顳下頜關節紊亂病(TMD)是一種常見的口腔頜面部疾病,前期癥狀不明顯,不易被發現。本文提出了一種可用于邊緣計算設備的TMD智能診斷系統,實現了在臨床診斷中快速篩查TMD,以輔助臨床對TMD進行早期干預。該系統首先對顳下頜關節各解剖部位進行自動化分割,然后對關節間隙進行定量測量,最后基于測量結果進行預測。在分割方面,本文利用半監督學習技術,實現了顳下頜關節部位的精確分割,平均戴斯系數(DC)達到了0.846。本文還提出顳下頜關節三維(3D)間隙區域自動提取算法,建立了TMD自動診斷模型,最終準確率達到83.87%。綜上,本文開發了TMD智能診斷系統,并將其部署在局域網內的邊緣計算設備上,以期實現隱私保障下的TMD的快速篩查和智能診斷。
引用本文: 張明浩, 楊東, 李小囡, 張倩, 劉之洋. 顳下頜關節紊亂病智能診斷系統的研究與實現. 生物醫學工程學雜志, 2024, 41(5): 869-877. doi: 10.7507/1001-5515.202402002 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
0 引言
顳下頜關節紊亂病(temporomandibular joint disorder,TMD)是一種常見的口腔頜面部疾病,是骨關節炎的一個重要分支,其主要表現為下頜運動異常、疼痛、彈響、雜音以及影響咀嚼等問題,部分患者可能會發生頭痛、口面疼痛、頸痛或肩胛骨疼痛等非特異性表現[1]。TMD在前期臨床癥狀不明顯,一般于病情中期被發現,使得其不易被及早發現及治療。錐形束計算機斷層成像(cone beam computed tomography,CBCT)能夠三維(3-dimension,3D)成像以顯示患者口腔全貌,目前已廣泛應用于口腔醫學診療中。與傳統計算機斷層成像(computed tomography,CT)相比,CBCT具有拍攝范圍廣、輻射劑量低、曝光時間短、分辨率高、偽影輕等優勢[2]。傅開元等[3]將顳下頜關節骨關節病的CBCT影像特征分為6種不同類型,能夠清晰地觀察到髁突位置改變和骨質結構改變[4],便于對TMD進行更加科學準確地診斷,有助于及早發現并控制TMD。
CBCT醫學影像的人工分析很大程度上依賴醫生豐富的臨床經驗和背景知識,主觀性較強,且會消耗大量人力。利用深度學習訓練神經網絡實現自動化的醫學影像分割,能夠取得較高的準確度并可消除由于個體主觀影響帶來的差異,且在分割圖上通過數學分析及定量計算能夠判斷患者髁突位置改變和骨質結構改變,進而對TMD進行自動診斷,降低醫生的工作量。但是,深度學習的訓練通常需要大量的有標簽數據。目前的公開數據集中,CBCT影像相關的數據集大多集中于牙齒分割[5-6]和牙神經槽分割[7-8],缺少關于顳下頜關節解剖結構分割標簽的CBCT影像。而在CBCT中,逐張標注相關解剖結構的工作量較大,標注成本較高,因此本文提出了采用小樣本學習訓練分割網絡的方法。
在影像分割方面,Chen等[9]提出的深度實驗室網絡(DeepLab)采用空洞卷積在減少信息丟失的情況下擴大了感受野,并加入全連接條件隨機場(conditional random field,CRF)解決邊緣分割不準確的問題。Ronneberger等[10]提出的U型網絡(U-Net)通過跳躍連接結構將編碼器底層特征與解碼器高層特征進行融合,以提高分割精度,在生物醫學領域取得了非常好的效果。對U-Net進行3D擴展構建的網絡(3D-Unet)[11],目前已廣泛應用于醫學影像分割。Schlemper等[12]提出將注意力機制引入U-Net結構,這種提出的注意力U-Net(attention U-Net,Attn-Unet)能夠有效地突出前景部分,幫助模型捕捉目標特征。Chen等[13]提出將變換器(transformer)結構融入進U-Net(transformer U-Net,TransUnet)中,使其同時具有U-Net和transformer的優點,在醫學影像分割任務上取得了更好的效果。Cao等[14]提出的移位窗口U-Net(Swin-Unet)采用了U-Net的U型結構,但完全使用了移位窗口transformer(Swin-Transformer)[15]進行編解碼,并設計了擴展層恢復特征圖分辨率,獲得了比單純卷積神經網絡(convolutional neural networks,CNN)模型或transformer與CNN結合模型更優的效果。
在小樣本學習方面,元學習方法利用支撐集所習得的經驗來指導問詢集的任務,使得機器“學會如何學習”[16]。Goodfellow等[17]提出的生成對抗網絡(generative adversarial nets,GAN)通過生成器與判別器之間的博弈,可以利用無標簽數據生成樣本,適用于小樣本學習。Zhang等[18]提出的類別不可知網絡(class-agnostic network,CANet)通過構建由密集比較模塊和迭代優化模塊組成的框架,在單樣本和5樣本訓練上取得了優秀的效果。Dong等[19]將原型網絡引入小樣本圖像分割中,通過度量學習與排列訓練,獲得了大幅超過基準模型的性能。Lai等[20]通過半監督學習的方式對有標簽數據與無標簽數據進行訓練,減少了標注的需求量。Ouyang等[21]提出了自適應局部原型池化,并采用自監督學習的方法,在醫學影像分割上獲得了優于有標注的少樣本方法。
基于上述研究,本文采用GAN進行CBCT影像分割,并采用半監督學習的方法,用無標簽數據加強分割效果;提出了顳下頜關節3D間隙區域提取算法,并建立了TMD自動診斷模型用于開發TMD智能診斷系統,最終將其部署在位于局域網內的邊緣計算設備上,以期在保障用戶隱私的前提下,實現TMD的快速篩查與智能診斷。
1 需求分析
根據臨床需求,本系統應包括用戶界面模塊、系統通信模塊、自動診斷模塊、結果顯示模塊,應具有登錄注冊功能、影像文件上傳功能、影像分割功能、3D區域特征提取功能、TMD診斷功能、同步異步展示功能,系統整體功能模塊如圖1所示。同時為了方便用戶使用,本系統還應使中間過程進行可視化展示,保證診斷流程高效準確,用戶交互界面友好和保障用戶信息安全。
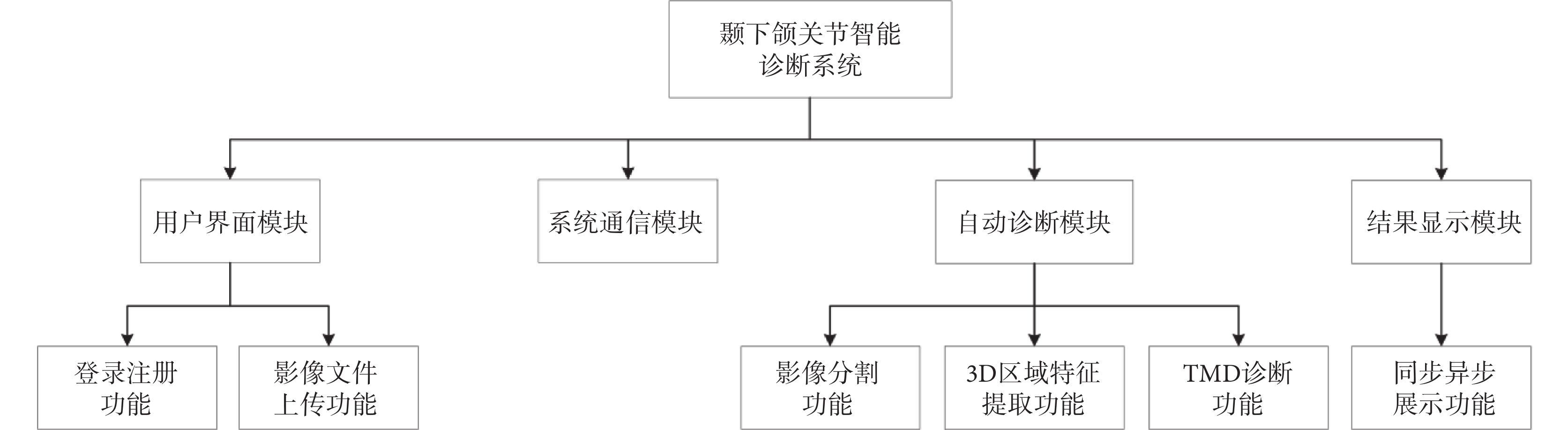 圖1
TMD智能診斷系統功能模塊
Figure1.
Functional modules of intelligent diagnostic system for TMD
圖1
TMD智能診斷系統功能模塊
Figure1.
Functional modules of intelligent diagnostic system for TMD
2 TMD自動診斷方法
TMD自動診斷方法的流程為:首先將CBCT影像進行分割,得到3D分割圖;再通過3D分割圖對顳下頜關節3D間隙區域進行提取;最終從獲得的3D區域中提取3D特征并通過TMD自動診斷模型獲得診斷結果。
2.1 口腔CBCT影像分割
2.1.1 口腔CBCT影像數據
本研究經南開大學生物醫學倫理委員會批準(批準號:NKUIRB2021115),所用數據經天津醫科大學口腔醫院授權,回溯性收集天津醫科大學口腔醫院采集的CBCT影像數據,所有數據由CBCT系統(KaVo 3D eXam,KaVo Dental,美國)采集。本文共收集CBCT影像131例,其中25例由醫師標注顳下頜關節附近的分割標簽,標注部位為顳骨、踝骨突和外耳道。首先,將數據劃分為訓練集和測試集,其中訓練集包含19例有標簽樣本和106例無標簽樣本,測試集包含6例有標簽樣本。考慮到有標簽樣本數量較少,本文采用GAN進行半監督學習[17],利用無標簽數據增強分割的效果。
2.1.2 影像分割網絡
影像分割網絡由生成器與判別器組成,其結構如圖2所示。
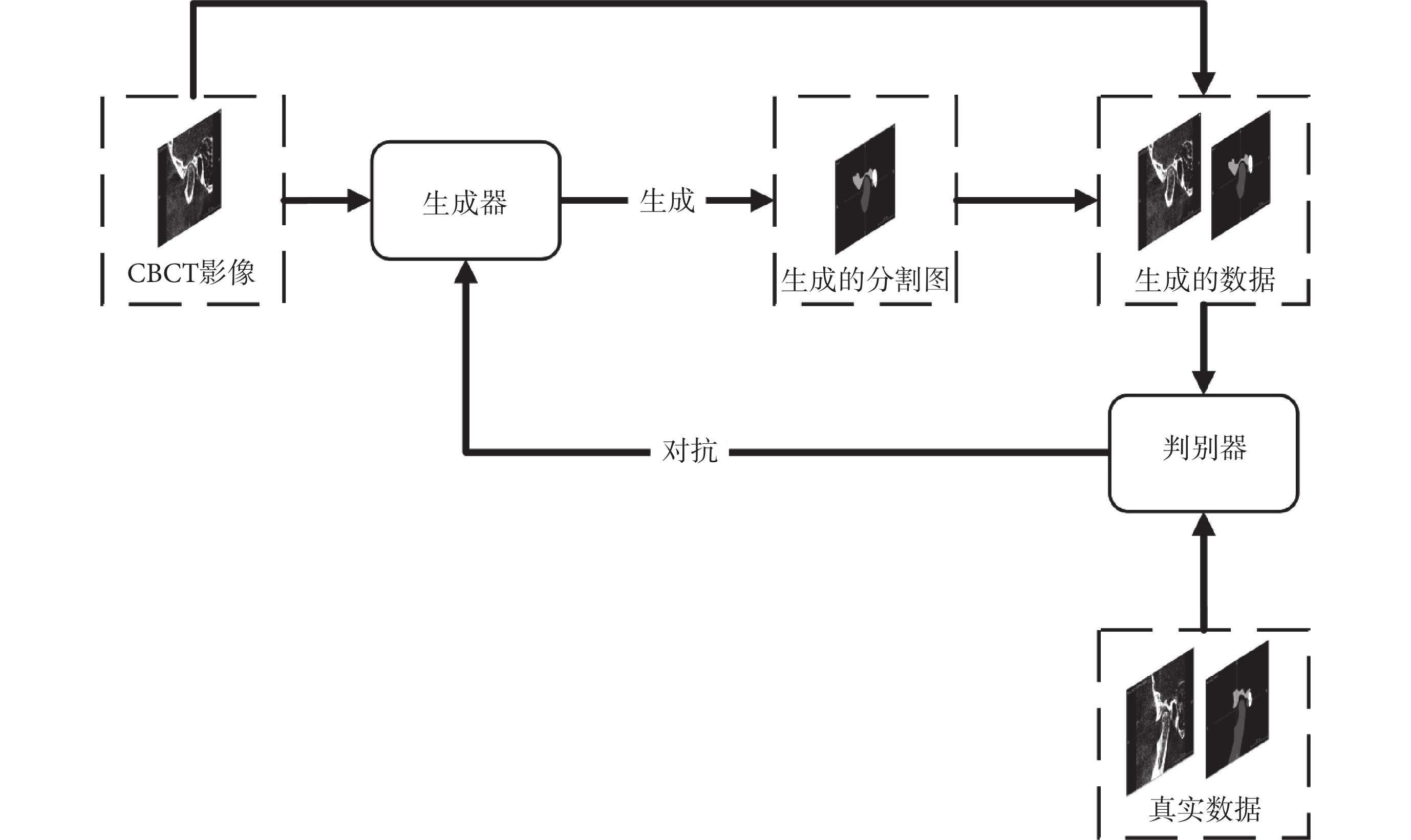 圖2
影像分割網絡
Figure2.
Image segmentation network
圖2
影像分割網絡
Figure2.
Image segmentation network
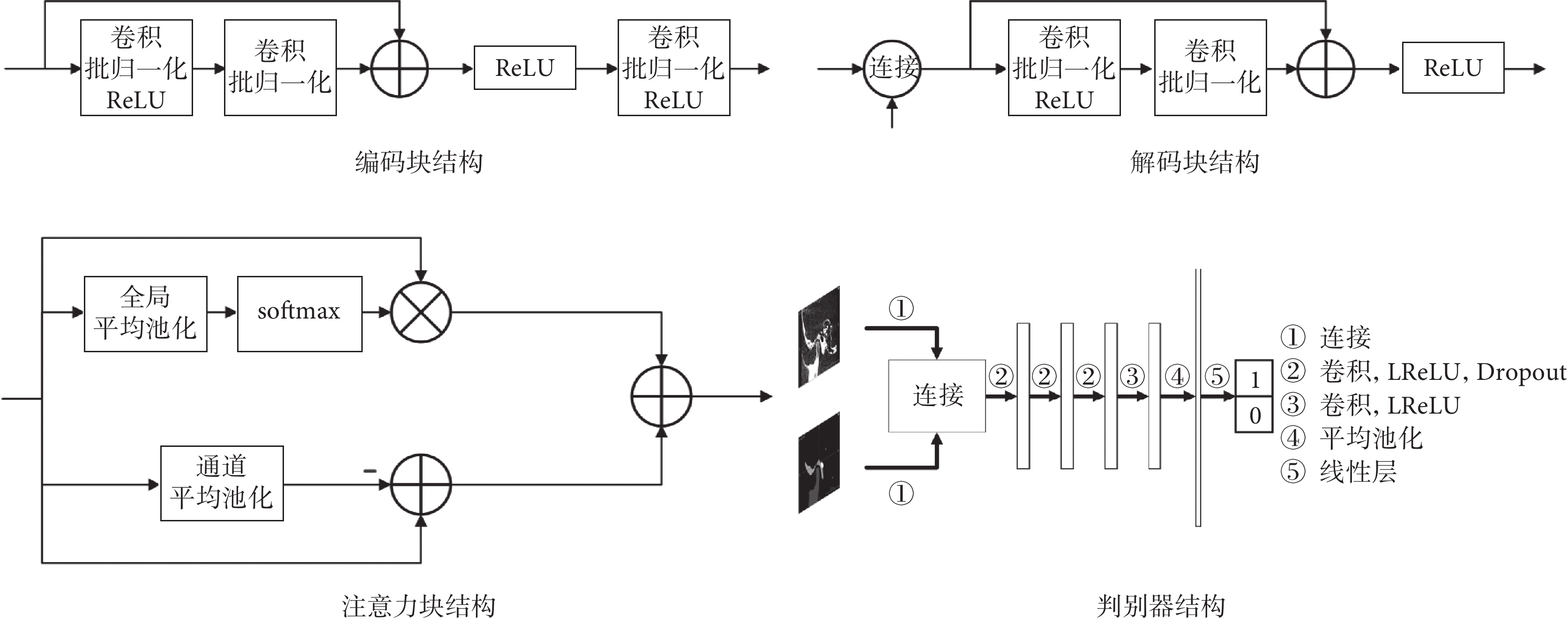
本文生成器采用U-Net作為基礎架構,并在每層編碼塊和解碼塊之間加入了跳躍連接結構。編碼塊在傳統的殘差塊之后額外增加一層卷積塊,包括卷積、批歸一化和線性整流函數(rectified linear unit,ReLU),使編碼器中的參數占比提升,從而能夠更好地從小樣本數據中提取信息。解碼塊采用U-Net的解碼器結構,將當前層跳躍連接結構輸出與上一層輸出進行連接并輸入解碼塊中,用于融合不同尺度的信息,并輸出影像分割結果。本文在跳躍連接結構中加入了注意力塊,其中包括空間注意力和通道注意力,來進一步提升網絡的性能,其中空間注意力包括全局平均池化和柔性最大化(softmax)操作,通道注意力包括通道平均池化操作。判別器采用較為簡單的神經網絡結構,其中包括卷積層、平均池化層、線性層,激活函數采用泄漏ReLU函數(leaky ReLU,LReLU),此外本文還在部分卷積層中加入了隨機失活(Dropout)以防止過擬合。輸入為病例CBCT影像與生成器的分割結果yseg的連接;輸出為二值:0或者1,輸出為0代表判別器判定輸入的影像為生成器偽造的分割圖,輸出為1代表判別器判定輸入的影像為病例的真實分割圖。各模塊結構如圖3所示。
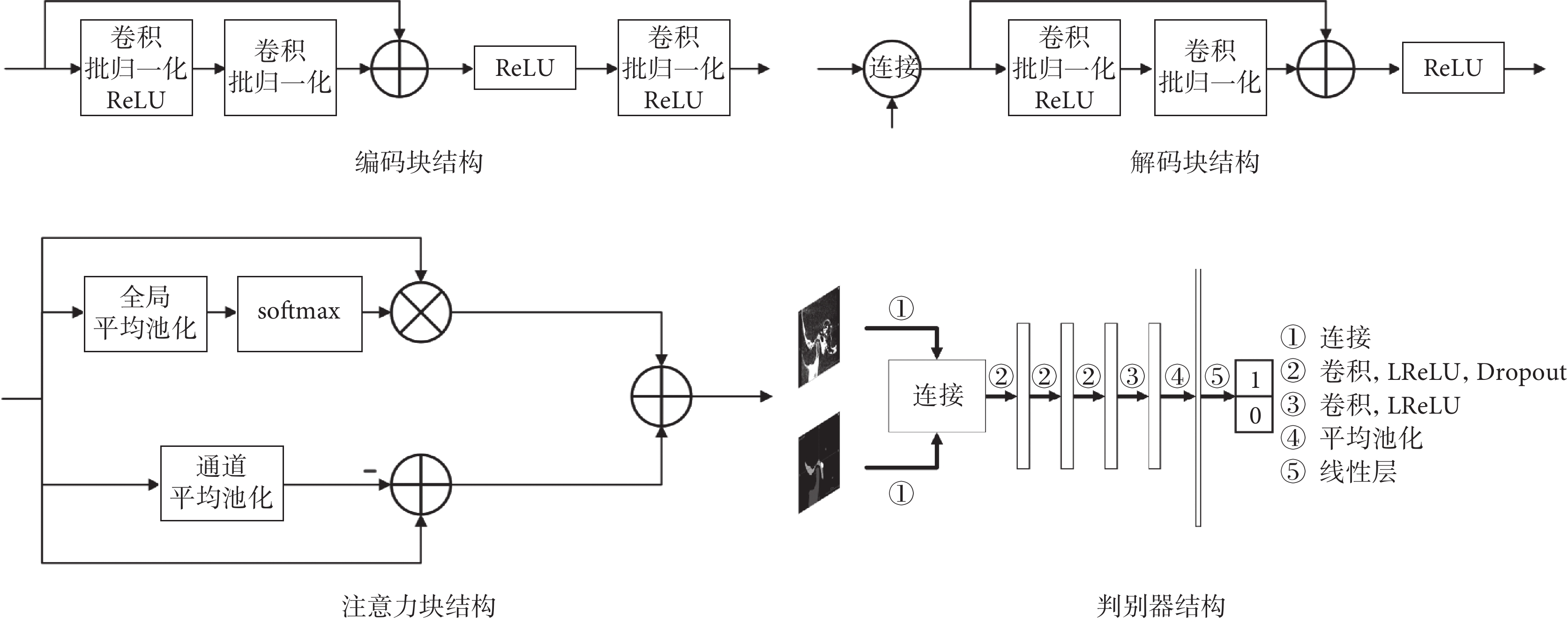 圖3
分割網絡各模塊結構
Figure3.
The structure of each module in the segmentation network
圖3
分割網絡各模塊結構
Figure3.
The structure of each module in the segmentation network
2.1.3 神經網絡訓練
CBCT影像中,不同的組織結構具有不同的CT值[22]。在醫學影像處理中,通常采用加窗函數的方法提取出要研究的部位,以提高醫生的效率。本文采用CBCT值區間為?600~700的窗函數對原始影像進行處理,并將數據歸一化為均值為0、方差為1的變量。其次,本文對訓練集數據進行數據增強,包括尺寸縮放、隨機旋轉、隨機裁剪、坐標軸翻轉、強度變化、強度縮放和彈性形變。最后,每個批次包括6個經過預處理的影像切塊,大小為128 × 128 × 128;其中4個切塊有標簽,2個無標簽。為了降低顯存占用,將樣本下采樣至96 × 96 × 96,其中CBCT影像采用三線性采樣,標簽采用最近鄰采樣。
在小樣本影像分割背景下,生成器損失函數需要充分考慮和利用各類有效信息。本文生成器損失函數由分割損失和對抗損失組成,如式(1)所示:
 |
其中,L為生成器損失函數,LCE為交叉熵損失函數,LDice為戴斯(Dice)損失函數,Ladv為判別器的損失函數,b為Ladv的權重系數,如式(2)~式(4)所示:
 |
 |
 |
其中,N為樣本數量,pi為樣本標簽,qi為生成器輸出,wi為第i個樣本的權重參數,yi為判別器輸出值,xi為二值標簽。
b為式(1)中Ladv的權重系數,本文引入半監督學習的溫度系數概念[23],其定義如式(5)所示:
 |
其中, ,n是當前循環計數值,r為溫度系數,本文默認取40.0。
,n是當前循環計數值,r為溫度系數,本文默認取40.0。
判別器的目的是分辨出輸入影像的來源,故判別器損失函數要將生成器輸出以及具有真實標簽的影像輸入判別器中進行判別,其損失函數如式(6)所示:
 |
其中,LD為判別器損失函數,LG和Llabel分別為判別器對生成器輸出的判別結果與其標簽的二分類交叉熵,二分類交叉熵表達式如式(7)所示:
 |
其中,LBCE為二分類交叉熵,N為樣本數量,wi為每個樣本的權重參數,xi為判別器輸出值,yi為判別器對生成器預測結果判別的標簽值。LG中yi的值為0,Llabel中yi的值為1。
本文生成器與判別器均訓練300輪,每輪訓練150次,共計45 000次梯度更新。生成器優化方式選擇無動量的均方根傳播算法(root mean square propagation,RMSprop),初始學習率為0.000 1,平滑常數β = 0.99,動量M = 0。生成器設有學習率衰減機制,其表達式如式(8)所示:
 |
其中,lr為當前學習率,lrinit為初始學習率,n為當前訓練輪次,nmax為訓練總輪次。
判別器的優化方式選用隨機梯度下降(stochastic gradient descent,SGD),初始學習率為0.001,動量M = 0.9,權重衰減λ = 0.000 1。
2.1.4 測試結果
本文實驗在配備深度學習加速顯卡(TITAN RTX,NVIDIA Corporation,美國)的服務器實現,使用Linux操作系統軟件Ubuntu 20.04(Canonical Ltd.,英國),實驗基于開源機器學習庫PyTorch(The Linux Foundation,美國)和開源醫療影像深度學習框架MONAI(MONAI Consortium,國際)實現。由于數據集中的有標簽數據存在邊緣區域標注不統一等問題,無法進行精確的戴斯系數(Dice coefficient,DC)計算,故本文計算DC時,在不影響關節間隙測量結果的情況下將預測結果中非人工標注區域的數值置零,即僅對影像中人工標注的區域進行DC計算。為驗證本文影像分割網絡的有效性,本文在相同的有標簽數據集上分別訓練了4種模型用于對比,包括未采用GAN結構的本文提出的分割模型(記作:本文模型-無GAN)、U-Net[10]、巢穴U-Net (U-Net++)[24]和Attn-Unet [12],這些模型在測試集(包含6例有標簽樣本,即樣本1~樣本6)上的結果如表1所示。從表1可以看出,本文提出的基于GAN的分割方法可以顯著提升分割準確率。若去掉GAN,其平均DC出現了顯著下降。此外,本文提出的分割網絡也表現出了優于U-Net、U-Net++、Attn-Unet等經典醫學影像分割網絡的性能,驗證了本文提出的分割方法的有效性。
2.2 顳下頜關節3D間隙區域提取方法
2.2.1 顳下頜關節3D間隙區域提取原理
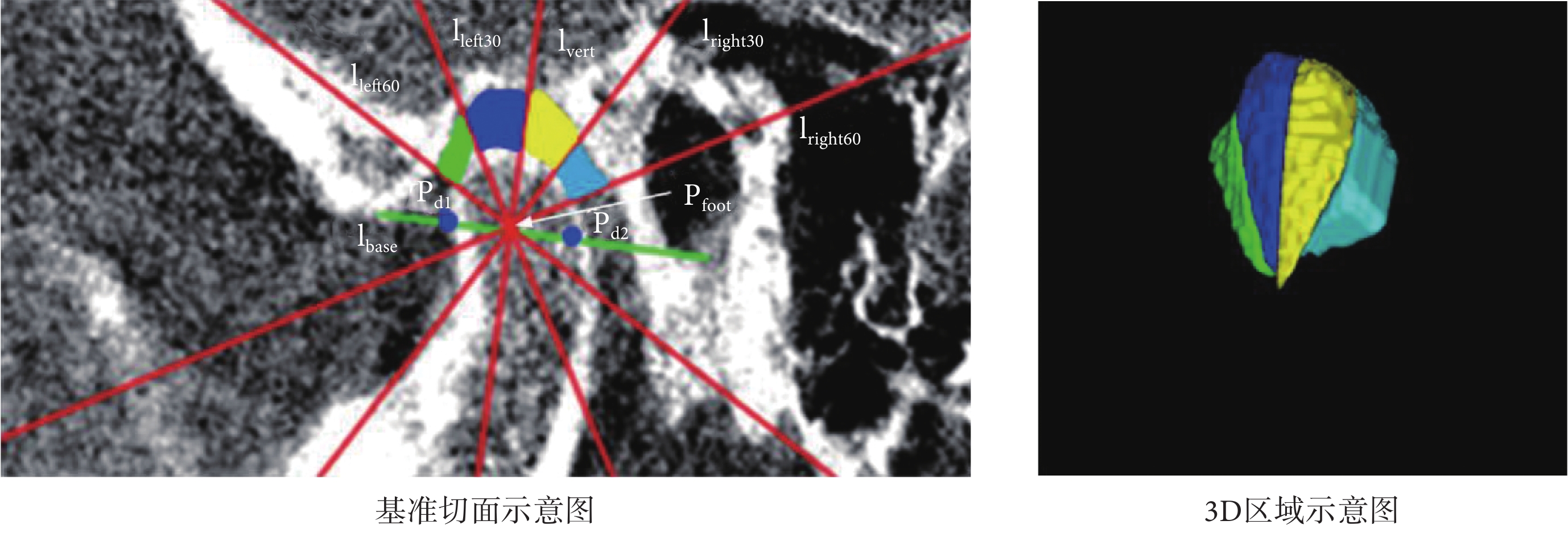
本文將Lee等[25]提出的顳下頜關節間隙測量模型擴展至3D區域,以獲取顳下頜關節3D間隙區域,如圖4所示。其步驟共分為三步:第一,選擇踝骨突的中間切面作為基準切面,記為切面S,此切面完整包含了關節構成的三個標志性器官,即顳骨、踝骨突、外耳道;第二,在切面S中,分別將左側顳骨最低點、外耳道最低點記為Pd1、Pd2,兩點所連線段記為lbase,該線段中點記為Pfoot,以Pfoot為垂足作lbase的垂線記為lvert,再分別作左右兩直角半區的三等分線,4條三等分線分別記為lleft30、lleft60、lright30、lright60;第三,以X軸為基準,將lvert、lleft30、lleft60、lright30、lright60擴展為平面對踝骨突邊緣和顳骨邊緣之間的區域進行切分,從而獲得4個顳下頜關節3D間隙區域R1~R4。
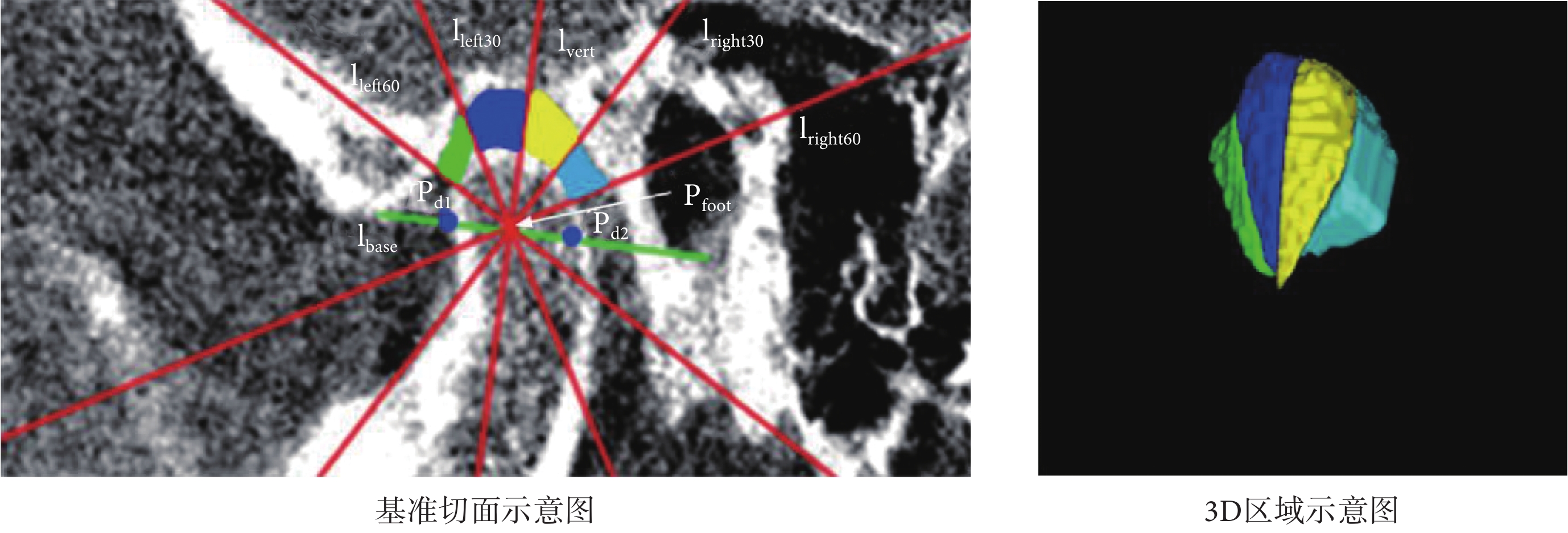 圖4
顳下頜關節3D區域提取示意圖
Figure4.
Temporomandibular joint 3D region extraction schematic diagram
圖4
顳下頜關節3D區域提取示意圖
Figure4.
Temporomandibular joint 3D region extraction schematic diagram
2.2.2 算法實現
本文的顳下頜關節3D間隙區域分區算法主要分為五個步驟,分別為:尋找切面、尋找定位點和切分線、線切分、圓切分、區域篩選。
第一步為尋找切面,本文將選擇3D關節區域中踝骨突的中間切面作為基準切面S,以此切面作為后續算法的基礎。
第二步為尋找定位點和切分線,定位點是關節區域劃分的起點,切分線為關節區域劃分的邊界。根據上述原理得到lbase、lvert、lleft30、lleft60、lright30、lright60和4個3D區域R1~R4。在獲取每個分區時,本文會設置對應分區的掩碼矩陣M,逐步計算出無關區域并在M中去除,最終M中遺留的區域為所尋找的關節分區。
第三步為線切分,即通過第二步中獲得的切分線來得到當前分區的30°扇形區域。以R1為例,在切面S中計算得到圍成R1的切分線的斜率與縱截距,進而得到分區內點的坐標,并在掩碼矩陣M中除去分區外的點。最后,將掩碼矩陣M從切面S以X軸方向擴展到3D影像以獲得3D影像的線切分結果。
第四步為圓切分,用以進一步細化關節間隙分區的位置。在切面S中,算法將在線切分的基礎上,計算得到包含當前關節間隙分區的半徑r,以Pfoot為圓心保留圓形區域內的點,即可獲得較為精細的關節分區。同樣,將這一掩碼結果從切面S以X軸方向擴展到3D影像,即可獲得3D影像的圓切分結果。對于r的選擇,本文分別計算Pfoot到當前分區內顳骨最低點、顳骨最左端的點、顳骨最右端的點的距離rb、rl、rr。首先取rl、rr中較小的距離記為rh,可以在排除異常值的情況下表征水平方向的分區半徑;其次,rb表征垂直方向的分區半徑,取rb、rh中較大的距離作為最終的分區半徑r。
第五步為區域篩選,用于篩選出切分后的影像中屬于關節內部的點。首先,計算各分區區域內背景點的連通域信息;其次,在切面S中,關節內部區域在各分區的占比很高,故本文選擇將切面S中最大連通域的區域序號作為3D影像的篩選準則,只保留當前序號的連通域,即可得到純凈的顳下頜關節3D間隙區域的分區。
2.3 TMD自動診斷模型
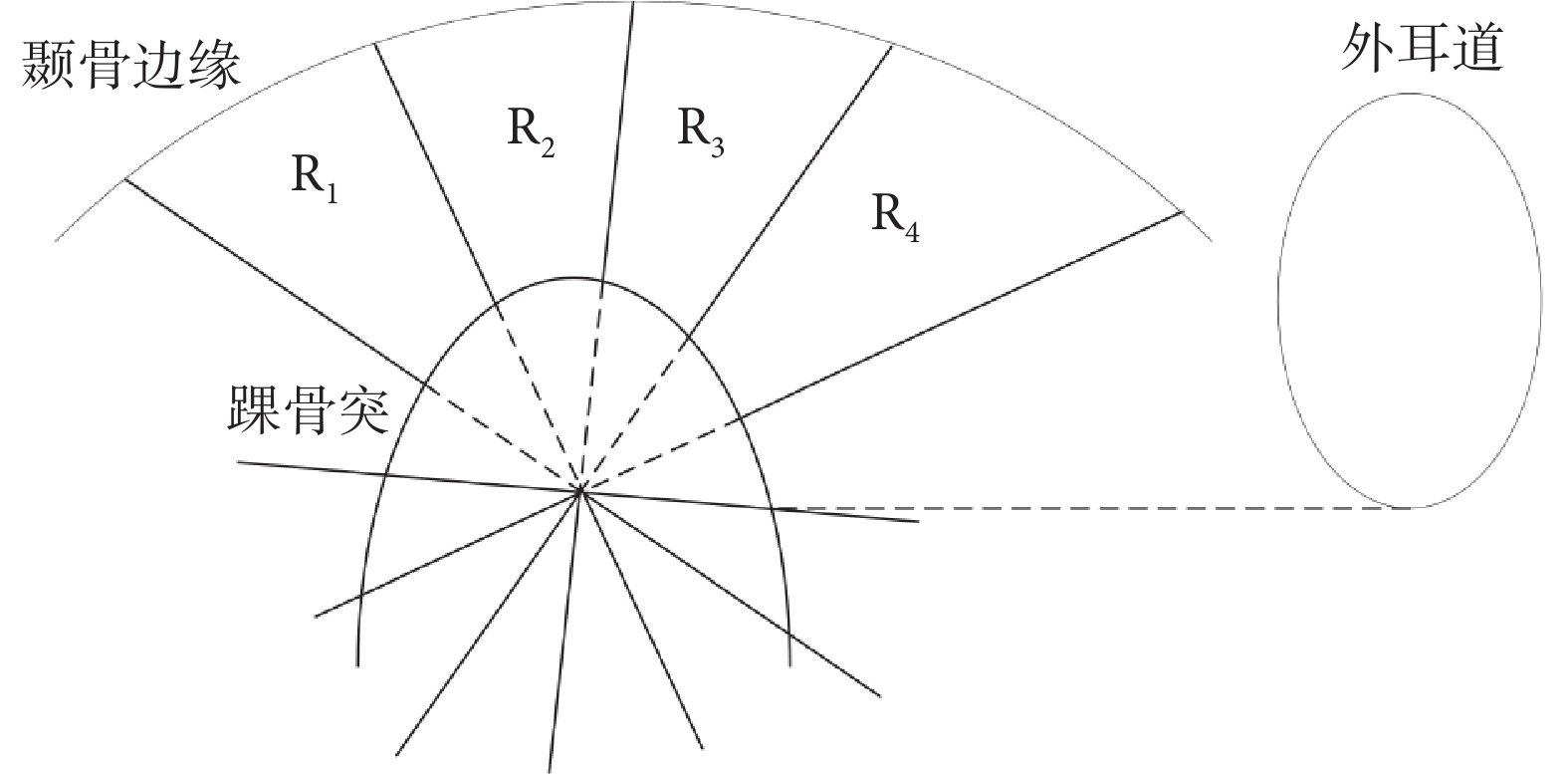
通過上述算法能夠提取出4個顳下頜關節3D間隙區域R1~R4,如圖5所示。每個區域能夠提取出最大二維(2-demension,2D)直徑、最小軸長度、網格體積、表面積、表面積體積比等共14個特征,則每個樣本能夠提取出56個特征,每個區域可提取出的特征如表2所示。通過皮爾遜相關系數選出其中7個特征用于TMD自動診斷模型的構建,選出的特征如表3所示。
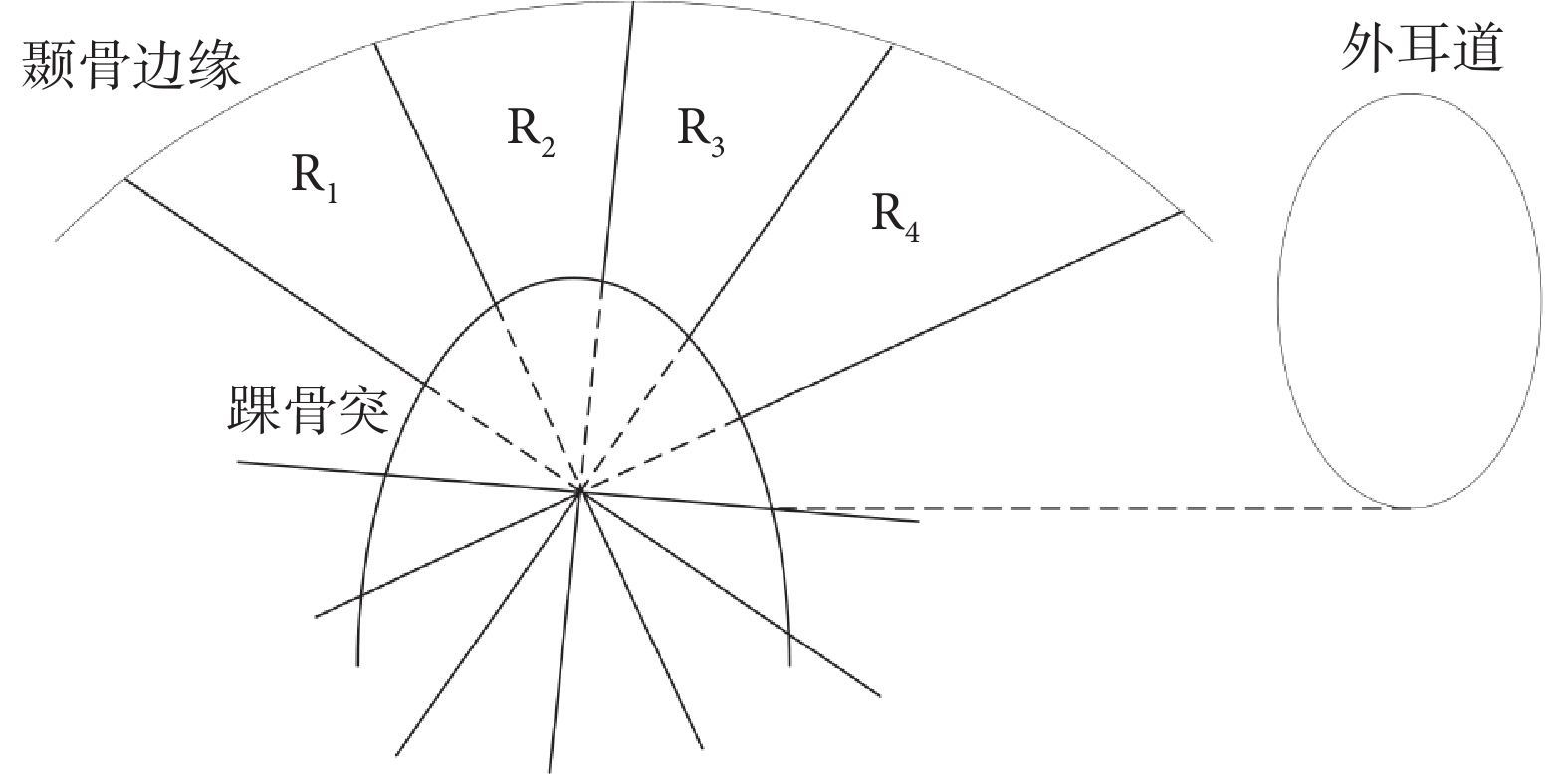 圖5
特征提取區域示意圖
Figure5.
Schematic diagram of regions for features extraction
圖5
特征提取區域示意圖
Figure5.
Schematic diagram of regions for features extraction
本研究經南開大學生物醫學倫理委員會批準(批準號NKUIRB2021115),所用數據經天津醫科大學口腔醫院授權。數據集包括76例口腔CBCT影像數據及對應電子病歷,每例CBCT影像可通過上述顳下頜關節3D間隙區域提取方法提取左右兩側的3D區域,每個區域可提取出14個特征,共構成152條數據,其中包括36條正例數據和116條負例數據,劃分為訓練集121條數據和測試集31條數據,每條數據包括56個特征及對應有無TMD的標簽。
TMD自動診斷模型采用線性支持向量機(support vector machine,SVM),以5折交叉驗證對特征進行篩選,并對所有樣本的特征進行標準化處理。評估指標采用準確率(accuracy,ACC)、F1分數(F1-score,F1)和曲線下面積(area under curve,AUC)。
為驗證本文TMD自動診斷模型的有效性,本文將TMD自動診斷模型(記作本文模型)分別與未經特征篩選的SVM、決策樹、隨機森林和多層感知機進行對比,對比結果如表4所示。雖然SVM模型的AUC值比本文模型高0.032 6,但其ACC遠低于本模型,其他模型在ACC、F1及AUC上均弱于本文模型,綜合三項評估指標,本文模型的綜合性能最強。
3 TMD智能診斷系統的構建
3.1 系統結構
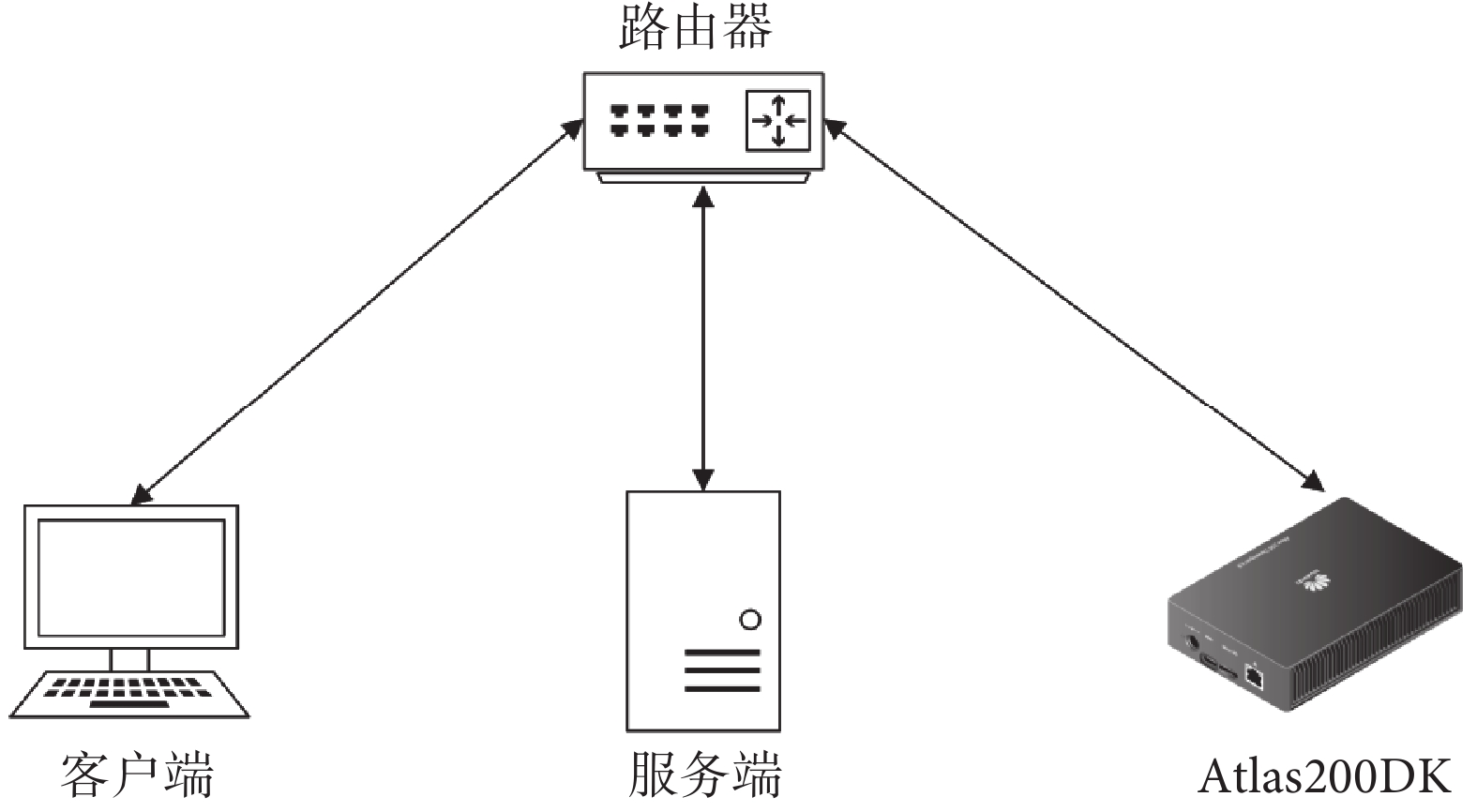
本系統包含服務端、高性能人工智能開發板(Atlas200DK,華為技術有限公司,中國)和客戶端,所有設備均部署于局域網內,其整體結構如圖6所示。其中,客戶端界面采用超文本標記語言HTML(World Wide Web Consortium,國際)和客戶端動態腳本JavaScript(Mozilla Foundation,美國)進行開發,服務端主要采用高級編程語言Python(Python Software Foundation,美國)和輕量級網頁應用框架Flask(Pallets Projects,美國)進行開發,Atlas200DK開發板部分主要采用了深度學習推理工具msame(華為技術有限公司,中國)進行推理。
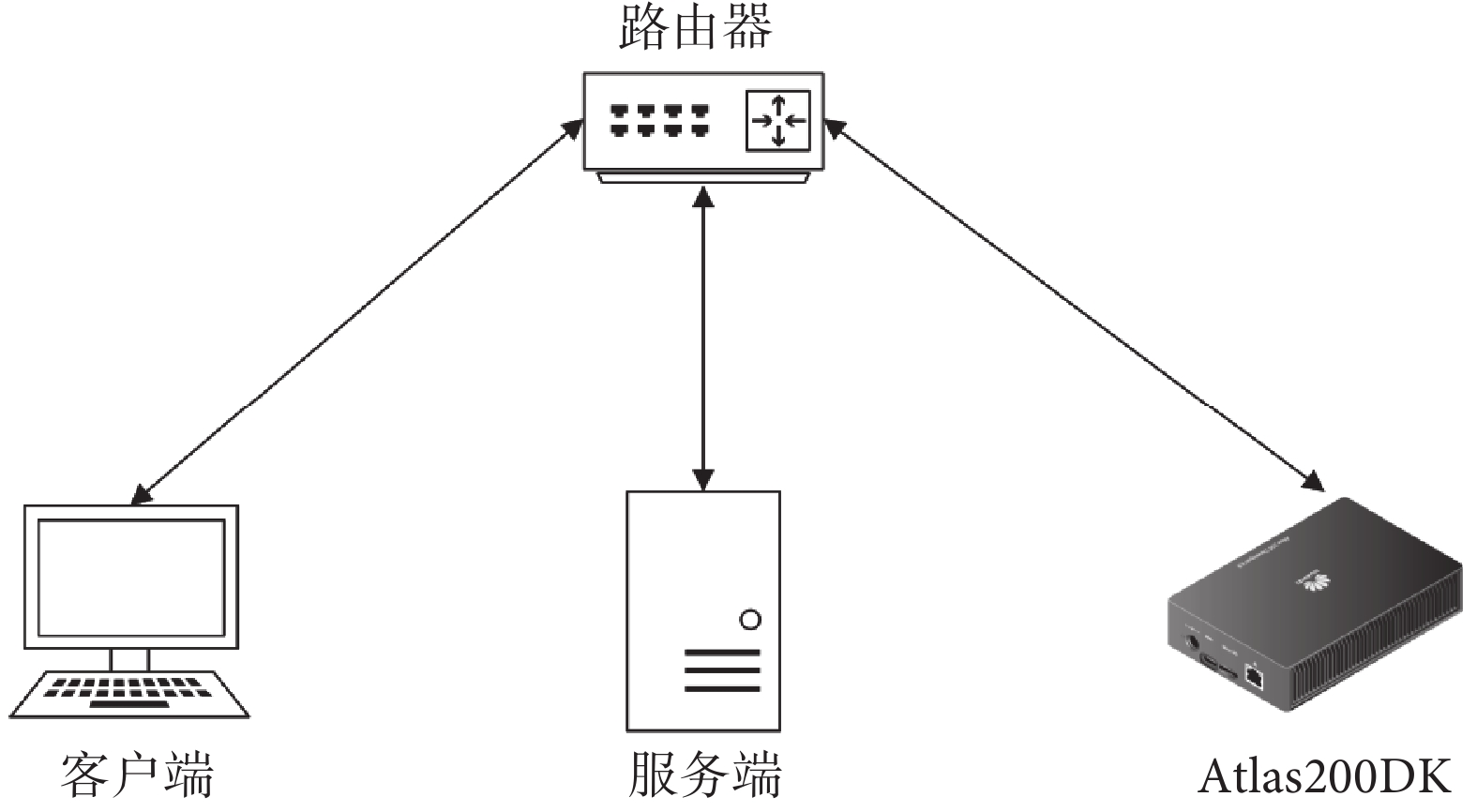 圖6
系統結構
Figure6.
System structure
圖6
系統結構
Figure6.
System structure
3.2 系統通信模塊
客戶端與服務端之間主要通過超文本傳輸協議(hypertext transfer protocol,HTTP)實現影像上傳以及診斷結果返回。服務端與Atlas200DK之間主要通過建立安全外殼協議(secure shell,SSH)連接以及通過SSH文件傳輸協議實現影像文件傳輸及推理結果返回。
3.3 自動診斷模塊
服務端接收到用戶上傳的影像文件后會先進行文件完整性驗證,通過完整性驗證的影像文件經預處理后會被傳輸至Atlas200DK進行影像分割。服務端接收到分割結果后,從分割圖中提取顳下頜關節3D間隙區域并提取其特征,送入訓練完成的SVM模型中,得到診斷結果。最終將結果返回給客戶端。
3.4 用戶界面和結果顯示模塊
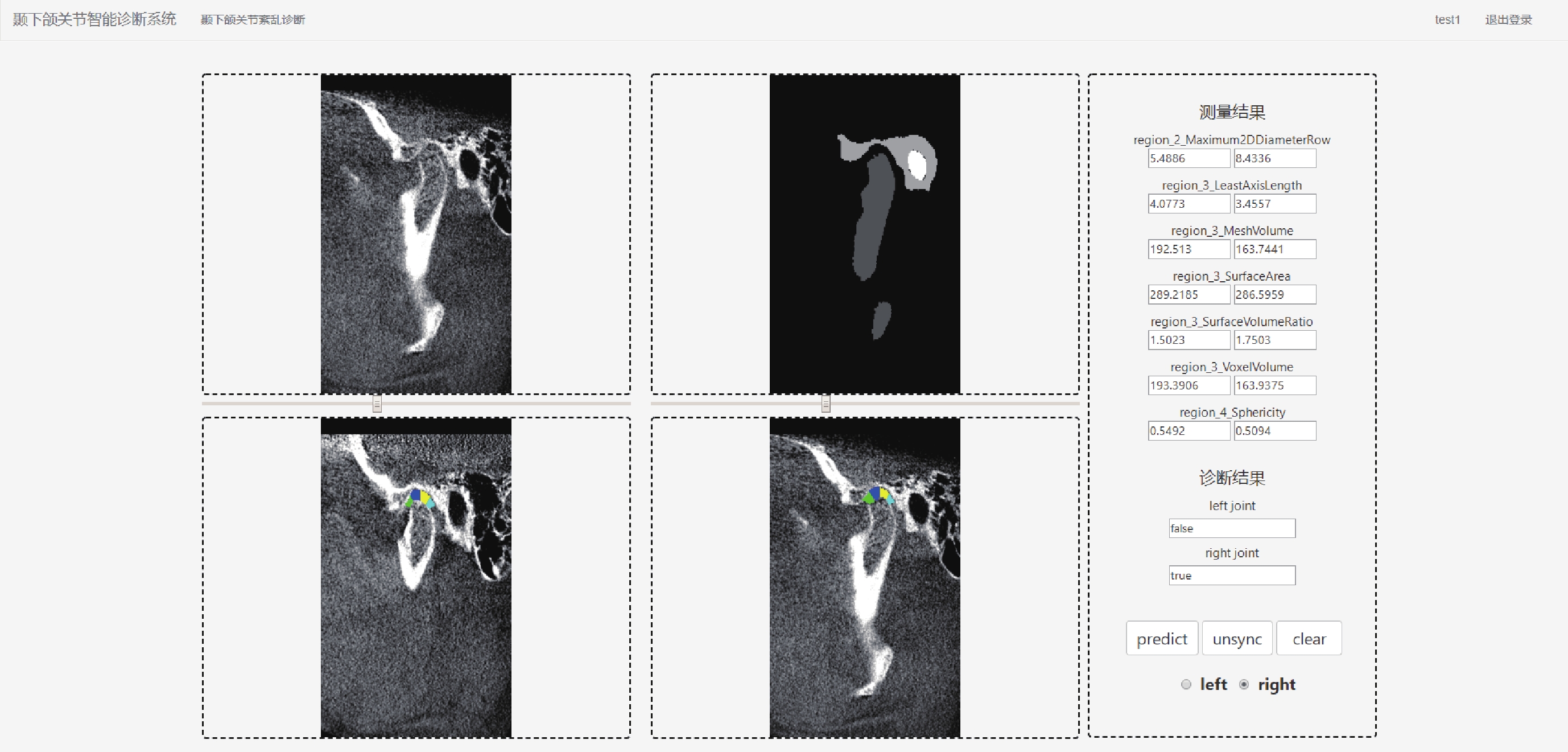
考慮到臨床需求,用戶界面和結果顯示模塊應具有登錄注冊、影像上傳、自動診斷和結果顯示功能。通過拖拽文件或點擊按鈕的方式完成影像上傳,預覽影像并確認無誤后點擊預測按鈕即可開始診斷。客戶端接收到診斷結果后,將原始影像、影像分割結果和顳下頜關節3D間隙區域提取結果展示在影像顯示框中,特征提取結果和診斷結果展示在結果顯示框內。為方便用戶使用,用戶界面還提供了左右側選擇、同步異步查看功能,點擊界面右下方的按鈕后拖動滑動條即可對比查看原始影像、分割結果和顳下頜關節3D間隙區域,如圖7所示。
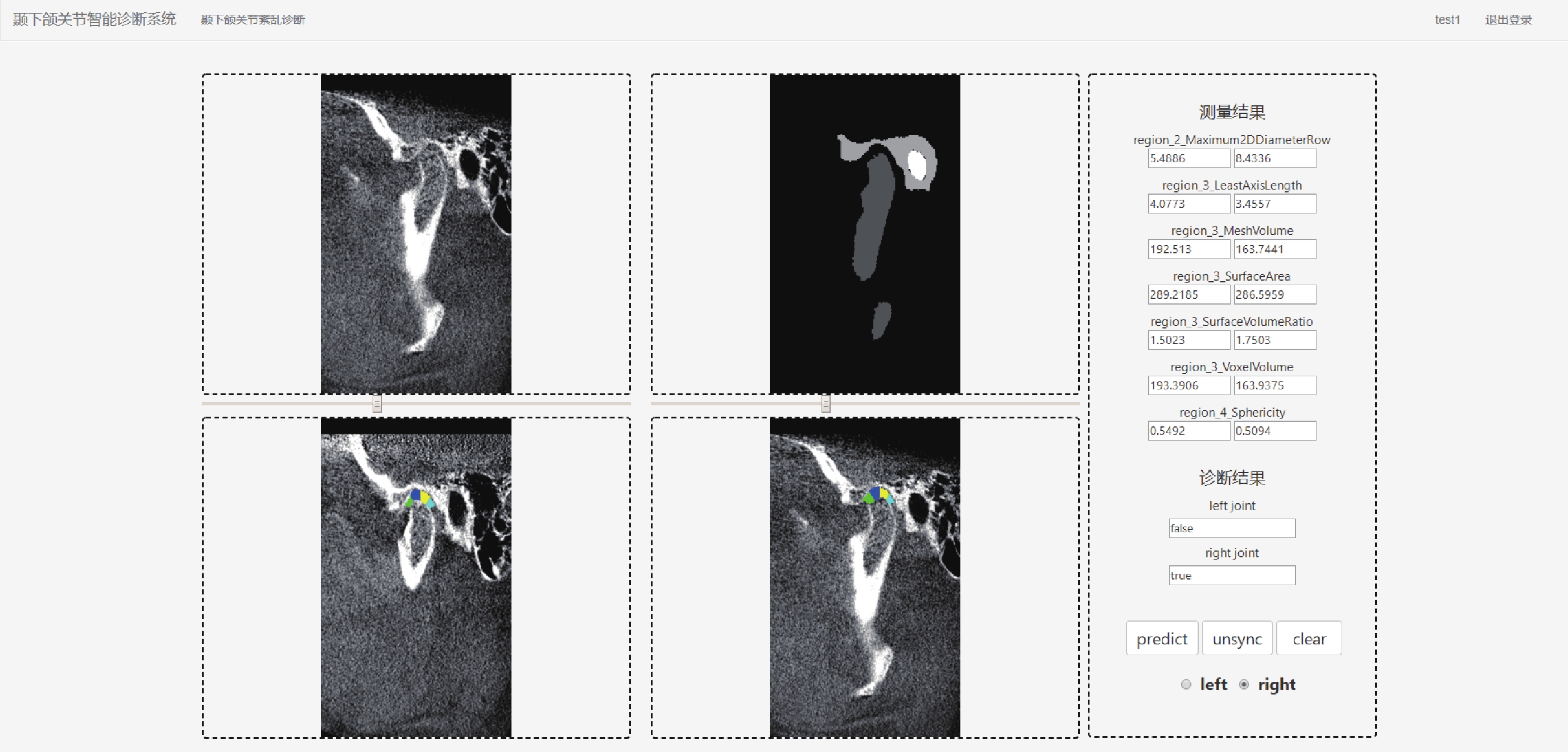 圖7
自動診斷結果界面截圖
Figure7.
Screenshot of the result interface of automatic diagnosis
圖7
自動診斷結果界面截圖
Figure7.
Screenshot of the result interface of automatic diagnosis
4 總結
本文完成了口腔CBCT影像分割模型的訓練,提出了一種顳下頜關節3D間隙區域提取的算法,并從中提取3D特征,進而建立了TMD自動診斷模型。最終,以此開發了一套基于邊緣計算的TMD智能診斷系統,實現了快速準確地分割、特征提取與診斷,即方便醫生使用,又降低了醫生的工作量。
臨床上存在顳下頜關節結構改變的患者中,具備TMD主訴患者的占比較小,使得本文采用的數據集規模較小。在CBCT影像分割方面,本文雖然采用GAN提高分割效果,但因數據集規模和有標簽數據規模較小的限制,影像分割模型的泛化能力相對較弱,未來本研究將進一步優化數據增強方法或改進模型結構,提高CBCT影像分割的準確性,增強模型泛化能力;在TMD自動診斷模型方面,本文雖然采用提取3D特征和特征篩選的方法來提高模型性能,但數據集規模較小的問題仍然導致模型F1值、AUC值較低,未來本研究將進一步收集TMD患者的CBCT影像及病歷數據,擴充數據集規模,提高模型性能。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:張明浩主要負責TMD自動診斷模型和TMD智能診斷系統的構建,論文撰寫及修訂;楊東主要負責口腔CBCT影像分割網絡的構建以及顳下頜關節3D間隙區域提取的實現;李小囡和張倩主要負責CBCT影像數據及電子病歷的收集;劉之洋主要負責實驗指導及論文審閱修訂。
倫理聲明:本研究通過了南開大學生物醫學倫理委員會的審批(批準號:NKUIRB2021115)。
0 引言
顳下頜關節紊亂病(temporomandibular joint disorder,TMD)是一種常見的口腔頜面部疾病,是骨關節炎的一個重要分支,其主要表現為下頜運動異常、疼痛、彈響、雜音以及影響咀嚼等問題,部分患者可能會發生頭痛、口面疼痛、頸痛或肩胛骨疼痛等非特異性表現[1]。TMD在前期臨床癥狀不明顯,一般于病情中期被發現,使得其不易被及早發現及治療。錐形束計算機斷層成像(cone beam computed tomography,CBCT)能夠三維(3-dimension,3D)成像以顯示患者口腔全貌,目前已廣泛應用于口腔醫學診療中。與傳統計算機斷層成像(computed tomography,CT)相比,CBCT具有拍攝范圍廣、輻射劑量低、曝光時間短、分辨率高、偽影輕等優勢[2]。傅開元等[3]將顳下頜關節骨關節病的CBCT影像特征分為6種不同類型,能夠清晰地觀察到髁突位置改變和骨質結構改變[4],便于對TMD進行更加科學準確地診斷,有助于及早發現并控制TMD。
CBCT醫學影像的人工分析很大程度上依賴醫生豐富的臨床經驗和背景知識,主觀性較強,且會消耗大量人力。利用深度學習訓練神經網絡實現自動化的醫學影像分割,能夠取得較高的準確度并可消除由于個體主觀影響帶來的差異,且在分割圖上通過數學分析及定量計算能夠判斷患者髁突位置改變和骨質結構改變,進而對TMD進行自動診斷,降低醫生的工作量。但是,深度學習的訓練通常需要大量的有標簽數據。目前的公開數據集中,CBCT影像相關的數據集大多集中于牙齒分割[5-6]和牙神經槽分割[7-8],缺少關于顳下頜關節解剖結構分割標簽的CBCT影像。而在CBCT中,逐張標注相關解剖結構的工作量較大,標注成本較高,因此本文提出了采用小樣本學習訓練分割網絡的方法。
在影像分割方面,Chen等[9]提出的深度實驗室網絡(DeepLab)采用空洞卷積在減少信息丟失的情況下擴大了感受野,并加入全連接條件隨機場(conditional random field,CRF)解決邊緣分割不準確的問題。Ronneberger等[10]提出的U型網絡(U-Net)通過跳躍連接結構將編碼器底層特征與解碼器高層特征進行融合,以提高分割精度,在生物醫學領域取得了非常好的效果。對U-Net進行3D擴展構建的網絡(3D-Unet)[11],目前已廣泛應用于醫學影像分割。Schlemper等[12]提出將注意力機制引入U-Net結構,這種提出的注意力U-Net(attention U-Net,Attn-Unet)能夠有效地突出前景部分,幫助模型捕捉目標特征。Chen等[13]提出將變換器(transformer)結構融入進U-Net(transformer U-Net,TransUnet)中,使其同時具有U-Net和transformer的優點,在醫學影像分割任務上取得了更好的效果。Cao等[14]提出的移位窗口U-Net(Swin-Unet)采用了U-Net的U型結構,但完全使用了移位窗口transformer(Swin-Transformer)[15]進行編解碼,并設計了擴展層恢復特征圖分辨率,獲得了比單純卷積神經網絡(convolutional neural networks,CNN)模型或transformer與CNN結合模型更優的效果。
在小樣本學習方面,元學習方法利用支撐集所習得的經驗來指導問詢集的任務,使得機器“學會如何學習”[16]。Goodfellow等[17]提出的生成對抗網絡(generative adversarial nets,GAN)通過生成器與判別器之間的博弈,可以利用無標簽數據生成樣本,適用于小樣本學習。Zhang等[18]提出的類別不可知網絡(class-agnostic network,CANet)通過構建由密集比較模塊和迭代優化模塊組成的框架,在單樣本和5樣本訓練上取得了優秀的效果。Dong等[19]將原型網絡引入小樣本圖像分割中,通過度量學習與排列訓練,獲得了大幅超過基準模型的性能。Lai等[20]通過半監督學習的方式對有標簽數據與無標簽數據進行訓練,減少了標注的需求量。Ouyang等[21]提出了自適應局部原型池化,并采用自監督學習的方法,在醫學影像分割上獲得了優于有標注的少樣本方法。
基于上述研究,本文采用GAN進行CBCT影像分割,并采用半監督學習的方法,用無標簽數據加強分割效果;提出了顳下頜關節3D間隙區域提取算法,并建立了TMD自動診斷模型用于開發TMD智能診斷系統,最終將其部署在位于局域網內的邊緣計算設備上,以期在保障用戶隱私的前提下,實現TMD的快速篩查與智能診斷。
1 需求分析
根據臨床需求,本系統應包括用戶界面模塊、系統通信模塊、自動診斷模塊、結果顯示模塊,應具有登錄注冊功能、影像文件上傳功能、影像分割功能、3D區域特征提取功能、TMD診斷功能、同步異步展示功能,系統整體功能模塊如圖1所示。同時為了方便用戶使用,本系統還應使中間過程進行可視化展示,保證診斷流程高效準確,用戶交互界面友好和保障用戶信息安全。
圖1
TMD智能診斷系統功能模塊
Figure1.
Functional modules of intelligent diagnostic system for TMD
2 TMD自動診斷方法
TMD自動診斷方法的流程為:首先將CBCT影像進行分割,得到3D分割圖;再通過3D分割圖對顳下頜關節3D間隙區域進行提取;最終從獲得的3D區域中提取3D特征并通過TMD自動診斷模型獲得診斷結果。
2.1 口腔CBCT影像分割
2.1.1 口腔CBCT影像數據
本研究經南開大學生物醫學倫理委員會批準(批準號:NKUIRB2021115),所用數據經天津醫科大學口腔醫院授權,回溯性收集天津醫科大學口腔醫院采集的CBCT影像數據,所有數據由CBCT系統(KaVo 3D eXam,KaVo Dental,美國)采集。本文共收集CBCT影像131例,其中25例由醫師標注顳下頜關節附近的分割標簽,標注部位為顳骨、踝骨突和外耳道。首先,將數據劃分為訓練集和測試集,其中訓練集包含19例有標簽樣本和106例無標簽樣本,測試集包含6例有標簽樣本。考慮到有標簽樣本數量較少,本文采用GAN進行半監督學習[17],利用無標簽數據增強分割的效果。
2.1.2 影像分割網絡
影像分割網絡由生成器與判別器組成,其結構如圖2所示。
圖2
影像分割網絡
Figure2.
Image segmentation network
本文生成器采用U-Net作為基礎架構,并在每層編碼塊和解碼塊之間加入了跳躍連接結構。編碼塊在傳統的殘差塊之后額外增加一層卷積塊,包括卷積、批歸一化和線性整流函數(rectified linear unit,ReLU),使編碼器中的參數占比提升,從而能夠更好地從小樣本數據中提取信息。解碼塊采用U-Net的解碼器結構,將當前層跳躍連接結構輸出與上一層輸出進行連接并輸入解碼塊中,用于融合不同尺度的信息,并輸出影像分割結果。本文在跳躍連接結構中加入了注意力塊,其中包括空間注意力和通道注意力,來進一步提升網絡的性能,其中空間注意力包括全局平均池化和柔性最大化(softmax)操作,通道注意力包括通道平均池化操作。判別器采用較為簡單的神經網絡結構,其中包括卷積層、平均池化層、線性層,激活函數采用泄漏ReLU函數(leaky ReLU,LReLU),此外本文還在部分卷積層中加入了隨機失活(Dropout)以防止過擬合。輸入為病例CBCT影像與生成器的分割結果yseg的連接;輸出為二值:0或者1,輸出為0代表判別器判定輸入的影像為生成器偽造的分割圖,輸出為1代表判別器判定輸入的影像為病例的真實分割圖。各模塊結構如圖3所示。
圖3
分割網絡各模塊結構
Figure3.
The structure of each module in the segmentation network
2.1.3 神經網絡訓練
CBCT影像中,不同的組織結構具有不同的CT值[22]。在醫學影像處理中,通常采用加窗函數的方法提取出要研究的部位,以提高醫生的效率。本文采用CBCT值區間為?600~700的窗函數對原始影像進行處理,并將數據歸一化為均值為0、方差為1的變量。其次,本文對訓練集數據進行數據增強,包括尺寸縮放、隨機旋轉、隨機裁剪、坐標軸翻轉、強度變化、強度縮放和彈性形變。最后,每個批次包括6個經過預處理的影像切塊,大小為128 × 128 × 128;其中4個切塊有標簽,2個無標簽。為了降低顯存占用,將樣本下采樣至96 × 96 × 96,其中CBCT影像采用三線性采樣,標簽采用最近鄰采樣。
在小樣本影像分割背景下,生成器損失函數需要充分考慮和利用各類有效信息。本文生成器損失函數由分割損失和對抗損失組成,如式(1)所示:
|
其中,L為生成器損失函數,LCE為交叉熵損失函數,LDice為戴斯(Dice)損失函數,Ladv為判別器的損失函數,b為Ladv的權重系數,如式(2)~式(4)所示:
|
|
|
其中,N為樣本數量,pi為樣本標簽,qi為生成器輸出,wi為第i個樣本的權重參數,yi為判別器輸出值,xi為二值標簽。
b為式(1)中Ladv的權重系數,本文引入半監督學習的溫度系數概念[23],其定義如式(5)所示:
|
其中,,n是當前循環計數值,r為溫度系數,本文默認取40.0。
判別器的目的是分辨出輸入影像的來源,故判別器損失函數要將生成器輸出以及具有真實標簽的影像輸入判別器中進行判別,其損失函數如式(6)所示:
|
其中,LD為判別器損失函數,LG和Llabel分別為判別器對生成器輸出的判別結果與其標簽的二分類交叉熵,二分類交叉熵表達式如式(7)所示:
|
其中,LBCE為二分類交叉熵,N為樣本數量,wi為每個樣本的權重參數,xi為判別器輸出值,yi為判別器對生成器預測結果判別的標簽值。LG中yi的值為0,Llabel中yi的值為1。
本文生成器與判別器均訓練300輪,每輪訓練150次,共計45 000次梯度更新。生成器優化方式選擇無動量的均方根傳播算法(root mean square propagation,RMSprop),初始學習率為0.000 1,平滑常數β = 0.99,動量M = 0。生成器設有學習率衰減機制,其表達式如式(8)所示:
|
其中,lr為當前學習率,lrinit為初始學習率,n為當前訓練輪次,nmax為訓練總輪次。
判別器的優化方式選用隨機梯度下降(stochastic gradient descent,SGD),初始學習率為0.001,動量M = 0.9,權重衰減λ = 0.000 1。
2.1.4 測試結果
本文實驗在配備深度學習加速顯卡(TITAN RTX,NVIDIA Corporation,美國)的服務器實現,使用Linux操作系統軟件Ubuntu 20.04(Canonical Ltd.,英國),實驗基于開源機器學習庫PyTorch(The Linux Foundation,美國)和開源醫療影像深度學習框架MONAI(MONAI Consortium,國際)實現。由于數據集中的有標簽數據存在邊緣區域標注不統一等問題,無法進行精確的戴斯系數(Dice coefficient,DC)計算,故本文計算DC時,在不影響關節間隙測量結果的情況下將預測結果中非人工標注區域的數值置零,即僅對影像中人工標注的區域進行DC計算。為驗證本文影像分割網絡的有效性,本文在相同的有標簽數據集上分別訓練了4種模型用于對比,包括未采用GAN結構的本文提出的分割模型(記作:本文模型-無GAN)、U-Net[10]、巢穴U-Net (U-Net++)[24]和Attn-Unet [12],這些模型在測試集(包含6例有標簽樣本,即樣本1~樣本6)上的結果如表1所示。從表1可以看出,本文提出的基于GAN的分割方法可以顯著提升分割準確率。若去掉GAN,其平均DC出現了顯著下降。此外,本文提出的分割網絡也表現出了優于U-Net、U-Net++、Attn-Unet等經典醫學影像分割網絡的性能,驗證了本文提出的分割方法的有效性。
2.2 顳下頜關節3D間隙區域提取方法
2.2.1 顳下頜關節3D間隙區域提取原理
本文將Lee等[25]提出的顳下頜關節間隙測量模型擴展至3D區域,以獲取顳下頜關節3D間隙區域,如圖4所示。其步驟共分為三步:第一,選擇踝骨突的中間切面作為基準切面,記為切面S,此切面完整包含了關節構成的三個標志性器官,即顳骨、踝骨突、外耳道;第二,在切面S中,分別將左側顳骨最低點、外耳道最低點記為Pd1、Pd2,兩點所連線段記為lbase,該線段中點記為Pfoot,以Pfoot為垂足作lbase的垂線記為lvert,再分別作左右兩直角半區的三等分線,4條三等分線分別記為lleft30、lleft60、lright30、lright60;第三,以X軸為基準,將lvert、lleft30、lleft60、lright30、lright60擴展為平面對踝骨突邊緣和顳骨邊緣之間的區域進行切分,從而獲得4個顳下頜關節3D間隙區域R1~R4。
圖4
顳下頜關節3D區域提取示意圖
Figure4.
Temporomandibular joint 3D region extraction schematic diagram
2.2.2 算法實現
本文的顳下頜關節3D間隙區域分區算法主要分為五個步驟,分別為:尋找切面、尋找定位點和切分線、線切分、圓切分、區域篩選。
第一步為尋找切面,本文將選擇3D關節區域中踝骨突的中間切面作為基準切面S,以此切面作為后續算法的基礎。
第二步為尋找定位點和切分線,定位點是關節區域劃分的起點,切分線為關節區域劃分的邊界。根據上述原理得到lbase、lvert、lleft30、lleft60、lright30、lright60和4個3D區域R1~R4。在獲取每個分區時,本文會設置對應分區的掩碼矩陣M,逐步計算出無關區域并在M中去除,最終M中遺留的區域為所尋找的關節分區。
第三步為線切分,即通過第二步中獲得的切分線來得到當前分區的30°扇形區域。以R1為例,在切面S中計算得到圍成R1的切分線的斜率與縱截距,進而得到分區內點的坐標,并在掩碼矩陣M中除去分區外的點。最后,將掩碼矩陣M從切面S以X軸方向擴展到3D影像以獲得3D影像的線切分結果。
第四步為圓切分,用以進一步細化關節間隙分區的位置。在切面S中,算法將在線切分的基礎上,計算得到包含當前關節間隙分區的半徑r,以Pfoot為圓心保留圓形區域內的點,即可獲得較為精細的關節分區。同樣,將這一掩碼結果從切面S以X軸方向擴展到3D影像,即可獲得3D影像的圓切分結果。對于r的選擇,本文分別計算Pfoot到當前分區內顳骨最低點、顳骨最左端的點、顳骨最右端的點的距離rb、rl、rr。首先取rl、rr中較小的距離記為rh,可以在排除異常值的情況下表征水平方向的分區半徑;其次,rb表征垂直方向的分區半徑,取rb、rh中較大的距離作為最終的分區半徑r。
第五步為區域篩選,用于篩選出切分后的影像中屬于關節內部的點。首先,計算各分區區域內背景點的連通域信息;其次,在切面S中,關節內部區域在各分區的占比很高,故本文選擇將切面S中最大連通域的區域序號作為3D影像的篩選準則,只保留當前序號的連通域,即可得到純凈的顳下頜關節3D間隙區域的分區。
2.3 TMD自動診斷模型
通過上述算法能夠提取出4個顳下頜關節3D間隙區域R1~R4,如圖5所示。每個區域能夠提取出最大二維(2-demension,2D)直徑、最小軸長度、網格體積、表面積、表面積體積比等共14個特征,則每個樣本能夠提取出56個特征,每個區域可提取出的特征如表2所示。通過皮爾遜相關系數選出其中7個特征用于TMD自動診斷模型的構建,選出的特征如表3所示。
圖5
特征提取區域示意圖
Figure5.
Schematic diagram of regions for features extraction
本研究經南開大學生物醫學倫理委員會批準(批準號NKUIRB2021115),所用數據經天津醫科大學口腔醫院授權。數據集包括76例口腔CBCT影像數據及對應電子病歷,每例CBCT影像可通過上述顳下頜關節3D間隙區域提取方法提取左右兩側的3D區域,每個區域可提取出14個特征,共構成152條數據,其中包括36條正例數據和116條負例數據,劃分為訓練集121條數據和測試集31條數據,每條數據包括56個特征及對應有無TMD的標簽。
TMD自動診斷模型采用線性支持向量機(support vector machine,SVM),以5折交叉驗證對特征進行篩選,并對所有樣本的特征進行標準化處理。評估指標采用準確率(accuracy,ACC)、F1分數(F1-score,F1)和曲線下面積(area under curve,AUC)。
為驗證本文TMD自動診斷模型的有效性,本文將TMD自動診斷模型(記作本文模型)分別與未經特征篩選的SVM、決策樹、隨機森林和多層感知機進行對比,對比結果如表4所示。雖然SVM模型的AUC值比本文模型高0.032 6,但其ACC遠低于本模型,其他模型在ACC、F1及AUC上均弱于本文模型,綜合三項評估指標,本文模型的綜合性能最強。
3 TMD智能診斷系統的構建
3.1 系統結構
本系統包含服務端、高性能人工智能開發板(Atlas200DK,華為技術有限公司,中國)和客戶端,所有設備均部署于局域網內,其整體結構如圖6所示。其中,客戶端界面采用超文本標記語言HTML(World Wide Web Consortium,國際)和客戶端動態腳本JavaScript(Mozilla Foundation,美國)進行開發,服務端主要采用高級編程語言Python(Python Software Foundation,美國)和輕量級網頁應用框架Flask(Pallets Projects,美國)進行開發,Atlas200DK開發板部分主要采用了深度學習推理工具msame(華為技術有限公司,中國)進行推理。
圖6
系統結構
Figure6.
System structure
3.2 系統通信模塊
客戶端與服務端之間主要通過超文本傳輸協議(hypertext transfer protocol,HTTP)實現影像上傳以及診斷結果返回。服務端與Atlas200DK之間主要通過建立安全外殼協議(secure shell,SSH)連接以及通過SSH文件傳輸協議實現影像文件傳輸及推理結果返回。
3.3 自動診斷模塊
服務端接收到用戶上傳的影像文件后會先進行文件完整性驗證,通過完整性驗證的影像文件經預處理后會被傳輸至Atlas200DK進行影像分割。服務端接收到分割結果后,從分割圖中提取顳下頜關節3D間隙區域并提取其特征,送入訓練完成的SVM模型中,得到診斷結果。最終將結果返回給客戶端。
3.4 用戶界面和結果顯示模塊
考慮到臨床需求,用戶界面和結果顯示模塊應具有登錄注冊、影像上傳、自動診斷和結果顯示功能。通過拖拽文件或點擊按鈕的方式完成影像上傳,預覽影像并確認無誤后點擊預測按鈕即可開始診斷。客戶端接收到診斷結果后,將原始影像、影像分割結果和顳下頜關節3D間隙區域提取結果展示在影像顯示框中,特征提取結果和診斷結果展示在結果顯示框內。為方便用戶使用,用戶界面還提供了左右側選擇、同步異步查看功能,點擊界面右下方的按鈕后拖動滑動條即可對比查看原始影像、分割結果和顳下頜關節3D間隙區域,如圖7所示。
圖7
自動診斷結果界面截圖
Figure7.
Screenshot of the result interface of automatic diagnosis
4 總結
本文完成了口腔CBCT影像分割模型的訓練,提出了一種顳下頜關節3D間隙區域提取的算法,并從中提取3D特征,進而建立了TMD自動診斷模型。最終,以此開發了一套基于邊緣計算的TMD智能診斷系統,實現了快速準確地分割、特征提取與診斷,即方便醫生使用,又降低了醫生的工作量。
臨床上存在顳下頜關節結構改變的患者中,具備TMD主訴患者的占比較小,使得本文采用的數據集規模較小。在CBCT影像分割方面,本文雖然采用GAN提高分割效果,但因數據集規模和有標簽數據規模較小的限制,影像分割模型的泛化能力相對較弱,未來本研究將進一步優化數據增強方法或改進模型結構,提高CBCT影像分割的準確性,增強模型泛化能力;在TMD自動診斷模型方面,本文雖然采用提取3D特征和特征篩選的方法來提高模型性能,但數據集規模較小的問題仍然導致模型F1值、AUC值較低,未來本研究將進一步收集TMD患者的CBCT影像及病歷數據,擴充數據集規模,提高模型性能。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:張明浩主要負責TMD自動診斷模型和TMD智能診斷系統的構建,論文撰寫及修訂;楊東主要負責口腔CBCT影像分割網絡的構建以及顳下頜關節3D間隙區域提取的實現;李小囡和張倩主要負責CBCT影像數據及電子病歷的收集;劉之洋主要負責實驗指導及論文審閱修訂。
倫理聲明:本研究通過了南開大學生物醫學倫理委員會的審批(批準號:NKUIRB2021115)。