引用本文: 劉敏, 陳芳, 鄧蓉, 趙靜. 人工智能在醫院感染領域中應用的文獻計量學分析. 華西醫學, 2024, 39(3): 399-405. doi: 10.7507/1002-0179.202402084 復制
版權信息: ?四川大學華西醫院華西期刊社《華西醫學》版權所有,未經授權不得轉載、改編
醫院感染(healthcare-associated infection, HAI),又稱醫療獲得性感染或醫院內感染,是指患者在接受醫療服務期間,在醫院或其他醫療保健機構內感染的情況[1]。盡管目前尚無 HAI 全球負擔的確切數據,但世界衛生組織估計每年全球有數億患者受到 HAI 影響,且其發生率呈遞增趨勢[2],中低收入國家可能面臨著更高的 HAI 負擔[3]。預防是管理 HAI 的最佳方法,包括建設標準化監測系統、制定感染預防和控制計劃、組建多學科團隊、嚴格管理抗菌藥物應用、提高醫務人員和政策制定者對 HAI 和預防的認識[4]。盡管過去 10 年在 HAI 預防方面取得了實質性進展[5],但仍不斷出現新的挑戰。
隨著計算機科學的發展,尤其是人工智能(artificial intelligence, AI)技術在醫療衛生領域嶄露頭角[6],為提高 HAI 的診斷準確性和有效防控提供了新的可能,這涉及到早期疾病診斷、感染源追蹤、感染風險評估、突發公共衛生事件管理等多個方面。盡管 AI 有著廣闊的發展前景,但缺乏在 HAI 方面的分析和討論。而文獻計量學分析可幫助學者們深入了解某一領域的應用發展、熱點趨勢和未來前景[7]。因此,本研究采用文獻計量學的方法,對 Web of Science 核心合集數據庫中的相關文獻進行檢索,并分析 AI 在 HAI 領域的研究趨勢,以期為本領域學者提供關于 HAI 未來研究方向的新見解。
1 資料與方法
1.1 納入與排除標準
1.1.1 納入標準
① 與HAI相關研究;② 文獻類型限定為“article”;③ 語種為中英文。
1.1.2 排除標準
① 重復發表的文獻;② 綜述、會議論文、會議摘要、信件等;③ 與研究主題不相關。
1.2 檢索策略
檢索 Web of Science Core Collection 的 Science Citation Index Expanded 數據庫,檢索時限為 1994年1月1日—2024年1月22日。以“Artificial intelligence”“Nosocomial infection”“Healthcare-associated infection”等為檢索詞進行組合檢索,檢索項選擇主題檢索。
1.3 文獻篩選與數據提取
由 2 名作者獨立地進行文獻篩選,對有異議的論文,將與有高級職稱的第 3 位作者討論以達成一致。所檢索的結果以純文本文件格式導出,記錄內容為“全記錄與引用的參考文獻”,包括作者、題名、關鍵詞、年份、國家、作者機構、摘要、參考文獻等,并在 Web of Science 數據庫中創建引文報告,導出論文發表情況、被引用分布情況、H 指數等。
1.4 質量控制
在進行文獻檢索前,明確研究問題,確保檢索結果符合研究需求。建立標準化的檢索流程,確定文獻篩選和數據提取的步驟、標準和方法。在進行文獻篩選和數據提取時,由 2 名作者獨立進行,減少主觀偏差。使用標準化的數據提取表格,確保數據提取結果的一致性和完整性。
1.5 統計學方法
采用 Excel 2019、VOSviewer(v1.6.19)和 CiteSpace(v.6.1.R6)軟件進行文獻計量學和可視化分析。利用 Excel 2019 對論文的發表、被引用情況進行分析,呈現AI應用于HAI領域的年發文量及年被引頻次情況。其趨勢變化可反映該領域研究活動的增長或減少,從而揭示學科發展動向和研究興趣演變[8]。
運用 VOSviewer(v1.6.19)進行國家、機構和作者的合作網絡分析。每個節點代表一個國家、機構或作者。節點大小代表節點出現的頻率,節點越大表示在合作網絡中的重要性越高。連接節點間的線表示存在合作關系,連線粗細表示總連接強度(total link strength, TLS),反映合作關系的密切程度[9]。
運用 CiteSpace(v6.1.R6)軟件實現關鍵詞共現、聚類及突現分析。將時間跨度設置為 1994 年—2024 年,時間切片設置為 1,將修剪方式設定為 Pathfinder,Pruning sliced networks,節點類型選擇關鍵詞。在共現圖譜中,圓形節點的大小與關鍵詞的共現頻率呈正相關。節點的顏色越接近紅色,表示該詞出現時間越晚;反之,則表示越早。介數中心性是衡量關鍵詞共現網絡中節點重要性程度的指標[10]。當關鍵詞的中心性≥0.1 時,節點外周會被標記明亮的粉色圓環[11]。關鍵詞聚類則可以更直觀地勾勒出研究領域內的潛在聯系和熱點方向[10]。聚類是基于關鍵詞的共現關系形成的,具有強相關性和高共現頻率的關鍵詞將被組合成一個聚類。在聚類中,具有最高共現頻率的關鍵詞將自動生成為聚類標簽。因此,聚類標簽可代表該領域中不同的研究方向。關鍵詞突現分析可識別出在某一時期內突然興起并頻繁出現的關鍵詞,從而預測研究領域的新熱點。突現分析不僅可量化關鍵詞的強度,確定其重要性,還能追蹤關鍵詞出現和消失的演化過程[12]。藍線表示時間間隔,紅線表示突現的持續時間。根據網絡結構和聚類的清晰度,可憑借模塊值(Q 值)和平均輪廓值(S 值)評價繪制出的圖譜效果。當 Q>0.3 表示聚類結構顯著,S>0.5 表示聚類效果合理[10]。
2 結果
2.1 文獻檢索結果
共檢索到文獻 722 篇。剔除 85 篇非“article”類型文獻、327 篇與研究主題不相關的文獻、5 篇重復文獻,最終獲得文獻 305 篇。
2.2 文獻發表情況
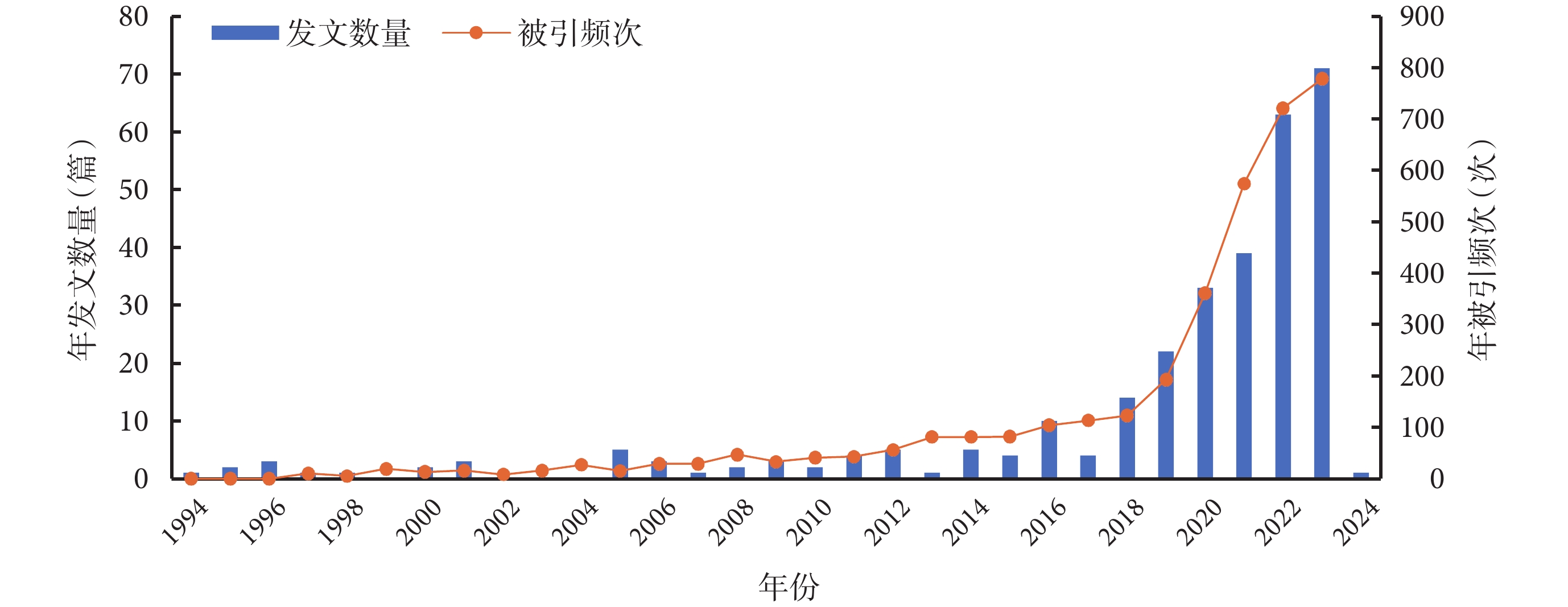
AI應用于 HAI 領域的年發文量及年被引頻次見圖1。可見,從 1994 年—2017 年發文數量少,增長較為緩慢;2018年—2024 年發文數量快速增加,并在 2023 年達到峰值(71 篇),被引用次數(778 次)也達到頂峰。305 篇文獻的H指數為 32,累積被引用次數為 3174 次,平均每篇文獻被引用 11.93 次。
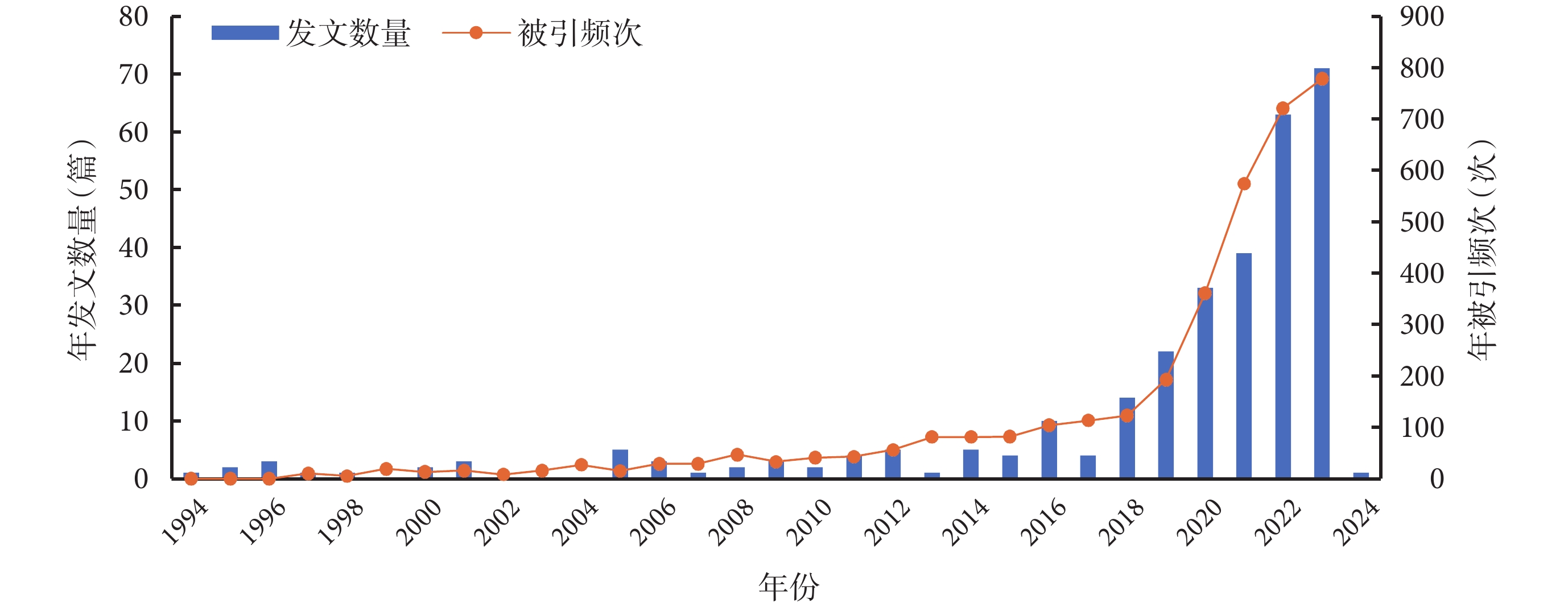 圖1
AI應用于 HAI 領域的年發文量及年被引頻次
圖1
AI應用于 HAI 領域的年發文量及年被引頻次
AI:人工智能;HAI:醫院感染
2.3 科研合作分析
2.3.1 國家/地區合作分析
AI應用于 HAI 領域發表的文獻來自 50 個國家/地區。發文量前 5 名的國家分別是美國(132 篇,占 43.3%),其次是中國(53 篇,占 17.4%)、英國(24 篇,占 7.9%)、法國(22 篇,占 7.2%)和荷蘭(16 篇,占 5.2%)。在被引用頻次方面,美國也以 1 997 次引用排名第 1 位,其次是瑞士(347 次)和英國(328 次),中國以 314 次引用居于第 4 位。國際合作分析顯示,以美國為中心進行的合作最多,其中英、美合作最為密切,其次是中、美兩國。
2.3.2 機構合作分析
共有 270 個機構開展了AI與 HAI 相關領域的研究,發文量大于 5 篇有 34 家。從發文數量來看,排名前 10 位的機構多數位于美國(8 家),中國和荷蘭分別有 1 家機構。美國哈佛大學是 AI 在HAI應用具有較高研究實力和影響力的機構,共發表了 12 篇論文,被引用 255 次。埃默里大學在本領域也做出了突出貢獻,發表了 11 篇論文,獲得 73 次引用。其余前 10 位的機構依次為麻省理工學院(8 篇)、猶他大學(8 篇)、加利福尼亞大學舊金山分校(7 篇)、浙江大學(7 篇)、烏特勒支大學(6 篇)、杜克大學(5 篇)、斯坦福大學(5 篇)及科羅拉多大學(5 篇)。關于機構間的合作,美國部分機構形成了較為密切的合作網絡,如埃默里大學和杜克大學,兩者 TLS 最粗。我國的浙江大學和中山大學進行的合作研究處于國內前列。
2.3.3 作者合作分析
共有 1 888 位作者為 AI 應用于 HAI 研究做出了貢獻。發文量前 5 位作者均來自美國,Evans HL教授是發文量最高的學者,為 6 篇;其他 4 名作者依次為 Huang Shuai、Elster Eric、Hensman Hannah、Schobel Seth。在被引用頻次方面,美國作者 Brossette SE 以 175 次引用排名第 1 位。同樣來自美國的 Sprague AP 和 Moser SA 分別以 174 次和 173 次引用位居第 2、3 位。部分作者構成了 4 個密切合作的研究群體,學者 Wicks EC、Shuai Huang、Lober WB 是鏈接多個團隊的關鍵人物。
2.4 研究熱點與趨勢分析
2.4.1 關鍵詞共現分析
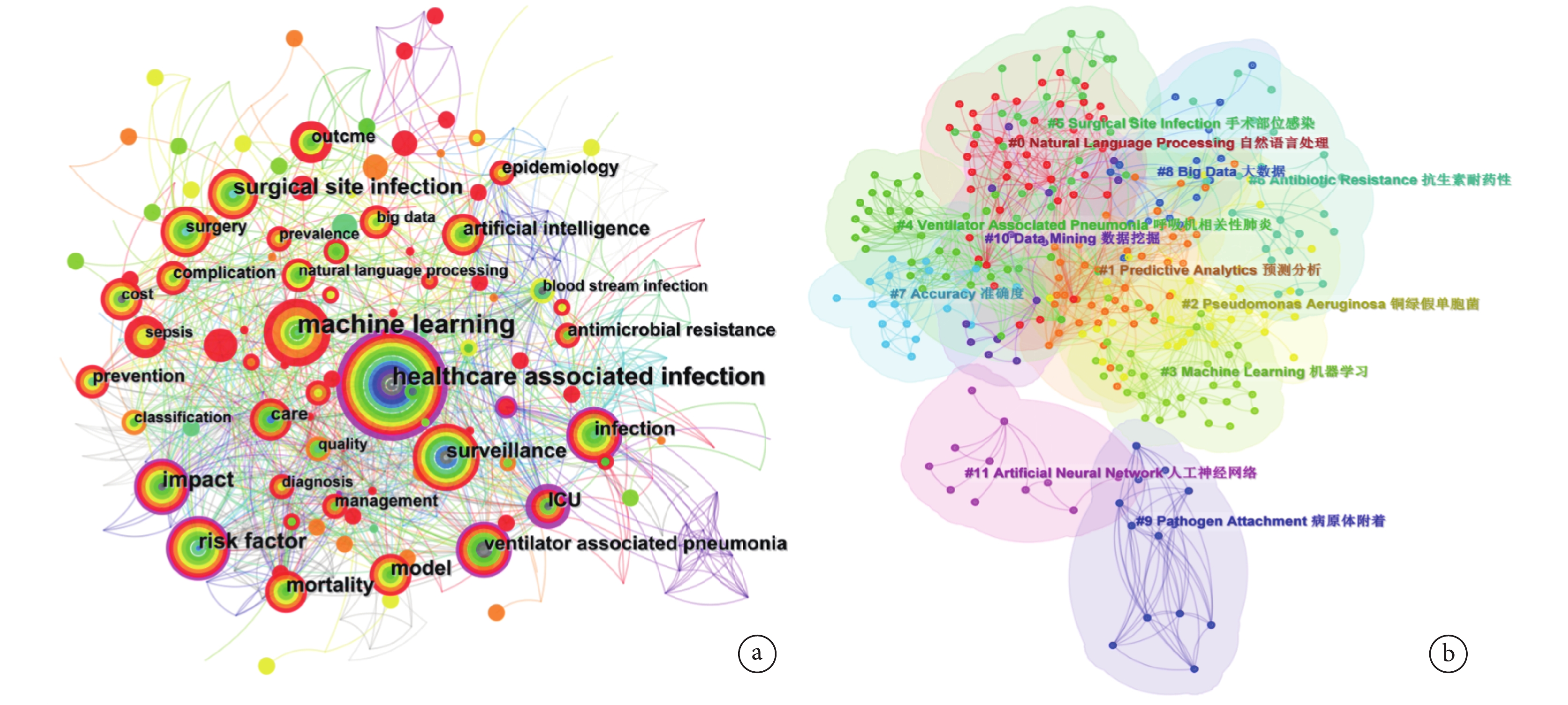
納入文獻共有 1 418 個關鍵詞,總出現頻率為 2 775 次。對部分同義關鍵詞進行合并后,得到出現頻率>30 次的有 machine learning(機器學習)、healthcare associated infection(醫療獲得性感染)、risk factor(危險因素)、surgical site infection(手術部位感染)和 impact(影響)。根據設定的參數,在 CiteSpace 中構建了一個由 334 個節點和 1 298 條線組成的關鍵詞共現網絡(圖2a)。在圖2a 中可見中心性≥0.1 的關鍵詞有 ICU(重癥監護病房,中心性為 0.24)、healthcare associated infection(醫療獲得性感染,中心性為 0.23)、risk factor(危險因素,中心性為 0.17)、infection(感染,中心性為 0.17)、bayesian network(貝葉斯網絡,中心性為 0.16)、impact(影響,中心性為 0.15)、ventilator associated pneumonia(呼吸機相關性肺炎,中心性為 0.13)、decision support(決策支持,中心性為 0.13)、discovery(探索,中心性為 0.11)、surveillance(監測,中心性為 0.10)。由此反映了本領域的主要研究熱點。
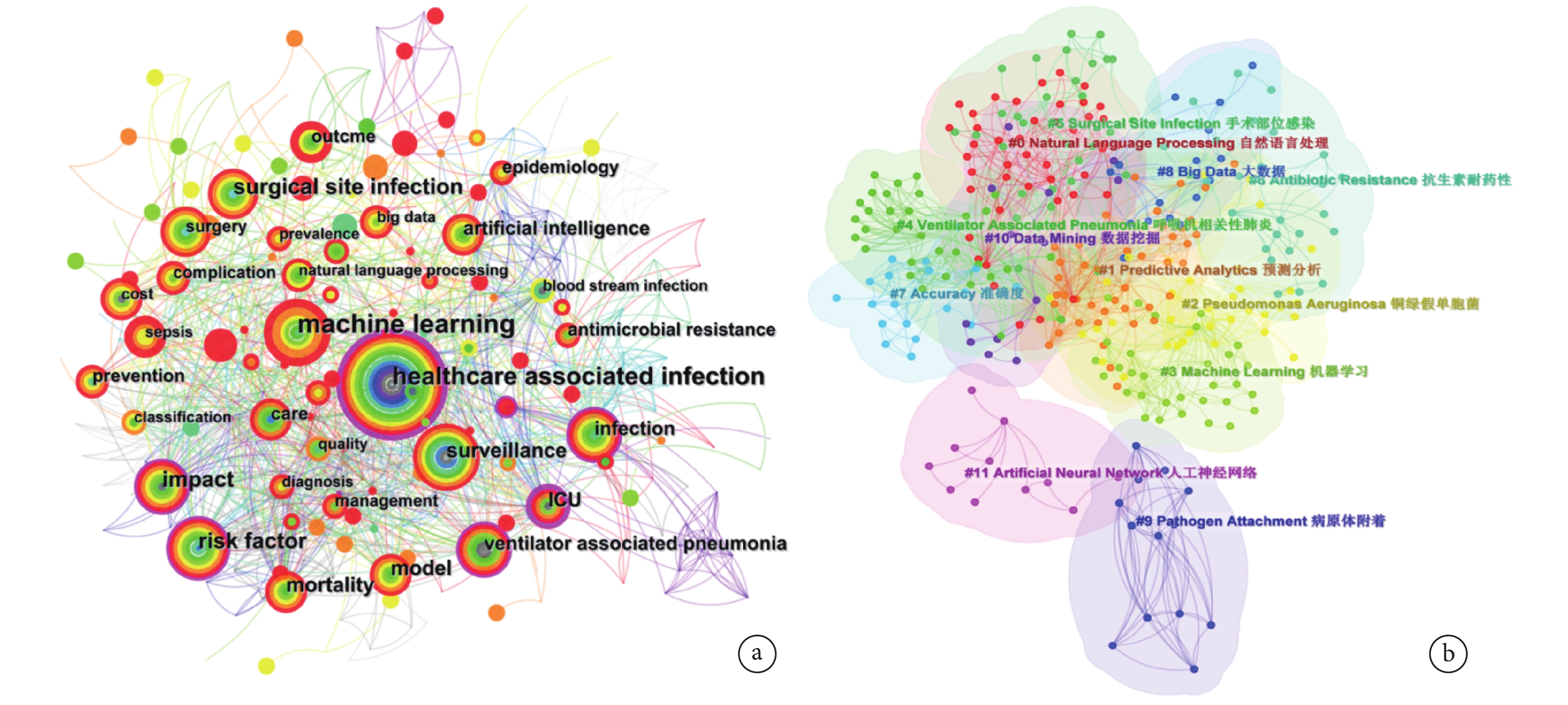 圖2
AI 應用于 HAI 領域的關鍵詞共現、聚類圖譜
圖2
AI 應用于 HAI 領域的關鍵詞共現、聚類圖譜
a. 關鍵詞共現圖譜,節點大小表示關鍵詞出現的頻率,節點的彩色圓環表示關鍵詞出現時間(出現時間越早,節點顏色越接近灰色;出現時間越晚,節點顏色越接近紅色),節點外部亮紅色圓環表示中心性大于 0.1;b. 關鍵詞聚類圖譜,不同色塊代表關鍵詞的不同聚類,數字標簽代表形成的關鍵詞聚類標簽。節點間的連線表示關鍵詞在同篇文獻中出現。AI:人工智能;HAI:醫院感染
2.4.2 關鍵詞聚類分析
共有 12 個關鍵詞聚類,聚類圖譜(圖2b)Q 為 0.5745,S 為 0.8146,表明聚類結構顯著,聚類效果合理。在圖2b 中,不同顏色模塊代表一個聚類,聚類顯示了AI在HAI領域中的主要應用方向,分別包括:AI算法及技術(#0 Natural Language Processing 自然語言處理、#3 Machine Learning 機器學習、#8 Big Data 大數據、#10 Data Mining 數據挖掘、#11 Artificial Neural Network 人工神經網絡)、HAI 的監控與預測(#1 Predictive Analytics 預測分析、#2 Pseudomonas Aeruginosa 銅綠假單胞菌、#4 Ventilator Associated Pneumonia 呼吸機相關性肺炎、#5 Surgical Site Infection 手術部位感染、#6 Antibiotic Resistance 抗生素耐藥性、#9 Pathogen Attachment 病原體附著)、HAI 診斷和預測的準確性探索(#7 Accuracy 準確度)。
2.4.3 關鍵詞突現分析
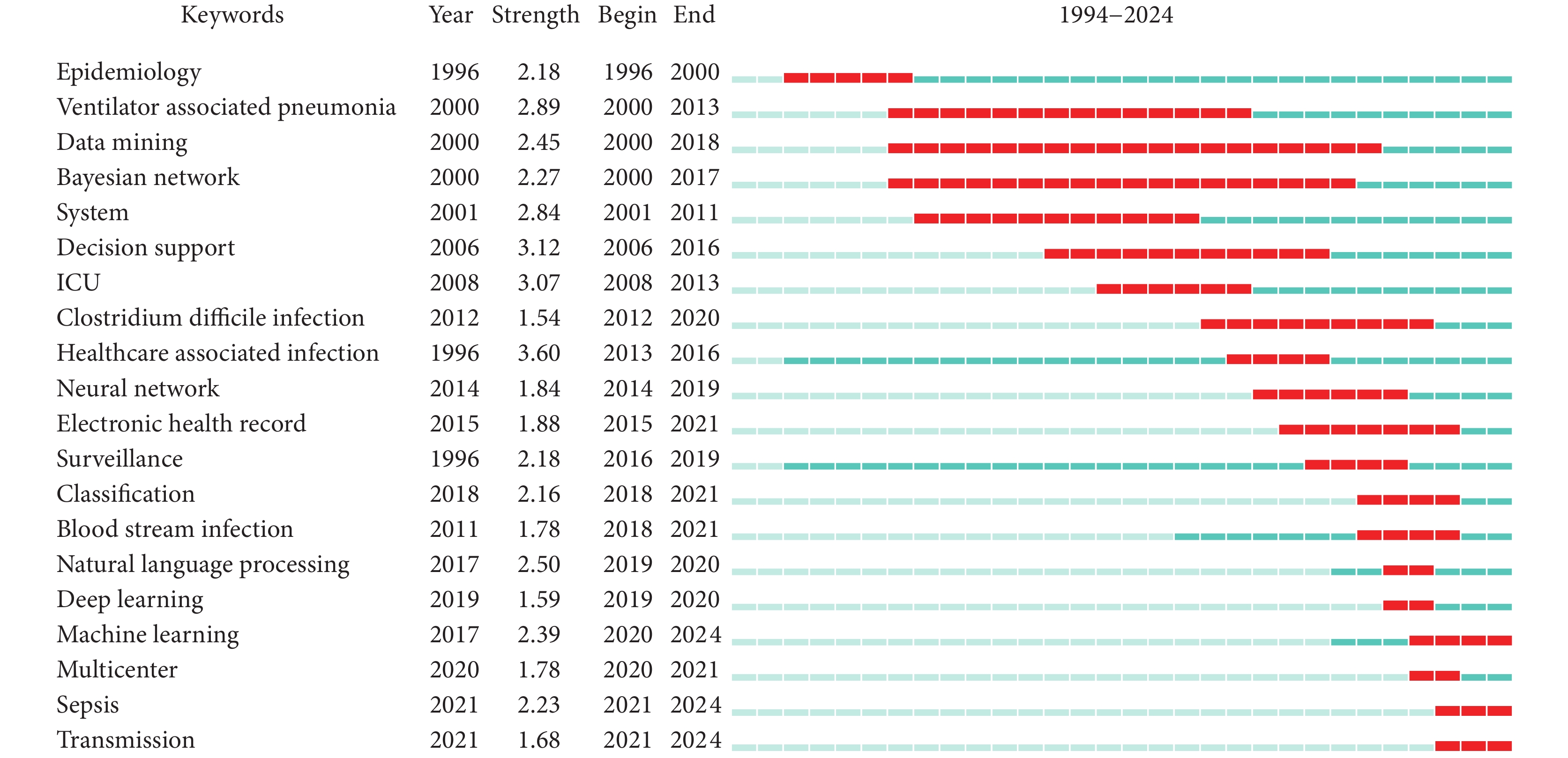
進行關鍵詞突現分析,得到前 20 個關鍵詞。由圖3 可知,突現強度最高的是 Healthcare Associated Infection(醫療獲得性感染),主要集中在 2006年—2016 年。突現時間最長的是 Data Mining(數據挖掘)。Natural Language Processing (自然語言處理)、Machine Learning(機器學習)、Deep Learning(深度學習)、Multicenter(多中心)、Sepsis(膿毒血癥)及 Transmission(傳播)是近 5 年內突現的關鍵詞,是新的研究熱點。其中 Machine Learning(機器學習)、Sepsis(膿毒血癥)及 Transmission(傳播)的突現持續時間尚未結束。
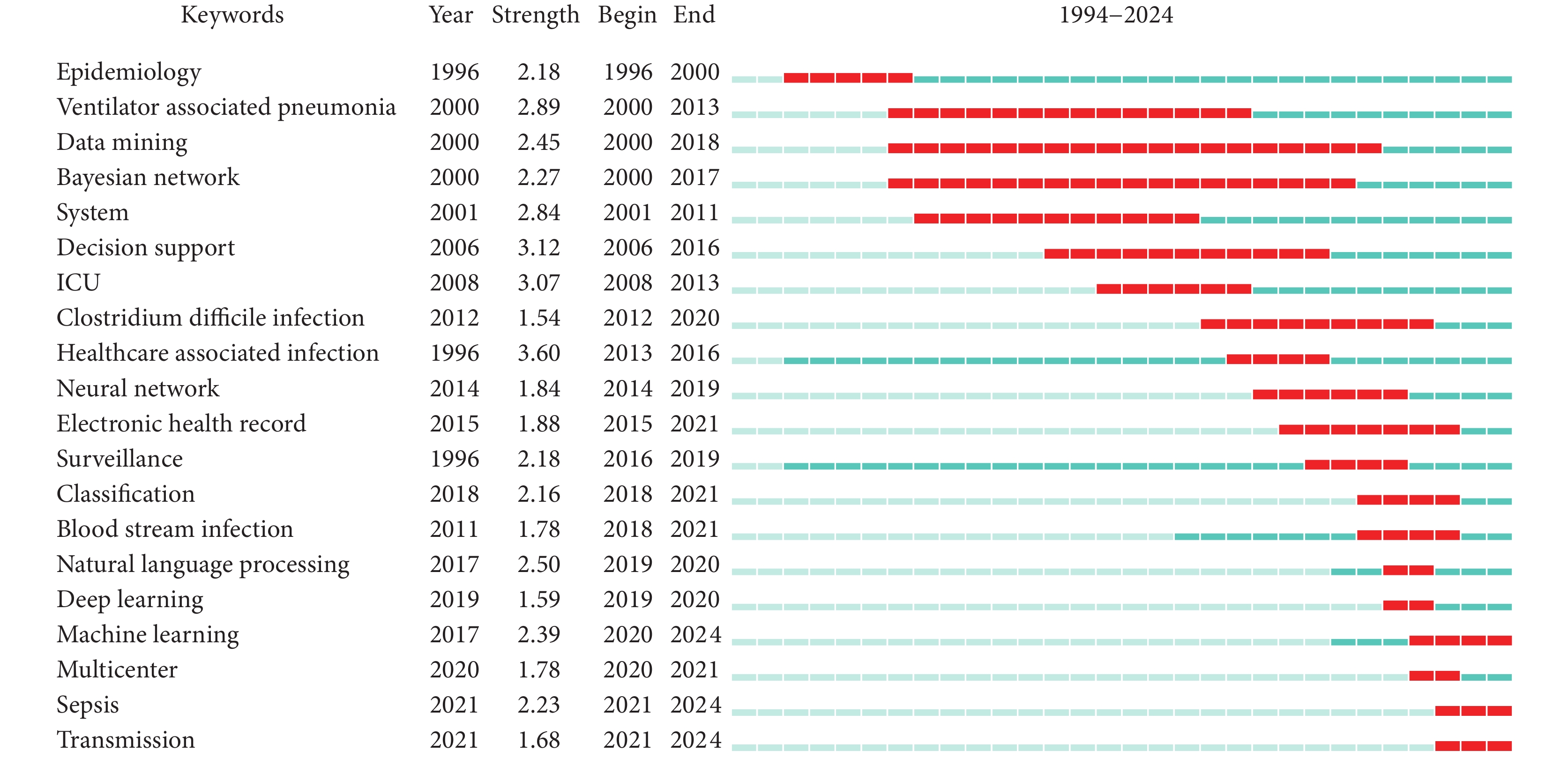 圖3
AI應用于 HAI 領域的關鍵詞突現圖譜
圖3
AI應用于 HAI 領域的關鍵詞突現圖譜
AI:人工智能;HAI:醫院感染;Kerwords:關鍵詞;Year:關鍵詞出現年份;Strength:突現強度;Begin:突現開始的年份;End:突現結束的年份。藍線條表示時間間隔,紅線條表示關鍵詞突現的持續時間
3 討論
目前,醫療領域向著自動化、智能化和精準化的方向發展。本研究通過總結AI技術在HAI領域的應用現狀,可為研究者更好地把握發展趨勢和新興研究熱點提供參考。
3.1 AI 應用于 HAI 領域研究的發文量、國家、機構、作者情況
1994 年—2017 年,AI 在 HAI 領域的研究數量增長較為緩慢。而在 2018 年后,對該領域的關注明顯增加,發文量呈指數增長,占總發文量的 80%,說明 AI 在 HAI 領域的應用潛力被逐漸發現。美國在這領域的發文情況處于領先地位,遠高于其他國家,且文獻被引用次數位列第 1 位,研究成果的學術影響力高。其他高收入國家如瑞士、英國、荷蘭等,在該領域發文數量和論文被引頻次都較高,表明其在AI領域有著雄厚的技術實力和研發能力[13],因此能展開深入研究,并持續發展。盡管 AI 技術有廣闊前景[14],但發展中國家因 AI 技術研發和人才培養相對滯后,互聯網和大容量存儲設備建設不完善,研發資金投入少,導致應用 AI 技術時面臨諸多挑戰。因此,應加強國際合作,特別是高收入國家應積極推動合作,建立 AI 與 HAI 應用領域方面的共建項目,進行經驗分享,并提供技術支持。
在發文量前 10 位的機構中,8 所來自美國,并形成了較為密切的合作關系。其中哈佛大學發文量最高,TLS 較強,在該領域具有很高的影響力,與許多其他機構保持合作關系。而我國將 AI 應用于 HAI 領域的研究少且起步晚,尚未進行廣泛的合作,在一定程度上限制了我國在該領域的發展。因此,不同國家的研究機構應積極搭建跨國、跨區域的多中心研究平臺,建立數據和資源共享機制,推進人才的跨國流動和培訓,促進機構間的合作和信息交流,從而推動學科獲得長足進步[15]。
在作者分析中,美國的多位學者在發文數量和被引次數中均位居前列,顯示其在該領域做出了突出貢獻。作者合作網絡顯示,國內外學者尚未進行深入的合作研究。AI 和 HAI 屬于交叉學科,涉及計算機科學、數學、統計學、生物醫學、流行病學等,跨學科合作和交叉學科人才培養可打破學科壁壘[16]。學者們除了加強本領域內的交流,還應促進學科間交叉融合,充分利用學科優勢,解決復雜的科學問題,以推動 AI 和 HAI 領域的創新和突破。
3.2 AI 應用于 HAI 領域研究的熱點變遷
AI 在 HAI 領域的研究主要聚焦在 AI 算法及技術、HAI 監控與預測、HAI 診斷和預測的準確性。關鍵詞突現分析揭示了以上研究熱點的演變過程。
3.2.1 AI 算法及技術
AI 算法及技術在 HAI 領域的演變過程經歷了從傳統的數據挖掘到更加復雜的深度學習和機器學習技術的發展。起初,數據挖掘技術被用于 HAI 以發現潛在的感染模式和規律[17]。隨著貝葉斯網絡[18]和神經網絡[19]等技術的引入,HAI 領域開始嘗試構建更復雜的模型,以進行風險評估、預測感染趨勢和臨床決策支持。自然語言處理技術被應用于處理醫療記錄和文本數據[20],以更高效地提取有關感染的信息。近年來,隨著深度學習[21]和機器學習[22]技術的快速發展,HAI 領域的研究向著更加智能化和自動化的方向發展。深度學習技術在圖像識別[21]和語音識別[23]等方面取得了顯著進展,為感染診斷和監測提供了更加準確和高效的方法。
3.2.2 HAI 監控與預測
HAI 監控與預測是醫療保健領域的重要任務,涉及到多方面的研究和實踐,包括不同的病原體和感染類型。首先,針對銅綠假單胞菌等常見病原體,從最初構建的計算機化專家系統進行菌株的耐藥性識別[24],到利用神經網絡和深度學習技術分析基因序列和傳播規律,預測其感染趨勢和變異特征[25]。運用機器學習算法提取抗菌藥物耐藥風險相關指標,以實現對住院患者耐藥性風險的預測[26]。呼吸機相關性肺炎等特定類型的感染,基于自然語言處理技術發現潛在感染風險[27],而神經網絡模型致力于實現患者的個性化監測和預警,提高預測準確性,助力早期診斷和治療[19]。病原體附著、血流感染和膿毒血癥等,從基于數據挖掘、神經網絡和機器學習的模型構建[28-30],到結合深度學習的高級算法[31-32],利用實驗室數據、生理參數和實時監測數據進行綜合分析,實現對感染嚴重程度和預后情況的監測。手術部位感染監測以往受限于手動檢索復雜的臨床變量,而 AI 技術帶來了革命性突破。通過樸素貝葉斯算法結合序列特征實現自動化監測[33],深度學習技術的引入構建了多模態風險評估模型,模型的預測性得到進一步優化[34]。基于圖像的深度學習模型被開發,可提供直觀、準確的傷口評估[35]。
3.2.3 HAI 診斷和預測的準確性
HAI 的準確診斷和預測對患者治療和預后至關重要。有研究運用一種新穎的、以數據為中心的 AI 技術,通過多任務學習,基于數千個研究變量,構建了艱難梭菌感染風險分層模型,用于 25 000 例患者,得到接受者操作特征曲線下面積(area under the receiver-operating characteristic curve, AUC)為 0.81[36]。目前該模型已用于該院住院患者每日風險評估。在血流感染監測方面,有研究利用多種數據挖掘方法建模,結果顯示 AdaBoost方法構建的模型具有最佳性能,準確率高達 89.7%,誤差率僅 10.3%,且模型構建時間短,僅 57 s[37]。有研究利用自然語言處理技術和深度學習技術構建了手術部位感染多模態風險評估模型,其中卷積神經網絡模型得到最高的 AUC(0.889),相較其他傳統機器學習方法,深度學習在模型準確性方面更有優勢[34]。Xu 等[38]采用 5 種機器學習算法開發了爆發性膿毒血癥預測模型,極限梯度提升模型得出最大的 AUC(0.977),其敏感性、特異性、準確度、陽性預測值、陰性預測值都最優。綜上,AI 在醫院感染診斷和預測中有巨大潛力,可提高模型準確性,為臨床決策提供更可靠的支持。
3.3 AI 應用于 HAI 領域的研究趨勢
突現分析揭示了關鍵詞的變化趨勢和關聯性,可幫助了解該領域的發展動向、研究熱點演變和知識結構,發現新的研究主題和重點。本研究發現,AI 應用于 HAI 領域研究趨勢從流行病學、決策支持,到監測、分類和傳播轉變,反映了研究者對 HAI 發生規律和傳播機制的逐步深入探索,AI 技術使得對 HAI 流行病學特征和傳播路徑的研究更加精細和深入。其次,從呼吸機相關性肺炎、艱難梭菌感染、血流感染到膿毒血癥的轉變,反映研究重點從單一感染類型向更廣泛、復雜的感染范圍拓展,AI 為不同類型的 HAI 研究提供了更多的解決方案。從數據挖掘、貝葉斯網絡、神經網絡、自然語言處理到深度學習和機器學習的轉變,說明了 AI 技術在 HAI 領域研究中的多樣化和不斷創新,各種 AI 算法和技術的應用使得對 HAI 數據的分析、預測和管理更加全面和高效。綜上,這些轉變反映了 HAI 領域研究的不斷進步和 AI 技術在該領域中的重要作用,為預防和控制 HAI 提供了更的思路和方法。
此外,機器學習、膿毒血癥及傳播的突現持續時間至今尚未結束,表明這些關鍵詞在 HAI 領域的研究中仍有持續的重要性和影響力。這可能反映了在當前的研究中,機器學習在分析 HAI 數據和預測感染風險方面發揮著關鍵作用,自動化和智能化、模型解釋性、強化學習、自監督學習和跨領域融合仍值得更深入的探究。HAI 作為膿毒癥發生的重要風險因素,二者間的內在聯系和臨床挑戰提示,未來研究應致力于深入發掘新型生物標志物,研發高效的即時診斷技術,制定精準的個體化診療方案,以及推進多組學在臨床診療中的應用。而在HAI傳播領域,感染源的時空溯源、病原體進化分析、預測傳播趨勢以及優化醫療資源配置等仍值得剖析。因此,這些關鍵詞的持續突現可能意味著學者們對于這些主題的興趣和重視程度仍然很高,并在未來的研究中仍將保持持續的關注和探索。
3.4 局限性
首先,本研究僅從單個數據庫提取和分析數據,可能因錯失某些重要文獻造成結果偏差。為確保更全面的文獻計量分析,未來可整合多個數據源。其次,本研究未納入以會議、評論、社論、筆記、信件、書籍章節或簡短調查形式發表的文獻,這可能限制了分析的全面性。第三,只考慮了以中英文撰寫的期刊論文,可能排除了其他語言的重要文獻。因此,未來可考慮將其他語言撰寫的論文納入分析范圍,以獲得更加全面和準確的研究結論。
綜上所述,AI 在 HAI 領域應用日益廣泛。與美國相比,我國在該領域仍有較大發展空間,中國學者們應積極推進跨國、跨區域的合作與交流,促進學科間的交叉融合,以提升我國在該領域的學術影響力。未來研究重點可能在于深入探究機器學習算法自動化和智能化發展、膿毒血癥精準化診療、HAI病原體進化分析及傳播趨勢預測等方面。
利益沖突:所有作者聲明不存在利益沖突。
醫院感染(healthcare-associated infection, HAI),又稱醫療獲得性感染或醫院內感染,是指患者在接受醫療服務期間,在醫院或其他醫療保健機構內感染的情況[1]。盡管目前尚無 HAI 全球負擔的確切數據,但世界衛生組織估計每年全球有數億患者受到 HAI 影響,且其發生率呈遞增趨勢[2],中低收入國家可能面臨著更高的 HAI 負擔[3]。預防是管理 HAI 的最佳方法,包括建設標準化監測系統、制定感染預防和控制計劃、組建多學科團隊、嚴格管理抗菌藥物應用、提高醫務人員和政策制定者對 HAI 和預防的認識[4]。盡管過去 10 年在 HAI 預防方面取得了實質性進展[5],但仍不斷出現新的挑戰。
隨著計算機科學的發展,尤其是人工智能(artificial intelligence, AI)技術在醫療衛生領域嶄露頭角[6],為提高 HAI 的診斷準確性和有效防控提供了新的可能,這涉及到早期疾病診斷、感染源追蹤、感染風險評估、突發公共衛生事件管理等多個方面。盡管 AI 有著廣闊的發展前景,但缺乏在 HAI 方面的分析和討論。而文獻計量學分析可幫助學者們深入了解某一領域的應用發展、熱點趨勢和未來前景[7]。因此,本研究采用文獻計量學的方法,對 Web of Science 核心合集數據庫中的相關文獻進行檢索,并分析 AI 在 HAI 領域的研究趨勢,以期為本領域學者提供關于 HAI 未來研究方向的新見解。
1 資料與方法
1.1 納入與排除標準
1.1.1 納入標準
① 與HAI相關研究;② 文獻類型限定為“article”;③ 語種為中英文。
1.1.2 排除標準
① 重復發表的文獻;② 綜述、會議論文、會議摘要、信件等;③ 與研究主題不相關。
1.2 檢索策略
檢索 Web of Science Core Collection 的 Science Citation Index Expanded 數據庫,檢索時限為 1994年1月1日—2024年1月22日。以“Artificial intelligence”“Nosocomial infection”“Healthcare-associated infection”等為檢索詞進行組合檢索,檢索項選擇主題檢索。
1.3 文獻篩選與數據提取
由 2 名作者獨立地進行文獻篩選,對有異議的論文,將與有高級職稱的第 3 位作者討論以達成一致。所檢索的結果以純文本文件格式導出,記錄內容為“全記錄與引用的參考文獻”,包括作者、題名、關鍵詞、年份、國家、作者機構、摘要、參考文獻等,并在 Web of Science 數據庫中創建引文報告,導出論文發表情況、被引用分布情況、H 指數等。
1.4 質量控制
在進行文獻檢索前,明確研究問題,確保檢索結果符合研究需求。建立標準化的檢索流程,確定文獻篩選和數據提取的步驟、標準和方法。在進行文獻篩選和數據提取時,由 2 名作者獨立進行,減少主觀偏差。使用標準化的數據提取表格,確保數據提取結果的一致性和完整性。
1.5 統計學方法
采用 Excel 2019、VOSviewer(v1.6.19)和 CiteSpace(v.6.1.R6)軟件進行文獻計量學和可視化分析。利用 Excel 2019 對論文的發表、被引用情況進行分析,呈現AI應用于HAI領域的年發文量及年被引頻次情況。其趨勢變化可反映該領域研究活動的增長或減少,從而揭示學科發展動向和研究興趣演變[8]。
運用 VOSviewer(v1.6.19)進行國家、機構和作者的合作網絡分析。每個節點代表一個國家、機構或作者。節點大小代表節點出現的頻率,節點越大表示在合作網絡中的重要性越高。連接節點間的線表示存在合作關系,連線粗細表示總連接強度(total link strength, TLS),反映合作關系的密切程度[9]。
運用 CiteSpace(v6.1.R6)軟件實現關鍵詞共現、聚類及突現分析。將時間跨度設置為 1994 年—2024 年,時間切片設置為 1,將修剪方式設定為 Pathfinder,Pruning sliced networks,節點類型選擇關鍵詞。在共現圖譜中,圓形節點的大小與關鍵詞的共現頻率呈正相關。節點的顏色越接近紅色,表示該詞出現時間越晚;反之,則表示越早。介數中心性是衡量關鍵詞共現網絡中節點重要性程度的指標[10]。當關鍵詞的中心性≥0.1 時,節點外周會被標記明亮的粉色圓環[11]。關鍵詞聚類則可以更直觀地勾勒出研究領域內的潛在聯系和熱點方向[10]。聚類是基于關鍵詞的共現關系形成的,具有強相關性和高共現頻率的關鍵詞將被組合成一個聚類。在聚類中,具有最高共現頻率的關鍵詞將自動生成為聚類標簽。因此,聚類標簽可代表該領域中不同的研究方向。關鍵詞突現分析可識別出在某一時期內突然興起并頻繁出現的關鍵詞,從而預測研究領域的新熱點。突現分析不僅可量化關鍵詞的強度,確定其重要性,還能追蹤關鍵詞出現和消失的演化過程[12]。藍線表示時間間隔,紅線表示突現的持續時間。根據網絡結構和聚類的清晰度,可憑借模塊值(Q 值)和平均輪廓值(S 值)評價繪制出的圖譜效果。當 Q>0.3 表示聚類結構顯著,S>0.5 表示聚類效果合理[10]。
2 結果
2.1 文獻檢索結果
共檢索到文獻 722 篇。剔除 85 篇非“article”類型文獻、327 篇與研究主題不相關的文獻、5 篇重復文獻,最終獲得文獻 305 篇。
2.2 文獻發表情況
AI應用于 HAI 領域的年發文量及年被引頻次見圖1。可見,從 1994 年—2017 年發文數量少,增長較為緩慢;2018年—2024 年發文數量快速增加,并在 2023 年達到峰值(71 篇),被引用次數(778 次)也達到頂峰。305 篇文獻的H指數為 32,累積被引用次數為 3174 次,平均每篇文獻被引用 11.93 次。
圖1
AI應用于 HAI 領域的年發文量及年被引頻次
AI:人工智能;HAI:醫院感染
2.3 科研合作分析
2.3.1 國家/地區合作分析
AI應用于 HAI 領域發表的文獻來自 50 個國家/地區。發文量前 5 名的國家分別是美國(132 篇,占 43.3%),其次是中國(53 篇,占 17.4%)、英國(24 篇,占 7.9%)、法國(22 篇,占 7.2%)和荷蘭(16 篇,占 5.2%)。在被引用頻次方面,美國也以 1 997 次引用排名第 1 位,其次是瑞士(347 次)和英國(328 次),中國以 314 次引用居于第 4 位。國際合作分析顯示,以美國為中心進行的合作最多,其中英、美合作最為密切,其次是中、美兩國。
2.3.2 機構合作分析
共有 270 個機構開展了AI與 HAI 相關領域的研究,發文量大于 5 篇有 34 家。從發文數量來看,排名前 10 位的機構多數位于美國(8 家),中國和荷蘭分別有 1 家機構。美國哈佛大學是 AI 在HAI應用具有較高研究實力和影響力的機構,共發表了 12 篇論文,被引用 255 次。埃默里大學在本領域也做出了突出貢獻,發表了 11 篇論文,獲得 73 次引用。其余前 10 位的機構依次為麻省理工學院(8 篇)、猶他大學(8 篇)、加利福尼亞大學舊金山分校(7 篇)、浙江大學(7 篇)、烏特勒支大學(6 篇)、杜克大學(5 篇)、斯坦福大學(5 篇)及科羅拉多大學(5 篇)。關于機構間的合作,美國部分機構形成了較為密切的合作網絡,如埃默里大學和杜克大學,兩者 TLS 最粗。我國的浙江大學和中山大學進行的合作研究處于國內前列。
2.3.3 作者合作分析
共有 1 888 位作者為 AI 應用于 HAI 研究做出了貢獻。發文量前 5 位作者均來自美國,Evans HL教授是發文量最高的學者,為 6 篇;其他 4 名作者依次為 Huang Shuai、Elster Eric、Hensman Hannah、Schobel Seth。在被引用頻次方面,美國作者 Brossette SE 以 175 次引用排名第 1 位。同樣來自美國的 Sprague AP 和 Moser SA 分別以 174 次和 173 次引用位居第 2、3 位。部分作者構成了 4 個密切合作的研究群體,學者 Wicks EC、Shuai Huang、Lober WB 是鏈接多個團隊的關鍵人物。
2.4 研究熱點與趨勢分析
2.4.1 關鍵詞共現分析
納入文獻共有 1 418 個關鍵詞,總出現頻率為 2 775 次。對部分同義關鍵詞進行合并后,得到出現頻率>30 次的有 machine learning(機器學習)、healthcare associated infection(醫療獲得性感染)、risk factor(危險因素)、surgical site infection(手術部位感染)和 impact(影響)。根據設定的參數,在 CiteSpace 中構建了一個由 334 個節點和 1 298 條線組成的關鍵詞共現網絡(圖2a)。在圖2a 中可見中心性≥0.1 的關鍵詞有 ICU(重癥監護病房,中心性為 0.24)、healthcare associated infection(醫療獲得性感染,中心性為 0.23)、risk factor(危險因素,中心性為 0.17)、infection(感染,中心性為 0.17)、bayesian network(貝葉斯網絡,中心性為 0.16)、impact(影響,中心性為 0.15)、ventilator associated pneumonia(呼吸機相關性肺炎,中心性為 0.13)、decision support(決策支持,中心性為 0.13)、discovery(探索,中心性為 0.11)、surveillance(監測,中心性為 0.10)。由此反映了本領域的主要研究熱點。
圖2
AI 應用于 HAI 領域的關鍵詞共現、聚類圖譜
a. 關鍵詞共現圖譜,節點大小表示關鍵詞出現的頻率,節點的彩色圓環表示關鍵詞出現時間(出現時間越早,節點顏色越接近灰色;出現時間越晚,節點顏色越接近紅色),節點外部亮紅色圓環表示中心性大于 0.1;b. 關鍵詞聚類圖譜,不同色塊代表關鍵詞的不同聚類,數字標簽代表形成的關鍵詞聚類標簽。節點間的連線表示關鍵詞在同篇文獻中出現。AI:人工智能;HAI:醫院感染
2.4.2 關鍵詞聚類分析
共有 12 個關鍵詞聚類,聚類圖譜(圖2b)Q 為 0.5745,S 為 0.8146,表明聚類結構顯著,聚類效果合理。在圖2b 中,不同顏色模塊代表一個聚類,聚類顯示了AI在HAI領域中的主要應用方向,分別包括:AI算法及技術(#0 Natural Language Processing 自然語言處理、#3 Machine Learning 機器學習、#8 Big Data 大數據、#10 Data Mining 數據挖掘、#11 Artificial Neural Network 人工神經網絡)、HAI 的監控與預測(#1 Predictive Analytics 預測分析、#2 Pseudomonas Aeruginosa 銅綠假單胞菌、#4 Ventilator Associated Pneumonia 呼吸機相關性肺炎、#5 Surgical Site Infection 手術部位感染、#6 Antibiotic Resistance 抗生素耐藥性、#9 Pathogen Attachment 病原體附著)、HAI 診斷和預測的準確性探索(#7 Accuracy 準確度)。
2.4.3 關鍵詞突現分析
進行關鍵詞突現分析,得到前 20 個關鍵詞。由圖3 可知,突現強度最高的是 Healthcare Associated Infection(醫療獲得性感染),主要集中在 2006年—2016 年。突現時間最長的是 Data Mining(數據挖掘)。Natural Language Processing (自然語言處理)、Machine Learning(機器學習)、Deep Learning(深度學習)、Multicenter(多中心)、Sepsis(膿毒血癥)及 Transmission(傳播)是近 5 年內突現的關鍵詞,是新的研究熱點。其中 Machine Learning(機器學習)、Sepsis(膿毒血癥)及 Transmission(傳播)的突現持續時間尚未結束。
圖3
AI應用于 HAI 領域的關鍵詞突現圖譜
AI:人工智能;HAI:醫院感染;Kerwords:關鍵詞;Year:關鍵詞出現年份;Strength:突現強度;Begin:突現開始的年份;End:突現結束的年份。藍線條表示時間間隔,紅線條表示關鍵詞突現的持續時間
3 討論
目前,醫療領域向著自動化、智能化和精準化的方向發展。本研究通過總結AI技術在HAI領域的應用現狀,可為研究者更好地把握發展趨勢和新興研究熱點提供參考。
3.1 AI 應用于 HAI 領域研究的發文量、國家、機構、作者情況
1994 年—2017 年,AI 在 HAI 領域的研究數量增長較為緩慢。而在 2018 年后,對該領域的關注明顯增加,發文量呈指數增長,占總發文量的 80%,說明 AI 在 HAI 領域的應用潛力被逐漸發現。美國在這領域的發文情況處于領先地位,遠高于其他國家,且文獻被引用次數位列第 1 位,研究成果的學術影響力高。其他高收入國家如瑞士、英國、荷蘭等,在該領域發文數量和論文被引頻次都較高,表明其在AI領域有著雄厚的技術實力和研發能力[13],因此能展開深入研究,并持續發展。盡管 AI 技術有廣闊前景[14],但發展中國家因 AI 技術研發和人才培養相對滯后,互聯網和大容量存儲設備建設不完善,研發資金投入少,導致應用 AI 技術時面臨諸多挑戰。因此,應加強國際合作,特別是高收入國家應積極推動合作,建立 AI 與 HAI 應用領域方面的共建項目,進行經驗分享,并提供技術支持。
在發文量前 10 位的機構中,8 所來自美國,并形成了較為密切的合作關系。其中哈佛大學發文量最高,TLS 較強,在該領域具有很高的影響力,與許多其他機構保持合作關系。而我國將 AI 應用于 HAI 領域的研究少且起步晚,尚未進行廣泛的合作,在一定程度上限制了我國在該領域的發展。因此,不同國家的研究機構應積極搭建跨國、跨區域的多中心研究平臺,建立數據和資源共享機制,推進人才的跨國流動和培訓,促進機構間的合作和信息交流,從而推動學科獲得長足進步[15]。
在作者分析中,美國的多位學者在發文數量和被引次數中均位居前列,顯示其在該領域做出了突出貢獻。作者合作網絡顯示,國內外學者尚未進行深入的合作研究。AI 和 HAI 屬于交叉學科,涉及計算機科學、數學、統計學、生物醫學、流行病學等,跨學科合作和交叉學科人才培養可打破學科壁壘[16]。學者們除了加強本領域內的交流,還應促進學科間交叉融合,充分利用學科優勢,解決復雜的科學問題,以推動 AI 和 HAI 領域的創新和突破。
3.2 AI 應用于 HAI 領域研究的熱點變遷
AI 在 HAI 領域的研究主要聚焦在 AI 算法及技術、HAI 監控與預測、HAI 診斷和預測的準確性。關鍵詞突現分析揭示了以上研究熱點的演變過程。
3.2.1 AI 算法及技術
AI 算法及技術在 HAI 領域的演變過程經歷了從傳統的數據挖掘到更加復雜的深度學習和機器學習技術的發展。起初,數據挖掘技術被用于 HAI 以發現潛在的感染模式和規律[17]。隨著貝葉斯網絡[18]和神經網絡[19]等技術的引入,HAI 領域開始嘗試構建更復雜的模型,以進行風險評估、預測感染趨勢和臨床決策支持。自然語言處理技術被應用于處理醫療記錄和文本數據[20],以更高效地提取有關感染的信息。近年來,隨著深度學習[21]和機器學習[22]技術的快速發展,HAI 領域的研究向著更加智能化和自動化的方向發展。深度學習技術在圖像識別[21]和語音識別[23]等方面取得了顯著進展,為感染診斷和監測提供了更加準確和高效的方法。
3.2.2 HAI 監控與預測
HAI 監控與預測是醫療保健領域的重要任務,涉及到多方面的研究和實踐,包括不同的病原體和感染類型。首先,針對銅綠假單胞菌等常見病原體,從最初構建的計算機化專家系統進行菌株的耐藥性識別[24],到利用神經網絡和深度學習技術分析基因序列和傳播規律,預測其感染趨勢和變異特征[25]。運用機器學習算法提取抗菌藥物耐藥風險相關指標,以實現對住院患者耐藥性風險的預測[26]。呼吸機相關性肺炎等特定類型的感染,基于自然語言處理技術發現潛在感染風險[27],而神經網絡模型致力于實現患者的個性化監測和預警,提高預測準確性,助力早期診斷和治療[19]。病原體附著、血流感染和膿毒血癥等,從基于數據挖掘、神經網絡和機器學習的模型構建[28-30],到結合深度學習的高級算法[31-32],利用實驗室數據、生理參數和實時監測數據進行綜合分析,實現對感染嚴重程度和預后情況的監測。手術部位感染監測以往受限于手動檢索復雜的臨床變量,而 AI 技術帶來了革命性突破。通過樸素貝葉斯算法結合序列特征實現自動化監測[33],深度學習技術的引入構建了多模態風險評估模型,模型的預測性得到進一步優化[34]。基于圖像的深度學習模型被開發,可提供直觀、準確的傷口評估[35]。
3.2.3 HAI 診斷和預測的準確性
HAI 的準確診斷和預測對患者治療和預后至關重要。有研究運用一種新穎的、以數據為中心的 AI 技術,通過多任務學習,基于數千個研究變量,構建了艱難梭菌感染風險分層模型,用于 25 000 例患者,得到接受者操作特征曲線下面積(area under the receiver-operating characteristic curve, AUC)為 0.81[36]。目前該模型已用于該院住院患者每日風險評估。在血流感染監測方面,有研究利用多種數據挖掘方法建模,結果顯示 AdaBoost方法構建的模型具有最佳性能,準確率高達 89.7%,誤差率僅 10.3%,且模型構建時間短,僅 57 s[37]。有研究利用自然語言處理技術和深度學習技術構建了手術部位感染多模態風險評估模型,其中卷積神經網絡模型得到最高的 AUC(0.889),相較其他傳統機器學習方法,深度學習在模型準確性方面更有優勢[34]。Xu 等[38]采用 5 種機器學習算法開發了爆發性膿毒血癥預測模型,極限梯度提升模型得出最大的 AUC(0.977),其敏感性、特異性、準確度、陽性預測值、陰性預測值都最優。綜上,AI 在醫院感染診斷和預測中有巨大潛力,可提高模型準確性,為臨床決策提供更可靠的支持。
3.3 AI 應用于 HAI 領域的研究趨勢
突現分析揭示了關鍵詞的變化趨勢和關聯性,可幫助了解該領域的發展動向、研究熱點演變和知識結構,發現新的研究主題和重點。本研究發現,AI 應用于 HAI 領域研究趨勢從流行病學、決策支持,到監測、分類和傳播轉變,反映了研究者對 HAI 發生規律和傳播機制的逐步深入探索,AI 技術使得對 HAI 流行病學特征和傳播路徑的研究更加精細和深入。其次,從呼吸機相關性肺炎、艱難梭菌感染、血流感染到膿毒血癥的轉變,反映研究重點從單一感染類型向更廣泛、復雜的感染范圍拓展,AI 為不同類型的 HAI 研究提供了更多的解決方案。從數據挖掘、貝葉斯網絡、神經網絡、自然語言處理到深度學習和機器學習的轉變,說明了 AI 技術在 HAI 領域研究中的多樣化和不斷創新,各種 AI 算法和技術的應用使得對 HAI 數據的分析、預測和管理更加全面和高效。綜上,這些轉變反映了 HAI 領域研究的不斷進步和 AI 技術在該領域中的重要作用,為預防和控制 HAI 提供了更的思路和方法。
此外,機器學習、膿毒血癥及傳播的突現持續時間至今尚未結束,表明這些關鍵詞在 HAI 領域的研究中仍有持續的重要性和影響力。這可能反映了在當前的研究中,機器學習在分析 HAI 數據和預測感染風險方面發揮著關鍵作用,自動化和智能化、模型解釋性、強化學習、自監督學習和跨領域融合仍值得更深入的探究。HAI 作為膿毒癥發生的重要風險因素,二者間的內在聯系和臨床挑戰提示,未來研究應致力于深入發掘新型生物標志物,研發高效的即時診斷技術,制定精準的個體化診療方案,以及推進多組學在臨床診療中的應用。而在HAI傳播領域,感染源的時空溯源、病原體進化分析、預測傳播趨勢以及優化醫療資源配置等仍值得剖析。因此,這些關鍵詞的持續突現可能意味著學者們對于這些主題的興趣和重視程度仍然很高,并在未來的研究中仍將保持持續的關注和探索。
3.4 局限性
首先,本研究僅從單個數據庫提取和分析數據,可能因錯失某些重要文獻造成結果偏差。為確保更全面的文獻計量分析,未來可整合多個數據源。其次,本研究未納入以會議、評論、社論、筆記、信件、書籍章節或簡短調查形式發表的文獻,這可能限制了分析的全面性。第三,只考慮了以中英文撰寫的期刊論文,可能排除了其他語言的重要文獻。因此,未來可考慮將其他語言撰寫的論文納入分析范圍,以獲得更加全面和準確的研究結論。
綜上所述,AI 在 HAI 領域應用日益廣泛。與美國相比,我國在該領域仍有較大發展空間,中國學者們應積極推進跨國、跨區域的合作與交流,促進學科間的交叉融合,以提升我國在該領域的學術影響力。未來研究重點可能在于深入探究機器學習算法自動化和智能化發展、膿毒血癥精準化診療、HAI病原體進化分析及傳播趨勢預測等方面。
利益沖突:所有作者聲明不存在利益沖突。