海燕負責實驗指導、論文寫作指導、數據審查和論文整體審查。