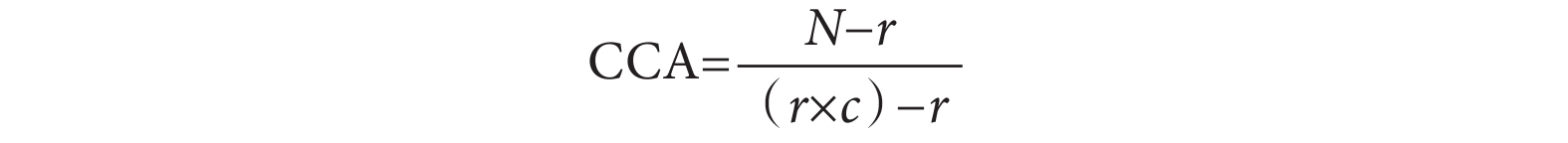傘形評價中的文獻重疊會影響研究結論的可靠性和準確性,產生偏倚風險較大的結果,因此評估文獻重疊程度以及如何處理文獻重疊變得非常重要。為了避免重復計算和減少偏倚風險,研究者需要量化文獻重疊程度并采取相應的處理策略。本文詳細介紹了文獻重疊程度的計算方法以及處理重疊文獻的不同策略,以期為國內學者對該方法的理解和應用提供參考和借鑒。
引用本文: 馬寧, 潘蓓, 鄧錫源, 王瀟曼, 李丹, 何欣, 劉曉緯, 毛長興, 劉一君, 牛軍強, 楊克虎. 傘形評價中文獻重疊的評估及處理. 中國循證醫學雜志, 2024, 24(10): 1212-1218. doi: 10.7507/1672-2531.202405025 復制
版權信息: ?四川大學華西醫院華西期刊社《中國循證醫學雜志》版權所有,未經授權不得轉載、改編
傘形評價(umbrella review),又稱傘狀綜述、傘狀評價、系統評價再評價,通過對已發表的系統評價和Meta分析進行綜合研究,從而為某個特定的研究主題提供更可靠的結論[1,2]。傘形評價的目的不只是去重復檢索、文獻篩選、偏倚風險評估及進行定性或定量分析,更是對來自多方面的證據的總結,以期為臨床決策和循證實踐提供更好的證據支持[3-5]。然而,隨著系統評價和Meta分析發表數量的逐年遞增[6],研究者通常會面臨一個問題:同一研究主題可能有多篇相關的系統評價和Meta分析存在,一篇原始研究通常會被多篇研究目的相似的系統評價和Meta分析納入[7],從而導致了文獻重疊的現象。如果直接將這些系統評價和Meta分析的結果進行合并,很大程度上是整合了相同的原始研究結果,會給重復計數較多的原始研究帶來不成比例的統計權重[4],產生偏倚風險較大的結果,進而影響結論的準確性及可靠性[8]。因此,在進行傘形評價時需要面對的一個重要挑戰就是避免重復計算[9]。有研究者建議刪除部分系統評價和Meta分析,雖然這樣做可以減少甚至完全消除重疊[9],但盲目刪除系統評價和Meta分析同樣也會造成研究結論的不完整性。所以研究者必須首先了解所納入的系統評價和Meta分析在多大程度上使用了相同的原始研究[10],在明確文獻重疊程度情況后應當制定相應的處理策略。因此量化文獻重疊程度以及處理重疊文獻成為了傘形評價研究的首要問題。本文將對常用的文獻重疊計算方法、程度分級以及明確文獻重疊后如何開展下一步研究進行具體介紹,以期為國內研究提供參考和借鑒。
1 文獻重疊程度計算
Pieper等[11]在2014年提出了通過生成一個引文矩陣并計算校正覆蓋面積(corrected covered area,CCA)指數進行重疊程度分析。隨著傘形評價的逐漸發展完善,CCA在檢驗傘形評價及范圍綜述中原始研究的文獻重疊程度方面得到了廣泛應用[12-17],并且在2018年發布的系統評價再評價首選報告項目[18]中提出將CCA作為衡量文獻重疊程度的工具,Cochrane[19]及部分指南[20]也推薦使用CCA進行文獻重疊量化。
1.1 CCA計算步驟
1.1.1 步驟一:創建一個引文矩陣
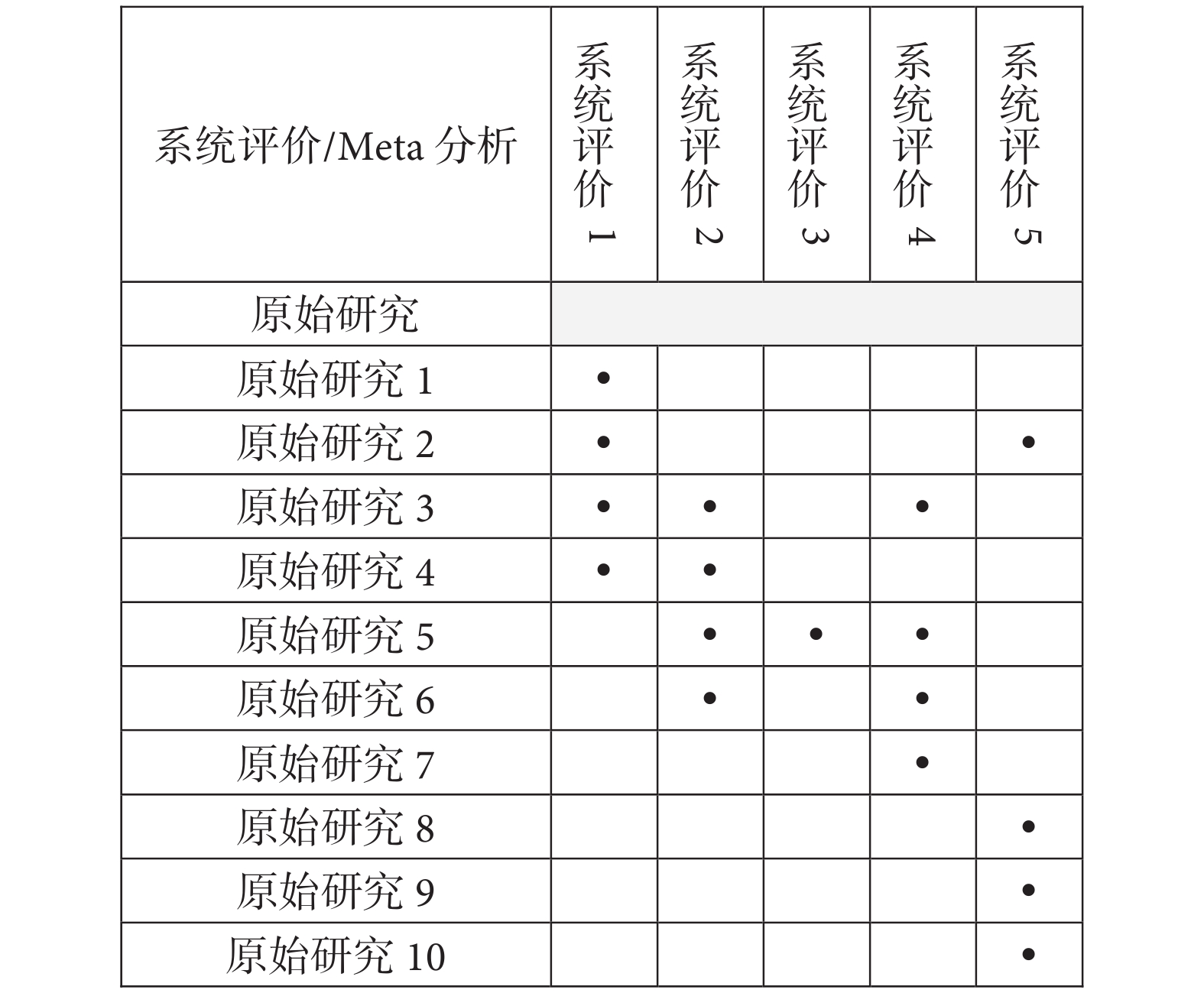
根據Pieper等[11]研究,首先我們應該創建一個引文矩陣,該矩陣為包含系統評價(列)及索引出版物(行)的交叉表。索引出版物(index publications;index case)是指所納入系統評價中首次出現的原始研究。它來自于系統評價作者所提供的引文,并考慮了拼寫錯誤或數字對調的情況。我們對每篇系統評價納入的原始研究在對應位置進行標記(圖1),如果一項原始研究被多篇系統評價納入,則該項原始研究只占一行,對于之后重復出現的原始研究進行刪除,這樣做是為了在一行中顯示出該原始研究在各篇系統評價中出現的次數。引文矩陣應由一名研究人員制作,另一名研究人員檢查其準確性。
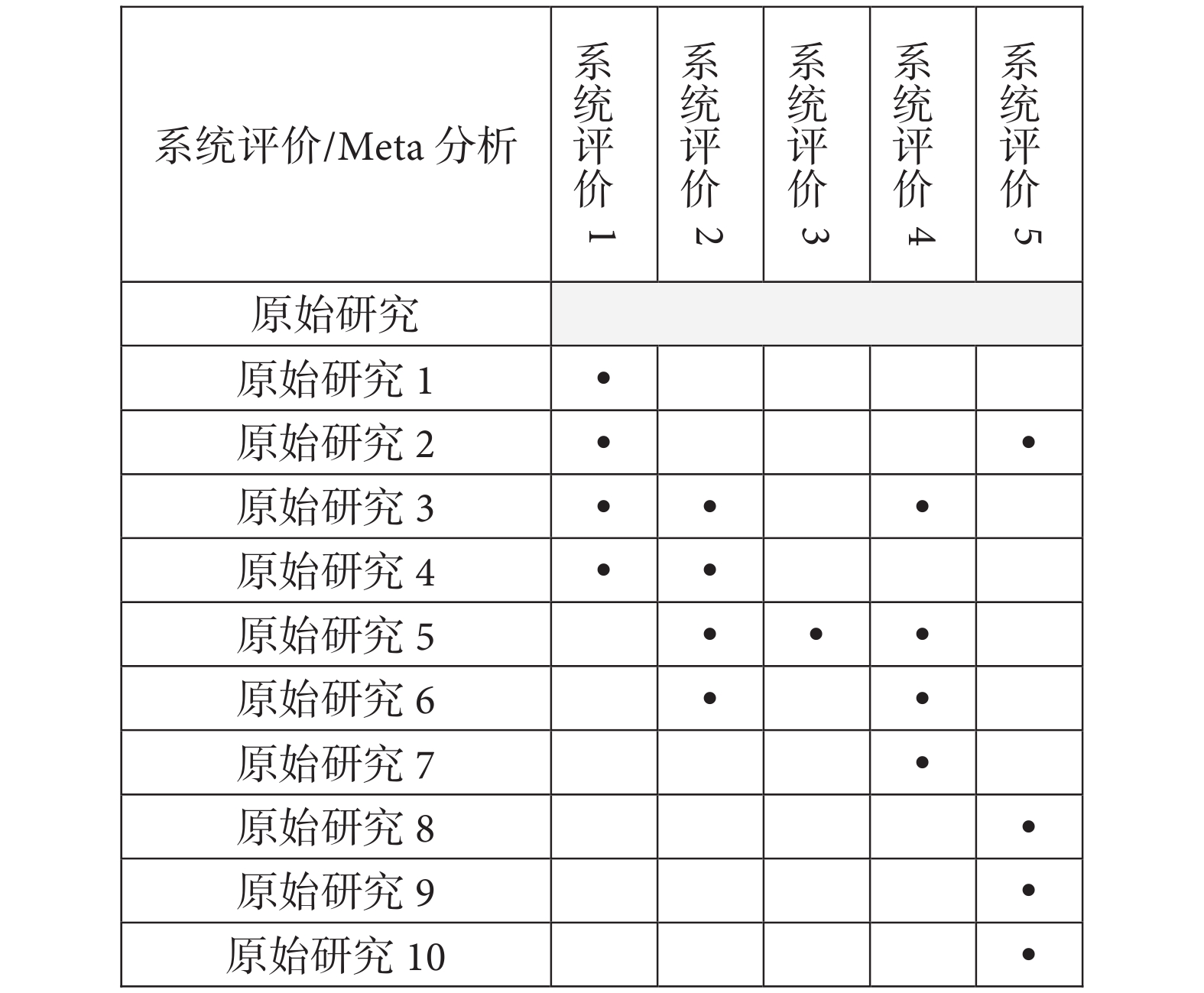 圖1
引文矩陣示例
圖1
引文矩陣示例
1.1.2 步驟二:計算CCA
CCA計算公式見圖2,其中N是指包括重復計數的出版物總數,即引文矩陣中標記框的數量;r是指行數,即索引出版物的數量;c是指列數,即系統評價的數量。我們將索引出版物在系統評價中重復出現的頻率除以索引出版物與系統評價的乘積減去索引出版物的數量從而計算出CCA,其結果的范圍為0%~100%。因為分子只計算被一篇以上系統評價包含的索引出版物數量,所以這代表了真正的重疊,并且減少了大型系統評價對結果的影響。
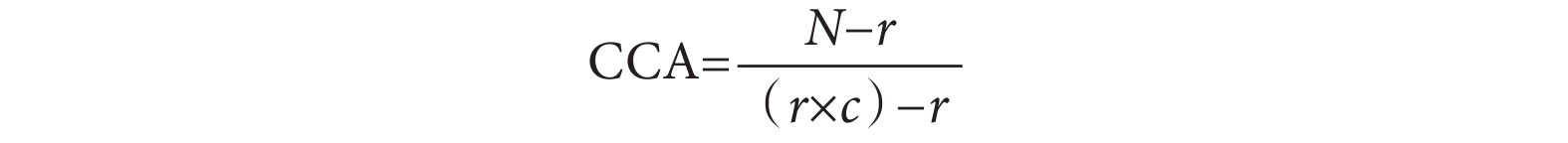 圖2
校正覆蓋面積(CCA)計算公式
圖2
校正覆蓋面積(CCA)計算公式
1.2 重疊程度分級
根據Pieper等[11]研究,CCA指數≤5%表示輕微重疊,6%~10%之間為中等程度重疊,11%~15%之間為高度重疊,≥15%則提示極高度重疊。
Pieper等通過創建一個引文矩陣計算CCA從而量化文獻重疊程度的方法是突破性的進展,得到了廣泛應用。CCA指數的衡量標準更多地取決于原始研究的數量,而不是系統評價和Meta分析的數量,這也使得原始研究與文獻重疊有了更高的相關性,相比其它評估指數更能反映原始研究的文獻重疊程度[9]。隨著科技的進步,當前已經有很多自動化工具可以用于CCA指數評估[10]。例如,Pérez-Bracchiglione等[21]開發了一款基于Excel的工具,名為“GROOVE”,操作簡單快捷;Bougioukas等[22]開發了一個名為“ccaR”的開源R包,也為CCA指數的評估提供了便利的方法。
1.3 CCA計算示例
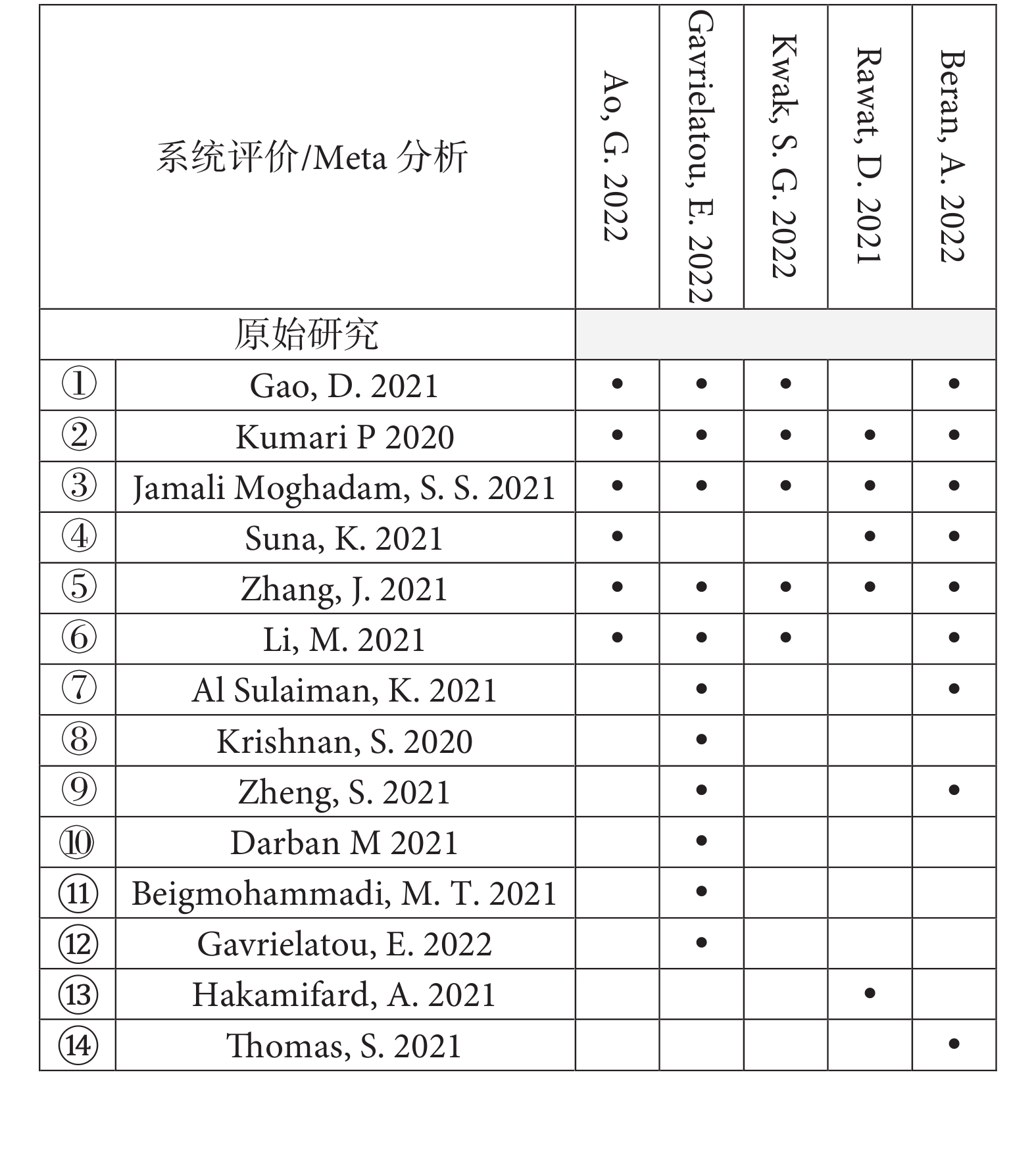
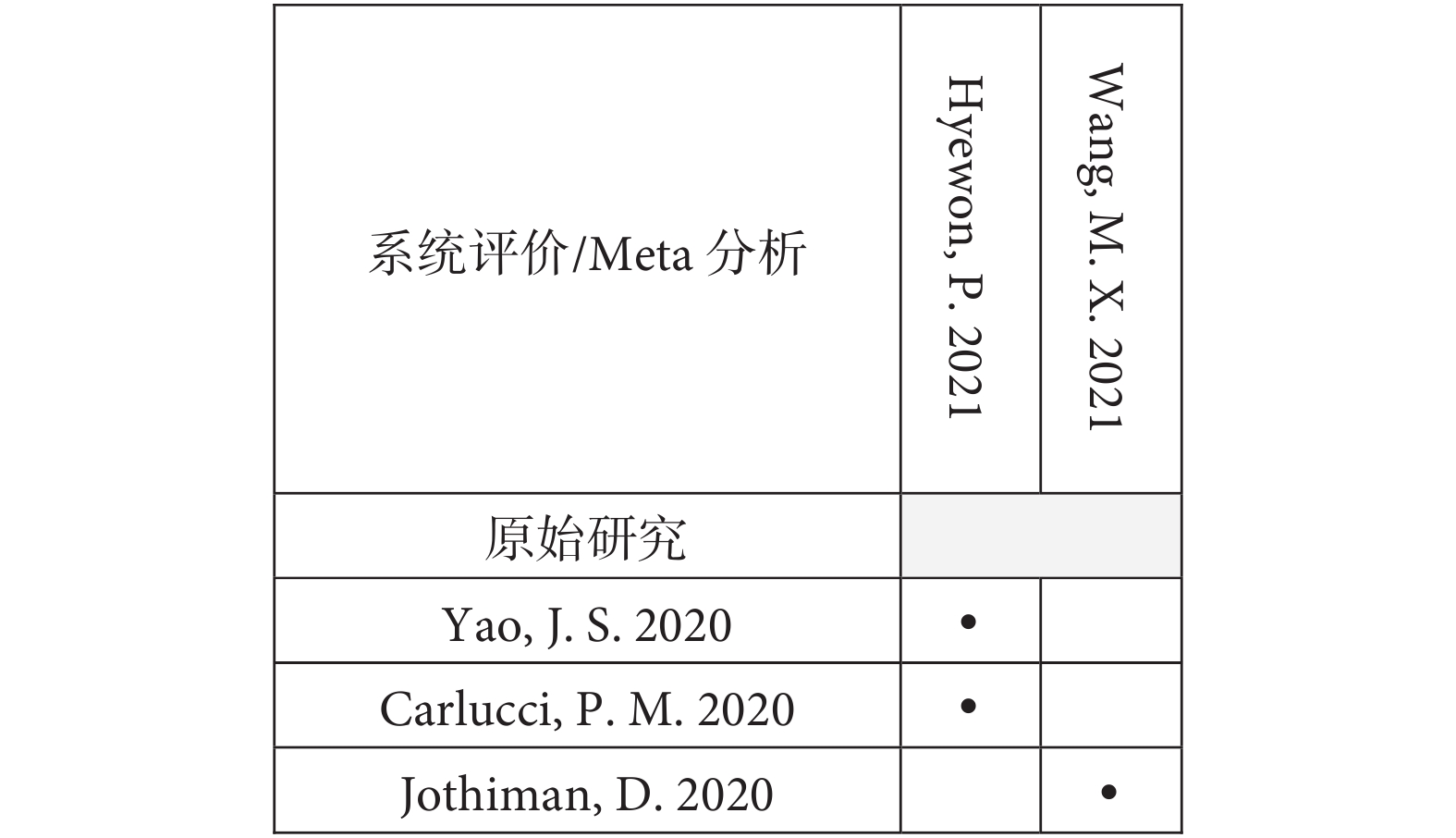
以本研究團隊發表的關于微量營養素對COVID-19影響的傘形評價為例[13],維生素C與COVID-19死亡率關聯這一結局中包含了5篇系統評價和14項原始研究(即索引出版物),其中3項原始研究被5篇系統評價納入,2項原始研究被4篇系統評價納入,1項原始研究被3篇系統評價納入,2項原始研究被兩篇系統評價納入,其余6項原始研究只被納入了一次,具體重疊情況見圖3。在這個例子中,N=36,r=14,c=5,CCA的結果為39.29%[(36?14)/(14×5?14)],提示極高程度重疊。鋅與COVID-19病人ICU住院率關聯這一結局包含了2篇系統評價和3項原始研究(圖4),一篇系統評價包含2項原始研究,另一篇系統評價包含1項原始研究,原始研究無重疊,則N=3,r=3,c=2,CCA的結果為0%[(3?3)/(3×2?3)],提示輕微重疊。
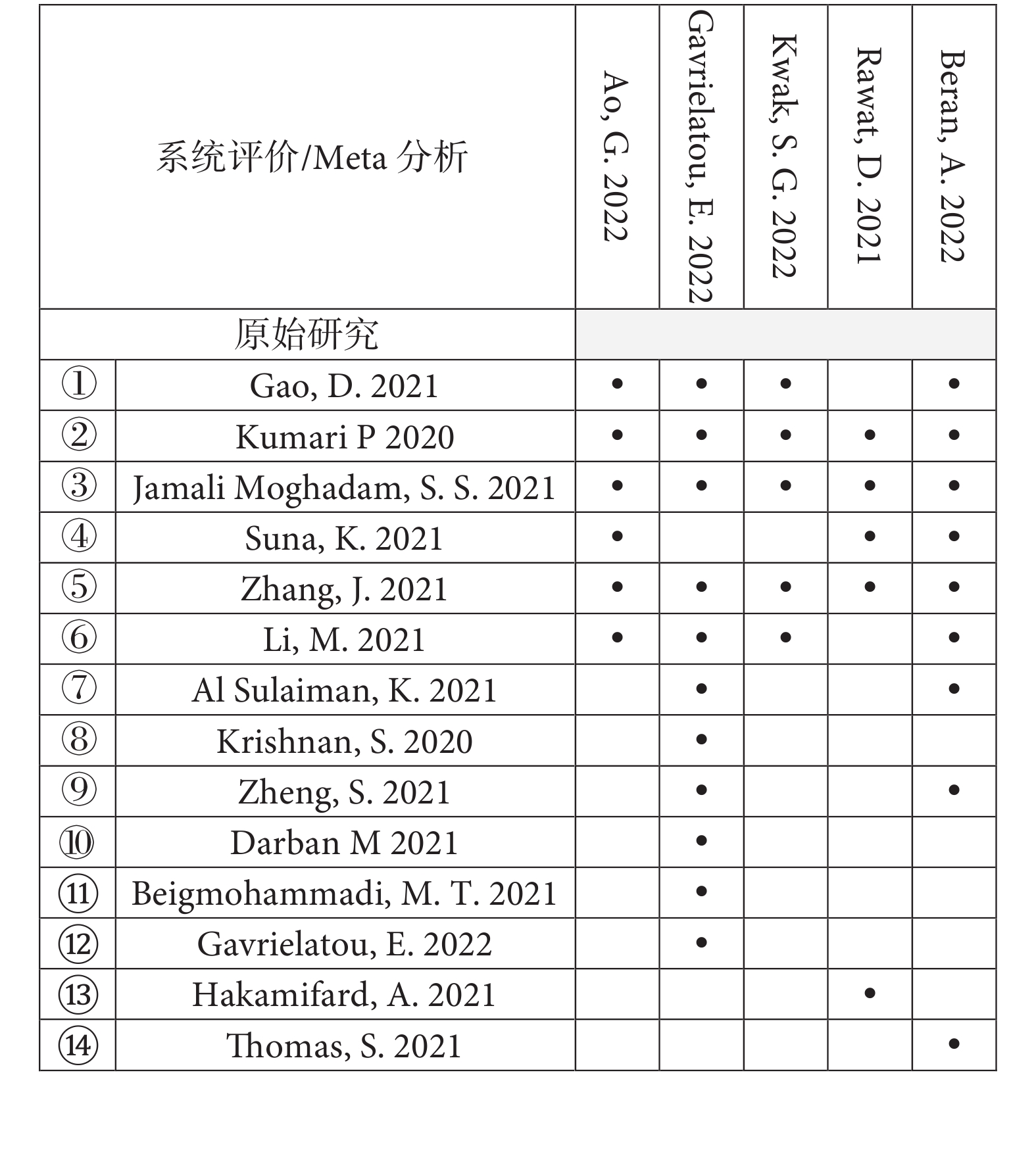 圖3
校正覆蓋面積計算示例1
圖3
校正覆蓋面積計算示例1
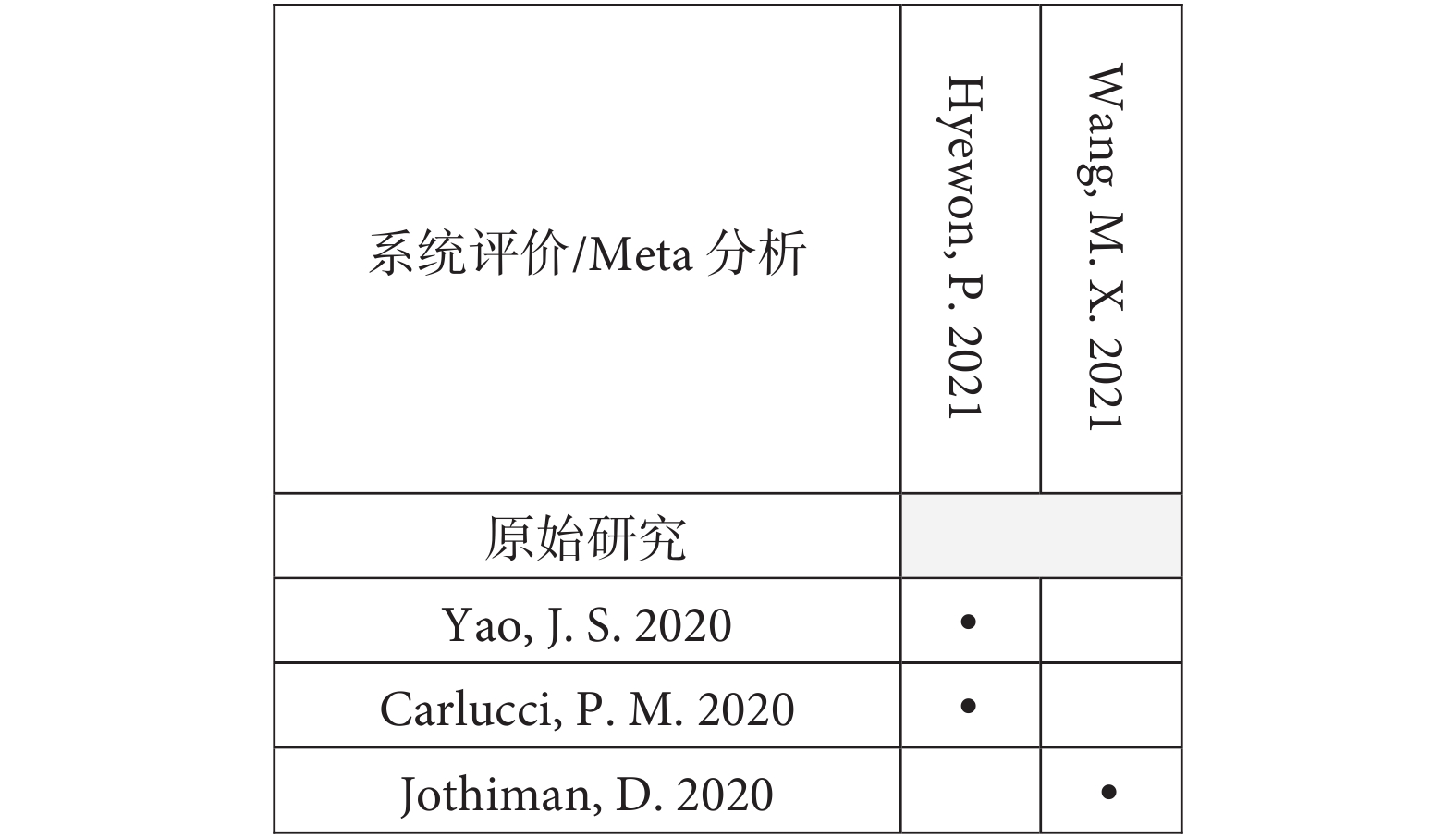 圖4
校正覆蓋面積計算示例2
圖4
校正覆蓋面積計算示例2
2 文獻重疊的處理
2.1 重疊程度較高(CCA≥6%)
2.1.1 使用決策規則/評估工具篩選系統評價和Meta分析
對于存在重疊的證據,可以僅選擇其中一篇或少數幾篇包含該結果的文獻進行進一步分析。這些研究可以是最新發表的、最相關或納入原始研究最全面的[19]。此外,也可以使用當前公認的質量評估工具(例如AMSTAR-2[23]等)來選出方法學質量最高的系統評價和Meta分析進行結果分析[24]。例如,2022年發表于BMJ的一篇傘形評價[25]納入了大量評估糖攝入對健康影響的Meta分析,他們使用的篩選標準是:① 在相隔超過24個月的多項Meta分析中選擇最新發表的一篇進行數據提取分析;② 在相同24個月期間發表的多項研究,選擇納入最多原始研究的Meta分析,如果數量相等,則納入AMSTAR評分最高的研究;③ 如果最新發表的研究沒有進行劑量-反應分析,其他研究進行了該分析,則兩項研究同時納入分析。另一篇發表于BMJ的傘形評價[26]評估了使用大麻的風險和益處,該文章的篩選標準是:如果同一結局存在多項Meta分析,選擇原始研究數量最多的Meta分析。
2.1.2 使用統計方法處理重疊
采用敏感性分析可以評估文獻重疊對結果造成的影響,從而識別出偏倚來源。例如Ferreira團隊發表于BMJ的傘形評價[27]通過納入因文獻重疊而排除的系統評價/Meta分析檢驗了重疊的研究對于效應估計的影響。除敏感性分析外,還可以考慮增加Meta分析估計值的方差以反映重疊文獻的不獨立性,從而更合理地評估重疊文獻對結果的影響[28,29]。
2.1.3 重新分析系統評價和Meta分析納入的所有原始研究
如Xie等[13]在研究微量營養素對COVID-19影響的傘形評價中,對于文獻重疊程度較高的結局,他們選擇整合現有Meta分析中所有相關原始研究的數據并重新進行分析。這種方法可以幫助研究者更充分地利用已有的所有研究成果,避免重復計算和數據浪費的問題。通過整合所有相關的原始研究數據,我們可以綜合考慮所有相關研究的設計、樣本規模、方法學質量等因素,有助于解決重疊文獻可能存在的偏倚和不一致性問題,從而獲得更加全面和深入的數據分析結果。
2.1.4 忽略系統評價和Meta分析中原始研究的重疊
Green等[30]在評估改善學齡兒童社會和情感健康的校本干預措施時,選擇忽略證據重疊的問題。他們表示:“雖然有幾項研究被包括在多個系統評價中,但很難確定系統評價之間研究重疊的確切程度,因為這不是本綜述的中心目標”。忽略系統評價和Meta分析中原始研究的重疊是一種在特定情況下可行的處理策略,能夠簡化分析過程。然而在采用這種方法時,我們需要謹慎權衡各種因素。
2.2 重疊程度較低(CCA≤5%)
如Xie等[13]在其發表的一篇傘形評價中表明,當重疊程度較輕時直接合并結果造成的偏倚是可接受的,因此可以直接利用現有的系統評價和Meta分析的效應估計進行結果分析。這種方法能夠節省時間和資源,避免不必要的重復工作,并且在通常情況下能夠提供對研究主題的合理和可靠的見解。
總之,對于重疊程度較高的情況,我們更傾向于采用刪除部分系統評價和Meta分析、重新分析原始研究這兩種較為徹底的處理方法,以確保結果的準確性和全面性。而對于重疊程度較輕的情況,則可以考慮直接合并現有的系統評價和Meta分析效應值進行結果分析,以提高效率并減少研究成本。目前尚缺乏統一且權威的指導方針或標準來明確不同處理策略的選擇,建議傘形評價研究者綜合考慮文獻質量、重疊程度、研究目的以及資源和時間成本等方面,最終選擇出最為適宜的文獻重疊處理方法。
3 Cochrane手冊中關于文獻重疊的處理[19 ]
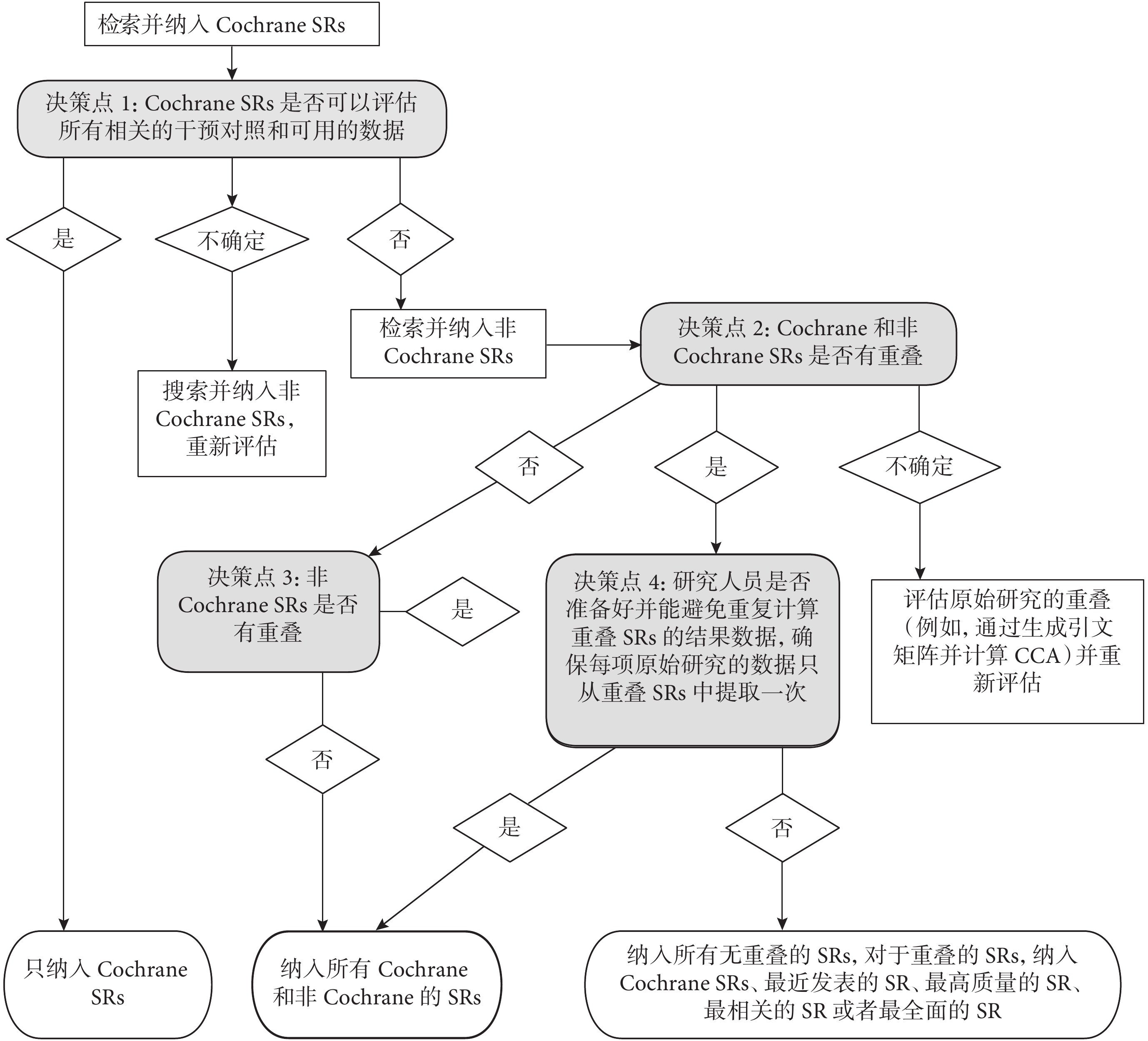
圖5展示了Cochrane手冊中推薦的決策工具,可以幫助研究者在傘形評價過程中確定是否存在重疊以及如何納入重疊的系統評級和Meta分析(改編自Pollock等[31])。主要決策點、包含決策和注意事項總結如下:
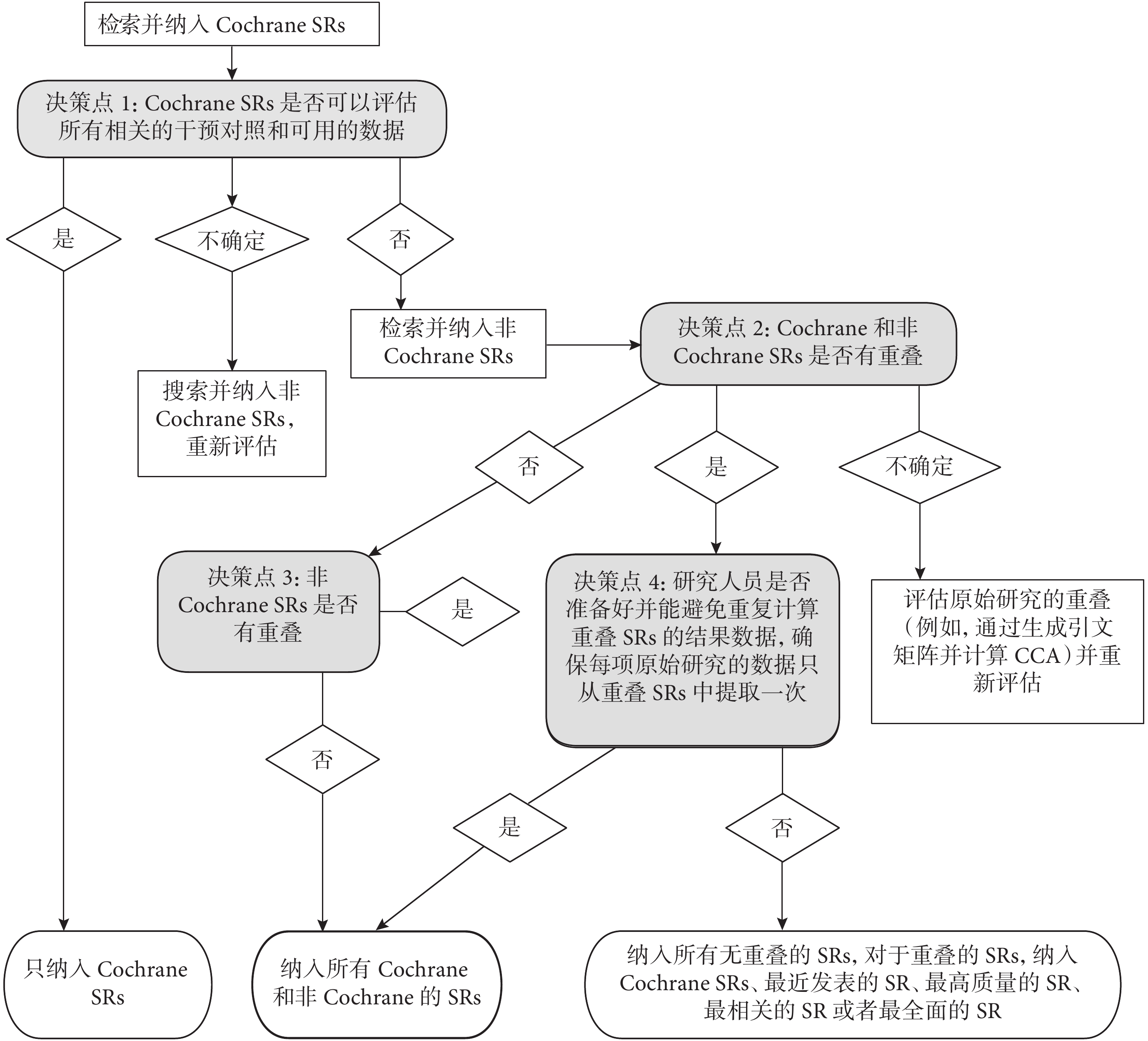
決策點1:如果相關的Cochrane系統評價是對主題的全面評估,那么僅納入Cochrane系統評價就會避免重疊問題。這是因為雖然會有多個非Cochrane系統評價發表,但Cochrane Library只能發表一篇關于任何給定主題的系統評價來避免重復工作,同時Cochrane系統評價更有可能是最新的、有更高方法學質量的文章。
決策點2和3:如果研究者認為Cochrane系統評價不全面,那么下一步可以選擇檢索和納入非Cochrane系統評價,并評估納入的系統評價是否包含重疊的原始研究。如果不存在重疊,作者便可以納入所有相關的Cochrane和非Cochrane系統評價,這種情況可能比較少見。如果研究者不確定Cochrane與非Cochrane系統評價之間是否存在重疊以及重疊程度大小,可以選擇使用CCA方法評估原始研究的重疊情況。
決策點4:如果相關系統評價之間存在重疊,作者可以納入所有的Cochrane和非Cochrane系統評價,但需要注意避免重復計算重疊原始研究的數據。雖然這是確保所有相關系統評價的數據都可以包含在傘形評價中的唯一方法,但應用這種方法耗時且復雜。因此對于不計劃或者無法避免重復計算重疊系統評價但仍希望納入非Cochrane系統評價的作者,可以采取預先制定標準來優先納入某些特定系統評價的方法。作者可以納入所有非重疊的系統評價,在重疊的多項系統評價中選擇Cochrane、最新發表、最高質量、最相關或者最全面的系統評價來實現結果分析。
總而言之,Cochrane手冊所建議的文獻重疊處理決策是:① 只納入Cochrane系統評價(以避免重復計算);② 納入所有的Cochrane和非Cochrane系統評價(需要避免重復計算);③ 納入所有的Cochrane和非Cochrane系統評價(無重復計算問題);④ 納入所有非Cochrane系統評價,對于其他重疊的系統評價,納入Cochrane、最新發表、最高質量、最相關或者最全面的系統評價(以避免重復計算)。
4 討論
隨著系統評價和Meta分析數量的增加,文獻重疊已成為傘形評價研究的一個首要問題。本文詳細介紹了通過CCA方法來量化文獻重疊程度的步驟和方法,強調了CCA方法在有效量化文獻重疊程度方面的實用性,從而為研究者制定合理的處理策略提供了支持。此外,本文結合實際案例深入探討了文獻重疊的不同處理策略:對于重疊程度較高的情況,建議采用刪除部分系統評價和Meta分析及重新分析原始研究數據等方法。對于重疊程度較輕的情況,可以直接合并現有的系統評價和Meta分析的效應值進行結果分析。
最近發布的系統評價再評價首選報告項目指南指出應當報告且在分析階段處理原始研究的重疊[32],然而僅有8%的傘形評價作者報告了[33]對研究中納入的系統評價和Meta分析重疊情況的分析。傘形評價中的文獻重疊是一個容易被忽略的問題,當文獻重疊被忽視或者處理不當時,可能會對研究結論準確性產生影響甚至導致錯誤的結論。因此,無論重疊程度高還是低,所有傘形評價研究者都應該分析重疊情況并進行報告。CCA指數作為反映文獻重疊程度的最佳近似值,易于理解,我們主張在未來的研究中計算和報告CCA指數。
雖然本文對文獻重疊問題進行了系統性的介紹和討論,但仍有許多方面可以進一步探索和完善。首先,對于文獻重疊的計算方法和處理策略的準確性和可靠性,還需要進一步的驗證和比較,以確定最佳的實踐方法。例如,雖然CCA方法被廣泛應用,但其在處理重疊文獻時可能存在一定的局限性。CCA的計算方法始終是通過引文矩陣,當傘形評價中包含的系統評價和Meta分析索引出版物數量較多時,工作量會很大且耗時較長[9];Kirvalidze等[7]指出CCA指數低估了重疊程度,尤其是在多篇系統評價和Meta分析納入的研究數量有明顯差異時,因此應當謹慎使用CCA指數。其次,現有處理策略在減輕重疊影響的方面雖有成效,但也面臨局限性。例如,在選擇質量最高的系統評價和Meta分析作為處理策略時可能導致部分重要文獻被遺漏,影響結果的全面性;多種評估工具的綜合使用可能引入更多主觀判斷,影響評估的一致性。因此,對于文獻重疊的不同程度,應進一步優化和標準化處理策略。針對存在高重疊程度的研究,可以探討更多樣化的整合方法,以確保研究結論的全面性和準確性,為傘形評價的發展提供堅實的基礎。
在未來的研究中,我們可以利用人工智能和自然語言處理技術來進一步優化文獻重疊的識別和處理過程,提高效率和準確性。人工智能技術的應用將使得文獻重疊分析更加智能化和自動化,有望大大縮短識別和處理重疊文獻的時間,減少人工成本和錯誤率。自然語言處理技術的引入則能夠更加精準地分析文本數據,從而有效地識別不同文獻的重疊情況,為后續處理提供更加可靠的基礎。其次,通過開發更加適宜高效的文獻重疊分析工具[34],可以幫助研究者更快地識別和處理重疊文獻,降低人工成本和錯誤率。這些工具不僅能夠簡化重復性的任務,還可以提供更直觀和便捷的界面,使得用戶能夠更輕松地進行文獻重疊分析和處理。這將極大地提升研究效率,使得研究者能夠更專注于數據分析和結果解釋,而非繁瑣的文獻管理工作。另外,與臨床醫生和決策者密切合作也是必要的,通過這種方式,我們可以更好地了解他們的需求,從而設計出更加貼近實際應用的傘形評價方法和工具,還可以進一步探索如何更好地利用傘形評價的結果為臨床決策提供支持。
文獻重疊問題是傘形評價研究中的一個重要挑戰,但通過不斷地研究和改進,希望能夠找到更有效的解決方案,為傘形評價研究提供更可靠和有用的結論,從而促進醫學研究的進步和臨床實踐的改進。
傘形評價(umbrella review),又稱傘狀綜述、傘狀評價、系統評價再評價,通過對已發表的系統評價和Meta分析進行綜合研究,從而為某個特定的研究主題提供更可靠的結論[1,2]。傘形評價的目的不只是去重復檢索、文獻篩選、偏倚風險評估及進行定性或定量分析,更是對來自多方面的證據的總結,以期為臨床決策和循證實踐提供更好的證據支持[3-5]。然而,隨著系統評價和Meta分析發表數量的逐年遞增[6],研究者通常會面臨一個問題:同一研究主題可能有多篇相關的系統評價和Meta分析存在,一篇原始研究通常會被多篇研究目的相似的系統評價和Meta分析納入[7],從而導致了文獻重疊的現象。如果直接將這些系統評價和Meta分析的結果進行合并,很大程度上是整合了相同的原始研究結果,會給重復計數較多的原始研究帶來不成比例的統計權重[4],產生偏倚風險較大的結果,進而影響結論的準確性及可靠性[8]。因此,在進行傘形評價時需要面對的一個重要挑戰就是避免重復計算[9]。有研究者建議刪除部分系統評價和Meta分析,雖然這樣做可以減少甚至完全消除重疊[9],但盲目刪除系統評價和Meta分析同樣也會造成研究結論的不完整性。所以研究者必須首先了解所納入的系統評價和Meta分析在多大程度上使用了相同的原始研究[10],在明確文獻重疊程度情況后應當制定相應的處理策略。因此量化文獻重疊程度以及處理重疊文獻成為了傘形評價研究的首要問題。本文將對常用的文獻重疊計算方法、程度分級以及明確文獻重疊后如何開展下一步研究進行具體介紹,以期為國內研究提供參考和借鑒。
1 文獻重疊程度計算
Pieper等[11]在2014年提出了通過生成一個引文矩陣并計算校正覆蓋面積(corrected covered area,CCA)指數進行重疊程度分析。隨著傘形評價的逐漸發展完善,CCA在檢驗傘形評價及范圍綜述中原始研究的文獻重疊程度方面得到了廣泛應用[12-17],并且在2018年發布的系統評價再評價首選報告項目[18]中提出將CCA作為衡量文獻重疊程度的工具,Cochrane[19]及部分指南[20]也推薦使用CCA進行文獻重疊量化。
1.1 CCA計算步驟
1.1.1 步驟一:創建一個引文矩陣
根據Pieper等[11]研究,首先我們應該創建一個引文矩陣,該矩陣為包含系統評價(列)及索引出版物(行)的交叉表。索引出版物(index publications;index case)是指所納入系統評價中首次出現的原始研究。它來自于系統評價作者所提供的引文,并考慮了拼寫錯誤或數字對調的情況。我們對每篇系統評價納入的原始研究在對應位置進行標記(圖1),如果一項原始研究被多篇系統評價納入,則該項原始研究只占一行,對于之后重復出現的原始研究進行刪除,這樣做是為了在一行中顯示出該原始研究在各篇系統評價中出現的次數。引文矩陣應由一名研究人員制作,另一名研究人員檢查其準確性。
圖1
引文矩陣示例
1.1.2 步驟二:計算CCA
CCA計算公式見圖2,其中N是指包括重復計數的出版物總數,即引文矩陣中標記框的數量;r是指行數,即索引出版物的數量;c是指列數,即系統評價的數量。我們將索引出版物在系統評價中重復出現的頻率除以索引出版物與系統評價的乘積減去索引出版物的數量從而計算出CCA,其結果的范圍為0%~100%。因為分子只計算被一篇以上系統評價包含的索引出版物數量,所以這代表了真正的重疊,并且減少了大型系統評價對結果的影響。
圖2
校正覆蓋面積(CCA)計算公式
1.2 重疊程度分級
根據Pieper等[11]研究,CCA指數≤5%表示輕微重疊,6%~10%之間為中等程度重疊,11%~15%之間為高度重疊,≥15%則提示極高度重疊。
Pieper等通過創建一個引文矩陣計算CCA從而量化文獻重疊程度的方法是突破性的進展,得到了廣泛應用。CCA指數的衡量標準更多地取決于原始研究的數量,而不是系統評價和Meta分析的數量,這也使得原始研究與文獻重疊有了更高的相關性,相比其它評估指數更能反映原始研究的文獻重疊程度[9]。隨著科技的進步,當前已經有很多自動化工具可以用于CCA指數評估[10]。例如,Pérez-Bracchiglione等[21]開發了一款基于Excel的工具,名為“GROOVE”,操作簡單快捷;Bougioukas等[22]開發了一個名為“ccaR”的開源R包,也為CCA指數的評估提供了便利的方法。
1.3 CCA計算示例
以本研究團隊發表的關于微量營養素對COVID-19影響的傘形評價為例[13],維生素C與COVID-19死亡率關聯這一結局中包含了5篇系統評價和14項原始研究(即索引出版物),其中3項原始研究被5篇系統評價納入,2項原始研究被4篇系統評價納入,1項原始研究被3篇系統評價納入,2項原始研究被兩篇系統評價納入,其余6項原始研究只被納入了一次,具體重疊情況見圖3。在這個例子中,N=36,r=14,c=5,CCA的結果為39.29%[(36?14)/(14×5?14)],提示極高程度重疊。鋅與COVID-19病人ICU住院率關聯這一結局包含了2篇系統評價和3項原始研究(圖4),一篇系統評價包含2項原始研究,另一篇系統評價包含1項原始研究,原始研究無重疊,則N=3,r=3,c=2,CCA的結果為0%[(3?3)/(3×2?3)],提示輕微重疊。
圖3
校正覆蓋面積計算示例1
圖4
校正覆蓋面積計算示例2
2 文獻重疊的處理
2.1 重疊程度較高(CCA≥6%)
2.1.1 使用決策規則/評估工具篩選系統評價和Meta分析
對于存在重疊的證據,可以僅選擇其中一篇或少數幾篇包含該結果的文獻進行進一步分析。這些研究可以是最新發表的、最相關或納入原始研究最全面的[19]。此外,也可以使用當前公認的質量評估工具(例如AMSTAR-2[23]等)來選出方法學質量最高的系統評價和Meta分析進行結果分析[24]。例如,2022年發表于BMJ的一篇傘形評價[25]納入了大量評估糖攝入對健康影響的Meta分析,他們使用的篩選標準是:① 在相隔超過24個月的多項Meta分析中選擇最新發表的一篇進行數據提取分析;② 在相同24個月期間發表的多項研究,選擇納入最多原始研究的Meta分析,如果數量相等,則納入AMSTAR評分最高的研究;③ 如果最新發表的研究沒有進行劑量-反應分析,其他研究進行了該分析,則兩項研究同時納入分析。另一篇發表于BMJ的傘形評價[26]評估了使用大麻的風險和益處,該文章的篩選標準是:如果同一結局存在多項Meta分析,選擇原始研究數量最多的Meta分析。
2.1.2 使用統計方法處理重疊
采用敏感性分析可以評估文獻重疊對結果造成的影響,從而識別出偏倚來源。例如Ferreira團隊發表于BMJ的傘形評價[27]通過納入因文獻重疊而排除的系統評價/Meta分析檢驗了重疊的研究對于效應估計的影響。除敏感性分析外,還可以考慮增加Meta分析估計值的方差以反映重疊文獻的不獨立性,從而更合理地評估重疊文獻對結果的影響[28,29]。
2.1.3 重新分析系統評價和Meta分析納入的所有原始研究
如Xie等[13]在研究微量營養素對COVID-19影響的傘形評價中,對于文獻重疊程度較高的結局,他們選擇整合現有Meta分析中所有相關原始研究的數據并重新進行分析。這種方法可以幫助研究者更充分地利用已有的所有研究成果,避免重復計算和數據浪費的問題。通過整合所有相關的原始研究數據,我們可以綜合考慮所有相關研究的設計、樣本規模、方法學質量等因素,有助于解決重疊文獻可能存在的偏倚和不一致性問題,從而獲得更加全面和深入的數據分析結果。
2.1.4 忽略系統評價和Meta分析中原始研究的重疊
Green等[30]在評估改善學齡兒童社會和情感健康的校本干預措施時,選擇忽略證據重疊的問題。他們表示:“雖然有幾項研究被包括在多個系統評價中,但很難確定系統評價之間研究重疊的確切程度,因為這不是本綜述的中心目標”。忽略系統評價和Meta分析中原始研究的重疊是一種在特定情況下可行的處理策略,能夠簡化分析過程。然而在采用這種方法時,我們需要謹慎權衡各種因素。
2.2 重疊程度較低(CCA≤5%)
如Xie等[13]在其發表的一篇傘形評價中表明,當重疊程度較輕時直接合并結果造成的偏倚是可接受的,因此可以直接利用現有的系統評價和Meta分析的效應估計進行結果分析。這種方法能夠節省時間和資源,避免不必要的重復工作,并且在通常情況下能夠提供對研究主題的合理和可靠的見解。
總之,對于重疊程度較高的情況,我們更傾向于采用刪除部分系統評價和Meta分析、重新分析原始研究這兩種較為徹底的處理方法,以確保結果的準確性和全面性。而對于重疊程度較輕的情況,則可以考慮直接合并現有的系統評價和Meta分析效應值進行結果分析,以提高效率并減少研究成本。目前尚缺乏統一且權威的指導方針或標準來明確不同處理策略的選擇,建議傘形評價研究者綜合考慮文獻質量、重疊程度、研究目的以及資源和時間成本等方面,最終選擇出最為適宜的文獻重疊處理方法。
3 Cochrane手冊中關于文獻重疊的處理[19 ]
圖5展示了Cochrane手冊中推薦的決策工具,可以幫助研究者在傘形評價過程中確定是否存在重疊以及如何納入重疊的系統評級和Meta分析(改編自Pollock等[31])。主要決策點、包含決策和注意事項總結如下:
決策點1:如果相關的Cochrane系統評價是對主題的全面評估,那么僅納入Cochrane系統評價就會避免重疊問題。這是因為雖然會有多個非Cochrane系統評價發表,但Cochrane Library只能發表一篇關于任何給定主題的系統評價來避免重復工作,同時Cochrane系統評價更有可能是最新的、有更高方法學質量的文章。
決策點2和3:如果研究者認為Cochrane系統評價不全面,那么下一步可以選擇檢索和納入非Cochrane系統評價,并評估納入的系統評價是否包含重疊的原始研究。如果不存在重疊,作者便可以納入所有相關的Cochrane和非Cochrane系統評價,這種情況可能比較少見。如果研究者不確定Cochrane與非Cochrane系統評價之間是否存在重疊以及重疊程度大小,可以選擇使用CCA方法評估原始研究的重疊情況。
決策點4:如果相關系統評價之間存在重疊,作者可以納入所有的Cochrane和非Cochrane系統評價,但需要注意避免重復計算重疊原始研究的數據。雖然這是確保所有相關系統評價的數據都可以包含在傘形評價中的唯一方法,但應用這種方法耗時且復雜。因此對于不計劃或者無法避免重復計算重疊系統評價但仍希望納入非Cochrane系統評價的作者,可以采取預先制定標準來優先納入某些特定系統評價的方法。作者可以納入所有非重疊的系統評價,在重疊的多項系統評價中選擇Cochrane、最新發表、最高質量、最相關或者最全面的系統評價來實現結果分析。
總而言之,Cochrane手冊所建議的文獻重疊處理決策是:① 只納入Cochrane系統評價(以避免重復計算);② 納入所有的Cochrane和非Cochrane系統評價(需要避免重復計算);③ 納入所有的Cochrane和非Cochrane系統評價(無重復計算問題);④ 納入所有非Cochrane系統評價,對于其他重疊的系統評價,納入Cochrane、最新發表、最高質量、最相關或者最全面的系統評價(以避免重復計算)。
4 討論
隨著系統評價和Meta分析數量的增加,文獻重疊已成為傘形評價研究的一個首要問題。本文詳細介紹了通過CCA方法來量化文獻重疊程度的步驟和方法,強調了CCA方法在有效量化文獻重疊程度方面的實用性,從而為研究者制定合理的處理策略提供了支持。此外,本文結合實際案例深入探討了文獻重疊的不同處理策略:對于重疊程度較高的情況,建議采用刪除部分系統評價和Meta分析及重新分析原始研究數據等方法。對于重疊程度較輕的情況,可以直接合并現有的系統評價和Meta分析的效應值進行結果分析。
最近發布的系統評價再評價首選報告項目指南指出應當報告且在分析階段處理原始研究的重疊[32],然而僅有8%的傘形評價作者報告了[33]對研究中納入的系統評價和Meta分析重疊情況的分析。傘形評價中的文獻重疊是一個容易被忽略的問題,當文獻重疊被忽視或者處理不當時,可能會對研究結論準確性產生影響甚至導致錯誤的結論。因此,無論重疊程度高還是低,所有傘形評價研究者都應該分析重疊情況并進行報告。CCA指數作為反映文獻重疊程度的最佳近似值,易于理解,我們主張在未來的研究中計算和報告CCA指數。
雖然本文對文獻重疊問題進行了系統性的介紹和討論,但仍有許多方面可以進一步探索和完善。首先,對于文獻重疊的計算方法和處理策略的準確性和可靠性,還需要進一步的驗證和比較,以確定最佳的實踐方法。例如,雖然CCA方法被廣泛應用,但其在處理重疊文獻時可能存在一定的局限性。CCA的計算方法始終是通過引文矩陣,當傘形評價中包含的系統評價和Meta分析索引出版物數量較多時,工作量會很大且耗時較長[9];Kirvalidze等[7]指出CCA指數低估了重疊程度,尤其是在多篇系統評價和Meta分析納入的研究數量有明顯差異時,因此應當謹慎使用CCA指數。其次,現有處理策略在減輕重疊影響的方面雖有成效,但也面臨局限性。例如,在選擇質量最高的系統評價和Meta分析作為處理策略時可能導致部分重要文獻被遺漏,影響結果的全面性;多種評估工具的綜合使用可能引入更多主觀判斷,影響評估的一致性。因此,對于文獻重疊的不同程度,應進一步優化和標準化處理策略。針對存在高重疊程度的研究,可以探討更多樣化的整合方法,以確保研究結論的全面性和準確性,為傘形評價的發展提供堅實的基礎。
在未來的研究中,我們可以利用人工智能和自然語言處理技術來進一步優化文獻重疊的識別和處理過程,提高效率和準確性。人工智能技術的應用將使得文獻重疊分析更加智能化和自動化,有望大大縮短識別和處理重疊文獻的時間,減少人工成本和錯誤率。自然語言處理技術的引入則能夠更加精準地分析文本數據,從而有效地識別不同文獻的重疊情況,為后續處理提供更加可靠的基礎。其次,通過開發更加適宜高效的文獻重疊分析工具[34],可以幫助研究者更快地識別和處理重疊文獻,降低人工成本和錯誤率。這些工具不僅能夠簡化重復性的任務,還可以提供更直觀和便捷的界面,使得用戶能夠更輕松地進行文獻重疊分析和處理。這將極大地提升研究效率,使得研究者能夠更專注于數據分析和結果解釋,而非繁瑣的文獻管理工作。另外,與臨床醫生和決策者密切合作也是必要的,通過這種方式,我們可以更好地了解他們的需求,從而設計出更加貼近實際應用的傘形評價方法和工具,還可以進一步探索如何更好地利用傘形評價的結果為臨床決策提供支持。
文獻重疊問題是傘形評價研究中的一個重要挑戰,但通過不斷地研究和改進,希望能夠找到更有效的解決方案,為傘形評價研究提供更可靠和有用的結論,從而促進醫學研究的進步和臨床實踐的改進。