針對表面肌電信號時域和頻域特征提取識別手勢的準確性易受影響及分類器識別率低的問題,本文提出一種將表面肌電信號處理為灰度圖,并結合卷積神經網絡作為分類器的手勢精確識別方法。首先,使用能量閾值法截取肌電信號的活動段,通過線性和冪運算對時域電壓值進行處理,生成灰度圖作為卷積神經網絡的輸入。其次,搭建多視野卷積神經網絡模型,使用1 × n和3 × n的異形卷積核,在同一卷積層內實現不同尺寸卷積核并行的結構,以優化對肌電信號的表達能力。實驗結果表明,所提出的方法對13種手勢和12種多指運動的識別準確率分別達到98.11%和98.75%,顯著高于現有機器學習方法。本文提出的基于肌電信號灰度圖與多視野卷積神經網絡的手勢識別方法,具有簡單高效的特點,能夠有效提升手勢識別的準確性,具有較強的應用潛力。
引用本文: 陳清正, 陶慶, 張小棟, 胡學政, 張天樂. 基于表面肌電信號灰度圖和多視野卷積神經網絡的手勢精確識別方法. 生物醫學工程學雜志, 2024, 41(6): 1153-1160. doi: 10.7507/1001-5515.202309007 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
0 引言
表面肌電信號(surface electromyography,sEMG)在康復工程[1]和外骨骼控制等領域得到了廣泛應用[2-4]。通過采集不同手勢的sEMG并進行分類,研究人員致力于構建高效的sEMG手勢識別模型[5-6]。然而,sEMG是一種非線性多電勢疊加的信號,與關節力矩、肌肉力有很強的非線性關系[7],這給其分類器的制作帶來了困難。
目前,機器學習算法是sEMG分類的主流算法,例如K最鄰近(K-nearest neighbor,KNN)[8-9]、線性判別分析(linear discriminant analysis,LDA)[10]、支持向量機(support vector machine,SVM)[11]、人工神經網絡(artificial neural network,ANN)等。為了提高識別精度,研究人員通常會先提取sEMG的有效部分,去除干擾信息,再提取時域、頻域、時頻域特征訓練分類器[12-13]。Narayan等[14]利用ANN和LDA對6種手勢進行分類,獲得了96.4%和94.5%的準確率。都明宇等[15]使用反向傳播(back propagation,BP)神經網絡對6種單指動作、13種多指動作、20種手部動作進行識別,獲得了98.5%、92.4%、90.9%的準確率。然而,這些特征提取方法的準確性易受多種因素影響,導致分類系統的魯棒性不足[16]。
近幾年,許多研究人員將深度學習算法應用于肌電信號的分類識別[17-20]。其中,卷積神經網絡(convolutional neural network,CNN)因其優異的特征提取能力而成為主要研究對象[21-23]。研究人員通過將sEMG轉化為圖像訓練CNN,取得了良好的識別效果。Ding等[24]使用原始肌電圖訓練CNN,在Ninapro-DB1[25]數據集上得到了較高的識別精度。許留凱等[26]將sEMG的能量密度繪制成相圖,將相圖作為CNN的輸入,在2、4、8種手勢識別實驗中均達到93%以上的識別精度。Duan等[17]將sEMG轉換為頻譜圖通過CNN對10種手勢進行識別,精度達94.06%。但是,這些方法未深入探討網絡深度和卷積核尺寸對模型性能的影響,且圖像化處理的流程較為復雜。
針對上述問題,本文提出一種基于sEMG灰度圖和多視野卷積神經網絡的手勢識別新方法。該方法通過對sEMG進行線性運算和冪運算,將運算后的矩陣轉化為灰度圖,結合CNN實現手勢識別。這種方法旨在更直觀地展示sEMG的時域特性[27],并利用CNN的多層結構提取更豐富的特征,實現多種手勢的精確識別。
1 表面肌電信號灰度圖獲取方法
1.1 表面肌電信號采集
本文采集人體右前臂4通道sEMG,采集區域如圖1左上所示。4個采集點距離肘關節40 mm,各采集通道圍繞前臂等距分布,采集通道的兩電極間隔20 mm。sEMG采集設備如圖1右上所示,為葡萄牙PLUX公司的Biosignalsplux Hybrid-8生物信號采集系統,采樣率為1 000 Hz。
 圖1
表面肌電信號采集
Figure1.
Surface electromyography signal acquisition
圖1
表面肌電信號采集
Figure1.
Surface electromyography signal acquisition
共有13名受試者參與sEMG采集(年齡22~27歲,男性8人,女性5人),受試者均無關節或神經疾病史,詳細信息參見附件1。本研究獲得西安交通大學第二附屬醫院醫學倫理委員會的審核批準(批文編號:2024YS239),所有受試者均簽署了知情同意書,并授權可使用相關數據。手勢動作如圖1下側所示,共采集13種手勢。為方便對sEMG有效部分的提取,對手勢的采集過程進行規范化。手勢的運動時間為1~2 s,完成一次動作之后放松3~4 s,之后再繼續動作。每次動作的時間間隔為5 s,以放松~動作~放松的形式循環采集20次。
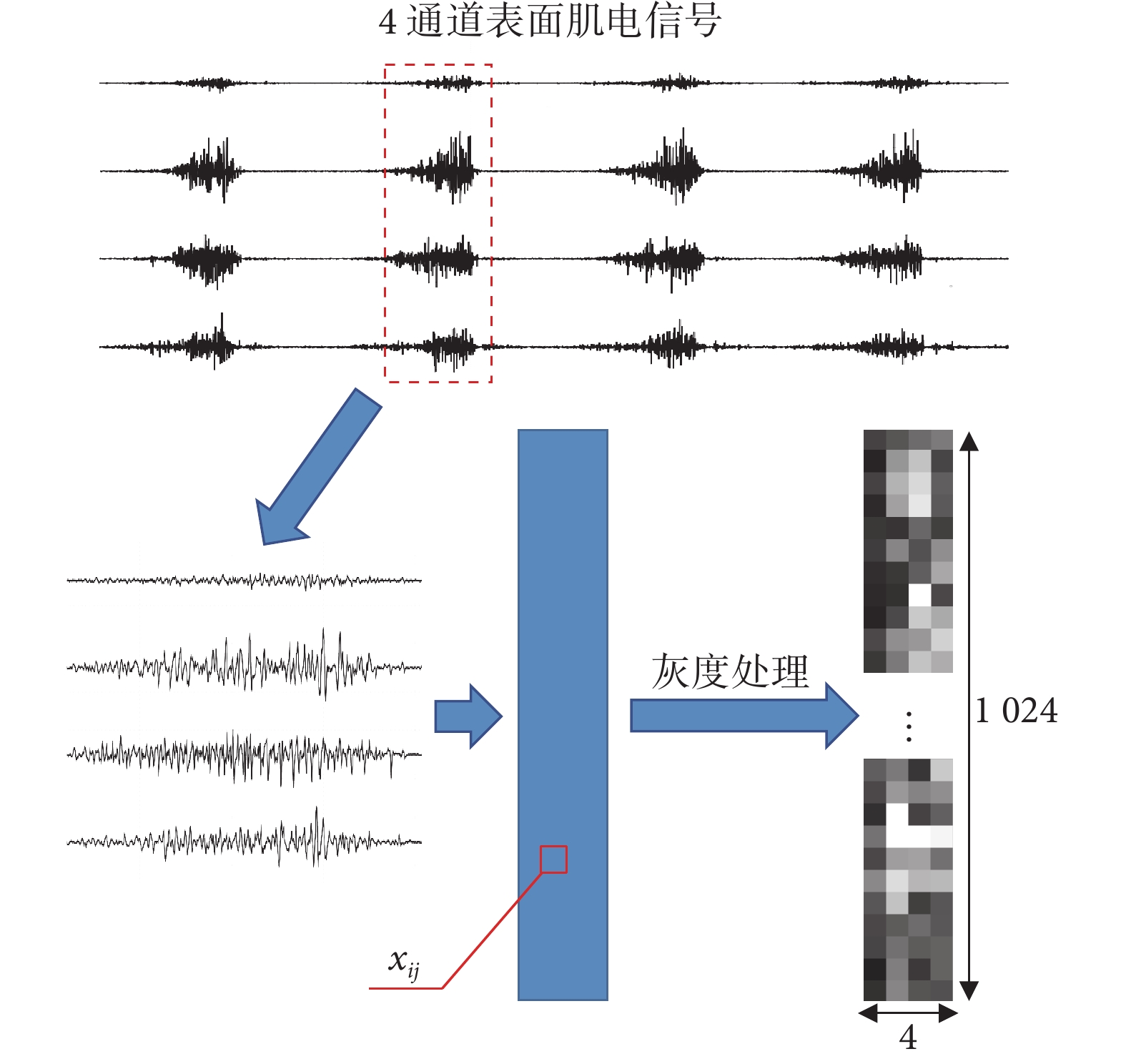
1.2 灰度圖提取算法
灰度圖的提取過程如圖2所示。使用10~250 Hz的帶通濾波器和50 Hz的陷波濾波器過濾信號中的噪聲。使用能量閾值來檢測sEMG的有效部分,閾值大小根據實驗需求而定。
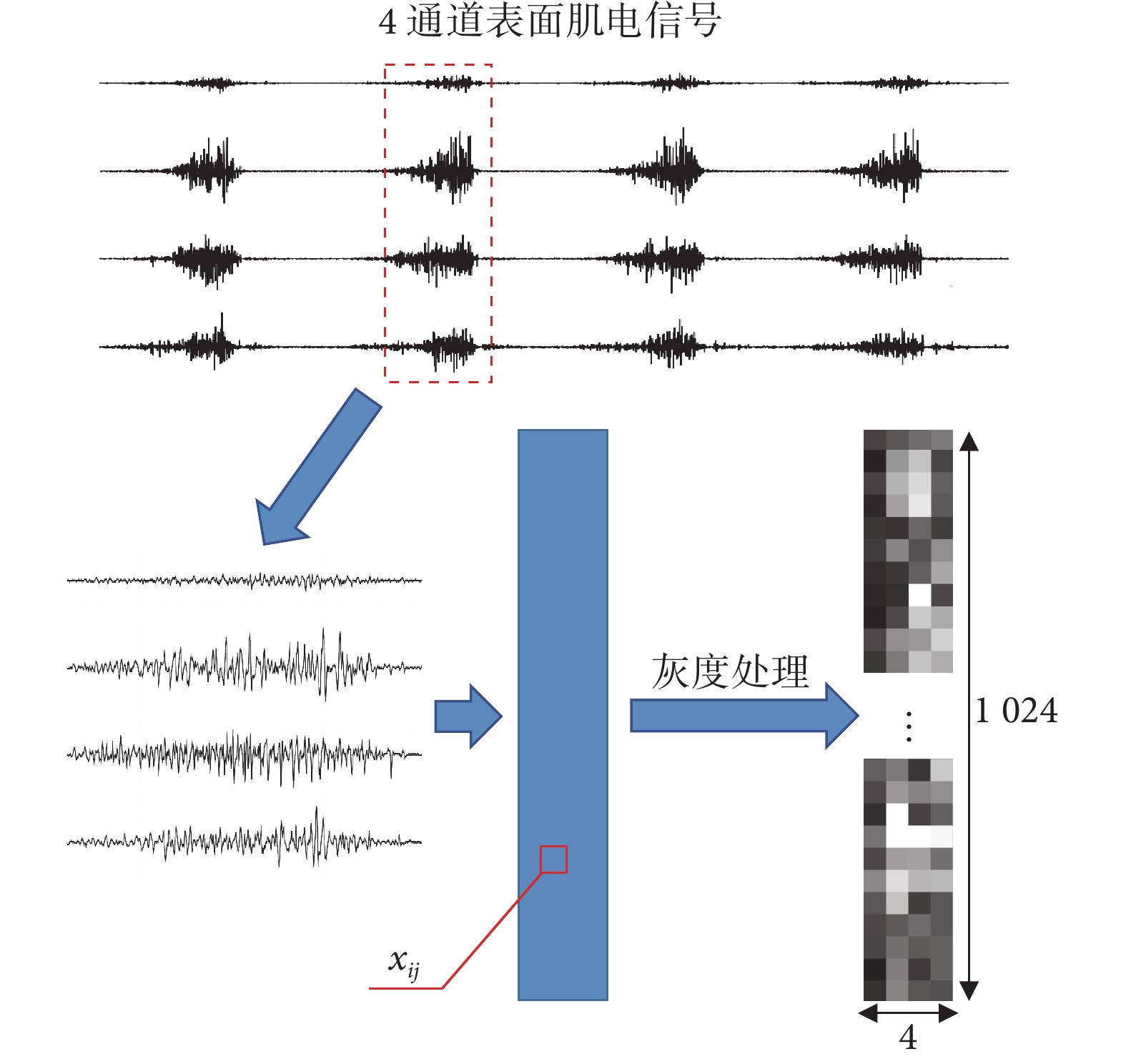 圖2
灰度圖提取過程
Figure2.
Extraction process of grayscale image
圖2
灰度圖提取過程
Figure2.
Extraction process of grayscale image
 |
式(1)中,n為采集通道數, 為第k窗口(窗口尺寸4 × 512,步長256,)內的能量均值,
為第k窗口(窗口尺寸4 × 512,步長256,)內的能量均值, 為j通道k窗口i時刻的電壓值。
為j通道k窗口i時刻的電壓值。
用尺寸4 × 1 536的窗口采樣連續5次超越閾值的數據作為樣本。樣本數量:13(受試者數量) × 13(手勢種類) × 20(重復次數) = 3 380。剔除部分不合格的樣本(采集過程中電極松脫和首尾不完整的信號)后得到3 330個樣本。之后用尺寸4 × 1 024的滑動窗口對每一個樣本進行交錯采樣,步長為512,最終得到6 660個擴充后的樣本。
PLUX采集系統所保存的原始數據不是sEMG的時域電壓值,通過式(2)對電壓值進行逆向求解。
 |
式中 為j通道、i時刻的電壓值,
為j通道、i時刻的電壓值, 為系統輸出的原始數值,n = 16,VCC(3V)為采集系統工作電壓。
為系統輸出的原始數值,n = 16,VCC(3V)為采集系統工作電壓。
求出的 數值較小,為匹配神經網絡的初始權重并降低迭代開始時的損失值[15],將電壓單位轉為mV,通過式(3)對電壓值進行線性增大,用指數0.8對電壓值進行壓縮,保留樣本的數值紋理。
數值較小,為匹配神經網絡的初始權重并降低迭代開始時的損失值[15],將電壓單位轉為mV,通過式(3)對電壓值進行線性增大,用指數0.8對電壓值進行壓縮,保留樣本的數值紋理。
 |
通過式(4)對電壓值進行過濾,去除干擾值。將樣本制成灰度圖片, 的大小為灰度圖像素點的亮度值。
的大小為灰度圖像素點的亮度值。
 |
通過式(5)對數據進行歸一化,為每個樣本貼上相應手勢動作的標簽0~12。
 |
2 多視野卷積神經網絡識別模型構建
2.1 網絡拓撲結構
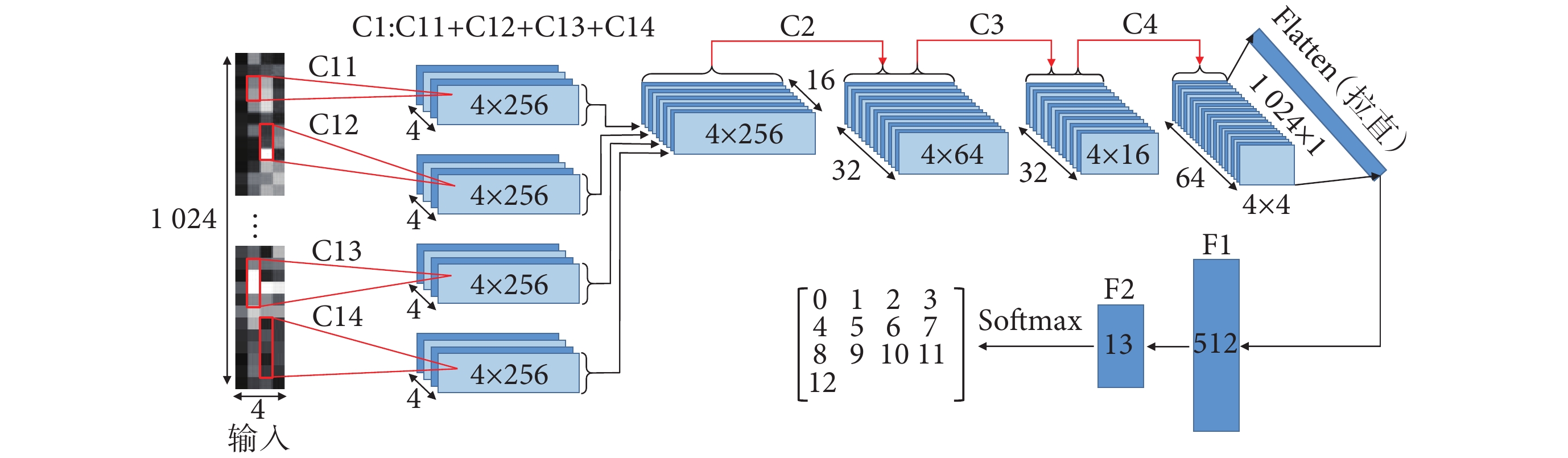
本文提出一種多視野卷積神經網絡(CNN4-M),通過卷積層提取sEMG特征,使用池化層縮減特征的時域維度。CNN4-M首層采用不同尺寸卷積核并行的結構,可從多尺度提取sEMG時域特征并映射至網絡中。針對sEMG數據特點,CNN4-M使用異形卷積核來提取時域特征。CNN4-M結構如圖3所示,C1、C2層使用尺寸為1×n的卷積核,對sEMG的每個通道分別進行特征提取。其中,C1為多視野卷積層,由C11、C12、C13、C14并聯組成。C3、C4層分別使用尺寸為3 × 9、3 × 5的卷積核,提取sEMG各通道之間的關聯特征。F1為512個神經元組成的全連接層,F2為13個神經元和Softmax函數組成的輸出層。
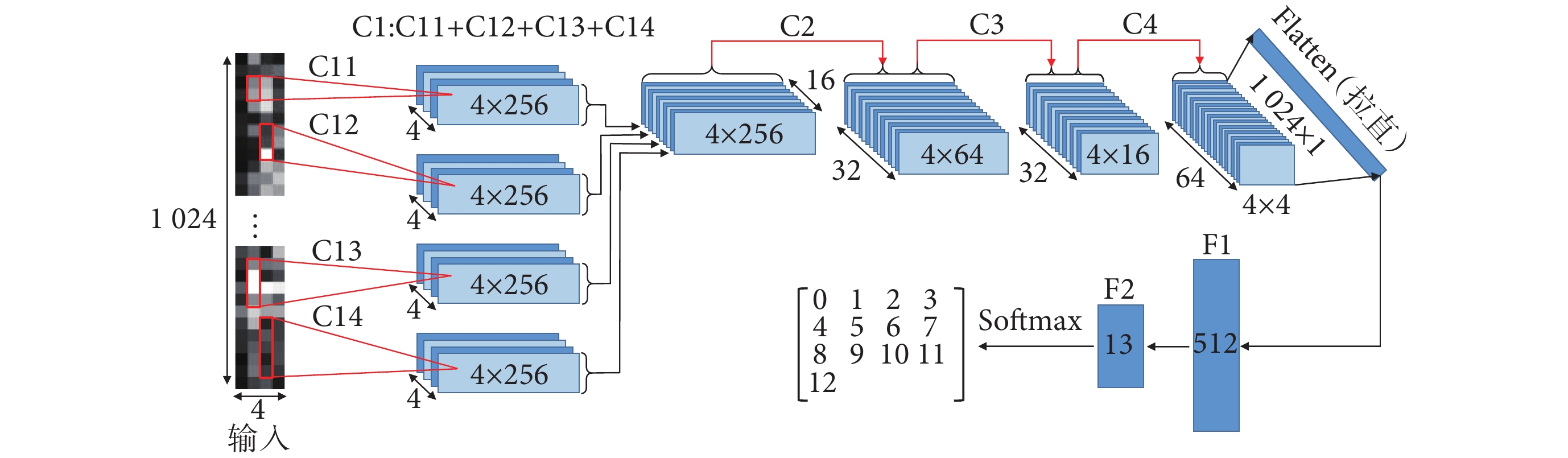 圖3
多視野卷積神經網絡結構
Figure3.
The structure of CNN4-M
圖3
多視野卷積神經網絡結構
Figure3.
The structure of CNN4-M
2.2 手勢識別模型的參數選擇
CNN4-M的模型參數如表1所示,模型的損失函數為交叉熵。其中,Conv為卷積操作;Max pooling為最大池化操作;BN為批量歸一化操作,有利于提升模型的非線性表達能力;Dropout為舍棄操作,可在模型訓練時將一部分神經元休眠不參與訓練,有利于減少模型的過擬合現象(本文中的Dropout參數均為0.2);FC為全連接層。Softmax函數可將神經元的輸出映射在(0,1)區間內,根據概率分布情況,生產預測結果。式(6)中, 為第i神經元輸出結果。ReLU為激活函數,可以為網絡引入非線性因素,提高模型的表達能力,式(7)中,當輸入x < 0時,輸出為0;x≥0時,輸出是x本身。
為第i神經元輸出結果。ReLU為激活函數,可以為網絡引入非線性因素,提高模型的表達能力,式(7)中,當輸入x < 0時,輸出為0;x≥0時,輸出是x本身。
 |
 |
3 實驗與分析
在本文中,深度學習模型構建所使用的工具和開發環境為:深度學習框架TensorFlow2.1;工具PyCharm IDE;環境Python 3.7。
3.1 訓練配置和評價指標
模型的訓練配置如下:將樣本(6 660)隨機分配,70%用于訓練,30%用于測試;優化器使用Adam[28],學習率為0.000 1;批次大小(每次輸入模型的樣本數量)為64,模型迭代1 000次,取模型最后一次訓練和驗證的結果。使用準確率(Accuracy)、精確率(Precision)、召回率(Recall)和F1 Score作為模型的評價指標。
 |
 |
 |
 |
式中,TP、TN分別為被正確識別出的同種手勢和不同種手勢的數量,FP、FN為被錯誤識別出的同種手勢和不同種手勢的數量
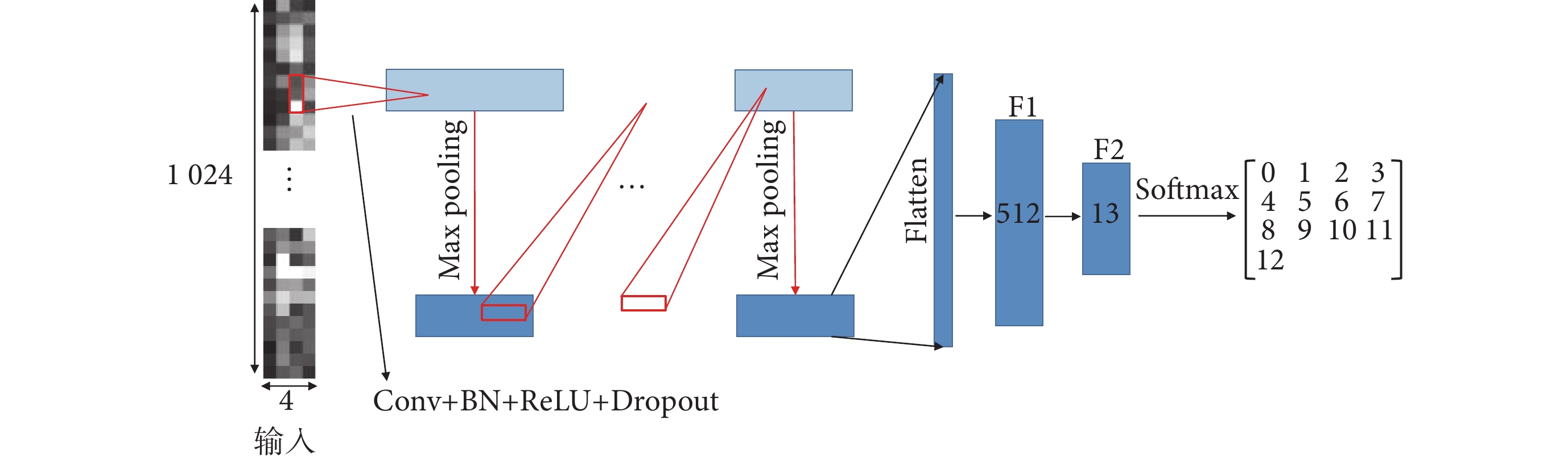
3.2 模型深度的選擇
不同深度模型對sEMG的表達能力有所不同,較深的模型識別性能較好[29],但隨著網絡深度的增加,可能出現梯度消失的情況[30]。為找到較優的模型深度,本小節通過調整模型的網絡深度搭建了6個模型。方法如圖4所示,將Conv + BN + ReLU + Dropout定義為標準層,使用不同數量的標準層,搭建不同深度的模型。其中,卷積核的尺寸均為1 × 9,步長為1;池化核的尺寸為1 × n,步長為1 × n。模型輸出特征數據的尺寸如表2所示,其中,FCNN為F1和 F2組成的全連接網絡模型。
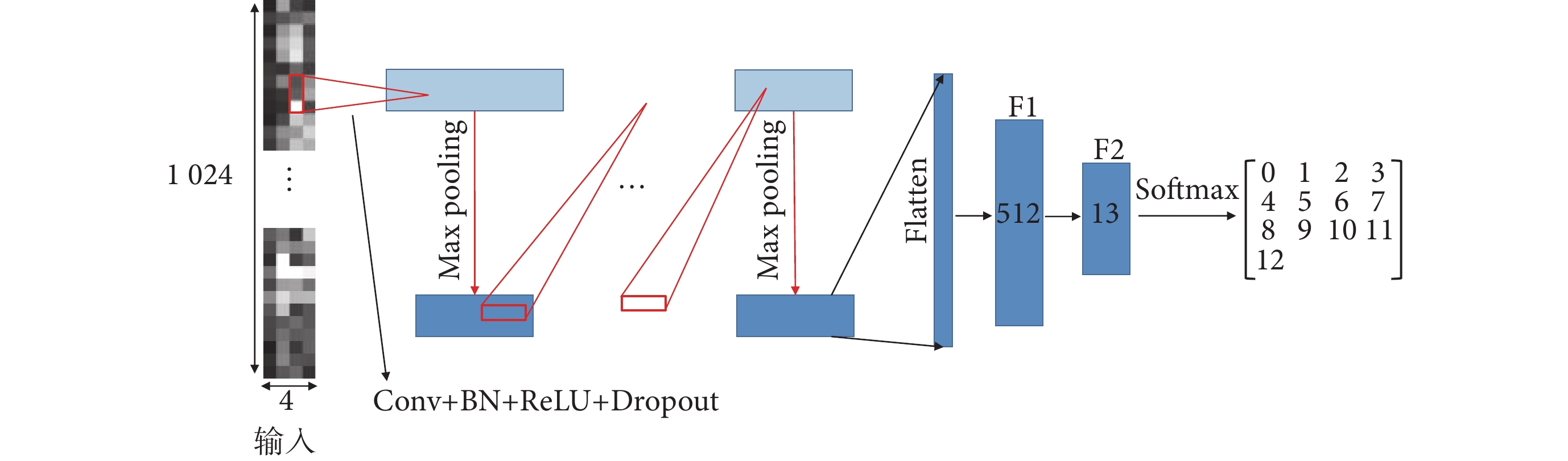 圖4
不同深度CNN模型的搭建方法
Figure4.
Methods for building CNN models with different depths
圖4
不同深度CNN模型的搭建方法
Figure4.
Methods for building CNN models with different depths
實驗結果如表3所示,ANOVA結果顯示F = 9 685.44,P = 3.33e-30(P<0.05),各模型的實驗結果存在顯著差異。FCNN的準確率最低,為30.18%,加入標準層后,CNN1的準確率提高到64.66%。深度為3、4、5層的模型都有不錯的識別準確率,其中深度為4層的CNN4準確率最高,為95.15%,相較于CNN3和CNN5的準確率分別提升了2.26%和1.41%(P<0.05)。
3.3 模型卷積核尺寸的調整
不同尺寸卷積核對sEMG的特征提取能力有所不同。本小節根據sEMG的特點,調整CNN4模型的卷積核尺寸分別搭建了3個模型,模型的卷積核尺寸如表4所示。CNN4-1第一層的卷積核尺寸調整為1 × 27,使用較大尺寸卷積核;CNN4-2在第一層使用4種不同尺寸的卷積核,從多個尺度提取sEMG的特征;CNN4-3的3、4層分別使用3 × 9、3 × 5的卷積核,提取sEMG各通道的協同特征。
實驗結果如表5所示,ANOVA結果為F = 1 792.40,P = 6.70E-20(P < 0.05),各模型的實驗結果存在顯著差異。CNN4-2、CNN4-3的準確率分別為97.40%、97.30%,對比CNN4分別提升了2.25%和2.15%(P < 0.05)。說明在模型中使用不同尺寸的卷積核可以有效提升對sEMG的表達能力。結合CNN4-2和CNN4-3結構特點的CNN4-M在所有評價指標上均顯著優于其他模型(P < 0.05)。對比CNN4,CNN4-M的準確率、精確率、召回率和F1 Score分別提升了3.00%、2.83%、3.05%和2.98%(P < 0.05),優化后的CNN4-M在準確性上更具優勢。
使用GPU(GTX1070ti)加速的情況下,CNN4-M識別每一個樣本花費的時間僅為0.567 ms。CNN4-M的混淆矩陣參見附件2,個別手勢的識別精度存在一定差異,這可能與手勢的復雜性和區分度有關。一些手勢更具顯著特征,信號表現較為獨特,因此模型更容易準確區分(例如0、6、7、12號手勢),而某些手勢可能與其他手勢的信號特征較為相似,導致模型較難有效區分(例如5號手勢)。
3.4 對比試驗
為獲取對比效果,本文使用BP神經網絡、決策樹(decision tree,DT)、SVM、KNN四種機器學習方法和Lenet、Alexnet、Vgg16、Resnet34四種CNN作對比實驗,數據使用包含13種手勢的自制數據集和Ninapro-DB1數據集。
Ninapro-DB1數據集內包含27個受試者的52種手部動作,每種動作重復10次,本文使用第一組12種多指運動的sEMG數據。Ninapro-DB1內sEMG的采樣率、通道數、采樣時間分別為:100 Hz、10通道、5 s。用尺寸為10 × 786的窗口裁剪連續2次超越閾值的數據作為樣本。樣本數量:27(受試者數量) × 12(手勢種類) × 10(重復次數) = 3 240。對數據進行擴充,用尺寸10 × 490的滑動窗口對每一個樣本進行交錯采樣,步長為296,得到6 480個擴充后的樣本。之后,通過式(3)~(5)對樣本進行處理。
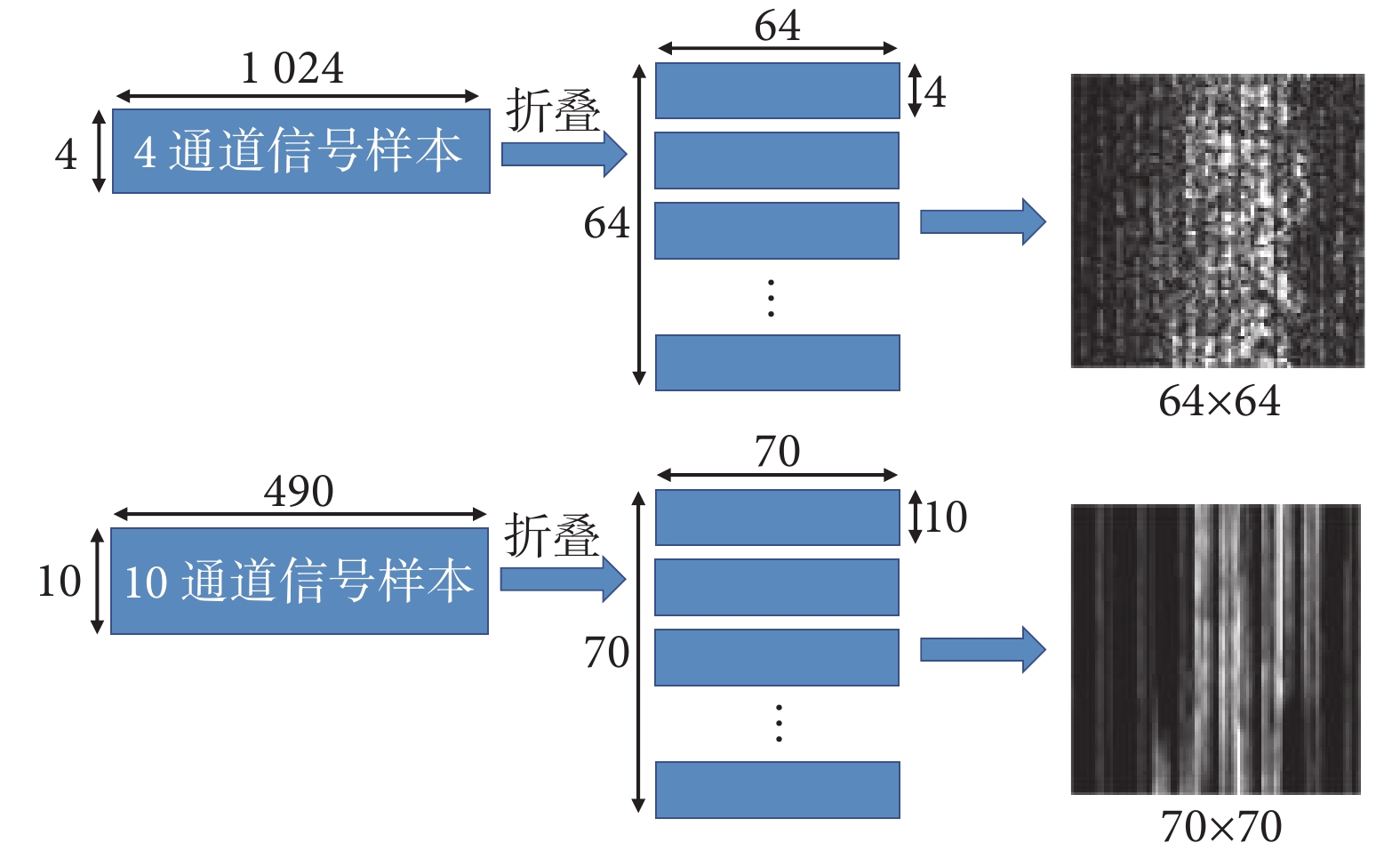
為適應Lenet、Alexnet、Vgg16、Resnet34的網絡結構,需對樣本的數據結構進行調整,自制數據集的樣本尺寸調整為64×64,Ninapro-DB1數據集的樣本尺寸調整為70×70,調整方法如圖5所示。
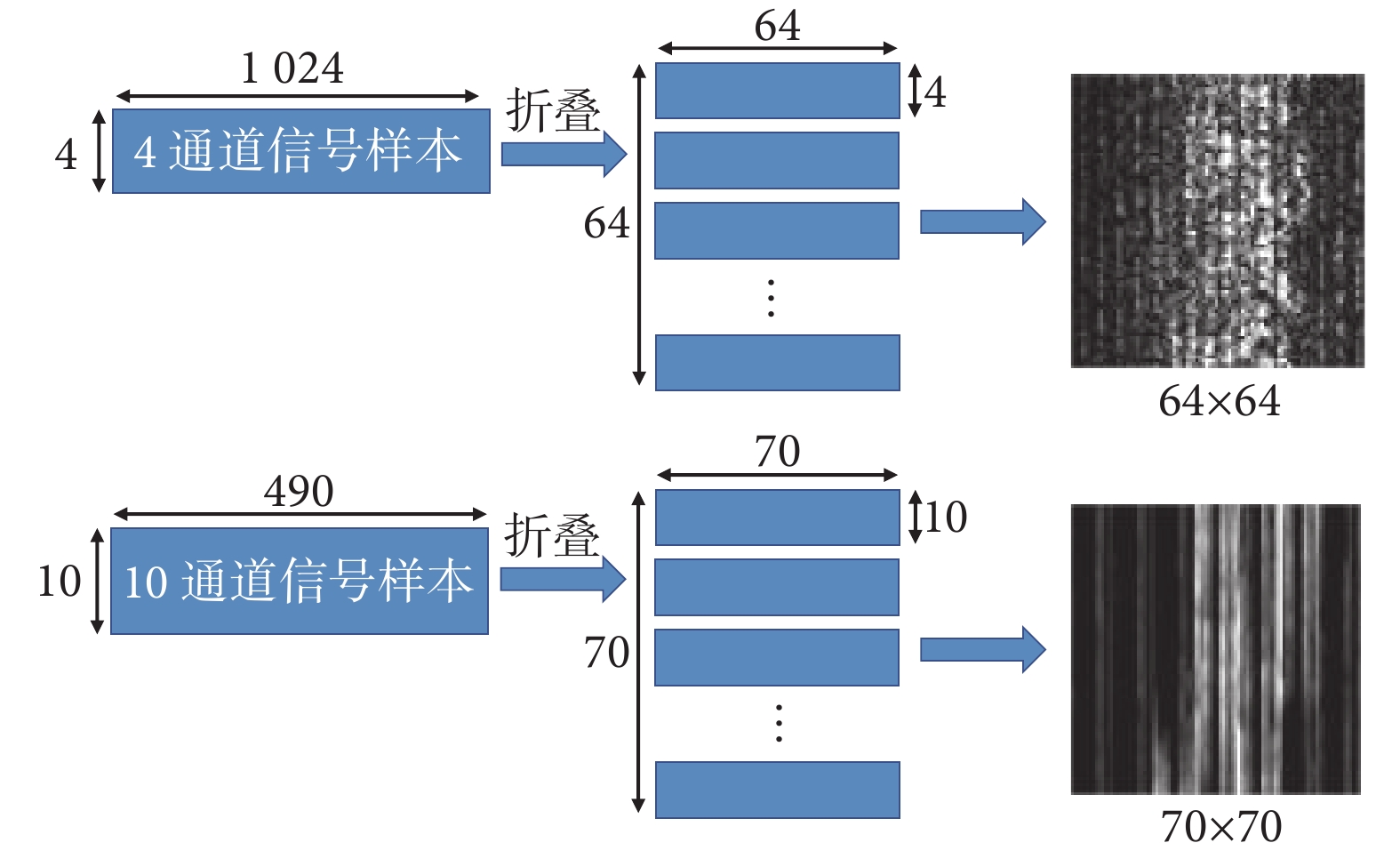 圖5
數據結構的調整
Figure5.
Data structure adjustment
圖5
數據結構的調整
Figure5.
Data structure adjustment
機器學習模型中,BP輸入層和隱含層節點數分別為40、60,輸出層節點數根據樣本類別數而定,學習率為0.01。SVM核函數使用徑向基函數核,核寬度調整為1。使用sEMG特征對機器學習模型進行訓練,提取sEMG每個通道的4個時域特征和2個頻域特征。時域特征為絕對平均值(mean absolute value,MAV)、均方根值(root mean square,RMS)、方差(variance,VAR)和波長(wave length,WL),頻域特征為平均功率頻率(mean power frequency,MPF)和中值頻率(median frequency,MF)。
 |
 |
 |
 |
 |
 |
式(12)~(17)中,L為窗口長度, 為第i窗口的第k數值,N為樣本個數,
為第i窗口的第k數值,N為樣本個數, 為功率譜的密度計算函數。
為功率譜的密度計算函數。
本文對CNN模型的尋優過程中使用7∶3比例來劃分訓練和測試樣本,這可能會導致數據泄露問題,讓模型準確率虛高。因此,在本小節使用交叉驗證方法來評估模型,讓實驗結果更可靠。
表6和表7是四種機器學習模型在自制數據集和Ninapro-DB1數據集上5折交叉驗證的準確率,其中“T”“F”“TF”分別表示4個時域特征組合、2個頻域特征組合、所有特征組合。結果顯示,DT、BP和KNN在使用時域特征(T)組合時的準確率最高,在自制數據集上的準確率分別為75.80%、91.77%和93.17%,在Ninapro-DB1數據集上的準確率分別為86.61%、94.60%和94.52%。SVM在使用所有特征組合(TF)時的準確率最高,在兩個數據集上的準確率分別為92.03%和95.58%。表6、表7各模型在不同特征組合下的識別準確率存在顯著差異(P<0.05)。
5折交叉驗證結果如表8所示,其中DT-T、BP-T、SVM-TF、KNN-T為表6~7中四種機器學習模型的最佳測試結果。在四種CNN中,Vgg16在自制數據集中的準確率最高,為94.18%,Resnet34在Ninapro-DB1數據集上的準確率最高,為98.06%。CNN4-M的準確率要高于四種機器學習模型和四種CNN,在自制數據集和Ninapro-DB1數據集上的準確率分別為98.11%和98.75%。
與本文相似研究的文獻結果展示在表9,其中DB2、DB3、DB5為Ninapro里的標準數據集。由表9可知,本文的方法在分類精度上有明顯優勢,在手勢分類數相近的情況下,本文所提手勢識別方法的分類精度高于以往的研究。
4 結論
本文提出了一種基于sEMG灰度圖和多視野卷積神經網絡的手勢精確識別方法。通過對sEMG電壓值的線性變換和冪計算,保留sEMG數值紋理并制成灰度圖,用灰度圖作為CNN的輸入。搭建多視野卷積神經網絡CNN4-M,對13種常見手勢及Ninapro-DB1內12種多指運動進行測試,識別精度可達98.11%和98.75%。對比四種常用的機器學習方法和四種經典CNN,CNN4-M擁有最高的識別精度。本文所制作的sEMG灰度圖在經典CNN上同樣擁有適用性,在Vgg16上的測試精度可達94.18%,在Resnet34上的測試精度可達98.06%。在下一步的研究中,將縮短訓練樣本的時域長度,提高模型對手勢識別的實時性。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:陳清正主要負責實驗流程、算法設計、論文編寫;陶慶、張小棟主要負責實驗指導、論文審閱修訂;胡學政、張天樂參與數據采集及預處理。
倫理聲明:本研究獲得了西安交通大學第二附屬醫院醫學倫理委員會的審批(批文編號:2024YS239)。
本文附件見本刊網站的電子版本(biomedeng.cn)。
0 引言
表面肌電信號(surface electromyography,sEMG)在康復工程[1]和外骨骼控制等領域得到了廣泛應用[2-4]。通過采集不同手勢的sEMG并進行分類,研究人員致力于構建高效的sEMG手勢識別模型[5-6]。然而,sEMG是一種非線性多電勢疊加的信號,與關節力矩、肌肉力有很強的非線性關系[7],這給其分類器的制作帶來了困難。
目前,機器學習算法是sEMG分類的主流算法,例如K最鄰近(K-nearest neighbor,KNN)[8-9]、線性判別分析(linear discriminant analysis,LDA)[10]、支持向量機(support vector machine,SVM)[11]、人工神經網絡(artificial neural network,ANN)等。為了提高識別精度,研究人員通常會先提取sEMG的有效部分,去除干擾信息,再提取時域、頻域、時頻域特征訓練分類器[12-13]。Narayan等[14]利用ANN和LDA對6種手勢進行分類,獲得了96.4%和94.5%的準確率。都明宇等[15]使用反向傳播(back propagation,BP)神經網絡對6種單指動作、13種多指動作、20種手部動作進行識別,獲得了98.5%、92.4%、90.9%的準確率。然而,這些特征提取方法的準確性易受多種因素影響,導致分類系統的魯棒性不足[16]。
近幾年,許多研究人員將深度學習算法應用于肌電信號的分類識別[17-20]。其中,卷積神經網絡(convolutional neural network,CNN)因其優異的特征提取能力而成為主要研究對象[21-23]。研究人員通過將sEMG轉化為圖像訓練CNN,取得了良好的識別效果。Ding等[24]使用原始肌電圖訓練CNN,在Ninapro-DB1[25]數據集上得到了較高的識別精度。許留凱等[26]將sEMG的能量密度繪制成相圖,將相圖作為CNN的輸入,在2、4、8種手勢識別實驗中均達到93%以上的識別精度。Duan等[17]將sEMG轉換為頻譜圖通過CNN對10種手勢進行識別,精度達94.06%。但是,這些方法未深入探討網絡深度和卷積核尺寸對模型性能的影響,且圖像化處理的流程較為復雜。
針對上述問題,本文提出一種基于sEMG灰度圖和多視野卷積神經網絡的手勢識別新方法。該方法通過對sEMG進行線性運算和冪運算,將運算后的矩陣轉化為灰度圖,結合CNN實現手勢識別。這種方法旨在更直觀地展示sEMG的時域特性[27],并利用CNN的多層結構提取更豐富的特征,實現多種手勢的精確識別。
1 表面肌電信號灰度圖獲取方法
1.1 表面肌電信號采集
本文采集人體右前臂4通道sEMG,采集區域如圖1左上所示。4個采集點距離肘關節40 mm,各采集通道圍繞前臂等距分布,采集通道的兩電極間隔20 mm。sEMG采集設備如圖1右上所示,為葡萄牙PLUX公司的Biosignalsplux Hybrid-8生物信號采集系統,采樣率為1 000 Hz。
圖1
表面肌電信號采集
Figure1.
Surface electromyography signal acquisition
共有13名受試者參與sEMG采集(年齡22~27歲,男性8人,女性5人),受試者均無關節或神經疾病史,詳細信息參見附件1。本研究獲得西安交通大學第二附屬醫院醫學倫理委員會的審核批準(批文編號:2024YS239),所有受試者均簽署了知情同意書,并授權可使用相關數據。手勢動作如圖1下側所示,共采集13種手勢。為方便對sEMG有效部分的提取,對手勢的采集過程進行規范化。手勢的運動時間為1~2 s,完成一次動作之后放松3~4 s,之后再繼續動作。每次動作的時間間隔為5 s,以放松~動作~放松的形式循環采集20次。
1.2 灰度圖提取算法
灰度圖的提取過程如圖2所示。使用10~250 Hz的帶通濾波器和50 Hz的陷波濾波器過濾信號中的噪聲。使用能量閾值來檢測sEMG的有效部分,閾值大小根據實驗需求而定。
圖2
灰度圖提取過程
Figure2.
Extraction process of grayscale image
|
式(1)中,n為采集通道數,為第k窗口(窗口尺寸4 × 512,步長256,)內的能量均值,為j通道k窗口i時刻的電壓值。
用尺寸4 × 1 536的窗口采樣連續5次超越閾值的數據作為樣本。樣本數量:13(受試者數量) × 13(手勢種類) × 20(重復次數) = 3 380。剔除部分不合格的樣本(采集過程中電極松脫和首尾不完整的信號)后得到3 330個樣本。之后用尺寸4 × 1 024的滑動窗口對每一個樣本進行交錯采樣,步長為512,最終得到6 660個擴充后的樣本。
PLUX采集系統所保存的原始數據不是sEMG的時域電壓值,通過式(2)對電壓值進行逆向求解。
|
式中為j通道、i時刻的電壓值,為系統輸出的原始數值,n = 16,VCC(3V)為采集系統工作電壓。
求出的數值較小,為匹配神經網絡的初始權重并降低迭代開始時的損失值[15],將電壓單位轉為mV,通過式(3)對電壓值進行線性增大,用指數0.8對電壓值進行壓縮,保留樣本的數值紋理。
|
通過式(4)對電壓值進行過濾,去除干擾值。將樣本制成灰度圖片,的大小為灰度圖像素點的亮度值。
|
通過式(5)對數據進行歸一化,為每個樣本貼上相應手勢動作的標簽0~12。
|
2 多視野卷積神經網絡識別模型構建
2.1 網絡拓撲結構
本文提出一種多視野卷積神經網絡(CNN4-M),通過卷積層提取sEMG特征,使用池化層縮減特征的時域維度。CNN4-M首層采用不同尺寸卷積核并行的結構,可從多尺度提取sEMG時域特征并映射至網絡中。針對sEMG數據特點,CNN4-M使用異形卷積核來提取時域特征。CNN4-M結構如圖3所示,C1、C2層使用尺寸為1×n的卷積核,對sEMG的每個通道分別進行特征提取。其中,C1為多視野卷積層,由C11、C12、C13、C14并聯組成。C3、C4層分別使用尺寸為3 × 9、3 × 5的卷積核,提取sEMG各通道之間的關聯特征。F1為512個神經元組成的全連接層,F2為13個神經元和Softmax函數組成的輸出層。
圖3
多視野卷積神經網絡結構
Figure3.
The structure of CNN4-M
2.2 手勢識別模型的參數選擇
CNN4-M的模型參數如表1所示,模型的損失函數為交叉熵。其中,Conv為卷積操作;Max pooling為最大池化操作;BN為批量歸一化操作,有利于提升模型的非線性表達能力;Dropout為舍棄操作,可在模型訓練時將一部分神經元休眠不參與訓練,有利于減少模型的過擬合現象(本文中的Dropout參數均為0.2);FC為全連接層。Softmax函數可將神經元的輸出映射在(0,1)區間內,根據概率分布情況,生產預測結果。式(6)中,為第i神經元輸出結果。ReLU為激活函數,可以為網絡引入非線性因素,提高模型的表達能力,式(7)中,當輸入x < 0時,輸出為0;x≥0時,輸出是x本身。
|
|
3 實驗與分析
在本文中,深度學習模型構建所使用的工具和開發環境為:深度學習框架TensorFlow2.1;工具PyCharm IDE;環境Python 3.7。
3.1 訓練配置和評價指標
模型的訓練配置如下:將樣本(6 660)隨機分配,70%用于訓練,30%用于測試;優化器使用Adam[28],學習率為0.000 1;批次大小(每次輸入模型的樣本數量)為64,模型迭代1 000次,取模型最后一次訓練和驗證的結果。使用準確率(Accuracy)、精確率(Precision)、召回率(Recall)和F1 Score作為模型的評價指標。
|
|
|
|
式中,TP、TN分別為被正確識別出的同種手勢和不同種手勢的數量,FP、FN為被錯誤識別出的同種手勢和不同種手勢的數量
3.2 模型深度的選擇
不同深度模型對sEMG的表達能力有所不同,較深的模型識別性能較好[29],但隨著網絡深度的增加,可能出現梯度消失的情況[30]。為找到較優的模型深度,本小節通過調整模型的網絡深度搭建了6個模型。方法如圖4所示,將Conv + BN + ReLU + Dropout定義為標準層,使用不同數量的標準層,搭建不同深度的模型。其中,卷積核的尺寸均為1 × 9,步長為1;池化核的尺寸為1 × n,步長為1 × n。模型輸出特征數據的尺寸如表2所示,其中,FCNN為F1和 F2組成的全連接網絡模型。
圖4
不同深度CNN模型的搭建方法
Figure4.
Methods for building CNN models with different depths
實驗結果如表3所示,ANOVA結果顯示F = 9 685.44,P = 3.33e-30(P<0.05),各模型的實驗結果存在顯著差異。FCNN的準確率最低,為30.18%,加入標準層后,CNN1的準確率提高到64.66%。深度為3、4、5層的模型都有不錯的識別準確率,其中深度為4層的CNN4準確率最高,為95.15%,相較于CNN3和CNN5的準確率分別提升了2.26%和1.41%(P<0.05)。
3.3 模型卷積核尺寸的調整
不同尺寸卷積核對sEMG的特征提取能力有所不同。本小節根據sEMG的特點,調整CNN4模型的卷積核尺寸分別搭建了3個模型,模型的卷積核尺寸如表4所示。CNN4-1第一層的卷積核尺寸調整為1 × 27,使用較大尺寸卷積核;CNN4-2在第一層使用4種不同尺寸的卷積核,從多個尺度提取sEMG的特征;CNN4-3的3、4層分別使用3 × 9、3 × 5的卷積核,提取sEMG各通道的協同特征。
實驗結果如表5所示,ANOVA結果為F = 1 792.40,P = 6.70E-20(P < 0.05),各模型的實驗結果存在顯著差異。CNN4-2、CNN4-3的準確率分別為97.40%、97.30%,對比CNN4分別提升了2.25%和2.15%(P < 0.05)。說明在模型中使用不同尺寸的卷積核可以有效提升對sEMG的表達能力。結合CNN4-2和CNN4-3結構特點的CNN4-M在所有評價指標上均顯著優于其他模型(P < 0.05)。對比CNN4,CNN4-M的準確率、精確率、召回率和F1 Score分別提升了3.00%、2.83%、3.05%和2.98%(P < 0.05),優化后的CNN4-M在準確性上更具優勢。
使用GPU(GTX1070ti)加速的情況下,CNN4-M識別每一個樣本花費的時間僅為0.567 ms。CNN4-M的混淆矩陣參見附件2,個別手勢的識別精度存在一定差異,這可能與手勢的復雜性和區分度有關。一些手勢更具顯著特征,信號表現較為獨特,因此模型更容易準確區分(例如0、6、7、12號手勢),而某些手勢可能與其他手勢的信號特征較為相似,導致模型較難有效區分(例如5號手勢)。
3.4 對比試驗
為獲取對比效果,本文使用BP神經網絡、決策樹(decision tree,DT)、SVM、KNN四種機器學習方法和Lenet、Alexnet、Vgg16、Resnet34四種CNN作對比實驗,數據使用包含13種手勢的自制數據集和Ninapro-DB1數據集。
Ninapro-DB1數據集內包含27個受試者的52種手部動作,每種動作重復10次,本文使用第一組12種多指運動的sEMG數據。Ninapro-DB1內sEMG的采樣率、通道數、采樣時間分別為:100 Hz、10通道、5 s。用尺寸為10 × 786的窗口裁剪連續2次超越閾值的數據作為樣本。樣本數量:27(受試者數量) × 12(手勢種類) × 10(重復次數) = 3 240。對數據進行擴充,用尺寸10 × 490的滑動窗口對每一個樣本進行交錯采樣,步長為296,得到6 480個擴充后的樣本。之后,通過式(3)~(5)對樣本進行處理。
為適應Lenet、Alexnet、Vgg16、Resnet34的網絡結構,需對樣本的數據結構進行調整,自制數據集的樣本尺寸調整為64×64,Ninapro-DB1數據集的樣本尺寸調整為70×70,調整方法如圖5所示。
圖5
數據結構的調整
Figure5.
Data structure adjustment
機器學習模型中,BP輸入層和隱含層節點數分別為40、60,輸出層節點數根據樣本類別數而定,學習率為0.01。SVM核函數使用徑向基函數核,核寬度調整為1。使用sEMG特征對機器學習模型進行訓練,提取sEMG每個通道的4個時域特征和2個頻域特征。時域特征為絕對平均值(mean absolute value,MAV)、均方根值(root mean square,RMS)、方差(variance,VAR)和波長(wave length,WL),頻域特征為平均功率頻率(mean power frequency,MPF)和中值頻率(median frequency,MF)。
|
|
|
|
|
|
式(12)~(17)中,L為窗口長度,為第i窗口的第k數值,N為樣本個數,為功率譜的密度計算函數。
本文對CNN模型的尋優過程中使用7∶3比例來劃分訓練和測試樣本,這可能會導致數據泄露問題,讓模型準確率虛高。因此,在本小節使用交叉驗證方法來評估模型,讓實驗結果更可靠。
表6和表7是四種機器學習模型在自制數據集和Ninapro-DB1數據集上5折交叉驗證的準確率,其中“T”“F”“TF”分別表示4個時域特征組合、2個頻域特征組合、所有特征組合。結果顯示,DT、BP和KNN在使用時域特征(T)組合時的準確率最高,在自制數據集上的準確率分別為75.80%、91.77%和93.17%,在Ninapro-DB1數據集上的準確率分別為86.61%、94.60%和94.52%。SVM在使用所有特征組合(TF)時的準確率最高,在兩個數據集上的準確率分別為92.03%和95.58%。表6、表7各模型在不同特征組合下的識別準確率存在顯著差異(P<0.05)。
5折交叉驗證結果如表8所示,其中DT-T、BP-T、SVM-TF、KNN-T為表6~7中四種機器學習模型的最佳測試結果。在四種CNN中,Vgg16在自制數據集中的準確率最高,為94.18%,Resnet34在Ninapro-DB1數據集上的準確率最高,為98.06%。CNN4-M的準確率要高于四種機器學習模型和四種CNN,在自制數據集和Ninapro-DB1數據集上的準確率分別為98.11%和98.75%。
與本文相似研究的文獻結果展示在表9,其中DB2、DB3、DB5為Ninapro里的標準數據集。由表9可知,本文的方法在分類精度上有明顯優勢,在手勢分類數相近的情況下,本文所提手勢識別方法的分類精度高于以往的研究。
4 結論
本文提出了一種基于sEMG灰度圖和多視野卷積神經網絡的手勢精確識別方法。通過對sEMG電壓值的線性變換和冪計算,保留sEMG數值紋理并制成灰度圖,用灰度圖作為CNN的輸入。搭建多視野卷積神經網絡CNN4-M,對13種常見手勢及Ninapro-DB1內12種多指運動進行測試,識別精度可達98.11%和98.75%。對比四種常用的機器學習方法和四種經典CNN,CNN4-M擁有最高的識別精度。本文所制作的sEMG灰度圖在經典CNN上同樣擁有適用性,在Vgg16上的測試精度可達94.18%,在Resnet34上的測試精度可達98.06%。在下一步的研究中,將縮短訓練樣本的時域長度,提高模型對手勢識別的實時性。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:陳清正主要負責實驗流程、算法設計、論文編寫;陶慶、張小棟主要負責實驗指導、論文審閱修訂;胡學政、張天樂參與數據采集及預處理。
倫理聲明:本研究獲得了西安交通大學第二附屬醫院醫學倫理委員會的審批(批文編號:2024YS239)。
本文附件見本刊網站的電子版本(biomedeng.cn)。