


日間手術已在我國發展 30 余年,但日間手術患者的準入決策仍主要基于專家經驗、頭腦風暴和機構推薦,缺乏科學的準入標準和普適性。四川大學華西醫院采用基于異構數據的半監督學習等方法,學習大量診療數據,以期構建更客觀準確的患者準入模型,幫助國家、醫院降低醫療成本,緩解當下醫療資源供需矛盾的尖銳問題,優化床位資源利用與配置,降低患者管理成本,并豐富和完善我國日間手術患者準入方法的理論研究,為我國日間手術行業的其他醫院提供借鑒和啟示。
引用本文: 蔣麗莎, 李文暢, 馬洪升. 基于異構數據學習的日間腹腔鏡膽囊切除術患者準入模型探索. 華西醫學, 2024, 39(2): 300-303. doi: 10.7507/1002-0179.202303118 復制
版權信息: ?四川大學華西醫院華西期刊社《華西醫學》版權所有,未經授權不得轉載、改編
近年來,日間手術這一新型醫療服務模式在醫療資源整合和高效利用等方面顯著緩解了我國醫療衛生行業的壓力[1]。其通過將患者術前檢查前移、術后康復護理后延,使既往需要住院的擇期手術能在 24 h 或 1 個工作日內完成[2-3],具有提高床位利用率、縮短入院前等待時間、降低醫療費用等諸多優點[4],已成為一些歐美國家主要的手術管理模式,且占傳統住院手術的比例高達 80%[5-6]。然而,當前我國日間手術的準入決策或標準仍是基于專家經驗、頭腦風暴和機構推薦。其中患者準入更是單純基于專家討論、頭腦風暴、經驗總結等[7-8],缺乏客觀和基于大數據科學模型的精細化準入標準,不利于日間手術的發展和醫療資源的利用。基于此,四川大學華西醫院(以下簡稱“華西醫院”)探索性采用機器學習算法,選擇國際上日間手術中最常見的腹腔鏡膽囊切除術(laparoscopic cholecystectomy, LC)為例,通過學習日間 LC 手術每年數以萬計的相關診療數據資源來產生更客觀準確的患者準入模型,以幫助降低醫療成本,緩解醫療資源供需矛盾,優化資源利用與配置。現將其中經驗分享如下。
1 日間手術準入與人工智能應用研究現狀
日間手術是由醫療供需矛盾催生出的新型醫療服務模式,近 20 年來在我國飛速發展的同時,其定義和相關規范也需要逐漸完成本土化、標準化和規范化[9-10]。我國 2012 年成立的日間手術合作聯盟對日間手術的定義為,傳統需要住院多日完成而采用日間手術的方式在 24 h 內就能完成的手術,不包括在診所或醫院開展的門診手術[11]。然而,相比于已經統一規范的日間手術定義,日間手術的準入標準仍然缺乏科學、客觀的決策依據。目前國內外關于日間手術術式與患者的評估主要以專家共識和規范為依據,不同地域和學術組織間存在較大差異,尚無利用科學研究方法和已有數據形成的統一的臨床準入決策體系,不利于日間手術的良性發展。
隨著人工智能、醫療大數據的發展,機器學習在我國醫療領域得到了廣泛應用[12],但基于機器學習的醫療決策支持系統發展則較為緩慢,其關鍵因素在于醫療數據的復雜性[13]。醫療數據存在于患者診療的各個關鍵環節,包括病史采集、輔助檢查、病歷記錄、診斷等,均產生了海量、不同結構的異構數據。目前我國日間手術領域內基于機器學習或人工智能的研究主要集中于術后護理的隨訪,如吳玲娣等[14]研究指出,人工智能在日間手術患者的出院后隨訪中發揮了積極作用,其在接通率和信息采集完整性上都有較好的表現,能有效提高患者信息采集率和患者滿意度,顯著提高了隨訪工作質量;宋志堅等[15]研究顯示,將人工智能語音系統運用到日間手術管理中,對于提升效率、延伸醫療服務、加強醫療安全均有積極作用;黃一敏等[16]研究顯示,人工智能可明顯改善日間手術傳統隨訪的質量、節省人力資源和提升工作效率。但相關研究中的方法不適用于日間手術準入決策的制定,目前國內尚未見人工智能應用于日間手術醫療決策方面的研究。
2 日間 LC 的多源異構數據庫構建
日間手術的電子病歷、檢驗和檢查等包含文字型數據、檢測圖像數據、生物信號檢測數據、介入性治療數據,內外科信息特征均涵蓋。在華西醫院日間 LC 多源異構數據庫構建項目中,首先需要進行數據的標準化工作,通過對信息的分類編碼標準化(代碼預先設定)、名詞術語標準化(自由進行代碼的復合)、信息交換格式標準化和信息結構化對日間手術的醫療數據進行標準化,然后需要進行醫學信息硬件與軟件的標準化、接口的標準化和文檔編制的標準化。其中,電子病歷可通過自然語言處理(natural language processing, NLP)和信息分類編碼完成。醫學標準的分類編碼為國際疾病分類(International Classification of Diseases, ICD),其為由世界衛生組織制定的國際統一的疾病分類方法,是一個根據疾病的病因、病理、臨床表現和解剖位置等特性,將疾病分門別類,使其成為一個有序的組合,并用編碼的方法來表示的系統。全世界通用的是第 10 次修訂本《疾病和有關健康問題的國際統計分類》,并被統稱為 ICD-10。生物信號和醫學圖像處理可通過數字化儀器設備所提供的信息,應用影像存儲與傳輸系統、實驗室信息系統等醫學信息系統接口整合到電子病歷中進行相應的處理。DICOM(醫學數字成像和通信)標準、HL7(衛生信息交換標準)和 XML(可擴展標記語言)也將會被使用,詳見表1。
3 基于機器學習的日間 LC 患者準入決策模型構建
在華西醫院對日間手術患者準入決策的研究中,首先我們從已建立的日間手術患者多模態數據倉庫中抽取出多個維度的數據。其中患者相關的數據主要包括患者基本信息、術后并發癥以及多種衡量術后患者情況的指標。具體來說,我們篩選出在 2010 年—2020 年于日間手術中心以及住院部接受 LC 診療產生的大量數據。對于這些數據中包含的患者,我們將已納入日間手術中心的 LC 患者定義為正例(positive),對于其他患者,由于存在雖然自身條件滿足日間手術準入標準,但受多種因素影響實際沒有做日間手術的可能性,我們將其標記為無標注數據(unlabeled data),然后利用半監督學習策略中的 PU 學習(positive and unlabeled learning,即正例和無標注學習)構建模型。
具體而言,PU 學習之所以可以從正例數據和無標注數據中進行學習,事實上是因為無標注數據是有幫助的。對于一個僅包含了正例數據的例子(圖1a),假設在一個線性分類器就已足夠的情況下,可以發現此時由于反例數據的未知,我們很難知道如何通過一條直線來分割正例和反例數據,導致有無限多可能的分法。然而,如果無標注數據被加入到數據空間中(圖1b),我們就可以清楚地看到分割線具體位置在何處,這就是無標注數據帶來的幫助。
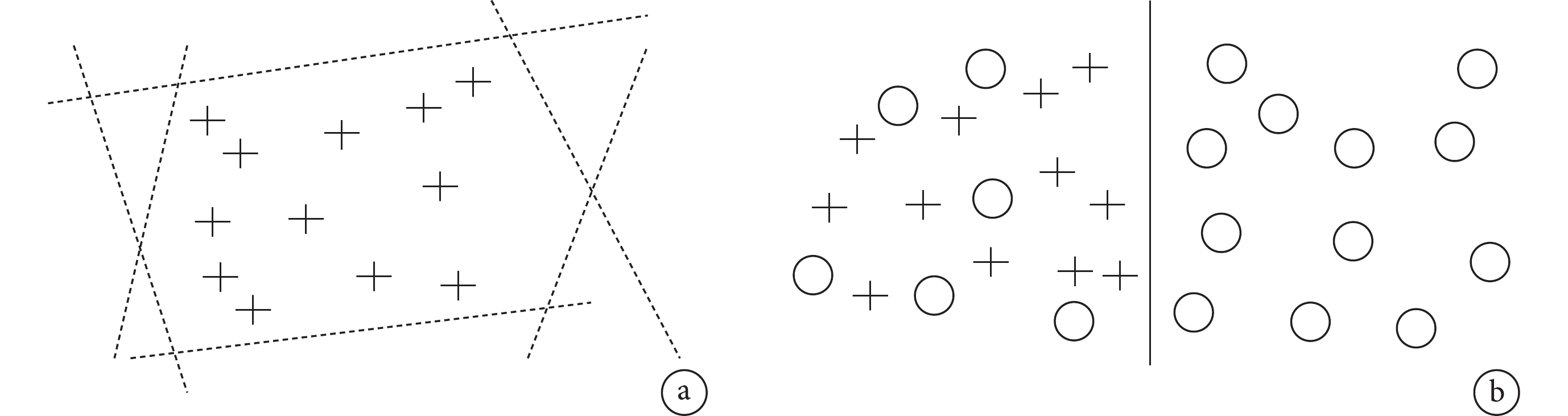 圖1
無標注數據的幫助性示意圖
圖1
無標注數據的幫助性示意圖
a. 只包括正例(+);b. 同時包括正例(+)和無標注數據(○)
基于這個思想,我們通過自訓練(self-training)的訓練方式將日間手術的準入問題轉化為了一個半監督問題。我們的算法包含了 4 個步驟,具體如框 1 所示。

其次,在將準入問題轉化為機器學習中的半監督學習問題之后,我們進行和患者準入模型中同樣的數據整合、預處理、向量化等工作,形成可以直接輸入模型的數據。在數據處理結束后,同樣地,我們嘗試使用 K 最近鄰、決策樹、支持向量機、隨機森林以及深度學習等多種算法模型訓練處理好的數據,結合交叉驗證的方法進行模型的選擇與參數調整,最終選擇出綜合表現最佳的模型。
最后,模型構建完成后,大量的無標注數據已被模型打上了標簽,我們將不同患者的標簽進行統計,并由專家判斷后設定閾值,如對于某未納入日間 LC 的患者,模型結果中該患者屬于日間 LC 的預測概率超過閾值,那么該患者為模型推薦可被納入日間 LC 的患者,反之則為不推薦。綜上所述,在進行日間 LC 患者準入決策模型構建中實際包含的具體任務和相關技術如表2 所示。
4 日間 LC 患者準入決策模型驗證
在建立了日間 LC 手術患者準入模型并對其進行評價之后,我們還需要對模型進行實證研究以證明其可用性和科學性。第 1 步,進行實證數據的收集,包括在訓練過程中所分出的測試集數據(該數據仍然來源于之前建立好的數據庫)、日間手術中心每天實時更新的診療相關數據,以及四川省日間手術質量控制中心(四川省衛生健康委員會掛靠華西醫院成立)和中國日間手術聯盟醫院提供的部分數據;第 2 步,以和建立數據庫同樣的方式對所收集的數據進行合并、異常數據清洗等處理,將實證數據變為數據庫的一部分;第 3 步,利用建立好且經過評價的患者準入模型對新數據進行判斷,并將結果與臨床醫生、醫院管理者進行交流,得到模型的效果反饋。
我們收集了 2009 年 1 月—2021 年 5 月在華西醫院接受 LC 手術治療的 55382 例患者的臨床數據,主要包括患者基本特征、檢驗結果和檢查結果。在數據輸入機器學習模型之前進行預處理以消除與研究目的無關的特征,利用 PU 學習和 NLP 方法建立了日間 LC 患者的智能準入模型,在真實患者數據集上取得了良好的性能。在使用 NLP 中的 BERT 方法下,LGB 預測模型的準確性和精準性表現最好,其受試者操作特征曲線下面積達 0.853。
5 日間 LC 患者準入終身學習決策
我們通過特征工程,根據機器學習算法輸出的特征重要性對參與模型訓練的特征進行篩選,找出對于日間手術患者準入預測模型相關性強的特征。由于各醫療機構間科室行政管理的差異,多個專科都可開展日間 LC 手術,各科室之間可能存在差異性,篩選出的相關性強的特征對部分科室的臨床意義并不大,但對日間手術患者準入判斷卻有較大意義。我們將該情況反饋給醫生,在臨床治療中加強對這一部分數據的采集;然后基于終身學習策略,運用不斷補充的新數據再次訓練模型,并注意知識遷移,不斷重復訓練模型,不斷迭代,提高模型判斷患者準入的準確性;最后對每一輪迭代得到的訓練好的模型進行實證。
6 小結與展望
基于真實世界數據形成的日間手術患者準入決策系統功能相近于醫療決策系統,同時兼具部分管理功能,目的是輔助醫生臨床決策、提升臨床工作效率,就像篩子一樣過濾掉絕大部分正常患者,剩下有異常的提醒醫生進行重點評估。華西醫院進行的基于異構數據學習的日間 LC 患者準入模型構建,旨在探索日間手術在醫療人工智能快速推進的背景下如何高效安全發展,并有機融入數字醫療與人工智能的發展趨勢,其距離臨床實際應用還需更多的理論研究和臨床數據支撐。不同醫療機構和醫生可借鑒本文研究方法,結合自身實際情況進行調整,在醫療安全和患者滿意的基礎上進一步探索提升醫療準確性和醫療效率的方法。利用機器學習技術開展日間手術準入決策的研究,可為緩解“看病難、看病貴”等社會問題以及我國日間手術的推進和廣泛開展提供助力,為我國國家層面統一制定日間手術準入標準規范提供有力的理論與實踐支持。
利益沖突:所有作者聲明不存在利益沖突。
近年來,日間手術這一新型醫療服務模式在醫療資源整合和高效利用等方面顯著緩解了我國醫療衛生行業的壓力[1]。其通過將患者術前檢查前移、術后康復護理后延,使既往需要住院的擇期手術能在 24 h 或 1 個工作日內完成[2-3],具有提高床位利用率、縮短入院前等待時間、降低醫療費用等諸多優點[4],已成為一些歐美國家主要的手術管理模式,且占傳統住院手術的比例高達 80%[5-6]。然而,當前我國日間手術的準入決策或標準仍是基于專家經驗、頭腦風暴和機構推薦。其中患者準入更是單純基于專家討論、頭腦風暴、經驗總結等[7-8],缺乏客觀和基于大數據科學模型的精細化準入標準,不利于日間手術的發展和醫療資源的利用。基于此,四川大學華西醫院(以下簡稱“華西醫院”)探索性采用機器學習算法,選擇國際上日間手術中最常見的腹腔鏡膽囊切除術(laparoscopic cholecystectomy, LC)為例,通過學習日間 LC 手術每年數以萬計的相關診療數據資源來產生更客觀準確的患者準入模型,以幫助降低醫療成本,緩解醫療資源供需矛盾,優化資源利用與配置。現將其中經驗分享如下。
1 日間手術準入與人工智能應用研究現狀
日間手術是由醫療供需矛盾催生出的新型醫療服務模式,近 20 年來在我國飛速發展的同時,其定義和相關規范也需要逐漸完成本土化、標準化和規范化[9-10]。我國 2012 年成立的日間手術合作聯盟對日間手術的定義為,傳統需要住院多日完成而采用日間手術的方式在 24 h 內就能完成的手術,不包括在診所或醫院開展的門診手術[11]。然而,相比于已經統一規范的日間手術定義,日間手術的準入標準仍然缺乏科學、客觀的決策依據。目前國內外關于日間手術術式與患者的評估主要以專家共識和規范為依據,不同地域和學術組織間存在較大差異,尚無利用科學研究方法和已有數據形成的統一的臨床準入決策體系,不利于日間手術的良性發展。
隨著人工智能、醫療大數據的發展,機器學習在我國醫療領域得到了廣泛應用[12],但基于機器學習的醫療決策支持系統發展則較為緩慢,其關鍵因素在于醫療數據的復雜性[13]。醫療數據存在于患者診療的各個關鍵環節,包括病史采集、輔助檢查、病歷記錄、診斷等,均產生了海量、不同結構的異構數據。目前我國日間手術領域內基于機器學習或人工智能的研究主要集中于術后護理的隨訪,如吳玲娣等[14]研究指出,人工智能在日間手術患者的出院后隨訪中發揮了積極作用,其在接通率和信息采集完整性上都有較好的表現,能有效提高患者信息采集率和患者滿意度,顯著提高了隨訪工作質量;宋志堅等[15]研究顯示,將人工智能語音系統運用到日間手術管理中,對于提升效率、延伸醫療服務、加強醫療安全均有積極作用;黃一敏等[16]研究顯示,人工智能可明顯改善日間手術傳統隨訪的質量、節省人力資源和提升工作效率。但相關研究中的方法不適用于日間手術準入決策的制定,目前國內尚未見人工智能應用于日間手術醫療決策方面的研究。
2 日間 LC 的多源異構數據庫構建
日間手術的電子病歷、檢驗和檢查等包含文字型數據、檢測圖像數據、生物信號檢測數據、介入性治療數據,內外科信息特征均涵蓋。在華西醫院日間 LC 多源異構數據庫構建項目中,首先需要進行數據的標準化工作,通過對信息的分類編碼標準化(代碼預先設定)、名詞術語標準化(自由進行代碼的復合)、信息交換格式標準化和信息結構化對日間手術的醫療數據進行標準化,然后需要進行醫學信息硬件與軟件的標準化、接口的標準化和文檔編制的標準化。其中,電子病歷可通過自然語言處理(natural language processing, NLP)和信息分類編碼完成。醫學標準的分類編碼為國際疾病分類(International Classification of Diseases, ICD),其為由世界衛生組織制定的國際統一的疾病分類方法,是一個根據疾病的病因、病理、臨床表現和解剖位置等特性,將疾病分門別類,使其成為一個有序的組合,并用編碼的方法來表示的系統。全世界通用的是第 10 次修訂本《疾病和有關健康問題的國際統計分類》,并被統稱為 ICD-10。生物信號和醫學圖像處理可通過數字化儀器設備所提供的信息,應用影像存儲與傳輸系統、實驗室信息系統等醫學信息系統接口整合到電子病歷中進行相應的處理。DICOM(醫學數字成像和通信)標準、HL7(衛生信息交換標準)和 XML(可擴展標記語言)也將會被使用,詳見表1。
3 基于機器學習的日間 LC 患者準入決策模型構建
在華西醫院對日間手術患者準入決策的研究中,首先我們從已建立的日間手術患者多模態數據倉庫中抽取出多個維度的數據。其中患者相關的數據主要包括患者基本信息、術后并發癥以及多種衡量術后患者情況的指標。具體來說,我們篩選出在 2010 年—2020 年于日間手術中心以及住院部接受 LC 診療產生的大量數據。對于這些數據中包含的患者,我們將已納入日間手術中心的 LC 患者定義為正例(positive),對于其他患者,由于存在雖然自身條件滿足日間手術準入標準,但受多種因素影響實際沒有做日間手術的可能性,我們將其標記為無標注數據(unlabeled data),然后利用半監督學習策略中的 PU 學習(positive and unlabeled learning,即正例和無標注學習)構建模型。
具體而言,PU 學習之所以可以從正例數據和無標注數據中進行學習,事實上是因為無標注數據是有幫助的。對于一個僅包含了正例數據的例子(圖1a),假設在一個線性分類器就已足夠的情況下,可以發現此時由于反例數據的未知,我們很難知道如何通過一條直線來分割正例和反例數據,導致有無限多可能的分法。然而,如果無標注數據被加入到數據空間中(圖1b),我們就可以清楚地看到分割線具體位置在何處,這就是無標注數據帶來的幫助。
圖1
無標注數據的幫助性示意圖
a. 只包括正例(+);b. 同時包括正例(+)和無標注數據(○)
基于這個思想,我們通過自訓練(self-training)的訓練方式將日間手術的準入問題轉化為了一個半監督問題。我們的算法包含了 4 個步驟,具體如框 1 所示。
其次,在將準入問題轉化為機器學習中的半監督學習問題之后,我們進行和患者準入模型中同樣的數據整合、預處理、向量化等工作,形成可以直接輸入模型的數據。在數據處理結束后,同樣地,我們嘗試使用 K 最近鄰、決策樹、支持向量機、隨機森林以及深度學習等多種算法模型訓練處理好的數據,結合交叉驗證的方法進行模型的選擇與參數調整,最終選擇出綜合表現最佳的模型。
最后,模型構建完成后,大量的無標注數據已被模型打上了標簽,我們將不同患者的標簽進行統計,并由專家判斷后設定閾值,如對于某未納入日間 LC 的患者,模型結果中該患者屬于日間 LC 的預測概率超過閾值,那么該患者為模型推薦可被納入日間 LC 的患者,反之則為不推薦。綜上所述,在進行日間 LC 患者準入決策模型構建中實際包含的具體任務和相關技術如表2 所示。
4 日間 LC 患者準入決策模型驗證
在建立了日間 LC 手術患者準入模型并對其進行評價之后,我們還需要對模型進行實證研究以證明其可用性和科學性。第 1 步,進行實證數據的收集,包括在訓練過程中所分出的測試集數據(該數據仍然來源于之前建立好的數據庫)、日間手術中心每天實時更新的診療相關數據,以及四川省日間手術質量控制中心(四川省衛生健康委員會掛靠華西醫院成立)和中國日間手術聯盟醫院提供的部分數據;第 2 步,以和建立數據庫同樣的方式對所收集的數據進行合并、異常數據清洗等處理,將實證數據變為數據庫的一部分;第 3 步,利用建立好且經過評價的患者準入模型對新數據進行判斷,并將結果與臨床醫生、醫院管理者進行交流,得到模型的效果反饋。
我們收集了 2009 年 1 月—2021 年 5 月在華西醫院接受 LC 手術治療的 55382 例患者的臨床數據,主要包括患者基本特征、檢驗結果和檢查結果。在數據輸入機器學習模型之前進行預處理以消除與研究目的無關的特征,利用 PU 學習和 NLP 方法建立了日間 LC 患者的智能準入模型,在真實患者數據集上取得了良好的性能。在使用 NLP 中的 BERT 方法下,LGB 預測模型的準確性和精準性表現最好,其受試者操作特征曲線下面積達 0.853。
5 日間 LC 患者準入終身學習決策
我們通過特征工程,根據機器學習算法輸出的特征重要性對參與模型訓練的特征進行篩選,找出對于日間手術患者準入預測模型相關性強的特征。由于各醫療機構間科室行政管理的差異,多個專科都可開展日間 LC 手術,各科室之間可能存在差異性,篩選出的相關性強的特征對部分科室的臨床意義并不大,但對日間手術患者準入判斷卻有較大意義。我們將該情況反饋給醫生,在臨床治療中加強對這一部分數據的采集;然后基于終身學習策略,運用不斷補充的新數據再次訓練模型,并注意知識遷移,不斷重復訓練模型,不斷迭代,提高模型判斷患者準入的準確性;最后對每一輪迭代得到的訓練好的模型進行實證。
6 小結與展望
基于真實世界數據形成的日間手術患者準入決策系統功能相近于醫療決策系統,同時兼具部分管理功能,目的是輔助醫生臨床決策、提升臨床工作效率,就像篩子一樣過濾掉絕大部分正常患者,剩下有異常的提醒醫生進行重點評估。華西醫院進行的基于異構數據學習的日間 LC 患者準入模型構建,旨在探索日間手術在醫療人工智能快速推進的背景下如何高效安全發展,并有機融入數字醫療與人工智能的發展趨勢,其距離臨床實際應用還需更多的理論研究和臨床數據支撐。不同醫療機構和醫生可借鑒本文研究方法,結合自身實際情況進行調整,在醫療安全和患者滿意的基礎上進一步探索提升醫療準確性和醫療效率的方法。利用機器學習技術開展日間手術準入決策的研究,可為緩解“看病難、看病貴”等社會問題以及我國日間手術的推進和廣泛開展提供助力,為我國國家層面統一制定日間手術準入標準規范提供有力的理論與實踐支持。
利益沖突:所有作者聲明不存在利益沖突。

