醫學影像報告自動生成任務面臨疾病類型多樣、報告描述缺乏專業性和流暢性等多重挑戰。為解決以上問題,本文提出一種基于記憶驅動的多模態醫學影像報告自動生成方法(mMIRmd),首先使用基于移位窗口的層次視覺轉換器(Swin-Transformer)提取患者醫學影像的多視角視覺特征,通過基于轉換器的雙向編碼模型(BERT)提取病史信息的語義特征,然后將多模態特征進行融合,提高模型對不同疾病類型的識別能力。其次,使用醫學文本預訓練的詞向量詞典對視覺特征標簽進行編碼,以提高生成報告的專業性。最后,在解碼器中引入記憶驅動模塊,解決醫學影像數據中的長距離依賴關系。本研究在印第安納大學收集的胸部X光數據集(IU X-Ray)和麻省理工學院聯合馬薩諸塞州總醫院發布的重癥監護X光醫療數據集(MIMIC-CXR)上進行驗證。實驗結果表明,本文所提方法能更好地關注患病區域,提高生成報告的準確性與流暢性,可以輔助放射科醫生快速完成醫學影像報告的撰寫。
引用本文: 邢素霞, 方俊澤, 鞠子涵, 郭正, 王瑜. 基于記憶驅動的多模態醫學影像報告自動生成研究. 生物醫學工程學雜志, 2024, 41(1): 60-69. doi: 10.7507/1001-5515.202304001 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
0 引言
醫學影像報告自動生成技術可以輔助醫生迅速關注異常區域,減少撰寫報告所需的時間,從而提高工作效率[1-5]。目前,醫學影像報告自動生成主要采用兩種模型結構,分別是基于深度學習的編碼器—解碼器結構,包括:卷積神經網絡(convolutional neural networks,CNN)、循環神經網絡(recurrent neural network,RNN)、CNN與RNN結合網絡(CNN-RNN)以及基于注意力機制的轉換器(transformer)結構[6-7]。相較于CNN-RNN,tansformer的注意力機制擁有更強的特征學習能力,能夠加權計算輸入數據中每個節點之間的關聯,且善于捕捉較長間隔的語義關聯[8-9]。Alfarghaly等[10]成功將transformer應用于醫學影像報告自動生成領域后,受到廣泛關注[11-12]。Srinivasan等[13]提出基于transformer的等級網絡(hierarchical net,HN),使用疾病標簽和多頭注意力(multi-head attention,MHA)實現了分層的醫學影像報告自動生成方法,提高了報告的準確性和可解釋性,但對于特定疾病的泛化能力有待提升。Liu等[14]提出探索提煉后驗和先驗知識模型(posterior-and-prior knowledge exploring-and-distilling,PPKED),首先確定異常區域和疾病類型,再利用先驗知識進行報告書寫,有效減輕了文本數據的偏見,但在處理復雜病例時還存在知識不完備的問題。Li等[15]提出一種自引導框架模型(self-guided framework,SGF),可以從無疾病標簽的醫學影像報告中獲取專業知識,并提取相關的細顆粒視覺特征來提升報告的精確度,但存在對語義理解依賴性不足的問題。You等[16]提出一種可以將視覺區域和疾病標簽分層對齊的對齊層次注意力和多粒度transformer(align hierarchical attention and multi-grained transformer,AlignTransformer),通過先預測疾病標簽,再將其與視覺區域分層對齊的方法學習多粒度視覺特征,解決視覺偏差問題,但有時生成的報告并不流暢。Chen等[17]提出一種跨模態記憶網絡(cross-modal memory networks,CMN),該網絡利用記憶存儲器保留特征信息,通過建立視覺與文本的聯系,解決圖文多模態映射,但對于復雜的或罕見的病例,模型缺乏足夠的泛化能力。
以上研究成果表明,基于transformer及其改進模型的研究在醫學影像報告自動生成任務中取得了優異表現,但同時,此類模型在識別和描述疾病特征方面還有一定的局限性,對罕見疾病的識別普遍較差,且由于模型對醫學術語、解剖結構或病變特點等方面理解不夠深入,導致對疾病的描述不夠專業,模型有時還會生成語句不通順或難以理解的文本,影響報告的理解和使用。基于以上問題,本文提出了一種基于記憶驅動的多模態醫學影像報告自動生成方法(multimodal medical imaging report based on memory drive,mMIRmd),以改善醫學影像報告自動生成的質量,著重解決疾病識別準確性、疾病描述專業性和報告文本流暢性等方面的問題,減少放射科醫生撰寫報告的負擔,輔助臨床醫生實現準確診斷。
1 數據驅動的多模態醫學影像報告自動生成方法
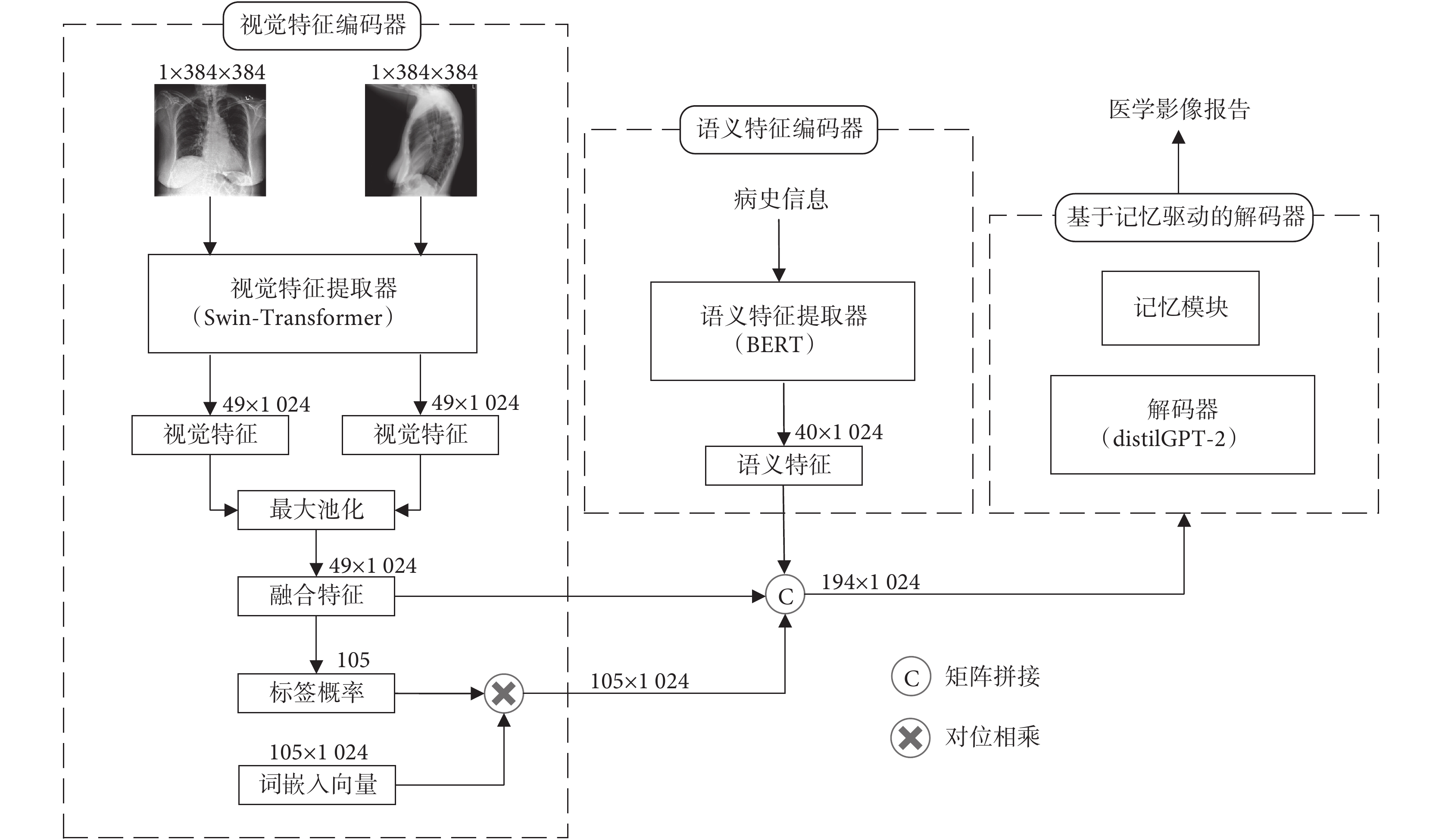
如圖1所示,展示了本文所提mMIRmd模型的整體結構,該模型包括視覺特征編碼器、語義特征編碼器和基于記憶驅動的解碼器三個部分。視覺特征編碼器,負責提取并融合正、側面兩張影像的視覺特征,并預測每種疾病標簽對應的概率。語義特征編碼器,負責提取病史信息中的語義特征。將視覺特征、編碼后的預測標簽概率和語義特征拼接后,輸入基于記憶驅動的解碼器。基于記憶驅動的解碼器,負責將上述拼接特征解碼并生成醫學影像報告。
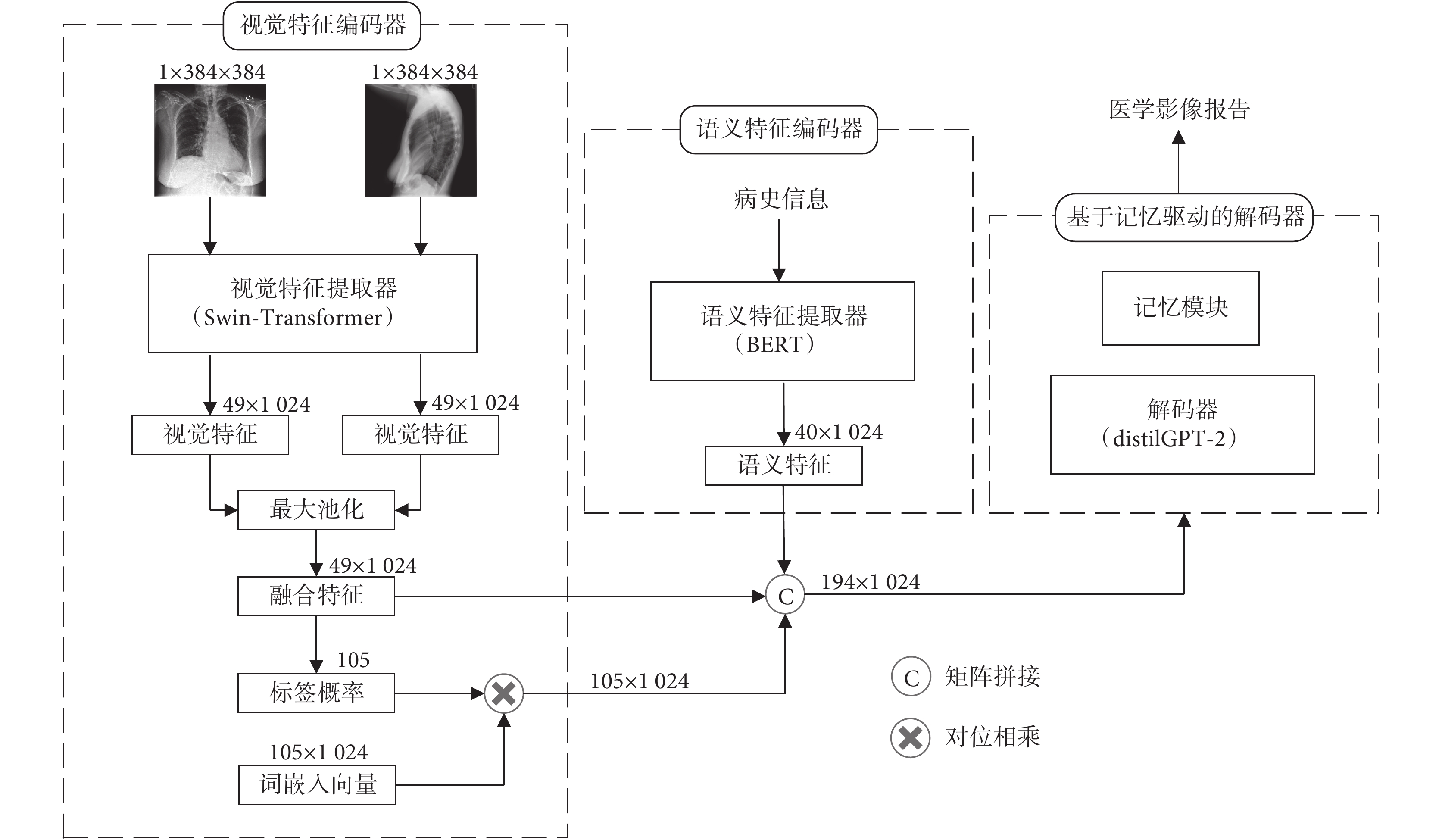 圖1
mMIRmd模型整體結構圖
Figure1.
The architecture of mMIRmd model
圖1
mMIRmd模型整體結構圖
Figure1.
The architecture of mMIRmd model
1.1 數據集
本文采用公開使用的印第安納大學(Indiana University,IU)收集的胸部X光(X-Ray)數據集(IU X-Ray)和麻省理工學院(Massachusetts Institute of Technology)聯合馬薩諸塞州總醫院(Massachusetts General Hospital)發布的重癥監護X光醫療數據集(medical information mart for intensive care chest X-Ray,MIMIC-CXR)[18-19]。
其中,IU X-Ray數據集包含7 470張正、側面胸部X光影像和3 955份影像報告。所有影像均被自動或人工進行標注。MIMIC-CXR中的數據包括來自65 379位患者的377 110張多視角的胸部X光影像和227 827份影像報告,并以14個胸部疾病專業術語作為結構化標簽,使用自動標記器根據影像報告文本對X光影像進行標注。每個標簽分為未提及(記為空白)、正類(記為“1”)、負類(記為“0”)和不確定(記為“?1”)等4種情況。
1.2 視覺特征編碼器
本文使用基于移位窗口的層次視覺transformer(hierarchical vision transformer using shifted windows,Swin-Transformer)作為視覺特征編碼器[20]。Swin-Transformer的分級注意力機制、窗口化設計和多層次特征交互使得模型能夠更好地捕捉醫學影像中的細節與處理分布不均勻的特征,并能夠同時關注整體特征和局部特征,在醫學影像視覺特征提取任務中取得了優異的表現。
數據集中每個病例包含正、側面兩個視角的醫學影像X1和X2,通過Swin-Transformer分別提取兩張影像的視覺特征,通過對應位置取最大值實現特征融合,使用平均池化層聚合特征圖,以激活函數為S型生長曲線(sigmoid)的全連接層作為分類器預測每個疾病標簽的概率分布。每個標簽均為獨立的二分類問題,損失函數LT為每個標簽的二分類交叉熵之和,如式(1)所示:
 |
式中, 和
和  分別代表真實標簽和預測標簽,其中
分別代表真實標簽和預測標簽,其中  ,
, ,t為標簽個數。采用詞嵌入詞典對視覺特征編碼器生成的標簽進行編碼,該詞典使用醫學文本進行預訓練。編碼后的標簽詞向量與標簽概率分布相乘得到標簽詞嵌入。
,t為標簽個數。采用詞嵌入詞典對視覺特征編碼器生成的標簽進行編碼,該詞典使用醫學文本進行預訓練。編碼后的標簽詞向量與標簽概率分布相乘得到標簽詞嵌入。
1.3 語義特征編碼器
醫學影像報告通常文本較長,包含豐富的疾病信息內容。基于transformer的雙向編碼模型(bidirectional encoder representations from transformers,BERT)具有強大的語義理解能力以及遷移學習優勢,其雙向transformer的結構可以捕捉文本之間的長距離關系,有助于解決醫學影像報告長文本的理解問題[21]。因此,本文選用BERT作為語義特征編碼器對患者病史信息進行編碼。
在使用BERT模型提取病史信息的語義特征過程中,移除模型中每個序列的特殊分類嵌入標記,直接使用最后一個隱藏層的全部輸出作為語義特征,更完整地保留語義信息,且有利于解碼器中注意力機制對語義特征的理解。
1.4 基于記憶驅動的解碼器
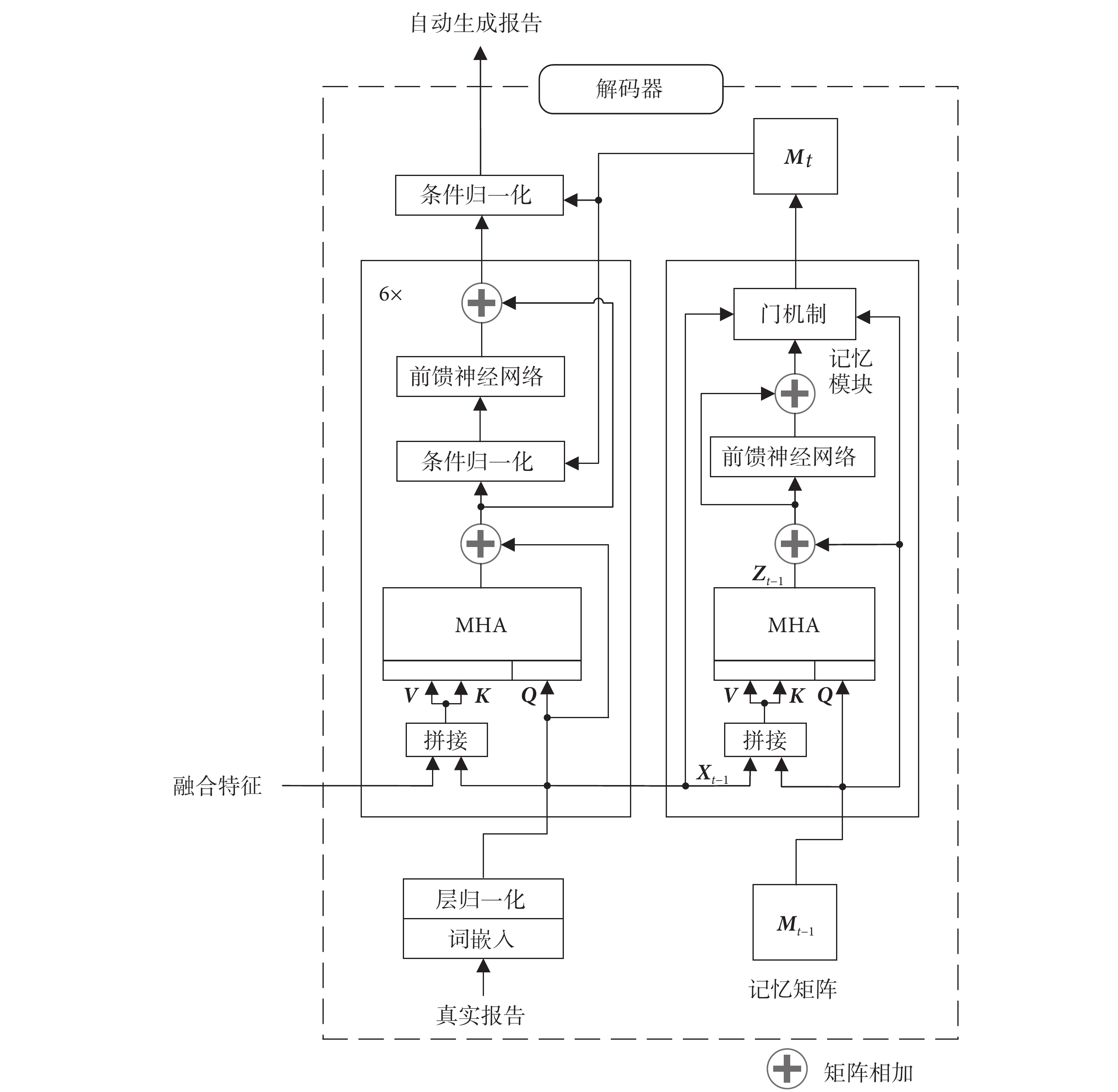
蒸餾生成式預訓練transformer(distil generative pre-trained transformer,distilGPT-2)對預訓練生成式transformer(generative pre-trained transformer,GPT-2)進行了知識蒸餾,在保持模型性能基本不變的前提下削減了34%的參數,從而有效提升模型訓練和推理的效率,使模型可以在相對較低的計算資源下生成高質量的醫學影像報告,因此本文選擇distilGPT-2作為解碼器,用于生成完整的醫學影像報告[22]。此外,在醫學影像報告自動生成任務中需要考慮大量專業背景知識,以確保生成的報告完整準確。記憶驅動模塊可以從真實報告中提取重要的片段和關鍵詞,使解碼器能夠更好地關注并記錄關鍵特征,從而提升生成報告的準確性和專業性[23]。基于記憶驅動的解碼器結構如圖2所示。
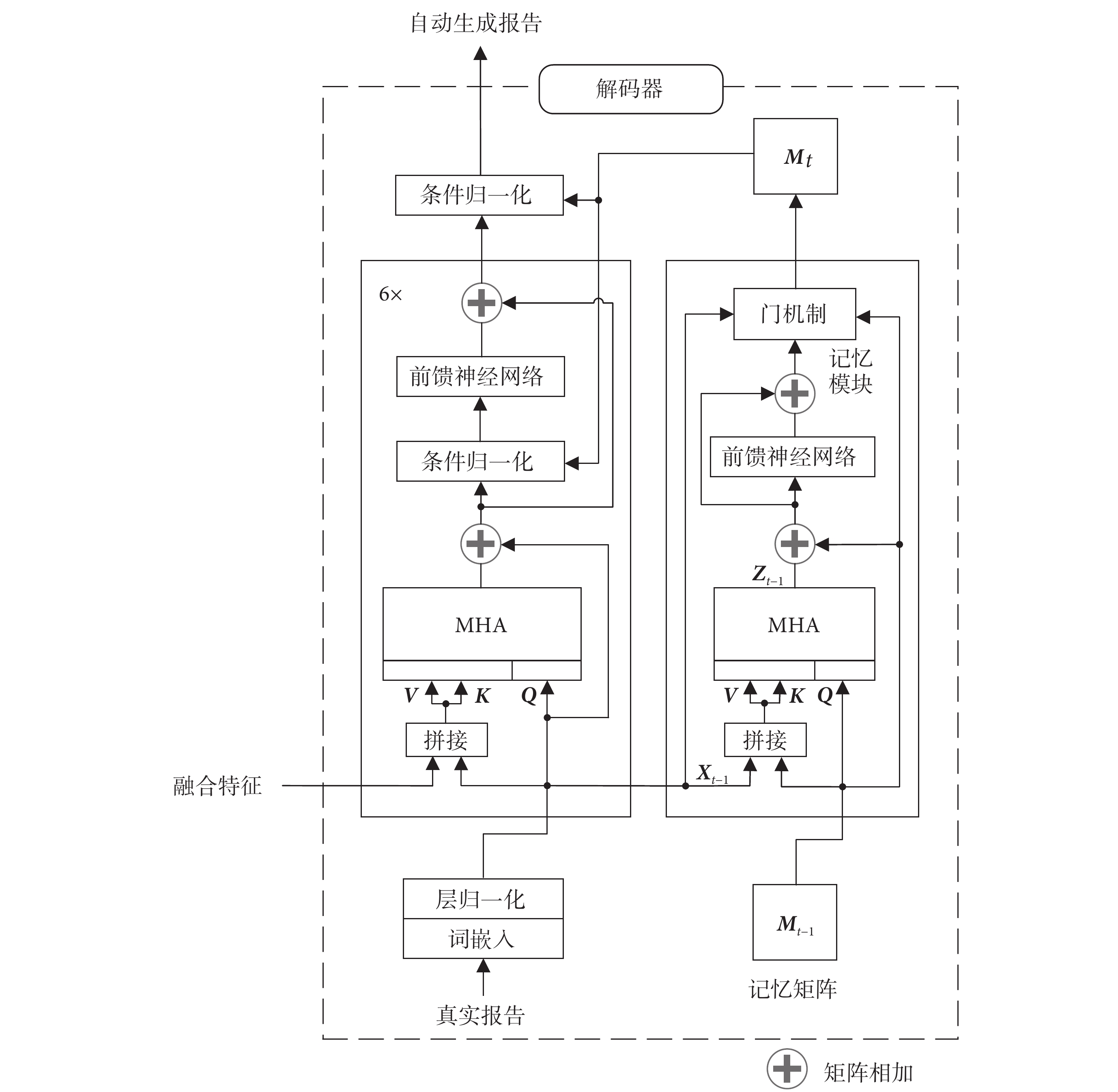 圖2
基于記憶驅動的解碼器結構圖
Figure2.
Memory-driven decoder architecture
圖2
基于記憶驅動的解碼器結構圖
Figure2.
Memory-driven decoder architecture
記憶驅動模塊通過記憶矩陣M記錄醫學影像報告中經常出現的醫學術語和表述方式,并隨著模型訓練不斷進行更新。在t時刻,上一時刻的記憶矩陣Mt ? 1作為記憶驅動模塊的輸入,真實報告詞嵌入X通過MHA輸入到記憶矩陣中,MHA的輸出Zt ? 1如式(2)所示:
 |
其中,柔性最大(softmax)作為歸一化指數函數,T為轉置符號,X t ? 1為上一步輸出的嵌入,[Mt ? 1; Xt ? 1]是Mt ? 1和Xt ? 1的點積拼接, 在第0時刻隨機初始化參數,Lm和D分別為記憶矩陣的長度和維度,且與報告詞嵌入維度一致,
在第0時刻隨機初始化參數,Lm和D分別為記憶矩陣的長度和維度,且與報告詞嵌入維度一致, 、
、 、
、 為參數矩陣,MHA中記憶矩陣作為查詢矩陣(query,Q)(以符號Q表示),記憶矩陣與醫學影像報告拼接作為鍵矩陣(key,K)(以符號K表示)和值矩陣(value,V)(以符號V表示)。與transformer結構類似,在注意力層后加入前饋神經網絡,并采用殘差連接,以提高模型的擬合能力,避免出現梯度消失和梯度爆炸[7]。隨著模型訓練的進行,醫學影像報告中的信息會不斷更新到記憶矩陣中,然而這種迭代更新的方式容易導致之前信息被覆蓋,并產生無用的冗余信息,對模型性能造成負面影響。對此,記憶驅動模塊引入門機制來決定哪些信息應該保留或更新[24]。
為參數矩陣,MHA中記憶矩陣作為查詢矩陣(query,Q)(以符號Q表示),記憶矩陣與醫學影像報告拼接作為鍵矩陣(key,K)(以符號K表示)和值矩陣(value,V)(以符號V表示)。與transformer結構類似,在注意力層后加入前饋神經網絡,并采用殘差連接,以提高模型的擬合能力,避免出現梯度消失和梯度爆炸[7]。隨著模型訓練的進行,醫學影像報告中的信息會不斷更新到記憶矩陣中,然而這種迭代更新的方式容易導致之前信息被覆蓋,并產生無用的冗余信息,對模型性能造成負面影響。對此,記憶驅動模塊引入門機制來決定哪些信息應該保留或更新[24]。
如圖2所示,使用條件歸一化替代原distilGPT-2解碼器中的層歸一化,通過學習參數的變化量而非參數本身來提高模型的泛化性,并防止其影響過多的模型參數進而影響核心信息的生成。
在解碼器中將視覺特征、編碼后的預測標簽概率和語義特征在空間維度進行拼接作為多模態特征。使用字節對編碼(byte pair encoding,BPE)的方式對真實報告進行編碼,在序列起始與末尾處分別添加相應標記,并使用補零操作將向量填充至最大序列長度。真實報告經詞嵌入后同多模態特征一起輸入到distilGPT-2的MHA。MHA由n個頭組成,且每個頭中使用歸一化的點乘注意力,如式(3)所示:
 |
其中,Atti(·)(i=1, ···, n)為每個頭使用的歸一化點乘注意力,MHA(·) 為MHA最終的輸出, 是詞嵌入后的真實報告,Lx是真實的序列長度,按每個批大小中的最大長度填充,F是視覺特征、編碼后的預測標簽概率和語義特征拼接后的多模態特征,
是詞嵌入后的真實報告,Lx是真實的序列長度,按每個批大小中的最大長度填充,F是視覺特征、編碼后的預測標簽概率和語義特征拼接后的多模態特征, 、
、 、
、 、
、 均為可訓練參數。真實報告作為Q,多模態特征與真實報告拼接作為K和V輸入distilGPT-2,令模型有效關注和理解特征中蘊含的多模態信息。解碼器使用真實報告單詞和預測單詞間的交叉熵作為損失函數,并對所有單詞的損失取平均值,損失函數LG如式(4)所示:
均為可訓練參數。真實報告作為Q,多模態特征與真實報告拼接作為K和V輸入distilGPT-2,令模型有效關注和理解特征中蘊含的多模態信息。解碼器使用真實報告單詞和預測單詞間的交叉熵作為損失函數,并對所有單詞的損失取平均值,損失函數LG如式(4)所示:
 |
其中, 和
和  分別代表真實報告和預測標簽,其中,
分別代表真實報告和預測標簽,其中, ,
, ,l為報告長度,m是詞嵌入詞典大小。最終,模型以端到端的形式訓練,損失函數為標簽分類損失函數LT與解碼器損失函數LG之和。
,l為報告長度,m是詞嵌入詞典大小。最終,模型以端到端的形式訓練,損失函數為標簽分類損失函數LT與解碼器損失函數LG之和。
1.5 遷移學習
與自然圖像相比,醫學影像獲取和標注成本較高,受患者隱私等因素限制,高質量的大規模醫學影像數據難以獲取,模型性能依然存在較大提升空間。遷移學習方法將在大規模數據集中訓練的模型應用于下游任務,為模型提供豐富的先驗特征,有效降低對數據量的依賴。
本文使用在自然圖像和文本數據中預訓練的模型參數初始化多視角視覺編碼器、語義編碼器和解碼器三部分,具體步驟如下:① 分別獲取在自然圖像數據集中訓練的Swin-Transformer、醫學文本數據庫預訓練的BERT和網頁文本數據集預訓練的distilGPT2模型參數[25]。② 針對本文模型調整預訓練參數,醫學影像是通道數為1的灰度圖像,需將Swin-Transformer模型第一個卷積層輸入通道數設置為1且不進行遷移。多模態特征通過注意力層輸入distilGPT2,為避免預訓練參數對輸入特征造成影響,僅初始化真實報告相關的權重參數。③ 移除預訓練模型分類器,使用模型主干初始化本文模型各部分,分類器和其他參數使用隨機初始化。④ 在醫學影像報告數據集中訓練遷移后的模型,并對遷移部分使用更小學習率,有助于在訓練過程中保留先驗信息,促進模型學習新特征。
2 數據處理和評價指標
2.1 數據處理
在數據清洗和預處理階段,只保留包含正、側面兩視角影像以及完整的病史信息、報告內容和相關標簽的樣本。報告和病史均轉換為小寫,刪除其中涉及患者個人信息的單詞,只生成“發現”部分的報告內容[26]。對IU X-Ray中的標簽進行合并和去重,并刪除正樣本數小于25的標簽[11],最終得到105個標簽,按7∶2∶1劃分訓練集、驗證集和測試集。MIMIC-CXR中將不確定的標簽統一作為正類,以降低漏診幾率,按官方提供的劃分方式劃分數據集。
2.2 評價指標
本文采用廣泛應用于自然語言生成領域的評價指標來評估模型生成的醫學影像報告質量。這些指標包括:雙語互譯質量評估輔助工具(bilingual evaluation understudy-ngram,BLEU-n)、生成單詞的最長公共子序列的召回率(recall-oriented understudy for gisting evaluation-longest common subsequence,ROUGE-L)和顯式順序翻譯評價指標(metric for evaluation of translation with explicit ORdering,METEOR)[27-29],得分越高代表生成報告的質量越高。
其中,BLEU-n通過N元模型(n-grams)劃分文本,計算生成報告與真實報告間劃分文本的共現程度,從而衡量生成報告的總體水平,劃分較少的文本數量可以反映生成報告的準確性,較高則更能體現生成報告的流暢性。ROUGE-L通過比較生成文本和真實文本之間最長公共子序列的長度,以及這個長度在真實文本中的最大可能長度,量化生成文本與真實文本之間的相似度。METEOR根據同義詞、詞干和復述計算兩個句子的相似度,能夠準確反映生成文本的質量。
3 實驗結果與分析
3.1 實施細節
在訓練過程中,所有醫學影像被縮小至384 × 384大小,在每張影像訓練前進行隨機裁剪、隨機旋轉、灰度變換等數據增強,確保每次訓練的輸入數據都具有一定的差異性,以模擬臨床真實情景。使用自適應矩估計優化器(adaptive moment estimation,Adam)優化模型,權重衰減為5 × 10?5,初始學習率為1 × 10?3,并采用余弦退火學習率衰減[30],批大小設置為4,IU X-Ray和MIMIC-CXR數據集分別在模型中訓練100輪次和20輪次。IU X-Ray數據集驗證和測試階段使用束寬(beam size)為5的束搜索策略生成報告,在樣本全部訓練5輪時,在驗證集中進行一次測試,并選擇BLEU-n(n = 1, 2, 3, 4)得分最高的模型用于測試集。
本研究編程語言為Python3.7(Python Software Foundation,荷蘭),深度學習框架是PyTorch(Facebook,美國),圖形處理器(graphics processing unit,GPU)硬件為NVIDIA GeForce RTX 3090(NVIDIA,美國)。
3.2 定量分析
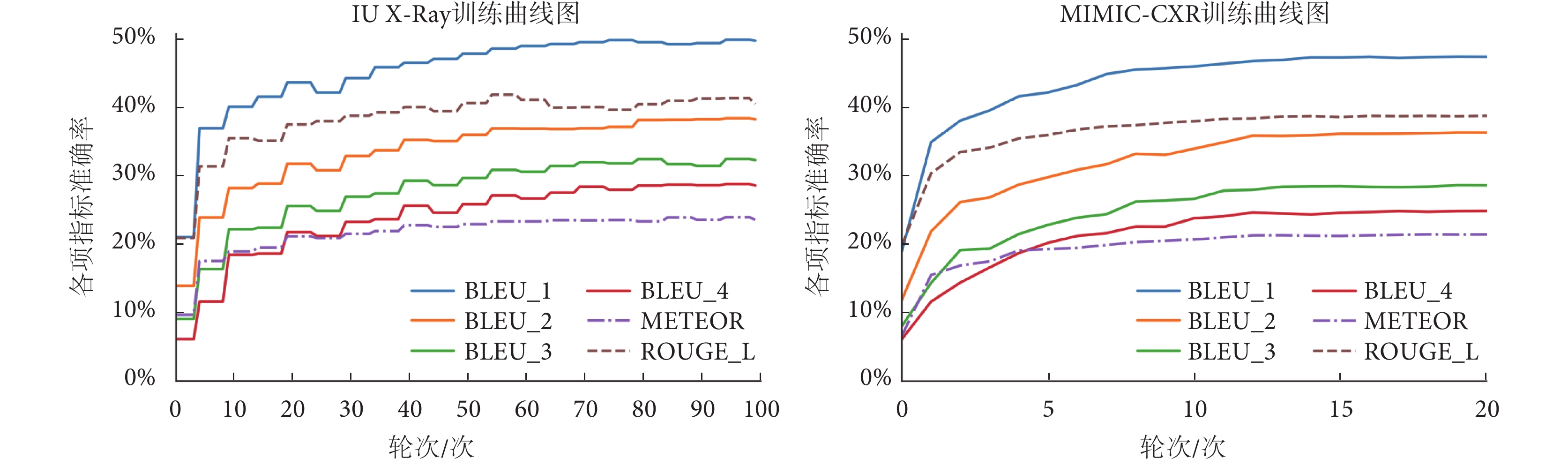
mMIRmd模型訓練過程曲線如圖3所示,其中IU X-Ray 數據集共訓練100輪次,每5輪次記錄一次;MIMIC-CXR數據集共訓練20輪次,每1輪次記錄一次。隨著訓練的進行,模型各項指標準確率逐漸提升,最終趨于收斂。在IU X-Ray和MIMIC-CXR 數據集上BLEU-1、BLEU-2、BLEU-3、BLEU-4、ROUGE-L和METEOR最高分別達到0.492、0.379、0.320、0.265、0.407、0.236和0.467、0.358、0.281、0.245、0.382、0.211。
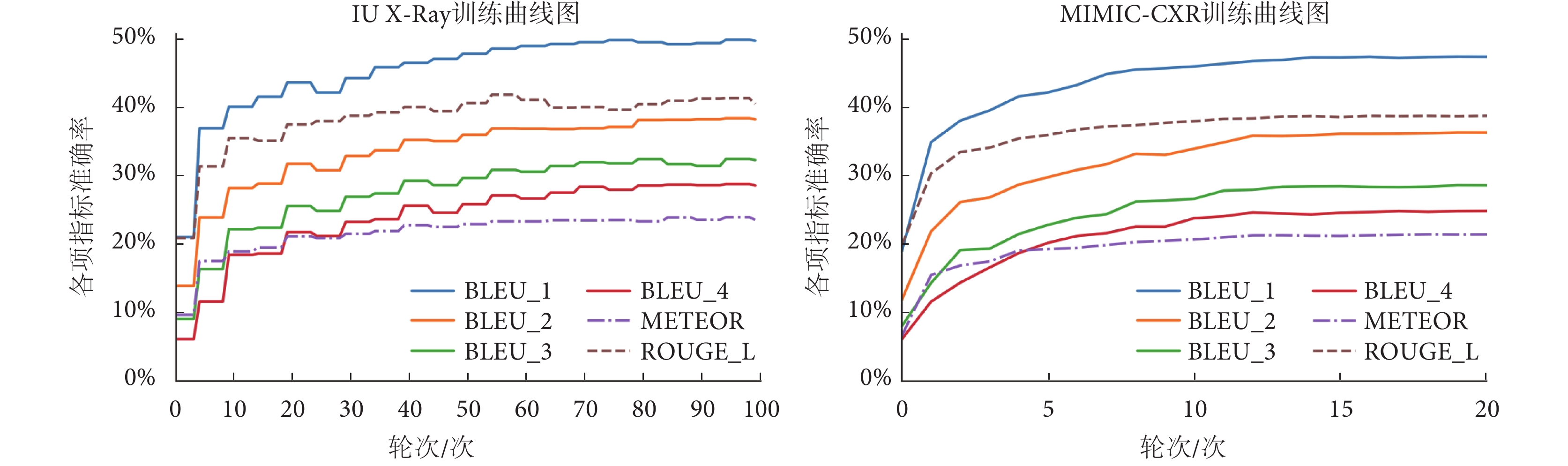 圖3
IU X-Ray和MIMIC-CXR數據集訓練過程曲線
Figure3.
Training process curves in IU X-Ray and MIMIC-CXR datasets
圖3
IU X-Ray和MIMIC-CXR數據集訓練過程曲線
Figure3.
Training process curves in IU X-Ray and MIMIC-CXR datasets
如表1所示,為驗證mMIRmd模型的有效性和泛化性,與CNN-RNN[7]、transformer[12]以及基于transformer的HN[14]、PPKED[15]、SGF[16]、AlignTransformer[17]、使用記憶存儲器的CMN[18]在IU X-Ray和MIMIC-CXR數據集中的結果進行對比,加粗字體代表最優性能。
本文模型在兩個數據集的所有評價指標中均取得了最高分。其中,BLEU-3、BLEU-4得分顯著超過其他方法,證明本文模型在文本流暢性上的優勢。BLEU-1、BLEU-2、ROUGE-L、METEOR得分同樣高于其他方法,證明多模態特征融合方法能夠更好關注疾病區域,生成正確的標簽信息,使報告各項指標有明顯提升。
在多模態模型基礎上,引入記憶驅動組成mMIRmd模型后,模型的所有評價指標得分均有提升,證明記憶驅動模塊和條件歸一化對于提高模型生成報告的質量起到了積極作用,記憶驅動模塊記錄的關鍵信息有效提升數據的長距離依賴性,使得報告準確性和流暢性均得到一定程度的提升。
3.3 消融實驗
消融實驗包括單視角影像(single vision,SV)、多視角影像(multi-perspective vision, MV)、疾病標簽(disease tag,T)、病史信息(medical history information,I)四種模態單獨或組合輸入解碼器。如表2所示,使用多視角影像結合疾病標簽和病史信息的方法(MV+T+I),在所有評價指標上取得了最高分,以加粗字體顯示。與單視角影像輸入相比,多視角影像包含更全面的視覺特征,從而顯著提升了所有評價指標得分。添加疾病標簽有助于引導模型生成正確的報告,對生成的醫學影像報告精度起到積極作用,BLEU-1、BLEU-2和BLEU-3得分均有小幅提升。病史信息為模型提供了多模態輸入,大幅提升了模型的所有評價指標。這表明病史信息與當前疾病狀態存在密切聯系,多模態特征提取和融合對醫學影像報告準確性和流暢性的提升起到了顯著效果。
3.4 遷移學習實驗結果
遷移學習對模型性能的影響實驗在IU X-Ray數據集中進行。如表3所示,展示了Swin-Transformer[20]、101層深度殘差網絡(residual network 101,ResNet101)[31]、121層稠密連接卷積網絡(densely connected convolutional networks 121,Densenet121)[32]、視覺transformer(vision transformer)[33]4種模型在遷移學習前后對多標簽分類的結果,實驗以單張影像作為輸入。觀察實驗結果可知,即使自然圖像與醫學影像間存在較大差異,自然圖像預訓練的模型遷移學習至醫學影像任務中仍能有效提升模型特征提取性能。與CNN模型相比,transformer模型提升幅度更大,使用遷移學習訓練的Swin-Transformer在相同模型體量下獲得了最高得分,以加粗字體顯示。
語義編碼器BERT和解碼器distilGPT2的遷移學習效果以生成醫學影像報告的質量為標準,實驗結果如表4所示,分別為隨機初始化模型參數(initialized without,w/o)、自然文本預訓練(pre-trained,Pre)參數遷移學習和醫學文本(biomedical text pre-trained,Bio)遷移學習,最佳結果以加粗字體顯示。
如表4所示,語義編碼器BERT使用遷移學習能夠提升病史信息特征提取質量,模型生成的醫學影像報告在所有評價指標中均獲得更高得分,使用醫學文本預訓練的BERT更有助于模型理解醫學相關術語和表達,報告質量得到進一步提升。在解碼器distilGPT2中使用遷移學習的方法令BLEU-1得分有小幅提升,BLEU-2、BLEU-3、BLEU-4、ROUGE-L和METEOR的提升幅度更大,表明預訓練模型能夠使生成的報告更加流暢,這得益于遷移學習帶來的豐富先驗知識,模型通過自然文本學習相關語法和表達方式,經醫學影像報告的微調,生成更貼近人類表達習慣的報告內容。
3.5 定性分析
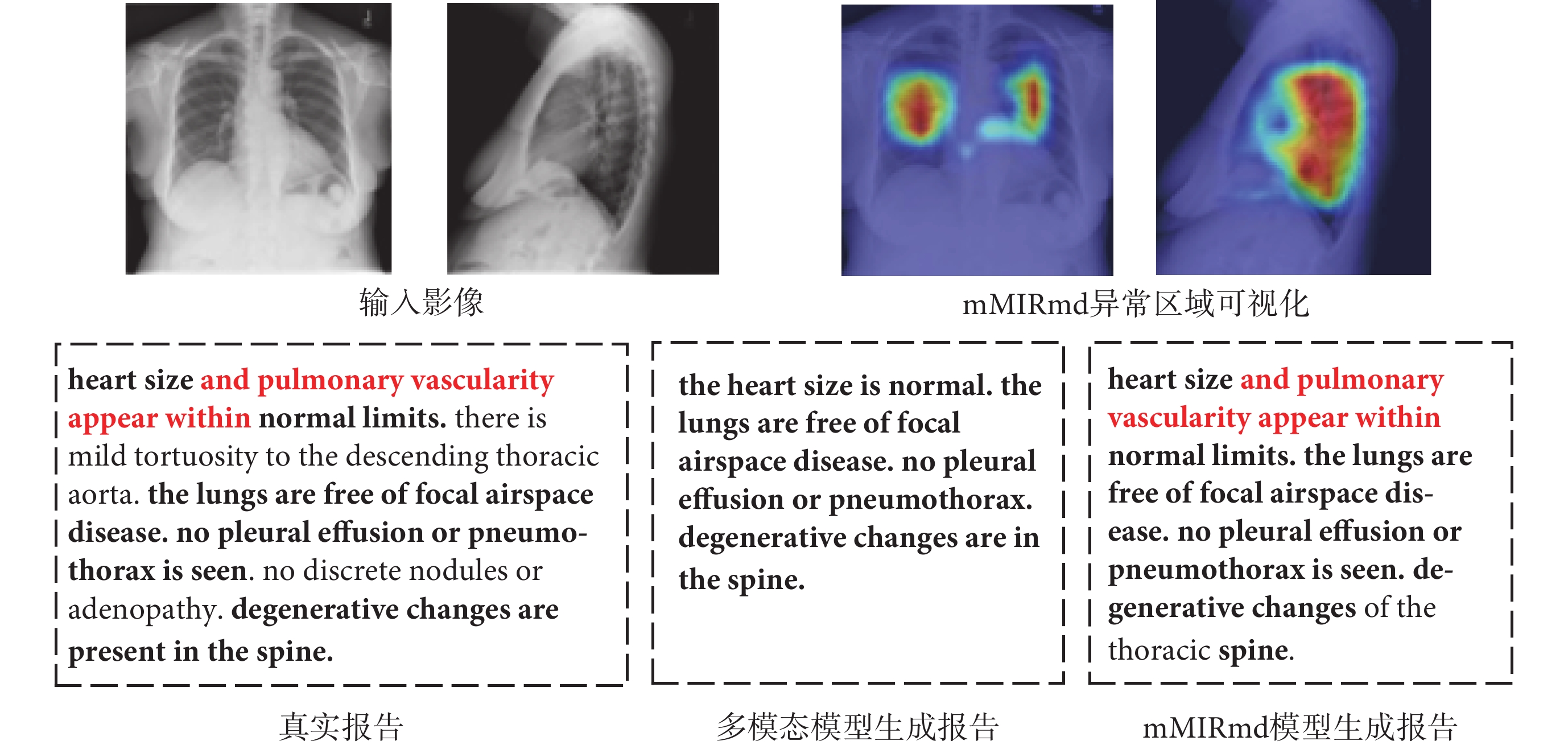
如圖4所示,展示了輸入的正、側面醫學影像、mMIRmd模型的異常區域可視化、真實報告和兩種模型生成的部分醫學影像報告,加粗字體代表正確描述的部分,紅色字體為加入記憶驅動模塊后額外生成的正確描述,使用梯度定位的深層網絡可視化方法(gradient-weighted class activation mapping,Grad-CAM)[34],并與未加入記憶驅動的多模態模型進行對比。觀察實驗結果可知,多模態模型能夠重點關注異常區域。例如,模型對“脊柱退行性改變(degenerative changes are in the spine)”等疾病能夠正確判斷,也能生成“局灶性(focal)”等對疾病狀態的描述,證明了模型的有效性。然而對“輕度主動脈彎曲(there is mild tortuosity to the descending thorcic aorta)”等早期或性狀不明顯的病變難以準確識別,且與真實報告相比,生成的報告在疾病的描述方式上仍存在一定差異。
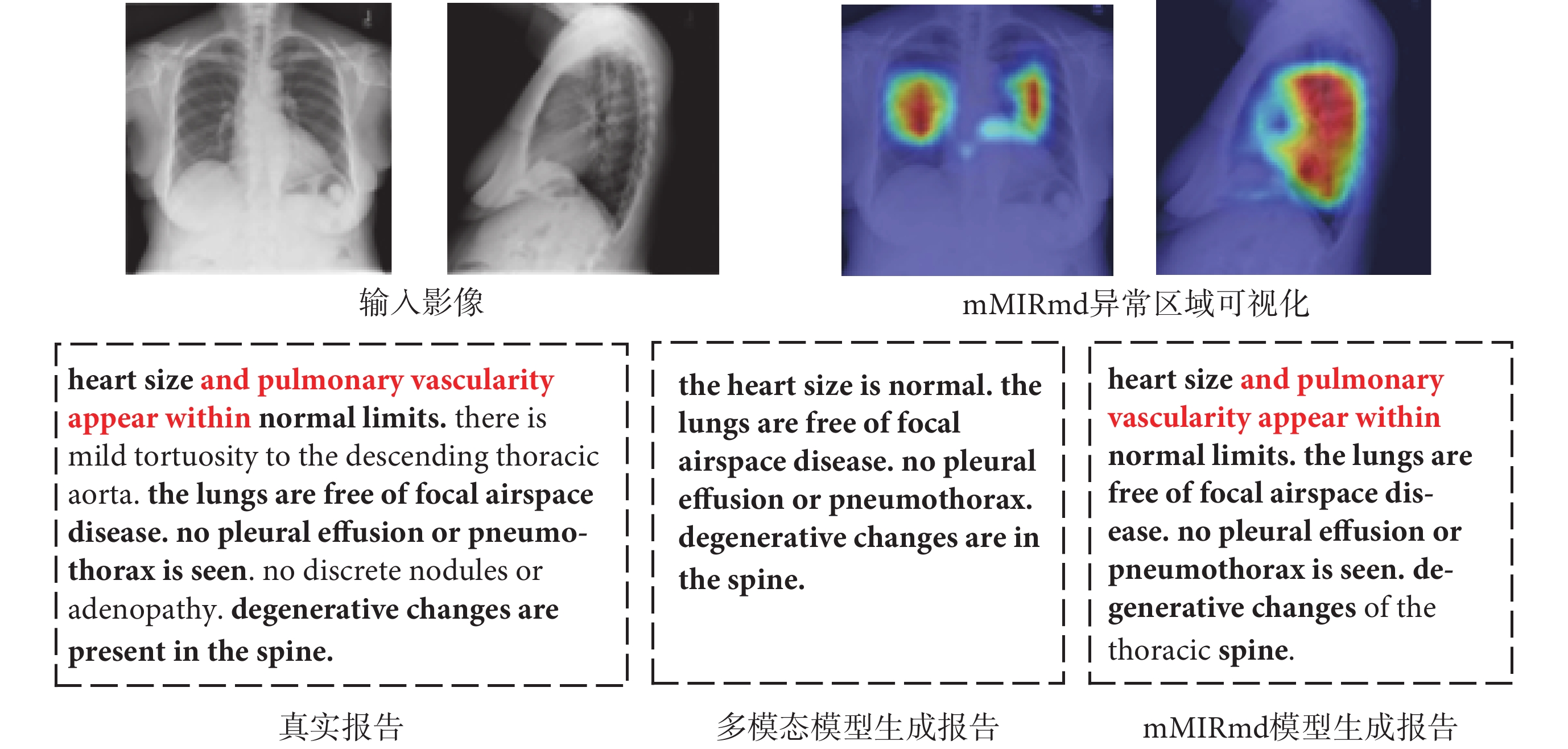 圖4
定性比較mMIRmd模型生成報告性能
Figure4.
Qualitative comparison of report generation performance of mMIRmd model
圖4
定性比較mMIRmd模型生成報告性能
Figure4.
Qualitative comparison of report generation performance of mMIRmd model
mMIRmd模型能夠正確生成“空腔疾病(airspace disease)”、“肺血管系統(pulmonary vascularity)”等專業醫學術語,生成報告在表述專業性和語言邏輯性方面有所提升,對正常器官的描述也更加全面,例如能正確處理“局灶性(focal)”和“胸腔積液(pleural effusion)”間的修飾關系,證明了記憶驅動的有效性。與多模態模型相比,mMIRmd模型生成的“心臟大小和肺血管分布在正常范圍內(heart size and pulmonary vascularity appear within normal limits)”能夠對位置進行準確描述,但沒有對“輕度主動脈彎曲(there is mild tortuosity to the descending thorcic aorta)”進行說明。同時,mMIRmd模型生成的報告與真實報告長度更加貼合,語句也更加通順流暢。由此可見,模型生成報告的精度有所提升,能夠清晰地表達出大部分病變的具體位置和屬性,通過異常區域可視化也顯示模型生成報告時能正確關注有意義的區域,但對情況復雜的患病情況以及特征不明顯疾病的識別和判斷仍然存在欠缺。
4 結論
針對醫學影像疾病類型多樣、報告描述缺乏專業性和流暢性等問題開展醫學影像報告自動生成研究,本文提出mMIRmd模型,通過多模態特征融合和記憶驅動的方法,有效提升生成報告的質量,異常區域可視化的引入進一步增強了模型的可解釋性,能夠反映疾病所在的具體位置。
本文的主要工作包括以下三方面:① 設計了一種能夠同時提取醫學影像視覺特征、病史信息語義特征以及融合編碼后標簽概率的多模態融合模型,提高了模型識別病變的能力。② 在Swin-Transformer編碼器中使用醫學文本預訓練的詞典對視覺特征標簽進行編碼,提高了生成報告的專業性。③ 通過在distilGPT-2解碼器中加入記憶驅動模塊,解決了醫學影像數據的長依賴關系,提高了報告生成的流暢性。然而,與醫生撰寫的報告相比,生成報告在患病細節的描述方面仍然存在一些欠缺,模型的疾病識別能力和泛化能力仍有提升空間。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:邢素霞主要負責論文思路和實驗設計;方俊澤主要負責算法實現和論文寫作;鞠子涵主要負責實驗設計和平臺搭建;郭正、王瑜主要負責論文修訂和分析記錄。
0 引言
醫學影像報告自動生成技術可以輔助醫生迅速關注異常區域,減少撰寫報告所需的時間,從而提高工作效率[1-5]。目前,醫學影像報告自動生成主要采用兩種模型結構,分別是基于深度學習的編碼器—解碼器結構,包括:卷積神經網絡(convolutional neural networks,CNN)、循環神經網絡(recurrent neural network,RNN)、CNN與RNN結合網絡(CNN-RNN)以及基于注意力機制的轉換器(transformer)結構[6-7]。相較于CNN-RNN,tansformer的注意力機制擁有更強的特征學習能力,能夠加權計算輸入數據中每個節點之間的關聯,且善于捕捉較長間隔的語義關聯[8-9]。Alfarghaly等[10]成功將transformer應用于醫學影像報告自動生成領域后,受到廣泛關注[11-12]。Srinivasan等[13]提出基于transformer的等級網絡(hierarchical net,HN),使用疾病標簽和多頭注意力(multi-head attention,MHA)實現了分層的醫學影像報告自動生成方法,提高了報告的準確性和可解釋性,但對于特定疾病的泛化能力有待提升。Liu等[14]提出探索提煉后驗和先驗知識模型(posterior-and-prior knowledge exploring-and-distilling,PPKED),首先確定異常區域和疾病類型,再利用先驗知識進行報告書寫,有效減輕了文本數據的偏見,但在處理復雜病例時還存在知識不完備的問題。Li等[15]提出一種自引導框架模型(self-guided framework,SGF),可以從無疾病標簽的醫學影像報告中獲取專業知識,并提取相關的細顆粒視覺特征來提升報告的精確度,但存在對語義理解依賴性不足的問題。You等[16]提出一種可以將視覺區域和疾病標簽分層對齊的對齊層次注意力和多粒度transformer(align hierarchical attention and multi-grained transformer,AlignTransformer),通過先預測疾病標簽,再將其與視覺區域分層對齊的方法學習多粒度視覺特征,解決視覺偏差問題,但有時生成的報告并不流暢。Chen等[17]提出一種跨模態記憶網絡(cross-modal memory networks,CMN),該網絡利用記憶存儲器保留特征信息,通過建立視覺與文本的聯系,解決圖文多模態映射,但對于復雜的或罕見的病例,模型缺乏足夠的泛化能力。
以上研究成果表明,基于transformer及其改進模型的研究在醫學影像報告自動生成任務中取得了優異表現,但同時,此類模型在識別和描述疾病特征方面還有一定的局限性,對罕見疾病的識別普遍較差,且由于模型對醫學術語、解剖結構或病變特點等方面理解不夠深入,導致對疾病的描述不夠專業,模型有時還會生成語句不通順或難以理解的文本,影響報告的理解和使用。基于以上問題,本文提出了一種基于記憶驅動的多模態醫學影像報告自動生成方法(multimodal medical imaging report based on memory drive,mMIRmd),以改善醫學影像報告自動生成的質量,著重解決疾病識別準確性、疾病描述專業性和報告文本流暢性等方面的問題,減少放射科醫生撰寫報告的負擔,輔助臨床醫生實現準確診斷。
1 數據驅動的多模態醫學影像報告自動生成方法
如圖1所示,展示了本文所提mMIRmd模型的整體結構,該模型包括視覺特征編碼器、語義特征編碼器和基于記憶驅動的解碼器三個部分。視覺特征編碼器,負責提取并融合正、側面兩張影像的視覺特征,并預測每種疾病標簽對應的概率。語義特征編碼器,負責提取病史信息中的語義特征。將視覺特征、編碼后的預測標簽概率和語義特征拼接后,輸入基于記憶驅動的解碼器。基于記憶驅動的解碼器,負責將上述拼接特征解碼并生成醫學影像報告。
圖1
mMIRmd模型整體結構圖
Figure1.
The architecture of mMIRmd model
1.1 數據集
本文采用公開使用的印第安納大學(Indiana University,IU)收集的胸部X光(X-Ray)數據集(IU X-Ray)和麻省理工學院(Massachusetts Institute of Technology)聯合馬薩諸塞州總醫院(Massachusetts General Hospital)發布的重癥監護X光醫療數據集(medical information mart for intensive care chest X-Ray,MIMIC-CXR)[18-19]。
其中,IU X-Ray數據集包含7 470張正、側面胸部X光影像和3 955份影像報告。所有影像均被自動或人工進行標注。MIMIC-CXR中的數據包括來自65 379位患者的377 110張多視角的胸部X光影像和227 827份影像報告,并以14個胸部疾病專業術語作為結構化標簽,使用自動標記器根據影像報告文本對X光影像進行標注。每個標簽分為未提及(記為空白)、正類(記為“1”)、負類(記為“0”)和不確定(記為“?1”)等4種情況。
1.2 視覺特征編碼器
本文使用基于移位窗口的層次視覺transformer(hierarchical vision transformer using shifted windows,Swin-Transformer)作為視覺特征編碼器[20]。Swin-Transformer的分級注意力機制、窗口化設計和多層次特征交互使得模型能夠更好地捕捉醫學影像中的細節與處理分布不均勻的特征,并能夠同時關注整體特征和局部特征,在醫學影像視覺特征提取任務中取得了優異的表現。
數據集中每個病例包含正、側面兩個視角的醫學影像X1和X2,通過Swin-Transformer分別提取兩張影像的視覺特征,通過對應位置取最大值實現特征融合,使用平均池化層聚合特征圖,以激活函數為S型生長曲線(sigmoid)的全連接層作為分類器預測每個疾病標簽的概率分布。每個標簽均為獨立的二分類問題,損失函數LT為每個標簽的二分類交叉熵之和,如式(1)所示:
|
式中, 和 分別代表真實標簽和預測標簽,其中 ,,t為標簽個數。采用詞嵌入詞典對視覺特征編碼器生成的標簽進行編碼,該詞典使用醫學文本進行預訓練。編碼后的標簽詞向量與標簽概率分布相乘得到標簽詞嵌入。
1.3 語義特征編碼器
醫學影像報告通常文本較長,包含豐富的疾病信息內容。基于transformer的雙向編碼模型(bidirectional encoder representations from transformers,BERT)具有強大的語義理解能力以及遷移學習優勢,其雙向transformer的結構可以捕捉文本之間的長距離關系,有助于解決醫學影像報告長文本的理解問題[21]。因此,本文選用BERT作為語義特征編碼器對患者病史信息進行編碼。
在使用BERT模型提取病史信息的語義特征過程中,移除模型中每個序列的特殊分類嵌入標記,直接使用最后一個隱藏層的全部輸出作為語義特征,更完整地保留語義信息,且有利于解碼器中注意力機制對語義特征的理解。
1.4 基于記憶驅動的解碼器
蒸餾生成式預訓練transformer(distil generative pre-trained transformer,distilGPT-2)對預訓練生成式transformer(generative pre-trained transformer,GPT-2)進行了知識蒸餾,在保持模型性能基本不變的前提下削減了34%的參數,從而有效提升模型訓練和推理的效率,使模型可以在相對較低的計算資源下生成高質量的醫學影像報告,因此本文選擇distilGPT-2作為解碼器,用于生成完整的醫學影像報告[22]。此外,在醫學影像報告自動生成任務中需要考慮大量專業背景知識,以確保生成的報告完整準確。記憶驅動模塊可以從真實報告中提取重要的片段和關鍵詞,使解碼器能夠更好地關注并記錄關鍵特征,從而提升生成報告的準確性和專業性[23]。基于記憶驅動的解碼器結構如圖2所示。
圖2
基于記憶驅動的解碼器結構圖
Figure2.
Memory-driven decoder architecture
記憶驅動模塊通過記憶矩陣M記錄醫學影像報告中經常出現的醫學術語和表述方式,并隨著模型訓練不斷進行更新。在t時刻,上一時刻的記憶矩陣Mt ? 1作為記憶驅動模塊的輸入,真實報告詞嵌入X通過MHA輸入到記憶矩陣中,MHA的輸出Zt ? 1如式(2)所示:
|
其中,柔性最大(softmax)作為歸一化指數函數,T為轉置符號,X t ? 1為上一步輸出的嵌入,[Mt ? 1; Xt ? 1]是Mt ? 1和Xt ? 1的點積拼接, 在第0時刻隨機初始化參數,Lm和D分別為記憶矩陣的長度和維度,且與報告詞嵌入維度一致,、、 為參數矩陣,MHA中記憶矩陣作為查詢矩陣(query,Q)(以符號Q表示),記憶矩陣與醫學影像報告拼接作為鍵矩陣(key,K)(以符號K表示)和值矩陣(value,V)(以符號V表示)。與transformer結構類似,在注意力層后加入前饋神經網絡,并采用殘差連接,以提高模型的擬合能力,避免出現梯度消失和梯度爆炸[7]。隨著模型訓練的進行,醫學影像報告中的信息會不斷更新到記憶矩陣中,然而這種迭代更新的方式容易導致之前信息被覆蓋,并產生無用的冗余信息,對模型性能造成負面影響。對此,記憶驅動模塊引入門機制來決定哪些信息應該保留或更新[24]。
如圖2所示,使用條件歸一化替代原distilGPT-2解碼器中的層歸一化,通過學習參數的變化量而非參數本身來提高模型的泛化性,并防止其影響過多的模型參數進而影響核心信息的生成。
在解碼器中將視覺特征、編碼后的預測標簽概率和語義特征在空間維度進行拼接作為多模態特征。使用字節對編碼(byte pair encoding,BPE)的方式對真實報告進行編碼,在序列起始與末尾處分別添加相應標記,并使用補零操作將向量填充至最大序列長度。真實報告經詞嵌入后同多模態特征一起輸入到distilGPT-2的MHA。MHA由n個頭組成,且每個頭中使用歸一化的點乘注意力,如式(3)所示:
|
其中,Atti(·)(i=1, ···, n)為每個頭使用的歸一化點乘注意力,MHA(·) 為MHA最終的輸出, 是詞嵌入后的真實報告,Lx是真實的序列長度,按每個批大小中的最大長度填充,F是視覺特征、編碼后的預測標簽概率和語義特征拼接后的多模態特征,、、、 均為可訓練參數。真實報告作為Q,多模態特征與真實報告拼接作為K和V輸入distilGPT-2,令模型有效關注和理解特征中蘊含的多模態信息。解碼器使用真實報告單詞和預測單詞間的交叉熵作為損失函數,并對所有單詞的損失取平均值,損失函數LG如式(4)所示:
|
其中, 和 分別代表真實報告和預測標簽,其中,,,l為報告長度,m是詞嵌入詞典大小。最終,模型以端到端的形式訓練,損失函數為標簽分類損失函數LT與解碼器損失函數LG之和。
1.5 遷移學習
與自然圖像相比,醫學影像獲取和標注成本較高,受患者隱私等因素限制,高質量的大規模醫學影像數據難以獲取,模型性能依然存在較大提升空間。遷移學習方法將在大規模數據集中訓練的模型應用于下游任務,為模型提供豐富的先驗特征,有效降低對數據量的依賴。
本文使用在自然圖像和文本數據中預訓練的模型參數初始化多視角視覺編碼器、語義編碼器和解碼器三部分,具體步驟如下:① 分別獲取在自然圖像數據集中訓練的Swin-Transformer、醫學文本數據庫預訓練的BERT和網頁文本數據集預訓練的distilGPT2模型參數[25]。② 針對本文模型調整預訓練參數,醫學影像是通道數為1的灰度圖像,需將Swin-Transformer模型第一個卷積層輸入通道數設置為1且不進行遷移。多模態特征通過注意力層輸入distilGPT2,為避免預訓練參數對輸入特征造成影響,僅初始化真實報告相關的權重參數。③ 移除預訓練模型分類器,使用模型主干初始化本文模型各部分,分類器和其他參數使用隨機初始化。④ 在醫學影像報告數據集中訓練遷移后的模型,并對遷移部分使用更小學習率,有助于在訓練過程中保留先驗信息,促進模型學習新特征。
2 數據處理和評價指標
2.1 數據處理
在數據清洗和預處理階段,只保留包含正、側面兩視角影像以及完整的病史信息、報告內容和相關標簽的樣本。報告和病史均轉換為小寫,刪除其中涉及患者個人信息的單詞,只生成“發現”部分的報告內容[26]。對IU X-Ray中的標簽進行合并和去重,并刪除正樣本數小于25的標簽[11],最終得到105個標簽,按7∶2∶1劃分訓練集、驗證集和測試集。MIMIC-CXR中將不確定的標簽統一作為正類,以降低漏診幾率,按官方提供的劃分方式劃分數據集。
2.2 評價指標
本文采用廣泛應用于自然語言生成領域的評價指標來評估模型生成的醫學影像報告質量。這些指標包括:雙語互譯質量評估輔助工具(bilingual evaluation understudy-ngram,BLEU-n)、生成單詞的最長公共子序列的召回率(recall-oriented understudy for gisting evaluation-longest common subsequence,ROUGE-L)和顯式順序翻譯評價指標(metric for evaluation of translation with explicit ORdering,METEOR)[27-29],得分越高代表生成報告的質量越高。
其中,BLEU-n通過N元模型(n-grams)劃分文本,計算生成報告與真實報告間劃分文本的共現程度,從而衡量生成報告的總體水平,劃分較少的文本數量可以反映生成報告的準確性,較高則更能體現生成報告的流暢性。ROUGE-L通過比較生成文本和真實文本之間最長公共子序列的長度,以及這個長度在真實文本中的最大可能長度,量化生成文本與真實文本之間的相似度。METEOR根據同義詞、詞干和復述計算兩個句子的相似度,能夠準確反映生成文本的質量。
3 實驗結果與分析
3.1 實施細節
在訓練過程中,所有醫學影像被縮小至384 × 384大小,在每張影像訓練前進行隨機裁剪、隨機旋轉、灰度變換等數據增強,確保每次訓練的輸入數據都具有一定的差異性,以模擬臨床真實情景。使用自適應矩估計優化器(adaptive moment estimation,Adam)優化模型,權重衰減為5 × 10?5,初始學習率為1 × 10?3,并采用余弦退火學習率衰減[30],批大小設置為4,IU X-Ray和MIMIC-CXR數據集分別在模型中訓練100輪次和20輪次。IU X-Ray數據集驗證和測試階段使用束寬(beam size)為5的束搜索策略生成報告,在樣本全部訓練5輪時,在驗證集中進行一次測試,并選擇BLEU-n(n = 1, 2, 3, 4)得分最高的模型用于測試集。
本研究編程語言為Python3.7(Python Software Foundation,荷蘭),深度學習框架是PyTorch(Facebook,美國),圖形處理器(graphics processing unit,GPU)硬件為NVIDIA GeForce RTX 3090(NVIDIA,美國)。
3.2 定量分析
mMIRmd模型訓練過程曲線如圖3所示,其中IU X-Ray 數據集共訓練100輪次,每5輪次記錄一次;MIMIC-CXR數據集共訓練20輪次,每1輪次記錄一次。隨著訓練的進行,模型各項指標準確率逐漸提升,最終趨于收斂。在IU X-Ray和MIMIC-CXR 數據集上BLEU-1、BLEU-2、BLEU-3、BLEU-4、ROUGE-L和METEOR最高分別達到0.492、0.379、0.320、0.265、0.407、0.236和0.467、0.358、0.281、0.245、0.382、0.211。
圖3
IU X-Ray和MIMIC-CXR數據集訓練過程曲線
Figure3.
Training process curves in IU X-Ray and MIMIC-CXR datasets
如表1所示,為驗證mMIRmd模型的有效性和泛化性,與CNN-RNN[7]、transformer[12]以及基于transformer的HN[14]、PPKED[15]、SGF[16]、AlignTransformer[17]、使用記憶存儲器的CMN[18]在IU X-Ray和MIMIC-CXR數據集中的結果進行對比,加粗字體代表最優性能。
本文模型在兩個數據集的所有評價指標中均取得了最高分。其中,BLEU-3、BLEU-4得分顯著超過其他方法,證明本文模型在文本流暢性上的優勢。BLEU-1、BLEU-2、ROUGE-L、METEOR得分同樣高于其他方法,證明多模態特征融合方法能夠更好關注疾病區域,生成正確的標簽信息,使報告各項指標有明顯提升。
在多模態模型基礎上,引入記憶驅動組成mMIRmd模型后,模型的所有評價指標得分均有提升,證明記憶驅動模塊和條件歸一化對于提高模型生成報告的質量起到了積極作用,記憶驅動模塊記錄的關鍵信息有效提升數據的長距離依賴性,使得報告準確性和流暢性均得到一定程度的提升。
3.3 消融實驗
消融實驗包括單視角影像(single vision,SV)、多視角影像(multi-perspective vision, MV)、疾病標簽(disease tag,T)、病史信息(medical history information,I)四種模態單獨或組合輸入解碼器。如表2所示,使用多視角影像結合疾病標簽和病史信息的方法(MV+T+I),在所有評價指標上取得了最高分,以加粗字體顯示。與單視角影像輸入相比,多視角影像包含更全面的視覺特征,從而顯著提升了所有評價指標得分。添加疾病標簽有助于引導模型生成正確的報告,對生成的醫學影像報告精度起到積極作用,BLEU-1、BLEU-2和BLEU-3得分均有小幅提升。病史信息為模型提供了多模態輸入,大幅提升了模型的所有評價指標。這表明病史信息與當前疾病狀態存在密切聯系,多模態特征提取和融合對醫學影像報告準確性和流暢性的提升起到了顯著效果。
3.4 遷移學習實驗結果
遷移學習對模型性能的影響實驗在IU X-Ray數據集中進行。如表3所示,展示了Swin-Transformer[20]、101層深度殘差網絡(residual network 101,ResNet101)[31]、121層稠密連接卷積網絡(densely connected convolutional networks 121,Densenet121)[32]、視覺transformer(vision transformer)[33]4種模型在遷移學習前后對多標簽分類的結果,實驗以單張影像作為輸入。觀察實驗結果可知,即使自然圖像與醫學影像間存在較大差異,自然圖像預訓練的模型遷移學習至醫學影像任務中仍能有效提升模型特征提取性能。與CNN模型相比,transformer模型提升幅度更大,使用遷移學習訓練的Swin-Transformer在相同模型體量下獲得了最高得分,以加粗字體顯示。
語義編碼器BERT和解碼器distilGPT2的遷移學習效果以生成醫學影像報告的質量為標準,實驗結果如表4所示,分別為隨機初始化模型參數(initialized without,w/o)、自然文本預訓練(pre-trained,Pre)參數遷移學習和醫學文本(biomedical text pre-trained,Bio)遷移學習,最佳結果以加粗字體顯示。
如表4所示,語義編碼器BERT使用遷移學習能夠提升病史信息特征提取質量,模型生成的醫學影像報告在所有評價指標中均獲得更高得分,使用醫學文本預訓練的BERT更有助于模型理解醫學相關術語和表達,報告質量得到進一步提升。在解碼器distilGPT2中使用遷移學習的方法令BLEU-1得分有小幅提升,BLEU-2、BLEU-3、BLEU-4、ROUGE-L和METEOR的提升幅度更大,表明預訓練模型能夠使生成的報告更加流暢,這得益于遷移學習帶來的豐富先驗知識,模型通過自然文本學習相關語法和表達方式,經醫學影像報告的微調,生成更貼近人類表達習慣的報告內容。
3.5 定性分析
如圖4所示,展示了輸入的正、側面醫學影像、mMIRmd模型的異常區域可視化、真實報告和兩種模型生成的部分醫學影像報告,加粗字體代表正確描述的部分,紅色字體為加入記憶驅動模塊后額外生成的正確描述,使用梯度定位的深層網絡可視化方法(gradient-weighted class activation mapping,Grad-CAM)[34],并與未加入記憶驅動的多模態模型進行對比。觀察實驗結果可知,多模態模型能夠重點關注異常區域。例如,模型對“脊柱退行性改變(degenerative changes are in the spine)”等疾病能夠正確判斷,也能生成“局灶性(focal)”等對疾病狀態的描述,證明了模型的有效性。然而對“輕度主動脈彎曲(there is mild tortuosity to the descending thorcic aorta)”等早期或性狀不明顯的病變難以準確識別,且與真實報告相比,生成的報告在疾病的描述方式上仍存在一定差異。
圖4
定性比較mMIRmd模型生成報告性能
Figure4.
Qualitative comparison of report generation performance of mMIRmd model
mMIRmd模型能夠正確生成“空腔疾病(airspace disease)”、“肺血管系統(pulmonary vascularity)”等專業醫學術語,生成報告在表述專業性和語言邏輯性方面有所提升,對正常器官的描述也更加全面,例如能正確處理“局灶性(focal)”和“胸腔積液(pleural effusion)”間的修飾關系,證明了記憶驅動的有效性。與多模態模型相比,mMIRmd模型生成的“心臟大小和肺血管分布在正常范圍內(heart size and pulmonary vascularity appear within normal limits)”能夠對位置進行準確描述,但沒有對“輕度主動脈彎曲(there is mild tortuosity to the descending thorcic aorta)”進行說明。同時,mMIRmd模型生成的報告與真實報告長度更加貼合,語句也更加通順流暢。由此可見,模型生成報告的精度有所提升,能夠清晰地表達出大部分病變的具體位置和屬性,通過異常區域可視化也顯示模型生成報告時能正確關注有意義的區域,但對情況復雜的患病情況以及特征不明顯疾病的識別和判斷仍然存在欠缺。
4 結論
針對醫學影像疾病類型多樣、報告描述缺乏專業性和流暢性等問題開展醫學影像報告自動生成研究,本文提出mMIRmd模型,通過多模態特征融合和記憶驅動的方法,有效提升生成報告的質量,異常區域可視化的引入進一步增強了模型的可解釋性,能夠反映疾病所在的具體位置。
本文的主要工作包括以下三方面:① 設計了一種能夠同時提取醫學影像視覺特征、病史信息語義特征以及融合編碼后標簽概率的多模態融合模型,提高了模型識別病變的能力。② 在Swin-Transformer編碼器中使用醫學文本預訓練的詞典對視覺特征標簽進行編碼,提高了生成報告的專業性。③ 通過在distilGPT-2解碼器中加入記憶驅動模塊,解決了醫學影像數據的長依賴關系,提高了報告生成的流暢性。然而,與醫生撰寫的報告相比,生成報告在患病細節的描述方面仍然存在一些欠缺,模型的疾病識別能力和泛化能力仍有提升空間。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:邢素霞主要負責論文思路和實驗設計;方俊澤主要負責算法實現和論文寫作;鞠子涵主要負責實驗設計和平臺搭建;郭正、王瑜主要負責論文修訂和分析記錄。