引用本文: 景城陽, 馮琳, 李嘉琛, 梁立榮, 廖星. 中醫臨床預測模型研究方法學質量的系統評價. 中國循證醫學雜志, 2024, 24(3): 312-321. doi: 10.7507/1672-2531.202307071 復制
版權信息: ?四川大學華西醫院華西期刊社《中國循證醫學雜志》版權所有,未經授權不得轉載、改編
預測模型因其在時效性方面的巨大應用價值而在醫學研究領域中備受矚目,其中應用于臨床實踐的預測模型主要包括診斷模型和預后模型兩大類。前者主要基于個體的臨床表現及特征以預測當前時點患病或已發生某種結局的概率,適用群體為特定疾病的疑似患者,常借助易采集、低成本、無創的各類指標形成高靈敏度或特異度的診斷方案,主要應用于疾病的二級預防,如腫瘤疾病的診斷、急性深靜脈血栓形成的門診篩查等;后者則通過個體當下的健康或疾病狀態以預測在未來時點出現某種事件/結局的概率,其適用群體除了已確診的患者外,還包括存在特定風險因素的健康人群或特殊群體,如具有高血壓家族史的健康個體、妊娠期高血糖孕婦等,常通過絕對概率來量化未來罹患某種疾病或發生某種疾病轉歸的風險,主要應用于疾病的一級和三級預防,如估計高危個體十年內發生心血管事件的風險、評估急性心衰患者住院期間死亡的概率等[1-3]。
具體臨床預測建模研究的開展包括模型的設計、構建、評價、驗證等不同階段[4]。在任一階段方法學層面的缺陷均可能引起不同程度的偏倚風險,進而影響預測模型性能評價的真實性[5, 6]。對于存在高偏倚風險的臨床預測模型而言,不僅無法評估其在臨床決策中產生的實際效益情況,其應用甚至還可能會對醫療實踐產生負面影響,例如基于模型預測結果采取不必要或不充分的臨床干預措施而造成醫療資源的浪費或錯誤利用[7]。因此,針對臨床預測模型開展嚴格的方法學質量評價對于其可靠性的確定和應用價值的探索具有重要意義。
近年來,隨著信息獲取成本的降低、建模技術的更新以及多學科交叉融合的發展,在中醫臨床領域中亦開始興起預測模型的研究浪潮[8]。盡管相關研究的數量在不斷增長,并創新性地應用了諸如中醫四診信息、中醫藥干預治療信息、中醫體質信息、舌脈信息等多類具有中醫藥特色的預測因子,但真正落地臨床實踐者卻寥寥無幾,僅在單中心或小區域范圍內被少量醫者采納;同時在各類中醫臨床實踐指南中亦未見關于具體預測模型應用的推薦意見,使得現有模型無法廣泛地鋪開應用于中醫臨床,造成了大量研究資源的浪費。除了研究者疏于開展對預測模型性能的后續臨床驗證外,缺乏對相關研究的方法學評價亦是限制其轉化應用的重要原因之一。因此,本研究擬對現有中醫臨床預測模型研究的方法學質量開展系統評價,以梳理、總結當前研究的具體偏倚風險情況及原因,為后續相關研究的開展與優化提供參考。
1 資料與方法
1.1 納入與排除標準
納入標準:① 研究類型為實證研究且發表類型為期刊論文;② 建模目的以臨床應用為導向,主要研究內容圍繞預測模型的構建、驗證或(和)更新;③ 模型類型為診斷模型或預后模型且建模變量數量不少于2個。
排除標準:① 發表類型為研究方案、會議論文、社論、評論或摘要者;② 研究內容僅針對現有預測模型開展建模過程的方法學評價,而無具體模型的呈現;③ 模型的構建或應用與中醫藥領域無明顯關聯;④ 重復發表的文獻;⑤ 無法獲取全文的文獻。
1.2 文獻檢索策略
計算機檢索CNKI、WanFang Data、VIP、SinoMed、PubMed、Embase和Web of Science數據庫,搜集與中醫臨床預測模型研究相關的中、英文文獻,檢索時限均從建庫至2023年3月31日。檢索采用主題詞與自由詞相結合的方式進行,并根據數據庫特征做適應性調整。中文檢索詞包括:中醫、中醫藥、中西醫、預測模型、預測規則、預后模型、診斷模型、風險預測、風險評分等;英文檢索詞包括:traditional Chinese medicine、traditional Chinese and western medicine 、clinical prediction model、clinical prediction rule、clinical forecast mode、diagnostic model、prognostic model、risk prediction、risk rule等。以PubMed為例,其具體檢索策略見附件一框1。
1.3 文獻篩選與資料提取
由2名研究者獨立篩選文獻、提取資料并交叉核對。如存在分歧,則通過討論或與第三方協商解決。文獻篩選首先閱讀文題和摘要,在排除明顯不相關的文獻后,進一步閱讀全文,以確定最終是否納入。基于CHARMS清單構建信息提取表[9],提取內容包括:① 文獻基本信息(包括標題、作者、發表年份、發表期刊);② 預測模型特征情況(包括模型設計、模型構建、模型性能、模型驗證);③ 偏倚風險評價關鍵因素(包括研究對象、預測因子、結局指標和統計分析)。
1.4 納入研究的方法學質量評價
采用預測模型偏倚風險評估工具(prediction model risk of bias assessment tool,PROBAST)對納入研究的偏倚風險進行評價[5]。PROBAST是基于德爾菲法開發的通用評估工具,可通過研究對象、預測因子、結局指標和統計分析4個維度及對應的20個標志性問題全面、系統地評價預測模型研究的方法學質量[5, 6]。
考慮到具體的預測模型研究可能基于不同建模方法或預測因子構建多個預測模型,因此在評價過程中,優先評價由作者推薦或定義的最佳模型;若作者未具體說明,則選擇區分度最佳者作為待評價模型。方法學評價由2名研究者根據PROBAST的等級評定標準獨立開展,任何分歧通過討論或與第三方協商解決。
1.5 統計分析
采用描述性分析方法,整理和總結納入研究的基本特征情況和方法學質量評價結果,并以表格、圖片等可視化方式呈現。計數資料以頻數及百分比表示。
2 結果
2.1 文獻篩選流程及結果
初檢共獲得相關文獻2 018篇,經逐層篩選后,最終納入合格文獻113篇[10-122],其中中文80篇,英文33篇。具體文獻篩選流程及結果見附件一圖1。
2.2 納入研究的類型及基本特征
113項中醫臨床預測模型研究分別包含診斷模型研究79項(69.9%),預后模型研究34項(30.1%)。基于PROBAST的分類標準,屬于模型構建的研究共計107項(94.7%),屬于模型構建與驗證(外部驗證)的研究共計6項(5.3%);其中有31項(27.4%)研究應用了多種建模方法(≥2種)。各項研究的具體基本特征情況見附件一表1。
所有預測模型涵蓋的病種數量共計49個,研究頻數位居前十的疾病分別為2型糖尿病、原發性高血壓、腦卒中、慢性心力衰竭、慢性乙型病毒性肝炎、原發性肝癌、非小細胞肺癌、骨質疏松癥、冠狀動脈粥樣硬化性心臟病、結直腸癌。參照2020年WHO ICD-10編碼標準,所有病種主要集中于11類疾病領域,按研究頻數從大到小依次為:循環系統疾病(28/113,24.78%)、內分泌系統疾病(21/113,18.58%)、腫瘤疾病(17/113,15.04%)、神經系統疾病(11/113,9.73%)、傳染性疾病(8/113,7.08%)、肌肉骨骼系統疾病(7/113,6.19%)、消化系統疾病(6/113,5.31%)、泌尿生殖系統疾病(6/113,5.31%)、呼吸系統疾病(5/113,4.42%)、精神障礙疾病(2/113,1.77%)、損傷性疾病(2/113,1.77%)。具體疾病名稱、所屬領域及相應研究頻數詳見附件一表2。
2.2.1 研究對象
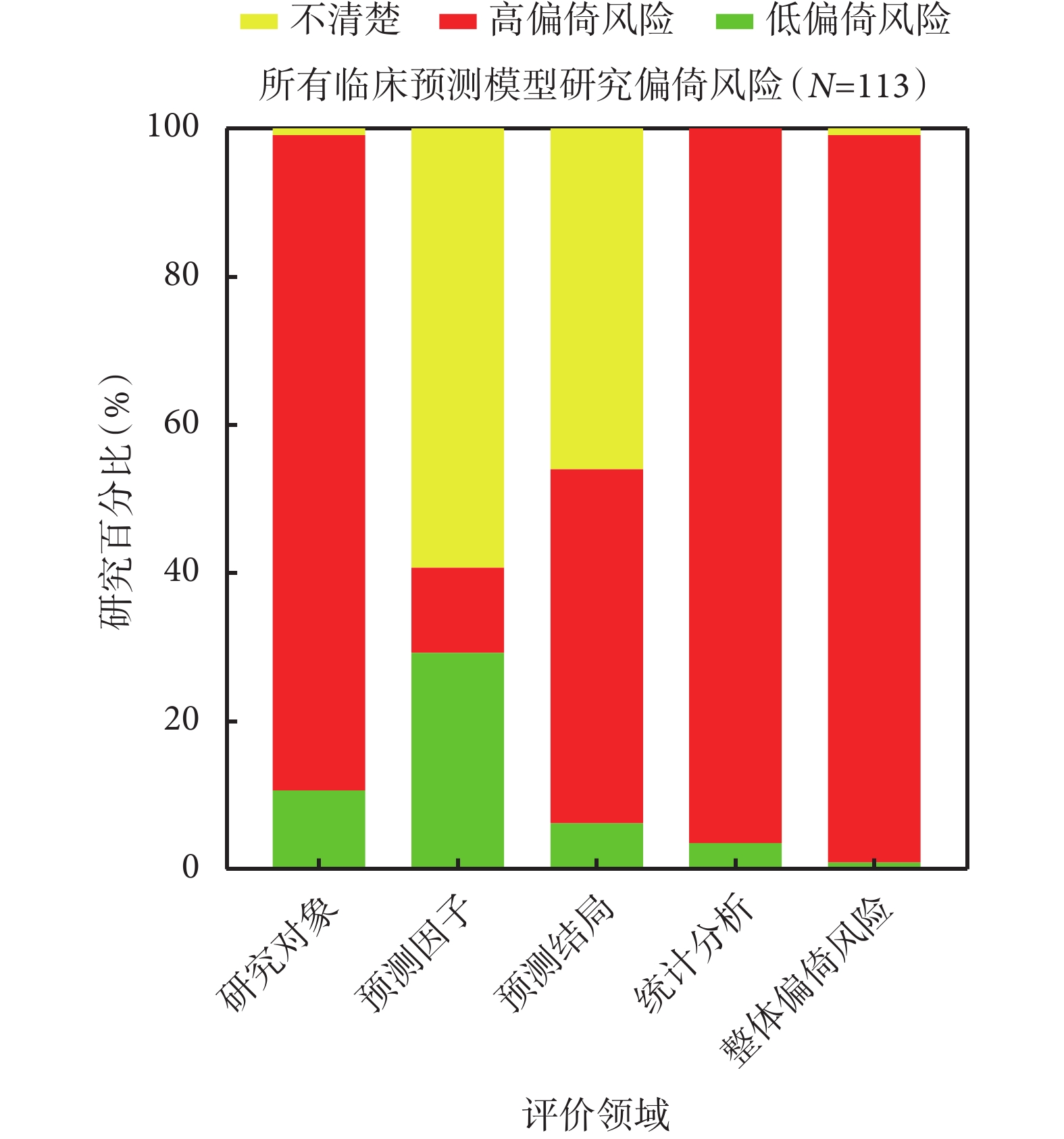
在研究對象領域,僅有12/113項(10.6%)研究的偏倚風險較低,其中在診斷模型研究(10.1%,8/79)與預后模型研究(11.8%,4/34)中的比例基本一致。
高達100/113項(88.5%)研究在研究對象選擇方面存在高偏倚風險,最為常見的原因是其建模數據來源存在偏倚,無論是診斷模型還是預后模型,建模樣本未源自前瞻性數據的研究所占比例均超過了88%(標志性問題1.1)。
超八成納入研究制定的研究對象納入和排除標準較為合理,但仍有10/79項(12.7%)診斷模型研究和4/34項(11.8%)預后模型研究未報告具體標準信息,故無法評價建模樣本能否代表模型的目標人群(標志性問題1.2)。另有1/113項(0.9%)研究因信息不全而無法評價此領域的偏倚風險。
2.2.2 預測因子
在預測因子領域,共計33/113項(29.2%)研究偏倚風險較低,其中在預后模型研究中的比例(41.2%,14/34)高于在診斷模型研究中的比例(24.1%,19/79)。
高達67/113項(59.3%)研究的偏倚風險不清,這主要與預測因子評估過程中盲法的應用有關,分別有49/79項(62.0%)診斷模型研究和20/34項(58.8%)預后模型研究未報告有關設盲的具體信息(標志性問題2.2)。
13/113項(11.5%)研究存在高偏倚風險亦主要與預測因子評估過程中明確未采用盲法有關(11/13,84.6%),且此領域的高偏倚風險全部集中于診斷模型研究中。
整體來看,納入研究在預測因子定義、評估范圍及有效性方面的偏倚風險普遍較低(標志性問題2.1,標志性問題2.3)。
2.2.3 預測結局
在預測結局領域,僅有7/113項(6.2%)研究的偏倚風險較低,其中在預后模型研究中的比例(8.8%,3/34)略高于在診斷模型研究中的比例(5.1%,4/79)。
共計54/113項(47.8%)研究在此領域存在高偏倚風險;其中診斷模型研究46/79項(58.2%),預后模型研究8/34項(23.5%)。產生高偏倚風險的主要原因在于53/113項(46.9%)研究的預測結局定義中包含了部分預測因子,導致兩者之間的關聯性可能被高估(標志性問題3.3)。
共計52/113項(46.0%)研究在此領域的偏倚風險不清;其中診斷模型研究29/79項(36.7%),預后模型研究23/34項(67.6%)。偏倚風險不清的首要原因在于97/113項(85.8%)研究未報告有關預測結局確定過程中是否設盲的具體信息(標志性問題3.5);其次則是33/113項(29.2%)研究缺乏足夠信息以判斷預測因子評估和結局確定的時間間隔是否合理(標志性問題3.6)。
整體來看,超八成納入研究對于預測結局定義、分類方法及其適用對象范圍的選擇較為合理(標志性問題3.1,標志性問題3.2,標志性問題3.4)。
2.2.4 統計分析
在統計分析領域,僅有4/113項(3.5%)研究的偏倚風險較低,其中在預后模型研究中的比例(8.8%,3/34)高于在診斷模型研究中的比例(1.3%,1/79)。
高達109/113項(96.5%)研究在此領域存在高偏倚風險,其中診斷模型研究78/79項(98.7%),預后模型研究31/34項(91.2%)。究其具體原因,38/79項(48.1%)診斷模型研究和13/34項(38.2%)預后模型研究的建模樣本量不足,即每變量事件數EPV<10(標志性問題4.1);9/79項(11.4%)診斷模型研究和10/34項(29.4%)預后模型研究對連續變量進行了錯誤處理/轉化或對分類變量采用了不一致的切點(標志性問題4.2);僅34/79項(43.0%)診斷模型研究和17/34項(50.0%)預后模型研究對缺失數據進行了合理處理(標志性問題4.4);34/79項(43.0%)診斷模型研究和19/34項(55.9%)預后模型研究僅基于單因素分析法篩選預測因子而可能遺漏重要的變量信息(標志性問題4.5);73/79項(92.4%)診斷模型研究和26/34項(76.5%)預后模型研究未能同時從區分度和校準度兩個角度正確、全面地評價模型性能(標志性問題4.7);73/79項(92.4%)診斷模型研究和20/34項(58.8%)預后模型研究未能采用正確的內部驗證方法以合理地評價模型的擬合情況(標志性問題4.8)。
整體來看,納入研究僅在統計分析數據集、數據復雜性解釋和預測因子權重/系數報告(此項僅針對基于回歸方法構建模型的研究而言)方面的偏倚風險普遍較低(標志性問題4.3,標志性問題4.6,標志性問題4.9)。
2.2.5 整體偏倚風險
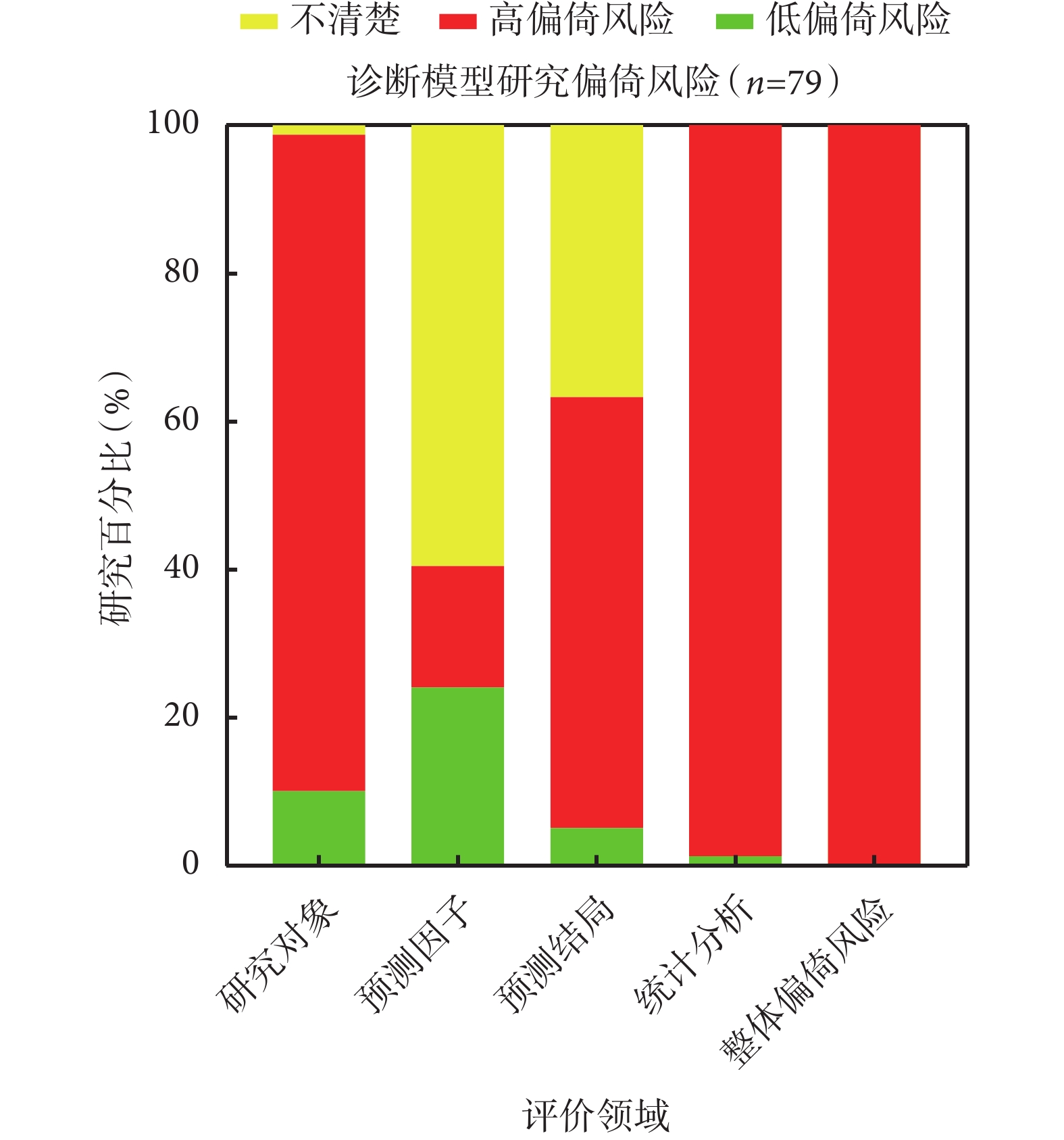
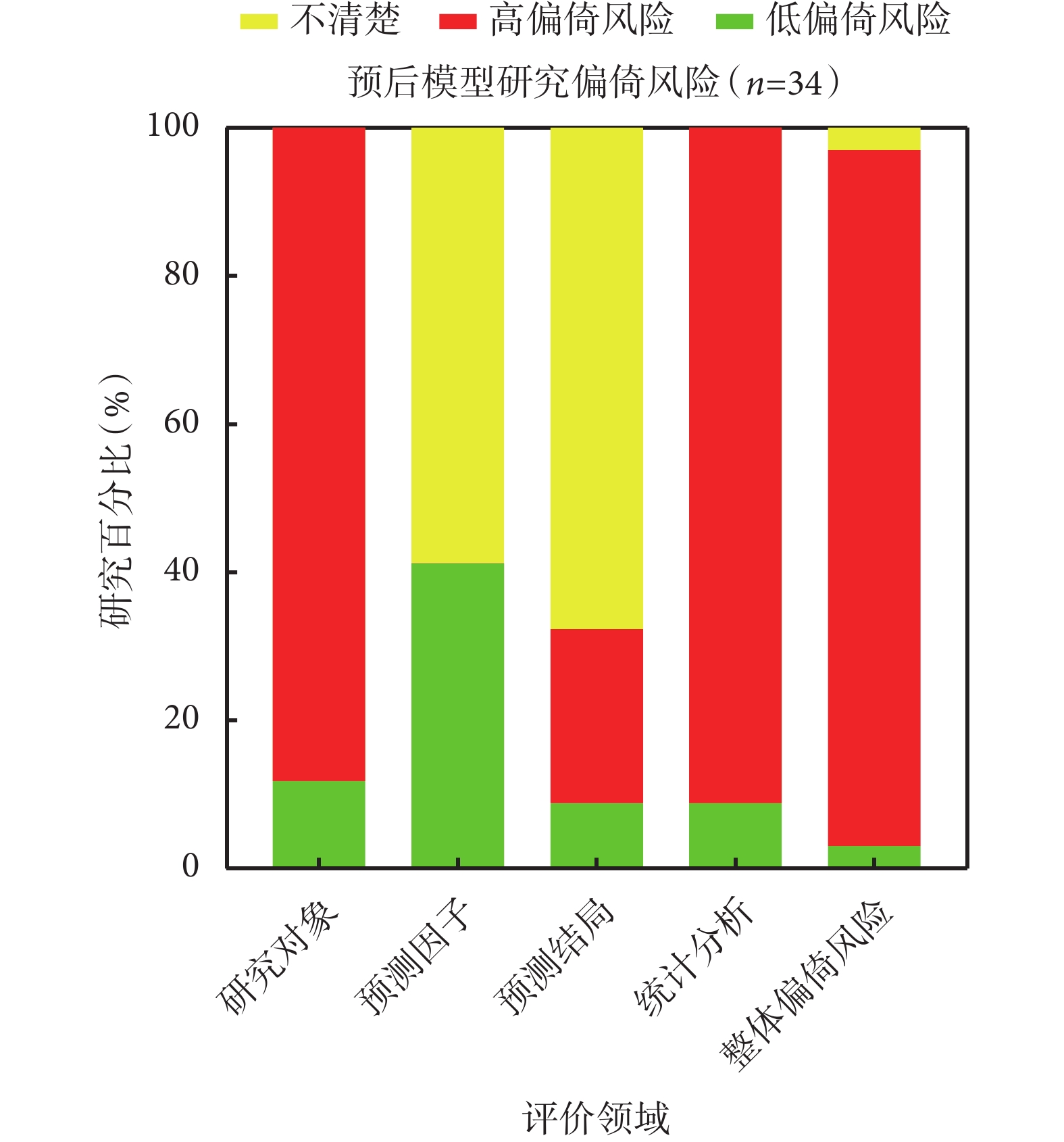
經整體偏倚風險判斷,共計111/113項(98.2%)研究存在高偏倚風險,其中診斷模型研究79/79項(100%),預后模型研究32/34項(94.1%);1/113項(0.9%)研究偏倚風險較低,1/113項(0.9%)研究偏倚風險不清,兩者均為預后模型研究。各領域具體的偏倚風險分布情況詳見圖1、圖2、圖3。納入研究偏倚風險情況的具體評價信息及統計結果詳見附件二。
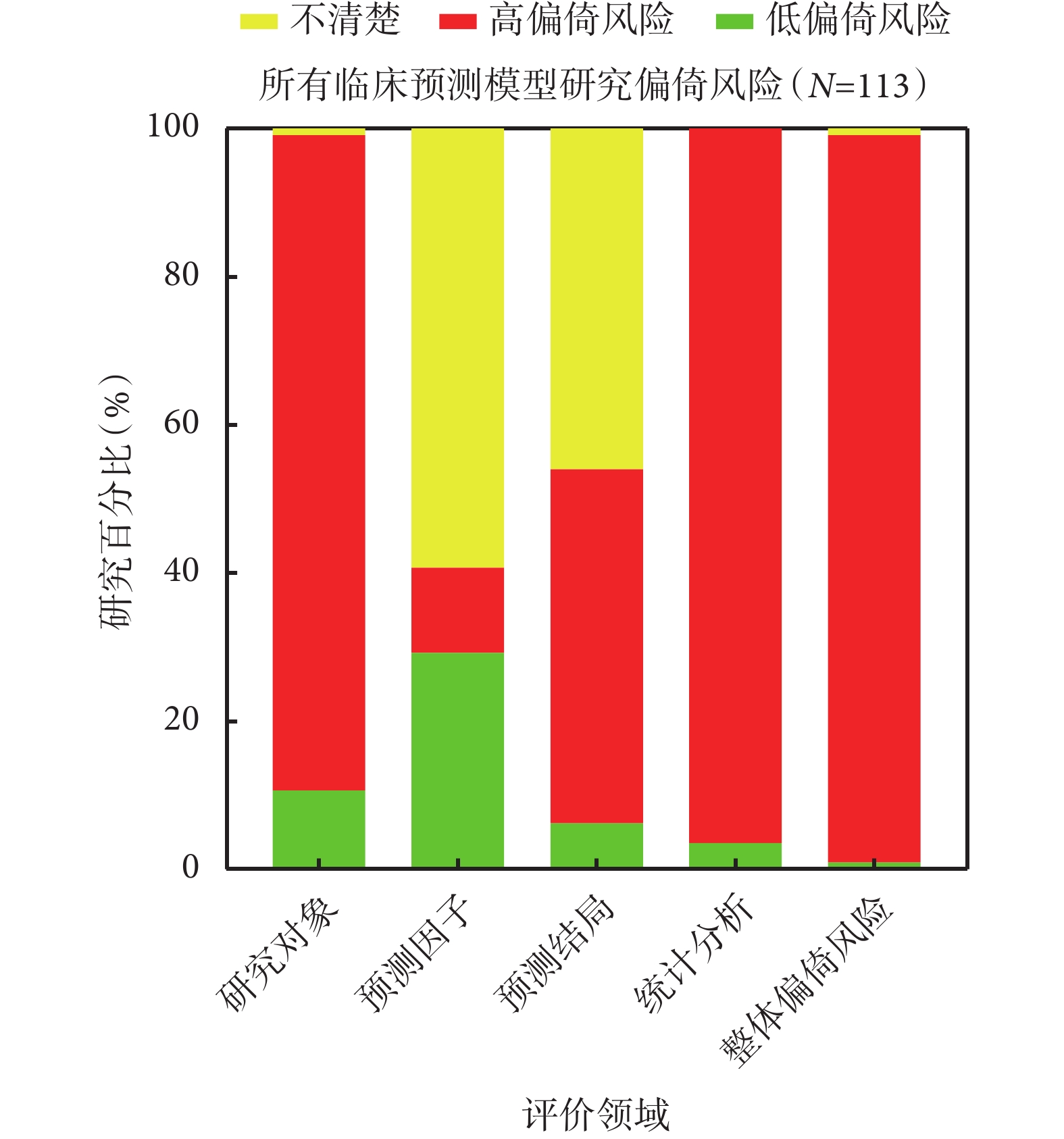 圖1
臨床預測模型研究偏倚風險
圖1
臨床預測模型研究偏倚風險
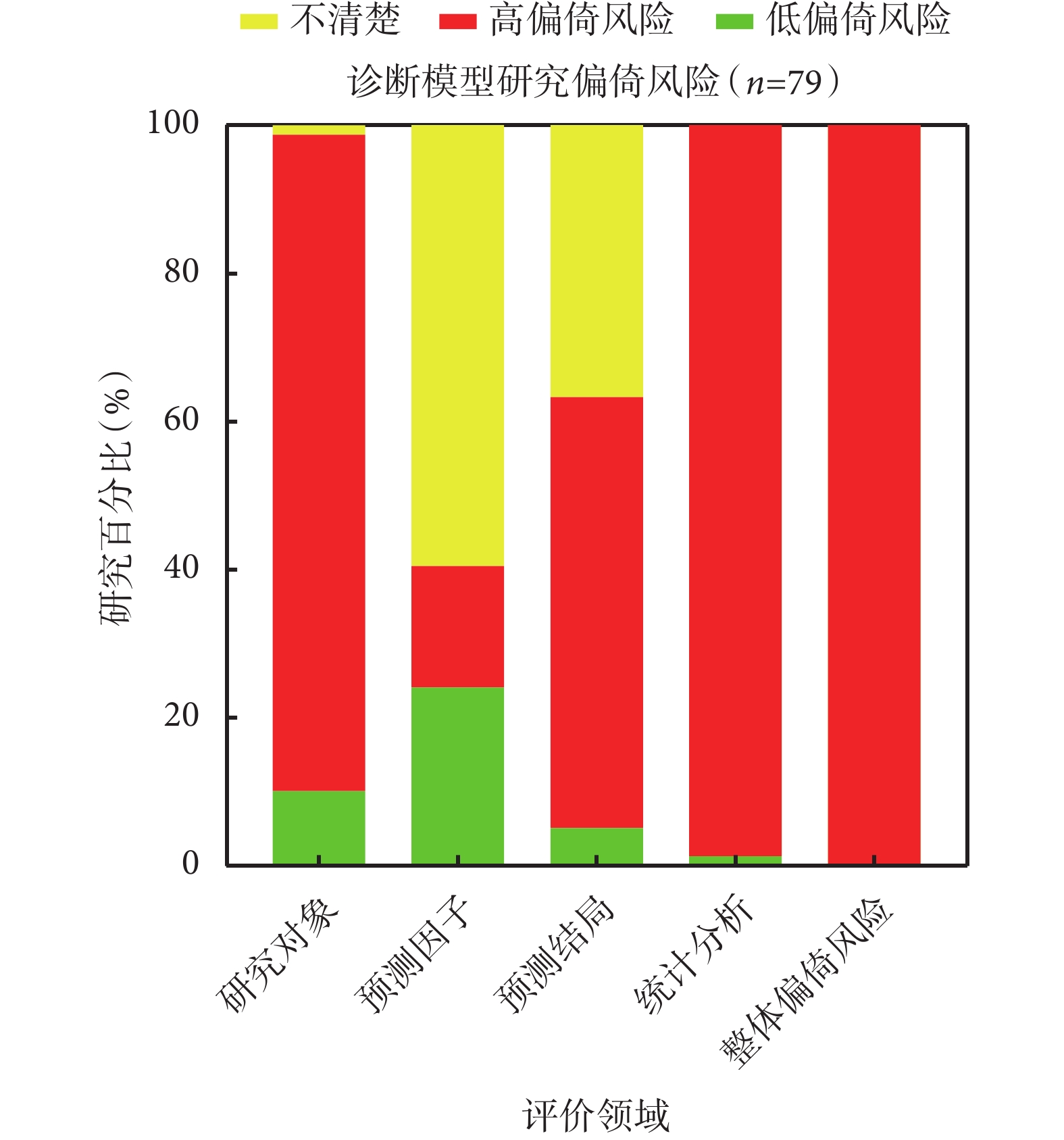 圖2
診斷模型研究偏倚風險
圖2
診斷模型研究偏倚風險
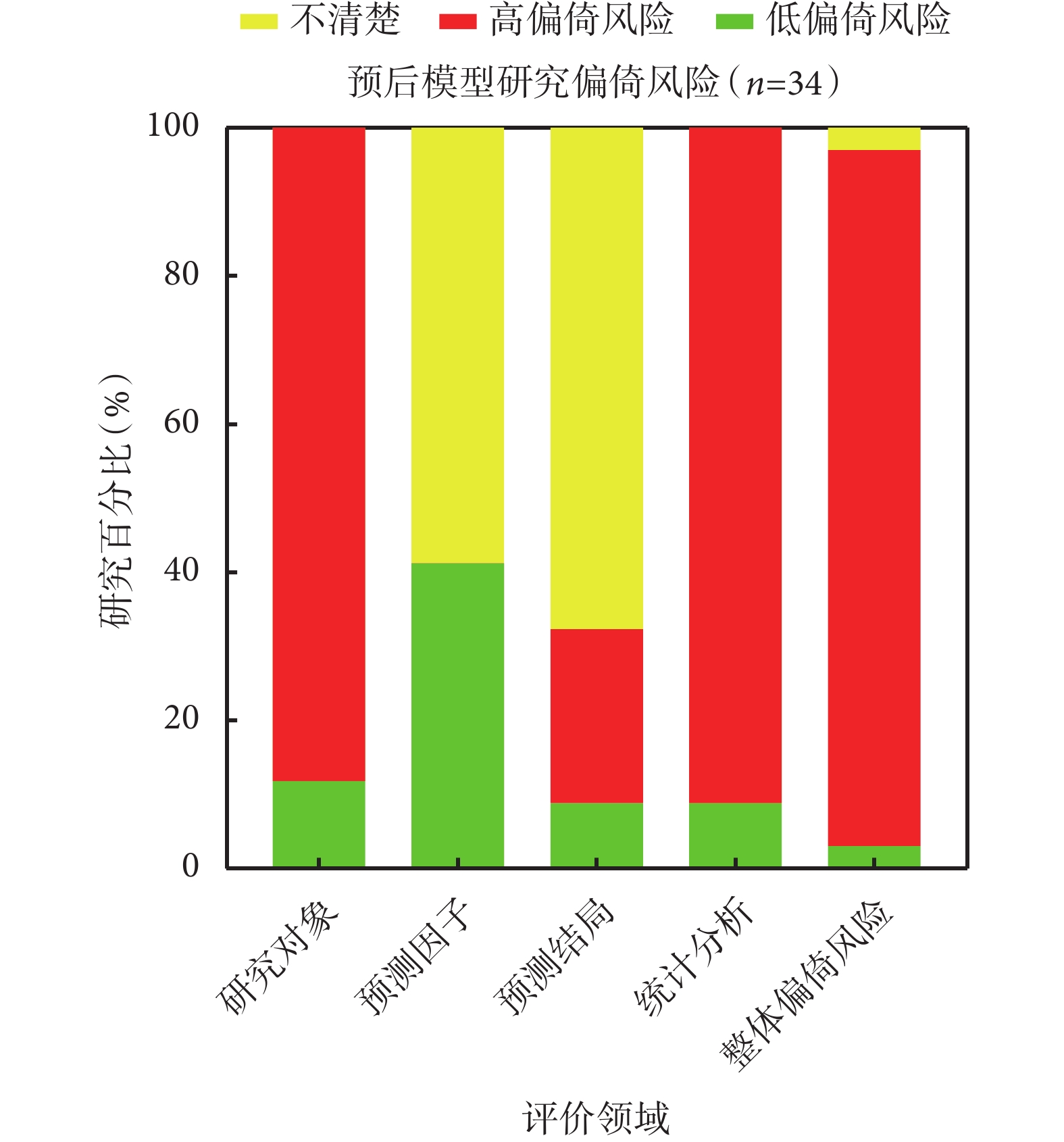 圖3
預后模型研究偏倚風險
圖3
預后模型研究偏倚風險
3 納入研究的方法學質量評價結果
基于PROBAST條目評價的方法學質量評價結果見附件一表3。
4 討論
現有中醫臨床預測模型應用范圍的分析結果表明,盡管當前研究涵蓋的病種數量已十分豐富(49種),但整體上仍聚焦于循環系統疾病、內分泌系統疾病、腫瘤疾病等疾病分類中的臨床常見多發病或慢性病,其中僅關于2型糖尿病和原發性高血壓預測建模研究就超過了10項。同時在所有納入研究中,以中醫證型作為預測結局的診斷模型研究數量(47項)位列第一,不僅反映了辨證在中醫診療實踐中的重要地位,更由于準確辨證是取得確切療效的前提,體現出此類預測建模研究的潛在實用價值。
隨著預測建模研究數量的不斷增長,已有臨床實踐指南將個別預測模型明確推薦用作日常醫療實踐中的風險評估工具,如由英國國家衛生保健卓越研究所(National Institute for Health and Care Excellence,NICE)制訂的指南分別將兩大骨質疏松預測模型FRAX和QFracture推薦用于90及85周歲高齡人群的骨質疏松風險評估,美國心臟病學會實踐指南將動脈粥樣硬化性心臟病預測模型PCE推薦用于40~79歲人群的十年心血管風險評估等[123, 124]。而在臨床推廣應用預測模型的同時,研究人員開始將更多的目光聚焦于相關研究的方法學質量上,所得結果卻不盡如人意。多項系統評價結果顯示,存在高偏倚風險的臨床預測模型研究在急診醫學、重癥醫學、老年醫學、影像學等多個學科領域中均占有極高的比例[125-128]。更有關于新型冠狀病毒肺炎的動態系統評價表明,其納入的所有57項(100%)基于機器學習方法構建的診斷模型研究與預后模型研究全部存在高偏倚風險,具體原因包括樣本代表性不足、模型過擬合、報告內容缺失等[129]。
本研究對現有中醫臨床預測模型研究方法學質量的評價結果亦呈現出顯著的相似性。在113項納入研究中,高達111項(98.2%)研究存在高偏倚風險。統計分析領域的高偏倚風險是造成研究整體偏倚風險上升的最常見原因,其中模型的性能評估和擬合情況是產生偏倚風險的重災區。在性能評估方面,僅有極少比例的研究在正確評估模型區分度的同時詳細報告其校準度。多數研究僅依賴Hosmer-Lemeshow擬合優度檢驗來體現其模型的校準優劣,但此舉無法替代校準曲線及曲線信息以具體呈現模型預測結局與真實觀察結局之間的一致性差異,同時檢驗本身也因在校準情況欠佳時的統計分析能力有限和在大樣本量檢驗中的靈敏度過高而備受詬病[130, 131]。在擬合情況方面,盡管有不少研究進行了模型的內部驗證以檢驗其數據擬合情況,但多是對建模數據集進行簡單隨機拆分,這已被證明為是一種不恰當的、易于引入選擇偏倚的內部驗證方法[132, 133];正確采用交叉驗證等內部驗證方法的研究不足兩成。此外,建模樣本量不足和采用單因素分析法篩選預測因子亦是造成統計分析領域高偏倚風險評價的常見原因;前者容易導致模型過擬合[134, 135],后者則可能遺漏無統計學顯著性但仍具備一定預測價值的預測因子[6]。針對以上常見的研究方法學欠缺之處,可參考以下建議以降低潛在的偏倚風險:① 基于每變量事件數(events per variable,EPV)計算建模樣本量;② 基于最優子集法、逐步法、Lasso回歸、嶺回歸等變量/特征篩選方法合理選擇預測因子;③ 通過區分度和校準度兩個維度全面評估模型性能,同時基于臨床效益維度呈現其臨床應用價值,并選取常用的綜合評價指標,如AUC、校準曲線的斜率及截距、臨床決策曲線分析的凈收益閾概率等;④ 通過Bootstrap、交叉驗證等重采樣法進行內部驗證以避免模型過擬合,同時結合模型應用范圍,采用適宜的外部驗證進一步評估其外推性(泛化能力)。
研究對象是第二大易產生高偏倚風險評價結果的領域,且主要與非前瞻性的研究設計有關,產生偏倚的原因在于回顧性數據的質量通常較差、且特定預測因子或預測結局的評估和測量無法進行[136]。其他易引起高偏倚風險的常見原因還包括結局的定義中包含了部分預測因子,因其可能導致預測因子和結局之間的關聯性被高估,如常見于診斷模型研究中的合并偏倚(incorporation bias)[137, 138]。正確的建模數據選取應參考PROBAST建議,采用前瞻性的數據來源開展預后模型研究,如基于前瞻性隊列研究或高質量的登記研究;而診斷模型研究的數據來源則盡可能基于橫斷面研究,或是巢式病例-對照研究/病例-隊列研究中經過統計學處理的抽樣樣本[6]。對于患者在個別變量上存在缺失值的情況,應盡量避免直接排除的處理方法,而采用回歸填補、多重填補等數據填補方法,并對結果開展事后的敏感性分析。
由于無法獲取研究特定信息而導致的偏倚風險不清普遍存在于所有評價領域中。相關信息缺失情況最為嚴重的是在評估預測因子和確定結局時對于盲法的使用情況,其次則是缺失數據的處理方法。其他偏倚風險不清的常見原因還包括無法獲悉對預測因子和結局進行數據采集的時間間隔、研究對象的納入與排除標準不清、結局的分類方法與定義不明等。任何關鍵信息的報告缺失都會為模型的偏倚風險評價工作帶來挑戰與不確定性。建議未來研究嚴格遵循《個體預后與診斷預測模型研究報告規范》(即TRIPOD聲明)中的相關條目以對研究內容進行規范、全面的報告[139]。
本研究首次系統地概括了當前中醫臨床預測建模研究的特征及應用的病種范圍,并進一步對其方法學質量進行了嚴格評價,通過評估研究對象、預測因子、預測結局及統計分析四個不同領域的偏倚風險,分析了不同偏倚的具體來源及可能產生的潛在影響;同時還針對現有研究的不足之處提出了相應的處理對策,對未來相關研究的開展與優化具有方法學層面的指導意義。但本研究尚有以下不足之處:① 僅基于常用的中、英文數據庫獲取研究文獻,未檢索和納入其他語種的文獻及灰色文獻,因此可能存在發表偏倚;② PROBAST中的評價條目在中醫臨床預測模型研究中的適用性仍有待考量,例如在以中醫證型作為預測結局的診斷模型研究中,常使用中醫證候和(或)證素作為預測因子,這也使得此類研究在標志性問題3.3中全部獲得了高偏倚風險的評價,進而導致整體偏倚風險為高風險。然而諸如此類預測因子與結局間的關聯關系是否真實地被高估卻難以形成定論。未來仍需要開發更適用于中醫臨床領域的相關方法學評價工具以提高評價結果的精確性。
綜上所述,現有中醫臨床預測模型研究的方法學質量普遍較差,幾乎均存在高偏倚風險。產生偏倚風險的原因包括非前瞻性設計的數據來源、結局定義包含預測因子、建模樣本量不足、特征選擇不合理、性能評估欠準確和內部驗證方法錯誤。未來建模研究需針對模型的設計、構建、評價和驗證進行全方位的方法學質量改進,并全面報告模型的所有關鍵信息,以促進其在醫療實踐中的轉化應用。
聲明 所有作者均聲明不存在利益沖突。
預測模型因其在時效性方面的巨大應用價值而在醫學研究領域中備受矚目,其中應用于臨床實踐的預測模型主要包括診斷模型和預后模型兩大類。前者主要基于個體的臨床表現及特征以預測當前時點患病或已發生某種結局的概率,適用群體為特定疾病的疑似患者,常借助易采集、低成本、無創的各類指標形成高靈敏度或特異度的診斷方案,主要應用于疾病的二級預防,如腫瘤疾病的診斷、急性深靜脈血栓形成的門診篩查等;后者則通過個體當下的健康或疾病狀態以預測在未來時點出現某種事件/結局的概率,其適用群體除了已確診的患者外,還包括存在特定風險因素的健康人群或特殊群體,如具有高血壓家族史的健康個體、妊娠期高血糖孕婦等,常通過絕對概率來量化未來罹患某種疾病或發生某種疾病轉歸的風險,主要應用于疾病的一級和三級預防,如估計高危個體十年內發生心血管事件的風險、評估急性心衰患者住院期間死亡的概率等[1-3]。
具體臨床預測建模研究的開展包括模型的設計、構建、評價、驗證等不同階段[4]。在任一階段方法學層面的缺陷均可能引起不同程度的偏倚風險,進而影響預測模型性能評價的真實性[5, 6]。對于存在高偏倚風險的臨床預測模型而言,不僅無法評估其在臨床決策中產生的實際效益情況,其應用甚至還可能會對醫療實踐產生負面影響,例如基于模型預測結果采取不必要或不充分的臨床干預措施而造成醫療資源的浪費或錯誤利用[7]。因此,針對臨床預測模型開展嚴格的方法學質量評價對于其可靠性的確定和應用價值的探索具有重要意義。
近年來,隨著信息獲取成本的降低、建模技術的更新以及多學科交叉融合的發展,在中醫臨床領域中亦開始興起預測模型的研究浪潮[8]。盡管相關研究的數量在不斷增長,并創新性地應用了諸如中醫四診信息、中醫藥干預治療信息、中醫體質信息、舌脈信息等多類具有中醫藥特色的預測因子,但真正落地臨床實踐者卻寥寥無幾,僅在單中心或小區域范圍內被少量醫者采納;同時在各類中醫臨床實踐指南中亦未見關于具體預測模型應用的推薦意見,使得現有模型無法廣泛地鋪開應用于中醫臨床,造成了大量研究資源的浪費。除了研究者疏于開展對預測模型性能的后續臨床驗證外,缺乏對相關研究的方法學評價亦是限制其轉化應用的重要原因之一。因此,本研究擬對現有中醫臨床預測模型研究的方法學質量開展系統評價,以梳理、總結當前研究的具體偏倚風險情況及原因,為后續相關研究的開展與優化提供參考。
1 資料與方法
1.1 納入與排除標準
納入標準:① 研究類型為實證研究且發表類型為期刊論文;② 建模目的以臨床應用為導向,主要研究內容圍繞預測模型的構建、驗證或(和)更新;③ 模型類型為診斷模型或預后模型且建模變量數量不少于2個。
排除標準:① 發表類型為研究方案、會議論文、社論、評論或摘要者;② 研究內容僅針對現有預測模型開展建模過程的方法學評價,而無具體模型的呈現;③ 模型的構建或應用與中醫藥領域無明顯關聯;④ 重復發表的文獻;⑤ 無法獲取全文的文獻。
1.2 文獻檢索策略
計算機檢索CNKI、WanFang Data、VIP、SinoMed、PubMed、Embase和Web of Science數據庫,搜集與中醫臨床預測模型研究相關的中、英文文獻,檢索時限均從建庫至2023年3月31日。檢索采用主題詞與自由詞相結合的方式進行,并根據數據庫特征做適應性調整。中文檢索詞包括:中醫、中醫藥、中西醫、預測模型、預測規則、預后模型、診斷模型、風險預測、風險評分等;英文檢索詞包括:traditional Chinese medicine、traditional Chinese and western medicine 、clinical prediction model、clinical prediction rule、clinical forecast mode、diagnostic model、prognostic model、risk prediction、risk rule等。以PubMed為例,其具體檢索策略見附件一框1。
1.3 文獻篩選與資料提取
由2名研究者獨立篩選文獻、提取資料并交叉核對。如存在分歧,則通過討論或與第三方協商解決。文獻篩選首先閱讀文題和摘要,在排除明顯不相關的文獻后,進一步閱讀全文,以確定最終是否納入。基于CHARMS清單構建信息提取表[9],提取內容包括:① 文獻基本信息(包括標題、作者、發表年份、發表期刊);② 預測模型特征情況(包括模型設計、模型構建、模型性能、模型驗證);③ 偏倚風險評價關鍵因素(包括研究對象、預測因子、結局指標和統計分析)。
1.4 納入研究的方法學質量評價
采用預測模型偏倚風險評估工具(prediction model risk of bias assessment tool,PROBAST)對納入研究的偏倚風險進行評價[5]。PROBAST是基于德爾菲法開發的通用評估工具,可通過研究對象、預測因子、結局指標和統計分析4個維度及對應的20個標志性問題全面、系統地評價預測模型研究的方法學質量[5, 6]。
考慮到具體的預測模型研究可能基于不同建模方法或預測因子構建多個預測模型,因此在評價過程中,優先評價由作者推薦或定義的最佳模型;若作者未具體說明,則選擇區分度最佳者作為待評價模型。方法學評價由2名研究者根據PROBAST的等級評定標準獨立開展,任何分歧通過討論或與第三方協商解決。
1.5 統計分析
采用描述性分析方法,整理和總結納入研究的基本特征情況和方法學質量評價結果,并以表格、圖片等可視化方式呈現。計數資料以頻數及百分比表示。
2 結果
2.1 文獻篩選流程及結果
初檢共獲得相關文獻2 018篇,經逐層篩選后,最終納入合格文獻113篇[10-122],其中中文80篇,英文33篇。具體文獻篩選流程及結果見附件一圖1。
2.2 納入研究的類型及基本特征
113項中醫臨床預測模型研究分別包含診斷模型研究79項(69.9%),預后模型研究34項(30.1%)。基于PROBAST的分類標準,屬于模型構建的研究共計107項(94.7%),屬于模型構建與驗證(外部驗證)的研究共計6項(5.3%);其中有31項(27.4%)研究應用了多種建模方法(≥2種)。各項研究的具體基本特征情況見附件一表1。
所有預測模型涵蓋的病種數量共計49個,研究頻數位居前十的疾病分別為2型糖尿病、原發性高血壓、腦卒中、慢性心力衰竭、慢性乙型病毒性肝炎、原發性肝癌、非小細胞肺癌、骨質疏松癥、冠狀動脈粥樣硬化性心臟病、結直腸癌。參照2020年WHO ICD-10編碼標準,所有病種主要集中于11類疾病領域,按研究頻數從大到小依次為:循環系統疾病(28/113,24.78%)、內分泌系統疾病(21/113,18.58%)、腫瘤疾病(17/113,15.04%)、神經系統疾病(11/113,9.73%)、傳染性疾病(8/113,7.08%)、肌肉骨骼系統疾病(7/113,6.19%)、消化系統疾病(6/113,5.31%)、泌尿生殖系統疾病(6/113,5.31%)、呼吸系統疾病(5/113,4.42%)、精神障礙疾病(2/113,1.77%)、損傷性疾病(2/113,1.77%)。具體疾病名稱、所屬領域及相應研究頻數詳見附件一表2。
2.2.1 研究對象
在研究對象領域,僅有12/113項(10.6%)研究的偏倚風險較低,其中在診斷模型研究(10.1%,8/79)與預后模型研究(11.8%,4/34)中的比例基本一致。
高達100/113項(88.5%)研究在研究對象選擇方面存在高偏倚風險,最為常見的原因是其建模數據來源存在偏倚,無論是診斷模型還是預后模型,建模樣本未源自前瞻性數據的研究所占比例均超過了88%(標志性問題1.1)。
超八成納入研究制定的研究對象納入和排除標準較為合理,但仍有10/79項(12.7%)診斷模型研究和4/34項(11.8%)預后模型研究未報告具體標準信息,故無法評價建模樣本能否代表模型的目標人群(標志性問題1.2)。另有1/113項(0.9%)研究因信息不全而無法評價此領域的偏倚風險。
2.2.2 預測因子
在預測因子領域,共計33/113項(29.2%)研究偏倚風險較低,其中在預后模型研究中的比例(41.2%,14/34)高于在診斷模型研究中的比例(24.1%,19/79)。
高達67/113項(59.3%)研究的偏倚風險不清,這主要與預測因子評估過程中盲法的應用有關,分別有49/79項(62.0%)診斷模型研究和20/34項(58.8%)預后模型研究未報告有關設盲的具體信息(標志性問題2.2)。
13/113項(11.5%)研究存在高偏倚風險亦主要與預測因子評估過程中明確未采用盲法有關(11/13,84.6%),且此領域的高偏倚風險全部集中于診斷模型研究中。
整體來看,納入研究在預測因子定義、評估范圍及有效性方面的偏倚風險普遍較低(標志性問題2.1,標志性問題2.3)。
2.2.3 預測結局
在預測結局領域,僅有7/113項(6.2%)研究的偏倚風險較低,其中在預后模型研究中的比例(8.8%,3/34)略高于在診斷模型研究中的比例(5.1%,4/79)。
共計54/113項(47.8%)研究在此領域存在高偏倚風險;其中診斷模型研究46/79項(58.2%),預后模型研究8/34項(23.5%)。產生高偏倚風險的主要原因在于53/113項(46.9%)研究的預測結局定義中包含了部分預測因子,導致兩者之間的關聯性可能被高估(標志性問題3.3)。
共計52/113項(46.0%)研究在此領域的偏倚風險不清;其中診斷模型研究29/79項(36.7%),預后模型研究23/34項(67.6%)。偏倚風險不清的首要原因在于97/113項(85.8%)研究未報告有關預測結局確定過程中是否設盲的具體信息(標志性問題3.5);其次則是33/113項(29.2%)研究缺乏足夠信息以判斷預測因子評估和結局確定的時間間隔是否合理(標志性問題3.6)。
整體來看,超八成納入研究對于預測結局定義、分類方法及其適用對象范圍的選擇較為合理(標志性問題3.1,標志性問題3.2,標志性問題3.4)。
2.2.4 統計分析
在統計分析領域,僅有4/113項(3.5%)研究的偏倚風險較低,其中在預后模型研究中的比例(8.8%,3/34)高于在診斷模型研究中的比例(1.3%,1/79)。
高達109/113項(96.5%)研究在此領域存在高偏倚風險,其中診斷模型研究78/79項(98.7%),預后模型研究31/34項(91.2%)。究其具體原因,38/79項(48.1%)診斷模型研究和13/34項(38.2%)預后模型研究的建模樣本量不足,即每變量事件數EPV<10(標志性問題4.1);9/79項(11.4%)診斷模型研究和10/34項(29.4%)預后模型研究對連續變量進行了錯誤處理/轉化或對分類變量采用了不一致的切點(標志性問題4.2);僅34/79項(43.0%)診斷模型研究和17/34項(50.0%)預后模型研究對缺失數據進行了合理處理(標志性問題4.4);34/79項(43.0%)診斷模型研究和19/34項(55.9%)預后模型研究僅基于單因素分析法篩選預測因子而可能遺漏重要的變量信息(標志性問題4.5);73/79項(92.4%)診斷模型研究和26/34項(76.5%)預后模型研究未能同時從區分度和校準度兩個角度正確、全面地評價模型性能(標志性問題4.7);73/79項(92.4%)診斷模型研究和20/34項(58.8%)預后模型研究未能采用正確的內部驗證方法以合理地評價模型的擬合情況(標志性問題4.8)。
整體來看,納入研究僅在統計分析數據集、數據復雜性解釋和預測因子權重/系數報告(此項僅針對基于回歸方法構建模型的研究而言)方面的偏倚風險普遍較低(標志性問題4.3,標志性問題4.6,標志性問題4.9)。
2.2.5 整體偏倚風險
經整體偏倚風險判斷,共計111/113項(98.2%)研究存在高偏倚風險,其中診斷模型研究79/79項(100%),預后模型研究32/34項(94.1%);1/113項(0.9%)研究偏倚風險較低,1/113項(0.9%)研究偏倚風險不清,兩者均為預后模型研究。各領域具體的偏倚風險分布情況詳見圖1、圖2、圖3。納入研究偏倚風險情況的具體評價信息及統計結果詳見附件二。
圖1
臨床預測模型研究偏倚風險
圖2
診斷模型研究偏倚風險
圖3
預后模型研究偏倚風險
3 納入研究的方法學質量評價結果
基于PROBAST條目評價的方法學質量評價結果見附件一表3。
4 討論
現有中醫臨床預測模型應用范圍的分析結果表明,盡管當前研究涵蓋的病種數量已十分豐富(49種),但整體上仍聚焦于循環系統疾病、內分泌系統疾病、腫瘤疾病等疾病分類中的臨床常見多發病或慢性病,其中僅關于2型糖尿病和原發性高血壓預測建模研究就超過了10項。同時在所有納入研究中,以中醫證型作為預測結局的診斷模型研究數量(47項)位列第一,不僅反映了辨證在中醫診療實踐中的重要地位,更由于準確辨證是取得確切療效的前提,體現出此類預測建模研究的潛在實用價值。
隨著預測建模研究數量的不斷增長,已有臨床實踐指南將個別預測模型明確推薦用作日常醫療實踐中的風險評估工具,如由英國國家衛生保健卓越研究所(National Institute for Health and Care Excellence,NICE)制訂的指南分別將兩大骨質疏松預測模型FRAX和QFracture推薦用于90及85周歲高齡人群的骨質疏松風險評估,美國心臟病學會實踐指南將動脈粥樣硬化性心臟病預測模型PCE推薦用于40~79歲人群的十年心血管風險評估等[123, 124]。而在臨床推廣應用預測模型的同時,研究人員開始將更多的目光聚焦于相關研究的方法學質量上,所得結果卻不盡如人意。多項系統評價結果顯示,存在高偏倚風險的臨床預測模型研究在急診醫學、重癥醫學、老年醫學、影像學等多個學科領域中均占有極高的比例[125-128]。更有關于新型冠狀病毒肺炎的動態系統評價表明,其納入的所有57項(100%)基于機器學習方法構建的診斷模型研究與預后模型研究全部存在高偏倚風險,具體原因包括樣本代表性不足、模型過擬合、報告內容缺失等[129]。
本研究對現有中醫臨床預測模型研究方法學質量的評價結果亦呈現出顯著的相似性。在113項納入研究中,高達111項(98.2%)研究存在高偏倚風險。統計分析領域的高偏倚風險是造成研究整體偏倚風險上升的最常見原因,其中模型的性能評估和擬合情況是產生偏倚風險的重災區。在性能評估方面,僅有極少比例的研究在正確評估模型區分度的同時詳細報告其校準度。多數研究僅依賴Hosmer-Lemeshow擬合優度檢驗來體現其模型的校準優劣,但此舉無法替代校準曲線及曲線信息以具體呈現模型預測結局與真實觀察結局之間的一致性差異,同時檢驗本身也因在校準情況欠佳時的統計分析能力有限和在大樣本量檢驗中的靈敏度過高而備受詬病[130, 131]。在擬合情況方面,盡管有不少研究進行了模型的內部驗證以檢驗其數據擬合情況,但多是對建模數據集進行簡單隨機拆分,這已被證明為是一種不恰當的、易于引入選擇偏倚的內部驗證方法[132, 133];正確采用交叉驗證等內部驗證方法的研究不足兩成。此外,建模樣本量不足和采用單因素分析法篩選預測因子亦是造成統計分析領域高偏倚風險評價的常見原因;前者容易導致模型過擬合[134, 135],后者則可能遺漏無統計學顯著性但仍具備一定預測價值的預測因子[6]。針對以上常見的研究方法學欠缺之處,可參考以下建議以降低潛在的偏倚風險:① 基于每變量事件數(events per variable,EPV)計算建模樣本量;② 基于最優子集法、逐步法、Lasso回歸、嶺回歸等變量/特征篩選方法合理選擇預測因子;③ 通過區分度和校準度兩個維度全面評估模型性能,同時基于臨床效益維度呈現其臨床應用價值,并選取常用的綜合評價指標,如AUC、校準曲線的斜率及截距、臨床決策曲線分析的凈收益閾概率等;④ 通過Bootstrap、交叉驗證等重采樣法進行內部驗證以避免模型過擬合,同時結合模型應用范圍,采用適宜的外部驗證進一步評估其外推性(泛化能力)。
研究對象是第二大易產生高偏倚風險評價結果的領域,且主要與非前瞻性的研究設計有關,產生偏倚的原因在于回顧性數據的質量通常較差、且特定預測因子或預測結局的評估和測量無法進行[136]。其他易引起高偏倚風險的常見原因還包括結局的定義中包含了部分預測因子,因其可能導致預測因子和結局之間的關聯性被高估,如常見于診斷模型研究中的合并偏倚(incorporation bias)[137, 138]。正確的建模數據選取應參考PROBAST建議,采用前瞻性的數據來源開展預后模型研究,如基于前瞻性隊列研究或高質量的登記研究;而診斷模型研究的數據來源則盡可能基于橫斷面研究,或是巢式病例-對照研究/病例-隊列研究中經過統計學處理的抽樣樣本[6]。對于患者在個別變量上存在缺失值的情況,應盡量避免直接排除的處理方法,而采用回歸填補、多重填補等數據填補方法,并對結果開展事后的敏感性分析。
由于無法獲取研究特定信息而導致的偏倚風險不清普遍存在于所有評價領域中。相關信息缺失情況最為嚴重的是在評估預測因子和確定結局時對于盲法的使用情況,其次則是缺失數據的處理方法。其他偏倚風險不清的常見原因還包括無法獲悉對預測因子和結局進行數據采集的時間間隔、研究對象的納入與排除標準不清、結局的分類方法與定義不明等。任何關鍵信息的報告缺失都會為模型的偏倚風險評價工作帶來挑戰與不確定性。建議未來研究嚴格遵循《個體預后與診斷預測模型研究報告規范》(即TRIPOD聲明)中的相關條目以對研究內容進行規范、全面的報告[139]。
本研究首次系統地概括了當前中醫臨床預測建模研究的特征及應用的病種范圍,并進一步對其方法學質量進行了嚴格評價,通過評估研究對象、預測因子、預測結局及統計分析四個不同領域的偏倚風險,分析了不同偏倚的具體來源及可能產生的潛在影響;同時還針對現有研究的不足之處提出了相應的處理對策,對未來相關研究的開展與優化具有方法學層面的指導意義。但本研究尚有以下不足之處:① 僅基于常用的中、英文數據庫獲取研究文獻,未檢索和納入其他語種的文獻及灰色文獻,因此可能存在發表偏倚;② PROBAST中的評價條目在中醫臨床預測模型研究中的適用性仍有待考量,例如在以中醫證型作為預測結局的診斷模型研究中,常使用中醫證候和(或)證素作為預測因子,這也使得此類研究在標志性問題3.3中全部獲得了高偏倚風險的評價,進而導致整體偏倚風險為高風險。然而諸如此類預測因子與結局間的關聯關系是否真實地被高估卻難以形成定論。未來仍需要開發更適用于中醫臨床領域的相關方法學評價工具以提高評價結果的精確性。
綜上所述,現有中醫臨床預測模型研究的方法學質量普遍較差,幾乎均存在高偏倚風險。產生偏倚風險的原因包括非前瞻性設計的數據來源、結局定義包含預測因子、建模樣本量不足、特征選擇不合理、性能評估欠準確和內部驗證方法錯誤。未來建模研究需針對模型的設計、構建、評價和驗證進行全方位的方法學質量改進,并全面報告模型的所有關鍵信息,以促進其在醫療實踐中的轉化應用。
聲明 所有作者均聲明不存在利益沖突。