心臟瓣膜病(HVD)是常見的心血管疾病之一,心音是用于檢測心臟瓣膜病的重要生理信號。本文提出了一種基于心音基本成分特征和包絡自相關特征的聯合分類模型,以檢測早期心臟瓣膜病。本文首先使用經驗模態分解(EMD)對5 min心音信號去噪,分割成心音信號樣本,并提取心音信號樣本的基本成分特征和包絡自相關特征,聯合上述兩類特征構建心音特征集;然后使用最大相關最小冗余(MRMR)算法選擇最優混合特征;最后分別使用決策樹、支持向量機(SVM)和K最鄰近(KNN)分類器對正常心音和早期心臟瓣膜病心音進行分類。經臨床數據驗證,本文模型分類正常心音和異常心音的準確率達到99.9%,分類正常心音、半月瓣異常心音和房室瓣異常心音的準確率達到99.8%,分類正常心音、單瓣膜異常心音和多瓣膜異常心音的準確率達到98.2%。在公開數據集上,本文模型也取得了較好的分類結果。綜上所述,本文方法對早期心臟瓣膜病的診斷具有重要的參考價值。
引用本文: 孫成法, 王新沛, 劉常春. 基于心音特征的早期心臟瓣膜病檢測方法. 生物醫學工程學雜志, 2023, 40(6): 1160-1167, 1174. doi: 10.7507/1001-5515.202112009 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
0 引言
心臟瓣膜病(heart valve disease,HVD)是常見的心血管疾病之一[1],嚴重時可導致心力衰竭、暈厥、猝死等。心臟瓣膜病的早期檢測可為疾病的早發現和及時干預提供依據。冠脈造影和超聲心動圖是診斷心臟瓣膜病的有效技術[2],但需要有專業技術經驗的醫生操作。聽診是臨床上初診心血管疾病以及檢測心臟瓣膜病的常用方法,無損無創,但其主要依賴于醫生的經驗診斷,效率低、主觀性強。心音自動檢測技術可以提高心臟瓣膜病的診斷效率和精度,從而減輕醫生的負擔,對早期心臟瓣膜病的診療具有重要的參考價值。
心音信號包含心臟瓣膜活動和血液流動的重要生理病理信息,是人體重要的生理信號。心音的每個心動周期一般包含第一心音(the first heart sound,S1)、收縮期、第二心音(the second heart sound,S2)和舒張期四個基本成分,心音檢測方法通常從基本成分的位置、持續時間、幅度、頻譜等方面進行分析[3-5]。目前,各種分段算法被用于分割去噪后的心音信號,以獲取心音基本成分,其中典型的心音分段算法包括包絡分段算法[3]、隱馬爾可夫方法[5-6]和深度學習[7]等。其中,Springer等[6]使用邏輯回歸估計觀測概率,并改進維特比,對心音信號分段,最終結果F1分數達到95.63%,是目前效果較好的心音分段算法。
心臟瓣膜病產生心雜音,從而改變心音基本成分間期、間期比、頻譜、小波系數和時頻圖等特征[8-10]。Potes等[8] 從心音信號中提取了124個時頻特征,使用自適應增強(adaptive boosting,Adaboost)分類器進行分類;同時提取4個頻帶信號,訓練一維卷積神經網絡(convolutional neural networks,CNN),兩者共同決策最終分類結果,靈敏性和特異性的平均值達到86.02%。Chen等[9]使用支持向量機(support vector machine,SVM)對心音時頻域特征進行評估和擴展,設計集成分類模型,得到了95.9%的靈敏性和91.7%的特異性。Oztavli等[10]提取了時頻特征、梅爾頻率倒譜系數(mel-frequency cepstral coefficients,MFCC)、心率等特征,用于檢測異常心音。
隨著技術發展,非分段心音檢測方法也取得重大突破[11-12]。Yadav等[11]提取了心音的MFCC和傅里葉變換特征,使用SVM分類正常和異常心音,其準確率、靈敏性和特異性分別為95%、100%和90%。Upretee等[12]提出了一種簡單的時變頻譜特征,即質心頻率,使用SVM和K最近鄰(k-nearest neighbor,KNN)分類,也取得了較好的分類結果。近年來,深度學習網絡聯合非分段心音的檢測方法被廣泛應用[13-16]。Krishnan等[13]采用非分段心音訓練一維CNN和前饋神經網絡,分類準確率達到85.7%。Meintjes等[14]和Singh等[16]將非分段心音變換為二維圖像,訓練CNN檢測異常心音,分類準確率分別達到86%和90%。Noman等[15]利用一維和二維CNN集成模型檢測異常心音,得到88.8%的準確率。
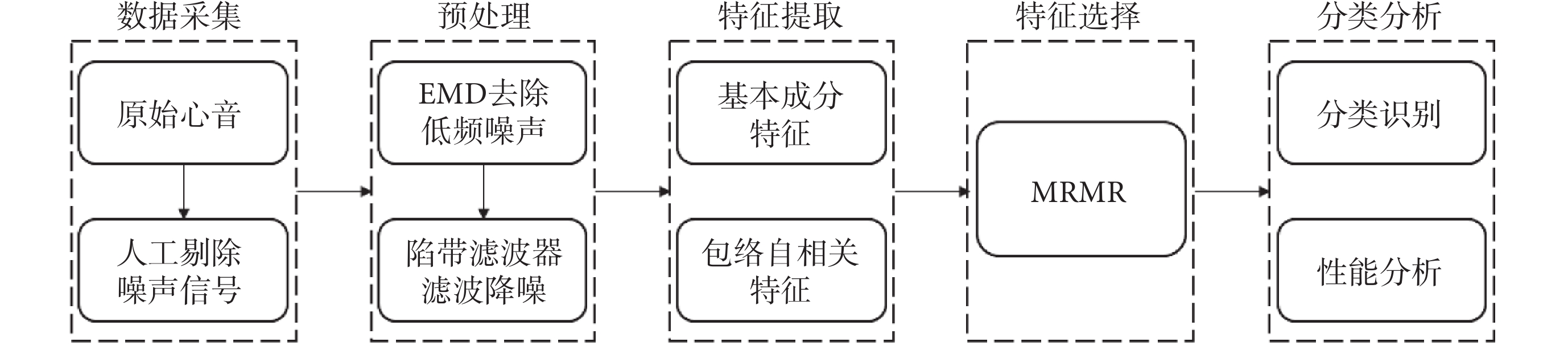
目前,國內外主要通過公開數據集作為數據來源研究心音檢測方法,但公開數據集樣本長度較短,且多數方法僅驗證了正常和異常心音或者幾種典型重度心臟瓣膜病心音的分類,數據類型較少,不夠完善。Li等[17]使用離散小波變換(discrete wavelet transform,DWT)分析心音信號,在公開數據集上檢測心臟瓣膜病,分類準確率為85.5%。在臨床上,心音采集易受各種噪聲干擾,使用現有模型分類,效果尚不滿足要求,因此本文提出基本成分特征和包絡自相關特征的聯合檢測模型。首先使用經驗模態分解(empirical mode decomposition,EMD)對心音信號去噪[4],然后對去噪后的心音信號進行分割,構建心音信號樣本集,并提取心音信號樣本的基本成分特征和包絡自相關特征,聯合上述兩類特征構建心音特征集;然后使用最大相關最小冗余(max-relevance and min-redundancy,MRMR)算法選擇最優混合特征集;最后使用決策樹、SVM和KNN分類器對正常心音和早期心臟瓣膜病心音進行分類,其流程如圖1所示。
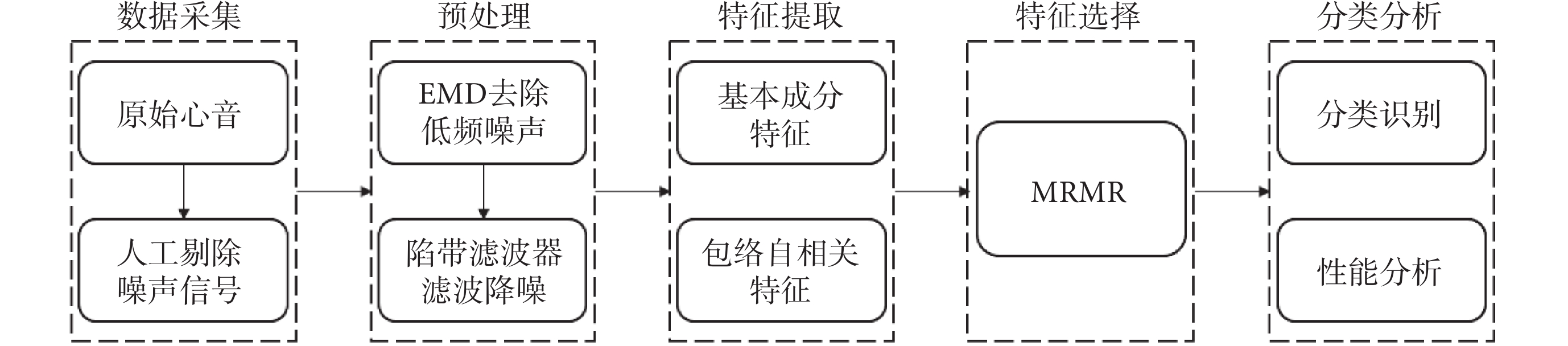 圖1
早期心臟瓣膜病檢測流程圖
Figure1.
Flowchart of early heart valve diseases detection
圖1
早期心臟瓣膜病檢測流程圖
Figure1.
Flowchart of early heart valve diseases detection
1 數據和方法
1.1 數據處理
1.1.1 數據采集
本研究共招募158例受試者入組,包括:① 健康受試者65例,男性30例,女性35例,年齡范圍51~74歲,平均年齡(62.44 ± 6.55)歲。② 早期心臟瓣膜病患者93例,男性60例,女性33例,年齡范圍45~86歲,平均年齡(67.05 ± 9.83)歲。
本文心音數據采集于千佛山醫院(山東第一醫科大學第一附屬醫院),試驗得到了山東第一醫科大學第一附屬醫院醫學倫理委員會的批準[倫審字(S374)號],所有受試者在試驗前均簽署知情同意書。試驗納入標準為計劃在兩天內進行造影和心臟超聲檢測的受試者。試驗入組標準:早期心臟瓣膜病患者,經造影和心臟超聲檢測證實至少有一個瓣膜發生輕度反流的受試者;健康受試者:經造影和心臟超聲檢測證實瓣膜沒有發生病變的受試者。排除標準:經過心血管或瓣膜手術干預的患者;嚴重瓣膜或心血管損傷的患者;精神異常的患者。
數據采集開始前,受試者在一個安靜且溫度可控(25 ± 3)℃的房間內以仰臥姿勢躺在測量床上休息10 min。然后將壓電傳感器置于受試者胸骨左緣第三肋間隙聽診位置,使用心血管系統狀態檢測儀(CVFD-Ⅱ,濟南匯醫融工科技有限公司,中國)采集數據,采樣頻率2 kHz,記錄心音信號約5 min。
1.1.2 數據降噪
本文使用EMD算法將原始心音信號分解為10個固有模態分量和殘差,然后計算原始心音信號與各固有模態分量的互相關系數,去除相關性系數低于0.1的低頻模態后重構信號,然后使用陷帶濾波器去除50 Hz的工頻噪聲。
1.1.3 心音樣本構建
將預處理后的心音信號按照15 s的長度分割為多個片段,刪除噪聲干擾大的片段,使用z分數(z-score)方法對心音片段進行歸一化處理,獲取了1 469個正常心音樣本和1 793個異常心音樣本,其中異常樣本包含五類,如表1所示。對已獲得的心音樣本按照下述方法分別提取基本成分特征和包絡自相關特征。
1.2 基本成分特征提取
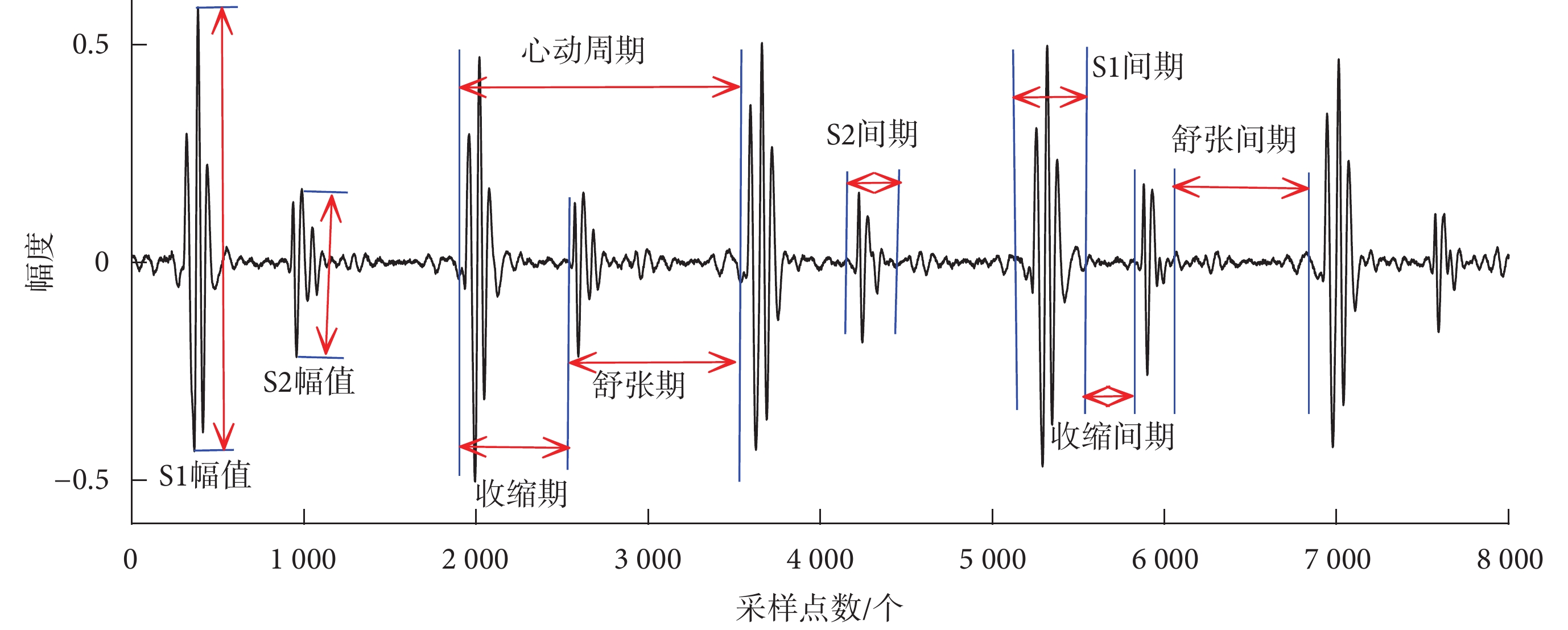
本文使用Springer等[6]的算法獲取S1、收縮期、S2和舒張期等心音基本成分,然后分別提取心音基本成分的時域特征、頻域特征和能量比特征。心音基本成分如圖2所示。
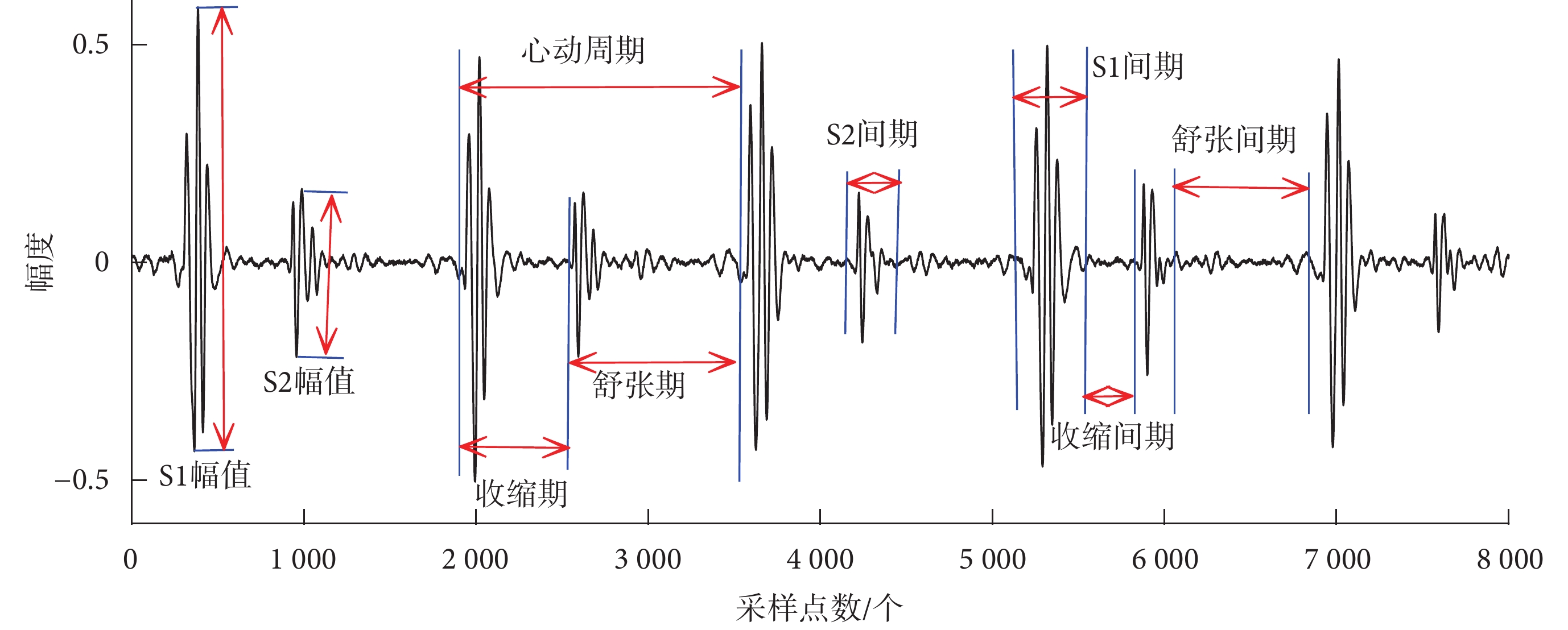 圖2
心音基本成分
Figure2.
The basic component of heart sound signal
圖2
心音基本成分
Figure2.
The basic component of heart sound signal
1.2.1 時域特征
心音基本成分的間期和幅度等變化反映了心臟功能的改變,是心臟瓣膜病診斷的重要生理病理特征。本文依據Liu等[18]的方法從每個心動周期中提取心音基本成分的間期、峰度、偏度、S1/收縮間期、S2/舒張間期、S1/S2幅值、收縮期/舒張期、心動周期,計算每個心音樣本的各時域特征的均值和標準差,獲得34個時域特征。
1.2.2 頻域特征
心臟瓣膜病變會產生微弱的高頻心雜音,因此心音信號的高頻譜中包含心臟瓣膜病變產生的高頻雜音成分。本文使用傅里葉變換計算心音基本成分的頻譜,然后分別提取各頻譜成分,并計算了低頻(0~50 Hz)成分占比、中低頻(50~200 Hz)成分占比、高頻(200 Hz以上)成分占比、低高頻成分之比和頻譜最大幅值對應的頻率,對每個心音樣本的各頻域特征計算均值,獲得97個頻域特征。
1.2.3 能量比特征
對比DWT,離散小波包變換(discrete wavelet packet transform,DWPT)可以對心音信號的低頻成分和高頻成分進行等頻帶分解[19],獲取心音的等頻帶信息,以驗證各頻帶信息對心臟瓣膜病檢測效果。本文使用四層DWPT對心音基本成分等頻帶分解,在第四層上重構了16個等頻帶信號,分別計算16個等頻帶、0~62.5 Hz、62.5~187.5 Hz和187.5~1 000 Hz頻帶信號的能量占比[20]。此外,還計算了心音基本成分在其心動周期內的能量占比。計算每個心音樣本的各能量比特征的均值和方差,獲得113個能量比特征。
1.3 包絡自相關特征提取
本文利用平均香農能量熵算法,計算心音樣本的包絡自相關,并使用主成分分析(principal component analysis,PCA)算法提取包絡自相關特征[21]。
平均香農能量熵算法首先通過加窗對心音信號平滑處理[3],每幀80個點,重疊40個點,計算每幀的平均香農能量熵,并對平均香農能量熵進行歸一化處理。包絡自相關Rhs(n)的計算如公式(1)所示:
 |
其中,Ehs(m)表示第m幀的歸一化平均香農能量熵,n表示時間延遲,取值范圍為[0,k ? 1],k表示平均香農能量熵的長度,在臨床數據集和公開數據集中分別為750和10。
本文利用PCA對包絡自相關降維,獲取了50個包絡自相關特征。
1.4 特征選擇方法
特征選擇算法可對高維特征向量降維,簡化模型的運算復雜度。MRMR算法是一種以互信息理論為基礎的特征選擇算法[22],計算每個特征的互信息的商(mutual information quotient,MIQ)(以符號MIQ表示),評估其分類貢獻,如式(2)所示:
 |
其中,VS表示特征與預測類別的相關性,WS表示特征間的冗余度總和,|S|表示特征總數,xi、xj表示特征向量,y表示預測類別,I(xi ; y)代表特征向量與預測類別的互信息,I(xi ; xj)代表兩特征向量的互信息。
1.5 分類器
本文使用決策樹、SVM和KNN三種分類器分別對正常心音和早期心臟瓣膜病心音進行分類。
決策樹是一種簡單快速的分類方法,以信息熵計算每個節點的屬性值,構建分類樹。
SVM是以統計理論為基礎的有監督分類算法[11-12],使用適當的核函數將輸入的心音特征向量映射到高維特征空間,利用類別邊緣間隔最大原則尋找最大超平面,對正常和異常樣本分類。
KNN是基于樣本學習的算法[4, 12],依據測試集樣本與訓練集樣本的距離衡量其相似度,在訓練集中查找與測試集心音樣本最近的k條記錄,然后按照投票方式決定測試樣本的類別。
1.6 性能評估指標
本文利用5折交叉驗證方法評估模型性能,將1 469個正常心音樣本和1 793個異常心音樣本分別平均劃分為5份,隨機取出4份作為訓練集,剩余的1份作為測試集,完成1次訓練和測試,得到第1次分類結果;迭代完成5次交叉驗證,最終結果為5次結果的平均值。準確率、靈敏性和特異性被用于評估正常和異常心音的二分類效果[17]。
多分類準確率(accuracy,ACC)(以符號ACC表示)計算結果如式(3)所示[23]:
 |
其中,Cii表示第i類被正確分類的心音樣本,Cij表示第i類被錯誤分類為第j類的心音樣本。n代表心音樣本的類別數,本文研究中分別取值為3、4、5、10。
1.7 統計分析
本文統計分析使用t檢驗方法分析兩類心音的基本成分特征和包絡自相關特征差異是否具有統計學意義。本文中任意兩類心音的特征值比較采用配對樣本的t檢驗,當P < 0.05時認為差異具有統計學意義。
2 結果與分析
本文按照二分類和三分類模式評估模型性能。二分類模式是區分正常心音與異常心音。依據心室流入道病變和心室流出途徑病變、單純瓣膜病和聯合瓣膜病的劃分方法[24-26],三分類模式包括:① 區分正常心音、半月瓣異常心音、房室瓣異常心音;② 區分正常心音、單瓣膜異常心音、多瓣膜異常心音。
2.1 最優混合特征選擇
依據式(2)評估所有特征的重要性指數,指數越大意味著對正常心音和異常心音的分類貢獻率越大。依據重要性指數,選擇出最優混合特征。其中二分類模式中選出42個基本成分特征和8個包絡自相關特征。三分類模式中,按病變部位分類和按病變瓣膜數分類兩種情況,都選出41個基本成分特征和9個包絡自相關特征。詳細描述如表2所示。
2.2 二分類模式結果
本文使用的異常心音來自早期心臟瓣膜病患者,將5類異常心音歸類為異常樣本,對正常樣本和異常樣本進行二分類檢測。正常心音樣本1 469個,異常心音樣本1 793個。分別使用基本成分特征、基本成分最優特征、包絡自相關特征、最優混合特征訓練分類器,識別正常心音和異常心音。
二分類模式的分類結果如表3所示,最優混合特征的檢測效果最佳,使用決策樹、SVM和KNN分類,其準確率均不低于99.0%。其中,尤以最優混合特征聯合決策樹的分類效果最佳,雖然其分類準確率與SVM相同,但決策樹獲取得了100.0%的靈敏性。結果還顯示,包絡自相關特征的分類結果優于基本成分特征。基本成分特征聯合KNN的分類結果最差,原因可能是特征維度過高,導致信息冗余;特征選擇后,基本成分最優特征的分類結果大幅提升。
2.3 三分類模式結果
本文使用了5類早期心臟瓣膜病心音信號,其類間樣本量不平衡;依據病變部位將異常心音樣本劃分為兩類,使用三分類算法與正常心音分類;再依據病變瓣膜數將異常心音樣本重新劃分為兩類,再使用三分類算法與正常心音樣本分類。依據病變部位劃分為兩類,分別是:半月瓣異常樣本和房室瓣異常樣本。半月瓣異常樣本,包括:主動脈瓣異常、主動脈瓣異常伴其他異常樣本;房室瓣異常樣本,包括:二尖瓣異常、三尖瓣異常、二尖瓣異常伴其他異常樣本。依據病變瓣膜數劃分為兩類,分別是:單瓣膜異常樣本和多瓣膜異常樣本。單瓣膜異常樣本,包括:二尖瓣異常、三尖瓣異常和主動脈瓣異常樣本;多瓣膜異常樣本,包括兩種或兩種以上瓣膜異常樣本。三分類模式的分類結果如表4所示,按病變部位劃分的兩類異常樣本與正常樣本之間的分類結果中,最優混合特征聯合SVM分類準確率最高,達到99.8%。按病變瓣膜數劃分的兩類異常樣本和正常樣本之間的分類結果中,最高準確率為98.2%。表4中還顯示,在三分類模式中,包絡自相關特征的最高分類結果高于基本成分特征。
2.4 正常與異常心音特征值比較
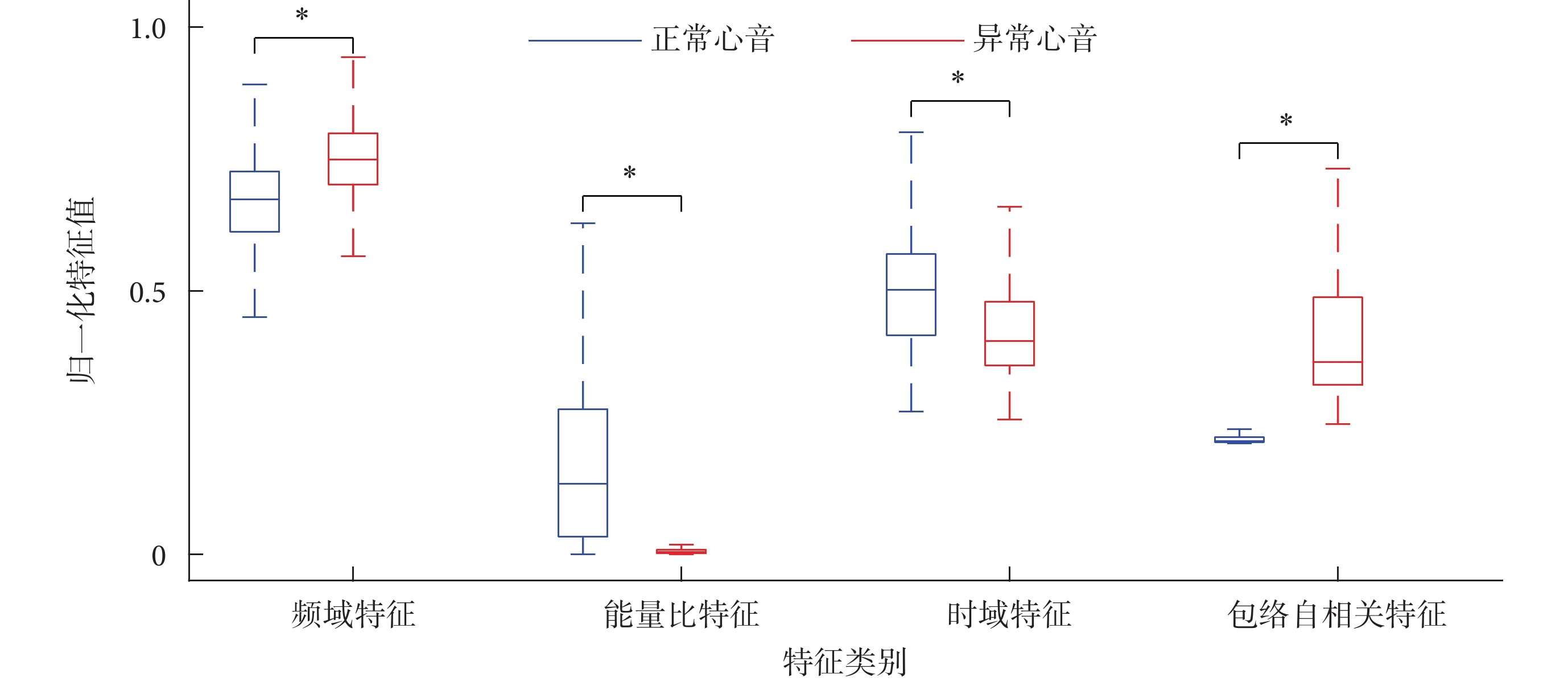
在二分類和三分類模式中,本文比較了每類特征中重要性指數最高的歸一化特征值,如圖3、圖4所示。其中,在二分類模式中,正常心音和異常心音特征比較如圖3所示。根據t檢驗的結果,頻域特征的差異(t = ?2.569,P < 0.01)、能量比特征的差異(t = ?3.701,P < 0.01)、時域特征的差異(t = ?0.174,P < 0.01)和包絡自相關特征的差異(t = ?4.142,P < 0.01),均具有統計學意義,這與心臟瓣膜病產生高頻心雜音的病理特性相吻合,表明異常心音的高頻成分、高頻段能量及波形發生改變。
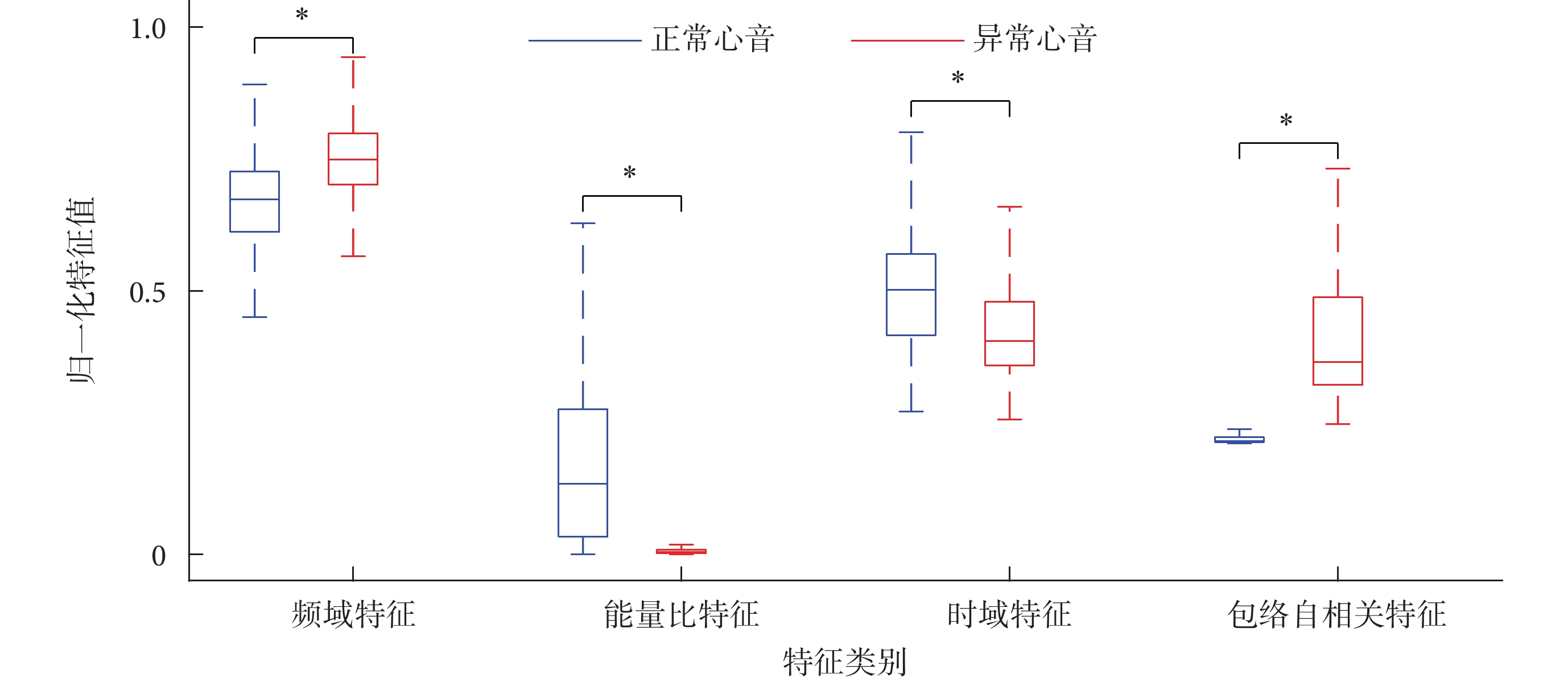 圖3
二分類模式中正常與異常心音的歸一化特征值比較(*P < 0.01)
Figure3.
Comparison of normalized feature values of normal and abnormal heart sound in binary classification (*P < 0.01)
圖3
二分類模式中正常與異常心音的歸一化特征值比較(*P < 0.01)
Figure3.
Comparison of normalized feature values of normal and abnormal heart sound in binary classification (*P < 0.01)
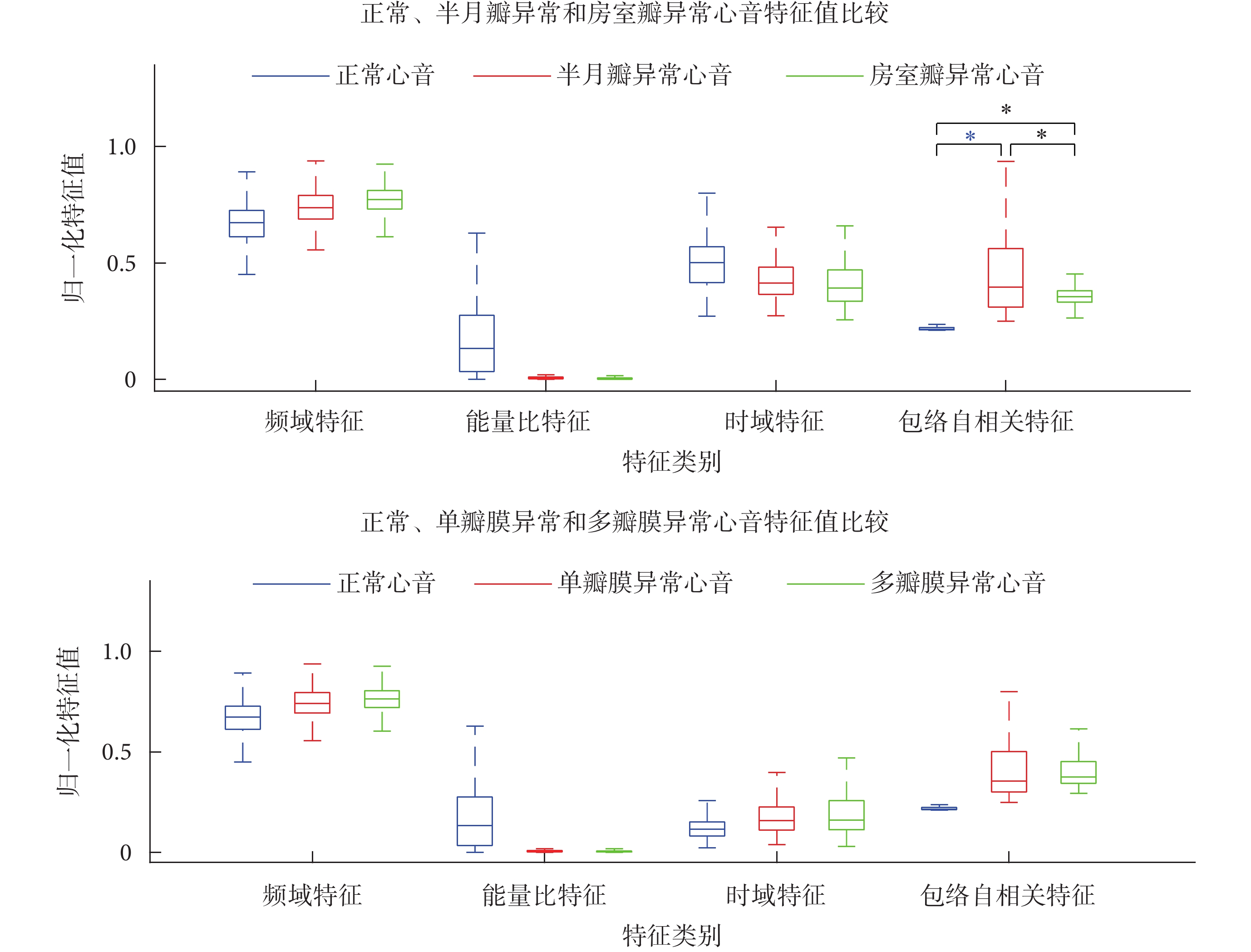
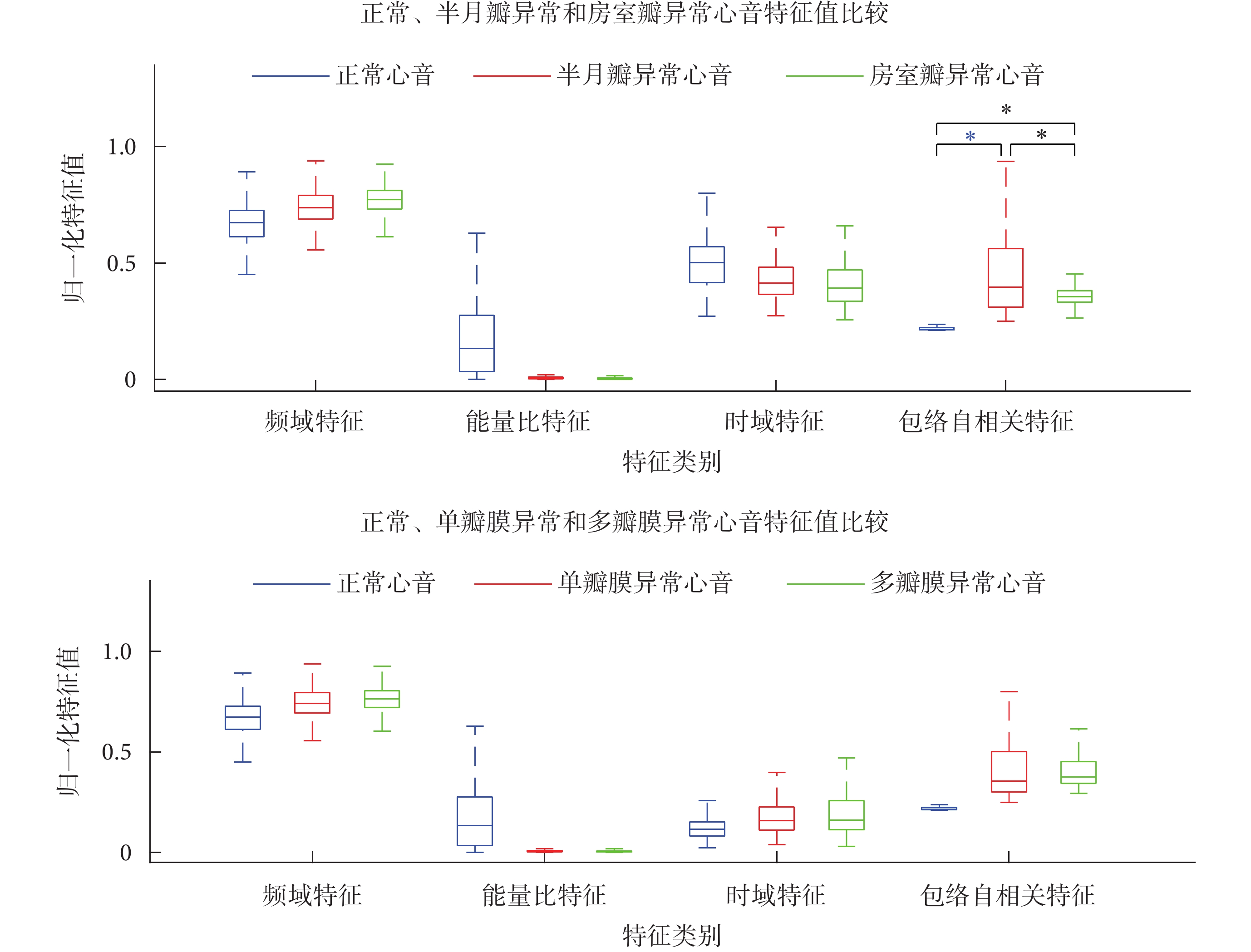 圖4
三分類模式中正常和異常心音歸一化特征值比較(*P < 0.01)
Figure4.
Comparison of normalized feature values of normal and abnormal heart sound in ternary classification (*P < 0.01)
圖4
三分類模式中正常和異常心音歸一化特征值比較(*P < 0.01)
Figure4.
Comparison of normalized feature values of normal and abnormal heart sound in ternary classification (*P < 0.01)
在三分類模式中,正常心音與兩種異常心音特征比較如圖4所示,在區分正常、房室瓣異常和半月瓣異常心音樣本中,比較任意兩類心音的包絡自相關特征,正常與半月瓣異常心音的差異(t = ?5.572,P < 0.01)、正常與房室瓣異常心音的差異(t = ?7.857,P < 0.01)和半月瓣異常與房室瓣異常心音的差異(t = ?5.105,P < 0.01),均具有統計學意義。但兩種異常心音特征的分類效果較差,原因可能是兩類異常心音樣本源自早期心臟瓣膜病患者,其高頻心雜音微弱,區分兩類異常心音的效果較差。在區分正常、單瓣膜異常和多瓣膜異常心音樣本中,包絡自相關特征對正常和多瓣膜異常心音的分類效果最佳;基本成分特征中的時域特征和頻域特征的分類貢獻率較差,使用單個特征值區分單瓣膜異常與多瓣膜異常心音樣本的效果較差。
3 討論
本文使用的臨床數據各類別樣本量不平衡,可能影響對模型泛化能力的驗證,因此本文還使用了三個不同的公開數據集來評估所用方法的有效性。平衡(Github)心音數據集是Yaseen等[27]提供的公開數據集,包含正常(normal,N)、主動脈瓣狹窄(aortic stenosis,AS)、二尖瓣反流(mitral regurgitation,MR)、二尖瓣狹窄(mitral stenosis,MS)和二尖瓣脫垂(mitral valve prolapse,MVP)5類心音,每類心音200個樣本。菲拉特(Firat)心音數據集來源于菲拉特大學醫院(Firat University Hospital)[28],包含N、AS(重度和輕度)、MS(重度和輕度)、MR(重度、中度和輕度)和三尖瓣反流(重度和中度)10類心音,共10 366個樣本。心音競賽數據集源于2011年心音分類競賽[29],共162例異常心音(心雜音、額外音和人為噪聲)。
在Github數據集上,分別對正常心音和4類異常心音進行二分類。結果顯示,所有分類器的分類結果均高于96.0%,最高分類準確率達到100.0%,表明本文模型在平衡數據集上也具有良好的分類性能;分別對4類(N、AS 、MR 和 MS)和5類(N、 AS、 MR 、 MS 和 MVP)心音進行多分類,結果顯示四分類和五分類的最高準確率分別為99.3%和99.1%。在Firat數據集中,對10類心音進行分類,SVM實現了99.1%的準確率,證明本文模型對混合因素的瓣膜病也具有較好的分類效果。為驗證二分類模型的泛化性能,本文對心臟瓣膜異常心音進行擴展,添加了心音競賽數據集[29]的非心臟瓣膜異常心音,結果顯示決策樹的分類準確率為99.8%。此外,依據三分類模式中異常心音的劃分標準,對Github數據集中的N、AS和二尖瓣異常(MR、MS、MVP)進行三分類驗證,最高準確率為97.2%;Firat數據集中的N、輕度AS、二尖瓣異常(輕度MS和輕度MR)的三分類最高準確率為99.5%,證明了本文三分類模型在公開數據集上也具有較好的分類效果。
此外,本文模型還與其他模型的檢測結果進行對比如表5所示。在Github數據集上本文模型取得了最高分類結果;在Firat數據集上本文模型也得到了較好的分類效果,準確率與Barua等[28]的分類結果相當。本文模型對輕度心臟瓣膜病、重度心臟瓣膜疾病、輕中重混合因素心臟瓣膜病進行檢測,均得到了較好的分類效果,證明模型具有良好的泛化能力。本文還驗證了包絡自相關特征的分類效果優于基本成分特征。此外,按病變部位分類和按瓣膜病變數分類,都取得了較好的檢測效果,表明本文方法對心臟瓣膜病變部位和病變程度的診斷具有一定參考價值。
4 總結
本文提出了心音基本成分特征和包絡自相關特征的聯合分類模型。經臨床數據驗證,在二分類模式中,正常心音和異常心音的分類準確率為99.9%;在三分類模式中,分類準確率分別達到99.8%和98.2%。在公開數據集上,本文模型也取得了較好的分類效果,證明本文模型具有較好的泛化能力。
本文利用MRMR算法篩選出最優混合特征,聯合分類器檢測早期心臟瓣膜病,取得了較好的分類效果。在臨床數據集上,三分類結果證明本文模型對心臟瓣膜病變部位和病變程度的臨床診斷具有一定參考價值。經臨床數據集和公開數據集驗證,本文模型對早期心臟瓣膜病、重度心臟瓣膜病、輕中重混合因素的心臟瓣膜病檢測都具有較好的效果。
在后期研究中,針對臨床上數據采集易受噪聲干擾、數據不平衡、疾病種類不全等問題,本課題組將構建不同心臟瓣膜病的心音數據集,設計合理的心音特征提取模型,開展臨床中度和重度心臟瓣膜病診斷的雙盲驗證。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:孫成法主要負責實驗流程、數據分析、程序設計和論文編寫;劉常春教授主要負責實驗指導和論文審閱;王新沛副教授主要負責實驗流程指導、數據分析指導和論文修改指導。
倫理聲明:本研究通過了山東第一醫科大學第一附屬醫院醫學倫理委員會的審批(倫審字(S374)號)。
0 引言
心臟瓣膜病(heart valve disease,HVD)是常見的心血管疾病之一[1],嚴重時可導致心力衰竭、暈厥、猝死等。心臟瓣膜病的早期檢測可為疾病的早發現和及時干預提供依據。冠脈造影和超聲心動圖是診斷心臟瓣膜病的有效技術[2],但需要有專業技術經驗的醫生操作。聽診是臨床上初診心血管疾病以及檢測心臟瓣膜病的常用方法,無損無創,但其主要依賴于醫生的經驗診斷,效率低、主觀性強。心音自動檢測技術可以提高心臟瓣膜病的診斷效率和精度,從而減輕醫生的負擔,對早期心臟瓣膜病的診療具有重要的參考價值。
心音信號包含心臟瓣膜活動和血液流動的重要生理病理信息,是人體重要的生理信號。心音的每個心動周期一般包含第一心音(the first heart sound,S1)、收縮期、第二心音(the second heart sound,S2)和舒張期四個基本成分,心音檢測方法通常從基本成分的位置、持續時間、幅度、頻譜等方面進行分析[3-5]。目前,各種分段算法被用于分割去噪后的心音信號,以獲取心音基本成分,其中典型的心音分段算法包括包絡分段算法[3]、隱馬爾可夫方法[5-6]和深度學習[7]等。其中,Springer等[6]使用邏輯回歸估計觀測概率,并改進維特比,對心音信號分段,最終結果F1分數達到95.63%,是目前效果較好的心音分段算法。
心臟瓣膜病產生心雜音,從而改變心音基本成分間期、間期比、頻譜、小波系數和時頻圖等特征[8-10]。Potes等[8] 從心音信號中提取了124個時頻特征,使用自適應增強(adaptive boosting,Adaboost)分類器進行分類;同時提取4個頻帶信號,訓練一維卷積神經網絡(convolutional neural networks,CNN),兩者共同決策最終分類結果,靈敏性和特異性的平均值達到86.02%。Chen等[9]使用支持向量機(support vector machine,SVM)對心音時頻域特征進行評估和擴展,設計集成分類模型,得到了95.9%的靈敏性和91.7%的特異性。Oztavli等[10]提取了時頻特征、梅爾頻率倒譜系數(mel-frequency cepstral coefficients,MFCC)、心率等特征,用于檢測異常心音。
隨著技術發展,非分段心音檢測方法也取得重大突破[11-12]。Yadav等[11]提取了心音的MFCC和傅里葉變換特征,使用SVM分類正常和異常心音,其準確率、靈敏性和特異性分別為95%、100%和90%。Upretee等[12]提出了一種簡單的時變頻譜特征,即質心頻率,使用SVM和K最近鄰(k-nearest neighbor,KNN)分類,也取得了較好的分類結果。近年來,深度學習網絡聯合非分段心音的檢測方法被廣泛應用[13-16]。Krishnan等[13]采用非分段心音訓練一維CNN和前饋神經網絡,分類準確率達到85.7%。Meintjes等[14]和Singh等[16]將非分段心音變換為二維圖像,訓練CNN檢測異常心音,分類準確率分別達到86%和90%。Noman等[15]利用一維和二維CNN集成模型檢測異常心音,得到88.8%的準確率。
目前,國內外主要通過公開數據集作為數據來源研究心音檢測方法,但公開數據集樣本長度較短,且多數方法僅驗證了正常和異常心音或者幾種典型重度心臟瓣膜病心音的分類,數據類型較少,不夠完善。Li等[17]使用離散小波變換(discrete wavelet transform,DWT)分析心音信號,在公開數據集上檢測心臟瓣膜病,分類準確率為85.5%。在臨床上,心音采集易受各種噪聲干擾,使用現有模型分類,效果尚不滿足要求,因此本文提出基本成分特征和包絡自相關特征的聯合檢測模型。首先使用經驗模態分解(empirical mode decomposition,EMD)對心音信號去噪[4],然后對去噪后的心音信號進行分割,構建心音信號樣本集,并提取心音信號樣本的基本成分特征和包絡自相關特征,聯合上述兩類特征構建心音特征集;然后使用最大相關最小冗余(max-relevance and min-redundancy,MRMR)算法選擇最優混合特征集;最后使用決策樹、SVM和KNN分類器對正常心音和早期心臟瓣膜病心音進行分類,其流程如圖1所示。
圖1
早期心臟瓣膜病檢測流程圖
Figure1.
Flowchart of early heart valve diseases detection
1 數據和方法
1.1 數據處理
1.1.1 數據采集
本研究共招募158例受試者入組,包括:① 健康受試者65例,男性30例,女性35例,年齡范圍51~74歲,平均年齡(62.44 ± 6.55)歲。② 早期心臟瓣膜病患者93例,男性60例,女性33例,年齡范圍45~86歲,平均年齡(67.05 ± 9.83)歲。
本文心音數據采集于千佛山醫院(山東第一醫科大學第一附屬醫院),試驗得到了山東第一醫科大學第一附屬醫院醫學倫理委員會的批準[倫審字(S374)號],所有受試者在試驗前均簽署知情同意書。試驗納入標準為計劃在兩天內進行造影和心臟超聲檢測的受試者。試驗入組標準:早期心臟瓣膜病患者,經造影和心臟超聲檢測證實至少有一個瓣膜發生輕度反流的受試者;健康受試者:經造影和心臟超聲檢測證實瓣膜沒有發生病變的受試者。排除標準:經過心血管或瓣膜手術干預的患者;嚴重瓣膜或心血管損傷的患者;精神異常的患者。
數據采集開始前,受試者在一個安靜且溫度可控(25 ± 3)℃的房間內以仰臥姿勢躺在測量床上休息10 min。然后將壓電傳感器置于受試者胸骨左緣第三肋間隙聽診位置,使用心血管系統狀態檢測儀(CVFD-Ⅱ,濟南匯醫融工科技有限公司,中國)采集數據,采樣頻率2 kHz,記錄心音信號約5 min。
1.1.2 數據降噪
本文使用EMD算法將原始心音信號分解為10個固有模態分量和殘差,然后計算原始心音信號與各固有模態分量的互相關系數,去除相關性系數低于0.1的低頻模態后重構信號,然后使用陷帶濾波器去除50 Hz的工頻噪聲。
1.1.3 心音樣本構建
將預處理后的心音信號按照15 s的長度分割為多個片段,刪除噪聲干擾大的片段,使用z分數(z-score)方法對心音片段進行歸一化處理,獲取了1 469個正常心音樣本和1 793個異常心音樣本,其中異常樣本包含五類,如表1所示。對已獲得的心音樣本按照下述方法分別提取基本成分特征和包絡自相關特征。
1.2 基本成分特征提取
本文使用Springer等[6]的算法獲取S1、收縮期、S2和舒張期等心音基本成分,然后分別提取心音基本成分的時域特征、頻域特征和能量比特征。心音基本成分如圖2所示。
圖2
心音基本成分
Figure2.
The basic component of heart sound signal
1.2.1 時域特征
心音基本成分的間期和幅度等變化反映了心臟功能的改變,是心臟瓣膜病診斷的重要生理病理特征。本文依據Liu等[18]的方法從每個心動周期中提取心音基本成分的間期、峰度、偏度、S1/收縮間期、S2/舒張間期、S1/S2幅值、收縮期/舒張期、心動周期,計算每個心音樣本的各時域特征的均值和標準差,獲得34個時域特征。
1.2.2 頻域特征
心臟瓣膜病變會產生微弱的高頻心雜音,因此心音信號的高頻譜中包含心臟瓣膜病變產生的高頻雜音成分。本文使用傅里葉變換計算心音基本成分的頻譜,然后分別提取各頻譜成分,并計算了低頻(0~50 Hz)成分占比、中低頻(50~200 Hz)成分占比、高頻(200 Hz以上)成分占比、低高頻成分之比和頻譜最大幅值對應的頻率,對每個心音樣本的各頻域特征計算均值,獲得97個頻域特征。
1.2.3 能量比特征
對比DWT,離散小波包變換(discrete wavelet packet transform,DWPT)可以對心音信號的低頻成分和高頻成分進行等頻帶分解[19],獲取心音的等頻帶信息,以驗證各頻帶信息對心臟瓣膜病檢測效果。本文使用四層DWPT對心音基本成分等頻帶分解,在第四層上重構了16個等頻帶信號,分別計算16個等頻帶、0~62.5 Hz、62.5~187.5 Hz和187.5~1 000 Hz頻帶信號的能量占比[20]。此外,還計算了心音基本成分在其心動周期內的能量占比。計算每個心音樣本的各能量比特征的均值和方差,獲得113個能量比特征。
1.3 包絡自相關特征提取
本文利用平均香農能量熵算法,計算心音樣本的包絡自相關,并使用主成分分析(principal component analysis,PCA)算法提取包絡自相關特征[21]。
平均香農能量熵算法首先通過加窗對心音信號平滑處理[3],每幀80個點,重疊40個點,計算每幀的平均香農能量熵,并對平均香農能量熵進行歸一化處理。包絡自相關Rhs(n)的計算如公式(1)所示:
|
其中,Ehs(m)表示第m幀的歸一化平均香農能量熵,n表示時間延遲,取值范圍為[0,k ? 1],k表示平均香農能量熵的長度,在臨床數據集和公開數據集中分別為750和10。
本文利用PCA對包絡自相關降維,獲取了50個包絡自相關特征。
1.4 特征選擇方法
特征選擇算法可對高維特征向量降維,簡化模型的運算復雜度。MRMR算法是一種以互信息理論為基礎的特征選擇算法[22],計算每個特征的互信息的商(mutual information quotient,MIQ)(以符號MIQ表示),評估其分類貢獻,如式(2)所示:
|
其中,VS表示特征與預測類別的相關性,WS表示特征間的冗余度總和,|S|表示特征總數,xi、xj表示特征向量,y表示預測類別,I(xi ; y)代表特征向量與預測類別的互信息,I(xi ; xj)代表兩特征向量的互信息。
1.5 分類器
本文使用決策樹、SVM和KNN三種分類器分別對正常心音和早期心臟瓣膜病心音進行分類。
決策樹是一種簡單快速的分類方法,以信息熵計算每個節點的屬性值,構建分類樹。
SVM是以統計理論為基礎的有監督分類算法[11-12],使用適當的核函數將輸入的心音特征向量映射到高維特征空間,利用類別邊緣間隔最大原則尋找最大超平面,對正常和異常樣本分類。
KNN是基于樣本學習的算法[4, 12],依據測試集樣本與訓練集樣本的距離衡量其相似度,在訓練集中查找與測試集心音樣本最近的k條記錄,然后按照投票方式決定測試樣本的類別。
1.6 性能評估指標
本文利用5折交叉驗證方法評估模型性能,將1 469個正常心音樣本和1 793個異常心音樣本分別平均劃分為5份,隨機取出4份作為訓練集,剩余的1份作為測試集,完成1次訓練和測試,得到第1次分類結果;迭代完成5次交叉驗證,最終結果為5次結果的平均值。準確率、靈敏性和特異性被用于評估正常和異常心音的二分類效果[17]。
多分類準確率(accuracy,ACC)(以符號ACC表示)計算結果如式(3)所示[23]:
|
其中,Cii表示第i類被正確分類的心音樣本,Cij表示第i類被錯誤分類為第j類的心音樣本。n代表心音樣本的類別數,本文研究中分別取值為3、4、5、10。
1.7 統計分析
本文統計分析使用t檢驗方法分析兩類心音的基本成分特征和包絡自相關特征差異是否具有統計學意義。本文中任意兩類心音的特征值比較采用配對樣本的t檢驗,當P < 0.05時認為差異具有統計學意義。
2 結果與分析
本文按照二分類和三分類模式評估模型性能。二分類模式是區分正常心音與異常心音。依據心室流入道病變和心室流出途徑病變、單純瓣膜病和聯合瓣膜病的劃分方法[24-26],三分類模式包括:① 區分正常心音、半月瓣異常心音、房室瓣異常心音;② 區分正常心音、單瓣膜異常心音、多瓣膜異常心音。
2.1 最優混合特征選擇
依據式(2)評估所有特征的重要性指數,指數越大意味著對正常心音和異常心音的分類貢獻率越大。依據重要性指數,選擇出最優混合特征。其中二分類模式中選出42個基本成分特征和8個包絡自相關特征。三分類模式中,按病變部位分類和按病變瓣膜數分類兩種情況,都選出41個基本成分特征和9個包絡自相關特征。詳細描述如表2所示。
2.2 二分類模式結果
本文使用的異常心音來自早期心臟瓣膜病患者,將5類異常心音歸類為異常樣本,對正常樣本和異常樣本進行二分類檢測。正常心音樣本1 469個,異常心音樣本1 793個。分別使用基本成分特征、基本成分最優特征、包絡自相關特征、最優混合特征訓練分類器,識別正常心音和異常心音。
二分類模式的分類結果如表3所示,最優混合特征的檢測效果最佳,使用決策樹、SVM和KNN分類,其準確率均不低于99.0%。其中,尤以最優混合特征聯合決策樹的分類效果最佳,雖然其分類準確率與SVM相同,但決策樹獲取得了100.0%的靈敏性。結果還顯示,包絡自相關特征的分類結果優于基本成分特征。基本成分特征聯合KNN的分類結果最差,原因可能是特征維度過高,導致信息冗余;特征選擇后,基本成分最優特征的分類結果大幅提升。
2.3 三分類模式結果
本文使用了5類早期心臟瓣膜病心音信號,其類間樣本量不平衡;依據病變部位將異常心音樣本劃分為兩類,使用三分類算法與正常心音分類;再依據病變瓣膜數將異常心音樣本重新劃分為兩類,再使用三分類算法與正常心音樣本分類。依據病變部位劃分為兩類,分別是:半月瓣異常樣本和房室瓣異常樣本。半月瓣異常樣本,包括:主動脈瓣異常、主動脈瓣異常伴其他異常樣本;房室瓣異常樣本,包括:二尖瓣異常、三尖瓣異常、二尖瓣異常伴其他異常樣本。依據病變瓣膜數劃分為兩類,分別是:單瓣膜異常樣本和多瓣膜異常樣本。單瓣膜異常樣本,包括:二尖瓣異常、三尖瓣異常和主動脈瓣異常樣本;多瓣膜異常樣本,包括兩種或兩種以上瓣膜異常樣本。三分類模式的分類結果如表4所示,按病變部位劃分的兩類異常樣本與正常樣本之間的分類結果中,最優混合特征聯合SVM分類準確率最高,達到99.8%。按病變瓣膜數劃分的兩類異常樣本和正常樣本之間的分類結果中,最高準確率為98.2%。表4中還顯示,在三分類模式中,包絡自相關特征的最高分類結果高于基本成分特征。
2.4 正常與異常心音特征值比較
在二分類和三分類模式中,本文比較了每類特征中重要性指數最高的歸一化特征值,如圖3、圖4所示。其中,在二分類模式中,正常心音和異常心音特征比較如圖3所示。根據t檢驗的結果,頻域特征的差異(t = ?2.569,P < 0.01)、能量比特征的差異(t = ?3.701,P < 0.01)、時域特征的差異(t = ?0.174,P < 0.01)和包絡自相關特征的差異(t = ?4.142,P < 0.01),均具有統計學意義,這與心臟瓣膜病產生高頻心雜音的病理特性相吻合,表明異常心音的高頻成分、高頻段能量及波形發生改變。
圖3
二分類模式中正常與異常心音的歸一化特征值比較(*P < 0.01)
Figure3.
Comparison of normalized feature values of normal and abnormal heart sound in binary classification (*P < 0.01)
圖4
三分類模式中正常和異常心音歸一化特征值比較(*P < 0.01)
Figure4.
Comparison of normalized feature values of normal and abnormal heart sound in ternary classification (*P < 0.01)
在三分類模式中,正常心音與兩種異常心音特征比較如圖4所示,在區分正常、房室瓣異常和半月瓣異常心音樣本中,比較任意兩類心音的包絡自相關特征,正常與半月瓣異常心音的差異(t = ?5.572,P < 0.01)、正常與房室瓣異常心音的差異(t = ?7.857,P < 0.01)和半月瓣異常與房室瓣異常心音的差異(t = ?5.105,P < 0.01),均具有統計學意義。但兩種異常心音特征的分類效果較差,原因可能是兩類異常心音樣本源自早期心臟瓣膜病患者,其高頻心雜音微弱,區分兩類異常心音的效果較差。在區分正常、單瓣膜異常和多瓣膜異常心音樣本中,包絡自相關特征對正常和多瓣膜異常心音的分類效果最佳;基本成分特征中的時域特征和頻域特征的分類貢獻率較差,使用單個特征值區分單瓣膜異常與多瓣膜異常心音樣本的效果較差。
3 討論
本文使用的臨床數據各類別樣本量不平衡,可能影響對模型泛化能力的驗證,因此本文還使用了三個不同的公開數據集來評估所用方法的有效性。平衡(Github)心音數據集是Yaseen等[27]提供的公開數據集,包含正常(normal,N)、主動脈瓣狹窄(aortic stenosis,AS)、二尖瓣反流(mitral regurgitation,MR)、二尖瓣狹窄(mitral stenosis,MS)和二尖瓣脫垂(mitral valve prolapse,MVP)5類心音,每類心音200個樣本。菲拉特(Firat)心音數據集來源于菲拉特大學醫院(Firat University Hospital)[28],包含N、AS(重度和輕度)、MS(重度和輕度)、MR(重度、中度和輕度)和三尖瓣反流(重度和中度)10類心音,共10 366個樣本。心音競賽數據集源于2011年心音分類競賽[29],共162例異常心音(心雜音、額外音和人為噪聲)。
在Github數據集上,分別對正常心音和4類異常心音進行二分類。結果顯示,所有分類器的分類結果均高于96.0%,最高分類準確率達到100.0%,表明本文模型在平衡數據集上也具有良好的分類性能;分別對4類(N、AS 、MR 和 MS)和5類(N、 AS、 MR 、 MS 和 MVP)心音進行多分類,結果顯示四分類和五分類的最高準確率分別為99.3%和99.1%。在Firat數據集中,對10類心音進行分類,SVM實現了99.1%的準確率,證明本文模型對混合因素的瓣膜病也具有較好的分類效果。為驗證二分類模型的泛化性能,本文對心臟瓣膜異常心音進行擴展,添加了心音競賽數據集[29]的非心臟瓣膜異常心音,結果顯示決策樹的分類準確率為99.8%。此外,依據三分類模式中異常心音的劃分標準,對Github數據集中的N、AS和二尖瓣異常(MR、MS、MVP)進行三分類驗證,最高準確率為97.2%;Firat數據集中的N、輕度AS、二尖瓣異常(輕度MS和輕度MR)的三分類最高準確率為99.5%,證明了本文三分類模型在公開數據集上也具有較好的分類效果。
此外,本文模型還與其他模型的檢測結果進行對比如表5所示。在Github數據集上本文模型取得了最高分類結果;在Firat數據集上本文模型也得到了較好的分類效果,準確率與Barua等[28]的分類結果相當。本文模型對輕度心臟瓣膜病、重度心臟瓣膜疾病、輕中重混合因素心臟瓣膜病進行檢測,均得到了較好的分類效果,證明模型具有良好的泛化能力。本文還驗證了包絡自相關特征的分類效果優于基本成分特征。此外,按病變部位分類和按瓣膜病變數分類,都取得了較好的檢測效果,表明本文方法對心臟瓣膜病變部位和病變程度的診斷具有一定參考價值。
4 總結
本文提出了心音基本成分特征和包絡自相關特征的聯合分類模型。經臨床數據驗證,在二分類模式中,正常心音和異常心音的分類準確率為99.9%;在三分類模式中,分類準確率分別達到99.8%和98.2%。在公開數據集上,本文模型也取得了較好的分類效果,證明本文模型具有較好的泛化能力。
本文利用MRMR算法篩選出最優混合特征,聯合分類器檢測早期心臟瓣膜病,取得了較好的分類效果。在臨床數據集上,三分類結果證明本文模型對心臟瓣膜病變部位和病變程度的臨床診斷具有一定參考價值。經臨床數據集和公開數據集驗證,本文模型對早期心臟瓣膜病、重度心臟瓣膜病、輕中重混合因素的心臟瓣膜病檢測都具有較好的效果。
在后期研究中,針對臨床上數據采集易受噪聲干擾、數據不平衡、疾病種類不全等問題,本課題組將構建不同心臟瓣膜病的心音數據集,設計合理的心音特征提取模型,開展臨床中度和重度心臟瓣膜病診斷的雙盲驗證。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:孫成法主要負責實驗流程、數據分析、程序設計和論文編寫;劉常春教授主要負責實驗指導和論文審閱;王新沛副教授主要負責實驗流程指導、數據分析指導和論文修改指導。
倫理聲明:本研究通過了山東第一醫科大學第一附屬醫院醫學倫理委員會的審批(倫審字(S374)號)。