引用本文: 任益鋒, 馬瓊, 蔣華, 付西, 李雪珂, 石薇, 由鳳鳴. 肺結節/早期肺癌預測模型的知識圖譜與可視化分析. 中國胸心血管外科臨床雜志, 2025, 32(1): 100-107. doi: 10.7507/1007-4848.202304026 復制
版權信息: ?四川大學華西醫院華西期刊社《中國胸心血管外科臨床雜志》版權所有,未經授權不得轉載、改編
肺癌是全球癌癥相關死亡的最常見原因,其早期診斷依然面臨挑戰[1-4]。盡管在肺癌治療方面已取得了長足進步,但晚期肺癌患者預后不佳的現狀仍然無法得到改善[5-7]。臨床生存結果與疾病分期密切相關已成為共識,研究[8]表明,早期診斷可使5年相對生存率從晚期肺癌的6%增加至中期肺癌的33%和早期肺癌的60%。現行的肺結節診療管理以隨訪監測為主,對于未達到手術指征的肺結節仍缺乏有效的干預措施,這不僅加重了患者的身心負擔,在一定程度上也增加了醫療資源的浪費。因此,早診早治是降低肺癌相關死亡率和減輕經濟負擔的有效策略。
隨著癌癥篩查技術的進步,特別是低劑量計算機斷層掃描(low-dose computed tomography,LDCT)分辨率的提高,每年有數十萬患者被診斷為肺結節[9-10]。研究[11]表明,由于假陽性率和過度診斷風險的增加,許多肺結節患者接受了非必要性手術操作。而在侵入性手術前精準評估肺結節的良惡性不僅能減少不必要的手術、減輕患者的身心負擔,還可延緩惡性結節的疾病進展、減少醫療資源浪費。值得一提的是,肺結節/早期肺癌風險預測模型已被證實可以顯著降低肺癌篩查中的假陽性率。目前已有指南建議使用預測模型進行肺癌篩查,例如美國國立綜合癌癥網絡(National Comprehensive Cancer Network,NCCN)發布的肺癌篩查指南[12]強調了采用風險預測模型識別肺結節高危人群的重要地位。
最初,肺結節/早期肺癌的預測模型變量主要基于患者的CT影像特征和臨床信息。但由于缺乏其他重要生物標志物等特征性變量,較高的假陽性和過度診療發生率一直無法避免[13-14]。基于多組學技術(包括影像組學、基因組學、蛋白質組學和代謝組學)尋找新的生物診斷標志物,為提高肺癌預測模型的準確性和敏感性提供了新的切入點。肺結節/早期肺癌預測模型的數量正在快速增加,然而目前這些研究尚未得到系統性定量研究。對現有文獻進行系統可視化分析有助于研究者更加直觀地了解肺結節/早期肺癌預測模型的研究現狀與趨勢,從而掌握該領域未來的研究方向。雖然已經有一些肺結節/早期肺癌風險預測模型的相關綜述[15],但仍然缺乏對這些模型的演變和趨勢的定量評估。文獻計量學可以表征某一學科的研究動態,通過知識圖譜的形式將大量文獻數據信息生動直觀地呈現出來,為今后的研究提供參考。
本研究對肺結節/早期肺癌風險預測模型的研究現狀進行表征,并通過文獻計量學和可視化分析探討該領域的研究趨勢和最新動態,為肺結節/早期肺癌預測模型領域提供整體研究的宏觀概括和熱點概覽,以期為未來可能的研究方向提供綜述性觀點。
1 資料與方法
1.1 數據來源與檢索策略
檢索中國知網、萬方、維普和Web of Science數據庫,檢索時間為2002年1月1日—2023年6月3日。以中國知網為例的檢索式為:SU=(肺結節+肺部結節+肺癌+肺腺癌+肺鱗癌+非小細胞肺癌)AND SU=(預測模型+預后模型+列線圖)。
1.2 文獻篩選與數據清洗
納入標準:已發表的有關肺結節/早期肺癌預測模型的論著或綜述;語種為中文或英文。排除標準:會議摘要、未公開發表文章、重復出版物、勘誤類文章、學位論文、信件以及與研究主題不相關文章。將檢索到的中文文獻以Refworks格式導入NoteExpress中進行查重,并且由兩名研究者獨自對文獻進行人工篩選。英文文獻從Web of Science中將完整記錄和引用的參考文獻的檢索結果導出為“純文本文件”,并以“download.txt”格式存儲。兩位作者獨立根據納入排除標準篩選文獻。如有分歧,通過第三位作者討論解決以達成共識。
篩選標題、作者、機構、關鍵詞等關鍵信息完整的文章并完成數據清洗。合并重復的機構,對于同一機構的不同名稱,采用現今被廣泛接受的規范名稱,同一學校不同學院均歸為學校,同一醫院不同科室均歸為醫院;合并重復的關鍵詞,將相同含義的關鍵詞進行合并。
1.3 文獻計量學與可視化分析
將完成數據清洗后的數據使用VOSviewer 1.6.18[16]、CiteSpace 6.1.R[17]和在線分析平臺(
中文文獻以RefWorks格式導出至VOSviewer 1.6.18中,繪制作者和機構的合作網絡,以及關鍵詞聚類和時間演化分析,由于中文數據庫無法導出參考文獻相關信息,故未進行參考文獻共被引分析。英文文獻清洗和數據篩選完成后,使用VOSviewer 1.6.18繪制期刊的被引頻次圖譜,作者、國家、機構的合作網絡、關鍵詞聚類分析和時間演化分析圖譜[19,21]。使用CiteSpace對高頻共被引參考文獻進行聚類分析。
2 結果
2.1 檢索結果
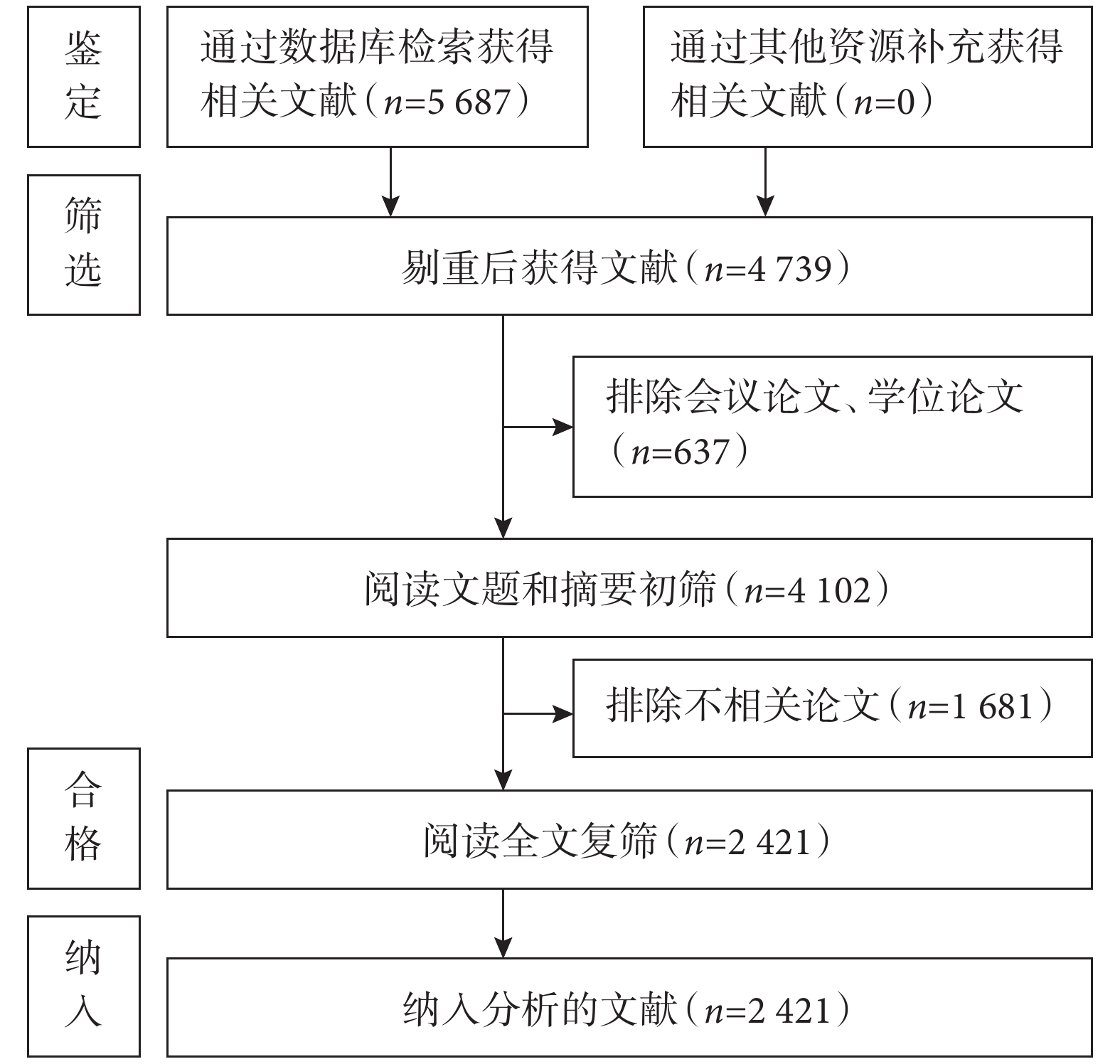
共檢索到
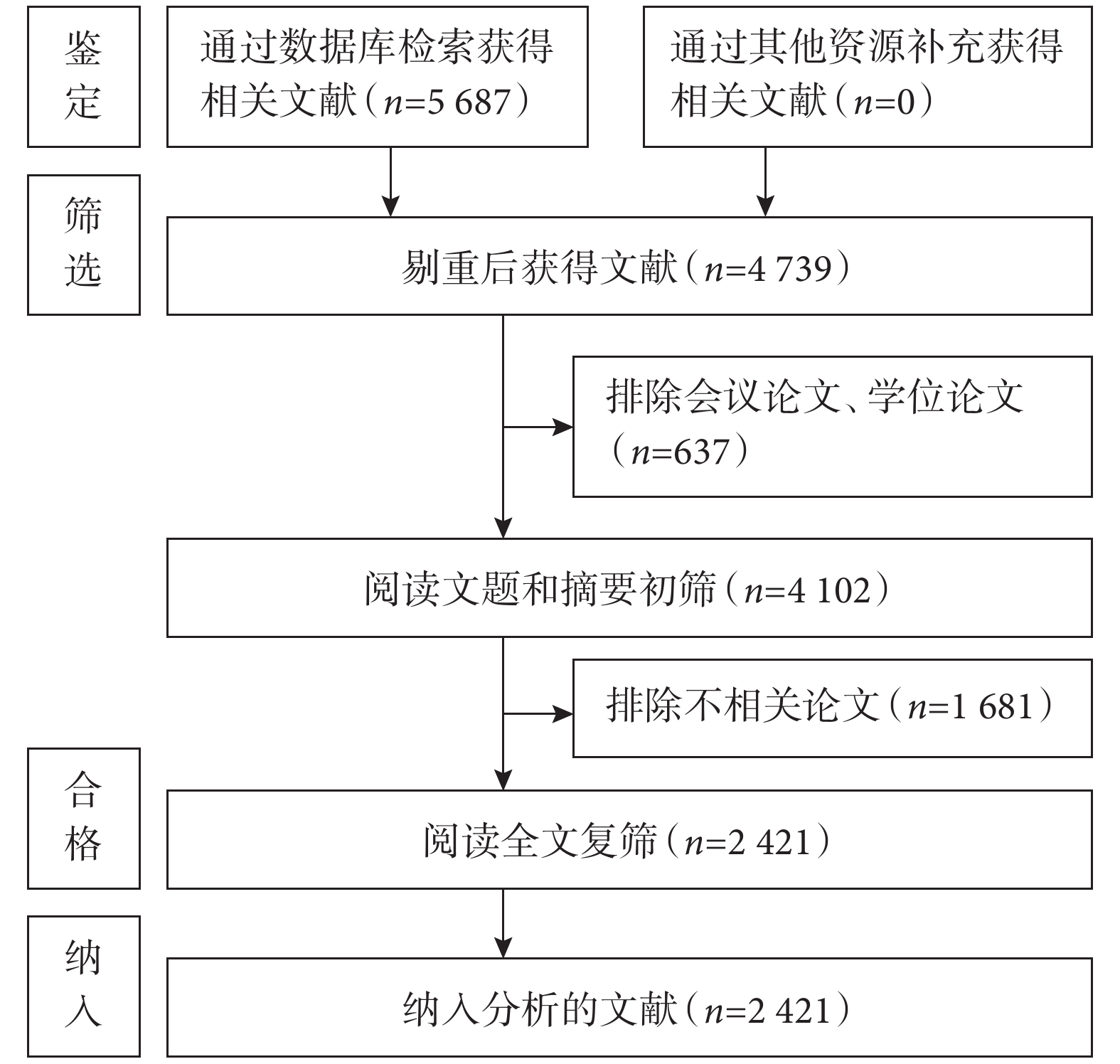 圖1
文獻篩選流程
圖1
文獻篩選流程
2.2 年發文量
英文文獻共
2.3 期刊分析
共有566種期刊發表了肺結節/早期肺癌預測模型相關的英文文章。發文量排名前10的英文期刊見附件表1,這些期刊共發表462篇英文文章。其中,發文量最多的期刊是Frontiers in Oncology(120篇),其次是Lung Cancer(47篇)和Cancers(42篇)。在發文量排名前10的學術期刊中,IF最高的期刊是Journal of Thoracic Oncology(IF=20.21)。中文期刊發文量最多的是《臨床放射學雜志》(13篇),其次是《中國胸心血管外科臨床雜志》(9篇)和《中國肺癌雜志》(7篇)。
當VOSviewer中的閾值設定為5時,英文期刊共現網絡有91個節點、3個集群和
2.4 國家/地區分析
對納入的英文文章進行國家/地區分析,結果表明共有64個國家/地區為肺結節/早期肺癌預測模型的研究做出了貢獻。中國發文量最多(
在VOSviewer中,我們將閾值設置為5以顯示國家/地區的合作關系。合作關系網絡圖包含了35個節點、7個集群和294條連線(附件圖3),最大的集群(橙色)由7個國家組成,以澳大利亞、韓國和印度為中心。美國是合作伙伴最多的國家(n=31),其次是英國(n=27)、意大利(n=27)、德國(n=27)、西班牙(n=27)和丹麥(n=27)。
2.5 機構合作分析
共有
英文發文量≥10篇的機構合作網絡見附件圖4a,包括102個節點、7個集群和802條連接線。紅色集群由復旦大學、上海交通大學、中山大學和北京協和醫學院為中心的32所機構組成,是最大的集群。哈佛醫學院有最多的合作者(n=34),其次是上海交通大學(n=33)、中山大學(n=32)和哈佛大學(n=32)。發表中文論文的機構之間的合作網絡見附件圖4b,包括9個節點、3個集群和12條連線。北京協和醫學院發文量最多,最大的合作網絡由南京醫科大學、上海交通大學、江蘇省啟東市肝癌研究所和清華大學共同組成。與中文文獻相比,發表英文文獻的機構之間的合作更加密切。
2.6 作者分析
發表英文論文的作者總數為
發表中文論文的作者總數為1 256人。其中,韓冬發表文章最多(5篇),其次為于楠(4篇)和張永奎(4篇)。中文作者合作網絡包括25個節點、4個集群和98條連線(附件圖5b)。紅色集群由8位作者組成,包括劉敏、王秋萍、郭曉娟、郭佑民等。
2.7 關鍵詞聚類、時間演化及突現分析
關鍵詞時間演化分析圖是根據其平均出現年份(average appearing year,AAY)進行著色,以探索隨時間推移的演變趨勢(附件圖7a)。英文文獻中最近出現的關鍵詞是“lncRNA”(AAY:2021.30)、“腫瘤微環境”(AAY:2021.08)、“免疫”(AAY:2020.88)、“癌癥統計”(AAY:2020.50)、“TCGA”(AAY:2020.61)、“諾莫圖”(AAY:2020.17)和“機器學習”(AAY:2019.91)。中文文獻關鍵詞時間演化分析結果顯示,新興關鍵詞有“列線圖”(AAY:2020.64)、“機器學習”(AAY:2020.79)、“預后模型”(AAY:2021.08)、“人工智能”(AAY:2021.40)。
英文文獻的關鍵詞突現分析顯示 “smoking”(25.44)的突現強度最高,其次為“risk model”(9.24)和“risk”(8.9)(附件圖8a)。近5年中出現的關鍵詞是“guidelines”“images”“poor prognosis”“feature”和“genome”。中文關鍵詞突現分析表明,“預后”(2.72)的突現強度最高,其次是“影像組學”(2.13)和“列線圖”(1.94)(附件圖8b)。截至2022年,影像組學、機器學習、預測、鑒別診斷和影響因素的熱度仍在升高,說明這是目前的研究熱點和今后的研究趨勢。
2.8 文獻共被引
我們列出了被引用最多的10篇英文文獻(附件表5)。可以看出,大多數共被引文獻均發表于頂級期刊,如The New England Journal of Medicine、CA: A Cancer Journal for Clinicians和Nature,這些研究中有一半以上與肺結節/早期肺癌的流行病學和預測模型有關。國家肺癌篩查試驗研究小組發表在The New England Journal of Medicine上的一篇題為“Reduced lung-cancer mortality with low-dose computed tomographic screening”的研究[22]被引頻次最高(291次)。這項對33個美國醫學中心的
納入的
3 討論
3.1 肺結節/早期肺癌預測模型研究的全球趨勢
文獻計量學融合了統計學、數學、文獻學等多學科,能夠對某一研究領域進行定量評估。我們共納入了2002—2023年間發表的
各個國家/地區之間也進行了合作,中國是發文量最高的國家,美國是被引頻次最多的國家。此外,美國當前處于國際合作的核心地位,與中國、日本、澳大利亞和新加坡等國家有密切聯系。發文量排名前10的機構包括8所中國院校和2所美國院校,這說明美國和中國的研究者在肺結節/早期肺癌預測模型方面的研究投入比其他國家更多。近年來,來自中國的文獻數量正不斷增加,這反映了中國對肺結節/早期肺癌預測模型研究的高度重視。來自利物浦大學分子與臨床癌癥醫學系的John K Field教授和中國醫學科學院的赫捷院士均發表了17篇文章,為肺結節/早期肺癌預測模型領域做出了巨大貢獻。
3.2 研究熱點與前沿
無創便捷的預測模型作為新興預測工具在肺癌早期預警及輔助診斷、療效實時監測、用藥指導和耐藥機制探索、預后判斷等臨床應用方面持續發揮巨大價值[25-26]。關鍵詞聚類分析有利于發現當前有關肺結節/早期肺癌預測模型的研究熱點。本研究顯示,預后、治療、生存和影像組學是當前肺結節/早期肺癌預測模型研究的重點。值得注意的是,英文文獻關鍵詞時間演化分析結果顯示,近年來lncRNA、腫瘤微環境、免疫、癌癥統計、TCGA、諾莫圖和機器學習出現頻次較高。由于機器學習的快速發展和不斷深入,肺結節/早期肺癌預測模型不斷優化。中文文獻關鍵詞分析表明該領域的新興關鍵詞有列線圖、機器學習、預后模型和人工智能等。中英文的關鍵詞突現分析結果表明,目前影像組學、基因組學、機器學習、預后預測、鑒別診斷是該領域的研究熱點和趨勢。隨著高通量測序技術的迅速發展,越來越多的新型診斷預測因子被納入模型變量,包括lncRNA、基因組學、微生物組學、免疫和影像組學等[27-28],有助于提高肺結節/早期肺癌預測模型的精準度和靈敏度,推動肺癌早診早治(附件圖10)。
應用最早最廣泛的肺結節/早期肺癌預測模型是Swensen等[29]建立的Mayo模型。大多數傳統模型將年齡、性別、種族、民族、受教育程度、體重指數、個人癌癥史、個人肺炎史、肺癌家族史以及吸煙史等多種臨床特征作為風險預測因素[30]。隨著肺癌篩查的普及,肺結節/早期肺癌預測模型引起了研究者的關注,越來越多的研究證實了肺結節/早期肺癌預測模型在肺癌早診早治中的潛力。近年來,人工智能、分子生物學和多組學技術的發展進一步催生了更多的新型診斷預測因子[5]。大量研究[31-33]表明,基于生物標志物、基因組學、影像組學等多模態數據的預測模型,特別是整合了多組學特征的模型,可以顯著提高肺癌預測的準確性和良惡性肺結節的鑒別能力[34-35]。Hu等[36]基于3個DNA甲基化生物標志物和1個影像學特征構建了預測模型,惡性肺結節診斷的曲線下面積(area under the curve,AUC)可達0.951,顯著高于Mayo模型(AUC=0.823)的預測效能。
基于關鍵詞分析,我們還發現機器學習和人工智能在肺結節/早期肺癌預測模型應用廣泛,越來越多的研究證明了機器學習和人工智能在肺結節/早期肺癌預測模型開發中的作用。人工智能可以幫助識別人類無法提取的特征和執行重復性的任務,通過將人工智能與影像組學、基因組學、轉錄組學、蛋白組學和臨床數據相結合,該集成數據能顯著提高肺結節/早期肺癌預測模型的準確性。Hosny等[37]提供了一種基于深度學習網絡和非小細胞肺癌患者CT圖像的肺癌預測模型,可用于肺癌死亡風險分層。Takahashi等[32]使用來自癌癥基因組圖譜的6個不同多組學數據集,基于無監督機器學習算法建立了肺癌患者預后預測模型。多組學與機器學習技術的結合在這一領域非常有前景,能顯著提高預測模型的預測效能。Chen等[38]通過機器學習算法構建了包含基因突變、cfDNA甲基化信號以及血清腫瘤蛋白標志物水平的多組學肺癌診斷模型,AUC為0.78,其診斷性能顯著高于任何單一組學構建的診斷模型,研究證明多組學數據整合可有效提高肺癌診斷預測模型的準確性。
被引頻次高的參考文獻大多集中在流行病學和肺癌預測模型上。2013年,美國預防服務工作組建議每年使用LDCT進行肺癌早篩[39]。隨著LDCT的廣泛使用和健康意識的提高,越來越多的預測模型被開發出來[3]。預測模型的開發減輕了患者的身心負擔和醫療系統負荷,并提高了診斷的準確性。由于肺癌持續存在的高發病率和死亡率,因此迫切需要更精準和可靠的預測模型應用于肺結節/早期肺癌,推動肺癌的精準醫療。
3.3 挑戰和前景
肺結節/早期肺癌預測模型在過去20年中發展迅猛,但仍存在一些需要解決的問題。首先,大部分預測模型基于單中心或小樣本回顧性研究數據,缺乏外部數據集進行驗證;部分樣本量相對較大的研究是在歐美國家開展的,限制了預測模型的推廣和應用。同時,由于算法和數據集的不同,模型的靈敏度和精確度也不同,導致尚未形成統一的診斷標準。此外,一些指南建議使用預測模型以降低LDCT的假陽性率,但是目前尚無全球公認的預測模型應用于臨床。最后,當前不同國家、機構和作者之間的交流合作不密切,未來需開展更多跨國家、跨區域、跨機構的大樣本多中心前瞻性研究,各國各機構之間消除學術壁壘,合作共贏,共同推動肺結節/早期肺癌預測模型的發展。
肺癌的發生、發展是一個多步驟連鎖事件,涉及諸多層面的復雜調控機制。近年來,分子生物學、高通量測序技術和各種質譜儀的快速發展,為進一步探索肺結節和肺癌的致病機制、危險因素和潛在預測因子提供了重要的理論和技術支持,這將會激發預測模型的進一步優化,以提高其靈敏度和準確性。液體活檢等新興檢測技術為亞臨床期的肺癌個體化診療提供了技術支持。海量的多組學數據有助于構建和優化肺結節/早期肺癌預測模型,有助于肺癌早診早治,推動精準醫學的發展。
本研究發現人工智能、機器學習、多組學等為現階段的研究熱點,探索多組學數據的融合算法亦是今后很長一段時間內的重點研究方向。近年來,基于多組學數據建立的預測模型不斷增多,為臨床決策和個體化治療提供了更為充分的理論依據。如Carrillo-Perez等[40]融合全切片數字成像(WSI)、RNA、miRNA、拷貝數變異(CNV)的多組學數據構建預測模型,其精度為96.81%,AUC為0.993,具有較高的準確性,利用多組學數據可以提高個性化醫療中的臨床決策支持系統的性能。與僅使用單組學數據相比,多組學融合能提高肺癌分期預測模型的準確性。Li等[33]使用隨機森林算法構建肺癌分期預測模型,其中微生物組聯合轉錄組預測模型的準確率為0.809,較單組學預測模型更精準,提高了肺癌分期預測能力。不同組學數據可通過人工智能的預測算法進行整合,以揭示系統生物學的復雜機制,發現新的生物標志物,有助于提高預測模型的準確性。故人工智能、機器學習和多組學在肺癌的早診早治中具有重要的研究意義,具有巨大的潛在價值和廣闊的應用前景,仍需要進一步進行臨床驗證。
該研究存在以下局限性:首先,我們只納入了2002—2023年發表的文章,這可能會導致選擇偏倚。第二,本研究納入了知網、萬方、維普和Web of Science數據庫中的相關文獻,但這也不可避免地遺漏了其他數據庫潛在文獻,今后可增加數據庫來源,提高研究的深度和廣度。第三,人工進行文獻信息整理、關鍵詞合并等數據清洗時可能存在潛在的選擇性偏倚。第四,由于中文數據庫尚無法直接導出引文數據,導致缺少中文文獻共被引分析。最后,許多作者與其他作者同名同姓,文獻計量軟件無法區分同名作者的貢獻度,難以避免作者信息的不準確。
綜上所述,該研究對近20年肺結節/早期肺癌預測模型相關文獻進行文獻計量學和可視化分析。研究表明:肺結節/肺癌預測模型正處于快速發展階段,具有巨大的臨床應用潛力。過去20年中,在肺結節/肺癌預測模型領域,涌現出了以中國和美國為代表的諸多富有強大科學創造力的國家,復旦大學在該領域中具有重要的學術影響力,以赫捷院士和John K Field教授為核心的研究團隊為肺癌的早診早治做出了巨大貢獻。預測模型、機器學習、人工智能和多組學技術是當前和未來研究的重點,并顯示出巨大的應用前景。最后,為提高預測模型的臨床實用性,我們建議使用來自大樣本、多中心研究的數據進行外部驗證,并加強跨國家、跨地區、跨學科的交叉合作,構建和優化更加精準的肺結節/早期肺癌預測模型,推動精準醫學的發展。
利益沖突:無。
作者貢獻:任益鋒、馬瓊、石薇、由鳳鳴負責論文構思及設計,分析數據及撰寫論文;蔣華、付西、李雪珂篩選文獻,提取資料,質量評估;任益鋒、馬瓊、石薇進行論文質量評價和修改論文;由鳳鳴負責對文章的知識性內容作批判性審閱與修改。
本文附件圖表見本刊網站電子版(
肺癌是全球癌癥相關死亡的最常見原因,其早期診斷依然面臨挑戰[1-4]。盡管在肺癌治療方面已取得了長足進步,但晚期肺癌患者預后不佳的現狀仍然無法得到改善[5-7]。臨床生存結果與疾病分期密切相關已成為共識,研究[8]表明,早期診斷可使5年相對生存率從晚期肺癌的6%增加至中期肺癌的33%和早期肺癌的60%。現行的肺結節診療管理以隨訪監測為主,對于未達到手術指征的肺結節仍缺乏有效的干預措施,這不僅加重了患者的身心負擔,在一定程度上也增加了醫療資源的浪費。因此,早診早治是降低肺癌相關死亡率和減輕經濟負擔的有效策略。
隨著癌癥篩查技術的進步,特別是低劑量計算機斷層掃描(low-dose computed tomography,LDCT)分辨率的提高,每年有數十萬患者被診斷為肺結節[9-10]。研究[11]表明,由于假陽性率和過度診斷風險的增加,許多肺結節患者接受了非必要性手術操作。而在侵入性手術前精準評估肺結節的良惡性不僅能減少不必要的手術、減輕患者的身心負擔,還可延緩惡性結節的疾病進展、減少醫療資源浪費。值得一提的是,肺結節/早期肺癌風險預測模型已被證實可以顯著降低肺癌篩查中的假陽性率。目前已有指南建議使用預測模型進行肺癌篩查,例如美國國立綜合癌癥網絡(National Comprehensive Cancer Network,NCCN)發布的肺癌篩查指南[12]強調了采用風險預測模型識別肺結節高危人群的重要地位。
最初,肺結節/早期肺癌的預測模型變量主要基于患者的CT影像特征和臨床信息。但由于缺乏其他重要生物標志物等特征性變量,較高的假陽性和過度診療發生率一直無法避免[13-14]。基于多組學技術(包括影像組學、基因組學、蛋白質組學和代謝組學)尋找新的生物診斷標志物,為提高肺癌預測模型的準確性和敏感性提供了新的切入點。肺結節/早期肺癌預測模型的數量正在快速增加,然而目前這些研究尚未得到系統性定量研究。對現有文獻進行系統可視化分析有助于研究者更加直觀地了解肺結節/早期肺癌預測模型的研究現狀與趨勢,從而掌握該領域未來的研究方向。雖然已經有一些肺結節/早期肺癌風險預測模型的相關綜述[15],但仍然缺乏對這些模型的演變和趨勢的定量評估。文獻計量學可以表征某一學科的研究動態,通過知識圖譜的形式將大量文獻數據信息生動直觀地呈現出來,為今后的研究提供參考。
本研究對肺結節/早期肺癌風險預測模型的研究現狀進行表征,并通過文獻計量學和可視化分析探討該領域的研究趨勢和最新動態,為肺結節/早期肺癌預測模型領域提供整體研究的宏觀概括和熱點概覽,以期為未來可能的研究方向提供綜述性觀點。
1 資料與方法
1.1 數據來源與檢索策略
檢索中國知網、萬方、維普和Web of Science數據庫,檢索時間為2002年1月1日—2023年6月3日。以中國知網為例的檢索式為:SU=(肺結節+肺部結節+肺癌+肺腺癌+肺鱗癌+非小細胞肺癌)AND SU=(預測模型+預后模型+列線圖)。
1.2 文獻篩選與數據清洗
納入標準:已發表的有關肺結節/早期肺癌預測模型的論著或綜述;語種為中文或英文。排除標準:會議摘要、未公開發表文章、重復出版物、勘誤類文章、學位論文、信件以及與研究主題不相關文章。將檢索到的中文文獻以Refworks格式導入NoteExpress中進行查重,并且由兩名研究者獨自對文獻進行人工篩選。英文文獻從Web of Science中將完整記錄和引用的參考文獻的檢索結果導出為“純文本文件”,并以“download.txt”格式存儲。兩位作者獨立根據納入排除標準篩選文獻。如有分歧,通過第三位作者討論解決以達成共識。
篩選標題、作者、機構、關鍵詞等關鍵信息完整的文章并完成數據清洗。合并重復的機構,對于同一機構的不同名稱,采用現今被廣泛接受的規范名稱,同一學校不同學院均歸為學校,同一醫院不同科室均歸為醫院;合并重復的關鍵詞,將相同含義的關鍵詞進行合并。
1.3 文獻計量學與可視化分析
將完成數據清洗后的數據使用VOSviewer 1.6.18[16]、CiteSpace 6.1.R[17]和在線分析平臺(
中文文獻以RefWorks格式導出至VOSviewer 1.6.18中,繪制作者和機構的合作網絡,以及關鍵詞聚類和時間演化分析,由于中文數據庫無法導出參考文獻相關信息,故未進行參考文獻共被引分析。英文文獻清洗和數據篩選完成后,使用VOSviewer 1.6.18繪制期刊的被引頻次圖譜,作者、國家、機構的合作網絡、關鍵詞聚類分析和時間演化分析圖譜[19,21]。使用CiteSpace對高頻共被引參考文獻進行聚類分析。
2 結果
2.1 檢索結果
共檢索到
圖1
文獻篩選流程
2.2 年發文量
英文文獻共
2.3 期刊分析
共有566種期刊發表了肺結節/早期肺癌預測模型相關的英文文章。發文量排名前10的英文期刊見附件表1,這些期刊共發表462篇英文文章。其中,發文量最多的期刊是Frontiers in Oncology(120篇),其次是Lung Cancer(47篇)和Cancers(42篇)。在發文量排名前10的學術期刊中,IF最高的期刊是Journal of Thoracic Oncology(IF=20.21)。中文期刊發文量最多的是《臨床放射學雜志》(13篇),其次是《中國胸心血管外科臨床雜志》(9篇)和《中國肺癌雜志》(7篇)。
當VOSviewer中的閾值設定為5時,英文期刊共現網絡有91個節點、3個集群和
2.4 國家/地區分析
對納入的英文文章進行國家/地區分析,結果表明共有64個國家/地區為肺結節/早期肺癌預測模型的研究做出了貢獻。中國發文量最多(
在VOSviewer中,我們將閾值設置為5以顯示國家/地區的合作關系。合作關系網絡圖包含了35個節點、7個集群和294條連線(附件圖3),最大的集群(橙色)由7個國家組成,以澳大利亞、韓國和印度為中心。美國是合作伙伴最多的國家(n=31),其次是英國(n=27)、意大利(n=27)、德國(n=27)、西班牙(n=27)和丹麥(n=27)。
2.5 機構合作分析
共有
英文發文量≥10篇的機構合作網絡見附件圖4a,包括102個節點、7個集群和802條連接線。紅色集群由復旦大學、上海交通大學、中山大學和北京協和醫學院為中心的32所機構組成,是最大的集群。哈佛醫學院有最多的合作者(n=34),其次是上海交通大學(n=33)、中山大學(n=32)和哈佛大學(n=32)。發表中文論文的機構之間的合作網絡見附件圖4b,包括9個節點、3個集群和12條連線。北京協和醫學院發文量最多,最大的合作網絡由南京醫科大學、上海交通大學、江蘇省啟東市肝癌研究所和清華大學共同組成。與中文文獻相比,發表英文文獻的機構之間的合作更加密切。
2.6 作者分析
發表英文論文的作者總數為
發表中文論文的作者總數為1 256人。其中,韓冬發表文章最多(5篇),其次為于楠(4篇)和張永奎(4篇)。中文作者合作網絡包括25個節點、4個集群和98條連線(附件圖5b)。紅色集群由8位作者組成,包括劉敏、王秋萍、郭曉娟、郭佑民等。
2.7 關鍵詞聚類、時間演化及突現分析
關鍵詞時間演化分析圖是根據其平均出現年份(average appearing year,AAY)進行著色,以探索隨時間推移的演變趨勢(附件圖7a)。英文文獻中最近出現的關鍵詞是“lncRNA”(AAY:2021.30)、“腫瘤微環境”(AAY:2021.08)、“免疫”(AAY:2020.88)、“癌癥統計”(AAY:2020.50)、“TCGA”(AAY:2020.61)、“諾莫圖”(AAY:2020.17)和“機器學習”(AAY:2019.91)。中文文獻關鍵詞時間演化分析結果顯示,新興關鍵詞有“列線圖”(AAY:2020.64)、“機器學習”(AAY:2020.79)、“預后模型”(AAY:2021.08)、“人工智能”(AAY:2021.40)。
英文文獻的關鍵詞突現分析顯示 “smoking”(25.44)的突現強度最高,其次為“risk model”(9.24)和“risk”(8.9)(附件圖8a)。近5年中出現的關鍵詞是“guidelines”“images”“poor prognosis”“feature”和“genome”。中文關鍵詞突現分析表明,“預后”(2.72)的突現強度最高,其次是“影像組學”(2.13)和“列線圖”(1.94)(附件圖8b)。截至2022年,影像組學、機器學習、預測、鑒別診斷和影響因素的熱度仍在升高,說明這是目前的研究熱點和今后的研究趨勢。
2.8 文獻共被引
我們列出了被引用最多的10篇英文文獻(附件表5)。可以看出,大多數共被引文獻均發表于頂級期刊,如The New England Journal of Medicine、CA: A Cancer Journal for Clinicians和Nature,這些研究中有一半以上與肺結節/早期肺癌的流行病學和預測模型有關。國家肺癌篩查試驗研究小組發表在The New England Journal of Medicine上的一篇題為“Reduced lung-cancer mortality with low-dose computed tomographic screening”的研究[22]被引頻次最高(291次)。這項對33個美國醫學中心的
納入的
3 討論
3.1 肺結節/早期肺癌預測模型研究的全球趨勢
文獻計量學融合了統計學、數學、文獻學等多學科,能夠對某一研究領域進行定量評估。我們共納入了2002—2023年間發表的
各個國家/地區之間也進行了合作,中國是發文量最高的國家,美國是被引頻次最多的國家。此外,美國當前處于國際合作的核心地位,與中國、日本、澳大利亞和新加坡等國家有密切聯系。發文量排名前10的機構包括8所中國院校和2所美國院校,這說明美國和中國的研究者在肺結節/早期肺癌預測模型方面的研究投入比其他國家更多。近年來,來自中國的文獻數量正不斷增加,這反映了中國對肺結節/早期肺癌預測模型研究的高度重視。來自利物浦大學分子與臨床癌癥醫學系的John K Field教授和中國醫學科學院的赫捷院士均發表了17篇文章,為肺結節/早期肺癌預測模型領域做出了巨大貢獻。
3.2 研究熱點與前沿
無創便捷的預測模型作為新興預測工具在肺癌早期預警及輔助診斷、療效實時監測、用藥指導和耐藥機制探索、預后判斷等臨床應用方面持續發揮巨大價值[25-26]。關鍵詞聚類分析有利于發現當前有關肺結節/早期肺癌預測模型的研究熱點。本研究顯示,預后、治療、生存和影像組學是當前肺結節/早期肺癌預測模型研究的重點。值得注意的是,英文文獻關鍵詞時間演化分析結果顯示,近年來lncRNA、腫瘤微環境、免疫、癌癥統計、TCGA、諾莫圖和機器學習出現頻次較高。由于機器學習的快速發展和不斷深入,肺結節/早期肺癌預測模型不斷優化。中文文獻關鍵詞分析表明該領域的新興關鍵詞有列線圖、機器學習、預后模型和人工智能等。中英文的關鍵詞突現分析結果表明,目前影像組學、基因組學、機器學習、預后預測、鑒別診斷是該領域的研究熱點和趨勢。隨著高通量測序技術的迅速發展,越來越多的新型診斷預測因子被納入模型變量,包括lncRNA、基因組學、微生物組學、免疫和影像組學等[27-28],有助于提高肺結節/早期肺癌預測模型的精準度和靈敏度,推動肺癌早診早治(附件圖10)。
應用最早最廣泛的肺結節/早期肺癌預測模型是Swensen等[29]建立的Mayo模型。大多數傳統模型將年齡、性別、種族、民族、受教育程度、體重指數、個人癌癥史、個人肺炎史、肺癌家族史以及吸煙史等多種臨床特征作為風險預測因素[30]。隨著肺癌篩查的普及,肺結節/早期肺癌預測模型引起了研究者的關注,越來越多的研究證實了肺結節/早期肺癌預測模型在肺癌早診早治中的潛力。近年來,人工智能、分子生物學和多組學技術的發展進一步催生了更多的新型診斷預測因子[5]。大量研究[31-33]表明,基于生物標志物、基因組學、影像組學等多模態數據的預測模型,特別是整合了多組學特征的模型,可以顯著提高肺癌預測的準確性和良惡性肺結節的鑒別能力[34-35]。Hu等[36]基于3個DNA甲基化生物標志物和1個影像學特征構建了預測模型,惡性肺結節診斷的曲線下面積(area under the curve,AUC)可達0.951,顯著高于Mayo模型(AUC=0.823)的預測效能。
基于關鍵詞分析,我們還發現機器學習和人工智能在肺結節/早期肺癌預測模型應用廣泛,越來越多的研究證明了機器學習和人工智能在肺結節/早期肺癌預測模型開發中的作用。人工智能可以幫助識別人類無法提取的特征和執行重復性的任務,通過將人工智能與影像組學、基因組學、轉錄組學、蛋白組學和臨床數據相結合,該集成數據能顯著提高肺結節/早期肺癌預測模型的準確性。Hosny等[37]提供了一種基于深度學習網絡和非小細胞肺癌患者CT圖像的肺癌預測模型,可用于肺癌死亡風險分層。Takahashi等[32]使用來自癌癥基因組圖譜的6個不同多組學數據集,基于無監督機器學習算法建立了肺癌患者預后預測模型。多組學與機器學習技術的結合在這一領域非常有前景,能顯著提高預測模型的預測效能。Chen等[38]通過機器學習算法構建了包含基因突變、cfDNA甲基化信號以及血清腫瘤蛋白標志物水平的多組學肺癌診斷模型,AUC為0.78,其診斷性能顯著高于任何單一組學構建的診斷模型,研究證明多組學數據整合可有效提高肺癌診斷預測模型的準確性。
被引頻次高的參考文獻大多集中在流行病學和肺癌預測模型上。2013年,美國預防服務工作組建議每年使用LDCT進行肺癌早篩[39]。隨著LDCT的廣泛使用和健康意識的提高,越來越多的預測模型被開發出來[3]。預測模型的開發減輕了患者的身心負擔和醫療系統負荷,并提高了診斷的準確性。由于肺癌持續存在的高發病率和死亡率,因此迫切需要更精準和可靠的預測模型應用于肺結節/早期肺癌,推動肺癌的精準醫療。
3.3 挑戰和前景
肺結節/早期肺癌預測模型在過去20年中發展迅猛,但仍存在一些需要解決的問題。首先,大部分預測模型基于單中心或小樣本回顧性研究數據,缺乏外部數據集進行驗證;部分樣本量相對較大的研究是在歐美國家開展的,限制了預測模型的推廣和應用。同時,由于算法和數據集的不同,模型的靈敏度和精確度也不同,導致尚未形成統一的診斷標準。此外,一些指南建議使用預測模型以降低LDCT的假陽性率,但是目前尚無全球公認的預測模型應用于臨床。最后,當前不同國家、機構和作者之間的交流合作不密切,未來需開展更多跨國家、跨區域、跨機構的大樣本多中心前瞻性研究,各國各機構之間消除學術壁壘,合作共贏,共同推動肺結節/早期肺癌預測模型的發展。
肺癌的發生、發展是一個多步驟連鎖事件,涉及諸多層面的復雜調控機制。近年來,分子生物學、高通量測序技術和各種質譜儀的快速發展,為進一步探索肺結節和肺癌的致病機制、危險因素和潛在預測因子提供了重要的理論和技術支持,這將會激發預測模型的進一步優化,以提高其靈敏度和準確性。液體活檢等新興檢測技術為亞臨床期的肺癌個體化診療提供了技術支持。海量的多組學數據有助于構建和優化肺結節/早期肺癌預測模型,有助于肺癌早診早治,推動精準醫學的發展。
本研究發現人工智能、機器學習、多組學等為現階段的研究熱點,探索多組學數據的融合算法亦是今后很長一段時間內的重點研究方向。近年來,基于多組學數據建立的預測模型不斷增多,為臨床決策和個體化治療提供了更為充分的理論依據。如Carrillo-Perez等[40]融合全切片數字成像(WSI)、RNA、miRNA、拷貝數變異(CNV)的多組學數據構建預測模型,其精度為96.81%,AUC為0.993,具有較高的準確性,利用多組學數據可以提高個性化醫療中的臨床決策支持系統的性能。與僅使用單組學數據相比,多組學融合能提高肺癌分期預測模型的準確性。Li等[33]使用隨機森林算法構建肺癌分期預測模型,其中微生物組聯合轉錄組預測模型的準確率為0.809,較單組學預測模型更精準,提高了肺癌分期預測能力。不同組學數據可通過人工智能的預測算法進行整合,以揭示系統生物學的復雜機制,發現新的生物標志物,有助于提高預測模型的準確性。故人工智能、機器學習和多組學在肺癌的早診早治中具有重要的研究意義,具有巨大的潛在價值和廣闊的應用前景,仍需要進一步進行臨床驗證。
該研究存在以下局限性:首先,我們只納入了2002—2023年發表的文章,這可能會導致選擇偏倚。第二,本研究納入了知網、萬方、維普和Web of Science數據庫中的相關文獻,但這也不可避免地遺漏了其他數據庫潛在文獻,今后可增加數據庫來源,提高研究的深度和廣度。第三,人工進行文獻信息整理、關鍵詞合并等數據清洗時可能存在潛在的選擇性偏倚。第四,由于中文數據庫尚無法直接導出引文數據,導致缺少中文文獻共被引分析。最后,許多作者與其他作者同名同姓,文獻計量軟件無法區分同名作者的貢獻度,難以避免作者信息的不準確。
綜上所述,該研究對近20年肺結節/早期肺癌預測模型相關文獻進行文獻計量學和可視化分析。研究表明:肺結節/肺癌預測模型正處于快速發展階段,具有巨大的臨床應用潛力。過去20年中,在肺結節/肺癌預測模型領域,涌現出了以中國和美國為代表的諸多富有強大科學創造力的國家,復旦大學在該領域中具有重要的學術影響力,以赫捷院士和John K Field教授為核心的研究團隊為肺癌的早診早治做出了巨大貢獻。預測模型、機器學習、人工智能和多組學技術是當前和未來研究的重點,并顯示出巨大的應用前景。最后,為提高預測模型的臨床實用性,我們建議使用來自大樣本、多中心研究的數據進行外部驗證,并加強跨國家、跨地區、跨學科的交叉合作,構建和優化更加精準的肺結節/早期肺癌預測模型,推動精準醫學的發展。
利益沖突:無。
作者貢獻:任益鋒、馬瓊、石薇、由鳳鳴負責論文構思及設計,分析數據及撰寫論文;蔣華、付西、李雪珂篩選文獻,提取資料,質量評估;任益鋒、馬瓊、石薇進行論文質量評價和修改論文;由鳳鳴負責對文章的知識性內容作批判性審閱與修改。
本文附件圖表見本刊網站電子版(