胃癌病理圖像是胃癌診斷的金標準,然而其復發預測任務面臨病灶組織形態特征不顯著、多級分辨率特征融合不足、無法有效利用上下文信息等問題。為此,提出了一種基于胃癌病理圖像分析的三階段復發預測方法。在第一階段,利用自監督學習框架SimCLR對低分辨率下的補丁圖像進行訓練以降低不同組織圖像的耦合度,從而獲得解耦后的增強特征。在第二階段,將獲取的低分辨率增強特征與對應高分辨率未增強特征進行融合,實現不同分辨率下的特征互補。在第三階段,針對補丁圖像數量差異較大導致位置編碼困難的問題,利用多尺度的局部鄰域進行位置編碼并利用自注意力機制獲得具有上下文信息的特征,隨后與卷積神經網絡所提取的局部特征進行融合。通過在臨床收集的數據上進行評估,與同類方法最佳性能相比,本文所提出的網絡模型在準確率、曲線下面積(AUC)指標上取得了最佳性能,分別提高了7.63%、4.51%,證明了該方法對胃癌復發預測的有效性。
引用本文: 周泓宇, 陶海波, 薛飛躍, 王彬, 金懷平, 李振輝. 基于多分辨率特征融合與上下文信息的胃癌復發預測方法. 生物醫學工程學雜志, 2024, 41(5): 886-894. doi: 10.7507/1001-5515.202403014 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
0 引言
胃癌是世界范圍內常見癌癥之一,在我國惡性腫瘤中發病率、死亡率均位列前三,每年死亡近29萬例[1-2]。雖然可以通過切除術治療胃癌,但仍有約60%的患者會在術后復發[3],因此復發預測是胃癌預后預測的重要組成部分。病理圖像能夠直接觀察病變組織,在器質性病變診斷中具有不可替代的作用,是醫學界公認的癌癥診斷金標準[4-5]。然而病理圖像具有尺寸巨大、病灶組織形態特征不顯著、病灶組織占比遠小于正常組織、多級分辨率蘊含豐富信息但缺乏細粒度標簽等特點,如圖1所示,這些特點使得臨床診斷過程較為耗時且診斷結果的一致性較低。為此,建立一個基于胃癌病理圖像的復發預測模型,對于胃癌的臨床預后預測具有重要意義。
 圖1
無像素級標簽數據和有像素級標簽數據示例
Figure1.
Examples of data without pixel-level labels and data with pixel-level labels
圖1
無像素級標簽數據和有像素級標簽數據示例
Figure1.
Examples of data without pixel-level labels and data with pixel-level labels
近年來,深度學習技術,如卷積神經網絡和殘差結構[6-7]等方法,被廣泛應用到醫學圖像分析領域。目前,諸多學者將深度學習方法應用于數字病理圖像預后預測領域,以期輔助臨床診斷,并逐漸發展為計算病理學[8-11]。Campanella等[12]引入多實例學習思想,將卷積神經網絡與循環神經網絡相結合,該模型在前列腺癌分類和乳腺癌轉移預測上取得了較好的效果。于凌濤等[13]結合遷移學習,探究了不同得分聚合規則對乳腺癌補丁圖像良惡性分類的影響,該模型在補丁圖像的預測上取得了一定效果。金懷平等[14]引入集成學習思想,通過集成多個異質子模型的結果預測胃癌是否轉移,其預測精度明顯優于僅使用單一模型。Ilse等[15]將多實例問題轉換為包級標簽的伯努利分布問題,提出了一種聚合算子計算不同補丁圖像的得分并獲得預測結果。Li等[16]采用最大池化對多實例學習進行改進,提出了一種基于最高得分實例的池化方式,進一步提高了準確率。Lu等[17]提出了一種基于弱監督深度學習的病理圖像分類方法,通過實例級聚類約束特征空間獲得較好的特征表示。Shao等[18]基于補丁圖像提出了相關性多實例學習框架,并在乳腺癌、腎細胞癌上驗證了所提框架的有效性。
雖然上述研究促進了深度學習在病理圖像預后預測中的應用,但針對胃癌病理圖像的復發預測研究仍然存在以下問題:① 現有研究大多基于像素級的細粒度標簽進行,僅使用患者級標簽的研究仍存在諸多挑戰。② 現有研究對數據的多分辨率重視不足,造成不同分辨率間大量相關信息丟失。③ 補丁圖像作為變長序列,進行位置編碼較為困難,導致不同補丁之間上下文信息利用不足,預測結果的可解釋性較低。
為解決上述問題,本文提出了一種基于多分辨率特征融合上下文信息的模型用于胃癌復發預測。針對僅有患者級標簽的問題,引入對比學習思想對補丁圖像進行特征差異化,從而實現特征解耦,為下游任務提供一個良好的特征表示。針對多分辨率重視不足的問題,提出了一種多分辨率特征融合方法,實現不同分辨率下的特征互補。針對病理圖像位置編碼困難的問題,引入條件位置編碼并進行改進,進一步利用不同實例之間的上下文信息,增強模型的可解釋性。
1 本文方法
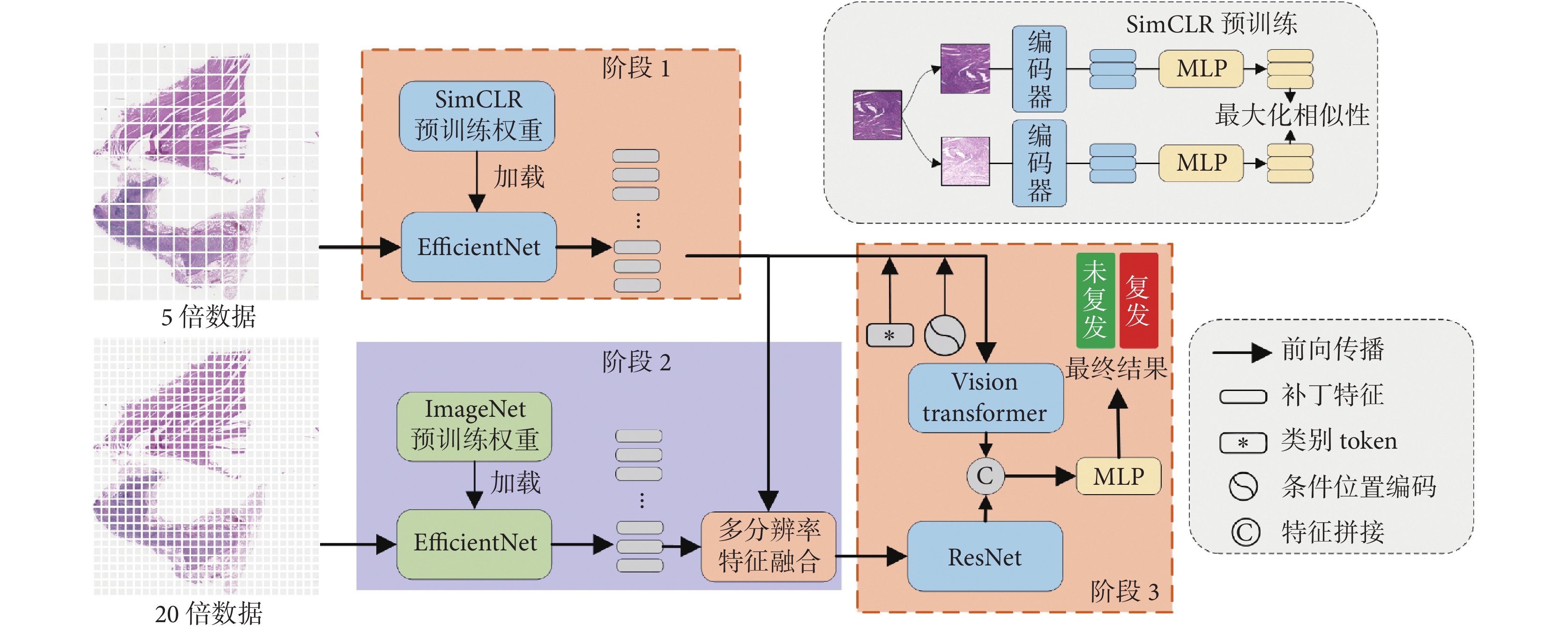
基于多分辨率特征融合與上下文信息的胃癌復發預測方法的主要原理結構如圖2所示,共分為三個階段:① 利用自監督學習框架SimCLR對低分辨率下的補丁圖像進行訓練,降低不同類型組織間的耦合度,從而獲得解耦后的增強特征。② 將獲取的低分辨率增強特征與對應高分辨率未增強特征進行融合,獲取數據的多分辨率信息,進一步提升預測的準確率。③ 利用多尺度的局部鄰域進行位置編碼,并將自注意力機制與卷積神經網絡所獲取的上下文特征、局部特征進行融合,通過分類頭獲得最終的預測結果。
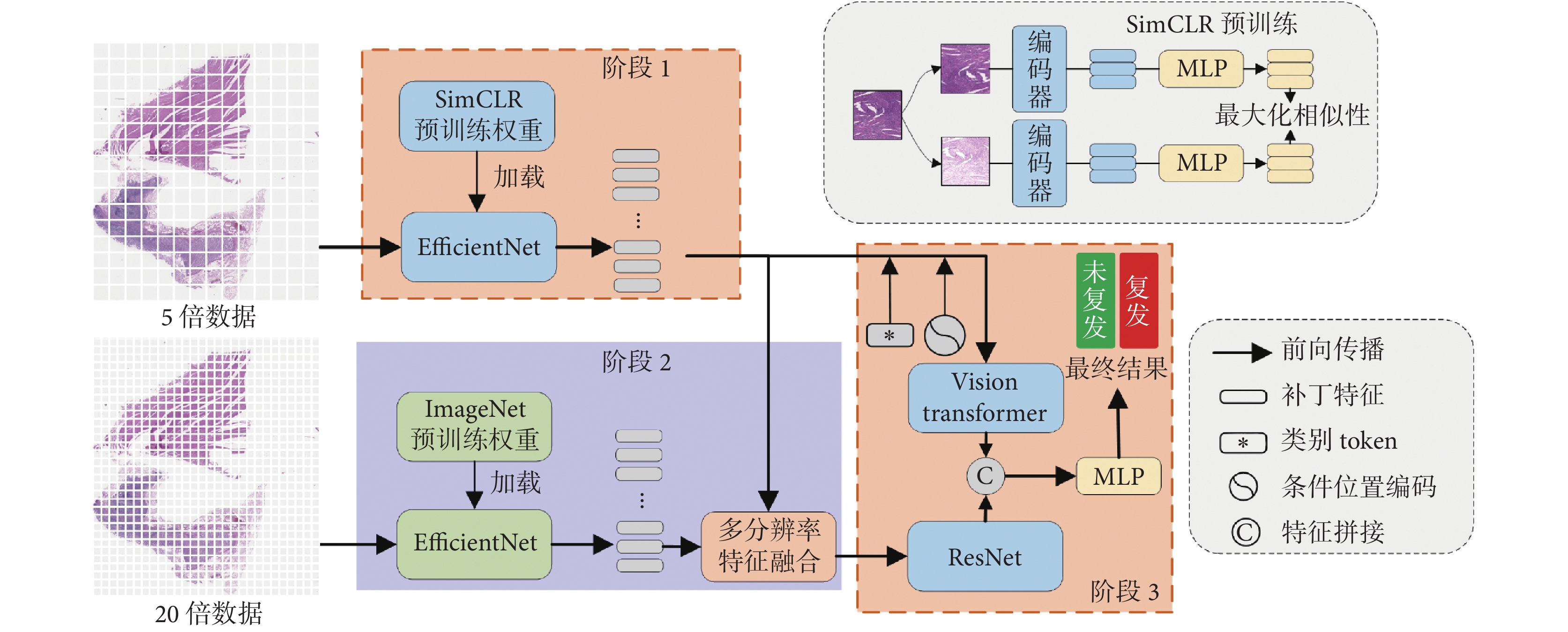 圖2
整體框架結構
Figure2.
Overall frame structure
圖2
整體框架結構
Figure2.
Overall frame structure
1.1 低分辨率補丁圖像特征解耦
基于病理圖像進行復發預測的研究大多是使用ImageNet數據集[19]的權重進行微調,忽略了自然圖像與病理圖像之間的巨大差異,導致提取到的特征耦合嚴重,預測結果并不理想。考慮到補丁圖像并沒有像素級標簽,因此引入自監督學習思想,在低分辨率補丁圖像上對特征提取器進行預訓練。通過對補丁圖像進行數據增強并差異化不同組織類型間的相似度,從而獲得增強的特征表示。SimCLR作為一種自監督學習模型,能夠學習到無標簽數據的潛在分布,進行有效的特征提取[20],其工作框架如圖2中SimCLR預訓練部分所示。為獲得更高的特征提取能力和提高訓練效率,我們使用EfficientNet V2 Small作為SimCLR的特征提取器[21],對提取到的特征 進行投影后使用對比損失函數計算損失。樣本
進行投影后使用對比損失函數計算損失。樣本 的投影過程可以表示為
的投影過程可以表示為 ,對比損失函數的公式如式(1)所示:
,對比損失函數的公式如式(1)所示:
 |
式中, 和
和 分別表示當前樣本
分別表示當前樣本 增強向量的最終表示,
增強向量的最終表示, 是調節參數,
是調節參數, 是當前批次中數據的總數。通過以上步驟,有效提高了特征的表示能力,從而避免因數據差異較小導致特征耦合嚴重的問題。
是當前批次中數據的總數。通過以上步驟,有效提高了特征的表示能力,從而避免因數據差異較小導致特征耦合嚴重的問題。
1.2 多分辨率補丁圖像特征融合
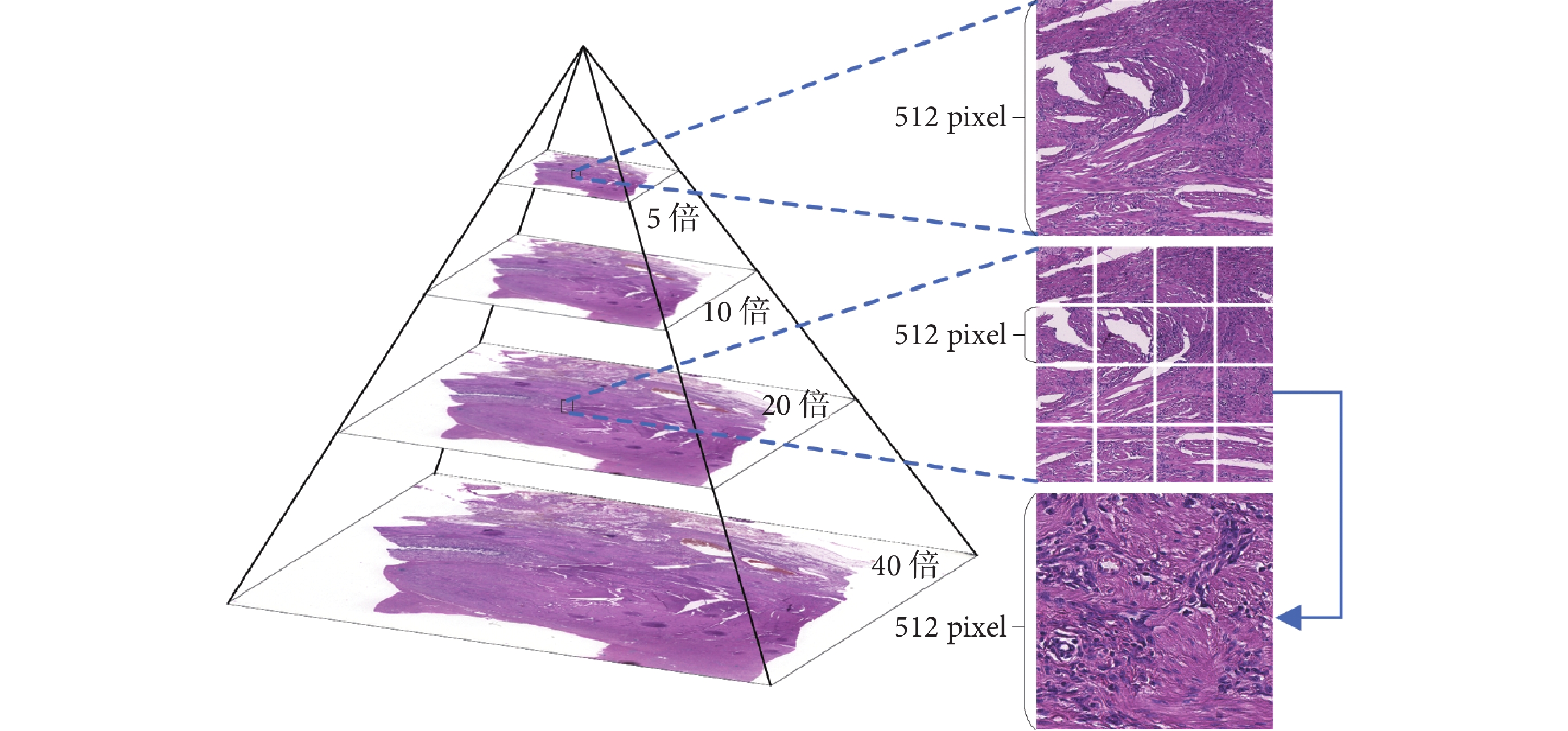
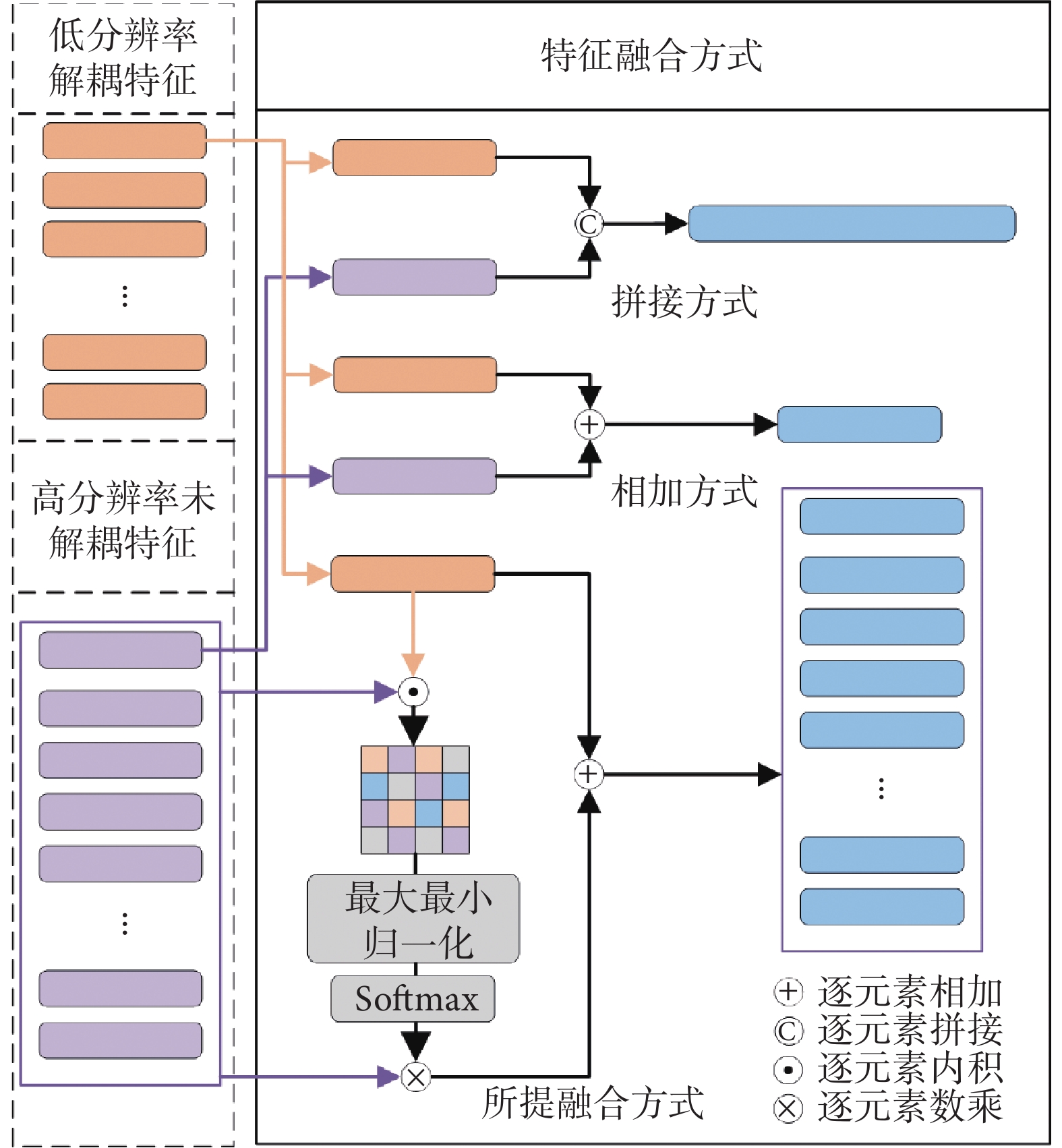
數字病理圖像具有金字塔結構,可以在多級分辨率下對圖像進行觀察,低分辨率下觀察組織的大范圍排列分布,高分辨率下分析單個細胞的形態,如圖3所示。為充分利用數字病理圖像不同分辨率下的特征,需要對多級分辨率下的補丁圖像進行特征融合。大多數研究使用圖4中的拼接方式、相加方式,這容易導致補丁圖像不同分辨率間的關聯信息丟失[14-16]。我們希望特征融合操作能夠具有一定的可解釋性,更多地利用已經解耦的優質低分辨率特征影響其對應的高分辨率特征,從而充分利用病理圖像多級分辨率所具有的優點。
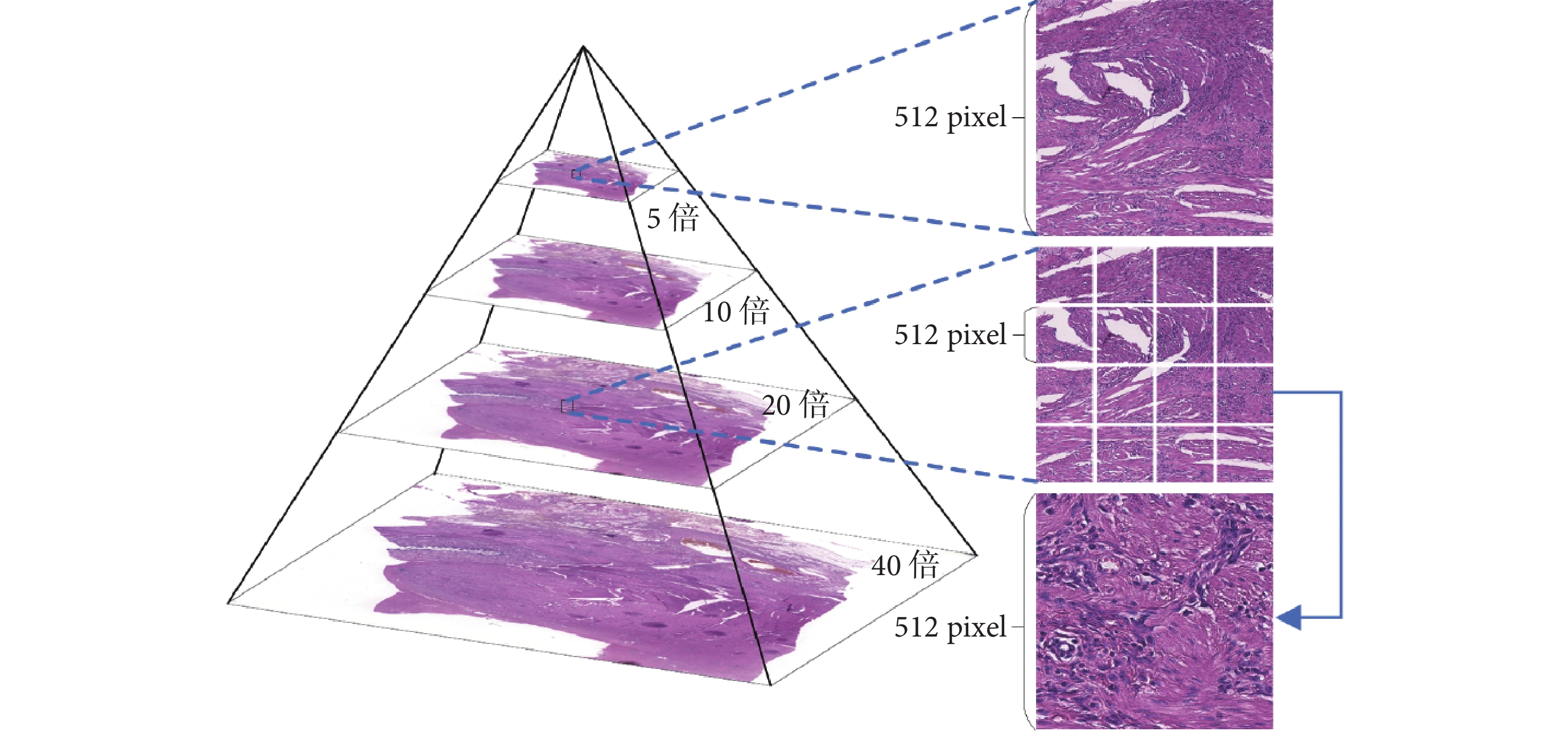 圖3
數字病理圖像結構圖
Figure3.
Structure diagram of digital pathology image
圖3
數字病理圖像結構圖
Figure3.
Structure diagram of digital pathology image
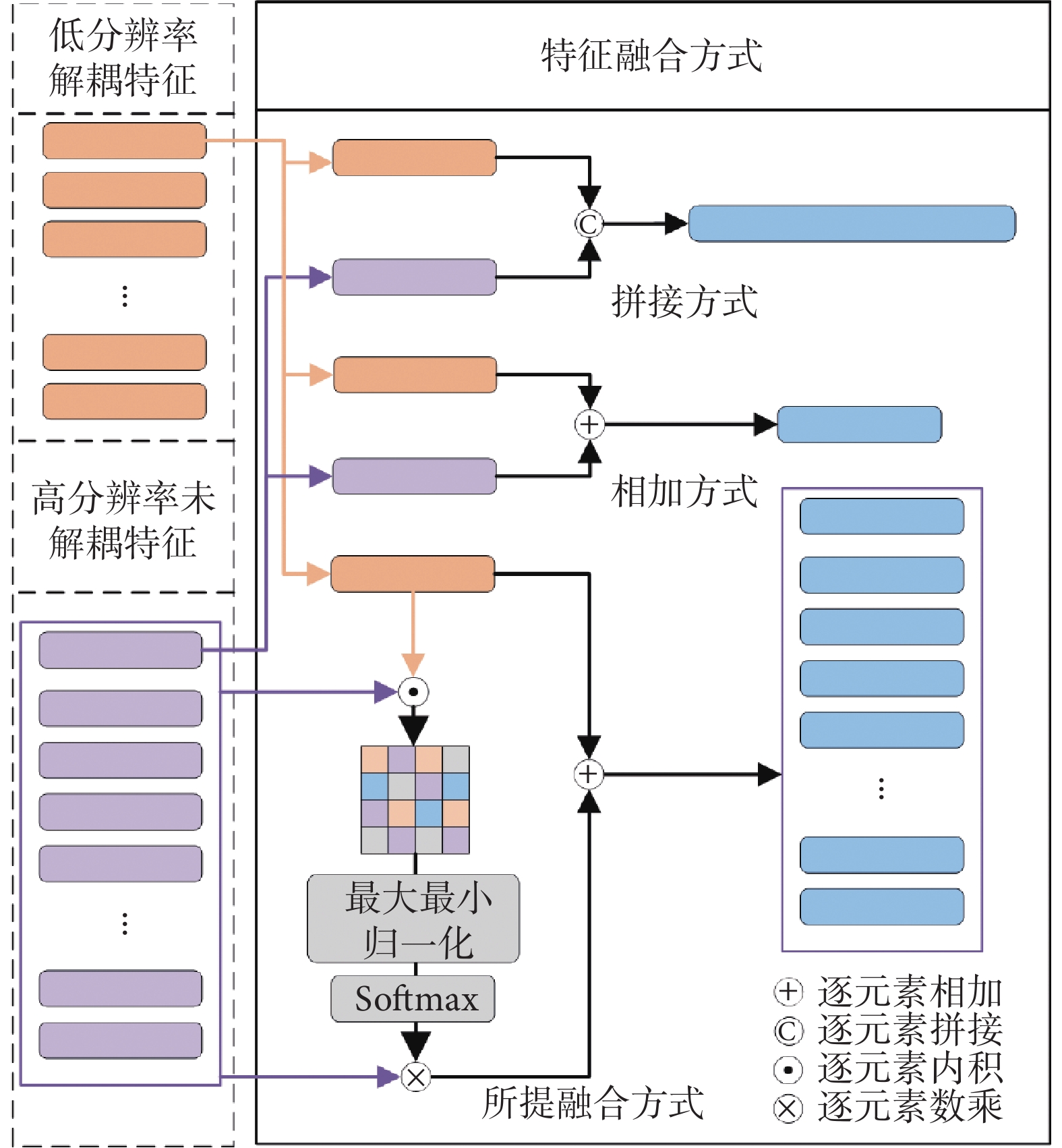 圖4
多分辨率特征融合方式
Figure4.
Multi-resolution feature fusion method
圖4
多分辨率特征融合方式
Figure4.
Multi-resolution feature fusion method
為實現上述思想,我們提出了一種特征融合方法,具體原理如圖4中所提融合方式所示。首先獲得單張數字病理圖像的補丁級深度特征,這些特征分別是經過特征解耦的低分辨率特征與直接使用ImageNet權重提取的高分辨率特征。其次,將低分辨率特征向量與其對應的所有高分辨率特征向量求內積,獲得相似度。然后,使用最大最小歸一化對同一個批次獲得的相似度分數進行歸一化處理,為避免丟失分數為0的高分辨率特征,使用softmax函數獲得最終的相似度。最后,用相似度分數與高分辨率原始特征相乘,并將結果與低分辨率特征進行融合,從而使得未解耦的高分辨率特征在一定程度上具有低分辨率特征的解耦性。
1.3 補丁圖像的上下文信息融合
在臨床治療中,病理學家需要反復觀察病理圖像的不同區域,利用不同組間的分布關系判斷腫瘤侵襲以及浸潤的程度,從而制定治療策略。在理論推導上,文獻[18]已經證明關注實例之間的相關性,可以有效降低多實例問題的信息熵,從而提高模型的決策性。
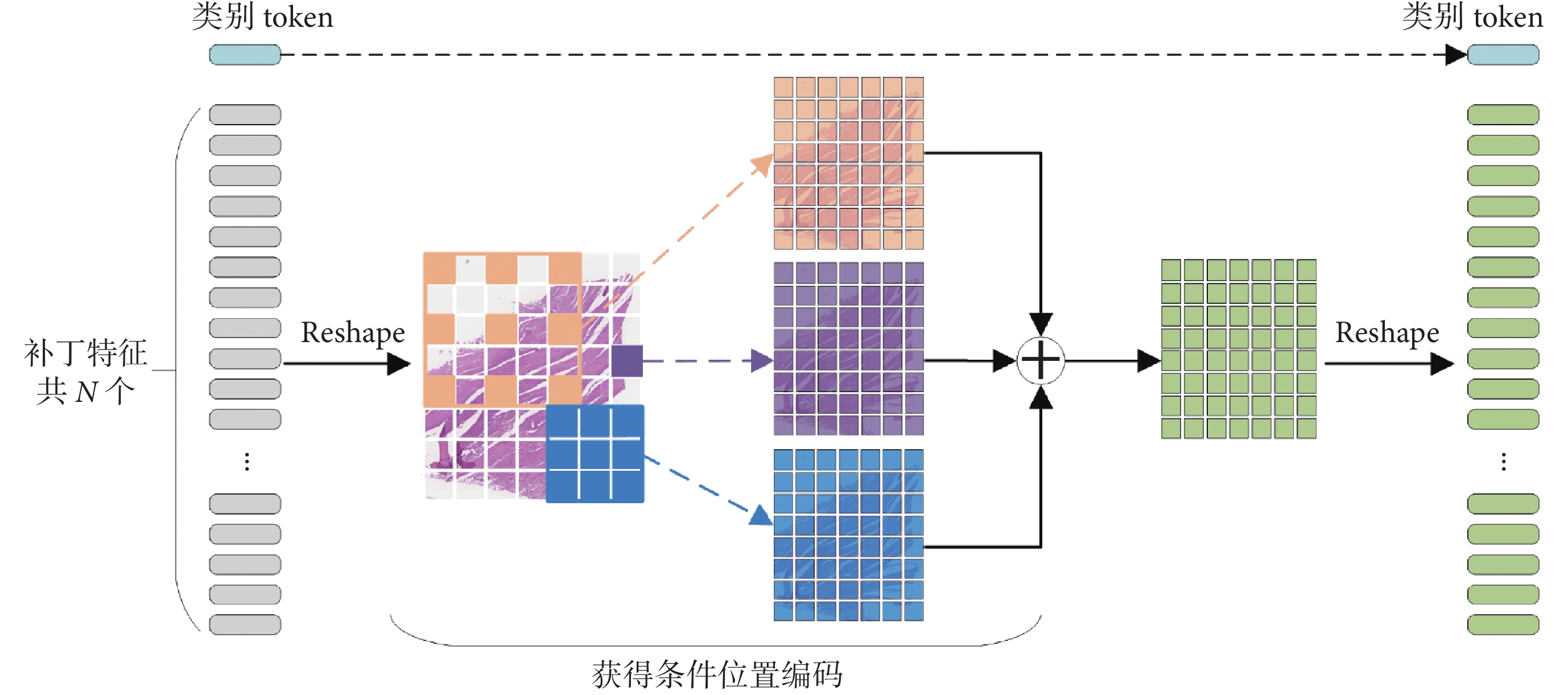
然而,不同數字病理圖像所含有的組織量并不相同,切分出的補丁圖像的數量并不固定,因此不同數字病理圖像裁切出的補丁圖像可以視為變長序列數據。但與自注意力機制搭配使用的傳統位置編碼,僅能對固定長度的序列數據進行位置編碼,無法適用于變長序列數據。文獻[22]基于卷積層提出條件位置編碼,但對數字病理圖像的深度特征進行編碼時存在感受野過小、上下文信息獲取不足等問題。因此結合數字病理圖像的特性,引入多尺度卷積對該方法進行一定的改進:使用1×1普通卷積、3×3普通卷積分別獲取當前補丁圖像特征以及與其聯系緊密的局部鄰域特征;使用擴張率為2的3×3空洞卷積,在不增加計算量的基礎上獲取與當前補丁圖像有一定聯系的局部鄰域特征。融合不同鄰域的特征圖,并將該特征圖重塑為補丁特征輸入到視覺轉換器(Vision Transformer,ViT)中[23],從而結合自注意力機制有效地獲得不同補丁圖像間的上下文信息,編碼過程如圖5所示。
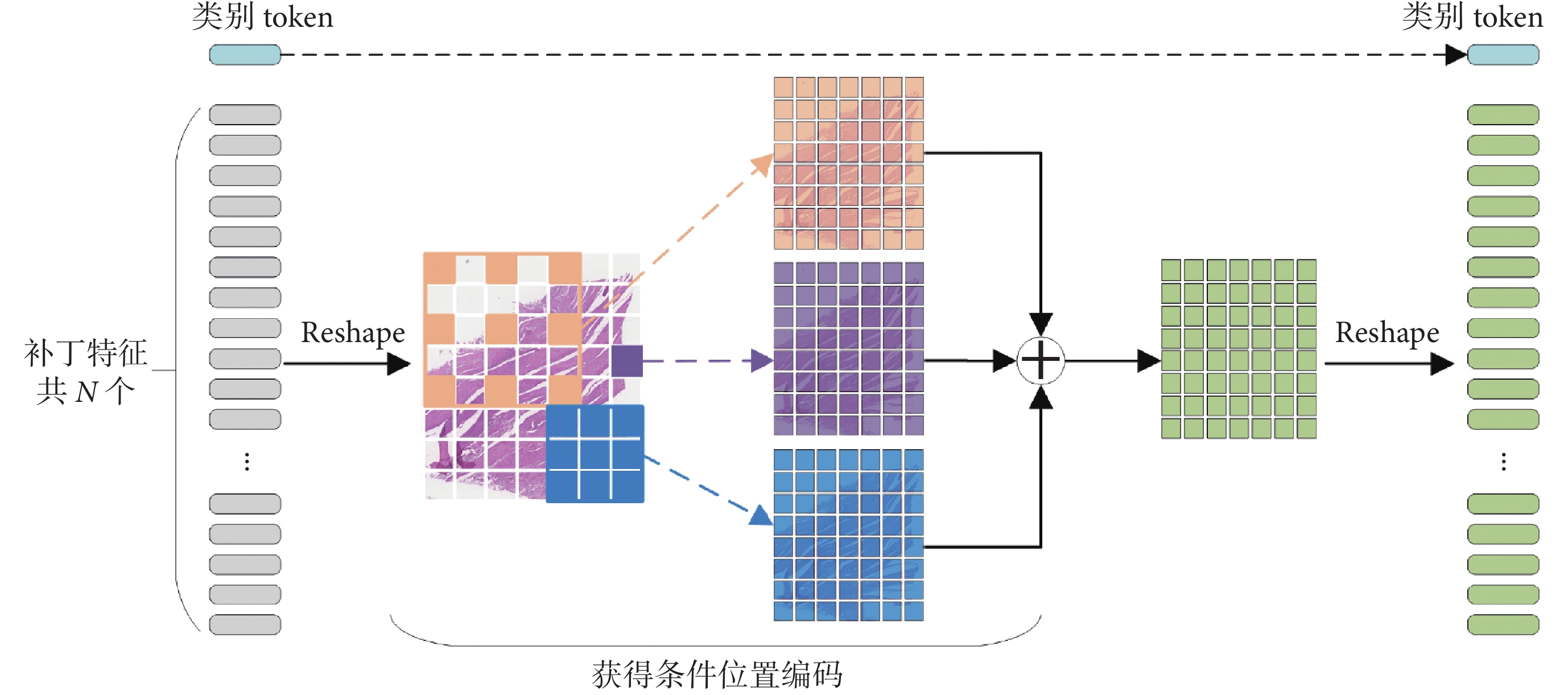 圖5
條件位置編碼
Figure5.
Conditional position encoding
圖5
條件位置編碼
Figure5.
Conditional position encoding
自注意力機制是ViT融合不同補丁圖像之間上下文信息的關鍵,它應用于數字病理圖像的基本原理可以概括如下:首先將提取到的補丁圖像特征 分別與可學習的系數投影矩陣
分別與可學習的系數投影矩陣 、
、 、
、 計算乘積,從而獲得
計算乘積,從而獲得 的映射表示
的映射表示 、
、 、
、 。緊接著,使用
。緊接著,使用 、
、 、
、 計算
計算 與其他輸入特征的相似性。使用
與其他輸入特征的相似性。使用 的映射
的映射 與其他特征的
與其他特征的 映射計算出注意力分數,并將該分數與其他特征的
映射計算出注意力分數,并將該分數與其他特征的 映射相乘并相加,從而得到
映射相乘并相加,從而得到 具有其他嵌入特征上下文信息的注意力輸出
具有其他嵌入特征上下文信息的注意力輸出 。當使用矩陣進行并行計算時,計算過程如式(2)所示:
。當使用矩陣進行并行計算時,計算過程如式(2)所示:
 |
式中, 、
、 、
、 分別是由不同特征的
分別是由不同特征的 、
、 、
、 組成的特征矩陣,
組成的特征矩陣, 是特征向量的維度,作為縮放因子控制點積的尺度。最后,拼接多頭自注意力機制的輸出并映射為最終輸出。多頭注意力機制的公式如式(3)所示:
是特征向量的維度,作為縮放因子控制點積的尺度。最后,拼接多頭自注意力機制的輸出并映射為最終輸出。多頭注意力機制的公式如式(3)所示:
 |
式中 是每個自注意力頭的輸出,
是每個自注意力頭的輸出, 是變換矩陣。
是變換矩陣。
2 實驗結果及分析
2.1 數據集與評價指標
本文數據由云南省腫瘤醫院提供,所有數據均通過倫理審查委員會同意并獲得授權可以使用,數據的患者級標簽由4名病理科主任醫生共同診斷。共使用214張數字病理圖像,其中復發數據108例,未復發數據106例。本文選取5倍和20倍分辨率進行補丁圖像切分,大小為512 pixel×512 pixel,丟棄組織占比不足15%的切片,分別獲得41 610張、60
本文使用準確率(accuracy,ACC)、召回率(recall,REC)、特異度(specificity,SPE)、F1分數(F1 score,F1)、受試者曲線下面積(area under curve,AUC)以及混淆矩陣作為模型的評價指標。各指標的計算方法如式(4)~(7)所示。
 |
 |
 |
 |
其中,TP是真陽性的樣本數,FP是假陽性的樣本數;相應地,TN與FN分別是真陰性與假陰性的樣本數。PRE是查準率,反映真陽性樣本在預測為陽性樣本中的比例。
2.2 實驗環境與參數設定
本文所有實驗采用Python 3.8.8和PyTorch 1.12.1。實驗設備GPU為NVIDIA GeForce RTX  =0.5,為了保證訓練效果,隨機抽選10%的數據進行驗證。在訓練所提方法階段,共迭代200輪,使用AdamW優化器進行迭代優化,初始學習率大小為2e-5,權重衰減設置為1e-5。訓練批次大小為1并引入預熱策略對學習率進行動態調整,在前60個迭代中將學習率由0緩慢增加到指定學習率。
=0.5,為了保證訓練效果,隨機抽選10%的數據進行驗證。在訓練所提方法階段,共迭代200輪,使用AdamW優化器進行迭代優化,初始學習率大小為2e-5,權重衰減設置為1e-5。訓練批次大小為1并引入預熱策略對學習率進行動態調整,在前60個迭代中將學習率由0緩慢增加到指定學習率。
2.3 消融實驗
消融實驗分為使用不同數據的單分支消融實驗和完整方法的整體消融實驗。通過比較表1中的數據可知所提方法的ACC、F1與AUC均為最佳,雖然REC、SPE并沒有獲得最佳值,但預測性能最為均衡。網絡6的REC接近SPE的兩倍,預測結果偏向正類,這表明該模型無法對負類樣本做出有效區分。同樣的,網絡7的SPE得分最高,但對正類樣本的預測可靠性較低。網絡1的ACC相比網絡2降低約8.75%,分析其原因可能是由于固定長度的位置編碼在變長序列數據上無法獲得有效訓練。高分辨率數據過多導致無法進行全局特征學習,因此僅通過卷積神經網絡進行特征提取,通過網絡4和網絡5可以發現簡單的卷積神經網絡在融合數據上的性能仍然優于ImageNet預訓練模型所提取的數據,網絡8也證明了多分辨率數據融合的重要性。
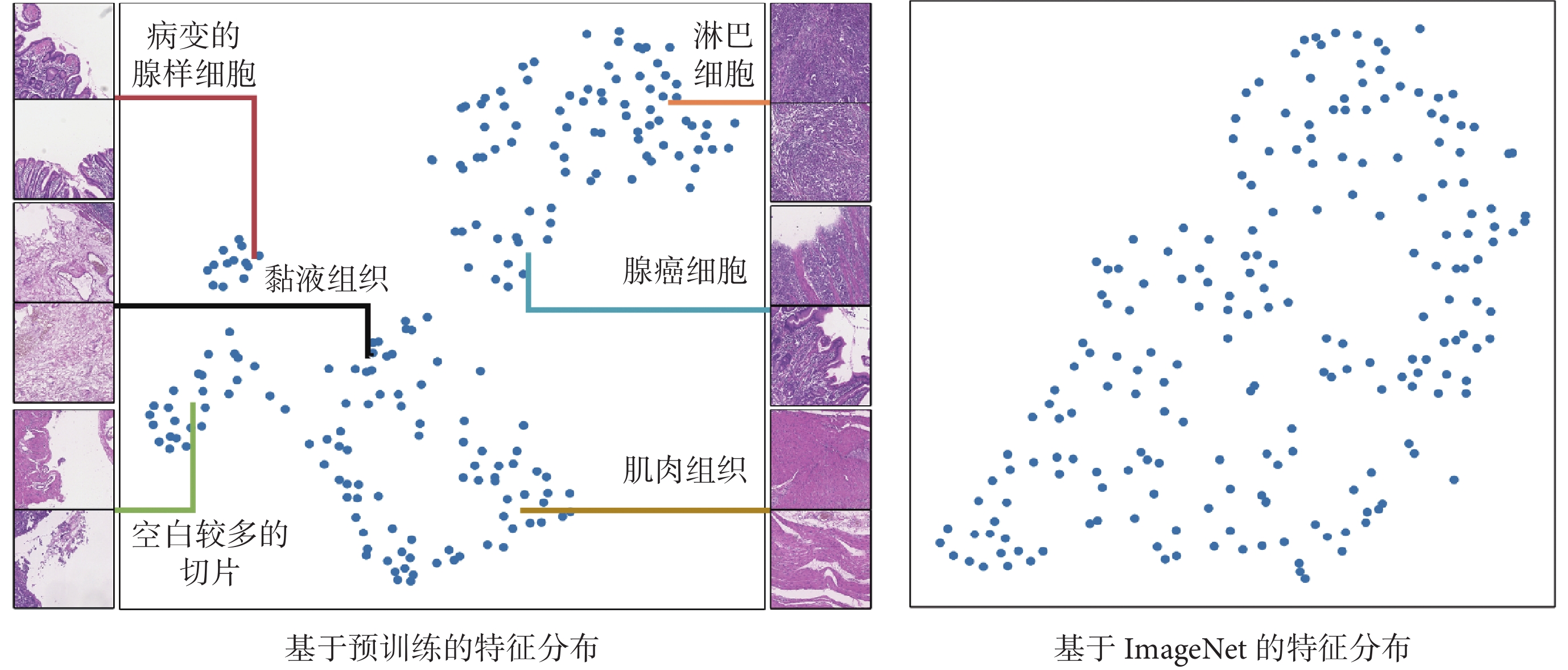
為進一步驗證特征解耦的必要性,分別對預訓練權重和ImageNet權重提取的補丁圖像特征進行可視化,如圖6所示。可以發現基于預訓練提取的特征被較為明確地劃分成了多個不同簇,而基于ImageNet權重提取的特征并沒有出現明顯的簇劃分,即無法進行有效的特征提取。這表明,使用對比學習方法的預訓練模型對于補丁圖像的特征提取能力要優于ImageNet權重。此外,通過查看不同簇所對應的補丁圖像,可以發現在整個數字病理圖像中腫瘤組織遠少于其他組織,這將會影響模型對不同實例的關注程度,但對所提方法而言,雖然正類實例占比較少,但由于特征耦合度低,模型更容易區分出不同組織的特征,結合其補丁圖像自身的上下文信息后,可以有效提高預測結果的準確性。
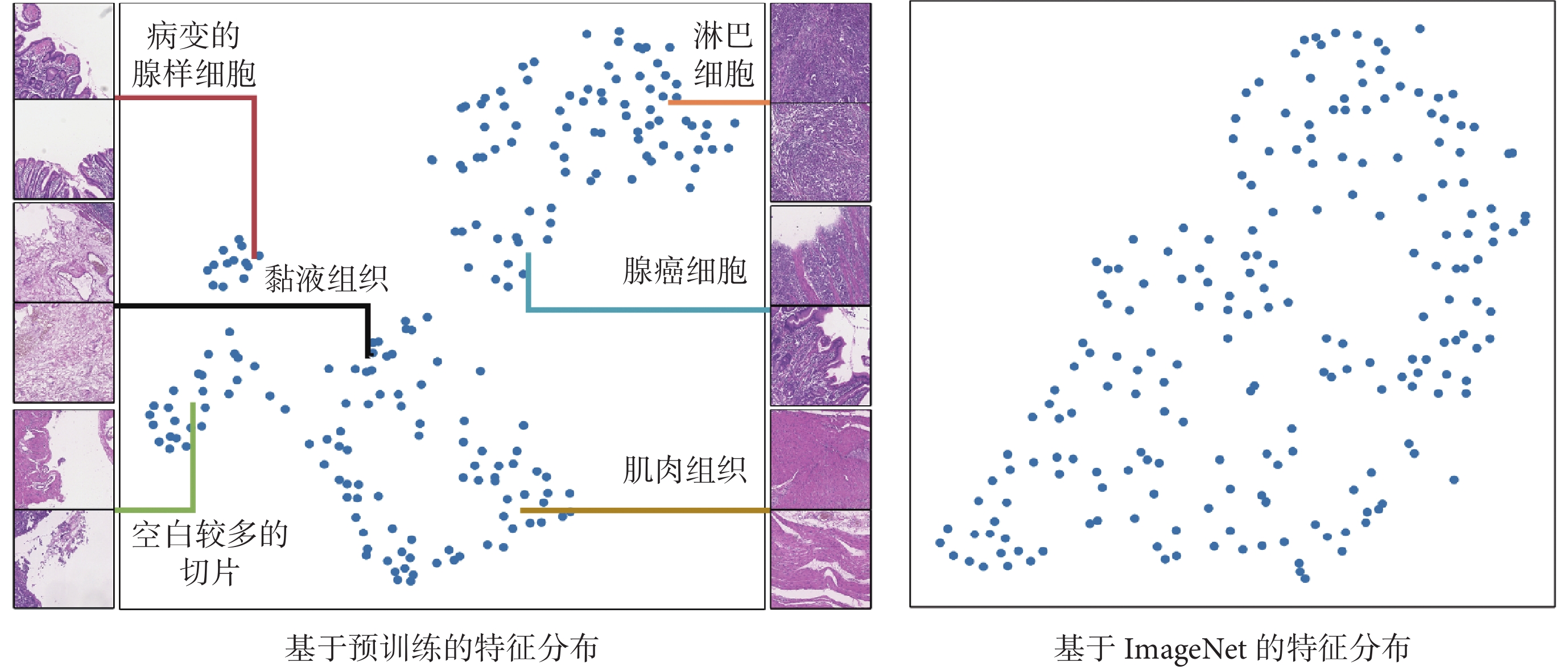 圖6
特征可視化
Figure6.
Feature visualization
圖6
特征可視化
Figure6.
Feature visualization
2.4 對比實驗
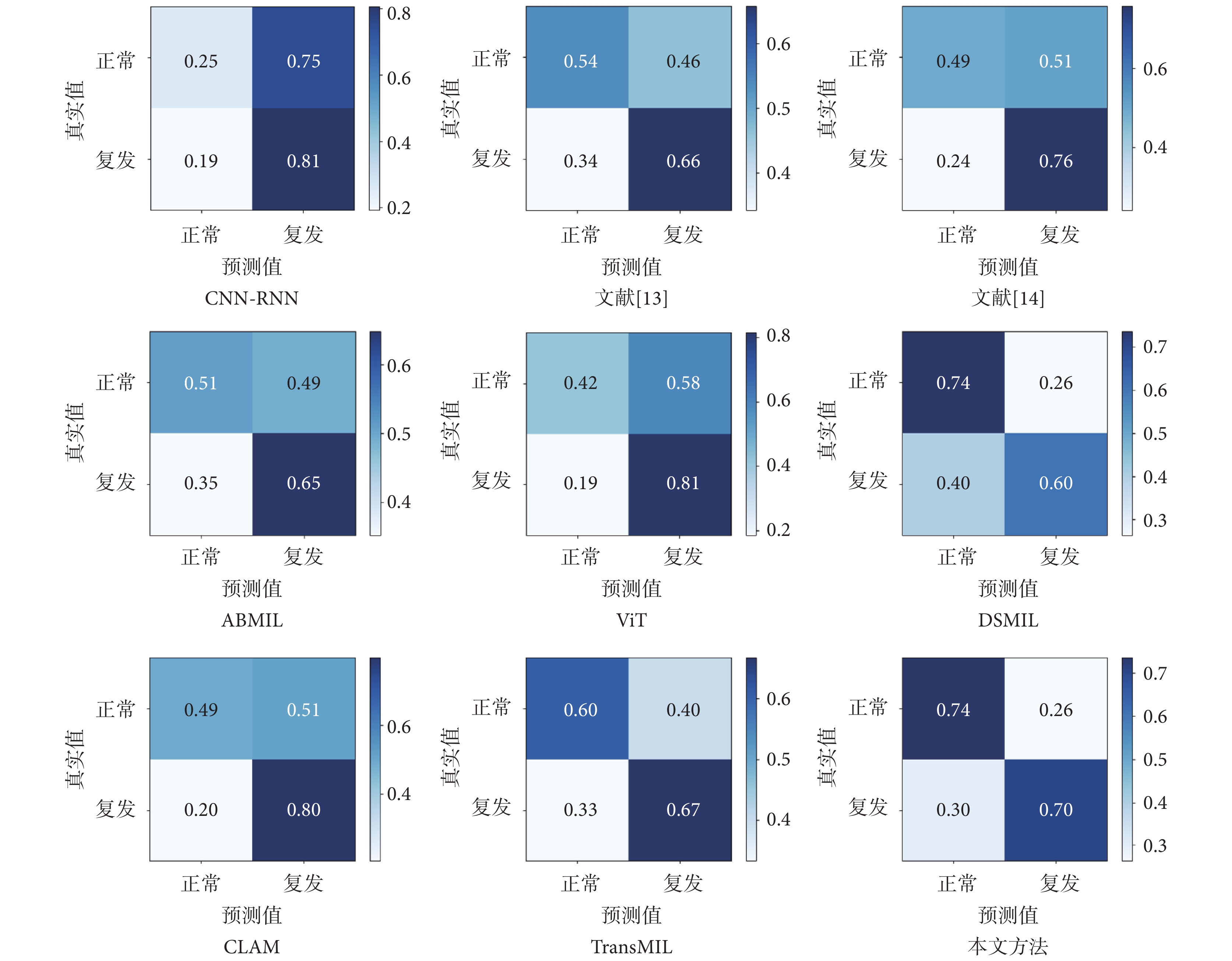
為進一步驗證所提方法的有效性,在相同的數據集上分別進行胃癌復發預測對比實驗,選擇如下對比方法:CNN-RNN[12]、文獻[13]、文獻[14]、ABMIL[15]、ViT[23]、DSMIL[16]、CLAM[17]、TransMIL[18]。實驗結果如表2所示,對應的混淆矩陣如圖7所示。
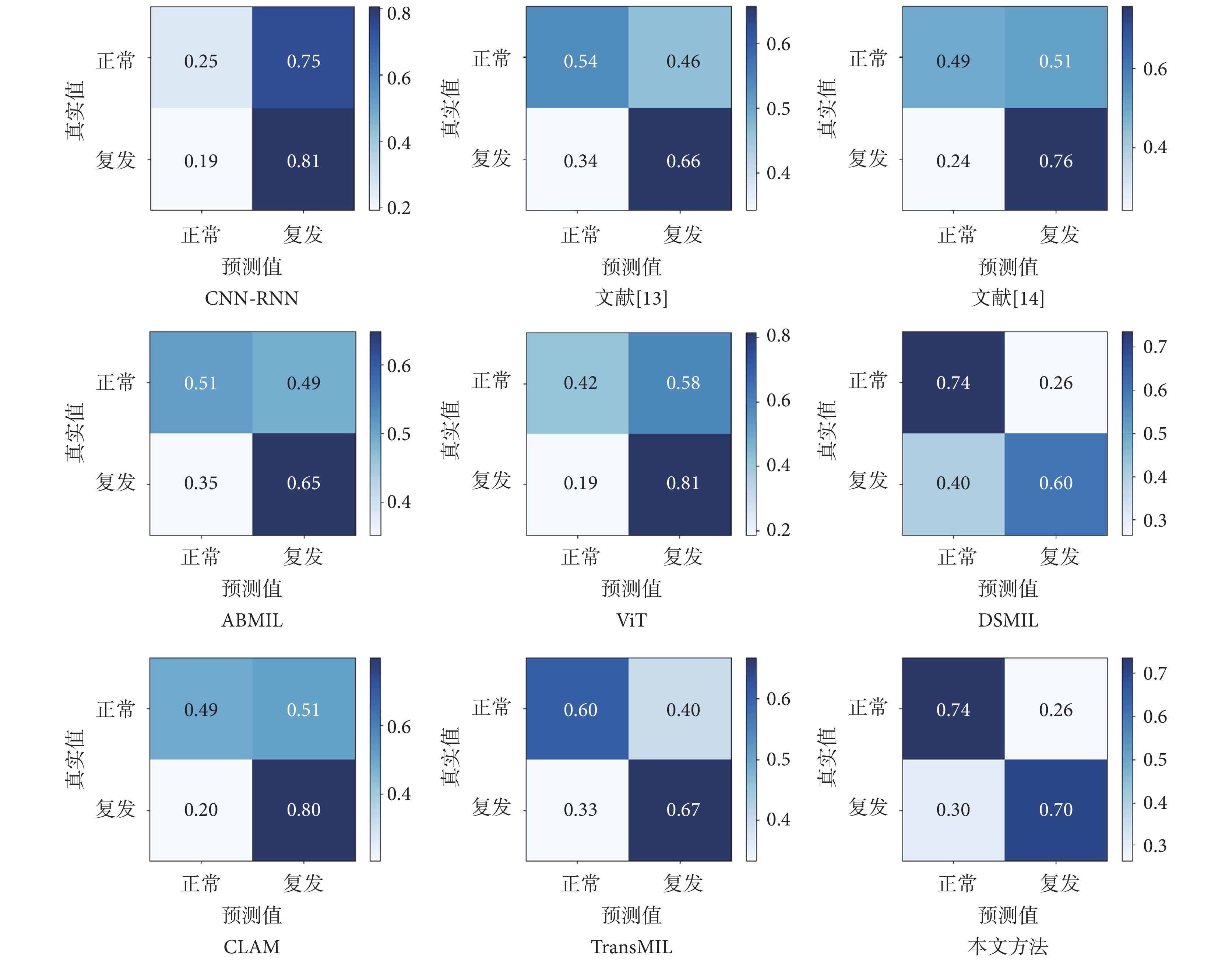 圖7
不同網絡混淆矩陣
Figure7.
Confusion matrices of different network
圖7
不同網絡混淆矩陣
Figure7.
Confusion matrices of different network
分析表2可以得出,本文所提方法的ACC、SPE、F1與AUC均為最優,準確率較TransMIL提升7.6%。在此基礎上,所提方法REC與SPE相差最小,對不同類別的預測最為均衡。這表明基于補丁圖像的特征解耦、多分辨率的特征融合、多尺度鄰域的條件位置編碼,所提方法對胃癌復發有良好的預測效果。而對比方法雖然有效地提高了準確率,但仍受限于無法充分利用病理圖像的多級分辨率和多實例的上下文信息,在性能上還存在一定的提升空間。
通過圖7混淆矩陣,可以發現對比方法的預測結果具有偏向性,對某個類別預測較為準確,但無法有效分辨出另一個類別。雖然TransMIL對預測偏向做出了一定改善,但本文所提方法對正類、負類的預測最為均衡,且性能最佳。
腫瘤細胞更容易與蘇木精結合,因此在病理圖像中通常呈現深紫色或藍紫色,如圖8未復發病理圖像左下方、復發病理圖像右側所示。在臨床診斷過程中,病理醫生重點關注腫瘤細胞聚集區域及其鄰近區域。同樣,深度學習模型在推理預測過程中,也應對這些反映疾病信息的區域進行重點關注,減少對其他信息較少區域的關注。為此,本文通過對模型獲得的注意力分數進行可視化,評估不同模型在圖像上關注的不同區域,圖8給出了不同方法對于示例病理圖像的注意力分數熱力圖,圖中每個矩形區域代表一個補丁圖像,顏色的深淺表示模型對當前補丁圖像的關注程度。通過對比熱力圖可以發現,相較于同類對比方法,本文方法更多地關注了腫瘤細胞聚集區域,在此基礎上又額外關注了少量肌肉、基質等鄰近區域,這些區域作為腫瘤區域的上下文信息,極有可能受到了腫瘤浸潤影響,從而有效提高了預測精度和可解釋性。ABMIL對不同區域實現了差異化關注,但關注區域不夠準確;ViT與CLAM存在對肌肉區域過多關注的問題;DSMIL基于關鍵實例計算其他實例得分,但相近的特征空間降低了模型對其他實例的差異化關注,導致對關鍵實例之外的區域關注程度近似,因此熱力圖也近似;TransMIL需要對注意力分數進行映射變換,因此其熱力圖僅能對一部分的補丁圖像給予差異化關注,雖然在復發病例的預測中降低了對肌肉區域的關注,但也在未復發病例的預測中忽略了大量的細胞聚集區域。
 圖8
不同網絡注意力分數熱力圖
Figure8.
Heat map of different network attention scores
圖8
不同網絡注意力分數熱力圖
Figure8.
Heat map of different network attention scores
3 結論
本文針對胃癌病理圖像復發預測所存在的問題,提出了一種基于多分辨率特征與上下文信息的胃癌復發預測方法。總體方案主要由三部分構成:基于自監督學習的特征解耦模塊,用于增強低分辨率圖像特征;所提的多分辨率特征融合方法,用于病理圖像多分辨率特征的使用;改進的條件位置編碼,為上下文信息的獲取提供了可靠的編碼方式。該方法提高了僅使用患者級標簽預測胃癌復發的性能,并在臨床收集的數據集上驗證了其有效性,這為臨床診斷、制定治療方案提供了有效依據,對于臨床實際應用有一定推動作用。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突
作者貢獻聲明:周泓宇主要負責實驗方案設計、程序編寫和論文撰寫;陶海波主要負責數據收集、醫學背景知識指導以及實驗結果分析;薛飛躍主要負責數據預處理與算法咨詢;王彬負責指導實驗,并對文章進行審閱;金懷平負責總體方案設計、實驗指導、論文撰寫、審閱與修訂;李振輝提供了基金支持、論文審閱和修改意見。
本文代碼倉庫地址:
倫理聲明:本研究通過了云南省腫瘤醫院倫理委員會的審批(批文編號:KYLX2022122)。
0 引言
胃癌是世界范圍內常見癌癥之一,在我國惡性腫瘤中發病率、死亡率均位列前三,每年死亡近29萬例[1-2]。雖然可以通過切除術治療胃癌,但仍有約60%的患者會在術后復發[3],因此復發預測是胃癌預后預測的重要組成部分。病理圖像能夠直接觀察病變組織,在器質性病變診斷中具有不可替代的作用,是醫學界公認的癌癥診斷金標準[4-5]。然而病理圖像具有尺寸巨大、病灶組織形態特征不顯著、病灶組織占比遠小于正常組織、多級分辨率蘊含豐富信息但缺乏細粒度標簽等特點,如圖1所示,這些特點使得臨床診斷過程較為耗時且診斷結果的一致性較低。為此,建立一個基于胃癌病理圖像的復發預測模型,對于胃癌的臨床預后預測具有重要意義。
圖1
無像素級標簽數據和有像素級標簽數據示例
Figure1.
Examples of data without pixel-level labels and data with pixel-level labels
近年來,深度學習技術,如卷積神經網絡和殘差結構[6-7]等方法,被廣泛應用到醫學圖像分析領域。目前,諸多學者將深度學習方法應用于數字病理圖像預后預測領域,以期輔助臨床診斷,并逐漸發展為計算病理學[8-11]。Campanella等[12]引入多實例學習思想,將卷積神經網絡與循環神經網絡相結合,該模型在前列腺癌分類和乳腺癌轉移預測上取得了較好的效果。于凌濤等[13]結合遷移學習,探究了不同得分聚合規則對乳腺癌補丁圖像良惡性分類的影響,該模型在補丁圖像的預測上取得了一定效果。金懷平等[14]引入集成學習思想,通過集成多個異質子模型的結果預測胃癌是否轉移,其預測精度明顯優于僅使用單一模型。Ilse等[15]將多實例問題轉換為包級標簽的伯努利分布問題,提出了一種聚合算子計算不同補丁圖像的得分并獲得預測結果。Li等[16]采用最大池化對多實例學習進行改進,提出了一種基于最高得分實例的池化方式,進一步提高了準確率。Lu等[17]提出了一種基于弱監督深度學習的病理圖像分類方法,通過實例級聚類約束特征空間獲得較好的特征表示。Shao等[18]基于補丁圖像提出了相關性多實例學習框架,并在乳腺癌、腎細胞癌上驗證了所提框架的有效性。
雖然上述研究促進了深度學習在病理圖像預后預測中的應用,但針對胃癌病理圖像的復發預測研究仍然存在以下問題:① 現有研究大多基于像素級的細粒度標簽進行,僅使用患者級標簽的研究仍存在諸多挑戰。② 現有研究對數據的多分辨率重視不足,造成不同分辨率間大量相關信息丟失。③ 補丁圖像作為變長序列,進行位置編碼較為困難,導致不同補丁之間上下文信息利用不足,預測結果的可解釋性較低。
為解決上述問題,本文提出了一種基于多分辨率特征融合上下文信息的模型用于胃癌復發預測。針對僅有患者級標簽的問題,引入對比學習思想對補丁圖像進行特征差異化,從而實現特征解耦,為下游任務提供一個良好的特征表示。針對多分辨率重視不足的問題,提出了一種多分辨率特征融合方法,實現不同分辨率下的特征互補。針對病理圖像位置編碼困難的問題,引入條件位置編碼并進行改進,進一步利用不同實例之間的上下文信息,增強模型的可解釋性。
1 本文方法
基于多分辨率特征融合與上下文信息的胃癌復發預測方法的主要原理結構如圖2所示,共分為三個階段:① 利用自監督學習框架SimCLR對低分辨率下的補丁圖像進行訓練,降低不同類型組織間的耦合度,從而獲得解耦后的增強特征。② 將獲取的低分辨率增強特征與對應高分辨率未增強特征進行融合,獲取數據的多分辨率信息,進一步提升預測的準確率。③ 利用多尺度的局部鄰域進行位置編碼,并將自注意力機制與卷積神經網絡所獲取的上下文特征、局部特征進行融合,通過分類頭獲得最終的預測結果。
圖2
整體框架結構
Figure2.
Overall frame structure
1.1 低分辨率補丁圖像特征解耦
基于病理圖像進行復發預測的研究大多是使用ImageNet數據集[19]的權重進行微調,忽略了自然圖像與病理圖像之間的巨大差異,導致提取到的特征耦合嚴重,預測結果并不理想。考慮到補丁圖像并沒有像素級標簽,因此引入自監督學習思想,在低分辨率補丁圖像上對特征提取器進行預訓練。通過對補丁圖像進行數據增強并差異化不同組織類型間的相似度,從而獲得增強的特征表示。SimCLR作為一種自監督學習模型,能夠學習到無標簽數據的潛在分布,進行有效的特征提取[20],其工作框架如圖2中SimCLR預訓練部分所示。為獲得更高的特征提取能力和提高訓練效率,我們使用EfficientNet V2 Small作為SimCLR的特征提取器[21],對提取到的特征進行投影后使用對比損失函數計算損失。樣本的投影過程可以表示為,對比損失函數的公式如式(1)所示:
|
式中,和分別表示當前樣本增強向量的最終表示,是調節參數,是當前批次中數據的總數。通過以上步驟,有效提高了特征的表示能力,從而避免因數據差異較小導致特征耦合嚴重的問題。
1.2 多分辨率補丁圖像特征融合
數字病理圖像具有金字塔結構,可以在多級分辨率下對圖像進行觀察,低分辨率下觀察組織的大范圍排列分布,高分辨率下分析單個細胞的形態,如圖3所示。為充分利用數字病理圖像不同分辨率下的特征,需要對多級分辨率下的補丁圖像進行特征融合。大多數研究使用圖4中的拼接方式、相加方式,這容易導致補丁圖像不同分辨率間的關聯信息丟失[14-16]。我們希望特征融合操作能夠具有一定的可解釋性,更多地利用已經解耦的優質低分辨率特征影響其對應的高分辨率特征,從而充分利用病理圖像多級分辨率所具有的優點。
圖3
數字病理圖像結構圖
Figure3.
Structure diagram of digital pathology image
圖4
多分辨率特征融合方式
Figure4.
Multi-resolution feature fusion method
為實現上述思想,我們提出了一種特征融合方法,具體原理如圖4中所提融合方式所示。首先獲得單張數字病理圖像的補丁級深度特征,這些特征分別是經過特征解耦的低分辨率特征與直接使用ImageNet權重提取的高分辨率特征。其次,將低分辨率特征向量與其對應的所有高分辨率特征向量求內積,獲得相似度。然后,使用最大最小歸一化對同一個批次獲得的相似度分數進行歸一化處理,為避免丟失分數為0的高分辨率特征,使用softmax函數獲得最終的相似度。最后,用相似度分數與高分辨率原始特征相乘,并將結果與低分辨率特征進行融合,從而使得未解耦的高分辨率特征在一定程度上具有低分辨率特征的解耦性。
1.3 補丁圖像的上下文信息融合
在臨床治療中,病理學家需要反復觀察病理圖像的不同區域,利用不同組間的分布關系判斷腫瘤侵襲以及浸潤的程度,從而制定治療策略。在理論推導上,文獻[18]已經證明關注實例之間的相關性,可以有效降低多實例問題的信息熵,從而提高模型的決策性。
然而,不同數字病理圖像所含有的組織量并不相同,切分出的補丁圖像的數量并不固定,因此不同數字病理圖像裁切出的補丁圖像可以視為變長序列數據。但與自注意力機制搭配使用的傳統位置編碼,僅能對固定長度的序列數據進行位置編碼,無法適用于變長序列數據。文獻[22]基于卷積層提出條件位置編碼,但對數字病理圖像的深度特征進行編碼時存在感受野過小、上下文信息獲取不足等問題。因此結合數字病理圖像的特性,引入多尺度卷積對該方法進行一定的改進:使用1×1普通卷積、3×3普通卷積分別獲取當前補丁圖像特征以及與其聯系緊密的局部鄰域特征;使用擴張率為2的3×3空洞卷積,在不增加計算量的基礎上獲取與當前補丁圖像有一定聯系的局部鄰域特征。融合不同鄰域的特征圖,并將該特征圖重塑為補丁特征輸入到視覺轉換器(Vision Transformer,ViT)中[23],從而結合自注意力機制有效地獲得不同補丁圖像間的上下文信息,編碼過程如圖5所示。
圖5
條件位置編碼
Figure5.
Conditional position encoding
自注意力機制是ViT融合不同補丁圖像之間上下文信息的關鍵,它應用于數字病理圖像的基本原理可以概括如下:首先將提取到的補丁圖像特征分別與可學習的系數投影矩陣、、計算乘積,從而獲得的映射表示、、。緊接著,使用、、計算與其他輸入特征的相似性。使用的映射與其他特征的映射計算出注意力分數,并將該分數與其他特征的映射相乘并相加,從而得到具有其他嵌入特征上下文信息的注意力輸出。當使用矩陣進行并行計算時,計算過程如式(2)所示:
|
式中,、、分別是由不同特征的、、組成的特征矩陣,是特征向量的維度,作為縮放因子控制點積的尺度。最后,拼接多頭自注意力機制的輸出并映射為最終輸出。多頭注意力機制的公式如式(3)所示:
|
式中是每個自注意力頭的輸出,是變換矩陣。
2 實驗結果及分析
2.1 數據集與評價指標
本文數據由云南省腫瘤醫院提供,所有數據均通過倫理審查委員會同意并獲得授權可以使用,數據的患者級標簽由4名病理科主任醫生共同診斷。共使用214張數字病理圖像,其中復發數據108例,未復發數據106例。本文選取5倍和20倍分辨率進行補丁圖像切分,大小為512 pixel×512 pixel,丟棄組織占比不足15%的切片,分別獲得41 610張、60
本文使用準確率(accuracy,ACC)、召回率(recall,REC)、特異度(specificity,SPE)、F1分數(F1 score,F1)、受試者曲線下面積(area under curve,AUC)以及混淆矩陣作為模型的評價指標。各指標的計算方法如式(4)~(7)所示。
|
|
|
|
其中,TP是真陽性的樣本數,FP是假陽性的樣本數;相應地,TN與FN分別是真陰性與假陰性的樣本數。PRE是查準率,反映真陽性樣本在預測為陽性樣本中的比例。
2.2 實驗環境與參數設定
本文所有實驗采用Python 3.8.8和PyTorch 1.12.1。實驗設備GPU為NVIDIA GeForce RTX =0.5,為了保證訓練效果,隨機抽選10%的數據進行驗證。在訓練所提方法階段,共迭代200輪,使用AdamW優化器進行迭代優化,初始學習率大小為2e-5,權重衰減設置為1e-5。訓練批次大小為1并引入預熱策略對學習率進行動態調整,在前60個迭代中將學習率由0緩慢增加到指定學習率。
2.3 消融實驗
消融實驗分為使用不同數據的單分支消融實驗和完整方法的整體消融實驗。通過比較表1中的數據可知所提方法的ACC、F1與AUC均為最佳,雖然REC、SPE并沒有獲得最佳值,但預測性能最為均衡。網絡6的REC接近SPE的兩倍,預測結果偏向正類,這表明該模型無法對負類樣本做出有效區分。同樣的,網絡7的SPE得分最高,但對正類樣本的預測可靠性較低。網絡1的ACC相比網絡2降低約8.75%,分析其原因可能是由于固定長度的位置編碼在變長序列數據上無法獲得有效訓練。高分辨率數據過多導致無法進行全局特征學習,因此僅通過卷積神經網絡進行特征提取,通過網絡4和網絡5可以發現簡單的卷積神經網絡在融合數據上的性能仍然優于ImageNet預訓練模型所提取的數據,網絡8也證明了多分辨率數據融合的重要性。
為進一步驗證特征解耦的必要性,分別對預訓練權重和ImageNet權重提取的補丁圖像特征進行可視化,如圖6所示。可以發現基于預訓練提取的特征被較為明確地劃分成了多個不同簇,而基于ImageNet權重提取的特征并沒有出現明顯的簇劃分,即無法進行有效的特征提取。這表明,使用對比學習方法的預訓練模型對于補丁圖像的特征提取能力要優于ImageNet權重。此外,通過查看不同簇所對應的補丁圖像,可以發現在整個數字病理圖像中腫瘤組織遠少于其他組織,這將會影響模型對不同實例的關注程度,但對所提方法而言,雖然正類實例占比較少,但由于特征耦合度低,模型更容易區分出不同組織的特征,結合其補丁圖像自身的上下文信息后,可以有效提高預測結果的準確性。
圖6
特征可視化
Figure6.
Feature visualization
2.4 對比實驗
為進一步驗證所提方法的有效性,在相同的數據集上分別進行胃癌復發預測對比實驗,選擇如下對比方法:CNN-RNN[12]、文獻[13]、文獻[14]、ABMIL[15]、ViT[23]、DSMIL[16]、CLAM[17]、TransMIL[18]。實驗結果如表2所示,對應的混淆矩陣如圖7所示。
圖7
不同網絡混淆矩陣
Figure7.
Confusion matrices of different network
分析表2可以得出,本文所提方法的ACC、SPE、F1與AUC均為最優,準確率較TransMIL提升7.6%。在此基礎上,所提方法REC與SPE相差最小,對不同類別的預測最為均衡。這表明基于補丁圖像的特征解耦、多分辨率的特征融合、多尺度鄰域的條件位置編碼,所提方法對胃癌復發有良好的預測效果。而對比方法雖然有效地提高了準確率,但仍受限于無法充分利用病理圖像的多級分辨率和多實例的上下文信息,在性能上還存在一定的提升空間。
通過圖7混淆矩陣,可以發現對比方法的預測結果具有偏向性,對某個類別預測較為準確,但無法有效分辨出另一個類別。雖然TransMIL對預測偏向做出了一定改善,但本文所提方法對正類、負類的預測最為均衡,且性能最佳。
腫瘤細胞更容易與蘇木精結合,因此在病理圖像中通常呈現深紫色或藍紫色,如圖8未復發病理圖像左下方、復發病理圖像右側所示。在臨床診斷過程中,病理醫生重點關注腫瘤細胞聚集區域及其鄰近區域。同樣,深度學習模型在推理預測過程中,也應對這些反映疾病信息的區域進行重點關注,減少對其他信息較少區域的關注。為此,本文通過對模型獲得的注意力分數進行可視化,評估不同模型在圖像上關注的不同區域,圖8給出了不同方法對于示例病理圖像的注意力分數熱力圖,圖中每個矩形區域代表一個補丁圖像,顏色的深淺表示模型對當前補丁圖像的關注程度。通過對比熱力圖可以發現,相較于同類對比方法,本文方法更多地關注了腫瘤細胞聚集區域,在此基礎上又額外關注了少量肌肉、基質等鄰近區域,這些區域作為腫瘤區域的上下文信息,極有可能受到了腫瘤浸潤影響,從而有效提高了預測精度和可解釋性。ABMIL對不同區域實現了差異化關注,但關注區域不夠準確;ViT與CLAM存在對肌肉區域過多關注的問題;DSMIL基于關鍵實例計算其他實例得分,但相近的特征空間降低了模型對其他實例的差異化關注,導致對關鍵實例之外的區域關注程度近似,因此熱力圖也近似;TransMIL需要對注意力分數進行映射變換,因此其熱力圖僅能對一部分的補丁圖像給予差異化關注,雖然在復發病例的預測中降低了對肌肉區域的關注,但也在未復發病例的預測中忽略了大量的細胞聚集區域。
圖8
不同網絡注意力分數熱力圖
Figure8.
Heat map of different network attention scores
3 結論
本文針對胃癌病理圖像復發預測所存在的問題,提出了一種基于多分辨率特征與上下文信息的胃癌復發預測方法。總體方案主要由三部分構成:基于自監督學習的特征解耦模塊,用于增強低分辨率圖像特征;所提的多分辨率特征融合方法,用于病理圖像多分辨率特征的使用;改進的條件位置編碼,為上下文信息的獲取提供了可靠的編碼方式。該方法提高了僅使用患者級標簽預測胃癌復發的性能,并在臨床收集的數據集上驗證了其有效性,這為臨床診斷、制定治療方案提供了有效依據,對于臨床實際應用有一定推動作用。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突
作者貢獻聲明:周泓宇主要負責實驗方案設計、程序編寫和論文撰寫;陶海波主要負責數據收集、醫學背景知識指導以及實驗結果分析;薛飛躍主要負責數據預處理與算法咨詢;王彬負責指導實驗,并對文章進行審閱;金懷平負責總體方案設計、實驗指導、論文撰寫、審閱與修訂;李振輝提供了基金支持、論文審閱和修改意見。
本文代碼倉庫地址:
倫理聲明:本研究通過了云南省腫瘤醫院倫理委員會的審批(批文編號:KYLX2022122)。