最近很多研究提出了醫學視覺問答(MVQA)的注意力模型。在醫學研究中,不僅“視覺注意力”的建模至關重要,對“問題注意力”進行建模同樣具有重大意義。為了在醫學圖像和問題的注意過程中進行雙向推理,本文提出一種新的MVQA架構,稱為MCAN。該架構融入一種跨模態共同注意網絡FCAF,用于識別問題中的關鍵詞和圖像中的主要部分。通過元學習通道注意模塊(MLCA)自適應地為每個單詞和區域進行權重評定,以反映模型在推理過程中對各個單詞和區域的重視程度。此外,本研究專門設計和制作了一種面向醫學領域的詞嵌入模型Med-GloVe,進一步提升模型的準確率和應用價值。實驗證明,本文提出的MCAN架構在Path-VQA數據集的自由形式問題上,準確率提高了7.7%;在VQA-RAD數據集的封閉式問題上,準確率提高了4.4%,有效提升了醫學視覺問答的準確性。
引用本文: 崔文成, 施文濤, 邵虹. 一種基于共同注意網絡的醫學視覺問答方法. 生物醫學工程學雜志, 2024, 41(3): 560-568, 576. doi: 10.7507/1001-5515.202307057 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
0 引言
醫學視覺問答(medical visual question answering,MVQA)是一項特定領域的視覺問答(visual question answering,VQA)任務,旨在根據醫學圖像和相應的臨床問題預測正確答案。這項任務要求深入理解醫學圖像內容和醫學文本的語義信息,常常需要常識性的理解[1-2]。MVQA不僅有助于臨床醫生和醫學生獲取第二診斷意見,提高他們解讀復雜醫學圖像的信心,而且也能為關心自己健康狀況的患者提供即時反饋,幫助他們更好地理解健康情況[3-4]。現有的MVQA方法主要基于四個部分來回答問題,即:視覺特征提取模塊、文本特征提取模塊、包含視覺特征和文本特征的融合推理模塊以及分類頭/生成頭。有許多研究者致力于對MVQA中的視覺特征提取模塊進行探索[2, 5],通常采用預訓練的Faster-RCNN[6-7]模型以提取圖像中的關鍵對象級特征。然而,由于醫學圖像數據標注的不足,這種特征提取技術在醫學領域的應用面臨限制。目前,主流的圖像特征提取技術大多仍在ImageNet數據集上進行預訓練[8],但醫學圖像與傳統圖像存在本質區別,導致這些方法無法有效提取醫學圖像的特征表示。因此,Finn等[9]使用模型無關元學習(model-agnostic meta-learning,MAML)初始化圖像特征提取權重,有效地使用小型標記訓練集來訓練MVQA框架。Zhang等[10]使用對比學習來訓練ResNet,不需要額外醫學信息微調也能取得較好的效果。Gong團隊[11]使用帶標簽的外部數據進行ResNet訓練,把訓練劃分為圖像解讀任務和問題與圖像匹配性任務,以抽取更適合文本的兼容圖像特征。
在自然語言處理(natural language processing,NLP)領域中,一些工作對文本特征進行建模。Agrawal等[12]在早期VQA模型中使用RNN對語言問題進行建模。Devlin等[13]提出使用雙向Transformer編碼器(bidirectional encoder representations from transformers,BERT)作為文本編碼器,將自然語言問題和文本描述圖像的特征進行融合。Gu等[14]與Yan等[15]先后提出了PubMedBERT和Clinical-BERT,它們都是在大規模生物醫學語料庫上做預訓練的語言表示模型。盡管它們有著出色的表現效果,但在處理非常專業或特定的術語和概念時會出現未登錄詞(out of vocabulary,OOV)的現象,將文本映射為一個錯誤的向量,這無疑對MVQA的精確度和表現力帶來不小影響。此外,這些模型所需的計算資源與時間成本較高,并非適用于所有語言編碼工作。
隨著深度學習技術的發展,融合視覺與自然語言的多模態學習任務引起了眾多學者的廣泛研究[16-17]。受通用VQA領域的啟發,將注意力機制應用于融合模塊,可以提高模型的準確性,因此在MVQA任務中廣泛應用[18-19]。融合模塊中的注意力機制通常會生成一個空間圖,突出顯示與回答問題相關的圖像區域,如多模態緊湊雙線性池[20]、堆疊注意力網絡[21](stacked attention networks,SAN)等注意力機制在MVQA中的應用[22-23],以學習醫學圖像和文本信息之間的聯合表示問題。SAN是一種典型的注意力算法,它利用問題特征作為查詢,對與答案相關的圖像區域進行排名,通過多層結構來多次查詢圖像,以此逐步推斷答案。但這種低級特征對復雜問題的推理效果有限,因為醫學問題中存在大量開放式問題,需要對視覺和文本特征進行精細理解才能預測正確的答案。除SAN之外,其他一些工作也采用了注意力機制,例如雙線性注意力網絡[24](bilinear attention networks,BAN)、注意力對注意力網絡[25]等。鄒品榮等[26]通過注意力機制建模不同類型對象間關系,以此實現對視覺對象間關系的動態交互和文本上下文表示充分理解。但上述方法都只關注視覺注意力,忽略了問題注意力。
1 方法
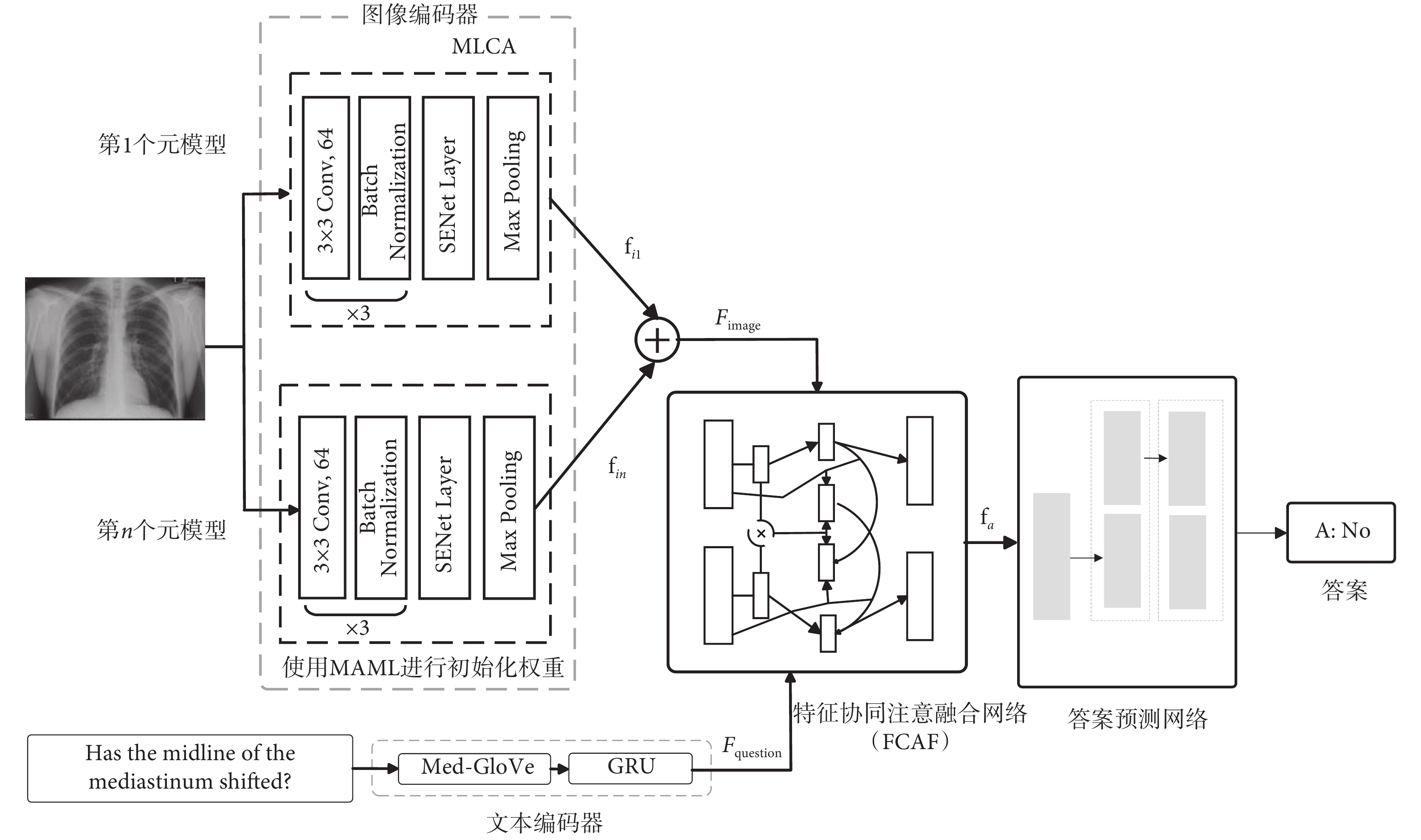
在MVQA任務中,因為醫學文本與醫學圖像信息之間需要建立關系,所以融合好文本和視覺信息的關鍵點非常重要[27]。受Co-attention機制[28]的啟發,本研究提出一個名為MCAN的新MVQA架構,總體結構如圖1所示。主要包含以下模塊:① 特征共同注意融合網絡FCAF。該網絡能有效捕捉跨模態交互信息,幫助更準確地理解文本和視覺特征,從而提高任務準確性。② 元學習通道注意模塊(meta-learning channel attention module,MLCA)。該模塊增強了MAML特征提取網絡,提升了關注重要信息的能力,進而提高了效率和擴展性。③ Med-GloVe模塊。該模塊是基于GloVe[29]算法,在醫學領域詞匯上進行增量訓練得到的。
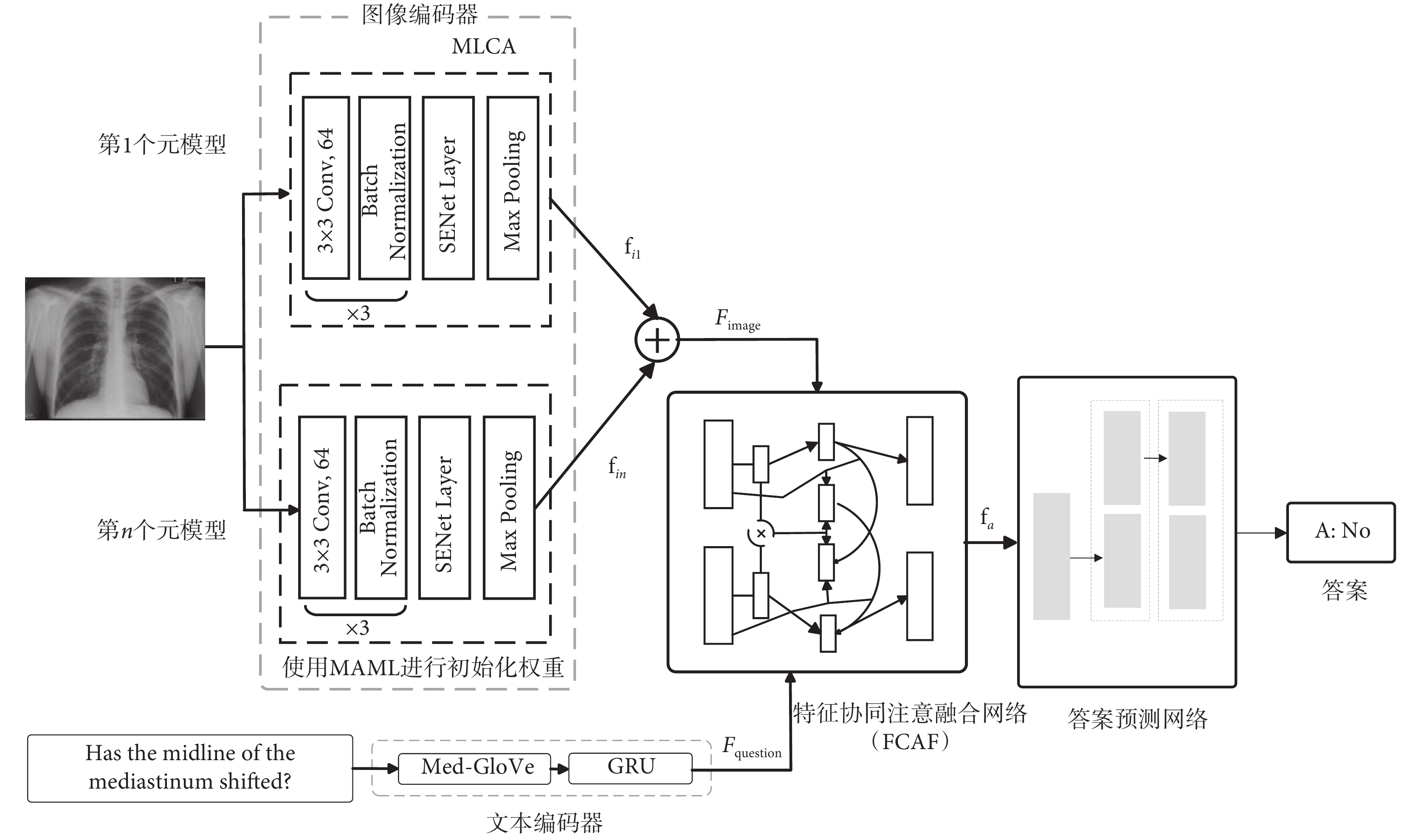 圖1
MCAN總體結構圖
Figure1.
General structure diagram of MCAN
圖1
MCAN總體結構圖
Figure1.
General structure diagram of MCAN
每個輸入圖像通過MLCA模塊后會得到一個由n個元模型得到的分支元模型特征圖  (n = 1, 2, ···, 5),這些向量相加后形成增強圖像特征
(n = 1, 2, ···, 5),這些向量相加后形成增強圖像特征 。單詞通過Med-GloVe模塊做詞嵌入后,被輸入到768維度的GRU模塊中,以生成問題嵌入
。單詞通過Med-GloVe模塊做詞嵌入后,被輸入到768維度的GRU模塊中,以生成問題嵌入  。將
。將  和
和  送入到FCAF網絡中進行特征映射后得到特征聯合表示向量
送入到FCAF網絡中進行特征映射后得到特征聯合表示向量  ,最后送入答案預測網絡中以預測答案。
,最后送入答案預測網絡中以預測答案。
1.1 特征共同注意融合網絡
FCAF模型通過同時對輸入的兩個序列  和
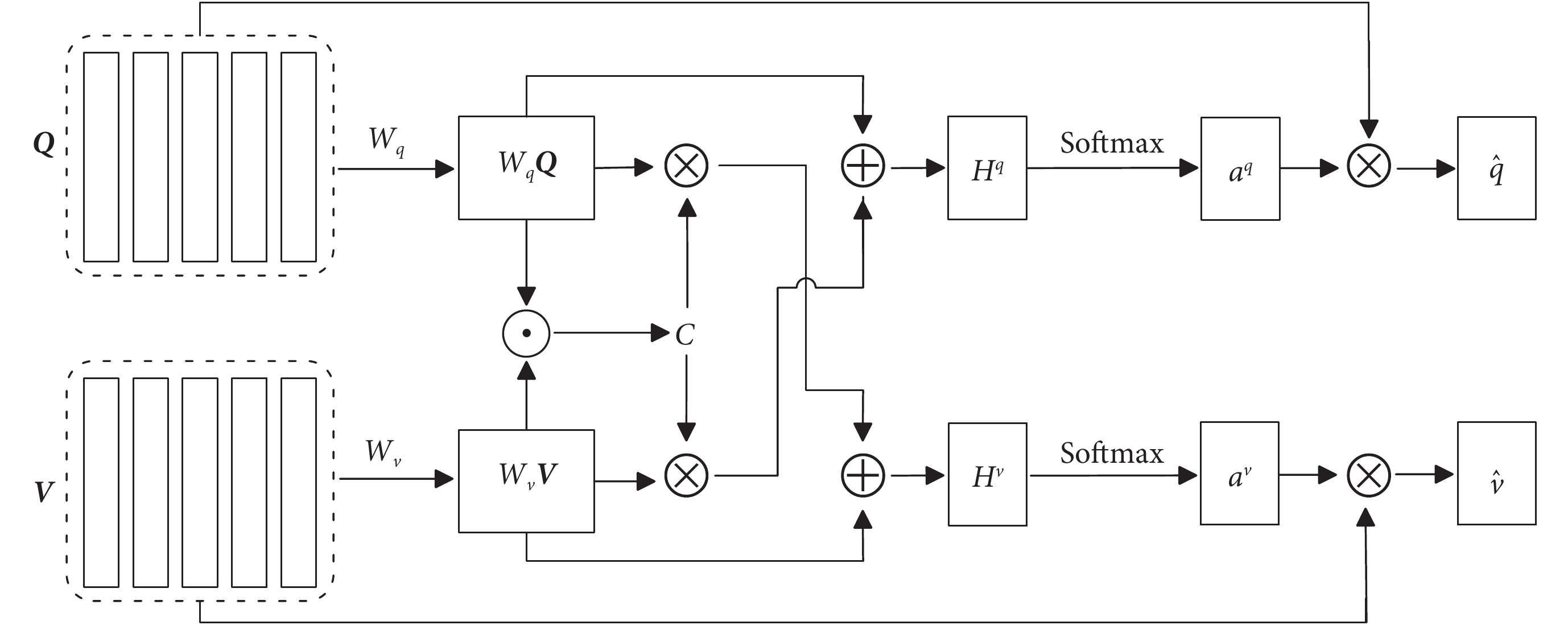
和  進行注意力計算,來實現問題和回答之間的交互和信息融合,模型結構如圖2所示。該模型將帶有醫學詞匯的自然語言文本劃分為三個層次進行圖文交互,即“單詞-詞組-句子”的編碼信息,利用每個層次得到的信息增強模型的融合能力。通過學習問題和影像的權重向量,在特征提取過程中將問題文本特征和視覺特征進行聯合輸入,實現問題和圖像的共同表征。主要包括問題注意力和圖像注意力。在問題注意力中,將問題和圖像特征分別投影到對應的注意力空間,并計算模態特征之間的相似度。利用相似度來加權平均問題文本的特征向量,從而得到與問題相關的特征向量。
進行注意力計算,來實現問題和回答之間的交互和信息融合,模型結構如圖2所示。該模型將帶有醫學詞匯的自然語言文本劃分為三個層次進行圖文交互,即“單詞-詞組-句子”的編碼信息,利用每個層次得到的信息增強模型的融合能力。通過學習問題和影像的權重向量,在特征提取過程中將問題文本特征和視覺特征進行聯合輸入,實現問題和圖像的共同表征。主要包括問題注意力和圖像注意力。在問題注意力中,將問題和圖像特征分別投影到對應的注意力空間,并計算模態特征之間的相似度。利用相似度來加權平均問題文本的特征向量,從而得到與問題相關的特征向量。
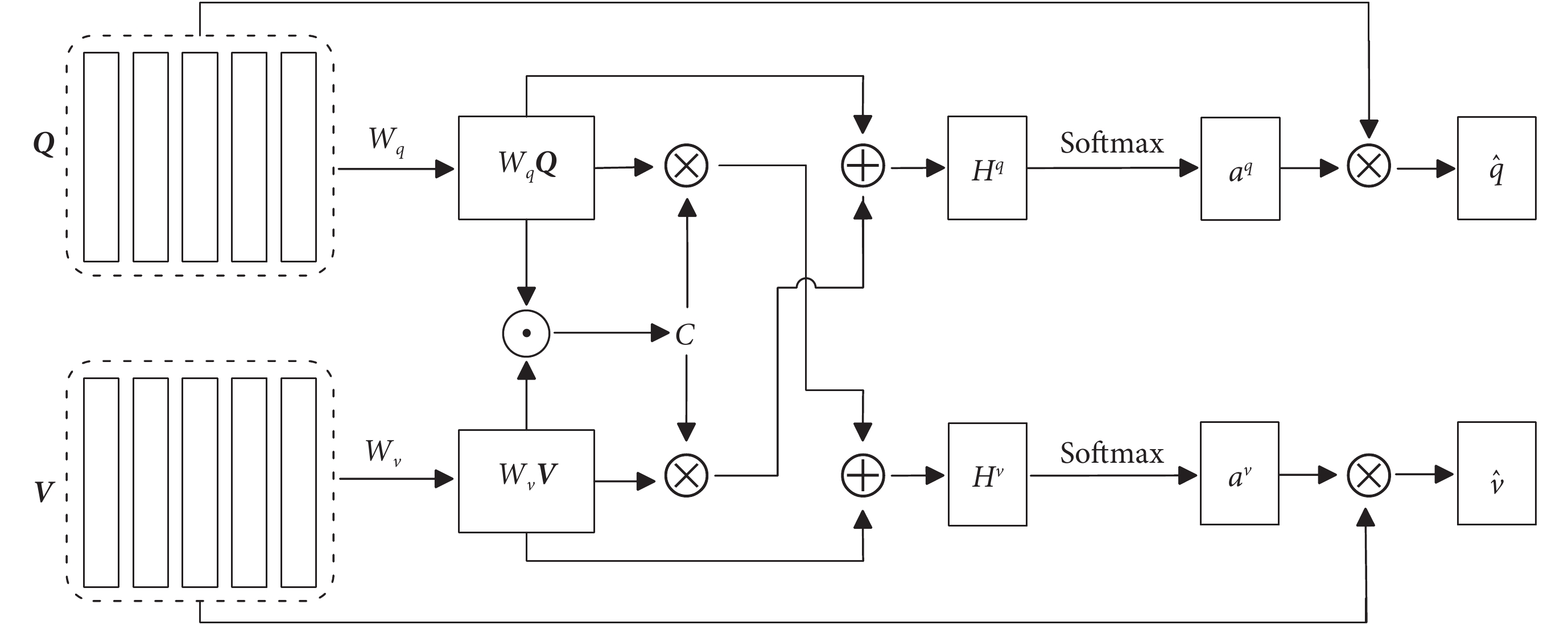 圖2
FCAF模型圖
Figure2.
Diagram of FCAF model
圖2
FCAF模型圖
Figure2.
Diagram of FCAF model
FCAF通過計算問題特征和圖像特征之間的相似度來連接問題和圖像。即給定問題特征映射  和圖像特征映射
和圖像特征映射  ,親和矩陣
,親和矩陣  的計算如式(1)所示:
的計算如式(1)所示:
 |
 '/> '/> |
 |
其中, 代表Sigmoid激活函數,
代表Sigmoid激活函數, 為學習權重,
為學習權重, 是Hadamard乘積,T為轉置符號,矢量g作為中間激活的門
是Hadamard乘積,T為轉置符號,矢量g作為中間激活的門  倍增作用。該公式設計靈感源自于GRU中的門控操作。在計算C之后,通過最大化其他模態位置上的親和力來計算圖像(或問題)注意力,即
倍增作用。該公式設計靈感源自于GRU中的門控操作。在計算C之后,通過最大化其他模態位置上的親和力來計算圖像(或問題)注意力,即  和
和  ,其中
,其中  為圖像空間位置k處的特征向量,
為圖像空間位置k處的特征向量, 表示在文本位置t處的特征向量,
表示在文本位置t處的特征向量, 和
和  是每個單詞區域
是每個單詞區域  和圖像區域
和圖像區域  各自的注意概率。相較于僅使用最大激活作為特征,FCAF模型引入親和力矩陣,通過式(2)中的策略加以利用,進而更精準地預測圖像與問題的注意力分布:
各自的注意概率。相較于僅使用最大激活作為特征,FCAF模型引入親和力矩陣,通過式(2)中的策略加以利用,進而更精準地預測圖像與問題的注意力分布:
 |
 |
 |
 |
其中, 為權重參數,基于上述的關注權重,將圖像和問題的關注向量計算為圖像特征和問題特征的加權和,其公式如(3)所示:
為權重參數,基于上述的關注權重,將圖像和問題的關注向量計算為圖像特征和問題特征的加權和,其公式如(3)所示:
 |
 |
此時,FCAF模型獲得了更關注問題的圖像向量 和更關注圖像的問題向量
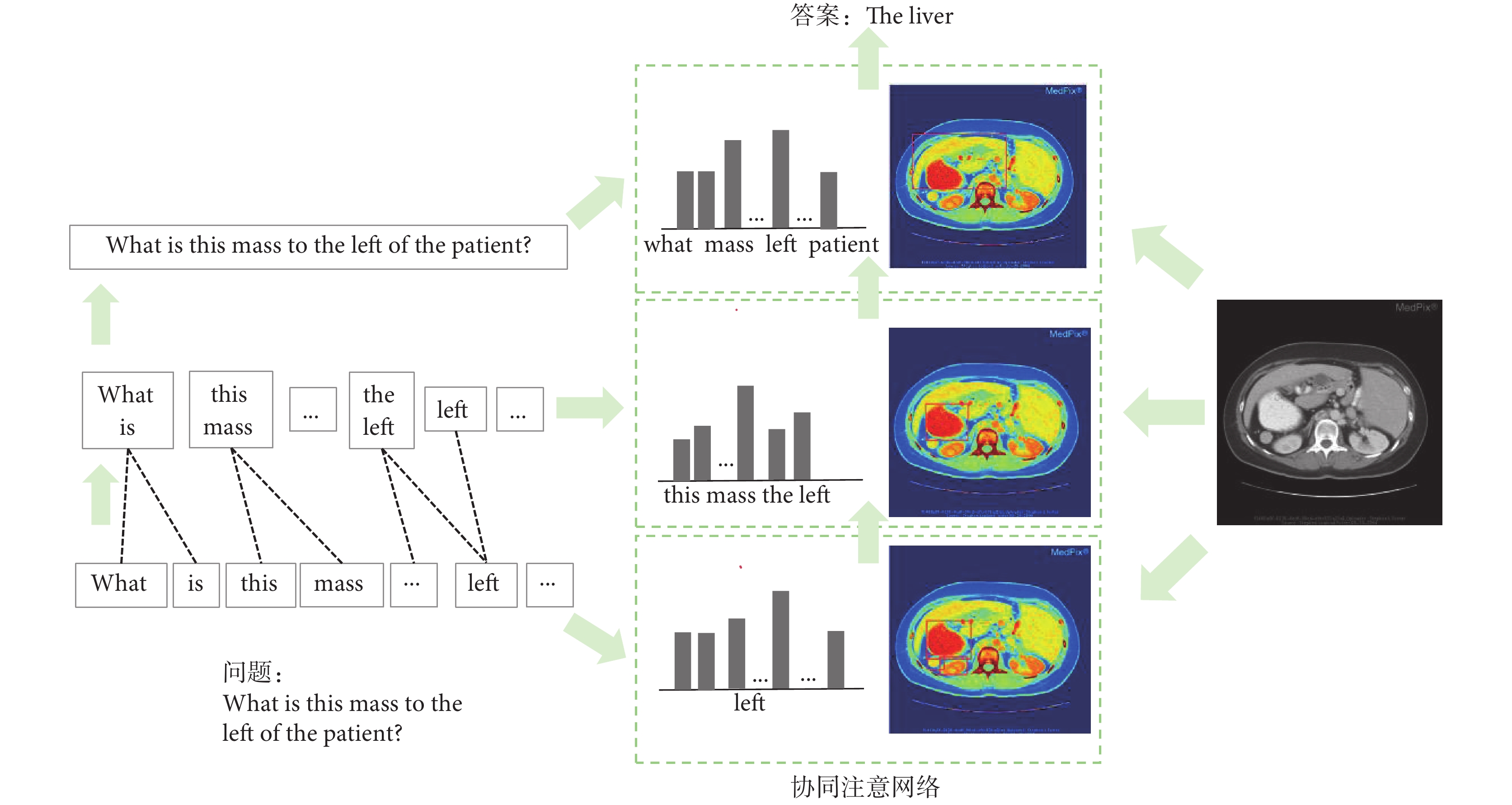
和更關注圖像的問題向量 。與以往僅關注視覺注意力的工作不同,FCAF模型內部的交互展現了圖像和問題之間的自然對稱性,即不僅讓圖像表示來引導問題的注意力,而且讓問題表示也引導圖像的注意力。模型將單詞表示與不同的過濾器進行卷積,并將各種n-gram響應集合到單一的短語級表示中。在句子層面,采用了循環神經網絡來編碼整個句子。模型建立了聯合的問題和圖像共同注意圖,遞歸組合以預測答案的分布。如圖3所示,最終答案預測基于所有參與的圖像和問題特征。
。與以往僅關注視覺注意力的工作不同,FCAF模型內部的交互展現了圖像和問題之間的自然對稱性,即不僅讓圖像表示來引導問題的注意力,而且讓問題表示也引導圖像的注意力。模型將單詞表示與不同的過濾器進行卷積,并將各種n-gram響應集合到單一的短語級表示中。在句子層面,采用了循環神經網絡來編碼整個句子。模型建立了聯合的問題和圖像共同注意圖,遞歸組合以預測答案的分布。如圖3所示,最終答案預測基于所有參與的圖像和問題特征。
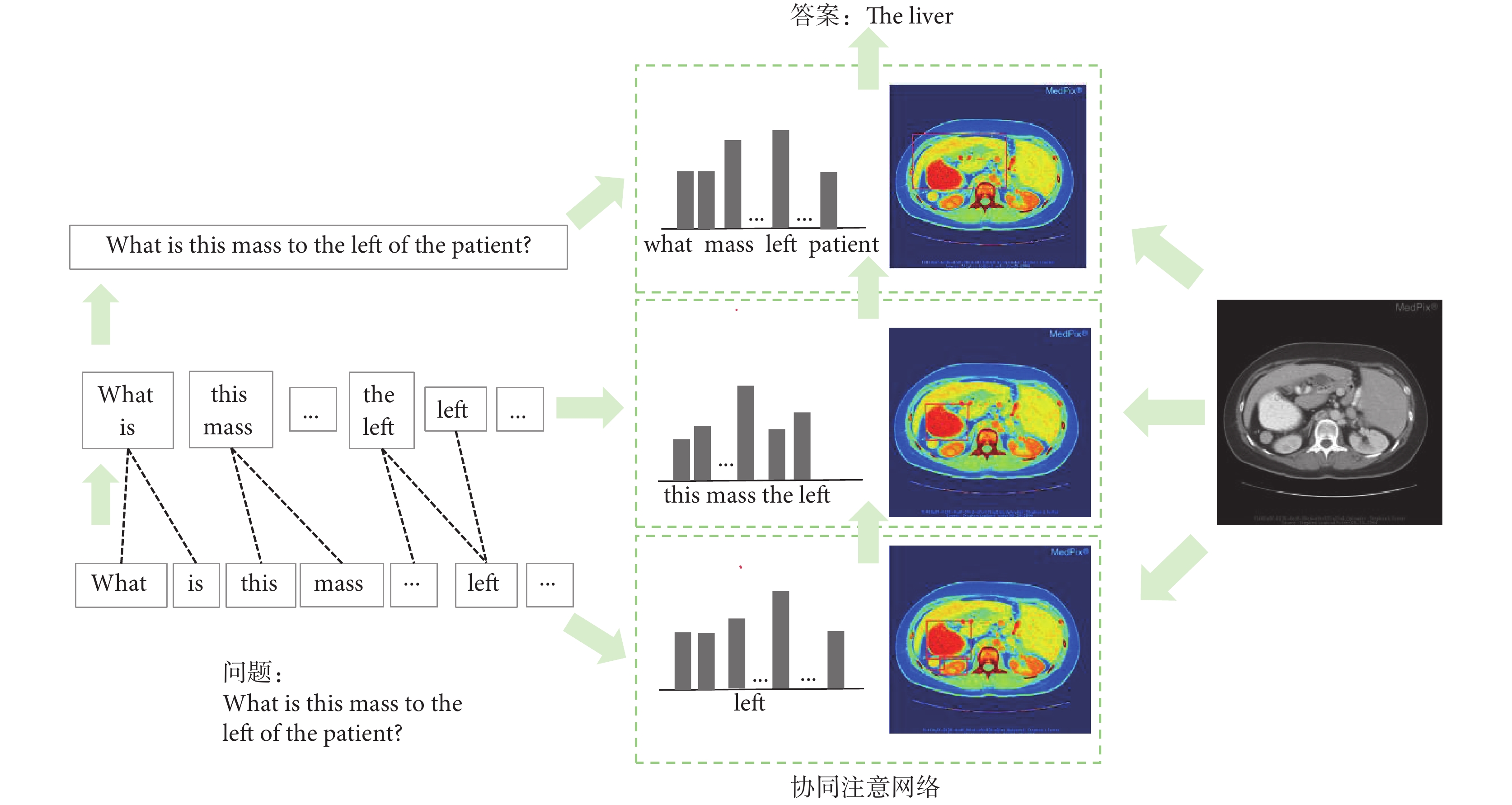 圖3
三層共同關注模型流程圖
Figure3.
Flowchart of the three-level co-attention model
圖3
三層共同關注模型流程圖
Figure3.
Flowchart of the three-level co-attention model
1.2 元學習通道注意模塊
由于缺乏足夠多的帶有注釋的醫學圖像,在自然圖像數據集上做預訓練的特征提取器通常在醫學領域不可用,該方法無法提取良好的特征表示。因此,本文引入MAML方法。MAML分類模型由帶有元參數 的參數化函數
的參數化函數 表示。當適應新的任務
表示。當適應新的任務 時,模型的參數
時,模型的參數 變為
變為 。令K = {
。令K = { }(n=1, 2, ···, M)為訓練MAML的數據集,其中M是樣本數。{
}(n=1, 2, ···, M)為訓練MAML的數據集,其中M是樣本數。{ }是一對圖像 (
}是一對圖像 ( ) 及其類標簽 (
) 及其類標簽 ( )。本實驗按照文獻[9]來設計MAML,共設計n個不同MAML。每個MAML由三個步幅為2的3 × 3卷積層和Batch Normalization組成,并以最大池化層結束;每個卷積層有64個濾波器,后面是ReLU層。MAML的詳細訓練在第2.3節中介紹。訓練后,元模型的權重用于在VQA框架中進行微調,如圖1所示。
)。本實驗按照文獻[9]來設計MAML,共設計n個不同MAML。每個MAML由三個步幅為2的3 × 3卷積層和Batch Normalization組成,并以最大池化層結束;每個卷積層有64個濾波器,后面是ReLU層。MAML的詳細訓練在第2.3節中介紹。訓練后,元模型的權重用于在VQA框架中進行微調,如圖1所示。
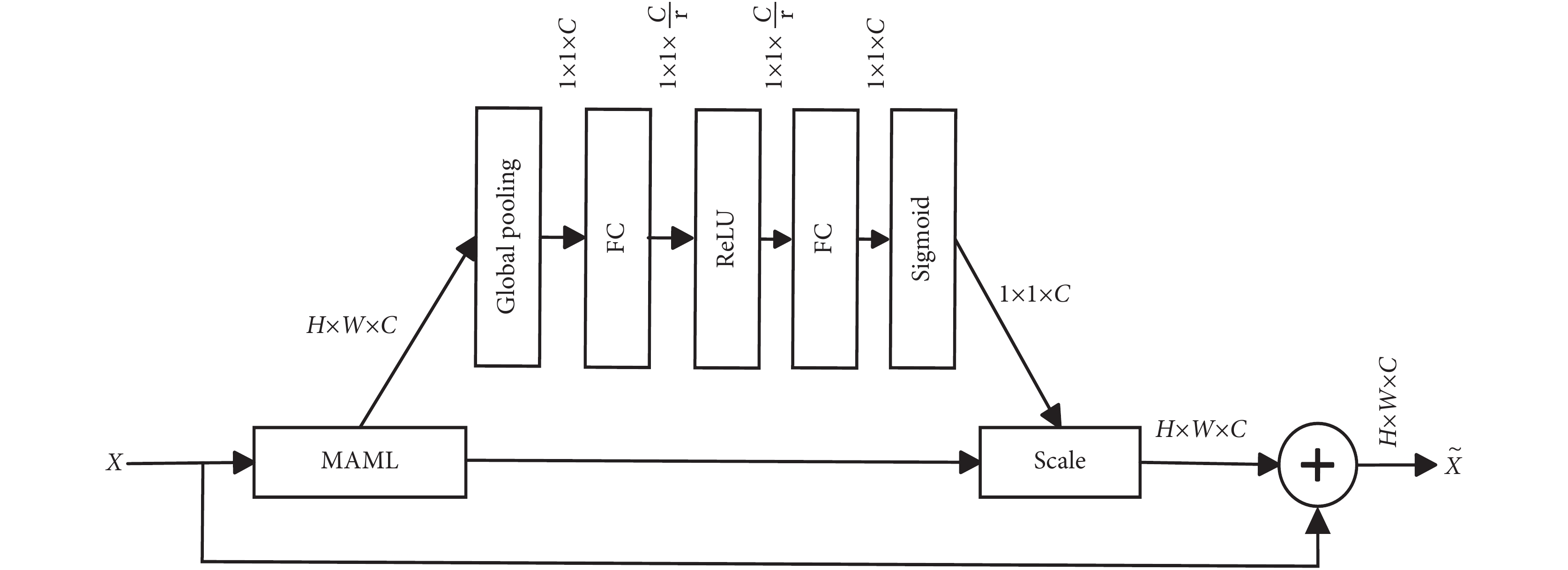
為了讓初始參數更好地泛化到新任務中學習醫學影像中的關鍵特征,受SENet[30]啟發,特征融合時從通道上將SENet融入特征融合模塊能夠自適應調整特征圖權重,使網絡在處理圖像特征時更加關注和強調醫學影像中的微小病癥特征信息,以獲得更好的定位識別能力。該模塊命名為MLCA,其結構如圖4所示。該模塊嵌入到MAML層后,模型對接收的特征圖進行全局平均池化操作,將特征圖的尺寸變為1 × 1。
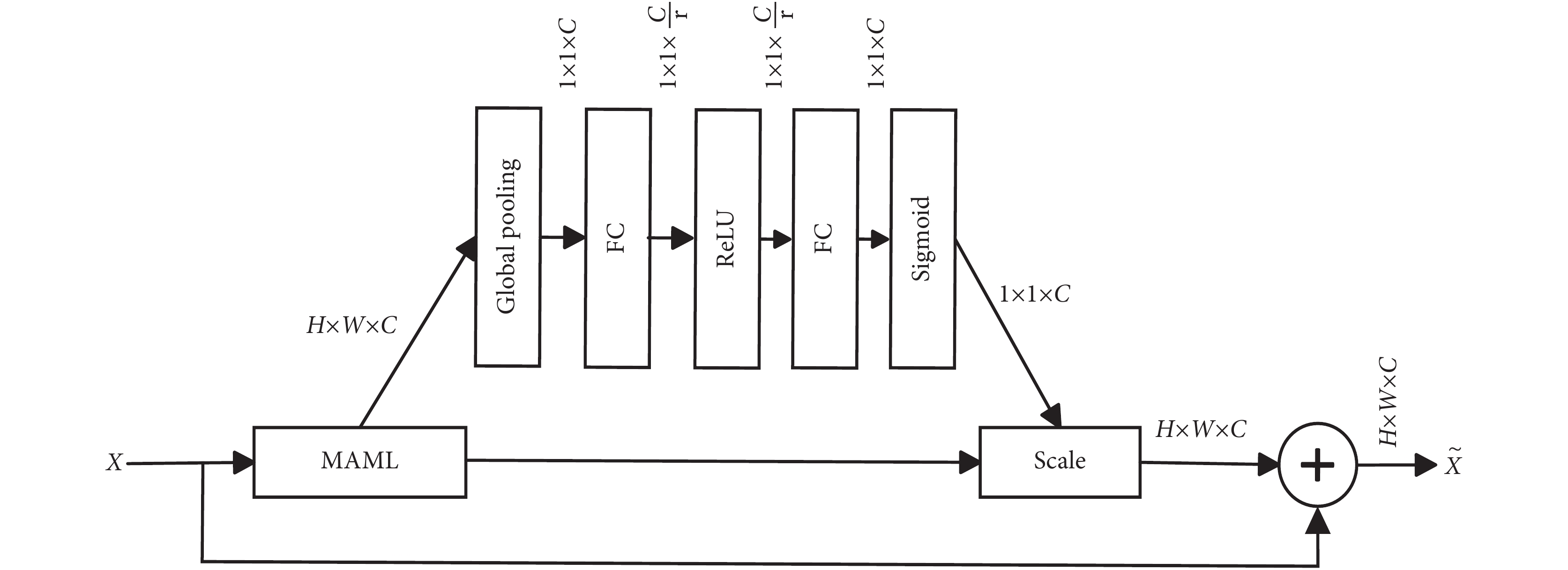 圖4
MLCA模塊
Figure4.
MLCA module
圖4
MLCA模塊
Figure4.
MLCA module
為了學習通道之間的依賴關系,模型保持通道數不變。在全局平均池化之后,SE塊包含一系列層,包括全連接層、激活層和Sigmoid等。在Scale層中,將學習到的通道權重與原始輸入的特征圖進行矩陣乘法。這一步驟實際上將學習到的權重應用到每個通道的每個特征點上,將通道中的每個特征點視為同等重要的位置,使每個特征點均受學習到的權重的影響。
1.3 Med-GloVe
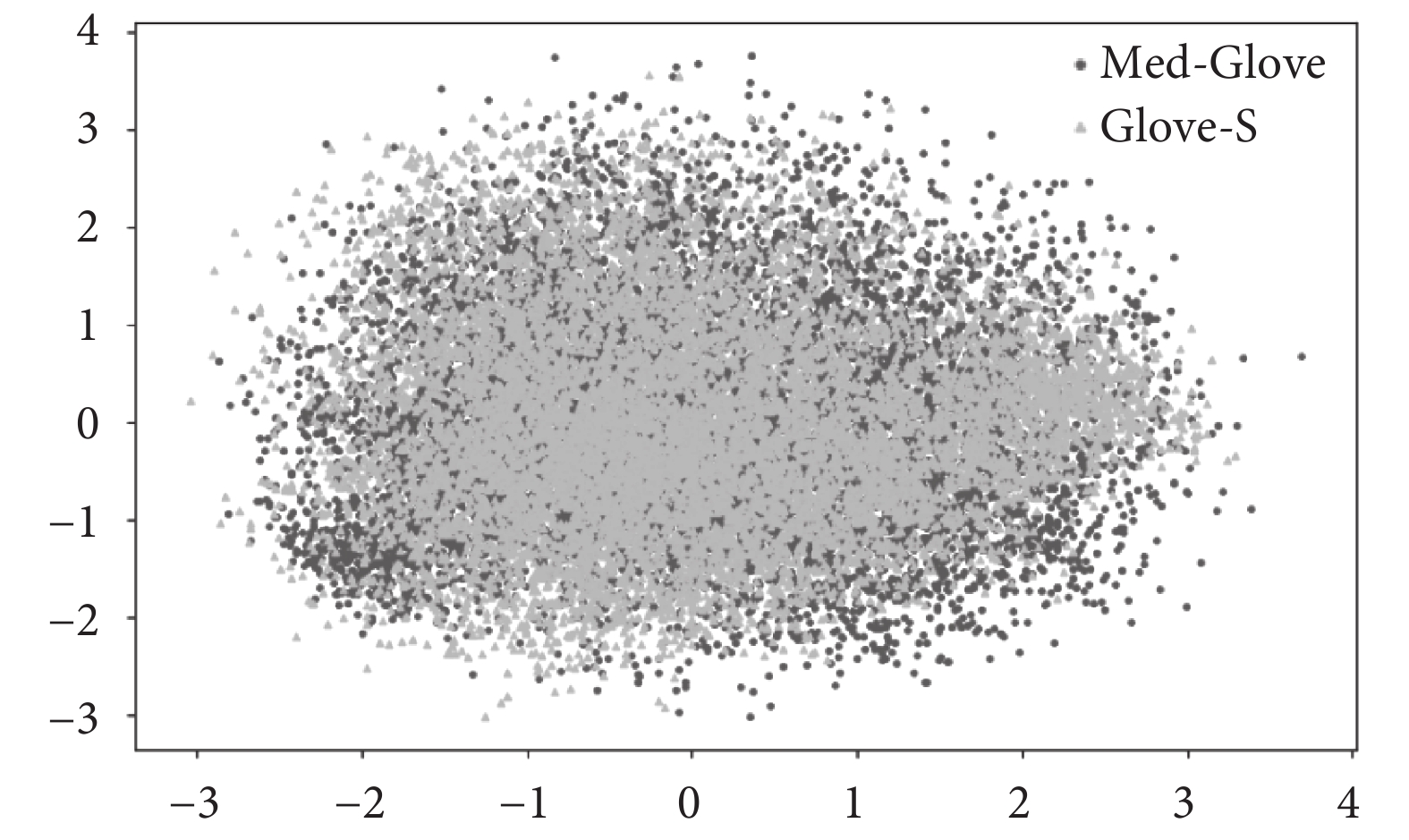
為了進行文本編碼,VQA中通常使用基于Wikipedia語料庫預訓練的公開GloVe詞向量對文本進行編碼[31-32],并采用門控循環單元(gated recurrent unit,GRU)[33]來提取文本序列的特征。這種方法有效捕捉了文本詞匯在問答語境中的語義和語法信息。但醫學文本的專業性和復雜性導致該方案中的GloVe詞向量無法直接被使用。為了解決該問題,本研究利用臨床診斷標準、病歷等醫學數據作為主要語料,通過回譯數據增強[34]方法來增加文本數據量,擴展詞表以挖掘醫學語言中的專業術語和概念,從而改善醫療文本數據的稀缺性問題。在GloVe-S的基礎上進行增量訓練,引入了額外的8 277個醫學專業詞匯,形成了Med-GloVe。具體的技術細節將在2.4節中詳述。將Med-GloVe與GloVe-S的詞向量通過主成分分析技術降維至二維空間,圖5直觀地展示了兩者在核心數據點位置上的偏移。這種偏移不僅證實了Med-GloVe的專業性和有效性,而且為醫學NLP相關任務提供了寶貴的資源。
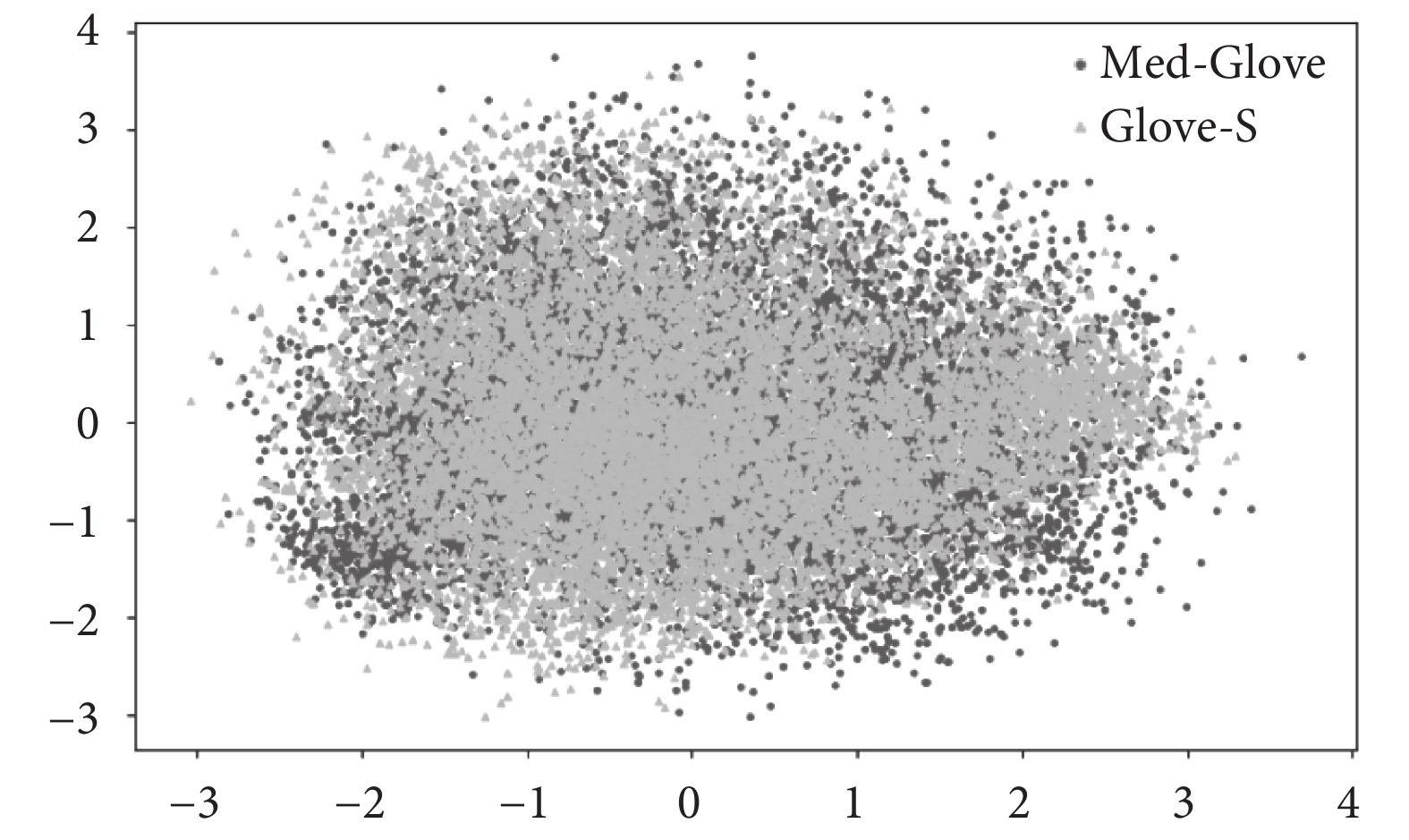 圖5
Med-Glove與GloVe-S詞表差異
Figure5.
Differences between Med-Glove and GloVe-S word lists
圖5
Med-Glove與GloVe-S詞表差異
Figure5.
Differences between Med-Glove and GloVe-S word lists
1.4 答案預測網絡
在本研究中,MVQA被視為分類任務,根據三個層次的圖像問題融合特征進行答案預測。多層感知器被用于對注意力特征執行遞歸編碼。受HiQiCA[35]的啟示,通過綜合應用所有從三個層次中提取出的圖像和問題特征對答案進行預測。圖6清晰地展示了對注意力特征執行遞歸編碼的過程。其中w、p、s分別代表單詞、詞組(2 ≤ 單詞數 ≤ 句子長度)和句子; 和
和 分別代表文本向量和視覺向量;
分別代表文本向量和視覺向量; 、
、 、
、 分別代表在單詞、詞組、句子層面上的文本和視覺特征融合后的向量;
分別代表在單詞、詞組、句子層面上的文本和視覺特征融合后的向量; 表示遞歸融合完成后最終句子向量。計算過程見式(4)。
表示遞歸融合完成后最終句子向量。計算過程見式(4)。
 圖6
預測答案編碼器
Figure6.
Encoding for predicting answers
圖6
預測答案編碼器
Figure6.
Encoding for predicting answers
 |
 |
 |
 |
 |
其中, 、
、 、
、 、
、 均為權重參數,
均為權重參數, 是兩個向量的連接操作。P是最終答案的概率。
是兩個向量的連接操作。P是最終答案的概率。
2 實驗與結果分析
2.1 數據集
本研究主要采用VQA-RAD[36]數據集和Path-VQA[37]數據集進行測試和對比分析。
VQA-RAD是一個手動標記的數據集,包含315張圖像和3 515個相關問題。這些圖像進一步細分為頭部(104張圖像)、胸部(107張圖像)和腹部(104張圖像)三個子類別。根據圖像對應的問答內容,這些圖像可以再分為三類:① 正常圖像;② 顯示異常的圖像,例如液體積聚、腫塊或腫瘤;③ 表現為器官異常的圖像,包括器官體積異常或位置不當。Path-VQA包含從兩本病理學教科書和PEIR數字圖書館收集的總計4 998張病理圖像以及32 799個問答對,該數據集中特有的一種Free-form問題,使得模型不僅要理解圖像與問題,還需要進行推理和解釋才能給出答案,展現出極高的挑戰性。
2.2 模型實驗設置
本模型在一塊NVIDIA RTX 3 090 GPU和一個Intel Core i7-12700K處理器下進行訓練,采用學習率衰減算法,并經過多次調整優化超參數。最終的超參數設定如表1所示。最終評價標準為BLEU,用以評估生成式問題答案與標準答案的相似度。
2.3 MAML的訓練
為構建MAML的訓練數據集,實驗開始前,依據VQA-RAD數據集中的問答對,對部分訓練數據進行人工劃分,篩選出大約3 200個問答對。根據VQA-RAD數據集中圖像對應問答內容的描述,圖像被歸入九種不同的類別,分別是正常頭部、異常頭部、異常頭部器官、正常胸部、異常胸部、異常胸部器官、正常腹部、異常腹部和異常腹部器官。在MAML訓練過程中,每次迭代都會選擇5個任務,每個任務從9個類別中隨機選出3個,而每個類別又隨機選取6張圖像,其中3張用于任務模型的更新,另外3張用于元模型的更新。參數用于更新MLCA模塊。
2.4 預訓練Med-GloVe
本研究從MedPub數據庫中收集醫學領域的相關文本數據,包括醫學論文、病例報告和醫學教材等。對這些文本數據進行預處理,處理步驟包括去除停用詞和進行詞形還原,通過詞頻分析識別出醫學領域中的專業詞匯和術語,為后續的訓練準備數據。根據分析結果,手動構建了一個包含約8 200個詞匯的醫學詞匯庫。本研究選擇了在大規模通用文本上預訓練的GloVe6B-300d模型,命名為GloVe-S,作為基礎模型。使用上述收集的醫學文本對GloVe-S模型進行增量訓練,在此過程中,特別注意醫學專有詞匯的引入,以確保這些專業術語在模型中得到充分的學習和表達。實驗過程中,通過調整訓練權重來優先處理醫學領域的新詞匯和術語,確保新詞匯能夠被有效地融入到本文提出的MCAN框架中。這種方法旨在提高模型對醫學專業內容的理解和應用能力,以期取得更準確的結果。
2.5 模型對比與分析
本文將兩個數據集與當前行業領先的MVQA模型進行對比以保證評估的公正性。GRU作為文本編碼器以確保文本編碼的一致性。需要特別指出,SAN通過多層注意力機制,逐層深化問題和影像之間的交互關系來更精細地理解問題和影像間的聯系。BAN通過對問題的語義表示和圖像的視覺特征進行雙線性匯聚,從而在更高層次上構建問題與圖像間的復雜關聯。MEVF利用大量外部醫學數據進行預訓練。如表2[9, 32, 37-38]、表3[32, 37-38]所示,將本文模型與現有模型分別在Path-VQA和VQA-RAD上進行比較,其中,N-maml表示為元模型數量。
實驗結果表明,本文提出的MCAN架構在Path-VQA和VQA-RAD兩個數據集的封閉式問題中展示出卓越的表現。在兩個數據集上,MCAN將封閉式問題的準確率從之前技術的84.0%和75.8%(MMQ[32])提升至86.22%和79.17%,提升幅度分別為2.6%和4.4%。此外,在Path-VQA數據集中,極具挑戰性的Free-form問題的準確率從之前技術的13.4%(MMQ[32])提升至14.43%,增幅為7.7%。這一成果得益于模型采用計算所有圖像位置與問題位置對的特征相似度的方法,從而更有效地連接圖像與問題。此外,實驗通過使用Med-GloVe的語言嵌入,在MVQA任務中的表現顯著優于未經醫學領域預訓練的GloVe,即證實了將通用語言模型替換為專門的醫學語言模型,不僅提高了模型在封閉式問題上的準確率,還凸顯了醫學文本理解在MVQA中的關鍵作用。
在圖像特征提取的注意力方法方面,借鑒SENet思想,通過學習通道間的關系來調整特征圖中每個通道的重要性,以增強模型在通道級別上的特征關注。為驗證所提模型有效性,表4[6, 16, 32, 37]中的實驗均未使用Med-GloVe。第三、第五行使用了SAN、BAN的基準方法,而“None”表示在其他條件不變下不使用注意力模型。本文將實驗分為基線模型與增強模型。對比結果顯示,增強模型的通道特征提取能顯著提升準確度,見增強模型部分(序號3對應序號6,序號4對應序號7),證明了在視覺特征提取模塊中引入SENet思想可有效提高醫學圖像特征的提取能力。
為了驗證Med-Glove的有效性,本次實驗均基于MMQ上進行消融驗證,如表5所示。相對于GloVe-S(MMQ[32]中使用的方案),使用Med-GloVe時,回答Free-form問題的準確率從13.40%提升到16.50%,Closed問題的準確率從84.00%提升到85.61%,Open問題的準確率從48.80%提升到50.17%。與GloVe-S相比,使用了更大詞表的GloVe-B,包含的詞匯數擴大了近20%,但該方法對于Open類型的問題,其準確率僅提升了0.18%。Med-GloVe與GloVe-S相比,規模僅增長2%,但在三類問題的回答上分別提升了23.13%、1.92%和2.8%的準確率。實驗結果強調了對詞嵌入模型進行領域特定調整的重要性,證明了所提出的Med-GloVe能顯著提高語義匹配的準確性和特定領域的精確度。
3 結論
本文介紹了一種新的MVQA架構MCAN,主要由三個模塊組成:共同注意特征融合模塊FCAF、元學習-通道注意模塊MLCA以及預訓練詞向量Med-GloVe。首先,FCAF模塊通過一種新的多模態特征融合技術實現圖文間的特征交互,有效整合視覺和文本信息至一個共同的表示空間中,以提升信息處理的整合性。其次,MLCA模塊通過自適應調整通道權重,增強了特征提取的表達力和模型的泛化能力。最后,通過融入專為MVQA設計的Med-GloVe,本架構顯著提高了模型對醫療文本序列關系的理解,進而提升了在生成式任務中的準確率。
實驗在VQA-RAD和Path-VQA數據集上進行,結果顯示,本文提出的FCAF模塊與經典融合注意力BAN模塊相比,在文本和圖像的精細化理解上有顯著提升,通過多層級聯增強了模型的推理能力。然而,實驗中發現,由于VQA-RAD和Path-VQA數據集中的醫學圖像細節與復雜性高于一般圖像,僅依賴FCAF模型難以達到理想的性能。此外,盡管采用Med-GloVe詞向量在一定程度上提升了模型的準確率,但面對醫學領域快速發展帶來的詞匯更新,仍存在OOV現象。為進一步提升MCAN架構在醫學領域的應用效果,未來的研究應繼續探索和優化這些方法,尤其是如何有效處理新出現的醫學詞匯,以及如何提升FCAF模型在處理開放性問題上的準確率。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:崔文成負責實驗方向提出和論文修改;施文濤負責數據收集、數據分析、代碼實現和論文寫作;邵虹負責實驗方向提出和論文修改。
0 引言
醫學視覺問答(medical visual question answering,MVQA)是一項特定領域的視覺問答(visual question answering,VQA)任務,旨在根據醫學圖像和相應的臨床問題預測正確答案。這項任務要求深入理解醫學圖像內容和醫學文本的語義信息,常常需要常識性的理解[1-2]。MVQA不僅有助于臨床醫生和醫學生獲取第二診斷意見,提高他們解讀復雜醫學圖像的信心,而且也能為關心自己健康狀況的患者提供即時反饋,幫助他們更好地理解健康情況[3-4]。現有的MVQA方法主要基于四個部分來回答問題,即:視覺特征提取模塊、文本特征提取模塊、包含視覺特征和文本特征的融合推理模塊以及分類頭/生成頭。有許多研究者致力于對MVQA中的視覺特征提取模塊進行探索[2, 5],通常采用預訓練的Faster-RCNN[6-7]模型以提取圖像中的關鍵對象級特征。然而,由于醫學圖像數據標注的不足,這種特征提取技術在醫學領域的應用面臨限制。目前,主流的圖像特征提取技術大多仍在ImageNet數據集上進行預訓練[8],但醫學圖像與傳統圖像存在本質區別,導致這些方法無法有效提取醫學圖像的特征表示。因此,Finn等[9]使用模型無關元學習(model-agnostic meta-learning,MAML)初始化圖像特征提取權重,有效地使用小型標記訓練集來訓練MVQA框架。Zhang等[10]使用對比學習來訓練ResNet,不需要額外醫學信息微調也能取得較好的效果。Gong團隊[11]使用帶標簽的外部數據進行ResNet訓練,把訓練劃分為圖像解讀任務和問題與圖像匹配性任務,以抽取更適合文本的兼容圖像特征。
在自然語言處理(natural language processing,NLP)領域中,一些工作對文本特征進行建模。Agrawal等[12]在早期VQA模型中使用RNN對語言問題進行建模。Devlin等[13]提出使用雙向Transformer編碼器(bidirectional encoder representations from transformers,BERT)作為文本編碼器,將自然語言問題和文本描述圖像的特征進行融合。Gu等[14]與Yan等[15]先后提出了PubMedBERT和Clinical-BERT,它們都是在大規模生物醫學語料庫上做預訓練的語言表示模型。盡管它們有著出色的表現效果,但在處理非常專業或特定的術語和概念時會出現未登錄詞(out of vocabulary,OOV)的現象,將文本映射為一個錯誤的向量,這無疑對MVQA的精確度和表現力帶來不小影響。此外,這些模型所需的計算資源與時間成本較高,并非適用于所有語言編碼工作。
隨著深度學習技術的發展,融合視覺與自然語言的多模態學習任務引起了眾多學者的廣泛研究[16-17]。受通用VQA領域的啟發,將注意力機制應用于融合模塊,可以提高模型的準確性,因此在MVQA任務中廣泛應用[18-19]。融合模塊中的注意力機制通常會生成一個空間圖,突出顯示與回答問題相關的圖像區域,如多模態緊湊雙線性池[20]、堆疊注意力網絡[21](stacked attention networks,SAN)等注意力機制在MVQA中的應用[22-23],以學習醫學圖像和文本信息之間的聯合表示問題。SAN是一種典型的注意力算法,它利用問題特征作為查詢,對與答案相關的圖像區域進行排名,通過多層結構來多次查詢圖像,以此逐步推斷答案。但這種低級特征對復雜問題的推理效果有限,因為醫學問題中存在大量開放式問題,需要對視覺和文本特征進行精細理解才能預測正確的答案。除SAN之外,其他一些工作也采用了注意力機制,例如雙線性注意力網絡[24](bilinear attention networks,BAN)、注意力對注意力網絡[25]等。鄒品榮等[26]通過注意力機制建模不同類型對象間關系,以此實現對視覺對象間關系的動態交互和文本上下文表示充分理解。但上述方法都只關注視覺注意力,忽略了問題注意力。
1 方法
在MVQA任務中,因為醫學文本與醫學圖像信息之間需要建立關系,所以融合好文本和視覺信息的關鍵點非常重要[27]。受Co-attention機制[28]的啟發,本研究提出一個名為MCAN的新MVQA架構,總體結構如圖1所示。主要包含以下模塊:① 特征共同注意融合網絡FCAF。該網絡能有效捕捉跨模態交互信息,幫助更準確地理解文本和視覺特征,從而提高任務準確性。② 元學習通道注意模塊(meta-learning channel attention module,MLCA)。該模塊增強了MAML特征提取網絡,提升了關注重要信息的能力,進而提高了效率和擴展性。③ Med-GloVe模塊。該模塊是基于GloVe[29]算法,在醫學領域詞匯上進行增量訓練得到的。
圖1
MCAN總體結構圖
Figure1.
General structure diagram of MCAN
每個輸入圖像通過MLCA模塊后會得到一個由n個元模型得到的分支元模型特征圖 (n = 1, 2, ···, 5),這些向量相加后形成增強圖像特征。單詞通過Med-GloVe模塊做詞嵌入后,被輸入到768維度的GRU模塊中,以生成問題嵌入 。將 和 送入到FCAF網絡中進行特征映射后得到特征聯合表示向量 ,最后送入答案預測網絡中以預測答案。
1.1 特征共同注意融合網絡
FCAF模型通過同時對輸入的兩個序列 和 進行注意力計算,來實現問題和回答之間的交互和信息融合,模型結構如圖2所示。該模型將帶有醫學詞匯的自然語言文本劃分為三個層次進行圖文交互,即“單詞-詞組-句子”的編碼信息,利用每個層次得到的信息增強模型的融合能力。通過學習問題和影像的權重向量,在特征提取過程中將問題文本特征和視覺特征進行聯合輸入,實現問題和圖像的共同表征。主要包括問題注意力和圖像注意力。在問題注意力中,將問題和圖像特征分別投影到對應的注意力空間,并計算模態特征之間的相似度。利用相似度來加權平均問題文本的特征向量,從而得到與問題相關的特征向量。
圖2
FCAF模型圖
Figure2.
Diagram of FCAF model
FCAF通過計算問題特征和圖像特征之間的相似度來連接問題和圖像。即給定問題特征映射 和圖像特征映射 ,親和矩陣 的計算如式(1)所示:
|
| '/> |
|
其中, 代表Sigmoid激活函數, 為學習權重, 是Hadamard乘積,T為轉置符號,矢量g作為中間激活的門 倍增作用。該公式設計靈感源自于GRU中的門控操作。在計算C之后,通過最大化其他模態位置上的親和力來計算圖像(或問題)注意力,即 和 ,其中 為圖像空間位置k處的特征向量, 表示在文本位置t處的特征向量, 和 是每個單詞區域 和圖像區域 各自的注意概率。相較于僅使用最大激活作為特征,FCAF模型引入親和力矩陣,通過式(2)中的策略加以利用,進而更精準地預測圖像與問題的注意力分布:
|
|
|
|
其中, 為權重參數,基于上述的關注權重,將圖像和問題的關注向量計算為圖像特征和問題特征的加權和,其公式如(3)所示:
|
|
此時,FCAF模型獲得了更關注問題的圖像向量和更關注圖像的問題向量。與以往僅關注視覺注意力的工作不同,FCAF模型內部的交互展現了圖像和問題之間的自然對稱性,即不僅讓圖像表示來引導問題的注意力,而且讓問題表示也引導圖像的注意力。模型將單詞表示與不同的過濾器進行卷積,并將各種n-gram響應集合到單一的短語級表示中。在句子層面,采用了循環神經網絡來編碼整個句子。模型建立了聯合的問題和圖像共同注意圖,遞歸組合以預測答案的分布。如圖3所示,最終答案預測基于所有參與的圖像和問題特征。
圖3
三層共同關注模型流程圖
Figure3.
Flowchart of the three-level co-attention model
1.2 元學習通道注意模塊
由于缺乏足夠多的帶有注釋的醫學圖像,在自然圖像數據集上做預訓練的特征提取器通常在醫學領域不可用,該方法無法提取良好的特征表示。因此,本文引入MAML方法。MAML分類模型由帶有元參數的參數化函數表示。當適應新的任務時,模型的參數變為。令K = {}(n=1, 2, ···, M)為訓練MAML的數據集,其中M是樣本數。{}是一對圖像 () 及其類標簽 ()。本實驗按照文獻[9]來設計MAML,共設計n個不同MAML。每個MAML由三個步幅為2的3 × 3卷積層和Batch Normalization組成,并以最大池化層結束;每個卷積層有64個濾波器,后面是ReLU層。MAML的詳細訓練在第2.3節中介紹。訓練后,元模型的權重用于在VQA框架中進行微調,如圖1所示。
為了讓初始參數更好地泛化到新任務中學習醫學影像中的關鍵特征,受SENet[30]啟發,特征融合時從通道上將SENet融入特征融合模塊能夠自適應調整特征圖權重,使網絡在處理圖像特征時更加關注和強調醫學影像中的微小病癥特征信息,以獲得更好的定位識別能力。該模塊命名為MLCA,其結構如圖4所示。該模塊嵌入到MAML層后,模型對接收的特征圖進行全局平均池化操作,將特征圖的尺寸變為1 × 1。
圖4
MLCA模塊
Figure4.
MLCA module
為了學習通道之間的依賴關系,模型保持通道數不變。在全局平均池化之后,SE塊包含一系列層,包括全連接層、激活層和Sigmoid等。在Scale層中,將學習到的通道權重與原始輸入的特征圖進行矩陣乘法。這一步驟實際上將學習到的權重應用到每個通道的每個特征點上,將通道中的每個特征點視為同等重要的位置,使每個特征點均受學習到的權重的影響。
1.3 Med-GloVe
為了進行文本編碼,VQA中通常使用基于Wikipedia語料庫預訓練的公開GloVe詞向量對文本進行編碼[31-32],并采用門控循環單元(gated recurrent unit,GRU)[33]來提取文本序列的特征。這種方法有效捕捉了文本詞匯在問答語境中的語義和語法信息。但醫學文本的專業性和復雜性導致該方案中的GloVe詞向量無法直接被使用。為了解決該問題,本研究利用臨床診斷標準、病歷等醫學數據作為主要語料,通過回譯數據增強[34]方法來增加文本數據量,擴展詞表以挖掘醫學語言中的專業術語和概念,從而改善醫療文本數據的稀缺性問題。在GloVe-S的基礎上進行增量訓練,引入了額外的8 277個醫學專業詞匯,形成了Med-GloVe。具體的技術細節將在2.4節中詳述。將Med-GloVe與GloVe-S的詞向量通過主成分分析技術降維至二維空間,圖5直觀地展示了兩者在核心數據點位置上的偏移。這種偏移不僅證實了Med-GloVe的專業性和有效性,而且為醫學NLP相關任務提供了寶貴的資源。
圖5
Med-Glove與GloVe-S詞表差異
Figure5.
Differences between Med-Glove and GloVe-S word lists
1.4 答案預測網絡
在本研究中,MVQA被視為分類任務,根據三個層次的圖像問題融合特征進行答案預測。多層感知器被用于對注意力特征執行遞歸編碼。受HiQiCA[35]的啟示,通過綜合應用所有從三個層次中提取出的圖像和問題特征對答案進行預測。圖6清晰地展示了對注意力特征執行遞歸編碼的過程。其中w、p、s分別代表單詞、詞組(2 ≤ 單詞數 ≤ 句子長度)和句子;和分別代表文本向量和視覺向量;、、分別代表在單詞、詞組、句子層面上的文本和視覺特征融合后的向量;表示遞歸融合完成后最終句子向量。計算過程見式(4)。
圖6
預測答案編碼器
Figure6.
Encoding for predicting answers
|
|
|
|
|
其中,、、、均為權重參數,是兩個向量的連接操作。P是最終答案的概率。
2 實驗與結果分析
2.1 數據集
本研究主要采用VQA-RAD[36]數據集和Path-VQA[37]數據集進行測試和對比分析。
VQA-RAD是一個手動標記的數據集,包含315張圖像和3 515個相關問題。這些圖像進一步細分為頭部(104張圖像)、胸部(107張圖像)和腹部(104張圖像)三個子類別。根據圖像對應的問答內容,這些圖像可以再分為三類:① 正常圖像;② 顯示異常的圖像,例如液體積聚、腫塊或腫瘤;③ 表現為器官異常的圖像,包括器官體積異常或位置不當。Path-VQA包含從兩本病理學教科書和PEIR數字圖書館收集的總計4 998張病理圖像以及32 799個問答對,該數據集中特有的一種Free-form問題,使得模型不僅要理解圖像與問題,還需要進行推理和解釋才能給出答案,展現出極高的挑戰性。
2.2 模型實驗設置
本模型在一塊NVIDIA RTX 3 090 GPU和一個Intel Core i7-12700K處理器下進行訓練,采用學習率衰減算法,并經過多次調整優化超參數。最終的超參數設定如表1所示。最終評價標準為BLEU,用以評估生成式問題答案與標準答案的相似度。
2.3 MAML的訓練
為構建MAML的訓練數據集,實驗開始前,依據VQA-RAD數據集中的問答對,對部分訓練數據進行人工劃分,篩選出大約3 200個問答對。根據VQA-RAD數據集中圖像對應問答內容的描述,圖像被歸入九種不同的類別,分別是正常頭部、異常頭部、異常頭部器官、正常胸部、異常胸部、異常胸部器官、正常腹部、異常腹部和異常腹部器官。在MAML訓練過程中,每次迭代都會選擇5個任務,每個任務從9個類別中隨機選出3個,而每個類別又隨機選取6張圖像,其中3張用于任務模型的更新,另外3張用于元模型的更新。參數用于更新MLCA模塊。
2.4 預訓練Med-GloVe
本研究從MedPub數據庫中收集醫學領域的相關文本數據,包括醫學論文、病例報告和醫學教材等。對這些文本數據進行預處理,處理步驟包括去除停用詞和進行詞形還原,通過詞頻分析識別出醫學領域中的專業詞匯和術語,為后續的訓練準備數據。根據分析結果,手動構建了一個包含約8 200個詞匯的醫學詞匯庫。本研究選擇了在大規模通用文本上預訓練的GloVe6B-300d模型,命名為GloVe-S,作為基礎模型。使用上述收集的醫學文本對GloVe-S模型進行增量訓練,在此過程中,特別注意醫學專有詞匯的引入,以確保這些專業術語在模型中得到充分的學習和表達。實驗過程中,通過調整訓練權重來優先處理醫學領域的新詞匯和術語,確保新詞匯能夠被有效地融入到本文提出的MCAN框架中。這種方法旨在提高模型對醫學專業內容的理解和應用能力,以期取得更準確的結果。
2.5 模型對比與分析
本文將兩個數據集與當前行業領先的MVQA模型進行對比以保證評估的公正性。GRU作為文本編碼器以確保文本編碼的一致性。需要特別指出,SAN通過多層注意力機制,逐層深化問題和影像之間的交互關系來更精細地理解問題和影像間的聯系。BAN通過對問題的語義表示和圖像的視覺特征進行雙線性匯聚,從而在更高層次上構建問題與圖像間的復雜關聯。MEVF利用大量外部醫學數據進行預訓練。如表2[9, 32, 37-38]、表3[32, 37-38]所示,將本文模型與現有模型分別在Path-VQA和VQA-RAD上進行比較,其中,N-maml表示為元模型數量。
實驗結果表明,本文提出的MCAN架構在Path-VQA和VQA-RAD兩個數據集的封閉式問題中展示出卓越的表現。在兩個數據集上,MCAN將封閉式問題的準確率從之前技術的84.0%和75.8%(MMQ[32])提升至86.22%和79.17%,提升幅度分別為2.6%和4.4%。此外,在Path-VQA數據集中,極具挑戰性的Free-form問題的準確率從之前技術的13.4%(MMQ[32])提升至14.43%,增幅為7.7%。這一成果得益于模型采用計算所有圖像位置與問題位置對的特征相似度的方法,從而更有效地連接圖像與問題。此外,實驗通過使用Med-GloVe的語言嵌入,在MVQA任務中的表現顯著優于未經醫學領域預訓練的GloVe,即證實了將通用語言模型替換為專門的醫學語言模型,不僅提高了模型在封閉式問題上的準確率,還凸顯了醫學文本理解在MVQA中的關鍵作用。
在圖像特征提取的注意力方法方面,借鑒SENet思想,通過學習通道間的關系來調整特征圖中每個通道的重要性,以增強模型在通道級別上的特征關注。為驗證所提模型有效性,表4[6, 16, 32, 37]中的實驗均未使用Med-GloVe。第三、第五行使用了SAN、BAN的基準方法,而“None”表示在其他條件不變下不使用注意力模型。本文將實驗分為基線模型與增強模型。對比結果顯示,增強模型的通道特征提取能顯著提升準確度,見增強模型部分(序號3對應序號6,序號4對應序號7),證明了在視覺特征提取模塊中引入SENet思想可有效提高醫學圖像特征的提取能力。
為了驗證Med-Glove的有效性,本次實驗均基于MMQ上進行消融驗證,如表5所示。相對于GloVe-S(MMQ[32]中使用的方案),使用Med-GloVe時,回答Free-form問題的準確率從13.40%提升到16.50%,Closed問題的準確率從84.00%提升到85.61%,Open問題的準確率從48.80%提升到50.17%。與GloVe-S相比,使用了更大詞表的GloVe-B,包含的詞匯數擴大了近20%,但該方法對于Open類型的問題,其準確率僅提升了0.18%。Med-GloVe與GloVe-S相比,規模僅增長2%,但在三類問題的回答上分別提升了23.13%、1.92%和2.8%的準確率。實驗結果強調了對詞嵌入模型進行領域特定調整的重要性,證明了所提出的Med-GloVe能顯著提高語義匹配的準確性和特定領域的精確度。
3 結論
本文介紹了一種新的MVQA架構MCAN,主要由三個模塊組成:共同注意特征融合模塊FCAF、元學習-通道注意模塊MLCA以及預訓練詞向量Med-GloVe。首先,FCAF模塊通過一種新的多模態特征融合技術實現圖文間的特征交互,有效整合視覺和文本信息至一個共同的表示空間中,以提升信息處理的整合性。其次,MLCA模塊通過自適應調整通道權重,增強了特征提取的表達力和模型的泛化能力。最后,通過融入專為MVQA設計的Med-GloVe,本架構顯著提高了模型對醫療文本序列關系的理解,進而提升了在生成式任務中的準確率。
實驗在VQA-RAD和Path-VQA數據集上進行,結果顯示,本文提出的FCAF模塊與經典融合注意力BAN模塊相比,在文本和圖像的精細化理解上有顯著提升,通過多層級聯增強了模型的推理能力。然而,實驗中發現,由于VQA-RAD和Path-VQA數據集中的醫學圖像細節與復雜性高于一般圖像,僅依賴FCAF模型難以達到理想的性能。此外,盡管采用Med-GloVe詞向量在一定程度上提升了模型的準確率,但面對醫學領域快速發展帶來的詞匯更新,仍存在OOV現象。為進一步提升MCAN架構在醫學領域的應用效果,未來的研究應繼續探索和優化這些方法,尤其是如何有效處理新出現的醫學詞匯,以及如何提升FCAF模型在處理開放性問題上的準確率。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:崔文成負責實驗方向提出和論文修改;施文濤負責數據收集、數據分析、代碼實現和論文寫作;邵虹負責實驗方向提出和論文修改。