引用本文: 王仕鴻, 陳永澤, 麥振華, 譚茜蔚, 楊子華, 王爽, 趙樂, 馬勇, 黃翠怡, 孔丹莉, 丁元林, 于海兵. 基于粒子群優化算法 BP 神經網絡的 2 型糖尿病危險因素分析及篩查模型構建. 華西醫學, 2024, 39(2): 251-258. doi: 10.7507/1002-0179.202311033 復制
版權信息: ?四川大學華西醫院華西期刊社《華西醫學》版權所有,未經授權不得轉載、改編
2 型糖尿病是一種以持續性血糖升高為主要特征的代謝性疾病[1]。糖尿病患者隨著病程的延長,可引起多種并發癥,嚴重影響患者的生活質量。截止 2021 年,全球糖尿病患病人數高達 5.73 億,消耗衛生總費用達 9 660 億美元[2],為醫療體系和社會經濟發展帶來沉重的負擔。進行糖尿病早期患病的篩查和診斷是預防糖尿病發生發展的有效途徑。粒子群優化算法(particle swarm optimization, PSO)BP 神經網絡是一種基于鳥群覓食行為而構建的神經網絡模型。相比較于以往的預測模型,如 BP 神經網絡、logistic 回歸模型等,PSO-BP 神經網絡具有預測精度高、結果穩定等優勢[3-4]。因此,本研究構建 PSO-BP 神經網絡的 2 型糖尿病篩查模型,并結合平均影響值(mean impact value, MIV)算法篩選 2 型糖尿病發病的危險因素,以更好的開展 2 型糖尿病的早期預防及高危人群的篩查。
1 對象與方法
1.1 研究對象
選擇 2021 年 7 月—2022 年 8 月廣東醫科大學附屬醫院和廣東醫科大學附屬第二醫院內分泌科 2 型糖尿病住院患者;并選擇同期在廣東醫科大學附屬醫院健康管理中心的健康體檢人群。2 型糖尿病住院患者的納入標準:符合 1999 年世界衛生組織規定的糖尿病分型診斷標準[5]。2 型糖尿病住院患者的排除標準:患有 1 型糖尿病、惡性腫瘤、心腦血管等疾病者。健康體檢人群的納入標準:均未患糖尿病。健康體檢人群的排除標準:患惡性腫瘤、心腦血管等疾病者。本研究已通過廣東醫科大學附屬醫院機構審查倫理委員會、廣東醫科大學附屬第二醫院醫學倫理委員會審查,所有研究對象均簽署了知情同意書。
本研究采用經驗算法進行樣本量的確定,既每組樣本量為變量個數的 20 倍。本研究自變量與因變量總數為 30 個,考慮 20%的剔除率,最終每組所需最小樣本量為 1.2×20×30=720 例。
1.2 研究方法
1.2.1 分組
2 型糖尿病住院患者為病例組,健康體檢人群為對照組。
1.2.2 觀察指標
由經過培訓的調查員統一收集研究對象的基本人口學特征(性別、年齡、居住地、文化程度、婚姻狀況、職業)、患病情況(糖尿病家族史、冠心病家族史、共病家族史)、生活習慣與自我保健情況(吸煙、飲酒、主食攝入、肉類攝入、蔬菜攝入、水果攝入、甜食攝入、食鹽類型、運動情況和睡眠時間)、體格檢查情況[腰臂比、體質量指數(body mass index, BMI)、收縮壓、舒張壓、心率]和臨床指標情況(空腹血糖、甘油三酯、總膽固醇、高密度脂蛋白膽固醇和低密度脂蛋白膽固醇)。
1.3 質量控制(質控)
在調查開展前,對調查員統一培訓,明確調查方式和詢問技巧。在調查過程中,由調查員向調查對象進行相關說明并簽署知情同意書。問卷填寫完畢后,由質控員進行問卷檢查,并及時填補缺漏項及糾正邏輯錯誤之處。采用 Epidata 軟件建立數據庫并進行數據的雙錄入,確保錄入質量。
1.4 統計學方法
1.4.1 數據整理與分析
服從正態分布的計量資料以均數±標準差表示,組間比較采用 t 檢驗。不服從正態分布的計量資料以中位數(下四分位數,上四分位數)表示,組間比較采用秩和檢驗。計數資料以頻數和構成比表示,組間比較采用χ2 檢驗或 Fisher 確切概率法。雙側檢驗水準α=0.05。
1.4.2 PSO-BP 神經網絡篩查模型建模步驟
PSO-BP 神經網絡模型構建過程如下[6-7]:① 確定輸入、輸出和隱藏層節點數,建立 BP 神經網絡;② 根據 BP 神經網絡初始化 PSO 算法參數,包括種群規模(m)、慣性權重(w)和學習因子(r1、r2)等。設置 PSO 算法最大迭代次數為 10 次,初始化 m 為 10, w 為 0.5,學習因子 r1=r2=2[7-9];③ 計算粒子適應度函數值,搜尋局部最優解 和全局最優解
和全局最優解 ;④ 根據
;④ 根據 和
和 更新粒子自身速度和位置;⑤ 判斷 PSO 算法是否滿足最大迭代次數或適應度函數值達到最小界限,滿足條件則輸出最優權值與閾值并賦予 BP 神經網絡,否則返回③繼續迭代直到滿足條件;⑥ 用新建立的 PSO-BP 神經網絡預測測試集,綜合評價 PSO-BP 神經網絡的各項性能。
更新粒子自身速度和位置;⑤ 判斷 PSO 算法是否滿足最大迭代次數或適應度函數值達到最小界限,滿足條件則輸出最優權值與閾值并賦予 BP 神經網絡,否則返回③繼續迭代直到滿足條件;⑥ 用新建立的 PSO-BP 神經網絡預測測試集,綜合評價 PSO-BP 神經網絡的各項性能。
隨機抽取 70%的樣本用于模型訓練,其余 30%的樣本用于評價模型優劣。把單因素分析中有統計學意義的變量作為輸入層,基于 MATLAB R2021b 軟件,分別構建 logistic 回歸模型、BP 神經網絡模型和 PSO-BP 神經網絡。在 PSO-BP 神經網絡訓練過程中,將抽取的 70%的訓練樣本再劃分為 3 個子集(訓練集、驗證集和測試集)。計算 PSO-BP 神經網絡模型訓練集、測試集、驗證集和總體的相關系數(correlation coefficient, R)。其中,訓練集用于模型參數確定,驗證集用于模型優化,測試集用于評價模型推廣能力。為消除輸入變量量綱不同對模型預測性能的影響,采用式①將變量歸一化至[0,1]區間。式中 Amin 為數據中最小值, Amax 為數據中最大值。t=1, 2, …, k,其中 k 為變量個數。
 |
1.4.3 MIV 算法
平均影響值(mean impact value, MIV)算法用于評價輸入變量對輸出變量的影響程度及方向,具有對非線性問題進行變量篩選的優勢[10]。MIV>0,表示輸入變量對輸出變量影響為正向。MIV<0,表示輸入變量對輸出變量影響為負向。根據 MIV 貢獻率對影響因素進行排序。將累積貢獻率前 85%的變量作為 2 型糖尿病發病的影響因素。
1.4.4 評價指標
篩查模型性能評價指標選用受試者工作特征曲線下面積(receiver operating characteristic curve, AUC)、靈敏度、特異度、約登指數、陽性似然比、陰性似然比、誤差均方根(root-mean-square error, RMSE)、決定系數(coefficient of determination, R2)和平均絕對誤差(mean absolute error, MAE)評價篩查模型的性能。其中 RMSE、R2 和 MAE 計算公式見式 ②③④。其中,Q 為測試集樣本量, 和
和 分別為實際值和預測值,MSE 為均方誤差。陰性似然比、RMSE 和 MAE 越小,AUC、靈敏度、特異度、約登指數、陽性似然比和 R2 越大,模型性能越高。
分別為實際值和預測值,MSE 為均方誤差。陰性似然比、RMSE 和 MAE 越小,AUC、靈敏度、特異度、約登指數、陽性似然比和 R2 越大,模型性能越高。
 |
 |
 |
2 結果
2.1 一般資料
病例組共納入患者 1 053 例,對照組共納入健康體檢人群 914 例。兩組一般資料比較見表1。可見,除食鹽類型、共病家族史、BMI、低密度脂蛋白膽固醇、總膽固醇、主食攝入外(P>0.05),其余指標兩組比較,差異均有統計學意義(P<0.05)。
2.2 2 型糖尿病篩查模型構建
2.2.1 BP 神經網絡模型建立
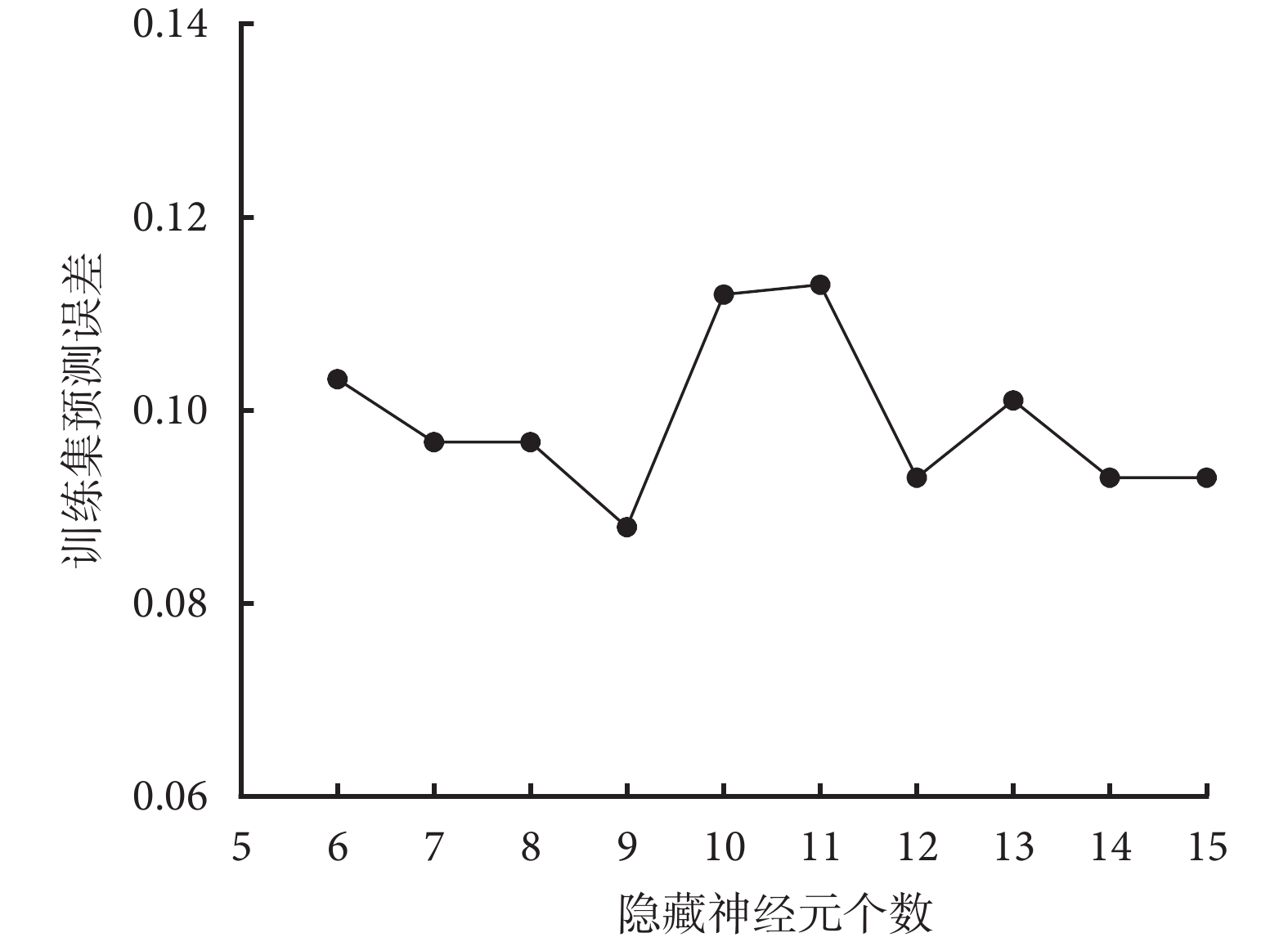
納入單因素分析中 P<0.05 的變量進行 BP 神經網絡模型的構建。BP 神經網絡隱藏神經元與誤差率見圖1。可見,當隱藏層數為 9 時,BP 神經網絡具有最小的預測誤差,因此,網絡隱藏層數選擇為 9。
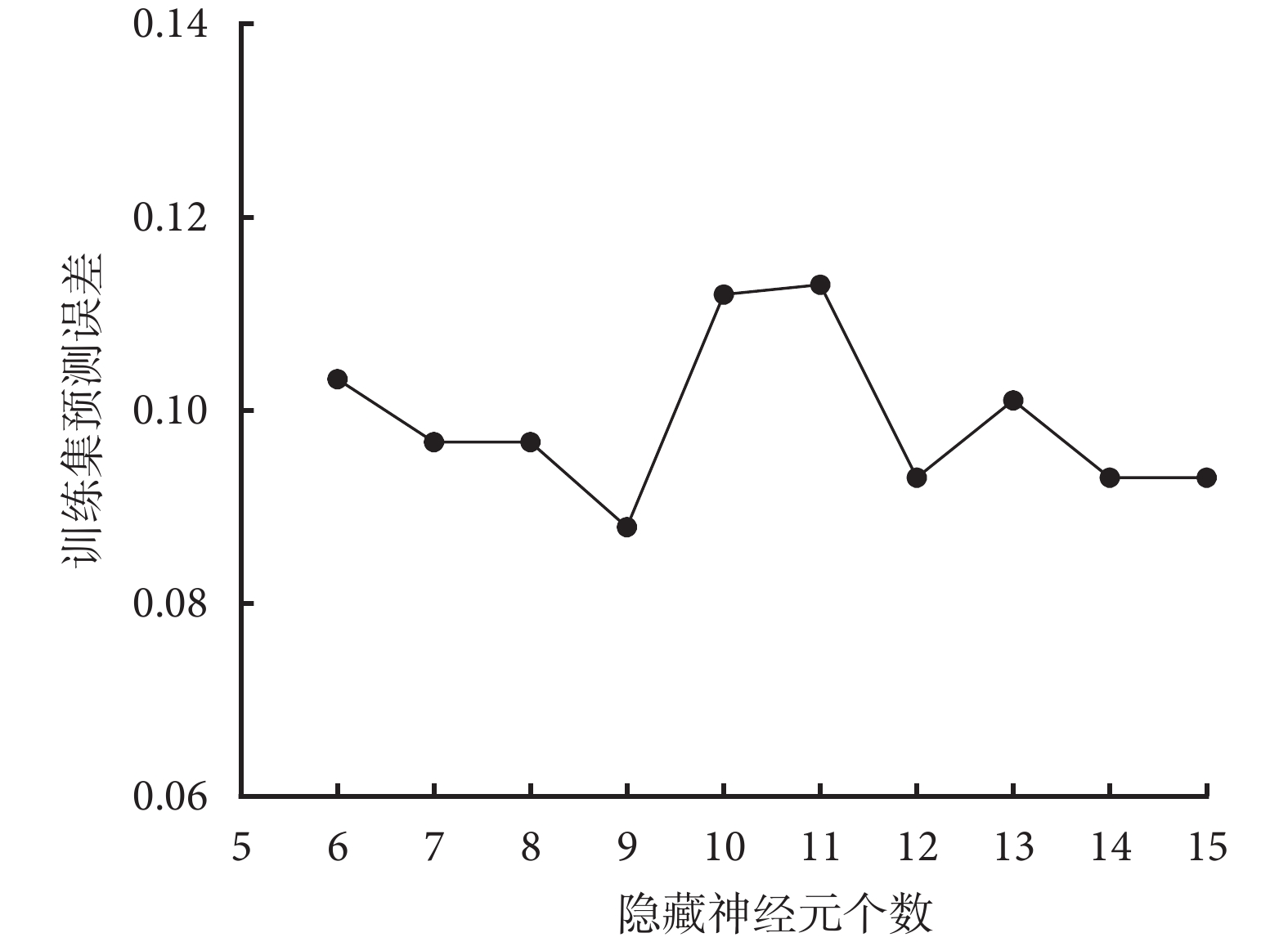 圖1
BP 神經網絡隱藏神經元與誤差率
圖1
BP 神經網絡隱藏神經元與誤差率
2.2.2 PSO-BP 神經網絡篩查模型訓練效果
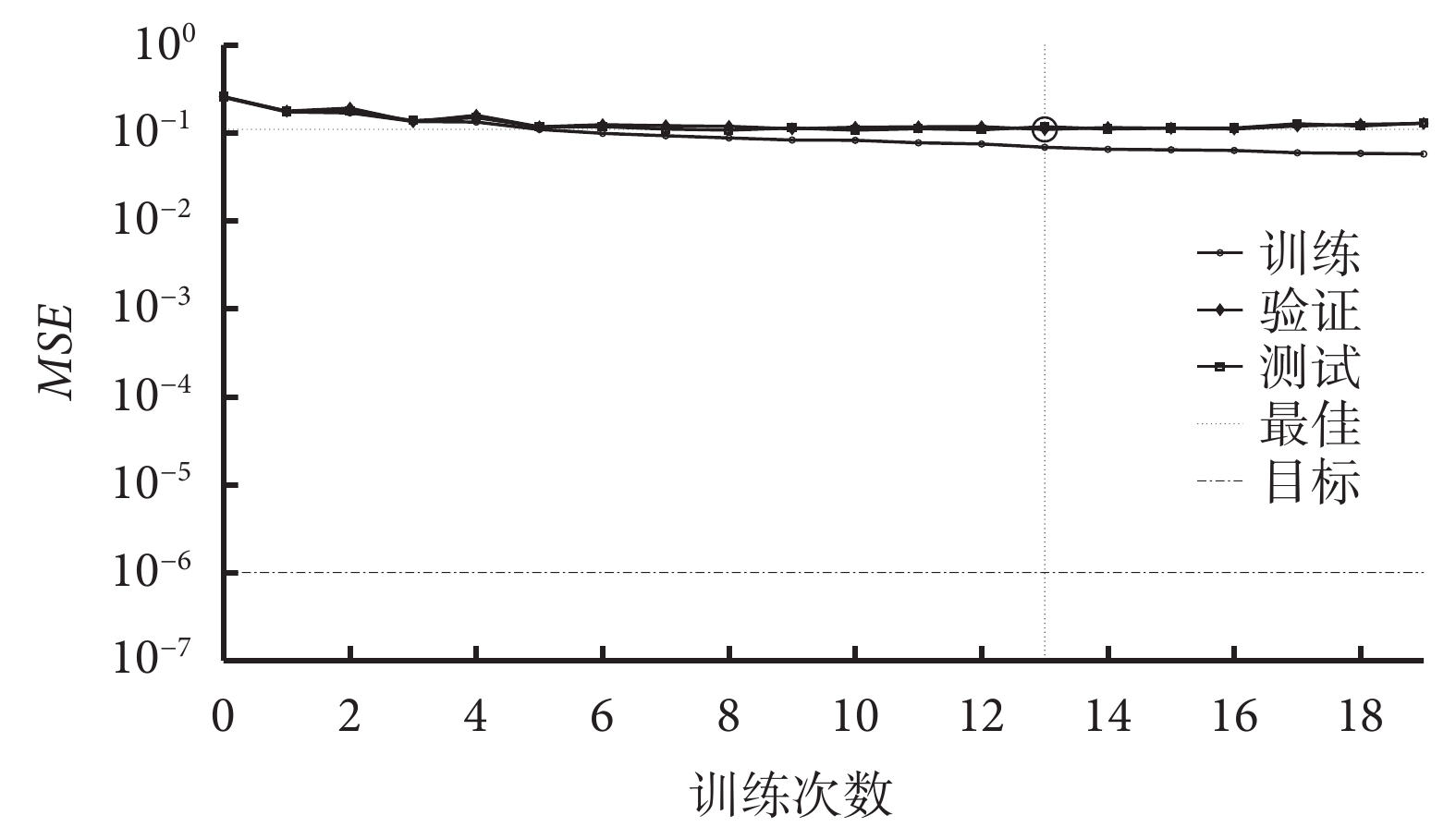
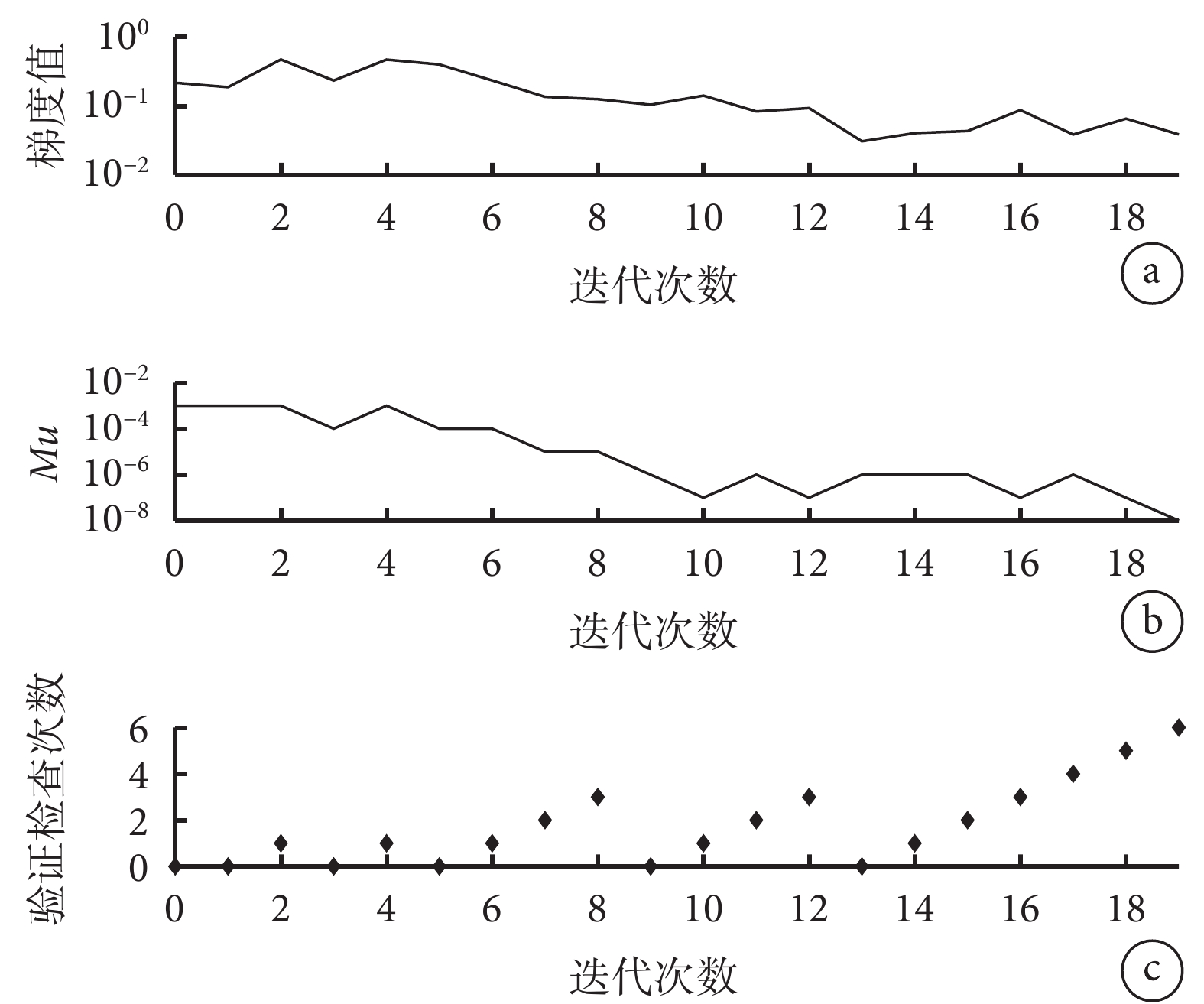
在 PSO-BP 神經網絡訓練過程中,隨著訓練次數的增加,模型在訓練集、測試集和驗證集上的 MSE 逐漸減少。PSO-BP 神經網絡均方誤差見圖2。可見,當模型訓練次數達到 13 次以后,測試集和驗證集的 MSE 逐漸趨于穩定,最佳的 MSE 為 0.109 41。同時,設置 PSO-BP 神經網絡學習率為 0.05,19 次迭代停止后,模型的梯度值為 0.038 533,誤差精度(Mu)為 1×10?8,驗證檢查次數為 6 次。見圖3。
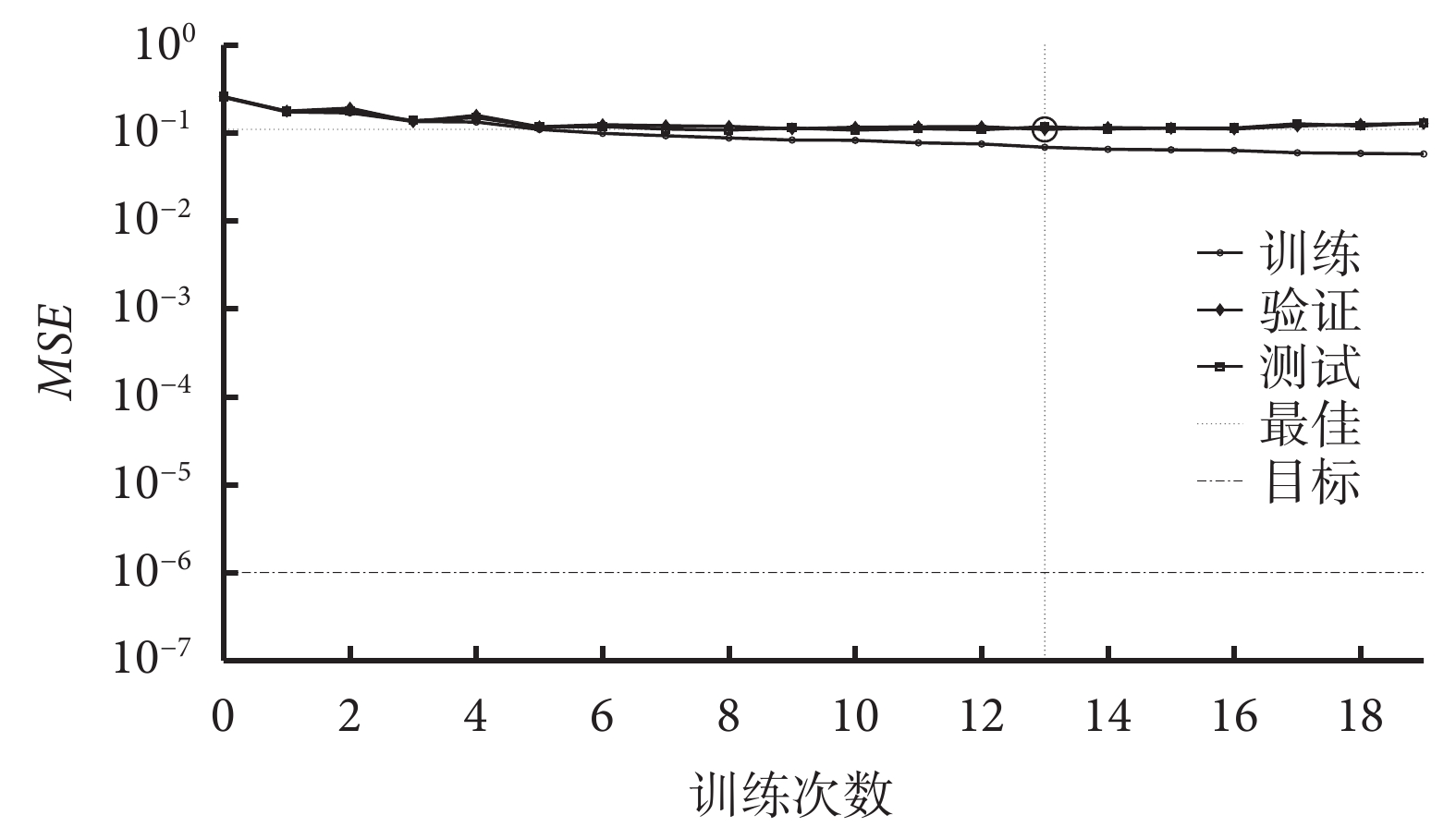 圖2
PSO-BP 神經網絡均方誤差
圖2
PSO-BP 神經網絡均方誤差
圓圈處表示訓練次數為 13 次,最佳驗證性能是第13次訓練的 0.109 41。
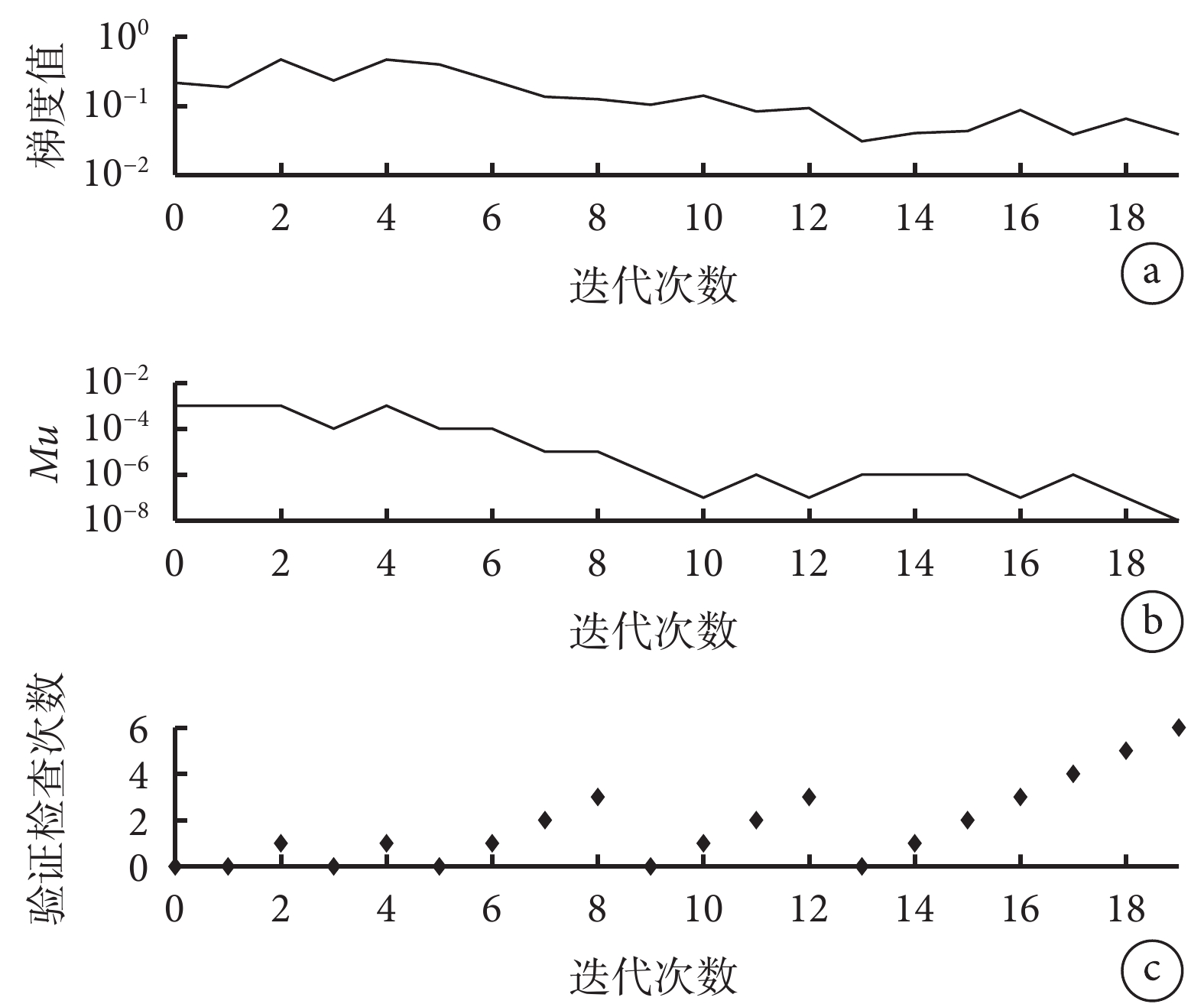 圖3
PSO-BP 神經網絡訓練過程
圖3
PSO-BP 神經網絡訓練過程
a. 迭代次數與模型梯度值的變化,梯度=0.038 533,在第19次迭代;b. 迭代次數與模型
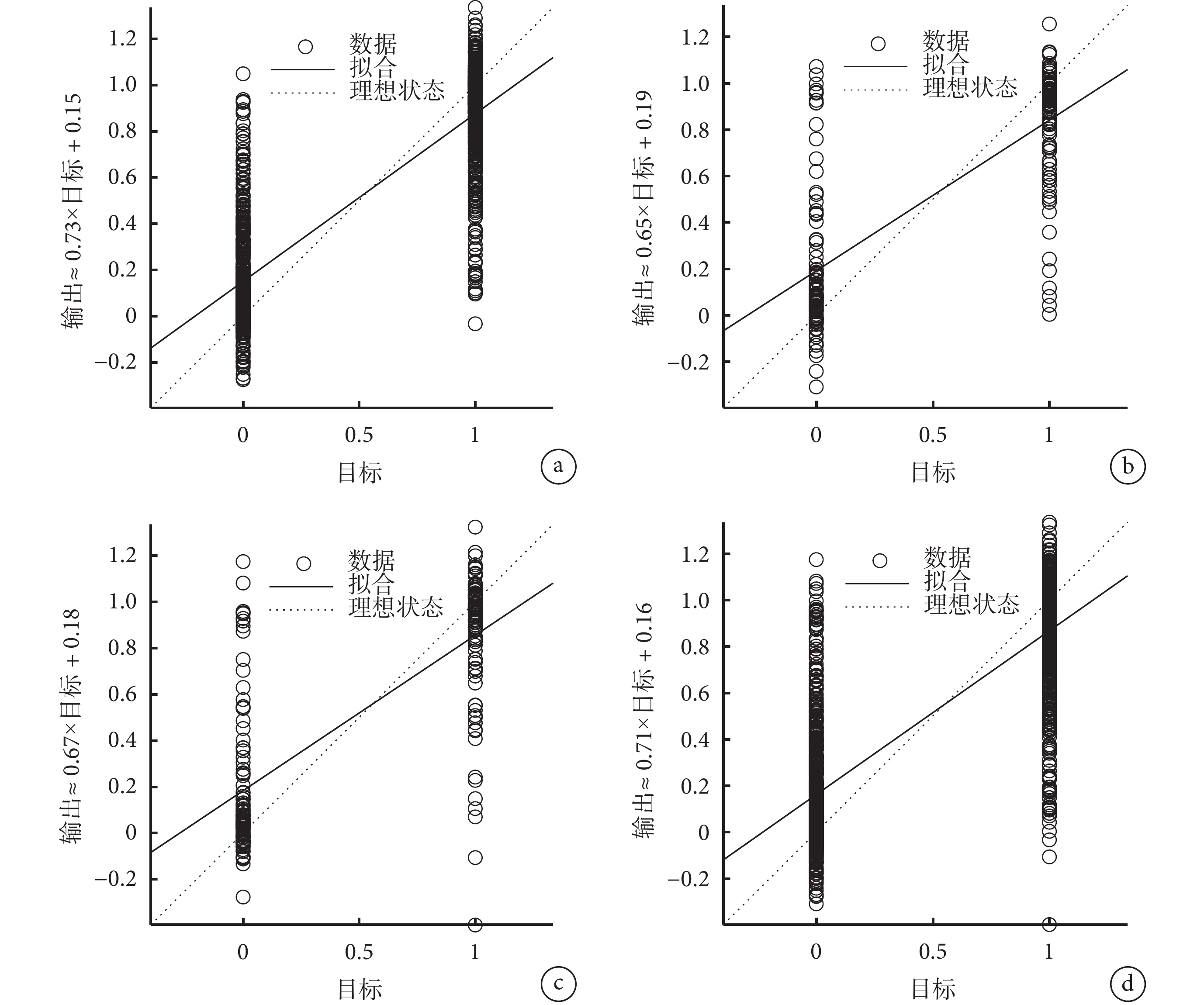
PSO-BP 神經網絡訓練效果見圖4。PSO-BP 神經網絡模型自身擬合效果較好,訓練集、測試集、驗證集和總體的 R 值分別為 0.850 56、0.745 85、0.757 24 和 0.820 07,且擬合直線均接近對角線。
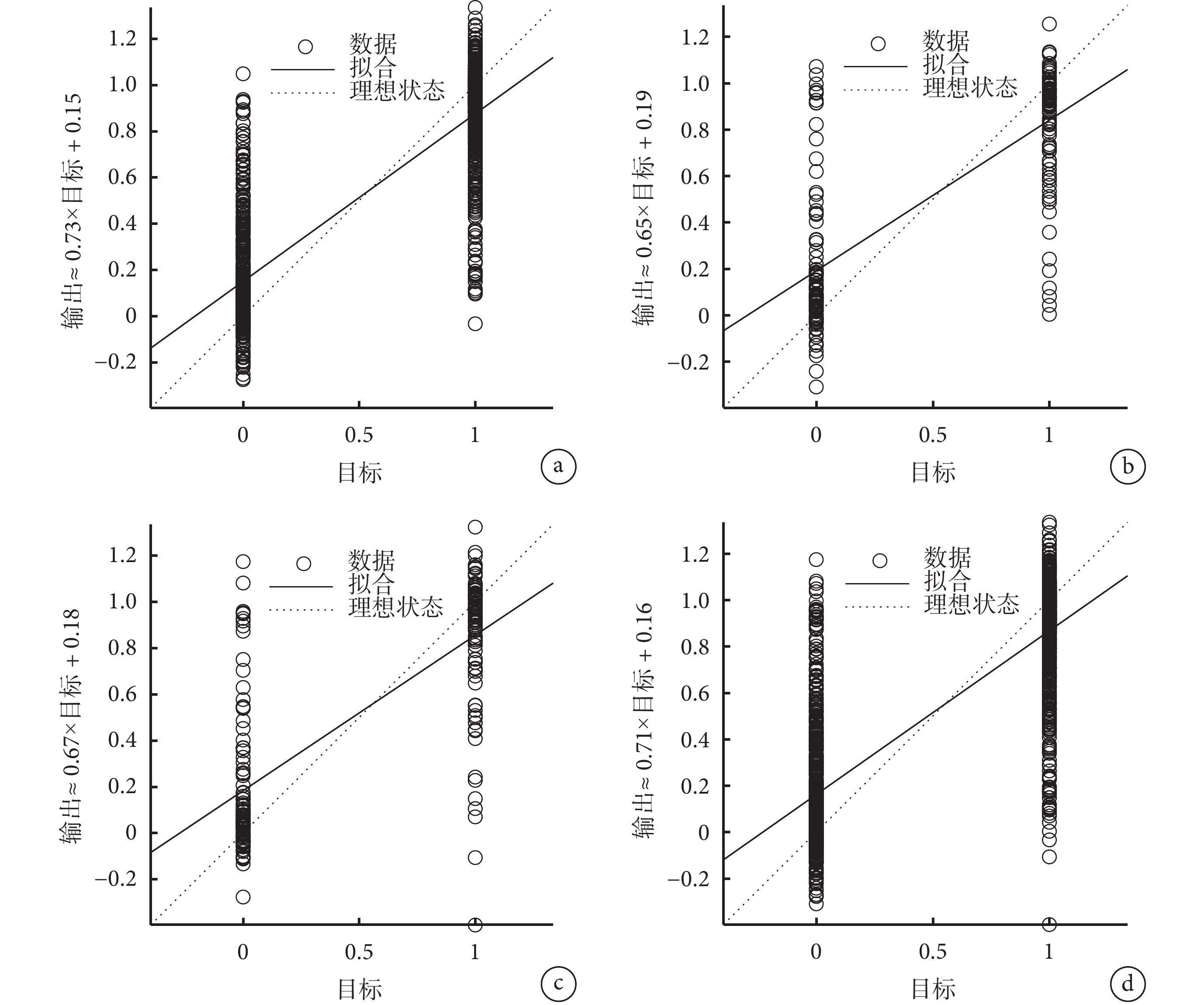 圖4
PSO-BP 神經網絡訓練效果
圖4
PSO-BP 神經網絡訓練效果
a. 訓練集,
2.2.3 PSO-BP 神經網絡篩查模型性能評價
不同篩查模型性能比較見表2。可見,相比傳統的 BP 神經網絡,PSO-BP 神經網絡模型在測試樣本上的 RMSE 和 MAE 分別下降 0.040 和 0.027,R2 上升 0.109。相比 logistic 回歸模型,PSO-BP 神經網絡模型在測試樣本上的 RMSE 和 MAE 分別下降 0.023 和 0.015,R2上升 0.061。此外,PSO-BP 神經網絡模型的靈敏度、特異度、約登指數和陽性似然比均高于 BP 神經網絡和 logistic 回歸模型,陰性似然比低于 BP 神經網絡和 logistic 回歸模型。PSO-BP 神經網絡模型的 AUC 低于logistic回歸模型,高于 BP 神經網絡。
2.3 MIV 算法篩選變量
2 型糖尿病影響因素 MIV 排序表見表3。累積貢獻率前 85%的變量分別為空腹血糖、心率、高密度脂蛋白膽固醇、蔬菜攝入、年齡、居住地、腰臂比、文化程度、婚姻狀況、水果攝入和肉類攝入。其中,與 2 型糖尿病發病呈正相關的因素為空腹血糖、心率、年齡、腰臂比和婚姻狀況,與 2 型糖尿病發病呈負相關的因素為高密度脂蛋白膽固醇、蔬菜攝入、居住地、文化程度、水果攝入和肉類攝入。
3 討論
糖尿病作為世界三大慢性非傳染性疾病之一,具有并發癥多、病程長、治療手段復雜等特征,對人類健康造成重大威脅[11]。糖尿病在我國的患病率約為 12%[12]。根據國際糖尿病聯盟數據,在糖尿病患者中,90%以上為 2 型糖尿病[13]。2 型糖尿病發病機制目前尚未完全明確,難以控制疾病進展和惡化,患者一旦確診多因各種并發癥導致死亡。因此,定期開展糖尿病危險因素篩查,對降低人群糖尿病發病率、延長壽命有重要意義。
BP 神經網絡有對多變量綜合處理的特點,在醫療衛生領域已廣泛應用于各種疾病發病的診斷和篩查[14]。但由于 BP 神經網絡的初始化權值有隨機性,在建模過程中易陷入局部最優,造成模型預測精度下降。PSO 粒子群算法有全局尋優的能力,可將最優權值和閾值賦予 BP 神經網絡,提高模型預測性能,避免網絡陷入局部最優。雖 PSO-BP 神經網絡模型的 AUC 略低于 logistic 回歸模型,但總體而言,PSO-BP 神經網絡篩查模型的性能最優,預測結果穩定,可應用于 2 型糖尿病篩查。為糖尿病的早期識別和診斷提供參考。醫護人員可根據預測結果給予個體相應的疾病干預措施,有利于預防糖尿病和各種并發癥的發生發展,降低患者死亡率。
MIV 算法篩選結果表明,2 型糖尿病的危險因素為空腹血糖、心率、年齡、腰臂比和婚姻狀況。其中,空腹血糖是 2 型糖尿病發病的最重要的危險因素,變量貢獻率為 0.174 07。空腹血糖≥7.0 mmol/L 是診斷糖尿病的重要指標。當個體空腹血糖值介于 6.1~7.0 mmol/L 時,應給予高度重視,必要時尋醫指導。本研究發現,心率與 2 型糖尿病發病呈正相關,與宗菁等[15]研究結論一致。心率升高可激活交感神經系統,導致血管收縮、骨骼肌攝取葡萄糖功能障礙[16],增大糖尿病發病風險。已婚人群中年齡越大、腰臂比越高者,越容易患 2 型糖尿病,與既往研究結論一致[17-20]。2 型糖尿病的保護因素為高密度脂蛋白膽固醇、蔬菜攝入、水果攝入、肉類攝入、居住地和文化程度。高密度脂蛋白膽固醇與胰島素抵抗呈負相關關系[21]。因此,正常偏高水平的高密度脂蛋白膽固醇對控制血糖升高有重要作用。適當增加蔬菜、水果攝入量可在一定程度上預防糖尿病發生,主要原因為:蔬菜、水果富含礦物質、維生素和膳食纖維等營養物質,有降低血糖作用[22]。城市居住地居民獲取糖尿病相關預防知識的渠道較多,加之醫療服務的可及性較高,因此其糖尿病發病風險低于農村或郊區居住地居民[23]。文化程度越高,對糖尿病預防知識了解和掌握程度越高,從而有意識的減少糖尿病相關危險因素暴露水平,降低其發病風險[24]。本研究結果顯示肉食攝入量較高者,糖尿病發病風險越低,與既往研究結論相駁[25-27]。可能原因為本研究收集的病例均為病程較長的糖尿病住院患者。由于目前健康宣傳教育、預防保健措施的不斷加強,糖尿病患者在患病后可能會有意識的減少肉類等脂肪食品攝入。本研究為回顧性的病例對照研究,當對糖尿病患者進行調查訪談時,患者可能把患病后的肉食攝入量狀況當成患病前的肉食攝入量狀況來回答。因此,可觀察到糖尿病患者的肉食攝入量低于正常人的情況。
綜上所述,PSO-BP 神經網絡模型總體性能較好,未來考慮將其推廣至其他疾病的早期篩查和診斷。MIV 算法變量篩選結果可為糖尿病防控提供理論依據。數據顯示,糖尿病未來發病率將呈現上升趨勢,預計到 2040 年全球糖尿病患者將達 6.42 億[28]。因此,應及早采取相關措施控制糖尿病發病率增長趨勢,如改善膳食模式、控制危險因素、高危人群定期篩查等。通過開展相關預防措施,降低人群中糖尿病發病率、延長患者預期壽命,對實現“健康中國 2030”戰略目標具有重要意義。
利益沖突:所有作者聲明不存在利益沖突。
2 型糖尿病是一種以持續性血糖升高為主要特征的代謝性疾病[1]。糖尿病患者隨著病程的延長,可引起多種并發癥,嚴重影響患者的生活質量。截止 2021 年,全球糖尿病患病人數高達 5.73 億,消耗衛生總費用達 9 660 億美元[2],為醫療體系和社會經濟發展帶來沉重的負擔。進行糖尿病早期患病的篩查和診斷是預防糖尿病發生發展的有效途徑。粒子群優化算法(particle swarm optimization, PSO)BP 神經網絡是一種基于鳥群覓食行為而構建的神經網絡模型。相比較于以往的預測模型,如 BP 神經網絡、logistic 回歸模型等,PSO-BP 神經網絡具有預測精度高、結果穩定等優勢[3-4]。因此,本研究構建 PSO-BP 神經網絡的 2 型糖尿病篩查模型,并結合平均影響值(mean impact value, MIV)算法篩選 2 型糖尿病發病的危險因素,以更好的開展 2 型糖尿病的早期預防及高危人群的篩查。
1 對象與方法
1.1 研究對象
選擇 2021 年 7 月—2022 年 8 月廣東醫科大學附屬醫院和廣東醫科大學附屬第二醫院內分泌科 2 型糖尿病住院患者;并選擇同期在廣東醫科大學附屬醫院健康管理中心的健康體檢人群。2 型糖尿病住院患者的納入標準:符合 1999 年世界衛生組織規定的糖尿病分型診斷標準[5]。2 型糖尿病住院患者的排除標準:患有 1 型糖尿病、惡性腫瘤、心腦血管等疾病者。健康體檢人群的納入標準:均未患糖尿病。健康體檢人群的排除標準:患惡性腫瘤、心腦血管等疾病者。本研究已通過廣東醫科大學附屬醫院機構審查倫理委員會、廣東醫科大學附屬第二醫院醫學倫理委員會審查,所有研究對象均簽署了知情同意書。
本研究采用經驗算法進行樣本量的確定,既每組樣本量為變量個數的 20 倍。本研究自變量與因變量總數為 30 個,考慮 20%的剔除率,最終每組所需最小樣本量為 1.2×20×30=720 例。
1.2 研究方法
1.2.1 分組
2 型糖尿病住院患者為病例組,健康體檢人群為對照組。
1.2.2 觀察指標
由經過培訓的調查員統一收集研究對象的基本人口學特征(性別、年齡、居住地、文化程度、婚姻狀況、職業)、患病情況(糖尿病家族史、冠心病家族史、共病家族史)、生活習慣與自我保健情況(吸煙、飲酒、主食攝入、肉類攝入、蔬菜攝入、水果攝入、甜食攝入、食鹽類型、運動情況和睡眠時間)、體格檢查情況[腰臂比、體質量指數(body mass index, BMI)、收縮壓、舒張壓、心率]和臨床指標情況(空腹血糖、甘油三酯、總膽固醇、高密度脂蛋白膽固醇和低密度脂蛋白膽固醇)。
1.3 質量控制(質控)
在調查開展前,對調查員統一培訓,明確調查方式和詢問技巧。在調查過程中,由調查員向調查對象進行相關說明并簽署知情同意書。問卷填寫完畢后,由質控員進行問卷檢查,并及時填補缺漏項及糾正邏輯錯誤之處。采用 Epidata 軟件建立數據庫并進行數據的雙錄入,確保錄入質量。
1.4 統計學方法
1.4.1 數據整理與分析
服從正態分布的計量資料以均數±標準差表示,組間比較采用 t 檢驗。不服從正態分布的計量資料以中位數(下四分位數,上四分位數)表示,組間比較采用秩和檢驗。計數資料以頻數和構成比表示,組間比較采用χ2 檢驗或 Fisher 確切概率法。雙側檢驗水準α=0.05。
1.4.2 PSO-BP 神經網絡篩查模型建模步驟
PSO-BP 神經網絡模型構建過程如下[6-7]:① 確定輸入、輸出和隱藏層節點數,建立 BP 神經網絡;② 根據 BP 神經網絡初始化 PSO 算法參數,包括種群規模(m)、慣性權重(w)和學習因子(r1、r2)等。設置 PSO 算法最大迭代次數為 10 次,初始化 m 為 10, w 為 0.5,學習因子 r1=r2=2[7-9];③ 計算粒子適應度函數值,搜尋局部最優解和全局最優解;④ 根據和更新粒子自身速度和位置;⑤ 判斷 PSO 算法是否滿足最大迭代次數或適應度函數值達到最小界限,滿足條件則輸出最優權值與閾值并賦予 BP 神經網絡,否則返回③繼續迭代直到滿足條件;⑥ 用新建立的 PSO-BP 神經網絡預測測試集,綜合評價 PSO-BP 神經網絡的各項性能。
隨機抽取 70%的樣本用于模型訓練,其余 30%的樣本用于評價模型優劣。把單因素分析中有統計學意義的變量作為輸入層,基于 MATLAB R2021b 軟件,分別構建 logistic 回歸模型、BP 神經網絡模型和 PSO-BP 神經網絡。在 PSO-BP 神經網絡訓練過程中,將抽取的 70%的訓練樣本再劃分為 3 個子集(訓練集、驗證集和測試集)。計算 PSO-BP 神經網絡模型訓練集、測試集、驗證集和總體的相關系數(correlation coefficient, R)。其中,訓練集用于模型參數確定,驗證集用于模型優化,測試集用于評價模型推廣能力。為消除輸入變量量綱不同對模型預測性能的影響,采用式①將變量歸一化至[0,1]區間。式中 Amin 為數據中最小值, Amax 為數據中最大值。t=1, 2, …, k,其中 k 為變量個數。
|
1.4.3 MIV 算法
平均影響值(mean impact value, MIV)算法用于評價輸入變量對輸出變量的影響程度及方向,具有對非線性問題進行變量篩選的優勢[10]。MIV>0,表示輸入變量對輸出變量影響為正向。MIV<0,表示輸入變量對輸出變量影響為負向。根據 MIV 貢獻率對影響因素進行排序。將累積貢獻率前 85%的變量作為 2 型糖尿病發病的影響因素。
1.4.4 評價指標
篩查模型性能評價指標選用受試者工作特征曲線下面積(receiver operating characteristic curve, AUC)、靈敏度、特異度、約登指數、陽性似然比、陰性似然比、誤差均方根(root-mean-square error, RMSE)、決定系數(coefficient of determination, R2)和平均絕對誤差(mean absolute error, MAE)評價篩查模型的性能。其中 RMSE、R2 和 MAE 計算公式見式 ②③④。其中,Q 為測試集樣本量,和分別為實際值和預測值,MSE 為均方誤差。陰性似然比、RMSE 和 MAE 越小,AUC、靈敏度、特異度、約登指數、陽性似然比和 R2 越大,模型性能越高。
|
|
|
2 結果
2.1 一般資料
病例組共納入患者 1 053 例,對照組共納入健康體檢人群 914 例。兩組一般資料比較見表1。可見,除食鹽類型、共病家族史、BMI、低密度脂蛋白膽固醇、總膽固醇、主食攝入外(P>0.05),其余指標兩組比較,差異均有統計學意義(P<0.05)。
2.2 2 型糖尿病篩查模型構建
2.2.1 BP 神經網絡模型建立
納入單因素分析中 P<0.05 的變量進行 BP 神經網絡模型的構建。BP 神經網絡隱藏神經元與誤差率見圖1。可見,當隱藏層數為 9 時,BP 神經網絡具有最小的預測誤差,因此,網絡隱藏層數選擇為 9。
圖1
BP 神經網絡隱藏神經元與誤差率
2.2.2 PSO-BP 神經網絡篩查模型訓練效果
在 PSO-BP 神經網絡訓練過程中,隨著訓練次數的增加,模型在訓練集、測試集和驗證集上的 MSE 逐漸減少。PSO-BP 神經網絡均方誤差見圖2。可見,當模型訓練次數達到 13 次以后,測試集和驗證集的 MSE 逐漸趨于穩定,最佳的 MSE 為 0.109 41。同時,設置 PSO-BP 神經網絡學習率為 0.05,19 次迭代停止后,模型的梯度值為 0.038 533,誤差精度(Mu)為 1×10?8,驗證檢查次數為 6 次。見圖3。
圖2
PSO-BP 神經網絡均方誤差
圓圈處表示訓練次數為 13 次,最佳驗證性能是第13次訓練的 0.109 41。
圖3
PSO-BP 神經網絡訓練過程
a. 迭代次數與模型梯度值的變化,梯度=0.038 533,在第19次迭代;b. 迭代次數與模型
PSO-BP 神經網絡訓練效果見圖4。PSO-BP 神經網絡模型自身擬合效果較好,訓練集、測試集、驗證集和總體的 R 值分別為 0.850 56、0.745 85、0.757 24 和 0.820 07,且擬合直線均接近對角線。
圖4
PSO-BP 神經網絡訓練效果
a. 訓練集,
2.2.3 PSO-BP 神經網絡篩查模型性能評價
不同篩查模型性能比較見表2。可見,相比傳統的 BP 神經網絡,PSO-BP 神經網絡模型在測試樣本上的 RMSE 和 MAE 分別下降 0.040 和 0.027,R2 上升 0.109。相比 logistic 回歸模型,PSO-BP 神經網絡模型在測試樣本上的 RMSE 和 MAE 分別下降 0.023 和 0.015,R2上升 0.061。此外,PSO-BP 神經網絡模型的靈敏度、特異度、約登指數和陽性似然比均高于 BP 神經網絡和 logistic 回歸模型,陰性似然比低于 BP 神經網絡和 logistic 回歸模型。PSO-BP 神經網絡模型的 AUC 低于logistic回歸模型,高于 BP 神經網絡。
2.3 MIV 算法篩選變量
2 型糖尿病影響因素 MIV 排序表見表3。累積貢獻率前 85%的變量分別為空腹血糖、心率、高密度脂蛋白膽固醇、蔬菜攝入、年齡、居住地、腰臂比、文化程度、婚姻狀況、水果攝入和肉類攝入。其中,與 2 型糖尿病發病呈正相關的因素為空腹血糖、心率、年齡、腰臂比和婚姻狀況,與 2 型糖尿病發病呈負相關的因素為高密度脂蛋白膽固醇、蔬菜攝入、居住地、文化程度、水果攝入和肉類攝入。
3 討論
糖尿病作為世界三大慢性非傳染性疾病之一,具有并發癥多、病程長、治療手段復雜等特征,對人類健康造成重大威脅[11]。糖尿病在我國的患病率約為 12%[12]。根據國際糖尿病聯盟數據,在糖尿病患者中,90%以上為 2 型糖尿病[13]。2 型糖尿病發病機制目前尚未完全明確,難以控制疾病進展和惡化,患者一旦確診多因各種并發癥導致死亡。因此,定期開展糖尿病危險因素篩查,對降低人群糖尿病發病率、延長壽命有重要意義。
BP 神經網絡有對多變量綜合處理的特點,在醫療衛生領域已廣泛應用于各種疾病發病的診斷和篩查[14]。但由于 BP 神經網絡的初始化權值有隨機性,在建模過程中易陷入局部最優,造成模型預測精度下降。PSO 粒子群算法有全局尋優的能力,可將最優權值和閾值賦予 BP 神經網絡,提高模型預測性能,避免網絡陷入局部最優。雖 PSO-BP 神經網絡模型的 AUC 略低于 logistic 回歸模型,但總體而言,PSO-BP 神經網絡篩查模型的性能最優,預測結果穩定,可應用于 2 型糖尿病篩查。為糖尿病的早期識別和診斷提供參考。醫護人員可根據預測結果給予個體相應的疾病干預措施,有利于預防糖尿病和各種并發癥的發生發展,降低患者死亡率。
MIV 算法篩選結果表明,2 型糖尿病的危險因素為空腹血糖、心率、年齡、腰臂比和婚姻狀況。其中,空腹血糖是 2 型糖尿病發病的最重要的危險因素,變量貢獻率為 0.174 07。空腹血糖≥7.0 mmol/L 是診斷糖尿病的重要指標。當個體空腹血糖值介于 6.1~7.0 mmol/L 時,應給予高度重視,必要時尋醫指導。本研究發現,心率與 2 型糖尿病發病呈正相關,與宗菁等[15]研究結論一致。心率升高可激活交感神經系統,導致血管收縮、骨骼肌攝取葡萄糖功能障礙[16],增大糖尿病發病風險。已婚人群中年齡越大、腰臂比越高者,越容易患 2 型糖尿病,與既往研究結論一致[17-20]。2 型糖尿病的保護因素為高密度脂蛋白膽固醇、蔬菜攝入、水果攝入、肉類攝入、居住地和文化程度。高密度脂蛋白膽固醇與胰島素抵抗呈負相關關系[21]。因此,正常偏高水平的高密度脂蛋白膽固醇對控制血糖升高有重要作用。適當增加蔬菜、水果攝入量可在一定程度上預防糖尿病發生,主要原因為:蔬菜、水果富含礦物質、維生素和膳食纖維等營養物質,有降低血糖作用[22]。城市居住地居民獲取糖尿病相關預防知識的渠道較多,加之醫療服務的可及性較高,因此其糖尿病發病風險低于農村或郊區居住地居民[23]。文化程度越高,對糖尿病預防知識了解和掌握程度越高,從而有意識的減少糖尿病相關危險因素暴露水平,降低其發病風險[24]。本研究結果顯示肉食攝入量較高者,糖尿病發病風險越低,與既往研究結論相駁[25-27]。可能原因為本研究收集的病例均為病程較長的糖尿病住院患者。由于目前健康宣傳教育、預防保健措施的不斷加強,糖尿病患者在患病后可能會有意識的減少肉類等脂肪食品攝入。本研究為回顧性的病例對照研究,當對糖尿病患者進行調查訪談時,患者可能把患病后的肉食攝入量狀況當成患病前的肉食攝入量狀況來回答。因此,可觀察到糖尿病患者的肉食攝入量低于正常人的情況。
綜上所述,PSO-BP 神經網絡模型總體性能較好,未來考慮將其推廣至其他疾病的早期篩查和診斷。MIV 算法變量篩選結果可為糖尿病防控提供理論依據。數據顯示,糖尿病未來發病率將呈現上升趨勢,預計到 2040 年全球糖尿病患者將達 6.42 億[28]。因此,應及早采取相關措施控制糖尿病發病率增長趨勢,如改善膳食模式、控制危險因素、高危人群定期篩查等。通過開展相關預防措施,降低人群中糖尿病發病率、延長患者預期壽命,對實現“健康中國 2030”戰略目標具有重要意義。
利益沖突:所有作者聲明不存在利益沖突。