可變形圖像配準在醫學圖像分析領域扮演著至關重要的角色。盡管目前已經提出了各種先進的配準模型,但準確和高效的可變形配準仍然具有挑戰性。鑒于Mamba最近在計算機視覺任務中展現出的優異性能,本文介紹了一種新模型,稱為MCRDP-Net。MCRDP-Net采用了Mamba塊和卷積塊結合的雙流網絡架構同時提取固定圖像和運動圖像的全局信息和局部信息;在解碼階段,采用了特征金字塔結構的網絡,以獲得運動圖像與固定圖像之間的全分辨率形變場,從而實現高效且精確的配準。本研究在公共腦部配準數據集OASIS和IXI上驗證了MCRDP-Net的有效性。實驗結果顯示,MCRDP-Net在醫學圖像配準任務中表現出顯著優勢,OASIS數據集上DSC、HD95和ASD分別達到0.815、8.123和0.521,IXI數據集上分別達到0.773、7.786和0.871。綜上所述,MCRDP-Net在可變形圖像配準任務中展現了優越的性能,證明了它在醫學圖像分析領域的潛力,能夠有效提升配準的準確性和效率,為后續的醫學研究與應用提供了有力支持。
引用本文: 付麟杰, 朱遙遙, 姚宇. 基于Mamba和卷積的雙流特征金字塔網絡用于腦部核磁共振圖像配準. 生物醫學工程學雜志, 2024, 41(6): 1177-1184. doi: 10.7507/1001-5515.202405026 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
0 引言
可變形圖像配準(deformable image registration,DIR)在醫學成像領域一直占據著核心地位。DIR應用范圍廣泛,包括術前規劃、疾病診斷以及術中導航[1-3]。DIR的關鍵在于求解非剛性變形場,通過該變形場對運動圖像進行扭曲,以實現與固定圖像在解剖學上的匹配。在基于深度學習的配準范式中,通常將固定圖像和運動圖像表示為 和
和 ,它們都是尺寸為H × W × L的三維數組,其中H、W、L分別代表圖像的高度、寬度和深度。
,它們都是尺寸為H × W × L的三維數組,其中H、W、L分別代表圖像的高度、寬度和深度。
為了實現圖像的精確配準,通常需要借助空間變換器網絡(spatial transformer network,STN)[4]。STN通過應用一個估計得到的采樣網格G來變換運動圖像,該網格尺寸為H × W × L × 3。采樣網格G由一個規則網格與一個變形場相結合得到。對于網格中的任意一點p,G(p)定義了固定圖像中與運動圖像中p點相對應的位置,從而將圖像配準問題轉化為尋找兩圖像間對應體素的相對位置關系。這一過程不僅有助于將單模態或多模態信息融合到統一的坐標系中,而且對于醫生進行精確診斷和治療至關重要[5-8]。
盡管現有的DIR方法眾多,配準的準確性和效率依然是該領域面臨的主要挑戰。傳統的配準技術雖然能夠計算出精確的微分同胚位移場,卻伴隨著巨大的計算開銷和時間延遲,難以滿足實時應用的需求[9]。相比之下,基于深度學習的配準方法,如VoxelMorph[10],不僅展現出快速配準的能力,而且在精度上可以與傳統方法相媲美。VoxelMorph作為一種開創性的基于卷積神經網絡(convolutional neural network,CNN)的DIR工作,專為無監督和弱監督配準設計,并利用了縮放和平方法來整合平滑速度場(stationary velocity field,SVF)。在VoxelMorph的基礎上,后續研究[11-17]進一步推動了DIR的準確性和多模態配準的發展。然而,由于卷積核尺寸的限制,VoxelMorph在全局建模方面存在局限。為了克服這一局限,一些研究開始探索使用Transformer架構來增強網絡的全局建模能力,如TransMorph[11]、Swin-VoxelMorph[18]和Vit-VNet[17]等。盡管如此,Transformer中的注意力機制也帶來了較高的計算復雜性。此外,一些研究[15-16]提出了從粗到細的逐步配準策略,旨在減少計算需求,同時保留對變形的廣泛捕獲能力,但在保持預測變形的連續性方面仍面臨挑戰。
針對這些挑戰,Mamba框架,特別是選擇性空間模型(selective state space model,SSM)變體,為順序特征中的高效特征處理提供了一種引人注目的解決方案[19-21]。Visual Mamba[22]通過在Mamba架構中引入選擇性掃描模塊,進一步提升了Mamba在計算機視覺任務中的優勢,并激發了Mamba在多種應用中的擴展[22-28]。在DIR領域,MambaMorph[29]和VMambaMorph[30]利用Mamba網絡作為配準模塊,成功實現了腦部圖像的配準。
基于這些背景和挑戰,本文提出了MCDP-Net。MCDP-Net采用雙流網絡分支,在使用混合Mamba塊和卷積塊的特征提取模塊的同時提取圖像的局部特征和全局特征,并將這些特征通過特征融合模塊進行融合后輸入解碼模塊。解碼模塊采用特征金字塔網絡,通過從底層到頂層的方式傳播語義信息,這不僅能夠有效地捕捉大的位移變化,同時還能保留圖像的細節,以實現高效且精確的醫學圖像配準。
1 算法框架
1.1 整體框架
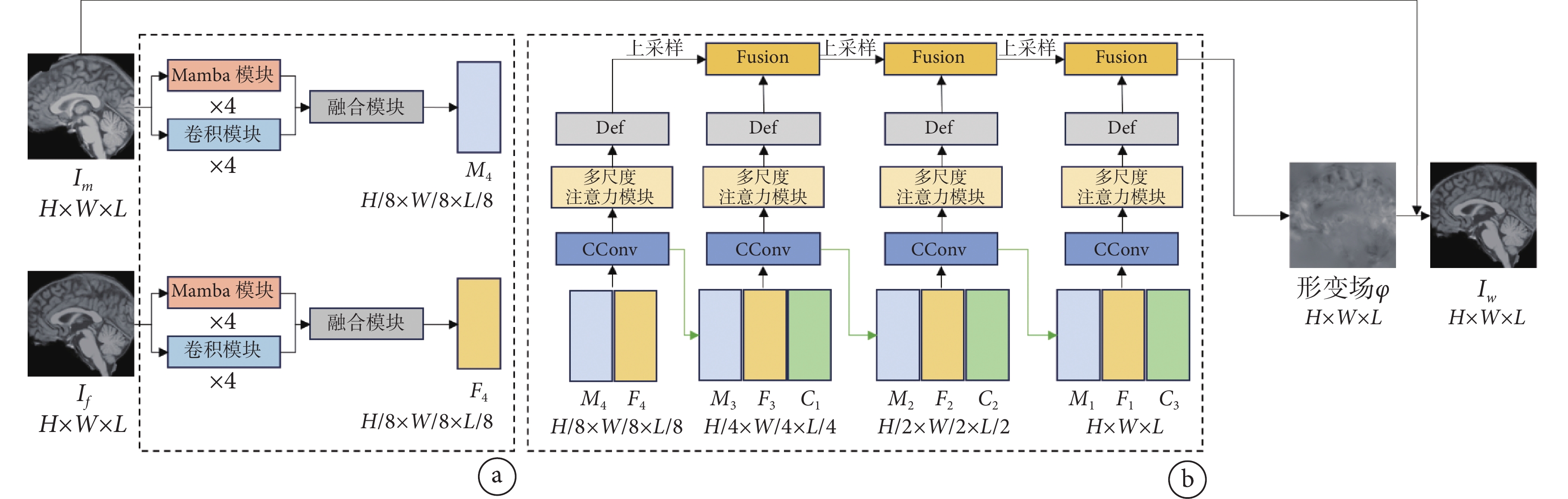
MCDP-Net模型的整體框架如圖1所示。本研究使用了對稱的雙流網絡框架,將運動圖像和固定圖像分別輸入兩個Mamba和卷積編碼器進行特征提取,以同時提取圖像的局部信息和全局信息,然后使用設計的融合模塊對Mamba塊和卷積塊提取的特征進行特征融合。之后將運動圖像特征和固定圖像特征進行拼接,輸入具有金字塔結構的解碼器進行上采樣,在這個過程中使用多尺度注意力模塊以獲得運動圖像與固定圖像的全分辨率形變場。最后,通過最小化損失函數估計形變量,使運動圖像變形為與固定圖像相似。
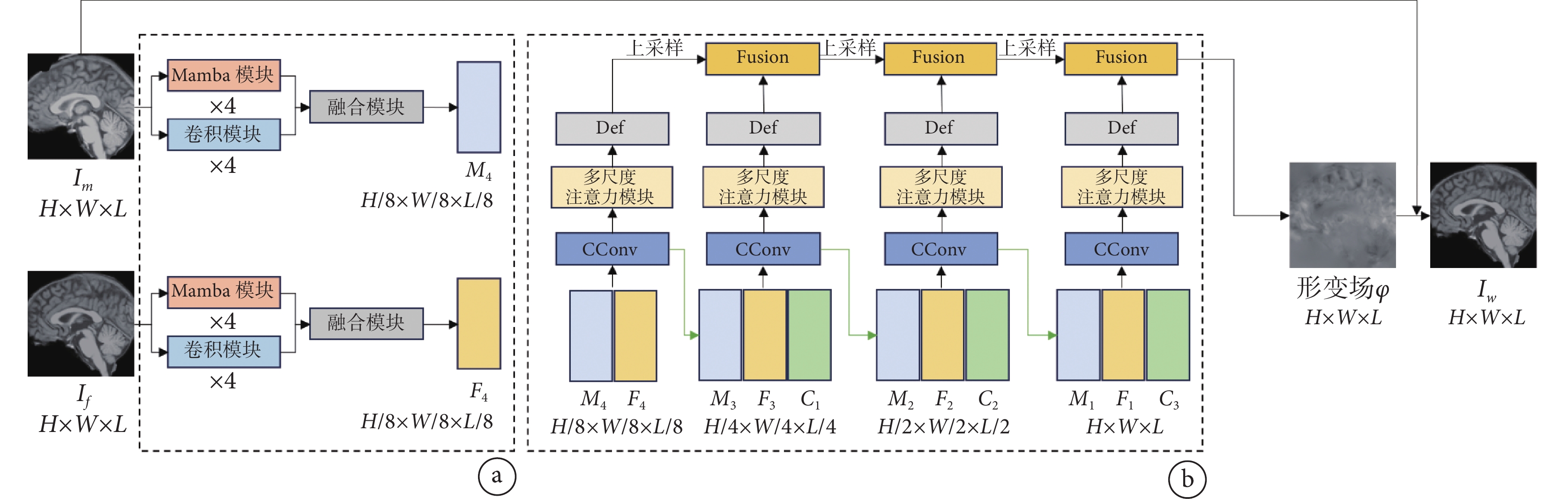 圖1
模型整體網絡架構
圖1
模型整體網絡架構
a. 雙流特征提取模塊,用于對圖像特征進行編碼并下采樣;b. 特征金字塔結構的解碼模塊,用于將圖a提取的特征進行解碼并上采樣,得到形變場
Figure1. Overall network architecture of the modela. the dual-flow feature extraction module, used for encoding image features and down sampling; b. the decoder module of the feature pyramid structure, used for decoding the features extracted by Fig. a and up sampling to obtain the deformation field
1.2 基于Mamba-卷積的雙流特征提取模塊
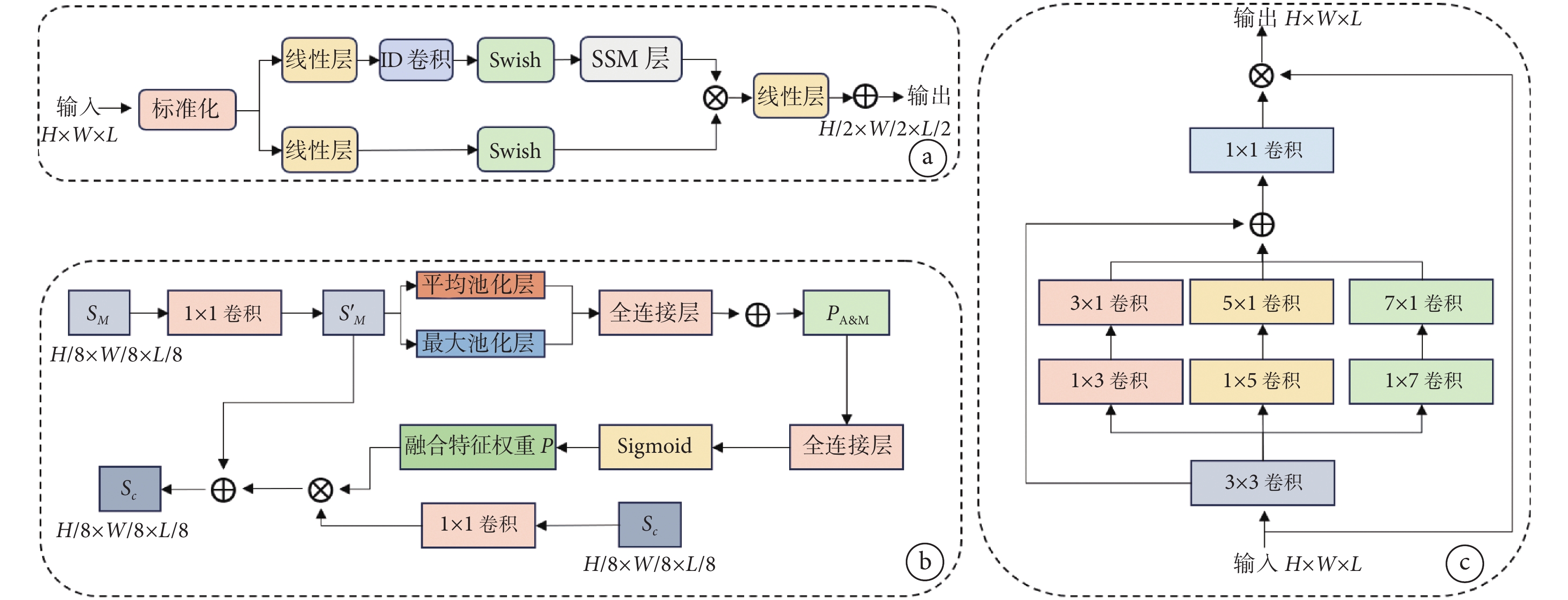
為了同時提取圖像的局部特征和全局特征,本研究設計了Mamba和卷積并行結構。如圖1a所示,首先使用對稱的雙流網絡框架,分別對運動圖像和固定圖像進行編碼。在每一個分支網絡中,使用并行的Mamba塊和卷積塊提取圖像的全局特征和局部特征,最后使用特征融合模塊對特征進行融合。以提取運動圖像特征為例,首先將運動圖像輸入四個連續的卷積塊,每個卷積塊由卷積→實例正則化→LReLU組成,得到特征 。同時將運動圖像輸入四個連續的Mamba塊,Mamba塊將圖像改變為形狀為B × L × C的張量作為輸入,得到相同形狀的輸出。B、L、C 分別表示批量大小、序列長度和通道數。Mamba塊結構如圖2a所示,首先將圖像輸入多層感知機(multilayer perceptron,MLP)線性投影并經過一個一維卷積層。在Swish層之后,在SSM層對張量進行處理,最后通過一個殘差連接得到
。同時將運動圖像輸入四個連續的Mamba塊,Mamba塊將圖像改變為形狀為B × L × C的張量作為輸入,得到相同形狀的輸出。B、L、C 分別表示批量大小、序列長度和通道數。Mamba塊結構如圖2a所示,首先將圖像輸入多層感知機(multilayer perceptron,MLP)線性投影并經過一個一維卷積層。在Swish層之后,在SSM層對張量進行處理,最后通過一個殘差連接得到  。為了更好地融合
。為了更好地融合 和
和 ,我們設計了一個特征融合模塊,如圖2b所示,將Mamba塊提取的特征
,我們設計了一個特征融合模塊,如圖2b所示,將Mamba塊提取的特征 輸入1 × 1的卷積塊以改變維度并獲得特征
輸入1 × 1的卷積塊以改變維度并獲得特征  =
=  。
。
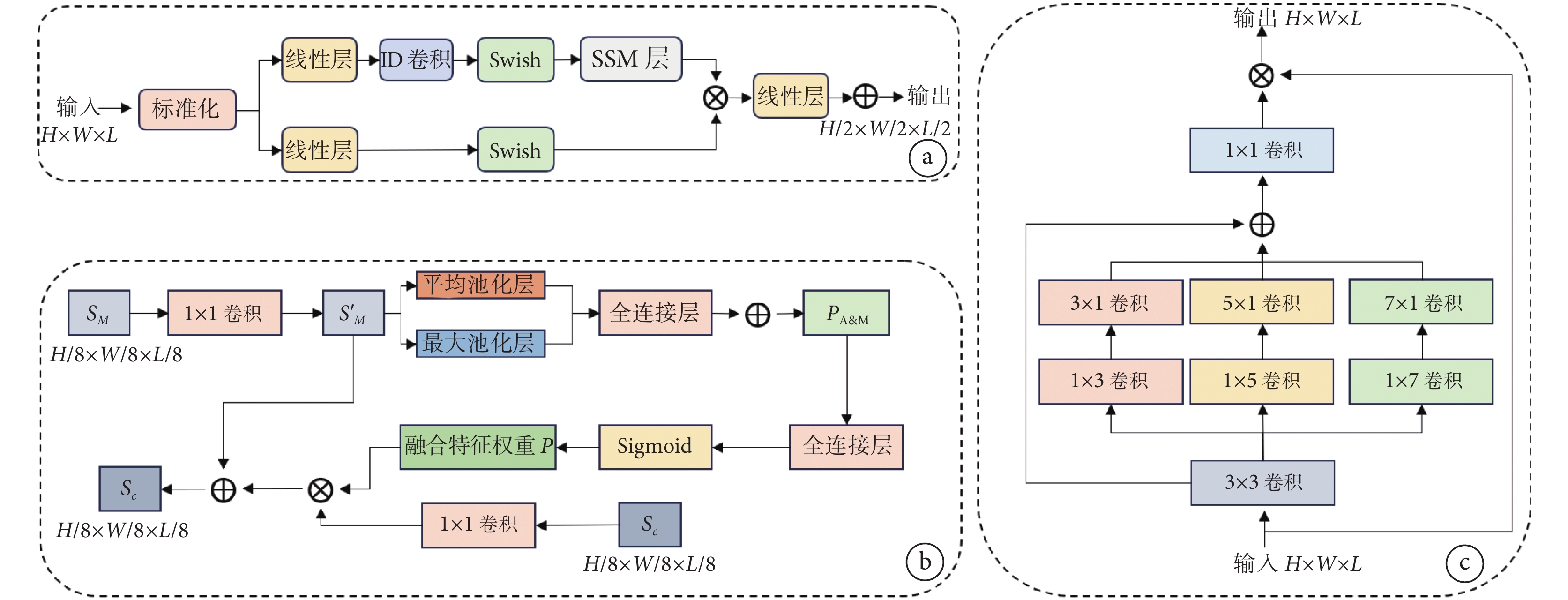 圖2
不同特征模塊的結構
圖2
不同特征模塊的結構
a. Mamba模塊,用于在編碼器階段提取圖像的全局信息;b. 特征融合模塊,用于將CNN和Mamba提取到的特征進行特征融合;c. 多尺度注意力模塊,用于在解碼器階段捕捉到不同尺度下的特征
Figure2. Structures of different feature modulesa. the Mamba module, used to extract global information from the image during the encoder; b. the feature fusion module, used to fuse the features extracted by the CNN and Mamba; c. the multi-scale attention module, used to capture features at different scales during the decoder
由于特征圖的每個通道都可以看作是一個特征檢測器[31],因此采用兩種池化策略來獲得更全面的信道依賴性。首先應用平均池化和最大池化計算通道上特征圖的統計特征,之后輸入共享的全連接層,并對兩種特征進行求和得到 ,然后將
,然后將 輸入全連接層和Sigmoid函數得到融合特征權重
輸入全連接層和Sigmoid函數得到融合特征權重 。整個過程可以用以下等式表示:
。整個過程可以用以下等式表示:
 '/> '/> |
 |
其中 和
和 代表全連接層,
代表全連接層, 為ReLU函數,
為ReLU函數, 為Sigmoid函數。
為Sigmoid函數。
然后,將信道依賴P作為權值,與卷積特征 相乘,得到細化的特征。最后,通過連接細化特征和殘差結構得到融合特征
相乘,得到細化的特征。最后,通過連接細化特征和殘差結構得到融合特征 ,可以表示如下:
,可以表示如下:
 '/> '/> |
1.3 基于特征金字塔結構的解碼模塊
為了準確地預測形變場,提升配準精度,解碼器網絡遞歸地融合多層次特征,并利用傳統的金字塔結構和多尺度注意力模塊逐步細化形變場。具體而言,解碼器結構(l = 4, 3, 2, 1)從粗到細逐步預測變形場,如圖1b所示。對于第1個解碼層,將特征圖  和
和  輸入到 CConv 中以生成融合特征圖
輸入到 CConv 中以生成融合特征圖  :
:
 |
其中CConv由兩個卷積→實例正則化→LReLU組成。之后將 輸入設計的多尺度注意力模塊以獲取不同通道之間的關系。多尺度注意力模塊包含多分支深度卷積以捕獲多尺度上下文和一個1 × 1卷積(見圖2c)來模擬不同通道之間的關系:
輸入設計的多尺度注意力模塊以獲取不同通道之間的關系。多尺度注意力模塊包含多分支深度卷積以捕獲多尺度上下文和一個1 × 1卷積(見圖2c)來模擬不同通道之間的關系:
 |
 |
然后將  輸入到 Def ,包含一個3 × 3的卷積塊和微分同胚層,以生成第一個形變場
輸入到 Def ,包含一個3 × 3的卷積塊和微分同胚層,以生成第一個形變場  :
:
 |
之后將 和
和 進行上采樣:
進行上采樣:
 |
 |
從第2個解碼層開始,執行以下操作:將 、
、 和
和 (
( = 2, 3, 4)進行拼接后輸入CConv中得到融合特征圖
= 2, 3, 4)進行拼接后輸入CConv中得到融合特征圖  ,然后將
,然后將 輸入多尺度注意力模塊和Def得到
輸入多尺度注意力模塊和Def得到 。通過融合不同層次的形變場,可以更有效地捕捉到不同尺度下的特征,特別是在處理大范圍變形時,粗糙的形變場可以幫助細致的形變場更快收斂,因此將
。通過融合不同層次的形變場,可以更有效地捕捉到不同尺度下的特征,特別是在處理大范圍變形時,粗糙的形變場可以幫助細致的形變場更快收斂,因此將 和
和 通過Fusion層進行融合,然后經過上采樣后輸入下一個解碼層:
通過Fusion層進行融合,然后經過上采樣后輸入下一個解碼層:
 |
其中Fusion層先使用STN得到將 配準到
配準到 的形變場,然后再將形變場與
的形變場,然后再將形變場與 相加。圖1中的形變場
相加。圖1中的形變場 表示固定圖像和運動圖像之間的變形關系,灰度值通常代表形變的程度。較亮的區域可能表示更大的變形,而較暗的區域表示較小的變形。通過這種方式,可以快速識別圖像中變形最顯著的區域。
表示固定圖像和運動圖像之間的變形關系,灰度值通常代表形變的程度。較亮的區域可能表示更大的變形,而較暗的區域表示較小的變形。通過這種方式,可以快速識別圖像中變形最顯著的區域。
最后,將待配準圖像 與最后一個解碼層得到的形變場
與最后一個解碼層得到的形變場 進行點乘得到配準后圖像:
進行點乘得到配準后圖像:
 |
1.4 損失函數
為了指導訓練,使用歸一化互相關(normalized cross correlation,NCC)[32]來評估固定圖像 和配準后的運動圖像
和配準后的運動圖像 之間的相似性:
之間的相似性:
 |
其中Ω表示整個體積域。體素 是體素p中心的
是體素p中心的 (n = 9)中的局部鄰域。
(n = 9)中的局部鄰域。 和
和 表示該局部鄰域內的平均體素值。
表示該局部鄰域內的平均體素值。
對于正則化,利用變形場梯度的L2范數來保證合理的變形:
 |
因此,總損失為:
 |
其中  是正則化項的權重,經過對比實驗,我們將之設置為1。
是正則化項的權重,經過對比實驗,我們將之設置為1。
2 實驗和結果分析
2.1 數據集
在本研究中,采用了兩個公開獲取的腦部磁共振成像(magnetic resonance imaging,MRI)數據集,對所提出的算法進行了全面評估。評估涉及的數據集包括OASIS[33]和IXI。這兩個數據集僅提供了原始圖像,并未包含任何預對齊處理,如單獨的預對齊或仿射預對齊。在本實驗中,所有圖像的尺寸被統一調整為160 × 160 × 160,體素大小統一設定為1 mm × 1 mm × 1 mm,以確保數據的一致性。
在實驗設計上,我們隨機選擇了一幅圖像作為參照的固定圖像。對于IXI數據集,采用403幅圖像作為訓練集,58幅圖像作為驗證集,以及115幅圖像作為測試集。此外還使用了46個帶有詳細注釋的感興趣區域(region of interest,ROI)來評估算法的性能。對于OASIS數據集,訓練集由394幅圖像組成,驗證集和測試集分別包含20幅圖像,評估過程中同樣使用了36個帶注釋的ROI。
實驗的執行和驗證均在PyTorch框架下進行,采用了一張配備24 GB顯存的RTX3090顯卡。在實驗設置中,選擇Adam作為優化器,并設置了批處理大小為1。整個訓練過程將學習率調整為0.000 1,以優化算法的收斂性能和模型的泛化能力。
2.2 評價指標
在本文中,采用了三種不同的指標來全面評估網絡的配準性能:戴斯相似性系數(Dice similarity coefficient,DSC)、95%的豪斯多夫距離(Hausdorff distance,HD)和平均表面距離(average surface distance,ASD)。
DSC系數用于量化固定圖像與運動圖像ROI之間的重疊程度,值域介于0~1,數值越接近1,表示重疊程度越高,配準效果越好。HD95衡量了運動圖像ROI中任意點到固定圖像ROI最近點的最大距離,理想情況下該值應盡可能接近0,以反映兩圖像ROI之間的高度一致性。ASD指標計算了運動圖像ROI中每個點到固定圖像ROI中最近點距離的平均值,ASD值越小,表示兩圖像ROI之間的對應點距離越接近,從而反映出更優的配準精度。
此外,我們還引入了J?指標,即具有非正雅可比行列式(表示為折疊體素)的體素的百分比,用以評估預測的非剛性變形場?的質量。在這一指標中,J?值越接近于0,表明預測的變形場越少包含異常值,即變形場的質量越高。通過這些綜合性的評估指標,能夠全面而準確地評價配準網絡的性能。
2.3 對比分析
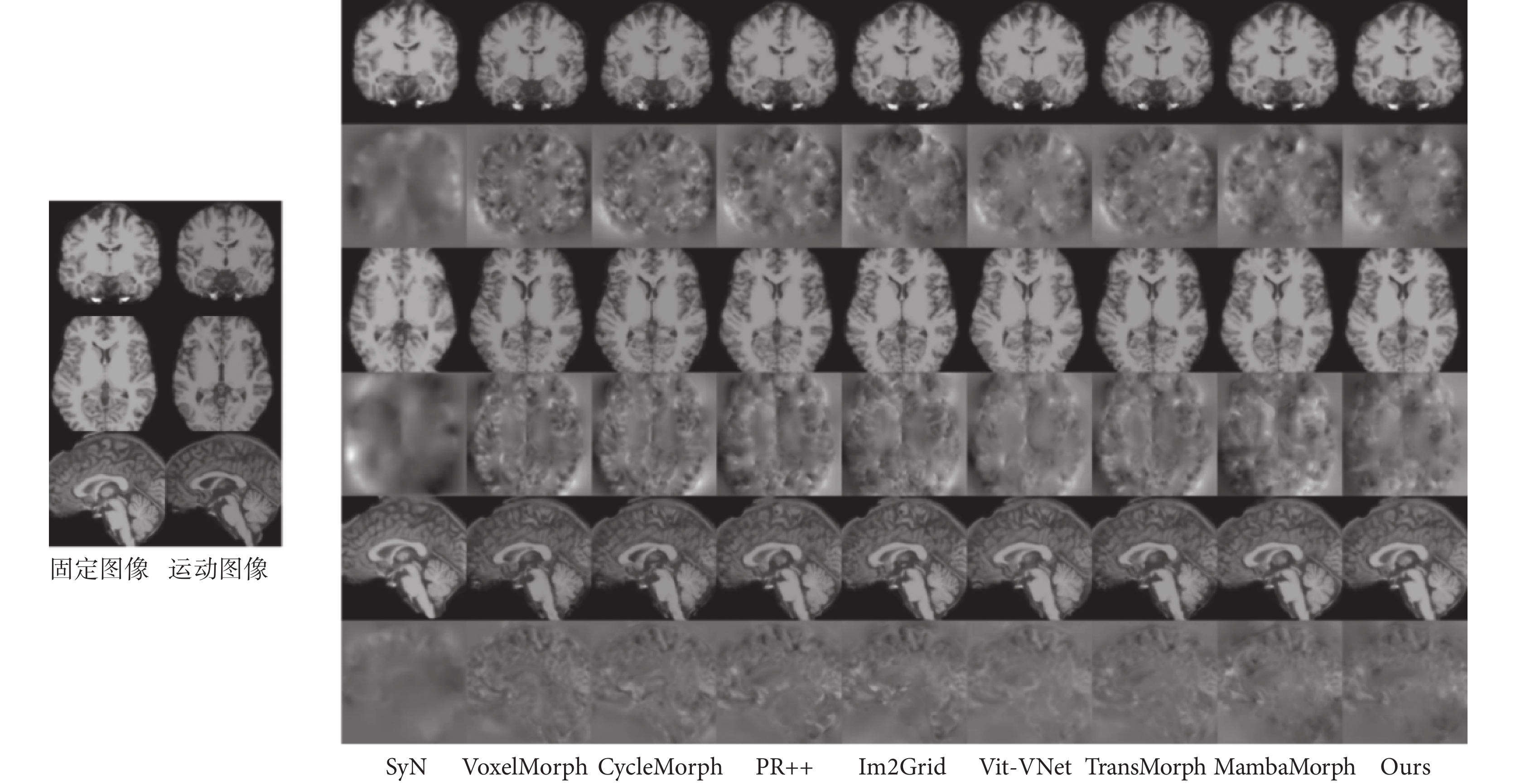
本研究將MCRDP-Net與SyN、VoxelMorph、CycleMorph、Im2Grid、PR++、TransMorph、Vit-VNet和MambaMorph進行了比較,結果如表1~2所示。其中SyN為非深度學習配準方法,VoxelMorph、CycleMorph、Im2Grid和PR++是基于CNN的深度學習配準方法,TransMorph和Vit-VNet是基于Transformer的深度學習配準方法,MambaMorph是基于Mamba的深度學習配準方法。由表1可以看出,在IXI數據集上,MCRDP-Net在DSC、HD95和ASD的度量方面始終獲得了最好的配準精度,分別達到了0.773、7.786和0.871。表中還列出了非正雅可比行列式(%|J?|≤0)的體素的百分比,顯示MCRDP-Net生成了高質量的非剛性變形場。在所有比較方法中,單級網絡(例如VoxelMorph和TransMorph)的性能比級聯結構和金字塔結構差(例如PR++)。由于使用SwinTransformer作為增強編碼器,TransMorph比VoxelMorph實現了更好的配準精度。在所有方法中,MambaMorph取得了與MCRDP-Net最接近的結果,這說明Mamba框架確實能夠實現更好的圖像變換。同樣的結論也出現在OASIS的實驗結果中,MCRDP-Net在OASIS數據集上DSC、HD95和ASD分別達到了0.815、8.123和0.521,為所有模型中的最優值,同時%|J?|≤0為0.031也是所有模型中最低的。圖3和圖4可視化了兩個數據集上不同方法在冠狀面、橫斷面和矢狀面的配準圖像和對應的變形場。可以看出,MCRDP-Net生成了更準確的配準圖像,并且可以一致地保留內部結構。特別是對于沒有初始仿射對齊的圖像,MCRDP-Net有效地補償了大變形并提供了高質量的配準。為了更詳細地理解模型在每個樣本上的性能差異,我們進一步分析了每例患者的DSC。這個分析不僅能評估整體性能,還能揭示模型在個體級別上的表現。實驗結果表明,MCRDP-Net在每個樣本上DSC得分的變化范圍相對較小,表明了MCRDP-Net在不同解剖結構和不同解剖變異下的穩健性。如圖4所示,MCRDP-Net在OASIS數據集上每個樣本的DSC都超過了其他方法,在IXI數據集上大多數樣本也達到了最佳的DSC,說明MCRDP-Net不僅在整體上優于其他模型,在個體級別上也能夠提供更一致和可靠的配準結果。這種細致的分析為模型性能的理解提供了更深入的見解,并為進一步改進和優化模型提供了有益的參考。
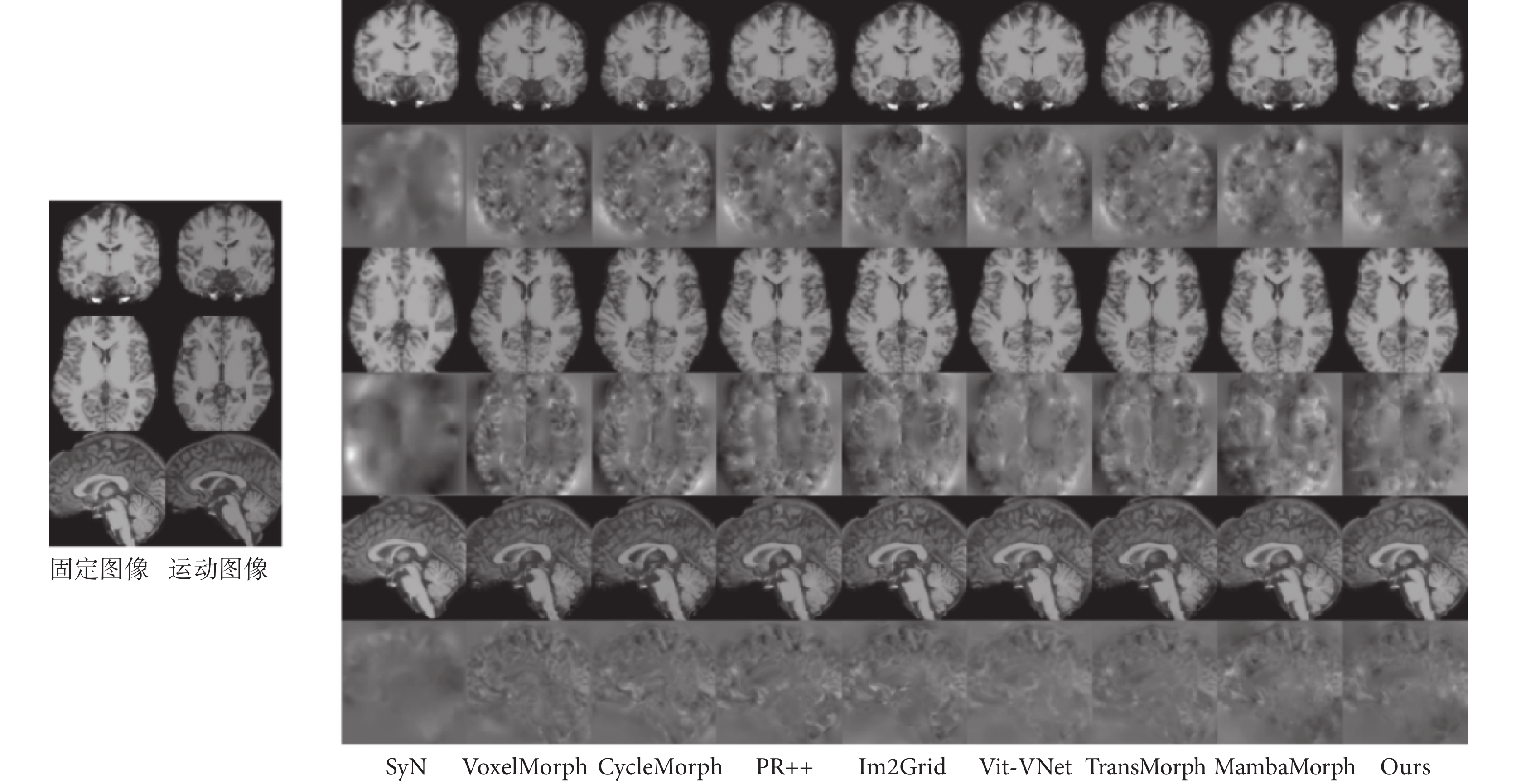 圖3
不同配準方法在IXI數據集上的可視化結果
圖3
不同配準方法在IXI數據集上的可視化結果
左邊分別為固定圖像、運動圖像在冠狀面、橫斷面和矢狀面上的圖像,右邊第一、三、五行分別為不同方法在冠狀面、橫斷面和矢狀面的配準后圖像,第二、四、六行為對應的變形場
Figure3. Visualization results of different registration methods on the IXI datasetthe left images are the images of the fixed image and the moving image on the coronal plane, cross section and sagittal plane, respectively; on the right, the first row, the third row and the fifth row are the images registered by different methods on the coronal plane, cross section and sagittal plane respectively, and the deformation fields corresponding to the second row, the fourth row and the sixth row
 圖4
不同配準方法在OASIS數據集上的可視化結果
圖4
不同配準方法在OASIS數據集上的可視化結果
左邊分別為固定圖像、運動圖像在冠狀面、橫斷面和矢狀面上的圖像,右邊第一、三、五行分別為不同方法在冠狀面、橫斷面和矢狀面的配準后圖像,第二、四、六行為對應的變形場
Figure4. Visualization results of different registration methods on the OASIS datasetthe left images are the images of the fixed image and the moving image on the coronal plane, cross section and sagittal plane, respectively; on the right, the first row, the third row and the fifth row are the images registered by different methods on the coronal plane, cross section and sagittal plane respectively, and the deformation fields corresponding to the second row, the fourth row and the sixth row
2.4 消融實驗
本研究在OASIS數據集上進行消融實驗,分別驗證了Mamba塊、融合模塊和多尺度注意力塊的作用,結果如表3所示。在沒有使用任何額外模塊時模型DSC為0.796,HD95為8.683,ASD為0.587。加入Mamba模塊后,模型性能略微提升,DSC達到0.804,HD95下降至8.601,ASD降至0.576。僅使用多尺度注意力模塊時,模型性能與僅使用Mamba模塊相似,DSC、HD95和ASD分別為0.803、8.603和0.569。同時使用Mamba模塊和特征融合模塊時,模型性能顯著提升,DSC達到了0.810,同時HD95和ASD也明顯下降。同樣地,同時使用Mamba模塊和多尺度注意力模塊也能使模型性能有所提升。而當所有模塊(Mamba模塊、特征融合模塊、多尺度注意力模塊)一起使用時,模型性能得到了最大的提升。這表明,在圖像配準任務中,同時應用這三個模塊可以取得最佳結果。Mamba模塊能提取全局特征,有效提取到較大形變的特征,并與卷積塊提取的特征結合,從而同時獲取圖像的全局信息和局部信息;特征融合模塊整合不同特征信息,使得模型對全局和局部信息的融合更準確;多尺度注意力模塊有助于模型在不同尺度下更好地生成形變場。
3 結論
本文提出了一種用于無監督腦部MRI配準的雙流金字塔網絡MCRDP-Net。MCRDP-Net充分利用了卷積和Mamba的優點同時提取局部特征和全局特征,金字塔網絡架構由粗到細預測不同尺度的形變場,能夠有效地捕捉大的位移變化,同時還能保留圖像的細節。本研究在兩個三維腦部MRI數據集上進行了圖像配準實驗。結果表明,MCRDP-Net實現了最先進的性能和配準效率。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:付麟杰負責實驗設計、代碼設計、實驗分析和論文寫作;朱遙遙負責數據分析和數據收集;姚宇負責提出研究的內容和意義、實驗可行性分析、基金支持和論文修訂。
0 引言
可變形圖像配準(deformable image registration,DIR)在醫學成像領域一直占據著核心地位。DIR應用范圍廣泛,包括術前規劃、疾病診斷以及術中導航[1-3]。DIR的關鍵在于求解非剛性變形場,通過該變形場對運動圖像進行扭曲,以實現與固定圖像在解剖學上的匹配。在基于深度學習的配準范式中,通常將固定圖像和運動圖像表示為和,它們都是尺寸為H × W × L的三維數組,其中H、W、L分別代表圖像的高度、寬度和深度。
為了實現圖像的精確配準,通常需要借助空間變換器網絡(spatial transformer network,STN)[4]。STN通過應用一個估計得到的采樣網格G來變換運動圖像,該網格尺寸為H × W × L × 3。采樣網格G由一個規則網格與一個變形場相結合得到。對于網格中的任意一點p,G(p)定義了固定圖像中與運動圖像中p點相對應的位置,從而將圖像配準問題轉化為尋找兩圖像間對應體素的相對位置關系。這一過程不僅有助于將單模態或多模態信息融合到統一的坐標系中,而且對于醫生進行精確診斷和治療至關重要[5-8]。
盡管現有的DIR方法眾多,配準的準確性和效率依然是該領域面臨的主要挑戰。傳統的配準技術雖然能夠計算出精確的微分同胚位移場,卻伴隨著巨大的計算開銷和時間延遲,難以滿足實時應用的需求[9]。相比之下,基于深度學習的配準方法,如VoxelMorph[10],不僅展現出快速配準的能力,而且在精度上可以與傳統方法相媲美。VoxelMorph作為一種開創性的基于卷積神經網絡(convolutional neural network,CNN)的DIR工作,專為無監督和弱監督配準設計,并利用了縮放和平方法來整合平滑速度場(stationary velocity field,SVF)。在VoxelMorph的基礎上,后續研究[11-17]進一步推動了DIR的準確性和多模態配準的發展。然而,由于卷積核尺寸的限制,VoxelMorph在全局建模方面存在局限。為了克服這一局限,一些研究開始探索使用Transformer架構來增強網絡的全局建模能力,如TransMorph[11]、Swin-VoxelMorph[18]和Vit-VNet[17]等。盡管如此,Transformer中的注意力機制也帶來了較高的計算復雜性。此外,一些研究[15-16]提出了從粗到細的逐步配準策略,旨在減少計算需求,同時保留對變形的廣泛捕獲能力,但在保持預測變形的連續性方面仍面臨挑戰。
針對這些挑戰,Mamba框架,特別是選擇性空間模型(selective state space model,SSM)變體,為順序特征中的高效特征處理提供了一種引人注目的解決方案[19-21]。Visual Mamba[22]通過在Mamba架構中引入選擇性掃描模塊,進一步提升了Mamba在計算機視覺任務中的優勢,并激發了Mamba在多種應用中的擴展[22-28]。在DIR領域,MambaMorph[29]和VMambaMorph[30]利用Mamba網絡作為配準模塊,成功實現了腦部圖像的配準。
基于這些背景和挑戰,本文提出了MCDP-Net。MCDP-Net采用雙流網絡分支,在使用混合Mamba塊和卷積塊的特征提取模塊的同時提取圖像的局部特征和全局特征,并將這些特征通過特征融合模塊進行融合后輸入解碼模塊。解碼模塊采用特征金字塔網絡,通過從底層到頂層的方式傳播語義信息,這不僅能夠有效地捕捉大的位移變化,同時還能保留圖像的細節,以實現高效且精確的醫學圖像配準。
1 算法框架
1.1 整體框架
MCDP-Net模型的整體框架如圖1所示。本研究使用了對稱的雙流網絡框架,將運動圖像和固定圖像分別輸入兩個Mamba和卷積編碼器進行特征提取,以同時提取圖像的局部信息和全局信息,然后使用設計的融合模塊對Mamba塊和卷積塊提取的特征進行特征融合。之后將運動圖像特征和固定圖像特征進行拼接,輸入具有金字塔結構的解碼器進行上采樣,在這個過程中使用多尺度注意力模塊以獲得運動圖像與固定圖像的全分辨率形變場。最后,通過最小化損失函數估計形變量,使運動圖像變形為與固定圖像相似。
圖1
模型整體網絡架構
a. 雙流特征提取模塊,用于對圖像特征進行編碼并下采樣;b. 特征金字塔結構的解碼模塊,用于將圖a提取的特征進行解碼并上采樣,得到形變場
Figure1. Overall network architecture of the modela. the dual-flow feature extraction module, used for encoding image features and down sampling; b. the decoder module of the feature pyramid structure, used for decoding the features extracted by Fig. a and up sampling to obtain the deformation field
1.2 基于Mamba-卷積的雙流特征提取模塊
為了同時提取圖像的局部特征和全局特征,本研究設計了Mamba和卷積并行結構。如圖1a所示,首先使用對稱的雙流網絡框架,分別對運動圖像和固定圖像進行編碼。在每一個分支網絡中,使用并行的Mamba塊和卷積塊提取圖像的全局特征和局部特征,最后使用特征融合模塊對特征進行融合。以提取運動圖像特征為例,首先將運動圖像輸入四個連續的卷積塊,每個卷積塊由卷積→實例正則化→LReLU組成,得到特征。同時將運動圖像輸入四個連續的Mamba塊,Mamba塊將圖像改變為形狀為B × L × C的張量作為輸入,得到相同形狀的輸出。B、L、C 分別表示批量大小、序列長度和通道數。Mamba塊結構如圖2a所示,首先將圖像輸入多層感知機(multilayer perceptron,MLP)線性投影并經過一個一維卷積層。在Swish層之后,在SSM層對張量進行處理,最后通過一個殘差連接得到 。為了更好地融合和,我們設計了一個特征融合模塊,如圖2b所示,將Mamba塊提取的特征輸入1 × 1的卷積塊以改變維度并獲得特征 = 。
圖2
不同特征模塊的結構
a. Mamba模塊,用于在編碼器階段提取圖像的全局信息;b. 特征融合模塊,用于將CNN和Mamba提取到的特征進行特征融合;c. 多尺度注意力模塊,用于在解碼器階段捕捉到不同尺度下的特征
Figure2. Structures of different feature modulesa. the Mamba module, used to extract global information from the image during the encoder; b. the feature fusion module, used to fuse the features extracted by the CNN and Mamba; c. the multi-scale attention module, used to capture features at different scales during the decoder
由于特征圖的每個通道都可以看作是一個特征檢測器[31],因此采用兩種池化策略來獲得更全面的信道依賴性。首先應用平均池化和最大池化計算通道上特征圖的統計特征,之后輸入共享的全連接層,并對兩種特征進行求和得到,然后將輸入全連接層和Sigmoid函數得到融合特征權重。整個過程可以用以下等式表示:
| '/> |
|
其中和代表全連接層,為ReLU函數,為Sigmoid函數。
然后,將信道依賴P作為權值,與卷積特征相乘,得到細化的特征。最后,通過連接細化特征和殘差結構得到融合特征,可以表示如下:
| '/> |
1.3 基于特征金字塔結構的解碼模塊
為了準確地預測形變場,提升配準精度,解碼器網絡遞歸地融合多層次特征,并利用傳統的金字塔結構和多尺度注意力模塊逐步細化形變場。具體而言,解碼器結構(l = 4, 3, 2, 1)從粗到細逐步預測變形場,如圖1b所示。對于第1個解碼層,將特征圖 和 輸入到 CConv 中以生成融合特征圖 :
|
其中CConv由兩個卷積→實例正則化→LReLU組成。之后將輸入設計的多尺度注意力模塊以獲取不同通道之間的關系。多尺度注意力模塊包含多分支深度卷積以捕獲多尺度上下文和一個1 × 1卷積(見圖2c)來模擬不同通道之間的關系:
|
|
然后將 輸入到 Def ,包含一個3 × 3的卷積塊和微分同胚層,以生成第一個形變場 :
|
之后將和進行上采樣:
|
|
從第2個解碼層開始,執行以下操作:將、和( = 2, 3, 4)進行拼接后輸入CConv中得到融合特征圖 ,然后將輸入多尺度注意力模塊和Def得到。通過融合不同層次的形變場,可以更有效地捕捉到不同尺度下的特征,特別是在處理大范圍變形時,粗糙的形變場可以幫助細致的形變場更快收斂,因此將和通過Fusion層進行融合,然后經過上采樣后輸入下一個解碼層:
|
其中Fusion層先使用STN得到將配準到的形變場,然后再將形變場與相加。圖1中的形變場表示固定圖像和運動圖像之間的變形關系,灰度值通常代表形變的程度。較亮的區域可能表示更大的變形,而較暗的區域表示較小的變形。通過這種方式,可以快速識別圖像中變形最顯著的區域。
最后,將待配準圖像與最后一個解碼層得到的形變場進行點乘得到配準后圖像:
|
1.4 損失函數
為了指導訓練,使用歸一化互相關(normalized cross correlation,NCC)[32]來評估固定圖像 和配準后的運動圖像之間的相似性:
|
其中Ω表示整個體積域。體素是體素p中心的(n = 9)中的局部鄰域。 和 表示該局部鄰域內的平均體素值。
對于正則化,利用變形場梯度的L2范數來保證合理的變形:
|
因此,總損失為:
|
其中 是正則化項的權重,經過對比實驗,我們將之設置為1。
2 實驗和結果分析
2.1 數據集
在本研究中,采用了兩個公開獲取的腦部磁共振成像(magnetic resonance imaging,MRI)數據集,對所提出的算法進行了全面評估。評估涉及的數據集包括OASIS[33]和IXI。這兩個數據集僅提供了原始圖像,并未包含任何預對齊處理,如單獨的預對齊或仿射預對齊。在本實驗中,所有圖像的尺寸被統一調整為160 × 160 × 160,體素大小統一設定為1 mm × 1 mm × 1 mm,以確保數據的一致性。
在實驗設計上,我們隨機選擇了一幅圖像作為參照的固定圖像。對于IXI數據集,采用403幅圖像作為訓練集,58幅圖像作為驗證集,以及115幅圖像作為測試集。此外還使用了46個帶有詳細注釋的感興趣區域(region of interest,ROI)來評估算法的性能。對于OASIS數據集,訓練集由394幅圖像組成,驗證集和測試集分別包含20幅圖像,評估過程中同樣使用了36個帶注釋的ROI。
實驗的執行和驗證均在PyTorch框架下進行,采用了一張配備24 GB顯存的RTX3090顯卡。在實驗設置中,選擇Adam作為優化器,并設置了批處理大小為1。整個訓練過程將學習率調整為0.000 1,以優化算法的收斂性能和模型的泛化能力。
2.2 評價指標
在本文中,采用了三種不同的指標來全面評估網絡的配準性能:戴斯相似性系數(Dice similarity coefficient,DSC)、95%的豪斯多夫距離(Hausdorff distance,HD)和平均表面距離(average surface distance,ASD)。
DSC系數用于量化固定圖像與運動圖像ROI之間的重疊程度,值域介于0~1,數值越接近1,表示重疊程度越高,配準效果越好。HD95衡量了運動圖像ROI中任意點到固定圖像ROI最近點的最大距離,理想情況下該值應盡可能接近0,以反映兩圖像ROI之間的高度一致性。ASD指標計算了運動圖像ROI中每個點到固定圖像ROI中最近點距離的平均值,ASD值越小,表示兩圖像ROI之間的對應點距離越接近,從而反映出更優的配準精度。
此外,我們還引入了J?指標,即具有非正雅可比行列式(表示為折疊體素)的體素的百分比,用以評估預測的非剛性變形場?的質量。在這一指標中,J?值越接近于0,表明預測的變形場越少包含異常值,即變形場的質量越高。通過這些綜合性的評估指標,能夠全面而準確地評價配準網絡的性能。
2.3 對比分析
本研究將MCRDP-Net與SyN、VoxelMorph、CycleMorph、Im2Grid、PR++、TransMorph、Vit-VNet和MambaMorph進行了比較,結果如表1~2所示。其中SyN為非深度學習配準方法,VoxelMorph、CycleMorph、Im2Grid和PR++是基于CNN的深度學習配準方法,TransMorph和Vit-VNet是基于Transformer的深度學習配準方法,MambaMorph是基于Mamba的深度學習配準方法。由表1可以看出,在IXI數據集上,MCRDP-Net在DSC、HD95和ASD的度量方面始終獲得了最好的配準精度,分別達到了0.773、7.786和0.871。表中還列出了非正雅可比行列式(%|J?|≤0)的體素的百分比,顯示MCRDP-Net生成了高質量的非剛性變形場。在所有比較方法中,單級網絡(例如VoxelMorph和TransMorph)的性能比級聯結構和金字塔結構差(例如PR++)。由于使用SwinTransformer作為增強編碼器,TransMorph比VoxelMorph實現了更好的配準精度。在所有方法中,MambaMorph取得了與MCRDP-Net最接近的結果,這說明Mamba框架確實能夠實現更好的圖像變換。同樣的結論也出現在OASIS的實驗結果中,MCRDP-Net在OASIS數據集上DSC、HD95和ASD分別達到了0.815、8.123和0.521,為所有模型中的最優值,同時%|J?|≤0為0.031也是所有模型中最低的。圖3和圖4可視化了兩個數據集上不同方法在冠狀面、橫斷面和矢狀面的配準圖像和對應的變形場。可以看出,MCRDP-Net生成了更準確的配準圖像,并且可以一致地保留內部結構。特別是對于沒有初始仿射對齊的圖像,MCRDP-Net有效地補償了大變形并提供了高質量的配準。為了更詳細地理解模型在每個樣本上的性能差異,我們進一步分析了每例患者的DSC。這個分析不僅能評估整體性能,還能揭示模型在個體級別上的表現。實驗結果表明,MCRDP-Net在每個樣本上DSC得分的變化范圍相對較小,表明了MCRDP-Net在不同解剖結構和不同解剖變異下的穩健性。如圖4所示,MCRDP-Net在OASIS數據集上每個樣本的DSC都超過了其他方法,在IXI數據集上大多數樣本也達到了最佳的DSC,說明MCRDP-Net不僅在整體上優于其他模型,在個體級別上也能夠提供更一致和可靠的配準結果。這種細致的分析為模型性能的理解提供了更深入的見解,并為進一步改進和優化模型提供了有益的參考。
圖3
不同配準方法在IXI數據集上的可視化結果
左邊分別為固定圖像、運動圖像在冠狀面、橫斷面和矢狀面上的圖像,右邊第一、三、五行分別為不同方法在冠狀面、橫斷面和矢狀面的配準后圖像,第二、四、六行為對應的變形場
Figure3. Visualization results of different registration methods on the IXI datasetthe left images are the images of the fixed image and the moving image on the coronal plane, cross section and sagittal plane, respectively; on the right, the first row, the third row and the fifth row are the images registered by different methods on the coronal plane, cross section and sagittal plane respectively, and the deformation fields corresponding to the second row, the fourth row and the sixth row
圖4
不同配準方法在OASIS數據集上的可視化結果
左邊分別為固定圖像、運動圖像在冠狀面、橫斷面和矢狀面上的圖像,右邊第一、三、五行分別為不同方法在冠狀面、橫斷面和矢狀面的配準后圖像,第二、四、六行為對應的變形場
Figure4. Visualization results of different registration methods on the OASIS datasetthe left images are the images of the fixed image and the moving image on the coronal plane, cross section and sagittal plane, respectively; on the right, the first row, the third row and the fifth row are the images registered by different methods on the coronal plane, cross section and sagittal plane respectively, and the deformation fields corresponding to the second row, the fourth row and the sixth row
2.4 消融實驗
本研究在OASIS數據集上進行消融實驗,分別驗證了Mamba塊、融合模塊和多尺度注意力塊的作用,結果如表3所示。在沒有使用任何額外模塊時模型DSC為0.796,HD95為8.683,ASD為0.587。加入Mamba模塊后,模型性能略微提升,DSC達到0.804,HD95下降至8.601,ASD降至0.576。僅使用多尺度注意力模塊時,模型性能與僅使用Mamba模塊相似,DSC、HD95和ASD分別為0.803、8.603和0.569。同時使用Mamba模塊和特征融合模塊時,模型性能顯著提升,DSC達到了0.810,同時HD95和ASD也明顯下降。同樣地,同時使用Mamba模塊和多尺度注意力模塊也能使模型性能有所提升。而當所有模塊(Mamba模塊、特征融合模塊、多尺度注意力模塊)一起使用時,模型性能得到了最大的提升。這表明,在圖像配準任務中,同時應用這三個模塊可以取得最佳結果。Mamba模塊能提取全局特征,有效提取到較大形變的特征,并與卷積塊提取的特征結合,從而同時獲取圖像的全局信息和局部信息;特征融合模塊整合不同特征信息,使得模型對全局和局部信息的融合更準確;多尺度注意力模塊有助于模型在不同尺度下更好地生成形變場。
3 結論
本文提出了一種用于無監督腦部MRI配準的雙流金字塔網絡MCRDP-Net。MCRDP-Net充分利用了卷積和Mamba的優點同時提取局部特征和全局特征,金字塔網絡架構由粗到細預測不同尺度的形變場,能夠有效地捕捉大的位移變化,同時還能保留圖像的細節。本研究在兩個三維腦部MRI數據集上進行了圖像配準實驗。結果表明,MCRDP-Net實現了最先進的性能和配準效率。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:付麟杰負責實驗設計、代碼設計、實驗分析和論文寫作;朱遙遙負責數據分析和數據收集;姚宇負責提出研究的內容和意義、實驗可行性分析、基金支持和論文修訂。