引用本文: 於曉平, 蘇志霞, 嚴凱, 沙泰寧, 何宇航, 張艷艷, 陶玉堅, 郭虹, 盧光玉, 龔衛娟. 呼出氣體揮發性有機化合物對肺囊性纖維化診斷價值的系統評價. 中國胸心血管外科臨床雜志, 2025, 32(2): 223-229. doi: 10.7507/1007-4848.202406075 復制
版權信息: ?四川大學華西醫院華西期刊社《中國胸心血管外科臨床雜志》版權所有,未經授權不得轉載、改編
囊性纖維化(cystic fibrosis,CF)是一種常染色體隱性遺傳病,由囊性纖維化跨膜傳導調節因子(cystic fibrosis transmembrane conductance regulator,CFTR)基因突變引起,常累及多個系統[1]。呼吸系統功能減退和肺部疾病惡化是CF患者重要的臨床癥狀[2-4]。CF患者呼吸道黏膜纖毛的清除和防御機制受損,易被機會致病菌定植、感染,進而引起慢性炎癥、支氣管阻塞、呼吸衰竭,甚至死亡[5]。CF在高加索人群中相對常見,發病率為1/4 000~1/3 000[6]。目前我國報道的CF數量僅為200例[7],而近10年CF患者數量超過了既往30年總和的2.5倍[8],這表明我國CF的發病率可能被嚴重低估。診斷CF通常依據臨床癥狀和體征,如果癥狀不典型,則進行汗液氯離子測定和/或基因分析[7]。然而,利用現有技術診斷CF存在汗液樣本采集不足、基因檢測費用高等問題[9]。因此,亟需開發一種新的輔助診斷技術,以提高對可疑患者的診斷準確性。
呼出氣體是一種豐富的介質,由氣相有機化合物、氣相無機化合物、水蒸氣和氣溶膠組成。其中,氣相有機化合物中包含了數千種以微量形式存在的揮發性有機化合物(volatile organic compounds,VOCs)[10]。大多數VOCs都參與了人體組織水平的內源性代謝過程。當出現病理狀況時,VOCs的種類和含量則通過體內氧化應激、細胞色素p-450和脂質代謝等途徑發生變化[11]。既往研究[12-13]發現,CF患者呼出氣體正戊烷、乙酸等化合物濃度高于對照組,而二甲基硫和1,2,4,5-四甲苯等化合物濃度較對照組顯著降低[14-15]。這些研究提示呼出氣體VOCs很可能作為CF的潛在生物標志物。相較于傳統的實驗室檢查或基因檢測,分析呼出氣體VOCs具有無創、操作簡捷等優點[16],有望成為輔助診斷CF的新方法。
近年來,全球開展了多項基于呼出氣體VOCs診斷CF的研究[12-15, 17-22],但研究結論尚有爭議。因此,本系統評價旨在全面分析呼出氣體VOCs對CF的診斷價值。
1 資料與方法
1.1 文獻納入和排除標準
納入標準:(1)研究對象為CF患者;(2)研究內容為識別CF患者特異性呼出氣體VOCs或構建基于呼出氣體VOCs的CF風險預測模型;(3)研究類型為隊列研究、病例對照研究和橫斷面研究等;(4)發表語言為中文或英文。排除標準:(1)VOCs來源于呼出氣體冷凝物或血液、尿液等其他生物樣本;(2)外源性VOCs;(3)摘要、綜述、會議論文等;(4)重復發表的文獻。
1.2 文獻檢索策略
計算機檢索PubMed、EMbase、Web of Science、Cochrane Library、中國知網、萬方、維普以及中國生物醫學文獻數據庫,搜集國內外公開發表的基于呼出氣體VOCs診斷CF的研究,并追溯納入研究的參考文獻。檢索時限為建庫至2024年8月7日。采用醫學主題詞與自由詞結合的方式進行文獻檢索。中文數據庫以中國知網為例,檢索式為:(主題“囊性纖維化”OR主題“肺囊性纖維化”OR主題“肺部囊性纖維化”)AND(主題“呼出氣體”OR主題“呼出氣體檢測”OR主題“呼出氣體分析”)AND(主題“揮發性有機化合物”OR主題“揮發性有機氣體”)。英文數據庫以PubMed為例,檢索式為:(((cystic fibrosis[MeSH Terms]) OR (fibrosis, cystic or mucoviscidosis or pulmonary cystic fibrosis or cystic fibrosis, pulmonary)) AND ((volatile organic compounds[MeSH Terms]) OR (compounds, volatile organic or organic compounds, volatile or volatile organic compound or compound, volatile organic or organic compound, volatile))) AND ((exhaled) OR (breath))。
1.3 文獻篩選與資料提取
剔除重復文獻后,由2名研究人員獨立完成文獻篩選與資料提取,并交叉核對。運用EndNote 20軟件剔除重復文獻,閱讀文章題目與摘要進行文獻初篩,再閱讀全文進行二次篩選,剔除不符合要求的文獻后,確定最終納入文獻。若存在意見分歧,則與第3名研究者討論解決。提取并歸納文獻資料:(1)文獻基本信息,包括第一作者、發表年份、國家、研究類型、樣本量等;(2)呼出氣體VOCs的識別情況;(3)基于VOCs的CF風險預測模型的構建及預測性能,包括候選變量、納入變量、模型構建及驗證方法、模型性能等。
1.4 文獻質量評價
采用紐卡斯爾-渥太華量表(Newcastle-Ottawa Scale,NOS)對納入研究進行質量評價[23-24],包括研究人群的選擇、組間可比性、暴露因素或結果測量3個方面。病例對照研究的NOS總分為9分,橫斷面研究的NOS總分為10分。評分≤4分為低質量,5~6分為中等質量,≥7分為高質量。
使用預測模型偏倚風險評估工具(prediction model risk of bias assessment tool,PROBAST)對納入預測模型研究的偏倚風險和適用性進行評估[25-26]。偏倚風險包括研究對象、預測因子、結果和統計分析4個領域,適用性包括研究對象、預測因子和結果3個領域。若2名研究者在質量評價過程中存在意見分歧,則與第3名研究者討論解決。
2 結果
2.1 文獻篩選流程及結果
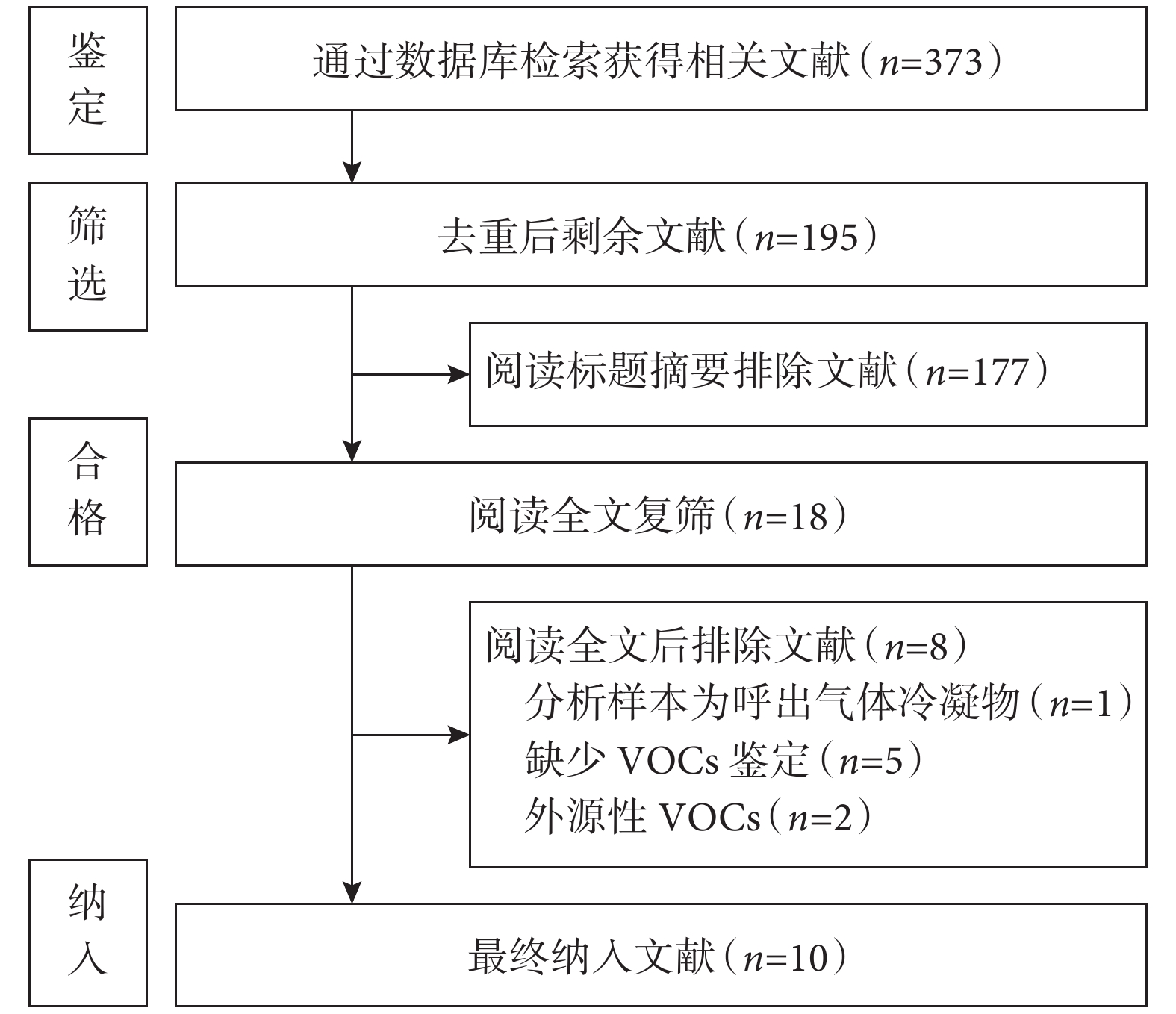
初步檢索得到文獻373篇,均為英文文獻。去重后剩余文獻195篇,閱讀題目與摘要后排除177篇,繼續閱讀全文后排除8篇,最終納入10篇文獻[12-15,17-22]。文獻篩選流程見圖1。
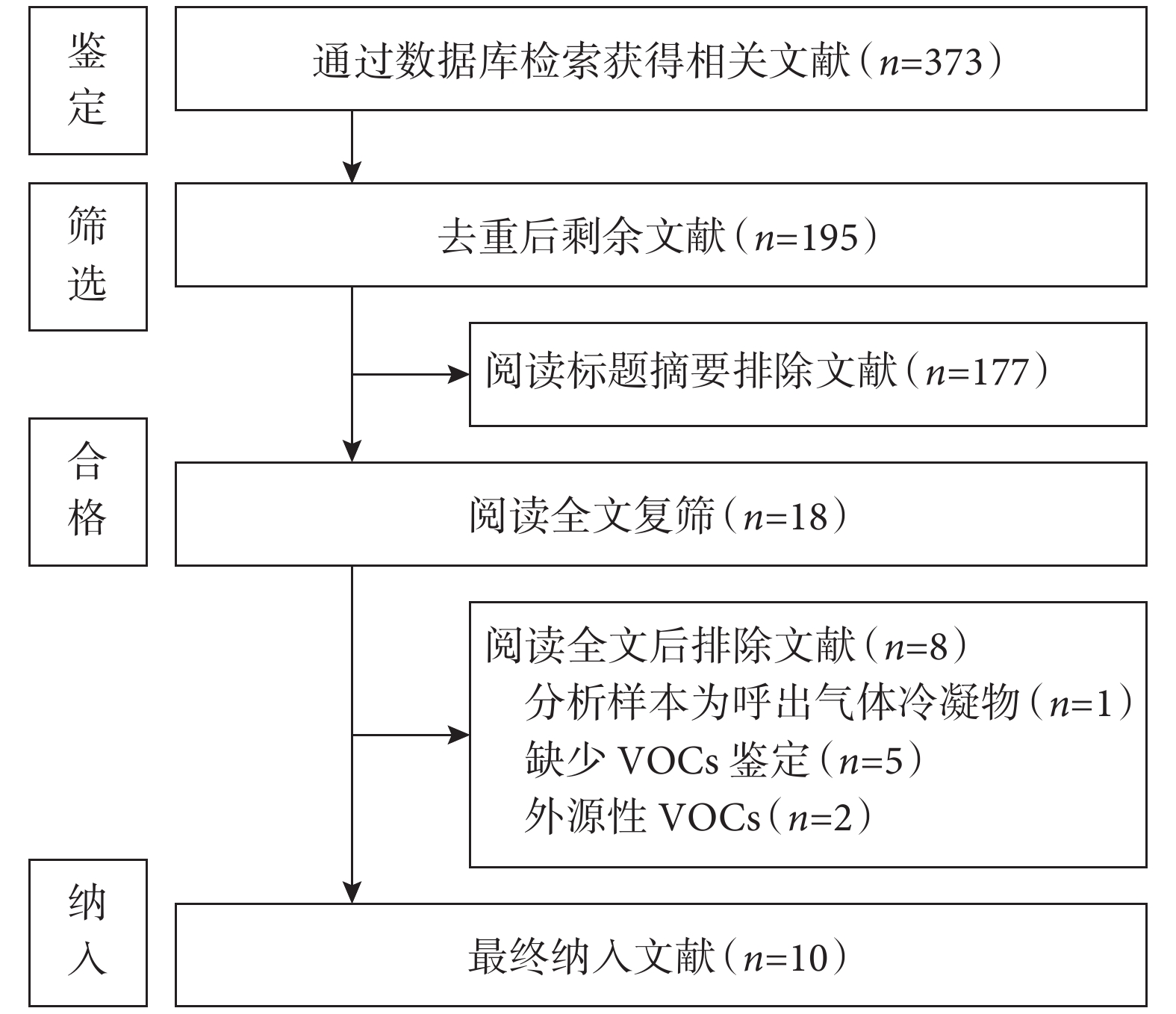 圖1
文獻篩選流程圖
圖1
文獻篩選流程圖
VOCs:揮發性有機化合物
2.2 納入研究的基本特征
納入的10項研究共包括404例CF患者和300例健康對照者。其中9項(90%)研究采用橫斷面研究設計,1項(10%)為病例對照研究。8項(80%)研究發表于近10年。納入研究的人群數據來自歐洲(n=9,90%)和北美洲(n=1,10%)。納入研究的NOS評分為7~10分,均為高質量文獻。納入文獻的基本特征見表1。PROBAST結果顯示,所有預測模型研究(n=5)總體偏倚風險為高偏倚風險,總體適用性不清楚。在模型的偏倚風險方面,所有研究在研究對象、預測因子和統計分析領域被評為高風險,在結果領域的偏倚風險未知。關于模型的適用性,所有研究在研究對象領域有較低的適用性風險,在預測因子和結果領域的風險未知;見表2。
2.3 呼出氣體VOCs的識別
納入的10項研究共識別75個呼出氣體VOCs,這些化合物多屬于酰基肉毒堿類、醛類、酸類和酯類。所有VOCs均僅被報告了一次。6項研究分析報道了CF患者與健康受試者呼出氣體VOCs的濃度差異。與CF相關的呼出氣體VOCs見附表1。
2.4 基于VOCs的CF風險預測模型的構建情況
5項預測模型研究[14-15,20-22]共構建7個基于呼出氣體VOCs的CF風險預測模型。樣本總量為18~199例,CF患者12~97例。僅有1個基于呼出氣體VOCs的模型納入了用力呼出75%肺活量時的瞬間呼氣流量和呼吸困難分級量表評分作為預測因子,其余模型納入的預測因子均為呼出氣體VOCs,納入模型頻數最多的化合物有:3,3-二甲基-1-己烯(n=2)、巴豆醇(n=2)、N-methyl-2-methylpropylamine(n=2)、苯甲醛(n=2)和苯并噻唑(n=2)。納入研究均采用機器學習算法構建模型。模型的構建情況和性能見表3。
2.5 模型預測性能
模型的區分度主要通過受試者工作特征曲線下面積(area under the curve,AUC)表示。6個模型報道了AUC值,范圍為0.771~0.988。所有研究均未提供模型的校準度信息。另外,5個模型報道了靈敏度和特異度指標,其中,靈敏度最高(100%)的模型,其特異度為73%;特異度最高(96.1%)的模型,其靈敏度為93.8%。4個預測模型報道了準確度,范圍為77%~100%。
2.6 模型驗證
4項研究基于模型開發隊列數據進行了內部驗證,包括K倍交叉驗證(n=2,50%)、留一法交叉驗證(n=1,25%)和計算機模擬重復采樣法(Bootstrap)(n=1,25%)。另外1項研究未對模型進行驗證。
3 討論
本系統評價納入的10項研究中,5項研究[12-13,17-19]僅報道了CF患者特異性呼出氣體VOCs,另外5項研究[14-15,20-22]在識別CF特異性呼出氣體VOCs的基礎上,開發了7個CF風險預測模型。通過對納入文獻報道的呼出氣體化合物及模型的構建方法、預測性能、內外部驗證情況等的比較,發現納入研究報道的VOCs存在顯著異質性,這些化合物多屬于酰基肉毒堿類、醛類、酸類和酯類。此外,基于呼出氣體VOCs的CF風險預測模型整體性能較好,但在模型開發和驗證過程中存在一些不足,需要對模型進一步優化。
本研究納入模型的預測因子多為呼出氣體VOCs,缺乏其他重要因素。既往研究[27-28]發現巨噬細胞、中性粒細胞、淋巴細胞等炎癥細胞以及8-異前列腺素和白細胞介素8等炎癥介質在CF發病機制中發揮了重要作用,提示機體炎性介質是預測CF的重要因素。此外,研究發現某些具有先天防御功能的蛋白質(如分泌型白細胞蛋白酶抑制劑、脂質運載蛋白-1和胱抑素SA),其豐度在肺部疾病頻繁加重的CF患者的痰液中升高[29],提示可尋找適用于臨床實踐的痰液標志物作為CF的預測因子。
本研究納入文獻均基于歐美人群開展,一方面可能是因為攜帶CFTR突變基因的高加索人群數量較大[30],另一方面可能是因為這些地區的人們對CF的重視程度高,國家資金投入大,診斷治療技術處于國際領先水平,有利于CF的檢出[31]。建議今后在構建CF風險預測模型時,綜合考慮呼出氣體VOCs、實驗室指標、體液標志物以及包括種族在內的人口學特征等多方面因素,以提高模型的準確性和臨床實用性。
本研究納入的CF風險預測模型具有良好的預測性能,但模型在開發和驗證過程中存在一些方法學缺陷,導致納入研究的偏倚風險普遍偏高。在數據來源方面,5項研究為單中心回顧性研究。雖然回顧性數據易獲取,但在構建模型時易產生回憶偏倚,且無法獲得預測因子和研究結局之間的因果關系。PROBAST推薦采用隊列研究或巢式病例對照研究等前瞻性數據以減少此類偏倚[25-26]。在樣本量方面,2項研究的每個自變量的事件數(events per variable,EPV)<10,導致建模過程可能出現過度擬合[32]。研究[33]表明,當模型開發研究的EPV≥20時,模型的回歸系數通常能較好地代表真實的回歸系數,構建的回歸模型準確性也較高。因此,為使模型更加準確,有必要選取大樣本量數據構建預測模型[25-26]。在篩選預測因子方面,4項研究采用單因素分析方法。在候選變量較多的情況下,一些變量間可能具有相關性,使用單因素分析可能會丟失重要變量[34]。相比之下,逐步回歸、LASSO回歸等多變量分析方法可避免多重共線性,同時能進行參數估計和變量選擇[35],在預測因子的篩選中應用逐漸廣泛[36]。今后構建CF風險預測模型時,可根據實際應用情況選擇合適的方法來篩選潛在的預測因子。此外,還應充分考慮臨床意義等非統計學方法以降低模型的偏倚風險[34]。最后,在模型性能評估方面,全面報道區分度(如AUC值、C指數)和校準度(如Hosmer-Lemeshow檢驗、Brier得分等)指標才能明確模型的預測效能[25-26],而納入研究均未提供校準度信息,使模型性能的評價不夠完整,在一定程度上限制了其臨床應用。值得注意的是,基于呼出氣體VOCs的CF風險預測模型目前尚處于開發階段,缺少模型驗證過程。預測模型的內部驗證用于檢驗模型開發過程的可重復性,防止過度擬合[37],而外部驗證關注模型的應用和推廣[38]。因此,為確保模型的臨床實用性,今后在考慮CF模型預測性能的同時,可以更多地關注模型的驗證和完善,以構建性能更好、外推性高的預測模型[39]。
酰基肉毒堿類、醛類、酸類和酯類是納入研究中報道頻率最高的化合物。然而,由于所有VOCs僅報道了1次,使研究間的比較非常復雜。實際上,要完全識別呼出氣體中數以千計的VOCs幾乎是不可能的[40],因為氣體樣本在采集和分析過程受很多因素的影響,如環境中的揮發性物質[41]、氣體采樣袋及分析儀器的本底污染物以及樣本存放時間等[42]都會影響檢測結果,且基于呼出氣體VOCs輔助診斷CF的研究尚處于起步階段。需開展更多研究進一步探索呼出氣體化合物與CF之間的關系。
本系統評價存在一些局限性。首先,本研究僅納入分析了英文文獻,可能導致選擇偏倚。其次,由于納入研究報道的呼出氣體VOCs、模型構建方法及預測性能等存在較大異質性,因此未能進行定量分析。最后,絕大多數納入研究屬于橫斷面研究,不能明確預測因子和結局之間的因果關系。
綜上所述,盡管各研究報道的呼出氣體VOCs有很大異質性,但基于這類氣體標志物的預測模型在輔助診斷CF方面具有一定價值,模型整體偏倚風險較高,需從模型構建及驗證等方面進一步優化,為臨床醫務工作者早期識別CF提供可靠、科學的工具。
利益沖突:無。
作者貢獻:龔衛娟、盧光玉提出研究思路,設計研究方案;於曉平、蘇志霞、嚴凱、沙泰寧、何宇航、張艷艷、陶玉堅、郭虹負責數據收集、清洗和統計學分析,繪制圖表等;於曉平、蘇志霞、盧光玉負責論文起草;龔衛娟負責最終版本修訂。
本文附件表1見本刊網站電子版。
囊性纖維化(cystic fibrosis,CF)是一種常染色體隱性遺傳病,由囊性纖維化跨膜傳導調節因子(cystic fibrosis transmembrane conductance regulator,CFTR)基因突變引起,常累及多個系統[1]。呼吸系統功能減退和肺部疾病惡化是CF患者重要的臨床癥狀[2-4]。CF患者呼吸道黏膜纖毛的清除和防御機制受損,易被機會致病菌定植、感染,進而引起慢性炎癥、支氣管阻塞、呼吸衰竭,甚至死亡[5]。CF在高加索人群中相對常見,發病率為1/4 000~1/3 000[6]。目前我國報道的CF數量僅為200例[7],而近10年CF患者數量超過了既往30年總和的2.5倍[8],這表明我國CF的發病率可能被嚴重低估。診斷CF通常依據臨床癥狀和體征,如果癥狀不典型,則進行汗液氯離子測定和/或基因分析[7]。然而,利用現有技術診斷CF存在汗液樣本采集不足、基因檢測費用高等問題[9]。因此,亟需開發一種新的輔助診斷技術,以提高對可疑患者的診斷準確性。
呼出氣體是一種豐富的介質,由氣相有機化合物、氣相無機化合物、水蒸氣和氣溶膠組成。其中,氣相有機化合物中包含了數千種以微量形式存在的揮發性有機化合物(volatile organic compounds,VOCs)[10]。大多數VOCs都參與了人體組織水平的內源性代謝過程。當出現病理狀況時,VOCs的種類和含量則通過體內氧化應激、細胞色素p-450和脂質代謝等途徑發生變化[11]。既往研究[12-13]發現,CF患者呼出氣體正戊烷、乙酸等化合物濃度高于對照組,而二甲基硫和1,2,4,5-四甲苯等化合物濃度較對照組顯著降低[14-15]。這些研究提示呼出氣體VOCs很可能作為CF的潛在生物標志物。相較于傳統的實驗室檢查或基因檢測,分析呼出氣體VOCs具有無創、操作簡捷等優點[16],有望成為輔助診斷CF的新方法。
近年來,全球開展了多項基于呼出氣體VOCs診斷CF的研究[12-15, 17-22],但研究結論尚有爭議。因此,本系統評價旨在全面分析呼出氣體VOCs對CF的診斷價值。
1 資料與方法
1.1 文獻納入和排除標準
納入標準:(1)研究對象為CF患者;(2)研究內容為識別CF患者特異性呼出氣體VOCs或構建基于呼出氣體VOCs的CF風險預測模型;(3)研究類型為隊列研究、病例對照研究和橫斷面研究等;(4)發表語言為中文或英文。排除標準:(1)VOCs來源于呼出氣體冷凝物或血液、尿液等其他生物樣本;(2)外源性VOCs;(3)摘要、綜述、會議論文等;(4)重復發表的文獻。
1.2 文獻檢索策略
計算機檢索PubMed、EMbase、Web of Science、Cochrane Library、中國知網、萬方、維普以及中國生物醫學文獻數據庫,搜集國內外公開發表的基于呼出氣體VOCs診斷CF的研究,并追溯納入研究的參考文獻。檢索時限為建庫至2024年8月7日。采用醫學主題詞與自由詞結合的方式進行文獻檢索。中文數據庫以中國知網為例,檢索式為:(主題“囊性纖維化”OR主題“肺囊性纖維化”OR主題“肺部囊性纖維化”)AND(主題“呼出氣體”OR主題“呼出氣體檢測”OR主題“呼出氣體分析”)AND(主題“揮發性有機化合物”OR主題“揮發性有機氣體”)。英文數據庫以PubMed為例,檢索式為:(((cystic fibrosis[MeSH Terms]) OR (fibrosis, cystic or mucoviscidosis or pulmonary cystic fibrosis or cystic fibrosis, pulmonary)) AND ((volatile organic compounds[MeSH Terms]) OR (compounds, volatile organic or organic compounds, volatile or volatile organic compound or compound, volatile organic or organic compound, volatile))) AND ((exhaled) OR (breath))。
1.3 文獻篩選與資料提取
剔除重復文獻后,由2名研究人員獨立完成文獻篩選與資料提取,并交叉核對。運用EndNote 20軟件剔除重復文獻,閱讀文章題目與摘要進行文獻初篩,再閱讀全文進行二次篩選,剔除不符合要求的文獻后,確定最終納入文獻。若存在意見分歧,則與第3名研究者討論解決。提取并歸納文獻資料:(1)文獻基本信息,包括第一作者、發表年份、國家、研究類型、樣本量等;(2)呼出氣體VOCs的識別情況;(3)基于VOCs的CF風險預測模型的構建及預測性能,包括候選變量、納入變量、模型構建及驗證方法、模型性能等。
1.4 文獻質量評價
采用紐卡斯爾-渥太華量表(Newcastle-Ottawa Scale,NOS)對納入研究進行質量評價[23-24],包括研究人群的選擇、組間可比性、暴露因素或結果測量3個方面。病例對照研究的NOS總分為9分,橫斷面研究的NOS總分為10分。評分≤4分為低質量,5~6分為中等質量,≥7分為高質量。
使用預測模型偏倚風險評估工具(prediction model risk of bias assessment tool,PROBAST)對納入預測模型研究的偏倚風險和適用性進行評估[25-26]。偏倚風險包括研究對象、預測因子、結果和統計分析4個領域,適用性包括研究對象、預測因子和結果3個領域。若2名研究者在質量評價過程中存在意見分歧,則與第3名研究者討論解決。
2 結果
2.1 文獻篩選流程及結果
初步檢索得到文獻373篇,均為英文文獻。去重后剩余文獻195篇,閱讀題目與摘要后排除177篇,繼續閱讀全文后排除8篇,最終納入10篇文獻[12-15,17-22]。文獻篩選流程見圖1。
圖1
文獻篩選流程圖
VOCs:揮發性有機化合物
2.2 納入研究的基本特征
納入的10項研究共包括404例CF患者和300例健康對照者。其中9項(90%)研究采用橫斷面研究設計,1項(10%)為病例對照研究。8項(80%)研究發表于近10年。納入研究的人群數據來自歐洲(n=9,90%)和北美洲(n=1,10%)。納入研究的NOS評分為7~10分,均為高質量文獻。納入文獻的基本特征見表1。PROBAST結果顯示,所有預測模型研究(n=5)總體偏倚風險為高偏倚風險,總體適用性不清楚。在模型的偏倚風險方面,所有研究在研究對象、預測因子和統計分析領域被評為高風險,在結果領域的偏倚風險未知。關于模型的適用性,所有研究在研究對象領域有較低的適用性風險,在預測因子和結果領域的風險未知;見表2。
2.3 呼出氣體VOCs的識別
納入的10項研究共識別75個呼出氣體VOCs,這些化合物多屬于酰基肉毒堿類、醛類、酸類和酯類。所有VOCs均僅被報告了一次。6項研究分析報道了CF患者與健康受試者呼出氣體VOCs的濃度差異。與CF相關的呼出氣體VOCs見附表1。
2.4 基于VOCs的CF風險預測模型的構建情況
5項預測模型研究[14-15,20-22]共構建7個基于呼出氣體VOCs的CF風險預測模型。樣本總量為18~199例,CF患者12~97例。僅有1個基于呼出氣體VOCs的模型納入了用力呼出75%肺活量時的瞬間呼氣流量和呼吸困難分級量表評分作為預測因子,其余模型納入的預測因子均為呼出氣體VOCs,納入模型頻數最多的化合物有:3,3-二甲基-1-己烯(n=2)、巴豆醇(n=2)、N-methyl-2-methylpropylamine(n=2)、苯甲醛(n=2)和苯并噻唑(n=2)。納入研究均采用機器學習算法構建模型。模型的構建情況和性能見表3。
2.5 模型預測性能
模型的區分度主要通過受試者工作特征曲線下面積(area under the curve,AUC)表示。6個模型報道了AUC值,范圍為0.771~0.988。所有研究均未提供模型的校準度信息。另外,5個模型報道了靈敏度和特異度指標,其中,靈敏度最高(100%)的模型,其特異度為73%;特異度最高(96.1%)的模型,其靈敏度為93.8%。4個預測模型報道了準確度,范圍為77%~100%。
2.6 模型驗證
4項研究基于模型開發隊列數據進行了內部驗證,包括K倍交叉驗證(n=2,50%)、留一法交叉驗證(n=1,25%)和計算機模擬重復采樣法(Bootstrap)(n=1,25%)。另外1項研究未對模型進行驗證。
3 討論
本系統評價納入的10項研究中,5項研究[12-13,17-19]僅報道了CF患者特異性呼出氣體VOCs,另外5項研究[14-15,20-22]在識別CF特異性呼出氣體VOCs的基礎上,開發了7個CF風險預測模型。通過對納入文獻報道的呼出氣體化合物及模型的構建方法、預測性能、內外部驗證情況等的比較,發現納入研究報道的VOCs存在顯著異質性,這些化合物多屬于酰基肉毒堿類、醛類、酸類和酯類。此外,基于呼出氣體VOCs的CF風險預測模型整體性能較好,但在模型開發和驗證過程中存在一些不足,需要對模型進一步優化。
本研究納入模型的預測因子多為呼出氣體VOCs,缺乏其他重要因素。既往研究[27-28]發現巨噬細胞、中性粒細胞、淋巴細胞等炎癥細胞以及8-異前列腺素和白細胞介素8等炎癥介質在CF發病機制中發揮了重要作用,提示機體炎性介質是預測CF的重要因素。此外,研究發現某些具有先天防御功能的蛋白質(如分泌型白細胞蛋白酶抑制劑、脂質運載蛋白-1和胱抑素SA),其豐度在肺部疾病頻繁加重的CF患者的痰液中升高[29],提示可尋找適用于臨床實踐的痰液標志物作為CF的預測因子。
本研究納入文獻均基于歐美人群開展,一方面可能是因為攜帶CFTR突變基因的高加索人群數量較大[30],另一方面可能是因為這些地區的人們對CF的重視程度高,國家資金投入大,診斷治療技術處于國際領先水平,有利于CF的檢出[31]。建議今后在構建CF風險預測模型時,綜合考慮呼出氣體VOCs、實驗室指標、體液標志物以及包括種族在內的人口學特征等多方面因素,以提高模型的準確性和臨床實用性。
本研究納入的CF風險預測模型具有良好的預測性能,但模型在開發和驗證過程中存在一些方法學缺陷,導致納入研究的偏倚風險普遍偏高。在數據來源方面,5項研究為單中心回顧性研究。雖然回顧性數據易獲取,但在構建模型時易產生回憶偏倚,且無法獲得預測因子和研究結局之間的因果關系。PROBAST推薦采用隊列研究或巢式病例對照研究等前瞻性數據以減少此類偏倚[25-26]。在樣本量方面,2項研究的每個自變量的事件數(events per variable,EPV)<10,導致建模過程可能出現過度擬合[32]。研究[33]表明,當模型開發研究的EPV≥20時,模型的回歸系數通常能較好地代表真實的回歸系數,構建的回歸模型準確性也較高。因此,為使模型更加準確,有必要選取大樣本量數據構建預測模型[25-26]。在篩選預測因子方面,4項研究采用單因素分析方法。在候選變量較多的情況下,一些變量間可能具有相關性,使用單因素分析可能會丟失重要變量[34]。相比之下,逐步回歸、LASSO回歸等多變量分析方法可避免多重共線性,同時能進行參數估計和變量選擇[35],在預測因子的篩選中應用逐漸廣泛[36]。今后構建CF風險預測模型時,可根據實際應用情況選擇合適的方法來篩選潛在的預測因子。此外,還應充分考慮臨床意義等非統計學方法以降低模型的偏倚風險[34]。最后,在模型性能評估方面,全面報道區分度(如AUC值、C指數)和校準度(如Hosmer-Lemeshow檢驗、Brier得分等)指標才能明確模型的預測效能[25-26],而納入研究均未提供校準度信息,使模型性能的評價不夠完整,在一定程度上限制了其臨床應用。值得注意的是,基于呼出氣體VOCs的CF風險預測模型目前尚處于開發階段,缺少模型驗證過程。預測模型的內部驗證用于檢驗模型開發過程的可重復性,防止過度擬合[37],而外部驗證關注模型的應用和推廣[38]。因此,為確保模型的臨床實用性,今后在考慮CF模型預測性能的同時,可以更多地關注模型的驗證和完善,以構建性能更好、外推性高的預測模型[39]。
酰基肉毒堿類、醛類、酸類和酯類是納入研究中報道頻率最高的化合物。然而,由于所有VOCs僅報道了1次,使研究間的比較非常復雜。實際上,要完全識別呼出氣體中數以千計的VOCs幾乎是不可能的[40],因為氣體樣本在采集和分析過程受很多因素的影響,如環境中的揮發性物質[41]、氣體采樣袋及分析儀器的本底污染物以及樣本存放時間等[42]都會影響檢測結果,且基于呼出氣體VOCs輔助診斷CF的研究尚處于起步階段。需開展更多研究進一步探索呼出氣體化合物與CF之間的關系。
本系統評價存在一些局限性。首先,本研究僅納入分析了英文文獻,可能導致選擇偏倚。其次,由于納入研究報道的呼出氣體VOCs、模型構建方法及預測性能等存在較大異質性,因此未能進行定量分析。最后,絕大多數納入研究屬于橫斷面研究,不能明確預測因子和結局之間的因果關系。
綜上所述,盡管各研究報道的呼出氣體VOCs有很大異質性,但基于這類氣體標志物的預測模型在輔助診斷CF方面具有一定價值,模型整體偏倚風險較高,需從模型構建及驗證等方面進一步優化,為臨床醫務工作者早期識別CF提供可靠、科學的工具。
利益沖突:無。
作者貢獻:龔衛娟、盧光玉提出研究思路,設計研究方案;於曉平、蘇志霞、嚴凱、沙泰寧、何宇航、張艷艷、陶玉堅、郭虹負責數據收集、清洗和統計學分析,繪制圖表等;於曉平、蘇志霞、盧光玉負責論文起草;龔衛娟負責最終版本修訂。
本文附件表1見本刊網站電子版。