在針灸臨床研究的腧穴數據挖掘工作中,文獻證據質量、樣本量、臨床療效等因素對結局質量的影響尚不明確,影響了數據挖掘類研究成果的證據轉化與臨床應用。本研究提出運用熵權和線性加權法對上述指標進行多指標決策以獲得腧穴處方綜合權重得分,通過加權腧穴處方進行后續數據挖掘工作的新流程。本文以偏頭痛研究為例將加權算法與經典算法結果進行對比,結果顯示本研究所提出的算法對選穴分散的研究更具意義,在聚類分析中能更好發現潛在的腧穴配伍規律。該算法將循證針灸學體系納入數據挖掘工作流程,為針灸學數據挖掘相關研究質量的提升提供了新思路,但后續仍需更多的研究加以驗證。
引用本文: 王喆, 陳芊秀, 董志浩, 宋慶雨, 陳新勇, 韓晶. 基于循證體系的針灸學數據挖掘算法構建與應用研究. 中國循證醫學雜志, 2024, 24(9): 1070-1078. doi: 10.7507/1672-2531.202309142 復制
版權信息: ?四川大學華西醫院華西期刊社《中國循證醫學雜志》版權所有,未經授權不得轉載、改編
在當今大數據時代的背景下,數據挖掘技術在針灸學中得到了廣泛實踐,成為從針灸文獻大數據中獲得有效信息、探索隱含知識的重要研究手段[1]。針灸學數據挖掘研究目前廣泛應用于腧穴配伍規律、針刺效應、針刺手法等方面。作為其最主要的應用場景—腧穴處方挖掘近年來增長迅速,在明確核心腧穴、探究配伍規律、構建針灸處方等方面發揮了關鍵作用[2]。針灸數據挖掘是文獻學、循證醫學、信息科學與針灸學的交叉學科,在實際開展中易受到原始信息質量、數據挖掘算法應用、結果解釋等方面的不確定因素的干擾,進而影響研究的嚴謹性。有學者認為,部分針灸學數據挖掘面臨證據來源的問題,基于低質量的原始數據提煉匯總的結論難以對臨床實踐起到真正的指導作用[3]。此外,有益的挖掘結果來源于高質量的醫案與有效的處方,有研究者發現,目前中醫藥數據挖掘對臨床療效與個案質量重視不足[4]。事實上,目前臨床針灸腧穴挖掘研究僅針對研究方案實施前所擬定的腧穴,而忽略了其研究結果的可靠性。正因如此,很長一段時間以來,相關研究成果在臨床指南構建中尚未形成規模化、規范化的應用體系。
上述問題的存在呼吁針灸數據挖掘提供新的思路與方案,有學者提出數據挖掘應考慮與循證醫學證據聯用[5],然而目前尚未有算法實現腧穴挖掘結果和循證醫學證據質量的有機整合。因此,如何在數據挖掘過程中充分考慮證據質量等級、臨床療效等諸多因素,進而基于研究質量較高、臨床療效較為明確的腧穴進行系統性挖掘分析,成為針灸數據挖掘算法改進的著眼點。針灸數據挖掘涉及兩大核心的算法:關聯規則和聚類分析,其中聚類分析又以共現矩陣為基礎。隨著數據挖掘技術在各領域的推廣應用,關聯規則衍生出加權關聯規則算法[6-8],其充分考慮了項目的權重在數據中的重要性,為發現事務數據中重要項目之間隱藏關系提供了有效方法[9]。共現矩陣則衍生出根據項目權重賦值的加權共現矩陣算法。基于加權體系的算法在包括生物信息學、計算機文本挖掘在內的諸多領域進行了廣泛應用[10,11],并在中藥處方挖掘中以療效為權重進行了探索[12,13]。這些新算法的出現,為我們解決針灸腧穴挖掘循證證據整合問題提供了思路。因此,本研究以針刺干預偏頭痛研究為例,提出綜合考慮證據質量等級和臨床療效的加權數據挖掘算法,以期為針灸數據挖掘研究方法學和中醫藥證據轉化應用提供有益補充。
1 資料與方法
1.1 納入與排除標準
1.1.1 研究類型
針刺治療偏頭痛的臨床研究。
1.1.2 研究對象
偏頭痛患者,病例來源、年齡、性別及病程長短不限。
1.1.3 干預措施
試驗組采用針刺療法(針具、選穴、留針時間、療程等不限),若研究類型包含對照組,則對照組的治療方法不限。
1.1.4 結局指標
頭痛視覺模擬評分(visual analogue scale,VAS)。
1.1.5 排除標準
① 干預措施為針刺聯合中西醫其他診療方案;② 重復發表的文獻;③ 無法獲取全文或數據不全的文獻。
1.2 文獻檢索策略
計算機檢索PubMed、Embase、Web of Science、CBM、WanFang Data、VIP和CNKI數據庫,搜集針刺治療偏頭痛的臨床研究,檢索時限均為2013年1月至2023年8月。檢索采用主題詞與自由詞相結合的方式進行,并根據各數據庫特點進行調整。同時檢索納入研究的參考文獻,以補充獲取相關資料。中文檢索詞包括:針灸、針刺、電針、體針、頭針、偏頭痛、頭風等;英文檢索詞包括:acupuncture、migraine、hemicrania等。
1.3 納入研究的偏倚風險評價
采用復旦大學JBI循證護理合作中心翻譯的中文版“JBI干預性研究證據預分級系統[14]”將納入研究按實驗性研究、類實驗性研究、觀察性-分析性研究、觀察性-描述性研究、專家意見劃分為1~5級。采用“JBI循證衛生保健中心質量評價工具”對不同類型研究進行質量評價[15-17]。其中,隨機對照研究共13分,考慮到針灸操作施術者的盲法難以實施[18],因此“是否對干預者采取了盲法”條目指定為“不適用”,排除該條標準后共12分;類實驗研究總分9分;病例報告總分8分。因不同研究條目總分不同,將不同研究類型得分除以總分進行標準化。
1.4 文獻篩選與資料提取
由2名研究者獨立篩選文獻、提取資料并交叉核對。如有分歧,則通過討論或與第三方協商解決。資料提取內容包括:作者、標題、發表年份、針刺方案、臨床療效指標等。
1.5 多指標決策計算文獻綜合權重[19 ]
1.5.1 構建決策矩陣
一個多指標決策問題由以下3個要素構成:n個評價指標fj(1≤j≤n)、m個決策方案Ai(1≤i≤m)、1個決策矩陣D=(xij)m×n(1≤i≤m,1≤j≤n),其中元素xij表示第i個方案,第j個指標的值。在本研究中,決策對象Ai為所有納入數據挖掘研究的文獻,決策指標包括:證據等級、文獻質量、樣本量、治療前后VAS差值,據此構建決策矩陣。
1.5.2 決策指標賦值及定義
各決策指標按如下規則賦分:證據等級按1~5級分別賦為1~5分;文獻質量、樣本量、VAS差值為連續型資料,直接納入后續多指標決策計算。其中“證據等級”定義為成本型指標,即分值越低(證據等級越高)對決策越有利,其余指標均為效益型指標,即分值越高對決策越有利。
1.5.3 標準化決策矩陣
采用線性比例變化法對不同量綱指標進行標準化后,得到的矩陣R=(rij)m×n。
1.5.4 指標權重計算及多指標決策
采用熵值法計算各決策指標權重。熵值法是一種客觀賦權法,依據各指標值所包含的信息量的大小來確定指標權重。采用簡單線性加權法進行多指標決策,該方法通過計算各評價方案的線性加權和,并以此作為各決策對象的得分依據。
1.6 加權關聯規則分析
本研究采用R軟件arules包計算關聯規則,根據Ayse等提出的加權關聯分析算法進行規則加權[6]。該算法由如幾下步驟組成:① 設定初始最小支持度;② 運用Eclat算法獲得關聯規則;③ 計算每個項的平均權重;④ 對于每個規則,根據規則中存在的項的權重計算規則權重(公式1);⑤ 計算規則的加權支持度(weighted support,WSP)(公式2),并進行Min-Max標準化處理;⑥ 根據設定的支持度進一步篩選關聯規則,采用加權關聯規則算法對支持度進行加權處理。
 |
 |
其中, 為一個項集(item set),
為一個項集(item set), 是第k個項集,
是第k個項集, 為該項集中項的個數,
為該項集中項的個數, 為第k項關聯規則。
為第k項關聯規則。
1.7 構建加權共現矩陣
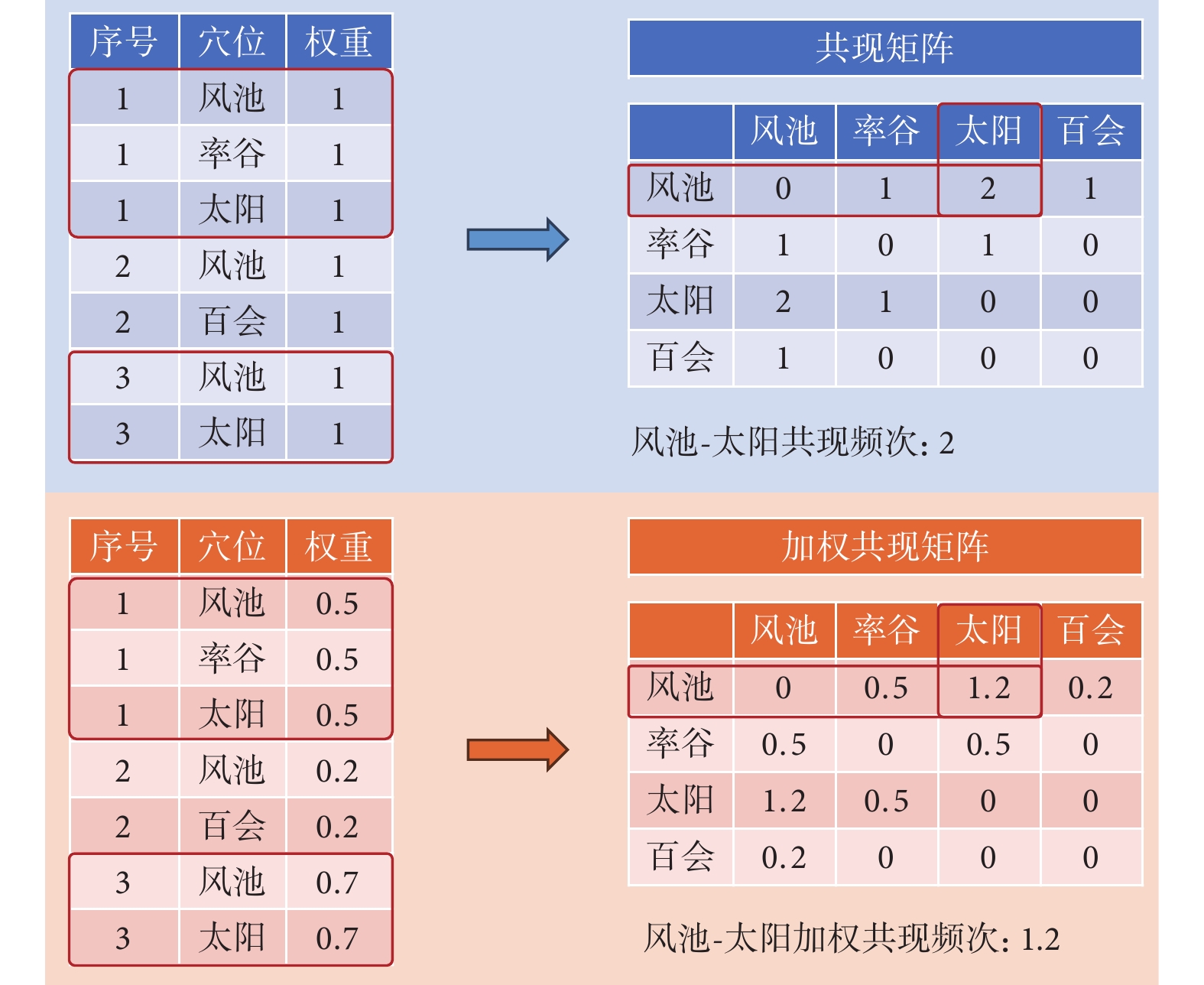
在進行復雜網絡分析和聚類分析時首先需構建共現矩陣。共現矩陣是一個展現不同類別之間鄰接關系的矩陣,而加權共現矩陣使其能夠反映鄰接類別的重要性。采用R語言for循環嵌套構建共現矩陣,在具體實現中首先對所有納入的穴位進行去重作為矩陣的行和列,然后遍歷每項研究,依次統計每對穴位共同出現在同一研究中的次數,從而構建出表示穴位共現關系的矩陣。在未加權矩陣中所有穴位權重相同,因而每對穴位共同出現1次記為1,而加權共現矩陣中,每對穴位所屬處方具有不同權重得分,故每對穴位共同出現1次記為1×處方權重系數。以圖1為例,在傳統共現矩陣中,有兩組處方中共同出現了風池和太陽,故其共現頻次為2。在加權共現矩陣中,處方1的權重為0.5,處方3權重為0.7,因而其加權共現頻次為1.2。
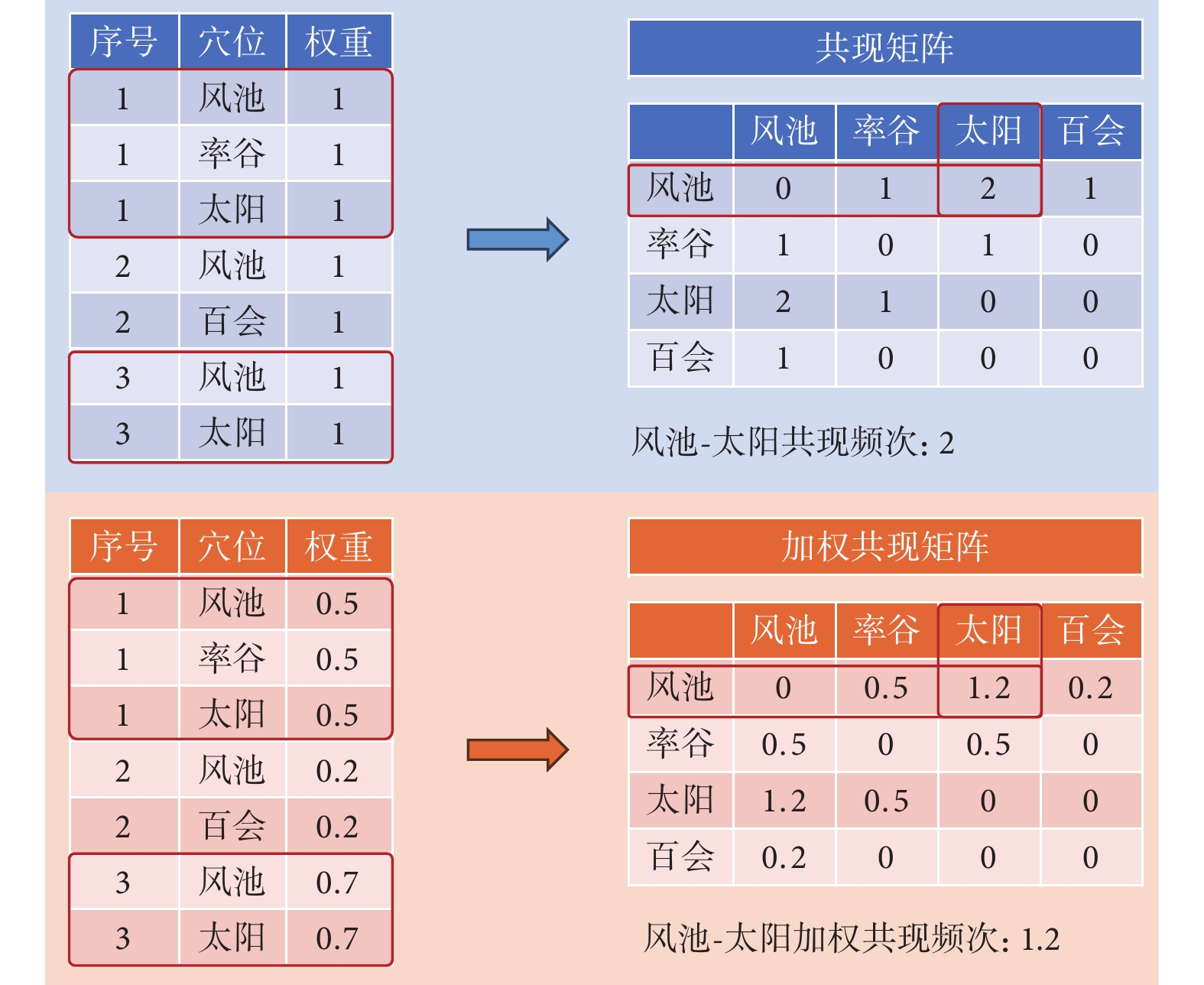 圖1
共現矩陣與加權共現矩陣對比示意圖
圖1
共現矩陣與加權共現矩陣對比示意圖
1.8 復雜網絡及聚類分析
運用Gephi 0.1.0對網絡進行可視化分析,計算網絡的度(degree centrality,DC)、加權度(weighted degree)、接近中心性(closeness centrality,CC)、中介中心性(betweenness centrality,BC)、圖密度、模塊度等參數,比較加權與加未權矩陣參數區別,根據Modularity的社團劃分算法進行聚類分析。根據腧穴共現頻次,對高頻共現穴對進行篩選,同時對高頻腧穴進行層次聚類分析。
2 結果
2.1 文獻篩選流程及結果
初檢共獲得文獻4 434篇,包括:PubMed(n=307)、Web of Science(n=372)、Embase(n=243)、CNKI(n=1 082)、WanFang Data(n=746)、VIP(n=563)、CBM(n=1 121),經逐層篩選后,最終納入117篇文獻,包含151條針灸處方,腧穴總頻次1 104次。
2.2 納入研究類型及質量評價結果
納入研究包含隨機對照試驗108篇、類實驗研究8篇、病例報道1篇。隨機對照試驗質量評價平均得分8.85±1.52分;類實驗研究平均得分5.00±2.20分;病例報道得分為6分。
2.3 熵權法確定各指標權重
采用熵值法確定不同決策指標的權重,按線性比例變化法對不同量綱指標進行標準化,分別計算各指標熵值、偏差度,據此計算各指標最終權重。結果顯示,文獻類型和文獻質量在最終評價中所占權重較低,而樣本量、VAS差值所占權重較高,其中又以VAS差值所占比例最高,見表1。
2.4 線性加權法進行多指標決策
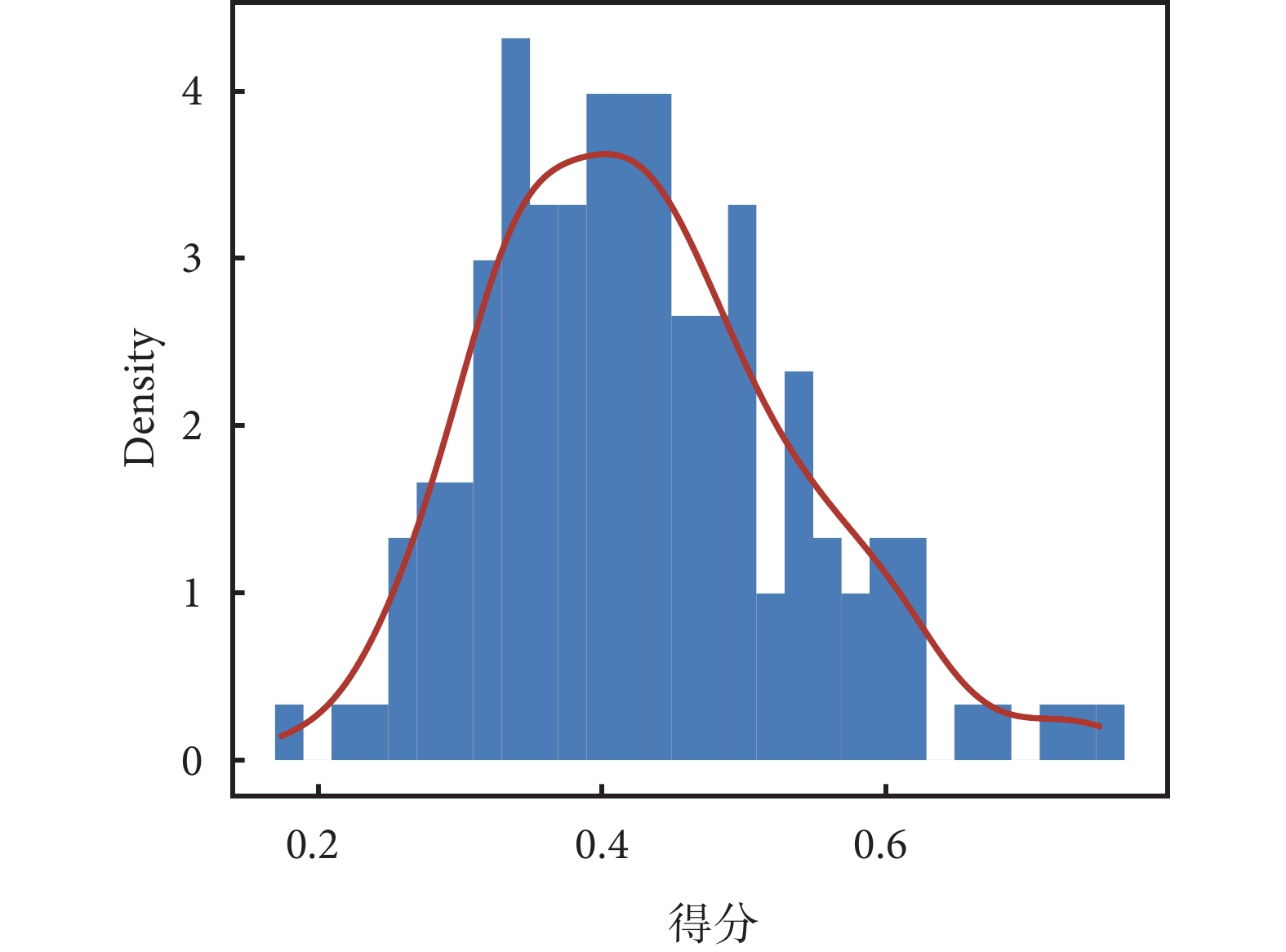
根據熵權法所獲得的各納入腧穴處方的權重系數,采用線性加權法計算各納入研究進行多指標決策,151條處方最終權重得分呈正偏態分布(Skewness=0.521,K-S P=0.029),最低得分為0.173,最高得分為0.752,平均得分為0.428±0.107,得分分布見圖2。
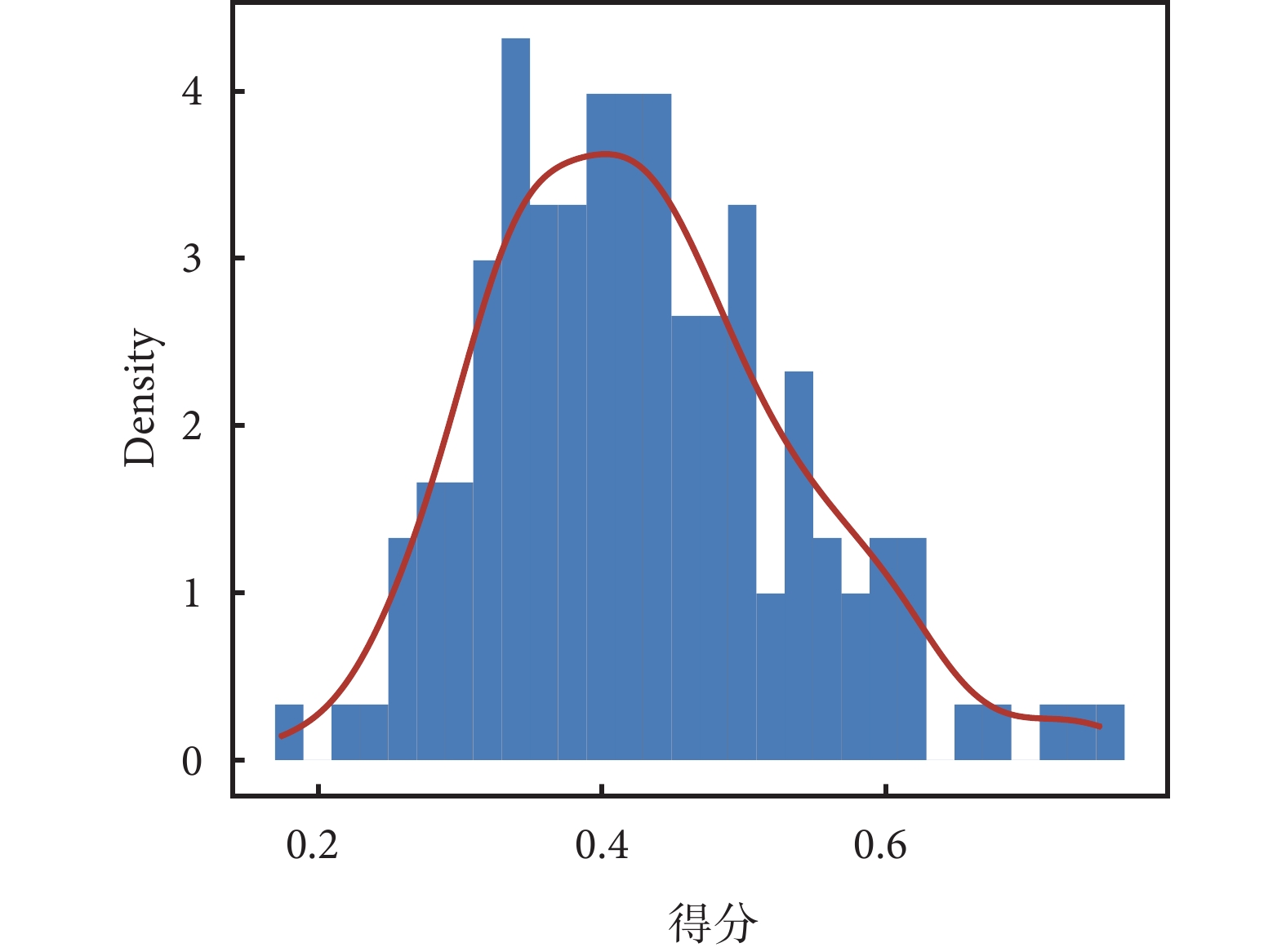 圖2
線性加權得分分布直方圖
圖2
線性加權得分分布直方圖
2.5 加權頻次分析
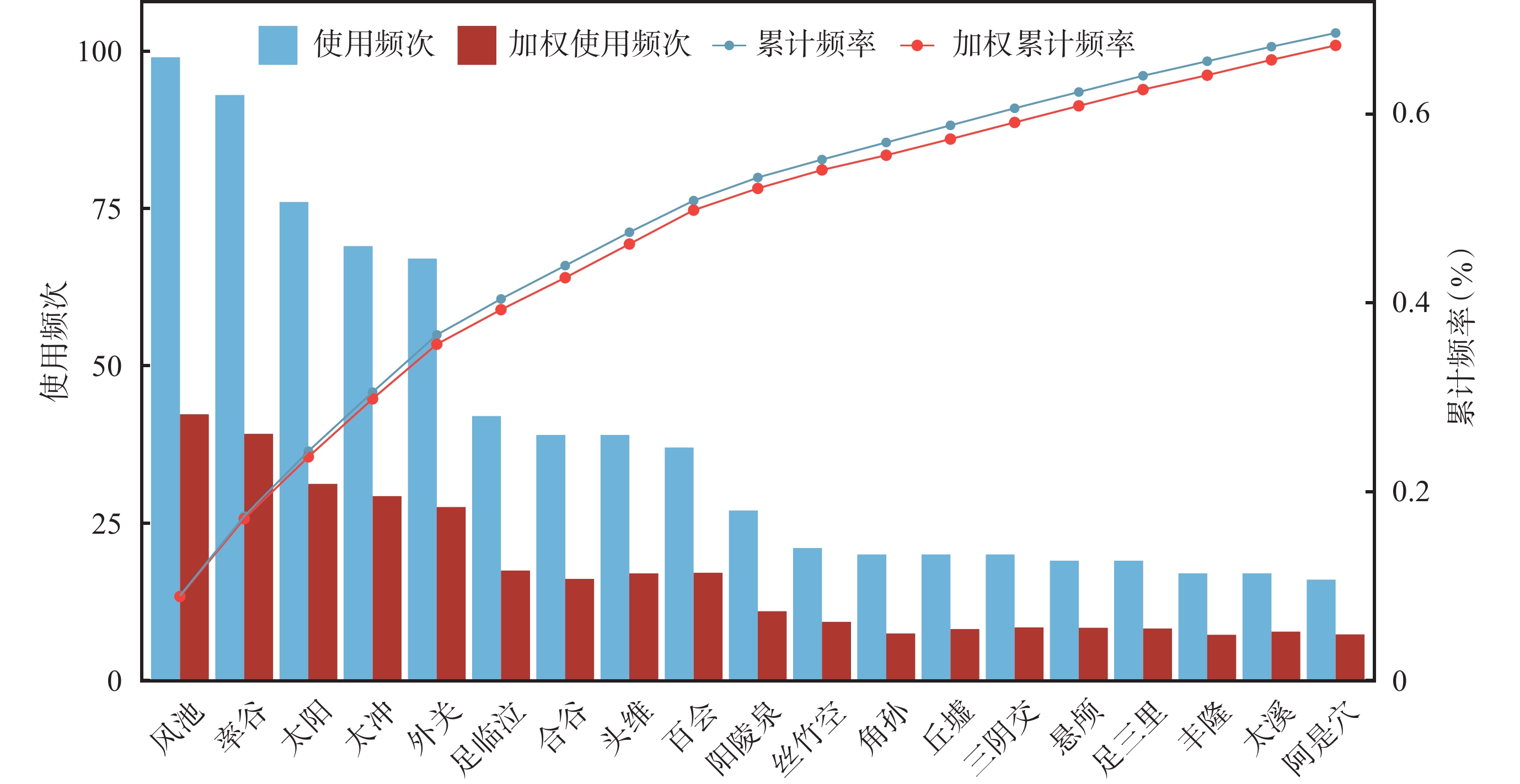
針刺治療偏頭痛的腧穴處方中,使用頻次大于15次的腧穴有20個。基于頻次統計和加權頻次統計所篩選出的高頻腧穴占比一致,累計頻率均大于70%。但加權算法對腧穴頻次排序產生影響,如足臨泣、合谷、頭維、百會、角孫、丘墟、三陰交、懸顱、足三里、豐隆、太溪、阿是穴等腧穴的頻次排序和加權頻次排序存在差異,見圖3。
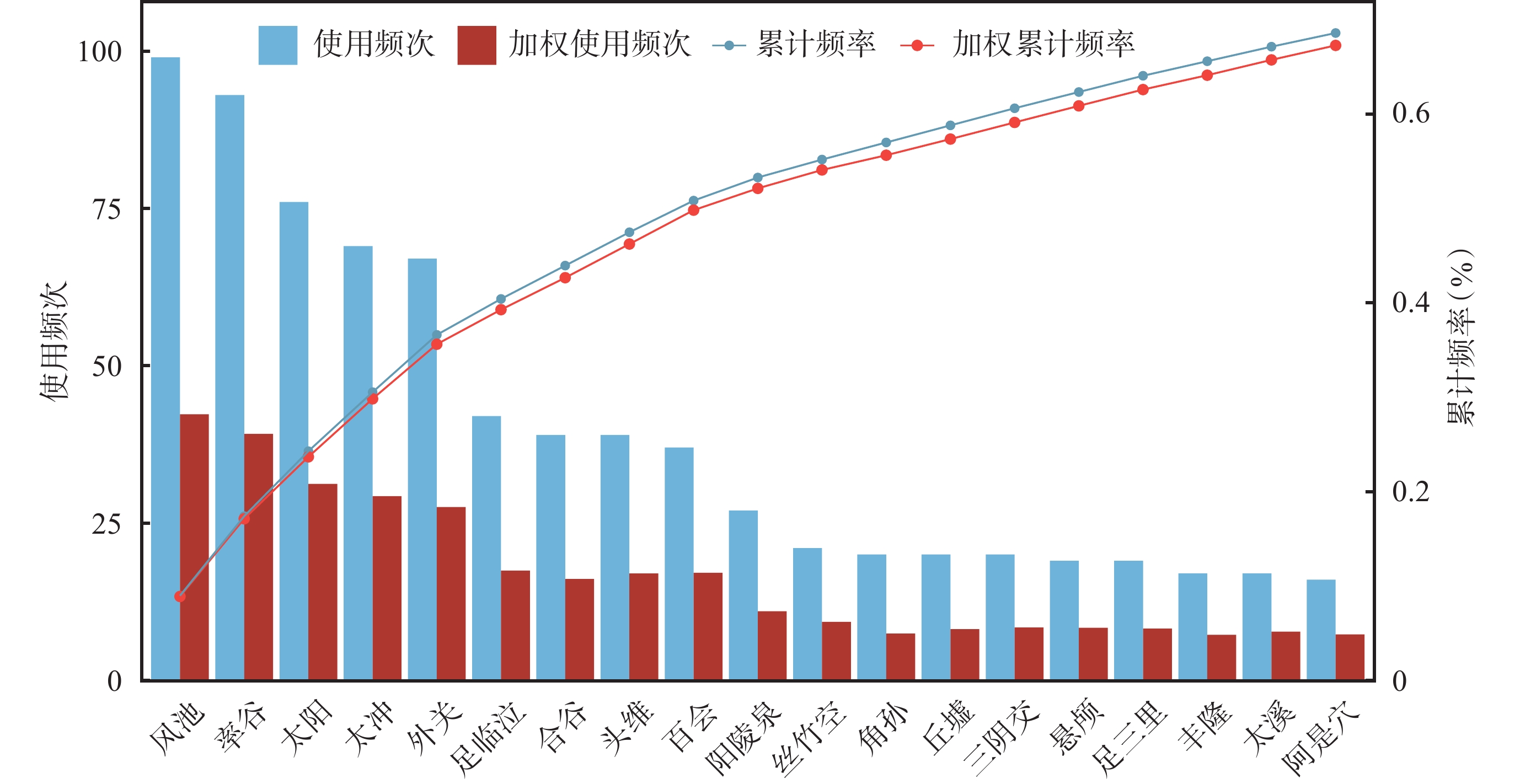 圖3
腧穴頻次和累計頻率分布圖
圖3
腧穴頻次和累計頻率分布圖
2.6 加權關聯規則分析
設置Eclat算法初始支持度為0.1,共獲得123條關聯規則。對其進行加權、標準化處理后,設定WSP>0.25、置信度>0.8為篩選條件,加權算法共獲得26項關聯規則,未加權算法獲得11項關聯規則。在本研究中,較傳統未加權算法相比,同等條件下加權算法發現更多關聯規則,且不同關聯規則間支持度區別更為明顯,詳見表2。
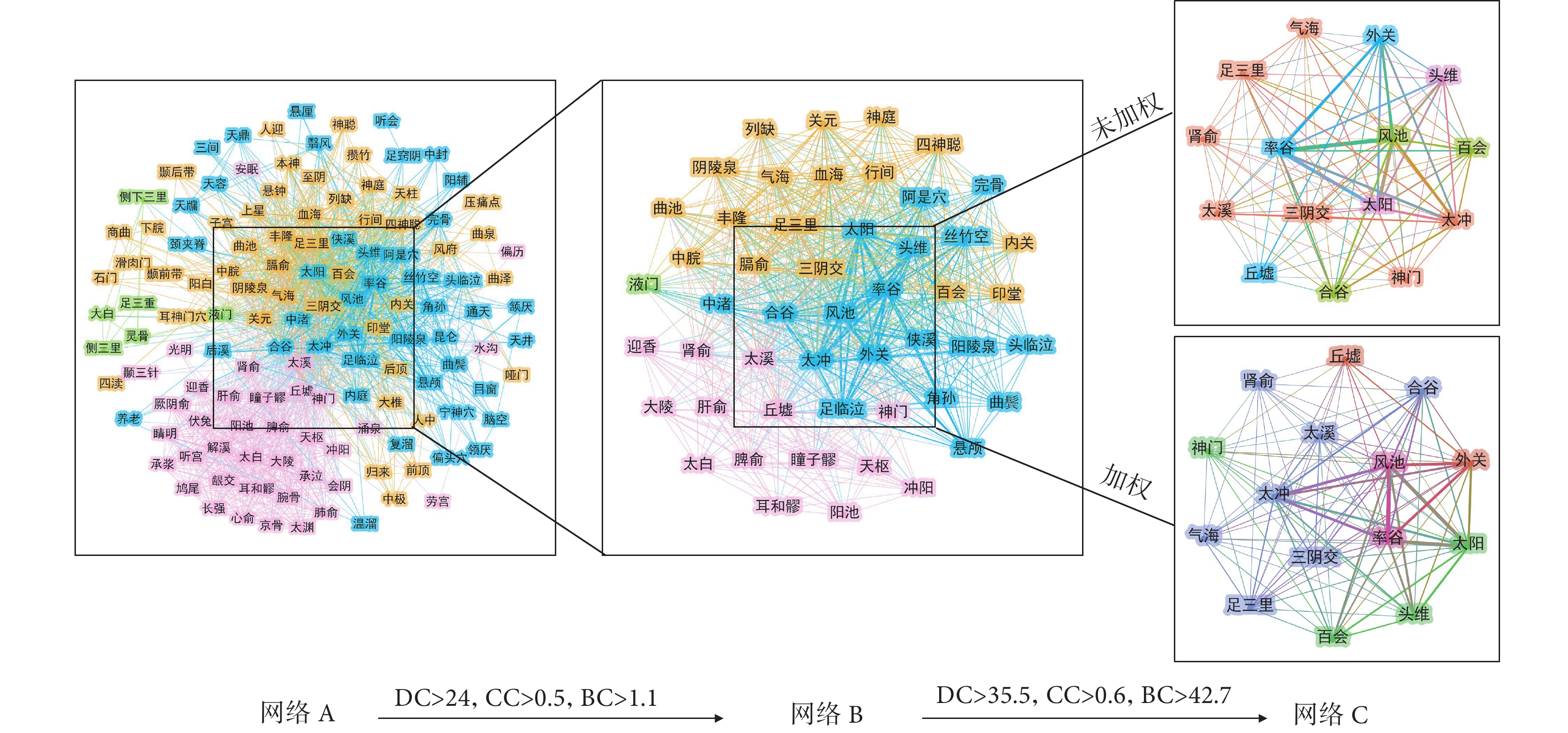
2.7 復雜網絡特征分析
分別構建基于頻次的共現矩陣和加權共現矩陣,運用Gephi軟件構建復雜網絡,共獲得132個節點、
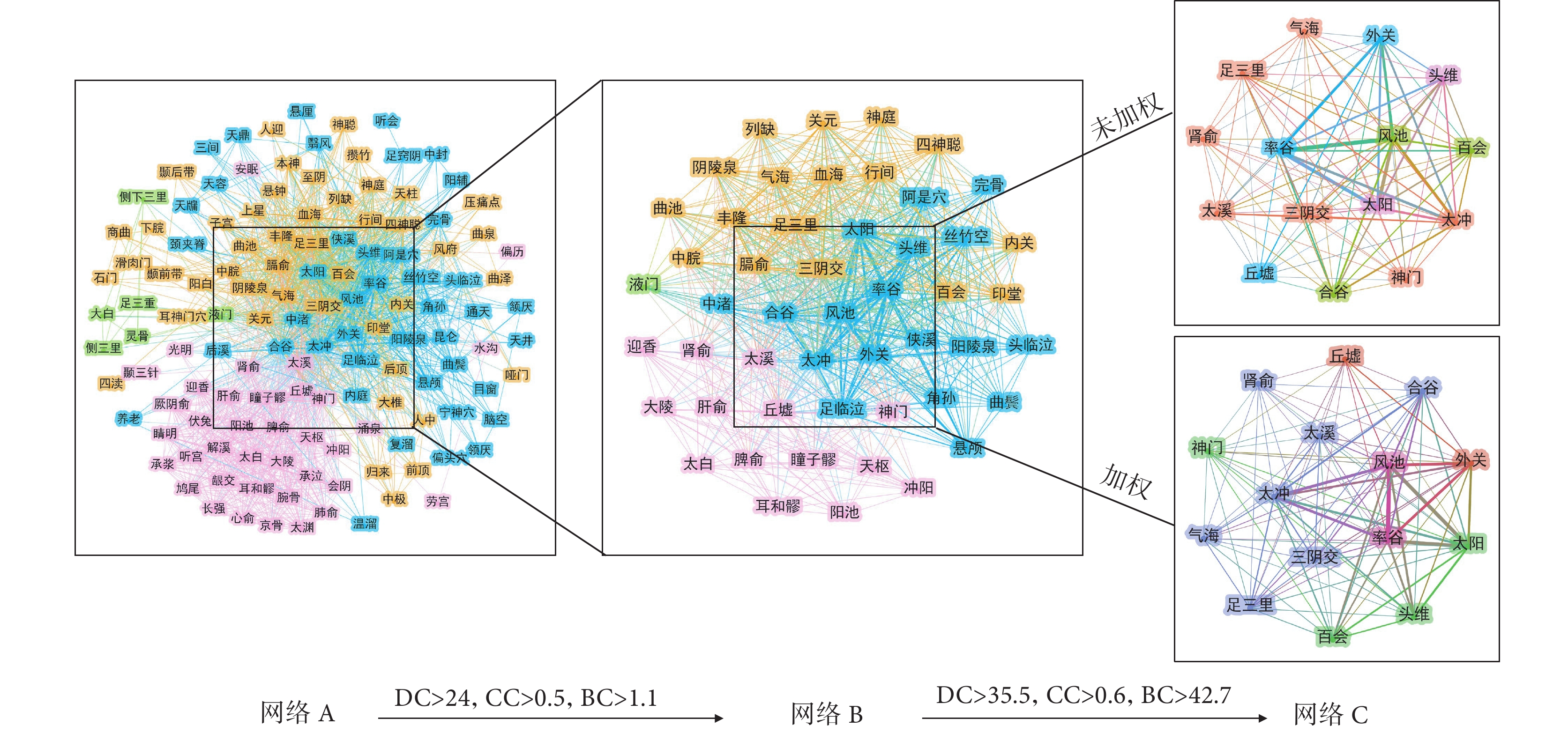 圖4
核心腧穴篩選流程圖
圖4
核心腧穴篩選流程圖
2.8 腧穴共現頻次分析
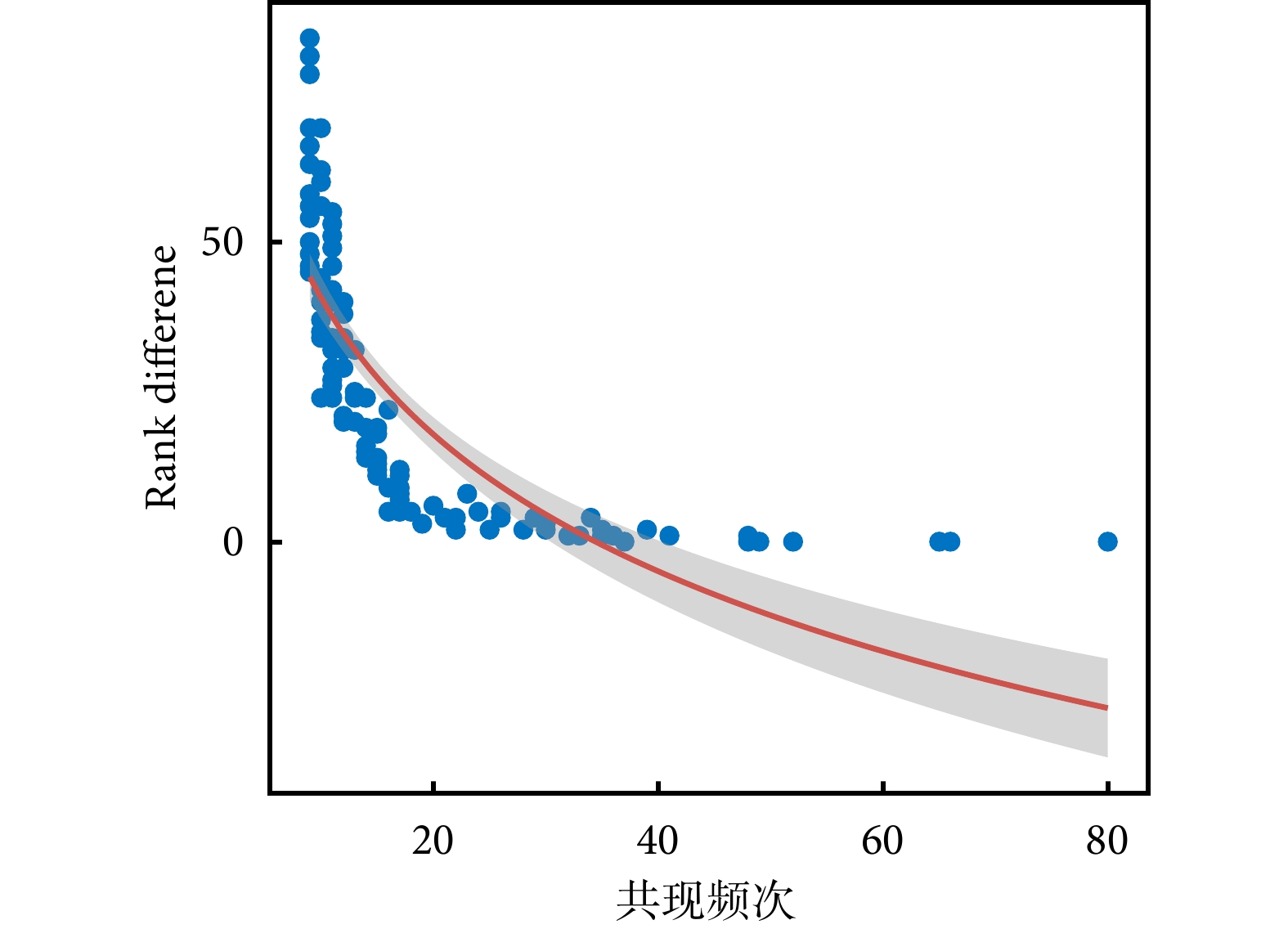
腧穴共現頻次為復雜網絡分析的邊權重。選取腧穴共現頻次大于30的組合進行對比展示,共篩選出16條穴對組合,加權算法對腧穴共現頻次排序存在影響,高頻腧穴組合受權重影響較小,而對部分腧穴有較大影響,如太沖-外關組合,見表4。進一步分析結果顯示,加權算法對腧穴共現頻次影響與腧穴頻次呈負相關(Spearman r=?0.961,P<0.001),見圖5。
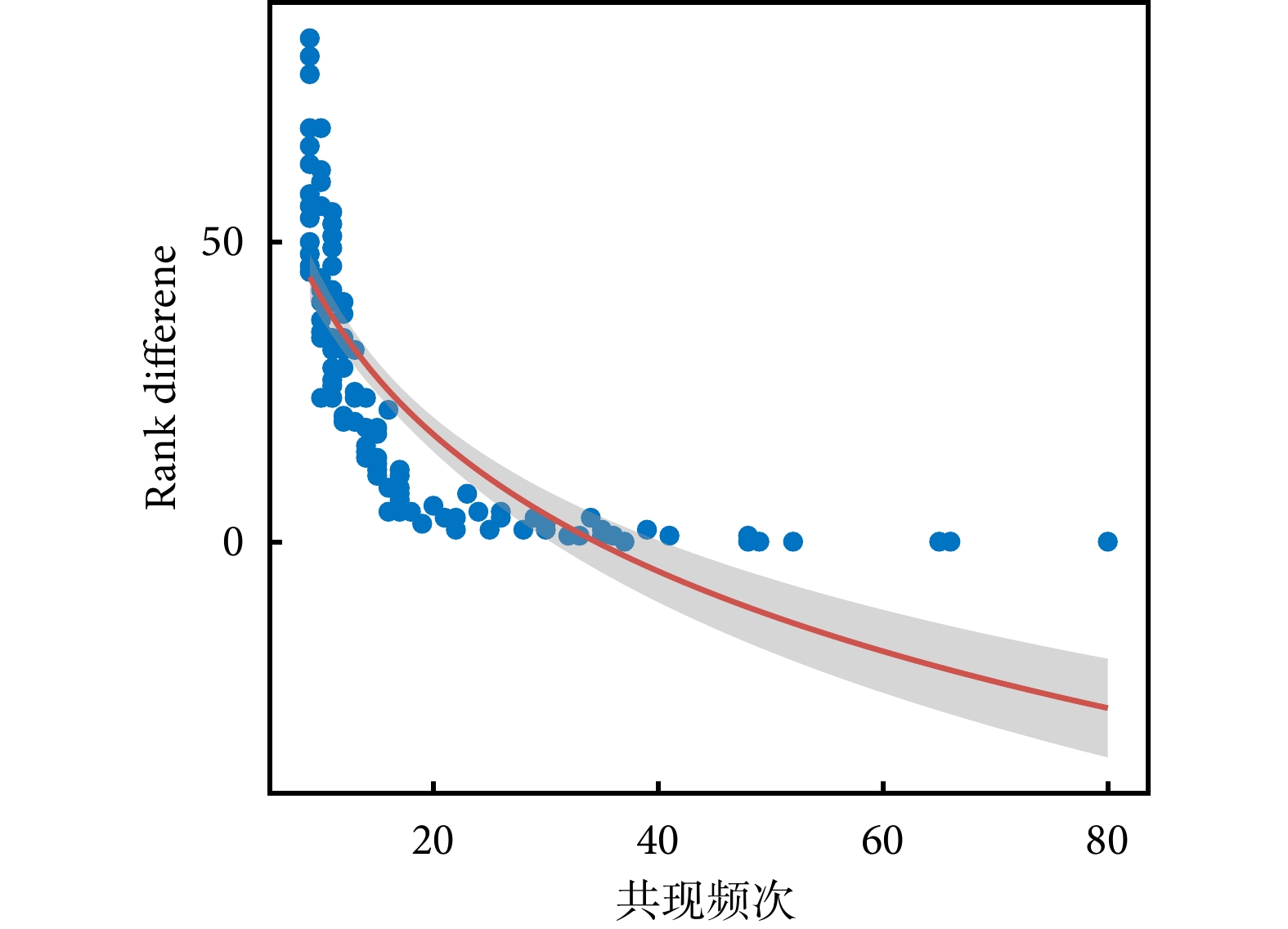 圖5
共現頻次與排序差值相關散點圖
圖5
共現頻次與排序差值相關散點圖
2.9 高頻腧穴層次聚類分析
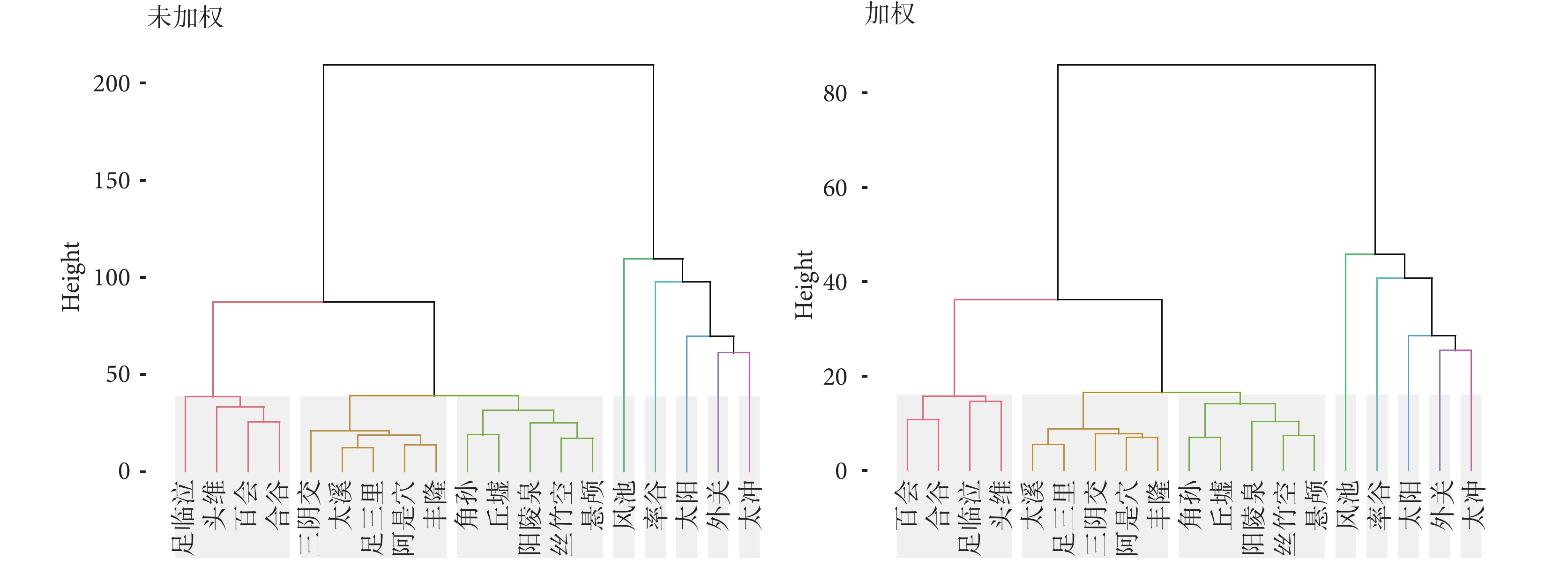
對高頻腧穴(頻次大于15)進行層次聚類分析,使用歐氏距離計算數據點之間的距離,使用Ward’s方法將數據點分組成簇,進而形成層次結構。結果顯示,未加權矩陣與加權矩陣聚類大類基本一致。但未加權聚類的樹狀圖總體高度更高,同時傾向于形成較大的簇,見圖6。
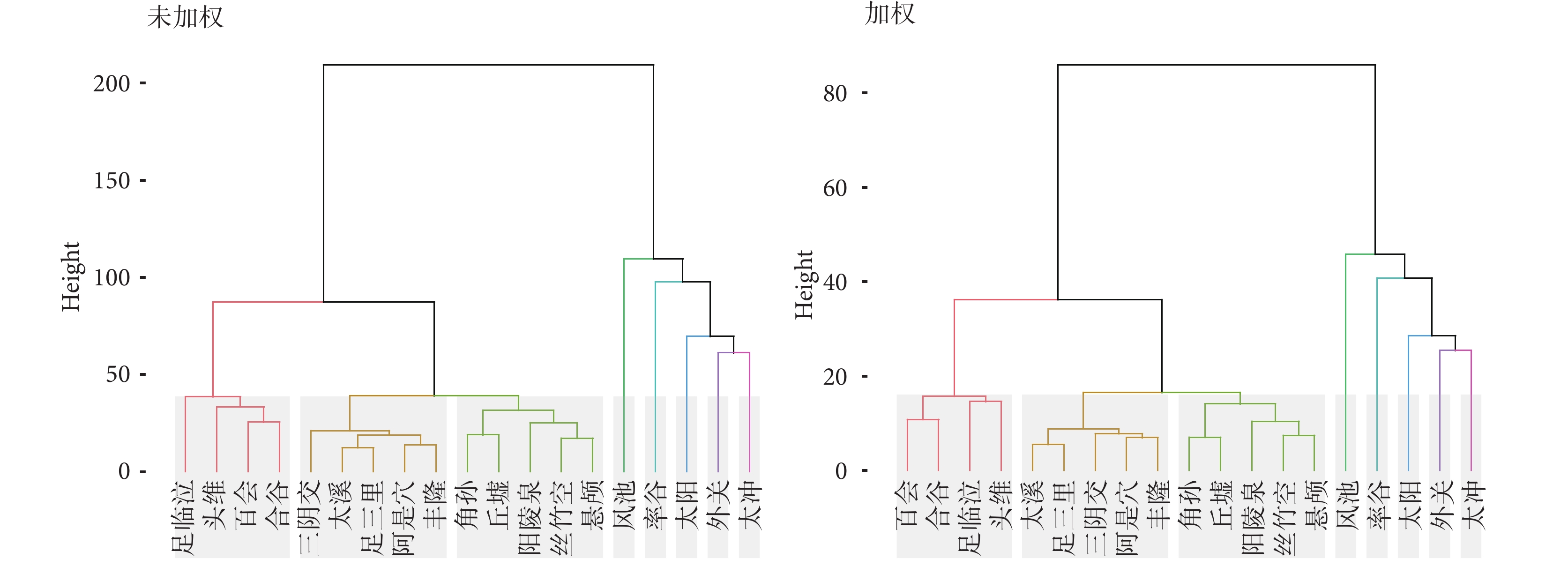 圖6
針刺治療偏頭痛的高頻腧穴層次聚類分析
圖6
針刺治療偏頭痛的高頻腧穴層次聚類分析
3 討論
針灸數據挖掘原始文獻內部特征評價一直是困擾臨床針灸數據挖掘類研究的問題,也是該類研究納入循證針灸學體系的阻礙之一。本研究在國內外數據科學領域相關加權數據挖掘算法的基礎上,提出“基于循證體系的針灸學數據挖掘算法”。該算法強調綜合考慮原始文獻的各種內部特征,采用熵權法對其各決策指標加權最終得到文獻的總權重后再行各種數據挖掘分析。本研究以偏頭痛為例應用該算法,并將其結果與經典數據挖掘算法進行比較,通過兩者結果差異探討經典算法與加權算法的臨床適用性,從而審視既往基于經典數據挖掘算法結論的臨床意義。
3.1 多指標決策和熵權法
恰當的決策指標選擇是發揮多指標決策優勢、進行合理決策的前提。本研究基于目前針灸腧穴挖掘所面臨的兩大難題—證據質量的模糊性與療效評價的不確定性出發,參考循證指南構建、系統評價等規范所體現出的證據評估要點,從證據等級、文獻質量、樣本量、臨床療效4個維度構建綜合決策指標。
首先,數據挖掘最終目的是探索出特定疾病潛在組方、組穴思路,而證據質量是給出推薦意見的重要考量因素[20],對證據質量進行分級,并在此基礎上結合患者價值觀和意愿作出推薦是循證醫學最顯著的特點[21]。在既往的數據挖掘過程中,文獻質量評價通常作為納入標準出現在研究中,但很少有研究者報告文獻質量評價的具體方法和結果。也有研究者在進行數據挖掘分析前構建“證據圖”,體現了原始證據質量的重視,但在實際操作中,證據評價和數據挖掘仍是兩個獨立的部分[4]。數據挖掘工作的特點在于對文獻數據的廣泛挖掘,過于限制證據質量則會影響文獻納入范圍,而納入研究證據質量過低則會降低數據挖掘的可信度。因此,將證據等級質量納入多指標決策成為一種可能的解決方案。JBI基于多元主義的哲學觀,提出多元化證據體系的來源適用于針灸學科數據挖掘工作的實際需要[14]。因此,本研究選用JBI提出的5級有效性研究證據預分類方案,并采用JBI提供的文獻質量評價工具對原始證據質量進行評價。
此外,樣本量大小是臨床研究設計的重要環節,直接關系到研究結論的可靠性、可重復性,以及研究效率的高低[22]。在一些指南中,樣本量作為證據分級或推薦等級的參考指標[23,24]。在針灸學領域,任玉蘭等提出的 “針灸臨床研究證據評價體系”也將樣本量作為研究質量評價的參數[25]。近年來,基于大數據的真實世界研究中醫藥領域應用場景日益廣泛[26],由此帶來不同研究間樣本量的差異逐漸增大。因而,在針灸學數據挖掘研究質量綜合評價過程中,樣本量應予以足夠的重視。
最后,轉化醫學的最終目標是提升療效而使患者獲益[27],選擇合適的、具有代表性的臨床療效評價指標是把握證據價值的關鍵。目前,療效指標作為權重指標在中藥處方挖掘中進行了探索性應用,如丁弋美等運用加權關聯規則分析對干燥綜合征的處方進行挖掘[13]、朱小林運用類似的思路分析了慢性腎臟病的中藥配伍[12]。在偏頭痛研究中,VAS評分、頭痛發作頻率、頭痛相關生活質量等指標是目前偏頭痛臨床試驗中常選用的指標,其中VAS對針刺的近期療效反應最為直接,同時可以體現針刺的長期療效[28]。考慮到多指標存在共線性關系、多指標帶來缺失值的增多,本研究最終選用VAS評分作為代表性指標。需要明確的是,辨證論治是中醫學科的鮮明特點,不同疾病在不同階段有著不同的特征及證候規律,分證、分期選擇合適的評價指標,并以此為亞組進行高質量的數據挖掘仍是今后數據挖掘工作的方向[29]。
確定測評指標體系的權重是系統測評的基礎[30]。指標體系權重的方法一般可分為主觀賦值法和客觀賦值法兩大類,熵值法是客觀賦權法的代表,其本質是根據指標所包含的信息量來決定其重要性。熵值法的應用既可最大限度利用數據的特征,與各種主觀賦權模型相比,熵值法能夠有效避免人為因素對指標權重的干擾,從而增強綜合評價結果的客觀性[19]。熵權法最終計算結果顯示樣本量、VAS評分差值是影響指標權重的主要因素,而文獻類型、文獻質量僅占較小的權重。究其原因,主要是納入的針刺干預偏頭痛臨床研究中92.3%為隨機對照研究,證據等級為1級,文獻質量評價在6~11分之間,證據等級與文獻質量在結果呈現上仍為等級資料,導致這兩項數據離散性較小,進而所占最終決策權重偏低。我們建議在后續研究中充分考慮文獻質量評價的實際情況,若該研究領域文獻質量整體較好可選用熵值法進行多指標決策,如文獻研究質量差異較大,可通過專家咨詢的方式以層次分析等方法確定指標權重。
3.2 加權數據挖掘算法與經典算法結果比較分析
以本研究為例,頻次統計和加權頻次統計結果對腧穴排序存在影響,但高頻腧穴如風池、率谷、太陽、太沖、外關受其影響較小,而中、低頻次腧穴則可因加權算法改變其原始順序。同樣的情況也出現在高頻腧穴組合的頻次差異上,據圖3所示,隨著腧穴頻次逐漸降低,加權與未加權算法對穴對共現頻次排序差異度的影響逐漸增大,一方面原因是加權算法對腧穴排序更加精確,減少了同一穴對共現頻次相同的情況,而另一方面則由于加權頻次是頻次和權重二者綜合影響的結果,高頻穴對排序時頻次占絕對優勢,而隨著頻次的降低權重因素的影響逐漸凸顯。偏頭痛文獻選穴較為集中,因而加權和未加權算法對高頻數據挖掘結果影響較小,若有研究選穴較為分散,則可能影響基于選穴頻次而采取的臨床決策。值得注意的是,選穴分散的研究往往更能體現腧穴數據挖掘研究方法的優勢和必要性。在關聯規則分析中,基于加權關聯規則分析算法的結果更能體現腧穴之間關聯程度的差異,使得不同穴位關聯規則支持度更為顯著。
從共現矩陣的網絡指標來看,加權共現矩陣具有更低的加權度。度就是一個節點連接邊的數量,加權度是考慮邊的權重后的總和。加權操作不會影響矩陣節點的共現關系,因此基于節點的指標在兩種算法間無明顯差異。但是,加權操作影響了邊的權重,在原始矩陣中所有邊的權重都為1,加權后的矩陣邊權重介于0~1之間,具有較低的整體加權度。這表明,在加權矩陣中,信息更加密集,更易突出高質量或療效較好的穴位。同樣,層次聚類分析結果也顯示加權矩陣和未加權矩陣聚類結構存在一定差異,加權處理影響了穴位共現矩陣的聚類結構。聚類的“高度”通常與簇內成員之間距離成正比[31]。未加權矩陣的樹狀圖總體上更高,表明形成簇的“距離”更大。因此,未加權的方法傾向于形成更大的簇,而這些簇中包含的成員數目相對較多。加權矩陣產生簇的高度較低,更傾向于形成小簇,其內的成員之間的相似度更高。具體在腧穴處方挖掘中,加權層次聚類分析可能更易發現潛在穴位配伍規律。從聚類結果看,基于復雜網絡社團聚類算法的核心處方聚類結果更能體現針灸學選學特點,如:太沖、合谷為四關穴,風池、率谷是膽經頭部要穴,外關、丘墟則體現出上下取穴的配伍原則。
綜上,在基于頻次和關聯規則的分析中,加權算法對高頻腧穴和關聯規則影響較小。數據挖掘的目的在于發現高頻條目,因而以往腧穴頻次集中研究中經典算法的結論仍然有效,而在選穴較為分散的研究中則更能體現出加權算法基于循證綜合評價后的優勢。在基于共現矩陣的網絡分析、社團聚類分析、層次聚類分析中,兩種算法的差異較大,加權后的矩陣信息更加集中,穴位間相似度增加,更有利于發現潛在的腧穴配伍規律。
3.3 加權數據挖掘算法拓展應用
本研究的應用對象為現代臨床針灸數據挖掘研究,針灸學數據挖掘技術在古籍挖掘中同樣具有廣泛應用。目前已有學者針對中醫古籍、針灸古籍進行了質量評級工作,可據此作為權重在古籍數據挖掘過程中進行賦權,進而開展基于中醫循證體系的古籍數據挖掘工作[32,33]。此外,《中共中央國務院關于促進中醫藥傳承創新發展的意見》指出,“加快構建中醫藥理論、人用經驗和臨床試驗相結合的中藥注冊審評證據體系”[34],人用經驗目前可作為支持中藥注冊審評證據體系的關鍵組成部分[35],目前已有學者提出中醫醫案臨床證據應用與療效評價體系[36],本研究提出的基于循證體系的加權數據挖掘算法可與名老中醫經驗挖掘進一步結合應用,以更好促進“人用經驗”向“循證證據”轉化。
3.4 結語
本研究從循證醫學角度出發對傳統數據挖掘算法進行了創新,提出了加權數據挖掘算法體系,使得數據挖掘結果綜合考慮了原始研究的證據質量與療效特征,整合了循證針灸學體系和數據挖掘工作流程,提升了數據挖掘結論的質量,增加了數據挖掘所得出的結論的合理性。相較于經典算法,本研究所提出的算法對發現潛在的優勢腧穴、探尋腧穴間隱含的配伍關系具有優勢。
需要注意的是,不同研究間臨床療效的差異不僅僅是由選穴差異所致,不同研究的針刺方法、電針應用等交互效應對患者的共同影響難以避免。本研究為探索性研究,諸類細節仍需后續多指標決策賦權時進一步優化考慮,如應進一步明確電針的使用、針刺的劑量-反應關系等因素對針刺療效的影響,考慮就不同疾病分期、證候分型特征等進行更為詳細的數據挖掘。在循證醫學的背景下,進行針灸學文獻研究的過程中原始研究的證據質量評價是所有研究者需謹慎對待的問題,如此才能推進適合針灸學科特色的循證醫學體系的進一步完善發展。
在當今大數據時代的背景下,數據挖掘技術在針灸學中得到了廣泛實踐,成為從針灸文獻大數據中獲得有效信息、探索隱含知識的重要研究手段[1]。針灸學數據挖掘研究目前廣泛應用于腧穴配伍規律、針刺效應、針刺手法等方面。作為其最主要的應用場景—腧穴處方挖掘近年來增長迅速,在明確核心腧穴、探究配伍規律、構建針灸處方等方面發揮了關鍵作用[2]。針灸數據挖掘是文獻學、循證醫學、信息科學與針灸學的交叉學科,在實際開展中易受到原始信息質量、數據挖掘算法應用、結果解釋等方面的不確定因素的干擾,進而影響研究的嚴謹性。有學者認為,部分針灸學數據挖掘面臨證據來源的問題,基于低質量的原始數據提煉匯總的結論難以對臨床實踐起到真正的指導作用[3]。此外,有益的挖掘結果來源于高質量的醫案與有效的處方,有研究者發現,目前中醫藥數據挖掘對臨床療效與個案質量重視不足[4]。事實上,目前臨床針灸腧穴挖掘研究僅針對研究方案實施前所擬定的腧穴,而忽略了其研究結果的可靠性。正因如此,很長一段時間以來,相關研究成果在臨床指南構建中尚未形成規模化、規范化的應用體系。
上述問題的存在呼吁針灸數據挖掘提供新的思路與方案,有學者提出數據挖掘應考慮與循證醫學證據聯用[5],然而目前尚未有算法實現腧穴挖掘結果和循證醫學證據質量的有機整合。因此,如何在數據挖掘過程中充分考慮證據質量等級、臨床療效等諸多因素,進而基于研究質量較高、臨床療效較為明確的腧穴進行系統性挖掘分析,成為針灸數據挖掘算法改進的著眼點。針灸數據挖掘涉及兩大核心的算法:關聯規則和聚類分析,其中聚類分析又以共現矩陣為基礎。隨著數據挖掘技術在各領域的推廣應用,關聯規則衍生出加權關聯規則算法[6-8],其充分考慮了項目的權重在數據中的重要性,為發現事務數據中重要項目之間隱藏關系提供了有效方法[9]。共現矩陣則衍生出根據項目權重賦值的加權共現矩陣算法。基于加權體系的算法在包括生物信息學、計算機文本挖掘在內的諸多領域進行了廣泛應用[10,11],并在中藥處方挖掘中以療效為權重進行了探索[12,13]。這些新算法的出現,為我們解決針灸腧穴挖掘循證證據整合問題提供了思路。因此,本研究以針刺干預偏頭痛研究為例,提出綜合考慮證據質量等級和臨床療效的加權數據挖掘算法,以期為針灸數據挖掘研究方法學和中醫藥證據轉化應用提供有益補充。
1 資料與方法
1.1 納入與排除標準
1.1.1 研究類型
針刺治療偏頭痛的臨床研究。
1.1.2 研究對象
偏頭痛患者,病例來源、年齡、性別及病程長短不限。
1.1.3 干預措施
試驗組采用針刺療法(針具、選穴、留針時間、療程等不限),若研究類型包含對照組,則對照組的治療方法不限。
1.1.4 結局指標
頭痛視覺模擬評分(visual analogue scale,VAS)。
1.1.5 排除標準
① 干預措施為針刺聯合中西醫其他診療方案;② 重復發表的文獻;③ 無法獲取全文或數據不全的文獻。
1.2 文獻檢索策略
計算機檢索PubMed、Embase、Web of Science、CBM、WanFang Data、VIP和CNKI數據庫,搜集針刺治療偏頭痛的臨床研究,檢索時限均為2013年1月至2023年8月。檢索采用主題詞與自由詞相結合的方式進行,并根據各數據庫特點進行調整。同時檢索納入研究的參考文獻,以補充獲取相關資料。中文檢索詞包括:針灸、針刺、電針、體針、頭針、偏頭痛、頭風等;英文檢索詞包括:acupuncture、migraine、hemicrania等。
1.3 納入研究的偏倚風險評價
采用復旦大學JBI循證護理合作中心翻譯的中文版“JBI干預性研究證據預分級系統[14]”將納入研究按實驗性研究、類實驗性研究、觀察性-分析性研究、觀察性-描述性研究、專家意見劃分為1~5級。采用“JBI循證衛生保健中心質量評價工具”對不同類型研究進行質量評價[15-17]。其中,隨機對照研究共13分,考慮到針灸操作施術者的盲法難以實施[18],因此“是否對干預者采取了盲法”條目指定為“不適用”,排除該條標準后共12分;類實驗研究總分9分;病例報告總分8分。因不同研究條目總分不同,將不同研究類型得分除以總分進行標準化。
1.4 文獻篩選與資料提取
由2名研究者獨立篩選文獻、提取資料并交叉核對。如有分歧,則通過討論或與第三方協商解決。資料提取內容包括:作者、標題、發表年份、針刺方案、臨床療效指標等。
1.5 多指標決策計算文獻綜合權重[19 ]
1.5.1 構建決策矩陣
一個多指標決策問題由以下3個要素構成:n個評價指標fj(1≤j≤n)、m個決策方案Ai(1≤i≤m)、1個決策矩陣D=(xij)m×n(1≤i≤m,1≤j≤n),其中元素xij表示第i個方案,第j個指標的值。在本研究中,決策對象Ai為所有納入數據挖掘研究的文獻,決策指標包括:證據等級、文獻質量、樣本量、治療前后VAS差值,據此構建決策矩陣。
1.5.2 決策指標賦值及定義
各決策指標按如下規則賦分:證據等級按1~5級分別賦為1~5分;文獻質量、樣本量、VAS差值為連續型資料,直接納入后續多指標決策計算。其中“證據等級”定義為成本型指標,即分值越低(證據等級越高)對決策越有利,其余指標均為效益型指標,即分值越高對決策越有利。
1.5.3 標準化決策矩陣
采用線性比例變化法對不同量綱指標進行標準化后,得到的矩陣R=(rij)m×n。
1.5.4 指標權重計算及多指標決策
采用熵值法計算各決策指標權重。熵值法是一種客觀賦權法,依據各指標值所包含的信息量的大小來確定指標權重。采用簡單線性加權法進行多指標決策,該方法通過計算各評價方案的線性加權和,并以此作為各決策對象的得分依據。
1.6 加權關聯規則分析
本研究采用R軟件arules包計算關聯規則,根據Ayse等提出的加權關聯分析算法進行規則加權[6]。該算法由如幾下步驟組成:① 設定初始最小支持度;② 運用Eclat算法獲得關聯規則;③ 計算每個項的平均權重;④ 對于每個規則,根據規則中存在的項的權重計算規則權重(公式1);⑤ 計算規則的加權支持度(weighted support,WSP)(公式2),并進行Min-Max標準化處理;⑥ 根據設定的支持度進一步篩選關聯規則,采用加權關聯規則算法對支持度進行加權處理。
|
|
其中,為一個項集(item set),是第k個項集,為該項集中項的個數,為第k項關聯規則。
1.7 構建加權共現矩陣
在進行復雜網絡分析和聚類分析時首先需構建共現矩陣。共現矩陣是一個展現不同類別之間鄰接關系的矩陣,而加權共現矩陣使其能夠反映鄰接類別的重要性。采用R語言for循環嵌套構建共現矩陣,在具體實現中首先對所有納入的穴位進行去重作為矩陣的行和列,然后遍歷每項研究,依次統計每對穴位共同出現在同一研究中的次數,從而構建出表示穴位共現關系的矩陣。在未加權矩陣中所有穴位權重相同,因而每對穴位共同出現1次記為1,而加權共現矩陣中,每對穴位所屬處方具有不同權重得分,故每對穴位共同出現1次記為1×處方權重系數。以圖1為例,在傳統共現矩陣中,有兩組處方中共同出現了風池和太陽,故其共現頻次為2。在加權共現矩陣中,處方1的權重為0.5,處方3權重為0.7,因而其加權共現頻次為1.2。
圖1
共現矩陣與加權共現矩陣對比示意圖
1.8 復雜網絡及聚類分析
運用Gephi 0.1.0對網絡進行可視化分析,計算網絡的度(degree centrality,DC)、加權度(weighted degree)、接近中心性(closeness centrality,CC)、中介中心性(betweenness centrality,BC)、圖密度、模塊度等參數,比較加權與加未權矩陣參數區別,根據Modularity的社團劃分算法進行聚類分析。根據腧穴共現頻次,對高頻共現穴對進行篩選,同時對高頻腧穴進行層次聚類分析。
2 結果
2.1 文獻篩選流程及結果
初檢共獲得文獻4 434篇,包括:PubMed(n=307)、Web of Science(n=372)、Embase(n=243)、CNKI(n=1 082)、WanFang Data(n=746)、VIP(n=563)、CBM(n=1 121),經逐層篩選后,最終納入117篇文獻,包含151條針灸處方,腧穴總頻次1 104次。
2.2 納入研究類型及質量評價結果
納入研究包含隨機對照試驗108篇、類實驗研究8篇、病例報道1篇。隨機對照試驗質量評價平均得分8.85±1.52分;類實驗研究平均得分5.00±2.20分;病例報道得分為6分。
2.3 熵權法確定各指標權重
采用熵值法確定不同決策指標的權重,按線性比例變化法對不同量綱指標進行標準化,分別計算各指標熵值、偏差度,據此計算各指標最終權重。結果顯示,文獻類型和文獻質量在最終評價中所占權重較低,而樣本量、VAS差值所占權重較高,其中又以VAS差值所占比例最高,見表1。
2.4 線性加權法進行多指標決策
根據熵權法所獲得的各納入腧穴處方的權重系數,采用線性加權法計算各納入研究進行多指標決策,151條處方最終權重得分呈正偏態分布(Skewness=0.521,K-S P=0.029),最低得分為0.173,最高得分為0.752,平均得分為0.428±0.107,得分分布見圖2。
圖2
線性加權得分分布直方圖
2.5 加權頻次分析
針刺治療偏頭痛的腧穴處方中,使用頻次大于15次的腧穴有20個。基于頻次統計和加權頻次統計所篩選出的高頻腧穴占比一致,累計頻率均大于70%。但加權算法對腧穴頻次排序產生影響,如足臨泣、合谷、頭維、百會、角孫、丘墟、三陰交、懸顱、足三里、豐隆、太溪、阿是穴等腧穴的頻次排序和加權頻次排序存在差異,見圖3。
圖3
腧穴頻次和累計頻率分布圖
2.6 加權關聯規則分析
設置Eclat算法初始支持度為0.1,共獲得123條關聯規則。對其進行加權、標準化處理后,設定WSP>0.25、置信度>0.8為篩選條件,加權算法共獲得26項關聯規則,未加權算法獲得11項關聯規則。在本研究中,較傳統未加權算法相比,同等條件下加權算法發現更多關聯規則,且不同關聯規則間支持度區別更為明顯,詳見表2。
2.7 復雜網絡特征分析
分別構建基于頻次的共現矩陣和加權共現矩陣,運用Gephi軟件構建復雜網絡,共獲得132個節點、
圖4
核心腧穴篩選流程圖
2.8 腧穴共現頻次分析
腧穴共現頻次為復雜網絡分析的邊權重。選取腧穴共現頻次大于30的組合進行對比展示,共篩選出16條穴對組合,加權算法對腧穴共現頻次排序存在影響,高頻腧穴組合受權重影響較小,而對部分腧穴有較大影響,如太沖-外關組合,見表4。進一步分析結果顯示,加權算法對腧穴共現頻次影響與腧穴頻次呈負相關(Spearman r=?0.961,P<0.001),見圖5。
圖5
共現頻次與排序差值相關散點圖
2.9 高頻腧穴層次聚類分析
對高頻腧穴(頻次大于15)進行層次聚類分析,使用歐氏距離計算數據點之間的距離,使用Ward’s方法將數據點分組成簇,進而形成層次結構。結果顯示,未加權矩陣與加權矩陣聚類大類基本一致。但未加權聚類的樹狀圖總體高度更高,同時傾向于形成較大的簇,見圖6。
圖6
針刺治療偏頭痛的高頻腧穴層次聚類分析
3 討論
針灸數據挖掘原始文獻內部特征評價一直是困擾臨床針灸數據挖掘類研究的問題,也是該類研究納入循證針灸學體系的阻礙之一。本研究在國內外數據科學領域相關加權數據挖掘算法的基礎上,提出“基于循證體系的針灸學數據挖掘算法”。該算法強調綜合考慮原始文獻的各種內部特征,采用熵權法對其各決策指標加權最終得到文獻的總權重后再行各種數據挖掘分析。本研究以偏頭痛為例應用該算法,并將其結果與經典數據挖掘算法進行比較,通過兩者結果差異探討經典算法與加權算法的臨床適用性,從而審視既往基于經典數據挖掘算法結論的臨床意義。
3.1 多指標決策和熵權法
恰當的決策指標選擇是發揮多指標決策優勢、進行合理決策的前提。本研究基于目前針灸腧穴挖掘所面臨的兩大難題—證據質量的模糊性與療效評價的不確定性出發,參考循證指南構建、系統評價等規范所體現出的證據評估要點,從證據等級、文獻質量、樣本量、臨床療效4個維度構建綜合決策指標。
首先,數據挖掘最終目的是探索出特定疾病潛在組方、組穴思路,而證據質量是給出推薦意見的重要考量因素[20],對證據質量進行分級,并在此基礎上結合患者價值觀和意愿作出推薦是循證醫學最顯著的特點[21]。在既往的數據挖掘過程中,文獻質量評價通常作為納入標準出現在研究中,但很少有研究者報告文獻質量評價的具體方法和結果。也有研究者在進行數據挖掘分析前構建“證據圖”,體現了原始證據質量的重視,但在實際操作中,證據評價和數據挖掘仍是兩個獨立的部分[4]。數據挖掘工作的特點在于對文獻數據的廣泛挖掘,過于限制證據質量則會影響文獻納入范圍,而納入研究證據質量過低則會降低數據挖掘的可信度。因此,將證據等級質量納入多指標決策成為一種可能的解決方案。JBI基于多元主義的哲學觀,提出多元化證據體系的來源適用于針灸學科數據挖掘工作的實際需要[14]。因此,本研究選用JBI提出的5級有效性研究證據預分類方案,并采用JBI提供的文獻質量評價工具對原始證據質量進行評價。
此外,樣本量大小是臨床研究設計的重要環節,直接關系到研究結論的可靠性、可重復性,以及研究效率的高低[22]。在一些指南中,樣本量作為證據分級或推薦等級的參考指標[23,24]。在針灸學領域,任玉蘭等提出的 “針灸臨床研究證據評價體系”也將樣本量作為研究質量評價的參數[25]。近年來,基于大數據的真實世界研究中醫藥領域應用場景日益廣泛[26],由此帶來不同研究間樣本量的差異逐漸增大。因而,在針灸學數據挖掘研究質量綜合評價過程中,樣本量應予以足夠的重視。
最后,轉化醫學的最終目標是提升療效而使患者獲益[27],選擇合適的、具有代表性的臨床療效評價指標是把握證據價值的關鍵。目前,療效指標作為權重指標在中藥處方挖掘中進行了探索性應用,如丁弋美等運用加權關聯規則分析對干燥綜合征的處方進行挖掘[13]、朱小林運用類似的思路分析了慢性腎臟病的中藥配伍[12]。在偏頭痛研究中,VAS評分、頭痛發作頻率、頭痛相關生活質量等指標是目前偏頭痛臨床試驗中常選用的指標,其中VAS對針刺的近期療效反應最為直接,同時可以體現針刺的長期療效[28]。考慮到多指標存在共線性關系、多指標帶來缺失值的增多,本研究最終選用VAS評分作為代表性指標。需要明確的是,辨證論治是中醫學科的鮮明特點,不同疾病在不同階段有著不同的特征及證候規律,分證、分期選擇合適的評價指標,并以此為亞組進行高質量的數據挖掘仍是今后數據挖掘工作的方向[29]。
確定測評指標體系的權重是系統測評的基礎[30]。指標體系權重的方法一般可分為主觀賦值法和客觀賦值法兩大類,熵值法是客觀賦權法的代表,其本質是根據指標所包含的信息量來決定其重要性。熵值法的應用既可最大限度利用數據的特征,與各種主觀賦權模型相比,熵值法能夠有效避免人為因素對指標權重的干擾,從而增強綜合評價結果的客觀性[19]。熵權法最終計算結果顯示樣本量、VAS評分差值是影響指標權重的主要因素,而文獻類型、文獻質量僅占較小的權重。究其原因,主要是納入的針刺干預偏頭痛臨床研究中92.3%為隨機對照研究,證據等級為1級,文獻質量評價在6~11分之間,證據等級與文獻質量在結果呈現上仍為等級資料,導致這兩項數據離散性較小,進而所占最終決策權重偏低。我們建議在后續研究中充分考慮文獻質量評價的實際情況,若該研究領域文獻質量整體較好可選用熵值法進行多指標決策,如文獻研究質量差異較大,可通過專家咨詢的方式以層次分析等方法確定指標權重。
3.2 加權數據挖掘算法與經典算法結果比較分析
以本研究為例,頻次統計和加權頻次統計結果對腧穴排序存在影響,但高頻腧穴如風池、率谷、太陽、太沖、外關受其影響較小,而中、低頻次腧穴則可因加權算法改變其原始順序。同樣的情況也出現在高頻腧穴組合的頻次差異上,據圖3所示,隨著腧穴頻次逐漸降低,加權與未加權算法對穴對共現頻次排序差異度的影響逐漸增大,一方面原因是加權算法對腧穴排序更加精確,減少了同一穴對共現頻次相同的情況,而另一方面則由于加權頻次是頻次和權重二者綜合影響的結果,高頻穴對排序時頻次占絕對優勢,而隨著頻次的降低權重因素的影響逐漸凸顯。偏頭痛文獻選穴較為集中,因而加權和未加權算法對高頻數據挖掘結果影響較小,若有研究選穴較為分散,則可能影響基于選穴頻次而采取的臨床決策。值得注意的是,選穴分散的研究往往更能體現腧穴數據挖掘研究方法的優勢和必要性。在關聯規則分析中,基于加權關聯規則分析算法的結果更能體現腧穴之間關聯程度的差異,使得不同穴位關聯規則支持度更為顯著。
從共現矩陣的網絡指標來看,加權共現矩陣具有更低的加權度。度就是一個節點連接邊的數量,加權度是考慮邊的權重后的總和。加權操作不會影響矩陣節點的共現關系,因此基于節點的指標在兩種算法間無明顯差異。但是,加權操作影響了邊的權重,在原始矩陣中所有邊的權重都為1,加權后的矩陣邊權重介于0~1之間,具有較低的整體加權度。這表明,在加權矩陣中,信息更加密集,更易突出高質量或療效較好的穴位。同樣,層次聚類分析結果也顯示加權矩陣和未加權矩陣聚類結構存在一定差異,加權處理影響了穴位共現矩陣的聚類結構。聚類的“高度”通常與簇內成員之間距離成正比[31]。未加權矩陣的樹狀圖總體上更高,表明形成簇的“距離”更大。因此,未加權的方法傾向于形成更大的簇,而這些簇中包含的成員數目相對較多。加權矩陣產生簇的高度較低,更傾向于形成小簇,其內的成員之間的相似度更高。具體在腧穴處方挖掘中,加權層次聚類分析可能更易發現潛在穴位配伍規律。從聚類結果看,基于復雜網絡社團聚類算法的核心處方聚類結果更能體現針灸學選學特點,如:太沖、合谷為四關穴,風池、率谷是膽經頭部要穴,外關、丘墟則體現出上下取穴的配伍原則。
綜上,在基于頻次和關聯規則的分析中,加權算法對高頻腧穴和關聯規則影響較小。數據挖掘的目的在于發現高頻條目,因而以往腧穴頻次集中研究中經典算法的結論仍然有效,而在選穴較為分散的研究中則更能體現出加權算法基于循證綜合評價后的優勢。在基于共現矩陣的網絡分析、社團聚類分析、層次聚類分析中,兩種算法的差異較大,加權后的矩陣信息更加集中,穴位間相似度增加,更有利于發現潛在的腧穴配伍規律。
3.3 加權數據挖掘算法拓展應用
本研究的應用對象為現代臨床針灸數據挖掘研究,針灸學數據挖掘技術在古籍挖掘中同樣具有廣泛應用。目前已有學者針對中醫古籍、針灸古籍進行了質量評級工作,可據此作為權重在古籍數據挖掘過程中進行賦權,進而開展基于中醫循證體系的古籍數據挖掘工作[32,33]。此外,《中共中央國務院關于促進中醫藥傳承創新發展的意見》指出,“加快構建中醫藥理論、人用經驗和臨床試驗相結合的中藥注冊審評證據體系”[34],人用經驗目前可作為支持中藥注冊審評證據體系的關鍵組成部分[35],目前已有學者提出中醫醫案臨床證據應用與療效評價體系[36],本研究提出的基于循證體系的加權數據挖掘算法可與名老中醫經驗挖掘進一步結合應用,以更好促進“人用經驗”向“循證證據”轉化。
3.4 結語
本研究從循證醫學角度出發對傳統數據挖掘算法進行了創新,提出了加權數據挖掘算法體系,使得數據挖掘結果綜合考慮了原始研究的證據質量與療效特征,整合了循證針灸學體系和數據挖掘工作流程,提升了數據挖掘結論的質量,增加了數據挖掘所得出的結論的合理性。相較于經典算法,本研究所提出的算法對發現潛在的優勢腧穴、探尋腧穴間隱含的配伍關系具有優勢。
需要注意的是,不同研究間臨床療效的差異不僅僅是由選穴差異所致,不同研究的針刺方法、電針應用等交互效應對患者的共同影響難以避免。本研究為探索性研究,諸類細節仍需后續多指標決策賦權時進一步優化考慮,如應進一步明確電針的使用、針刺的劑量-反應關系等因素對針刺療效的影響,考慮就不同疾病分期、證候分型特征等進行更為詳細的數據挖掘。在循證醫學的背景下,進行針灸學文獻研究的過程中原始研究的證據質量評價是所有研究者需謹慎對待的問題,如此才能推進適合針灸學科特色的循證醫學體系的進一步完善發展。