現有肌炎超聲圖像的分類方法存在分類性能差或計算成本高的問題。針對上述問題,本文提出了一種基于軟閾值注意力機制的輕量級神經網絡。該網絡的主干采用深度可分離卷積與常規卷積搭建,通過軟閾值注意力機制自適應去除冗余特征,有效捕獲關鍵特征,從而提高分類表現。與目前分類正確率最高的雙分支特征融合肌炎分類網絡相比,本文提出網絡的分類正確率提高了5.9%,達到了96.1%,且其計算量僅為現有方法的0.25%。因此,該網絡能以較低的存儲與計算成本為醫生提供更準確的輔助診斷結果,具有較強的實用價值。
引用本文: 譚浩, 郎恂, 王濤, 何冰冰, 李支堯, 盧宇, 張榆鋒. 基于輕量級神經網絡的特發性肌炎超聲圖像分類. 生物醫學工程學雜志, 2024, 41(5): 895-902. doi: 10.7507/1001-5515.202301023 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
0 引言
特發性炎癥性肌病(idiopathic inflammatory myopathies,IIMs)是一組自身免疫性肌肉疾病[1],主要包括多發性肌炎(polymyositis,PM)、皮肌炎(dermatomyositis,DM)和包涵體肌炎(inclusion body myositis,IBM)三種亞型疾病。治療延誤會使患者的殘疾率和死亡率顯著增加[2]。此外,上述三類亞型疾病雖同屬肌肉炎癥疾病,但其危害與治療方式存在顯著區別[3],及早進行病理篩查,有助于對不同亞型疾病進行靶向治療,增加患者治愈率。定量超聲是一種無創、操作方便的成像技術,能動態觀察肌肉組織[4]。Botar-Jid等[5]發現肌肉超聲圖像的顏色特征與患PM、DM的概率顯著相關,證明了超聲彈性成像在檢測IIMs上的可行性。此外,Noto等[6]研究發現,患有IBM的肌肉在超聲顯影中的平均灰度普遍高于PM和DM,表明超聲圖像的回聲強度可以區分不同的IIMs亞型疾病。然而,由于超聲圖像具有高噪聲、低分辨率特點,通過人工視覺來分辨超聲圖像上細微的差距十分耗時,且其準確性很大程度上取決于醫生的主觀經驗[7]。因此,有必要采用計算機輔助診斷的方法,提高IIMs診斷效率,有效減少醫生的工作量[8]。
在傳統機器學習領域,Nodera等[9]提取肌肉超聲圖像的灰度共生紋理特征,采用隨機森林(random forest,RF)分類器對PM、DM以及IBM進行三分類,分類正確率為58.8%。2017年,Burlina等[10]首次對比了傳統機器學習和深度學習在IIMs分類上的表現,實驗結果表明AlexNet網絡分類表現更好,準確率達到72.3%。為進一步提升IIMs的分類正確率,U?ar[11]結合VGG16與VGG19網絡,構造了一個高模型復雜度的VGG(16+19)網絡,分類正確率達到90.2%。U?ar的模型雖然可以提高分類正確率,但以高模型復雜度為代價,隨著模型復雜度增加,系統存儲與計算成本也相應增加,因此該網絡在實際應用中將受到限制。
綜上,如何以較低的算法復雜度獲得較高的分類正確率成為了一個重要挑戰。鑒于此,本文提出一種基于軟閾值注意力機制的輕量級卷積神經網絡(lightweight convolutional neural network with soft threshold attention,LCNN-STA)來平衡分類正確率和模型復雜度。MobileNetV1作為經典的輕量級神經網絡,其搭載的深度可分離卷積模塊(depthwise separable convolution,DSC)相比于傳統的卷積模塊(conventional convolution,CConv)具有更小的參數量和計算量[12]。因此,本文借鑒MobileNetV1的構建思想,交替使用DSC與CConv來構造輕量級卷積神經網絡(lightweight convolution neural network,LCNN)為本文的主干網絡。此外,鑒于DSC的參數量較小、擬合能力受到一定限制,為進一步提升分類性能,本文構建了軟閾值注意力機制(soft threshold attention,STA),旨在消除冗余的噪聲特征,以強化網絡對關鍵特征的捕獲能力。
1 相關工作
1.1 網絡的整體結構
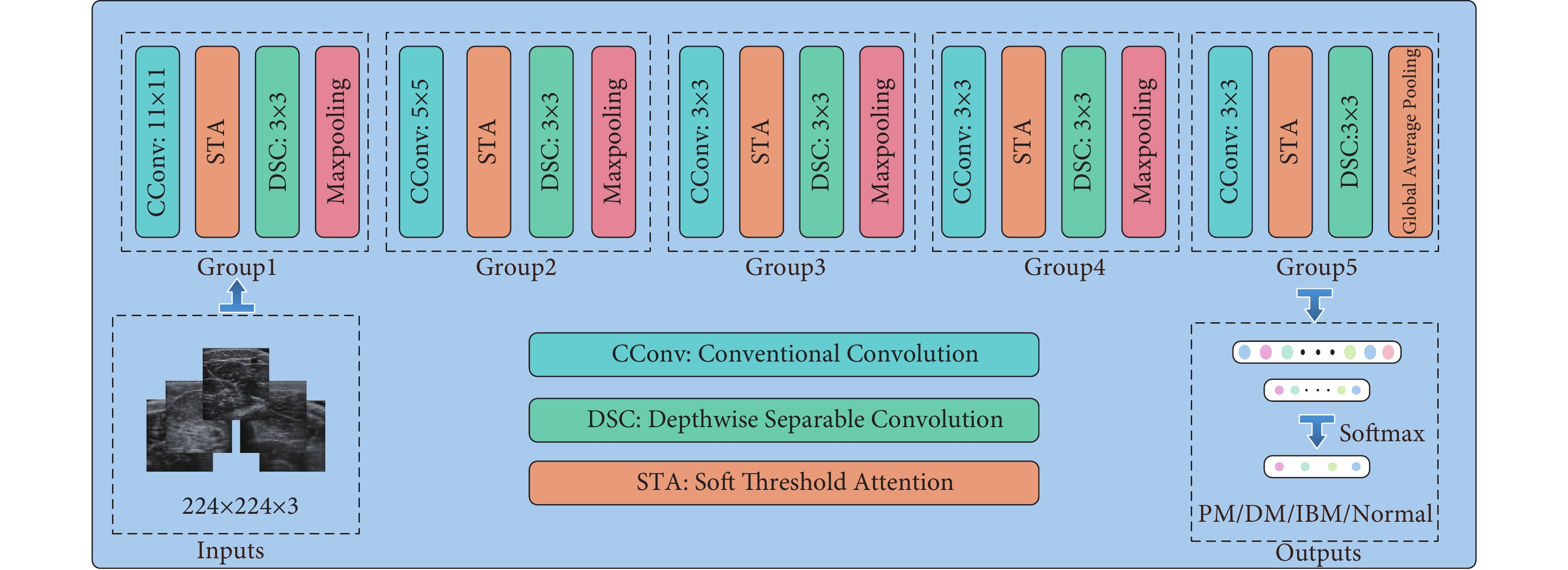
本文設計的輕量級神經網絡LCNN-STA,其結構如圖1所示。受MobileNetV1啟發,設計了5個卷積組,且每個卷積組都由DSC與CConv交替搭建而成。每個卷積塊后面均采用批量歸一化層與線性整流函數進行數據歸一化與激活,加速網絡的收斂速度[13]。此外,本文還提出一種全新的STA注意力機制,通過自適應伸縮的閾值來捕獲關鍵的特征。該模塊被添加在DSC與CConv模塊之間,用于彌補DSC模塊提取特征能力不足的缺點。
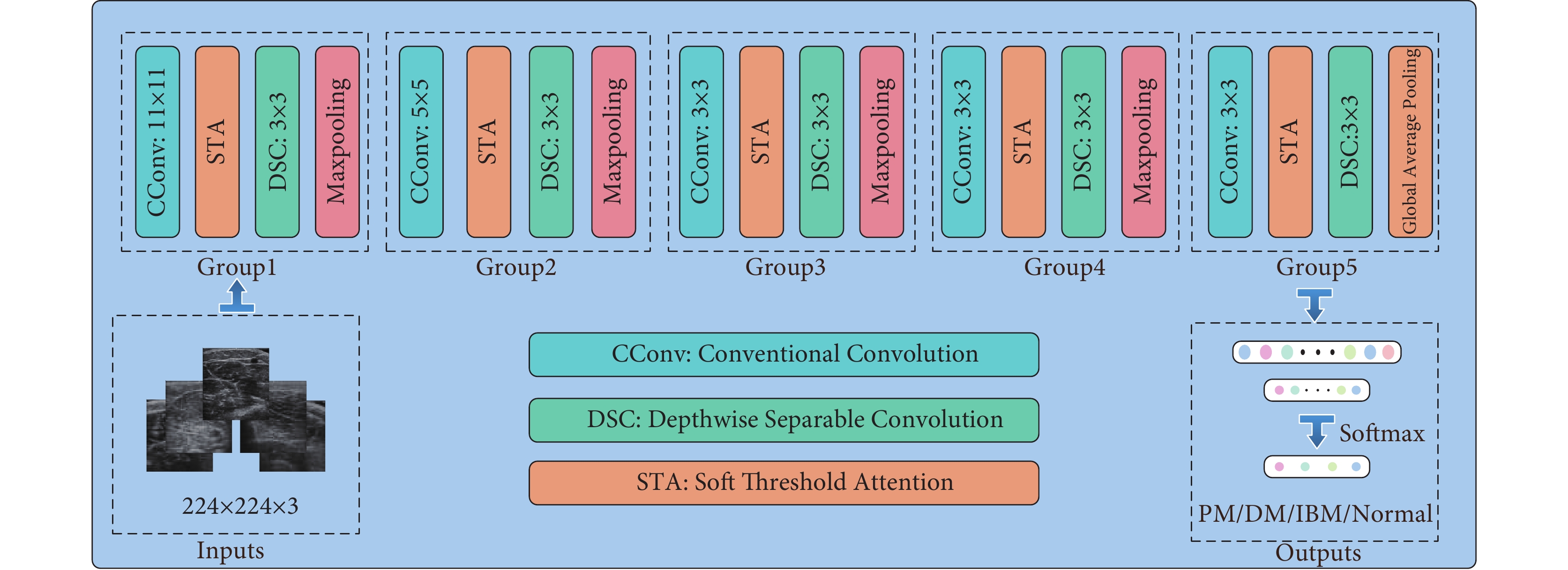 圖1
LCNN-STA網絡結構圖
Figure1.
The structure of the LCNN-STA
圖1
LCNN-STA網絡結構圖
Figure1.
The structure of the LCNN-STA
LCNN-STA網絡的輸入為3通道肌肉超聲圖像,大小為224×224。網絡主要由構建的5個卷積組進行特征提取,在前兩個卷積組中分別采用11×11與5×5的卷積核來快速減少特征圖的大小,增加特征提取的感受野。逐步下采樣后,采用全局平均池化層(global average pooling,GAP)將二維圖像特征池化為一維特征點。與直接采用全連接層(fully connected,FC)不同,采用GAP層作為過渡層可較大程度地減少網絡的參數量,從而改善過擬合現象[14]。最后,特征數據經過softmax激活函數后得到IIMs的分類結果。
1.2 深度可分離卷積
卷積神經網絡中的參數量和計算量分別決定了算法的空間和時間復雜度。傳統的卷積塊CConv,其參數量和計算量分別如式(1)和式(2)所示:
 |
 |
其中 表示經過卷積后的特征圖大小,
表示經過卷積后的特征圖大小, 和
和 分別表示卷積前后的特征通道數,
分別表示卷積前后的特征通道數, 表示卷積核的大小。在本文中,對于同一DSC或者CConv,卷積前后的通道數是相同的,所以
表示卷積核的大小。在本文中,對于同一DSC或者CConv,卷積前后的通道數是相同的,所以 。而DSC模塊包括逐通道卷積和逐點卷積兩部分,其參數量和計算量如下:
。而DSC模塊包括逐通道卷積和逐點卷積兩部分,其參數量和計算量如下:
(1)逐通道卷積指的是一個卷積核只負責一個通道,卷積前后的通道數一致。假設輸出特征圖大小為 ,通道數為
,通道數為 ,則逐通道卷積的參數量和計算量分別為
,則逐通道卷積的參數量和計算量分別為 和
和 。
。
(2)由于逐通道卷積僅對獨立的通道進行卷積,無法有效地利用不同通道在相同空間上的圖像特征,所以需采用逐點卷積將不同通道的特征圖進行組合。假設逐點卷積后的特征圖大小為 ,通道數為
,通道數為 ,則該卷積過程的參數量和計算量分別為
,則該卷積過程的參數量和計算量分別為 和
和 。
。
將逐通道卷積和逐點卷積的參數量和計算量進行疊加,可得出DSC模塊的參數量和計算量,如下所示:
 |
 |
為進行定量比較,假設特征圖大小、通道數在DSC與CConv模塊進行卷積前后相同,則 ,
, 。因此,DSC與CConv模塊的參數量之比和計算量之比分別如式(5)和式(6)所示:
。因此,DSC與CConv模塊的參數量之比和計算量之比分別如式(5)和式(6)所示:
 |
 |
特別地,當輸出通道為256、卷積核大小為3 × 3時,DSC模塊的參數量和計算量僅為CConv模塊的1/9。因此,DSC是本文構建輕量級神經網絡的關鍵模塊。
1.3 注意力機制
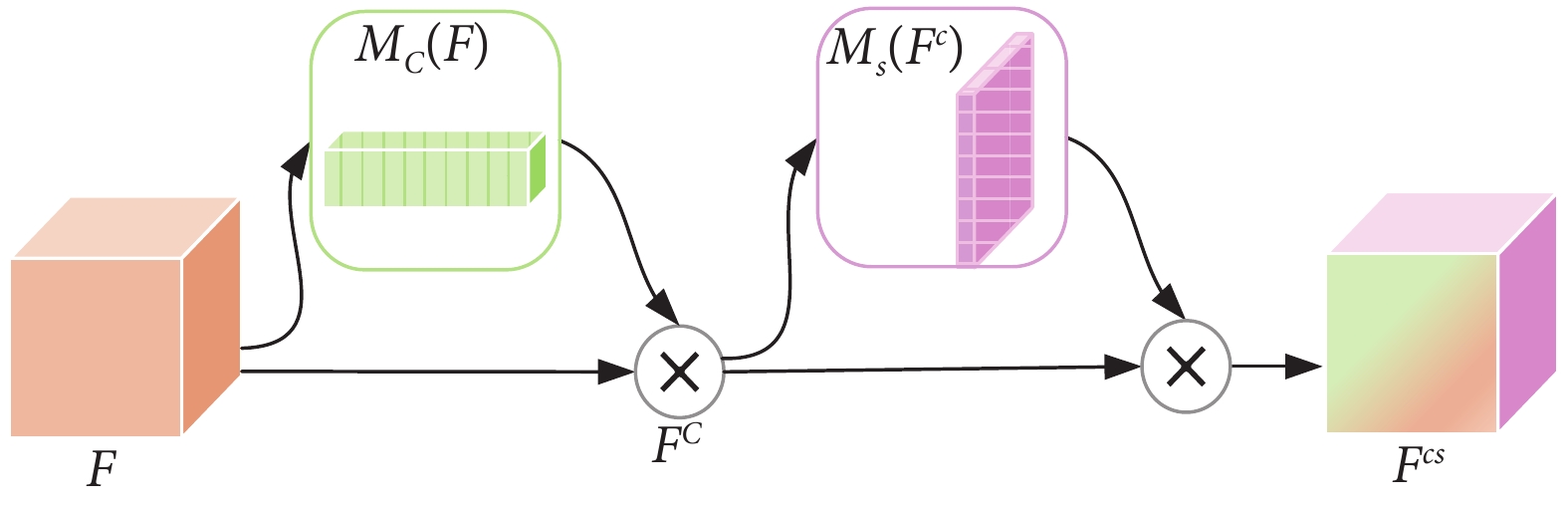
擠壓和激勵網絡(squeeze and excitation,SE)是神經網絡中應用廣泛的注意力機制[15]。SE通過GAP層來計算通道注意力,以較低的計算成本帶來顯著的性能收益。然而,SE忽略了空間信息的重要性,而空間信息是捕獲重要特征的關鍵[16]。針對SE的缺點,Woo等[17]提出了卷積塊注意力機制(convolution block attention module,CBAM),其結構如圖2所示。CBAM先對輸入特征 按通道進行池化,獲取通道激勵
按通道進行池化,獲取通道激勵 ,再將
,再將 與
與 進行逐通道相乘,獲得通道注意力特征塊
進行逐通道相乘,獲得通道注意力特征塊 。然后將特征塊
。然后將特征塊 按空間進行池化,獲得空間激勵
按空間進行池化,獲得空間激勵 。最后將
。最后將 與
與 相乘獲得特征塊
相乘獲得特征塊 ,有效結合通道注意力和空間注意力。
,有效結合通道注意力和空間注意力。
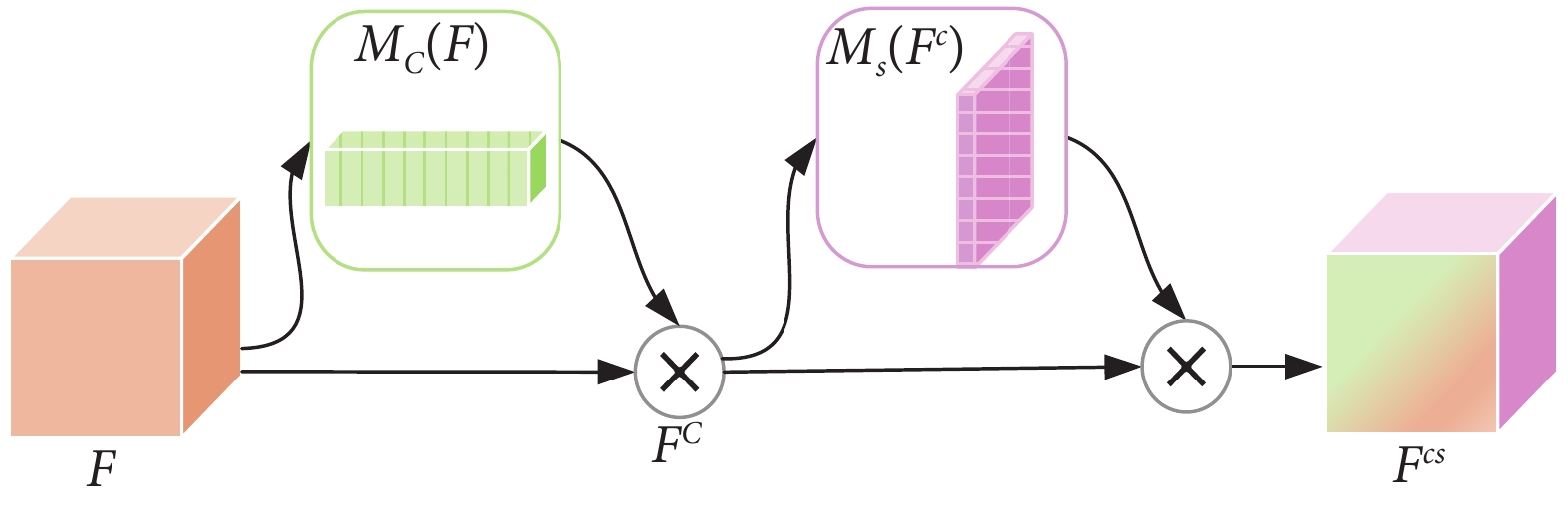 圖2
CBAM結構圖
Figure2.
The structure of the CBAM module
圖2
CBAM結構圖
Figure2.
The structure of the CBAM module
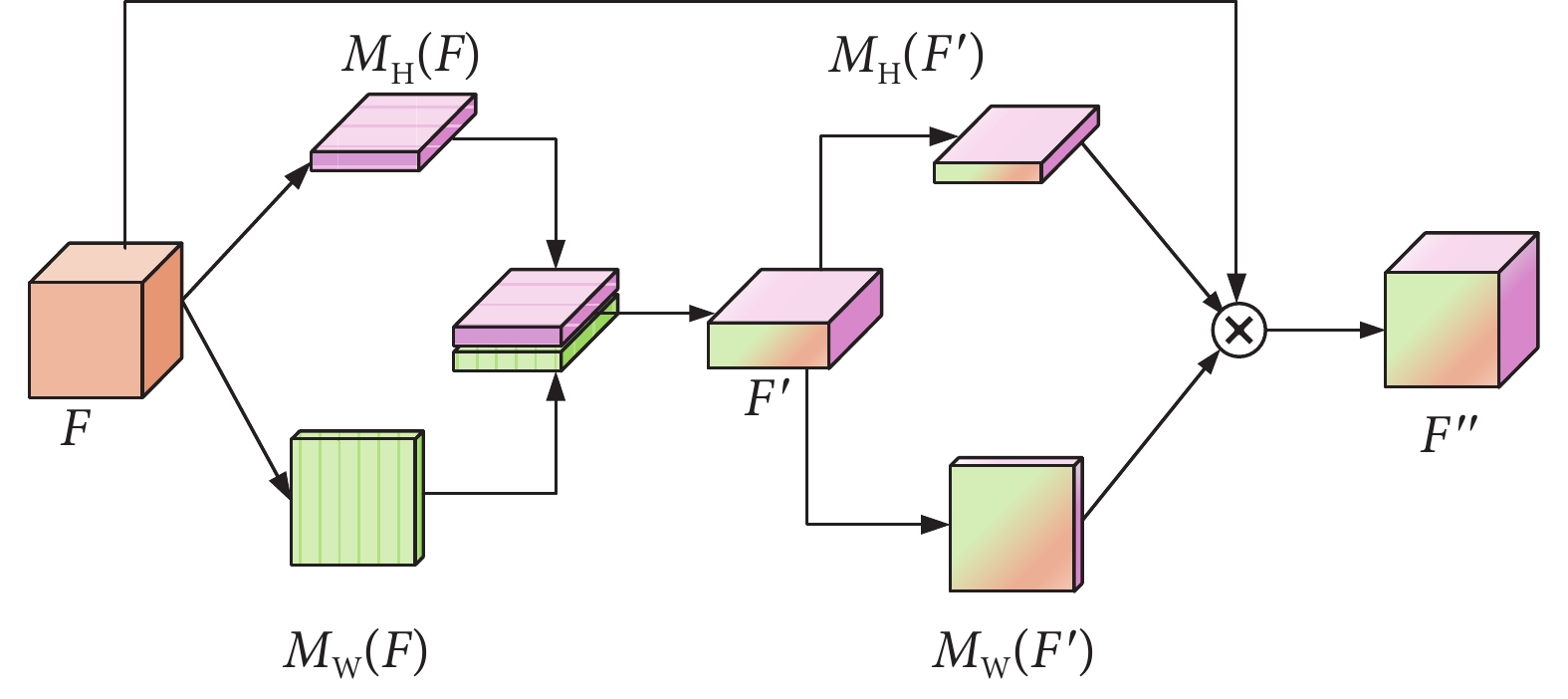
然而,研究表明卷積只能捕獲卷積核覆蓋的局部關系,難以處理復雜的多分類場景[18]。為此,Hou等[19]基于通道注意力機制計算成本低的優勢,將空間信息嵌入通道注意力中,提出了坐標軸注意機制(coordinate attention,CA),如圖3所示。CA通過GAP層對輸入特征塊 的縱向H和橫向W進行信息壓縮,分別獲得激勵
的縱向H和橫向W進行信息壓縮,分別獲得激勵 和激勵
和激勵 。然后將
。然后將 與
與 進行拼接,通過卷積生成特征塊
進行拼接,通過卷積生成特征塊 。隨后將
。隨后將 進行拆分,分別通過卷積生成新的激勵函數
進行拆分,分別通過卷積生成新的激勵函數 與
與 。最后,將
。最后,將 、
、 與
與 相乘,在獲得通道注意力的同時,捕捉空間中縱向和橫向的關鍵信息。
相乘,在獲得通道注意力的同時,捕捉空間中縱向和橫向的關鍵信息。
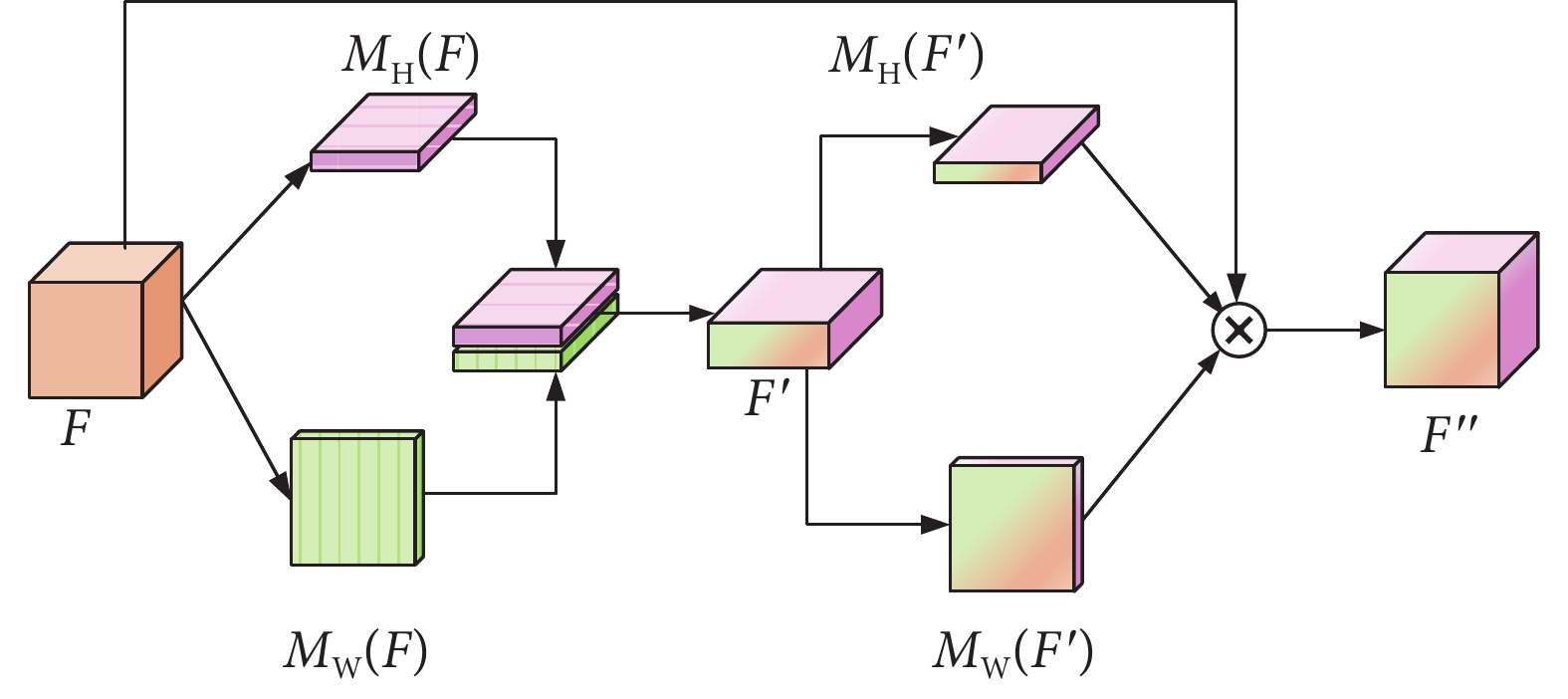 圖3
CA結構圖
Figure3.
The structure of the CA module
圖3
CA結構圖
Figure3.
The structure of the CA module
本文的分類對象是肌肉超聲圖像,屬于高噪聲圖像。CA注意力機制直接將空間注意力嵌入通道中,將部分噪聲信號作為有效的特征進行學習。因此,有必要采取去噪算法來優化該注意力機制。小波軟閾值法是一種經典的去噪方法,通常分為小波分解、閾值選擇和小波重構三個步驟[20]。如式(7)所示,經過信號分解后,當特征 的絕對值小于軟閾值
的絕對值小于軟閾值 時,判斷為噪聲信號被過濾,而當
時,判斷為噪聲信號被過濾,而當 的絕對值大于
的絕對值大于 時,判斷為有用的特征,并將其減去
時,判斷為有用的特征,并將其減去 從而獲得去噪后的特征值
從而獲得去噪后的特征值 。因此,
。因此, 的選取是去噪過程中的關鍵步驟[21]。
的選取是去噪過程中的關鍵步驟[21]。
 |
 的選取不當會造成信號的失真,因此本文借鑒了Zhao等[22]提出的自適應工業信號去噪方法,將軟閾值插入神經網絡模型中,該閾值將根據網絡的迭代發生自適應改變,對現有的CA進行改進,消除主觀因素帶來的誤差。
的選取不當會造成信號的失真,因此本文借鑒了Zhao等[22]提出的自適應工業信號去噪方法,將軟閾值插入神經網絡模型中,該閾值將根據網絡的迭代發生自適應改變,對現有的CA進行改進,消除主觀因素帶來的誤差。
本文提出的STA注意力機制如圖4左圖所示。在CA的基礎上添加了自適應收縮(adaptive shrinkage,AS)模塊,該模塊中的閾值參數會根據網絡的迭代發生自適應改變。具體地,將AS模塊分別添加在CA的H分支和W分支上。AS模塊的結構如圖4右圖所示,假設輸入特征為 ,其中C和W分別為特征圖的通道數與寬度,經過三層卷積塊后,對二維特征圖進行GAP操作,壓縮W方向上的信息為一維向量
,其中C和W分別為特征圖的通道數與寬度,經過三層卷積塊后,對二維特征圖進行GAP操作,壓縮W方向上的信息為一維向量 。然后輸入至閾值的自適應調整模塊,該模塊由兩層FC構建,其參數根據網絡的迭代發生改變,使輸入的一維向量
。然后輸入至閾值的自適應調整模塊,該模塊由兩層FC構建,其參數根據網絡的迭代發生改變,使輸入的一維向量 發生自適應變化。根據式(7)可知,如果軟閾值過大,大部分特征值會被強制轉化為0,于是在FC層的末端添加Sigmoid激活函數,使得每個通道的向量都放縮到(0,1)的范圍內,防止梯度彌散與梯度爆炸,該過程如下式所示:
發生自適應變化。根據式(7)可知,如果軟閾值過大,大部分特征值會被強制轉化為0,于是在FC層的末端添加Sigmoid激活函數,使得每個通道的向量都放縮到(0,1)的范圍內,防止梯度彌散與梯度爆炸,該過程如下式所示:
 圖4
STA結構圖
Figure4.
The structure of the STA module
圖4
STA結構圖
Figure4.
The structure of the STA module
 |
其中i為通道的索引, ,
, 為第i通道的特征值,
為第i通道的特征值, 為對應通道的閾值軟化參數。將
為對應通道的閾值軟化參數。將 作用在
作用在 的對應通道上,獲得自適應伸縮的閾值,如下所示:
的對應通道上,獲得自適應伸縮的閾值,如下所示:
 '/> '/> |
式中 為一維向量
為一維向量 的第i個通道特征值,經過C輪乘積后,獲得一維軟閾值
的第i個通道特征值,經過C輪乘積后,獲得一維軟閾值 。最后,
。最后, 每個通道的一維數據根據對應的軟閾值進行去噪,所有的通道去噪完成后,再次組合通道特征進行輸出。
每個通道的一維數據根據對應的軟閾值進行去噪,所有的通道去噪完成后,再次組合通道特征進行輸出。
2 實驗與分析
2.1 數據集
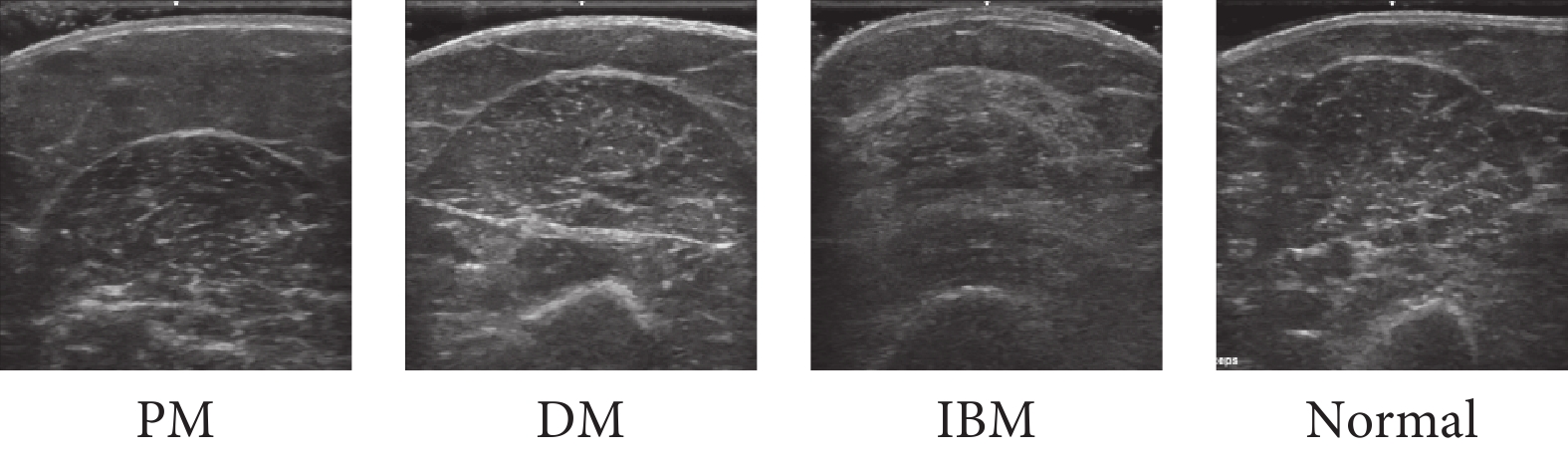
本文實驗數據來自Burlina等[10]公開的數據集。該數據集來源于美國的約翰·霍普金斯肌炎診所,包含3 214張肌肉超聲圖像,分別采集自肱二頭肌、三角肌、指深屈肌、橈腕屈肌、腓腸肌、股直肌和脛骨前肌,共7個肌肉部位。該數據集涉及14名PM患者、14名DM患者、19名IBM患者以及33名健康志愿者(Normal),共80人,并已通過歐洲醫學肌肉協會進行標簽的制定[23]。本文的分類場景為4分類,目的是對PM、DM、IBM以及Normal進行區分,圖5展示了這4類超聲圖像的一組典型樣本(肱二頭肌部位)。
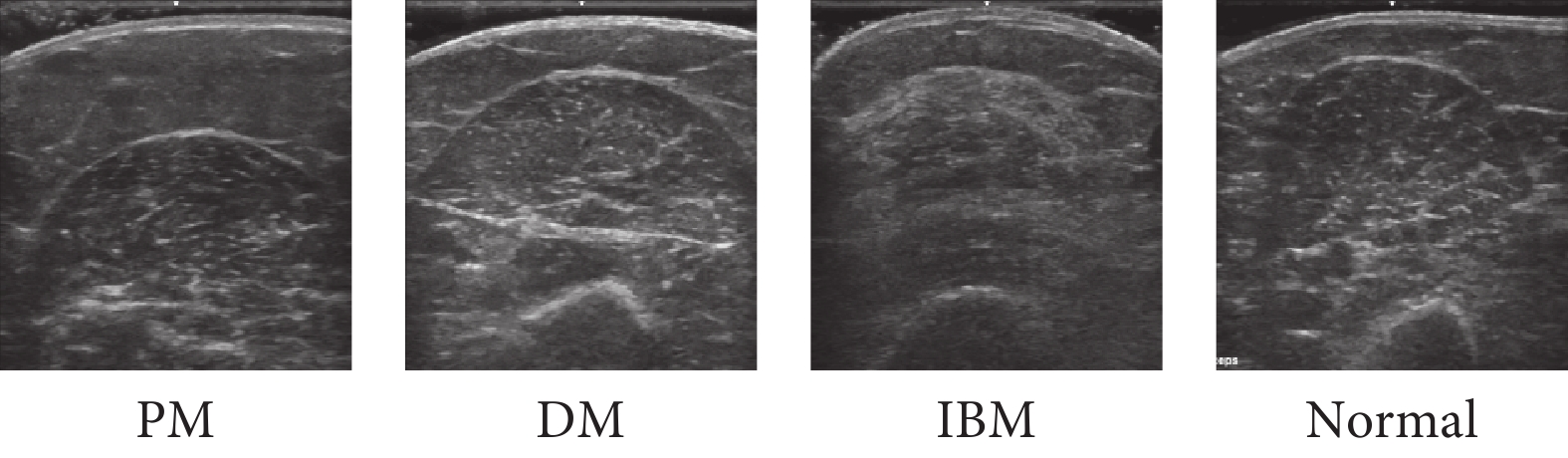 圖5
不同類別的肌肉超聲樣本圖
Figure5.
Samples of ultrasound images
圖5
不同類別的肌肉超聲樣本圖
Figure5.
Samples of ultrasound images
本文采用五折交叉驗證方法,所有數據被隨機分為5個大小相等的子集,訓練集和測試集的比例為4∶1。其中每個受試者的七個肌肉部位均采集了對應的超聲圖片,因此存在同一患者某一部位的超聲圖片作為訓練集,而另一部位的超聲圖片作為測試集的情況。具體的,每個數據子集的疾病類別和超聲圖像數量選取細節如表1所示。
2.2 實驗環境與參數
LCNN-STA基于Python3.6 語言,在Keras2.6.0框架與Tensorflow2.0后端中進行構建。實驗設備的參數如下:GPU為NVIDIA GeForce GTX
2.3 評價指標
為定量評價所提網絡對IIMs的分類性能,采用正確率(ACC)、精確度(PRE)、靈敏度(SEN)以及綜合指標(F1-score)來進行模型評價。具體地,這些指標的計算見式(10):
 |
其中TP、TN、FP和FN分別為真陽性、真陰性、假陽性和假陰性的數量。
2.4 主干網絡的消融實驗
本文主干網絡指的是通過借鑒MobileNetV1的構建思想,交替使用DSC與CConv來構建的LCNN網絡。不同的主干網絡對同一數據集的分類效果有所差異。為客觀評價所提出的主干網絡,本節比較了目前流行的輕量級神經網絡。這些模型都是基于DSC與CConv構建的,包括GhostNet;EfficientNetV1、V2以及MobileNetV1、V2、V3系列,采用的超參數同表2。各網絡的分類效果如表3所示。可以看到,對于IIMs分類,本文所提出的主干網絡在參數量最低的情況下,獲得了最佳的分類表現,分類正確率達到93.5%。
2.5 注意力機制的消融實驗
1.2小節提到,DSC的參數量較小,擬合能力有限。為此,本文采用注意力機制來加強網絡捕獲關鍵特征的能力,從而提高分類表現。本文在所提的主干網絡LCNN中分別添加了目前較為流行的注意力機制,用于比較各種注意力機制對IIMs的分類效果,包括SE、CBAM、CA以及自主構建的STA注意力機制。
表4展示了各注意力機制下網絡的分類性能指標,相比于SE、CBAM以及CA,STA的參數量與計算量有輕微增加。其中搭載了STA的網絡在單張超聲圖像上的預測時間與現有CA注意力機制相比,增加了0.7 ms,但分類正確率提升明顯,達到96.1%。表明本文設計的STA注意力機制在IIMs分類中要優于其他注意力機制。
為直觀突出STA的優勢,采用Grad-CAM[24]作為可視化工具,作用于網絡最后一層卷積層,用于定位不同的注意力機制所關注的重點特征區域。圖6第一列展示了7個部位的超聲原圖,肌肉信息區域已根據臨床專家建議,采用紅色曲線標明。圖6中紅色光暈覆蓋部位為各注意力機制重點關注的信息區域。對比發現,本文提出的STA相比其他注意力機制更能準確定位到肌肉信息區域,且覆蓋的肌肉信息區更加全面。
 圖6
不同注意力機制下的肌肉特征熱力圖
Figure6.
Heat map of muscle characteristics under different attentional mechanisms
圖6
不同注意力機制下的肌肉特征熱力圖
Figure6.
Heat map of muscle characteristics under different attentional mechanisms
2.6 與現有IIMs分類方法的對比
為了進一步證明LCNN-STA在IIMs分類表現和模型復雜度方面的優越性,我們將它與現有IIMs分類的相關方法進行了比較,結果如表5所示。其中Burlina-RF和Burlina-Alexnet僅針對肌炎進行二分類,即區分患病與健康的肌肉超聲圖像,并未對肌炎的亞型疾病進行分類,因此直接引用原文給出的實驗數據作為對比。具體的,在傳統機器學習方法中,Nodera等通過RF進行了三分類,分類正確率僅有58.8%。Burlina等比較了傳統機器學習和深度學習在IIMs中的分類效果,采用的Alexnet正確率到達76.2%。U?ar針對深度學習中IIMs分類效果不佳的問題,將VGG16與VGG19網絡進行合并,構建了一個模型復雜度較大的雙分支特征融合肌炎分類網絡VGG(16+19)(計算量達到34 877.0 MB),使分類正確率達到90.2%。該作者公布了已訓練的模型結構和參數,并且標明了訓練和測試數據的圖片編號。本文通過復現該作者上傳的模型,保持相同的數據集劃分標準,得出了表5中關于LCNN-STA的實驗結果。本文提出的LCNN-STA計算量為86 MB,僅占VGG(16+19)方法的0.25%,在相同的實驗超參數和實驗數據情況下,分類正確率提升了5.9%,因此具有更高的實際應用價值。
3 結論
本文針對現有的IIMs分類方法不能兼顧正確率與算法復雜度的問題,提出了LCNN-STA網絡。該網絡以DSC與CConv為基礎卷積模塊,構建了輕量級主干網絡。與目前流行的輕量級網絡相比,我們所構建的主干網絡以最小的算法復雜度獲得了最佳的分類表現。另外,為彌補DSC模塊擬合能力不足的缺點,進一步加強主干網絡的分類表現,本文在DSC與CConv模塊之間添加了STA注意力機制,用于加強關鍵語義特征的提取,摒棄冗余的噪聲特征。通過消融實驗證明了STA注意力機制能夠更加精準定位到肌肉信息區,分類表現有了較大提升。實驗結果表明,與現有的IIMs方法相比,LCNN-STA以極低的算法復雜度,較大程度上提高了IIMs分類性能,突出了其較高的臨床應用潛力。IIMs作為特發性疾病,可獲取樣本較少,在下一步研究中,我們考慮使用生成對抗網絡來合成更多有效的數據進行模型訓練,以進一步提高所提網絡的泛化性和魯棒性。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:譚浩負責實驗設計與實踐和論文寫作;王濤、盧宇負責數據整理;何冰冰、張榆鋒負責超聲數據分析;李支堯負責醫學指導和數據審查;郎恂負責理論研究、論文整體審查潤色和論文寫作指導。
0 引言
特發性炎癥性肌病(idiopathic inflammatory myopathies,IIMs)是一組自身免疫性肌肉疾病[1],主要包括多發性肌炎(polymyositis,PM)、皮肌炎(dermatomyositis,DM)和包涵體肌炎(inclusion body myositis,IBM)三種亞型疾病。治療延誤會使患者的殘疾率和死亡率顯著增加[2]。此外,上述三類亞型疾病雖同屬肌肉炎癥疾病,但其危害與治療方式存在顯著區別[3],及早進行病理篩查,有助于對不同亞型疾病進行靶向治療,增加患者治愈率。定量超聲是一種無創、操作方便的成像技術,能動態觀察肌肉組織[4]。Botar-Jid等[5]發現肌肉超聲圖像的顏色特征與患PM、DM的概率顯著相關,證明了超聲彈性成像在檢測IIMs上的可行性。此外,Noto等[6]研究發現,患有IBM的肌肉在超聲顯影中的平均灰度普遍高于PM和DM,表明超聲圖像的回聲強度可以區分不同的IIMs亞型疾病。然而,由于超聲圖像具有高噪聲、低分辨率特點,通過人工視覺來分辨超聲圖像上細微的差距十分耗時,且其準確性很大程度上取決于醫生的主觀經驗[7]。因此,有必要采用計算機輔助診斷的方法,提高IIMs診斷效率,有效減少醫生的工作量[8]。
在傳統機器學習領域,Nodera等[9]提取肌肉超聲圖像的灰度共生紋理特征,采用隨機森林(random forest,RF)分類器對PM、DM以及IBM進行三分類,分類正確率為58.8%。2017年,Burlina等[10]首次對比了傳統機器學習和深度學習在IIMs分類上的表現,實驗結果表明AlexNet網絡分類表現更好,準確率達到72.3%。為進一步提升IIMs的分類正確率,U?ar[11]結合VGG16與VGG19網絡,構造了一個高模型復雜度的VGG(16+19)網絡,分類正確率達到90.2%。U?ar的模型雖然可以提高分類正確率,但以高模型復雜度為代價,隨著模型復雜度增加,系統存儲與計算成本也相應增加,因此該網絡在實際應用中將受到限制。
綜上,如何以較低的算法復雜度獲得較高的分類正確率成為了一個重要挑戰。鑒于此,本文提出一種基于軟閾值注意力機制的輕量級卷積神經網絡(lightweight convolutional neural network with soft threshold attention,LCNN-STA)來平衡分類正確率和模型復雜度。MobileNetV1作為經典的輕量級神經網絡,其搭載的深度可分離卷積模塊(depthwise separable convolution,DSC)相比于傳統的卷積模塊(conventional convolution,CConv)具有更小的參數量和計算量[12]。因此,本文借鑒MobileNetV1的構建思想,交替使用DSC與CConv來構造輕量級卷積神經網絡(lightweight convolution neural network,LCNN)為本文的主干網絡。此外,鑒于DSC的參數量較小、擬合能力受到一定限制,為進一步提升分類性能,本文構建了軟閾值注意力機制(soft threshold attention,STA),旨在消除冗余的噪聲特征,以強化網絡對關鍵特征的捕獲能力。
1 相關工作
1.1 網絡的整體結構
本文設計的輕量級神經網絡LCNN-STA,其結構如圖1所示。受MobileNetV1啟發,設計了5個卷積組,且每個卷積組都由DSC與CConv交替搭建而成。每個卷積塊后面均采用批量歸一化層與線性整流函數進行數據歸一化與激活,加速網絡的收斂速度[13]。此外,本文還提出一種全新的STA注意力機制,通過自適應伸縮的閾值來捕獲關鍵的特征。該模塊被添加在DSC與CConv模塊之間,用于彌補DSC模塊提取特征能力不足的缺點。
圖1
LCNN-STA網絡結構圖
Figure1.
The structure of the LCNN-STA
LCNN-STA網絡的輸入為3通道肌肉超聲圖像,大小為224×224。網絡主要由構建的5個卷積組進行特征提取,在前兩個卷積組中分別采用11×11與5×5的卷積核來快速減少特征圖的大小,增加特征提取的感受野。逐步下采樣后,采用全局平均池化層(global average pooling,GAP)將二維圖像特征池化為一維特征點。與直接采用全連接層(fully connected,FC)不同,采用GAP層作為過渡層可較大程度地減少網絡的參數量,從而改善過擬合現象[14]。最后,特征數據經過softmax激活函數后得到IIMs的分類結果。
1.2 深度可分離卷積
卷積神經網絡中的參數量和計算量分別決定了算法的空間和時間復雜度。傳統的卷積塊CConv,其參數量和計算量分別如式(1)和式(2)所示:
|
|
其中表示經過卷積后的特征圖大小,和分別表示卷積前后的特征通道數,表示卷積核的大小。在本文中,對于同一DSC或者CConv,卷積前后的通道數是相同的,所以。而DSC模塊包括逐通道卷積和逐點卷積兩部分,其參數量和計算量如下:
(1)逐通道卷積指的是一個卷積核只負責一個通道,卷積前后的通道數一致。假設輸出特征圖大小為,通道數為,則逐通道卷積的參數量和計算量分別為和。
(2)由于逐通道卷積僅對獨立的通道進行卷積,無法有效地利用不同通道在相同空間上的圖像特征,所以需采用逐點卷積將不同通道的特征圖進行組合。假設逐點卷積后的特征圖大小為,通道數為,則該卷積過程的參數量和計算量分別為和。
將逐通道卷積和逐點卷積的參數量和計算量進行疊加,可得出DSC模塊的參數量和計算量,如下所示:
|
|
為進行定量比較,假設特征圖大小、通道數在DSC與CConv模塊進行卷積前后相同,則,。因此,DSC與CConv模塊的參數量之比和計算量之比分別如式(5)和式(6)所示:
|
|
特別地,當輸出通道為256、卷積核大小為3 × 3時,DSC模塊的參數量和計算量僅為CConv模塊的1/9。因此,DSC是本文構建輕量級神經網絡的關鍵模塊。
1.3 注意力機制
擠壓和激勵網絡(squeeze and excitation,SE)是神經網絡中應用廣泛的注意力機制[15]。SE通過GAP層來計算通道注意力,以較低的計算成本帶來顯著的性能收益。然而,SE忽略了空間信息的重要性,而空間信息是捕獲重要特征的關鍵[16]。針對SE的缺點,Woo等[17]提出了卷積塊注意力機制(convolution block attention module,CBAM),其結構如圖2所示。CBAM先對輸入特征按通道進行池化,獲取通道激勵,再將與進行逐通道相乘,獲得通道注意力特征塊。然后將特征塊按空間進行池化,獲得空間激勵。最后將與相乘獲得特征塊,有效結合通道注意力和空間注意力。
圖2
CBAM結構圖
Figure2.
The structure of the CBAM module
然而,研究表明卷積只能捕獲卷積核覆蓋的局部關系,難以處理復雜的多分類場景[18]。為此,Hou等[19]基于通道注意力機制計算成本低的優勢,將空間信息嵌入通道注意力中,提出了坐標軸注意機制(coordinate attention,CA),如圖3所示。CA通過GAP層對輸入特征塊的縱向H和橫向W進行信息壓縮,分別獲得激勵和激勵。然后將與進行拼接,通過卷積生成特征塊。隨后將進行拆分,分別通過卷積生成新的激勵函數與。最后,將、與相乘,在獲得通道注意力的同時,捕捉空間中縱向和橫向的關鍵信息。
圖3
CA結構圖
Figure3.
The structure of the CA module
本文的分類對象是肌肉超聲圖像,屬于高噪聲圖像。CA注意力機制直接將空間注意力嵌入通道中,將部分噪聲信號作為有效的特征進行學習。因此,有必要采取去噪算法來優化該注意力機制。小波軟閾值法是一種經典的去噪方法,通常分為小波分解、閾值選擇和小波重構三個步驟[20]。如式(7)所示,經過信號分解后,當特征的絕對值小于軟閾值時,判斷為噪聲信號被過濾,而當的絕對值大于時,判斷為有用的特征,并將其減去從而獲得去噪后的特征值。因此,的選取是去噪過程中的關鍵步驟[21]。
|
的選取不當會造成信號的失真,因此本文借鑒了Zhao等[22]提出的自適應工業信號去噪方法,將軟閾值插入神經網絡模型中,該閾值將根據網絡的迭代發生自適應改變,對現有的CA進行改進,消除主觀因素帶來的誤差。
本文提出的STA注意力機制如圖4左圖所示。在CA的基礎上添加了自適應收縮(adaptive shrinkage,AS)模塊,該模塊中的閾值參數會根據網絡的迭代發生自適應改變。具體地,將AS模塊分別添加在CA的H分支和W分支上。AS模塊的結構如圖4右圖所示,假設輸入特征為,其中C和W分別為特征圖的通道數與寬度,經過三層卷積塊后,對二維特征圖進行GAP操作,壓縮W方向上的信息為一維向量。然后輸入至閾值的自適應調整模塊,該模塊由兩層FC構建,其參數根據網絡的迭代發生改變,使輸入的一維向量發生自適應變化。根據式(7)可知,如果軟閾值過大,大部分特征值會被強制轉化為0,于是在FC層的末端添加Sigmoid激活函數,使得每個通道的向量都放縮到(0,1)的范圍內,防止梯度彌散與梯度爆炸,該過程如下式所示:
圖4
STA結構圖
Figure4.
The structure of the STA module
|
其中i為通道的索引,,為第i通道的特征值,為對應通道的閾值軟化參數。將作用在的對應通道上,獲得自適應伸縮的閾值,如下所示:
| '/> |
式中為一維向量的第i個通道特征值,經過C輪乘積后,獲得一維軟閾值。最后,每個通道的一維數據根據對應的軟閾值進行去噪,所有的通道去噪完成后,再次組合通道特征進行輸出。
2 實驗與分析
2.1 數據集
本文實驗數據來自Burlina等[10]公開的數據集。該數據集來源于美國的約翰·霍普金斯肌炎診所,包含3 214張肌肉超聲圖像,分別采集自肱二頭肌、三角肌、指深屈肌、橈腕屈肌、腓腸肌、股直肌和脛骨前肌,共7個肌肉部位。該數據集涉及14名PM患者、14名DM患者、19名IBM患者以及33名健康志愿者(Normal),共80人,并已通過歐洲醫學肌肉協會進行標簽的制定[23]。本文的分類場景為4分類,目的是對PM、DM、IBM以及Normal進行區分,圖5展示了這4類超聲圖像的一組典型樣本(肱二頭肌部位)。
圖5
不同類別的肌肉超聲樣本圖
Figure5.
Samples of ultrasound images
本文采用五折交叉驗證方法,所有數據被隨機分為5個大小相等的子集,訓練集和測試集的比例為4∶1。其中每個受試者的七個肌肉部位均采集了對應的超聲圖片,因此存在同一患者某一部位的超聲圖片作為訓練集,而另一部位的超聲圖片作為測試集的情況。具體的,每個數據子集的疾病類別和超聲圖像數量選取細節如表1所示。
2.2 實驗環境與參數
LCNN-STA基于Python3.6 語言,在Keras2.6.0框架與Tensorflow2.0后端中進行構建。實驗設備的參數如下:GPU為NVIDIA GeForce GTX
2.3 評價指標
為定量評價所提網絡對IIMs的分類性能,采用正確率(ACC)、精確度(PRE)、靈敏度(SEN)以及綜合指標(F1-score)來進行模型評價。具體地,這些指標的計算見式(10):
|
其中TP、TN、FP和FN分別為真陽性、真陰性、假陽性和假陰性的數量。
2.4 主干網絡的消融實驗
本文主干網絡指的是通過借鑒MobileNetV1的構建思想,交替使用DSC與CConv來構建的LCNN網絡。不同的主干網絡對同一數據集的分類效果有所差異。為客觀評價所提出的主干網絡,本節比較了目前流行的輕量級神經網絡。這些模型都是基于DSC與CConv構建的,包括GhostNet;EfficientNetV1、V2以及MobileNetV1、V2、V3系列,采用的超參數同表2。各網絡的分類效果如表3所示。可以看到,對于IIMs分類,本文所提出的主干網絡在參數量最低的情況下,獲得了最佳的分類表現,分類正確率達到93.5%。
2.5 注意力機制的消融實驗
1.2小節提到,DSC的參數量較小,擬合能力有限。為此,本文采用注意力機制來加強網絡捕獲關鍵特征的能力,從而提高分類表現。本文在所提的主干網絡LCNN中分別添加了目前較為流行的注意力機制,用于比較各種注意力機制對IIMs的分類效果,包括SE、CBAM、CA以及自主構建的STA注意力機制。
表4展示了各注意力機制下網絡的分類性能指標,相比于SE、CBAM以及CA,STA的參數量與計算量有輕微增加。其中搭載了STA的網絡在單張超聲圖像上的預測時間與現有CA注意力機制相比,增加了0.7 ms,但分類正確率提升明顯,達到96.1%。表明本文設計的STA注意力機制在IIMs分類中要優于其他注意力機制。
為直觀突出STA的優勢,采用Grad-CAM[24]作為可視化工具,作用于網絡最后一層卷積層,用于定位不同的注意力機制所關注的重點特征區域。圖6第一列展示了7個部位的超聲原圖,肌肉信息區域已根據臨床專家建議,采用紅色曲線標明。圖6中紅色光暈覆蓋部位為各注意力機制重點關注的信息區域。對比發現,本文提出的STA相比其他注意力機制更能準確定位到肌肉信息區域,且覆蓋的肌肉信息區更加全面。
圖6
不同注意力機制下的肌肉特征熱力圖
Figure6.
Heat map of muscle characteristics under different attentional mechanisms
2.6 與現有IIMs分類方法的對比
為了進一步證明LCNN-STA在IIMs分類表現和模型復雜度方面的優越性,我們將它與現有IIMs分類的相關方法進行了比較,結果如表5所示。其中Burlina-RF和Burlina-Alexnet僅針對肌炎進行二分類,即區分患病與健康的肌肉超聲圖像,并未對肌炎的亞型疾病進行分類,因此直接引用原文給出的實驗數據作為對比。具體的,在傳統機器學習方法中,Nodera等通過RF進行了三分類,分類正確率僅有58.8%。Burlina等比較了傳統機器學習和深度學習在IIMs中的分類效果,采用的Alexnet正確率到達76.2%。U?ar針對深度學習中IIMs分類效果不佳的問題,將VGG16與VGG19網絡進行合并,構建了一個模型復雜度較大的雙分支特征融合肌炎分類網絡VGG(16+19)(計算量達到34 877.0 MB),使分類正確率達到90.2%。該作者公布了已訓練的模型結構和參數,并且標明了訓練和測試數據的圖片編號。本文通過復現該作者上傳的模型,保持相同的數據集劃分標準,得出了表5中關于LCNN-STA的實驗結果。本文提出的LCNN-STA計算量為86 MB,僅占VGG(16+19)方法的0.25%,在相同的實驗超參數和實驗數據情況下,分類正確率提升了5.9%,因此具有更高的實際應用價值。
3 結論
本文針對現有的IIMs分類方法不能兼顧正確率與算法復雜度的問題,提出了LCNN-STA網絡。該網絡以DSC與CConv為基礎卷積模塊,構建了輕量級主干網絡。與目前流行的輕量級網絡相比,我們所構建的主干網絡以最小的算法復雜度獲得了最佳的分類表現。另外,為彌補DSC模塊擬合能力不足的缺點,進一步加強主干網絡的分類表現,本文在DSC與CConv模塊之間添加了STA注意力機制,用于加強關鍵語義特征的提取,摒棄冗余的噪聲特征。通過消融實驗證明了STA注意力機制能夠更加精準定位到肌肉信息區,分類表現有了較大提升。實驗結果表明,與現有的IIMs方法相比,LCNN-STA以極低的算法復雜度,較大程度上提高了IIMs分類性能,突出了其較高的臨床應用潛力。IIMs作為特發性疾病,可獲取樣本較少,在下一步研究中,我們考慮使用生成對抗網絡來合成更多有效的數據進行模型訓練,以進一步提高所提網絡的泛化性和魯棒性。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:譚浩負責實驗設計與實踐和論文寫作;王濤、盧宇負責數據整理;何冰冰、張榆鋒負責超聲數據分析;李支堯負責醫學指導和數據審查;郎恂負責理論研究、論文整體審查潤色和論文寫作指導。