為輔助基層超聲科醫生從兒童腹部超聲圖像中準確且快速地檢測出腸套疊病灶,本文提出了一種基于改進YOLOv8n的兒童腸套疊檢測算法EMC-YOLOv8n。首先,采用具有級聯分組注意力模塊的EfficientViT網絡作為主干網絡,以提高目標檢測速度。其次,利用改進后的C2fMBC模塊替換頸部網絡中的C2f模塊,降低網絡復雜度,并在每個C2fMBC模塊之后引入坐標注意力機制模塊,以增強對位置信息的關注度。最后,在自建的兒童腸套疊數據集上進行實驗。結果表明,EMC-YOLOv8n算法的召回率(Recall)、平均檢測精度(mAP@0.5)及精確度(Precision)相較基線算法分別提高了3.9%、2.1%及0.9%。盡管網絡參數量及計算量略微增加,但檢測精度得到顯著提升,能夠高效完成檢測任務,極具經濟及社會價值。
引用本文: 劉晨雨, 徐健, 李軻, 王璐. 基于改進YOLOv8n的兒童腸套疊B型超聲圖像特征檢測. 生物醫學工程學雜志, 2024, 41(5): 903-910. doi: 10.7507/1001-5515.202401017 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
0 引言
腸套疊是一種常見的兒科消化道疾病,主要發生在6個月至3歲之間的兒童中,其病理特征為一段腸管套入相鄰的腸腔內,引起腸腔堵塞,導致患者出現腹痛、嘔吐等癥狀,嚴重時可能導致腸道壞死等并發癥,甚至危及生命[1]。及時的診斷和治療對緩解患者疼痛至關重要。臨床上常用的腸套疊診斷方法包括X線片、計算機斷層掃描(computed tomography,CT)和B型超聲(brightness-mode ultrasound)。X線片可以顯示腸道積氣和堆疊現象,但對早期診斷不敏感;CT可以提供更詳細的圖像信息,但高昂的費用和較高的輻射限制了其應用;相比之下,B超是一種無創、無痛的診斷方法,在探頭掃描時通常以動圖的形式來呈現,使醫生能夠更直觀地觀察到腸套疊的位置,并且由于經濟實惠,更容易成為首選[2-4]。在B超圖像中,腸套疊的表現形式主要有兩種,分別為橫切面的“同心圓”型和縱切面的“套筒”型[5]。醫生通常通過識別橫切面的“同心圓”型來判斷腸套疊的存在,而縱切面的“套筒”型則作為輔助診斷手段[6]。但人工識別這些特征不僅容易受到主觀因素的影響,還會耗費大量高級人力資源。
近年來,快速發展的深度學習技術已在醫學領域中得到廣泛應用,特別是醫學圖像分割[7]和目標檢測[8]等方面。目標檢測技術主要分為兩階段算法和單階段算法,前者以其較高的準確率為優勢,代表性算法包括Mask R-CNN[9]和Fast R-CNN[10]等;后者則以較快的檢測速率為特點,代表性算法包括YOLO系列[11]和SSD[12]等。Kim等[13]開發和測試了一種基于YOLOv3的深度學習算法來檢測兒童腹部X線片中是否存在腸套疊病灶,實驗表明該算法的精確度略高于放射科醫生。Kwon等[14]研究開發了一種深度卷積神經網絡(deep convolutional neural network,DCNN)算法,該算法使用SSD+殘差網絡(ResNet)在兒童腹部X線片中檢測腸套疊病灶。Li等[15]研究開發了一種基于人工智能的超聲圖像“同心圓”征象自動檢測系統,使用改進的Faster R-CNN算法模型作為框架來檢測“同心圓”標志,提高了兒科腸套疊診斷的效率和準確性。Kim等[16]開發了基于YOLOv5架構的深度學習模型,以每秒幾十幀的速度以及高精度在灰度超聲圖像上診斷出腸套疊,證明了該算法的可行性。
顯然,目標檢測技術在兒童腸套疊圖像分析中已有廣泛應用,但仍存在一些不足之處,例如,文獻[13]和文獻[14]使用的X線片對早期診斷不敏感,而文獻[15]和文獻[16]采用了復雜度較高的算法模型。為解決這些問題,本文通過改進YOLOv8n算法,并結合醫學B超圖像,提出了一種基于EMC-YOLOv8n算法的兒童腸套疊特征檢測方法,旨在提高檢測精確度和準確性的同時,簡化模型的復雜度和提高診斷效率,從而更好地輔助醫生進行診斷。
1 方法
1.1 改進后的模型架構
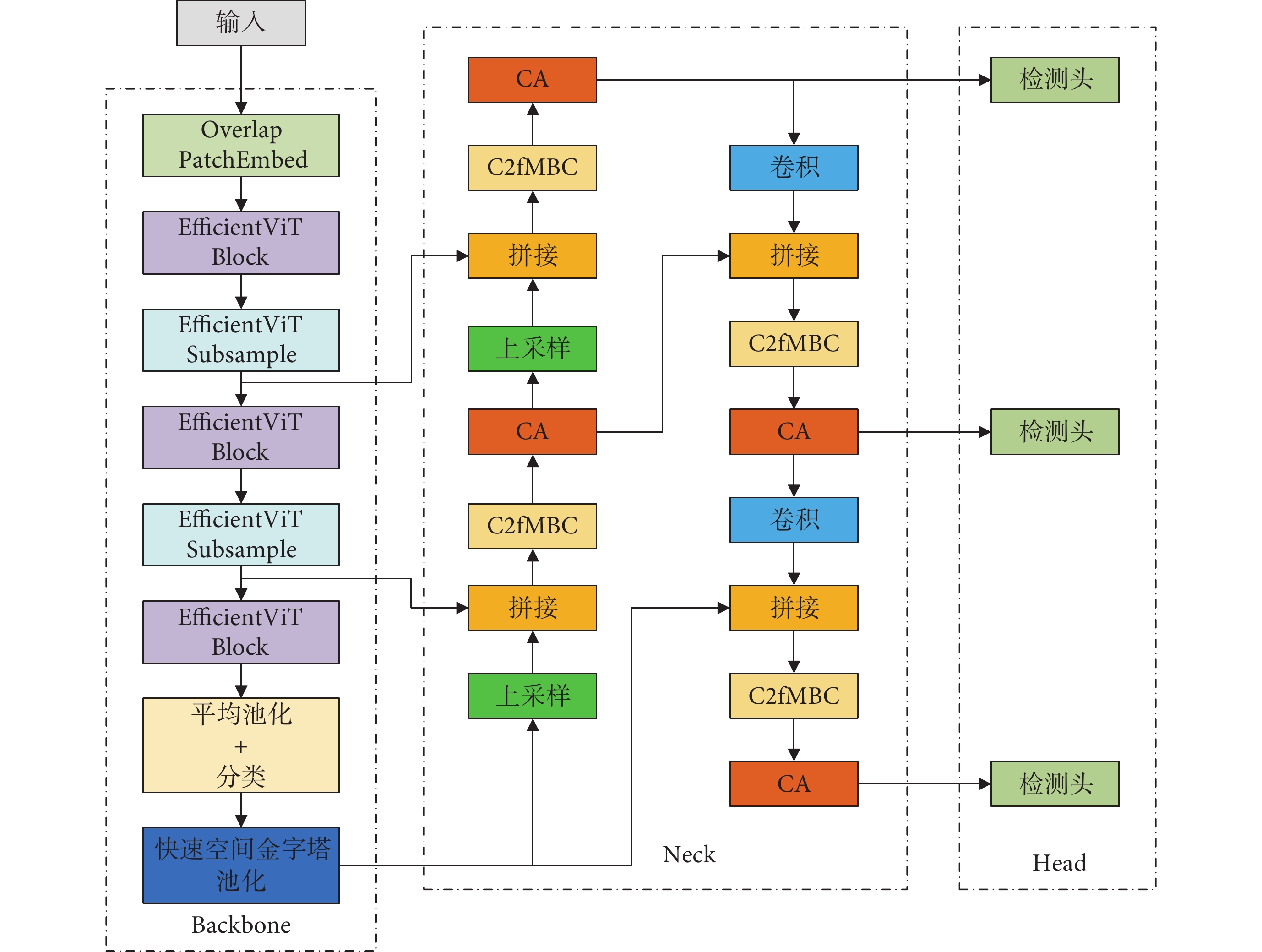
在2023年,Ultralytics團隊發布了最新的YOLOv8算法,旨在提升精度和速度,并優化網絡參數,以解決現有模型的不足,該算法的網絡結構主要由主干(Backbone)、頸部(Neck)和頭部(Head)組成[17]。本文選取了該系列中參數量最小的YOLOv8n模型進行改進,首先引入內存高效視覺轉換器網絡(memory efficient vision transformer,EfficientViT)[18]替換原有的跨階段Darknet53網絡(cross stage partial darknet-53,CSPDarknet53)[19]作為主干網絡,以提高內存效率,增強不同特征通道之間的高效通信,提高注意力多樣性和目標檢測速度。在頸部網絡,本文設計了C2fMBC模塊替換C2f模塊[20],進一步降低網絡的參數量和復雜度,同時保持模型的高效性。此外,在每個C2fMBC模塊之后加入坐標注意力機制(coordinate attention,CA)[21],使模型更加關注目標的通道特征,增強特征表達并提高模型性能。改進后的EMC-YOLOv8n模型架構如圖1所示。
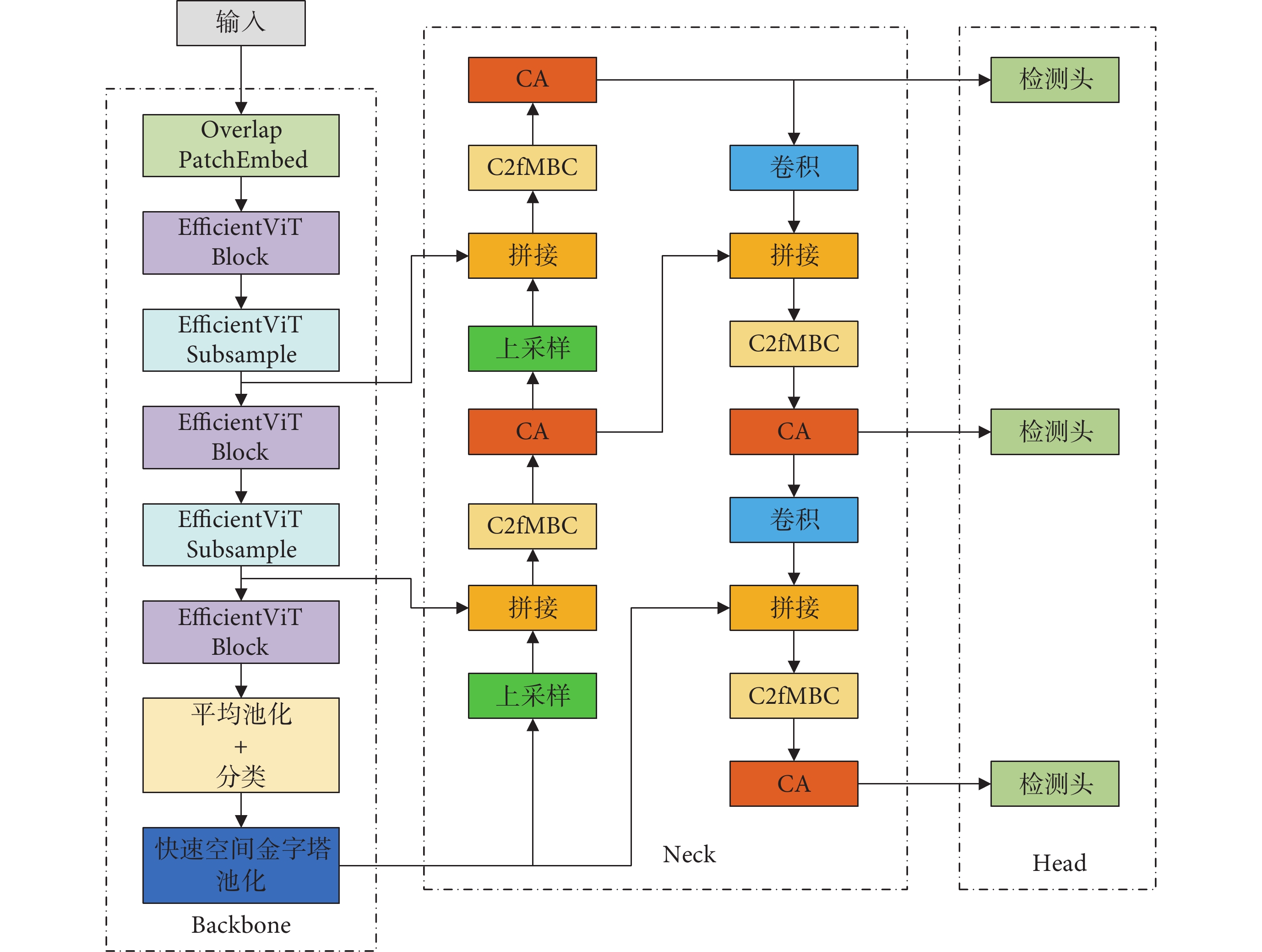 圖1
EMC-YOLOv8n網絡結構
Figure1.
EMC-YOLOv8n network structure
圖1
EMC-YOLOv8n網絡結構
Figure1.
EMC-YOLOv8n network structure
1.2 EfficientViT網絡架構
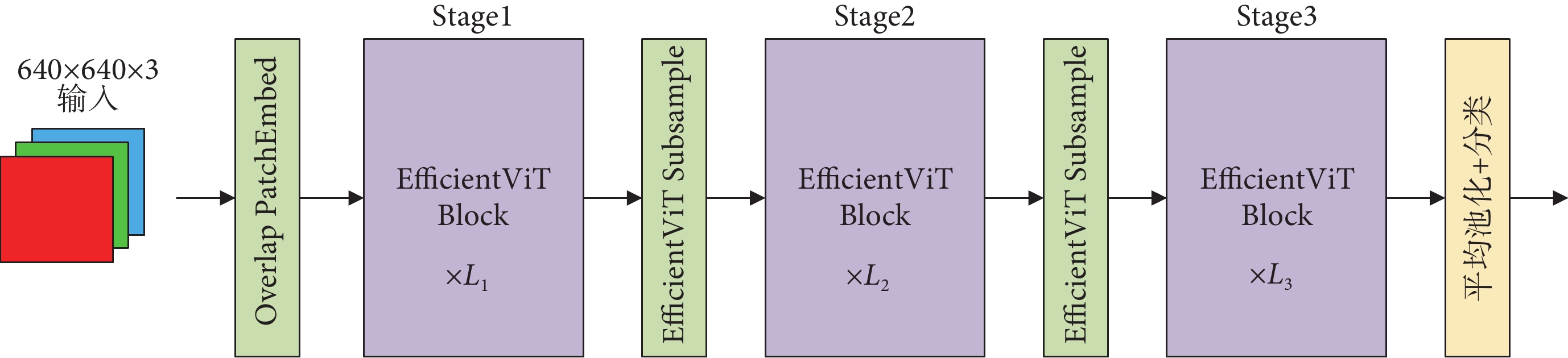
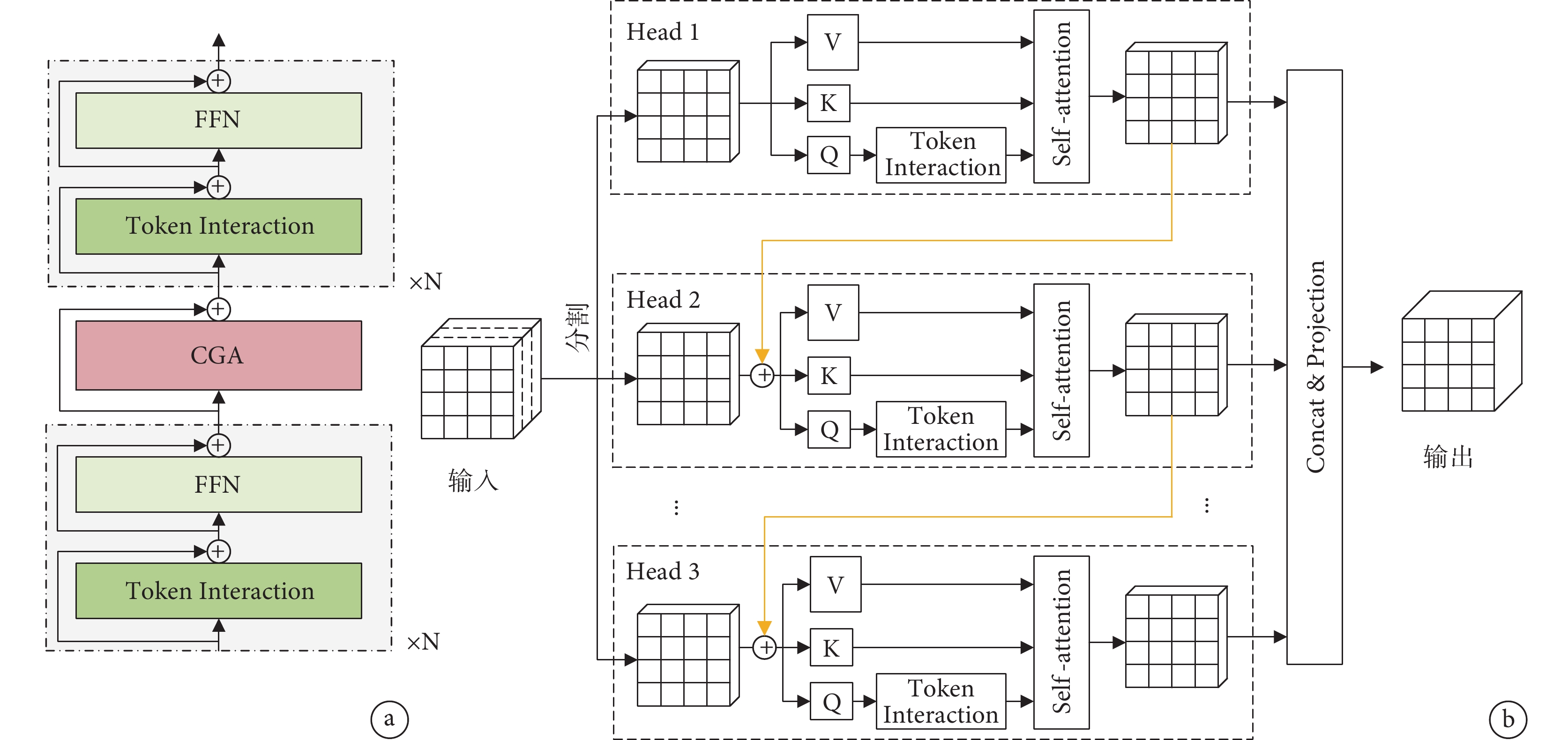
為加快腸套疊特征提取的速度,本文引入EfficientViT網絡作為基線模型YOLOv8n的主干網絡,其網絡結構如圖2所示。引入重疊補丁編碼(Overlap PatchEmbed)[22]的作用是將輸入圖像分割成重疊的小塊,有助于更好地獲取腸套疊圖像中的局部信息。為提高特征提取過程中的效率,構建一個夾層布局模塊,稱為EfficientViT Block,其結構如圖3a所示。即在N個前饋神經網絡(feedforward neural network,FFN)層之間加入了一個級聯分組注意力模塊(cascaded group attention,CGA),可在提高特征通道間高效通信的同時增強模型性能。其中,CGA模塊結構如圖3b所示。首先,將輸入特征分割成部分小特征傳送給不同的注意力頭部,以減小計算冗余。然后,將頭部分段成Q、K、V層,為了學習更豐富的特征來增加模型容量,在Q投影之后設計一個新的令牌交互層(token interaction),使自注意力能夠同時捕捉局部和全局關系,來增強特征表示。隨后,將每個頭部的輸出與下一個頭部的輸入相加,在不增加額外參數的情況下提升了網絡的深度和表達能力。最后,使用線性層連接和映射多個頭部輸出以獲得最終輸出,表示為:
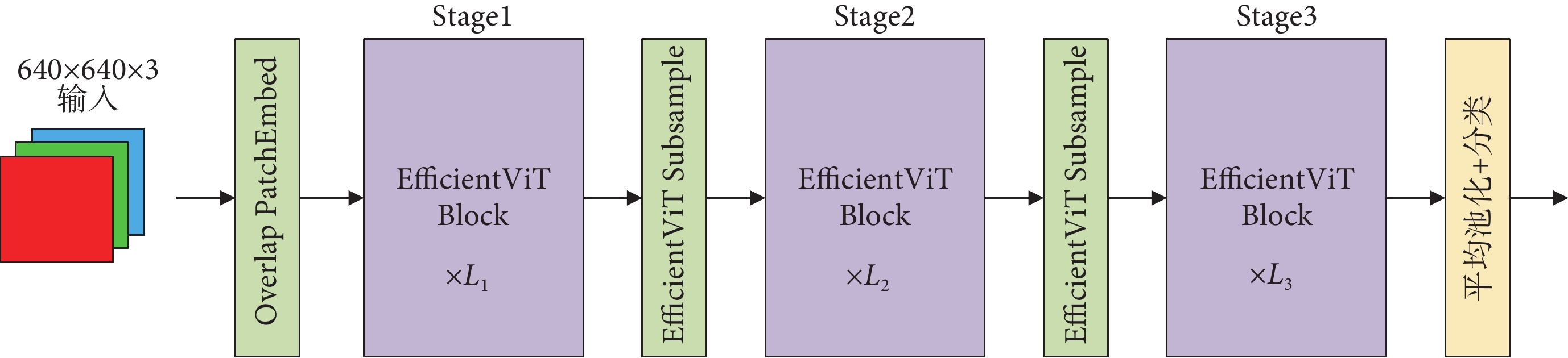 圖2
EfficientViT結構
Figure2.
EfficientViT structure
圖2
EfficientViT結構
Figure2.
EfficientViT structure
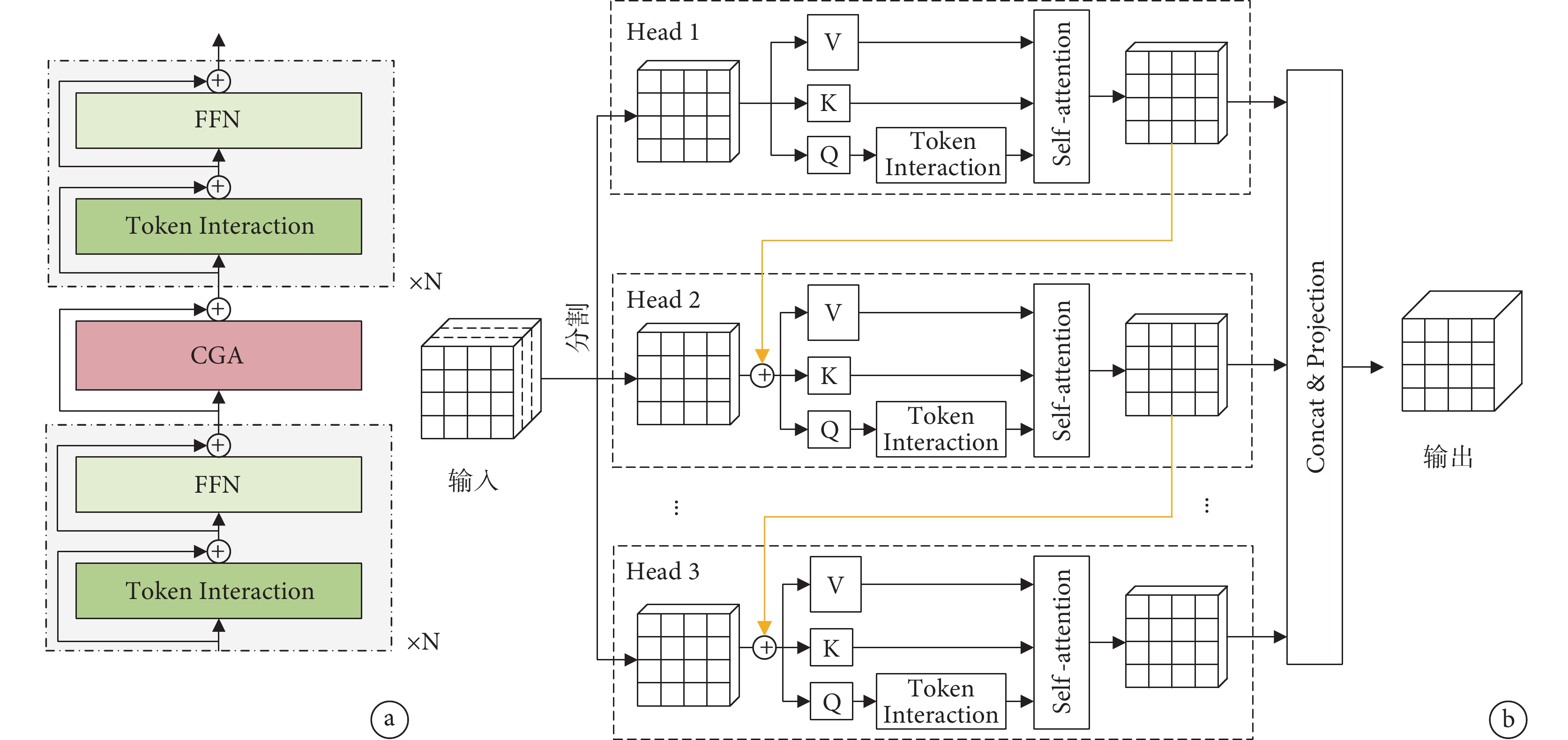 圖3
EfficientViT Block結構
圖3
EfficientViT Block結構
a. EfficientViT Block展開圖;b. CGA結構
Figure3. EfficientViT block structurea. EfficientViT block expanded diagram; b. cascaded group attention
 |
 |
 '/> '/> |
其中,式(1)、(2)中第j個頭部計算了 上的自注意力,即
上的自注意力,即 ,其中
,其中 ,h為頭部總數。
,h為頭部總數。 、
、 和
和 是將輸入特征映射到不同子空間的投影層,而
是將輸入特征映射到不同子空間的投影層,而 是一個線性層,將連接的輸出特征投影回與輸入一致的維度。式(3)中
是一個線性層,將連接的輸出特征投影回與輸入一致的維度。式(3)中 是第j個輸入分割
是第j個輸入分割 和由公式(1)、(2)計算的第(j ? 1)個頭部輸出
和由公式(1)、(2)計算的第(j ? 1)個頭部輸出 的總和。它替換了
的總和。它替換了 成為在計算自注意力時第j個頭部的輸入特征。
成為在計算自注意力時第j個頭部的輸入特征。
1.3 C2fMBC模塊
為降低網絡模型的復雜度并提高特征提取效率,本文設計了C2fMBC模塊來替換原模型中的C2f模塊,C2fMBC模塊如圖4所示。具體而言,C2fMBC模塊去除了高效卷積神經網絡(efficient convolutional neural network,EfficientNet)中移動翻轉瓶頸卷積(mobile inverted bottleneck convolution,MBConv)模塊[23]的壓縮激勵(squeeze and excitation,SE)模塊,并替換了原網絡模型中C2f模塊的瓶頸層(Bottleneck),從而在降低模型復雜度的同時增強了特征提取能力。此外,改進后的模型對多尺度信息更加敏感,有助于檢測不同大小的目標,實現了在減少網絡參數的同時保持較高的檢測精度。
 圖4
C2fMBC模塊
Figure4.
C2fMBC module
圖4
C2fMBC模塊
Figure4.
C2fMBC module
MBConv模塊如圖5所示。首先,通過逐點卷積(pointwise convolution,PW Conv)擴展輸入特征圖的維度。然后經過批處理歸一化(BatchNorm,BN)和Swish激活函數來加速模型訓練收斂并解決梯度消失問題。接著,通過深度可分離卷積(depthwise convolution,DWConv)減少計算量并提高計算效率。之后,再經過BN層和Swish激活函數,通過PW Conv壓縮特征圖的維度。最后,加入隨機失活層(Dropout)減少模型的過擬合,同時引入倒置殘差結構和線性瓶頸以提高模型的表達能力和訓練效率。
 圖5
MBConv模塊
Figure5.
MBConv module
圖5
MBConv模塊
Figure5.
MBConv module
1.4 注意力機制
由于超聲圖像中存在大量干擾信息,為使模型更加關注腸套疊特征并精確提取其位置信息,在改進的YOLOv8n算法的頸部網絡C2fMBC模塊之后加入了CA以進行局部特征信息融合。CA通過坐標信息嵌入和坐標注意力生成,將圖像中的目標位置數據整合到通道注意力中,使模型能夠在整體區域內更好地定位并檢測目標,該模塊結構如圖6所示。
 圖6
CA模塊
Figure6.
CA module
圖6
CA模塊
Figure6.
CA module
將輸入特征張量分別沿水平方向和垂直方向進行全局平均池化操作,得到一對一維特征編碼。這兩種變換匯聚了各自方向上的特征,使注意力模塊保留了一條空間方向的依賴關系,并獲取了另一條空間方向的位置信息。將上述坐標信息整合后的特征通過空間維度進行連接,并使用共享卷積核減少通道數。然后,通過BN和非線性激活函數(Non-Linear)在垂直和水平方向上對空間信息進行編碼[21]。接著,將編碼后的信息進行分割,并分別使用兩個卷積核調整特征圖通道數,使之與輸入特征圖的通道數一致,并通過sigmoid激活函數進行平滑處理。最后,進行歸一化和加權融合。
2 實驗過程與結果
2.1 數據集構建
本文實驗所用數據集由空軍軍醫大學附屬西京醫院超聲醫學科授權提供。由于本研究為回顧性實驗,所有圖像均經過脫敏處理,去除了任何可能識別患者身份的信息,以確保數據隱私保護和合法合規的使用。數據來自2022年10月至2023年7月期間1~5歲確診為腸套疊兒童的B超圖像,共收集210例腸套疊患者的B超圖像,每位患者保留8張圖像,總計1 680張。為擴充數據集,在保持病灶標簽不變的情況下,采用數據增強技術。通過調整對比度和亮度,將圖像數量擴充至3 360張,這些圖像按比例劃分為訓練集2 352張,驗證集672張,測試集336張。所有圖像均由空軍軍醫大學附屬西京醫院和空軍軍醫大學附屬唐都醫院超聲醫學科醫生手動標注,標簽類型分別為同心圓(circle)型和套筒(sleeve)型。最終得到circle型圖像1 812張,sleeve型圖像1 548張。
2.2 實驗環境配置與評估指標
本文實驗基于深度學習框架PyTorch,在Windows 10 64位操作系統上進行訓練。硬件平臺包括英特爾i7-7 800X處理器與NVIDIA GeForce RTX 3 090Ti顯卡,顯卡配備6 GB顯存。開發環境使用CUDA 11.3加速計算。實驗中,批處理大小(Batch Size)設置為16,訓練輪數(Epochs)為200次,以充分優化模型性能。
本文采用準確率(precision,Pre)、召回率(recall,Rec)、平均精度(mean average precision,mAP)、模型參數量(parameters,Par)、浮點運算數以及幀率作為評估指標。計算公式如下:
 |
 |
 |
 |
其中,真陽性(true positive,TP)指模型正確檢測出腸套疊病灶區域,假陽性(false positive,FP)指模型將非腸套疊病灶區域誤檢測為腸套疊病灶區域;假陰性(false negative,FN)指模型未能檢測到實際存在的腸套疊病灶; 表示類別索引值為i的AP值,N表示訓練數據集中樣本的類別數(本實驗中N為2)。其次mAP@0.5、mAP@.5:.95分別表示閾值IoU設置為0.5、0.5~0.95時的mAP值。
表示類別索引值為i的AP值,N表示訓練數據集中樣本的類別數(本實驗中N為2)。其次mAP@0.5、mAP@.5:.95分別表示閾值IoU設置為0.5、0.5~0.95時的mAP值。
2.3 消融實驗
在進行不同模塊組合對模型檢測性能影響的評估中,以YOLOv8n作為基線模型,并在數據集和各種配置參數一致的情況下進行了消融實驗,結果如表1所示。結果表明,基線模型YOLOv8n的mAP最低,但其幀率最高,且Par和浮點運算數最少。實驗2通過將主干網絡替換為EfficientViT網絡模型,加快了特征提取速度,盡管增加了Par和浮點運算數,但mAP有了顯著的提升。實驗3則在實驗2的基礎上,將頸部網絡的C2f模塊替換為C2fMBC模塊,不僅減少了模型的Par和浮點運算數,還進一步提升了檢測精度,表現出更高的mAP。實驗4則在實驗3的基礎上,添加了CA,以精確提取目標的位置信息,取得了實驗中最優的Pre、Rec和mAP。因此,證明了本文提出改進方案的有效性和可行性。
2.4 對比實驗
為驗證本文所提出的EMC-YOLOv8n算法的優越性,在相同數據集和配置參數條件下,與當前主流算法Faster R-CNN、SSD和YOLOv5s進行了對比實驗,結果如表2所示。結果表明,Faster R-CNN的mAP及幀率較低且Par較多。SSD雖然具有較高的幀率,但其網絡模型過于復雜,不利于實際應用。YOLOv5s在模型參數量方面有所優化,但其mAP尚未達到預期要求。綜上所述,本文提出的EMC-YOLOv8n算法在mAP、Par、浮點運算數和幀率上均表現出明顯優勢。相較于其他主流算法,EMC-YOLOv8n在綜合性能上有顯著提升,體現了該算法的優越性。
2.5 算法檢測驗證
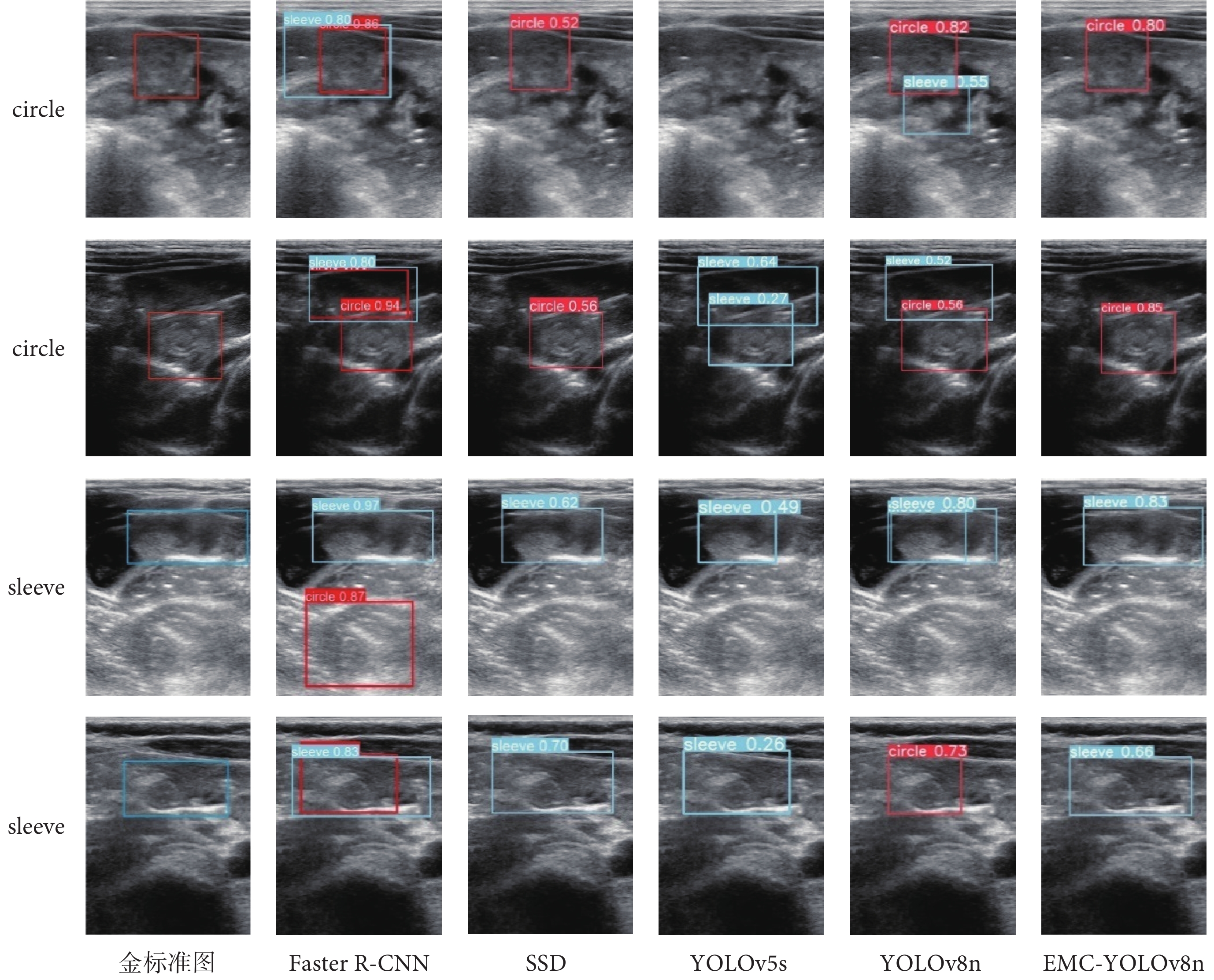
為了評估本文提出的EMC-YOLOv8n算法在檢測兒童腸套疊方面的可視化效果,我們將它與Faster R-CNN、SSD、YOLOv5s和YOLOv8n進行了對比,結果如圖7所示。圖像中第一、二行為circle型病灶的檢測結果,第三、四行為sleeve型病灶的檢測結果,第一列則為醫生標注的病灶圖(紅色框表示circle,藍色框表示sleeve)。從圖像的第一、二行可以看出:Faster R-CNN和YOLOv8n能夠檢測到circle型病灶,但存在誤檢測現象。SSD在識別circle型病灶方面較為準確,但在病灶范圍和檢測精度上存在不足。YOLOv5s未能有效檢測出circle型病灶,并存在誤檢測現象。相比之下,EMC-YOLOv8n不僅能夠準確檢測出circle型病灶的位置和大小,還具有較高的檢測精度。從圖像的第三、四行可以看出:Faster R-CNN將非腸套疊區域誤檢測為circle型病灶,YOLOv8n存在重復檢測和誤檢測現象。SSD和YOLOv5s能夠識別sleeve型病灶,但在識別精度和識別范圍上存在問題。而EMC-YOLOv8n在檢測sleeve型病灶時,同樣表現出高精度和準確的范圍識別。綜合來看,本文提出的EMC-YOLOv8n算法在檢測circle和sleeve兩種類型病灶時,無論是在檢測范圍還是檢測精度上,都表現出了顯著的優勢,體現了該算法在綜合性能上的實用性。
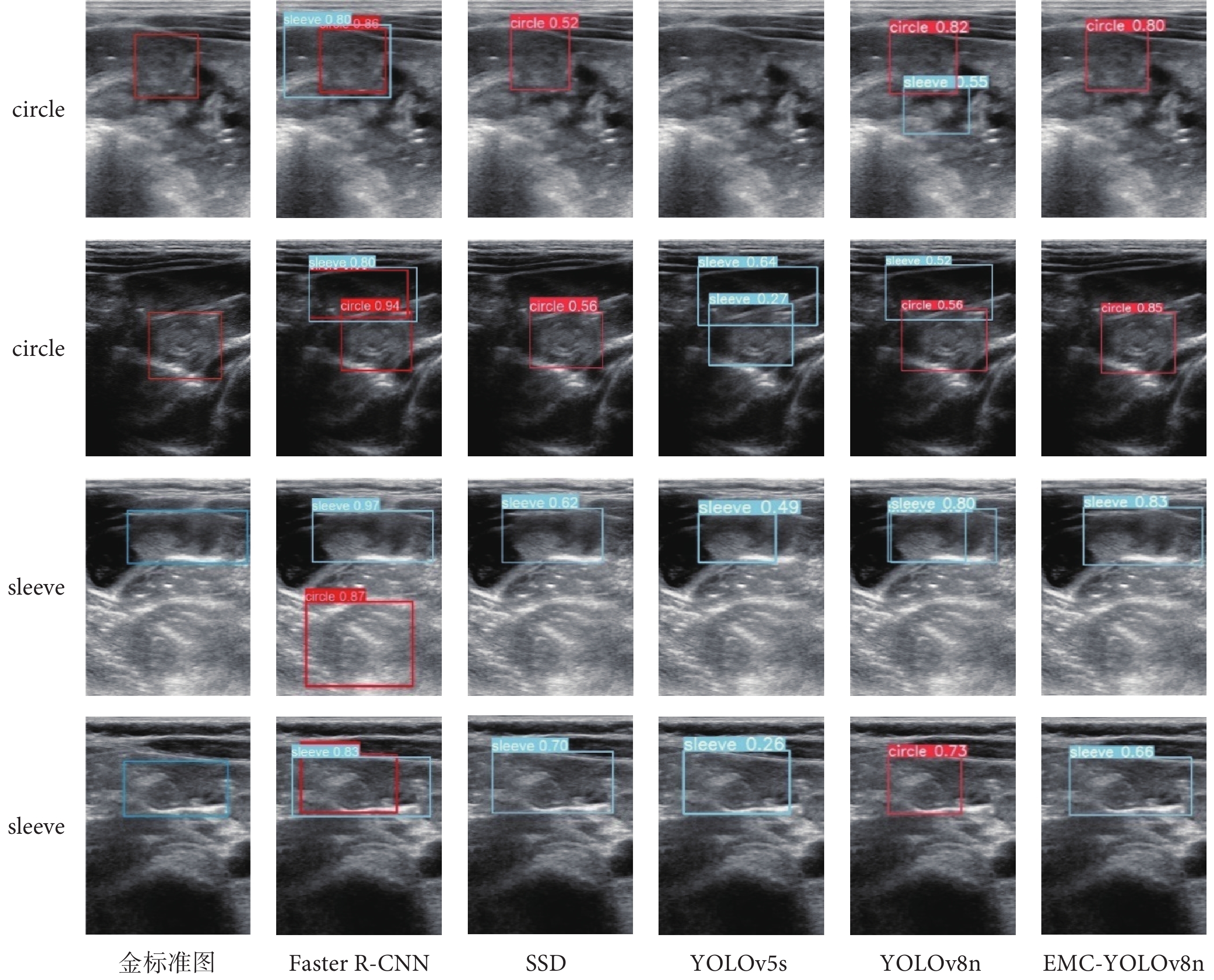 圖7
不同算法對比實驗的可視化結果圖
Figure7.
Visualisation of the experiment results comparing different algorithms
圖7
不同算法對比實驗的可視化結果圖
Figure7.
Visualisation of the experiment results comparing different algorithms
3 討論
我們的研究結果相較于先前的研究具有顯著優勢。文獻[13]和文獻[14]分別使用YOLOv3算法和SSD+Resnet算法在X線片上檢測兒童腸套疊病灶,但由于X線片的檢出率低、特異性差,導致整體檢測精度不高。文獻[15]和文獻[16]分別使用改進的Faster R-CNN算法和YOLOv5算法在B超圖像上通過“同心圓”征象檢測兒童腸套疊病灶,但Faster R-CNN和YOLOv5模型參數多、檢測速度慢,不適合在醫院中部署。我們利用EMC-YOLOv8n算法對兒童B超圖像的橫切面circle型和縱切面sleeve型腸套疊病灶進行檢測。與先前研究相比,我們的研究在檢測精度和速度上均有顯著提升,并在最新的YOLOv8算法上實施改進,增添橫切面的sleeve型作為輔助檢測依據。
但是,盡管取得了這些進展,我們的研究仍存在一定局限性。首先,對于深度學習而言,數據集的豐富性至關重要,而我們使用的數據集相對有限。未來工作將重點補充數據集,以更好地訓練模型。其次,我們的實驗數據僅來源于一臺機器,未來將考慮引入多家醫院的設備數據以提高實驗結果的泛化性。最后,接下來應在保持檢測精度的基礎上,設計更為優化的模塊以提高檢測速度,并向網絡模型的輕量化方向發展。此外,我們計劃制作硬件系統,并將平臺部署到醫院中,以實現實際應用。
4 結論
本文提出了一種用于檢測兒童腹部B超圖像中腸套疊病灶的EMC-YOLOv8n算法,通過引入EfficientViT網絡作為YOLOv8n的主干網絡,并設計C2fMBC模塊替換原有的C2f模塊,從而在減少模型復雜度的同時大幅提高檢測速度。此外,本文還引入了CA注意力機制,以增強模型對位置信息的獲取能力。為了提高模型的魯棒性和泛化能力,本文在自建數據集上進行了數據增強。大量實驗結果表明,本文提出的算法在檢測兒童腸套疊方面具有優異的精度和可靠性,為超聲科醫生提供了一種準確且快速的輔助診斷工具。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:劉晨雨負責本文實驗設計、算法實現、數據分析及論文撰寫。徐健在論文審核和總體指導方面提供了重要支持。李軻在數據收集與標注方面做出了重要貢獻,并協助撰寫了部分醫學理論相關內容。王璐則在數據標注的準確性檢查及醫學理論指導方面發揮了關鍵作用。
0 引言
腸套疊是一種常見的兒科消化道疾病,主要發生在6個月至3歲之間的兒童中,其病理特征為一段腸管套入相鄰的腸腔內,引起腸腔堵塞,導致患者出現腹痛、嘔吐等癥狀,嚴重時可能導致腸道壞死等并發癥,甚至危及生命[1]。及時的診斷和治療對緩解患者疼痛至關重要。臨床上常用的腸套疊診斷方法包括X線片、計算機斷層掃描(computed tomography,CT)和B型超聲(brightness-mode ultrasound)。X線片可以顯示腸道積氣和堆疊現象,但對早期診斷不敏感;CT可以提供更詳細的圖像信息,但高昂的費用和較高的輻射限制了其應用;相比之下,B超是一種無創、無痛的診斷方法,在探頭掃描時通常以動圖的形式來呈現,使醫生能夠更直觀地觀察到腸套疊的位置,并且由于經濟實惠,更容易成為首選[2-4]。在B超圖像中,腸套疊的表現形式主要有兩種,分別為橫切面的“同心圓”型和縱切面的“套筒”型[5]。醫生通常通過識別橫切面的“同心圓”型來判斷腸套疊的存在,而縱切面的“套筒”型則作為輔助診斷手段[6]。但人工識別這些特征不僅容易受到主觀因素的影響,還會耗費大量高級人力資源。
近年來,快速發展的深度學習技術已在醫學領域中得到廣泛應用,特別是醫學圖像分割[7]和目標檢測[8]等方面。目標檢測技術主要分為兩階段算法和單階段算法,前者以其較高的準確率為優勢,代表性算法包括Mask R-CNN[9]和Fast R-CNN[10]等;后者則以較快的檢測速率為特點,代表性算法包括YOLO系列[11]和SSD[12]等。Kim等[13]開發和測試了一種基于YOLOv3的深度學習算法來檢測兒童腹部X線片中是否存在腸套疊病灶,實驗表明該算法的精確度略高于放射科醫生。Kwon等[14]研究開發了一種深度卷積神經網絡(deep convolutional neural network,DCNN)算法,該算法使用SSD+殘差網絡(ResNet)在兒童腹部X線片中檢測腸套疊病灶。Li等[15]研究開發了一種基于人工智能的超聲圖像“同心圓”征象自動檢測系統,使用改進的Faster R-CNN算法模型作為框架來檢測“同心圓”標志,提高了兒科腸套疊診斷的效率和準確性。Kim等[16]開發了基于YOLOv5架構的深度學習模型,以每秒幾十幀的速度以及高精度在灰度超聲圖像上診斷出腸套疊,證明了該算法的可行性。
顯然,目標檢測技術在兒童腸套疊圖像分析中已有廣泛應用,但仍存在一些不足之處,例如,文獻[13]和文獻[14]使用的X線片對早期診斷不敏感,而文獻[15]和文獻[16]采用了復雜度較高的算法模型。為解決這些問題,本文通過改進YOLOv8n算法,并結合醫學B超圖像,提出了一種基于EMC-YOLOv8n算法的兒童腸套疊特征檢測方法,旨在提高檢測精確度和準確性的同時,簡化模型的復雜度和提高診斷效率,從而更好地輔助醫生進行診斷。
1 方法
1.1 改進后的模型架構
在2023年,Ultralytics團隊發布了最新的YOLOv8算法,旨在提升精度和速度,并優化網絡參數,以解決現有模型的不足,該算法的網絡結構主要由主干(Backbone)、頸部(Neck)和頭部(Head)組成[17]。本文選取了該系列中參數量最小的YOLOv8n模型進行改進,首先引入內存高效視覺轉換器網絡(memory efficient vision transformer,EfficientViT)[18]替換原有的跨階段Darknet53網絡(cross stage partial darknet-53,CSPDarknet53)[19]作為主干網絡,以提高內存效率,增強不同特征通道之間的高效通信,提高注意力多樣性和目標檢測速度。在頸部網絡,本文設計了C2fMBC模塊替換C2f模塊[20],進一步降低網絡的參數量和復雜度,同時保持模型的高效性。此外,在每個C2fMBC模塊之后加入坐標注意力機制(coordinate attention,CA)[21],使模型更加關注目標的通道特征,增強特征表達并提高模型性能。改進后的EMC-YOLOv8n模型架構如圖1所示。
圖1
EMC-YOLOv8n網絡結構
Figure1.
EMC-YOLOv8n network structure
1.2 EfficientViT網絡架構
為加快腸套疊特征提取的速度,本文引入EfficientViT網絡作為基線模型YOLOv8n的主干網絡,其網絡結構如圖2所示。引入重疊補丁編碼(Overlap PatchEmbed)[22]的作用是將輸入圖像分割成重疊的小塊,有助于更好地獲取腸套疊圖像中的局部信息。為提高特征提取過程中的效率,構建一個夾層布局模塊,稱為EfficientViT Block,其結構如圖3a所示。即在N個前饋神經網絡(feedforward neural network,FFN)層之間加入了一個級聯分組注意力模塊(cascaded group attention,CGA),可在提高特征通道間高效通信的同時增強模型性能。其中,CGA模塊結構如圖3b所示。首先,將輸入特征分割成部分小特征傳送給不同的注意力頭部,以減小計算冗余。然后,將頭部分段成Q、K、V層,為了學習更豐富的特征來增加模型容量,在Q投影之后設計一個新的令牌交互層(token interaction),使自注意力能夠同時捕捉局部和全局關系,來增強特征表示。隨后,將每個頭部的輸出與下一個頭部的輸入相加,在不增加額外參數的情況下提升了網絡的深度和表達能力。最后,使用線性層連接和映射多個頭部輸出以獲得最終輸出,表示為:
圖2
EfficientViT結構
Figure2.
EfficientViT structure
圖3
EfficientViT Block結構
a. EfficientViT Block展開圖;b. CGA結構
Figure3. EfficientViT block structurea. EfficientViT block expanded diagram; b. cascaded group attention
|
|
| '/> |
其中,式(1)、(2)中第j個頭部計算了上的自注意力,即,其中,h為頭部總數。、和是將輸入特征映射到不同子空間的投影層,而是一個線性層,將連接的輸出特征投影回與輸入一致的維度。式(3)中是第j個輸入分割和由公式(1)、(2)計算的第(j ? 1)個頭部輸出的總和。它替換了成為在計算自注意力時第j個頭部的輸入特征。
1.3 C2fMBC模塊
為降低網絡模型的復雜度并提高特征提取效率,本文設計了C2fMBC模塊來替換原模型中的C2f模塊,C2fMBC模塊如圖4所示。具體而言,C2fMBC模塊去除了高效卷積神經網絡(efficient convolutional neural network,EfficientNet)中移動翻轉瓶頸卷積(mobile inverted bottleneck convolution,MBConv)模塊[23]的壓縮激勵(squeeze and excitation,SE)模塊,并替換了原網絡模型中C2f模塊的瓶頸層(Bottleneck),從而在降低模型復雜度的同時增強了特征提取能力。此外,改進后的模型對多尺度信息更加敏感,有助于檢測不同大小的目標,實現了在減少網絡參數的同時保持較高的檢測精度。
圖4
C2fMBC模塊
Figure4.
C2fMBC module
MBConv模塊如圖5所示。首先,通過逐點卷積(pointwise convolution,PW Conv)擴展輸入特征圖的維度。然后經過批處理歸一化(BatchNorm,BN)和Swish激活函數來加速模型訓練收斂并解決梯度消失問題。接著,通過深度可分離卷積(depthwise convolution,DWConv)減少計算量并提高計算效率。之后,再經過BN層和Swish激活函數,通過PW Conv壓縮特征圖的維度。最后,加入隨機失活層(Dropout)減少模型的過擬合,同時引入倒置殘差結構和線性瓶頸以提高模型的表達能力和訓練效率。
圖5
MBConv模塊
Figure5.
MBConv module
1.4 注意力機制
由于超聲圖像中存在大量干擾信息,為使模型更加關注腸套疊特征并精確提取其位置信息,在改進的YOLOv8n算法的頸部網絡C2fMBC模塊之后加入了CA以進行局部特征信息融合。CA通過坐標信息嵌入和坐標注意力生成,將圖像中的目標位置數據整合到通道注意力中,使模型能夠在整體區域內更好地定位并檢測目標,該模塊結構如圖6所示。
圖6
CA模塊
Figure6.
CA module
將輸入特征張量分別沿水平方向和垂直方向進行全局平均池化操作,得到一對一維特征編碼。這兩種變換匯聚了各自方向上的特征,使注意力模塊保留了一條空間方向的依賴關系,并獲取了另一條空間方向的位置信息。將上述坐標信息整合后的特征通過空間維度進行連接,并使用共享卷積核減少通道數。然后,通過BN和非線性激活函數(Non-Linear)在垂直和水平方向上對空間信息進行編碼[21]。接著,將編碼后的信息進行分割,并分別使用兩個卷積核調整特征圖通道數,使之與輸入特征圖的通道數一致,并通過sigmoid激活函數進行平滑處理。最后,進行歸一化和加權融合。
2 實驗過程與結果
2.1 數據集構建
本文實驗所用數據集由空軍軍醫大學附屬西京醫院超聲醫學科授權提供。由于本研究為回顧性實驗,所有圖像均經過脫敏處理,去除了任何可能識別患者身份的信息,以確保數據隱私保護和合法合規的使用。數據來自2022年10月至2023年7月期間1~5歲確診為腸套疊兒童的B超圖像,共收集210例腸套疊患者的B超圖像,每位患者保留8張圖像,總計1 680張。為擴充數據集,在保持病灶標簽不變的情況下,采用數據增強技術。通過調整對比度和亮度,將圖像數量擴充至3 360張,這些圖像按比例劃分為訓練集2 352張,驗證集672張,測試集336張。所有圖像均由空軍軍醫大學附屬西京醫院和空軍軍醫大學附屬唐都醫院超聲醫學科醫生手動標注,標簽類型分別為同心圓(circle)型和套筒(sleeve)型。最終得到circle型圖像1 812張,sleeve型圖像1 548張。
2.2 實驗環境配置與評估指標
本文實驗基于深度學習框架PyTorch,在Windows 10 64位操作系統上進行訓練。硬件平臺包括英特爾i7-7 800X處理器與NVIDIA GeForce RTX 3 090Ti顯卡,顯卡配備6 GB顯存。開發環境使用CUDA 11.3加速計算。實驗中,批處理大小(Batch Size)設置為16,訓練輪數(Epochs)為200次,以充分優化模型性能。
本文采用準確率(precision,Pre)、召回率(recall,Rec)、平均精度(mean average precision,mAP)、模型參數量(parameters,Par)、浮點運算數以及幀率作為評估指標。計算公式如下:
|
|
|
|
其中,真陽性(true positive,TP)指模型正確檢測出腸套疊病灶區域,假陽性(false positive,FP)指模型將非腸套疊病灶區域誤檢測為腸套疊病灶區域;假陰性(false negative,FN)指模型未能檢測到實際存在的腸套疊病灶;表示類別索引值為i的AP值,N表示訓練數據集中樣本的類別數(本實驗中N為2)。其次mAP@0.5、mAP@.5:.95分別表示閾值IoU設置為0.5、0.5~0.95時的mAP值。
2.3 消融實驗
在進行不同模塊組合對模型檢測性能影響的評估中,以YOLOv8n作為基線模型,并在數據集和各種配置參數一致的情況下進行了消融實驗,結果如表1所示。結果表明,基線模型YOLOv8n的mAP最低,但其幀率最高,且Par和浮點運算數最少。實驗2通過將主干網絡替換為EfficientViT網絡模型,加快了特征提取速度,盡管增加了Par和浮點運算數,但mAP有了顯著的提升。實驗3則在實驗2的基礎上,將頸部網絡的C2f模塊替換為C2fMBC模塊,不僅減少了模型的Par和浮點運算數,還進一步提升了檢測精度,表現出更高的mAP。實驗4則在實驗3的基礎上,添加了CA,以精確提取目標的位置信息,取得了實驗中最優的Pre、Rec和mAP。因此,證明了本文提出改進方案的有效性和可行性。
2.4 對比實驗
為驗證本文所提出的EMC-YOLOv8n算法的優越性,在相同數據集和配置參數條件下,與當前主流算法Faster R-CNN、SSD和YOLOv5s進行了對比實驗,結果如表2所示。結果表明,Faster R-CNN的mAP及幀率較低且Par較多。SSD雖然具有較高的幀率,但其網絡模型過于復雜,不利于實際應用。YOLOv5s在模型參數量方面有所優化,但其mAP尚未達到預期要求。綜上所述,本文提出的EMC-YOLOv8n算法在mAP、Par、浮點運算數和幀率上均表現出明顯優勢。相較于其他主流算法,EMC-YOLOv8n在綜合性能上有顯著提升,體現了該算法的優越性。
2.5 算法檢測驗證
為了評估本文提出的EMC-YOLOv8n算法在檢測兒童腸套疊方面的可視化效果,我們將它與Faster R-CNN、SSD、YOLOv5s和YOLOv8n進行了對比,結果如圖7所示。圖像中第一、二行為circle型病灶的檢測結果,第三、四行為sleeve型病灶的檢測結果,第一列則為醫生標注的病灶圖(紅色框表示circle,藍色框表示sleeve)。從圖像的第一、二行可以看出:Faster R-CNN和YOLOv8n能夠檢測到circle型病灶,但存在誤檢測現象。SSD在識別circle型病灶方面較為準確,但在病灶范圍和檢測精度上存在不足。YOLOv5s未能有效檢測出circle型病灶,并存在誤檢測現象。相比之下,EMC-YOLOv8n不僅能夠準確檢測出circle型病灶的位置和大小,還具有較高的檢測精度。從圖像的第三、四行可以看出:Faster R-CNN將非腸套疊區域誤檢測為circle型病灶,YOLOv8n存在重復檢測和誤檢測現象。SSD和YOLOv5s能夠識別sleeve型病灶,但在識別精度和識別范圍上存在問題。而EMC-YOLOv8n在檢測sleeve型病灶時,同樣表現出高精度和準確的范圍識別。綜合來看,本文提出的EMC-YOLOv8n算法在檢測circle和sleeve兩種類型病灶時,無論是在檢測范圍還是檢測精度上,都表現出了顯著的優勢,體現了該算法在綜合性能上的實用性。
圖7
不同算法對比實驗的可視化結果圖
Figure7.
Visualisation of the experiment results comparing different algorithms
3 討論
我們的研究結果相較于先前的研究具有顯著優勢。文獻[13]和文獻[14]分別使用YOLOv3算法和SSD+Resnet算法在X線片上檢測兒童腸套疊病灶,但由于X線片的檢出率低、特異性差,導致整體檢測精度不高。文獻[15]和文獻[16]分別使用改進的Faster R-CNN算法和YOLOv5算法在B超圖像上通過“同心圓”征象檢測兒童腸套疊病灶,但Faster R-CNN和YOLOv5模型參數多、檢測速度慢,不適合在醫院中部署。我們利用EMC-YOLOv8n算法對兒童B超圖像的橫切面circle型和縱切面sleeve型腸套疊病灶進行檢測。與先前研究相比,我們的研究在檢測精度和速度上均有顯著提升,并在最新的YOLOv8算法上實施改進,增添橫切面的sleeve型作為輔助檢測依據。
但是,盡管取得了這些進展,我們的研究仍存在一定局限性。首先,對于深度學習而言,數據集的豐富性至關重要,而我們使用的數據集相對有限。未來工作將重點補充數據集,以更好地訓練模型。其次,我們的實驗數據僅來源于一臺機器,未來將考慮引入多家醫院的設備數據以提高實驗結果的泛化性。最后,接下來應在保持檢測精度的基礎上,設計更為優化的模塊以提高檢測速度,并向網絡模型的輕量化方向發展。此外,我們計劃制作硬件系統,并將平臺部署到醫院中,以實現實際應用。
4 結論
本文提出了一種用于檢測兒童腹部B超圖像中腸套疊病灶的EMC-YOLOv8n算法,通過引入EfficientViT網絡作為YOLOv8n的主干網絡,并設計C2fMBC模塊替換原有的C2f模塊,從而在減少模型復雜度的同時大幅提高檢測速度。此外,本文還引入了CA注意力機制,以增強模型對位置信息的獲取能力。為了提高模型的魯棒性和泛化能力,本文在自建數據集上進行了數據增強。大量實驗結果表明,本文提出的算法在檢測兒童腸套疊方面具有優異的精度和可靠性,為超聲科醫生提供了一種準確且快速的輔助診斷工具。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:劉晨雨負責本文實驗設計、算法實現、數據分析及論文撰寫。徐健在論文審核和總體指導方面提供了重要支持。李軻在數據收集與標注方面做出了重要貢獻,并協助撰寫了部分醫學理論相關內容。王璐則在數據標注的準確性檢查及醫學理論指導方面發揮了關鍵作用。