主動脈夾層分割中存在主動脈夾層與周圍器官和血管的對比度低、夾層形態差異大以及背景噪聲大等問題。針對以上問題,本文提出一種基于強化學習的B型主動脈夾層定位方法,借助兩階段分割模型,使用深度強化學習執行第一階段的主動脈定位任務,保證定位目標的完整性;在第二階段,使用第一階段的粗分割結果作為輸入,得到精細的分割結果。為了提高一階段分割結果的召回率(Recall),使定位結果更完整地包含分割目標,本文設計了基于Recall變化方向的強化學習獎勵函數;同時,將定位窗口與視野窗口分離,減少分割目標缺失的情況。本文選取Unet、TransUnet、SwinUnet以及MT-Unet作為基準分割模型,通過實驗驗證,本文的兩階段分割流程結果中多數指標均優于基準結果,其中Dice指標分別提高1.34%、0.89%、27.66%和7.37%。綜上,將本文的B型夾層定位方法加入分割流程,最終的分割精度較基準模型結果有所提升,對于分割效果較差的模型提升效果更顯著。
引用本文: 曾安, 林先揚, 趙靖亮, 潘丹, 楊寶瑤, 劉鑫. 基于強化學習的B型主動脈夾層定位方法. 生物醫學工程學雜志, 2024, 41(5): 878-885. doi: 10.7507/1001-5515.202309047 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
0 引言
主動脈夾層(aortic dissection,AD)是一種危險的心血管疾病[1-2],是由內膜撕裂或者腔內出血和血腫形成引起的內膜穿孔,使主動脈腔內的血液從主動脈內膜撕裂處進入主動脈中膜,從而形成主動脈壁的真假兩腔分離的狀態。Stanford分型根據是否累及升主動脈,將夾層分為AB兩類,其中所有未累及升主動脈的夾層為B型主動脈夾層。在主動脈夾層的診斷和治療中,手動分割主動脈夾層區域是一項繁瑣、費時的任務,人的主觀性會影響診斷準確性和治療效果。即使是在同一部位,主動脈撕裂內膜的方向、主動脈橫截面的形狀位置以及主動脈弓的形態學屬性均有一定差異,再加上主動脈內部的血液流速和血管壁的厚度等因素的影響,使得主動脈夾層圖像分割[3]具有挑戰性。
基于主動脈夾層的傳統分割方法,已經提出了多種策略,包括Hough變換法[4]、基于空間連續性先驗模型法[5]、多尺度小波分析法[6]以及基于圖像去噪的方法[7]等。這些方法在小規模數據集上展現了良好的分割效果,然而,它們都依賴于手動選擇初始特征或者過多的人工處理,從而限制了其準確性和擴展性。因此,需要進一步研究和發展更準確、自動化且可靠的主動脈夾層分割方法。目前深度學習技術是應用于醫學圖像分割的主流方法。
主動脈圖像存在各種噪聲和偽影,如果直接作為深度學習網絡的輸入,網絡需要分辨非分割目標信息,分散了對分割目標的專注學習,可能會減少分割細節的精確度。對于一些魯棒性較差的分割網絡,影響更為顯著。針對以上問題,Zhu等[8]提出了由粗到細的兩階段分割模型,兩階段方法可以有效減少輸入圖像的噪聲和干擾信號。文獻[8]使用深度學習提取感興趣區域,文獻[9]在此基礎上增加了形態學處理方法,但這些方法在粗分割階段缺乏有效的糾錯機制,使得模型的定位結果往往不可靠,會影響最終的分割效果。
而深度強化學習通過自主學習和決策,可以適應各種復雜環境和任務、處理高維數據,可以解決基于深度學習帶來的粗分割問題。Man等[10]在粗分割階段使用強化學習實現自主定位,提高了分割目標的定位效果。但文獻[10]使用基于自然圖像預訓練的VGG[11]網絡進行特征提取,這種方式不能很好地利用醫學圖像特有的特征。同時它的獎勵函數使用了強化學習在目標檢測應用中的常規獎勵函數[12],不能很好地適配粗分割階段的任務目標,定位結果存在一定的目標缺失情況,Recall尚有較大的提升空間。針對上述問題,受文獻[10]的啟發,本文提出針對B型主動脈夾層圖像的兩階段分割流程。首先,為了豐富醫學切片圖像的特征信息,本文將基于Resnet[13]的修改網絡作為特征提取網絡,對主動脈切片數據進行特征提取;其次,使用深度強化學習訓練自適應環境定位的智能體,減少主動脈夾層形態差異帶來的影響,保證定位窗口盡可能包含分割目標的同時,減小窗口的尺寸,去除更多的冗余信息;最后,選取Unet[14]、TransUnet[15]、SwinUnet[16]、MT-Unet[17]作為細分割階段模型,將經過粗分割的切片結果集合作為基準分割網絡的輸入,得到最終的分割結果,進一步提高基準分割網絡的分割精度。
1 方法
1.1 整體流程
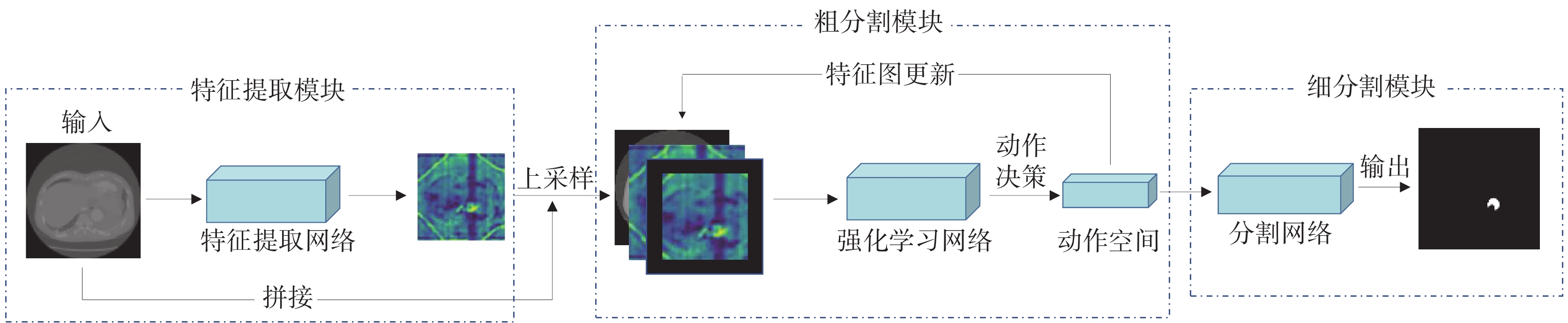
本文提出基于強化學習的B型主動脈夾層兩階段分割方法,整體流程如圖1所示。本方法可分為特征提取、粗分割和細分割三個階段。首先,對主動脈夾層數據進行特征提取,獲取醫學圖像相關特征,與原圖像組合得到強化學習網絡的初始輸入。其次,使用強化學習探索每個樣本的粗分割定位序列,通過獎勵信號驅動網絡更新,將訓練結束的強化學習網絡應用于所有主動脈夾層數據得到粗分割結果集合。最后,將粗分割結果作為分割網絡的輸入得到細分割結果。
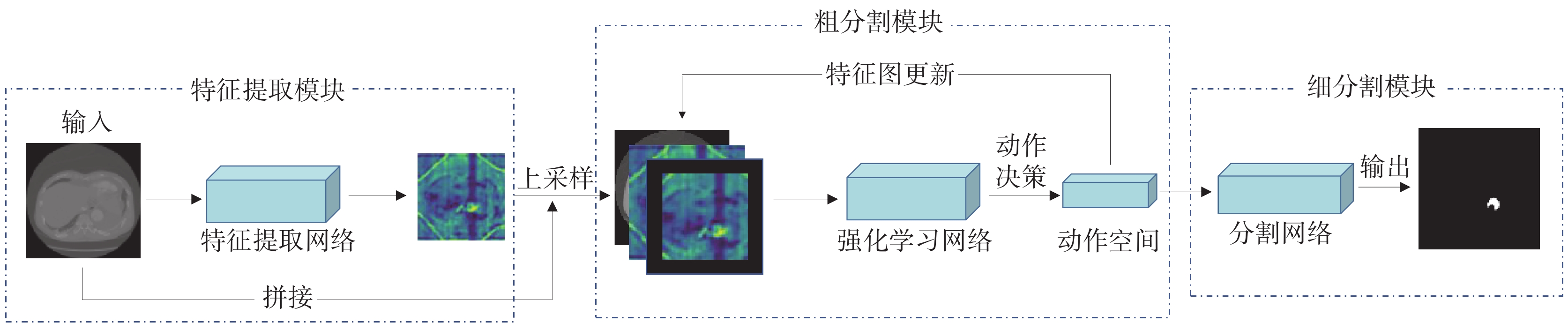 圖1
B型主動脈夾層分割方法
Figure1.
Segmentation method for type B aortic dissection
圖1
B型主動脈夾層分割方法
Figure1.
Segmentation method for type B aortic dissection
1.2 強化學習介紹
強化學習[18]是機器學習中的一種重要分支,強化學習的核心要素是狀態、動作和獎勵。智能體通過與環境的交互,根據采取不同行為帶來的即時獎勵進行狀態轉移,從中學習到適用當前環境與對應目標任務的最佳行為策略,與深度學習的結合使強化學習能夠處理復雜的高維狀態空間。深度Q網絡(deep Q-network,DQN)[19]是常用的深度強化學習模型之一,DQN通過Bellman方程 [20]預測動作價值Q,對動作選擇策略進行迭代更新。隨著強化學習的發展,產生了多種提高DQN性能的技術,例如Double DQN[21]、Dueling DQN[22]和循環DQN[23]等。
DQN普遍存在估計Q值過高的問題,而Double DQN可以有效緩解DQN的估計偏差。Double DQN使用兩個結構相同的神經網絡:評估網絡 和目標網絡
和目標網絡 ,前者用于預測最佳的動作,后者用于評估所選動作的Q值。目標Q值的計算方法以及Double DQN的損失函數如式(1)、式(2)所示。
,前者用于預測最佳的動作,后者用于評估所選動作的Q值。目標Q值的計算方法以及Double DQN的損失函數如式(1)、式(2)所示。
 '/> '/> |
 |
1.3 特征提取模塊
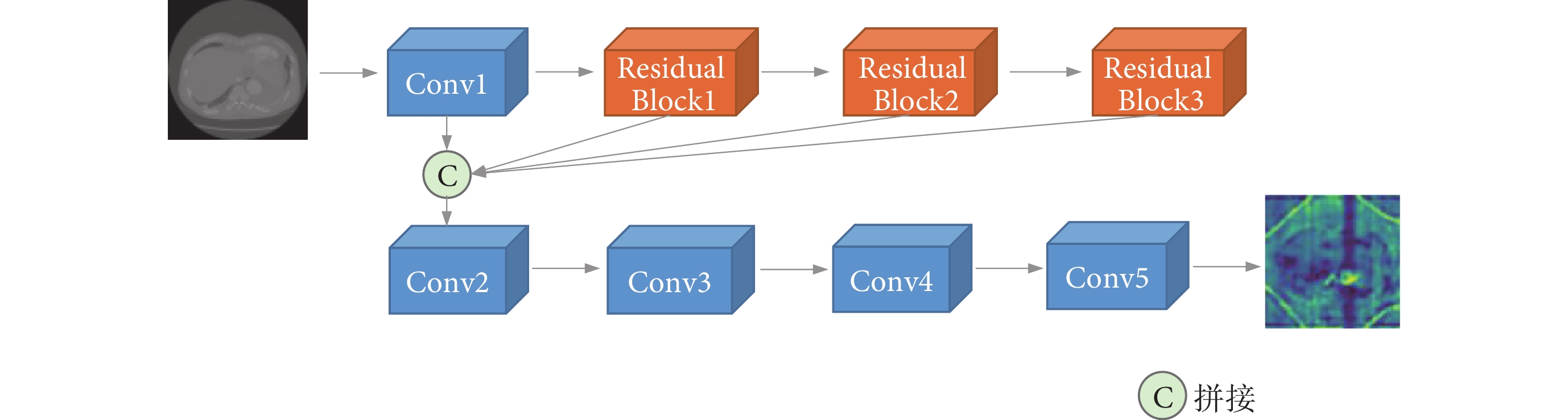
特征提取網絡結構如圖2所示。由于單通道的醫學切片特征信息較少,直接使用原始切片訓練強化學習網絡容易造成過擬合,常見做法是將切片與相鄰切片組合作為訓練樣本,這種方式雖然豐富了切片的信息,但同時加入了更多的冗余信息。為了豐富切片的特征信息,同時減少引入更多的冗余信息,影響網絡的訓練,本文針對B型主動脈夾層數據從零訓練特征提取網絡。特征提取網絡結構參考文獻[24],網絡由若干個殘差塊以及卷積層組成,將多個中間殘差塊的結果進行拼接,獲取不同維度的特征信息,最終輸出單通道的特征圖像。在訓練過程中,將網絡的輸出結果與下采樣后的B型夾層掩碼進行展平匹配,使它能夠專注B型主動脈夾層的關鍵特征,生成凸顯夾層特征的特征圖像,最后將原圖像與特征圖像組合作為強化學習網絡的輸入。特征圖像能夠為強化學習網絡提供更多的目標特征信息,同時減少冗余信息的引入,而原圖像的作用是補充特征圖像中可能丟失的其他關鍵特征信息,進一步提高粗分割階段的定位準確性。
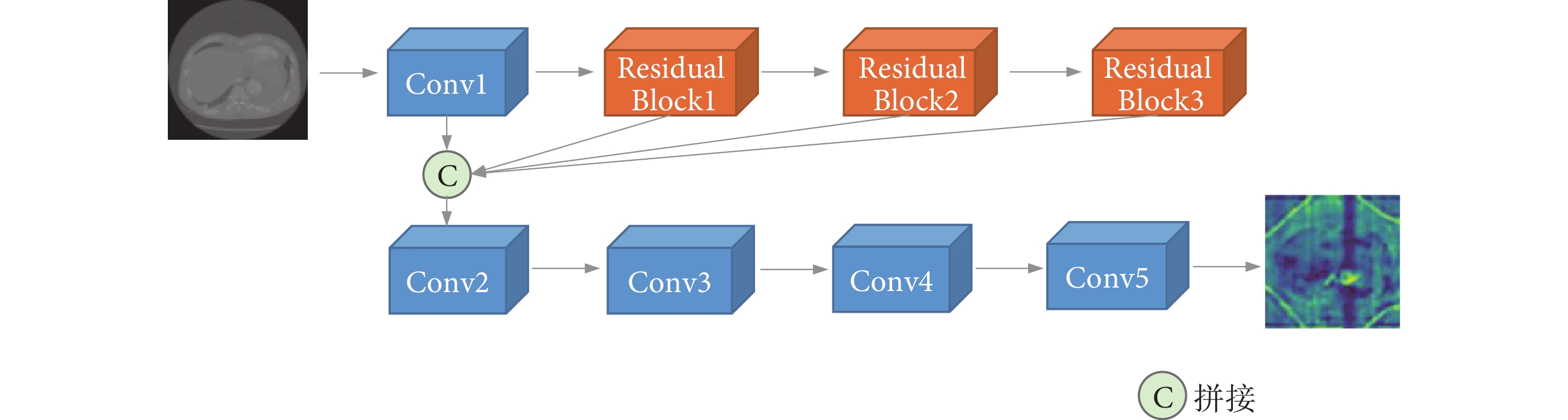 圖2
特征提取網絡結構
Figure2.
Feature extraction network structure
圖2
特征提取網絡結構
Figure2.
Feature extraction network structure
1.4 粗分割模塊
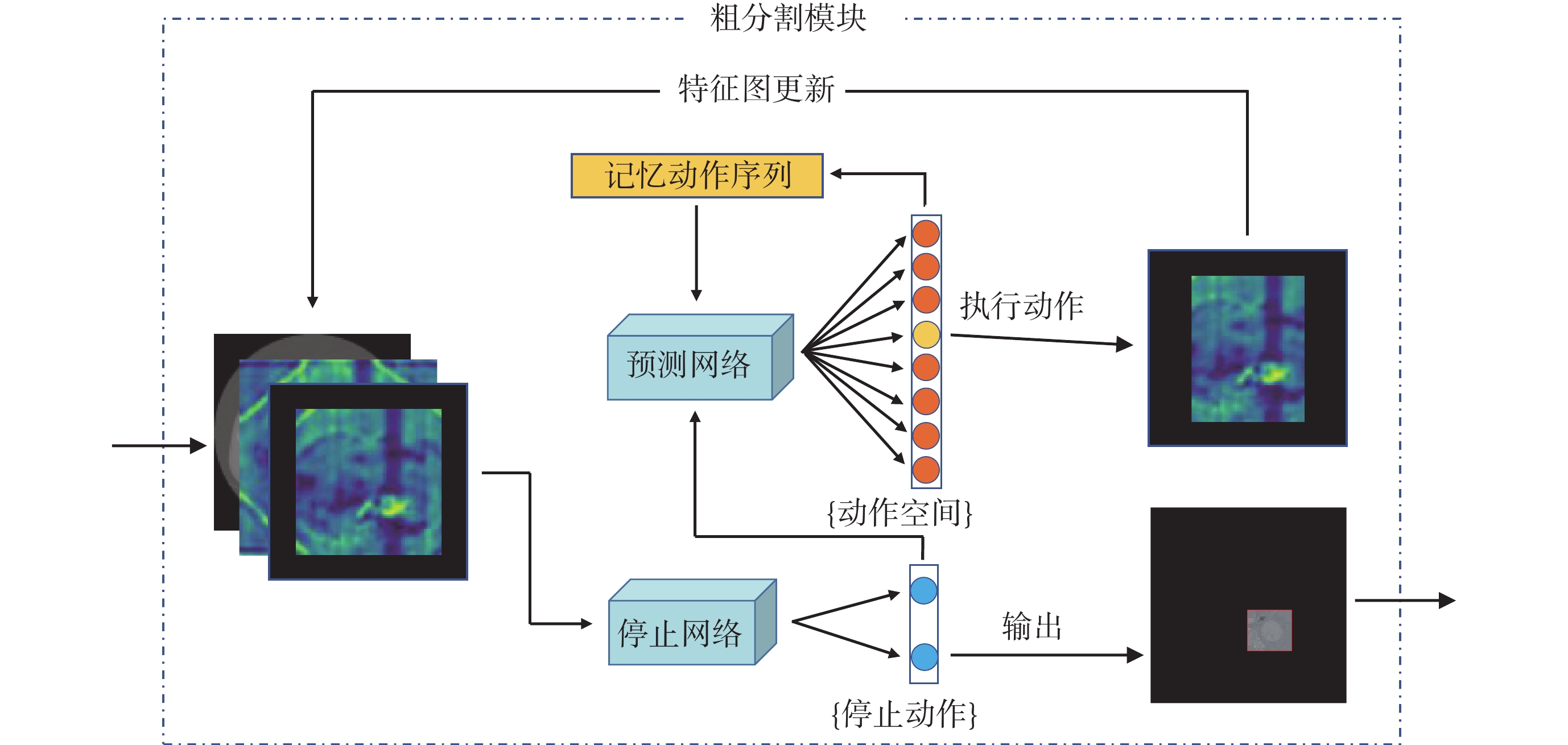
粗分割模塊的具體結構如圖3所示。本文將粗分割階段的定位問題轉換為馬爾可夫決策過程(Markov decision process,MDP),定義粗分割任務下智能體的狀態、動作以及獎勵要素。模塊首先將切片狀態輸入停止網絡,判斷定位序列是否結束;如果選擇繼續執行,則重新將狀態輸入預測網絡進行動作決策,之后在初始狀態圖像上執行相應動作的裁剪操作,實現一次狀態轉移,循環執行多次直至序列結束。
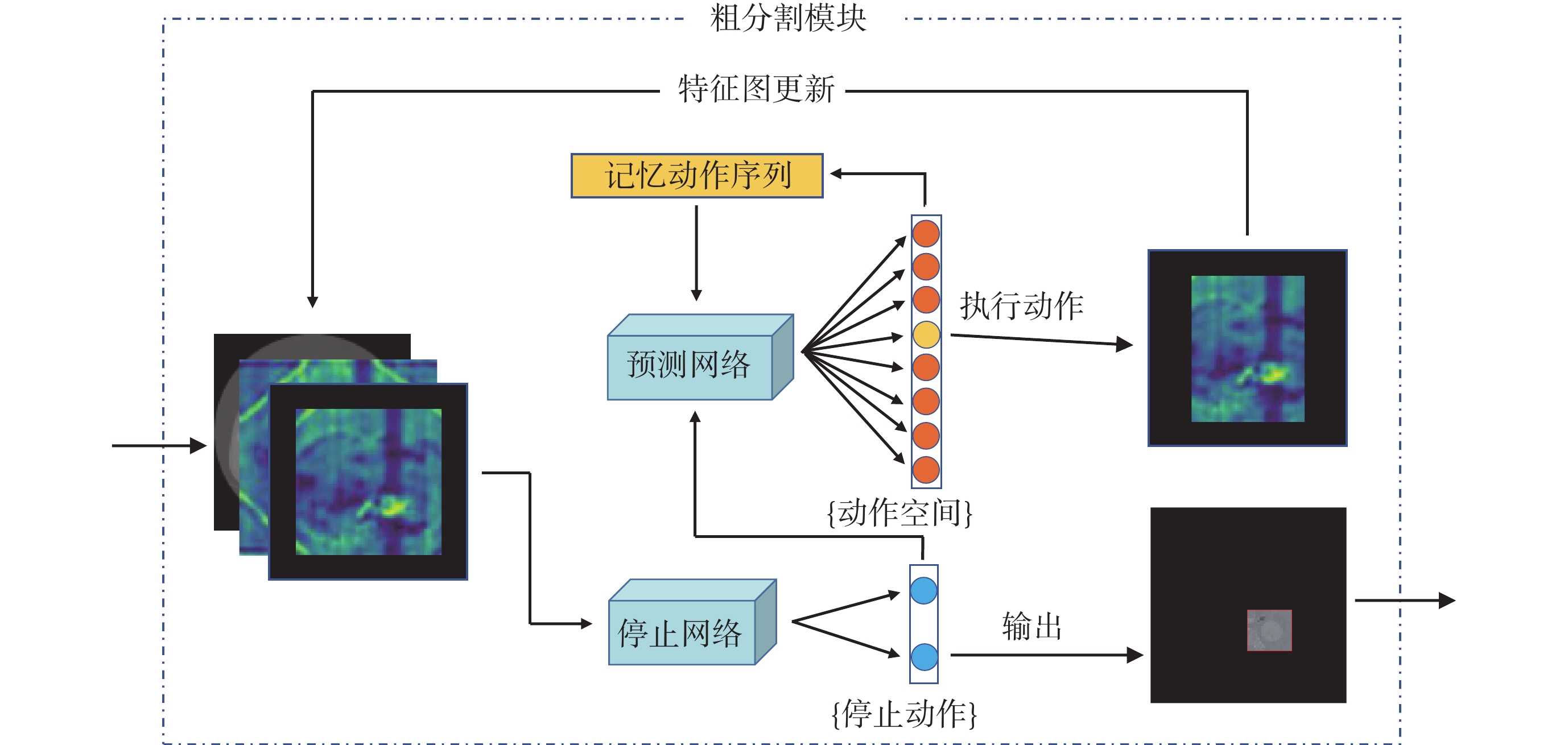 圖3
粗分割模塊結構
Figure3.
Coarse segmentation module structure
圖3
粗分割模塊結構
Figure3.
Coarse segmentation module structure
1.4.1 深度強化學習模型
為了實現最佳定位策略,本文采用Double DQN作為粗分割階段的定位算法,強化學習網絡使用基于殘差塊的網絡結構,由若干個殘差塊以及全連接層組成,整體結構如圖4所示。將記憶動作序列與卷積層結果拼接,作為全連接層的輸入,最后輸出多個動作的估計Q值。
 圖4
預測網絡結構
Figure4.
Predicting network structure
圖4
預測網絡結構
Figure4.
Predicting network structure
1.4.2 狀態設計
本文的強化學習狀態由當前定位窗口內容與記憶動作向量組成。首先通過特征提取網絡得到夾層切片的特征圖像,然后組合原始切片與兩個相同特征圖像得到一個3通道的圖像數據,作為切片的初始狀態。同時增加記憶向量作為預測網絡輸入的一部分,記憶向量是一個二進制向量,記錄單次狀態轉移之前最近的10次歷史動作。
1.4.3 窗口分離
對于定位任務,常見的狀態轉移方法是使用變換后的新窗口對初始狀態進行裁剪,將窗口內容作為新的狀態數據,其余部分置0。但這種裁剪方式存在以下問題: ① 當定位窗口的尺寸逐漸減小,通過窗口裁剪得到新狀態的有效內容也會逐步減少,對于小目標定位任務,該問題更加突出。為了解決在后序階段狀態的有效數據占比小的問題,在狀態轉移的過程中,本文只對狀態數據的其中一個特征圖像進行窗口裁剪,保持原始切片和另一個特征切片內容不變。② 當窗口只包含少部分目標內容,該裁剪方式會使狀態丟失大部分目標信息。智能體難以從少量的特征信息中定位目標的方向位置,增加了完全丟失目標的可能性,進而定位失敗。為了避免發生窗口嚴重缺失的問題,本文將單一窗口分離出定位窗口和視野窗口。視野窗口是在定位窗口的基礎上增加若干個像素寬度得到的新窗口,在狀態轉移的過程中使用視野窗口的內容作為狀態數據,但在評價定位效果時使用定位窗口。當定位窗口已經發生缺失,視野窗口的存在可以彌補一部分分割目標的特征數據,進而減少定位失敗的情況。
在定位窗口的最后調整階段,此時窗口的寬高長度較短,窗口執行動作后的變化幅度小,重復出現相似程度較高狀態的可能性較大,即窗口容易出現在曾經定位過的位置。對于相似的狀態,智能體可能會提供同樣的動作建議,導致之后的動作序列陷入某種搜索軌跡循環。循環序列會占用有限的執行步數,在一定程度上會影響最后的定位結果。為了避免重復出現相似狀態,本文對視野窗口的尺寸進行隨機化設置,在一定范圍內隨機選取視野窗口的擴張大小,盡可能增大每個狀態之間的差異程度。
1.4.4 動作設計
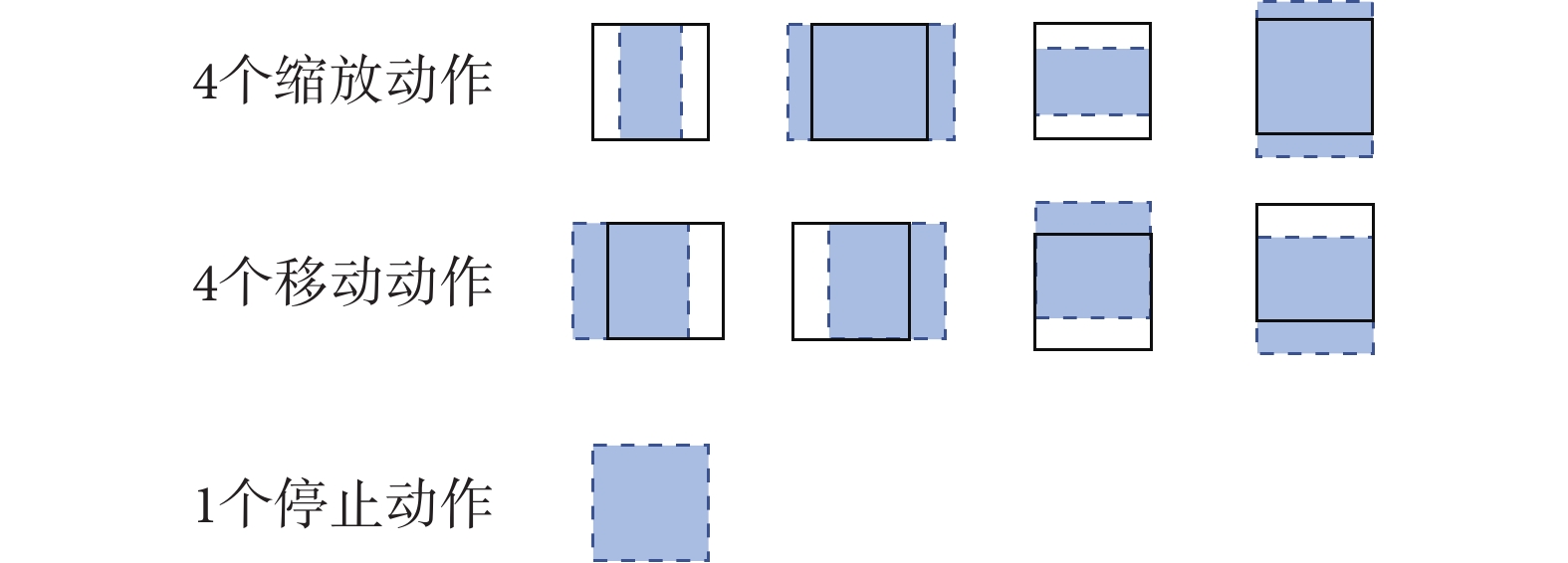
本文的強化網絡動作集合由8個窗口的變換操作和一個停止操作組成。如圖5所示,變換操作分為4個移動動作和4個縮放動作。文獻[10]采取的縮放操作始終保持窗口的形狀為正方形,對于一些長寬比例差異較大的主動脈夾層數據,該方案會引入較多的冗余信息,不適用于目標形態不統一的任務,因此本文采用自由程度更高的縮放操作。本文的縮放操作可以對包圍框的不同方向分別進行縮放,同時在縮放時保持窗口的中心位置不變,有助于進一步縮小定位范圍。縮放和移動動作的初始變換比例都是對應方向上窗口邊長的1/5。為了使窗口在最后的調整階段能進行更細微的調整,在執行一定步數之后會進一步減小變換比例。當智能體選擇了停止動作或者搜索步數達到預設的最大值,表示一個定位序列的結束。
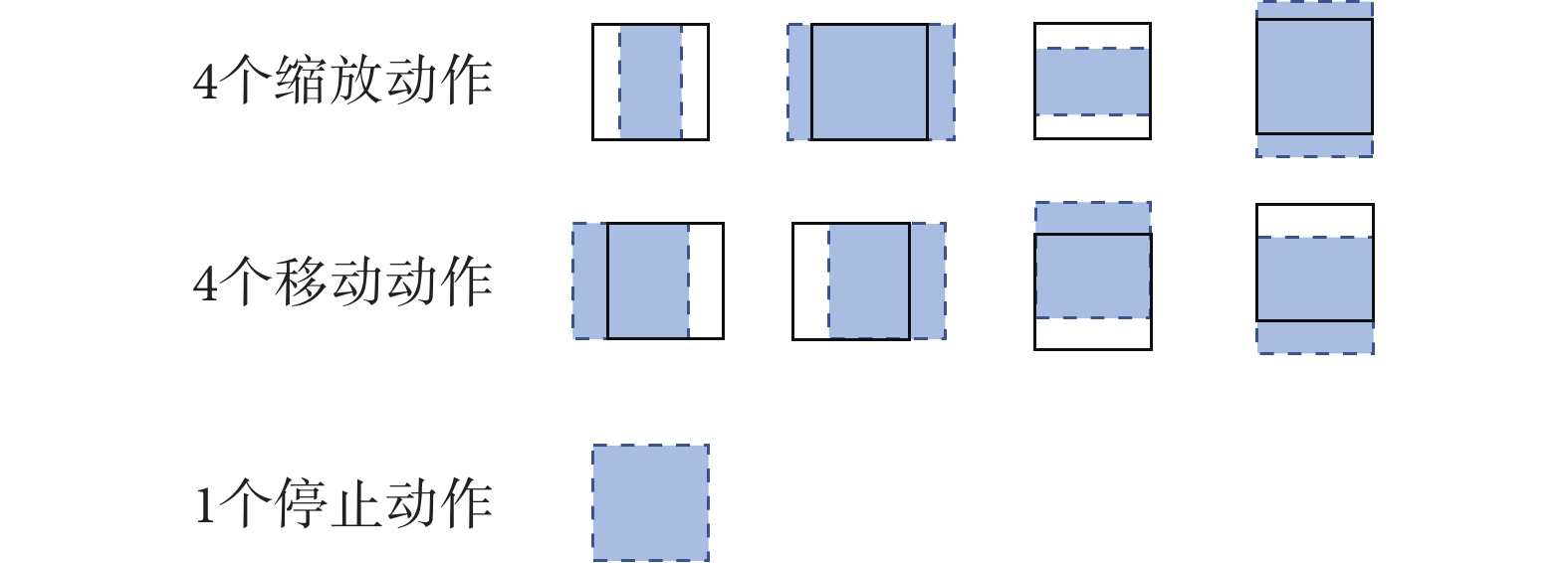 圖5
動作集合
Figure5.
Action collection
圖5
動作集合
Figure5.
Action collection
1.4.5 獎勵函數設計
即時獎勵用于評估智能體選擇的動作好壞,智能體的目標就是最大化累計獎勵。對于目標檢測問題,一般采用的評估指標是IoU,IoU是用于衡量兩個矩形框重合程度的重要指標。在粗分割階段需要特別注重Recall指標,Recall描述了窗口內包含目標對象的完整程度。其具體計算公式如式(3)、式(4)所示,其中g表示分割目標的最小包圍框,w表示定位窗口。
 |
 |
式(5)和式(6)分別表示前后狀態的Recall和IoU指標變化。基于強化學習的目標檢測問題[12]一般采取如式(7)所示的單步獎勵函數,其中 表示狀態s執行動作
表示狀態s執行動作 得到的即時獎勵,
得到的即時獎勵, 表示除停止動作以外的變換動作,w表示執行動作前的窗口,
表示除停止動作以外的變換動作,w表示執行動作前的窗口, 表示執行動作后的窗口。
表示執行動作后的窗口。
 '/> '/> |
 '/> '/> |
 '/> '/> |
在該獎勵函數的驅動下,即使定位窗口缺失一部分目標,智能體也會優先選擇增大IoU的動作。但由于IoU和Recall的變化方向不完全一致,因此可能會出現IoU增加而Recall不變甚至下降的情況,因此使用該獎勵函數難以保證定位窗口較完整地包含分割目標。針對粗分割任務,需要優先保證相鄰狀態的Recall保持遞增或維持最大值,以上兩種情況的獎勵分數應該最大。本文設計的獎勵函數如式(8)所示。
 |
本文的獎勵函數分為兩部分,常規動作獎勵以及移動懲罰項。常規動作獎勵如式(9)所示,整體的取值范圍為[?2,2],該獎勵函數在優先考慮Recall變化的情況下根據IoU的變化給予相應的分值。滿足 的獎勵為
的獎勵為 + 1 ,其中同時增加IoU與Recall的動作獎勵最大;
+ 1 ,其中同時增加IoU與Recall的動作獎勵最大; 的獎勵函數為
的獎勵函數為 ,為了提高維持完整包圍目標的動作優先級,如果此時
,為了提高維持完整包圍目標的動作優先級,如果此時 ,本文額外將獎勵結果翻倍,即獎勵為
,本文額外將獎勵結果翻倍,即獎勵為 ;其他條件不符合粗分割任務的要求,因此直接提供負值獎勵。
;其他條件不符合粗分割任務的要求,因此直接提供負值獎勵。
 '/> '/> |
移動懲罰項用于限制執行移動動作的次數,如式(10)所示。在定位過程中,大部分獲取獎勵的動作是縮放,移動只有發生缺失時才可能提供獎勵,多數情況獎勵為0,更多的作用是縮小窗口與目標的中心距離。窗口連續執行過多的移動動作,一方面會增加無效動作的占比,另一方面容易產生循環動作序列,使窗口在有限步數內不能準確地定位目標。因此本文增加了一個懲罰項,當移動動作的連續執行次數達到5次及以上時,給予一個較大的負值獎勵。
 |
本文的停止獎勵采取常規的閾值獎勵函數,對窗口的IoU和Recall指標進行閾值判斷,如式(11)所示。執行停止動作 ,若當前窗口w與目標包圍框g的IoU和Recall均大于各自的閾值
,若當前窗口w與目標包圍框g的IoU和Recall均大于各自的閾值 和
和 ,則獎勵為正值,否則為負值。
,則獎勵為正值,否則為負值。
 |
1.4.6 細分割模塊
將B型主動脈夾層數據經過粗分割模塊處理,獲取每個切片的目標包圍框,得到所有切片的粗分割結果。本文選取Unet[14]、TransUnet[15]、SwinUnet[16]、MT-Unet[17]作為細分割階段模型,將粗分割結果集合作為輸入,得到分割精度更高的結果圖像。
2 實驗設計與分析
2.1 數據集
本文的實驗數據來自廣東省人民醫院公開的主動脈夾層CT血管造影(computed tomography angiography,CTA)圖像[25],原始數據包含100個B型主動脈夾層的三維數據樣例,其中片間距為0.75 mm,體素大小為0.25 mm×0.25 mm×0.25 mm。該數據集包含3種標注數據,分別對應主動脈真腔、假腔以及假腔血栓。本文實驗只使用假腔標簽,并從橫斷面方向篩選出包含B型夾層的切片數據,共計26 306張,最后進行歸一化處理。實驗數據根據樣例進行劃分,訓練集和測試集的比例為7∶3。
2.2 參數設置與評價指標
強化學習網絡使用Adam優化器進行參數更新,訓練batch大小為100,學習率為1 × 10?5,訓練epoch設置為4,評估網絡的參數每100次更新后分配給目標網絡。特征網絡和分割網絡的batch為20,學習率為1 × 10?4,訓練epoch為30。為了讓智能體在訓練早期盡可能探索更多種情況的搜索序列,本文在訓練過程中采用ε-greedy[26]搜索策略,智能體隨機選擇動作的概率是ε,根據最大Q值選擇動作的概率為1-ε,其初始值為0.5,隨著迭代次數的增加,ε會逐漸減少。智能體尋找目標的最大步長設置為40,回放經驗池的大小為50 000,折扣因子γ為0.9。停止獎勵中的 為0.27,
為0.27, 為0.97。定位窗口的初始邊長為圖像邊長的3/4。針對窗口越界問題,本文采取的方法是:當出現越界情況時,重新隨機選擇動作,而不是進行邊界裁剪。
為0.97。定位窗口的初始邊長為圖像邊長的3/4。針對窗口越界問題,本文采取的方法是:當出現越界情況時,重新隨機選擇動作,而不是進行邊界裁剪。
實驗采用IoU、Dice相似系數、精確率(Precision)以及分類任務的召回率(Recall2,與包圍框的Recall區分)四種指標衡量分割模型的性能,IoU的公式如式(3)所示,其他指標的公式如下所示。
 |
 |
 |
式(13)、式(14)中的TP、FP和FN分別代表真陽性數量、假陽性數量和假陰性數量。
2.3 實驗結果與分析
2.3.1 B型主動脈夾層定位過程
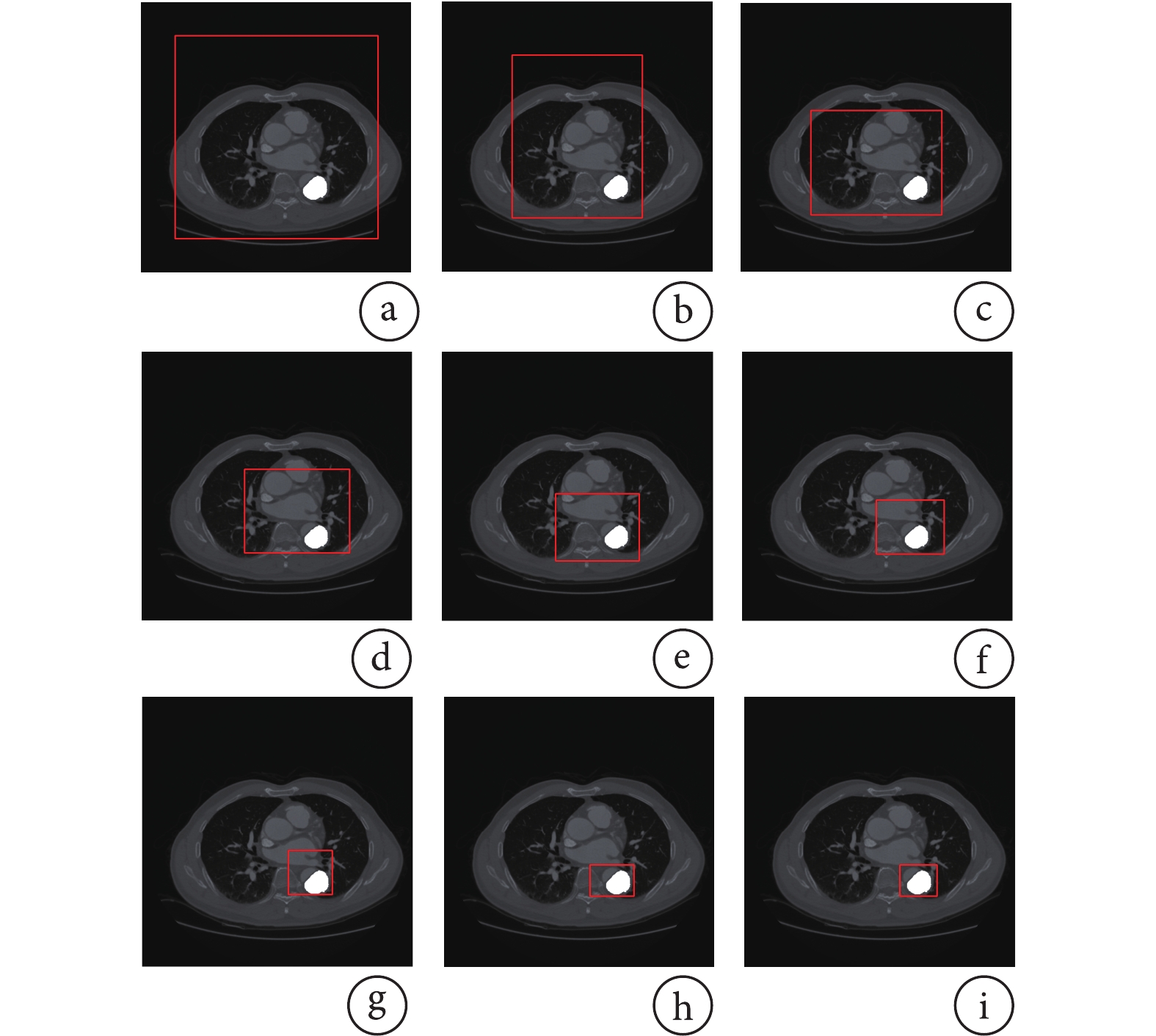
圖6展示了一個樣本的定位序列。白色標記為目標對象,紅色包圍框為每一步的定位結果。每一步動作在保持高Recall指標的前提下,盡可能縮小包圍框的尺寸。最終,窗口定位到待分割目標位置,除去其他冗余內容。
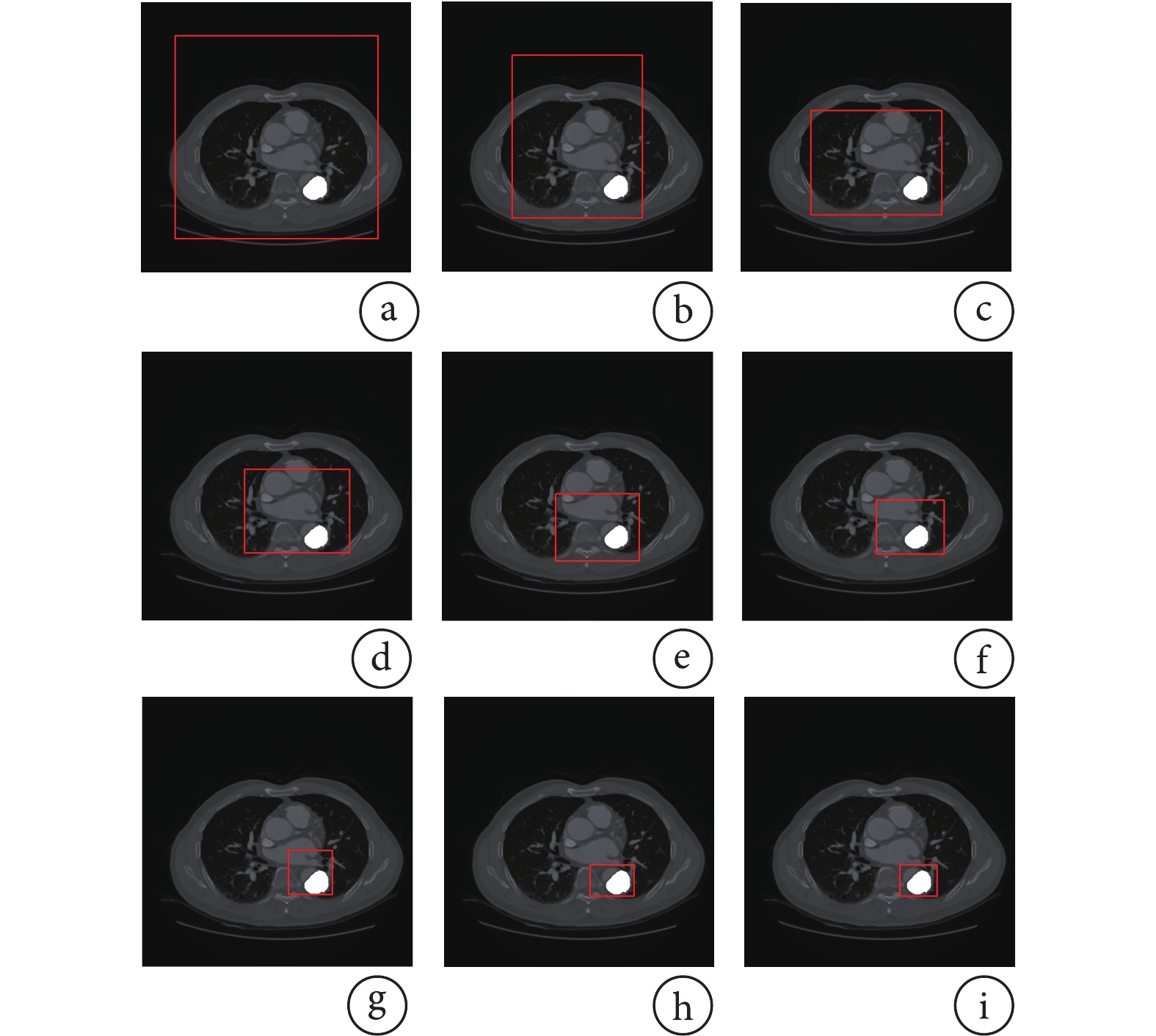 圖6
B型主動脈夾層定位過程
圖6
B型主動脈夾層定位過程
a-i. 定位過程的窗口變換示意圖
Figure6. Localization process of type B aortic dissectiona-i. window transformation diagram of the localization process
2.3.2 定位策略對比
采用不同定位策略的結果如表1所示。可以看出基于R1的IoU指標總是高于R2,而基于R2的Recall指標更高,這是獎勵函數驅動的結果。R1促使智能體朝著提高IoU的方向行動,而本文的R2獎勵優先考慮Recall。加入窗口分離可以進一步提升Recall,窗口分離可以有效避免產生循環序列,一定程度上減少智能體在定位目標過程中的無效步數。由于粗分割階段對結果的完整性要求更高,因此在后續的分割模型對比中,本文選擇Recall表現最高的定位策略作為B型夾層的定位方法;而對于目標檢測等僅對IoU有高要求的任務可以選擇R1對應的獎勵函數。
2.3.3 分割方法對比
為了驗證本文方法的有效性,將本文提出的分割流程應用于多種分割模型,與對應的基準分割結果進行對比。所有的比較實驗均在本文的數據集上進行,采用相同的數據劃分方式以及參數設置。該實驗使用的分割模型如下:
(1)Unet[14]是經典的醫學分割模型,通過對稱的編碼器-解碼器的U型網絡架構以及跳躍式連接將編碼器和解碼器中對應的特征圖相連接,從而引入更多的上下文信息。
(2)TransUnet[15]是將Transformer和Unet結合的分割模型,通過Transformer的自注意力機制來提取圖像特征,從而捕捉到更全局的語義信息,在一些復雜場景表現更加準確。
(3)SwinUnet[16]在Unet的基礎上,將所有的卷積block換成了Swin-Transformer block。相比Transformer,Swin-Transformer采取了分層的方式組織注意力機制,提高了模型的感受野和特征表達能力。
(4)MT-Unet[17]將Unet的部分內容替換為新的混合Transformer模塊(mixed transformer module,MTM),MTM首先通過局部-全局高斯加權自注意(local-global Gaussian-weighted self-attention,LGG-SA)有效地計算窗口內部相似度,對不同粒度的短期和長期依賴進行建模。然后,通過外部注意挖掘數據樣本之間的聯系。
表2展示了不同分割方法的分割結果。與直接使用分割模型相比,使用本文方法的分割結果在各項指標上均有提升,其中Dice指標分別提高了1.34%、0.89%、27.66%和7.37%。對于基礎分割效果較好的分割模型,如Unet、TransUnet以及MT-Unet,分割精度仍有一定的提升,提升空間較小的原因是這些模型受背景因素的影響較小,因此本文方法的提升上限較低;而對于基礎分割效果較差的模型,如SwinUnet,能夠顯著提高分割精度。使用本文方法可以去除分割目標以外的大部分冗余信息,將分割模型的關注點集中在有效范圍內,增大目標與背景間的特征差異,因此對于容易受到背景干擾的數據集或魯棒性較差的分割模型有一定的輔助作用;同時提供一種可以進一步提高模型精度上限的參考方法。
3 結論
針對主動脈夾層分割問題,本文提出了基于Double DQN的B型主動脈夾層目標定位方法。本文對常規定位獎勵函數進行分析與討論,指出它們在粗分割應用中存在的缺點與不足,并設計出適合該問題的獎勵函數,同時提出能有效避免發生目標缺失的窗口分離機制。實驗表明,本文提出的獎勵函數能有效地指導智能體實現主動脈夾層的定位任務,在優先保證高Recall的同時,盡可能縮小窗口的大小,除去大部分的冗余信息,在一定程度上進一步提高了分割網絡模型的分割精度,實驗結果證明了該項改進的有效性。此外本文的方法雖然提高了目標的完整性,但定位窗口對目標窗口的靠攏程度仍有一定的提升空間。在今后的研究中,將研究可以平衡二者的獎勵函數,保持原本完整性的同時進一步減少數據冗余;同時嘗試應用于其他主動脈夾層分型數據,以驗證該方法在其他夾層類型的可行性。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:林先揚主要負責數據記錄與分析、算法程序與設計以及論文編寫,曾安、趙靖亮、潘丹、楊寶瑤主要負責實驗流程、協調溝通、計劃安排、提供實驗指導以及論文審閱修訂,劉鑫主要負責論文審閱修訂。
0 引言
主動脈夾層(aortic dissection,AD)是一種危險的心血管疾病[1-2],是由內膜撕裂或者腔內出血和血腫形成引起的內膜穿孔,使主動脈腔內的血液從主動脈內膜撕裂處進入主動脈中膜,從而形成主動脈壁的真假兩腔分離的狀態。Stanford分型根據是否累及升主動脈,將夾層分為AB兩類,其中所有未累及升主動脈的夾層為B型主動脈夾層。在主動脈夾層的診斷和治療中,手動分割主動脈夾層區域是一項繁瑣、費時的任務,人的主觀性會影響診斷準確性和治療效果。即使是在同一部位,主動脈撕裂內膜的方向、主動脈橫截面的形狀位置以及主動脈弓的形態學屬性均有一定差異,再加上主動脈內部的血液流速和血管壁的厚度等因素的影響,使得主動脈夾層圖像分割[3]具有挑戰性。
基于主動脈夾層的傳統分割方法,已經提出了多種策略,包括Hough變換法[4]、基于空間連續性先驗模型法[5]、多尺度小波分析法[6]以及基于圖像去噪的方法[7]等。這些方法在小規模數據集上展現了良好的分割效果,然而,它們都依賴于手動選擇初始特征或者過多的人工處理,從而限制了其準確性和擴展性。因此,需要進一步研究和發展更準確、自動化且可靠的主動脈夾層分割方法。目前深度學習技術是應用于醫學圖像分割的主流方法。
主動脈圖像存在各種噪聲和偽影,如果直接作為深度學習網絡的輸入,網絡需要分辨非分割目標信息,分散了對分割目標的專注學習,可能會減少分割細節的精確度。對于一些魯棒性較差的分割網絡,影響更為顯著。針對以上問題,Zhu等[8]提出了由粗到細的兩階段分割模型,兩階段方法可以有效減少輸入圖像的噪聲和干擾信號。文獻[8]使用深度學習提取感興趣區域,文獻[9]在此基礎上增加了形態學處理方法,但這些方法在粗分割階段缺乏有效的糾錯機制,使得模型的定位結果往往不可靠,會影響最終的分割效果。
而深度強化學習通過自主學習和決策,可以適應各種復雜環境和任務、處理高維數據,可以解決基于深度學習帶來的粗分割問題。Man等[10]在粗分割階段使用強化學習實現自主定位,提高了分割目標的定位效果。但文獻[10]使用基于自然圖像預訓練的VGG[11]網絡進行特征提取,這種方式不能很好地利用醫學圖像特有的特征。同時它的獎勵函數使用了強化學習在目標檢測應用中的常規獎勵函數[12],不能很好地適配粗分割階段的任務目標,定位結果存在一定的目標缺失情況,Recall尚有較大的提升空間。針對上述問題,受文獻[10]的啟發,本文提出針對B型主動脈夾層圖像的兩階段分割流程。首先,為了豐富醫學切片圖像的特征信息,本文將基于Resnet[13]的修改網絡作為特征提取網絡,對主動脈切片數據進行特征提取;其次,使用深度強化學習訓練自適應環境定位的智能體,減少主動脈夾層形態差異帶來的影響,保證定位窗口盡可能包含分割目標的同時,減小窗口的尺寸,去除更多的冗余信息;最后,選取Unet[14]、TransUnet[15]、SwinUnet[16]、MT-Unet[17]作為細分割階段模型,將經過粗分割的切片結果集合作為基準分割網絡的輸入,得到最終的分割結果,進一步提高基準分割網絡的分割精度。
1 方法
1.1 整體流程
本文提出基于強化學習的B型主動脈夾層兩階段分割方法,整體流程如圖1所示。本方法可分為特征提取、粗分割和細分割三個階段。首先,對主動脈夾層數據進行特征提取,獲取醫學圖像相關特征,與原圖像組合得到強化學習網絡的初始輸入。其次,使用強化學習探索每個樣本的粗分割定位序列,通過獎勵信號驅動網絡更新,將訓練結束的強化學習網絡應用于所有主動脈夾層數據得到粗分割結果集合。最后,將粗分割結果作為分割網絡的輸入得到細分割結果。
圖1
B型主動脈夾層分割方法
Figure1.
Segmentation method for type B aortic dissection
1.2 強化學習介紹
強化學習[18]是機器學習中的一種重要分支,強化學習的核心要素是狀態、動作和獎勵。智能體通過與環境的交互,根據采取不同行為帶來的即時獎勵進行狀態轉移,從中學習到適用當前環境與對應目標任務的最佳行為策略,與深度學習的結合使強化學習能夠處理復雜的高維狀態空間。深度Q網絡(deep Q-network,DQN)[19]是常用的深度強化學習模型之一,DQN通過Bellman方程 [20]預測動作價值Q,對動作選擇策略進行迭代更新。隨著強化學習的發展,產生了多種提高DQN性能的技術,例如Double DQN[21]、Dueling DQN[22]和循環DQN[23]等。
DQN普遍存在估計Q值過高的問題,而Double DQN可以有效緩解DQN的估計偏差。Double DQN使用兩個結構相同的神經網絡:評估網絡和目標網絡,前者用于預測最佳的動作,后者用于評估所選動作的Q值。目標Q值的計算方法以及Double DQN的損失函數如式(1)、式(2)所示。
| '/> |
|
1.3 特征提取模塊
特征提取網絡結構如圖2所示。由于單通道的醫學切片特征信息較少,直接使用原始切片訓練強化學習網絡容易造成過擬合,常見做法是將切片與相鄰切片組合作為訓練樣本,這種方式雖然豐富了切片的信息,但同時加入了更多的冗余信息。為了豐富切片的特征信息,同時減少引入更多的冗余信息,影響網絡的訓練,本文針對B型主動脈夾層數據從零訓練特征提取網絡。特征提取網絡結構參考文獻[24],網絡由若干個殘差塊以及卷積層組成,將多個中間殘差塊的結果進行拼接,獲取不同維度的特征信息,最終輸出單通道的特征圖像。在訓練過程中,將網絡的輸出結果與下采樣后的B型夾層掩碼進行展平匹配,使它能夠專注B型主動脈夾層的關鍵特征,生成凸顯夾層特征的特征圖像,最后將原圖像與特征圖像組合作為強化學習網絡的輸入。特征圖像能夠為強化學習網絡提供更多的目標特征信息,同時減少冗余信息的引入,而原圖像的作用是補充特征圖像中可能丟失的其他關鍵特征信息,進一步提高粗分割階段的定位準確性。
圖2
特征提取網絡結構
Figure2.
Feature extraction network structure
1.4 粗分割模塊
粗分割模塊的具體結構如圖3所示。本文將粗分割階段的定位問題轉換為馬爾可夫決策過程(Markov decision process,MDP),定義粗分割任務下智能體的狀態、動作以及獎勵要素。模塊首先將切片狀態輸入停止網絡,判斷定位序列是否結束;如果選擇繼續執行,則重新將狀態輸入預測網絡進行動作決策,之后在初始狀態圖像上執行相應動作的裁剪操作,實現一次狀態轉移,循環執行多次直至序列結束。
圖3
粗分割模塊結構
Figure3.
Coarse segmentation module structure
1.4.1 深度強化學習模型
為了實現最佳定位策略,本文采用Double DQN作為粗分割階段的定位算法,強化學習網絡使用基于殘差塊的網絡結構,由若干個殘差塊以及全連接層組成,整體結構如圖4所示。將記憶動作序列與卷積層結果拼接,作為全連接層的輸入,最后輸出多個動作的估計Q值。
圖4
預測網絡結構
Figure4.
Predicting network structure
1.4.2 狀態設計
本文的強化學習狀態由當前定位窗口內容與記憶動作向量組成。首先通過特征提取網絡得到夾層切片的特征圖像,然后組合原始切片與兩個相同特征圖像得到一個3通道的圖像數據,作為切片的初始狀態。同時增加記憶向量作為預測網絡輸入的一部分,記憶向量是一個二進制向量,記錄單次狀態轉移之前最近的10次歷史動作。
1.4.3 窗口分離
對于定位任務,常見的狀態轉移方法是使用變換后的新窗口對初始狀態進行裁剪,將窗口內容作為新的狀態數據,其余部分置0。但這種裁剪方式存在以下問題: ① 當定位窗口的尺寸逐漸減小,通過窗口裁剪得到新狀態的有效內容也會逐步減少,對于小目標定位任務,該問題更加突出。為了解決在后序階段狀態的有效數據占比小的問題,在狀態轉移的過程中,本文只對狀態數據的其中一個特征圖像進行窗口裁剪,保持原始切片和另一個特征切片內容不變。② 當窗口只包含少部分目標內容,該裁剪方式會使狀態丟失大部分目標信息。智能體難以從少量的特征信息中定位目標的方向位置,增加了完全丟失目標的可能性,進而定位失敗。為了避免發生窗口嚴重缺失的問題,本文將單一窗口分離出定位窗口和視野窗口。視野窗口是在定位窗口的基礎上增加若干個像素寬度得到的新窗口,在狀態轉移的過程中使用視野窗口的內容作為狀態數據,但在評價定位效果時使用定位窗口。當定位窗口已經發生缺失,視野窗口的存在可以彌補一部分分割目標的特征數據,進而減少定位失敗的情況。
在定位窗口的最后調整階段,此時窗口的寬高長度較短,窗口執行動作后的變化幅度小,重復出現相似程度較高狀態的可能性較大,即窗口容易出現在曾經定位過的位置。對于相似的狀態,智能體可能會提供同樣的動作建議,導致之后的動作序列陷入某種搜索軌跡循環。循環序列會占用有限的執行步數,在一定程度上會影響最后的定位結果。為了避免重復出現相似狀態,本文對視野窗口的尺寸進行隨機化設置,在一定范圍內隨機選取視野窗口的擴張大小,盡可能增大每個狀態之間的差異程度。
1.4.4 動作設計
本文的強化網絡動作集合由8個窗口的變換操作和一個停止操作組成。如圖5所示,變換操作分為4個移動動作和4個縮放動作。文獻[10]采取的縮放操作始終保持窗口的形狀為正方形,對于一些長寬比例差異較大的主動脈夾層數據,該方案會引入較多的冗余信息,不適用于目標形態不統一的任務,因此本文采用自由程度更高的縮放操作。本文的縮放操作可以對包圍框的不同方向分別進行縮放,同時在縮放時保持窗口的中心位置不變,有助于進一步縮小定位范圍。縮放和移動動作的初始變換比例都是對應方向上窗口邊長的1/5。為了使窗口在最后的調整階段能進行更細微的調整,在執行一定步數之后會進一步減小變換比例。當智能體選擇了停止動作或者搜索步數達到預設的最大值,表示一個定位序列的結束。
圖5
動作集合
Figure5.
Action collection
1.4.5 獎勵函數設計
即時獎勵用于評估智能體選擇的動作好壞,智能體的目標就是最大化累計獎勵。對于目標檢測問題,一般采用的評估指標是IoU,IoU是用于衡量兩個矩形框重合程度的重要指標。在粗分割階段需要特別注重Recall指標,Recall描述了窗口內包含目標對象的完整程度。其具體計算公式如式(3)、式(4)所示,其中g表示分割目標的最小包圍框,w表示定位窗口。
|
|
式(5)和式(6)分別表示前后狀態的Recall和IoU指標變化。基于強化學習的目標檢測問題[12]一般采取如式(7)所示的單步獎勵函數,其中表示狀態s執行動作得到的即時獎勵,表示除停止動作以外的變換動作,w表示執行動作前的窗口,表示執行動作后的窗口。
| '/> |
| '/> |
| '/> |
在該獎勵函數的驅動下,即使定位窗口缺失一部分目標,智能體也會優先選擇增大IoU的動作。但由于IoU和Recall的變化方向不完全一致,因此可能會出現IoU增加而Recall不變甚至下降的情況,因此使用該獎勵函數難以保證定位窗口較完整地包含分割目標。針對粗分割任務,需要優先保證相鄰狀態的Recall保持遞增或維持最大值,以上兩種情況的獎勵分數應該最大。本文設計的獎勵函數如式(8)所示。
|
本文的獎勵函數分為兩部分,常規動作獎勵以及移動懲罰項。常規動作獎勵如式(9)所示,整體的取值范圍為[?2,2],該獎勵函數在優先考慮Recall變化的情況下根據IoU的變化給予相應的分值。滿足的獎勵為 + 1 ,其中同時增加IoU與Recall的動作獎勵最大;的獎勵函數為,為了提高維持完整包圍目標的動作優先級,如果此時,本文額外將獎勵結果翻倍,即獎勵為;其他條件不符合粗分割任務的要求,因此直接提供負值獎勵。
| '/> |
移動懲罰項用于限制執行移動動作的次數,如式(10)所示。在定位過程中,大部分獲取獎勵的動作是縮放,移動只有發生缺失時才可能提供獎勵,多數情況獎勵為0,更多的作用是縮小窗口與目標的中心距離。窗口連續執行過多的移動動作,一方面會增加無效動作的占比,另一方面容易產生循環動作序列,使窗口在有限步數內不能準確地定位目標。因此本文增加了一個懲罰項,當移動動作的連續執行次數達到5次及以上時,給予一個較大的負值獎勵。
|
本文的停止獎勵采取常規的閾值獎勵函數,對窗口的IoU和Recall指標進行閾值判斷,如式(11)所示。執行停止動作,若當前窗口w與目標包圍框g的IoU和Recall均大于各自的閾值和,則獎勵為正值,否則為負值。
|
1.4.6 細分割模塊
將B型主動脈夾層數據經過粗分割模塊處理,獲取每個切片的目標包圍框,得到所有切片的粗分割結果。本文選取Unet[14]、TransUnet[15]、SwinUnet[16]、MT-Unet[17]作為細分割階段模型,將粗分割結果集合作為輸入,得到分割精度更高的結果圖像。
2 實驗設計與分析
2.1 數據集
本文的實驗數據來自廣東省人民醫院公開的主動脈夾層CT血管造影(computed tomography angiography,CTA)圖像[25],原始數據包含100個B型主動脈夾層的三維數據樣例,其中片間距為0.75 mm,體素大小為0.25 mm×0.25 mm×0.25 mm。該數據集包含3種標注數據,分別對應主動脈真腔、假腔以及假腔血栓。本文實驗只使用假腔標簽,并從橫斷面方向篩選出包含B型夾層的切片數據,共計26 306張,最后進行歸一化處理。實驗數據根據樣例進行劃分,訓練集和測試集的比例為7∶3。
2.2 參數設置與評價指標
強化學習網絡使用Adam優化器進行參數更新,訓練batch大小為100,學習率為1 × 10?5,訓練epoch設置為4,評估網絡的參數每100次更新后分配給目標網絡。特征網絡和分割網絡的batch為20,學習率為1 × 10?4,訓練epoch為30。為了讓智能體在訓練早期盡可能探索更多種情況的搜索序列,本文在訓練過程中采用ε-greedy[26]搜索策略,智能體隨機選擇動作的概率是ε,根據最大Q值選擇動作的概率為1-ε,其初始值為0.5,隨著迭代次數的增加,ε會逐漸減少。智能體尋找目標的最大步長設置為40,回放經驗池的大小為50 000,折扣因子γ為0.9。停止獎勵中的為0.27,為0.97。定位窗口的初始邊長為圖像邊長的3/4。針對窗口越界問題,本文采取的方法是:當出現越界情況時,重新隨機選擇動作,而不是進行邊界裁剪。
實驗采用IoU、Dice相似系數、精確率(Precision)以及分類任務的召回率(Recall2,與包圍框的Recall區分)四種指標衡量分割模型的性能,IoU的公式如式(3)所示,其他指標的公式如下所示。
|
|
|
式(13)、式(14)中的TP、FP和FN分別代表真陽性數量、假陽性數量和假陰性數量。
2.3 實驗結果與分析
2.3.1 B型主動脈夾層定位過程
圖6展示了一個樣本的定位序列。白色標記為目標對象,紅色包圍框為每一步的定位結果。每一步動作在保持高Recall指標的前提下,盡可能縮小包圍框的尺寸。最終,窗口定位到待分割目標位置,除去其他冗余內容。
圖6
B型主動脈夾層定位過程
a-i. 定位過程的窗口變換示意圖
Figure6. Localization process of type B aortic dissectiona-i. window transformation diagram of the localization process
2.3.2 定位策略對比
采用不同定位策略的結果如表1所示。可以看出基于R1的IoU指標總是高于R2,而基于R2的Recall指標更高,這是獎勵函數驅動的結果。R1促使智能體朝著提高IoU的方向行動,而本文的R2獎勵優先考慮Recall。加入窗口分離可以進一步提升Recall,窗口分離可以有效避免產生循環序列,一定程度上減少智能體在定位目標過程中的無效步數。由于粗分割階段對結果的完整性要求更高,因此在后續的分割模型對比中,本文選擇Recall表現最高的定位策略作為B型夾層的定位方法;而對于目標檢測等僅對IoU有高要求的任務可以選擇R1對應的獎勵函數。
2.3.3 分割方法對比
為了驗證本文方法的有效性,將本文提出的分割流程應用于多種分割模型,與對應的基準分割結果進行對比。所有的比較實驗均在本文的數據集上進行,采用相同的數據劃分方式以及參數設置。該實驗使用的分割模型如下:
(1)Unet[14]是經典的醫學分割模型,通過對稱的編碼器-解碼器的U型網絡架構以及跳躍式連接將編碼器和解碼器中對應的特征圖相連接,從而引入更多的上下文信息。
(2)TransUnet[15]是將Transformer和Unet結合的分割模型,通過Transformer的自注意力機制來提取圖像特征,從而捕捉到更全局的語義信息,在一些復雜場景表現更加準確。
(3)SwinUnet[16]在Unet的基礎上,將所有的卷積block換成了Swin-Transformer block。相比Transformer,Swin-Transformer采取了分層的方式組織注意力機制,提高了模型的感受野和特征表達能力。
(4)MT-Unet[17]將Unet的部分內容替換為新的混合Transformer模塊(mixed transformer module,MTM),MTM首先通過局部-全局高斯加權自注意(local-global Gaussian-weighted self-attention,LGG-SA)有效地計算窗口內部相似度,對不同粒度的短期和長期依賴進行建模。然后,通過外部注意挖掘數據樣本之間的聯系。
表2展示了不同分割方法的分割結果。與直接使用分割模型相比,使用本文方法的分割結果在各項指標上均有提升,其中Dice指標分別提高了1.34%、0.89%、27.66%和7.37%。對于基礎分割效果較好的分割模型,如Unet、TransUnet以及MT-Unet,分割精度仍有一定的提升,提升空間較小的原因是這些模型受背景因素的影響較小,因此本文方法的提升上限較低;而對于基礎分割效果較差的模型,如SwinUnet,能夠顯著提高分割精度。使用本文方法可以去除分割目標以外的大部分冗余信息,將分割模型的關注點集中在有效范圍內,增大目標與背景間的特征差異,因此對于容易受到背景干擾的數據集或魯棒性較差的分割模型有一定的輔助作用;同時提供一種可以進一步提高模型精度上限的參考方法。
3 結論
針對主動脈夾層分割問題,本文提出了基于Double DQN的B型主動脈夾層目標定位方法。本文對常規定位獎勵函數進行分析與討論,指出它們在粗分割應用中存在的缺點與不足,并設計出適合該問題的獎勵函數,同時提出能有效避免發生目標缺失的窗口分離機制。實驗表明,本文提出的獎勵函數能有效地指導智能體實現主動脈夾層的定位任務,在優先保證高Recall的同時,盡可能縮小窗口的大小,除去大部分的冗余信息,在一定程度上進一步提高了分割網絡模型的分割精度,實驗結果證明了該項改進的有效性。此外本文的方法雖然提高了目標的完整性,但定位窗口對目標窗口的靠攏程度仍有一定的提升空間。在今后的研究中,將研究可以平衡二者的獎勵函數,保持原本完整性的同時進一步減少數據冗余;同時嘗試應用于其他主動脈夾層分型數據,以驗證該方法在其他夾層類型的可行性。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:林先揚主要負責數據記錄與分析、算法程序與設計以及論文編寫,曾安、趙靖亮、潘丹、楊寶瑤主要負責實驗流程、協調溝通、計劃安排、提供實驗指導以及論文審閱修訂,劉鑫主要負責論文審閱修訂。