針對前額單通道腦電信號特征提取能力不足,導致疲勞檢測精度降低的問題,本文提出一種基于有監督對比學習的疲勞特征提取及分類算法。首先,通過經典模態分解對原始信號進行濾波,提高信噪比;其次,考慮到一維信號在信息表達上的局限性,利用有重疊采樣將信號轉換為二維結構,同時表達信號短期內和長期間變化;由深度可分離卷積構建特征提取網絡,加速模型運算;最后,通過聯合有監督對比損失與均方誤差損失對模型進行全局優化。實驗表明,該算法對三種疲勞狀態分類的平均準確度可達75.80%,相較于其它先進算法均有較大幅度提高,顯著提高了單通道腦電信號進行疲勞檢測的準確性與可行性。本文研究為單通道腦電信號應用提供了有力支持,也為疲勞檢測研究提供了新思路。
引用本文: 楊慧舟, 劉云飛, 夏麗娟. 前額單通道腦電信號的疲勞特征提取及分類算法. 生物醫學工程學雜志, 2024, 41(4): 732-741. doi: 10.7507/1001-5515.202312026 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
0 引言
近年來,隨著機動車保有量的快速增加,交通事故的發生數量也在不斷增加。據統計,交通事故的首要原因是疲勞駕駛,約有20%~30%的事故發生在駕駛員降低警惕時[1]。因此,在駕駛過程中及時地向駕駛員提供警惕提醒至關重要。
目前針對駕駛員疲勞檢測的研究,主要基于非生理性信息與生理性信息。基于非生理性信息的研究,大多從車輛的駕駛狀態[2-4]與駕駛員的面部動作[5-7]進行判斷,但獲取相關信息時易受光線干擾,影響檢測準確度[8]。相較于非生理性信息,生理性信號記錄人體生理變化,能夠更加客觀地反映駕駛員的狀態。尤其是腦電圖(electroencephalography,EEG)直接記錄神經信號,被認為是疲勞檢測的黃金標準[9]。
在基于EEG信號的疲勞檢測算法中,有效的特征提取是提高檢測精度的關鍵因素。當前研究中的特征提取方式主要分為兩種:手動特征提取和基于深度學習的自動特征提取。手動提取的特征集中在信號時域、頻域和時頻域上,以時頻特征的應用最為廣泛。Shi等[10]提出使用微分熵(differential entropy,DE)進行疲勞檢測,并與其它四個特征的性能進行比較,實驗證明DE是反映疲勞變化最穩定的EEG特征。Wu等[11]通過短時傅里葉變換提取EEG信號中的功率譜密度(power spectral density,PSD)特征,與DE特征相結合用于疲勞檢測,結果顯示相較于其它方法,平均誤差有所減少。盡管手動提取特征在疲勞檢測中已經被證實為有效方法,但該過程很大程度上依賴于專家經驗,而且只能提取固定的一類或幾類特征,無法完全表征EEG信號。此外,手動提取的特征在不同樣本個體上的檢測精度存在較大差異,魯棒性不佳。鑒于上述問題,一些學者研究基于深度學習的特征提取網絡,從EEG信號中自適應地實現特征提取,以提高算法對不同個體的適應性。Lawhern等[12]提出針對EEG信號的緊湊型神經網絡(EEGNet),將EEG信號直接輸入到網絡中實現特征提取與分類,并使用交叉熵(cross entropy,CE)損失函數減小預測結果與真實標簽的差異。Ko等[13]首先從EEG信號中提取DE特征,然后通過警戒卷積神經網絡(vigilance convolutional neural network,VIGNet)進一步提取深層次特征,該方法與傳統方法相比更具解釋性和魯棒性。Shi等[14]提出自動編碼長短期記憶網絡(autoencoder to long short-term memory network,CAE-LSTM),首先通過自動編碼器對手動提取的EEG特征進行編碼,然后利用長短期記憶網絡(long short-term memory,LSTM)進行疲勞識別,最后使用均方誤差(mean square error,MSE)作為損失函數提高分類精度,實驗證明所提算法檢測精度有所提高。Zhang等[15]提出LSTM與膠囊網絡相結合的膠囊記憶模型(LSTM with attention capsule network,LSTM-AttCaps),通過低級膠囊層和高級膠囊層挖掘特征中的關鍵局部信息和全局信息。總結上述方法可知,基于深度學習的特征提取方式,除了與網絡本身設計有關,還依賴于損失函數對于網絡的優化,但常用的CE損失與MSE損失是通過提高預測精度間接提高網絡提取特征能力,而非直接根據提取的特征對網絡進行優化,因此在這些損失優化下提取出的特征,表征準確性仍有提升的空間。
目前,大多數有關EEG信號的疲勞檢測研究都基于國際10-20標準導聯系統,采集頭皮上多通道信號。這種穿戴設備體積較大、不易移動,難以日常佩戴以檢測疲勞[16-17]。已有研究證明,從人體前額能采集到高質量EEG信號,并且其單通道的設置減小了算法運算量及設備功耗,具有極高的實用價值[18-20]。但單通道EEG信號在疲勞檢測時的精度普遍較低,還需進一步提升[21-23]。
針對上述問題,本文將對前額單通道EEG信號下的特征提取及分類算法展開研究,提出基于深度學習的特征提取網絡,以期對特征進行自適應地提取;同時希望對信號進行一定預處理,以提高信號的質量和數量,使網絡盡可能獲取足夠多的深層信息。此外,為進一步加強網絡提取有效特征的能力,可從特征本身考慮,直接根據提取出的特征設計相應損失函數反饋至網絡,以提高特征表征疲勞的準確性。期望通過本文研究,能找到更為有效的特征提取方法,進一步提高單通道EEG信號的疲勞檢測精度,為EEG疲勞檢測提供新思路。
1 模型和方法
1.1 整體框架
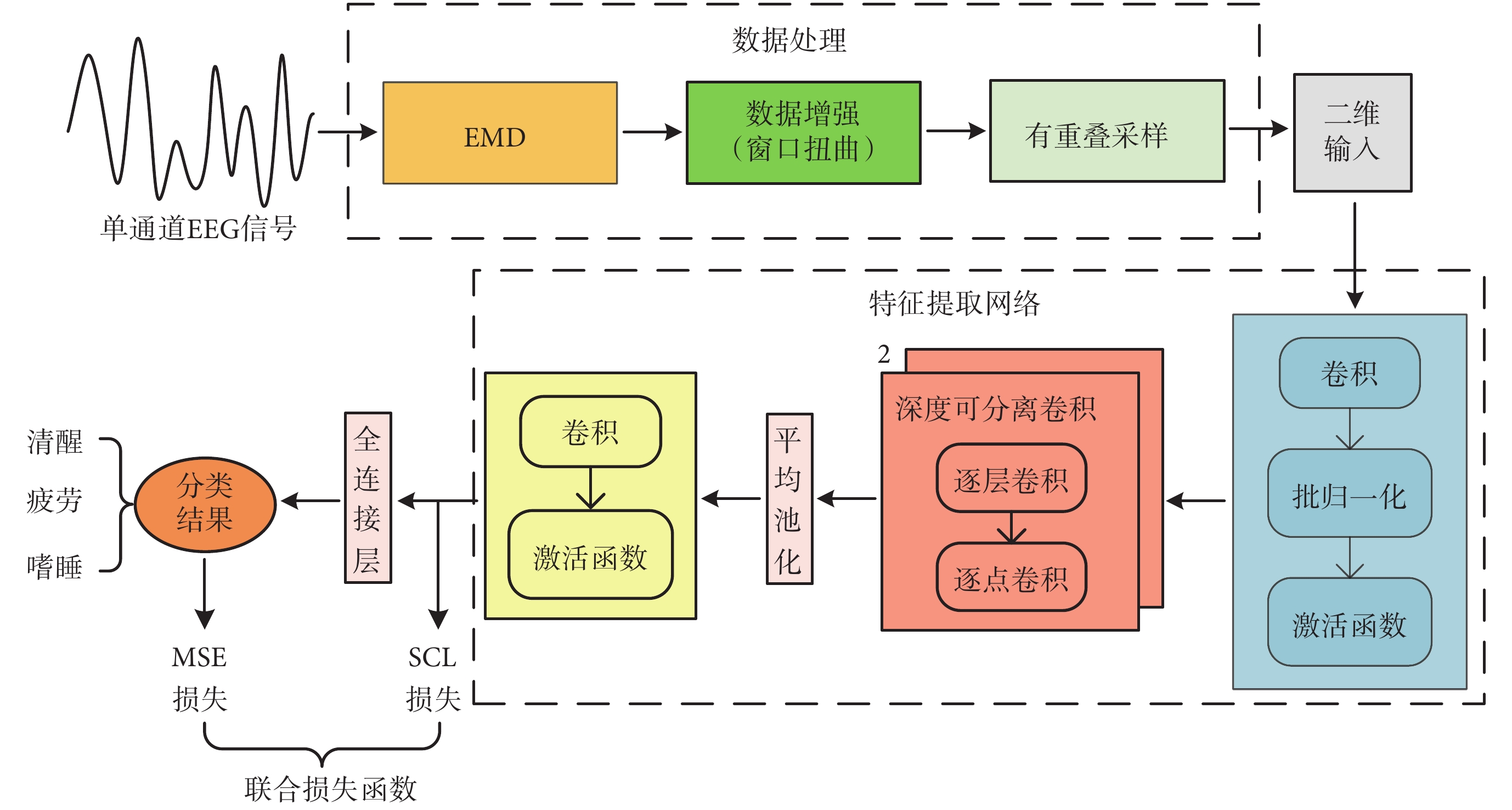
本文所提出算法主要包括數據處理與特征提取兩部分,整體流程如圖1所示。在數據處理階段, EEG信號首先通過經典模態分解(empirical mode decomposition,EMD)濾除高頻噪聲,其次將信號根據所屬的疲勞程度類別進行數據增強,以平衡不同類別間的數據量,最后對信號進行有重疊的采樣,實現從一維信號到二維輸入的轉變。在特征提取階段,構建以深度可分離卷積為核心的神經網絡來加快模型運行速度,并通過卷積、池化等方式實現對特征的有效提取。最后,通過全連接層得到分類結果。為提高分類效果,由有監督對比學習(supervised contrastive learning,SCL)損失和MSE損失共同構成的損失函數,對特征提取網絡進行參數優化。
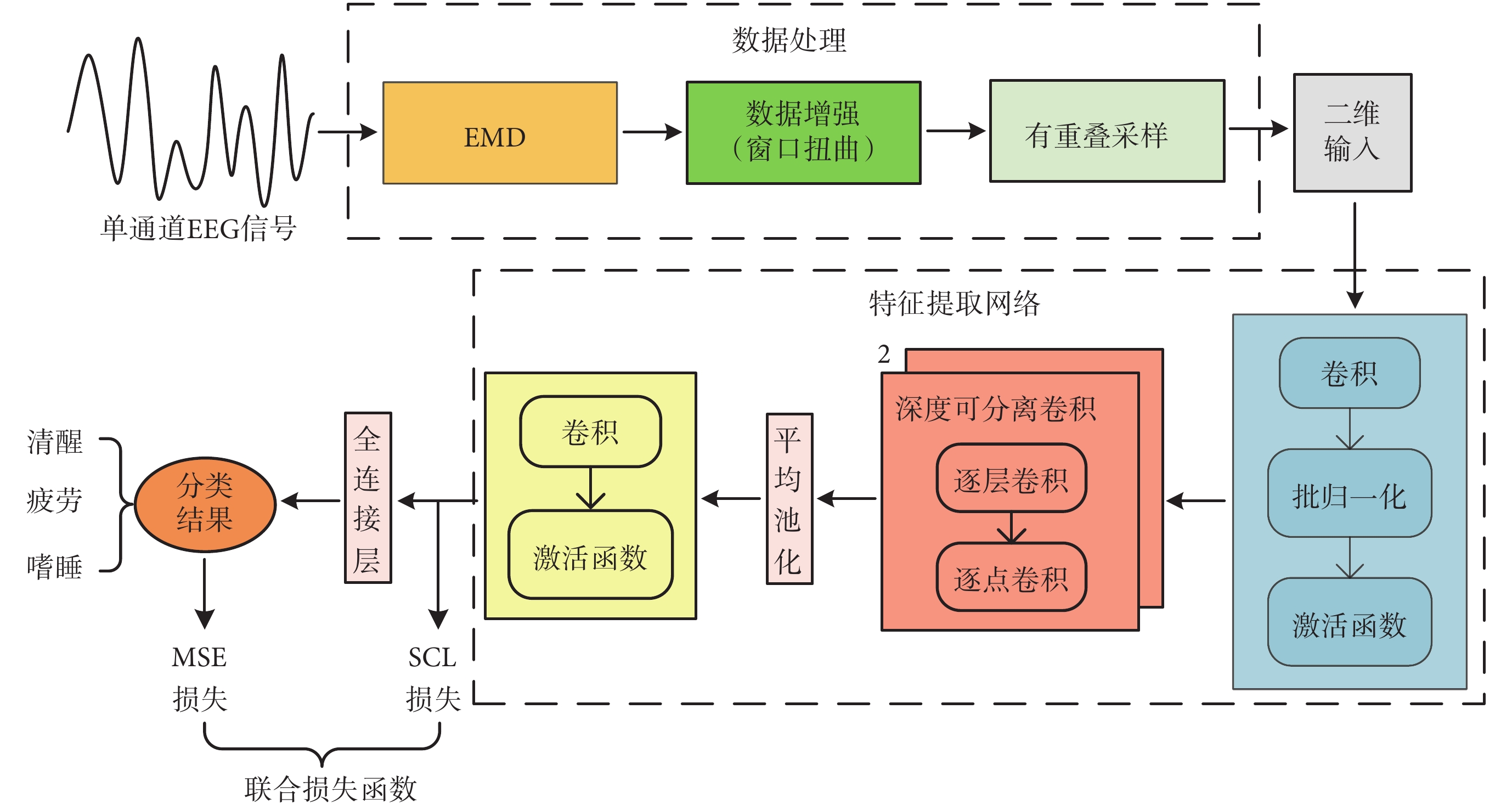 圖1
算法整體框架
Figure1.
Overall framework of the proposed algorithm
圖1
算法整體框架
Figure1.
Overall framework of the proposed algorithm
1.2 EEG信號預處理
1.2.1 基于EMD的信號降噪
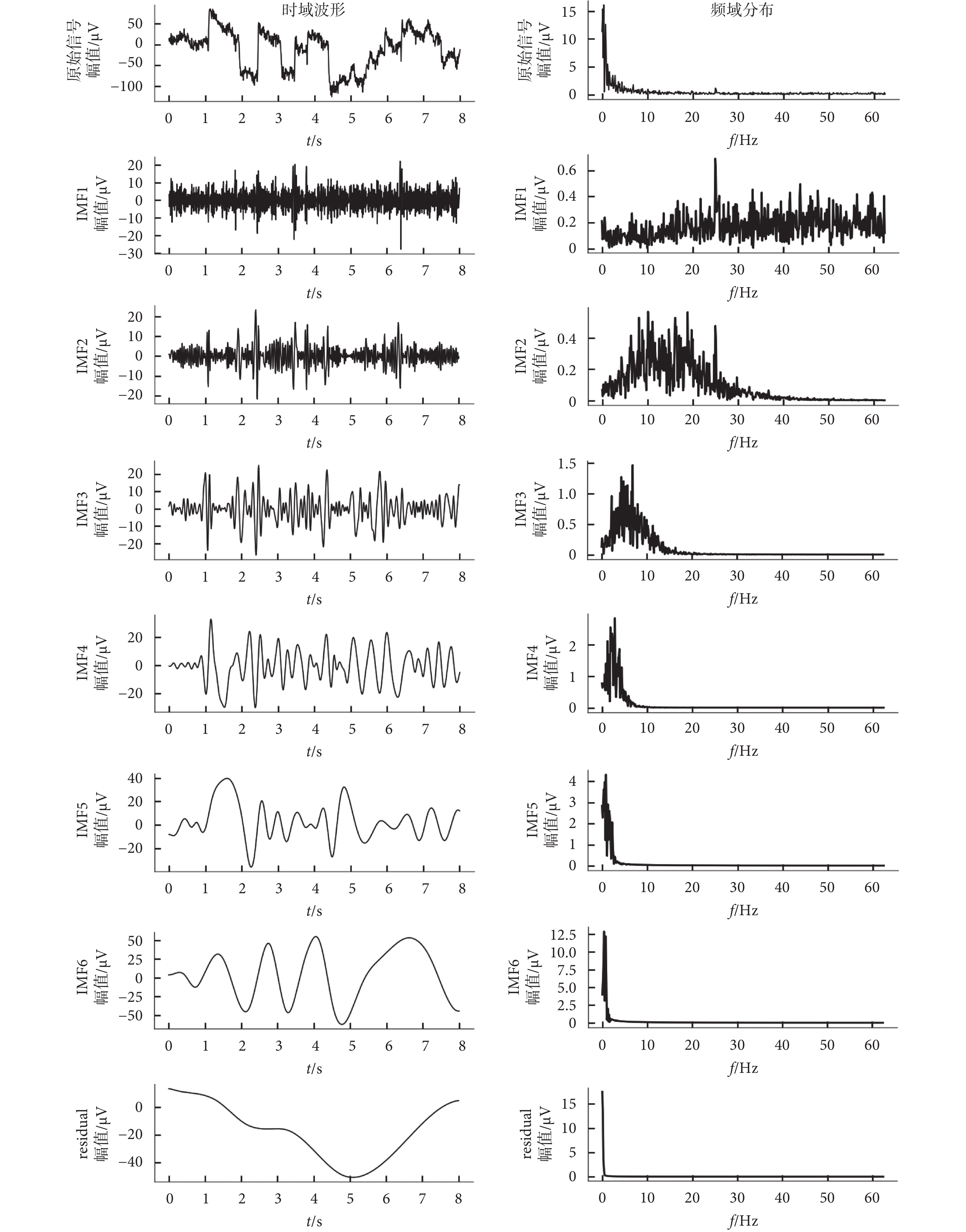
EMD能夠根據信號自身特性,將信號自適應地分解為不同頻率的多個分量,實現對特定頻率的有效提取[24]。對EEG信號進行EMD算法分解后的結果如圖2所示,第一縱列,依次為原始信號及原始信號分解后的6個固有模態函數(intrinsic mode function,IMF)分量(IMF1~IMF6)和一個殘余量(residual),第二縱列為第一列中各信號對應的頻域表達。
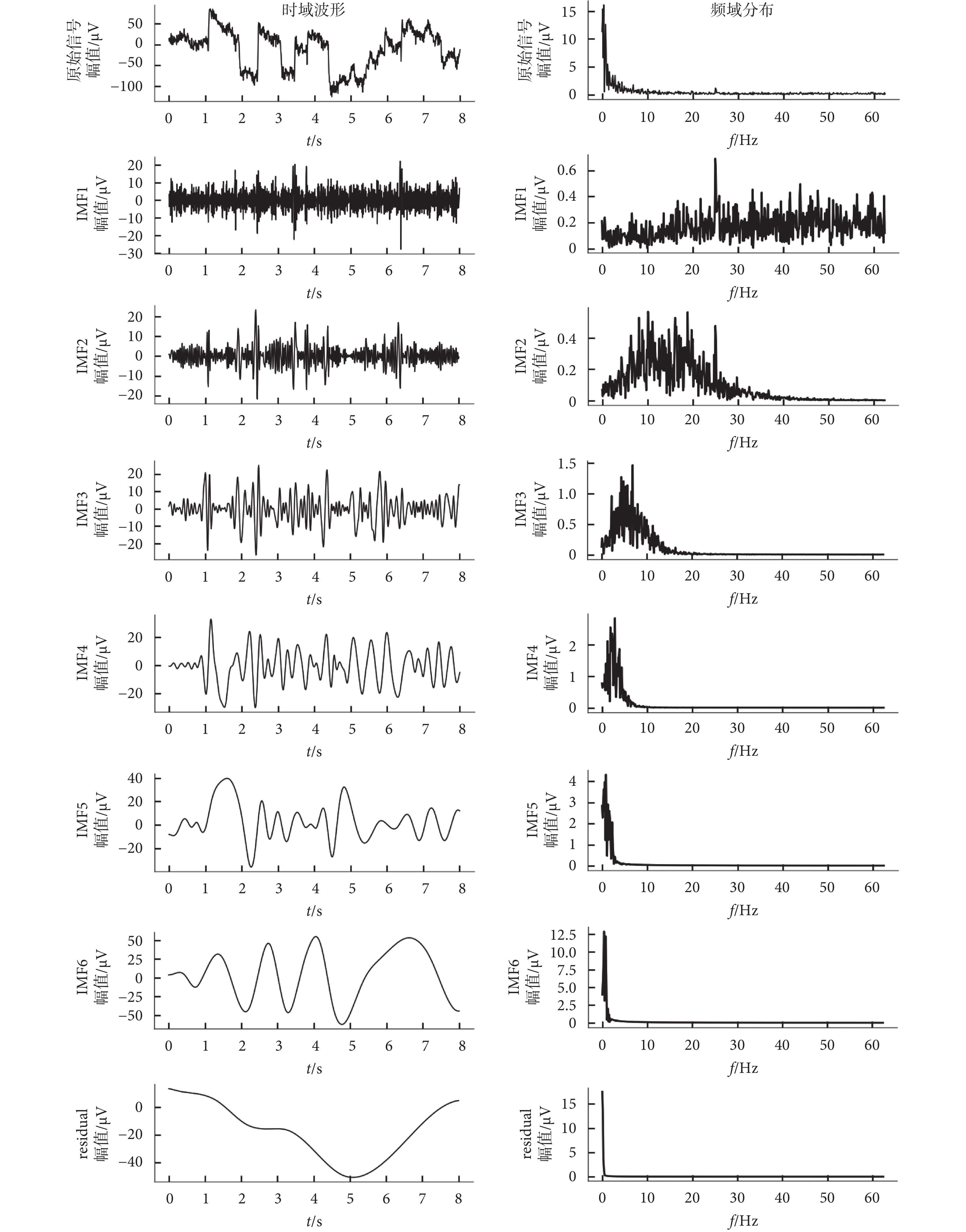 圖2
EMD分解時/頻域結果
Figure2.
Time/frequency domain results of EMD decomposition
圖2
EMD分解時/頻域結果
Figure2.
Time/frequency domain results of EMD decomposition
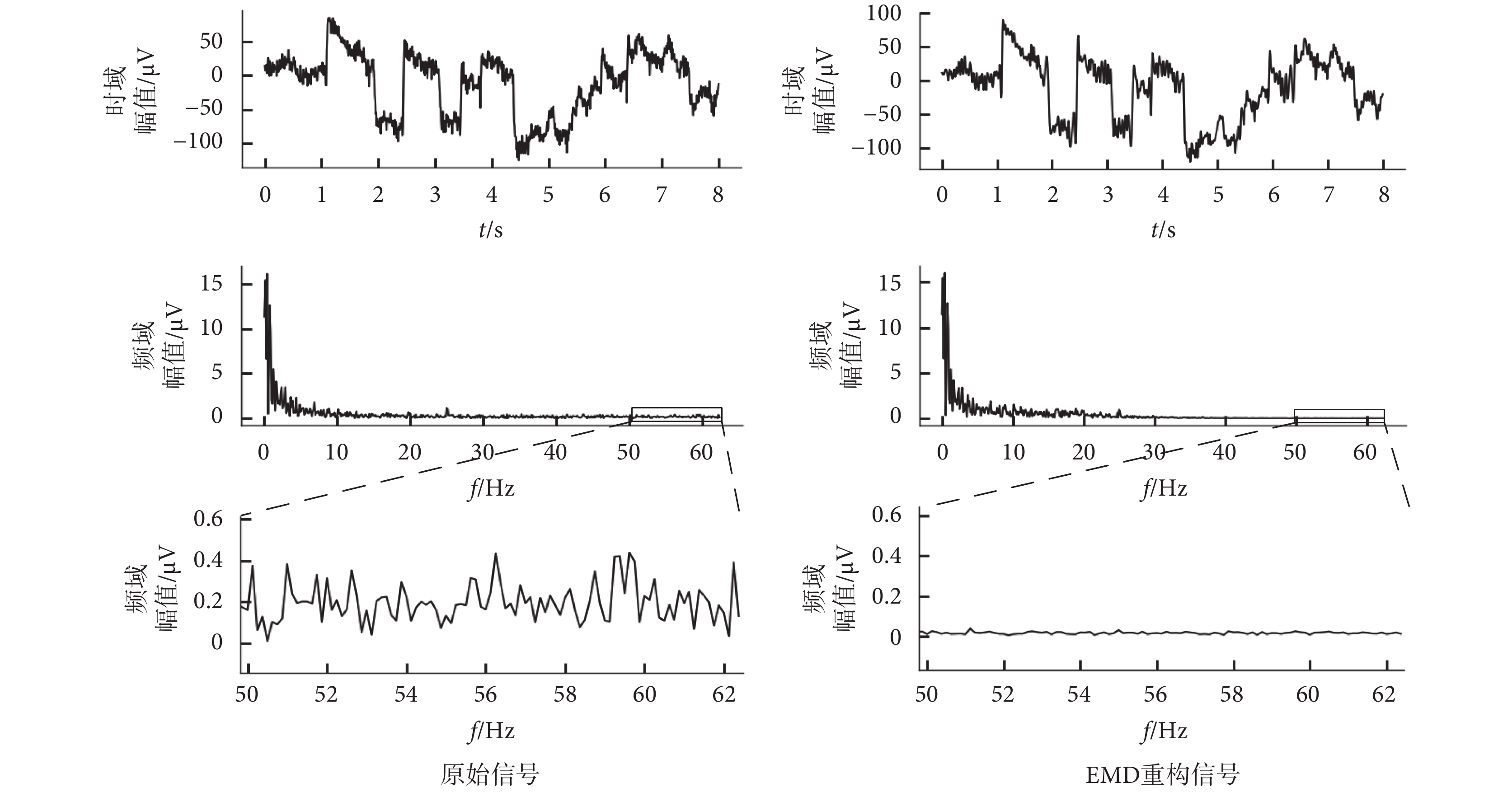
考慮到EEG信號中的噪聲頻率通常在50 Hz以上,因此在保留大部分低頻信號的前提下,濾除IMF1分量實現對EEG信號的濾波。原始信號和重構信號的時域、頻域結果如圖3所示。從時域結果可以看出,重構后的信號毛刺更少。從頻域結果比較可以看出,重構后的信號在保留了大部分低頻有效信號的同時,有效抑制了高頻噪聲。此外,對原始信號和重構信號進行信噪比分析,將IMF1分量作為噪聲信號,得到原始信號與重構信號的信噪比分別為16.49 dB和17.58 dB,信噪比的提升證明了濾波的有效性。
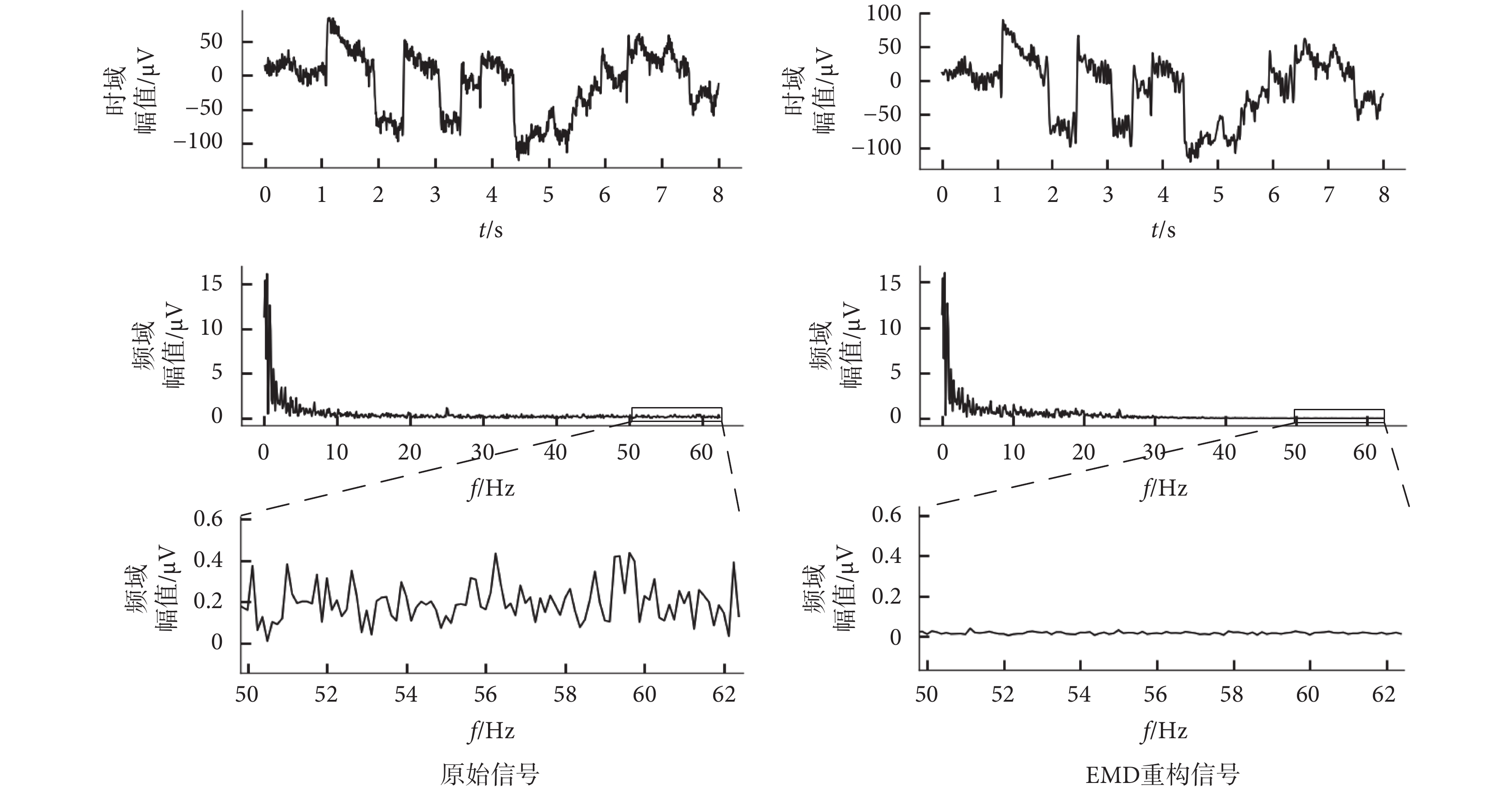 圖3
原始信號和EMD重構信號的時/頻域圖
Figure3.
Time/frequency domain diagram of original signal and EMD reconstructed signal
圖3
原始信號和EMD重構信號的時/頻域圖
Figure3.
Time/frequency domain diagram of original signal and EMD reconstructed signal
1.2.2 數據增強與數據重構
為了避免模型在訓練過程中只專注于對某一類別的學習,需要確保不同類別數據的數量近似相等,從而實現對特征的有效提取。因此,在對信號進行特征提取前,需要進行數據擴充。本文使用窗口扭曲的方法對數據進行擴充,即以固定長度的時間序列窗口對信號進行隨機選取,并對選中的數據進行拉伸或壓縮[25]。本文中,時間序列窗口大小為信號數據量的10%,拉伸系數設置為2,壓縮系數設置為0.5。數據增強應用于訓練集中,以數量最多的一類數據作為目標數,擴充其它類別數據,實現數據平衡。
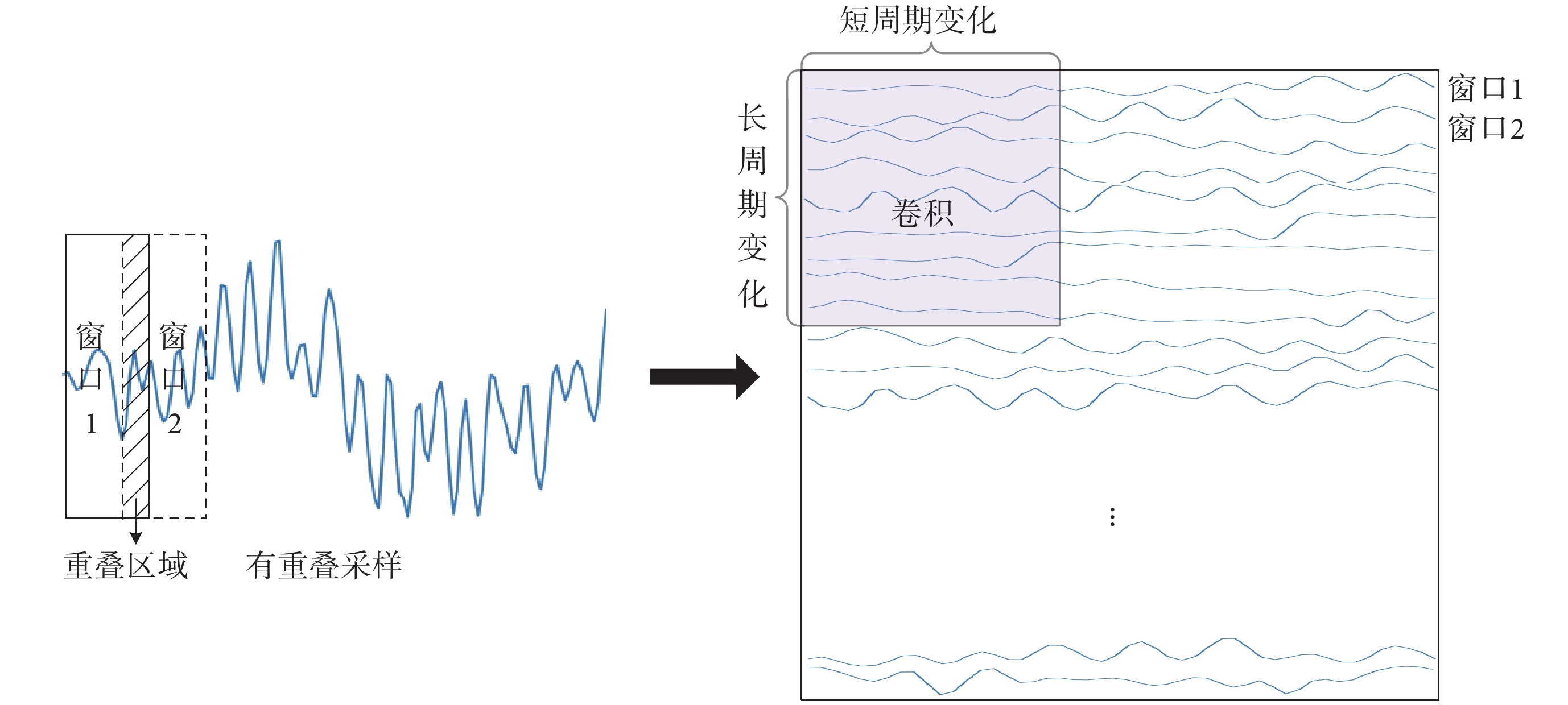
EEG信號作為時間序列信號,其傳統的一維結構包含的信息量較少,只能呈現相鄰時間點上的變化。目前已有研究證明,將信號由一維結構變化為二維結構,更有利于信息的表達與后續網絡的特征提取[26]。因此,本文通過窗口大小為48,重疊大小為28的有重疊采樣將一維信號轉化為二維結構,打破原始一維結構中表示能力的瓶頸,同時表達短期內變化的信號與長期間變化的信息,使網絡獲得更多的信息量,以便進行下一步的特征提取。具體數據重構方式如圖4所示。
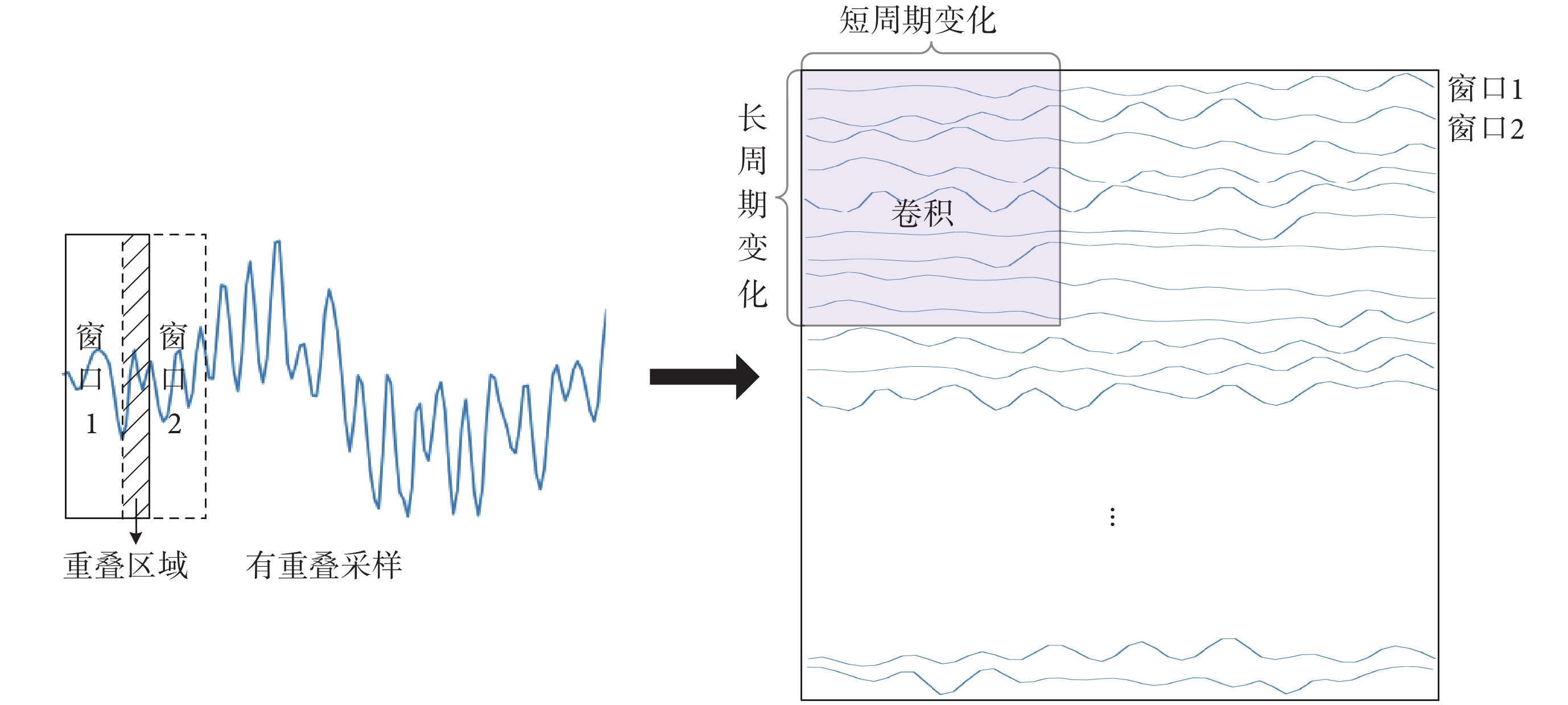 圖4
有重疊采樣進行數據重構
Figure4.
Data reconstruction with overlapping sampling
圖4
有重疊采樣進行數據重構
Figure4.
Data reconstruction with overlapping sampling
1.3 疲勞特征提取網絡設計
特征提取網絡的設計如圖1所示,具體的網絡結構參數如表1所示。二維結構的信號首先經過卷積進行特征的初步提取,同時通過批歸一化加速網絡的學習速度。為了提高網絡的運算速度,使用硬自門控激活函數(hardswish,HS)作為激活函數(以符號HS表示)[27],其計算方法如式(1)所示:
 |
其中,x代表該激活函數的輸入值,即神經網絡中某一層的輸出值。
初步提取的特征經過兩層深度可分離卷積層進行進一步的處理。與傳統的卷積相比,深度可分離卷積將卷積分為兩部分:深度卷積和逐點卷積,通過對每個通道單獨進行卷積實現模型參數量的減少,降低計算成本。經過深度可分離卷積可得到尺寸為12 × 16 × 16的特征,為了進一步提高網絡訓練速度,使用平均池化層對樣本進行降采樣。通過卷積層與hardswish激活函數對降采樣后的特征進行最終的提取,并通過全連接層得到最后的疲勞分類結果。
1.4 損失函數設計
為實現對特征的有效提取,本文提出使用SCL損失對特征提取網絡進行優化。經典的對比學習在構建正負樣本對時,通常將樣本本身與其增強后的數據樣本作為正樣本對,而其它樣本作為負樣本對,這樣的方式很容易忽略同一類樣本的關聯特征。因此,本文選擇以樣本標簽作為條件的SCL損失進行特征提取(以符號LSCL表示)[28],其計算方法如式(2)所示:
 |
其中,M表示每個批次數據量的大小。yi和yj分別表示錨點樣本i和樣本j的標簽。 表示一個批次中標簽為yi的樣本數量。li ≠ j ∈{0, 1},
表示一個批次中標簽為yi的樣本數量。li ≠ j ∈{0, 1}, 和
和 是相似的指標函數。例如,若i ≠ j,li ≠ j ∈{0, 1} = 1,否則li ≠ j ∈{0, 1} = 0。
是相似的指標函數。例如,若i ≠ j,li ≠ j ∈{0, 1} = 1,否則li ≠ j ∈{0, 1} = 0。 為樣本i和樣本j之間的余弦相似度,其中Vi和Vj分別表示為樣本i和樣本j的高等特征向量,T為轉置符號。同理,si,k表示樣本i和樣本k之間的余弦相似度。τ表示溫度參數,用于調節相似度計算的敏感度,在本文中將其設置為0.07。
為樣本i和樣本j之間的余弦相似度,其中Vi和Vj分別表示為樣本i和樣本j的高等特征向量,T為轉置符號。同理,si,k表示樣本i和樣本k之間的余弦相似度。τ表示溫度參數,用于調節相似度計算的敏感度,在本文中將其設置為0.07。
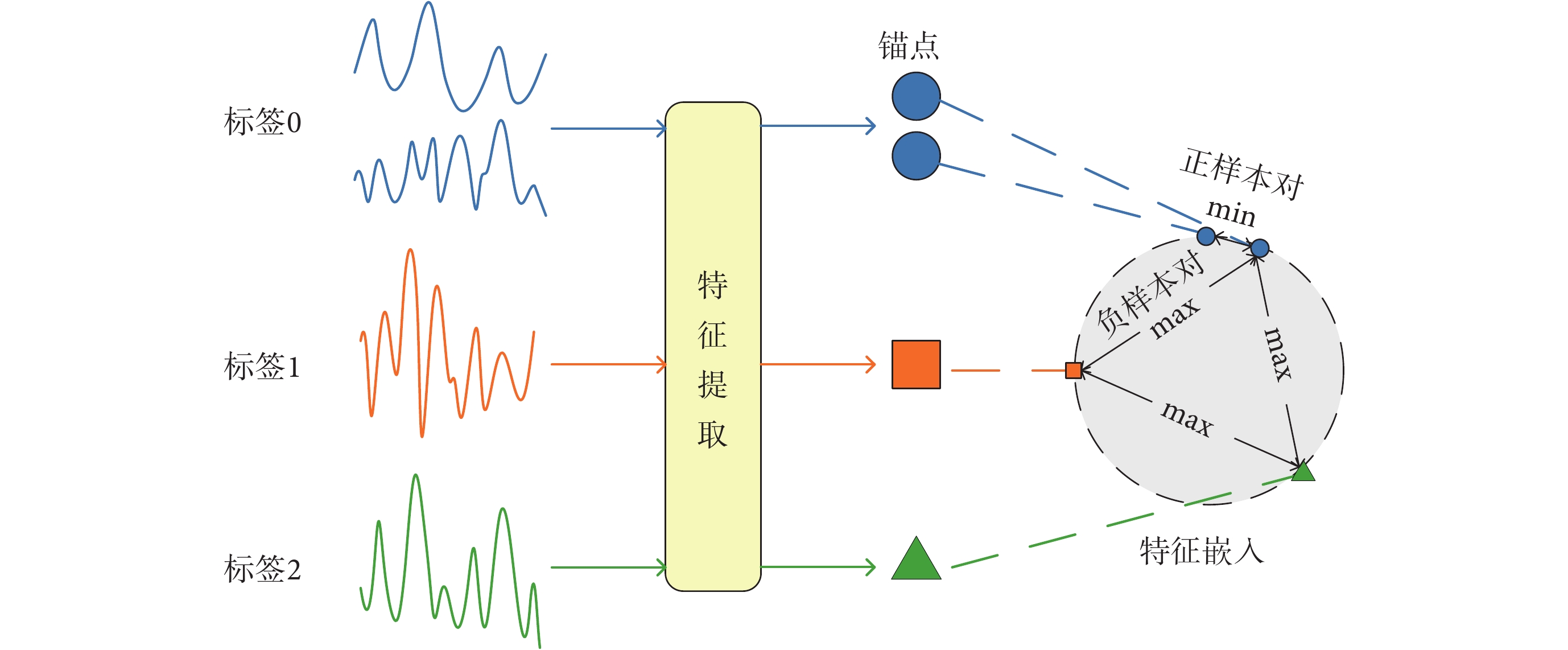
利用SCL損失進行特征提取,優化方式如圖5所示。在采集EEG信號時,根據不同疲勞程度為其賦予相應的標簽,即“標簽0”、“標簽1”和“標簽2”。對EEG信號進行特征提取后,能夠獲得對應的特征值。取其中某個特征作為錨點,將與錨點具有相同標簽的特征和錨點組成一對正樣本對,與錨點具有不同標簽的特征和錨點組成負樣本對。所有特征嵌入到特征空間中,通過SCL損失最小化(min)正樣本對之間的特征距離,同時最大化(max)負樣本對之間的特征距離,實現對所提取特征的優化。
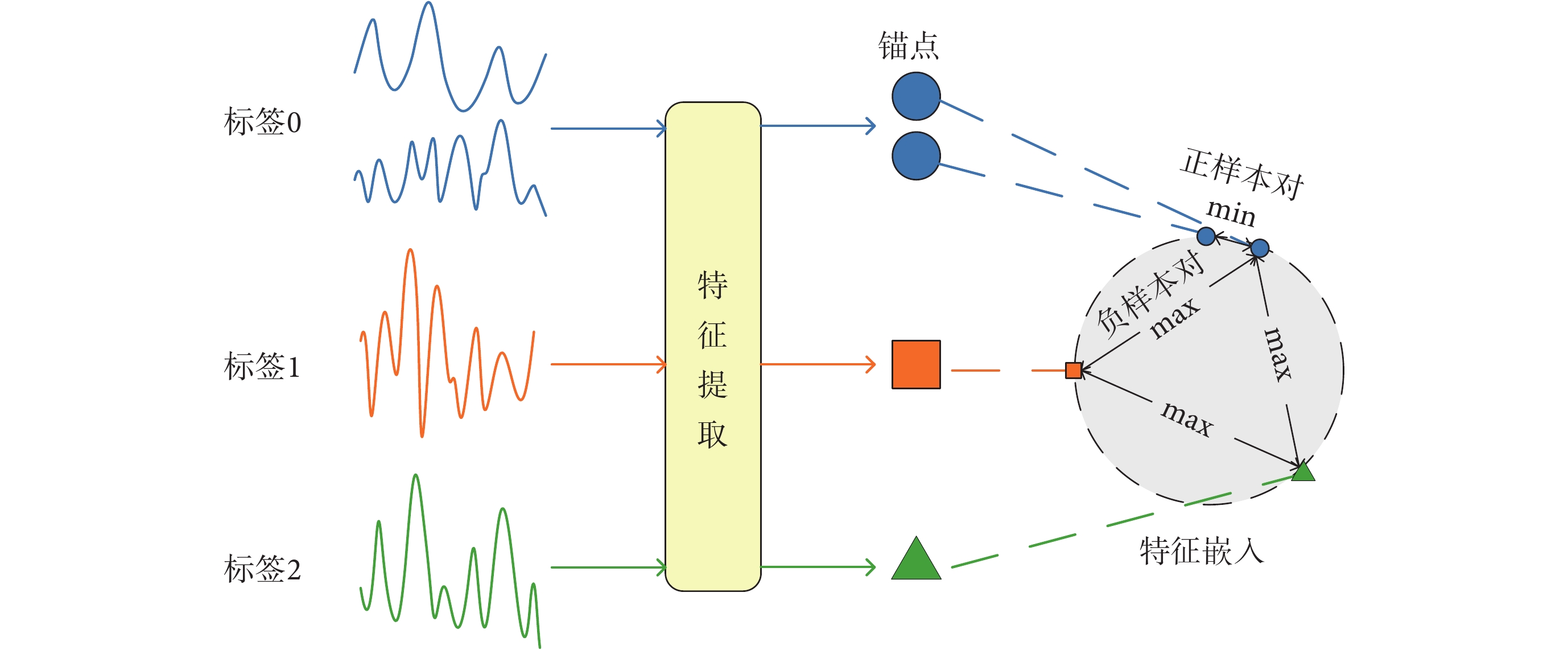 圖5
SCL特征提取優化方式
Figure5.
Optimizing method for feature extraction by SCL
圖5
SCL特征提取優化方式
Figure5.
Optimizing method for feature extraction by SCL
SCL損失需要對大量的特征樣本進行比較,從不同類型特征的對比中挖掘有效信息。因此,需要保證同一批次中不同標簽的樣本數量均衡。針對這一問題,可采用前文所述的數據增強方式對樣本量較少的類別進行擴充。此外,本文將批尺寸(batch size)設定為較大的數值,即256,以確保網絡在訓練過程中能夠獲取到足夠數量的數據。
在使用SCL損失對特征提取進行訓練的基礎上,為了提高算法的分類精度,引入MSE損失(以符號LMSE表示),如式(3)所示:
 |
其中,M表示樣本數量,un是第n個樣本的真實標簽,vn是第n個樣本的預測標簽。
因此,本算法的總損失函數L表示為SCL損失和MSE損失的和,如式(4)所示:
 |
1.5 實驗數據
本文實驗使用的EEG信號來自上海交通大學(Shanghai Jiao Tong University,JSTU)仿腦計算與機器智能研究中心(center for brain-like computing and machine intelligence,BCMI)構建的警覺度估計EEG數據集(the SJTU emotion EEG dataset-vigilance,SEED-VIG),該數據集可在BCMI主頁進行公開下載[29]。數據集記錄了23名測試者連續模擬駕駛2 h的EEG信號,采集的EEG通道包括頭皮17個通道和前額4個通道。
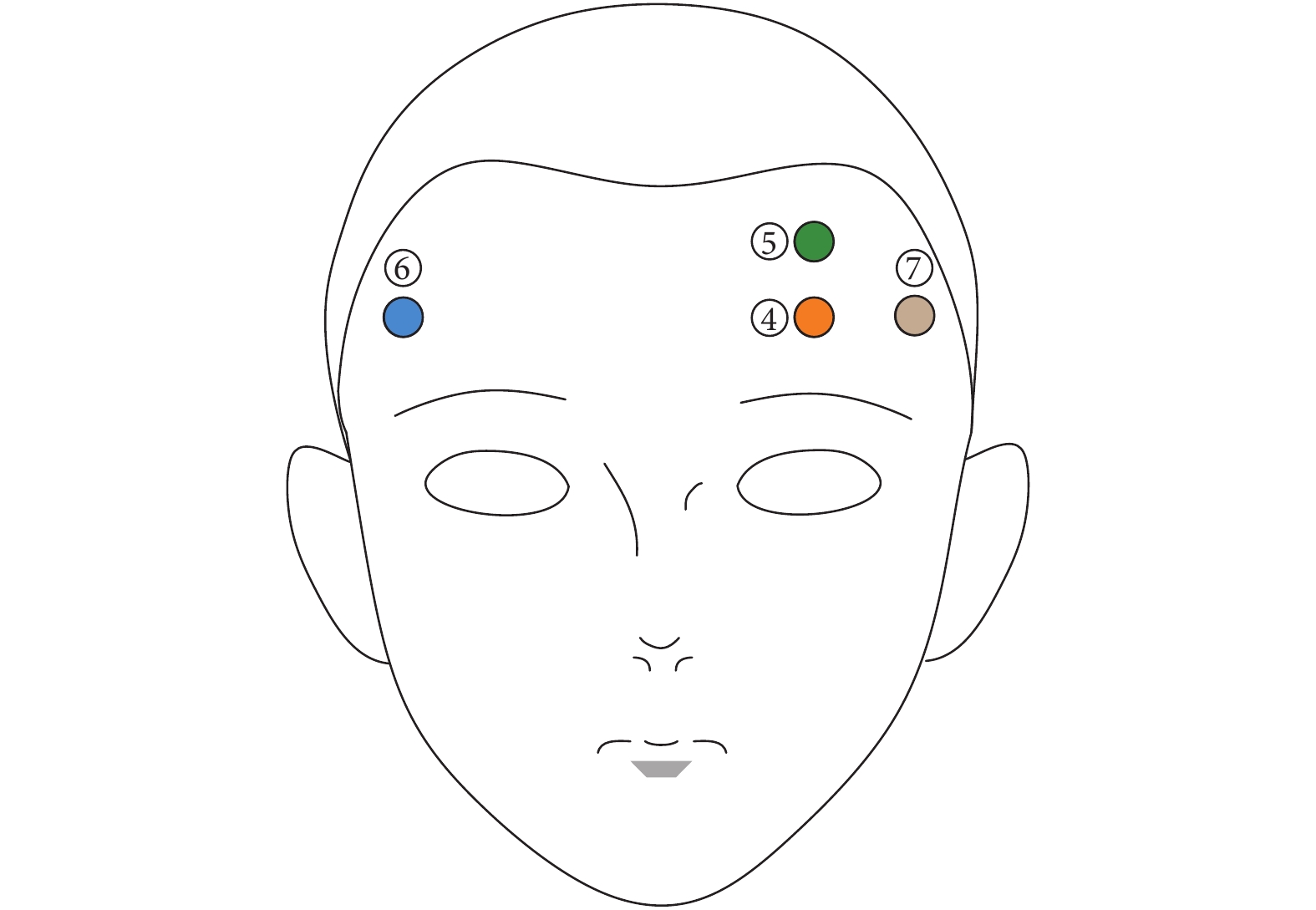
為了研究本文提出的單通道EEG信號疲勞檢測算法的有效性,根據已有研究選擇前額通道 ⑤ 的信號作為算法輸入,通道 ⑤ 電極位置與其它電極相對位置如圖6所示[17, 30]。
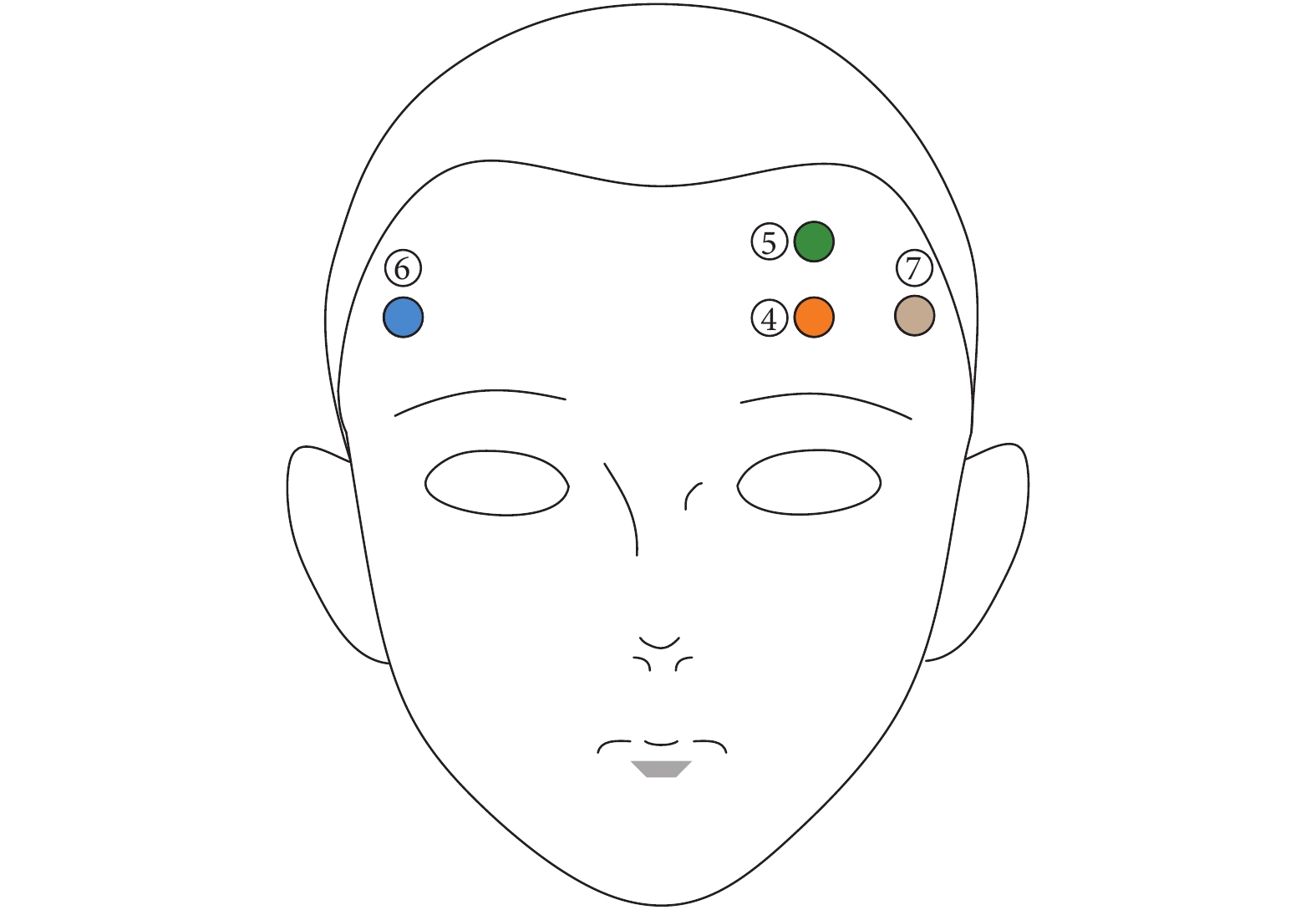 圖6
SEED-VIG數據集采集前額EEG信號電極位置
Figure6.
The electrode positions for collecting forehead EEG signals in the SEED-VIG dataset
圖6
SEED-VIG數據集采集前額EEG信號電極位置
Figure6.
The electrode positions for collecting forehead EEG signals in the SEED-VIG dataset
數據集使用閉眼百分比(percent of eye closure,PERCLOS)算法(以符號PCS表示)作為疲勞程度標簽,計算方式如式(5)所示:
 |
其數值為0~1之間的連續值,值越小表示測試者越清醒。根據閾值,可將疲勞程度分為三種狀態:[0, 0.35)為清醒,[0.35, 0.7)為疲勞,[0.7, 1]為嗜睡。
2 實驗結果與分析
2.1 評估指標
實驗軟件環境采用深度學習框架pytorch 1.12(Facebook Inc.,美國)。所提出模型使用自適應矩估計(adaptive moment estimation,Adam)優化算法,初始學習率為0.001,訓練輪次為100輪,batch size設置為256。使用準確率(accuracy,ACC)和F1分數(F1 score,F1)兩個指標進行評估,具體定義如式(6)~式(7)所示:
 |
 |
其中,TP為模型分類正確的正樣本,FP為模型分類錯誤的負樣本,TN為模型分類正確的負樣本,FN為模型分類錯誤的正樣本。 表示模型的精確率,
表示模型的精確率, 表示模型的召回率。
表示模型的召回率。
2.2 同類算法對比
為了對所提出算法的有效性進行進一步的驗證,將所提出算法與傳統方法以及現有先進算法進行比較。使用支持向量機(support vector machine,SVM)代表傳統方法進行對比,PSD和DE作為特征。特征提取方式為:經過EMD濾波后的單通道信號通過8 s非重疊窗口的短期傅里葉變換計算全頻帶的PSD和DE,然后以2 Hz 頻率分辨率從總頻段(1~50 Hz)中提取25個頻帶上的50個特征作為SVM的輸入。在SVM中使用徑向基函數(radial basis function,RBF)作為核函數,RBF尺度因子γ在[1.000, 0.100, 0.010, 0.001]內調整,懲罰因子C在[0.001, 0.010, 0.100, 1. 000]內調整。與現有先進算法如EEGNet[12]、VIGNet[13]、CAE-LSTM[14]和LSTM-AttCaps[15]進行比較,將卷積核由多通道空間卷積核變為1×1卷積核,使算法適用于單通道EEG信號的特征提取。
2.3 結果比較
為保證實驗的準確性與可靠性,本文在SEED-VIG數據集中采用五折交叉的方式對不同算法進行驗證。在對訓練集與測試集進行劃分時,保持EEG信號的時序結構,不對信號進行打亂處理。所提出算法與其它算法的平均精度如表2所示,每列最優值用加粗字體表示。
分析表2可知,本文算法相較于其它先進算法,準確度均值有所提高,最大值提升明顯,證明了所提出特征提取及分類算法的有效性。同時,標準差的減小和綜合指標F1的提高也說明了本文特征提取方法對不同樣本個體的適應性,展現了良好的魯棒性和泛化能力。
3 消融實驗
為了驗證所提出方法中各個模塊的有效性,本文分別對濾波方式、數據增強和損失函數進行了消融實驗,具體結果如表3所示,每列最優值用加粗字體表示。
不同于EEG信號處理中常用的帶通濾波器,本文提出使用EMD對EEG信號進行濾波。因此在濾波模塊的消融實驗中,分別對不進行濾波、1~50 Hz帶通濾波器和EMD濾波的效果進行比較。從結果可以看出原始信號中存在的高頻噪聲對檢測精度有著較大的影響,對信號進行一定濾波處理是必要的。兩種濾波方式的結果對比可知,使用EMD對信號進行自適應濾波的效果較好,提高的F1指標證明了該方法的魯棒性。帶通濾波器相較于EMD濾波,雖然計算方式較簡單,但對噪聲的抑制效果不理想,尤其是在噪聲頻率與目標信號頻率存在重疊區域時。
從數據增強模塊的消融實驗結果中可以看出,在對數據進行增強后,ACC和F1均有極大的提升。相較于其它模塊,有無數據增強對精度的影響最大,說明了該模塊的重要性。數據增強可以很好地平衡不同類別內的數據量,使SCL損失在每一個批次內能夠獲取足夠多的正負樣本對,從而學習到能夠區分不同類別的特征,提高疲勞檢測的準確度。
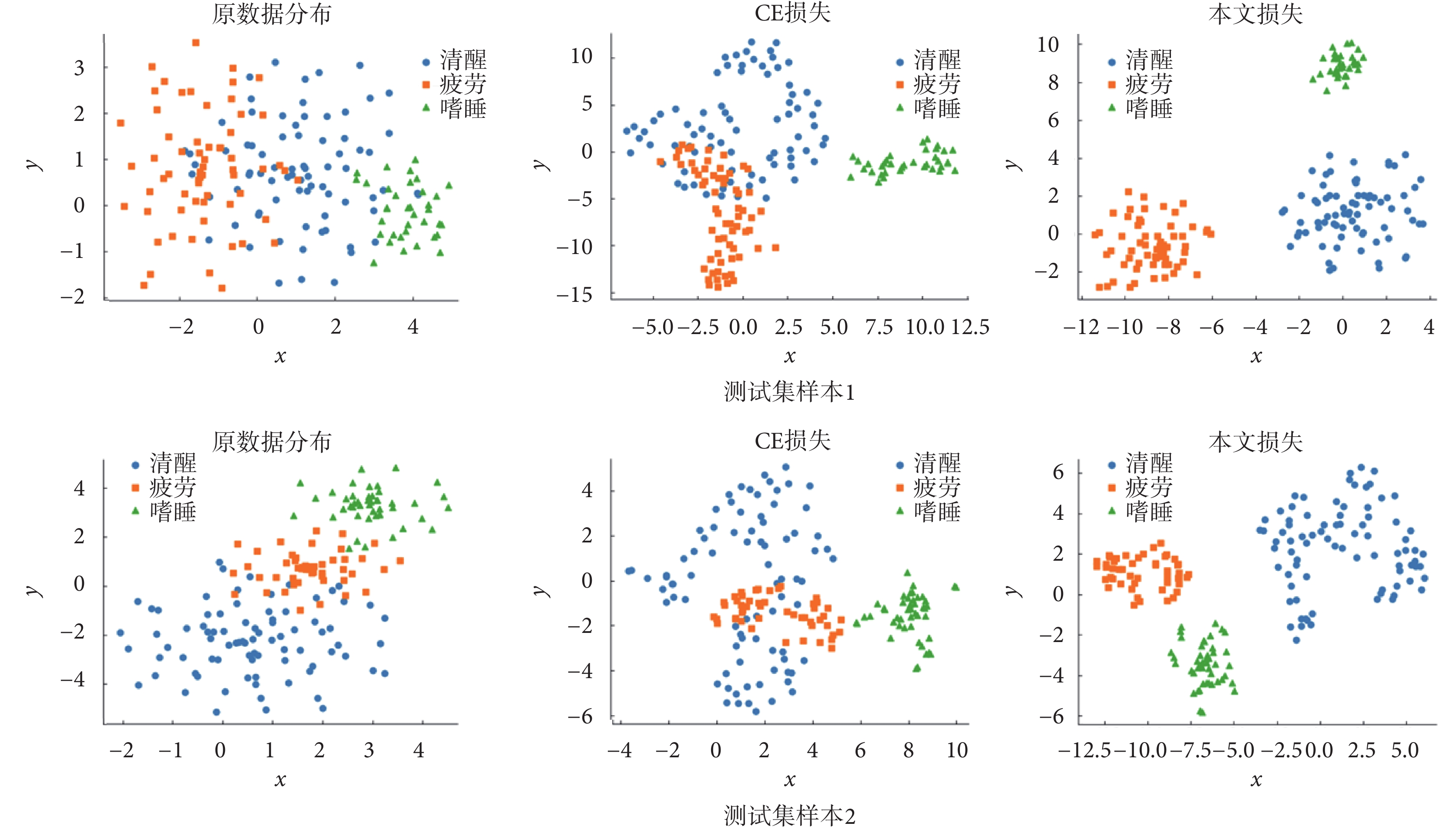
本文提出使用SCL損失與MSE損失作為聯合損失優化模型參數,而在一般的分類任務網絡中,常用CE損失作為損失函數[12-13]。因此,本文對兩種損失函數進行了實驗比較。表3中的實驗結果表明,本文提出的聯合損失函數相較于CE損失,模型檢測結果顯著提升,驗證了聯合損失對網絡的優化性能。為了進一步證明所提出損失類型在特征提取中的能力,分別對兩組隨機選取的測試集樣本(測試集樣本1、測試集樣本2)中原始數據分布、CE損失優化下的特征和本文損失優化下的特征使用t-分布隨機近鄰嵌入(t-distributed stochastic neighbor embedding,t-SNE)方法[31]進行可視化,結果如圖7所示。
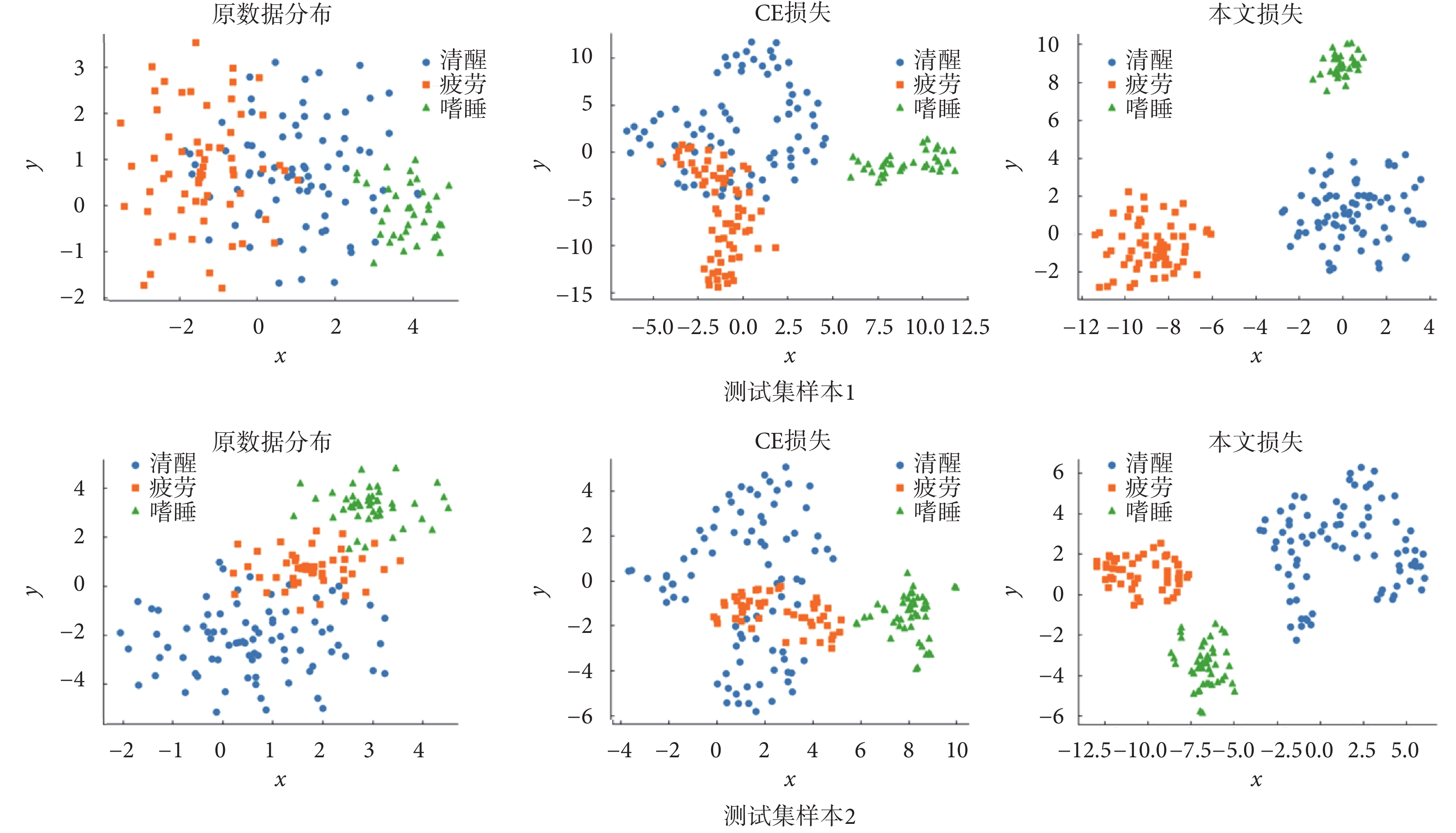 圖7
原數據分布和不同損失下的特征可視化
Figure7.
Visualization of original data distribution and features under different losses
圖7
原數據分布和不同損失下的特征可視化
Figure7.
Visualization of original data distribution and features under different losses
根據圖7中特征的降維分布可看出,CE損失優化下提取的特征雖然能夠大致區分不同疲勞程度,但劃分邊界不清晰,不同類別的特征存在混疊的情況。相較之下,本文所提出損失在SCL損失的影響下,不僅有效地縮小了同類別內特征的距離,同時顯著擴大了不同類別間特征的距離,根據所提取的特征能夠更加清晰地劃分疲勞程度。此外,MSE損失的引入使網絡持續減少預測類別與實際類別間的誤差,進一步提高了網絡檢測精度。綜上,本文所提出聯合損失函數加強了算法魯棒性和對不同樣本個體數據的適應能力,具有良好的可解釋性。
4 結束語
本文針對單通道EEG信號疲勞檢測算法中的特征表達偏差問題,提出基于SCL損失的特征提取及分類算法。算法通過EMD濾波、數據增強、數據重構等預處理方法,顯著提升了信號的質量、數量與信息表達量。同時,本文提出SCL損失與MSE損失相結合的聯合損失函數,實現特征有效提取。本文所提算法與現有算法在公開數據集上進行對比實驗,結果表明,本文算法顯著提升了檢測精度和魯棒性。此外,消融實驗和可視化結果驗證了各模塊的有效性。考慮到目前多模態融合在疲勞檢測中的優異表現,在下一步的研究中,可以將EEG信號與其它信號的信息進行結合,進一步提高疲勞檢測的準確度。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:所有作者都參與了本研究的構思和設計。楊慧舟負責編寫模型代碼和撰寫論文初稿,劉云飛指導了論文寫作并提出修改意見,夏麗娟完成了文章的審閱及校對。所有作者都閱讀并批準了最終稿件。
0 引言
近年來,隨著機動車保有量的快速增加,交通事故的發生數量也在不斷增加。據統計,交通事故的首要原因是疲勞駕駛,約有20%~30%的事故發生在駕駛員降低警惕時[1]。因此,在駕駛過程中及時地向駕駛員提供警惕提醒至關重要。
目前針對駕駛員疲勞檢測的研究,主要基于非生理性信息與生理性信息。基于非生理性信息的研究,大多從車輛的駕駛狀態[2-4]與駕駛員的面部動作[5-7]進行判斷,但獲取相關信息時易受光線干擾,影響檢測準確度[8]。相較于非生理性信息,生理性信號記錄人體生理變化,能夠更加客觀地反映駕駛員的狀態。尤其是腦電圖(electroencephalography,EEG)直接記錄神經信號,被認為是疲勞檢測的黃金標準[9]。
在基于EEG信號的疲勞檢測算法中,有效的特征提取是提高檢測精度的關鍵因素。當前研究中的特征提取方式主要分為兩種:手動特征提取和基于深度學習的自動特征提取。手動提取的特征集中在信號時域、頻域和時頻域上,以時頻特征的應用最為廣泛。Shi等[10]提出使用微分熵(differential entropy,DE)進行疲勞檢測,并與其它四個特征的性能進行比較,實驗證明DE是反映疲勞變化最穩定的EEG特征。Wu等[11]通過短時傅里葉變換提取EEG信號中的功率譜密度(power spectral density,PSD)特征,與DE特征相結合用于疲勞檢測,結果顯示相較于其它方法,平均誤差有所減少。盡管手動提取特征在疲勞檢測中已經被證實為有效方法,但該過程很大程度上依賴于專家經驗,而且只能提取固定的一類或幾類特征,無法完全表征EEG信號。此外,手動提取的特征在不同樣本個體上的檢測精度存在較大差異,魯棒性不佳。鑒于上述問題,一些學者研究基于深度學習的特征提取網絡,從EEG信號中自適應地實現特征提取,以提高算法對不同個體的適應性。Lawhern等[12]提出針對EEG信號的緊湊型神經網絡(EEGNet),將EEG信號直接輸入到網絡中實現特征提取與分類,并使用交叉熵(cross entropy,CE)損失函數減小預測結果與真實標簽的差異。Ko等[13]首先從EEG信號中提取DE特征,然后通過警戒卷積神經網絡(vigilance convolutional neural network,VIGNet)進一步提取深層次特征,該方法與傳統方法相比更具解釋性和魯棒性。Shi等[14]提出自動編碼長短期記憶網絡(autoencoder to long short-term memory network,CAE-LSTM),首先通過自動編碼器對手動提取的EEG特征進行編碼,然后利用長短期記憶網絡(long short-term memory,LSTM)進行疲勞識別,最后使用均方誤差(mean square error,MSE)作為損失函數提高分類精度,實驗證明所提算法檢測精度有所提高。Zhang等[15]提出LSTM與膠囊網絡相結合的膠囊記憶模型(LSTM with attention capsule network,LSTM-AttCaps),通過低級膠囊層和高級膠囊層挖掘特征中的關鍵局部信息和全局信息。總結上述方法可知,基于深度學習的特征提取方式,除了與網絡本身設計有關,還依賴于損失函數對于網絡的優化,但常用的CE損失與MSE損失是通過提高預測精度間接提高網絡提取特征能力,而非直接根據提取的特征對網絡進行優化,因此在這些損失優化下提取出的特征,表征準確性仍有提升的空間。
目前,大多數有關EEG信號的疲勞檢測研究都基于國際10-20標準導聯系統,采集頭皮上多通道信號。這種穿戴設備體積較大、不易移動,難以日常佩戴以檢測疲勞[16-17]。已有研究證明,從人體前額能采集到高質量EEG信號,并且其單通道的設置減小了算法運算量及設備功耗,具有極高的實用價值[18-20]。但單通道EEG信號在疲勞檢測時的精度普遍較低,還需進一步提升[21-23]。
針對上述問題,本文將對前額單通道EEG信號下的特征提取及分類算法展開研究,提出基于深度學習的特征提取網絡,以期對特征進行自適應地提取;同時希望對信號進行一定預處理,以提高信號的質量和數量,使網絡盡可能獲取足夠多的深層信息。此外,為進一步加強網絡提取有效特征的能力,可從特征本身考慮,直接根據提取出的特征設計相應損失函數反饋至網絡,以提高特征表征疲勞的準確性。期望通過本文研究,能找到更為有效的特征提取方法,進一步提高單通道EEG信號的疲勞檢測精度,為EEG疲勞檢測提供新思路。
1 模型和方法
1.1 整體框架
本文所提出算法主要包括數據處理與特征提取兩部分,整體流程如圖1所示。在數據處理階段, EEG信號首先通過經典模態分解(empirical mode decomposition,EMD)濾除高頻噪聲,其次將信號根據所屬的疲勞程度類別進行數據增強,以平衡不同類別間的數據量,最后對信號進行有重疊的采樣,實現從一維信號到二維輸入的轉變。在特征提取階段,構建以深度可分離卷積為核心的神經網絡來加快模型運行速度,并通過卷積、池化等方式實現對特征的有效提取。最后,通過全連接層得到分類結果。為提高分類效果,由有監督對比學習(supervised contrastive learning,SCL)損失和MSE損失共同構成的損失函數,對特征提取網絡進行參數優化。
圖1
算法整體框架
Figure1.
Overall framework of the proposed algorithm
1.2 EEG信號預處理
1.2.1 基于EMD的信號降噪
EMD能夠根據信號自身特性,將信號自適應地分解為不同頻率的多個分量,實現對特定頻率的有效提取[24]。對EEG信號進行EMD算法分解后的結果如圖2所示,第一縱列,依次為原始信號及原始信號分解后的6個固有模態函數(intrinsic mode function,IMF)分量(IMF1~IMF6)和一個殘余量(residual),第二縱列為第一列中各信號對應的頻域表達。
圖2
EMD分解時/頻域結果
Figure2.
Time/frequency domain results of EMD decomposition
考慮到EEG信號中的噪聲頻率通常在50 Hz以上,因此在保留大部分低頻信號的前提下,濾除IMF1分量實現對EEG信號的濾波。原始信號和重構信號的時域、頻域結果如圖3所示。從時域結果可以看出,重構后的信號毛刺更少。從頻域結果比較可以看出,重構后的信號在保留了大部分低頻有效信號的同時,有效抑制了高頻噪聲。此外,對原始信號和重構信號進行信噪比分析,將IMF1分量作為噪聲信號,得到原始信號與重構信號的信噪比分別為16.49 dB和17.58 dB,信噪比的提升證明了濾波的有效性。
圖3
原始信號和EMD重構信號的時/頻域圖
Figure3.
Time/frequency domain diagram of original signal and EMD reconstructed signal
1.2.2 數據增強與數據重構
為了避免模型在訓練過程中只專注于對某一類別的學習,需要確保不同類別數據的數量近似相等,從而實現對特征的有效提取。因此,在對信號進行特征提取前,需要進行數據擴充。本文使用窗口扭曲的方法對數據進行擴充,即以固定長度的時間序列窗口對信號進行隨機選取,并對選中的數據進行拉伸或壓縮[25]。本文中,時間序列窗口大小為信號數據量的10%,拉伸系數設置為2,壓縮系數設置為0.5。數據增強應用于訓練集中,以數量最多的一類數據作為目標數,擴充其它類別數據,實現數據平衡。
EEG信號作為時間序列信號,其傳統的一維結構包含的信息量較少,只能呈現相鄰時間點上的變化。目前已有研究證明,將信號由一維結構變化為二維結構,更有利于信息的表達與后續網絡的特征提取[26]。因此,本文通過窗口大小為48,重疊大小為28的有重疊采樣將一維信號轉化為二維結構,打破原始一維結構中表示能力的瓶頸,同時表達短期內變化的信號與長期間變化的信息,使網絡獲得更多的信息量,以便進行下一步的特征提取。具體數據重構方式如圖4所示。
圖4
有重疊采樣進行數據重構
Figure4.
Data reconstruction with overlapping sampling
1.3 疲勞特征提取網絡設計
特征提取網絡的設計如圖1所示,具體的網絡結構參數如表1所示。二維結構的信號首先經過卷積進行特征的初步提取,同時通過批歸一化加速網絡的學習速度。為了提高網絡的運算速度,使用硬自門控激活函數(hardswish,HS)作為激活函數(以符號HS表示)[27],其計算方法如式(1)所示:
|
其中,x代表該激活函數的輸入值,即神經網絡中某一層的輸出值。
初步提取的特征經過兩層深度可分離卷積層進行進一步的處理。與傳統的卷積相比,深度可分離卷積將卷積分為兩部分:深度卷積和逐點卷積,通過對每個通道單獨進行卷積實現模型參數量的減少,降低計算成本。經過深度可分離卷積可得到尺寸為12 × 16 × 16的特征,為了進一步提高網絡訓練速度,使用平均池化層對樣本進行降采樣。通過卷積層與hardswish激活函數對降采樣后的特征進行最終的提取,并通過全連接層得到最后的疲勞分類結果。
1.4 損失函數設計
為實現對特征的有效提取,本文提出使用SCL損失對特征提取網絡進行優化。經典的對比學習在構建正負樣本對時,通常將樣本本身與其增強后的數據樣本作為正樣本對,而其它樣本作為負樣本對,這樣的方式很容易忽略同一類樣本的關聯特征。因此,本文選擇以樣本標簽作為條件的SCL損失進行特征提取(以符號LSCL表示)[28],其計算方法如式(2)所示:
|
其中,M表示每個批次數據量的大小。yi和yj分別表示錨點樣本i和樣本j的標簽。表示一個批次中標簽為yi的樣本數量。li ≠ j ∈{0, 1},和是相似的指標函數。例如,若i ≠ j,li ≠ j ∈{0, 1} = 1,否則li ≠ j ∈{0, 1} = 0。為樣本i和樣本j之間的余弦相似度,其中Vi和Vj分別表示為樣本i和樣本j的高等特征向量,T為轉置符號。同理,si,k表示樣本i和樣本k之間的余弦相似度。τ表示溫度參數,用于調節相似度計算的敏感度,在本文中將其設置為0.07。
利用SCL損失進行特征提取,優化方式如圖5所示。在采集EEG信號時,根據不同疲勞程度為其賦予相應的標簽,即“標簽0”、“標簽1”和“標簽2”。對EEG信號進行特征提取后,能夠獲得對應的特征值。取其中某個特征作為錨點,將與錨點具有相同標簽的特征和錨點組成一對正樣本對,與錨點具有不同標簽的特征和錨點組成負樣本對。所有特征嵌入到特征空間中,通過SCL損失最小化(min)正樣本對之間的特征距離,同時最大化(max)負樣本對之間的特征距離,實現對所提取特征的優化。
圖5
SCL特征提取優化方式
Figure5.
Optimizing method for feature extraction by SCL
SCL損失需要對大量的特征樣本進行比較,從不同類型特征的對比中挖掘有效信息。因此,需要保證同一批次中不同標簽的樣本數量均衡。針對這一問題,可采用前文所述的數據增強方式對樣本量較少的類別進行擴充。此外,本文將批尺寸(batch size)設定為較大的數值,即256,以確保網絡在訓練過程中能夠獲取到足夠數量的數據。
在使用SCL損失對特征提取進行訓練的基礎上,為了提高算法的分類精度,引入MSE損失(以符號LMSE表示),如式(3)所示:
|
其中,M表示樣本數量,un是第n個樣本的真實標簽,vn是第n個樣本的預測標簽。
因此,本算法的總損失函數L表示為SCL損失和MSE損失的和,如式(4)所示:
|
1.5 實驗數據
本文實驗使用的EEG信號來自上海交通大學(Shanghai Jiao Tong University,JSTU)仿腦計算與機器智能研究中心(center for brain-like computing and machine intelligence,BCMI)構建的警覺度估計EEG數據集(the SJTU emotion EEG dataset-vigilance,SEED-VIG),該數據集可在BCMI主頁進行公開下載[29]。數據集記錄了23名測試者連續模擬駕駛2 h的EEG信號,采集的EEG通道包括頭皮17個通道和前額4個通道。
為了研究本文提出的單通道EEG信號疲勞檢測算法的有效性,根據已有研究選擇前額通道 ⑤ 的信號作為算法輸入,通道 ⑤ 電極位置與其它電極相對位置如圖6所示[17, 30]。
圖6
SEED-VIG數據集采集前額EEG信號電極位置
Figure6.
The electrode positions for collecting forehead EEG signals in the SEED-VIG dataset
數據集使用閉眼百分比(percent of eye closure,PERCLOS)算法(以符號PCS表示)作為疲勞程度標簽,計算方式如式(5)所示:
|
其數值為0~1之間的連續值,值越小表示測試者越清醒。根據閾值,可將疲勞程度分為三種狀態:[0, 0.35)為清醒,[0.35, 0.7)為疲勞,[0.7, 1]為嗜睡。
2 實驗結果與分析
2.1 評估指標
實驗軟件環境采用深度學習框架pytorch 1.12(Facebook Inc.,美國)。所提出模型使用自適應矩估計(adaptive moment estimation,Adam)優化算法,初始學習率為0.001,訓練輪次為100輪,batch size設置為256。使用準確率(accuracy,ACC)和F1分數(F1 score,F1)兩個指標進行評估,具體定義如式(6)~式(7)所示:
|
|
其中,TP為模型分類正確的正樣本,FP為模型分類錯誤的負樣本,TN為模型分類正確的負樣本,FN為模型分類錯誤的正樣本。表示模型的精確率,表示模型的召回率。
2.2 同類算法對比
為了對所提出算法的有效性進行進一步的驗證,將所提出算法與傳統方法以及現有先進算法進行比較。使用支持向量機(support vector machine,SVM)代表傳統方法進行對比,PSD和DE作為特征。特征提取方式為:經過EMD濾波后的單通道信號通過8 s非重疊窗口的短期傅里葉變換計算全頻帶的PSD和DE,然后以2 Hz 頻率分辨率從總頻段(1~50 Hz)中提取25個頻帶上的50個特征作為SVM的輸入。在SVM中使用徑向基函數(radial basis function,RBF)作為核函數,RBF尺度因子γ在[1.000, 0.100, 0.010, 0.001]內調整,懲罰因子C在[0.001, 0.010, 0.100, 1. 000]內調整。與現有先進算法如EEGNet[12]、VIGNet[13]、CAE-LSTM[14]和LSTM-AttCaps[15]進行比較,將卷積核由多通道空間卷積核變為1×1卷積核,使算法適用于單通道EEG信號的特征提取。
2.3 結果比較
為保證實驗的準確性與可靠性,本文在SEED-VIG數據集中采用五折交叉的方式對不同算法進行驗證。在對訓練集與測試集進行劃分時,保持EEG信號的時序結構,不對信號進行打亂處理。所提出算法與其它算法的平均精度如表2所示,每列最優值用加粗字體表示。
分析表2可知,本文算法相較于其它先進算法,準確度均值有所提高,最大值提升明顯,證明了所提出特征提取及分類算法的有效性。同時,標準差的減小和綜合指標F1的提高也說明了本文特征提取方法對不同樣本個體的適應性,展現了良好的魯棒性和泛化能力。
3 消融實驗
為了驗證所提出方法中各個模塊的有效性,本文分別對濾波方式、數據增強和損失函數進行了消融實驗,具體結果如表3所示,每列最優值用加粗字體表示。
不同于EEG信號處理中常用的帶通濾波器,本文提出使用EMD對EEG信號進行濾波。因此在濾波模塊的消融實驗中,分別對不進行濾波、1~50 Hz帶通濾波器和EMD濾波的效果進行比較。從結果可以看出原始信號中存在的高頻噪聲對檢測精度有著較大的影響,對信號進行一定濾波處理是必要的。兩種濾波方式的結果對比可知,使用EMD對信號進行自適應濾波的效果較好,提高的F1指標證明了該方法的魯棒性。帶通濾波器相較于EMD濾波,雖然計算方式較簡單,但對噪聲的抑制效果不理想,尤其是在噪聲頻率與目標信號頻率存在重疊區域時。
從數據增強模塊的消融實驗結果中可以看出,在對數據進行增強后,ACC和F1均有極大的提升。相較于其它模塊,有無數據增強對精度的影響最大,說明了該模塊的重要性。數據增強可以很好地平衡不同類別內的數據量,使SCL損失在每一個批次內能夠獲取足夠多的正負樣本對,從而學習到能夠區分不同類別的特征,提高疲勞檢測的準確度。
本文提出使用SCL損失與MSE損失作為聯合損失優化模型參數,而在一般的分類任務網絡中,常用CE損失作為損失函數[12-13]。因此,本文對兩種損失函數進行了實驗比較。表3中的實驗結果表明,本文提出的聯合損失函數相較于CE損失,模型檢測結果顯著提升,驗證了聯合損失對網絡的優化性能。為了進一步證明所提出損失類型在特征提取中的能力,分別對兩組隨機選取的測試集樣本(測試集樣本1、測試集樣本2)中原始數據分布、CE損失優化下的特征和本文損失優化下的特征使用t-分布隨機近鄰嵌入(t-distributed stochastic neighbor embedding,t-SNE)方法[31]進行可視化,結果如圖7所示。
圖7
原數據分布和不同損失下的特征可視化
Figure7.
Visualization of original data distribution and features under different losses
根據圖7中特征的降維分布可看出,CE損失優化下提取的特征雖然能夠大致區分不同疲勞程度,但劃分邊界不清晰,不同類別的特征存在混疊的情況。相較之下,本文所提出損失在SCL損失的影響下,不僅有效地縮小了同類別內特征的距離,同時顯著擴大了不同類別間特征的距離,根據所提取的特征能夠更加清晰地劃分疲勞程度。此外,MSE損失的引入使網絡持續減少預測類別與實際類別間的誤差,進一步提高了網絡檢測精度。綜上,本文所提出聯合損失函數加強了算法魯棒性和對不同樣本個體數據的適應能力,具有良好的可解釋性。
4 結束語
本文針對單通道EEG信號疲勞檢測算法中的特征表達偏差問題,提出基于SCL損失的特征提取及分類算法。算法通過EMD濾波、數據增強、數據重構等預處理方法,顯著提升了信號的質量、數量與信息表達量。同時,本文提出SCL損失與MSE損失相結合的聯合損失函數,實現特征有效提取。本文所提算法與現有算法在公開數據集上進行對比實驗,結果表明,本文算法顯著提升了檢測精度和魯棒性。此外,消融實驗和可視化結果驗證了各模塊的有效性。考慮到目前多模態融合在疲勞檢測中的優異表現,在下一步的研究中,可以將EEG信號與其它信號的信息進行結合,進一步提高疲勞檢測的準確度。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:所有作者都參與了本研究的構思和設計。楊慧舟負責編寫模型代碼和撰寫論文初稿,劉云飛指導了論文寫作并提出修改意見,夏麗娟完成了文章的審閱及校對。所有作者都閱讀并批準了最終稿件。