利用臨床預測模型指導臨床決策從而為患者提供精準的診療服務已成為臨床實踐的共識和趨勢。但許多臨床預測模型由于研究方法不規范,證據質量不高,最終能夠實現臨床應用的較少。本文結合預測模型研究的國內外進展,從數據收集、模型構建、性能評估、模型驗證、模型呈現和模型更新6個方面介紹臨床預測模型的開發過程以及臨床預測模型研究的報告規范和偏倚風險評估工具,以期為國內研究者提供方法學參考。
引用本文: 莫航灃, 陳亞萍, 韓慧, 章亞平, 劉雨今, 張妹, 魯小丹, 華雨婷, 諸宇佳, 蔡婷婷, 夏云輝, 沈建通. 臨床預測模型研究方法與步驟. 中國循證醫學雜志, 2024, 24(2): 228-236. doi: 10.7507/1672-2531.202308135 復制
版權信息: ?四川大學華西醫院華西期刊社《中國循證醫學雜志》版權所有,未經授權不得轉載、改編
臨床預測模型又稱風險預測模型、預測指數、預測規則、風險評分,是一種通過納入多個變量(如臨床指標、生化指標、影像學等)預測結局發生情況的統計學模型[1-3],可對患者的疾病發生、嚴重程度分層、風險和轉歸等臨床情況進行預測,幫助醫生更準確地評估患者的疾病風險和預后,提高臨床決策的準確性和個體化程度[4]。目前,大量預測模型在不同領域發表,同一個領域或同一個臨床問題甚至存在多個模型,如:胰腺癌臨床風險預測模型存在38種[5],COVID-19預后模型存在353種[6],2型糖尿病患者心力衰竭預后模型存在58種[7],難治性心肺衰竭患者體外膜氧合支持的死亡率預測模型58種[8],全膝關節置換術患者生活質量的預后模型存在12種[9],但這些模型很少在臨床使用和推廣。其中一個主要原因是這些預測模型研究的質量不高,模型在開發過程中存在各種問題,如結局指標不明確、缺少多方面性能評估、缺少外部驗證等。例如,有研究者對涉及COVID-19的31個預測模型進行評價顯示:大多研究過程中缺少完整研究設計和校準度的評估,所有模型都存在高偏倚風險[10]。因此,預測模型研究需要遵循規范的研究方法和流程。本文將詳細介紹臨床預測模型的基本類型、開發步驟和方法,旨在為研究者提供有關臨床預測模型研究的方法指導。
1 臨床預測模型研究及類型
1.1 臨床預測模型分類
臨床預測模型包括診斷模型和預后模型。診斷模型的預測目標是人群在當前時間點患有某種特定結果或疾病的概率,其重點關注當前狀態[11]。預后模型估計個體在將來特定時間內(可以是今后幾小時甚至幾年)發生某種結局的概率[2,11]。預后模型不僅限于特定疾病患者的結局,也可以是非患病人群發生某種結果的風險預測[11]。診斷模型與預后模型的區別如表1。
1.2 臨床預測模型研究分類
臨床預測模型研究包括無外部驗證的模型開發研究、有外部驗證的模型開發研究、預測模型驗證研究和預測模型臨床效果研究四類,不同類型的預測模型研究證據強度不同,如表2所示,級別越高,證據可靠性越好[12-14]。
2 臨床預測模型開發研究基本步驟
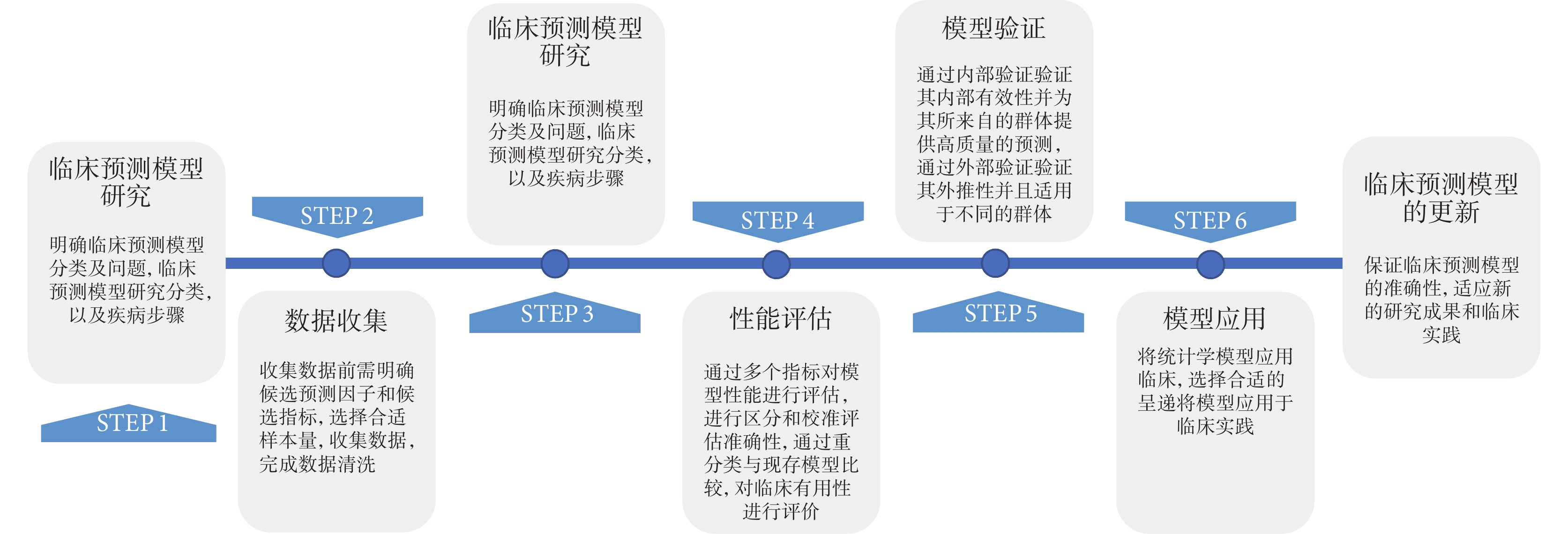
臨床預測模型開發的過程包括數據收集、模型構建、性能評估、模型驗證、模型呈現和更新等環節(圖1)。
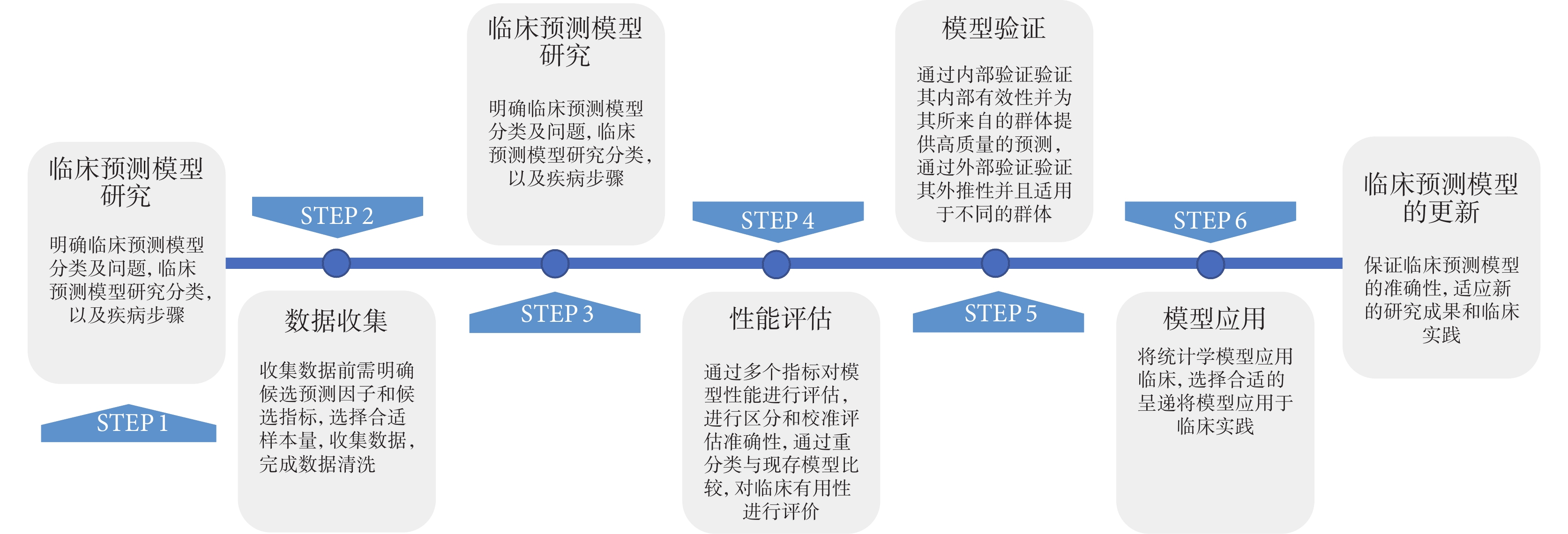 圖1
臨床預測模型開發基本步驟
圖1
臨床預測模型開發基本步驟
2.1 數據收集
2.1.1 數據來源
恰當的數據來源可為模型開發提供豐富、有代表性的樣本。診斷模型的數據來源主要為橫斷面研究和病例-對照研究,預后模型的數據來源則包括前瞻性隊列研究、回顧性研究、疾病注冊數據庫和巢式病例-對照研究,詳見表3[4]。此外,有學者提出某些情況下隨機臨床試驗的數據可額外應用于預后模型的研究[15]。
2.1.2 潛在預測因子選擇
研究者需通過查閱文獻和資料,選擇要納入的潛在預測因子,即與結局可能相關的因素。預測因子主要包括:人口統計學特征(如年齡、性別、種族、教育、社會經濟地位)、疾病類型和嚴重程度(如主要診斷、表現特征)、病史特征(如既往疾病發作、風險因素)、共病(伴隨疾病)、病理學特征、醫學影像、遺傳特征、身體功能狀態(如Karnofsky評分、世界衛生組織表現評分)以及主觀健康狀況和生活質量(心理、認知、心理社會功能)等[16]。對于預后模型,避免納入與結局直接相關或直接確定的強相關預測因子,在患者明確已有其中一個陽性變量下,其已是預后結局明確的高危患者。相反,研究者應該關注與結局存在不確定性的預測因子,探究預測因子對結局事件的影響。
2.1.3 確定結局指標
對于診斷預測模型,其結局指標為疾病的存在與否。需要注意的是,預測因子測量和參考標準(金標準)之間的時間窗應盡可能短,在此期間不要開始任何干預。預后預測模型的結局指標相對于診斷模型更復雜,分為致死事件、非致死事件、以病人為中心和廣泛負擔的結局[17],見表4。生存結局是臨床預測模型尤其是預后模型經常考慮的指標,研究者需要進行一定時間的隨訪,記錄一段時間后結局的發生狀況或多個時間節點的生存情況[18]。在選擇結局指標時,需要綜合考慮多個因素,確保選定的指標具有以下特點:良好的臨床相關性,能夠準確反映疾病的存在與否;較好的識別性,能夠通過可靠的測量方法進行準確評估并且定義明確;良好的敏感性和特異性,能夠正確識別真正發生的事件和排除未發生的事件;高可用性和可行性,易于在臨床實踐中獲取和記錄。此外,收集結局資料時是否采用盲法評估,尤其對主觀性結局,會直接影響模型的預測情況以及造成偏倚。
2.1.4 樣本量估計
足夠的樣本量可確保模型的性能,避免過度擬合等問題,但過多的樣本量并不能提高模型的性能表現。EPV(events per variable)原則是估算樣本量常用的方法,即臨床預測模型中每個事件(發生的結局)對應的可用樣本數量與預測變量的數量之比。如果結局事件發生率小于20%,EPV最好為20,至少為10,即每個變量至少有10個結局事件(樣本量=變量數×10/發生率);如果事件發生率在20%~80%,EPV需更高[19]。樣本量有時會受到未發生結局事件數量和預測因子效應及每一類預測因子事件數影響,這時使用EVP原則來確定樣本量會受到質疑[20]。因此研究者也可根據樣本量估算公式進行計算。例如:二分類結局預測模型研究所需樣本量的計算公式為[21]:
 |
其中,需估計總結局事件的95%可信區間( )以及絕對誤差范圍(
)以及絕對誤差范圍( )。
)。
此外,在進行以時間為終點的生存事件結局的臨床預測模型時需使用不同方法計算樣本量,且兩種類型的模型都可根據二分類結局模型的目標收縮因子和最小潛在過度擬合程度分別計算所需樣本量,最后選擇所需最小樣本量[21]。
2.1.5 數據清洗
數據清洗主要包括:缺失值處理、編碼預測因子、限制候選預測因子。缺失數據為常見的問題,分為完全隨機缺失、隨機缺失和非隨機缺失[22],見表5。預測因子和結局的缺失在收集數據過程中都會發生且大多數無法避免,研究者可嘗試使用替代值法、刪除缺失值、最大似然估計、插補法及多重插補法等方法處理[22,23]。
分類變量在建模時編碼為啞變量(虛擬變量);有序變量可視為無序變量,使用啞變量編碼,或舍去小類別使用大類別。對于連續變量預測因子,可保留連續性變量或轉換為等級資料,盡量避免轉化為二分類變量,因為二分法會導致信息丟失,降低模型的效度[24]。最明顯的影響可能是某些變量剛超過閾值或達到閾值,對個體沒有太大的影響,但對結果產生影響。如剛達60歲的變量歸入60歲以上,實際對目標結局影響有限。通過箱線圖檢查連續變量分布的離群值,即異常值和極值,研究者應先考慮是否發生輸入錯誤以及檢查其生物學合理性。在處理離群值時,推薦使用Winsorization(縮尾處理)代替移除法,該方法通過將離群值移到整體數據分布的中心,具有比簡單的離群值移除法更好的性能[25]。限制候選預測因子除在研究設計時考慮入選的預測因子外,建模前研究者可通過減少有效的自由度來使模型更穩定。限制候選預測因子可采用預測因子的分布、合并相似變量、平均預測因子效益等方法。
2.2 模型構建
2.2.1 篩選預測變量
構建臨床預測模型時,從潛在的預測因子中選擇與結局事件密切相關的變量并納入最終模型,這一過程稱為選擇主效應,又稱篩選預測變量。篩選預測變量的方法包括全模型策略和篩選模型策略[26]。全模型策略不進行預測因子的篩選并要求將全部的潛在預測因子納入模型,可避免過度擬合以及篩選偏倚,但存在易受到主觀性影響、信息偏差、數據缺失和過度復雜性等問題[27]。因此推薦基于一定準則的篩選模型策略,常用的方法包括向后法(backward elimination,BE)、向前法(forward selection,FS)、逐步向前法、逐步后退法、增強后向剔除法、最佳子集選擇、單變量分析和LASSO回歸等,各方法的特點及優缺點詳見表6[28]。單變量分析是一種常見的變量篩選方法,首先對每個變量進行單變量分析,并將滿足顯著性水平(通常是P<0.05)的變量納入模型。但單變量分析忽略了變量之間的相互作用和潛在的共線性問題,不推薦使用。此外,在選擇變量時,不僅依賴于顯著性水平,還需要綜合考慮可能存在的混雜因素和其他獨立因素[29]。
2.2.2 模型擬合
使用篩選后的預測變量和其他需要考慮的變量,通過多因素模型來估計它們與感興趣結局變量之間的關系,該過程為模型擬合,又稱模型構建。不同的結局變量,適用的模型也不同,詳見表7。Logistic回歸、Cox回歸等傳統方法相對簡單,易于解釋結果,可以較為靈活的選擇特征,得到每個預測因子對結果的影響,但存在變量相關性較強或交互作用時準確度可能下降,且由于是參數化模型,存在偏差或過度擬合問題。傳統方法具有可解釋性強和對小樣本數據穩健的特點,但受限于線性關系的假設,難以處理復雜的非線性模式。機器學習和人工智能等現代方法在一定程度上彌補傳統方法的局限,包括決策樹、支持向量機、彈性網、LASSO回歸、神經網絡、貝葉斯網絡、規則學習等。機器學習方法在處理非線性關系、提供高準確度以及自動特征提取方面表現出色,但可解釋性較差,需要大量數據訓練,并存在過擬合的風險[30]。
由于機器學習和人工智能缺乏可解釋性和透明性,使用過程中難以解釋其每個變量影響和決策過程,因此又稱黑箱算法[31]。為了解釋黑箱算法的過程以及不同特征對預測結果的影響以及提高其解釋性。研究者可根據研究目的、研究性質、變量和變量屬性等,選擇合適的可視化解釋工具展示每個變量對結局影響,如SHAP、LIME、ALE、DeepLIFT、DeepTaylor等[32]。
2.3 模型性能評估
臨床預測模型的性能評估包括整體性能、區分度、校準、重分類和臨床有用性5個方面[33]。開發預后模型時,可能面臨多個時間節點下的生存情況,則需對模型的性能進行多次評估。
2.3.1 整體性能
模型整體性能是評估預測模型在數據集上的擬合程度或預測能力的指標,常用的評估指標包括R2和布里爾評分(Brier score)。R2衡量模型對目標變量變異性的解釋程度,取值范圍從0到1,越接近1表示模型解釋能力越好。布里爾分數則用于衡量模型對觀測結果與真實結果之間的差異程度,適用于二分類問題,取值范圍從0到0.25,越接近0表示模型預測準確性越高。
2.3.2 區分度
區分度指模型在預測事件與非事件之間進行區分的能力。常用的區分能力指標包括C統計量(也稱為Concordance統計量,C-statistic)和區分斜率。C統計量表示模型對于隨機選擇一對事件和非事件的患者,正確判斷哪個風險更高的能力,C統計量在0.5~1之間,較高的值表示較好的區分能力,接近0.5表示區分度較低,越接近1表示模型越理想[34]。如果模型是二分類結局變量,受試者工作特征曲線下面積等于C統計量,可用于評估模型的區分能力。區分斜率用于描述預測模型中特定指標(例如連續變量)與預測結局之間的關系,在臨床預測模型中能根據個體特征或子群之間的差異對斜率進行個性化解釋和應用,提高模型的準確性和個體化的臨床決策能力。
2.3.3 校準度
校準度或擬合優度指模型預測值與實際觀察值之間的一致性[34]。常用的校準度指標包括大規模校準、校準斜率和Hosmer-Lemeshow統計量。大規模校準關注整體的校準情況,校準斜率則表示模型的預測風險與實際觀察風險之間的比例關系,而Hosmer-Lemeshow統計量用于評估模型的整體校準程度。
2.3.4 重分類
重分類用于新舊預測模型比較并衡量模型的改進和增益,常見的重分類統計指標如凈重新分類指數(net reclassification index,NRI)和綜合判別改善指數(integrated discrimination improvement,IDI)[35]。NRI衡量了改進模型相對于基準模型在重新分類中的凈改善情況,考慮了事件和非事件的正確分類以及錯誤分類的情況,可以評估改進模型的分類準確性。而IDI衡量了改進模型相對于基準模型在整體區分能力上的提升,通過計算改進模型和基準模型的預測概率之間的差異得到綜合指標。
2.3.5 臨床效益
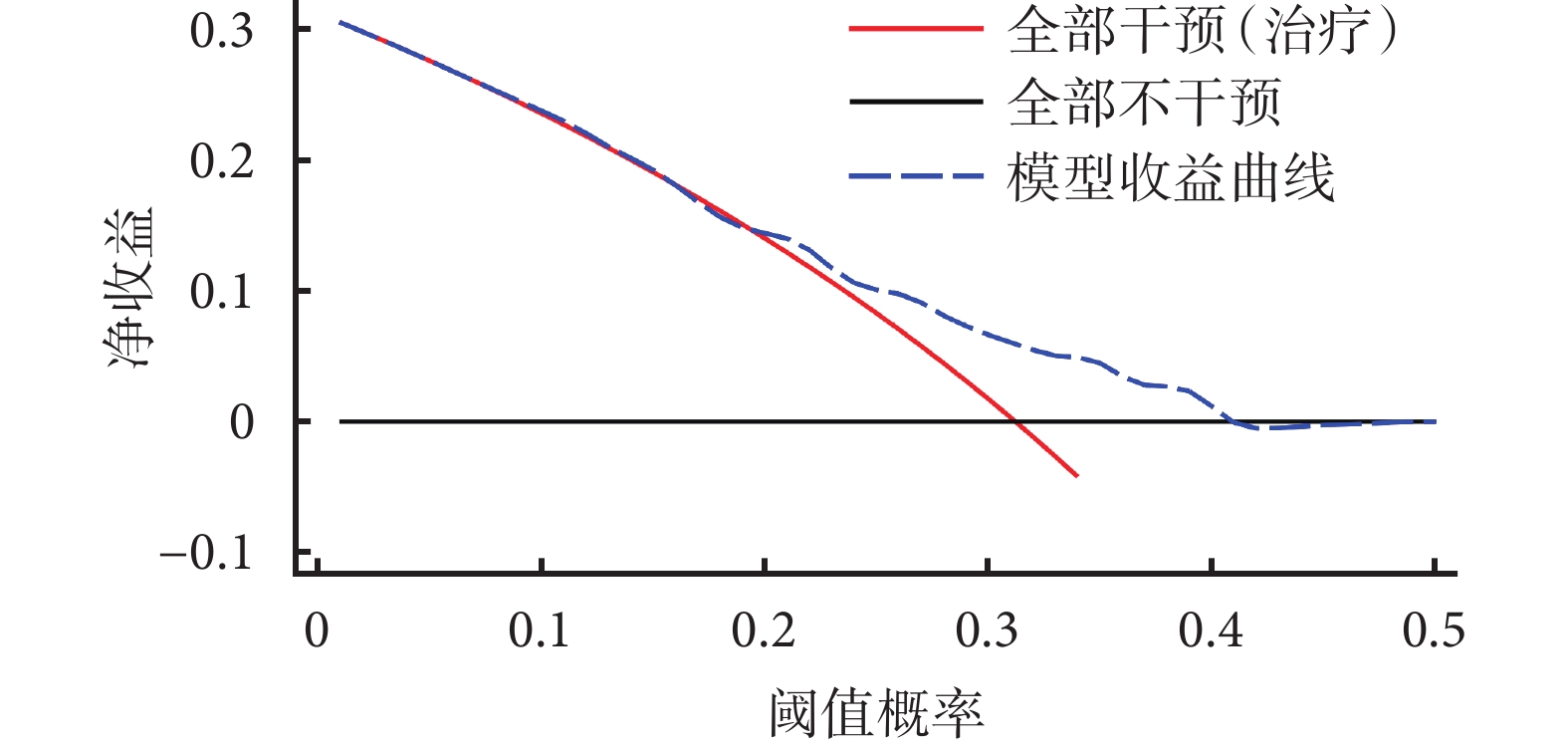
臨床效益與臨床實踐密切相關,它通過確定閾值、評估凈收益和制定決策規則來評估預測模型的實用性和經濟效益[36,37]。評估模型的臨床效益可衡量模型在減少不良結果、提高治療效果或優化資源利用方面的效益,通過分析決策曲線(decision curve analysis,DCA)評估預測模型在實際決策中的效果并確定最佳的決策閾值。在決策曲線中,存在兩種極端情況:全部干預(治療)和全部不干預(圖2),只有模型的曲線在兩者之上其臨床效益才有應用價值,并且研究者可根據凈收益情況確定最佳閾值概率。Kaplan-Meier分析是一種用于生存分析的統計方法,用于評估事件發生時間(如生存時間、治療失敗等)和患者生存率之間的關系。Kaplan-Meier分析不僅可以觀察不同預測因子或變量對患者生存率的影響,也能展示預測模型的預測情況與實際情況的差別。
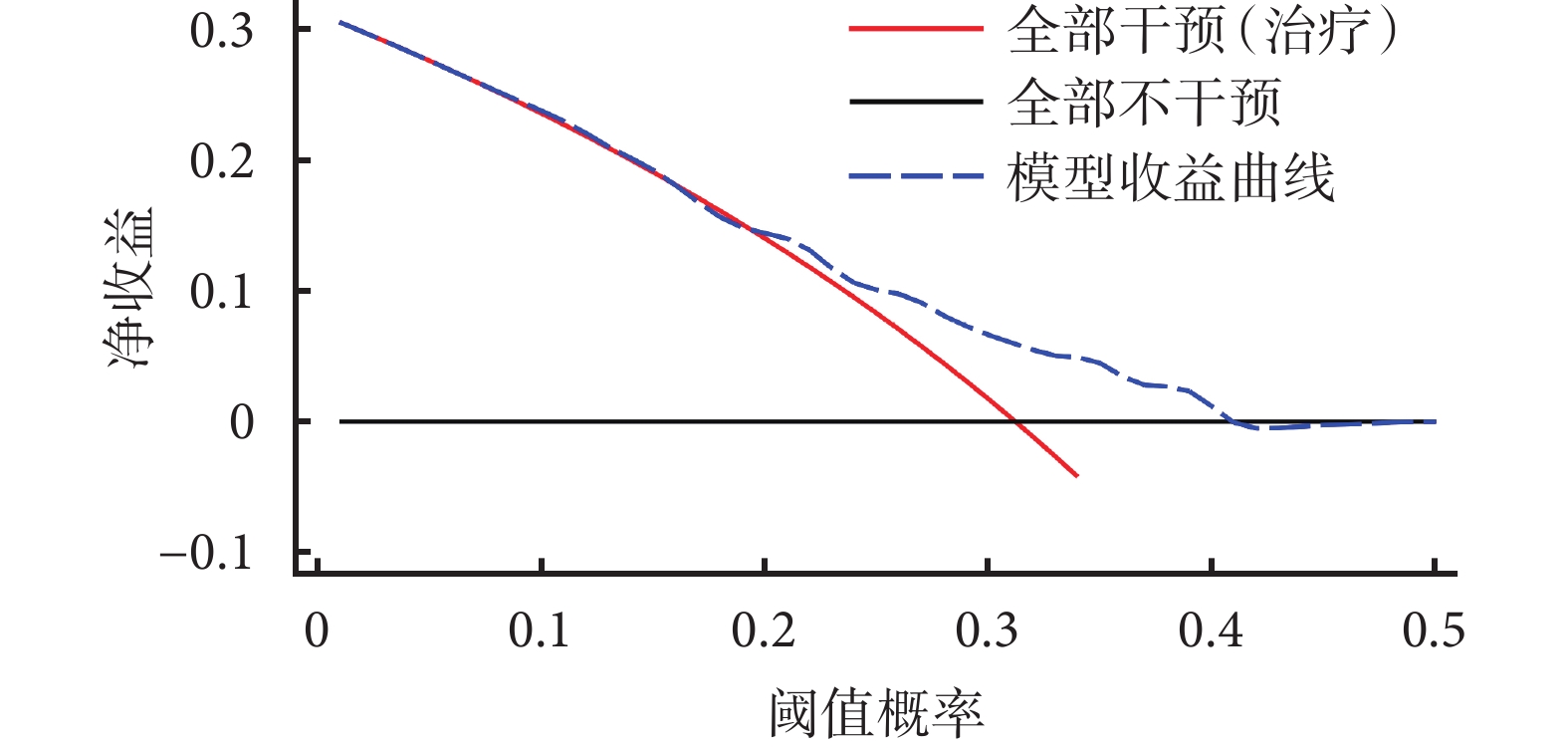 圖2
決策曲線
圖2
決策曲線
橫坐標為閾值概率,模型預測的概率超過閾值概率即為陽性或事件發生。在患者的預測概率達到閾值概率時,即采取相應的措施。但采取相應的措施不一定獲得有利的結果,非陽性的病人可能也會被錯誤的定為陽性。此時,縱坐標為除去誤診(有弊)后的收益,即為凈收益。黑色橫線與紅色斜線代表兩種極端情況。黑色橫線代表全部不干預,此時凈收益為0,無治療受益。紅色斜線代表所有患者都進行了干預,但凈收益隨著閾值概率增加而減少。
2.4 模型驗證
模型驗證是評估預測模型性能和泛化能力的重要步驟,它包括內部驗證和外部驗證。內部驗證通過在同一數據集上進行模型訓練和評估來估計模型的性能,可以檢查模型是否過度擬合或欠擬合。而外部驗證則在獨立的數據集上對模型進行評估,以驗證模型的外推能力。
2.4.1 內部驗證
內部驗證指基于開發數據集進行模型評估得到模型的性能指標。內部驗證方式從數據使用特征分為表觀驗證、隨機拆分驗證、交叉驗證、Bootstrap方法和“內部-外部”交叉驗證,如表8[4,38]。有研究表明隨機拆分驗證在大樣本量時才有較好的表現,小樣本量時不具有很好表現,但大樣本量時表觀驗證優于隨機拆分驗證,因此隨機拆分驗證應該被更有效的技術取代,如加強法Bootstrap[38,39]。在大樣本量、多中心的情況下,按時段分割數據、按中心分割數據或“內部-外部”交叉驗證更具有效度[40]。無論是傳統方法還是機器學習方法,在進行內部驗證時所采用的方法在本質上并無明顯差異。但機器學習在內部驗證中使用區分度和校準度等傳統性能指標外,還存在更復雜的指標,包含ABS、平衡精度(balanced accuracy,BAC)、AUC、F1得分和概率精度(probabilistic accuracy,PAC)[41];其數據集規模和多樣性要求也更高。
2.4.2 外部驗證
外部驗證關注模型的可移植性和外推性,使用獨立于開發樣本的數據集來評估模型的性能,提供模型在其他數據集上性能的可靠估計,其數據來源需要專業知識以及流行病學研究的相關知識和專家來判斷其有效性,才能夠合理用于開發模型的外部驗證[42]。根據“經驗法則”,臨床預測模型外部驗證的樣本量至少需要100個陽性事件或陰性事件,理想情況下需要200個(或更多)事件[43]。然而,一些研究指出這一規定可能存在一定的不確定性,并提出了一種基于Logistic的樣本量方法,這種方法更加適合于外部驗證預后模型[44]。如表9所示,根據數據來源將外部驗證分為:時段驗證、地理驗證、領域驗證、獨立驗證[4]。目前外部驗證面臨的主要問題是:缺少不同中心(相似)患者的共享數據庫,分散地、單獨地使用區域的患者數據驗證模型的有效性是不準確的[1,40]。
2.5 模型呈現
臨床預測模型的基本形式一般為數學統計模型,為增加模型的臨床適用性和可操作性,往往需對模型進行可視化呈現。常見的呈現形式包括:回歸公式、簡化表格評分系統、圖形分數評分、列線圖、移動網站和程序[45]。簡化表格評分系統和圖形分數評分臨床上相對簡單易理解,但可能會存在誤差。列線圖是一種直觀易懂的可視化工具,能夠整合多個預測因素并幫助進行個體風險評估和決策制定,但依賴于特定模型并可能存在信息簡化和解讀誤差的限制。移動網站和程序可以通過輸入特定臨床信息得出結局的發生概率,方便快捷且利于個性化,但對設備可能有要求。最佳的呈現形式應該基于環境和使用人群,研究者應根據實際情況選擇合適的呈現形式。
2.6 模型更新
理想的預測模型能在不同的時間和地點為患者提供準確的預測結果。當使用的環境和開發模型的樣本類似或無新相關指標出現時,可以通過觀察結果和模型預測比較來評估模型的效度。更新模型時,研究者可以僅更新風險基線,也可以對模型進行重校準、重評估、擴展、修訂、系數收縮,需要注意的是風險生存模型需要更新預后指數以及按照時間點重新校準[4]。更新模型的主要方法可以歸結為回歸系數更新、Meta-model法及動態模型構建三類[46]。
3 預測模型研究報告規范
預測模型研究報告遵循個體預后與診斷模型研究報告規范(transparent reporting of a multivariable prediction model for individual prognosis or diagnosis,TRIPOD),適用于模型開發、驗證和更新研究,也用于評估研究報告時作為參考。TRIPOD包含22個項目清單,涵蓋了預測模型研究的報告要求,如研究目的、數據收集、模型開發和驗證、結果解釋和模型應用等[11,13,47],旨在提高預測模型研究的透明度和報告質量。機器學習預測模型在遵循傳統的TRIPOD聲明時,面臨一些特殊挑戰和不足之處。首先,機器學習模型通常被認為是黑箱模型,其內部決策過程和特征的影響難以解釋,與TRIPOD聲明中要求的模型透明度存在矛盾。其次,涉及最關鍵輸入變量的特征選擇和改進及轉換原始數據的特征工程為機器學習的重要步驟,但TRIPOD聲明未提供詳細的報告指導,導致無法為機器學習建模過程提供幫助[41]。最后,機器學習模型的驗證策略通常更復雜,其性能評估指標包含傳統指標和專用指標,可能導致在報告和理解方面存在困難,需更具體的指導。
4 臨床預測模型研究質量評價
與其他研究一樣,開發臨床預測模型也會產生偏倚風險,PROBAST(prediction model risk of bias assessment tool)工具用于評估預測模型開發研究偏倚風險及其適用性,為模型的選擇、改進和應用提供支持。PROBAST工具包括研究對象、預測變量、結局和統計分析4個領域共20個條目,涵蓋了預測模型開發和驗證過程中的關鍵偏倚風險來源,如樣本選擇、數據收集、模型選擇和評估等[48,49]。研究者進行模型開發研究時可作為參考,提高模型研究的質量。此外,PROBAST工具基于傳統建模方法開發,用于評價機器學習模型時仍存在一些不足。其主要區別體現在機器學習模型開發、驗證、性能評估方面存在不同方法和額外指標,僅使用PROBAST工具對模型的質量和偏倚風險評估可能不適用[50,51]。
5 總結
預測模型研究質量關系到預測模型能否指導臨床決策,研究者需確保采用合適且準確的步驟。預測模型開發過程包括明確研究設計、數據收集、模型開發、性能評估、模型驗證、模型呈現和更新。預測模型的研究報告遵循TRIPOD聲明,偏倚風險和適用性評價采用PROBAST工具。隨著數字化和智能化醫療時代的發展,機器學習和人工智能模型已經拓展到臨床決策和護理等領域,不再局限于影像學和生物信息學。因此,機器學習和人工智能模型也帶來了新的挑戰,涉及模型的復雜性、解釋性、特征處理、模型評估以及性能指標的詳細報告。由于機器學習和人工智能模型的特殊性,現有的評估框架和標準可能不再適用,因此需要制定新的評估框架或標準,以應對這些新挑戰。機器學習和人工智能預測的相關評估工具PROBAST-AI和TRIPOD-AI規范正在研究和開發中,以幫助研究者更好地報告和評估模型的質量[52]。新的規范將有助于確保臨床預測模型在臨床實踐中的可靠性和可用性,促進數字醫療領域的發展。
臨床預測模型又稱風險預測模型、預測指數、預測規則、風險評分,是一種通過納入多個變量(如臨床指標、生化指標、影像學等)預測結局發生情況的統計學模型[1-3],可對患者的疾病發生、嚴重程度分層、風險和轉歸等臨床情況進行預測,幫助醫生更準確地評估患者的疾病風險和預后,提高臨床決策的準確性和個體化程度[4]。目前,大量預測模型在不同領域發表,同一個領域或同一個臨床問題甚至存在多個模型,如:胰腺癌臨床風險預測模型存在38種[5],COVID-19預后模型存在353種[6],2型糖尿病患者心力衰竭預后模型存在58種[7],難治性心肺衰竭患者體外膜氧合支持的死亡率預測模型58種[8],全膝關節置換術患者生活質量的預后模型存在12種[9],但這些模型很少在臨床使用和推廣。其中一個主要原因是這些預測模型研究的質量不高,模型在開發過程中存在各種問題,如結局指標不明確、缺少多方面性能評估、缺少外部驗證等。例如,有研究者對涉及COVID-19的31個預測模型進行評價顯示:大多研究過程中缺少完整研究設計和校準度的評估,所有模型都存在高偏倚風險[10]。因此,預測模型研究需要遵循規范的研究方法和流程。本文將詳細介紹臨床預測模型的基本類型、開發步驟和方法,旨在為研究者提供有關臨床預測模型研究的方法指導。
1 臨床預測模型研究及類型
1.1 臨床預測模型分類
臨床預測模型包括診斷模型和預后模型。診斷模型的預測目標是人群在當前時間點患有某種特定結果或疾病的概率,其重點關注當前狀態[11]。預后模型估計個體在將來特定時間內(可以是今后幾小時甚至幾年)發生某種結局的概率[2,11]。預后模型不僅限于特定疾病患者的結局,也可以是非患病人群發生某種結果的風險預測[11]。診斷模型與預后模型的區別如表1。
1.2 臨床預測模型研究分類
臨床預測模型研究包括無外部驗證的模型開發研究、有外部驗證的模型開發研究、預測模型驗證研究和預測模型臨床效果研究四類,不同類型的預測模型研究證據強度不同,如表2所示,級別越高,證據可靠性越好[12-14]。
2 臨床預測模型開發研究基本步驟
臨床預測模型開發的過程包括數據收集、模型構建、性能評估、模型驗證、模型呈現和更新等環節(圖1)。
圖1
臨床預測模型開發基本步驟
2.1 數據收集
2.1.1 數據來源
恰當的數據來源可為模型開發提供豐富、有代表性的樣本。診斷模型的數據來源主要為橫斷面研究和病例-對照研究,預后模型的數據來源則包括前瞻性隊列研究、回顧性研究、疾病注冊數據庫和巢式病例-對照研究,詳見表3[4]。此外,有學者提出某些情況下隨機臨床試驗的數據可額外應用于預后模型的研究[15]。
2.1.2 潛在預測因子選擇
研究者需通過查閱文獻和資料,選擇要納入的潛在預測因子,即與結局可能相關的因素。預測因子主要包括:人口統計學特征(如年齡、性別、種族、教育、社會經濟地位)、疾病類型和嚴重程度(如主要診斷、表現特征)、病史特征(如既往疾病發作、風險因素)、共病(伴隨疾病)、病理學特征、醫學影像、遺傳特征、身體功能狀態(如Karnofsky評分、世界衛生組織表現評分)以及主觀健康狀況和生活質量(心理、認知、心理社會功能)等[16]。對于預后模型,避免納入與結局直接相關或直接確定的強相關預測因子,在患者明確已有其中一個陽性變量下,其已是預后結局明確的高危患者。相反,研究者應該關注與結局存在不確定性的預測因子,探究預測因子對結局事件的影響。
2.1.3 確定結局指標
對于診斷預測模型,其結局指標為疾病的存在與否。需要注意的是,預測因子測量和參考標準(金標準)之間的時間窗應盡可能短,在此期間不要開始任何干預。預后預測模型的結局指標相對于診斷模型更復雜,分為致死事件、非致死事件、以病人為中心和廣泛負擔的結局[17],見表4。生存結局是臨床預測模型尤其是預后模型經常考慮的指標,研究者需要進行一定時間的隨訪,記錄一段時間后結局的發生狀況或多個時間節點的生存情況[18]。在選擇結局指標時,需要綜合考慮多個因素,確保選定的指標具有以下特點:良好的臨床相關性,能夠準確反映疾病的存在與否;較好的識別性,能夠通過可靠的測量方法進行準確評估并且定義明確;良好的敏感性和特異性,能夠正確識別真正發生的事件和排除未發生的事件;高可用性和可行性,易于在臨床實踐中獲取和記錄。此外,收集結局資料時是否采用盲法評估,尤其對主觀性結局,會直接影響模型的預測情況以及造成偏倚。
2.1.4 樣本量估計
足夠的樣本量可確保模型的性能,避免過度擬合等問題,但過多的樣本量并不能提高模型的性能表現。EPV(events per variable)原則是估算樣本量常用的方法,即臨床預測模型中每個事件(發生的結局)對應的可用樣本數量與預測變量的數量之比。如果結局事件發生率小于20%,EPV最好為20,至少為10,即每個變量至少有10個結局事件(樣本量=變量數×10/發生率);如果事件發生率在20%~80%,EPV需更高[19]。樣本量有時會受到未發生結局事件數量和預測因子效應及每一類預測因子事件數影響,這時使用EVP原則來確定樣本量會受到質疑[20]。因此研究者也可根據樣本量估算公式進行計算。例如:二分類結局預測模型研究所需樣本量的計算公式為[21]:
|
其中,需估計總結局事件的95%可信區間()以及絕對誤差范圍()。
此外,在進行以時間為終點的生存事件結局的臨床預測模型時需使用不同方法計算樣本量,且兩種類型的模型都可根據二分類結局模型的目標收縮因子和最小潛在過度擬合程度分別計算所需樣本量,最后選擇所需最小樣本量[21]。
2.1.5 數據清洗
數據清洗主要包括:缺失值處理、編碼預測因子、限制候選預測因子。缺失數據為常見的問題,分為完全隨機缺失、隨機缺失和非隨機缺失[22],見表5。預測因子和結局的缺失在收集數據過程中都會發生且大多數無法避免,研究者可嘗試使用替代值法、刪除缺失值、最大似然估計、插補法及多重插補法等方法處理[22,23]。
分類變量在建模時編碼為啞變量(虛擬變量);有序變量可視為無序變量,使用啞變量編碼,或舍去小類別使用大類別。對于連續變量預測因子,可保留連續性變量或轉換為等級資料,盡量避免轉化為二分類變量,因為二分法會導致信息丟失,降低模型的效度[24]。最明顯的影響可能是某些變量剛超過閾值或達到閾值,對個體沒有太大的影響,但對結果產生影響。如剛達60歲的變量歸入60歲以上,實際對目標結局影響有限。通過箱線圖檢查連續變量分布的離群值,即異常值和極值,研究者應先考慮是否發生輸入錯誤以及檢查其生物學合理性。在處理離群值時,推薦使用Winsorization(縮尾處理)代替移除法,該方法通過將離群值移到整體數據分布的中心,具有比簡單的離群值移除法更好的性能[25]。限制候選預測因子除在研究設計時考慮入選的預測因子外,建模前研究者可通過減少有效的自由度來使模型更穩定。限制候選預測因子可采用預測因子的分布、合并相似變量、平均預測因子效益等方法。
2.2 模型構建
2.2.1 篩選預測變量
構建臨床預測模型時,從潛在的預測因子中選擇與結局事件密切相關的變量并納入最終模型,這一過程稱為選擇主效應,又稱篩選預測變量。篩選預測變量的方法包括全模型策略和篩選模型策略[26]。全模型策略不進行預測因子的篩選并要求將全部的潛在預測因子納入模型,可避免過度擬合以及篩選偏倚,但存在易受到主觀性影響、信息偏差、數據缺失和過度復雜性等問題[27]。因此推薦基于一定準則的篩選模型策略,常用的方法包括向后法(backward elimination,BE)、向前法(forward selection,FS)、逐步向前法、逐步后退法、增強后向剔除法、最佳子集選擇、單變量分析和LASSO回歸等,各方法的特點及優缺點詳見表6[28]。單變量分析是一種常見的變量篩選方法,首先對每個變量進行單變量分析,并將滿足顯著性水平(通常是P<0.05)的變量納入模型。但單變量分析忽略了變量之間的相互作用和潛在的共線性問題,不推薦使用。此外,在選擇變量時,不僅依賴于顯著性水平,還需要綜合考慮可能存在的混雜因素和其他獨立因素[29]。
2.2.2 模型擬合
使用篩選后的預測變量和其他需要考慮的變量,通過多因素模型來估計它們與感興趣結局變量之間的關系,該過程為模型擬合,又稱模型構建。不同的結局變量,適用的模型也不同,詳見表7。Logistic回歸、Cox回歸等傳統方法相對簡單,易于解釋結果,可以較為靈活的選擇特征,得到每個預測因子對結果的影響,但存在變量相關性較強或交互作用時準確度可能下降,且由于是參數化模型,存在偏差或過度擬合問題。傳統方法具有可解釋性強和對小樣本數據穩健的特點,但受限于線性關系的假設,難以處理復雜的非線性模式。機器學習和人工智能等現代方法在一定程度上彌補傳統方法的局限,包括決策樹、支持向量機、彈性網、LASSO回歸、神經網絡、貝葉斯網絡、規則學習等。機器學習方法在處理非線性關系、提供高準確度以及自動特征提取方面表現出色,但可解釋性較差,需要大量數據訓練,并存在過擬合的風險[30]。
由于機器學習和人工智能缺乏可解釋性和透明性,使用過程中難以解釋其每個變量影響和決策過程,因此又稱黑箱算法[31]。為了解釋黑箱算法的過程以及不同特征對預測結果的影響以及提高其解釋性。研究者可根據研究目的、研究性質、變量和變量屬性等,選擇合適的可視化解釋工具展示每個變量對結局影響,如SHAP、LIME、ALE、DeepLIFT、DeepTaylor等[32]。
2.3 模型性能評估
臨床預測模型的性能評估包括整體性能、區分度、校準、重分類和臨床有用性5個方面[33]。開發預后模型時,可能面臨多個時間節點下的生存情況,則需對模型的性能進行多次評估。
2.3.1 整體性能
模型整體性能是評估預測模型在數據集上的擬合程度或預測能力的指標,常用的評估指標包括R2和布里爾評分(Brier score)。R2衡量模型對目標變量變異性的解釋程度,取值范圍從0到1,越接近1表示模型解釋能力越好。布里爾分數則用于衡量模型對觀測結果與真實結果之間的差異程度,適用于二分類問題,取值范圍從0到0.25,越接近0表示模型預測準確性越高。
2.3.2 區分度
區分度指模型在預測事件與非事件之間進行區分的能力。常用的區分能力指標包括C統計量(也稱為Concordance統計量,C-statistic)和區分斜率。C統計量表示模型對于隨機選擇一對事件和非事件的患者,正確判斷哪個風險更高的能力,C統計量在0.5~1之間,較高的值表示較好的區分能力,接近0.5表示區分度較低,越接近1表示模型越理想[34]。如果模型是二分類結局變量,受試者工作特征曲線下面積等于C統計量,可用于評估模型的區分能力。區分斜率用于描述預測模型中特定指標(例如連續變量)與預測結局之間的關系,在臨床預測模型中能根據個體特征或子群之間的差異對斜率進行個性化解釋和應用,提高模型的準確性和個體化的臨床決策能力。
2.3.3 校準度
校準度或擬合優度指模型預測值與實際觀察值之間的一致性[34]。常用的校準度指標包括大規模校準、校準斜率和Hosmer-Lemeshow統計量。大規模校準關注整體的校準情況,校準斜率則表示模型的預測風險與實際觀察風險之間的比例關系,而Hosmer-Lemeshow統計量用于評估模型的整體校準程度。
2.3.4 重分類
重分類用于新舊預測模型比較并衡量模型的改進和增益,常見的重分類統計指標如凈重新分類指數(net reclassification index,NRI)和綜合判別改善指數(integrated discrimination improvement,IDI)[35]。NRI衡量了改進模型相對于基準模型在重新分類中的凈改善情況,考慮了事件和非事件的正確分類以及錯誤分類的情況,可以評估改進模型的分類準確性。而IDI衡量了改進模型相對于基準模型在整體區分能力上的提升,通過計算改進模型和基準模型的預測概率之間的差異得到綜合指標。
2.3.5 臨床效益
臨床效益與臨床實踐密切相關,它通過確定閾值、評估凈收益和制定決策規則來評估預測模型的實用性和經濟效益[36,37]。評估模型的臨床效益可衡量模型在減少不良結果、提高治療效果或優化資源利用方面的效益,通過分析決策曲線(decision curve analysis,DCA)評估預測模型在實際決策中的效果并確定最佳的決策閾值。在決策曲線中,存在兩種極端情況:全部干預(治療)和全部不干預(圖2),只有模型的曲線在兩者之上其臨床效益才有應用價值,并且研究者可根據凈收益情況確定最佳閾值概率。Kaplan-Meier分析是一種用于生存分析的統計方法,用于評估事件發生時間(如生存時間、治療失敗等)和患者生存率之間的關系。Kaplan-Meier分析不僅可以觀察不同預測因子或變量對患者生存率的影響,也能展示預測模型的預測情況與實際情況的差別。
圖2
決策曲線
橫坐標為閾值概率,模型預測的概率超過閾值概率即為陽性或事件發生。在患者的預測概率達到閾值概率時,即采取相應的措施。但采取相應的措施不一定獲得有利的結果,非陽性的病人可能也會被錯誤的定為陽性。此時,縱坐標為除去誤診(有弊)后的收益,即為凈收益。黑色橫線與紅色斜線代表兩種極端情況。黑色橫線代表全部不干預,此時凈收益為0,無治療受益。紅色斜線代表所有患者都進行了干預,但凈收益隨著閾值概率增加而減少。
2.4 模型驗證
模型驗證是評估預測模型性能和泛化能力的重要步驟,它包括內部驗證和外部驗證。內部驗證通過在同一數據集上進行模型訓練和評估來估計模型的性能,可以檢查模型是否過度擬合或欠擬合。而外部驗證則在獨立的數據集上對模型進行評估,以驗證模型的外推能力。
2.4.1 內部驗證
內部驗證指基于開發數據集進行模型評估得到模型的性能指標。內部驗證方式從數據使用特征分為表觀驗證、隨機拆分驗證、交叉驗證、Bootstrap方法和“內部-外部”交叉驗證,如表8[4,38]。有研究表明隨機拆分驗證在大樣本量時才有較好的表現,小樣本量時不具有很好表現,但大樣本量時表觀驗證優于隨機拆分驗證,因此隨機拆分驗證應該被更有效的技術取代,如加強法Bootstrap[38,39]。在大樣本量、多中心的情況下,按時段分割數據、按中心分割數據或“內部-外部”交叉驗證更具有效度[40]。無論是傳統方法還是機器學習方法,在進行內部驗證時所采用的方法在本質上并無明顯差異。但機器學習在內部驗證中使用區分度和校準度等傳統性能指標外,還存在更復雜的指標,包含ABS、平衡精度(balanced accuracy,BAC)、AUC、F1得分和概率精度(probabilistic accuracy,PAC)[41];其數據集規模和多樣性要求也更高。
2.4.2 外部驗證
外部驗證關注模型的可移植性和外推性,使用獨立于開發樣本的數據集來評估模型的性能,提供模型在其他數據集上性能的可靠估計,其數據來源需要專業知識以及流行病學研究的相關知識和專家來判斷其有效性,才能夠合理用于開發模型的外部驗證[42]。根據“經驗法則”,臨床預測模型外部驗證的樣本量至少需要100個陽性事件或陰性事件,理想情況下需要200個(或更多)事件[43]。然而,一些研究指出這一規定可能存在一定的不確定性,并提出了一種基于Logistic的樣本量方法,這種方法更加適合于外部驗證預后模型[44]。如表9所示,根據數據來源將外部驗證分為:時段驗證、地理驗證、領域驗證、獨立驗證[4]。目前外部驗證面臨的主要問題是:缺少不同中心(相似)患者的共享數據庫,分散地、單獨地使用區域的患者數據驗證模型的有效性是不準確的[1,40]。
2.5 模型呈現
臨床預測模型的基本形式一般為數學統計模型,為增加模型的臨床適用性和可操作性,往往需對模型進行可視化呈現。常見的呈現形式包括:回歸公式、簡化表格評分系統、圖形分數評分、列線圖、移動網站和程序[45]。簡化表格評分系統和圖形分數評分臨床上相對簡單易理解,但可能會存在誤差。列線圖是一種直觀易懂的可視化工具,能夠整合多個預測因素并幫助進行個體風險評估和決策制定,但依賴于特定模型并可能存在信息簡化和解讀誤差的限制。移動網站和程序可以通過輸入特定臨床信息得出結局的發生概率,方便快捷且利于個性化,但對設備可能有要求。最佳的呈現形式應該基于環境和使用人群,研究者應根據實際情況選擇合適的呈現形式。
2.6 模型更新
理想的預測模型能在不同的時間和地點為患者提供準確的預測結果。當使用的環境和開發模型的樣本類似或無新相關指標出現時,可以通過觀察結果和模型預測比較來評估模型的效度。更新模型時,研究者可以僅更新風險基線,也可以對模型進行重校準、重評估、擴展、修訂、系數收縮,需要注意的是風險生存模型需要更新預后指數以及按照時間點重新校準[4]。更新模型的主要方法可以歸結為回歸系數更新、Meta-model法及動態模型構建三類[46]。
3 預測模型研究報告規范
預測模型研究報告遵循個體預后與診斷模型研究報告規范(transparent reporting of a multivariable prediction model for individual prognosis or diagnosis,TRIPOD),適用于模型開發、驗證和更新研究,也用于評估研究報告時作為參考。TRIPOD包含22個項目清單,涵蓋了預測模型研究的報告要求,如研究目的、數據收集、模型開發和驗證、結果解釋和模型應用等[11,13,47],旨在提高預測模型研究的透明度和報告質量。機器學習預測模型在遵循傳統的TRIPOD聲明時,面臨一些特殊挑戰和不足之處。首先,機器學習模型通常被認為是黑箱模型,其內部決策過程和特征的影響難以解釋,與TRIPOD聲明中要求的模型透明度存在矛盾。其次,涉及最關鍵輸入變量的特征選擇和改進及轉換原始數據的特征工程為機器學習的重要步驟,但TRIPOD聲明未提供詳細的報告指導,導致無法為機器學習建模過程提供幫助[41]。最后,機器學習模型的驗證策略通常更復雜,其性能評估指標包含傳統指標和專用指標,可能導致在報告和理解方面存在困難,需更具體的指導。
4 臨床預測模型研究質量評價
與其他研究一樣,開發臨床預測模型也會產生偏倚風險,PROBAST(prediction model risk of bias assessment tool)工具用于評估預測模型開發研究偏倚風險及其適用性,為模型的選擇、改進和應用提供支持。PROBAST工具包括研究對象、預測變量、結局和統計分析4個領域共20個條目,涵蓋了預測模型開發和驗證過程中的關鍵偏倚風險來源,如樣本選擇、數據收集、模型選擇和評估等[48,49]。研究者進行模型開發研究時可作為參考,提高模型研究的質量。此外,PROBAST工具基于傳統建模方法開發,用于評價機器學習模型時仍存在一些不足。其主要區別體現在機器學習模型開發、驗證、性能評估方面存在不同方法和額外指標,僅使用PROBAST工具對模型的質量和偏倚風險評估可能不適用[50,51]。
5 總結
預測模型研究質量關系到預測模型能否指導臨床決策,研究者需確保采用合適且準確的步驟。預測模型開發過程包括明確研究設計、數據收集、模型開發、性能評估、模型驗證、模型呈現和更新。預測模型的研究報告遵循TRIPOD聲明,偏倚風險和適用性評價采用PROBAST工具。隨著數字化和智能化醫療時代的發展,機器學習和人工智能模型已經拓展到臨床決策和護理等領域,不再局限于影像學和生物信息學。因此,機器學習和人工智能模型也帶來了新的挑戰,涉及模型的復雜性、解釋性、特征處理、模型評估以及性能指標的詳細報告。由于機器學習和人工智能模型的特殊性,現有的評估框架和標準可能不再適用,因此需要制定新的評估框架或標準,以應對這些新挑戰。機器學習和人工智能預測的相關評估工具PROBAST-AI和TRIPOD-AI規范正在研究和開發中,以幫助研究者更好地報告和評估模型的質量[52]。新的規范將有助于確保臨床預測模型在臨床實踐中的可靠性和可用性,促進數字醫療領域的發展。