引用本文: 粟宇霜, 李艷, 高虹, 蒲在春, 陳娟, 劉夢婷, 賀雅勰, 何彬, 楊琴. 食管癌術后吻合口瘺風險預測模型的系統評價與Meta分析. 中國胸心血管外科臨床雜志, 2025, 32(2): 230-236. doi: 10.7507/1007-4848.202310031 復制
版權信息: ?四川大學華西醫院華西期刊社《中國胸心血管外科臨床雜志》版權所有,未經授權不得轉載、改編
食管癌是消化道較常見惡性腫瘤之一,起源于食管或食管胃交界處的惡性腫瘤,發病率位居全世界惡性腫瘤第7位,死亡率位居第6位[1],嚴重威脅居民健康。手術治療為大部分食管癌患者的首選方案。食管癌術后最致命的并發癥為吻合口瘺(anastomotic leakage,AL),發病率約為5%~30%[2]。不僅影響患者生活質量,還會增加經濟壓力,甚至影響遠期壽命[3]。預測模型是以數學模型為基礎,結合預測因子,計算某事件結局的概率[4]。近年來,國內外許多研究者[5-20]針對食管癌術后AL專門建立風險預測模型。但對于模型的構建過程、性能以及數據樣本偏倚等缺乏全面的對比研究,該工具是否能夠應用于臨床尚不明確。因此,本研究針對國內外食管癌術后AL預測模型的研究進行系統評價,為臨床醫護人員篩選AL相關風險預測模型提供指導。
1 資料與方法
1.1 納入和排除標準
1.1.1 納入標準
(1)研究對象為年齡≥18歲且病理檢查確診為食管癌患者;(2)研究內容為構建和/或驗證食管癌術后AL預測模型;(3)研究設計為回顧性研究或前瞻性研究;(4)結局指標為術后發生AL,診斷方式采用CT、造影等影像學檢查和/或臨床特征綜合判斷[21],采用食管癌國際協作小組[22]提出的AL定義;(5)語言為中文或英文。
1.1.2 排除標準
(1)重復發表的文獻;(2)綜述、個案、會議摘要等文獻;(3)無法獲取原文的文獻。
1.2 文獻檢索策略
計算機檢索中華醫學期刊全文數據庫、維普、萬方、中國知網、中國生物文獻數據庫、EMbase、Web of Science、Cochrane Library、PubMed公開發表的關于食管癌術后AL風險預測模型的研究,檢索時間為建庫至2023年10月1日。中文檢索詞包括:食管癌、食道癌、食管腫瘤、食道占位、吻合口瘺、食管瘺、吻合口漏、預測、預測模型、模型。英文檢索詞包括:esophageal neoplasm、neoplasm、esophageal、esophagus neoplasm、esophagus neoplasms、neoplasm、esophagus、neoplasms、esophagus、neoplasms、esophageal、cancer of esophagus、esophagus cancer、esophageal cancer、anastomotic fistula、esophageal fistula、anastomotic leak、prediction、prediction model、model。
1.3 文獻篩選與資料提取
根據納排標準,由兩名研究員負責進行文獻篩查。若存在分歧,則咨詢第三方建議。按照Moons等[23]關于預測模型系統評價的數據收集條目(checklist for critical appraisal and data extraction for systematic reviews of prediction modelling studies,CHARMS),制訂數據收集表,包括:第一作者、出版日期、國家、研究類型、隨訪時間、地點、結局指標、研究的樣本量、構建模型的方法、建模數量、受試者工作特征曲線下面積(area under the curve,AUC)及校正方法、模型使用的驗證方法、預測模型包含的影響因素、模型呈現方式等。
1.4 質量評價
采用PROBAST(prediction model risk of bias assessment tool)[24]評價工具評估文獻的偏倚風險和適用性。從4個角度衡量模型的偏倚風險,即研究對象、預測因子、結果以及數據分析。適用性評價從3個角度進行,評價步驟與偏倚風險分析步驟相似。不同角度的評估標準為“低”“高”和“不清楚”3個分級,根據上述特征選擇最佳模型。PROBAST不僅能評估單個模型,也能進行多個模型的比較。
1.5 統計學分析
使用Stata 15軟件對模型納入的預測因子進行Meta分析,OR值及95%CI作為效應統計量。采用Q檢驗及I2統計量評估多個研究的異質性。若P>0.1或I2<50%,認為研究間異質性小,選擇固定效應模型;若P≤0.1或I2≥50%,則認為研究間異質性較大,進一步行敏感性分析,若異質性不能消除,則選擇隨機效應模型。雙側檢驗水準α=0.05。
2 結果
2.1 文獻檢索結果
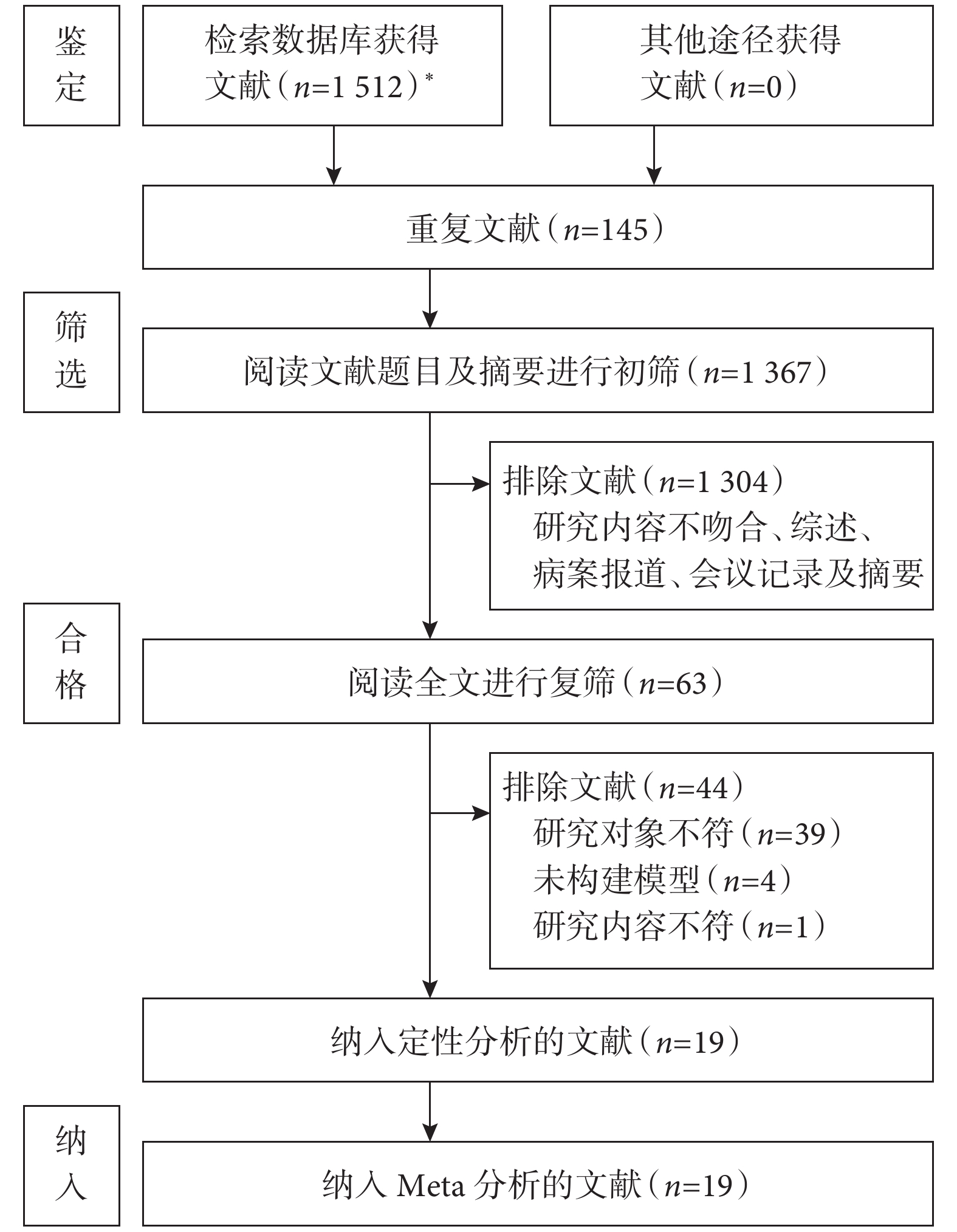
通過檢索相關數據庫,獲取相關研究
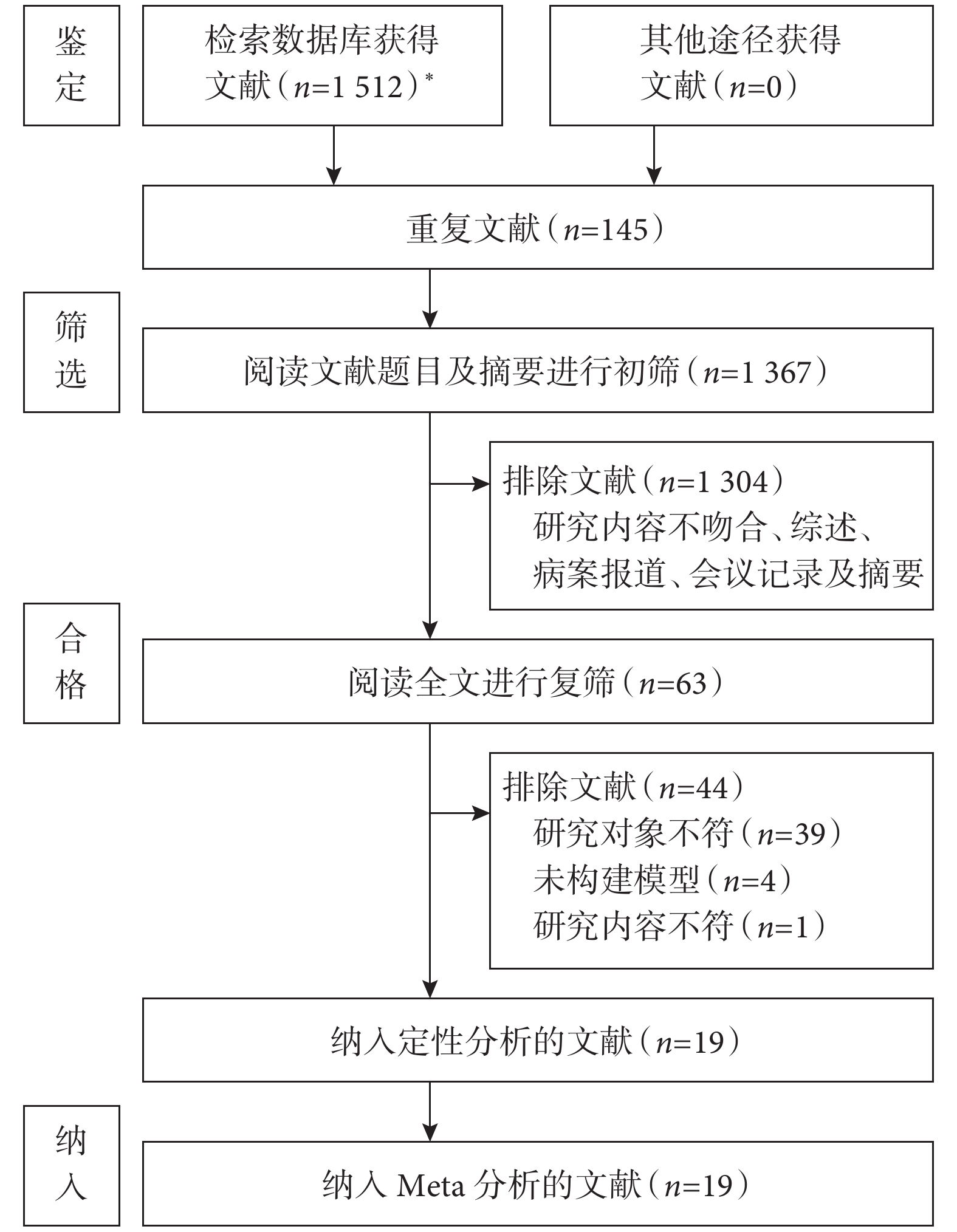 圖1
文獻流程圖
圖1
文獻流程圖
*:包括中國知網(
2.2 納入文獻的基本特征
本研究納入文獻均為近5年內發表文獻,發表國家主要為中國,均為回顧性研究,其中中文文獻14篇[5-13,18-19,25-27],英文文獻5篇[14-15,20,28-29],食管癌術后患者AL的發病率在7.0%~23.9%之間。納入文獻基本特征見附件表1。
2.3 風險預測模型的基本特征
19篇文獻[5-15,18-20,25-29]共構建25個食管癌患者術后AL風險預測模型,在模型構建方面,3篇文獻[10-11,20]采用機器學習和logistic回歸的方法分別建立預測模型,其余研究僅采用logistic回歸分析建立模型。在連續變量的處理方法中,9篇文獻[7,9,12,15,25-29]維持了連續變量的連續性,10篇文獻[5-6,8,10-11,13-14,18-20]將連續型變量轉換為分類變量。在變量選擇方面,6篇文獻[10-11,14,20,25-26]采用機器學習和單因素分析共同篩選變量,其余文獻基于單因素分析;見附件表2。本研究納入模型的AUC為0.670~0.960,靈敏度為43%~92%,特異度為78.9%~96.3%,其中23個預測模型[5-13,15,18-20,25,27-29]的預測性能較高(AUC>0.7);13篇文獻[5,7-11,13-14,19,25-27,29]均報道了區分度和校準度;在模型驗證方面,僅1篇文獻[19]進行外部驗證,10篇文獻[7,9-10,13-14,19-20,26-27,29]進行內部驗證,采用的方法主要是Bootstrap法和樣本拆分法。模型呈現形式以列線圖分析評分為主(n=13),其他方式為β系數繪制風險評分公式(n=5),1篇文獻[10]未給出具體模型。預測模型的性能及呈現形式見表1。
2.4 文獻質量評價
由兩位研究員使用PROBAST量表[24]對文獻質量進行全面評估,并仔細審查評價結果,確保其準確性。在研究對象領域,因研究設計為回顧性研究均為高偏倚風險;在預測因子領域,均為低偏倚風險;在數據分析領域,均為高偏倚風險。評價為高偏倚風險的原因包括:(1)文獻建模組的樣本量不足;每個自變量的發生次數(events per variable,EPV)<20例;(2)研究將連續型變量轉換為分類變量;(3)研究基于單因素分析篩選變量;(4)未報告是否進行模型校準度檢驗;(5)文獻未報道是否進行內部驗證。在結果領域,均為低偏倚風險。在預測因子領域,所有的預測因子采用相同定義,但結局指標目前沒有標準化,診斷方式多采用臨床特征結合影像或內鏡檢查結果,有5篇文獻[13,20,25-27]采用食管癌國際協作小組的AL定義。食管癌患者平均年齡通常在63~65歲之間[30],因此適用性評價均為好。整體評估顯示,所有研究偏倚風險高,但預測模型適用性好;見附件表3。
2.5 Meta分析結果
采用文獻數量≥3篇的預測因子進行Meta分析,結果顯示:低蛋白血癥、術后呼吸系統并發癥、切口愈合不良、術前胸腹部手術史、術前合并糖尿病、術前合并心血管系統疾病、術前新輔助治療、術前呼吸系統疾病、吻合方法、手術方式、美國麻醉醫師協會(American Society of Anesthesiologists,ASA)評分是食管癌患者術后AL的獨立危險因子(P<0.05)。納入低蛋白血癥的5篇文獻[8,10-11,18-19]中,無論術前還是術后,低蛋白血癥都是食管癌患者術后AL的獨立危險因子[OR=9.362,95%CI(3.237,27.080),Z=4.13,P<0.001]。吻合部位不同可能是吻合方法統計學異質性的主要來源,亞組分析結果提示組內統計學差異較小,手工吻合是食管癌術后AL的獨立危險因素[OR=2.965,95%CI(1.762,4.991),Z=4.09,P<0.001],相同吻合部位的手工吻合AL平均發生率為機械吻合的1.83倍。年齡和預后營養指數不是食管癌術后AL的獨立危險因子(P>0.05)。其余研究敏感性分析中,依次刪除相關研究后統計合并效應量,結果無顯著差異。Meta分析結果見表2。
3 討論
食管癌術后AL發病率和病死率高,AL風險預測模型具備早期發現高風險患者的能力,可指導醫護人員及早采取預防措施,降低AL發生率。本研究納入25個AL風險預測模型進行分析,建模方法主要為logistic回歸,模型表現形式主要為列線圖,大多數模型表現出較好的預測性能(AUC>0.7),但缺乏模型校準度領域評估及模型驗證方面的研究。
3.1 食管癌患者術后吻合口瘺預測模型尚處于探索階段
本研究中大多數AL模型的區分度高,但是對于模型的構建、驗證、結果報告并未深入優化。模型的構建步驟包括:明確研究方向、確定資料來源、變量篩選、數據預處理等。在資料來源方面,本研究納入的25個預測模型中,所有研究均采用回顧性研究,因隊列研究具有良好的代表性,未來在優化模型時建議選擇前瞻性數據或注冊數據作為建模數據[31],以減少數據偏倚風險[24]。截至目前,AL診斷沒有金標準,診斷方式多采用臨床特征與影像特征結合的綜合判斷,其中5篇文獻[13,20,25-27]采用了食管癌國際協作小組[22]提出的AL定義;在變量篩選方面,大多數研究基于單因素logistic回歸,可能會增加錯誤預測因子的選擇風險[32]。目前有研究[33]提出新的變量篩選方法,如LASSO回歸、Ridge回歸、ElasticNet回歸等,可減少過度擬合風險,建議未來變量的篩選可結合臨床實際采用新方法,以提高篩選的準確性;對缺失數據進行報道和處理可避免模型出現過度擬合情況[34] ,建議未來研究對缺失數據進行完善。
在處理連續變量時,將連續性數據轉化成分類變量后進行建模,可能會導致模型效能丟失過多。但在模型處于臨床推廣階段時,為了提高研究者應用的方便性,可進行數據轉換[35]。在性能評估方面,核心指標包含區分度及校準度,區分度常使用AUC值或C指數表示,當其值>0.7時,模型區分度優良;校準度用H-L擬合優度檢驗或者校準曲線等方法評估。當前研究缺乏性能評估,模型出現過度擬合,某種意義上抑制了模型的適用性。納入研究平均樣本量388例,均屬于小樣本研究,缺乏內部驗證可能會導致模型性能的評估偏高,因此內部驗證至關重要。此外,外部驗證可提高模型的可推廣性[36],但需進行建模與驗模數據集的基線比較。目前,預測模型研究取得一定進展,但在模型構建、驗證、報告等方面仍需進一步研究。
3.2 食管癌術后吻合口瘺的預測因子
本研究結果顯示,食管癌患者術后AL的預測因子包含4個方面:基礎疾病因素、手術因素、感染因素、營養因素。低蛋白血癥、術后呼吸系統并發癥、切口愈合不良、術前胸腹部手術史、術前合并糖尿病、術前合并心血管系統疾病、術前新輔助治療、術前呼吸系統疾病、吻合方法、手術方式 、ASA評分是食管癌術后AL的常見預測因子,新模型的建立可著重考慮以上11個因子,大部分因子具有客觀性且便于收集,模型更具便捷性。Lindenmann等[28]認為,較年輕的患者更容易出現AL,因為年輕患者在術后往往比年長患者更早恢復劇烈運動。也有研究[37]認為,隨著年齡的增長,體內血管病變發生率增加,從而影響吻合口周圍的供血。因此,年齡和預后營養指數與AL的關系未來需要深入研究。由于吻合的復雜性和精確性[38],吻合方式被認為是AL風險較大的影響因素,機械吻合操作方式可顯著縮短手術時間從而減少吻合口感染的風險,且吻合口徑一致,可有效避免黏膜破壞和潰爛,正在被廣泛采用。
3.3 數據轉換
當數據類型是連續型數據時,通常使用均數差(MD)或標準化均數差(SMD)為效應統計量。Friedrich等[39]提出另一種效應測量方法,即均值比(ration of means,ROM),實驗結果表明ROM、MD和SMD的統計性能特征相當,ROM可作為連續型數據均值差分法的合理替代方法。連續型數據的變量,在預測模型中未獲取OR值時,可采用ROM代替。相對于SMD效應量,使用 ROM可更好地解釋預測變量對結局的影響程度。
3.4 對未來模型研究的啟示
開發精準預測工具有助于臨床決策及指導臨床實踐。針對食管癌患者術后AL預測模型的研究,未來可從以下幾方面進行深入優化:(1)新模型的建立可著重考慮以上Meta分析的13個因子與放射學特征相結合,實現多元化;(2)數據采集時建議使用盲法;(3)可采用EPV值或Riley等[40]提出的機器學習樣本量計算方法計算樣本量;(4)將連續型變量轉換成分類數據前,建議寫明分組依據;(5)避免僅基于單因素分析篩選變量,建議與機器學習相關算法、專業知識背景相結合;(6)建議進行大樣本、多中心研究,提高模型適用性;(7)建議預測模型根據AL嚴重程度分級[22]及AL的診斷時機進行預測。
本研究具有一定的局限性:(1)本研究只納入了關于食管癌患者AL預測模型的中英文文獻;(2)部分預測因素涉及的研究較少,未進行Meta分析,可能對預測結局有影響。綜上所述,本研究共納入25個預測模型,大部分模型區分度較好,但預測模型質量還有很大的提升空間。未來,需要進一步完善相關研究,促進研究向臨床轉化,為患者制定精準化方案,減少AL的發生。
利益沖突:無。
作者貢獻:粟宇霜負責研究設計、數據采集、論文撰寫與修改;李艷、高虹參與研究設計和數據采集;蒲在春、陳娟負責統計分析,參與論文撰寫;劉夢婷、賀雅勰負責整理數據和修改論文;楊琴、何彬對研究設計、研究內容進行指導和修訂。
本文附件表1~3見本刊網站電子版。
食管癌是消化道較常見惡性腫瘤之一,起源于食管或食管胃交界處的惡性腫瘤,發病率位居全世界惡性腫瘤第7位,死亡率位居第6位[1],嚴重威脅居民健康。手術治療為大部分食管癌患者的首選方案。食管癌術后最致命的并發癥為吻合口瘺(anastomotic leakage,AL),發病率約為5%~30%[2]。不僅影響患者生活質量,還會增加經濟壓力,甚至影響遠期壽命[3]。預測模型是以數學模型為基礎,結合預測因子,計算某事件結局的概率[4]。近年來,國內外許多研究者[5-20]針對食管癌術后AL專門建立風險預測模型。但對于模型的構建過程、性能以及數據樣本偏倚等缺乏全面的對比研究,該工具是否能夠應用于臨床尚不明確。因此,本研究針對國內外食管癌術后AL預測模型的研究進行系統評價,為臨床醫護人員篩選AL相關風險預測模型提供指導。
1 資料與方法
1.1 納入和排除標準
1.1.1 納入標準
(1)研究對象為年齡≥18歲且病理檢查確診為食管癌患者;(2)研究內容為構建和/或驗證食管癌術后AL預測模型;(3)研究設計為回顧性研究或前瞻性研究;(4)結局指標為術后發生AL,診斷方式采用CT、造影等影像學檢查和/或臨床特征綜合判斷[21],采用食管癌國際協作小組[22]提出的AL定義;(5)語言為中文或英文。
1.1.2 排除標準
(1)重復發表的文獻;(2)綜述、個案、會議摘要等文獻;(3)無法獲取原文的文獻。
1.2 文獻檢索策略
計算機檢索中華醫學期刊全文數據庫、維普、萬方、中國知網、中國生物文獻數據庫、EMbase、Web of Science、Cochrane Library、PubMed公開發表的關于食管癌術后AL風險預測模型的研究,檢索時間為建庫至2023年10月1日。中文檢索詞包括:食管癌、食道癌、食管腫瘤、食道占位、吻合口瘺、食管瘺、吻合口漏、預測、預測模型、模型。英文檢索詞包括:esophageal neoplasm、neoplasm、esophageal、esophagus neoplasm、esophagus neoplasms、neoplasm、esophagus、neoplasms、esophagus、neoplasms、esophageal、cancer of esophagus、esophagus cancer、esophageal cancer、anastomotic fistula、esophageal fistula、anastomotic leak、prediction、prediction model、model。
1.3 文獻篩選與資料提取
根據納排標準,由兩名研究員負責進行文獻篩查。若存在分歧,則咨詢第三方建議。按照Moons等[23]關于預測模型系統評價的數據收集條目(checklist for critical appraisal and data extraction for systematic reviews of prediction modelling studies,CHARMS),制訂數據收集表,包括:第一作者、出版日期、國家、研究類型、隨訪時間、地點、結局指標、研究的樣本量、構建模型的方法、建模數量、受試者工作特征曲線下面積(area under the curve,AUC)及校正方法、模型使用的驗證方法、預測模型包含的影響因素、模型呈現方式等。
1.4 質量評價
采用PROBAST(prediction model risk of bias assessment tool)[24]評價工具評估文獻的偏倚風險和適用性。從4個角度衡量模型的偏倚風險,即研究對象、預測因子、結果以及數據分析。適用性評價從3個角度進行,評價步驟與偏倚風險分析步驟相似。不同角度的評估標準為“低”“高”和“不清楚”3個分級,根據上述特征選擇最佳模型。PROBAST不僅能評估單個模型,也能進行多個模型的比較。
1.5 統計學分析
使用Stata 15軟件對模型納入的預測因子進行Meta分析,OR值及95%CI作為效應統計量。采用Q檢驗及I2統計量評估多個研究的異質性。若P>0.1或I2<50%,認為研究間異質性小,選擇固定效應模型;若P≤0.1或I2≥50%,則認為研究間異質性較大,進一步行敏感性分析,若異質性不能消除,則選擇隨機效應模型。雙側檢驗水準α=0.05。
2 結果
2.1 文獻檢索結果
通過檢索相關數據庫,獲取相關研究
圖1
文獻流程圖
*:包括中國知網(
2.2 納入文獻的基本特征
本研究納入文獻均為近5年內發表文獻,發表國家主要為中國,均為回顧性研究,其中中文文獻14篇[5-13,18-19,25-27],英文文獻5篇[14-15,20,28-29],食管癌術后患者AL的發病率在7.0%~23.9%之間。納入文獻基本特征見附件表1。
2.3 風險預測模型的基本特征
19篇文獻[5-15,18-20,25-29]共構建25個食管癌患者術后AL風險預測模型,在模型構建方面,3篇文獻[10-11,20]采用機器學習和logistic回歸的方法分別建立預測模型,其余研究僅采用logistic回歸分析建立模型。在連續變量的處理方法中,9篇文獻[7,9,12,15,25-29]維持了連續變量的連續性,10篇文獻[5-6,8,10-11,13-14,18-20]將連續型變量轉換為分類變量。在變量選擇方面,6篇文獻[10-11,14,20,25-26]采用機器學習和單因素分析共同篩選變量,其余文獻基于單因素分析;見附件表2。本研究納入模型的AUC為0.670~0.960,靈敏度為43%~92%,特異度為78.9%~96.3%,其中23個預測模型[5-13,15,18-20,25,27-29]的預測性能較高(AUC>0.7);13篇文獻[5,7-11,13-14,19,25-27,29]均報道了區分度和校準度;在模型驗證方面,僅1篇文獻[19]進行外部驗證,10篇文獻[7,9-10,13-14,19-20,26-27,29]進行內部驗證,采用的方法主要是Bootstrap法和樣本拆分法。模型呈現形式以列線圖分析評分為主(n=13),其他方式為β系數繪制風險評分公式(n=5),1篇文獻[10]未給出具體模型。預測模型的性能及呈現形式見表1。
2.4 文獻質量評價
由兩位研究員使用PROBAST量表[24]對文獻質量進行全面評估,并仔細審查評價結果,確保其準確性。在研究對象領域,因研究設計為回顧性研究均為高偏倚風險;在預測因子領域,均為低偏倚風險;在數據分析領域,均為高偏倚風險。評價為高偏倚風險的原因包括:(1)文獻建模組的樣本量不足;每個自變量的發生次數(events per variable,EPV)<20例;(2)研究將連續型變量轉換為分類變量;(3)研究基于單因素分析篩選變量;(4)未報告是否進行模型校準度檢驗;(5)文獻未報道是否進行內部驗證。在結果領域,均為低偏倚風險。在預測因子領域,所有的預測因子采用相同定義,但結局指標目前沒有標準化,診斷方式多采用臨床特征結合影像或內鏡檢查結果,有5篇文獻[13,20,25-27]采用食管癌國際協作小組的AL定義。食管癌患者平均年齡通常在63~65歲之間[30],因此適用性評價均為好。整體評估顯示,所有研究偏倚風險高,但預測模型適用性好;見附件表3。
2.5 Meta分析結果
采用文獻數量≥3篇的預測因子進行Meta分析,結果顯示:低蛋白血癥、術后呼吸系統并發癥、切口愈合不良、術前胸腹部手術史、術前合并糖尿病、術前合并心血管系統疾病、術前新輔助治療、術前呼吸系統疾病、吻合方法、手術方式、美國麻醉醫師協會(American Society of Anesthesiologists,ASA)評分是食管癌患者術后AL的獨立危險因子(P<0.05)。納入低蛋白血癥的5篇文獻[8,10-11,18-19]中,無論術前還是術后,低蛋白血癥都是食管癌患者術后AL的獨立危險因子[OR=9.362,95%CI(3.237,27.080),Z=4.13,P<0.001]。吻合部位不同可能是吻合方法統計學異質性的主要來源,亞組分析結果提示組內統計學差異較小,手工吻合是食管癌術后AL的獨立危險因素[OR=2.965,95%CI(1.762,4.991),Z=4.09,P<0.001],相同吻合部位的手工吻合AL平均發生率為機械吻合的1.83倍。年齡和預后營養指數不是食管癌術后AL的獨立危險因子(P>0.05)。其余研究敏感性分析中,依次刪除相關研究后統計合并效應量,結果無顯著差異。Meta分析結果見表2。
3 討論
食管癌術后AL發病率和病死率高,AL風險預測模型具備早期發現高風險患者的能力,可指導醫護人員及早采取預防措施,降低AL發生率。本研究納入25個AL風險預測模型進行分析,建模方法主要為logistic回歸,模型表現形式主要為列線圖,大多數模型表現出較好的預測性能(AUC>0.7),但缺乏模型校準度領域評估及模型驗證方面的研究。
3.1 食管癌患者術后吻合口瘺預測模型尚處于探索階段
本研究中大多數AL模型的區分度高,但是對于模型的構建、驗證、結果報告并未深入優化。模型的構建步驟包括:明確研究方向、確定資料來源、變量篩選、數據預處理等。在資料來源方面,本研究納入的25個預測模型中,所有研究均采用回顧性研究,因隊列研究具有良好的代表性,未來在優化模型時建議選擇前瞻性數據或注冊數據作為建模數據[31],以減少數據偏倚風險[24]。截至目前,AL診斷沒有金標準,診斷方式多采用臨床特征與影像特征結合的綜合判斷,其中5篇文獻[13,20,25-27]采用了食管癌國際協作小組[22]提出的AL定義;在變量篩選方面,大多數研究基于單因素logistic回歸,可能會增加錯誤預測因子的選擇風險[32]。目前有研究[33]提出新的變量篩選方法,如LASSO回歸、Ridge回歸、ElasticNet回歸等,可減少過度擬合風險,建議未來變量的篩選可結合臨床實際采用新方法,以提高篩選的準確性;對缺失數據進行報道和處理可避免模型出現過度擬合情況[34] ,建議未來研究對缺失數據進行完善。
在處理連續變量時,將連續性數據轉化成分類變量后進行建模,可能會導致模型效能丟失過多。但在模型處于臨床推廣階段時,為了提高研究者應用的方便性,可進行數據轉換[35]。在性能評估方面,核心指標包含區分度及校準度,區分度常使用AUC值或C指數表示,當其值>0.7時,模型區分度優良;校準度用H-L擬合優度檢驗或者校準曲線等方法評估。當前研究缺乏性能評估,模型出現過度擬合,某種意義上抑制了模型的適用性。納入研究平均樣本量388例,均屬于小樣本研究,缺乏內部驗證可能會導致模型性能的評估偏高,因此內部驗證至關重要。此外,外部驗證可提高模型的可推廣性[36],但需進行建模與驗模數據集的基線比較。目前,預測模型研究取得一定進展,但在模型構建、驗證、報告等方面仍需進一步研究。
3.2 食管癌術后吻合口瘺的預測因子
本研究結果顯示,食管癌患者術后AL的預測因子包含4個方面:基礎疾病因素、手術因素、感染因素、營養因素。低蛋白血癥、術后呼吸系統并發癥、切口愈合不良、術前胸腹部手術史、術前合并糖尿病、術前合并心血管系統疾病、術前新輔助治療、術前呼吸系統疾病、吻合方法、手術方式 、ASA評分是食管癌術后AL的常見預測因子,新模型的建立可著重考慮以上11個因子,大部分因子具有客觀性且便于收集,模型更具便捷性。Lindenmann等[28]認為,較年輕的患者更容易出現AL,因為年輕患者在術后往往比年長患者更早恢復劇烈運動。也有研究[37]認為,隨著年齡的增長,體內血管病變發生率增加,從而影響吻合口周圍的供血。因此,年齡和預后營養指數與AL的關系未來需要深入研究。由于吻合的復雜性和精確性[38],吻合方式被認為是AL風險較大的影響因素,機械吻合操作方式可顯著縮短手術時間從而減少吻合口感染的風險,且吻合口徑一致,可有效避免黏膜破壞和潰爛,正在被廣泛采用。
3.3 數據轉換
當數據類型是連續型數據時,通常使用均數差(MD)或標準化均數差(SMD)為效應統計量。Friedrich等[39]提出另一種效應測量方法,即均值比(ration of means,ROM),實驗結果表明ROM、MD和SMD的統計性能特征相當,ROM可作為連續型數據均值差分法的合理替代方法。連續型數據的變量,在預測模型中未獲取OR值時,可采用ROM代替。相對于SMD效應量,使用 ROM可更好地解釋預測變量對結局的影響程度。
3.4 對未來模型研究的啟示
開發精準預測工具有助于臨床決策及指導臨床實踐。針對食管癌患者術后AL預測模型的研究,未來可從以下幾方面進行深入優化:(1)新模型的建立可著重考慮以上Meta分析的13個因子與放射學特征相結合,實現多元化;(2)數據采集時建議使用盲法;(3)可采用EPV值或Riley等[40]提出的機器學習樣本量計算方法計算樣本量;(4)將連續型變量轉換成分類數據前,建議寫明分組依據;(5)避免僅基于單因素分析篩選變量,建議與機器學習相關算法、專業知識背景相結合;(6)建議進行大樣本、多中心研究,提高模型適用性;(7)建議預測模型根據AL嚴重程度分級[22]及AL的診斷時機進行預測。
本研究具有一定的局限性:(1)本研究只納入了關于食管癌患者AL預測模型的中英文文獻;(2)部分預測因素涉及的研究較少,未進行Meta分析,可能對預測結局有影響。綜上所述,本研究共納入25個預測模型,大部分模型區分度較好,但預測模型質量還有很大的提升空間。未來,需要進一步完善相關研究,促進研究向臨床轉化,為患者制定精準化方案,減少AL的發生。
利益沖突:無。
作者貢獻:粟宇霜負責研究設計、數據采集、論文撰寫與修改;李艷、高虹參與研究設計和數據采集;蒲在春、陳娟負責統計分析,參與論文撰寫;劉夢婷、賀雅勰負責整理數據和修改論文;楊琴、何彬對研究設計、研究內容進行指導和修訂。
本文附件表1~3見本刊網站電子版。