大型語言模型(LLM)是基于海量數據進行預訓練的超大型深度學習模型,ChatGPT是LLM在生成模型應用方面的代表。隨著ChatGPT于2022年底發布,生成式聊天機器人已被普遍應用于醫學各領域。作為指導臨床實踐的重要學科,循證醫學中ChatGPT等聊天機器人的應用也在逐漸增加,但目前其在循證醫學領域應用的潛力、環節等內容尚不清楚。本文主要通過對相關文獻的回顧和總結,凝練和探討ChatGPT在循證醫學領域應用的前景、挑戰以及注意事項,從證據的生產、綜合、評價以及傳播和實施四個方面進行闡述,旨在為研究人員提供最新進展和未來研究建議。
引用本文: 羅旭飛, 呂晗, 史乾靈, 王子君, 劉輝, 朱迪, 王曄, 陳耀龍. 大語言模型在循證醫學領域的應用. 中國循證醫學雜志, 2024, 24(4): 373-377. doi: 10.7507/1672-2531.202312067 復制
版權信息: ?四川大學華西醫院華西期刊社《中國循證醫學雜志》版權所有,未經授權不得轉載、改編
2022年底,基于大型語言模型(large language model,LLM)的多個生成式聊天機器人(Chatbots)先后全球發布,給各個領域帶來了巨大的機遇和挑戰[1]。代表性產品包括ChatGPT(chat generative pre-training transformer)、Google Bard、Microsoft Bing、Claude等。ChatGPT作為生成式聊天機器人的典型代表,能夠為醫學領域的知識獲取、診療決策咨詢、醫學圖像識別、醫學研究質量評估、醫學語言潤色等方面提供多方面的支持,有望顯著提高醫學診療與研究的效率[2-5]。
循證醫學作為支撐醫療決策與高質量醫學研究的關鍵學科,在為醫學實踐提供高質量研究證據的同時,還承擔了證據評價、實施及傳播的重要角色。在循證醫學領域,LLM具有哪些潛在應用場景、存在何種挑戰和不足,仍有待分析和探討。
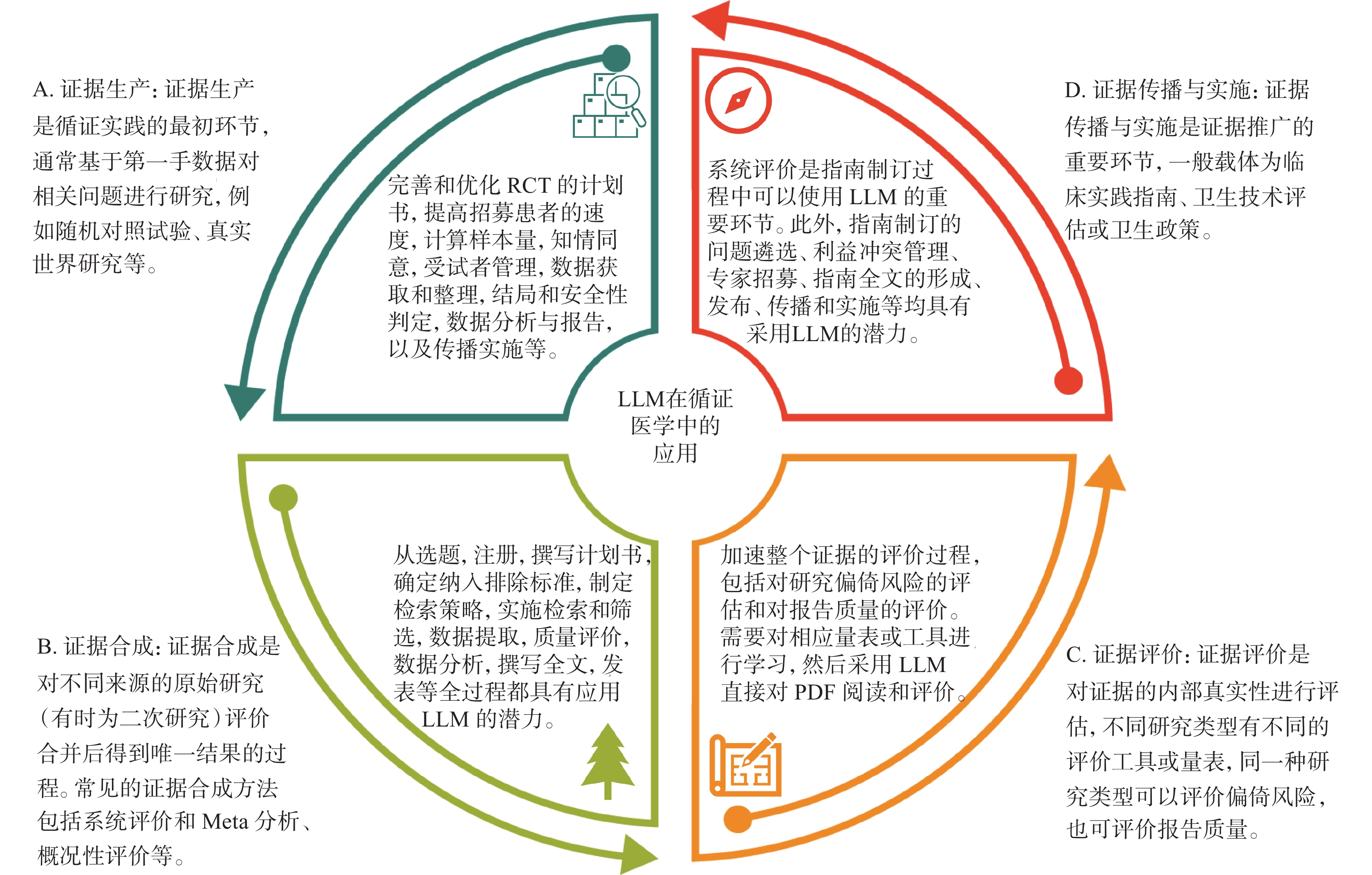
本文以基于LLM的最常見工具ChatGPT為例,從臨床研究(證據生產)、系統評價(證據合成)、循證評價(證據評價)以及臨床實踐指南(證據傳播和實施)4個方面(圖1),深入探討LLM在循證醫學領域的應用前景、面臨的挑戰以及需要注意的事項,為研究者提供借鑒和參考。
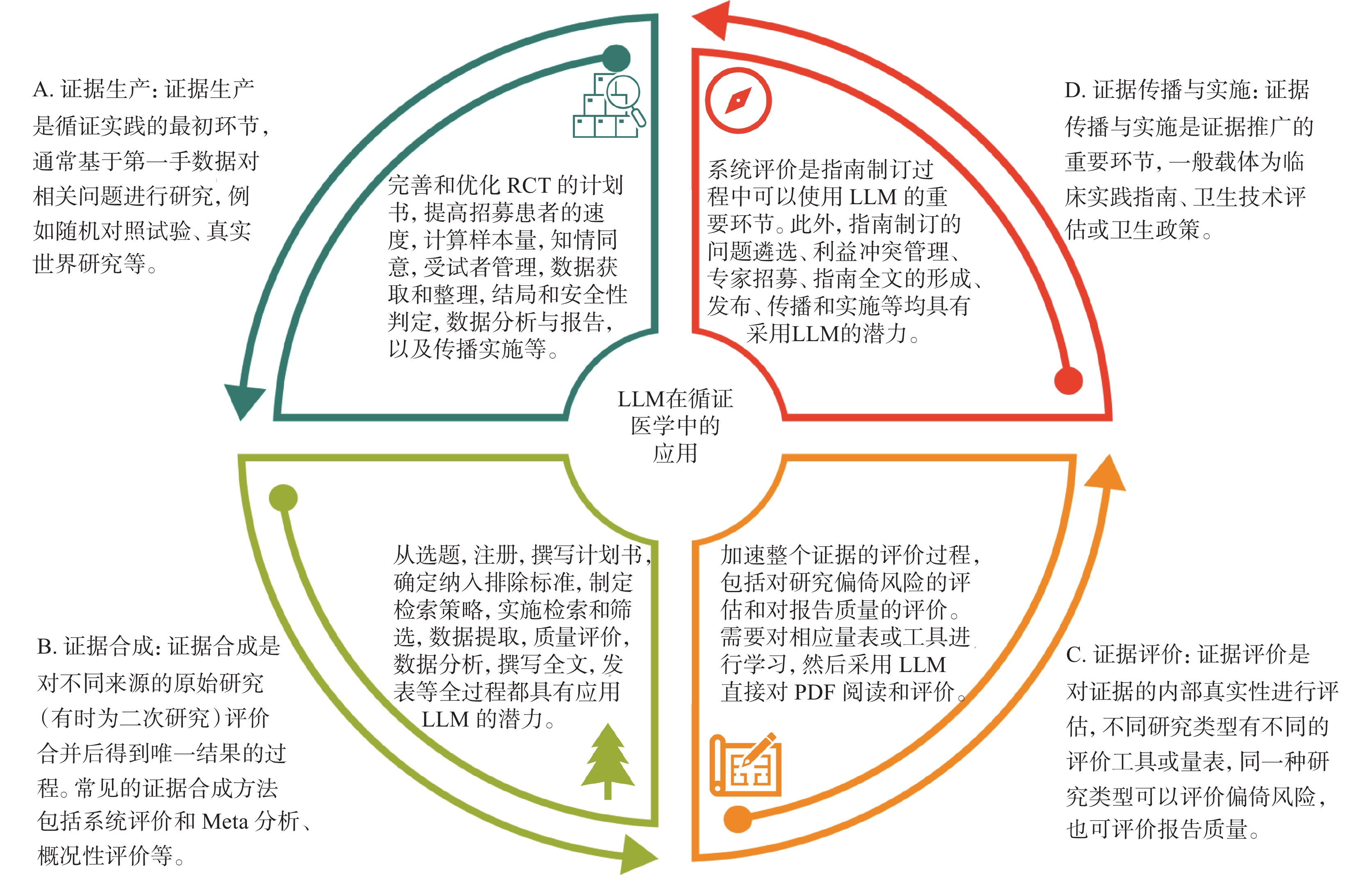 圖1
大語言模型(LLM)在循證醫學領域的應用
圖1
大語言模型(LLM)在循證醫學領域的應用
1 LLM和臨床研究
臨床研究是評估干預措施療效和安全性的重要手段,隨機對照試驗(randomized controlled trial, RCT)被認為是評估新藥和干預措施的最佳標準[6]。已有研究表明,ChatGPT等LLM工具可以幫助完善和優化RCT的計劃書[7]、提高RCT招募患者的速度[8]、計算樣本量[9]、初擬知情同意文件、協助管理受試者并整理數據,在結果和安全性判定、數據分析與報告、傳播實施[10]等多方面也具有一定優勢。經個性化交互,ChatGPT還可計算橫斷面等多種研究設計的樣本量。ChatGPT也可應用于真實世界研究[11]和觀察性研究[12]的設計和優化,其應用的環節包括數據清理和預處理、模型訓練以及結果解釋。然而,研究者需要注意應用LLM的潛在的風險,包括數據的偏倚和不公平性、隱私和數據安全、數據的可解釋性以及監管問題等[10]。
2 LLM和系統評價
系統評價和Meta分析是經過系統檢索和嚴格評價后的證據,是臨床實踐指南制訂的重要基石。系統評價的制作步驟一般包括確定選題、注冊、撰寫計劃書、確定納入和排除標準、制定檢索策略、實施檢索、篩選文獻、提取數據、評價偏倚風險、數據分析和合成、證據質量分級、撰寫全文和投稿發表[13-15]。目前,已經有許多研究[16-20]探討LLM在系統評價和Meta分析制作過程中的應用策略,在多個研究步驟中發揮作用,顯著降低了研究耗時、提升了研究效率和效果[21](表1)。
3 LLM和循證評價
證據評價是采用量表或評價工具,對不同研究類型的內部真實性進行評價,一般包括偏倚風險評價和報告質量評價。針對RCT,常用的偏倚風險評價工具為RoB[30]或RoB 2[31]工具,也可采用報告規范CONSORT[32] 評價RCT的報告質量。然而,在RCT研究偏倚風險判斷方面,ChatGPT與RoB 2的一致性較低,提示目前ChatGPT難以可靠地評估RCT的偏倚風險[33]。近期也有研究采用ChatGPT評價RCT的報告質量,Bland-Altman分析顯示人工評估和ChatGPT在總體得分的平均差異小,僅為4.92%[95%CI(0.62%,0.37%)],提示LLM在一定程度上也可以協助評估文獻,提高評估效率[34]。
4 LLM和臨床實踐指南
臨床實踐指南是基于系統評價的證據,考慮證據質量、患者偏好、利弊平衡后形成的指導臨床實踐的文件[35]。系統評價是指南制訂的重要環節,如果采用LLM提高系統評價的效率和效果,也將有力加速指南的制訂過程。此外,ChatGPT也可協助遴選指南優先回答的臨床問題[36]、查找相關領域的專家[37]以組建更權威的指南制訂工作組、幫助識別利益沖突[38]、協助解決爭議問題并達成共識[39]、制訂和優化指南的傳播與實施策略、推薦投稿期刊、協助改編指南等[40]。但鑒于指南制訂具有嚴謹的規范和流程,仍需多領域專家對LLM提供的結果進行嚴格驗證。
5 LLM在循證醫學領域的應用前景和挑戰
隨著人工智能的不斷發展,其在循證醫學領域的應用范圍逐漸擴大,從研究的生產到評價,再到實施,圍繞證據生態系統的全過程,LLM可發揮不同的優勢。從整體效果而言,LLM不僅可以幫助完善研究設計,還可以參與研究評價、生成研究結果,顯著加速了研究過程,節約大量的時間和資源,具有較高的應用前景。
然而,LLM依然面臨諸多挑戰[41]。首先,在制作系統評價或制訂臨床實踐指南的整個過程中,尚無基于LLM“一體化”的應用平臺或系統,目前應用的軟件或半自動化軟件需要在不同的工具或軟件之間切換才能完成全部任務;其次,針對ChatGPT等工具自動生成的內容,可能存在潛在的偏倚,LLM常常生成錯誤或不準確的內容,需要人工進行驗證,也需要對結果的可解釋性進行探討;同時,在循證醫學領域應用 ChatGPT等LLM工具,需要考慮潛在的隱私、倫理問題[42]以及學術造假問題,ChatGPT的訓練數據并非完全來自專門的醫療數據庫,面對錯綜復雜的醫學,應用時應該更加注意這些問題;最后,LLM本身也可能會影響研究者的使用,比如文本長度的限制、文獻更新滯后的問題,以及不同的LLM產品在不同國家和地區的可及性問題等。
LLM的應用既存在獲益也存在風險,是一把“雙刃劍”[43-45],關鍵在于我們如何在遵循規則的前提下發揮其最大的作用。因此,我們建議在循證領域應用LLM工具時,政策制定者應該制訂嚴格的指導和監管方針,研究者應該開發透明和科學的LLM工具以及相應的報告指南[46-48],使用者應該積極接受LLM的訓練,使用LLM時嚴格遵循相關的指導指南,并參考相應研究機構和期刊的要求[49]。
2022年底,基于大型語言模型(large language model,LLM)的多個生成式聊天機器人(Chatbots)先后全球發布,給各個領域帶來了巨大的機遇和挑戰[1]。代表性產品包括ChatGPT(chat generative pre-training transformer)、Google Bard、Microsoft Bing、Claude等。ChatGPT作為生成式聊天機器人的典型代表,能夠為醫學領域的知識獲取、診療決策咨詢、醫學圖像識別、醫學研究質量評估、醫學語言潤色等方面提供多方面的支持,有望顯著提高醫學診療與研究的效率[2-5]。
循證醫學作為支撐醫療決策與高質量醫學研究的關鍵學科,在為醫學實踐提供高質量研究證據的同時,還承擔了證據評價、實施及傳播的重要角色。在循證醫學領域,LLM具有哪些潛在應用場景、存在何種挑戰和不足,仍有待分析和探討。
本文以基于LLM的最常見工具ChatGPT為例,從臨床研究(證據生產)、系統評價(證據合成)、循證評價(證據評價)以及臨床實踐指南(證據傳播和實施)4個方面(圖1),深入探討LLM在循證醫學領域的應用前景、面臨的挑戰以及需要注意的事項,為研究者提供借鑒和參考。
圖1
大語言模型(LLM)在循證醫學領域的應用
1 LLM和臨床研究
臨床研究是評估干預措施療效和安全性的重要手段,隨機對照試驗(randomized controlled trial, RCT)被認為是評估新藥和干預措施的最佳標準[6]。已有研究表明,ChatGPT等LLM工具可以幫助完善和優化RCT的計劃書[7]、提高RCT招募患者的速度[8]、計算樣本量[9]、初擬知情同意文件、協助管理受試者并整理數據,在結果和安全性判定、數據分析與報告、傳播實施[10]等多方面也具有一定優勢。經個性化交互,ChatGPT還可計算橫斷面等多種研究設計的樣本量。ChatGPT也可應用于真實世界研究[11]和觀察性研究[12]的設計和優化,其應用的環節包括數據清理和預處理、模型訓練以及結果解釋。然而,研究者需要注意應用LLM的潛在的風險,包括數據的偏倚和不公平性、隱私和數據安全、數據的可解釋性以及監管問題等[10]。
2 LLM和系統評價
系統評價和Meta分析是經過系統檢索和嚴格評價后的證據,是臨床實踐指南制訂的重要基石。系統評價的制作步驟一般包括確定選題、注冊、撰寫計劃書、確定納入和排除標準、制定檢索策略、實施檢索、篩選文獻、提取數據、評價偏倚風險、數據分析和合成、證據質量分級、撰寫全文和投稿發表[13-15]。目前,已經有許多研究[16-20]探討LLM在系統評價和Meta分析制作過程中的應用策略,在多個研究步驟中發揮作用,顯著降低了研究耗時、提升了研究效率和效果[21](表1)。
3 LLM和循證評價
證據評價是采用量表或評價工具,對不同研究類型的內部真實性進行評價,一般包括偏倚風險評價和報告質量評價。針對RCT,常用的偏倚風險評價工具為RoB[30]或RoB 2[31]工具,也可采用報告規范CONSORT[32] 評價RCT的報告質量。然而,在RCT研究偏倚風險判斷方面,ChatGPT與RoB 2的一致性較低,提示目前ChatGPT難以可靠地評估RCT的偏倚風險[33]。近期也有研究采用ChatGPT評價RCT的報告質量,Bland-Altman分析顯示人工評估和ChatGPT在總體得分的平均差異小,僅為4.92%[95%CI(0.62%,0.37%)],提示LLM在一定程度上也可以協助評估文獻,提高評估效率[34]。
4 LLM和臨床實踐指南
臨床實踐指南是基于系統評價的證據,考慮證據質量、患者偏好、利弊平衡后形成的指導臨床實踐的文件[35]。系統評價是指南制訂的重要環節,如果采用LLM提高系統評價的效率和效果,也將有力加速指南的制訂過程。此外,ChatGPT也可協助遴選指南優先回答的臨床問題[36]、查找相關領域的專家[37]以組建更權威的指南制訂工作組、幫助識別利益沖突[38]、協助解決爭議問題并達成共識[39]、制訂和優化指南的傳播與實施策略、推薦投稿期刊、協助改編指南等[40]。但鑒于指南制訂具有嚴謹的規范和流程,仍需多領域專家對LLM提供的結果進行嚴格驗證。
5 LLM在循證醫學領域的應用前景和挑戰
隨著人工智能的不斷發展,其在循證醫學領域的應用范圍逐漸擴大,從研究的生產到評價,再到實施,圍繞證據生態系統的全過程,LLM可發揮不同的優勢。從整體效果而言,LLM不僅可以幫助完善研究設計,還可以參與研究評價、生成研究結果,顯著加速了研究過程,節約大量的時間和資源,具有較高的應用前景。
然而,LLM依然面臨諸多挑戰[41]。首先,在制作系統評價或制訂臨床實踐指南的整個過程中,尚無基于LLM“一體化”的應用平臺或系統,目前應用的軟件或半自動化軟件需要在不同的工具或軟件之間切換才能完成全部任務;其次,針對ChatGPT等工具自動生成的內容,可能存在潛在的偏倚,LLM常常生成錯誤或不準確的內容,需要人工進行驗證,也需要對結果的可解釋性進行探討;同時,在循證醫學領域應用 ChatGPT等LLM工具,需要考慮潛在的隱私、倫理問題[42]以及學術造假問題,ChatGPT的訓練數據并非完全來自專門的醫療數據庫,面對錯綜復雜的醫學,應用時應該更加注意這些問題;最后,LLM本身也可能會影響研究者的使用,比如文本長度的限制、文獻更新滯后的問題,以及不同的LLM產品在不同國家和地區的可及性問題等。
LLM的應用既存在獲益也存在風險,是一把“雙刃劍”[43-45],關鍵在于我們如何在遵循規則的前提下發揮其最大的作用。因此,我們建議在循證領域應用LLM工具時,政策制定者應該制訂嚴格的指導和監管方針,研究者應該開發透明和科學的LLM工具以及相應的報告指南[46-48],使用者應該積極接受LLM的訓練,使用LLM時嚴格遵循相關的指導指南,并參考相應研究機構和期刊的要求[49]。