引用本文: 郝潔, 彭慶龍, 叢山, 李姣, 孫海霞. 基于提示學習的醫學量表問題文本多分類研究. 中國循證醫學雜志, 2024, 24(1): 76-82. doi: 10.7507/1672-2531.202307139 復制
版權信息: ?四川大學華西醫院華西期刊社《中國循證醫學雜志》版權所有,未經授權不得轉載、改編
量表是服務于科學測量的一種工具[1],其突出功能是將抽象的概念轉化為可觀察的具體定量問題,便于評估對象理解與使用。在醫學領域,量表常被用于疾病篩查、診斷、康復評估等科學研究與醫療服務實踐活動中[2,3],如用于肺癌癥狀篩查的量表(M.D. Anderson symptom inventory-lung cancer,MDASI-LC)[4]。量表開發過程復雜[1],尋求和復用現存量表往往是用戶的優先選擇。在此過程中,用戶對量表的檢索需求不僅僅是整個量表文檔,還包括量表中所包含的測量概念,以及測量概念對應的測量問題條目等。目前醫學量表數據庫,如MDCalc[5],多以整個量表文檔為最小檢索單位,無法滿足對測量問題條目的語義檢索。測量概念及其對應的問題條目檢索主要由人工逐篇瀏覽,極大耗費了用戶的時間和精力。對不同測量對象和目標,量表的結構也有所不同,其中問題條目是量表的最小構成元素,若干問題條目組成一個領域,對應更高層次的抽象概念。因此,基于功能范疇和領域概念對量表中問題條目進行精準分類,有助于解決這一問題。
然而,目前尚未見到有關醫學量表問題條目分類研究的公開報道。現有醫學文本分類研究主要集中在粗粒度的科技論文、電子病歷,細粒度的疾病、藥物、基因等分類任務上[6-8]。此外,醫學量表問題條目文本字符往往較短,屬于短文本分類,而目前廣泛應用于短文本分類研究的深度學習模型[9,10],往往需要海量的數據驅動,才能達到預期的分類效果。但有關醫學量表的標注語料庫還未引起重視,現有醫學文本分類研究語料多以醫學科技論文、電子病歷、藥物說明書等為基礎構建而成[6]。基于此現狀,探索醫學量表問題條目精確分類,需人工標注醫學量表問題條目,構建語料庫。
考慮到人工成本問題,初步形成小規模語料集,在小樣本文本分類的框架下,結合簡單通用的文本數據增強(easy data augmentation,EDA)技術[11]和基于預訓練語言模型的提示學習(prompt learning)方法[12],可以在相對較低資源下實現醫學量表問題條目的精確分類。鑒于此,本文研究首先構建首個小規模醫學量表問題條目語料集,標注問題條目的功能范疇和領域概念;然后引入EDA數據增強方法,低成本滿足模型對于語料樣本量的標注需求;最后應用提示學習的方法,添加特定提示模板,在較少輸入樣本下保持較優的模型性能,實現醫學量表問題條目的精確分類。本文研究進一步拓展了醫學文本分類研究范圍,為醫學量表問題文本分類研究提供了第一手的研究資料;同時,本文所展示的研究思路也可為后續醫學量表分類研究起到一定的借鑒作用。
1 相關研究基礎
文本分類研究是指實現計算機對載有信息的文本按照預設的分類體系自動映射的研究。根據預設的類別不同,文本分類可以分為二分類和多分類,多分類任務可以通過多個二分類模型完成。根據自然語言處理技術的發展,文本分類研究經歷了4種范式[12]。第一范式是指未引入神經網絡之前的傳統機器學習方法,需要繁雜的人工特征工程,極易導致文本特征數據維度爆炸、模型泛化能力差等問題。引入神經網絡標志著文本分類研究進入第二范式。當前文本多分類研究的主流框架是以神經網絡為代表的深度學習方法,即第二范式,能夠自動學習文本與分類任務相關聯的特征,無需人工特征工程的干預,分類效果普遍優于傳統的機器學習方法[13]。Facebook基于淺層神經網絡開發FastText[14],能夠自動計算高維度詞向量,處理速度快。Yoon Kim于2014年首次實現了應用卷積神經網絡(convolutional neural network,CNN)進行句子分類的TextCNN模型[15]。Liu等[16]基于循環神經網絡(recurrent neural network,RNN)的3種不同共享信息機制提出了多任務學習下的文本分類TextRNN模型。對于短文本多分類,結構相對簡單的FastText和TextCNN通常作為基線模型。
第二范式雖然簡化了文本表示工作,但需要大量的標注語料訓練神經網絡模型。為了解決標注成本高的問題,通過大規模無標注語料學習通用語言表示的預訓練語言模型被提出,標志著第三范式的開始。第三范式即針對特定的下游任務,只需用相對較少的標注語料微調已有的預訓練語言模型,不需要大規模的特定語料標注。其中具有代表性的預訓練語言模型是2018年谷歌提出的BERT(bidirectional encoder representation from transformers)模型。BERT模型經超大規模語料訓練得到,本身已具有較優的文本表示能力,兼顧了上下文、同義詞、一詞多義等情況[17],極大提升了短文本語義方面的理解。對于醫學短文本分類任務,可通過微調現有BERT模型,解決因隱私安全等因素導致的語料相對較少問題[18],并提高分類精度[10,19,20]。
隨著第三范式的發展,預訓練語言模型的參數規模在急劇增加,導致微調階段所需的標注語料更多。對于少樣本學習,使用第三范式容易出現模型訓練過擬合或不穩定等問題。提示學習是最近興起的第四范式,即預訓練、提示再預測。相比于第三范式需根據下游任務微調預訓練語言模型,提示學習能夠結合模型自身在預訓練階段學習到的先驗知識和針對下游任務的模板提示進行學習,充分挖掘模型本身能力,減少訓練所需的下游數據,極大提升少樣本學習的效率[12]。HealthPrompt在沒有任何訓練數據的前提下,通過添加提示模板,依然獲得了對電子病歷文本的較優分類效果[21]。
對于少樣本學習,除了在建模方法上采用前沿范式,還可以在文本預處理階段使用文本數據增強技術,通過利用有限的標注語料,擴增語料訓練模型,有效解決因數據稀缺導致的訓練模型過擬合現象,提高模型泛化能力[22]。文本數據增強技術一般分為有監督、半監督、無監督方法。針對語料規模較小,普遍應用有監督的數據增強方法,一種是回譯,另一種是EDA。回譯通過將原有語料翻譯為其他語言再翻譯回原語言的方法,增加語料[23]。但由于語言本身邏輯順序等差異,通過回譯產生的新語料與原語料差別較大,一般用于機器翻譯任務。EDA即基于原有的標注語料,通過同義詞替換、隨機刪除、隨機插入、隨機交換4種方式產生和原有語料類似的新語料,能夠在較少程度改變文本的原義的同時,實現對原語料集的快速擴充[11,24]。有研究表明,原始語料越少,EDA的提升效果越顯著[11]。
2 研究方法
2.1 研究流程
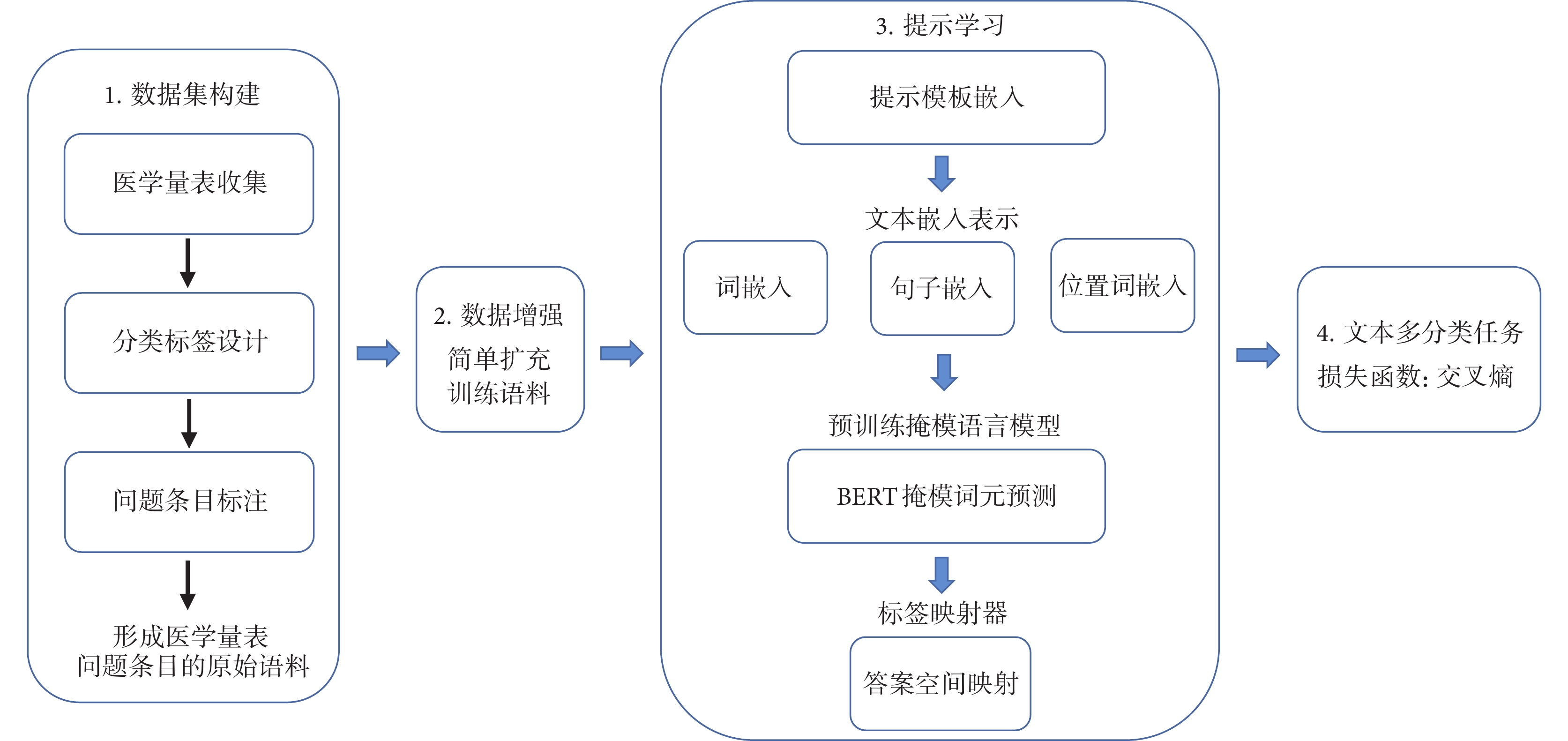
本研究流程如圖1所示。針對目前有關醫學量表的研究語料缺乏現狀,首先構建一個人工標注的醫學量表問題條目語料集。其中,根據收集到的量表設計問題條目分類體系,進行人工標注,實現對問題條目的語料集標注。然后,在數據預處理階段,對構建的原始語料集應用EDA技術,快速實現對訓練所需語料的擴充。最后依據提示學習方法框架,構造針對量表問題文本分類任務的提示模板,將原始語料轉換成模板格式輸入預訓練掩模語言模型(pre-trained masked language model,Pre-trained MLM)如BERT,通過提示模板讓模型縮小預測搜索空間進行完形填空,再將填空的詞語映射到分類標簽,完成問題條目的文本多分類任務。
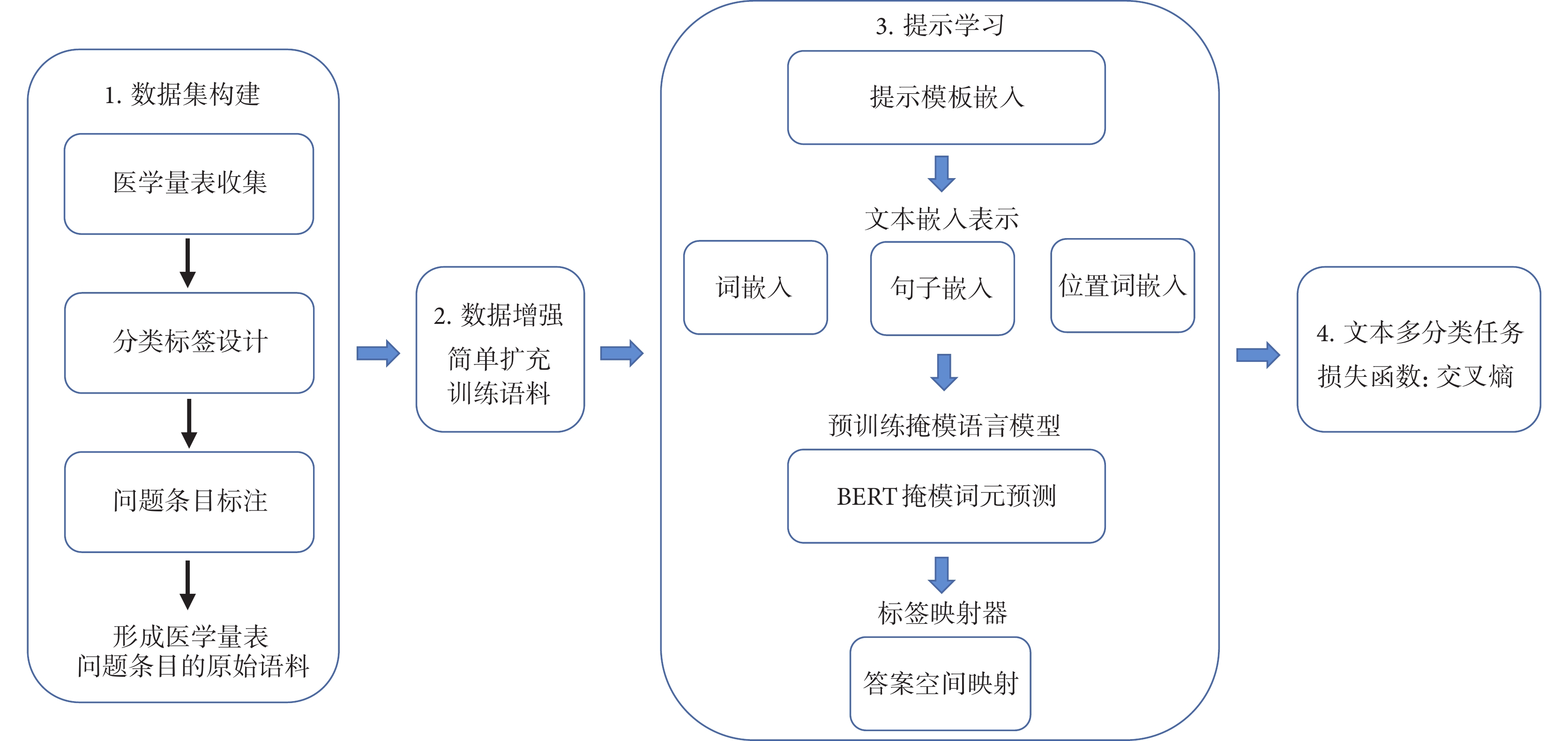 圖1
研究流程圖
圖1
研究流程圖
2.2 數據集構建
2.2.1 肺癌臨床評估量表問題條目采集
以肺癌疾病為例,收集用于肺癌篩查、診斷和康復類臨床評估量表21份,包括MDASI-LC、肺癌治療功能評估量表(functional assessment of cancer therapy-lung,FACT-L)等。臨床量表在不同應用場景下會被改編成不同版本,如問題條目數量視角下的完整版和簡版。研究剔除因版本所致的重復量表后,最終獲得17份臨床評估量表。進一步抽取量表題目和量表中包含的文本類問題項目,形成原始語料。
2.2.2 分類標簽設計:“功能-領域”
功能,代表醫學量表的測量目標;領域,代表醫學量表中包括的測量概念。對醫學量表的每個問題條目進行“功能-領域”組合標簽分類標注,有助于同時從測量目標和測量概念發現和復用現有問題條目。
通常情況下,量表的名稱就指明了測量目標,如MDASI-LC的測量目標是對癥狀痛苦的篩查,其量表全稱中有“symptom”這一關鍵詞。領域通常表現為量表中的測量模塊;一個測量模塊往往包括多個問題條目。如FACT-L的測量領域包括軀體狀況、社會/家庭狀況、情感狀況等6個高層級概念,共設置38個問題條目。通過對收集的17份量表的測量目標及測量模塊分析,提煉功能維度標簽4個:生活質量評估(quality of life)、癥狀痛苦評定(symptom)、患病風險評估(risk assessment)、預后預測(prognostic index);領域維度標簽5個:軀體狀況(physical well-being)、心理狀況(psychological well-being)、社會狀況(social well-being)、健康風險因素(health risks)、臨床檢查指標(clinical examination)。
2.2.3 問題條目標注
本研究通過以下步驟對17份量表中的問題條目進行基于“功能-領域”的分類標注:首先,剔除重復的問題條目;其次,由5名標注人員(其中3人具有醫學信息學背景、2人具有臨床醫學背景)背靠背標注全部問題條目,每一個問題條目需要分別標注出功能和領域;然后,對標注結果進行一致性分析,3人及以上標注一致即認為該問題條目標注一致;最后,對不一致的標注結果,5人逐條討論,直至達成一致。
2.3 數據增強
本研究采用普遍使用的EDA數據增強工具包TextAttack中EmbeddingAugmenter方法[24],實現對原始數據集中劃分為訓練集的語料各類別一倍的擴充。EmbeddingAugmenter方法是對過濾掉停用詞后的單詞進行增強,通過確保替換詞和原單詞的余弦相似度至少為0.8作為約束條件,在詞向量空間中用鄰近詞替換單詞的方式來增強文本。
2.4 提示學習方法
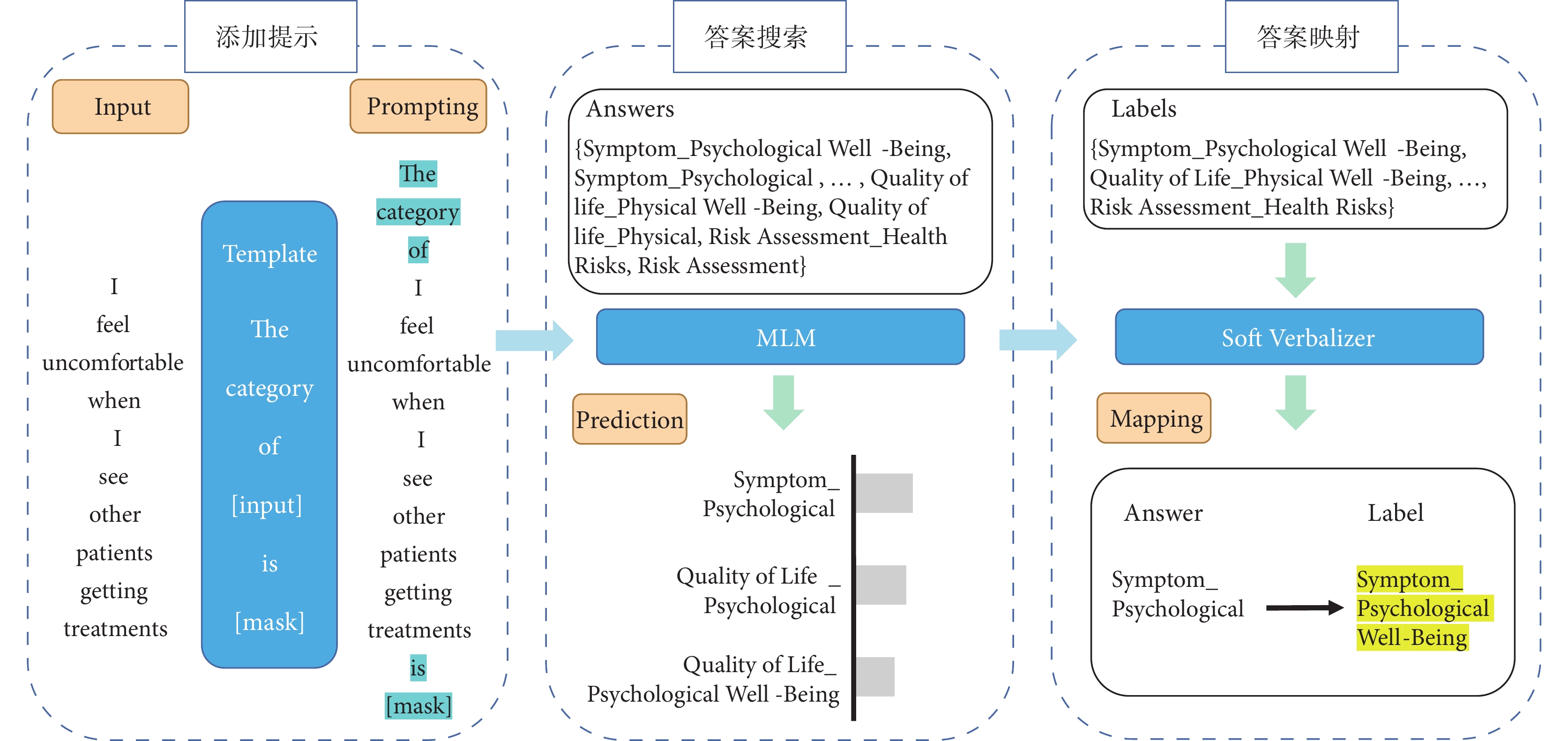
本研究應用提示學習方法框架[25],分3個步驟進行訓練與預測:① 造提示模板,添加模板輸入;② 造答案空間,搜索答案、預測概率;③ 預測答案映射到組合標簽。提示學習訓練流程見圖2。
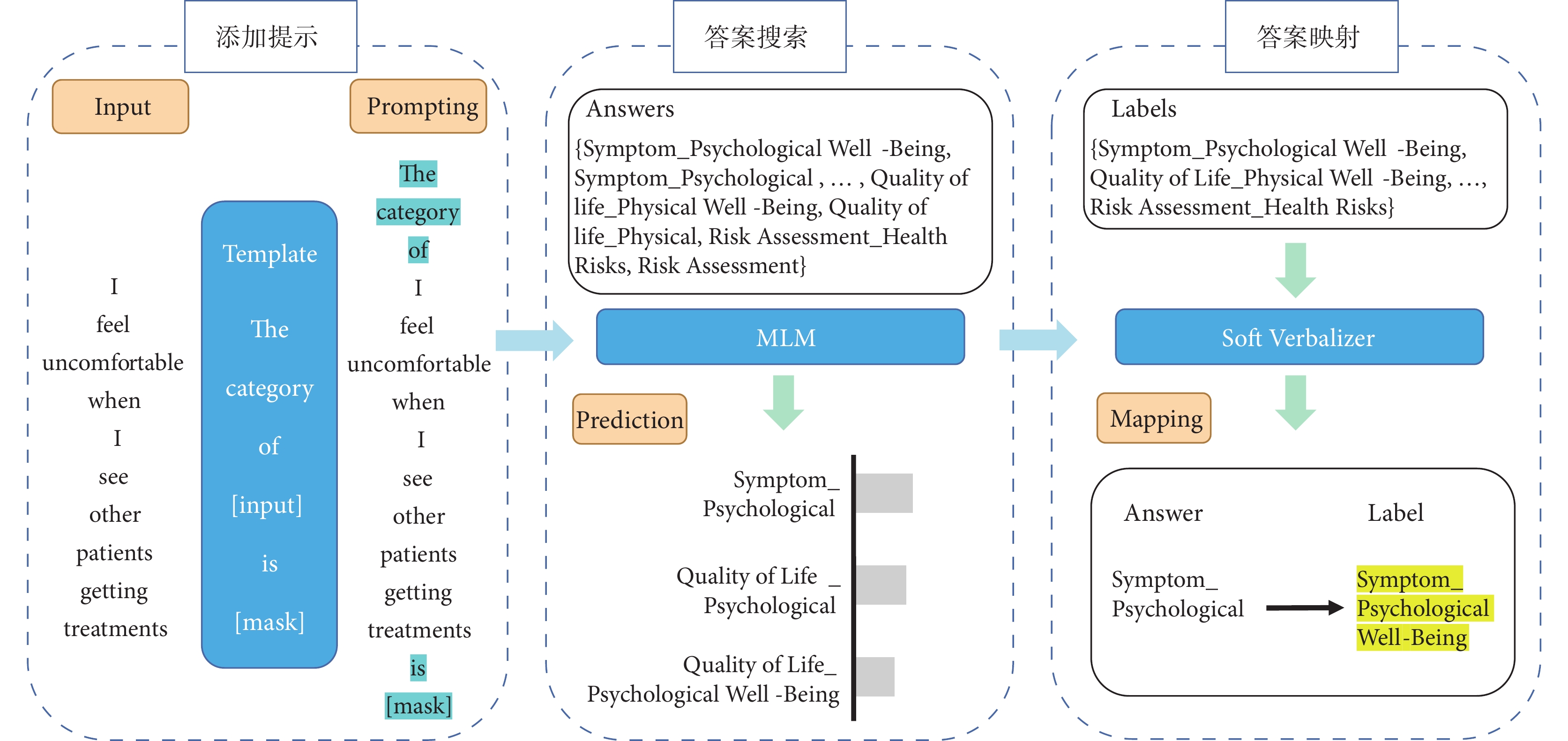 圖2
提示學習訓練流程
圖2
提示學習訓練流程
首先,構建多分類任務的提示模板,將模板添加到原始問題條目輸入。本研究定義模板為:The category of <問題條目輸入> is <Mask>,其中<Mask>為模型預測的輸出,即組合標簽。例如原始問題條目為 “I feel uncomfortable when I see other patients getting treatments”;添加定義的提示模板后,模型的輸入轉換為
“I feel uncomfortable when I see other patients getting treatments”;添加定義的提示模板后,模型的輸入轉換為 “The category of <I feel uncomfortable when I see other patients getting treatments> is <Mask>”。
“The category of <I feel uncomfortable when I see other patients getting treatments> is <Mask>”。
然后,依據組合標簽詞構建答案空間中對應的答案標簽。將 輸入MLM中,模型在答案空間Z中通過計算P(<Mask>
輸入MLM中,模型在答案空間Z中通過計算P(<Mask> )搜索答案標簽[25]。如果答案標簽A的概率大于答案標簽B的概率,則模型輸出答案標簽A作為<Mask>的值,即預測答案
)搜索答案標簽[25]。如果答案標簽A的概率大于答案標簽B的概率,則模型輸出答案標簽A作為<Mask>的值,即預測答案 。
。
最后,標簽映射器(verbalizer)將上一步模型搜索得到的答案 與原始問題條目的組合標簽分類進行映射,得到預測的組合標簽。
與原始問題條目的組合標簽分類進行映射,得到預測的組合標簽。
2.5 分類任務
本研究屬于多分類任務,因此選用激活函數LogSoftmax和對應的損失函數交叉熵(CrossEntropy)。與傳統BERT微調不同的是,基于提示學習的分類模型并不是將獲取到的句向量輸入至LogSoftmax層,而是將搜索答案空間得到的預測的<Mask>詞向量,輸入到verbalizer中進行LogSoftmax[25],其公式為 ,其中
,其中 。
。
得到詞向量的概率分布映射為標簽的概率分布,最后對預測的標簽與真實的標簽計算損失,其計算公式為 ,其中
,其中 表示一個樣本的非LogSoftmax預測輸出,
表示一個樣本的非LogSoftmax預測輸出, 表示該樣本的標簽,
表示該樣本的標簽, 代表標簽數量。
代表標簽數量。
2.6 實驗設置
首先,將原始問題條目,按照普遍使用的8∶2比例[26]隨機分層劃分為訓練集和測試集。其次,對訓練集中的問題條目進行數據增強,用于模型訓練。
提示學習方法采用Pytorch深度學習框架,在NVIDIA GeForce 3090ti顯卡上進行計算,具體環境配置如表1。在同一隨機劃分的訓練集上,通過多次對參數進行經驗微調,選取效果最好的一組參數作為正式使用的參數,最終參數設定見表2。
研究選取了無預訓練模型加載的傳統短文本分類模型FastText、TextCNN、TextRNN及加載預訓練模型bert-base-uncased的BERT、融合對抗學習的GAN-BERT[27]模型,與引入提示學習的方法進行對比實驗。其中TextRNN、FastText、TextCNN的參數設定為batch_size=64,num_epochs=50,learning_rate=0.008,decay_rate=0.95。為了保證實驗結果的魯棒性,每個模型重復訓練5次,模型性能取均值。
2.7 評價指標
研究選擇常用于多分類任務的準確率(accuracy,ACC)和Macro-F1分數作為評價指標。準確率即所有預測正確的正類和負類占總體的比重,其具體計算公式為 ,其中TP代表預測正確的正類樣本數量,TN代表預測正確的負類樣本數量,P代表正類樣本數量,N代表負類樣本數量。
,其中TP代表預測正確的正類樣本數量,TN代表預測正確的負類樣本數量,P代表正類樣本數量,N代表負類樣本數量。
Macro-F1分數是對每一分類進行F1分數(F1-score)的計算再求均值,由于其對每一分類給予相同的權重評估,不易受數據不平衡的影響,其具體計算公式為 ,其中F1-score根據精確率(precision)和召回率(recall)計算,即
,其中F1-score根據精確率(precision)和召回率(recall)計算,即 ,
, ,
, ,FN代表預測錯誤的負類樣本數量,FP代表預測錯誤的正類樣本數量。
,FN代表預測錯誤的負類樣本數量,FP代表預測錯誤的正類樣本數量。
3 結果
3.1 數據集統計
研究供納入347個問題條目進行標注,人工標注一致性為96.3%。最終形成的問題條目語料共涉及9種組合分類標簽。問題條目及分類標注結果示例見表3。
對原始訓練集(275條)問題條目進行數據增強后,獲得550條問題條目。表4列出了應用數據增強前后的訓練語料分類標簽頻數對比。從表4中的原始頻數分別可以看出,量表問題條目的分類是極不均衡的,最大的分類標簽組合是“quality of life_physical well-being”和“quality of life_social well-being”,頻數均為80,即均包含80個問題條目,而“symptom_psychological well-being”標簽組合頻數僅包含4個問題條目。
3.2 評價結果
表5列出了提示學習方法和5種基線模型在醫學量表問題條目數據分類任務中的平均準確率和平均Macro-F1分數。評價結果顯示,提示學習方法的分類效果顯著優于所有基線模型,達到了準確率0.9083±0.0222(均值±標準差)和Macro-F1分數0.8016±0.0565。基線模型中,沒有加載預訓練語言模型的TextRNN、FastText、TextCNN分類效果較差,加載了預訓練語言模型的BERT分類效果有了顯著提升,引入了對抗學習的GAN-BERT略優于微調的BERT模型,其準確率和Macro-F1分數分別達到了0.8453±0.0102和0.7632±0.0121。提示學習方法的分類準確率比最優的基線模型GAN-BERT提高了約6%,Macro-F1分數提高了約4%,驗證了引入提示學習,確實可以大幅提升小樣本、短文本語料的分類效果。
對于數據增強后的數據集,提示學習方法和5種基線模型的分類效果均比在原始數據集上訓練提升了約2%。通過數據增強后的訓練語料,提示學習方法最終可達到0.9311±0.0125的準確率和Macro-F1分數為0.9012±0.0158。由此可見,采用簡單數據增強的方法擴充語料,可以在一定程度上提升模型的預測準確性。
在對提示學習方法中錯誤預測的問題條目進一步分析中,我們發現其中大部分錯誤預測的問題條目來自于分類標注過程中存在爭議的問題條目。例如,“I have difficulty with transportation to and from my medical appointments and/or other places”,模型預測的領域層標簽屬于社會狀況,實際標注為軀體狀況。然而,該條目的領域層標簽標注是經由討論確定。在第一輪的獨立標注中,其中2人預標注為社會狀況,其他3人分別預標注為軀體狀況、心理狀況、健康風險因素。
4 討論
分類是實現文本數據資源知識組織、檢索、發現與問答等智能化知識管理與知識服務的基礎任務。為促進醫學量表資源的智能化細粒度知識管理與服務,本文針對醫學量表中的問題條目文本進行了自動多分類研究。
基于醫學量表問題條目分類研究語料缺乏現狀,本文首先構建了一個支持醫學量表問題條目文本多分類研究的小樣本標注數據集和標簽體系。小樣本標注數據集可直接或經擴展后用于后續醫學量表問題條目分類研究。與一般醫學文本分類標簽命名只單一考慮語義(如“癥狀”類標簽)或語用(如“生活質量評估”類標簽)相比,本研究中的“功能-領域”這一組合分類標簽命名同時考慮了醫學量表問題條目文本的語用和語義特征。“功能”部分側重于體現語用特征,回答為什么要測量;“領域”部分側重于體現語義特征,回答為了實現這樣的目標需要測量什么。因此,“功能-領域”組合分類標簽有助于從宏觀的測量目標和微觀的測量對象維度揭示、組織和發現現存醫學量表問題條目。此外,研究中的“功能”和“領域”兩個維度的分類標簽系獨立構建而成,能夠方便后續研究分別從“功能”和“領域”進行標簽命名體系擴展或刪減;即便是基于本研究已構建的標簽,還可組配出更多的分類標簽,用于標注更多的語料。
本文提出了一種基于提示學習的量表問題條目文本多分類方法。該方法通過簡單增加自定義提示模板,加強BERT模型嵌入表示與組合標簽的關聯性,將多分類任務轉化為較為容易的完形填空任務,從而較好地完成了少樣本語料情況下的醫學量表問題條目多分類任務。在自建的肺癌臨床評估量表問題條目語料上,其分類效果顯著優于所有基線模型,再結合EDA技術,可以進一步提高分類精度。研究也發現,部分醫學量表問題在語言表述上偏向于大眾化、口語化,在使用情境上可用于多個測量目標與概念對象,一定程度上影響著該方法的分類效果。
綜上所述,未來醫學量表問題條目分類研究工作可圍繞如下方面展開:① 構建外部數據集,進一步驗證提示學習方法對于醫學量表問題條目的分類有效性;② 從預訓練模型選擇出發,研究不同預訓練模型對不同功能量表問題文本多分類任務的適用性;③ 開展基于小樣本的醫學量表問題文本多標簽分類研究;④ 探究應用融合外部醫學知識的掩模機制[28,29]來優化量表問題文本分類效果。
量表是服務于科學測量的一種工具[1],其突出功能是將抽象的概念轉化為可觀察的具體定量問題,便于評估對象理解與使用。在醫學領域,量表常被用于疾病篩查、診斷、康復評估等科學研究與醫療服務實踐活動中[2,3],如用于肺癌癥狀篩查的量表(M.D. Anderson symptom inventory-lung cancer,MDASI-LC)[4]。量表開發過程復雜[1],尋求和復用現存量表往往是用戶的優先選擇。在此過程中,用戶對量表的檢索需求不僅僅是整個量表文檔,還包括量表中所包含的測量概念,以及測量概念對應的測量問題條目等。目前醫學量表數據庫,如MDCalc[5],多以整個量表文檔為最小檢索單位,無法滿足對測量問題條目的語義檢索。測量概念及其對應的問題條目檢索主要由人工逐篇瀏覽,極大耗費了用戶的時間和精力。對不同測量對象和目標,量表的結構也有所不同,其中問題條目是量表的最小構成元素,若干問題條目組成一個領域,對應更高層次的抽象概念。因此,基于功能范疇和領域概念對量表中問題條目進行精準分類,有助于解決這一問題。
然而,目前尚未見到有關醫學量表問題條目分類研究的公開報道。現有醫學文本分類研究主要集中在粗粒度的科技論文、電子病歷,細粒度的疾病、藥物、基因等分類任務上[6-8]。此外,醫學量表問題條目文本字符往往較短,屬于短文本分類,而目前廣泛應用于短文本分類研究的深度學習模型[9,10],往往需要海量的數據驅動,才能達到預期的分類效果。但有關醫學量表的標注語料庫還未引起重視,現有醫學文本分類研究語料多以醫學科技論文、電子病歷、藥物說明書等為基礎構建而成[6]。基于此現狀,探索醫學量表問題條目精確分類,需人工標注醫學量表問題條目,構建語料庫。
考慮到人工成本問題,初步形成小規模語料集,在小樣本文本分類的框架下,結合簡單通用的文本數據增強(easy data augmentation,EDA)技術[11]和基于預訓練語言模型的提示學習(prompt learning)方法[12],可以在相對較低資源下實現醫學量表問題條目的精確分類。鑒于此,本文研究首先構建首個小規模醫學量表問題條目語料集,標注問題條目的功能范疇和領域概念;然后引入EDA數據增強方法,低成本滿足模型對于語料樣本量的標注需求;最后應用提示學習的方法,添加特定提示模板,在較少輸入樣本下保持較優的模型性能,實現醫學量表問題條目的精確分類。本文研究進一步拓展了醫學文本分類研究范圍,為醫學量表問題文本分類研究提供了第一手的研究資料;同時,本文所展示的研究思路也可為后續醫學量表分類研究起到一定的借鑒作用。
1 相關研究基礎
文本分類研究是指實現計算機對載有信息的文本按照預設的分類體系自動映射的研究。根據預設的類別不同,文本分類可以分為二分類和多分類,多分類任務可以通過多個二分類模型完成。根據自然語言處理技術的發展,文本分類研究經歷了4種范式[12]。第一范式是指未引入神經網絡之前的傳統機器學習方法,需要繁雜的人工特征工程,極易導致文本特征數據維度爆炸、模型泛化能力差等問題。引入神經網絡標志著文本分類研究進入第二范式。當前文本多分類研究的主流框架是以神經網絡為代表的深度學習方法,即第二范式,能夠自動學習文本與分類任務相關聯的特征,無需人工特征工程的干預,分類效果普遍優于傳統的機器學習方法[13]。Facebook基于淺層神經網絡開發FastText[14],能夠自動計算高維度詞向量,處理速度快。Yoon Kim于2014年首次實現了應用卷積神經網絡(convolutional neural network,CNN)進行句子分類的TextCNN模型[15]。Liu等[16]基于循環神經網絡(recurrent neural network,RNN)的3種不同共享信息機制提出了多任務學習下的文本分類TextRNN模型。對于短文本多分類,結構相對簡單的FastText和TextCNN通常作為基線模型。
第二范式雖然簡化了文本表示工作,但需要大量的標注語料訓練神經網絡模型。為了解決標注成本高的問題,通過大規模無標注語料學習通用語言表示的預訓練語言模型被提出,標志著第三范式的開始。第三范式即針對特定的下游任務,只需用相對較少的標注語料微調已有的預訓練語言模型,不需要大規模的特定語料標注。其中具有代表性的預訓練語言模型是2018年谷歌提出的BERT(bidirectional encoder representation from transformers)模型。BERT模型經超大規模語料訓練得到,本身已具有較優的文本表示能力,兼顧了上下文、同義詞、一詞多義等情況[17],極大提升了短文本語義方面的理解。對于醫學短文本分類任務,可通過微調現有BERT模型,解決因隱私安全等因素導致的語料相對較少問題[18],并提高分類精度[10,19,20]。
隨著第三范式的發展,預訓練語言模型的參數規模在急劇增加,導致微調階段所需的標注語料更多。對于少樣本學習,使用第三范式容易出現模型訓練過擬合或不穩定等問題。提示學習是最近興起的第四范式,即預訓練、提示再預測。相比于第三范式需根據下游任務微調預訓練語言模型,提示學習能夠結合模型自身在預訓練階段學習到的先驗知識和針對下游任務的模板提示進行學習,充分挖掘模型本身能力,減少訓練所需的下游數據,極大提升少樣本學習的效率[12]。HealthPrompt在沒有任何訓練數據的前提下,通過添加提示模板,依然獲得了對電子病歷文本的較優分類效果[21]。
對于少樣本學習,除了在建模方法上采用前沿范式,還可以在文本預處理階段使用文本數據增強技術,通過利用有限的標注語料,擴增語料訓練模型,有效解決因數據稀缺導致的訓練模型過擬合現象,提高模型泛化能力[22]。文本數據增強技術一般分為有監督、半監督、無監督方法。針對語料規模較小,普遍應用有監督的數據增強方法,一種是回譯,另一種是EDA。回譯通過將原有語料翻譯為其他語言再翻譯回原語言的方法,增加語料[23]。但由于語言本身邏輯順序等差異,通過回譯產生的新語料與原語料差別較大,一般用于機器翻譯任務。EDA即基于原有的標注語料,通過同義詞替換、隨機刪除、隨機插入、隨機交換4種方式產生和原有語料類似的新語料,能夠在較少程度改變文本的原義的同時,實現對原語料集的快速擴充[11,24]。有研究表明,原始語料越少,EDA的提升效果越顯著[11]。
2 研究方法
2.1 研究流程
本研究流程如圖1所示。針對目前有關醫學量表的研究語料缺乏現狀,首先構建一個人工標注的醫學量表問題條目語料集。其中,根據收集到的量表設計問題條目分類體系,進行人工標注,實現對問題條目的語料集標注。然后,在數據預處理階段,對構建的原始語料集應用EDA技術,快速實現對訓練所需語料的擴充。最后依據提示學習方法框架,構造針對量表問題文本分類任務的提示模板,將原始語料轉換成模板格式輸入預訓練掩模語言模型(pre-trained masked language model,Pre-trained MLM)如BERT,通過提示模板讓模型縮小預測搜索空間進行完形填空,再將填空的詞語映射到分類標簽,完成問題條目的文本多分類任務。
圖1
研究流程圖
2.2 數據集構建
2.2.1 肺癌臨床評估量表問題條目采集
以肺癌疾病為例,收集用于肺癌篩查、診斷和康復類臨床評估量表21份,包括MDASI-LC、肺癌治療功能評估量表(functional assessment of cancer therapy-lung,FACT-L)等。臨床量表在不同應用場景下會被改編成不同版本,如問題條目數量視角下的完整版和簡版。研究剔除因版本所致的重復量表后,最終獲得17份臨床評估量表。進一步抽取量表題目和量表中包含的文本類問題項目,形成原始語料。
2.2.2 分類標簽設計:“功能-領域”
功能,代表醫學量表的測量目標;領域,代表醫學量表中包括的測量概念。對醫學量表的每個問題條目進行“功能-領域”組合標簽分類標注,有助于同時從測量目標和測量概念發現和復用現有問題條目。
通常情況下,量表的名稱就指明了測量目標,如MDASI-LC的測量目標是對癥狀痛苦的篩查,其量表全稱中有“symptom”這一關鍵詞。領域通常表現為量表中的測量模塊;一個測量模塊往往包括多個問題條目。如FACT-L的測量領域包括軀體狀況、社會/家庭狀況、情感狀況等6個高層級概念,共設置38個問題條目。通過對收集的17份量表的測量目標及測量模塊分析,提煉功能維度標簽4個:生活質量評估(quality of life)、癥狀痛苦評定(symptom)、患病風險評估(risk assessment)、預后預測(prognostic index);領域維度標簽5個:軀體狀況(physical well-being)、心理狀況(psychological well-being)、社會狀況(social well-being)、健康風險因素(health risks)、臨床檢查指標(clinical examination)。
2.2.3 問題條目標注
本研究通過以下步驟對17份量表中的問題條目進行基于“功能-領域”的分類標注:首先,剔除重復的問題條目;其次,由5名標注人員(其中3人具有醫學信息學背景、2人具有臨床醫學背景)背靠背標注全部問題條目,每一個問題條目需要分別標注出功能和領域;然后,對標注結果進行一致性分析,3人及以上標注一致即認為該問題條目標注一致;最后,對不一致的標注結果,5人逐條討論,直至達成一致。
2.3 數據增強
本研究采用普遍使用的EDA數據增強工具包TextAttack中EmbeddingAugmenter方法[24],實現對原始數據集中劃分為訓練集的語料各類別一倍的擴充。EmbeddingAugmenter方法是對過濾掉停用詞后的單詞進行增強,通過確保替換詞和原單詞的余弦相似度至少為0.8作為約束條件,在詞向量空間中用鄰近詞替換單詞的方式來增強文本。
2.4 提示學習方法
本研究應用提示學習方法框架[25],分3個步驟進行訓練與預測:① 造提示模板,添加模板輸入;② 造答案空間,搜索答案、預測概率;③ 預測答案映射到組合標簽。提示學習訓練流程見圖2。
圖2
提示學習訓練流程
首先,構建多分類任務的提示模板,將模板添加到原始問題條目輸入。本研究定義模板為:The category of <問題條目輸入> is <Mask>,其中<Mask>為模型預測的輸出,即組合標簽。例如原始問題條目為“I feel uncomfortable when I see other patients getting treatments”;添加定義的提示模板后,模型的輸入轉換為“The category of <I feel uncomfortable when I see other patients getting treatments> is <Mask>”。
然后,依據組合標簽詞構建答案空間中對應的答案標簽。將輸入MLM中,模型在答案空間Z中通過計算P(<Mask>)搜索答案標簽[25]。如果答案標簽A的概率大于答案標簽B的概率,則模型輸出答案標簽A作為<Mask>的值,即預測答案。
最后,標簽映射器(verbalizer)將上一步模型搜索得到的答案與原始問題條目的組合標簽分類進行映射,得到預測的組合標簽。
2.5 分類任務
本研究屬于多分類任務,因此選用激活函數LogSoftmax和對應的損失函數交叉熵(CrossEntropy)。與傳統BERT微調不同的是,基于提示學習的分類模型并不是將獲取到的句向量輸入至LogSoftmax層,而是將搜索答案空間得到的預測的<Mask>詞向量,輸入到verbalizer中進行LogSoftmax[25],其公式為,其中。
得到詞向量的概率分布映射為標簽的概率分布,最后對預測的標簽與真實的標簽計算損失,其計算公式為,其中表示一個樣本的非LogSoftmax預測輸出,表示該樣本的標簽,代表標簽數量。
2.6 實驗設置
首先,將原始問題條目,按照普遍使用的8∶2比例[26]隨機分層劃分為訓練集和測試集。其次,對訓練集中的問題條目進行數據增強,用于模型訓練。
提示學習方法采用Pytorch深度學習框架,在NVIDIA GeForce 3090ti顯卡上進行計算,具體環境配置如表1。在同一隨機劃分的訓練集上,通過多次對參數進行經驗微調,選取效果最好的一組參數作為正式使用的參數,最終參數設定見表2。
研究選取了無預訓練模型加載的傳統短文本分類模型FastText、TextCNN、TextRNN及加載預訓練模型bert-base-uncased的BERT、融合對抗學習的GAN-BERT[27]模型,與引入提示學習的方法進行對比實驗。其中TextRNN、FastText、TextCNN的參數設定為batch_size=64,num_epochs=50,learning_rate=0.008,decay_rate=0.95。為了保證實驗結果的魯棒性,每個模型重復訓練5次,模型性能取均值。
2.7 評價指標
研究選擇常用于多分類任務的準確率(accuracy,ACC)和Macro-F1分數作為評價指標。準確率即所有預測正確的正類和負類占總體的比重,其具體計算公式為,其中TP代表預測正確的正類樣本數量,TN代表預測正確的負類樣本數量,P代表正類樣本數量,N代表負類樣本數量。
Macro-F1分數是對每一分類進行F1分數(F1-score)的計算再求均值,由于其對每一分類給予相同的權重評估,不易受數據不平衡的影響,其具體計算公式為,其中F1-score根據精確率(precision)和召回率(recall)計算,即,,,FN代表預測錯誤的負類樣本數量,FP代表預測錯誤的正類樣本數量。
3 結果
3.1 數據集統計
研究供納入347個問題條目進行標注,人工標注一致性為96.3%。最終形成的問題條目語料共涉及9種組合分類標簽。問題條目及分類標注結果示例見表3。
對原始訓練集(275條)問題條目進行數據增強后,獲得550條問題條目。表4列出了應用數據增強前后的訓練語料分類標簽頻數對比。從表4中的原始頻數分別可以看出,量表問題條目的分類是極不均衡的,最大的分類標簽組合是“quality of life_physical well-being”和“quality of life_social well-being”,頻數均為80,即均包含80個問題條目,而“symptom_psychological well-being”標簽組合頻數僅包含4個問題條目。
3.2 評價結果
表5列出了提示學習方法和5種基線模型在醫學量表問題條目數據分類任務中的平均準確率和平均Macro-F1分數。評價結果顯示,提示學習方法的分類效果顯著優于所有基線模型,達到了準確率0.9083±0.0222(均值±標準差)和Macro-F1分數0.8016±0.0565。基線模型中,沒有加載預訓練語言模型的TextRNN、FastText、TextCNN分類效果較差,加載了預訓練語言模型的BERT分類效果有了顯著提升,引入了對抗學習的GAN-BERT略優于微調的BERT模型,其準確率和Macro-F1分數分別達到了0.8453±0.0102和0.7632±0.0121。提示學習方法的分類準確率比最優的基線模型GAN-BERT提高了約6%,Macro-F1分數提高了約4%,驗證了引入提示學習,確實可以大幅提升小樣本、短文本語料的分類效果。
對于數據增強后的數據集,提示學習方法和5種基線模型的分類效果均比在原始數據集上訓練提升了約2%。通過數據增強后的訓練語料,提示學習方法最終可達到0.9311±0.0125的準確率和Macro-F1分數為0.9012±0.0158。由此可見,采用簡單數據增強的方法擴充語料,可以在一定程度上提升模型的預測準確性。
在對提示學習方法中錯誤預測的問題條目進一步分析中,我們發現其中大部分錯誤預測的問題條目來自于分類標注過程中存在爭議的問題條目。例如,“I have difficulty with transportation to and from my medical appointments and/or other places”,模型預測的領域層標簽屬于社會狀況,實際標注為軀體狀況。然而,該條目的領域層標簽標注是經由討論確定。在第一輪的獨立標注中,其中2人預標注為社會狀況,其他3人分別預標注為軀體狀況、心理狀況、健康風險因素。
4 討論
分類是實現文本數據資源知識組織、檢索、發現與問答等智能化知識管理與知識服務的基礎任務。為促進醫學量表資源的智能化細粒度知識管理與服務,本文針對醫學量表中的問題條目文本進行了自動多分類研究。
基于醫學量表問題條目分類研究語料缺乏現狀,本文首先構建了一個支持醫學量表問題條目文本多分類研究的小樣本標注數據集和標簽體系。小樣本標注數據集可直接或經擴展后用于后續醫學量表問題條目分類研究。與一般醫學文本分類標簽命名只單一考慮語義(如“癥狀”類標簽)或語用(如“生活質量評估”類標簽)相比,本研究中的“功能-領域”這一組合分類標簽命名同時考慮了醫學量表問題條目文本的語用和語義特征。“功能”部分側重于體現語用特征,回答為什么要測量;“領域”部分側重于體現語義特征,回答為了實現這樣的目標需要測量什么。因此,“功能-領域”組合分類標簽有助于從宏觀的測量目標和微觀的測量對象維度揭示、組織和發現現存醫學量表問題條目。此外,研究中的“功能”和“領域”兩個維度的分類標簽系獨立構建而成,能夠方便后續研究分別從“功能”和“領域”進行標簽命名體系擴展或刪減;即便是基于本研究已構建的標簽,還可組配出更多的分類標簽,用于標注更多的語料。
本文提出了一種基于提示學習的量表問題條目文本多分類方法。該方法通過簡單增加自定義提示模板,加強BERT模型嵌入表示與組合標簽的關聯性,將多分類任務轉化為較為容易的完形填空任務,從而較好地完成了少樣本語料情況下的醫學量表問題條目多分類任務。在自建的肺癌臨床評估量表問題條目語料上,其分類效果顯著優于所有基線模型,再結合EDA技術,可以進一步提高分類精度。研究也發現,部分醫學量表問題在語言表述上偏向于大眾化、口語化,在使用情境上可用于多個測量目標與概念對象,一定程度上影響著該方法的分類效果。
綜上所述,未來醫學量表問題條目分類研究工作可圍繞如下方面展開:① 構建外部數據集,進一步驗證提示學習方法對于醫學量表問題條目的分類有效性;② 從預訓練模型選擇出發,研究不同預訓練模型對不同功能量表問題文本多分類任務的適用性;③ 開展基于小樣本的醫學量表問題文本多標簽分類研究;④ 探究應用融合外部醫學知識的掩模機制[28,29]來優化量表問題文本分類效果。