隨機對照試驗(randomized controlled trial,RCT)是評估干預與結局指標因果效應的“金標準”。然而,由于研究成本高昂和倫理限制,在臨床實際中,尤其是在外科領域中開展RCT面臨受試者招募困難、盲法實施困難和干預標準化困難等諸多挑戰。在此情況下,基于目標試驗模擬(target trial emulation,TTE)框架、利用真實世界數據按照RCT研究設計原則進行因果推斷,有助于識別并減少傳統觀察性研究因設計缺陷產生的永恒時間偏倚、混雜偏倚、選擇偏倚或碰撞偏倚,以得到接近RCT 的高質量證據,提高真實世界數據研究的臨床指導價值。但TTE存在無法完全消除混雜、源數據質量要求高和暫缺報告規范等局限,故研究者應充分認識以免做出錯誤的因果推斷。本文擬就TTE的框架簡介、實施要點、應用范圍、應用案例及框架優缺點進行概述。
引用本文: 袁馳, 周祎靈, 曹雨滋, 張豪杰, 王依倩, 李舍予. 基于真實世界數據的觀察性研究因果推斷. 中國胸心血管外科臨床雜志, 2024, 31(12): 1743-1752. doi: 10.7507/1007-4848.202407072 復制
版權信息: ?四川大學華西醫院華西期刊社《中國胸心血管外科臨床雜志》版權所有,未經授權不得轉載、改編
隨機對照試驗(randomized controlled trial,RCT )是評估干預與結局指標因果效應以及干預成本效益的“金標準”[1]。不同于其他研究設計,RCT 可通過隨機化消除組間及組內差異、平衡混雜因素并減少選擇偏倚,采用盲法減少測量偏倚和實施偏倚,并通過對照原則消除各種非試驗因素(如時間)引起的因果效應[2]。然而,RCT 時間和經濟成本高昂,受試者招募困難,且倫理顧慮較多,因此,從可行性的角度,并非所有臨床問題均可由RCT 解決[3-4]。此外,為追求內部效度,RCT 納入人群往往高度均一,而排除特殊人群(如老年患者或多種合并癥患者、致死性急性疾病患者等),使其外推性和普適性受限[5]。當需要及時性證據或評估干預的長期療效時,RCT 并非首選[5-6]。此外,相較于藥物RCT ,外科手術操作的不可逆性使患者招募困難、臨床決策者與實施者一致性使盲法實施困難、醫師的個體化操作習慣使手術干預標準化困難,也使得在外科領域開展RCT 面臨更多挑戰[7-9]。例如,老年早期肺癌患者中行根治手術是否獲益更多目前尚無定論[10],亟需高質量循證醫學證據,但由于此類人群合并癥多且基礎條件差,接受手術機會有限,存在倫理限制等問題,故該主題的RCT 設計和實施均面臨嚴重的可行性問題。此時,開展設計嚴謹的觀察性研究,尤其是真實世界數據分析研究,可能為臨床決策提供高質量證據[11]。
真實世界數據來源廣泛,包括電子病歷(electronic medical record)、電子健康檔案(electronic health record)、藥品與疾病登記(drug dispensation register)或醫療保險資料(health care claims)等[6]。基于多源性真實世界數據的觀察性研究可提高結論的外推性,并能持續評估干預的安全性、有效性以及研究結論的穩健性,利用觀察性真實世界數據進行因果推斷也漸受青睞[3, 11]。相較于RCT ,基于真實世界數據估計因果效應更依賴于滿足因果推斷以及所用統計模型的基本假設,因此從觀察性研究中得出的因果推論本質上較RCT 更具推測性[3, 12-14]。有觀點認為,觀察性研究干預缺乏隨機分配是影響其因果效應估計的關鍵[3, 15]。盡管使用統計學方法平衡組間混雜因素以模仿隨機分配可減少混雜[15-16],但僅此無法完成合理的因果效應估計,若觀察性研究透明性差且設計存在缺陷,還可導致選擇偏倚、永恒時間偏倚和現使用者偏倚等產生錯誤估計效應,從而誤導臨床決策[17-19]。
在RCT 不可及而又需要進行因果推斷時,為得出接近RCT 的穩健因果推論,可行的方法是遵循已有或假設的RCT (即“目標試驗”,target trial)研究設計和分析原則來分析觀察性真實世界數據,以上研究框架被稱為“目標試驗模擬(target trial emulation,TTE)”[20]。該框架可基于高質量觀察性真實世界數據,對目標試驗進行模擬分析,幫助控制觀察性研究設計及分析中可能存在的偏倚,盡量避免錯誤的因果推論,以期得到類似RCT 的高質量結果,為衛生決策提供可靠證據[21-22]。本文擬就TTE的框架簡介、實施要點、應用范圍、應用案例及框架優缺點進行概述。
1 TTE框架簡介
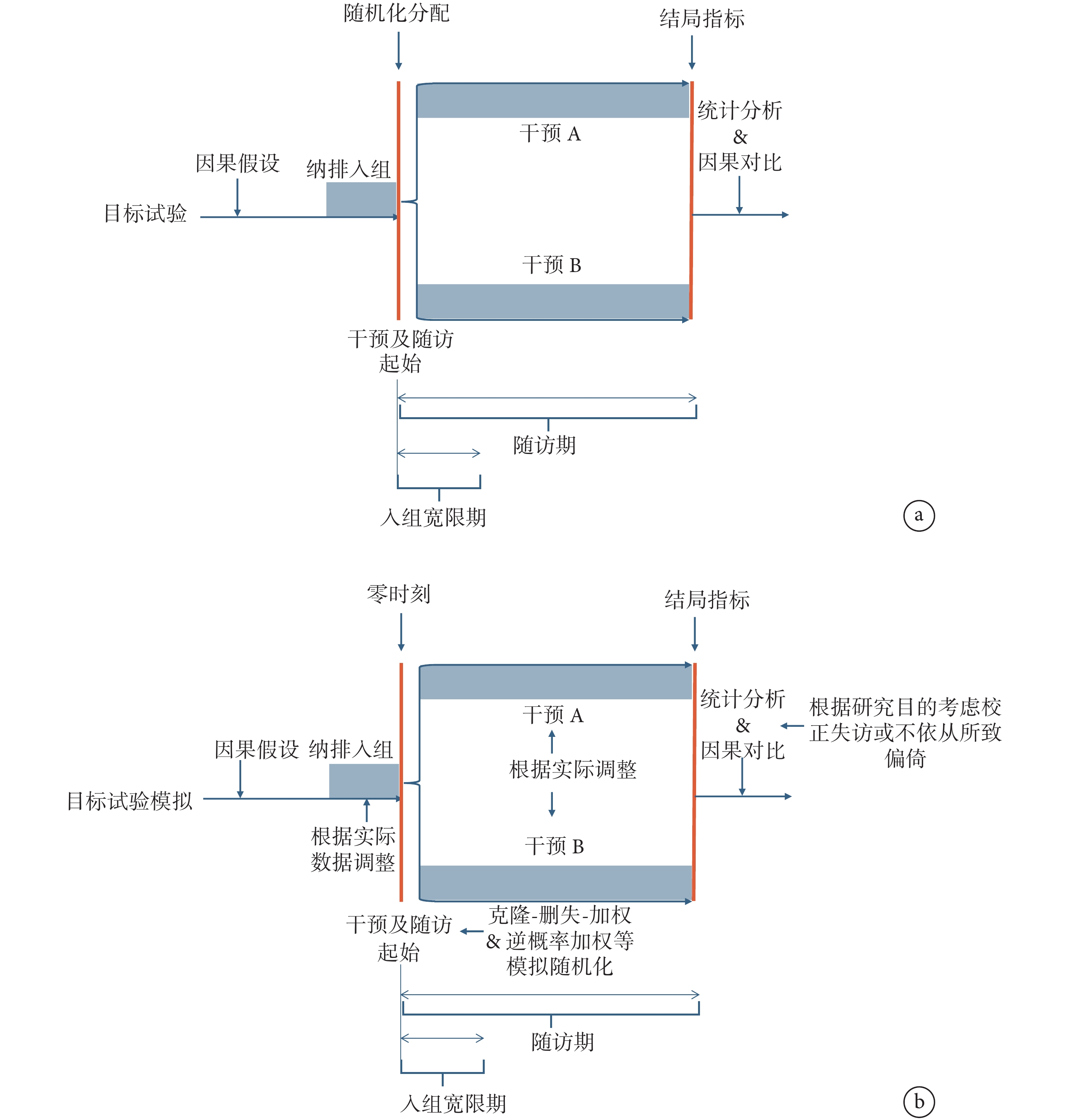
TTE是基于目標試驗研究設計來分析觀察性真實世界數據以完成因果效應估計的研究框架。針對每一個研究干預的因果效應的問題,在可獲觀察性數據的限制下,設計一個理想的假設RCT,這個RCT被稱作解決該研究問題的目標試驗。目標試驗應在目標試驗方案中被明確指定,詳細定義諸如納入排除標準、干預措施、分配程序、治療起點、盲法、零時刻、隨訪期、結局指標、分析方案與因果對比等關鍵要素。受可獲數據所限,需評估目標試驗是否可用現有觀察性數據模擬。如不可行,需迭代重新指定目標試驗,直至可模擬。如更新目標試驗仍無法回答原研究問題,則尋找其他觀察性數據源。完成目標試驗方案后,利用現有真實世界數據構建設計嚴謹的觀察性研究去正確模擬目標試驗的每個要素(圖1)。
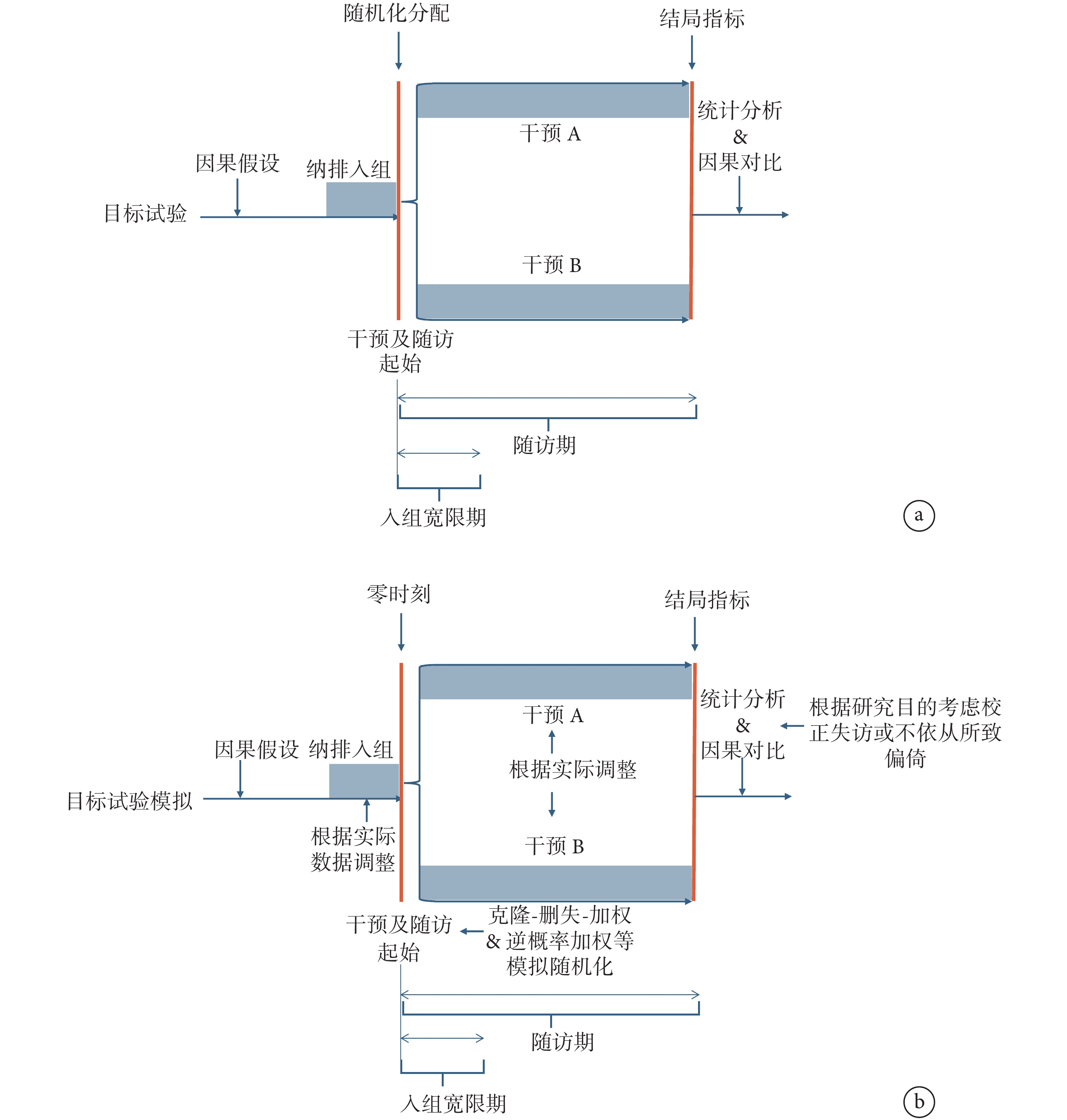 圖1
目標試驗及目標試驗模擬流程圖
圖1
目標試驗及目標試驗模擬流程圖
a:目標試驗流程;b:目標試驗模擬流程
TTE框架將理想的目標試驗與觀察性研究置于同一度量標準上,并在方案中明確指定每個要素,有助于減少混雜、避免永恒時間偏倚和選擇偏倚、克服傳統觀察性數據因果分析中可避免的陷阱[23],同時提高研究設計的透明度。具體來說,該框架要求研究者提出具體干預措施,除明確干預的種類、劑量以及時間外,還需確定干預是啟動治療還是持續治療[如:“是否啟動阿茲夫定治療”還是“隨訪期間全程使用阿茲夫定”對重癥新型冠狀病毒感染(COVID-19)患者全因死亡的影響]。此外,研究者還需根據研究目的及數據源質量確定是否設置入組寬限期及其時長。真實世界中,隨訪開始和某些干預啟動(如手術)之間可能存在延遲,因此設置寬限期將允許研究對象在符合納入排除標準后一段時間再分配干預措施,以增加TTE樣本量并使模擬更貼近RCT 。另外,在RCT 中,隨機化的目的在于平衡干預分配時的混雜因素,因此在TTE中模擬隨機分配時,可采用傾向性評分(匹配、分層、調整和逆概率加權)或參數g-formula (parametric g-formula) 等統計學方法平衡組間混雜因素,并通過標準化平均差異來評估(絕對差異<10%被認為平衡)[24]。
在TTE研究中需明確定義研究開始的基線時間點,即零時刻,并確保零時刻時研究對象符合納入排除標準入組、干預分配和隨訪開始3大時間點同時開始,否則可引發永恒時間偏倚(詳見2.4)[20, 25]。然而,由于研究目的不同,同一個人可以在一個或多個不同的時間點滿足納入與排除標準。例如,當研究目的為“比較在接受血液透析3個月的患者中使用高劑量與低劑量促紅細胞生成素療效”時,零時刻可設置為血液透析3個月后;然而,當研究目的為“比較在絕經后女性中,啟動雌激素加孕激素治療與不啟動治療的效果”時,一名女士在絕經后有多個可以作為零時刻的時間點。此時有兩種方式來確定零時刻:(1)統一選擇單一符合條件的時刻(例如,第一個符合條件的時間或隨機選擇的符合條件時間);(2)所有符合條件的時刻或其中的一個大子集。后者需要根據干預和協變量數據收集的頻率模擬多個不同零時刻的嵌套試驗[26]。
在進行數據統計分析前,需要對數據分析集進行定義,并按照該定義進行數據分析。常見的數據分析集包括意向性分析 (intention-to-treat population,ITT),調整后ITT(modified ITT,mITT)和符合方案集分析(per-protocol analysis,PP)。在RCT 中,ITT納入所有隨機化后患者,無論失訪或中途改變治療方案均按照分配方案進行分析,由于干預分配是隨機的,RCT的ITT分析不會受混雜因素的影響。mITT在ITT人群的基礎上,僅做最必要的排除,即排除不滿足主要納入與排除標準者、未接受干預者和隨機化后缺失所有數據者;PP則僅對依從干預的人群進行分析[27]。在TTE研究中,由于觀察性研究缺乏隨機化,且觀察性數據的完整性可能受各種主客觀因素影響(如在單中心電子病歷數據中,若患者零時刻后某藥處方數據突然中斷,原因既可能與藥物相關,如不耐受、效果差停藥或死亡,也可能與藥物本身無關,如患者改變就醫機構所致就診記錄中斷),因此更多采用PP分析,如因研究目的確實需要ITT分析,則應采用mITT進行分析,且對基線混雜因素進行充分調整[24-25, 28]。
TTE框架并不偏好任何識別分析策略或者統計方法,但要求研究者在從提出研究問題到結果解釋的每一個步驟中明確提出并指定合理的假設,提高結果的有效性和解釋性。在實際解決問題過程中,研究者可自由選擇最適合其研究問題的方法,在不深入研究問題細節的情況下,最好的建議也許是使用能夠滿足研究因果目標的最簡單方法。此外,相比傳統分析僅提供風險比,該框架估算各干預措施下結局的絕對風險,更有助于臨床決策[20, 29-30] 。
2 TTE框架實施要點
為確保按照RCT 研究設計開展TTE,以下實施要點應充分考慮在內,以避免得出錯誤結論。
2.1 先驗設計納入與排除標準
TTE框架的納入與排除標準應根據RCT 要求設計,既可參考已發表研究方案,也可自行重新設計,但最好在審查數據前先驗設計,以免錯誤引入基線后信息作為納入與排除標準[31]。此外,若設計納入與排除標準時未考慮目標人群既往是否接受過目標干預,則可因現使用者依從性較好、藥物長期效應等因素對結局指標造成影響,產生現使用者偏倚[17]。
2.2 考慮影響干預的因素
對于某些特定干預而言,在規劃干預細節時,應結合臨床實際考慮可能影響干預的因素。例如在評估手術干預時,與固定劑量藥物干預不同,手術干預的標準化與外科醫師的熟練度、患者的解剖學和病理學特點以及護士、助手和麻醉師團隊的配合、術后管理與康復流程密切相關,因此為盡量保證干預的標準性和一致性,如果目標數據源包含此類信息,制定目標試驗時需充分納入考慮[7]。
2.3 充足信息模擬隨機分配
為通過模擬隨機化平衡組間混雜因素,目標數據庫應包含充足數據信息以供校正,可采用有向無環圖輔助識別和指定協變量[32]。
2.4 確保零時刻時入組、分配及隨訪“三點對齊”
以上3大時間點RCT 中在隨機化時即對齊,但在觀察性研究中,常由于零時刻設置不明產生各種已知和未知偏倚[33-34]。通常來說,研究對象需在符合條件入組至干預措施分配之間(即“永恒時間”)存活或未發生結局指標才能接受干預,否則被歸為對照或非干預組[35]。當研究對象還未暴露于干預但隨訪已開始時,永恒時間被歸類于干預暴露至結局指標發生的時間段內(即隨訪時間),或入組后干預組隨訪起點晚于對照組,導致永恒時間被錯誤刪失,均可引入永恒時間偏倚,導致干預與結局指標的效應估計產生偏差[36]。例如,在觀察性數據中,只有存活到計劃手術日期的患者才會接受手術,如果以上3大時間點在設計階段未對齊,則從入組至接受手術之前(即“永恒時間”)內死亡的患者將會被錯誤劃分至對照組,導致手術獲益被人為夸大[37]。
2.5 根據實際確定入組寬限期
設置入組寬限期時,其長短不應對最終結局產生影響,可通過設置不同寬限期的敏感性分析和“克隆-刪失加權法”來防止在寬限期內發生的事件被分配至各組的偏倚,避免寬限期的設置與零時刻產生沖突[26]。
2.6 合理設置隨訪時長
TTE中隨訪時長的設置除考慮結局指標自然病程和發生率以及預估樣本量外,還應考慮目標數據集的中位隨訪時間,以使設置合理。如現有數據不滿足有意義的隨訪時長,則需更換數據源。
2.7 準確確立結局指標
與RCT 一樣,應事先定義主要和次要結局指標以及對應測量方法。最好采用驗證措施評估結局指標準確性(如:在電子病歷數據中通過ICD編碼篩查加人工審核臨床癥狀及檢驗學指標多重確認“泌尿道感染”這一結局指標)。此外,由于現實中臨床醫師通常知曉個體干預措施,這可能影響其對結局指標的主觀判斷,因此應盡可能選擇客觀性較強的結局指標(如死亡等)[26]。
2.8 合理處置缺失變量
當納入排除標準中涉及的變量存在缺失時,如直接排除缺失變量個體進行分析可能產生偏倚,可在納入排除患者之前對完全隨機缺失或隨機缺失類型且缺失量較小(傳統認為缺失率上限應<20%)缺失變量進行多重插補以增加樣本量[39],并消除選擇偏倚[21, 40]。
2.9 統計方案并非TTE最關鍵要素
有觀點錯誤認為,通過TTE完成因果效應估計的關鍵在于運用高級統計學模型,但實際上TTE研究要點在于遵循設計臨床試驗的原則來衡量因果效應,統計學方法僅為研究設計的一部分。此外,研究仍需遵守因果推斷基本假設,如無干擾性、可交換性、正性和一致性等[12-14, 21]。
3 應用范圍
目前TTE框架最常應用于藥物流行病學領域,可持續監測獲批藥物的安全性和有效性[41-43]或探索藥物新適應證[44],尤其適用于諸如COVID-19等突發公共衛生事件[45-46]。Gupta等[47]使用危重COVID-19患者的觀察性數據來模擬目標試驗,發現入住ICU前2 d接受托珠單抗治療的患者院內死亡風險較低,隨后的一項大型RCT [48]證實了以上結論。除此之外,TTE還用于探究飲食干預或社會因素與健康結局的關聯[49-50],以及提高藥物靶標孟德爾隨機化研究質量[51]。另外,當研究旨在估計相對風險(率)而非絕對風險(率),并且有關治療或混雜因素的信息對于整個隊列不可用,但可為一小部分病例和對照所獲取時,TTE框架還可拓展至巢式病例對照設計,因后者可視作對潛在隊列的有效抽樣[52-53]。
相較于藥物、飲食或社會因素等干預,外科干預的依從性在分配時幾乎確定,故使用TTE框架評估單次外科干預因果效應的結果相對更穩健[25]。在這種情況下,TTE可大量擴充樣本以補充既往結果(如減肥手術與癌癥風險[54]),評估因倫理限制RCT 難以納入(如健康狀況更差、合并癥發生率更高的老年患者[37, 55-56])、預后較差(如胰腺癌患者[12])以及現實中難以招募的患者(如大量愿意在異地就醫接受陌生外科醫師手術干預的患者[14]、內鏡切除后切緣陰性同時接受額外手術的早期結直腸癌患者[57]),或暫缺RCT 證據的病種(如局限性高危前列腺癌手術或放療的選擇[58])。為評估文首所提及的老年早期肺癌患者行根治手術的獲益,Maringe等[37]基于TTE框架進行研究設計,使用英國國家癌癥登記處記錄的癌癥患者數據和二級護理管理記錄,納入診斷年齡70~89歲且一般情況良好的非小細胞肺癌Ⅰ期或Ⅱ期患者,通過符合方案集分析探究診斷后6個月內接受手術對患者1年生存期的影響。在進行因果推斷前,Maringe等[37]評估了因果假設的合理性,如正性(一般情況良好的非小細胞肺癌老年患者仍有非零概率接受或不接受手術)、一致性(早期非小細胞肺癌手術程序標準化高)和可交換性(由于采用克隆方法,兩組在基線時相同)等。此外,在理想假設下,進行手術的決定是完全隨機,或者基于與結局指標無關的患者特征作出的;但事實上,觀察性數據中大多數患者的手術干預決策是基于與結局指標生存相關的特征(如年齡、體能狀態和合并癥指數等),即混雜因素所作出的,因此Maringe等采用逆概率刪失加權法(inverse probability of censoring weighting)確保手術干預決策的隨機性[59]。研究結果顯示,即使考慮到手術等待時間,老年人群診斷后6個月內接受手術也可在第1年延長至13 d[95%CI(8,20)]的預期壽命,填補此類人群研究領域空白[37]。
4 應用案例
應用抗病毒藥物是治療COVID-19的主要措施之一。2022年2月,奈瑪特韋-利托那韋獲中國國家藥品監督管理局的應急附條件批準,成為COVID-19高危患者的標準抗病毒藥物之一。彼時該藥在國內外缺乏大型RCT 評估療效,且批準初期藥物可及的不確定性使患者是否接受奈瑪特韋-利托那韋治療基本成為隨機事件(即接受治療更多取決于是否有藥,而非臨床特征),而另一替代藥物阿茲夫定的有效性和安全性證據仍顯不足。為及時獲得有關奈瑪特韋-利托那韋療效的高質量證據,本團隊基于2022年12月1日—2023年1月19日四川省3家三甲醫院的住院患者信息以及四川省疾病預防控制中心數據庫的出院后全因死亡記錄和疫苗接種信息,通過TTE框架評估了阿茲夫定和奈瑪特韋-利托那韋在中國Omicron BA.5.2亞變種流行期間對中重癥COVID-19患者的療效[60]。
4.1 提出因果問題
在中重癥COVID-19成人患者中,如果所有患者接受為期5 d的奈瑪特韋-利托那韋或阿茲夫定治療,與未接受抗病毒治療患者相比,入院后30 d內全因死亡、開始有創機械通氣及其復合結局的平均風險是多少?
4.2 研究流程
(1)確定納入排除標準 與目標試驗相同(表1),但由于電子病歷中的時間評估和記錄未標準化,故納入入院前后1個日歷日內,而非24 h內首次出現新冠病毒核酸檢測陽性(以下簡稱“核酸陽性”)患者,并排除基線風險可能更高以至無機會口服藥物以及入組前30 d或入組后2 d內肝腎功能指標信息不全者。
(2)確定干預措施 由于該多中心隊列中無法獲得出院后口服藥物給藥的信息,故假設出院后的藥物管理與出院當天的藥物管理保持一致(表1)。
(3)干預措施分配 考慮急診入院并在急診已用藥的情況,根據在零時刻前1 d至零時刻結束時是否接受了阿茲夫定、奈瑪特韋-利托那韋或無抗病毒治療來分類患者,通過逆概率加權調整基線混雜因素來模擬隨機化。
(4)零時刻 由于入組時刻當日藥物醫囑信息可能不全,故每個參與者的零時刻設置為入組時刻次日結束時。對于入院后24 h內核酸陽性的患者,入組時刻為檢測時間;入院前24 h內核酸陽性的患者,入組時刻為入院時間。
(5)確定結局指標 主要結局指標包括全因死亡和有創機械通氣的單獨與復合結局;次要結局指標及安全性結局指標見表1。
(6)隨訪 研究從零時刻開始隨訪所有參與者,直至死亡或零時刻后30 d。
(7)因果對比 PP分析。
(8)統計學分析 通過逆概率加權調整基線混雜因素,使用加權Cox比例風險回歸估計風險比和95%CI,采用共享脆弱性Cox模型減少同一醫院內結果的內部同質性,使用治療權重生成調整后累積發病率。采用“克隆-刪失-加權”法完成PP分析。首先采用克隆方法,并對偏離指定干預或在零時刻后第5 天之前出院的參與者進行刪失處理。然后使用刪失加權法來處理因刪失引入的選擇偏倚,并調整年齡、性別、COVID-19的基線嚴重程度以及刪失前1 d的特征。
(9)亞組分析 年齡、性別、病情嚴重程度、疾病危險因素和發病到入院日期。
(10)敏感性分析 第一,消除永恒時間偏倚:分別將零時刻設置為入組時刻及入組時刻次日結束時并使用嵌套式TTE分析;第二,設置寬限期:評估在隨機分配后5 d內(說明書推薦用藥時期)開始使用阿茲夫定和奈瑪特韋-利托那韋的效果;第三,其他敏感性分析:將首次核酸陽性時間更改為“入院前7 d或入院后24 h內”或“入院前3 d或入院后24 h內”;排除在隨機分配前15 d內使用相互作用藥物的患者;刪除在隨機分配后的30 d或者死亡之前出院的患者。
4.3 研究結果
與無抗病毒治療相比,阿茲夫定[HR=0.47,95%CI(0.24,0.92)]和奈瑪特韋-利托那韋[HR=0.38,95%CI(0.18,0.81)]均可以減少中重度COVID-19成人患者入院后30 d內的全因死亡和有創機械通氣的復合結局以及獨立結局,前者還可降低心肺復蘇事件發生率,后者還可降低進展為重癥COVID-19的風險,亞組分析未發現交互作用效應,敏感性分析均證實了結果的穩健性。奈瑪特韋-利托那韋組的安全性結局指標發生率總體較阿茲夫定和對照組更高。
5 TTE框架局限性
盡管TTE可減少觀察性研究因研究設計缺陷引發的偏倚,但該框架并非解決所有因果問題的“靈丹妙藥”,其不可避免存在諸多局限(表2)。
(1)盡管TTE可改善觀察性研究設計,但框架本身并不能消除混雜[26]。由于采用觀察性真實世界數據,TTE研究仍可能存在未知混雜因素,并也會受測量偏倚、缺失數據等因素影響,可通過回溯因果假設、研究設計及數據來源,并使用敏感性分析和定量偏倚分析(quantitative bias analysis)進行檢驗[11, 21, 61]。
(2)觀察性的研究設計使得滿足正性假設上存在挑戰,因此無法模擬安慰劑對照,或者模擬患者存在禁忌證的用藥,也無法模擬盲法試驗[20]。
(3)TTE研究結論的穩健性依賴于數據來源及數據質量(諸如保險索賠數據等可能無法提供足夠的臨床信息以供矯正混雜因素),也依賴于做出的所有推斷因果的假設,因此需使用不同的假設分析作為敏感性分析以檢驗結論穩健性。
(4)TTE框架各要素的合理設計對研究者臨床經驗要求較高,譬如上述案例中干預措施和零時刻的選擇即分別考慮臨床實際中存在“急診入院且已用藥”或“入組當日藥物醫囑信息不全”的情況并做相應調整和敏感性分析,故完成高質量TTE研究有賴于跨學科團隊(研究者、數據收集者、流行病學家及臨床醫師)通體合作。
(5)由于暫缺適用于TTE研究的報告規范,部分TTE研究的框架各組分未正確設定,研究報告質量缺乏一致性[62],引發學界對TTE研究過程透明性和研究結果可重復性的擔憂[63-65]。
6 小結
在無法進行RCT 時,利用真實世界數據通過TTE框架估計因果效應已成為一種研究新思路。與RCT 類似的是,該框架將研究設計步驟與研究分析過程分離,有助于克服傳統觀察性研究因設計缺陷產生的偏倚,同時明確研究假設及研究過程,提高真實世界數據研究的臨床指導價值。但研究者需充分認識到TTE設計的局限性,避免在因果假設模糊、數據質量有限或框架要素設置不明的情況下盲目開展TTE研究,以免做出錯誤的因果推斷。
利益沖突:無。
作者貢獻:袁馳負責撰寫和修改論文;周祎靈負責設計和修改論文;曹雨滋、張豪杰和王依倩負責收集文獻相關資料;李舍予負責選題和指導。
隨機對照試驗(randomized controlled trial,RCT )是評估干預與結局指標因果效應以及干預成本效益的“金標準”[1]。不同于其他研究設計,RCT 可通過隨機化消除組間及組內差異、平衡混雜因素并減少選擇偏倚,采用盲法減少測量偏倚和實施偏倚,并通過對照原則消除各種非試驗因素(如時間)引起的因果效應[2]。然而,RCT 時間和經濟成本高昂,受試者招募困難,且倫理顧慮較多,因此,從可行性的角度,并非所有臨床問題均可由RCT 解決[3-4]。此外,為追求內部效度,RCT 納入人群往往高度均一,而排除特殊人群(如老年患者或多種合并癥患者、致死性急性疾病患者等),使其外推性和普適性受限[5]。當需要及時性證據或評估干預的長期療效時,RCT 并非首選[5-6]。此外,相較于藥物RCT ,外科手術操作的不可逆性使患者招募困難、臨床決策者與實施者一致性使盲法實施困難、醫師的個體化操作習慣使手術干預標準化困難,也使得在外科領域開展RCT 面臨更多挑戰[7-9]。例如,老年早期肺癌患者中行根治手術是否獲益更多目前尚無定論[10],亟需高質量循證醫學證據,但由于此類人群合并癥多且基礎條件差,接受手術機會有限,存在倫理限制等問題,故該主題的RCT 設計和實施均面臨嚴重的可行性問題。此時,開展設計嚴謹的觀察性研究,尤其是真實世界數據分析研究,可能為臨床決策提供高質量證據[11]。
真實世界數據來源廣泛,包括電子病歷(electronic medical record)、電子健康檔案(electronic health record)、藥品與疾病登記(drug dispensation register)或醫療保險資料(health care claims)等[6]。基于多源性真實世界數據的觀察性研究可提高結論的外推性,并能持續評估干預的安全性、有效性以及研究結論的穩健性,利用觀察性真實世界數據進行因果推斷也漸受青睞[3, 11]。相較于RCT ,基于真實世界數據估計因果效應更依賴于滿足因果推斷以及所用統計模型的基本假設,因此從觀察性研究中得出的因果推論本質上較RCT 更具推測性[3, 12-14]。有觀點認為,觀察性研究干預缺乏隨機分配是影響其因果效應估計的關鍵[3, 15]。盡管使用統計學方法平衡組間混雜因素以模仿隨機分配可減少混雜[15-16],但僅此無法完成合理的因果效應估計,若觀察性研究透明性差且設計存在缺陷,還可導致選擇偏倚、永恒時間偏倚和現使用者偏倚等產生錯誤估計效應,從而誤導臨床決策[17-19]。
在RCT 不可及而又需要進行因果推斷時,為得出接近RCT 的穩健因果推論,可行的方法是遵循已有或假設的RCT (即“目標試驗”,target trial)研究設計和分析原則來分析觀察性真實世界數據,以上研究框架被稱為“目標試驗模擬(target trial emulation,TTE)”[20]。該框架可基于高質量觀察性真實世界數據,對目標試驗進行模擬分析,幫助控制觀察性研究設計及分析中可能存在的偏倚,盡量避免錯誤的因果推論,以期得到類似RCT 的高質量結果,為衛生決策提供可靠證據[21-22]。本文擬就TTE的框架簡介、實施要點、應用范圍、應用案例及框架優缺點進行概述。
1 TTE框架簡介
TTE是基于目標試驗研究設計來分析觀察性真實世界數據以完成因果效應估計的研究框架。針對每一個研究干預的因果效應的問題,在可獲觀察性數據的限制下,設計一個理想的假設RCT,這個RCT被稱作解決該研究問題的目標試驗。目標試驗應在目標試驗方案中被明確指定,詳細定義諸如納入排除標準、干預措施、分配程序、治療起點、盲法、零時刻、隨訪期、結局指標、分析方案與因果對比等關鍵要素。受可獲數據所限,需評估目標試驗是否可用現有觀察性數據模擬。如不可行,需迭代重新指定目標試驗,直至可模擬。如更新目標試驗仍無法回答原研究問題,則尋找其他觀察性數據源。完成目標試驗方案后,利用現有真實世界數據構建設計嚴謹的觀察性研究去正確模擬目標試驗的每個要素(圖1)。
圖1
目標試驗及目標試驗模擬流程圖
a:目標試驗流程;b:目標試驗模擬流程
TTE框架將理想的目標試驗與觀察性研究置于同一度量標準上,并在方案中明確指定每個要素,有助于減少混雜、避免永恒時間偏倚和選擇偏倚、克服傳統觀察性數據因果分析中可避免的陷阱[23],同時提高研究設計的透明度。具體來說,該框架要求研究者提出具體干預措施,除明確干預的種類、劑量以及時間外,還需確定干預是啟動治療還是持續治療[如:“是否啟動阿茲夫定治療”還是“隨訪期間全程使用阿茲夫定”對重癥新型冠狀病毒感染(COVID-19)患者全因死亡的影響]。此外,研究者還需根據研究目的及數據源質量確定是否設置入組寬限期及其時長。真實世界中,隨訪開始和某些干預啟動(如手術)之間可能存在延遲,因此設置寬限期將允許研究對象在符合納入排除標準后一段時間再分配干預措施,以增加TTE樣本量并使模擬更貼近RCT 。另外,在RCT 中,隨機化的目的在于平衡干預分配時的混雜因素,因此在TTE中模擬隨機分配時,可采用傾向性評分(匹配、分層、調整和逆概率加權)或參數g-formula (parametric g-formula) 等統計學方法平衡組間混雜因素,并通過標準化平均差異來評估(絕對差異<10%被認為平衡)[24]。
在TTE研究中需明確定義研究開始的基線時間點,即零時刻,并確保零時刻時研究對象符合納入排除標準入組、干預分配和隨訪開始3大時間點同時開始,否則可引發永恒時間偏倚(詳見2.4)[20, 25]。然而,由于研究目的不同,同一個人可以在一個或多個不同的時間點滿足納入與排除標準。例如,當研究目的為“比較在接受血液透析3個月的患者中使用高劑量與低劑量促紅細胞生成素療效”時,零時刻可設置為血液透析3個月后;然而,當研究目的為“比較在絕經后女性中,啟動雌激素加孕激素治療與不啟動治療的效果”時,一名女士在絕經后有多個可以作為零時刻的時間點。此時有兩種方式來確定零時刻:(1)統一選擇單一符合條件的時刻(例如,第一個符合條件的時間或隨機選擇的符合條件時間);(2)所有符合條件的時刻或其中的一個大子集。后者需要根據干預和協變量數據收集的頻率模擬多個不同零時刻的嵌套試驗[26]。
在進行數據統計分析前,需要對數據分析集進行定義,并按照該定義進行數據分析。常見的數據分析集包括意向性分析 (intention-to-treat population,ITT),調整后ITT(modified ITT,mITT)和符合方案集分析(per-protocol analysis,PP)。在RCT 中,ITT納入所有隨機化后患者,無論失訪或中途改變治療方案均按照分配方案進行分析,由于干預分配是隨機的,RCT的ITT分析不會受混雜因素的影響。mITT在ITT人群的基礎上,僅做最必要的排除,即排除不滿足主要納入與排除標準者、未接受干預者和隨機化后缺失所有數據者;PP則僅對依從干預的人群進行分析[27]。在TTE研究中,由于觀察性研究缺乏隨機化,且觀察性數據的完整性可能受各種主客觀因素影響(如在單中心電子病歷數據中,若患者零時刻后某藥處方數據突然中斷,原因既可能與藥物相關,如不耐受、效果差停藥或死亡,也可能與藥物本身無關,如患者改變就醫機構所致就診記錄中斷),因此更多采用PP分析,如因研究目的確實需要ITT分析,則應采用mITT進行分析,且對基線混雜因素進行充分調整[24-25, 28]。
TTE框架并不偏好任何識別分析策略或者統計方法,但要求研究者在從提出研究問題到結果解釋的每一個步驟中明確提出并指定合理的假設,提高結果的有效性和解釋性。在實際解決問題過程中,研究者可自由選擇最適合其研究問題的方法,在不深入研究問題細節的情況下,最好的建議也許是使用能夠滿足研究因果目標的最簡單方法。此外,相比傳統分析僅提供風險比,該框架估算各干預措施下結局的絕對風險,更有助于臨床決策[20, 29-30] 。
2 TTE框架實施要點
為確保按照RCT 研究設計開展TTE,以下實施要點應充分考慮在內,以避免得出錯誤結論。
2.1 先驗設計納入與排除標準
TTE框架的納入與排除標準應根據RCT 要求設計,既可參考已發表研究方案,也可自行重新設計,但最好在審查數據前先驗設計,以免錯誤引入基線后信息作為納入與排除標準[31]。此外,若設計納入與排除標準時未考慮目標人群既往是否接受過目標干預,則可因現使用者依從性較好、藥物長期效應等因素對結局指標造成影響,產生現使用者偏倚[17]。
2.2 考慮影響干預的因素
對于某些特定干預而言,在規劃干預細節時,應結合臨床實際考慮可能影響干預的因素。例如在評估手術干預時,與固定劑量藥物干預不同,手術干預的標準化與外科醫師的熟練度、患者的解剖學和病理學特點以及護士、助手和麻醉師團隊的配合、術后管理與康復流程密切相關,因此為盡量保證干預的標準性和一致性,如果目標數據源包含此類信息,制定目標試驗時需充分納入考慮[7]。
2.3 充足信息模擬隨機分配
為通過模擬隨機化平衡組間混雜因素,目標數據庫應包含充足數據信息以供校正,可采用有向無環圖輔助識別和指定協變量[32]。
2.4 確保零時刻時入組、分配及隨訪“三點對齊”
以上3大時間點RCT 中在隨機化時即對齊,但在觀察性研究中,常由于零時刻設置不明產生各種已知和未知偏倚[33-34]。通常來說,研究對象需在符合條件入組至干預措施分配之間(即“永恒時間”)存活或未發生結局指標才能接受干預,否則被歸為對照或非干預組[35]。當研究對象還未暴露于干預但隨訪已開始時,永恒時間被歸類于干預暴露至結局指標發生的時間段內(即隨訪時間),或入組后干預組隨訪起點晚于對照組,導致永恒時間被錯誤刪失,均可引入永恒時間偏倚,導致干預與結局指標的效應估計產生偏差[36]。例如,在觀察性數據中,只有存活到計劃手術日期的患者才會接受手術,如果以上3大時間點在設計階段未對齊,則從入組至接受手術之前(即“永恒時間”)內死亡的患者將會被錯誤劃分至對照組,導致手術獲益被人為夸大[37]。
2.5 根據實際確定入組寬限期
設置入組寬限期時,其長短不應對最終結局產生影響,可通過設置不同寬限期的敏感性分析和“克隆-刪失加權法”來防止在寬限期內發生的事件被分配至各組的偏倚,避免寬限期的設置與零時刻產生沖突[26]。
2.6 合理設置隨訪時長
TTE中隨訪時長的設置除考慮結局指標自然病程和發生率以及預估樣本量外,還應考慮目標數據集的中位隨訪時間,以使設置合理。如現有數據不滿足有意義的隨訪時長,則需更換數據源。
2.7 準確確立結局指標
與RCT 一樣,應事先定義主要和次要結局指標以及對應測量方法。最好采用驗證措施評估結局指標準確性(如:在電子病歷數據中通過ICD編碼篩查加人工審核臨床癥狀及檢驗學指標多重確認“泌尿道感染”這一結局指標)。此外,由于現實中臨床醫師通常知曉個體干預措施,這可能影響其對結局指標的主觀判斷,因此應盡可能選擇客觀性較強的結局指標(如死亡等)[26]。
2.8 合理處置缺失變量
當納入排除標準中涉及的變量存在缺失時,如直接排除缺失變量個體進行分析可能產生偏倚,可在納入排除患者之前對完全隨機缺失或隨機缺失類型且缺失量較小(傳統認為缺失率上限應<20%)缺失變量進行多重插補以增加樣本量[39],并消除選擇偏倚[21, 40]。
2.9 統計方案并非TTE最關鍵要素
有觀點錯誤認為,通過TTE完成因果效應估計的關鍵在于運用高級統計學模型,但實際上TTE研究要點在于遵循設計臨床試驗的原則來衡量因果效應,統計學方法僅為研究設計的一部分。此外,研究仍需遵守因果推斷基本假設,如無干擾性、可交換性、正性和一致性等[12-14, 21]。
3 應用范圍
目前TTE框架最常應用于藥物流行病學領域,可持續監測獲批藥物的安全性和有效性[41-43]或探索藥物新適應證[44],尤其適用于諸如COVID-19等突發公共衛生事件[45-46]。Gupta等[47]使用危重COVID-19患者的觀察性數據來模擬目標試驗,發現入住ICU前2 d接受托珠單抗治療的患者院內死亡風險較低,隨后的一項大型RCT [48]證實了以上結論。除此之外,TTE還用于探究飲食干預或社會因素與健康結局的關聯[49-50],以及提高藥物靶標孟德爾隨機化研究質量[51]。另外,當研究旨在估計相對風險(率)而非絕對風險(率),并且有關治療或混雜因素的信息對于整個隊列不可用,但可為一小部分病例和對照所獲取時,TTE框架還可拓展至巢式病例對照設計,因后者可視作對潛在隊列的有效抽樣[52-53]。
相較于藥物、飲食或社會因素等干預,外科干預的依從性在分配時幾乎確定,故使用TTE框架評估單次外科干預因果效應的結果相對更穩健[25]。在這種情況下,TTE可大量擴充樣本以補充既往結果(如減肥手術與癌癥風險[54]),評估因倫理限制RCT 難以納入(如健康狀況更差、合并癥發生率更高的老年患者[37, 55-56])、預后較差(如胰腺癌患者[12])以及現實中難以招募的患者(如大量愿意在異地就醫接受陌生外科醫師手術干預的患者[14]、內鏡切除后切緣陰性同時接受額外手術的早期結直腸癌患者[57]),或暫缺RCT 證據的病種(如局限性高危前列腺癌手術或放療的選擇[58])。為評估文首所提及的老年早期肺癌患者行根治手術的獲益,Maringe等[37]基于TTE框架進行研究設計,使用英國國家癌癥登記處記錄的癌癥患者數據和二級護理管理記錄,納入診斷年齡70~89歲且一般情況良好的非小細胞肺癌Ⅰ期或Ⅱ期患者,通過符合方案集分析探究診斷后6個月內接受手術對患者1年生存期的影響。在進行因果推斷前,Maringe等[37]評估了因果假設的合理性,如正性(一般情況良好的非小細胞肺癌老年患者仍有非零概率接受或不接受手術)、一致性(早期非小細胞肺癌手術程序標準化高)和可交換性(由于采用克隆方法,兩組在基線時相同)等。此外,在理想假設下,進行手術的決定是完全隨機,或者基于與結局指標無關的患者特征作出的;但事實上,觀察性數據中大多數患者的手術干預決策是基于與結局指標生存相關的特征(如年齡、體能狀態和合并癥指數等),即混雜因素所作出的,因此Maringe等采用逆概率刪失加權法(inverse probability of censoring weighting)確保手術干預決策的隨機性[59]。研究結果顯示,即使考慮到手術等待時間,老年人群診斷后6個月內接受手術也可在第1年延長至13 d[95%CI(8,20)]的預期壽命,填補此類人群研究領域空白[37]。
4 應用案例
應用抗病毒藥物是治療COVID-19的主要措施之一。2022年2月,奈瑪特韋-利托那韋獲中國國家藥品監督管理局的應急附條件批準,成為COVID-19高危患者的標準抗病毒藥物之一。彼時該藥在國內外缺乏大型RCT 評估療效,且批準初期藥物可及的不確定性使患者是否接受奈瑪特韋-利托那韋治療基本成為隨機事件(即接受治療更多取決于是否有藥,而非臨床特征),而另一替代藥物阿茲夫定的有效性和安全性證據仍顯不足。為及時獲得有關奈瑪特韋-利托那韋療效的高質量證據,本團隊基于2022年12月1日—2023年1月19日四川省3家三甲醫院的住院患者信息以及四川省疾病預防控制中心數據庫的出院后全因死亡記錄和疫苗接種信息,通過TTE框架評估了阿茲夫定和奈瑪特韋-利托那韋在中國Omicron BA.5.2亞變種流行期間對中重癥COVID-19患者的療效[60]。
4.1 提出因果問題
在中重癥COVID-19成人患者中,如果所有患者接受為期5 d的奈瑪特韋-利托那韋或阿茲夫定治療,與未接受抗病毒治療患者相比,入院后30 d內全因死亡、開始有創機械通氣及其復合結局的平均風險是多少?
4.2 研究流程
(1)確定納入排除標準 與目標試驗相同(表1),但由于電子病歷中的時間評估和記錄未標準化,故納入入院前后1個日歷日內,而非24 h內首次出現新冠病毒核酸檢測陽性(以下簡稱“核酸陽性”)患者,并排除基線風險可能更高以至無機會口服藥物以及入組前30 d或入組后2 d內肝腎功能指標信息不全者。
(2)確定干預措施 由于該多中心隊列中無法獲得出院后口服藥物給藥的信息,故假設出院后的藥物管理與出院當天的藥物管理保持一致(表1)。
(3)干預措施分配 考慮急診入院并在急診已用藥的情況,根據在零時刻前1 d至零時刻結束時是否接受了阿茲夫定、奈瑪特韋-利托那韋或無抗病毒治療來分類患者,通過逆概率加權調整基線混雜因素來模擬隨機化。
(4)零時刻 由于入組時刻當日藥物醫囑信息可能不全,故每個參與者的零時刻設置為入組時刻次日結束時。對于入院后24 h內核酸陽性的患者,入組時刻為檢測時間;入院前24 h內核酸陽性的患者,入組時刻為入院時間。
(5)確定結局指標 主要結局指標包括全因死亡和有創機械通氣的單獨與復合結局;次要結局指標及安全性結局指標見表1。
(6)隨訪 研究從零時刻開始隨訪所有參與者,直至死亡或零時刻后30 d。
(7)因果對比 PP分析。
(8)統計學分析 通過逆概率加權調整基線混雜因素,使用加權Cox比例風險回歸估計風險比和95%CI,采用共享脆弱性Cox模型減少同一醫院內結果的內部同質性,使用治療權重生成調整后累積發病率。采用“克隆-刪失-加權”法完成PP分析。首先采用克隆方法,并對偏離指定干預或在零時刻后第5 天之前出院的參與者進行刪失處理。然后使用刪失加權法來處理因刪失引入的選擇偏倚,并調整年齡、性別、COVID-19的基線嚴重程度以及刪失前1 d的特征。
(9)亞組分析 年齡、性別、病情嚴重程度、疾病危險因素和發病到入院日期。
(10)敏感性分析 第一,消除永恒時間偏倚:分別將零時刻設置為入組時刻及入組時刻次日結束時并使用嵌套式TTE分析;第二,設置寬限期:評估在隨機分配后5 d內(說明書推薦用藥時期)開始使用阿茲夫定和奈瑪特韋-利托那韋的效果;第三,其他敏感性分析:將首次核酸陽性時間更改為“入院前7 d或入院后24 h內”或“入院前3 d或入院后24 h內”;排除在隨機分配前15 d內使用相互作用藥物的患者;刪除在隨機分配后的30 d或者死亡之前出院的患者。
4.3 研究結果
與無抗病毒治療相比,阿茲夫定[HR=0.47,95%CI(0.24,0.92)]和奈瑪特韋-利托那韋[HR=0.38,95%CI(0.18,0.81)]均可以減少中重度COVID-19成人患者入院后30 d內的全因死亡和有創機械通氣的復合結局以及獨立結局,前者還可降低心肺復蘇事件發生率,后者還可降低進展為重癥COVID-19的風險,亞組分析未發現交互作用效應,敏感性分析均證實了結果的穩健性。奈瑪特韋-利托那韋組的安全性結局指標發生率總體較阿茲夫定和對照組更高。
5 TTE框架局限性
盡管TTE可減少觀察性研究因研究設計缺陷引發的偏倚,但該框架并非解決所有因果問題的“靈丹妙藥”,其不可避免存在諸多局限(表2)。
(1)盡管TTE可改善觀察性研究設計,但框架本身并不能消除混雜[26]。由于采用觀察性真實世界數據,TTE研究仍可能存在未知混雜因素,并也會受測量偏倚、缺失數據等因素影響,可通過回溯因果假設、研究設計及數據來源,并使用敏感性分析和定量偏倚分析(quantitative bias analysis)進行檢驗[11, 21, 61]。
(2)觀察性的研究設計使得滿足正性假設上存在挑戰,因此無法模擬安慰劑對照,或者模擬患者存在禁忌證的用藥,也無法模擬盲法試驗[20]。
(3)TTE研究結論的穩健性依賴于數據來源及數據質量(諸如保險索賠數據等可能無法提供足夠的臨床信息以供矯正混雜因素),也依賴于做出的所有推斷因果的假設,因此需使用不同的假設分析作為敏感性分析以檢驗結論穩健性。
(4)TTE框架各要素的合理設計對研究者臨床經驗要求較高,譬如上述案例中干預措施和零時刻的選擇即分別考慮臨床實際中存在“急診入院且已用藥”或“入組當日藥物醫囑信息不全”的情況并做相應調整和敏感性分析,故完成高質量TTE研究有賴于跨學科團隊(研究者、數據收集者、流行病學家及臨床醫師)通體合作。
(5)由于暫缺適用于TTE研究的報告規范,部分TTE研究的框架各組分未正確設定,研究報告質量缺乏一致性[62],引發學界對TTE研究過程透明性和研究結果可重復性的擔憂[63-65]。
6 小結
在無法進行RCT 時,利用真實世界數據通過TTE框架估計因果效應已成為一種研究新思路。與RCT 類似的是,該框架將研究設計步驟與研究分析過程分離,有助于克服傳統觀察性研究因設計缺陷產生的偏倚,同時明確研究假設及研究過程,提高真實世界數據研究的臨床指導價值。但研究者需充分認識到TTE設計的局限性,避免在因果假設模糊、數據質量有限或框架要素設置不明的情況下盲目開展TTE研究,以免做出錯誤的因果推斷。
利益沖突:無。
作者貢獻:袁馳負責撰寫和修改論文;周祎靈負責設計和修改論文;曹雨滋、張豪杰和王依倩負責收集文獻相關資料;李舍予負責選題和指導。