結直腸息肉的早期診斷和治療對于預防結直腸癌至關重要。本文提出一種用于結直腸息肉自動檢測與輔助診斷的輕量化卷積神經網絡,首先基于53層卷積層骨干網絡,引入空間金字塔池化模塊,實現具有不同感受野大小的特征提取。然后,采用特征金字塔網絡對骨干網絡中不同尺度的特征圖進行交叉融合,利用空間注意力模塊提高對息肉圖像邊界和細節的感知能力。再進一步通過位置模式注意力模塊,在不同層級的特征圖中自動挖掘關鍵特征并整合,以實現快速高效準確的結直腸息肉自動檢測。本文基于臨床數據集對所提模型進行評估,其精度達到0.998 2,召回率達到0.998 8,F1分數達到0.998 4,平均精度(mAP)在交并比(IOU)為0.5時達到0.995 3,幀率74 幀/s,參數量9.08 M。相較于現有主流方法,本文所提出方法具有輕量化、運行配置要求低、高檢測速度、高精度等特點,可為結直腸癌的早期檢測和診斷提供可行的技術方法和重要工具。
引用本文: 李奕揚, 趙佳漪, 余若伊, 劉輝翔, 梁爽, 谷宇. 基于多尺度多層次特征融合和輕量化卷積神經網絡的結直腸息肉檢測. 生物醫學工程學雜志, 2024, 41(5): 911-918. doi: 10.7507/1001-5515.202312014 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
0 引言
結直腸癌是世界范圍內的第三大惡性腫瘤,而中國結直腸癌發生率、死亡率均處于世界較高水平。據統計,2020年中國結直腸癌發病人數55.5萬例,位列中國各癌種第二位,占中國總癌種發病人數的12.2%,占全球該類癌癥發病人數的28.8%;總死亡人數28.6萬例,位列中國各癌種死亡人數的第五位,占中國總癌種死亡人數的9.5%,占全球該類癌癥死亡人數的30.6%[1]。80%~95%的結直腸癌是在多基因、多機制的作用下由結直腸息肉經過約5~10年演變而來[2]。結直腸息肉主要分為腺瘤型息肉和增生型息肉,腺瘤型的致癌率遠高于增生型[3],因此早期息肉的準確分型對于后續治療計劃的制定至關重要[4]。
雖然結直腸息肉檢查方法有多種,但結腸鏡檢查是診斷腸道病變的“金標準”,在息肉檢出與診斷中較為有效[5]。研究顯示,平均腺瘤檢出率每增加1.0%,結直腸癌發生風險可降低3.0%[6]。但結腸鏡檢查可能受腸道準備的清潔程度[7]、退鏡時間[8]以及內鏡醫師的技術水平等因素影響[9-10]。Bretthauer等[11]在多中心大樣本臨床數據上的研究表明,不同內鏡醫師之間由于主觀因素影響,腺瘤檢出率差異高達10倍。盡管有研究嘗試通過提高內鏡操作技術和腸道準備質量來提高息肉和腺瘤的檢出率,但結果并不理想[12]。因此,目前亟需一種更客觀且自動化的息肉檢測方法。
在醫學圖像檢測識別中,人工智能(artificial intelligence,AI)輔助診斷已獲得廣泛應用[13]。通過AI輔助檢測,可以有效提升息肉檢出率[14-15]。研究顯示,當借助AI輔助進行人工診斷時,息肉檢出率比純人工檢測顯著提升[16]。AI的深度學習目標檢測算法具有強大的表征學習能力和擬合能力,應用于息肉檢測已取得了一定效果[17]。根據是否存在候選區域生成網絡,目標檢測算法主要分為兩種類型:兩階段目標檢測算法和單階段目標檢測算法[18]。兩階段目標檢測算法步驟為:先提取候選區域,再對每個區域進行分類和定位。例如,有研究采用區域卷積神經網絡(region-based convolutional neural network,R-CNN)在結直腸息肉的檢測方面取得了顯著的進步[19],但在檢測速度上仍不能滿足臨床檢驗的需求[20]。而單階段目標檢測算法通過將目標分類和邊界框回歸兩個任務合并為一個步驟,可以更高效地進行目標檢測。現有的單階段目標檢測算法,如“你只需看一次(you only look once,YOLO)”[21]、單次多框檢測器(single shot multi-box detector,SSD)[22]等,檢測速度較快,初步實現了實時目標的檢測;但在檢測小目標時,由于目標所占的像素區域較少,隨著網絡深度的加深容易丟失細節特征,導致算法精度受限[23]。此外,現有基于輕量化目標檢測模型難以同時滿足小體量和較高準確率的需要[24],對臨床場景下硬件計算能力具有較高要求。
為了解決以上問題,本文擬提出基于輕量化卷積神經網絡的結直腸息肉檢測算法,以期在結直腸息肉檢測領域實現以下目標:
(1)本研究擬通過在主干網絡中引入空間金字塔池化(spatial pyramid pooling,SPP),增強模型在不同空間尺度下的特征提取能力以及整合能力。
(2)本研究擬在特征網絡融合部分,采用特征金字塔網絡(feature pyramid network,FPN),通過多層次特征交互的網絡結構加強模型的表達能力,在此基礎上引入空間注意力模塊(spatial attention module,SAM),對圖像中的息肉病變區域賦予更高的注意權重,以提高模型感知能力。
(3)本研究擬引入位置模式注意力(positional pattern attention,PPA)模塊進行信息聚合,以期降低目標檢測模型參數規模,實現低配置下保持較快檢測速度和高準確度的特性。
1 方法
1.1 整體流程
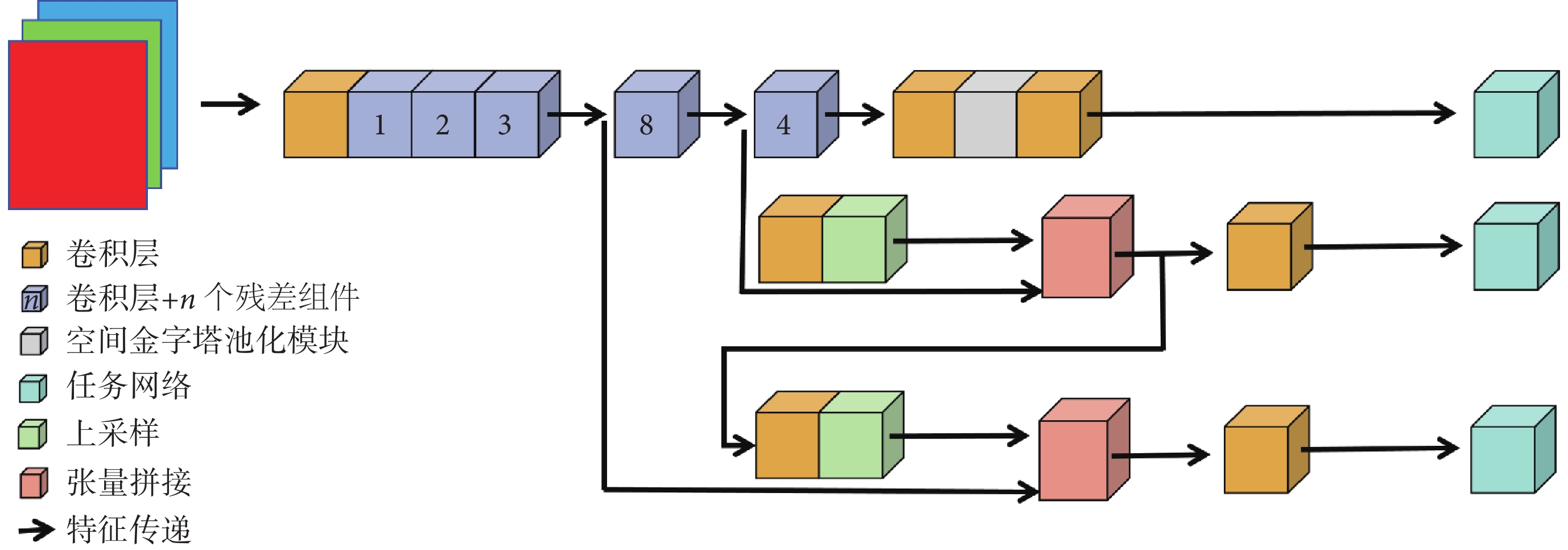
結直腸息肉的形狀和顏色多樣,表面特點不一,在內鏡下易產生噪聲和偽影[25],傳統目標檢測方法在識別過程中易受噪聲影響產生檢測誤差[26]。針對上述問題,本文提出一種基于輕量化卷積神經網絡的結直腸息肉檢測模型。如圖1所示,本研究所提出模型以YOLO系列X版本小模型(YOLO X-small,YOLOX-S)的目標檢測模塊作為檢測框架的基準模型。
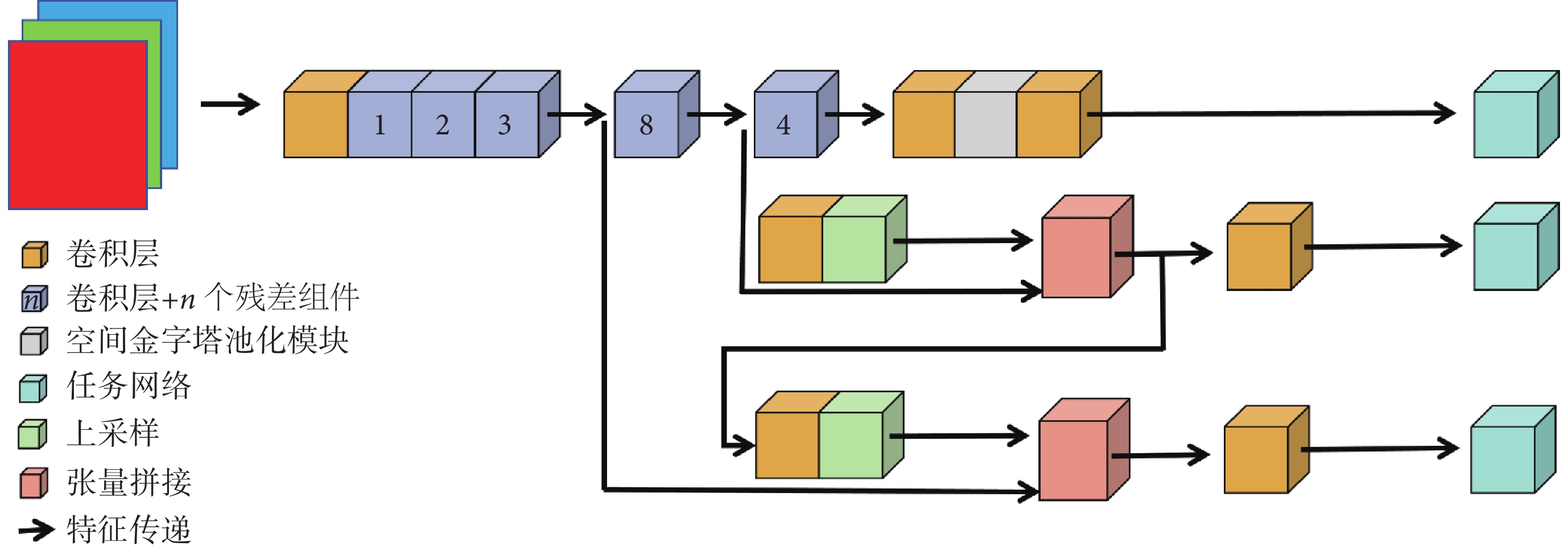 圖1
YOLOX流程圖
Figure1.
YOLOX flowchart
圖1
YOLOX流程圖
Figure1.
YOLOX flowchart
為實現結直腸息肉圖像的特征有效提取,在主干網絡部分,本研究選擇53層深度卷積神經網絡架構作為特征提取模塊,并在此基礎上增加SPP模塊整合輸出特征;特征融合網絡中,本研究采用 FPN 模塊對骨干網絡提取的不同尺度的特征圖進行融合;本研究采用SAM模塊,通過注意力機制增強模型對息肉圖像邊界和上下文細節的表示能力。最后,本研究通過增加PPA模塊,在不同層級的特征圖中自適應挖掘顯著特征并實現聚合,以期提高模型的檢測性能。在預測部分,模型通過解耦頭并行處理分類和回歸任務,最終輸出待檢測目標息肉的邊界框坐標及息肉分型等信息。
1.2 基于SPP模塊提取多尺度特征
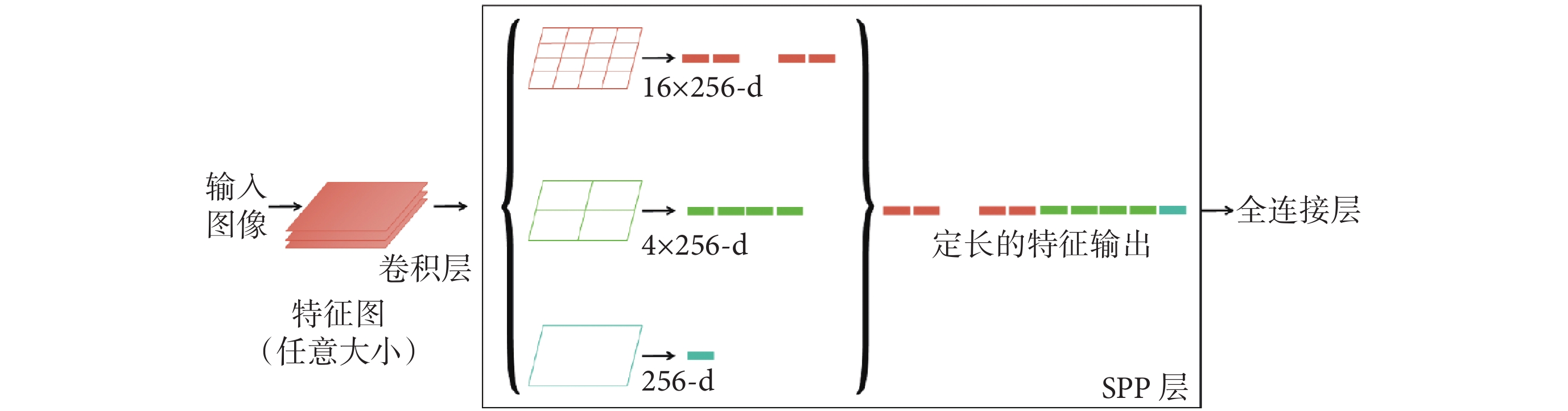
本模型引入SPP模塊解決圖像尺寸和目標大小變化的問題,實現在不同特征圖尺寸上的特征池化,且有效減少了模型的參數數量。使用SPP模塊進行目標檢測時,可以對不同大小的池化特征圖進行扁平化,得到固定大小的向量。如圖2所示,扁平化后的向量通過級聯方式形成高層次特征表示,從而更好地捕捉目標的細節和上下文信息。如圖3所示,該模塊的引入可以提高模型對不同尺寸息肉圖像進行特征提取時的適應能力。
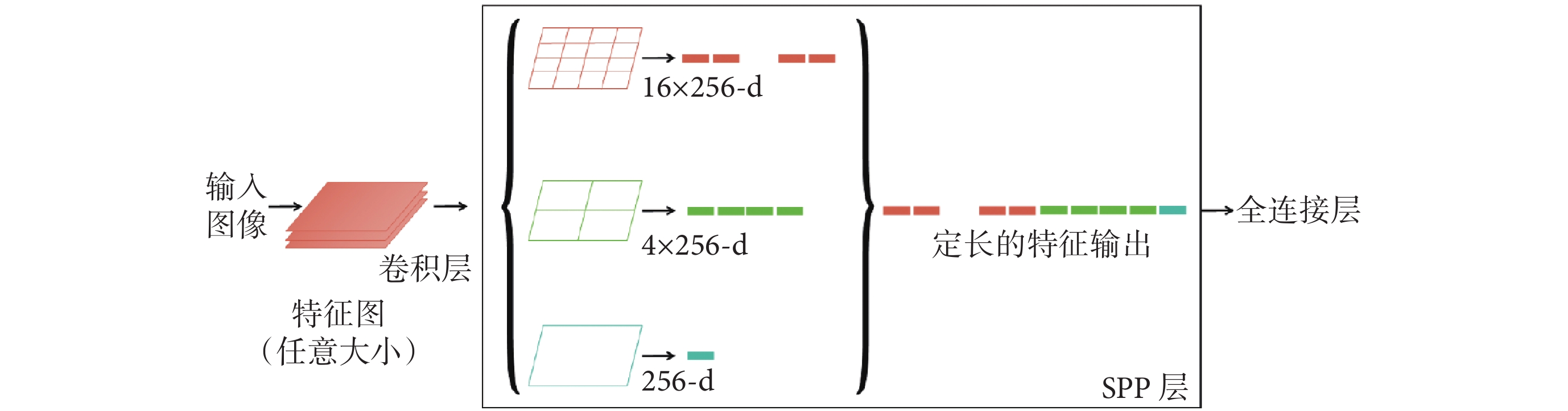 圖2
SPP示意圖
Figure2.
SPP schematic
圖2
SPP示意圖
Figure2.
SPP schematic
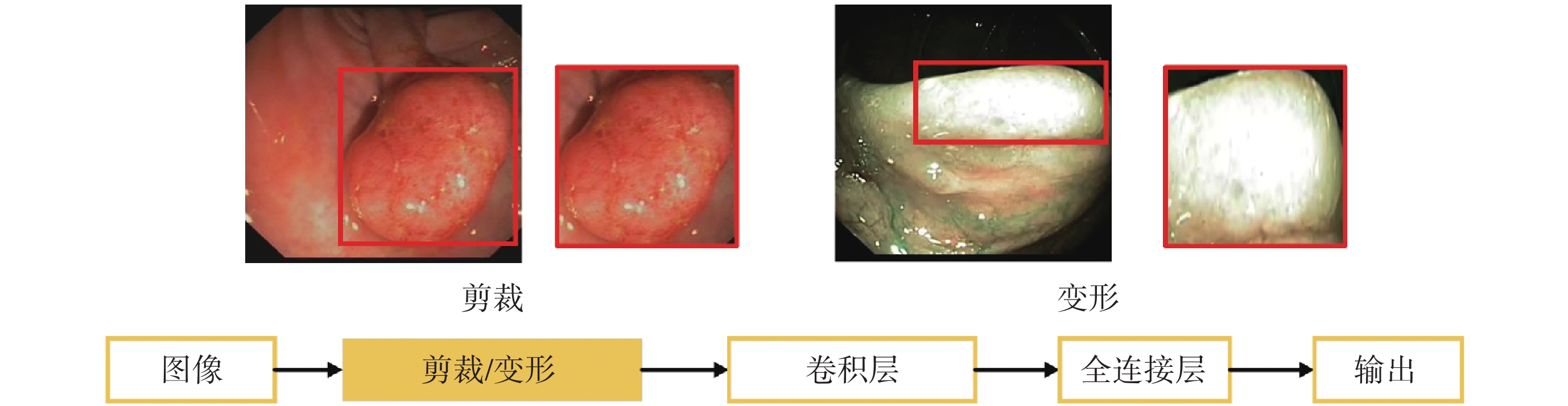 圖3
SPP實現過程
Figure3.
SPP realization process
圖3
SPP實現過程
Figure3.
SPP realization process
1.3 利用FPN多尺度特征融合
結直腸息肉的表面存在許多血管結構或不規則面,基于模型的骨干網絡進行圖像特征提取過程時,常常會忽略掉一些尺寸較小的細節特征,從而導致漏檢或誤檢的出現。本研究在特征融合網絡中引入FPN模塊以提取不同尺度的特征,并利用不同層級的特征進行目標檢測。本研究構建了基于自底向上的圖像金字塔,并通過在底層特征圖與高層特征圖間建立橫向連接,以保留底層特征的細節信息,并充分利用高層特征的語義信息。本研究還引入了自頂向下的跨尺度連接將高層特征圖融合到底層特征圖中,使特征圖具有更豐富的上下文和語義信息,在多尺度下對圖像進行目標檢測,從而提高檢測的準確度。
1.4 引入SAM增強感知能力
早期結直腸增生尚未形成明顯息肉時,其顏色、紋理與正常腸組織相近,傳統算法難以對其進行有效區分。為有效應對此類場景,本模型引入了SAM模塊,增強模型對重要區域的關注度,提升其對結直腸息肉的感知能力。
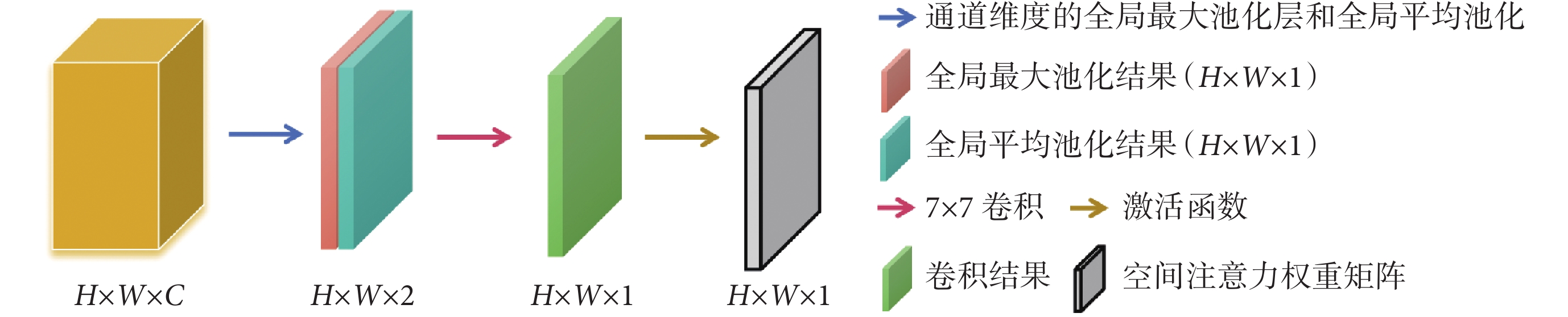
如圖4所示,SAM模塊由特征映射和空間注意力機制兩部分組成,將高(height,H)(符號記為H)、寬(width,W)(符號記為W)、通道數(channels,C)(符號記為C)的特征圖作為輸入,通過特征映射將其轉換為高維特征表示,采用卷積、池化和激活函數提取輸入數據的特征。SAM模塊的核心是空間注意力機制,其根據特定的注意力方式對特征映射中的每個位置進行權重計算,有效提高了模型對結直腸息肉及其邊緣像素的關注程度,同時忽略背景中的無用信息。
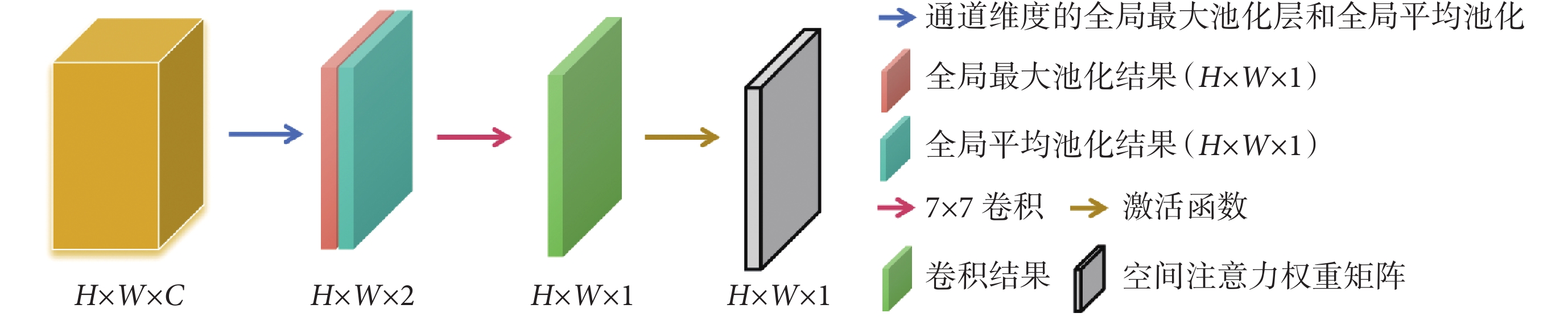 圖4
SAM模塊示意圖
Figure4.
SAM module schematic
圖4
SAM模塊示意圖
Figure4.
SAM module schematic
1.5 使用PPA模塊進行信息聚合
本研究引入了PPA模塊,以期增強目標檢測任務的性能并增強泛化能力。輸入的圖像在經過多層卷積和池化的操作后,產生不同尺度的特征圖。本研究首先將特征圖分割成多個塊,并在每個塊上應用注意力機制,采用PPA模塊在不同層級的特征圖中自適應地尋找重要特征并進行整合。模型的注意力機制通過計算每個特征塊內特征的全局平均池化值與全局最大池化值之間的比例,獲得該特征塊的重要性系數。根據重要性系數再對每個特征塊進行加權平均,最后得到了經過注意力機制篩選和聚合后的特征。通過整合不同層級的特征,并利用注意力機制選擇最重要的特征,PPA模塊保留了原始特征的豐富表示,有效提升了模型的檢測性能,增強了泛化能力。
1.6 任務網絡頭部設計
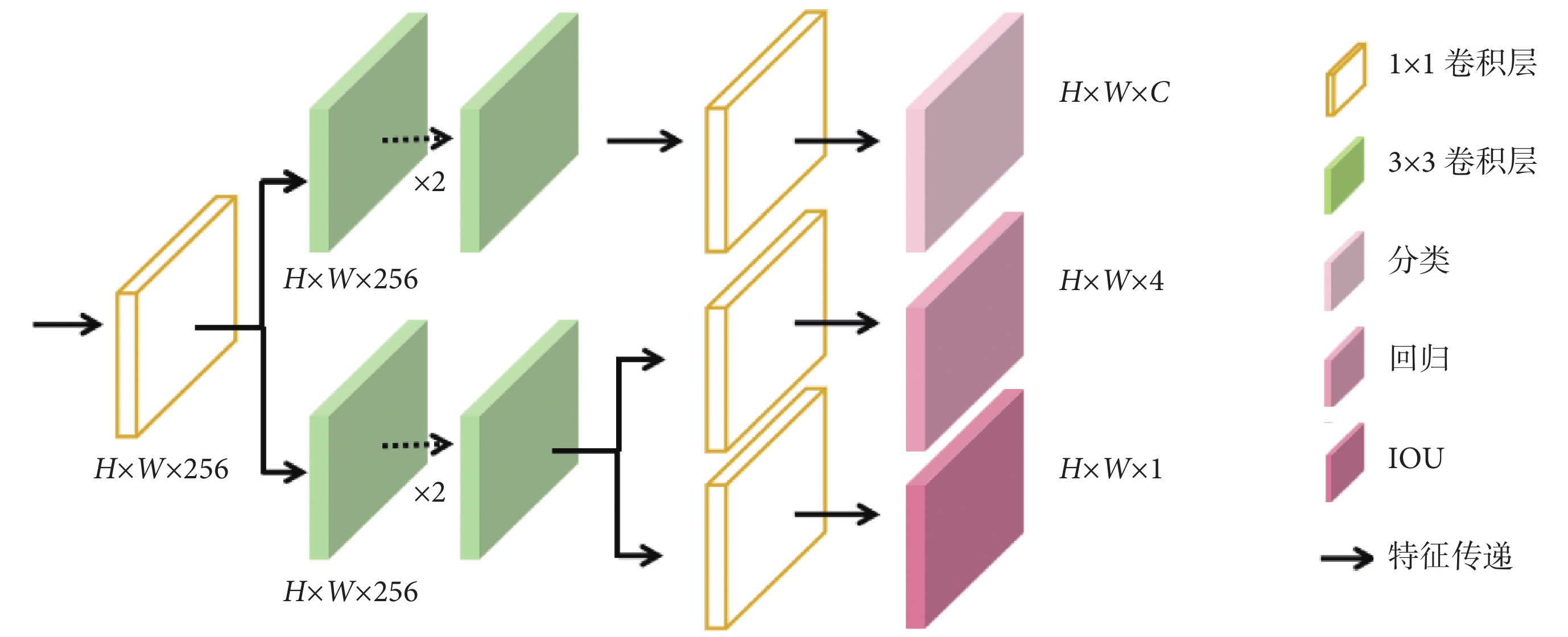
本研究在任務網絡頭部設計使用解耦機制,將輸出端的H × W × 256的特征圖解耦為對應目標的分類、回歸和交并比(intersection over union,IOU)特征并完成相應的任務,如圖5所示。
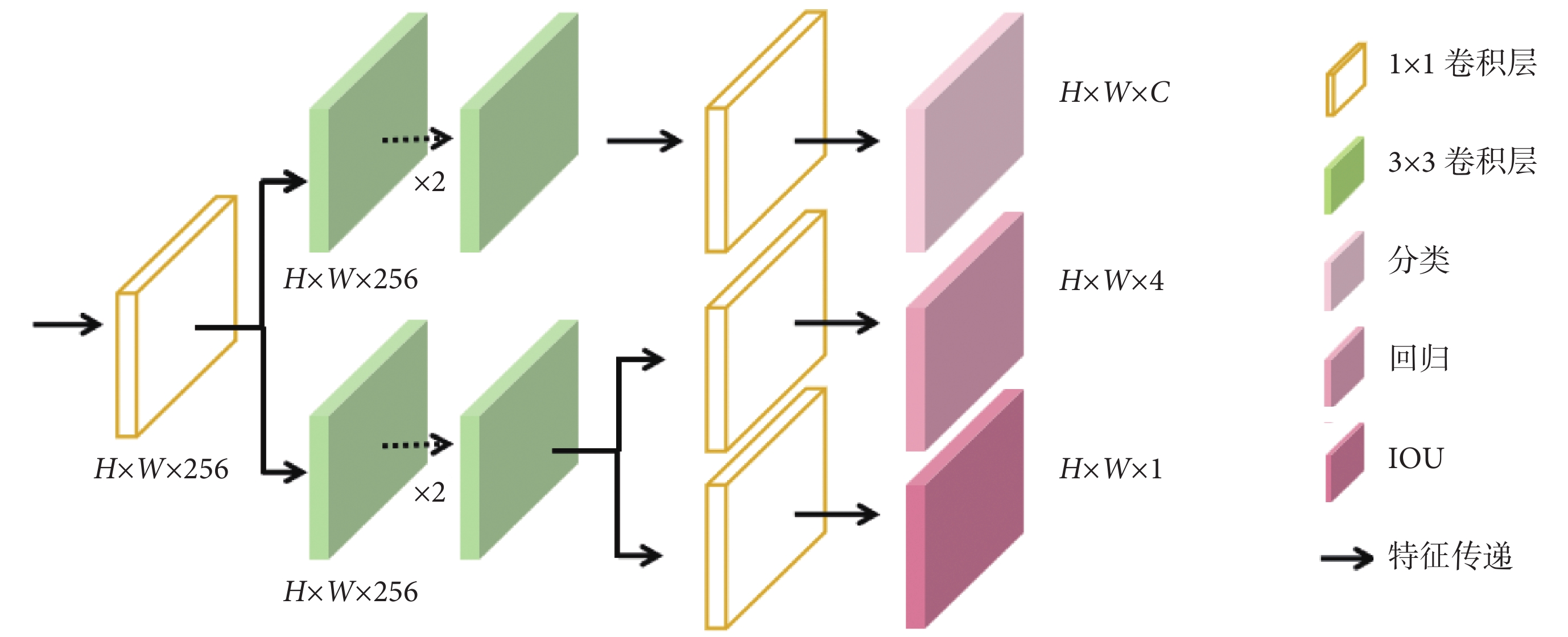 圖5
解耦頭網絡結構圖
Figure5.
Decoupled head network architecture
圖5
解耦頭網絡結構圖
Figure5.
Decoupled head network architecture
目標分類分支中采用卷積層和全連接層構建分類網絡,將卷積特征圖轉換為目標類別預測。此分支中使用交叉熵損失函數衡量分類預測的準確性,計算預測標簽和真實標簽之間的差異, 如式(1)所示:
 |
其中,Lcls為分類損失函數,y為真實標簽,p為模型預測出的概率值。位置回歸分支通過卷積層和全連接層將卷積特征圖轉換為邊界框的位置信息(邊界框的中心坐標、寬度和高度),并采用平滑L1損失函數來衡量預測邊界框與真實邊界框之間的位置差異,如式(2)所示:
 |
其中Lreg為回歸損失函數,x是預測值與真實值之間的差異。在預測階段,對解耦頭的輸出進行歸一化操作,得到每個特征點屬于每個類別的概率。模型利用對象置信度篩選出包含物體的預測框,根據回歸參數調整框的位置,為每個預測框分配最高置信度的類別。模型的損失函數L采用跨階段局部整合方法將分類和回歸任務的損失函數綜合,如式(3)所示:
 |
其中,λ為超參數,本文設置為1。
2 數據及參數設置
2.1 數據集介紹
本研究采用的數據集來自2023年“第八屆全國大學生生物醫學工程創新設計競賽”,如圖6所示,其提供了具有無息肉、增生性息肉、腺瘤性息肉等三種類別的28 773 張直腸息肉內鏡圖像,可公開獲取。本研究依照交叉驗證的方式,為保證數據獨立互斥,將實驗數據集按照6:2:2的比例劃分為訓練集、驗證集與測試集,數據分布如表1所示。
 圖6
數據集示例圖像
Figure6.
Example images of the dataset
圖6
數據集示例圖像
Figure6.
Example images of the dataset
2.2 參數設置及指標評價
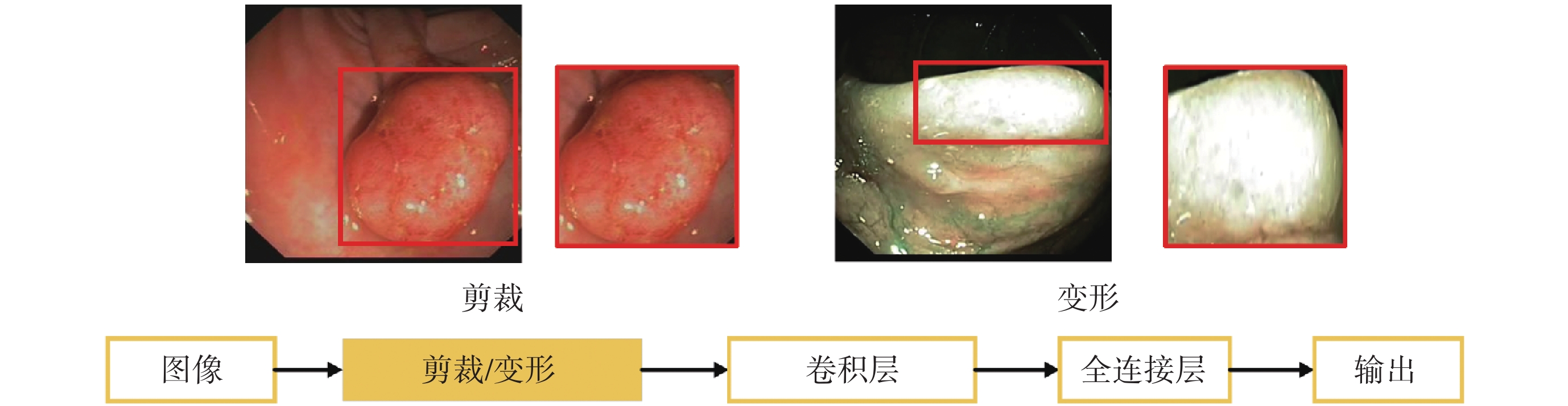
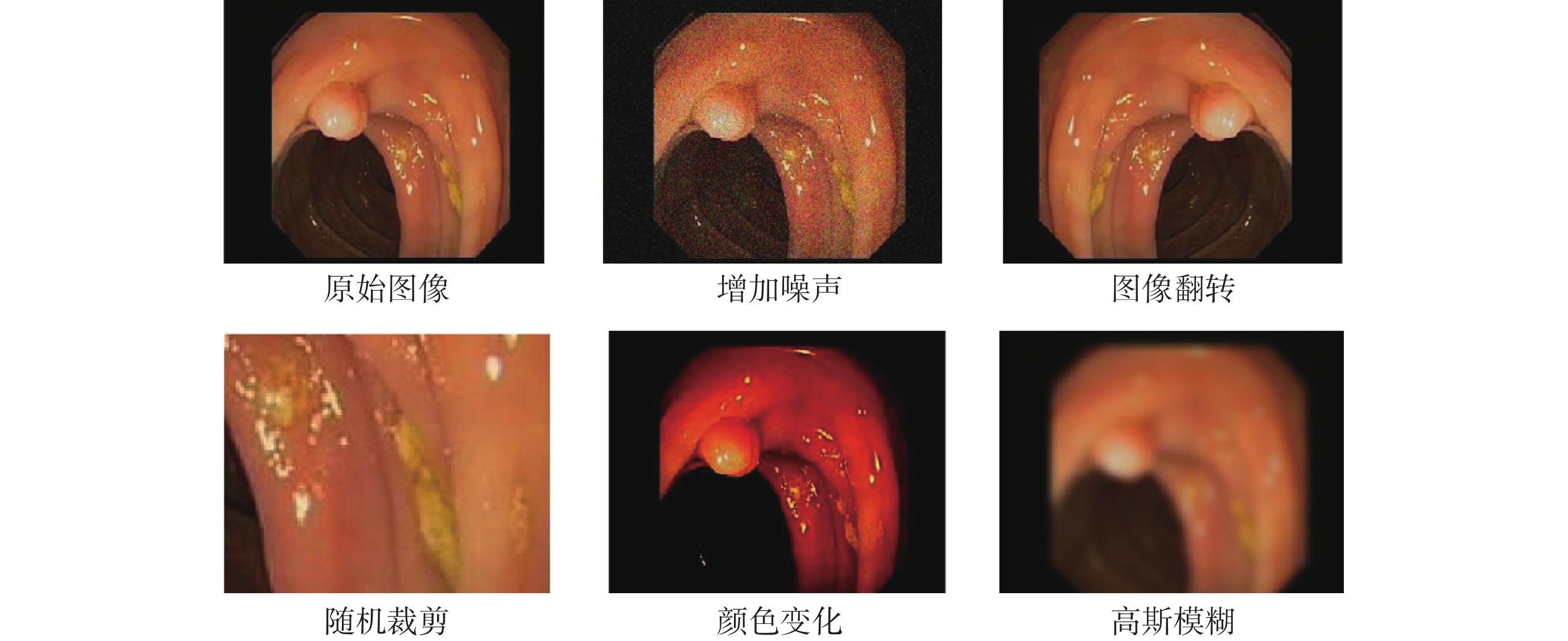
如圖7所示,本研究在結直腸息肉自動檢測任務中對原始圖像采用增加噪聲、圖像翻轉、隨機剪裁、顏色變化和高斯模糊等數據增強方式增加訓練樣本量,采用學習率調度器固定步長衰減(step learning rate,stepLR)策略在訓練過程中動態調整學習率,學習率初始值為1 × 10?4,訓練批次大小為16,輪次為200,并利用隨機梯度下降(stochastic gradient descent,SGD)優化器更新模型的參數,每隔10輪次對模型進行評估,保存當前最優模型權重。
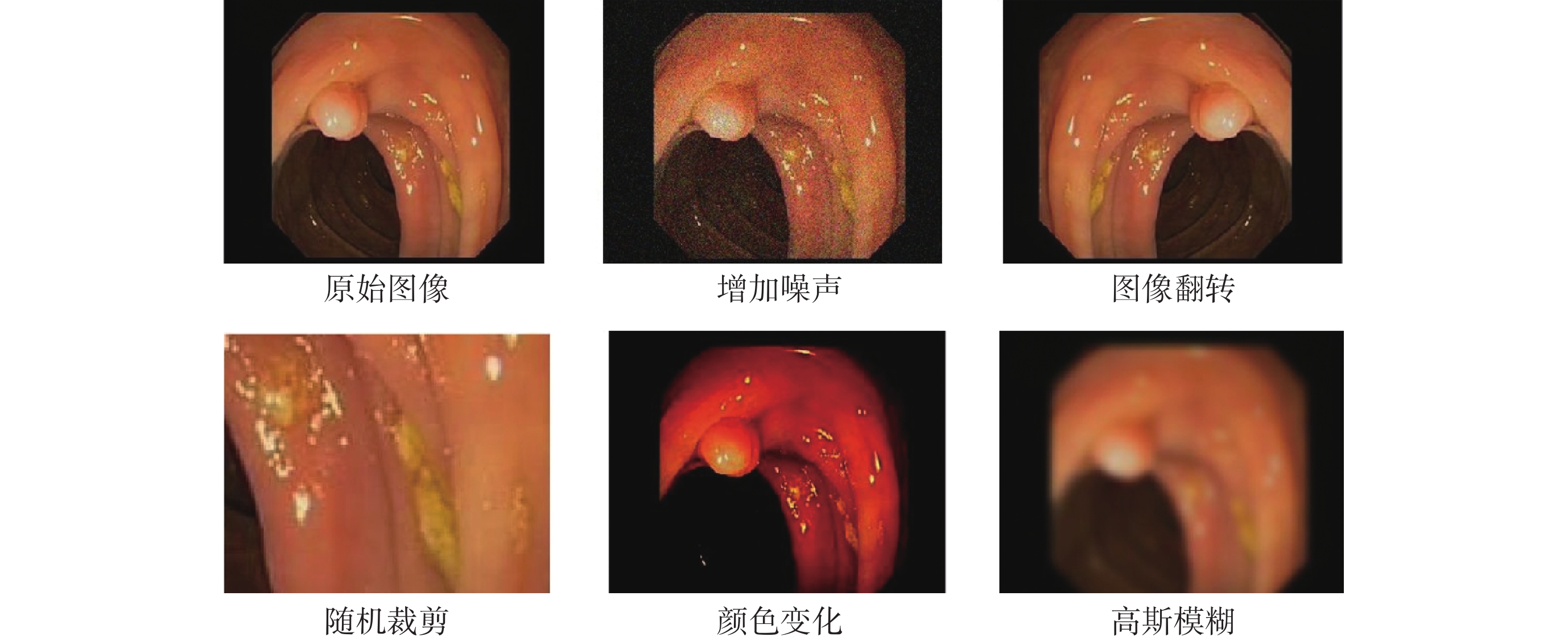 圖7
數據增強示例
Figure7.
Example of data enhancement
圖7
數據增強示例
Figure7.
Example of data enhancement
本研究分別采用精度(precision,pre)、召回率(recall,rec)、F1分數(f1-score, f1),以及平均精確度均值(mean average precision,mAP)在IOU閾值為0.5時的值(符號記為mAP@0.5)等指標評估模型的性能,如式(4)~式(6)所示:
 |
 |
 |
其中,真陽性(true positive,TP)為正樣本分類正確的數量;假陽性(false positive,FP)為正樣本分類錯誤的數量;真陰性(true negative,TN)為負樣本分類正確的數量;假陰性(false ngative, FN)為負樣本分類錯誤的數量。
mAP@0.5的計算需要先計算IOU(符號記為IOU),如式(7)所示:
 |
其中,A為預測框面積,B為真實框面積。若IOU > 0.5,則該預測框為TP,否則為FP;若沒有預測框IOU > 0.5,則為FN。對于息肉的每個類別計算平均精確度(average precision,AP)(符號記為AP),如式(8)所示:
 '/> '/> |
其中,r為rec值, 是在F ≥
是在F ≥  時的最大pre值。最后,根據各類別的AP計算mAP(符號記為mAP),如式(9)所示:
時的最大pre值。最后,根據各類別的AP計算mAP(符號記為mAP),如式(9)所示:
 |
其中,num為類別數。
為進一步測試模型運行速度,使用幀率(frames per second,FPS)(符號記為FPS)作為模型推理速度的評價指標,計算公式如式(10)所示:
 |
其中,N為預測圖像數量,t為總預測時間。
3 結果及討論
結直腸息肉的檢測在結直腸癌的早期防治中具有關鍵作用,腸鏡是臨床診斷腸道病變檢測的“金標準”,但是腸鏡結果易受到腸道準備的清潔程度、退鏡時間以及醫師主觀因素的影響,導致檢測準確性下降。因此,為滿足臨床對于檢測模型的小體量和高準確率的要求,本文提出一種基于多尺度多層次特征融合和輕量化卷積神經網絡的結直腸息肉檢測模型。
3.1 對比實驗結果及討論
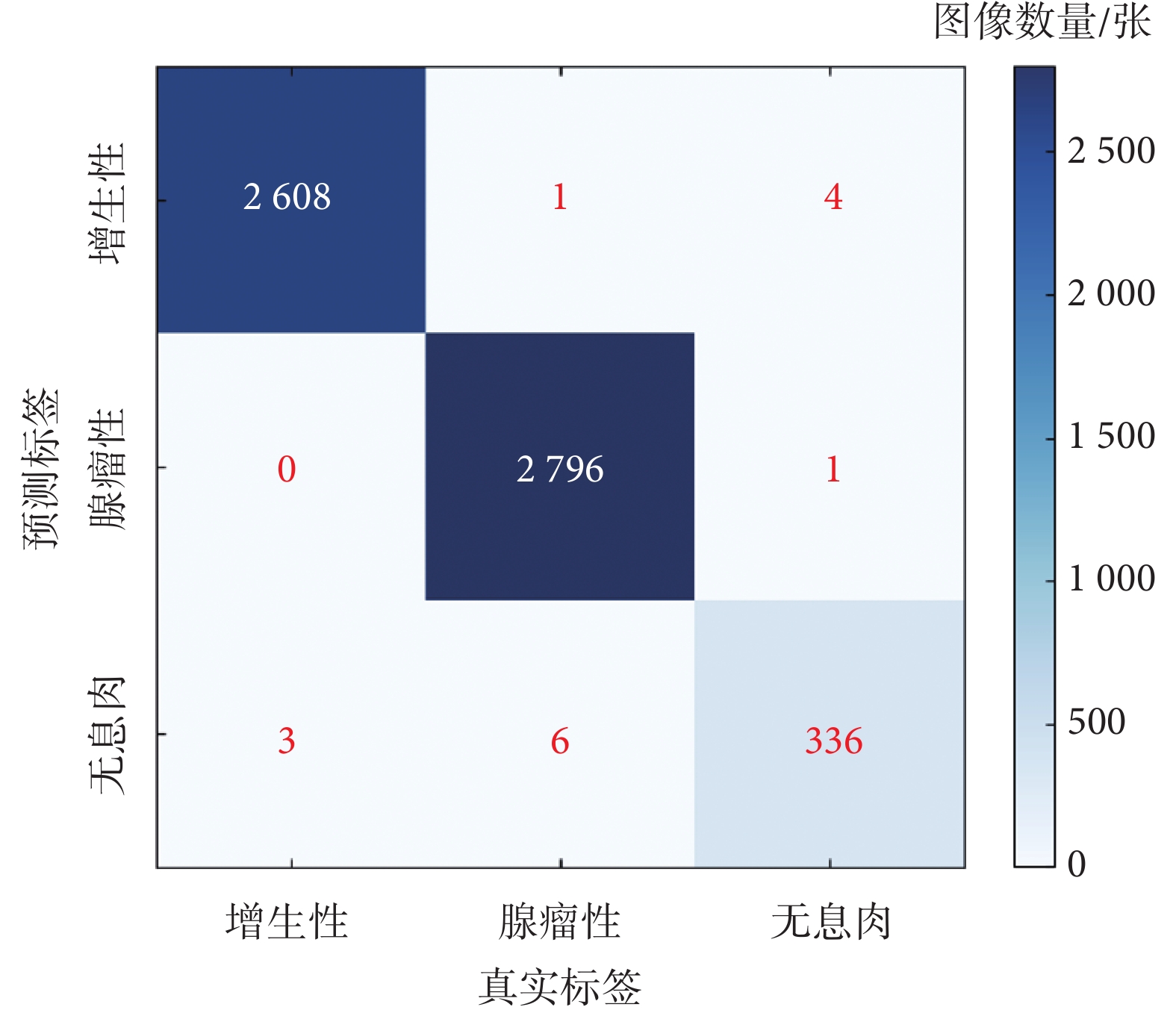
在獨立測試集上調整置信度閾值,設置初始閾值為0.05,以0.05的步長逐漸增加評估模型在不同閾值下的檢測性能,并考察pre、rec、f1和mAP@0.5指標的變化情況。結果顯示,最佳結果為閾值0.05時,pre為0.998 2,rec為 0.998 8,f1為 0.998 4,mAP@0.5達到0.995 3,混淆矩陣的詳細信息如圖8所示。
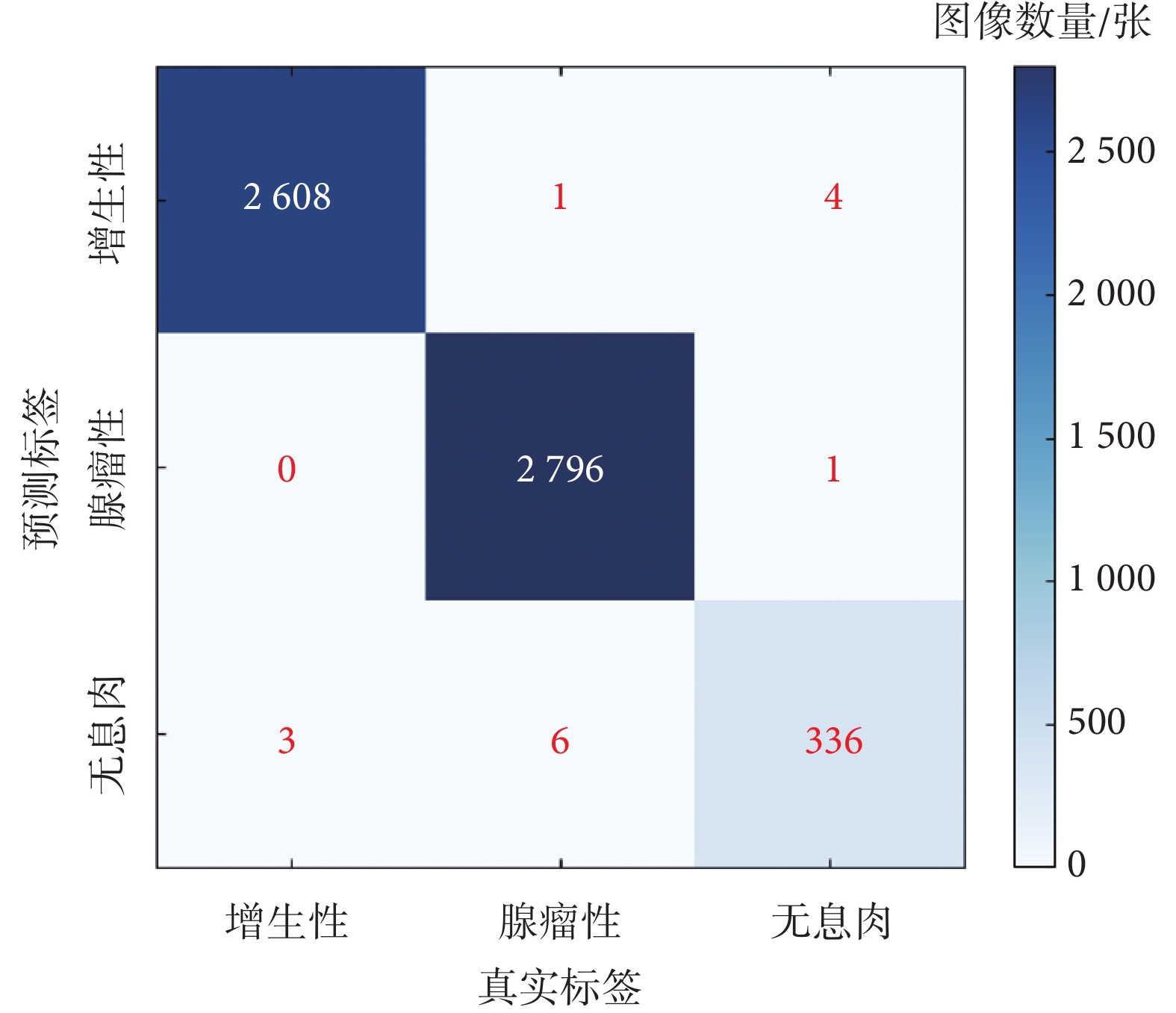 圖8
混淆矩陣
Figure8.
Confusion matrix
圖8
混淆矩陣
Figure8.
Confusion matrix
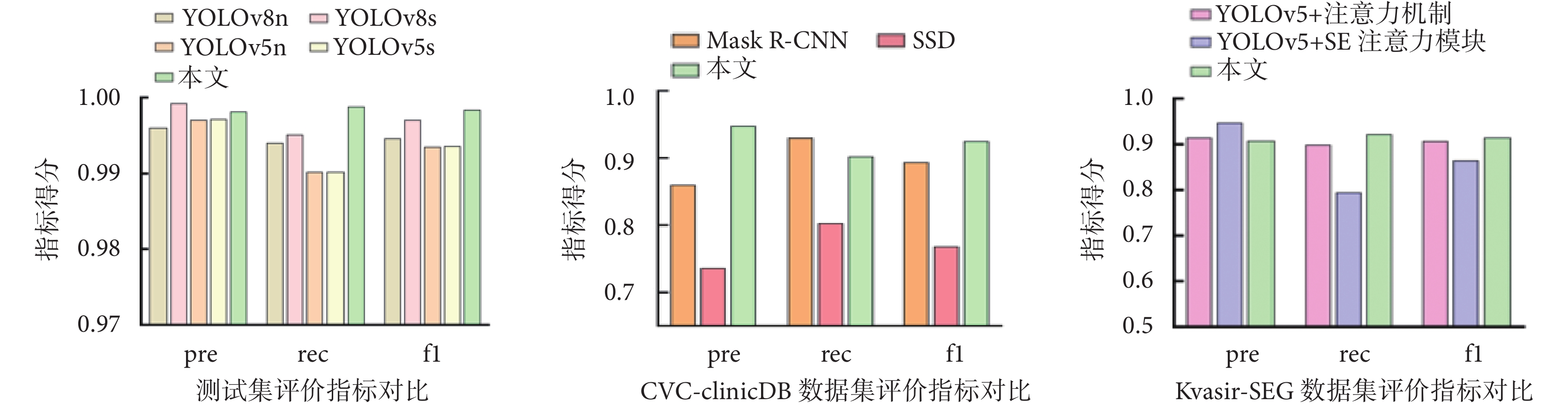
為進一步驗證模型性能,本模型在原有測試集基礎上,進一步增加了多個公開數據集的對比實驗。在測試集上與具有先進性能的YOLO系列v8版本的小模型(YOLO v8-small,YOLOv8s)、YOLO系列v8版本的微模型(YOLO v8-nano,YOLOv8n),以及YOLO系列v5版的小模型(YOLO v5-small,YOLOv5s),以及YOLO系列v5版本的微模型(YOLO v5-nano,YOLOv5n)算法進行對比,結果表明本研究提出模型在性能上優于現有其他模型。本模型在挪威癌癥協會與挪威科技大學聯合構建的克瓦希爾分割數據(Kvasir segmentation dataset,Kvasir-SEG)公開數據集[27-28]上測試的結果表明,與分別增加傳統注意力機制(YOLOv5+注意力機制)與擠壓和激勵網絡(squeeze and excitation networks,SE)注意力模塊(YOLOv5+SE注意力模塊)的模型對比,本模型可達到最高的性能表現。此外,在西班牙巴塞羅那大學與加泰羅尼亞視覺中心(center for visual computing,CVC)聯合構建的公開數據庫中的結腸鏡視頻數據庫(colonoscopy video clips database,Clinic DB)(CVC-Clinic DB)[29-30]上測試的結果表明,本研究所提出模型在性能指標上優于同為單階段目標檢測算法的SSD和掩膜R-CNN(Mask R-CNN),實驗結果如圖9所示。
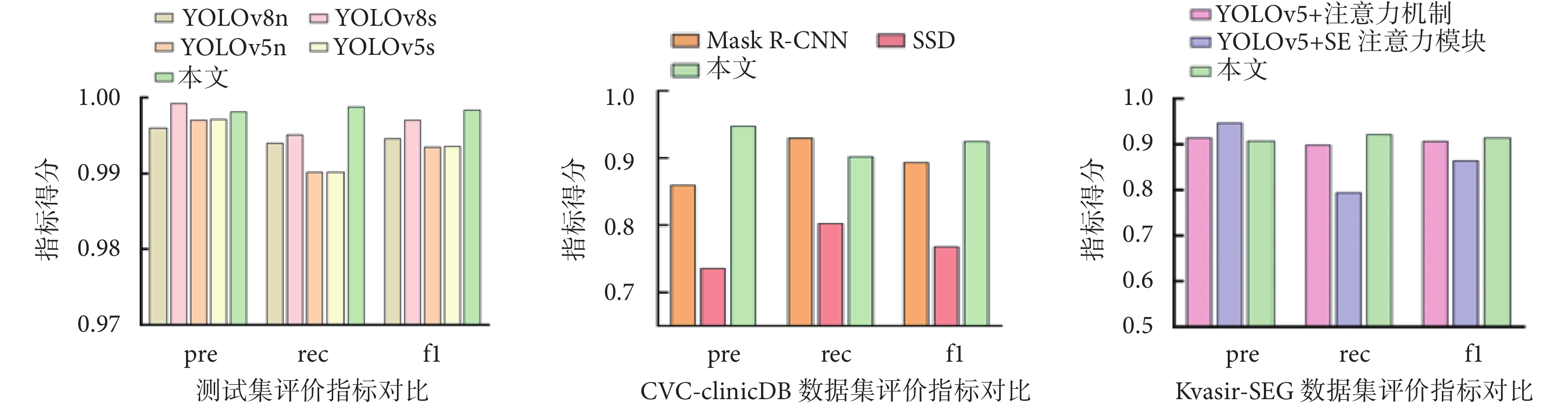 圖9
不同模型性能對比
Figure9.
Comparison of the different models’ performance
圖9
不同模型性能對比
Figure9.
Comparison of the different models’ performance
本文模型選取不同計算機處理器對幀率進行評測。測試集的5 755張圖像,在英特爾i5中央處理器(i5-8350U,Intel Inc.,美國)上幀率為4.55 幀/s,在英偉達特斯拉V100圖形處理器(Tesla V100,Nvidia Inc.,美國)上幀率為74 幀/s,實驗結果顯示在不同計算機處理器上都具有了較快的推理能力。
3.2 消融實驗結果及討論
本模型引入了SPP模塊用于多尺度特征提取,采用FPN模塊對骨干網絡中多層次的特征圖進行融合,引入基于SAM模塊的注意力機制,以增強對息肉邊界和細節特征的融合效果。同時,引入PPA模塊,用于在不同層級的特征圖中尋找重要特征并進行整合。為了深入理解和驗證研究的關鍵組成部分對整體結果的貢獻,將YOLOX-S結合FPN構建的模塊(YOLOX-S+FPN)作為基線模型,分別添加SPP、SAM、PPA模塊構建:YOLOX-S+FPN模塊+SPP模塊、YOLOX-S+FPN模塊+SAM模塊、YOLOX-S+FPN模塊+PPA模塊。然后,針對SPP、SAM和PPA等模塊進行消融實驗,結果如表2所示。
3.3 超參數敏感性實驗結果及討論
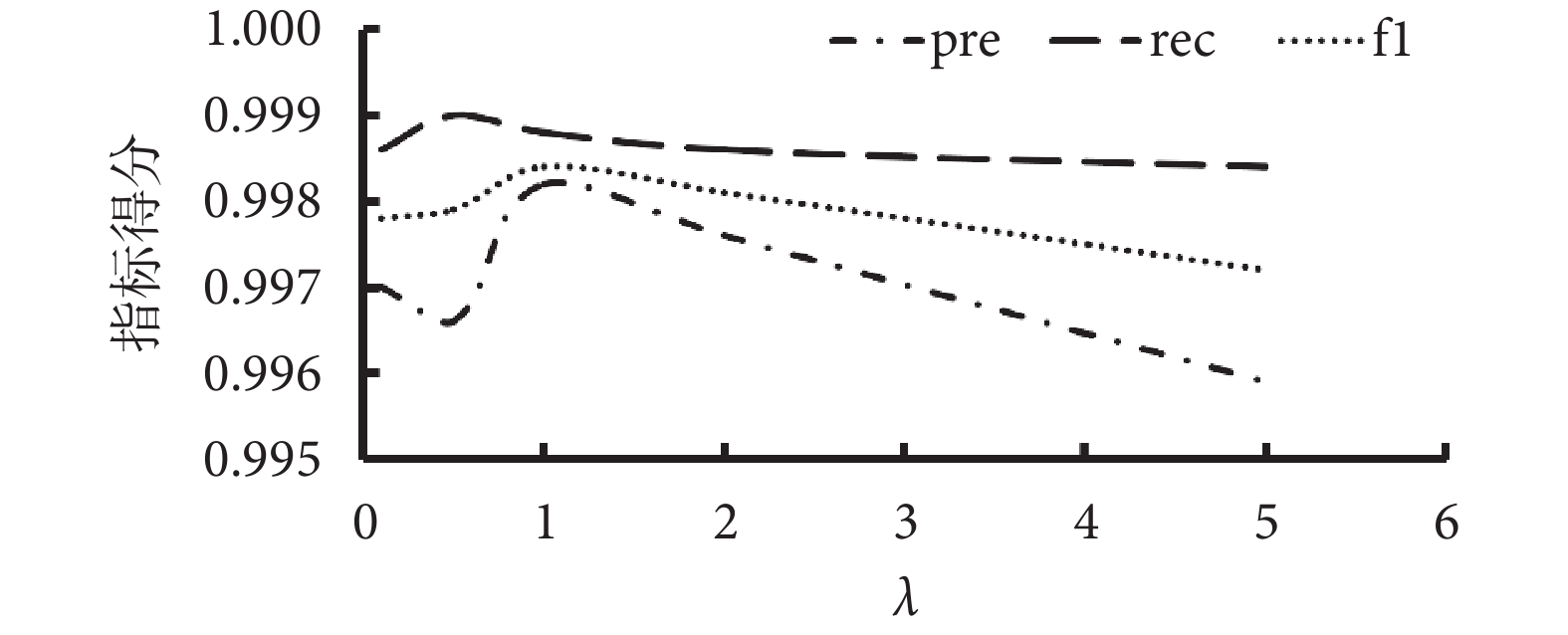
為進一步探索本研究所提出模型的最優參數,本研究針對損失函數中的超參數值λ的選擇進行超參數敏感性實驗。實驗中λ最小值從0.1取值,步長為0.05,在測試集上進行實驗,如圖10所示,結果顯示在λ取值為1時,模型的綜合性能達到最高,并且能夠較好地平衡分類與回歸任務,因此在訓練中取值固定為1。
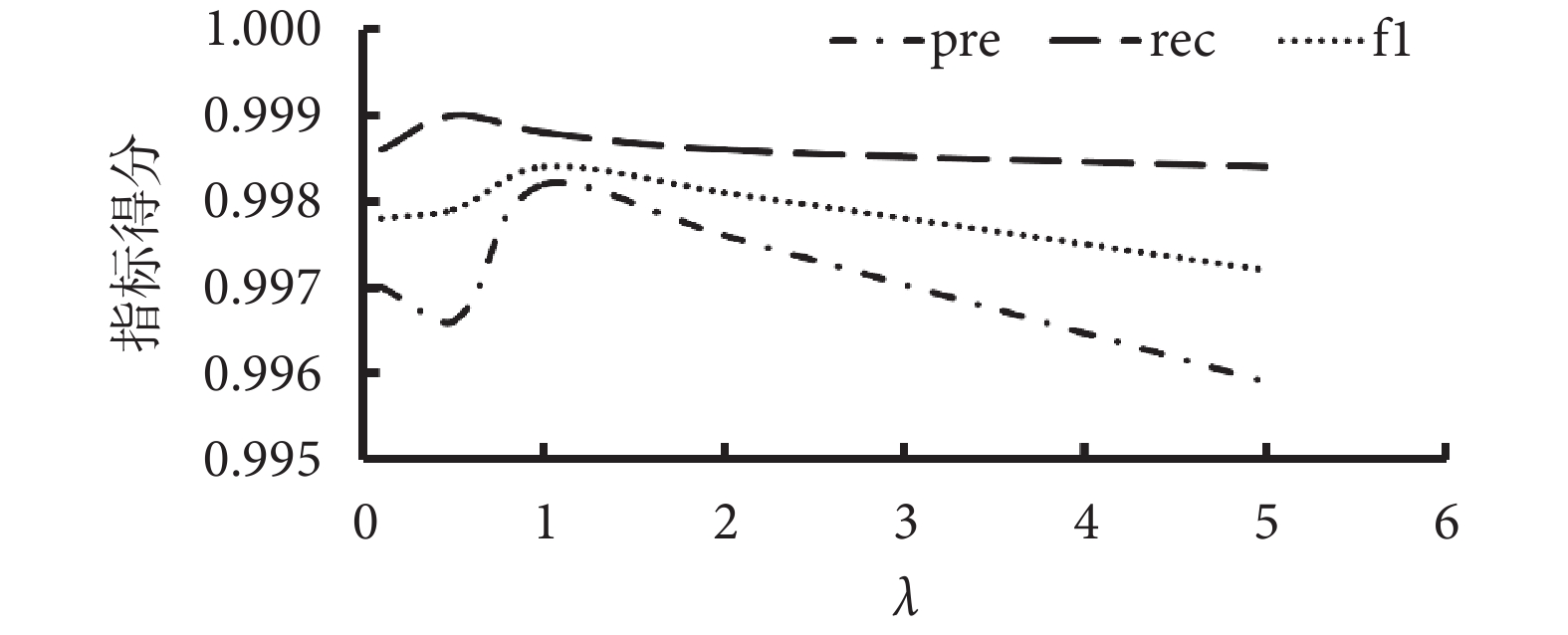 圖10
超參數敏感性實驗結果圖
Figure10.
Hyper-parameter sensitivity experiment results
圖10
超參數敏感性實驗結果圖
Figure10.
Hyper-parameter sensitivity experiment results
4 總結
本研究提出了基于輕量化卷積神經網絡的結直腸息肉檢測模型,通過利用SPP、FPN、SAM和PPA模塊進行多尺度多層次特征融合,性能得到較大提升。在獨立測試集上取得pre為0.998 2,rec為0.998 8,f1為0.998 4以及mAP@0.5為0.995 3的性能。同時,模型的參數量為9.08 M,在Tesla V100計算顯卡的測試平臺上幀率達到74 幀/s。
本文所提出的模型具有體量小、精度高且速度快的特點,適合在臨床場景中進行快速部署和應用。未來,本研究擬從模型通用性、無監督訓練角度,進一步開展相關研究,提升模型的通用性以及泛化性。綜上所述,本研究為結直腸息肉圖像的檢測與診斷提供了關鍵工具,有助于提高檢測過程中的精準度和效率。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻說明:李奕揚主要負責整體實驗的設計、算法修改及論文撰寫;趙佳漪主要負責醫學背景指導、實驗數據分析及論文撰寫;余若伊主要負責實驗數據的分析、數據處理方案設計及論文撰寫;劉輝翔負責數據處理與論文修訂;梁爽負責整體實驗的設計、算法技術指導與論文修訂;谷宇負責實驗概念設計、論文修訂。
0 引言
結直腸癌是世界范圍內的第三大惡性腫瘤,而中國結直腸癌發生率、死亡率均處于世界較高水平。據統計,2020年中國結直腸癌發病人數55.5萬例,位列中國各癌種第二位,占中國總癌種發病人數的12.2%,占全球該類癌癥發病人數的28.8%;總死亡人數28.6萬例,位列中國各癌種死亡人數的第五位,占中國總癌種死亡人數的9.5%,占全球該類癌癥死亡人數的30.6%[1]。80%~95%的結直腸癌是在多基因、多機制的作用下由結直腸息肉經過約5~10年演變而來[2]。結直腸息肉主要分為腺瘤型息肉和增生型息肉,腺瘤型的致癌率遠高于增生型[3],因此早期息肉的準確分型對于后續治療計劃的制定至關重要[4]。
雖然結直腸息肉檢查方法有多種,但結腸鏡檢查是診斷腸道病變的“金標準”,在息肉檢出與診斷中較為有效[5]。研究顯示,平均腺瘤檢出率每增加1.0%,結直腸癌發生風險可降低3.0%[6]。但結腸鏡檢查可能受腸道準備的清潔程度[7]、退鏡時間[8]以及內鏡醫師的技術水平等因素影響[9-10]。Bretthauer等[11]在多中心大樣本臨床數據上的研究表明,不同內鏡醫師之間由于主觀因素影響,腺瘤檢出率差異高達10倍。盡管有研究嘗試通過提高內鏡操作技術和腸道準備質量來提高息肉和腺瘤的檢出率,但結果并不理想[12]。因此,目前亟需一種更客觀且自動化的息肉檢測方法。
在醫學圖像檢測識別中,人工智能(artificial intelligence,AI)輔助診斷已獲得廣泛應用[13]。通過AI輔助檢測,可以有效提升息肉檢出率[14-15]。研究顯示,當借助AI輔助進行人工診斷時,息肉檢出率比純人工檢測顯著提升[16]。AI的深度學習目標檢測算法具有強大的表征學習能力和擬合能力,應用于息肉檢測已取得了一定效果[17]。根據是否存在候選區域生成網絡,目標檢測算法主要分為兩種類型:兩階段目標檢測算法和單階段目標檢測算法[18]。兩階段目標檢測算法步驟為:先提取候選區域,再對每個區域進行分類和定位。例如,有研究采用區域卷積神經網絡(region-based convolutional neural network,R-CNN)在結直腸息肉的檢測方面取得了顯著的進步[19],但在檢測速度上仍不能滿足臨床檢驗的需求[20]。而單階段目標檢測算法通過將目標分類和邊界框回歸兩個任務合并為一個步驟,可以更高效地進行目標檢測。現有的單階段目標檢測算法,如“你只需看一次(you only look once,YOLO)”[21]、單次多框檢測器(single shot multi-box detector,SSD)[22]等,檢測速度較快,初步實現了實時目標的檢測;但在檢測小目標時,由于目標所占的像素區域較少,隨著網絡深度的加深容易丟失細節特征,導致算法精度受限[23]。此外,現有基于輕量化目標檢測模型難以同時滿足小體量和較高準確率的需要[24],對臨床場景下硬件計算能力具有較高要求。
為了解決以上問題,本文擬提出基于輕量化卷積神經網絡的結直腸息肉檢測算法,以期在結直腸息肉檢測領域實現以下目標:
(1)本研究擬通過在主干網絡中引入空間金字塔池化(spatial pyramid pooling,SPP),增強模型在不同空間尺度下的特征提取能力以及整合能力。
(2)本研究擬在特征網絡融合部分,采用特征金字塔網絡(feature pyramid network,FPN),通過多層次特征交互的網絡結構加強模型的表達能力,在此基礎上引入空間注意力模塊(spatial attention module,SAM),對圖像中的息肉病變區域賦予更高的注意權重,以提高模型感知能力。
(3)本研究擬引入位置模式注意力(positional pattern attention,PPA)模塊進行信息聚合,以期降低目標檢測模型參數規模,實現低配置下保持較快檢測速度和高準確度的特性。
1 方法
1.1 整體流程
結直腸息肉的形狀和顏色多樣,表面特點不一,在內鏡下易產生噪聲和偽影[25],傳統目標檢測方法在識別過程中易受噪聲影響產生檢測誤差[26]。針對上述問題,本文提出一種基于輕量化卷積神經網絡的結直腸息肉檢測模型。如圖1所示,本研究所提出模型以YOLO系列X版本小模型(YOLO X-small,YOLOX-S)的目標檢測模塊作為檢測框架的基準模型。
圖1
YOLOX流程圖
Figure1.
YOLOX flowchart
為實現結直腸息肉圖像的特征有效提取,在主干網絡部分,本研究選擇53層深度卷積神經網絡架構作為特征提取模塊,并在此基礎上增加SPP模塊整合輸出特征;特征融合網絡中,本研究采用 FPN 模塊對骨干網絡提取的不同尺度的特征圖進行融合;本研究采用SAM模塊,通過注意力機制增強模型對息肉圖像邊界和上下文細節的表示能力。最后,本研究通過增加PPA模塊,在不同層級的特征圖中自適應挖掘顯著特征并實現聚合,以期提高模型的檢測性能。在預測部分,模型通過解耦頭并行處理分類和回歸任務,最終輸出待檢測目標息肉的邊界框坐標及息肉分型等信息。
1.2 基于SPP模塊提取多尺度特征
本模型引入SPP模塊解決圖像尺寸和目標大小變化的問題,實現在不同特征圖尺寸上的特征池化,且有效減少了模型的參數數量。使用SPP模塊進行目標檢測時,可以對不同大小的池化特征圖進行扁平化,得到固定大小的向量。如圖2所示,扁平化后的向量通過級聯方式形成高層次特征表示,從而更好地捕捉目標的細節和上下文信息。如圖3所示,該模塊的引入可以提高模型對不同尺寸息肉圖像進行特征提取時的適應能力。
圖2
SPP示意圖
Figure2.
SPP schematic
圖3
SPP實現過程
Figure3.
SPP realization process
1.3 利用FPN多尺度特征融合
結直腸息肉的表面存在許多血管結構或不規則面,基于模型的骨干網絡進行圖像特征提取過程時,常常會忽略掉一些尺寸較小的細節特征,從而導致漏檢或誤檢的出現。本研究在特征融合網絡中引入FPN模塊以提取不同尺度的特征,并利用不同層級的特征進行目標檢測。本研究構建了基于自底向上的圖像金字塔,并通過在底層特征圖與高層特征圖間建立橫向連接,以保留底層特征的細節信息,并充分利用高層特征的語義信息。本研究還引入了自頂向下的跨尺度連接將高層特征圖融合到底層特征圖中,使特征圖具有更豐富的上下文和語義信息,在多尺度下對圖像進行目標檢測,從而提高檢測的準確度。
1.4 引入SAM增強感知能力
早期結直腸增生尚未形成明顯息肉時,其顏色、紋理與正常腸組織相近,傳統算法難以對其進行有效區分。為有效應對此類場景,本模型引入了SAM模塊,增強模型對重要區域的關注度,提升其對結直腸息肉的感知能力。
如圖4所示,SAM模塊由特征映射和空間注意力機制兩部分組成,將高(height,H)(符號記為H)、寬(width,W)(符號記為W)、通道數(channels,C)(符號記為C)的特征圖作為輸入,通過特征映射將其轉換為高維特征表示,采用卷積、池化和激活函數提取輸入數據的特征。SAM模塊的核心是空間注意力機制,其根據特定的注意力方式對特征映射中的每個位置進行權重計算,有效提高了模型對結直腸息肉及其邊緣像素的關注程度,同時忽略背景中的無用信息。
圖4
SAM模塊示意圖
Figure4.
SAM module schematic
1.5 使用PPA模塊進行信息聚合
本研究引入了PPA模塊,以期增強目標檢測任務的性能并增強泛化能力。輸入的圖像在經過多層卷積和池化的操作后,產生不同尺度的特征圖。本研究首先將特征圖分割成多個塊,并在每個塊上應用注意力機制,采用PPA模塊在不同層級的特征圖中自適應地尋找重要特征并進行整合。模型的注意力機制通過計算每個特征塊內特征的全局平均池化值與全局最大池化值之間的比例,獲得該特征塊的重要性系數。根據重要性系數再對每個特征塊進行加權平均,最后得到了經過注意力機制篩選和聚合后的特征。通過整合不同層級的特征,并利用注意力機制選擇最重要的特征,PPA模塊保留了原始特征的豐富表示,有效提升了模型的檢測性能,增強了泛化能力。
1.6 任務網絡頭部設計
本研究在任務網絡頭部設計使用解耦機制,將輸出端的H × W × 256的特征圖解耦為對應目標的分類、回歸和交并比(intersection over union,IOU)特征并完成相應的任務,如圖5所示。
圖5
解耦頭網絡結構圖
Figure5.
Decoupled head network architecture
目標分類分支中采用卷積層和全連接層構建分類網絡,將卷積特征圖轉換為目標類別預測。此分支中使用交叉熵損失函數衡量分類預測的準確性,計算預測標簽和真實標簽之間的差異, 如式(1)所示:
|
其中,Lcls為分類損失函數,y為真實標簽,p為模型預測出的概率值。位置回歸分支通過卷積層和全連接層將卷積特征圖轉換為邊界框的位置信息(邊界框的中心坐標、寬度和高度),并采用平滑L1損失函數來衡量預測邊界框與真實邊界框之間的位置差異,如式(2)所示:
|
其中Lreg為回歸損失函數,x是預測值與真實值之間的差異。在預測階段,對解耦頭的輸出進行歸一化操作,得到每個特征點屬于每個類別的概率。模型利用對象置信度篩選出包含物體的預測框,根據回歸參數調整框的位置,為每個預測框分配最高置信度的類別。模型的損失函數L采用跨階段局部整合方法將分類和回歸任務的損失函數綜合,如式(3)所示:
|
其中,λ為超參數,本文設置為1。
2 數據及參數設置
2.1 數據集介紹
本研究采用的數據集來自2023年“第八屆全國大學生生物醫學工程創新設計競賽”,如圖6所示,其提供了具有無息肉、增生性息肉、腺瘤性息肉等三種類別的28 773 張直腸息肉內鏡圖像,可公開獲取。本研究依照交叉驗證的方式,為保證數據獨立互斥,將實驗數據集按照6:2:2的比例劃分為訓練集、驗證集與測試集,數據分布如表1所示。
圖6
數據集示例圖像
Figure6.
Example images of the dataset
2.2 參數設置及指標評價
如圖7所示,本研究在結直腸息肉自動檢測任務中對原始圖像采用增加噪聲、圖像翻轉、隨機剪裁、顏色變化和高斯模糊等數據增強方式增加訓練樣本量,采用學習率調度器固定步長衰減(step learning rate,stepLR)策略在訓練過程中動態調整學習率,學習率初始值為1 × 10?4,訓練批次大小為16,輪次為200,并利用隨機梯度下降(stochastic gradient descent,SGD)優化器更新模型的參數,每隔10輪次對模型進行評估,保存當前最優模型權重。
圖7
數據增強示例
Figure7.
Example of data enhancement
本研究分別采用精度(precision,pre)、召回率(recall,rec)、F1分數(f1-score, f1),以及平均精確度均值(mean average precision,mAP)在IOU閾值為0.5時的值(符號記為mAP@0.5)等指標評估模型的性能,如式(4)~式(6)所示:
|
|
|
其中,真陽性(true positive,TP)為正樣本分類正確的數量;假陽性(false positive,FP)為正樣本分類錯誤的數量;真陰性(true negative,TN)為負樣本分類正確的數量;假陰性(false ngative, FN)為負樣本分類錯誤的數量。
mAP@0.5的計算需要先計算IOU(符號記為IOU),如式(7)所示:
|
其中,A為預測框面積,B為真實框面積。若IOU > 0.5,則該預測框為TP,否則為FP;若沒有預測框IOU > 0.5,則為FN。對于息肉的每個類別計算平均精確度(average precision,AP)(符號記為AP),如式(8)所示:
| '/> |
其中,r為rec值,是在F ≥ 時的最大pre值。最后,根據各類別的AP計算mAP(符號記為mAP),如式(9)所示:
|
其中,num為類別數。
為進一步測試模型運行速度,使用幀率(frames per second,FPS)(符號記為FPS)作為模型推理速度的評價指標,計算公式如式(10)所示:
|
其中,N為預測圖像數量,t為總預測時間。
3 結果及討論
結直腸息肉的檢測在結直腸癌的早期防治中具有關鍵作用,腸鏡是臨床診斷腸道病變檢測的“金標準”,但是腸鏡結果易受到腸道準備的清潔程度、退鏡時間以及醫師主觀因素的影響,導致檢測準確性下降。因此,為滿足臨床對于檢測模型的小體量和高準確率的要求,本文提出一種基于多尺度多層次特征融合和輕量化卷積神經網絡的結直腸息肉檢測模型。
3.1 對比實驗結果及討論
在獨立測試集上調整置信度閾值,設置初始閾值為0.05,以0.05的步長逐漸增加評估模型在不同閾值下的檢測性能,并考察pre、rec、f1和mAP@0.5指標的變化情況。結果顯示,最佳結果為閾值0.05時,pre為0.998 2,rec為 0.998 8,f1為 0.998 4,mAP@0.5達到0.995 3,混淆矩陣的詳細信息如圖8所示。
圖8
混淆矩陣
Figure8.
Confusion matrix
為進一步驗證模型性能,本模型在原有測試集基礎上,進一步增加了多個公開數據集的對比實驗。在測試集上與具有先進性能的YOLO系列v8版本的小模型(YOLO v8-small,YOLOv8s)、YOLO系列v8版本的微模型(YOLO v8-nano,YOLOv8n),以及YOLO系列v5版的小模型(YOLO v5-small,YOLOv5s),以及YOLO系列v5版本的微模型(YOLO v5-nano,YOLOv5n)算法進行對比,結果表明本研究提出模型在性能上優于現有其他模型。本模型在挪威癌癥協會與挪威科技大學聯合構建的克瓦希爾分割數據(Kvasir segmentation dataset,Kvasir-SEG)公開數據集[27-28]上測試的結果表明,與分別增加傳統注意力機制(YOLOv5+注意力機制)與擠壓和激勵網絡(squeeze and excitation networks,SE)注意力模塊(YOLOv5+SE注意力模塊)的模型對比,本模型可達到最高的性能表現。此外,在西班牙巴塞羅那大學與加泰羅尼亞視覺中心(center for visual computing,CVC)聯合構建的公開數據庫中的結腸鏡視頻數據庫(colonoscopy video clips database,Clinic DB)(CVC-Clinic DB)[29-30]上測試的結果表明,本研究所提出模型在性能指標上優于同為單階段目標檢測算法的SSD和掩膜R-CNN(Mask R-CNN),實驗結果如圖9所示。
圖9
不同模型性能對比
Figure9.
Comparison of the different models’ performance
本文模型選取不同計算機處理器對幀率進行評測。測試集的5 755張圖像,在英特爾i5中央處理器(i5-8350U,Intel Inc.,美國)上幀率為4.55 幀/s,在英偉達特斯拉V100圖形處理器(Tesla V100,Nvidia Inc.,美國)上幀率為74 幀/s,實驗結果顯示在不同計算機處理器上都具有了較快的推理能力。
3.2 消融實驗結果及討論
本模型引入了SPP模塊用于多尺度特征提取,采用FPN模塊對骨干網絡中多層次的特征圖進行融合,引入基于SAM模塊的注意力機制,以增強對息肉邊界和細節特征的融合效果。同時,引入PPA模塊,用于在不同層級的特征圖中尋找重要特征并進行整合。為了深入理解和驗證研究的關鍵組成部分對整體結果的貢獻,將YOLOX-S結合FPN構建的模塊(YOLOX-S+FPN)作為基線模型,分別添加SPP、SAM、PPA模塊構建:YOLOX-S+FPN模塊+SPP模塊、YOLOX-S+FPN模塊+SAM模塊、YOLOX-S+FPN模塊+PPA模塊。然后,針對SPP、SAM和PPA等模塊進行消融實驗,結果如表2所示。
3.3 超參數敏感性實驗結果及討論
為進一步探索本研究所提出模型的最優參數,本研究針對損失函數中的超參數值λ的選擇進行超參數敏感性實驗。實驗中λ最小值從0.1取值,步長為0.05,在測試集上進行實驗,如圖10所示,結果顯示在λ取值為1時,模型的綜合性能達到最高,并且能夠較好地平衡分類與回歸任務,因此在訓練中取值固定為1。
圖10
超參數敏感性實驗結果圖
Figure10.
Hyper-parameter sensitivity experiment results
4 總結
本研究提出了基于輕量化卷積神經網絡的結直腸息肉檢測模型,通過利用SPP、FPN、SAM和PPA模塊進行多尺度多層次特征融合,性能得到較大提升。在獨立測試集上取得pre為0.998 2,rec為0.998 8,f1為0.998 4以及mAP@0.5為0.995 3的性能。同時,模型的參數量為9.08 M,在Tesla V100計算顯卡的測試平臺上幀率達到74 幀/s。
本文所提出的模型具有體量小、精度高且速度快的特點,適合在臨床場景中進行快速部署和應用。未來,本研究擬從模型通用性、無監督訓練角度,進一步開展相關研究,提升模型的通用性以及泛化性。綜上所述,本研究為結直腸息肉圖像的檢測與診斷提供了關鍵工具,有助于提高檢測過程中的精準度和效率。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻說明:李奕揚主要負責整體實驗的設計、算法修改及論文撰寫;趙佳漪主要負責醫學背景指導、實驗數據分析及論文撰寫;余若伊主要負責實驗數據的分析、數據處理方案設計及論文撰寫;劉輝翔負責數據處理與論文修訂;梁爽負責整體實驗的設計、算法技術指導與論文修訂;谷宇負責實驗概念設計、論文修訂。