生理學研究發現,大鼠進行空間定位依賴內嗅—海馬CA3結構中的網格細胞與位置細胞,而內嗅—海馬結構與前額葉皮層之間的動態聯系是導航的關鍵。基于此,本文提出一種仿鼠腦內嗅—海馬—前額葉信息傳遞回路的空間導航方法,旨在為移動機器人賦予強大的空間導航能力。在海馬CA3—前額葉空間導航模型的基礎上,本文構建以海馬CA1區位置細胞為基本單元的動態自組織模型優化導航路徑。隨后通過海馬CA3區位置細胞與前額葉皮層動作神經元將優化后的路徑回饋至脈沖神經網絡,提高模型收斂速度的同時還有助于建立導航習慣的長期記憶。為驗證方法的有效性,本文分別設計了二維仿真實驗和三維仿真平臺的機器人實驗。實驗結果表明:本文方法不僅能夠在導航效率、收斂速度等方面超越其他算法,而且對動態變化的導航任務具有較好的適應性。同時,本文方法還能夠很好地應用在移動機器人平臺上。
引用本文: 廖詣深, 于乃功. 仿鼠腦內嗅—海馬—前額葉信息傳遞回路的空間導航方法. 生物醫學工程學雜志, 2024, 41(1): 80-89. doi: 10.7507/1001-5515.202303047 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
0 引言
環境認知與導航是各類高等哺乳動物特有的一種能力[1]。對于自主移動式機器人來說,具備像高等哺乳動物一樣的智能行為是在復雜未知的環境中快速而準確地實現面向目標導航的必要條件。導航包含定位與決策兩個部分[2]。定位是確定自身在環境中的位置,而決策則代表如何正確地指導機器人從當前位置運動至目標點。大鼠作為哺乳動物的一員,也擁有著卓越的導航能力。生理學研究表明,內嗅—海馬結構是大鼠實現定位的關鍵腦區[3],其內部存在多種對空間位置有著特異性放電作用的神經元細胞(空間細胞),例如:位置細胞[4]、網格細胞[5]、邊界細胞[6]、頭朝向細胞[7]等。其中,自運動信息被認為是輸入至內嗅皮層網格細胞結構[8],并通過神經網絡投射至海馬CA3區的位置細胞群,從而實現對自運動信息的路徑積分[9]。隨后,海馬CA1區位置細胞接收CA3區位置細胞所投射的位置信息,實現對空間位置集合的存儲與記憶[10]。由于位置細胞是定位的主要神經元,其放電活動并不能預測未來行為的方向,而決策是導航過程中必不可少的組成部分,因此可以推斷在大鼠腦結構中必定存在承擔決策任務的相關腦區。研究表明,前額葉皮層是大腦產生命令和運動控制的關鍵腦區[11],且內嗅—海馬結構與前額葉皮層之間的動態聯系是決定未來行為的關鍵因素[12]。
近年來,基于仿生認知機制的空間導航方法的研究成為熱點,主要包括兩個研究方向:① 仿生環境認知地圖構建與導航。該研究方向旨在構建仿鼠腦運行機制的精確環境認知地圖,隨后基于認知地圖進行路徑規劃與導航[13-15]。而基于地圖的路徑規劃與導航方法較為工程化,因而缺乏仿生性。② 基于仿生認知機制的空間認知與導航習慣養成。該研究方向旨在構建導航模型指導機器人對空間環境進行探索,并隨著機器人的探索逐漸獲得對應環境的導航能力。2004年,Oudeyer等[16]提出一種智能自適應好奇心學習理論,使機器人在沒有先驗知識的環境中不斷探索,逐漸完成對環境的認知。隨后在2018年和2021年,張曉平等[17]和阮曉鋼等[18]構建了基于好奇心學習理論的環境認知模型,并在此基礎上實現移動機器人的路徑規劃。而仿鼠腦認知機制的導航習慣養成相關研究工作可以追溯到2009年,Kulvicius等[19]利用簡單的前饋神經網絡構建海馬位置細胞到動作神經元之間的連接關系,并使用Q-learning算法實現面向目標的導航。2013年,Frémaux等[20]使用脈沖神經網絡作為位置細胞到動作神經元之間的連接結構,引入STDP學習規則調整網絡的連接權值,提升了導航模型發現目標區域的速度。隨后在2017年和2021年,Zannone團隊[21-22]將乙酰膽堿和多巴胺的順序神經調節機制加入STDP學習規則(Sn-Plast模型),使智能體能夠有效地導航到不斷變化的獎勵位置,增強了模型的適應能力。但上述方法都容易陷入局部最優,導致輸出的路徑并不是當前導航任務的最優路徑。
基于上述研究事實,本文提出一種仿鼠腦內嗅—海馬—前額葉信息傳遞回路的空間導航方法,旨在為移動機器人賦予強大的定位與決策能力。本文的主要貢獻如下:① 構建以海馬CA1區的位置細胞為基本單元的動態自組織模型,能夠根據環境信息優化海馬CA3—前額葉脈沖神經網絡模型輸出的導航路徑,從而提高導航效率;② 通過優化后的導航路徑得出動作神經元和海馬CA3位置細胞群的理論放電率,并以此為監督信號調整脈沖神經網絡的連接權值,實現了將優化后的導航路徑及時回饋至脈沖神經網絡,提高模型收斂速度的同時還有助于建立導航習慣的長期記憶。
1 模型的建立
1.1 模型的整體結構
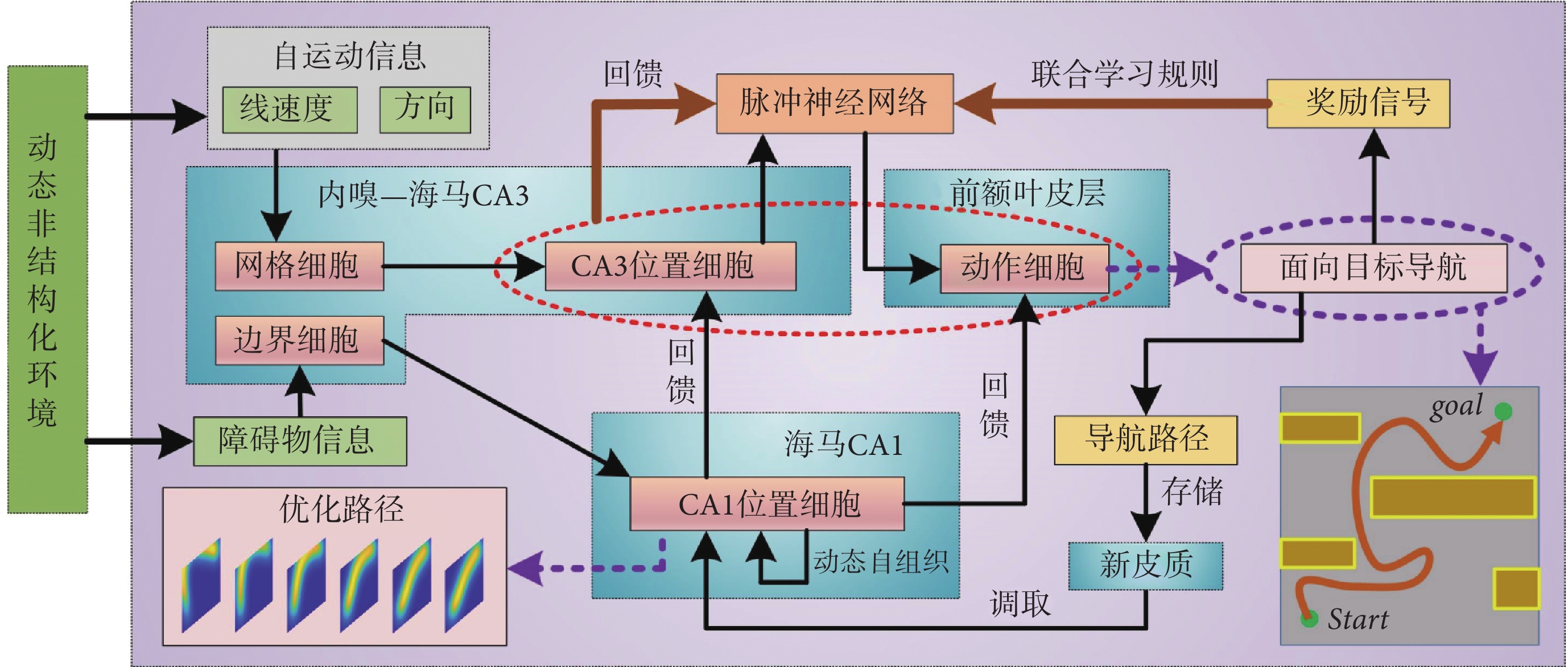
本節對仿鼠腦內嗅—海馬—前額葉信息傳遞回路的空間導航方法的整體結構進行詳細說明。隨著機器人在環境中探索,自運動信息首先被輸入至網格細胞模型,隨后通過神經網絡連接將空間信息投射至海馬CA3區位置細胞模型,實現路徑積分功能[23]。機器人探索過程中,使用聯合學習規則Sn-Plast調節海馬CA3區位置細胞到前額葉皮層動作神經元之間脈沖神經網絡的權值大小[22]。待探索至目標點時,海馬CA1區位置細胞通過動態自組織對形成的導航路徑進行優化。由于導航行為需要動作神經元的放電率為指導,而動作神經元的放電率由脈沖神經元的權值和海馬CA3區位置細胞群的放電率共同決定,故利用優化后的導航路徑計算出動作神經元和海馬CA3區位置細胞群的理論放電率序列,并以此為監督信號調整脈沖神經網絡的連接權值。導航方法的整體運行機制如圖1所示。
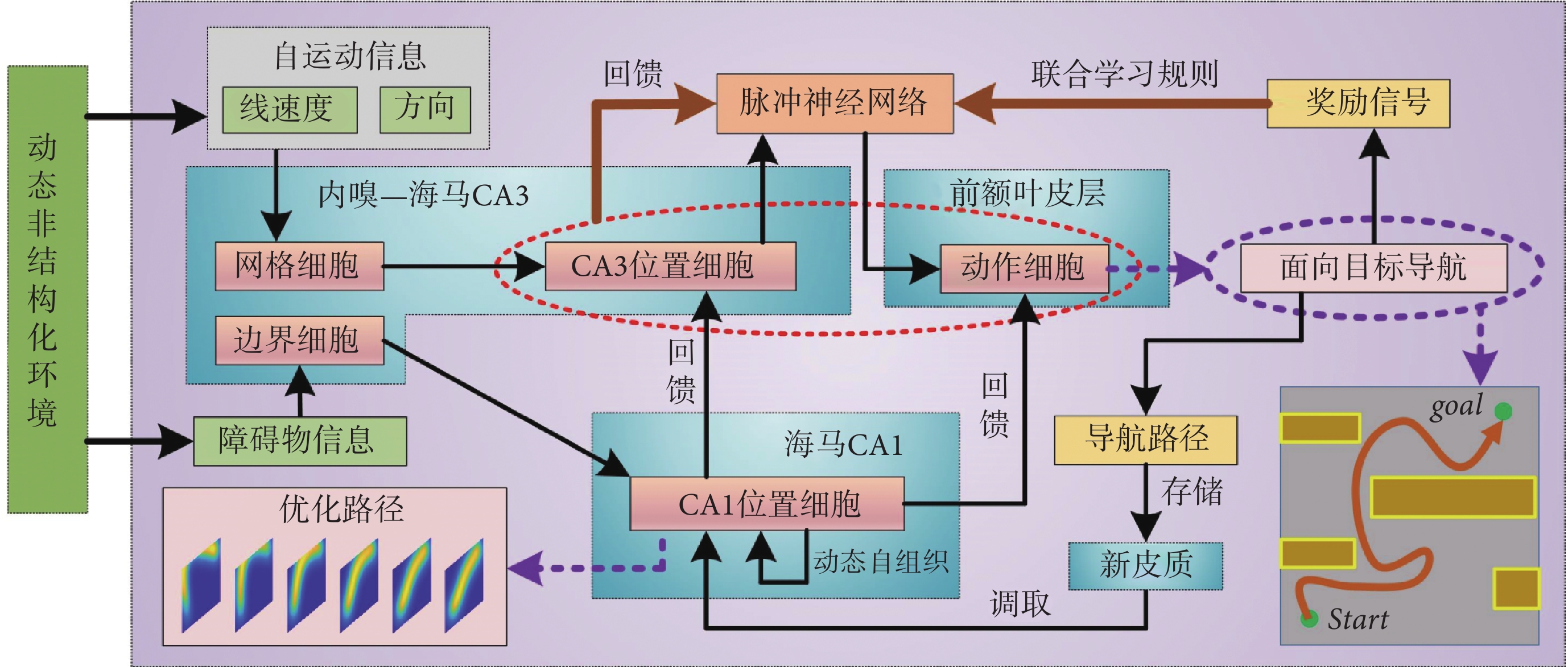 圖1
導航方法的整體運行機制示意圖
Figure1.
The overall operating mechanism of navigation method
圖1
導航方法的整體運行機制示意圖
Figure1.
The overall operating mechanism of navigation method
1.2 導航路徑優化方法
導航路徑實際上是由多個路徑點組成的,每個海馬CA1位置細胞可以看作是一個記憶單元,存儲一個路徑點信息。設第 i 個位置細胞為  。
。 代表放電野中心坐標。
代表放電野中心坐標。 代表智能體在
代表智能體在  處的頭朝向角度,其初始值為相鄰兩個位置細胞
處的頭朝向角度,其初始值為相鄰兩個位置細胞  和
和  放電野中心連線與x軸正方向之間的夾角。設t時刻第i個位置細胞放電野中心位置的更新量為
放電野中心連線與x軸正方向之間的夾角。設t時刻第i個位置細胞放電野中心位置的更新量為  ,頭朝向角度的修正量為
,頭朝向角度的修正量為  ,相關數學表達式如下。
,相關數學表達式如下。
 |
 |
 |
式(3)中, 代表初始時刻位置細胞
代表初始時刻位置細胞  和
和  放電野中心之間的距離,
放電野中心之間的距離, 代表松弛因子,
代表松弛因子, 代表初始時刻
代表初始時刻  與
與  之間的差值,
之間的差值, 代表求解角度差的函數。得到修正量之后,即可對放電野中心和頭朝向角度進行修正。放電野中心坐標修正的數學表達式如下:
代表求解角度差的函數。得到修正量之后,即可對放電野中心和頭朝向角度進行修正。放電野中心坐標修正的數學表達式如下:
 |
 |
頭朝向角度修正的數學表達式如下:
 |
 |
式(4)~(7)中, 代表修正增益。然而,實際物理環境中通常存在許多障礙物,因此路徑的優化過程也要考慮障礙物的影響。生理學研究表明,內嗅皮層的邊界細胞是大鼠感知環境邊界和障礙的主要神經元,同樣也是海馬體的信息輸入源之一[24]。因此,本文基于邊界細胞的放電機制對路徑優化過程進行分段。首先,將環境中的所有障礙物離散化,并將離散化的障礙物位置集定義為
代表修正增益。然而,實際物理環境中通常存在許多障礙物,因此路徑的優化過程也要考慮障礙物的影響。生理學研究表明,內嗅皮層的邊界細胞是大鼠感知環境邊界和障礙的主要神經元,同樣也是海馬體的信息輸入源之一[24]。因此,本文基于邊界細胞的放電機制對路徑優化過程進行分段。首先,將環境中的所有障礙物離散化,并將離散化的障礙物位置集定義為  。設
。設  代表 t 時刻第 i 個位置細胞放電野中心與障礙物之間的最短距離,其數學表達式如下:
代表 t 時刻第 i 個位置細胞放電野中心與障礙物之間的最短距離,其數學表達式如下:
 |
在導航路徑優化的過程中,當某個位置細胞的放電野中心逐漸靠近障礙物且與障礙物之間的距離足夠小的時候,則固定該位置細胞的放電野中心位置(位置不再改變)。設t時刻已經被固定放電野中心的位置細胞集合為  ,當
,當  時,
時, 。
。 隨著迭代次數增加的數學表達式如下:
隨著迭代次數增加的數學表達式如下:
 |
 |
式(10)和(11)中, 代表將集合中的元素從小到大排序,
代表將集合中的元素從小到大排序, 代表最短距離判據閾值。設函數
代表最短距離判據閾值。設函數 代表對第
代表對第  個位置細胞到第
個位置細胞到第  個位置細胞之間的所有位置細胞放電野中心進行路徑優化,其中
個位置細胞之間的所有位置細胞放電野中心進行路徑優化,其中  。定義集合
。定義集合  中的第 i 個元素為
中的第 i 個元素為  ,故導航路徑的優化過程可以表示為如下公式:
,故導航路徑的優化過程可以表示為如下公式:
 |
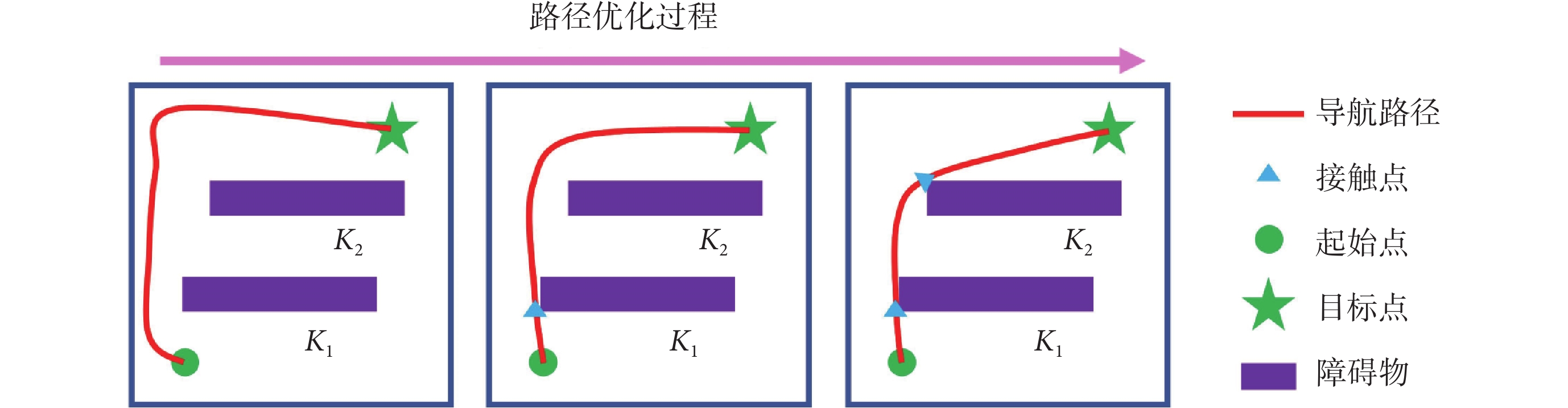
上述步驟可以對導航路徑進行分段校正,以確保模型在有障礙物的環境中仍能實現高效的面向目標的導航。導航路徑分段修正的運行機制如圖2所示。
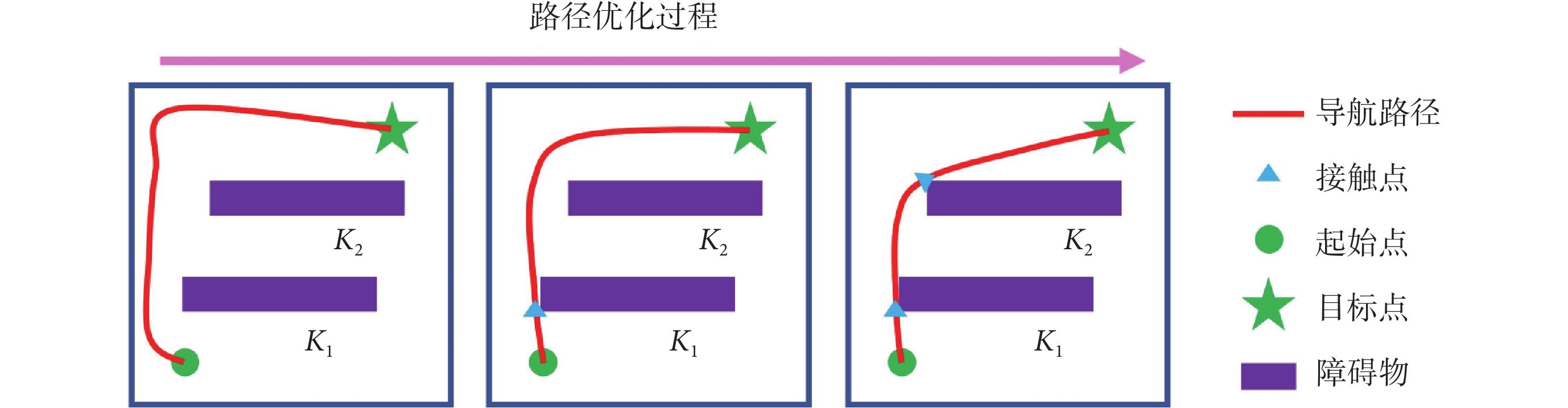 圖2
導航路徑分段優化的運行機制
Figure2.
Operation mechanism of navigation path segment optimization
圖2
導航路徑分段優化的運行機制
Figure2.
Operation mechanism of navigation path segment optimization
在導航路徑優化過程中,隨著迭代次數的增加,更新量 的值逐漸減小。此時再繼續進行迭代更新所產生的效果不顯著且耗費處理器的計算時間,影響算法的實時性。基于此,本文提出一種收斂度的判據方法。首先定義
的值逐漸減小。此時再繼續進行迭代更新所產生的效果不顯著且耗費處理器的計算時間,影響算法的實時性。基于此,本文提出一種收斂度的判據方法。首先定義 時刻的路徑收斂量為
時刻的路徑收斂量為 ,其數學表達式如式(12)所示:
,其數學表達式如式(12)所示:
 |
設收斂判據比例因子為ρ,當滿足 時,判斷此時無需再繼續進行更新迭代,反之則繼續執行更新迭代。導航路徑優化方法的收斂性證明過程見附件1。
時,判斷此時無需再繼續進行更新迭代,反之則繼續執行更新迭代。導航路徑優化方法的收斂性證明過程見附件1。
1.3 導航路徑回饋
待導航路徑優化后,需要將優化后的導航路徑回饋至脈沖神經網絡。首先計算動作神經元和海馬CA3區位置細胞群的理論放電率作為監督信號來調整脈沖神經網絡的連接權值,相關數學表達式如式(13)和(14)所示。
 |
 |
式(13)代表第j個動作神經元的放電率表達,其中  代表放電率閾值,
代表放電率閾值, 代表動作神經元放電率調整因子,
代表動作神經元放電率調整因子, 代表神經元的個數,
代表神經元的個數, 代表當前的頭朝向角度(路徑優化后相鄰兩個CA1區位置細胞
代表當前的頭朝向角度(路徑優化后相鄰兩個CA1區位置細胞  和
和  放電野中心連線與x軸正方向之間的夾角)。式(14)代表CA3區位置細胞的放電率表達,其中
放電野中心連線與x軸正方向之間的夾角)。式(14)代表CA3區位置細胞的放電率表達,其中  代表位置細胞的放電野中心,
代表位置細胞的放電野中心, 代表位置野半徑調整因子,
代表位置野半徑調整因子, 表示0至1之間隨機的一個數。智能體在t時刻的動作
表示0至1之間隨機的一個數。智能體在t時刻的動作  由動作神經元的放電活動所決定,其數學表達式如下:
由動作神經元的放電活動所決定,其數學表達式如下:
 |
式(15)中, 為第j個動作神經元在t時刻所代表的動作,
為第j個動作神經元在t時刻所代表的動作, 代表第j個動作神經元的放電脈沖,
代表第j個動作神經元的放電脈沖, 代表濾波器,相應的數學表達式如式(16)至(18)所示。
代表濾波器,相應的數學表達式如式(16)至(18)所示。
 |
 |
式(16)中, 代表動作步長,
代表動作步長, 代表第j個動作神經元的偏好方向。式(17)中,
代表第j個動作神經元的偏好方向。式(17)中, 代表階躍函數,
代表階躍函數, 和
和  均為時間常數。當機器人運動至目標區域時,使用STDP規則與資格跡結合的可塑性規則[22]對突觸權重進行更新,數學表達式如式(18)所示。
均為時間常數。當機器人運動至目標區域時,使用STDP規則與資格跡結合的可塑性規則[22]對突觸權重進行更新,數學表達式如式(18)所示。
 |
式(18)中, 代表學習率;A代表神經調節函數;W代表STDP窗口函數,其數學表達式為
代表學習率;A代表神經調節函數;W代表STDP窗口函數,其數學表達式為  ;
; 代表資格跡。
代表資格跡。 和
和  分別代表第j個動作神經元和第i個位置細胞所產生脈沖的到達時間。綜上,導航方法的工作流程可以簡述如下:首先采集機器人的自運動信息,按照信息流順序依次計算各空間神經元的放電率,并利用全體動作神經元的放電活動指導機器人移動。當機器人運動至目標區域時,利用CA1位置細胞動態自組織模型調整導航路徑,并將優化后的導航路徑與先前所有路徑的長度進行對比。若當前路徑是最短路徑則計算CA3位置細胞和動作神經元的理論放電率,并作為監督信號調整脈沖神經網絡的連接權值。
分別代表第j個動作神經元和第i個位置細胞所產生脈沖的到達時間。綜上,導航方法的工作流程可以簡述如下:首先采集機器人的自運動信息,按照信息流順序依次計算各空間神經元的放電率,并利用全體動作神經元的放電活動指導機器人移動。當機器人運動至目標區域時,利用CA1位置細胞動態自組織模型調整導航路徑,并將優化后的導航路徑與先前所有路徑的長度進行對比。若當前路徑是最短路徑則計算CA3位置細胞和動作神經元的理論放電率,并作為監督信號調整脈沖神經網絡的連接權值。
1.4 動態導航過程
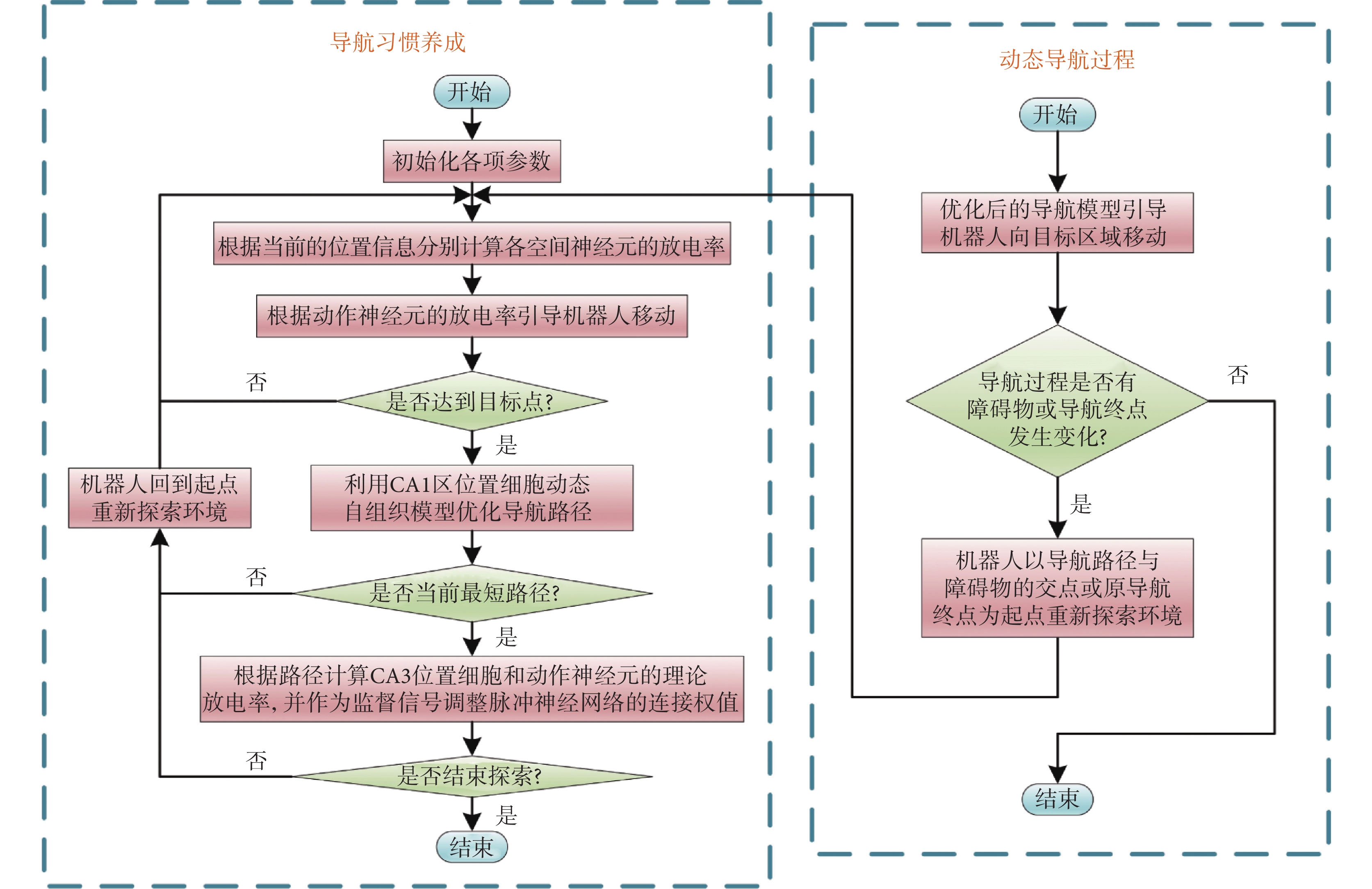
當機器人處于靜態環境中,機器人只需要探索環境并搜索導航路徑即可。然而,空間環境或導航任務通常是不斷變化的,這就需要機器人擁有較強的適應能力。導航過程發生改變主要包括以下兩種情況:① 原導航路徑發生阻塞;② 導航終點發生改變。導航過程發生改變后,機器人將以導航路徑與障礙物的交點或原導航終點為起點重新探索環境。導航方法的運行流程如圖3所示。
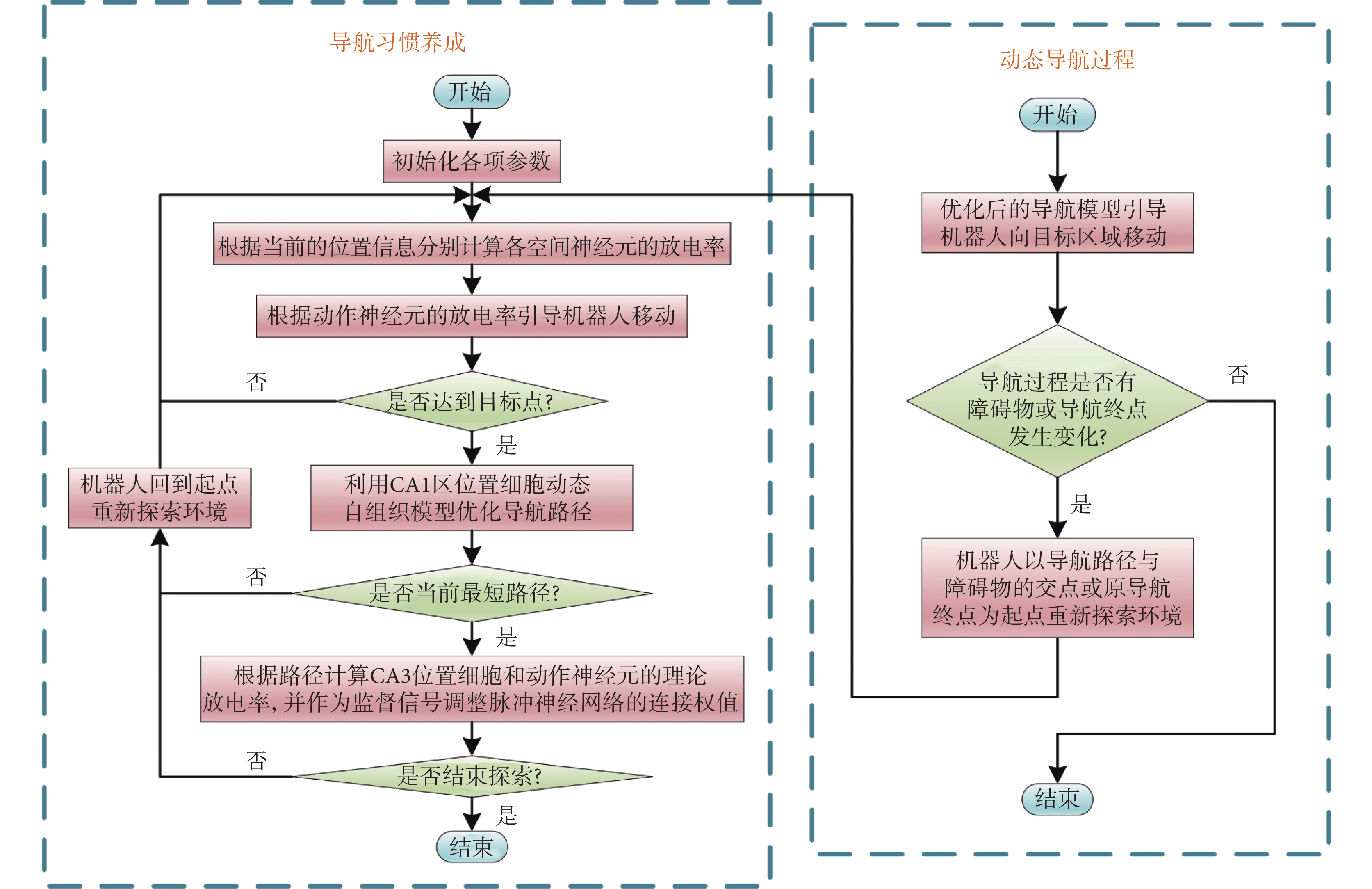 圖3
導航方法的運行流程圖
Figure3.
Operation process of the navigation method
圖3
導航方法的運行流程圖
Figure3.
Operation process of the navigation method
2 實驗驗證
2.1 實驗說明與參數設定
本節通過設計二維仿真實驗在模型收斂速度、導航效率、動態導航任務的適應能力等方面進行測試,并在此基礎上設計機器人平臺的三維仿真實驗進一步驗證模型的有效性。內嗅—海馬CA3信息傳遞模型的參數設定與文獻[23]一致,海馬CA3—前額葉空間導航模型的參數設定與文獻[22]一致。本文模型涉及的參數設定如下:修正增益 設定為0.5,松弛因子
設定為0.5,松弛因子 設定為0.3,收斂判據比例因子為
設定為0.3,收斂判據比例因子為 設定為0.001,動作神經元放電率閾值
設定為0.001,動作神經元放電率閾值 設定為0.9,動作神經元放電率調整因子
設定為0.9,動作神經元放電率調整因子 設定為1 000,距離判據閾值
設定為1 000,距離判據閾值 設定為0.1。
設定為0.1。
2.2 二維仿真實驗
2.2.1 導航習慣養成實驗
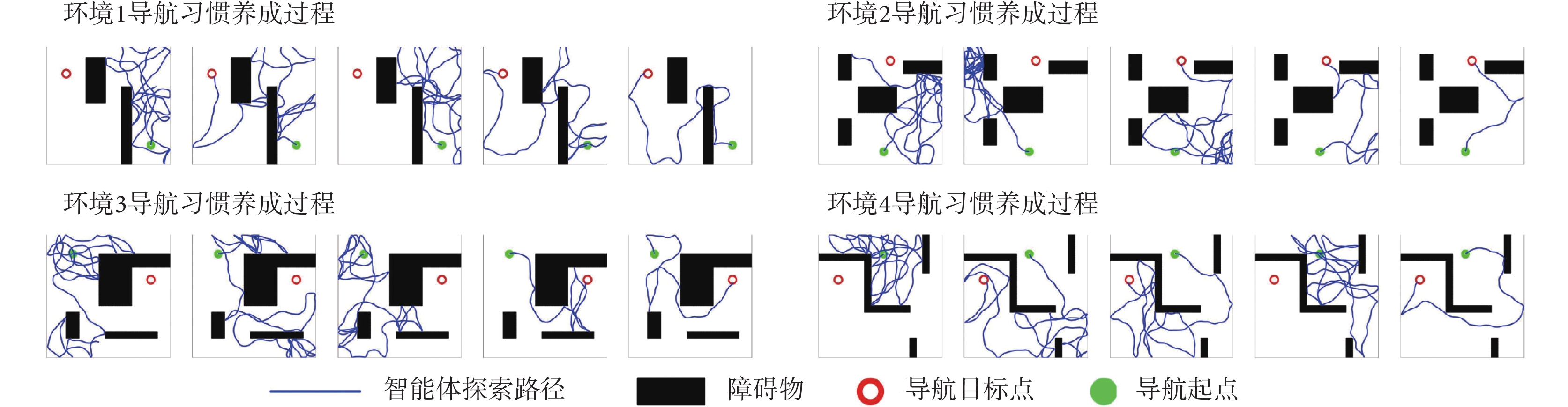
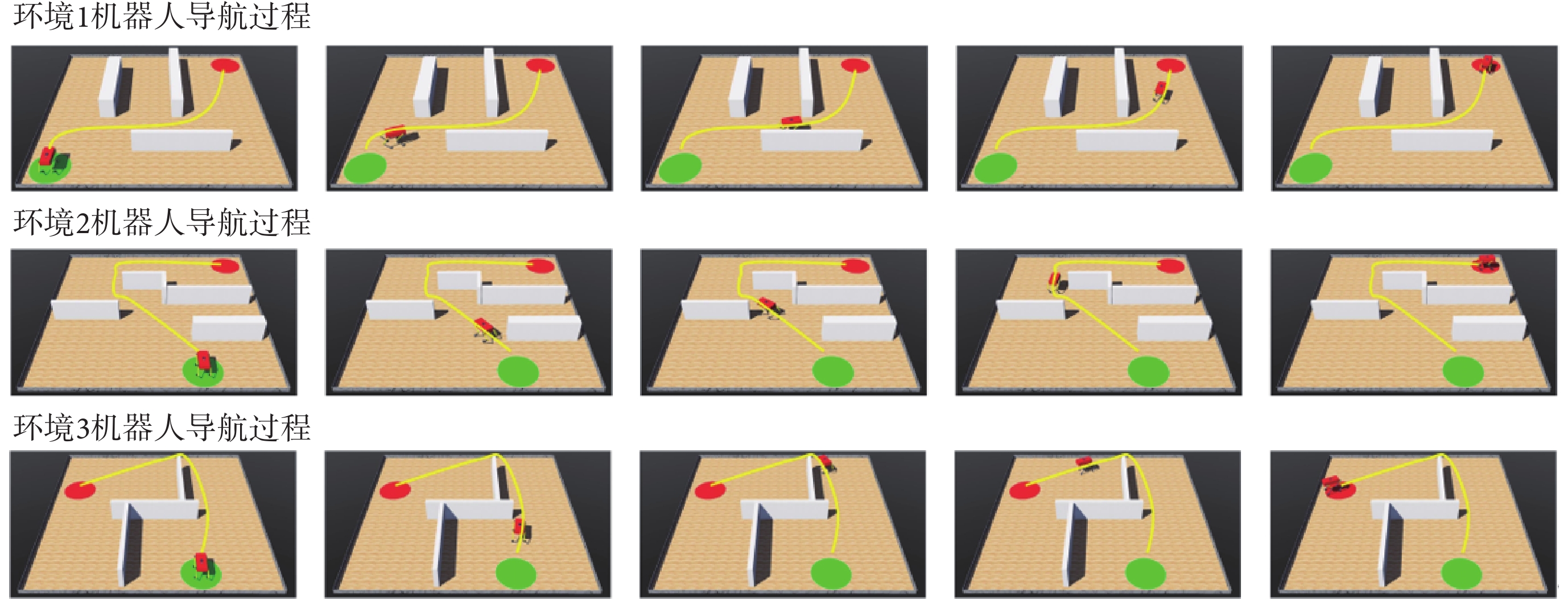
本節對所提出的模型性能進行二維仿真實驗驗證,分別構建四個不同的空間區域進行導航實驗,區域面積均設定為10 m × 10 m。空間區域內設置障礙物以及導航的起點與終點。以Sn-Plast模型引導智能體在四個空間區域中探索,并養成相應的導航習慣。單次導航習慣養成過程中的探索次數設定為30,單次探索過程的最大路徑長度設定為80 m。智能體在空間區域中的導航習慣養成過程如圖4所示,其中從左至右代表探索環境次數的增加。
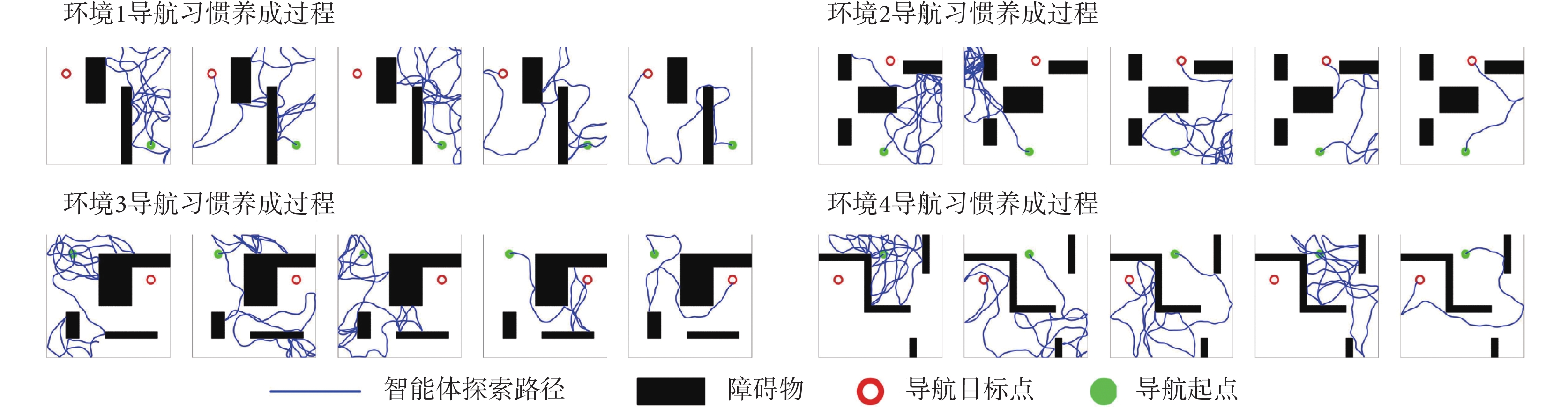 圖4
Sn-Plast模型引導下智能體的導航習慣養成過程
Figure4.
The formation process of navigation habits of agents under the guidance of Sn-Plast model
圖4
Sn-Plast模型引導下智能體的導航習慣養成過程
Figure4.
The formation process of navigation habits of agents under the guidance of Sn-Plast model
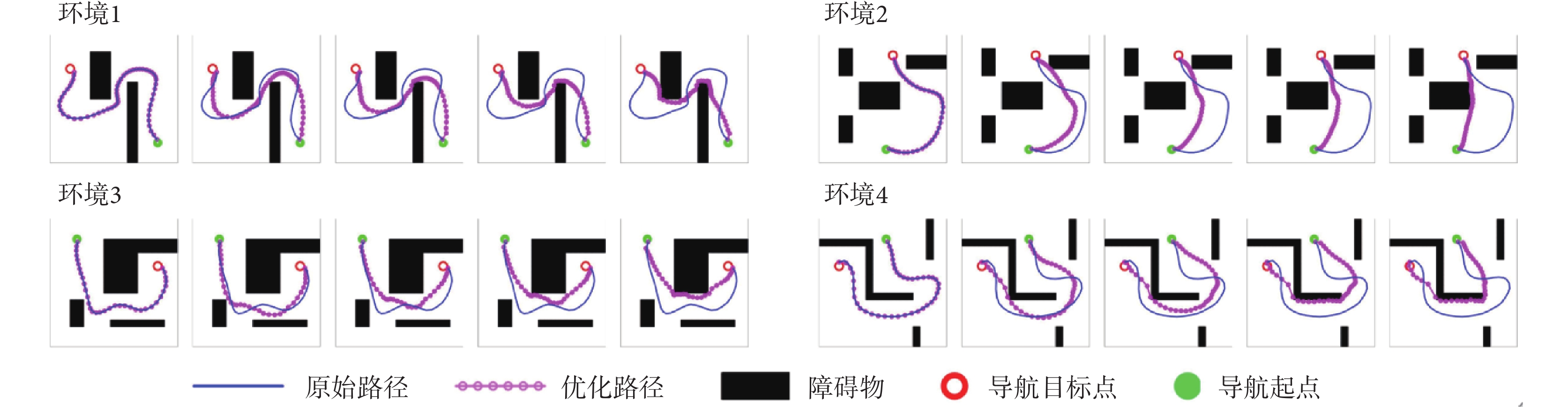
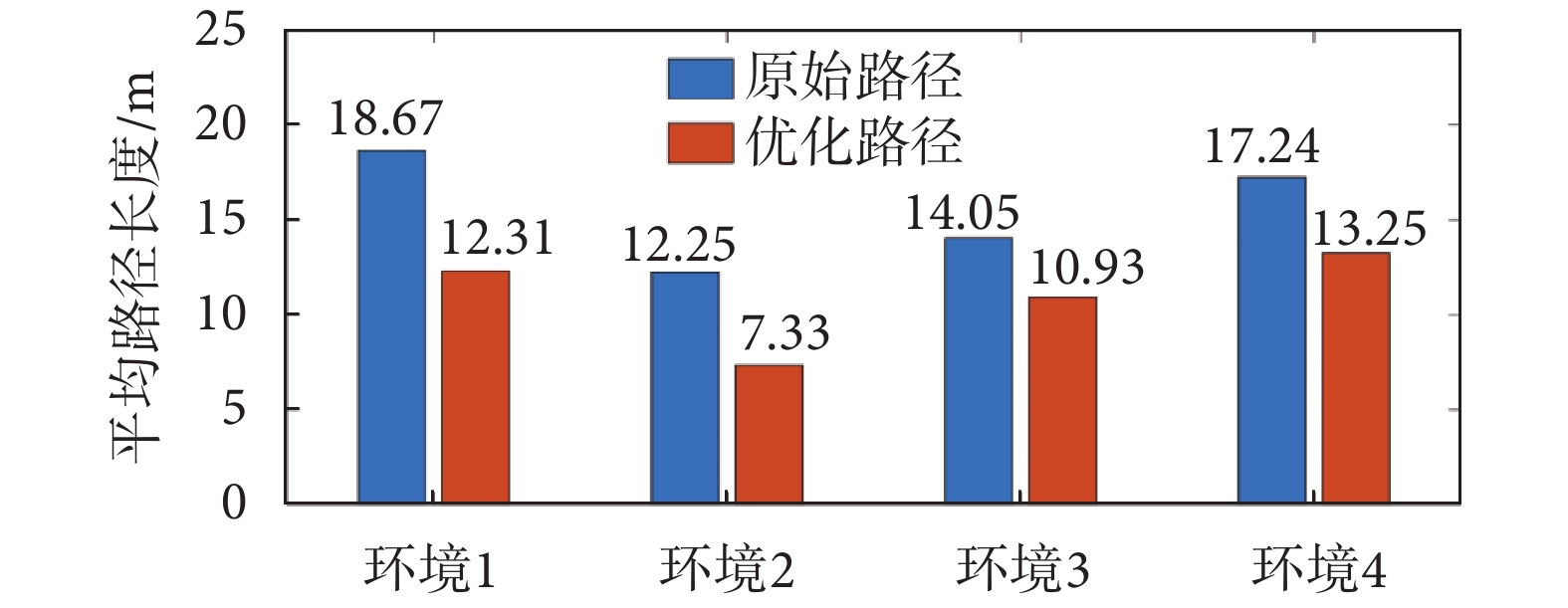
從圖4中可以看出,在Sn-Plast模型的引導下機器人能夠通過不斷探索環境而逐漸習得如何從起點出發運動至目標點,養成對應當前任務的導航習慣。但從導航結果來看也同時存在兩點不足:① 模型無法快速收斂(當智能體探索至目標區域時,在接下來的探索任務中依舊會出現無法運動至目標區域的情況);② 導航路徑比較彎曲,并不是最優導航路徑。因此本文通過CA1區位置細胞動態自組織模型對導航路徑進行優化。隨后將優化后的路徑通過CA3位置細胞和動作神經元回饋至脈沖神經網絡,強化模型對路徑的記憶,解決模型無法快速收斂的問題。圖5所示為導航路徑的優化過程,圖中從左至右代表優化模型迭代次數的增加。圖6所示為原始路徑與優化路徑的長度統計結果。從圖5和圖6中可以看出,隨著優化模型迭代次數的增加,優化路徑較原始路徑顯著縮短,驗證了模型的有效性。
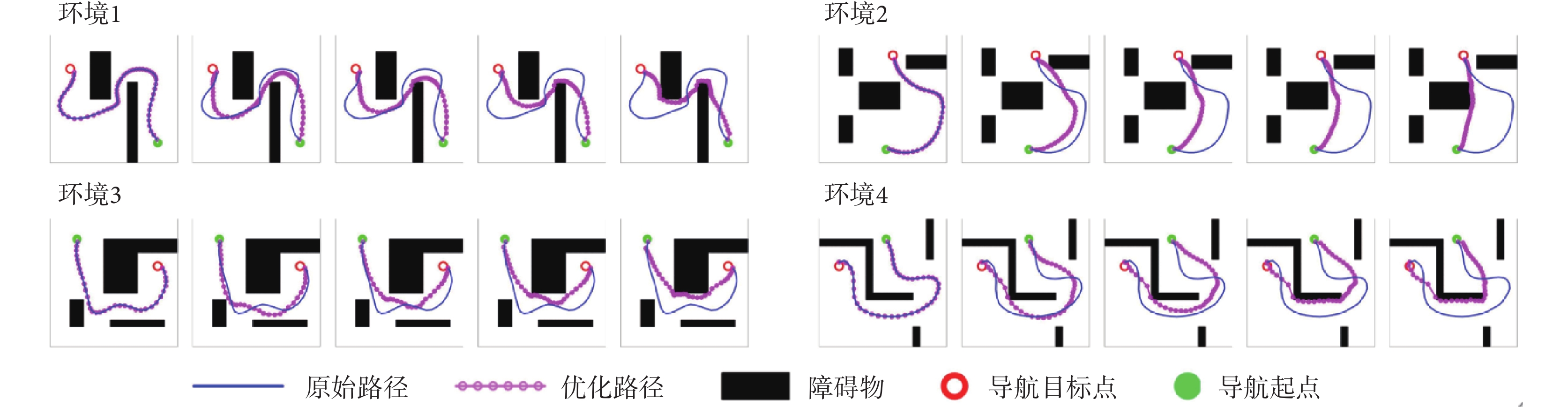 圖5
導航路徑的優化過程
Figure5.
Optimization process of navigation path
圖5
導航路徑的優化過程
Figure5.
Optimization process of navigation path
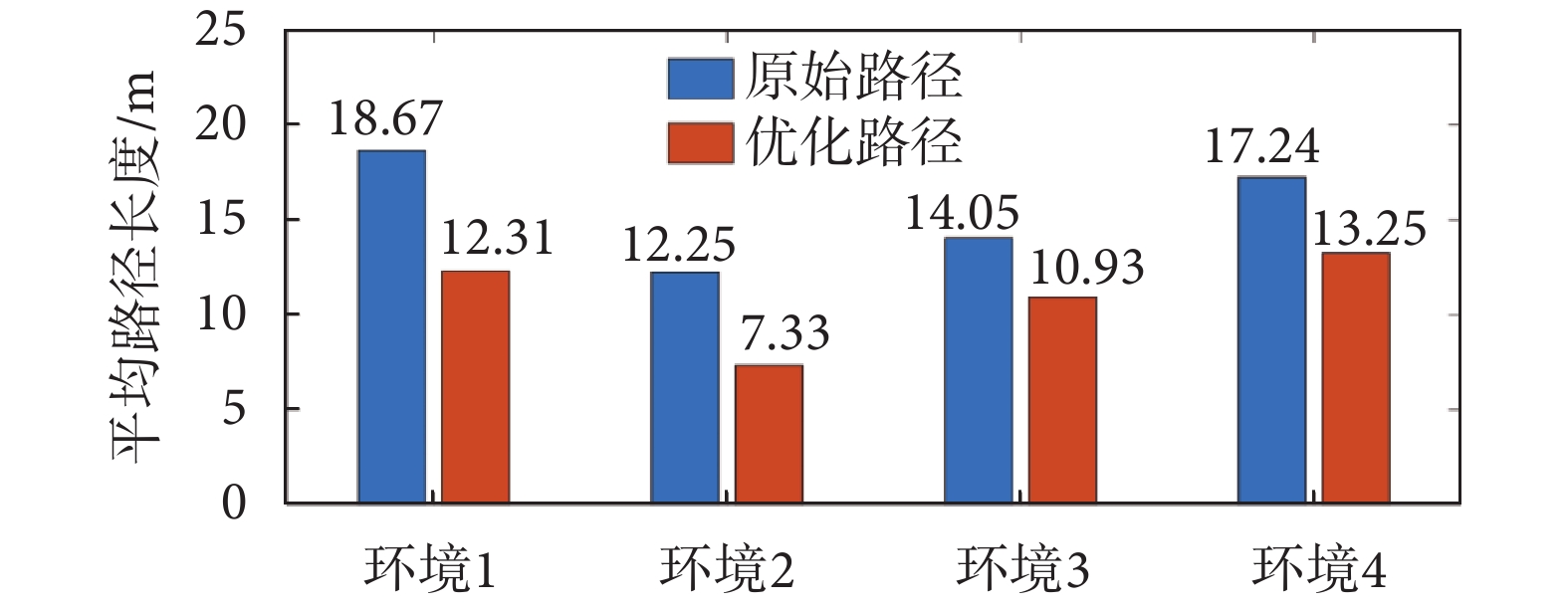 圖6
原始路徑和優化路徑的平均長度統計
Figure6.
Average length statistics of original paths and optimized paths
圖6
原始路徑和優化路徑的平均長度統計
Figure6.
Average length statistics of original paths and optimized paths
2.2.2 對比實驗與消融實驗
為了突出本文方法的優勢,將之與Q-learning算法[19]、SARSA算法[25]以及智能好奇心算法(intelligent adaptive curiosity,IAC)[16]進行對比。鑒于本文導航方法由導航習慣養成模塊(Sn-Plast)、路徑優化模塊(path optimization,PO)和路徑回饋模塊(path feedback,PF)組成,為了體現各模塊的作用,增加消融實驗以測試每個模塊對模型性能的影響。對比的性能指標如下:導航路徑平均長度、發現目標區域后收斂的概率、首次發現目標區域所需的探索次數以及完成導航習慣養成所需的平均探索次數。為量化模型的收斂性能,收斂判據如下:當智能體發現目標區域并且在接下來的四次探索任務中均能夠運動至目標區域,則判斷模型已收斂;反之亦然。定義發現目標區域后收斂的概率為  ,其數學表達式如式(19)所示。
,其數學表達式如式(19)所示。
 |
式(19)中, 代表發現目標區域的次數,
代表發現目標區域的次數, 代表發現目標區域且接下來的四次探索任務均能夠運動至目標區域的次數。導航路徑平均長度
代表發現目標區域且接下來的四次探索任務均能夠運動至目標區域的次數。導航路徑平均長度 代表所有發現目標的路徑長度平均值,其數學表達式如式(20)所示。
代表所有發現目標的路徑長度平均值,其數學表達式如式(20)所示。
 |
式(20)中, 代表第
代表第 次發現目標區域的探索路徑長度。完成導航習慣養成所需的平均探索次數代表算法收斂所需的平均探索次數,該指標能夠綜合反映算法引導智能體發現目標區域的速度和收斂速度。單次導航習慣養成過程中的探索次數設定為20,單次探索過程的最大路徑長度設定為80 m。算法導航的實驗結果見表1。
次發現目標區域的探索路徑長度。完成導航習慣養成所需的平均探索次數代表算法收斂所需的平均探索次數,該指標能夠綜合反映算法引導智能體發現目標區域的速度和收斂速度。單次導航習慣養成過程中的探索次數設定為20,單次探索過程的最大路徑長度設定為80 m。算法導航的實驗結果見表1。
從表1可以看出,各算法均能夠使智能體養成對應空間的導航習慣。SARSA算法具有最差的導航性能,其收斂速度和導航路徑長度均不及其他算法。Q-learning算法在導航路徑長度上優于SARSA、Sn-Plast和IAC算法,但其發現目標區域的速度較Sn-Plast更慢。這主要是因為Sn-Plast算法融合了改進的STDP學習規則和資格跡,能夠在一定程度上減少重復區域探索的次數。但是,雖然Sn-Plast能夠更快地發現目標區域,卻不能及時收斂(首次發現目標所需探索次數與養成導航習慣所需探索次數之間存在較大差異)。由于PO模塊的作用,使得Sn-Plast + PO算法在導航路徑長度上優于Q-learning算法,但由于沒有信息回饋,導致Sn-Plast + PO算法與Sn-Plast一樣無法及時收斂。而Sn-Plast + PO + PF算法在收斂速度、導航路徑以及發現目標區域的速度三個方面均表現最佳,不僅能夠保持Sn-Plast算法的優點,而且能夠對已經生成的導航路徑進行優化與回饋,從而快速形成最優導航路徑的穩定記憶。
2.2.3 動態導航實驗
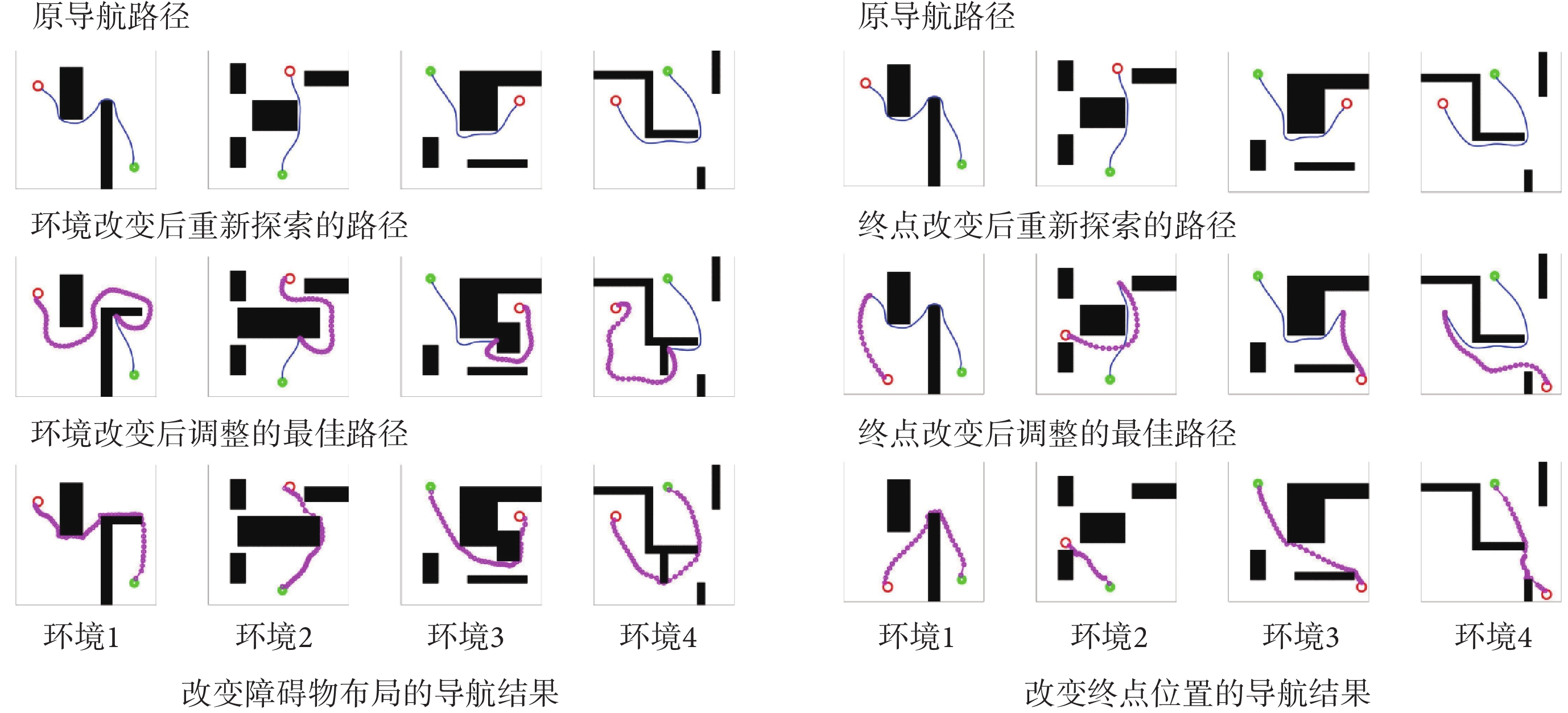
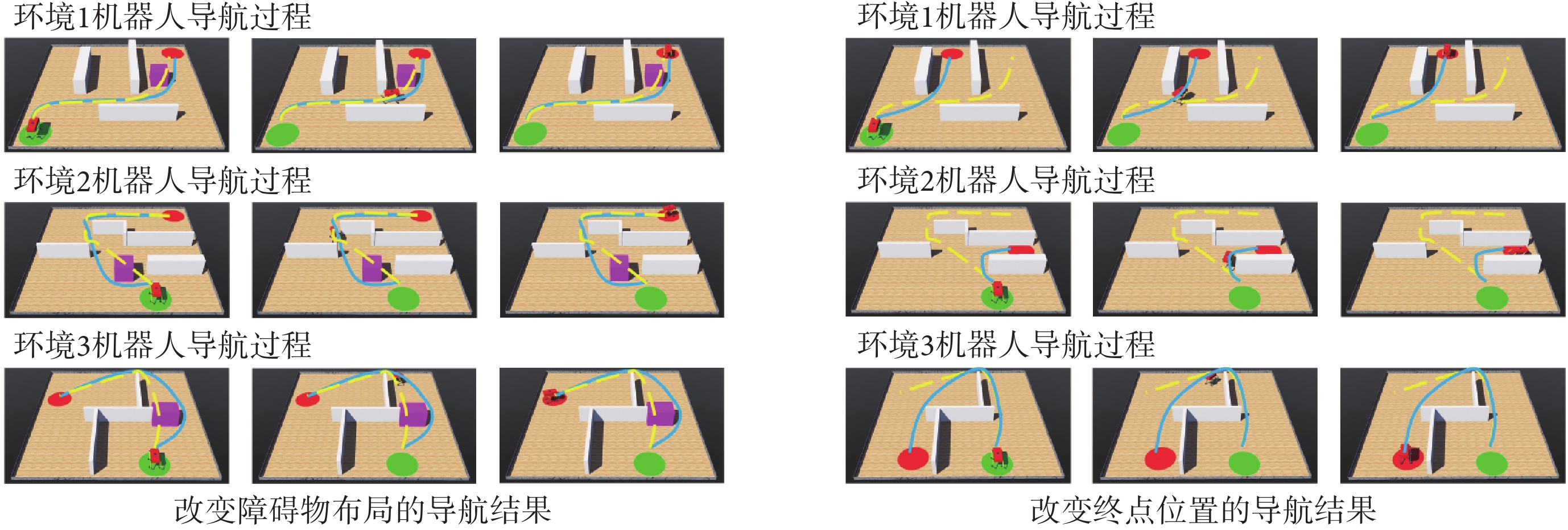
為驗證模型對導航任務動態變化的適應能力,分別在原導航路徑上增加障礙物以及改變導航任務的終點,以此觀察算法應對環境變化與導航任務發生變化時所做出的行為。模型的相關參數設定與前文一致。在智能體沿導航路徑運動的過程中,若檢測到前方有障礙物則說明空間環境中障礙物的布局已經發生了改變;若達到原導航終點位置時未發現目標則說明導航終點的位置發生了變化。此時算法將根據上述情形分別指導智能體以導航路徑與障礙物的交點或原導航終點為起點重新探索環境,并重新養成對應新環境或導航任務的最佳導航習慣。智能體在四個空間區域內進行動態導航實驗的部分結果如圖7所示,圖中各元素的含義與圖5中保持一致。
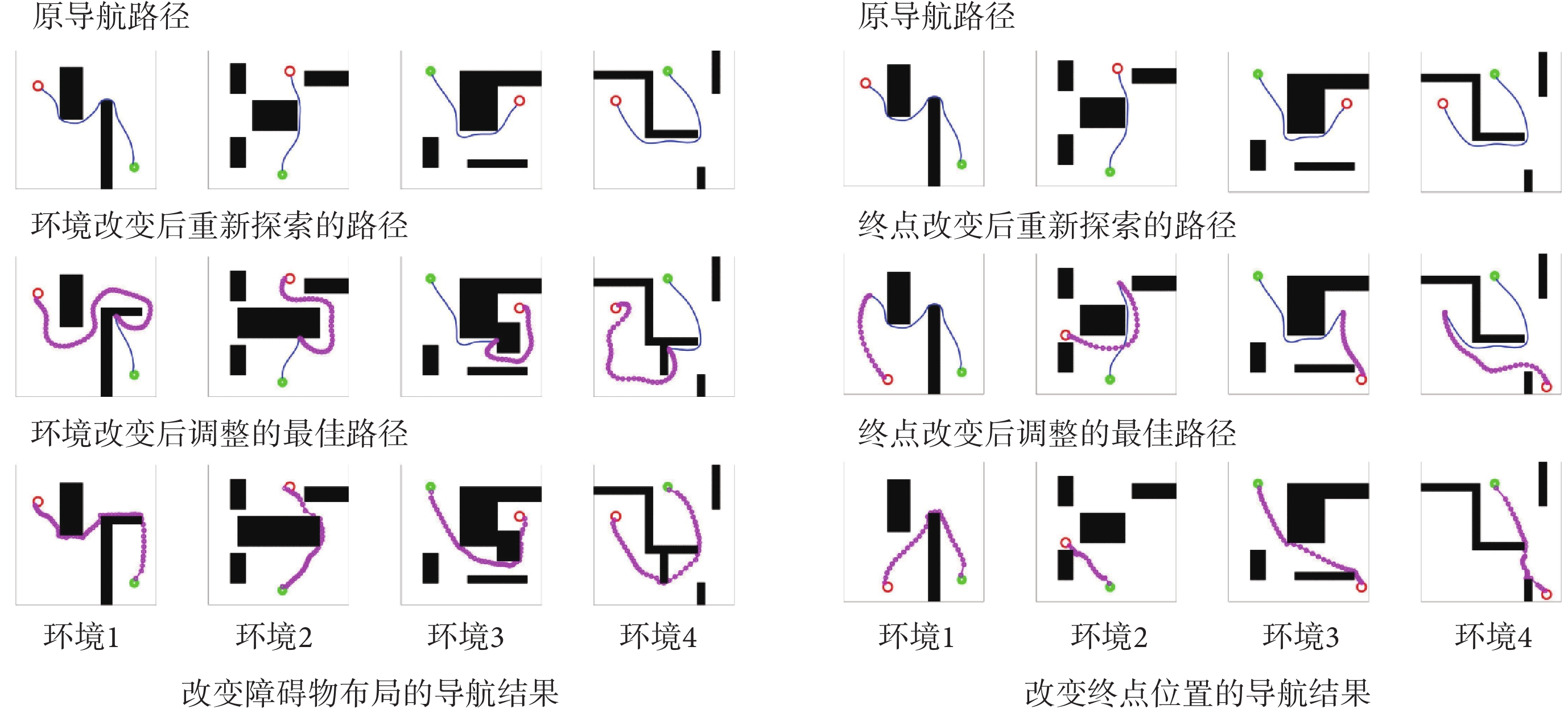 圖7
動態導航任務的實驗結果
Figure7.
Navigation results for dynamic navigation tasks
圖7
動態導航任務的實驗結果
Figure7.
Navigation results for dynamic navigation tasks
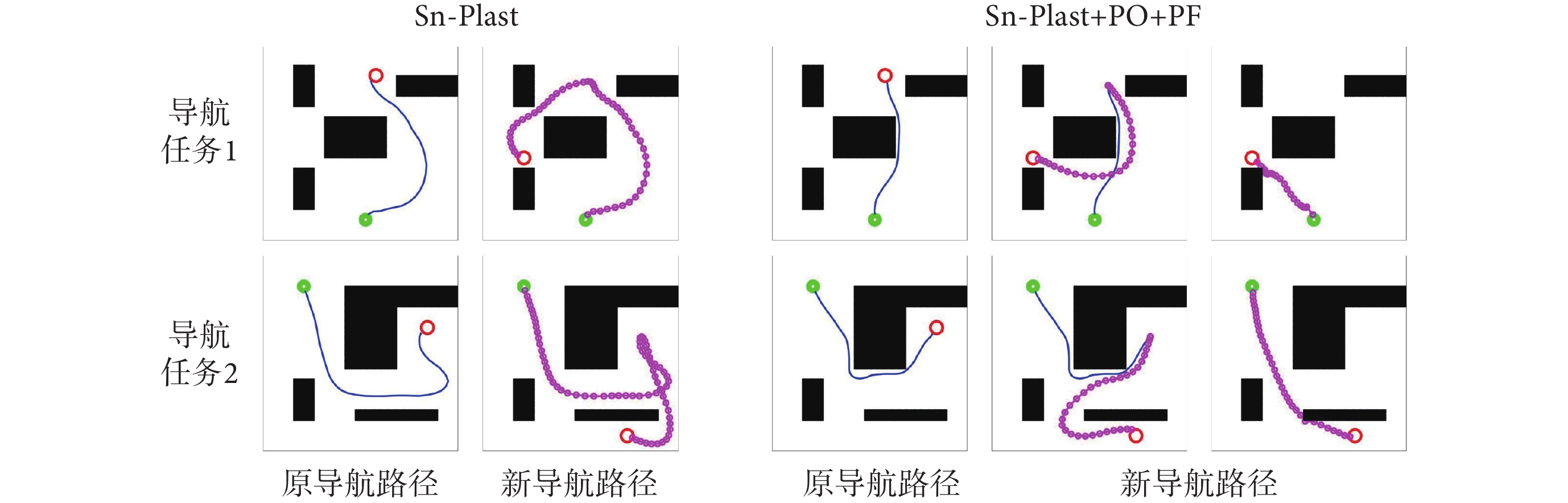
圖7左圖第二行圖片中藍色線條代表原始導航路徑中未接觸新障礙物的部分,粉色線條代表以原導航路徑與障礙物的交點為起點重新養成的導航習慣。圖7右圖第二行圖片中粉色線條代表以原導航終點為起點重新養成的導航習慣。結果表明,本文算法能夠及時有效地指導智能體對已發生改變的環境做出調整。為進一步證明本文算法對于動態導航任務具有較高的靈活性,設計兩組容易使算法陷入局部最優的動態導航實驗,將本文算法與Sn-Plast算法進行對比,導航軌跡如圖8所示。從圖中可以看出,當導航任務發生改變時,Sn-Plast算法形成的新導航路徑會陷入新起點至目標點導航任務的局部最優,而Sn-Plast+PO+PF算法則能夠統籌優化原軌跡與新軌跡所組成的新軌跡,實時判斷是否為當前的最優路徑,從而生成適應新導航任務的最優路徑。此外,關于從原起點和新起點出發對算法性能影響的討論見附件2。
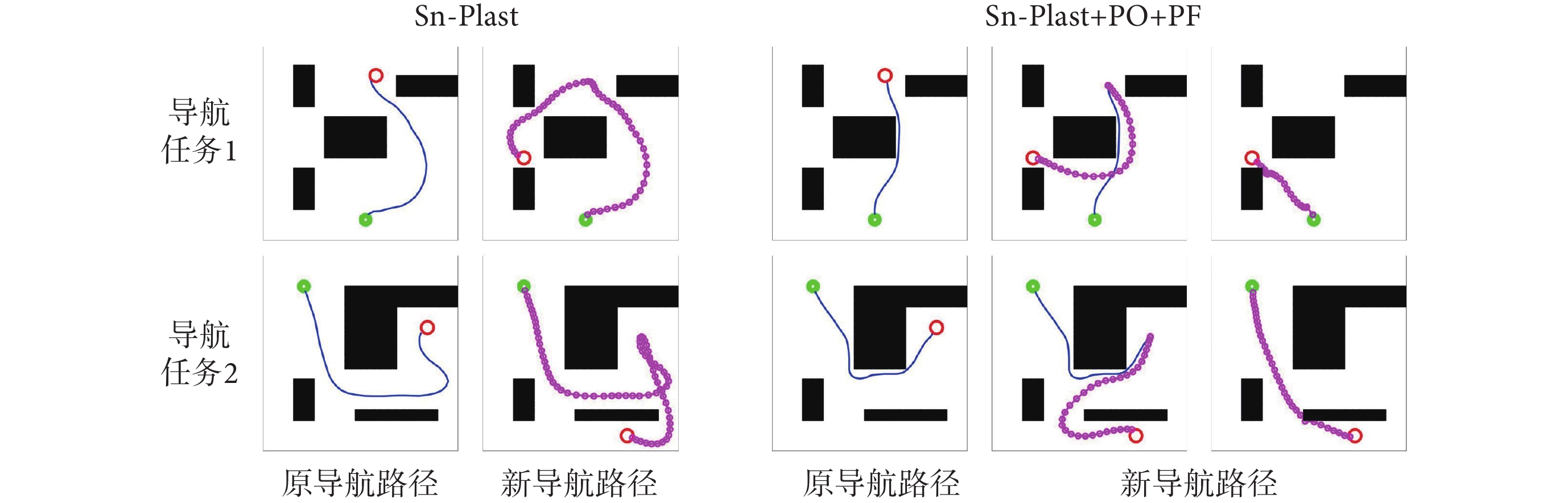 圖8
動態導航任務的軌跡對比結果
Figure8.
Track comparison of dynamic navigation tasks
圖8
動態導航任務的軌跡對比結果
Figure8.
Track comparison of dynamic navigation tasks
2.3 機器人平臺三維仿真實驗
為進一步驗證模型的有效性,本文使用Webots仿真軟件進行三維仿真實驗。在仿真軟件中使用剛體、角度傳感器、電機、接觸傳感器、攝像頭、GPS傳感器以及IMU搭建四足機器人的物理模型。仿真環境的大小為10 m×10 m,四足機器人在該環境中自主探索。通過獲取機器人的GPS傳感信息來解算自身在環境中的位置。機器人的正前方安裝有深度攝像頭來判斷前方是否有障礙物。利用本文算法計算下一時刻機器人應當達到的位置坐標,隨后控制四足機器人到達指定位置,以此引導四足機器人在空間環境中進行探索并養成導航習慣。分別在Webots軟件中構建三個仿真環境進行實驗,空間中隨機設置起點、終點以及圍墻、方塊等障礙物,算法的各項參數與前文保持一致。導航習慣養成后機器人在算法的引導下完成導航任務的過程如圖9所示,圖中黃色線條代表機器人的導航軌跡。隨后效仿二維實驗在環境中原機器人導航路徑上增加方塊形障礙物以及改變導航終點位置,機器人在算法的引導下完成新導航任務的過程如圖10所示,圖中黃色虛線和藍色線條分別代表導航任務發生改變前后的機器人導航軌跡。可以看出,本文算法不但能夠引導機器人探索環境并養成對應的導航習慣,而且可以及時有效地指導智能體適應動態變化的環境和導航終點。機器人的物理結構及其在空間環境中導航的視頻文件見附件3~6。
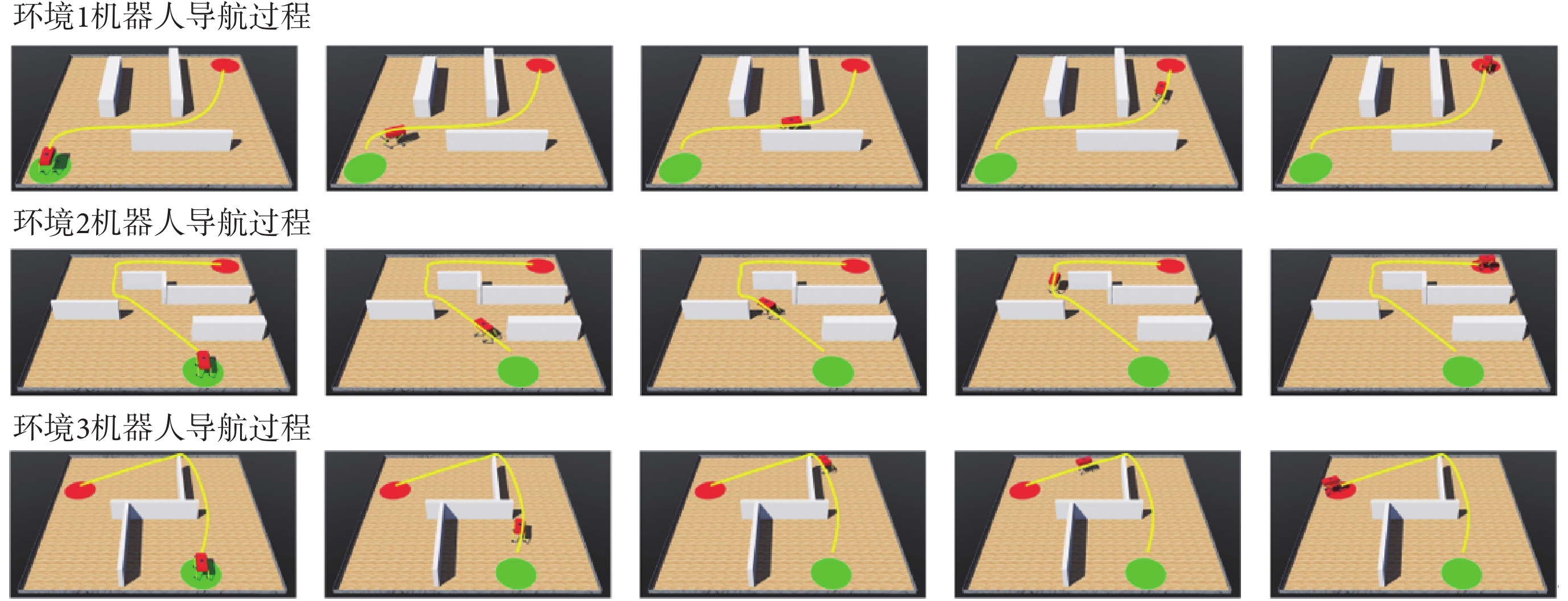 圖9
機器人在算法的引導下完成導航任務的過程
Figure9.
The process of robot completing navigation task under the guidance of algorithm
圖9
機器人在算法的引導下完成導航任務的過程
Figure9.
The process of robot completing navigation task under the guidance of algorithm
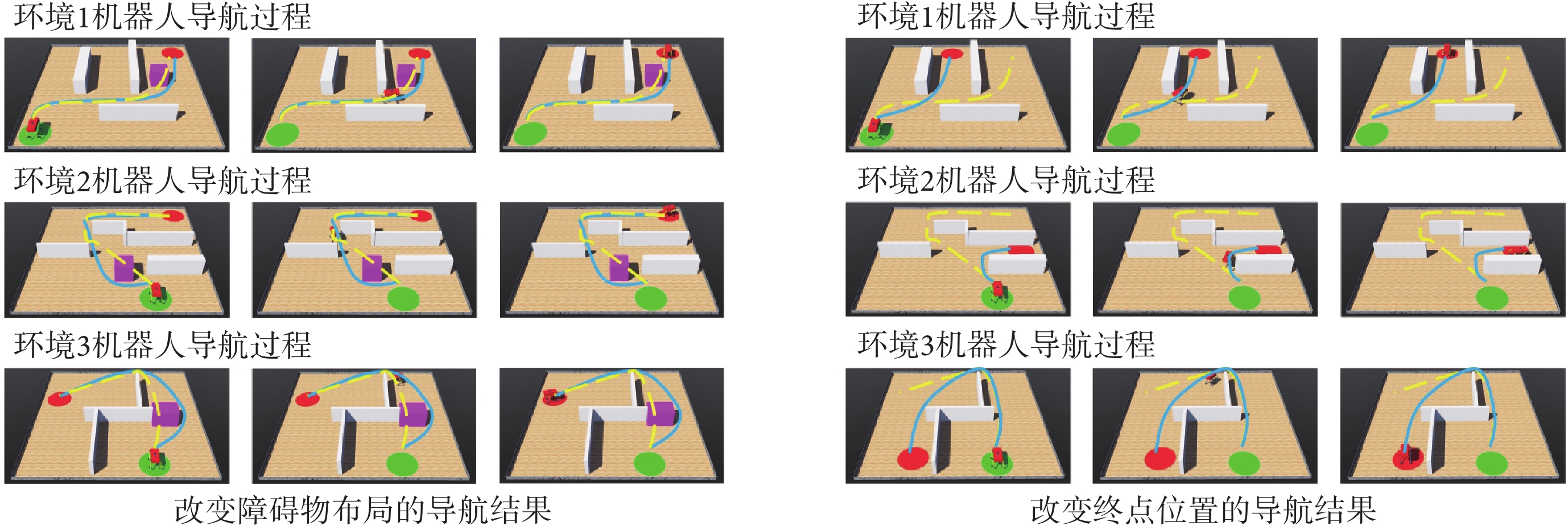 圖10
機器人完成動態導航任務的運動過程
Figure10.
Motion process of robot completing dynamic navigation task
圖10
機器人完成動態導航任務的運動過程
Figure10.
Motion process of robot completing dynamic navigation task
3 結論
本文提出一種仿鼠腦內嗅—海馬—前額葉信息傳遞回路的空間導航方法,其特點在于:① 構建以海馬CA1區的位置細胞為基本單元的動態自組織模型以優化導航路徑;② 能夠通過空間細胞的放電作用將路徑信息回饋至脈沖神經網絡,提高算法收斂速度的同時還有助于建立導航習慣的長期記憶。實驗結果表明了方法的有效性和可行性,且相較于其他導航方法,本文方法在導航效率、收斂速度以及對環境中動態障礙的適應性等方面更有優勢。三維仿真平臺的機器人實驗表明本文方法能夠很好地應用在移動機器人平臺上。
然而本文方法也存在以下不足:① 導航任務局限于給定空間內進行。② 機器人在運動的過程中通常存在累計誤差,導致定位不準。而本文僅在真實位置的引導下進行實驗驗證,未考慮由于定位不夠精確而影響算法導航性能的情況。③ 在環境發生改變的時候還是需要在局部空間內進行探索與路徑優化,不能根據改變之后的環境直接對當前路徑進行調整。因此下一步的研究方向為:① 將算法擴展到能夠在任意大小空間范圍內實現導航任務;② 結合多種外源信息作為輸入,力求使機器人在與環境的交互過程中漸進地形成和發展對環境的認知能力,提升導航過程的定位精度進而增強模型的魯棒性。綜上,本文研究成果為仿鼠腦認知機制的機器人導航方法奠定了基礎。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:于乃功對相關工作進行了調查,發現了現有方法的不足,提出了本文的核心觀點與研究思路;廖詣深針對該研究思路進行了實現,并設計了實驗對本文方法進行了驗證。
本文附件見本刊網站的電子版本(biomedeng.cn)。
0 引言
環境認知與導航是各類高等哺乳動物特有的一種能力[1]。對于自主移動式機器人來說,具備像高等哺乳動物一樣的智能行為是在復雜未知的環境中快速而準確地實現面向目標導航的必要條件。導航包含定位與決策兩個部分[2]。定位是確定自身在環境中的位置,而決策則代表如何正確地指導機器人從當前位置運動至目標點。大鼠作為哺乳動物的一員,也擁有著卓越的導航能力。生理學研究表明,內嗅—海馬結構是大鼠實現定位的關鍵腦區[3],其內部存在多種對空間位置有著特異性放電作用的神經元細胞(空間細胞),例如:位置細胞[4]、網格細胞[5]、邊界細胞[6]、頭朝向細胞[7]等。其中,自運動信息被認為是輸入至內嗅皮層網格細胞結構[8],并通過神經網絡投射至海馬CA3區的位置細胞群,從而實現對自運動信息的路徑積分[9]。隨后,海馬CA1區位置細胞接收CA3區位置細胞所投射的位置信息,實現對空間位置集合的存儲與記憶[10]。由于位置細胞是定位的主要神經元,其放電活動并不能預測未來行為的方向,而決策是導航過程中必不可少的組成部分,因此可以推斷在大鼠腦結構中必定存在承擔決策任務的相關腦區。研究表明,前額葉皮層是大腦產生命令和運動控制的關鍵腦區[11],且內嗅—海馬結構與前額葉皮層之間的動態聯系是決定未來行為的關鍵因素[12]。
近年來,基于仿生認知機制的空間導航方法的研究成為熱點,主要包括兩個研究方向:① 仿生環境認知地圖構建與導航。該研究方向旨在構建仿鼠腦運行機制的精確環境認知地圖,隨后基于認知地圖進行路徑規劃與導航[13-15]。而基于地圖的路徑規劃與導航方法較為工程化,因而缺乏仿生性。② 基于仿生認知機制的空間認知與導航習慣養成。該研究方向旨在構建導航模型指導機器人對空間環境進行探索,并隨著機器人的探索逐漸獲得對應環境的導航能力。2004年,Oudeyer等[16]提出一種智能自適應好奇心學習理論,使機器人在沒有先驗知識的環境中不斷探索,逐漸完成對環境的認知。隨后在2018年和2021年,張曉平等[17]和阮曉鋼等[18]構建了基于好奇心學習理論的環境認知模型,并在此基礎上實現移動機器人的路徑規劃。而仿鼠腦認知機制的導航習慣養成相關研究工作可以追溯到2009年,Kulvicius等[19]利用簡單的前饋神經網絡構建海馬位置細胞到動作神經元之間的連接關系,并使用Q-learning算法實現面向目標的導航。2013年,Frémaux等[20]使用脈沖神經網絡作為位置細胞到動作神經元之間的連接結構,引入STDP學習規則調整網絡的連接權值,提升了導航模型發現目標區域的速度。隨后在2017年和2021年,Zannone團隊[21-22]將乙酰膽堿和多巴胺的順序神經調節機制加入STDP學習規則(Sn-Plast模型),使智能體能夠有效地導航到不斷變化的獎勵位置,增強了模型的適應能力。但上述方法都容易陷入局部最優,導致輸出的路徑并不是當前導航任務的最優路徑。
基于上述研究事實,本文提出一種仿鼠腦內嗅—海馬—前額葉信息傳遞回路的空間導航方法,旨在為移動機器人賦予強大的定位與決策能力。本文的主要貢獻如下:① 構建以海馬CA1區的位置細胞為基本單元的動態自組織模型,能夠根據環境信息優化海馬CA3—前額葉脈沖神經網絡模型輸出的導航路徑,從而提高導航效率;② 通過優化后的導航路徑得出動作神經元和海馬CA3位置細胞群的理論放電率,并以此為監督信號調整脈沖神經網絡的連接權值,實現了將優化后的導航路徑及時回饋至脈沖神經網絡,提高模型收斂速度的同時還有助于建立導航習慣的長期記憶。
1 模型的建立
1.1 模型的整體結構
本節對仿鼠腦內嗅—海馬—前額葉信息傳遞回路的空間導航方法的整體結構進行詳細說明。隨著機器人在環境中探索,自運動信息首先被輸入至網格細胞模型,隨后通過神經網絡連接將空間信息投射至海馬CA3區位置細胞模型,實現路徑積分功能[23]。機器人探索過程中,使用聯合學習規則Sn-Plast調節海馬CA3區位置細胞到前額葉皮層動作神經元之間脈沖神經網絡的權值大小[22]。待探索至目標點時,海馬CA1區位置細胞通過動態自組織對形成的導航路徑進行優化。由于導航行為需要動作神經元的放電率為指導,而動作神經元的放電率由脈沖神經元的權值和海馬CA3區位置細胞群的放電率共同決定,故利用優化后的導航路徑計算出動作神經元和海馬CA3區位置細胞群的理論放電率序列,并以此為監督信號調整脈沖神經網絡的連接權值。導航方法的整體運行機制如圖1所示。
圖1
導航方法的整體運行機制示意圖
Figure1.
The overall operating mechanism of navigation method
1.2 導航路徑優化方法
導航路徑實際上是由多個路徑點組成的,每個海馬CA1位置細胞可以看作是一個記憶單元,存儲一個路徑點信息。設第 i 個位置細胞為 。 代表放電野中心坐標。 代表智能體在 處的頭朝向角度,其初始值為相鄰兩個位置細胞 和 放電野中心連線與x軸正方向之間的夾角。設t時刻第i個位置細胞放電野中心位置的更新量為 ,頭朝向角度的修正量為 ,相關數學表達式如下。
|
|
|
式(3)中, 代表初始時刻位置細胞 和 放電野中心之間的距離, 代表松弛因子, 代表初始時刻 與 之間的差值, 代表求解角度差的函數。得到修正量之后,即可對放電野中心和頭朝向角度進行修正。放電野中心坐標修正的數學表達式如下:
|
|
頭朝向角度修正的數學表達式如下:
|
|
式(4)~(7)中, 代表修正增益。然而,實際物理環境中通常存在許多障礙物,因此路徑的優化過程也要考慮障礙物的影響。生理學研究表明,內嗅皮層的邊界細胞是大鼠感知環境邊界和障礙的主要神經元,同樣也是海馬體的信息輸入源之一[24]。因此,本文基于邊界細胞的放電機制對路徑優化過程進行分段。首先,將環境中的所有障礙物離散化,并將離散化的障礙物位置集定義為 。設 代表 t 時刻第 i 個位置細胞放電野中心與障礙物之間的最短距離,其數學表達式如下:
|
在導航路徑優化的過程中,當某個位置細胞的放電野中心逐漸靠近障礙物且與障礙物之間的距離足夠小的時候,則固定該位置細胞的放電野中心位置(位置不再改變)。設t時刻已經被固定放電野中心的位置細胞集合為 ,當 時,。 隨著迭代次數增加的數學表達式如下:
|
|
式(10)和(11)中, 代表將集合中的元素從小到大排序, 代表最短距離判據閾值。設函數 代表對第 個位置細胞到第 個位置細胞之間的所有位置細胞放電野中心進行路徑優化,其中 。定義集合 中的第 i 個元素為 ,故導航路徑的優化過程可以表示為如下公式:
|
上述步驟可以對導航路徑進行分段校正,以確保模型在有障礙物的環境中仍能實現高效的面向目標的導航。導航路徑分段修正的運行機制如圖2所示。
圖2
導航路徑分段優化的運行機制
Figure2.
Operation mechanism of navigation path segment optimization
在導航路徑優化過程中,隨著迭代次數的增加,更新量的值逐漸減小。此時再繼續進行迭代更新所產生的效果不顯著且耗費處理器的計算時間,影響算法的實時性。基于此,本文提出一種收斂度的判據方法。首先定義時刻的路徑收斂量為,其數學表達式如式(12)所示:
|
設收斂判據比例因子為ρ,當滿足 時,判斷此時無需再繼續進行更新迭代,反之則繼續執行更新迭代。導航路徑優化方法的收斂性證明過程見附件1。
1.3 導航路徑回饋
待導航路徑優化后,需要將優化后的導航路徑回饋至脈沖神經網絡。首先計算動作神經元和海馬CA3區位置細胞群的理論放電率作為監督信號來調整脈沖神經網絡的連接權值,相關數學表達式如式(13)和(14)所示。
|
|
式(13)代表第j個動作神經元的放電率表達,其中 代表放電率閾值, 代表動作神經元放電率調整因子, 代表神經元的個數, 代表當前的頭朝向角度(路徑優化后相鄰兩個CA1區位置細胞 和 放電野中心連線與x軸正方向之間的夾角)。式(14)代表CA3區位置細胞的放電率表達,其中 代表位置細胞的放電野中心, 代表位置野半徑調整因子, 表示0至1之間隨機的一個數。智能體在t時刻的動作 由動作神經元的放電活動所決定,其數學表達式如下:
|
式(15)中, 為第j個動作神經元在t時刻所代表的動作, 代表第j個動作神經元的放電脈沖, 代表濾波器,相應的數學表達式如式(16)至(18)所示。
|
|
式(16)中, 代表動作步長, 代表第j個動作神經元的偏好方向。式(17)中, 代表階躍函數, 和 均為時間常數。當機器人運動至目標區域時,使用STDP規則與資格跡結合的可塑性規則[22]對突觸權重進行更新,數學表達式如式(18)所示。
|
式(18)中, 代表學習率;A代表神經調節函數;W代表STDP窗口函數,其數學表達式為 ; 代表資格跡。 和 分別代表第j個動作神經元和第i個位置細胞所產生脈沖的到達時間。綜上,導航方法的工作流程可以簡述如下:首先采集機器人的自運動信息,按照信息流順序依次計算各空間神經元的放電率,并利用全體動作神經元的放電活動指導機器人移動。當機器人運動至目標區域時,利用CA1位置細胞動態自組織模型調整導航路徑,并將優化后的導航路徑與先前所有路徑的長度進行對比。若當前路徑是最短路徑則計算CA3位置細胞和動作神經元的理論放電率,并作為監督信號調整脈沖神經網絡的連接權值。
1.4 動態導航過程
當機器人處于靜態環境中,機器人只需要探索環境并搜索導航路徑即可。然而,空間環境或導航任務通常是不斷變化的,這就需要機器人擁有較強的適應能力。導航過程發生改變主要包括以下兩種情況:① 原導航路徑發生阻塞;② 導航終點發生改變。導航過程發生改變后,機器人將以導航路徑與障礙物的交點或原導航終點為起點重新探索環境。導航方法的運行流程如圖3所示。
圖3
導航方法的運行流程圖
Figure3.
Operation process of the navigation method
2 實驗驗證
2.1 實驗說明與參數設定
本節通過設計二維仿真實驗在模型收斂速度、導航效率、動態導航任務的適應能力等方面進行測試,并在此基礎上設計機器人平臺的三維仿真實驗進一步驗證模型的有效性。內嗅—海馬CA3信息傳遞模型的參數設定與文獻[23]一致,海馬CA3—前額葉空間導航模型的參數設定與文獻[22]一致。本文模型涉及的參數設定如下:修正增益設定為0.5,松弛因子設定為0.3,收斂判據比例因子為設定為0.001,動作神經元放電率閾值設定為0.9,動作神經元放電率調整因子設定為1 000,距離判據閾值設定為0.1。
2.2 二維仿真實驗
2.2.1 導航習慣養成實驗
本節對所提出的模型性能進行二維仿真實驗驗證,分別構建四個不同的空間區域進行導航實驗,區域面積均設定為10 m × 10 m。空間區域內設置障礙物以及導航的起點與終點。以Sn-Plast模型引導智能體在四個空間區域中探索,并養成相應的導航習慣。單次導航習慣養成過程中的探索次數設定為30,單次探索過程的最大路徑長度設定為80 m。智能體在空間區域中的導航習慣養成過程如圖4所示,其中從左至右代表探索環境次數的增加。
圖4
Sn-Plast模型引導下智能體的導航習慣養成過程
Figure4.
The formation process of navigation habits of agents under the guidance of Sn-Plast model
從圖4中可以看出,在Sn-Plast模型的引導下機器人能夠通過不斷探索環境而逐漸習得如何從起點出發運動至目標點,養成對應當前任務的導航習慣。但從導航結果來看也同時存在兩點不足:① 模型無法快速收斂(當智能體探索至目標區域時,在接下來的探索任務中依舊會出現無法運動至目標區域的情況);② 導航路徑比較彎曲,并不是最優導航路徑。因此本文通過CA1區位置細胞動態自組織模型對導航路徑進行優化。隨后將優化后的路徑通過CA3位置細胞和動作神經元回饋至脈沖神經網絡,強化模型對路徑的記憶,解決模型無法快速收斂的問題。圖5所示為導航路徑的優化過程,圖中從左至右代表優化模型迭代次數的增加。圖6所示為原始路徑與優化路徑的長度統計結果。從圖5和圖6中可以看出,隨著優化模型迭代次數的增加,優化路徑較原始路徑顯著縮短,驗證了模型的有效性。
圖5
導航路徑的優化過程
Figure5.
Optimization process of navigation path
圖6
原始路徑和優化路徑的平均長度統計
Figure6.
Average length statistics of original paths and optimized paths
2.2.2 對比實驗與消融實驗
為了突出本文方法的優勢,將之與Q-learning算法[19]、SARSA算法[25]以及智能好奇心算法(intelligent adaptive curiosity,IAC)[16]進行對比。鑒于本文導航方法由導航習慣養成模塊(Sn-Plast)、路徑優化模塊(path optimization,PO)和路徑回饋模塊(path feedback,PF)組成,為了體現各模塊的作用,增加消融實驗以測試每個模塊對模型性能的影響。對比的性能指標如下:導航路徑平均長度、發現目標區域后收斂的概率、首次發現目標區域所需的探索次數以及完成導航習慣養成所需的平均探索次數。為量化模型的收斂性能,收斂判據如下:當智能體發現目標區域并且在接下來的四次探索任務中均能夠運動至目標區域,則判斷模型已收斂;反之亦然。定義發現目標區域后收斂的概率為 ,其數學表達式如式(19)所示。
|
式(19)中,代表發現目標區域的次數,代表發現目標區域且接下來的四次探索任務均能夠運動至目標區域的次數。導航路徑平均長度代表所有發現目標的路徑長度平均值,其數學表達式如式(20)所示。
|
式(20)中,代表第次發現目標區域的探索路徑長度。完成導航習慣養成所需的平均探索次數代表算法收斂所需的平均探索次數,該指標能夠綜合反映算法引導智能體發現目標區域的速度和收斂速度。單次導航習慣養成過程中的探索次數設定為20,單次探索過程的最大路徑長度設定為80 m。算法導航的實驗結果見表1。
從表1可以看出,各算法均能夠使智能體養成對應空間的導航習慣。SARSA算法具有最差的導航性能,其收斂速度和導航路徑長度均不及其他算法。Q-learning算法在導航路徑長度上優于SARSA、Sn-Plast和IAC算法,但其發現目標區域的速度較Sn-Plast更慢。這主要是因為Sn-Plast算法融合了改進的STDP學習規則和資格跡,能夠在一定程度上減少重復區域探索的次數。但是,雖然Sn-Plast能夠更快地發現目標區域,卻不能及時收斂(首次發現目標所需探索次數與養成導航習慣所需探索次數之間存在較大差異)。由于PO模塊的作用,使得Sn-Plast + PO算法在導航路徑長度上優于Q-learning算法,但由于沒有信息回饋,導致Sn-Plast + PO算法與Sn-Plast一樣無法及時收斂。而Sn-Plast + PO + PF算法在收斂速度、導航路徑以及發現目標區域的速度三個方面均表現最佳,不僅能夠保持Sn-Plast算法的優點,而且能夠對已經生成的導航路徑進行優化與回饋,從而快速形成最優導航路徑的穩定記憶。
2.2.3 動態導航實驗
為驗證模型對導航任務動態變化的適應能力,分別在原導航路徑上增加障礙物以及改變導航任務的終點,以此觀察算法應對環境變化與導航任務發生變化時所做出的行為。模型的相關參數設定與前文一致。在智能體沿導航路徑運動的過程中,若檢測到前方有障礙物則說明空間環境中障礙物的布局已經發生了改變;若達到原導航終點位置時未發現目標則說明導航終點的位置發生了變化。此時算法將根據上述情形分別指導智能體以導航路徑與障礙物的交點或原導航終點為起點重新探索環境,并重新養成對應新環境或導航任務的最佳導航習慣。智能體在四個空間區域內進行動態導航實驗的部分結果如圖7所示,圖中各元素的含義與圖5中保持一致。
圖7
動態導航任務的實驗結果
Figure7.
Navigation results for dynamic navigation tasks
圖7左圖第二行圖片中藍色線條代表原始導航路徑中未接觸新障礙物的部分,粉色線條代表以原導航路徑與障礙物的交點為起點重新養成的導航習慣。圖7右圖第二行圖片中粉色線條代表以原導航終點為起點重新養成的導航習慣。結果表明,本文算法能夠及時有效地指導智能體對已發生改變的環境做出調整。為進一步證明本文算法對于動態導航任務具有較高的靈活性,設計兩組容易使算法陷入局部最優的動態導航實驗,將本文算法與Sn-Plast算法進行對比,導航軌跡如圖8所示。從圖中可以看出,當導航任務發生改變時,Sn-Plast算法形成的新導航路徑會陷入新起點至目標點導航任務的局部最優,而Sn-Plast+PO+PF算法則能夠統籌優化原軌跡與新軌跡所組成的新軌跡,實時判斷是否為當前的最優路徑,從而生成適應新導航任務的最優路徑。此外,關于從原起點和新起點出發對算法性能影響的討論見附件2。
圖8
動態導航任務的軌跡對比結果
Figure8.
Track comparison of dynamic navigation tasks
2.3 機器人平臺三維仿真實驗
為進一步驗證模型的有效性,本文使用Webots仿真軟件進行三維仿真實驗。在仿真軟件中使用剛體、角度傳感器、電機、接觸傳感器、攝像頭、GPS傳感器以及IMU搭建四足機器人的物理模型。仿真環境的大小為10 m×10 m,四足機器人在該環境中自主探索。通過獲取機器人的GPS傳感信息來解算自身在環境中的位置。機器人的正前方安裝有深度攝像頭來判斷前方是否有障礙物。利用本文算法計算下一時刻機器人應當達到的位置坐標,隨后控制四足機器人到達指定位置,以此引導四足機器人在空間環境中進行探索并養成導航習慣。分別在Webots軟件中構建三個仿真環境進行實驗,空間中隨機設置起點、終點以及圍墻、方塊等障礙物,算法的各項參數與前文保持一致。導航習慣養成后機器人在算法的引導下完成導航任務的過程如圖9所示,圖中黃色線條代表機器人的導航軌跡。隨后效仿二維實驗在環境中原機器人導航路徑上增加方塊形障礙物以及改變導航終點位置,機器人在算法的引導下完成新導航任務的過程如圖10所示,圖中黃色虛線和藍色線條分別代表導航任務發生改變前后的機器人導航軌跡。可以看出,本文算法不但能夠引導機器人探索環境并養成對應的導航習慣,而且可以及時有效地指導智能體適應動態變化的環境和導航終點。機器人的物理結構及其在空間環境中導航的視頻文件見附件3~6。
圖9
機器人在算法的引導下完成導航任務的過程
Figure9.
The process of robot completing navigation task under the guidance of algorithm
圖10
機器人完成動態導航任務的運動過程
Figure10.
Motion process of robot completing dynamic navigation task
3 結論
本文提出一種仿鼠腦內嗅—海馬—前額葉信息傳遞回路的空間導航方法,其特點在于:① 構建以海馬CA1區的位置細胞為基本單元的動態自組織模型以優化導航路徑;② 能夠通過空間細胞的放電作用將路徑信息回饋至脈沖神經網絡,提高算法收斂速度的同時還有助于建立導航習慣的長期記憶。實驗結果表明了方法的有效性和可行性,且相較于其他導航方法,本文方法在導航效率、收斂速度以及對環境中動態障礙的適應性等方面更有優勢。三維仿真平臺的機器人實驗表明本文方法能夠很好地應用在移動機器人平臺上。
然而本文方法也存在以下不足:① 導航任務局限于給定空間內進行。② 機器人在運動的過程中通常存在累計誤差,導致定位不準。而本文僅在真實位置的引導下進行實驗驗證,未考慮由于定位不夠精確而影響算法導航性能的情況。③ 在環境發生改變的時候還是需要在局部空間內進行探索與路徑優化,不能根據改變之后的環境直接對當前路徑進行調整。因此下一步的研究方向為:① 將算法擴展到能夠在任意大小空間范圍內實現導航任務;② 結合多種外源信息作為輸入,力求使機器人在與環境的交互過程中漸進地形成和發展對環境的認知能力,提升導航過程的定位精度進而增強模型的魯棒性。綜上,本文研究成果為仿鼠腦認知機制的機器人導航方法奠定了基礎。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:于乃功對相關工作進行了調查,發現了現有方法的不足,提出了本文的核心觀點與研究思路;廖詣深針對該研究思路進行了實現,并設計了實驗對本文方法進行了驗證。
本文附件見本刊網站的電子版本(biomedeng.cn)。