離散選擇實驗(discrete choice experiment,DCE)是一種評估多因素對個體選擇產生影響的陳述性偏好分析方法,被國內外學者探究用于健康效用測量。該方法被認為可減輕傳統效用測量方法的認知負擔,具有較好的發展潛力。通過研究國內外已開展的采用DCE進行健康效用測量的實證研究,結合有關DCE模型構建的方法學指南,本文概述了DCE的方法學背景、用于測量健康效用的實踐流程,并對相關的應用挑戰進行了討論。
引用本文: 張曉路, 李睿, 高鑫, 肖非易, 羅川朝, 彭馨, 郭武棟, 李雪. 基于離散選擇實驗測量健康效用的方法學研究. 中國循證醫學雜志, 2024, 24(12): 1442-1450. doi: 10.7507/1672-2531.202405008 復制
版權信息: ?四川大學華西醫院華西期刊社《中國循證醫學雜志》版權所有,未經授權不得轉載、改編
生命質量(quality of life,QoL)是一個用以衡量個人軀體功能、精神健康、經濟水平和社會關系等多方面綜合質量水平的概念。隨著社會的發展,人們越來越注重對自身健康質量的管理,由此產生了有關健康相關生活質量(health-related quality of life,HRQOL)的研究。HRQOL是指受疾病、傷殘、衰老或治療導致的身體缺陷、身體功能狀態改變、認知改變或社會功能改變而影響生存時間的價值,該價值也受個體偏好和主觀判斷的影響[1,2]。為了對HRQOL進行量化研究,醫學工作者嘗試借鑒傳統經濟學的概念—效用(utility),在藥物經濟學中評價個人或群體對某種醫療干預措施導致的健康結果的偏好程度[3]。目前,最常用的藥物經濟學評價方法是成本-效用分析(cost-utility analysis,CUA),并被國內最新版的藥物經濟學指南所推薦[4]。
衡量效用的指標一般包括質量調整生命年(quality-adjusted life years,QALYs)、傷殘調整生命年(disability-adjusted life years,DALYs)、挽救年輕生命當量(saved young life equivalents,SAVEs)等。其中,QALYs是最常用的指標,其計算方法為:特定健康狀態下的生存年數乘以該健康狀態QoL的權重(即健康效用)。因此,健康效用是計算QALYs的關鍵。通常規定,死亡的健康效用值為0,完全健康的健康效用值為1,其他健康狀態的效用值則以完全健康和死亡標定測得,取值范圍為0~1。存在小于0的效用值,以描述“生不如死”的健康狀態[3]。
通常,健康效用的測量需采用基于偏好的技術方法,常見偏好測量方法及對比結果如表1所示[5,6]。其中,DCE作為一種新興的效用測量方法,基于完善的理論測量框架,可提供統計學上穩健的實驗設計與建模方法,僅需對選擇集進行選擇即可測量出個體偏好,更接近于真實世界下的決策場景,被認為可能減輕患者認知負擔且易于通過線上收集數據,因此具有較高的發展潛力[7]。目前DCE在國外健康效用測量領域中的應用已相對成熟,在EQ-5D[8]、SF-6DV2[9]、FACT-8D[10]和QLU-C10D[11]等量表的效用值積分體系構建中均有運用,但在國內相關領域尚處于起步階段。本文旨在介紹DCE應用于健康效用測量的方法學原理、步驟和挑戰等,希望為國內相關研究提供參考。
1 DCE方法學背景
1.1 DCE在醫療領域的發展歷程
20世紀50年代后,DCE相關理論研究開始興起。隨著研究的持續深入,DCE方法學不斷發展,其應用領域也在逐漸擴大(圖1)[12,13]。20世紀90年代早期,DCE開始被應用于醫療健康領域,可提供醫療決策主體對不同醫療干預屬性水平的偏好信息( 值)、水平間的權衡信息以及選擇某種特定干預的概率(uptake rates,UR)等[14-16]。近年,該方法已經逐漸發展成為量化患者偏好[17]、醫務工作者就業偏好[18]、醫療資源配置以及其他醫療相關主體偏好的常用方法,可為醫療政策制定提供決策依據[12]。21世紀以來,科研工作者不斷探索將DCE方法應用于健康效用測量,但受限于該方法自身的局限性及效用測量的客觀要求,DCE在效用測量領域的應用方法尚未達成共識,仍處于積極探索階段。因此,本研究所提出的基于DCE測量健康效用的方法學,僅是對國內外現有研究的總結與思考,以促進該方法在國內的應用和發展。
值)、水平間的權衡信息以及選擇某種特定干預的概率(uptake rates,UR)等[14-16]。近年,該方法已經逐漸發展成為量化患者偏好[17]、醫務工作者就業偏好[18]、醫療資源配置以及其他醫療相關主體偏好的常用方法,可為醫療政策制定提供決策依據[12]。21世紀以來,科研工作者不斷探索將DCE方法應用于健康效用測量,但受限于該方法自身的局限性及效用測量的客觀要求,DCE在效用測量領域的應用方法尚未達成共識,仍處于積極探索階段。因此,本研究所提出的基于DCE測量健康效用的方法學,僅是對國內外現有研究的總結與思考,以促進該方法在國內的應用和發展。
 圖1
DCE方法學的發展歷程
圖1
DCE方法學的發展歷程
1.2 DCE方法學原理
DCE是一種評估多因素對個體選擇產生影響的偏好分析方法。該方法超越了傳統的定性方法、排序方法以及一些分級方法,可提供關于偏好強度、權衡(如支付意愿)以及接受概率的定量信息[19]。通常,偏好測量可分為基于現實場景的顯示性偏好(revealed preference,RP)和基于假設場景的陳述性偏好(stated preference,SP)[20-22]。DCE作為一種SP方法,起源于數學心理學,它將隨機效用理論與消費者理論、實驗設計理論和計量經濟學分析相結合所形成[23]。該方法假設:在特定場景下,具有特定個體屬性的理性主體,面對現存的具有特定屬性的選擇集I,會基于效用最大化準則,選擇可為其提供最大效用的方案j。由于其他外部觀察者通常不能準確得知,對于決策者來說效用最大的選擇,因此只能計算反映決策者在全部選擇集I中選擇選項j的概率,如公式(1)所示[24,25]:
 |
其中, 和
和  分別代表兩種選擇可為決策者帶來的效用,
分別代表兩種選擇可為決策者帶來的效用, 由可解釋的系統性系數
由可解釋的系統性系數  (固定)和不可解釋的隨機性系數
(固定)和不可解釋的隨機性系數  (隨機)組成,如公式(2)所示:
(隨機)組成,如公式(2)所示:
 |
其中,隨機項 一般被認為是由于選項的不可觀測屬性、偏好變化,模型設定誤差和/或測量誤差所形成的變量;而
一般被認為是由于選項的不可觀測屬性、偏好變化,模型設定誤差和/或測量誤差所形成的變量;而 可解釋為由商品或服務和決策主體的個體屬性所構成的變量,因此可進一步建立模型如公式(3)所示:
可解釋為由商品或服務和決策主體的個體屬性所構成的變量,因此可進一步建立模型如公式(3)所示:
 |
其中, 為商品或服務特征的變量合集,
為商品或服務特征的變量合集, 為決策主體的個人特征,
為決策主體的個人特征, 和
和 分別為對應變量的系數。通過上述3個公式的相互銜接,即可實現將決策者選擇選項j的概率,同商品或服務特征以及決策主體的個人特征等變量進行數理統計,從而獲得定量的偏好測量結果。
分別為對應變量的系數。通過上述3個公式的相互銜接,即可實現將決策者選擇選項j的概率,同商品或服務特征以及決策主體的個人特征等變量進行數理統計,從而獲得定量的偏好測量結果。
2 DCE測量健康效用的主要步驟
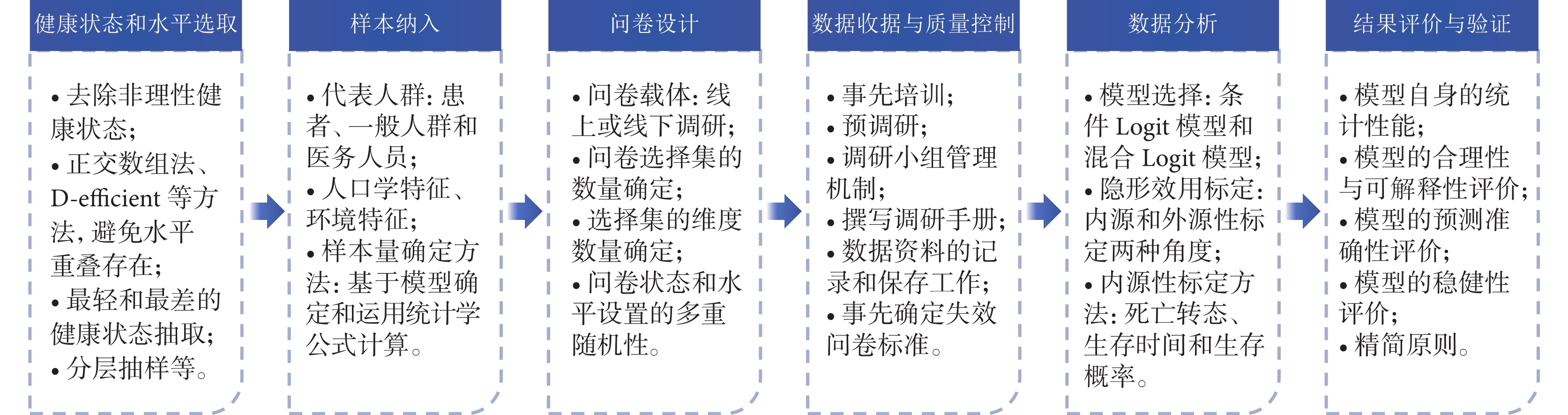
傳統DCE的設計和實施主要包括以下步驟:概念選擇,屬性和水平設置,實驗設計,問卷設計,試點測試,抽樣方法和樣本量計算,數據收集,數據清洗,計量經濟學分析,政策分析、解釋與轉化等[24]。由于采用DCE測量健康效用時,通常是針對已經建立了健康狀態分類系統(health state classification system,HSCS)[26]的非效用量表,其概念、屬性、水平等均已確定,數據分析結果也僅用于建立評分算法,無需政策轉化。因此,參照國內外已開展的相關研究[8-11],研究將利用DCE測量健康效用的過程分為6個關鍵步驟(圖2)。
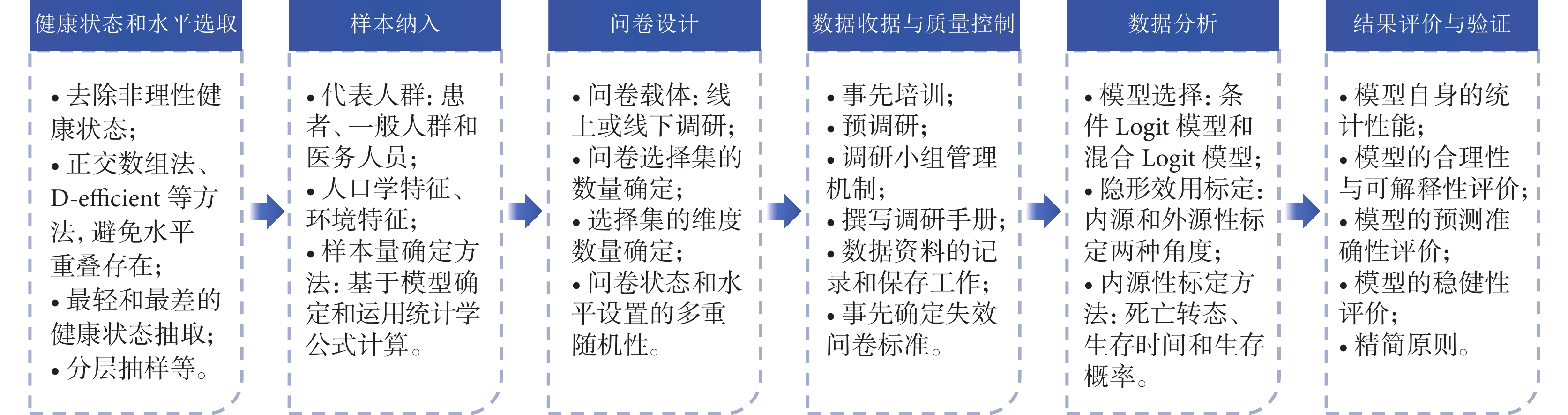 圖2
DCE測量健康效用的關鍵步驟
圖2
DCE測量健康效用的關鍵步驟
2.1 健康狀態和水平選取
盡管效用量表的條目大多較為精簡,但通過多水平的指數運算,其可描述的健康狀態數量依舊龐大。如SF-6Dv2可描述18 750(55×6)種健康狀態、QLU-C10D為1 048 576(410)種、FACT-8D為390 625(58)種,即使是較簡單的EQ-5D-5L也可描述3 125(55)種健康狀態。這導致DCE等直接效用測量方法,通常無法測量全部的健康狀態,需通過部分因子設計,選取典型的狀態來建立效用預測模型,實現對全部健康狀態效用值的間接測量。
典型健康狀態的選取,國內外不同研究的做法不盡相同。研究通過總結,整理了以下常見的健康狀態選取思路:① 在抽樣前,應首先去除無法想象、無法理解或不太可能存在的非理性健康狀態,如“我無法四處走動”,但“我進行日常活動沒有困難”(以EQ-5D-5L為例)的相關健康狀態明顯存在矛盾;② 采用正交數組法或D-efficient等方法進行隨機抽取,確保不同維度的不同水平獲得相同的抽樣機會,同時應避免水平重疊,以優化實驗設計,提高實驗效率;③ 有研究[27]會額外選取除完全健康以外最輕的健康狀態(如12 111、11 211等)和最差的健康狀態(如55 555),以直觀觀察每個維度由1水平變為2水平時效用值的細微差異和受訪者認為的最低效用值;④ 可考慮依據所有健康狀態總分范圍(如EQ-5D-5L為5~25分)將其劃分成輕型(如5~10分)、中型(10~20分)和重型(20~25分),然后采取分層抽樣的方法進行抽取[28];⑤ 不同健康狀態組成的選擇集應避免出現絕對優勢或絕對劣勢的情形,如由12 111(選擇集A)和23 222(選擇集B)兩個狀態所組成的選擇集,前者相較于后者具有明顯優勢,此時按照理性人的假設應選擇前者,無需再由受訪者進行權衡。
2.2 樣本納入
樣本選取是DCE研究的關鍵部分,應充分考慮抽樣的代表性,兼顧樣本大小的充分性與可行性,保證樣本能真實反映總體的多樣性,同時對特殊群體應具有包容性。通常應關注目標人群定義、樣本代表性、抽樣方法以及樣本量等內容[29]。其中,目標人群主要包括患者、一般人群和醫務人員3種[3]。然而在現階段,無論針對EQ-5D、SF-6D等普適性量表,還是QLU-C10D、FACT-8D等疾病特異量表,國內外的相關研究主要均是選擇一般人群作為代表[28]。同時,人口學特征(如性別、年齡、教育水平、城鄉背景等)、環境特征(如地理位置、經濟發展水平等)及自我報告健康狀況等會顯著影響樣本的代表性,應根據地區或國家人群特征統計情況,采用分層抽樣、分階段抽樣和隨機抽樣等多種方法進行抽樣,并采取t檢驗、卡方檢驗等統計方法測試樣本的代表性[27,30]。
樣本量的確定主要有兩種思路:一是通過經驗法,判斷滿足DCE建模對樣本量的要求,以單個DCE問題所需樣本數量來確定樣本總量。如,在SF-6Dv2開發中國人群的效用值積分體系研究[27]中,提出每個DCE問題應至少提供15個樣本,才能確保模型系數的穩健性;二是采用統計學思維,根據相關公式計算所需的最小樣本量。如,公式(4)是目前使用較為廣泛的一種,其中N表示所需樣本量,c為維度的最大水平數量,t為選擇集的選項數量,a為維度的數量[31]。以EQ-5D-3L為例,其維度數量a=5,水平數c=3,假設選擇集的選項數量為2,則所需樣本量 ,即
,即 150人。另有研究提出,應根據置信水平(
150人。另有研究提出,應根據置信水平( )、功效水平(
)、功效水平( )和效應大小(
)和效應大小( )計算DCE所需樣本量,如公式(5)所示。由于公式中所含參數較多,計算較復雜,通常需借助統計軟件,具體可參考Esther等[32]分享的案例和代碼。
)計算DCE所需樣本量,如公式(5)所示。由于公式中所含參數較多,計算較復雜,通常需借助統計軟件,具體可參考Esther等[32]分享的案例和代碼。
 |
 |
2.3 問卷設計
DCE問卷設計本質上是將選取的健康狀態,以兩個或多個進行組合的方式形成一個選擇集,再將合理數量的選擇集捆綁在一起,形成一份調研問卷。在這個過程中,應注意以下幾個方面的問題:① 問卷載體應根據調研方式進行確定:若采用線下訪談的方式,可采用紙質問卷或電子設備輔助填寫的方式;若采用線上途徑,可能需開發端側的電子問卷系統,以提高調研效率。② 問卷選擇集的數量應適宜,在兼顧數據收集效率的同時,避免受試者因回答過多問題而產生疲勞和厭倦,導致問卷填寫質量降低。傳統DCE在健康領域應用的選擇集數量平均為14個,數量范圍處于12~18個[24]。在國內外應用DCE健康效用測量領域的實證研究中,選擇集數量通常在6~16個[28]。③ 每個選擇集的維度數量應適宜,過多的維度數量可能會顯著增加受訪者的認知負擔。④ 問卷維度及水平組合應遵循三重隨機原則,包括健康狀態選取的隨機性、健康狀態作為選項A或B的隨機性、不同維度順序的隨機性等[7,10,27]。⑤ 設定效度選擇集,用于評價受訪者是否理性作答調研問卷,如在選擇集中設定明顯較優的選項。⑥ 在問卷開頭設置預熱選擇集,用于向受訪者介紹問卷填寫方法。⑦ 在最后加入對DCE問卷整體評價的問題,收集受訪者對調研的難易程度、可理解性等評價結果。
除此以外,選擇集的數量也是問卷設計應關注的重點。以EQ-5D-3L為例,共計有243(35)種健康狀態。假設根據健康狀態選取原則,去除非理性健康狀態后,剩余100種健康狀態,若以2個健康狀態作為一個選擇集,根據排列組合可得到100×99/2=4 950個組合。若進一步去除前述可能存在的絕對優勢和絕對劣勢的組合后,剩余4 000個選擇集,應確定從中抽取的選擇集數量即為該部分討論的核心,但該問題目前尚未建立共識。有研究[27]認為DCE問卷應至少包含150個選擇集來確保建模的統計效率;QLU-C10D在澳大利亞開發效用值積分體系時,根據Fatih等[33]學者開發的選擇集數量確定方法,抽取了960個選擇集[11];Abdulrahman等[34]學者系統回顧了不同樣本抽取方法(如正交數組法、D-efficient等),對應的選擇集數量計算方法,可供參考;另有學者[32,35]提倡根據以往的研究經驗及具體項目的實際情況而定。
2.4 數據收集與質量控制
數據收集是使用設計好的問卷,在研究確定的樣本人群中開展調研的過程。為確保數據收集的規范性和所獲數據的高質量,應考慮建立適當的質量控制方法。可采取的措施可能包括但不限于以下幾方面:① 對調研人員開展事先培訓,包括DCE基本原理、問卷使用方法等,確保所有工作人員對調研內容具有相同的理解、標準和程序,相互間可良好互動;② 受訪者在正式填寫問卷前,應接受預訪談,以充分理解DCE問卷的原理和作答方式;③ 建立調研小組管理機制,指定調研總指揮、隊長、記錄員、質量監管人員等專屬人員;④ 撰寫調研手冊,對調研任務要求、注意事項、工作安排等進行明確,確保整個調研有規可依、有法可循;⑤ 做好原始數據資料的記錄和保存工作,數據載體包括訪談錄音、知情同意書、問卷等,重要資料應做好備份;⑥ 事先確定失效問卷標準,對調研過程中表現出不配合、填寫時間過短、未依照調研規則填寫問卷的受訪者,可考慮將相關數據判定為失效,含有缺失數據的問卷應結合實際判定是否錄入數據庫;⑦ 建議在調研結束當天完成數據錄入,避免因時間流逝導致對失效問卷的標記模糊和后期大量問卷錄入導致的錯誤率升高;⑧ 數據錄入工作應由兩名以上人員參與,對所有選擇均相同或呈現分布規律等大概率存在質量缺陷的數據,應做好標記,由小組集體決定是否納入。
2.5 數據分析
在DCE應用于醫療領域的傳統數據分析中,需充分考慮數據整理的形式、使用的統計軟件、分析結果的解讀等,具體可參考世界衛生組織發布的指南[24]。相較于傳統DCE,將DCE用于健康效用測量時,需進一步注意以下3個方面:① DCE用于測量健康效用值時,其實際測量為不同健康狀態的內在效用,即假設該效用與受訪者個人屬性相互獨立,因此公式(3)中的 將不予考慮,個人屬性主要反映在抽樣中;② 測量健康效用使用最廣泛的DCE模型是條件Logit模型(condition logit model,CLM)和混合Logit模型(mixed logit model,MLM),其他模型使用較少:前者假設受訪者對健康狀態的偏好是均質的(即偏好不隨個體變化),這符合上述效用測量的假設,但它不能處理隨機偏好,后者通過引入隨機參數,可解釋隨機偏好,但缺點是計算復雜,對數據及樣本量有較高要求[11,19,24];③ DCE直接分析得到的是隱形效用,并未標定在0~1之間,無法直接用于計算QALYs,因此需采用合適的方法進行標定[3]。目前,主流的標定方法可分為內源性標定和外源性標定兩種:前者是在問卷設計階段,將用于標定的變量維度納入問卷,作為受訪者選擇時的考慮因素;后者是在數據收集時,與DCE同步使用其他效用測量方法(如TTO法),受訪者需作答兩份問卷,通過TTO的效用測量結果來標定DCE。
將不予考慮,個人屬性主要反映在抽樣中;② 測量健康效用使用最廣泛的DCE模型是條件Logit模型(condition logit model,CLM)和混合Logit模型(mixed logit model,MLM),其他模型使用較少:前者假設受訪者對健康狀態的偏好是均質的(即偏好不隨個體變化),這符合上述效用測量的假設,但它不能處理隨機偏好,后者通過引入隨機參數,可解釋隨機偏好,但缺點是計算復雜,對數據及樣本量有較高要求[11,19,24];③ DCE直接分析得到的是隱形效用,并未標定在0~1之間,無法直接用于計算QALYs,因此需采用合適的方法進行標定[3]。目前,主流的標定方法可分為內源性標定和外源性標定兩種:前者是在問卷設計階段,將用于標定的變量維度納入問卷,作為受訪者選擇時的考慮因素;后者是在數據收集時,與DCE同步使用其他效用測量方法(如TTO法),受訪者需作答兩份問卷,通過TTO的效用測量結果來標定DCE。
內源性標定最常采用生存時間進行標定,也稱為DCETTO法。即在問卷設計階段,將生存時間(如1年、4年、7年和10年)設置成問卷維度之一(圖3a)。受訪者在作答選擇集時,需同時考慮健康狀態以及在該狀態下的生存時間,從而選擇可為其帶來更大效用的選項[30]。如公式(6)為CLM,公式(7)為MLM,其中 為效用值,
為效用值, 為生存時間,
為生存時間, 為健康狀態水平的虛擬變量,
為健康狀態水平的虛擬變量, 和
和 是對應系數(即平均偏好系數),
是對應系數(即平均偏好系數), 為誤差項,
為誤差項, 和
和 是圍繞平均偏好系數的個體偏差。由
是圍繞平均偏好系數的個體偏差。由 的系數與
的系數與 系數的比值(
系數的比值( )即為標定后的系數,如公式(8)所示。另有研究利用“立即死亡”狀態的系數進行標定(圖3b),分析數據時采用Death系數,對不同健康狀態的隱形效用進行調整[27]。Robinson等[36]針對DCE開發了采用風險概率標定的方法(圖3c),即將不同概率的“完全健康狀態+死亡狀態”和“完全健康狀態+待研究健康狀態”為不同選項,要求受訪者進行選擇,以風險概率進行標定,該方法可認為是傳統標準博弈法(standard gamble,SG)與DCE的結合,因此研究稱其為DCESG方法。
)即為標定后的系數,如公式(8)所示。另有研究利用“立即死亡”狀態的系數進行標定(圖3b),分析數據時采用Death系數,對不同健康狀態的隱形效用進行調整[27]。Robinson等[36]針對DCE開發了采用風險概率標定的方法(圖3c),即將不同概率的“完全健康狀態+死亡狀態”和“完全健康狀態+待研究健康狀態”為不同選項,要求受訪者進行選擇,以風險概率進行標定,該方法可認為是傳統標準博弈法(standard gamble,SG)與DCE的結合,因此研究稱其為DCESG方法。
 圖3
DCE常見內源性標定方法示例(以EQ-5D維度為參考)
圖3
DCE常見內源性標定方法示例(以EQ-5D維度為參考)
a:采用生存時間(DCETTO)標定;b:采用死亡狀態(DCEdeath)標定;c:采用生存概率(DCESG)標定。
 |
 |
 |
其中,i=1,...,I(受訪者編號);j=選擇A或B;s=1,...,S(選擇集)。
外源性標定方法主要采用傳統方法直接測出的,或通過傳統方法建模估計出的最差效用值進行標定。在隱性效用進行調整時,如公式(9)所示,采用傳統方法得出的最差效用值 與DCE方法測出的最差健康狀態的隱性效用值
與DCE方法測出的最差健康狀態的隱性效用值 的比值作為調整系數,對DCE得出的隱性系數
的比值作為調整系數,對DCE得出的隱性系數 進行調整,得到調整后的系數
進行調整,得到調整后的系數 。此外,另有研究采用映射的方法對DCE測量的隱性效用值進行轉換,即通過隱性效用值構建計量經濟學模型,估算出量表可描述的全部健康狀態的效用值,再建立其與傳統效用測量方法所得到的效用值的對應函數關系,從而實現對隱性效用的標定[27]。
。此外,另有研究采用映射的方法對DCE測量的隱性效用值進行轉換,即通過隱性效用值構建計量經濟學模型,估算出量表可描述的全部健康狀態的效用值,再建立其與傳統效用測量方法所得到的效用值的對應函數關系,從而實現對隱性效用的標定[27]。
 |
2.6 結果評價與驗證
對基于DCE所構建的效用值積分體系模型,需建立標準進行評價,以驗證DCE模型自身的穩健性、何種DCE隱性效用轉化結果更優以及預測的準確性等。通常,DCE模型評價可考慮以下幾方面[10,11,23,24,27]:① 評價模型自身的統計性能:可采用模型參數估計的顯著性(P-values)、置信區間、模型整體的擬合優度(如McFadden’s R2、赤池信息準則-AIC或貝葉斯信息準則-BIC等)等指標進行評價;② 模型的合理性:可從模型系數的邏輯一致性角度進行評價(即系數的單調性和非正性);③ 模型的可解釋性:從邊際效用和相對重要性角度評價不同維度水平的改變對效用值的邊際影響,對結果采用常識或一般理論進行解釋(如該量表所描述的最差健康狀態的效用值是否應小于0);④ 模型的預測準確性:該評價一般需借助外部驗證手段,即在進行DCE研究的同時開展基于其他效用測量方法的研究,將多種研究(包括此前開展的同類研究)的結果使用統計學參數(如組內相關系數、平均絕對誤差以及均方根誤差等)進行對比,以綜合評價模型的預測準確性;⑤ 模型的穩健性:評估測量結果對關鍵假設和參數的敏感程度;⑥ 精簡原則:當模型的各項指標接近,精準程度相當,則優先選擇最精簡的模型;⑦ 敏感性分析:可嘗試去掉答錯效度選擇集的受訪者、作答時間過短的受訪者、總是選擇A或B的受訪者,以及在理解性方面存在問題的受訪者,使用剩余數據重新建模,比較不同數據結果。
3 討論
DCE被應用于健康效用測量領域最重要的原因是其可能改善傳統效用測量方法的認知負擔,但該優勢很可能會隨著量表維度的增加而消失。傳統通用量表(如EQ-5D和SF-6D)因維度數量少,因此對DCE的適用性較強。然而,隨著量表對測量精度要求的不斷提高,越來越多新開發量表希望通過增加維度數量,來提升量表的敏感性,以實現對患者效用的精確測量,尤其是一些疾病別量表。但維度數量的增加,將導致受訪者對不同健康狀態的理解負擔加重,從而降低問卷有效作答率。因此,DCE在高維度量表效用值積分體系的開發應用可能存在挑戰。
目前,國內外已有解決該挑戰的一些探索案例。如,FACT-8D[10]和QLU-C10D量表[11]在開發效用值積分體系時,嘗試采用強制重疊的方法,人為設定其中部分維度相同,僅保留少數幾個存在差異的維度。受訪者作答時,僅需重點考慮存在差異的維度即可。該法實質是以犧牲統計效率(部分數據被預先設定)為代價,換取作答效率,從而有效降低認知負擔。與FACT-8D等不同,CQ-11D量表[30]在開發時,主要采用視覺輔助認知的方式,通過預先設定每個水平對應的關鍵詞顏色,幫助受訪者、識別、記憶和理解每個健康狀態。該法不失為一種探索和嘗試,但對減輕認知負擔所發揮的作用還需進一步驗證。
量表是HRQOL測量工具的總稱,種類繁多,可滿足各類疾病患者的測量需要,如慢病、短暫性疾病、病癥痛苦疾病及高死亡風險疾病等。由于不同疾病自身的特征不同,患者治療經歷往往存在差異,因此受訪者對各種標定方法的敏感程度可能不盡相同。例如,長期臥床、生活不能自理的疾病,受訪者可能更易將生存時間與健康狀態相關聯;高死亡風險疾病,受訪者可能會參照對疾病已有的生存概率,理性選擇不同概率健康狀態的選項;病癥痛苦的疾病,患者可能有更多聯想生死的瞬間,以死亡進行標定或許會收集更多死亡選項數據;而對內源標定維度(生存時間、死亡以及生存概率)難以想象的疾病,還可考慮使用映射等外源性標定方法。
研究認為,合理選擇DCE的標定方法,不應僅從方法學角度考慮,還應充分結合疾病自身的特征。已有研究表明,DCE減輕受訪者的認知負擔,具有相應的前提和條件[27]。因此,當受訪者可充分想象標定維度和健康維度相關聯的場景(如以中度運動障礙、輕度認知障礙等存活10年)時,才能有效減輕認知負擔,降低假想偏差,提高測量精度。
健康效用的測量,在本質上是在求解一個不可觀察的變量值。由于研究對象的特殊性,導致測量結果往往缺乏衡量其精確程度的金標準。大量研究表明,DCE同其他傳統效用測量方法(如TTO等),甚至同基于不同標定技術、不同模型的DCE測量法,在獲得的結果上均可能存在異質性[27]。異質性的具體來源包括:樣本量、人口特征、模型技術、研究設計以及假想偏差等[22]。因此,運用合理的方法,識別并解釋可能存在的異質性,提高測量的準確性與可靠性,是DCE用于健康狀態效用測量的關鍵環節。
目前可采用的檢驗異質性的方法,可能包括但不限于:① 采用已驗證的測量工具進行檢驗;② 多種測量方法交叉驗證;③ 靈敏度分析;④ 同行評審或專家驗證;⑤ 重復性與可靠性(如內部一致性檢驗和重測信度等)測試;⑥ 同類研究對比分析;⑦ 參與者反饋驗證等[37,38]。在QLU-C10D的效用值積分體系開發研究中,心理健康維度以抑郁癥為代表條目,其在基于澳大利亞人群的效用系數排名為第四名,而抑郁和焦慮在流行病學上確實是澳大利亞最常見的精神障礙,這種交叉驗證可用于證明建模所得心理維度系數的合理性[10]。另有研究探索使用前沿科技減小異質性,如使用眼球追蹤技術可捕獲受訪者進行選擇時關注的主要維度,為結果分析提供參考;使用虛擬現實技術可幫助受訪者理解甚至感知不同健康狀態,將有助于提高測量結果的準確性[39,40]。研究認為,異質性是DCE用于健康效用測量時,可能影響測量結果準確性、合理性與可解釋性的關鍵因素,其有效解決途徑最根本的還是要靠重復性地驗證分析。
采用DCE開展健康效用測量在本質上屬統計推斷研究,其結果將受到目標人群、人口特征和樣本量的顯著影響。現階段,無論是普適性量表還是疾病別量表,國內外開展的健康效用測量研究所使用的人群代表主要為一般人群[7,8,10,11,27]。希望從社會視角反映社會公眾的總體健康偏好,兼顧社會公平[3]。但研究認為,受制于生活條件、健康水平、治療經歷等背景因素,不同受訪者的健康偏好往往存在差異。實際經歷過病癥的患者,更易聯想DCE調查中不同健康狀態的主觀感受,其效用測量結果可能會高于一般人群[3]。疾病別量表作為一類針對患者人群所研發的量表,在開發階段、驗證階段所針對的人群均為患者,但在構建效用值積分體系階段,目前卻主要是基于一般人群。這不僅違背了疾病別量表的研發初衷,也難以充分體現疾病別量表與普適性量表的受眾差異。此外,許多疾病別量表特有條目是針對患者設計,一般人群可能無法充分理解條目所描述的疾病特征,這也可能會增大測量結果的誤差。
在抽樣人群代表性方面,研究認為還應考慮DCE方法學本身對受訪者認知水平的要求,即調研參與人群應具備足夠的文化素質,以確保其可以充分理解調研任務,提升調研質量。所以,在抽樣設計時,可能需要考慮從樣本總體中,排除部分受教育水平較低或具有認知障礙的人群。目前,我國受教育程度低于初中的人群約占總體的30%,高中以下人群約占64%[41]。因此,若不對受教育水平設置權重,僅依靠傳統隨機抽樣法,將很可能導致在實際調研中,無效測量高發,從而影響測量結果的準確性。但若區別對待不同人群,也可能存在人群歧視,將有違倫理道德。因此,如何在測量準確性、倫理道德以及社會公平之間進行平衡,也是值得思考的問題。
4 總結
本研究系統介紹了DCE在醫療領域的發展歷程、方法學原理、用于健康效用測量時的步驟及現有的方法學挑戰等內容。對實際研究中可能存在的關鍵問題,如健康狀態的選取原則、樣本納入方法、隱性效用標定思路等,本研究結合相關報道和實踐經驗進行了分析。現階段,DCE方法在健康效用測量領域應用的主要挑戰包括:多維度量表可能會顯著提升受訪人員認知負擔、DCE標定方法尚未完全成熟、DCE效用測量結果與傳統研究可能存在異質性、疾病別效用量表的抽樣人群尚存爭議等。針對以上挑戰,研究分別討論了解決或完善的相關思路。
DCE作為一套擁有成熟理論的偏好分析方法,其在健康效用測量領域的應用潛力巨大。未來,DCE研究應持續對基礎模型進行創新優化,使其更能模擬真實世界中的實際場景。同時可更多探索采用數字技術、人工智能技術、虛擬現實技術等前沿科技來解決DCE當前面臨的挑戰,使DCE相關研究的實踐工作步入標準化軌道。希望本文可以公正、客觀、科學地解讀DCE在健康效用測量中應用的方法與挑戰,為國內相關研究提供參考,推動DCE在國內健康效用測量領域的應用與發展。
生命質量(quality of life,QoL)是一個用以衡量個人軀體功能、精神健康、經濟水平和社會關系等多方面綜合質量水平的概念。隨著社會的發展,人們越來越注重對自身健康質量的管理,由此產生了有關健康相關生活質量(health-related quality of life,HRQOL)的研究。HRQOL是指受疾病、傷殘、衰老或治療導致的身體缺陷、身體功能狀態改變、認知改變或社會功能改變而影響生存時間的價值,該價值也受個體偏好和主觀判斷的影響[1,2]。為了對HRQOL進行量化研究,醫學工作者嘗試借鑒傳統經濟學的概念—效用(utility),在藥物經濟學中評價個人或群體對某種醫療干預措施導致的健康結果的偏好程度[3]。目前,最常用的藥物經濟學評價方法是成本-效用分析(cost-utility analysis,CUA),并被國內最新版的藥物經濟學指南所推薦[4]。
衡量效用的指標一般包括質量調整生命年(quality-adjusted life years,QALYs)、傷殘調整生命年(disability-adjusted life years,DALYs)、挽救年輕生命當量(saved young life equivalents,SAVEs)等。其中,QALYs是最常用的指標,其計算方法為:特定健康狀態下的生存年數乘以該健康狀態QoL的權重(即健康效用)。因此,健康效用是計算QALYs的關鍵。通常規定,死亡的健康效用值為0,完全健康的健康效用值為1,其他健康狀態的效用值則以完全健康和死亡標定測得,取值范圍為0~1。存在小于0的效用值,以描述“生不如死”的健康狀態[3]。
通常,健康效用的測量需采用基于偏好的技術方法,常見偏好測量方法及對比結果如表1所示[5,6]。其中,DCE作為一種新興的效用測量方法,基于完善的理論測量框架,可提供統計學上穩健的實驗設計與建模方法,僅需對選擇集進行選擇即可測量出個體偏好,更接近于真實世界下的決策場景,被認為可能減輕患者認知負擔且易于通過線上收集數據,因此具有較高的發展潛力[7]。目前DCE在國外健康效用測量領域中的應用已相對成熟,在EQ-5D[8]、SF-6DV2[9]、FACT-8D[10]和QLU-C10D[11]等量表的效用值積分體系構建中均有運用,但在國內相關領域尚處于起步階段。本文旨在介紹DCE應用于健康效用測量的方法學原理、步驟和挑戰等,希望為國內相關研究提供參考。
1 DCE方法學背景
1.1 DCE在醫療領域的發展歷程
20世紀50年代后,DCE相關理論研究開始興起。隨著研究的持續深入,DCE方法學不斷發展,其應用領域也在逐漸擴大(圖1)[12,13]。20世紀90年代早期,DCE開始被應用于醫療健康領域,可提供醫療決策主體對不同醫療干預屬性水平的偏好信息(值)、水平間的權衡信息以及選擇某種特定干預的概率(uptake rates,UR)等[14-16]。近年,該方法已經逐漸發展成為量化患者偏好[17]、醫務工作者就業偏好[18]、醫療資源配置以及其他醫療相關主體偏好的常用方法,可為醫療政策制定提供決策依據[12]。21世紀以來,科研工作者不斷探索將DCE方法應用于健康效用測量,但受限于該方法自身的局限性及效用測量的客觀要求,DCE在效用測量領域的應用方法尚未達成共識,仍處于積極探索階段。因此,本研究所提出的基于DCE測量健康效用的方法學,僅是對國內外現有研究的總結與思考,以促進該方法在國內的應用和發展。
圖1
DCE方法學的發展歷程
1.2 DCE方法學原理
DCE是一種評估多因素對個體選擇產生影響的偏好分析方法。該方法超越了傳統的定性方法、排序方法以及一些分級方法,可提供關于偏好強度、權衡(如支付意愿)以及接受概率的定量信息[19]。通常,偏好測量可分為基于現實場景的顯示性偏好(revealed preference,RP)和基于假設場景的陳述性偏好(stated preference,SP)[20-22]。DCE作為一種SP方法,起源于數學心理學,它將隨機效用理論與消費者理論、實驗設計理論和計量經濟學分析相結合所形成[23]。該方法假設:在特定場景下,具有特定個體屬性的理性主體,面對現存的具有特定屬性的選擇集I,會基于效用最大化準則,選擇可為其提供最大效用的方案j。由于其他外部觀察者通常不能準確得知,對于決策者來說效用最大的選擇,因此只能計算反映決策者在全部選擇集I中選擇選項j的概率,如公式(1)所示[24,25]:
|
其中, 和 分別代表兩種選擇可為決策者帶來的效用, 由可解釋的系統性系數 (固定)和不可解釋的隨機性系數 (隨機)組成,如公式(2)所示:
|
其中,隨機項一般被認為是由于選項的不可觀測屬性、偏好變化,模型設定誤差和/或測量誤差所形成的變量;而可解釋為由商品或服務和決策主體的個體屬性所構成的變量,因此可進一步建立模型如公式(3)所示:
|
其中,為商品或服務特征的變量合集,為決策主體的個人特征,和分別為對應變量的系數。通過上述3個公式的相互銜接,即可實現將決策者選擇選項j的概率,同商品或服務特征以及決策主體的個人特征等變量進行數理統計,從而獲得定量的偏好測量結果。
2 DCE測量健康效用的主要步驟
傳統DCE的設計和實施主要包括以下步驟:概念選擇,屬性和水平設置,實驗設計,問卷設計,試點測試,抽樣方法和樣本量計算,數據收集,數據清洗,計量經濟學分析,政策分析、解釋與轉化等[24]。由于采用DCE測量健康效用時,通常是針對已經建立了健康狀態分類系統(health state classification system,HSCS)[26]的非效用量表,其概念、屬性、水平等均已確定,數據分析結果也僅用于建立評分算法,無需政策轉化。因此,參照國內外已開展的相關研究[8-11],研究將利用DCE測量健康效用的過程分為6個關鍵步驟(圖2)。
圖2
DCE測量健康效用的關鍵步驟
2.1 健康狀態和水平選取
盡管效用量表的條目大多較為精簡,但通過多水平的指數運算,其可描述的健康狀態數量依舊龐大。如SF-6Dv2可描述18 750(55×6)種健康狀態、QLU-C10D為1 048 576(410)種、FACT-8D為390 625(58)種,即使是較簡單的EQ-5D-5L也可描述3 125(55)種健康狀態。這導致DCE等直接效用測量方法,通常無法測量全部的健康狀態,需通過部分因子設計,選取典型的狀態來建立效用預測模型,實現對全部健康狀態效用值的間接測量。
典型健康狀態的選取,國內外不同研究的做法不盡相同。研究通過總結,整理了以下常見的健康狀態選取思路:① 在抽樣前,應首先去除無法想象、無法理解或不太可能存在的非理性健康狀態,如“我無法四處走動”,但“我進行日常活動沒有困難”(以EQ-5D-5L為例)的相關健康狀態明顯存在矛盾;② 采用正交數組法或D-efficient等方法進行隨機抽取,確保不同維度的不同水平獲得相同的抽樣機會,同時應避免水平重疊,以優化實驗設計,提高實驗效率;③ 有研究[27]會額外選取除完全健康以外最輕的健康狀態(如12 111、11 211等)和最差的健康狀態(如55 555),以直觀觀察每個維度由1水平變為2水平時效用值的細微差異和受訪者認為的最低效用值;④ 可考慮依據所有健康狀態總分范圍(如EQ-5D-5L為5~25分)將其劃分成輕型(如5~10分)、中型(10~20分)和重型(20~25分),然后采取分層抽樣的方法進行抽取[28];⑤ 不同健康狀態組成的選擇集應避免出現絕對優勢或絕對劣勢的情形,如由12 111(選擇集A)和23 222(選擇集B)兩個狀態所組成的選擇集,前者相較于后者具有明顯優勢,此時按照理性人的假設應選擇前者,無需再由受訪者進行權衡。
2.2 樣本納入
樣本選取是DCE研究的關鍵部分,應充分考慮抽樣的代表性,兼顧樣本大小的充分性與可行性,保證樣本能真實反映總體的多樣性,同時對特殊群體應具有包容性。通常應關注目標人群定義、樣本代表性、抽樣方法以及樣本量等內容[29]。其中,目標人群主要包括患者、一般人群和醫務人員3種[3]。然而在現階段,無論針對EQ-5D、SF-6D等普適性量表,還是QLU-C10D、FACT-8D等疾病特異量表,國內外的相關研究主要均是選擇一般人群作為代表[28]。同時,人口學特征(如性別、年齡、教育水平、城鄉背景等)、環境特征(如地理位置、經濟發展水平等)及自我報告健康狀況等會顯著影響樣本的代表性,應根據地區或國家人群特征統計情況,采用分層抽樣、分階段抽樣和隨機抽樣等多種方法進行抽樣,并采取t檢驗、卡方檢驗等統計方法測試樣本的代表性[27,30]。
樣本量的確定主要有兩種思路:一是通過經驗法,判斷滿足DCE建模對樣本量的要求,以單個DCE問題所需樣本數量來確定樣本總量。如,在SF-6Dv2開發中國人群的效用值積分體系研究[27]中,提出每個DCE問題應至少提供15個樣本,才能確保模型系數的穩健性;二是采用統計學思維,根據相關公式計算所需的最小樣本量。如,公式(4)是目前使用較為廣泛的一種,其中N表示所需樣本量,c為維度的最大水平數量,t為選擇集的選項數量,a為維度的數量[31]。以EQ-5D-3L為例,其維度數量a=5,水平數c=3,假設選擇集的選項數量為2,則所需樣本量,即150人。另有研究提出,應根據置信水平()、功效水平()和效應大小()計算DCE所需樣本量,如公式(5)所示。由于公式中所含參數較多,計算較復雜,通常需借助統計軟件,具體可參考Esther等[32]分享的案例和代碼。
|
|
2.3 問卷設計
DCE問卷設計本質上是將選取的健康狀態,以兩個或多個進行組合的方式形成一個選擇集,再將合理數量的選擇集捆綁在一起,形成一份調研問卷。在這個過程中,應注意以下幾個方面的問題:① 問卷載體應根據調研方式進行確定:若采用線下訪談的方式,可采用紙質問卷或電子設備輔助填寫的方式;若采用線上途徑,可能需開發端側的電子問卷系統,以提高調研效率。② 問卷選擇集的數量應適宜,在兼顧數據收集效率的同時,避免受試者因回答過多問題而產生疲勞和厭倦,導致問卷填寫質量降低。傳統DCE在健康領域應用的選擇集數量平均為14個,數量范圍處于12~18個[24]。在國內外應用DCE健康效用測量領域的實證研究中,選擇集數量通常在6~16個[28]。③ 每個選擇集的維度數量應適宜,過多的維度數量可能會顯著增加受訪者的認知負擔。④ 問卷維度及水平組合應遵循三重隨機原則,包括健康狀態選取的隨機性、健康狀態作為選項A或B的隨機性、不同維度順序的隨機性等[7,10,27]。⑤ 設定效度選擇集,用于評價受訪者是否理性作答調研問卷,如在選擇集中設定明顯較優的選項。⑥ 在問卷開頭設置預熱選擇集,用于向受訪者介紹問卷填寫方法。⑦ 在最后加入對DCE問卷整體評價的問題,收集受訪者對調研的難易程度、可理解性等評價結果。
除此以外,選擇集的數量也是問卷設計應關注的重點。以EQ-5D-3L為例,共計有243(35)種健康狀態。假設根據健康狀態選取原則,去除非理性健康狀態后,剩余100種健康狀態,若以2個健康狀態作為一個選擇集,根據排列組合可得到100×99/2=4 950個組合。若進一步去除前述可能存在的絕對優勢和絕對劣勢的組合后,剩余4 000個選擇集,應確定從中抽取的選擇集數量即為該部分討論的核心,但該問題目前尚未建立共識。有研究[27]認為DCE問卷應至少包含150個選擇集來確保建模的統計效率;QLU-C10D在澳大利亞開發效用值積分體系時,根據Fatih等[33]學者開發的選擇集數量確定方法,抽取了960個選擇集[11];Abdulrahman等[34]學者系統回顧了不同樣本抽取方法(如正交數組法、D-efficient等),對應的選擇集數量計算方法,可供參考;另有學者[32,35]提倡根據以往的研究經驗及具體項目的實際情況而定。
2.4 數據收集與質量控制
數據收集是使用設計好的問卷,在研究確定的樣本人群中開展調研的過程。為確保數據收集的規范性和所獲數據的高質量,應考慮建立適當的質量控制方法。可采取的措施可能包括但不限于以下幾方面:① 對調研人員開展事先培訓,包括DCE基本原理、問卷使用方法等,確保所有工作人員對調研內容具有相同的理解、標準和程序,相互間可良好互動;② 受訪者在正式填寫問卷前,應接受預訪談,以充分理解DCE問卷的原理和作答方式;③ 建立調研小組管理機制,指定調研總指揮、隊長、記錄員、質量監管人員等專屬人員;④ 撰寫調研手冊,對調研任務要求、注意事項、工作安排等進行明確,確保整個調研有規可依、有法可循;⑤ 做好原始數據資料的記錄和保存工作,數據載體包括訪談錄音、知情同意書、問卷等,重要資料應做好備份;⑥ 事先確定失效問卷標準,對調研過程中表現出不配合、填寫時間過短、未依照調研規則填寫問卷的受訪者,可考慮將相關數據判定為失效,含有缺失數據的問卷應結合實際判定是否錄入數據庫;⑦ 建議在調研結束當天完成數據錄入,避免因時間流逝導致對失效問卷的標記模糊和后期大量問卷錄入導致的錯誤率升高;⑧ 數據錄入工作應由兩名以上人員參與,對所有選擇均相同或呈現分布規律等大概率存在質量缺陷的數據,應做好標記,由小組集體決定是否納入。
2.5 數據分析
在DCE應用于醫療領域的傳統數據分析中,需充分考慮數據整理的形式、使用的統計軟件、分析結果的解讀等,具體可參考世界衛生組織發布的指南[24]。相較于傳統DCE,將DCE用于健康效用測量時,需進一步注意以下3個方面:① DCE用于測量健康效用值時,其實際測量為不同健康狀態的內在效用,即假設該效用與受訪者個人屬性相互獨立,因此公式(3)中的將不予考慮,個人屬性主要反映在抽樣中;② 測量健康效用使用最廣泛的DCE模型是條件Logit模型(condition logit model,CLM)和混合Logit模型(mixed logit model,MLM),其他模型使用較少:前者假設受訪者對健康狀態的偏好是均質的(即偏好不隨個體變化),這符合上述效用測量的假設,但它不能處理隨機偏好,后者通過引入隨機參數,可解釋隨機偏好,但缺點是計算復雜,對數據及樣本量有較高要求[11,19,24];③ DCE直接分析得到的是隱形效用,并未標定在0~1之間,無法直接用于計算QALYs,因此需采用合適的方法進行標定[3]。目前,主流的標定方法可分為內源性標定和外源性標定兩種:前者是在問卷設計階段,將用于標定的變量維度納入問卷,作為受訪者選擇時的考慮因素;后者是在數據收集時,與DCE同步使用其他效用測量方法(如TTO法),受訪者需作答兩份問卷,通過TTO的效用測量結果來標定DCE。
內源性標定最常采用生存時間進行標定,也稱為DCETTO法。即在問卷設計階段,將生存時間(如1年、4年、7年和10年)設置成問卷維度之一(圖3a)。受訪者在作答選擇集時,需同時考慮健康狀態以及在該狀態下的生存時間,從而選擇可為其帶來更大效用的選項[30]。如公式(6)為CLM,公式(7)為MLM,其中為效用值,為生存時間,為健康狀態水平的虛擬變量,和是對應系數(即平均偏好系數),為誤差項,和是圍繞平均偏好系數的個體偏差。由的系數與系數的比值()即為標定后的系數,如公式(8)所示。另有研究利用“立即死亡”狀態的系數進行標定(圖3b),分析數據時采用Death系數,對不同健康狀態的隱形效用進行調整[27]。Robinson等[36]針對DCE開發了采用風險概率標定的方法(圖3c),即將不同概率的“完全健康狀態+死亡狀態”和“完全健康狀態+待研究健康狀態”為不同選項,要求受訪者進行選擇,以風險概率進行標定,該方法可認為是傳統標準博弈法(standard gamble,SG)與DCE的結合,因此研究稱其為DCESG方法。
圖3
DCE常見內源性標定方法示例(以EQ-5D維度為參考)
a:采用生存時間(DCETTO)標定;b:采用死亡狀態(DCEdeath)標定;c:采用生存概率(DCESG)標定。
|
|
|
其中,i=1,...,I(受訪者編號);j=選擇A或B;s=1,...,S(選擇集)。
外源性標定方法主要采用傳統方法直接測出的,或通過傳統方法建模估計出的最差效用值進行標定。在隱性效用進行調整時,如公式(9)所示,采用傳統方法得出的最差效用值與DCE方法測出的最差健康狀態的隱性效用值的比值作為調整系數,對DCE得出的隱性系數進行調整,得到調整后的系數。此外,另有研究采用映射的方法對DCE測量的隱性效用值進行轉換,即通過隱性效用值構建計量經濟學模型,估算出量表可描述的全部健康狀態的效用值,再建立其與傳統效用測量方法所得到的效用值的對應函數關系,從而實現對隱性效用的標定[27]。
|
2.6 結果評價與驗證
對基于DCE所構建的效用值積分體系模型,需建立標準進行評價,以驗證DCE模型自身的穩健性、何種DCE隱性效用轉化結果更優以及預測的準確性等。通常,DCE模型評價可考慮以下幾方面[10,11,23,24,27]:① 評價模型自身的統計性能:可采用模型參數估計的顯著性(P-values)、置信區間、模型整體的擬合優度(如McFadden’s R2、赤池信息準則-AIC或貝葉斯信息準則-BIC等)等指標進行評價;② 模型的合理性:可從模型系數的邏輯一致性角度進行評價(即系數的單調性和非正性);③ 模型的可解釋性:從邊際效用和相對重要性角度評價不同維度水平的改變對效用值的邊際影響,對結果采用常識或一般理論進行解釋(如該量表所描述的最差健康狀態的效用值是否應小于0);④ 模型的預測準確性:該評價一般需借助外部驗證手段,即在進行DCE研究的同時開展基于其他效用測量方法的研究,將多種研究(包括此前開展的同類研究)的結果使用統計學參數(如組內相關系數、平均絕對誤差以及均方根誤差等)進行對比,以綜合評價模型的預測準確性;⑤ 模型的穩健性:評估測量結果對關鍵假設和參數的敏感程度;⑥ 精簡原則:當模型的各項指標接近,精準程度相當,則優先選擇最精簡的模型;⑦ 敏感性分析:可嘗試去掉答錯效度選擇集的受訪者、作答時間過短的受訪者、總是選擇A或B的受訪者,以及在理解性方面存在問題的受訪者,使用剩余數據重新建模,比較不同數據結果。
3 討論
DCE被應用于健康效用測量領域最重要的原因是其可能改善傳統效用測量方法的認知負擔,但該優勢很可能會隨著量表維度的增加而消失。傳統通用量表(如EQ-5D和SF-6D)因維度數量少,因此對DCE的適用性較強。然而,隨著量表對測量精度要求的不斷提高,越來越多新開發量表希望通過增加維度數量,來提升量表的敏感性,以實現對患者效用的精確測量,尤其是一些疾病別量表。但維度數量的增加,將導致受訪者對不同健康狀態的理解負擔加重,從而降低問卷有效作答率。因此,DCE在高維度量表效用值積分體系的開發應用可能存在挑戰。
目前,國內外已有解決該挑戰的一些探索案例。如,FACT-8D[10]和QLU-C10D量表[11]在開發效用值積分體系時,嘗試采用強制重疊的方法,人為設定其中部分維度相同,僅保留少數幾個存在差異的維度。受訪者作答時,僅需重點考慮存在差異的維度即可。該法實質是以犧牲統計效率(部分數據被預先設定)為代價,換取作答效率,從而有效降低認知負擔。與FACT-8D等不同,CQ-11D量表[30]在開發時,主要采用視覺輔助認知的方式,通過預先設定每個水平對應的關鍵詞顏色,幫助受訪者、識別、記憶和理解每個健康狀態。該法不失為一種探索和嘗試,但對減輕認知負擔所發揮的作用還需進一步驗證。
量表是HRQOL測量工具的總稱,種類繁多,可滿足各類疾病患者的測量需要,如慢病、短暫性疾病、病癥痛苦疾病及高死亡風險疾病等。由于不同疾病自身的特征不同,患者治療經歷往往存在差異,因此受訪者對各種標定方法的敏感程度可能不盡相同。例如,長期臥床、生活不能自理的疾病,受訪者可能更易將生存時間與健康狀態相關聯;高死亡風險疾病,受訪者可能會參照對疾病已有的生存概率,理性選擇不同概率健康狀態的選項;病癥痛苦的疾病,患者可能有更多聯想生死的瞬間,以死亡進行標定或許會收集更多死亡選項數據;而對內源標定維度(生存時間、死亡以及生存概率)難以想象的疾病,還可考慮使用映射等外源性標定方法。
研究認為,合理選擇DCE的標定方法,不應僅從方法學角度考慮,還應充分結合疾病自身的特征。已有研究表明,DCE減輕受訪者的認知負擔,具有相應的前提和條件[27]。因此,當受訪者可充分想象標定維度和健康維度相關聯的場景(如以中度運動障礙、輕度認知障礙等存活10年)時,才能有效減輕認知負擔,降低假想偏差,提高測量精度。
健康效用的測量,在本質上是在求解一個不可觀察的變量值。由于研究對象的特殊性,導致測量結果往往缺乏衡量其精確程度的金標準。大量研究表明,DCE同其他傳統效用測量方法(如TTO等),甚至同基于不同標定技術、不同模型的DCE測量法,在獲得的結果上均可能存在異質性[27]。異質性的具體來源包括:樣本量、人口特征、模型技術、研究設計以及假想偏差等[22]。因此,運用合理的方法,識別并解釋可能存在的異質性,提高測量的準確性與可靠性,是DCE用于健康狀態效用測量的關鍵環節。
目前可采用的檢驗異質性的方法,可能包括但不限于:① 采用已驗證的測量工具進行檢驗;② 多種測量方法交叉驗證;③ 靈敏度分析;④ 同行評審或專家驗證;⑤ 重復性與可靠性(如內部一致性檢驗和重測信度等)測試;⑥ 同類研究對比分析;⑦ 參與者反饋驗證等[37,38]。在QLU-C10D的效用值積分體系開發研究中,心理健康維度以抑郁癥為代表條目,其在基于澳大利亞人群的效用系數排名為第四名,而抑郁和焦慮在流行病學上確實是澳大利亞最常見的精神障礙,這種交叉驗證可用于證明建模所得心理維度系數的合理性[10]。另有研究探索使用前沿科技減小異質性,如使用眼球追蹤技術可捕獲受訪者進行選擇時關注的主要維度,為結果分析提供參考;使用虛擬現實技術可幫助受訪者理解甚至感知不同健康狀態,將有助于提高測量結果的準確性[39,40]。研究認為,異質性是DCE用于健康效用測量時,可能影響測量結果準確性、合理性與可解釋性的關鍵因素,其有效解決途徑最根本的還是要靠重復性地驗證分析。
采用DCE開展健康效用測量在本質上屬統計推斷研究,其結果將受到目標人群、人口特征和樣本量的顯著影響。現階段,無論是普適性量表還是疾病別量表,國內外開展的健康效用測量研究所使用的人群代表主要為一般人群[7,8,10,11,27]。希望從社會視角反映社會公眾的總體健康偏好,兼顧社會公平[3]。但研究認為,受制于生活條件、健康水平、治療經歷等背景因素,不同受訪者的健康偏好往往存在差異。實際經歷過病癥的患者,更易聯想DCE調查中不同健康狀態的主觀感受,其效用測量結果可能會高于一般人群[3]。疾病別量表作為一類針對患者人群所研發的量表,在開發階段、驗證階段所針對的人群均為患者,但在構建效用值積分體系階段,目前卻主要是基于一般人群。這不僅違背了疾病別量表的研發初衷,也難以充分體現疾病別量表與普適性量表的受眾差異。此外,許多疾病別量表特有條目是針對患者設計,一般人群可能無法充分理解條目所描述的疾病特征,這也可能會增大測量結果的誤差。
在抽樣人群代表性方面,研究認為還應考慮DCE方法學本身對受訪者認知水平的要求,即調研參與人群應具備足夠的文化素質,以確保其可以充分理解調研任務,提升調研質量。所以,在抽樣設計時,可能需要考慮從樣本總體中,排除部分受教育水平較低或具有認知障礙的人群。目前,我國受教育程度低于初中的人群約占總體的30%,高中以下人群約占64%[41]。因此,若不對受教育水平設置權重,僅依靠傳統隨機抽樣法,將很可能導致在實際調研中,無效測量高發,從而影響測量結果的準確性。但若區別對待不同人群,也可能存在人群歧視,將有違倫理道德。因此,如何在測量準確性、倫理道德以及社會公平之間進行平衡,也是值得思考的問題。
4 總結
本研究系統介紹了DCE在醫療領域的發展歷程、方法學原理、用于健康效用測量時的步驟及現有的方法學挑戰等內容。對實際研究中可能存在的關鍵問題,如健康狀態的選取原則、樣本納入方法、隱性效用標定思路等,本研究結合相關報道和實踐經驗進行了分析。現階段,DCE方法在健康效用測量領域應用的主要挑戰包括:多維度量表可能會顯著提升受訪人員認知負擔、DCE標定方法尚未完全成熟、DCE效用測量結果與傳統研究可能存在異質性、疾病別效用量表的抽樣人群尚存爭議等。針對以上挑戰,研究分別討論了解決或完善的相關思路。
DCE作為一套擁有成熟理論的偏好分析方法,其在健康效用測量領域的應用潛力巨大。未來,DCE研究應持續對基礎模型進行創新優化,使其更能模擬真實世界中的實際場景。同時可更多探索采用數字技術、人工智能技術、虛擬現實技術等前沿科技來解決DCE當前面臨的挑戰,使DCE相關研究的實踐工作步入標準化軌道。希望本文可以公正、客觀、科學地解讀DCE在健康效用測量中應用的方法與挑戰,為國內相關研究提供參考,推動DCE在國內健康效用測量領域的應用與發展。